
機械翻訳システム及びそのためのコンピュータプログラム
【課題】 翻訳可能な文の範囲を拡大できる機械翻訳装置を提供する。
【解決手段】 機械翻訳システム32は、入力文30を翻訳する機械翻訳システムであって、翻訳可能文からなるコーパス46と、入力文を翻訳する第1の機械翻訳装置42とを含む。機械翻訳装置は、訳文の訳質の指標を出力する。機械翻訳システム32はさらに、訳質が悪い場合には入力文30と類似した文をコーパス46から検索する類似文検索部48と、類似文検索部48により検索された文を翻訳する第2の機械翻訳装置50とを含む。
【解決手段】 機械翻訳システム32は、入力文30を翻訳する機械翻訳システムであって、翻訳可能文からなるコーパス46と、入力文を翻訳する第1の機械翻訳装置42とを含む。機械翻訳装置は、訳文の訳質の指標を出力する。機械翻訳システム32はさらに、訳質が悪い場合には入力文30と類似した文をコーパス46から検索する類似文検索部48と、類似文検索部48により検索された文を翻訳する第2の機械翻訳装置50とを含む。
【発明の詳細な説明】
【技術分野】
【0001】
この発明は機械翻訳技術に関し、特に、話し言葉のように機械翻訳が困難な文を多く含む原文に対する翻訳性能を向上させるための技術に関する。
【背景技術】
【0002】
音声翻訳は、音声発話をリアルタイムで翻訳して音声で出力することを目的とする。その構成技術には、音声認識、機械翻訳、及び音声合成がある。
【0003】
音声翻訳における機械翻訳部は、音声認識部から出力される発話文を翻訳対象とする。しかしこれらの文は話し言葉特有の性質を有するため、その翻訳には困難が伴う。例えば、話し言葉発話には言いよどみ、言直し、繰返し、助詞省略などのような不適格性が多く出現する。これらの現象は形態素解析及び構文解析などの処理の精度低下を招く。加えて、話し言葉では様々な待遇表現が多用されるという点も言語現象を複雑にしている。例えば、話し言葉においては、「して下さい」「していただけませんか」「をお願いします」等と書き言葉ではあまり見られない様々な文末表現が出現する。
【0004】
また音声認識に由来する問題点として、音声認識部から得られる発話が翻訳処理に適した「文」であるとは限らないことが挙げられる。音声認識では無音区間により発話を分割する。しかし話し言葉では、文中に長い無音区間が出現したり、文と文との間に短い無音区間が出現したりすることが多い。そのため、音声認識部から得られる発話は、意味的にまとまりのある文とは限らない。
【0005】
こうした問題を解決するための一つの手段は、いわゆる前処理と呼ばれる技術である。これは、機械翻訳に与える前に、機械翻訳に有利な文となるように入力文を書換える技術をいう。これはまた、前編集とも呼ばれる。
【0006】
前処理に関し、非特許文献1は、省略要素の補完、冗長表現の簡素化、構文組替えなどの変換規則を人手で作成し、入力文に適用することを試みている。また非特許文献2は、機械翻訳に与えられた長文の入力文を短文に分割することで機械翻訳の精度の向上を試みている。非特許文献3は、構文解析の失敗を導く現象として、倒置、省略、挿入、及び強調を取上げ、これらの現象を解消する書換え規則を適用することで構文解析の成功率向上を図っている。さらに非特許文献4は、表現の簡素化及び重要でない語の削除など、局所的な書換え規則を入力文に適用している。さらに非特許文献5は、無音区間の情報と、認識された発話のn−グラムとを利用して、意味的にまとまりのある文を得るために発話単位の接合及び分割を試みている。
【0007】
【非特許文献1】白井諭他3名、「日英機械翻訳における原文自動書き換え型翻訳方式とその効果」、情報処理学会論文誌、36(1)、12−21、1995年
【非特許文献2】金淵培他1名、「日英機械翻訳のための日本語長文自動短文分割と主語の補完」、情報処理学会論文誌、35(6)、1018−1028、1994年
【非特許文献3】吉見毅彦他2名、「頑健な英日機械翻訳システム実現のための原文自動前編集」、自然言語処理、7(4)、99−118、2000年
【非特許文献4】ヤマモト、K.、「パラフレーザとトランスファとの相互作用による機械翻訳」、第19回計算機言語国際大会(COLING−2002)、pp.1107−1113、2002年(Yamamoto, K., "Machine Translation by Interaction between Paraphraser and Transfer." In Proc. of the 19th International Conference on Computational Linguistics (COLING-2002), pp. 1107-1113, 2002.)
【非特許文献5】竹澤寿幸他1名、「発話単位の分割または接合による言語処理単位への変換手法」、自然言語処理、6(2)、80003−95、1999年
【0008】
【非特許文献6】タケザワ、T.他4名、「実世界における旅行会話の言語翻訳のための、広範囲のバイリンガルコーパスに向けて」第3回LREC−2002予稿集、pp.147−152、2002年(Takezawa, T. et al., "Toward a Broad-coverage Bilingual Corpus for Speech Translation of Travel Conversations in the Real World", In Proc. of the 3rd LREC, pp. 147-152, 2002)
【非特許文献7】タケザワ、T.他1名、「コーパスベースの発話翻訳のための機械翻訳を用いた2言語対話の収集」、Eurospeech−2003、pp.2757−2760、2003年(Takezawa, T. et al., "Collecting Machine-Translation-Aided Bilingual Dialogues for Corpus-Based Speech Translation." In Eurospeech-2003, pp. 2757-2760, 2003)
【非特許文献8】キクイ、G.他3名、「発話間翻訳のためのコーパスの作成」、Eurospeech−2003予稿集、pp.381−384、2003(Kikui, G. et al., "Creating Corpora for Speech-to-Speech Translation." In Eurospeech-2003, pp. 381-384, 2003)
【発明の開示】
【発明が解決しようとする課題】
【0009】
しかし、上記した従来の技術では、前編集のための書換え規則を用意するために大きなコストがかかるという問題点がある。また、従来技術の大部分では、構文解析の情報も要するため、構文解析が正しく行なえないと正しい前処理を行なうことができないという問題点もある。話し言葉では、既に説明したように不適格性を含む入力文が大部分であり、構文解析の精度を高くすることはむずかしく、その点で上記した従来技術を話し言葉翻訳に有効に適用することは困難である。
【0010】
それゆえに本発明の目的は、話し言葉のように不適格性を多く含む入力文を対象とする場合であっても翻訳可能な文の範囲を拡大できる機械翻訳システムを提供することである。
【課題を解決するための手段】
【0011】
本発明の第1の局面に係る機械翻訳システムは、第1の言語の入力文を第2の言語に翻訳するための機械翻訳システムであって、第2の言語への翻訳が可能であるとして予め選択された、第1の言語の複数の文を含む第1のコーパスと、入力文を第2の言語に翻訳するための第1の機械翻訳手段と、第1の機械翻訳手段による訳文の訳質の指標を出力するための指標出力手段と、指標出力手段の出力する指標が訳質が悪いことを示す所定の条件に合致することに応答して、入力文と所定の関係にある文を第1のコーパスから検索するための検索手段と、検索手段により検索された文を第2の言語に翻訳するための第2の機械翻訳手段とを含む。
【0012】
第1の機械翻訳手段の訳質の指標により訳質が悪い場合、入力文に対し所定の関係にある文を第1のコーパスから検索し、その文を第2の機械翻訳手段によって翻訳して入力文に対する訳文とする。第1のコーパス中の文は翻訳可能として選ばれた文であるから、第2の機械翻訳手段により翻訳できる可能性が高い。第1の機械翻訳手段の訳質が悪い場合でも、入力文と所定の関係にある文に対する翻訳で訳文が置換えられるので、訳質が悪い翻訳をそのまま出力することが避けられる。その結果、機械翻訳システムで翻訳可能な入力文の範囲を、第1の機械翻訳手段により翻訳可能な文の範囲と比較して広げることができる。
【0013】
好ましくは、検索手段は、指標出力手段の出力する指標が所定の条件に合致していることに応答して、入力文との間で所定の算出方式に従い算出される類似度によって最も入力文と類似していると判定される文を第1のコーパスから検索するための類似文検索手段を含む。
【0014】
第1の機械翻訳手段による訳質が悪い場合、入力文に対し最も類似している文を第1のコーパスから検索しそれを第2の機械翻訳手段により翻訳する。入力文に最も類似している文を第2の機械翻訳手段で訳すため、その結果得られる訳文は入力文に対する訳文と同様の内容を表す。第1の機械翻訳手段による訳質の悪い翻訳をそのまま出さず、かつ第2の機械翻訳によって得られた、入力文とほぼ同じ内容の訳文を出力できる。
【0015】
さらに好ましくは、類似文検索手段は、第1のコーパスに含まれる複数の文の各々と、入力文との間の共通部分に基づいて定義される類似度を算出するための類似度算出手段と、類似度算出手段により算出された類似度に基づき、最も入力文と類似していると判定された文を第1のコーパスより抽出するための手段とを含む。
【0016】
入力文と第1のコーパスの各文とが類似しているか否かが、入力文との間の共通部分に基づいて定義される類似度で表される。実験結果から、このように定義した類似度により、入力文とよく似た内容の文を第1のコーパスから検索できることが分かっている。
【0017】
より好ましくは、類似度算出手段は、入力文の単語数、候補文の単語数、及び入力文及び候補文に共通する単語数を算出するための単語数算出手段と、入力文と、類似度の算出対象となる候補文との間の類似度を、次の式
適合率=(入力文と候補文に共通する単語数)/候補文の単語数
再現率=(入力文と候補文に共通する単語数)/入力文の単語数
で定義される適合率と再現率との双方の関数として算出するための手段を含む。
【0018】
適合率と再現率との関数を用いれば、入力文と候補文との間で共通する部分の大きさを的確に表した類似度を算出できる。
【0019】
単語数算出手段は、入力文の単語数、候補文の単語数、並びに入力文及び候補文に共通する単語数を、各単語の種類に従って予め定められる重みを乗じて算出するための手段を含んでもよい。
【0020】
単語の種類によって、文の内容を表す際の重みを変える。その結果、例えば文の内容を表す上で重要な種類の単語と、そうでない単語との重みを区別でき、目的に応じて適切な候補文を検索するための類似度が算出できる。
【0021】
好ましくは、算出するための手段は、入力文の単語数、候補文の単語数並びに入力文及び候補文に共通する単語数を、内容語には予め定める第1の重みを、機能語には予め定める第2の重みを、それぞれ乗じて算出するための手段を含み、第2の重みは、第1の重みよりも小さな正の値である。
【0022】
内容語の方が、機能語と比較して文の内容を表す上でより重要と考えられる。そこでこのように内容語に対する第1の重みを機能語に対する第2の重みより大きくすることで、文の内容に重点をおいて入力文に類似する候補文を検索できる。
【0023】
さらに好ましくは、単語数算出手段は、入力文の単語数、候補文の単語数、並びに入力文及び候補文に共通する単語数を、文中のn−グラム数(n>0)により算出するための手段を含む。nの値は実験により定めることが好ましく、例えばn=1でもよく、n=2でもよい。
【0024】
このようにn−グラムによって単語数を算出すると良い結果が得られることが実験により分かっている。
【0025】
好ましくは、単語数算出手段は、入力文の単語数及び候補文の単語数をそれぞれ算出するための手段と、入力文及び候補文に共通する単語数を、入力文及び候補文の双方に共通して、一致した順序で出現する単語数により算出するための手段とを含む。
【0026】
共通単語数をこのように算出した場合にも比較的良い結果が得られることが実験により分かっている。
【0027】
さらに好ましくは、類似度算出手段は、入力文と、候補文との間の類似度を以下の式
類似度=2×適合率×再現率/(適合率+再現率)
に従って算出するための手段を含む。
【0028】
このようにして定めた類似度を用いて検索した文は、入力文に対し類似した内容を表すものであることが多いことが実験により分かった。従ってこの類似度を用いることで第1の機械翻訳手段では良好な翻訳が得られない場合でも、入力文と同様の内容を表す訳文を第2の機械翻訳手段の翻訳により得ることができる。
【0029】
より好ましくは、類似文検索手段はさらに、入力文に含まれない内容語を含む候補文を抽出するための手段による抽出の対象から除外するための手段を含む。
【0030】
このように入力文に含まれない内容語は、文の意味に対し不必要な限定を付加するものであることが多い。そうした内容語を含む候補文を除外することで、最終的に得られる訳文が入力文の内容を的確に伝えるものとなる確率を上げることができる。
【0031】
好ましくは、抽出するための手段は、類似度算出手段により算出された類似度に基づき、最も入力文と類似していると判定され、かつ入力文に含まれない内容語を含まない候補文であって、かつ以下の条件
(1)入力文に含まれる内容語のうち、候補文にない内容語が1語以内である、又は
(2)入力文と共通する内容語が2語以上である、
のいずれかを充足する候補文を第1のコーパスより抽出するための手段を含む。
【0032】
実験では、このような条件を付した場合に最もよい結果が得られた。
【0033】
さらに好ましくは、第1の機械翻訳手段は、互いに良好な訳である第1の言語の文と第2の言語の文とからなる用例を複数個含む2言語用例コーパスと、所定の類似基準に従って入力文との間で最も類似している第1の言語の文を含む用例を2言語用例コーパスから検索するための手段と、検索するための手段により検索された第1の言語の文の対訳である第2の言語の文を、検索するための手段により検索された第1の言語の文及び入力文の間の相違に基づき修正することにより、入力文の翻訳を行なう用例翻訳手段とを含み、指標出力手段は、検索するための手段によって検索された第1の言語の文と入力文との間で定義される所定の類似度が、予め定める基準を充足しているか否かを判定し、判定結果を指標として出力するための手段を含む。
【0034】
第1の機械翻訳手段として用例翻訳手段を用いることで、用例翻訳における用例文検索の過程で得られた類似度を訳質の指標として用いることが可能になる。訳質を評価するために独立した機能モジュールは必要ない。
【0035】
より好ましくは、第1の機械翻訳手段と第2の機械翻訳手段とが同一の機械翻訳手段により実現される。
【0036】
第1の機械翻訳手段と第2の機械翻訳手段とを同一の機械翻訳手段により実現することで、翻訳に必要な資源の増大を防ぎながら、翻訳可能な文の範囲を広げることができる。
【0037】
本発明の第2の局面に係るコンピュータプログラムは、コンピュータにより実行されると、当該コンピュータを、上記したいずれかの機械翻訳システムとして動作させるものである。
【発明を実施するための最良の形態】
【0038】
本実施の形態に係る機械翻訳システムは、音声翻訳において、翻訳が困難と判定される発話文について、予め準備した翻訳可能文のコーパスからその文に類似する文を検索することにより、機械翻訳可能な文の範囲を拡大させるシステムである。以下、この実施の形態に係る機械翻訳システムの構成及び動作の順に説明する。なお、以下の説明において同一の部品には同一の参照番号を付してある。それらの名称及び機能もそれぞれ同一である。従ってそれらについての詳細な説明は繰返さない。
【0039】
なお、以下の実施の形態のシステムの構成の説明中では、予備実験の結果に従って予め決定したパラメータ値を用いている。それらの予備実験は日本語を対象として行なっており、実験では2種類の日本語コーパスを用いた。入力文の集合である発話コーパスと、入力文との類似文を検索する基となる候補文の集合体である候補文コーパスとである。
【0040】
発話コーパスには、旅行中のある状況を想定して行なわれた対話を書き起こして作成した発話コーパス(非特許文献7)から抽出した437文の異なり文を用いた(第1の発話コーパス)。非特許文献7の発話コーパスのうち、第1の発話コーパス以外の部分(第2の発話コーパス)は最後に説明する実験に使用している。候補文コーパスには、旅行会話の基本的な表現を収録したコーパス(非特許文献8記載)を使用した(第1の基本表現コーパス)。第1の基本表現コーパスには異なりで176,145文が含まれている。
【0041】
[構成]
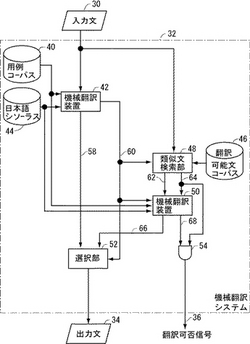
図1は、本発明の一実施の形態に係る機械翻訳システム32のブロック図である。図1を参照して、この機械翻訳システム32は、日本語の入力文30を英語に翻訳することを試み、翻訳可能であれば出力文34を出力し、さらに翻訳が不可能であるか否かを示す翻訳可否信号36を出力するものである。後述するようにこの機械翻訳システム32は、コンピュータシステム及びその上で実行されるコンピュータプログラムにより実現可能である。
【0042】
機械翻訳システム32は、用例に基づく機械翻訳システム(用例翻訳システム)であって、日本語の文(これを用例文と呼ぶ。)とそれに対する英語の訳との対を多数含むコンピュータ読取可能な2言語用例コーパス(以下単に「用例コーパス」と呼ぶ。)40と、入力文30に類似する日本語文を用例コーパス40の中で検索し、検索された日本語文に対する英語訳を、入力文30と検索された用例文との相違に基づいて修正することによって入力文30の翻訳を行ない翻訳結果58を出力するとともに、検索された用例文と入力文30との類似度が所定の値を上回っているか否かを表す判定信号を出力するための機械翻訳装置42とを含む。なお機械翻訳装置42で使用する類似度は正の値であり、値が小さいほど用例文と入力文30とが類似していることを示す。
【0043】
本実施の形態では、用例翻訳を用いているため、入力文とよく似た用例文が見つかれば訳質の高い翻訳が得られる可能性が高い。用例文が入力文に似ていなければ、一般的に訳質が低くなる。そこで、この類似度を翻訳結果の訳質の指標として用いる。
【0044】
機械翻訳装置42は、この検索にあたって、入力文30と用例文との間の類似度を、単語を単位とした編集距離(入力文30を用例文に変換するまでに必要な、単語の削除、挿入、及び置換数)に基づいて算出する。従って本実施の形態では、一致する文同士の類似度は0となる。判定信号60は、検索された用例文の類似度が規定の基準を上回っている場合、すなわち検索された用例文と入力文30とがそれほど類似していない場合には論理1レベルとなり、それ以外の場合には論理0レベルとなる。さらにこの編集距離は、単語の意味的な距離により補正される。すなわち、意味的に近い関係にある2語の置換は、その意味的な距離が近いほど編集距離が小さくなるように補正される。機械翻訳システム32は、この補正処理を行なうために、コンピュータ読取可能なシソーラス44を含む。すなわち、意味的に近い関係にある2語の置換は、シソーラス上の各語の階層の差の大きさに応じて重みを減少させる。
【0045】
機械翻訳システム32はさらに、予め準備された、翻訳可能な文の集まりからなるコンピュータ読取可能な翻訳可能文コーパス46と、入力文30と判定信号60とを受けるように接続され、判定信号60が論理1レベルであるとき(すなわち機械翻訳装置42による翻訳が不可能と判定されたとき)に、入力文30に最も類似する文であってかつ類似度が所定の値より小さい類似文62を翻訳可能文コーパス46から検索して出力し、あわせて上記した条件を充足する類似文62が検索されたか否かを示す検索結果信号64を出力するための類似文検索部48とを含む。検索結果信号64は、上記した条件を充足する文があったときには論理0レベルをとり、なかったときには論理1レベルをとる。
【0046】
機械翻訳システム32はさらに、用例コーパス40及び日本語シソーラス44に接続され、かつ機械翻訳装置42から判定信号60を、類似文検索部48から類似文62及び検索結果信号64を、それぞれ受けるように接続され、検索結果信号64が論理0レベルであるとき(すなわち所定の条件を充足する類似文62が検索されたとき)に、機械翻訳装置42と同様にして用例コーパス40及び日本語シソーラス44を用いて類似文62に対する用例翻訳を行ない、翻訳結果66及び翻訳ができたか否かを表す翻訳可否信号68を出力するための機械翻訳装置50とを含む。翻訳可否信号68は、機械翻訳装置50による翻訳が不可能である場合には論理1レベルをとり、可能である場合には論理0レベルをとる。翻訳可能文コーパス46に、機械翻訳装置50では翻訳できない文が入っている可能性もあるため、このように翻訳可否信号68により実際に機械翻訳装置50による翻訳ができたか否かを表示する。
【0047】
機械翻訳システム32はさらに、翻訳可否信号68と検索結果信号64とをそれぞれ受けるように接続された二つの入力を持つANDゲート54と、機械翻訳装置42からの翻訳結果58と機械翻訳装置50からの翻訳結果66とを受けるように接続され、判定信号60が論理0レベルのときは翻訳結果58を、それ以外のときには翻訳結果66を、それぞれ選択して出力文34として出力するための選択部52とを含む。
【0048】
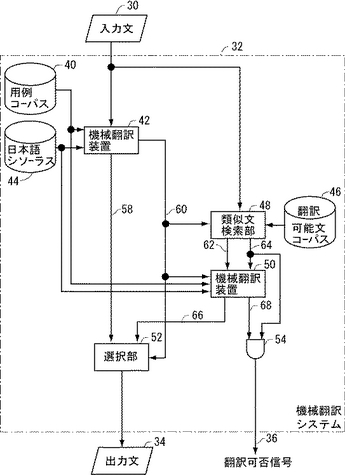
図2は、図1に示す類似文検索部48による処理を説明するための模式図である。図2を参照して、一般に、機械翻訳システム32への入力文は、用例コーパス40(図1参照)を用いた用例翻訳が可能な文からなる翻訳可能文集合80と、翻訳が不可能な文からなる翻訳不能文集合82とに分けられる。図1に示す機械翻訳装置42による入力文30の翻訳が不能と判定された場合、すなわち入力文30が翻訳不能文集合82に属する場合、類似文検索部48の類似文検索技術84によって、予め準備した翻訳可能文コーパス46から、入力文30に類似した文を検索する。すなわち、類似文検索技術84は、翻訳不能文90、92、94、96、98等を、(もしあれば)それらに類似する翻訳可能文100、102、又は104に置換することにより、本来翻訳不能文であった入力文30の翻訳を可能とする技術である。これにより、機械翻訳システム32による翻訳可能な文の範囲が広がることになる。
【0049】
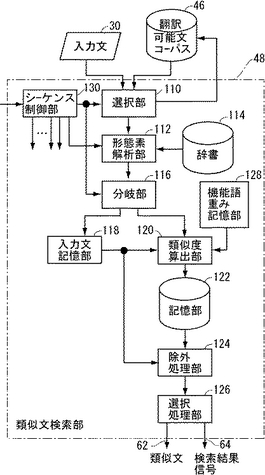
図3は、図1に示す類似文検索部48の構成を示す図である。図3を参照して、類似文検索部48は、入力文30と翻訳可能文コーパス46中の全ての文とを順次選択するための選択部110と、選択部110の出力する文に対して形態素解析を行なうための形態素解析部112と、形態素解析部112が形態素解析を行なう際に使用する単語情報を記憶するためのコンピュータ読取可能な辞書114と、形態素解析部112による入力文30の解析結果を第1の出力に、翻訳可能文コーパス46の各文の解析結果を第2の出力に、それぞれ分岐させるための分岐部116と、分岐部116の第1の出力に接続され、分岐部116から出力される入力文30の形態素解析結果を記憶するための入力文記憶部118と、分岐部116の第2の出力に接続され、翻訳可能文コーパス46の各文(以下「候補文」と呼ぶ。)に対する形態素解析結果と、入力文記憶部118に記憶された入力文30に対する形態素解析結果との間で類似度を算出するための類似度算出部120とを含む。
【0050】
形態素解析部112が行なう形態素解析では、数字列は特殊記号を用いて汎化される。名詞には地名、組織名、人名などの属性情報が付与されるので、これらの名詞も属性情報を用いて汎化される。類似文検索処理で2語が一致していると認定されるためには、語の基本形か属性情報が一致し、かつ品詞も一致することが必要十分条件である。
【0051】
本実施の形態では、類似度算出部120による類似度算出は、入力文30と候補文との間の共通部分が入力文30と候補文との双方に対して占める比率を基として行なう。共通部分が双方の文に対して占める比率が高いほど、入力文30に対するその候補文の類似度が高くなる。本実施の形態では、類似度としてF値を用いる。F値は以下の式(1)により定義される。
【0052】
F値=2PR/(P+R) (1)
ただし
P(適合率)=入力文と候補文に共通する単語数/候補文の単語数
R(再現率)=入力文と候補文に共通する単語数/入力文の単語数
2文間の共通部分の定義としては、一般にn−グラム、単語列、単語集合の3方式がよく用いられる。本実施の形態では、n−グラムを用いて共通部分を定義する。この方式については後述する。
【0053】
図3を参照して、本実施の形態ではさらに、共通する単語数の算出においては、内容語に対する機能語の重みを変えている。この重みは正の値である。またこの重みは可変であることが望ましい。そのために類似文検索部48は、類似度算出部120に接続され、機能語に対する重みを記憶し類似度算出部120に与えるための機能語重み記憶部128を含む。
【0054】
類似文検索部48はさらに、類似度算出部120によって、翻訳可能文コーパス46に含まれる各文と入力文30との間で算出された類似度を形態素解析結果とともに記憶するための記憶部122と、入力文記憶部118に記憶された入力文30の形態素解析結果と、記憶部122に記憶された、翻訳可能文コーパス46の各文の形態素解析結果とに基づいて、入力文30にない内容語を含む候補文を除外する処理を行なうための除外処理部124と、除外処理部124による除外がされなかった候補文のうちで、入力文30に最も類似する候補文であって、かつ(1)入力文に含まれる内容語のうち、候補文にない内容語が1語以内であるか、又は(2)入力文と共通する内容語が2語以上であること、という条件を満たすものを類似文62として出力するとともに、上記条件を満たす類似文が存在したか否かを検索結果信号64として出力するための選択処理部126と、判定信号60の値が論理1レベルである場合に、類似文検索部48の各機能部を制御して、入力文30と最も類似する文を翻訳可能文コーパス46から検索するように動作させるためのシーケンス制御部130とを含む。
【0055】
類似文検索部48による類似文の検索では、上記したように様々な条件を課したり、特定の方式を採用したりしている。これは、実際に種々の実験をした結果、上記した条件を課したり方式を採用したりしたことにより得られた類似文から、最終的に入力文30に対する好ましい訳文を得ることができる可能性が高いということが判明したためである。以下、各条件について説明する。
【0056】
なお、以下の説明では類似文について種々の評価をしている。その評価基準を図4に示す。評価基準は、対話の場面においてどの程度まで入力文の代用文としての役割を果たすかという観点により定めた。図4に示すように、評価ランクは、代用できる度合いが高い順にA1,A2,B1,B2の4段階である。検索された文のうちA1,A2ランクの文が類似文として適切とされ、B1,B2の文は不適切とされる。
【0057】
図4中、「代用文としての評価」は、検索された文を入力文の代用文として用いた場合に果たす役割の目安を表す。代用文としての適性は主に「意味的差異」を判断基準とし、丁寧度などの副次的情報は評価対象としない。
【0058】
評価例を図5に示す。例1の候補文は、表現の違いはあるものの入力文と同じ意味を表しており、評価はA1となる。例2の候補文は複文からなる入力文の主文部分であり、主要な部分を捉えているといえる。ただし、主文の要求の原因を示す副文が欠落しているために評価A2となる。例3の候補文は複文からなる入力文の副文部分であり、主要部分を表していないため評価B1となる。例4の候補文は主文を捉えているが重要な目的語が欠落しているため評価B1となる。例5の候補文は「明日は」という入力文にない条件を付加している。このような条件は、会話においては重大かつ発見が困難な誤解である。従って例5の評価はB2となる。例6の候補文はモダリティという基本レベルで入力文と異なるため、評価はB2となる。
【0059】
<類似度算出方式>
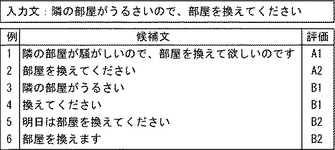
類似文検索部48の類似度算出部120による類似度算出の基本方式として、前述したとおりF値を用いる。その差異の入力文と候補文との共通部分の定義として、n−グラム、単語列、又は単語集合を用いるものがある。本実施の形態ではn−グラムを用いている。以下、n−グラムを用いた類似度算出方式について説明する。
【0060】
n−グラムによる方式では、入力文と候補文とで共通するn−グラムを基に類似度を算出する。この算出では各n−グラムに対して重み付けを行なう。本実施の形態では、この重みとして、BLEUと呼ばれる翻訳文自動評価方式で採用されているものと同じ式を採用した。すなわち本実施の形態では、例えば適合率Pは以下の式で算出される。
【0061】
【数1】

ただしpnは各nにおける適合率を表しており、下式で表される。
【0062】
【数2】
Count(x)は候補文x中の頻度、Countclip(x)は、入力文中のxの頻度と候補文中のxの頻度のいずれか少ない方を表す。再現率もこれと同様の考え方で算出される。
【0063】
なお、本実施の形態ではn−グラムとしてバイグラムまでを用いる。nの大きさは、適用対象となる翻訳のドメインの性質(構成単語数)によって異なる。旅行会話などであれn=2まで、新聞記事などの場合であればn=4程度がよいと考えられる。
【0064】
比較のため、類似度算出方式として、共通部分の定義として単語列を用いる方式(最長共通単語列に基づく方式)について説明する。この方式は、入力文と候補文との間でDP(Dynamic Programming)マッチングを行なって得られる最長共通単語列を利用して類似度を算出する。端的に言えば、語順を考慮した上での共通単語を抽出するという方式である。
【0065】
DPマッチングを利用した方式では、編集距離を用いる方式が多く用いられるが、ここでは「共通部分に基づく類似度」を基本としているため、この最長共通単語列について考える。編集距離と最長共通単語列は相補的な関係にあり、入力文との編集距離が最も大きい候補文は最長共通単語列が短くなるという性質がある。なお、予備実験において、編集距離に基づく方式と最長共通単語列に基づく方式とではほとんど性能差がないことが判明している。
【0066】
また、3基本方式のうち、単語集合に基づくものは、文を単語集合とみなし、入力文と候補文との両方で共通する単語数を共通部分とする方式である。この方式は、n−グラム方式においてn=1とした場合に相当する。
【0067】
図6に、各基本方式によるF値算出例を示す。なお、図6の単語列方式において、共通単語として「です」が除外されているが、これは「です」の位置が入力文と候補文との間で大きく異なっており、DPマッチングの過程で採用されなかったためである。
【0068】
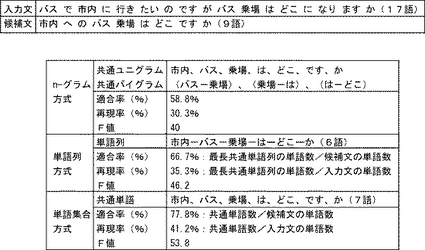
<入力文にない内容語を含む候補文の除外>
除外処理部124では、入力文にない内容語を含んだ候補文は類似文として採用されず除外されている。これは、予備実験より、そのような候補文は入力文の代用とならない場合が多く生じることが判明したためである。余剰内容語を含む候補文は、入力文の文意をさらに限定したものであることが多く、その場合には入力文を候補文と置換えると誤解を生じる危険性が高い。
【0069】
図7に、余剰内容語を含むことで不適切となる候補文の例を示す。例1では、候補文には「現金」という内容語が加わり「クレジットカード」が欠落している。この例では、入力文と候補文との意味は全く異なったものとなっている。例2では、候補文の方に「七時」という内容語が追加されているが、これにより入力文の文意に重大な制約条件を付与してしまっている。例3の場合にも、候補文に加わっている「中華」という内容語は、入力文の文意に不適切な制約を課してしまっている。
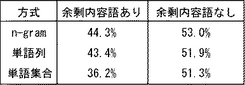
【0070】
上記した各基本方式について余剰内容語を含む候補文を検索対象とする方式(余剰内容語あり)としない方式(余剰内容語なし)で類似文を検索し、評価を行なった。ここで、内容語は名詞、動詞、形容詞、数字、ローマ字などと定義し、機能語は、判定詞、助詞、助動詞、接続詞、副詞、感動詞などと定義している。サ変動詞「する」はほとんど具体的意味を表していないと考えられるので、機能語として扱った。実験結果を図8に示す。
【0071】
図8を参照して、どの方式を用いても、余剰内容語を含まないという制約を課すことにより、検索精度に8%の改善が見られる。
【0072】
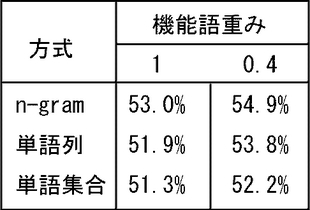
<内容語と機能語の重み付け>
話し言葉を対象として、共通単語により2文間の類似度を測る場合、内容語と比較すると機能語の価値は低いと考えられる。その理由として、話し言葉では助詞の欠落や多様な文末表現により表されるように、機能語の多様性が大きいことが挙げられる。同じ意味を表す機能語が多様な表現をとる場合、入力文と候補文との間における機能語の一致度の大小は有効な指標とはならない。また、旅行会話のように会話内容が大体定まっているドメインでは、含まれる内容語によりそれらの関係、格関係や修飾関係、はほとんど一意に定まることが多い。例えば、(泥棒、私、財布、盗む)という内容語を含む文には、理論的には様々な意味の文が考えられるが、実際には「泥棒が私の財布を盗んだ」という文以外はほとんど起こりえない。つまり、内容語集合により自ずとそれらの関係が限定されるなら、機能語の果たす役割は小さくなる。
【0073】
以上から、類似文の検索のための類似度の算出においては、内容語に対する重みと比較すると機能語の重みを小さくすることが望ましいと考えられる。実際に、内容語の重みを1とし、機能語の重みを内容語と同じ1とした場合と0.4とした場合とで、検索精度を比較する実験を行なった。n−グラム方式のバイグラムにおいては、バイグラムを構成する2単語が共に機能語である場合だけ重みを0.4、それ以外の場合を1とした。実験結果を図9に示す。
【0074】
図9を参照して、いずれの方式においても検索精度が1〜2%程度向上している。端的にいえば、機能語の重みを減らすことで主要な情報を多く共通する候補文を優先する効果がある。この効果が現れた事例を図10に示す。
【0075】
図10において、検索文中の共通単語を太字で表している。機能語の重みを減らすことにより、文末部分が異なるものの主要な情報を全て含んだ文を出力することができている。
【0076】
実験により、基本方式にn−グラム方式を採用した上で、入力文にない内容語を含む候補文の除外と機能語の重み減少とを採用した場合に、最も高い正解率が得られた。本実施の形態の構成は、その場合に対応している。なお、この処理での機能語の重みの値(本実施の形態では0.4)は図3に示す機能語重み記憶部128に記憶される。
【0077】
<選択処理部126による候補文の選択>
候補文の集合として用いる翻訳可能文コーパス46は、入力文30として現れる発話を全て網羅しているわけではない。翻訳可能文コーパス46中の文では代用できない入力文30が与えられる場合も多いと考えられる。従って、検索された文を類似文として認定する条件を設け、類似度が高い文であっても条件を満足しない場合は類似文として選択しないようにする必要がある。前述したとおり、選択処理部126は、次の二つの条件のいずれかを満たす候補文のみを類似文として選択する。以下、これら条件を採用した理由について説明する。
【0078】
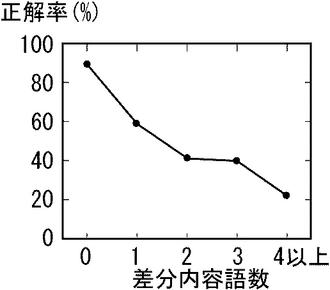
(1)入力文と比較して候補文に不足している内容語の数が1語以下
(2)入力文と候補文とで共通する語数が2語以上
入力文では、入力文にない内容語を持つ候補文は除外するというヒューリスティックを導入した。従って、検索された候補文が持つ内容語集合は常に入力文30の内容語集合の部分集合である。検索された候補文の内容語集合を基に類似度を考えると、最も一致度が高いのは両文の内容語集合が一致する場合である。そして、検索された文に不足する内容語の数が増加するに従って類似度が下がっていく。
【0079】
検索された候補文について、入力文と比較して不足している内容語の数と、その正解率との関係を図11に示す。入力文と検索された候補文との間で内容語集合が一致している場合は正解率は89.1%という高い値となっている。不足する内容語の数が増えると正解率が大きく減少していく。不足内容語数が2以上の場合には正解率が50%を下回り、十分な精度といえない。そこで、上記した(1)の条件を課すことにした。
【0080】
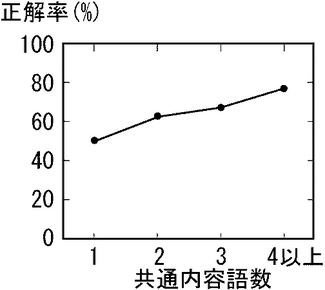
次に、条件(2)について考える。類似文は入力文の大意を表す文であればよいという観点から考えると、検索された候補文と入力文との、大意を表す部分についての内容語が共通していれば、他の部分の内容語が共通していなくても十分であると考えられる。従って、候補文と入力文とで共通する内容語の数(以下「共通内容語数」)により類似文の判定ができると考えられる。
【0081】
図12に、共通内容語数と、それに対する検索された候補文の正解率との関係を示す。図12から、大きな傾向として、共通内容語数が増えると正解率は向上する。ただしその傾きは緩やかである。不足している内容語数に関する条件(1)では、境界の正解率は58.8%であった。そこで、図12から、この正解率に近い条件として、共通内容語数が2語以上の候補文のみ、類似文として選択することとする。共通内容語数が2語の場合の正解率は、63.0%である。
【0082】
[動作]
以上に構成を述べた本実施の形態に係る機械翻訳システム32は、以下のように動作する。図1を参照して、予め用例コーパス40及びシソーラス44、並びに翻訳可能文コーパス46が準備されているものとする。機械翻訳装置42は、日本語の入力文30が与えられると、シソーラス44を参照して用例コーパス40中の各用例のうちで入力文30に最も類似した日本語文を持つ用例文を検索する。この検索では、入力文30と各用例文の日本語文との間の編集距離が最も近い用例文が検索される。ただし、編集距離算出の際、語の置換については、シソーラス44を参照して得られる、置換される2語間の意味的距離により編集距離の重み付けがなされる。このようにして算出された編集距離が、入力文30と用例文との類似度となる。
【0083】
機械翻訳装置42は、検索された用例文のうち類似度が最も小さなものを選択する。機械翻訳装置42はこの際、選択された用例文の類似度が所定の値を上回っていれば、すなわち選択された用例文と入力文30とがそれほど類似していない場合には判定信号60の値を論理1レベルとし、それ以外の場合には論理0レベルとする。
【0084】
機械翻訳装置42は、選択された用例文と入力文30との類似度が所定の値以下であれば、用例文の英語部分を、入力文30と用例文の日本語部分との相違に基づいて修正することで入力文30の翻訳文を生成し、翻訳結果58を出力する。翻訳結果58は選択部52に与えられる。
【0085】
判定信号60の値が論理0レベルの場合、選択部52は翻訳結果58を選択して出力文34として出力する。
【0086】
判定信号60の値が論理1レベルの場合には、次のような処理が行なわれる。類似文検索部48は、入力文30と類似する候補文を翻訳可能文コーパス46の中から検索する。すなわち、図3を参照して、選択部110は、シーケンス制御部130の制御に従い、まず入力文30を選択し、形態素解析部112に与える。形態素解析部112は辞書114を参照して入力文30を形態素解析し、単語列に分解して分岐部116に与える。この際、各単語には辞書114を参照して得られる各種の情報が付与される。分岐部116は、シーケンス制御部130の制御に従い、形態素解析部112の出力する単語列を入力文記憶部118に与える。入力文記憶部118はこの単語列を格納する。
【0087】
次に選択部110は、シーケンス制御部130の制御に従い、翻訳可能文コーパス46に含まれる用例文のうち1番目の日本語部分を読出し、形態素解析部112に与える。形態素解析部112はこの日本語部分を辞書114を参照して形態素解析し、得られた単語列を分岐部116に与える。この場合も、各単語には属性情報が付与される。分岐部116は、シーケンス制御部130の制御に従い、今度はこの単語列を類似度算出部120に与える。
【0088】
類似度算出部120は、分岐部116から与えられる用例文の形態素解析結果と入力文記憶部118に記憶された入力文30の形態素解析結果とに基づき、式(1)に示すn−グラムを用いた類似度算出方式に従い、入力文30と翻訳可能文コーパス46の1番目の候補文との類似度を算出し、記憶部122に与える。このとき、類似度算出における入力文30と候補文との共通単語数のうち、機能語数には、機能語重み記憶部128に記憶された値が重みとして乗じられる。記憶部122はこの類似度を、1番目の候補文の形態素解析結果とともに記憶する。
【0089】
以下、シーケンス制御部130の制御に従い、翻訳可能文コーパス46に記憶されている各候補文が形態素解析部112により形態素解析され、入力文30との間の類似度が類似度算出部120により算出される。その結果得られた各候補文の類似度が、その候補文の形態素解析結果とともに記憶部122に記憶される。
【0090】
全ての候補文について類似度が算出されると、除外処理部124が入力文記憶部118に記憶された入力文30の形態素解析結果を参照し、候補文の中で入力文30にない内容語を日本語部分に含む候補文を除外し、それ以外の候補文と類似度とを選択処理部126に与える。選択処理部126は、与えられた候補文のうち、(1)入力文に含まれる内容語のうちで候補文にない内容語が1語以内であること、又は(2)入力文と共通する内容語が2語以上であること、という前述の条件を満たし、かつ入力文30に最も類似する候補文を類似文62として出力するとともに、上記条件を満たす類似文が存在したか否かを検索結果信号64として出力する。検索結果信号64は、上記した条件を充足する文があったときには論理0レベルをとり、なかったときには論理1レベルをとる。
【0091】
再び図1を参照して、機械翻訳装置50は、検索結果信号64が論理0レベルであるときは、類似文検索部48からの類似文62に対し、用例コーパス40及びシソーラス44を用いた用例翻訳を行なう。この用例翻訳処理は、機械翻訳装置42で行なわれるものと同じである。機械翻訳装置50は、用例コーパス40から適切な用例文を検索できなかったときは信号68を論理1レベルとして処理を終了する。用例コーパス40から適切な用例文を検索できたときは、機械翻訳装置50はその用例文の日本語部分と類似文62との相違を基に、用例文の英語部分を修正することで類似文62の翻訳を行なう。そして、この翻訳処理の結果を翻訳結果66として選択部52に与える。
【0092】
選択部52は、判定信号60が論理1レベルのときには、このようにして機械翻訳装置50から選択部52に与えられた翻訳結果66を選択し、出力文34として出力する。
【0093】
以上のように機械翻訳システム32は、入力文30に対し、機械翻訳装置42が機械翻訳可能な場合には、その翻訳結果を出力文34として出力する。入力文30が機械翻訳装置42による翻訳のできない文であるときには、図2に示す翻訳不能文90、92、94、96、98を翻訳可能文コーパス46中の文100、102、104等に置換するのと同様、この入力文30を翻訳可能文コーパス46中のいずれかの候補文と置換える。翻訳可能文コーパス46は予め翻訳可能な文を集めて準備されたものであるので、機械翻訳装置50においてはこの候補文を翻訳できる可能性が高い。その結果、機械翻訳システム32が翻訳できる文の範囲は、類似文検索部48による類似文の検索を行なわなかった場合と比較して広くなるという効果が得られる。
【0094】
なお、前述したとおり類似文検索部48により翻訳可能文コーパス46から類似文を検索できないような入力文30もあり得る。その場合には検索結果信号64が論理1レベルとなり、翻訳可否信号36が論理1レベルとなる。
【0095】
また、翻訳可能文コーパス46が翻訳可能文からなる以上、類似文検索部48による類似文の検索ができれば機械翻訳装置50による翻訳も可能と考えられる。ただし、翻訳可能文コーパス46の内容に不備がある場合も考えられるので、機械翻訳装置50から翻訳可否信号68を出力するようにしている。すなわち、翻訳可否信号68が論理0レベルであれば機械翻訳装置50による翻訳が可能ということであり、翻訳可否信号68が論理1レベルであれば機械翻訳装置50による翻訳が不可能ということになる。
【0096】
ANDゲート54は検索結果信号64と翻訳可否信号68とのANDをとっているので、その出力ANDゲート54が論理1レベルであれば翻訳ができなかったことが分かり、それ以外の場合には翻訳が可能であったことが分かる。
【0097】
[実験結果]
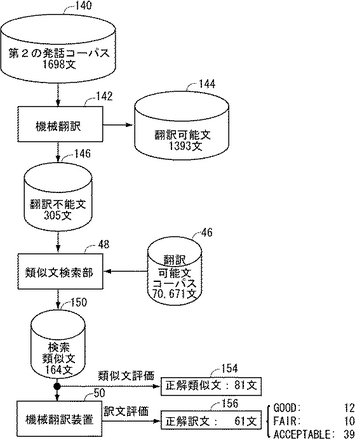
以上述べた実施の形態に係る機械翻訳システム32の類似文検索部48を用いて日英翻訳を行なう実験を行なった。この実験では、二種類のコーパスを使用する。翻訳不能文の集合である翻訳不能文コーパスと、図1に示す翻訳可能文コーパス46とである。
【0098】
図13を参照して、翻訳不能文コーパス146は、発明の実施の形態に関する冒頭の説明で言及した第2の発話コーパス140の各文を機械翻訳142に与え、翻訳不能となった文を集めることで作成した。第2の発話コーパス140は1,698文を含み、その中で翻訳可能文からなるコーパス144は1393文であり、翻訳が不能な文からなる翻訳不能文コーパス146は305文であった。
【0099】
翻訳可能文コーパス46は、発明の実施の形態の説明の冒頭で言及した第1の基本表現コーパスの中から機械翻訳で翻訳可能と判定された70,671文を含む。
【0100】
翻訳不能文コーパス146の各文を類似文検索部48に与えたところ、得られた類似文からなる検索類似文コーパス150は164文となった。すなわち、164文の翻訳不能文について類似文を検索することができた。検索された類似文164文について類似性を人手で評価したところ、図13の正解類似文154にも示すとおり、81文については正しい類似文であることが判明した。
【0101】
さらに、検索された類似文164文を機械翻訳装置50に与えて得られる翻訳文と、入力文とを評価者に提示して翻訳文としての評価を行なった。翻訳文は、英語のネイティブスピーカによりGood,Fair,Acceptable,Badの4種類のランクで評価される。この内、Good,Fair及びAcceptableの評価の文を「適切な訳文」とする。なお、この評価基準は機械翻訳の訳質評価のために定めたものであり、図4に示した類似文の評価基準とは別のものである。
【0102】
図13に示すように、この結果、正解訳文156として61文が得られた。内訳は、Goodが12文、Fairが10文、Acceptableが39文である。
【0103】
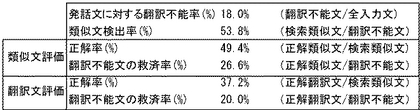
図14に、類似文、翻訳文における正解率及び翻訳不能文の救済率をそれぞれ示す。図14を参照して、類似文、つまり入力文と同一言語の段階では翻訳不能文の26.6%について類似文検索により適切な類似文を検索できた。また、翻訳文の段階でも、翻訳不能文の20%について適切な訳文を得ることができた。
【0104】
以上のとおり、本実施の形態に係る機械翻訳システム32によれば、単言語コーパスという入手が容易な言語資源を用いた類似文検索技術を機械翻訳と組合わせることで、既存の機械翻訳の翻訳可能文の範囲を拡大することができる。前編集のための規則を定めるという手間のかかる作業なしに、話し言葉のように同じ意味で多くのバリエーションがある入力文の翻訳可能性を高めることができる。
【0105】
なお、上記した実施の形態では、類似文検索における類似度算出方式として、入力文と候補文とに共通するn−グラムを用いる方式を採用した。しかし本発明はそのような方式に限定されるわけではない。例えば、入力文と候補文との間の最長共通単語列に基づく類似度算出方式を用いてもよいし、入力文と候補文との単語集合の共通部分に基づく類似度算出方式を用いてもよい。また、これ以外の類似度算出方式を用いてもよいが、その場合でも入力文と候補文とが内容上でどの程度類似しているかを有効に示す類似度を採用することが望ましい。
【0106】
また、上記した実施の形態では、n−グラムに基づく類似度算出方式において、内容語の重みを1としたときの機能語の重みを0.4としている。しかしこの重みはそのような値に限定されるわけではなく、機能語に対しては内容語の重み以下の重みであればどのような重みを付与するようにしてもよい。
【0107】
さらに、上に説明した各パラメータの値は、対象となる言語により、また対象となるドメインにより変わり得るものである。それらは、実際に本発明を実施する環境にあわせて行なう実験に基づいて決定することが望ましい。
【0108】
上記した実施の形態では、機械翻訳装置として用例翻訳を使用している。そして,用例翻訳の過程において入力文とよく類似した用例文が得られたか否かを訳質の指標として用いている。この場合、用例翻訳の過程で訳質が評価できる。しかし本発明はそのような実施の形態には限定されない。例えば、機械翻訳装置として任意のものを用い、その出力する訳文の訳質を何らかの基準に従って評価し、その結果を類似文検索するか否かを決定するための指標として用いても良い。例えば予め準備された複数個の参照訳との比較結果により訳質を評価したり、訳文を言語モデル又は翻訳モデル又はその双方を用いて評価したりするようにしてもよい。この場合、それらは機械翻訳装置とは独立した機能モジュールとして機械翻訳システム内に設けることができる。逆に言えば、上記した実施の形態での第1の機械翻訳装置のように翻訳過程で訳質の指標に相当するものが得られる場合、訳質を評価するための独立した機能モジュールは不要である。
【0109】
[コンピュータによる実現]
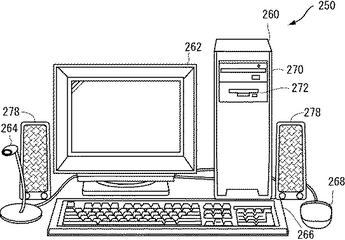
上記した実施の形態に係る機械翻訳システム32は、コンピュータシステムにより実現できる。図15は上記した実施の形態による機械翻訳システム32を実現するコンピュータシステム250の全体構成を示す外観図である。システム250はマイクロフォン264及びスピーカ278の組と、CD−ROM(Compact Disc Read−Only Memory)ドライブ270及びFD(Flexible Disk)ドライブ272を有するコンピュータ260と、いずれもコンピュータ260に接続されたモニタ262、キーボード266及びマウス268とを含む。
【0110】
マイクロフォン264とスピーカ278とは、必要であれば音声翻訳の入力及び出力に用いられるものであって、この発明の一部を構成するものではない。従って、システムのうちマイクロフォン264及びスピーカ278に関する部分の詳細はここでは説明しない。
【0111】
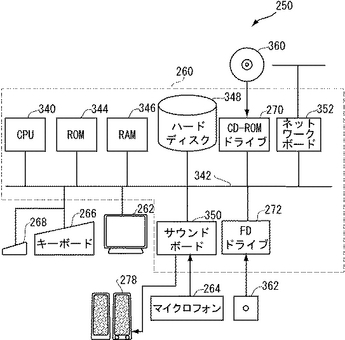
図16はコンピュータ260のハードウェアブロック図である。図16を参照して、コンピュータ260は、CPU(Central Processing Unit:中央処理装置)340と、CPU340に接続されたバス342と、バス342に接続された読出専用メモリ(ROM)344と、バス342に接続されたランダムアクセスメモリ(RAM)346と、バス342に接続されたハードディスク348と、CD−ROM(コンパクト・ディスクROM)360が装着され、CD−ROMからデータを読出すCD−ROMドライブ270と、FD(フレキシブル・ディスク)362が装着され、FDからデータを読出し、データを書込むFDドライブ272と、マイクロフォン264及びスピーカ278が接続されるサウンドボード350と、バス342に接続されローカルエリアネットワーク(LAN)等のデータ通信ネットワークに接続する機能を提供するネットワークボード352とを含む。
【0112】
図1〜図14を参照して説明した実施の形態に係る機械翻訳システム32は、コンピュータシステム250のハードウェア、その上で実行されるコンピュータプログラム、及びコンピュータシステム250のハードディスク348、RAM346等に格納される各種のコーパスなどのデータにより実現可能である。コンピュータプログラムの構成については後述する。それらコンピュータプログラム及びコーパスなどのデータ(以下「プログラム等」と呼ぶ。)はCD−ROM360などの記憶媒体に格納されて流通する。それらプログラム等はそうした記憶媒体からハードディスク348に読込まれる。システムの起動時には、プログラムはハードディスク348から読出されてRAM346にロードされ、CPU340により読出されて実行される。プログラムの読出アドレスは図示しないプログラムカウンタにより指定される。プログラムカウンタの内容は,プログラムの実行に伴って書換えられる。データの読出及び書込アドレスはプログラムに従った演算結果によって指定される。
【0113】
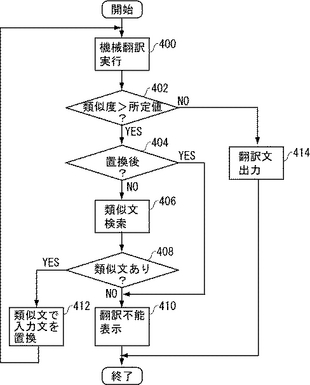
図17は、上記した実施の形態に係る機械翻訳システム32を実現するプログラムのフローチャートである。各ステップの内容の詳細については図1〜図14を参照して説明したとおりである。ここでは、プログラムにより機械翻訳システム32を実現する際のプログラムの全体の好ましい構成を示す。
【0114】
図17を参照して、ステップ400で、入力文に対して機械翻訳を実行する。この機械翻訳は用例翻訳によるものであり、用例翻訳の基となる用例文の類似度が翻訳結果とともに得られる。ステップ402では、この類似度の値が所定の値より大きいか否かが判定される。前述したとおり、本実施の形態で使用される用例翻訳では、二つの文が類似しているほど類似度は小さくなり、両者が完全に一致していると類似度は0となる。もし両者が類似していれば(すなわち類似度>所定値という条件が成立していなければ)、制御はステップ414に進み、ステップ400で得られた翻訳文を全体の翻訳結果として出力し処理を終了する。両者が類似していなければ制御はステップ404に進む。
【0115】
ステップ404では、この機械翻訳処理の結果が、入力文に対する機械翻訳処理により得られたものか、入力文を類似文で置換した後の機械翻訳処理により得られたものかを判定する。置換後であれば制御はステップ410に進み、翻訳不能であった旨の出力(表示)をステップ410で行なって処理を終了する。置換前であれば制御はステップ406に進む。
【0116】
ステップ406では、入力文に対する類似文を翻訳可能文コーパスから検索する処理が行なわれる。ここで検索される類似文が満たすべき条件については既に説明したとおりである。この後、ステップ408において、ステップ406で入力文に類似するという条件を満足した翻訳可能文(類似文)が検索されたか否かを判定する。ここで類似文がなかったと判定された場合、ステップ410で翻訳不能を表示して処理を終了する。類似文があれば、ステップ412に進む。
【0117】
ステップ412では、検索された類似文で入力文を置換する処理を行なう。制御はステップ400に戻る。この後、置換された文に対してステップ400、402、414という処理が実行されるか、又はステップ400、402、404、410という処理が実行され、全体の機械翻訳処理が終了する。
【0118】
以上のように、図1では機械翻訳装置42と機械翻訳装置50とを別のものとして示したが、これらを同一のもので実現するようにしてもよい。このように同一のもので機械翻訳装置42と機械翻訳装置50とを実現することで、翻訳に必要な資源の増大を防ぎながら、翻訳可能な文の範囲を広げることができる。もちろん、両者が別々のものでもよい。また、両者が別々の場合、両者の機械翻訳の原理は互いに同一でもよいし、同一でなくてもよい。
【0119】
今回開示された実施の形態は単に例示であって、本発明が上記した実施の形態のみに制限されるわけではない。本発明の範囲は、発明の詳細な説明の記載を参酌した上で、特許請求の範囲の各請求項によって示され、そこに記載された文言と均等の意味及び範囲内でのすべての変更を含む。
【図面の簡単な説明】
【0120】
【図1】本発明の一実施の形態に係る機械翻訳システム32のブロック図である。
【図2】機械翻訳システム32における類似文検索技術の概念を示す図である。
【図3】機械翻訳システム32の類似文検索部48のブロック図である。
【図4】類似文を評価する際の評価基準を説明する図である。
【図5】入力文に対する様々な類似文の候補の評価例を示す図である。
【図6】類似度算出の3つの基本方式によるF値算出例を示す図である。
【図7】余剰内容語を含むことで不適切となる候補文の例を示す図である。
【図8】類似度算出の3つの基本方式における、余剰内容語の存在の影響を示す図である。
【図9】類似度算出の3つの基本方式における、機能語の重みの影響を表形式で示す図である。
【図10】機能語の重みを減らすことによる検索結果への影響を表形式で示す図である。
【図11】検索された類似文において入力文と比較して不足している内容語の数と、その正解率との関係を示す図である。
【図12】入力文との共通内容語数と検索された候補文の正解率との関係を示す図である。
【図13】実験において使用したコーパスと実験結果とを示す図である。
【図14】実験において得られた類似文、翻訳文における正解率及び翻訳不能文の救済率をそれぞれ示す図である。
【図15】本発明の一実施の形態による機械翻訳システムを実現するコンピュータシステム250の外観図である。
【図16】図15に示すコンピュータ260のハードウェアブロック図である。
【図17】本発明の一実施の形態に係る機械翻訳システムをコンピュータシステムで実現するためのプログラムのフローチャートである。
【符号の説明】
【0121】
32 機械翻訳システム、36,68 翻訳可否信号、40 用例コーパス、42 機械翻訳装置、44 シソーラス、46 翻訳可能文コーパス、48 類似文検索部、50 機械翻訳装置、52,110 選択部、54 ANDゲート、58 翻訳結果、60 判定信号、62 類似文、64 検索結果信号、66 翻訳結果、80 翻訳可能文集合、82 翻訳不能文集合、84 類似文検索技術、112 形態素解析部、114 辞書、116 分岐部、118 入力文記憶部、120 類似度算出部、122 記憶部、124 除外処理部、126 選択処理部、128 機能語重み記憶部、130 シーケンス制御部
【技術分野】
【0001】
この発明は機械翻訳技術に関し、特に、話し言葉のように機械翻訳が困難な文を多く含む原文に対する翻訳性能を向上させるための技術に関する。
【背景技術】
【0002】
音声翻訳は、音声発話をリアルタイムで翻訳して音声で出力することを目的とする。その構成技術には、音声認識、機械翻訳、及び音声合成がある。
【0003】
音声翻訳における機械翻訳部は、音声認識部から出力される発話文を翻訳対象とする。しかしこれらの文は話し言葉特有の性質を有するため、その翻訳には困難が伴う。例えば、話し言葉発話には言いよどみ、言直し、繰返し、助詞省略などのような不適格性が多く出現する。これらの現象は形態素解析及び構文解析などの処理の精度低下を招く。加えて、話し言葉では様々な待遇表現が多用されるという点も言語現象を複雑にしている。例えば、話し言葉においては、「して下さい」「していただけませんか」「をお願いします」等と書き言葉ではあまり見られない様々な文末表現が出現する。
【0004】
また音声認識に由来する問題点として、音声認識部から得られる発話が翻訳処理に適した「文」であるとは限らないことが挙げられる。音声認識では無音区間により発話を分割する。しかし話し言葉では、文中に長い無音区間が出現したり、文と文との間に短い無音区間が出現したりすることが多い。そのため、音声認識部から得られる発話は、意味的にまとまりのある文とは限らない。
【0005】
こうした問題を解決するための一つの手段は、いわゆる前処理と呼ばれる技術である。これは、機械翻訳に与える前に、機械翻訳に有利な文となるように入力文を書換える技術をいう。これはまた、前編集とも呼ばれる。
【0006】
前処理に関し、非特許文献1は、省略要素の補完、冗長表現の簡素化、構文組替えなどの変換規則を人手で作成し、入力文に適用することを試みている。また非特許文献2は、機械翻訳に与えられた長文の入力文を短文に分割することで機械翻訳の精度の向上を試みている。非特許文献3は、構文解析の失敗を導く現象として、倒置、省略、挿入、及び強調を取上げ、これらの現象を解消する書換え規則を適用することで構文解析の成功率向上を図っている。さらに非特許文献4は、表現の簡素化及び重要でない語の削除など、局所的な書換え規則を入力文に適用している。さらに非特許文献5は、無音区間の情報と、認識された発話のn−グラムとを利用して、意味的にまとまりのある文を得るために発話単位の接合及び分割を試みている。
【0007】
【非特許文献1】白井諭他3名、「日英機械翻訳における原文自動書き換え型翻訳方式とその効果」、情報処理学会論文誌、36(1)、12−21、1995年
【非特許文献2】金淵培他1名、「日英機械翻訳のための日本語長文自動短文分割と主語の補完」、情報処理学会論文誌、35(6)、1018−1028、1994年
【非特許文献3】吉見毅彦他2名、「頑健な英日機械翻訳システム実現のための原文自動前編集」、自然言語処理、7(4)、99−118、2000年
【非特許文献4】ヤマモト、K.、「パラフレーザとトランスファとの相互作用による機械翻訳」、第19回計算機言語国際大会(COLING−2002)、pp.1107−1113、2002年(Yamamoto, K., "Machine Translation by Interaction between Paraphraser and Transfer." In Proc. of the 19th International Conference on Computational Linguistics (COLING-2002), pp. 1107-1113, 2002.)
【非特許文献5】竹澤寿幸他1名、「発話単位の分割または接合による言語処理単位への変換手法」、自然言語処理、6(2)、80003−95、1999年
【0008】
【非特許文献6】タケザワ、T.他4名、「実世界における旅行会話の言語翻訳のための、広範囲のバイリンガルコーパスに向けて」第3回LREC−2002予稿集、pp.147−152、2002年(Takezawa, T. et al., "Toward a Broad-coverage Bilingual Corpus for Speech Translation of Travel Conversations in the Real World", In Proc. of the 3rd LREC, pp. 147-152, 2002)
【非特許文献7】タケザワ、T.他1名、「コーパスベースの発話翻訳のための機械翻訳を用いた2言語対話の収集」、Eurospeech−2003、pp.2757−2760、2003年(Takezawa, T. et al., "Collecting Machine-Translation-Aided Bilingual Dialogues for Corpus-Based Speech Translation." In Eurospeech-2003, pp. 2757-2760, 2003)
【非特許文献8】キクイ、G.他3名、「発話間翻訳のためのコーパスの作成」、Eurospeech−2003予稿集、pp.381−384、2003(Kikui, G. et al., "Creating Corpora for Speech-to-Speech Translation." In Eurospeech-2003, pp. 381-384, 2003)
【発明の開示】
【発明が解決しようとする課題】
【0009】
しかし、上記した従来の技術では、前編集のための書換え規則を用意するために大きなコストがかかるという問題点がある。また、従来技術の大部分では、構文解析の情報も要するため、構文解析が正しく行なえないと正しい前処理を行なうことができないという問題点もある。話し言葉では、既に説明したように不適格性を含む入力文が大部分であり、構文解析の精度を高くすることはむずかしく、その点で上記した従来技術を話し言葉翻訳に有効に適用することは困難である。
【0010】
それゆえに本発明の目的は、話し言葉のように不適格性を多く含む入力文を対象とする場合であっても翻訳可能な文の範囲を拡大できる機械翻訳システムを提供することである。
【課題を解決するための手段】
【0011】
本発明の第1の局面に係る機械翻訳システムは、第1の言語の入力文を第2の言語に翻訳するための機械翻訳システムであって、第2の言語への翻訳が可能であるとして予め選択された、第1の言語の複数の文を含む第1のコーパスと、入力文を第2の言語に翻訳するための第1の機械翻訳手段と、第1の機械翻訳手段による訳文の訳質の指標を出力するための指標出力手段と、指標出力手段の出力する指標が訳質が悪いことを示す所定の条件に合致することに応答して、入力文と所定の関係にある文を第1のコーパスから検索するための検索手段と、検索手段により検索された文を第2の言語に翻訳するための第2の機械翻訳手段とを含む。
【0012】
第1の機械翻訳手段の訳質の指標により訳質が悪い場合、入力文に対し所定の関係にある文を第1のコーパスから検索し、その文を第2の機械翻訳手段によって翻訳して入力文に対する訳文とする。第1のコーパス中の文は翻訳可能として選ばれた文であるから、第2の機械翻訳手段により翻訳できる可能性が高い。第1の機械翻訳手段の訳質が悪い場合でも、入力文と所定の関係にある文に対する翻訳で訳文が置換えられるので、訳質が悪い翻訳をそのまま出力することが避けられる。その結果、機械翻訳システムで翻訳可能な入力文の範囲を、第1の機械翻訳手段により翻訳可能な文の範囲と比較して広げることができる。
【0013】
好ましくは、検索手段は、指標出力手段の出力する指標が所定の条件に合致していることに応答して、入力文との間で所定の算出方式に従い算出される類似度によって最も入力文と類似していると判定される文を第1のコーパスから検索するための類似文検索手段を含む。
【0014】
第1の機械翻訳手段による訳質が悪い場合、入力文に対し最も類似している文を第1のコーパスから検索しそれを第2の機械翻訳手段により翻訳する。入力文に最も類似している文を第2の機械翻訳手段で訳すため、その結果得られる訳文は入力文に対する訳文と同様の内容を表す。第1の機械翻訳手段による訳質の悪い翻訳をそのまま出さず、かつ第2の機械翻訳によって得られた、入力文とほぼ同じ内容の訳文を出力できる。
【0015】
さらに好ましくは、類似文検索手段は、第1のコーパスに含まれる複数の文の各々と、入力文との間の共通部分に基づいて定義される類似度を算出するための類似度算出手段と、類似度算出手段により算出された類似度に基づき、最も入力文と類似していると判定された文を第1のコーパスより抽出するための手段とを含む。
【0016】
入力文と第1のコーパスの各文とが類似しているか否かが、入力文との間の共通部分に基づいて定義される類似度で表される。実験結果から、このように定義した類似度により、入力文とよく似た内容の文を第1のコーパスから検索できることが分かっている。
【0017】
より好ましくは、類似度算出手段は、入力文の単語数、候補文の単語数、及び入力文及び候補文に共通する単語数を算出するための単語数算出手段と、入力文と、類似度の算出対象となる候補文との間の類似度を、次の式
適合率=(入力文と候補文に共通する単語数)/候補文の単語数
再現率=(入力文と候補文に共通する単語数)/入力文の単語数
で定義される適合率と再現率との双方の関数として算出するための手段を含む。
【0018】
適合率と再現率との関数を用いれば、入力文と候補文との間で共通する部分の大きさを的確に表した類似度を算出できる。
【0019】
単語数算出手段は、入力文の単語数、候補文の単語数、並びに入力文及び候補文に共通する単語数を、各単語の種類に従って予め定められる重みを乗じて算出するための手段を含んでもよい。
【0020】
単語の種類によって、文の内容を表す際の重みを変える。その結果、例えば文の内容を表す上で重要な種類の単語と、そうでない単語との重みを区別でき、目的に応じて適切な候補文を検索するための類似度が算出できる。
【0021】
好ましくは、算出するための手段は、入力文の単語数、候補文の単語数並びに入力文及び候補文に共通する単語数を、内容語には予め定める第1の重みを、機能語には予め定める第2の重みを、それぞれ乗じて算出するための手段を含み、第2の重みは、第1の重みよりも小さな正の値である。
【0022】
内容語の方が、機能語と比較して文の内容を表す上でより重要と考えられる。そこでこのように内容語に対する第1の重みを機能語に対する第2の重みより大きくすることで、文の内容に重点をおいて入力文に類似する候補文を検索できる。
【0023】
さらに好ましくは、単語数算出手段は、入力文の単語数、候補文の単語数、並びに入力文及び候補文に共通する単語数を、文中のn−グラム数(n>0)により算出するための手段を含む。nの値は実験により定めることが好ましく、例えばn=1でもよく、n=2でもよい。
【0024】
このようにn−グラムによって単語数を算出すると良い結果が得られることが実験により分かっている。
【0025】
好ましくは、単語数算出手段は、入力文の単語数及び候補文の単語数をそれぞれ算出するための手段と、入力文及び候補文に共通する単語数を、入力文及び候補文の双方に共通して、一致した順序で出現する単語数により算出するための手段とを含む。
【0026】
共通単語数をこのように算出した場合にも比較的良い結果が得られることが実験により分かっている。
【0027】
さらに好ましくは、類似度算出手段は、入力文と、候補文との間の類似度を以下の式
類似度=2×適合率×再現率/(適合率+再現率)
に従って算出するための手段を含む。
【0028】
このようにして定めた類似度を用いて検索した文は、入力文に対し類似した内容を表すものであることが多いことが実験により分かった。従ってこの類似度を用いることで第1の機械翻訳手段では良好な翻訳が得られない場合でも、入力文と同様の内容を表す訳文を第2の機械翻訳手段の翻訳により得ることができる。
【0029】
より好ましくは、類似文検索手段はさらに、入力文に含まれない内容語を含む候補文を抽出するための手段による抽出の対象から除外するための手段を含む。
【0030】
このように入力文に含まれない内容語は、文の意味に対し不必要な限定を付加するものであることが多い。そうした内容語を含む候補文を除外することで、最終的に得られる訳文が入力文の内容を的確に伝えるものとなる確率を上げることができる。
【0031】
好ましくは、抽出するための手段は、類似度算出手段により算出された類似度に基づき、最も入力文と類似していると判定され、かつ入力文に含まれない内容語を含まない候補文であって、かつ以下の条件
(1)入力文に含まれる内容語のうち、候補文にない内容語が1語以内である、又は
(2)入力文と共通する内容語が2語以上である、
のいずれかを充足する候補文を第1のコーパスより抽出するための手段を含む。
【0032】
実験では、このような条件を付した場合に最もよい結果が得られた。
【0033】
さらに好ましくは、第1の機械翻訳手段は、互いに良好な訳である第1の言語の文と第2の言語の文とからなる用例を複数個含む2言語用例コーパスと、所定の類似基準に従って入力文との間で最も類似している第1の言語の文を含む用例を2言語用例コーパスから検索するための手段と、検索するための手段により検索された第1の言語の文の対訳である第2の言語の文を、検索するための手段により検索された第1の言語の文及び入力文の間の相違に基づき修正することにより、入力文の翻訳を行なう用例翻訳手段とを含み、指標出力手段は、検索するための手段によって検索された第1の言語の文と入力文との間で定義される所定の類似度が、予め定める基準を充足しているか否かを判定し、判定結果を指標として出力するための手段を含む。
【0034】
第1の機械翻訳手段として用例翻訳手段を用いることで、用例翻訳における用例文検索の過程で得られた類似度を訳質の指標として用いることが可能になる。訳質を評価するために独立した機能モジュールは必要ない。
【0035】
より好ましくは、第1の機械翻訳手段と第2の機械翻訳手段とが同一の機械翻訳手段により実現される。
【0036】
第1の機械翻訳手段と第2の機械翻訳手段とを同一の機械翻訳手段により実現することで、翻訳に必要な資源の増大を防ぎながら、翻訳可能な文の範囲を広げることができる。
【0037】
本発明の第2の局面に係るコンピュータプログラムは、コンピュータにより実行されると、当該コンピュータを、上記したいずれかの機械翻訳システムとして動作させるものである。
【発明を実施するための最良の形態】
【0038】
本実施の形態に係る機械翻訳システムは、音声翻訳において、翻訳が困難と判定される発話文について、予め準備した翻訳可能文のコーパスからその文に類似する文を検索することにより、機械翻訳可能な文の範囲を拡大させるシステムである。以下、この実施の形態に係る機械翻訳システムの構成及び動作の順に説明する。なお、以下の説明において同一の部品には同一の参照番号を付してある。それらの名称及び機能もそれぞれ同一である。従ってそれらについての詳細な説明は繰返さない。
【0039】
なお、以下の実施の形態のシステムの構成の説明中では、予備実験の結果に従って予め決定したパラメータ値を用いている。それらの予備実験は日本語を対象として行なっており、実験では2種類の日本語コーパスを用いた。入力文の集合である発話コーパスと、入力文との類似文を検索する基となる候補文の集合体である候補文コーパスとである。
【0040】
発話コーパスには、旅行中のある状況を想定して行なわれた対話を書き起こして作成した発話コーパス(非特許文献7)から抽出した437文の異なり文を用いた(第1の発話コーパス)。非特許文献7の発話コーパスのうち、第1の発話コーパス以外の部分(第2の発話コーパス)は最後に説明する実験に使用している。候補文コーパスには、旅行会話の基本的な表現を収録したコーパス(非特許文献8記載)を使用した(第1の基本表現コーパス)。第1の基本表現コーパスには異なりで176,145文が含まれている。
【0041】
[構成]
図1は、本発明の一実施の形態に係る機械翻訳システム32のブロック図である。図1を参照して、この機械翻訳システム32は、日本語の入力文30を英語に翻訳することを試み、翻訳可能であれば出力文34を出力し、さらに翻訳が不可能であるか否かを示す翻訳可否信号36を出力するものである。後述するようにこの機械翻訳システム32は、コンピュータシステム及びその上で実行されるコンピュータプログラムにより実現可能である。
【0042】
機械翻訳システム32は、用例に基づく機械翻訳システム(用例翻訳システム)であって、日本語の文(これを用例文と呼ぶ。)とそれに対する英語の訳との対を多数含むコンピュータ読取可能な2言語用例コーパス(以下単に「用例コーパス」と呼ぶ。)40と、入力文30に類似する日本語文を用例コーパス40の中で検索し、検索された日本語文に対する英語訳を、入力文30と検索された用例文との相違に基づいて修正することによって入力文30の翻訳を行ない翻訳結果58を出力するとともに、検索された用例文と入力文30との類似度が所定の値を上回っているか否かを表す判定信号を出力するための機械翻訳装置42とを含む。なお機械翻訳装置42で使用する類似度は正の値であり、値が小さいほど用例文と入力文30とが類似していることを示す。
【0043】
本実施の形態では、用例翻訳を用いているため、入力文とよく似た用例文が見つかれば訳質の高い翻訳が得られる可能性が高い。用例文が入力文に似ていなければ、一般的に訳質が低くなる。そこで、この類似度を翻訳結果の訳質の指標として用いる。
【0044】
機械翻訳装置42は、この検索にあたって、入力文30と用例文との間の類似度を、単語を単位とした編集距離(入力文30を用例文に変換するまでに必要な、単語の削除、挿入、及び置換数)に基づいて算出する。従って本実施の形態では、一致する文同士の類似度は0となる。判定信号60は、検索された用例文の類似度が規定の基準を上回っている場合、すなわち検索された用例文と入力文30とがそれほど類似していない場合には論理1レベルとなり、それ以外の場合には論理0レベルとなる。さらにこの編集距離は、単語の意味的な距離により補正される。すなわち、意味的に近い関係にある2語の置換は、その意味的な距離が近いほど編集距離が小さくなるように補正される。機械翻訳システム32は、この補正処理を行なうために、コンピュータ読取可能なシソーラス44を含む。すなわち、意味的に近い関係にある2語の置換は、シソーラス上の各語の階層の差の大きさに応じて重みを減少させる。
【0045】
機械翻訳システム32はさらに、予め準備された、翻訳可能な文の集まりからなるコンピュータ読取可能な翻訳可能文コーパス46と、入力文30と判定信号60とを受けるように接続され、判定信号60が論理1レベルであるとき(すなわち機械翻訳装置42による翻訳が不可能と判定されたとき)に、入力文30に最も類似する文であってかつ類似度が所定の値より小さい類似文62を翻訳可能文コーパス46から検索して出力し、あわせて上記した条件を充足する類似文62が検索されたか否かを示す検索結果信号64を出力するための類似文検索部48とを含む。検索結果信号64は、上記した条件を充足する文があったときには論理0レベルをとり、なかったときには論理1レベルをとる。
【0046】
機械翻訳システム32はさらに、用例コーパス40及び日本語シソーラス44に接続され、かつ機械翻訳装置42から判定信号60を、類似文検索部48から類似文62及び検索結果信号64を、それぞれ受けるように接続され、検索結果信号64が論理0レベルであるとき(すなわち所定の条件を充足する類似文62が検索されたとき)に、機械翻訳装置42と同様にして用例コーパス40及び日本語シソーラス44を用いて類似文62に対する用例翻訳を行ない、翻訳結果66及び翻訳ができたか否かを表す翻訳可否信号68を出力するための機械翻訳装置50とを含む。翻訳可否信号68は、機械翻訳装置50による翻訳が不可能である場合には論理1レベルをとり、可能である場合には論理0レベルをとる。翻訳可能文コーパス46に、機械翻訳装置50では翻訳できない文が入っている可能性もあるため、このように翻訳可否信号68により実際に機械翻訳装置50による翻訳ができたか否かを表示する。
【0047】
機械翻訳システム32はさらに、翻訳可否信号68と検索結果信号64とをそれぞれ受けるように接続された二つの入力を持つANDゲート54と、機械翻訳装置42からの翻訳結果58と機械翻訳装置50からの翻訳結果66とを受けるように接続され、判定信号60が論理0レベルのときは翻訳結果58を、それ以外のときには翻訳結果66を、それぞれ選択して出力文34として出力するための選択部52とを含む。
【0048】
図2は、図1に示す類似文検索部48による処理を説明するための模式図である。図2を参照して、一般に、機械翻訳システム32への入力文は、用例コーパス40(図1参照)を用いた用例翻訳が可能な文からなる翻訳可能文集合80と、翻訳が不可能な文からなる翻訳不能文集合82とに分けられる。図1に示す機械翻訳装置42による入力文30の翻訳が不能と判定された場合、すなわち入力文30が翻訳不能文集合82に属する場合、類似文検索部48の類似文検索技術84によって、予め準備した翻訳可能文コーパス46から、入力文30に類似した文を検索する。すなわち、類似文検索技術84は、翻訳不能文90、92、94、96、98等を、(もしあれば)それらに類似する翻訳可能文100、102、又は104に置換することにより、本来翻訳不能文であった入力文30の翻訳を可能とする技術である。これにより、機械翻訳システム32による翻訳可能な文の範囲が広がることになる。
【0049】
図3は、図1に示す類似文検索部48の構成を示す図である。図3を参照して、類似文検索部48は、入力文30と翻訳可能文コーパス46中の全ての文とを順次選択するための選択部110と、選択部110の出力する文に対して形態素解析を行なうための形態素解析部112と、形態素解析部112が形態素解析を行なう際に使用する単語情報を記憶するためのコンピュータ読取可能な辞書114と、形態素解析部112による入力文30の解析結果を第1の出力に、翻訳可能文コーパス46の各文の解析結果を第2の出力に、それぞれ分岐させるための分岐部116と、分岐部116の第1の出力に接続され、分岐部116から出力される入力文30の形態素解析結果を記憶するための入力文記憶部118と、分岐部116の第2の出力に接続され、翻訳可能文コーパス46の各文(以下「候補文」と呼ぶ。)に対する形態素解析結果と、入力文記憶部118に記憶された入力文30に対する形態素解析結果との間で類似度を算出するための類似度算出部120とを含む。
【0050】
形態素解析部112が行なう形態素解析では、数字列は特殊記号を用いて汎化される。名詞には地名、組織名、人名などの属性情報が付与されるので、これらの名詞も属性情報を用いて汎化される。類似文検索処理で2語が一致していると認定されるためには、語の基本形か属性情報が一致し、かつ品詞も一致することが必要十分条件である。
【0051】
本実施の形態では、類似度算出部120による類似度算出は、入力文30と候補文との間の共通部分が入力文30と候補文との双方に対して占める比率を基として行なう。共通部分が双方の文に対して占める比率が高いほど、入力文30に対するその候補文の類似度が高くなる。本実施の形態では、類似度としてF値を用いる。F値は以下の式(1)により定義される。
【0052】
F値=2PR/(P+R) (1)
ただし
P(適合率)=入力文と候補文に共通する単語数/候補文の単語数
R(再現率)=入力文と候補文に共通する単語数/入力文の単語数
2文間の共通部分の定義としては、一般にn−グラム、単語列、単語集合の3方式がよく用いられる。本実施の形態では、n−グラムを用いて共通部分を定義する。この方式については後述する。
【0053】
図3を参照して、本実施の形態ではさらに、共通する単語数の算出においては、内容語に対する機能語の重みを変えている。この重みは正の値である。またこの重みは可変であることが望ましい。そのために類似文検索部48は、類似度算出部120に接続され、機能語に対する重みを記憶し類似度算出部120に与えるための機能語重み記憶部128を含む。
【0054】
類似文検索部48はさらに、類似度算出部120によって、翻訳可能文コーパス46に含まれる各文と入力文30との間で算出された類似度を形態素解析結果とともに記憶するための記憶部122と、入力文記憶部118に記憶された入力文30の形態素解析結果と、記憶部122に記憶された、翻訳可能文コーパス46の各文の形態素解析結果とに基づいて、入力文30にない内容語を含む候補文を除外する処理を行なうための除外処理部124と、除外処理部124による除外がされなかった候補文のうちで、入力文30に最も類似する候補文であって、かつ(1)入力文に含まれる内容語のうち、候補文にない内容語が1語以内であるか、又は(2)入力文と共通する内容語が2語以上であること、という条件を満たすものを類似文62として出力するとともに、上記条件を満たす類似文が存在したか否かを検索結果信号64として出力するための選択処理部126と、判定信号60の値が論理1レベルである場合に、類似文検索部48の各機能部を制御して、入力文30と最も類似する文を翻訳可能文コーパス46から検索するように動作させるためのシーケンス制御部130とを含む。
【0055】
類似文検索部48による類似文の検索では、上記したように様々な条件を課したり、特定の方式を採用したりしている。これは、実際に種々の実験をした結果、上記した条件を課したり方式を採用したりしたことにより得られた類似文から、最終的に入力文30に対する好ましい訳文を得ることができる可能性が高いということが判明したためである。以下、各条件について説明する。
【0056】
なお、以下の説明では類似文について種々の評価をしている。その評価基準を図4に示す。評価基準は、対話の場面においてどの程度まで入力文の代用文としての役割を果たすかという観点により定めた。図4に示すように、評価ランクは、代用できる度合いが高い順にA1,A2,B1,B2の4段階である。検索された文のうちA1,A2ランクの文が類似文として適切とされ、B1,B2の文は不適切とされる。
【0057】
図4中、「代用文としての評価」は、検索された文を入力文の代用文として用いた場合に果たす役割の目安を表す。代用文としての適性は主に「意味的差異」を判断基準とし、丁寧度などの副次的情報は評価対象としない。
【0058】
評価例を図5に示す。例1の候補文は、表現の違いはあるものの入力文と同じ意味を表しており、評価はA1となる。例2の候補文は複文からなる入力文の主文部分であり、主要な部分を捉えているといえる。ただし、主文の要求の原因を示す副文が欠落しているために評価A2となる。例3の候補文は複文からなる入力文の副文部分であり、主要部分を表していないため評価B1となる。例4の候補文は主文を捉えているが重要な目的語が欠落しているため評価B1となる。例5の候補文は「明日は」という入力文にない条件を付加している。このような条件は、会話においては重大かつ発見が困難な誤解である。従って例5の評価はB2となる。例6の候補文はモダリティという基本レベルで入力文と異なるため、評価はB2となる。
【0059】
<類似度算出方式>
類似文検索部48の類似度算出部120による類似度算出の基本方式として、前述したとおりF値を用いる。その差異の入力文と候補文との共通部分の定義として、n−グラム、単語列、又は単語集合を用いるものがある。本実施の形態ではn−グラムを用いている。以下、n−グラムを用いた類似度算出方式について説明する。
【0060】
n−グラムによる方式では、入力文と候補文とで共通するn−グラムを基に類似度を算出する。この算出では各n−グラムに対して重み付けを行なう。本実施の形態では、この重みとして、BLEUと呼ばれる翻訳文自動評価方式で採用されているものと同じ式を採用した。すなわち本実施の形態では、例えば適合率Pは以下の式で算出される。
【0061】
【数1】
ただしpnは各nにおける適合率を表しており、下式で表される。
【0062】
【数2】
Count(x)は候補文x中の頻度、Countclip(x)は、入力文中のxの頻度と候補文中のxの頻度のいずれか少ない方を表す。再現率もこれと同様の考え方で算出される。
【0063】
なお、本実施の形態ではn−グラムとしてバイグラムまでを用いる。nの大きさは、適用対象となる翻訳のドメインの性質(構成単語数)によって異なる。旅行会話などであれn=2まで、新聞記事などの場合であればn=4程度がよいと考えられる。
【0064】
比較のため、類似度算出方式として、共通部分の定義として単語列を用いる方式(最長共通単語列に基づく方式)について説明する。この方式は、入力文と候補文との間でDP(Dynamic Programming)マッチングを行なって得られる最長共通単語列を利用して類似度を算出する。端的に言えば、語順を考慮した上での共通単語を抽出するという方式である。
【0065】
DPマッチングを利用した方式では、編集距離を用いる方式が多く用いられるが、ここでは「共通部分に基づく類似度」を基本としているため、この最長共通単語列について考える。編集距離と最長共通単語列は相補的な関係にあり、入力文との編集距離が最も大きい候補文は最長共通単語列が短くなるという性質がある。なお、予備実験において、編集距離に基づく方式と最長共通単語列に基づく方式とではほとんど性能差がないことが判明している。
【0066】
また、3基本方式のうち、単語集合に基づくものは、文を単語集合とみなし、入力文と候補文との両方で共通する単語数を共通部分とする方式である。この方式は、n−グラム方式においてn=1とした場合に相当する。
【0067】
図6に、各基本方式によるF値算出例を示す。なお、図6の単語列方式において、共通単語として「です」が除外されているが、これは「です」の位置が入力文と候補文との間で大きく異なっており、DPマッチングの過程で採用されなかったためである。
【0068】
<入力文にない内容語を含む候補文の除外>
除外処理部124では、入力文にない内容語を含んだ候補文は類似文として採用されず除外されている。これは、予備実験より、そのような候補文は入力文の代用とならない場合が多く生じることが判明したためである。余剰内容語を含む候補文は、入力文の文意をさらに限定したものであることが多く、その場合には入力文を候補文と置換えると誤解を生じる危険性が高い。
【0069】
図7に、余剰内容語を含むことで不適切となる候補文の例を示す。例1では、候補文には「現金」という内容語が加わり「クレジットカード」が欠落している。この例では、入力文と候補文との意味は全く異なったものとなっている。例2では、候補文の方に「七時」という内容語が追加されているが、これにより入力文の文意に重大な制約条件を付与してしまっている。例3の場合にも、候補文に加わっている「中華」という内容語は、入力文の文意に不適切な制約を課してしまっている。
【0070】
上記した各基本方式について余剰内容語を含む候補文を検索対象とする方式(余剰内容語あり)としない方式(余剰内容語なし)で類似文を検索し、評価を行なった。ここで、内容語は名詞、動詞、形容詞、数字、ローマ字などと定義し、機能語は、判定詞、助詞、助動詞、接続詞、副詞、感動詞などと定義している。サ変動詞「する」はほとんど具体的意味を表していないと考えられるので、機能語として扱った。実験結果を図8に示す。
【0071】
図8を参照して、どの方式を用いても、余剰内容語を含まないという制約を課すことにより、検索精度に8%の改善が見られる。
【0072】
<内容語と機能語の重み付け>
話し言葉を対象として、共通単語により2文間の類似度を測る場合、内容語と比較すると機能語の価値は低いと考えられる。その理由として、話し言葉では助詞の欠落や多様な文末表現により表されるように、機能語の多様性が大きいことが挙げられる。同じ意味を表す機能語が多様な表現をとる場合、入力文と候補文との間における機能語の一致度の大小は有効な指標とはならない。また、旅行会話のように会話内容が大体定まっているドメインでは、含まれる内容語によりそれらの関係、格関係や修飾関係、はほとんど一意に定まることが多い。例えば、(泥棒、私、財布、盗む)という内容語を含む文には、理論的には様々な意味の文が考えられるが、実際には「泥棒が私の財布を盗んだ」という文以外はほとんど起こりえない。つまり、内容語集合により自ずとそれらの関係が限定されるなら、機能語の果たす役割は小さくなる。
【0073】
以上から、類似文の検索のための類似度の算出においては、内容語に対する重みと比較すると機能語の重みを小さくすることが望ましいと考えられる。実際に、内容語の重みを1とし、機能語の重みを内容語と同じ1とした場合と0.4とした場合とで、検索精度を比較する実験を行なった。n−グラム方式のバイグラムにおいては、バイグラムを構成する2単語が共に機能語である場合だけ重みを0.4、それ以外の場合を1とした。実験結果を図9に示す。
【0074】
図9を参照して、いずれの方式においても検索精度が1〜2%程度向上している。端的にいえば、機能語の重みを減らすことで主要な情報を多く共通する候補文を優先する効果がある。この効果が現れた事例を図10に示す。
【0075】
図10において、検索文中の共通単語を太字で表している。機能語の重みを減らすことにより、文末部分が異なるものの主要な情報を全て含んだ文を出力することができている。
【0076】
実験により、基本方式にn−グラム方式を採用した上で、入力文にない内容語を含む候補文の除外と機能語の重み減少とを採用した場合に、最も高い正解率が得られた。本実施の形態の構成は、その場合に対応している。なお、この処理での機能語の重みの値(本実施の形態では0.4)は図3に示す機能語重み記憶部128に記憶される。
【0077】
<選択処理部126による候補文の選択>
候補文の集合として用いる翻訳可能文コーパス46は、入力文30として現れる発話を全て網羅しているわけではない。翻訳可能文コーパス46中の文では代用できない入力文30が与えられる場合も多いと考えられる。従って、検索された文を類似文として認定する条件を設け、類似度が高い文であっても条件を満足しない場合は類似文として選択しないようにする必要がある。前述したとおり、選択処理部126は、次の二つの条件のいずれかを満たす候補文のみを類似文として選択する。以下、これら条件を採用した理由について説明する。
【0078】
(1)入力文と比較して候補文に不足している内容語の数が1語以下
(2)入力文と候補文とで共通する語数が2語以上
入力文では、入力文にない内容語を持つ候補文は除外するというヒューリスティックを導入した。従って、検索された候補文が持つ内容語集合は常に入力文30の内容語集合の部分集合である。検索された候補文の内容語集合を基に類似度を考えると、最も一致度が高いのは両文の内容語集合が一致する場合である。そして、検索された文に不足する内容語の数が増加するに従って類似度が下がっていく。
【0079】
検索された候補文について、入力文と比較して不足している内容語の数と、その正解率との関係を図11に示す。入力文と検索された候補文との間で内容語集合が一致している場合は正解率は89.1%という高い値となっている。不足する内容語の数が増えると正解率が大きく減少していく。不足内容語数が2以上の場合には正解率が50%を下回り、十分な精度といえない。そこで、上記した(1)の条件を課すことにした。
【0080】
次に、条件(2)について考える。類似文は入力文の大意を表す文であればよいという観点から考えると、検索された候補文と入力文との、大意を表す部分についての内容語が共通していれば、他の部分の内容語が共通していなくても十分であると考えられる。従って、候補文と入力文とで共通する内容語の数(以下「共通内容語数」)により類似文の判定ができると考えられる。
【0081】
図12に、共通内容語数と、それに対する検索された候補文の正解率との関係を示す。図12から、大きな傾向として、共通内容語数が増えると正解率は向上する。ただしその傾きは緩やかである。不足している内容語数に関する条件(1)では、境界の正解率は58.8%であった。そこで、図12から、この正解率に近い条件として、共通内容語数が2語以上の候補文のみ、類似文として選択することとする。共通内容語数が2語の場合の正解率は、63.0%である。
【0082】
[動作]
以上に構成を述べた本実施の形態に係る機械翻訳システム32は、以下のように動作する。図1を参照して、予め用例コーパス40及びシソーラス44、並びに翻訳可能文コーパス46が準備されているものとする。機械翻訳装置42は、日本語の入力文30が与えられると、シソーラス44を参照して用例コーパス40中の各用例のうちで入力文30に最も類似した日本語文を持つ用例文を検索する。この検索では、入力文30と各用例文の日本語文との間の編集距離が最も近い用例文が検索される。ただし、編集距離算出の際、語の置換については、シソーラス44を参照して得られる、置換される2語間の意味的距離により編集距離の重み付けがなされる。このようにして算出された編集距離が、入力文30と用例文との類似度となる。
【0083】
機械翻訳装置42は、検索された用例文のうち類似度が最も小さなものを選択する。機械翻訳装置42はこの際、選択された用例文の類似度が所定の値を上回っていれば、すなわち選択された用例文と入力文30とがそれほど類似していない場合には判定信号60の値を論理1レベルとし、それ以外の場合には論理0レベルとする。
【0084】
機械翻訳装置42は、選択された用例文と入力文30との類似度が所定の値以下であれば、用例文の英語部分を、入力文30と用例文の日本語部分との相違に基づいて修正することで入力文30の翻訳文を生成し、翻訳結果58を出力する。翻訳結果58は選択部52に与えられる。
【0085】
判定信号60の値が論理0レベルの場合、選択部52は翻訳結果58を選択して出力文34として出力する。
【0086】
判定信号60の値が論理1レベルの場合には、次のような処理が行なわれる。類似文検索部48は、入力文30と類似する候補文を翻訳可能文コーパス46の中から検索する。すなわち、図3を参照して、選択部110は、シーケンス制御部130の制御に従い、まず入力文30を選択し、形態素解析部112に与える。形態素解析部112は辞書114を参照して入力文30を形態素解析し、単語列に分解して分岐部116に与える。この際、各単語には辞書114を参照して得られる各種の情報が付与される。分岐部116は、シーケンス制御部130の制御に従い、形態素解析部112の出力する単語列を入力文記憶部118に与える。入力文記憶部118はこの単語列を格納する。
【0087】
次に選択部110は、シーケンス制御部130の制御に従い、翻訳可能文コーパス46に含まれる用例文のうち1番目の日本語部分を読出し、形態素解析部112に与える。形態素解析部112はこの日本語部分を辞書114を参照して形態素解析し、得られた単語列を分岐部116に与える。この場合も、各単語には属性情報が付与される。分岐部116は、シーケンス制御部130の制御に従い、今度はこの単語列を類似度算出部120に与える。
【0088】
類似度算出部120は、分岐部116から与えられる用例文の形態素解析結果と入力文記憶部118に記憶された入力文30の形態素解析結果とに基づき、式(1)に示すn−グラムを用いた類似度算出方式に従い、入力文30と翻訳可能文コーパス46の1番目の候補文との類似度を算出し、記憶部122に与える。このとき、類似度算出における入力文30と候補文との共通単語数のうち、機能語数には、機能語重み記憶部128に記憶された値が重みとして乗じられる。記憶部122はこの類似度を、1番目の候補文の形態素解析結果とともに記憶する。
【0089】
以下、シーケンス制御部130の制御に従い、翻訳可能文コーパス46に記憶されている各候補文が形態素解析部112により形態素解析され、入力文30との間の類似度が類似度算出部120により算出される。その結果得られた各候補文の類似度が、その候補文の形態素解析結果とともに記憶部122に記憶される。
【0090】
全ての候補文について類似度が算出されると、除外処理部124が入力文記憶部118に記憶された入力文30の形態素解析結果を参照し、候補文の中で入力文30にない内容語を日本語部分に含む候補文を除外し、それ以外の候補文と類似度とを選択処理部126に与える。選択処理部126は、与えられた候補文のうち、(1)入力文に含まれる内容語のうちで候補文にない内容語が1語以内であること、又は(2)入力文と共通する内容語が2語以上であること、という前述の条件を満たし、かつ入力文30に最も類似する候補文を類似文62として出力するとともに、上記条件を満たす類似文が存在したか否かを検索結果信号64として出力する。検索結果信号64は、上記した条件を充足する文があったときには論理0レベルをとり、なかったときには論理1レベルをとる。
【0091】
再び図1を参照して、機械翻訳装置50は、検索結果信号64が論理0レベルであるときは、類似文検索部48からの類似文62に対し、用例コーパス40及びシソーラス44を用いた用例翻訳を行なう。この用例翻訳処理は、機械翻訳装置42で行なわれるものと同じである。機械翻訳装置50は、用例コーパス40から適切な用例文を検索できなかったときは信号68を論理1レベルとして処理を終了する。用例コーパス40から適切な用例文を検索できたときは、機械翻訳装置50はその用例文の日本語部分と類似文62との相違を基に、用例文の英語部分を修正することで類似文62の翻訳を行なう。そして、この翻訳処理の結果を翻訳結果66として選択部52に与える。
【0092】
選択部52は、判定信号60が論理1レベルのときには、このようにして機械翻訳装置50から選択部52に与えられた翻訳結果66を選択し、出力文34として出力する。
【0093】
以上のように機械翻訳システム32は、入力文30に対し、機械翻訳装置42が機械翻訳可能な場合には、その翻訳結果を出力文34として出力する。入力文30が機械翻訳装置42による翻訳のできない文であるときには、図2に示す翻訳不能文90、92、94、96、98を翻訳可能文コーパス46中の文100、102、104等に置換するのと同様、この入力文30を翻訳可能文コーパス46中のいずれかの候補文と置換える。翻訳可能文コーパス46は予め翻訳可能な文を集めて準備されたものであるので、機械翻訳装置50においてはこの候補文を翻訳できる可能性が高い。その結果、機械翻訳システム32が翻訳できる文の範囲は、類似文検索部48による類似文の検索を行なわなかった場合と比較して広くなるという効果が得られる。
【0094】
なお、前述したとおり類似文検索部48により翻訳可能文コーパス46から類似文を検索できないような入力文30もあり得る。その場合には検索結果信号64が論理1レベルとなり、翻訳可否信号36が論理1レベルとなる。
【0095】
また、翻訳可能文コーパス46が翻訳可能文からなる以上、類似文検索部48による類似文の検索ができれば機械翻訳装置50による翻訳も可能と考えられる。ただし、翻訳可能文コーパス46の内容に不備がある場合も考えられるので、機械翻訳装置50から翻訳可否信号68を出力するようにしている。すなわち、翻訳可否信号68が論理0レベルであれば機械翻訳装置50による翻訳が可能ということであり、翻訳可否信号68が論理1レベルであれば機械翻訳装置50による翻訳が不可能ということになる。
【0096】
ANDゲート54は検索結果信号64と翻訳可否信号68とのANDをとっているので、その出力ANDゲート54が論理1レベルであれば翻訳ができなかったことが分かり、それ以外の場合には翻訳が可能であったことが分かる。
【0097】
[実験結果]
以上述べた実施の形態に係る機械翻訳システム32の類似文検索部48を用いて日英翻訳を行なう実験を行なった。この実験では、二種類のコーパスを使用する。翻訳不能文の集合である翻訳不能文コーパスと、図1に示す翻訳可能文コーパス46とである。
【0098】
図13を参照して、翻訳不能文コーパス146は、発明の実施の形態に関する冒頭の説明で言及した第2の発話コーパス140の各文を機械翻訳142に与え、翻訳不能となった文を集めることで作成した。第2の発話コーパス140は1,698文を含み、その中で翻訳可能文からなるコーパス144は1393文であり、翻訳が不能な文からなる翻訳不能文コーパス146は305文であった。
【0099】
翻訳可能文コーパス46は、発明の実施の形態の説明の冒頭で言及した第1の基本表現コーパスの中から機械翻訳で翻訳可能と判定された70,671文を含む。
【0100】
翻訳不能文コーパス146の各文を類似文検索部48に与えたところ、得られた類似文からなる検索類似文コーパス150は164文となった。すなわち、164文の翻訳不能文について類似文を検索することができた。検索された類似文164文について類似性を人手で評価したところ、図13の正解類似文154にも示すとおり、81文については正しい類似文であることが判明した。
【0101】
さらに、検索された類似文164文を機械翻訳装置50に与えて得られる翻訳文と、入力文とを評価者に提示して翻訳文としての評価を行なった。翻訳文は、英語のネイティブスピーカによりGood,Fair,Acceptable,Badの4種類のランクで評価される。この内、Good,Fair及びAcceptableの評価の文を「適切な訳文」とする。なお、この評価基準は機械翻訳の訳質評価のために定めたものであり、図4に示した類似文の評価基準とは別のものである。
【0102】
図13に示すように、この結果、正解訳文156として61文が得られた。内訳は、Goodが12文、Fairが10文、Acceptableが39文である。
【0103】
図14に、類似文、翻訳文における正解率及び翻訳不能文の救済率をそれぞれ示す。図14を参照して、類似文、つまり入力文と同一言語の段階では翻訳不能文の26.6%について類似文検索により適切な類似文を検索できた。また、翻訳文の段階でも、翻訳不能文の20%について適切な訳文を得ることができた。
【0104】
以上のとおり、本実施の形態に係る機械翻訳システム32によれば、単言語コーパスという入手が容易な言語資源を用いた類似文検索技術を機械翻訳と組合わせることで、既存の機械翻訳の翻訳可能文の範囲を拡大することができる。前編集のための規則を定めるという手間のかかる作業なしに、話し言葉のように同じ意味で多くのバリエーションがある入力文の翻訳可能性を高めることができる。
【0105】
なお、上記した実施の形態では、類似文検索における類似度算出方式として、入力文と候補文とに共通するn−グラムを用いる方式を採用した。しかし本発明はそのような方式に限定されるわけではない。例えば、入力文と候補文との間の最長共通単語列に基づく類似度算出方式を用いてもよいし、入力文と候補文との単語集合の共通部分に基づく類似度算出方式を用いてもよい。また、これ以外の類似度算出方式を用いてもよいが、その場合でも入力文と候補文とが内容上でどの程度類似しているかを有効に示す類似度を採用することが望ましい。
【0106】
また、上記した実施の形態では、n−グラムに基づく類似度算出方式において、内容語の重みを1としたときの機能語の重みを0.4としている。しかしこの重みはそのような値に限定されるわけではなく、機能語に対しては内容語の重み以下の重みであればどのような重みを付与するようにしてもよい。
【0107】
さらに、上に説明した各パラメータの値は、対象となる言語により、また対象となるドメインにより変わり得るものである。それらは、実際に本発明を実施する環境にあわせて行なう実験に基づいて決定することが望ましい。
【0108】
上記した実施の形態では、機械翻訳装置として用例翻訳を使用している。そして,用例翻訳の過程において入力文とよく類似した用例文が得られたか否かを訳質の指標として用いている。この場合、用例翻訳の過程で訳質が評価できる。しかし本発明はそのような実施の形態には限定されない。例えば、機械翻訳装置として任意のものを用い、その出力する訳文の訳質を何らかの基準に従って評価し、その結果を類似文検索するか否かを決定するための指標として用いても良い。例えば予め準備された複数個の参照訳との比較結果により訳質を評価したり、訳文を言語モデル又は翻訳モデル又はその双方を用いて評価したりするようにしてもよい。この場合、それらは機械翻訳装置とは独立した機能モジュールとして機械翻訳システム内に設けることができる。逆に言えば、上記した実施の形態での第1の機械翻訳装置のように翻訳過程で訳質の指標に相当するものが得られる場合、訳質を評価するための独立した機能モジュールは不要である。
【0109】
[コンピュータによる実現]
上記した実施の形態に係る機械翻訳システム32は、コンピュータシステムにより実現できる。図15は上記した実施の形態による機械翻訳システム32を実現するコンピュータシステム250の全体構成を示す外観図である。システム250はマイクロフォン264及びスピーカ278の組と、CD−ROM(Compact Disc Read−Only Memory)ドライブ270及びFD(Flexible Disk)ドライブ272を有するコンピュータ260と、いずれもコンピュータ260に接続されたモニタ262、キーボード266及びマウス268とを含む。
【0110】
マイクロフォン264とスピーカ278とは、必要であれば音声翻訳の入力及び出力に用いられるものであって、この発明の一部を構成するものではない。従って、システムのうちマイクロフォン264及びスピーカ278に関する部分の詳細はここでは説明しない。
【0111】
図16はコンピュータ260のハードウェアブロック図である。図16を参照して、コンピュータ260は、CPU(Central Processing Unit:中央処理装置)340と、CPU340に接続されたバス342と、バス342に接続された読出専用メモリ(ROM)344と、バス342に接続されたランダムアクセスメモリ(RAM)346と、バス342に接続されたハードディスク348と、CD−ROM(コンパクト・ディスクROM)360が装着され、CD−ROMからデータを読出すCD−ROMドライブ270と、FD(フレキシブル・ディスク)362が装着され、FDからデータを読出し、データを書込むFDドライブ272と、マイクロフォン264及びスピーカ278が接続されるサウンドボード350と、バス342に接続されローカルエリアネットワーク(LAN)等のデータ通信ネットワークに接続する機能を提供するネットワークボード352とを含む。
【0112】
図1〜図14を参照して説明した実施の形態に係る機械翻訳システム32は、コンピュータシステム250のハードウェア、その上で実行されるコンピュータプログラム、及びコンピュータシステム250のハードディスク348、RAM346等に格納される各種のコーパスなどのデータにより実現可能である。コンピュータプログラムの構成については後述する。それらコンピュータプログラム及びコーパスなどのデータ(以下「プログラム等」と呼ぶ。)はCD−ROM360などの記憶媒体に格納されて流通する。それらプログラム等はそうした記憶媒体からハードディスク348に読込まれる。システムの起動時には、プログラムはハードディスク348から読出されてRAM346にロードされ、CPU340により読出されて実行される。プログラムの読出アドレスは図示しないプログラムカウンタにより指定される。プログラムカウンタの内容は,プログラムの実行に伴って書換えられる。データの読出及び書込アドレスはプログラムに従った演算結果によって指定される。
【0113】
図17は、上記した実施の形態に係る機械翻訳システム32を実現するプログラムのフローチャートである。各ステップの内容の詳細については図1〜図14を参照して説明したとおりである。ここでは、プログラムにより機械翻訳システム32を実現する際のプログラムの全体の好ましい構成を示す。
【0114】
図17を参照して、ステップ400で、入力文に対して機械翻訳を実行する。この機械翻訳は用例翻訳によるものであり、用例翻訳の基となる用例文の類似度が翻訳結果とともに得られる。ステップ402では、この類似度の値が所定の値より大きいか否かが判定される。前述したとおり、本実施の形態で使用される用例翻訳では、二つの文が類似しているほど類似度は小さくなり、両者が完全に一致していると類似度は0となる。もし両者が類似していれば(すなわち類似度>所定値という条件が成立していなければ)、制御はステップ414に進み、ステップ400で得られた翻訳文を全体の翻訳結果として出力し処理を終了する。両者が類似していなければ制御はステップ404に進む。
【0115】
ステップ404では、この機械翻訳処理の結果が、入力文に対する機械翻訳処理により得られたものか、入力文を類似文で置換した後の機械翻訳処理により得られたものかを判定する。置換後であれば制御はステップ410に進み、翻訳不能であった旨の出力(表示)をステップ410で行なって処理を終了する。置換前であれば制御はステップ406に進む。
【0116】
ステップ406では、入力文に対する類似文を翻訳可能文コーパスから検索する処理が行なわれる。ここで検索される類似文が満たすべき条件については既に説明したとおりである。この後、ステップ408において、ステップ406で入力文に類似するという条件を満足した翻訳可能文(類似文)が検索されたか否かを判定する。ここで類似文がなかったと判定された場合、ステップ410で翻訳不能を表示して処理を終了する。類似文があれば、ステップ412に進む。
【0117】
ステップ412では、検索された類似文で入力文を置換する処理を行なう。制御はステップ400に戻る。この後、置換された文に対してステップ400、402、414という処理が実行されるか、又はステップ400、402、404、410という処理が実行され、全体の機械翻訳処理が終了する。
【0118】
以上のように、図1では機械翻訳装置42と機械翻訳装置50とを別のものとして示したが、これらを同一のもので実現するようにしてもよい。このように同一のもので機械翻訳装置42と機械翻訳装置50とを実現することで、翻訳に必要な資源の増大を防ぎながら、翻訳可能な文の範囲を広げることができる。もちろん、両者が別々のものでもよい。また、両者が別々の場合、両者の機械翻訳の原理は互いに同一でもよいし、同一でなくてもよい。
【0119】
今回開示された実施の形態は単に例示であって、本発明が上記した実施の形態のみに制限されるわけではない。本発明の範囲は、発明の詳細な説明の記載を参酌した上で、特許請求の範囲の各請求項によって示され、そこに記載された文言と均等の意味及び範囲内でのすべての変更を含む。
【図面の簡単な説明】
【0120】
【図1】本発明の一実施の形態に係る機械翻訳システム32のブロック図である。
【図2】機械翻訳システム32における類似文検索技術の概念を示す図である。
【図3】機械翻訳システム32の類似文検索部48のブロック図である。
【図4】類似文を評価する際の評価基準を説明する図である。
【図5】入力文に対する様々な類似文の候補の評価例を示す図である。
【図6】類似度算出の3つの基本方式によるF値算出例を示す図である。
【図7】余剰内容語を含むことで不適切となる候補文の例を示す図である。
【図8】類似度算出の3つの基本方式における、余剰内容語の存在の影響を示す図である。
【図9】類似度算出の3つの基本方式における、機能語の重みの影響を表形式で示す図である。
【図10】機能語の重みを減らすことによる検索結果への影響を表形式で示す図である。
【図11】検索された類似文において入力文と比較して不足している内容語の数と、その正解率との関係を示す図である。
【図12】入力文との共通内容語数と検索された候補文の正解率との関係を示す図である。
【図13】実験において使用したコーパスと実験結果とを示す図である。
【図14】実験において得られた類似文、翻訳文における正解率及び翻訳不能文の救済率をそれぞれ示す図である。
【図15】本発明の一実施の形態による機械翻訳システムを実現するコンピュータシステム250の外観図である。
【図16】図15に示すコンピュータ260のハードウェアブロック図である。
【図17】本発明の一実施の形態に係る機械翻訳システムをコンピュータシステムで実現するためのプログラムのフローチャートである。
【符号の説明】
【0121】
32 機械翻訳システム、36,68 翻訳可否信号、40 用例コーパス、42 機械翻訳装置、44 シソーラス、46 翻訳可能文コーパス、48 類似文検索部、50 機械翻訳装置、52,110 選択部、54 ANDゲート、58 翻訳結果、60 判定信号、62 類似文、64 検索結果信号、66 翻訳結果、80 翻訳可能文集合、82 翻訳不能文集合、84 類似文検索技術、112 形態素解析部、114 辞書、116 分岐部、118 入力文記憶部、120 類似度算出部、122 記憶部、124 除外処理部、126 選択処理部、128 機能語重み記憶部、130 シーケンス制御部
【特許請求の範囲】
【請求項1】
第1の言語の入力文を第2の言語に翻訳するための機械翻訳システムであって、
前記第2の言語への翻訳が可能であるとして予め選択された、前記第1の言語の複数の文を含む第1のコーパスと、
前記入力文を前記第2の言語に翻訳するための第1の機械翻訳手段と、
前記第1の機械翻訳手段による訳文の訳質の指標を出力するための指標出力手段と、
前記指標出力手段の出力する前記指標が前記訳質が悪いことを示す所定の条件に合致することに応答して、前記入力文と所定の関係にある文を前記第1のコーパスから検索するための検索手段と、
前記検索手段により検索された前記文を前記第2の言語に翻訳するための第2の機械翻訳手段とを含む、機械翻訳システム。
【請求項2】
前記検索手段は、前記指標出力手段の出力する前記指標が前記所定の条件に合致していることに応答して、前記入力文との間で所定の算出方式に従い算出される類似度によって最も前記入力文と類似していると判定される文を前記第1のコーパスから検索するための類似文検索手段を含む、請求項1に記載の機械翻訳システム。
【請求項3】
前記類似文検索手段は、
前記第1のコーパスに含まれる前記複数の文の各々と、前記入力文との間の共通部分に基づいて定義される類似度を算出するための類似度算出手段と、
前記類似度算出手段により算出された類似度に基づき、最も前記入力文と類似していると判定された文を前記第1のコーパスより抽出するための手段とを含む、請求項2に記載の機械翻訳システム。
【請求項4】
前記類似度算出手段は、
前記入力文の単語数、前記候補文の単語数、及び前記入力文及び前記候補文に共通する単語数を算出するための単語数算出手段と、
前記入力文と、類似度の算出対象となる候補文との間の前記類似度を、次の式
適合率=(入力文と候補文に共通する単語数)/候補文の単語数
再現率=(入力文と候補文に共通する単語数)/入力文の単語数
で定義される適合率と再現率との双方の関数として算出するための手段を含む、請求項3に記載の機械翻訳システム。
【請求項5】
前記単語数算出手段は、前記入力文の単語数、前記候補文の単語数、並びに前記入力文及び前記候補文に共通する単語数を、各単語の種類に従って予め定められる重みを乗じて算出するための手段を含む、請求項4に記載の機械翻訳システム。
【請求項6】
前記第1の機械翻訳手段は、
互いに良好な訳である前記第1の言語の文と前記第2の言語の文とからなる用例を複数個含む2言語用例コーパスと、
所定の類似基準に従って前記入力文との間で最も類似している前記第1の言語の文を含む用例を前記2言語用例コーパスから検索するための手段と、
前記検索するための手段により検索された前記第1の言語の文の対訳である前記第2の言語の文を、前記検索するための手段により検索された前記第1の言語の文及び前記入力文の間の相違に基づき修正することにより、前記入力文の翻訳を行なう用例翻訳手段とを含み、
前記指標出力手段は、前記検索するための手段によって検索された前記第1の言語の文と前記入力文との間で定義される所定の類似度が、予め定める基準を充足しているか否かを判定し、判定結果を前記指標として出力するための手段を含む、請求項1〜請求項5のいずれかに記載の機械翻訳システム。
【請求項7】
コンピュータにより実行されると、当該コンピュータを、請求項1〜請求項6のいずれかに記載の機械翻訳システムとして動作させる、コンピュータプログラム。
【請求項1】
第1の言語の入力文を第2の言語に翻訳するための機械翻訳システムであって、
前記第2の言語への翻訳が可能であるとして予め選択された、前記第1の言語の複数の文を含む第1のコーパスと、
前記入力文を前記第2の言語に翻訳するための第1の機械翻訳手段と、
前記第1の機械翻訳手段による訳文の訳質の指標を出力するための指標出力手段と、
前記指標出力手段の出力する前記指標が前記訳質が悪いことを示す所定の条件に合致することに応答して、前記入力文と所定の関係にある文を前記第1のコーパスから検索するための検索手段と、
前記検索手段により検索された前記文を前記第2の言語に翻訳するための第2の機械翻訳手段とを含む、機械翻訳システム。
【請求項2】
前記検索手段は、前記指標出力手段の出力する前記指標が前記所定の条件に合致していることに応答して、前記入力文との間で所定の算出方式に従い算出される類似度によって最も前記入力文と類似していると判定される文を前記第1のコーパスから検索するための類似文検索手段を含む、請求項1に記載の機械翻訳システム。
【請求項3】
前記類似文検索手段は、
前記第1のコーパスに含まれる前記複数の文の各々と、前記入力文との間の共通部分に基づいて定義される類似度を算出するための類似度算出手段と、
前記類似度算出手段により算出された類似度に基づき、最も前記入力文と類似していると判定された文を前記第1のコーパスより抽出するための手段とを含む、請求項2に記載の機械翻訳システム。
【請求項4】
前記類似度算出手段は、
前記入力文の単語数、前記候補文の単語数、及び前記入力文及び前記候補文に共通する単語数を算出するための単語数算出手段と、
前記入力文と、類似度の算出対象となる候補文との間の前記類似度を、次の式
適合率=(入力文と候補文に共通する単語数)/候補文の単語数
再現率=(入力文と候補文に共通する単語数)/入力文の単語数
で定義される適合率と再現率との双方の関数として算出するための手段を含む、請求項3に記載の機械翻訳システム。
【請求項5】
前記単語数算出手段は、前記入力文の単語数、前記候補文の単語数、並びに前記入力文及び前記候補文に共通する単語数を、各単語の種類に従って予め定められる重みを乗じて算出するための手段を含む、請求項4に記載の機械翻訳システム。
【請求項6】
前記第1の機械翻訳手段は、
互いに良好な訳である前記第1の言語の文と前記第2の言語の文とからなる用例を複数個含む2言語用例コーパスと、
所定の類似基準に従って前記入力文との間で最も類似している前記第1の言語の文を含む用例を前記2言語用例コーパスから検索するための手段と、
前記検索するための手段により検索された前記第1の言語の文の対訳である前記第2の言語の文を、前記検索するための手段により検索された前記第1の言語の文及び前記入力文の間の相違に基づき修正することにより、前記入力文の翻訳を行なう用例翻訳手段とを含み、
前記指標出力手段は、前記検索するための手段によって検索された前記第1の言語の文と前記入力文との間で定義される所定の類似度が、予め定める基準を充足しているか否かを判定し、判定結果を前記指標として出力するための手段を含む、請求項1〜請求項5のいずれかに記載の機械翻訳システム。
【請求項7】
コンピュータにより実行されると、当該コンピュータを、請求項1〜請求項6のいずれかに記載の機械翻訳システムとして動作させる、コンピュータプログラム。
【図1】

【図2】
【図3】
【図4】

【図5】
【図6】
【図7】

【図8】
【図9】
【図10】

【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【公開番号】特開2006−4366(P2006−4366A)
【公開日】平成18年1月5日(2006.1.5)
【国際特許分類】
【出願番号】特願2004−182858(P2004−182858)
【出願日】平成16年6月21日(2004.6.21)
【国等の委託研究の成果に係る記載事項】(出願人による申告)平成16度独立行政法人情報通信研究機構、研究テーマ「大規模コーパスベース音声対話翻訳技術の研究開発」に関する委託研究、産業活力再生特別措置法第30条の適用を受ける特許出願
【出願人】(393031586)株式会社国際電気通信基礎技術研究所 (905)
【Fターム(参考)】
【公開日】平成18年1月5日(2006.1.5)
【国際特許分類】
【出願日】平成16年6月21日(2004.6.21)
【国等の委託研究の成果に係る記載事項】(出願人による申告)平成16度独立行政法人情報通信研究機構、研究テーマ「大規模コーパスベース音声対話翻訳技術の研究開発」に関する委託研究、産業活力再生特別措置法第30条の適用を受ける特許出願
【出願人】(393031586)株式会社国際電気通信基礎技術研究所 (905)
【Fターム(参考)】
[ Back to top ]