
画像処理プログラム、画像処理装置および画像処理方法
【課題】画像ファイルを生成するための画像形成処理プログラム等を提供すること。
【解決手段】MFPで機能する画像処理プログラムは、複数ページを備える原稿の1ページ分のページ画像をスキャンして得られるページスキャンデータを複数含むスキャンスキャンファイルの複数個を、データ記憶領域に記憶させる。また、スキャンファイルに含まれている複数のページスキャンデータ各々が表すページ画像内の所定の特徴に基づく、スキャンファイルとしての特性に基づいて、当該特性が近似するスキャンファイルを抽出する。
【解決手段】MFPで機能する画像処理プログラムは、複数ページを備える原稿の1ページ分のページ画像をスキャンして得られるページスキャンデータを複数含むスキャンスキャンファイルの複数個を、データ記憶領域に記憶させる。また、スキャンファイルに含まれている複数のページスキャンデータ各々が表すページ画像内の所定の特徴に基づく、スキャンファイルとしての特性に基づいて、当該特性が近似するスキャンファイルを抽出する。
【発明の詳細な説明】
【技術分野】
【0001】
本明細書に記載の技術は、画像ファイルを生成するための画像処理プログラム等に関する。
【背景技術】
【0002】
特許文献1には、複数ページを備える特定の原稿を複数の分割原稿に分割し、分割原稿の各々を複数台のスキャナを用いて分散してスキャン処理を行う技術が開示されている。複数台のスキャナの各々で分割原稿を読み取ると、スキャナごとに分割ファイルが生成されるため、スキャナごとに生成された複数の分割ファイルをユーザの指定する順に従って結合し、特定の原稿に対応する1つの統合ファイルを作成する。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2005−176191号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、スキャナでは特定の原稿のみならず他の原稿もスキャンされる。よって、各スキャナで生成されるファイルには、特定の原稿から生成された分割ファイルと、他の原稿から生成された他ファイルとが混在する。すると、特定の原稿に対応する1つの統合ファイルを作成する場合には、分割ファイルと他ファイルとが混在して存在している状態から、ユーザが分割ファイルのみをピックアップして結合するなどの手間が発生する。本明細書では、このような不便性を解消することができる技術を提供する。
【課題を解決するための手段】
【0005】
本明細書に記載の画像処理プログラムは、コンピュータが読み取り可能な画像処理プログラムであって、複数ページを備えるスキャン対象物の1ページ分のページ画像をスキャンして得られるページスキャンデータを複数含むスキャンデータ集合の複数個を記憶部に記憶させる記憶制御手段と、スキャンデータ集合に含まれている複数のページスキャンデータ各々が表すページ画像内の所定の特徴に基づく、スキャンデータ集合としての特性に基づいて、当該特性が近似するスキャンデータ集合を抽出する第1抽出手段と、してコンピュータを機能させることを特徴とする。
【0006】
このように構成された画像処理プログラムによって、コンピュータを上記各手段として機能させれば、第1抽出手段によって、スキャンデータ集合としての特性が互いに類似している複数のスキャンデータ集合を抽出することができる。これにより、特定のスキャン対象物から生成されたスキャンデータ集合と他のスキャン対象物から生成されたスキャンデータ集合とが混在して記憶部に記憶されている場合においても、特定のスキャン対象物から生成されたスキャンデータ集合のみを自動で抽出することが可能となる。
【0007】
また、請求項2に記載の画像処理プログラムでは、算出手段によって特定値を算出することによって、スキャンデータ集合の単位で、スキャンデータ集合としての特性を数値化することができる。よって、特性が近似するスキャンデータ集合を抽出し易くすることができる。
【0008】
また、請求項3に記載の画像処理プログラムでは、第1抽出手段が抽出した複数のスキャンデータ集合を結合して、スキャン対象物に関する1のデータ集合を生成することができる。これにより、特定のスキャン対象物から生成されたスキャンデータ集合をユーザがピックアップした上で結合する必要を無くすことができるため、不便性を解消することができる。
【0009】
また、請求項4に記載の画像処理プログラムでは、第1抽出手段で抽出されたスキャンデータ集合を、第1抽出手段で抽出されていない他のスキャンデータ集合と区別して、ユーザに認識させることができる。また、第1抽出手段で抽出された複数のスキャンデータ集合を、1つのグループとしてユーザに認識させることができる。
【0010】
また、請求項5に記載の画像処理プログラムでは、第1抽出手段で抽出された複数のスキャンデータ集合のうちから、同一の属性情報が対応付けられているスキャンデータ集合をさらに抽出することができる。これにより、特定のスキャン対象物から生成されたスキャンデータ集合をより効率よく抽出することが可能となる。
【0011】
また、請求項6に記載の画像処理プログラムでは、互いに特徴が近似している複数のスキャンデータ集合に加えて、同一の属性情報が対応付けられている複数のスキャンデータ集合も表示させることが可能となる。よって、表示されるスキャンデータ集合の対象を、より広げることが可能となる。
【0012】
また、請求項7に記載の画像処理プログラムでは、第1抽出手段で抽出されたスキャンデータ集合と第2抽出手段によって抽出されたスキャンデータ集合とを区別して、ユーザに認識させることができる。
【0013】
また、請求項8に記載の画像処理プログラムでは、互いに特徴点が類似している複数のスキャンデータ集合を抽出する処理を、複数の特徴点の各々に対して行うことができる。これにより、特定のスキャン対象物から生成されたスキャンデータ集合と他のスキャン対象物から生成されたスキャンデータ集合とを区別する判断基準を増やすことができるため、特定のスキャン対象物から生成されたスキャンデータ集合をより効率よく抽出することが可能となる。
【0014】
また、請求項9に記載の画像処理プログラムでは、第1抽出手段で複数のスキャンデータ集合を抽出するために用いられた特徴を、ユーザに認識させることができる。
【図面の簡単な説明】
【0015】
【図1】通信システムの構成を示すブロック図である。
【図2】通信システムの動作フローチャートである。
【図3】MFPの動作フローチャートである。
【図4】MFPの動作フローチャートである。
【図5】MFPの動作フローチャートである。
【図6】特徴記憶テーブルの一例である。
【図7】特徴記憶テーブルの一例である。
【図8】近似閾値テーブルの一例である。
【図9】表示画面の表示例である。
【図10】表示画面の表示例である。
【発明を実施するための形態】
【0016】
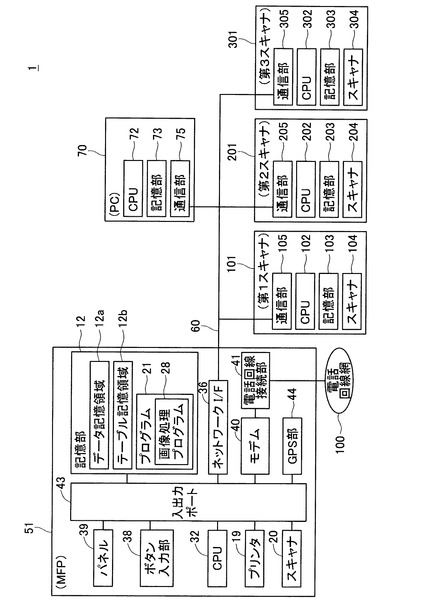
図1に、本明細書に係る実施形態として例示される通信システム1のブロック図を示す。通信システム1は、MFP(Multifunction Peripheral)51、第1スキャナ101、第2スキャナ201、第3スキャナ301、PC(Personal Computer)70を備える。MFP51は、プリンタ機能、スキャナ機能、コピー機能、ファクシミリ機能などを備える多機能周辺装置である。MFP51、第1スキャナ101ないし第3スキャナ301、PC70は、LAN60を介して互いに通信可能に接続されている。
【0017】
MFP51の構成について説明する。第1MFP51は、記憶部12、プリンタ19、スキャナ20、CPU32、ネットワークI/F36、ボタン入力部38、パネル39、モデム40、電話回線接続部41、GPS部44、を主に備えている。これらの構成要素は、入出力ポート43を介して互いに通信可能とされている。
【0018】
ボタン入力部38は、第1MFP51の各機能を実行するためのキーである。ボタン入力部38は、タッチパネルとして、パネル39と一体に構成されていてもよい。パネル39は、MFP51の各種機能情報を表示する。プリンタ19は、印刷を実行する部位である。スキャナ20は、読み取りを実行する部位である。GPS部44は、MFP51の位置情報を取得する部位である。モデム40は、ファクシミリ機能によって送信する原稿データを、電話回線網100に伝送可能な信号に変調して電話回線接続部41を介して送信したり、電話回線網100から電話回線接続部41を介して入力された信号を受信し、原稿データへ復調するものである。
【0019】
CPU32は、記憶部12に記憶されるプログラムに従って処理を実行する。以降、画像処理プログラム28やオペレーティングシステムなど、プログラムを実行するCPU32のことを、単にプログラム名でも記載する場合がある。例えば「画像処理プログラム28が」という記載は、画像処理プログラム28を実行するCPU32が」を意味する場合がある。なお、記憶部12は、RAM(Random Access Memory)、ROM(Read Only Memory)、フラッシュメモリ、HDD(ハードディスク)、CPU32が備えるバッファなどが組み合わされて構成されている。
【0020】
記憶部12は、プログラム21を記憶する。プログラム21は、基本プログラム(図示省略)、画像処理プログラム28等を含む。基本プログラムは、ネットワークI/F36に通信を実行させるためのプログラム等を含む。また基本プログラムは、GPS部24が算出した情報を各プログラムが取得するためのAPI(Application Programming Interface)を提供するプログラムでもある。また画像処理プログラム28は、後述する画像処理の動作フローをCPU32に実行させるためのプログラムである。
【0021】
また記憶部12は、データ記憶領域12aおよびテーブル記憶領域12bを備える。データ記憶領域12aには、後述する、スキャンファイルなどが記憶される。またテーブル記憶領域12bには、特徴記憶テーブルTB1、TB2および近似閾値テーブルTB3が記憶される。
【0022】
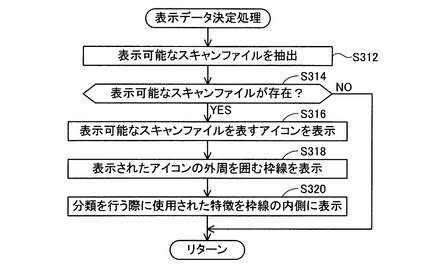
図6に、特徴記憶テーブルTB1の一例を示す。特徴記憶テーブルTB1は、ページスキャンデータの各ページについての特徴を記憶するテーブルである。特徴記憶テーブルTB1は、ファイル番号410、ページ番号411、ページ内最大フォントサイズ412、ページ内最小フォントサイズ413、各フォントサイズ文字数414、地色RGB値415、を記憶する。ファイル番号410は、スキャンファイルの各々を識別するための連続番号である。ページ番号411は、1つのスキャンファイルに含まれている複数のページスキャンデータの各々を識別するためのページ番号である。ページ内最大フォントサイズ412は、1ページ分のページスキャンデータによって表示されるページ画像内のフォントの中の、最大フォントのサイズである。ページ内最小フォントサイズ413は、1ページ分のページスキャンデータによって表示されるページ画像内のフォントの中の、最小フォントのサイズである。各フォントサイズ文字数414は、各サイズのフォントがそれぞれ何文字ずつあるかを示すデータである。すなわち各フォントサイズ文字数414は、文字数を度数、ポイント数を階級としたヒストグラムである。図6の例では、6ポイントから20ポイントまでの15種類のサイズのフォントの各々について、文字数が記憶されている。地色RGB値415は、ページスキャンデータによって表示されるページ画像内において、紙の地色(黄色系、蛍光色、など)をRGBの数値で表したものである。
【0023】
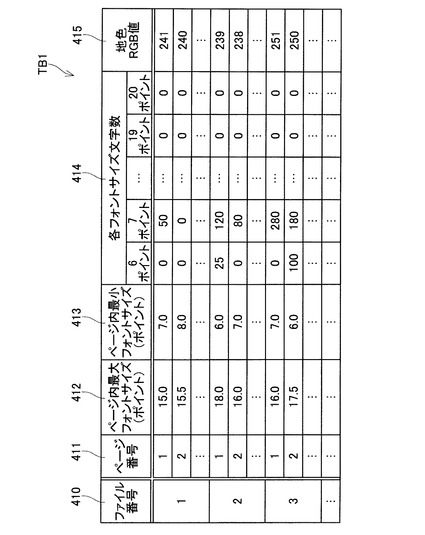
図7に、特徴記憶テーブルTB2の一例を示す。特徴記憶テーブルTB2は、スキャンファイルとしての特徴を記憶するテーブルである。特徴記憶テーブルTB2は、ファイル番号508、ユーザ情報509、スキャナ情報510、ファイル内最大フォントサイズ511、ファイル内最小フォントサイズ512、平均フォントサイズ513、フォントサイズ標準偏差514、地色平均値515、地色標準偏差516、タグ情報517を記憶する。ファイル番号508は、スキャンファイルの各々を識別するための連続番号である。ユーザ情報509は、スキャンファイルの作成をスキャナに指示したユーザを示す情報である。ユーザ情報509の一例としては、ユーザ名やパスワードなどが挙げられる。スキャナ情報510は、スキャンファイルを作成したスキャナを示す情報である。ファイル内最大フォントサイズ511は、スキャンファイルに含まれる全てのページ画像内の文字の中で、最大のフォントサイズである。ファイル内最小フォントサイズ512は、スキャンファイルに含まれる全てのページ画像内の文字の中で、最小のフォントサイズである。平均フォントサイズ513は、スキャンファイルに含まれる全てのページ画像内の全文字について、フォントサイズの平均値を算出した値である。フォントサイズ標準偏差514は、スキャンファイルに含まれる全てのページ画像内の全文字について、フォントサイズの標準偏差を算出した値である。地色平均値515は、スキャンファイルに含まれる全てのページ画像について、紙の地色のRGB値の平均値を算出した値である。地色標準偏差516は、スキャンファイルに含まれる全てのページ画像について、紙の地色のRGB値の標準偏差を算出した値である。タグ情報517は、互いに近似する特徴を有するスキャンファイルを同じグループに分類するための情報である。
【0024】
図8に、近似閾値テーブルTB3の一例を示す。近似閾値テーブルTB3は、各種の特徴ごとに、近似閾値520を記憶するテーブルである。近似閾値520は、後述する分類処理(S218)において、特徴が近似するか否かの判断に用いられる値である。
【0025】
第1スキャナ101の構成について説明する。第1スキャナ101は、CPU102、記憶部103、スキャナ104、通信部105を主に備えている。CPU102は、スキャナ104などの各機能の制御を行う。スキャナ104は、複数ページを備える原稿を1ページずつスキャンして、ページスキャンデータを生成する。そして、複数ページ分のページスキャンデータを含むスキャンファイルを生成する。記憶部103は、生成されたスキャンファイルを記憶する。通信部105は、LAN60上の各種の機器と通信を実行する。なお、第2スキャナ201および第3スキャナ301の構成は、第1スキャナ101と同様であるため、ここでは詳細な説明は省略する。
【0026】
PC70の構成について説明する。PC70は、CPU72、記憶部73、通信部75を主に備えている。これらの構成の機能は、MFP51で説明した構成の機能と同様であるため、ここでは詳細な説明は省略する。
【0027】
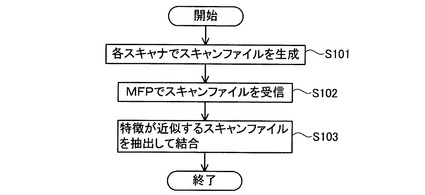
<通信システムの動作>
本実施形態に係る通信システム1の動作を説明する。図2を用いて、通信システム1の動作の全体フローを説明する。S101において、1の原稿を複数の分割原稿に分割した上で、分割原稿の各々のスキャンファイルを生成する処理が行われる。スキャンファイルは、第1スキャナ101ないし第3スキャナ301を用いて生成することが可能である。具体的には、ユーザによって1の原稿が複数の分割原稿に分割され、分割原稿の各々が第1スキャナ101ないし第3スキャナ301にセットされる。そして、第1スキャナ101ないし第3スキャナ301の操作部(不図示)を用いてスキャン実行操作を実行することで、分割原稿の各々についてのスキャンファイルが生成され、記憶部に記憶される。
【0028】
S102において、MFP51は、第1スキャナ101ないし第3スキャナ301の各々から、LAN60およびネットワークI/F36を介して、分割原稿についてのスキャンファイルを受信する。そしてスキャンファイルごとに特徴を抽出する、特徴保存処理を実行する。
【0029】
S103において、MFP51は、特徴が近似するスキャンファイルを、データ記憶領域12aに記憶されている多数のスキャンファイルの中から抽出して結合する、結合処理を実行する。これにより、分割前の1の原稿についての、1のスキャンファイルが完成する。以下、MFP51で行われる特徴保存処理(S102)および結合処理(S103)について、図3ないし図5のフローを用いて詳説する。
【0030】
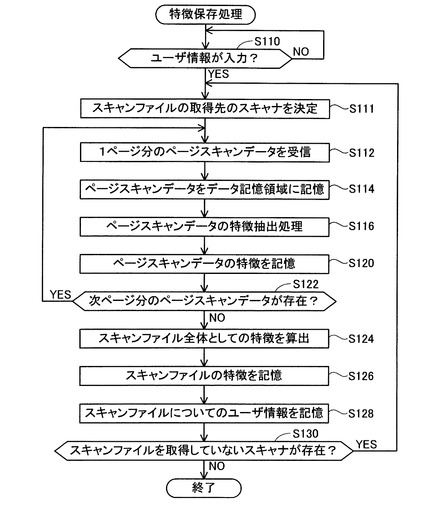
<特徴保存処理>
図3を用いて、特徴保存処理の内容を説明する。S110においてCPU32は、ユーザ情報509であるユーザ名の入力処理が、ボタン入力部38を介して行われたか否かを判断する。入力処理が行われていない場合(S110:NO)にはS110へ戻り、入力処理が完了した場合(S110:YES)にはS111へ進む。S111においてCPU32は、スキャンファイルの取得先のスキャナを、第1スキャナ101ないし第3スキャナ301の中から決定する。S112において、CPU32は、取得先として決定されたスキャナから、スキャンファイルを構成する複数のページスキャンデータのうちから、1ページ分のページスキャンデータを受信する。S114において、CPU32は、受信したページスキャンデータをデータ記憶領域12aに記憶する。
【0031】
S116において、CPU32は、受信したページスキャンデータに対して特徴を抽出する処理を行う。抽出される特徴は、ページ内最大フォントサイズ412、ページ内最小フォントサイズ413、各フォントサイズ文字数414、地色RGB値415、である(図6、特徴記憶テーブルTB1参照)。ページスキャンデータ内の特徴を抽出する方法の具体例を説明する。まず、画像認識技術によって、ページスキャンデータによって表示されるページ画像内から、文字が記載されている文字領域を一字ずつ矩形形状に抽出する。そして、それぞれの文字領域の高さを計測することで、使用されているフォントのサイズ(ポイント数)を取得する。これにより、ページ内最大フォントサイズ412およびページ内最小フォントサイズ413を抽出することができる。また、文字領域の数を計測することで、フォントのサイズごとに、使用されている文字数を取得する。これにより、各フォントサイズ文字数414を抽出することができる。また、文字領域以外の領域を抽出し、抽出した領域の色を測定することで、地色RGB値415を抽出することができる。
【0032】
S120において、CPU32は、S116で抽出したページスキャンデータの各特徴を、特徴記憶テーブルTB1(図6)に記憶する。このとき、今回処理を行っているスキャンファイルに対応するファイル番号410の列内であって、今回処理を行っているページスキャンデータに対応するページ番号411に対応する列に、各特徴を記憶する。S122において、CPU32は、次ページ分のページスキャンデータが存在するか否かを判断する。次ページが存在する場合(S122:YES)にはS112へ戻り、スキャンファイル内の次のページデータに対して、S112からS120までの処理を行う。一方、次ページが存在しない場合(S122:NO)には、1つのスキャンファイル内の全ページについて処理が完了したと判断され、S124へ進む。
【0033】
S124において、CPU32は、特徴記憶テーブルTB1に保存されている、スキャンファイルを構成する複数のページスキャンデータの特徴を用いて、スキャンファイル全体としての特徴を算出する処理を行う。算出される特徴は、ファイル内最大フォントサイズ511、ファイル内最小フォントサイズ512、平均フォントサイズ513、フォントサイズ標準偏差514、地色平均値515、地色標準偏差516、である(図7、特徴記憶テーブルTB2参照)。スキャンファイルの特徴を算出する方法の具体例を説明する。ファイル内最大フォントサイズ511は、複数のページスキャンデータの各々におけるページ内最大フォントサイズ412のうち、最大値を選択することで取得することができる。ファイル内最小フォントサイズ512は、複数のページスキャンデータの各々におけるページ内最小フォントサイズ413のうち、最小値を選択することで取得することができる。平均フォントサイズ513およびフォントサイズ標準偏差514は、複数のページスキャンデータの各々における各フォントサイズ文字数414を用いて計算を行うことで、取得することができる。地色平均値515および地色標準偏差516は、複数のページスキャンデータの各々における地色RGB値415を用いて計算を行うことで、取得することができる。
【0034】
S126において、CPU32は、S124で抽出したスキャンファイルの各特徴を、特徴記憶テーブルTB2(図7)に記憶する。このとき、今回処理を行っているスキャンファイルに対応するファイル番号508の列内に、各特徴を記憶する。S128において、CPU32は、スキャンファイルについてのユーザ情報509(スキャンファイルを作成したユーザ名)を、特徴記憶テーブルTB2(図7)に記憶する。このとき、今回処理を行っているスキャンファイルに対応するファイル番号508の列内に、ユーザ情報509を記憶する。
【0035】
S130において、CPU32は、まだスキャンファイルを取得していないスキャナが存在するか否かを判断する。未取得のスキャナが存在する場合(S130:YES)にはS111へ戻り、次のスキャンファイルの取得先のスキャナを、第1スキャナ101ないし第3スキャナ301のうちから決定する。そして、再度S112からS128の処理を実行する。一方、未取得のスキャナが存在しない場合(S130:NO)には、特徴保存処理を終了する。
【0036】
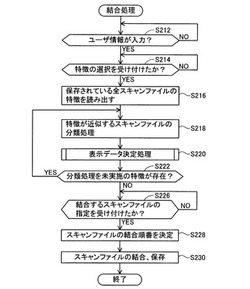
<結合処理>
図4および図5を用いて、結合処理の内容を説明する。S212において、ユーザ情報509であるユーザ名の入力処理が、ボタン入力部38を介して行われたか否かを判断する。入力処理が行われていない場合(S212:NO)にはS212へ戻り、入力処理が完了した場合(S212:YES)にはS214へ進む。
【0037】
S214において、CPU32は、近似するスキャンファイルを抽出する際に用いる特徴の選択を受け付けたか否かを判断する。具体例としては、パネル39に各種の特徴(ファイル内最大フォントサイズ511、平均フォントサイズ513、フォントサイズ標準偏差514など)を表示し、ユーザによる特徴の選択を受け付ける。S214では、複数の特徴の選択を受け付けることも可能である。特徴の選択を受け付けていない場合(S214:NO)にはS214へ戻り、選択を受け付けた場合(S214:YES)にはS216へ進む。
【0038】
S216においてCPU32は、特徴記憶テーブルTB2(図7)から、保存されている全てのスキャンファイルについて、特徴を読み出す。S218において、CPU32は、互いに特徴が近似するスキャンファイルを同一のグループに分類する、分類処理を行う。具体的には、S214で選択された特徴(複数の特徴が選択されている場合には、そのうちの1つの特徴)を、S216で読み出した全てのスキャンファイルについて比較し、特徴が近似するスキャンファイルを抽出する。そして、抽出したスキャンファイルに同一のタグ情報517を割り当てて、特徴記憶テーブルTB2に記憶させる。特徴が近似するか否かの判断方法の一例としては、S214で選択された特徴を表す数値が、近似閾値テーブルTB3(図8)に記憶されている近似閾値520の範囲内であるか否かを判断する方法が挙げられる。例えばS214において、ファイル内最大フォントサイズ511が選択された場合には、ファイル内最大フォントサイズが互いに±0.5ポイント(近似閾値520)の範囲内であるスキャンファイルが、互いに特徴が近似するスキャンファイルとして抽出される。なお、S214で複数の特徴が選択された場合には、複数の特徴の各々に対して、S218の分類処理が行われる。
【0039】
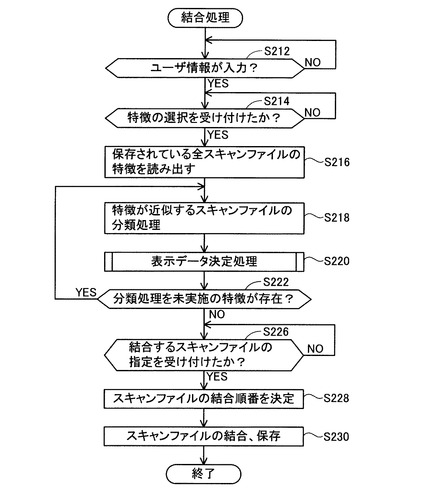
S220において、CPU32は、表示データ決定処理を実行する。図5のフローを用いて、表示データ決定処理の内容を説明する。S312において、CPU32は、特徴記憶テーブルTB2に記憶されているスキャンファイルのうちから、今回S218で分類処理が行われたスキャンファイル(タグ情報517が付けられているスキャンファイル)を抽出する。そして抽出したスキャンファイルのうちから、表示可能なスキャンファイルをさらに抽出する。表示可能なスキャンファイルとは、S212で入力されたユーザ情報と同一のユーザ情報を有するスキャンファイルである。すなわち、特徴保存処理を実行しているユーザと同一のユーザによって作成されたスキャンファイルである。
【0040】
S314において、CPU32は、表示可能なスキャンファイルが存在するか否かを判断する。存在しない場合(S314:NO)にはS222(図4)へ進み、存在する場合(S314:YES)にはS316へ進む。
【0041】
S316において、CPU32は、表示可能なスキャンファイルを表すアイコンを、パネル39に表示する。表示可能なスキャンファイルが複数存在する場合には、複数のアイコンを、順に整列するように表示する。
【0042】
S318において、CPU32は、S316で表示されたアイコンの外周を囲む枠線を、パネル39に表示する。S320において、CPU32は、分類を行う際に使用された特徴を、S318で表示された枠線の内側に表示する。そして表示データ決定処理が終了し、S222(図4)へ進む。
【0043】
S222において、CPU32は、分類処理を未実施の特徴が存在するか否かを判断する。未実施の特徴が存在する場合(S222:YES)には、S218へ戻り、S214で選択された複数の特徴のうち、分類処理を未実施の特徴について、S218およびS220を実行する。一方、未実施の特徴が存在しない場合(S222:NO)には、S214で選択された複数の特徴の全てに対してS218およびS220の処理が実行された場合か、S214で1つのみの特徴が選択された場合であると判断され、S226へ進む。
【0044】
S226において、CPU32は、結合するスキャンファイルの指定を受け付けたか否かを判断する。具体的には、パネル39に表示されている、枠線で囲われたアイコンのグループの何れかを指定する操作が入力されたか否かを判断する。指定を受け付けていない場合(S226:NO)にはS226へ戻り、指定を受け付けた場合(S226:YES)にはS228へ進む。
【0045】
S228において、CPU32は、複数のスキャンファイルを結合する際の結合順番を決定する。結合順番の決定は、ユーザによる入力を受け付けることで行なわれても良い。または、画像認識技術により各スキャンファイルのページ番号を認識している場合には、ページ番号が順番に並ぶように自動で結合順番を決定することも可能である。
【0046】
S230において、CPU32は、複数のスキャンファイルを互いに結合し、データ記憶領域12aに記憶する。これにより、分割前の元の原稿についての、1つのスキャンファイルが完成する。
【0047】
<具体動作例>
本実施形態に係る画像処理の具体動作例を、図6ないし図9を用いて説明する。本実施形態では、例として、第1の原稿を2つに分割して第1スキャナ101および第2スキャナ201でスキャン処理するとともに、第2の原稿を分割せずに第3スキャナ301でスキャン処理する場合を説明する。また、特徴保存処理(図3)によって、図6に示すような特徴記憶テーブルTB1が作成された場合を説明する。また、図6に示す特徴記憶テーブルTB1に基づいて、特徴保存処理(図3)によって、図7に示すような特徴記憶テーブルTB2が作成された場合を説明する。図6の特徴記憶テーブルTB1および図7の特徴記憶テーブルTB2では、第1の原稿の前半部のスキャンファイルが、ファイル番号410=「1」の列に記憶されている。また、第2の原稿のスキャンファイルが、ファイル番号410=「2」の列に記憶されている。また、第1の原稿の後半部のスキャンファイルが、ファイル番号410=「3」の列に記憶されている。また、結合処理(図4)のS212において、ユーザ情報509としてユーザ名=「ユーザA」が入力された場合を説明する。またS214において、近似するスキャンファイルを抽出する際に用いる特徴として、ファイル内最大フォントサイズ511および平均フォントサイズ513が選択された場合を説明する。
【0048】
近似するスキャンファイルを抽出するための特徴として、ファイル内最大フォントサイズ511を用いる場合における、結合処理を説明する。S218(図4)において、ファイル内最大フォントサイズ511の特徴について、各スキャンファイルが比較される。そして、ファイル内最大フォントサイズ511が互いに±0.5ポイントの範囲内であるスキャンファイル(ファイル番号508=「2」、「3」のスキャンファイル)(図7、領域A1参照)が、特徴が互いに近似するファイルとして抽出される。また、抽出されたスキャンファイルに同一のタグ情報517=「ファイル内最大フォントサイズが近似」が割り当てられ、特徴記憶テーブルTB2に記憶される(図7、領域A11)。
【0049】
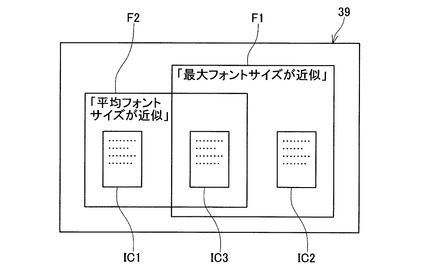
表示データ決定処理へ進み、S312において、今回分類処理が行われたスキャンファイル(ファイル番号508=「2」、「3」のスキャンファイル)が抽出される。そして、表示可能なスキャンファイル(ユーザ情報509が「ユーザA」であるスキャンファイル)として、ファイル番号508=「2」、「3」のスキャンファイルが抽出される。S316において、図9に示すように、ファイル番号508=「2」および「3」のスキャンファイルの各々を表すアイコンIC2およびIC3が、パネル39に横に並んだ状態で表示される。また、表示されたアイコンIC2およびIC3の外周を囲む枠線F1が表示される(S318)。また、分類を行う際に使用された特徴である「最大フォントサイズが近似」が、枠線F1の内側に表示される(S320)。
【0050】
次に、近似するスキャンファイルを抽出するための特徴として、平均フォントサイズ513を用いる場合における、結合処理を説明する。S218(図4)において、平均フォントサイズ513の特徴について、各スキャンファイルが比較される。そして、平均フォントサイズ513が互いに±1ポイントの範囲内であるスキャンファイル(ファイル番号508=「1」、「3」、「4」のスキャンファイル)(図7、領域A2参照)が、特徴が互いに近似するファイルとして抽出される。また、抽出されたスキャンファイルに同一のタグ情報517=「平均フォントサイズが近似」が割り当てられ、特徴記憶テーブルTB2に記憶される(図7、領域A12)。
【0051】
表示データ決定処理へ進み、S312において、今回分類処理が行われたスキャンファイル(ファイル番号508=「1」、「3」、「4」のスキャンファイル)が抽出される。そして、表示可能なスキャンファイル(ユーザ情報509が「ユーザA」であるスキャンファイル)として、ファイル番号508=「1」、「3」のスキャンファイルが抽出される。S316において、図9に示すように、ファイル番号508=「1」のスキャンファイルを表すアイコンIC1が、パネル39に追加して表示される。また、アイコンIC1およびIC3の外周を囲む枠線F2が表示される(S318)。また、分類を行う際に使用された特徴である「平均フォントサイズが近似」が、枠線F2の内側に表示される(S320)。
【0052】
S226において、枠線F2で囲われたアイコンのグループを指定するユーザ操作の入力が受け付けられる。S228において、アイコンIC1で表されるスキャンファイルが1番目、アイコンIC3で表されるスキャンファイルが2番目、という内容の結合順番のユーザ入力が受け付けられる。S230において、CPU32は、アイコンIC1で表されるスキャンファイル(第1の原稿の前半部)と、アイコンIC3で表されるスキャンファイル(第1の原稿の後半部)とを互いに結合し、データ記憶領域12aに記憶する。これにより、分割前の第1の原稿についての、1つのスキャンファイルが完成する。
【0053】
<効果>
本実施形態に係る画像処理の効果を説明する。分類処理(S218)によって、複数のページスキャンデータによって構成されるスキャンファイルの全体としての特性を比較し、当該特性が互いに類似している複数のスキャンファイルを抽出することができる。これにより、特定の原稿から生成された複数のスキャンファイルと他の原稿から生成されたスキャンファイルとが混在してデータ記憶領域12aに記憶されている場合においても、特定の原稿から生成された複数のスキャンファイルのみを自動で抽出することが可能となる。
【0054】
また、分類処理(S218)によって同一グループに分類された複数のスキャンファイル同士を結合(S230)して、1の原稿についての1のスキャンファイルを生成することができる。これにより、特定の原稿から生成された複数のスキャンファイルをユーザがピックアップした上で結合する必要を無くすことができるため、不便性を解消することができる。
【0055】
また、分類処理(S218)によって同一グループに分類された複数のスキャンファイルを、分類処理(S218)によって同一グループに分類された複数のスキャンファイルを囲う枠線を表示する(S318)ことによって、同一グループに分類された複数のスキャンファイルを、1つのグループとしてユーザに認識させることができる。また、同一グループに分類された複数のスキャンファイルを、他のスキャンファイルと区別してユーザに認識させることができる。
【0056】
また、分類処理(S218)によって同一グループに分類された複数のスキャンファイルのうちから、表示可能なスキャンファイル(特徴保存処理を実行しているユーザと同一のユーザによって作成されたスキャンファイル)をさらに抽出することができる(S312)。これにより、特定の原稿から生成されたスキャンファイルを、より効率よく抽出することが可能となる。
【0057】
また、分類処理(S218)を、複数の特徴点(例:ファイル内最大フォントサイズ511、平均フォントサイズ513、など)の各々に対して行うことができる。これにより、特定の原稿から生成されたスキャンファイルと他の原稿から生成されたスキャンファイルとを区別する判断基準を増やすことができるため、特定の原稿から生成されたスキャンファイルをより効率よく抽出することが可能となる。
【0058】
また、分類を行う際に使用された特徴を、枠線の内側に表示することができる(S320)。これにより、分類処理(S218)で複数のスキャンファイルを抽出するために用いられた特徴を、ユーザに認識させることができる。
【0059】
以上、本発明の具体例を詳細に説明したが、これらは例示にすぎず、特許請求の範囲を限定するものではない。特許請求の範囲に記載の技術には、以上に例示した具体例を様々に変形、変更したものが含まれる。
【0060】
<変形例>
S312で表示可能ではないと判断されたスキャンファイルを、S312で表示可能と判断されたスキャンファイルとともに表示するとしてもよい。これにより、特徴保存処理を実行しているユーザ以外の他のユーザが作成したスキャンファイルも、S316における表示処理の対象とすることができるため、スキャンファイルの表示対象をより広げることが可能となる。またこの場合、表示可能ではないと判断されたスキャンファイルと、表示可能と判断されたスキャンファイルとを区別できるように、スキャンファイルを作成したユーザを表示するとしてもよい。
【0061】
本変形例における変形動作例を、図10を用いて説明する。なお、変形動作例における前提条件は、前述の具体動作例と同様である。近似するスキャンファイルを抽出するための特徴として、平均フォントサイズ513を用いる場合には、ファイル番号508=「1」、「3」、「4」のスキャンファイル(図7、領域A2参照)が、特徴が互いに近似するファイルとして抽出される。ここで、ファイル番号508=「4」のスキャンファイルは、特徴保存処理を実行しているユーザ(ユーザA)以外の他のユーザ(ユーザB)が作成したスキャンファイルである。よって、表示データ決定処理(S316)において、図10に示すように、ファイル番号508=「4」のスキャンファイルを表すアイコンIC4が、パネル39に追加して表示される。また、アイコンIC1、IC3、IC4の外周を囲む枠線F2aが表示される(S318)。また、アイコンIC1およびIC3で表されるスキャンファイルがユーザAによって作成され、アイコンIC4で表されるスキャンファイルがユーザBによって作成された旨が、枠線F2aの内側に表示される。これにより、第1抽出手段で抽出されたスキャンファイルと第2抽出手段によって抽出されたスキャンファイルとを区別して、ユーザに認識させることができる。
【0062】
また、同一グループに分類された複数のスキャンファイルを他のスキャンファイルと区別して表示する方法は、枠線で囲う方法(S318)に限られない。例えば、同一グループに属するスキャンファイルを表す各アイコンを、他のアイコンと異なる態様(アイコンの大きさを異ならせる、アイコンの色を異ならせる、アイコンを点滅表示させる、など)で表示してもよい。または、同一グループに属するスキャンファイルを表す各アイコンを、互いに関連付けて表示(例:同一グループの複数アイコンを、その一部が互いに重なるように表示)する態様であってもよい。
【0063】
また、抽出される特徴(S116)は、本実施形態で示したものに限られない。例えば、行間のポイント数や、文字間のポイント数などを用いても良い。また、特徴を抽出する際に用いられる算出値は、平均値や標準偏差に限られず、各種の統計に用いられる算出値(例:メディアン値)であってもよい。
【0064】
また、各スキャンファイルを識別するための識別情報を特徴として用いて、結合対象のスキャンファイルを抽出するとしてもよい。識別情報の例としては、スキャナの設置場所や、スキャナが接続されているルータのIDなどが挙げられる。ユーザが1の原稿を複数の分割原稿に分割して、複数のスキャナでスキャン処理を行う場合には、互いに距離が近いスキャナを使用する場合が多い。よって、識別設置場所が互いに近接している複数のスキャナの各々で生成されたスキャンファイルを抽出することや、同一のルータに接続されている複数のスキャナの各々で生成されたスキャンファイルを抽出することにより、結合処理の対象となるスキャンファイルを自動で抽出することが可能となる。また、スキャナの設置場所は、各スキャナに備えられているGPS部により取得される形態であってもよいし、予めユーザによって各スキャナに登録される形態であってもよい。
【0065】
画像処理プログラム28がMFP51の記憶部12に記憶されている場合を説明したが、この形態に限られず、LAN60に接続されている他の機器の記憶部に記憶されていてもよい。例えば、PC70の記憶部73に画像処理プログラム28が記憶されている場合には、PC70のCPU72によって、図2ないし図5のフローを実行することができる。
【0066】
また、スキャンファイル生成に使用されるスキャナは外付けのスキャナに限られず、MFP51が備えるスキャナ20を使用することも可能である。この場合、LAN60を介してスキャンファイルを受信する処理(S112、S114)を省略することができる。また、1の原稿を複数の分割原稿に分割する際の分割数は、2分割に限られず、3分割以上でもよい。
【0067】
互いに特徴が近似するスキャンファイルを同一のグループに分類する方法は、タグ情報517を割り当てる方法(S218)に限られず、各種の方法が可能である。例えば、同一のグループに属する複数のスキャンファイルを、同一のフォルダに格納する方法であってもよい。
【0068】
スキャンファイル全体としての特徴を算出する処理(S124)は、スキャンファイルを構成するページスキャンデータの全てを使用する形態に限られない。ページスキャンデータの一部を抽出(例:偶数ページを抽出、所定ページごとに抽出)し、抽出したページスキャンデータについて計算を行うことで、スキャンファイル全体としての特徴を算出するとしてもよい。これにより、計算量を抑えることができる。
【0069】
各フォントサイズ文字数414は、6ポイントから20ポイントまでの15種類のサイズのフォントの各々について、文字数をカウントしたが、この形態に限られない。15種類より多いまたは少ないサイズのフォントの各々について文字数をカウントしてもよい。
【0070】
S112からS122において、ページスキャンデータを受信して特徴を抽出する処理を、1ページ分ずつ繰り返す形態を説明したが、この形態に限られない。スキャンファイルを構成する全ページ分のページスキャンデータを受信した後に、各ページについて特徴を抽出する処理を実行してもよい。
【0071】
S212における、ユーザ情報509の入力処理は省略することが可能である。この場合、S312では、S110で入力されたユーザ情報509を用いて、表示可能なスキャンファイル抽出する処理を実行すればよい。
【0072】
また、本明細書または図面に説明した技術要素は、単独であるいは各種の組合せによって技術的有用性を発揮するものであり、出願時請求項記載の組合せに限定されるものではない。また、本明細書または図面に例示した技術は複数目的を同時に達成するものであり、そのうちの一つの目的を達成すること自体で技術的有用性を持つものである。
【0073】
なお、CPU32はコンピュータの一例である。原稿はスキャン対象物の一例である。スキャンファイルはスキャンデータ集合の一例である。S114を実行するCPU32は記憶制御手段、記憶手段の一例である。ページ内最大フォントサイズ412、地色RGB値415などは所定の特徴の一例である。ファイル内最大フォントサイズ511、平均フォントサイズ513などは特性の一例である。S218を実行するCPU32は第1抽出手段、第1抽出ステップの一例である。フォントサイズ、地色のRGB値などは所定の特徴を表す数値の一例である。S124を実行するCPU32は算出手段の一例である。S230を実行するCPU32はデータ処理制御手段の一例である。S318を実行するCPU32は表示制御手段の一例である。ユーザ情報509は属性情報の一例である。S312を実行するCPU32は第2抽出手段の一例である。
【0074】
なお、各プログラムは一つのプログラムモジュールから構成されるものであってもよいし、複数のプログラムモジュールから構成されるものであってもよい。また、各一例は置換可能な他の構成であってもよく、本発明の範疇である。プログラム(画像処理プログラム28など)に基づく処理を実行するコンピュータ(CPU32など)であってもよいし、オペレーティングシステムや他のアプリケーションなど、画像処理プログラム以外のプログラムに基づく処理を実行するコンピュータであってもよいし、コンピュータの指示に従って動作するハード構成(パネル39など)であってもよいし、コンピュータとハード構成とが連動した構成であってもよい。もちろん、複数のプログラムに基づく処理を連動させて処理を実行するコンピュータであってもよいし、複数のプログラムに基づく処理を連動させて処理を実行するコンピュータの指示に従って動作するハード構成であってもよい。
【符号の説明】
【0075】
1:通信システム、28:画像処理プログラム、32:CPU、51:MFP、101:第1スキャナ、201:第2スキャナ、301:第3スキャナ、TB1、TB2:特徴記憶テーブル
【技術分野】
【0001】
本明細書に記載の技術は、画像ファイルを生成するための画像処理プログラム等に関する。
【背景技術】
【0002】
特許文献1には、複数ページを備える特定の原稿を複数の分割原稿に分割し、分割原稿の各々を複数台のスキャナを用いて分散してスキャン処理を行う技術が開示されている。複数台のスキャナの各々で分割原稿を読み取ると、スキャナごとに分割ファイルが生成されるため、スキャナごとに生成された複数の分割ファイルをユーザの指定する順に従って結合し、特定の原稿に対応する1つの統合ファイルを作成する。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2005−176191号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、スキャナでは特定の原稿のみならず他の原稿もスキャンされる。よって、各スキャナで生成されるファイルには、特定の原稿から生成された分割ファイルと、他の原稿から生成された他ファイルとが混在する。すると、特定の原稿に対応する1つの統合ファイルを作成する場合には、分割ファイルと他ファイルとが混在して存在している状態から、ユーザが分割ファイルのみをピックアップして結合するなどの手間が発生する。本明細書では、このような不便性を解消することができる技術を提供する。
【課題を解決するための手段】
【0005】
本明細書に記載の画像処理プログラムは、コンピュータが読み取り可能な画像処理プログラムであって、複数ページを備えるスキャン対象物の1ページ分のページ画像をスキャンして得られるページスキャンデータを複数含むスキャンデータ集合の複数個を記憶部に記憶させる記憶制御手段と、スキャンデータ集合に含まれている複数のページスキャンデータ各々が表すページ画像内の所定の特徴に基づく、スキャンデータ集合としての特性に基づいて、当該特性が近似するスキャンデータ集合を抽出する第1抽出手段と、してコンピュータを機能させることを特徴とする。
【0006】
このように構成された画像処理プログラムによって、コンピュータを上記各手段として機能させれば、第1抽出手段によって、スキャンデータ集合としての特性が互いに類似している複数のスキャンデータ集合を抽出することができる。これにより、特定のスキャン対象物から生成されたスキャンデータ集合と他のスキャン対象物から生成されたスキャンデータ集合とが混在して記憶部に記憶されている場合においても、特定のスキャン対象物から生成されたスキャンデータ集合のみを自動で抽出することが可能となる。
【0007】
また、請求項2に記載の画像処理プログラムでは、算出手段によって特定値を算出することによって、スキャンデータ集合の単位で、スキャンデータ集合としての特性を数値化することができる。よって、特性が近似するスキャンデータ集合を抽出し易くすることができる。
【0008】
また、請求項3に記載の画像処理プログラムでは、第1抽出手段が抽出した複数のスキャンデータ集合を結合して、スキャン対象物に関する1のデータ集合を生成することができる。これにより、特定のスキャン対象物から生成されたスキャンデータ集合をユーザがピックアップした上で結合する必要を無くすことができるため、不便性を解消することができる。
【0009】
また、請求項4に記載の画像処理プログラムでは、第1抽出手段で抽出されたスキャンデータ集合を、第1抽出手段で抽出されていない他のスキャンデータ集合と区別して、ユーザに認識させることができる。また、第1抽出手段で抽出された複数のスキャンデータ集合を、1つのグループとしてユーザに認識させることができる。
【0010】
また、請求項5に記載の画像処理プログラムでは、第1抽出手段で抽出された複数のスキャンデータ集合のうちから、同一の属性情報が対応付けられているスキャンデータ集合をさらに抽出することができる。これにより、特定のスキャン対象物から生成されたスキャンデータ集合をより効率よく抽出することが可能となる。
【0011】
また、請求項6に記載の画像処理プログラムでは、互いに特徴が近似している複数のスキャンデータ集合に加えて、同一の属性情報が対応付けられている複数のスキャンデータ集合も表示させることが可能となる。よって、表示されるスキャンデータ集合の対象を、より広げることが可能となる。
【0012】
また、請求項7に記載の画像処理プログラムでは、第1抽出手段で抽出されたスキャンデータ集合と第2抽出手段によって抽出されたスキャンデータ集合とを区別して、ユーザに認識させることができる。
【0013】
また、請求項8に記載の画像処理プログラムでは、互いに特徴点が類似している複数のスキャンデータ集合を抽出する処理を、複数の特徴点の各々に対して行うことができる。これにより、特定のスキャン対象物から生成されたスキャンデータ集合と他のスキャン対象物から生成されたスキャンデータ集合とを区別する判断基準を増やすことができるため、特定のスキャン対象物から生成されたスキャンデータ集合をより効率よく抽出することが可能となる。
【0014】
また、請求項9に記載の画像処理プログラムでは、第1抽出手段で複数のスキャンデータ集合を抽出するために用いられた特徴を、ユーザに認識させることができる。
【図面の簡単な説明】
【0015】
【図1】通信システムの構成を示すブロック図である。
【図2】通信システムの動作フローチャートである。
【図3】MFPの動作フローチャートである。
【図4】MFPの動作フローチャートである。
【図5】MFPの動作フローチャートである。
【図6】特徴記憶テーブルの一例である。
【図7】特徴記憶テーブルの一例である。
【図8】近似閾値テーブルの一例である。
【図9】表示画面の表示例である。
【図10】表示画面の表示例である。
【発明を実施するための形態】
【0016】
図1に、本明細書に係る実施形態として例示される通信システム1のブロック図を示す。通信システム1は、MFP(Multifunction Peripheral)51、第1スキャナ101、第2スキャナ201、第3スキャナ301、PC(Personal Computer)70を備える。MFP51は、プリンタ機能、スキャナ機能、コピー機能、ファクシミリ機能などを備える多機能周辺装置である。MFP51、第1スキャナ101ないし第3スキャナ301、PC70は、LAN60を介して互いに通信可能に接続されている。
【0017】
MFP51の構成について説明する。第1MFP51は、記憶部12、プリンタ19、スキャナ20、CPU32、ネットワークI/F36、ボタン入力部38、パネル39、モデム40、電話回線接続部41、GPS部44、を主に備えている。これらの構成要素は、入出力ポート43を介して互いに通信可能とされている。
【0018】
ボタン入力部38は、第1MFP51の各機能を実行するためのキーである。ボタン入力部38は、タッチパネルとして、パネル39と一体に構成されていてもよい。パネル39は、MFP51の各種機能情報を表示する。プリンタ19は、印刷を実行する部位である。スキャナ20は、読み取りを実行する部位である。GPS部44は、MFP51の位置情報を取得する部位である。モデム40は、ファクシミリ機能によって送信する原稿データを、電話回線網100に伝送可能な信号に変調して電話回線接続部41を介して送信したり、電話回線網100から電話回線接続部41を介して入力された信号を受信し、原稿データへ復調するものである。
【0019】
CPU32は、記憶部12に記憶されるプログラムに従って処理を実行する。以降、画像処理プログラム28やオペレーティングシステムなど、プログラムを実行するCPU32のことを、単にプログラム名でも記載する場合がある。例えば「画像処理プログラム28が」という記載は、画像処理プログラム28を実行するCPU32が」を意味する場合がある。なお、記憶部12は、RAM(Random Access Memory)、ROM(Read Only Memory)、フラッシュメモリ、HDD(ハードディスク)、CPU32が備えるバッファなどが組み合わされて構成されている。
【0020】
記憶部12は、プログラム21を記憶する。プログラム21は、基本プログラム(図示省略)、画像処理プログラム28等を含む。基本プログラムは、ネットワークI/F36に通信を実行させるためのプログラム等を含む。また基本プログラムは、GPS部24が算出した情報を各プログラムが取得するためのAPI(Application Programming Interface)を提供するプログラムでもある。また画像処理プログラム28は、後述する画像処理の動作フローをCPU32に実行させるためのプログラムである。
【0021】
また記憶部12は、データ記憶領域12aおよびテーブル記憶領域12bを備える。データ記憶領域12aには、後述する、スキャンファイルなどが記憶される。またテーブル記憶領域12bには、特徴記憶テーブルTB1、TB2および近似閾値テーブルTB3が記憶される。
【0022】
図6に、特徴記憶テーブルTB1の一例を示す。特徴記憶テーブルTB1は、ページスキャンデータの各ページについての特徴を記憶するテーブルである。特徴記憶テーブルTB1は、ファイル番号410、ページ番号411、ページ内最大フォントサイズ412、ページ内最小フォントサイズ413、各フォントサイズ文字数414、地色RGB値415、を記憶する。ファイル番号410は、スキャンファイルの各々を識別するための連続番号である。ページ番号411は、1つのスキャンファイルに含まれている複数のページスキャンデータの各々を識別するためのページ番号である。ページ内最大フォントサイズ412は、1ページ分のページスキャンデータによって表示されるページ画像内のフォントの中の、最大フォントのサイズである。ページ内最小フォントサイズ413は、1ページ分のページスキャンデータによって表示されるページ画像内のフォントの中の、最小フォントのサイズである。各フォントサイズ文字数414は、各サイズのフォントがそれぞれ何文字ずつあるかを示すデータである。すなわち各フォントサイズ文字数414は、文字数を度数、ポイント数を階級としたヒストグラムである。図6の例では、6ポイントから20ポイントまでの15種類のサイズのフォントの各々について、文字数が記憶されている。地色RGB値415は、ページスキャンデータによって表示されるページ画像内において、紙の地色(黄色系、蛍光色、など)をRGBの数値で表したものである。
【0023】
図7に、特徴記憶テーブルTB2の一例を示す。特徴記憶テーブルTB2は、スキャンファイルとしての特徴を記憶するテーブルである。特徴記憶テーブルTB2は、ファイル番号508、ユーザ情報509、スキャナ情報510、ファイル内最大フォントサイズ511、ファイル内最小フォントサイズ512、平均フォントサイズ513、フォントサイズ標準偏差514、地色平均値515、地色標準偏差516、タグ情報517を記憶する。ファイル番号508は、スキャンファイルの各々を識別するための連続番号である。ユーザ情報509は、スキャンファイルの作成をスキャナに指示したユーザを示す情報である。ユーザ情報509の一例としては、ユーザ名やパスワードなどが挙げられる。スキャナ情報510は、スキャンファイルを作成したスキャナを示す情報である。ファイル内最大フォントサイズ511は、スキャンファイルに含まれる全てのページ画像内の文字の中で、最大のフォントサイズである。ファイル内最小フォントサイズ512は、スキャンファイルに含まれる全てのページ画像内の文字の中で、最小のフォントサイズである。平均フォントサイズ513は、スキャンファイルに含まれる全てのページ画像内の全文字について、フォントサイズの平均値を算出した値である。フォントサイズ標準偏差514は、スキャンファイルに含まれる全てのページ画像内の全文字について、フォントサイズの標準偏差を算出した値である。地色平均値515は、スキャンファイルに含まれる全てのページ画像について、紙の地色のRGB値の平均値を算出した値である。地色標準偏差516は、スキャンファイルに含まれる全てのページ画像について、紙の地色のRGB値の標準偏差を算出した値である。タグ情報517は、互いに近似する特徴を有するスキャンファイルを同じグループに分類するための情報である。
【0024】
図8に、近似閾値テーブルTB3の一例を示す。近似閾値テーブルTB3は、各種の特徴ごとに、近似閾値520を記憶するテーブルである。近似閾値520は、後述する分類処理(S218)において、特徴が近似するか否かの判断に用いられる値である。
【0025】
第1スキャナ101の構成について説明する。第1スキャナ101は、CPU102、記憶部103、スキャナ104、通信部105を主に備えている。CPU102は、スキャナ104などの各機能の制御を行う。スキャナ104は、複数ページを備える原稿を1ページずつスキャンして、ページスキャンデータを生成する。そして、複数ページ分のページスキャンデータを含むスキャンファイルを生成する。記憶部103は、生成されたスキャンファイルを記憶する。通信部105は、LAN60上の各種の機器と通信を実行する。なお、第2スキャナ201および第3スキャナ301の構成は、第1スキャナ101と同様であるため、ここでは詳細な説明は省略する。
【0026】
PC70の構成について説明する。PC70は、CPU72、記憶部73、通信部75を主に備えている。これらの構成の機能は、MFP51で説明した構成の機能と同様であるため、ここでは詳細な説明は省略する。
【0027】
<通信システムの動作>
本実施形態に係る通信システム1の動作を説明する。図2を用いて、通信システム1の動作の全体フローを説明する。S101において、1の原稿を複数の分割原稿に分割した上で、分割原稿の各々のスキャンファイルを生成する処理が行われる。スキャンファイルは、第1スキャナ101ないし第3スキャナ301を用いて生成することが可能である。具体的には、ユーザによって1の原稿が複数の分割原稿に分割され、分割原稿の各々が第1スキャナ101ないし第3スキャナ301にセットされる。そして、第1スキャナ101ないし第3スキャナ301の操作部(不図示)を用いてスキャン実行操作を実行することで、分割原稿の各々についてのスキャンファイルが生成され、記憶部に記憶される。
【0028】
S102において、MFP51は、第1スキャナ101ないし第3スキャナ301の各々から、LAN60およびネットワークI/F36を介して、分割原稿についてのスキャンファイルを受信する。そしてスキャンファイルごとに特徴を抽出する、特徴保存処理を実行する。
【0029】
S103において、MFP51は、特徴が近似するスキャンファイルを、データ記憶領域12aに記憶されている多数のスキャンファイルの中から抽出して結合する、結合処理を実行する。これにより、分割前の1の原稿についての、1のスキャンファイルが完成する。以下、MFP51で行われる特徴保存処理(S102)および結合処理(S103)について、図3ないし図5のフローを用いて詳説する。
【0030】
<特徴保存処理>
図3を用いて、特徴保存処理の内容を説明する。S110においてCPU32は、ユーザ情報509であるユーザ名の入力処理が、ボタン入力部38を介して行われたか否かを判断する。入力処理が行われていない場合(S110:NO)にはS110へ戻り、入力処理が完了した場合(S110:YES)にはS111へ進む。S111においてCPU32は、スキャンファイルの取得先のスキャナを、第1スキャナ101ないし第3スキャナ301の中から決定する。S112において、CPU32は、取得先として決定されたスキャナから、スキャンファイルを構成する複数のページスキャンデータのうちから、1ページ分のページスキャンデータを受信する。S114において、CPU32は、受信したページスキャンデータをデータ記憶領域12aに記憶する。
【0031】
S116において、CPU32は、受信したページスキャンデータに対して特徴を抽出する処理を行う。抽出される特徴は、ページ内最大フォントサイズ412、ページ内最小フォントサイズ413、各フォントサイズ文字数414、地色RGB値415、である(図6、特徴記憶テーブルTB1参照)。ページスキャンデータ内の特徴を抽出する方法の具体例を説明する。まず、画像認識技術によって、ページスキャンデータによって表示されるページ画像内から、文字が記載されている文字領域を一字ずつ矩形形状に抽出する。そして、それぞれの文字領域の高さを計測することで、使用されているフォントのサイズ(ポイント数)を取得する。これにより、ページ内最大フォントサイズ412およびページ内最小フォントサイズ413を抽出することができる。また、文字領域の数を計測することで、フォントのサイズごとに、使用されている文字数を取得する。これにより、各フォントサイズ文字数414を抽出することができる。また、文字領域以外の領域を抽出し、抽出した領域の色を測定することで、地色RGB値415を抽出することができる。
【0032】
S120において、CPU32は、S116で抽出したページスキャンデータの各特徴を、特徴記憶テーブルTB1(図6)に記憶する。このとき、今回処理を行っているスキャンファイルに対応するファイル番号410の列内であって、今回処理を行っているページスキャンデータに対応するページ番号411に対応する列に、各特徴を記憶する。S122において、CPU32は、次ページ分のページスキャンデータが存在するか否かを判断する。次ページが存在する場合(S122:YES)にはS112へ戻り、スキャンファイル内の次のページデータに対して、S112からS120までの処理を行う。一方、次ページが存在しない場合(S122:NO)には、1つのスキャンファイル内の全ページについて処理が完了したと判断され、S124へ進む。
【0033】
S124において、CPU32は、特徴記憶テーブルTB1に保存されている、スキャンファイルを構成する複数のページスキャンデータの特徴を用いて、スキャンファイル全体としての特徴を算出する処理を行う。算出される特徴は、ファイル内最大フォントサイズ511、ファイル内最小フォントサイズ512、平均フォントサイズ513、フォントサイズ標準偏差514、地色平均値515、地色標準偏差516、である(図7、特徴記憶テーブルTB2参照)。スキャンファイルの特徴を算出する方法の具体例を説明する。ファイル内最大フォントサイズ511は、複数のページスキャンデータの各々におけるページ内最大フォントサイズ412のうち、最大値を選択することで取得することができる。ファイル内最小フォントサイズ512は、複数のページスキャンデータの各々におけるページ内最小フォントサイズ413のうち、最小値を選択することで取得することができる。平均フォントサイズ513およびフォントサイズ標準偏差514は、複数のページスキャンデータの各々における各フォントサイズ文字数414を用いて計算を行うことで、取得することができる。地色平均値515および地色標準偏差516は、複数のページスキャンデータの各々における地色RGB値415を用いて計算を行うことで、取得することができる。
【0034】
S126において、CPU32は、S124で抽出したスキャンファイルの各特徴を、特徴記憶テーブルTB2(図7)に記憶する。このとき、今回処理を行っているスキャンファイルに対応するファイル番号508の列内に、各特徴を記憶する。S128において、CPU32は、スキャンファイルについてのユーザ情報509(スキャンファイルを作成したユーザ名)を、特徴記憶テーブルTB2(図7)に記憶する。このとき、今回処理を行っているスキャンファイルに対応するファイル番号508の列内に、ユーザ情報509を記憶する。
【0035】
S130において、CPU32は、まだスキャンファイルを取得していないスキャナが存在するか否かを判断する。未取得のスキャナが存在する場合(S130:YES)にはS111へ戻り、次のスキャンファイルの取得先のスキャナを、第1スキャナ101ないし第3スキャナ301のうちから決定する。そして、再度S112からS128の処理を実行する。一方、未取得のスキャナが存在しない場合(S130:NO)には、特徴保存処理を終了する。
【0036】
<結合処理>
図4および図5を用いて、結合処理の内容を説明する。S212において、ユーザ情報509であるユーザ名の入力処理が、ボタン入力部38を介して行われたか否かを判断する。入力処理が行われていない場合(S212:NO)にはS212へ戻り、入力処理が完了した場合(S212:YES)にはS214へ進む。
【0037】
S214において、CPU32は、近似するスキャンファイルを抽出する際に用いる特徴の選択を受け付けたか否かを判断する。具体例としては、パネル39に各種の特徴(ファイル内最大フォントサイズ511、平均フォントサイズ513、フォントサイズ標準偏差514など)を表示し、ユーザによる特徴の選択を受け付ける。S214では、複数の特徴の選択を受け付けることも可能である。特徴の選択を受け付けていない場合(S214:NO)にはS214へ戻り、選択を受け付けた場合(S214:YES)にはS216へ進む。
【0038】
S216においてCPU32は、特徴記憶テーブルTB2(図7)から、保存されている全てのスキャンファイルについて、特徴を読み出す。S218において、CPU32は、互いに特徴が近似するスキャンファイルを同一のグループに分類する、分類処理を行う。具体的には、S214で選択された特徴(複数の特徴が選択されている場合には、そのうちの1つの特徴)を、S216で読み出した全てのスキャンファイルについて比較し、特徴が近似するスキャンファイルを抽出する。そして、抽出したスキャンファイルに同一のタグ情報517を割り当てて、特徴記憶テーブルTB2に記憶させる。特徴が近似するか否かの判断方法の一例としては、S214で選択された特徴を表す数値が、近似閾値テーブルTB3(図8)に記憶されている近似閾値520の範囲内であるか否かを判断する方法が挙げられる。例えばS214において、ファイル内最大フォントサイズ511が選択された場合には、ファイル内最大フォントサイズが互いに±0.5ポイント(近似閾値520)の範囲内であるスキャンファイルが、互いに特徴が近似するスキャンファイルとして抽出される。なお、S214で複数の特徴が選択された場合には、複数の特徴の各々に対して、S218の分類処理が行われる。
【0039】
S220において、CPU32は、表示データ決定処理を実行する。図5のフローを用いて、表示データ決定処理の内容を説明する。S312において、CPU32は、特徴記憶テーブルTB2に記憶されているスキャンファイルのうちから、今回S218で分類処理が行われたスキャンファイル(タグ情報517が付けられているスキャンファイル)を抽出する。そして抽出したスキャンファイルのうちから、表示可能なスキャンファイルをさらに抽出する。表示可能なスキャンファイルとは、S212で入力されたユーザ情報と同一のユーザ情報を有するスキャンファイルである。すなわち、特徴保存処理を実行しているユーザと同一のユーザによって作成されたスキャンファイルである。
【0040】
S314において、CPU32は、表示可能なスキャンファイルが存在するか否かを判断する。存在しない場合(S314:NO)にはS222(図4)へ進み、存在する場合(S314:YES)にはS316へ進む。
【0041】
S316において、CPU32は、表示可能なスキャンファイルを表すアイコンを、パネル39に表示する。表示可能なスキャンファイルが複数存在する場合には、複数のアイコンを、順に整列するように表示する。
【0042】
S318において、CPU32は、S316で表示されたアイコンの外周を囲む枠線を、パネル39に表示する。S320において、CPU32は、分類を行う際に使用された特徴を、S318で表示された枠線の内側に表示する。そして表示データ決定処理が終了し、S222(図4)へ進む。
【0043】
S222において、CPU32は、分類処理を未実施の特徴が存在するか否かを判断する。未実施の特徴が存在する場合(S222:YES)には、S218へ戻り、S214で選択された複数の特徴のうち、分類処理を未実施の特徴について、S218およびS220を実行する。一方、未実施の特徴が存在しない場合(S222:NO)には、S214で選択された複数の特徴の全てに対してS218およびS220の処理が実行された場合か、S214で1つのみの特徴が選択された場合であると判断され、S226へ進む。
【0044】
S226において、CPU32は、結合するスキャンファイルの指定を受け付けたか否かを判断する。具体的には、パネル39に表示されている、枠線で囲われたアイコンのグループの何れかを指定する操作が入力されたか否かを判断する。指定を受け付けていない場合(S226:NO)にはS226へ戻り、指定を受け付けた場合(S226:YES)にはS228へ進む。
【0045】
S228において、CPU32は、複数のスキャンファイルを結合する際の結合順番を決定する。結合順番の決定は、ユーザによる入力を受け付けることで行なわれても良い。または、画像認識技術により各スキャンファイルのページ番号を認識している場合には、ページ番号が順番に並ぶように自動で結合順番を決定することも可能である。
【0046】
S230において、CPU32は、複数のスキャンファイルを互いに結合し、データ記憶領域12aに記憶する。これにより、分割前の元の原稿についての、1つのスキャンファイルが完成する。
【0047】
<具体動作例>
本実施形態に係る画像処理の具体動作例を、図6ないし図9を用いて説明する。本実施形態では、例として、第1の原稿を2つに分割して第1スキャナ101および第2スキャナ201でスキャン処理するとともに、第2の原稿を分割せずに第3スキャナ301でスキャン処理する場合を説明する。また、特徴保存処理(図3)によって、図6に示すような特徴記憶テーブルTB1が作成された場合を説明する。また、図6に示す特徴記憶テーブルTB1に基づいて、特徴保存処理(図3)によって、図7に示すような特徴記憶テーブルTB2が作成された場合を説明する。図6の特徴記憶テーブルTB1および図7の特徴記憶テーブルTB2では、第1の原稿の前半部のスキャンファイルが、ファイル番号410=「1」の列に記憶されている。また、第2の原稿のスキャンファイルが、ファイル番号410=「2」の列に記憶されている。また、第1の原稿の後半部のスキャンファイルが、ファイル番号410=「3」の列に記憶されている。また、結合処理(図4)のS212において、ユーザ情報509としてユーザ名=「ユーザA」が入力された場合を説明する。またS214において、近似するスキャンファイルを抽出する際に用いる特徴として、ファイル内最大フォントサイズ511および平均フォントサイズ513が選択された場合を説明する。
【0048】
近似するスキャンファイルを抽出するための特徴として、ファイル内最大フォントサイズ511を用いる場合における、結合処理を説明する。S218(図4)において、ファイル内最大フォントサイズ511の特徴について、各スキャンファイルが比較される。そして、ファイル内最大フォントサイズ511が互いに±0.5ポイントの範囲内であるスキャンファイル(ファイル番号508=「2」、「3」のスキャンファイル)(図7、領域A1参照)が、特徴が互いに近似するファイルとして抽出される。また、抽出されたスキャンファイルに同一のタグ情報517=「ファイル内最大フォントサイズが近似」が割り当てられ、特徴記憶テーブルTB2に記憶される(図7、領域A11)。
【0049】
表示データ決定処理へ進み、S312において、今回分類処理が行われたスキャンファイル(ファイル番号508=「2」、「3」のスキャンファイル)が抽出される。そして、表示可能なスキャンファイル(ユーザ情報509が「ユーザA」であるスキャンファイル)として、ファイル番号508=「2」、「3」のスキャンファイルが抽出される。S316において、図9に示すように、ファイル番号508=「2」および「3」のスキャンファイルの各々を表すアイコンIC2およびIC3が、パネル39に横に並んだ状態で表示される。また、表示されたアイコンIC2およびIC3の外周を囲む枠線F1が表示される(S318)。また、分類を行う際に使用された特徴である「最大フォントサイズが近似」が、枠線F1の内側に表示される(S320)。
【0050】
次に、近似するスキャンファイルを抽出するための特徴として、平均フォントサイズ513を用いる場合における、結合処理を説明する。S218(図4)において、平均フォントサイズ513の特徴について、各スキャンファイルが比較される。そして、平均フォントサイズ513が互いに±1ポイントの範囲内であるスキャンファイル(ファイル番号508=「1」、「3」、「4」のスキャンファイル)(図7、領域A2参照)が、特徴が互いに近似するファイルとして抽出される。また、抽出されたスキャンファイルに同一のタグ情報517=「平均フォントサイズが近似」が割り当てられ、特徴記憶テーブルTB2に記憶される(図7、領域A12)。
【0051】
表示データ決定処理へ進み、S312において、今回分類処理が行われたスキャンファイル(ファイル番号508=「1」、「3」、「4」のスキャンファイル)が抽出される。そして、表示可能なスキャンファイル(ユーザ情報509が「ユーザA」であるスキャンファイル)として、ファイル番号508=「1」、「3」のスキャンファイルが抽出される。S316において、図9に示すように、ファイル番号508=「1」のスキャンファイルを表すアイコンIC1が、パネル39に追加して表示される。また、アイコンIC1およびIC3の外周を囲む枠線F2が表示される(S318)。また、分類を行う際に使用された特徴である「平均フォントサイズが近似」が、枠線F2の内側に表示される(S320)。
【0052】
S226において、枠線F2で囲われたアイコンのグループを指定するユーザ操作の入力が受け付けられる。S228において、アイコンIC1で表されるスキャンファイルが1番目、アイコンIC3で表されるスキャンファイルが2番目、という内容の結合順番のユーザ入力が受け付けられる。S230において、CPU32は、アイコンIC1で表されるスキャンファイル(第1の原稿の前半部)と、アイコンIC3で表されるスキャンファイル(第1の原稿の後半部)とを互いに結合し、データ記憶領域12aに記憶する。これにより、分割前の第1の原稿についての、1つのスキャンファイルが完成する。
【0053】
<効果>
本実施形態に係る画像処理の効果を説明する。分類処理(S218)によって、複数のページスキャンデータによって構成されるスキャンファイルの全体としての特性を比較し、当該特性が互いに類似している複数のスキャンファイルを抽出することができる。これにより、特定の原稿から生成された複数のスキャンファイルと他の原稿から生成されたスキャンファイルとが混在してデータ記憶領域12aに記憶されている場合においても、特定の原稿から生成された複数のスキャンファイルのみを自動で抽出することが可能となる。
【0054】
また、分類処理(S218)によって同一グループに分類された複数のスキャンファイル同士を結合(S230)して、1の原稿についての1のスキャンファイルを生成することができる。これにより、特定の原稿から生成された複数のスキャンファイルをユーザがピックアップした上で結合する必要を無くすことができるため、不便性を解消することができる。
【0055】
また、分類処理(S218)によって同一グループに分類された複数のスキャンファイルを、分類処理(S218)によって同一グループに分類された複数のスキャンファイルを囲う枠線を表示する(S318)ことによって、同一グループに分類された複数のスキャンファイルを、1つのグループとしてユーザに認識させることができる。また、同一グループに分類された複数のスキャンファイルを、他のスキャンファイルと区別してユーザに認識させることができる。
【0056】
また、分類処理(S218)によって同一グループに分類された複数のスキャンファイルのうちから、表示可能なスキャンファイル(特徴保存処理を実行しているユーザと同一のユーザによって作成されたスキャンファイル)をさらに抽出することができる(S312)。これにより、特定の原稿から生成されたスキャンファイルを、より効率よく抽出することが可能となる。
【0057】
また、分類処理(S218)を、複数の特徴点(例:ファイル内最大フォントサイズ511、平均フォントサイズ513、など)の各々に対して行うことができる。これにより、特定の原稿から生成されたスキャンファイルと他の原稿から生成されたスキャンファイルとを区別する判断基準を増やすことができるため、特定の原稿から生成されたスキャンファイルをより効率よく抽出することが可能となる。
【0058】
また、分類を行う際に使用された特徴を、枠線の内側に表示することができる(S320)。これにより、分類処理(S218)で複数のスキャンファイルを抽出するために用いられた特徴を、ユーザに認識させることができる。
【0059】
以上、本発明の具体例を詳細に説明したが、これらは例示にすぎず、特許請求の範囲を限定するものではない。特許請求の範囲に記載の技術には、以上に例示した具体例を様々に変形、変更したものが含まれる。
【0060】
<変形例>
S312で表示可能ではないと判断されたスキャンファイルを、S312で表示可能と判断されたスキャンファイルとともに表示するとしてもよい。これにより、特徴保存処理を実行しているユーザ以外の他のユーザが作成したスキャンファイルも、S316における表示処理の対象とすることができるため、スキャンファイルの表示対象をより広げることが可能となる。またこの場合、表示可能ではないと判断されたスキャンファイルと、表示可能と判断されたスキャンファイルとを区別できるように、スキャンファイルを作成したユーザを表示するとしてもよい。
【0061】
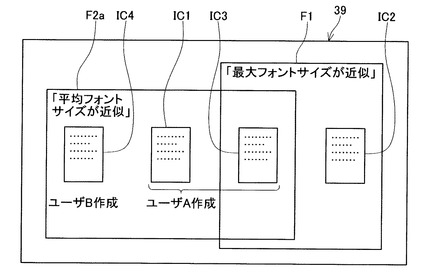
本変形例における変形動作例を、図10を用いて説明する。なお、変形動作例における前提条件は、前述の具体動作例と同様である。近似するスキャンファイルを抽出するための特徴として、平均フォントサイズ513を用いる場合には、ファイル番号508=「1」、「3」、「4」のスキャンファイル(図7、領域A2参照)が、特徴が互いに近似するファイルとして抽出される。ここで、ファイル番号508=「4」のスキャンファイルは、特徴保存処理を実行しているユーザ(ユーザA)以外の他のユーザ(ユーザB)が作成したスキャンファイルである。よって、表示データ決定処理(S316)において、図10に示すように、ファイル番号508=「4」のスキャンファイルを表すアイコンIC4が、パネル39に追加して表示される。また、アイコンIC1、IC3、IC4の外周を囲む枠線F2aが表示される(S318)。また、アイコンIC1およびIC3で表されるスキャンファイルがユーザAによって作成され、アイコンIC4で表されるスキャンファイルがユーザBによって作成された旨が、枠線F2aの内側に表示される。これにより、第1抽出手段で抽出されたスキャンファイルと第2抽出手段によって抽出されたスキャンファイルとを区別して、ユーザに認識させることができる。
【0062】
また、同一グループに分類された複数のスキャンファイルを他のスキャンファイルと区別して表示する方法は、枠線で囲う方法(S318)に限られない。例えば、同一グループに属するスキャンファイルを表す各アイコンを、他のアイコンと異なる態様(アイコンの大きさを異ならせる、アイコンの色を異ならせる、アイコンを点滅表示させる、など)で表示してもよい。または、同一グループに属するスキャンファイルを表す各アイコンを、互いに関連付けて表示(例:同一グループの複数アイコンを、その一部が互いに重なるように表示)する態様であってもよい。
【0063】
また、抽出される特徴(S116)は、本実施形態で示したものに限られない。例えば、行間のポイント数や、文字間のポイント数などを用いても良い。また、特徴を抽出する際に用いられる算出値は、平均値や標準偏差に限られず、各種の統計に用いられる算出値(例:メディアン値)であってもよい。
【0064】
また、各スキャンファイルを識別するための識別情報を特徴として用いて、結合対象のスキャンファイルを抽出するとしてもよい。識別情報の例としては、スキャナの設置場所や、スキャナが接続されているルータのIDなどが挙げられる。ユーザが1の原稿を複数の分割原稿に分割して、複数のスキャナでスキャン処理を行う場合には、互いに距離が近いスキャナを使用する場合が多い。よって、識別設置場所が互いに近接している複数のスキャナの各々で生成されたスキャンファイルを抽出することや、同一のルータに接続されている複数のスキャナの各々で生成されたスキャンファイルを抽出することにより、結合処理の対象となるスキャンファイルを自動で抽出することが可能となる。また、スキャナの設置場所は、各スキャナに備えられているGPS部により取得される形態であってもよいし、予めユーザによって各スキャナに登録される形態であってもよい。
【0065】
画像処理プログラム28がMFP51の記憶部12に記憶されている場合を説明したが、この形態に限られず、LAN60に接続されている他の機器の記憶部に記憶されていてもよい。例えば、PC70の記憶部73に画像処理プログラム28が記憶されている場合には、PC70のCPU72によって、図2ないし図5のフローを実行することができる。
【0066】
また、スキャンファイル生成に使用されるスキャナは外付けのスキャナに限られず、MFP51が備えるスキャナ20を使用することも可能である。この場合、LAN60を介してスキャンファイルを受信する処理(S112、S114)を省略することができる。また、1の原稿を複数の分割原稿に分割する際の分割数は、2分割に限られず、3分割以上でもよい。
【0067】
互いに特徴が近似するスキャンファイルを同一のグループに分類する方法は、タグ情報517を割り当てる方法(S218)に限られず、各種の方法が可能である。例えば、同一のグループに属する複数のスキャンファイルを、同一のフォルダに格納する方法であってもよい。
【0068】
スキャンファイル全体としての特徴を算出する処理(S124)は、スキャンファイルを構成するページスキャンデータの全てを使用する形態に限られない。ページスキャンデータの一部を抽出(例:偶数ページを抽出、所定ページごとに抽出)し、抽出したページスキャンデータについて計算を行うことで、スキャンファイル全体としての特徴を算出するとしてもよい。これにより、計算量を抑えることができる。
【0069】
各フォントサイズ文字数414は、6ポイントから20ポイントまでの15種類のサイズのフォントの各々について、文字数をカウントしたが、この形態に限られない。15種類より多いまたは少ないサイズのフォントの各々について文字数をカウントしてもよい。
【0070】
S112からS122において、ページスキャンデータを受信して特徴を抽出する処理を、1ページ分ずつ繰り返す形態を説明したが、この形態に限られない。スキャンファイルを構成する全ページ分のページスキャンデータを受信した後に、各ページについて特徴を抽出する処理を実行してもよい。
【0071】
S212における、ユーザ情報509の入力処理は省略することが可能である。この場合、S312では、S110で入力されたユーザ情報509を用いて、表示可能なスキャンファイル抽出する処理を実行すればよい。
【0072】
また、本明細書または図面に説明した技術要素は、単独であるいは各種の組合せによって技術的有用性を発揮するものであり、出願時請求項記載の組合せに限定されるものではない。また、本明細書または図面に例示した技術は複数目的を同時に達成するものであり、そのうちの一つの目的を達成すること自体で技術的有用性を持つものである。
【0073】
なお、CPU32はコンピュータの一例である。原稿はスキャン対象物の一例である。スキャンファイルはスキャンデータ集合の一例である。S114を実行するCPU32は記憶制御手段、記憶手段の一例である。ページ内最大フォントサイズ412、地色RGB値415などは所定の特徴の一例である。ファイル内最大フォントサイズ511、平均フォントサイズ513などは特性の一例である。S218を実行するCPU32は第1抽出手段、第1抽出ステップの一例である。フォントサイズ、地色のRGB値などは所定の特徴を表す数値の一例である。S124を実行するCPU32は算出手段の一例である。S230を実行するCPU32はデータ処理制御手段の一例である。S318を実行するCPU32は表示制御手段の一例である。ユーザ情報509は属性情報の一例である。S312を実行するCPU32は第2抽出手段の一例である。
【0074】
なお、各プログラムは一つのプログラムモジュールから構成されるものであってもよいし、複数のプログラムモジュールから構成されるものであってもよい。また、各一例は置換可能な他の構成であってもよく、本発明の範疇である。プログラム(画像処理プログラム28など)に基づく処理を実行するコンピュータ(CPU32など)であってもよいし、オペレーティングシステムや他のアプリケーションなど、画像処理プログラム以外のプログラムに基づく処理を実行するコンピュータであってもよいし、コンピュータの指示に従って動作するハード構成(パネル39など)であってもよいし、コンピュータとハード構成とが連動した構成であってもよい。もちろん、複数のプログラムに基づく処理を連動させて処理を実行するコンピュータであってもよいし、複数のプログラムに基づく処理を連動させて処理を実行するコンピュータの指示に従って動作するハード構成であってもよい。
【符号の説明】
【0075】
1:通信システム、28:画像処理プログラム、32:CPU、51:MFP、101:第1スキャナ、201:第2スキャナ、301:第3スキャナ、TB1、TB2:特徴記憶テーブル
【特許請求の範囲】
【請求項1】
コンピュータが読み取り可能な画像処理プログラムであって、
複数ページを備えるスキャン対象物の1ページ分のページ画像をスキャンして得られるページスキャンデータを複数含むスキャンデータ集合の複数個を記憶部に記憶させる記憶制御手段と、
スキャンデータ集合に含まれている複数のページスキャンデータ各々が表すページ画像内の所定の特徴に基づく、スキャンデータ集合としての特性に基づいて、当該特性が近似するスキャンデータ集合を抽出する第1抽出手段と、
して前記コンピュータを機能させることを特徴とする画像処理プログラム。
【請求項2】
スキャンデータ集合に含まれている複数のページスキャンデータ各々が表すページ画像内の所定の特徴を表す数値を、スキャンデータ集合に含まれている複数のページスキャンデータ分用いて、スキャンデータ集合の特性値を算出する算出手段と、して前記コンピュータをさらに機能させ、
前記第1抽出手段は、前記算出手段が算出した特性値に基づいて、前記特性が近似するスキャンデータ集合を抽出することを特徴とする請求項1に記載の画像処理プログラム。
【請求項3】
前記第1抽出手段が抽出した複数のスキャンデータ集合を互いに結合して前記スキャン対象物に関する1のデータ集合を生成する処理を、データ処理部に実行させるデータ処理制御手段として前記コンピュータをさらに機能させることを特徴とする請求項1または2に記載の画像処理プログラム。
【請求項4】
前記第1抽出手段が抽出した複数のスキャンデータ集合を互いに関連付けて、前記第1抽出手段で抽出されていない他のスキャンデータ集合とは異なる態様で表示部に表示させる表示制御手段として前記コンピュータをさらに機能させることを特徴とする請求項1ないし3の何れか1項に記載の画像処理プログラム。
【請求項5】
前記記憶制御手段は、前記複数のスキャンデータ集合の各々に対応付けて該スキャンデータ集合の作成をスキャナに指示したユーザを示す、または、該スキャンデータ集合を作成したスキャナを示す属性情報を記憶部に記憶させており、
同一の属性情報が対応付けられているスキャンデータ集合を抽出する第2抽出手段として前記コンピュータをさらに機能させ、
前記表示制御手段は、前記第1抽出手段によって抽出されたスキャンデータ集合であって、かつ、前記第2抽出手段によって抽出されたスキャンデータ集合を互いに関連付けて前記表示部に表示させることを特徴とする請求項4に記載の画像処理プログラム。
【請求項6】
前記表示制御手段は、
前記第1抽出手段によって抽出されたスキャンデータ集合と、前記第1抽出手段によって抽出されなかったものの、前記第2抽出手段によって抽出されたスキャンデータ集合と、を表示部に表示させることを特徴とする請求項5に記載の画像処理プログラム。
【請求項7】
前記表示制御手段は、
前記第1抽出手段によって抽出されたスキャンデータ集合と、前記第2抽出手段によって抽出されたスキャンデータ集合とを異なる態様で表示部に表示させることを特徴とする請求項6に記載の画像処理プログラム。
【請求項8】
前記算出手段は、前記複数のスキャンデータ集合の各々について、複数種類の特徴に関する複数種類の特定値を算出し、
前記第1抽出手段は、前記複数種類の特徴の種類ごとに、スキャンデータ集合を抽出する処理を実行し、
前記表示制御手段は、前記第1抽出手段が抽出した複数のスキャンデータ集合を互いに関連付けて表示部に表示させる処理を、前記複数種類の特徴の種類ごとに抽出されたスキャンデータ集合の各々に対して実行することを特徴とする請求項4ないし7の何れか1項に記載の画像処理プログラム。
【請求項9】
前記表示制御手段は、
前記第1抽出手段が抽出した複数のスキャンデータ集合を関連付けている前記所定の特徴を表示部に表示させることを特徴とする請求項4ないし8の何れか1項に記載の画像処理プログラム。
【請求項10】
画像処理装置であって、
複数ページを備えるスキャン対象物の1ページ分のページ画像をスキャンして得られるページスキャンデータを複数含むスキャンデータ集合の複数個を記憶する記憶手段と、
スキャンデータ集合に含まれている複数のページスキャンデータ各々が表すページ画像内の所定の特徴に基づく、スキャンデータ集合としての特性に基づいて、当該特性が近似するスキャンデータ集合を抽出する第1抽出手段と、
を備えることを特徴とする画像処理装置。
【請求項11】
画像処理方法であって、
複数ページを備えるスキャン対象物の1ページ分のページ画像をスキャンして得られるページスキャンデータを複数含むスキャンデータ集合の複数個を記憶部に記憶させる記憶制御ステップと、
スキャンデータ集合に含まれている複数のページスキャンデータ各々が表すページ画像内の所定の特徴に基づく、スキャンデータ集合としての特性に基づいて、当該特性が近似するスキャンデータ集合を抽出する第1抽出ステップと、
を備えることを特徴とする画像処理方法。
【請求項1】
コンピュータが読み取り可能な画像処理プログラムであって、
複数ページを備えるスキャン対象物の1ページ分のページ画像をスキャンして得られるページスキャンデータを複数含むスキャンデータ集合の複数個を記憶部に記憶させる記憶制御手段と、
スキャンデータ集合に含まれている複数のページスキャンデータ各々が表すページ画像内の所定の特徴に基づく、スキャンデータ集合としての特性に基づいて、当該特性が近似するスキャンデータ集合を抽出する第1抽出手段と、
して前記コンピュータを機能させることを特徴とする画像処理プログラム。
【請求項2】
スキャンデータ集合に含まれている複数のページスキャンデータ各々が表すページ画像内の所定の特徴を表す数値を、スキャンデータ集合に含まれている複数のページスキャンデータ分用いて、スキャンデータ集合の特性値を算出する算出手段と、して前記コンピュータをさらに機能させ、
前記第1抽出手段は、前記算出手段が算出した特性値に基づいて、前記特性が近似するスキャンデータ集合を抽出することを特徴とする請求項1に記載の画像処理プログラム。
【請求項3】
前記第1抽出手段が抽出した複数のスキャンデータ集合を互いに結合して前記スキャン対象物に関する1のデータ集合を生成する処理を、データ処理部に実行させるデータ処理制御手段として前記コンピュータをさらに機能させることを特徴とする請求項1または2に記載の画像処理プログラム。
【請求項4】
前記第1抽出手段が抽出した複数のスキャンデータ集合を互いに関連付けて、前記第1抽出手段で抽出されていない他のスキャンデータ集合とは異なる態様で表示部に表示させる表示制御手段として前記コンピュータをさらに機能させることを特徴とする請求項1ないし3の何れか1項に記載の画像処理プログラム。
【請求項5】
前記記憶制御手段は、前記複数のスキャンデータ集合の各々に対応付けて該スキャンデータ集合の作成をスキャナに指示したユーザを示す、または、該スキャンデータ集合を作成したスキャナを示す属性情報を記憶部に記憶させており、
同一の属性情報が対応付けられているスキャンデータ集合を抽出する第2抽出手段として前記コンピュータをさらに機能させ、
前記表示制御手段は、前記第1抽出手段によって抽出されたスキャンデータ集合であって、かつ、前記第2抽出手段によって抽出されたスキャンデータ集合を互いに関連付けて前記表示部に表示させることを特徴とする請求項4に記載の画像処理プログラム。
【請求項6】
前記表示制御手段は、
前記第1抽出手段によって抽出されたスキャンデータ集合と、前記第1抽出手段によって抽出されなかったものの、前記第2抽出手段によって抽出されたスキャンデータ集合と、を表示部に表示させることを特徴とする請求項5に記載の画像処理プログラム。
【請求項7】
前記表示制御手段は、
前記第1抽出手段によって抽出されたスキャンデータ集合と、前記第2抽出手段によって抽出されたスキャンデータ集合とを異なる態様で表示部に表示させることを特徴とする請求項6に記載の画像処理プログラム。
【請求項8】
前記算出手段は、前記複数のスキャンデータ集合の各々について、複数種類の特徴に関する複数種類の特定値を算出し、
前記第1抽出手段は、前記複数種類の特徴の種類ごとに、スキャンデータ集合を抽出する処理を実行し、
前記表示制御手段は、前記第1抽出手段が抽出した複数のスキャンデータ集合を互いに関連付けて表示部に表示させる処理を、前記複数種類の特徴の種類ごとに抽出されたスキャンデータ集合の各々に対して実行することを特徴とする請求項4ないし7の何れか1項に記載の画像処理プログラム。
【請求項9】
前記表示制御手段は、
前記第1抽出手段が抽出した複数のスキャンデータ集合を関連付けている前記所定の特徴を表示部に表示させることを特徴とする請求項4ないし8の何れか1項に記載の画像処理プログラム。
【請求項10】
画像処理装置であって、
複数ページを備えるスキャン対象物の1ページ分のページ画像をスキャンして得られるページスキャンデータを複数含むスキャンデータ集合の複数個を記憶する記憶手段と、
スキャンデータ集合に含まれている複数のページスキャンデータ各々が表すページ画像内の所定の特徴に基づく、スキャンデータ集合としての特性に基づいて、当該特性が近似するスキャンデータ集合を抽出する第1抽出手段と、
を備えることを特徴とする画像処理装置。
【請求項11】
画像処理方法であって、
複数ページを備えるスキャン対象物の1ページ分のページ画像をスキャンして得られるページスキャンデータを複数含むスキャンデータ集合の複数個を記憶部に記憶させる記憶制御ステップと、
スキャンデータ集合に含まれている複数のページスキャンデータ各々が表すページ画像内の所定の特徴に基づく、スキャンデータ集合としての特性に基づいて、当該特性が近似するスキャンデータ集合を抽出する第1抽出ステップと、
を備えることを特徴とする画像処理方法。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】

【図9】
【図10】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【公開番号】特開2013−61769(P2013−61769A)
【公開日】平成25年4月4日(2013.4.4)
【国際特許分類】
【出願番号】特願2011−199476(P2011−199476)
【出願日】平成23年9月13日(2011.9.13)
【出願人】(000005267)ブラザー工業株式会社 (13,856)
【Fターム(参考)】
【公開日】平成25年4月4日(2013.4.4)
【国際特許分類】
【出願日】平成23年9月13日(2011.9.13)
【出願人】(000005267)ブラザー工業株式会社 (13,856)
【Fターム(参考)】
[ Back to top ]