
機械翻訳装置及び機械翻訳プログラム
【課題】翻訳辞書に登録されていない未知語であっても、精度の高い訳語を出力することができる機械翻訳装置を提供することである。
【解決手段】綴り対応表106には、未知語に対応できるようにするために、あらかじめ第一言語の語句中の一文字以上の文字からなる字句及びこれに対応する第二言語の文字による綴りの一以上の字句が対応づけられて記憶されている。未知語処理部105は、入力処理部102で分解された語句が翻訳辞書部104に存在しないときは、その未知語をさらに一文字以上の文字からなる字句に分解し、その分解した字句を綴り対応表106から検索して第二言語の字句を抽出する。そして、その抽出した第二言語の字句を合成して未知語の訳語を求める。
【解決手段】綴り対応表106には、未知語に対応できるようにするために、あらかじめ第一言語の語句中の一文字以上の文字からなる字句及びこれに対応する第二言語の文字による綴りの一以上の字句が対応づけられて記憶されている。未知語処理部105は、入力処理部102で分解された語句が翻訳辞書部104に存在しないときは、その未知語をさらに一文字以上の文字からなる字句に分解し、その分解した字句を綴り対応表106から検索して第二言語の字句を抽出する。そして、その抽出した第二言語の字句を合成して未知語の訳語を求める。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、コンピュータを利用して第一言語(原言語)の文章を第二言語(目的言語)の文章に自動的に翻訳する機械翻訳装置及び機械翻訳プログラムに関する。
【背景技術】
【0002】
コンピュータを利用して、第一の自然言語で書かれた文章を第二の自然言語の文章に自動的に翻訳する機械翻訳装置やソフトウェアが実用化されている。例えばパソコン用翻訳ソフトウェアには多くの商品があり、また、インターネットで機械翻訳サービスが提供されている例もある。
【0003】
例えば、第一の自然言語としての日本語を第二の自然言語としての英語に翻訳する場合を考える。まず、翻訳前の原文を形態素解析により、いくつかの単語に分割する。そして、分割された単語ごとに、あらかじめ用意した原語−訳語間のデータベースである翻訳辞書を検索して、適切な訳語を選択して日本語を英語に翻訳する。
【0004】
ここで、原語−訳語間の翻訳辞書の見出しの中に、探している単語が見つからない場合には、訳語を得ることができず、翻訳前の単語は未知語として扱われる。そうすると、訳文として出力した英文の中には、未知語となった一部の語が、原語すなわち日本語のまま出現することがある。
【0005】
これを回避するため、例えばカタカナ表記の単語については、いわゆる外来語として、そのままローマ字表記に変換して出力するという方法がある。この場合、そのようにして得た変換後のローマ字表記は、本来の英単語の綴りとは大きく異なることが多い。よって、変換後のローマ字表記からは本来の英単語を推察さえできないということもある。
【0006】
そこで、翻訳辞書に見つからなかったカタカナの未知語を処理するために、カタカナ1文字ごとに分割して、それらを1単語とみなし、1字単語の連鎖として解析をするというものがある(例えば、特許文献1参照)。
【0007】
また、単に1字単語とするのではなく、複数の文字からなるカタカナ文字列としていくつかに分割し、それらの「読み」に着目して、同一の読みをもつ他の表記(例えば、ひらがな文字や漢字混じりによる表記)が翻訳辞書にあるかどうかを探すことにより、かかる場合には未知語ではなく翻訳辞書に登録されている単語として取り扱う形態素解析方法もある(例えば、特許文献2参照)。
【特許文献1】特開昭62−208169号公報
【特許文献2】特開平5−20304号公報
【発明の開示】
【発明が解決しようとする課題】
【0008】
しかしながら、従来技術においては、翻訳が成功するか否かは、原語を1字単語もしくは他の表記に変換したとしても、最終的には翻訳辞書に登録されているかどうかに依存している。つまり、それらが翻訳辞書に登録されていない場合には、依然として、適切に翻訳をすることができない。
【0009】
また、カタカナ表記の原語をいわゆる外来語としてローマ字表記に変換するようにしても、もともと外来語ではない語句については極めて不適切であった。
【0010】
そこで、本発明の目的は、翻訳辞書に登録されていない未知語であっても、精度の高い訳語を出力することができる機械翻訳装置及び機械翻訳プログラムを提供することである。
【課題を解決するための手段】
【0011】
本発明に係る機械翻訳装置は、第一言語の語句とそれに対応する第二言語の語句とを対にして記憶する翻訳辞書部と、第一言語の原文を形態素解析していくつかの語句に分解する入力処理部と、前記入力処理部で分解された語句を前記翻訳辞書部から検索し第二言語の語句を訳語として選び出す翻訳辞書検索部と、第一言語の語句中の一文字以上の文字からなる字句及びこれに対応する第二言語の文字による綴りの一以上の字句を対応づけて記憶する綴り対応表と、前記入力処理部で分解された語句が前記翻訳辞書部に存在しないときはその未知語をさらに一文字以上の文字からなる字句に分解しその分解した字句を前記綴り対応表から検索し第二言語の字句を抽出しその抽出した第二言語の字句を合成して未知語の訳語を求める未知語処理部と、前記翻訳辞書部検索部や前記未知語処理部から出力された訳語を受け取り組み立てて訳文として出力する出力処理部とを備えたことを特徴とする。
【発明の効果】
【0012】
本発明によれば、翻訳辞書に登録されていない未知語について、精度よく訳語を出力することができる。
【発明を実施するための最良の形態】
【0013】
本発明を実施する最良の形態を説明する。第一言語の原文の語句のうち翻訳辞書に登録されていない語句、すなわち未知語について、さらに字句に分割し、その字句に対応する第二言語の綴りのデータベースを参照して綴りを得て、これらの綴りの組み合わせにより第二言語の語句を得る。これにより、未知語を含んだ原文であっても、精度良く翻訳することができる。
【0014】
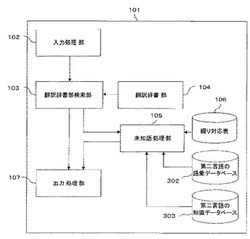
以下、本発明の実施の形態では、本発明の機械翻訳装置について、第一言語を日本語としたときに、第二言語として英語に翻訳する場合について説明する。図1は、本発明の実施の形態に係る機械翻訳装置のブロック図である。
【0015】
機械翻訳装置101は、入力処理部102と、翻訳辞書検索部103と、翻訳辞書部104と、未知語処理部105と、綴り対応表106と、出力部処理部107と、第二言語の語彙データベース302、第二言語の知識データベース303とを備える。第二言語の知識データベース303は翻訳辞書部104内に設けてもよい。
【0016】
機械翻訳装置101は、第一言語(原言語)で記載された翻訳対象の文書すなわち原文を電子データとして入力とし、その翻訳を行い、第二言語で記載された翻訳結果の文書すなわち訳文を出力する。入力処理部102は、原文を取り込む。そして、原文を構成する語句を、形態素解析などにより抽出し、翻訳辞書部検索部103へ出力する。
【0017】
翻訳辞書部検索部103は、翻訳辞書部104の中に、前記の語句が見出し語としてあるかどうかを検索する。翻訳辞書部104は、第一言語から第二言語への翻訳を行うための辞書であり、第一言語の語句すなわち原語と、これに対応する第二言語の語句すなわち訳語を格納している。翻訳辞書部104の中に見出し語として登録されている原語については、その訳語を出力処理部107へ送る。
【0018】
未知語処理部105は、翻訳辞書部104の中に見出し語として登録されていない原語(例えば、外来語や新語など)を、未知語として扱い、これを適切な訳語に変換するものである。綴り対応表106は第一言語の原語の字句に対応する第二言語の綴りの候補をあらかじめ登録するものであり、第二言語の語彙データベース302は未知語の候補となる第二言語の語句をあらかじめ記憶するものであり、また、第二言語の知識データベース303は第二言語の語句の綴りに加え、語句の意味、品詞、分野、共起情報等の属性情報を蓄積するものである。これらは、未知語処理部105が未知語を処理する際に参照される。
【0019】
出力処理部107は、翻訳辞書部検索部103または未知語処理部105から出力された訳語を受け取り、これらを組み立てて訳文として出力する処理を行うものである。
【0020】
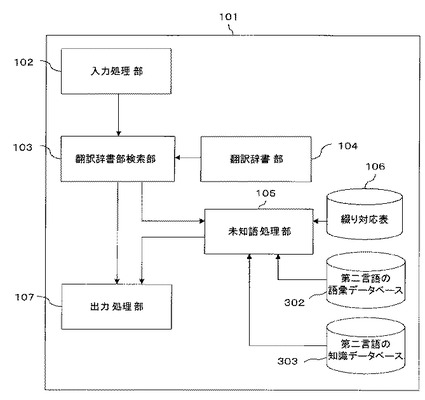
図2は本発明の実施の形態に係わる機械翻訳装置のハードウエア構成図である。本発明の実施の形態に係わる機械翻訳装置101はコンピュータで構成される。すなわち、中央処理制御装置201、ROM(Read Only Memory)202、RAM(Random Access Memory)203をバス210に接続し、一方、入力装置204、表示装置205、通信制御装置206、記憶装置207及びリムーバブルディスク208を入出力インターフェース209に接続し、この入出力インターフェース209をバス210に接続して構成される。
【0021】
中央処理制御装置201は、入力装置204からの入力信号に基づいてROM202からブートプログラムを読み出して実行し、更に記憶装置207に記憶されたオペレーティングシステムを読み出す。更に中央処理制御装置201は、入力装置204や通信制御装置206などの入力信号に基づいて、各種装置の制御を行い、RAM203や記憶装置207などに記憶されたプログラム及びデータを読み出してRAM203にロードするとともに、RAM203から読み出されたプログラムのコマンドに基づいて、データの計算又は加工など、後述する一連の処理を実現する処理装置である。
【0022】
入力装置204は、操作者が各種の操作を入力するキーボード、マウスなどの入力デバイスにより構成されており、操作者の操作に基づいて入力信号を作成し、入出力インタフェース209及びバス210を介して中央処理制御装置201に送信される。表示装置205は、CRT(Cathode Ray Tube)ディスプレイや液晶ディスプレイなどであり、中央処理制御装置201からバス210及び入出力インタフェース209を介して表示装置205において表示させる出力信号を受信し、例えば中央処理制御装置201の処理結果などを表示する装置である。通信制御装置206は、LANカードやモデムなどの装置であり、機械翻訳装置101をインターネットやLANなどの通信ネットワークに接続する装置である。通信制御装置206を介して通信ネットワークと送受信したデータは入力信号又は出力信号として、入出力インタフェース及びバス210を介して中央処理制御装置201に送受信される。
【0023】
記憶装置207は磁気ディスク装置であって、中央処理制御装置201で実行されるプログラムやデータが記憶されている。リムーバブルディスク208は、光ディスクやフレキシブルディスクのことであり、ディスクドライブによって読み書きされた信号は、入出力インタフェース209及びバス210を介して中央処理制御装置201に送受信される。
【0024】
このようなコンピュータを本発明の実施の形態の機械翻訳装置101として機能させるにあたっては、記憶装置207に機械翻訳プログラムを記憶するとともに、翻訳辞書部104を記憶する。また、機械翻訳プログラムが機械翻訳装置101の中央処理制御装置201に読み込まれ実行されることによって、入力処理部102、翻訳辞書部検索部103、未知語処理部105及び出力処理部107が実現される。機械翻訳装置101の綴り対応表106、第二言語の語彙データベース302、第二言語の知識データベース303は、RAM203に格納される。なお、第二言語の知識データベース303は翻訳辞書部104内に設けられる場合には記憶装置207に格納される。機械翻訳装置101の入力処理部102については、入力装置204や通信制御装置206にてその機能を実装することができ、または、記憶装置207やリムーバブルディスク208からデータを入力するようにしてもよい。機械翻訳装置101の出力処理部107については、表示装置205や通信制御装置206にてその機能を実装することができ、または、記憶装置207やリムーバブルディスク208にデータを出力するようにしてもよい。
【0025】
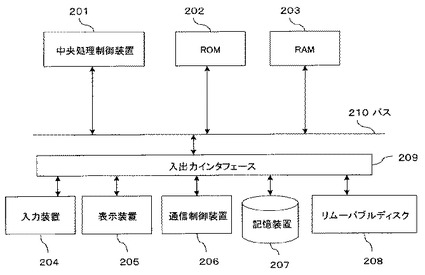
図3は、機械翻訳装置101における未知語変換部105のブロック図である。未知語変換部105は、字句分割部105aと、訳語合成部105bと、綴り対応表検索部301とを備え、綴り対応表106を参照する。また、必要に応じ、第二言語の語彙データベース302と、第二言語の知識データベース303とを参照する。
【0026】
未知語変換部105が先述した第一言語の未知語を受け取ると、その未知語を字句分割部105aによりいくつかの字句に分割する。分割した各々の字句について、綴り対応表検索部301が綴り対応表106を検索し、当該字句が見つかれば、綴り対応表106に登録されている綴りにより当該字句を変換する。訳語合成部105bは、必要に応じて第二言語の語彙データベース302や第二言語の知識データベース303を参照しながら、各々の字句の綴りを合成することにより、もとの原語に対する訳語を出力する。
【0027】
以下、未知語変換部105の各構成部について詳細に説明する。字句分割部105aは、未知語をいくつかの字句に分割する。まず、分割された各字句の文字数ができるだけ大きくなるようにする。そのために、まずは2つに分割する。例えば、「ユビキタス」が未知語であるとしたときに、「ユビ」という字句と「キタス」という字句とに分割する。その後の綴り対応表検索部301の処理で各字句の適切な訳語が見つからなければ、分割箇所を前後にずらしたり、分割箇所を増やしたりすることを繰り返す。例えば、「ユビキ」と「タス」というように分割箇所をずらす。それでも綴り対応表検索部301の処理で各軸の適切な訳語が見つからない場合は分割数を増やす。例えば、「ユ」「ビキ」「タス」という三つの字句に分割したり、「ユビ」「キ」「タス」という三つの字句に分割するようにする。
【0028】
このようにすることで、未知語をはじめから1文字単位にまで分割することなく、大まかに分割された字句によって早期のうちに適切な訳語を見つける可能性が高まるから、効率的に未知語を翻訳することができる。
【0029】
綴り対応表検索部301は、字句分割部105aから渡された字句ごとに、綴り対応表106を検索する。ここで、字句分割部105aでの各種分割の態様によっても当該字句が、綴り対応表106に見つからなかった場合には、デフォルト動作として、当該字句をローマ字表記に変換する。例えば、「ユビ」は「yubi」というように変換する。
【0030】
綴り対応表106は、第一原語の文字もしくは文字列に対応する第二原語の綴りの候補があらかじめ登録されているものである。特に、第一原語が日本語であり、第二原語が英語である場合には、日本語の表音文字をローマ字に対応させることはもちろん、単純に日本語の表音文字をローマ字に対応させるだけでなく、日本人が行いがちな外来語の取扱いを、この綴り対応表106に登録しておく。例えば、mouthはマウスとすることが多いので「ス」は「th」とし、meterはメートルとすることが多いので「トル」は「ter」とするが如きである。
【0031】
綴り対応表検索部301は、このような綴り対応表106から分割された言語の各字句の綴りを抽出する。訳語合成部105bは、綴り対応表検索部301から分割された言語の各字句の綴りを受け取ると、これを合成して訳語として出力する。ここで、綴り対応表106において、複数の綴りの候補が見つかることがあるから、各々を組み合わせて合成した訳語も複数の候補があり得ることになる。そこで、各々の綴りの候補おける優先度を考慮して、複数の訳語の各々に優先度を決定することにより、最も適切な訳語を選択することができる。具体的には、次の(1)〜(4)の処理のいずれかを行うようにする。
【0032】
(1)合成した訳語として、第二言語においてはありえないもの、もしくはあまり出現しないものを排除する。もしくは訳語としての優先度を低くする。
【0033】
(2)ローマ字表記のものについては訳語としての優先度を低くする。
【0034】
(3)第二言語の語彙データベース302を検索し、この中で見つかったものについては訳語としての優先度を高くする。
【0035】
(4)第二言語の知識データベース303を参照し、原語に関する分野の情報から、その分野の単語がもつ傾向を調べ、これを訳語の合成における優先度の設定に利用する。例えば、化学式に使われる物質名や植物の名前などには、特徴のある綴りをもつものが多いので、原語が化学式に使われる物質名や植物の名前である場合には、そのような特徴のある綴りの優先度を高くする。
【0036】
第二言語の語彙データベース302は、第二言語の未知語の候補となる語句をを語彙として収集したものである。未知語の候補となる語句は、新語、造語、外来語、略語、商標名などであり、例えば、第二言語の一般的な雑誌や新聞記事から単語を収集する。従って、機械翻訳装置101の翻訳辞書部104の見出し語としては登録されていないような単語や活用形の単語も含み得る。この語彙データベース302においては、単語の意味や用法はわからなくてもよく、訳語合成部105bが、その綴りの単語が存在するかどうかを調べるために参照できればよい。これにより、訳語合成部105bが出力する訳語の精度を効果的に向上することができる。
【0037】
次に、第二言語の知識データベース303は、第二言語の単語の綴りだけでなく、単語の意味、品詞、分野、共起情報など、様々な種類の膨大な量の情報が蓄積されているものである。これは、一般的には機械翻訳装置に備わっているものである。前述の処理(4)で述べたように、訳語合成部105bがこれを参照することによって、合成した複数の訳語の各々について、訳語としての優先度を設定することができ、訳語合成部105bが出力する訳語の精度を効果的に向上することができる。
【0038】
図4は、綴り対応表106の説明図である。綴り対応表106は、第一言語の字句401を見出し語として、これに対応する第二言語の綴り402をあらかじめ登録しておくものである。例えば、前述したように、英語の「meter」は日本語の「メートル」という外来語として取扱っているように、英語の「ter」という綴りは日本語の「トル」という字句が対応する。また、例えば、英語の「th」という綴りは日本語の「ス」という字句が対応していることが多い。
【0039】
このような対応を、綴り対応表106にあらかじめ登録しておくことにより、従来のように未知語を単なるローマ字表記に変換するだけでなく、より現実的で適切な訳語に翻訳することができる。
【0040】
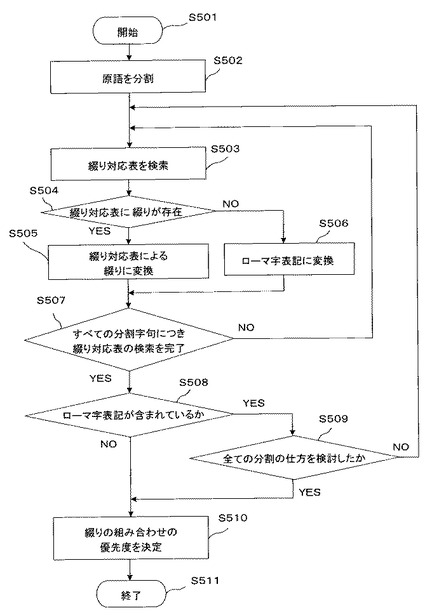
図5は、未知語変換部105の処理内容を示すフローチャートである。翻訳辞書検索部103から未知語として取り扱われる原語を受け取ることにより処理を開始する(S501)。その原語を、字句分割部105aにより、いくつかの字句に分割する(S502)。
【0041】
分割した各々の字句について、綴り対応表検索部301が綴り対応表106を検索する(S503)。当該字句が綴り対応表106に存在するか否かを判定し(S504)、当該字句が綴り対応表106に存在する場合は、当該字句を綴り対応表に登録されている綴りにより変換する(S505)。一方、当該字句が綴り対応表106に存在しない場合には、ローマ字表記に変換する(S506)。
【0042】
そして、すべての分割字句につき綴り対応表106の検索を完了したか否かを判定し(S507)、すべての分割字句につき綴り対応表106の検索を完了していないときはステップS503に戻る。すべての分割字句につき綴り対応表106の検索を完了したときは、ローマ字表記が含まれているか否かを判定し(S508)、ローマ字表記が含まれるときは、未知語に対するすべての分割の仕方を検討したか否かを判定し(S509)、別の分割の仕方がある場合にはステップS502に戻り、その別の分割の仕方で未知語を再分割する。ステップS509の判定ですべての分割の仕方を検討しているとき、または、ステップS508の判定でローマ字表記が含まれていないときは、訳語合成部105bは綴りの組み合わせの優先度を決定し(S510)、処理を終了する(S511)。
【0043】
本発明の実施の形態によれば、翻訳中に未知語が見つかった場合、語句全体では未知語であっても、分解した字句ごとに綴りが得られれば、それらを繋ぎ合わせることにより訳語を導き出すことができる。その際に、字句の単なる綴りの変換だけでなく、例えば外来語の日本語読みを決める際に日本人が行いがちな変換をあらかじめ取り込んでおくことにより、さらに精度の高い訳語を導き出すことができる。
【0044】
第二言語の知識データベースを使用することにより、綴りだけでなく意味、品詞、分野、共起など、様々な種類の膨大な量の情報を基にして訳語間の優先度を決めることができる。同様に、あらかじめ未知語の候補を記憶した第二言語の語彙データベースに蓄積された情報を使用して、訳語間の優先度を決めることができる。
【図面の簡単な説明】
【0045】
【図1】本発明の実施の形態に係わる機械翻訳装置のブロック図である。
【図2】本発明の実施の形態に係わる機械翻訳装置のハードウエア構成図である。
【図3】本発明の実施の形態に係わる機械翻訳装置の未知語変換部のブロック図である。
【図4】本発明の実施の形態に係わる機械翻訳装置の綴り対応表の説明図である。
【図5】本発明の実施の形態に係る機械翻訳装置の未知語変換部の処理内容のフローチャートである。
【符号の説明】
【0046】
101…機械翻訳装置、102…入力処理部、103…翻訳辞書検索部、104…翻訳辞書部、105…未知語処理部、105a…字句分割部、105b…訳語合成部、106…綴り対応表、107…出力処理部
【技術分野】
【0001】
本発明は、コンピュータを利用して第一言語(原言語)の文章を第二言語(目的言語)の文章に自動的に翻訳する機械翻訳装置及び機械翻訳プログラムに関する。
【背景技術】
【0002】
コンピュータを利用して、第一の自然言語で書かれた文章を第二の自然言語の文章に自動的に翻訳する機械翻訳装置やソフトウェアが実用化されている。例えばパソコン用翻訳ソフトウェアには多くの商品があり、また、インターネットで機械翻訳サービスが提供されている例もある。
【0003】
例えば、第一の自然言語としての日本語を第二の自然言語としての英語に翻訳する場合を考える。まず、翻訳前の原文を形態素解析により、いくつかの単語に分割する。そして、分割された単語ごとに、あらかじめ用意した原語−訳語間のデータベースである翻訳辞書を検索して、適切な訳語を選択して日本語を英語に翻訳する。
【0004】
ここで、原語−訳語間の翻訳辞書の見出しの中に、探している単語が見つからない場合には、訳語を得ることができず、翻訳前の単語は未知語として扱われる。そうすると、訳文として出力した英文の中には、未知語となった一部の語が、原語すなわち日本語のまま出現することがある。
【0005】
これを回避するため、例えばカタカナ表記の単語については、いわゆる外来語として、そのままローマ字表記に変換して出力するという方法がある。この場合、そのようにして得た変換後のローマ字表記は、本来の英単語の綴りとは大きく異なることが多い。よって、変換後のローマ字表記からは本来の英単語を推察さえできないということもある。
【0006】
そこで、翻訳辞書に見つからなかったカタカナの未知語を処理するために、カタカナ1文字ごとに分割して、それらを1単語とみなし、1字単語の連鎖として解析をするというものがある(例えば、特許文献1参照)。
【0007】
また、単に1字単語とするのではなく、複数の文字からなるカタカナ文字列としていくつかに分割し、それらの「読み」に着目して、同一の読みをもつ他の表記(例えば、ひらがな文字や漢字混じりによる表記)が翻訳辞書にあるかどうかを探すことにより、かかる場合には未知語ではなく翻訳辞書に登録されている単語として取り扱う形態素解析方法もある(例えば、特許文献2参照)。
【特許文献1】特開昭62−208169号公報
【特許文献2】特開平5−20304号公報
【発明の開示】
【発明が解決しようとする課題】
【0008】
しかしながら、従来技術においては、翻訳が成功するか否かは、原語を1字単語もしくは他の表記に変換したとしても、最終的には翻訳辞書に登録されているかどうかに依存している。つまり、それらが翻訳辞書に登録されていない場合には、依然として、適切に翻訳をすることができない。
【0009】
また、カタカナ表記の原語をいわゆる外来語としてローマ字表記に変換するようにしても、もともと外来語ではない語句については極めて不適切であった。
【0010】
そこで、本発明の目的は、翻訳辞書に登録されていない未知語であっても、精度の高い訳語を出力することができる機械翻訳装置及び機械翻訳プログラムを提供することである。
【課題を解決するための手段】
【0011】
本発明に係る機械翻訳装置は、第一言語の語句とそれに対応する第二言語の語句とを対にして記憶する翻訳辞書部と、第一言語の原文を形態素解析していくつかの語句に分解する入力処理部と、前記入力処理部で分解された語句を前記翻訳辞書部から検索し第二言語の語句を訳語として選び出す翻訳辞書検索部と、第一言語の語句中の一文字以上の文字からなる字句及びこれに対応する第二言語の文字による綴りの一以上の字句を対応づけて記憶する綴り対応表と、前記入力処理部で分解された語句が前記翻訳辞書部に存在しないときはその未知語をさらに一文字以上の文字からなる字句に分解しその分解した字句を前記綴り対応表から検索し第二言語の字句を抽出しその抽出した第二言語の字句を合成して未知語の訳語を求める未知語処理部と、前記翻訳辞書部検索部や前記未知語処理部から出力された訳語を受け取り組み立てて訳文として出力する出力処理部とを備えたことを特徴とする。
【発明の効果】
【0012】
本発明によれば、翻訳辞書に登録されていない未知語について、精度よく訳語を出力することができる。
【発明を実施するための最良の形態】
【0013】
本発明を実施する最良の形態を説明する。第一言語の原文の語句のうち翻訳辞書に登録されていない語句、すなわち未知語について、さらに字句に分割し、その字句に対応する第二言語の綴りのデータベースを参照して綴りを得て、これらの綴りの組み合わせにより第二言語の語句を得る。これにより、未知語を含んだ原文であっても、精度良く翻訳することができる。
【0014】
以下、本発明の実施の形態では、本発明の機械翻訳装置について、第一言語を日本語としたときに、第二言語として英語に翻訳する場合について説明する。図1は、本発明の実施の形態に係る機械翻訳装置のブロック図である。
【0015】
機械翻訳装置101は、入力処理部102と、翻訳辞書検索部103と、翻訳辞書部104と、未知語処理部105と、綴り対応表106と、出力部処理部107と、第二言語の語彙データベース302、第二言語の知識データベース303とを備える。第二言語の知識データベース303は翻訳辞書部104内に設けてもよい。
【0016】
機械翻訳装置101は、第一言語(原言語)で記載された翻訳対象の文書すなわち原文を電子データとして入力とし、その翻訳を行い、第二言語で記載された翻訳結果の文書すなわち訳文を出力する。入力処理部102は、原文を取り込む。そして、原文を構成する語句を、形態素解析などにより抽出し、翻訳辞書部検索部103へ出力する。
【0017】
翻訳辞書部検索部103は、翻訳辞書部104の中に、前記の語句が見出し語としてあるかどうかを検索する。翻訳辞書部104は、第一言語から第二言語への翻訳を行うための辞書であり、第一言語の語句すなわち原語と、これに対応する第二言語の語句すなわち訳語を格納している。翻訳辞書部104の中に見出し語として登録されている原語については、その訳語を出力処理部107へ送る。
【0018】
未知語処理部105は、翻訳辞書部104の中に見出し語として登録されていない原語(例えば、外来語や新語など)を、未知語として扱い、これを適切な訳語に変換するものである。綴り対応表106は第一言語の原語の字句に対応する第二言語の綴りの候補をあらかじめ登録するものであり、第二言語の語彙データベース302は未知語の候補となる第二言語の語句をあらかじめ記憶するものであり、また、第二言語の知識データベース303は第二言語の語句の綴りに加え、語句の意味、品詞、分野、共起情報等の属性情報を蓄積するものである。これらは、未知語処理部105が未知語を処理する際に参照される。
【0019】
出力処理部107は、翻訳辞書部検索部103または未知語処理部105から出力された訳語を受け取り、これらを組み立てて訳文として出力する処理を行うものである。
【0020】
図2は本発明の実施の形態に係わる機械翻訳装置のハードウエア構成図である。本発明の実施の形態に係わる機械翻訳装置101はコンピュータで構成される。すなわち、中央処理制御装置201、ROM(Read Only Memory)202、RAM(Random Access Memory)203をバス210に接続し、一方、入力装置204、表示装置205、通信制御装置206、記憶装置207及びリムーバブルディスク208を入出力インターフェース209に接続し、この入出力インターフェース209をバス210に接続して構成される。
【0021】
中央処理制御装置201は、入力装置204からの入力信号に基づいてROM202からブートプログラムを読み出して実行し、更に記憶装置207に記憶されたオペレーティングシステムを読み出す。更に中央処理制御装置201は、入力装置204や通信制御装置206などの入力信号に基づいて、各種装置の制御を行い、RAM203や記憶装置207などに記憶されたプログラム及びデータを読み出してRAM203にロードするとともに、RAM203から読み出されたプログラムのコマンドに基づいて、データの計算又は加工など、後述する一連の処理を実現する処理装置である。
【0022】
入力装置204は、操作者が各種の操作を入力するキーボード、マウスなどの入力デバイスにより構成されており、操作者の操作に基づいて入力信号を作成し、入出力インタフェース209及びバス210を介して中央処理制御装置201に送信される。表示装置205は、CRT(Cathode Ray Tube)ディスプレイや液晶ディスプレイなどであり、中央処理制御装置201からバス210及び入出力インタフェース209を介して表示装置205において表示させる出力信号を受信し、例えば中央処理制御装置201の処理結果などを表示する装置である。通信制御装置206は、LANカードやモデムなどの装置であり、機械翻訳装置101をインターネットやLANなどの通信ネットワークに接続する装置である。通信制御装置206を介して通信ネットワークと送受信したデータは入力信号又は出力信号として、入出力インタフェース及びバス210を介して中央処理制御装置201に送受信される。
【0023】
記憶装置207は磁気ディスク装置であって、中央処理制御装置201で実行されるプログラムやデータが記憶されている。リムーバブルディスク208は、光ディスクやフレキシブルディスクのことであり、ディスクドライブによって読み書きされた信号は、入出力インタフェース209及びバス210を介して中央処理制御装置201に送受信される。
【0024】
このようなコンピュータを本発明の実施の形態の機械翻訳装置101として機能させるにあたっては、記憶装置207に機械翻訳プログラムを記憶するとともに、翻訳辞書部104を記憶する。また、機械翻訳プログラムが機械翻訳装置101の中央処理制御装置201に読み込まれ実行されることによって、入力処理部102、翻訳辞書部検索部103、未知語処理部105及び出力処理部107が実現される。機械翻訳装置101の綴り対応表106、第二言語の語彙データベース302、第二言語の知識データベース303は、RAM203に格納される。なお、第二言語の知識データベース303は翻訳辞書部104内に設けられる場合には記憶装置207に格納される。機械翻訳装置101の入力処理部102については、入力装置204や通信制御装置206にてその機能を実装することができ、または、記憶装置207やリムーバブルディスク208からデータを入力するようにしてもよい。機械翻訳装置101の出力処理部107については、表示装置205や通信制御装置206にてその機能を実装することができ、または、記憶装置207やリムーバブルディスク208にデータを出力するようにしてもよい。
【0025】
図3は、機械翻訳装置101における未知語変換部105のブロック図である。未知語変換部105は、字句分割部105aと、訳語合成部105bと、綴り対応表検索部301とを備え、綴り対応表106を参照する。また、必要に応じ、第二言語の語彙データベース302と、第二言語の知識データベース303とを参照する。
【0026】
未知語変換部105が先述した第一言語の未知語を受け取ると、その未知語を字句分割部105aによりいくつかの字句に分割する。分割した各々の字句について、綴り対応表検索部301が綴り対応表106を検索し、当該字句が見つかれば、綴り対応表106に登録されている綴りにより当該字句を変換する。訳語合成部105bは、必要に応じて第二言語の語彙データベース302や第二言語の知識データベース303を参照しながら、各々の字句の綴りを合成することにより、もとの原語に対する訳語を出力する。
【0027】
以下、未知語変換部105の各構成部について詳細に説明する。字句分割部105aは、未知語をいくつかの字句に分割する。まず、分割された各字句の文字数ができるだけ大きくなるようにする。そのために、まずは2つに分割する。例えば、「ユビキタス」が未知語であるとしたときに、「ユビ」という字句と「キタス」という字句とに分割する。その後の綴り対応表検索部301の処理で各字句の適切な訳語が見つからなければ、分割箇所を前後にずらしたり、分割箇所を増やしたりすることを繰り返す。例えば、「ユビキ」と「タス」というように分割箇所をずらす。それでも綴り対応表検索部301の処理で各軸の適切な訳語が見つからない場合は分割数を増やす。例えば、「ユ」「ビキ」「タス」という三つの字句に分割したり、「ユビ」「キ」「タス」という三つの字句に分割するようにする。
【0028】
このようにすることで、未知語をはじめから1文字単位にまで分割することなく、大まかに分割された字句によって早期のうちに適切な訳語を見つける可能性が高まるから、効率的に未知語を翻訳することができる。
【0029】
綴り対応表検索部301は、字句分割部105aから渡された字句ごとに、綴り対応表106を検索する。ここで、字句分割部105aでの各種分割の態様によっても当該字句が、綴り対応表106に見つからなかった場合には、デフォルト動作として、当該字句をローマ字表記に変換する。例えば、「ユビ」は「yubi」というように変換する。
【0030】
綴り対応表106は、第一原語の文字もしくは文字列に対応する第二原語の綴りの候補があらかじめ登録されているものである。特に、第一原語が日本語であり、第二原語が英語である場合には、日本語の表音文字をローマ字に対応させることはもちろん、単純に日本語の表音文字をローマ字に対応させるだけでなく、日本人が行いがちな外来語の取扱いを、この綴り対応表106に登録しておく。例えば、mouthはマウスとすることが多いので「ス」は「th」とし、meterはメートルとすることが多いので「トル」は「ter」とするが如きである。
【0031】
綴り対応表検索部301は、このような綴り対応表106から分割された言語の各字句の綴りを抽出する。訳語合成部105bは、綴り対応表検索部301から分割された言語の各字句の綴りを受け取ると、これを合成して訳語として出力する。ここで、綴り対応表106において、複数の綴りの候補が見つかることがあるから、各々を組み合わせて合成した訳語も複数の候補があり得ることになる。そこで、各々の綴りの候補おける優先度を考慮して、複数の訳語の各々に優先度を決定することにより、最も適切な訳語を選択することができる。具体的には、次の(1)〜(4)の処理のいずれかを行うようにする。
【0032】
(1)合成した訳語として、第二言語においてはありえないもの、もしくはあまり出現しないものを排除する。もしくは訳語としての優先度を低くする。
【0033】
(2)ローマ字表記のものについては訳語としての優先度を低くする。
【0034】
(3)第二言語の語彙データベース302を検索し、この中で見つかったものについては訳語としての優先度を高くする。
【0035】
(4)第二言語の知識データベース303を参照し、原語に関する分野の情報から、その分野の単語がもつ傾向を調べ、これを訳語の合成における優先度の設定に利用する。例えば、化学式に使われる物質名や植物の名前などには、特徴のある綴りをもつものが多いので、原語が化学式に使われる物質名や植物の名前である場合には、そのような特徴のある綴りの優先度を高くする。
【0036】
第二言語の語彙データベース302は、第二言語の未知語の候補となる語句をを語彙として収集したものである。未知語の候補となる語句は、新語、造語、外来語、略語、商標名などであり、例えば、第二言語の一般的な雑誌や新聞記事から単語を収集する。従って、機械翻訳装置101の翻訳辞書部104の見出し語としては登録されていないような単語や活用形の単語も含み得る。この語彙データベース302においては、単語の意味や用法はわからなくてもよく、訳語合成部105bが、その綴りの単語が存在するかどうかを調べるために参照できればよい。これにより、訳語合成部105bが出力する訳語の精度を効果的に向上することができる。
【0037】
次に、第二言語の知識データベース303は、第二言語の単語の綴りだけでなく、単語の意味、品詞、分野、共起情報など、様々な種類の膨大な量の情報が蓄積されているものである。これは、一般的には機械翻訳装置に備わっているものである。前述の処理(4)で述べたように、訳語合成部105bがこれを参照することによって、合成した複数の訳語の各々について、訳語としての優先度を設定することができ、訳語合成部105bが出力する訳語の精度を効果的に向上することができる。
【0038】
図4は、綴り対応表106の説明図である。綴り対応表106は、第一言語の字句401を見出し語として、これに対応する第二言語の綴り402をあらかじめ登録しておくものである。例えば、前述したように、英語の「meter」は日本語の「メートル」という外来語として取扱っているように、英語の「ter」という綴りは日本語の「トル」という字句が対応する。また、例えば、英語の「th」という綴りは日本語の「ス」という字句が対応していることが多い。
【0039】
このような対応を、綴り対応表106にあらかじめ登録しておくことにより、従来のように未知語を単なるローマ字表記に変換するだけでなく、より現実的で適切な訳語に翻訳することができる。
【0040】
図5は、未知語変換部105の処理内容を示すフローチャートである。翻訳辞書検索部103から未知語として取り扱われる原語を受け取ることにより処理を開始する(S501)。その原語を、字句分割部105aにより、いくつかの字句に分割する(S502)。
【0041】
分割した各々の字句について、綴り対応表検索部301が綴り対応表106を検索する(S503)。当該字句が綴り対応表106に存在するか否かを判定し(S504)、当該字句が綴り対応表106に存在する場合は、当該字句を綴り対応表に登録されている綴りにより変換する(S505)。一方、当該字句が綴り対応表106に存在しない場合には、ローマ字表記に変換する(S506)。
【0042】
そして、すべての分割字句につき綴り対応表106の検索を完了したか否かを判定し(S507)、すべての分割字句につき綴り対応表106の検索を完了していないときはステップS503に戻る。すべての分割字句につき綴り対応表106の検索を完了したときは、ローマ字表記が含まれているか否かを判定し(S508)、ローマ字表記が含まれるときは、未知語に対するすべての分割の仕方を検討したか否かを判定し(S509)、別の分割の仕方がある場合にはステップS502に戻り、その別の分割の仕方で未知語を再分割する。ステップS509の判定ですべての分割の仕方を検討しているとき、または、ステップS508の判定でローマ字表記が含まれていないときは、訳語合成部105bは綴りの組み合わせの優先度を決定し(S510)、処理を終了する(S511)。
【0043】
本発明の実施の形態によれば、翻訳中に未知語が見つかった場合、語句全体では未知語であっても、分解した字句ごとに綴りが得られれば、それらを繋ぎ合わせることにより訳語を導き出すことができる。その際に、字句の単なる綴りの変換だけでなく、例えば外来語の日本語読みを決める際に日本人が行いがちな変換をあらかじめ取り込んでおくことにより、さらに精度の高い訳語を導き出すことができる。
【0044】
第二言語の知識データベースを使用することにより、綴りだけでなく意味、品詞、分野、共起など、様々な種類の膨大な量の情報を基にして訳語間の優先度を決めることができる。同様に、あらかじめ未知語の候補を記憶した第二言語の語彙データベースに蓄積された情報を使用して、訳語間の優先度を決めることができる。
【図面の簡単な説明】
【0045】
【図1】本発明の実施の形態に係わる機械翻訳装置のブロック図である。
【図2】本発明の実施の形態に係わる機械翻訳装置のハードウエア構成図である。
【図3】本発明の実施の形態に係わる機械翻訳装置の未知語変換部のブロック図である。
【図4】本発明の実施の形態に係わる機械翻訳装置の綴り対応表の説明図である。
【図5】本発明の実施の形態に係る機械翻訳装置の未知語変換部の処理内容のフローチャートである。
【符号の説明】
【0046】
101…機械翻訳装置、102…入力処理部、103…翻訳辞書検索部、104…翻訳辞書部、105…未知語処理部、105a…字句分割部、105b…訳語合成部、106…綴り対応表、107…出力処理部
【特許請求の範囲】
【請求項1】
第一言語の語句とそれに対応する第二言語の語句とを対にして記憶する翻訳辞書部と、第一言語の原文を形態素解析していくつかの語句に分解する入力処理部と、前記入力処理部で分解された語句を前記翻訳辞書部から検索し第二言語の語句を訳語として選び出す翻訳辞書検索部と、第一言語の語句中の一文字以上の文字からなる字句及びこれに対応する第二言語の文字による綴りの一以上の字句を対応づけて記憶する綴り対応表と、前記入力処理部で分解された語句が前記翻訳辞書部に存在しないときはその未知語をさらに一文字以上の文字からなる字句に分解しその分解した字句を前記綴り対応表から検索し第二言語の字句を抽出しその抽出した第二言語の字句を合成して未知語の訳語を求める未知語処理部と、前記翻訳辞書部検索部や前記未知語処理部から出力された訳語を受け取り組み立てて訳文として出力する出力処理部とを備えたことを特徴とする機械翻訳装置。
【請求項2】
前記綴り対応表は、第二言語の語句に対して第一言語の発音で表現した語句を一文字以上の文字からなる字句に分割して得られた第一言語の字句と、この分割された第一言語の字句に対応する第二言語の字句の綴りの部分とをあらかじめ対応づけて記憶したことを特徴とする請求項1に記載の機械翻訳装置。
【請求項3】
第二言語の語句の綴りに加え、語句の意味、品詞、分野、共起情報等の属性情報を蓄積した第二言語の知識データベースを有し、前記未知語処理部は、第二言語の字句を合成して未知語の訳語を求めるにあたり、前記第二言語の知識データベースを参照し属性情報を基に前記未知語の訳語の優先度を決めることを特徴とする請求項1または2記載の機械翻訳装置。
【請求項4】
前記未知語の候補となる第二言語の語句をあらかじめ記憶する第二言語の語彙データベースを有し、前記未知語処理部は、第二言語の字句を合成して未知語の訳語を求めるにあたり、前記第二言語の語彙データベースを参照し合致するものがあるときは前記未知語の訳語としての優先度を高くすることを特徴とする請求項1乃至3のいずれか1項記載の機械翻訳装置。
【請求項5】
コンピュータを、第一言語の原文を形態素解析していくつかの語句に分解する手段と、第一言語の語句とそれに対応する第二言語の語句とを対にして記憶した翻訳辞書部から分解された第一言語の語句を検索し第二言語の語句を訳語として選び出す手段と、分解された第一言語の語句が前記翻訳辞書部に存在しないときはその未知語をさらに一文字以上の文字からなる字句に分解する手段と、第一言語の語句中の一文字以上の文字からなる字句及びこれに対応する第二言語の文字による綴りの一以上の字句を対応づけて記憶した綴り対応表から前記分解した字句を検索して第二言語の字句を抽出する手段と、抽出した第二言語の字句を合成して未知語の訳語を求める手段と、前記分解された語句の訳語や前記未知語の訳語を受け取り組み立てて訳文として出力する手段として機能させるための機械翻訳プログラム。
【請求項1】
第一言語の語句とそれに対応する第二言語の語句とを対にして記憶する翻訳辞書部と、第一言語の原文を形態素解析していくつかの語句に分解する入力処理部と、前記入力処理部で分解された語句を前記翻訳辞書部から検索し第二言語の語句を訳語として選び出す翻訳辞書検索部と、第一言語の語句中の一文字以上の文字からなる字句及びこれに対応する第二言語の文字による綴りの一以上の字句を対応づけて記憶する綴り対応表と、前記入力処理部で分解された語句が前記翻訳辞書部に存在しないときはその未知語をさらに一文字以上の文字からなる字句に分解しその分解した字句を前記綴り対応表から検索し第二言語の字句を抽出しその抽出した第二言語の字句を合成して未知語の訳語を求める未知語処理部と、前記翻訳辞書部検索部や前記未知語処理部から出力された訳語を受け取り組み立てて訳文として出力する出力処理部とを備えたことを特徴とする機械翻訳装置。
【請求項2】
前記綴り対応表は、第二言語の語句に対して第一言語の発音で表現した語句を一文字以上の文字からなる字句に分割して得られた第一言語の字句と、この分割された第一言語の字句に対応する第二言語の字句の綴りの部分とをあらかじめ対応づけて記憶したことを特徴とする請求項1に記載の機械翻訳装置。
【請求項3】
第二言語の語句の綴りに加え、語句の意味、品詞、分野、共起情報等の属性情報を蓄積した第二言語の知識データベースを有し、前記未知語処理部は、第二言語の字句を合成して未知語の訳語を求めるにあたり、前記第二言語の知識データベースを参照し属性情報を基に前記未知語の訳語の優先度を決めることを特徴とする請求項1または2記載の機械翻訳装置。
【請求項4】
前記未知語の候補となる第二言語の語句をあらかじめ記憶する第二言語の語彙データベースを有し、前記未知語処理部は、第二言語の字句を合成して未知語の訳語を求めるにあたり、前記第二言語の語彙データベースを参照し合致するものがあるときは前記未知語の訳語としての優先度を高くすることを特徴とする請求項1乃至3のいずれか1項記載の機械翻訳装置。
【請求項5】
コンピュータを、第一言語の原文を形態素解析していくつかの語句に分解する手段と、第一言語の語句とそれに対応する第二言語の語句とを対にして記憶した翻訳辞書部から分解された第一言語の語句を検索し第二言語の語句を訳語として選び出す手段と、分解された第一言語の語句が前記翻訳辞書部に存在しないときはその未知語をさらに一文字以上の文字からなる字句に分解する手段と、第一言語の語句中の一文字以上の文字からなる字句及びこれに対応する第二言語の文字による綴りの一以上の字句を対応づけて記憶した綴り対応表から前記分解した字句を検索して第二言語の字句を抽出する手段と、抽出した第二言語の字句を合成して未知語の訳語を求める手段と、前記分解された語句の訳語や前記未知語の訳語を受け取り組み立てて訳文として出力する手段として機能させるための機械翻訳プログラム。
【図1】


【図2】
【図3】
【図4】

【図5】
【図2】
【図3】
【図4】
【図5】
【公開番号】特開2008−27027(P2008−27027A)
【公開日】平成20年2月7日(2008.2.7)
【国際特許分類】
【出願番号】特願2006−196519(P2006−196519)
【出願日】平成18年7月19日(2006.7.19)
【出願人】(000003078)株式会社東芝 (54,554)
【出願人】(301063496)東芝ソリューション株式会社 (1,478)
【Fターム(参考)】
【公開日】平成20年2月7日(2008.2.7)
【国際特許分類】
【出願日】平成18年7月19日(2006.7.19)
【出願人】(000003078)株式会社東芝 (54,554)
【出願人】(301063496)東芝ソリューション株式会社 (1,478)
【Fターム(参考)】
[ Back to top ]