
生体異常の検出および/または予測
【課題】ノイズを考慮した改良型解析法を提供すること。
【解決手段】データ処理ルーチンを用いて生物学的または物理学的な入力データを解析することによって、脳障害などの生体異常を検出および/または予測する。このデータ処理ルーチンは、生体異常と相関する生物学的データに関連した一連の適用パラメータを含む。このデータ処理ルーチンは、例えば、PD2iデータ系列のようなデータ系列を生じさせるためのアルゴリズムを用いる。このデータ系列を用いて、生体異常の開始を検出または予測する。データ系列中のノイズを低減するために、所定の値よりも小さいときには、その勾配を所定の値に設置する。さらにノイズを低減させるために、データ系列内のノイズの区間を測定して、ノイズ区間が所定の範囲内であれば、そのデータ系列を別の所定の数で割って、そのデータ系列のために新しい数値を生み出す。
【解決手段】データ処理ルーチンを用いて生物学的または物理学的な入力データを解析することによって、脳障害などの生体異常を検出および/または予測する。このデータ処理ルーチンは、生体異常と相関する生物学的データに関連した一連の適用パラメータを含む。このデータ処理ルーチンは、例えば、PD2iデータ系列のようなデータ系列を生じさせるためのアルゴリズムを用いる。このデータ系列を用いて、生体異常の開始を検出または予測する。データ系列中のノイズを低減するために、所定の値よりも小さいときには、その勾配を所定の値に設置する。さらにノイズを低減させるために、データ系列内のノイズの区間を測定して、ノイズ区間が所定の範囲内であれば、そのデータ系列を別の所定の数で割って、そのデータ系列のために新しい数値を生み出す。
【発明の詳細な説明】
【技術分野】
【0001】
(関連出願の相互参照)
本出願は、2003年1月29日出願の米国実用特許出願第10/353,849号および2003年2月6日出願の米国仮出願第60/445,495号の優先権を主張するものである。これらの出願は参照することにより本明細書に組み込まれる。
【背景技術】
【0002】
(背景)
本発明は、生物学的または物理学的なデータを評価する方法およびシステムに係るものである。より具体的には、本発明は、生体異常を検出および/または予測するために、生物学的または物理学的なデータを評価する方法およびシステムに係るものである。
【0003】
単線検流計の発明以来、電気生理学的電位の記録を医学に利用できるようになった。1930年代以来、電気生理学が心外傷および脳てんかん発作の診断に有効となっている。
【0004】
現代医学の最新技術は、心電図中に見られるRR間隔の解析または脳電図に見られる棘波(spikes)の解析によって、突然心臓死やてんかん発作など、将来の臨床転帰を予測できることを示している。このような解析および予測は、予測された転帰を示す患者と示さない患者の大規模なグループ間における転帰を区別するために使用する場合には統計的に有意義であるが、各患者に用いる場合には、既知の解析法はそれほど正確ではない。既知の解析手段のこの一般的な不具合が、多くの間違った予測を生む原因となっている。すなわち、これらの方法では、予測の統計な検出感度および特異性が低い。
【0005】
検討の対象となっている生物系において「病理的な」ものが進行していることは通常分かっているが、現在利用できる解析法は、各患者別に使用できるほど検出感度と特異性が高くない。
【0006】
この技術分野で広く見られる不正確さという問題は、現行の解析手段が、(1)確率論的なものであって(すなわち、データにおけるランダムな変動に基づいていて)(2)定常性(すなわち、データ生成する系が記録採集中変化してはならないこと)が要求され、また、(3)線形性(すなわち、当技術分野において「カオス」と呼ばれるデータの非線形性に対して感度が低いこと)であることによる。
【0007】
「D0」(ハウスドルフ次元)、「D1」(情報次元)、「D2」(相関次元)など、次元の理論的記述が数多く知られている。
【0008】
D2は、系の次元の評価、またはその生成されたデータのサンプルの評価値からの自由度数の評価を可能にする。何人かの研究者が、生物学的データにD2を用いている。しかし、データの定常性という仮定が成立しえないことが明らかになっている。
【0009】
これ以外の理論的記述であって、脳、心臓または骨格筋からのデータに固有の非定常性に対してより検出感度が低いポイント別スケーリング次元(Pointwise Scaling Dimension))すなわち「D2i」開発されている。これは、おそらく、生物学的データについて、D2よりも有益な評価法である。しかしながら、D2iには、依然として、データの非定常性に関係する可能性のある、かなりの評価誤差がある。
【0010】
D2およびD2iのどちらよりも、非定常データ(すなわち、異なったカオス発生器から得たサブエポック(subepoch)をリンクして作成されたデータ)における次元の変化を検出することに優れているポイント相関次元法アルゴリズム(PD2)が開発されている。
【0011】
その時間依存性を強調するために「PD2i」と名付けられた、改良されたPD2アルゴリズムが開発されている。これは、決定論的であって、データ中に存在する原因のある変化に基づく解析手段を用いる。このアルゴリズムは、データの定常性を必要とせず、実際に、データ中の非定常的変化を探知する。また、PD2iは、非カオスな線形データだけでなく、カオス的データに対しても感度が高い。PD2iは、総合的には相関次元を評価するアルゴリズムである従前の解析手段に基づいているが、データの非定常性に対して感度が低い。この特徴ゆえに、PD2iは、他の測定法ではできない、高い感度と特異性をもった臨床転帰の予測を行うことができる。
【0012】
PD2iアルゴリズムは、米国特許第5,709,214号および第5,720,294号に詳細に記載されており、参照することにより本明細書に組み込まれる。理解を簡単にするため、PD2iの簡単な説明と、この測定法と他の方法の比較を下に説明する。
【0013】
PD2iのモデルは、C(r,n,ref*,)〜r expD2であり、ここで、ref*は、さまざまなm−次元の基準ベクトルを作成するための許容可能な基準点である。なぜなら、これらは、線形性(LC)および収束性(CC)の基準に合致した最長のスケーリング領域PLを有するはずだからである。各ref*は、m−次元の基準ベクトルのそれぞれにおいて新しい座標から始まり、また、この新しい座標が何らかの値のものであるから、PD2iのそれは、統計目的についてはそれぞれ互いから独立していてもよい。
【0014】
PD2iアルゴリズムは、プロット長(Plot Length)と呼ばれるパラメータの使用によって線形スケーリングと収束が判別される、小さなlog−r値の範囲に限定される。このエントリの値は、小さなlog−r末端から開始する各log−logプロットについて、線形スケーリング領域が求められるポイントの割合を決定する。
【0015】
非定常データでは、例えば、ローレンツのサブエポックにおける複数のj−ベクトルから差し引かれると正弦波になるサブエポックにおける固定した基準ベクトル(i−ベクトル)の間の小さなlog−r値は、特に高目の埋め込み次元において、数多くの小さなベクトル差長は作り出さない。すなわち、ローレンツのサブエポックに対するj−ベクトルが、代わりに正弦波のサブエポックの中に存在すれば作成される小さなlog−rベクトル差長と比較して、たくさんの小さなlog−rベクトル差長があるわけではない。非線形性データからのベクトル差長のすべてを混合して序列をつけると、基準ベクトルを含むものに関して定常的なサブエポック間の小さなlog−r値だけが、スケーリング領域、すなわち、線形性と収束性を調べられる領域に寄与する。この小さなlog−r値の領域が他の非定常サブエポックによる有意な悪影響を受けると、線形性または収束性の基準には合致せず、その評価値は、PD2i法によって拒絶される。
【0016】
当技術分野に導入されたPD2iアルゴリズムは、データの非定常性が存在する場合(すなわち、生物学的データでは常態の場合)には、線形スケーリング領域の最小の初期部分を考慮すべきであるというアイデアである。これは、i−ベクトル(基準ベクトル)が存在するのと同一種であるデータのサブエポックにj−ベクトルが存在すれば、その場合、およびその場合にだけ、すなわち、その制限内で、またはデータ長が大きくなるにつれて、最小のlog−rベクトルがたくさん作成されるからである。したがって、基準ベクトルが存在するデータ種に関して非定常性のデータ種による相関積分への悪影響を避けるために、当業者は、「フロッピーテール(floppy tail)」の向こうのすぐ近くにある相関積分中の勾配だけに注目しなければならない。
【0017】
「フロッピーテール」とは、有限のデータ長である結果、相関積分のこの部分にはポイントが存在しないために線形スケーリングが生じない極度に小さいlog−r範囲である。したがって、PD2iスケーリングを、「フロッピーテール」より上のlog−r範囲の最小部分に限定することによって、PD2iアルゴリズムは、データの非定常性に対する感度がなくなる。ここで、D2iは、常に線形スケーリング領域全体を使用するが、この領域は、非定常性がデータ中に存在すれば、常に悪影響を受ける。
【0018】
図1Aは、logC(r,n,nref*)対logrのプロットを示す。これは、PD2iアルゴリズムの背後にある重要なアイデアを図解している。それは、データの非定常性が存在する場合に考慮すべきは、線形スケーリング領域の最小の初期部分であるというものである。この場合、データは、正弦波、ローレンツデータ、正弦波、ヘノン(Henon)データ、正弦波、およびランダムなノイズからの1200ポイントのデータサブエポックを連結して作成した。基準ベクトルはローレンツサブエポックの中にあった。埋め込み次元m=1のときの相関積分のために、LC=0.30という線形性の判断基準によって、フロッピーテール(「FT」)に対するセグメントを避ける。すなわち、全区間(D2i)に対する線形スケーリング領域を、プロット長PL=1.00、収束性基準CC=0.40、および最小スケーリングMS=10ポイントによって決定する。i−およびj−ベクトルがともにローレンツデータ(PD2i)内にある、種特異的なスケーリング領域は、プロット長をPL=0.15以下に変えることによって設定される。勾配の収束対埋め込み次元が生じた後の高い方の埋め込み次元(例、m=12)で、PD2iセグメントに対する勾配は、D2iのそれとは異なる。これは、D2iセグメントの上部(D2i−PD2i)が、i−ベクトルがその中に入る種について非定常的なデータ種にj−ベクトルが入るという、非定常性のi−jベクトル差異によって悪影響を受けるからである。
【0019】
PD2iについてのこの短距離勾配の評価値は、線形領域のいずれのlog−logプロットに関しても完全に妥当であって、勾配を決定するために、すべてのデータポイントを用いるか、初期セグメントだけを使用するかは問題ではない。したがって、「フロッピーテール」(線形性基準LCを設定することによって、その後部を避ける)の上にある小さな区間に対して実験的にプロット長を設定することによって、データの中の非定常性を僅かな誤差を出すだけで追跡できる。そして、この誤差は、もっぱらデータ長が有限であることによるものであって、非定常性による悪影響によるものではない。
【0020】
このように、「フロッピーテール」の真上にあるスケーリング領域のその部分、すなわち、(1)線形性基準であるLC、(2)最小スケーリング基準であるMS、および(3)プロット長基準であるPLによって決定される部分だけを調べるためのアルゴリズムを適当に調整することで、当業者は、データの非定常性に対する測定の感度を除去することができる。
【0021】
これは、どのようにして、i−ベクトルが入っているデータ種と同じデータ種にj−ベクトルを由来させるかという「トリック」であって、このことは、i−およびj−ベクトル上に画像マーカーを置いて、相対積分の中のマーカーを観察することによって、実験的に証明できる。スケーリング領域のこの初期部分は、数学的には、制限内でのみ悪影響を受けないと見なされるが、実際上は、有限データに対しては非常にうまく働く。このことは、連結データによってコンピュータ的に証明することができる。正弦型、ローレンツ型、ヘノン型、およびその他の型の既知の線形および非線形のデータ発生器によって作成された、データの連結サブエポック上でPD2iを用いると、短いスケーリングセグメントは、互いに関して定常的なi−およびj−ベクトル差長によってのみできるベクトル差を有する。すなわち、1,2000ポイントサブエポックに関する誤差は、それらの値の上限から5.0%よりも少ないことが分かっており、そして、これらの誤差は、データ長が有限であることによるものであって、スケーリングによる悪影響によるものではない。
【0022】
図1Bは、2種類の非線形アルゴリズムであるポイント相関次元法(PD2i)とポイント別スケーリング次元(D2i)による、一連のデータの自由度の計算を比較したものを示している。これらのアルゴリズムはともに時間依存的で、非定常データに対して用いると、古典的なD2アルゴリズムよりも正確である。生理学的なデータの大部分は、この系がオーガナイズされる方法(このメカニズムは非線形性である)のせいで非線形性である。生理系は、無制御な神経調節作用(例えば、静かに座って心拍データを生成しているときに、突然何か「恐ろしい」ことを考えてしまうなど)のせいで本質的に非定常性である。
【0023】
異なった統計的特性を有する数学的発生器によって生成された別々のデータ系列をリンクすることによって、非定常データをノイズのないものにすることができる。物理的な発生器には、常に、何らかの低レベルのノイズがある。図1Bに示されたデータ(DATA)は、正弦型(S)、ローレンツ型(L)、ヘロン(H)、およびランダムな(R)数学的発生器のサブエポックからできていた。それぞれのサブエポック(S、L、H、R)は、標準偏差は異なるが、同じような平均値をもつという、異なった確率論的特性を有するため、データ系列は当然ながら非定常的である。データについて計算されたPD2iおよびD2i結果が、その下の2つのトレースに示されており、それらは非常に異なっている。D2iアルゴリズムはPD2iに最も近似した比較アルゴリズムであるが、PD2iのように相関積分内の小さなlog−rスケーリング領域を制限しない。このスケーリング制限のおかげで、PD2iが非定常データによく適合するようになっている。
【0024】
デフォルトのパラメータ(LC=0.3、CC=0.4、Tau=1、PL=0.15)を用いて図1Bに示したPD2iの結果は、1,200データポイントのサブエポックに対するものである。各サブエポックのPD2iの平均は、各データ型単独につき(長いデータ長を使用して)計算されたD2の既知のその値の4%以内にある。S、L、H、およびRのデータに対する既知のD2値は、それぞれ1.00、2.06、1.26、および無限である。D2i値を見ると、全く異なった結果(すなわち、スプリアスな(偽の)結果)が見られる。D2iも時間依存的であるため、PD2iに最も近似したアルゴリズムであることに留意されたい。しかしながら、D2iはD2値自体同様データの定常性を必要とする。定常性データでは、D2=D2i=PD2iである。PD2iだけが非定常データに対する自由度の適正な数をトレースできる。同一の非定常データについて計算されたD2の単独値は、示されたD2i値の平均によって近似されている。
【0025】
PD2iによる解析のため、電気生理学的シグナルは、増幅され(1,000の増加)、デジタル化される(1,000Hz)。デジタル化されたシグナルは、処理の前にさらに低減する(例えば、ECGデータをRR間隔データに変換する)ことが可能である。RR間隔データの解析は、異なった病理学的転帰(例えば、心室細動「VF」や心室頻脈「VT」)を有する大きな被験患者グループの間のリスク予測を可能にすることが繰り返し判明している。PD2iは、高リスク患者からサンプル抽出されたRRデータを使用して、後にVFになった患者とそうならなかった患者を区別できることが示されている。
【0026】
最適な低ノイズのプリアンプと高速1,000Hzのデジタイザーによって得られるデジタルECGから作成されるRR間隔データについては、非線形アルゴリズムにとって問題となりうる低レベルのノイズが依然として存在する。また、RR間隔を作成するために使用されるアルゴリズムも、ノイズを増加させる結果となりうる。すべてのRR間隔探知器のうち最も正確なものは、3点移動式の「凸状オペレータ」を使用する。例えば、データ全体を走査する移動ウインドウの中の3点を、ウインドウがR−波のピークをまさに跨ぐときに、その出力が最大になるよう調整することができる。すなわち、ポイント1が前R−波の基線上にあり、ポイント2がR−波上にあり、ポイント3が再び基線上にある。ウインドウがデータを走査すると、データストリーム中のポイント2の位置が、それぞれのR−波のピークを正確に識別する。このアルゴリズムは、それぞれのR−波のdV/dtが最大である場合に、R−波が一定のレベルを上回るか、または検出される時にポイントを測定するアルゴリズムよりもかなりノイズのないRRデータを生み出す。
【0027】
最適なアルゴリズムで計算されたRR間隔は、最大振幅が約+/−5整数であると観測される低レベルのノイズを維持できる。この10整数の範囲は、平均したR−波のピークに対する1000の整数からのものである(すなわち、1%のノイズ)。不十分な電極調製、強い周囲の電磁場、中程度にノイズがあるプリアンプの使用、またはより低いデジタル化速度の使用によって、低レベルのノイズを容易に増加させることができる。例えば、1つの整数=1msec(すなわち、フルスケールの12ビットデジタイザーの25%増し)の場合の増加で、ユーザがデータ取得に慎重でないなら、1%という最適なノイズレベルが容易に2倍または3倍になりうる。このようなノイズの増加は、忙しい臨床場面で生じやすいため、ノイズレベルの取得後について検討しなければならない。
【発明の概要】
【発明が解決しようとする課題】
【0028】
このように、ノイズを考慮した改良型解析法が必要とされている。また、医学の分野において、例えば脳障害などの生体異常を検出するために、そのような測定法に対する需要がある。
【課題を解決するための手段】
【0029】
(概要)
以下の説明を添付図面と併せて参照すれば、本発明の目的、利点および特徴がより明らかになる。
【0030】
例示的な実施態様によると、データ処理ルーチンを用いて、入力された生物学的または物理学的なデータを解析することによって、生体異常が検出および/または予測される。このデータ処理ルーチンは、生体異常に相関する生物学的データと関連する適用パラメータのセットを含む。このデータ処理ルーチンは、アルゴリズムを用いて、例えば、生体異常の開始を検出または予測するために用いられるPD2iデータ系列などのデータ系列を作成する。
【0031】
本発明の一態様によれば、データ系列におけるノイズを低減するために、勾配が、例えば0.5という所定の値よりも少ない場合には、それを、例えば0などの所定の数に設定する。
【0032】
発明の別の一態様によると、データ系列中のノイズ区間が決定されていて、該ノイズ区間が所定範囲内にあれば、該データ系列を別の所定の数、例えば2で割って、該データ系列のために新しい数値が生成される。
【0033】
例示的な実施態様によると、データ系列中のノイズを低減させると、心不整脈、脳てんかん発作、および心筋虚血などの生体異常の検出/予測が改善される。
また、本発明に係る方法および装置を利用して、ヒトのプリオン病(クロイツフェルト−ヤコブ病)や、アルツハイマー病など、さまざまな痴呆(心臓血管性、外傷性、遺伝性)などの脳障害の発症を検出および予測することもできる。また、本発明に係る方法を利用して、ウシ海綿状脳症、羊のスクレイピー、およびヘラジカの消耗性疾患の発症を検出および予測することができる。
本発明はまた、以下の項目を提供する。
(項目1)
生体異常を検出または予測する方法であって、
データ系列を作成するために生体異常と相関する生物学的データに関連する適用パラメータのセットを含むデータ処理ルーチンを使用して、入力された生物学的または物理的なデータを解析するステップ;
該データ系列の勾配が所定の値より小さいかどうか判定するステップ;
該勾配が所定の値より小さければ、該勾配を所定の数に設定するステップ;および
該データ系列を使用して、生体異常の発症を検出または予測するステップ
を含む方法。
(項目2)
前記データ処理ルーチンが、データ系列PD2iを作成するために以下のアルゴリズム:
PD2i⊆logC(n,r,nref*)/logrを使用し、
式中、⊆はスケールを意味し、Cは、PD2iに対する相関積分であって、その中でnはデータ長に相当し、rはスケーリング範囲に相当し、またnref*は、非定常データの効果をもたない制限された小さなlog−r範囲の中でC/logrのスケーリング領域の勾配を評価するための基準ベクトルの位置に相当している、項目1に記載の方法。
(項目3)
前記所定の値が約0.5である、項目1に記載の方法。
(項目4)
前記所定の数が0である、項目1に記載の方法。
(項目5)
前記データ系列内でノイズ区間を決定すること、および
該ノイズ区間が、所定の範囲内にあれば、該データ系列を別の所定の数で割り、該データ系列に対する新しい値を生成するために解析ステップを繰り返すことをさらに含む、項目1に記載の方法。
(項目6)
前記所定の数が2である、項目5に記載の方法。
(項目7)
前記所定の範囲が、xが数字であるときに−xから+xである、項目5に記載の方法。
(項目8)
前記所定の範囲が−5から+5である、項目7に記載の方法。
(項目9)
前記入力される生物学的データまたは物理学的データが電気生理学的データを含む、項目1に記載の方法。
(項目10)
前記入力される生物学的データまたは物理学的データが、心臓不整脈および脳てんかん発作の少なくとも一つの発症を検出または予測するため、および/または心筋虚血の重篤度を測定するために解析されるECGデータを含む、項目9に記載の方法。
(項目11)
生体異常を検出または予測する方法であって、
データ系列を作成するために生体異常と相関する生物学的データに関連する適用パラメータのセットを含むデータ処理ルーチンを使用して、入力された生物学的または物理的なデータを解析するステップ;
該データ系列内でノイズ区間を決定するステップ、および
該ノイズ区間が、所定の範囲内にあれば、該データ系列を所定の数で割り、該データ系列に対する新しい値を生成するために解析ステップを繰り返すステップ、または、
該ノイズ区間が所定の範囲を外れた場合には、生体異常の発症を検出または予測するために該データ系列を使用するステップを含む方法。
(項目12)
前記データ処理ルーチンが、データ系列PD2iを作成するために以下のアルゴリズム:
PD2i⊆logC(n,r,nref*)/logrを使用し、
式中、⊆はスケールを意味し、Cは、PD2iに対する相関積分であって、その中でnはデータ長に相当し、rはスケーリング範囲に相当し、またnref*は、非定常データの効果をもたない制限された小さなlog−r範囲の中でC/logrのスケーリング領域の勾配を評価するための基準ベクトルの位置に相当している、項目11に記載の方法。
(項目13)
前記所定の数が2である、項目11に記載の方法。
(項目14)
前記所定の範囲が、xが数字であるときに−xから+xである、項目11に記載の方法。
(項目15)
前記所定の範囲が−5から+5である、項目14に記載の方法。
(項目16)
前記データ系列の勾配が、所定の値よりも小さいか否かを決定すること、および
該勾配が所定の値よりも少ないとき、該勾配を別の所定の数に設定することをさらに含む、項目11に記載の方法。
(項目17)
前記所定の値が約0.5である、項目16に記載の方法。
(項目18)
前記別の所定の数が0である、項目16に記載の方法。
(項目19)
前記生物学的データまたは物理学的データが電気生理学的データを含む、項目11に記載の方法。
(項目20)
前記電気生理学的データが、心臓不整脈および脳てんかん発作の少なくとも一つの発症を検出または予測するため、および/または心筋虚血の重篤度を測定するために解析されるECGデータを含む、項目19に記載の方法。
(項目21)
生体異常を検出または予測するための装置であって、
データ系列を作成するために生体異常と相関する生物学的データに関連する適用パラメータのセットを含むデータ処理ルーチンを使用して、入力された生物学的または物理的なデータを解析するための手段;
該データ系列の勾配が所定の値より小さいかどうか判定するための手段;
該勾配が所定の値より小さければ、該勾配を所定の数に設定するための手段;および
該データ系列を使用して、生体異常の発症を検出または予測するための手段
を含む装置。
(項目22)
前記データ処理ルーチンが、データ系列PD2iを作成するために以下のアルゴリズム:
PD2i⊆logC(n,r,nref*)/logrを使用し、
式中、⊆はスケールを意味し、Cは、PD2iに対する相関積分であって、その中でnはデータ長に相当し、rはスケーリング範囲に相当し、またnref*は、非定常データの効果をもたない制限された小さなlog−r範囲の中でC/logrのスケーリング領域の勾配を評価するための基準ベクトルの位置に相当している、項目21に記載の装置。
(項目23)
前記所定の値が約0.5である、項目21に記載の装置。
(項目24)
前記別の所定の数が0である、項目21に記載の装置。
(項目25)
前記データ系列内でノイズ区間を決定するための手段、および
該ノイズ区間が、所定の範囲内にあれば、該データ系列を別の所定の数で割り、該データ系列に対する新しい値を生成するために、割られたデータ系列を解析手段に提供するための手段をさらに含む、項目21に記載の装置。
(項目26)
前記所定の数が2である、項目25に記載の装置。
(項目27)
前記所定の範囲が、xが数字であるときに−xから+xである、項目25に記載の装置。
(項目28)
前記所定の範囲が−5から+5である、項目27に記載の装置。
(項目29)
前記入力される生物学的データまたは物理学的データが電気生理学的データを含む、項目21に記載の装置。
(項目30)
前記入力される生物学的データまたは物理学的データが、心臓不整脈および脳てんかん発作の少なくとも一つの発症を検出または予測するため、および/または心筋虚血の重篤度を測定するために解析されるECGデータを含む、項目29に記載の方法。
(項目31)
生体異常を検出または予測するための装置であって、
データ系列を作成するために生体異常と相関する生物学的データに関連する適用パラメータのセットを含むデータ処理ルーチンを使用して、入力された生物学的または物理的なデータを解析するための手段;
該データ系列内でノイズ区間を決定するための手段;
該ノイズ区間が、所定の範囲内にあれば、該データ系列を所定の数で割り、該データ系列に対する新しい値を生成するために、割られたデータ系列を該解析手段に提供するための手段;および
該ノイズ区間が所定の範囲を外れた場合には、生体異常の発症を検出または予測するために該データ系列を使用するための手段を含む装置。
(項目32)
前記データ処理ルーチンが、データ系列PD2iを作成するために以下のアルゴリズム:
PD2i⊆logC(n,r,nref*)/logrを使用し、
式中、⊆はスケールを意味し、Cは、PD2iに対する相関積分であって、その中でnはデータ長に相当し、rはスケーリング範囲に相当し、またnref*は、非定常データの効果をもたない制限された小さなlog−r範囲の中でC/logrのスケーリング領域の勾配を評価するための基準ベクトルの位置に相当している、項目31に記載の装置。
(項目33)
前記所定の数が2である、項目31に記載の装置。
(項目34)
前記所定の範囲が、xが数字であるときに−xから+xである、項目31に記載の装置。
(項目35)
前記所定の範囲が−5から+5である、項目34に記載の装置。
(項目36)
前記データ系列の勾配が所定の値より小さいかどうか判定するための手段;および
該勾配が所定の値より小さければ、該勾配を別の所定の数に設定するための手段をさらに含む、項目31に記載の装置。
(項目37)
前記所定の値が約0.5である、項目36に記載の装置。
(項目38)
前記別の所定の数が0である、項目36に記載の装置。
(項目39)
前記生物学的データまたは物理学的データが電気生理学的データを含む、項目31に記載の装置。
(項目40)
前記電気生理学的データが、心臓不整脈および脳てんかん発作の少なくとも一つの発症を検出または予測するため、および/または心筋虚血の重篤度を測定するために解析されるECGデータを含む、項目39に記載の装置。
(項目41)
脳障害を検出または予測する方法であって、
データ系列を作成するために脳障害と相関する生物学的データに関連する適用パラメータのセットを含むデータ処理ルーチンを使用して、入力された生物学的または物理的なデータを解析するステップ;
該データ系列の勾配が所定の値より小さいかどうか判定するステップ;
該勾配が所定の値より小さければ、該勾配を所定の数に設定するステップ;および
該データ系列を使用して、脳障害の発症を検出または予測するステップ
を含む方法。
(項目42)
前記脳障害がウシ海綿状脳症である、項目41に記載の方法。
(項目43)
前記脳障害がアルツハイマー病である、項目41に記載の方法。
(項目44)
前記データ処理ルーチンが、データ系列PD2iを作成するために以下のアルゴリズム:
PD2i⊆logC(n,r,nref*)/logrを使用し、
式中、⊆はスケールを意味し、Cは、PD2iに対する相関積分であって、その中でnはデータ長に相当し、rはスケーリング範囲に相当し、またnref*は、非定常データの効果をもたない制限された小さなlog−r範囲の中でC/logrのスケーリング領域の勾配を評価するための基準ベクトルの位置に相当している、項目41に記載の方法。
(項目45)
前記所定の値が約0.5である、項目41に記載の方法。
(項目46)
前記所定の数が0である、項目41に記載の方法。
(項目47)
前記データ系列内でノイズ区間を決定すること、および
該ノイズ区間が、所定の範囲内にあれば、該データ系列を別の所定の数で割り、該データ系列に対する新しい値を生成するために解析ステップを繰り返すことをさらに含む、項目41に記載の方法。
(項目48)
前記別の所定の数が2である、項目47に記載の方法。
(項目49)
前記所定の範囲が、xが数字であるときに−xから+xである、項目47に記載の方法。
(項目50)
前記所定の範囲が−5から+5である、項目49に記載の方法。
(項目51)
前記入力される生物学的データまたは物理学的データが電気生理学的データを含む、項目41に記載の方法。
(項目52)
脳障害を検出または予測する方法であって、
データ系列を作成するために脳障害と相関する生物学的データに関連する適用パラメータのセットを含むデータ処理ルーチンを使用して、入力された生物学的または物理的なデータを解析するステップ;
該データ系列内でノイズ区間を決定するステップ、および
該ノイズ区間が、所定の範囲内にあれば、該データ系列を所定の数で割り、該データ系列に対する新しい値を生成するために解析ステップを繰り返すステップ、または、
該ノイズ区間が所定の範囲を外れた場合には、生体異常の発症を検出または予測するために該データ系列を使用するステップを含む方法。
(項目53)
前記脳障害がウシ海綿状脳症である、項目52に記載の方法。
(項目54)
前記脳障害がアルツハイマー病である、項目52に記載の方法。
(項目55)
前記データ処理ルーチンが、データ系列PD2iを作成するために以下のアルゴリズム:
PD2i⊆logC(n,r,nref*)/logrを使用し、
式中、⊆はスケールを意味し、Cは、PD2iに対する相関積分であって、その中でnはデータ長に相当し、rはスケーリング範囲に相当し、またnref*は、非定常データの効果をもたない制限された小さなlog−r範囲の中でC/logrのスケーリング領域の勾配を評価するための基準ベクトルの位置に相当している、項目52に記載の方法。
(項目56)
前記別の所定の数が2である、項目52に記載の方法。
(項目57)
前記所定の範囲が、xが数字であるときに−xから+xである、項目52に記載の方法。
(項目58)
前記所定の範囲が−5から+5である、項目57に記載の方法。
(項目59)
前記データ系列の勾配が所定の値より小さいかどうか判定すること;および
該勾配が所定の値より小さければ、該勾配を別の所定の数に設定するステップをさらに含む、項目52に記載の方法。
(項目60)
前記所定の値が約0.5である、項目59に記載の方法。
(項目61)
前記別の所定の数が0である、項目59に記載の方法。
(項目62)
前記生物学的データまたは物理学的データが電気生理学的データを含む、項目52に記載の方法。
【図面の簡単な説明】
【0034】
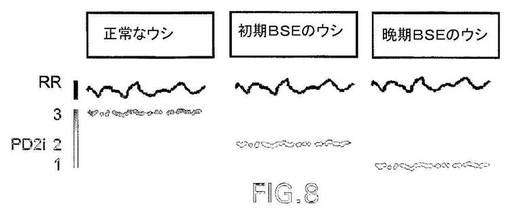
【図1A】図1Aは、通常のPD2iアルゴリズムのための、C(r,n,ref*)対logrのプロットを図示したものである。
【図1B】図1Bは、無ノイズの非定常データに適用したときの2つの時間依存性アルゴリズムによる自由度(次元)の計算結果を図示したものである。
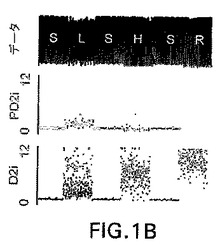
【図2】図2Aおよび2Bは、非定常データに低レベルのノイズを加えたときのPD2iの結果を図示したものである。
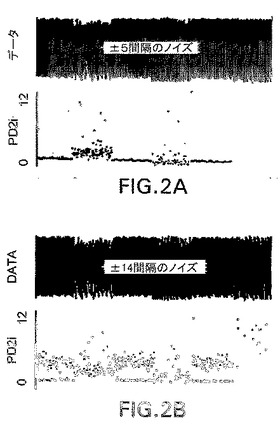
【図3】図3は、2つのデジタル式ECGから生成された2組のRR間隔における低レベルのノイズの検査を図示したものである。
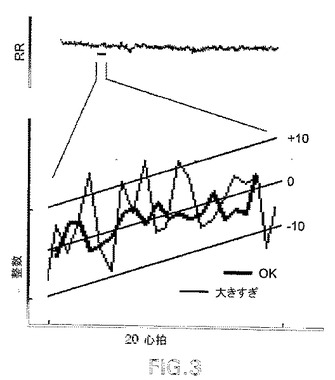
【図4】図4A〜4Fは、急性心筋梗塞の対照患者のRR間隔における低レベルノイズを図示したもの(挿入図)である。図4G〜4Lは、不整脈によって死亡した患者のRR間隔における低レベルのノイズを図示したものである。
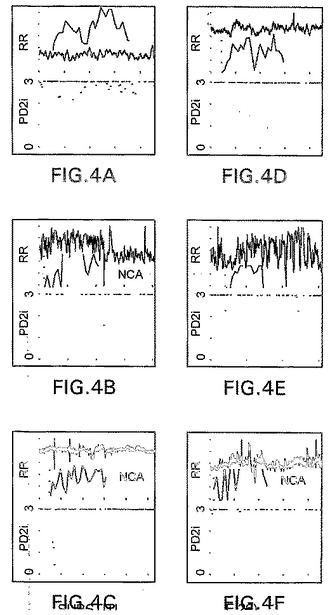
【図5A】図5Aは心臓病学におけるECGデータに適用されたNCAの論理の典型的なフローチャートを図示したものである。
【図5B】図5Bは神経生理学におけるEEGデータとそれに関連する概念に適用されたNCAの論理の典型的なフローチャートを図示したものである。
【図6A】図6は、例示的な実施態様に従ってソフトウェアで実行されたNCAの典型的フローチャートを図示したものである。
【図6B】図6は、例示的な実施態様に従ってソフトウェアで実行されたNCAの典型的フローチャートを図示したものである。
【図6C】図6は、例示的な実施態様に従ってソフトウェアで実行されたNCAの典型的フローチャートを図示したものである。
【図6D】図6は、例示的な実施態様に従ってソフトウェアで実行されたNCAの典型的フローチャートを図示したものである。
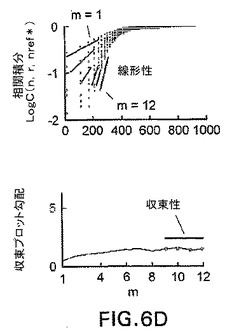
【図7】図7は、10年後になるまで確認されなかった早期痴呆の患者の心拍(RR)のPD2iと、同じ年齢の正常な被験者のそれとの比較を図示したものである。
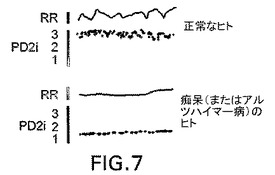
【図8】図8は、初期および後期のウシ海綿状脳症(BSE)のウシの心拍(RR)のPD2iの関係を図示したものである。
【発明を実施するための形態】
【0035】
(詳細な説明)
例示的な実施態様によると、低レベルのノイズによる非線形的解析測定値への寄与をなくすために、PD2iのような技術が開発されている。
【0036】
ノイズがなぜ重要であるかを示すために、図2Aおよび2Bを参照されたい。図2Aおよび2Bにおいて、データは、図1Bに関して説明したとおり、同じS、L、H、およびRのデータである。定義上、このデータは、数学的発生器によって作成されたため、どんなノイズもない。
【0037】
図2Aでは、∀5の整数という低レベルのノイズが、非定常データ系列に加えられている。各サブエポックにおける1200のデータポイントからいくつか大きな数値が出てきたが、各サブエポックに対するPD2iの平均値は有意に変動しなかった。
【0038】
しかしながら、∀14の整数のノイズを加えると、ここでスプリアスなPD2i値がもたらされ、図2Bに示されるように、その平均値はすべてほぼ同一である。
【0039】
例示的な実施態様によると、NCA(ノイズ考慮アルゴリズム)法は、高い倍率(例えば、y軸は全スケールで40の整数であり、x軸は全スケールで20心拍数である)で低レベルのノイズを調べ、ノイズが所定の範囲を外れているか否か、例えば、ノイズの動的範囲が∀5の整数より大きいか否かを判定する。もし大きい場合には、ノイズを∀5の整数の範囲内に戻す数でデータ系列を割り算する。この例では、12ビットの整数データの低レベルのビットだけがノイズを含んでいるため、データ系列を2で割ることができる。
【0040】
m=12よりも小さい埋め込み次元で計算すると、相関積分の線形スケーリング領域は、低レベルのノイズ(例えば、∀5の整数という動的範囲をもつ)から作成された場合には、0.5未満の勾配を有するため、低レベルのノイズと真の小さな勾配データとを区別することは不可能である。好都合なことに、生物学的データでは0.5未満の勾配にめったに遭遇しないので、勾配を0.5以下(相関積分に見られる)から0にアルゴリズムで設定すれば、これらの小さい自然な勾配を検出することはなくなって、PD2i値への低レベルノイズの寄与も排除できる。この「アルゴリズム的現象」こそが、実験データを説明し、ノイズがないデータに付加されると−5から5の間の区間内でノイズの効果が生じない(図2A)ことを説明するものである。しかしながら、わずかに大きい振幅のノイズが、非線形アルゴリズムで起こると予想されるノイズ効果を示す(例えば、図2B)。
【0041】
生理的なデータへの応用に基づくと、低レベルノイズを常に考慮して、それを、∀5の整数の間などの所定の範囲の中に何とかして保つか、または、実証的なデータに基づく関連した範囲内に保つ必要があると、今や理解できる。このような考慮をすることによって、図2Bに示されているような、低次元データ(すなわち、自由度がほとんどないデータ)に対するPD2iの見せかけの増加が防止できる。この概念を裏付けは、その簡単な説明(「アルゴリズムの現象」)の中にあるが、さらに一層説得力があるのは、おそらくNCAの使用を支持する実証的なデータである。これらのデータをここで提示する。
【0042】
図3の上部は、不整脈によって死亡した(AD)患者からの臨床RR間隔データを示している。このRR間隔データの20回分の心拍という小セグメントを拡大して、図3の下部に示す。直線回帰は、このデータセグメントにおけるシグナルのなだらかな変化を表し、のこぎりの歯のような上下変動はノイズを表している。ECGとRRはどちらも同じように見えるが、データの低レベル(20回の心拍、40整数のy軸)での観察結果によって、一方には±5整数の範囲にわたるデータ変動(OK)があり、もう一方には、±10整数の変動(大きすぎる)があることを明らかになった。大きい方の振幅セグメント(「大きすぎる」)は、確認・補正されていないが、図2Bに示すように、PD2i値が見かけ上より大きくなっているようである。このようにPD2i値が見かけ上より大きくなることの帰結は、PD2iによるテストでは、致命的な不整脈原性に対する患者の心臓の脆弱性に関して間違った臨床予測を行うおそれがあるというものである。
【0043】
例示的な実施態様によると、図3(大きすぎる)に示されているような、より大きい振幅セグメントは、ノイズ考慮アルゴリズム(NCA)を使用して確認および補正を行うことができる。
【0044】
表1〜4は、NCAの概念を支持する研究の一部として得られた臨床データを示している。表1〜4に示された研究の目標は、各患者のデジタルECGに対して行なわれたPD2i−テストから、不整脈による死(AD)の発生を予測することであった。救急治療室で胸痛を示し、Harvard Medical Schoolのプロトコルによって心臓に高リスクありと判定された320人の患者を調べたところ、3人の患者のうちのおよそ1人が、有意なデータを提供するためにNCAの適用を必要とした。NCAが開発され、適用されていなかったなら、低レベルのノイズが大きすぎたこれらのケースにおいて、これらの患者から得られたデータは無意味であったろう。
【0045】
表1Aは、いくつかの非線形的決定論アルゴリズム(PD2i、DFA、1/f−勾配、ApEn)で解析されたデータセットについて、予測AD転帰の分割表(すなわち、真陽性、真陰性、偽陽性、偽陰性)と相対危険度の統計値(Rel)を示す。表1Bは、より普通の線形的な確率論的アルゴリズム(SDNN、平均NN、LF/HF、LF(ln))で解析されたデータセットについて、予測AD転帰の分割表およびRelを示す。
【0046】
表1Aおよび1Bは、救急部門で胸痛を示し、推定急性リスク−MIが>7%である320人の高リスク患者(N)におけるHRVアルゴリズムの比較結果を示す。すべての被験者が、ECGを記録され、12ヶ月の追跡調査を完了させた。定義された不整脈死の転帰は、陽性または陰性のHRVテスト(PまたはN)によって真予測または偽予測(TまたはF)で表現される。表中の略語は以下のように表示される:SEN=感度(%);SPE=特異性(%);REL=相対危険度統計値;SUR=代理棄却;OUT=外れ値棄却(>3SD)、AF=心房性細動棄却。
【0047】
【表1】

** p≦0.001;2項確率検定;多重検定アルファ・プロテクション(要求されるアルファレベルは8倍小さい)によって;(P+Q)n×8倍プロテクションの拡大は、p≦0.001であるP=0.00016を意味する;また、2×2分割表において行対列に対するフィッシャーの直接確率検定によってp≦0.001である;その他はすべて2項確率検定では有意でない。
* フィッシャーの直接確率検定のみでp≦0.001;すなわち、2項確率検定では有意でない。
PD2i=ポイント相関次元法(最小PD2i≦1.4次元ならば陽性で、12PD2i値よりも大きい体系的低次元偏位をもつ);無作為化相代理棄却(SUR)の場合は、FN≦33%の場合と同一であった。
DFA−OUT=ディトレンドされたゆらぎ解析(Detrended Fluctuation Analysis)(正規外範囲が0.85から1.15であれば、α1[短期間]は陽性);無作為化配列代理棄却(SUR)。
1f/S=1/f勾配(0.04Hzから0.4Hzにわたって積分されたlog[マイクロボルト2/Hz]対log[Hz]の勾配について≦−1.075であれば陽性)
ApEn=近似エントロピー(切点≦1.0ユニットについて陽性、勾配距離)
SDNN=正常な心拍からの標準偏差(≦65msecであれば陽性;≦50msec、TP=17であれば陽性)。
MNN=正常なRR間隔の平均値(≦750msecであれば陽性)
LF/HF=低周波パワー(0.04から1.15Hz)/高周波パワー(0.15から0.4Hz)(陽性、≦1.6)
LF(ln)=自然対数によって正規化された低周波パワー(0.04から1.15Hz)(陽性、≦5.5)
#このAD患者だけは、79日目に死んだため、真のFNではない可能性がある。2つの正常な臨床ECGの前にデジタルECGを記録し、その後第3の陽性結果が記録された(すなわち、この患者は、ECGが記録された時にTNであったかもしれない「急性MIを発症しつつある」に分類されるべきであったかもしれない)。
【0048】
表1Aおよび1Bに提示されたデータからわかるように、PD2iアルゴリズムだけが、この救急治療室のコホートにおいて、統計的に有意な感度、特異性、および相対危険度の統計値を示した。表2は、高リスク心臓病患者の様々なサブグループに関する相対危険度の統計値を示している。表2に提示されたデータからすべての中でPD2iがもっとも機能することは明らかである。
【0049】
表2は、救急治療室の320人の高リスク心臓病患者において、不整脈による死亡をアルゴリズムによって予測するための相対危険度を示している。
【0050】
【表2】
**p≦0.001、*p≦0.05、2×2分割表において行対列に対するフィッシャーの直接確率検定による;>という記号は、FN=0であるためRRが無限大になってしまったことを意味する;示された数値は、FN=1を使用した。相対危険度=真の陽性/偽陰性×[真の陰性+偽陰性/真陽性+偽陽性]
表3はRR間隔データに対してNCAを使用した場合としない場合で、救急治療室の320人の高リスク心臓病患者における不整脈による死亡予測におけるPD2iの成績を示している。
【0051】
【表3】
**p≦0.001
#統計的な有意性なし
表3は、NCAを使用するか否かが、相対危険度の統計値に関する実験結果をどのように変えるかを具体的に示している。ノイズの検討なしには、PD2iは、そのような顕著な予測成果を挙げることはなく、その他のいかなるアルゴリズムもそれほど有効ではなかったであろう。
【0052】
表4は、ADを予測する際にも有効な、別のPD2i測定評価基準を具体的に示している。 表4は、ECGの記録を採って180日以内に死亡した16人の不整脈による死亡患者、および彼らに適合した対照であって、急性心筋梗塞の記録はあったが、追跡調査した1年以内には死ななかった対照について、自由度(次元)3から0の間にあるすべてのPD2i値の割合を示している。2つのグループの平均値は、非常に統計的に有意であった(P<0.0000001、t検定)。
【0053】
【表4】
*これらの数値は、3から0の範囲で何らかのスケーリングを生じた過剰な異所性収縮によるものであった。
【0054】
**p<0.000001、t検定;すべてのAD被験者は、PD2i<1.4LDEおよび0<PD2i>3.0基準に適合していた;感度=100%、特異性=100%。
【0055】
表4から分かるように、死亡していない高リスクのER患者(陰性テスト)では、彼らのPD2iの大部分は3次元(自由度)を超えている。死亡する患者(陽性テスト)では、彼らのPD2iの大部分が3次元より低い。この%PD2i<3評価基準は、AD患者を、彼らに適合する、急性心筋梗塞を患っていたが、ADでは死ななかった対照から完全に分けた(感度=100%、特異性=100%)。また、これらの結果も、分布が重なるのを避けるため、および感度と特異性を100%に保つためには、NCAの使用に完全に依存している。すなわち、RR間隔における低レベルノイズが高すぎたために、ノイズビットが取り除かれたそれらの被験者は、ファイル名の終わりで−nで示してある。
【0056】
(不整脈死を予測するためのPD2i評価基準)
上記表1〜4のそれぞれは、1.4またはそれよりも低いPD2iに対する低次元偏位(LDE)の観察結果に基づいていた。すなわち、PD2i<1.4は、ADを予測するための評価基準であった。この評価基準を用いた偽陰性(FN)の予測結果は全くなかった。FNというケースは、患者が「あなたは大丈夫」と言われたのに、帰宅すると数日または数週間内にADで死亡するということなので、薬剤にとって受け容れ難い。偽陽性のケースは、かなりの数が予想される。というのも、このコホートは、急性心筋梗塞、単一形態の異所性病巣、およびその他の高リスクな診断結果をもつ患者を擁する高リスク集団であるからである。これらの陽性テスト患者は、確かに、危険にさらされているため入院するべきであるが、おそらく、病院で適用される薬剤または外科的介入のおかげで、彼らは死なない。言い換えると、FPの分類は、薬剤にとって受け容れ難いものではない。PD2iをこれらのER患者に適用することについて重要なのは、1)すべてのADは陽性テスト患者で生じたこと、および2)1年間の追跡調査の間誰も死ななかったので、51%の陰性テスト患者は安全に退院できたということである。これらの臨床結果はすべて有意義であるが、感度と特異性を100%に保ち、相対的リスク高く保つことは、NCAの使用に完全に依存している。
【0057】
図4A〜4Lは、PD2i<1.4LEDおよび%PD2i<3という評価基準を図示するが、両者とも、NCAがいくつかのケース(NCA)で用いられていなかったなら、大きく変わっていたであろう。これらは互いに関連するが、NCAで調べられたデータにこれら2つの基準を使用するのが、おそらく、高リスク心臓病患者におけるADを予測するのに最良かつ最も普遍的な方法であろう。この組み合わせは、AD患者とその急性MI対照者について見られたように、統計的な感度と特異性を100%に保つ(表4;図4A〜4L)。
【0058】
図4A〜4Fは、6人の急性心筋梗塞(急性MI)の対照患者のRR間隔における低レベルのノイズを示している。図4G〜4Lは、6人の不整脈死(AD)患者のRR間隔における低レベルのノイズを示している。
【0059】
各パネルの長いセグメントは、15分間のECGにおけるRR−間隔のすべてを表す。短いセグメントは、より高い増幅率で小さな20心拍数のセグメントからの低レベルのノイズをトレースしたものを表す。したがって、各パネルにおいて、ノイズは、より大きな動的な動きに重ねられている。増幅率は、すべての対象(長いRRトレース=500から1000整数;短いRRトレース=0から40整数)について同一である。
【0060】
∀5整数(1msec=1整数)よりも大きいと判断されたノイズ範囲をもつそれらの被験者には、PD2iを計算する前にノイズ考慮アルゴリズム(NCA)を行った。このようにして、NCAを、例えば、図4B、4C、および4Fに示されている対照被験者、および図4Kおよび4Lに示されているAD被験者に適用した。
【0061】
各RRiに対応するPD2i値が、0から3次元(自由度)のスケールで表示されている。AD被験者については、図4G〜4Lに表されているように、3.0よりも小さなPD2i値が数多くある。表4は、すべての被験者について、平均して83%のPD2i値が3.0を下回ることを示している。
【0062】
臨床データに関する予測可能性の結果は、データのノイズ内容を考慮しないと統計的に有意とはいえなかっただろう。上記した適用場面のすべてで実際に使用されたNCAは、1)ノイズの動的範囲が10整数という区間を外れるか否か観察すること、および、もし外れていたら、2)過剰なノイズを取り除くのに足りる程度RR間隔の振幅を低減することを含む。約3分の1の被験者でNCAが必要とされた。各データポイントを、ノイズの動的範囲が10整数より小さくなるまで低減するだけの値で掛け算するのではなく、乗数を0.5にした(すなわち、12ビットのデータの全ビットを取り除いた)。
【0063】
NCAの適用はすべて、データの結果に対して盲検の状態で行った(NCAを用いたPD2i解析が完了してから、不整脈による死亡を確定した)。この処理で、実験者がバイアスをかける可能性が排除されるため、統計的な解析のための設計に必要とされる。
【0064】
例示的な実施態様によると、上記したようなノイズ考慮アルゴリズムは、ソフトウェアで実行することができる。ノイズ区間の決定は、例えば、コンピュータモニター上に表示されたデータに基づいて目視により行なうことができる。データは、例えば、表示されたセグメントの平均付近を中心とする∀40整数のフルスケールなど、固定倍率で表示することができる。数値が±5の整数範囲を外れている場合には、ユーザは、所定の値でデータ系列を割る決断をすることができるが、この割り算を自動的に行なわせることもできる。
【0065】
図5Aは、ECGデータに適用されるNCAの論理に関する例示的フローチャートを図示したものである。例示的な実施態様によると、被験者から得られたECGを、通常の増幅器で収集し、デジタル化してから、解析のために入力データとしてコンピュータに入力される。まず、ECGデータからRRおよびQTの間隔を作成し;次に、PD2iソフトウェア(PD2−02.EXE)およびQTvsRR−QTソフトウェア(QT.EXE)によって解析する。
【0066】
例示的な実施態様によれば、NCAは、2つのポイントにおいて、例えば、PD2iソフトウェアおよびQTvsRR−QTソフトウェアの実行の一部として、また、PD2iソフトウェアおよびQTvsRR−QTソフトウェアを実行した後に適用される。例えば、NCAを、PD2iとQTvsRR−QTのソフトウェアを実行している間に適用して、log c(n,r,nref*)対log rの勾配が0.5より小さく、ゼロより大きい場合には0に設定されるようにすることができる。また、PD2iとQTvsRR−QTのソフトウェアを実行した後にNCAを適用して、低レベルのノイズが所定の区間を外れた場合、例えば、−5と5の間の区間の外にある場合には、PD2iデータ系列を所定の整数で割ることができる。そのような割り算が行われる場合には、割り算されたデータに対して、PD2iとQTvsRR−QTのソフトウェアを再実行することによって、PD2iの計算を繰り返す。
【0067】
PD2iとQTvsRR−QTのソフトウェアの実行が終了した後に、ポイント相関次元を時間の関数として計算して表示する。また、QTvsRR−QTのプロットも作成して表示する。そして、危険度を評価するために画像レポートが作成される。デジタル化されたECGは、保存のためオフロードすることができる。
【0068】
上記の説明は、致命的な心臓不整脈の前兆としてECGデータから作成された非定常的な心拍間隔において、決定論的な低次元偏位を検出する検出/予測法を改良することに非常に関係がある。また、上記説明は、その前に観察された排除区域において、致命的な心臓不整脈の前兆として、QTvsRR−QTを連結プロットした(jointly−plotted)心拍の部分間隔の動態の検出を向上させることにも関係する。しかしながら、本発明は、例えば脳電図(EEG)のデータを用いる別の生体異常の検出/予測法を改良することにも応用することができる。例えば、NCAは、異常な認識状態の指標として、非定常的なEEGデータから作成された決定論的次元再構築における持続的な変化の検出を向上させるために応用できる可能性がある。また、NCAを応用して、初期の発作性てんかん行動の前兆として、EEG電位の決定論的次元変化の中で、拡大した分散の検出を向上させることができるかもしれない。
【0069】
図5Bは、神経の解析を受けているてんかん患者または正常な被験者にNCAアルゴリズムを実施する例を示している。被験者から得られたEEGデータを、通常の増幅器で作成し、デジタル化してから、解析のために入力データとしてコンピュータに入力される。次に、PD2iソフトウェア(PD2−02.exe)を実行して、勾配を必要に応じて、例えば0などに設定する。次に、低レベルのノイズが所定の区間から外れていたら、PD2iデータ系列を所定の整数で割り、また、PD2iとQTvsRR−QTのソフトウェアを再実行することによって、割られたデータに対してPD2iの計算を繰り返す。
【0070】
次に、ポイント相関次元をプロットしてから、てんかん病巣の位置および/または認識状態の変化を評価するために画像レポートを作成する。
【0071】
NCAは、例えば、マイクロコンピュータ上で実行できる。別々の要素として示されているが、図5Aおよび5Bに示されている一つまたは全部の要素をCPUで実行することができる。
【0072】
上記説明の焦点は、主に、ECGデータとEEGデータを査定することにあるが、本発明を他で同じように応用することが可能であると理解できよう。電気生理学的シグナルの発生源はさまざまなであり、画像レポートの構成は、医学的および/または生理学的な対象に特異であろう。すべての解析法は、PD2iアルゴリズムおよびNCAをソフトウェアという形で使用して、他の確認分析を伴うことも可能である。
【0073】
また、本発明は脳障害の発症を検出または予測する方法であって、以下のステップ:データ系列を作成するために脳障害と相関する生物学的データに関連する適用パラメータのセットを含むデータ処理ルーチンを使用して、入力された生物学的または物理的なデータ解析すること、該データ系列の勾配が所定の値より小さいかどうか判定すること;および、勾配が所定の値より小さければ、勾配を所定の数字に設定すること、および該データ系列を使用して、脳障害の発症を検出または予測することを含む方法を提供する。
【0074】
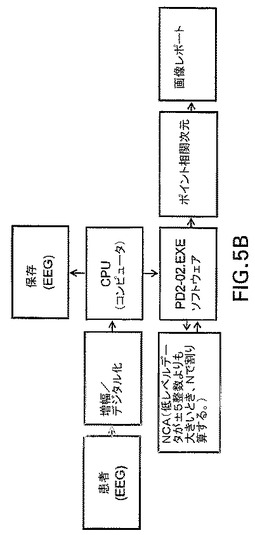
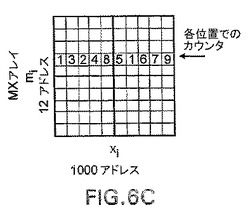
図6は、例示的な実施態様にしたがって、ソフトウェアとしてNCAを実施できる処理を具体的に示すフローチャートである。このフローは、データの収集から始まる。このデータから、i−ベクトルおよびj−ベクトルを作成して、互いからサブトラクトする(i−j DIFF)。これらのベクトル差長を、それらの数値(X、1から1000)に従って、使用される埋め込み次元(m、1から12)でMXARAYの中にエントリする。このエントリは、MXARAYの各位置におけるカウンタの増分として作成される。
【0075】
ベクトル差長の作成が完了したら、次に、カウンタ番号(3、7、9、8、2、6、7、4・・・)を用いて各埋め込み次元に対する相関積分を行なうが、これは、各m.sub.1について、Xの関数としての累積ヒストグラムを作成し、次に、それらの累積値(例えば、PLOTlogC(n,r)対logr)のlog−logプロットを作成して行なわれる。この累積ヒストグラムは、各埋め込み次元(m)に対する相関積分にプロットされたlog−logデータとなる。
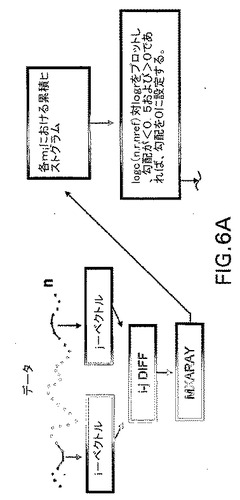
【0076】
そして、相関積分を5つの評価基準についてテストする。まず、各mにおける勾配が0.5未満であるか否を判定する。勾配は0.5未満であれば、0と設定する。次に、線形評価基準(LC)の中にある最も長い線形スケーリング領域を見つける。これは、LCによって各相関積分を調べて、セットパラメータの限界の中に含まれる2次導関数の最も長いセグメントを見つけることによって行なわれ(LC=0.30は、平均勾配の±15%の偏差に含まれることを意味する)、この反復LCテストは、「フロッピーテール」(すなわち、有限なデータ長のために不安定な最小log−r領域)を超える範囲を見つけて、LC基準を超えるまで相関積分を増加させる(相関積分の一番上の太字体の部分)。
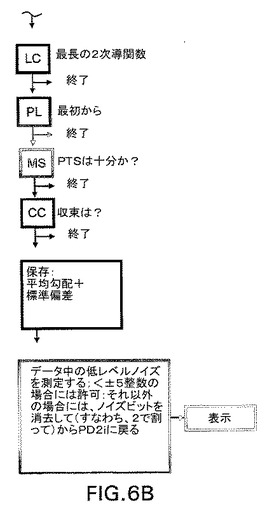
【0077】
次に、プロット長の評価基準(PL)の中にセグメントが含まれるか否か判定される。含まれるとすると、次に、相関積分のスケーリング領域がPL評価基準によってリセットされ;この値は、相関積分の最小のデータポイントからその評価基準値(例えば、15%、相関積分の最上層から2番目の層へ)に設定される。この領域の上下の限界を観察すると、それらが、最小スケーリング(MS)評価基準に必要とされるデータポイントの数、例えば10個を少なくとも持っているか否かが分かる。すべての相関積分(m−1からm=12)の選択された領域をプロットして、CCによって調べて、高い方の埋め込み次元(例えば、m=9からm=12)で収束が起きるか否か、すなわち、選択された領域が、平均値付近の標準偏差が、CCによって設定された限界内に存在する同じ勾配を本質的に有するか否かを確認する(すなわち、CC=0.40は、平均値の±20%の範囲内に平均値付近の偏差があることを意味する)。CC評価基準に合格すると、その平均勾配と標準偏差がファイルするために保存されて、例えば、表示される。
【0078】
最後に、動的範囲が−5から+5の区間を外れているか否かをテストするために、ユーザによって低レベルノイズが調べられる。外れている場合には、データファイルからノイズビットを取り除き(すなわち、各データポイント値を2で割り)、次に、変更されたファイルを再計算し、表示し、保存する。
【0079】
フロー内の初期の評価基準(LC、PL、MS)のどれかで失敗すると、プログラムは終了して、PD2i参照ベクトルを次のデータポイントに移して、また最初から始動する。失敗がCCで起こった場合には、後になってCCを変更することが望ましくなる場合かもしれないので、終了せずに、平均値と標準偏差が保存される。すなわち、CCは、後の画像ルーチンでPD2i(すなわち、m=9からm=12の平均勾配)をプロットすべきか否かを決定するフィルターである。
【実施例】
【0080】
本出願人は、HRVにおける自由度について研究を行い、心臓移植をうけた人(4)では、心拍変動が非常に規則的でほとんど全く変化しないことを発見した。これらの移植レシピエントにおけるHRVの非線形解析は、1.0という自由度だけを示した。これに対して、正常な被験者では、この変位が豊かで、3から5という自由度をもっていた。麻痺させられた心臓におけるこの結果は、まず第一にHRVを生み出すのは、脳によって計画された(brain−projected)心臓に対する神経作用であることを示唆している。
【0081】
心拍の動力学の非線形的分析は、その基本となる力学を高感度に探知するものである。それは、他のHRV測定法では検出できない、致死性の不整脈に対する脆弱性を明確に検出することができる(5)。また、内在心臓神経系だけが心拍間隔を調節するのに利用できるとき(6、7)、または前頭葉に関連する高度な認識系が関係するとき(8)には、調節ニューロンの変化も検出できる。
【0082】
(HRVおよび認識機能)
高齢者におけるHRVと認識機能および日常生活能力の活性との関連性は明確ではない(9)。HRVの全パワー(すなわち、パワー・スペクトルのLF、LF/HF比)は、正常な高齢被験者よりも高齢被験者の痴呆グループの方が有意に低いことが分かっていた(9)。したがって、HRVの減少に関係するのは年齢そのものではない。むしろ、この結果は、心臓に向けられた高度な神経活動の欠如こそが、HRVを減少させる原因であることを明らかにした脱神経研究を確認するものである。
【0083】
進行性の全体的な神経的課題のどの時点で、HRVが実際に変化し始めるかを知ることは重要である。変動の振幅または振動力の変化は、下行性神経離断に相当する全神経系関与を伴うが、後期の結果であって医学的にはそれほど役に立たない。おそらく、自由度の変化によって捕捉されるプロセスにおいて、より微妙な変化が初期に起きる。BSEおよび/またはアルツハイマー病の開始段階におけるように、初期の全体的な問題が、全ニューロンのいくつかに影響を与えるため、HRVの自由度の数が有意に減少するという可能性が非常に高い。その場合、HRVのこの非線形的測法は、病気のプロセスにおいて10年後にもたらされる結果の前触れとなるかもしれない。
【0084】
ある高齢の被験者(SGW)が研究された。この被験者は健康であり(1週間に3回テニスをした)、認知障害はなかった。この被験者は、昔の名前(例えば、様々な出版物の作者など)を思い出すのにいくらか困難はあったものの、他の短期または長期の記憶喪失の発症も痴呆の発症も確実になかった。しかしながら、この被験者のHRVは、当時で2.0次元から1.0次元の範囲の値まで大きく低下していた。非線形的次元(自由度)のこのような低下は、その値が、他のより若い正常な被験者の値と同じ範囲の5から3である適合年齢の対照には当てはまらなかった。SGWと適合年齢の正常な被験者との間における平均PD2i値の差は、統計的な有意性が非常に高かった(t−検定、p<0.001)。この10年間にわたる研究で最も重要な観察結果は、10年後に、この具体的な被験者(SGW)が重篤な短期記憶喪失を発症して、重篤な痴呆を示したということであった(図7)。
【0085】
HRVの自由度(次元)の持続的減少は、来るべき神経性痴呆の長期的予測因子であると考えられる。これと同じメカニズムが、初期の段階でウシ海綿状脳症をウシにおいて検出すること、そして発病するまでにやはり10年かかるヒトにおける同様のプリオン病(ヤコブ−クロイツフェルト病)について、似ているかもしれない。
【0086】
以前の研究でHRVを評価するために用いられたパワースペクトル・アルゴリズムは、線形的な確率論的モデルであって、呼吸調節における変化が、平均値付近に無作為に分布しており、かつ、定常的なデータ系列であることを必要とするモデルを前提としている。どのような行動も呼吸を妨げて、データに非線形的で非定常的な変化を生じさせるため、これらの前提はいずれも、そのような生理学的なデータ系列において妥当ではない。
【0087】
出願人は、非線形型アルゴリズムであるポイント相関次元(PD2i)は、非線形の決定論的モデルに基づいており、非定常的データという問題に取り組むものであることを示した。それは、非定常的データ系列における変動の自由度の変化を正確に追跡することができる(10)。以前の研究で使用されたパワー・スペクトル(1)はデータの定常性を必要とするので、理性的に行動する動物に存在する可能性は低かった。
【0088】
高リスク心臓病患者において、臨床的な心拍変動研究にPD2iアルゴリズムを適用すると、パワー・スペクトルなど、当技術分野において一般的に使用されている他のアルゴリズム(11,12)と比べて、PD2iアルゴリズムは、不整脈による死亡という転帰の予測性において著しく優れていた。
【0089】
本発明は、ヒトにおける心拍変動のPD2iでの減少が、脳痴呆の症例において進行性の脳障害を予測することを明らかにする。この同じ非線形の心拍測定法は、同様に動物、特にウシ海綿状脳症に感染したウシにおける進行性の脳疾患を予測することができる。心拍の脳による調節が、PD2の高次元をもたらしていることが示されている(4)。さらに、脳炎が進行するにつれて、PD2iの次元減少と量的な関係を持ちうることが開示されている(図8)。同じ予測法を、ヒトのプリオン病(ヤコブ−クロイツフェルト病)、およびアルツハイマー病など、さまざまな痴呆(心臓血管性、外傷性、遺伝性)などであるが、これらに限定されるものではない、ヒトにおける他の広範な脳障害の初期段階における検出に用いることができる。この技術は、ウシ海綿状脳症、ヒツジスクレイピー、ヘラジカ消耗性疾患などであるが、これらに限定されるものではない、動物における類似または同等の病気にも利用することができる。
【0090】
心拍間隔の変動が、進行性の全体疾患の初期に対する生理的病理をコードしている理由は、心拍を調節するために競合するさまざまな求心−遠心ループの「協同性」(10)を測定するからである。これらの求心−遠心ループは、全体が心臓に含まれる内在神経系(6、7)から、前頭葉(8)を通って輪になる内在神経系まで到達する。したがって、この技術は、心拍の自律神経による調節におけるすべてのレベルの中枢神経系および末梢神経系のサンプリングを行なう。
【0091】
HRVにおける変化を量的に記述することにおける、PD2iアルゴリズムに特有の正確さは、それが、非線形性の決定論的モデルに基づいていて、データの非定常性の問題を処理する結果である。
【0092】
本発明を具体的な実施態様に関して説明してきたが、発明の修正および変更は、本発明の範囲を逸脱するものではないと解することができる。例えば、NCAについては、PD2iデータ系列にそれを応用するところで説明されているが、NCAも、他のタイプのアルゴリズム、例えば、D2、D2i、またはその他の予測アルゴリズムにおいてノイズを低減させる際に役立ちうると解すべきである。
【0093】
当然ながら、以上の説明および添付した図面は例示にすぎない。発明の範囲と精神から離れることなく、さまざまな変更を想定できる。
【0094】
上記説明は、もっぱら例示として意図されており、いかなる意味においても、本発明を制限するものではない。
【0095】
この出願の全範囲でさまざまな刊行物が引用されている。これら刊行物の開示内容は、その全体が、最新の技術をより完全に説明するために参照することによって本明細書に組み込まれる。また、開示された刊行物は、それらに含まれる資料であって、引用文献が依拠される文で検討されている資料については、個別的および特異的に本明細書に組み込まれる。
【0096】
【表5】
【技術分野】
【0001】
(関連出願の相互参照)
本出願は、2003年1月29日出願の米国実用特許出願第10/353,849号および2003年2月6日出願の米国仮出願第60/445,495号の優先権を主張するものである。これらの出願は参照することにより本明細書に組み込まれる。
【背景技術】
【0002】
(背景)
本発明は、生物学的または物理学的なデータを評価する方法およびシステムに係るものである。より具体的には、本発明は、生体異常を検出および/または予測するために、生物学的または物理学的なデータを評価する方法およびシステムに係るものである。
【0003】
単線検流計の発明以来、電気生理学的電位の記録を医学に利用できるようになった。1930年代以来、電気生理学が心外傷および脳てんかん発作の診断に有効となっている。
【0004】
現代医学の最新技術は、心電図中に見られるRR間隔の解析または脳電図に見られる棘波(spikes)の解析によって、突然心臓死やてんかん発作など、将来の臨床転帰を予測できることを示している。このような解析および予測は、予測された転帰を示す患者と示さない患者の大規模なグループ間における転帰を区別するために使用する場合には統計的に有意義であるが、各患者に用いる場合には、既知の解析法はそれほど正確ではない。既知の解析手段のこの一般的な不具合が、多くの間違った予測を生む原因となっている。すなわち、これらの方法では、予測の統計な検出感度および特異性が低い。
【0005】
検討の対象となっている生物系において「病理的な」ものが進行していることは通常分かっているが、現在利用できる解析法は、各患者別に使用できるほど検出感度と特異性が高くない。
【0006】
この技術分野で広く見られる不正確さという問題は、現行の解析手段が、(1)確率論的なものであって(すなわち、データにおけるランダムな変動に基づいていて)(2)定常性(すなわち、データ生成する系が記録採集中変化してはならないこと)が要求され、また、(3)線形性(すなわち、当技術分野において「カオス」と呼ばれるデータの非線形性に対して感度が低いこと)であることによる。
【0007】
「D0」(ハウスドルフ次元)、「D1」(情報次元)、「D2」(相関次元)など、次元の理論的記述が数多く知られている。
【0008】
D2は、系の次元の評価、またはその生成されたデータのサンプルの評価値からの自由度数の評価を可能にする。何人かの研究者が、生物学的データにD2を用いている。しかし、データの定常性という仮定が成立しえないことが明らかになっている。
【0009】
これ以外の理論的記述であって、脳、心臓または骨格筋からのデータに固有の非定常性に対してより検出感度が低いポイント別スケーリング次元(Pointwise Scaling Dimension))すなわち「D2i」開発されている。これは、おそらく、生物学的データについて、D2よりも有益な評価法である。しかしながら、D2iには、依然として、データの非定常性に関係する可能性のある、かなりの評価誤差がある。
【0010】
D2およびD2iのどちらよりも、非定常データ(すなわち、異なったカオス発生器から得たサブエポック(subepoch)をリンクして作成されたデータ)における次元の変化を検出することに優れているポイント相関次元法アルゴリズム(PD2)が開発されている。
【0011】
その時間依存性を強調するために「PD2i」と名付けられた、改良されたPD2アルゴリズムが開発されている。これは、決定論的であって、データ中に存在する原因のある変化に基づく解析手段を用いる。このアルゴリズムは、データの定常性を必要とせず、実際に、データ中の非定常的変化を探知する。また、PD2iは、非カオスな線形データだけでなく、カオス的データに対しても感度が高い。PD2iは、総合的には相関次元を評価するアルゴリズムである従前の解析手段に基づいているが、データの非定常性に対して感度が低い。この特徴ゆえに、PD2iは、他の測定法ではできない、高い感度と特異性をもった臨床転帰の予測を行うことができる。
【0012】
PD2iアルゴリズムは、米国特許第5,709,214号および第5,720,294号に詳細に記載されており、参照することにより本明細書に組み込まれる。理解を簡単にするため、PD2iの簡単な説明と、この測定法と他の方法の比較を下に説明する。
【0013】
PD2iのモデルは、C(r,n,ref*,)〜r expD2であり、ここで、ref*は、さまざまなm−次元の基準ベクトルを作成するための許容可能な基準点である。なぜなら、これらは、線形性(LC)および収束性(CC)の基準に合致した最長のスケーリング領域PLを有するはずだからである。各ref*は、m−次元の基準ベクトルのそれぞれにおいて新しい座標から始まり、また、この新しい座標が何らかの値のものであるから、PD2iのそれは、統計目的についてはそれぞれ互いから独立していてもよい。
【0014】
PD2iアルゴリズムは、プロット長(Plot Length)と呼ばれるパラメータの使用によって線形スケーリングと収束が判別される、小さなlog−r値の範囲に限定される。このエントリの値は、小さなlog−r末端から開始する各log−logプロットについて、線形スケーリング領域が求められるポイントの割合を決定する。
【0015】
非定常データでは、例えば、ローレンツのサブエポックにおける複数のj−ベクトルから差し引かれると正弦波になるサブエポックにおける固定した基準ベクトル(i−ベクトル)の間の小さなlog−r値は、特に高目の埋め込み次元において、数多くの小さなベクトル差長は作り出さない。すなわち、ローレンツのサブエポックに対するj−ベクトルが、代わりに正弦波のサブエポックの中に存在すれば作成される小さなlog−rベクトル差長と比較して、たくさんの小さなlog−rベクトル差長があるわけではない。非線形性データからのベクトル差長のすべてを混合して序列をつけると、基準ベクトルを含むものに関して定常的なサブエポック間の小さなlog−r値だけが、スケーリング領域、すなわち、線形性と収束性を調べられる領域に寄与する。この小さなlog−r値の領域が他の非定常サブエポックによる有意な悪影響を受けると、線形性または収束性の基準には合致せず、その評価値は、PD2i法によって拒絶される。
【0016】
当技術分野に導入されたPD2iアルゴリズムは、データの非定常性が存在する場合(すなわち、生物学的データでは常態の場合)には、線形スケーリング領域の最小の初期部分を考慮すべきであるというアイデアである。これは、i−ベクトル(基準ベクトル)が存在するのと同一種であるデータのサブエポックにj−ベクトルが存在すれば、その場合、およびその場合にだけ、すなわち、その制限内で、またはデータ長が大きくなるにつれて、最小のlog−rベクトルがたくさん作成されるからである。したがって、基準ベクトルが存在するデータ種に関して非定常性のデータ種による相関積分への悪影響を避けるために、当業者は、「フロッピーテール(floppy tail)」の向こうのすぐ近くにある相関積分中の勾配だけに注目しなければならない。
【0017】
「フロッピーテール」とは、有限のデータ長である結果、相関積分のこの部分にはポイントが存在しないために線形スケーリングが生じない極度に小さいlog−r範囲である。したがって、PD2iスケーリングを、「フロッピーテール」より上のlog−r範囲の最小部分に限定することによって、PD2iアルゴリズムは、データの非定常性に対する感度がなくなる。ここで、D2iは、常に線形スケーリング領域全体を使用するが、この領域は、非定常性がデータ中に存在すれば、常に悪影響を受ける。
【0018】
図1Aは、logC(r,n,nref*)対logrのプロットを示す。これは、PD2iアルゴリズムの背後にある重要なアイデアを図解している。それは、データの非定常性が存在する場合に考慮すべきは、線形スケーリング領域の最小の初期部分であるというものである。この場合、データは、正弦波、ローレンツデータ、正弦波、ヘノン(Henon)データ、正弦波、およびランダムなノイズからの1200ポイントのデータサブエポックを連結して作成した。基準ベクトルはローレンツサブエポックの中にあった。埋め込み次元m=1のときの相関積分のために、LC=0.30という線形性の判断基準によって、フロッピーテール(「FT」)に対するセグメントを避ける。すなわち、全区間(D2i)に対する線形スケーリング領域を、プロット長PL=1.00、収束性基準CC=0.40、および最小スケーリングMS=10ポイントによって決定する。i−およびj−ベクトルがともにローレンツデータ(PD2i)内にある、種特異的なスケーリング領域は、プロット長をPL=0.15以下に変えることによって設定される。勾配の収束対埋め込み次元が生じた後の高い方の埋め込み次元(例、m=12)で、PD2iセグメントに対する勾配は、D2iのそれとは異なる。これは、D2iセグメントの上部(D2i−PD2i)が、i−ベクトルがその中に入る種について非定常的なデータ種にj−ベクトルが入るという、非定常性のi−jベクトル差異によって悪影響を受けるからである。
【0019】
PD2iについてのこの短距離勾配の評価値は、線形領域のいずれのlog−logプロットに関しても完全に妥当であって、勾配を決定するために、すべてのデータポイントを用いるか、初期セグメントだけを使用するかは問題ではない。したがって、「フロッピーテール」(線形性基準LCを設定することによって、その後部を避ける)の上にある小さな区間に対して実験的にプロット長を設定することによって、データの中の非定常性を僅かな誤差を出すだけで追跡できる。そして、この誤差は、もっぱらデータ長が有限であることによるものであって、非定常性による悪影響によるものではない。
【0020】
このように、「フロッピーテール」の真上にあるスケーリング領域のその部分、すなわち、(1)線形性基準であるLC、(2)最小スケーリング基準であるMS、および(3)プロット長基準であるPLによって決定される部分だけを調べるためのアルゴリズムを適当に調整することで、当業者は、データの非定常性に対する測定の感度を除去することができる。
【0021】
これは、どのようにして、i−ベクトルが入っているデータ種と同じデータ種にj−ベクトルを由来させるかという「トリック」であって、このことは、i−およびj−ベクトル上に画像マーカーを置いて、相対積分の中のマーカーを観察することによって、実験的に証明できる。スケーリング領域のこの初期部分は、数学的には、制限内でのみ悪影響を受けないと見なされるが、実際上は、有限データに対しては非常にうまく働く。このことは、連結データによってコンピュータ的に証明することができる。正弦型、ローレンツ型、ヘノン型、およびその他の型の既知の線形および非線形のデータ発生器によって作成された、データの連結サブエポック上でPD2iを用いると、短いスケーリングセグメントは、互いに関して定常的なi−およびj−ベクトル差長によってのみできるベクトル差を有する。すなわち、1,2000ポイントサブエポックに関する誤差は、それらの値の上限から5.0%よりも少ないことが分かっており、そして、これらの誤差は、データ長が有限であることによるものであって、スケーリングによる悪影響によるものではない。
【0022】
図1Bは、2種類の非線形アルゴリズムであるポイント相関次元法(PD2i)とポイント別スケーリング次元(D2i)による、一連のデータの自由度の計算を比較したものを示している。これらのアルゴリズムはともに時間依存的で、非定常データに対して用いると、古典的なD2アルゴリズムよりも正確である。生理学的なデータの大部分は、この系がオーガナイズされる方法(このメカニズムは非線形性である)のせいで非線形性である。生理系は、無制御な神経調節作用(例えば、静かに座って心拍データを生成しているときに、突然何か「恐ろしい」ことを考えてしまうなど)のせいで本質的に非定常性である。
【0023】
異なった統計的特性を有する数学的発生器によって生成された別々のデータ系列をリンクすることによって、非定常データをノイズのないものにすることができる。物理的な発生器には、常に、何らかの低レベルのノイズがある。図1Bに示されたデータ(DATA)は、正弦型(S)、ローレンツ型(L)、ヘロン(H)、およびランダムな(R)数学的発生器のサブエポックからできていた。それぞれのサブエポック(S、L、H、R)は、標準偏差は異なるが、同じような平均値をもつという、異なった確率論的特性を有するため、データ系列は当然ながら非定常的である。データについて計算されたPD2iおよびD2i結果が、その下の2つのトレースに示されており、それらは非常に異なっている。D2iアルゴリズムはPD2iに最も近似した比較アルゴリズムであるが、PD2iのように相関積分内の小さなlog−rスケーリング領域を制限しない。このスケーリング制限のおかげで、PD2iが非定常データによく適合するようになっている。
【0024】
デフォルトのパラメータ(LC=0.3、CC=0.4、Tau=1、PL=0.15)を用いて図1Bに示したPD2iの結果は、1,200データポイントのサブエポックに対するものである。各サブエポックのPD2iの平均は、各データ型単独につき(長いデータ長を使用して)計算されたD2の既知のその値の4%以内にある。S、L、H、およびRのデータに対する既知のD2値は、それぞれ1.00、2.06、1.26、および無限である。D2i値を見ると、全く異なった結果(すなわち、スプリアスな(偽の)結果)が見られる。D2iも時間依存的であるため、PD2iに最も近似したアルゴリズムであることに留意されたい。しかしながら、D2iはD2値自体同様データの定常性を必要とする。定常性データでは、D2=D2i=PD2iである。PD2iだけが非定常データに対する自由度の適正な数をトレースできる。同一の非定常データについて計算されたD2の単独値は、示されたD2i値の平均によって近似されている。
【0025】
PD2iによる解析のため、電気生理学的シグナルは、増幅され(1,000の増加)、デジタル化される(1,000Hz)。デジタル化されたシグナルは、処理の前にさらに低減する(例えば、ECGデータをRR間隔データに変換する)ことが可能である。RR間隔データの解析は、異なった病理学的転帰(例えば、心室細動「VF」や心室頻脈「VT」)を有する大きな被験患者グループの間のリスク予測を可能にすることが繰り返し判明している。PD2iは、高リスク患者からサンプル抽出されたRRデータを使用して、後にVFになった患者とそうならなかった患者を区別できることが示されている。
【0026】
最適な低ノイズのプリアンプと高速1,000Hzのデジタイザーによって得られるデジタルECGから作成されるRR間隔データについては、非線形アルゴリズムにとって問題となりうる低レベルのノイズが依然として存在する。また、RR間隔を作成するために使用されるアルゴリズムも、ノイズを増加させる結果となりうる。すべてのRR間隔探知器のうち最も正確なものは、3点移動式の「凸状オペレータ」を使用する。例えば、データ全体を走査する移動ウインドウの中の3点を、ウインドウがR−波のピークをまさに跨ぐときに、その出力が最大になるよう調整することができる。すなわち、ポイント1が前R−波の基線上にあり、ポイント2がR−波上にあり、ポイント3が再び基線上にある。ウインドウがデータを走査すると、データストリーム中のポイント2の位置が、それぞれのR−波のピークを正確に識別する。このアルゴリズムは、それぞれのR−波のdV/dtが最大である場合に、R−波が一定のレベルを上回るか、または検出される時にポイントを測定するアルゴリズムよりもかなりノイズのないRRデータを生み出す。
【0027】
最適なアルゴリズムで計算されたRR間隔は、最大振幅が約+/−5整数であると観測される低レベルのノイズを維持できる。この10整数の範囲は、平均したR−波のピークに対する1000の整数からのものである(すなわち、1%のノイズ)。不十分な電極調製、強い周囲の電磁場、中程度にノイズがあるプリアンプの使用、またはより低いデジタル化速度の使用によって、低レベルのノイズを容易に増加させることができる。例えば、1つの整数=1msec(すなわち、フルスケールの12ビットデジタイザーの25%増し)の場合の増加で、ユーザがデータ取得に慎重でないなら、1%という最適なノイズレベルが容易に2倍または3倍になりうる。このようなノイズの増加は、忙しい臨床場面で生じやすいため、ノイズレベルの取得後について検討しなければならない。
【発明の概要】
【発明が解決しようとする課題】
【0028】
このように、ノイズを考慮した改良型解析法が必要とされている。また、医学の分野において、例えば脳障害などの生体異常を検出するために、そのような測定法に対する需要がある。
【課題を解決するための手段】
【0029】
(概要)
以下の説明を添付図面と併せて参照すれば、本発明の目的、利点および特徴がより明らかになる。
【0030】
例示的な実施態様によると、データ処理ルーチンを用いて、入力された生物学的または物理学的なデータを解析することによって、生体異常が検出および/または予測される。このデータ処理ルーチンは、生体異常に相関する生物学的データと関連する適用パラメータのセットを含む。このデータ処理ルーチンは、アルゴリズムを用いて、例えば、生体異常の開始を検出または予測するために用いられるPD2iデータ系列などのデータ系列を作成する。
【0031】
本発明の一態様によれば、データ系列におけるノイズを低減するために、勾配が、例えば0.5という所定の値よりも少ない場合には、それを、例えば0などの所定の数に設定する。
【0032】
発明の別の一態様によると、データ系列中のノイズ区間が決定されていて、該ノイズ区間が所定範囲内にあれば、該データ系列を別の所定の数、例えば2で割って、該データ系列のために新しい数値が生成される。
【0033】
例示的な実施態様によると、データ系列中のノイズを低減させると、心不整脈、脳てんかん発作、および心筋虚血などの生体異常の検出/予測が改善される。
また、本発明に係る方法および装置を利用して、ヒトのプリオン病(クロイツフェルト−ヤコブ病)や、アルツハイマー病など、さまざまな痴呆(心臓血管性、外傷性、遺伝性)などの脳障害の発症を検出および予測することもできる。また、本発明に係る方法を利用して、ウシ海綿状脳症、羊のスクレイピー、およびヘラジカの消耗性疾患の発症を検出および予測することができる。
本発明はまた、以下の項目を提供する。
(項目1)
生体異常を検出または予測する方法であって、
データ系列を作成するために生体異常と相関する生物学的データに関連する適用パラメータのセットを含むデータ処理ルーチンを使用して、入力された生物学的または物理的なデータを解析するステップ;
該データ系列の勾配が所定の値より小さいかどうか判定するステップ;
該勾配が所定の値より小さければ、該勾配を所定の数に設定するステップ;および
該データ系列を使用して、生体異常の発症を検出または予測するステップ
を含む方法。
(項目2)
前記データ処理ルーチンが、データ系列PD2iを作成するために以下のアルゴリズム:
PD2i⊆logC(n,r,nref*)/logrを使用し、
式中、⊆はスケールを意味し、Cは、PD2iに対する相関積分であって、その中でnはデータ長に相当し、rはスケーリング範囲に相当し、またnref*は、非定常データの効果をもたない制限された小さなlog−r範囲の中でC/logrのスケーリング領域の勾配を評価するための基準ベクトルの位置に相当している、項目1に記載の方法。
(項目3)
前記所定の値が約0.5である、項目1に記載の方法。
(項目4)
前記所定の数が0である、項目1に記載の方法。
(項目5)
前記データ系列内でノイズ区間を決定すること、および
該ノイズ区間が、所定の範囲内にあれば、該データ系列を別の所定の数で割り、該データ系列に対する新しい値を生成するために解析ステップを繰り返すことをさらに含む、項目1に記載の方法。
(項目6)
前記所定の数が2である、項目5に記載の方法。
(項目7)
前記所定の範囲が、xが数字であるときに−xから+xである、項目5に記載の方法。
(項目8)
前記所定の範囲が−5から+5である、項目7に記載の方法。
(項目9)
前記入力される生物学的データまたは物理学的データが電気生理学的データを含む、項目1に記載の方法。
(項目10)
前記入力される生物学的データまたは物理学的データが、心臓不整脈および脳てんかん発作の少なくとも一つの発症を検出または予測するため、および/または心筋虚血の重篤度を測定するために解析されるECGデータを含む、項目9に記載の方法。
(項目11)
生体異常を検出または予測する方法であって、
データ系列を作成するために生体異常と相関する生物学的データに関連する適用パラメータのセットを含むデータ処理ルーチンを使用して、入力された生物学的または物理的なデータを解析するステップ;
該データ系列内でノイズ区間を決定するステップ、および
該ノイズ区間が、所定の範囲内にあれば、該データ系列を所定の数で割り、該データ系列に対する新しい値を生成するために解析ステップを繰り返すステップ、または、
該ノイズ区間が所定の範囲を外れた場合には、生体異常の発症を検出または予測するために該データ系列を使用するステップを含む方法。
(項目12)
前記データ処理ルーチンが、データ系列PD2iを作成するために以下のアルゴリズム:
PD2i⊆logC(n,r,nref*)/logrを使用し、
式中、⊆はスケールを意味し、Cは、PD2iに対する相関積分であって、その中でnはデータ長に相当し、rはスケーリング範囲に相当し、またnref*は、非定常データの効果をもたない制限された小さなlog−r範囲の中でC/logrのスケーリング領域の勾配を評価するための基準ベクトルの位置に相当している、項目11に記載の方法。
(項目13)
前記所定の数が2である、項目11に記載の方法。
(項目14)
前記所定の範囲が、xが数字であるときに−xから+xである、項目11に記載の方法。
(項目15)
前記所定の範囲が−5から+5である、項目14に記載の方法。
(項目16)
前記データ系列の勾配が、所定の値よりも小さいか否かを決定すること、および
該勾配が所定の値よりも少ないとき、該勾配を別の所定の数に設定することをさらに含む、項目11に記載の方法。
(項目17)
前記所定の値が約0.5である、項目16に記載の方法。
(項目18)
前記別の所定の数が0である、項目16に記載の方法。
(項目19)
前記生物学的データまたは物理学的データが電気生理学的データを含む、項目11に記載の方法。
(項目20)
前記電気生理学的データが、心臓不整脈および脳てんかん発作の少なくとも一つの発症を検出または予測するため、および/または心筋虚血の重篤度を測定するために解析されるECGデータを含む、項目19に記載の方法。
(項目21)
生体異常を検出または予測するための装置であって、
データ系列を作成するために生体異常と相関する生物学的データに関連する適用パラメータのセットを含むデータ処理ルーチンを使用して、入力された生物学的または物理的なデータを解析するための手段;
該データ系列の勾配が所定の値より小さいかどうか判定するための手段;
該勾配が所定の値より小さければ、該勾配を所定の数に設定するための手段;および
該データ系列を使用して、生体異常の発症を検出または予測するための手段
を含む装置。
(項目22)
前記データ処理ルーチンが、データ系列PD2iを作成するために以下のアルゴリズム:
PD2i⊆logC(n,r,nref*)/logrを使用し、
式中、⊆はスケールを意味し、Cは、PD2iに対する相関積分であって、その中でnはデータ長に相当し、rはスケーリング範囲に相当し、またnref*は、非定常データの効果をもたない制限された小さなlog−r範囲の中でC/logrのスケーリング領域の勾配を評価するための基準ベクトルの位置に相当している、項目21に記載の装置。
(項目23)
前記所定の値が約0.5である、項目21に記載の装置。
(項目24)
前記別の所定の数が0である、項目21に記載の装置。
(項目25)
前記データ系列内でノイズ区間を決定するための手段、および
該ノイズ区間が、所定の範囲内にあれば、該データ系列を別の所定の数で割り、該データ系列に対する新しい値を生成するために、割られたデータ系列を解析手段に提供するための手段をさらに含む、項目21に記載の装置。
(項目26)
前記所定の数が2である、項目25に記載の装置。
(項目27)
前記所定の範囲が、xが数字であるときに−xから+xである、項目25に記載の装置。
(項目28)
前記所定の範囲が−5から+5である、項目27に記載の装置。
(項目29)
前記入力される生物学的データまたは物理学的データが電気生理学的データを含む、項目21に記載の装置。
(項目30)
前記入力される生物学的データまたは物理学的データが、心臓不整脈および脳てんかん発作の少なくとも一つの発症を検出または予測するため、および/または心筋虚血の重篤度を測定するために解析されるECGデータを含む、項目29に記載の方法。
(項目31)
生体異常を検出または予測するための装置であって、
データ系列を作成するために生体異常と相関する生物学的データに関連する適用パラメータのセットを含むデータ処理ルーチンを使用して、入力された生物学的または物理的なデータを解析するための手段;
該データ系列内でノイズ区間を決定するための手段;
該ノイズ区間が、所定の範囲内にあれば、該データ系列を所定の数で割り、該データ系列に対する新しい値を生成するために、割られたデータ系列を該解析手段に提供するための手段;および
該ノイズ区間が所定の範囲を外れた場合には、生体異常の発症を検出または予測するために該データ系列を使用するための手段を含む装置。
(項目32)
前記データ処理ルーチンが、データ系列PD2iを作成するために以下のアルゴリズム:
PD2i⊆logC(n,r,nref*)/logrを使用し、
式中、⊆はスケールを意味し、Cは、PD2iに対する相関積分であって、その中でnはデータ長に相当し、rはスケーリング範囲に相当し、またnref*は、非定常データの効果をもたない制限された小さなlog−r範囲の中でC/logrのスケーリング領域の勾配を評価するための基準ベクトルの位置に相当している、項目31に記載の装置。
(項目33)
前記所定の数が2である、項目31に記載の装置。
(項目34)
前記所定の範囲が、xが数字であるときに−xから+xである、項目31に記載の装置。
(項目35)
前記所定の範囲が−5から+5である、項目34に記載の装置。
(項目36)
前記データ系列の勾配が所定の値より小さいかどうか判定するための手段;および
該勾配が所定の値より小さければ、該勾配を別の所定の数に設定するための手段をさらに含む、項目31に記載の装置。
(項目37)
前記所定の値が約0.5である、項目36に記載の装置。
(項目38)
前記別の所定の数が0である、項目36に記載の装置。
(項目39)
前記生物学的データまたは物理学的データが電気生理学的データを含む、項目31に記載の装置。
(項目40)
前記電気生理学的データが、心臓不整脈および脳てんかん発作の少なくとも一つの発症を検出または予測するため、および/または心筋虚血の重篤度を測定するために解析されるECGデータを含む、項目39に記載の装置。
(項目41)
脳障害を検出または予測する方法であって、
データ系列を作成するために脳障害と相関する生物学的データに関連する適用パラメータのセットを含むデータ処理ルーチンを使用して、入力された生物学的または物理的なデータを解析するステップ;
該データ系列の勾配が所定の値より小さいかどうか判定するステップ;
該勾配が所定の値より小さければ、該勾配を所定の数に設定するステップ;および
該データ系列を使用して、脳障害の発症を検出または予測するステップ
を含む方法。
(項目42)
前記脳障害がウシ海綿状脳症である、項目41に記載の方法。
(項目43)
前記脳障害がアルツハイマー病である、項目41に記載の方法。
(項目44)
前記データ処理ルーチンが、データ系列PD2iを作成するために以下のアルゴリズム:
PD2i⊆logC(n,r,nref*)/logrを使用し、
式中、⊆はスケールを意味し、Cは、PD2iに対する相関積分であって、その中でnはデータ長に相当し、rはスケーリング範囲に相当し、またnref*は、非定常データの効果をもたない制限された小さなlog−r範囲の中でC/logrのスケーリング領域の勾配を評価するための基準ベクトルの位置に相当している、項目41に記載の方法。
(項目45)
前記所定の値が約0.5である、項目41に記載の方法。
(項目46)
前記所定の数が0である、項目41に記載の方法。
(項目47)
前記データ系列内でノイズ区間を決定すること、および
該ノイズ区間が、所定の範囲内にあれば、該データ系列を別の所定の数で割り、該データ系列に対する新しい値を生成するために解析ステップを繰り返すことをさらに含む、項目41に記載の方法。
(項目48)
前記別の所定の数が2である、項目47に記載の方法。
(項目49)
前記所定の範囲が、xが数字であるときに−xから+xである、項目47に記載の方法。
(項目50)
前記所定の範囲が−5から+5である、項目49に記載の方法。
(項目51)
前記入力される生物学的データまたは物理学的データが電気生理学的データを含む、項目41に記載の方法。
(項目52)
脳障害を検出または予測する方法であって、
データ系列を作成するために脳障害と相関する生物学的データに関連する適用パラメータのセットを含むデータ処理ルーチンを使用して、入力された生物学的または物理的なデータを解析するステップ;
該データ系列内でノイズ区間を決定するステップ、および
該ノイズ区間が、所定の範囲内にあれば、該データ系列を所定の数で割り、該データ系列に対する新しい値を生成するために解析ステップを繰り返すステップ、または、
該ノイズ区間が所定の範囲を外れた場合には、生体異常の発症を検出または予測するために該データ系列を使用するステップを含む方法。
(項目53)
前記脳障害がウシ海綿状脳症である、項目52に記載の方法。
(項目54)
前記脳障害がアルツハイマー病である、項目52に記載の方法。
(項目55)
前記データ処理ルーチンが、データ系列PD2iを作成するために以下のアルゴリズム:
PD2i⊆logC(n,r,nref*)/logrを使用し、
式中、⊆はスケールを意味し、Cは、PD2iに対する相関積分であって、その中でnはデータ長に相当し、rはスケーリング範囲に相当し、またnref*は、非定常データの効果をもたない制限された小さなlog−r範囲の中でC/logrのスケーリング領域の勾配を評価するための基準ベクトルの位置に相当している、項目52に記載の方法。
(項目56)
前記別の所定の数が2である、項目52に記載の方法。
(項目57)
前記所定の範囲が、xが数字であるときに−xから+xである、項目52に記載の方法。
(項目58)
前記所定の範囲が−5から+5である、項目57に記載の方法。
(項目59)
前記データ系列の勾配が所定の値より小さいかどうか判定すること;および
該勾配が所定の値より小さければ、該勾配を別の所定の数に設定するステップをさらに含む、項目52に記載の方法。
(項目60)
前記所定の値が約0.5である、項目59に記載の方法。
(項目61)
前記別の所定の数が0である、項目59に記載の方法。
(項目62)
前記生物学的データまたは物理学的データが電気生理学的データを含む、項目52に記載の方法。
【図面の簡単な説明】
【0034】
【図1A】図1Aは、通常のPD2iアルゴリズムのための、C(r,n,ref*)対logrのプロットを図示したものである。
【図1B】図1Bは、無ノイズの非定常データに適用したときの2つの時間依存性アルゴリズムによる自由度(次元)の計算結果を図示したものである。
【図2】図2Aおよび2Bは、非定常データに低レベルのノイズを加えたときのPD2iの結果を図示したものである。
【図3】図3は、2つのデジタル式ECGから生成された2組のRR間隔における低レベルのノイズの検査を図示したものである。
【図4】図4A〜4Fは、急性心筋梗塞の対照患者のRR間隔における低レベルノイズを図示したもの(挿入図)である。図4G〜4Lは、不整脈によって死亡した患者のRR間隔における低レベルのノイズを図示したものである。
【図5A】図5Aは心臓病学におけるECGデータに適用されたNCAの論理の典型的なフローチャートを図示したものである。
【図5B】図5Bは神経生理学におけるEEGデータとそれに関連する概念に適用されたNCAの論理の典型的なフローチャートを図示したものである。
【図6A】図6は、例示的な実施態様に従ってソフトウェアで実行されたNCAの典型的フローチャートを図示したものである。
【図6B】図6は、例示的な実施態様に従ってソフトウェアで実行されたNCAの典型的フローチャートを図示したものである。
【図6C】図6は、例示的な実施態様に従ってソフトウェアで実行されたNCAの典型的フローチャートを図示したものである。
【図6D】図6は、例示的な実施態様に従ってソフトウェアで実行されたNCAの典型的フローチャートを図示したものである。
【図7】図7は、10年後になるまで確認されなかった早期痴呆の患者の心拍(RR)のPD2iと、同じ年齢の正常な被験者のそれとの比較を図示したものである。
【図8】図8は、初期および後期のウシ海綿状脳症(BSE)のウシの心拍(RR)のPD2iの関係を図示したものである。
【発明を実施するための形態】
【0035】
(詳細な説明)
例示的な実施態様によると、低レベルのノイズによる非線形的解析測定値への寄与をなくすために、PD2iのような技術が開発されている。
【0036】
ノイズがなぜ重要であるかを示すために、図2Aおよび2Bを参照されたい。図2Aおよび2Bにおいて、データは、図1Bに関して説明したとおり、同じS、L、H、およびRのデータである。定義上、このデータは、数学的発生器によって作成されたため、どんなノイズもない。
【0037】
図2Aでは、∀5の整数という低レベルのノイズが、非定常データ系列に加えられている。各サブエポックにおける1200のデータポイントからいくつか大きな数値が出てきたが、各サブエポックに対するPD2iの平均値は有意に変動しなかった。
【0038】
しかしながら、∀14の整数のノイズを加えると、ここでスプリアスなPD2i値がもたらされ、図2Bに示されるように、その平均値はすべてほぼ同一である。
【0039】
例示的な実施態様によると、NCA(ノイズ考慮アルゴリズム)法は、高い倍率(例えば、y軸は全スケールで40の整数であり、x軸は全スケールで20心拍数である)で低レベルのノイズを調べ、ノイズが所定の範囲を外れているか否か、例えば、ノイズの動的範囲が∀5の整数より大きいか否かを判定する。もし大きい場合には、ノイズを∀5の整数の範囲内に戻す数でデータ系列を割り算する。この例では、12ビットの整数データの低レベルのビットだけがノイズを含んでいるため、データ系列を2で割ることができる。
【0040】
m=12よりも小さい埋め込み次元で計算すると、相関積分の線形スケーリング領域は、低レベルのノイズ(例えば、∀5の整数という動的範囲をもつ)から作成された場合には、0.5未満の勾配を有するため、低レベルのノイズと真の小さな勾配データとを区別することは不可能である。好都合なことに、生物学的データでは0.5未満の勾配にめったに遭遇しないので、勾配を0.5以下(相関積分に見られる)から0にアルゴリズムで設定すれば、これらの小さい自然な勾配を検出することはなくなって、PD2i値への低レベルノイズの寄与も排除できる。この「アルゴリズム的現象」こそが、実験データを説明し、ノイズがないデータに付加されると−5から5の間の区間内でノイズの効果が生じない(図2A)ことを説明するものである。しかしながら、わずかに大きい振幅のノイズが、非線形アルゴリズムで起こると予想されるノイズ効果を示す(例えば、図2B)。
【0041】
生理的なデータへの応用に基づくと、低レベルノイズを常に考慮して、それを、∀5の整数の間などの所定の範囲の中に何とかして保つか、または、実証的なデータに基づく関連した範囲内に保つ必要があると、今や理解できる。このような考慮をすることによって、図2Bに示されているような、低次元データ(すなわち、自由度がほとんどないデータ)に対するPD2iの見せかけの増加が防止できる。この概念を裏付けは、その簡単な説明(「アルゴリズムの現象」)の中にあるが、さらに一層説得力があるのは、おそらくNCAの使用を支持する実証的なデータである。これらのデータをここで提示する。
【0042】
図3の上部は、不整脈によって死亡した(AD)患者からの臨床RR間隔データを示している。このRR間隔データの20回分の心拍という小セグメントを拡大して、図3の下部に示す。直線回帰は、このデータセグメントにおけるシグナルのなだらかな変化を表し、のこぎりの歯のような上下変動はノイズを表している。ECGとRRはどちらも同じように見えるが、データの低レベル(20回の心拍、40整数のy軸)での観察結果によって、一方には±5整数の範囲にわたるデータ変動(OK)があり、もう一方には、±10整数の変動(大きすぎる)があることを明らかになった。大きい方の振幅セグメント(「大きすぎる」)は、確認・補正されていないが、図2Bに示すように、PD2i値が見かけ上より大きくなっているようである。このようにPD2i値が見かけ上より大きくなることの帰結は、PD2iによるテストでは、致命的な不整脈原性に対する患者の心臓の脆弱性に関して間違った臨床予測を行うおそれがあるというものである。
【0043】
例示的な実施態様によると、図3(大きすぎる)に示されているような、より大きい振幅セグメントは、ノイズ考慮アルゴリズム(NCA)を使用して確認および補正を行うことができる。
【0044】
表1〜4は、NCAの概念を支持する研究の一部として得られた臨床データを示している。表1〜4に示された研究の目標は、各患者のデジタルECGに対して行なわれたPD2i−テストから、不整脈による死(AD)の発生を予測することであった。救急治療室で胸痛を示し、Harvard Medical Schoolのプロトコルによって心臓に高リスクありと判定された320人の患者を調べたところ、3人の患者のうちのおよそ1人が、有意なデータを提供するためにNCAの適用を必要とした。NCAが開発され、適用されていなかったなら、低レベルのノイズが大きすぎたこれらのケースにおいて、これらの患者から得られたデータは無意味であったろう。
【0045】
表1Aは、いくつかの非線形的決定論アルゴリズム(PD2i、DFA、1/f−勾配、ApEn)で解析されたデータセットについて、予測AD転帰の分割表(すなわち、真陽性、真陰性、偽陽性、偽陰性)と相対危険度の統計値(Rel)を示す。表1Bは、より普通の線形的な確率論的アルゴリズム(SDNN、平均NN、LF/HF、LF(ln))で解析されたデータセットについて、予測AD転帰の分割表およびRelを示す。
【0046】
表1Aおよび1Bは、救急部門で胸痛を示し、推定急性リスク−MIが>7%である320人の高リスク患者(N)におけるHRVアルゴリズムの比較結果を示す。すべての被験者が、ECGを記録され、12ヶ月の追跡調査を完了させた。定義された不整脈死の転帰は、陽性または陰性のHRVテスト(PまたはN)によって真予測または偽予測(TまたはF)で表現される。表中の略語は以下のように表示される:SEN=感度(%);SPE=特異性(%);REL=相対危険度統計値;SUR=代理棄却;OUT=外れ値棄却(>3SD)、AF=心房性細動棄却。
【0047】
【表1】
** p≦0.001;2項確率検定;多重検定アルファ・プロテクション(要求されるアルファレベルは8倍小さい)によって;(P+Q)n×8倍プロテクションの拡大は、p≦0.001であるP=0.00016を意味する;また、2×2分割表において行対列に対するフィッシャーの直接確率検定によってp≦0.001である;その他はすべて2項確率検定では有意でない。
* フィッシャーの直接確率検定のみでp≦0.001;すなわち、2項確率検定では有意でない。
PD2i=ポイント相関次元法(最小PD2i≦1.4次元ならば陽性で、12PD2i値よりも大きい体系的低次元偏位をもつ);無作為化相代理棄却(SUR)の場合は、FN≦33%の場合と同一であった。
DFA−OUT=ディトレンドされたゆらぎ解析(Detrended Fluctuation Analysis)(正規外範囲が0.85から1.15であれば、α1[短期間]は陽性);無作為化配列代理棄却(SUR)。
1f/S=1/f勾配(0.04Hzから0.4Hzにわたって積分されたlog[マイクロボルト2/Hz]対log[Hz]の勾配について≦−1.075であれば陽性)
ApEn=近似エントロピー(切点≦1.0ユニットについて陽性、勾配距離)
SDNN=正常な心拍からの標準偏差(≦65msecであれば陽性;≦50msec、TP=17であれば陽性)。
MNN=正常なRR間隔の平均値(≦750msecであれば陽性)
LF/HF=低周波パワー(0.04から1.15Hz)/高周波パワー(0.15から0.4Hz)(陽性、≦1.6)
LF(ln)=自然対数によって正規化された低周波パワー(0.04から1.15Hz)(陽性、≦5.5)
#このAD患者だけは、79日目に死んだため、真のFNではない可能性がある。2つの正常な臨床ECGの前にデジタルECGを記録し、その後第3の陽性結果が記録された(すなわち、この患者は、ECGが記録された時にTNであったかもしれない「急性MIを発症しつつある」に分類されるべきであったかもしれない)。
【0048】
表1Aおよび1Bに提示されたデータからわかるように、PD2iアルゴリズムだけが、この救急治療室のコホートにおいて、統計的に有意な感度、特異性、および相対危険度の統計値を示した。表2は、高リスク心臓病患者の様々なサブグループに関する相対危険度の統計値を示している。表2に提示されたデータからすべての中でPD2iがもっとも機能することは明らかである。
【0049】
表2は、救急治療室の320人の高リスク心臓病患者において、不整脈による死亡をアルゴリズムによって予測するための相対危険度を示している。
【0050】
【表2】
**p≦0.001、*p≦0.05、2×2分割表において行対列に対するフィッシャーの直接確率検定による;>という記号は、FN=0であるためRRが無限大になってしまったことを意味する;示された数値は、FN=1を使用した。相対危険度=真の陽性/偽陰性×[真の陰性+偽陰性/真陽性+偽陽性]
表3はRR間隔データに対してNCAを使用した場合としない場合で、救急治療室の320人の高リスク心臓病患者における不整脈による死亡予測におけるPD2iの成績を示している。
【0051】
【表3】
**p≦0.001
#統計的な有意性なし
表3は、NCAを使用するか否かが、相対危険度の統計値に関する実験結果をどのように変えるかを具体的に示している。ノイズの検討なしには、PD2iは、そのような顕著な予測成果を挙げることはなく、その他のいかなるアルゴリズムもそれほど有効ではなかったであろう。
【0052】
表4は、ADを予測する際にも有効な、別のPD2i測定評価基準を具体的に示している。 表4は、ECGの記録を採って180日以内に死亡した16人の不整脈による死亡患者、および彼らに適合した対照であって、急性心筋梗塞の記録はあったが、追跡調査した1年以内には死ななかった対照について、自由度(次元)3から0の間にあるすべてのPD2i値の割合を示している。2つのグループの平均値は、非常に統計的に有意であった(P<0.0000001、t検定)。
【0053】
【表4】
*これらの数値は、3から0の範囲で何らかのスケーリングを生じた過剰な異所性収縮によるものであった。
【0054】
**p<0.000001、t検定;すべてのAD被験者は、PD2i<1.4LDEおよび0<PD2i>3.0基準に適合していた;感度=100%、特異性=100%。
【0055】
表4から分かるように、死亡していない高リスクのER患者(陰性テスト)では、彼らのPD2iの大部分は3次元(自由度)を超えている。死亡する患者(陽性テスト)では、彼らのPD2iの大部分が3次元より低い。この%PD2i<3評価基準は、AD患者を、彼らに適合する、急性心筋梗塞を患っていたが、ADでは死ななかった対照から完全に分けた(感度=100%、特異性=100%)。また、これらの結果も、分布が重なるのを避けるため、および感度と特異性を100%に保つためには、NCAの使用に完全に依存している。すなわち、RR間隔における低レベルノイズが高すぎたために、ノイズビットが取り除かれたそれらの被験者は、ファイル名の終わりで−nで示してある。
【0056】
(不整脈死を予測するためのPD2i評価基準)
上記表1〜4のそれぞれは、1.4またはそれよりも低いPD2iに対する低次元偏位(LDE)の観察結果に基づいていた。すなわち、PD2i<1.4は、ADを予測するための評価基準であった。この評価基準を用いた偽陰性(FN)の予測結果は全くなかった。FNというケースは、患者が「あなたは大丈夫」と言われたのに、帰宅すると数日または数週間内にADで死亡するということなので、薬剤にとって受け容れ難い。偽陽性のケースは、かなりの数が予想される。というのも、このコホートは、急性心筋梗塞、単一形態の異所性病巣、およびその他の高リスクな診断結果をもつ患者を擁する高リスク集団であるからである。これらの陽性テスト患者は、確かに、危険にさらされているため入院するべきであるが、おそらく、病院で適用される薬剤または外科的介入のおかげで、彼らは死なない。言い換えると、FPの分類は、薬剤にとって受け容れ難いものではない。PD2iをこれらのER患者に適用することについて重要なのは、1)すべてのADは陽性テスト患者で生じたこと、および2)1年間の追跡調査の間誰も死ななかったので、51%の陰性テスト患者は安全に退院できたということである。これらの臨床結果はすべて有意義であるが、感度と特異性を100%に保ち、相対的リスク高く保つことは、NCAの使用に完全に依存している。
【0057】
図4A〜4Lは、PD2i<1.4LEDおよび%PD2i<3という評価基準を図示するが、両者とも、NCAがいくつかのケース(NCA)で用いられていなかったなら、大きく変わっていたであろう。これらは互いに関連するが、NCAで調べられたデータにこれら2つの基準を使用するのが、おそらく、高リスク心臓病患者におけるADを予測するのに最良かつ最も普遍的な方法であろう。この組み合わせは、AD患者とその急性MI対照者について見られたように、統計的な感度と特異性を100%に保つ(表4;図4A〜4L)。
【0058】
図4A〜4Fは、6人の急性心筋梗塞(急性MI)の対照患者のRR間隔における低レベルのノイズを示している。図4G〜4Lは、6人の不整脈死(AD)患者のRR間隔における低レベルのノイズを示している。
【0059】
各パネルの長いセグメントは、15分間のECGにおけるRR−間隔のすべてを表す。短いセグメントは、より高い増幅率で小さな20心拍数のセグメントからの低レベルのノイズをトレースしたものを表す。したがって、各パネルにおいて、ノイズは、より大きな動的な動きに重ねられている。増幅率は、すべての対象(長いRRトレース=500から1000整数;短いRRトレース=0から40整数)について同一である。
【0060】
∀5整数(1msec=1整数)よりも大きいと判断されたノイズ範囲をもつそれらの被験者には、PD2iを計算する前にノイズ考慮アルゴリズム(NCA)を行った。このようにして、NCAを、例えば、図4B、4C、および4Fに示されている対照被験者、および図4Kおよび4Lに示されているAD被験者に適用した。
【0061】
各RRiに対応するPD2i値が、0から3次元(自由度)のスケールで表示されている。AD被験者については、図4G〜4Lに表されているように、3.0よりも小さなPD2i値が数多くある。表4は、すべての被験者について、平均して83%のPD2i値が3.0を下回ることを示している。
【0062】
臨床データに関する予測可能性の結果は、データのノイズ内容を考慮しないと統計的に有意とはいえなかっただろう。上記した適用場面のすべてで実際に使用されたNCAは、1)ノイズの動的範囲が10整数という区間を外れるか否か観察すること、および、もし外れていたら、2)過剰なノイズを取り除くのに足りる程度RR間隔の振幅を低減することを含む。約3分の1の被験者でNCAが必要とされた。各データポイントを、ノイズの動的範囲が10整数より小さくなるまで低減するだけの値で掛け算するのではなく、乗数を0.5にした(すなわち、12ビットのデータの全ビットを取り除いた)。
【0063】
NCAの適用はすべて、データの結果に対して盲検の状態で行った(NCAを用いたPD2i解析が完了してから、不整脈による死亡を確定した)。この処理で、実験者がバイアスをかける可能性が排除されるため、統計的な解析のための設計に必要とされる。
【0064】
例示的な実施態様によると、上記したようなノイズ考慮アルゴリズムは、ソフトウェアで実行することができる。ノイズ区間の決定は、例えば、コンピュータモニター上に表示されたデータに基づいて目視により行なうことができる。データは、例えば、表示されたセグメントの平均付近を中心とする∀40整数のフルスケールなど、固定倍率で表示することができる。数値が±5の整数範囲を外れている場合には、ユーザは、所定の値でデータ系列を割る決断をすることができるが、この割り算を自動的に行なわせることもできる。
【0065】
図5Aは、ECGデータに適用されるNCAの論理に関する例示的フローチャートを図示したものである。例示的な実施態様によると、被験者から得られたECGを、通常の増幅器で収集し、デジタル化してから、解析のために入力データとしてコンピュータに入力される。まず、ECGデータからRRおよびQTの間隔を作成し;次に、PD2iソフトウェア(PD2−02.EXE)およびQTvsRR−QTソフトウェア(QT.EXE)によって解析する。
【0066】
例示的な実施態様によれば、NCAは、2つのポイントにおいて、例えば、PD2iソフトウェアおよびQTvsRR−QTソフトウェアの実行の一部として、また、PD2iソフトウェアおよびQTvsRR−QTソフトウェアを実行した後に適用される。例えば、NCAを、PD2iとQTvsRR−QTのソフトウェアを実行している間に適用して、log c(n,r,nref*)対log rの勾配が0.5より小さく、ゼロより大きい場合には0に設定されるようにすることができる。また、PD2iとQTvsRR−QTのソフトウェアを実行した後にNCAを適用して、低レベルのノイズが所定の区間を外れた場合、例えば、−5と5の間の区間の外にある場合には、PD2iデータ系列を所定の整数で割ることができる。そのような割り算が行われる場合には、割り算されたデータに対して、PD2iとQTvsRR−QTのソフトウェアを再実行することによって、PD2iの計算を繰り返す。
【0067】
PD2iとQTvsRR−QTのソフトウェアの実行が終了した後に、ポイント相関次元を時間の関数として計算して表示する。また、QTvsRR−QTのプロットも作成して表示する。そして、危険度を評価するために画像レポートが作成される。デジタル化されたECGは、保存のためオフロードすることができる。
【0068】
上記の説明は、致命的な心臓不整脈の前兆としてECGデータから作成された非定常的な心拍間隔において、決定論的な低次元偏位を検出する検出/予測法を改良することに非常に関係がある。また、上記説明は、その前に観察された排除区域において、致命的な心臓不整脈の前兆として、QTvsRR−QTを連結プロットした(jointly−plotted)心拍の部分間隔の動態の検出を向上させることにも関係する。しかしながら、本発明は、例えば脳電図(EEG)のデータを用いる別の生体異常の検出/予測法を改良することにも応用することができる。例えば、NCAは、異常な認識状態の指標として、非定常的なEEGデータから作成された決定論的次元再構築における持続的な変化の検出を向上させるために応用できる可能性がある。また、NCAを応用して、初期の発作性てんかん行動の前兆として、EEG電位の決定論的次元変化の中で、拡大した分散の検出を向上させることができるかもしれない。
【0069】
図5Bは、神経の解析を受けているてんかん患者または正常な被験者にNCAアルゴリズムを実施する例を示している。被験者から得られたEEGデータを、通常の増幅器で作成し、デジタル化してから、解析のために入力データとしてコンピュータに入力される。次に、PD2iソフトウェア(PD2−02.exe)を実行して、勾配を必要に応じて、例えば0などに設定する。次に、低レベルのノイズが所定の区間から外れていたら、PD2iデータ系列を所定の整数で割り、また、PD2iとQTvsRR−QTのソフトウェアを再実行することによって、割られたデータに対してPD2iの計算を繰り返す。
【0070】
次に、ポイント相関次元をプロットしてから、てんかん病巣の位置および/または認識状態の変化を評価するために画像レポートを作成する。
【0071】
NCAは、例えば、マイクロコンピュータ上で実行できる。別々の要素として示されているが、図5Aおよび5Bに示されている一つまたは全部の要素をCPUで実行することができる。
【0072】
上記説明の焦点は、主に、ECGデータとEEGデータを査定することにあるが、本発明を他で同じように応用することが可能であると理解できよう。電気生理学的シグナルの発生源はさまざまなであり、画像レポートの構成は、医学的および/または生理学的な対象に特異であろう。すべての解析法は、PD2iアルゴリズムおよびNCAをソフトウェアという形で使用して、他の確認分析を伴うことも可能である。
【0073】
また、本発明は脳障害の発症を検出または予測する方法であって、以下のステップ:データ系列を作成するために脳障害と相関する生物学的データに関連する適用パラメータのセットを含むデータ処理ルーチンを使用して、入力された生物学的または物理的なデータ解析すること、該データ系列の勾配が所定の値より小さいかどうか判定すること;および、勾配が所定の値より小さければ、勾配を所定の数字に設定すること、および該データ系列を使用して、脳障害の発症を検出または予測することを含む方法を提供する。
【0074】
図6は、例示的な実施態様にしたがって、ソフトウェアとしてNCAを実施できる処理を具体的に示すフローチャートである。このフローは、データの収集から始まる。このデータから、i−ベクトルおよびj−ベクトルを作成して、互いからサブトラクトする(i−j DIFF)。これらのベクトル差長を、それらの数値(X、1から1000)に従って、使用される埋め込み次元(m、1から12)でMXARAYの中にエントリする。このエントリは、MXARAYの各位置におけるカウンタの増分として作成される。
【0075】
ベクトル差長の作成が完了したら、次に、カウンタ番号(3、7、9、8、2、6、7、4・・・)を用いて各埋め込み次元に対する相関積分を行なうが、これは、各m.sub.1について、Xの関数としての累積ヒストグラムを作成し、次に、それらの累積値(例えば、PLOTlogC(n,r)対logr)のlog−logプロットを作成して行なわれる。この累積ヒストグラムは、各埋め込み次元(m)に対する相関積分にプロットされたlog−logデータとなる。
【0076】
そして、相関積分を5つの評価基準についてテストする。まず、各mにおける勾配が0.5未満であるか否を判定する。勾配は0.5未満であれば、0と設定する。次に、線形評価基準(LC)の中にある最も長い線形スケーリング領域を見つける。これは、LCによって各相関積分を調べて、セットパラメータの限界の中に含まれる2次導関数の最も長いセグメントを見つけることによって行なわれ(LC=0.30は、平均勾配の±15%の偏差に含まれることを意味する)、この反復LCテストは、「フロッピーテール」(すなわち、有限なデータ長のために不安定な最小log−r領域)を超える範囲を見つけて、LC基準を超えるまで相関積分を増加させる(相関積分の一番上の太字体の部分)。
【0077】
次に、プロット長の評価基準(PL)の中にセグメントが含まれるか否か判定される。含まれるとすると、次に、相関積分のスケーリング領域がPL評価基準によってリセットされ;この値は、相関積分の最小のデータポイントからその評価基準値(例えば、15%、相関積分の最上層から2番目の層へ)に設定される。この領域の上下の限界を観察すると、それらが、最小スケーリング(MS)評価基準に必要とされるデータポイントの数、例えば10個を少なくとも持っているか否かが分かる。すべての相関積分(m−1からm=12)の選択された領域をプロットして、CCによって調べて、高い方の埋め込み次元(例えば、m=9からm=12)で収束が起きるか否か、すなわち、選択された領域が、平均値付近の標準偏差が、CCによって設定された限界内に存在する同じ勾配を本質的に有するか否かを確認する(すなわち、CC=0.40は、平均値の±20%の範囲内に平均値付近の偏差があることを意味する)。CC評価基準に合格すると、その平均勾配と標準偏差がファイルするために保存されて、例えば、表示される。
【0078】
最後に、動的範囲が−5から+5の区間を外れているか否かをテストするために、ユーザによって低レベルノイズが調べられる。外れている場合には、データファイルからノイズビットを取り除き(すなわち、各データポイント値を2で割り)、次に、変更されたファイルを再計算し、表示し、保存する。
【0079】
フロー内の初期の評価基準(LC、PL、MS)のどれかで失敗すると、プログラムは終了して、PD2i参照ベクトルを次のデータポイントに移して、また最初から始動する。失敗がCCで起こった場合には、後になってCCを変更することが望ましくなる場合かもしれないので、終了せずに、平均値と標準偏差が保存される。すなわち、CCは、後の画像ルーチンでPD2i(すなわち、m=9からm=12の平均勾配)をプロットすべきか否かを決定するフィルターである。
【実施例】
【0080】
本出願人は、HRVにおける自由度について研究を行い、心臓移植をうけた人(4)では、心拍変動が非常に規則的でほとんど全く変化しないことを発見した。これらの移植レシピエントにおけるHRVの非線形解析は、1.0という自由度だけを示した。これに対して、正常な被験者では、この変位が豊かで、3から5という自由度をもっていた。麻痺させられた心臓におけるこの結果は、まず第一にHRVを生み出すのは、脳によって計画された(brain−projected)心臓に対する神経作用であることを示唆している。
【0081】
心拍の動力学の非線形的分析は、その基本となる力学を高感度に探知するものである。それは、他のHRV測定法では検出できない、致死性の不整脈に対する脆弱性を明確に検出することができる(5)。また、内在心臓神経系だけが心拍間隔を調節するのに利用できるとき(6、7)、または前頭葉に関連する高度な認識系が関係するとき(8)には、調節ニューロンの変化も検出できる。
【0082】
(HRVおよび認識機能)
高齢者におけるHRVと認識機能および日常生活能力の活性との関連性は明確ではない(9)。HRVの全パワー(すなわち、パワー・スペクトルのLF、LF/HF比)は、正常な高齢被験者よりも高齢被験者の痴呆グループの方が有意に低いことが分かっていた(9)。したがって、HRVの減少に関係するのは年齢そのものではない。むしろ、この結果は、心臓に向けられた高度な神経活動の欠如こそが、HRVを減少させる原因であることを明らかにした脱神経研究を確認するものである。
【0083】
進行性の全体的な神経的課題のどの時点で、HRVが実際に変化し始めるかを知ることは重要である。変動の振幅または振動力の変化は、下行性神経離断に相当する全神経系関与を伴うが、後期の結果であって医学的にはそれほど役に立たない。おそらく、自由度の変化によって捕捉されるプロセスにおいて、より微妙な変化が初期に起きる。BSEおよび/またはアルツハイマー病の開始段階におけるように、初期の全体的な問題が、全ニューロンのいくつかに影響を与えるため、HRVの自由度の数が有意に減少するという可能性が非常に高い。その場合、HRVのこの非線形的測法は、病気のプロセスにおいて10年後にもたらされる結果の前触れとなるかもしれない。
【0084】
ある高齢の被験者(SGW)が研究された。この被験者は健康であり(1週間に3回テニスをした)、認知障害はなかった。この被験者は、昔の名前(例えば、様々な出版物の作者など)を思い出すのにいくらか困難はあったものの、他の短期または長期の記憶喪失の発症も痴呆の発症も確実になかった。しかしながら、この被験者のHRVは、当時で2.0次元から1.0次元の範囲の値まで大きく低下していた。非線形的次元(自由度)のこのような低下は、その値が、他のより若い正常な被験者の値と同じ範囲の5から3である適合年齢の対照には当てはまらなかった。SGWと適合年齢の正常な被験者との間における平均PD2i値の差は、統計的な有意性が非常に高かった(t−検定、p<0.001)。この10年間にわたる研究で最も重要な観察結果は、10年後に、この具体的な被験者(SGW)が重篤な短期記憶喪失を発症して、重篤な痴呆を示したということであった(図7)。
【0085】
HRVの自由度(次元)の持続的減少は、来るべき神経性痴呆の長期的予測因子であると考えられる。これと同じメカニズムが、初期の段階でウシ海綿状脳症をウシにおいて検出すること、そして発病するまでにやはり10年かかるヒトにおける同様のプリオン病(ヤコブ−クロイツフェルト病)について、似ているかもしれない。
【0086】
以前の研究でHRVを評価するために用いられたパワースペクトル・アルゴリズムは、線形的な確率論的モデルであって、呼吸調節における変化が、平均値付近に無作為に分布しており、かつ、定常的なデータ系列であることを必要とするモデルを前提としている。どのような行動も呼吸を妨げて、データに非線形的で非定常的な変化を生じさせるため、これらの前提はいずれも、そのような生理学的なデータ系列において妥当ではない。
【0087】
出願人は、非線形型アルゴリズムであるポイント相関次元(PD2i)は、非線形の決定論的モデルに基づいており、非定常的データという問題に取り組むものであることを示した。それは、非定常的データ系列における変動の自由度の変化を正確に追跡することができる(10)。以前の研究で使用されたパワー・スペクトル(1)はデータの定常性を必要とするので、理性的に行動する動物に存在する可能性は低かった。
【0088】
高リスク心臓病患者において、臨床的な心拍変動研究にPD2iアルゴリズムを適用すると、パワー・スペクトルなど、当技術分野において一般的に使用されている他のアルゴリズム(11,12)と比べて、PD2iアルゴリズムは、不整脈による死亡という転帰の予測性において著しく優れていた。
【0089】
本発明は、ヒトにおける心拍変動のPD2iでの減少が、脳痴呆の症例において進行性の脳障害を予測することを明らかにする。この同じ非線形の心拍測定法は、同様に動物、特にウシ海綿状脳症に感染したウシにおける進行性の脳疾患を予測することができる。心拍の脳による調節が、PD2の高次元をもたらしていることが示されている(4)。さらに、脳炎が進行するにつれて、PD2iの次元減少と量的な関係を持ちうることが開示されている(図8)。同じ予測法を、ヒトのプリオン病(ヤコブ−クロイツフェルト病)、およびアルツハイマー病など、さまざまな痴呆(心臓血管性、外傷性、遺伝性)などであるが、これらに限定されるものではない、ヒトにおける他の広範な脳障害の初期段階における検出に用いることができる。この技術は、ウシ海綿状脳症、ヒツジスクレイピー、ヘラジカ消耗性疾患などであるが、これらに限定されるものではない、動物における類似または同等の病気にも利用することができる。
【0090】
心拍間隔の変動が、進行性の全体疾患の初期に対する生理的病理をコードしている理由は、心拍を調節するために競合するさまざまな求心−遠心ループの「協同性」(10)を測定するからである。これらの求心−遠心ループは、全体が心臓に含まれる内在神経系(6、7)から、前頭葉(8)を通って輪になる内在神経系まで到達する。したがって、この技術は、心拍の自律神経による調節におけるすべてのレベルの中枢神経系および末梢神経系のサンプリングを行なう。
【0091】
HRVにおける変化を量的に記述することにおける、PD2iアルゴリズムに特有の正確さは、それが、非線形性の決定論的モデルに基づいていて、データの非定常性の問題を処理する結果である。
【0092】
本発明を具体的な実施態様に関して説明してきたが、発明の修正および変更は、本発明の範囲を逸脱するものではないと解することができる。例えば、NCAについては、PD2iデータ系列にそれを応用するところで説明されているが、NCAも、他のタイプのアルゴリズム、例えば、D2、D2i、またはその他の予測アルゴリズムにおいてノイズを低減させる際に役立ちうると解すべきである。
【0093】
当然ながら、以上の説明および添付した図面は例示にすぎない。発明の範囲と精神から離れることなく、さまざまな変更を想定できる。
【0094】
上記説明は、もっぱら例示として意図されており、いかなる意味においても、本発明を制限するものではない。
【0095】
この出願の全範囲でさまざまな刊行物が引用されている。これら刊行物の開示内容は、その全体が、最新の技術をより完全に説明するために参照することによって本明細書に組み込まれる。また、開示された刊行物は、それらに含まれる資料であって、引用文献が依拠される文で検討されている資料については、個別的および特異的に本明細書に組み込まれる。
【0096】
【表5】
【特許請求の範囲】
【請求項1】
明細書中に記載の発明。
【請求項1】
明細書中に記載の発明。
【図1A】


【図1B】
【図2】
【図3】
【図4】
【図5A】

【図5B】
【図6A】
【図6B】
【図6C】
【図6D】
【図7】
【図8】
【図1B】
【図2】
【図3】
【図4】
【図5A】
【図5B】
【図6A】
【図6B】
【図6C】
【図6D】
【図7】
【図8】
【公開番号】特開2010−264264(P2010−264264A)
【公開日】平成22年11月25日(2010.11.25)
【国際特許分類】
【出願番号】特願2010−152544(P2010−152544)
【出願日】平成22年7月2日(2010.7.2)
【分割の表示】特願2006−503131(P2006−503131)の分割
【原出願日】平成16年1月29日(2004.1.29)
【出願人】(504299586)ヴァイコー テクノロジーズ, インコーポレイテッド (3)
【Fターム(参考)】
【公開日】平成22年11月25日(2010.11.25)
【国際特許分類】
【出願日】平成22年7月2日(2010.7.2)
【分割の表示】特願2006−503131(P2006−503131)の分割
【原出願日】平成16年1月29日(2004.1.29)
【出願人】(504299586)ヴァイコー テクノロジーズ, インコーポレイテッド (3)
【Fターム(参考)】
[ Back to top ]