
構成情報管理装置、分散情報管理システム、分散情報管理方法および分散情報管理プログラム
【課題】検索処理の高速化を実現することを課題とする。
【解決手段】構成情報管理装置1は、管理対象に関する情報を示す構成要素と構成要素間の接続関係に関する情報を示す要素関係とを他の構成情報管理装置と分散して記憶する構成情報記憶部を有する。そして、構成情報管理装置1は、接続関係にある構成要素および要素関係の一群であるクラスタについて登録要求を受け付けた場合に、クラスタの格納先を決定し、構成情報憶部または他の構成情報管理装置に格納するように制御する。そして、構成情報管理装置1は、構成要素または要素関係を検索対象とした検索要求を受け付けた場合に、検索対象を含むクラスタの格納先を特定し、クラスタの格納先から検索対象の構成要素または要素関係を検索する。
【解決手段】構成情報管理装置1は、管理対象に関する情報を示す構成要素と構成要素間の接続関係に関する情報を示す要素関係とを他の構成情報管理装置と分散して記憶する構成情報記憶部を有する。そして、構成情報管理装置1は、接続関係にある構成要素および要素関係の一群であるクラスタについて登録要求を受け付けた場合に、クラスタの格納先を決定し、構成情報憶部または他の構成情報管理装置に格納するように制御する。そして、構成情報管理装置1は、構成要素または要素関係を検索対象とした検索要求を受け付けた場合に、検索対象を含むクラスタの格納先を特定し、クラスタの格納先から検索対象の構成要素または要素関係を検索する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、構成情報管理装置、分散情報管理システム、分散情報管理方法および分散情報管理プログラムに関する。
【背景技術】
【0002】
近年、ITシステムは、オープン化やマルチベンダー化が進んでおり、サーバ台数の増加やストレージ容量の増大と相まって大規模化・複雑化している。このため、運用コストが増大しているだけでなく、人的ミスによるシステム停止やサービス品質低下の多発が大きな問題となっている。そこで、こうした問題を解決するため、サーバやストレージ、アプリケーションといったITシステムの構成情報の管理が重要となる。
【0003】
ITシステムの構成情報を管理する装置として、MDR(Management Data Repository)と呼ばれるデータベースが知られている。MDRは、ITシステムの運用管理データを保持し、運用管理ミドルウェアのデータベースに相当する。
【0004】
ここで、データセンタの運用においては、サーバ管理やネットワーク管理、サービス管理、資産管理など、それぞれの管理業務に最適化された運用管理ミドルウェアが存在する。また、各運用管理ミドルウェアは、固有のMDRを有し、それぞれの業務に関する構成情報をMDRに入力する。このように、各MDRは構成情報を他のMDRと独立して管理するため、MDRへのアクセス方法やMDRで管理される構成情報のデータ形式がMDRごとに異なる場合があり、各MDRを連携させる場合は人を介さざるをえないのが実情であった。
【0005】
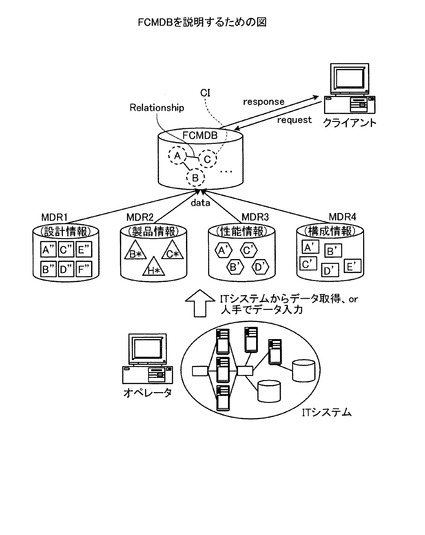
そこで、複数のMDRに散在する各種の構成情報を仮想的に統合するFCMDB(Federated Configuration Management Database)と呼ばれるデータベースを有する分散情報管理システムが開発された。例えば、図24に示すように、分散情報管理システムは、複数のMDRおよびFCMDBを有し、MDRとFCMDBとはネットワークを介して接続されている。図24は、FCMDBを説明するための図である。
【0006】
各MDRは、ITシステム内に存在する機器等の構成に関する情報を管理する。かかる複数のMDRは、MDRごとに扱うデータの種別・量が異なる。例えば、図24に示すように、MDR1が設計情報を管理し、MDR2が製品情報を管理し、MDR3が性能情報を管理し、MDR4が構成情報を管理する。
【0007】
FCMDBは、複数のMDRに分散して管理される同一対象に関する構成情報を統合して管理する。具体的には、FCMDBは、ITシステムを構成する機器、ソフトウェア、データログ等の構成要素(CI,Configuration Item)や各CI間の関係(以下、「リレーションシップ」という)を管理する。例えば、図24の例では、FCMDBに管理されているCI「C」とは、MDR1に記憶されている設計情報C’’、MDR3に記憶されている性能情報C^、MDR4に記憶されているC’のデータを統合したものである。
【0008】
このように、FCMDBは、複数のMDRに分散して管理される同一対象に関する構成情報を統合して管理する。これにより、システム管理者等の作業者は、パッチの適用作業やハードウェアの保守作業など、システム運用におけるあらゆるシーンにおいて、FCMDBにより仮想統合された構成情報を参照することでITシステム全体の構成を容易に把握することができる。
【0009】
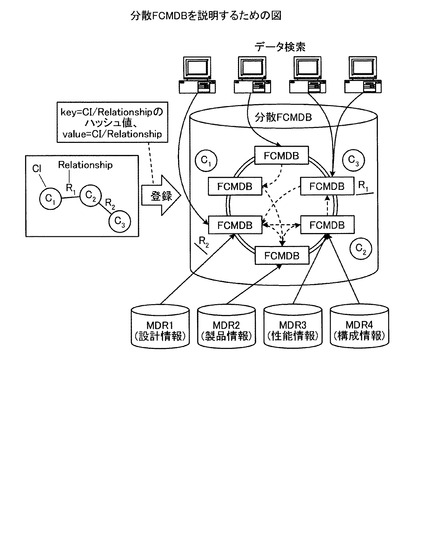
また、スケーラビリティ向上のため、FCMDBを複数有する分散FCMDBが知られている。図25に示すように、分散FCMDBは、MDRの情報を複数のFCMDBで分散管理し、データ登録やデータ検索を複数のFCMDBで分散処理している。図25は、分散FCMDBを説明するための図である。例えば、図25に示すように、分散FCMDBは、3つのCI(C1、C2、C3)と二つのリレーションシップ(R1、R2)とが接続されたデータを登録する場合に、C1、R2、C2、C3およびR1をそれぞれ異なるFCMDBに分散して登録する。
【0010】
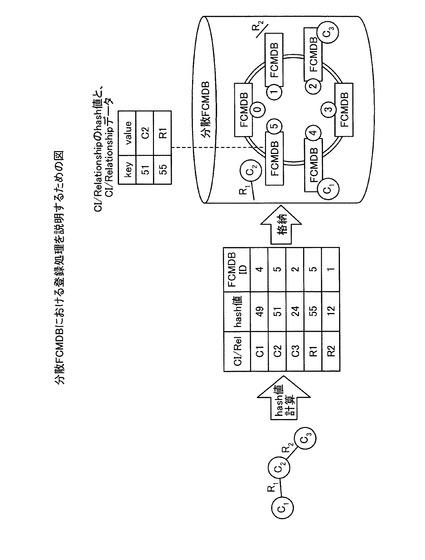
ここで、図26を用いて、分散FCMDBにおける登録処理を具体的に説明する。図26に示すように、分散FCMDBは、3つのCI(C1、C2、C3)と二つのリレーションシップ(R1、R2)とが接続されたデータを登録する場合に、各CIおよび各リレーションシップのIDなどを用いて、それぞれハッシュ値を計算する。そして、各CIおよび各リレーションシップのハッシュ値をキーとして、各CIおよび各リレーションシップをFCMDBに分散して登録する。
【0011】
例えば、図26に示すように、登録要求を受け付けたFCMDBは、C2のハッシュ値「51」を計算し、ハッシュ値「51」を担当する担当FCMDB「5」にC2のデータを転送する。そして、担当FCMDB「5」は、C2のデータを受信し、C2のデータを格納する。担当FCMDB「5」は、ハッシュ値が「51〜59」のCIおよびリレーションシップを担当しており、図26の例では、ハッシュ値「51」のC2とハッシュ値「55」のR1とを格納している。
【0012】
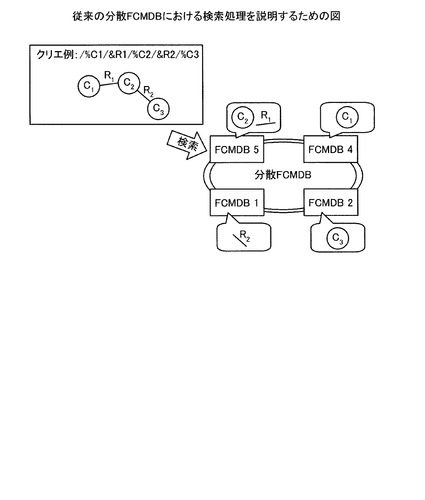
また、分散FCMDBでは、ノードであるCI、エッジであるリレーションシップからなるグラフが分散格納されているため、FCMDBがクライアント端末から検索要求を受け付けた場合に、FCMDB間で通信を行って検索処理を行う。ここで、図27を用いて、分散FCMDBにおける検索処理を具体的に説明する。図27に示すように、分散FCMDBにおけるFCMDB1が検索要求として、クエリ「%CI1/&R1/%CI2/&R2/%CI3」を受け付けた場合の検索処理について説明する。ここで、クエリ「%CI1/&R1/%CI2/&R2/%CI3」とは、C1とR1で関連付いているC2と、さらにR2で関連付いているC3との検索を要求するクエリである。
【0013】
検索要求を受け付けたFCMDB5は、先頭のC1を検索し、C1を保持するFCMDB4と通信を行ってC1のIDを得る。そして、FCMDBは、C1のIDをソースICまたはターゲットICとするR1を検索し、自装置からC2のIDを得る。続いて、検索要求を受け付けたFCMDB5は、C2のIDをソースICまたはターゲットICとするR2を検索し、R2を保持するFCMDB1と通信を行ってC3のIDを得る。そして、FCMDBは、C3のIDを元に、C3を保持するFCMDB2を特定し、FCMDBと通信を行ってC3の情報を得る。その後、FCMDBは、クライアント端末に対してCI3のデータを検索結果として出力する。
【先行技術文献】
【特許文献】
【0014】
【特許文献1】特開2009−169863号公報
【特許文献2】特開2004−272369号公報
【発明の概要】
【発明が解決しようとする課題】
【0015】
しかしながら、上記した分散FCMDBの技術では、CI、リレーションシップが各FCMDBに分散して登録させているので、検索時にはリレーションシップを辿るような検索処理を行う結果、FCMDB間で通信を頻繁に行って検索処理を実行することとなる。このため、検索処理の処理速度が遅くなるという課題があった。
【0016】
なお、キャッシュ機構を用いて、検索の処理速度を速くすることも考えられる。例えば、クエリの結果をキャッシュ用メモリに保持させ、次回の検索処理時に同じクエリを受け付けた場合には、キャッシュ用メモリからクエリの結果を読み出し、検索結果として出力することができる。しかしながら、同じクエリを受け付けるとは限らず、また、FCMDB内のデータも更新されていくものであるから、キャッシュ用メモリのヒット率は低く、検索処理の高速化を図ることができない。
【0017】
そこで、この発明は、上述した従来技術の課題を解決するためになされたものであり、検索処理時のFCMDB間の通信回数を減らし、検索処理の高速化を図ることを目的とする。
【課題を解決するための手段】
【0018】
本願の開示する構成情報管理装置は、一つの態様において、管理対象に関する情報を示す構成要素と構成要素間の接続関係に関する情報を示す要素関係とを他の構成情報管理装置と分散して記憶する構成情報記憶部を有する。そして、構成情報管理装置は、接続関係にある構成要素および要素関係の一群であるクラスタについて登録要求を受け付けた場合に、クラスタの格納先を決定し、構成情報憶部または他の構成情報管理装置に格納するように制御する。そして、構成情報管理装置は、構成要素または要素関係を検索対象とした検索要求を受け付けた場合に、検索対象を含むクラスタの格納先を特定し、クラスタの格納先から検索対象の構成要素または要素関係を検索する。
【発明の効果】
【0019】
本願の開示する構成情報管理装置、分散情報管理システム、分散情報管理方法および分散情報管理プログラムの一つの態様によれば、検索処理時のFCMDB間の通信回数を減らし、検索処理の高速化を実現するという効果を奏する。
【図面の簡単な説明】
【0020】
【図1】図1は、実施例1に係る構成情報管理装置の構成を示すブロック図である。
【図2】図2は、実施例2に係るFCMDBの構成を示すブロック図である。
【図3】図3は、クラスタ検索表のデータ構造を説明するための図である。
【図4】図4は、FCMDB検索表のデータ構造を説明するための図である。
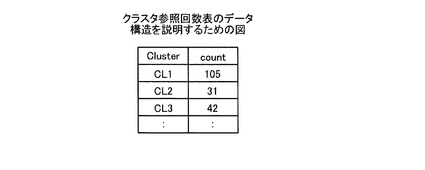
【図5】図5は、クラスタ参照回数表のデータ構造を説明するための図である。
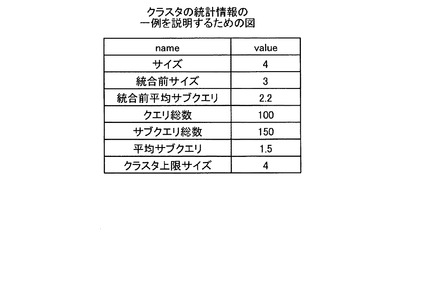
【図6】図6は、クラスタの統計情報の一例を説明するための図である。
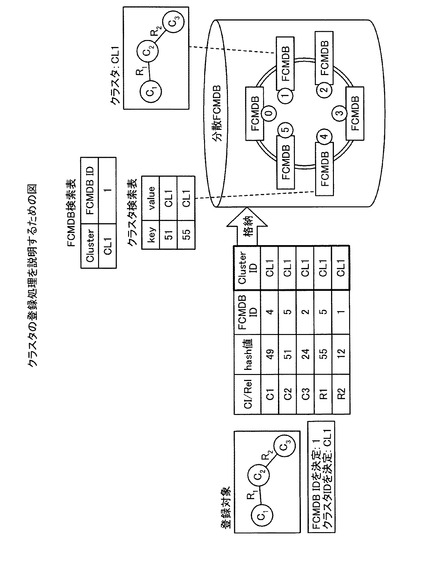
【図7】図7は、クラスタの登録処理を説明するための図である。
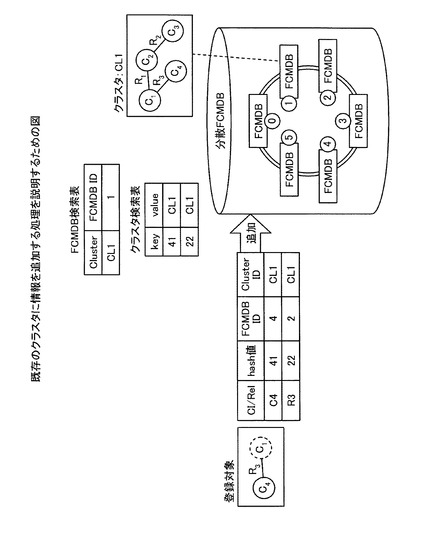
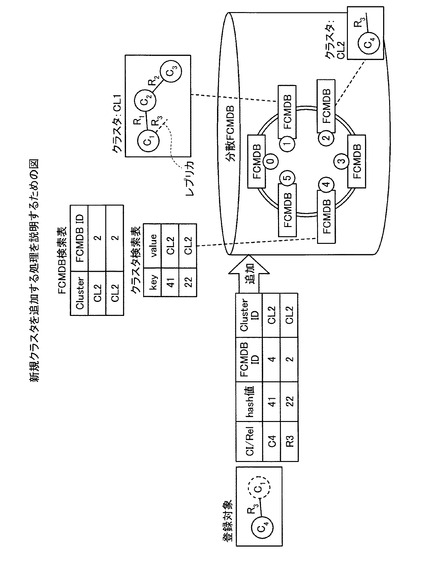
【図8】図8は、既存のクラスタに情報を追加する処理を説明するための図である。
【図9】図9は、新規クラスタを追加する処理を説明するための図である。
【図10】図10は、同一FCMDB内で検索が終了する検索処理を説明するための図である。
【図11】図11は、FCMDBをまたがった検索処理を説明するための図である。
【図12】図12は、クラスタの再配置処理を説明するための図である。
【図13】図13は、クラスタの統合処理を説明するための図である。
【図14】図14は、クラスタの分割処理を説明するための図である。
【図15】図15は、クラスタ上限サイズ決定処理を説明するための図である。
【図16】図16は、各FCMDBに記憶されるクラスタと検索に必要なサブクエリとの関係を説明するための図である。
【図17】図17は、登録処理を説明するためのフローチャートである。
【図18−1】図18−1は、検索処理を説明するためのフローチャートである。
【図18−2】図18−2は、検索処理を説明するためのフローチャートである。
【図19】図19は、クラスタの再配置または統合処理の実行を判断するフローチャートである。
【図20】図20は、クラスタの再配置処理を説明するためのフローチャートである。
【図21】図21は、クラスタの統合処理を説明するためのフローチャートである。
【図22】図22は、クラスタの分割処理を説明するためのフローチャートである。
【図23】図23は、クラスタの上限サイズを決定する処理を説明するためのフローチャートである。
【図24】図24は、FCMDBを説明するための図である。
【図25】図25は、分散FCMDBを説明するための図である。
【図26】図26は、分散FCMDBにおける登録処理を説明するための図である。
【図27】図27は、従来の分散FCMDBにおける検索処理を説明するための図である。
【発明を実施するための形態】
【0021】
以下に添付図面を参照して、この発明に係る構成情報管理装置、分散情報管理システム、分散情報管理方法および分散情報管理プログラムの実施例を詳細に説明する。
【実施例1】
【0022】
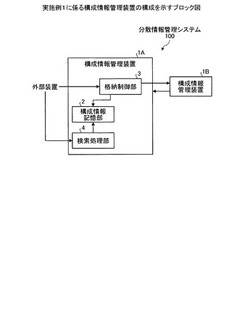
まず最初に、図1を用いて、実施例1に係る構成情報管理装置の構成を説明する。図1は、実施例1に係る構成情報管理装置の構成を示すブロック図である。図1に示すように、分散情報管理システム100は、複数の構成情報管理装置1A、1Bを有し、構成情報管理装置1Aと構成情報管理装置1Bとが接続されている。また、構成情報管理装置1Aは、構成情報記憶部2、格納制御部3、検索処理部4を有する。
【0023】
構成情報記憶部2は、管理対象に関する情報を示す構成要素と構成要素間の接続関係に関する情報を示す要素関係とを他の構成情報管理装置と分散して記憶する。格納制御部3は、接続関係にある構成要素および要素関係の一群であるクラスタについて登録要求を受け付けた場合に、該クラスタの格納先を決定し、構成情報記憶部2または他の構成情報管理装置1Bに格納するように制御する。
【0024】
検索処理部4は、構成要素または要素関係を検索対象とした検索要求を受け付けた場合に、検索対象を含むクラスタの格納先を特定し、クラスタの格納先から検索対象の構成要素または前記要素関係を検索する。
【0025】
つまり、分散情報管理システム100では、接続関係にある構成要素および要素関係の一群であるクラスタを一つの構成情報管理装置に配置する結果、検索処理時のFCMDB間の通信回数を減らし、検索処理の高速化を実現することが可能である。
【0026】
このように、構成情報管理装置1は、管理対象に関する情報を示す構成要素と構成要素間の接続関係に関する情報を示す要素関係とを他の構成情報管理装置と分散して記憶する構成情報記憶部2を有する。そして、構成情報管理装置1は、接続関係にある構成要素および要素関係の一群であるクラスタについて登録要求を受け付けた場合に、クラスタの格納先を決定し、構成情報憶部2または他の構成情報管理装置1Bに格納するように制御する。そして、構成情報管理装置1は、構成要素または要素関係を検索対象とした検索要求を受け付けた場合に、検索対象を含むクラスタの格納先を特定し、クラスタの格納先から検索対象の構成要素または要素関係を検索する。このため、検索処理時のFCMDB間の通信回数を減らし、検索処理の高速化を実現することが可能である。
【実施例2】
【0027】
[FCMDBの構成]
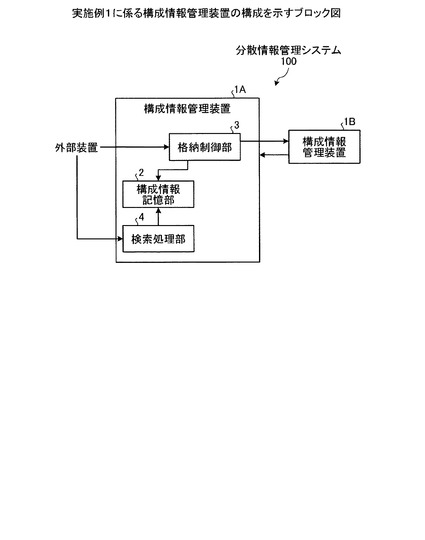
次に、図2を用いて、FCMDBの構成を説明する。図2は、実施例2に係るFCMDBの構成を示すブロック図である。同図に示すように、このFCMDB10は、データ登録サービス処理部11、クラスタ検索表記憶部12、FCMDB検索表記憶部13、ローカルデータ記憶部14を有する。また、FCMDB10は、クラスタ最適化実行部15、参照回数記憶部16、データ検索サービス受付部17、FCMDB間データ送受信部18を有する。かかるFCMDB10は、ネットワークを介してクライアント端末、MDR、他のFCMDBと接続される。以下にこれらの各部の処理を説明する。
【0028】
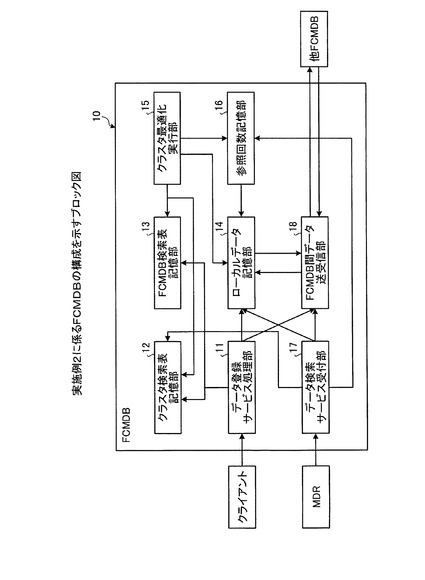
クラスタ検索表記憶部12は、CIおよびリレーションシップのハッシュ値と、接続関係にあるCIおよびリレーションシップの一群であるクラスタを一意に識別するクラスタIDとが対応付けられたクラスタ検索表を記憶する。具体的には、クラスタ検索表記憶部12は、図3に例示するように、CIおよびリレーションシップのハッシュ値を示す「Key」とクラスタIDを示す「Value」とが対応付けて記憶されている。図3は、クラスタ検索表のデータ構造を説明するための図である。
【0029】
FCMDB検索表記憶部13は、クラスタIDとクラスタを保持するFCMDBIDを記憶する。具体的には、図4に例示するように、クラスタを一意に識別するクラスタIDを示す「Cluster」とクラスタを保持するFCMDBを一意に識別する「FCMDB ID」とを対応付けて記憶する。図4は、FCMDB検索表のデータ構造を説明するための図である。
【0030】
参照回数記憶部16は、クラスタをまたいで参照された回数を記憶する。具体的には、参照回数記憶部16は、図5に例示するように、クラスタを一意に識別するクラスタIDを示す「Cluster」と、そのクラスタをまたいで参照した回数(サブクエリ発行数)を示す「count」とを対応付けて記憶する。
【0031】
ローカルデータ記憶部14は、管理対象に関する情報を示すCIと、CI間の接続関係を示すリレーションシップとを記憶する。具体的には、ローカルデータ記憶部14は、後述するデータ登録サービス処理部11によって格納するように通知されたCIまたはリレーションシップを記憶する。なお、リレーションシップは、接続するCIを示すsourceおよびtargetをデータとして保持する。
【0032】
また、ローカルデータ記憶部14は、自記憶部に記憶されているクラスタに関する統計情報を記憶する。具体的には、ローカルデータ記憶部14は、図6に例示するように、クラスタ内のCI数である「サイズ」、統合前のサイズである「統合前サイズ」、統合前の平均サブクエリである「統合前平均サブクエリ」を記憶する。また、ローカルデータ記憶部14は、図6に例示するように、クラスタに対するクエリがあるたびに値が1加算されるクエリの総数である「クエリ総数」を記憶する。また、ローカルデータ記憶部14は、図6に例示するように、クラスタ内でクエリが収まった場合は1加算され、外のクラスタにまたがってサブクエリが発行された場合には、サブクエリが発行されるたびに加算される「サブクエリ総数」を記憶する。
【0033】
また、ローカルデータ記憶部14は、図6に例示するように、サブクエリ総数をクエリ総数で除算した値である「平均サブクエリ」、クラスタサイズの上限値である「クラスタ上限サイズ」を記憶する。例えば、「クラスタ上限サイズ」は、初期値が「3」であるが、後述するクラスタ最適化実行部15によって値が変化する。
【0034】
データ登録サービス処理部11は、接続関係にあるCIおよびリレーションシップの一群であるクラスタについて登録要求を受け付けた場合に、クラスタの格納先を決定し、ローカルデータ記憶部14または他のFCMDBに格納するように制御する。
【0035】
また、データ登録サービス処理部11は、格納したCIおよびリレーションシップの一群について、各CIおよび各リレーションシップの格納先をそれぞれ決定し、CIおよびリレーションシップの一群の格納先を示すクラスタ検索表およびFCMDB検索表を格納するように制御する。
【0036】
ここで、図7の例を用いて、クラスタ登録処理を具体的に説明する。図7は、クラスタの登録処理を説明するための図である。図7の例では、登録対象である3つのCI(C1、C2、C3)と二つのリレーションシップ(R1、R2)とが接続されたデータの塊をクラスタとする。
【0037】
FCMDB10は、登録対象である3つのCI(C1、C2、C3)と二つのリレーションシップ(R1、R2)の登録要求を受け付けると、クラスタ検索表記憶部12が保持するクラスタ検索表で検索対象を検索し、登録対象のクラスタがすでにFCMDBに存在するか判定する。この結果、登録を受け付けたFCMDB10は、登録対象の属するクラスタがFCMDBに存在しない場合には、クラスタが管理するFCMDB IDをランダムに決定し、さらに、決定されたFCMDB IDと時刻からクラスタIDを決定する。図7の例では、FCMDB IDが「1」で、クラスタIDが「CL1」とする。
【0038】
そして、FCMDB10は、クラスタをFCMDB IDが「1」のFCMDBに格納し、FCMDB検索表にCL1とFCMDB1とを対応付けて記憶させる。続いて、FCMDB10は、クラスタ内部のCIおよびリレーションシップそれぞれのハッシュ値を計算し、各ハッシュ値からそれを管理するFCMDBを決定する。例えば、図7に例示するように、FCMDB10は、C2のハッシュ値が「51」であり、R1のハッシュ値が「55」である場合には、C2およびR1の管理するFCMDBとして、FCMDB IDが「5」のFCMDBを決定する。
【0039】
その後、FCMDB10は、決定されたFCMDBのクラスタ検索表に対して、クラスタIDを登録するように制御する。例えば、FCMDB10は、FCMDB IDが「5」のFCMDBの検索表に対して、C2のハッシュ値「51」とクラスタID「CL1」とを対応付けて記憶するように制御する。つまり、ハッシュ値に対して担当するFCMDBは、従来と同様であるが、FCMDBにCI・リレーションシップのデータそのものではなく、クラスタIDを格納しておき、検索時にCI・リレーションシップのデータを含むクラスタの格納先FCMDBを取得できるようになっている。
【0040】
また、FCMDB10は、登録対象のリレーションシップのソースまたはターゲットとなるCIがすでに存在する場合には、そのCIの属するクラスタに登録対象を追加する。ここで、既存のクラスタに情報を追加する処理について図8を用いて、説明する。図8は、既存のクラスタに情報を追加する処理を説明するための図である。図8に示すように、登録対象であるCI「C4」、リレーションシップ「R3」の登録要求を受け付けると、クラスタ検索表記憶部12が保持するクラスタ検索表で検索対象を検索し、登録対象が属するクラスタがすでにFCMDBに存在するか判定する。
【0041】
この結果、登録を受け付けたFCMDB10は、登録対象の属するクラスタがFCMDBに存在する場合には、C4およびR3が属するクラスタにC4を追加するために、FCMDB IDが「1」のFCMDB「1」にC4、R3を格納する。
【0042】
続いて、FCMDB10は、C4およびR3それぞれのハッシュ値を計算し、各ハッシュ値からそれを管理するFCMDBを決定する。例えば、図8に例示するように、FCMDB10は、C4のハッシュ値が「41」であり、R3のハッシュ値が「22」である場合には、C4の管理するFCMDBとして、FCMDB IDが「4」のFCMDBを決定し、R3の管理するFCMDBとして、FCMDB IDが「2」のFCMDBを決定する。
【0043】
その後、FCMDB10は、決定されたFCMDBのクラスタ検索表に対して、クラスタIDを登録するように制御する。例えば、FCMDB10は、FCMDB IDが「4」のFCMDBの検索表に対して、C4のハッシュ値「41」とクラスタID「CL1」とを対応付けて記憶するように制御する。
【0044】
また、FCMDB10は、登録対象のリレーションシップのソースまたはターゲットとなるCIがすでに存在するが、クラスタ「CL1」のサイズがクラスタ上限サイズを超えてしまう場合には、そのCIの属するクラスタに登録対象を追加しない。ここで、新規クラスタに情報を追加する処理について図9を用いて、説明する。図9は、新規クラスタを追加する処理を説明するための図である。図9に示すように、登録対象であるCI「C4」、リレーションシップ「R3」の登録要求を受け付けると、クラスタ検索表記憶部12が保持するクラスタ検索表で検索対象を検索し、登録対象が属するクラスタがすでにFCMDBに存在するか判定する。
【0045】
この結果、登録を受け付けたFCMDB10は、登録対象の属するクラスタ「CL1」がFCMDB「1」に存在すると判定されたが、C4およびR3をクラスタ「CL1」に追加すると、クラスタ「CL1」のサイズがクラスタ上限サイズを超えてしまう。この場合には、登録を受け付けたFCMDB10は、新規クラスタ「CL2」にC4およびR3を登録し、クラスタ「CL1」にR3のレプリカを登録する。つまり、クラスタのエッジとなるリレーションシップのみレプリカを持たせることで、記憶領域の使用量を抑えつつ、検索処理の高速化を実現する。
【0046】
図2の説明に戻って、データ検索サービス受付部17は、CIまたはリレーションシップを検索対象とした検索要求を受け付けた場合に、検索対象を含むクラスタの格納先を特定し、クラスタの格納先から検索対象のCIまたはリレーションシップを検索する。
【0047】
具体的には、データ検索サービス受付部17は、検索要求であるクエリ式をクライアント端末から受け付けた場合には、クエリの先頭のCIのハッシュ値を計算し、そのハッシュ値を担当するFCMDBのクラスタ検索表からハッシュ値に対応するクラスタIDを取得する。続いて、データ検索サービス受付部17は、FCMDB検索表からクラスタIDに対応するFCMDB IDを取得し、そのFCMDB IDのFCMDBに対してクエリを発行する。
【0048】
そして、クエリを受け付けたFCMDBがクエリを処理し、検索要求を受け付けたFCMDBにクエリの結果を返す。ここで、クエリを受け付けたFCMDBは、接続関係にあるCIまたはリレーションシップの一群であるクラスタを保持するので、サブクエリを発行することなくクエリを処理することができる。その後、検索要求を受け付けたFCMDBのデータ検索サービス受付部17は、クエリの結果を受信すると、クエリの結果を検索結果としてクライアント端末に出力する。
【0049】
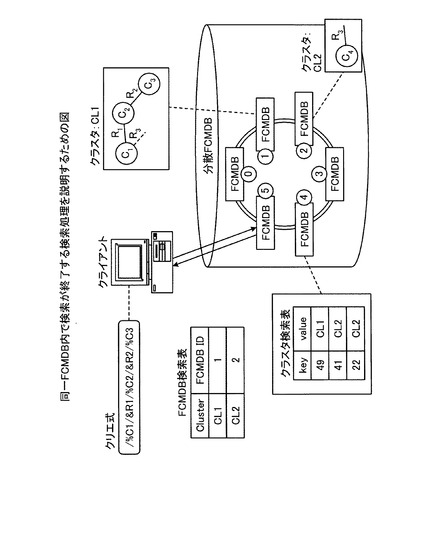
ここで、図10の例を用いて検索処理について説明する。図10は、同一FCMDB内で検索が終了する検索処理を説明するための図である。図10に示すように、FCMDB「5」は、検索要求であるクエリ式「%C1/&R1/%C2/&R2/%C3」をクライアント端末から受け付けた場合には、クエリの先頭のCI「C1」について、ハッシュ値「49」を算出し、FCMDB「4」のクラスタ検索表からハッシュ値に対応するクラスタID「1」を取得する。続いて、FCMDB「5」は、FCMDB検索表からクラスタID「1」に対応するFCMDB ID「1」を取得し、そのFCMDB ID「1」のFCMDBに対してクエリを発行する。
【0050】
そして、クエリを受け付けたFCMDB「1」は、クエリを処理し、検索要求を受け付けたFCMDB「5」にクエリの結果を返す。その後、検索要求を受け付けたFCMDB「5」は、クエリの結果を受信すると、クエリの結果を検索結果としてクライアント端末に出力する。このように、FCMDB「1」がサブクエリを発行することなく検索処理を完了し、検索結果であるCI「C3」を得ることができるので、高速な検索処理を実現することができる。
【0051】
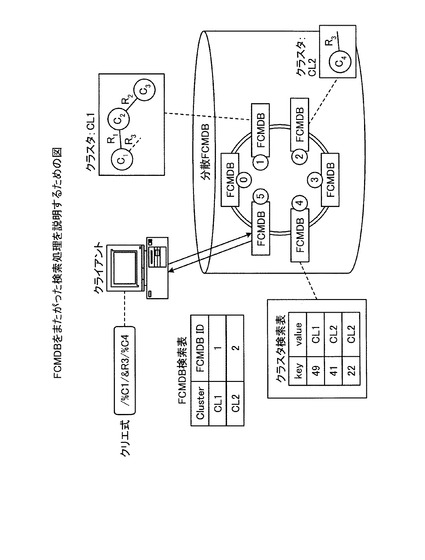
また、FCMDBは、クラスタをまたがったクエリを行う場合がある。このような場合におけるFCMFBの検索処理について、図11を用いて説明する。図11は、FCMDBをまたがった検索処理を説明するための図である。図11に示すように、FCMDB「5」は、検索要求であるクエリ式「%C1/&R3/%C4」をクライアント端末から受け付けた場合には、クエリの先頭のCI「C1」について、ハッシュ値「49」を算出し、FCMDB「4」のクラスタ検索表からハッシュ値に対応するクラスタID「1」を取得する。続いて、FCMDB「5」は、FCMDB検索表からクラスタID「1」に対応するFCMDB ID「1」を取得し、そのFCMDB ID「1」のFCMDBに対してクエリを発行する。
【0052】
そして、クエリを受け付けたFCMDB「1」は、クエリ式に従って探索を行い、R3の先がクラスタ「CL1」に存在しないので、クエリ式の「%C4」以下のクエリを分割してサブクエリとする。続いて、FCMDB「1」は、サブクエリの先頭のCI「C4」について、ハッシュ値「41」を算出し、FCMDB「4」のクラスタ検索表からハッシュ値に対応するクラスタID「2」を取得する。続いて、FCMDB「1」は、FCMDB検索表からクラスタID「2」に対応するFCMDB ID「2」を取得し、そのFCMDB ID「2」のFCMDBに対してサブクエリを発行する。
【0053】
そして、サブクエリを受け付けたFCMDB「2」は、サブクエリ処理を行ってクエリの結果であるC4を検索し、FCMDB「1」を介して、FCMDB「5」にC4を送信する。そして、FCMDB「5」は、クエリの結果であるC4を受信すると、クエリの結果を検索結果としてクライアント端末に出力する。
【0054】
クラスタ最適化実行部15は、クラスタの再配置、統合、分割を実行する。具体的には、クラスタ最適化実行部15は、クラスタの再配置処理として、参照回数記憶部16によって記憶されたクラスタ参照回数表における参照回数をFCMDB IDごとに集計する。そして、各FCMDB IDごとの参照回数合計が所定の閾値以上であって、かつ、そのクラスタの位置するFCMDB IDと参照回数が多かったFCMDBとが異なる場合には、参照回数が多かったFCMDBにクラスタを移動して再配置する。
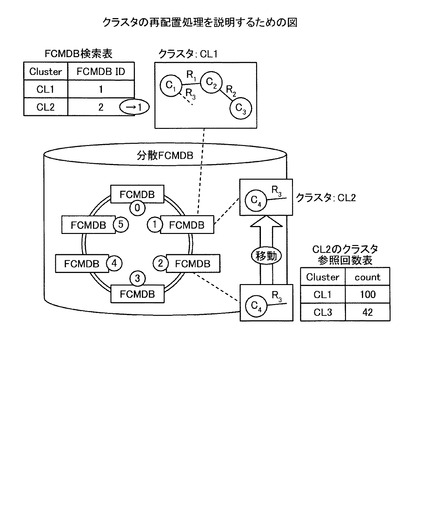
【0055】
例えば、図12の例を用いてクラスタの再配置処理について説明する。図12は、クラスタの再配置処理を説明するための図である。図12に示すように、FCMDB2は、クラスタCL2のクラスタ参照回数表における参照回数をFCMDB IDごとに集計する。そして、FCMDB2は、FCMDB IDが「1」の参照回数合計が閾値「100」以上であって、かつ、そのクラスタの位置するFCMDB ID「2」と参照回数が多かったFCMDB「1」とが異なると判定し、参照回数が多かったFCMDB「1」にクラスタをコピーする。そして、FCMDB2は、クラスタCL2とFCMDB ID「1」とを対応付けて記憶するようにFCMDBノード検索表を修正し、クラスタCL2のデータを削除する。
【0056】
また、クラスタ最適化実行部15は、クラスタの統合処理として、参照回数記憶部16によって記憶されたクラスタ参照回数表における参照回数合計が所定の閾値以上であり、かつ、クラスタが同一のFCMDBに保持されている場合には、クラスタ同士を統合する。
【0057】
例えば、図13の例を用いてクラスタの統合処理について説明する。図13は、クラスタの統合処理を説明するための図である。図13に示すように、FCMDB1は、クラスタCL2のクラスタ参照回数表における参照回数をFCMDB IDごとに集計する。そして、FCMDB1は、FCMDB IDが「1」の参照回数合計が閾値以上であって、かつ、そのクラスタの位置するFCMDB ID「1」と参照回数が多かったFCMDB「1」とが同じであると判定する。
【0058】
この場合に、FCMDB1は、クラスタCL1にクラスタCL2の要素を追加するとともに、クラスタ検索表にあるクラスタIDがCL2のデータをCL1に修正する。そして、FCMDB1は、FCMDBノード検索表にあるクラスタIDがCL2のデータを削除するとともに、クラスタCL2のデータを削除する。つまり、参照回数が大きいクラスタ間は強く関係するもとみなし、同一のクラスタに統合する。
【0059】
また、クラスタ最適化実行部15は、クラスタ統合後、クラスタのサイズがクラスタ上限サイズを超えている場合には、クラスタ内のリレーションシップの参照回数に基づいて分割する。ここで、参照回数とは、各リレーションシップについて、クエリの処理で参照された回数である。例えば、クラスタ最適化実行部15は、クラスタ内のCIについて、接続されたリレーションシップの参照回数の合計が大きいCIを選択する。そして、クラスタ最適化実行部15は、選択されたCIから参照回数の大きいリレーションシップの順にリレーションシップおよびCIを追加していき、CI数がクラスタ上限サイズを超えない範囲で選択したものを新たなクラスタとする。
【0060】
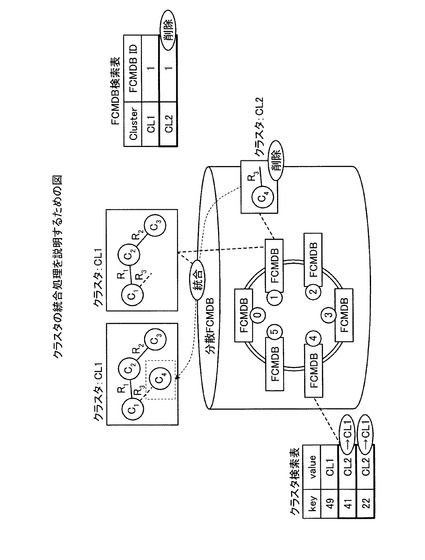
ここで、図14の例を用いてクラスタの分割処理について説明する。図14は、クラスタの分割処理を説明するための図である。図14の例では、クラスタ上限サイズを「3」とする。また、図14の例では、リレーションシップR1の参照回数が「20」であり、リレーションシップR2の参照回数が「25」であり、リレーションR3の参照回数が「10」であるものとする。このため、図14の例では、クラスタ内における各CIであるC1〜C4に接続されたリレーションシップの参照回数の合計について、C1が「30」、C2が「45」、C3が「25」、C4が「10」となる。
【0061】
そして、クラスタ最適化実行部15は、接続されたリレーションシップの参照回数の合計が最も大きい「C2」を選択し、選択された「C2」から参照回数の大きいリレーションシップであるR2およびC3、R1およびC1の順に追加する。そして、クラスタ最適化実行部15は、CI数がクラスタサイズの上限「3」に到達するため、C1、R1、C2、R2、C3およびR3のレプリカを新たなクラスタCL3とし、C4およびR3をクラスタCL4として分割する。
【0062】
また、クラスタ最適化実行部15は、上記の分割処理を行う前であってクラスタ統合後に、サブクエリ数の削減効果に応じて、クラスタ上限サイズを調整する。例えば、クラスタ最適化実行部15は、サイズ増加率よりもサブクエリ数改善率の方が大きいか判定し、サイズ増加率よりもサブクエリ数改善率の方が大きい場合には、クラスタ上限サイズを大きくする。また、クラスタ最適化実行部15は、サイズ増加率よりもサブクエリ数改善率の方が大きくない場合には、クラスタ上限サイズを小さくする。ここで、サイズ増加率とは、クラスタ統合後のサイズをクラスタ統合前のサイズで除算した値であり、サブクエリ数改善率とは、統合後のサブクエリ数を統合前のサブクエリ数で除算した値である。
【0063】
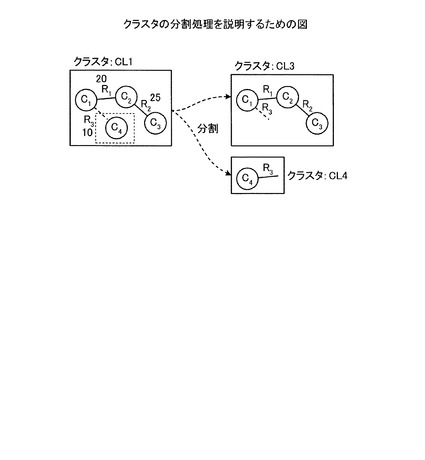
ここで、図15の例を用いてクラスタ上限サイズ決定処理について説明する。図15は、クラスタ上限サイズ決定処理を説明するための図である。図15の例では、クラスタCL3の初期状態は、クラスタのサイズsbが「3」であり、クラスタ上限サイズが「3」であるものとする。そして、統合クラスタが統合された結果、クラスタのサイズsbが「4」であり、統合前サイズsaが「3」となり、サイズ増加率sb/sa=1.33となる。また、統合前平均サブクエリqaが「2.2」であり、平均サブクエリqbが「1.5」であり、サブクエリ数改善率qa/qb=1.47となる。そして、FCMDBは、サイズ増加率sb/sa「1.33」とサブクエリ数改善率qa/qb「1.47」とを比較し、サイズ増加率よりもサブクエリ数改善率の方が大きいと判定し、クラスタ上限サイズ「3」を統合後のクラスタサイズである「4」に調整する。
【0064】
さらに、統合クラスタが統合された結果、クラスタのサイズsbが「6」であり、統合前サイズsaが「4」となり、サイズ増加率sb/sa=1.5となる。また、統合前平均サブクエリqaが「1.5」であり、平均サブクエリqbが「1.3」であり、サブクエリ数改善率qa/qb=1.15となる。そして、FCMDBは、サイズ増加率sb/sa「1.5」とサブクエリ数改善率qa/qb「1.15」とを比較し、サイズ増加率よりもサブクエリ数改善率の方が小さいと判定し、クラスタ上限サイズ「4」統合前サイズの「4」のままとする。この場合には、FCMDBは、クラスタのサイズがクラスタ上限サイズを超えているので、上記した分割処理を実行する。
【0065】
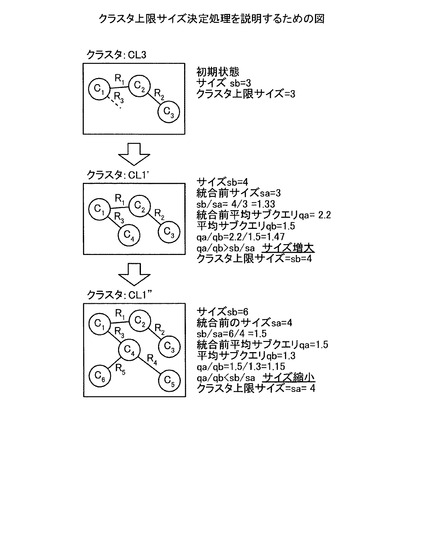
上記のように、関連が高いCIおよびリレーションシップ群を登録するので、図16に示すように、例えば、FCMDB1における同一クラスタ内のC1からC2への探索を行う場合に、サブクエリを最低1回発行するだけよい。また、各FCMDBにCIまたはリレーションシップのレプリカを格納しないので、データ量が少なくてよい。図16は、各FCNDBに記憶されるクラスタと検索に必要なサブクエリとの関係を説明するための図である。
【0066】
[FCMDBによる処理]
次に、図17〜図23を用いて、実施例2に係るFCMDB10による処理を説明する。図17は、登録処理を説明するためのフローチャートである。図18−1および図18−2は、検索処理を説明するためのフローチャートである。図19は、クラスタの再配置処理または統合処理の実行を判断する処理を説明するためのフローチャートである。図20は、クラスタの再配置処理を説明するためのフローチャートである。図21は、クラスタの統合処理を説明するためのフローチャートである。図22は、クラスタの分割処理を説明するためのフローチャートである。図23は、クラスタの上限サイズを決定する処理を説明するためのフローチャートである。
【0067】
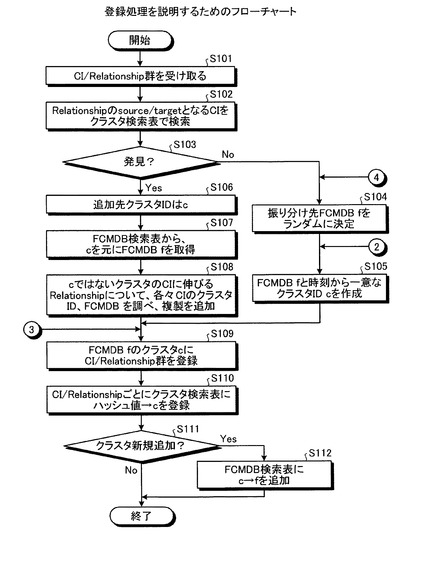
図17に示すように、FCMDB10は、CI/リレーションシップ群を受信すると(ステップS101)、受信したリレーションシップのsourceまたはtargetとなるCIをクラスタ検索表で検索する(ステップS102)。そして、FCMDB10は、検索の結果、クラスタ検索表からsourceまたはtargetとなるCIを発見したか判定する(ステップS103)。
【0068】
この結果、FCMDB10は、クラスタ検索表からsourceまたはtargetとなるCIを発見しなかった場合には、CI/リレーションシップ群の振り分け先FCMDB(f)をランダムに決定する(ステップS104)。そして、FCMDB10は、振り分け先FCMDB(f)と現時刻から、一意のクラスタID(c)を作成する(ステップS105)。
【0069】
そして、FCMDB10は、FCMDB(f)にクラスタID(c)としてCI/リレーションシップ群を登録し(ステップS109)、CI/リレーションシップごとのハッシュ値をクラスタ検索表に登録する(ステップS110)。その後、FCMDB10は、クラスタ(c)を新規追加したか判定し(ステップS111)、クラスタ(c)を新規追加していないと判定された場合には、処理を終了する。また、FCMDB10は、クラスタ(c)を新規追加したと判定された場合には、FCMDB検索表に、クラスタID(c)と、FCMDBのID(f)とを対応付けて追加する(ステップS112)。
【0070】
また、ステップS103に戻って、FCMDB10は、クラスタ検索表からsourceまたはtargetとなるCIを発見した場合には、発見されたクラスタのID(c)を取得する(ステップS106)。そして、FCMDB10は、FCMDB検索表から、クラスタ(c)が登録されたFCMDB(f)を取得する(ステップS107)。その後、FCMDB10は、クラスタ(c)以外のクラスタが有するCIをsourceまたはtargetとするリレーションシップについて、各々CIのクラスタID、FCMDBを調べ、リレーションシップのレプリカを追加する。(ステップS108)。
【0071】
そして、FCMDB10は、FCMDB(f)にクラスタID(c)としてCI/リレーションシップ群を登録し(ステップS109)、CI/リレーションシップごとのハッシュ値をクラスタ検索表に登録する(ステップS110)。その後、FCMDB10は、クラスタ(c)を新規追加したか判定し(ステップS111)、クラスタ(c)を新規追加していないと判定された場合には、処理を終了する。また、FCMDB10は、クラスタ(c)を新規追加したと判定された場合には、FCMDB検索表に、クラスタID(c)と、FCMDBのID(f)とを対応付けて追加する(ステップS112)。
【0072】
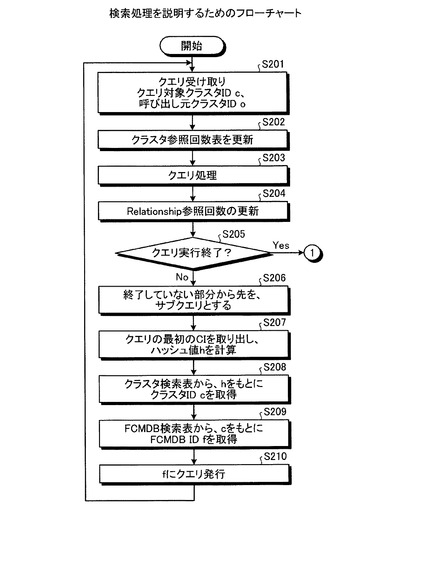
次に、図18−1および図18−2を用いて検索処理の処理手順を説明する。図18−1に示すように、FCMDB10は、クエリ対象クラスタのIDが(c)で、呼び出し元クラスタのIDが(o)であるクエリを受信する(ステップS201)。そして、FCMDB10は、クラスタ参照回数表を更新し(ステップS202)、受信されたクエリの処理を実行する(ステップS203)。
【0073】
続いて、FCMDB10は、リレーションシップ参照回数を更新し(ステップS204)、受信されたクエリの処理を最後まで実行したか判定する(ステップS205)。この結果、FCMDB10は、FCMDB10は、受信されたクエリの処理を最後まで実行した場合には、ステップS211に進む。また、受信されたクエリの処理を最後まで実行していない場合には、終了していない部分から先をサブクエリとする(ステップS206)。
【0074】
そして、FCMDB10は、サブクエリの最初のCIを取り出し、ハッシュ値(h)を計算し(ステップS207)、クラスタ検索表からハッシュ値(h)をもとにクラスタID(c)を取得する(ステップS208)。続いて、FCMDB10は、FCMDB検索表からクラスタID(c)をもとにFCMDBID(f)を取得し(ステップS209)、FCMDB(f)へクエリを送信する(ステップS210)。そして、クエリを受信したFCMDBは、ステップS201の処理を開始する。
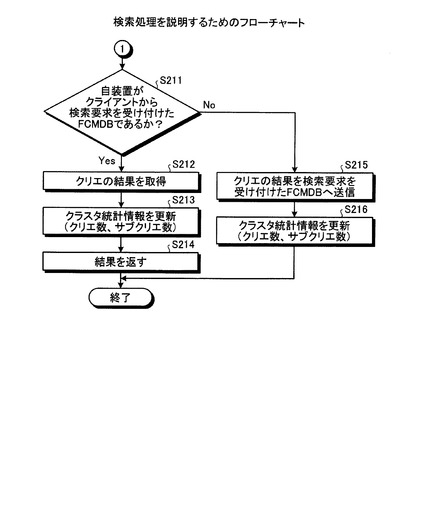
【0075】
その後、FCMDB10は、自装置がクライアントからクエリを受信したFCMDBか判定し(ステップS211)、自装置がクエリを受信したFCMDBである場合には、クエリの結果を取得する(ステップS212)。そして、FCMDB10は、クラスタ統計情報を更新し(ステップS213)、クライアントにクエリの結果を返す(ステップS214)。また、FCMDB10は、自装置がクエリを受信したFCMDBでない場合には、クエリの結果を検索要求を受け付けたFCMDBへ送信し(ステップS215)、クラスタ統計情報を更新する(ステップS216)。
【0076】
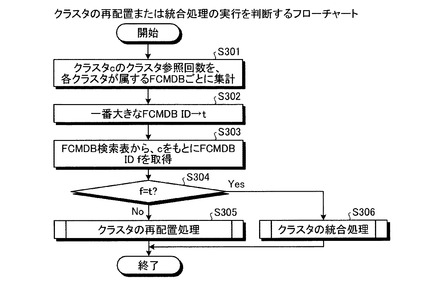
次に、図19を用いて、クラスタの再配置処理または統合処理の実行を判断する処理を説明する。図19に示すように、FCMDB10は、クラスタ(c)に対するクラスタ参照回数を各クラスタが属するFCMDBごとに集計する(ステップS301)。そして、FCMDB10は、クラスタ(c)に対するクラスタ参照回数が最も大きいFCMDB(t)を特定する(ステップS302)。
【0077】
そして、FCMDB10は、FCMDB検索表から、クラスタ(c)が記憶されたFCMDB(f)を取得する(ステップS303)。そして、FCMDB(t)とFCMDB(f)とが同一であるか判定し(ステップS304)、FCMDB(t)とFCMDB(f)とが同一でない場合には、クラスタの再配置処理(後に、図20を用いて詳述)を行う(ステップS305)。また、FCMDB10は、FCMDB(t)とFCMDB(f)とが同一である場合には、クラスタの統合処理(後に、図21を用いて詳述)を行う(ステップS306)。
【0078】
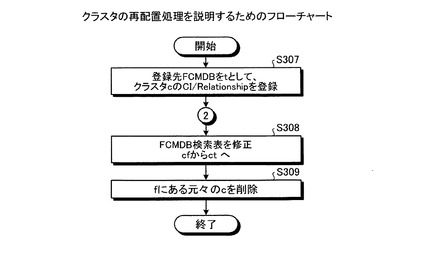
次に、図20を用いて、クラスタの再配置処理を説明する。図20に示すように、FCMDB10は、登録先FCMDBをtとして、クラスタ(c)のCI/リレーションシップを登録し(ステップS307)、クラスタ分割処理(後に図22を用いて後述)に移行した後、FCMDB検索表のうちクラスタ(c)を記憶するFCMDB(f)をFCMDB(t)へ修正する(ステップS308)。その後、FCMDBは、FCMDB(f)に記憶された元々のクラスタ(c)を削除して(ステップS309)、処理を終了する。
【0079】
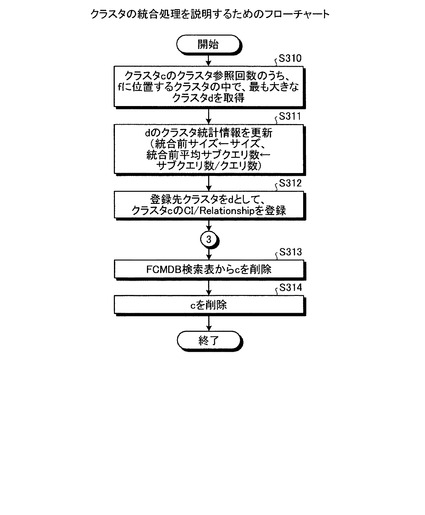
次に、図21を用いて、クラスタの統合処理を説明する。図21に示すように、FCMDB10は、FCMDB(f)に記憶されたクラスタのうち、クラスタ参照回数が最も大きなクラスタ(d)を取得する(ステップS310)。そして、FCMDB10は、クラスタ(d)のクラスタ統計情報のうち、統合前のサイズを現在のサイズに更新し、統合前平均サブクエリ数をサブクエリ数/クエリ数に更新する(ステップS311)。
【0080】
その後、FCMDB10は、クラスタ(c)のCI/Relatopmshipをクラスタ(d)に登録し(ステップS312)、ステップS109に移行して登録処理を行う。その後、FCMDB10は、FCMDB検索表からクラスタ(c)を削除し(ステップS313)、FCMDB(f)に記憶されたクラスタ(c)を削除して(ステップS314)、処理を終了する。
【0081】
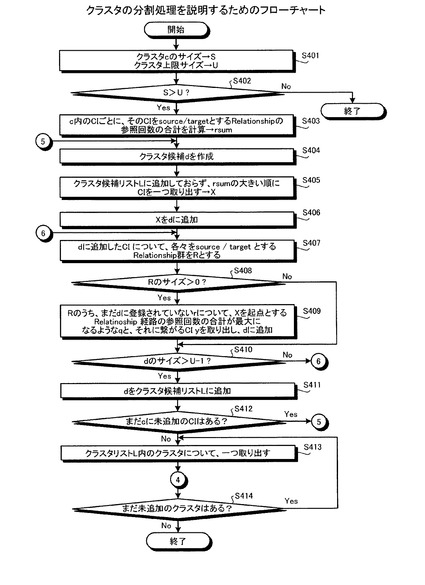
次に、図22を用いて、クラスタの分割処理を説明する。図22に示すように、FCMDBは、クラスタ(c)のサイズSとクラスタ上限サイズUを判定する(ステップS401)。この結果、クラスタ(c)のサイズSがクラスタ上限サイズUよりも大きいか判定する(ステップS402)。この結果、FCMDB10は、クラスタ(c)のサイズSがクラスタ上限サイズUよりも大きくない場合には、クラスタの分割処理を終了する。
【0082】
また、FCMDB10は、クラスタ(c)のサイズSがクラスタ上限サイズUよりも大きい場合には、クラスタ(c)内のCIごとに、そのCIをsourceまたはtargetとするリレーションシップの参照回数の合計を計算する(ステップS403)。そして、FCMDB10は、新たなクラスタ候補としてクラスタ(d)を作成し(ステップS404)、クラスタ候補リストLに追加しておらず、リレーションシップの参照回数の大きい順にCI(x)を一つ取り出す(ステップS405)。
【0083】
続いて、FCMDB10は、CI(x)をクラスタ(d)に追加し(ステップS406)、クラスタ(d)に追加された各CIをsourceまたはtargetとするリレーションシップの一群(R)を選択する(ステップS407)。そして、FCMDB10は、Rのサイズが0よりも大きいか判定する(ステップS408)。その後、FCMDB10は、Rのサイズが0よりも大きい場合には、Rlationship群(R)のうち、CI(x)を起点としてリレーションシップ経路の参照回数の合計が最大となるようなリレーションシップ(q)とそれにつながるCI(y)とをクラスタ(d)に追加する(ステップS409)。
【0084】
そして、FCMDB10は、クラスタ(d)のサイズがクラスタ上限サイズUに1を減算した値U−1よりも大きいか判定し(ステップS410)、クラスタ(d)のサイズがU−1よりも大きくない場合には、ステップS407の処理に戻る。また、FCMDB10は、クラスタ(d)のサイズがU−1よりも大きい場合には、クラスタ(d)をクラスタ候補リストLに追加し(ステップS411)、まだクラスタ(c)に追加されていないCIが存在するか判定する(ステップS412)。
【0085】
この結果、FCMDB10は、まだクラスタ(c)に追加されていないCIが存在する場合には、ステップS404の処理に戻る。また、FCMDB10は、クラスタ(c)に追加されていないCIが存在しない場合には、クラスタ候補リストL内のクラスタについて、まだ登録されていないクラスタを一つ取り出す(ステップS413)。そして、FCMDB10は、ステップS104の処理に移行して、登録処理を行い、クラスタ候補リストL内に未追加のクラスタはあるか判定する(ステップS414)。この結果、FCMDB10は、クラスタ候補リストL内に未追加のクラスタはある場合には、ステップS413に戻る。また、FCMDB10は、クラスタ候補リストL内に未追加のクラスタはある場合には、処理を終了する。
【0086】
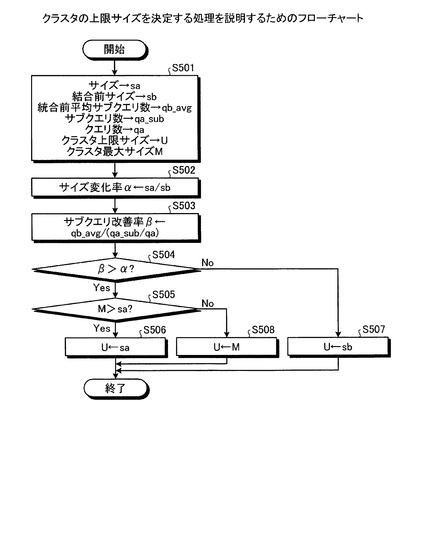
次に、図23を用いて。クラスタの上限サイズを決定する処理を説明する。図23に示すように、FCMDB10は、クラスタの統計情報を取得する(ステップS501)。ここでクラスタの統計情報とは、クラスタのサイズ、クラスタの結合前のサイズ、統合前平均サブクエリ数、サブクエリ数、クエリ数、クラスタ上限サイズ、クラスタ最大サイズのことをいう。
【0087】
そして、FCMDB10は、サイズ変化率αを算出し(ステップS502)、サブクエリ改善率βを算出する(ステップS503)。続いて、FCMDB10は、サブクエリ改善率βがサイズ変化率αよりも大きいか判定し(ステップS504)、サブクエリ改善率βがサイズ変化率αよりも大きくない場合には、クラスタ上限サイズUを結合前サイズsbと同じ値になるよう調整する(ステップ507)。
【0088】
また、FCMDB10は、サブクエリ改善率βがサイズ変化率αよりも大きい場合には、クラスタ最大サイズMがクラスタサイズsaよりも大きいか判定する(ステップS505)。この結果、FCMDB10は、クラスタ最大サイズMがクラスタサイズsaよりも大きい場合には、クラスタ上限サイズUをクラスタサイズsaと同じ値になるよう調整して(ステップS506)、処理を終了する。また、FCMDB10は、クラスタ最大サイズMがクラスタサイズsaよりも大きくない場合には、クラスタ上限サイズUをクラスタ最大サイズMと同じ値に調整して(ステップS508)、処理を終了する。
【0089】
[実施例2の効果]
上述してきたように、FCMDB10は、管理対象に関する情報を示すCIとCI間の接続関係に関する情報を示すリレーションシップとを他のFCMDBと分散して記憶するローカルデータ記憶部14を有する。そして、FCMDB10は、接続関係にあるCIおよびリレーションシップの一群であるクラスタについて登録要求を受け付けた場合に、クラスタの格納先を決定し、ローカルデータ記憶部14または他のFCMDBに格納するように制御する。そして、FCMDB10は、CIまたはリレーションシップを検索対象とした検索要求を受け付けた場合に、検索対象を含むクラスタの格納先を特定し、クラスタの格納先から検索対象のCIまたはリレーションシップを検索する。このため、検索処理時のFCMDB間の通信回数を減らし、検索処理の高速化を実現することが可能である。
【0090】
また、実施例2によれば、FCMDB10は、検索処理において複数のクラスタ間をまたいで参照回数が所定の閾値以上であって、かつ、複数のクラスタそれぞれが異なるFCMDBに格納されている場合には、複数のクラスタが格納されるFCMDBが同じになるように再配置する。このため、参照回数からクラスタ間をまたがった検索であるサブクエリが発生する回数が多いクラスタ同士を同じるFCMDBに格納することで、ネットワーク経由のサブクエリを低減し、検索処理の高速化を実現することが可能である。
【0091】
また、実施例2によれば、FCMDB10は、検索処理において複数のクラスタ間をまたいで参照した回数が所定の閾値以上であって、かつ、複数のクラスタが同じFCMDBに格納されている場合には、クラスタ同士を統合する。このため、参照回数からクラスタ間をまたがった検索であるサブクエリが発生する回数が多いクラスタ同士を一つのクラスタとすることで、ネットワーク経由のサブクエリを低減し、検索処理の高速化を実現することが可能である。
【0092】
また、実施例2によれば、FCMDB10は、クラスタに含まれるCIおよびリレーションシップの数がクラスタ上限サイズ以上である場合には、クラスタ内のリレーションシップが検索処理時に参照された回数を用いて、クラスタを分割する。このため、大きくなりすぎたクラスタの大きさを最適化させることで、クエリの分散に役立ち、関連検索を高速化することが可能である。
【0093】
また、実施例2によれば、FCMDB10は、クラスタ間をまたいだ検索処理の回数の削減数とクラスタに含まれるCIおよびリレーションシップの増加数との関係に応じて、クラスタ上限サイズを設定する。このため、クラスタの上限サイズをサブクエリの削減度合いに応じて調整することで、サブクエリを削減しつつ、クエリの分散に役立ち、関連検索を高速化することが可能である。
【実施例3】
【0094】
さて、これまで実施例1、2について説明したが、本実施例は上述した実施例以外にも、種々の異なる形態にて実施されてよいものである。そこで、以下では実施例3として本発明に含まれる他の実施例を説明する。
【0095】
(1)システム構成等
また、図示した各装置の各構成要素は機能概念的なものであり、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散・統合の具体的形態は図示のものに限られず、その全部または一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的または物理的に分散・統合して構成することができる。例えば、データ登録サービス処理部11とクラスタ検索表記憶部12を統合してもよい。
【0096】
(2)プログラム
なお、本実施例で説明した分散情報管理方法は、あらかじめ用意されたプログラムをパーソナルコンピュータやワークステーションなどのコンピュータで実行することによって実現することができる。このプログラムは、インターネットなどのネットワークを介して配布することができる。また、このプログラムは、ハードディスク、フレキシブルディスク(FD)、CD−ROM、MO、DVDなどのコンピュータで読み取り可能な記録媒体に記録され、コンピュータによって記録媒体から読み出されることによって実行することもできる。
【符号の説明】
【0097】
1A、1B 構成情報管理装置
2 構成情報記憶部
3 格納制御部
4 検索処理部
10 FCMDB
11 データ登録サービス処理部
12 クラスタ検索表記憶部
13 FCMDB検索表記憶部
14 ローカルデータ記憶部
15 クラスタ最適化実行部
16 参照回数記憶部
17 データ検索サービス受付部
18 FCMDB間データ送受信部
【技術分野】
【0001】
本発明は、構成情報管理装置、分散情報管理システム、分散情報管理方法および分散情報管理プログラムに関する。
【背景技術】
【0002】
近年、ITシステムは、オープン化やマルチベンダー化が進んでおり、サーバ台数の増加やストレージ容量の増大と相まって大規模化・複雑化している。このため、運用コストが増大しているだけでなく、人的ミスによるシステム停止やサービス品質低下の多発が大きな問題となっている。そこで、こうした問題を解決するため、サーバやストレージ、アプリケーションといったITシステムの構成情報の管理が重要となる。
【0003】
ITシステムの構成情報を管理する装置として、MDR(Management Data Repository)と呼ばれるデータベースが知られている。MDRは、ITシステムの運用管理データを保持し、運用管理ミドルウェアのデータベースに相当する。
【0004】
ここで、データセンタの運用においては、サーバ管理やネットワーク管理、サービス管理、資産管理など、それぞれの管理業務に最適化された運用管理ミドルウェアが存在する。また、各運用管理ミドルウェアは、固有のMDRを有し、それぞれの業務に関する構成情報をMDRに入力する。このように、各MDRは構成情報を他のMDRと独立して管理するため、MDRへのアクセス方法やMDRで管理される構成情報のデータ形式がMDRごとに異なる場合があり、各MDRを連携させる場合は人を介さざるをえないのが実情であった。
【0005】
そこで、複数のMDRに散在する各種の構成情報を仮想的に統合するFCMDB(Federated Configuration Management Database)と呼ばれるデータベースを有する分散情報管理システムが開発された。例えば、図24に示すように、分散情報管理システムは、複数のMDRおよびFCMDBを有し、MDRとFCMDBとはネットワークを介して接続されている。図24は、FCMDBを説明するための図である。
【0006】
各MDRは、ITシステム内に存在する機器等の構成に関する情報を管理する。かかる複数のMDRは、MDRごとに扱うデータの種別・量が異なる。例えば、図24に示すように、MDR1が設計情報を管理し、MDR2が製品情報を管理し、MDR3が性能情報を管理し、MDR4が構成情報を管理する。
【0007】
FCMDBは、複数のMDRに分散して管理される同一対象に関する構成情報を統合して管理する。具体的には、FCMDBは、ITシステムを構成する機器、ソフトウェア、データログ等の構成要素(CI,Configuration Item)や各CI間の関係(以下、「リレーションシップ」という)を管理する。例えば、図24の例では、FCMDBに管理されているCI「C」とは、MDR1に記憶されている設計情報C’’、MDR3に記憶されている性能情報C^、MDR4に記憶されているC’のデータを統合したものである。
【0008】
このように、FCMDBは、複数のMDRに分散して管理される同一対象に関する構成情報を統合して管理する。これにより、システム管理者等の作業者は、パッチの適用作業やハードウェアの保守作業など、システム運用におけるあらゆるシーンにおいて、FCMDBにより仮想統合された構成情報を参照することでITシステム全体の構成を容易に把握することができる。
【0009】
また、スケーラビリティ向上のため、FCMDBを複数有する分散FCMDBが知られている。図25に示すように、分散FCMDBは、MDRの情報を複数のFCMDBで分散管理し、データ登録やデータ検索を複数のFCMDBで分散処理している。図25は、分散FCMDBを説明するための図である。例えば、図25に示すように、分散FCMDBは、3つのCI(C1、C2、C3)と二つのリレーションシップ(R1、R2)とが接続されたデータを登録する場合に、C1、R2、C2、C3およびR1をそれぞれ異なるFCMDBに分散して登録する。
【0010】
ここで、図26を用いて、分散FCMDBにおける登録処理を具体的に説明する。図26に示すように、分散FCMDBは、3つのCI(C1、C2、C3)と二つのリレーションシップ(R1、R2)とが接続されたデータを登録する場合に、各CIおよび各リレーションシップのIDなどを用いて、それぞれハッシュ値を計算する。そして、各CIおよび各リレーションシップのハッシュ値をキーとして、各CIおよび各リレーションシップをFCMDBに分散して登録する。
【0011】
例えば、図26に示すように、登録要求を受け付けたFCMDBは、C2のハッシュ値「51」を計算し、ハッシュ値「51」を担当する担当FCMDB「5」にC2のデータを転送する。そして、担当FCMDB「5」は、C2のデータを受信し、C2のデータを格納する。担当FCMDB「5」は、ハッシュ値が「51〜59」のCIおよびリレーションシップを担当しており、図26の例では、ハッシュ値「51」のC2とハッシュ値「55」のR1とを格納している。
【0012】
また、分散FCMDBでは、ノードであるCI、エッジであるリレーションシップからなるグラフが分散格納されているため、FCMDBがクライアント端末から検索要求を受け付けた場合に、FCMDB間で通信を行って検索処理を行う。ここで、図27を用いて、分散FCMDBにおける検索処理を具体的に説明する。図27に示すように、分散FCMDBにおけるFCMDB1が検索要求として、クエリ「%CI1/&R1/%CI2/&R2/%CI3」を受け付けた場合の検索処理について説明する。ここで、クエリ「%CI1/&R1/%CI2/&R2/%CI3」とは、C1とR1で関連付いているC2と、さらにR2で関連付いているC3との検索を要求するクエリである。
【0013】
検索要求を受け付けたFCMDB5は、先頭のC1を検索し、C1を保持するFCMDB4と通信を行ってC1のIDを得る。そして、FCMDBは、C1のIDをソースICまたはターゲットICとするR1を検索し、自装置からC2のIDを得る。続いて、検索要求を受け付けたFCMDB5は、C2のIDをソースICまたはターゲットICとするR2を検索し、R2を保持するFCMDB1と通信を行ってC3のIDを得る。そして、FCMDBは、C3のIDを元に、C3を保持するFCMDB2を特定し、FCMDBと通信を行ってC3の情報を得る。その後、FCMDBは、クライアント端末に対してCI3のデータを検索結果として出力する。
【先行技術文献】
【特許文献】
【0014】
【特許文献1】特開2009−169863号公報
【特許文献2】特開2004−272369号公報
【発明の概要】
【発明が解決しようとする課題】
【0015】
しかしながら、上記した分散FCMDBの技術では、CI、リレーションシップが各FCMDBに分散して登録させているので、検索時にはリレーションシップを辿るような検索処理を行う結果、FCMDB間で通信を頻繁に行って検索処理を実行することとなる。このため、検索処理の処理速度が遅くなるという課題があった。
【0016】
なお、キャッシュ機構を用いて、検索の処理速度を速くすることも考えられる。例えば、クエリの結果をキャッシュ用メモリに保持させ、次回の検索処理時に同じクエリを受け付けた場合には、キャッシュ用メモリからクエリの結果を読み出し、検索結果として出力することができる。しかしながら、同じクエリを受け付けるとは限らず、また、FCMDB内のデータも更新されていくものであるから、キャッシュ用メモリのヒット率は低く、検索処理の高速化を図ることができない。
【0017】
そこで、この発明は、上述した従来技術の課題を解決するためになされたものであり、検索処理時のFCMDB間の通信回数を減らし、検索処理の高速化を図ることを目的とする。
【課題を解決するための手段】
【0018】
本願の開示する構成情報管理装置は、一つの態様において、管理対象に関する情報を示す構成要素と構成要素間の接続関係に関する情報を示す要素関係とを他の構成情報管理装置と分散して記憶する構成情報記憶部を有する。そして、構成情報管理装置は、接続関係にある構成要素および要素関係の一群であるクラスタについて登録要求を受け付けた場合に、クラスタの格納先を決定し、構成情報憶部または他の構成情報管理装置に格納するように制御する。そして、構成情報管理装置は、構成要素または要素関係を検索対象とした検索要求を受け付けた場合に、検索対象を含むクラスタの格納先を特定し、クラスタの格納先から検索対象の構成要素または要素関係を検索する。
【発明の効果】
【0019】
本願の開示する構成情報管理装置、分散情報管理システム、分散情報管理方法および分散情報管理プログラムの一つの態様によれば、検索処理時のFCMDB間の通信回数を減らし、検索処理の高速化を実現するという効果を奏する。
【図面の簡単な説明】
【0020】
【図1】図1は、実施例1に係る構成情報管理装置の構成を示すブロック図である。
【図2】図2は、実施例2に係るFCMDBの構成を示すブロック図である。
【図3】図3は、クラスタ検索表のデータ構造を説明するための図である。
【図4】図4は、FCMDB検索表のデータ構造を説明するための図である。
【図5】図5は、クラスタ参照回数表のデータ構造を説明するための図である。
【図6】図6は、クラスタの統計情報の一例を説明するための図である。
【図7】図7は、クラスタの登録処理を説明するための図である。
【図8】図8は、既存のクラスタに情報を追加する処理を説明するための図である。
【図9】図9は、新規クラスタを追加する処理を説明するための図である。
【図10】図10は、同一FCMDB内で検索が終了する検索処理を説明するための図である。
【図11】図11は、FCMDBをまたがった検索処理を説明するための図である。
【図12】図12は、クラスタの再配置処理を説明するための図である。
【図13】図13は、クラスタの統合処理を説明するための図である。
【図14】図14は、クラスタの分割処理を説明するための図である。
【図15】図15は、クラスタ上限サイズ決定処理を説明するための図である。
【図16】図16は、各FCMDBに記憶されるクラスタと検索に必要なサブクエリとの関係を説明するための図である。
【図17】図17は、登録処理を説明するためのフローチャートである。
【図18−1】図18−1は、検索処理を説明するためのフローチャートである。
【図18−2】図18−2は、検索処理を説明するためのフローチャートである。
【図19】図19は、クラスタの再配置または統合処理の実行を判断するフローチャートである。
【図20】図20は、クラスタの再配置処理を説明するためのフローチャートである。
【図21】図21は、クラスタの統合処理を説明するためのフローチャートである。
【図22】図22は、クラスタの分割処理を説明するためのフローチャートである。
【図23】図23は、クラスタの上限サイズを決定する処理を説明するためのフローチャートである。
【図24】図24は、FCMDBを説明するための図である。
【図25】図25は、分散FCMDBを説明するための図である。
【図26】図26は、分散FCMDBにおける登録処理を説明するための図である。
【図27】図27は、従来の分散FCMDBにおける検索処理を説明するための図である。
【発明を実施するための形態】
【0021】
以下に添付図面を参照して、この発明に係る構成情報管理装置、分散情報管理システム、分散情報管理方法および分散情報管理プログラムの実施例を詳細に説明する。
【実施例1】
【0022】
まず最初に、図1を用いて、実施例1に係る構成情報管理装置の構成を説明する。図1は、実施例1に係る構成情報管理装置の構成を示すブロック図である。図1に示すように、分散情報管理システム100は、複数の構成情報管理装置1A、1Bを有し、構成情報管理装置1Aと構成情報管理装置1Bとが接続されている。また、構成情報管理装置1Aは、構成情報記憶部2、格納制御部3、検索処理部4を有する。
【0023】
構成情報記憶部2は、管理対象に関する情報を示す構成要素と構成要素間の接続関係に関する情報を示す要素関係とを他の構成情報管理装置と分散して記憶する。格納制御部3は、接続関係にある構成要素および要素関係の一群であるクラスタについて登録要求を受け付けた場合に、該クラスタの格納先を決定し、構成情報記憶部2または他の構成情報管理装置1Bに格納するように制御する。
【0024】
検索処理部4は、構成要素または要素関係を検索対象とした検索要求を受け付けた場合に、検索対象を含むクラスタの格納先を特定し、クラスタの格納先から検索対象の構成要素または前記要素関係を検索する。
【0025】
つまり、分散情報管理システム100では、接続関係にある構成要素および要素関係の一群であるクラスタを一つの構成情報管理装置に配置する結果、検索処理時のFCMDB間の通信回数を減らし、検索処理の高速化を実現することが可能である。
【0026】
このように、構成情報管理装置1は、管理対象に関する情報を示す構成要素と構成要素間の接続関係に関する情報を示す要素関係とを他の構成情報管理装置と分散して記憶する構成情報記憶部2を有する。そして、構成情報管理装置1は、接続関係にある構成要素および要素関係の一群であるクラスタについて登録要求を受け付けた場合に、クラスタの格納先を決定し、構成情報憶部2または他の構成情報管理装置1Bに格納するように制御する。そして、構成情報管理装置1は、構成要素または要素関係を検索対象とした検索要求を受け付けた場合に、検索対象を含むクラスタの格納先を特定し、クラスタの格納先から検索対象の構成要素または要素関係を検索する。このため、検索処理時のFCMDB間の通信回数を減らし、検索処理の高速化を実現することが可能である。
【実施例2】
【0027】
[FCMDBの構成]
次に、図2を用いて、FCMDBの構成を説明する。図2は、実施例2に係るFCMDBの構成を示すブロック図である。同図に示すように、このFCMDB10は、データ登録サービス処理部11、クラスタ検索表記憶部12、FCMDB検索表記憶部13、ローカルデータ記憶部14を有する。また、FCMDB10は、クラスタ最適化実行部15、参照回数記憶部16、データ検索サービス受付部17、FCMDB間データ送受信部18を有する。かかるFCMDB10は、ネットワークを介してクライアント端末、MDR、他のFCMDBと接続される。以下にこれらの各部の処理を説明する。
【0028】
クラスタ検索表記憶部12は、CIおよびリレーションシップのハッシュ値と、接続関係にあるCIおよびリレーションシップの一群であるクラスタを一意に識別するクラスタIDとが対応付けられたクラスタ検索表を記憶する。具体的には、クラスタ検索表記憶部12は、図3に例示するように、CIおよびリレーションシップのハッシュ値を示す「Key」とクラスタIDを示す「Value」とが対応付けて記憶されている。図3は、クラスタ検索表のデータ構造を説明するための図である。
【0029】
FCMDB検索表記憶部13は、クラスタIDとクラスタを保持するFCMDBIDを記憶する。具体的には、図4に例示するように、クラスタを一意に識別するクラスタIDを示す「Cluster」とクラスタを保持するFCMDBを一意に識別する「FCMDB ID」とを対応付けて記憶する。図4は、FCMDB検索表のデータ構造を説明するための図である。
【0030】
参照回数記憶部16は、クラスタをまたいで参照された回数を記憶する。具体的には、参照回数記憶部16は、図5に例示するように、クラスタを一意に識別するクラスタIDを示す「Cluster」と、そのクラスタをまたいで参照した回数(サブクエリ発行数)を示す「count」とを対応付けて記憶する。
【0031】
ローカルデータ記憶部14は、管理対象に関する情報を示すCIと、CI間の接続関係を示すリレーションシップとを記憶する。具体的には、ローカルデータ記憶部14は、後述するデータ登録サービス処理部11によって格納するように通知されたCIまたはリレーションシップを記憶する。なお、リレーションシップは、接続するCIを示すsourceおよびtargetをデータとして保持する。
【0032】
また、ローカルデータ記憶部14は、自記憶部に記憶されているクラスタに関する統計情報を記憶する。具体的には、ローカルデータ記憶部14は、図6に例示するように、クラスタ内のCI数である「サイズ」、統合前のサイズである「統合前サイズ」、統合前の平均サブクエリである「統合前平均サブクエリ」を記憶する。また、ローカルデータ記憶部14は、図6に例示するように、クラスタに対するクエリがあるたびに値が1加算されるクエリの総数である「クエリ総数」を記憶する。また、ローカルデータ記憶部14は、図6に例示するように、クラスタ内でクエリが収まった場合は1加算され、外のクラスタにまたがってサブクエリが発行された場合には、サブクエリが発行されるたびに加算される「サブクエリ総数」を記憶する。
【0033】
また、ローカルデータ記憶部14は、図6に例示するように、サブクエリ総数をクエリ総数で除算した値である「平均サブクエリ」、クラスタサイズの上限値である「クラスタ上限サイズ」を記憶する。例えば、「クラスタ上限サイズ」は、初期値が「3」であるが、後述するクラスタ最適化実行部15によって値が変化する。
【0034】
データ登録サービス処理部11は、接続関係にあるCIおよびリレーションシップの一群であるクラスタについて登録要求を受け付けた場合に、クラスタの格納先を決定し、ローカルデータ記憶部14または他のFCMDBに格納するように制御する。
【0035】
また、データ登録サービス処理部11は、格納したCIおよびリレーションシップの一群について、各CIおよび各リレーションシップの格納先をそれぞれ決定し、CIおよびリレーションシップの一群の格納先を示すクラスタ検索表およびFCMDB検索表を格納するように制御する。
【0036】
ここで、図7の例を用いて、クラスタ登録処理を具体的に説明する。図7は、クラスタの登録処理を説明するための図である。図7の例では、登録対象である3つのCI(C1、C2、C3)と二つのリレーションシップ(R1、R2)とが接続されたデータの塊をクラスタとする。
【0037】
FCMDB10は、登録対象である3つのCI(C1、C2、C3)と二つのリレーションシップ(R1、R2)の登録要求を受け付けると、クラスタ検索表記憶部12が保持するクラスタ検索表で検索対象を検索し、登録対象のクラスタがすでにFCMDBに存在するか判定する。この結果、登録を受け付けたFCMDB10は、登録対象の属するクラスタがFCMDBに存在しない場合には、クラスタが管理するFCMDB IDをランダムに決定し、さらに、決定されたFCMDB IDと時刻からクラスタIDを決定する。図7の例では、FCMDB IDが「1」で、クラスタIDが「CL1」とする。
【0038】
そして、FCMDB10は、クラスタをFCMDB IDが「1」のFCMDBに格納し、FCMDB検索表にCL1とFCMDB1とを対応付けて記憶させる。続いて、FCMDB10は、クラスタ内部のCIおよびリレーションシップそれぞれのハッシュ値を計算し、各ハッシュ値からそれを管理するFCMDBを決定する。例えば、図7に例示するように、FCMDB10は、C2のハッシュ値が「51」であり、R1のハッシュ値が「55」である場合には、C2およびR1の管理するFCMDBとして、FCMDB IDが「5」のFCMDBを決定する。
【0039】
その後、FCMDB10は、決定されたFCMDBのクラスタ検索表に対して、クラスタIDを登録するように制御する。例えば、FCMDB10は、FCMDB IDが「5」のFCMDBの検索表に対して、C2のハッシュ値「51」とクラスタID「CL1」とを対応付けて記憶するように制御する。つまり、ハッシュ値に対して担当するFCMDBは、従来と同様であるが、FCMDBにCI・リレーションシップのデータそのものではなく、クラスタIDを格納しておき、検索時にCI・リレーションシップのデータを含むクラスタの格納先FCMDBを取得できるようになっている。
【0040】
また、FCMDB10は、登録対象のリレーションシップのソースまたはターゲットとなるCIがすでに存在する場合には、そのCIの属するクラスタに登録対象を追加する。ここで、既存のクラスタに情報を追加する処理について図8を用いて、説明する。図8は、既存のクラスタに情報を追加する処理を説明するための図である。図8に示すように、登録対象であるCI「C4」、リレーションシップ「R3」の登録要求を受け付けると、クラスタ検索表記憶部12が保持するクラスタ検索表で検索対象を検索し、登録対象が属するクラスタがすでにFCMDBに存在するか判定する。
【0041】
この結果、登録を受け付けたFCMDB10は、登録対象の属するクラスタがFCMDBに存在する場合には、C4およびR3が属するクラスタにC4を追加するために、FCMDB IDが「1」のFCMDB「1」にC4、R3を格納する。
【0042】
続いて、FCMDB10は、C4およびR3それぞれのハッシュ値を計算し、各ハッシュ値からそれを管理するFCMDBを決定する。例えば、図8に例示するように、FCMDB10は、C4のハッシュ値が「41」であり、R3のハッシュ値が「22」である場合には、C4の管理するFCMDBとして、FCMDB IDが「4」のFCMDBを決定し、R3の管理するFCMDBとして、FCMDB IDが「2」のFCMDBを決定する。
【0043】
その後、FCMDB10は、決定されたFCMDBのクラスタ検索表に対して、クラスタIDを登録するように制御する。例えば、FCMDB10は、FCMDB IDが「4」のFCMDBの検索表に対して、C4のハッシュ値「41」とクラスタID「CL1」とを対応付けて記憶するように制御する。
【0044】
また、FCMDB10は、登録対象のリレーションシップのソースまたはターゲットとなるCIがすでに存在するが、クラスタ「CL1」のサイズがクラスタ上限サイズを超えてしまう場合には、そのCIの属するクラスタに登録対象を追加しない。ここで、新規クラスタに情報を追加する処理について図9を用いて、説明する。図9は、新規クラスタを追加する処理を説明するための図である。図9に示すように、登録対象であるCI「C4」、リレーションシップ「R3」の登録要求を受け付けると、クラスタ検索表記憶部12が保持するクラスタ検索表で検索対象を検索し、登録対象が属するクラスタがすでにFCMDBに存在するか判定する。
【0045】
この結果、登録を受け付けたFCMDB10は、登録対象の属するクラスタ「CL1」がFCMDB「1」に存在すると判定されたが、C4およびR3をクラスタ「CL1」に追加すると、クラスタ「CL1」のサイズがクラスタ上限サイズを超えてしまう。この場合には、登録を受け付けたFCMDB10は、新規クラスタ「CL2」にC4およびR3を登録し、クラスタ「CL1」にR3のレプリカを登録する。つまり、クラスタのエッジとなるリレーションシップのみレプリカを持たせることで、記憶領域の使用量を抑えつつ、検索処理の高速化を実現する。
【0046】
図2の説明に戻って、データ検索サービス受付部17は、CIまたはリレーションシップを検索対象とした検索要求を受け付けた場合に、検索対象を含むクラスタの格納先を特定し、クラスタの格納先から検索対象のCIまたはリレーションシップを検索する。
【0047】
具体的には、データ検索サービス受付部17は、検索要求であるクエリ式をクライアント端末から受け付けた場合には、クエリの先頭のCIのハッシュ値を計算し、そのハッシュ値を担当するFCMDBのクラスタ検索表からハッシュ値に対応するクラスタIDを取得する。続いて、データ検索サービス受付部17は、FCMDB検索表からクラスタIDに対応するFCMDB IDを取得し、そのFCMDB IDのFCMDBに対してクエリを発行する。
【0048】
そして、クエリを受け付けたFCMDBがクエリを処理し、検索要求を受け付けたFCMDBにクエリの結果を返す。ここで、クエリを受け付けたFCMDBは、接続関係にあるCIまたはリレーションシップの一群であるクラスタを保持するので、サブクエリを発行することなくクエリを処理することができる。その後、検索要求を受け付けたFCMDBのデータ検索サービス受付部17は、クエリの結果を受信すると、クエリの結果を検索結果としてクライアント端末に出力する。
【0049】
ここで、図10の例を用いて検索処理について説明する。図10は、同一FCMDB内で検索が終了する検索処理を説明するための図である。図10に示すように、FCMDB「5」は、検索要求であるクエリ式「%C1/&R1/%C2/&R2/%C3」をクライアント端末から受け付けた場合には、クエリの先頭のCI「C1」について、ハッシュ値「49」を算出し、FCMDB「4」のクラスタ検索表からハッシュ値に対応するクラスタID「1」を取得する。続いて、FCMDB「5」は、FCMDB検索表からクラスタID「1」に対応するFCMDB ID「1」を取得し、そのFCMDB ID「1」のFCMDBに対してクエリを発行する。
【0050】
そして、クエリを受け付けたFCMDB「1」は、クエリを処理し、検索要求を受け付けたFCMDB「5」にクエリの結果を返す。その後、検索要求を受け付けたFCMDB「5」は、クエリの結果を受信すると、クエリの結果を検索結果としてクライアント端末に出力する。このように、FCMDB「1」がサブクエリを発行することなく検索処理を完了し、検索結果であるCI「C3」を得ることができるので、高速な検索処理を実現することができる。
【0051】
また、FCMDBは、クラスタをまたがったクエリを行う場合がある。このような場合におけるFCMFBの検索処理について、図11を用いて説明する。図11は、FCMDBをまたがった検索処理を説明するための図である。図11に示すように、FCMDB「5」は、検索要求であるクエリ式「%C1/&R3/%C4」をクライアント端末から受け付けた場合には、クエリの先頭のCI「C1」について、ハッシュ値「49」を算出し、FCMDB「4」のクラスタ検索表からハッシュ値に対応するクラスタID「1」を取得する。続いて、FCMDB「5」は、FCMDB検索表からクラスタID「1」に対応するFCMDB ID「1」を取得し、そのFCMDB ID「1」のFCMDBに対してクエリを発行する。
【0052】
そして、クエリを受け付けたFCMDB「1」は、クエリ式に従って探索を行い、R3の先がクラスタ「CL1」に存在しないので、クエリ式の「%C4」以下のクエリを分割してサブクエリとする。続いて、FCMDB「1」は、サブクエリの先頭のCI「C4」について、ハッシュ値「41」を算出し、FCMDB「4」のクラスタ検索表からハッシュ値に対応するクラスタID「2」を取得する。続いて、FCMDB「1」は、FCMDB検索表からクラスタID「2」に対応するFCMDB ID「2」を取得し、そのFCMDB ID「2」のFCMDBに対してサブクエリを発行する。
【0053】
そして、サブクエリを受け付けたFCMDB「2」は、サブクエリ処理を行ってクエリの結果であるC4を検索し、FCMDB「1」を介して、FCMDB「5」にC4を送信する。そして、FCMDB「5」は、クエリの結果であるC4を受信すると、クエリの結果を検索結果としてクライアント端末に出力する。
【0054】
クラスタ最適化実行部15は、クラスタの再配置、統合、分割を実行する。具体的には、クラスタ最適化実行部15は、クラスタの再配置処理として、参照回数記憶部16によって記憶されたクラスタ参照回数表における参照回数をFCMDB IDごとに集計する。そして、各FCMDB IDごとの参照回数合計が所定の閾値以上であって、かつ、そのクラスタの位置するFCMDB IDと参照回数が多かったFCMDBとが異なる場合には、参照回数が多かったFCMDBにクラスタを移動して再配置する。
【0055】
例えば、図12の例を用いてクラスタの再配置処理について説明する。図12は、クラスタの再配置処理を説明するための図である。図12に示すように、FCMDB2は、クラスタCL2のクラスタ参照回数表における参照回数をFCMDB IDごとに集計する。そして、FCMDB2は、FCMDB IDが「1」の参照回数合計が閾値「100」以上であって、かつ、そのクラスタの位置するFCMDB ID「2」と参照回数が多かったFCMDB「1」とが異なると判定し、参照回数が多かったFCMDB「1」にクラスタをコピーする。そして、FCMDB2は、クラスタCL2とFCMDB ID「1」とを対応付けて記憶するようにFCMDBノード検索表を修正し、クラスタCL2のデータを削除する。
【0056】
また、クラスタ最適化実行部15は、クラスタの統合処理として、参照回数記憶部16によって記憶されたクラスタ参照回数表における参照回数合計が所定の閾値以上であり、かつ、クラスタが同一のFCMDBに保持されている場合には、クラスタ同士を統合する。
【0057】
例えば、図13の例を用いてクラスタの統合処理について説明する。図13は、クラスタの統合処理を説明するための図である。図13に示すように、FCMDB1は、クラスタCL2のクラスタ参照回数表における参照回数をFCMDB IDごとに集計する。そして、FCMDB1は、FCMDB IDが「1」の参照回数合計が閾値以上であって、かつ、そのクラスタの位置するFCMDB ID「1」と参照回数が多かったFCMDB「1」とが同じであると判定する。
【0058】
この場合に、FCMDB1は、クラスタCL1にクラスタCL2の要素を追加するとともに、クラスタ検索表にあるクラスタIDがCL2のデータをCL1に修正する。そして、FCMDB1は、FCMDBノード検索表にあるクラスタIDがCL2のデータを削除するとともに、クラスタCL2のデータを削除する。つまり、参照回数が大きいクラスタ間は強く関係するもとみなし、同一のクラスタに統合する。
【0059】
また、クラスタ最適化実行部15は、クラスタ統合後、クラスタのサイズがクラスタ上限サイズを超えている場合には、クラスタ内のリレーションシップの参照回数に基づいて分割する。ここで、参照回数とは、各リレーションシップについて、クエリの処理で参照された回数である。例えば、クラスタ最適化実行部15は、クラスタ内のCIについて、接続されたリレーションシップの参照回数の合計が大きいCIを選択する。そして、クラスタ最適化実行部15は、選択されたCIから参照回数の大きいリレーションシップの順にリレーションシップおよびCIを追加していき、CI数がクラスタ上限サイズを超えない範囲で選択したものを新たなクラスタとする。
【0060】
ここで、図14の例を用いてクラスタの分割処理について説明する。図14は、クラスタの分割処理を説明するための図である。図14の例では、クラスタ上限サイズを「3」とする。また、図14の例では、リレーションシップR1の参照回数が「20」であり、リレーションシップR2の参照回数が「25」であり、リレーションR3の参照回数が「10」であるものとする。このため、図14の例では、クラスタ内における各CIであるC1〜C4に接続されたリレーションシップの参照回数の合計について、C1が「30」、C2が「45」、C3が「25」、C4が「10」となる。
【0061】
そして、クラスタ最適化実行部15は、接続されたリレーションシップの参照回数の合計が最も大きい「C2」を選択し、選択された「C2」から参照回数の大きいリレーションシップであるR2およびC3、R1およびC1の順に追加する。そして、クラスタ最適化実行部15は、CI数がクラスタサイズの上限「3」に到達するため、C1、R1、C2、R2、C3およびR3のレプリカを新たなクラスタCL3とし、C4およびR3をクラスタCL4として分割する。
【0062】
また、クラスタ最適化実行部15は、上記の分割処理を行う前であってクラスタ統合後に、サブクエリ数の削減効果に応じて、クラスタ上限サイズを調整する。例えば、クラスタ最適化実行部15は、サイズ増加率よりもサブクエリ数改善率の方が大きいか判定し、サイズ増加率よりもサブクエリ数改善率の方が大きい場合には、クラスタ上限サイズを大きくする。また、クラスタ最適化実行部15は、サイズ増加率よりもサブクエリ数改善率の方が大きくない場合には、クラスタ上限サイズを小さくする。ここで、サイズ増加率とは、クラスタ統合後のサイズをクラスタ統合前のサイズで除算した値であり、サブクエリ数改善率とは、統合後のサブクエリ数を統合前のサブクエリ数で除算した値である。
【0063】
ここで、図15の例を用いてクラスタ上限サイズ決定処理について説明する。図15は、クラスタ上限サイズ決定処理を説明するための図である。図15の例では、クラスタCL3の初期状態は、クラスタのサイズsbが「3」であり、クラスタ上限サイズが「3」であるものとする。そして、統合クラスタが統合された結果、クラスタのサイズsbが「4」であり、統合前サイズsaが「3」となり、サイズ増加率sb/sa=1.33となる。また、統合前平均サブクエリqaが「2.2」であり、平均サブクエリqbが「1.5」であり、サブクエリ数改善率qa/qb=1.47となる。そして、FCMDBは、サイズ増加率sb/sa「1.33」とサブクエリ数改善率qa/qb「1.47」とを比較し、サイズ増加率よりもサブクエリ数改善率の方が大きいと判定し、クラスタ上限サイズ「3」を統合後のクラスタサイズである「4」に調整する。
【0064】
さらに、統合クラスタが統合された結果、クラスタのサイズsbが「6」であり、統合前サイズsaが「4」となり、サイズ増加率sb/sa=1.5となる。また、統合前平均サブクエリqaが「1.5」であり、平均サブクエリqbが「1.3」であり、サブクエリ数改善率qa/qb=1.15となる。そして、FCMDBは、サイズ増加率sb/sa「1.5」とサブクエリ数改善率qa/qb「1.15」とを比較し、サイズ増加率よりもサブクエリ数改善率の方が小さいと判定し、クラスタ上限サイズ「4」統合前サイズの「4」のままとする。この場合には、FCMDBは、クラスタのサイズがクラスタ上限サイズを超えているので、上記した分割処理を実行する。
【0065】
上記のように、関連が高いCIおよびリレーションシップ群を登録するので、図16に示すように、例えば、FCMDB1における同一クラスタ内のC1からC2への探索を行う場合に、サブクエリを最低1回発行するだけよい。また、各FCMDBにCIまたはリレーションシップのレプリカを格納しないので、データ量が少なくてよい。図16は、各FCNDBに記憶されるクラスタと検索に必要なサブクエリとの関係を説明するための図である。
【0066】
[FCMDBによる処理]
次に、図17〜図23を用いて、実施例2に係るFCMDB10による処理を説明する。図17は、登録処理を説明するためのフローチャートである。図18−1および図18−2は、検索処理を説明するためのフローチャートである。図19は、クラスタの再配置処理または統合処理の実行を判断する処理を説明するためのフローチャートである。図20は、クラスタの再配置処理を説明するためのフローチャートである。図21は、クラスタの統合処理を説明するためのフローチャートである。図22は、クラスタの分割処理を説明するためのフローチャートである。図23は、クラスタの上限サイズを決定する処理を説明するためのフローチャートである。
【0067】
図17に示すように、FCMDB10は、CI/リレーションシップ群を受信すると(ステップS101)、受信したリレーションシップのsourceまたはtargetとなるCIをクラスタ検索表で検索する(ステップS102)。そして、FCMDB10は、検索の結果、クラスタ検索表からsourceまたはtargetとなるCIを発見したか判定する(ステップS103)。
【0068】
この結果、FCMDB10は、クラスタ検索表からsourceまたはtargetとなるCIを発見しなかった場合には、CI/リレーションシップ群の振り分け先FCMDB(f)をランダムに決定する(ステップS104)。そして、FCMDB10は、振り分け先FCMDB(f)と現時刻から、一意のクラスタID(c)を作成する(ステップS105)。
【0069】
そして、FCMDB10は、FCMDB(f)にクラスタID(c)としてCI/リレーションシップ群を登録し(ステップS109)、CI/リレーションシップごとのハッシュ値をクラスタ検索表に登録する(ステップS110)。その後、FCMDB10は、クラスタ(c)を新規追加したか判定し(ステップS111)、クラスタ(c)を新規追加していないと判定された場合には、処理を終了する。また、FCMDB10は、クラスタ(c)を新規追加したと判定された場合には、FCMDB検索表に、クラスタID(c)と、FCMDBのID(f)とを対応付けて追加する(ステップS112)。
【0070】
また、ステップS103に戻って、FCMDB10は、クラスタ検索表からsourceまたはtargetとなるCIを発見した場合には、発見されたクラスタのID(c)を取得する(ステップS106)。そして、FCMDB10は、FCMDB検索表から、クラスタ(c)が登録されたFCMDB(f)を取得する(ステップS107)。その後、FCMDB10は、クラスタ(c)以外のクラスタが有するCIをsourceまたはtargetとするリレーションシップについて、各々CIのクラスタID、FCMDBを調べ、リレーションシップのレプリカを追加する。(ステップS108)。
【0071】
そして、FCMDB10は、FCMDB(f)にクラスタID(c)としてCI/リレーションシップ群を登録し(ステップS109)、CI/リレーションシップごとのハッシュ値をクラスタ検索表に登録する(ステップS110)。その後、FCMDB10は、クラスタ(c)を新規追加したか判定し(ステップS111)、クラスタ(c)を新規追加していないと判定された場合には、処理を終了する。また、FCMDB10は、クラスタ(c)を新規追加したと判定された場合には、FCMDB検索表に、クラスタID(c)と、FCMDBのID(f)とを対応付けて追加する(ステップS112)。
【0072】
次に、図18−1および図18−2を用いて検索処理の処理手順を説明する。図18−1に示すように、FCMDB10は、クエリ対象クラスタのIDが(c)で、呼び出し元クラスタのIDが(o)であるクエリを受信する(ステップS201)。そして、FCMDB10は、クラスタ参照回数表を更新し(ステップS202)、受信されたクエリの処理を実行する(ステップS203)。
【0073】
続いて、FCMDB10は、リレーションシップ参照回数を更新し(ステップS204)、受信されたクエリの処理を最後まで実行したか判定する(ステップS205)。この結果、FCMDB10は、FCMDB10は、受信されたクエリの処理を最後まで実行した場合には、ステップS211に進む。また、受信されたクエリの処理を最後まで実行していない場合には、終了していない部分から先をサブクエリとする(ステップS206)。
【0074】
そして、FCMDB10は、サブクエリの最初のCIを取り出し、ハッシュ値(h)を計算し(ステップS207)、クラスタ検索表からハッシュ値(h)をもとにクラスタID(c)を取得する(ステップS208)。続いて、FCMDB10は、FCMDB検索表からクラスタID(c)をもとにFCMDBID(f)を取得し(ステップS209)、FCMDB(f)へクエリを送信する(ステップS210)。そして、クエリを受信したFCMDBは、ステップS201の処理を開始する。
【0075】
その後、FCMDB10は、自装置がクライアントからクエリを受信したFCMDBか判定し(ステップS211)、自装置がクエリを受信したFCMDBである場合には、クエリの結果を取得する(ステップS212)。そして、FCMDB10は、クラスタ統計情報を更新し(ステップS213)、クライアントにクエリの結果を返す(ステップS214)。また、FCMDB10は、自装置がクエリを受信したFCMDBでない場合には、クエリの結果を検索要求を受け付けたFCMDBへ送信し(ステップS215)、クラスタ統計情報を更新する(ステップS216)。
【0076】
次に、図19を用いて、クラスタの再配置処理または統合処理の実行を判断する処理を説明する。図19に示すように、FCMDB10は、クラスタ(c)に対するクラスタ参照回数を各クラスタが属するFCMDBごとに集計する(ステップS301)。そして、FCMDB10は、クラスタ(c)に対するクラスタ参照回数が最も大きいFCMDB(t)を特定する(ステップS302)。
【0077】
そして、FCMDB10は、FCMDB検索表から、クラスタ(c)が記憶されたFCMDB(f)を取得する(ステップS303)。そして、FCMDB(t)とFCMDB(f)とが同一であるか判定し(ステップS304)、FCMDB(t)とFCMDB(f)とが同一でない場合には、クラスタの再配置処理(後に、図20を用いて詳述)を行う(ステップS305)。また、FCMDB10は、FCMDB(t)とFCMDB(f)とが同一である場合には、クラスタの統合処理(後に、図21を用いて詳述)を行う(ステップS306)。
【0078】
次に、図20を用いて、クラスタの再配置処理を説明する。図20に示すように、FCMDB10は、登録先FCMDBをtとして、クラスタ(c)のCI/リレーションシップを登録し(ステップS307)、クラスタ分割処理(後に図22を用いて後述)に移行した後、FCMDB検索表のうちクラスタ(c)を記憶するFCMDB(f)をFCMDB(t)へ修正する(ステップS308)。その後、FCMDBは、FCMDB(f)に記憶された元々のクラスタ(c)を削除して(ステップS309)、処理を終了する。
【0079】
次に、図21を用いて、クラスタの統合処理を説明する。図21に示すように、FCMDB10は、FCMDB(f)に記憶されたクラスタのうち、クラスタ参照回数が最も大きなクラスタ(d)を取得する(ステップS310)。そして、FCMDB10は、クラスタ(d)のクラスタ統計情報のうち、統合前のサイズを現在のサイズに更新し、統合前平均サブクエリ数をサブクエリ数/クエリ数に更新する(ステップS311)。
【0080】
その後、FCMDB10は、クラスタ(c)のCI/Relatopmshipをクラスタ(d)に登録し(ステップS312)、ステップS109に移行して登録処理を行う。その後、FCMDB10は、FCMDB検索表からクラスタ(c)を削除し(ステップS313)、FCMDB(f)に記憶されたクラスタ(c)を削除して(ステップS314)、処理を終了する。
【0081】
次に、図22を用いて、クラスタの分割処理を説明する。図22に示すように、FCMDBは、クラスタ(c)のサイズSとクラスタ上限サイズUを判定する(ステップS401)。この結果、クラスタ(c)のサイズSがクラスタ上限サイズUよりも大きいか判定する(ステップS402)。この結果、FCMDB10は、クラスタ(c)のサイズSがクラスタ上限サイズUよりも大きくない場合には、クラスタの分割処理を終了する。
【0082】
また、FCMDB10は、クラスタ(c)のサイズSがクラスタ上限サイズUよりも大きい場合には、クラスタ(c)内のCIごとに、そのCIをsourceまたはtargetとするリレーションシップの参照回数の合計を計算する(ステップS403)。そして、FCMDB10は、新たなクラスタ候補としてクラスタ(d)を作成し(ステップS404)、クラスタ候補リストLに追加しておらず、リレーションシップの参照回数の大きい順にCI(x)を一つ取り出す(ステップS405)。
【0083】
続いて、FCMDB10は、CI(x)をクラスタ(d)に追加し(ステップS406)、クラスタ(d)に追加された各CIをsourceまたはtargetとするリレーションシップの一群(R)を選択する(ステップS407)。そして、FCMDB10は、Rのサイズが0よりも大きいか判定する(ステップS408)。その後、FCMDB10は、Rのサイズが0よりも大きい場合には、Rlationship群(R)のうち、CI(x)を起点としてリレーションシップ経路の参照回数の合計が最大となるようなリレーションシップ(q)とそれにつながるCI(y)とをクラスタ(d)に追加する(ステップS409)。
【0084】
そして、FCMDB10は、クラスタ(d)のサイズがクラスタ上限サイズUに1を減算した値U−1よりも大きいか判定し(ステップS410)、クラスタ(d)のサイズがU−1よりも大きくない場合には、ステップS407の処理に戻る。また、FCMDB10は、クラスタ(d)のサイズがU−1よりも大きい場合には、クラスタ(d)をクラスタ候補リストLに追加し(ステップS411)、まだクラスタ(c)に追加されていないCIが存在するか判定する(ステップS412)。
【0085】
この結果、FCMDB10は、まだクラスタ(c)に追加されていないCIが存在する場合には、ステップS404の処理に戻る。また、FCMDB10は、クラスタ(c)に追加されていないCIが存在しない場合には、クラスタ候補リストL内のクラスタについて、まだ登録されていないクラスタを一つ取り出す(ステップS413)。そして、FCMDB10は、ステップS104の処理に移行して、登録処理を行い、クラスタ候補リストL内に未追加のクラスタはあるか判定する(ステップS414)。この結果、FCMDB10は、クラスタ候補リストL内に未追加のクラスタはある場合には、ステップS413に戻る。また、FCMDB10は、クラスタ候補リストL内に未追加のクラスタはある場合には、処理を終了する。
【0086】
次に、図23を用いて。クラスタの上限サイズを決定する処理を説明する。図23に示すように、FCMDB10は、クラスタの統計情報を取得する(ステップS501)。ここでクラスタの統計情報とは、クラスタのサイズ、クラスタの結合前のサイズ、統合前平均サブクエリ数、サブクエリ数、クエリ数、クラスタ上限サイズ、クラスタ最大サイズのことをいう。
【0087】
そして、FCMDB10は、サイズ変化率αを算出し(ステップS502)、サブクエリ改善率βを算出する(ステップS503)。続いて、FCMDB10は、サブクエリ改善率βがサイズ変化率αよりも大きいか判定し(ステップS504)、サブクエリ改善率βがサイズ変化率αよりも大きくない場合には、クラスタ上限サイズUを結合前サイズsbと同じ値になるよう調整する(ステップ507)。
【0088】
また、FCMDB10は、サブクエリ改善率βがサイズ変化率αよりも大きい場合には、クラスタ最大サイズMがクラスタサイズsaよりも大きいか判定する(ステップS505)。この結果、FCMDB10は、クラスタ最大サイズMがクラスタサイズsaよりも大きい場合には、クラスタ上限サイズUをクラスタサイズsaと同じ値になるよう調整して(ステップS506)、処理を終了する。また、FCMDB10は、クラスタ最大サイズMがクラスタサイズsaよりも大きくない場合には、クラスタ上限サイズUをクラスタ最大サイズMと同じ値に調整して(ステップS508)、処理を終了する。
【0089】
[実施例2の効果]
上述してきたように、FCMDB10は、管理対象に関する情報を示すCIとCI間の接続関係に関する情報を示すリレーションシップとを他のFCMDBと分散して記憶するローカルデータ記憶部14を有する。そして、FCMDB10は、接続関係にあるCIおよびリレーションシップの一群であるクラスタについて登録要求を受け付けた場合に、クラスタの格納先を決定し、ローカルデータ記憶部14または他のFCMDBに格納するように制御する。そして、FCMDB10は、CIまたはリレーションシップを検索対象とした検索要求を受け付けた場合に、検索対象を含むクラスタの格納先を特定し、クラスタの格納先から検索対象のCIまたはリレーションシップを検索する。このため、検索処理時のFCMDB間の通信回数を減らし、検索処理の高速化を実現することが可能である。
【0090】
また、実施例2によれば、FCMDB10は、検索処理において複数のクラスタ間をまたいで参照回数が所定の閾値以上であって、かつ、複数のクラスタそれぞれが異なるFCMDBに格納されている場合には、複数のクラスタが格納されるFCMDBが同じになるように再配置する。このため、参照回数からクラスタ間をまたがった検索であるサブクエリが発生する回数が多いクラスタ同士を同じるFCMDBに格納することで、ネットワーク経由のサブクエリを低減し、検索処理の高速化を実現することが可能である。
【0091】
また、実施例2によれば、FCMDB10は、検索処理において複数のクラスタ間をまたいで参照した回数が所定の閾値以上であって、かつ、複数のクラスタが同じFCMDBに格納されている場合には、クラスタ同士を統合する。このため、参照回数からクラスタ間をまたがった検索であるサブクエリが発生する回数が多いクラスタ同士を一つのクラスタとすることで、ネットワーク経由のサブクエリを低減し、検索処理の高速化を実現することが可能である。
【0092】
また、実施例2によれば、FCMDB10は、クラスタに含まれるCIおよびリレーションシップの数がクラスタ上限サイズ以上である場合には、クラスタ内のリレーションシップが検索処理時に参照された回数を用いて、クラスタを分割する。このため、大きくなりすぎたクラスタの大きさを最適化させることで、クエリの分散に役立ち、関連検索を高速化することが可能である。
【0093】
また、実施例2によれば、FCMDB10は、クラスタ間をまたいだ検索処理の回数の削減数とクラスタに含まれるCIおよびリレーションシップの増加数との関係に応じて、クラスタ上限サイズを設定する。このため、クラスタの上限サイズをサブクエリの削減度合いに応じて調整することで、サブクエリを削減しつつ、クエリの分散に役立ち、関連検索を高速化することが可能である。
【実施例3】
【0094】
さて、これまで実施例1、2について説明したが、本実施例は上述した実施例以外にも、種々の異なる形態にて実施されてよいものである。そこで、以下では実施例3として本発明に含まれる他の実施例を説明する。
【0095】
(1)システム構成等
また、図示した各装置の各構成要素は機能概念的なものであり、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散・統合の具体的形態は図示のものに限られず、その全部または一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的または物理的に分散・統合して構成することができる。例えば、データ登録サービス処理部11とクラスタ検索表記憶部12を統合してもよい。
【0096】
(2)プログラム
なお、本実施例で説明した分散情報管理方法は、あらかじめ用意されたプログラムをパーソナルコンピュータやワークステーションなどのコンピュータで実行することによって実現することができる。このプログラムは、インターネットなどのネットワークを介して配布することができる。また、このプログラムは、ハードディスク、フレキシブルディスク(FD)、CD−ROM、MO、DVDなどのコンピュータで読み取り可能な記録媒体に記録され、コンピュータによって記録媒体から読み出されることによって実行することもできる。
【符号の説明】
【0097】
1A、1B 構成情報管理装置
2 構成情報記憶部
3 格納制御部
4 検索処理部
10 FCMDB
11 データ登録サービス処理部
12 クラスタ検索表記憶部
13 FCMDB検索表記憶部
14 ローカルデータ記憶部
15 クラスタ最適化実行部
16 参照回数記憶部
17 データ検索サービス受付部
18 FCMDB間データ送受信部
【特許請求の範囲】
【請求項1】
管理対象に関する情報を示す構成要素と該構成要素間の接続関係に関する情報を示す要素関係とを他の構成情報管理装置と分散して記憶する構成情報記憶部と、
接続関係にある前記構成要素および前記要素関係の一群であるクラスタについて登録要求を受け付けた場合に、該クラスタの格納先を決定し、前記構成情報記憶部または前記他の構成情報管理装置に格納するように制御する格納制御部と、
前記構成要素または前記要素関係を検索対象とした検索要求を受け付けた場合に、該検索対象を含むクラスタの格納先を特定し、該クラスタの格納先から検索対象の前記構成要素または前記要素関係を検索する検索処理部と、
を有することを特徴とする構成情報管理装置。
【請求項2】
検索処理において複数のクラスタ間をまたいで参照した回数が所定の閾値以上であって、かつ、該複数のクラスタそれぞれが異なる構成情報管理装置に格納されている場合には、該複数のクラスタが格納される構成情報管理装置が同じになるように再配置するクラスタ再配置処理部をさらに有することを特徴とする請求項1に記載の構成情報管理装置。
【請求項3】
検索処理において複数のクラスタ間をまたいで参照した回数が所定の閾値以上であって、かつ、該複数のクラスタが同じ構成情報管理装置に格納されている場合には、該複数のクラスタを統合するクラスタ統合部をさらに有することを特徴とする請求項1または2に記載の構成情報管理装置。
【請求項4】
前記クラスタに含まれる前記構成要素および前記要素関係の数がクラスタ上限値以上である場合には、該クラスタ内の要素関係が検索処理時に参照された回数を用いて、該クラスタを分割するクラスタ分割部をさらに有することを特徴とする請求項1〜3のいずれか一つに記載の構成情報管理装置。
【請求項5】
前記クラスタ間をまたいだ検索処理の回数の削減数と該クラスタに含まれる前記構成要素および前記要素関係の増加数との関係に応じて、前記クラスタ上限値を設定する上限値設定部をさらに有することを特徴とする請求項4に記載の構成情報管理装置。
【請求項6】
管理対象に関する情報を示す構成要素と該構成要素間の接続関係に関する情報を示す要素関係とを複数の構成情報管理装置で分散して記憶する分散情報管理システムであって、
前記構成情報管理装置は、
前記構成要素および前記要素関係を他の構成情報管理装置で分散して記憶する構成情報記憶部と、
接続関係にある前記構成要素および前記要素関係の一群であるクラスタについて登録要求を受け付けた場合に、該クラスタの格納先を決定し、前記構成情報記憶部または前記他の構成情報管理装置に格納するように制御する格納制御部と、
前記構成要素または前記要素関係を検索対象とした検索要求を受け付けた場合に、該検索対象を含むクラスタの格納先を特定し、該クラスタの格納先から検索対象の前記構成要素または前記要素関係を検索する検索処理部と、
を有することを特徴とする分散情報管理システム。
【請求項7】
接続関係にある構成要素および該構成要素間の接続関係に関する情報を示す要素関係の一群であるクラスタについて登録要求を受け付けた場合に、該クラスタの格納先を決定し、前記構成要素および前記要素関係を他の構成情報管理装置と分散して記憶する構成情報記憶部または前記他の構成情報管理装置に格納するように制御する格納制御ステップと、
前記構成要素または前記要素関係を検索対象とした検索要求を受け付けた場合に、該検索対象を含むクラスタの格納先を特定し、該クラスタの格納先から検索対象の前記構成要素または前記要素関係を検索する検索処理ステップと、
を含んだことを特徴とする分散情報管理方法。
【請求項8】
接続関係にある構成要素および該構成要素間の接続関係に関する情報を示す要素関係の一群であるクラスタについて登録要求を受け付けた場合に、該クラスタの格納先を決定し、前記構成要素および前記要素関係を他の構成情報管理装置と分散して記憶する構成情報記憶部または前記他の構成情報管理装置に格納するように制御する格納制御手順と、
前記構成要素または前記要素関係を検索対象とした検索要求を受け付けた場合に、該検索対象を含むクラスタの格納先を特定し、該クラスタの格納先から検索対象の前記構成要素または前記要素関係を検索する検索処理手順と、
をコンピュータに実行させることを特徴とする分散情報管理プログラム。
【請求項1】
管理対象に関する情報を示す構成要素と該構成要素間の接続関係に関する情報を示す要素関係とを他の構成情報管理装置と分散して記憶する構成情報記憶部と、
接続関係にある前記構成要素および前記要素関係の一群であるクラスタについて登録要求を受け付けた場合に、該クラスタの格納先を決定し、前記構成情報記憶部または前記他の構成情報管理装置に格納するように制御する格納制御部と、
前記構成要素または前記要素関係を検索対象とした検索要求を受け付けた場合に、該検索対象を含むクラスタの格納先を特定し、該クラスタの格納先から検索対象の前記構成要素または前記要素関係を検索する検索処理部と、
を有することを特徴とする構成情報管理装置。
【請求項2】
検索処理において複数のクラスタ間をまたいで参照した回数が所定の閾値以上であって、かつ、該複数のクラスタそれぞれが異なる構成情報管理装置に格納されている場合には、該複数のクラスタが格納される構成情報管理装置が同じになるように再配置するクラスタ再配置処理部をさらに有することを特徴とする請求項1に記載の構成情報管理装置。
【請求項3】
検索処理において複数のクラスタ間をまたいで参照した回数が所定の閾値以上であって、かつ、該複数のクラスタが同じ構成情報管理装置に格納されている場合には、該複数のクラスタを統合するクラスタ統合部をさらに有することを特徴とする請求項1または2に記載の構成情報管理装置。
【請求項4】
前記クラスタに含まれる前記構成要素および前記要素関係の数がクラスタ上限値以上である場合には、該クラスタ内の要素関係が検索処理時に参照された回数を用いて、該クラスタを分割するクラスタ分割部をさらに有することを特徴とする請求項1〜3のいずれか一つに記載の構成情報管理装置。
【請求項5】
前記クラスタ間をまたいだ検索処理の回数の削減数と該クラスタに含まれる前記構成要素および前記要素関係の増加数との関係に応じて、前記クラスタ上限値を設定する上限値設定部をさらに有することを特徴とする請求項4に記載の構成情報管理装置。
【請求項6】
管理対象に関する情報を示す構成要素と該構成要素間の接続関係に関する情報を示す要素関係とを複数の構成情報管理装置で分散して記憶する分散情報管理システムであって、
前記構成情報管理装置は、
前記構成要素および前記要素関係を他の構成情報管理装置で分散して記憶する構成情報記憶部と、
接続関係にある前記構成要素および前記要素関係の一群であるクラスタについて登録要求を受け付けた場合に、該クラスタの格納先を決定し、前記構成情報記憶部または前記他の構成情報管理装置に格納するように制御する格納制御部と、
前記構成要素または前記要素関係を検索対象とした検索要求を受け付けた場合に、該検索対象を含むクラスタの格納先を特定し、該クラスタの格納先から検索対象の前記構成要素または前記要素関係を検索する検索処理部と、
を有することを特徴とする分散情報管理システム。
【請求項7】
接続関係にある構成要素および該構成要素間の接続関係に関する情報を示す要素関係の一群であるクラスタについて登録要求を受け付けた場合に、該クラスタの格納先を決定し、前記構成要素および前記要素関係を他の構成情報管理装置と分散して記憶する構成情報記憶部または前記他の構成情報管理装置に格納するように制御する格納制御ステップと、
前記構成要素または前記要素関係を検索対象とした検索要求を受け付けた場合に、該検索対象を含むクラスタの格納先を特定し、該クラスタの格納先から検索対象の前記構成要素または前記要素関係を検索する検索処理ステップと、
を含んだことを特徴とする分散情報管理方法。
【請求項8】
接続関係にある構成要素および該構成要素間の接続関係に関する情報を示す要素関係の一群であるクラスタについて登録要求を受け付けた場合に、該クラスタの格納先を決定し、前記構成要素および前記要素関係を他の構成情報管理装置と分散して記憶する構成情報記憶部または前記他の構成情報管理装置に格納するように制御する格納制御手順と、
前記構成要素または前記要素関係を検索対象とした検索要求を受け付けた場合に、該検索対象を含むクラスタの格納先を特定し、該クラスタの格納先から検索対象の前記構成要素または前記要素関係を検索する検索処理手順と、
をコンピュータに実行させることを特徴とする分散情報管理プログラム。
【図1】


【図2】
【図3】
【図4】

【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18−1】
【図18−2】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18−1】
【図18−2】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【公開番号】特開2011−150545(P2011−150545A)
【公開日】平成23年8月4日(2011.8.4)
【国際特許分類】
【出願番号】特願2010−11417(P2010−11417)
【出願日】平成22年1月21日(2010.1.21)
【出願人】(000005223)富士通株式会社 (25,993)
【Fターム(参考)】
【公開日】平成23年8月4日(2011.8.4)
【国際特許分類】
【出願日】平成22年1月21日(2010.1.21)
【出願人】(000005223)富士通株式会社 (25,993)
【Fターム(参考)】
[ Back to top ]