
概念処理装置及びプログラム
【課題】出来事に関する内容を説明する際に、その説明をどのように構成したらよいかの適切な構成要素を得る。
【解決手段】概念処理装置1の抽出部3は、ある種類の出来事を説明している記事データから目次などを示す項目名データを抽出し、抽出した各項目名データが記事データに出現する数をカウントする。一般化処理部4は、抽出された項目名データを比較し、項目名の一部が重複、あるいは、上位概念が共通する場合、項目名データを統合してニュース要素候補データを得る。また、各ニュース要素候補データの出現数を、そのニュース要素候補データに統合された項目名データそれぞれの出現数の合計により算出する。オントロジー生成部5は、出現数が所定より多いニュース要素候補データをニュース要素データとして選択し、出来事の種類のデータを上位階層とし、ニュース要素データを下位階層としたオントロジーを生成してオントロジー記憶部8に書き込む。
【解決手段】概念処理装置1の抽出部3は、ある種類の出来事を説明している記事データから目次などを示す項目名データを抽出し、抽出した各項目名データが記事データに出現する数をカウントする。一般化処理部4は、抽出された項目名データを比較し、項目名の一部が重複、あるいは、上位概念が共通する場合、項目名データを統合してニュース要素候補データを得る。また、各ニュース要素候補データの出現数を、そのニュース要素候補データに統合された項目名データそれぞれの出現数の合計により算出する。オントロジー生成部5は、出現数が所定より多いニュース要素候補データをニュース要素データとして選択し、出来事の種類のデータを上位階層とし、ニュース要素データを下位階層としたオントロジーを生成してオントロジー記憶部8に書き込む。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、概念処理装置及びプログラムに関する。
【背景技術】
【0002】
インターネット上のニュースサイトなどの登場により、ユーザは事件や事故などの様々な出来事(以下、「ニュースイベント」と記載する。)に関するニュース記事を検索し、閲覧することが可能となった。しかし、ユーザがあるニュースイベントに関してその全体像をつかみたい際には、適切なキーワードによってそのニュースイベントに関するニュース記事群を検索し、検索の結果得られたニュース記事群を1つ1つ閲覧した上で、自分の中で記事の内容を再構成して概要を知る、といった作業が必要であった。
【0003】
一方で、近年その規模を拡大し続けているWikipedia(登録商標)(http://www.wikipedia.org/、ウィキメディア財団)のような「集合知」を蓄積するサイトには、言葉の解説だけでなく、ニュースイベントに関する解説記事なども含まれている。ユーザは、そのようなサイトに含まれている解説記事を読むことにより、ニュースイベントに関する概要を知ることができるようになってきた。例えば、「新潟県中越沖地震」について集合知蓄積サイトが提供している記事を読めば、ユーザはその地震に関する全体像をつかむことができる。
【0004】
しかし、このようなサイトでも、すべてのニュースイベントを網羅的に記述してはおらず、多くのユーザの興味を引くと考えられる重要なニュースイベントのみが記事として含まれる。従って、そのサイトに含まれないニュースイベントに関しては、ユーザ自身が従来のように自力でニュース記事などを検索し、その概要を知るしかない。そこで、膨大な量のニュース記事などから、あるニュースイベントに関する「まとめ記事」を自動で生成できるようになれば、ユーザの負担は大きく減ることが予想される。非特許文献1では、このような技術を実現するために、ニュースオントロジーという概念が提案されている。
【0005】
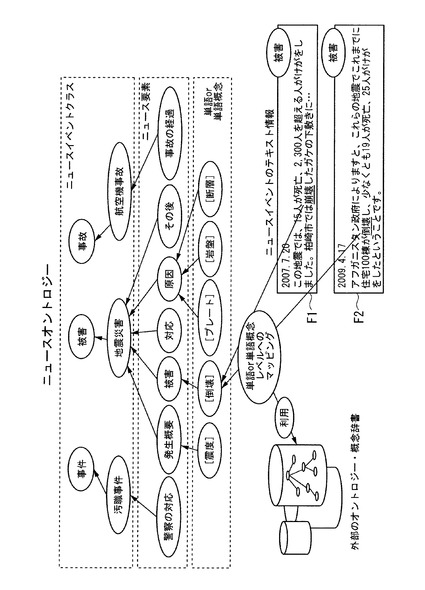
図10は、ニュースオントロジーについて示す図である。この技術では、あるニュースイベントに関連した情報を伝えるニュース記事群が、それぞれ特定の役割を持っていると仮定する。例えば、ある記事F1、F2は「地震災害」という種類のニュースイベント(以下、ニュースイベントの種類を「ニュースイベントクラス」と記載する。)に属するテキスト情報であり、このニュースイベントクラス「地震災害」に関して「被害」の内容を示す役割を持っていると仮定する。このような役割を「ニュース要素」とし、様々な種類のニュースイベントの特徴をそのニュース要素の集合で表している。
【0006】
各ニュース要素は、そのニュース要素に含まれる単語(あるいはその単語の上位概念)の集合で表現する。つまり、ニュースイベントクラスごとに、そのニュースイベントクラスを構成するニュース要素群を記述し、さらにそれらのニュース要素に対応した特徴的な単語(概念)群をオントロジーとして記述する。例えば、図10に示すように、ニュースイベントクラスには、「汚職事件」、「地震災害」、「航空機事故」などがあり、ニュースイベントクラス「地震災害」は、ニュース要素「発生概要」、「被害」、「対応」、「原因」、「その後」から構成される。そして、ニュース要素「発生概要」には単語「震度」が含まれ、ニュース要素「被害」には単語「倒壊」が含まれ、ニュース要素「原因」には単語「プレート」が含まれるという情報を構造化していく。各ニュース要素に含まれる単語は、そのニュース要素に対応付けられた記事に出現する頻度が高い単語である。特許文献1には、文書内の重要キーワードを抽出する技術について記載されている。
【0007】
このようなニュースオントロジーを作成しておくことにより、特定のニュース要素に対応する記事のみを取り出してくる、また複数の記事をそのニュース要素ごとに組み合わせてまとめ記事を作る、といったサービスに利用が可能である。
【先行技術文献】
【特許文献】
【0008】
【特許文献1】特開2010−204866号公報
【非特許文献】
【0009】
【非特許文献1】宮崎 勝他,「外部知識を用いたニュースオントロジー構築手法の検討」,2009年映像情報メディア学会冬季大会講演予稿集,発表番号1−4,2009年
【発明の概要】
【発明が解決しようとする課題】
【0010】
事件や事故などのニュースイベントについて人に説明するとき、例えば、「地震災害」について説明するときには、ニュース要素として示される「発生概要」、「被害」、「対応」、「原因」、「その後」のようなカテゴリーに分けて内容を説明するとわかりやすい。しかし、このニュースイベントクラス「地震災害」のニュース要素群は、「汚職事件」、「航空機事故」などのニュースイベントクラスを説明するニュース要素とは一致しない。このように、個々のニュースイベントクラスによってニュース要素は異なる。上述した非特許文献1の技術では、膨大な数のニュースイベントクラスごとにニュース要素群を手作業で決めなければならなかった。そのため、非常に膨大な時間と労力を必要とする。
【0011】
ニュースイベントクラスを構成するニュース要素は、そのニュースイベントクラスについて記述された文書に含まれる重要なキーワードである、とも考えることができる。特定文書中の重要キーワードを獲得する手法は数多く検討されており、例えばTF−IDFのような単語の頻度情報を指標として用いた重要キーワード抽出手法により、重要と思われる文書中の単語群を抽出することは容易に実現可能である。しかし、これによって得られた単語の重要度は必ずしも説明における文書作成者の意図を正確に反映しているとは限らない。つまり、単語の重要度は、あるニュースイベントを伝える際に、「どのような種類の情報」を「どのように構成」して提示すべきか、ということを記述した構造化知識を表しているものではない。
【0012】
本発明は、このような事情を考慮してなされたもので、出来事に関する内容を説明する際に、その説明をどのように構成したらよいかの適切な構成要素を得ることができる概念処理装置及びコンピュータプログラムを提供する。
【課題を解決するための手段】
【0013】
[1] 本発明の一態様は、見出しデータを含む記事データを記憶する記事データ記憶部と、前記記事データ記憶部から前記記事データを読み出し、前記見出しデータを抽出する抽出部と、前記抽出部が抽出した複数の前記見出しデータに出現する文字が共通出現パターンを有する場合に前記共通出現パターンに基づき統合後の見出しデータを生成し、前記抽出部が抽出した複数の前記見出しデータが共通の上位概念を有する場合に前記共通の上位概念に基づき統合後の見出しデータを生成する一般化処理を行なった結果の見出しデータを構成要素データとして出力する一般化処理部と、を備えることを特徴とする概念処理装置である。
この態様によれば、概念処理装置は、ある同一の種類の出来事に関する内容が記述された複数の記事データから説明の目次とし記載されている項目名、あるいは、ニュースのタイトルやリード文などの見出しデータを取得し、取得した見出しデータが示す見出しが表層的に一致する場合や、同一の上位概念を有する場合に統合を行なう。概念処理装置は、統合を行なった結果の見出しデータを、出来事を説明する際の構成要素を示すデータとして出力する。
これにより、集合知蓄積サイトなどにより提供されるある出来事に関する記事データや、ニュース記事の記事データを利用して、人間がある出来事を伝える際に、どのような構成を利用するのかの知識に基づいた構成要素を取得することができる。また、取得した構成要素を記事等の分類に利用することにより、その出来事についてのまとめ記事の生成に活用することが可能となる。
【0014】
[2] 本発明の一態様は、上述する概念処理装置であって、前記一般化処理部により得られた前記構成要素データの下層に、前記構成要素データに統合された前記見出しデータを付加したオントロジー、または、前記一般化処理部により得られた前記構成要素データの下層に、前記記事データが示す階層化された見出しデータに含まれる前記構成要素データの下層の見出しデータを付加したオントロジーデータを生成するオントロジー生成部をさらに備える、ことを特徴とする。
この態様によれば、概念処理装置は、構成要素の下層に、その構成要素データに統合されたために削除された見出しデータを付加したり、記事データに含まれる階層構造の目次から得られたその構成要素の下層の見出しデータを付加したりすることによって、階層化されたオントロジーデータを生成する。
これにより、詳細な構成要素を得ることができるとともに、それらの構成要素間の関係をわかりやすく分類することができる。
【0015】
[3] 本発明の一態様は、上述する概念処理装置であって、前記一般化処理部により得られた前記構成要素データの順序を前記記事データが示す前記見出しデータの出現順に基づいて決定し、決定した出現順を示す情報を前記構成要素データに付加したオントロジーデータを生成するオントロジー生成部をさらに備える、ことを特徴とする。
この態様によれば、概念処理装置は、記事データから得られる出現順に基づいて構成要素データを順番に並べたオントロジーデータを生成する。
これにより、ある出来事を説明する際に、どのような順序で説明を構成すればよいかを知ることができる。
【0016】
[4] 本発明の一態様は、上述する概念処理装置であって、前記一般化処理部は、前記一般化処理において、複数の前記見出しデータが示す見出しが後方一致、前方一致、または、部分一致する場合、あるいは、複数の前記見出しデータが示す見出しに同一の順序で共通して現われる文字数が所定以上である場合に、前記複数の見出しデータを、前記複数の見出しデータのうち最も短い見出しの見出しデータに統合し、共通の上位概念を有する前記見出データを、前記上位概念を示す見出しデータに統合し、前記見出しデータから構成要素として不適切であると判断するための所定の条件に合致する見出しデータを削除する、ことを特徴とする。
この態様によれば、概念処理装置は、ある見出しデータの見出しが、他の見出しデータの見出しの一部として含まれる場合や、見出しデータの見出しに共通して出現する文字数が多い場合は、文字数が短い見出しの見出しデータに統合し、上位概念が共通する見出しの見出しデータは、その上位概念を見出しとした見出しデータに統合する。また、概念処理装置は、例えば、数値が含まれる見出しや、文字数が多い見出しなど、記事データの内容に特化している可能性が高い見出しの見出しデータを削除する。
これにより、記事を検索したり、分類したりする際のキーワードとして利用しやすい、一般的な言葉で表した構成要素を得ることが可能となる。
【0017】
[5] 本発明の一態様は、概念処理装置として用いられるコンピュータを、見出しデータを含む記事データを記憶する記事データ記憶部、前記記事データ記憶部から前記記事データを読み出し、前記見出しデータを抽出する抽出部、前記抽出部が抽出した複数の前記見出しデータに出現する文字が共通出現パターンを有する場合に前記共通出現パターンに基づき統合後の見出しデータを生成し、前記抽出部が抽出した複数の前記見出しデータが共通の上位概念を有する場合に前記共通の上位概念に基づき統合後の見出しデータを生成する一般化処理を行なった結果の見出しデータを構成要素データとして出力する一般化処理部、として機能させることを特徴とするプログラムである。
【発明の効果】
【0018】
本発明によれば、ある出来事を説明するために出来事に関する内容を説明する際に、その説明をどのように構成したらよいかの適切な構成要素を得ることが可能となる。
【図面の簡単な説明】
【0019】
【図1】本発明の第1の実施形態による概念処理装置の機能ブロック図である。
【図2】同実施形態に用いられる記事データの例を示す図である。
【図3】同実施形態による概念処理装置の処理フローを示す図である。
【図4】同実施形態による表層的な情報を用いた統合処理を示す図である。
【図5】同実施形態による意味的な情報を用いた統合処理を示す図である。
【図6】同実施形態による削除処理を示す図である。
【図7】本発明の第2の実施形態による多層化オントロジーデータの例を示す図である。
【図8】本発明の第4の実施形態によるニュース要素間の前後関係が含まれるオントロジーの例を示す図である。
【図9】本発明の第5の実施形態に用いられる記事データの例を示す図である。
【図10】従来技術におけるニュースオントロジーデータの例を示す図である。
【発明を実施するための形態】
【0020】
以下、図面を参照しながら本発明の実施形態を詳細に説明する。
【0021】
[1.第1の実施形態]
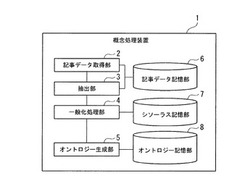
図1は、本発明の第1の実施形態による概念処理装置1の構成を示す機能ブロック部である。概念処理装置1は、例えば、1台または複数台のサーバ等のコンピュータ装置により実現することができる。概念処理装置1は、記事データ取得部2、抽出部3、一般化処理部4、オントロジー生成部5、記事データ記憶部6、シソーラス記憶部7、及び、オントロジー記憶部8を備えて構成される。
【0022】
記事データ取得部2は、オントロジー生成対象のニュースイベントクラスについてのニュース記事をデータ化した記事データを取得し、記事データ記憶部6に書き込む。ニュースイベントとは、事件や事故などの出来事であり、ある特定の種類のニュースイベントをニュースイベントクラスという。オントロジーとは、ニュースイベントクラスと、そのニュースイベントクラスのニュース要素との対応付けである。ニュース要素とは、ニュースイベントクラスについての説明の構成要素であり、説明内容をカテゴリー分けしたものである。記事データ取得部2は、インターネットなどの公衆網やイントラネットなどの私設網であるネットワークを介して接続される他のサーバ等から記事データを読み出してもよく、コンピュータ読み取り可能な記録媒体から記事データを読み出してもよい。
【0023】
記事データは、半構造化テキスト情報であり、構造化テキスト情報及び非構造化テキスト情報を含む。構造化テキスト情報は、章や節などの項目を記述したテキストデータと、そのテキストデータの文字の大きさ、フォント、表示位置などを示すスタイルデータとを含む。項目は、出来事に関する説明を内容のまとまりごとに分類したものであり、項目には、内容がすぐわかるようにつけられた見出しである項目名が含まれている。非構造化テキスト情報は、構造化テキスト情報で示される章や節などの項目についての説明などを記述したテキストデータと、そのテキストデータのスタイルデータとを含む。記事データがHTML(Hypertext Markup Language)データである場合、スタイルデータはタグに相当する。なお、記事データは、構造化テキスト情報のみを含んでもよく、画像データなどの他の情報が含まれてもよい。
【0024】
抽出部3は、記事データ記憶部6に記憶されている記事データ内の構造化テキスト情報から見出しデータとして、項目名を示す項目名データを抽出し、取得した記事データのうち、抽出した各項目名データが構造化テキスト情報に出現する記事データの数をカウントする。抽出部3は、抽出した項目名データを、当該項目名データについてカウントした出現数と対応付けて一般化処理部4に出力する。
【0025】
一般化処理部4は、抽出部3から入力された項目名データを比較し、重複する項目名や、同様の意味の項目名を示す項目名データを統合したり、ニュース要素として用いることが好ましくない項目名の項目名データを削除したりする一般化処理を行なう。項目名データを統合する際、一般化処理部4は、統合の対象となる項目名データの出現数を合算し、統合後の項目名データの出現数とする。また、一般化処理部4は、同様の意味を示す項目名データを統合する際、シソーラス記憶部7に記憶されている概念辞書データを参照する。一般化処理部4は、統合処理、削除処理を行なった結果残った項目名データをニュース要素データの候補として、出現数とともにオントロジー生成部5へ出力する。
【0026】
オントロジー生成部5は、一般化処理部4から入力されたニュース要素データの候補の中から、オントロジーを構成するニュース要素データを出現数に基づいて抽出する。オントロジー生成部5は、オントロジー生成対象のニュースイベントクラスを階層構造の上位階層とし、抽出したニュース要素データが示すニュース要素を下位階層とした木構造のオントロジーを示すオントロジーデータを生成し、オントロジー記憶部8に書き込む。
【0027】
記事データ記憶部6、シソーラス記憶部7及びオントロジー記憶部8は、ハードディスク装置や半導体メモリなどで実現される。記事データ記憶部6は、記事データ取得部2が取得した記事データを記憶する。シソーラス記憶部7は、上位の概念の言葉と、下位の概念の言葉の対応付けを木構造などで示す概念辞書データを記憶する。概念辞書データは、ネットワーク構造になっているものでもよい。オントロジー記憶部8は、オントロジー生成部5により生成されたオントロジーデータを記憶する。
【0028】
続いて、本実施形態の概念処理装置1の動作について説明する。本実施形態では、人手により編集された構造化テキスト情報を含んだ記事データを用いてニュース要素群を抽出する。つまり、概念処理装置1が利用する目次等の項目は、人手により編集されたものであり、従って、ニュースイベントクラスの出来事を説明する際に人間がどのように説明を構成するかの知識を利用してニュース要素群を抽出することができる。
記事データとして、集合知蓄積サイト、例えば、Wikipedia(登録商標)により提供されるHTML(Hypertext Markup Language)文書データを用いる。
【0029】
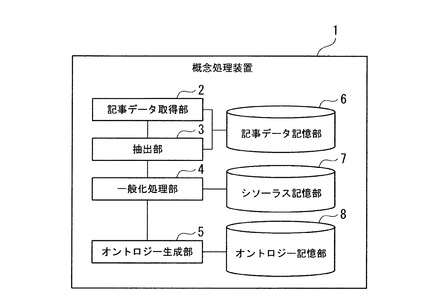
図2は、概念処理装置1が利用する記事データが示す記事の例を示す図であり、「新潟県中越沖地震」に関してWikipedia(登録商標)が提供する記事の抜粋を示している。図2(a)は、記事データに含まれる構造化テキスト情報が示す項目の表示であり、図2(b)は、構造化テキスト情報が示す項目に含まれる項目名と非構造化テキスト情報が示す本文の表示(抜粋)である。
【0030】
図2(a)に示すように、構造化テキスト情報に含まれるテキストデータには、章や節などの複数の項目に分けてその内容が記述されている。項目は、図2(b)に示すような出来事に関する説明を内容のまとまりごとに分類したものであり、項目名(タイトル)が含まれている。これらの項目名は、記事データが属するニュースイベントクラスを説明するために必要なニュース要素をそのまま示していると考えることができる。つまり、図2(a)では、ニュースイベントクラス「地震」は、「概要」、「発生要因」、「被害」、「政府・自治体対応」、…などの項目名の項目によりその内容を伝えることができることを表しており、これらの項目名を、ニュース要素の候補とみなすことができる。
【0031】
しかし、すべての地震関連の記事データの内容がこのような項目で構成されているわけではない。さらには、このような内容の記事データが存在しない地震もある。そのため、本実施形態では、ニュース要素を複数の記事に共通して出現する項目名から抽出する。このように、人手により編集されたテキスト情報の構造からニュース要素に該当する候補を抽出し、それらを一般化することによりニュース要素を抽出する。
【0032】
なお、上記の記事データは、例えば、上位クラス「地震」、下位クラス「日本の地震」のように、階層化されたカテゴリーと予め対応付けられている。そこで、特定のニュースイベントクラスに属する記事データを収集するためには、キーワード検索を行なったり、その記事データと対応付けられているカテゴリーの情報を利用したりすることが可能である。
【0033】
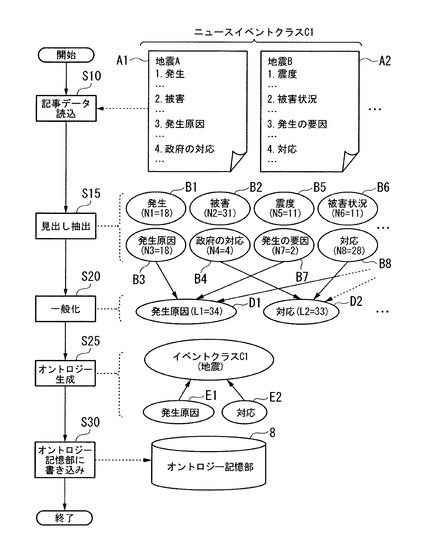
図3は、本実施形態の概念処理装置1の処理フローを示す図である。
まず、概念処理装置1の記事データ取得部2は、特定のニュースイベントクラスに属する記事データを取得する(ステップS10)。例えば、記事データ取得部2は、インターネットなどのネットワークを介して接続される集合知蓄積サイトのサーバから、ニュースイベントクラスC1「地震」に対応付けられた記事データA1、A2、…を読み出す。取得する記事データの数の制限はない。記事データ取得部2は、取得した記事データを抽出部3に出力する。
【0034】
抽出部3は、記事データ取得部2から入力された各記事データ内の構造化テキスト情報が示す章や節、目次のデータなどから項目名のテキストデータである項目名データを抽出する(ステップS15)。具体的には、以下の処理を行なう。
【0035】
記事データ内の構造化テキスト情報にはスタイルデータが含まれており、このスタイルデータが示す文字の大きさなどから、そのスタイルデータに対応したテキストデータが章や節、目次などの項目に含まれる項目名の項目名データであることを容易に判定することができる。記事データがHTML文書データである場合、この文字の大きさなどのスタイルデータはタグに記述されている。抽出部3は、各記事データA1、A2、…に含まれる構造化テキスト情報から、項目名データであることが示されるタグを特定し、特定したタグに対応したテキストデータを項目名データとして抽出する。抽出部3は、1章の下位の階層に1.1節があるなど、項目が階層化されているときは第1階層の項目の項目名データのみを抽出するが、全ての階層の項目の項目名データを抽出してもよい。
【0036】
上記処理により、複数の記事データから同じ項目名データが抽出される場合がある。そこで、抽出部3は、全ての記事データから項目名データを抽出すると、完全一致する同一の項目名データについては統合して1つのみを残し、重複をなくす。抽出部3は、重複をなくした結果得られた項目名データBi(iは1以上の整数)それぞれについて、その項目名データを構造化テキスト情報に含む記事データの数である出現記事数Niを得る。具体的には、重複がなかった項目名データの出現記事数は1であり、重複があった項目名データの出現記事数は統合前の当該項目名データの数である。抽出部3は、項目名データとその項目名データの出現記事数の組(B1、N1)、(B2、N2)、…を一般化処理部4へ出力する。
【0037】
一般化処理部4は、抽出部3から入力された項目名データについて一般化処理を行なう(ステップS20)。一般化処理には、統合処理と削除処理がある。統合処理において、一般化処理部4は、複数の項目名データが統合の対象となるかを検証し、対象となる場合には1つの項目名データに統合する。さらに、統合処理において、一般化処理部4は、統合の結果残った項目名データそれぞれについて、統合の対象となった各項目名データの出現記事数を合計した出現記事数を算出する。また、削除処理において、一般化処理部4は、各項目名データが削除の対象となるかを検証し、対象となる場合には削除を行なう。一般化処理部4は、一般化処理後に残った項目名データのリストであるニュース要素候補データ群を得る(ステップS20)。ニュース要素候補データとは、ニュース要素データの候補となるデータである。なお、統合処理及び削除処理の詳細については後述する。一般化処理部4は、ニュース要素候補データDj(jは1以上の整数)と、その出現記事数Ljの組(D1、L1)、(D2、L2)、…をオントロジー生成部5に出力する。
【0038】
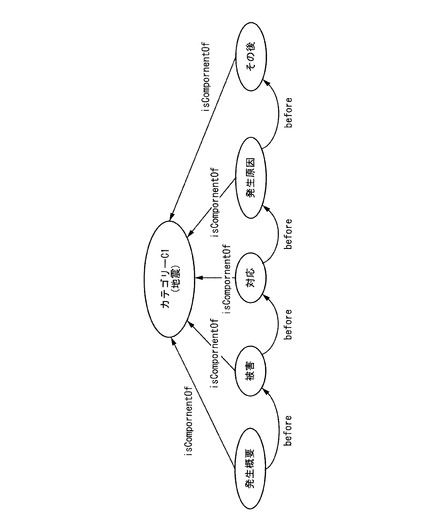
オントロジー生成部5は、一般化処理部4から入力されたニュース要素候補データD1、D2、…の中から出現記事数が所定の条件を満たすニュース要素候補データをニュース要素データE1、E2、…として選択する。例えば、所定の条件は、出現記事数が所定数以上のニュース要素候補データ、出現記事数が多い順に所定数または所定割合のニュース要素候補データなどとすることができる。オントロジー生成部5は、ニュースイベントクラスC1「地震」を示すニュースイベントクラスデータを第1階層とし、選択したニュース要素データE1「発生原因」、ニュース要素データE2「対応」、…を第2階層としたオントロジーの構造を作成する(ステップS25)。オントロジー生成部5は、作成されたオントロジーをオントロジー記述言語などにより記述したオントロジーデータを生成し、オントロジー記憶部8に書き込む(ステップS30)。生成されたオントロジーは、図3に示す2階層である。
【0039】
次に、図4〜図6を用いて、図3のステップS20において一般化処理部4が実行する一般化処理の詳細を説明する。
【0040】
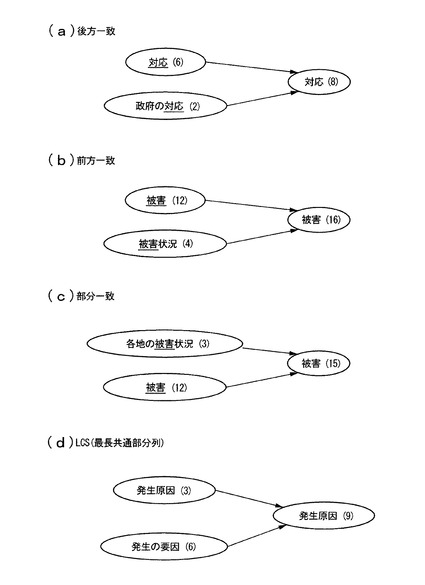
図4は、項目名の表層的な特徴に注目した統合処理を示す。表層的な特徴に注目した統合処理では、複数の項目名データに出現する文字が共通の出現パターンを有する場合にそれらの項目名データの統合を行なう。なお、各項目名データの後ろの括弧内に記載されている数値は、出現記事数を示す。以下、項目名「X」を示す項目名データを項目名データ「X」と記載する。
図4(a)は、後方一致による統合処理を示す。一般化処理部4は、一方の項目名データが示す項目名が他方の項目名データが示す項目名の末尾に一致していると判断した場合にこれらの項目名データを統合し、項目名の長さが短い方を統合後の項目名データとする。同図に示すように、項目名データ「対応」と項目名データ「政府の対応」は後方一致しており、これら2つの項目名データは、長さが短い項目名の項目名データ「対応」に統合される。一般化処理部4は、統合後の項目名データ「対応」の出現記事数を、統合前の項目名データ「対応」の出現記事数「6」と、項目名データ「政府の対応」の出現記事数「2」を合算した「8」とする。
【0041】
図4(b)は、前方一致による統合処理を示す。一般化処理部4は、一方の項目名データが示す項目名が他方の項目名データが示す項目名の先頭に一致していると判断した場合にこれらの項目名データを統合し、項目名の長さが短い方を統合後の項目名データとする。同図に示すように、項目名データ「被害」と項目名データ「被害状況」は、前方一致しており、これら2つの項目名データは、長さが短い項目名の項目名データ「被害」に統合される。一般化処理部4は、統合後の項目名データ「被害」の出現記事数を、統合前の項目名データ「被害」の出現記事数「12」と、項目名データ「被害状況」の出現記事数「4」を合算した「16」とする。
【0042】
図4(c)は、部分一致による統合処理を示す。一般化処理部4は、一方の項目名データの項目名が他方の項目名データの項目名の先頭あるいは末尾以外に含まれていると判断した場合にこれらの項目名データを統合し、他方の項目名に含まれている項目名の項目名データを統合後の項目名データとする。同図に示すように、項目名データ「各地の被害状況」と項目名データ「被害」は部分一致しており、これら2つの項目名データは、項目名「各地の被害状況」に含まれている項目名「被害」の項目名データに統合される。一般化処理部4は、統合後の項目名データ「被害」の出現記事数を、統合前の項目名データ「各地の被害状況」の出現記事数「3」と、項目名データ「被害」の出現記事数「12」を合算した「15」とする。
【0043】
図4(d)は、LCS(最長共通部分列)による統合処理を示す。一般化処理部4は、一方の項目名データが示す項目名と、他方の項目名データが示す項目名とに共通して同じ順番に出現する文字数を抽出し、抽出された文字数が所定数以上であると判断した場合にこれらの項目名データを統合し、項目名の長さが短い方を統合後の項目名データとする。同図に示すように、項目名データ「発生原因」と項目名データ「発生の要因」の場合、「発」、「生」、「因」が共通して同じ順番に出現する。一般化処理部4は、抽出された文字数「3」が、統合すべきと判断する閾値「3」以上であると判断し、これら2つの項目名データを、長さが短いほうの項目名データ「発生原因」に統合する。一般化処理部4は、統合後の項目名データ「発生原因」の出現記事数を、統合前の項目名データ「発生原因」の出現記事数「3」と、項目名データ「発生の要因」の出現記事数「6」を合算した「9」とする。
【0044】
上記のように、一般化処理部4は、項目名の表層的な一致によって項目名データを統合するか否かを判断し、統合対象となった場合は、統合対象の項目名データのうち文字数の少ない項目名の項目名データを統合後の項目名データとしている。
【0045】
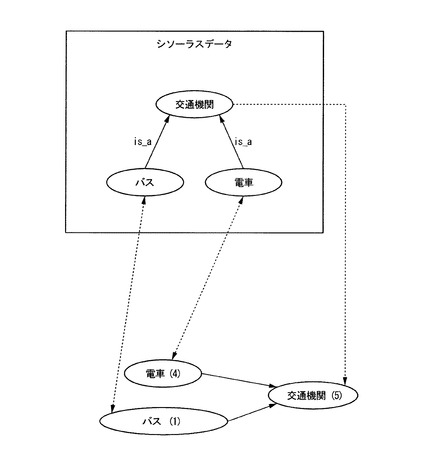
図5は、項目名の意味的な特徴に基づいた統合処理を示す。意味的な特徴に基づいた統合処理では、複数の項目名に関連付けられる意味が共通概念を有する場合にそれら項目名の項目名データの統合を行なう。一般化処理部4は、シソーラスなどの概念辞書を用いて統合処理を行う。
シソーラス記憶部7に記憶されている概念辞書データには、共通の上位概念を持つ複数の下位概念が示されている。そこで、一般化処理部4は、上位概念が共通である下位概念の項目名を示す複数の項目名データを、これら項目名に共通の上位概念を項目名とした項目名データに統合する。
同図に示すように、概念辞書データに、「バス」、「電車」が共通の上位概念「交通機関」を持つ下位概念であることが示されている。一般化処理部4は、項目名データ「バス」、「電車」を、新たな項目名データ「交通機関」に統合する。一般化処理部4は、統合後の項目名データ「交通機関」の出現記事数を、統合前の項目名データ「電車」の出現記事数「4」と、項目名データ「バス」の出現記事数「1」を合算した「5」とする。
【0046】
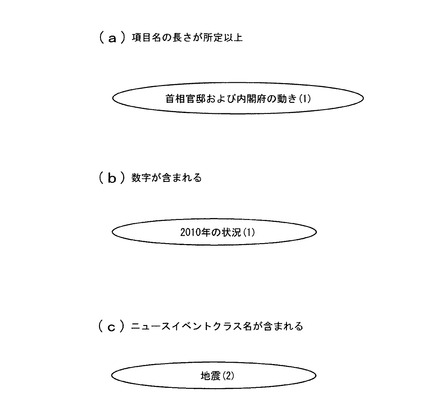
図6は、ニュース要素として不適な項目名データを削除する削除処理を示す。
図6(a)は、文字数判定による削除処理を示す。一般化処理部4は、文字数が所定以上である項目名を示す項目名データを削除する。これは、長すぎる項目名は、その項目名が含まれている記事データが取り扱っている内容に特有の項目名であると考えられ、ニュースイベントクラス全体に共通した項目である可能性が低いためである。
【0047】
図6(b)は、数字が含まれる場合の削除処理を示す。一般化処理部4は、数字が含まれている項目名を示す項目名データを削除する。各記事データは、ある特定の出来事について記述されていることが多い。例えば、ニュースイベントクラス「地震」に対応付けられた記事データであっても、その内容は、関東大震災について説明した記事、最近起こった地震の被害からの復旧状況について説明した記事などが含まれる。数字は、特定の出来事のみに関連する年や数値などの事例を表すことが多く、数値が含まれる項目名はニュースイベントクラス全体に共通している可能性が低いため、削除の対象とする。
【0048】
図6(c)は、ニュースイベントクラスと同じ項目名を示す項目名データの削除処理を示す。一般化処理部4は、ニュースイベントクラスと同じ項目名を示す項目名データを削除する。
【0049】
一般化処理部4は、上記の統合処理、削除処理などの一般化処理を行い、最終的に残った項目名データがニュース要素候補データとなる。
なお、上述した各統合処理、各削除処理の全てを実行してもよく、一部のみを実行してもよい。また、各統合処理、各削除処理の実行順序は任意である。実行する統合処理、削除処理と、その実行順によってニュース要素候補データとして得られる結果は異なるため、システム設計者は目的によってそれらを柔軟に組み合わせて決定することが可能である。
【0050】
日本語の特性として、重要な内容は後ろに置かれることが多い。また、概念辞書には、一般的な単語を概念として用いていることが多い。そのため、例えば、最初に後方一致による統合処理を行い、その後、前方一致、部分一致、LCSによる統合処理、削除処理を行い、短く文字数の一般的な項目名データとなった後に、意味的な特徴に基づいた統合処理を行なうことが考えられる。
【0051】
各統合処理の詳細な処理例について説明する。
まず、後方一致による統合処理の詳細な処理例について説明する。一般化処理部4は、処理対象の項目名データ群の中の一つの項目名データに着目し、着目している項目名データが示す項目名と、処理対象の項目名データ群に含まれる他の項目名データが示す項目名それぞれとを比較して後方一致するか否かを判断する。後方一致する項目名データがあった場合、一般化処理部4は、着目している項目名データと、後方一致すると判断した各項目名データとを合わせた項目名データの中で、最も文字数が少ない項目名の項目名データを統合後の項目名データとする。一般化処理部4は、着目している項目名データの出現記事数と、後方一致すると判断した各項目名データの出現記事数との合算により、統合後の項目名データの出現記事数を算出する。一般化処理部4は、処理対象の項目名データ群から、統合の結果残らなかった項目名データを除外する。
続いて、一般化処理部4は、処理対象の項目名データ群の中から、統合の結果残った項目名データ以外でまだ着目していない項目名データの一つに着目し、同様の処理を繰り返す。一般化処理部4は、処理対象の項目名データ群に、まだ着目していない項目名データがなくなった場合、後方一致による統合処理を終了する。統合後の項目名データ、及び、他の項目と後方一致しなかった項目名データが、後方一致による統合処理の結果残った項目名データである。
【0052】
前方一致による統合処理の処理手順も、後方一致による統合処理と同様である。
部分一致による統合処理の場合、後方一致による統合処理と以下の点が異なる。一般化処理部4は、着目している項目名データの示す項目名が、他の項目名データの示す項目名の部分として含まれているか否かを判断する。一般化処理部4は、着目している項目名データを統合後の項目名データとし、他の項目名データに統合済みを示す情報を対応づけるのみで処理対象の項目名データ群からは除外しない。一般化処理部4は、処理対象の項目名データ群の中から、統合済みを示す情報が付加されていない項目名データの一つに着目して同様の処理を繰り返す。処理終了時に、統合済みを示す情報が付加されていない項目名データは、統合後の項目名データ、または、他の項目と部分一致しなかった項目名データであり、部分一致による統合処理の結果残った項目名データである。
【0053】
意味的な特徴に基づいた統合処理の場合、後方一致による統合処理と以下の点が異なる。一般化処理部4は、着目している項目名データが示す項目名と、他の項目名データが示す項目名それぞれについて、上位概念が同じであるか否かを判断し、上位概念が同じ項目名の項目名データがあった場合、処理対象の項目名データ群からそれらの項目名データを除外し、上位概念の項目名を示す項目名データを生成する。上位概念を示す項目名の項目名データ、及び、他の項目名データと上位概念が一致しなかった項目名データが、意味的な特徴に基づいた統合処理の結果残った項目名データである。
【0054】
以上第1の実施形態について説明したが、図3のステップS10で記事データ取得部2が読み込む記事データに、非構造化テキスト情報の記事データが含まれてもよい。非構造化テキスト情報内のテキストデータは、説明のみを記述しており、項目は記述されていない。抽出部3は、ステップS15において、非構造化テキスト情報内のテキストデータから、任意の既存のキーワード抽出処理によってキーワードを抽出し、この抽出したキーワードを示すデータを項目名データとして同様に処理を行なう。
【0055】
また、図3のステップS20において、一般化処理部4は、異なる記事データから抽出された項目名データの組み合わせについてのみ統合処理を行なってもよい。この場合、抽出部3は、各項目名データに抽出元の記事データを特定する抽出元情報を付加して一般化処理部4に出力する。一般化処理部4は、同じ記事データから読み出されたことを示す抽出元情報が付加された項目名データの組み合わせについては、統合処理を行なわない。
【0056】
[2.第2の実施形態]
上述した第1の実施形態では、2階層からなるオントロジーを生成しているが、本実施形態では、3階層以上のオントロジーを生成する。以下、第1の実施形態との差分を説明する。
【0057】
図4、図5に示す各統合処理において、一般化処理部4は、統合の結果残らなかった項目名データを示す削除項目名情報と、どの項目名データに統合されたかを示す上位階層情報とを対応付けた統合情報を生成する。例えば、図4(a)に示す後方一致の場合、項目名データ「政府の対応」を設定した削除項目名情報と、項目名データ「対応」を設定した上位階層情報とを対応付けた統合情報が生成される。また、図5に示す意味的な特徴に基づいた統合処理の場合、項目名データ「電車」及び項目名データ「バス」を設定した削除項目名情報と、項目名データ「交通機関」を設定した上位階層情報とを対応付けた統合情報が生成される。
【0058】
図3のステップS25において、一般化処理部4は、ニュース要素候補データと、その出現記事数の組に併せて、統合情報をオントロジー生成部5に出力する。ステップS30において、オントロジー生成部5は、まず、ニュースイベントクラスを第1階層とし、出現記事数に基づいて選択したニュース要素データを第2階層とした木構造のニュースオントロジーを作成する。続いて、オントロジー生成部5は、第2階層のニュース要素それぞれについて、上位階層情報が第2階層のニュース要素データと一致する統合情報を特定し、特定した統合情報の削除項目名情報から項目名データを読み出す。オントロジー生成部5は、第2階層の各ニュース要素データに対応した統合情報の削除項目名から読み出した項目名データを、当該ニュース要素データの下位のニュース要素データとして付加し、第3階層まで階層化された木構造のニュースオントロジーをオントロジー記述言語などにより記述したオントロジーデータを作成する。
【0059】
オントロジー生成部5は、第3階層以下についても同様の処理を行なって、4階層以上の木構造のニュースオントロジーを作成してもよい。オントロジー生成部5は、作成されたオントロジーをオントロジー記述言語などにより記述したオントロジーデータを生成し、オントロジー記憶部8に書き込む。
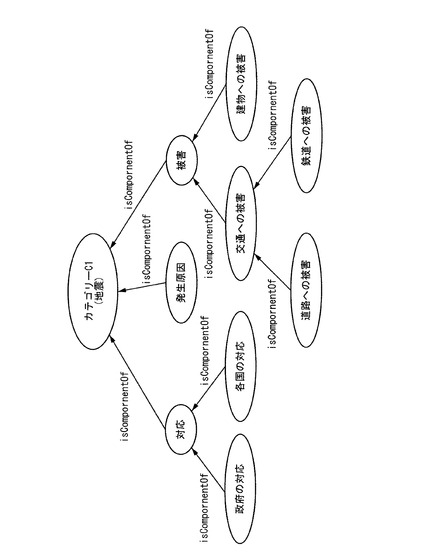
【0060】
図7は、本実施形態により生成されたニュースオントロジーデータを示す図である。同図では、ニュースイベントクラスであるカテゴリーC1を最上位階層とした4階層の木構造のニュースオントロジーを示している。
【0061】
[3.第3の実施形態]
上述した第2の実施形態では、項目が統合されたときの情報を用いて木構造のオントロジーを生成しているが、本実施形態では、記事データに含まれる目次が階層化されている場合、その階層構造を用いて木構造のオントロジーを生成する。以下、第1の実施形態との差分を説明する。
【0062】
図3のステップS15において、抽出部3は、各記事データに含まれる構造化テキスト情報から、項目名データと、項目名データ間の階層関係を読み出しておく。例えば、図2(a)に示す構造化テキスト情報の場合、項目名データ「概要」の下位階層の項目名データは、項目名「本震」、「本震(震度4以上を観測した市町村」、…の項目名データであり、項目名データ「被害」の下位階層の項目名データは項目名「交通機関」、…の項目名データであり、項目名データ「交通機関」の下位階層の項目名データは項目名「高速道路」、「一般道路」、…の項目名データであることが読み出される。
【0063】
図3のステップS30において、オントロジー生成部5は、まず、ニュースイベントクラスデータを第1階層とし、出現記事数に基づいて選択したニュース要素データを第2階層とした木構造のニュースオントロジーを作成する。オントロジー生成部5は、第2階層のニュース要素データを抽出部3に出力し、抽出部3は、第2階層のニュース要素データと一致する項目名データの下位階層の項目名データを返送する。オントロジー生成部5は、第2階層のニュース要素それぞれに、当該第2階層のニュース要素データの下位階層の項目名データを付加し、第3階層まで階層化された木構造のニュースオントロジーの構造を生成する。オントロジー生成部5は、生成された構造のオントロジーをオントロジー記述言語などにより記述したオントロジーデータを作成する。
オントロジー生成部5は、第3階層以下についても同様の処理を行ない、4階層以上の木構造のニュースオントロジーの構造を生成し、生成された構造のオントロジーを示すオントロジーデータを作成してもよい。
【0064】
なお、ニュース要素データが意味的な特徴に基づいた統合処理によって得られた項目名データである場合、オントロジー生成部5は、その統合前の項目名データに対応した下位階層の項目名データを抽出部3からさらに取得して、ニュース要素データの下位階層に付加してもよい。例えば、第2の実施形態と同様に、一般化処理部4は、統合情報を生成してオントロジー生成部5に出力する。オントロジー生成部5は、第2階層のニュース要素データそれぞれについて、上位階層情報が第2階層のニュース要素データと一致する統合情報を特定し、特定した統合情報の削除項目名情報から項目名データを読み出して抽出部3に出力する。抽出部3は、オントロジー生成部5から入力された項目名データの下位階層の項目名データを返送し、オントロジー生成部5は、返送された下位階層の項目名データをニュース要素データの下位階層に付加する。
【0065】
[4.第4の実施形態]
上述した第1の実施形態では、各ニュース要素データ間の前後関係については考慮していない。しかし、ある出来事を説明する際には、通常、ニュース要素をわかりやすい順番に並べる。例えば、ニュースイベントクラス「地震」について、ニュース要素「被害」、「その後」、…が抽出されたとしても、ニュース要素「被害」に関する内容より先にニュース要素「その後」に関する内容を説明することはない。そこで、本実施形態では、ニュース要素データ間の前後関係についても抽出する。これよって、複数の記事や情報をニュース要素データ別にまとめたまとめ記事を生成する際などに、適切な順番で並べることが可能となる。以下、第1の実施形態との差分を説明する。
【0066】
図3のステップS15において、抽出部3は、各記事データに含まれる構造化テキスト情報から、項目名データ間の前後関係を読み出しておく。例えば、図2(a)に示す構造化テキスト情報の場合、項目名データは「概要」、「発生要因」、「被害」、「政府・自治体対応」、…の順であることが読み出される。抽出部3は、項目名データ間の前後関係を示す順序情報をオントロジー生成部5に出力する。
【0067】
図3のステップS30において、オントロジー生成部5は、出現記事数に基づいてニュース要素データを選択する。オントロジー生成部5は、これらのニュース要素データのうち2以上が項目名データとして含まれる記事データから得られた前後関係を順序情報から読み出す。これにより、オントロジー生成部5は、ニュース要素データ間の前後関係の統計情報を得ると、この統計情報に基づいて最も多く現われるニュース要素データの並び順を判断する。オントロジー生成部5は、ニュースイベントクラスデータを第1階層とし、判断した並び順に従って並べたニュース要素データを第2階層としたオントロジーの構造を作成する。オントロジー生成部5は、作成されたオントロジーをオントロジー記述言語などにより記述したオントロジーデータを生成し、オントロジー記憶部8に書き込む。
【0068】
なお、ニュース要素データが意味的な特徴に基づいた統合処理によって得られた項目名データである場合、オントロジー生成部5は、ニュース要素データに統合される前の項目名データを用い、順序情報からニュース要素データの前後関係の統計情報を得てもよい。
【0069】
図8は、本実施形態により生成されたニュースオントロジーを示す図である。同図では、ニュースイベントクラス「地震」の下位階層に、ニュース要素が「発生概要」、「被害」、「対応」、「発生要因」、「その後」の順に並べられたニュースオントロジーを示している。
【0070】
[5.第5の実施形態]
上述した実施形態では、半構造化テキスト情報を含む記事データを利用して、ニュースイベントクラスを構成するニュース要素データ群を抽出している。本実施形態では、同様の処理によって、ニュース記事からニュースオントロジーを構築する。
日常、放送などで利用されている一般的なニュース記事は、ニュースのタイトル、及び、その内容を表す本文よって構成されている。そこで、見出しとして、項目名ではなく、ニュースのタイトルを用いて第1の実施形態と同様の処理を行うことにより、オントロジーを構築することができる。以下、第1の実施形態との差分を説明する。
【0071】
図9は、本実施形態において用いられる記事データについて示す図である。同図に示すように、記事データA’1、A’2、…は、ニュースのタイトルと、ニュースの内容を示すテキストデータである。
【0072】
図2のステップS10において、概念処理装置1の記事データ取得部2は、図9に示す特定のニュースイベントクラスに属する記事データA’1、A’2、…を取得する。ステップS15において、抽出部3は、記事データ取得部2が取得した記事データA’1、A’2、…から記事のタイトルを読み出す。概念処理装置1は、抽出部3が読み出したタイトルを見出しデータとし、読み出した見出しデータを第1の実施形態における項目データの代わりに用いて同様の処理を行なう。これにより、一般化処理が施された見出しデータからニュース要素データ群を得て、ニュースオントロジーを構築することができる。
【0073】
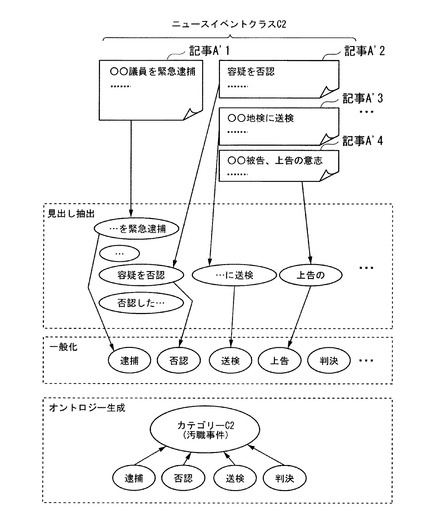
また、記事データにニュースの日付の情報が含まれている場合、ステップS15において、抽出部3は、タイトルと日付の情報を対応付けて読み出しておく。そして、図3のステップS30において、オントロジー生成部5は、選択したニュース要素データに対応した日付を抽出部3から取得する。ニュースイベントクラスデータを第1階層とし、日付順に並べたニュース要素データを第2階層としたオントロジーの構造を作成する。同じニュース要素データについて複数の日付が読み出された場合は、その中で最も早い日付としてもよく、最も多く出現する日付としてもよい。これにより、例えば、ニュースイベントクラス「汚職事件」に関しては「逮捕」、「否認」、「送検」、「判決」、「上告」などのニュース要素データがこの順番で表れる、といった知識を記述したオントロジーを構築することができる。
このオントロジーを利用することによって、高度なニュース検索・提示サービスを提供することも可能となる。
【0074】
なお、ニュースの内容部分の最初の1文はリード文と呼ばれ、そのニュースの概要を示す重要な内容を含んでいる。そこで、ステップS15において、抽出部3は、記事データ取得部2が取得した記事データからニュース本文の最初の1文を見出しデータとして読み出し、読み出した見出しデータを第1の実施形態における項目名データの代わりに用いることもできる。
【0075】
[6.効果]
以上説明した本発明の実施形態によれば、あるニュースイベントに関する情報を伝えるために必要なニュース要素群を得ることができる。このようなニュース要素群を得るために、本実施形態では、人間がニュースイベントに関する情報を伝える際に、どのような構成を利用するのかの知識を利用する。この知識として、人手によって編集された構造情報、例えば、Wikipedia(登録商標)が提供する記事データを利用することができる。また、Wikipedia(登録商標)が適用する記事データには、カテゴリーの情報が付与されているため、この情報を利用してニュースイベントクラスに属する記事データを容易に読み出すことができる。そして、地震災害、汚職事件、航空機事故、など、特定の種類のニュースイベントクラスを構成する項目を構造情報から抽出した後、一般化処理を行なうことによってニュース要素群を自動抽出する。これにより、様々な種類のニュースイベントクラスの構造を自動で獲得することが可能となり、ニュースオントロジーの構築を効率化することが可能となる。
また、この抽出されたオントロジーにより示される構造を、ユーザの要求に合わせてニュース項目を再構成するために利用すれば、複数の記事コンテンツを統合してある出来事に関するまとめ記事を作成したり、出来事の特定要素(例えば、その出来事の「原因」など)に対応した記事のみを探し出したりする処理に用いることができる。
また、ニュース原稿などを記事データとし、ニュースのタイトルや、リード文などを見出しとして利用することもできる。
【0076】
[7.その他]
上述した概念処理装置1は、内部にコンピュータシステムを有している。そして、概念処理装置1の各部の動作の過程は、プログラムの形式でコンピュータ読み取り可能な記録媒体に記憶されており、このプログラムをコンピュータシステムが読み出して実行することによって、上記処理が行われる。ここでいうコンピュータシステムとは、CPU及び各種メモリやOS、周辺機器等のハードウェアを含むものである。
【0077】
また、「コンピュータシステム」は、WWWシステムを利用している場合であれば、ホームページ提供環境(あるいは表示環境)も含むものとする。
また、「コンピュータ読み取り可能な記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、CD−ROM等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶部のことをいう。さらに「コンピュータ読み取り可能な記録媒体」とは、インターネット等のネットワークや電話回線等の通信回線を介してプログラムを送信する場合の通信線のように、短時間の間、動的にプログラムを保持するもの、その場合のサーバやクライアントとなるコンピュータシステム内部の揮発性メモリのように、一定時間プログラムを保持しているものも含むものとする。また上記プログラムは、前述した機能の一部を実現するためのものであっても良く、さらに前述した機能をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるものであっても良い。
【符号の説明】
【0078】
1…概念処理装置
2…記事データ取得部
3…抽出部
4…一般化処理部
5…オントロジー生成部
6…記事データ記憶部
7…シソーラス記憶部
8…オントロジー記憶部
【技術分野】
【0001】
本発明は、概念処理装置及びプログラムに関する。
【背景技術】
【0002】
インターネット上のニュースサイトなどの登場により、ユーザは事件や事故などの様々な出来事(以下、「ニュースイベント」と記載する。)に関するニュース記事を検索し、閲覧することが可能となった。しかし、ユーザがあるニュースイベントに関してその全体像をつかみたい際には、適切なキーワードによってそのニュースイベントに関するニュース記事群を検索し、検索の結果得られたニュース記事群を1つ1つ閲覧した上で、自分の中で記事の内容を再構成して概要を知る、といった作業が必要であった。
【0003】
一方で、近年その規模を拡大し続けているWikipedia(登録商標)(http://www.wikipedia.org/、ウィキメディア財団)のような「集合知」を蓄積するサイトには、言葉の解説だけでなく、ニュースイベントに関する解説記事なども含まれている。ユーザは、そのようなサイトに含まれている解説記事を読むことにより、ニュースイベントに関する概要を知ることができるようになってきた。例えば、「新潟県中越沖地震」について集合知蓄積サイトが提供している記事を読めば、ユーザはその地震に関する全体像をつかむことができる。
【0004】
しかし、このようなサイトでも、すべてのニュースイベントを網羅的に記述してはおらず、多くのユーザの興味を引くと考えられる重要なニュースイベントのみが記事として含まれる。従って、そのサイトに含まれないニュースイベントに関しては、ユーザ自身が従来のように自力でニュース記事などを検索し、その概要を知るしかない。そこで、膨大な量のニュース記事などから、あるニュースイベントに関する「まとめ記事」を自動で生成できるようになれば、ユーザの負担は大きく減ることが予想される。非特許文献1では、このような技術を実現するために、ニュースオントロジーという概念が提案されている。
【0005】
図10は、ニュースオントロジーについて示す図である。この技術では、あるニュースイベントに関連した情報を伝えるニュース記事群が、それぞれ特定の役割を持っていると仮定する。例えば、ある記事F1、F2は「地震災害」という種類のニュースイベント(以下、ニュースイベントの種類を「ニュースイベントクラス」と記載する。)に属するテキスト情報であり、このニュースイベントクラス「地震災害」に関して「被害」の内容を示す役割を持っていると仮定する。このような役割を「ニュース要素」とし、様々な種類のニュースイベントの特徴をそのニュース要素の集合で表している。
【0006】
各ニュース要素は、そのニュース要素に含まれる単語(あるいはその単語の上位概念)の集合で表現する。つまり、ニュースイベントクラスごとに、そのニュースイベントクラスを構成するニュース要素群を記述し、さらにそれらのニュース要素に対応した特徴的な単語(概念)群をオントロジーとして記述する。例えば、図10に示すように、ニュースイベントクラスには、「汚職事件」、「地震災害」、「航空機事故」などがあり、ニュースイベントクラス「地震災害」は、ニュース要素「発生概要」、「被害」、「対応」、「原因」、「その後」から構成される。そして、ニュース要素「発生概要」には単語「震度」が含まれ、ニュース要素「被害」には単語「倒壊」が含まれ、ニュース要素「原因」には単語「プレート」が含まれるという情報を構造化していく。各ニュース要素に含まれる単語は、そのニュース要素に対応付けられた記事に出現する頻度が高い単語である。特許文献1には、文書内の重要キーワードを抽出する技術について記載されている。
【0007】
このようなニュースオントロジーを作成しておくことにより、特定のニュース要素に対応する記事のみを取り出してくる、また複数の記事をそのニュース要素ごとに組み合わせてまとめ記事を作る、といったサービスに利用が可能である。
【先行技術文献】
【特許文献】
【0008】
【特許文献1】特開2010−204866号公報
【非特許文献】
【0009】
【非特許文献1】宮崎 勝他,「外部知識を用いたニュースオントロジー構築手法の検討」,2009年映像情報メディア学会冬季大会講演予稿集,発表番号1−4,2009年
【発明の概要】
【発明が解決しようとする課題】
【0010】
事件や事故などのニュースイベントについて人に説明するとき、例えば、「地震災害」について説明するときには、ニュース要素として示される「発生概要」、「被害」、「対応」、「原因」、「その後」のようなカテゴリーに分けて内容を説明するとわかりやすい。しかし、このニュースイベントクラス「地震災害」のニュース要素群は、「汚職事件」、「航空機事故」などのニュースイベントクラスを説明するニュース要素とは一致しない。このように、個々のニュースイベントクラスによってニュース要素は異なる。上述した非特許文献1の技術では、膨大な数のニュースイベントクラスごとにニュース要素群を手作業で決めなければならなかった。そのため、非常に膨大な時間と労力を必要とする。
【0011】
ニュースイベントクラスを構成するニュース要素は、そのニュースイベントクラスについて記述された文書に含まれる重要なキーワードである、とも考えることができる。特定文書中の重要キーワードを獲得する手法は数多く検討されており、例えばTF−IDFのような単語の頻度情報を指標として用いた重要キーワード抽出手法により、重要と思われる文書中の単語群を抽出することは容易に実現可能である。しかし、これによって得られた単語の重要度は必ずしも説明における文書作成者の意図を正確に反映しているとは限らない。つまり、単語の重要度は、あるニュースイベントを伝える際に、「どのような種類の情報」を「どのように構成」して提示すべきか、ということを記述した構造化知識を表しているものではない。
【0012】
本発明は、このような事情を考慮してなされたもので、出来事に関する内容を説明する際に、その説明をどのように構成したらよいかの適切な構成要素を得ることができる概念処理装置及びコンピュータプログラムを提供する。
【課題を解決するための手段】
【0013】
[1] 本発明の一態様は、見出しデータを含む記事データを記憶する記事データ記憶部と、前記記事データ記憶部から前記記事データを読み出し、前記見出しデータを抽出する抽出部と、前記抽出部が抽出した複数の前記見出しデータに出現する文字が共通出現パターンを有する場合に前記共通出現パターンに基づき統合後の見出しデータを生成し、前記抽出部が抽出した複数の前記見出しデータが共通の上位概念を有する場合に前記共通の上位概念に基づき統合後の見出しデータを生成する一般化処理を行なった結果の見出しデータを構成要素データとして出力する一般化処理部と、を備えることを特徴とする概念処理装置である。
この態様によれば、概念処理装置は、ある同一の種類の出来事に関する内容が記述された複数の記事データから説明の目次とし記載されている項目名、あるいは、ニュースのタイトルやリード文などの見出しデータを取得し、取得した見出しデータが示す見出しが表層的に一致する場合や、同一の上位概念を有する場合に統合を行なう。概念処理装置は、統合を行なった結果の見出しデータを、出来事を説明する際の構成要素を示すデータとして出力する。
これにより、集合知蓄積サイトなどにより提供されるある出来事に関する記事データや、ニュース記事の記事データを利用して、人間がある出来事を伝える際に、どのような構成を利用するのかの知識に基づいた構成要素を取得することができる。また、取得した構成要素を記事等の分類に利用することにより、その出来事についてのまとめ記事の生成に活用することが可能となる。
【0014】
[2] 本発明の一態様は、上述する概念処理装置であって、前記一般化処理部により得られた前記構成要素データの下層に、前記構成要素データに統合された前記見出しデータを付加したオントロジー、または、前記一般化処理部により得られた前記構成要素データの下層に、前記記事データが示す階層化された見出しデータに含まれる前記構成要素データの下層の見出しデータを付加したオントロジーデータを生成するオントロジー生成部をさらに備える、ことを特徴とする。
この態様によれば、概念処理装置は、構成要素の下層に、その構成要素データに統合されたために削除された見出しデータを付加したり、記事データに含まれる階層構造の目次から得られたその構成要素の下層の見出しデータを付加したりすることによって、階層化されたオントロジーデータを生成する。
これにより、詳細な構成要素を得ることができるとともに、それらの構成要素間の関係をわかりやすく分類することができる。
【0015】
[3] 本発明の一態様は、上述する概念処理装置であって、前記一般化処理部により得られた前記構成要素データの順序を前記記事データが示す前記見出しデータの出現順に基づいて決定し、決定した出現順を示す情報を前記構成要素データに付加したオントロジーデータを生成するオントロジー生成部をさらに備える、ことを特徴とする。
この態様によれば、概念処理装置は、記事データから得られる出現順に基づいて構成要素データを順番に並べたオントロジーデータを生成する。
これにより、ある出来事を説明する際に、どのような順序で説明を構成すればよいかを知ることができる。
【0016】
[4] 本発明の一態様は、上述する概念処理装置であって、前記一般化処理部は、前記一般化処理において、複数の前記見出しデータが示す見出しが後方一致、前方一致、または、部分一致する場合、あるいは、複数の前記見出しデータが示す見出しに同一の順序で共通して現われる文字数が所定以上である場合に、前記複数の見出しデータを、前記複数の見出しデータのうち最も短い見出しの見出しデータに統合し、共通の上位概念を有する前記見出データを、前記上位概念を示す見出しデータに統合し、前記見出しデータから構成要素として不適切であると判断するための所定の条件に合致する見出しデータを削除する、ことを特徴とする。
この態様によれば、概念処理装置は、ある見出しデータの見出しが、他の見出しデータの見出しの一部として含まれる場合や、見出しデータの見出しに共通して出現する文字数が多い場合は、文字数が短い見出しの見出しデータに統合し、上位概念が共通する見出しの見出しデータは、その上位概念を見出しとした見出しデータに統合する。また、概念処理装置は、例えば、数値が含まれる見出しや、文字数が多い見出しなど、記事データの内容に特化している可能性が高い見出しの見出しデータを削除する。
これにより、記事を検索したり、分類したりする際のキーワードとして利用しやすい、一般的な言葉で表した構成要素を得ることが可能となる。
【0017】
[5] 本発明の一態様は、概念処理装置として用いられるコンピュータを、見出しデータを含む記事データを記憶する記事データ記憶部、前記記事データ記憶部から前記記事データを読み出し、前記見出しデータを抽出する抽出部、前記抽出部が抽出した複数の前記見出しデータに出現する文字が共通出現パターンを有する場合に前記共通出現パターンに基づき統合後の見出しデータを生成し、前記抽出部が抽出した複数の前記見出しデータが共通の上位概念を有する場合に前記共通の上位概念に基づき統合後の見出しデータを生成する一般化処理を行なった結果の見出しデータを構成要素データとして出力する一般化処理部、として機能させることを特徴とするプログラムである。
【発明の効果】
【0018】
本発明によれば、ある出来事を説明するために出来事に関する内容を説明する際に、その説明をどのように構成したらよいかの適切な構成要素を得ることが可能となる。
【図面の簡単な説明】
【0019】
【図1】本発明の第1の実施形態による概念処理装置の機能ブロック図である。
【図2】同実施形態に用いられる記事データの例を示す図である。
【図3】同実施形態による概念処理装置の処理フローを示す図である。
【図4】同実施形態による表層的な情報を用いた統合処理を示す図である。
【図5】同実施形態による意味的な情報を用いた統合処理を示す図である。
【図6】同実施形態による削除処理を示す図である。
【図7】本発明の第2の実施形態による多層化オントロジーデータの例を示す図である。
【図8】本発明の第4の実施形態によるニュース要素間の前後関係が含まれるオントロジーの例を示す図である。
【図9】本発明の第5の実施形態に用いられる記事データの例を示す図である。
【図10】従来技術におけるニュースオントロジーデータの例を示す図である。
【発明を実施するための形態】
【0020】
以下、図面を参照しながら本発明の実施形態を詳細に説明する。
【0021】
[1.第1の実施形態]
図1は、本発明の第1の実施形態による概念処理装置1の構成を示す機能ブロック部である。概念処理装置1は、例えば、1台または複数台のサーバ等のコンピュータ装置により実現することができる。概念処理装置1は、記事データ取得部2、抽出部3、一般化処理部4、オントロジー生成部5、記事データ記憶部6、シソーラス記憶部7、及び、オントロジー記憶部8を備えて構成される。
【0022】
記事データ取得部2は、オントロジー生成対象のニュースイベントクラスについてのニュース記事をデータ化した記事データを取得し、記事データ記憶部6に書き込む。ニュースイベントとは、事件や事故などの出来事であり、ある特定の種類のニュースイベントをニュースイベントクラスという。オントロジーとは、ニュースイベントクラスと、そのニュースイベントクラスのニュース要素との対応付けである。ニュース要素とは、ニュースイベントクラスについての説明の構成要素であり、説明内容をカテゴリー分けしたものである。記事データ取得部2は、インターネットなどの公衆網やイントラネットなどの私設網であるネットワークを介して接続される他のサーバ等から記事データを読み出してもよく、コンピュータ読み取り可能な記録媒体から記事データを読み出してもよい。
【0023】
記事データは、半構造化テキスト情報であり、構造化テキスト情報及び非構造化テキスト情報を含む。構造化テキスト情報は、章や節などの項目を記述したテキストデータと、そのテキストデータの文字の大きさ、フォント、表示位置などを示すスタイルデータとを含む。項目は、出来事に関する説明を内容のまとまりごとに分類したものであり、項目には、内容がすぐわかるようにつけられた見出しである項目名が含まれている。非構造化テキスト情報は、構造化テキスト情報で示される章や節などの項目についての説明などを記述したテキストデータと、そのテキストデータのスタイルデータとを含む。記事データがHTML(Hypertext Markup Language)データである場合、スタイルデータはタグに相当する。なお、記事データは、構造化テキスト情報のみを含んでもよく、画像データなどの他の情報が含まれてもよい。
【0024】
抽出部3は、記事データ記憶部6に記憶されている記事データ内の構造化テキスト情報から見出しデータとして、項目名を示す項目名データを抽出し、取得した記事データのうち、抽出した各項目名データが構造化テキスト情報に出現する記事データの数をカウントする。抽出部3は、抽出した項目名データを、当該項目名データについてカウントした出現数と対応付けて一般化処理部4に出力する。
【0025】
一般化処理部4は、抽出部3から入力された項目名データを比較し、重複する項目名や、同様の意味の項目名を示す項目名データを統合したり、ニュース要素として用いることが好ましくない項目名の項目名データを削除したりする一般化処理を行なう。項目名データを統合する際、一般化処理部4は、統合の対象となる項目名データの出現数を合算し、統合後の項目名データの出現数とする。また、一般化処理部4は、同様の意味を示す項目名データを統合する際、シソーラス記憶部7に記憶されている概念辞書データを参照する。一般化処理部4は、統合処理、削除処理を行なった結果残った項目名データをニュース要素データの候補として、出現数とともにオントロジー生成部5へ出力する。
【0026】
オントロジー生成部5は、一般化処理部4から入力されたニュース要素データの候補の中から、オントロジーを構成するニュース要素データを出現数に基づいて抽出する。オントロジー生成部5は、オントロジー生成対象のニュースイベントクラスを階層構造の上位階層とし、抽出したニュース要素データが示すニュース要素を下位階層とした木構造のオントロジーを示すオントロジーデータを生成し、オントロジー記憶部8に書き込む。
【0027】
記事データ記憶部6、シソーラス記憶部7及びオントロジー記憶部8は、ハードディスク装置や半導体メモリなどで実現される。記事データ記憶部6は、記事データ取得部2が取得した記事データを記憶する。シソーラス記憶部7は、上位の概念の言葉と、下位の概念の言葉の対応付けを木構造などで示す概念辞書データを記憶する。概念辞書データは、ネットワーク構造になっているものでもよい。オントロジー記憶部8は、オントロジー生成部5により生成されたオントロジーデータを記憶する。
【0028】
続いて、本実施形態の概念処理装置1の動作について説明する。本実施形態では、人手により編集された構造化テキスト情報を含んだ記事データを用いてニュース要素群を抽出する。つまり、概念処理装置1が利用する目次等の項目は、人手により編集されたものであり、従って、ニュースイベントクラスの出来事を説明する際に人間がどのように説明を構成するかの知識を利用してニュース要素群を抽出することができる。
記事データとして、集合知蓄積サイト、例えば、Wikipedia(登録商標)により提供されるHTML(Hypertext Markup Language)文書データを用いる。
【0029】
図2は、概念処理装置1が利用する記事データが示す記事の例を示す図であり、「新潟県中越沖地震」に関してWikipedia(登録商標)が提供する記事の抜粋を示している。図2(a)は、記事データに含まれる構造化テキスト情報が示す項目の表示であり、図2(b)は、構造化テキスト情報が示す項目に含まれる項目名と非構造化テキスト情報が示す本文の表示(抜粋)である。
【0030】
図2(a)に示すように、構造化テキスト情報に含まれるテキストデータには、章や節などの複数の項目に分けてその内容が記述されている。項目は、図2(b)に示すような出来事に関する説明を内容のまとまりごとに分類したものであり、項目名(タイトル)が含まれている。これらの項目名は、記事データが属するニュースイベントクラスを説明するために必要なニュース要素をそのまま示していると考えることができる。つまり、図2(a)では、ニュースイベントクラス「地震」は、「概要」、「発生要因」、「被害」、「政府・自治体対応」、…などの項目名の項目によりその内容を伝えることができることを表しており、これらの項目名を、ニュース要素の候補とみなすことができる。
【0031】
しかし、すべての地震関連の記事データの内容がこのような項目で構成されているわけではない。さらには、このような内容の記事データが存在しない地震もある。そのため、本実施形態では、ニュース要素を複数の記事に共通して出現する項目名から抽出する。このように、人手により編集されたテキスト情報の構造からニュース要素に該当する候補を抽出し、それらを一般化することによりニュース要素を抽出する。
【0032】
なお、上記の記事データは、例えば、上位クラス「地震」、下位クラス「日本の地震」のように、階層化されたカテゴリーと予め対応付けられている。そこで、特定のニュースイベントクラスに属する記事データを収集するためには、キーワード検索を行なったり、その記事データと対応付けられているカテゴリーの情報を利用したりすることが可能である。
【0033】
図3は、本実施形態の概念処理装置1の処理フローを示す図である。
まず、概念処理装置1の記事データ取得部2は、特定のニュースイベントクラスに属する記事データを取得する(ステップS10)。例えば、記事データ取得部2は、インターネットなどのネットワークを介して接続される集合知蓄積サイトのサーバから、ニュースイベントクラスC1「地震」に対応付けられた記事データA1、A2、…を読み出す。取得する記事データの数の制限はない。記事データ取得部2は、取得した記事データを抽出部3に出力する。
【0034】
抽出部3は、記事データ取得部2から入力された各記事データ内の構造化テキスト情報が示す章や節、目次のデータなどから項目名のテキストデータである項目名データを抽出する(ステップS15)。具体的には、以下の処理を行なう。
【0035】
記事データ内の構造化テキスト情報にはスタイルデータが含まれており、このスタイルデータが示す文字の大きさなどから、そのスタイルデータに対応したテキストデータが章や節、目次などの項目に含まれる項目名の項目名データであることを容易に判定することができる。記事データがHTML文書データである場合、この文字の大きさなどのスタイルデータはタグに記述されている。抽出部3は、各記事データA1、A2、…に含まれる構造化テキスト情報から、項目名データであることが示されるタグを特定し、特定したタグに対応したテキストデータを項目名データとして抽出する。抽出部3は、1章の下位の階層に1.1節があるなど、項目が階層化されているときは第1階層の項目の項目名データのみを抽出するが、全ての階層の項目の項目名データを抽出してもよい。
【0036】
上記処理により、複数の記事データから同じ項目名データが抽出される場合がある。そこで、抽出部3は、全ての記事データから項目名データを抽出すると、完全一致する同一の項目名データについては統合して1つのみを残し、重複をなくす。抽出部3は、重複をなくした結果得られた項目名データBi(iは1以上の整数)それぞれについて、その項目名データを構造化テキスト情報に含む記事データの数である出現記事数Niを得る。具体的には、重複がなかった項目名データの出現記事数は1であり、重複があった項目名データの出現記事数は統合前の当該項目名データの数である。抽出部3は、項目名データとその項目名データの出現記事数の組(B1、N1)、(B2、N2)、…を一般化処理部4へ出力する。
【0037】
一般化処理部4は、抽出部3から入力された項目名データについて一般化処理を行なう(ステップS20)。一般化処理には、統合処理と削除処理がある。統合処理において、一般化処理部4は、複数の項目名データが統合の対象となるかを検証し、対象となる場合には1つの項目名データに統合する。さらに、統合処理において、一般化処理部4は、統合の結果残った項目名データそれぞれについて、統合の対象となった各項目名データの出現記事数を合計した出現記事数を算出する。また、削除処理において、一般化処理部4は、各項目名データが削除の対象となるかを検証し、対象となる場合には削除を行なう。一般化処理部4は、一般化処理後に残った項目名データのリストであるニュース要素候補データ群を得る(ステップS20)。ニュース要素候補データとは、ニュース要素データの候補となるデータである。なお、統合処理及び削除処理の詳細については後述する。一般化処理部4は、ニュース要素候補データDj(jは1以上の整数)と、その出現記事数Ljの組(D1、L1)、(D2、L2)、…をオントロジー生成部5に出力する。
【0038】
オントロジー生成部5は、一般化処理部4から入力されたニュース要素候補データD1、D2、…の中から出現記事数が所定の条件を満たすニュース要素候補データをニュース要素データE1、E2、…として選択する。例えば、所定の条件は、出現記事数が所定数以上のニュース要素候補データ、出現記事数が多い順に所定数または所定割合のニュース要素候補データなどとすることができる。オントロジー生成部5は、ニュースイベントクラスC1「地震」を示すニュースイベントクラスデータを第1階層とし、選択したニュース要素データE1「発生原因」、ニュース要素データE2「対応」、…を第2階層としたオントロジーの構造を作成する(ステップS25)。オントロジー生成部5は、作成されたオントロジーをオントロジー記述言語などにより記述したオントロジーデータを生成し、オントロジー記憶部8に書き込む(ステップS30)。生成されたオントロジーは、図3に示す2階層である。
【0039】
次に、図4〜図6を用いて、図3のステップS20において一般化処理部4が実行する一般化処理の詳細を説明する。
【0040】
図4は、項目名の表層的な特徴に注目した統合処理を示す。表層的な特徴に注目した統合処理では、複数の項目名データに出現する文字が共通の出現パターンを有する場合にそれらの項目名データの統合を行なう。なお、各項目名データの後ろの括弧内に記載されている数値は、出現記事数を示す。以下、項目名「X」を示す項目名データを項目名データ「X」と記載する。
図4(a)は、後方一致による統合処理を示す。一般化処理部4は、一方の項目名データが示す項目名が他方の項目名データが示す項目名の末尾に一致していると判断した場合にこれらの項目名データを統合し、項目名の長さが短い方を統合後の項目名データとする。同図に示すように、項目名データ「対応」と項目名データ「政府の対応」は後方一致しており、これら2つの項目名データは、長さが短い項目名の項目名データ「対応」に統合される。一般化処理部4は、統合後の項目名データ「対応」の出現記事数を、統合前の項目名データ「対応」の出現記事数「6」と、項目名データ「政府の対応」の出現記事数「2」を合算した「8」とする。
【0041】
図4(b)は、前方一致による統合処理を示す。一般化処理部4は、一方の項目名データが示す項目名が他方の項目名データが示す項目名の先頭に一致していると判断した場合にこれらの項目名データを統合し、項目名の長さが短い方を統合後の項目名データとする。同図に示すように、項目名データ「被害」と項目名データ「被害状況」は、前方一致しており、これら2つの項目名データは、長さが短い項目名の項目名データ「被害」に統合される。一般化処理部4は、統合後の項目名データ「被害」の出現記事数を、統合前の項目名データ「被害」の出現記事数「12」と、項目名データ「被害状況」の出現記事数「4」を合算した「16」とする。
【0042】
図4(c)は、部分一致による統合処理を示す。一般化処理部4は、一方の項目名データの項目名が他方の項目名データの項目名の先頭あるいは末尾以外に含まれていると判断した場合にこれらの項目名データを統合し、他方の項目名に含まれている項目名の項目名データを統合後の項目名データとする。同図に示すように、項目名データ「各地の被害状況」と項目名データ「被害」は部分一致しており、これら2つの項目名データは、項目名「各地の被害状況」に含まれている項目名「被害」の項目名データに統合される。一般化処理部4は、統合後の項目名データ「被害」の出現記事数を、統合前の項目名データ「各地の被害状況」の出現記事数「3」と、項目名データ「被害」の出現記事数「12」を合算した「15」とする。
【0043】
図4(d)は、LCS(最長共通部分列)による統合処理を示す。一般化処理部4は、一方の項目名データが示す項目名と、他方の項目名データが示す項目名とに共通して同じ順番に出現する文字数を抽出し、抽出された文字数が所定数以上であると判断した場合にこれらの項目名データを統合し、項目名の長さが短い方を統合後の項目名データとする。同図に示すように、項目名データ「発生原因」と項目名データ「発生の要因」の場合、「発」、「生」、「因」が共通して同じ順番に出現する。一般化処理部4は、抽出された文字数「3」が、統合すべきと判断する閾値「3」以上であると判断し、これら2つの項目名データを、長さが短いほうの項目名データ「発生原因」に統合する。一般化処理部4は、統合後の項目名データ「発生原因」の出現記事数を、統合前の項目名データ「発生原因」の出現記事数「3」と、項目名データ「発生の要因」の出現記事数「6」を合算した「9」とする。
【0044】
上記のように、一般化処理部4は、項目名の表層的な一致によって項目名データを統合するか否かを判断し、統合対象となった場合は、統合対象の項目名データのうち文字数の少ない項目名の項目名データを統合後の項目名データとしている。
【0045】
図5は、項目名の意味的な特徴に基づいた統合処理を示す。意味的な特徴に基づいた統合処理では、複数の項目名に関連付けられる意味が共通概念を有する場合にそれら項目名の項目名データの統合を行なう。一般化処理部4は、シソーラスなどの概念辞書を用いて統合処理を行う。
シソーラス記憶部7に記憶されている概念辞書データには、共通の上位概念を持つ複数の下位概念が示されている。そこで、一般化処理部4は、上位概念が共通である下位概念の項目名を示す複数の項目名データを、これら項目名に共通の上位概念を項目名とした項目名データに統合する。
同図に示すように、概念辞書データに、「バス」、「電車」が共通の上位概念「交通機関」を持つ下位概念であることが示されている。一般化処理部4は、項目名データ「バス」、「電車」を、新たな項目名データ「交通機関」に統合する。一般化処理部4は、統合後の項目名データ「交通機関」の出現記事数を、統合前の項目名データ「電車」の出現記事数「4」と、項目名データ「バス」の出現記事数「1」を合算した「5」とする。
【0046】
図6は、ニュース要素として不適な項目名データを削除する削除処理を示す。
図6(a)は、文字数判定による削除処理を示す。一般化処理部4は、文字数が所定以上である項目名を示す項目名データを削除する。これは、長すぎる項目名は、その項目名が含まれている記事データが取り扱っている内容に特有の項目名であると考えられ、ニュースイベントクラス全体に共通した項目である可能性が低いためである。
【0047】
図6(b)は、数字が含まれる場合の削除処理を示す。一般化処理部4は、数字が含まれている項目名を示す項目名データを削除する。各記事データは、ある特定の出来事について記述されていることが多い。例えば、ニュースイベントクラス「地震」に対応付けられた記事データであっても、その内容は、関東大震災について説明した記事、最近起こった地震の被害からの復旧状況について説明した記事などが含まれる。数字は、特定の出来事のみに関連する年や数値などの事例を表すことが多く、数値が含まれる項目名はニュースイベントクラス全体に共通している可能性が低いため、削除の対象とする。
【0048】
図6(c)は、ニュースイベントクラスと同じ項目名を示す項目名データの削除処理を示す。一般化処理部4は、ニュースイベントクラスと同じ項目名を示す項目名データを削除する。
【0049】
一般化処理部4は、上記の統合処理、削除処理などの一般化処理を行い、最終的に残った項目名データがニュース要素候補データとなる。
なお、上述した各統合処理、各削除処理の全てを実行してもよく、一部のみを実行してもよい。また、各統合処理、各削除処理の実行順序は任意である。実行する統合処理、削除処理と、その実行順によってニュース要素候補データとして得られる結果は異なるため、システム設計者は目的によってそれらを柔軟に組み合わせて決定することが可能である。
【0050】
日本語の特性として、重要な内容は後ろに置かれることが多い。また、概念辞書には、一般的な単語を概念として用いていることが多い。そのため、例えば、最初に後方一致による統合処理を行い、その後、前方一致、部分一致、LCSによる統合処理、削除処理を行い、短く文字数の一般的な項目名データとなった後に、意味的な特徴に基づいた統合処理を行なうことが考えられる。
【0051】
各統合処理の詳細な処理例について説明する。
まず、後方一致による統合処理の詳細な処理例について説明する。一般化処理部4は、処理対象の項目名データ群の中の一つの項目名データに着目し、着目している項目名データが示す項目名と、処理対象の項目名データ群に含まれる他の項目名データが示す項目名それぞれとを比較して後方一致するか否かを判断する。後方一致する項目名データがあった場合、一般化処理部4は、着目している項目名データと、後方一致すると判断した各項目名データとを合わせた項目名データの中で、最も文字数が少ない項目名の項目名データを統合後の項目名データとする。一般化処理部4は、着目している項目名データの出現記事数と、後方一致すると判断した各項目名データの出現記事数との合算により、統合後の項目名データの出現記事数を算出する。一般化処理部4は、処理対象の項目名データ群から、統合の結果残らなかった項目名データを除外する。
続いて、一般化処理部4は、処理対象の項目名データ群の中から、統合の結果残った項目名データ以外でまだ着目していない項目名データの一つに着目し、同様の処理を繰り返す。一般化処理部4は、処理対象の項目名データ群に、まだ着目していない項目名データがなくなった場合、後方一致による統合処理を終了する。統合後の項目名データ、及び、他の項目と後方一致しなかった項目名データが、後方一致による統合処理の結果残った項目名データである。
【0052】
前方一致による統合処理の処理手順も、後方一致による統合処理と同様である。
部分一致による統合処理の場合、後方一致による統合処理と以下の点が異なる。一般化処理部4は、着目している項目名データの示す項目名が、他の項目名データの示す項目名の部分として含まれているか否かを判断する。一般化処理部4は、着目している項目名データを統合後の項目名データとし、他の項目名データに統合済みを示す情報を対応づけるのみで処理対象の項目名データ群からは除外しない。一般化処理部4は、処理対象の項目名データ群の中から、統合済みを示す情報が付加されていない項目名データの一つに着目して同様の処理を繰り返す。処理終了時に、統合済みを示す情報が付加されていない項目名データは、統合後の項目名データ、または、他の項目と部分一致しなかった項目名データであり、部分一致による統合処理の結果残った項目名データである。
【0053】
意味的な特徴に基づいた統合処理の場合、後方一致による統合処理と以下の点が異なる。一般化処理部4は、着目している項目名データが示す項目名と、他の項目名データが示す項目名それぞれについて、上位概念が同じであるか否かを判断し、上位概念が同じ項目名の項目名データがあった場合、処理対象の項目名データ群からそれらの項目名データを除外し、上位概念の項目名を示す項目名データを生成する。上位概念を示す項目名の項目名データ、及び、他の項目名データと上位概念が一致しなかった項目名データが、意味的な特徴に基づいた統合処理の結果残った項目名データである。
【0054】
以上第1の実施形態について説明したが、図3のステップS10で記事データ取得部2が読み込む記事データに、非構造化テキスト情報の記事データが含まれてもよい。非構造化テキスト情報内のテキストデータは、説明のみを記述しており、項目は記述されていない。抽出部3は、ステップS15において、非構造化テキスト情報内のテキストデータから、任意の既存のキーワード抽出処理によってキーワードを抽出し、この抽出したキーワードを示すデータを項目名データとして同様に処理を行なう。
【0055】
また、図3のステップS20において、一般化処理部4は、異なる記事データから抽出された項目名データの組み合わせについてのみ統合処理を行なってもよい。この場合、抽出部3は、各項目名データに抽出元の記事データを特定する抽出元情報を付加して一般化処理部4に出力する。一般化処理部4は、同じ記事データから読み出されたことを示す抽出元情報が付加された項目名データの組み合わせについては、統合処理を行なわない。
【0056】
[2.第2の実施形態]
上述した第1の実施形態では、2階層からなるオントロジーを生成しているが、本実施形態では、3階層以上のオントロジーを生成する。以下、第1の実施形態との差分を説明する。
【0057】
図4、図5に示す各統合処理において、一般化処理部4は、統合の結果残らなかった項目名データを示す削除項目名情報と、どの項目名データに統合されたかを示す上位階層情報とを対応付けた統合情報を生成する。例えば、図4(a)に示す後方一致の場合、項目名データ「政府の対応」を設定した削除項目名情報と、項目名データ「対応」を設定した上位階層情報とを対応付けた統合情報が生成される。また、図5に示す意味的な特徴に基づいた統合処理の場合、項目名データ「電車」及び項目名データ「バス」を設定した削除項目名情報と、項目名データ「交通機関」を設定した上位階層情報とを対応付けた統合情報が生成される。
【0058】
図3のステップS25において、一般化処理部4は、ニュース要素候補データと、その出現記事数の組に併せて、統合情報をオントロジー生成部5に出力する。ステップS30において、オントロジー生成部5は、まず、ニュースイベントクラスを第1階層とし、出現記事数に基づいて選択したニュース要素データを第2階層とした木構造のニュースオントロジーを作成する。続いて、オントロジー生成部5は、第2階層のニュース要素それぞれについて、上位階層情報が第2階層のニュース要素データと一致する統合情報を特定し、特定した統合情報の削除項目名情報から項目名データを読み出す。オントロジー生成部5は、第2階層の各ニュース要素データに対応した統合情報の削除項目名から読み出した項目名データを、当該ニュース要素データの下位のニュース要素データとして付加し、第3階層まで階層化された木構造のニュースオントロジーをオントロジー記述言語などにより記述したオントロジーデータを作成する。
【0059】
オントロジー生成部5は、第3階層以下についても同様の処理を行なって、4階層以上の木構造のニュースオントロジーを作成してもよい。オントロジー生成部5は、作成されたオントロジーをオントロジー記述言語などにより記述したオントロジーデータを生成し、オントロジー記憶部8に書き込む。
【0060】
図7は、本実施形態により生成されたニュースオントロジーデータを示す図である。同図では、ニュースイベントクラスであるカテゴリーC1を最上位階層とした4階層の木構造のニュースオントロジーを示している。
【0061】
[3.第3の実施形態]
上述した第2の実施形態では、項目が統合されたときの情報を用いて木構造のオントロジーを生成しているが、本実施形態では、記事データに含まれる目次が階層化されている場合、その階層構造を用いて木構造のオントロジーを生成する。以下、第1の実施形態との差分を説明する。
【0062】
図3のステップS15において、抽出部3は、各記事データに含まれる構造化テキスト情報から、項目名データと、項目名データ間の階層関係を読み出しておく。例えば、図2(a)に示す構造化テキスト情報の場合、項目名データ「概要」の下位階層の項目名データは、項目名「本震」、「本震(震度4以上を観測した市町村」、…の項目名データであり、項目名データ「被害」の下位階層の項目名データは項目名「交通機関」、…の項目名データであり、項目名データ「交通機関」の下位階層の項目名データは項目名「高速道路」、「一般道路」、…の項目名データであることが読み出される。
【0063】
図3のステップS30において、オントロジー生成部5は、まず、ニュースイベントクラスデータを第1階層とし、出現記事数に基づいて選択したニュース要素データを第2階層とした木構造のニュースオントロジーを作成する。オントロジー生成部5は、第2階層のニュース要素データを抽出部3に出力し、抽出部3は、第2階層のニュース要素データと一致する項目名データの下位階層の項目名データを返送する。オントロジー生成部5は、第2階層のニュース要素それぞれに、当該第2階層のニュース要素データの下位階層の項目名データを付加し、第3階層まで階層化された木構造のニュースオントロジーの構造を生成する。オントロジー生成部5は、生成された構造のオントロジーをオントロジー記述言語などにより記述したオントロジーデータを作成する。
オントロジー生成部5は、第3階層以下についても同様の処理を行ない、4階層以上の木構造のニュースオントロジーの構造を生成し、生成された構造のオントロジーを示すオントロジーデータを作成してもよい。
【0064】
なお、ニュース要素データが意味的な特徴に基づいた統合処理によって得られた項目名データである場合、オントロジー生成部5は、その統合前の項目名データに対応した下位階層の項目名データを抽出部3からさらに取得して、ニュース要素データの下位階層に付加してもよい。例えば、第2の実施形態と同様に、一般化処理部4は、統合情報を生成してオントロジー生成部5に出力する。オントロジー生成部5は、第2階層のニュース要素データそれぞれについて、上位階層情報が第2階層のニュース要素データと一致する統合情報を特定し、特定した統合情報の削除項目名情報から項目名データを読み出して抽出部3に出力する。抽出部3は、オントロジー生成部5から入力された項目名データの下位階層の項目名データを返送し、オントロジー生成部5は、返送された下位階層の項目名データをニュース要素データの下位階層に付加する。
【0065】
[4.第4の実施形態]
上述した第1の実施形態では、各ニュース要素データ間の前後関係については考慮していない。しかし、ある出来事を説明する際には、通常、ニュース要素をわかりやすい順番に並べる。例えば、ニュースイベントクラス「地震」について、ニュース要素「被害」、「その後」、…が抽出されたとしても、ニュース要素「被害」に関する内容より先にニュース要素「その後」に関する内容を説明することはない。そこで、本実施形態では、ニュース要素データ間の前後関係についても抽出する。これよって、複数の記事や情報をニュース要素データ別にまとめたまとめ記事を生成する際などに、適切な順番で並べることが可能となる。以下、第1の実施形態との差分を説明する。
【0066】
図3のステップS15において、抽出部3は、各記事データに含まれる構造化テキスト情報から、項目名データ間の前後関係を読み出しておく。例えば、図2(a)に示す構造化テキスト情報の場合、項目名データは「概要」、「発生要因」、「被害」、「政府・自治体対応」、…の順であることが読み出される。抽出部3は、項目名データ間の前後関係を示す順序情報をオントロジー生成部5に出力する。
【0067】
図3のステップS30において、オントロジー生成部5は、出現記事数に基づいてニュース要素データを選択する。オントロジー生成部5は、これらのニュース要素データのうち2以上が項目名データとして含まれる記事データから得られた前後関係を順序情報から読み出す。これにより、オントロジー生成部5は、ニュース要素データ間の前後関係の統計情報を得ると、この統計情報に基づいて最も多く現われるニュース要素データの並び順を判断する。オントロジー生成部5は、ニュースイベントクラスデータを第1階層とし、判断した並び順に従って並べたニュース要素データを第2階層としたオントロジーの構造を作成する。オントロジー生成部5は、作成されたオントロジーをオントロジー記述言語などにより記述したオントロジーデータを生成し、オントロジー記憶部8に書き込む。
【0068】
なお、ニュース要素データが意味的な特徴に基づいた統合処理によって得られた項目名データである場合、オントロジー生成部5は、ニュース要素データに統合される前の項目名データを用い、順序情報からニュース要素データの前後関係の統計情報を得てもよい。
【0069】
図8は、本実施形態により生成されたニュースオントロジーを示す図である。同図では、ニュースイベントクラス「地震」の下位階層に、ニュース要素が「発生概要」、「被害」、「対応」、「発生要因」、「その後」の順に並べられたニュースオントロジーを示している。
【0070】
[5.第5の実施形態]
上述した実施形態では、半構造化テキスト情報を含む記事データを利用して、ニュースイベントクラスを構成するニュース要素データ群を抽出している。本実施形態では、同様の処理によって、ニュース記事からニュースオントロジーを構築する。
日常、放送などで利用されている一般的なニュース記事は、ニュースのタイトル、及び、その内容を表す本文よって構成されている。そこで、見出しとして、項目名ではなく、ニュースのタイトルを用いて第1の実施形態と同様の処理を行うことにより、オントロジーを構築することができる。以下、第1の実施形態との差分を説明する。
【0071】
図9は、本実施形態において用いられる記事データについて示す図である。同図に示すように、記事データA’1、A’2、…は、ニュースのタイトルと、ニュースの内容を示すテキストデータである。
【0072】
図2のステップS10において、概念処理装置1の記事データ取得部2は、図9に示す特定のニュースイベントクラスに属する記事データA’1、A’2、…を取得する。ステップS15において、抽出部3は、記事データ取得部2が取得した記事データA’1、A’2、…から記事のタイトルを読み出す。概念処理装置1は、抽出部3が読み出したタイトルを見出しデータとし、読み出した見出しデータを第1の実施形態における項目データの代わりに用いて同様の処理を行なう。これにより、一般化処理が施された見出しデータからニュース要素データ群を得て、ニュースオントロジーを構築することができる。
【0073】
また、記事データにニュースの日付の情報が含まれている場合、ステップS15において、抽出部3は、タイトルと日付の情報を対応付けて読み出しておく。そして、図3のステップS30において、オントロジー生成部5は、選択したニュース要素データに対応した日付を抽出部3から取得する。ニュースイベントクラスデータを第1階層とし、日付順に並べたニュース要素データを第2階層としたオントロジーの構造を作成する。同じニュース要素データについて複数の日付が読み出された場合は、その中で最も早い日付としてもよく、最も多く出現する日付としてもよい。これにより、例えば、ニュースイベントクラス「汚職事件」に関しては「逮捕」、「否認」、「送検」、「判決」、「上告」などのニュース要素データがこの順番で表れる、といった知識を記述したオントロジーを構築することができる。
このオントロジーを利用することによって、高度なニュース検索・提示サービスを提供することも可能となる。
【0074】
なお、ニュースの内容部分の最初の1文はリード文と呼ばれ、そのニュースの概要を示す重要な内容を含んでいる。そこで、ステップS15において、抽出部3は、記事データ取得部2が取得した記事データからニュース本文の最初の1文を見出しデータとして読み出し、読み出した見出しデータを第1の実施形態における項目名データの代わりに用いることもできる。
【0075】
[6.効果]
以上説明した本発明の実施形態によれば、あるニュースイベントに関する情報を伝えるために必要なニュース要素群を得ることができる。このようなニュース要素群を得るために、本実施形態では、人間がニュースイベントに関する情報を伝える際に、どのような構成を利用するのかの知識を利用する。この知識として、人手によって編集された構造情報、例えば、Wikipedia(登録商標)が提供する記事データを利用することができる。また、Wikipedia(登録商標)が適用する記事データには、カテゴリーの情報が付与されているため、この情報を利用してニュースイベントクラスに属する記事データを容易に読み出すことができる。そして、地震災害、汚職事件、航空機事故、など、特定の種類のニュースイベントクラスを構成する項目を構造情報から抽出した後、一般化処理を行なうことによってニュース要素群を自動抽出する。これにより、様々な種類のニュースイベントクラスの構造を自動で獲得することが可能となり、ニュースオントロジーの構築を効率化することが可能となる。
また、この抽出されたオントロジーにより示される構造を、ユーザの要求に合わせてニュース項目を再構成するために利用すれば、複数の記事コンテンツを統合してある出来事に関するまとめ記事を作成したり、出来事の特定要素(例えば、その出来事の「原因」など)に対応した記事のみを探し出したりする処理に用いることができる。
また、ニュース原稿などを記事データとし、ニュースのタイトルや、リード文などを見出しとして利用することもできる。
【0076】
[7.その他]
上述した概念処理装置1は、内部にコンピュータシステムを有している。そして、概念処理装置1の各部の動作の過程は、プログラムの形式でコンピュータ読み取り可能な記録媒体に記憶されており、このプログラムをコンピュータシステムが読み出して実行することによって、上記処理が行われる。ここでいうコンピュータシステムとは、CPU及び各種メモリやOS、周辺機器等のハードウェアを含むものである。
【0077】
また、「コンピュータシステム」は、WWWシステムを利用している場合であれば、ホームページ提供環境(あるいは表示環境)も含むものとする。
また、「コンピュータ読み取り可能な記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、CD−ROM等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶部のことをいう。さらに「コンピュータ読み取り可能な記録媒体」とは、インターネット等のネットワークや電話回線等の通信回線を介してプログラムを送信する場合の通信線のように、短時間の間、動的にプログラムを保持するもの、その場合のサーバやクライアントとなるコンピュータシステム内部の揮発性メモリのように、一定時間プログラムを保持しているものも含むものとする。また上記プログラムは、前述した機能の一部を実現するためのものであっても良く、さらに前述した機能をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるものであっても良い。
【符号の説明】
【0078】
1…概念処理装置
2…記事データ取得部
3…抽出部
4…一般化処理部
5…オントロジー生成部
6…記事データ記憶部
7…シソーラス記憶部
8…オントロジー記憶部
【特許請求の範囲】
【請求項1】
見出しデータを含む記事データを記憶する記事データ記憶部と、
前記記事データ記憶部から前記記事データを読み出し、前記見出しデータを抽出する抽出部と、
前記抽出部が抽出した複数の前記見出しデータに出現する文字が共通出現パターンを有する場合に前記共通出現パターンに基づき統合後の見出しデータを生成し、前記抽出部が抽出した複数の前記見出しデータが共通の上位概念を有する場合に前記共通の上位概念に基づき統合後の見出しデータを生成する一般化処理を行なった結果の見出しデータを構成要素データとして出力する一般化処理部と、
を備えることを特徴とする概念処理装置。
【請求項2】
前記一般化処理部により得られた前記構成要素データの下層に、前記構成要素データに統合された前記見出しデータを付加したオントロジー、または、前記一般化処理部により得られた前記構成要素データの下層に、前記記事データが示す階層化された見出しデータに含まれる前記構成要素データの下層の見出しデータを付加したオントロジーデータを生成するオントロジー生成部をさらに備える、
ことを特徴とする請求項1に記載の概念処理装置。
【請求項3】
前記一般化処理部により得られた前記構成要素データの順序を前記記事データが示す前記見出しデータの出現順に基づいて決定し、決定した出現順を示す情報を前記構成要素データに付加したオントロジーデータを生成するオントロジー生成部をさらに備える、
ことを特徴とする請求項1に記載の概念処理装置。
【請求項4】
前記一般化処理部は、前記一般化処理において、複数の前記見出しデータが示す見出しが後方一致、前方一致、または、部分一致する場合、あるいは、複数の前記見出しデータが示す見出しに同一の順序で共通して現われる文字数が所定以上である場合に、前記複数の見出しデータを、前記複数の見出しデータのうち最も短い見出しの見出しデータに統合し、共通の上位概念を有する前記見出データを、前記上位概念を示す見出しデータに統合し、前記見出しデータから構成要素として不適切であると判断するための所定の条件に合致する見出しデータを削除する、
ことを特徴とする請求項1に記載の概念処理装置。
【請求項5】
概念処理装置として用いられるコンピュータを、
見出しデータを含む記事データを記憶する記事データ記憶部、
前記記事データ記憶部から前記記事データを読み出し、前記見出しデータを抽出する抽出部、
前記抽出部が抽出した複数の前記見出しデータに出現する文字が共通出現パターンを有する場合に前記共通出現パターンに基づき統合後の見出しデータを生成し、前記抽出部が抽出した複数の前記見出しデータが共通の上位概念を有する場合に前記共通の上位概念に基づき統合後の見出しデータを生成する一般化処理を行なった結果の見出しデータを構成要素データとして出力する一般化処理部と、
として機能させることを特徴とするプログラム。
【請求項1】
見出しデータを含む記事データを記憶する記事データ記憶部と、
前記記事データ記憶部から前記記事データを読み出し、前記見出しデータを抽出する抽出部と、
前記抽出部が抽出した複数の前記見出しデータに出現する文字が共通出現パターンを有する場合に前記共通出現パターンに基づき統合後の見出しデータを生成し、前記抽出部が抽出した複数の前記見出しデータが共通の上位概念を有する場合に前記共通の上位概念に基づき統合後の見出しデータを生成する一般化処理を行なった結果の見出しデータを構成要素データとして出力する一般化処理部と、
を備えることを特徴とする概念処理装置。
【請求項2】
前記一般化処理部により得られた前記構成要素データの下層に、前記構成要素データに統合された前記見出しデータを付加したオントロジー、または、前記一般化処理部により得られた前記構成要素データの下層に、前記記事データが示す階層化された見出しデータに含まれる前記構成要素データの下層の見出しデータを付加したオントロジーデータを生成するオントロジー生成部をさらに備える、
ことを特徴とする請求項1に記載の概念処理装置。
【請求項3】
前記一般化処理部により得られた前記構成要素データの順序を前記記事データが示す前記見出しデータの出現順に基づいて決定し、決定した出現順を示す情報を前記構成要素データに付加したオントロジーデータを生成するオントロジー生成部をさらに備える、
ことを特徴とする請求項1に記載の概念処理装置。
【請求項4】
前記一般化処理部は、前記一般化処理において、複数の前記見出しデータが示す見出しが後方一致、前方一致、または、部分一致する場合、あるいは、複数の前記見出しデータが示す見出しに同一の順序で共通して現われる文字数が所定以上である場合に、前記複数の見出しデータを、前記複数の見出しデータのうち最も短い見出しの見出しデータに統合し、共通の上位概念を有する前記見出データを、前記上位概念を示す見出しデータに統合し、前記見出しデータから構成要素として不適切であると判断するための所定の条件に合致する見出しデータを削除する、
ことを特徴とする請求項1に記載の概念処理装置。
【請求項5】
概念処理装置として用いられるコンピュータを、
見出しデータを含む記事データを記憶する記事データ記憶部、
前記記事データ記憶部から前記記事データを読み出し、前記見出しデータを抽出する抽出部、
前記抽出部が抽出した複数の前記見出しデータに出現する文字が共通出現パターンを有する場合に前記共通出現パターンに基づき統合後の見出しデータを生成し、前記抽出部が抽出した複数の前記見出しデータが共通の上位概念を有する場合に前記共通の上位概念に基づき統合後の見出しデータを生成する一般化処理を行なった結果の見出しデータを構成要素データとして出力する一般化処理部と、
として機能させることを特徴とするプログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【公開番号】特開2012−128509(P2012−128509A)
【公開日】平成24年7月5日(2012.7.5)
【国際特許分類】
【出願番号】特願2010−277233(P2010−277233)
【出願日】平成22年12月13日(2010.12.13)
【出願人】(000004352)日本放送協会 (2,206)
【Fターム(参考)】
【公開日】平成24年7月5日(2012.7.5)
【国際特許分類】
【出願日】平成22年12月13日(2010.12.13)
【出願人】(000004352)日本放送協会 (2,206)
【Fターム(参考)】
[ Back to top ]