
機械翻訳装置、方法及びプログラム
【課題】第1言語の文書の原文が構文解析に失敗した場合でも、ユーザに負担を課すことなく読みやすい訳文を生成できるとともに、開発者による機械翻訳のチューニングの効率化や省力化を図ることである。
【解決手段】文書解析手段30は、第1言語で表現された文書の各原文を構文解析する。訳文生成手段33は、文書解析手段30で構文解析に成功したときは原文の訳文を生成する。第1言語単語除去手段34は、文書解析手段30で構文解析に失敗したときは原文から1単語を除去した単語列を作成する。また、文書解析手段30は、第1言語単語除去手段34で得られた1単語を除去した単語列を構文解析し、訳文生成手段33は、1単語を除去した単語列の構文解析に成功したときはその単語列の訳文を生成し、1単語を除去した単語列の構文解析に失敗したときは原文の不完全な訳文を生成する。
【解決手段】文書解析手段30は、第1言語で表現された文書の各原文を構文解析する。訳文生成手段33は、文書解析手段30で構文解析に成功したときは原文の訳文を生成する。第1言語単語除去手段34は、文書解析手段30で構文解析に失敗したときは原文から1単語を除去した単語列を作成する。また、文書解析手段30は、第1言語単語除去手段34で得られた1単語を除去した単語列を構文解析し、訳文生成手段33は、1単語を除去した単語列の構文解析に成功したときはその単語列の訳文を生成し、1単語を除去した単語列の構文解析に失敗したときは原文の不完全な訳文を生成する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明の実施形態は、自然言語文書を処理して第1言語を第2言語に機械翻訳する機械翻訳装置、方法及びプログラムに関する。
【背景技術】
【0002】
機械翻訳の特徴として、ある1単語が加わるととたんに第1言語の原文の構文解析に失敗し、部分訳として出力されることがある。こうした部分訳は、人間にとって非常に読みづらいものであることが多い。
【0003】
一方、人間による翻訳の場合、正しく構文解析できなくても、第2言語の文法知識から、第2言語において自然な文書に独自に直して訳文として作成することが多いため、このような読みづらい訳文になることは少ない。人間の訳文はたとえ誤訳だとしても、読みづらさの違いにより、機械の訳文が必要以上に低く評価されやすい。
【0004】
換言すると、1単語を除いて原文に対する訳文の評点と原文通りに翻訳した場合の訳文の評点との落差は非常に大きい。人間の翻訳では、ある1単語が加わることで、これほど大きな訳質の差がみられることは少ないと思われる。つまり、このような特徴があることで、機械翻訳の訳質が必要以上に低くみられてしまうことがある。
【0005】
こうした失敗の原因となる単語は、誤植であることもある。すなわち、入力を間違え、たまたま、そこには現れ得ない品詞の単語が入ってしまうことがある。こうした誤植は、母国語話者であれば、自然に検出できることが多いが、第1言語の知識が欠如している者にとっては、誤植であることが峻別できない。
【0006】
従来より、機械翻訳において、構文解析に失敗した場合の対策として、主に2つの方法が採られてきた。一つは、機械翻訳装置が扱えるように、原文を編集するものであり、前編集と呼ばれる。これは、例えば、原文における係り受け関係を指定する、構成要素の切れ目を指定するなど、原文は変えずに情報を付加する方法、原文そのものの表現を、例えば産業日本語などの機械処理になじむ言語に則って書き換えたり、省略されている語を補う方法などがある。いずれも、第1言語の知識、およびどういった表現は機械にとって扱いにくいかという知識が必要であり、特殊な技術を要する。また、編集自体、負荷の大きい作業である。場合によっては、人間が直接翻訳した方が効率が高いこともある。
【0007】
もう一つの方法は、原文において、構文解析に成功した部分(部分訳)をうまく組み合わせて、訳文を生成する方法である。例えば、単文ごとの分割、句ごとの分割、節ごとの分割、または単語ごとの分割のいずれか複数を含む分割手段を有し、もっとも大きなテキストの構成要素から順に、より小さなテキストの構成要素に分割することによって部分訳を作成し、それらを一組にして全体の翻訳結果を合成するようにしたものがある(例えば、特許文献1参照)。
【0008】
しかし、部分訳を組み合わせるものでは、部分訳を合成しても全体の訳になるとは限らない場合がある。すなわち、非単調性が存在する(http://www.jaist.ac.jp/~kshirai/lec/i223/14.pdf)。
【0009】
単文レベルの合成であれば別だが、それより低いレベルの部分訳の合成となると、それらをどのように組み合わせればよいかという知識は、非常に高度な知識であり、お互いの修飾関係を把握しておく必要がある。単純に前から、順に合成していっても、意味をなさない訳文になる可能性が高い。
【0010】
このことから、合成はもともと人間が行うことを前提としているものもある(例えば、特許文献2参照)。すなわち、特許文献2には以下のように書かれている。「部分訳として翻訳された結果は、翻訳者が編集手段によって自由に並び替えたり、連結をし、文全体を構成すればよい。部分訳自体は正しく翻訳されている可能性が高いので、翻訳結果の修正の手間が省ける。」
このように従来の方式では、何らかの人間の介在が前提となっている。前編集の方法をとる場合、第1言語の知識を必要とし、負荷の高い作業、いわゆるチューニングが発生する。これは、通常の第1言語の知識だけでなく、どのような言語表現が機械にとって処理しにくいかといった(人間が処理しやすい言語表現とは必ずしも一致しない)特殊な知識も必要とする。したがって、パーソナル・ユーザのように、単に大意をつかむために、機械翻訳を利用している場合には適切といえない。特に、第1言語をまったく解さないユーザの場合は、特にそのことがいえる。
【0011】
また、部分訳を合成する場合であるが、分割した単位が単純な関係にある場合は、それらを結合するだけで、理解可能な訳文が生成されることが予測される(非特許文献1参照)。しかし、分割が多くなるほど、それらの関係は複雑になり、どのようにそれらを組み合わせるかを判断することは困難になる。また、単純に長文であるため、解析しにくい場合は、従来の場合で処理可能であろうが、ある単語が原因で全体の構文解析を難しくしている場合は、極端にいえば、単語レベルまで分割しなければ処理できない。単語ごとの翻訳を合成した結果は、他との関係を参照していないので、正しい解釈とならないと予想される。そもそも、「全体は部分の総和以上のものである」というゲシュタルト的な考えに立てば、このように部分訳を単純に合成するだけでは、正しい意味解釈の目的を十分果たせない。
【0012】
視点を変えて、機械翻訳装置の開発者の立場からすると、従来のような方式は、簡単にいえば、現状のシステムが受け入れやすい方法に原文を変えるものであり、システム自体の改善にはつながらない。原文そのものは変えずに、システムを頑強にすることによって受理できるようにするという位置づけになっていない。また、構文解析の失敗の原因は具体的にどこであるか効率的に特定できていない。現状では、原文を少しずつ変化させてみて、開発者が自らの経験知から、原因を探りあてるということが行われている。
【先行技術文献】
【特許文献】
【0013】
【特許文献1】特開平5−2604号公報
【特許文献2】特開平6−124303号公報
【非特許文献】
【0014】
【非特許文献1】吉田 節行(2007) 山形大学工学部情報科学科平成18年度卒業論文「特許文の機械翻訳における正しい係り受け判定のための文章分割」平成19年3月 (http://isyus2.yz.yamagata-u.ac.jp/xoops/kenkyuu_seika/2007/2007_B4_yoshida.pdf)
【発明の概要】
【発明が解決しようとする課題】
【0015】
本発明が解決しようとする課題は、第1言語の文書の原文が構文解析に失敗した場合でも、ユーザに負担を課すことなく読みやすい訳文を生成できるとともに、開発者による機械翻訳のチューニングの効率化や省力化を図ることができる機械翻訳装置、方法及びプログラムを提供することである。
【課題を解決するための手段】
【0016】
本発明の実施形態に係る機械翻訳装置は、機械翻訳プログラム、翻訳対象の第1言語の原文を翻訳目的の第2言語の訳文に翻訳するための機械翻訳辞書を記憶した記憶装置と、前記機械翻訳プログラムを演算実行する演算制御装置とを備える。
【0017】
文書解析手段は、第1言語で表現された文書の各原文を構文解析する。訳文生成手段は、文書解析手段で構文解析に成功したときは原文の訳文を生成する。第1言語単語除去手段は、文書解析手段で構文解析に失敗したときは原文から1単語を除去した単語列を作成する。
【0018】
また、文書解析手段は、第1言語単語除去手段で得られた1単語を除去した単語列を構文解析し、訳文生成手段は、1単語を除去した単語列の構文解析に成功したときはその単語列の訳文を生成し、1単語を除去した単語列の構文解析に失敗したときは原文の不完全な訳文を生成する。
【図面の簡単な説明】
【0019】
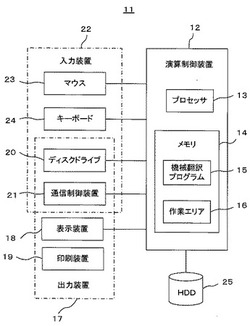
【図1】本発明の実施形態に係る機械翻訳装置のハードウエア構成を示すブロック構成図。
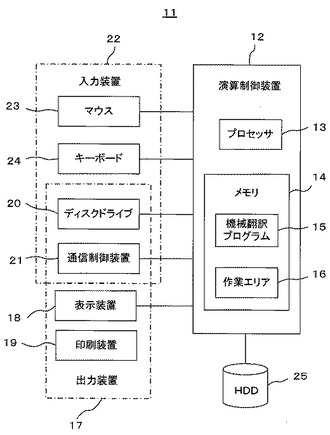
【図2】本発明の実施例1に係る機械翻訳装置の機能ブロック図。
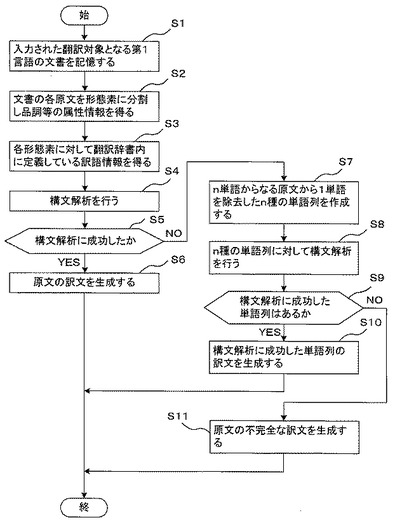
【図3】本発明の実施例1に係る機械翻訳装置の処理内容を示すフローチャート。
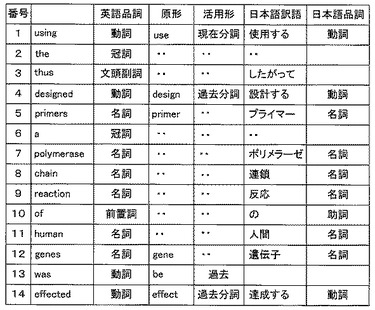
【図4】本発明の実施例1での翻訳対象となる第1言語の文書の一例の説明図。
【図5】図4の文番号1の原文に対して、図3の処理を行った場合の形態素解析情報の説明図。
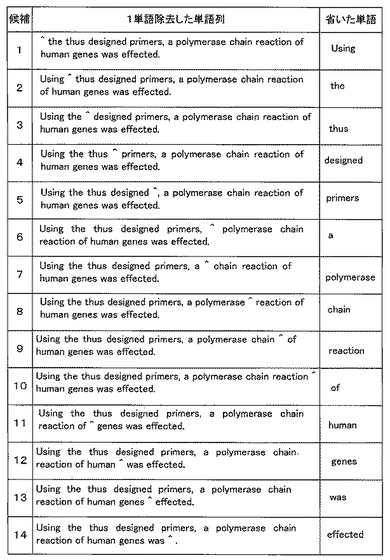
【図6】14単語からなる図4の文番号1の原文から1単語を除去した14個の単語列の説明図。
【図7】本発明の実施例1による訳文の表示画面の一例の説明図。
【図8】本発明の実施例2に係る機械翻訳装置の機能ブロック図
【図9】本発明の実施例2に係る機械翻訳装置の処理内容を示すフローチャート。
【図10】本発明の実施例3に係る機械翻訳装置の機能ブロック図。
【図11】本発明の実施例3に係る機械翻訳装置の処理内容を示すフローチャート。
【図12】図4の文番号1の原文からthusという語を除去した単語列に対しての辞書引き結果の説明図。
【図13】本発明の実施例3における第1言語解析文法辞書の一例を示す説明図。
【図14】本発明の実施例4に係る機械翻訳装置の機能ブロック図。
【図15】本発明の実施例4に係る機械翻訳装置の処理内容を示すフローチャート。
【図16】本発明の実施例4に係る機械翻訳装置のコーパス検索手段での検索結果の一例の説明図。
【図17】本発明の実施例5に係る機械翻訳装置の機能ブロック図。
【図18】本発明の実施例5に係る機械翻訳装置の処理内容を示すフローチャート。
【図19】本発明の実施例5における辞書登録問い合わせ画面の一例を示す説明図。
【発明を実施するための形態】
【0020】
以下、本発明の実施形態を図面に基づいて説明する。図1は本発明の実施形態に係る機械翻訳装置のハードウエア構成を示すブロック構成図である。
【0021】
図1において、機械翻訳装置11は、例えば一般的なコンピュータに機械翻訳プログラムなどのソフトウェアプログラムがインストールされ、そのソフトウェアプログラムが演算制御装置12のプロセッサ13において実行されることにより実現される。
【0022】
演算制御装置12は機械翻訳に関する各種演算を行うものであり、演算制御装置12はプロセッサ13とメモリ14とを有し、メモリ14には翻訳に関する機械翻訳プログラム15が記憶され、プロセッサ13により処理が実行される際には作業エリア16が用いられる。演算制御装置12の演算結果等は出力装置17である表示装置18、印刷装置19、ディスクドライブ20に出力され、また、通信制御装置21を介して通信ネットワークに出力される。
【0023】
入力装置22は演算制御装置12に情報を入力するものであり、例えば、マウス23、キーボード24、ディスクドライブ20、通信制御装置21から構成され、例えば、マウス23やキーボード24は表示装置18を介して演算制御装置12に各種指令を入力し、キーボード24、ディスクドライブ20、通信制御装置21は翻訳対象の文書を入力する。
【0024】
すなわち、ディスクドライブ20は翻訳対象の文書のファイルを記憶媒体に入出力するものであり、通信制御装置21は機械翻訳装置11をインターネットやLANなどの通信ネットワークに接続するものである。通信制御装置21はLANカードやモデムなどの装置であり、通信制御装置21を介して通信ネットワークと送受信したデータは入力信号又は出力信号として演算制御装置12に送受信される。さらに、演算制御装置12の演算結果や翻訳に必要な知識・規則を蓄積した翻訳辞書等を記憶するハードディスクドライブ(HDD)25が設けられている。
【0025】
(実施例1)
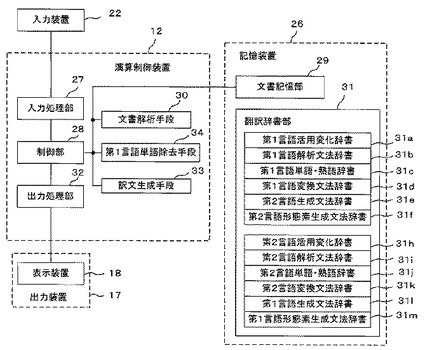
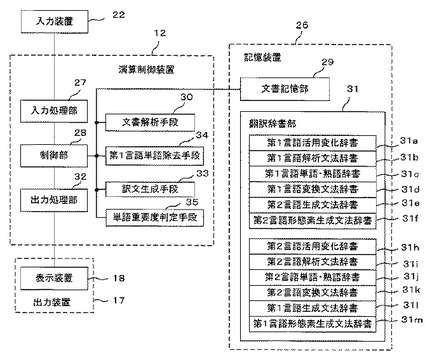
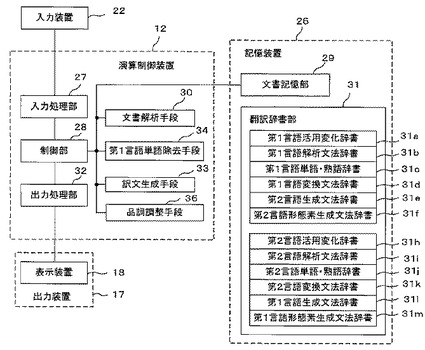
図2は本発明の実施例1に係る機械翻訳装置11の機能ブロック図である。図2において、演算制御装置12内の各機能ブロックは、上述の機械翻訳プログラム15を構成する各プログラムに対応する。すなわち、プロセッサ13が機械翻訳プログラム15を構成する各プログラムを実行することで、演算制御装置12は、各機能ブロックとして機能することとなる。また、記憶装置26の各ブロックは、演算制御装置12内のメモリ14及びハードディスクドライブ25の記憶領域に対応する。
【0026】
入力装置22は、翻訳対象となる文書の電子データを入力するものであり、ユーザの入力操作に基づく(対訳)の入力が可能である。入力装置22から入力される文書は、翻訳対象となる第1言語文書である。
【0027】
なお、入力装置22としては、OCR(光学式文字読み取り装置)や、磁気テープ、磁気ディスク、光ディスク等、コンピュータ可読媒体からの読み込み装置を採用することも可能であり、入力装置22によって入力された翻訳対象となる第1言語文書は、演算制御装置12の入力処理部27により入力処理されて取り込まれ、制御部28を介して記憶装置26の文書記憶部29に記憶される。また、入力装置22は、入力処理部27を介して制御部28に対して各種コマンドを与える。制御部28は、入力処理部27、出力処理部32、文書解析手段30を制御するとともに、記憶装置26とのデータの授受の制御も行う。
【0028】
文書解析手段30は、第1言語で表現された文書の各原文を構文解析するものである。すなわち、制御部28からの指示に従って、後述する記憶装置26の機械翻訳辞書である翻訳辞書部31を用いて、入力装置22によって入力され、文書記憶部29に記憶された翻訳対象となる第1言語文書の原文を解析し、その解析情報を文書記憶部29に記憶する。また、その解析結果は、必要に応じて、制御部28及び出力処理部32を介して出力装置17に出力される。以下の説明では、出力装置17は表示装置18である場合について説明する。
【0029】
訳文生成手段33は、文書解析手段30で構文解析に成功したときは原文の訳文を生成するものであり、その訳文を文書記憶部29に記憶するとともに、必要に応じて、制御部28及び出力処理部32を介して表示装置18に表示・出力する。
【0030】
第1言語単語除去手段34は、文書解析手段30で構文解析に失敗したとき、原文から1単語を除去した単語列を作成するものであり、文書解析手段30で構文解析に失敗したときは、n単語からなる原文(word1, word2, word3,.., wordn)から、1単語を除去したn種の単語列を作成するものである。すなわち、
word2, word3, word4, ..wordn(word1を除去)
word1, word3,word4,…wordn(word2を除去)
…
word1, word2, word3,…wordn-1(wordnを除去)
のようなn−1単語からなる単語の並びをn種作成した上で、それぞれに対して構文解析を行う。これらの構文解析の結果は、必要に応じて、制御部28及び出力処理部32を介して表示装置18に表示・出力される。
【0031】
出力処理部32は、制御部28を介して供給された(対訳)文書、解析結果、構文解析失敗箇所、専門用語調整後の新たな翻訳結果を表示装置18に出力処理するものであり、これにより、表示装置18の表示画面上に翻訳情報画面が表示される。また、出力処理部32は制御部28への各種コマンドに対する制御部28からの応答を表示する。
【0032】
なお、出力装置17として表示装置18を示しているが、出力装置17としては、前述したように、表示装置18だけではなく、印字機等の印刷装置、磁気テープ、磁気ディスク、光ディスク等のコンピュータ可読媒体への出力装置や、他のメディアに文書を送信する送信装置(通信制御装置21)等を採用することもできる。
【0033】
翻訳辞書部31は、文書解析手段30が翻訳対象となる第1言語文書を解析する際に用いる各種辞書データを格納している。翻訳辞書部31は、第1言語から第2言語への翻訳を行うための辞書、及び第2言語から第1言語への翻訳を行うための辞書を格納している。
【0034】
第1言語から第2言語への翻訳を行うための辞書は、語尾等に変化のある第1言語の単語・熟語をその原形に変換するための第1言語活用変化辞書31a、第1言語を解析するための文法が記憶された第1言語解析文法辞書31b、第1言語の単語・熟語に対応する第2言語の訳語がその品詞情報と共に記憶される第1言語単語・熟語辞書31c、第1言語から第2言語への変換情報が記憶された第1言語変換文法辞書31d、第2言語の文の構造を決定する第2言語生成文法辞書31e、さらに語尾等の語形を変化させて翻訳文を完成させる第2言語形態素生成文法辞書31fから構成される。
【0035】
また、第2言語から第1言語への翻訳を行うための辞書は、語尾等に変化のある第2言語の単語・熟語をその原形に変換するための第2言語活用変化辞書31h、第2言語を解析するための文法が記憶された第2言語解析文法辞書31i、第2言語の単語・熟語に対応する第1言語の訳語がその品詞情報と共に記憶される第2言語単語・熟語辞書31j、第2言語から第1言語への変換情報が記憶された第2言語変換文法辞書31k、第1言語の文の構造を決定する第1言語生成文法辞書31l、さらに語尾等の語形を変化させて翻訳文を完成させる第1言語形態素生成文法辞書31mから構成される。
【0036】
なお、図2では、第1言語文書を解析する際に有用と思われる辞書を挙げたが、第1言語文書を解析する際に必ずしもすべてを使用する必要はない。
【0037】
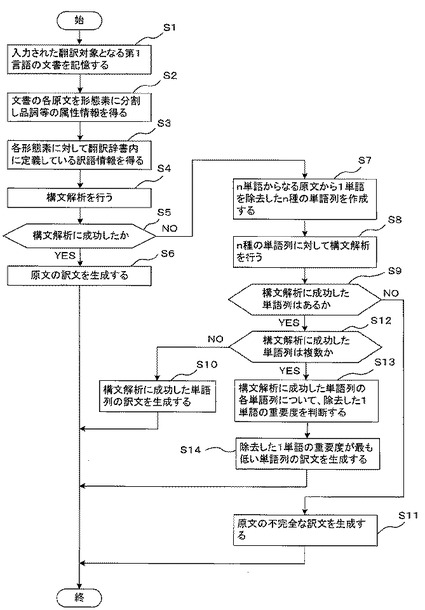
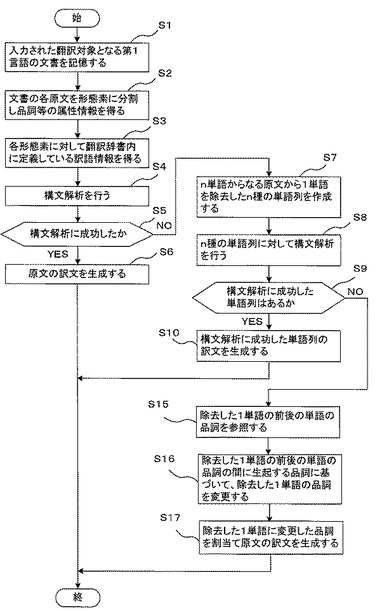
図3は、本発明の実施例1に係わる機械翻訳装置の処理内容を示すフローチャートである。まず、制御部28は、入力装置22から入力処理部27を介して入力された翻訳対象となる第1言語の文書を記憶する(S1)。すなわち、翻訳対象となる第1言語の文書を記憶装置26の文書記憶部29に記憶する。
【0038】
図4は、翻訳対象となる第1言語の文書の一例の説明図である。以下の説明では、英語を第1言語とし日本語を第2言語とした場合を例にとり説明する。
【0039】
次に、制御部28は文書解析手段30を起動する。文書解析手段30は、文書記憶部29から第1言語の文書を読み出し、第1言語の文書の各原文(各文)をそれぞれ形態素に分割し、品詞等の属性情報を得る(S2)。これは、翻訳対象となる第1言語の文書の各原文の統語的特徴を得るためである。
【0040】
ステップS2においては、翻訳辞書部31の第1言語から第2言語への翻訳を行うための辞書、具体的には第1言語活用変化辞書31aと第1言語解析文法辞書31bとの照合により、各単語につき、品詞、原形、属性が付与され、また、各形態素がどのような関係を有するかを示す文構造(係り受け関係)を得る。
【0041】
次に、文書解析手段30は第1言語単語・熟語辞書31cを用いて、それぞれの形態素に対して翻訳辞書部31内に定義している訳語情報を得る(S3)。さらに、構文解析を行う(S4)。そして、訳文生成手段33は構文解析に成功したかを判断し(S5)、構文解析に成功ならば原文の訳文を生成する(S6)。すなわち、第1言語変換文法辞書31d、第2言語生成文法辞書31e、第2言語形態素生成文法辞書31fを用いて第2言語の構造に変換し、構文解析に成功ならば、訳語の形態素生成を行い最終的な訳文を得る。
【0042】
一方、ステップS5において訳文生成手段33が構文解析に成功しなかった(失敗した)と判断したときは、第1言語単語除去手段34は、n単語からなる原文から1単語を除去したn種の単語列を作成する(S7)。これは、n単語からなる原文(word1, word2, word3,..wordn)から1単語を除去した単語列を構文解析し、その構文解析に成功するかどうかの可能性を探るためである。
【0043】
そこで、文書解析手段30は、n単語からなる原文(word1, word2, word3,.. wordn)から1単語を除去したn種の単語列に対して構文解析を行う(S8)。そして、訳文生成手段33は、構文解析に成功した単語列があるかを判断し(S9)、構文解析に成功した単語列があるときは、構文解析に成功した単語列の訳文を生成する(S10)。すなわち、訳文生成手段33は構造変換・形態素生成を行い訳文を得る。
【0044】
一方、構文解析に成功した単語列がないときは、訳文生成手段33は、n種の単語列すべてを棄却し、原文の不完全な訳文を生成する(S11)。すなわち、1単語を除去しない元の原文を形態素解析し、可能な部分の構造変換・形態素生成を行い、構文解析に失敗した不完全な訳文を得る。
【0045】
以上の説明では、第1言語単語除去手段34は、文書解析手段30で構文解析に失敗したときに、原文から1単語を除去した単語列を作成するようにしたが、1単語を除去した単語列に対して構文解析に成功しないときは、1単語ではなく隣接する2単語を除去した単語列を作成し、1単語の除去の場合と同様に、そのそれぞれに対して構文解析を行い、構文解析に成功するものがあれば、翻訳処理まで進めるようにしてもよい。
【0046】
2単語を除去する際は、n単語から構成される文の場合、n−1の組ができる。また、2単語を除去した単語列に対しても構文解析に成功しないときは、隣接する3単語を除去するようにしてもよい。どこで処理を終了とするかについては、除去する単語の最大値を予め設定しておき、その上限まで実行することや、上限を設けずに成功する単語列ができるまで、単語を除去するようにしてもよい。
【0047】
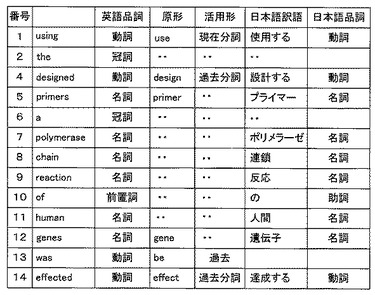
図5は、図4の文番号1の原文に対して、図3の処理を行った場合の形態素解析情報の説明図である。文番号1の原文は14単語から構成されている。いま、図3のステップS5の判定で、構文解析に成功しなかったと判定されたとする。図3のステップS7〜S10の処理がない場合(従来の場合)には、文番号1の原文の不完全な訳文として、例えば、「使用したがってプライマーを設計する、人間の遺伝子のポリメラーゼ連鎖反応が達成された」という部分訳が出力されるものとする(S11)。
【0048】
本発明の実施形態の実施例1では、図3のステップS7〜S10の処理を行う。まず、図3のステップS7において、図6に示すように14通りの単語列を作成する。図6は、14単語からなる図4の文番号1の原文から1単語を除去した14個の単語列の説明図である。「^」は省いた単語がもと存在していた位置を示す。
【0049】
候補1は省いた単語が「using」である単語列、候補2は省いた単語が「the」である単語列、候補3は省いた単語が「thus」である単語列、候補4は省いた単語が「designed」である単語列、候補5は省いた単語が「primers」である単語列、候補6は省いた単語が「a」である単語列、候補7は省いた単語が「polymerase」である単語列、候補8は省いた単語が「chain」である単語列、候補9は省いた単語が「reaction」である単語列、候補10は省いた単語が「of」である単語列、候補11は省いた単語が「human」である単語列、候補12は省いた単語が「genes」である単語列、候補13は省いた単語が「was」である単語列、候補14は省いた単語が「effected」である単語列である。
【0050】
図3のステップS8では、これら14候補について構文解析を行う。この例では、候補3の単語列のみが構文解析に成功したものとする。その場合、ステップS9では、構文解析に成功した単語列があると判定されるので、ステップS10において、その構文解析に成功した候補3の単語列の訳文を生成する。つまり、候補3の単語列に対して構造変換・形態素生成を行い、最終的に訳文として、例えば、次のような日本語の構文として適切な訳文を得る。「設計されたプライマーを使用して、人間の遺伝子のポリメラーゼ連鎖反応が達成された。」
これは、先のすべての単語を取り込んで翻訳した結果、「使用したがってプライマーを設計する、人間の遺伝子のポリメラーゼ連鎖反応が達成された」と比較して、「使用」と「プライマー」との関係が明らかになっていること、「使用」「したがって」と日本語として接続していない表現がないことから、読みやすさが増していることがわかる。”thus”を省くことによる情報量の損失の量よりも、構成要素の関係の明確化による増大する情報の量のほうが高いといえる。つまり、大意をつかむには十分である。
【0051】
ここで、実際にユーザに提示する場合は、例えば、図7に示すように表示装置18に表示・出力する。図7に示すように、通常の翻訳とは異なり、1単語を除いて翻訳してあることを、例えば、翻訳モードの欄に概要モード翻訳であることを表示し、その1単語が何で、どこに位置していたかを、例えば、原文の省いた単語を四角で囲って表示する。色違いやアンダーラインを表示して省いた単語を識別できるように表示してもよい。また、図7では図示を省略しているが、その1単語の辞書引き結果をあわせて表示するようにしてもよい。
【0052】
図7では、1単語を除去した原文と訳文との翻訳方式を「概要モード翻訳」と通常の単語を省かない翻訳方式を「通常モード翻訳」と称して区別して表示している。また、四角で囲った単語は省いた単語がどれかをユーザが一目でわかるようになっている。省いた単語の意味が表示されていれば、ユーザは機械翻訳の訳文の中に除去した1単語(除去語)の訳語をうまく取り込んで、もともとの原文の意味を理解しようと試みることもできる。訳文を作成することが必須でなければ、意味をとる上ではこれで十分である。
【0053】
実施例1によれば、構文解析に成功しないときは、1語を除去して構文解析に成功したときは、その訳文を提供するので、構成要素の関係の明らかな訳文を提供でき、原文の不完全な訳文を少なくできる。
【0054】
(実施例2)
図8は、本発明の実施例2に係る機械翻訳装置の機能ブロック図である。この実施例2は、図2に示した実施例1に対し、文書解析手段30で構文解析に成功した1単語を除去した単語列が複数あるときは、その複数の各単語列について除去した1単語の重要度を判断する単語重要度判定手段35を追加して設け、訳文生成手段33は、単語重要度判定手段で除去した1単語の重要度が最も低いと判定された単語列の訳文を生成するようにしたものである。
【0055】
また、図9は本発明の実施例2に係る機械翻訳装置の処理内容を示すフローチャートである。図3に示した実施例1のフローチャートに対し、ステップS12〜S14が追加されている。図2と同一要素には同一符号を付し、図3と同一ステップには同一符号を付し重複する説明は省略する。
【0056】
図9のステップS9において、訳文生成手段33は構文解析に成功した単語列はあると判断したときは、訳文生成手段33は、さらに構文解析に成功した単語列は複数かどうかを判断する(S12)、そして、構文解析に成功した単語列の候補が複数あった場合には、単語重要度判定手段35は、構文解析に成功した単語列の各単語列について、除去した1単語の重要度を判断する(S13)。そして、訳文生成手段33は、除去した1単語の重要度が最も低い単語列の訳文を生成する。
【0057】
このように、構文解析に成功した単語列の候補が複数あった場合、翻訳対象とする文書の意味を解釈する際の相対的な重要度が最も低い単語を除去した単語列の訳文を生成する。これにより、1単語を除去した場合でも翻訳対象とする文書の意味を保持した訳文が得られる。
【0058】
次に、単語重要度判定手段35での単語の重要度を判定するための判断基準について説明する。この判断基準として、次のような分類を用いる。例えば、内容語は機能語より重要度が高いとする。一般に、機能語は文の中の機能を示し実質的な意味を有していないという点で、内容語よりも重要度が低いと考えることができるからである。また、同じ機能語の中でも、特に第2言語には対応するものがない機能語の場合は、重要性が低いとする。例えば、冠詞は日本語にはないため、省略しても少なくとも大意をつかむ用途に大きな影響はないからである。
【0059】
また、品詞について、名詞や動詞は形容詞や副詞よりも重要性が高いという基準を設ける。英語の品詞で内容語となるものにはおおざっぱにいえば、名詞、動詞、形容詞、副詞があるが、このうち、文の骨格となるのは名詞と動詞である。名詞を修飾する形容詞、動詞を修飾する副詞により表出する意味は、いわば付加的な情報である。したがって、名詞や動詞は、形容詞や副詞よりも重要性が高いという基準を設ける。なお、否定辞のように、その有無で、文の意味がまったく逆になるものも重要度を高くする。
【0060】
さらに、辞書由来情報について、専門用語は非専門用語より重要度が高いとする。一般に、専門用語は、標準的な単語(非専門用語)より意味が限定されており、単語が有する情報量が多いと考えられるからである。
【0061】
以上のような単語の重要度の判断基準を用いることで、除去された単語(除去した1単語)の重要度が最も低いものを優先して訳文として生成する。ここで、最も低い候補を一つに絞り込めない場合は、その残ったすべてを訳文として提供することもできる。あるいは、任意に一つに選択することもできる。
【0062】
実施例2によれば、除去した1単語の重要度が最も低いと判定された単語列の訳文を生成するので、1単語を除去した場合でも翻訳対象とする文書の意味を保持した訳文が得られる。
【0063】
(実施例3)
図10は、本発明の実施例3に係る機械翻訳装置の機能ブロック図である。この実施例3は、図2に示した実施例1に対し、1単語を除去した単語列の構文解析に成功したときは、除去した1単語の直前の単語の品詞と直後の単語の品詞とを参照し、それらの品詞の間に生起し得る品詞を翻訳辞書部31に基づいて抽出し、その生起し得る品詞に基づいて除去した1単語の品詞を変更して調整する品詞調整手段36を設け、訳文生成手段33は、1単語を除去した単語列の訳文を生成することに代えて、品詞調整手段36で変更した品詞を、除去した1単語に割当て原文の訳文を生成するようにしたものである。
【0064】
また、図11は本発明の実施例3に係る機械翻訳装置の処理内容を示すフローチャートである。図3に示した実施例1のフローチャートに対し、ステップS15〜S17が追加されている。図2と同一要素には同一符号を付し、図3と同一ステップには同一符号を付し重複する説明は省略する。
【0065】
実施例1では、原文から単語を除去して、現状レベルで最大限改善可能な訳文を生成することに主眼があるのに対し、実施例3では、原文から単語を除去せずとも、構文解析が可能なように形態素解析能力を高めるようにしたものである。すなわち、図11のステップS9で構文解析に成功しなかったときは、ステップS15〜S17の処理を行う。
【0066】
ステップS9において、訳文生成手段33が構文解析に成功した単語列はないと判断したときは、品詞調整手段36は、除去した1単語の前後の単語の品詞を参照し(S15)、品詞調整手段36は、除去した1単語の前後の単語の品詞間に生起する品詞に基づいて、除去した1単語の品詞を変更する(S16)。そして、訳文生成手段33は、除去した1単語に変更した品詞を割当て原文の訳文を生成する(S17)。
【0067】
例として、図4の文番号1の原文を用いて説明する。前述したように、文番号1の原文のままでは文書解析手段30は構文解析に失敗し、thusという語を除去すると、初めて形態素解析に成功するものであるとする。図12は、図4の文番号1の原文からthusという語を除去した単語列に対しての辞書引き結果の説明図である。
【0068】
品詞調整手段36は、除去した1単語(すなわちここではthus)の前後の任意の数の単語を取り出しその品詞を調べる(S15)。ここでは、除去した1単語(thus)の前後の単語を2単語ずつ取り出すことにする。除去した1単語(thus)の前の2単語は直前のtheとその前のusingであり、除去した1単語(thus)の後ろの2単語は直後のdesignedとその後ろのprimersである。図12より、thusの前のtheは冠詞、その前のusingは現在分詞である。一方、thusの後ろのdesignedは過去分詞であり、そのまた後ろのprimersは名詞である。
【0069】
一方、第1言語解析文法辞書31bは英語の品詞列として生起可能な組を例えば、図13のような形でもっている。図13は説明のためのものであるので、第1言語解析文法辞書の内容{英語の品詞列として生起可能な組の知識(a)〜(d)}を非常に簡略化して示している。品詞調整手段36は、これを除去した1単語の品詞の判断に用いる。
【0070】
冠詞は名詞句の冒頭に来る品詞であり、その前の単語とは大きな切れ目と判断できる。このことから、ここでは、”the thus designed primers”に着目することになる。
【0071】
品詞調整手段36は、図13に示す品詞列として生起可能な組の知識と、過去分詞は形容詞のようにふるまう用法があるという知識とから、”the designed primers”は図13に示す生起可能な組の知識(c)に該当することがわかる。
【0072】
ここで、生起可能な組の知識(d)を参照して、thusを知識(d)の副詞に割り当てれば、英語の品詞の並びとして適切なものになることがわかる。つまり、”thus designed”を形容詞句とし、それを分解した、thusは副詞、designedは形容詞とみる。つまり、thusの品詞を副詞と変更する。
【0073】
これを一般化していうと、第1言語解析文法辞書の知識とステップS15で得られた品詞とを結果を照らし合わせ、除去した1単語として構文的に許される品詞に変更する(S16)。次に、訳文生成手段33は除去した1単語をこの新たな品詞に設定して、もとの何も省略していない状態の原文を翻訳し直す(S17)。
【0074】
ここで、最初の辞書引きで抽出された訳語を適用可能な場合はそれを用いて訳文を作成し(S6)、可能でない場合は外部からその訳語を補うようにする。thusの最初の辞書引きで抽出された訳語は接続詞としての訳語(したがって)であった。そこで、例えば、「このように」といった別の訳語を与えることが考えられる。すると、例えば、元の原文に対して「このように設計されたプライマーを使用して、人間の遺伝子のポリメラーゼ連鎖反応が達成された。」のような訳文を得ることができる。
【0075】
以上を今後の構文解析に生かすために、このような用法のthusが生起する環境を条件部分として、thusの品詞を調整するという規則を追加するようにしてもよい。つまり、前に冠詞、後ろに形容詞があった場合、thusの品詞を副詞に変更するという規則を追加する。
【0076】
このように問題となった単語の品詞を調整する以外に、図13のような第1言語解析文法辞書を精緻化して、除去した1単語を受理できるようにする。別の見方をすれば、前者は個別規則での対応、後者は一般規則での対応である。
【0077】
実施例3によれば、1単語を除去した単語列の訳文を生成することに代えて、品詞調整手段36で変更した品詞を除去した1単語に割当て原文の訳文を生成するので、翻訳対象とする文書の意味を保持した訳文が得られる。
【0078】
(実施例4)
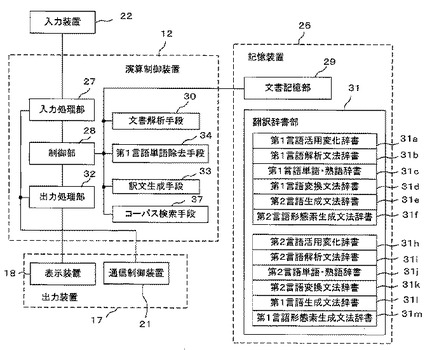
図14は、本発明の実施例4に係る機械翻訳装置の機能ブロック図である。この実施例4は、図2に示した実施例1に対し、1単語を除いた単語列が構文解析に成功したときは、除去した1単語の前後m語のm単語の単語列をコーパスから検索するコーパス検索手段を設けたものである。
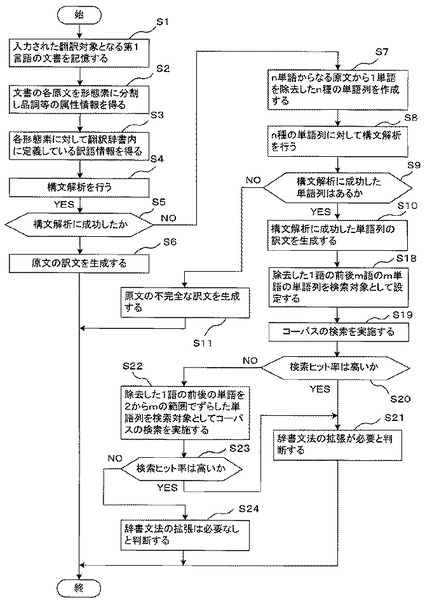
【0079】
コーパス検索手段37は、記憶装置26に記憶された図示省略のコーパス、通信制御装置21を介して通信ネットワークに接続されたサーバのコーパスにアクセスして、除去した1単語の前後m語のm単語の単語列をコーパスから検索する。
【0080】
また、図15は本発明の実施例4に係る機械翻訳装置の処理内容を示すフローチャートである。図3に示した実施例1のフローチャートに対し、ステップS18〜S24が追加されている。図2と同一要素には同一符号を付し、図3と同一ステップには同一符号を付し重複する説明は省略する。
【0081】
実施例3では、除去した1単語の前後の品詞から除去した1単語の新たな品詞を推測したが、これは実際には高度な知識を要し、新たな品詞が得られない可能性もある。そこで、問題となった単語とその前後の並びが、英語の文書において頻度が低ければ、その例文だけ意味が解釈できればよいとし、特に辞書文法を拡張する必要もないと考えられる。一方、頻度が高ければ、その語を省かない原文を構文解析できるようにしておく必要がある。そこで、実施例4では、除去した1単語を扱うことが全体の辞書文法開発において、どの程度重要かの指針を与えることとする。
【0082】
以下、例文として、図4の文番号2の原文を用いて説明する。文番号2の原文での除去した1単語はplacedであるとする。図15のステップS9で構文解析に成功した単語列があるときは、構文解析に成功した単語列の訳文を生成し(S10)、その後に、除去した1語の前後m語のm単語の単語列を検索対象として設定する(S18)。
【0083】
すなわち、除去した1単語の前後m語を検索対象として設定する。例えば、除去した1単語を文頭からn番目の語として、wordnと表記すると、検索対象語は、wordn-m, wordn-m+1,….wordn-1, wordn(除去した1単語)、wordn+1,..wordn+mとなる。例えば、mを3に設定すると、除去した1単語がplacedであることから、“making it better placed to withstand shocks”が検索対象となる。
【0084】
次に、検索対象につきコーパスの検索を実施し(S19)、検索ヒット率は高いかを判断する(S20)。検索ヒット率は、検索対象の語数を考慮して、コーパスにから検索されたヒット件数が予め設定した基準値を超えたか否かで、検索ヒット率が高いか低いかを判断する。検索ヒット率が高い場合は辞書文法の拡張が必要と判断する(S21)。
【0085】
一方、検索ヒット率が低い場合は、除去した1語の前後の単語を1からmの範囲でずらしたものを検索対象としてコーパスの検索を実施する(S22)。そして、検索ヒット率は高いかを判断し(S23)、検索ヒット率が高い場合は辞書文法の拡張が必要と判断する(S21)。一方、検索ヒット率が低い場合は辞書文法の拡張は必要なしと判断する(S24)。
【0086】
ステップS22では、m=3とした場合には、3×3−1=8通りの検索を試みることになる。この8通りは以下となる。
【0087】
(1)better placed to withstand shocks (前1単語、後ろ3単語) 22
(2)better placed to withstand(前1単語、後ろ2単語)26,800
(3)better placed to (前1単語、後ろ1単語) 4,600,000
(4)it better placed to withstand shocks (前2単語、後ろ3単語) 1
(5)it better placed to withstand (前2単語、後ろ2単語) 1,820
(6)it better placed to (前2単語、後ろ1単語) 286,000
(7)making it better placed to withstand (前3単語、後ろ2単語)114
(8)making it better placed to (前3単語、後ろ1単語) 6,410
右の数字は、ある実際の検索サイトを使って検索した場合のヒット件数を示すものである。検索対象の単語の数が少ないほど、検索ヒット率が高まるのは当然である。しかし、検索対象の語数が同一であっても、検索ヒット率には大きな差があることがわかる。例えば、同じ4語であっても、making it better placed toは6,000台、it better placed to withstandは1,800台、better placed to withstand shocksは20程度と幅がある。3単語の場合はit better placed toが群を抜いて高く、辞書文法が扱えるようにする必要があると判断できる。このことから、検索対象の語数ごとに予め設定した基準値を決めておき、コーパスにから検索されたヒット件数がその基準値を超えたときに検索ヒット率が高いと判断する。
【0088】
このように、検索ヒット率が高い検索語の組み合わせがあることになり、その組み合わせは辞書文法の拡張が必要と判断される。一方、検索ヒット率が高い検索語の組み合わせがない場合は、辞書文法の拡張必要なしという判断を下すことができる。
【0089】
以上の説明では、除去した1単語の前後m語のm単語の単語列を検索対象としたが、これに代えて、除去した1単語に先行するi個の単語、除去した1単語に後続するj個の単語、除去した1単語を任意の単語に置き換えたi+j+1個の単語列を検索対象とすることも可能である。
【0090】
ここでは、i=3、j=1であるとし、前の語3単語making it better、後ろ1単語 toを検索対象とする。図16はその検索結果の一例の説明図である。ここで囲みのある単語は除去した1単語placedと同じ位置にある任意の単語である。図16によれば、making it better (任意の単語) toの場合には、除去した1単語placedと同じ位置にableが起こりやすいことがわかる。任意の単語であるableの他の語としては、suited, adapted, equippedがあり、いずれも適合するといったニュアンスがある点で共通している。こうした情報は、”making it better placed to”を解釈するための文法を記述する上で参考となる情報である。
【0091】
実施例4によれば、1単語を除いた単語列が構文解析に成功したときは、除去した1単語の前後m語のm単語の単語列、または、除去した1単語に先行するi個の単語、除去した1単語に後続するj個の単語、除去した1単語を任意の単語に置き換えたi+j+1個の単語列をコーパスから検索するので、除去した1単語(除去語)をどのように扱うことが全体の辞書文法開発においてどの程度重要かの指針を与えることができる。
【0092】
(実施例5)
図17は、本発明の実施例5に係る機械翻訳装置の機能ブロック図である。この実施例5は、図2に示した実施例1に対し、1単語を除いた単語列が構文解析に成功したときは、除去した1単語Bの直前の単語Aと除去した単語Bとから構成される2語の単語列AB、または、除去した単語Bと除去した単語Bの直後の単語Cとから構成される2語の単語列BCを見出し語とした品詞の辞書登録をユーザに問い合わせる辞書登録問い合わせ手段38を設けたものである。
【0093】
また、図18は本発明の実施例5に係る機械翻訳装置の処理内容を示すフローチャートである。図3に示した実施例1のフローチャートに対し、ステップS25が追加されている。図2と同一要素には同一符号を付し、図3と同一ステップには同一符号を付し重複する説明は省略する。
【0094】
実施例5は、除去した1単語を適切な品詞として辞書に取り込むために辞書登録を行うものである。図18のステップS9にて構文解析に成功した単語列がある場合、構文解析に成功するということは、除去した1単語をB、除去した1単語の直前の単語をA、除去した1単語の直後の単語をCとすると、複合語ABを直前の単語Aと同一の品詞に割り当てるか、複合語BCを直後の単語Cと同一の品詞に割り当てれば、構文解析が成功することを意味する。
【0095】
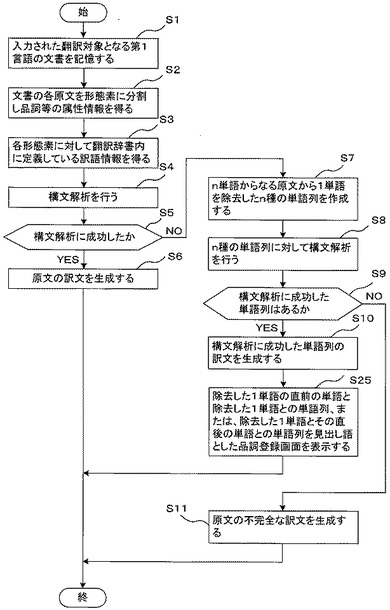
以下、例文として、図4の文番号3の原文を用いて説明する。図4の文番号3の原文において、文書解析手段30が単語doを省くと構文解析に成功するものとする。この場合、除去した1単語doの直前の単語は冠詞の”the”であり、直後の単語は名詞のstatementである。従って、機械的には、”the do”を冠詞として、あるいは、”do statement”を名詞として解釈すれば、全体の構文解析は成功する。
【0096】
前者は英語として、適切とはいえないため後者をとる。つまり、”do statement”の品詞を名詞として、見出し語”do statement”を人間が与える訳語とともに辞書登録を行えるようにする。
【0097】
すなわち、辞書登録問い合わせ手段38は、文書解析手段30により、1単語を除いた単語列が構文解析に成功したときは、図19に示すような辞書登録問い合わせ画面を表示装置18に表示出力する。図19では、見出し語”do statement”を辞書登録するか否かの辞書登録問い合わせ画面を示している。これは、前述したように、”the do”を冠詞することは英語として、適切とはいえないためである。なお、”the do”を冠詞する辞書登録問い合わせ画面を表示するようにしてもよい。第1言語の知識を有するユーザは、”the do”を冠詞する辞書登録問い合わせ画面を見て、そのような辞書登録は適切でないと判断することになる。
【0098】
実施例5によれば、除去した1単語Bの直前の単語Aと除去した単語Bとから構成される2語の単語列AB、または、除去した単語Bと除去した単語Bの直後の単語Cとから構成される2語の単語列BCを見出し語とした品詞の辞書登録をユーザに問い合わせるので、除去した1単語を適切な品詞として辞書登録することを促すことができる。これにより、機械翻訳装置のユーザあるいは開発者は翻訳辞書の増強を図ることができる。
【0099】
本発明のいくつかの実施例を説明したが、これらの実施例は、例として提示したものであり、発明の範囲を限定することは意図していない。これら新規な実施例は、その他の様々な形態で実施されることが可能であり、発明の要旨を逸脱しない範囲で、種々の省略、置き換え、変更を行うことができる。これら実施例やその変形は、発明の範囲や要旨に含まれるとともに、特許請求の範囲に記載された発明とその均等の範囲に含まれる。
【符号の説明】
【0100】
11…機械翻訳装置、12…演算制御装置、13…プロセッサ、14…メモリ、15…機械翻訳プログラム、16…作業エリア、17…出力装置、18…表示装置、19…印刷装置、20…ディスクドライブ、21…通信制御装置、22…入力装置、23…マウス、24…キーボード、25…ハードディスクドライブ(HDD)、26…記憶装置、27…入力処理部、28…制御部、29…文書記憶部、30…文書解析手段、31…翻訳辞書部、32…出力処理部、33…訳文生成手段、34…第1言語単語除去手段、35…単語重要度判定手段、36…品詞調整手段、37…コーパス検索手段、38…辞書登録問い合わせ手段
【技術分野】
【0001】
本発明の実施形態は、自然言語文書を処理して第1言語を第2言語に機械翻訳する機械翻訳装置、方法及びプログラムに関する。
【背景技術】
【0002】
機械翻訳の特徴として、ある1単語が加わるととたんに第1言語の原文の構文解析に失敗し、部分訳として出力されることがある。こうした部分訳は、人間にとって非常に読みづらいものであることが多い。
【0003】
一方、人間による翻訳の場合、正しく構文解析できなくても、第2言語の文法知識から、第2言語において自然な文書に独自に直して訳文として作成することが多いため、このような読みづらい訳文になることは少ない。人間の訳文はたとえ誤訳だとしても、読みづらさの違いにより、機械の訳文が必要以上に低く評価されやすい。
【0004】
換言すると、1単語を除いて原文に対する訳文の評点と原文通りに翻訳した場合の訳文の評点との落差は非常に大きい。人間の翻訳では、ある1単語が加わることで、これほど大きな訳質の差がみられることは少ないと思われる。つまり、このような特徴があることで、機械翻訳の訳質が必要以上に低くみられてしまうことがある。
【0005】
こうした失敗の原因となる単語は、誤植であることもある。すなわち、入力を間違え、たまたま、そこには現れ得ない品詞の単語が入ってしまうことがある。こうした誤植は、母国語話者であれば、自然に検出できることが多いが、第1言語の知識が欠如している者にとっては、誤植であることが峻別できない。
【0006】
従来より、機械翻訳において、構文解析に失敗した場合の対策として、主に2つの方法が採られてきた。一つは、機械翻訳装置が扱えるように、原文を編集するものであり、前編集と呼ばれる。これは、例えば、原文における係り受け関係を指定する、構成要素の切れ目を指定するなど、原文は変えずに情報を付加する方法、原文そのものの表現を、例えば産業日本語などの機械処理になじむ言語に則って書き換えたり、省略されている語を補う方法などがある。いずれも、第1言語の知識、およびどういった表現は機械にとって扱いにくいかという知識が必要であり、特殊な技術を要する。また、編集自体、負荷の大きい作業である。場合によっては、人間が直接翻訳した方が効率が高いこともある。
【0007】
もう一つの方法は、原文において、構文解析に成功した部分(部分訳)をうまく組み合わせて、訳文を生成する方法である。例えば、単文ごとの分割、句ごとの分割、節ごとの分割、または単語ごとの分割のいずれか複数を含む分割手段を有し、もっとも大きなテキストの構成要素から順に、より小さなテキストの構成要素に分割することによって部分訳を作成し、それらを一組にして全体の翻訳結果を合成するようにしたものがある(例えば、特許文献1参照)。
【0008】
しかし、部分訳を組み合わせるものでは、部分訳を合成しても全体の訳になるとは限らない場合がある。すなわち、非単調性が存在する(http://www.jaist.ac.jp/~kshirai/lec/i223/14.pdf)。
【0009】
単文レベルの合成であれば別だが、それより低いレベルの部分訳の合成となると、それらをどのように組み合わせればよいかという知識は、非常に高度な知識であり、お互いの修飾関係を把握しておく必要がある。単純に前から、順に合成していっても、意味をなさない訳文になる可能性が高い。
【0010】
このことから、合成はもともと人間が行うことを前提としているものもある(例えば、特許文献2参照)。すなわち、特許文献2には以下のように書かれている。「部分訳として翻訳された結果は、翻訳者が編集手段によって自由に並び替えたり、連結をし、文全体を構成すればよい。部分訳自体は正しく翻訳されている可能性が高いので、翻訳結果の修正の手間が省ける。」
このように従来の方式では、何らかの人間の介在が前提となっている。前編集の方法をとる場合、第1言語の知識を必要とし、負荷の高い作業、いわゆるチューニングが発生する。これは、通常の第1言語の知識だけでなく、どのような言語表現が機械にとって処理しにくいかといった(人間が処理しやすい言語表現とは必ずしも一致しない)特殊な知識も必要とする。したがって、パーソナル・ユーザのように、単に大意をつかむために、機械翻訳を利用している場合には適切といえない。特に、第1言語をまったく解さないユーザの場合は、特にそのことがいえる。
【0011】
また、部分訳を合成する場合であるが、分割した単位が単純な関係にある場合は、それらを結合するだけで、理解可能な訳文が生成されることが予測される(非特許文献1参照)。しかし、分割が多くなるほど、それらの関係は複雑になり、どのようにそれらを組み合わせるかを判断することは困難になる。また、単純に長文であるため、解析しにくい場合は、従来の場合で処理可能であろうが、ある単語が原因で全体の構文解析を難しくしている場合は、極端にいえば、単語レベルまで分割しなければ処理できない。単語ごとの翻訳を合成した結果は、他との関係を参照していないので、正しい解釈とならないと予想される。そもそも、「全体は部分の総和以上のものである」というゲシュタルト的な考えに立てば、このように部分訳を単純に合成するだけでは、正しい意味解釈の目的を十分果たせない。
【0012】
視点を変えて、機械翻訳装置の開発者の立場からすると、従来のような方式は、簡単にいえば、現状のシステムが受け入れやすい方法に原文を変えるものであり、システム自体の改善にはつながらない。原文そのものは変えずに、システムを頑強にすることによって受理できるようにするという位置づけになっていない。また、構文解析の失敗の原因は具体的にどこであるか効率的に特定できていない。現状では、原文を少しずつ変化させてみて、開発者が自らの経験知から、原因を探りあてるということが行われている。
【先行技術文献】
【特許文献】
【0013】
【特許文献1】特開平5−2604号公報
【特許文献2】特開平6−124303号公報
【非特許文献】
【0014】
【非特許文献1】吉田 節行(2007) 山形大学工学部情報科学科平成18年度卒業論文「特許文の機械翻訳における正しい係り受け判定のための文章分割」平成19年3月 (http://isyus2.yz.yamagata-u.ac.jp/xoops/kenkyuu_seika/2007/2007_B4_yoshida.pdf)
【発明の概要】
【発明が解決しようとする課題】
【0015】
本発明が解決しようとする課題は、第1言語の文書の原文が構文解析に失敗した場合でも、ユーザに負担を課すことなく読みやすい訳文を生成できるとともに、開発者による機械翻訳のチューニングの効率化や省力化を図ることができる機械翻訳装置、方法及びプログラムを提供することである。
【課題を解決するための手段】
【0016】
本発明の実施形態に係る機械翻訳装置は、機械翻訳プログラム、翻訳対象の第1言語の原文を翻訳目的の第2言語の訳文に翻訳するための機械翻訳辞書を記憶した記憶装置と、前記機械翻訳プログラムを演算実行する演算制御装置とを備える。
【0017】
文書解析手段は、第1言語で表現された文書の各原文を構文解析する。訳文生成手段は、文書解析手段で構文解析に成功したときは原文の訳文を生成する。第1言語単語除去手段は、文書解析手段で構文解析に失敗したときは原文から1単語を除去した単語列を作成する。
【0018】
また、文書解析手段は、第1言語単語除去手段で得られた1単語を除去した単語列を構文解析し、訳文生成手段は、1単語を除去した単語列の構文解析に成功したときはその単語列の訳文を生成し、1単語を除去した単語列の構文解析に失敗したときは原文の不完全な訳文を生成する。
【図面の簡単な説明】
【0019】
【図1】本発明の実施形態に係る機械翻訳装置のハードウエア構成を示すブロック構成図。
【図2】本発明の実施例1に係る機械翻訳装置の機能ブロック図。
【図3】本発明の実施例1に係る機械翻訳装置の処理内容を示すフローチャート。
【図4】本発明の実施例1での翻訳対象となる第1言語の文書の一例の説明図。
【図5】図4の文番号1の原文に対して、図3の処理を行った場合の形態素解析情報の説明図。
【図6】14単語からなる図4の文番号1の原文から1単語を除去した14個の単語列の説明図。
【図7】本発明の実施例1による訳文の表示画面の一例の説明図。
【図8】本発明の実施例2に係る機械翻訳装置の機能ブロック図
【図9】本発明の実施例2に係る機械翻訳装置の処理内容を示すフローチャート。
【図10】本発明の実施例3に係る機械翻訳装置の機能ブロック図。
【図11】本発明の実施例3に係る機械翻訳装置の処理内容を示すフローチャート。
【図12】図4の文番号1の原文からthusという語を除去した単語列に対しての辞書引き結果の説明図。
【図13】本発明の実施例3における第1言語解析文法辞書の一例を示す説明図。
【図14】本発明の実施例4に係る機械翻訳装置の機能ブロック図。
【図15】本発明の実施例4に係る機械翻訳装置の処理内容を示すフローチャート。
【図16】本発明の実施例4に係る機械翻訳装置のコーパス検索手段での検索結果の一例の説明図。
【図17】本発明の実施例5に係る機械翻訳装置の機能ブロック図。
【図18】本発明の実施例5に係る機械翻訳装置の処理内容を示すフローチャート。
【図19】本発明の実施例5における辞書登録問い合わせ画面の一例を示す説明図。
【発明を実施するための形態】
【0020】
以下、本発明の実施形態を図面に基づいて説明する。図1は本発明の実施形態に係る機械翻訳装置のハードウエア構成を示すブロック構成図である。
【0021】
図1において、機械翻訳装置11は、例えば一般的なコンピュータに機械翻訳プログラムなどのソフトウェアプログラムがインストールされ、そのソフトウェアプログラムが演算制御装置12のプロセッサ13において実行されることにより実現される。
【0022】
演算制御装置12は機械翻訳に関する各種演算を行うものであり、演算制御装置12はプロセッサ13とメモリ14とを有し、メモリ14には翻訳に関する機械翻訳プログラム15が記憶され、プロセッサ13により処理が実行される際には作業エリア16が用いられる。演算制御装置12の演算結果等は出力装置17である表示装置18、印刷装置19、ディスクドライブ20に出力され、また、通信制御装置21を介して通信ネットワークに出力される。
【0023】
入力装置22は演算制御装置12に情報を入力するものであり、例えば、マウス23、キーボード24、ディスクドライブ20、通信制御装置21から構成され、例えば、マウス23やキーボード24は表示装置18を介して演算制御装置12に各種指令を入力し、キーボード24、ディスクドライブ20、通信制御装置21は翻訳対象の文書を入力する。
【0024】
すなわち、ディスクドライブ20は翻訳対象の文書のファイルを記憶媒体に入出力するものであり、通信制御装置21は機械翻訳装置11をインターネットやLANなどの通信ネットワークに接続するものである。通信制御装置21はLANカードやモデムなどの装置であり、通信制御装置21を介して通信ネットワークと送受信したデータは入力信号又は出力信号として演算制御装置12に送受信される。さらに、演算制御装置12の演算結果や翻訳に必要な知識・規則を蓄積した翻訳辞書等を記憶するハードディスクドライブ(HDD)25が設けられている。
【0025】
(実施例1)
図2は本発明の実施例1に係る機械翻訳装置11の機能ブロック図である。図2において、演算制御装置12内の各機能ブロックは、上述の機械翻訳プログラム15を構成する各プログラムに対応する。すなわち、プロセッサ13が機械翻訳プログラム15を構成する各プログラムを実行することで、演算制御装置12は、各機能ブロックとして機能することとなる。また、記憶装置26の各ブロックは、演算制御装置12内のメモリ14及びハードディスクドライブ25の記憶領域に対応する。
【0026】
入力装置22は、翻訳対象となる文書の電子データを入力するものであり、ユーザの入力操作に基づく(対訳)の入力が可能である。入力装置22から入力される文書は、翻訳対象となる第1言語文書である。
【0027】
なお、入力装置22としては、OCR(光学式文字読み取り装置)や、磁気テープ、磁気ディスク、光ディスク等、コンピュータ可読媒体からの読み込み装置を採用することも可能であり、入力装置22によって入力された翻訳対象となる第1言語文書は、演算制御装置12の入力処理部27により入力処理されて取り込まれ、制御部28を介して記憶装置26の文書記憶部29に記憶される。また、入力装置22は、入力処理部27を介して制御部28に対して各種コマンドを与える。制御部28は、入力処理部27、出力処理部32、文書解析手段30を制御するとともに、記憶装置26とのデータの授受の制御も行う。
【0028】
文書解析手段30は、第1言語で表現された文書の各原文を構文解析するものである。すなわち、制御部28からの指示に従って、後述する記憶装置26の機械翻訳辞書である翻訳辞書部31を用いて、入力装置22によって入力され、文書記憶部29に記憶された翻訳対象となる第1言語文書の原文を解析し、その解析情報を文書記憶部29に記憶する。また、その解析結果は、必要に応じて、制御部28及び出力処理部32を介して出力装置17に出力される。以下の説明では、出力装置17は表示装置18である場合について説明する。
【0029】
訳文生成手段33は、文書解析手段30で構文解析に成功したときは原文の訳文を生成するものであり、その訳文を文書記憶部29に記憶するとともに、必要に応じて、制御部28及び出力処理部32を介して表示装置18に表示・出力する。
【0030】
第1言語単語除去手段34は、文書解析手段30で構文解析に失敗したとき、原文から1単語を除去した単語列を作成するものであり、文書解析手段30で構文解析に失敗したときは、n単語からなる原文(word1, word2, word3,.., wordn)から、1単語を除去したn種の単語列を作成するものである。すなわち、
word2, word3, word4, ..wordn(word1を除去)
word1, word3,word4,…wordn(word2を除去)
…
word1, word2, word3,…wordn-1(wordnを除去)
のようなn−1単語からなる単語の並びをn種作成した上で、それぞれに対して構文解析を行う。これらの構文解析の結果は、必要に応じて、制御部28及び出力処理部32を介して表示装置18に表示・出力される。
【0031】
出力処理部32は、制御部28を介して供給された(対訳)文書、解析結果、構文解析失敗箇所、専門用語調整後の新たな翻訳結果を表示装置18に出力処理するものであり、これにより、表示装置18の表示画面上に翻訳情報画面が表示される。また、出力処理部32は制御部28への各種コマンドに対する制御部28からの応答を表示する。
【0032】
なお、出力装置17として表示装置18を示しているが、出力装置17としては、前述したように、表示装置18だけではなく、印字機等の印刷装置、磁気テープ、磁気ディスク、光ディスク等のコンピュータ可読媒体への出力装置や、他のメディアに文書を送信する送信装置(通信制御装置21)等を採用することもできる。
【0033】
翻訳辞書部31は、文書解析手段30が翻訳対象となる第1言語文書を解析する際に用いる各種辞書データを格納している。翻訳辞書部31は、第1言語から第2言語への翻訳を行うための辞書、及び第2言語から第1言語への翻訳を行うための辞書を格納している。
【0034】
第1言語から第2言語への翻訳を行うための辞書は、語尾等に変化のある第1言語の単語・熟語をその原形に変換するための第1言語活用変化辞書31a、第1言語を解析するための文法が記憶された第1言語解析文法辞書31b、第1言語の単語・熟語に対応する第2言語の訳語がその品詞情報と共に記憶される第1言語単語・熟語辞書31c、第1言語から第2言語への変換情報が記憶された第1言語変換文法辞書31d、第2言語の文の構造を決定する第2言語生成文法辞書31e、さらに語尾等の語形を変化させて翻訳文を完成させる第2言語形態素生成文法辞書31fから構成される。
【0035】
また、第2言語から第1言語への翻訳を行うための辞書は、語尾等に変化のある第2言語の単語・熟語をその原形に変換するための第2言語活用変化辞書31h、第2言語を解析するための文法が記憶された第2言語解析文法辞書31i、第2言語の単語・熟語に対応する第1言語の訳語がその品詞情報と共に記憶される第2言語単語・熟語辞書31j、第2言語から第1言語への変換情報が記憶された第2言語変換文法辞書31k、第1言語の文の構造を決定する第1言語生成文法辞書31l、さらに語尾等の語形を変化させて翻訳文を完成させる第1言語形態素生成文法辞書31mから構成される。
【0036】
なお、図2では、第1言語文書を解析する際に有用と思われる辞書を挙げたが、第1言語文書を解析する際に必ずしもすべてを使用する必要はない。
【0037】
図3は、本発明の実施例1に係わる機械翻訳装置の処理内容を示すフローチャートである。まず、制御部28は、入力装置22から入力処理部27を介して入力された翻訳対象となる第1言語の文書を記憶する(S1)。すなわち、翻訳対象となる第1言語の文書を記憶装置26の文書記憶部29に記憶する。
【0038】
図4は、翻訳対象となる第1言語の文書の一例の説明図である。以下の説明では、英語を第1言語とし日本語を第2言語とした場合を例にとり説明する。
【0039】
次に、制御部28は文書解析手段30を起動する。文書解析手段30は、文書記憶部29から第1言語の文書を読み出し、第1言語の文書の各原文(各文)をそれぞれ形態素に分割し、品詞等の属性情報を得る(S2)。これは、翻訳対象となる第1言語の文書の各原文の統語的特徴を得るためである。
【0040】
ステップS2においては、翻訳辞書部31の第1言語から第2言語への翻訳を行うための辞書、具体的には第1言語活用変化辞書31aと第1言語解析文法辞書31bとの照合により、各単語につき、品詞、原形、属性が付与され、また、各形態素がどのような関係を有するかを示す文構造(係り受け関係)を得る。
【0041】
次に、文書解析手段30は第1言語単語・熟語辞書31cを用いて、それぞれの形態素に対して翻訳辞書部31内に定義している訳語情報を得る(S3)。さらに、構文解析を行う(S4)。そして、訳文生成手段33は構文解析に成功したかを判断し(S5)、構文解析に成功ならば原文の訳文を生成する(S6)。すなわち、第1言語変換文法辞書31d、第2言語生成文法辞書31e、第2言語形態素生成文法辞書31fを用いて第2言語の構造に変換し、構文解析に成功ならば、訳語の形態素生成を行い最終的な訳文を得る。
【0042】
一方、ステップS5において訳文生成手段33が構文解析に成功しなかった(失敗した)と判断したときは、第1言語単語除去手段34は、n単語からなる原文から1単語を除去したn種の単語列を作成する(S7)。これは、n単語からなる原文(word1, word2, word3,..wordn)から1単語を除去した単語列を構文解析し、その構文解析に成功するかどうかの可能性を探るためである。
【0043】
そこで、文書解析手段30は、n単語からなる原文(word1, word2, word3,.. wordn)から1単語を除去したn種の単語列に対して構文解析を行う(S8)。そして、訳文生成手段33は、構文解析に成功した単語列があるかを判断し(S9)、構文解析に成功した単語列があるときは、構文解析に成功した単語列の訳文を生成する(S10)。すなわち、訳文生成手段33は構造変換・形態素生成を行い訳文を得る。
【0044】
一方、構文解析に成功した単語列がないときは、訳文生成手段33は、n種の単語列すべてを棄却し、原文の不完全な訳文を生成する(S11)。すなわち、1単語を除去しない元の原文を形態素解析し、可能な部分の構造変換・形態素生成を行い、構文解析に失敗した不完全な訳文を得る。
【0045】
以上の説明では、第1言語単語除去手段34は、文書解析手段30で構文解析に失敗したときに、原文から1単語を除去した単語列を作成するようにしたが、1単語を除去した単語列に対して構文解析に成功しないときは、1単語ではなく隣接する2単語を除去した単語列を作成し、1単語の除去の場合と同様に、そのそれぞれに対して構文解析を行い、構文解析に成功するものがあれば、翻訳処理まで進めるようにしてもよい。
【0046】
2単語を除去する際は、n単語から構成される文の場合、n−1の組ができる。また、2単語を除去した単語列に対しても構文解析に成功しないときは、隣接する3単語を除去するようにしてもよい。どこで処理を終了とするかについては、除去する単語の最大値を予め設定しておき、その上限まで実行することや、上限を設けずに成功する単語列ができるまで、単語を除去するようにしてもよい。
【0047】
図5は、図4の文番号1の原文に対して、図3の処理を行った場合の形態素解析情報の説明図である。文番号1の原文は14単語から構成されている。いま、図3のステップS5の判定で、構文解析に成功しなかったと判定されたとする。図3のステップS7〜S10の処理がない場合(従来の場合)には、文番号1の原文の不完全な訳文として、例えば、「使用したがってプライマーを設計する、人間の遺伝子のポリメラーゼ連鎖反応が達成された」という部分訳が出力されるものとする(S11)。
【0048】
本発明の実施形態の実施例1では、図3のステップS7〜S10の処理を行う。まず、図3のステップS7において、図6に示すように14通りの単語列を作成する。図6は、14単語からなる図4の文番号1の原文から1単語を除去した14個の単語列の説明図である。「^」は省いた単語がもと存在していた位置を示す。
【0049】
候補1は省いた単語が「using」である単語列、候補2は省いた単語が「the」である単語列、候補3は省いた単語が「thus」である単語列、候補4は省いた単語が「designed」である単語列、候補5は省いた単語が「primers」である単語列、候補6は省いた単語が「a」である単語列、候補7は省いた単語が「polymerase」である単語列、候補8は省いた単語が「chain」である単語列、候補9は省いた単語が「reaction」である単語列、候補10は省いた単語が「of」である単語列、候補11は省いた単語が「human」である単語列、候補12は省いた単語が「genes」である単語列、候補13は省いた単語が「was」である単語列、候補14は省いた単語が「effected」である単語列である。
【0050】
図3のステップS8では、これら14候補について構文解析を行う。この例では、候補3の単語列のみが構文解析に成功したものとする。その場合、ステップS9では、構文解析に成功した単語列があると判定されるので、ステップS10において、その構文解析に成功した候補3の単語列の訳文を生成する。つまり、候補3の単語列に対して構造変換・形態素生成を行い、最終的に訳文として、例えば、次のような日本語の構文として適切な訳文を得る。「設計されたプライマーを使用して、人間の遺伝子のポリメラーゼ連鎖反応が達成された。」
これは、先のすべての単語を取り込んで翻訳した結果、「使用したがってプライマーを設計する、人間の遺伝子のポリメラーゼ連鎖反応が達成された」と比較して、「使用」と「プライマー」との関係が明らかになっていること、「使用」「したがって」と日本語として接続していない表現がないことから、読みやすさが増していることがわかる。”thus”を省くことによる情報量の損失の量よりも、構成要素の関係の明確化による増大する情報の量のほうが高いといえる。つまり、大意をつかむには十分である。
【0051】
ここで、実際にユーザに提示する場合は、例えば、図7に示すように表示装置18に表示・出力する。図7に示すように、通常の翻訳とは異なり、1単語を除いて翻訳してあることを、例えば、翻訳モードの欄に概要モード翻訳であることを表示し、その1単語が何で、どこに位置していたかを、例えば、原文の省いた単語を四角で囲って表示する。色違いやアンダーラインを表示して省いた単語を識別できるように表示してもよい。また、図7では図示を省略しているが、その1単語の辞書引き結果をあわせて表示するようにしてもよい。
【0052】
図7では、1単語を除去した原文と訳文との翻訳方式を「概要モード翻訳」と通常の単語を省かない翻訳方式を「通常モード翻訳」と称して区別して表示している。また、四角で囲った単語は省いた単語がどれかをユーザが一目でわかるようになっている。省いた単語の意味が表示されていれば、ユーザは機械翻訳の訳文の中に除去した1単語(除去語)の訳語をうまく取り込んで、もともとの原文の意味を理解しようと試みることもできる。訳文を作成することが必須でなければ、意味をとる上ではこれで十分である。
【0053】
実施例1によれば、構文解析に成功しないときは、1語を除去して構文解析に成功したときは、その訳文を提供するので、構成要素の関係の明らかな訳文を提供でき、原文の不完全な訳文を少なくできる。
【0054】
(実施例2)
図8は、本発明の実施例2に係る機械翻訳装置の機能ブロック図である。この実施例2は、図2に示した実施例1に対し、文書解析手段30で構文解析に成功した1単語を除去した単語列が複数あるときは、その複数の各単語列について除去した1単語の重要度を判断する単語重要度判定手段35を追加して設け、訳文生成手段33は、単語重要度判定手段で除去した1単語の重要度が最も低いと判定された単語列の訳文を生成するようにしたものである。
【0055】
また、図9は本発明の実施例2に係る機械翻訳装置の処理内容を示すフローチャートである。図3に示した実施例1のフローチャートに対し、ステップS12〜S14が追加されている。図2と同一要素には同一符号を付し、図3と同一ステップには同一符号を付し重複する説明は省略する。
【0056】
図9のステップS9において、訳文生成手段33は構文解析に成功した単語列はあると判断したときは、訳文生成手段33は、さらに構文解析に成功した単語列は複数かどうかを判断する(S12)、そして、構文解析に成功した単語列の候補が複数あった場合には、単語重要度判定手段35は、構文解析に成功した単語列の各単語列について、除去した1単語の重要度を判断する(S13)。そして、訳文生成手段33は、除去した1単語の重要度が最も低い単語列の訳文を生成する。
【0057】
このように、構文解析に成功した単語列の候補が複数あった場合、翻訳対象とする文書の意味を解釈する際の相対的な重要度が最も低い単語を除去した単語列の訳文を生成する。これにより、1単語を除去した場合でも翻訳対象とする文書の意味を保持した訳文が得られる。
【0058】
次に、単語重要度判定手段35での単語の重要度を判定するための判断基準について説明する。この判断基準として、次のような分類を用いる。例えば、内容語は機能語より重要度が高いとする。一般に、機能語は文の中の機能を示し実質的な意味を有していないという点で、内容語よりも重要度が低いと考えることができるからである。また、同じ機能語の中でも、特に第2言語には対応するものがない機能語の場合は、重要性が低いとする。例えば、冠詞は日本語にはないため、省略しても少なくとも大意をつかむ用途に大きな影響はないからである。
【0059】
また、品詞について、名詞や動詞は形容詞や副詞よりも重要性が高いという基準を設ける。英語の品詞で内容語となるものにはおおざっぱにいえば、名詞、動詞、形容詞、副詞があるが、このうち、文の骨格となるのは名詞と動詞である。名詞を修飾する形容詞、動詞を修飾する副詞により表出する意味は、いわば付加的な情報である。したがって、名詞や動詞は、形容詞や副詞よりも重要性が高いという基準を設ける。なお、否定辞のように、その有無で、文の意味がまったく逆になるものも重要度を高くする。
【0060】
さらに、辞書由来情報について、専門用語は非専門用語より重要度が高いとする。一般に、専門用語は、標準的な単語(非専門用語)より意味が限定されており、単語が有する情報量が多いと考えられるからである。
【0061】
以上のような単語の重要度の判断基準を用いることで、除去された単語(除去した1単語)の重要度が最も低いものを優先して訳文として生成する。ここで、最も低い候補を一つに絞り込めない場合は、その残ったすべてを訳文として提供することもできる。あるいは、任意に一つに選択することもできる。
【0062】
実施例2によれば、除去した1単語の重要度が最も低いと判定された単語列の訳文を生成するので、1単語を除去した場合でも翻訳対象とする文書の意味を保持した訳文が得られる。
【0063】
(実施例3)
図10は、本発明の実施例3に係る機械翻訳装置の機能ブロック図である。この実施例3は、図2に示した実施例1に対し、1単語を除去した単語列の構文解析に成功したときは、除去した1単語の直前の単語の品詞と直後の単語の品詞とを参照し、それらの品詞の間に生起し得る品詞を翻訳辞書部31に基づいて抽出し、その生起し得る品詞に基づいて除去した1単語の品詞を変更して調整する品詞調整手段36を設け、訳文生成手段33は、1単語を除去した単語列の訳文を生成することに代えて、品詞調整手段36で変更した品詞を、除去した1単語に割当て原文の訳文を生成するようにしたものである。
【0064】
また、図11は本発明の実施例3に係る機械翻訳装置の処理内容を示すフローチャートである。図3に示した実施例1のフローチャートに対し、ステップS15〜S17が追加されている。図2と同一要素には同一符号を付し、図3と同一ステップには同一符号を付し重複する説明は省略する。
【0065】
実施例1では、原文から単語を除去して、現状レベルで最大限改善可能な訳文を生成することに主眼があるのに対し、実施例3では、原文から単語を除去せずとも、構文解析が可能なように形態素解析能力を高めるようにしたものである。すなわち、図11のステップS9で構文解析に成功しなかったときは、ステップS15〜S17の処理を行う。
【0066】
ステップS9において、訳文生成手段33が構文解析に成功した単語列はないと判断したときは、品詞調整手段36は、除去した1単語の前後の単語の品詞を参照し(S15)、品詞調整手段36は、除去した1単語の前後の単語の品詞間に生起する品詞に基づいて、除去した1単語の品詞を変更する(S16)。そして、訳文生成手段33は、除去した1単語に変更した品詞を割当て原文の訳文を生成する(S17)。
【0067】
例として、図4の文番号1の原文を用いて説明する。前述したように、文番号1の原文のままでは文書解析手段30は構文解析に失敗し、thusという語を除去すると、初めて形態素解析に成功するものであるとする。図12は、図4の文番号1の原文からthusという語を除去した単語列に対しての辞書引き結果の説明図である。
【0068】
品詞調整手段36は、除去した1単語(すなわちここではthus)の前後の任意の数の単語を取り出しその品詞を調べる(S15)。ここでは、除去した1単語(thus)の前後の単語を2単語ずつ取り出すことにする。除去した1単語(thus)の前の2単語は直前のtheとその前のusingであり、除去した1単語(thus)の後ろの2単語は直後のdesignedとその後ろのprimersである。図12より、thusの前のtheは冠詞、その前のusingは現在分詞である。一方、thusの後ろのdesignedは過去分詞であり、そのまた後ろのprimersは名詞である。
【0069】
一方、第1言語解析文法辞書31bは英語の品詞列として生起可能な組を例えば、図13のような形でもっている。図13は説明のためのものであるので、第1言語解析文法辞書の内容{英語の品詞列として生起可能な組の知識(a)〜(d)}を非常に簡略化して示している。品詞調整手段36は、これを除去した1単語の品詞の判断に用いる。
【0070】
冠詞は名詞句の冒頭に来る品詞であり、その前の単語とは大きな切れ目と判断できる。このことから、ここでは、”the thus designed primers”に着目することになる。
【0071】
品詞調整手段36は、図13に示す品詞列として生起可能な組の知識と、過去分詞は形容詞のようにふるまう用法があるという知識とから、”the designed primers”は図13に示す生起可能な組の知識(c)に該当することがわかる。
【0072】
ここで、生起可能な組の知識(d)を参照して、thusを知識(d)の副詞に割り当てれば、英語の品詞の並びとして適切なものになることがわかる。つまり、”thus designed”を形容詞句とし、それを分解した、thusは副詞、designedは形容詞とみる。つまり、thusの品詞を副詞と変更する。
【0073】
これを一般化していうと、第1言語解析文法辞書の知識とステップS15で得られた品詞とを結果を照らし合わせ、除去した1単語として構文的に許される品詞に変更する(S16)。次に、訳文生成手段33は除去した1単語をこの新たな品詞に設定して、もとの何も省略していない状態の原文を翻訳し直す(S17)。
【0074】
ここで、最初の辞書引きで抽出された訳語を適用可能な場合はそれを用いて訳文を作成し(S6)、可能でない場合は外部からその訳語を補うようにする。thusの最初の辞書引きで抽出された訳語は接続詞としての訳語(したがって)であった。そこで、例えば、「このように」といった別の訳語を与えることが考えられる。すると、例えば、元の原文に対して「このように設計されたプライマーを使用して、人間の遺伝子のポリメラーゼ連鎖反応が達成された。」のような訳文を得ることができる。
【0075】
以上を今後の構文解析に生かすために、このような用法のthusが生起する環境を条件部分として、thusの品詞を調整するという規則を追加するようにしてもよい。つまり、前に冠詞、後ろに形容詞があった場合、thusの品詞を副詞に変更するという規則を追加する。
【0076】
このように問題となった単語の品詞を調整する以外に、図13のような第1言語解析文法辞書を精緻化して、除去した1単語を受理できるようにする。別の見方をすれば、前者は個別規則での対応、後者は一般規則での対応である。
【0077】
実施例3によれば、1単語を除去した単語列の訳文を生成することに代えて、品詞調整手段36で変更した品詞を除去した1単語に割当て原文の訳文を生成するので、翻訳対象とする文書の意味を保持した訳文が得られる。
【0078】
(実施例4)
図14は、本発明の実施例4に係る機械翻訳装置の機能ブロック図である。この実施例4は、図2に示した実施例1に対し、1単語を除いた単語列が構文解析に成功したときは、除去した1単語の前後m語のm単語の単語列をコーパスから検索するコーパス検索手段を設けたものである。
【0079】
コーパス検索手段37は、記憶装置26に記憶された図示省略のコーパス、通信制御装置21を介して通信ネットワークに接続されたサーバのコーパスにアクセスして、除去した1単語の前後m語のm単語の単語列をコーパスから検索する。
【0080】
また、図15は本発明の実施例4に係る機械翻訳装置の処理内容を示すフローチャートである。図3に示した実施例1のフローチャートに対し、ステップS18〜S24が追加されている。図2と同一要素には同一符号を付し、図3と同一ステップには同一符号を付し重複する説明は省略する。
【0081】
実施例3では、除去した1単語の前後の品詞から除去した1単語の新たな品詞を推測したが、これは実際には高度な知識を要し、新たな品詞が得られない可能性もある。そこで、問題となった単語とその前後の並びが、英語の文書において頻度が低ければ、その例文だけ意味が解釈できればよいとし、特に辞書文法を拡張する必要もないと考えられる。一方、頻度が高ければ、その語を省かない原文を構文解析できるようにしておく必要がある。そこで、実施例4では、除去した1単語を扱うことが全体の辞書文法開発において、どの程度重要かの指針を与えることとする。
【0082】
以下、例文として、図4の文番号2の原文を用いて説明する。文番号2の原文での除去した1単語はplacedであるとする。図15のステップS9で構文解析に成功した単語列があるときは、構文解析に成功した単語列の訳文を生成し(S10)、その後に、除去した1語の前後m語のm単語の単語列を検索対象として設定する(S18)。
【0083】
すなわち、除去した1単語の前後m語を検索対象として設定する。例えば、除去した1単語を文頭からn番目の語として、wordnと表記すると、検索対象語は、wordn-m, wordn-m+1,….wordn-1, wordn(除去した1単語)、wordn+1,..wordn+mとなる。例えば、mを3に設定すると、除去した1単語がplacedであることから、“making it better placed to withstand shocks”が検索対象となる。
【0084】
次に、検索対象につきコーパスの検索を実施し(S19)、検索ヒット率は高いかを判断する(S20)。検索ヒット率は、検索対象の語数を考慮して、コーパスにから検索されたヒット件数が予め設定した基準値を超えたか否かで、検索ヒット率が高いか低いかを判断する。検索ヒット率が高い場合は辞書文法の拡張が必要と判断する(S21)。
【0085】
一方、検索ヒット率が低い場合は、除去した1語の前後の単語を1からmの範囲でずらしたものを検索対象としてコーパスの検索を実施する(S22)。そして、検索ヒット率は高いかを判断し(S23)、検索ヒット率が高い場合は辞書文法の拡張が必要と判断する(S21)。一方、検索ヒット率が低い場合は辞書文法の拡張は必要なしと判断する(S24)。
【0086】
ステップS22では、m=3とした場合には、3×3−1=8通りの検索を試みることになる。この8通りは以下となる。
【0087】
(1)better placed to withstand shocks (前1単語、後ろ3単語) 22
(2)better placed to withstand(前1単語、後ろ2単語)26,800
(3)better placed to (前1単語、後ろ1単語) 4,600,000
(4)it better placed to withstand shocks (前2単語、後ろ3単語) 1
(5)it better placed to withstand (前2単語、後ろ2単語) 1,820
(6)it better placed to (前2単語、後ろ1単語) 286,000
(7)making it better placed to withstand (前3単語、後ろ2単語)114
(8)making it better placed to (前3単語、後ろ1単語) 6,410
右の数字は、ある実際の検索サイトを使って検索した場合のヒット件数を示すものである。検索対象の単語の数が少ないほど、検索ヒット率が高まるのは当然である。しかし、検索対象の語数が同一であっても、検索ヒット率には大きな差があることがわかる。例えば、同じ4語であっても、making it better placed toは6,000台、it better placed to withstandは1,800台、better placed to withstand shocksは20程度と幅がある。3単語の場合はit better placed toが群を抜いて高く、辞書文法が扱えるようにする必要があると判断できる。このことから、検索対象の語数ごとに予め設定した基準値を決めておき、コーパスにから検索されたヒット件数がその基準値を超えたときに検索ヒット率が高いと判断する。
【0088】
このように、検索ヒット率が高い検索語の組み合わせがあることになり、その組み合わせは辞書文法の拡張が必要と判断される。一方、検索ヒット率が高い検索語の組み合わせがない場合は、辞書文法の拡張必要なしという判断を下すことができる。
【0089】
以上の説明では、除去した1単語の前後m語のm単語の単語列を検索対象としたが、これに代えて、除去した1単語に先行するi個の単語、除去した1単語に後続するj個の単語、除去した1単語を任意の単語に置き換えたi+j+1個の単語列を検索対象とすることも可能である。
【0090】
ここでは、i=3、j=1であるとし、前の語3単語making it better、後ろ1単語 toを検索対象とする。図16はその検索結果の一例の説明図である。ここで囲みのある単語は除去した1単語placedと同じ位置にある任意の単語である。図16によれば、making it better (任意の単語) toの場合には、除去した1単語placedと同じ位置にableが起こりやすいことがわかる。任意の単語であるableの他の語としては、suited, adapted, equippedがあり、いずれも適合するといったニュアンスがある点で共通している。こうした情報は、”making it better placed to”を解釈するための文法を記述する上で参考となる情報である。
【0091】
実施例4によれば、1単語を除いた単語列が構文解析に成功したときは、除去した1単語の前後m語のm単語の単語列、または、除去した1単語に先行するi個の単語、除去した1単語に後続するj個の単語、除去した1単語を任意の単語に置き換えたi+j+1個の単語列をコーパスから検索するので、除去した1単語(除去語)をどのように扱うことが全体の辞書文法開発においてどの程度重要かの指針を与えることができる。
【0092】
(実施例5)
図17は、本発明の実施例5に係る機械翻訳装置の機能ブロック図である。この実施例5は、図2に示した実施例1に対し、1単語を除いた単語列が構文解析に成功したときは、除去した1単語Bの直前の単語Aと除去した単語Bとから構成される2語の単語列AB、または、除去した単語Bと除去した単語Bの直後の単語Cとから構成される2語の単語列BCを見出し語とした品詞の辞書登録をユーザに問い合わせる辞書登録問い合わせ手段38を設けたものである。
【0093】
また、図18は本発明の実施例5に係る機械翻訳装置の処理内容を示すフローチャートである。図3に示した実施例1のフローチャートに対し、ステップS25が追加されている。図2と同一要素には同一符号を付し、図3と同一ステップには同一符号を付し重複する説明は省略する。
【0094】
実施例5は、除去した1単語を適切な品詞として辞書に取り込むために辞書登録を行うものである。図18のステップS9にて構文解析に成功した単語列がある場合、構文解析に成功するということは、除去した1単語をB、除去した1単語の直前の単語をA、除去した1単語の直後の単語をCとすると、複合語ABを直前の単語Aと同一の品詞に割り当てるか、複合語BCを直後の単語Cと同一の品詞に割り当てれば、構文解析が成功することを意味する。
【0095】
以下、例文として、図4の文番号3の原文を用いて説明する。図4の文番号3の原文において、文書解析手段30が単語doを省くと構文解析に成功するものとする。この場合、除去した1単語doの直前の単語は冠詞の”the”であり、直後の単語は名詞のstatementである。従って、機械的には、”the do”を冠詞として、あるいは、”do statement”を名詞として解釈すれば、全体の構文解析は成功する。
【0096】
前者は英語として、適切とはいえないため後者をとる。つまり、”do statement”の品詞を名詞として、見出し語”do statement”を人間が与える訳語とともに辞書登録を行えるようにする。
【0097】
すなわち、辞書登録問い合わせ手段38は、文書解析手段30により、1単語を除いた単語列が構文解析に成功したときは、図19に示すような辞書登録問い合わせ画面を表示装置18に表示出力する。図19では、見出し語”do statement”を辞書登録するか否かの辞書登録問い合わせ画面を示している。これは、前述したように、”the do”を冠詞することは英語として、適切とはいえないためである。なお、”the do”を冠詞する辞書登録問い合わせ画面を表示するようにしてもよい。第1言語の知識を有するユーザは、”the do”を冠詞する辞書登録問い合わせ画面を見て、そのような辞書登録は適切でないと判断することになる。
【0098】
実施例5によれば、除去した1単語Bの直前の単語Aと除去した単語Bとから構成される2語の単語列AB、または、除去した単語Bと除去した単語Bの直後の単語Cとから構成される2語の単語列BCを見出し語とした品詞の辞書登録をユーザに問い合わせるので、除去した1単語を適切な品詞として辞書登録することを促すことができる。これにより、機械翻訳装置のユーザあるいは開発者は翻訳辞書の増強を図ることができる。
【0099】
本発明のいくつかの実施例を説明したが、これらの実施例は、例として提示したものであり、発明の範囲を限定することは意図していない。これら新規な実施例は、その他の様々な形態で実施されることが可能であり、発明の要旨を逸脱しない範囲で、種々の省略、置き換え、変更を行うことができる。これら実施例やその変形は、発明の範囲や要旨に含まれるとともに、特許請求の範囲に記載された発明とその均等の範囲に含まれる。
【符号の説明】
【0100】
11…機械翻訳装置、12…演算制御装置、13…プロセッサ、14…メモリ、15…機械翻訳プログラム、16…作業エリア、17…出力装置、18…表示装置、19…印刷装置、20…ディスクドライブ、21…通信制御装置、22…入力装置、23…マウス、24…キーボード、25…ハードディスクドライブ(HDD)、26…記憶装置、27…入力処理部、28…制御部、29…文書記憶部、30…文書解析手段、31…翻訳辞書部、32…出力処理部、33…訳文生成手段、34…第1言語単語除去手段、35…単語重要度判定手段、36…品詞調整手段、37…コーパス検索手段、38…辞書登録問い合わせ手段
【特許請求の範囲】
【請求項1】
機械翻訳プログラム、翻訳対象の第1言語の原文を翻訳目的の第2言語の訳文に翻訳するための機械翻訳辞書を記憶した記憶装置と、前記機械翻訳プログラムを演算実行する演算制御装置とを備えた機械翻訳装置において、前記機械翻訳プログラムは、
第1言語で表現された文書の各原文を構文解析する文書解析手段と、
前記文書解析手段で構文解析に成功したときは前記原文の訳文を生成する訳文生成手段と、
前記文書解析手段で構文解析に失敗したときは前記原文から1単語を除去した単語列を作成する第1言語単語除去手段とを備え、
前記文書解析手段は、前記第1言語単語除去手段で得られた1単語を除去した単語列を構文解析し、
前記訳文生成手段は、前記1単語を除去した単語列の構文解析に成功したときはその単語列の訳文を生成し、前記1単語を除去した単語列の構文解析に失敗したときは前記原文の不完全な訳文を生成する機械翻訳装置。
【請求項2】
前記文書解析手段で構文解析に成功した前記1単語を除去した単語列が複数あるときは、その複数の各単語列について除去した単語の重要度を判断する単語重要度判定手段を設け、
前記訳文生成手段は、前記単語重要度判定手段で除去した単語の重要度が最も低いと判定された単語列の訳文を生成する請求項1記載の機械翻訳装置。
【請求項3】
前記1単語を除去した単語列の構文解析に成功したときは、除去した単語の直前の単語の品詞と直後の単語の品詞とを参照し、それらの品詞の間に生起し得る品詞を前記機械翻訳辞書に基づいて抽出し、その生起し得る品詞に基づいて前記除去した1単語の品詞を変更する品詞調整手段を設け、
前記訳文生成手段は、前記1単語を除去した単語列の訳文を生成することに代えて、前記品詞調整手段で変更した品詞を前記除去した1単語に割当て前記原文の訳文を生成する請求項1記載の機械翻訳装置。
【請求項4】
前記1単語を除去した単語列が構文解析に成功したときは、除去した1単語の前後m語のm単語の単語列、または、除去した1単語に先行するi個の単語、除去した1単語に後続するj個の単語、除去した1単語を任意の単語に置き換えたi+j+1個の単語列をコーパスから検索するコーパス検索手段を備えた請求項1記載の機械翻訳装置。
【請求項5】
前記1単語を除去した単語列が構文解析に成功したときは、除去した1単語の直前の単語と除去した1単語とから構成される2語の単語列、または、除去した1単語と除去した1単語の直後の単語とから構成される2語の単語列を見出し語とした品詞の辞書登録をユーザに問い合わせる辞書登録問い合わせ手段を備えた請求項1記載の機械翻訳装置。
【請求項6】
機械翻訳プログラム、翻訳対象の第1言語の原文を翻訳目的の第2言語の訳文に翻訳するための機械翻訳辞書を記憶した記憶装置と、前記機械翻訳プログラムを演算実行する演算制御装置とを備えたコンピュータを操作して、
入力装置から入力された第1言語で表現された文書の各原文を構文解析し、
前記原文の構文解析に成功したときは前記原文の訳文を生成し、
前記原文の構文解析に失敗したときは前記原文から1単語を除去した単語列を作成し、
前記1単語を除去した単語列を構文解析し、
前記1単語を除去した単語列の構文解析に成功したときはその単語列の訳文を生成し、
前記1単語を除去した単語列の構文解析に失敗したときは前記原文の不完全な訳文を生成する機械翻訳方法。
【請求項7】
機械翻訳プログラム、翻訳対象の第1言語の原文を翻訳目的の第2言語の訳文に翻訳するための機械翻訳辞書を記憶した記憶装置と、前記機械翻訳プログラムを演算実行する演算制御装置とを備えたコンピュータに用いられ、前記コンピュータに、
入力装置から入力された第1言語で表現された文書の各原文を構文解析する機能と、
前記原文の構文解析に成功したときは前記原文の訳文を生成する機能と、
前記原文の構文解析に失敗したときは前記原文から1単語を除去した単語列を作成する機能と、
前記1単語を除去した単語列を構文解析する機能と、
前記1単語を除去した単語列の構文解析に成功したときはその単語列の訳文を生成する機能と、
前記1単語を除去した単語列の構文解析に失敗したときは前記原文の不完全な訳文を生成する機能とを実現させるための機械翻訳プログラム。
【請求項1】
機械翻訳プログラム、翻訳対象の第1言語の原文を翻訳目的の第2言語の訳文に翻訳するための機械翻訳辞書を記憶した記憶装置と、前記機械翻訳プログラムを演算実行する演算制御装置とを備えた機械翻訳装置において、前記機械翻訳プログラムは、
第1言語で表現された文書の各原文を構文解析する文書解析手段と、
前記文書解析手段で構文解析に成功したときは前記原文の訳文を生成する訳文生成手段と、
前記文書解析手段で構文解析に失敗したときは前記原文から1単語を除去した単語列を作成する第1言語単語除去手段とを備え、
前記文書解析手段は、前記第1言語単語除去手段で得られた1単語を除去した単語列を構文解析し、
前記訳文生成手段は、前記1単語を除去した単語列の構文解析に成功したときはその単語列の訳文を生成し、前記1単語を除去した単語列の構文解析に失敗したときは前記原文の不完全な訳文を生成する機械翻訳装置。
【請求項2】
前記文書解析手段で構文解析に成功した前記1単語を除去した単語列が複数あるときは、その複数の各単語列について除去した単語の重要度を判断する単語重要度判定手段を設け、
前記訳文生成手段は、前記単語重要度判定手段で除去した単語の重要度が最も低いと判定された単語列の訳文を生成する請求項1記載の機械翻訳装置。
【請求項3】
前記1単語を除去した単語列の構文解析に成功したときは、除去した単語の直前の単語の品詞と直後の単語の品詞とを参照し、それらの品詞の間に生起し得る品詞を前記機械翻訳辞書に基づいて抽出し、その生起し得る品詞に基づいて前記除去した1単語の品詞を変更する品詞調整手段を設け、
前記訳文生成手段は、前記1単語を除去した単語列の訳文を生成することに代えて、前記品詞調整手段で変更した品詞を前記除去した1単語に割当て前記原文の訳文を生成する請求項1記載の機械翻訳装置。
【請求項4】
前記1単語を除去した単語列が構文解析に成功したときは、除去した1単語の前後m語のm単語の単語列、または、除去した1単語に先行するi個の単語、除去した1単語に後続するj個の単語、除去した1単語を任意の単語に置き換えたi+j+1個の単語列をコーパスから検索するコーパス検索手段を備えた請求項1記載の機械翻訳装置。
【請求項5】
前記1単語を除去した単語列が構文解析に成功したときは、除去した1単語の直前の単語と除去した1単語とから構成される2語の単語列、または、除去した1単語と除去した1単語の直後の単語とから構成される2語の単語列を見出し語とした品詞の辞書登録をユーザに問い合わせる辞書登録問い合わせ手段を備えた請求項1記載の機械翻訳装置。
【請求項6】
機械翻訳プログラム、翻訳対象の第1言語の原文を翻訳目的の第2言語の訳文に翻訳するための機械翻訳辞書を記憶した記憶装置と、前記機械翻訳プログラムを演算実行する演算制御装置とを備えたコンピュータを操作して、
入力装置から入力された第1言語で表現された文書の各原文を構文解析し、
前記原文の構文解析に成功したときは前記原文の訳文を生成し、
前記原文の構文解析に失敗したときは前記原文から1単語を除去した単語列を作成し、
前記1単語を除去した単語列を構文解析し、
前記1単語を除去した単語列の構文解析に成功したときはその単語列の訳文を生成し、
前記1単語を除去した単語列の構文解析に失敗したときは前記原文の不完全な訳文を生成する機械翻訳方法。
【請求項7】
機械翻訳プログラム、翻訳対象の第1言語の原文を翻訳目的の第2言語の訳文に翻訳するための機械翻訳辞書を記憶した記憶装置と、前記機械翻訳プログラムを演算実行する演算制御装置とを備えたコンピュータに用いられ、前記コンピュータに、
入力装置から入力された第1言語で表現された文書の各原文を構文解析する機能と、
前記原文の構文解析に成功したときは前記原文の訳文を生成する機能と、
前記原文の構文解析に失敗したときは前記原文から1単語を除去した単語列を作成する機能と、
前記1単語を除去した単語列を構文解析する機能と、
前記1単語を除去した単語列の構文解析に成功したときはその単語列の訳文を生成する機能と、
前記1単語を除去した単語列の構文解析に失敗したときは前記原文の不完全な訳文を生成する機能とを実現させるための機械翻訳プログラム。
【図1】


【図2】
【図3】
【図4】

【図5】
【図6】
【図7】

【図8】
【図9】
【図10】
【図11】
【図12】
【図13】

【図14】
【図15】
【図16】

【図17】
【図18】
【図19】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【公開番号】特開2013−11993(P2013−11993A)
【公開日】平成25年1月17日(2013.1.17)
【国際特許分類】
【出願番号】特願2011−143491(P2011−143491)
【出願日】平成23年6月28日(2011.6.28)
【出願人】(000003078)株式会社東芝 (54,554)
【出願人】(301063496)東芝ソリューション株式会社 (1,478)
【Fターム(参考)】
【公開日】平成25年1月17日(2013.1.17)
【国際特許分類】
【出願日】平成23年6月28日(2011.6.28)
【出願人】(000003078)株式会社東芝 (54,554)
【出願人】(301063496)東芝ソリューション株式会社 (1,478)
【Fターム(参考)】
[ Back to top ]