
画像処理用のタイルレンダリング
【課題】実際に、バックエンドワークを実行することなく、当該バックエンドワークに要する時間を推算し、タイルを分割する方法を提供する。
【解決手段】フロンドエンドのカウンタが、コストモデルおよびヒューリスティック(heuristic)関する情報であって、タイルを分割して、順序付けられたワークをコアに配送するときに用いられる可能性のある情報を記録する。専用のラスタライザ(specialrasterizer)は、サブタイルの外側の三角形状および断片を放棄する。
【解決手段】フロンドエンドのカウンタが、コストモデルおよびヒューリスティック(heuristic)関する情報であって、タイルを分割して、順序付けられたワークをコアに配送するときに用いられる可能性のある情報を記録する。専用のラスタライザ(specialrasterizer)は、サブタイルの外側の三角形状および断片を放棄する。
【発明の詳細な説明】
【背景技術】
【0001】
タイリング・レンダリング・アーキテクチャ(tiling rendering architecture)は、コンピュータにより生成される画像を、別々にレンダリングされる部分に小分けする。それぞれの部分はタイルと呼ばれる。タイリング・レンダリング・アーキテクチャのパイプラインは、しばしば、フロントエンドおよびバックエンドにより構成される。フロントエンドは、シーン(scene )中の頂点において頂点シェーディング(vertex-shading)を実行し、結果として生じる三角形状(triangle)のそれぞれを、三角形状のそれぞれが重なる(overlap)タイルに振り分ける。ここで、非幾何学的属性のシェーディングは、バックエンドによる処理まで先延ばしにされてよいことに留意すべきである。バックエンドは、フロントエンドの後に生じる。バックエンドは、何らかの残っている属性について頂点シェーディングを実行して、それらの三角形状をラスタライズし(rasterizing)、結果として生じる断片(fragment)をピクセルシェーディング(pixel-shading)することによって、それぞれのタイルを別々に処理する。
【0002】
独立した多数の、コアと呼ばれる実行ユニットを有する並列ハードウエアにおいて、そのリソースを十分に活用するためには、コアの間でレンダリングワーク(rendering work)を均等に分配する手順(strategy)を要する。すなわち、レンダリングワークは、バランスよくロードされる必要がある。レンダリング性能は、レンダリングワークがどのように分配されたということに大きく依存するので、このことは、非常に重要である。
【0003】
フロントエンドは、それぞれのコアが並列に処理できるように、シーンの形状(scene geometry)を適切な大きさ(chunk)に分割してよい。そのような塊(chunk)は、ジオメトリバッチと呼ばれる。シーンの形状は、任意に分割することができるので、フロントエンドにおいて、良好なロード・バランスを容易に実現することができる。それぞれのタイルは、別々に処理されることができるので、バックエンドは、本質的に並列である。しかしながら、このことにより、良好なロード・バランスが保証されるわけではない。シーンにおける形状(geometry)の分布およびシェーディングの複雑さにもよるが、大部分のワーク(work)は、たった数枚のタイルで終了する。最悪の場合には、単一のタイルがコストのかかる(expensive)タイルであり、残りのタイルがコストのかからない(cheap)タイルである。コストのかかるタイルを選択したコアは、そのタイルを処理するのに多くの時間を必要とするので、これは、ロードの不均衡をもたらす。残りのコアはすぐにワークを終了するので、この間、何もしない(idle)。
【図面の簡単な説明】
【0004】
【図1】一実施形態に係るフローチャートを示す。
【図2】一実施形態に係るフローチャートを示す。
【図3】一実施形態に係るフローチャートを示す。
【図4】一実施形態に係るシステム構成を示す。
【発明を実施するための形態】
【0005】
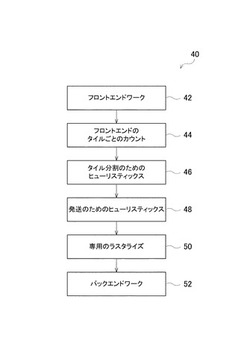
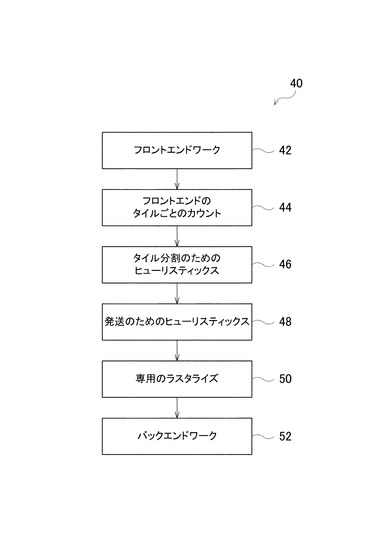
技術の組み合わせが、タイリング・レンダリング・パイプラインにおいて、バックエンドのロードのバランスをとるのに用いられてよい。図1に示すように、フロントエンドワーク(front-end work)42の後、いくつかの実施形態においては、要素は、特定のタイルのコストの推算(estimate)に用いられるパイプライン40と、コストモデル(cost model)に必要となる情報を記録するフロントエンドのタイルごとのカウンタ(front-end per-tile counter)44と、タイルを分割するときに用いられるヒューリスティック(heuristic)46と、コアへのワークの発送(dispatching)を順序付ける(order)ためのヒューリスティック48と、サブタイルの外側にある三角形状および断片を放棄する(discard)、専用の(special)ラスタライザ(rasterizer)50とを有する。次に、バックエンドワーク(back-end work)52がなされてよい。
【0006】
単一のコアが特定のタイルのバックエンドワークを実行するのに要する時間を正確に調べるただ1つの方法は、実際にそのワークを実行することである。しかしながら、実際にそのワークをすることなく、要求される時間の近似値を把握することが好ましい。そこで、一実施形態において、コストのかからない(inexpensive)コスト推算モデルが、特定のタイルのバックエンドワークを実行するのにどれくらいの時間が必要とされるのかを見積もる。全てのタイルについて見積もりがなされた場合、全てのタイルのワークを、利用可能なコアに均等に分配することができる可能性(chance)がはるかに高くなる。
【0007】
コスト推算モデルは、ある特定のタイルをバックエンドで処理するのに必要とされる時間を見積もる典型的なフロントエンドから記録されうるデータを使用してよい。単一の三角形状のコストを見積もるためには、当該三角形状が、おおよそどの程度の数のサンプルをカバーするのかを把握する必要がある。理想的には、「親」タイルと三角形状とが交差する領域が、三角形状がカバーするサンプルの数を評価する基準(measure)として用いられてよい。しかし、これにはそれぞれの三角形状のコストのかかるクリッピング(expensive clipping)が関係してくる場合があるので、計算できないこともある。逆に、例えば、もし、三角形状がタイルの全体を覆っている場合などには、重なり合うタイル(overlapping tile)を決定するときにフロントエンドにおいて得られた所見(observation)を用いて、三角形状のそれぞれを大まかに分類することができる。加えて、本当に小さな三角形状であれば、ラスタライザにおいて、専用のコードパス(special code path)を用いるであろうから、このような三角形状には、専用の分類を行う必要があろう。その区別された(different)分類は、三角形状のタイプ(triangle type)と呼ばれる。ここで、三角形状のタイプは、ピクセルシェーディングまたはzバッファモードといった現在のレンダリング状態と無関係であることに留意すべきである。特定のタイルに関するデータは、これに限定されるものではないが、そのタイルに蓄えられた(binned)特定の三角形状のタイプを有する三角形状の数、ピクセルシェーディングのコストの合計(例えば、そのタイルに蓄えられた(binned)特定の三角形状のタイプを有する三角形状のそれぞれに関する単一の断片に対して、特定の(certain )ピクセルシェーディングを実行するのに必要なサイクル)、および、特定の(specific)レンダリング状態に調和する(adhering)タイルに蓄えられた(binned)特定の三角形状のタイプを有する三角形状の数を含んでよい。特定のレンダリング状態としては、ステンシル専用(stencil-only)の状態、または、早期Zカル(early-z-cull)が有効な状態を例示することができる。
【0008】
タイルに重なる三角形状を含むジオメトリバッチの数のような上位の構成概念(higher level construct)に関するカウンタを含めることは、有益である。それぞれのジオメトリバッチは、一般的に、ある程度のオーバーヘッドを招く。
【0009】
モデルは、このデータを用いて、線形項と対数項とを形成してよい。いくつかの実施形態において、線形項および対数項の加重和(weighted sum)は、タイルを処理するのに要する時間を示す。対数項は、隠蔽(occlusion)のモデル化に役立つ。すなわち、三角形状が目に見えるもの(visible)である場合、三角形状によって覆われたピクセルについて全てのシェーディングを計算する必要があるので、通常、その三角形状の処理には、より長い時間を要する。三角形状が、すでにレンダリングされている三角形状によって隠蔽されている(occluded)(隠されている(obscured))場合、より少ないコストで実行することができる。ピクセルごとに、重なり合う三角形状の数の対数を1つにまとめるモデルが用いられてよい。1993年のパラレルレンダリング・シンポジウムの議事録の49〜56ページに掲載されているCox、MichaelおよびPat Hanrahanによる「オブジェクト・パラレル・レンダリング(object-parallel rendering)のためのピクセル結合:分散型スヌーピング・アルゴリズム」を参照されたい。
【0010】
加重和の重みは、モデルを実測のタイミングにフィッティングさせることで決定される。フィッティングは、実行時に、適当な間隔でまたはオフラインで、多数のシーンから提供されたデータを用いて実施されてよい。使用される対数関数は、底が2の対数(the floor of the 2-logarithm)であってよい。底が2の対数は、整数を効率よく計算することができる。非線形モデルの1つは式(1)である。
【数1】

ここで、tは処理時間であり、xiはカウンタの値である。A、Bi、CおよびDiは、フィッティングによって見出された定数である。このモデルは非線形であるので、オフラインでフィッティングすることが好ましい。寄与するカウンタがないときに、結果として生じる値が0であることを確かにする目的で、対数項の中に1という値が追加されている。
【0011】
線形モデルの1つは、式(2)である。
【数2】
このモデルは、線形のフィッティングを実行するコストが比較的少ないので、実行時にフィッティングする(runtime fitting)ことが好ましい。
【0012】
全てのカウンタに対して対数項を含めるのは意味をなさない。目的は、断片が隠蔽されている場合に、シェーディング時間が短くなるように、隠蔽をモデル化することなので、いくつかの実施形態においては、early-z-cullが有効な形状に関するシェーディングを利用するカウンタだけが含まれてよい。すなわち、他の対数項に関する定数は、0であろう。
【0013】
コストの推算において、どの項を含むかの決定は、レンダリング・パイプラインの実装者次第である。線形モデル(式(2))が用いられる場合、フレームnをレンダリングしているときに、全ての情報が収集されてよい。そして、フレームn+1のレンダリングを開始する前に、収集された情報に基づいて、係数が再計算される。次に、式(2)の中でこれらの係数が使用されて、それぞれのタイルのコストを推算する。例えば式(3)のような移動平均の更新情報(sliding average update)を用いて、係数を更新してよい。
an+1=kanew+(1−k)an (3)
ここで、aiは、線形モデルの全ての係数、すなわちA、BjおよびCjを含むベクトルである。
【0014】
このアプローチは、コスト推算モデルにおける急転(sudden jump)を抑制する。そうしなければ、同一のフレームについて複数回レンダリングを実行した場合であっても、値が振動する。モデルの変更によりタイルの分割方法が変更するので、振動が起こうる。このことは、モデルの修正に用いられた実測値(measurement)を次々に変更してよい。kの値は、ユーザ次第で、0から1の範囲内に設定される。k=1の場合、前回のaの値が使用されず、k=0の場合、新しい値が使用されない(それゆえ、無意味である。)。kの値は、0と1との間のどこか、例えば、k=0.5となるであろう。
【0015】
フロントエンドは、コスト推算モデルにより要求される情報に関するタイルごとのカウンタ(per-tile counter)を含めるよう修正される。フロントエンドに先立って、そのようなカウンタの全てが0に初期化される。三角形状がタイルに蓄積される(binned)たびに、その三角形状のタイプが決定され、当該三角形状のタイプに関するカウンタがインクリメントされる。例えば、特定の三角形状のタイプに関するピクセル・シェーダのコスト(pixel shader cost)の合計値を収容するカウンタのような、その他のカウンタもまた、それに応じて修正される。
【0016】
ここで、例えば、オフライン・フィッティングから予め重みが分かっている場合には、重みを予め掛けておくことで、線形項に関する全てのカウンタを単一の値にしておくことができ、これにより、記憶装置に対する要求(storage requirement)を低減させることができる。
【0017】
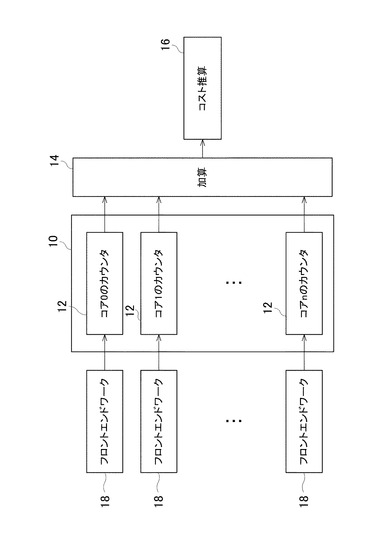
典型的には、いくつかのコアが同一のカウンタにアクセスするので、図2に示すように、それぞれのコアについて、固有のカウンタ12の集合(set)10を有することは有益である。このように、コア間の同期(inter-core synchronization)を抑制することができる。これらのコアごとのカウンタ(per-core counter)12はフロントエンドワーク18に結合され、タイルに関するコストを推算する場合、(14に示されるように)累算されて、コスト推算モデル16により使用される一式の(set)カウンタとなる。
【0018】
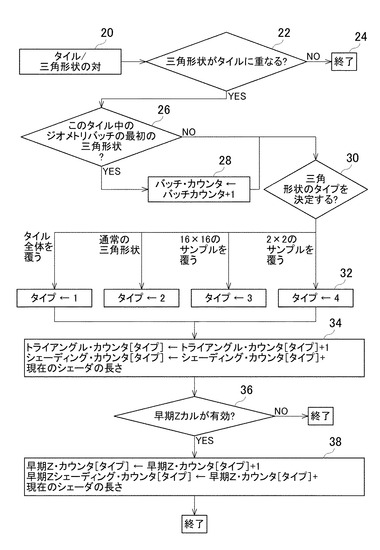
三角形状がタイルに蓄積される(binned)場合に、フロントエンドがそのカウンタをインクリメントする方法の一例が、図3に示されている。20において、タイル/三角形状の対(tile/triangle pair)が受信される。菱形22のチェックは、三角形状がタイルに重なるか否かを決定する。三角形状がタイルと重ならない場合には、24に示すように、フローが終了する。三角形状がタイルと重なる場合には、菱形26のチェックは、この三角形状が、このタイルのジオメトリバッチの最初の三角形状であるか否かを決定する。この三角形状が、このタイルのジオメトリバッチの最初の三角形状である場合、28において、バッチ・カウンタがインクリメントされる。次に、菱形30において、三角形状のタイプが決定される。32に示される次の段階において、三角形状がタイルの全体を覆っている場合には、タイプ1が示される。他のタイプに当てはまらない場合には、タイプ2が示される。三角形状が16×16のサンプルを覆っている場合には、タイプ3が示される。三角形状が2×2のサンプルを覆っている場合には、タイプ4が示される。ラスタライズするアーキテクチャによっては、その他の三角形状のタイプが用いられてよい。次に、34において、トライアングル・カウンタ[タイプ]がインクリメントされ、現在のシェーダの長さ(shader length)がシェーダ・カウンタ[タイプ]に追加される。
【0019】
菱形36のチェックにおいて、早期Zカル(early-z-cull)が有効であるか否かが決定される(すなわち、ピクセルをシェーディングする前に、Zカリング(Z-culling)が実施されているか否かが決定される。)。早期Zカル(early-z-cull)が有効でない場合、フローは終了する。そうでない場合、ブロック38において、早期Zカル・カウンタ[タイプ]がインクリメントされ、現在のシェーダの長さ(shader length)が早期Zシェーダ・カウンタ(Early-Z-Shading-Counter)[タイプ]に追加される。
【0020】
フロントエンドの後、分割のためのヒューリスティック46(splitting heuristic)(図1)が用いられて、どのタイルを分割するかが決定される。一例として、あるタイルが128×128ピクセルを覆っている場合、そのタイルは、2つの重なり合っていない64×128ピクセルのサブタイルに分割されてよい。そのようなサブタイルのレンダリング時間に関するコストは、そのタイル全体のレンダリング時間のおおよそ半分になると考えられる。したがって、タイルが分割され、サブタイルのバックエンドワークが2つのコアによって並列に処理される場合、もしかすると、タイルを分割することにより、タイルをレンダリングするのに要する時間を50%に減らすことができるかもしれない。
【0021】
分割のためのヒューリスティックの第1のステップは、コスト推算モデルおよびタイルごとのカウンタを用いて、すべてのタイルのコストを推算することである。次に、(タイル全体のコストと比較したときのサブタイルのコストは、ピクセル中におけるサブタイルの面積に直接的に比例するという仮定のもと、)n個のもっともコストのかかるタイルが選択され、それぞれのサブタイルのコストが特定の閾値thを下回るまで、繰り返し分割される。通常、タイルを分割することに関連するオーバーヘッドが存在する。それゆえ、本当に必要な場合に限って分割することが有益である。過度の分割は、パフォーマンスの低下を招く可能性がある。あるシーンの中に、いくつかの独立したレンダリング対象、および/または、同時に複数のインフライトな(in flight)フレームが含まれる場合、コストのかかるタイルでさえ、分割することは有益ではないかもしれない。このため、閾値thは、同時発生の(concurrent)レンダリング対象中のワークの総量に応じて修正される。
【0022】
順序付けのためのヒューリスティック48(ordering heuristic)(図1)は、コストのかかるタイルのバックエンドワークが、できるだけ早く開始されるように試みる。これにより、バックエンドの最後に、ロードの不均衡が低減される。それゆえ、分割の後、推算されたコストに基づいて、タイルがソートされる。次に、その順序で、もっともコストのかかる(サブ)タイルから、利用可能なコアに発送される。分割段階の間にタイルがソートされる場合には、タイルを再度ソートする必要はない。この場合、サブタイルは、ワーク列(work queue)中の適切な位置に挿入され、概算コストを利用した順序を保証してよい。
【0023】
タイルを分割する目的で、専用のラスタライザ50(図1)が用いられてよい。専用のラスタライザを用いなければ、タイルを分割することのメリットが少なくなるであろう。分割の後、タイルの三角形状をサブタイルの間で再分配してよい。すなわち、三角形状がどのサブタイルに重なるかを検証して、そのようなサブタイルのそれぞれについて、サブタイルの三角形状のリスト(triangle list)の中に、その三角形状を記載する。しかしながら、この方法は、フロントエンド/バックエンドに分割されたパイプラインではうまく機能しない場合がある。この実行には、単に、現在のパイプラインに多くの変更が必要であろう。よりよい方法は、サブタイルを処理するそれぞれのコアに、「親」タイルの三角形状のリスト全体を調べさせることである。次に、専用のラスタライザが、サブタイルの領域の外側の三角形状を放棄する(discard)。走査変換(scan conversion)の間に、サブタイルの外側の断片(fragment)を効率よく放棄するように変更されてもよい。階層的ラスタライゼーション(hierarchical rasterization)の間、コアが、サブタイルのピクセル領域の外側のピクセル領域に達すると、専用のラスタライザは、階層的トラバーサル(hierarchical traversal)を単に終了させる。これにより、現在のパイプラインに対する変更が非常に小さくコンパクトになり、いくつかの実施形態において、非常に好ましい。サブタイルの全く外側に存在する三角形状を迅速に却下する目的で、それが、走査変換に先立つ三角形状結合ボックステスト(triangle bounding-box test)に組み込まれてもよい。一実施形態において、タイルが、常に、長手方向(longer axis)に沿って半分に分割され、結果として、(親タイルの次元が2のべき乗であると仮定すると、)常に2のべき乗の次元になる。例えば、効率のよいシフト操作を用いて、大抵の却下テスト(rejection test)が実施されてよい。
【0024】
いくつかの実施形態において、ラスタライゼーションに基づくレンダラーを用いたオフライン・レンダリングが用いられてよい。この場合、レンダリングにはるかに多くのコストがかかるので、推算のコストは、相対的に小さくなるであろう。それゆえ、その意味でも、このような技術を用いることは意味がある。加えて、より高次の基本形状(higher order primitive)(例えば、置換されたベジエ曲面(displaced Bezier surface)、置換された細分化曲面(displaced subdivision surface)および任意の変位シェーダ(arbitrary displacement shader))についても、いくつかの実施形態を利用することで、大きな効果が得られる場合がある。
【0025】
いくつかの実施形態は、単一のレンダリング対象のロードを均等化して、利用を最大化し、レイテンシを最小化してよい。同時に、メモリのフットプリントはあまり増加しなくてもよい。いくつかのケースにおいて、専用のラスタライザは、その実行を実質的に容易にする。
【0026】
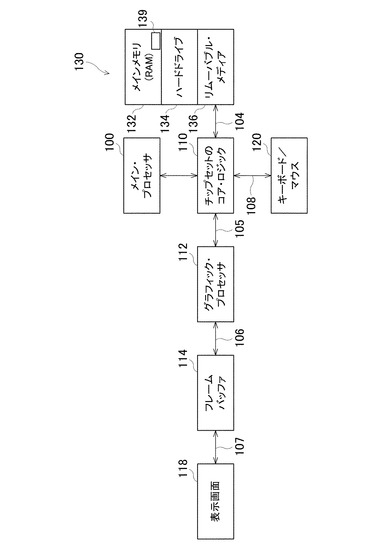
図4に示されるコンピュータ・システム(computer system)130は、バス104によってチップセットのコア・ロジック110に結合されるハードドライブ134およびリムーバブル・メディア(removable medium)136を備えてよい。バス108を介して、キーボードおよびマウス120またはその他の通常の要素が、チップセットのコア・ロジックに結合されてよい。一実施形態において、コア・ロジックは、バス105を介して、グラフィックプロセッサ112およびメインまたはホストプロセッサ100に結合されてよい。グラフィックプロセッサ112は、バス106を介して、フレームバッファ114に結合されてもよい。フレームバッファ114は、バス107を介して、表示画面118に結合されてもよい。一実施形態において、グラフィックプロセッサ112は、単一命令複数データ(SIMD)アーキテクチャを用いた、マルチスレッド、マルチコアの並列プロセッサであってよい。図2に示されるように、グラフィックプロセッサは、複数のコアを含んでよく、それぞれのコアは、カウンタと関連付けられてよい。
【0027】
ソフトウエアにより実行される場合、適切なコードが、メインメモリ132またはグラフィックプロセッサに含まれるなんらかの利用可能なメモリを含む、なんらかの適切な半導体、磁気的または光学的な記憶装置に記憶されてよい。一実施形態において、図1から図3までのシーケンスを実行するコード139が、メインメモリ132またはグラフィックプロセッサ112のような、不揮発性の機械またはコンピュータが読み込むことができる媒体に記憶されてよく、一実施形態において、プロセッサ100またはグラフィックプロセッサ112により実行されてよい。
【0028】
図1から図3は、フローチャートである。いくつかの実施形態において、これらのフローチャートに記載されたシーケンスが、ハードウエア、ソフトウエアまたはファームウエアにおいて実行されてよい。ソフトウエアの実施形態において、半導体メモリ、磁気メモリまたは光学メモリのようなコンピュータ可読媒体を用いて命令が記憶されてよく、プロセッサにより実行されて、図1から図3に記載されたフローチャートの1以上に示されるシーケンスが実行されてよい。
【0029】
本明細書に記載される画像処理技術は、様々なハードウエア・アーキテクチャにおいて実現されてよい。例えば、グラフィック機能が1つのチップセットに統合されてよい。他には、独立した(discrete)グラフィックプロセッサが用いられてよい。さらに他の実施形態において、グラフィック機能が、マルチコア・プロセッサを含む、汎用のプロセッサにより実現されてもよい。
【0030】
本明細書を通して、「一実施形態」または「ある実施形態」という表現は、その実施形態に関連して記載される特定の特徴、構造または特性が、本発明の範囲内に含まれる少なくとも1つの実現手段の中に含まれることを意味する。例えば、「一実施形態」または「ある実施形態中」という用語が出現しても、必ずしも、同一の実施形態を参照しているとは限らない。さらに、特定の特徴、構造または特性は、説明された特定の態様以外にも、その他の適切な実施形態の中で用いられてよく、そのような態様は、すべて、本出願の特許請求の範囲の範囲内に含まれてよい。
【0031】
本発明は、限られた数の実施形態に関連して説明されているけれども、当業者は、それらから、多数の改造および変更(variation)を認識することができるであろう。添付の特許請求の範囲は、本発明の真の精神および範囲内に含まれるように、そのような改造および変更をカバーすることが意図されている。
(項目1)
タイリングレンダリングを実施するパイプライン中で、バックエンドワークに要する時間を推算する段階を有する、
タイルを分割する方法。
(項目2)
上記推算されたコストに基づいて、タイルを複数のサブタイルに分割するかいなかを決定する段階を有する、
項目1に記載の方法。
(項目3)
三角形状のタイプを識別する段階と、
上記タイプを上記推算に用いる段階と、
を有する、
項目1に記載の方法。
(項目4)
三角形状がタイルの全体を覆うか否かに基づいて、上記三角形状の上記タイプを識別する段階を有する、
項目3に記載の方法。
(項目5)
三角形状によって覆われるサンプルの数に基づいて、三角形状のタイプを識別する段階を有する、
項目2に記載の方法。
(項目6)
早期Zカルが有効化されているか否かを決定して、上記時間を推算する段階を有する、
項目1に記載の方法。
(項目7)
複数のコアを用いる段階と、
特定のタイルから分割された特定のサブタイルを処理するそれぞれのコアが、上記タイル中のすべての三角形状を調べて、どの上記三角形状が、上記コアに割り当てられたサブタイルの範囲内にあるかを決定することを可能にする段階と、
を有する、
項目1に記載の方法。
(項目8)
コンピュータに、
タイリングレンダリングを実施するパイプライン中で、コスト推算モデルを用いて、タイルごとに、バックエンドワークに要する時間を推算する手順、
を実行させるためのプログラム。
(項目9)
上記コンピュータに、
上記コスト推算モデルを用いて、タイルをサブタイルに分割するか否かを決定する手順、
をさらに実行させるための項目8に記載のプログラム。
(項目10)
上記コンピュータに、
三角形状のタイプを識別する手順と、
上記タイプを推算に用いる手順と、
をさらに実行させるための項目8に記載のプログラム。
(項目11)
上記コンピュータに、
三角形状がタイルの全体を覆うか否かに基づいて、上記三角形状の上記タイプを識別する手順、
をさらに実行させるための項目10に記載のプログラム。
(項目12)
上記コンピュータに、
上記三角形状によって覆われるサンプルの数に基づいて、上記三角形状の上記タイプを識別する手順、
をさらに実行させるための項目10に記載のプログラム。
(項目13)
上記コンピュータに、
早期Zカルが有効化されているか否かを決定して、上記時間を推算する手順、
をさらに実行させるための項目8に記載のプログラム。
(項目14)
上記コンピュータに、
複数のコアを用いる手順と、
特定のタイルから分割された特定のサブタイルを処理するそれぞれのコアが、上記タイル中の全ての三角形状を調べて、どの上記三角形状が、上記コアに割り当てられたサブタイルの範囲内にあるかを決定することを可能にする手順と、
をさらに実行させるための項目8に記載のプログラム。
(項目15)
タイルを分割するか否かを決定するコスト推算ユニットと、
コアのそれぞれが、上記タイル中の全ての三角形状を調べて、どの上記三角形状が、上記コアに割り当てられたサブタイルの範囲内にあるかを決定することで、分割されていないタイル、および、特定のタイルから分割された特定のサブタイルを処理することができるマルチコア・プロセッサ(multiple-core processor)と、
を備える、
装置。
(項目16)
上記コアのそれぞれに関する、一式のカウンタであって、コスト推算モデルに利用される一式のカウンタを備える、
項目15に記載の装置。
(項目17)
上記カウンタが加算装置に結合される、
項目16に記載の装置。
(項目18)
上記コスト推算ユニットが、上記加算装置に結合される、
項目17に記載の装置。
(項目19)
タイリングレンダリングを実施するパイプライン中で、バックエンドワークに要する時間を推算する推算ユニットを備える、
項目15に記載の装置。
(項目20)
上記推算ユニットが、三角形状のタイプを識別して、上記タイプを上記推算に用いる、
項目19に記載の装置。
【背景技術】
【0001】
タイリング・レンダリング・アーキテクチャ(tiling rendering architecture)は、コンピュータにより生成される画像を、別々にレンダリングされる部分に小分けする。それぞれの部分はタイルと呼ばれる。タイリング・レンダリング・アーキテクチャのパイプラインは、しばしば、フロントエンドおよびバックエンドにより構成される。フロントエンドは、シーン(scene )中の頂点において頂点シェーディング(vertex-shading)を実行し、結果として生じる三角形状(triangle)のそれぞれを、三角形状のそれぞれが重なる(overlap)タイルに振り分ける。ここで、非幾何学的属性のシェーディングは、バックエンドによる処理まで先延ばしにされてよいことに留意すべきである。バックエンドは、フロントエンドの後に生じる。バックエンドは、何らかの残っている属性について頂点シェーディングを実行して、それらの三角形状をラスタライズし(rasterizing)、結果として生じる断片(fragment)をピクセルシェーディング(pixel-shading)することによって、それぞれのタイルを別々に処理する。
【0002】
独立した多数の、コアと呼ばれる実行ユニットを有する並列ハードウエアにおいて、そのリソースを十分に活用するためには、コアの間でレンダリングワーク(rendering work)を均等に分配する手順(strategy)を要する。すなわち、レンダリングワークは、バランスよくロードされる必要がある。レンダリング性能は、レンダリングワークがどのように分配されたということに大きく依存するので、このことは、非常に重要である。
【0003】
フロントエンドは、それぞれのコアが並列に処理できるように、シーンの形状(scene geometry)を適切な大きさ(chunk)に分割してよい。そのような塊(chunk)は、ジオメトリバッチと呼ばれる。シーンの形状は、任意に分割することができるので、フロントエンドにおいて、良好なロード・バランスを容易に実現することができる。それぞれのタイルは、別々に処理されることができるので、バックエンドは、本質的に並列である。しかしながら、このことにより、良好なロード・バランスが保証されるわけではない。シーンにおける形状(geometry)の分布およびシェーディングの複雑さにもよるが、大部分のワーク(work)は、たった数枚のタイルで終了する。最悪の場合には、単一のタイルがコストのかかる(expensive)タイルであり、残りのタイルがコストのかからない(cheap)タイルである。コストのかかるタイルを選択したコアは、そのタイルを処理するのに多くの時間を必要とするので、これは、ロードの不均衡をもたらす。残りのコアはすぐにワークを終了するので、この間、何もしない(idle)。
【図面の簡単な説明】
【0004】
【図1】一実施形態に係るフローチャートを示す。
【図2】一実施形態に係るフローチャートを示す。
【図3】一実施形態に係るフローチャートを示す。
【図4】一実施形態に係るシステム構成を示す。
【発明を実施するための形態】
【0005】
技術の組み合わせが、タイリング・レンダリング・パイプラインにおいて、バックエンドのロードのバランスをとるのに用いられてよい。図1に示すように、フロントエンドワーク(front-end work)42の後、いくつかの実施形態においては、要素は、特定のタイルのコストの推算(estimate)に用いられるパイプライン40と、コストモデル(cost model)に必要となる情報を記録するフロントエンドのタイルごとのカウンタ(front-end per-tile counter)44と、タイルを分割するときに用いられるヒューリスティック(heuristic)46と、コアへのワークの発送(dispatching)を順序付ける(order)ためのヒューリスティック48と、サブタイルの外側にある三角形状および断片を放棄する(discard)、専用の(special)ラスタライザ(rasterizer)50とを有する。次に、バックエンドワーク(back-end work)52がなされてよい。
【0006】
単一のコアが特定のタイルのバックエンドワークを実行するのに要する時間を正確に調べるただ1つの方法は、実際にそのワークを実行することである。しかしながら、実際にそのワークをすることなく、要求される時間の近似値を把握することが好ましい。そこで、一実施形態において、コストのかからない(inexpensive)コスト推算モデルが、特定のタイルのバックエンドワークを実行するのにどれくらいの時間が必要とされるのかを見積もる。全てのタイルについて見積もりがなされた場合、全てのタイルのワークを、利用可能なコアに均等に分配することができる可能性(chance)がはるかに高くなる。
【0007】
コスト推算モデルは、ある特定のタイルをバックエンドで処理するのに必要とされる時間を見積もる典型的なフロントエンドから記録されうるデータを使用してよい。単一の三角形状のコストを見積もるためには、当該三角形状が、おおよそどの程度の数のサンプルをカバーするのかを把握する必要がある。理想的には、「親」タイルと三角形状とが交差する領域が、三角形状がカバーするサンプルの数を評価する基準(measure)として用いられてよい。しかし、これにはそれぞれの三角形状のコストのかかるクリッピング(expensive clipping)が関係してくる場合があるので、計算できないこともある。逆に、例えば、もし、三角形状がタイルの全体を覆っている場合などには、重なり合うタイル(overlapping tile)を決定するときにフロントエンドにおいて得られた所見(observation)を用いて、三角形状のそれぞれを大まかに分類することができる。加えて、本当に小さな三角形状であれば、ラスタライザにおいて、専用のコードパス(special code path)を用いるであろうから、このような三角形状には、専用の分類を行う必要があろう。その区別された(different)分類は、三角形状のタイプ(triangle type)と呼ばれる。ここで、三角形状のタイプは、ピクセルシェーディングまたはzバッファモードといった現在のレンダリング状態と無関係であることに留意すべきである。特定のタイルに関するデータは、これに限定されるものではないが、そのタイルに蓄えられた(binned)特定の三角形状のタイプを有する三角形状の数、ピクセルシェーディングのコストの合計(例えば、そのタイルに蓄えられた(binned)特定の三角形状のタイプを有する三角形状のそれぞれに関する単一の断片に対して、特定の(certain )ピクセルシェーディングを実行するのに必要なサイクル)、および、特定の(specific)レンダリング状態に調和する(adhering)タイルに蓄えられた(binned)特定の三角形状のタイプを有する三角形状の数を含んでよい。特定のレンダリング状態としては、ステンシル専用(stencil-only)の状態、または、早期Zカル(early-z-cull)が有効な状態を例示することができる。
【0008】
タイルに重なる三角形状を含むジオメトリバッチの数のような上位の構成概念(higher level construct)に関するカウンタを含めることは、有益である。それぞれのジオメトリバッチは、一般的に、ある程度のオーバーヘッドを招く。
【0009】
モデルは、このデータを用いて、線形項と対数項とを形成してよい。いくつかの実施形態において、線形項および対数項の加重和(weighted sum)は、タイルを処理するのに要する時間を示す。対数項は、隠蔽(occlusion)のモデル化に役立つ。すなわち、三角形状が目に見えるもの(visible)である場合、三角形状によって覆われたピクセルについて全てのシェーディングを計算する必要があるので、通常、その三角形状の処理には、より長い時間を要する。三角形状が、すでにレンダリングされている三角形状によって隠蔽されている(occluded)(隠されている(obscured))場合、より少ないコストで実行することができる。ピクセルごとに、重なり合う三角形状の数の対数を1つにまとめるモデルが用いられてよい。1993年のパラレルレンダリング・シンポジウムの議事録の49〜56ページに掲載されているCox、MichaelおよびPat Hanrahanによる「オブジェクト・パラレル・レンダリング(object-parallel rendering)のためのピクセル結合:分散型スヌーピング・アルゴリズム」を参照されたい。
【0010】
加重和の重みは、モデルを実測のタイミングにフィッティングさせることで決定される。フィッティングは、実行時に、適当な間隔でまたはオフラインで、多数のシーンから提供されたデータを用いて実施されてよい。使用される対数関数は、底が2の対数(the floor of the 2-logarithm)であってよい。底が2の対数は、整数を効率よく計算することができる。非線形モデルの1つは式(1)である。
【数1】
ここで、tは処理時間であり、xiはカウンタの値である。A、Bi、CおよびDiは、フィッティングによって見出された定数である。このモデルは非線形であるので、オフラインでフィッティングすることが好ましい。寄与するカウンタがないときに、結果として生じる値が0であることを確かにする目的で、対数項の中に1という値が追加されている。
【0011】
線形モデルの1つは、式(2)である。
【数2】
このモデルは、線形のフィッティングを実行するコストが比較的少ないので、実行時にフィッティングする(runtime fitting)ことが好ましい。
【0012】
全てのカウンタに対して対数項を含めるのは意味をなさない。目的は、断片が隠蔽されている場合に、シェーディング時間が短くなるように、隠蔽をモデル化することなので、いくつかの実施形態においては、early-z-cullが有効な形状に関するシェーディングを利用するカウンタだけが含まれてよい。すなわち、他の対数項に関する定数は、0であろう。
【0013】
コストの推算において、どの項を含むかの決定は、レンダリング・パイプラインの実装者次第である。線形モデル(式(2))が用いられる場合、フレームnをレンダリングしているときに、全ての情報が収集されてよい。そして、フレームn+1のレンダリングを開始する前に、収集された情報に基づいて、係数が再計算される。次に、式(2)の中でこれらの係数が使用されて、それぞれのタイルのコストを推算する。例えば式(3)のような移動平均の更新情報(sliding average update)を用いて、係数を更新してよい。
an+1=kanew+(1−k)an (3)
ここで、aiは、線形モデルの全ての係数、すなわちA、BjおよびCjを含むベクトルである。
【0014】
このアプローチは、コスト推算モデルにおける急転(sudden jump)を抑制する。そうしなければ、同一のフレームについて複数回レンダリングを実行した場合であっても、値が振動する。モデルの変更によりタイルの分割方法が変更するので、振動が起こうる。このことは、モデルの修正に用いられた実測値(measurement)を次々に変更してよい。kの値は、ユーザ次第で、0から1の範囲内に設定される。k=1の場合、前回のaの値が使用されず、k=0の場合、新しい値が使用されない(それゆえ、無意味である。)。kの値は、0と1との間のどこか、例えば、k=0.5となるであろう。
【0015】
フロントエンドは、コスト推算モデルにより要求される情報に関するタイルごとのカウンタ(per-tile counter)を含めるよう修正される。フロントエンドに先立って、そのようなカウンタの全てが0に初期化される。三角形状がタイルに蓄積される(binned)たびに、その三角形状のタイプが決定され、当該三角形状のタイプに関するカウンタがインクリメントされる。例えば、特定の三角形状のタイプに関するピクセル・シェーダのコスト(pixel shader cost)の合計値を収容するカウンタのような、その他のカウンタもまた、それに応じて修正される。
【0016】
ここで、例えば、オフライン・フィッティングから予め重みが分かっている場合には、重みを予め掛けておくことで、線形項に関する全てのカウンタを単一の値にしておくことができ、これにより、記憶装置に対する要求(storage requirement)を低減させることができる。
【0017】
典型的には、いくつかのコアが同一のカウンタにアクセスするので、図2に示すように、それぞれのコアについて、固有のカウンタ12の集合(set)10を有することは有益である。このように、コア間の同期(inter-core synchronization)を抑制することができる。これらのコアごとのカウンタ(per-core counter)12はフロントエンドワーク18に結合され、タイルに関するコストを推算する場合、(14に示されるように)累算されて、コスト推算モデル16により使用される一式の(set)カウンタとなる。
【0018】
三角形状がタイルに蓄積される(binned)場合に、フロントエンドがそのカウンタをインクリメントする方法の一例が、図3に示されている。20において、タイル/三角形状の対(tile/triangle pair)が受信される。菱形22のチェックは、三角形状がタイルに重なるか否かを決定する。三角形状がタイルと重ならない場合には、24に示すように、フローが終了する。三角形状がタイルと重なる場合には、菱形26のチェックは、この三角形状が、このタイルのジオメトリバッチの最初の三角形状であるか否かを決定する。この三角形状が、このタイルのジオメトリバッチの最初の三角形状である場合、28において、バッチ・カウンタがインクリメントされる。次に、菱形30において、三角形状のタイプが決定される。32に示される次の段階において、三角形状がタイルの全体を覆っている場合には、タイプ1が示される。他のタイプに当てはまらない場合には、タイプ2が示される。三角形状が16×16のサンプルを覆っている場合には、タイプ3が示される。三角形状が2×2のサンプルを覆っている場合には、タイプ4が示される。ラスタライズするアーキテクチャによっては、その他の三角形状のタイプが用いられてよい。次に、34において、トライアングル・カウンタ[タイプ]がインクリメントされ、現在のシェーダの長さ(shader length)がシェーダ・カウンタ[タイプ]に追加される。
【0019】
菱形36のチェックにおいて、早期Zカル(early-z-cull)が有効であるか否かが決定される(すなわち、ピクセルをシェーディングする前に、Zカリング(Z-culling)が実施されているか否かが決定される。)。早期Zカル(early-z-cull)が有効でない場合、フローは終了する。そうでない場合、ブロック38において、早期Zカル・カウンタ[タイプ]がインクリメントされ、現在のシェーダの長さ(shader length)が早期Zシェーダ・カウンタ(Early-Z-Shading-Counter)[タイプ]に追加される。
【0020】
フロントエンドの後、分割のためのヒューリスティック46(splitting heuristic)(図1)が用いられて、どのタイルを分割するかが決定される。一例として、あるタイルが128×128ピクセルを覆っている場合、そのタイルは、2つの重なり合っていない64×128ピクセルのサブタイルに分割されてよい。そのようなサブタイルのレンダリング時間に関するコストは、そのタイル全体のレンダリング時間のおおよそ半分になると考えられる。したがって、タイルが分割され、サブタイルのバックエンドワークが2つのコアによって並列に処理される場合、もしかすると、タイルを分割することにより、タイルをレンダリングするのに要する時間を50%に減らすことができるかもしれない。
【0021】
分割のためのヒューリスティックの第1のステップは、コスト推算モデルおよびタイルごとのカウンタを用いて、すべてのタイルのコストを推算することである。次に、(タイル全体のコストと比較したときのサブタイルのコストは、ピクセル中におけるサブタイルの面積に直接的に比例するという仮定のもと、)n個のもっともコストのかかるタイルが選択され、それぞれのサブタイルのコストが特定の閾値thを下回るまで、繰り返し分割される。通常、タイルを分割することに関連するオーバーヘッドが存在する。それゆえ、本当に必要な場合に限って分割することが有益である。過度の分割は、パフォーマンスの低下を招く可能性がある。あるシーンの中に、いくつかの独立したレンダリング対象、および/または、同時に複数のインフライトな(in flight)フレームが含まれる場合、コストのかかるタイルでさえ、分割することは有益ではないかもしれない。このため、閾値thは、同時発生の(concurrent)レンダリング対象中のワークの総量に応じて修正される。
【0022】
順序付けのためのヒューリスティック48(ordering heuristic)(図1)は、コストのかかるタイルのバックエンドワークが、できるだけ早く開始されるように試みる。これにより、バックエンドの最後に、ロードの不均衡が低減される。それゆえ、分割の後、推算されたコストに基づいて、タイルがソートされる。次に、その順序で、もっともコストのかかる(サブ)タイルから、利用可能なコアに発送される。分割段階の間にタイルがソートされる場合には、タイルを再度ソートする必要はない。この場合、サブタイルは、ワーク列(work queue)中の適切な位置に挿入され、概算コストを利用した順序を保証してよい。
【0023】
タイルを分割する目的で、専用のラスタライザ50(図1)が用いられてよい。専用のラスタライザを用いなければ、タイルを分割することのメリットが少なくなるであろう。分割の後、タイルの三角形状をサブタイルの間で再分配してよい。すなわち、三角形状がどのサブタイルに重なるかを検証して、そのようなサブタイルのそれぞれについて、サブタイルの三角形状のリスト(triangle list)の中に、その三角形状を記載する。しかしながら、この方法は、フロントエンド/バックエンドに分割されたパイプラインではうまく機能しない場合がある。この実行には、単に、現在のパイプラインに多くの変更が必要であろう。よりよい方法は、サブタイルを処理するそれぞれのコアに、「親」タイルの三角形状のリスト全体を調べさせることである。次に、専用のラスタライザが、サブタイルの領域の外側の三角形状を放棄する(discard)。走査変換(scan conversion)の間に、サブタイルの外側の断片(fragment)を効率よく放棄するように変更されてもよい。階層的ラスタライゼーション(hierarchical rasterization)の間、コアが、サブタイルのピクセル領域の外側のピクセル領域に達すると、専用のラスタライザは、階層的トラバーサル(hierarchical traversal)を単に終了させる。これにより、現在のパイプラインに対する変更が非常に小さくコンパクトになり、いくつかの実施形態において、非常に好ましい。サブタイルの全く外側に存在する三角形状を迅速に却下する目的で、それが、走査変換に先立つ三角形状結合ボックステスト(triangle bounding-box test)に組み込まれてもよい。一実施形態において、タイルが、常に、長手方向(longer axis)に沿って半分に分割され、結果として、(親タイルの次元が2のべき乗であると仮定すると、)常に2のべき乗の次元になる。例えば、効率のよいシフト操作を用いて、大抵の却下テスト(rejection test)が実施されてよい。
【0024】
いくつかの実施形態において、ラスタライゼーションに基づくレンダラーを用いたオフライン・レンダリングが用いられてよい。この場合、レンダリングにはるかに多くのコストがかかるので、推算のコストは、相対的に小さくなるであろう。それゆえ、その意味でも、このような技術を用いることは意味がある。加えて、より高次の基本形状(higher order primitive)(例えば、置換されたベジエ曲面(displaced Bezier surface)、置換された細分化曲面(displaced subdivision surface)および任意の変位シェーダ(arbitrary displacement shader))についても、いくつかの実施形態を利用することで、大きな効果が得られる場合がある。
【0025】
いくつかの実施形態は、単一のレンダリング対象のロードを均等化して、利用を最大化し、レイテンシを最小化してよい。同時に、メモリのフットプリントはあまり増加しなくてもよい。いくつかのケースにおいて、専用のラスタライザは、その実行を実質的に容易にする。
【0026】
図4に示されるコンピュータ・システム(computer system)130は、バス104によってチップセットのコア・ロジック110に結合されるハードドライブ134およびリムーバブル・メディア(removable medium)136を備えてよい。バス108を介して、キーボードおよびマウス120またはその他の通常の要素が、チップセットのコア・ロジックに結合されてよい。一実施形態において、コア・ロジックは、バス105を介して、グラフィックプロセッサ112およびメインまたはホストプロセッサ100に結合されてよい。グラフィックプロセッサ112は、バス106を介して、フレームバッファ114に結合されてもよい。フレームバッファ114は、バス107を介して、表示画面118に結合されてもよい。一実施形態において、グラフィックプロセッサ112は、単一命令複数データ(SIMD)アーキテクチャを用いた、マルチスレッド、マルチコアの並列プロセッサであってよい。図2に示されるように、グラフィックプロセッサは、複数のコアを含んでよく、それぞれのコアは、カウンタと関連付けられてよい。
【0027】
ソフトウエアにより実行される場合、適切なコードが、メインメモリ132またはグラフィックプロセッサに含まれるなんらかの利用可能なメモリを含む、なんらかの適切な半導体、磁気的または光学的な記憶装置に記憶されてよい。一実施形態において、図1から図3までのシーケンスを実行するコード139が、メインメモリ132またはグラフィックプロセッサ112のような、不揮発性の機械またはコンピュータが読み込むことができる媒体に記憶されてよく、一実施形態において、プロセッサ100またはグラフィックプロセッサ112により実行されてよい。
【0028】
図1から図3は、フローチャートである。いくつかの実施形態において、これらのフローチャートに記載されたシーケンスが、ハードウエア、ソフトウエアまたはファームウエアにおいて実行されてよい。ソフトウエアの実施形態において、半導体メモリ、磁気メモリまたは光学メモリのようなコンピュータ可読媒体を用いて命令が記憶されてよく、プロセッサにより実行されて、図1から図3に記載されたフローチャートの1以上に示されるシーケンスが実行されてよい。
【0029】
本明細書に記載される画像処理技術は、様々なハードウエア・アーキテクチャにおいて実現されてよい。例えば、グラフィック機能が1つのチップセットに統合されてよい。他には、独立した(discrete)グラフィックプロセッサが用いられてよい。さらに他の実施形態において、グラフィック機能が、マルチコア・プロセッサを含む、汎用のプロセッサにより実現されてもよい。
【0030】
本明細書を通して、「一実施形態」または「ある実施形態」という表現は、その実施形態に関連して記載される特定の特徴、構造または特性が、本発明の範囲内に含まれる少なくとも1つの実現手段の中に含まれることを意味する。例えば、「一実施形態」または「ある実施形態中」という用語が出現しても、必ずしも、同一の実施形態を参照しているとは限らない。さらに、特定の特徴、構造または特性は、説明された特定の態様以外にも、その他の適切な実施形態の中で用いられてよく、そのような態様は、すべて、本出願の特許請求の範囲の範囲内に含まれてよい。
【0031】
本発明は、限られた数の実施形態に関連して説明されているけれども、当業者は、それらから、多数の改造および変更(variation)を認識することができるであろう。添付の特許請求の範囲は、本発明の真の精神および範囲内に含まれるように、そのような改造および変更をカバーすることが意図されている。
(項目1)
タイリングレンダリングを実施するパイプライン中で、バックエンドワークに要する時間を推算する段階を有する、
タイルを分割する方法。
(項目2)
上記推算されたコストに基づいて、タイルを複数のサブタイルに分割するかいなかを決定する段階を有する、
項目1に記載の方法。
(項目3)
三角形状のタイプを識別する段階と、
上記タイプを上記推算に用いる段階と、
を有する、
項目1に記載の方法。
(項目4)
三角形状がタイルの全体を覆うか否かに基づいて、上記三角形状の上記タイプを識別する段階を有する、
項目3に記載の方法。
(項目5)
三角形状によって覆われるサンプルの数に基づいて、三角形状のタイプを識別する段階を有する、
項目2に記載の方法。
(項目6)
早期Zカルが有効化されているか否かを決定して、上記時間を推算する段階を有する、
項目1に記載の方法。
(項目7)
複数のコアを用いる段階と、
特定のタイルから分割された特定のサブタイルを処理するそれぞれのコアが、上記タイル中のすべての三角形状を調べて、どの上記三角形状が、上記コアに割り当てられたサブタイルの範囲内にあるかを決定することを可能にする段階と、
を有する、
項目1に記載の方法。
(項目8)
コンピュータに、
タイリングレンダリングを実施するパイプライン中で、コスト推算モデルを用いて、タイルごとに、バックエンドワークに要する時間を推算する手順、
を実行させるためのプログラム。
(項目9)
上記コンピュータに、
上記コスト推算モデルを用いて、タイルをサブタイルに分割するか否かを決定する手順、
をさらに実行させるための項目8に記載のプログラム。
(項目10)
上記コンピュータに、
三角形状のタイプを識別する手順と、
上記タイプを推算に用いる手順と、
をさらに実行させるための項目8に記載のプログラム。
(項目11)
上記コンピュータに、
三角形状がタイルの全体を覆うか否かに基づいて、上記三角形状の上記タイプを識別する手順、
をさらに実行させるための項目10に記載のプログラム。
(項目12)
上記コンピュータに、
上記三角形状によって覆われるサンプルの数に基づいて、上記三角形状の上記タイプを識別する手順、
をさらに実行させるための項目10に記載のプログラム。
(項目13)
上記コンピュータに、
早期Zカルが有効化されているか否かを決定して、上記時間を推算する手順、
をさらに実行させるための項目8に記載のプログラム。
(項目14)
上記コンピュータに、
複数のコアを用いる手順と、
特定のタイルから分割された特定のサブタイルを処理するそれぞれのコアが、上記タイル中の全ての三角形状を調べて、どの上記三角形状が、上記コアに割り当てられたサブタイルの範囲内にあるかを決定することを可能にする手順と、
をさらに実行させるための項目8に記載のプログラム。
(項目15)
タイルを分割するか否かを決定するコスト推算ユニットと、
コアのそれぞれが、上記タイル中の全ての三角形状を調べて、どの上記三角形状が、上記コアに割り当てられたサブタイルの範囲内にあるかを決定することで、分割されていないタイル、および、特定のタイルから分割された特定のサブタイルを処理することができるマルチコア・プロセッサ(multiple-core processor)と、
を備える、
装置。
(項目16)
上記コアのそれぞれに関する、一式のカウンタであって、コスト推算モデルに利用される一式のカウンタを備える、
項目15に記載の装置。
(項目17)
上記カウンタが加算装置に結合される、
項目16に記載の装置。
(項目18)
上記コスト推算ユニットが、上記加算装置に結合される、
項目17に記載の装置。
(項目19)
タイリングレンダリングを実施するパイプライン中で、バックエンドワークに要する時間を推算する推算ユニットを備える、
項目15に記載の装置。
(項目20)
上記推算ユニットが、三角形状のタイプを識別して、上記タイプを上記推算に用いる、
項目19に記載の装置。
【特許請求の範囲】
【請求項1】
タイリングレンダリングを実施するパイプライン中で、タイルごとに、バックエンドワークに要する時間を推算する段階と、
前記推算された前記時間に基づいて、複数のサブタイルに分割するか否かを、タイルごとに決定する段階と、
前記複数のサブタイルの前記バックエンドワークに要する時間を推算する段階と、
前記タイルを分割して得られる前記複数のサブタイルのそれぞれの前記バックエンドワークに要する時間が特定の閾値を下回るまで、前記複数のサブタイルのそれぞれを繰り返し分割し、
前記バックエンドワークが実行されるタイル又はサブタイルの前記バックエンドワークに要する時間に基づいて、前記バックエンドワークが実行されるタイル又はサブタイルをソートする段階と、
前記バックエンドワークが実行されるタイル又はサブタイルを、前記バックエンドワークに要する時間が最も大きなものから順番に、利用可能なコアに発送する段階と、
を有し、
前記特定の閾値は、同時発生のレンダリング対象中のワークの総量に応じて修正される、
タイルを分割する方法。
【請求項2】
三角形状のタイプを識別する段階と、
前記タイプを前記推算に用いる段階と、
を有する、
請求項1に記載の方法。
【請求項3】
三角形状がタイルの全体を覆うか否かに基づいて、前記三角形状の前記タイプを識別する段階を有する、
請求項2に記載の方法。
【請求項4】
三角形状によって覆われるサンプルの数に基づいて、前記三角形状の前記タイプを識別する段階を有する、
請求項2に記載の方法。
【請求項5】
早期Zカルが有効化されているか否かを決定して、前記時間を推算する段階を有する、
請求項1から請求項4までの何れか一項に記載の方法。
【請求項6】
複数のコアを用いる段階と、
特定のタイルから分割された特定のサブタイルを処理するそれぞれのコアが、前記タイル中のすべての三角形状を調べて、どの前記三角形状が、前記コアに割り当てられたサブタイルの範囲内にあるかを決定することを可能にする段階と、
を有する、
請求項1から請求項5までの何れか一項に記載の方法。
【請求項7】
コンピュータに、
タイリングレンダリングを実施するパイプライン中で、コスト推算モデルを用いて、タイルごとに、バックエンドワークに要する時間を推算する手順と、
前記推算された前記時間に基づいて、複数のサブタイルに分割するか否かを、前記タイルごとに決定する手順と、
前記複数のサブタイルの前記バックエンドワークに要する時間を推算する手順と、
前記タイルを分割して得られる前記複数のサブタイルのそれぞれの前記バックエンドワークに要する時間が特定の閾値を下回るまで、前記複数のサブタイルのそれぞれを繰り返し分割する手順と、
前記バックエンドワークが実行されるタイル又はサブタイルの前記バックエンドワークに要する時間に基づいて、前記バックエンドワークが実行されるタイル又はサブタイルをソートする手順と、
前記バックエンドワークが実行されるタイル又はサブタイルを、前記バックエンドワークに要する時間が最も大きなものから順番に、利用可能なコアに発送する手順と、
を実行させるためのプログラムであって、
前記特定の閾値は、同時発生のレンダリング対象中のワークの総量に応じて修正される、
プログラム。
【請求項8】
前記コンピュータに、
三角形状のタイプを識別する手順と、
前記タイプを推算に用いる手順と、
をさらに実行させるための請求項7に記載のプログラム。
【請求項9】
前記コンピュータに、
三角形状がタイルの全体を覆うか否かに基づいて、前記三角形状の前記タイプを識別する手順、
をさらに実行させるための請求項8に記載のプログラム。
【請求項10】
前記コンピュータに、
前記三角形状によって覆われるサンプルの数に基づいて、前記三角形状の前記タイプを識別する手順、
をさらに実行させるための請求項8に記載のプログラム。
【請求項11】
前記コンピュータに、
早期Zカルが有効化されているか否かを決定して、前記時間を推算する手順、
をさらに実行させるための請求項7から請求項10までの何れか一項に記載のプログラム。
【請求項12】
前記コンピュータに、
複数のコアを用いる手順と、
特定のタイルから分割された特定のサブタイルを処理するそれぞれのコアが、前記タイル中の全ての三角形状を調べて、どの前記三角形状が、前記コアに割り当てられたサブタイルの範囲内にあるかを決定することを可能にする手順と、
をさらに実行させるための請求項7から請求項11までの何れか一項に記載のプログラム。
【請求項13】
タイルを分割するか否かを決定するコスト推算ユニットと、
コアのそれぞれが、前記タイル中の全ての三角形状を調べて、どの前記三角形状が、前記コアに割り当てられたサブタイルの範囲内にあるかを決定することで、分割されていないタイル、および、特定のタイルから分割された特定のサブタイルを処理することができるマルチコア・プロセッサ(multiple-core processor)と、
タイリングレンダリングを実施するパイプライン中で、バックエンドワークに要する時間を推算する推算ユニットと、
を備え、
前記推算ユニットは、タイルごとに、前記バックエンドワークに要する時間を推算し、
前記コスト推算ユニットは、前記推算ユニットが前記タイルごとに推算した前記時間に基づいて、複数のサブタイルに分割するか否かを、前記タイルごとに決定し、
前記推算ユニットは、前記複数のサブタイルの前記バックエンドワークに要する時間を推算し、
前記コスト推算ユニットは、前記タイルを分割して得られる前記複数のサブタイルのそれぞれの前記バックエンドワークに要する時間が特定の閾値を下回るまで、前記複数のサブタイルのそれぞれを繰り返し分割し、
前記マルチコア・プロセッサは、
前記バックエンドワークが実行されるタイル又はサブタイルの前記バックエンドワークに要する時間に基づいて、前記バックエンドワークが実行されるタイル又はサブタイルをソートし、
前記バックエンドワークが実行されるタイル又はサブタイルを、前記バックエンドワークに要する時間が最も大きなものから順番に、利用可能なコアに発送し、
前記特定の閾値は、同時発生のレンダリング対象中のワークの総量に応じて修正される、
装置。
【請求項14】
前記コアのそれぞれに関する、一式のカウンタであって、コスト推算モデルに利用される一式のカウンタを備える、
請求項13に記載の装置。
【請求項15】
前記カウンタが加算装置に結合される、
請求項14に記載の装置。
【請求項16】
前記コスト推算ユニットが、前記加算装置に結合される、
請求項15に記載の装置。
【請求項17】
前記推算ユニットが、三角形状のタイプを識別して、前記タイプを前記推算に用いる、
請求項13から請求項16までの何れか一項に記載の装置。
【請求項1】
タイリングレンダリングを実施するパイプライン中で、タイルごとに、バックエンドワークに要する時間を推算する段階と、
前記推算された前記時間に基づいて、複数のサブタイルに分割するか否かを、タイルごとに決定する段階と、
前記複数のサブタイルの前記バックエンドワークに要する時間を推算する段階と、
前記タイルを分割して得られる前記複数のサブタイルのそれぞれの前記バックエンドワークに要する時間が特定の閾値を下回るまで、前記複数のサブタイルのそれぞれを繰り返し分割し、
前記バックエンドワークが実行されるタイル又はサブタイルの前記バックエンドワークに要する時間に基づいて、前記バックエンドワークが実行されるタイル又はサブタイルをソートする段階と、
前記バックエンドワークが実行されるタイル又はサブタイルを、前記バックエンドワークに要する時間が最も大きなものから順番に、利用可能なコアに発送する段階と、
を有し、
前記特定の閾値は、同時発生のレンダリング対象中のワークの総量に応じて修正される、
タイルを分割する方法。
【請求項2】
三角形状のタイプを識別する段階と、
前記タイプを前記推算に用いる段階と、
を有する、
請求項1に記載の方法。
【請求項3】
三角形状がタイルの全体を覆うか否かに基づいて、前記三角形状の前記タイプを識別する段階を有する、
請求項2に記載の方法。
【請求項4】
三角形状によって覆われるサンプルの数に基づいて、前記三角形状の前記タイプを識別する段階を有する、
請求項2に記載の方法。
【請求項5】
早期Zカルが有効化されているか否かを決定して、前記時間を推算する段階を有する、
請求項1から請求項4までの何れか一項に記載の方法。
【請求項6】
複数のコアを用いる段階と、
特定のタイルから分割された特定のサブタイルを処理するそれぞれのコアが、前記タイル中のすべての三角形状を調べて、どの前記三角形状が、前記コアに割り当てられたサブタイルの範囲内にあるかを決定することを可能にする段階と、
を有する、
請求項1から請求項5までの何れか一項に記載の方法。
【請求項7】
コンピュータに、
タイリングレンダリングを実施するパイプライン中で、コスト推算モデルを用いて、タイルごとに、バックエンドワークに要する時間を推算する手順と、
前記推算された前記時間に基づいて、複数のサブタイルに分割するか否かを、前記タイルごとに決定する手順と、
前記複数のサブタイルの前記バックエンドワークに要する時間を推算する手順と、
前記タイルを分割して得られる前記複数のサブタイルのそれぞれの前記バックエンドワークに要する時間が特定の閾値を下回るまで、前記複数のサブタイルのそれぞれを繰り返し分割する手順と、
前記バックエンドワークが実行されるタイル又はサブタイルの前記バックエンドワークに要する時間に基づいて、前記バックエンドワークが実行されるタイル又はサブタイルをソートする手順と、
前記バックエンドワークが実行されるタイル又はサブタイルを、前記バックエンドワークに要する時間が最も大きなものから順番に、利用可能なコアに発送する手順と、
を実行させるためのプログラムであって、
前記特定の閾値は、同時発生のレンダリング対象中のワークの総量に応じて修正される、
プログラム。
【請求項8】
前記コンピュータに、
三角形状のタイプを識別する手順と、
前記タイプを推算に用いる手順と、
をさらに実行させるための請求項7に記載のプログラム。
【請求項9】
前記コンピュータに、
三角形状がタイルの全体を覆うか否かに基づいて、前記三角形状の前記タイプを識別する手順、
をさらに実行させるための請求項8に記載のプログラム。
【請求項10】
前記コンピュータに、
前記三角形状によって覆われるサンプルの数に基づいて、前記三角形状の前記タイプを識別する手順、
をさらに実行させるための請求項8に記載のプログラム。
【請求項11】
前記コンピュータに、
早期Zカルが有効化されているか否かを決定して、前記時間を推算する手順、
をさらに実行させるための請求項7から請求項10までの何れか一項に記載のプログラム。
【請求項12】
前記コンピュータに、
複数のコアを用いる手順と、
特定のタイルから分割された特定のサブタイルを処理するそれぞれのコアが、前記タイル中の全ての三角形状を調べて、どの前記三角形状が、前記コアに割り当てられたサブタイルの範囲内にあるかを決定することを可能にする手順と、
をさらに実行させるための請求項7から請求項11までの何れか一項に記載のプログラム。
【請求項13】
タイルを分割するか否かを決定するコスト推算ユニットと、
コアのそれぞれが、前記タイル中の全ての三角形状を調べて、どの前記三角形状が、前記コアに割り当てられたサブタイルの範囲内にあるかを決定することで、分割されていないタイル、および、特定のタイルから分割された特定のサブタイルを処理することができるマルチコア・プロセッサ(multiple-core processor)と、
タイリングレンダリングを実施するパイプライン中で、バックエンドワークに要する時間を推算する推算ユニットと、
を備え、
前記推算ユニットは、タイルごとに、前記バックエンドワークに要する時間を推算し、
前記コスト推算ユニットは、前記推算ユニットが前記タイルごとに推算した前記時間に基づいて、複数のサブタイルに分割するか否かを、前記タイルごとに決定し、
前記推算ユニットは、前記複数のサブタイルの前記バックエンドワークに要する時間を推算し、
前記コスト推算ユニットは、前記タイルを分割して得られる前記複数のサブタイルのそれぞれの前記バックエンドワークに要する時間が特定の閾値を下回るまで、前記複数のサブタイルのそれぞれを繰り返し分割し、
前記マルチコア・プロセッサは、
前記バックエンドワークが実行されるタイル又はサブタイルの前記バックエンドワークに要する時間に基づいて、前記バックエンドワークが実行されるタイル又はサブタイルをソートし、
前記バックエンドワークが実行されるタイル又はサブタイルを、前記バックエンドワークに要する時間が最も大きなものから順番に、利用可能なコアに発送し、
前記特定の閾値は、同時発生のレンダリング対象中のワークの総量に応じて修正される、
装置。
【請求項14】
前記コアのそれぞれに関する、一式のカウンタであって、コスト推算モデルに利用される一式のカウンタを備える、
請求項13に記載の装置。
【請求項15】
前記カウンタが加算装置に結合される、
請求項14に記載の装置。
【請求項16】
前記コスト推算ユニットが、前記加算装置に結合される、
請求項15に記載の装置。
【請求項17】
前記推算ユニットが、三角形状のタイプを識別して、前記タイプを前記推算に用いる、
請求項13から請求項16までの何れか一項に記載の装置。
【図1】

【図2】
【図3】
【図4】
【図2】
【図3】
【図4】
【公開番号】特開2013−101673(P2013−101673A)
【公開日】平成25年5月23日(2013.5.23)
【国際特許分類】
【出願番号】特願2013−10873(P2013−10873)
【出願日】平成25年1月24日(2013.1.24)
【分割の表示】特願2011−105128(P2011−105128)の分割
【原出願日】平成23年5月10日(2011.5.10)
【出願人】(591003943)インテル・コーポレーション (1,101)
【Fターム(参考)】
【公開日】平成25年5月23日(2013.5.23)
【国際特許分類】
【出願日】平成25年1月24日(2013.1.24)
【分割の表示】特願2011−105128(P2011−105128)の分割
【原出願日】平成23年5月10日(2011.5.10)
【出願人】(591003943)インテル・コーポレーション (1,101)
【Fターム(参考)】
[ Back to top ]