
画像から音楽を生成する音楽生成装置
【課題】顔の表情や景色などのイメージに適合させた音楽を生成することのできる音楽データ生成装置を提供することを目的とする。
【解決手段】画像から音楽データを生成する音楽データ生成装置において、画像中に顔が含まれているか否かを解析する顔検出手段と、当該顔検出手段によって画像中に顔が含まれていることが判定された場合、当該顔の属性を解析する顔属性解析手段と、当該顔属性解析手段によって解析された顔の属性に基づいて音楽データを生成する音楽データ生成手段とを備える。また、画像中に顔が含まれていない場合、直線要素などから景色の種別を判定し、その景色の種別に応じた音楽を生成できるようにする。
【解決手段】画像から音楽データを生成する音楽データ生成装置において、画像中に顔が含まれているか否かを解析する顔検出手段と、当該顔検出手段によって画像中に顔が含まれていることが判定された場合、当該顔の属性を解析する顔属性解析手段と、当該顔属性解析手段によって解析された顔の属性に基づいて音楽データを生成する音楽データ生成手段とを備える。また、画像中に顔が含まれていない場合、直線要素などから景色の種別を判定し、その景色の種別に応じた音楽を生成できるようにする。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、カメラなどによって撮影された画像に含まれる顔や景色などに基づいて、自動的にその画像のイメージに適合した音楽を生成することのできる装置に関するものである。
【背景技術】
【0002】
近年、携帯電話を用いたメールサービスなどとして、メール本文の内容に基づいた音楽を生成し、これを第三者に送信できるようにしたサービスなどが存在している。また、これ以外にも、画像を相手に送信する際、その画像に基づいて独自の音楽を生成して、メール本文とともに送信できるようにしたシステムも提案されている。
【0003】
例えば、下記の特許文献1には、カメラで撮影された画像から独自の音楽データを生成するようにしたシステムが提案されている。このシステムの詳細について説明すると、カメラによって取得された画像を256階調に量子化する手段と、その解析された結果に基づいて音楽データを生成する手段とを備えている。この量子化された情報から音楽データを生成する場合は、あらかじめ各画素の輝度に対応した音声情報をテンプレートとして保持しておき、このテンプレートを参照して各画素の輝度に対応する音高を当てはめていく。具体的には、解析された画素の輝度が「0〜10」であった場合は、基準となるオクターブから1オクターブ上の「A」の音高を当てはめ、また、ある画素の輝度が「247〜255」であった場合には、基準となるオクターブから1オクターブ下の「H」の音を当てはめる。そして、これらの音高を画像の縦軸方向、あるいは、横軸方向に並べていき音楽データを生成するようにしたものである。
【特許文献1】特開2001−350473号公報
【発明の開示】
【発明が解決しようとする課題】
【0004】
しかしながら、このような方法で音楽データを生成する場合においては、次のような問題を生ずる。すなわち、上記特許文献1のように、単に256階調に量子化された情報から音楽データを生成する方法では、画像から受けるイメージと実際に出力される音楽のイメージが異なる場合がある。例えば、被写体として笑顔を有する人間が写っていたとしても、景色や照明などが暗かったために基準オクターブから下の低い音高が当てはめられたり、暗いイメージを有する音楽が生成されたりすることがある。また、一般に、携帯電話を用いて被写体を撮影する際、人間を被写体とすることが多いが、上記特許文献1では、人間の顔の表情などに特化して音楽を生成するものではないため、顔の表情や性別、年齢層などの属性に応じた音楽を生成することができない。
【0005】
さらには、撮影された画像が都会などの人工的な景色や、山や海などの自然の景色であった場合、それぞれの画像から受けるイメージが異なり、例えば、オフィスビルの建ち並んだ人工的な景色からは比較的緊張感のある堅いイメージを受け、また、森や林などの山の画像からは、癒しの雰囲気を有する柔らかなイメージを受けることが多い。また、海の画像からは、爽やかなイメージを受けることが多い。従って、これらの景色から音楽を生成する場合においても、同様に、その景色のイメージに適合した音楽を生成できるようにすることが好ましい。
【0006】
そこで、本発明は、上記課題を解決するために、顔の表情や景色などのイメージに適合した音楽を生成することのできる音楽データ生成装置を提供することを目的とするものである。
【課題を解決するための手段】
【0007】
すなわち、本発明は上記課題を解決するために、画像から音楽データを生成する音楽データ生成装置において、画像中に顔が含まれているか否かを検出する顔検出手段と、当該顔検出手段によって画像中に顔が含まれていることが検出された場合、当該顔の属性を解析する顔属性解析手段と、当該顔属性解析手段によって解析された顔の属性に基づいて音楽データを生成する音楽データ生成手段とを備えるようにしたものである。
【0008】
このようにすれば、顔の属性、すなわち、顔の表情や性別、年齢層などに応じて音楽を生成することができるため、その画像のイメージに適合した音楽を生成することができる。すなわち、笑顔を有する被写体の画像からは明るいイメージを有する音楽を生成することができ、また、男性の画像からは男性的なイメージ、女性の画像からは女性的なイメージを有する音楽を生成することができるようになる。
【0009】
また、画像に顔が含まれていない場合には、景色の属性、すなわち、人工的な景色や、山や海などの景色の種別を判定し、その判定された種別の属性に応じて音楽データを生成する。
【0010】
このようにすれば、画像に顔が含まれていない場合であっても、都会や自然の景色のイメージに適合した音楽を生成することができるようになる。
【0011】
さらには、画像中に含まれる顔の属性と景色の属性の両方を用いて音楽データを生成することもできる。
【0012】
このようにすれば、顔の属性だけでなく、景色の属性も考慮して音楽データを生成するので、より画像のイメージに適合した音楽を生成することができるようになる。
【0013】
また、顔の属性を解析する場合、顔の表情、性別、年齢層などを解析し、これらの解析結果に基づいて音楽データを生成する。
【0014】
このようにすれば、例えば、男性のみが被写体となっている画像からは、男性的なイメージを有する音楽を生成することができ、また、被写体の年齢層が高い場合は、その年齢層に適合した音楽を生成することができるようになる。
【0015】
また、上述のように景色の種類を判別する場合、画像中に含まれる直線の種類や数などの情報に基づいて景色の種類を判別する。
【0016】
一般的に、都会や建物の中などの人工的な景色であれば、直線的な構成要素の量が比較的に多くなり、また、自然の景色であれば、直線的な構成要素よりもランダムな構成要素の割合が増えるが、このように直線を含むか否かから景色の種類を判別すれば、より正確に景色の種類に適合した音楽を生成することができるようになる。
【0017】
また、音楽データを生成する場合、音楽データベースの中に、顔の属性や景色の属性に対応するメロディ素片をあらかじめ格納しておき、これらの音楽データベースの中から複数のメロディ素片を抽出して連結することにより音楽データを生成する。
【0018】
このようにすれば、例えば、あらかじめイメージの分かっている音楽に対して属性を割り当てておき、これを分割して他のメロディ素片と連結するようにすれば、確実にその属性に対応した音楽を生成することができるようになる。しかも、メロディ素片の連結方法をランダムにすれば毎回異なった音楽を生成することができるようになる。
【発明の効果】
【0019】
本発明は、画像から音楽データを生成する音楽データ生成装置において、画像中に顔が含まれているか否かを検出する顔検出手段と、当該顔検出手段によって画像中に顔が含まれていることが検出された場合、当該顔の属性を解析する顔属性解析手段と、当該顔属性解析手段によって解析された顔の属性に基づいて音楽データを生成する音楽データ生成手段とを備えるようにしたので、例えば、笑顔を有する被写体の画像からは明るいイメージを有する音楽を生成することができ、また、男性の画像からは男性的なイメージを、女性の画像からは女性的なイメージを有する音楽を生成することができるようになる。
【発明を実施するための最良の形態】
【0020】
以下、本発明の一実施の形態について図面を参照して説明する。
【0021】
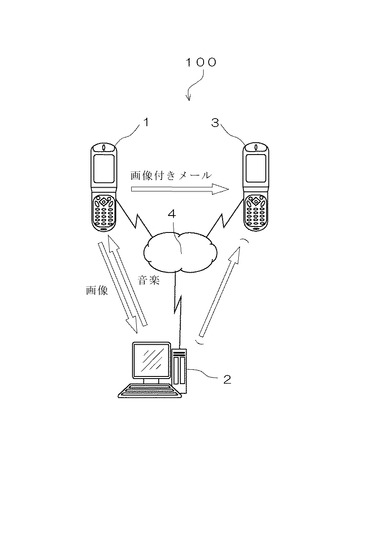
本実施の形態における音楽データ生成システム100は、図1に示すように、画像付きのメールを第三者に送信する第一の端末装置1と、この第一の端末装置1にネットワーク4を介して接続される音楽データ生成装置2と、この音楽データ生成装置2によって生成された音楽をメール本文や画像とともに受信する第二の端末装置3とを少なくとも備えて構成される。
【0022】
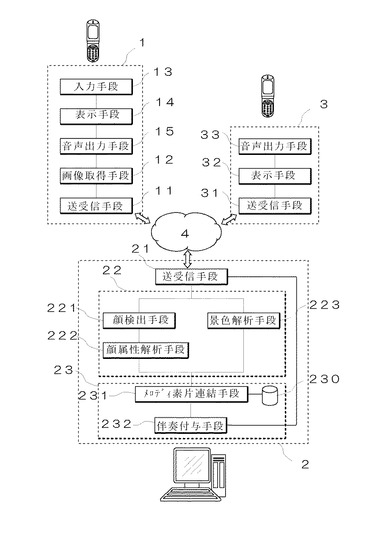
まず、第一の端末装置1の構成について説明すると、第一の端末装置1は、カメラ付き携帯電話などで構成され、図2に示すように、データを送受信する送受信手段11と、カメラなどの画像取得手段12と、テンキーなどの入力手段13と、文字や画像などを表示する表示手段14と、音楽データなどを出力するための音声出力手段15とを備えている。この第一の端末装置1の作用について説明すると、第一の端末装置1は、画像取得手段12によって取得した画像を送受信手段11を介して音楽データ生成装置2に送信し、そこで生成された音楽データを受信するとともに、その受信した音楽データを画像とともに第二の端末装置3に送信する。
【0023】
一方、第二の端末装置3は、同様に携帯電話などによって構成されるもので、少なくとも、第一の端末装置1から送信されてきたメール本文・画像・音楽データを受信するための送受信手段31と、これら送信されてきたメール本文や画像を表示出力する表示手段32と、音楽データを音声出力するための音声出力手段33とを備えている。この第二の端末装置3は、第一の端末装置1からメールを受信すると、ディスプレイなどの表示手段32にメール本文や画像などを表示するとともに、その画像の表示に同期して音楽を出力する。
【0024】
なお、この実施の形態では、第一の端末装置1や第二の端末装置3として、携帯電話を例に挙げて説明するが、必ずしも携帯電話である必要はなく、パーソナルコンピュータやPDAなどのようにメールの送受信機能や音声出力機能を有する端末装置であればよい。また、画像取得手段についても、端末装置に付属するカメラによって画像を取得するようにしてもよく、もしくは、LANやUSBケーブル、もしくは、カードリーダーやスキャナなどよって外部の端末装置に格納されている画像を用いるようにしてもよい。
【0025】
一方、音楽データ生成装置2は、これらの第一の端末装置1や第二の端末装置3にインターネットなどのネットワーク4を介して接続されるもので、第一の端末装置1から送信されてきた画像に基づいて、その画像のイメージに適合した音楽を生成する。この音楽データ生成装置2の機能ブロックについて説明すると、音楽データ生成装置2は、まず、第一の端末装置1や第二の端末装置3とデータを送受信するための送受信手段21を備えている。この送受信手段21は第一の端末装置1から画像のデータを受信し、また、その受信した画像から生成した音楽を第一の端末装置1に送信する。ここで生成された音楽については、この実施の形態では第一の端末装置1に返信されるが、音楽データ生成装置2から直接第二の端末装置3に送信するようにしてもよい。
【0026】
また、この音楽データ生成装置2は、第一の端末装置1から送信されてきた画像のイメージに適合した音楽を生成する画像解析手段22や音楽データ生成手段23を備えている。この画像解析手段22や音楽データ生成手段23について詳細に説明する。
【0027】
まず、画像解析手段22は、顔検出手段221と景色解析手段223を備えており、顔検出手段221によって、画像中に人物の顔が含まれているか否かを検出し、画像中に顔が含まれていると判定された場合は、その人間の数を把握する。そして、顔属性解析手段222によってその顔の表情や性別、年齢層などを解析する。
【0028】
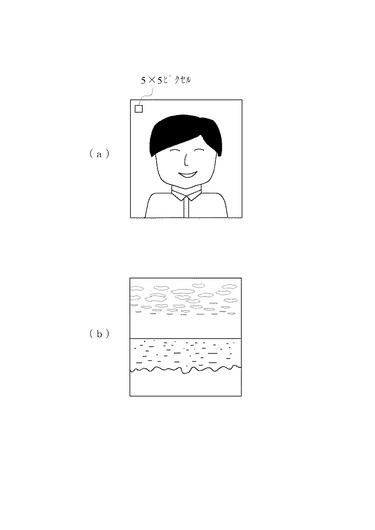
まず、この顔検出手段221について説明すると、顔検出手段221は、送信されてきた画像を量子化し、図3(a)に示すような画像について5ピクセル×5ピクセル程度の領域ごとのRGB値を見ていき、肌色の領域を検出する。連結した肌色領域の周囲形状の複雑さを領域重心から周囲までの距離のばらつき(標準偏差)などで表し、閾値以内ならその周囲にそれと見合う程度の広さの黒領域があれば顔と判定する。ただし、見落としを救済するために、逆に黒領域の下に肌色領域が少しでもあれば、それも顔と判定する。そして、この顔の検出を、画像中のすべての領域について行い、これによって画像中に含まれる人間の数を推定する。なお、顔の検出方法に関しては、上記方法以外にも種々の方法を採用することができる。例えば、種々の顔の標準パターン(正面、斜め横、横)を持っておき、その拡大・縮小と微少回転によって整合のとれる部分の画像があるかどうかを判定することによって顔を検出するようにしてもよい。
【0029】
また、顔属性解析手段222は、このように検出された顔の領域の画像に基づいて、次のようにして顔の表情や性別、年齢層などを解析する。
【0030】
まず、顔の表情を解析する場合は、可能であれば(ほぼ正面を向いて、顔がある程度の大きさに写っている場合)顔領域内における色相などから唇の領域を抽出し、その唇領域の外径、内径、口領域の面積、歯領域の面積などを求める。そして、その唇の領域が大きい場合や、もしくは、その領域の中央部分に歯の白い色相が存在している場合は、笑顔を持った明るい表情の画像であると判定する。一方、唇の面積が小さく、しかも、中央部分に歯の白い色相が存在しない場合や、唇の形状が「への字形状」をしている場合は、暗い表情の画像であると判定する。
【0031】
また、性別は、髪の毛の長さ、髭部分の濃さ、唇の色などに基づいて判定する。例えば、輝度の低い画素数が少ない場合(すなわち、髪の毛が少ない場合)や髭の存在位置に輝度の低い画素が存在している場合(すなわち、髭が存在する場合)は男性的な顔であると判定する。一方、唇周辺に赤に近い画素が集中している場合(すなわち、口紅を塗っている場合)は女性的な顔であると判定する。これらの髪の毛の長さや、髭の有無、唇の色などを総合的に勘案して男性的であるか女性的であるかを判定する。
【0032】
一方、年齢層(幼児/成人/老人)については、目が検出できれば、目の位置(上・下の肌色境界までの距離比)で判定し、額のしわ(検出できれば40歳以上)、髪の毛の量(極端に少なければ老人男性)などを用いて判定する。この年齢の判定方法に関しては、種々の方法を用いることができ、例えば、特許出願2003−381989号公報に記載される方法や、特許公開2002−330943号公報に記載される方法などを用いることができる。
【0033】
景色解析手段223は、画像中に含まれる景色の種別を判定する。景色の種別としては、例えば、オフィスビルなどの建ち並んだ人工的な景色や、木々の生い茂った森や林などの山の景色、大きな湖や海などの景色などがある。これらの景色の種別は次のようにして判定する。例えば、オフィスビルや道路、自動車などを有する人工的な景色であれば比較的直線的な要素を多く含むため、情報量を落とすために、まず画像を2値化し、Hough変換を用いて画像中に明瞭な直線が1本でも検出できる場合は人工的な景色であると判定する。直線の判定にはHough変換を用いる。これによっていかなる方向の線があっても、また、途中で直線が途切れていても検出することができる。また、直線がなく、輪郭が不規則な緑の領域がある場合には、木々の生い茂った森や林など、背景に木があると判定する。一方、図3(b)に示すように、ほぼ水平な一本の直線が存在し、その下方に短い水平成分が多数存在する場合は、波の存在する海や湖、あるいは大きな川の景色であると判定する。
【0034】
そして、このように解析された人間の数や、顔の表情や性別、年齢層、景色の種別などに基づいて、その画像のイメージに適合した音楽を生成する。音楽データ生成手段23は、これらの人間の数や、顔の表情や性別、年齢層、景色の種別などに基づいて、次のようにして音楽データを生成する。
【0035】
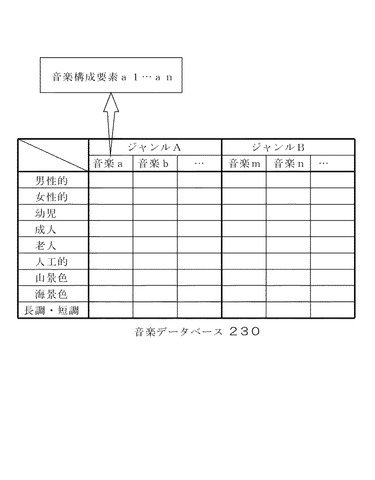
まず、一般的に、画像中に女性が多く含まれる場合は、その画像からは、比較的高い音域で構成された音楽やテンポのゆっくりした音楽、あるいは、オルゴールなどの比較的音色の柔らかな音楽をイメージすることが多い。一方、画像中に男性が多く含まれている場合は、その画像からは、比較的低い音域で構成された音楽や、テンポの速い音楽、あるいは、煩雑な音楽をイメージすることが多い。また、画像中に老人が多く含まれている場合は、軍歌や50年以上昔に流行した歌をイメージし、男女が写っている場合は甘い旋律がふさわしく、また、画像中に幼児が含まれている場合は、その画像からは童謡などの音楽をイメージするのが自然である。一方、人物像の背景や風景写真については、人工的な画像からは、比較的テンポの速い都会的な音楽をイメージすることが多く、また、山の景色からは、クラシックなどのように比較的穏やかな音楽をイメージすることが多い。また、海の景色からは、爽やかな音楽をイメージすることが多い。そこで、このように画像のイメージに適合した音楽を生成すべく、一つの実施例として、例えば、図4に示すように、既存の音楽デーデータベースを作っておき、タイトルの他に歌詞を音符と対応させて格納しておく。図4は、ジャンル毎に分類された音楽a、b…音楽m、音楽n…について男性的、女性的などの属性を割り当てたものである。さらに、曲のイメージをマニュアルで言語表現しておいてもよい。そして、人間によって「男性的/女性的、幼児/成人/老人、人工/自然、山/海」などの属性を音楽に割り当てて音楽データベース230に検索語彙として格納しておく。なお、これらの属性は、人間が実際にその音楽を視聴することによって割り当てておくようにしてもよく、あるいは、歌手が男性である場合は「男性的」、女性である場合は「女性的」であるというように自動的に属性を割り当てておくようにしてもよい。また年齢層の属性については、その音楽が作曲された年代に応じて図4のようなテーブルをあらかじめ用意しておき、その年代に応じた属性を自動的に割り当てるようにしてもよい。さらには、その音楽に歌詞や曲名が含まれている場合は、その歌詞や曲名を、例えば、「オフィス」や「山」や「海」などのキーワードで検索を行い、そのキーワードにヒットする音楽に「人工的」「山」「海」などの属性を割り当てるようにしてもよい。そして、音楽データベース230は、このように属性の割り当てられた音楽のメロディを一小節毎もしくは数小節毎に分割してメロディ素片として格納しておく。
【0036】
音楽データ生成手段23は、メロディ素片連結手段231と伴奏付与手段232を備えて構成されるもので、メロディ素片連結手段231は、画像解析手段22によって解析された画像の属性に基づき、その属性を有するメロディ素片をランダムに連結して数小節からなるメロディを生成する。ただし、メロディ素片を連結する場合は、あらかじめ調や旋法を統一させておく必要があるため、前述の音楽データベース230の中では、調や旋法を統一しておくものとする。また、生成された音楽の最終音はトニック(主音)である必要があるため、連結に際しては、最終音がトニックとなっている小節を選択する。そして、このようにしてメロディ素片を連結することによってメロディを生成するとともに、伴奏付与手段232によって伴奏を付与していく。伴奏付与手段232によって伴奏を付与する場合、あらかじめ定められたコード進行に従い、複数の和音を適宜組み合わせながら伴奏を付与していく。
【0037】
次に、このように構成された音楽データ生成システム100を用いて音楽データを生成する場合のフローチャートについて図6および図7を用いて説明する。
【0038】
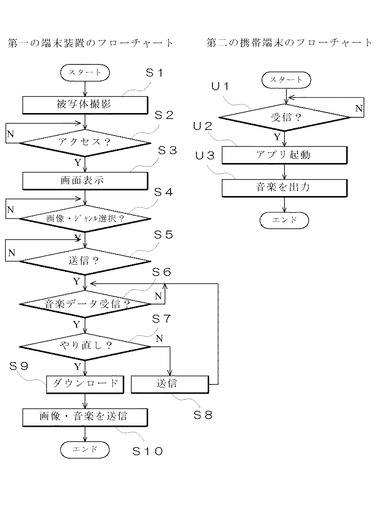
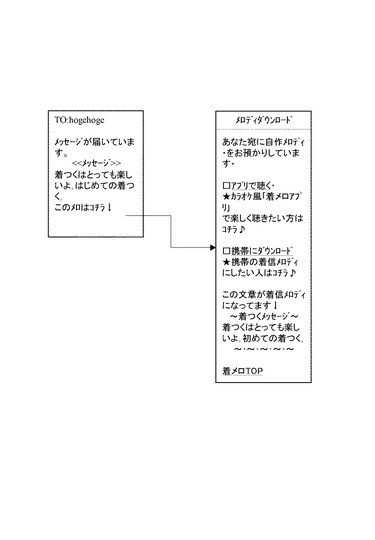
まず、画像に基づいて音楽データを生成する場合、第一の端末装置1のユーザは、カメラなどの画像取得手段12を介して被写体を撮影し(ステップS1)、その画像をメモリに格納しておく。そして、その端末装置を音楽データ生成装置2にアクセスして(ステップS2)、図8や図9に示すような画面を表示する(ステップS3)。図9に示す画面には、音楽生成もととなる画像を選択する画面と、生成される音楽のジャンルを選択する画面が含まれている。そして、ユーザはこの画面に従って所望の画像を選択するとともに、音楽のジャンルを選択して(ステップS4)、その選択された画像や音楽のジャンルを音楽データ生成装置2に送信する(ステップS5)。
【0039】
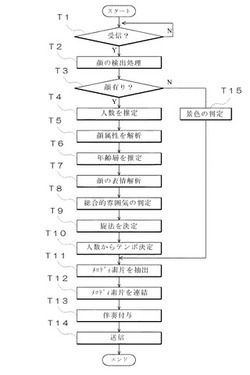
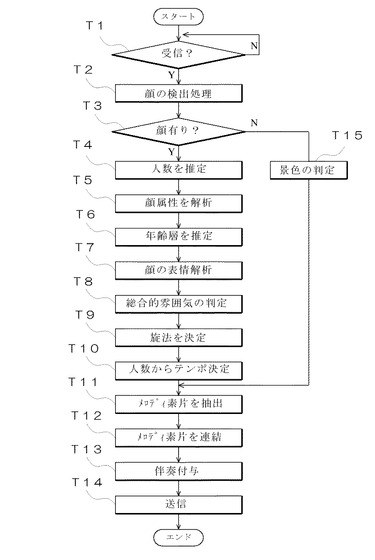
音楽データ生成装置2は、第一の端末装置1からその選択された画像やジャンルに関するデータを受信すると(図7、ステップT1)まず、その画像中に人間の顔が存在するか否かを判定する(ステップT2)。この判定に際しては、画像中における肌色領域を探索し、その肌色領域の大きさに見合う程度の黒領域の存在を上と左で確認するなどの手段を用いて行う。そこで、人間の顔が存在すると判定された場合(ステップT3)、次に、その顔から人間の数を推定するとともに(ステップT4)、画像中に含まれる顔の属性を解析する(ステップT5)。次いで、各顔の年齢層を推定して「幼児/成人/老人」という属性を付与し(ステップT6)、各顔が明るい表情を有しているか、あるいは、暗い表情を有しているかを解析して(ステップT7)、画像中に含まれるすべての顔の雰囲気についての総合的な判定を行う(ステップT8)。そして、この判定された顔の雰囲気(平均値)に基づいて、顔の表情が明るい場合は「長調」、暗い場合は「短調」と決定する(ステップT9)。また、画像中に含まれる人間の数に応じて、図5に示す人数に応じた店舗である参照テーブルを参照して、音楽のテンポを指定し(ステップT10)、例えば、人数が多いほど音楽のテンポを速くする。
【0040】
このように人間の数や顔の年齢層や表情などを解析すると、音楽データ生成手段23は、その算出された属性を用いて図4の音楽データベース230を参照し、年齢層に応じた音楽のメロディ素片を抽出する(ステップT11)。また、平均的な顔の表情が明るい場合は「長調」の音楽のメロディ素片を抽出し、平均的な顔の表情が暗い場合は「短調」の音楽のメロディ素片を抽出する(ステップT11)。そして、このように抽出されたメロディ素片をランダムに連結するとともに、最後にトニックを有するメロディ素片を連結する(ステップT12)。そして、この連結されたメロディに対して所定のコード進行に従った伴奏付けを行い(ステップT13)、最終的に生成された音楽データを第一の端末装置1に送信する(ステップT14)。
【0041】
一方、画像中に顔が存在しない場合は(ステップT3:No)、画像中に含まれる背景の種類を判別し(ステップT15)、縦横斜めの直線量が多く白系統の色相が多い場合は「人工的」な音楽のメロディ素片を抽出する。また、直線量が少なく薄い青や緑系統の色相が多い場合は、「山」の属性が付与された音楽のメロディ素片を抽出し、水平な長い直線と平行な短い直線が多く濃紺系統の色相が多い場合は「海」の属性が付与されたメロディ素片を抽出する(ステップT11)。
【0042】
そして、このように抽出されたメロディ素片をランダムに連結するとともに、最後にトニックを有するメロディ素片を連結して(ステップT12)伴奏付けを行い(ステップT13)、このように生成された音楽データを第一の端末装置1に送信する(ステップT14)。
【0043】
第一の端末装置1では、このように生成された音楽データを受信すると(ステップS6)、図10に示すメロディ作成完了を知らせる画面を表示して、専用のアプリケーションによってユーザの視聴を受け付ける。そして、視聴の結果、やり直しが必要であれば、ユーザによって「やり直し」ボタンの入力を受け付け(ステップS7)、その情報を音楽データ生成装置2に送信し(ステップS8)、新たな音楽データの生成を指示する。一方、この音楽データでよいと判断された場合は、ユーザによるダウンロードボタンの入力を受け付け(ステップS9)、生成された音楽データをメモリに格納するとともに、第二の端末装置3にメール本文や画像などとともに送信する(ステップS10)。
【0044】
このメールを受信した第二の端末装置3側では(ステップU1)、メールの受信に伴って図11に示す専用のアプリケーションを起動し(ステップU2)、メール本文を表示するとともに画像の表示に同期させ音楽データを出力する(ステップU3)。
【0045】
このように上記実施の形態によれば、人間の数、顔の表情や性別、年齢層、景色などに基づいて音楽データを生成するようにしたので、その画像のイメージに適合した音楽を生成することができるようになる。
【0046】
しかも、画像のイメージに適合させた音楽を生成する場合、あらかじめ、音楽データベース230に各音楽のイメージに適合する属性を割り当てておき、この音楽を小節毎に分割して他のメロディ素片と連結するようにしたので、確実に画像のイメージに適合した音楽を生成することができるようになる。しかも、メロディ素片の組み合わせを変えることによって毎回異なった音楽を生成することができるようになる。
【0047】
なお、本発明は上記実施の形態に限定されることなく、種々の形態で実施することができる。
【0048】
例えば、上記実施の形態では、第一の端末装置1から画像を送信し、音楽データ生成装置2で音楽を生成するようにしているが、音楽データ生成装置2を用いて音楽を生成させる場合に限らず、一台の端末装置によって画像の取得と音楽の生成を行うようにしてもよい。また、上記実施の形態のように、第一の端末装置1から音楽データ生成装置2に画像を送信して音楽データを生成させるのではなく、別途新たに画像の解析装置を設けておき、一旦そこに画像を送信して画像を解析させた後、その解析結果を音楽データ生成装置2に送信し、そこで音楽データを生成させるようにしてもよい。この場合、本発明との関係において、他の解析装置と音楽データ生成装置2が、本発明における音楽データ生成装置2を構成することとなる。
【0049】
また、上記実施の形態では、音楽データベース230に既存の音楽を分割して格納しておき、この音楽を数小節ずつ連結して音楽データを生成するようにしているが、解析された人間の数、顔の表情や性別、年齢層などによって独自のアルゴリズムを用いて一から音楽データを生成するようにしてもよい。
【0050】
さらには、上記実施の形態では、画像中に顔が含まれていない場合は景色の種別によって音楽データを生成するようにしているが、必ずしも顔が含まれていない場合にのみ景色の種別を用いる必要はなく、顔の属性と景色の属性の両方を考慮して音楽データを生成するようにしてもよい。
【図面の簡単な説明】
【0051】
【図1】本発明の一実施の形態を示す音楽データ生成システムの概略図
【図2】同形態における音楽データ生成システムの機能ブロック図
【図3】同形態における音楽生成もととなる画像を示す図
【図4】同形態における音楽データ生成装置の音楽データベースの例
【図5】同形態における音楽データ生成装置の音楽データベースの例
【図6】同形態における音楽データ生成システムにおける第一の端末装置と第二の端末装置のフローチャート
【図7】同形態における音楽データ生成システムにおける音楽データ生成装置のフローチャート
【図8】同形態における第一の端末装置の表示例
【図9】同形態における第一の端末装置の表示例
【図10】同形態における第一の端末装置の表示例
【図11】同形態における第一の端末装置の表示例
【符号の説明】
【0052】
100・・・音楽データ生成システム
1・・・第一の端末装置
2・・・音楽データ生成装置
3・・・第二の端末装置
4・・・ネットワーク
11・・・送受信手段
12・・・画像取得手段
13・・・入力手段
14・・・表示手段
15・・・音声出力手段
31・・・送受信手段
32・・・表示手段
33・・・音声出力手段
21・・・送受信手段
22・・・画像解析手段
221・・・顔検出手段
222・・・顔属性解析手段
223・・・景色解析手段
23・・・音楽データ生成手段
230・・・音楽データベース
231・・・メロディ素片連結手段
232・・・伴奏付与手段
【技術分野】
【0001】
本発明は、カメラなどによって撮影された画像に含まれる顔や景色などに基づいて、自動的にその画像のイメージに適合した音楽を生成することのできる装置に関するものである。
【背景技術】
【0002】
近年、携帯電話を用いたメールサービスなどとして、メール本文の内容に基づいた音楽を生成し、これを第三者に送信できるようにしたサービスなどが存在している。また、これ以外にも、画像を相手に送信する際、その画像に基づいて独自の音楽を生成して、メール本文とともに送信できるようにしたシステムも提案されている。
【0003】
例えば、下記の特許文献1には、カメラで撮影された画像から独自の音楽データを生成するようにしたシステムが提案されている。このシステムの詳細について説明すると、カメラによって取得された画像を256階調に量子化する手段と、その解析された結果に基づいて音楽データを生成する手段とを備えている。この量子化された情報から音楽データを生成する場合は、あらかじめ各画素の輝度に対応した音声情報をテンプレートとして保持しておき、このテンプレートを参照して各画素の輝度に対応する音高を当てはめていく。具体的には、解析された画素の輝度が「0〜10」であった場合は、基準となるオクターブから1オクターブ上の「A」の音高を当てはめ、また、ある画素の輝度が「247〜255」であった場合には、基準となるオクターブから1オクターブ下の「H」の音を当てはめる。そして、これらの音高を画像の縦軸方向、あるいは、横軸方向に並べていき音楽データを生成するようにしたものである。
【特許文献1】特開2001−350473号公報
【発明の開示】
【発明が解決しようとする課題】
【0004】
しかしながら、このような方法で音楽データを生成する場合においては、次のような問題を生ずる。すなわち、上記特許文献1のように、単に256階調に量子化された情報から音楽データを生成する方法では、画像から受けるイメージと実際に出力される音楽のイメージが異なる場合がある。例えば、被写体として笑顔を有する人間が写っていたとしても、景色や照明などが暗かったために基準オクターブから下の低い音高が当てはめられたり、暗いイメージを有する音楽が生成されたりすることがある。また、一般に、携帯電話を用いて被写体を撮影する際、人間を被写体とすることが多いが、上記特許文献1では、人間の顔の表情などに特化して音楽を生成するものではないため、顔の表情や性別、年齢層などの属性に応じた音楽を生成することができない。
【0005】
さらには、撮影された画像が都会などの人工的な景色や、山や海などの自然の景色であった場合、それぞれの画像から受けるイメージが異なり、例えば、オフィスビルの建ち並んだ人工的な景色からは比較的緊張感のある堅いイメージを受け、また、森や林などの山の画像からは、癒しの雰囲気を有する柔らかなイメージを受けることが多い。また、海の画像からは、爽やかなイメージを受けることが多い。従って、これらの景色から音楽を生成する場合においても、同様に、その景色のイメージに適合した音楽を生成できるようにすることが好ましい。
【0006】
そこで、本発明は、上記課題を解決するために、顔の表情や景色などのイメージに適合した音楽を生成することのできる音楽データ生成装置を提供することを目的とするものである。
【課題を解決するための手段】
【0007】
すなわち、本発明は上記課題を解決するために、画像から音楽データを生成する音楽データ生成装置において、画像中に顔が含まれているか否かを検出する顔検出手段と、当該顔検出手段によって画像中に顔が含まれていることが検出された場合、当該顔の属性を解析する顔属性解析手段と、当該顔属性解析手段によって解析された顔の属性に基づいて音楽データを生成する音楽データ生成手段とを備えるようにしたものである。
【0008】
このようにすれば、顔の属性、すなわち、顔の表情や性別、年齢層などに応じて音楽を生成することができるため、その画像のイメージに適合した音楽を生成することができる。すなわち、笑顔を有する被写体の画像からは明るいイメージを有する音楽を生成することができ、また、男性の画像からは男性的なイメージ、女性の画像からは女性的なイメージを有する音楽を生成することができるようになる。
【0009】
また、画像に顔が含まれていない場合には、景色の属性、すなわち、人工的な景色や、山や海などの景色の種別を判定し、その判定された種別の属性に応じて音楽データを生成する。
【0010】
このようにすれば、画像に顔が含まれていない場合であっても、都会や自然の景色のイメージに適合した音楽を生成することができるようになる。
【0011】
さらには、画像中に含まれる顔の属性と景色の属性の両方を用いて音楽データを生成することもできる。
【0012】
このようにすれば、顔の属性だけでなく、景色の属性も考慮して音楽データを生成するので、より画像のイメージに適合した音楽を生成することができるようになる。
【0013】
また、顔の属性を解析する場合、顔の表情、性別、年齢層などを解析し、これらの解析結果に基づいて音楽データを生成する。
【0014】
このようにすれば、例えば、男性のみが被写体となっている画像からは、男性的なイメージを有する音楽を生成することができ、また、被写体の年齢層が高い場合は、その年齢層に適合した音楽を生成することができるようになる。
【0015】
また、上述のように景色の種類を判別する場合、画像中に含まれる直線の種類や数などの情報に基づいて景色の種類を判別する。
【0016】
一般的に、都会や建物の中などの人工的な景色であれば、直線的な構成要素の量が比較的に多くなり、また、自然の景色であれば、直線的な構成要素よりもランダムな構成要素の割合が増えるが、このように直線を含むか否かから景色の種類を判別すれば、より正確に景色の種類に適合した音楽を生成することができるようになる。
【0017】
また、音楽データを生成する場合、音楽データベースの中に、顔の属性や景色の属性に対応するメロディ素片をあらかじめ格納しておき、これらの音楽データベースの中から複数のメロディ素片を抽出して連結することにより音楽データを生成する。
【0018】
このようにすれば、例えば、あらかじめイメージの分かっている音楽に対して属性を割り当てておき、これを分割して他のメロディ素片と連結するようにすれば、確実にその属性に対応した音楽を生成することができるようになる。しかも、メロディ素片の連結方法をランダムにすれば毎回異なった音楽を生成することができるようになる。
【発明の効果】
【0019】
本発明は、画像から音楽データを生成する音楽データ生成装置において、画像中に顔が含まれているか否かを検出する顔検出手段と、当該顔検出手段によって画像中に顔が含まれていることが検出された場合、当該顔の属性を解析する顔属性解析手段と、当該顔属性解析手段によって解析された顔の属性に基づいて音楽データを生成する音楽データ生成手段とを備えるようにしたので、例えば、笑顔を有する被写体の画像からは明るいイメージを有する音楽を生成することができ、また、男性の画像からは男性的なイメージを、女性の画像からは女性的なイメージを有する音楽を生成することができるようになる。
【発明を実施するための最良の形態】
【0020】
以下、本発明の一実施の形態について図面を参照して説明する。
【0021】
本実施の形態における音楽データ生成システム100は、図1に示すように、画像付きのメールを第三者に送信する第一の端末装置1と、この第一の端末装置1にネットワーク4を介して接続される音楽データ生成装置2と、この音楽データ生成装置2によって生成された音楽をメール本文や画像とともに受信する第二の端末装置3とを少なくとも備えて構成される。
【0022】
まず、第一の端末装置1の構成について説明すると、第一の端末装置1は、カメラ付き携帯電話などで構成され、図2に示すように、データを送受信する送受信手段11と、カメラなどの画像取得手段12と、テンキーなどの入力手段13と、文字や画像などを表示する表示手段14と、音楽データなどを出力するための音声出力手段15とを備えている。この第一の端末装置1の作用について説明すると、第一の端末装置1は、画像取得手段12によって取得した画像を送受信手段11を介して音楽データ生成装置2に送信し、そこで生成された音楽データを受信するとともに、その受信した音楽データを画像とともに第二の端末装置3に送信する。
【0023】
一方、第二の端末装置3は、同様に携帯電話などによって構成されるもので、少なくとも、第一の端末装置1から送信されてきたメール本文・画像・音楽データを受信するための送受信手段31と、これら送信されてきたメール本文や画像を表示出力する表示手段32と、音楽データを音声出力するための音声出力手段33とを備えている。この第二の端末装置3は、第一の端末装置1からメールを受信すると、ディスプレイなどの表示手段32にメール本文や画像などを表示するとともに、その画像の表示に同期して音楽を出力する。
【0024】
なお、この実施の形態では、第一の端末装置1や第二の端末装置3として、携帯電話を例に挙げて説明するが、必ずしも携帯電話である必要はなく、パーソナルコンピュータやPDAなどのようにメールの送受信機能や音声出力機能を有する端末装置であればよい。また、画像取得手段についても、端末装置に付属するカメラによって画像を取得するようにしてもよく、もしくは、LANやUSBケーブル、もしくは、カードリーダーやスキャナなどよって外部の端末装置に格納されている画像を用いるようにしてもよい。
【0025】
一方、音楽データ生成装置2は、これらの第一の端末装置1や第二の端末装置3にインターネットなどのネットワーク4を介して接続されるもので、第一の端末装置1から送信されてきた画像に基づいて、その画像のイメージに適合した音楽を生成する。この音楽データ生成装置2の機能ブロックについて説明すると、音楽データ生成装置2は、まず、第一の端末装置1や第二の端末装置3とデータを送受信するための送受信手段21を備えている。この送受信手段21は第一の端末装置1から画像のデータを受信し、また、その受信した画像から生成した音楽を第一の端末装置1に送信する。ここで生成された音楽については、この実施の形態では第一の端末装置1に返信されるが、音楽データ生成装置2から直接第二の端末装置3に送信するようにしてもよい。
【0026】
また、この音楽データ生成装置2は、第一の端末装置1から送信されてきた画像のイメージに適合した音楽を生成する画像解析手段22や音楽データ生成手段23を備えている。この画像解析手段22や音楽データ生成手段23について詳細に説明する。
【0027】
まず、画像解析手段22は、顔検出手段221と景色解析手段223を備えており、顔検出手段221によって、画像中に人物の顔が含まれているか否かを検出し、画像中に顔が含まれていると判定された場合は、その人間の数を把握する。そして、顔属性解析手段222によってその顔の表情や性別、年齢層などを解析する。
【0028】
まず、この顔検出手段221について説明すると、顔検出手段221は、送信されてきた画像を量子化し、図3(a)に示すような画像について5ピクセル×5ピクセル程度の領域ごとのRGB値を見ていき、肌色の領域を検出する。連結した肌色領域の周囲形状の複雑さを領域重心から周囲までの距離のばらつき(標準偏差)などで表し、閾値以内ならその周囲にそれと見合う程度の広さの黒領域があれば顔と判定する。ただし、見落としを救済するために、逆に黒領域の下に肌色領域が少しでもあれば、それも顔と判定する。そして、この顔の検出を、画像中のすべての領域について行い、これによって画像中に含まれる人間の数を推定する。なお、顔の検出方法に関しては、上記方法以外にも種々の方法を採用することができる。例えば、種々の顔の標準パターン(正面、斜め横、横)を持っておき、その拡大・縮小と微少回転によって整合のとれる部分の画像があるかどうかを判定することによって顔を検出するようにしてもよい。
【0029】
また、顔属性解析手段222は、このように検出された顔の領域の画像に基づいて、次のようにして顔の表情や性別、年齢層などを解析する。
【0030】
まず、顔の表情を解析する場合は、可能であれば(ほぼ正面を向いて、顔がある程度の大きさに写っている場合)顔領域内における色相などから唇の領域を抽出し、その唇領域の外径、内径、口領域の面積、歯領域の面積などを求める。そして、その唇の領域が大きい場合や、もしくは、その領域の中央部分に歯の白い色相が存在している場合は、笑顔を持った明るい表情の画像であると判定する。一方、唇の面積が小さく、しかも、中央部分に歯の白い色相が存在しない場合や、唇の形状が「への字形状」をしている場合は、暗い表情の画像であると判定する。
【0031】
また、性別は、髪の毛の長さ、髭部分の濃さ、唇の色などに基づいて判定する。例えば、輝度の低い画素数が少ない場合(すなわち、髪の毛が少ない場合)や髭の存在位置に輝度の低い画素が存在している場合(すなわち、髭が存在する場合)は男性的な顔であると判定する。一方、唇周辺に赤に近い画素が集中している場合(すなわち、口紅を塗っている場合)は女性的な顔であると判定する。これらの髪の毛の長さや、髭の有無、唇の色などを総合的に勘案して男性的であるか女性的であるかを判定する。
【0032】
一方、年齢層(幼児/成人/老人)については、目が検出できれば、目の位置(上・下の肌色境界までの距離比)で判定し、額のしわ(検出できれば40歳以上)、髪の毛の量(極端に少なければ老人男性)などを用いて判定する。この年齢の判定方法に関しては、種々の方法を用いることができ、例えば、特許出願2003−381989号公報に記載される方法や、特許公開2002−330943号公報に記載される方法などを用いることができる。
【0033】
景色解析手段223は、画像中に含まれる景色の種別を判定する。景色の種別としては、例えば、オフィスビルなどの建ち並んだ人工的な景色や、木々の生い茂った森や林などの山の景色、大きな湖や海などの景色などがある。これらの景色の種別は次のようにして判定する。例えば、オフィスビルや道路、自動車などを有する人工的な景色であれば比較的直線的な要素を多く含むため、情報量を落とすために、まず画像を2値化し、Hough変換を用いて画像中に明瞭な直線が1本でも検出できる場合は人工的な景色であると判定する。直線の判定にはHough変換を用いる。これによっていかなる方向の線があっても、また、途中で直線が途切れていても検出することができる。また、直線がなく、輪郭が不規則な緑の領域がある場合には、木々の生い茂った森や林など、背景に木があると判定する。一方、図3(b)に示すように、ほぼ水平な一本の直線が存在し、その下方に短い水平成分が多数存在する場合は、波の存在する海や湖、あるいは大きな川の景色であると判定する。
【0034】
そして、このように解析された人間の数や、顔の表情や性別、年齢層、景色の種別などに基づいて、その画像のイメージに適合した音楽を生成する。音楽データ生成手段23は、これらの人間の数や、顔の表情や性別、年齢層、景色の種別などに基づいて、次のようにして音楽データを生成する。
【0035】
まず、一般的に、画像中に女性が多く含まれる場合は、その画像からは、比較的高い音域で構成された音楽やテンポのゆっくりした音楽、あるいは、オルゴールなどの比較的音色の柔らかな音楽をイメージすることが多い。一方、画像中に男性が多く含まれている場合は、その画像からは、比較的低い音域で構成された音楽や、テンポの速い音楽、あるいは、煩雑な音楽をイメージすることが多い。また、画像中に老人が多く含まれている場合は、軍歌や50年以上昔に流行した歌をイメージし、男女が写っている場合は甘い旋律がふさわしく、また、画像中に幼児が含まれている場合は、その画像からは童謡などの音楽をイメージするのが自然である。一方、人物像の背景や風景写真については、人工的な画像からは、比較的テンポの速い都会的な音楽をイメージすることが多く、また、山の景色からは、クラシックなどのように比較的穏やかな音楽をイメージすることが多い。また、海の景色からは、爽やかな音楽をイメージすることが多い。そこで、このように画像のイメージに適合した音楽を生成すべく、一つの実施例として、例えば、図4に示すように、既存の音楽デーデータベースを作っておき、タイトルの他に歌詞を音符と対応させて格納しておく。図4は、ジャンル毎に分類された音楽a、b…音楽m、音楽n…について男性的、女性的などの属性を割り当てたものである。さらに、曲のイメージをマニュアルで言語表現しておいてもよい。そして、人間によって「男性的/女性的、幼児/成人/老人、人工/自然、山/海」などの属性を音楽に割り当てて音楽データベース230に検索語彙として格納しておく。なお、これらの属性は、人間が実際にその音楽を視聴することによって割り当てておくようにしてもよく、あるいは、歌手が男性である場合は「男性的」、女性である場合は「女性的」であるというように自動的に属性を割り当てておくようにしてもよい。また年齢層の属性については、その音楽が作曲された年代に応じて図4のようなテーブルをあらかじめ用意しておき、その年代に応じた属性を自動的に割り当てるようにしてもよい。さらには、その音楽に歌詞や曲名が含まれている場合は、その歌詞や曲名を、例えば、「オフィス」や「山」や「海」などのキーワードで検索を行い、そのキーワードにヒットする音楽に「人工的」「山」「海」などの属性を割り当てるようにしてもよい。そして、音楽データベース230は、このように属性の割り当てられた音楽のメロディを一小節毎もしくは数小節毎に分割してメロディ素片として格納しておく。
【0036】
音楽データ生成手段23は、メロディ素片連結手段231と伴奏付与手段232を備えて構成されるもので、メロディ素片連結手段231は、画像解析手段22によって解析された画像の属性に基づき、その属性を有するメロディ素片をランダムに連結して数小節からなるメロディを生成する。ただし、メロディ素片を連結する場合は、あらかじめ調や旋法を統一させておく必要があるため、前述の音楽データベース230の中では、調や旋法を統一しておくものとする。また、生成された音楽の最終音はトニック(主音)である必要があるため、連結に際しては、最終音がトニックとなっている小節を選択する。そして、このようにしてメロディ素片を連結することによってメロディを生成するとともに、伴奏付与手段232によって伴奏を付与していく。伴奏付与手段232によって伴奏を付与する場合、あらかじめ定められたコード進行に従い、複数の和音を適宜組み合わせながら伴奏を付与していく。
【0037】
次に、このように構成された音楽データ生成システム100を用いて音楽データを生成する場合のフローチャートについて図6および図7を用いて説明する。
【0038】
まず、画像に基づいて音楽データを生成する場合、第一の端末装置1のユーザは、カメラなどの画像取得手段12を介して被写体を撮影し(ステップS1)、その画像をメモリに格納しておく。そして、その端末装置を音楽データ生成装置2にアクセスして(ステップS2)、図8や図9に示すような画面を表示する(ステップS3)。図9に示す画面には、音楽生成もととなる画像を選択する画面と、生成される音楽のジャンルを選択する画面が含まれている。そして、ユーザはこの画面に従って所望の画像を選択するとともに、音楽のジャンルを選択して(ステップS4)、その選択された画像や音楽のジャンルを音楽データ生成装置2に送信する(ステップS5)。
【0039】
音楽データ生成装置2は、第一の端末装置1からその選択された画像やジャンルに関するデータを受信すると(図7、ステップT1)まず、その画像中に人間の顔が存在するか否かを判定する(ステップT2)。この判定に際しては、画像中における肌色領域を探索し、その肌色領域の大きさに見合う程度の黒領域の存在を上と左で確認するなどの手段を用いて行う。そこで、人間の顔が存在すると判定された場合(ステップT3)、次に、その顔から人間の数を推定するとともに(ステップT4)、画像中に含まれる顔の属性を解析する(ステップT5)。次いで、各顔の年齢層を推定して「幼児/成人/老人」という属性を付与し(ステップT6)、各顔が明るい表情を有しているか、あるいは、暗い表情を有しているかを解析して(ステップT7)、画像中に含まれるすべての顔の雰囲気についての総合的な判定を行う(ステップT8)。そして、この判定された顔の雰囲気(平均値)に基づいて、顔の表情が明るい場合は「長調」、暗い場合は「短調」と決定する(ステップT9)。また、画像中に含まれる人間の数に応じて、図5に示す人数に応じた店舗である参照テーブルを参照して、音楽のテンポを指定し(ステップT10)、例えば、人数が多いほど音楽のテンポを速くする。
【0040】
このように人間の数や顔の年齢層や表情などを解析すると、音楽データ生成手段23は、その算出された属性を用いて図4の音楽データベース230を参照し、年齢層に応じた音楽のメロディ素片を抽出する(ステップT11)。また、平均的な顔の表情が明るい場合は「長調」の音楽のメロディ素片を抽出し、平均的な顔の表情が暗い場合は「短調」の音楽のメロディ素片を抽出する(ステップT11)。そして、このように抽出されたメロディ素片をランダムに連結するとともに、最後にトニックを有するメロディ素片を連結する(ステップT12)。そして、この連結されたメロディに対して所定のコード進行に従った伴奏付けを行い(ステップT13)、最終的に生成された音楽データを第一の端末装置1に送信する(ステップT14)。
【0041】
一方、画像中に顔が存在しない場合は(ステップT3:No)、画像中に含まれる背景の種類を判別し(ステップT15)、縦横斜めの直線量が多く白系統の色相が多い場合は「人工的」な音楽のメロディ素片を抽出する。また、直線量が少なく薄い青や緑系統の色相が多い場合は、「山」の属性が付与された音楽のメロディ素片を抽出し、水平な長い直線と平行な短い直線が多く濃紺系統の色相が多い場合は「海」の属性が付与されたメロディ素片を抽出する(ステップT11)。
【0042】
そして、このように抽出されたメロディ素片をランダムに連結するとともに、最後にトニックを有するメロディ素片を連結して(ステップT12)伴奏付けを行い(ステップT13)、このように生成された音楽データを第一の端末装置1に送信する(ステップT14)。
【0043】
第一の端末装置1では、このように生成された音楽データを受信すると(ステップS6)、図10に示すメロディ作成完了を知らせる画面を表示して、専用のアプリケーションによってユーザの視聴を受け付ける。そして、視聴の結果、やり直しが必要であれば、ユーザによって「やり直し」ボタンの入力を受け付け(ステップS7)、その情報を音楽データ生成装置2に送信し(ステップS8)、新たな音楽データの生成を指示する。一方、この音楽データでよいと判断された場合は、ユーザによるダウンロードボタンの入力を受け付け(ステップS9)、生成された音楽データをメモリに格納するとともに、第二の端末装置3にメール本文や画像などとともに送信する(ステップS10)。
【0044】
このメールを受信した第二の端末装置3側では(ステップU1)、メールの受信に伴って図11に示す専用のアプリケーションを起動し(ステップU2)、メール本文を表示するとともに画像の表示に同期させ音楽データを出力する(ステップU3)。
【0045】
このように上記実施の形態によれば、人間の数、顔の表情や性別、年齢層、景色などに基づいて音楽データを生成するようにしたので、その画像のイメージに適合した音楽を生成することができるようになる。
【0046】
しかも、画像のイメージに適合させた音楽を生成する場合、あらかじめ、音楽データベース230に各音楽のイメージに適合する属性を割り当てておき、この音楽を小節毎に分割して他のメロディ素片と連結するようにしたので、確実に画像のイメージに適合した音楽を生成することができるようになる。しかも、メロディ素片の組み合わせを変えることによって毎回異なった音楽を生成することができるようになる。
【0047】
なお、本発明は上記実施の形態に限定されることなく、種々の形態で実施することができる。
【0048】
例えば、上記実施の形態では、第一の端末装置1から画像を送信し、音楽データ生成装置2で音楽を生成するようにしているが、音楽データ生成装置2を用いて音楽を生成させる場合に限らず、一台の端末装置によって画像の取得と音楽の生成を行うようにしてもよい。また、上記実施の形態のように、第一の端末装置1から音楽データ生成装置2に画像を送信して音楽データを生成させるのではなく、別途新たに画像の解析装置を設けておき、一旦そこに画像を送信して画像を解析させた後、その解析結果を音楽データ生成装置2に送信し、そこで音楽データを生成させるようにしてもよい。この場合、本発明との関係において、他の解析装置と音楽データ生成装置2が、本発明における音楽データ生成装置2を構成することとなる。
【0049】
また、上記実施の形態では、音楽データベース230に既存の音楽を分割して格納しておき、この音楽を数小節ずつ連結して音楽データを生成するようにしているが、解析された人間の数、顔の表情や性別、年齢層などによって独自のアルゴリズムを用いて一から音楽データを生成するようにしてもよい。
【0050】
さらには、上記実施の形態では、画像中に顔が含まれていない場合は景色の種別によって音楽データを生成するようにしているが、必ずしも顔が含まれていない場合にのみ景色の種別を用いる必要はなく、顔の属性と景色の属性の両方を考慮して音楽データを生成するようにしてもよい。
【図面の簡単な説明】
【0051】
【図1】本発明の一実施の形態を示す音楽データ生成システムの概略図
【図2】同形態における音楽データ生成システムの機能ブロック図
【図3】同形態における音楽生成もととなる画像を示す図
【図4】同形態における音楽データ生成装置の音楽データベースの例
【図5】同形態における音楽データ生成装置の音楽データベースの例
【図6】同形態における音楽データ生成システムにおける第一の端末装置と第二の端末装置のフローチャート
【図7】同形態における音楽データ生成システムにおける音楽データ生成装置のフローチャート
【図8】同形態における第一の端末装置の表示例
【図9】同形態における第一の端末装置の表示例
【図10】同形態における第一の端末装置の表示例
【図11】同形態における第一の端末装置の表示例
【符号の説明】
【0052】
100・・・音楽データ生成システム
1・・・第一の端末装置
2・・・音楽データ生成装置
3・・・第二の端末装置
4・・・ネットワーク
11・・・送受信手段
12・・・画像取得手段
13・・・入力手段
14・・・表示手段
15・・・音声出力手段
31・・・送受信手段
32・・・表示手段
33・・・音声出力手段
21・・・送受信手段
22・・・画像解析手段
221・・・顔検出手段
222・・・顔属性解析手段
223・・・景色解析手段
23・・・音楽データ生成手段
230・・・音楽データベース
231・・・メロディ素片連結手段
232・・・伴奏付与手段
【特許請求の範囲】
【請求項1】
画像から音楽データを生成する音楽データ生成装置において、
画像中に顔が含まれているか否かを検出する顔検出手段と、
当該顔検出手段によって画像中に顔が含まれていることが検出された場合、当該顔の属性を解析する顔属性解析手段と、
当該顔属性解析手段によって解析された顔の属性に基づいて音楽データを生成する音楽データ生成手段と、
を備えたことを特徴とする音楽データ生成装置。
【請求項2】
画像から音楽データを生成する音楽データ生成装置において、
画像中に顔が含まれているか否かを検出する顔検出手段と、
前記顔検出手段によって画像中に顔が含まれていないことが検出された場合、画像の景色の属性を解析する景色解析手段と、
当該景色解析手段によって解析された景色の属性に応じて音楽データを生成する音楽データを生成する音楽データ生成手段と、
を備えたことを特徴とする音楽データ生成装置。
【請求項3】
画像から音楽データを生成する音楽データ生成装置において、
画像中に顔が含まれているか否かを検出する顔検出手段と、
当該顔検出手段によって画像中に顔が含まれていることが検出された場合、顔の属性を解析する顔属性解析手段と、
画像の景色の属性を解析する景色解析手段と、
前記顔属性解析手段によって解析された顔の属性、および、前記景色解析手段によって解析された景色の属性に基づいて音楽データを生成する音楽データ生成手段と、
を備えたことを特徴とする音楽データ生成装置。
【請求項4】
前記顔属性解析手段が、表情、性別、年齢層の少なくともいずれか一つを解析するものである請求項1または3に記載の音楽データ生成装置。
【請求項5】
前記景色解析手段が、画像中に含まれる直線の種類または数に基づいて景色の属性を解析するものである請求項2または3に記載の音楽データ生成装置。
【請求項6】
前記音楽データ生成手段が、属性や景色の属性に基づいて音楽データベースの中から複数のメロディ素片を抽出し、当該メロディ素片を連結することによって音楽データを生成するものである請求項1から5いずれか1項に記載の音楽データ生成装置。
【請求項1】
画像から音楽データを生成する音楽データ生成装置において、
画像中に顔が含まれているか否かを検出する顔検出手段と、
当該顔検出手段によって画像中に顔が含まれていることが検出された場合、当該顔の属性を解析する顔属性解析手段と、
当該顔属性解析手段によって解析された顔の属性に基づいて音楽データを生成する音楽データ生成手段と、
を備えたことを特徴とする音楽データ生成装置。
【請求項2】
画像から音楽データを生成する音楽データ生成装置において、
画像中に顔が含まれているか否かを検出する顔検出手段と、
前記顔検出手段によって画像中に顔が含まれていないことが検出された場合、画像の景色の属性を解析する景色解析手段と、
当該景色解析手段によって解析された景色の属性に応じて音楽データを生成する音楽データを生成する音楽データ生成手段と、
を備えたことを特徴とする音楽データ生成装置。
【請求項3】
画像から音楽データを生成する音楽データ生成装置において、
画像中に顔が含まれているか否かを検出する顔検出手段と、
当該顔検出手段によって画像中に顔が含まれていることが検出された場合、顔の属性を解析する顔属性解析手段と、
画像の景色の属性を解析する景色解析手段と、
前記顔属性解析手段によって解析された顔の属性、および、前記景色解析手段によって解析された景色の属性に基づいて音楽データを生成する音楽データ生成手段と、
を備えたことを特徴とする音楽データ生成装置。
【請求項4】
前記顔属性解析手段が、表情、性別、年齢層の少なくともいずれか一つを解析するものである請求項1または3に記載の音楽データ生成装置。
【請求項5】
前記景色解析手段が、画像中に含まれる直線の種類または数に基づいて景色の属性を解析するものである請求項2または3に記載の音楽データ生成装置。
【請求項6】
前記音楽データ生成手段が、属性や景色の属性に基づいて音楽データベースの中から複数のメロディ素片を抽出し、当該メロディ素片を連結することによって音楽データを生成するものである請求項1から5いずれか1項に記載の音楽データ生成装置。
【図1】


【図2】
【図3】
【図4】
【図5】

【図6】
【図7】
【図8】
【図9】

【図10】

【図11】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【公開番号】特開2007−219393(P2007−219393A)
【公開日】平成19年8月30日(2007.8.30)
【国際特許分類】
【出願番号】特願2006−42494(P2006−42494)
【出願日】平成18年2月20日(2006.2.20)
【新規性喪失の例外の表示】特許法第30条第1項適用申請有り 2005年10月15日 同志社大学・大阪電気通信大学主催の「2005年度同志社大学リエゾンフェア ネオカデンフォーラム2005」において文書をもって発表
【出願人】(503027931)学校法人同志社 (346)
【出願人】(307010096)フリュー株式会社 (210)
【Fターム(参考)】
【公開日】平成19年8月30日(2007.8.30)
【国際特許分類】
【出願日】平成18年2月20日(2006.2.20)
【新規性喪失の例外の表示】特許法第30条第1項適用申請有り 2005年10月15日 同志社大学・大阪電気通信大学主催の「2005年度同志社大学リエゾンフェア ネオカデンフォーラム2005」において文書をもって発表
【出願人】(503027931)学校法人同志社 (346)
【出願人】(307010096)フリュー株式会社 (210)
【Fターム(参考)】
[ Back to top ]