
構造化文書管理装置、方法およびプログラム

【課題】構造照合処理を高速に行うことができる構造化文書管理装置、方法およびプログラムを提供することである。
【解決手段】実施形態の構造化文書管理装置は、入力されたクエリデータが、構造化文書データの論理構造における階層の上下関係を指定する第1条件と、要素IDで特定される要素の順序関係を指定する第2条件とを含む場合に、クエリデータ分解手段が、該クエリデータを、第1条件のみを含む第1の部分クエリデータと、第1の部分クエリデータによる照合結果を、第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解する。構造照合処理手段は、構造化文書データのデータ集合に対して第1の部分クエリデータによる照合を行い、照合結果を出力する。結合演算処理手段は、構造照合処理手段から出力された照合結果を、第2の部分クエリデータに含まれる結合演算の手順に従って結合演算処理する。
【解決手段】実施形態の構造化文書管理装置は、入力されたクエリデータが、構造化文書データの論理構造における階層の上下関係を指定する第1条件と、要素IDで特定される要素の順序関係を指定する第2条件とを含む場合に、クエリデータ分解手段が、該クエリデータを、第1条件のみを含む第1の部分クエリデータと、第1の部分クエリデータによる照合結果を、第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解する。構造照合処理手段は、構造化文書データのデータ集合に対して第1の部分クエリデータによる照合を行い、照合結果を出力する。結合演算処理手段は、構造照合処理手段から出力された照合結果を、第2の部分クエリデータに含まれる結合演算の手順に従って結合演算処理する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明の実施形態は、構造化文書管理装置、方法およびプログラムに関する。
【背景技術】
【0002】
従来、XML(Extensible Markup Language)などで記述された構造化文書データを記憶・検索するための構造化文書管理装置が知られている。構造化文書管理装置における構造化文書データの検索のために、RDBMS(Relational Database Managemant System)における問い合わせ言語SQLのように、XMLデータに対する問い合わせ言語XQuery(XML Query Language)が策定されており、多くの構造化文書管理装置でサポートされている。
【0003】
XQueryは、XMLデータ集合をデータベースのように扱うための言語であり、条件に合致するデータ集合の取り出しや集計・分析を行うための手段が提供されている。XMLデータは親子や兄弟などの要素が組み合わさった階層化された論理構造(階層構造)を持つため、条件にはこの階層構造に関する条件(構造条件)を指定することができる。
【0004】
構造条件の処理には、構造化文書管理装置が記憶している構造化文書データが条件に合致する構造を持つかを照合する構造照合処理を行う必要がある。この構造照合処理は、構造条件が階層の上下関係を指定する条件のみであれば比較的高速に処理することが可能であるが、構造条件の中にXMLデータに含まれる要素の順序関係を指定する条件が含まれる場合は、高速に処理することが難しい。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2007−226452号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
本発明が解決しようとする課題は、構造照合処理を高速に行うことができる構造化文書管理装置、方法およびプログラムを提供することである。
【課題を解決するための手段】
【0007】
実施形態の構造化文書管理装置は、構造化文書データ受付手段と、識別子付与手段と、構造化文書データ記憶手段と、クエリデータ受付手段と、クエリデータ分解手段と、構造照合処理手段と、結合演算処理手段と、を備える。構造化文書データ受付手段は、階層化された論理構造を有する構造化文書データの入力を受け付ける。識別子付与手段は、入力された前記構造化文書データに出現する要素に該構造化文書データ内での出現順序が要素間で比較可能な識別子を付与する。構造化文書データ記憶手段は、前記要素に前記識別子が付与された前記構造化文書データを記憶する。クエリデータ受付手段は、クエリデータの入力を受け付ける。クエリデータ分解手段は、入力されたクエリデータが、前記構造化文書データの論理構造における階層の上下関係を指定する第1条件と、前記識別子で特定される前記要素の順序関係を指定する第2条件とを含む場合に、該クエリデータを、前記第1条件のみを含む第1の部分クエリデータと、前記第1の部分クエリデータによる照合結果を前記第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解する。構造照合処理手段は、前記構造化文書データ記憶手段が記憶する前記構造化文書データのデータ集合に対して、前記第1の部分クエリデータによる照合を行い、照合結果を出力する。結合演算処理手段は、前記照合結果を、前記第2の部分クエリデータに含まれる結合演算の手順に従って結合演算処理する。
【図面の簡単な説明】
【0008】
【図1】構造化文書管理システムのシステム構築例を示す模式図。
【図2】サーバおよびクライアント端末のモジュール構成図。
【図3】第1の実施形態におけるサーバおよびクライアント端末の概略構成を示すブロック図。
【図4】構造化文書データの一例を示す説明図。
【図5】図4に例示した構造化文書データに対して要素IDを付与した要素ID付与済み構造化文書データの一例を示す説明図。
【図6】クエリデータの一例を示す説明図。
【図7】検索処理部による検索処理の流れを示すフローチャート。
【図8】クエリデータ解析処理の流れを示すフローチャート。
【図9】図6に例示したクエリデータについてクエリデータ解析処理を行った結果である第1の部分クエリデータと第2の部分クエリデータの一例を示す説明図。
【図10】構造照合処理の概略を示す説明図。
【図11】図9に例示した第1の部分クエリデータを用いて図5に例示した要素ID付与済み構造化文書データについて構造照合処理を行った結果である構造照合処理結果データの一例を示す説明図。
【図12】図9に例示した第2の部分クエリデータを用いて図11に例示した構造照合処理結果データについて結合演算処理を行う場合の説明図。
【図13】図9に例示したクエリデータの結果データを示す説明図。
【図14】第2の実施形態におけるサーバおよびクライアント端末の概略構成を示すブロック図。
【図15】構造ガイドデータの一例を示す説明図。
【図16】クエリデータの一例を示す説明図。
【図17】第2の実施形態におけるクエリデータ解析処理の流れを示すフローチャート。
【図18】図16に例示したクエリデータについて図17のステップS215までの処理を行った結果である第1の部分クエリデータと第2の部分クエリデータの一例を示す説明図。
【図19】構造条件書き換え処理の流れを示すフローチャート。
【図20】図18に例示した第1の部分クエリデータについて構造条件書き換え処理を行った結果を示す説明図。
【図21】図20に例示した構造条件書き換え処理後の第1の部分クエリデータを用いて図5に例示した要素ID付与済み構造化文書データについて構造照合処理を行った結果である構造照合処理結果データの一例を示す説明図。
【図22】図20に例示した第2の部分クエリデータを用いて図21に例示した構造照合処理結果データについて結合演算処理を行う場合の説明図。
【図23】図16に例示したクエリデータの結果データを示す説明図。
【図24】クエリデータの一例を示す説明図。
【図25】第3の実施形態におけるクエリデータ解析処理の流れを示すフローチャート。
【図26】図24に例示したposition関数を含むクエリデータについてクエリデータ解析処理を行った結果である第1の部分クエリデータと第2の部分クエリデータの一例を示す説明図。
【図27】図24に例示したlast関数を含むクエリデータについてクエリデータ解析処理を行った結果である第1の部分クエリデータと第2の部分クエリデータの一例を示す説明図。
【図28】図26に例示した第1のクエリデータを用いて図5に例示した要素ID付与済み構造化文書データについて構造照合処理を行った結果である構造照合処理結果データの一例を示す説明図。
【図29】図26に例示した第2の部分クエリデータを用いて図28に例示した構造照合処理結果データについて結合演算処理を行う場合の説明図。
【図30】図27に例示した第1のクエリデータを用いて図5に例示した要素ID付与済み構造化文書データについて構造照合処理を行った結果である構造照合処理結果データの一例を示す説明図。
【図31】図27に例示した第2の部分クエリデータを用いて図30に例示した構造照合処理結果データについて結合演算処理を行う場合の説明図。
【図32】図24に例示したposition関数を含むクエリデータの結果データを示す説明図。
【図33】図24に例示したlast関数を含むクエリデータの結果データを示す説明図。
【図34】第4の実施形態におけるサーバおよびクライアント端末の概略構成を示すブロック図。
【図35】クエリデータの一例を示す説明図。
【図36】第4の実施形態における検索処理の流れを示すフローチャート。
【図37】第4の実施形態におけるクエリデータ解析処理の流れを示すフローチャート。
【図38】図35に例示したクエリデータについてクエリデータ解析処理を行った結果である第1の部分クエリデータの一例を示す説明図。
【図39】図38に例示した第1の部分クエリデータを用いて図5に例示した要素ID付与済み構造化文書データについて構造照合処理を行った結果である構造照合処理結果データの一例を示す説明図。
【図40】図35に例示したクエリデータの結果データを示す説明図。
【発明を実施するための形態】
【0009】
以下、実施形態の構造化文書管理装置、方法およびプログラムを、図面を参照して説明する。
【0010】
[第1の実施形態]
まず、第1の実施形態について、図1乃至図13を参照して説明する。図1は、第1の実施形態にかかる構造化文書管理システムのシステム構築例を示す模式図である。ここでは、実施形態の構造化文書管理システムとして、図1に示すように、構造化文書管理装置であるサーバコンピュータ(以下、サーバという。)1に、LAN(Local Area Network)等のネットワーク2を介して、クライアントコンピュータ(以下、クライアント端末という。)3が複数台接続されたサーバクライアントシステムを想定する。
【0011】
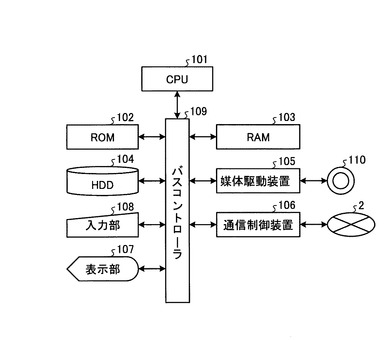
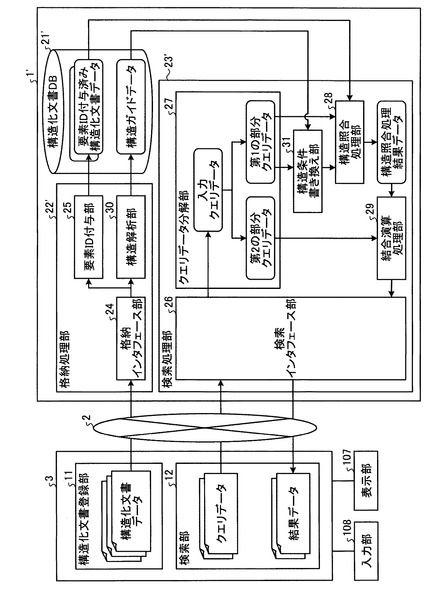
図2は、サーバ1およびクライアント端末3のモジュール構成図である。サーバ1およびクライアント端末3は、例えば、通常のコンピュータを利用したハードウェア構成を有している。すなわち、サーバ1およびクライアント端末3は、情報処理を行うCPU(Central Processing Unit)101、BIOSなどを記憶した読出し専用メモリであるROM(Read Only Memory)102、各種データを書き換え可能に記憶するRAM(Random Access Memory)103、各種データベースとして機能するとともに各種のプログラムを格納するHDD(Hard Disc Drive)104、記憶媒体110を用いて情報を保管したり外部に情報を配布したり外部から情報を入手するためのCD−ROMドライブ等の媒体駆動装置105、ネットワーク2を介して外部の他のコンピュータと通信により情報を伝達するための通信制御装置106、処理経過や結果等を操作者に表示するCRT(Cathode Ray Tube)やLCD(Liquid Crystal Display)等の表示部107、並びに操作者がCPU101に命令や情報等を入力するためのキーボードやマウス等の入力部108等を備えた構成であり、これらの各部間で送受信されるデータをバスコントローラ109が調停して動作する。
【0012】
このようなサーバ1およびクライアント端末3では、ユーザが電源を投入するとCPU101がROM102内のローダーというプログラムを起動させ、HDD104よりOS(Operating System)というコンピュータのハードウェアとソフトウェアとを管理するプログラムをRAM103に読み込み、このOSを起動させる。このようなOSは、ユーザの操作に応じてプログラムを起動したり、情報を読み込んだり、保存を行ったりする。OSのうち代表的なものとしては、Windows(登録商標)、UNIX(登録商標)等が知られている。これらのOS上で動作するプログラムをアプリケーションプログラムと呼んでいる。なお、アプリケーションプログラムは、所定のOS上で動作するものに限らず、後述の各種処理の一部の実行をOSに肩代わりさせるものであってもよいし、所定のアプリケーションソフトやOSなどを構成する一群のプログラムファイルの一部として含まれているものであってもよい。
【0013】
ここで、サーバ1は、アプリケーションプログラムとして、構造化文書管理プログラムをHDD104に記憶している。この意味で、HDD104は、構造化文書管理プログラムを記憶する記憶媒体として機能する。また、一般的には、サーバ1のHDD104にインストールされるアプリケーションプログラムは、CD−ROMやDVDなどの各種の光ディスク、各種光磁気ディスク、フレキシブルディスクなどの各種磁気ディスク、半導体メモリ等の各種方式のメディア等の記憶媒体110に記録されて提供される。このため、CD−ROM等の光情報記録メディアやFD等の磁気メディア等の可搬性を有する記憶媒体110も、構造化文書管理プログラムを記憶する記憶媒体となり得る。さらには、構造化文書管理プログラムは、例えば通信制御装置106を介して外部から取り込まれ、HDD104にインストールされてもよい。
【0014】
サーバ1は、OS上で動作する構造化文書管理プログラムが起動すると、この構造化文書管理プログラムに従い、CPU101が各種の演算処理を実行して各部を集中的に制御する。一方、クライアント端末3は、OS上で動作するアプリケーションプログラムが起動すると、このアプリケーションプログラムに従い、CPU101が各種の演算処理を実行して各部を集中的に制御する。サーバ1およびクライアント端末3のCPU101が実行する各種の演算処理のうち、実施形態の構造化文書管理システムにおいて特徴的な処理について、以下に説明する。
【0015】
図3は、第1の実施形態におけるサーバ1およびクライアント端末3の概略構成を示すブロック図である。図3に示すように、クライアント端末3は、アプリケーションプログラムにより実現される機能構成として、構造化文書登録部11と、検索部12とを備える。
【0016】
構造化文書登録部11は、入力部108から入力された構造化文書データやクライアント端末3のHDD104に予め記憶された構造化文書データを、後述するサーバ1の構造化文書データベース(構造化文書DB)21に登録するためのものである。この構造化文書登録部11は、登録すべき構造化文書データとともに格納要求をサーバ1に送信する。
【0017】
図4は、構造化文書データの一例を示したものである。構造化文書データを記述するための代表的な言語としてXML(Extensible Markup Language)が挙げられる。図4に示す構造化文書データは、XMLで記述されたものである。XMLでは、文書構造を構成する個々のパーツを「要素」(エレメント:Element)と呼び、要素はタグ(tag)を使って記述する。具体的には、要素の始まりを示すタグ(開始タグ)と、終わりを示すタグ(終了タグ)の2つのタグでデータを挟み込んで、1つの要素を表現している。なお、開始タグと終了タグで挟み込まれたテキストデータは、当該開始タグと終了タグで表された1つの要素に含まれるテキスト要素である。
【0018】
図4に示す例では、<books>というタグで囲まれたルート要素が存在する。この<books>要素は、<book>のタグで囲まれた3つの子要素を包含する。<book>要素は、<title>、<author>の各タグで囲まれた複数の子要素を包含する。<title>要素は、「XMLデータベース」などのテキスト要素をもつ。
【0019】
1番目の<book>要素は、2つの<author>要素を持ち、これら2つの<author>要素が<title>要素の後に出現する順序であるが、2,3番目の<book>要素は、1つの<author>要素のみを持ち、<author>要素の後に<title>要素が出現している。
【0020】
検索部12は、ユーザにより入力部108から入力された指示に従って、構造化文書DB21から所望のデータを検索するための検索条件などが記述されたクエリデータを作成し、当該クエリデータを含む検索要求をサーバ1へ送信する。また、検索部12は、サーバ1から送信された当該検索要求に対応する結果データを受け取り、これを表示部107に表示する。
【0021】
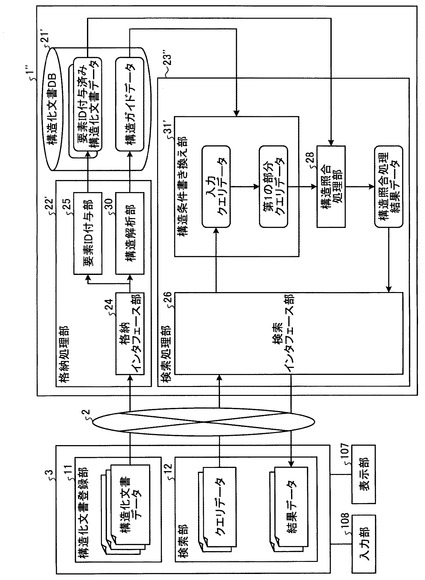
一方、サーバ1は、構造化文書管理プログラムにより実現される機能構成として、格納処理部22と、検索処理部23とを備える。また、サーバ1は、HDD104などの記憶装置を利用した構造化文書DB21を備える。
【0022】
格納処理部22は、クライアント端末3からの格納要求を受けて、クライアント端末3から送信された構造化文書データを構造化文書DB21に格納する処理を行う。この格納処理部22は、格納インタフェース部24と、要素ID付与部25とを備えている。
【0023】
格納インタフェース部24は、構造化文書データの入力を受け付けて(構造化文書データ受付手段)、構造化文書データを構造化文書DB21に格納するために要素ID付与部25を呼び出す。
【0024】
要素ID付与部25は、識別子付与手段として機能するものであって、クライアント端末3から送信された構造化文書データを構文解析し、そこに出現する要素に要素間で出現順序が比較可能な識別子(以下、要素IDという。)を付与した上で、要素IDが付与された構造化文書データ(以下、要素ID付与済み構造化文書データという。)を構造化文書DB21(構造化文書データ記憶手段)に格納する。
【0025】
ここで、要素IDは、その大小で構造化文書データ中での要素の出現順序が判定できるように付与される。図4に例示した構造化文書データに対して要素IDを付与した要素ID付与済み構造化文書データの例を図5に示す。図5では、要素IDを付与する方法の一例として、ルート要素より要素の出現順に従ってE1、E2、E3、・・・と付与している。このように付与すれば、要素間の出現順序を要素IDの比較で判定することができる。
【0026】
例えば、図4に例示した構造化文書データにおける<books>の1番目の<book>要素は、その中に2つの<author>要素を持ち、これら2つの<author>要素の出現順序は、子に<first>要素を持つ<author>要素が先に出現し、子に<last>要素を持つ<author>要素が後に出現する順となっている。ここで、図5でそれぞれに付与された要素IDを比較すると、E5<E8であり、要素IDとしてE8を付与された要素である、子に<last>要素を持つ<author>要素が、要素IDとしてE8を付与された要素である、子に<first>要素を持つ<author>要素よりも後に出現することが判定できる。また、図5では、要素ID付与済み構造化文書データの形式が図4の構造化文書データとほぼ同一であるが、先に述べたように、その大小で要素の出現順序が判定できるように要素IDが付与されていれば、要素ID付与済み構造化文書データの形式は特に限定されるものではない。
【0027】
検索処理部23は、クライアント端末3からの検索要求を受けて、クエリデータにより指定された条件に合致するデータを構造化文書DB21から探し出し、この探し出したデータを結果データとして返す処理を行う。この検索処理部23は、検索インタフェース部26と、クエリデータ分解部27と、構造照合処理部28と、結合演算処理部29とを備えている。
【0028】
検索インタフェース部26は、クエリデータの入力を受け付けて(クエリデータ受付手段)、受け付けたクエリデータにより指定された条件を満足する結果データを得るためにクエリデータ分解部27を呼び出す。
【0029】
クエリデータ分解部27は、クエリデータ分解手段として機能するものであって、クライアント端末3から送信され、検索インタフェース部26を介して入力されたクエリデータ(以下、入力クエリデータという。)を構文解析し、この入力クエリデータが、構造化文書データの論理構造における階層の上下関係を指定する条件(第1条件)と、要素IDで特定される要素の順序関係を指定する条件(第2条件)とを含む場合に、入力クエリデータを、第1条件のみを含む第1の部分クエリデータと、第1の部分クエリデータによる照合結果を第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解する。
【0030】
構造照合処理部28は、構造照合処理手段として機能するものであって、構造化文書DB21に格納されている要素ID付与済み構造化文書データのデータ集合に対して、第1の部分クエリデータによる構造条件の照合処理を行い、その照合結果を構造照合処理結果データとして出力する。
【0031】
結合演算処理部29は、結合演算処理手段として機能するものであって、構造照合処理部28から出力された第1の部分クエリデータによる照合結果である構造照合処理結果データに対して、第2のクエリデータに含まれる結合演算の手順に従って結合演算を行い、結合演算結果データを出力する。なお、結合演算処理部29は、第2の部分クエリデータが空ならば、構造照合処理部28から出力された構造照合処理結果データをそのまま出力するか、または自身の処理を省略する。
【0032】
検索インタフェース部26は、結合演算処理部29から出力された結合演算処理結果データを、検索の結果データとしてクライアント端末3へ返却する。
【0033】
図6は、クエリデータの一例を示す説明図である。XMLでは、W3Cで提案されているXQueryという問合せ言語があり、図6に示すクエリデータは、このXQueryに基づいた問合せ記述方法に則っている。図6には、下記のような意味の複雑な階層構造に関する条件(構造条件)を含むクエリデータQ1が示されている。
Q1:構造化文書DB21の各構造化文書データについて、階層のどこかに「book」という要素があり、その「book」という要素は、その中に「author」という要素を持ち、さらにこの「author」という要素の中に、「first」と「last」という2つの要素を持つような「book」要素であり、さらにその「book」要素よりも後に出現する「book」要素について、その中にある「title」の一覧を返す。
【0034】
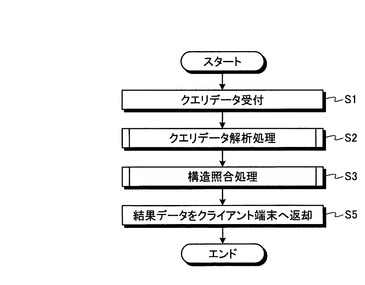
図7は、サーバ1の検索処理部23による検索処理の流れを示すフローチャートである。まず、検索インタフェース部26により、クライアント端末3からネットワーク2経由で送信されたクエリデータの入力が受け付けられる(ステップS1)。
【0035】
次に、クエリデータ分解部27により、入力クエリデータについてのクエリデータ解析処理が行われる(ステップS2)。クエリデータ分解部27によるクエリデータ解析処理の一例を、図8を参照して説明する。
【0036】
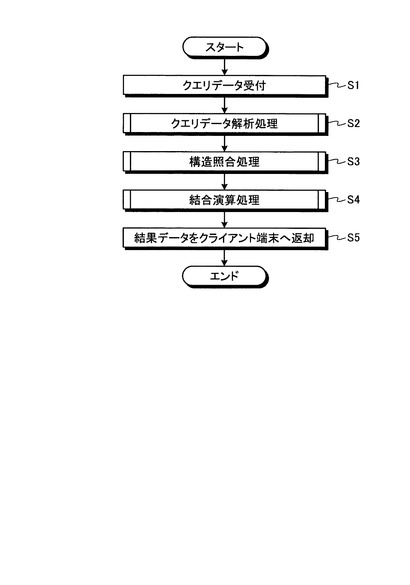
図8は、クエリデータ解析処理の流れを示すフローチャートである。クエリデータ分解部27は、はじめに、入力クエリデータのすべてを便宜的に第1の部分クエリデータとする(ステップS201)。このとき、第2の部分クエリデータは空としておく。
【0037】
次に、クエリデータ分解部27は、第1の部分クエリデータをチェックして、第1の部分クエリデータ(ここでは入力クエリデータと同じ)に、ある構造を持つ要素間の順序関係に関する構造条件、つまり、要素IDで特定される要素の順序関係を指定するような条件が含まれるかどうかを判定する(ステップS202)。そして、クエリデータ分解部27は、そのような構造条件が含まれていれば(ステップS202:Yes)、第1の部分クエリデータを、階層の上下関係を指定する条件のみを含む構造条件、つまり、順序関係に関する構造条件での照合の対象となる構造それぞれを指定するような構造条件に分解し(ステップS203)、分解された構造条件すべてを第1の部分クエリデータとする(ステップS204)。そして、クエリデータ分解部27は、分解された各構造条件の構造照合処理結果間で、そこに含まれる要素IDの結合演算を指示する内容を、第2の部分クエリデータとし(ステップS205)、クエリデータ解析処理を終了する。
【0038】
一方、ステップS202の判定で、第1の部分クエリデータ(ここでは入力クエリデータと同じ)に上述した順序関係に関する構造条件が含まれなければ(ステップS202:No)、クエリデータ分解部27は、ステップS203からステップS205の処理を行うことなく、クエリデータ解析処理を終了する。
【0039】
図9は、図6に例示したクエリデータQ1についてのクエリデータ解析処理の結果である第1の部分クエリデータQ1_Aと第2の部分クエリデータQ1_Bの一例を示す図である。図9において、第1の部分クエリデータQ1_Aは、構造条件PP1とPP2を含んでいる。また、第2の部分クエリデータQ1_Bは、Q1_Aによる構造照合処理の照合結果を、上述した順序関係に関する構造条件に応じて結合演算する手順を含んでいる。図6に例示したクエリデータQ1は、順序関係に関する構造条件「following−sibling」が含まれているため、クエリデータQ1は、この構造条件での照合の対象となる構造を指定する構造条件PP1,PP2に分解され、これらPP1,PP2による構造照合処理の照合結果を「following−sibling」に応じて結合演算する手順が、第2の部分クエリデータQ1_Bとされる。なお、図中のQ1_BにあるT1,T2は、それぞれPP1,PP2を構造照合処理した結果を識別する記号である。また、図中のQ1_A,Q1_Bにある[1],[2],[3]は、T1,T2に含まれる要素ID群を識別する記号である。
【0040】
クエリデータ分解部27によるクエリデータ解析処理が終了すると、次に、構造照合処理部28により、第1の部分クエリデータに含まれる構造条件の構造照合処理が行われる(ステップS3)。ここで、構造照合処理とは、構造化文書データについて、指定された構造条件をXQueryで定められた仕様で解釈して照合し、結果として構造条件に合致する構造化文書データまたは構造化文書データ中の要素を得る処理をいう。
【0041】
ここで、図5に例示した要素ID付与済み構造化文書データと、図9に例示した第1の部分クエリデータQ1_Aに含まれる構造条件PP1,PP2とを用いて、一般的な構造照合処理を行った場合の処理の概要を、図10を参照して説明する。以下では、構造条件中の/で区切られた部分を単にパスと呼称する。
【0042】
第1の部分クエリデータQ1_Aに含まれる構造条件PP1の照合について、構造条件PP1を左から見て、まず先頭のパス//book(/descendant−or−self::book)の照合を行う。これは、XQuery仕様で、「ルート要素以下のどこかの階層構造にある要素で、名前がbookである要素を選択する」ことを意味する。これに従い、図5に例示した要素ID付与済み構造化文書データ中の要素の構造を照合すると、ルート要素<books>以下の3つの<book>要素、E2,E13,E21が選択される(1.1)。
【0043】
次の[author[first and last]]とは、「前の構造照合で得られた要素について、その子にauthorという要素があり、さらにそのauthor要素は、その子としてfirstとlastという要素を両方含んでいるような要素のみをさらに選択する」ことを意味する。これに従い各<book>要素より下位の要素の構造を照合して<book>要素を選択すると、結果として、要素IDがE13,E21であるbook要素が得られる(1.2)。
【0044】
同様に、第1の部分クエリデータQ1_Aに含まれる構造条件PP2の照合について、先頭のパス//bookについては先のPP1の例と同じ意味であり、3つの<book>要素、E2,E13,E21が選択される(2.1)。次に続くパス/title(/child::title)とは、「前のパス照合で得られた要素に対して子供の階層構造の位置にある要素で、名前がtitleである要素を選択する」ことを意味する。これに従い、前の構造照合で得られた各<book>要素に対して子供の構造位置にある要素を照合すると、要素IDがE2の<book>要素からは要素IDがE3の<title>要素が得られ、要素IDがE13の<book>要素からは要素IDがE19の<title>要素が得られ、要素IDがE21の<book>要素からは要素IDがE27の<title>要素が得られる(2.2)。
【0045】
なお、ここで概説した構造条件およびパスの構造照合処理の方法は一例であり、構造条件およびパスの構造照合処理の方法には、特許文献1に記載されているようなものをはじめ、様々なものがある。本実施形態における構造照合処理部28は、入力された構造条件に合致する構造を持つ構造化文書データ中の要素を取得するものであれば、内部の具体的な処理方法については特に限定されるものではない。
【0046】
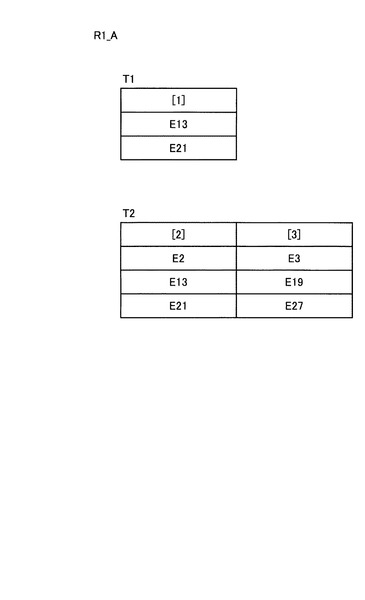
図5に例示した要素ID付与済み構造化文書データについて、図9に例示した第1の部分クエリデータQ1_Aに含まれる構造条件PP1,PP2の構造照合処理を行った結果である構造照合処理結果データR1_Aを図11に示す。図中のT1,T2は、それぞれ構造条件PP1,PP2の構造照合処理の結果であり、T1としては構造条件PP1に合致する構造を持つ要素の要素ID群[1]が得られ、T2としては構造条件PP2に合致する構造を持つ要素の要素ID群[2],[3]が得られる。なお、図11ではT1,T2を表で示しているが、構造照合処理結果データの具体的なデータ構造は特に限定されるものではない。
【0047】
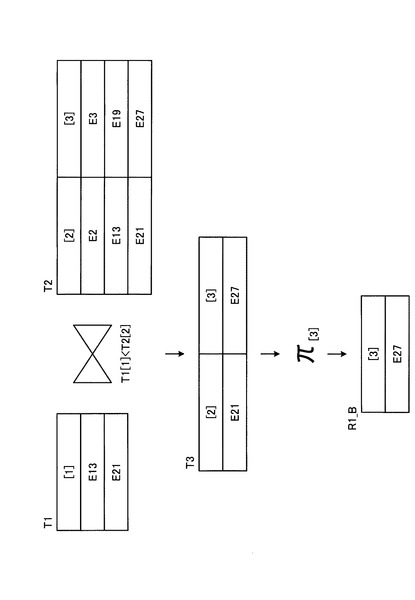
構造照合処理部28による構造照合処理が終了すると、次に、結合演算処理部29により、構造照合処理部28の処理結果である構造照合処理結果データについて、第2の部分クエリデータに含まれる手順に従って結合演算処理が行われる(ステップS4)。
【0048】
図12は、図9に例示した第2の部分クエリデータQ1_Bを用いて図11に例示した構造照合処理結果データR1_Aについて結合演算処理を行う場合の処理の概要を説明する図である。結合演算処理は、従来のRDB(Relational Database)で行われている結合演算(JOIN)などと同じである。
【0049】
図12の例では、T1[1]<T2[2]という順序関係に関する条件に従ってT1とT2との結合演算が行われ、T3が得られる。そして、T3について[3]のみを取り出すことにより、結合演算処理の結果として、図12に示すような中間結果R1_Bが得られる。この中間結果R1_Bは、図6に例示したクエリデータQ1を、上述したようなクエリデータ解析処理を行わずにそのまま処理した場合の結果と一致する。
【0050】
結合演算処理部29による結合演算処理が終了すると、最後に、検索インタフェース部26により、結合演算処理部29による結合演算処理の結果(中間結果)として得られる要素IDが、それに対応する構造化文書データとして文字列化され、結果データとしてクライアント端末3に返却される(ステップS5)。図12に示した中間結果R1_Bが得られた場合には、この中間結果R1_Bに含まれる要素IDであるE27に対応する構造化文書データが文字列化され、クエリデータQ1の結果データR1として、図13に示すデータがクライアント端末3に返却される。
【0051】
以上、具体的な例を挙げながら説明したように、本実施形態によれば、サーバ1が、構造化文書データの登録時に、その構造化文書データに出現する各要素に要素間で出現順序が比較可能な要素IDを付与して、要素ID付与済み構造化文書データを構造化文書DB21に格納する。また、サーバ1は、構造化文書データの検索時には、クライアント端末3からの入力クエリデータを構文解析して、入力クエリデータが、構造化文書データの論理構造における階層の上下関係を指定する第1条件と、要素IDで特定される要素の順序関係を指定する第2条件とを含む場合に、その入力クエリデータを、第1条件のみを含む第1の部分クエリデータと、第1の部分クエリデータによる照合結果を、第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解して処理するようにしている。したがって、入力クエリデータが複雑な構造条件を含む場合でも、この入力クエリデータを単純な構造条件の構造照合処理と結合演算処理とで処理することで、構造照合処理の高速化を実現し、複雑な構造条件を含むクエリデータによる検索を高速に実行することができる。
【0052】
なお、上記の具体例では、入力クエリデータに、要素IDで特定される要素の順序関係を指定する条件(順序関係に関する構造条件)として「following−sibling」が含まれる場合を例示して説明したが、要素の順序関係を指定する他の条件、例えば「following」や「preceeding」、「preceeding−sibling」などが含まれる場合であっても、上記の具体例と同様に処理することができる。
【0053】
[第2の実施形態]
次に、第2の実施形態について、図5、図7、図14乃至図23を参照して説明する。本実施形態は、第1の部分クエリデータが、構造化文書データの論理構造における階層を下位から上位へと辿る条件を含む場合に、その条件を、構造化文書データの論理構造における階層を下位から上位へと辿る条件に書き換えるようにした例である。なお、以下の説明において、上述した第1の実施形態と共通の構成については同一の符号を付し、重複した説明を省略する。
【0054】
図14は、本実施形態におけるサーバ1’およびクライアント端末3の概略構成を示すブロック図である。本実施形態では、サーバ1’の格納処理部22’に構造解析部30が設けられている。また、サーバ1’の構造化文書DB21’には、要素ID付与済み構造化文書データとともに、構造化文書DB21’に格納された要素ID付与済み構造化文書データそれぞれの階層化された論理構造を集約した情報である構造ガイドデータが格納されている(構造ガイドデータ記憶手段)。また、サーバ1’の検索処理部23’には、構造条件書き換え部31が設けられている。なお、クライアント端末3の構成は第1の実施形態と同じである。
【0055】
構造解析部30は、構造ガイドデータ更新手段として機能するものであり、クライアント端末3から送信された構造化文書データの階層化された論理構造を解析し、その論理構造が構造ガイドデータに反映されるように、構造化文書DB21’に格納されている構造ガイドデータを更新する。
【0056】
構造ガイドデータは、構造化文書DB21’に格納された要素ID付与済み構造化文書データそれぞれの階層化された論理構造を集約した情報であり、要素ID付与済み構造化文書データ中に出現する一意な階層構造に関する情報を保持するものである。図4に例示した構造化文書データに対応する構造ガイドデータは、例えば図15に示すようなものとなる。構造解析部30は、まず、クライアント端末3から送信された構造化文書データの階層化された論理構造を解析して図15に示すような構造ガイドデータを新規に生成する。そして、構造解析部30は、新規に生成した構造ガイドデータを構造化文書DB21’に格納されている構造ガイドデータ(つまり、構造化文書DB21’に格納された要素ID付与済み構造化文書データの論理構造を集約した構造ガイドデータ)と比較し、新規に生成した構造ガイドデータが、構造化文書DB21’に格納されている構造ガイドデータにはない新たな階層構造に関する情報を含む場合に、その新たな階層構造に関する情報を、構造化文書DB21’に格納されている構造ガイドデータに追加するかたちで、構造化文書DB21’に格納されている構造ガイドデータを更新する。
【0057】
構造条件書き換え部31は、条件書き換え手段として機能するものであって、クエリデータ分解部27によって入力クエリデータを分解して得られた第1の部分クエリデータが、構造化文書データの論理構造における階層を下位から上位へと辿る条件、つまり構造化文書データのリーフ要素(葉)からルート要素(根)方向に構造を照合するような条件を含む場合に、該条件を、構造化文書DB21’に格納されている構造ガイドデータに基づいて、構造化文書データの論理構造における階層を上位から下位へと辿る条件、つまり構造化文書データのルート要素(根)からリーフ要素(葉)方向に構造を照合するような条件に書き換える。
【0058】
図16は、本実施形態で想定するクエリデータの一例を示す説明図である。この図16に示すクエリデータQ2は、第1の実施形態で説明したクエリデータQ1と同じくXQueryで記述されており、下記のような意味の複雑な階層構造に関する条件(構造条件)を含んでいる。
Q2:構造化文書DB21’の各構造化文書データについて、階層のどこかに「book」という要素があり、その「book」という要素はその中に「author」という要素を持ち、さらにこの「author」という要素の中に、「first」と「last」という2つの要素を持つような「book」要素であり、さらにその「book」要素よりも後に出現する「book」要素の子である「title」要素の、親要素の子であるような「author」要素の一覧を返す。
【0059】
クエリデータQ2では、クエリデータQ1に加えて「/parent」というパスが出現している。XQueryでの/descendant、/descendant−or−selfや/(child)が、構造化文書のルート要素(根)からリーフ要素(葉)方向に構造を照合するパスであるのに対して、/parentや/ancestorは構造化文書データのリーフ要素(葉)からルート要素(根)方向に、階層構造内での親や先祖要素を照合するパスである。
【0060】
本実施形態おける検索処理部23’による検索処理の流れは、図7に示した第1の実施形態のものと同様である。ただし、本実施形態では、ステップS2のクエリデータ解析処理の中で、構造条件書き換え部31による構造条件書き換え処理が実施される。
【0061】
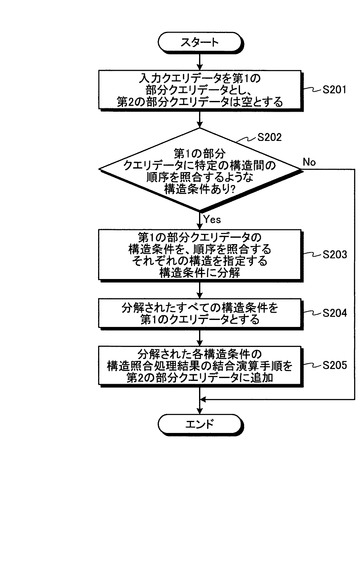
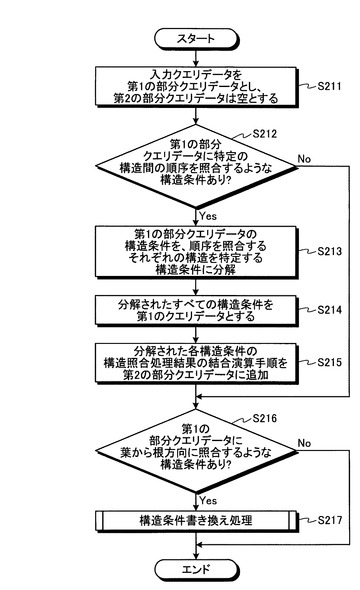
図17は、本実施形態におけるクエリデータ解析処理の流れを示すフローチャートである。この図17のフローチャートにおいて、ステップS211〜ステップS215までの処理は、第1の実施形態で説明した図8のステップS201〜ステップS205と同様であるため、説明を省略する。
【0062】
本実施形態におけるクエリデータ解析処理では、ステップS215の処理の次に、構造条件書き換え部31が、これまでの処理で作成された第1の部分クエリデータに、構造化文書データの階層構造を葉から根方向へ照合するような構造条件が含まれるかどうかを判定する(ステップS216)。そして、構造条件書き換え部31は、第1の部分クエリデータに、構造化文書データの階層構造を葉から根方向へ照合するような構造条件が含まれていれば(ステップS216:Yes)、構造条件書き換え処理を行って、構造化文書データの階層構造を葉から根方向へ照合する構造条件を、根から葉方向へ照合する構造条件に書き換える(ステップS217)。
【0063】
一方、ステップS216の判定で、第1の部分クエリデータに、構造化文書データの階層構造を葉から根方向へ照合するような構造条件が含まれなければ(ステップS216:No)、ステップS217の構造条件書き換え処理を行うことなく、クエリデータ解析処理を終了する。
【0064】
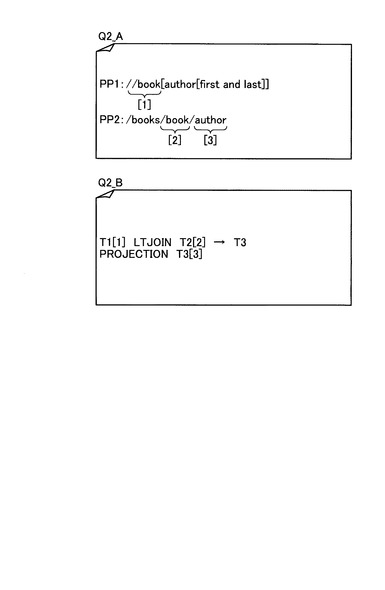
図18は、図16に例示したクエリデータQ2について、図17のステップS215までの処理を行った結果である第1の部分クエリデータQ2_Aと第2の部分クエリデータQ2_Bの例を示す図である。図18において、第1の部分クエリデータQ2_Aは、構造条件PP1とPP2を含んでいる。また、第2の部分クエリデータQ2_Bは、Q2_Aによる構造照合処理の照合結果を、上述した順序関係に関する構造条件に応じて結合演算する手順を含んでいる。この図18の例では、第1の部分クエリデータQ2_Aの構造条件PP2が、/parentのパスを含んでいる。このため、構造条件書き換え部31による構造条件書き換え処理が行われることになる。
【0065】
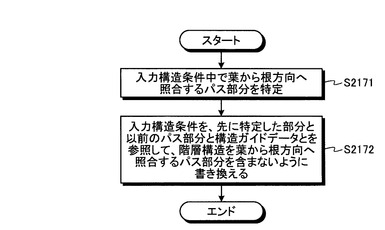
図19は、図17のステップS217で行われる構造条件書き換え処理を示すフローチャートである。構造条件書き換え部31は、まず、第1の部分クエリデータのうち、構造化文書データの階層構造を葉から根方向へ照合するパスが含まれる構造条件(以下、入力構造条件という。)の中で、葉から根方向へ照合するパス部分を特定する(ステップS2171)。次に、構造条件書き換え部31は、入力構造条件を、特定したパス部分より前のパスと、特定したパス部分より後のパスと、構造ガイドデータとを参照して、葉から根方向へ照合するパス部分を含まない同じ意味のパスに書き換える(ステップS2172)。
【0066】
ここで、図18に例示した第1の部分クエリデータQ2_Aにある構造条件PP2を、図15に例示した構造ガイドデータを参照して書き換える場合を例に挙げて、ステップS2172での処理の概要を説明する。なお、ここでは説明を簡単にするために、図15に例示した構造ガイドデータを参照しているが、実際には構造化文書DB21’に格納された構造ガイドデータが参照される。
【0067】
第1の部分クエリデータQ2_Aにある構造条件PP2の/parent::node()部分について、その直前のパスは/titleである。図15に例示した構造ガイドデータを参照すると、titleを末尾に持つ構造は/books/book/titleである。/parent::node()は親要素を指定するため、/parent::node()の指定する構造は/books/bookとわかる。さらに、/parent::node()の次のパスである/authorについても、ここまでで特定された構造は/books/bookであるから、/books/bookの後に/authorが続く構造があるかを構造ガイドデータで確認すると、存在するので、構造条件PP2の書き換え結果として/books/book/authorが得られる。
【0068】
図20は、図18に例示した第1の部分クエリデータQ2_Aについて、構造条件書き換え処理を行った結果を示す図である。なお、図中の第2の部分クエリデータQ2_Bは、図18に例示したものと同じである。
【0069】
本実施形態では、構造条件書き換え部31による構造条件書き換え処理を経て、構造照合処理部28による構造照合処理が行われる(ステップS3)。このとき、第1の部分クエリデータに含まれる構造条件は、葉から根方向へ照合するパス部分を含まないものに書き換えられているため、構造照合処理部28による構造照合処理は、すべて根から葉方向への照合のみで実現することができ、極めて高速な処理が可能である。
【0070】
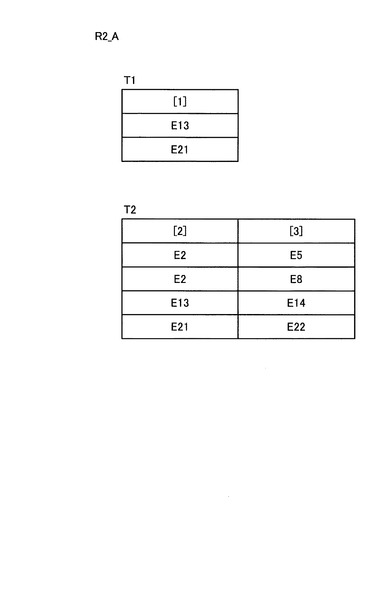
図5に例示した要素ID付与済み構造化文書データについて、図20に例示した構造条件書き換え処理後の第1の部分クエリデータQ2_Aに含まれる構造条件PP1,PP2による構造照合処理を行った結果である構造照合処理結果データR2_Aを図21に示す。図中のT1,T2は、それぞれ構造条件PP1,PP2の構造照合処理の結果であり、T1としては構造条件PP1に合致する構造を持つ要素の要素ID群[1]が得られ、T2としては構造条件PP2に合致する構造を持つ要素の要素ID群[2],[3]が得られる。
【0071】
本実施形態においても、構造照合処理部28による構造照合処理が終了すると、結合演算処理部29により、構造照合処理部28の処理結果である構造照合処理結果データについて、第2の部分クエリデータに含まれる手順に従って結合演算処理が行われる(ステップS4)。
【0072】
図22は、図20に例示した第2の部分クエリデータQ2_Bを用いて図21に例示した構造照合処理結果データR2_Aについて結合演算処理を行う場合の処理の概要を説明する図である。図22の例では、T1[1]<T2[2]という順序関係に関する条件に従ってT1とT2との結合演算が行われ、T3が得られる。そして、T3について[3]のみを取り出すことにより、結合演算処理の結果として、図22に示すような中間結果R2_Bが得られる。この中間結果R2_Bは、図16に例示したクエリデータQ2を、上述したようなクエリデータ解析処理を行わずにそのまま処理した場合の結果と一致する。
【0073】
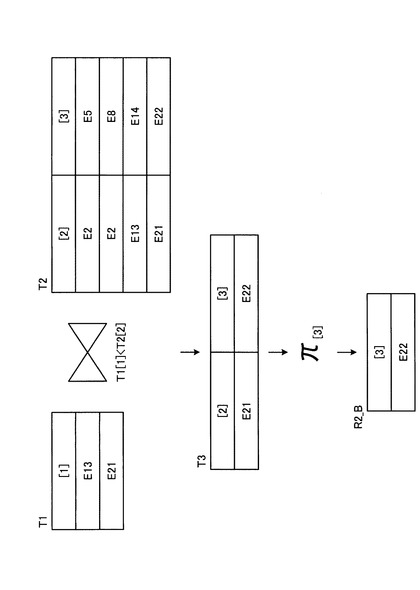
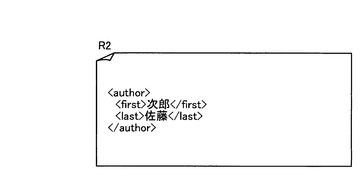
最後に、検索インタフェース部26により、結合演算処理部29による結合演算処理の結果(中間結果)として得られる要素IDが、それに対応する構造化文書データとして文字列化され、結果データとしてクライアント端末3に返却される(ステップS5)。図22に示した中間結果R2_Bが得られた場合には、この中間結果R2_Bに含まれる要素IDであるE22に対応する構造化文書データが文字列化され、クエリデータQ2の結果データR2として、図23に示すデータがクライアント端末3に返却される。
【0074】
以上、具体的な例を挙げながら説明したように、本実施形態によれば、第1の部分クエリデータが構造化文書データの論理構造における階層を下位から上位へと辿る条件、つまり構造化文書データのリーフ要素(葉)からルート要素(根)方向に構造を照合するような条件を含む場合に、該条件を、構造化文書DB21’に格納されている構造ガイドデータに基づいて、構造化文書データのルート要素(根)からリーフ要素(葉)方向に構造を照合するような条件に書き換える。そして、入力クエリデータを単純な構造条件の構造照合処理と結合演算処理とで処理するようにしている。したがって、入力クエリデータが構造化文書データのリーフ要素(葉)からルート要素(根)方向に構造を照合するような条件を含む複雑なものであっても、構造照合処理の高速化を実現し、複雑な構造条件を含むクエリデータによる検索を高速に実行することができる。
【0075】
なお、上記の具体例では、第1の部分クエリデータに、構造化文書データの論理構造における階層を下位から上位へと辿る条件(構造化文書データのリーフ要素(葉)からルート要素(根)方向に構造を照合するような条件)として「parent」が含まれる場合を例示して説明したが、構造化文書データの論理構造における階層を下位から上位へと辿る他の条件、例えば「ancestor」や「ancestor−or−self」などが含まれる場合であっても、上記の具体例と同様に処理することができる。
【0076】
[第3の実施形態]
次に、第3の実施形態について、図3、図5、図7、図24乃至図33を参照して説明する。本実施形態は、入力クエリデータに含まれる要素の順序関係を指定する条件が、position関数やlast関数の場合の例である。本実施形態におけるサーバ1およびクライアント端末3の構成は、図3に示した第1の実施形態のものと同様である。なお、以下の説明において、上述した第1の実施形態と共通の構成については同一の符号を付し、重複した説明を省略する。
【0077】
図24は、本実施形態で想定するクエリデータの一例を示す説明図である。この図24に示すクエリデータQ3_1,Q3_2は、第1の実施形態で説明したクエリデータQ1や第2の実施形態で説明したクエリデータQ2と同じくXQueryで記述されており、下記のような意味の複雑な階層構造に関する条件(構造条件)を含んでいる。
Q3_1:構造化文書DB21の各構造化文書データについて、階層のどこかに「book」という要素があり、その「book」という要素の中にある「author」要素のうち、1番目に出現するものの一覧を返す。
Q3_2:構造化文書DB21の各構造化文書データについて、階層のどこかに「book」という要素があり、その「book」という要素の中にある「author」要素のうち、最後に出現するものの一覧を返す。
【0078】
クエリデータQ3_1には、[position()=1]という表現がある。これは、XQueryで、[position()=1]が付与されているパスに該当するノードのうち、1番目にあるもののみを選択する指定である。一方、クエリデータQ3_2には、[last()]という表現がある。これは、[last()]が付与されているパスに該当するノードのうち、最後のものを選択する指定となる。
【0079】
本実施形態おける検索処理部23による検索処理の流れは、図7に示した第1の実施形態のものと同様である。ただし、本実施形態では、ステップS2のクエリデータ解析処理の内容が第1の実施形態と相違している。
【0080】
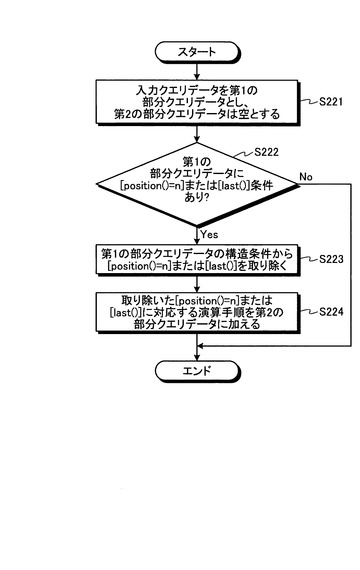
図25は、本実施形態におけるクエリデータ解析処理の流れを示すフローチャートである。クエリデータ分解部27は、第1の実施形態と同様に、はじめに、入力クエリデータのすべてを便宜的に第1の部分クエリデータとする(ステップS221)。このとき、第2の部分クエリデータは空としておく。
【0081】
次に、クエリデータ分解部27は、第1の部分クエリデータをチェックして、第1の部分クエリデータ(ここでは入力クエリデータと同じ)に、[position()=n]や[last()]といった条件が含まれるかどうかを判定する(ステップS222)。そして、クエリデータ分解部27は、そのような構造条件が含まれていれば(ステップS222:Yes)、第1の部分クエリデータ(ここでは入力クエリデータと同じ)から[position()=n]や[last()]といった条件を取り除いたものを、第1の部分クエリデータとする(ステップS223)。そして、クエリデータ分解部27は、ステップS223で取り除いた条件が[position()=n]であれば、第1の部分クエリデータによる構造照合処理結果からn番目に出現する要素を選択する演算指示を第2の部分クエリデータとし、ステップS223で取り除いた条件が[last()]であれば、第1の部分クエリデータによる構造照合処理結果から最後に出現する要素を選択する演算指示を第2の部分クエリデータとして(ステップS224)、クエリデータ解析処理を終了する。
【0082】
一方、ステップS222の判定で、第1の部分クエリデータ(ここでは入力クエリデータと同じ)に[position()=n]や[last()]といった条件が含まれなければ(ステップS222:No)、クエリデータ分解部27は、ステップS223およびステップS224の処理を行うことなく、クエリデータ解析処理を終了する。
【0083】
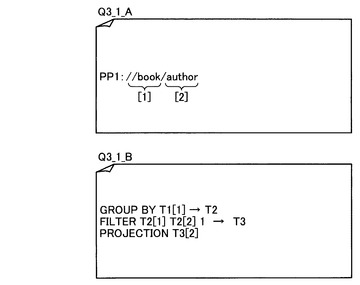
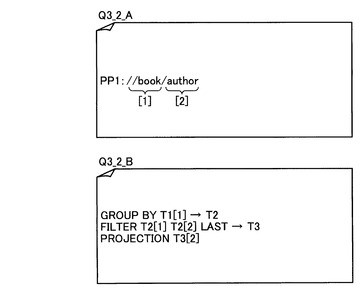
図26は、図24に例示したクエリデータQ3_1についてのクエリデータ解析処理の結果である第1の部分クエリデータQ3_1_Aと第2の部分クエリデータQ3_1_Bの一例を示す図である。また、図27は、図24に例示したクエリデータQ3_2についてのクエリデータ解析処理の結果である第1の部分クエリデータQ3_2_Aと第2の部分クエリデータQ3_2_Bの一例を示す図である。ここで、“GROUP BY (X)”という演算指示は、(X)で指定した部分の要素IDが同一のものをグループ化する演算指示である。また、“FILTER (X) (Y) (Z)”という演算指示は、(X)で指定するグループについて、(Y)で指定する部分の要素IDが、(Z)の順番にあるもののみを残す、という演算指示である。図26に例示した第2の部分クエリデータQ3_1_Bにあるように(Z)が1のときは、(Y)で指定する部分の要素IDが最も小さなものを残すという演算指示となり、図27に例示した第2の部分クエリデータQ3_2_Bにあるように(Z)がLASTのときは、(Y)で指定する部分の要素IDが最も大きなものを残すという演算指示となる。
【0084】
クエリデータ分解部27によるクエリデータ解析処理が終了すると、第1の実施形態と同様に、構造照合処理部28により、第1の部分クエリデータに含まれる構造条件の構造照合処理が行われる(ステップS3)。
【0085】
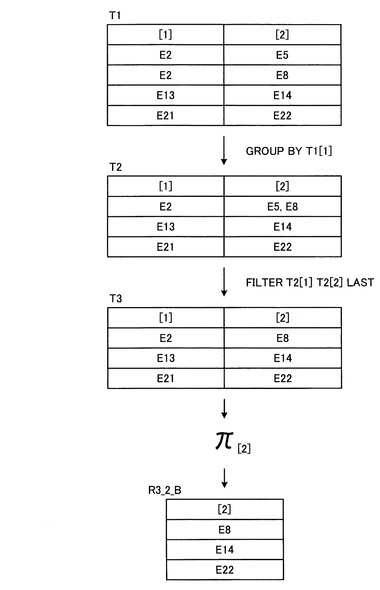
図5に例示した要素ID付与済み構造化文書データについて、図26に例示した第1の部分クエリデータQ3_1_Aに含まれる構造条件PP1による構造照合処理を行った結果である構造照合処理結果データR3_1_Aを図28に示す。また、図5に例示した要素ID付与済み構造化文書データについて、図27に例示した第1の部分クエリデータQ3_2_Aに含まれる構造条件PP1による構造照合処理を行った結果である構造照合処理結果データR3_2_Aを図30に示す。図中のT1は構造条件PP1の構造照合処理の結果であり、図28の構造照合処理結果データR3_1_Aと、図30の構造照合処理結果データR3_2_Aのいずれにおいても、構造条件PP1に合致する構造を持つ要素の要素ID群[1],[2]が得られる。
【0086】
構造照合処理部28による構造照合処理が終了すると、第1の実施形態と同様に、結合演算処理部29により、構造照合処理部28の処理結果である構造照合処理結果データについて、第2の部分クエリデータに含まれる手順に従って結合演算処理が行われる(ステップS4)。
【0087】
図29は、図26に例示した第2の部分クエリデータQ3_1_Bを用いて図28に例示した構造照合処理結果データR3_1_Aについて結合演算処理を行う場合の処理の概要を説明する図である。また、図31は、図27に例示した第2の部分クエリデータQ3_2_Bを用いて図30に例示した構造照合処理結果データR3_2_Aについて結合演算処理を行う場合の処理の概要を説明する図である。
【0088】
図29の例および図31の例では、“GROUP BY T1[1]”という演算指示に従って、T1の要素ID群の中で同一の要素IDがグループ化され、T2が得られる。そして、図29の例では、“FILTER T2[1] T2[2] 1”という演算指示に従って、T2[1]について、T2[2]の要素IDが最も小さいものを残す演算処理によりT3が得られ、T3について[2]のみを取り出すことにより、結合演算処理の結果として、図29に示すような中間結果R3_1_Bが得られる。また、図31の例では、“FILTER T2[1] T2[2] LAST”という演算指示に従って、T2[1]について、T2[2]の要素IDが最も大きいものを残す演算処理によりT3が得られ、T3について[2]のみを取り出すことにより、結合演算処理の結果として、図31に示すような中間結果R3_2_Bが得られる。これらの中間結果R3_1_B,R3_2_Bは、図24に例示したクエリデータQ3_1,Q3_2を、上述したようなクエリデータ解析処理を行わずにそのまま処理した場合の結果と一致する。
【0089】
最後に、検索インタフェース部26により、結合演算処理部29による結合演算処理の結果(中間結果)として得られる要素IDが、それに対応する構造化文書データとして文字列化され、結果データとしてクライアント端末3に返却される(ステップS5)。図29に示した中間結果R3_1_Bが得られた場合には、この中間結果R3_1_Bに含まれる要素IDであるE5,E14,E22に対応する構造化文書データが文字列化され、クエリデータQ3_1の結果データR3_1として、図32に示すデータがクライアント端末3に返却される。また、図31に示した中間結果R3_2_Bが得られた場合には、この中間結果R3_2_Bに含まれる要素IDであるE8,E14,E22に対応する構造化文書データが文字列化され、クエリデータQ3_2の結果データR3_2として、図33に示すデータがクライアント端末3に返却される。
【0090】
以上、具体的な例を挙げながら説明したように、本実施形態によれば、入力クエリデータが要素の順序関係を指定する条件としてposition関数やlast関数を含む場合に、その入力クエリデータを、階層の上下関係を指定する条件のみを含む第1の部分クエリデータと、第1の部分クエリデータによる照合結果を、position関数やlast関数で示される条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解して処理するようにしている。したがって、入力クエリデータがposition関数やlast関数を含む複雑なものであっても、この入力クエリデータを単純な構造条件の構造照合処理と結合演算処理とで処理することで、構造照合処理の高速化を実現し、複雑な構造条件を含むクエリデータによる検索を高速に実行することができる。
【0091】
[第4の実施形態]
次に、第4の実施形態について、図5、図19、図34乃至図40を参照して説明する。本実施形態は、第2の実施形態と同様の構造条件の書き換えを行うが、入力クエリデータに要素の順序関係を指定する条件(第2条件)が含まれておらず、第2のクエリデータに基づく結合演算処理を行わない例である。なお、以下の説明において、上述した第2の実施形態と共通の構成については同一の符号を付し、重複した説明を省略する。
【0092】
図34は、本実施形態におけるサーバ1’’およびクライアント端末3の概略構成を示すブロック図である。本実施形態では、サーバ1’’の検索処理部23’’にクエリデータ分解部27が設けられておらず、クライアント端末3から送信された入力クエリデータは、構造条件書き換え部31’に入力される。また、サーバ1’’の検索処理部23’’に結合演算処理部29が設けられておらず、構造照合処理部28による構造照合処理の結果である構造照合処理結果データが、そのまま検索インタフェース部26に渡される。なお、クライアント端末3の構成は第2の実施形態と同じである。
【0093】
図35は、本実施形態で想定するクエリデータの一例を示す説明図である。この図35に示すクエリデータQ4は、第1乃至第3の実施形態で説明したクエリデータと同じくXQueryで記述されており、下記のような意味の複雑な階層構造に関する条件(構造条件)を含んでいる。
Q4:構造化文書DB21’の各構造化文書データについて、階層のどこかに「title」という要素があり、その先祖の「book」という要素の子要素である「publisher」という要素の一覧を返す。
【0094】
クエリデータQ4では、第2の実施形態で説明した/ancestorという構造化文書データのリーフ要素(葉)からルート要素(根)方向に、階層構造内での先祖要素を照合するパスが含まれているが、第1の実施形態で説明したクエリデータQ1に含まれる/following−siblingのような、ある構造を持つ要素間の順序関係に関する構造を照合するパスは含まれていない。
【0095】
図36は、本実施形態におけるサーバ1’’の検索処理部23’’による検索処理の流れを示すフローチャートである。まず、検索インタフェース部26により、クライアント端末3からネットワーク2経由で送信されたクエリデータの入力が受け付けられる(ステップS1)。このクエリデータは、構造条件書き換え部31’に入力される。
【0096】
次に、構造条件書き換え部31’により、入力クエリデータについてのクエリデータ解析処理が行われる(ステップS2)。構造条件書き換え部31’によるクエリデータ解析処理の一例を、図37を参照して説明する。
【0097】
図37は、構造条件書き換え部31’によるクエリデータ解析処理の流れを示すフローチャートである。構造条件書き換え部31’は、はじめに、入力クエリデータを第1の部分クエリデータとする(ステップS231)。次に、構造条件書き換え部31’は、第1の部分クエリデータをチェックして、第1の部分クエリデータに、構造化文書データの階層構造を葉から根方向へ照合するような構造条件が含まれるかどうかを判定する(ステップS232)。そして、構造条件書き換え部31’は、第1の部分クエリデータに、構造化文書データの階層構造を葉から根方向へ照合するような構造条件が含まれていれば(ステップS232:Yes)、構造条件書き換え処理を行って、構造化文書データの階層構造を葉から根方向へ照合する構造条件を、根から葉方向へ照合する構造条件に書き換える(ステップS233)。
【0098】
一方、ステップS232の判定で、第1の部分クエリデータに、構造化文書データの階層構造を葉から根方向へ照合するような構造条件が含まれなければ(ステップS232:No)、ステップS233の構造条件書き換え処理を行うことなく、クエリデータ解析処理を終了する。
【0099】
ステップS233で行われる構造条件書き換え処理は第2の実施形態と同様であり、処理内容は図19に示したフローチャートの通りである。ここでは、図35に例示したクエリデータQ4を、図15に例示した構造ガイドデータを参照して書き換える処理の概要を説明する。なお、ここでは説明を簡単にするために、図15に例示した構造ガイドデータを参照しているが、実際には構造化文書DB21’に格納された構造ガイドデータが参照される。
【0100】
クエリデータQ4の/ancestor::book部分について、その直前のパスは/titleである。ここで、図15に例示した構造ガイドデータを参照すると、titleを末尾に持つ構造は/books/book/titleである。/ancestorは先祖要素を指定するため、/ancestorの指定する構造は/books/book、/booksであるが、::bookとbook要素を指定しているので、/ancestor::bookの指定する構造は/books/bookとなる。さらに、/ancestor::bookの次のパスである/publisherについても、ここまでで特定された構造は/books/bookであるから、/books/bookの後に/publisherが続く構造があるかを構造ガイドデータで確認すると、存在するので、クエリデータQ4に対する構造条件書き換え処理の結果として、/books/book/publisherが得られる。
【0101】
図38は、図35に例示したクエリデータQ4について、構造条件書き換え処理を行った結果の第1の部分クエリデータQ4_Aを示す図である。図35に例示したクエリデータQ4は、構造条件書き換え処理により、/books/book/publisherといった、構造化文書データの階層構造を根から葉方向へ照合する構造条件に書き換えられる。
【0102】
構造条件書き換え部31’によるクエリデータ解析処理が終了すると、第1乃至第3の実施形態と同様に、構造照合処理部28により、第1の部分クエリデータに含まれる構造条件の構造照合処理が行われる(ステップS3)。
【0103】
図5に例示した要素ID付与済み構造化文書データについて、図38に例示した第1の部分クエリデータQ4_Aによる構造照合処理を行った結果である構造照合処理結果データR4_Aを図39に示す。図中のT1は/books/book/publisherという構造条件の構造照合処理の結果であり、このような構造を持つ要素の要素ID群[1]が得られる。
【0104】
本実施形態では、この構造照合処理部28による構造照合処理の結果がそのまま中間結果として検索インタフェース部26に渡される。そして、最後に、検索インタフェース部26により、構造照合処理部28による構造照合処理の結果(中間結果)として得られる要素IDが、それに対応する構造化文書データとして文字列化され、結果データとしてクライアント端末3に返却される(ステップS5)。図39に示した中間結果R4_Aが得られた場合には、この中間結果R4_Aに含まれる要素IDであるE11,E29に対応する構造化文書データが文字列化され、クエリデータQ4の結果データR4として、図40に示すデータがクライアント端末3に返却される。
【0105】
以上、具体的な例を挙げながら説明したように、本実施形態によれば、入力クエリデータが、要素IDで特定される要素の順序関係を指定する条件(第2条件)を含まず、構造化文書データの論理構造における階層を下位から上位へと辿る条件、つまり構造化文書データのリーフ要素(葉)からルート要素(根)方向に構造を照合するような条件を含む場合に、該条件を、構造化文書DB21’に格納されている構造ガイドデータに基づいて、構造化文書データのルート要素(根)からリーフ要素(葉)方向に構造を照合するような条件に書き換える。そして、入力クエリデータを単純な構造条件の構造照合処理のみで処理するようにしている。したがって、入力クエリデータが構造化文書データのリーフ要素(葉)からルート要素(根)方向に構造を照合するような条件を含む複雑なものであっても、構造照合処理の高速化を実現し、複雑な構造条件を含むクエリデータによる検索を高速に実行することができる。
【0106】
なお、上記の具体例では、入力クエリデータに含まれる、構造化文書データの論理構造における階層を下位から上位へと辿る条件(構造化文書データのリーフ要素(葉)からルート要素(根)方向に構造を照合するような条件)として「ancestor」を例示したが、構造化文書データの論理構造における階層を下位から上位へと辿る他の条件、例えば「parent」や「ancestor−or−self」などが入力クエリデータに含まれる場合であっても、上記の具体例と同様に処理することができる。
【0107】
以上説明した第1乃至第4の実施形態におけるサーバ1、サーバ1’、サーバ1’’の機能は、例えば、コンピュータの演算装置であるCPU101が、アプリケーションプログラムとして実装された構造化文書管理プログラムを実行することにより実現される。
【0108】
第1乃至第4の実施形態におけるサーバ1、サーバ1’、サーバ1’’で実行される構造化文書管理プログラムは、例えば、インストール可能な形式又は実行可能な形式のファイルでCD−ROM、フレキシブルディスク(FD)、CD−R、DVD(Digital Versatile Disc)などのコンピュータで読み取り可能な記憶媒体110に記録されて提供される。
【0109】
また、第1乃至第4の実施形態におけるサーバ1、サーバ1’、サーバ1’’で実行される構造化文書管理プログラムを、インターネットなどのネットワーク2に接続されたコンピュータ上に格納し、ネットワーク2経由でダウンロードさせることにより提供するように構成してもよい。また、第1乃至第4の実施形態におけるサーバ1、サーバ1’、サーバ1’’で実行される構造化文書管理プログラムを、インターネットなどのネットワーク2経由で提供または配布するように構成してもよい。さらに、第1乃至第4の実施形態におけるサーバ1、サーバ1’、サーバ1’’で実行される構造化文書管理プログラムを、ROM102などに予め組み込んで提供するように構成してもよい。
【0110】
第1乃至第4の実施形態におけるサーバ1、サーバ1’、サーバ1’’で実行される構造化文書管理プログラムは、格納インタフェース部24、要素ID付与部25、検索インタフェース部26、クエリデータ分解部27、構造照合処理部28、結合演算処理部29、構造解析部30、構造条件書き換え部31,31’などを含むモジュール構成となっており、実際のハードウェアとしてはCPU(プロセッサ)101がHDD104などから構造化文書管理プログラムを読み出して実行することにより上記各部が主記憶装置(例えばRAM103)上にロードされ、格納インタフェース部24、要素ID付与部25、検索インタフェース部26、クエリデータ分解部27、構造照合処理部28、結合演算処理部29、構造解析部30、構造条件書き換え部31,31’などが主記憶装置上に生成されるようになっている。
【0111】
以上述べた少なくとも一つの実施形態にかかる構造化文書管理システムによれば、入力クエリデータを単純な構造条件に変えて構造照合処理を実行するようにしているので、入力クエリデータが複雑な構造条件を含む場合でも、構造照合処理の高速化を実現し、複雑な構造条件を含むクエリデータによる検索を高速に実行することができる。
【0112】
なお、本発明のいくつかの実施形態を説明したが、これらの実施形態は、例として提示したものであり、発明の範囲を限定することは意図していない。これら新規な実施形態は、その他の様々な形態で実施されることが可能であり、発明の要旨を逸脱しない範囲で、種々の省略、置き換え、変更を行うことができる。これら実施形態やその変形は、発明の範囲や要旨に含まれるとともに、請求の範囲に記載された発明とその均等の範囲に含まれる。
【符号の説明】
【0113】
1,1’,1’’サーバ
24 格納インタフェース部
25 要素ID付与部
26 検索インタフェース部
27 クエリデータ分解部
28 構造照合処理部
29 結合演算処理部
30 構造解析部
31,31’構造条件書き換え部
【技術分野】
【0001】
本発明の実施形態は、構造化文書管理装置、方法およびプログラムに関する。
【背景技術】
【0002】
従来、XML(Extensible Markup Language)などで記述された構造化文書データを記憶・検索するための構造化文書管理装置が知られている。構造化文書管理装置における構造化文書データの検索のために、RDBMS(Relational Database Managemant System)における問い合わせ言語SQLのように、XMLデータに対する問い合わせ言語XQuery(XML Query Language)が策定されており、多くの構造化文書管理装置でサポートされている。
【0003】
XQueryは、XMLデータ集合をデータベースのように扱うための言語であり、条件に合致するデータ集合の取り出しや集計・分析を行うための手段が提供されている。XMLデータは親子や兄弟などの要素が組み合わさった階層化された論理構造(階層構造)を持つため、条件にはこの階層構造に関する条件(構造条件)を指定することができる。
【0004】
構造条件の処理には、構造化文書管理装置が記憶している構造化文書データが条件に合致する構造を持つかを照合する構造照合処理を行う必要がある。この構造照合処理は、構造条件が階層の上下関係を指定する条件のみであれば比較的高速に処理することが可能であるが、構造条件の中にXMLデータに含まれる要素の順序関係を指定する条件が含まれる場合は、高速に処理することが難しい。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2007−226452号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
本発明が解決しようとする課題は、構造照合処理を高速に行うことができる構造化文書管理装置、方法およびプログラムを提供することである。
【課題を解決するための手段】
【0007】
実施形態の構造化文書管理装置は、構造化文書データ受付手段と、識別子付与手段と、構造化文書データ記憶手段と、クエリデータ受付手段と、クエリデータ分解手段と、構造照合処理手段と、結合演算処理手段と、を備える。構造化文書データ受付手段は、階層化された論理構造を有する構造化文書データの入力を受け付ける。識別子付与手段は、入力された前記構造化文書データに出現する要素に該構造化文書データ内での出現順序が要素間で比較可能な識別子を付与する。構造化文書データ記憶手段は、前記要素に前記識別子が付与された前記構造化文書データを記憶する。クエリデータ受付手段は、クエリデータの入力を受け付ける。クエリデータ分解手段は、入力されたクエリデータが、前記構造化文書データの論理構造における階層の上下関係を指定する第1条件と、前記識別子で特定される前記要素の順序関係を指定する第2条件とを含む場合に、該クエリデータを、前記第1条件のみを含む第1の部分クエリデータと、前記第1の部分クエリデータによる照合結果を前記第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解する。構造照合処理手段は、前記構造化文書データ記憶手段が記憶する前記構造化文書データのデータ集合に対して、前記第1の部分クエリデータによる照合を行い、照合結果を出力する。結合演算処理手段は、前記照合結果を、前記第2の部分クエリデータに含まれる結合演算の手順に従って結合演算処理する。
【図面の簡単な説明】
【0008】
【図1】構造化文書管理システムのシステム構築例を示す模式図。
【図2】サーバおよびクライアント端末のモジュール構成図。
【図3】第1の実施形態におけるサーバおよびクライアント端末の概略構成を示すブロック図。
【図4】構造化文書データの一例を示す説明図。
【図5】図4に例示した構造化文書データに対して要素IDを付与した要素ID付与済み構造化文書データの一例を示す説明図。
【図6】クエリデータの一例を示す説明図。
【図7】検索処理部による検索処理の流れを示すフローチャート。
【図8】クエリデータ解析処理の流れを示すフローチャート。
【図9】図6に例示したクエリデータについてクエリデータ解析処理を行った結果である第1の部分クエリデータと第2の部分クエリデータの一例を示す説明図。
【図10】構造照合処理の概略を示す説明図。
【図11】図9に例示した第1の部分クエリデータを用いて図5に例示した要素ID付与済み構造化文書データについて構造照合処理を行った結果である構造照合処理結果データの一例を示す説明図。
【図12】図9に例示した第2の部分クエリデータを用いて図11に例示した構造照合処理結果データについて結合演算処理を行う場合の説明図。
【図13】図9に例示したクエリデータの結果データを示す説明図。
【図14】第2の実施形態におけるサーバおよびクライアント端末の概略構成を示すブロック図。
【図15】構造ガイドデータの一例を示す説明図。
【図16】クエリデータの一例を示す説明図。
【図17】第2の実施形態におけるクエリデータ解析処理の流れを示すフローチャート。
【図18】図16に例示したクエリデータについて図17のステップS215までの処理を行った結果である第1の部分クエリデータと第2の部分クエリデータの一例を示す説明図。
【図19】構造条件書き換え処理の流れを示すフローチャート。
【図20】図18に例示した第1の部分クエリデータについて構造条件書き換え処理を行った結果を示す説明図。
【図21】図20に例示した構造条件書き換え処理後の第1の部分クエリデータを用いて図5に例示した要素ID付与済み構造化文書データについて構造照合処理を行った結果である構造照合処理結果データの一例を示す説明図。
【図22】図20に例示した第2の部分クエリデータを用いて図21に例示した構造照合処理結果データについて結合演算処理を行う場合の説明図。
【図23】図16に例示したクエリデータの結果データを示す説明図。
【図24】クエリデータの一例を示す説明図。
【図25】第3の実施形態におけるクエリデータ解析処理の流れを示すフローチャート。
【図26】図24に例示したposition関数を含むクエリデータについてクエリデータ解析処理を行った結果である第1の部分クエリデータと第2の部分クエリデータの一例を示す説明図。
【図27】図24に例示したlast関数を含むクエリデータについてクエリデータ解析処理を行った結果である第1の部分クエリデータと第2の部分クエリデータの一例を示す説明図。
【図28】図26に例示した第1のクエリデータを用いて図5に例示した要素ID付与済み構造化文書データについて構造照合処理を行った結果である構造照合処理結果データの一例を示す説明図。
【図29】図26に例示した第2の部分クエリデータを用いて図28に例示した構造照合処理結果データについて結合演算処理を行う場合の説明図。
【図30】図27に例示した第1のクエリデータを用いて図5に例示した要素ID付与済み構造化文書データについて構造照合処理を行った結果である構造照合処理結果データの一例を示す説明図。
【図31】図27に例示した第2の部分クエリデータを用いて図30に例示した構造照合処理結果データについて結合演算処理を行う場合の説明図。
【図32】図24に例示したposition関数を含むクエリデータの結果データを示す説明図。
【図33】図24に例示したlast関数を含むクエリデータの結果データを示す説明図。
【図34】第4の実施形態におけるサーバおよびクライアント端末の概略構成を示すブロック図。
【図35】クエリデータの一例を示す説明図。
【図36】第4の実施形態における検索処理の流れを示すフローチャート。
【図37】第4の実施形態におけるクエリデータ解析処理の流れを示すフローチャート。
【図38】図35に例示したクエリデータについてクエリデータ解析処理を行った結果である第1の部分クエリデータの一例を示す説明図。
【図39】図38に例示した第1の部分クエリデータを用いて図5に例示した要素ID付与済み構造化文書データについて構造照合処理を行った結果である構造照合処理結果データの一例を示す説明図。
【図40】図35に例示したクエリデータの結果データを示す説明図。
【発明を実施するための形態】
【0009】
以下、実施形態の構造化文書管理装置、方法およびプログラムを、図面を参照して説明する。
【0010】
[第1の実施形態]
まず、第1の実施形態について、図1乃至図13を参照して説明する。図1は、第1の実施形態にかかる構造化文書管理システムのシステム構築例を示す模式図である。ここでは、実施形態の構造化文書管理システムとして、図1に示すように、構造化文書管理装置であるサーバコンピュータ(以下、サーバという。)1に、LAN(Local Area Network)等のネットワーク2を介して、クライアントコンピュータ(以下、クライアント端末という。)3が複数台接続されたサーバクライアントシステムを想定する。
【0011】
図2は、サーバ1およびクライアント端末3のモジュール構成図である。サーバ1およびクライアント端末3は、例えば、通常のコンピュータを利用したハードウェア構成を有している。すなわち、サーバ1およびクライアント端末3は、情報処理を行うCPU(Central Processing Unit)101、BIOSなどを記憶した読出し専用メモリであるROM(Read Only Memory)102、各種データを書き換え可能に記憶するRAM(Random Access Memory)103、各種データベースとして機能するとともに各種のプログラムを格納するHDD(Hard Disc Drive)104、記憶媒体110を用いて情報を保管したり外部に情報を配布したり外部から情報を入手するためのCD−ROMドライブ等の媒体駆動装置105、ネットワーク2を介して外部の他のコンピュータと通信により情報を伝達するための通信制御装置106、処理経過や結果等を操作者に表示するCRT(Cathode Ray Tube)やLCD(Liquid Crystal Display)等の表示部107、並びに操作者がCPU101に命令や情報等を入力するためのキーボードやマウス等の入力部108等を備えた構成であり、これらの各部間で送受信されるデータをバスコントローラ109が調停して動作する。
【0012】
このようなサーバ1およびクライアント端末3では、ユーザが電源を投入するとCPU101がROM102内のローダーというプログラムを起動させ、HDD104よりOS(Operating System)というコンピュータのハードウェアとソフトウェアとを管理するプログラムをRAM103に読み込み、このOSを起動させる。このようなOSは、ユーザの操作に応じてプログラムを起動したり、情報を読み込んだり、保存を行ったりする。OSのうち代表的なものとしては、Windows(登録商標)、UNIX(登録商標)等が知られている。これらのOS上で動作するプログラムをアプリケーションプログラムと呼んでいる。なお、アプリケーションプログラムは、所定のOS上で動作するものに限らず、後述の各種処理の一部の実行をOSに肩代わりさせるものであってもよいし、所定のアプリケーションソフトやOSなどを構成する一群のプログラムファイルの一部として含まれているものであってもよい。
【0013】
ここで、サーバ1は、アプリケーションプログラムとして、構造化文書管理プログラムをHDD104に記憶している。この意味で、HDD104は、構造化文書管理プログラムを記憶する記憶媒体として機能する。また、一般的には、サーバ1のHDD104にインストールされるアプリケーションプログラムは、CD−ROMやDVDなどの各種の光ディスク、各種光磁気ディスク、フレキシブルディスクなどの各種磁気ディスク、半導体メモリ等の各種方式のメディア等の記憶媒体110に記録されて提供される。このため、CD−ROM等の光情報記録メディアやFD等の磁気メディア等の可搬性を有する記憶媒体110も、構造化文書管理プログラムを記憶する記憶媒体となり得る。さらには、構造化文書管理プログラムは、例えば通信制御装置106を介して外部から取り込まれ、HDD104にインストールされてもよい。
【0014】
サーバ1は、OS上で動作する構造化文書管理プログラムが起動すると、この構造化文書管理プログラムに従い、CPU101が各種の演算処理を実行して各部を集中的に制御する。一方、クライアント端末3は、OS上で動作するアプリケーションプログラムが起動すると、このアプリケーションプログラムに従い、CPU101が各種の演算処理を実行して各部を集中的に制御する。サーバ1およびクライアント端末3のCPU101が実行する各種の演算処理のうち、実施形態の構造化文書管理システムにおいて特徴的な処理について、以下に説明する。
【0015】
図3は、第1の実施形態におけるサーバ1およびクライアント端末3の概略構成を示すブロック図である。図3に示すように、クライアント端末3は、アプリケーションプログラムにより実現される機能構成として、構造化文書登録部11と、検索部12とを備える。
【0016】
構造化文書登録部11は、入力部108から入力された構造化文書データやクライアント端末3のHDD104に予め記憶された構造化文書データを、後述するサーバ1の構造化文書データベース(構造化文書DB)21に登録するためのものである。この構造化文書登録部11は、登録すべき構造化文書データとともに格納要求をサーバ1に送信する。
【0017】
図4は、構造化文書データの一例を示したものである。構造化文書データを記述するための代表的な言語としてXML(Extensible Markup Language)が挙げられる。図4に示す構造化文書データは、XMLで記述されたものである。XMLでは、文書構造を構成する個々のパーツを「要素」(エレメント:Element)と呼び、要素はタグ(tag)を使って記述する。具体的には、要素の始まりを示すタグ(開始タグ)と、終わりを示すタグ(終了タグ)の2つのタグでデータを挟み込んで、1つの要素を表現している。なお、開始タグと終了タグで挟み込まれたテキストデータは、当該開始タグと終了タグで表された1つの要素に含まれるテキスト要素である。
【0018】
図4に示す例では、<books>というタグで囲まれたルート要素が存在する。この<books>要素は、<book>のタグで囲まれた3つの子要素を包含する。<book>要素は、<title>、<author>の各タグで囲まれた複数の子要素を包含する。<title>要素は、「XMLデータベース」などのテキスト要素をもつ。
【0019】
1番目の<book>要素は、2つの<author>要素を持ち、これら2つの<author>要素が<title>要素の後に出現する順序であるが、2,3番目の<book>要素は、1つの<author>要素のみを持ち、<author>要素の後に<title>要素が出現している。
【0020】
検索部12は、ユーザにより入力部108から入力された指示に従って、構造化文書DB21から所望のデータを検索するための検索条件などが記述されたクエリデータを作成し、当該クエリデータを含む検索要求をサーバ1へ送信する。また、検索部12は、サーバ1から送信された当該検索要求に対応する結果データを受け取り、これを表示部107に表示する。
【0021】
一方、サーバ1は、構造化文書管理プログラムにより実現される機能構成として、格納処理部22と、検索処理部23とを備える。また、サーバ1は、HDD104などの記憶装置を利用した構造化文書DB21を備える。
【0022】
格納処理部22は、クライアント端末3からの格納要求を受けて、クライアント端末3から送信された構造化文書データを構造化文書DB21に格納する処理を行う。この格納処理部22は、格納インタフェース部24と、要素ID付与部25とを備えている。
【0023】
格納インタフェース部24は、構造化文書データの入力を受け付けて(構造化文書データ受付手段)、構造化文書データを構造化文書DB21に格納するために要素ID付与部25を呼び出す。
【0024】
要素ID付与部25は、識別子付与手段として機能するものであって、クライアント端末3から送信された構造化文書データを構文解析し、そこに出現する要素に要素間で出現順序が比較可能な識別子(以下、要素IDという。)を付与した上で、要素IDが付与された構造化文書データ(以下、要素ID付与済み構造化文書データという。)を構造化文書DB21(構造化文書データ記憶手段)に格納する。
【0025】
ここで、要素IDは、その大小で構造化文書データ中での要素の出現順序が判定できるように付与される。図4に例示した構造化文書データに対して要素IDを付与した要素ID付与済み構造化文書データの例を図5に示す。図5では、要素IDを付与する方法の一例として、ルート要素より要素の出現順に従ってE1、E2、E3、・・・と付与している。このように付与すれば、要素間の出現順序を要素IDの比較で判定することができる。
【0026】
例えば、図4に例示した構造化文書データにおける<books>の1番目の<book>要素は、その中に2つの<author>要素を持ち、これら2つの<author>要素の出現順序は、子に<first>要素を持つ<author>要素が先に出現し、子に<last>要素を持つ<author>要素が後に出現する順となっている。ここで、図5でそれぞれに付与された要素IDを比較すると、E5<E8であり、要素IDとしてE8を付与された要素である、子に<last>要素を持つ<author>要素が、要素IDとしてE8を付与された要素である、子に<first>要素を持つ<author>要素よりも後に出現することが判定できる。また、図5では、要素ID付与済み構造化文書データの形式が図4の構造化文書データとほぼ同一であるが、先に述べたように、その大小で要素の出現順序が判定できるように要素IDが付与されていれば、要素ID付与済み構造化文書データの形式は特に限定されるものではない。
【0027】
検索処理部23は、クライアント端末3からの検索要求を受けて、クエリデータにより指定された条件に合致するデータを構造化文書DB21から探し出し、この探し出したデータを結果データとして返す処理を行う。この検索処理部23は、検索インタフェース部26と、クエリデータ分解部27と、構造照合処理部28と、結合演算処理部29とを備えている。
【0028】
検索インタフェース部26は、クエリデータの入力を受け付けて(クエリデータ受付手段)、受け付けたクエリデータにより指定された条件を満足する結果データを得るためにクエリデータ分解部27を呼び出す。
【0029】
クエリデータ分解部27は、クエリデータ分解手段として機能するものであって、クライアント端末3から送信され、検索インタフェース部26を介して入力されたクエリデータ(以下、入力クエリデータという。)を構文解析し、この入力クエリデータが、構造化文書データの論理構造における階層の上下関係を指定する条件(第1条件)と、要素IDで特定される要素の順序関係を指定する条件(第2条件)とを含む場合に、入力クエリデータを、第1条件のみを含む第1の部分クエリデータと、第1の部分クエリデータによる照合結果を第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解する。
【0030】
構造照合処理部28は、構造照合処理手段として機能するものであって、構造化文書DB21に格納されている要素ID付与済み構造化文書データのデータ集合に対して、第1の部分クエリデータによる構造条件の照合処理を行い、その照合結果を構造照合処理結果データとして出力する。
【0031】
結合演算処理部29は、結合演算処理手段として機能するものであって、構造照合処理部28から出力された第1の部分クエリデータによる照合結果である構造照合処理結果データに対して、第2のクエリデータに含まれる結合演算の手順に従って結合演算を行い、結合演算結果データを出力する。なお、結合演算処理部29は、第2の部分クエリデータが空ならば、構造照合処理部28から出力された構造照合処理結果データをそのまま出力するか、または自身の処理を省略する。
【0032】
検索インタフェース部26は、結合演算処理部29から出力された結合演算処理結果データを、検索の結果データとしてクライアント端末3へ返却する。
【0033】
図6は、クエリデータの一例を示す説明図である。XMLでは、W3Cで提案されているXQueryという問合せ言語があり、図6に示すクエリデータは、このXQueryに基づいた問合せ記述方法に則っている。図6には、下記のような意味の複雑な階層構造に関する条件(構造条件)を含むクエリデータQ1が示されている。
Q1:構造化文書DB21の各構造化文書データについて、階層のどこかに「book」という要素があり、その「book」という要素は、その中に「author」という要素を持ち、さらにこの「author」という要素の中に、「first」と「last」という2つの要素を持つような「book」要素であり、さらにその「book」要素よりも後に出現する「book」要素について、その中にある「title」の一覧を返す。
【0034】
図7は、サーバ1の検索処理部23による検索処理の流れを示すフローチャートである。まず、検索インタフェース部26により、クライアント端末3からネットワーク2経由で送信されたクエリデータの入力が受け付けられる(ステップS1)。
【0035】
次に、クエリデータ分解部27により、入力クエリデータについてのクエリデータ解析処理が行われる(ステップS2)。クエリデータ分解部27によるクエリデータ解析処理の一例を、図8を参照して説明する。
【0036】
図8は、クエリデータ解析処理の流れを示すフローチャートである。クエリデータ分解部27は、はじめに、入力クエリデータのすべてを便宜的に第1の部分クエリデータとする(ステップS201)。このとき、第2の部分クエリデータは空としておく。
【0037】
次に、クエリデータ分解部27は、第1の部分クエリデータをチェックして、第1の部分クエリデータ(ここでは入力クエリデータと同じ)に、ある構造を持つ要素間の順序関係に関する構造条件、つまり、要素IDで特定される要素の順序関係を指定するような条件が含まれるかどうかを判定する(ステップS202)。そして、クエリデータ分解部27は、そのような構造条件が含まれていれば(ステップS202:Yes)、第1の部分クエリデータを、階層の上下関係を指定する条件のみを含む構造条件、つまり、順序関係に関する構造条件での照合の対象となる構造それぞれを指定するような構造条件に分解し(ステップS203)、分解された構造条件すべてを第1の部分クエリデータとする(ステップS204)。そして、クエリデータ分解部27は、分解された各構造条件の構造照合処理結果間で、そこに含まれる要素IDの結合演算を指示する内容を、第2の部分クエリデータとし(ステップS205)、クエリデータ解析処理を終了する。
【0038】
一方、ステップS202の判定で、第1の部分クエリデータ(ここでは入力クエリデータと同じ)に上述した順序関係に関する構造条件が含まれなければ(ステップS202:No)、クエリデータ分解部27は、ステップS203からステップS205の処理を行うことなく、クエリデータ解析処理を終了する。
【0039】
図9は、図6に例示したクエリデータQ1についてのクエリデータ解析処理の結果である第1の部分クエリデータQ1_Aと第2の部分クエリデータQ1_Bの一例を示す図である。図9において、第1の部分クエリデータQ1_Aは、構造条件PP1とPP2を含んでいる。また、第2の部分クエリデータQ1_Bは、Q1_Aによる構造照合処理の照合結果を、上述した順序関係に関する構造条件に応じて結合演算する手順を含んでいる。図6に例示したクエリデータQ1は、順序関係に関する構造条件「following−sibling」が含まれているため、クエリデータQ1は、この構造条件での照合の対象となる構造を指定する構造条件PP1,PP2に分解され、これらPP1,PP2による構造照合処理の照合結果を「following−sibling」に応じて結合演算する手順が、第2の部分クエリデータQ1_Bとされる。なお、図中のQ1_BにあるT1,T2は、それぞれPP1,PP2を構造照合処理した結果を識別する記号である。また、図中のQ1_A,Q1_Bにある[1],[2],[3]は、T1,T2に含まれる要素ID群を識別する記号である。
【0040】
クエリデータ分解部27によるクエリデータ解析処理が終了すると、次に、構造照合処理部28により、第1の部分クエリデータに含まれる構造条件の構造照合処理が行われる(ステップS3)。ここで、構造照合処理とは、構造化文書データについて、指定された構造条件をXQueryで定められた仕様で解釈して照合し、結果として構造条件に合致する構造化文書データまたは構造化文書データ中の要素を得る処理をいう。
【0041】
ここで、図5に例示した要素ID付与済み構造化文書データと、図9に例示した第1の部分クエリデータQ1_Aに含まれる構造条件PP1,PP2とを用いて、一般的な構造照合処理を行った場合の処理の概要を、図10を参照して説明する。以下では、構造条件中の/で区切られた部分を単にパスと呼称する。
【0042】
第1の部分クエリデータQ1_Aに含まれる構造条件PP1の照合について、構造条件PP1を左から見て、まず先頭のパス//book(/descendant−or−self::book)の照合を行う。これは、XQuery仕様で、「ルート要素以下のどこかの階層構造にある要素で、名前がbookである要素を選択する」ことを意味する。これに従い、図5に例示した要素ID付与済み構造化文書データ中の要素の構造を照合すると、ルート要素<books>以下の3つの<book>要素、E2,E13,E21が選択される(1.1)。
【0043】
次の[author[first and last]]とは、「前の構造照合で得られた要素について、その子にauthorという要素があり、さらにそのauthor要素は、その子としてfirstとlastという要素を両方含んでいるような要素のみをさらに選択する」ことを意味する。これに従い各<book>要素より下位の要素の構造を照合して<book>要素を選択すると、結果として、要素IDがE13,E21であるbook要素が得られる(1.2)。
【0044】
同様に、第1の部分クエリデータQ1_Aに含まれる構造条件PP2の照合について、先頭のパス//bookについては先のPP1の例と同じ意味であり、3つの<book>要素、E2,E13,E21が選択される(2.1)。次に続くパス/title(/child::title)とは、「前のパス照合で得られた要素に対して子供の階層構造の位置にある要素で、名前がtitleである要素を選択する」ことを意味する。これに従い、前の構造照合で得られた各<book>要素に対して子供の構造位置にある要素を照合すると、要素IDがE2の<book>要素からは要素IDがE3の<title>要素が得られ、要素IDがE13の<book>要素からは要素IDがE19の<title>要素が得られ、要素IDがE21の<book>要素からは要素IDがE27の<title>要素が得られる(2.2)。
【0045】
なお、ここで概説した構造条件およびパスの構造照合処理の方法は一例であり、構造条件およびパスの構造照合処理の方法には、特許文献1に記載されているようなものをはじめ、様々なものがある。本実施形態における構造照合処理部28は、入力された構造条件に合致する構造を持つ構造化文書データ中の要素を取得するものであれば、内部の具体的な処理方法については特に限定されるものではない。
【0046】
図5に例示した要素ID付与済み構造化文書データについて、図9に例示した第1の部分クエリデータQ1_Aに含まれる構造条件PP1,PP2の構造照合処理を行った結果である構造照合処理結果データR1_Aを図11に示す。図中のT1,T2は、それぞれ構造条件PP1,PP2の構造照合処理の結果であり、T1としては構造条件PP1に合致する構造を持つ要素の要素ID群[1]が得られ、T2としては構造条件PP2に合致する構造を持つ要素の要素ID群[2],[3]が得られる。なお、図11ではT1,T2を表で示しているが、構造照合処理結果データの具体的なデータ構造は特に限定されるものではない。
【0047】
構造照合処理部28による構造照合処理が終了すると、次に、結合演算処理部29により、構造照合処理部28の処理結果である構造照合処理結果データについて、第2の部分クエリデータに含まれる手順に従って結合演算処理が行われる(ステップS4)。
【0048】
図12は、図9に例示した第2の部分クエリデータQ1_Bを用いて図11に例示した構造照合処理結果データR1_Aについて結合演算処理を行う場合の処理の概要を説明する図である。結合演算処理は、従来のRDB(Relational Database)で行われている結合演算(JOIN)などと同じである。
【0049】
図12の例では、T1[1]<T2[2]という順序関係に関する条件に従ってT1とT2との結合演算が行われ、T3が得られる。そして、T3について[3]のみを取り出すことにより、結合演算処理の結果として、図12に示すような中間結果R1_Bが得られる。この中間結果R1_Bは、図6に例示したクエリデータQ1を、上述したようなクエリデータ解析処理を行わずにそのまま処理した場合の結果と一致する。
【0050】
結合演算処理部29による結合演算処理が終了すると、最後に、検索インタフェース部26により、結合演算処理部29による結合演算処理の結果(中間結果)として得られる要素IDが、それに対応する構造化文書データとして文字列化され、結果データとしてクライアント端末3に返却される(ステップS5)。図12に示した中間結果R1_Bが得られた場合には、この中間結果R1_Bに含まれる要素IDであるE27に対応する構造化文書データが文字列化され、クエリデータQ1の結果データR1として、図13に示すデータがクライアント端末3に返却される。
【0051】
以上、具体的な例を挙げながら説明したように、本実施形態によれば、サーバ1が、構造化文書データの登録時に、その構造化文書データに出現する各要素に要素間で出現順序が比較可能な要素IDを付与して、要素ID付与済み構造化文書データを構造化文書DB21に格納する。また、サーバ1は、構造化文書データの検索時には、クライアント端末3からの入力クエリデータを構文解析して、入力クエリデータが、構造化文書データの論理構造における階層の上下関係を指定する第1条件と、要素IDで特定される要素の順序関係を指定する第2条件とを含む場合に、その入力クエリデータを、第1条件のみを含む第1の部分クエリデータと、第1の部分クエリデータによる照合結果を、第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解して処理するようにしている。したがって、入力クエリデータが複雑な構造条件を含む場合でも、この入力クエリデータを単純な構造条件の構造照合処理と結合演算処理とで処理することで、構造照合処理の高速化を実現し、複雑な構造条件を含むクエリデータによる検索を高速に実行することができる。
【0052】
なお、上記の具体例では、入力クエリデータに、要素IDで特定される要素の順序関係を指定する条件(順序関係に関する構造条件)として「following−sibling」が含まれる場合を例示して説明したが、要素の順序関係を指定する他の条件、例えば「following」や「preceeding」、「preceeding−sibling」などが含まれる場合であっても、上記の具体例と同様に処理することができる。
【0053】
[第2の実施形態]
次に、第2の実施形態について、図5、図7、図14乃至図23を参照して説明する。本実施形態は、第1の部分クエリデータが、構造化文書データの論理構造における階層を下位から上位へと辿る条件を含む場合に、その条件を、構造化文書データの論理構造における階層を下位から上位へと辿る条件に書き換えるようにした例である。なお、以下の説明において、上述した第1の実施形態と共通の構成については同一の符号を付し、重複した説明を省略する。
【0054】
図14は、本実施形態におけるサーバ1’およびクライアント端末3の概略構成を示すブロック図である。本実施形態では、サーバ1’の格納処理部22’に構造解析部30が設けられている。また、サーバ1’の構造化文書DB21’には、要素ID付与済み構造化文書データとともに、構造化文書DB21’に格納された要素ID付与済み構造化文書データそれぞれの階層化された論理構造を集約した情報である構造ガイドデータが格納されている(構造ガイドデータ記憶手段)。また、サーバ1’の検索処理部23’には、構造条件書き換え部31が設けられている。なお、クライアント端末3の構成は第1の実施形態と同じである。
【0055】
構造解析部30は、構造ガイドデータ更新手段として機能するものであり、クライアント端末3から送信された構造化文書データの階層化された論理構造を解析し、その論理構造が構造ガイドデータに反映されるように、構造化文書DB21’に格納されている構造ガイドデータを更新する。
【0056】
構造ガイドデータは、構造化文書DB21’に格納された要素ID付与済み構造化文書データそれぞれの階層化された論理構造を集約した情報であり、要素ID付与済み構造化文書データ中に出現する一意な階層構造に関する情報を保持するものである。図4に例示した構造化文書データに対応する構造ガイドデータは、例えば図15に示すようなものとなる。構造解析部30は、まず、クライアント端末3から送信された構造化文書データの階層化された論理構造を解析して図15に示すような構造ガイドデータを新規に生成する。そして、構造解析部30は、新規に生成した構造ガイドデータを構造化文書DB21’に格納されている構造ガイドデータ(つまり、構造化文書DB21’に格納された要素ID付与済み構造化文書データの論理構造を集約した構造ガイドデータ)と比較し、新規に生成した構造ガイドデータが、構造化文書DB21’に格納されている構造ガイドデータにはない新たな階層構造に関する情報を含む場合に、その新たな階層構造に関する情報を、構造化文書DB21’に格納されている構造ガイドデータに追加するかたちで、構造化文書DB21’に格納されている構造ガイドデータを更新する。
【0057】
構造条件書き換え部31は、条件書き換え手段として機能するものであって、クエリデータ分解部27によって入力クエリデータを分解して得られた第1の部分クエリデータが、構造化文書データの論理構造における階層を下位から上位へと辿る条件、つまり構造化文書データのリーフ要素(葉)からルート要素(根)方向に構造を照合するような条件を含む場合に、該条件を、構造化文書DB21’に格納されている構造ガイドデータに基づいて、構造化文書データの論理構造における階層を上位から下位へと辿る条件、つまり構造化文書データのルート要素(根)からリーフ要素(葉)方向に構造を照合するような条件に書き換える。
【0058】
図16は、本実施形態で想定するクエリデータの一例を示す説明図である。この図16に示すクエリデータQ2は、第1の実施形態で説明したクエリデータQ1と同じくXQueryで記述されており、下記のような意味の複雑な階層構造に関する条件(構造条件)を含んでいる。
Q2:構造化文書DB21’の各構造化文書データについて、階層のどこかに「book」という要素があり、その「book」という要素はその中に「author」という要素を持ち、さらにこの「author」という要素の中に、「first」と「last」という2つの要素を持つような「book」要素であり、さらにその「book」要素よりも後に出現する「book」要素の子である「title」要素の、親要素の子であるような「author」要素の一覧を返す。
【0059】
クエリデータQ2では、クエリデータQ1に加えて「/parent」というパスが出現している。XQueryでの/descendant、/descendant−or−selfや/(child)が、構造化文書のルート要素(根)からリーフ要素(葉)方向に構造を照合するパスであるのに対して、/parentや/ancestorは構造化文書データのリーフ要素(葉)からルート要素(根)方向に、階層構造内での親や先祖要素を照合するパスである。
【0060】
本実施形態おける検索処理部23’による検索処理の流れは、図7に示した第1の実施形態のものと同様である。ただし、本実施形態では、ステップS2のクエリデータ解析処理の中で、構造条件書き換え部31による構造条件書き換え処理が実施される。
【0061】
図17は、本実施形態におけるクエリデータ解析処理の流れを示すフローチャートである。この図17のフローチャートにおいて、ステップS211〜ステップS215までの処理は、第1の実施形態で説明した図8のステップS201〜ステップS205と同様であるため、説明を省略する。
【0062】
本実施形態におけるクエリデータ解析処理では、ステップS215の処理の次に、構造条件書き換え部31が、これまでの処理で作成された第1の部分クエリデータに、構造化文書データの階層構造を葉から根方向へ照合するような構造条件が含まれるかどうかを判定する(ステップS216)。そして、構造条件書き換え部31は、第1の部分クエリデータに、構造化文書データの階層構造を葉から根方向へ照合するような構造条件が含まれていれば(ステップS216:Yes)、構造条件書き換え処理を行って、構造化文書データの階層構造を葉から根方向へ照合する構造条件を、根から葉方向へ照合する構造条件に書き換える(ステップS217)。
【0063】
一方、ステップS216の判定で、第1の部分クエリデータに、構造化文書データの階層構造を葉から根方向へ照合するような構造条件が含まれなければ(ステップS216:No)、ステップS217の構造条件書き換え処理を行うことなく、クエリデータ解析処理を終了する。
【0064】
図18は、図16に例示したクエリデータQ2について、図17のステップS215までの処理を行った結果である第1の部分クエリデータQ2_Aと第2の部分クエリデータQ2_Bの例を示す図である。図18において、第1の部分クエリデータQ2_Aは、構造条件PP1とPP2を含んでいる。また、第2の部分クエリデータQ2_Bは、Q2_Aによる構造照合処理の照合結果を、上述した順序関係に関する構造条件に応じて結合演算する手順を含んでいる。この図18の例では、第1の部分クエリデータQ2_Aの構造条件PP2が、/parentのパスを含んでいる。このため、構造条件書き換え部31による構造条件書き換え処理が行われることになる。
【0065】
図19は、図17のステップS217で行われる構造条件書き換え処理を示すフローチャートである。構造条件書き換え部31は、まず、第1の部分クエリデータのうち、構造化文書データの階層構造を葉から根方向へ照合するパスが含まれる構造条件(以下、入力構造条件という。)の中で、葉から根方向へ照合するパス部分を特定する(ステップS2171)。次に、構造条件書き換え部31は、入力構造条件を、特定したパス部分より前のパスと、特定したパス部分より後のパスと、構造ガイドデータとを参照して、葉から根方向へ照合するパス部分を含まない同じ意味のパスに書き換える(ステップS2172)。
【0066】
ここで、図18に例示した第1の部分クエリデータQ2_Aにある構造条件PP2を、図15に例示した構造ガイドデータを参照して書き換える場合を例に挙げて、ステップS2172での処理の概要を説明する。なお、ここでは説明を簡単にするために、図15に例示した構造ガイドデータを参照しているが、実際には構造化文書DB21’に格納された構造ガイドデータが参照される。
【0067】
第1の部分クエリデータQ2_Aにある構造条件PP2の/parent::node()部分について、その直前のパスは/titleである。図15に例示した構造ガイドデータを参照すると、titleを末尾に持つ構造は/books/book/titleである。/parent::node()は親要素を指定するため、/parent::node()の指定する構造は/books/bookとわかる。さらに、/parent::node()の次のパスである/authorについても、ここまでで特定された構造は/books/bookであるから、/books/bookの後に/authorが続く構造があるかを構造ガイドデータで確認すると、存在するので、構造条件PP2の書き換え結果として/books/book/authorが得られる。
【0068】
図20は、図18に例示した第1の部分クエリデータQ2_Aについて、構造条件書き換え処理を行った結果を示す図である。なお、図中の第2の部分クエリデータQ2_Bは、図18に例示したものと同じである。
【0069】
本実施形態では、構造条件書き換え部31による構造条件書き換え処理を経て、構造照合処理部28による構造照合処理が行われる(ステップS3)。このとき、第1の部分クエリデータに含まれる構造条件は、葉から根方向へ照合するパス部分を含まないものに書き換えられているため、構造照合処理部28による構造照合処理は、すべて根から葉方向への照合のみで実現することができ、極めて高速な処理が可能である。
【0070】
図5に例示した要素ID付与済み構造化文書データについて、図20に例示した構造条件書き換え処理後の第1の部分クエリデータQ2_Aに含まれる構造条件PP1,PP2による構造照合処理を行った結果である構造照合処理結果データR2_Aを図21に示す。図中のT1,T2は、それぞれ構造条件PP1,PP2の構造照合処理の結果であり、T1としては構造条件PP1に合致する構造を持つ要素の要素ID群[1]が得られ、T2としては構造条件PP2に合致する構造を持つ要素の要素ID群[2],[3]が得られる。
【0071】
本実施形態においても、構造照合処理部28による構造照合処理が終了すると、結合演算処理部29により、構造照合処理部28の処理結果である構造照合処理結果データについて、第2の部分クエリデータに含まれる手順に従って結合演算処理が行われる(ステップS4)。
【0072】
図22は、図20に例示した第2の部分クエリデータQ2_Bを用いて図21に例示した構造照合処理結果データR2_Aについて結合演算処理を行う場合の処理の概要を説明する図である。図22の例では、T1[1]<T2[2]という順序関係に関する条件に従ってT1とT2との結合演算が行われ、T3が得られる。そして、T3について[3]のみを取り出すことにより、結合演算処理の結果として、図22に示すような中間結果R2_Bが得られる。この中間結果R2_Bは、図16に例示したクエリデータQ2を、上述したようなクエリデータ解析処理を行わずにそのまま処理した場合の結果と一致する。
【0073】
最後に、検索インタフェース部26により、結合演算処理部29による結合演算処理の結果(中間結果)として得られる要素IDが、それに対応する構造化文書データとして文字列化され、結果データとしてクライアント端末3に返却される(ステップS5)。図22に示した中間結果R2_Bが得られた場合には、この中間結果R2_Bに含まれる要素IDであるE22に対応する構造化文書データが文字列化され、クエリデータQ2の結果データR2として、図23に示すデータがクライアント端末3に返却される。
【0074】
以上、具体的な例を挙げながら説明したように、本実施形態によれば、第1の部分クエリデータが構造化文書データの論理構造における階層を下位から上位へと辿る条件、つまり構造化文書データのリーフ要素(葉)からルート要素(根)方向に構造を照合するような条件を含む場合に、該条件を、構造化文書DB21’に格納されている構造ガイドデータに基づいて、構造化文書データのルート要素(根)からリーフ要素(葉)方向に構造を照合するような条件に書き換える。そして、入力クエリデータを単純な構造条件の構造照合処理と結合演算処理とで処理するようにしている。したがって、入力クエリデータが構造化文書データのリーフ要素(葉)からルート要素(根)方向に構造を照合するような条件を含む複雑なものであっても、構造照合処理の高速化を実現し、複雑な構造条件を含むクエリデータによる検索を高速に実行することができる。
【0075】
なお、上記の具体例では、第1の部分クエリデータに、構造化文書データの論理構造における階層を下位から上位へと辿る条件(構造化文書データのリーフ要素(葉)からルート要素(根)方向に構造を照合するような条件)として「parent」が含まれる場合を例示して説明したが、構造化文書データの論理構造における階層を下位から上位へと辿る他の条件、例えば「ancestor」や「ancestor−or−self」などが含まれる場合であっても、上記の具体例と同様に処理することができる。
【0076】
[第3の実施形態]
次に、第3の実施形態について、図3、図5、図7、図24乃至図33を参照して説明する。本実施形態は、入力クエリデータに含まれる要素の順序関係を指定する条件が、position関数やlast関数の場合の例である。本実施形態におけるサーバ1およびクライアント端末3の構成は、図3に示した第1の実施形態のものと同様である。なお、以下の説明において、上述した第1の実施形態と共通の構成については同一の符号を付し、重複した説明を省略する。
【0077】
図24は、本実施形態で想定するクエリデータの一例を示す説明図である。この図24に示すクエリデータQ3_1,Q3_2は、第1の実施形態で説明したクエリデータQ1や第2の実施形態で説明したクエリデータQ2と同じくXQueryで記述されており、下記のような意味の複雑な階層構造に関する条件(構造条件)を含んでいる。
Q3_1:構造化文書DB21の各構造化文書データについて、階層のどこかに「book」という要素があり、その「book」という要素の中にある「author」要素のうち、1番目に出現するものの一覧を返す。
Q3_2:構造化文書DB21の各構造化文書データについて、階層のどこかに「book」という要素があり、その「book」という要素の中にある「author」要素のうち、最後に出現するものの一覧を返す。
【0078】
クエリデータQ3_1には、[position()=1]という表現がある。これは、XQueryで、[position()=1]が付与されているパスに該当するノードのうち、1番目にあるもののみを選択する指定である。一方、クエリデータQ3_2には、[last()]という表現がある。これは、[last()]が付与されているパスに該当するノードのうち、最後のものを選択する指定となる。
【0079】
本実施形態おける検索処理部23による検索処理の流れは、図7に示した第1の実施形態のものと同様である。ただし、本実施形態では、ステップS2のクエリデータ解析処理の内容が第1の実施形態と相違している。
【0080】
図25は、本実施形態におけるクエリデータ解析処理の流れを示すフローチャートである。クエリデータ分解部27は、第1の実施形態と同様に、はじめに、入力クエリデータのすべてを便宜的に第1の部分クエリデータとする(ステップS221)。このとき、第2の部分クエリデータは空としておく。
【0081】
次に、クエリデータ分解部27は、第1の部分クエリデータをチェックして、第1の部分クエリデータ(ここでは入力クエリデータと同じ)に、[position()=n]や[last()]といった条件が含まれるかどうかを判定する(ステップS222)。そして、クエリデータ分解部27は、そのような構造条件が含まれていれば(ステップS222:Yes)、第1の部分クエリデータ(ここでは入力クエリデータと同じ)から[position()=n]や[last()]といった条件を取り除いたものを、第1の部分クエリデータとする(ステップS223)。そして、クエリデータ分解部27は、ステップS223で取り除いた条件が[position()=n]であれば、第1の部分クエリデータによる構造照合処理結果からn番目に出現する要素を選択する演算指示を第2の部分クエリデータとし、ステップS223で取り除いた条件が[last()]であれば、第1の部分クエリデータによる構造照合処理結果から最後に出現する要素を選択する演算指示を第2の部分クエリデータとして(ステップS224)、クエリデータ解析処理を終了する。
【0082】
一方、ステップS222の判定で、第1の部分クエリデータ(ここでは入力クエリデータと同じ)に[position()=n]や[last()]といった条件が含まれなければ(ステップS222:No)、クエリデータ分解部27は、ステップS223およびステップS224の処理を行うことなく、クエリデータ解析処理を終了する。
【0083】
図26は、図24に例示したクエリデータQ3_1についてのクエリデータ解析処理の結果である第1の部分クエリデータQ3_1_Aと第2の部分クエリデータQ3_1_Bの一例を示す図である。また、図27は、図24に例示したクエリデータQ3_2についてのクエリデータ解析処理の結果である第1の部分クエリデータQ3_2_Aと第2の部分クエリデータQ3_2_Bの一例を示す図である。ここで、“GROUP BY (X)”という演算指示は、(X)で指定した部分の要素IDが同一のものをグループ化する演算指示である。また、“FILTER (X) (Y) (Z)”という演算指示は、(X)で指定するグループについて、(Y)で指定する部分の要素IDが、(Z)の順番にあるもののみを残す、という演算指示である。図26に例示した第2の部分クエリデータQ3_1_Bにあるように(Z)が1のときは、(Y)で指定する部分の要素IDが最も小さなものを残すという演算指示となり、図27に例示した第2の部分クエリデータQ3_2_Bにあるように(Z)がLASTのときは、(Y)で指定する部分の要素IDが最も大きなものを残すという演算指示となる。
【0084】
クエリデータ分解部27によるクエリデータ解析処理が終了すると、第1の実施形態と同様に、構造照合処理部28により、第1の部分クエリデータに含まれる構造条件の構造照合処理が行われる(ステップS3)。
【0085】
図5に例示した要素ID付与済み構造化文書データについて、図26に例示した第1の部分クエリデータQ3_1_Aに含まれる構造条件PP1による構造照合処理を行った結果である構造照合処理結果データR3_1_Aを図28に示す。また、図5に例示した要素ID付与済み構造化文書データについて、図27に例示した第1の部分クエリデータQ3_2_Aに含まれる構造条件PP1による構造照合処理を行った結果である構造照合処理結果データR3_2_Aを図30に示す。図中のT1は構造条件PP1の構造照合処理の結果であり、図28の構造照合処理結果データR3_1_Aと、図30の構造照合処理結果データR3_2_Aのいずれにおいても、構造条件PP1に合致する構造を持つ要素の要素ID群[1],[2]が得られる。
【0086】
構造照合処理部28による構造照合処理が終了すると、第1の実施形態と同様に、結合演算処理部29により、構造照合処理部28の処理結果である構造照合処理結果データについて、第2の部分クエリデータに含まれる手順に従って結合演算処理が行われる(ステップS4)。
【0087】
図29は、図26に例示した第2の部分クエリデータQ3_1_Bを用いて図28に例示した構造照合処理結果データR3_1_Aについて結合演算処理を行う場合の処理の概要を説明する図である。また、図31は、図27に例示した第2の部分クエリデータQ3_2_Bを用いて図30に例示した構造照合処理結果データR3_2_Aについて結合演算処理を行う場合の処理の概要を説明する図である。
【0088】
図29の例および図31の例では、“GROUP BY T1[1]”という演算指示に従って、T1の要素ID群の中で同一の要素IDがグループ化され、T2が得られる。そして、図29の例では、“FILTER T2[1] T2[2] 1”という演算指示に従って、T2[1]について、T2[2]の要素IDが最も小さいものを残す演算処理によりT3が得られ、T3について[2]のみを取り出すことにより、結合演算処理の結果として、図29に示すような中間結果R3_1_Bが得られる。また、図31の例では、“FILTER T2[1] T2[2] LAST”という演算指示に従って、T2[1]について、T2[2]の要素IDが最も大きいものを残す演算処理によりT3が得られ、T3について[2]のみを取り出すことにより、結合演算処理の結果として、図31に示すような中間結果R3_2_Bが得られる。これらの中間結果R3_1_B,R3_2_Bは、図24に例示したクエリデータQ3_1,Q3_2を、上述したようなクエリデータ解析処理を行わずにそのまま処理した場合の結果と一致する。
【0089】
最後に、検索インタフェース部26により、結合演算処理部29による結合演算処理の結果(中間結果)として得られる要素IDが、それに対応する構造化文書データとして文字列化され、結果データとしてクライアント端末3に返却される(ステップS5)。図29に示した中間結果R3_1_Bが得られた場合には、この中間結果R3_1_Bに含まれる要素IDであるE5,E14,E22に対応する構造化文書データが文字列化され、クエリデータQ3_1の結果データR3_1として、図32に示すデータがクライアント端末3に返却される。また、図31に示した中間結果R3_2_Bが得られた場合には、この中間結果R3_2_Bに含まれる要素IDであるE8,E14,E22に対応する構造化文書データが文字列化され、クエリデータQ3_2の結果データR3_2として、図33に示すデータがクライアント端末3に返却される。
【0090】
以上、具体的な例を挙げながら説明したように、本実施形態によれば、入力クエリデータが要素の順序関係を指定する条件としてposition関数やlast関数を含む場合に、その入力クエリデータを、階層の上下関係を指定する条件のみを含む第1の部分クエリデータと、第1の部分クエリデータによる照合結果を、position関数やlast関数で示される条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解して処理するようにしている。したがって、入力クエリデータがposition関数やlast関数を含む複雑なものであっても、この入力クエリデータを単純な構造条件の構造照合処理と結合演算処理とで処理することで、構造照合処理の高速化を実現し、複雑な構造条件を含むクエリデータによる検索を高速に実行することができる。
【0091】
[第4の実施形態]
次に、第4の実施形態について、図5、図19、図34乃至図40を参照して説明する。本実施形態は、第2の実施形態と同様の構造条件の書き換えを行うが、入力クエリデータに要素の順序関係を指定する条件(第2条件)が含まれておらず、第2のクエリデータに基づく結合演算処理を行わない例である。なお、以下の説明において、上述した第2の実施形態と共通の構成については同一の符号を付し、重複した説明を省略する。
【0092】
図34は、本実施形態におけるサーバ1’’およびクライアント端末3の概略構成を示すブロック図である。本実施形態では、サーバ1’’の検索処理部23’’にクエリデータ分解部27が設けられておらず、クライアント端末3から送信された入力クエリデータは、構造条件書き換え部31’に入力される。また、サーバ1’’の検索処理部23’’に結合演算処理部29が設けられておらず、構造照合処理部28による構造照合処理の結果である構造照合処理結果データが、そのまま検索インタフェース部26に渡される。なお、クライアント端末3の構成は第2の実施形態と同じである。
【0093】
図35は、本実施形態で想定するクエリデータの一例を示す説明図である。この図35に示すクエリデータQ4は、第1乃至第3の実施形態で説明したクエリデータと同じくXQueryで記述されており、下記のような意味の複雑な階層構造に関する条件(構造条件)を含んでいる。
Q4:構造化文書DB21’の各構造化文書データについて、階層のどこかに「title」という要素があり、その先祖の「book」という要素の子要素である「publisher」という要素の一覧を返す。
【0094】
クエリデータQ4では、第2の実施形態で説明した/ancestorという構造化文書データのリーフ要素(葉)からルート要素(根)方向に、階層構造内での先祖要素を照合するパスが含まれているが、第1の実施形態で説明したクエリデータQ1に含まれる/following−siblingのような、ある構造を持つ要素間の順序関係に関する構造を照合するパスは含まれていない。
【0095】
図36は、本実施形態におけるサーバ1’’の検索処理部23’’による検索処理の流れを示すフローチャートである。まず、検索インタフェース部26により、クライアント端末3からネットワーク2経由で送信されたクエリデータの入力が受け付けられる(ステップS1)。このクエリデータは、構造条件書き換え部31’に入力される。
【0096】
次に、構造条件書き換え部31’により、入力クエリデータについてのクエリデータ解析処理が行われる(ステップS2)。構造条件書き換え部31’によるクエリデータ解析処理の一例を、図37を参照して説明する。
【0097】
図37は、構造条件書き換え部31’によるクエリデータ解析処理の流れを示すフローチャートである。構造条件書き換え部31’は、はじめに、入力クエリデータを第1の部分クエリデータとする(ステップS231)。次に、構造条件書き換え部31’は、第1の部分クエリデータをチェックして、第1の部分クエリデータに、構造化文書データの階層構造を葉から根方向へ照合するような構造条件が含まれるかどうかを判定する(ステップS232)。そして、構造条件書き換え部31’は、第1の部分クエリデータに、構造化文書データの階層構造を葉から根方向へ照合するような構造条件が含まれていれば(ステップS232:Yes)、構造条件書き換え処理を行って、構造化文書データの階層構造を葉から根方向へ照合する構造条件を、根から葉方向へ照合する構造条件に書き換える(ステップS233)。
【0098】
一方、ステップS232の判定で、第1の部分クエリデータに、構造化文書データの階層構造を葉から根方向へ照合するような構造条件が含まれなければ(ステップS232:No)、ステップS233の構造条件書き換え処理を行うことなく、クエリデータ解析処理を終了する。
【0099】
ステップS233で行われる構造条件書き換え処理は第2の実施形態と同様であり、処理内容は図19に示したフローチャートの通りである。ここでは、図35に例示したクエリデータQ4を、図15に例示した構造ガイドデータを参照して書き換える処理の概要を説明する。なお、ここでは説明を簡単にするために、図15に例示した構造ガイドデータを参照しているが、実際には構造化文書DB21’に格納された構造ガイドデータが参照される。
【0100】
クエリデータQ4の/ancestor::book部分について、その直前のパスは/titleである。ここで、図15に例示した構造ガイドデータを参照すると、titleを末尾に持つ構造は/books/book/titleである。/ancestorは先祖要素を指定するため、/ancestorの指定する構造は/books/book、/booksであるが、::bookとbook要素を指定しているので、/ancestor::bookの指定する構造は/books/bookとなる。さらに、/ancestor::bookの次のパスである/publisherについても、ここまでで特定された構造は/books/bookであるから、/books/bookの後に/publisherが続く構造があるかを構造ガイドデータで確認すると、存在するので、クエリデータQ4に対する構造条件書き換え処理の結果として、/books/book/publisherが得られる。
【0101】
図38は、図35に例示したクエリデータQ4について、構造条件書き換え処理を行った結果の第1の部分クエリデータQ4_Aを示す図である。図35に例示したクエリデータQ4は、構造条件書き換え処理により、/books/book/publisherといった、構造化文書データの階層構造を根から葉方向へ照合する構造条件に書き換えられる。
【0102】
構造条件書き換え部31’によるクエリデータ解析処理が終了すると、第1乃至第3の実施形態と同様に、構造照合処理部28により、第1の部分クエリデータに含まれる構造条件の構造照合処理が行われる(ステップS3)。
【0103】
図5に例示した要素ID付与済み構造化文書データについて、図38に例示した第1の部分クエリデータQ4_Aによる構造照合処理を行った結果である構造照合処理結果データR4_Aを図39に示す。図中のT1は/books/book/publisherという構造条件の構造照合処理の結果であり、このような構造を持つ要素の要素ID群[1]が得られる。
【0104】
本実施形態では、この構造照合処理部28による構造照合処理の結果がそのまま中間結果として検索インタフェース部26に渡される。そして、最後に、検索インタフェース部26により、構造照合処理部28による構造照合処理の結果(中間結果)として得られる要素IDが、それに対応する構造化文書データとして文字列化され、結果データとしてクライアント端末3に返却される(ステップS5)。図39に示した中間結果R4_Aが得られた場合には、この中間結果R4_Aに含まれる要素IDであるE11,E29に対応する構造化文書データが文字列化され、クエリデータQ4の結果データR4として、図40に示すデータがクライアント端末3に返却される。
【0105】
以上、具体的な例を挙げながら説明したように、本実施形態によれば、入力クエリデータが、要素IDで特定される要素の順序関係を指定する条件(第2条件)を含まず、構造化文書データの論理構造における階層を下位から上位へと辿る条件、つまり構造化文書データのリーフ要素(葉)からルート要素(根)方向に構造を照合するような条件を含む場合に、該条件を、構造化文書DB21’に格納されている構造ガイドデータに基づいて、構造化文書データのルート要素(根)からリーフ要素(葉)方向に構造を照合するような条件に書き換える。そして、入力クエリデータを単純な構造条件の構造照合処理のみで処理するようにしている。したがって、入力クエリデータが構造化文書データのリーフ要素(葉)からルート要素(根)方向に構造を照合するような条件を含む複雑なものであっても、構造照合処理の高速化を実現し、複雑な構造条件を含むクエリデータによる検索を高速に実行することができる。
【0106】
なお、上記の具体例では、入力クエリデータに含まれる、構造化文書データの論理構造における階層を下位から上位へと辿る条件(構造化文書データのリーフ要素(葉)からルート要素(根)方向に構造を照合するような条件)として「ancestor」を例示したが、構造化文書データの論理構造における階層を下位から上位へと辿る他の条件、例えば「parent」や「ancestor−or−self」などが入力クエリデータに含まれる場合であっても、上記の具体例と同様に処理することができる。
【0107】
以上説明した第1乃至第4の実施形態におけるサーバ1、サーバ1’、サーバ1’’の機能は、例えば、コンピュータの演算装置であるCPU101が、アプリケーションプログラムとして実装された構造化文書管理プログラムを実行することにより実現される。
【0108】
第1乃至第4の実施形態におけるサーバ1、サーバ1’、サーバ1’’で実行される構造化文書管理プログラムは、例えば、インストール可能な形式又は実行可能な形式のファイルでCD−ROM、フレキシブルディスク(FD)、CD−R、DVD(Digital Versatile Disc)などのコンピュータで読み取り可能な記憶媒体110に記録されて提供される。
【0109】
また、第1乃至第4の実施形態におけるサーバ1、サーバ1’、サーバ1’’で実行される構造化文書管理プログラムを、インターネットなどのネットワーク2に接続されたコンピュータ上に格納し、ネットワーク2経由でダウンロードさせることにより提供するように構成してもよい。また、第1乃至第4の実施形態におけるサーバ1、サーバ1’、サーバ1’’で実行される構造化文書管理プログラムを、インターネットなどのネットワーク2経由で提供または配布するように構成してもよい。さらに、第1乃至第4の実施形態におけるサーバ1、サーバ1’、サーバ1’’で実行される構造化文書管理プログラムを、ROM102などに予め組み込んで提供するように構成してもよい。
【0110】
第1乃至第4の実施形態におけるサーバ1、サーバ1’、サーバ1’’で実行される構造化文書管理プログラムは、格納インタフェース部24、要素ID付与部25、検索インタフェース部26、クエリデータ分解部27、構造照合処理部28、結合演算処理部29、構造解析部30、構造条件書き換え部31,31’などを含むモジュール構成となっており、実際のハードウェアとしてはCPU(プロセッサ)101がHDD104などから構造化文書管理プログラムを読み出して実行することにより上記各部が主記憶装置(例えばRAM103)上にロードされ、格納インタフェース部24、要素ID付与部25、検索インタフェース部26、クエリデータ分解部27、構造照合処理部28、結合演算処理部29、構造解析部30、構造条件書き換え部31,31’などが主記憶装置上に生成されるようになっている。
【0111】
以上述べた少なくとも一つの実施形態にかかる構造化文書管理システムによれば、入力クエリデータを単純な構造条件に変えて構造照合処理を実行するようにしているので、入力クエリデータが複雑な構造条件を含む場合でも、構造照合処理の高速化を実現し、複雑な構造条件を含むクエリデータによる検索を高速に実行することができる。
【0112】
なお、本発明のいくつかの実施形態を説明したが、これらの実施形態は、例として提示したものであり、発明の範囲を限定することは意図していない。これら新規な実施形態は、その他の様々な形態で実施されることが可能であり、発明の要旨を逸脱しない範囲で、種々の省略、置き換え、変更を行うことができる。これら実施形態やその変形は、発明の範囲や要旨に含まれるとともに、請求の範囲に記載された発明とその均等の範囲に含まれる。
【符号の説明】
【0113】
1,1’,1’’サーバ
24 格納インタフェース部
25 要素ID付与部
26 検索インタフェース部
27 クエリデータ分解部
28 構造照合処理部
29 結合演算処理部
30 構造解析部
31,31’構造条件書き換え部
【特許請求の範囲】
【請求項1】
階層化された論理構造を有する構造化文書データの入力を受け付ける構造化文書データ受付手段と、
入力された前記構造化文書データに出現する要素に該構造化文書データ内での出現順序が要素間で比較可能な識別子を付与する識別子付与手段と、
前記要素に前記識別子が付与された前記構造化文書データを記憶する構造化文書データ記憶手段と、
クエリデータの入力を受け付けるクエリデータ受付手段と、
入力されたクエリデータが、前記構造化文書データの論理構造における階層の上下関係を指定する第1条件と、前記識別子で特定される前記要素の順序関係を指定する第2条件とを含む場合に、該クエリデータを、前記第1条件のみを含む第1の部分クエリデータと、前記第1の部分クエリデータによる照合結果を前記第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解するクエリデータ分解手段と、
前記構造化文書データ記憶手段が記憶する前記構造化文書データのデータ集合に対して、前記第1の部分クエリデータによる照合を行い、照合結果を出力する構造照合処理手段と、
前記照合結果を、前記第2の部分クエリデータに含まれる結合演算の手順に従って結合演算処理する結合演算処理手段と、
を備えることを特徴とする構造化文書管理装置。
【請求項2】
前記構造化文書データ記憶手段が記憶する前記構造化文書データそれぞれの階層化された論理構造を集約した情報である構造ガイドデータを記憶する構造ガイドデータ記憶手段と、
入力された前記構造化文書データの階層化された論理構造が前記構造ガイドデータに反映されるように、該構造ガイドデータを更新する構造ガイドデータ更新手段と、
前記第1の部分クエリデータが前記階層を下位から上位へと辿る条件を含む場合に、該条件を、前記構造ガイドデータに基づいて、前記階層を上位から下位に辿る条件に書き換える条件書き換え手段と、をさらに備えることを特徴とする請求項1に記載の構造化文書管理装置。
【請求項3】
階層化された論理構造を有する構造化文書データの入力を受け付ける構造化文書データ受付手段と、
入力された前記構造化文書データに出現する要素に該構造化文書データ内での出現順序が要素間で比較可能な識別子を付与する識別子付与手段と、
前記要素に前記識別子が付与された前記構造化文書データを記憶する構造化文書データ記憶手段と、
前記構造化文書データ記憶手段が記憶する前記構造化文書データそれぞれの階層化された論理構造を集約した情報である構造ガイドデータを記憶する構造ガイドデータ記憶手段と、
入力された前記構造化文書データの階層化された論理構造が前記構造ガイドデータに反映されるように、該構造ガイドデータを更新する構造ガイドデータ更新手段と、
クエリデータの入力を受け付けるクエリデータ受付手段と、
入力されたクエリデータが、前記構造化文書データの論理構造における階層を下位から上位へと辿る条件を含む場合に、該条件を、前記構造ガイドデータに基づいて、前記階層を上位から下位に辿る条件に書き換える条件書き換え手段と、
前記構造化文書データ記憶手段が記憶する前記構造化文書データのデータ集合に対して、前記条件書き換え手段が書き換えた条件による照合を行い、照合結果を出力する構造照合処理手段と、を備えることを特徴とする構造化文書管理装置。
【請求項4】
階層化された論理構造を有する構造化文書データの入力を受け付けるステップと、
入力された前記構造化文書データに出現する要素に該構造化文書データ内での出現順序が要素間で比較可能な識別子を付与して記憶装置に格納するステップと、
クエリデータの入力を受け付けるステップと、
入力されたクエリデータが、前記構造化文書データの論理構造における階層の上下関係を指定する第1条件と、前記識別子で特定される前記要素の順序関係を指定する第2条件とを含む場合に、該クエリデータを、前記第1条件のみを含む第1の部分クエリデータと、前記第1の部分クエリデータによる照合結果を前記第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解するステップと、
前記記憶装置に格納された前記構造化文書データのデータ集合に対して、前記第1の部分クエリデータによる照合を行い、照合結果を出力するステップと、
前記照合結果を、前記第2の部分クエリデータに含まれる結合演算の手順に従って結合演算処理するステップと、を含むことを特徴とする構造化文書管理方法。
【請求項5】
コンピュータに、
階層化された論理構造を有する構造化文書データの入力を受け付ける機能と、
入力された前記構造化文書データに出現する要素に該構造化文書データ内での出現順序が要素間で比較可能な識別子を付与して記憶装置に格納する機能と、
クエリデータの入力を受け付ける機能と、
入力されたクエリデータが、前記構造化文書データの論理構造における階層の上下関係を指定する第1条件と、前記識別子で特定される前記要素の順序関係を指定する第2条件とを含む場合に、該クエリデータを、前記第1条件のみを含む第1の部分クエリデータと、前記第1の部分クエリデータによる照合結果を前記第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解する機能と、
前記記憶装置に格納された前記構造化文書データのデータ集合に対して、前記第1の部分クエリデータによる照合を行い、照合結果を出力する機能と、
前記照合結果を、前記第2の部分クエリデータに含まれる結合演算の手順に従って結合演算処理する機能と、を実現させることを特徴とする構造化文書管理プログラム。
【請求項1】
階層化された論理構造を有する構造化文書データの入力を受け付ける構造化文書データ受付手段と、
入力された前記構造化文書データに出現する要素に該構造化文書データ内での出現順序が要素間で比較可能な識別子を付与する識別子付与手段と、
前記要素に前記識別子が付与された前記構造化文書データを記憶する構造化文書データ記憶手段と、
クエリデータの入力を受け付けるクエリデータ受付手段と、
入力されたクエリデータが、前記構造化文書データの論理構造における階層の上下関係を指定する第1条件と、前記識別子で特定される前記要素の順序関係を指定する第2条件とを含む場合に、該クエリデータを、前記第1条件のみを含む第1の部分クエリデータと、前記第1の部分クエリデータによる照合結果を前記第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解するクエリデータ分解手段と、
前記構造化文書データ記憶手段が記憶する前記構造化文書データのデータ集合に対して、前記第1の部分クエリデータによる照合を行い、照合結果を出力する構造照合処理手段と、
前記照合結果を、前記第2の部分クエリデータに含まれる結合演算の手順に従って結合演算処理する結合演算処理手段と、
を備えることを特徴とする構造化文書管理装置。
【請求項2】
前記構造化文書データ記憶手段が記憶する前記構造化文書データそれぞれの階層化された論理構造を集約した情報である構造ガイドデータを記憶する構造ガイドデータ記憶手段と、
入力された前記構造化文書データの階層化された論理構造が前記構造ガイドデータに反映されるように、該構造ガイドデータを更新する構造ガイドデータ更新手段と、
前記第1の部分クエリデータが前記階層を下位から上位へと辿る条件を含む場合に、該条件を、前記構造ガイドデータに基づいて、前記階層を上位から下位に辿る条件に書き換える条件書き換え手段と、をさらに備えることを特徴とする請求項1に記載の構造化文書管理装置。
【請求項3】
階層化された論理構造を有する構造化文書データの入力を受け付ける構造化文書データ受付手段と、
入力された前記構造化文書データに出現する要素に該構造化文書データ内での出現順序が要素間で比較可能な識別子を付与する識別子付与手段と、
前記要素に前記識別子が付与された前記構造化文書データを記憶する構造化文書データ記憶手段と、
前記構造化文書データ記憶手段が記憶する前記構造化文書データそれぞれの階層化された論理構造を集約した情報である構造ガイドデータを記憶する構造ガイドデータ記憶手段と、
入力された前記構造化文書データの階層化された論理構造が前記構造ガイドデータに反映されるように、該構造ガイドデータを更新する構造ガイドデータ更新手段と、
クエリデータの入力を受け付けるクエリデータ受付手段と、
入力されたクエリデータが、前記構造化文書データの論理構造における階層を下位から上位へと辿る条件を含む場合に、該条件を、前記構造ガイドデータに基づいて、前記階層を上位から下位に辿る条件に書き換える条件書き換え手段と、
前記構造化文書データ記憶手段が記憶する前記構造化文書データのデータ集合に対して、前記条件書き換え手段が書き換えた条件による照合を行い、照合結果を出力する構造照合処理手段と、を備えることを特徴とする構造化文書管理装置。
【請求項4】
階層化された論理構造を有する構造化文書データの入力を受け付けるステップと、
入力された前記構造化文書データに出現する要素に該構造化文書データ内での出現順序が要素間で比較可能な識別子を付与して記憶装置に格納するステップと、
クエリデータの入力を受け付けるステップと、
入力されたクエリデータが、前記構造化文書データの論理構造における階層の上下関係を指定する第1条件と、前記識別子で特定される前記要素の順序関係を指定する第2条件とを含む場合に、該クエリデータを、前記第1条件のみを含む第1の部分クエリデータと、前記第1の部分クエリデータによる照合結果を前記第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解するステップと、
前記記憶装置に格納された前記構造化文書データのデータ集合に対して、前記第1の部分クエリデータによる照合を行い、照合結果を出力するステップと、
前記照合結果を、前記第2の部分クエリデータに含まれる結合演算の手順に従って結合演算処理するステップと、を含むことを特徴とする構造化文書管理方法。
【請求項5】
コンピュータに、
階層化された論理構造を有する構造化文書データの入力を受け付ける機能と、
入力された前記構造化文書データに出現する要素に該構造化文書データ内での出現順序が要素間で比較可能な識別子を付与して記憶装置に格納する機能と、
クエリデータの入力を受け付ける機能と、
入力されたクエリデータが、前記構造化文書データの論理構造における階層の上下関係を指定する第1条件と、前記識別子で特定される前記要素の順序関係を指定する第2条件とを含む場合に、該クエリデータを、前記第1条件のみを含む第1の部分クエリデータと、前記第1の部分クエリデータによる照合結果を前記第2条件に応じて結合演算する手順を含む第2の部分クエリデータとに分解する機能と、
前記記憶装置に格納された前記構造化文書データのデータ集合に対して、前記第1の部分クエリデータによる照合を行い、照合結果を出力する機能と、
前記照合結果を、前記第2の部分クエリデータに含まれる結合演算の手順に従って結合演算処理する機能と、を実現させることを特徴とする構造化文書管理プログラム。
【図1】



【図2】
【図3】

【図4】

【図5】

【図6】

【図7】
【図8】
【図9】

【図10】

【図11】
【図12】
【図13】

【図14】
【図15】

【図16】

【図17】
【図18】

【図19】
【図20】
【図21】
【図22】
【図23】
【図24】

【図25】
【図26】
【図27】
【図28】

【図29】

【図30】

【図31】
【図32】

【図33】
【図34】
【図35】

【図36】
【図37】

【図38】

【図39】

【図40】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【図30】
【図31】
【図32】
【図33】
【図34】
【図35】
【図36】
【図37】
【図38】
【図39】
【図40】
【公開番号】特開2012−194950(P2012−194950A)
【公開日】平成24年10月11日(2012.10.11)
【国際特許分類】
【出願番号】特願2011−60371(P2011−60371)
【出願日】平成23年3月18日(2011.3.18)
【出願人】(000003078)株式会社東芝 (54,554)
【出願人】(301063496)東芝ソリューション株式会社 (1,478)
【Fターム(参考)】
【公開日】平成24年10月11日(2012.10.11)
【国際特許分類】
【出願日】平成23年3月18日(2011.3.18)
【出願人】(000003078)株式会社東芝 (54,554)
【出願人】(301063496)東芝ソリューション株式会社 (1,478)
【Fターム(参考)】
[ Back to top ]