
演算処理装置
【課題】三角関数を演算する演算処理装置において、命令数を削減し、スループットを向上する。
【解決手段】浮動小数点積和回路(100)に、OR回路(188)と、セレクタ(184)と、EOR回路(186)を設け、rd=(rs1*rs1)|(rs2[0]<<63)の演算を定義する第1の三角関数演算補助命令と、rd=((rs2[0])?1.0:rs1)^(rs2[1]<<63)の演算を定義する第2の三角関数演算補助命令とにより、又は、rd=(rs1*rs1)|((〜rs2[0]<<63)の演算を定義する第3の三角関数演算補助命令と、rd=((rs2[0])?rs1:1.0)^((rs2[1]^rs2[0])<<63))の演算を定義する第4の三角関数演算補助命令とにより、三角関数のテーラー級数展開の展開点と展開関数を演算する。
【解決手段】浮動小数点積和回路(100)に、OR回路(188)と、セレクタ(184)と、EOR回路(186)を設け、rd=(rs1*rs1)|(rs2[0]<<63)の演算を定義する第1の三角関数演算補助命令と、rd=((rs2[0])?1.0:rs1)^(rs2[1]<<63)の演算を定義する第2の三角関数演算補助命令とにより、又は、rd=(rs1*rs1)|((〜rs2[0]<<63)の演算を定義する第3の三角関数演算補助命令と、rd=((rs2[0])?rs1:1.0)^((rs2[1]^rs2[0])<<63))の演算を定義する第4の三角関数演算補助命令とにより、三角関数のテーラー級数展開の展開点と展開関数を演算する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、数学関数の計算を行う演算処理装置に関する。
【背景技術】
【0002】
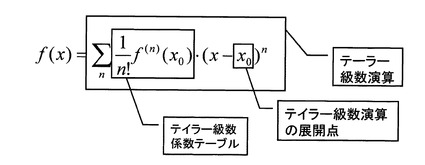
三角関数等の数学関数を演算する演算処理装置は、スーパーコンピュータを含む種々のコンピュータで利用されている。このような演算処理装置は、一般的に、数学関数を、テーラー級数演算を用いて近似的に計算する。例えば、数学関数f(x)は、図22に示すような、テーラー級数演算式で表現できる。
【0003】
図22に示すテーラー級数演算により、任意の値(入力引数)xにおける数学関数f(x)の値を計算するために、演算処理装置の計算は、テーラー級数演算の展開点x0を決定し、その展開点に対応したテーラー級数係数((1/n!)・f(n)(x0))のテーブルを決定する前処理部部分と、テーラー級数係数テーブルを用いて、図22のテーラー級数演算を実行する後処理部分とに、分けられる。
【0004】
例えば、数学関数が、sin関数である場合には、図23に示すような、テーラー級数演算の展開点x0を決定し、その展開点に対応したテーラー級数係数((1/n!)・f(n)(x0))のテーブルを決定する。
【0005】
即ち、sin関数の場合、周期性があるため、π/2の整数倍を、入力引数x近傍の展開点とすると、入力引数xを、π/2で割った時の商(q)から、テーラー級数展開点x0を計算する。そして、商(q)を「4」で割った余り(q%4)に対応する、展開関数と、そのテーラー級数係数を、決定する。
【0006】
例えば、余りが、「0」では、展開関数は、sin(x−xo)であり、そのテーラー級数係数((1/n!)・f(n)(x0))=(−1)n/(2*n+1)!であり、図22のテーラー級数は、Σ(−1)n/(2*n+1)!*(x−x0)(2n+1)である。図23では、「**」は、べき乗を示し、「!」は、かい乗、「*」は、乗算を示す。
【0007】
従来技術では、三角関数のテーラー級数演算実行前の、テーラー級数展開関数の決定と、その展開関数への入力引数の算出処理は、ロード命令やシフト命令等の命令を使用して、浮動小数点レジスタと、整数レジスタ間のデータ転送や、マスク演算、シフト演算などの整数演算器を使用した演算処理とにより、行っていた。
【先行技術文献】
【特許文献】
【0008】
【特許文献1】特開2008−234076号公報(図1〜図7)
【特許文献2】特開2002−063152号公報(図1〜図7)
【発明の概要】
【発明が解決しようとする課題】
【0009】
近年の演算処理の高速化の要求に従い、数学関数のテーラー級数演算の高速化が要求される。従来技術では、テーラー級数展開関数の決定と、その展開関数への入力引数の算出処理を、ロード命令やシフト命令等の命令を使用して、浮動小数点レジスタと、整数レジスタ間のデータ転送や、マスク演算、シフト演算などの複雑な処理が必要となり、浮動小数点演算以外のオーバーヘッド(整数演算命令やメモリアクセス命令等)が発生していた。
【0010】
即ち、数学関数演算全体を処理するのに、多くの命令を必要とし、命令発行スループットの圧迫などの性能低下要因が存在した。
【0011】
従って、本発明の目的は、数学関数演算の高速化する演算処理装置を提供することにある。
【課題を解決するための手段】
【0012】
この目的の達成のため、演算処理装置は、3つの入力rs1、rs2、rs3を受け、浮動小数点積和演算を行う浮動小数点積和回路と、浮動小数点積和回路の出力の最上位ビットと、入力rs2の最下位ビットrs2[0]とのOR(論理和演算)を演算するOR回路(論理和演算回路)と、入力rs1と、値「1.0」とのいずれかを選択するセレクタと、入力rs2の最下位から1ビット上位のビットrs2[1]とセレクタの最上位ビットとのEOR(排他的論理和演算)を計算するEOR回路(排他的論理和演算回路)とを有し、rd=(rs1*rs1)|(rs2[0]<<63)の演算を定義する第1の三角関数演算補助命令と、rd=((rs2[0])?1.0:rs1)^(rs2[1]<<63)の演算を定義する第2の三角関数演算補助命令とにより、前記三角関数のテーラー級数展開の展開点と展開関数を演算する。
【0013】
又、この目的の達成のため、演算処理装置は、3つの入力rs1、rs2、rs3を受け、浮動小数点積和演算を行う浮動小数点積和回路と、浮動小数点積和回路の出力の最上位ビットと、入力rs2の最下位ビットrs2[0]の反転信号とのORを演算するOR回路と、入力rs1と、値「1.0」とのいずれかを選択するセレクタと、入力rs2の最下位から1ビット上位のビットrs2[1]と前記最下位ビットrs2[0]とのEORを演算する第1のEOR回路と、前記セレクタの最上位ビットと前記第1のEOR回路の出力とのEORを演算する第2のEOR回路とを有し、rd=(rs1*rs1)|((〜rs2[0]<<63)の演算を定義する第3の三角関数演算補助命令と、rd=((rs2[0])?rs1:1.0)^((rs2[1]^rs2[0])<<63))の演算を定義する第4の三角関数演算補助命令とにより、前記三角関数のテーラー級数展開の展開点と展開関数を演算する。
【発明の効果】
【0014】
浮動小数点積和回路に、OR回路と、セレクタと、EOR回路を設け、rd=(rs1*rs1)|(rs2[0]<<63)の演算を定義する第1の三角関数演算補助命令と、rd=((rs2[0])?1.0:rs1)^(rs2[1]<<63)の演算を定義する第2の三角関数演算補助命令とにより、又は、rd=(rs1*rs1)|((〜rs2[0])<<63)の演算を定義する第3の三角関数演算補助命令と、rd=((rs2[0])?rs1:1.0)^((rs2[1]^rs2[0])<<63))の演算を定義する第4の三角関数演算補助命令とにより、三角関数のテーラー級数展開の展開点と展開関数を演算するため、命令数を削減でき、且つ高速な演算が可能となる。
【図面の簡単な説明】
【0015】
【図1】本発明の演算処理装置の第1の実施の形態の回路図である。
【図2】図1に使用される演算補助命令の説明図である。
【図3】図2の演算補助命令2の演算処理の説明図である。
【図4】図2の演算補助命令3の演算処理の説明図である。
【図5】三角関数のテーラー級数の説明図である。
【図6】図5のテーラー級数演算の説明図である。
【図7】第1の実施の形態の三角関数演算補助命令を使用したsin関数演算の前処理の命令列の説明図である。
【図8】図7の第1の実施の形態の命令列と、演算内容の説明図である。
【図9】図1の係数テーブルセットの一実施の形態の構成図である。
【図10】アッセンブラ記述による従来の後処理の命令列と、本実施の形態による後処理の命令列との説明図である。
【図11】アセンブラ記述のよるオペレーションコードと、演算内容との関係図である。
【図12】テーラー級数演算順序の説明図である。
【図13】non−SIMD(Single Instruction stream Multiplie Data stream)の場合の命令数の比較図である。
【図14】non−SIMDの場合の演算スループットの比較図である。
【図15】SIMD(Single Instruction stream Multiplie Data stream)の場合の命令数の比較図である。
【図16】SIMDの場合の演算スループットの比較図である。
【図17】本発明の演算処理装置の第2の実施の形態の回路図である。
【図18】図17に使用される演算補助命令の説明図である。
【図19】図17の三角関数のテーラー級数の説明図である。
【図20】第2の実施の形態の三角関数演算補助命令を使用したsin関数演算の前処理の命令列の説明図である。
【図21】図20の第2の実施の形態の命令列と、演算内容の説明図である。
【図22】従来の三角関数のテーラー級数展開の説明図である。
【図23】従来の展開点、展開関数の決定処理の説明図である。
【発明を実施するための形態】
【0016】
以下、実施の形態の例を、演算処理装置の第1の実施の形態、前処理の説明、後処理の説明、演算処理装置の第2の実施の形態、他の実施の形態の順で説明するが、開示の演算処理装置は、この実施の形態に限られない。
【0017】
(演算処理装置の第1の実施の形態)
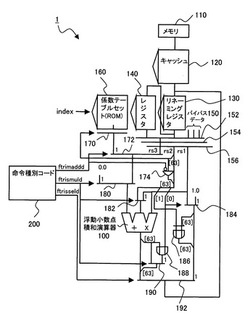
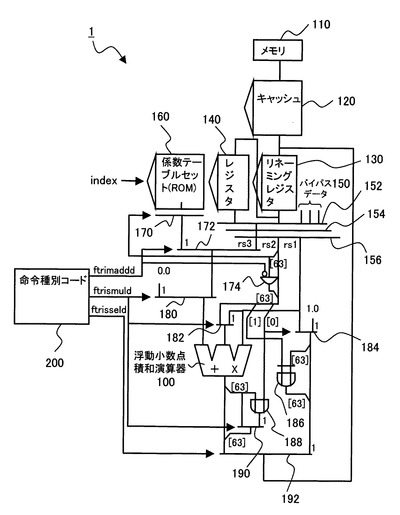
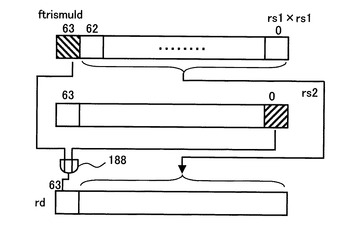
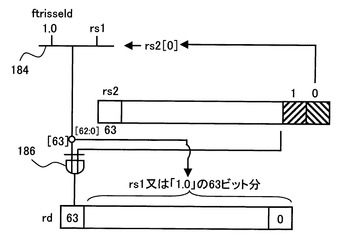
図1は、本発明の演算処理装置の第1の実施の形態の回路図、図2は、図1に使用される演算補助命令の説明図、図3、図4は、その演算補助命令の演算処理の説明図である。
【0018】
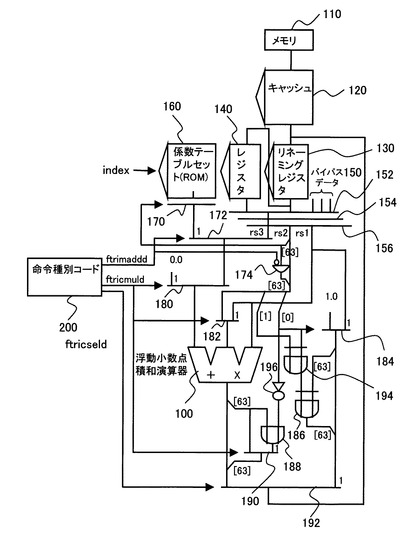
図1に示すように、命令種別コード200に、図2に示す三角関数のテーラー級数演算実行前の、テーラー級数展開関数の決定と、その展開関数への入力引数の算出処理(前処理工程)を行う命令として、専用の三角関数演算補助命令を設けた。
【0019】
図2では、sin関数のアッセンブラ命令の例を示し、三角関数演算補助命令2(ftrismuld)と、三角関数演算補助命令3(ftrisseld)とが、前工程の補助命令であり、三角関数演算補助命令1(ftrimaddd)が、後述する後工程の補助命令である。
【0020】
三角関数演算補助命令2(ftrismuld)は、被演算対象であるオペランドフィールドに、<積和演算の積演算の一方のレジスタ番号:rs1>,<積和演算の積演算の他方のレジスタ番号:rs2>、<積和演算の演算結果の出力レジスタ番号:rd>を定義する。
【0021】
そして、三角関数演算補助命令2(ftrismuld)は、rd=(rs1*rs1)|(rs2[0]<<63)を演算する命令である。即ち、図3に示すように、レジスタrs1の値を二乗し、レジスタrs2の「0」ビット目のデータrs[0]を、63ビット左シフトし(最上位までシフトし)、レジスタrs1の二乗の63ビット目と、63ビットシフトしたrs2[0]とのORをOR回路188で演算し、rs1の二乗の値(64ビット)の63ビット目を、OR演算結果で置き換え、出力レジスタrdに格納する演算を行う。
【0022】
一方、三角関数演算補助命令3(ftrisseld)は、オペランドフィールドに、<積和演算の積演算の一方のレジスタ番号:rs1>,<積和演算の積演算の他方のレジスタ番号:rs2>、<積和演算の演算結果の出力レジスタ番号:rd>を定義する。
【0023】
そして、三角関数演算補助命令3(ftrisseld)は、rd=((rs2[0])?1.0:rs1)^(rs2[1]<<63)を演算する命令である。即ち、図4に示すように、レジスタrs2の「0」ビット目の値rs2[0]で、セレクタ184を選択する。セレクタ184は、値「1.0」(64ビット)と、レジスタrs1のデータ(64ビット)が入力され、rs2[0]=1なら、値「1.0」を、rs2[0]=0なら、レジスタrs1のデータを選択する。そして、セレクタ184の出力の63ビット目の値と、レジスタrs2の「1」ビット目の値rs2[1]のEORを、EOR回路186で演算し、セレクタ184の出力の63ビット目を、EOR演算結果で置き換え、出力レジスタrdに格納する演算を行う。
【0024】
更に、後工程で使用する三角関数演算補助命令1(ftrimmddd)は、オペランドフィールドに、<積和演算の積演算の一方のレジスタ番号:rs1>,<積和演算の積演算の他方のレジスタ番号:rs2>、<テーラー級数の次数番号:index>,<積和演算の演算結果の出力レジスタ番号:rd>を定義する。
【0025】
そして、三角関数演算補助命令1(ftrimaddd)は、rd=((rs1*fabs(rs2)+T[rs2[63]][index])を実行する命令である。後述するように、この演算補助命令は、T[rs[63]]で決定された展開関数のindexで指定される次数のテーラー級数係数を、テーブルから引き出し、レジスタrs1に、レジスタrs2の絶対値(fabs(rs2))を乗じた結果と、加算する演算を行う。
【0026】
図1に戻り、演算処理装置1は、メモリ(メインメモリ)110と、メインメモリ110のデータの一部を記憶するキャッシュメモリ120と、リネーミングレジスタ130と、レジスタファイル140と、バイパスデータ150と、マルチプレクサ152〜156と、浮動小数点積和演算器100とを有する。
【0027】
レジスタファイル140は、浮動小数点積和演算器100が、演算を実行するときに使用する全てのレジスタを備えている。リネーミングレジスタ130は、オペランドデータの逆依存と出力依存を解消するために設けられている。バイパスデータ150は、演算処理装置1の命令パイプラインにおいて、データハザードを解消するためのバイパシング(bypassing)で使用されるデータ(演算結果データ)である。リネーミングレジスタ130のエントリに格納されているレジスタ値は、リタイア(retire)時に、レジスタファイル140に移される。
【0028】
係数テーブルセット(ROM)160、セレクタ170,172、一入力反転型AND回路(一入力反転型論理積演算回路)174は、後述する後処理で使用される。係数テーブルセット160は、図9にて詳述するテーラー級数の各次数の係数を格納する。この係数テーブルセット160は、次数を指定するindexと、決定された展開関数で、セレクタ170より、対応する展開関数の次数のテーラー級数の係数が、読み出さられる。
【0029】
セレクタ172は、前述の三角関数演算補助命令1(ftrimaddd)で操作され、セレクタ170の出力か、レジスタrs3のいずれかを出力する。一入力反転型AND回路174は、後述する後処理で使用され、前述の三角関数演算補助命令1(ftrimaddd)のフラグを反転し、反転出力とレジスタrs2の63ビット目rs2[63]とのANDを演算する。
【0030】
セレクタ180は、前述の三角関数演算補助命令2(ftrismuld)で操作され、セレクタ172の出力か、値「1.0」かのいずれかを、浮動小数点積和演算器100の和入力に、出力する。セレクタ182は、前述の三角関数演算補助命令2(ftrismuld)で操作され、レジスタrs2の出力か、レジスタrs1かのいずれかを、浮動小数点積和演算器100の積入力に、出力する。
【0031】
セレクタ184は、図4で説明したように、前述の三角関数演算補助命令3(ftrisseld)で操作され、値「1.0」(64ビット)と、レジスタrs1のデータ(64ビット)が入力され、レジスタrs2の「0」ビット目の値rs2[0]で、いずれかを選択する。EOR回路186は、セレクタ184の出力の63ビット目の値と、レジスタrs2の「1」ビット目の値rs2[1]のEORを、EOR回路186で演算する。
【0032】
OR回路188は、図3で説明したように、浮動小数点積和演算器100が演算したレジスタrs1の二乗の63ビット目と、63ビットシフトしたrs[0]とのORを演算する。セレクタ190は、浮動小数点積和演算器100が演算したデータの63ビット目の値か、OR回路188の出力かのいずれかを選択する。セレクタ192は、前述の三角関数演算補助命令3(ftrisseld)で操作され、浮動小数点積和演算器100の出力か、セレクタ184の出力かのいずれかを出力する。
【0033】
この演算処理装置1は、通常の構成であるメモリ(メインメモリ)110と、メインメモリ110のデータの一部を記憶するキャッシュメモリ120と、リネーミングレジスタ130と、レジスタファイル140と、バイパスデータ150と、マルチプレクサ152〜156と、浮動小数点積和演算器100とを有する。
【0034】
これに加え、前処理のため、セレクタ180,182,184,190,192、EOR回路186、OR回路188とを有する。又、後処理のため、係数テーブルセット160、セレクタ170,172、AND回路174とを有する。
【0035】
(前処理の説明)
図5は、テーラー級数の説明図、図6は、テーラー級数演算の説明図、図7は、本実施の形態の三角関数演算補助命令を使用したsin関数演算のための前処理の命令列の説明図、図8は、図7の本実施の形態の命令列と、演算内容の説明図である。
【0036】
テーラー級数演算実行の前処理は、テーラー級数演算が、高次で収束するように、入力引数近傍のテーラー級数演算の展開点の決定し、その展開点で級数展開したときのテーラー級数展開関数、およびテーラー級数係数を決定する。
【0037】
先ず、図5により、テーラー級数展開式を説明する。図23でも説明したように、sin関数のテーラー級数展開式は、y(=x−x0)の奇関数式(y(2n+1))で表される。一方、cos関数のテーラー級数展開式は、y(=x−x0)の偶関数式(y2n)で表される。
【0038】
ここで、テーラー級数の各次数の係数を、a3,・・a15,b2,・・b14で表すと、図6に示すように、sin(y),cos(y),−sin(y),−cos(y)のテーラー級数展開式に、共通性が現れる。即ち、偶関数の多項式(y0−a3・y2+・・・−a15・y14)に、yを掛けたものが、sin(y)であり、多項式(y0−b2・y2+・・・−b14・y14)に、1.0を掛けたものが、cos(y)である。同様に、多項式(y0−a3・y2+・・・−a15・y14)に、−yを掛けたものが、−sin(y)であり、多項式(y0−b2・y2+・・・−b14・y14)に、−1.0を掛けたものが、−cos(y)である。
【0039】
この関係を利用して、後処理のテーラー級数演算を高速化するため、前処理では、展開点の演算、テーラー級数展開関数の決定の他に、「y」、「1.0」を選択的に、後処理に与える。
【0040】
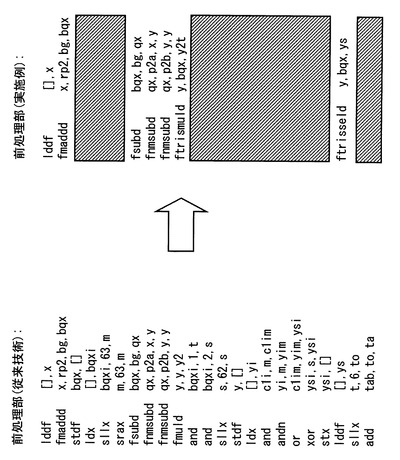
図7は、従来技術によるsin関数演算のアセンブラ記述のよる前処理の命令列と、本実施の形態によるアセンブラ記述のよるsin関数演算の前処理の命令列とを対比した図である。図7から明らかなように、本実施の形態では、三角関数演算補助命令2(ftrismuld),3(ftrisseld)を用いることにより、従来の命令列のロード、シフト命令、マスク命令等を削除でき、転送処理やシフト演算、マスク演算などの複雑な処理を省け、高速に演算できる。
【0041】
図8は、アセンブラ記述のよるオペレーションコードと、演算内容との関係図であり、図1の構成を使用して、具体的に説明する。ロード命令(lddf)で、xに、入力引数memを、ロードする。次に、積和命令fmaddd(floating multipy add double)により、bqx=((x*rp2)+bg)を演算する。
【0042】
ここで、レジスタrp2には、1/(π/2)がセットされており、レジスタbgには、値「1.5*2**52」がセットさている。浮動小数点積和演算器100は、この命令により、レジスタファイル140のxと、rp2との積を演算し、この積とbgの和を演算する。
【0043】
これにより、展開関数と符号を決定する商qx=int(x/(π/2))が、演算結果bqxの仮数部の下位51ビットに得られる。又、値「1.5*2**52」を加算する意味は、52乗の値を加算すると、小数点以下が四捨五入され、所謂、丸め処理を実行される。
【0044】
次に、差命令fsubd(floating substract double)により、qx=bqx−bgを演算する。浮動小数点積和演算器100は、この命令により、レジスタファイル140のbqxから、bgを引き算し、差qxを演算する。このbgを足して、引くことにより、小数点以下の四捨五入を行う。
【0045】
次に、積和命令fnmsubd(floating negative multiply subtract double)により、y=x−(qx*p2a)を演算する。レジスタp2aには、「π/2」の上位の値がセットされている。浮動小数点積和演算器100は、この命令により、レジスタファイル140のqxと、p2aとの積を演算し、レジスタに格納した後、この積とxを読み出し、差を演算する。
【0046】
次に、積和命令fnmsubdにより、y=y−(qx*p2b)を演算する。レジスタp2bには、「π/2」の下位の値がセットされている。浮動小数点積和演算器100は、この命令により、レジスタファイル140のqxと、p2bとの積を演算し、レジスタに格納した後、この積とyを読み出し、差を演算する。
【0047】
これにより、テーラー級数演算の(x−x0)が、yとして得られる。ここで、2つの積和命令を用いているのは、π/2の値を、上位と下位に分け、演算し、小数点以下の精度を高めるためである。
【0048】
次に、三角関数演算補助命令2(ftrismuld)により、y2t=(y*y)|(bqx[0]<<63)を演算する。即ち、命令種別コード200の「ftrismuld」により、通常、rs2を選択するセレクタ182を切り替え、セレクタ182からrs1を出力する。このため、浮動小数点積和演算器100は、レジスタrs1の値yを二乗する。そして、OR回路188は、レジスタrs2の「0」ビット目のデータrs2[0]が入力され、且つ演算器100からの出力y**2の63ビット目が入力される。そして、セレクタ190を介し、演算器100の出力の63ビット目に出力する。
【0049】
即ち、図3で示したように、左シフトし(最上位までシフトし)、レジスタrs1の二乗の63ビット目と、63ビットシフトしたrs2[0]とのORをOR回路188で演算し、rs1の二乗の値(64ビット)の63ビット目を、OR演算結果で置き換え、セレクタ192を介し、レジスタファイル140の出力レジスタrdに格納する演算を行う。
【0050】
図4で説明したように、bqxの仮数部下位51ビットは、商qxであり、bqxの最下位ビットbqx[0]は、テーラー展開関数が、sin関数か、cos関数かを示すため、y2tは、63ビット目が、テーラー展開関数の種類(sin又はcos)を示し、62〜0ビットが、図6で説明したy(x−x0)の二乗データとなる。
【0051】
次に、三角関数演算補助命令3(ftrisseld)により、rd=(rs2[0])?1.0:rs1)^(rs2[1]<<63)を演算する。ここでは、ys=(bqx[0])?1.0:y)^(bqx[1]<<63)を演算する。
【0052】
図4にも示したように、レジスタrs2の「0」ビット目の値rs2[0]で、セレクタ184を選択する。セレクタ184は、値「1.0」(64ビット)と、レジスタrs1のデータ(64ビット)が入力され、rs2[0](bqx[0])=1なら、値「1.0」を、rs2[0](bqx[0])=0なら、レジスタrs1のデータyを選択する。そして、セレクタ184の出力の63ビット目の値と、レジスタrs2の「1」ビット目の値rs2[1](bqx[1])のEORを、EOR回路186で演算し、セレクタ184の出力の63ビット目を、EOR演算結果で置き換え、セレクタ192を介し、出力レジスタrdに格納する演算を行う。
【0053】
この出力ysの63ビット目は、テーラー展開関数の符号(+又は−)を示し、62〜0ビットが、図6で説明したy(x−x0)又は「1.0」となる。
【0054】
このようにして、三角関数演算補助命令2,3と、これにより動作するセレクタ180,182,184,190,192、EOR回路186、OR回路188とを設けることにより、命令数を少なくして、テーラー級数展開関数の決定の他に、テーラー級数演算の「y」、「1.0」を決定できる。このため、前処理を高速化できる。
【0055】
(後処理の説明)
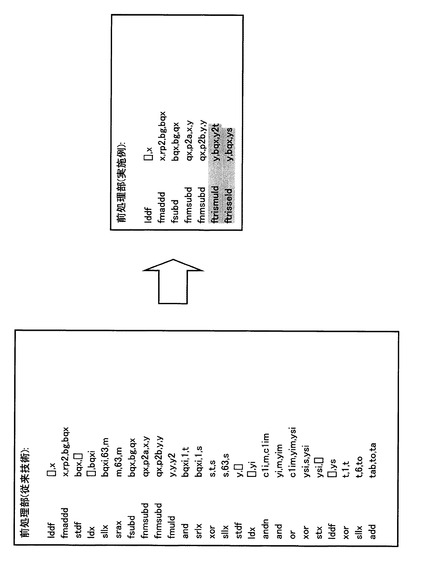
次に、三角関数演算補助命令1を用いた後処理を説明する。図9は、図1の係数テーブルセットの一実施の形態の構成図である。図10は、アッセンブラ記述による従来の後処理の命令列と、本実施の形態による後処理の命令列との説明図、図11は、アセンブラ記述のよるオペレーションコードと、演算内容との関係図である。
【0056】
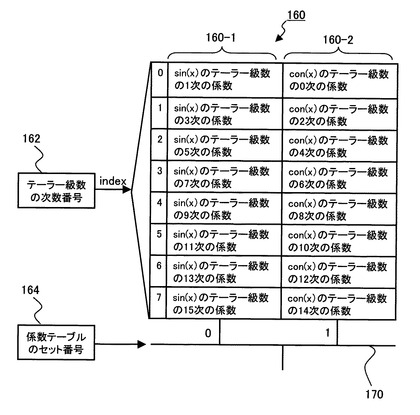
図9に示すように、係数テーブルセット160は、sin関数のテーラー級数の1次〜15次の係数を格納したsin関数部160−1と、cos関数のテーラー級数の1次〜15次の係数を格納したcos関数部160−2とを有する。
【0057】
係数テーブルセット160に接続されたセレクタ170が、係数テーブルのセット番号(図4のbqx[0]、y2t[63])により、sin関数又はcos関数を選択する。又、テーラー級数の次数番号を示すindexにより、係数テーブルセット160の次数が指定される。
【0058】
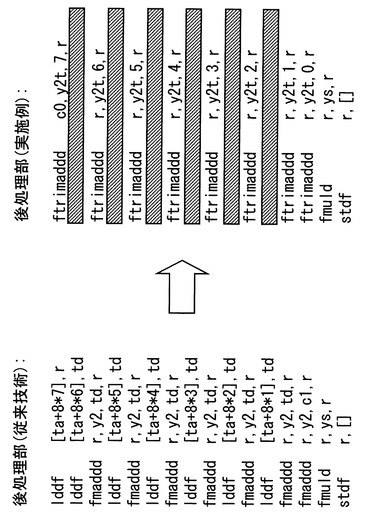
図10は、従来技術によるsin関数演算のアセンブラ記述のよる後処理の命令列と、本実施の形態によるアセンブラ記述のよるsin関数演算の後処理の命令列とを対比した図である。図10から明らかなように、本実施の形態では、三角関数演算補助命令1(ftrimaddd)を用いることにより、従来の命令列のロード命令等を削除でき、転送処理やシフト演算、マスク演算などの複雑な処理を省け、高速に演算できる。
【0059】
図11は、アセンブラ記述のよるオペレーションコードと、演算内容との関係図であり、図12は、図11の演算順序の説明図である。図12に示すように、演算順序は、次数の高いものを先に演算して、順次、その演算結果を用いて、次数の低いものを加算していく。即ち、次数の高い係数(1/15!)を呼び出し,次に、三角関数演算補助命令1(ftrimaddd)により、((前回の次数の係数*y2)+今回の次数の係数)を演算する。
【0060】
図11の演算処理を、図1,図9の構成を使用して、具体的に説明する。三角関数演算補助命令1(ftrimaddd)により、rd=((rs1*fabs(rs2)+T[rs2[63]][index])を実行する。先ず、rs1=co=0.0とし、rs2[63]=y2t[63]、index=7(次数15)で、係数テーブルセット160をアクセスし、sin関数の次数15の係数(1/15!)を取り出し、セレクタ172を介し、演算器100に入力させる。
【0061】
演算器100は、rs1=co=0.0であるから、演算結果rは、図12のように、r=1/15!となる。
【0062】
次に、三角関数演算補助命令1(ftrimaddd)とオペレーションコードr、y2t、6、rを指定する。演算補助命令1により、T[y2t[63]]で決定された展開関数のindex=6で指定される次数のテーラー級数係数を、セレクタ170,172を介し、テーブル160から引き出す。
【0063】
一方、rs2=y2tの63ビット目は、AND回路174に入力する。AND回路174の反転入力には、三角関数演算補助命令1(ftrimaddd)のフラグ「1」が入力されているため、AND回路174の出力は、「0」である。このため、rs2=y2tの63ビット目は、「0」になり、セレクタ182を介し、演算器100に入力する。一方、レジスタrs1には、前述のrが格納されているため、演算器100は、(r=r*y2t[62:0]+係数)の演算を行い、レジスタファイル140に、rとして格納する。
【0064】
以下、同様に、次数を、順次、5,4,3,2,1,0と下げ、三角関数演算補助命令1(ftrimaddd)とオペレーションコードにより、同様に演算を行う。これにより、図12の最後段の演算結果rが得られる。
【0065】
次に、積命令(fmuld:multiply)とr、rs2=ys、rを指定する。この積命令で、演算器100は、r=r*ysを演算する。ysは、y又は1.0又は−y又は−1.0であるため、演算器100が計算するr=r*ysは、図6で説明したテーラー展開級数となる。
【0066】
更に、ストア命令(stdf)により、この結果rを、レジスタファイル140のエントリmemにストアする。
【0067】
このようにして、三角関数演算補助命令1と、これにより動作する係数テーブルセット160、セレクタ170,172,AND回路174とを設けることにより、命令数を少なくして、テーラー級数展開関数の演算が可能となり、後処理を高速化できる。
【0068】
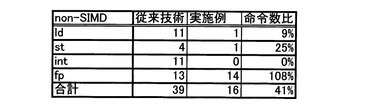
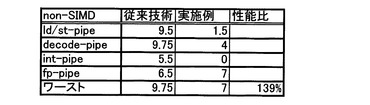
次に、本実施の形態と従来技術との命令数と、性能とを比較する。図13は、non−SIMD(Single Instruction stream Multiplie Data stream)の場合の命令数の比較図、図14は、non−SIMDの場合の演算スループットの比較図である。
【0069】
図13に示すように、従来技術では、ロード命令(ld)、ストア命令(st)、整数演算命令(Int)が多いが、本実施の形態では、ロード命令(ld)、ストア命令(st)、整数演算命令(Int)が殆どなくなり、命令数が、半分以下(40%)に減少する。
【0070】
又、図14に示すように、三角関数演算のみをベクトル演算する場合に、演算スループットが、従来に比し、1.4倍に向上する。他の演算と並行して、三角関数の演算を実行する場合、ld/st pipe(メモリアクセス命令であるロード命令/ストア命令のパイプライン)を消費しないので、更に、演算スループットを向上できる。しかも、命令数が少なく、浮動小数点演算命令に限定しているため、ソフトウェアパイプライニングで、適切な命令スケジューリングを実施しやすくなり、性能向上につながる。
【0071】
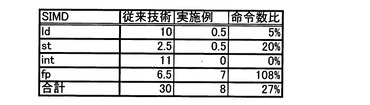
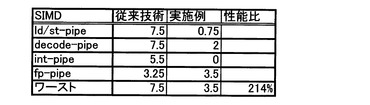
図15は、SIMD(Single Instruction stream Multiplie Data stream)の場合の命令数の比較図、図16は、SIMDの場合の演算スループットの比較図である。
【0072】
図15に示すように、従来技術では、ロード命令(ld)、ストア命令(st)、整数演算命令(Int)が多いが、本実施の形態では、ロード命令(ld)、ストア命令(st)、整数演算命令(Int)が殆どなくなり、命令数が、約1/4(27%)に減少する。整数演算命令を含まないため、SIMD化に適している。
【0073】
又、図15に示すように、三角関数演算のみをベクトル演算する場合に、演算スループットが、従来に比し、2.1倍に向上する。
【0074】
(演算処理装置の第2の実施の形態)
図17は、本発明の演算処理装置の第2の実施の形態の回路図、図18は、図17に使用されるcos関数演算のテーラー級数の展開点を、展開関数の説明図、図19は、図17のcos演算補助命令の説明図、図20、図21は、その演算補助命令の演算処理の説明図である。
【0075】
図17において、図1と同一のものは、同一に記号で示してある。図1との相違点は、OR回路190の入力段に、反転回路196を設け、EOR回路186の入力段に、EOR回路194を設けた点である。又、図17に示すように、命令種別コード200に、図18に示す三角関数(cos関数)のテーラー級数演算実行前の、テーラー級数展開関数の決定と、その展開関数への入力引数の算出処理(前処理工程)を行う命令として、専用の三角関数演算補助命令を設けた。
【0076】
更に、図18において、図23のsin関数の場合と、展開点の定義、展開関数のテーラー級数式は同じであるが、商qの剰余の値に対応する展開関数が、図23とは、異なる。
【0077】
図19では、cos関数のアッセンブラ命令の例を示し、三角関数演算補助命令4(ftricmuld)と、三角関数演算補助命令5(ftricseld)とを、前工程の補助命令として設けた。尚、図2の三角関数演算補助命令1(ftrimaddd)は、同様に、後工程の補助命令として、使用する。
【0078】
三角関数演算補助命令4(ftricmuld)は、オペランドフィールドに、<積和演算の積演算の一方のレジスタ番号:rs1>,<積和演算の積演算の他方のレジスタ番号:rs2>、<積和演算の演算結果の出力レジスタ番号:rd>を定義する。
【0079】
そして、三角関数演算補助命令4(ftricmuld)は、rd=(rs1*rs1)|((〜rs2[0]<<63)を演算する命令である。即ち、図3と同様に、レジスタrs1の値を二乗し、レジスタrs2の「0」ビット目のデータrs2[0]のビットワイズノット(反転回路196による)を、63ビット左シフトし(最上位までシフトし)、レジスタrs1の二乗の63ビット目と、63ビットシフトしたrs2[0]とのORを演算し、rs1の二乗の値(64ビット)の63ビット目を、OR演算結果で置き換え、出力レジスタrdに格納する演算を行う。
【0080】
一方、三角関数演算補助命令5(ftricseld)は、オペランドフィールドに、<積和演算の積演算の一方のレジスタ番号:rs1>,<積和演算の積演算の他方のレジスタ番号:rs2>、<積和演算の演算結果の出力レジスタ番号:rd>を定義する。
【0081】
そして、三角関数演算補助命令5(ftricseld)は、rd=(rs2[0])?rs1:1.0)^((rs2[1]^rs2[0])<<63))を演算する命令である。即ち、図4と同様に、レジスタrs2の「0」ビット目の値rs2[0]で、セレクタ184を選択する。セレクタ184は、値「1.0」(64ビット)と、レジスタrs1のデータ(64ビット)が入力され、rs2[0]=0なら、値「1.0」を、rs2[0]=1なら、レジスタrs1のデータを選択する。そして、レジスタrs2の「1」、「0」ビット目の値rs2[1]、rs2[0]のEORを、EOR回路194で演算する。更に、セレクタ184の出力の63ビット目の値と、EOR回路194の出力とのEORを、EOR回路186で演算し、セレクタ184の出力の63ビット目を、EOR演算結果で置き換え、出力レジスタrdに格納する演算を行う。
【0082】
図20は、従来技術によるcos関数演算のアセンブラ記述のよる前処理の命令列と、本実施の形態によるアセンブラ記述のよるcos関数演算の前処理の命令列とを対比した図である。図20から明らかなように、本実施の形態では、三角関数演算補助命令4(ftricmuld),5(ftricseld)を用いることにより、従来の命令列のロード、シフト命令、マスク命令等を削除でき、転送処理やシフト演算、マスク演算などの複雑な処理を省け、高速に演算できる。
【0083】
図21は、アセンブラ記述のよるオペレーションコードと、演算内容との関係図であり、図17の構成を使用して、具体的に説明する。図8のsin関数と同様に、ロード命令(lddf)で、xに、入力引数memを、ロードする。
【0084】
次に、積和命令(fmaddd:multipy&add)により、bqx=((x*rp2)+bg)を演算する。ここで、レジスタrp2には、1/(π/2)がセットされており、レジスタbgには、値「1.5*2**52」がセットさている。浮動小数点積和演算器100は、この命令により、レジスタファイル140のxと、rp2との積を演算し、この積とbgの和を演算する。
【0085】
これにより、展開関数と符号を決定する商qx=int(x/(π/2))が,演算結果bqxの仮数部の下位51ビットに得られる。又、値「1.5*2**52」を加算する意味は、52乗の値を加算すると、小数点以下が四捨五入され、所謂、丸め処理を実行される。
【0086】
次に、差命令(fsubd:substract)により、qx=bqx−bgを演算する。浮動小数点積和演算器100は、この命令により、レジスタファイル140のbgxから、bgを引き算し、差qxを演算する。このbgを足して、引くことにより、四捨五入を行う。
【0087】
次に、積和命令(fnmsubd:multiply&subtract)により、y=x−(qx*p2a)を演算する。レジスタp2aには、「π/2」の上位の値がセットされている。浮動小数点積和演算器100は、この命令により、レジスタファイル140のqxと、p2aとの積を演算し、レジスタに格納した後、この積とxを読み出し、差を演算する。
【0088】
次に、積和命令(fnmsubd:multiply&subtract)により、y=y−(qx*p2b)を演算する。レジスタp2bには、「π/2」の下位の値がセットされている。浮動小数点積和演算器100は、この命令により、レジスタファイル140のqxと、p2bとの積を演算し、レジスタに格納した後、この積とyを読み出し、差を演算する。
【0089】
これにより、テーラー級数演算の(x−x0)が、yとして得られる。ここで、2つの積和命令を用いているのは、π/2の値を、上位と下位に分け、演算し、小数点以下の精度を高めるためである。
【0090】
ここまでは、図8のsin関数と同一の演算である。次に、三角関数演算補助命令4(ftricmuld)により、y2t=(y*y)|(〜bqx[0]<<63)を演算する。即ち、命令種別コード200の「ftricmuld」により、通常、rs2を選択するセレクタ182を切り替え、セレクタ182からrs1を出力する。このため、浮動小数点積和演算器100は、レジスタrs1の値yを二乗する。
【0091】
そして、OR回路188は、レジスタrs2の「0」ビット目のデータrs2[0]を反転回路196で反転した(ビットワイズノット)ビットが入力され、且つ演算器100からの出力y**2の63ビット目が入力される。そして、セレクタ190を介し、演算器100の出力の63ビット目に出力する。
【0092】
即ち、図3で示したように、左シフトし(最上位までシフトし)、レジスタrs1の二乗の63ビット目と、63ビットシフトし、反転したrs[0]とのORをOR回路188で演算し、rs1の二乗の値(64ビット)の63ビット目を、OR演算結果で置き換え、セレクタ192を介し、レジスタファイル140の出力レジスタrdに格納する演算を行う。
【0093】
図4で説明したように、bqxの仮数部下位51ビットは、商qxであり、bqxの最下位ビットbqx[0]は、テーラー展開関数が、sin関数か、cos関数かを示すため、y2tは、63ビット目が、テーラー展開関数の種類(sin又はcos)を示し、62〜0ビットが、図6で説明したy(x−x0)の二乗データとなる。
【0094】
次に、三角関数演算補助命令5(ftricseld)により、rd=((rs2[0]=bqx[0])?rs1=y:1.0)^((rs2[1]^rs2[0])<<63)を演算する。ここでは、ys=((bqx[0])?y:1.0)^((bqx[1]^bqx[0])<<63)を演算する。
【0095】
図4にも示したように、レジスタrs2の「0」ビット目の値rs2[0]で、セレクタ184を選択する。セレクタ184は、値「1.0」(64ビット)と、レジスタrs1のデータ(64ビット)が入力され、rs2[0](bqx[0])=0なら、値「1.0」を、rs2[0](bqx[0])=1なら、レジスタrs1のデータyを選択する。
【0096】
そして、レジスタrs2の「1」、「0」ビット目の値rs2[1](bqx[1])、rs2[0](bqx[0])のEORを、EOR回路194で演算する。更に、セレクタ184の出力のセレクタ184の出力の63ビット目の値と、EOR回路194の出力とのEORを、EOR回路186で演算し、セレクタ184の出力の63ビット目を、EOR演算結果で置き換え、セレクタ192を介し、出力レジスタrdに格納する演算を行う。
【0097】
この出力ysの63ビット目は、テーラー展開関数の符号(+又は−)を示し、62〜0ビットが、図6で説明したy(x−x0)又は「1.0」となる。尚、cos関数の場合、前述の反転回路196、EOR回路194の付加で、図18に示したような、qの剰余と、対応する展開関数、図6の「y」、「1.0」が指定される。
【0098】
このようにして、三角関数演算補助命令4,5と、これにより動作するセレクタ180,182,184,190,192、EOR回路186、194、OR回路188、反転回路196とを設けることにより、命令数を少なくして、テーラー級数展開関数の決定の他に、テーラー級数演算の「y」、「1.0」を決定できる。このため、前処理を高速化できる。
【0099】
尚、後処理は、図9乃至図12の実施の形態と同じである。
【0100】
(他の実施の形態)
前述の実施の形態では、後処理も高速化する補助命令を用いているが、このような補助命令を用いない場合にも、適用できる。又、図17の構成では、sin関数の演算も同様に可能であり、sin関数の補助命令2,3を適用し、sin関数とcos関数の両方を高速化できる構成も採用できる。更に、命令列を、SIMDで構成しても良い。
【0101】
以上、本発明を実施の形態により説明したが、本発明の趣旨の範囲内において、本発明は、種々の変形が可能であり、本発明の範囲からこれらを排除するものではない。
【0102】
(付記1)
3つの入力rs1、rs2、rs3を受け、浮動小数点積和演算を行う浮動小数点積和回路と、浮動小数点積和回路の出力の最上位ビットと、入力rs2の最下位ビットrs2[0]とのORを演算するOR回路と、入力rs1と、値「1.0」とのいずれかを選択するセレクタと、入力rs2の最下位から1ビット上位のビットrs2[1]とセレクタの最上位ビットとのEORを計算するEOR回路とを有し、rd=(rs1*rs1)|(rs2[0]<<63)の演算を定義する第1の三角関数演算補助命令と、rd=((rs2[0])?1.0:rs1)^(rs2[1]<<63)の演算を定義する第2の三角関数演算補助命令とにより、前記三角関数のテーラー級数展開の展開点と展開関数を演算することを特徴とする演算処理装置。
【0103】
(付記2)
3つの入力rs1、rs2、rs3を受け、浮動小数点積和演算を行う浮動小数点積和回路と、浮動小数点積和回路の出力の最上位ビットと、入力rs2の最下位ビットrs2[0]の反転信号とのORを演算するOR回路と、入力rs1と、値「1.0」とのいずれかを選択するセレクタと、入力rs2の最下位から1ビット上位のビットrs2[1]と前記最下位ビットrs2[0]とのEORを演算する第1のEOR回路と、前記セレクタの最上位ビットと前記第1のEOR回路の出力とのEORを演算する第2のEOR回路とを有し、rd=(rs1*rs1)|((〜rs2[0])<<63)の演算を定義する第3の三角関数演算補助命令と、rd=((rs2[0])?rs1:1.0)^((rs2[1]^rs2[0])<<63))の演算を定義する第4の三角関数演算補助命令とにより、前記三角関数のテーラー級数展開の展開点と展開関数を演算することを特徴とする演算処理装置。
【0104】
(付記3)
前記三角関数が、正弦関数(sin)であることを特徴とする付記1の演算処理装置。
【0105】
(付記4)
前記三角関数が、余弦関数(cos)であることを特徴とする付記2の演算処理装置。
【0106】
(付記5)
前記入力rs1と前記入力rs2を選択し、前記浮動小数点積和演算器に、出力する第2のセレクタを更に有することを特徴とする付記1の演算処理装置。
【0107】
(付記6)
前記入力rs1と前記入力rs2を選択し、前記浮動小数点積和演算器に、出力する第2のセレクタを更に有することを特徴とする付記2の演算処理装置。
【0108】
(付記7)
前記三角関数のテーラー級数の各次数の係数を格納する係数テーブルと、前記演算された展開関数により、前記係数テーブルの係数を読み出す回路とを有し、前記浮動小数点演算器が、前記演算された展開点と、前記読み出された係数とを用いて、前記三角関数のテーラー級数演算を実行することを特徴とする付記1の演算処理装置。
【0109】
(付記8)
前記三角関数のテーラー級数の各次数の係数を格納する係数テーブルと、前記演算された展開関数により、前記係数テーブルの係数を読み出す回路とを有し、前記浮動小数点演算器が、前記演算された展開点と、前記読み出された係数とを用いて、前記三角関数のテーラー級数演算を実行することを特徴とする付記2の演算処理装置。
【産業上の利用可能性】
【0110】
浮動小数点積和回路に、OR回路と、セレクタと、EOR回路を設け、rd=(rs1*rs1)|(rs2[0]<<63)の演算を定義する第1の三角関数演算補助命令と、rd=((rs2[0])?1.0:rs1)^(rs2[1]<<63)の演算を定義する第2の三角関数演算補助命令とにより、又は、rd=(rs1*rs1)|((〜rs2[0])<<63)の演算を定義する第3の三角関数演算補助命令と、rd=((rs2[0])?rs1:1.0)^((rs2[1]^rs2[0])<<63))の演算を定義する第4の三角関数演算補助命令とにより、三角関数のテーラー級数展開の展開点と展開関数を演算するため、命令数を削減でき、且つ高速な演算が可能となる。
【符号の説明】
【0111】
100 浮動小数点積和回路
140 レジスタファイル
160 係数テーブルセット
152、154、156 マルチプレクサ
170、172、180、182、184、190、192 セレクタ
174 AND回路
188 OR回路
186、194 EOR回路
200 命令種別コード
【技術分野】
【0001】
本発明は、数学関数の計算を行う演算処理装置に関する。
【背景技術】
【0002】
三角関数等の数学関数を演算する演算処理装置は、スーパーコンピュータを含む種々のコンピュータで利用されている。このような演算処理装置は、一般的に、数学関数を、テーラー級数演算を用いて近似的に計算する。例えば、数学関数f(x)は、図22に示すような、テーラー級数演算式で表現できる。
【0003】
図22に示すテーラー級数演算により、任意の値(入力引数)xにおける数学関数f(x)の値を計算するために、演算処理装置の計算は、テーラー級数演算の展開点x0を決定し、その展開点に対応したテーラー級数係数((1/n!)・f(n)(x0))のテーブルを決定する前処理部部分と、テーラー級数係数テーブルを用いて、図22のテーラー級数演算を実行する後処理部分とに、分けられる。
【0004】
例えば、数学関数が、sin関数である場合には、図23に示すような、テーラー級数演算の展開点x0を決定し、その展開点に対応したテーラー級数係数((1/n!)・f(n)(x0))のテーブルを決定する。
【0005】
即ち、sin関数の場合、周期性があるため、π/2の整数倍を、入力引数x近傍の展開点とすると、入力引数xを、π/2で割った時の商(q)から、テーラー級数展開点x0を計算する。そして、商(q)を「4」で割った余り(q%4)に対応する、展開関数と、そのテーラー級数係数を、決定する。
【0006】
例えば、余りが、「0」では、展開関数は、sin(x−xo)であり、そのテーラー級数係数((1/n!)・f(n)(x0))=(−1)n/(2*n+1)!であり、図22のテーラー級数は、Σ(−1)n/(2*n+1)!*(x−x0)(2n+1)である。図23では、「**」は、べき乗を示し、「!」は、かい乗、「*」は、乗算を示す。
【0007】
従来技術では、三角関数のテーラー級数演算実行前の、テーラー級数展開関数の決定と、その展開関数への入力引数の算出処理は、ロード命令やシフト命令等の命令を使用して、浮動小数点レジスタと、整数レジスタ間のデータ転送や、マスク演算、シフト演算などの整数演算器を使用した演算処理とにより、行っていた。
【先行技術文献】
【特許文献】
【0008】
【特許文献1】特開2008−234076号公報(図1〜図7)
【特許文献2】特開2002−063152号公報(図1〜図7)
【発明の概要】
【発明が解決しようとする課題】
【0009】
近年の演算処理の高速化の要求に従い、数学関数のテーラー級数演算の高速化が要求される。従来技術では、テーラー級数展開関数の決定と、その展開関数への入力引数の算出処理を、ロード命令やシフト命令等の命令を使用して、浮動小数点レジスタと、整数レジスタ間のデータ転送や、マスク演算、シフト演算などの複雑な処理が必要となり、浮動小数点演算以外のオーバーヘッド(整数演算命令やメモリアクセス命令等)が発生していた。
【0010】
即ち、数学関数演算全体を処理するのに、多くの命令を必要とし、命令発行スループットの圧迫などの性能低下要因が存在した。
【0011】
従って、本発明の目的は、数学関数演算の高速化する演算処理装置を提供することにある。
【課題を解決するための手段】
【0012】
この目的の達成のため、演算処理装置は、3つの入力rs1、rs2、rs3を受け、浮動小数点積和演算を行う浮動小数点積和回路と、浮動小数点積和回路の出力の最上位ビットと、入力rs2の最下位ビットrs2[0]とのOR(論理和演算)を演算するOR回路(論理和演算回路)と、入力rs1と、値「1.0」とのいずれかを選択するセレクタと、入力rs2の最下位から1ビット上位のビットrs2[1]とセレクタの最上位ビットとのEOR(排他的論理和演算)を計算するEOR回路(排他的論理和演算回路)とを有し、rd=(rs1*rs1)|(rs2[0]<<63)の演算を定義する第1の三角関数演算補助命令と、rd=((rs2[0])?1.0:rs1)^(rs2[1]<<63)の演算を定義する第2の三角関数演算補助命令とにより、前記三角関数のテーラー級数展開の展開点と展開関数を演算する。
【0013】
又、この目的の達成のため、演算処理装置は、3つの入力rs1、rs2、rs3を受け、浮動小数点積和演算を行う浮動小数点積和回路と、浮動小数点積和回路の出力の最上位ビットと、入力rs2の最下位ビットrs2[0]の反転信号とのORを演算するOR回路と、入力rs1と、値「1.0」とのいずれかを選択するセレクタと、入力rs2の最下位から1ビット上位のビットrs2[1]と前記最下位ビットrs2[0]とのEORを演算する第1のEOR回路と、前記セレクタの最上位ビットと前記第1のEOR回路の出力とのEORを演算する第2のEOR回路とを有し、rd=(rs1*rs1)|((〜rs2[0]<<63)の演算を定義する第3の三角関数演算補助命令と、rd=((rs2[0])?rs1:1.0)^((rs2[1]^rs2[0])<<63))の演算を定義する第4の三角関数演算補助命令とにより、前記三角関数のテーラー級数展開の展開点と展開関数を演算する。
【発明の効果】
【0014】
浮動小数点積和回路に、OR回路と、セレクタと、EOR回路を設け、rd=(rs1*rs1)|(rs2[0]<<63)の演算を定義する第1の三角関数演算補助命令と、rd=((rs2[0])?1.0:rs1)^(rs2[1]<<63)の演算を定義する第2の三角関数演算補助命令とにより、又は、rd=(rs1*rs1)|((〜rs2[0])<<63)の演算を定義する第3の三角関数演算補助命令と、rd=((rs2[0])?rs1:1.0)^((rs2[1]^rs2[0])<<63))の演算を定義する第4の三角関数演算補助命令とにより、三角関数のテーラー級数展開の展開点と展開関数を演算するため、命令数を削減でき、且つ高速な演算が可能となる。
【図面の簡単な説明】
【0015】
【図1】本発明の演算処理装置の第1の実施の形態の回路図である。
【図2】図1に使用される演算補助命令の説明図である。
【図3】図2の演算補助命令2の演算処理の説明図である。
【図4】図2の演算補助命令3の演算処理の説明図である。
【図5】三角関数のテーラー級数の説明図である。
【図6】図5のテーラー級数演算の説明図である。
【図7】第1の実施の形態の三角関数演算補助命令を使用したsin関数演算の前処理の命令列の説明図である。
【図8】図7の第1の実施の形態の命令列と、演算内容の説明図である。
【図9】図1の係数テーブルセットの一実施の形態の構成図である。
【図10】アッセンブラ記述による従来の後処理の命令列と、本実施の形態による後処理の命令列との説明図である。
【図11】アセンブラ記述のよるオペレーションコードと、演算内容との関係図である。
【図12】テーラー級数演算順序の説明図である。
【図13】non−SIMD(Single Instruction stream Multiplie Data stream)の場合の命令数の比較図である。
【図14】non−SIMDの場合の演算スループットの比較図である。
【図15】SIMD(Single Instruction stream Multiplie Data stream)の場合の命令数の比較図である。
【図16】SIMDの場合の演算スループットの比較図である。
【図17】本発明の演算処理装置の第2の実施の形態の回路図である。
【図18】図17に使用される演算補助命令の説明図である。
【図19】図17の三角関数のテーラー級数の説明図である。
【図20】第2の実施の形態の三角関数演算補助命令を使用したsin関数演算の前処理の命令列の説明図である。
【図21】図20の第2の実施の形態の命令列と、演算内容の説明図である。
【図22】従来の三角関数のテーラー級数展開の説明図である。
【図23】従来の展開点、展開関数の決定処理の説明図である。
【発明を実施するための形態】
【0016】
以下、実施の形態の例を、演算処理装置の第1の実施の形態、前処理の説明、後処理の説明、演算処理装置の第2の実施の形態、他の実施の形態の順で説明するが、開示の演算処理装置は、この実施の形態に限られない。
【0017】
(演算処理装置の第1の実施の形態)
図1は、本発明の演算処理装置の第1の実施の形態の回路図、図2は、図1に使用される演算補助命令の説明図、図3、図4は、その演算補助命令の演算処理の説明図である。
【0018】
図1に示すように、命令種別コード200に、図2に示す三角関数のテーラー級数演算実行前の、テーラー級数展開関数の決定と、その展開関数への入力引数の算出処理(前処理工程)を行う命令として、専用の三角関数演算補助命令を設けた。
【0019】
図2では、sin関数のアッセンブラ命令の例を示し、三角関数演算補助命令2(ftrismuld)と、三角関数演算補助命令3(ftrisseld)とが、前工程の補助命令であり、三角関数演算補助命令1(ftrimaddd)が、後述する後工程の補助命令である。
【0020】
三角関数演算補助命令2(ftrismuld)は、被演算対象であるオペランドフィールドに、<積和演算の積演算の一方のレジスタ番号:rs1>,<積和演算の積演算の他方のレジスタ番号:rs2>、<積和演算の演算結果の出力レジスタ番号:rd>を定義する。
【0021】
そして、三角関数演算補助命令2(ftrismuld)は、rd=(rs1*rs1)|(rs2[0]<<63)を演算する命令である。即ち、図3に示すように、レジスタrs1の値を二乗し、レジスタrs2の「0」ビット目のデータrs[0]を、63ビット左シフトし(最上位までシフトし)、レジスタrs1の二乗の63ビット目と、63ビットシフトしたrs2[0]とのORをOR回路188で演算し、rs1の二乗の値(64ビット)の63ビット目を、OR演算結果で置き換え、出力レジスタrdに格納する演算を行う。
【0022】
一方、三角関数演算補助命令3(ftrisseld)は、オペランドフィールドに、<積和演算の積演算の一方のレジスタ番号:rs1>,<積和演算の積演算の他方のレジスタ番号:rs2>、<積和演算の演算結果の出力レジスタ番号:rd>を定義する。
【0023】
そして、三角関数演算補助命令3(ftrisseld)は、rd=((rs2[0])?1.0:rs1)^(rs2[1]<<63)を演算する命令である。即ち、図4に示すように、レジスタrs2の「0」ビット目の値rs2[0]で、セレクタ184を選択する。セレクタ184は、値「1.0」(64ビット)と、レジスタrs1のデータ(64ビット)が入力され、rs2[0]=1なら、値「1.0」を、rs2[0]=0なら、レジスタrs1のデータを選択する。そして、セレクタ184の出力の63ビット目の値と、レジスタrs2の「1」ビット目の値rs2[1]のEORを、EOR回路186で演算し、セレクタ184の出力の63ビット目を、EOR演算結果で置き換え、出力レジスタrdに格納する演算を行う。
【0024】
更に、後工程で使用する三角関数演算補助命令1(ftrimmddd)は、オペランドフィールドに、<積和演算の積演算の一方のレジスタ番号:rs1>,<積和演算の積演算の他方のレジスタ番号:rs2>、<テーラー級数の次数番号:index>,<積和演算の演算結果の出力レジスタ番号:rd>を定義する。
【0025】
そして、三角関数演算補助命令1(ftrimaddd)は、rd=((rs1*fabs(rs2)+T[rs2[63]][index])を実行する命令である。後述するように、この演算補助命令は、T[rs[63]]で決定された展開関数のindexで指定される次数のテーラー級数係数を、テーブルから引き出し、レジスタrs1に、レジスタrs2の絶対値(fabs(rs2))を乗じた結果と、加算する演算を行う。
【0026】
図1に戻り、演算処理装置1は、メモリ(メインメモリ)110と、メインメモリ110のデータの一部を記憶するキャッシュメモリ120と、リネーミングレジスタ130と、レジスタファイル140と、バイパスデータ150と、マルチプレクサ152〜156と、浮動小数点積和演算器100とを有する。
【0027】
レジスタファイル140は、浮動小数点積和演算器100が、演算を実行するときに使用する全てのレジスタを備えている。リネーミングレジスタ130は、オペランドデータの逆依存と出力依存を解消するために設けられている。バイパスデータ150は、演算処理装置1の命令パイプラインにおいて、データハザードを解消するためのバイパシング(bypassing)で使用されるデータ(演算結果データ)である。リネーミングレジスタ130のエントリに格納されているレジスタ値は、リタイア(retire)時に、レジスタファイル140に移される。
【0028】
係数テーブルセット(ROM)160、セレクタ170,172、一入力反転型AND回路(一入力反転型論理積演算回路)174は、後述する後処理で使用される。係数テーブルセット160は、図9にて詳述するテーラー級数の各次数の係数を格納する。この係数テーブルセット160は、次数を指定するindexと、決定された展開関数で、セレクタ170より、対応する展開関数の次数のテーラー級数の係数が、読み出さられる。
【0029】
セレクタ172は、前述の三角関数演算補助命令1(ftrimaddd)で操作され、セレクタ170の出力か、レジスタrs3のいずれかを出力する。一入力反転型AND回路174は、後述する後処理で使用され、前述の三角関数演算補助命令1(ftrimaddd)のフラグを反転し、反転出力とレジスタrs2の63ビット目rs2[63]とのANDを演算する。
【0030】
セレクタ180は、前述の三角関数演算補助命令2(ftrismuld)で操作され、セレクタ172の出力か、値「1.0」かのいずれかを、浮動小数点積和演算器100の和入力に、出力する。セレクタ182は、前述の三角関数演算補助命令2(ftrismuld)で操作され、レジスタrs2の出力か、レジスタrs1かのいずれかを、浮動小数点積和演算器100の積入力に、出力する。
【0031】
セレクタ184は、図4で説明したように、前述の三角関数演算補助命令3(ftrisseld)で操作され、値「1.0」(64ビット)と、レジスタrs1のデータ(64ビット)が入力され、レジスタrs2の「0」ビット目の値rs2[0]で、いずれかを選択する。EOR回路186は、セレクタ184の出力の63ビット目の値と、レジスタrs2の「1」ビット目の値rs2[1]のEORを、EOR回路186で演算する。
【0032】
OR回路188は、図3で説明したように、浮動小数点積和演算器100が演算したレジスタrs1の二乗の63ビット目と、63ビットシフトしたrs[0]とのORを演算する。セレクタ190は、浮動小数点積和演算器100が演算したデータの63ビット目の値か、OR回路188の出力かのいずれかを選択する。セレクタ192は、前述の三角関数演算補助命令3(ftrisseld)で操作され、浮動小数点積和演算器100の出力か、セレクタ184の出力かのいずれかを出力する。
【0033】
この演算処理装置1は、通常の構成であるメモリ(メインメモリ)110と、メインメモリ110のデータの一部を記憶するキャッシュメモリ120と、リネーミングレジスタ130と、レジスタファイル140と、バイパスデータ150と、マルチプレクサ152〜156と、浮動小数点積和演算器100とを有する。
【0034】
これに加え、前処理のため、セレクタ180,182,184,190,192、EOR回路186、OR回路188とを有する。又、後処理のため、係数テーブルセット160、セレクタ170,172、AND回路174とを有する。
【0035】
(前処理の説明)
図5は、テーラー級数の説明図、図6は、テーラー級数演算の説明図、図7は、本実施の形態の三角関数演算補助命令を使用したsin関数演算のための前処理の命令列の説明図、図8は、図7の本実施の形態の命令列と、演算内容の説明図である。
【0036】
テーラー級数演算実行の前処理は、テーラー級数演算が、高次で収束するように、入力引数近傍のテーラー級数演算の展開点の決定し、その展開点で級数展開したときのテーラー級数展開関数、およびテーラー級数係数を決定する。
【0037】
先ず、図5により、テーラー級数展開式を説明する。図23でも説明したように、sin関数のテーラー級数展開式は、y(=x−x0)の奇関数式(y(2n+1))で表される。一方、cos関数のテーラー級数展開式は、y(=x−x0)の偶関数式(y2n)で表される。
【0038】
ここで、テーラー級数の各次数の係数を、a3,・・a15,b2,・・b14で表すと、図6に示すように、sin(y),cos(y),−sin(y),−cos(y)のテーラー級数展開式に、共通性が現れる。即ち、偶関数の多項式(y0−a3・y2+・・・−a15・y14)に、yを掛けたものが、sin(y)であり、多項式(y0−b2・y2+・・・−b14・y14)に、1.0を掛けたものが、cos(y)である。同様に、多項式(y0−a3・y2+・・・−a15・y14)に、−yを掛けたものが、−sin(y)であり、多項式(y0−b2・y2+・・・−b14・y14)に、−1.0を掛けたものが、−cos(y)である。
【0039】
この関係を利用して、後処理のテーラー級数演算を高速化するため、前処理では、展開点の演算、テーラー級数展開関数の決定の他に、「y」、「1.0」を選択的に、後処理に与える。
【0040】
図7は、従来技術によるsin関数演算のアセンブラ記述のよる前処理の命令列と、本実施の形態によるアセンブラ記述のよるsin関数演算の前処理の命令列とを対比した図である。図7から明らかなように、本実施の形態では、三角関数演算補助命令2(ftrismuld),3(ftrisseld)を用いることにより、従来の命令列のロード、シフト命令、マスク命令等を削除でき、転送処理やシフト演算、マスク演算などの複雑な処理を省け、高速に演算できる。
【0041】
図8は、アセンブラ記述のよるオペレーションコードと、演算内容との関係図であり、図1の構成を使用して、具体的に説明する。ロード命令(lddf)で、xに、入力引数memを、ロードする。次に、積和命令fmaddd(floating multipy add double)により、bqx=((x*rp2)+bg)を演算する。
【0042】
ここで、レジスタrp2には、1/(π/2)がセットされており、レジスタbgには、値「1.5*2**52」がセットさている。浮動小数点積和演算器100は、この命令により、レジスタファイル140のxと、rp2との積を演算し、この積とbgの和を演算する。
【0043】
これにより、展開関数と符号を決定する商qx=int(x/(π/2))が、演算結果bqxの仮数部の下位51ビットに得られる。又、値「1.5*2**52」を加算する意味は、52乗の値を加算すると、小数点以下が四捨五入され、所謂、丸め処理を実行される。
【0044】
次に、差命令fsubd(floating substract double)により、qx=bqx−bgを演算する。浮動小数点積和演算器100は、この命令により、レジスタファイル140のbqxから、bgを引き算し、差qxを演算する。このbgを足して、引くことにより、小数点以下の四捨五入を行う。
【0045】
次に、積和命令fnmsubd(floating negative multiply subtract double)により、y=x−(qx*p2a)を演算する。レジスタp2aには、「π/2」の上位の値がセットされている。浮動小数点積和演算器100は、この命令により、レジスタファイル140のqxと、p2aとの積を演算し、レジスタに格納した後、この積とxを読み出し、差を演算する。
【0046】
次に、積和命令fnmsubdにより、y=y−(qx*p2b)を演算する。レジスタp2bには、「π/2」の下位の値がセットされている。浮動小数点積和演算器100は、この命令により、レジスタファイル140のqxと、p2bとの積を演算し、レジスタに格納した後、この積とyを読み出し、差を演算する。
【0047】
これにより、テーラー級数演算の(x−x0)が、yとして得られる。ここで、2つの積和命令を用いているのは、π/2の値を、上位と下位に分け、演算し、小数点以下の精度を高めるためである。
【0048】
次に、三角関数演算補助命令2(ftrismuld)により、y2t=(y*y)|(bqx[0]<<63)を演算する。即ち、命令種別コード200の「ftrismuld」により、通常、rs2を選択するセレクタ182を切り替え、セレクタ182からrs1を出力する。このため、浮動小数点積和演算器100は、レジスタrs1の値yを二乗する。そして、OR回路188は、レジスタrs2の「0」ビット目のデータrs2[0]が入力され、且つ演算器100からの出力y**2の63ビット目が入力される。そして、セレクタ190を介し、演算器100の出力の63ビット目に出力する。
【0049】
即ち、図3で示したように、左シフトし(最上位までシフトし)、レジスタrs1の二乗の63ビット目と、63ビットシフトしたrs2[0]とのORをOR回路188で演算し、rs1の二乗の値(64ビット)の63ビット目を、OR演算結果で置き換え、セレクタ192を介し、レジスタファイル140の出力レジスタrdに格納する演算を行う。
【0050】
図4で説明したように、bqxの仮数部下位51ビットは、商qxであり、bqxの最下位ビットbqx[0]は、テーラー展開関数が、sin関数か、cos関数かを示すため、y2tは、63ビット目が、テーラー展開関数の種類(sin又はcos)を示し、62〜0ビットが、図6で説明したy(x−x0)の二乗データとなる。
【0051】
次に、三角関数演算補助命令3(ftrisseld)により、rd=(rs2[0])?1.0:rs1)^(rs2[1]<<63)を演算する。ここでは、ys=(bqx[0])?1.0:y)^(bqx[1]<<63)を演算する。
【0052】
図4にも示したように、レジスタrs2の「0」ビット目の値rs2[0]で、セレクタ184を選択する。セレクタ184は、値「1.0」(64ビット)と、レジスタrs1のデータ(64ビット)が入力され、rs2[0](bqx[0])=1なら、値「1.0」を、rs2[0](bqx[0])=0なら、レジスタrs1のデータyを選択する。そして、セレクタ184の出力の63ビット目の値と、レジスタrs2の「1」ビット目の値rs2[1](bqx[1])のEORを、EOR回路186で演算し、セレクタ184の出力の63ビット目を、EOR演算結果で置き換え、セレクタ192を介し、出力レジスタrdに格納する演算を行う。
【0053】
この出力ysの63ビット目は、テーラー展開関数の符号(+又は−)を示し、62〜0ビットが、図6で説明したy(x−x0)又は「1.0」となる。
【0054】
このようにして、三角関数演算補助命令2,3と、これにより動作するセレクタ180,182,184,190,192、EOR回路186、OR回路188とを設けることにより、命令数を少なくして、テーラー級数展開関数の決定の他に、テーラー級数演算の「y」、「1.0」を決定できる。このため、前処理を高速化できる。
【0055】
(後処理の説明)
次に、三角関数演算補助命令1を用いた後処理を説明する。図9は、図1の係数テーブルセットの一実施の形態の構成図である。図10は、アッセンブラ記述による従来の後処理の命令列と、本実施の形態による後処理の命令列との説明図、図11は、アセンブラ記述のよるオペレーションコードと、演算内容との関係図である。
【0056】
図9に示すように、係数テーブルセット160は、sin関数のテーラー級数の1次〜15次の係数を格納したsin関数部160−1と、cos関数のテーラー級数の1次〜15次の係数を格納したcos関数部160−2とを有する。
【0057】
係数テーブルセット160に接続されたセレクタ170が、係数テーブルのセット番号(図4のbqx[0]、y2t[63])により、sin関数又はcos関数を選択する。又、テーラー級数の次数番号を示すindexにより、係数テーブルセット160の次数が指定される。
【0058】
図10は、従来技術によるsin関数演算のアセンブラ記述のよる後処理の命令列と、本実施の形態によるアセンブラ記述のよるsin関数演算の後処理の命令列とを対比した図である。図10から明らかなように、本実施の形態では、三角関数演算補助命令1(ftrimaddd)を用いることにより、従来の命令列のロード命令等を削除でき、転送処理やシフト演算、マスク演算などの複雑な処理を省け、高速に演算できる。
【0059】
図11は、アセンブラ記述のよるオペレーションコードと、演算内容との関係図であり、図12は、図11の演算順序の説明図である。図12に示すように、演算順序は、次数の高いものを先に演算して、順次、その演算結果を用いて、次数の低いものを加算していく。即ち、次数の高い係数(1/15!)を呼び出し,次に、三角関数演算補助命令1(ftrimaddd)により、((前回の次数の係数*y2)+今回の次数の係数)を演算する。
【0060】
図11の演算処理を、図1,図9の構成を使用して、具体的に説明する。三角関数演算補助命令1(ftrimaddd)により、rd=((rs1*fabs(rs2)+T[rs2[63]][index])を実行する。先ず、rs1=co=0.0とし、rs2[63]=y2t[63]、index=7(次数15)で、係数テーブルセット160をアクセスし、sin関数の次数15の係数(1/15!)を取り出し、セレクタ172を介し、演算器100に入力させる。
【0061】
演算器100は、rs1=co=0.0であるから、演算結果rは、図12のように、r=1/15!となる。
【0062】
次に、三角関数演算補助命令1(ftrimaddd)とオペレーションコードr、y2t、6、rを指定する。演算補助命令1により、T[y2t[63]]で決定された展開関数のindex=6で指定される次数のテーラー級数係数を、セレクタ170,172を介し、テーブル160から引き出す。
【0063】
一方、rs2=y2tの63ビット目は、AND回路174に入力する。AND回路174の反転入力には、三角関数演算補助命令1(ftrimaddd)のフラグ「1」が入力されているため、AND回路174の出力は、「0」である。このため、rs2=y2tの63ビット目は、「0」になり、セレクタ182を介し、演算器100に入力する。一方、レジスタrs1には、前述のrが格納されているため、演算器100は、(r=r*y2t[62:0]+係数)の演算を行い、レジスタファイル140に、rとして格納する。
【0064】
以下、同様に、次数を、順次、5,4,3,2,1,0と下げ、三角関数演算補助命令1(ftrimaddd)とオペレーションコードにより、同様に演算を行う。これにより、図12の最後段の演算結果rが得られる。
【0065】
次に、積命令(fmuld:multiply)とr、rs2=ys、rを指定する。この積命令で、演算器100は、r=r*ysを演算する。ysは、y又は1.0又は−y又は−1.0であるため、演算器100が計算するr=r*ysは、図6で説明したテーラー展開級数となる。
【0066】
更に、ストア命令(stdf)により、この結果rを、レジスタファイル140のエントリmemにストアする。
【0067】
このようにして、三角関数演算補助命令1と、これにより動作する係数テーブルセット160、セレクタ170,172,AND回路174とを設けることにより、命令数を少なくして、テーラー級数展開関数の演算が可能となり、後処理を高速化できる。
【0068】
次に、本実施の形態と従来技術との命令数と、性能とを比較する。図13は、non−SIMD(Single Instruction stream Multiplie Data stream)の場合の命令数の比較図、図14は、non−SIMDの場合の演算スループットの比較図である。
【0069】
図13に示すように、従来技術では、ロード命令(ld)、ストア命令(st)、整数演算命令(Int)が多いが、本実施の形態では、ロード命令(ld)、ストア命令(st)、整数演算命令(Int)が殆どなくなり、命令数が、半分以下(40%)に減少する。
【0070】
又、図14に示すように、三角関数演算のみをベクトル演算する場合に、演算スループットが、従来に比し、1.4倍に向上する。他の演算と並行して、三角関数の演算を実行する場合、ld/st pipe(メモリアクセス命令であるロード命令/ストア命令のパイプライン)を消費しないので、更に、演算スループットを向上できる。しかも、命令数が少なく、浮動小数点演算命令に限定しているため、ソフトウェアパイプライニングで、適切な命令スケジューリングを実施しやすくなり、性能向上につながる。
【0071】
図15は、SIMD(Single Instruction stream Multiplie Data stream)の場合の命令数の比較図、図16は、SIMDの場合の演算スループットの比較図である。
【0072】
図15に示すように、従来技術では、ロード命令(ld)、ストア命令(st)、整数演算命令(Int)が多いが、本実施の形態では、ロード命令(ld)、ストア命令(st)、整数演算命令(Int)が殆どなくなり、命令数が、約1/4(27%)に減少する。整数演算命令を含まないため、SIMD化に適している。
【0073】
又、図15に示すように、三角関数演算のみをベクトル演算する場合に、演算スループットが、従来に比し、2.1倍に向上する。
【0074】
(演算処理装置の第2の実施の形態)
図17は、本発明の演算処理装置の第2の実施の形態の回路図、図18は、図17に使用されるcos関数演算のテーラー級数の展開点を、展開関数の説明図、図19は、図17のcos演算補助命令の説明図、図20、図21は、その演算補助命令の演算処理の説明図である。
【0075】
図17において、図1と同一のものは、同一に記号で示してある。図1との相違点は、OR回路190の入力段に、反転回路196を設け、EOR回路186の入力段に、EOR回路194を設けた点である。又、図17に示すように、命令種別コード200に、図18に示す三角関数(cos関数)のテーラー級数演算実行前の、テーラー級数展開関数の決定と、その展開関数への入力引数の算出処理(前処理工程)を行う命令として、専用の三角関数演算補助命令を設けた。
【0076】
更に、図18において、図23のsin関数の場合と、展開点の定義、展開関数のテーラー級数式は同じであるが、商qの剰余の値に対応する展開関数が、図23とは、異なる。
【0077】
図19では、cos関数のアッセンブラ命令の例を示し、三角関数演算補助命令4(ftricmuld)と、三角関数演算補助命令5(ftricseld)とを、前工程の補助命令として設けた。尚、図2の三角関数演算補助命令1(ftrimaddd)は、同様に、後工程の補助命令として、使用する。
【0078】
三角関数演算補助命令4(ftricmuld)は、オペランドフィールドに、<積和演算の積演算の一方のレジスタ番号:rs1>,<積和演算の積演算の他方のレジスタ番号:rs2>、<積和演算の演算結果の出力レジスタ番号:rd>を定義する。
【0079】
そして、三角関数演算補助命令4(ftricmuld)は、rd=(rs1*rs1)|((〜rs2[0]<<63)を演算する命令である。即ち、図3と同様に、レジスタrs1の値を二乗し、レジスタrs2の「0」ビット目のデータrs2[0]のビットワイズノット(反転回路196による)を、63ビット左シフトし(最上位までシフトし)、レジスタrs1の二乗の63ビット目と、63ビットシフトしたrs2[0]とのORを演算し、rs1の二乗の値(64ビット)の63ビット目を、OR演算結果で置き換え、出力レジスタrdに格納する演算を行う。
【0080】
一方、三角関数演算補助命令5(ftricseld)は、オペランドフィールドに、<積和演算の積演算の一方のレジスタ番号:rs1>,<積和演算の積演算の他方のレジスタ番号:rs2>、<積和演算の演算結果の出力レジスタ番号:rd>を定義する。
【0081】
そして、三角関数演算補助命令5(ftricseld)は、rd=(rs2[0])?rs1:1.0)^((rs2[1]^rs2[0])<<63))を演算する命令である。即ち、図4と同様に、レジスタrs2の「0」ビット目の値rs2[0]で、セレクタ184を選択する。セレクタ184は、値「1.0」(64ビット)と、レジスタrs1のデータ(64ビット)が入力され、rs2[0]=0なら、値「1.0」を、rs2[0]=1なら、レジスタrs1のデータを選択する。そして、レジスタrs2の「1」、「0」ビット目の値rs2[1]、rs2[0]のEORを、EOR回路194で演算する。更に、セレクタ184の出力の63ビット目の値と、EOR回路194の出力とのEORを、EOR回路186で演算し、セレクタ184の出力の63ビット目を、EOR演算結果で置き換え、出力レジスタrdに格納する演算を行う。
【0082】
図20は、従来技術によるcos関数演算のアセンブラ記述のよる前処理の命令列と、本実施の形態によるアセンブラ記述のよるcos関数演算の前処理の命令列とを対比した図である。図20から明らかなように、本実施の形態では、三角関数演算補助命令4(ftricmuld),5(ftricseld)を用いることにより、従来の命令列のロード、シフト命令、マスク命令等を削除でき、転送処理やシフト演算、マスク演算などの複雑な処理を省け、高速に演算できる。
【0083】
図21は、アセンブラ記述のよるオペレーションコードと、演算内容との関係図であり、図17の構成を使用して、具体的に説明する。図8のsin関数と同様に、ロード命令(lddf)で、xに、入力引数memを、ロードする。
【0084】
次に、積和命令(fmaddd:multipy&add)により、bqx=((x*rp2)+bg)を演算する。ここで、レジスタrp2には、1/(π/2)がセットされており、レジスタbgには、値「1.5*2**52」がセットさている。浮動小数点積和演算器100は、この命令により、レジスタファイル140のxと、rp2との積を演算し、この積とbgの和を演算する。
【0085】
これにより、展開関数と符号を決定する商qx=int(x/(π/2))が,演算結果bqxの仮数部の下位51ビットに得られる。又、値「1.5*2**52」を加算する意味は、52乗の値を加算すると、小数点以下が四捨五入され、所謂、丸め処理を実行される。
【0086】
次に、差命令(fsubd:substract)により、qx=bqx−bgを演算する。浮動小数点積和演算器100は、この命令により、レジスタファイル140のbgxから、bgを引き算し、差qxを演算する。このbgを足して、引くことにより、四捨五入を行う。
【0087】
次に、積和命令(fnmsubd:multiply&subtract)により、y=x−(qx*p2a)を演算する。レジスタp2aには、「π/2」の上位の値がセットされている。浮動小数点積和演算器100は、この命令により、レジスタファイル140のqxと、p2aとの積を演算し、レジスタに格納した後、この積とxを読み出し、差を演算する。
【0088】
次に、積和命令(fnmsubd:multiply&subtract)により、y=y−(qx*p2b)を演算する。レジスタp2bには、「π/2」の下位の値がセットされている。浮動小数点積和演算器100は、この命令により、レジスタファイル140のqxと、p2bとの積を演算し、レジスタに格納した後、この積とyを読み出し、差を演算する。
【0089】
これにより、テーラー級数演算の(x−x0)が、yとして得られる。ここで、2つの積和命令を用いているのは、π/2の値を、上位と下位に分け、演算し、小数点以下の精度を高めるためである。
【0090】
ここまでは、図8のsin関数と同一の演算である。次に、三角関数演算補助命令4(ftricmuld)により、y2t=(y*y)|(〜bqx[0]<<63)を演算する。即ち、命令種別コード200の「ftricmuld」により、通常、rs2を選択するセレクタ182を切り替え、セレクタ182からrs1を出力する。このため、浮動小数点積和演算器100は、レジスタrs1の値yを二乗する。
【0091】
そして、OR回路188は、レジスタrs2の「0」ビット目のデータrs2[0]を反転回路196で反転した(ビットワイズノット)ビットが入力され、且つ演算器100からの出力y**2の63ビット目が入力される。そして、セレクタ190を介し、演算器100の出力の63ビット目に出力する。
【0092】
即ち、図3で示したように、左シフトし(最上位までシフトし)、レジスタrs1の二乗の63ビット目と、63ビットシフトし、反転したrs[0]とのORをOR回路188で演算し、rs1の二乗の値(64ビット)の63ビット目を、OR演算結果で置き換え、セレクタ192を介し、レジスタファイル140の出力レジスタrdに格納する演算を行う。
【0093】
図4で説明したように、bqxの仮数部下位51ビットは、商qxであり、bqxの最下位ビットbqx[0]は、テーラー展開関数が、sin関数か、cos関数かを示すため、y2tは、63ビット目が、テーラー展開関数の種類(sin又はcos)を示し、62〜0ビットが、図6で説明したy(x−x0)の二乗データとなる。
【0094】
次に、三角関数演算補助命令5(ftricseld)により、rd=((rs2[0]=bqx[0])?rs1=y:1.0)^((rs2[1]^rs2[0])<<63)を演算する。ここでは、ys=((bqx[0])?y:1.0)^((bqx[1]^bqx[0])<<63)を演算する。
【0095】
図4にも示したように、レジスタrs2の「0」ビット目の値rs2[0]で、セレクタ184を選択する。セレクタ184は、値「1.0」(64ビット)と、レジスタrs1のデータ(64ビット)が入力され、rs2[0](bqx[0])=0なら、値「1.0」を、rs2[0](bqx[0])=1なら、レジスタrs1のデータyを選択する。
【0096】
そして、レジスタrs2の「1」、「0」ビット目の値rs2[1](bqx[1])、rs2[0](bqx[0])のEORを、EOR回路194で演算する。更に、セレクタ184の出力のセレクタ184の出力の63ビット目の値と、EOR回路194の出力とのEORを、EOR回路186で演算し、セレクタ184の出力の63ビット目を、EOR演算結果で置き換え、セレクタ192を介し、出力レジスタrdに格納する演算を行う。
【0097】
この出力ysの63ビット目は、テーラー展開関数の符号(+又は−)を示し、62〜0ビットが、図6で説明したy(x−x0)又は「1.0」となる。尚、cos関数の場合、前述の反転回路196、EOR回路194の付加で、図18に示したような、qの剰余と、対応する展開関数、図6の「y」、「1.0」が指定される。
【0098】
このようにして、三角関数演算補助命令4,5と、これにより動作するセレクタ180,182,184,190,192、EOR回路186、194、OR回路188、反転回路196とを設けることにより、命令数を少なくして、テーラー級数展開関数の決定の他に、テーラー級数演算の「y」、「1.0」を決定できる。このため、前処理を高速化できる。
【0099】
尚、後処理は、図9乃至図12の実施の形態と同じである。
【0100】
(他の実施の形態)
前述の実施の形態では、後処理も高速化する補助命令を用いているが、このような補助命令を用いない場合にも、適用できる。又、図17の構成では、sin関数の演算も同様に可能であり、sin関数の補助命令2,3を適用し、sin関数とcos関数の両方を高速化できる構成も採用できる。更に、命令列を、SIMDで構成しても良い。
【0101】
以上、本発明を実施の形態により説明したが、本発明の趣旨の範囲内において、本発明は、種々の変形が可能であり、本発明の範囲からこれらを排除するものではない。
【0102】
(付記1)
3つの入力rs1、rs2、rs3を受け、浮動小数点積和演算を行う浮動小数点積和回路と、浮動小数点積和回路の出力の最上位ビットと、入力rs2の最下位ビットrs2[0]とのORを演算するOR回路と、入力rs1と、値「1.0」とのいずれかを選択するセレクタと、入力rs2の最下位から1ビット上位のビットrs2[1]とセレクタの最上位ビットとのEORを計算するEOR回路とを有し、rd=(rs1*rs1)|(rs2[0]<<63)の演算を定義する第1の三角関数演算補助命令と、rd=((rs2[0])?1.0:rs1)^(rs2[1]<<63)の演算を定義する第2の三角関数演算補助命令とにより、前記三角関数のテーラー級数展開の展開点と展開関数を演算することを特徴とする演算処理装置。
【0103】
(付記2)
3つの入力rs1、rs2、rs3を受け、浮動小数点積和演算を行う浮動小数点積和回路と、浮動小数点積和回路の出力の最上位ビットと、入力rs2の最下位ビットrs2[0]の反転信号とのORを演算するOR回路と、入力rs1と、値「1.0」とのいずれかを選択するセレクタと、入力rs2の最下位から1ビット上位のビットrs2[1]と前記最下位ビットrs2[0]とのEORを演算する第1のEOR回路と、前記セレクタの最上位ビットと前記第1のEOR回路の出力とのEORを演算する第2のEOR回路とを有し、rd=(rs1*rs1)|((〜rs2[0])<<63)の演算を定義する第3の三角関数演算補助命令と、rd=((rs2[0])?rs1:1.0)^((rs2[1]^rs2[0])<<63))の演算を定義する第4の三角関数演算補助命令とにより、前記三角関数のテーラー級数展開の展開点と展開関数を演算することを特徴とする演算処理装置。
【0104】
(付記3)
前記三角関数が、正弦関数(sin)であることを特徴とする付記1の演算処理装置。
【0105】
(付記4)
前記三角関数が、余弦関数(cos)であることを特徴とする付記2の演算処理装置。
【0106】
(付記5)
前記入力rs1と前記入力rs2を選択し、前記浮動小数点積和演算器に、出力する第2のセレクタを更に有することを特徴とする付記1の演算処理装置。
【0107】
(付記6)
前記入力rs1と前記入力rs2を選択し、前記浮動小数点積和演算器に、出力する第2のセレクタを更に有することを特徴とする付記2の演算処理装置。
【0108】
(付記7)
前記三角関数のテーラー級数の各次数の係数を格納する係数テーブルと、前記演算された展開関数により、前記係数テーブルの係数を読み出す回路とを有し、前記浮動小数点演算器が、前記演算された展開点と、前記読み出された係数とを用いて、前記三角関数のテーラー級数演算を実行することを特徴とする付記1の演算処理装置。
【0109】
(付記8)
前記三角関数のテーラー級数の各次数の係数を格納する係数テーブルと、前記演算された展開関数により、前記係数テーブルの係数を読み出す回路とを有し、前記浮動小数点演算器が、前記演算された展開点と、前記読み出された係数とを用いて、前記三角関数のテーラー級数演算を実行することを特徴とする付記2の演算処理装置。
【産業上の利用可能性】
【0110】
浮動小数点積和回路に、OR回路と、セレクタと、EOR回路を設け、rd=(rs1*rs1)|(rs2[0]<<63)の演算を定義する第1の三角関数演算補助命令と、rd=((rs2[0])?1.0:rs1)^(rs2[1]<<63)の演算を定義する第2の三角関数演算補助命令とにより、又は、rd=(rs1*rs1)|((〜rs2[0])<<63)の演算を定義する第3の三角関数演算補助命令と、rd=((rs2[0])?rs1:1.0)^((rs2[1]^rs2[0])<<63))の演算を定義する第4の三角関数演算補助命令とにより、三角関数のテーラー級数展開の展開点と展開関数を演算するため、命令数を削減でき、且つ高速な演算が可能となる。
【符号の説明】
【0111】
100 浮動小数点積和回路
140 レジスタファイル
160 係数テーブルセット
152、154、156 マルチプレクサ
170、172、180、182、184、190、192 セレクタ
174 AND回路
188 OR回路
186、194 EOR回路
200 命令種別コード
【特許請求の範囲】
【請求項1】
3つの入力rs1、rs2、rs3を受け、浮動小数点積和演算を行う浮動小数点積和回路と、
浮動小数点積和回路の出力の最上位ビットと、入力rs2の最下位ビットrs2[0]とのORを演算するOR回路と、
入力rs1と、値「1.0」とのいずれかを選択するセレクタと、
入力rs2の最下位から1ビット上位のビットrs2[1]とセレクタの最上位ビットとのEORを計算するEOR回路とを有し、
rd=(rs1*rs1)|(rs2[0]<<63)の演算を定義する第1の三角関数演算補助命令と、rd=((rs2[0])?1.0:rs1)^(rs2[1]<<63)の演算を定義する第2の三角関数演算補助命令とにより、前記三角関数のテーラー級数展開の展開点と展開関数を演算する
ことを特徴とする演算処理装置。
【請求項2】
3つの入力rs1、rs2、rs3を受け、浮動小数点積和演算を行う浮動小数点積和回路と、
浮動小数点積和回路の出力の最上位ビットと、入力rs2の最下位ビットrs2[0]の反転信号とのORを演算するOR回路と、
入力rs1と、値「1.0」とのいずれかを選択するセレクタと、
入力rs2の最下位から1ビット上位のビットrs2[1]と前記最下位ビットrs2[0]とのEORを演算する第1のEOR回路と、
前記セレクタの最上位ビットと前記第1のEOR回路の出力とのEORを演算する第2のEOR回路とを有し、
rd=(rs1*rs1)|((〜rs2[0])<<63)の演算を定義する第3の三角関数演算補助命令と、rd=((rs2[0])?rs1:1.0)^((rs2[1]^rs2[0])<<63))の演算を定義する第4の三角関数演算補助命令とにより、前記三角関数のテーラー級数展開の展開点と展開関数を演算する
ことを特徴とする演算処理装置。
【請求項3】
前記三角関数が、正弦関数(sin)である
ことを特徴とする請求項1の演算処理装置。
【請求項4】
前記三角関数が、余弦関数(cos)である
ことを特徴とする請求項2の演算処理装置。
【請求項5】
前記三角関数のテーラー級数の各次数の係数を格納する係数テーブルと、
前記演算された展開関数により、前記係数テーブルの係数を読み出す回路とを有し、
前記浮動小数点演算器が、前記演算された展開点と、前記読み出された係数とを用いて、前記三角関数のテーラー級数演算を実行する
ことを特徴とする請求項1の演算処理装置。
【請求項1】
3つの入力rs1、rs2、rs3を受け、浮動小数点積和演算を行う浮動小数点積和回路と、
浮動小数点積和回路の出力の最上位ビットと、入力rs2の最下位ビットrs2[0]とのORを演算するOR回路と、
入力rs1と、値「1.0」とのいずれかを選択するセレクタと、
入力rs2の最下位から1ビット上位のビットrs2[1]とセレクタの最上位ビットとのEORを計算するEOR回路とを有し、
rd=(rs1*rs1)|(rs2[0]<<63)の演算を定義する第1の三角関数演算補助命令と、rd=((rs2[0])?1.0:rs1)^(rs2[1]<<63)の演算を定義する第2の三角関数演算補助命令とにより、前記三角関数のテーラー級数展開の展開点と展開関数を演算する
ことを特徴とする演算処理装置。
【請求項2】
3つの入力rs1、rs2、rs3を受け、浮動小数点積和演算を行う浮動小数点積和回路と、
浮動小数点積和回路の出力の最上位ビットと、入力rs2の最下位ビットrs2[0]の反転信号とのORを演算するOR回路と、
入力rs1と、値「1.0」とのいずれかを選択するセレクタと、
入力rs2の最下位から1ビット上位のビットrs2[1]と前記最下位ビットrs2[0]とのEORを演算する第1のEOR回路と、
前記セレクタの最上位ビットと前記第1のEOR回路の出力とのEORを演算する第2のEOR回路とを有し、
rd=(rs1*rs1)|((〜rs2[0])<<63)の演算を定義する第3の三角関数演算補助命令と、rd=((rs2[0])?rs1:1.0)^((rs2[1]^rs2[0])<<63))の演算を定義する第4の三角関数演算補助命令とにより、前記三角関数のテーラー級数展開の展開点と展開関数を演算する
ことを特徴とする演算処理装置。
【請求項3】
前記三角関数が、正弦関数(sin)である
ことを特徴とする請求項1の演算処理装置。
【請求項4】
前記三角関数が、余弦関数(cos)である
ことを特徴とする請求項2の演算処理装置。
【請求項5】
前記三角関数のテーラー級数の各次数の係数を格納する係数テーブルと、
前記演算された展開関数により、前記係数テーブルの係数を読み出す回路とを有し、
前記浮動小数点演算器が、前記演算された展開点と、前記読み出された係数とを用いて、前記三角関数のテーラー級数演算を実行する
ことを特徴とする請求項1の演算処理装置。
【図1】


【図2】

【図3】
【図4】
【図5】
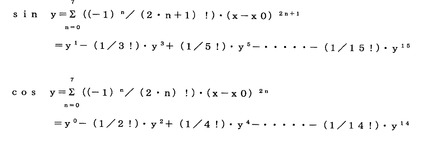
【図6】

【図7】
【図8】

【図9】
【図10】
【図11】

【図12】

【図13】
【図14】
【図15】
【図16】
【図17】
【図18】

【図19】

【図20】
【図21】

【図22】
【図23】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【公開番号】特開2011−13728(P2011−13728A)
【公開日】平成23年1月20日(2011.1.20)
【国際特許分類】
【出願番号】特願2009−154890(P2009−154890)
【出願日】平成21年6月30日(2009.6.30)
【出願人】(000005223)富士通株式会社 (25,993)
【公開日】平成23年1月20日(2011.1.20)
【国際特許分類】
【出願日】平成21年6月30日(2009.6.30)
【出願人】(000005223)富士通株式会社 (25,993)
[ Back to top ]