
画像処理装置およびプログラム
【課題】複数の頁から構成される原稿の特徴文字列を、本構成を有していない場合と比較して効率的に決定可能な画像処理装置を提供する。
【解決手段】特徴文字列候補抽出部32は、原稿に関する文字列である特徴文字列の候補を、頁ごとに1つずつ抽出する。頁情報算出部34は、特徴文字列候補それぞれに関する頁に関する頁情報を頁ごとに算出する。特徴文字列決定部36は、各頁から特徴文字列候補が算出されその特徴文字列候補に関する頁情報が算出されるごとに、その特徴文字列候補に関する頁情報に基づいて、原稿全体の特徴文字列を決定する。
【解決手段】特徴文字列候補抽出部32は、原稿に関する文字列である特徴文字列の候補を、頁ごとに1つずつ抽出する。頁情報算出部34は、特徴文字列候補それぞれに関する頁に関する頁情報を頁ごとに算出する。特徴文字列決定部36は、各頁から特徴文字列候補が算出されその特徴文字列候補に関する頁情報が算出されるごとに、その特徴文字列候補に関する頁情報に基づいて、原稿全体の特徴文字列を決定する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、画像処理装置およびプログラムに関する。
【背景技術】
【0002】
特許文献1は、タイトル文字列の近傍に記載されるキーワード文字列の位置及びキーワード文字列に対するタイトル文字列の相対的な位置に基づいてタイトル文字列の位置を取得し、そのタイトル文字列の位置に基づいてタイトル文字列のデータを出力するタイトル抽出装置を開示する。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2008−77454号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
本発明の目的は、複数の頁から構成される原稿の特徴文字列を、本構成を有していない場合と比較して効率的に決定可能な画像処理装置を提供することである。
【課題を解決するための手段】
【0005】
請求項1にかかる本発明は、複数の頁から構成される原稿の各頁から原稿に関する文字列である特徴文字列の候補を頁ごとに抽出する候補抽出手段と、前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、前記候補抽出手段によって頁ごとに抽出された特徴文字列の候補それぞれについて、所定の条件に従って、その頁に関する情報に基づいて係数を算出する係数算出手段と、前記係数算出手段によって1つの頁から抽出された特徴文字列の候補について係数が算出されるごとに、前記係数算出手段によって算出された係数が所定の基準値を超えているか否かを判断し、前記算出された係数が所定の第1の基準値を超えた場合に、前記第1の基準値を超えた係数に関する候補を前記原稿の特徴文字列として決定する特徴文字列決定手段とを有する画像処理装置である。
【0006】
請求項2にかかる本発明は、前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、少なくとも前記候補抽出手段の処理に要する時間を頁ごとに算出する時間算出手段をさらに有し、前記時間算出手段によって1つの頁について前記候補抽出手段の処理に要する時間が算出されるごとに、前記特徴文字列決定手段は、前記時間算出手段によって算出された頁ごとの時間の累積時間が所定の基準時間を超えたか否かを判断し、前記累積時間が所定の基準時間を超えた場合に、算出済みの前記係数のうちの最大の係数に関する候補を前記原稿の特徴文字列として決定する請求項1に記載の画像処理装置である。
【0007】
請求項3にかかる本発明は、前記特徴文字列決定手段は、前記時間の累積時間が所定の基準時間を超えた場合であって、算出済みの前記係数のうちの最大の係数が前記第1の基準値よりも小さい第2の基準値以下であるとき、所定の情報に関する文字列を前記原稿の特徴文字列として決定する請求項2に記載の画像処理装置である。
【0008】
請求項4にかかる本発明は、前記特徴文字列決定手段は、原稿の全ての頁について前記算出された係数が前記第1の基準値を超えなかった場合に、算出された係数のうちの最大の係数に関する特徴文字列の候補を前記原稿の特徴文字列として決定する請求項1に記載の画像処理装置である。
【0009】
請求項5にかかる本発明は、前記特徴文字列決定手段は、原稿の全ての頁について前記係数が第1の基準値を超えなかった場合であって、算出済みの係数のうちの最大の係数が前記第1の基準値よりも小さい第2の基準値以下であるとき、所定の情報に関する文字列を前記原稿の特徴文字列として決定する請求項4に記載の画像処理装置である。
【0010】
請求項6にかかる本発明は、複数の頁から構成される原稿の各頁から原稿に関する文字列である特徴文字列の候補を頁ごとに抽出する候補抽出手段と、前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、前記候補抽出手段によって頁ごとに抽出された特徴文字列の候補それぞれについて、所定の条件に従って、その頁に関する情報に基づいて係数を算出する係数算出手段と、前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、少なくとも前記候補抽出手段の処理に要する時間を頁ごとに算出する時間算出手段と、前記時間算出手段によって1つの頁について前記候補抽出手段の処理に要する時間が算出されるごとに、前記時間算出手段によって算出された頁ごとの時間の累積時間が所定の基準時間を超えたか否かを判断し、前記累積時間が所定の基準時間を超えた場合に、算出済みの前記係数のうちの最大の係数に関する候補を前記原稿の特徴文字列として決定する特徴文字列決定手段とを有する画像処理装置である。
【0011】
請求項7にかかる本発明は、前記特徴文字列決定手段は、前記時間の累積時間が所定の基準時間を超えた場合であって、算出済みの係数のうちの最大の係数が前記第1の基準値よりも小さい第2の基準値以下であるとき、所定の情報に関する文字列を前記原稿の特徴文字列として決定する請求項6に記載の画像処理装置である。
【0012】
請求項8にかかる本発明は、複数の頁から構成される原稿の各頁から原稿に関する文字列である特徴文字列の候補を頁ごとに抽出する候補抽出ステップと、前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、前記候補抽出ステップにおいて頁ごとに抽出された特徴文字列の候補それぞれについて、所定の条件に従って、その頁に関する情報に基づいて係数を算出する係数算出ステップと、前記係数算出手段によって1つの頁から抽出された特徴文字列の候補について係数が算出されるごとに、前記係数算出ステップによって算出された係数が所定の基準値を超えているか否かを判断し、前記算出された係数が所定の第1の基準値を超えた場合に、前記第1の基準値を超えた係数に関する候補を前記原稿の特徴文字列として決定する特徴文字列決定ステップとをコンピュータに実行させる画像処理プログラムである。
【発明の効果】
【0013】
請求項1に係る本発明によれば、複数の頁から構成される原稿の特徴文字列を、本構成を有していない場合と比較して効率的に決定可能な画像処理装置を提供することができる。
【0014】
請求項2に係る本発明によれば、請求項1に係る本発明により得られる効果に加えて、原稿の特徴文字列の決定に要する時間を、本構成を有していない場合と比較して削減することができる。
【0015】
請求項3に係る本発明によれば、請求項2に係る本発明により得られる効果に加えて、原稿の特徴文字列として不適切な文字列が特徴文字列として決定されることを排除できる。
【0016】
請求項4に係る本発明によれば、請求項1に係る本発明により得られる効果に加えて、全頁の処理後に原稿の特徴文字列を決定できる。
【0017】
請求項5に係る本発明によれば、請求項4に係る本発明により得られる効果に加えて、原稿の特徴文字列として不適切な文字列が特徴文字列として決定されることを排除できる。
【0018】
請求項6に係る本発明によれば、複数の頁から構成される原稿の特徴文字列の決定に要する時間を、本構成を有していない場合と比較して削減可能な画像処理装置を提供できる。
【0019】
請求項7に係る本発明によれば、請求項6に係る本発明により得られる効果に加えて、原稿の特徴文字列として不適切な文字列が特徴文字列として決定されることを排除できる。
【0020】
請求項8に係る本発明によれば、複数の頁から構成される原稿の特徴文字列を、本構成を有していない場合と比較して効率的に決定可能な画像処理プログラムを提供することができる。
【図面の簡単な説明】
【0021】
【図1】本実施形態にかかる画像処理装置のハードウェア構成を例示する図である。
【図2】図1に示した画像処理装置において動作する処理プログラムである。
【図3】図2に示した特徴文字列候補抽出部の構成を示す図である。
【図4】図2に示した頁情報算出部の構成を示す図である。
【図5】図2に示した特徴文字列決定部の構成を示す図である。
【図6】位置配点基準情報と規模配点基準情報と頻度配点基準情報とを例示する図である。
【図7】処理プログラムの処理を示すフローチャートである。
【図8】本実施形態に係る画像処理装置の処理結果を例示する図である。
【発明を実施するための形態】
【0022】
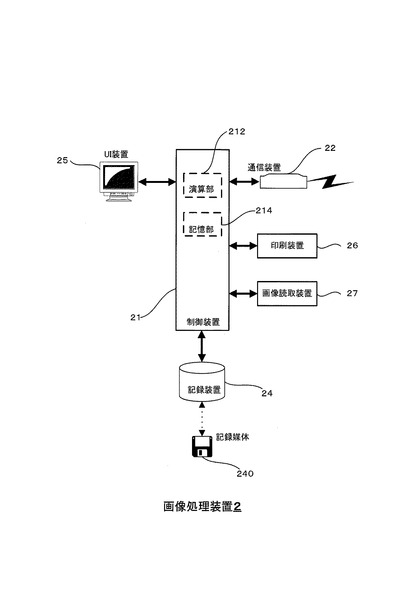
図1は、本実施形態にかかる画像処理装置2のハードウェア構成を例示する図である。
図1に例示するように、画像処理装置2は、CPU等の演算部212及びメモリ等の記憶部214などを含む制御装置21と、通信装置22と、記録装置24と、ユーザインターフェース装置(UI装置)25と、印刷装置26と、画像読取装置27とから構成される。
【0023】
UI装置25は、LCD(Liquid Crystal Display)表示装置あるいはCRT(Cathode Ray Tube)表示装置等の表示装置およびキーボード・タッチパネルなどを含む。
印刷装置26は、例えばプリンタ等であって、文字データまたは画像データ等を用紙等の記録媒体に印刷する。
画像読取装置27は、例えばスキャナ等であって、原稿等の記録媒体から画像等を読み取って、例えばビットマップ形式の読取情報に変換する。
つまり、画像処理装置2は、情報処理および他の画像処理装置又は端末との通信が可能なコンピュータとしてのハードウェア構成部分を有している。
また、以下の各図において、実質的に同じ構成部分および処理には同じ番号が付される。
なお、本実施形態において、画像処理装置2は印刷装置26および画像読取装置27を有するとしたが、画像処理装置は、印刷装置および画像読取装置を有さない例えばPCであってもよく、この場合、画像処理装置は、画像読取装置とLAN(Local Area Network)等を介して接続されていてもよい。
【0024】
図2は、図1に示した画像処理装置2において動作する処理プログラム3の構成を示す図である。
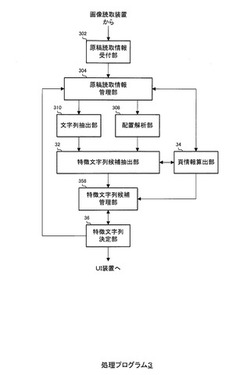
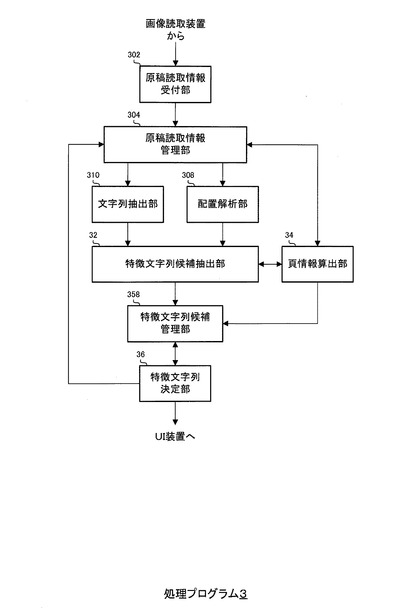
図2に示すように、処理プログラム3は、原稿読取情報受付部302、原稿読取情報管理部304、配置解析部308、文字列抽出部310、特徴文字列候補抽出部32、頁情報算出部34、特徴文字列候補管理部358および特徴文字列決定部36から構成される。
処理プログラム3は、たとえば、記憶媒体240(図1)を介して画像処理装置2に供給され、記憶部214にロードされ、画像処理装置2にインストールされたOS(図示せず)上で、画像処理装置2のハードウェア資源を具体的に利用して実行される。
なお、本実施形態においては、処理プログラム3は、ソフトウェアで実現されるとしているが、処理プログラム3の全部又は一部は、例えばFPGA(Field Programmable Gate Array)などのハードウェアで実現されてもよい。
【0025】
図3は、図2に示した特徴文字列候補抽出部32の構成を示す図である。
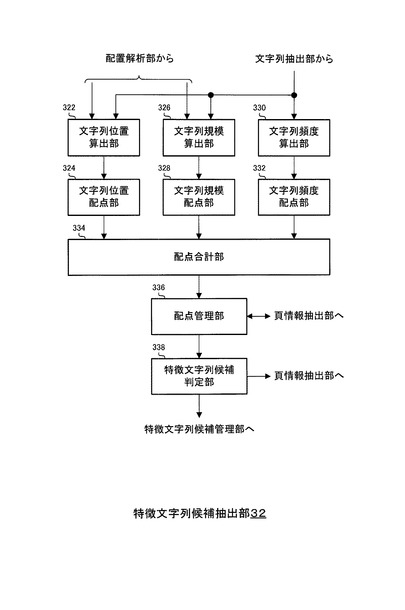
図3に示すように、特徴文字列候補抽出部32は、文字列位置算出部322、文字列位置配点部324、文字列規模算出部326、文字列規模配点部328、文字列頻度算出部330、文字列頻度配点部332、配点合計部334、配点格納部336および特徴文字列候補判定部338から構成される。
図4は、図2に示した頁情報算出部34の構成を示す図である。
図4に示すように、頁情報算出部34は、配点抽出部342、候補係数算出部344、処理時間算出部346、累積処理時間算出部348および処理時間管理部350から構成される。
【0026】
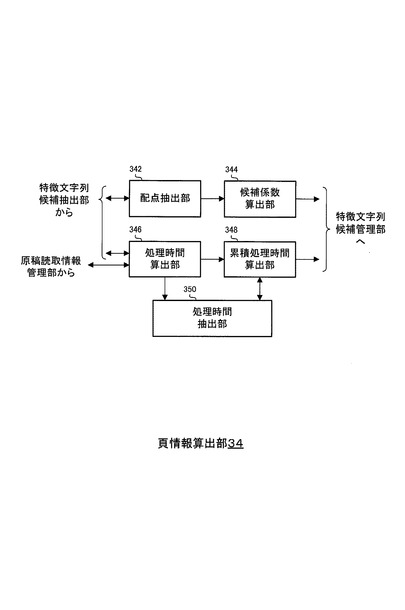
図5は、図2に示した特徴文字列決定部36の構成を示す図である。
図5に示すように、特徴文字列決定部36は、候補係数比較部362、累積処理時間比較部364、処理頁数判断部366および特徴文字列判定部368から構成される。
【0027】
処理プログラム3(図2)において、原稿読取情報受付部302は、画像読取装置27から得られた読取情報(原稿読取情報)を受け付け、受け付けた原稿読取情報を原稿読取情報管理部304に対して出力する。
原稿読取情報管理部304は、原稿読取情報受付部302からの原稿読取情報を記憶し、管理する。
また、原稿読取情報管理部304は、原稿が複数頁から構成される場合、特徴文字列決定部36からの命令に応じて、配置解析部308および文字列抽出部310が頁ごとに処理を行うように制御する。
つまり、原稿読取情報管理部304は、1つの頁の処理が終了した後、特徴文字列決定部36から次の頁の処理を行うことを示す命令を受け入れた場合のみに、配置解析部308および文字列抽出部310が頁ごとに処理を行うように制御する。
【0028】
配置解析部308は、原稿読取情報を解析して、原稿に含まれる文字、表、写真等の自然画、CG(Computer Graphics)又は絵画等を分類(オブジェクト分類)し、それぞれについて位置情報を対応付ける。
さらに、配置解析部308は、解析結果を示す情報(配置情報)を、特徴文字列候補抽出部32に対して出力する。
ここで、配置情報は、原稿読取情報に対応する原稿において、どの位置にどれだけの規模でどのオブジェクト(文字、表、写真等の自然画、CG又は絵画等)が含まれるかを示す情報である。
【0029】
この配置情報は、例えば、各オブジェクトの位置を示す位置情報と、各オブジェクトの規模(寸法又は面積等)を示す規模情報とを含む。
ここで、位置情報は、例えば、位置座標等の絶対的な位置を示すものであってもよいし、他の文字列等との相対的な位置関係を示すものであってもよい。
同様に、規模情報は、例えば、フォントサイズ又は占有面積等の、そのオブジェクトの絶対的な規模を示すものであってもよいし、他のオブジェクトとの間の相対的な規模を示すものであってもよく、あるいは、オブジェクトの規模の平均値との差を示すものであってもよい。
また、上述した配置解析部308による分類は、例えば、原稿に含まれる各種の線、枠線、罫線又は色情報の検出と、エッジ検出と、パターンマッチングとによって行われる。しかし、これらの手法に限られない。
【0030】
文字列抽出部310は、例えばOCR(Optical Character Recognition:光学文字認識)機能を使用することによって原稿読取情報を解析し、原稿に含まれる文字列を、例えば形態素解析によってその文字列単独で所定の語義を有する形式で抽出する。
ここで、文字認識とは、読み取って得られた文字の画像データを前もって記憶されたパターンと照合することによって、その文字を特定して、文字データ(文字列)を生成することをいう。
また、形態素解析とは、例えば、予め記憶されている文法の規則に関する情報と単語が登録された辞書とに基づいて、1つの文章を形態素(意味を持つ最小の言語単位)に分類し、分類された形態素の品詞を判別する処理をいう。
また、この形態素解析の処理において、文字列の言語が判別される(つまり、例えば、その文字列が日本語か英語かまたはその他の言語かが判別される)。
さらに、文字列抽出部310は、抽出された各文字列を、特徴文字列候補抽出部32に対して出力する。
【0031】
特徴文字列候補抽出部32は、原稿に関する文字列である特徴文字列の候補(特徴文字列候補)を、頁ごとに1つずつ抽出して、特徴文字列候補管理部358に対して出力する。
ここで、特徴文字列とは、例えば原稿の題名(タイトル)等であって、人間が原稿を識別するための文字列である。
また、特徴文字列は、原稿読取情報を電子データ(電子ファイル)等に変換した場合に、その電子データまたはその電子データを保管するパスフォルダ(ディレクトリ)等の名前としてもよい。
また、特徴文字列候補とは、特徴文字列となりうる文字列であって、原稿を構成する頁ごとに判定される。
そして、後述する処理によって、ある特徴文字列候補が特徴文字列の条件を満たすと判定されれば、その特徴文字列候補が、その原稿全体についての特徴文字列として決定される。
【0032】
特徴文字列候補抽出部32において、文字列位置算出部322(図3)は、配置解析部308から、処理対象の頁についての配置情報を受け入れ、文字列抽出部310から、処理対象の頁における文字列を受け入れる。
また、文字列位置算出部322は、受け入れた配置情報に含まれる位置情報に基づいて、受け入れた各文字列について位置情報を算出し、各文字列とその位置情報とを関連付けて、文字列位置配点部324に対して出力する。
文字列規模算出部326は、配置解析部308から、処理対象の頁についての配置情報を受け入れ、文字列抽出部310から、処理対象の頁における文字列を受け入れる。
また、文字列規模算出部326は、受け入れた配置情報に含まれる規模情報に基づいて、受け入れた各文字列について規模情報を算出し、各文字列とその規模情報とを関連付けて、文字列規模配点部328に対して出力する。
文字列頻度算出部330は、文字列抽出部310から、処理対象の頁における文字列を受け入れる。
また、文字列頻度算出部330は、受け入れた文字列それぞれについて、処理対象における出現頻度を算出してその出現頻度を示す頻度情報を生成し、各文字列とその頻度情報とを関連付けて、文字列頻度配点部332に対して出力する。
【0033】
文字列位置配点部324は、文字列の位置情報と文字列について算出される点数との関係を示す配点基準を示す情報(位置配点基準情報)を、予め記憶している。
文字列位置配点部324は、その位置配点基準情報に従って、各文字列について、点数(位置配点)を算出し、各文字列とその位置配点とを対応付けて、配点合計部334に対して出力する。
文字列規模配点部328は、文字列の規模情報と文字列について算出される点数との関係を示す配点基準を示す情報(規模配点基準情報)を、予め記憶している。
文字列規模配点部328は、その規模配点基準情報に従って、各文字列について、点数(規模配点)を算出し、各文字列とその規模配点とを対応付けて、配点合計部334に対して出力する。
文字列頻度配点部332は、文字列の頻度情報と文字列について算出される点数との関係を示す配点基準を示す情報(規模配点基準情報)を、予め記憶している。
文字列頻度配点部332は、その頻度配点基準情報に従って、各文字列について、点数(頻度配点)を算出し、各文字列とその頻度配点とを対応付けて、配点合計部334に対して出力する。
【0034】
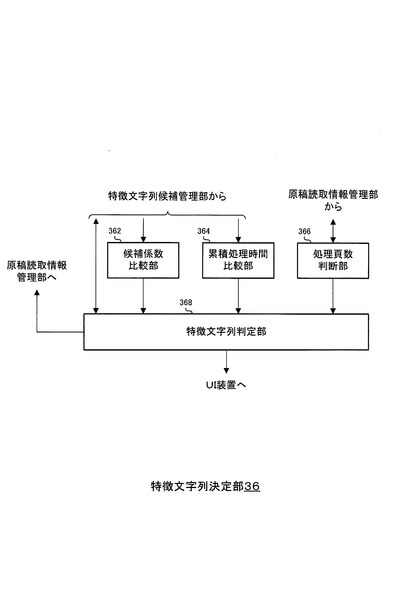
図6は、位置配点基準情報と規模配点基準情報と頻度配点基準情報とを例示する図であり、(A)は位置配点基準情報を説明するための図であり、(B)は位置配点基準情報を例示し、(C)は規模配点基準情報を例示し、(D)は頻度配点基準情報を例示する。
図6(A)に示すように、例えば、位置配点基準情報は、原稿頁の縦方向を、上端を0%、下端を100%とする相対的な位置座標で表し、原稿頁の横方向を、左端を0%、右端を100%とする相対的な位置座標で表す。
また、例えば、位置配点基準情報は、文字列の中央を、文字列の位置算出の基準点としている。
【0035】
この場合、図6(B)に示した例においては、文字列位置配点部324は、位置配点基準情報に従って、文字列が縦方向20%超(つまり、下側4/5)に存在する場合はその文字列について0.0点を算出し、文字列が縦方向20%以下(つまり、上側1/5)に存在する場合はその文字列について0.1点を算出する。
また、図6(B)に示した例においては、文字列位置配点部324は、位置配点基準情報に従って、文字列が横方向40%未満または60%超に存在する場合はその文字列について0.0点を算出し、文字列が横方向40%以上60%以下に存在する場合はその文字列について0.1点を算出する。
例えば、図6(A)に示した例においては、文字列位置配点部324は、文字列「著者富士太郎」について、0.0(縦方向)+0.1(横方向)=0.1点を算出する。
【0036】
図6(C)に示した例においては、文字列規模配点部328は、規模配点基準情報に従って、例えば処理対象の文字列の規模(フォントサイズ等)が、処理対象の原稿頁の全ての文字列の規模の平均の2倍未満であれば、その文字列について0.0点を算出し、平均の2倍以上5倍未満であれば、その文字列について0.1点を算出し、平均の5倍以上であれば、その文字列について0.5点を算出する。
図6(D)に示した例においては、文字列頻度配点部332は、処理対象の原稿頁において処理対象の文字列の出現頻度(出現数)が1個以下であれば、その文字列について0.0点を算出し、出現頻度が2個以上4個以下であれば、その文字列について0.3点を算出し、出現頻度が5個以上であれば、その文字列について0.5点を算出する。
【0037】
なお、処理対象の原稿頁に同じ文字列が複数存在する場合、文字列位置配点部324は、文字列が出現するごとに点数を算出して、算出された各点数を合計したものをその文字列に対応する位置配点としてもよいし、算出された各点数の最大値をその文字列に対応する位置配点としてもよい。
同様に、処理対象の原稿頁に同じ文字列が複数存在する場合、文字列規模配点部328は、文字列が出現するごとに点数を算出して、算出された各点数を合計したものをその文字列に対応する規模配点としてもよいし、算出された各点数の最大値をその文字列に対応する規模配点としてもよい。
【0038】
配点合計部334(図3)は、互いに異なる各文字列それぞれについて、位置配点と、規模配点と、頻度配点とを合計し、その文字列にその合計点を付与し、文字列と付与された合計点(付与配点)とを対応付けて、配点管理部336に対して出力する。
配点管理部336は、文字列とその付与配点とを対応付けて、互いに異なる文字列ごとに記憶し、管理する。
なお、配点管理部336は、付与配点だけでなく、付与配点の内訳(つまり、位置配点、規模配点および頻度配点)を、文字列ごとに記憶してもよい。
【0039】
特徴文字列候補判定部338は、原稿の各頁における全ての文字列について付与配点が算出された場合に、最大の付与配点に関する文字列を、その頁の特徴文字列候補として決定し、決定した特徴文字列候補を、特徴文字列候補管理部358および頁情報算出部34に対して出力する。
特徴文字列候補管理部358(図2)は、特徴文字列候補抽出部32によって決定された特徴文字列候補と、後述する頁情報とを、頁ごとに記憶し、管理する。
【0040】
なお、本実施形態においては、配点合計部334は、位置配点と規模配点と頻度配点との全てを合計して付与配点を算出するとしたが、位置配点、規模配点および頻度配点の少なくとも1つを付与配点としても、任意の2つの合計を付与配点としてもよい。
この場合、付与配点を構成しない位置配点、規模配点または頻度配点については、算出の対象としなくてもよい。
つまり、例えば、付与配点が規模配点と頻度配点との合計である場合、文字列位置算出部322は、各文字列について位置情報を算出しなくともよく、文字列位置配点部324は、位置配点を算出しなくてもよい。
さらに、本実施形態においては、配点合計部334は、位置配点と規模配点と頻度配点との全てを合計して付与配点を算出するとしたが、その他の基準で配点を算出して付与配点に付加してもよい。
【0041】
頁情報算出部34(図2)は、特徴文字列候補それぞれに関する頁に関する情報(頁情報)を頁ごとに算出して、その頁情報を、特徴文字列候補管理部358に対して出力する。
ここで、頁情報とは、少なくとも、候補係数と処理時間とを含み、頁ごとに算出される。
候補係数とは、対応する特徴文字列候補の、その原稿全体の特徴文字列としての確からしさを示す指標(確度)であって、例えば、その特徴文字列候補の各頁における位置、規模および頻度等から算出される。
また、処理時間とは、少なくとも、各頁から特徴文字列候補が抽出されるのに要する期間をいう。
【0042】
頁情報算出部34において、配点抽出部342(図4)は、特徴文字列候補抽出部32から特徴文字列候補を受け入れ、その特徴文字列候補に付与された付与配点を、特徴文字列候補抽出部32の配点管理部336から抽出する。
また、配点抽出部342は、抽出された付与配点を、候補係数算出部344に対して出力する。
候補係数算出部344は、配点抽出部342からの付与配点に基づいて候補係数を算出する。
また、候補係数算出部344は、候補係数を、その候補係数に関する特徴文字列候補と対応付けて、特徴文字列候補管理部358に対して出力する。
【0043】
なお、候補係数算出部344は、候補係数の算出に際し、付与配点をそのまま候補係数としてもよいが、処理された頁が進むにつれて、付与配点に対する重み付けが低くなるようにしてもよい。
つまり、[候補係数]=a[付与配点]とした場合に、aは全ての頁について1であってもよいし、処理された頁が進むにつれて、aが小さくなるようにしてもよい。
【0044】
例えば、1番目に処理された頁の特徴文字列候補#1の付与配点がS1であり、2番目に処理された頁の特徴文字列候補#2の付与配点がS2であり、3番目に処理された頁の特徴文字列候補#3の付与配点がS3であるとする。
この場合、候補係数算出部344は、特徴文字列候補#1に関する候補係数をS1とし、特徴文字列候補#2に関する候補係数をS2×0.9とし、特徴文字列候補#3に関する候補係数をS3×0.8として、候補係数を算出してもよい。
【0045】
また、候補係数算出部344は、原稿の作成者に応じて、候補係数の重み付けを変更してもよい。
例えば、原稿の作成者が総務部門である場合には、帳票に関する文字列が特徴文字列候補であると判断されたときに、その特徴文字列候補の付与配点に対する重み付けを高くして候補係数が算出され、原稿の作成者が開発部門である場合には、図面に関する文字列が特徴文字列候補であると判断されたときに、その特徴文字列候補の付与配点に対する重み付けを高くして候補係数が算出されてもよい。
なお、原稿の作成者を特定する方法としては、例えば、使用者がUI装置25を操作して入力することによって特定する方法、または、原稿に記載された作成者に関する文字列を認識することによって特定する方法がある。しかしながら、これらの方法に限られない。
また、特徴文字列候補が作成者に関連する文字列であるか否かを判断する方法としては、例えば、作成者とその作成者に関連する文字列の対応表を記憶した辞書等を使用する方法がある。しかしながら、これらの方法に限られない。
【0046】
なお、上記実施形態においては、配点抽出部342は、特徴文字列候補抽出部32から抽出された付与配点に基づいて候補係数を算出するとしたが、付与配点に基づいて候補係数を算出しなくてもよい。
例えば、特徴文字列候補に関する位置配点、規模配点および頻度配点のうちの任意の1つ以上を合計してもよく、さらに、いずれかの重み付けを変更するようにしてもよい。
【0047】
具体的には、例えば、
[式1][候補係数]=a×[位置配点]+b×[規模配点]+c×[頻度配点]
とする。
このとき、付与配点をそのまま候補係数とする場合は、式1においてa=b=c=1であるが、a≠b、b≠c、c≠aとしてもよい。
また、上記式1において、a、b、cの任意の1つまたは2つが0であってもよい。
【0048】
さらに、頁情報算出部34は、特徴文字列候補抽出部32から何らかの情報を抽出しなくても、別途、各頁における文字列およびその配置等に基づいて、候補係数を算出してもよい。
この場合、特徴文字候補抽出部32が使用した位置配点基準情報、規模配点基準情報および規模配点基準情報とは別の基準を使用して、候補係数を算出してもよい。
【0049】
処理時間算出部346は、ある1つの頁から、少なくとも特徴文字列候補が抽出されるのに要する時間(処理時間)を算出する。
具体的には、処理時間算出部346は、原稿読取情報管理部304から、処理対象である頁について配置解析部308または文字列抽出部310のいずれか早い方が処理を開始した時刻を、その頁の処理の開始時刻として抽出する。
また、処理時間算出部346は、特徴文字列候補抽出部32から、処理対象である頁について特徴文字列候補が抽出された時刻を、その頁の処理の終了時刻として抽出する。
さらに、処理時間算出部346は、終了時刻から開始時刻を減算することによって、処理時間を算出し、算出された処理時間を示す情報(処理時間情報)を、累積処理時間算出部348および処理時間管理部350に対して出力する。
【0050】
なお、処理時間算出部346は、ある1つの頁から、特徴文字列候補が抽出されるのに要する時間と、配点抽出部342および候補係数算出部344の処理に要する時間との合計時間を、処理時間として算出してもよい。
この場合、処理時間算出部346は、候補係数算出部344から、候補係数が算出された時刻を、その頁の処理の終了時刻として抽出し、その終了時刻から開始時刻を減算することによって、処理時間を算出してもよい。
【0051】
処理時間管理部350は、処理時間情報を記憶し、管理する。
累積処理時間算出部348は、処理時間算出部346からある頁に関する処理時間情報を受け入れた場合に、処理時間管理部350から、その頁についての処理以前に処理された全ての頁に関する処理時間情報を抽出する。
さらに、累積処理時間算出部348は、ある頁に関する処理時間情報が示す処理時間と、以前に処理された全ての頁についての処理時間情報が示す処理時間それぞれとを合計して、累積処理時間を算出する。
さらに、累積処理時間算出部348は、算出された累積処理時間を示す情報(累積処理時間情報)を、その頁に対応する特徴文字列候補に関する累積処理時間を示す情報として、特徴文字列候補管理部358に対して出力する。
【0052】
特徴文字列候補管理部358(図2)は、頁ごとに、特徴文字列候補と、その特徴文字列候補に関する候補係数と、その特徴文字列候補に関する累積処理時間とを記憶し、管理する。
特徴文字列決定部36は、各頁から特徴文字列候補が算出されその特徴文字列候補に関する頁情報(候補係数および累積処理時間)が算出されるごとに、その特徴文字列候補に関する頁情報(候補係数および累積処理時間)に基づいて、原稿全体の特徴文字列を決定する。
特徴文字列決定部36において、候補係数比較部362(図5)は、各頁について候補係数が算出され特徴文字列候補管理部358に記憶された場合に、その都度、その候補係数を、特徴文字列候補管理部358から抽出する。
また、候補係数比較部362は、候補係数と所定の候補係数基準値とを比較し、その候補係数が、候補係数基準値を超えているか否か判断する。
候補係数が候補係数基準値を超えている場合、候補係数比較部362は、その旨を示す情報(候補係数基準値超過情報)を、特徴文字列判定部368に対して出力し、候補係数が候補係数基準値を超えていない場合、候補係数比較部362は、その旨を示す情報(候補係数基準値未超過情報)を、特徴文字列判定部368に対して出力する。
【0053】
特徴文字列判定部368は、候補係数比較部362から候補係数基準値超過情報を受け入れた場合に、その候補係数に関する特徴文字列候補を特徴文字列候補管理部358から抽出し、その特徴文字列候補を原稿全体の特徴文字列として決定する。
さらに、特徴文字列判定部368は、決定した特徴文字列をUI装置25に出力してUI装置25に表示させる。
この場合、処理プログラム3は、処理されていない頁についての処理をすることなく、全ての処理を終了する。
つまり、候補係数基準値を超えた候補係数が存在する場合、たとえ未だ特徴文字列候補が抽出されていない頁があったとしても、その未処理の頁について処理はなされない。
【0054】
累積処理時間比較部364は、各頁について累積処理時間が算出され特徴文字列候補管理部358に記憶された場合に、その都度、その累積処理時間を示す累積処理時間情報を、特徴文字列候補管理部358から抽出する。
また、累積処理時間比較部364は、累積処理時間情報が示す累積処理時間と所定の累積処理時間基準値とを比較し、その累積処理時間が、累積処理時間基準値を超えているか否か判断する。
累積処理時間が累積処理時間基準値を超えている場合、累積処理時間比較部364は、その旨を示す情報(累積処理時間基準値超過情報)を、特徴文字列判定部368に対して出力し、累積処理時間が累積処理時間基準値を超えていない場合、累積処理時間比較部364は、その旨を示す情報(累積処理時間基準値未超過情報)を、特徴文字列判定部368に対して出力する。
【0055】
特徴文字列判定部368は、累積処理時間比較部364から累積処理時間基準値超過情報を受け入れた場合に、処理がなされた全ての頁に関する候補係数それぞれを、特徴文字列候補管理部358から抽出する。
また、特徴文字列判定部368は、抽出された候補係数のうち、最大の候補係数に関する特徴文字列候補を、特徴文字列候補管理部358から抽出し、その特徴文字列候補を原稿全体の特徴文字列として決定する。
さらに、特徴文字列判定部368は、決定した特徴文字列をUI装置25に出力してUI装置25に表示させる。
この場合、処理プログラム3は、処理されていない頁についての処理をすることなく、全ての処理を終了する。
つまり、累積処理時間が累積処理時間基準値を超えた場合、たとえ未だ特徴文字列候補が抽出されていない頁があったとしても、その未処理の頁について処理はなされない。
【0056】
なお、特徴文字列判定部368は、抽出された候補係数のうち最大の候補係数が、所定の最低候補係数基準値以下である場合、その最大の候補係数に関する特徴文字列に関わらず、所定の情報に関する文字列を、特徴文字列として決定してもよい。
この最低候補係数基準値は、候補係数基準値よりも小さい値であって、特徴文字列候補が特徴文字列として妥当であるための最低の基準を示す。
つまり、候補係数が最低候補係数基準値以下である場合、その特徴文字列候補は、その頁における他の文字列よりも付与配点が高かったが、原稿全体の特徴文字列として決定される程の付与配点を付与されておらず、したがって、その特徴文字列候補を特徴文字列とすると、その特徴文字列が原稿の内容を表していないことがある。
よって、そのような場合に、特徴文字列判定部368は、所定の情報(例えば、日時に関する情報またはユーザID等)を、特徴文字列として決定する。
【0057】
処理頁数判断部366は、原稿読取情報管理部304によって管理されている情報に基づいて、全ての頁について処理が終了したか(全ての頁について特徴文字列候補が抽出され、候補係数および累積処理時間が算出されたか)を判断する。
全ての頁について処理が終了した場合には、処理頁数判断部366は、その旨を示す情報(全頁終了情報)を、特徴文字列判定部368に対して出力し、全ての頁について処理が終了していない場合には、処理頁数判断部366は、その旨を示す情報(全頁未終了情報)を、特徴文字列判定部368に対して出力する。
【0058】
特徴文字列判定部368は、処理頁数判断部366から全頁終了情報を受け入れた場合、処理がなされた全ての頁に関する候補係数それぞれを、特徴文字列候補管理部358から抽出する。
また、特徴文字列判定部368は、抽出された候補係数のうち、最大の候補係数に関する特徴文字列候補を、特徴文字列候補管理部358から抽出し、その特徴文字列候補を原稿全体の特徴文字列として決定する。
さらに、特徴文字列判定部368は、決定した特徴文字列をUI装置25に出力してUI装置25に表示させる。
なお、特徴文字列判定部368は、累積処理時間が累積処理時間基準値を超過した場合と同様に、抽出された候補係数のうち最大の候補係数が、所定の最低候補係数基準値以下である場合、その最大の候補係数に関する特徴文字列に関わらず、所定の情報に関する文字列を、特徴文字列として決定してもよい。
【0059】
一方、特徴文字列判定部368は、候補係数比較部362から候補係数基準値未超過情報を受け入れ、累積処理時間比較部364から累積処理時間基準値未超過情報を受け入れ、かつ、処理頁数判断部366から全頁未終了情報を受け入れた場合、特徴文字列判定部368は、原稿読取情報管理部304に対し、次の頁について処理を実行する旨を示す命令を出力する。
これにより、原稿読取情報管理部304は、次の頁について、配置解析部308および文字列抽出部310が処理を行うように制御し、配置解析部308および文字列抽出部310が処理を行い、特徴文字列候補抽出部32がその次の頁について特徴文字列候補を抽出する。
【0060】
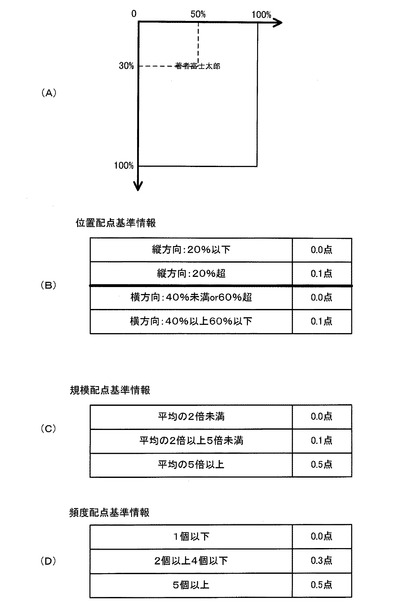
図7は、処理プログラム3の処理を示すフローチャート(S10)である。
ステップ100(S100)において、原稿読取情報受付部302は、原稿を読み取って得られた原稿読取情報を受け付ける。
ステップ102(S102)において、原稿読取情報管理部304は、処理対象の頁を1頁目とする。
ステップ104(S104)において、原稿読取情報に基づいて、頁ごとに、配置解析部308が配置情報を生成し、文字列抽出部310が文字列を抽出する。
【0061】
ステップ106(S106)において、特徴文字列候補抽出部32は、頁ごとに、特徴文字列候補を抽出する。
ステップ108(S108)において、頁情報算出部34は、候補係数を算出する。
ステップ110(S110)において、頁情報算出部34は、累積処理時間を算出する。
【0062】
ステップ112(S112)において、特徴文字列決定部36は、累積処理時間が累積処理時間基準値を超過するか否か判断し、超過すると判断する場合は、処理はS122に進み、超過しないと判断する場合は、処理はS114に進む。
ステップ114(S114)において、特徴文字列決定部36は、候補係数が候補係数基準値を超過するか否か判断し、超過すると判断する場合は、処理はS120に進み、超過しないと判断する場合は、処理はS116に進む。
ステップ116(S116)において、特徴文字列決定部36は、全ての頁について処理が終了したか否か判断し、終了したと判断した場合は、処理はS122に進み、終了していないと判断した場合は、処理はS118に進む。
ステップ118(S118)において、原稿読取情報管理部304は、次の頁を処理対象とする。
【0063】
ステップ120(S120)において、特徴文字列決定部36は、候補係数基準値を超過した候補係数に関する特徴文字列候補を、原稿の特徴文字列として決定し、処理を終了する。
ステップ122(S122)において、特徴文字列決定部36は、最大の候補係数が最低候補係数基準値を超過するか否か判断し、超過すると判断する場合は、処理はS124に進み、超過しないと判断する場合は、処理はS126に進む。
ステップ124(S124)において、特徴文字列決定部36は、最大の候補係数に関する特徴文字列候補を、原稿の特徴文字列として決定し、処理を終了する。
ステップ126(S126)において、特徴文字列決定部36は、所定の情報に関する文字列を、原稿の特徴文字列として決定し、処理を終了する。
なお、上述した本実施形態において、S102で最初の処理対象頁を1頁目とするとしたが、処理対象とする頁の順序は、原稿の頁の順序と同じでなくてもよい。
【0064】
以下、本実施形態に係る画像処理装置2の処理を、具体的に例を挙げて説明する。
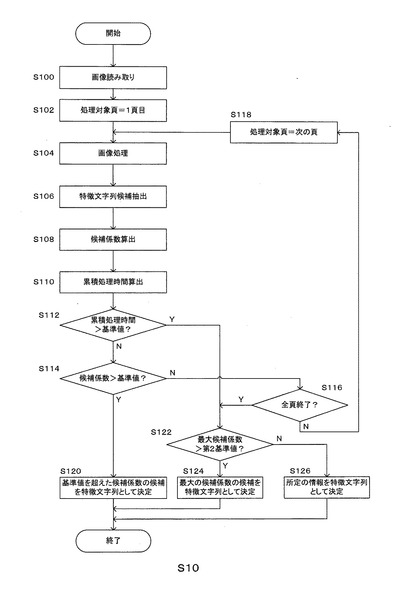
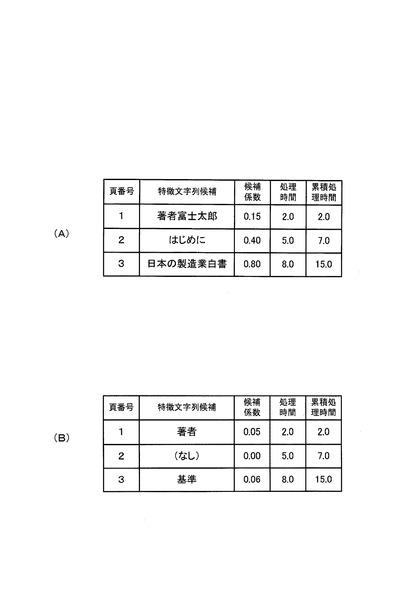
図8(A),(B)は、本実施形態に係る画像処理装置2の処理結果を例示する図であり、(A)は第1の例を示し、(B)は第2の例を示す。
図8(A)に示した例においては、第1頁について、特徴文字列候補#1「著者富士太郎」が抽出され、その特徴文字列候補#1「著者富士太郎」の候補係数#1は0.15であり、第1頁についての処理時間#1は2.0である。このとき、累積処理時間#1は2.0である。
なお、処理時間および累積処理時間の単位は、例えば、ミリ秒、秒または分等であるが、これらに限られない。
【0065】
また、第2頁について、特徴文字列候補#2「はじめに」が抽出され、その特徴文字列候補#2「はじめに」の候補係数#2は0.40であり、第2頁についての処理時間#2は5.0である。このとき、累積処理時間#2は7.0(=2.0+5.0)である。
また、第3頁について、特徴文字列候補#3「日本の製造業白書」が抽出され、その特徴文字列候補#3「日本の製造業白書」の候補係数#3は0.80であり、第3頁についての処理時間#3は8.0である。このとき、累積処理時間#3は15.0(=2.0+5.0+8.0)である。
【0066】
ここで、候補係数基準値が0.70であり、累積処理時間基準値が20.0であり、最低候補係数基準値が0.10である場合、特徴文字列候補#3「日本の製造業白書」の候補係数#3は候補係数基準値を超過している。
したがって、特徴文字列決定部36は、特徴文字列候補#3「日本の製造業白書」を、その原稿の特徴文字列として決定する。
この場合、たとえ第4頁以降の頁が存在しても、これらの頁について特徴文字列候補は抽出されない。
【0067】
また、候補係数基準値が0.85であり、累積処理時間基準値が10.0であり、最低候補係数基準値が0.10である場合、第2頁における累積処理時間#2は累積処理時間基準値を超過していないが、第3頁における累積処理時間#3は、累積処理時間基準値を超過している。
また、その時点において最大の候補係数である候補係数#3は、最低候補係数基準値を超過している。
したがって、特徴文字列決定部36は、その時点において最大の候補係数である候補係数#3に関する特徴文字列候補#3「日本の製造業白書」を、その原稿の特徴文字列として決定する。
この場合、たとえ第4頁以降の頁が存在しても、これらの頁について特徴文字列候補は抽出されない。
【0068】
また、候補係数基準値が0.85であり、累積処理時間基準値が20.0であり、第3頁が最終頁である場合、特徴文字列決定部36は、その時点において最大の候補係数である候補係数#3に関する特徴文字列候補#3「日本の製造業白書」を、その原稿の特徴文字列として決定する。
【0069】
図8(B)に示した例においては、第1頁について、特徴文字列候補#1「著者」が抽出され、その特徴文字列候補#1「著者」の候補係数#1は0.05であり、第1頁についての処理時間#1は2.0である。このとき、累積処理時間#1は2.0である。
また、第2頁については、白紙等であったため、特徴文字列候補#2は抽出されず、したがって、特徴文字列候補#2の候補係数#2は0.00である。また、第2頁についての処理時間#2は5.0である。このとき、累積処理時間#2は7.0(=2.0+5.0)である。
また、第3頁について、特徴文字列候補#3「基準」が抽出され、その特徴文字列候補#3「基準」の候補係数#3は0.06であり、第3頁についての処理時間#3は8.0である。このとき、累積処理時間#3は15.0(=2.0+5.0+8.0)である。
【0070】
ここで、候補係数基準値が0.85であり、累積処理時間基準値が10.0であり、最低候補係数基準値が0.10である場合、第2頁における累積処理時間#2は累積処理時間基準値を超過していないが、第3頁における累積処理時間#3は、累積処理時間基準値を超過している。
また、その時点において最大の候補係数である候補係数#3は、最低候補係数基準値以下である。
したがって、特徴文字列決定部36は、特徴文字列候補#3「基準」に関わらず、所定の情報に関する文字列を、その原稿の特徴文字列として決定する。
この場合、たとえ第4頁以降の頁が存在しても、これらの頁について特徴文字列候補は抽出されない。
【符号の説明】
【0071】
2・・・画像処理装置,
3・・・処理プログラム,
302・・・原稿読取情報受付部,
304・・・原稿読取情報管理部,
308・・・配置解析部,
310・・・文字列抽出部,
32・・・特徴文字列候補抽出部,
322・・・文字列位置算出部,
324・・・文字列位置配点部,
326・・・文字列規模算出部,
328・・・文字列規模配点部,
330・・・文字列頻度算出部,
332・・・文字列頻度配点部,
334・・・配点合計部,
336・・・配点格納部,
338・・・特徴文字列候補判定部,
34・・・頁情報算出部,
342・・・配点抽出部,
344・・・候補係数算出部,
346・・・処理時間算出部,
348・・・累積処理時間算出部,
350・・・処理時間管理部,
358・・・特徴文字列候補管理部,
36・・・特徴文字列決定部,
362・・・候補係数比較部,
364・・・累積処理時間比較部,
366・・・処理頁数判断部,
368・・・特徴文字列判定部,
【技術分野】
【0001】
本発明は、画像処理装置およびプログラムに関する。
【背景技術】
【0002】
特許文献1は、タイトル文字列の近傍に記載されるキーワード文字列の位置及びキーワード文字列に対するタイトル文字列の相対的な位置に基づいてタイトル文字列の位置を取得し、そのタイトル文字列の位置に基づいてタイトル文字列のデータを出力するタイトル抽出装置を開示する。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2008−77454号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
本発明の目的は、複数の頁から構成される原稿の特徴文字列を、本構成を有していない場合と比較して効率的に決定可能な画像処理装置を提供することである。
【課題を解決するための手段】
【0005】
請求項1にかかる本発明は、複数の頁から構成される原稿の各頁から原稿に関する文字列である特徴文字列の候補を頁ごとに抽出する候補抽出手段と、前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、前記候補抽出手段によって頁ごとに抽出された特徴文字列の候補それぞれについて、所定の条件に従って、その頁に関する情報に基づいて係数を算出する係数算出手段と、前記係数算出手段によって1つの頁から抽出された特徴文字列の候補について係数が算出されるごとに、前記係数算出手段によって算出された係数が所定の基準値を超えているか否かを判断し、前記算出された係数が所定の第1の基準値を超えた場合に、前記第1の基準値を超えた係数に関する候補を前記原稿の特徴文字列として決定する特徴文字列決定手段とを有する画像処理装置である。
【0006】
請求項2にかかる本発明は、前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、少なくとも前記候補抽出手段の処理に要する時間を頁ごとに算出する時間算出手段をさらに有し、前記時間算出手段によって1つの頁について前記候補抽出手段の処理に要する時間が算出されるごとに、前記特徴文字列決定手段は、前記時間算出手段によって算出された頁ごとの時間の累積時間が所定の基準時間を超えたか否かを判断し、前記累積時間が所定の基準時間を超えた場合に、算出済みの前記係数のうちの最大の係数に関する候補を前記原稿の特徴文字列として決定する請求項1に記載の画像処理装置である。
【0007】
請求項3にかかる本発明は、前記特徴文字列決定手段は、前記時間の累積時間が所定の基準時間を超えた場合であって、算出済みの前記係数のうちの最大の係数が前記第1の基準値よりも小さい第2の基準値以下であるとき、所定の情報に関する文字列を前記原稿の特徴文字列として決定する請求項2に記載の画像処理装置である。
【0008】
請求項4にかかる本発明は、前記特徴文字列決定手段は、原稿の全ての頁について前記算出された係数が前記第1の基準値を超えなかった場合に、算出された係数のうちの最大の係数に関する特徴文字列の候補を前記原稿の特徴文字列として決定する請求項1に記載の画像処理装置である。
【0009】
請求項5にかかる本発明は、前記特徴文字列決定手段は、原稿の全ての頁について前記係数が第1の基準値を超えなかった場合であって、算出済みの係数のうちの最大の係数が前記第1の基準値よりも小さい第2の基準値以下であるとき、所定の情報に関する文字列を前記原稿の特徴文字列として決定する請求項4に記載の画像処理装置である。
【0010】
請求項6にかかる本発明は、複数の頁から構成される原稿の各頁から原稿に関する文字列である特徴文字列の候補を頁ごとに抽出する候補抽出手段と、前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、前記候補抽出手段によって頁ごとに抽出された特徴文字列の候補それぞれについて、所定の条件に従って、その頁に関する情報に基づいて係数を算出する係数算出手段と、前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、少なくとも前記候補抽出手段の処理に要する時間を頁ごとに算出する時間算出手段と、前記時間算出手段によって1つの頁について前記候補抽出手段の処理に要する時間が算出されるごとに、前記時間算出手段によって算出された頁ごとの時間の累積時間が所定の基準時間を超えたか否かを判断し、前記累積時間が所定の基準時間を超えた場合に、算出済みの前記係数のうちの最大の係数に関する候補を前記原稿の特徴文字列として決定する特徴文字列決定手段とを有する画像処理装置である。
【0011】
請求項7にかかる本発明は、前記特徴文字列決定手段は、前記時間の累積時間が所定の基準時間を超えた場合であって、算出済みの係数のうちの最大の係数が前記第1の基準値よりも小さい第2の基準値以下であるとき、所定の情報に関する文字列を前記原稿の特徴文字列として決定する請求項6に記載の画像処理装置である。
【0012】
請求項8にかかる本発明は、複数の頁から構成される原稿の各頁から原稿に関する文字列である特徴文字列の候補を頁ごとに抽出する候補抽出ステップと、前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、前記候補抽出ステップにおいて頁ごとに抽出された特徴文字列の候補それぞれについて、所定の条件に従って、その頁に関する情報に基づいて係数を算出する係数算出ステップと、前記係数算出手段によって1つの頁から抽出された特徴文字列の候補について係数が算出されるごとに、前記係数算出ステップによって算出された係数が所定の基準値を超えているか否かを判断し、前記算出された係数が所定の第1の基準値を超えた場合に、前記第1の基準値を超えた係数に関する候補を前記原稿の特徴文字列として決定する特徴文字列決定ステップとをコンピュータに実行させる画像処理プログラムである。
【発明の効果】
【0013】
請求項1に係る本発明によれば、複数の頁から構成される原稿の特徴文字列を、本構成を有していない場合と比較して効率的に決定可能な画像処理装置を提供することができる。
【0014】
請求項2に係る本発明によれば、請求項1に係る本発明により得られる効果に加えて、原稿の特徴文字列の決定に要する時間を、本構成を有していない場合と比較して削減することができる。
【0015】
請求項3に係る本発明によれば、請求項2に係る本発明により得られる効果に加えて、原稿の特徴文字列として不適切な文字列が特徴文字列として決定されることを排除できる。
【0016】
請求項4に係る本発明によれば、請求項1に係る本発明により得られる効果に加えて、全頁の処理後に原稿の特徴文字列を決定できる。
【0017】
請求項5に係る本発明によれば、請求項4に係る本発明により得られる効果に加えて、原稿の特徴文字列として不適切な文字列が特徴文字列として決定されることを排除できる。
【0018】
請求項6に係る本発明によれば、複数の頁から構成される原稿の特徴文字列の決定に要する時間を、本構成を有していない場合と比較して削減可能な画像処理装置を提供できる。
【0019】
請求項7に係る本発明によれば、請求項6に係る本発明により得られる効果に加えて、原稿の特徴文字列として不適切な文字列が特徴文字列として決定されることを排除できる。
【0020】
請求項8に係る本発明によれば、複数の頁から構成される原稿の特徴文字列を、本構成を有していない場合と比較して効率的に決定可能な画像処理プログラムを提供することができる。
【図面の簡単な説明】
【0021】
【図1】本実施形態にかかる画像処理装置のハードウェア構成を例示する図である。
【図2】図1に示した画像処理装置において動作する処理プログラムである。
【図3】図2に示した特徴文字列候補抽出部の構成を示す図である。
【図4】図2に示した頁情報算出部の構成を示す図である。
【図5】図2に示した特徴文字列決定部の構成を示す図である。
【図6】位置配点基準情報と規模配点基準情報と頻度配点基準情報とを例示する図である。
【図7】処理プログラムの処理を示すフローチャートである。
【図8】本実施形態に係る画像処理装置の処理結果を例示する図である。
【発明を実施するための形態】
【0022】
図1は、本実施形態にかかる画像処理装置2のハードウェア構成を例示する図である。
図1に例示するように、画像処理装置2は、CPU等の演算部212及びメモリ等の記憶部214などを含む制御装置21と、通信装置22と、記録装置24と、ユーザインターフェース装置(UI装置)25と、印刷装置26と、画像読取装置27とから構成される。
【0023】
UI装置25は、LCD(Liquid Crystal Display)表示装置あるいはCRT(Cathode Ray Tube)表示装置等の表示装置およびキーボード・タッチパネルなどを含む。
印刷装置26は、例えばプリンタ等であって、文字データまたは画像データ等を用紙等の記録媒体に印刷する。
画像読取装置27は、例えばスキャナ等であって、原稿等の記録媒体から画像等を読み取って、例えばビットマップ形式の読取情報に変換する。
つまり、画像処理装置2は、情報処理および他の画像処理装置又は端末との通信が可能なコンピュータとしてのハードウェア構成部分を有している。
また、以下の各図において、実質的に同じ構成部分および処理には同じ番号が付される。
なお、本実施形態において、画像処理装置2は印刷装置26および画像読取装置27を有するとしたが、画像処理装置は、印刷装置および画像読取装置を有さない例えばPCであってもよく、この場合、画像処理装置は、画像読取装置とLAN(Local Area Network)等を介して接続されていてもよい。
【0024】
図2は、図1に示した画像処理装置2において動作する処理プログラム3の構成を示す図である。
図2に示すように、処理プログラム3は、原稿読取情報受付部302、原稿読取情報管理部304、配置解析部308、文字列抽出部310、特徴文字列候補抽出部32、頁情報算出部34、特徴文字列候補管理部358および特徴文字列決定部36から構成される。
処理プログラム3は、たとえば、記憶媒体240(図1)を介して画像処理装置2に供給され、記憶部214にロードされ、画像処理装置2にインストールされたOS(図示せず)上で、画像処理装置2のハードウェア資源を具体的に利用して実行される。
なお、本実施形態においては、処理プログラム3は、ソフトウェアで実現されるとしているが、処理プログラム3の全部又は一部は、例えばFPGA(Field Programmable Gate Array)などのハードウェアで実現されてもよい。
【0025】
図3は、図2に示した特徴文字列候補抽出部32の構成を示す図である。
図3に示すように、特徴文字列候補抽出部32は、文字列位置算出部322、文字列位置配点部324、文字列規模算出部326、文字列規模配点部328、文字列頻度算出部330、文字列頻度配点部332、配点合計部334、配点格納部336および特徴文字列候補判定部338から構成される。
図4は、図2に示した頁情報算出部34の構成を示す図である。
図4に示すように、頁情報算出部34は、配点抽出部342、候補係数算出部344、処理時間算出部346、累積処理時間算出部348および処理時間管理部350から構成される。
【0026】
図5は、図2に示した特徴文字列決定部36の構成を示す図である。
図5に示すように、特徴文字列決定部36は、候補係数比較部362、累積処理時間比較部364、処理頁数判断部366および特徴文字列判定部368から構成される。
【0027】
処理プログラム3(図2)において、原稿読取情報受付部302は、画像読取装置27から得られた読取情報(原稿読取情報)を受け付け、受け付けた原稿読取情報を原稿読取情報管理部304に対して出力する。
原稿読取情報管理部304は、原稿読取情報受付部302からの原稿読取情報を記憶し、管理する。
また、原稿読取情報管理部304は、原稿が複数頁から構成される場合、特徴文字列決定部36からの命令に応じて、配置解析部308および文字列抽出部310が頁ごとに処理を行うように制御する。
つまり、原稿読取情報管理部304は、1つの頁の処理が終了した後、特徴文字列決定部36から次の頁の処理を行うことを示す命令を受け入れた場合のみに、配置解析部308および文字列抽出部310が頁ごとに処理を行うように制御する。
【0028】
配置解析部308は、原稿読取情報を解析して、原稿に含まれる文字、表、写真等の自然画、CG(Computer Graphics)又は絵画等を分類(オブジェクト分類)し、それぞれについて位置情報を対応付ける。
さらに、配置解析部308は、解析結果を示す情報(配置情報)を、特徴文字列候補抽出部32に対して出力する。
ここで、配置情報は、原稿読取情報に対応する原稿において、どの位置にどれだけの規模でどのオブジェクト(文字、表、写真等の自然画、CG又は絵画等)が含まれるかを示す情報である。
【0029】
この配置情報は、例えば、各オブジェクトの位置を示す位置情報と、各オブジェクトの規模(寸法又は面積等)を示す規模情報とを含む。
ここで、位置情報は、例えば、位置座標等の絶対的な位置を示すものであってもよいし、他の文字列等との相対的な位置関係を示すものであってもよい。
同様に、規模情報は、例えば、フォントサイズ又は占有面積等の、そのオブジェクトの絶対的な規模を示すものであってもよいし、他のオブジェクトとの間の相対的な規模を示すものであってもよく、あるいは、オブジェクトの規模の平均値との差を示すものであってもよい。
また、上述した配置解析部308による分類は、例えば、原稿に含まれる各種の線、枠線、罫線又は色情報の検出と、エッジ検出と、パターンマッチングとによって行われる。しかし、これらの手法に限られない。
【0030】
文字列抽出部310は、例えばOCR(Optical Character Recognition:光学文字認識)機能を使用することによって原稿読取情報を解析し、原稿に含まれる文字列を、例えば形態素解析によってその文字列単独で所定の語義を有する形式で抽出する。
ここで、文字認識とは、読み取って得られた文字の画像データを前もって記憶されたパターンと照合することによって、その文字を特定して、文字データ(文字列)を生成することをいう。
また、形態素解析とは、例えば、予め記憶されている文法の規則に関する情報と単語が登録された辞書とに基づいて、1つの文章を形態素(意味を持つ最小の言語単位)に分類し、分類された形態素の品詞を判別する処理をいう。
また、この形態素解析の処理において、文字列の言語が判別される(つまり、例えば、その文字列が日本語か英語かまたはその他の言語かが判別される)。
さらに、文字列抽出部310は、抽出された各文字列を、特徴文字列候補抽出部32に対して出力する。
【0031】
特徴文字列候補抽出部32は、原稿に関する文字列である特徴文字列の候補(特徴文字列候補)を、頁ごとに1つずつ抽出して、特徴文字列候補管理部358に対して出力する。
ここで、特徴文字列とは、例えば原稿の題名(タイトル)等であって、人間が原稿を識別するための文字列である。
また、特徴文字列は、原稿読取情報を電子データ(電子ファイル)等に変換した場合に、その電子データまたはその電子データを保管するパスフォルダ(ディレクトリ)等の名前としてもよい。
また、特徴文字列候補とは、特徴文字列となりうる文字列であって、原稿を構成する頁ごとに判定される。
そして、後述する処理によって、ある特徴文字列候補が特徴文字列の条件を満たすと判定されれば、その特徴文字列候補が、その原稿全体についての特徴文字列として決定される。
【0032】
特徴文字列候補抽出部32において、文字列位置算出部322(図3)は、配置解析部308から、処理対象の頁についての配置情報を受け入れ、文字列抽出部310から、処理対象の頁における文字列を受け入れる。
また、文字列位置算出部322は、受け入れた配置情報に含まれる位置情報に基づいて、受け入れた各文字列について位置情報を算出し、各文字列とその位置情報とを関連付けて、文字列位置配点部324に対して出力する。
文字列規模算出部326は、配置解析部308から、処理対象の頁についての配置情報を受け入れ、文字列抽出部310から、処理対象の頁における文字列を受け入れる。
また、文字列規模算出部326は、受け入れた配置情報に含まれる規模情報に基づいて、受け入れた各文字列について規模情報を算出し、各文字列とその規模情報とを関連付けて、文字列規模配点部328に対して出力する。
文字列頻度算出部330は、文字列抽出部310から、処理対象の頁における文字列を受け入れる。
また、文字列頻度算出部330は、受け入れた文字列それぞれについて、処理対象における出現頻度を算出してその出現頻度を示す頻度情報を生成し、各文字列とその頻度情報とを関連付けて、文字列頻度配点部332に対して出力する。
【0033】
文字列位置配点部324は、文字列の位置情報と文字列について算出される点数との関係を示す配点基準を示す情報(位置配点基準情報)を、予め記憶している。
文字列位置配点部324は、その位置配点基準情報に従って、各文字列について、点数(位置配点)を算出し、各文字列とその位置配点とを対応付けて、配点合計部334に対して出力する。
文字列規模配点部328は、文字列の規模情報と文字列について算出される点数との関係を示す配点基準を示す情報(規模配点基準情報)を、予め記憶している。
文字列規模配点部328は、その規模配点基準情報に従って、各文字列について、点数(規模配点)を算出し、各文字列とその規模配点とを対応付けて、配点合計部334に対して出力する。
文字列頻度配点部332は、文字列の頻度情報と文字列について算出される点数との関係を示す配点基準を示す情報(規模配点基準情報)を、予め記憶している。
文字列頻度配点部332は、その頻度配点基準情報に従って、各文字列について、点数(頻度配点)を算出し、各文字列とその頻度配点とを対応付けて、配点合計部334に対して出力する。
【0034】
図6は、位置配点基準情報と規模配点基準情報と頻度配点基準情報とを例示する図であり、(A)は位置配点基準情報を説明するための図であり、(B)は位置配点基準情報を例示し、(C)は規模配点基準情報を例示し、(D)は頻度配点基準情報を例示する。
図6(A)に示すように、例えば、位置配点基準情報は、原稿頁の縦方向を、上端を0%、下端を100%とする相対的な位置座標で表し、原稿頁の横方向を、左端を0%、右端を100%とする相対的な位置座標で表す。
また、例えば、位置配点基準情報は、文字列の中央を、文字列の位置算出の基準点としている。
【0035】
この場合、図6(B)に示した例においては、文字列位置配点部324は、位置配点基準情報に従って、文字列が縦方向20%超(つまり、下側4/5)に存在する場合はその文字列について0.0点を算出し、文字列が縦方向20%以下(つまり、上側1/5)に存在する場合はその文字列について0.1点を算出する。
また、図6(B)に示した例においては、文字列位置配点部324は、位置配点基準情報に従って、文字列が横方向40%未満または60%超に存在する場合はその文字列について0.0点を算出し、文字列が横方向40%以上60%以下に存在する場合はその文字列について0.1点を算出する。
例えば、図6(A)に示した例においては、文字列位置配点部324は、文字列「著者富士太郎」について、0.0(縦方向)+0.1(横方向)=0.1点を算出する。
【0036】
図6(C)に示した例においては、文字列規模配点部328は、規模配点基準情報に従って、例えば処理対象の文字列の規模(フォントサイズ等)が、処理対象の原稿頁の全ての文字列の規模の平均の2倍未満であれば、その文字列について0.0点を算出し、平均の2倍以上5倍未満であれば、その文字列について0.1点を算出し、平均の5倍以上であれば、その文字列について0.5点を算出する。
図6(D)に示した例においては、文字列頻度配点部332は、処理対象の原稿頁において処理対象の文字列の出現頻度(出現数)が1個以下であれば、その文字列について0.0点を算出し、出現頻度が2個以上4個以下であれば、その文字列について0.3点を算出し、出現頻度が5個以上であれば、その文字列について0.5点を算出する。
【0037】
なお、処理対象の原稿頁に同じ文字列が複数存在する場合、文字列位置配点部324は、文字列が出現するごとに点数を算出して、算出された各点数を合計したものをその文字列に対応する位置配点としてもよいし、算出された各点数の最大値をその文字列に対応する位置配点としてもよい。
同様に、処理対象の原稿頁に同じ文字列が複数存在する場合、文字列規模配点部328は、文字列が出現するごとに点数を算出して、算出された各点数を合計したものをその文字列に対応する規模配点としてもよいし、算出された各点数の最大値をその文字列に対応する規模配点としてもよい。
【0038】
配点合計部334(図3)は、互いに異なる各文字列それぞれについて、位置配点と、規模配点と、頻度配点とを合計し、その文字列にその合計点を付与し、文字列と付与された合計点(付与配点)とを対応付けて、配点管理部336に対して出力する。
配点管理部336は、文字列とその付与配点とを対応付けて、互いに異なる文字列ごとに記憶し、管理する。
なお、配点管理部336は、付与配点だけでなく、付与配点の内訳(つまり、位置配点、規模配点および頻度配点)を、文字列ごとに記憶してもよい。
【0039】
特徴文字列候補判定部338は、原稿の各頁における全ての文字列について付与配点が算出された場合に、最大の付与配点に関する文字列を、その頁の特徴文字列候補として決定し、決定した特徴文字列候補を、特徴文字列候補管理部358および頁情報算出部34に対して出力する。
特徴文字列候補管理部358(図2)は、特徴文字列候補抽出部32によって決定された特徴文字列候補と、後述する頁情報とを、頁ごとに記憶し、管理する。
【0040】
なお、本実施形態においては、配点合計部334は、位置配点と規模配点と頻度配点との全てを合計して付与配点を算出するとしたが、位置配点、規模配点および頻度配点の少なくとも1つを付与配点としても、任意の2つの合計を付与配点としてもよい。
この場合、付与配点を構成しない位置配点、規模配点または頻度配点については、算出の対象としなくてもよい。
つまり、例えば、付与配点が規模配点と頻度配点との合計である場合、文字列位置算出部322は、各文字列について位置情報を算出しなくともよく、文字列位置配点部324は、位置配点を算出しなくてもよい。
さらに、本実施形態においては、配点合計部334は、位置配点と規模配点と頻度配点との全てを合計して付与配点を算出するとしたが、その他の基準で配点を算出して付与配点に付加してもよい。
【0041】
頁情報算出部34(図2)は、特徴文字列候補それぞれに関する頁に関する情報(頁情報)を頁ごとに算出して、その頁情報を、特徴文字列候補管理部358に対して出力する。
ここで、頁情報とは、少なくとも、候補係数と処理時間とを含み、頁ごとに算出される。
候補係数とは、対応する特徴文字列候補の、その原稿全体の特徴文字列としての確からしさを示す指標(確度)であって、例えば、その特徴文字列候補の各頁における位置、規模および頻度等から算出される。
また、処理時間とは、少なくとも、各頁から特徴文字列候補が抽出されるのに要する期間をいう。
【0042】
頁情報算出部34において、配点抽出部342(図4)は、特徴文字列候補抽出部32から特徴文字列候補を受け入れ、その特徴文字列候補に付与された付与配点を、特徴文字列候補抽出部32の配点管理部336から抽出する。
また、配点抽出部342は、抽出された付与配点を、候補係数算出部344に対して出力する。
候補係数算出部344は、配点抽出部342からの付与配点に基づいて候補係数を算出する。
また、候補係数算出部344は、候補係数を、その候補係数に関する特徴文字列候補と対応付けて、特徴文字列候補管理部358に対して出力する。
【0043】
なお、候補係数算出部344は、候補係数の算出に際し、付与配点をそのまま候補係数としてもよいが、処理された頁が進むにつれて、付与配点に対する重み付けが低くなるようにしてもよい。
つまり、[候補係数]=a[付与配点]とした場合に、aは全ての頁について1であってもよいし、処理された頁が進むにつれて、aが小さくなるようにしてもよい。
【0044】
例えば、1番目に処理された頁の特徴文字列候補#1の付与配点がS1であり、2番目に処理された頁の特徴文字列候補#2の付与配点がS2であり、3番目に処理された頁の特徴文字列候補#3の付与配点がS3であるとする。
この場合、候補係数算出部344は、特徴文字列候補#1に関する候補係数をS1とし、特徴文字列候補#2に関する候補係数をS2×0.9とし、特徴文字列候補#3に関する候補係数をS3×0.8として、候補係数を算出してもよい。
【0045】
また、候補係数算出部344は、原稿の作成者に応じて、候補係数の重み付けを変更してもよい。
例えば、原稿の作成者が総務部門である場合には、帳票に関する文字列が特徴文字列候補であると判断されたときに、その特徴文字列候補の付与配点に対する重み付けを高くして候補係数が算出され、原稿の作成者が開発部門である場合には、図面に関する文字列が特徴文字列候補であると判断されたときに、その特徴文字列候補の付与配点に対する重み付けを高くして候補係数が算出されてもよい。
なお、原稿の作成者を特定する方法としては、例えば、使用者がUI装置25を操作して入力することによって特定する方法、または、原稿に記載された作成者に関する文字列を認識することによって特定する方法がある。しかしながら、これらの方法に限られない。
また、特徴文字列候補が作成者に関連する文字列であるか否かを判断する方法としては、例えば、作成者とその作成者に関連する文字列の対応表を記憶した辞書等を使用する方法がある。しかしながら、これらの方法に限られない。
【0046】
なお、上記実施形態においては、配点抽出部342は、特徴文字列候補抽出部32から抽出された付与配点に基づいて候補係数を算出するとしたが、付与配点に基づいて候補係数を算出しなくてもよい。
例えば、特徴文字列候補に関する位置配点、規模配点および頻度配点のうちの任意の1つ以上を合計してもよく、さらに、いずれかの重み付けを変更するようにしてもよい。
【0047】
具体的には、例えば、
[式1][候補係数]=a×[位置配点]+b×[規模配点]+c×[頻度配点]
とする。
このとき、付与配点をそのまま候補係数とする場合は、式1においてa=b=c=1であるが、a≠b、b≠c、c≠aとしてもよい。
また、上記式1において、a、b、cの任意の1つまたは2つが0であってもよい。
【0048】
さらに、頁情報算出部34は、特徴文字列候補抽出部32から何らかの情報を抽出しなくても、別途、各頁における文字列およびその配置等に基づいて、候補係数を算出してもよい。
この場合、特徴文字候補抽出部32が使用した位置配点基準情報、規模配点基準情報および規模配点基準情報とは別の基準を使用して、候補係数を算出してもよい。
【0049】
処理時間算出部346は、ある1つの頁から、少なくとも特徴文字列候補が抽出されるのに要する時間(処理時間)を算出する。
具体的には、処理時間算出部346は、原稿読取情報管理部304から、処理対象である頁について配置解析部308または文字列抽出部310のいずれか早い方が処理を開始した時刻を、その頁の処理の開始時刻として抽出する。
また、処理時間算出部346は、特徴文字列候補抽出部32から、処理対象である頁について特徴文字列候補が抽出された時刻を、その頁の処理の終了時刻として抽出する。
さらに、処理時間算出部346は、終了時刻から開始時刻を減算することによって、処理時間を算出し、算出された処理時間を示す情報(処理時間情報)を、累積処理時間算出部348および処理時間管理部350に対して出力する。
【0050】
なお、処理時間算出部346は、ある1つの頁から、特徴文字列候補が抽出されるのに要する時間と、配点抽出部342および候補係数算出部344の処理に要する時間との合計時間を、処理時間として算出してもよい。
この場合、処理時間算出部346は、候補係数算出部344から、候補係数が算出された時刻を、その頁の処理の終了時刻として抽出し、その終了時刻から開始時刻を減算することによって、処理時間を算出してもよい。
【0051】
処理時間管理部350は、処理時間情報を記憶し、管理する。
累積処理時間算出部348は、処理時間算出部346からある頁に関する処理時間情報を受け入れた場合に、処理時間管理部350から、その頁についての処理以前に処理された全ての頁に関する処理時間情報を抽出する。
さらに、累積処理時間算出部348は、ある頁に関する処理時間情報が示す処理時間と、以前に処理された全ての頁についての処理時間情報が示す処理時間それぞれとを合計して、累積処理時間を算出する。
さらに、累積処理時間算出部348は、算出された累積処理時間を示す情報(累積処理時間情報)を、その頁に対応する特徴文字列候補に関する累積処理時間を示す情報として、特徴文字列候補管理部358に対して出力する。
【0052】
特徴文字列候補管理部358(図2)は、頁ごとに、特徴文字列候補と、その特徴文字列候補に関する候補係数と、その特徴文字列候補に関する累積処理時間とを記憶し、管理する。
特徴文字列決定部36は、各頁から特徴文字列候補が算出されその特徴文字列候補に関する頁情報(候補係数および累積処理時間)が算出されるごとに、その特徴文字列候補に関する頁情報(候補係数および累積処理時間)に基づいて、原稿全体の特徴文字列を決定する。
特徴文字列決定部36において、候補係数比較部362(図5)は、各頁について候補係数が算出され特徴文字列候補管理部358に記憶された場合に、その都度、その候補係数を、特徴文字列候補管理部358から抽出する。
また、候補係数比較部362は、候補係数と所定の候補係数基準値とを比較し、その候補係数が、候補係数基準値を超えているか否か判断する。
候補係数が候補係数基準値を超えている場合、候補係数比較部362は、その旨を示す情報(候補係数基準値超過情報)を、特徴文字列判定部368に対して出力し、候補係数が候補係数基準値を超えていない場合、候補係数比較部362は、その旨を示す情報(候補係数基準値未超過情報)を、特徴文字列判定部368に対して出力する。
【0053】
特徴文字列判定部368は、候補係数比較部362から候補係数基準値超過情報を受け入れた場合に、その候補係数に関する特徴文字列候補を特徴文字列候補管理部358から抽出し、その特徴文字列候補を原稿全体の特徴文字列として決定する。
さらに、特徴文字列判定部368は、決定した特徴文字列をUI装置25に出力してUI装置25に表示させる。
この場合、処理プログラム3は、処理されていない頁についての処理をすることなく、全ての処理を終了する。
つまり、候補係数基準値を超えた候補係数が存在する場合、たとえ未だ特徴文字列候補が抽出されていない頁があったとしても、その未処理の頁について処理はなされない。
【0054】
累積処理時間比較部364は、各頁について累積処理時間が算出され特徴文字列候補管理部358に記憶された場合に、その都度、その累積処理時間を示す累積処理時間情報を、特徴文字列候補管理部358から抽出する。
また、累積処理時間比較部364は、累積処理時間情報が示す累積処理時間と所定の累積処理時間基準値とを比較し、その累積処理時間が、累積処理時間基準値を超えているか否か判断する。
累積処理時間が累積処理時間基準値を超えている場合、累積処理時間比較部364は、その旨を示す情報(累積処理時間基準値超過情報)を、特徴文字列判定部368に対して出力し、累積処理時間が累積処理時間基準値を超えていない場合、累積処理時間比較部364は、その旨を示す情報(累積処理時間基準値未超過情報)を、特徴文字列判定部368に対して出力する。
【0055】
特徴文字列判定部368は、累積処理時間比較部364から累積処理時間基準値超過情報を受け入れた場合に、処理がなされた全ての頁に関する候補係数それぞれを、特徴文字列候補管理部358から抽出する。
また、特徴文字列判定部368は、抽出された候補係数のうち、最大の候補係数に関する特徴文字列候補を、特徴文字列候補管理部358から抽出し、その特徴文字列候補を原稿全体の特徴文字列として決定する。
さらに、特徴文字列判定部368は、決定した特徴文字列をUI装置25に出力してUI装置25に表示させる。
この場合、処理プログラム3は、処理されていない頁についての処理をすることなく、全ての処理を終了する。
つまり、累積処理時間が累積処理時間基準値を超えた場合、たとえ未だ特徴文字列候補が抽出されていない頁があったとしても、その未処理の頁について処理はなされない。
【0056】
なお、特徴文字列判定部368は、抽出された候補係数のうち最大の候補係数が、所定の最低候補係数基準値以下である場合、その最大の候補係数に関する特徴文字列に関わらず、所定の情報に関する文字列を、特徴文字列として決定してもよい。
この最低候補係数基準値は、候補係数基準値よりも小さい値であって、特徴文字列候補が特徴文字列として妥当であるための最低の基準を示す。
つまり、候補係数が最低候補係数基準値以下である場合、その特徴文字列候補は、その頁における他の文字列よりも付与配点が高かったが、原稿全体の特徴文字列として決定される程の付与配点を付与されておらず、したがって、その特徴文字列候補を特徴文字列とすると、その特徴文字列が原稿の内容を表していないことがある。
よって、そのような場合に、特徴文字列判定部368は、所定の情報(例えば、日時に関する情報またはユーザID等)を、特徴文字列として決定する。
【0057】
処理頁数判断部366は、原稿読取情報管理部304によって管理されている情報に基づいて、全ての頁について処理が終了したか(全ての頁について特徴文字列候補が抽出され、候補係数および累積処理時間が算出されたか)を判断する。
全ての頁について処理が終了した場合には、処理頁数判断部366は、その旨を示す情報(全頁終了情報)を、特徴文字列判定部368に対して出力し、全ての頁について処理が終了していない場合には、処理頁数判断部366は、その旨を示す情報(全頁未終了情報)を、特徴文字列判定部368に対して出力する。
【0058】
特徴文字列判定部368は、処理頁数判断部366から全頁終了情報を受け入れた場合、処理がなされた全ての頁に関する候補係数それぞれを、特徴文字列候補管理部358から抽出する。
また、特徴文字列判定部368は、抽出された候補係数のうち、最大の候補係数に関する特徴文字列候補を、特徴文字列候補管理部358から抽出し、その特徴文字列候補を原稿全体の特徴文字列として決定する。
さらに、特徴文字列判定部368は、決定した特徴文字列をUI装置25に出力してUI装置25に表示させる。
なお、特徴文字列判定部368は、累積処理時間が累積処理時間基準値を超過した場合と同様に、抽出された候補係数のうち最大の候補係数が、所定の最低候補係数基準値以下である場合、その最大の候補係数に関する特徴文字列に関わらず、所定の情報に関する文字列を、特徴文字列として決定してもよい。
【0059】
一方、特徴文字列判定部368は、候補係数比較部362から候補係数基準値未超過情報を受け入れ、累積処理時間比較部364から累積処理時間基準値未超過情報を受け入れ、かつ、処理頁数判断部366から全頁未終了情報を受け入れた場合、特徴文字列判定部368は、原稿読取情報管理部304に対し、次の頁について処理を実行する旨を示す命令を出力する。
これにより、原稿読取情報管理部304は、次の頁について、配置解析部308および文字列抽出部310が処理を行うように制御し、配置解析部308および文字列抽出部310が処理を行い、特徴文字列候補抽出部32がその次の頁について特徴文字列候補を抽出する。
【0060】
図7は、処理プログラム3の処理を示すフローチャート(S10)である。
ステップ100(S100)において、原稿読取情報受付部302は、原稿を読み取って得られた原稿読取情報を受け付ける。
ステップ102(S102)において、原稿読取情報管理部304は、処理対象の頁を1頁目とする。
ステップ104(S104)において、原稿読取情報に基づいて、頁ごとに、配置解析部308が配置情報を生成し、文字列抽出部310が文字列を抽出する。
【0061】
ステップ106(S106)において、特徴文字列候補抽出部32は、頁ごとに、特徴文字列候補を抽出する。
ステップ108(S108)において、頁情報算出部34は、候補係数を算出する。
ステップ110(S110)において、頁情報算出部34は、累積処理時間を算出する。
【0062】
ステップ112(S112)において、特徴文字列決定部36は、累積処理時間が累積処理時間基準値を超過するか否か判断し、超過すると判断する場合は、処理はS122に進み、超過しないと判断する場合は、処理はS114に進む。
ステップ114(S114)において、特徴文字列決定部36は、候補係数が候補係数基準値を超過するか否か判断し、超過すると判断する場合は、処理はS120に進み、超過しないと判断する場合は、処理はS116に進む。
ステップ116(S116)において、特徴文字列決定部36は、全ての頁について処理が終了したか否か判断し、終了したと判断した場合は、処理はS122に進み、終了していないと判断した場合は、処理はS118に進む。
ステップ118(S118)において、原稿読取情報管理部304は、次の頁を処理対象とする。
【0063】
ステップ120(S120)において、特徴文字列決定部36は、候補係数基準値を超過した候補係数に関する特徴文字列候補を、原稿の特徴文字列として決定し、処理を終了する。
ステップ122(S122)において、特徴文字列決定部36は、最大の候補係数が最低候補係数基準値を超過するか否か判断し、超過すると判断する場合は、処理はS124に進み、超過しないと判断する場合は、処理はS126に進む。
ステップ124(S124)において、特徴文字列決定部36は、最大の候補係数に関する特徴文字列候補を、原稿の特徴文字列として決定し、処理を終了する。
ステップ126(S126)において、特徴文字列決定部36は、所定の情報に関する文字列を、原稿の特徴文字列として決定し、処理を終了する。
なお、上述した本実施形態において、S102で最初の処理対象頁を1頁目とするとしたが、処理対象とする頁の順序は、原稿の頁の順序と同じでなくてもよい。
【0064】
以下、本実施形態に係る画像処理装置2の処理を、具体的に例を挙げて説明する。
図8(A),(B)は、本実施形態に係る画像処理装置2の処理結果を例示する図であり、(A)は第1の例を示し、(B)は第2の例を示す。
図8(A)に示した例においては、第1頁について、特徴文字列候補#1「著者富士太郎」が抽出され、その特徴文字列候補#1「著者富士太郎」の候補係数#1は0.15であり、第1頁についての処理時間#1は2.0である。このとき、累積処理時間#1は2.0である。
なお、処理時間および累積処理時間の単位は、例えば、ミリ秒、秒または分等であるが、これらに限られない。
【0065】
また、第2頁について、特徴文字列候補#2「はじめに」が抽出され、その特徴文字列候補#2「はじめに」の候補係数#2は0.40であり、第2頁についての処理時間#2は5.0である。このとき、累積処理時間#2は7.0(=2.0+5.0)である。
また、第3頁について、特徴文字列候補#3「日本の製造業白書」が抽出され、その特徴文字列候補#3「日本の製造業白書」の候補係数#3は0.80であり、第3頁についての処理時間#3は8.0である。このとき、累積処理時間#3は15.0(=2.0+5.0+8.0)である。
【0066】
ここで、候補係数基準値が0.70であり、累積処理時間基準値が20.0であり、最低候補係数基準値が0.10である場合、特徴文字列候補#3「日本の製造業白書」の候補係数#3は候補係数基準値を超過している。
したがって、特徴文字列決定部36は、特徴文字列候補#3「日本の製造業白書」を、その原稿の特徴文字列として決定する。
この場合、たとえ第4頁以降の頁が存在しても、これらの頁について特徴文字列候補は抽出されない。
【0067】
また、候補係数基準値が0.85であり、累積処理時間基準値が10.0であり、最低候補係数基準値が0.10である場合、第2頁における累積処理時間#2は累積処理時間基準値を超過していないが、第3頁における累積処理時間#3は、累積処理時間基準値を超過している。
また、その時点において最大の候補係数である候補係数#3は、最低候補係数基準値を超過している。
したがって、特徴文字列決定部36は、その時点において最大の候補係数である候補係数#3に関する特徴文字列候補#3「日本の製造業白書」を、その原稿の特徴文字列として決定する。
この場合、たとえ第4頁以降の頁が存在しても、これらの頁について特徴文字列候補は抽出されない。
【0068】
また、候補係数基準値が0.85であり、累積処理時間基準値が20.0であり、第3頁が最終頁である場合、特徴文字列決定部36は、その時点において最大の候補係数である候補係数#3に関する特徴文字列候補#3「日本の製造業白書」を、その原稿の特徴文字列として決定する。
【0069】
図8(B)に示した例においては、第1頁について、特徴文字列候補#1「著者」が抽出され、その特徴文字列候補#1「著者」の候補係数#1は0.05であり、第1頁についての処理時間#1は2.0である。このとき、累積処理時間#1は2.0である。
また、第2頁については、白紙等であったため、特徴文字列候補#2は抽出されず、したがって、特徴文字列候補#2の候補係数#2は0.00である。また、第2頁についての処理時間#2は5.0である。このとき、累積処理時間#2は7.0(=2.0+5.0)である。
また、第3頁について、特徴文字列候補#3「基準」が抽出され、その特徴文字列候補#3「基準」の候補係数#3は0.06であり、第3頁についての処理時間#3は8.0である。このとき、累積処理時間#3は15.0(=2.0+5.0+8.0)である。
【0070】
ここで、候補係数基準値が0.85であり、累積処理時間基準値が10.0であり、最低候補係数基準値が0.10である場合、第2頁における累積処理時間#2は累積処理時間基準値を超過していないが、第3頁における累積処理時間#3は、累積処理時間基準値を超過している。
また、その時点において最大の候補係数である候補係数#3は、最低候補係数基準値以下である。
したがって、特徴文字列決定部36は、特徴文字列候補#3「基準」に関わらず、所定の情報に関する文字列を、その原稿の特徴文字列として決定する。
この場合、たとえ第4頁以降の頁が存在しても、これらの頁について特徴文字列候補は抽出されない。
【符号の説明】
【0071】
2・・・画像処理装置,
3・・・処理プログラム,
302・・・原稿読取情報受付部,
304・・・原稿読取情報管理部,
308・・・配置解析部,
310・・・文字列抽出部,
32・・・特徴文字列候補抽出部,
322・・・文字列位置算出部,
324・・・文字列位置配点部,
326・・・文字列規模算出部,
328・・・文字列規模配点部,
330・・・文字列頻度算出部,
332・・・文字列頻度配点部,
334・・・配点合計部,
336・・・配点格納部,
338・・・特徴文字列候補判定部,
34・・・頁情報算出部,
342・・・配点抽出部,
344・・・候補係数算出部,
346・・・処理時間算出部,
348・・・累積処理時間算出部,
350・・・処理時間管理部,
358・・・特徴文字列候補管理部,
36・・・特徴文字列決定部,
362・・・候補係数比較部,
364・・・累積処理時間比較部,
366・・・処理頁数判断部,
368・・・特徴文字列判定部,
【特許請求の範囲】
【請求項1】
複数の頁から構成される原稿の各頁から原稿に関する文字列である特徴文字列の候補を頁ごとに抽出する候補抽出手段と、
前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、前記候補抽出手段によって頁ごとに抽出された特徴文字列の候補それぞれについて、所定の条件に従って、その頁に関する情報に基づいて係数を算出する係数算出手段と、
前記係数算出手段によって1つの頁から抽出された特徴文字列の候補について係数が算出されるごとに、前記係数算出手段によって算出された係数が所定の基準値を超えているか否かを判断し、前記算出された係数が所定の第1の基準値を超えた場合に、前記第1の基準値を超えた係数に関する候補を前記原稿の特徴文字列として決定する特徴文字列決定手段と
を有する画像処理装置。
【請求項2】
前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、少なくとも前記候補抽出手段の処理に要する時間を頁ごとに算出する時間算出手段
をさらに有し、
前記時間算出手段によって1つの頁について前記候補抽出手段の処理に要する時間が算出されるごとに、前記特徴文字列決定手段は、前記時間算出手段によって算出された頁ごとの時間の累積時間が所定の基準時間を超えたか否かを判断し、前記累積時間が所定の基準時間を超えた場合に、算出済みの前記係数のうちの最大の係数に関する候補を前記原稿の特徴文字列として決定する
請求項1に記載の画像処理装置。
【請求項3】
前記特徴文字列決定手段は、前記時間の累積時間が所定の基準時間を超えた場合であって、算出済みの前記係数のうちの最大の係数が前記第1の基準値よりも小さい第2の基準値以下であるとき、所定の情報に関する文字列を前記原稿の特徴文字列として決定する
請求項2に記載の画像処理装置。
【請求項4】
前記特徴文字列決定手段は、原稿の全ての頁について前記算出された係数が前記第1の基準値を超えなかった場合に、算出された係数のうちの最大の係数に関する特徴文字列の候補を前記原稿の特徴文字列として決定する
請求項1に記載の画像処理装置。
【請求項5】
前記特徴文字列決定手段は、原稿の全ての頁について前記係数が第1の基準値を超えなかった場合であって、算出済みの前記係数のうちの最大の係数が前記第1の基準値よりも小さい第2の基準値以下であるとき、所定の情報に関する文字列を前記原稿の特徴文字列として決定する
請求項4に記載の画像処理装置。
【請求項6】
複数の頁から構成される原稿の各頁から原稿に関する文字列である特徴文字列の候補を頁ごとに抽出する候補抽出手段と、
前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、前記候補抽出手段によって頁ごとに抽出された特徴文字列の候補それぞれについて、所定の条件に従って、その頁に関する情報に基づいて係数を算出する係数算出手段と、
前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、少なくとも前記候補抽出手段の処理に要する時間を頁ごとに算出する時間算出手段と、
前記時間算出手段によって1つの頁について前記候補抽出手段の処理に要する時間が算出されるごとに、前記時間算出手段によって算出された頁ごとの時間の累積時間が所定の基準時間を超えたか否かを判断し、前記累積時間が所定の基準時間を超えた場合に、算出済みの係数のうちの最大の係数に関する候補を前記原稿の特徴文字列として決定する特徴文字列決定手段と
を有する画像処理装置。
【請求項7】
前記特徴文字列決定手段は、前記時間の累積時間が所定の基準時間を超えた場合であって、算出済みの前記係数のうちの最大の係数が前記第1の基準値よりも小さい第2の基準値以下であるとき、所定の情報に関する文字列を前記原稿の特徴文字列として決定する
請求項6に記載の画像処理装置。
【請求項8】
複数の頁から構成される原稿の各頁から原稿に関する文字列である特徴文字列の候補を頁ごとに抽出する候補抽出ステップと、
前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、前記候補抽出ステップにおいて頁ごとに抽出された特徴文字列の候補それぞれについて、所定の条件に従って、その頁に関する情報に基づいて係数を算出する係数算出ステップと、
前記係数算出手段によって1つの頁から抽出された特徴文字列の候補について係数が算出されるごとに、前記係数算出ステップによって算出された係数が所定の基準値を超えているか否かを判断し、前記算出された係数が所定の第1の基準値を超えた場合に、前記第1の基準値を超えた係数に関する候補を前記原稿の特徴文字列として決定する特徴文字列決定ステップと
をコンピュータに実行させる画像処理プログラム。
【請求項1】
複数の頁から構成される原稿の各頁から原稿に関する文字列である特徴文字列の候補を頁ごとに抽出する候補抽出手段と、
前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、前記候補抽出手段によって頁ごとに抽出された特徴文字列の候補それぞれについて、所定の条件に従って、その頁に関する情報に基づいて係数を算出する係数算出手段と、
前記係数算出手段によって1つの頁から抽出された特徴文字列の候補について係数が算出されるごとに、前記係数算出手段によって算出された係数が所定の基準値を超えているか否かを判断し、前記算出された係数が所定の第1の基準値を超えた場合に、前記第1の基準値を超えた係数に関する候補を前記原稿の特徴文字列として決定する特徴文字列決定手段と
を有する画像処理装置。
【請求項2】
前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、少なくとも前記候補抽出手段の処理に要する時間を頁ごとに算出する時間算出手段
をさらに有し、
前記時間算出手段によって1つの頁について前記候補抽出手段の処理に要する時間が算出されるごとに、前記特徴文字列決定手段は、前記時間算出手段によって算出された頁ごとの時間の累積時間が所定の基準時間を超えたか否かを判断し、前記累積時間が所定の基準時間を超えた場合に、算出済みの前記係数のうちの最大の係数に関する候補を前記原稿の特徴文字列として決定する
請求項1に記載の画像処理装置。
【請求項3】
前記特徴文字列決定手段は、前記時間の累積時間が所定の基準時間を超えた場合であって、算出済みの前記係数のうちの最大の係数が前記第1の基準値よりも小さい第2の基準値以下であるとき、所定の情報に関する文字列を前記原稿の特徴文字列として決定する
請求項2に記載の画像処理装置。
【請求項4】
前記特徴文字列決定手段は、原稿の全ての頁について前記算出された係数が前記第1の基準値を超えなかった場合に、算出された係数のうちの最大の係数に関する特徴文字列の候補を前記原稿の特徴文字列として決定する
請求項1に記載の画像処理装置。
【請求項5】
前記特徴文字列決定手段は、原稿の全ての頁について前記係数が第1の基準値を超えなかった場合であって、算出済みの前記係数のうちの最大の係数が前記第1の基準値よりも小さい第2の基準値以下であるとき、所定の情報に関する文字列を前記原稿の特徴文字列として決定する
請求項4に記載の画像処理装置。
【請求項6】
複数の頁から構成される原稿の各頁から原稿に関する文字列である特徴文字列の候補を頁ごとに抽出する候補抽出手段と、
前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、前記候補抽出手段によって頁ごとに抽出された特徴文字列の候補それぞれについて、所定の条件に従って、その頁に関する情報に基づいて係数を算出する係数算出手段と、
前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、少なくとも前記候補抽出手段の処理に要する時間を頁ごとに算出する時間算出手段と、
前記時間算出手段によって1つの頁について前記候補抽出手段の処理に要する時間が算出されるごとに、前記時間算出手段によって算出された頁ごとの時間の累積時間が所定の基準時間を超えたか否かを判断し、前記累積時間が所定の基準時間を超えた場合に、算出済みの係数のうちの最大の係数に関する候補を前記原稿の特徴文字列として決定する特徴文字列決定手段と
を有する画像処理装置。
【請求項7】
前記特徴文字列決定手段は、前記時間の累積時間が所定の基準時間を超えた場合であって、算出済みの前記係数のうちの最大の係数が前記第1の基準値よりも小さい第2の基準値以下であるとき、所定の情報に関する文字列を前記原稿の特徴文字列として決定する
請求項6に記載の画像処理装置。
【請求項8】
複数の頁から構成される原稿の各頁から原稿に関する文字列である特徴文字列の候補を頁ごとに抽出する候補抽出ステップと、
前記候補抽出手段によって1つの頁から特徴文字列の候補が抽出されるごとに、前記候補抽出ステップにおいて頁ごとに抽出された特徴文字列の候補それぞれについて、所定の条件に従って、その頁に関する情報に基づいて係数を算出する係数算出ステップと、
前記係数算出手段によって1つの頁から抽出された特徴文字列の候補について係数が算出されるごとに、前記係数算出ステップによって算出された係数が所定の基準値を超えているか否かを判断し、前記算出された係数が所定の第1の基準値を超えた場合に、前記第1の基準値を超えた係数に関する候補を前記原稿の特徴文字列として決定する特徴文字列決定ステップと
をコンピュータに実行させる画像処理プログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【公開番号】特開2012−190315(P2012−190315A)
【公開日】平成24年10月4日(2012.10.4)
【国際特許分類】
【出願番号】特願2011−53977(P2011−53977)
【出願日】平成23年3月11日(2011.3.11)
【出願人】(000005496)富士ゼロックス株式会社 (21,908)
【Fターム(参考)】
【公開日】平成24年10月4日(2012.10.4)
【国際特許分類】
【出願日】平成23年3月11日(2011.3.11)
【出願人】(000005496)富士ゼロックス株式会社 (21,908)
【Fターム(参考)】
[ Back to top ]