
生体認証方法、及び、生体認証に用いるクライアント端末、認証サーバ
【課題】
生体情報を入力しユーザIDを出力するような生体認証システム(1:N認証システム)において、サーバに対し生体情報を秘匿したまま照合するキャンセラブル生体認証を実現する際に、サーバ側での1:N照合を高速化させる。
【解決手段】
登録時は、ダミー特徴量に対し特徴量xの類似検索を行い、最近傍ダミー特徴量D[i*]に対応する変換パラメータR[i*]を用いて、特徴量xを変換する(変換特徴量T)。変換特徴量TとグループID=i*をサーバへ送信し、サーバは該当グループのDBへ変換特徴量Tを登録する。認証時は、登録時と同様に、特徴量yの類似検索を行い最近傍ダミー特徴量D[i*]し、対応する変換パラメータR[i*]を用いて特徴量yを変換する(変換特徴量V)。変換特徴量VとグループID=i*をサーバへ送信する。サーバは、該当グループのDB内のテンプレートと変換特徴量Vとの間で1:1照合を実行する。
生体情報を入力しユーザIDを出力するような生体認証システム(1:N認証システム)において、サーバに対し生体情報を秘匿したまま照合するキャンセラブル生体認証を実現する際に、サーバ側での1:N照合を高速化させる。
【解決手段】
登録時は、ダミー特徴量に対し特徴量xの類似検索を行い、最近傍ダミー特徴量D[i*]に対応する変換パラメータR[i*]を用いて、特徴量xを変換する(変換特徴量T)。変換特徴量TとグループID=i*をサーバへ送信し、サーバは該当グループのDBへ変換特徴量Tを登録する。認証時は、登録時と同様に、特徴量yの類似検索を行い最近傍ダミー特徴量D[i*]し、対応する変換パラメータR[i*]を用いて特徴量yを変換する(変換特徴量V)。変換特徴量VとグループID=i*をサーバへ送信する。サーバは、該当グループのDB内のテンプレートと変換特徴量Vとの間で1:1照合を実行する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、個人の生体情報を用いて本人を認証する生体認証方法およびシステムに関する。
【背景技術】
【0002】
生体情報を用いた個人認証システムは、初期の登録時に個人の生体情報を取得し、特徴量と呼ばれる情報を抽出して登録する。この登録される特徴量をテンプレートという。認証時には、再び個人から生体情報を取得して特徴量を抽出し、先に登録されたテンプレートと照合して本人か否かを確認する。
【0003】
クライアント装置(クライアントという)とサーバ装置(サーバという)がネットワークを介して接続されたシステムにおいて、サーバがクライアント側にいるユーザを生体認証する場合、典型的にはサーバがテンプレートを保持する。クライアントは認証時にユーザの生体情報を取得し、特徴量を抽出してサーバへ送信し、サーバは特徴量をテンプレートと照合して本人か否かを確認する。
【0004】
しかし、テンプレートは個人を特定することのできる情報であるため、個人情報として厳密な管理が必要とされ、高い管理コストが必要となる。また、例え厳密に管理されていても、プライバシの観点からテンプレートを登録することに心理的な抵抗を感じる人も多い。また、生体情報は一生涯変わることがなく、パスワードや暗号鍵のように容易に変更することができない。他の生体情報に取り替えることが考えられるが、一人の個人が持つ一種類の生体情報の数には限りがある(例えば指紋は指の数)ため、根本的な解決策とはならない。このため、仮にテンプレートが漏洩して偽造の危険が生じた場合、これ以降その生体認証を安全に使用することができなくなるという問題がある。さらに、異なるシステムに対して同じ生体情報を登録している場合には他のシステムまで脅威に晒されることになる。
【0005】
そこで、生体情報の登録時に特徴量を一定の関数(一種の暗号化)とクライアントが持つ秘密のパラメータ(一種の暗号鍵)で変換し、元の情報を秘匿した状態でテンプレートとしてサーバに保管し、認証時にクライアントが新たに抽出した生体情報の特徴量を、同じ関数とパラメータで変換してサーバへ送信し、サーバは受信した特徴量とテンプレートを変換された状態のまま照合する方法(キャンセラブル生体認証という)が,非特許文献1で提案されている。
【0006】
この方法によれば、クライアントが変換パラメータを秘密に保持することで、サーバは認証時においても元の特徴量を知ることができず、個人のプライバシが保護される。
またテンプレートが漏洩した場合にも、変換パラメータを変更して再度テンプレートを作成、登録することで、安全性を保つことができる。更に異なるシステムに対して同じ生体情報を用いる場合に、各々異なるパラメータで変換したテンプレートを登録することで、一つのテンプレートが漏洩しても他のシステムの安全性が低下することを防止することができる。
【先行技術文献】
【非特許文献】
【0007】
【非特許文献1】N.K.Ratha, J.H.Connell, R.M.Bolle, ‘Enhancing security and privacy in biometric−based authentication systems.’ IBM System Journal 40(3) (2001)
【発明の概要】
【発明が解決しようとする課題】
【0008】
上記非特許文献1によれば、登録時、クライアントはユーザの生体から抽出した特徴量画像xを変換パラメータθを用いて変換し,変換特徴量Tを作成し、サーバに登録する。変換パラメータθはICカードなどに保存してユーザが秘密裏に管理する。
【0009】
認証時にはクライアントがあらたにユーザの生体から抽出した特徴量画像yを、ユーザのICカードから読み出した変換パラメータθを用いて変換し,変換特徴量Vを作成し、サーバに送信する。サーバはTとVの類似度を計算し、一致/不一致を判定する。
【0010】
このように秘密の変換パラメータθによってx、yを変換して求めたT,Vをサーバに送信することで、サーバに対してx、yを秘匿したまま、サーバが照合処理を実行可能とする。
【0011】
ところで,(ユーザIDを入力せずに)生体情報を入力しユーザIDを出力するようなシステム(以下,1:N認証と呼ぶ)にキャンセラブル生体認証を適用する場合,単純には,サーバのDB内にある全ての変換特徴量Tと照合を行う必要がある。しかし,大規模なDBの場合一般に,全てのTと照合するには処理時間が長くなり,実用的でない問題がある。
【課題を解決するための手段】
【0012】
本発明は、キャンセラブル生体認証を1:N認証システムに適用するに際し,サーバ側での1:N照合に要する時間を短縮し,処理を高速化させる生体認証技術を提供する。
【0013】
本発明は以上の課題を解決するため、クライアントとサーバとを含むシステムにおいて、個人のIDを用いずに、生体情報を用いて個人を認証する生体認証方法における生体情報の登録方法において、類似する特徴量でグループを構成する場合の、グループの代表となるダミー特徴量を予め設定しておき、クライアントにおいて、登録対象となる特徴量が属すべきグループを、ダミー特徴量に基づき特定する概略処理を行い、サーバにおいて、上記特定したグループに、上記登録用の変換特徴量を登録する処理を行う、ことを特徴とする。
【0014】
また、本発明は、クライアントとサーバとを含むシステムにおいて、個人のIDを用いずに、生体情報を用いて個人を認証する生体認証方法において、類似する特徴量でグループを構成し、グループの代表となるダミー特徴量を予め設定しておき、クライアントにおいて、認証対象となる特徴量が属するグループを、上記ダミー特徴量に基づき特定する概略処理を行い、サーバにおいて、特定したグループを対象に、類似するいずれか一つの特徴量を特定する詳細処理を行う、ことを特徴とする。
【0015】
さらに、上記特徴量は、個人から抽出した生体情報を所定のパラメータで変換した変換特徴量であることを特徴とする。
【0016】
本発明は、より具体的には、クライアント端末は、個人の生体情報から抽出した認証用特徴量を変換パラメータで変換した認証用変換特徴量を認証サーバに送信し、認証サーバは、複数の登録用変換特徴量と個人を特定する情報と対応付けて格納するデータベースを備え、データベースを検索して、認証用変換特徴量に最も類似する登録用変換特徴量に対応付けられた個人を特定する生体認証方法において、
クライアント端末は、予め、生体情報の登録用特徴量と認証用特徴量とを複数のグループのいずれかに分類するための基準とするダミー特徴量と、グループを識別するためのインデックスと、各々のダミー特徴量に対応した変換パラメータと、をクライアント側データベースに記憶し、
認証サーバは、変換パラメータにより登録用特徴量から変換された登録用変換特徴量と、登録用特徴量の抽出元である個人を特定する情報と、を、インデックスに基づき、複数のグループのいずれかに分類して記憶するための登録用変換特徴量データベースを備え、
生体情報の登録時の処理として、
クライアント端末は、
個人から取得した生体情報から登録用特徴量を抽出するステップと、
クライアント側データベースを検索して、登録用特徴量に類似した一つの登録用ダミー特徴量を特定するステップと、
特定した登録用ダミー特徴量に対応した変換パラメータを用いて、登録用特徴量を変換して、登録用変換特徴量を作成するステップと、
登録用変換特徴量と、特定した登録用ダミー特徴量のグループを識別する登録用インデックスと、登録用特徴量の抽出元である個人を特定する情報と、を認証サーバへと送信するステップと、を備え、
認証サーバは、
登録用変換特徴量データベースの登録用インデックスに対応したグループに、受信した登録用変換特徴量と、個人を特定する情報と、を対応付けて登録するステップと、を備えることを特徴とする。
【0017】
また、本発明の認証時の処理として、
クライアント端末は、
個人から取得した生体情報から認証用特徴量を抽出するステップと、
クライアント側データベースを検索して、認証用特徴量に類似した一つの認証用ダミー特徴量を特定するステップと、
特定した認証用ダミー特徴量に対応した変換パラメータを用いて、認証用特徴量を変換して、認証用変換特徴量を作成するステップと、
認証用変換特徴量と、特定した認証用ダミー特徴量のグループを識別する認証用インデックスと、を、認証サーバへと送信するステップと、を備え、
認証サーバは、
登録用変換特徴量データベースの認証用インデックスに対応したグループを検索して、認証用変換特徴量に最も類似した登録用変換特徴量を特定するステップと、
特定した登録用変換特徴量に対応づけられた個人を特定するステップと、
特定した個人に関わる情報をクライアント端末に送信するステップと、を備えることを特徴とする。
【0018】
上記態様によれば、生体情報を入力してユーザIDを出力する1:N生体認証システムにおいて、サーバ側での1:N照合に要する時間を短縮し,処理を高速化させることができる。
【発明の効果】
【0019】
本発明によれば、ユーザの生体情報を秘匿したまま高速認証が可能な、1:N生体認証システムを実現可能になる。
【図面の簡単な説明】
【0020】
【図1】第一の実施形態の機能構成を例示するブロック図である。
【図2】実施形態におけるダミー特徴量作成処理を例示する流れ図である。
【図3】実施形態におけるダミー特徴量のハッシュテーブル差作成処理を例示する流れ図である。
【図4】実施形態における登録処理を例示する流れ図である。
【図5】実施形態における1:N認証処理を例示する流れ図である。
【図6】実施形態におけるハードウェア構成を例示するブロック図である。
【発明を実施するための形態】
【0021】
以下、図面を参照して、本発明の実施形態について説明する。
【0022】
本実施形態では、キャンセラブル生体認証を1:N認証に適用した,1:Nキャンセラブル生体認証システムを例にあげて説明する。
【0023】
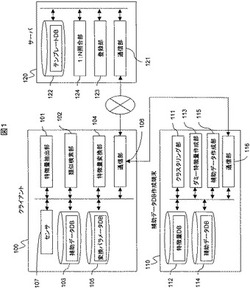
図1に、1:Nキャンセラブル生体認証システムのシステム構成を示す。
【0024】
本実施例の1:Nキャンセラブル生体認証システムは、登録・認証時の生体情報取得、特徴量抽出、ダミー特徴量との類似検索,および特徴量の変換を行うクライアント端末(以下、クライアント)100と、ダミー特徴量を含む補助データDBの作成などを行う補助データDB作成端末(以下、補助データDB作成端末)110と、テンプレートの保管と1:N照合を行う認証サーバ(以下、サーバ)120とが、インターネットやイントラネットなどのネットワークを介し接続して構成される。
【0025】
クライアント100は、ユーザ自身か又は信頼できる第三者によって管理され、生体情報(例えば指紋や静脈など)を取得するセンサ107を有する。例えば小売店舗でクレジット決済を行う場合、クライアント100は店舗が管理するクレジット端末であり、サーバ120はクレジット会社が管理するサーバマシンとするような構成も可能である。
【0026】
クライアント100は、センサ107が取得した生体情報から特徴量を抽出する特徴量抽出部101と、複数のダミー特徴量が予め格納された補助データDB103と,補助データDB103内のダミー特徴量との類似検索を行う類似検索部102と,ダミー特徴量おのおのに対応する変換パラメータを格納した変換パラメータDB105と,登録用または認証用の特徴量を変換して、登録用変換特徴量(以下、テンプレートという)または認証用変換特徴量を作成する特徴量変換部104と、サーバとの通信を行う通信部106から構成される。
【0027】
ここで生体情報とは、例えば指紋画像や静脈画像、虹彩画像といったデータであり、特徴量とは、例えば指紋や静脈の画像を強調処理して2値化した画像や、あるいは虹彩画像から作成するアイリスコード(虹彩コード)と呼ばれるビット列などを含む。2つの特徴量の間の類似度は、たとえば相互相関により計算されるものなどがある。相互相関に基づいて類似度を計算する照合アルゴリズムに対しては、2つの特徴量に特殊な変換を施して
元の特徴量を秘匿したまま、それらを元に戻すことなく類似度を計算するアルゴリズム(相関不変ランダムフィルタリング)が知られている。なお相関不変ランダムフィルタリングの詳細については、特開2007−293807号公報(文献1という)や比良田 他,”画像マッチングに適用可能なキャンセラブル生体認証方式の脆弱性分析と安全性向上”, SCIS2007予稿集CD−ROM(文献2という)に開示されている。
【0028】
補助データDB作成端末110は、ダミー特徴量を作成する元となる特徴量のDBである特徴量DB112、特徴量DB内の特徴量の集合に対してクラスタリングを行うクラスタリング部111、クラスタリング結果を利用してダミー特徴量を作成するダミー特徴量作成部113、クライアントにてダミー特徴量との類似検索に用いる補助データを作成する補助データ作成部115、補助データを格納する補助データDB114、クライアント100と通信を行う通信部116とから構成される。
【0029】
サーバ120は、クライアント100と通信を行う通信部121、テンプレートを管理するデータベース(テンプレートDB。以下、データベースをDBと記す)122、クライアントから受信したテンプレートをテンプレートDB122に登録する登録部123、クライアントから受信した変換特徴量とテンプレートDB122内の複数のテンプレートとの照合を行う1:N照合部124とから構成される。
【0030】
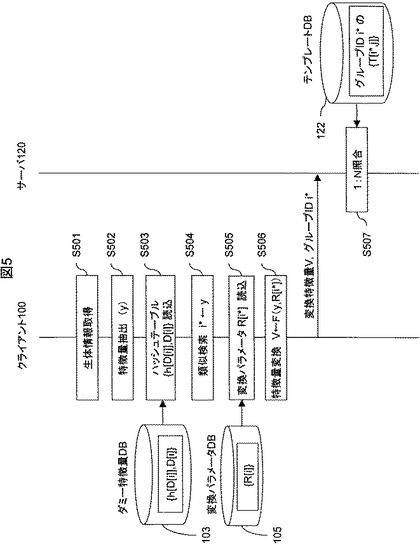
図6に、本実施形態におけるクライアント100、サーバ120のハードウェア構成を示す。これらは図のようにCPU600、メモリ601、HDD602、入力装置603、出力装置604、通信装置605とから構成することができる。
【0031】
クライアント100、補助データDB作成端末110、サーバ120の上記機能構成や、以下に説明する各処理は、それぞれのCPU600がメモリ601またはHDD602に格納されたプログラムを実行することにより、具現化される。また、各プログラムは、予めそれぞれのメモリ601、HDD602に格納されていても良いし、必要に応じて、当該装置が利用可能な、着脱可能な記憶媒体や、通信媒体である通信ネットワークまたは通信ネットワーク上を伝搬する搬送波やデジタル信号を介して、他の装置から導入されても良い。
【0032】
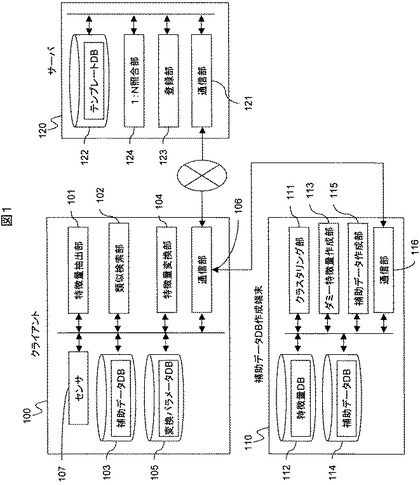
次に、図2を用いて、本実施形態におけるダミー特徴量の作成処理フローを説明する。
ここでは一例として、Jiawei Han and Micheline Kamber, “Data Mining”, pp.348−353, Morgan Kaufmann Publishers, 2001(文献3という)記載のセントロイドを用いた方法を示す。これ以外の方法でダミー特徴量を生成してもよい。
【0033】
事前にシステム開発の段階で,開発者など有志から生体情報を収集しておき,特徴量の集合{x[i]}を作成しておく。特徴量DB112に格納しておく。ここで例えば生体情報が指静脈画像の場合、特徴量抽出の方法は、N.Miura, A.Nagasaka, T.Miyatake, “Feature extraction of nger−vein patterns based on repeated line tracking and its application to personal identication.” Machine Vision and Applications 15(4) (2004) 194−203(文献4という)に記載の方法などを用いることができる。
【0034】
クラスタリング部111は,特徴量の集合{x[i]}を読込みクラスタリングを行う(S201)。クラスタリングによって,類似した特徴量同士がグループ化される。クラスタリングの詳細は文献3を参照のこと。特徴量のグループの集合を{G[j]}とする。G[j]には,特徴量x[j,k]が含まれる。ここで,iは特徴量DB内の特徴量のインデックス,jはグループのインデックス,kはグループjに含まれる特徴量のインデックス。
【0035】
クラスタリングの具体的な方法としては例えば, k−means 法が利用できる。ここでk−means 法の概要を説明する。k−means 法は,非階層的クラスタ分析の代表的手法であり,典型的にはユークリッド空間を仮定する。この方法では,クラスタ数をあらかじめ指定し(ここではk),対象をk 個のクラスに分割する。非類似度としてユークリッド距離の2乗をとり,クラスタの中心と各対象との間の非類似度を分類の基準とする。k−means法はクラスタ数を指定できるため,各クラスタ間での対象数の偏りを軽減できるメリットがある。k−means 法のアルゴリズムは以下のとおり。
step1. [初期値]k 個のクラスタ中心あるいは初期分割をランダムに与える。
step2. [割り当て] 各対象を最も近いクラスタ中心に割り当てる。
step3. [中心の更新] すべての対象の割り当てが一つ前のステップと変化が無ければ終了。そうでなければ,各クラスタの重心を新しい中心としてstep2 に戻る。
【0036】
ここで,クラスタの中心の各座標は,そのクラスタに含まれる対象の座標の重みつき平均で表され,またクラスタの重心の各座標は重みつきの無い平均で表される。
【0037】
ダミー特徴量作成部113は,グループG[j]ごとのセントロイドD[j]を作成する(S202)。セントロイドとは,グループに含まれる特徴量の重心となる特徴量のことである。詳細は文献3を参照のこと。作成したセントロイドの集合{D[j]}をダミー特徴量の集合{D[j]}として、補助データDB114に書き出す(S203)。
【0038】
次に,本実施形態における変換パラメータDB105の作成方法を説明する。ここで変換パラメータは,ダミー特徴量D[i]それぞれに対し,個別に作成し対応づける。ダミー特徴量D[i]に対応する変換パラメータをR[i]とする。変換パラメータR[i]の作成方法であるが,たとえば指静脈画像の場合,文献1や文献2に記載の方法を用いることができる。具体的には,各画素の値が乱数となるような2次元のランダムフィルタを作成すればよい。乱数は,疑似乱数生成器などを用いて発生させる。このランダムフィルタを変換パラメータR[i]とする。
【0039】
本実施形態におけるダミー特徴量との類似検索方法は,ここでは一例として, P. Indyk and R. Motwani,”Approximate nearest neighbors: towards removing the curse of dimensionality”, Proc. of the Symposium on Theory of Computing, 1998.(文献5という)に記載のLocality−Sensitive Hashing(以下,LSHと呼ぶ)を用いるものとする。これ以外の方法で類似検索をしても良い。たとえば、Vidal Ruiz, “An algorithm for finding nearest neighbours in (approximately) constant average time,” Pattern Recognition Letters pp.145−157, 1986.(文献6という)記載のApproximating and Eliminating Search Algorithm(以下、AESAと呼ぶ)などが利用できる。
【0040】
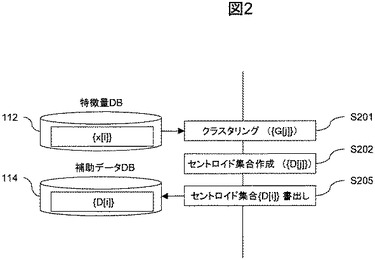
LSHでは,ハッシュテーブルが必要となる。図3を用いて,ハッシュテーブル作成方法を説明する。
補助データ作成部115は、補助データDB114に格納されているダミー特徴量集合{D[i]}を読み込む(S301)。
【0041】
補助データ作成部115は、ハッシュテーブルを作成する(S302)。ここでは一例として、M.Datar, N.Immorlica,P.Indyk, and V.Mirrokni,”Locality−sensitive hashing scheme based on p−stable distributions.”, Proc. of the ACM Symposium on Computational Geometry, 2004.(文献7という)記載の方法を用いるものとする。これ以外の方法でも良い。文献7では,特徴量ベクトルvに対し,以下の式でハッシュを作成する。
【0042】
【数1】

【0043】
なお、LSHで用いるハッシュ関数は、局所性に鋭敏なハッシュ関数と呼ばれ、以下のように定義される(以下,局所鋭敏ハッシュ関数と呼ぶ)。対象とする元の空間をS、生成されるハッシュ値の空間をU とする。ハッシュ関数集合H = { h : S →U } が次を満たすとき,局所鋭敏ハッシュ関数集合と定義される:
(a) もし点v がq から半径r1 以内に存在する場合,v とq のハッシュ値が衝突する確率はp1 以上、
(b) もし点v がq から半径r2(= cr1) 以内に存在しない場合,v とq のハッシュ値が衝突する確率はp2(p2 < p1) 以下。
(式1)を用いて,ダミー特徴量D[i]のハッシュh[D[i]]を作成する。ハッシュテーブルは,(h[D[i]],D[i])を要素とするテーブルとして作成する。なお,LSHを用いた類似検索については後述する。
【0044】
以上で作成したハッシュテーブルを補助データDB114に格納する。
【0045】
そして、補助データDB作成端末は、補助データDB114のデータをクライアントに送信する。クライアントは、受信したデータを補助データDB103に格納しておく。
次に,図4を用いて,本実施形態における登録処理のフローを説明する。
【0046】
センサ107は、ユーザの生体情報を取得する(S401)。
【0047】
特徴量抽出部101は、生体情報から特徴量xを抽出する(S402)。特徴量抽出の方法は,たとえば指静脈画像であれば,文献4に記載の方法などを用いることができる。
【0048】
類似検索部102は、ハッシュテーブル{h[D[i]],D[i]}を補助データDB103から読み込む(S403)。
【0049】
類似検索部102は、読み込んだハッシュテーブル{h[D[i]],D[i]}を検索して,特徴量xに類似するダミー特徴量を特定する(S404)。
ここでは,たとえば一例として,文献5および文献7記載のLSHという方法を用いるものとする。これ以外の方法、たとえば文献6記載のAESAを用いても良い。
【0050】
まず(式1)を用いて,特徴量xのハッシュ値h[x]を算出する。次に読み込んだハッシュテーブル{h[D[i]],D[i]}内のハッシュの集合{h[D[i]]}に対し,ハッシュh[x]と一致するものを検索する。ハッシュ値が一致するダミー特徴量D[i]は一般に一つ以上存在する。これらをハッシュ一致ダミー特徴量D*[i]と呼ぶ。そして,複数存在する場合は、それぞれのハッシュ一致ダミー特徴量D*[i]と特徴量xを照合する。照合の方法はたとえば相互相関を用いたものがある。相互相関が最大となるハッシュ一致ダミー特徴量を、特徴量xに最も類似したダミー特徴量とする。これを最近傍ダミー特徴量D*[i*]と呼ぶ。類似検索の結果は、最近傍ダミー特徴量D*[i*]のインデックスi*とする。
【0051】
特徴量変換部104は、最近傍ダミー特徴量D*[i*]に対応する変換パラメータR[i*]を読み出す(S405)。
【0052】
特徴量変換部104は、変換パラメータR[i*]を用いて,特徴量xを変換する(S406)。たとえば指静脈認証など,2つの特徴量の間の類似度は相互相関により計算されるものなどがある。相互相関に基づいて類似度を計算する照合アルゴリズムに対しては、2つの特徴量に特殊な変換を施して秘匿したまま、それらを元に戻すことなく類似度を計算するアルゴリズム(相関不変ランダムフィルタリング)が知られている(詳細については文献1や文献2を参照)。この場合,変換パラメータR[i*]は,各画素値が乱数であるランダムフィルタである。変換処理では,まず特徴量xを基底変換(数論変換やフーリエ変換など)し(基底変換後のデータをXとする),つぎにXに対してランダムフィルタを画素ごとに乗算する。以上が代表的な変換処理の例であるが,そのほかの方法を用いてもよい。
【0053】
変換後の特徴量TをテンプレートTとし、最近傍ダミー特徴量D*[i*]のインデックスi*をグループIDとする。テンプレートTと、グループIDi*をサーバ120へ送信する。
【0054】
サーバ120は、テンプレートDB122の、i*をIDとするグループにテンプレートTを登録する(S407)。
【0055】
次に,図5を用いて,本実施形態における1:N認証処理のフローを説明する。
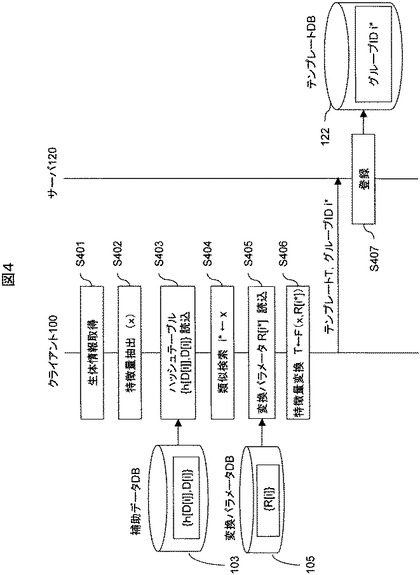
センサ107は、ユーザの生体情報を取得する(S501)。
【0056】
特徴量抽出部101は、生体情報から特徴量yを抽出する(S502)。特徴量抽出の方法は,たとえば指静脈画像であれば,文献4に記載の方法などを用いることができる。
【0057】
類似検索部102は、ハッシュテーブル{h[D[i]],D[i]}を補助データDB103から読み込む(S503)。
【0058】
類似検索部102は、読み込んだハッシュテーブル{h[D[i]],D[i]}を検索して,特徴量yに類似するダミー特徴量を特定する(S504)。ここでは,たとえば一例として,文献2および文献5記載のLSHという方法を用いるものとするが、これ以外の方法でも良い。他には例えば、文献6記載のAESAを用いても良い。
【0059】
まず(式1)を用いて,特徴量yのハッシュ値h[y]を算出する。次に読み込んだハッシュテーブル{h[D[i]],D[i]}内のハッシュ集合{h[D[i]]}に対し,ハッシュh[y]と一致するものを検索する。ハッシュ値が一致するダミー特徴量D[i]は一般に一つ以上存在する。これらをハッシュ一致ダミー特徴量D*[i]と呼ぶ。そして,複数存在する場合は、それぞれのハッシュ一致ダミー特徴量D*[i]と特徴量yを照合する。照合の方法はたとえば相互相関を用いたものがある。相互相関が最大となるハッシュ一致ダミー特徴量を、特徴量yに最も類似したダミー特徴量とする。これを最近傍ダミー特徴量D*[i*]と呼ぶ。類似検索の結果は、最近傍ダミー特徴量D*[i*]のインデックスi*とする。
【0060】
特徴量変換部104は、最近傍ダミー特徴量D*[i*]に対応する変換パラメータR[i*]を読み出す(S505)。
【0061】
特徴量変換部104は、変換パラメータR[i*]を用いて,特徴量yを変換する(S506)。たとえば指静脈認証など,2つの特徴量の間の類似度は相互相関により計算されるものなどがある。相互相関に基づいて類似度を計算する照合アルゴリズムに対しては、2つの特徴量に特殊な変換を施して秘匿したまま、それらを元に戻すことなく類似度を計算するアルゴリズム(相関不変ランダムフィルタリング)が知られている(詳細については文献1や文献2を参照)。この場合,変換パラメータR[i*]は,各画素値が乱数であるランダムフィルタである。変換処理では,まず特徴量yを基底変換(数論変換やフーリエ変換など)し(基底変換後のデータをYとする),つぎにYに対してランダムフィルタを画素ごとに除算する。以上が代表的な変換処理の例であるが,そのほかの方法を用いてもよい。
【0062】
最近傍ダミー特徴量D*[i*]のインデックスi*をグループIDとする。変換特徴量VとグループIDi*をサーバ120へ送信する。
【0063】
サーバ120は、変換特徴量Vと、テンプレートDB122の、i*をIDとするグループに含まれるテンプレートとの1:N照合を行う(S507)。たとえば指静脈認証など,2つの特徴量の間の類似度は相互相関により計算されるものなどがある。相互相関に基づいて類似度を計算する照合アルゴリズムに対しては、2つの特徴量に特殊な変換を施して秘匿したまま、それらを元に戻すことなく類似度を計算するアルゴリズム(相関不変ランダムフィルタリング)が知られている。詳細については文献1や文献2を参照のこと。この場合,グループi* 内で変換パラメータは共通であるため、1:N照合は、グループi* 内のテンプレートそれぞれと変換特徴量Vとの1:1照合を1回ずつ実行し、最も相関が高いテンプレートのIDを結果として出力することで実現できる。
【0064】
本実施例によれば、認証時には、クライアント100側でダミー特徴量との類似検索を以って該当グループへの割り当てを実行することで、サーバ120側での1:N照合の対象となるテンプレート数を大幅に絞り込める。これによって、サーバ側の処理負荷を削減し、1:N照合の処理時間を大幅に短縮できる。
【0065】
以上のように、本実施例によれば、1:N認証において、サーバ側処理負荷を削減し、処理を高速化することが可能である。また、クライアント100には特定の個人に属する生体情報の特徴量ではなく、ダミー特徴量が保持されているため、プライバシやセキュリティの問題はない。
【0066】
上記実施形態は、生体情報に基づいてユーザ認証を行う任意のアプリケーションに対して適用可能である。例えば、社内ネットワークにおける情報アクセス制御、インターネットバンキングシステムやATMにおける本人確認、会員向けWebサイトへのログイン、保護エリアへの入場時の個人認証、パソコンのログインなどへの適用が可能である。
【符号の説明】
【0067】
100:クライアント、101:特徴量抽出部、102:類似検索部、103:補助データDB部、104:特徴量変換部、105:変換パラメータDB部、106:通信部、107:センサ、110:補助データDB作成端末、111:クラスタリング部、112:特徴量DB部、113:ダミー特徴量作成部、114:補助データDB部、補助データ作成部、116:通信部、120:サーバ、121:通信部、122:テンプレートDB部、123:登録部、124:1:N照合部、600:CPU、601:メモリ、602:HDD、603:入力装置、604:出力装置、605:通信装置。
【技術分野】
【0001】
本発明は、個人の生体情報を用いて本人を認証する生体認証方法およびシステムに関する。
【背景技術】
【0002】
生体情報を用いた個人認証システムは、初期の登録時に個人の生体情報を取得し、特徴量と呼ばれる情報を抽出して登録する。この登録される特徴量をテンプレートという。認証時には、再び個人から生体情報を取得して特徴量を抽出し、先に登録されたテンプレートと照合して本人か否かを確認する。
【0003】
クライアント装置(クライアントという)とサーバ装置(サーバという)がネットワークを介して接続されたシステムにおいて、サーバがクライアント側にいるユーザを生体認証する場合、典型的にはサーバがテンプレートを保持する。クライアントは認証時にユーザの生体情報を取得し、特徴量を抽出してサーバへ送信し、サーバは特徴量をテンプレートと照合して本人か否かを確認する。
【0004】
しかし、テンプレートは個人を特定することのできる情報であるため、個人情報として厳密な管理が必要とされ、高い管理コストが必要となる。また、例え厳密に管理されていても、プライバシの観点からテンプレートを登録することに心理的な抵抗を感じる人も多い。また、生体情報は一生涯変わることがなく、パスワードや暗号鍵のように容易に変更することができない。他の生体情報に取り替えることが考えられるが、一人の個人が持つ一種類の生体情報の数には限りがある(例えば指紋は指の数)ため、根本的な解決策とはならない。このため、仮にテンプレートが漏洩して偽造の危険が生じた場合、これ以降その生体認証を安全に使用することができなくなるという問題がある。さらに、異なるシステムに対して同じ生体情報を登録している場合には他のシステムまで脅威に晒されることになる。
【0005】
そこで、生体情報の登録時に特徴量を一定の関数(一種の暗号化)とクライアントが持つ秘密のパラメータ(一種の暗号鍵)で変換し、元の情報を秘匿した状態でテンプレートとしてサーバに保管し、認証時にクライアントが新たに抽出した生体情報の特徴量を、同じ関数とパラメータで変換してサーバへ送信し、サーバは受信した特徴量とテンプレートを変換された状態のまま照合する方法(キャンセラブル生体認証という)が,非特許文献1で提案されている。
【0006】
この方法によれば、クライアントが変換パラメータを秘密に保持することで、サーバは認証時においても元の特徴量を知ることができず、個人のプライバシが保護される。
またテンプレートが漏洩した場合にも、変換パラメータを変更して再度テンプレートを作成、登録することで、安全性を保つことができる。更に異なるシステムに対して同じ生体情報を用いる場合に、各々異なるパラメータで変換したテンプレートを登録することで、一つのテンプレートが漏洩しても他のシステムの安全性が低下することを防止することができる。
【先行技術文献】
【非特許文献】
【0007】
【非特許文献1】N.K.Ratha, J.H.Connell, R.M.Bolle, ‘Enhancing security and privacy in biometric−based authentication systems.’ IBM System Journal 40(3) (2001)
【発明の概要】
【発明が解決しようとする課題】
【0008】
上記非特許文献1によれば、登録時、クライアントはユーザの生体から抽出した特徴量画像xを変換パラメータθを用いて変換し,変換特徴量Tを作成し、サーバに登録する。変換パラメータθはICカードなどに保存してユーザが秘密裏に管理する。
【0009】
認証時にはクライアントがあらたにユーザの生体から抽出した特徴量画像yを、ユーザのICカードから読み出した変換パラメータθを用いて変換し,変換特徴量Vを作成し、サーバに送信する。サーバはTとVの類似度を計算し、一致/不一致を判定する。
【0010】
このように秘密の変換パラメータθによってx、yを変換して求めたT,Vをサーバに送信することで、サーバに対してx、yを秘匿したまま、サーバが照合処理を実行可能とする。
【0011】
ところで,(ユーザIDを入力せずに)生体情報を入力しユーザIDを出力するようなシステム(以下,1:N認証と呼ぶ)にキャンセラブル生体認証を適用する場合,単純には,サーバのDB内にある全ての変換特徴量Tと照合を行う必要がある。しかし,大規模なDBの場合一般に,全てのTと照合するには処理時間が長くなり,実用的でない問題がある。
【課題を解決するための手段】
【0012】
本発明は、キャンセラブル生体認証を1:N認証システムに適用するに際し,サーバ側での1:N照合に要する時間を短縮し,処理を高速化させる生体認証技術を提供する。
【0013】
本発明は以上の課題を解決するため、クライアントとサーバとを含むシステムにおいて、個人のIDを用いずに、生体情報を用いて個人を認証する生体認証方法における生体情報の登録方法において、類似する特徴量でグループを構成する場合の、グループの代表となるダミー特徴量を予め設定しておき、クライアントにおいて、登録対象となる特徴量が属すべきグループを、ダミー特徴量に基づき特定する概略処理を行い、サーバにおいて、上記特定したグループに、上記登録用の変換特徴量を登録する処理を行う、ことを特徴とする。
【0014】
また、本発明は、クライアントとサーバとを含むシステムにおいて、個人のIDを用いずに、生体情報を用いて個人を認証する生体認証方法において、類似する特徴量でグループを構成し、グループの代表となるダミー特徴量を予め設定しておき、クライアントにおいて、認証対象となる特徴量が属するグループを、上記ダミー特徴量に基づき特定する概略処理を行い、サーバにおいて、特定したグループを対象に、類似するいずれか一つの特徴量を特定する詳細処理を行う、ことを特徴とする。
【0015】
さらに、上記特徴量は、個人から抽出した生体情報を所定のパラメータで変換した変換特徴量であることを特徴とする。
【0016】
本発明は、より具体的には、クライアント端末は、個人の生体情報から抽出した認証用特徴量を変換パラメータで変換した認証用変換特徴量を認証サーバに送信し、認証サーバは、複数の登録用変換特徴量と個人を特定する情報と対応付けて格納するデータベースを備え、データベースを検索して、認証用変換特徴量に最も類似する登録用変換特徴量に対応付けられた個人を特定する生体認証方法において、
クライアント端末は、予め、生体情報の登録用特徴量と認証用特徴量とを複数のグループのいずれかに分類するための基準とするダミー特徴量と、グループを識別するためのインデックスと、各々のダミー特徴量に対応した変換パラメータと、をクライアント側データベースに記憶し、
認証サーバは、変換パラメータにより登録用特徴量から変換された登録用変換特徴量と、登録用特徴量の抽出元である個人を特定する情報と、を、インデックスに基づき、複数のグループのいずれかに分類して記憶するための登録用変換特徴量データベースを備え、
生体情報の登録時の処理として、
クライアント端末は、
個人から取得した生体情報から登録用特徴量を抽出するステップと、
クライアント側データベースを検索して、登録用特徴量に類似した一つの登録用ダミー特徴量を特定するステップと、
特定した登録用ダミー特徴量に対応した変換パラメータを用いて、登録用特徴量を変換して、登録用変換特徴量を作成するステップと、
登録用変換特徴量と、特定した登録用ダミー特徴量のグループを識別する登録用インデックスと、登録用特徴量の抽出元である個人を特定する情報と、を認証サーバへと送信するステップと、を備え、
認証サーバは、
登録用変換特徴量データベースの登録用インデックスに対応したグループに、受信した登録用変換特徴量と、個人を特定する情報と、を対応付けて登録するステップと、を備えることを特徴とする。
【0017】
また、本発明の認証時の処理として、
クライアント端末は、
個人から取得した生体情報から認証用特徴量を抽出するステップと、
クライアント側データベースを検索して、認証用特徴量に類似した一つの認証用ダミー特徴量を特定するステップと、
特定した認証用ダミー特徴量に対応した変換パラメータを用いて、認証用特徴量を変換して、認証用変換特徴量を作成するステップと、
認証用変換特徴量と、特定した認証用ダミー特徴量のグループを識別する認証用インデックスと、を、認証サーバへと送信するステップと、を備え、
認証サーバは、
登録用変換特徴量データベースの認証用インデックスに対応したグループを検索して、認証用変換特徴量に最も類似した登録用変換特徴量を特定するステップと、
特定した登録用変換特徴量に対応づけられた個人を特定するステップと、
特定した個人に関わる情報をクライアント端末に送信するステップと、を備えることを特徴とする。
【0018】
上記態様によれば、生体情報を入力してユーザIDを出力する1:N生体認証システムにおいて、サーバ側での1:N照合に要する時間を短縮し,処理を高速化させることができる。
【発明の効果】
【0019】
本発明によれば、ユーザの生体情報を秘匿したまま高速認証が可能な、1:N生体認証システムを実現可能になる。
【図面の簡単な説明】
【0020】
【図1】第一の実施形態の機能構成を例示するブロック図である。
【図2】実施形態におけるダミー特徴量作成処理を例示する流れ図である。
【図3】実施形態におけるダミー特徴量のハッシュテーブル差作成処理を例示する流れ図である。
【図4】実施形態における登録処理を例示する流れ図である。
【図5】実施形態における1:N認証処理を例示する流れ図である。
【図6】実施形態におけるハードウェア構成を例示するブロック図である。
【発明を実施するための形態】
【0021】
以下、図面を参照して、本発明の実施形態について説明する。
【0022】
本実施形態では、キャンセラブル生体認証を1:N認証に適用した,1:Nキャンセラブル生体認証システムを例にあげて説明する。
【0023】
図1に、1:Nキャンセラブル生体認証システムのシステム構成を示す。
【0024】
本実施例の1:Nキャンセラブル生体認証システムは、登録・認証時の生体情報取得、特徴量抽出、ダミー特徴量との類似検索,および特徴量の変換を行うクライアント端末(以下、クライアント)100と、ダミー特徴量を含む補助データDBの作成などを行う補助データDB作成端末(以下、補助データDB作成端末)110と、テンプレートの保管と1:N照合を行う認証サーバ(以下、サーバ)120とが、インターネットやイントラネットなどのネットワークを介し接続して構成される。
【0025】
クライアント100は、ユーザ自身か又は信頼できる第三者によって管理され、生体情報(例えば指紋や静脈など)を取得するセンサ107を有する。例えば小売店舗でクレジット決済を行う場合、クライアント100は店舗が管理するクレジット端末であり、サーバ120はクレジット会社が管理するサーバマシンとするような構成も可能である。
【0026】
クライアント100は、センサ107が取得した生体情報から特徴量を抽出する特徴量抽出部101と、複数のダミー特徴量が予め格納された補助データDB103と,補助データDB103内のダミー特徴量との類似検索を行う類似検索部102と,ダミー特徴量おのおのに対応する変換パラメータを格納した変換パラメータDB105と,登録用または認証用の特徴量を変換して、登録用変換特徴量(以下、テンプレートという)または認証用変換特徴量を作成する特徴量変換部104と、サーバとの通信を行う通信部106から構成される。
【0027】
ここで生体情報とは、例えば指紋画像や静脈画像、虹彩画像といったデータであり、特徴量とは、例えば指紋や静脈の画像を強調処理して2値化した画像や、あるいは虹彩画像から作成するアイリスコード(虹彩コード)と呼ばれるビット列などを含む。2つの特徴量の間の類似度は、たとえば相互相関により計算されるものなどがある。相互相関に基づいて類似度を計算する照合アルゴリズムに対しては、2つの特徴量に特殊な変換を施して
元の特徴量を秘匿したまま、それらを元に戻すことなく類似度を計算するアルゴリズム(相関不変ランダムフィルタリング)が知られている。なお相関不変ランダムフィルタリングの詳細については、特開2007−293807号公報(文献1という)や比良田 他,”画像マッチングに適用可能なキャンセラブル生体認証方式の脆弱性分析と安全性向上”, SCIS2007予稿集CD−ROM(文献2という)に開示されている。
【0028】
補助データDB作成端末110は、ダミー特徴量を作成する元となる特徴量のDBである特徴量DB112、特徴量DB内の特徴量の集合に対してクラスタリングを行うクラスタリング部111、クラスタリング結果を利用してダミー特徴量を作成するダミー特徴量作成部113、クライアントにてダミー特徴量との類似検索に用いる補助データを作成する補助データ作成部115、補助データを格納する補助データDB114、クライアント100と通信を行う通信部116とから構成される。
【0029】
サーバ120は、クライアント100と通信を行う通信部121、テンプレートを管理するデータベース(テンプレートDB。以下、データベースをDBと記す)122、クライアントから受信したテンプレートをテンプレートDB122に登録する登録部123、クライアントから受信した変換特徴量とテンプレートDB122内の複数のテンプレートとの照合を行う1:N照合部124とから構成される。
【0030】
図6に、本実施形態におけるクライアント100、サーバ120のハードウェア構成を示す。これらは図のようにCPU600、メモリ601、HDD602、入力装置603、出力装置604、通信装置605とから構成することができる。
【0031】
クライアント100、補助データDB作成端末110、サーバ120の上記機能構成や、以下に説明する各処理は、それぞれのCPU600がメモリ601またはHDD602に格納されたプログラムを実行することにより、具現化される。また、各プログラムは、予めそれぞれのメモリ601、HDD602に格納されていても良いし、必要に応じて、当該装置が利用可能な、着脱可能な記憶媒体や、通信媒体である通信ネットワークまたは通信ネットワーク上を伝搬する搬送波やデジタル信号を介して、他の装置から導入されても良い。
【0032】
次に、図2を用いて、本実施形態におけるダミー特徴量の作成処理フローを説明する。
ここでは一例として、Jiawei Han and Micheline Kamber, “Data Mining”, pp.348−353, Morgan Kaufmann Publishers, 2001(文献3という)記載のセントロイドを用いた方法を示す。これ以外の方法でダミー特徴量を生成してもよい。
【0033】
事前にシステム開発の段階で,開発者など有志から生体情報を収集しておき,特徴量の集合{x[i]}を作成しておく。特徴量DB112に格納しておく。ここで例えば生体情報が指静脈画像の場合、特徴量抽出の方法は、N.Miura, A.Nagasaka, T.Miyatake, “Feature extraction of nger−vein patterns based on repeated line tracking and its application to personal identication.” Machine Vision and Applications 15(4) (2004) 194−203(文献4という)に記載の方法などを用いることができる。
【0034】
クラスタリング部111は,特徴量の集合{x[i]}を読込みクラスタリングを行う(S201)。クラスタリングによって,類似した特徴量同士がグループ化される。クラスタリングの詳細は文献3を参照のこと。特徴量のグループの集合を{G[j]}とする。G[j]には,特徴量x[j,k]が含まれる。ここで,iは特徴量DB内の特徴量のインデックス,jはグループのインデックス,kはグループjに含まれる特徴量のインデックス。
【0035】
クラスタリングの具体的な方法としては例えば, k−means 法が利用できる。ここでk−means 法の概要を説明する。k−means 法は,非階層的クラスタ分析の代表的手法であり,典型的にはユークリッド空間を仮定する。この方法では,クラスタ数をあらかじめ指定し(ここではk),対象をk 個のクラスに分割する。非類似度としてユークリッド距離の2乗をとり,クラスタの中心と各対象との間の非類似度を分類の基準とする。k−means法はクラスタ数を指定できるため,各クラスタ間での対象数の偏りを軽減できるメリットがある。k−means 法のアルゴリズムは以下のとおり。
step1. [初期値]k 個のクラスタ中心あるいは初期分割をランダムに与える。
step2. [割り当て] 各対象を最も近いクラスタ中心に割り当てる。
step3. [中心の更新] すべての対象の割り当てが一つ前のステップと変化が無ければ終了。そうでなければ,各クラスタの重心を新しい中心としてstep2 に戻る。
【0036】
ここで,クラスタの中心の各座標は,そのクラスタに含まれる対象の座標の重みつき平均で表され,またクラスタの重心の各座標は重みつきの無い平均で表される。
【0037】
ダミー特徴量作成部113は,グループG[j]ごとのセントロイドD[j]を作成する(S202)。セントロイドとは,グループに含まれる特徴量の重心となる特徴量のことである。詳細は文献3を参照のこと。作成したセントロイドの集合{D[j]}をダミー特徴量の集合{D[j]}として、補助データDB114に書き出す(S203)。
【0038】
次に,本実施形態における変換パラメータDB105の作成方法を説明する。ここで変換パラメータは,ダミー特徴量D[i]それぞれに対し,個別に作成し対応づける。ダミー特徴量D[i]に対応する変換パラメータをR[i]とする。変換パラメータR[i]の作成方法であるが,たとえば指静脈画像の場合,文献1や文献2に記載の方法を用いることができる。具体的には,各画素の値が乱数となるような2次元のランダムフィルタを作成すればよい。乱数は,疑似乱数生成器などを用いて発生させる。このランダムフィルタを変換パラメータR[i]とする。
【0039】
本実施形態におけるダミー特徴量との類似検索方法は,ここでは一例として, P. Indyk and R. Motwani,”Approximate nearest neighbors: towards removing the curse of dimensionality”, Proc. of the Symposium on Theory of Computing, 1998.(文献5という)に記載のLocality−Sensitive Hashing(以下,LSHと呼ぶ)を用いるものとする。これ以外の方法で類似検索をしても良い。たとえば、Vidal Ruiz, “An algorithm for finding nearest neighbours in (approximately) constant average time,” Pattern Recognition Letters pp.145−157, 1986.(文献6という)記載のApproximating and Eliminating Search Algorithm(以下、AESAと呼ぶ)などが利用できる。
【0040】
LSHでは,ハッシュテーブルが必要となる。図3を用いて,ハッシュテーブル作成方法を説明する。
補助データ作成部115は、補助データDB114に格納されているダミー特徴量集合{D[i]}を読み込む(S301)。
【0041】
補助データ作成部115は、ハッシュテーブルを作成する(S302)。ここでは一例として、M.Datar, N.Immorlica,P.Indyk, and V.Mirrokni,”Locality−sensitive hashing scheme based on p−stable distributions.”, Proc. of the ACM Symposium on Computational Geometry, 2004.(文献7という)記載の方法を用いるものとする。これ以外の方法でも良い。文献7では,特徴量ベクトルvに対し,以下の式でハッシュを作成する。
【0042】
【数1】
【0043】
なお、LSHで用いるハッシュ関数は、局所性に鋭敏なハッシュ関数と呼ばれ、以下のように定義される(以下,局所鋭敏ハッシュ関数と呼ぶ)。対象とする元の空間をS、生成されるハッシュ値の空間をU とする。ハッシュ関数集合H = { h : S →U } が次を満たすとき,局所鋭敏ハッシュ関数集合と定義される:
(a) もし点v がq から半径r1 以内に存在する場合,v とq のハッシュ値が衝突する確率はp1 以上、
(b) もし点v がq から半径r2(= cr1) 以内に存在しない場合,v とq のハッシュ値が衝突する確率はp2(p2 < p1) 以下。
(式1)を用いて,ダミー特徴量D[i]のハッシュh[D[i]]を作成する。ハッシュテーブルは,(h[D[i]],D[i])を要素とするテーブルとして作成する。なお,LSHを用いた類似検索については後述する。
【0044】
以上で作成したハッシュテーブルを補助データDB114に格納する。
【0045】
そして、補助データDB作成端末は、補助データDB114のデータをクライアントに送信する。クライアントは、受信したデータを補助データDB103に格納しておく。
次に,図4を用いて,本実施形態における登録処理のフローを説明する。
【0046】
センサ107は、ユーザの生体情報を取得する(S401)。
【0047】
特徴量抽出部101は、生体情報から特徴量xを抽出する(S402)。特徴量抽出の方法は,たとえば指静脈画像であれば,文献4に記載の方法などを用いることができる。
【0048】
類似検索部102は、ハッシュテーブル{h[D[i]],D[i]}を補助データDB103から読み込む(S403)。
【0049】
類似検索部102は、読み込んだハッシュテーブル{h[D[i]],D[i]}を検索して,特徴量xに類似するダミー特徴量を特定する(S404)。
ここでは,たとえば一例として,文献5および文献7記載のLSHという方法を用いるものとする。これ以外の方法、たとえば文献6記載のAESAを用いても良い。
【0050】
まず(式1)を用いて,特徴量xのハッシュ値h[x]を算出する。次に読み込んだハッシュテーブル{h[D[i]],D[i]}内のハッシュの集合{h[D[i]]}に対し,ハッシュh[x]と一致するものを検索する。ハッシュ値が一致するダミー特徴量D[i]は一般に一つ以上存在する。これらをハッシュ一致ダミー特徴量D*[i]と呼ぶ。そして,複数存在する場合は、それぞれのハッシュ一致ダミー特徴量D*[i]と特徴量xを照合する。照合の方法はたとえば相互相関を用いたものがある。相互相関が最大となるハッシュ一致ダミー特徴量を、特徴量xに最も類似したダミー特徴量とする。これを最近傍ダミー特徴量D*[i*]と呼ぶ。類似検索の結果は、最近傍ダミー特徴量D*[i*]のインデックスi*とする。
【0051】
特徴量変換部104は、最近傍ダミー特徴量D*[i*]に対応する変換パラメータR[i*]を読み出す(S405)。
【0052】
特徴量変換部104は、変換パラメータR[i*]を用いて,特徴量xを変換する(S406)。たとえば指静脈認証など,2つの特徴量の間の類似度は相互相関により計算されるものなどがある。相互相関に基づいて類似度を計算する照合アルゴリズムに対しては、2つの特徴量に特殊な変換を施して秘匿したまま、それらを元に戻すことなく類似度を計算するアルゴリズム(相関不変ランダムフィルタリング)が知られている(詳細については文献1や文献2を参照)。この場合,変換パラメータR[i*]は,各画素値が乱数であるランダムフィルタである。変換処理では,まず特徴量xを基底変換(数論変換やフーリエ変換など)し(基底変換後のデータをXとする),つぎにXに対してランダムフィルタを画素ごとに乗算する。以上が代表的な変換処理の例であるが,そのほかの方法を用いてもよい。
【0053】
変換後の特徴量TをテンプレートTとし、最近傍ダミー特徴量D*[i*]のインデックスi*をグループIDとする。テンプレートTと、グループIDi*をサーバ120へ送信する。
【0054】
サーバ120は、テンプレートDB122の、i*をIDとするグループにテンプレートTを登録する(S407)。
【0055】
次に,図5を用いて,本実施形態における1:N認証処理のフローを説明する。
センサ107は、ユーザの生体情報を取得する(S501)。
【0056】
特徴量抽出部101は、生体情報から特徴量yを抽出する(S502)。特徴量抽出の方法は,たとえば指静脈画像であれば,文献4に記載の方法などを用いることができる。
【0057】
類似検索部102は、ハッシュテーブル{h[D[i]],D[i]}を補助データDB103から読み込む(S503)。
【0058】
類似検索部102は、読み込んだハッシュテーブル{h[D[i]],D[i]}を検索して,特徴量yに類似するダミー特徴量を特定する(S504)。ここでは,たとえば一例として,文献2および文献5記載のLSHという方法を用いるものとするが、これ以外の方法でも良い。他には例えば、文献6記載のAESAを用いても良い。
【0059】
まず(式1)を用いて,特徴量yのハッシュ値h[y]を算出する。次に読み込んだハッシュテーブル{h[D[i]],D[i]}内のハッシュ集合{h[D[i]]}に対し,ハッシュh[y]と一致するものを検索する。ハッシュ値が一致するダミー特徴量D[i]は一般に一つ以上存在する。これらをハッシュ一致ダミー特徴量D*[i]と呼ぶ。そして,複数存在する場合は、それぞれのハッシュ一致ダミー特徴量D*[i]と特徴量yを照合する。照合の方法はたとえば相互相関を用いたものがある。相互相関が最大となるハッシュ一致ダミー特徴量を、特徴量yに最も類似したダミー特徴量とする。これを最近傍ダミー特徴量D*[i*]と呼ぶ。類似検索の結果は、最近傍ダミー特徴量D*[i*]のインデックスi*とする。
【0060】
特徴量変換部104は、最近傍ダミー特徴量D*[i*]に対応する変換パラメータR[i*]を読み出す(S505)。
【0061】
特徴量変換部104は、変換パラメータR[i*]を用いて,特徴量yを変換する(S506)。たとえば指静脈認証など,2つの特徴量の間の類似度は相互相関により計算されるものなどがある。相互相関に基づいて類似度を計算する照合アルゴリズムに対しては、2つの特徴量に特殊な変換を施して秘匿したまま、それらを元に戻すことなく類似度を計算するアルゴリズム(相関不変ランダムフィルタリング)が知られている(詳細については文献1や文献2を参照)。この場合,変換パラメータR[i*]は,各画素値が乱数であるランダムフィルタである。変換処理では,まず特徴量yを基底変換(数論変換やフーリエ変換など)し(基底変換後のデータをYとする),つぎにYに対してランダムフィルタを画素ごとに除算する。以上が代表的な変換処理の例であるが,そのほかの方法を用いてもよい。
【0062】
最近傍ダミー特徴量D*[i*]のインデックスi*をグループIDとする。変換特徴量VとグループIDi*をサーバ120へ送信する。
【0063】
サーバ120は、変換特徴量Vと、テンプレートDB122の、i*をIDとするグループに含まれるテンプレートとの1:N照合を行う(S507)。たとえば指静脈認証など,2つの特徴量の間の類似度は相互相関により計算されるものなどがある。相互相関に基づいて類似度を計算する照合アルゴリズムに対しては、2つの特徴量に特殊な変換を施して秘匿したまま、それらを元に戻すことなく類似度を計算するアルゴリズム(相関不変ランダムフィルタリング)が知られている。詳細については文献1や文献2を参照のこと。この場合,グループi* 内で変換パラメータは共通であるため、1:N照合は、グループi* 内のテンプレートそれぞれと変換特徴量Vとの1:1照合を1回ずつ実行し、最も相関が高いテンプレートのIDを結果として出力することで実現できる。
【0064】
本実施例によれば、認証時には、クライアント100側でダミー特徴量との類似検索を以って該当グループへの割り当てを実行することで、サーバ120側での1:N照合の対象となるテンプレート数を大幅に絞り込める。これによって、サーバ側の処理負荷を削減し、1:N照合の処理時間を大幅に短縮できる。
【0065】
以上のように、本実施例によれば、1:N認証において、サーバ側処理負荷を削減し、処理を高速化することが可能である。また、クライアント100には特定の個人に属する生体情報の特徴量ではなく、ダミー特徴量が保持されているため、プライバシやセキュリティの問題はない。
【0066】
上記実施形態は、生体情報に基づいてユーザ認証を行う任意のアプリケーションに対して適用可能である。例えば、社内ネットワークにおける情報アクセス制御、インターネットバンキングシステムやATMにおける本人確認、会員向けWebサイトへのログイン、保護エリアへの入場時の個人認証、パソコンのログインなどへの適用が可能である。
【符号の説明】
【0067】
100:クライアント、101:特徴量抽出部、102:類似検索部、103:補助データDB部、104:特徴量変換部、105:変換パラメータDB部、106:通信部、107:センサ、110:補助データDB作成端末、111:クラスタリング部、112:特徴量DB部、113:ダミー特徴量作成部、114:補助データDB部、補助データ作成部、116:通信部、120:サーバ、121:通信部、122:テンプレートDB部、123:登録部、124:1:N照合部、600:CPU、601:メモリ、602:HDD、603:入力装置、604:出力装置、605:通信装置。
【特許請求の範囲】
【請求項1】
クライアント端末は、個人の生体情報から抽出した認証用特徴量を変換パラメータで変換した認証用変換特徴量を認証サーバに送信し、
前記認証サーバは、複数の登録用変換特徴量と個人を特定する情報と対応付けて格納するデータベースを備え、前記データベースを検索して、前記認証用変換特徴量に最も類似する前記登録用変換特徴量に対応付けられた個人を特定する生体認証方法において、
前記クライアント端末は、予め、生体情報の登録用特徴量と前記認証用特徴量とを複数のグループのいずれかに分類するための基準とするダミー特徴量と、前記グループを識別するためのインデックスと、各々の前記ダミー特徴量に対応した変換パラメータと、をクライアント側データベースに記憶し、
前記認証サーバは、前記変換パラメータにより前記登録用特徴量から変換された登録用変換特徴量と、前記登録用特徴量の抽出元である個人を特定する情報と、を、前記インデックスに基づき、前記複数のグループのいずれかに分類して記憶するための登録用変換特徴量データベースを備え、
生体情報の登録時の処理として、
前記クライアント端末における、
個人から取得した生体情報から前記登録用特徴量を抽出するステップと、
前記クライアント側データベースを検索して、前記登録用特徴量に類似した一つの登録用ダミー特徴量を特定するステップと、
前記特定した登録用ダミー特徴量に対応した前記変換パラメータを用いて、前記登録用特徴量を変換して、登録用変換特徴量を作成するステップと、
前記登録用変換特徴量と、特定した前記登録用ダミー特徴量のグループを識別する登録用インデックスと、前記登録用特徴量の抽出元である前記個人を特定する情報と、を前記認証サーバへと送信するステップと、
前記認証サーバにおける、
前記登録用変換特徴量データベースの前記登録用インデックスに対応したグループに、受信した前記登録用変換特徴量と、前記個人を特定する情報と、を対応付けて登録するステップと、を含む
ことを特徴とする生体認証方法。
【請求項2】
請求項1に記載の生体認証方法において、
予め、抽出した複数の前記登録用特徴量を、所定の基準に従って複数のグループに分割し、
一つのグループに含まれる前記登録用特徴量から算出したセントロイドを当該グループに対応する前記ダミー特徴量とする
ことを特徴とする生体認証方法。
【請求項3】
請求項1または2に記載の生体認証情報の登録方法によって登録された生体認証情報に基づく生体認証方法において、
認証時の処理として、
前記クライアント端末における、
個人から取得した生体情報から認証用特徴量を抽出するステップと、
前記クライアント側データベースを検索して、前記認証用特徴量に類似した一つの認証用ダミー特徴量を特定するステップと、
前記特定した認証用ダミー特徴量に対応した前記変換パラメータを用いて、前記認証用特徴量を変換して、認証用変換特徴量を作成するステップと、
前記認証用変換特徴量と、特定した前記認証用ダミー特徴量のグループを識別する認証用インデックスと、を、前記認証サーバへと送信するステップと、
前記認証サーバにおける、
前記登録用変換特徴量データベースの前記認証用インデックスに対応したグループを検索して、前記認証用変換特徴量に最も類似した前記登録用変換特徴量を特定するステップと、
特定した前記登録用変換特徴量に対応づけられた個人を特定するステップと、
特定した前記個人に関わる情報を前記クライアント端末に送信するステップと、を含む
ことを特徴とする生体認証方法。
【請求項4】
請求項1ないし3いずれか一に記載の生体認証方法において、
前記クライアント端末における、前記登録用特徴量に類似した一つの登録用ダミー特徴量を特定するステップと、前記認証用特徴量に類似した一つの認証用ダミー特徴量を特定するステップと、において、
Locality−Sensitive HashingまたはApproximating and Eliminating Search Algorithmを用いる
ことを特徴とする生体認証方法。
【請求項5】
個人の生体情報から抽出した登録用特徴量を変換パラメータで変換した登録用変換特徴量を認証サーバに送信し、登録させる生体認証に用いるクライアント端末であって、
予め、生体情報の登録用特徴量と認証用特徴量とを複数のグループのいずれかに分類するための基準とするダミー特徴量と、前記グループを識別するためのインデックスと、各々の前記ダミー特徴量に対応した変換パラメータと、をクライアント側データベースに記憶し、
個人から取得した生体情報から前記登録用特徴量を抽出し、
前記クライアント側データベースを検索して、前記登録用特徴量に類似した一つの登録用ダミー特徴量を特定し、
前記特定した登録用ダミー特徴量に対応した前記変換パラメータを用いて、前記登録用特徴量を変換して、登録用変換特徴量を作成し、
前記登録用変換特徴量と、特定した前記登録用ダミー特徴量のグループを識別する登録用インデックスと、前記登録用特徴量の抽出元である前記個人を特定する情報と、を前記認証サーバへと送信する
ことを特徴とする生体認証に用いるクライアント端末。
【請求項6】
請求項5に記載の生体認証に用いるクライアント端末において、
予め、抽出した複数の前記登録用特徴量を、所定の基準に従って複数のグループに分割し、
一つのグループに含まれる前記登録用特徴量から算出したセントロイドを当該グループに対応する前記ダミー特徴量とする
ことを特徴とする生体認証に用いるクライアント端末。
【請求項7】
請求項5または6に記載の生体認証に用いるクライアント端末において、
個人から取得した生体情報から認証用特徴量を抽出し、
前記クライアント側データベースを検索して、前記認証用特徴量に類似した一つの認証用ダミー特徴量を特定し、
前記特定した認証用ダミー特徴量に対応した前記変換パラメータを用いて、前記認証用特徴量を変換して、認証用変換特徴量を作成し、
前記認証用変換特徴量と、特定した前記認証用ダミー特徴量のグループを識別する認証用インデックスと、を、前記認証サーバへと送信し、
前記認証サーバから、特定した個人に関わる情報を受信する
ことを特徴とする生体認証に用いるクライアント端末。
【請求項8】
請求項5ないし7いずれか一に記載の生体認証に用いるクライアント端末において、
前記登録用特徴量に類似した一つの登録用ダミー特徴量の特定において、
Locality−Sensitive HashingまたはApproximating and Eliminating Search Algorithmを用いる
ことを特徴とする生体認証に用いるクライアント端末。
【請求項9】
複数の登録用変換特徴量と個人を特定する情報と対応付けて格納するデータベースを備え、前記データベースを検索して、認証用変換特徴量に最も類似する前記登録用変換特徴量に対応付けられた個人を特定する生体認証方法に用いる認証サーバであって、
前記データベースに格納される前記登録用変換特徴量は、所定の基準に従い、複数の、インデックスが付与されたグループに分割されており、
前記登録用変換特徴量と、前記グループを識別するインデックスと、前記登録用特徴量の抽出元である前記個人を特定する情報と、を受信し、
前記データベースの前記インデックスに対応したグループに、受信した前記登録用変換特徴量と、前記個人を特定する情報と、を対応付けて登録する
ことを特徴とする認証サーバ。
【請求項10】
請求応9に記載の認証サーバにおいて、
前記認証用変換特徴量と、前記グループを識別するインデックスと、を受信し、
前記データベースの前記インデックスに対応したグループを検索して、前記認証用変換特徴量に最も類似した前記登録用変換特徴量を特定し、
特定した前記認証用変換特徴量に対応づけられた個人を特定し、
特定した前記個人に関わる情報を、前記認証用変換特徴量の送信元に送信する
ことを特徴とする認証サーバ。
【請求項1】
クライアント端末は、個人の生体情報から抽出した認証用特徴量を変換パラメータで変換した認証用変換特徴量を認証サーバに送信し、
前記認証サーバは、複数の登録用変換特徴量と個人を特定する情報と対応付けて格納するデータベースを備え、前記データベースを検索して、前記認証用変換特徴量に最も類似する前記登録用変換特徴量に対応付けられた個人を特定する生体認証方法において、
前記クライアント端末は、予め、生体情報の登録用特徴量と前記認証用特徴量とを複数のグループのいずれかに分類するための基準とするダミー特徴量と、前記グループを識別するためのインデックスと、各々の前記ダミー特徴量に対応した変換パラメータと、をクライアント側データベースに記憶し、
前記認証サーバは、前記変換パラメータにより前記登録用特徴量から変換された登録用変換特徴量と、前記登録用特徴量の抽出元である個人を特定する情報と、を、前記インデックスに基づき、前記複数のグループのいずれかに分類して記憶するための登録用変換特徴量データベースを備え、
生体情報の登録時の処理として、
前記クライアント端末における、
個人から取得した生体情報から前記登録用特徴量を抽出するステップと、
前記クライアント側データベースを検索して、前記登録用特徴量に類似した一つの登録用ダミー特徴量を特定するステップと、
前記特定した登録用ダミー特徴量に対応した前記変換パラメータを用いて、前記登録用特徴量を変換して、登録用変換特徴量を作成するステップと、
前記登録用変換特徴量と、特定した前記登録用ダミー特徴量のグループを識別する登録用インデックスと、前記登録用特徴量の抽出元である前記個人を特定する情報と、を前記認証サーバへと送信するステップと、
前記認証サーバにおける、
前記登録用変換特徴量データベースの前記登録用インデックスに対応したグループに、受信した前記登録用変換特徴量と、前記個人を特定する情報と、を対応付けて登録するステップと、を含む
ことを特徴とする生体認証方法。
【請求項2】
請求項1に記載の生体認証方法において、
予め、抽出した複数の前記登録用特徴量を、所定の基準に従って複数のグループに分割し、
一つのグループに含まれる前記登録用特徴量から算出したセントロイドを当該グループに対応する前記ダミー特徴量とする
ことを特徴とする生体認証方法。
【請求項3】
請求項1または2に記載の生体認証情報の登録方法によって登録された生体認証情報に基づく生体認証方法において、
認証時の処理として、
前記クライアント端末における、
個人から取得した生体情報から認証用特徴量を抽出するステップと、
前記クライアント側データベースを検索して、前記認証用特徴量に類似した一つの認証用ダミー特徴量を特定するステップと、
前記特定した認証用ダミー特徴量に対応した前記変換パラメータを用いて、前記認証用特徴量を変換して、認証用変換特徴量を作成するステップと、
前記認証用変換特徴量と、特定した前記認証用ダミー特徴量のグループを識別する認証用インデックスと、を、前記認証サーバへと送信するステップと、
前記認証サーバにおける、
前記登録用変換特徴量データベースの前記認証用インデックスに対応したグループを検索して、前記認証用変換特徴量に最も類似した前記登録用変換特徴量を特定するステップと、
特定した前記登録用変換特徴量に対応づけられた個人を特定するステップと、
特定した前記個人に関わる情報を前記クライアント端末に送信するステップと、を含む
ことを特徴とする生体認証方法。
【請求項4】
請求項1ないし3いずれか一に記載の生体認証方法において、
前記クライアント端末における、前記登録用特徴量に類似した一つの登録用ダミー特徴量を特定するステップと、前記認証用特徴量に類似した一つの認証用ダミー特徴量を特定するステップと、において、
Locality−Sensitive HashingまたはApproximating and Eliminating Search Algorithmを用いる
ことを特徴とする生体認証方法。
【請求項5】
個人の生体情報から抽出した登録用特徴量を変換パラメータで変換した登録用変換特徴量を認証サーバに送信し、登録させる生体認証に用いるクライアント端末であって、
予め、生体情報の登録用特徴量と認証用特徴量とを複数のグループのいずれかに分類するための基準とするダミー特徴量と、前記グループを識別するためのインデックスと、各々の前記ダミー特徴量に対応した変換パラメータと、をクライアント側データベースに記憶し、
個人から取得した生体情報から前記登録用特徴量を抽出し、
前記クライアント側データベースを検索して、前記登録用特徴量に類似した一つの登録用ダミー特徴量を特定し、
前記特定した登録用ダミー特徴量に対応した前記変換パラメータを用いて、前記登録用特徴量を変換して、登録用変換特徴量を作成し、
前記登録用変換特徴量と、特定した前記登録用ダミー特徴量のグループを識別する登録用インデックスと、前記登録用特徴量の抽出元である前記個人を特定する情報と、を前記認証サーバへと送信する
ことを特徴とする生体認証に用いるクライアント端末。
【請求項6】
請求項5に記載の生体認証に用いるクライアント端末において、
予め、抽出した複数の前記登録用特徴量を、所定の基準に従って複数のグループに分割し、
一つのグループに含まれる前記登録用特徴量から算出したセントロイドを当該グループに対応する前記ダミー特徴量とする
ことを特徴とする生体認証に用いるクライアント端末。
【請求項7】
請求項5または6に記載の生体認証に用いるクライアント端末において、
個人から取得した生体情報から認証用特徴量を抽出し、
前記クライアント側データベースを検索して、前記認証用特徴量に類似した一つの認証用ダミー特徴量を特定し、
前記特定した認証用ダミー特徴量に対応した前記変換パラメータを用いて、前記認証用特徴量を変換して、認証用変換特徴量を作成し、
前記認証用変換特徴量と、特定した前記認証用ダミー特徴量のグループを識別する認証用インデックスと、を、前記認証サーバへと送信し、
前記認証サーバから、特定した個人に関わる情報を受信する
ことを特徴とする生体認証に用いるクライアント端末。
【請求項8】
請求項5ないし7いずれか一に記載の生体認証に用いるクライアント端末において、
前記登録用特徴量に類似した一つの登録用ダミー特徴量の特定において、
Locality−Sensitive HashingまたはApproximating and Eliminating Search Algorithmを用いる
ことを特徴とする生体認証に用いるクライアント端末。
【請求項9】
複数の登録用変換特徴量と個人を特定する情報と対応付けて格納するデータベースを備え、前記データベースを検索して、認証用変換特徴量に最も類似する前記登録用変換特徴量に対応付けられた個人を特定する生体認証方法に用いる認証サーバであって、
前記データベースに格納される前記登録用変換特徴量は、所定の基準に従い、複数の、インデックスが付与されたグループに分割されており、
前記登録用変換特徴量と、前記グループを識別するインデックスと、前記登録用特徴量の抽出元である前記個人を特定する情報と、を受信し、
前記データベースの前記インデックスに対応したグループに、受信した前記登録用変換特徴量と、前記個人を特定する情報と、を対応付けて登録する
ことを特徴とする認証サーバ。
【請求項10】
請求応9に記載の認証サーバにおいて、
前記認証用変換特徴量と、前記グループを識別するインデックスと、を受信し、
前記データベースの前記インデックスに対応したグループを検索して、前記認証用変換特徴量に最も類似した前記登録用変換特徴量を特定し、
特定した前記認証用変換特徴量に対応づけられた個人を特定し、
特定した前記個人に関わる情報を、前記認証用変換特徴量の送信元に送信する
ことを特徴とする認証サーバ。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図2】
【図3】
【図4】
【図5】
【図6】
【公開番号】特開2010−286937(P2010−286937A)
【公開日】平成22年12月24日(2010.12.24)
【国際特許分類】
【出願番号】特願2009−138778(P2009−138778)
【出願日】平成21年6月10日(2009.6.10)
【出願人】(000005108)株式会社日立製作所 (27,607)
【Fターム(参考)】
【公開日】平成22年12月24日(2010.12.24)
【国際特許分類】
【出願日】平成21年6月10日(2009.6.10)
【出願人】(000005108)株式会社日立製作所 (27,607)
【Fターム(参考)】
[ Back to top ]