
画像処理装置および画像処理方法、並びにプログラム
【課題】本発明は、メモリの帯域の無駄な消費を抑制すると共に、主メモリへの重複アクセスを抑制することができる画像処理装置を提供する。
【解決手段】主メモリ102上に展開された画像データから主走査方向及び副走査方向に分割された矩形の単位で画像データを読み取り画像処理を行う画像処理装置100において、分割された矩形を囲む矩形の領域であって、隣り合う2つの矩形間の境界を含むように互いに重複する部分を有する参照領域に対して画像処理を行う画像処理手段が、重複する部分に画像処理を行うときに、読み取った画像データをキャッシュに格納する。
【解決手段】主メモリ102上に展開された画像データから主走査方向及び副走査方向に分割された矩形の単位で画像データを読み取り画像処理を行う画像処理装置100において、分割された矩形を囲む矩形の領域であって、隣り合う2つの矩形間の境界を含むように互いに重複する部分を有する参照領域に対して画像処理を行う画像処理手段が、重複する部分に画像処理を行うときに、読み取った画像データをキャッシュに格納する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、画像処理装置および画像処理方法、並びにプログラムに関するものである。
【背景技術】
【0002】
従来、メモリに格納された画像データに対して画像処理を実行する画像処理装置には、矩形領域単位で画像処理を実行するものがあった。矩形領域単位で画像処理を行う画像処理部が対象となる矩形領域に対して画像処理(例えばフィルタ処理)を実行するために、図17(a)、図17(b)に示すように、より大きな参照領域を必要とする画像処理装置が開示されている(例えば、特許文献1参照)。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2004−220584号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、上記従来の技術では、画像処理部が対象領域の画像処理を行うために、対象領域より広い参照領域を画像データが展開されたメモリから読み取る必要がある。メモリに格納された画像データは、対象領域の大きさの単位で縦横に分割されるので、参照領域としては縦横に隣接した矩形領域と重複した部分を持つことになる。そのため、画像処理部は、重複した部分に対して、画像全体の画像処理を行う過程において複数回重複して読み取りを行う必要があり、メモリの帯域を無駄に消費するという問題がある。
【0005】
本発明は、上記問題に鑑みて成されたものであり、メモリの帯域の無駄な消費を抑制すると共に、主メモリへの重複アクセスを抑制することができる画像処理装置および方法、並びにプログラムを提供することを目的とする。
【課題を解決するための手段】
【0006】
上記目的を達成するために、請求項1記載の画像処理装置は、画像データを記憶する第1記憶手段と、前記第1記憶手段に記憶された画像データを所定サイズの複数の矩形画像データに分割して読み出す読み出し手段と、前記複数の矩形画像データを囲む参照領域の画像データであって、隣り合う2つの矩形画像データ間の境界を含むように互いに重複する部分を有する参照領域の画像データを記憶する第2記憶手段と、前記読み出し手段により読み出された前記複数の矩形画像データと、前記第2記憶手段に記憶された前記参照領域の画像データに基づいて画像処理を行う画像処理手段と、前記画像処理手段からの要求に応じて前記参照領域の画像データを前記第2記憶手段から前記画像処理手段へ転送するよう制御するキャッシュ制御手段とを備えることを特徴とする。
【0007】
上記目的を達成するために、請求項4記載の画像処理方法は、画像データを記憶する第1記憶手段に記憶する第1記憶工程と、前記第1記憶手段に記憶された画像データを所定サイズの複数の矩形画像データに分割して読み出す読み出し工程と、前記複数の矩形画像データを囲む参照領域の画像データであって、隣り合う2つの矩形画像データ間の境界を含むように互い重複する部分を有する参照領域の画像データを第2記憶手段に記憶する第2記憶工程と、前記読み出し工程にて読み出された前記複数の矩形画像データと、前記第2記憶手段に記憶された前記参照領域の画像データに基づいて画像処理手段により画像処理を行う画像処理工程と、前記画像処理手段からの要求に応じて前記参照領域の画像データを前記第2記憶手段から前記画像処理手段へ転送するよう制御するキャッシュ制御工程とを備えることを特徴とする。
【発明の効果】
【0008】
本発明によれば、メモリ上に展開された画像データに対して、注目画素としての各矩形領域を順番通りに画像処理することなく、メモリの帯域の無駄な消費を抑制すると共に、主メモリへの重複アクセスを抑制することができる。
【図面の簡単な説明】
【0009】
【図1】本発明の第1の実施形態に係る画像処理装置の概略構成を示すブロック図である。
【図2】矩形領域と該矩形領域を画像処理するために必要な参照領域との関係を示す図である。
【図3】第1の実施形態において使用する定数の定義を説明するための図である。
【図4】主メモリ上の画像データとキャッシュ1上の記憶領域との対応関係を示す図である。
【図5】主メモリ上の画像データとキャッシュ2上の記憶領域との対応関係を示す図である。
【図6】第1の実施形態におけるキャッシュ制御部の制御処理を示すフローチャートである。
【図7】(a)は、主メモリのアドレスとキャッシュ1のアドレスとの対応関係を示す図であり、(b)は、主メモリのアドレスとキャッシュ2のアドレスとの対応関係を示す図である。
【図8】画像処理部A,Bに実装されるスムージング回路の概略構成を示す図である。
【図9】画像処理部Aがキャッシュ制御部へ画像データリード要求を出力する際に実行する処理のフローチャートである。
【図10】画像処理部Aの詳細構成を示すブロック図である。
【図11】3ステートラッチバッファの概略構成を示す回路図である。
【図12】図10におけるSRAMの周辺回路の動作を示すタイムチャートである。
【図13】7×7のウィンドウを示す図である。
【図14】図10の論理回路にて行われるスムージング処理の一例を示す図である(その1)。
【図15】図10の論理回路にて行われるスムージング処理の一例を示す図である(その2)。
【図16】図10の論理回路にて行われるスムージング処理の一例を示す図である(その3)。
【図17】スムージングによって得られる画像の一例を示す図である。
【図18】本発明の第2の実施形態において使用する定数の定義を説明するための図である。
【図19】第2の実施形態における主メモリ上の画像データとキャッシュ1上の記憶領域との対応関係を示す図である。
【図20】第2の実施形態において主メモリ上の画像データとキャッシュ2上の記憶領域との対応関係を示す図である。
【図21】第2の実施形態におけるキャッシュ制御部の制御処理を示すフローチャートである。
【発明を実施するための形態】
【0010】
以下、本発明の実施の形態を図面を参照して詳細に説明する。
【0011】
[第1の実施形態]
図1は、本発明の第1の実施形態に係る画像処理装置の概略構成を示すブロック図である。
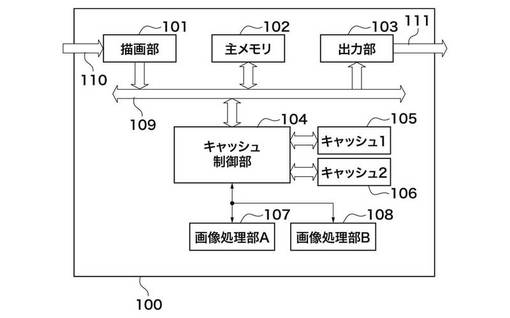
【0012】
図1において、100は画像処理装置であり、画像データ110を入力し、描画して画像処理を施した後に、画像データ111として出力する。
【0013】
101は描画部であり、入力された画像データ110を、バス109を介して主メモリ102へ展開する。主メモリ102は、描画された画像データ110を記憶するものである(第1記憶手段)。主メモリ102は、必要とされる容量と帯域からDDR SDRAM規格のメモリを想定する。また、主メモリ102は2ページ分の画像データを記憶するものとする。これにより、主メモリ102へ描画されるデータと画像処理のために読み出されるデータは別ページに割り当てることが可能となり、書き込みと読み出しの調停が容易となる。
【0014】
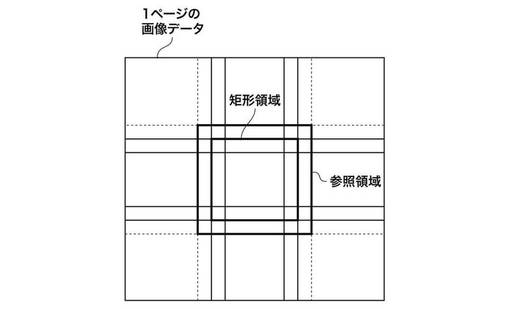
画像処理部A107と画像処理部B108は、独立して画像処理を行う画像処理回路である。画像処理としては、エッジ強調処理などのフィルタリング処理、スムージング処理などが想定される。いずれも周辺画素を参照して注目画素の値を更新するかまたは画素補完を行うものである。対象とする画素の処理を行う場合、その周辺画素、例えば9×9の周辺領域を参照するものとする。このような画像処理を対象となる矩形領域(矩形画像データ)間の境界部の画素に施すことを考えれば、対象矩形領域に対して主走査方向と副走査方向にそれぞれ4画素ずつ大きな領域が参照領域として必要となる。矩形領域と該矩形領域を画像処理するために必要な参照領域との関係を図2に示す。
【0015】
図2では、副走査方向(副方向)及び主走査方向(主方向)に矩形の単位で所定サイズ(例えば3×3)に分割された1ページの画像データの一例を示している。例えば、図2の中央の矩形が画像処理の対象となる矩形領域とすると、矩形を囲む矩形の領域であって、隣り合う2つの矩形画像データ間の境界を含むように互いに重複する部分を有する領域が、対象矩形領域を画像処理するために必要な参照領域である。さらに、ページ内の各矩形領域のそれぞれに対して参照領域を考えれば、主走査方向(図の横方向)の重複部分と副走査方向(図の縦方向)の重複部分とが交差する部分が格子状になることがわかる。
【0016】
画像処理装置100では、2つの画像処理部A107,B108により、主メモリ102上の画像データにおける2つの矩形領域に対して同時に平行して画像処理を施すことが可能である。なお、画像処理部が2つであることは本発明を限定するものではない。また、画像処理の種類は本発明を限定するものではない。
【0017】
図1に戻って、104はキャッシュ制御部である。キャッシュ制御部104は、画像処理部A107,B108から出力される画像データリード命令を受信する。画像データリード命令はデータのアドレス情報を持っている。一度の命令で転送されるデータ量は、主メモリ102の転送単位と同じ32バイトである。キャッシュ制御部104は、受信した画像データリード命令を主メモリ102へ渡すと共に、該画像データリード命令に応じてキャッシュ1_105及びキャッシュ2_106を制御し、後述する処理を行う。
【0018】
キャッシュ1_105(第1のキャッシュ)は、主メモリ102上に展開された画像データの副走査方向に隣接する2つの矩形領域(矩形画像データ)間の重複部分のデータをキャッシュするSRAMである(第2記憶手段)。キャッシュ2_106(第2のキャッシュ)は、主メモリ102上に展開された画像データの主走査方向に隣接する2つの矩形領域(矩形画像データ)間の重複部分のデータをキャッシュするSRAMである(第2記憶手段)。
【0019】
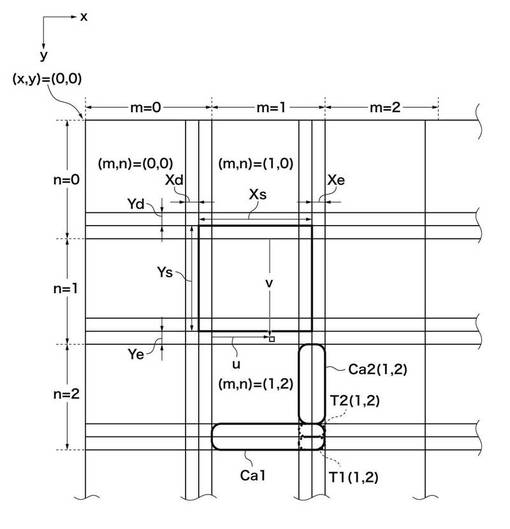
次に、第1の実施形態において使用する定数の定義を図3を参照して説明する。
【0020】
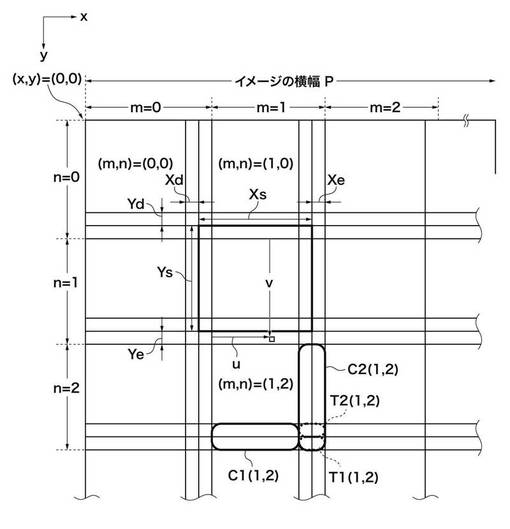
図3において、x,yは画像上の座標を表し、画像の左上が原点であり、xが右方向、yが左方向となる。Xs,Ysは矩形の大きさを示す定数である。Xd,Xeは参照領域がx方向に矩形領域よりはみ出る量を示す定数である。Yd,Yeは参照領域がy方向に矩形領域よりはみ出る量を示す定数である。mは対象座標が矩形単位でx方向にいくつめかを示す変数である。nは対象座標が矩形単位でy方向にいくつめかを示す変数である。uは対象座標が属する(m,n)で区別される領域の中でのx方向の相対位置を示す変数である。vは対象座標が属する(m,n)で区別される領域の中でのy方向の相対位置を示す変数である。
【0021】
例えば、(m,n)=(1,2)で示される領域の中でキャッシュ1_105のメモリに対応するのがC1(1,2)で示される領域である。また、キャッシュ2_106のメモリに対応するのがC2(1,2)で示される領域である。さらにC2(1,2)内のT1(1,2)で示される領域がC1(1,2)に対応するタグ情報とフラグ情報を格納する領域であり、T2(1,2)はC2(1,2)に対応するタグ情報とフラグ情報を格納する領域である。
【0022】
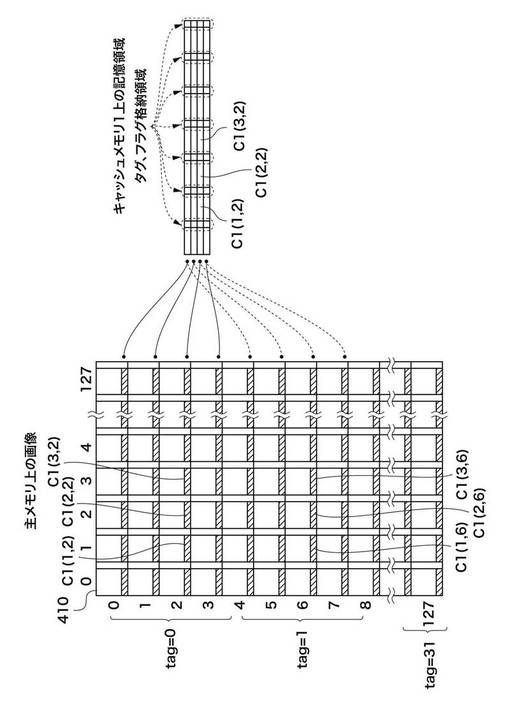
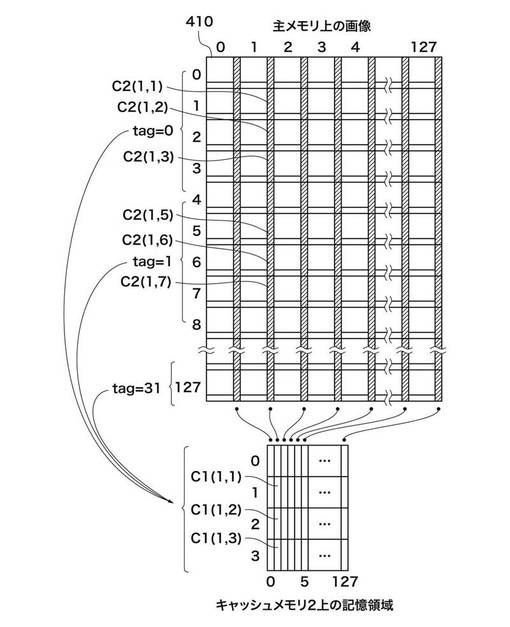
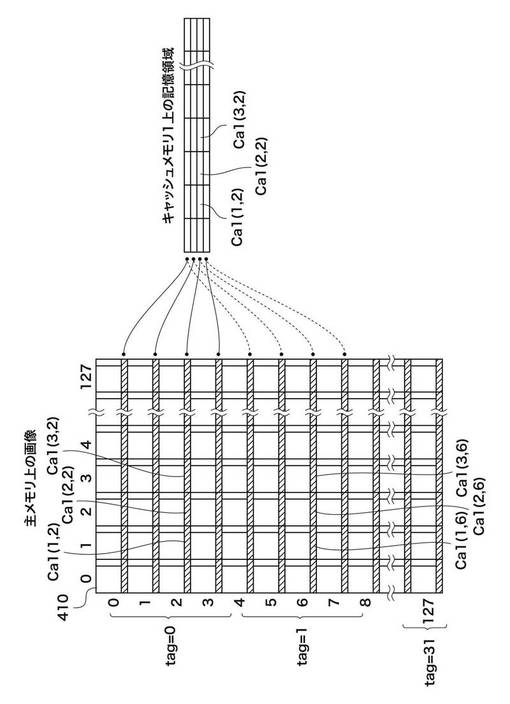
図4は、第1の実施形態における主メモリ102上の画像データとキャッシュ1_105上の記憶領域との対応関係を示す図である。図5は、第1の実施形態における主メモリ102上の画像データとキャッシュ2_106上の記憶領域との対応関係を示す図である。
【0023】
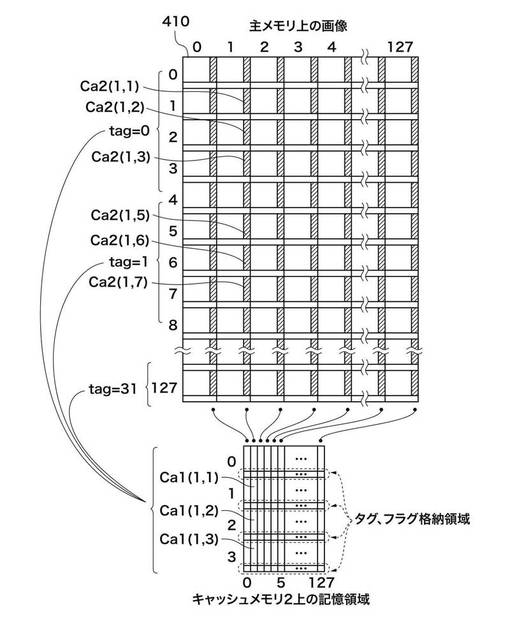
図4及び図5に示す410は主メモリ102に展開された画像とする。アドレスは画像の左上が原点であり、主走査がX方向、副走査がY方向となる。ここで、主走査方向の長さは矩形領域128個分としている。
【0024】
図4において、画像410内の任意の重複部分C1(m、n)は、キャッシュ1_105上の一つの記憶領域に対応する。本実施形態において、キャッシュ1_105は、主走査方向は全範囲、副走査方向は矩形単位で4個分の領域内の重複部分に相当する容量を保持している。例えば、画像410内のC1(1,2)、C1(2,2)、C1(3,2)の領域は、キャッシュ1_105内のC1(1,2)、C1(2,2)、C1(3,2)の領域に対応する。また、画像410内のC1(1,6)、C1(2,6)、C1(3,6)も、キャッシュ1_105内のC1(1,2)、C1(2,2)、C1(3,2)の領域に対応する。つまり、C1(1,2)のデータがキャッシュされた後に、C1(1,6)がアクセスされたならば、キャッシュ1_105内のデータは上書きされることになる。
【0025】
キャッシュ制御部104は、副走査方向の矩形4個分のアドレス領域内でデコードを行い、キャッシュメモリのアドレスを算出する。そのアドレス領域を他と区別する上位アドレスは、タグ情報としてキャッシュに記憶する必要がある。また、キャッシュ内のデータが有効であるか否かを決定するためのフラグ情報も必要である。
【0026】
図5において、画像410内の任意の重複部分C2(m、n)は、キャッシュ2_106の一つの記憶領域に対応する。本実施形態においては、キャッシュ2_106は、主走査方向は全範囲、副走査方向は矩形単位で4個分の領域内の重複部分に相当する容量を保持している。例えば、画像410内のC2(1,1)、C2(1,2)、C2(1,3)の領域は、キャッシュ2_106内のC2(1,1)、C2(1,2)、C2(1,3)の領域に対応する。また、画像410内のC2(1,5)、C2(1,6)、C2(1,7)も、キャッシュ2_106内のC2(1,1)、C2(1,2)、C2(1,3)の領域に対応する。つまり、C2(1,1)のデータがキャッシュされた後に、C2(1、5)がアクセスされたならば、キャッシュ2_106内のデータは上書きされることになる。なお、キャッシュメモリのサイズと主メモリ102上の記憶領域をどのよう分けてキャッシュメモリに対応させるかなども本発明の制限するところではない。
【0027】
上述したタグ情報とフラグ情報は、一般的なキャッシュにおいてはキャッシュのデータ単位ごとに用意される。しかし、本実施形態におけるシステムでは、キャッシュメモリへの更新の単位が必ず矩形の各辺に当たる領域であるので、それら各辺に属する領域に一組のタグ情報とフラグ情報を格納することが可能である。つまり、タグ情報とフラグ情報のための格納領域を一般のキャッシュシステムに比べて削減することが可能である。なお、キャッシュとタグの情報を格納するために、別のSRAMを用意してもよい。ただし、SRAMのデバイスとしての個数増加は、半導体上の使用面積として影響が大きいので、より好適な実装形態としてはキャッシュ1の空き領域に格納する方法がある。
【0028】
上記空き領域は、重複する部分が格子状に交差する領域である。この格子状の領域は、キャッシュ2に割り当てられているので、キャッシュメモリとしてはデータのために使用されない領域になっている。格子状の重複部分が交差する領域は、キャッシュ1に含める実装形態も当然可能である(第2の実施形態)。
【0029】
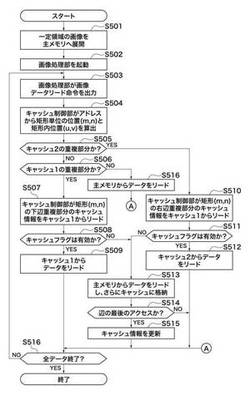
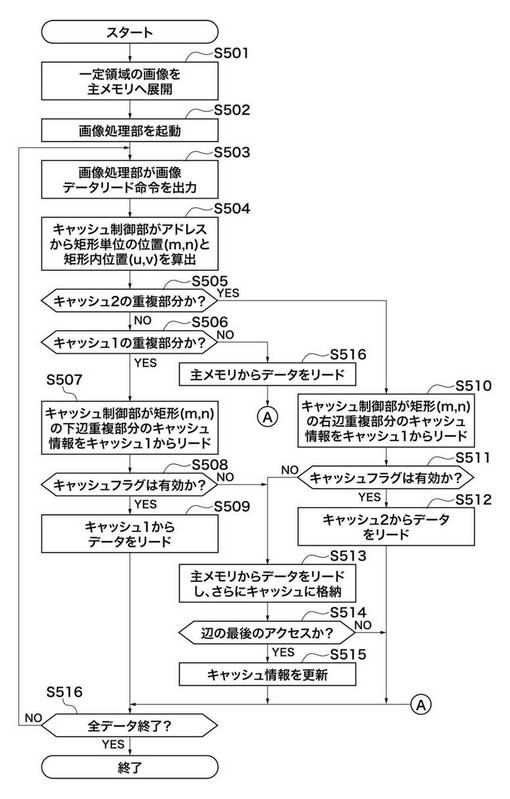
図6は、第1の実施形態におけるキャッシュ制御部104の制御処理を示すフローチャートである。
【0030】
図6において、主メモリ102への画像描画動作であるステップS501とステップS502以降の処理が時分割になっているがこれは説明のわかり易さのためである。先に述べたように、主メモリ102を2つの領域に分割し、一方を描画するための領域、他方を読み出すための領域として使用し、両方の動作が終了したときは役割を切り替えて行う方がパフォーマンスの点で好ましい。
【0031】
ステップS503において、画像処理部A107または画像処理部B108がキャッシュ制御部104に画像処理のために画像データリード命令を出力する。2つの画像処理部A107,B108は独立して読取動作を行い、キャッシュ制御部104は2つの画像処理部から出力された命令からどちらかの命令を選択して、ステップS504以降の処理を実行する。
【0032】
ステップS504において、キャッシュ制御部104は、受信した画像データリード命令に含まれるアドレス情報に基づいて、矩形単位の位置(m,n)と矩形内の相対位置(u,v)を算出する。算出方法は以下の式による。
【0033】
x=A%P
y=A/P
m=(|x−Xe|)/Xs
n=(|y−Ye|)/Ys
u=(x−Xe)%Xs
v=(y−Ye)%Ys
Aは画像データリード要求のアドレスであり,%は除算の余りを求めるものであり、/は除算の商を求めるものである。除算の処理のプロセスを簡略化するために、P,Xs,Ysは2のべき乗であることが好ましい。2のべき乗による割り算はビットシフト処理により置き換えられる。
【0034】
ステップS505において、キャッシュ制御部104は、要求アドレスがキャッシュ2_106の重複部分内であるかどうかを判断する。上記アドレスがキャッシュ2_106の重複部分内であることの条件式を以下に示す。
【0035】
Xs−Xd≦u<Xs+Xe
ステップS505の判別の結果、要求アドレスがキャッシュ2_106の重複部分内であると判断されたときは(ステップS505でYES)、ステップS510に進む。
【0036】
ステップS510において、(m,n)で指定される矩形の右辺重複部のキャッシュ情報(キャッシュのタグとフラグの情報)をキャッシュ1_105からリードする。キャッシュ1_105上のキャッシュ情報が格納されているアドレスは以下の式により与えられる。
【0037】
n(Yd+Ye)P+Xs(m+1)
次に、ステップS511において、右辺重複部のキャッシュフラグが有効であれば(ステップS511でYES)、ステップS512にて、キャッシュ制御部104は、キャッシュ2_106からデータをリードする。キャッシュ2_106上のデータが格納されているアドレスは以下の式により与えられる。
【0038】
y(Xd+Xe)P/Xs+m(Xd+Xe)+u−Xs+Xd+Xe
ステップS511において、右辺重複部のキャッシュフラグが無効であれば(ステップS511でNO)、ステップS513にて、キャッシュ制御部104は、主メモリ102からデータをリードし、さらにキャッシュの相当するアドレスにデータを格納する。そのアドレスは上記の式で与えられる。
【0039】
次に、ステップS514にて、キャッシュ制御部104は、辺の最後のアクセスであるか否かを判定し、Yesのときのみキャッシュ情報(キャッシュのタグとフラグの情報)をキャッシュ1_105の該当個所に格納して更新する(ステップS515)。アドレスは先に述べた式で与えられる。
【0040】
ステップS505の判別の結果、要求アドレスがキャッシュ2_106の重複部分内でないと判断されたときは(ステップS505でNO)、ステップS506へ分岐する。さらに、要求アドレスがキャッシュ1_105の重複部分内であるかどうか、次式によって判断する。次式が成立したときは、キャッシュ1_105の重複部分であることを意味する。
【0041】
Ys−Yd≦v<Ys+Ye
ステップS506の判別の結果、重複部分外であれば(ステップS506でNO)、キャッシュ制御部104は、主メモリ102からデータをリードする(ステップS516)。一方、要求アドレスがキャッシュ1_105の重複部分内であると判断されたときは(ステップS506でYES)、ステップS507にて、キャッシュ制御部104は、キャッシュ1_105からデータをリードする。キャッシュ1_105のデータが格納されているアドレスは以下の式により与えられる。
【0042】
P{n(Yd+Ye)+v−Ys+Yd+Ye}+x
ステップS508において、右辺重複部のキャッシュフラグが無効であれば(ステップS508でNO)、ステップS513へ進む。一方、右辺重複部のキャッシュフラグが有効であれば(ステップS508でYES)、ステップS509にて、キャッシュ制御部104は、キャッシュ1_105からデータをリードする。
【0043】
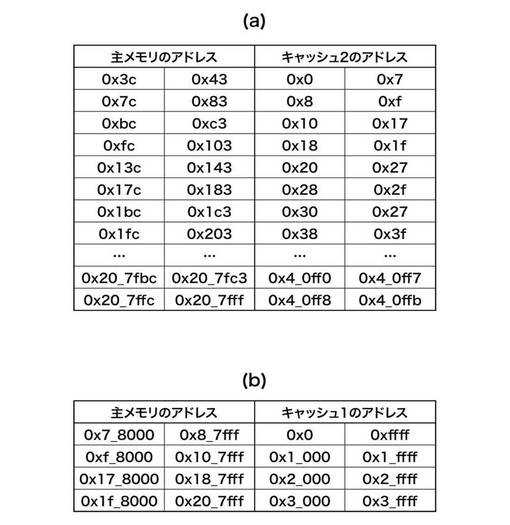
以上が1回のデータ転送要求に対するキャッシュ制御部104の制御フローであり、それらはステップS516によって全データの処理終了が判断されるまで繰り返される。例えば、Xs=Ys=0x40(64)、Xe=Ye=Xd=Yd=4、P=0x2000(8192)、ページの副走査方向のサイズ=0x2000(8192)とする。そうすると、主メモリ102のアドレスとキャッシュ1_105のアドレスとの対応関係と主メモリ102のアドレスとキャッシュ2_106のアドレスとの関係は図7(a)、図7(b)のようになる。ただし、ここで記載されるアドレスは、画素の単位で表現している。つまり、1画素につき1バイトであれば表のとおりであるが、例えば1画素が4バイトの領域をとるシステムであれば、アドレスは4を乗じた値になる。
【0044】
図8は、画像処理部A107に実装されるスムージング回路の概略構成を示す図である。なお、図示例では、画像処理部B108は、画像処理部A107と同一の構成を有することから、その記載を省略する。
【0045】
画像処理部A107,B108は、それぞれスムージング機能を有する。2つの画像処理部A107,B108を並列に動作させることにより、全体の処理のパフォーマンスを向上することが可能である。
【0046】
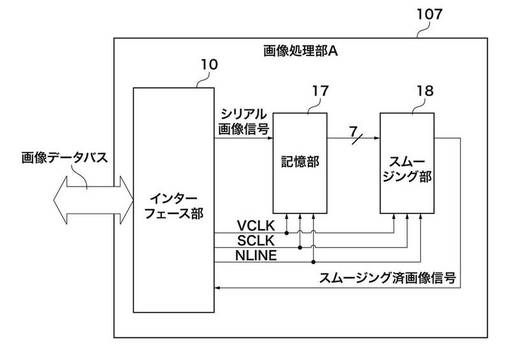
画像処理部A107,B108は、バスインターフェースであるインターフェース部10が必要な画像データ、つまり矩形領域の周囲の重複部分を含むエリアの画像データを主メモリ102から読み取る。そして、内部で処理した後に、矩形領域のエリアのみの画像データを出力部103へ渡す。
【0047】
インターフェース部10は、受信したデータをシリアルデータに変換して記憶部17へVCLKに同期させて転送する。記憶部17は、インターフェース部10より送られてくる画像信号を受け、記憶部17が主走査7ラインを記憶し、スムージング部18がそれをウィンドウ状に主走査7ドットに展開してスムージング処理を行って出力する。
【0048】
画像処理部A107,B108がエッジ強調などのフィルタリングを行う画像処理であった場合においても、注目画素(矩形領域)の周辺画素(参照領域)を参照する点で同様な回路構成になる。つまり、画像データバスとのインターフェースと周辺画素を記憶するための記憶部が記憶部17であり、周辺画素から注目画素のデータを決定する論理決定部がスムージング部18に相当する。
【0049】
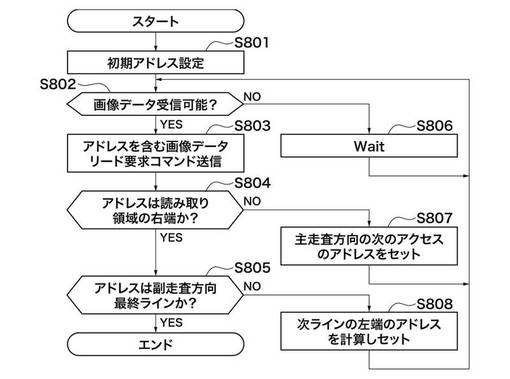
図9は、画像処理部A107がキャッシュ制御部104へ画像データリード要求を出力する際に実行する処理のフローチャートである。なお、画像処理部B108についても同様の処理を実行するものである。
【0050】
まず、ステップS801では、画像処理部A107は、不図示のアドレスレジスタに初期アドレスの設定を行う。このアドレスレジスタの値は、画像データリード要求コマンド送信時に使用される。また、このアドレスは、重複部分を含む矩形領域のアドレスである。
【0051】
ステップS802において、画像処理部A107は、画像データが受信可能かどうかを判断する。この結果、NOであれば、YESになるまでステップS806において待機(Wait)する。画像データが受信可能であれば、ステップS803において、アドレスを含む画像データリード要求コマンドをキャッシュ制御部104へ送信する。
【0052】
次に、ステップS804において、画像処理部A107は、アドレスの値をチェックして、重複部分を含む画像読み取り領域の右端でなければ、ステップS807へ遷移する。そして、主走査方向の次のアクセスアドレスを上記アドレスレジスタへセットし、ステップS802へ戻る。一方、カレントのアドレスが画像読み取り領域の右端であれば、ステップS805において、カレントのラインが最終ラインであるかどうかの検査がなされ、Yesであれば本処理を終了する。一方、Noであれば、ステップS808において、次ラインの左端のアドレスが上記アドレスレジスタへセットされ、ステップS802へ戻る。
【0053】
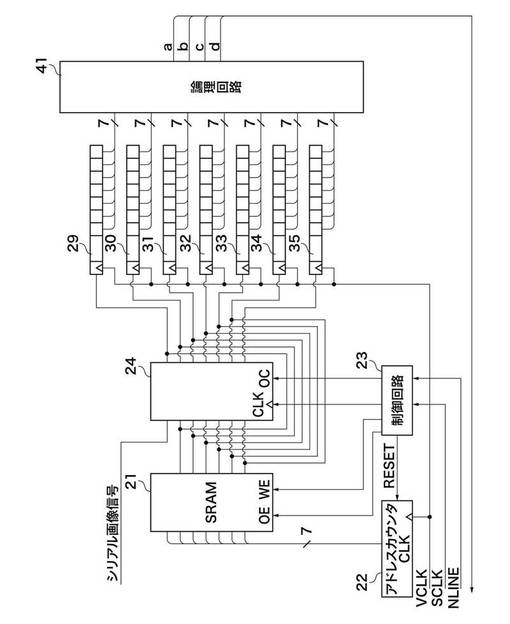
図10は、画像処理部A107の詳細構成を示すブロック図である。
【0054】
同図に示した画像処理部A107には、図8のインターフェース部10から画像転送クロックVCLKと画像クロックVCLKと同位相で8倍の周波数のシステムクロックSCLK、そして画像クロックVCLKに同期してシリアル画像信号が送られてくる。シリアル画像信号は、3ステートラッチバッファ24の入力端の1つであるD0端子に入力され、D0に対応する3ステートラッチバッファ24の出力Q0は、シフトレジスタ29に入力されると共に、SRAM21のデータ端子であるI/O1にも入力される。また、SRAM21のアドレスAD0〜AD6は、アドレスカウンタ22より供給される7本のアドレスラインと接続されている。なお、これら7本のアドレスラインにて展開されるアドレス長は、矩形の1ラインと周辺の画像データを記憶するのに十分である。
【0055】
また、SRAM21への読み出し信号OE、書き込み信号WE、3ステートラッチバッファ24のラッチ信号CLK、出力イネーブル信号OC、及びアドレスカウンタ22のクリア信号RESETは、制御回路23にて生成される。
【0056】
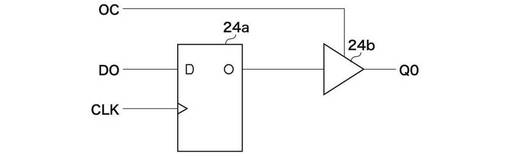
制御回路23は、画像クロックVCLKの1周期間にシステムクロックSCLKにより複数のステートを作り出している。SCLKはVCLKの8倍の周波数なので、画像クロックVLCKの1周期の間に最大8つのステップを実行することができる。なお、3ステートラッチバッファ24の各バッファは、図11に示すように、ラッチ回路24aとバッファ回路24bとから構成されている。
【0057】
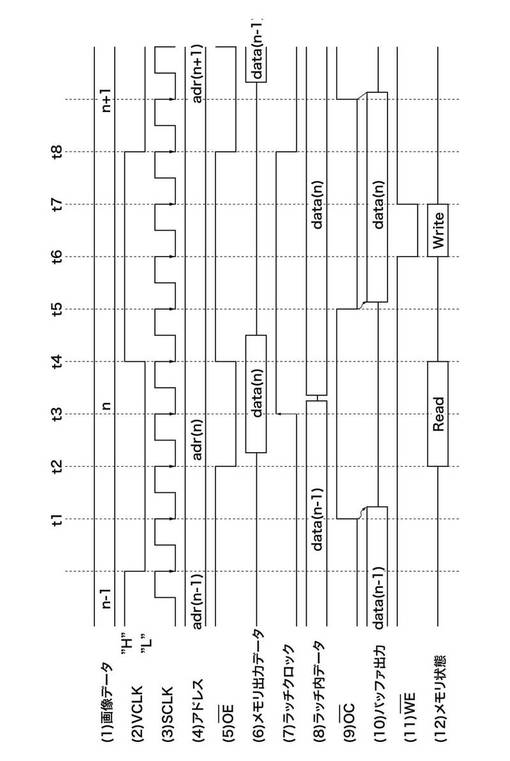
次に、図10におけるSRAM21の周辺回路の動作を図12を参照して説明する。なお、以下の説明では、第n番目の画素のデータをdata(n)、そのデータが格納されるアドレスをadr(n)と記す。
【0058】
図12において、画像クロックVLCK(2)が論理ローレベルになってから第1番目のクロックが入る(時刻t1)。そのとき、3ステートラッチバッファ24の出力イネーブル信号OC(9)がFALSE状態になり、3ステートラッチバッファ24内部のバッファ回路はハイインピーダンス状態となる。すると、今まで出力されていたデータdata(n−1)((10)バッファ出力参照)の出力が止まり、SRAM21のデータバスには何も入力されない状態となる。
【0059】
第2番目のクロックが入ると(時刻t2)、OE信号(5)がTRUE状態となる。同時にSRAM21はリード状態となって((12)メモリ状態参照)、アドレスadr(n)に格納されていたデータdata(n)がデータバス上に出力される((6)メモリ出力データ参照)。
【0060】
第3番目のクロックにて(時刻t3)、ラッチクロック(7)が立ち上がるので、データバス上に出力されていたデータdata(n)が3ステートラッチバッファ24の内部でラッチされる。しかし、このときは、出力イネーブル信号OC(9)がFALSE状態のままなので、データは3ステートラッチバッファ24の外部には出力されない。そのため、バスの衝突は起こらない。
【0061】
第4番目のクロックが入ると(時刻t4)、SRAM21の出力イネーブル信号OE(5)がFALSE状態になり、SRAM21はフローテイング状態となる。そして、第5番目のクロックが入ると(時刻t5)、3ステートラッチバッファ24の出力イネーブル信号OC(9)がTRUE状態に変化し、ラッチされていたデータdata(n)が出力されてSRAM21に送られる。しかし、SRAM21は、ライトイネーブル信号WE(11)がFALSE状態であるため、書き込みは行われない。
【0062】
第6番目のクロックにて(時刻t6)、SRAM21のライトイネーブル信号WE(11)がTRUE状態となり、SRAM21にdata(n)が書き込まれる。そして、第7番目のクロックが入力されると(時刻t7)、ライトイネーブル信号WEがFALSE状態となって書き込み動作が完了する。第8番目のクロックが入力されると(時刻t8)、アドレスがadr(n)からadr(n+1)に更新され、一画素のデータに関しての一連の動作が完了する。
【0063】
以上の動作が3ステートラッチバッファ24及びSRAM21にて行なわれることで、画像クロックVCLKの1サイクルの間にSRAM21の端子から出力されたデータが同じアドレスの別端子に入力される。さらに、順次データが送られることによって、常に7ラインの画像データが記憶される。同時に、シフトレジスタ29〜35に対しても画像データが供給される。
【0064】
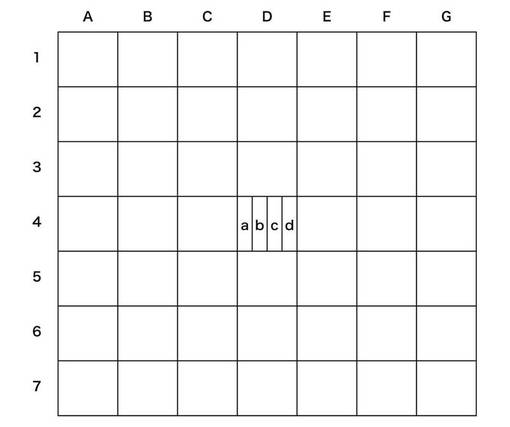
シフトレジスタ29〜35は、それぞれ7ビットのビット長を有する。それらは、3ステートラッチバッファ24から送られてくる7ラインの画像データに対して直列−並列変換を施すことで主走査方向7ドットずつに展開して、論理回路41に対しては、計49ドットの画像データを送出する。論理回路41では、送出された49ビットの画像データを、図13に示すような7×7のウィンドウにあてはめ、以下に説明する定められた論理に従って注目画素D4を主走査方向に1/4の大きさの4ドットa,b,c,dに分割する。さらに、レーザ光量の大小を指定する信号LPを決定する。なお、ここでは、レーザ光量指定信号Pは、画像クロックVCLK単位に変化するものとする。
【0065】
論理回路41は、ANDロジツク回路にて構成され、シフトレジスタ29〜35からの計49個のデータの論理積をとり、その結果に応じて、1画素を4分割したa,b,c,d区画の印字、非印字を表わすVDO信号とレーザ光量指定信号LPを出力する。このレーザ光量指定信号LPは、1ドット単位で変化し、VDO信号は、1/4ドット単位に変化する。
【0066】
図14〜図16は、図10の論理回路41にて行われるスムージング処理を説明するための図である。
【0067】
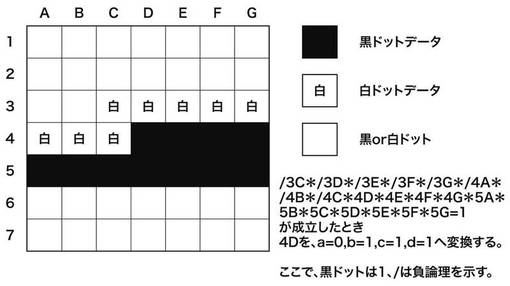
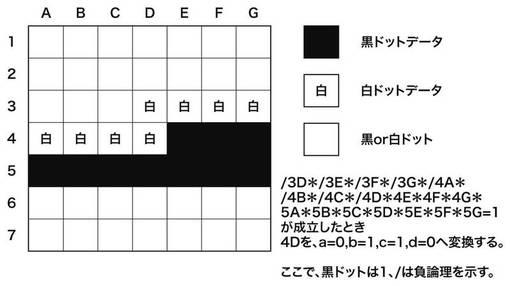
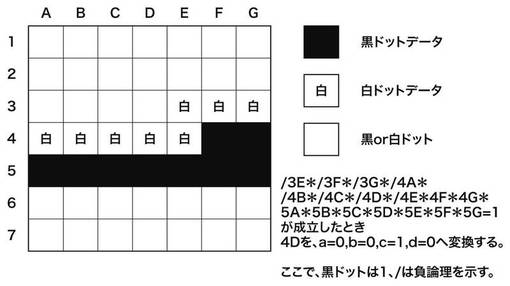
図14において、図の右上に示す論理が成立する。つまり、3C,3D,3E,3F,3G,4A,4B,4Cが0(白)、4D,4E,4F,4G,5A,5B,5C,5D,5E,5F,5Gが1(黒)の場合は、注目画素4DのVDOをa=0,b=1,c=1,d=0とする。同様に、図15の場合、注目画素4DのVDOをa=0,b=1,c=1,d=0とする。また、図16の場合、注目画素4DのVDOをa=0,b=0,c=1,d=0とする。以上のスムージング処理により得られる画像の一例を図17に示す。図17(a)は、スムージング処理前の画像を示す図であり、図17(b)はスムージング処理後の画像を示す図である。図17(a)において、ドットで示される画素は、図14〜図16における黒ドットデータに相当する。また、図17(b)において、ドットで示される画素は1画素の全区画を印字することを示す。また、図17(b)において、1画素内の一部が黒で埋められている画素は1画素の一部の区画(黒色)を印字し他の区画(白色)を非印字とすることを示す。
【0068】
図17(a)及び図17(b)では、画像処理部が出力する矩形の単位を64×64であるときの例を示している。画像処理部としては重複部を含む70×70の画像領域を処理する。上述のように、1画素を1/4分割し、各区画を印字または非印字にすることで、エッジや文字の輪郭を滑らかにすることができる。これは、この処理にて感光ドラム上の潜像電位を滑らかにすることができるためであり、電子写真特有の現象である。なお、本実施形態では、水平に近いラインのスムージング処理について説明したが、垂直に近いライン、斜め線、文字の輪郭という部分も、49画素の論理のデータの論理積をとることで検出できる。いずれの場合も感光ドラム上の潜像電位を滑らかにつなぎ、印字結果を滑らかにするよう注目画素の印字面積及びレーザ光量が決定される。また、論理回路41の出力であるa,b,c,dは、インターフェース部10にてデータバスのプロトコルに変換され出力される。
【0069】
上記第1の実施形態によれば、主メモリ102上に展開された画像データに対して、注目画素としての各矩形領域を順番通りに画像処理することなく、メモリの帯域の無駄な消費を抑制すると共に、主メモリへの重複アクセスを抑制することができる。
【0070】
また、上記第1の実施形態によれば、画像処理の速度的なパフォーマンスの向上が可能となる。なぜなら、画像処理部とキャッシュメモリ間のアクセスレイテンシは、画像処理部と主メモリのアクセスレイテンシよりも短いためである。これは主メモリとしてはコストは安いが制御が煩雑であるDRAMを使用すること、主メモリは他のデバイスからのアクセスが可能な構成でそれらとの調停のためレイテンシは増えることによる。キャッシュメモリとしてはSRAMが使用されるので画像処理部がデータを要求してからそれを得るまでのレインテンシは短い。例えば、一つの矩形のサイズを64×64、参照エリアのサイズが74×74とする。そのとき、従来は、重複するアクセスの全体に対する割合が下記となる。この分の主メモリの帯域が無駄に消費されるわけであり、本発明によれば、この無駄をなくすことが可能となる。
【0071】
(70^2−64^2)/64^2×100=20(パーセント)
[第2の実施形態]
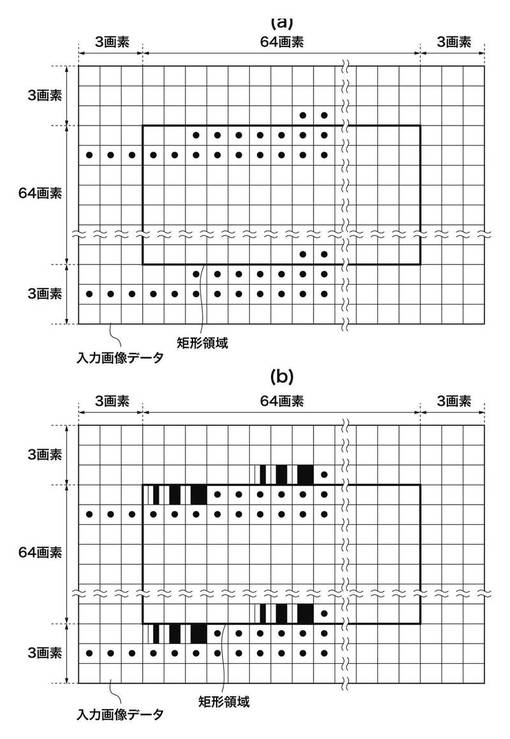
本発明の第2の実施形態は、図18に示すように、格子状の重複部分が交差する領域の主走査方向の辺の延長領域を含む点で、上記第1の実施形態と異なる。以下に、上記第1の実施の形態と異なる点のみを説明する。
【0072】
図18は、本発明の第2の実施形態において使用する定数の定義を説明するための図である。
【0073】
図18において、例えば、図3におけるC1(1,2)に対して、Ca1(1,2)が横の辺の延長領域(T1(1,2)、T2(1,2))を含むようになっている。そして、図3におけるC2(1,2)に対して、Ca2(1,2)が縦の辺の延長領域T1(1,2)、T2(1,2)分短くなっている。
【0074】
図19は、第2の実施形態における主メモリ上の画像データとキャッシュ1上の記憶領域との対応関係を示す図である。図20は、第2の実施形態において主メモリ上の画像データとキャッシュ2上の記憶領域との対応関係を示す図である。なお、図3、図4と同一の構成要素については同一の符号を付して、その説明を省略する。
【0075】
図19において、画像410内の任意の重複部分Ca1(m、n)は、キャッシュ1_105上の一つの記憶領域に対応する。本実施形態において、キャッシュ1_105は、主走査方向は全範囲、副走査方向は矩形単位で4個分の領域内の重複部分に相当する容量を保持している。例えば、画像410内のCa1(1,2)、Ca1(2,2)、Ca1(3,2)の領域は、キャッシュ1_105内のCa1(1,2)、Ca1(2,2)、Ca1(3,2)の領域に対応する。また、画像410内のCa1(1,6)、Ca1(2,6)、Ca1(3,6)も、キャッシュ1_105内のCa1(1,2)、Ca1(2,2)、Ca1(3,2)の領域に対応する。つまり、Ca1(1,2)のデータがキャッシュされた後に、Ca1(1,6)がアクセスされたならば、キャッシュ1_105内のデータは上書きされることになる。
【0076】
図20において、画像410内の任意の重複部分Ca2(m、n)は、キャッシュ2_106の一つの記憶領域に対応する。本実施形態においては、キャッシュ2_106は、主走査方向は全範囲、副走査方向は矩形単位で4個分の領域内の重複部分に相当する容量を保持している。例えば、画像410内のCa2(1,1)、Ca2(1,2)、Ca2(1,3)の領域は、キャッシュ2_106内のCa2(1,1)、Ca2(1,2)、Ca2(1,3)の領域に対応する。また、画像410内のCa2(1,5)、Ca2(1,6)、Ca2(1,7)も、キャッシュ2_106内のCa2(1,1)、Ca2(1,2)、Ca2(1,3)の領域に対応する。つまり、Ca2(1,1)のデータがキャッシュされた後に、Ca2(1、5)がアクセスされたならば、キャッシュ2_106内のデータは上書きされることになる。
【0077】
キャッシュ制御部104は、副走査方向の矩形4個分のアドレス領域内でデコードを行い、キャッシュメモリのアドレスを算出する。そのアドレス領域を他と区別する上位アドレスは、タグ情報としてキャッシュに保持される必要がある。また、キャッシュ内のデータが有効であるか否かを決定するためのフラグ情報も必要である。
【0078】
上述したタグ情報とフラグ情報は、一般的なキャッシュにおいてはキャッシュの各データ単位ごとに用意される。しかし、本実施形態におけるシステムでは、キャッシュメモリへの更新の単位が必ず矩形の各辺に当たる領域であるので、それら各辺に属する領域に一組のタグ情報とフラグ情報を格納することが可能である。つまり、タグ情報とフラグ情報のための格納領域を一般のキャッシュシステムに比べて削減することが可能である。なお、キャッシュとタグの情報を格納するために、別のSRAMを用意してもよい。ただし、SRAMのデバイスとしての個数増加は、半導体上の使用面積として影響が大きいので、より好適な実装形態としてはキャッシュ2の空き領域に格納する方法がある。
【0079】
上記空き領域は、重複部分が格子状に交差する領域である。この格子状の領域は、キャッシュ1に割り当てられているので、キャッシュメモリとしてはデータのために使用されない領域になっている。格子状の重複部分の交点に当たる領域は、キャッシュ1に含める実装形態も当然可能である(第1の実施形態)。
【0080】
図21は、第2の実施形態におけるキャッシュ制御部の制御処理を示すフローチャートである。なお、図6の処理を同一のステップについては同一のステップ番号を付して、その説明は省略する。
【0081】
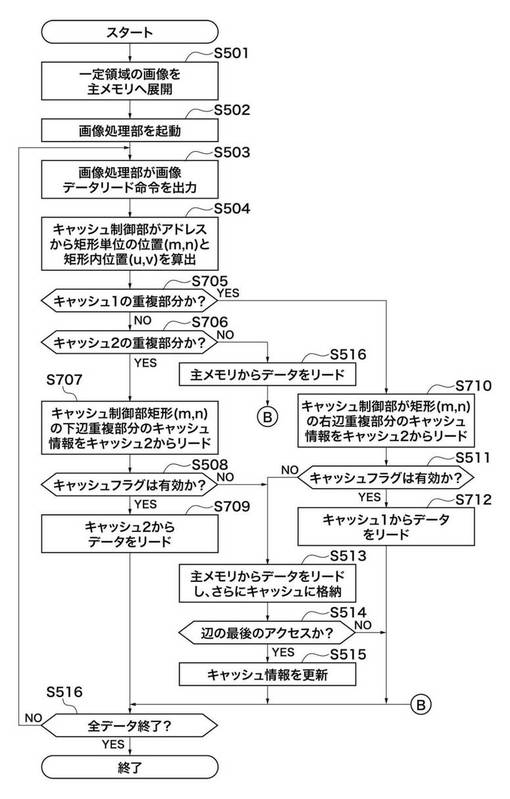
図21において、ステップS705では、キャッシュ制御部104は、要求アドレスがキャッシュ1_105の重複部分内であるかどうかを判断する。上記アドレスがキャッシュ1_105の重複部分内であることの条件式を以下に示す。
【0082】
Ys−Yd≦v<Ys+Ye
ステップS705の判別の結果、要求アドレスがキャッシュ1_105の重複部分内であると判断されたときは(ステップS705でYES)、ステップS710に進む。
【0083】
ステップS710において、(m,n)で指定される矩形の右辺重複部のキャッシュ情報(キャッシュのタグとフラグの情報)をキャッシュ2_106からリードする。キャッシュ2_106上のキャッシュ情報が格納されているアドレスは以下の式により与えられる。
【0084】
(Ys+1)(Xd+Xe)P/Xs+m(Xd+Xe)
次に、ステップS511において、右辺重複部のキャッシュフラグが有効であれば(ステップS511でYES)、ステップS712にて、キャッシュ制御部104は、キャッシュ1_105からデータをリードする。キャッシュ1_105上のデータが格納されているアドレスは以下の式により与えられる。
【0085】
P{n(Yd+Ye)+v−Ys+Yd+Ye}+x
ステップS705の判別の結果、要求アドレスがキャッシュ1_105の重複部分内でないと判断されたときは(ステップS705でNO)、ステップS706へ分岐する。そして、さらに要求アドレスがキャッシュ2_106の重複部分内であるかどうか、次式によって判断する。次式が成立したときは、キャッシュ2_106の重複部分であることを意味する。
【0086】
Xs−Xd≦u<Xs+Xe
ステップS706の判別の結果、重複部分外であれば(ステップS706でNO)、ステップS516へ進む。一方、要求アドレスがキャッシュ2_106の重複部分内であると判断されたときは(ステップS706でYES)、ステップS707にて、キャッシュ制御部104は、キャッシュ2_106からデータをリードする。キャッシュ2_106のデータが格納されているアドレスは以下の式により与えられる。
【0087】
y(Xd+Xe)P/Xs+m(Xd+Xe)+u−Xs+Xd+Xe
ステップS508において、右辺重複部のキャッシュフラグが無効であれば(ステップS508でNO)、ステップS513へ進む。一方、右辺重複部のキャッシュフラグが有効であれば(ステップS508でYES)、ステップS709にて、キャッシュ制御部104は、キャッシュ2_106からデータをリードする。
【0088】
以上、第2の実施形態によれば、上記第1の実施形態による効果を奏することができる。
【0089】
また、本発明の目的は、以下の処理を実行することによっても達成される。即ち、上述した実施形態の機能を実現するソフトウェアのプログラムコードを記録した記憶媒体を、システム或いは装置に供給し、そのシステム或いは装置のコンピュータ(またはCPUやMPU等)が記憶媒体に格納されたプログラムコードを読み出す処理である。この場合、記憶媒体から読み出されたプログラムコード自体が前述した実施の形態の機能を実現することになり、そのプログラムコード及び該プログラムコードを記憶した記憶媒体は本発明を構成することになる。
【符号の説明】
【0090】
100 画像処理装置
101 描画部
102 主メモリ
103 出力部
104 キャッシュ制御部
105 キャッシュ1
106 キャッシュ2
107 画像処理部A
108 画像処理部B
【技術分野】
【0001】
本発明は、画像処理装置および画像処理方法、並びにプログラムに関するものである。
【背景技術】
【0002】
従来、メモリに格納された画像データに対して画像処理を実行する画像処理装置には、矩形領域単位で画像処理を実行するものがあった。矩形領域単位で画像処理を行う画像処理部が対象となる矩形領域に対して画像処理(例えばフィルタ処理)を実行するために、図17(a)、図17(b)に示すように、より大きな参照領域を必要とする画像処理装置が開示されている(例えば、特許文献1参照)。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2004−220584号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、上記従来の技術では、画像処理部が対象領域の画像処理を行うために、対象領域より広い参照領域を画像データが展開されたメモリから読み取る必要がある。メモリに格納された画像データは、対象領域の大きさの単位で縦横に分割されるので、参照領域としては縦横に隣接した矩形領域と重複した部分を持つことになる。そのため、画像処理部は、重複した部分に対して、画像全体の画像処理を行う過程において複数回重複して読み取りを行う必要があり、メモリの帯域を無駄に消費するという問題がある。
【0005】
本発明は、上記問題に鑑みて成されたものであり、メモリの帯域の無駄な消費を抑制すると共に、主メモリへの重複アクセスを抑制することができる画像処理装置および方法、並びにプログラムを提供することを目的とする。
【課題を解決するための手段】
【0006】
上記目的を達成するために、請求項1記載の画像処理装置は、画像データを記憶する第1記憶手段と、前記第1記憶手段に記憶された画像データを所定サイズの複数の矩形画像データに分割して読み出す読み出し手段と、前記複数の矩形画像データを囲む参照領域の画像データであって、隣り合う2つの矩形画像データ間の境界を含むように互いに重複する部分を有する参照領域の画像データを記憶する第2記憶手段と、前記読み出し手段により読み出された前記複数の矩形画像データと、前記第2記憶手段に記憶された前記参照領域の画像データに基づいて画像処理を行う画像処理手段と、前記画像処理手段からの要求に応じて前記参照領域の画像データを前記第2記憶手段から前記画像処理手段へ転送するよう制御するキャッシュ制御手段とを備えることを特徴とする。
【0007】
上記目的を達成するために、請求項4記載の画像処理方法は、画像データを記憶する第1記憶手段に記憶する第1記憶工程と、前記第1記憶手段に記憶された画像データを所定サイズの複数の矩形画像データに分割して読み出す読み出し工程と、前記複数の矩形画像データを囲む参照領域の画像データであって、隣り合う2つの矩形画像データ間の境界を含むように互い重複する部分を有する参照領域の画像データを第2記憶手段に記憶する第2記憶工程と、前記読み出し工程にて読み出された前記複数の矩形画像データと、前記第2記憶手段に記憶された前記参照領域の画像データに基づいて画像処理手段により画像処理を行う画像処理工程と、前記画像処理手段からの要求に応じて前記参照領域の画像データを前記第2記憶手段から前記画像処理手段へ転送するよう制御するキャッシュ制御工程とを備えることを特徴とする。
【発明の効果】
【0008】
本発明によれば、メモリ上に展開された画像データに対して、注目画素としての各矩形領域を順番通りに画像処理することなく、メモリの帯域の無駄な消費を抑制すると共に、主メモリへの重複アクセスを抑制することができる。
【図面の簡単な説明】
【0009】
【図1】本発明の第1の実施形態に係る画像処理装置の概略構成を示すブロック図である。
【図2】矩形領域と該矩形領域を画像処理するために必要な参照領域との関係を示す図である。
【図3】第1の実施形態において使用する定数の定義を説明するための図である。
【図4】主メモリ上の画像データとキャッシュ1上の記憶領域との対応関係を示す図である。
【図5】主メモリ上の画像データとキャッシュ2上の記憶領域との対応関係を示す図である。
【図6】第1の実施形態におけるキャッシュ制御部の制御処理を示すフローチャートである。
【図7】(a)は、主メモリのアドレスとキャッシュ1のアドレスとの対応関係を示す図であり、(b)は、主メモリのアドレスとキャッシュ2のアドレスとの対応関係を示す図である。
【図8】画像処理部A,Bに実装されるスムージング回路の概略構成を示す図である。
【図9】画像処理部Aがキャッシュ制御部へ画像データリード要求を出力する際に実行する処理のフローチャートである。
【図10】画像処理部Aの詳細構成を示すブロック図である。
【図11】3ステートラッチバッファの概略構成を示す回路図である。
【図12】図10におけるSRAMの周辺回路の動作を示すタイムチャートである。
【図13】7×7のウィンドウを示す図である。
【図14】図10の論理回路にて行われるスムージング処理の一例を示す図である(その1)。
【図15】図10の論理回路にて行われるスムージング処理の一例を示す図である(その2)。
【図16】図10の論理回路にて行われるスムージング処理の一例を示す図である(その3)。
【図17】スムージングによって得られる画像の一例を示す図である。
【図18】本発明の第2の実施形態において使用する定数の定義を説明するための図である。
【図19】第2の実施形態における主メモリ上の画像データとキャッシュ1上の記憶領域との対応関係を示す図である。
【図20】第2の実施形態において主メモリ上の画像データとキャッシュ2上の記憶領域との対応関係を示す図である。
【図21】第2の実施形態におけるキャッシュ制御部の制御処理を示すフローチャートである。
【発明を実施するための形態】
【0010】
以下、本発明の実施の形態を図面を参照して詳細に説明する。
【0011】
[第1の実施形態]
図1は、本発明の第1の実施形態に係る画像処理装置の概略構成を示すブロック図である。
【0012】
図1において、100は画像処理装置であり、画像データ110を入力し、描画して画像処理を施した後に、画像データ111として出力する。
【0013】
101は描画部であり、入力された画像データ110を、バス109を介して主メモリ102へ展開する。主メモリ102は、描画された画像データ110を記憶するものである(第1記憶手段)。主メモリ102は、必要とされる容量と帯域からDDR SDRAM規格のメモリを想定する。また、主メモリ102は2ページ分の画像データを記憶するものとする。これにより、主メモリ102へ描画されるデータと画像処理のために読み出されるデータは別ページに割り当てることが可能となり、書き込みと読み出しの調停が容易となる。
【0014】
画像処理部A107と画像処理部B108は、独立して画像処理を行う画像処理回路である。画像処理としては、エッジ強調処理などのフィルタリング処理、スムージング処理などが想定される。いずれも周辺画素を参照して注目画素の値を更新するかまたは画素補完を行うものである。対象とする画素の処理を行う場合、その周辺画素、例えば9×9の周辺領域を参照するものとする。このような画像処理を対象となる矩形領域(矩形画像データ)間の境界部の画素に施すことを考えれば、対象矩形領域に対して主走査方向と副走査方向にそれぞれ4画素ずつ大きな領域が参照領域として必要となる。矩形領域と該矩形領域を画像処理するために必要な参照領域との関係を図2に示す。
【0015】
図2では、副走査方向(副方向)及び主走査方向(主方向)に矩形の単位で所定サイズ(例えば3×3)に分割された1ページの画像データの一例を示している。例えば、図2の中央の矩形が画像処理の対象となる矩形領域とすると、矩形を囲む矩形の領域であって、隣り合う2つの矩形画像データ間の境界を含むように互いに重複する部分を有する領域が、対象矩形領域を画像処理するために必要な参照領域である。さらに、ページ内の各矩形領域のそれぞれに対して参照領域を考えれば、主走査方向(図の横方向)の重複部分と副走査方向(図の縦方向)の重複部分とが交差する部分が格子状になることがわかる。
【0016】
画像処理装置100では、2つの画像処理部A107,B108により、主メモリ102上の画像データにおける2つの矩形領域に対して同時に平行して画像処理を施すことが可能である。なお、画像処理部が2つであることは本発明を限定するものではない。また、画像処理の種類は本発明を限定するものではない。
【0017】
図1に戻って、104はキャッシュ制御部である。キャッシュ制御部104は、画像処理部A107,B108から出力される画像データリード命令を受信する。画像データリード命令はデータのアドレス情報を持っている。一度の命令で転送されるデータ量は、主メモリ102の転送単位と同じ32バイトである。キャッシュ制御部104は、受信した画像データリード命令を主メモリ102へ渡すと共に、該画像データリード命令に応じてキャッシュ1_105及びキャッシュ2_106を制御し、後述する処理を行う。
【0018】
キャッシュ1_105(第1のキャッシュ)は、主メモリ102上に展開された画像データの副走査方向に隣接する2つの矩形領域(矩形画像データ)間の重複部分のデータをキャッシュするSRAMである(第2記憶手段)。キャッシュ2_106(第2のキャッシュ)は、主メモリ102上に展開された画像データの主走査方向に隣接する2つの矩形領域(矩形画像データ)間の重複部分のデータをキャッシュするSRAMである(第2記憶手段)。
【0019】
次に、第1の実施形態において使用する定数の定義を図3を参照して説明する。
【0020】
図3において、x,yは画像上の座標を表し、画像の左上が原点であり、xが右方向、yが左方向となる。Xs,Ysは矩形の大きさを示す定数である。Xd,Xeは参照領域がx方向に矩形領域よりはみ出る量を示す定数である。Yd,Yeは参照領域がy方向に矩形領域よりはみ出る量を示す定数である。mは対象座標が矩形単位でx方向にいくつめかを示す変数である。nは対象座標が矩形単位でy方向にいくつめかを示す変数である。uは対象座標が属する(m,n)で区別される領域の中でのx方向の相対位置を示す変数である。vは対象座標が属する(m,n)で区別される領域の中でのy方向の相対位置を示す変数である。
【0021】
例えば、(m,n)=(1,2)で示される領域の中でキャッシュ1_105のメモリに対応するのがC1(1,2)で示される領域である。また、キャッシュ2_106のメモリに対応するのがC2(1,2)で示される領域である。さらにC2(1,2)内のT1(1,2)で示される領域がC1(1,2)に対応するタグ情報とフラグ情報を格納する領域であり、T2(1,2)はC2(1,2)に対応するタグ情報とフラグ情報を格納する領域である。
【0022】
図4は、第1の実施形態における主メモリ102上の画像データとキャッシュ1_105上の記憶領域との対応関係を示す図である。図5は、第1の実施形態における主メモリ102上の画像データとキャッシュ2_106上の記憶領域との対応関係を示す図である。
【0023】
図4及び図5に示す410は主メモリ102に展開された画像とする。アドレスは画像の左上が原点であり、主走査がX方向、副走査がY方向となる。ここで、主走査方向の長さは矩形領域128個分としている。
【0024】
図4において、画像410内の任意の重複部分C1(m、n)は、キャッシュ1_105上の一つの記憶領域に対応する。本実施形態において、キャッシュ1_105は、主走査方向は全範囲、副走査方向は矩形単位で4個分の領域内の重複部分に相当する容量を保持している。例えば、画像410内のC1(1,2)、C1(2,2)、C1(3,2)の領域は、キャッシュ1_105内のC1(1,2)、C1(2,2)、C1(3,2)の領域に対応する。また、画像410内のC1(1,6)、C1(2,6)、C1(3,6)も、キャッシュ1_105内のC1(1,2)、C1(2,2)、C1(3,2)の領域に対応する。つまり、C1(1,2)のデータがキャッシュされた後に、C1(1,6)がアクセスされたならば、キャッシュ1_105内のデータは上書きされることになる。
【0025】
キャッシュ制御部104は、副走査方向の矩形4個分のアドレス領域内でデコードを行い、キャッシュメモリのアドレスを算出する。そのアドレス領域を他と区別する上位アドレスは、タグ情報としてキャッシュに記憶する必要がある。また、キャッシュ内のデータが有効であるか否かを決定するためのフラグ情報も必要である。
【0026】
図5において、画像410内の任意の重複部分C2(m、n)は、キャッシュ2_106の一つの記憶領域に対応する。本実施形態においては、キャッシュ2_106は、主走査方向は全範囲、副走査方向は矩形単位で4個分の領域内の重複部分に相当する容量を保持している。例えば、画像410内のC2(1,1)、C2(1,2)、C2(1,3)の領域は、キャッシュ2_106内のC2(1,1)、C2(1,2)、C2(1,3)の領域に対応する。また、画像410内のC2(1,5)、C2(1,6)、C2(1,7)も、キャッシュ2_106内のC2(1,1)、C2(1,2)、C2(1,3)の領域に対応する。つまり、C2(1,1)のデータがキャッシュされた後に、C2(1、5)がアクセスされたならば、キャッシュ2_106内のデータは上書きされることになる。なお、キャッシュメモリのサイズと主メモリ102上の記憶領域をどのよう分けてキャッシュメモリに対応させるかなども本発明の制限するところではない。
【0027】
上述したタグ情報とフラグ情報は、一般的なキャッシュにおいてはキャッシュのデータ単位ごとに用意される。しかし、本実施形態におけるシステムでは、キャッシュメモリへの更新の単位が必ず矩形の各辺に当たる領域であるので、それら各辺に属する領域に一組のタグ情報とフラグ情報を格納することが可能である。つまり、タグ情報とフラグ情報のための格納領域を一般のキャッシュシステムに比べて削減することが可能である。なお、キャッシュとタグの情報を格納するために、別のSRAMを用意してもよい。ただし、SRAMのデバイスとしての個数増加は、半導体上の使用面積として影響が大きいので、より好適な実装形態としてはキャッシュ1の空き領域に格納する方法がある。
【0028】
上記空き領域は、重複する部分が格子状に交差する領域である。この格子状の領域は、キャッシュ2に割り当てられているので、キャッシュメモリとしてはデータのために使用されない領域になっている。格子状の重複部分が交差する領域は、キャッシュ1に含める実装形態も当然可能である(第2の実施形態)。
【0029】
図6は、第1の実施形態におけるキャッシュ制御部104の制御処理を示すフローチャートである。
【0030】
図6において、主メモリ102への画像描画動作であるステップS501とステップS502以降の処理が時分割になっているがこれは説明のわかり易さのためである。先に述べたように、主メモリ102を2つの領域に分割し、一方を描画するための領域、他方を読み出すための領域として使用し、両方の動作が終了したときは役割を切り替えて行う方がパフォーマンスの点で好ましい。
【0031】
ステップS503において、画像処理部A107または画像処理部B108がキャッシュ制御部104に画像処理のために画像データリード命令を出力する。2つの画像処理部A107,B108は独立して読取動作を行い、キャッシュ制御部104は2つの画像処理部から出力された命令からどちらかの命令を選択して、ステップS504以降の処理を実行する。
【0032】
ステップS504において、キャッシュ制御部104は、受信した画像データリード命令に含まれるアドレス情報に基づいて、矩形単位の位置(m,n)と矩形内の相対位置(u,v)を算出する。算出方法は以下の式による。
【0033】
x=A%P
y=A/P
m=(|x−Xe|)/Xs
n=(|y−Ye|)/Ys
u=(x−Xe)%Xs
v=(y−Ye)%Ys
Aは画像データリード要求のアドレスであり,%は除算の余りを求めるものであり、/は除算の商を求めるものである。除算の処理のプロセスを簡略化するために、P,Xs,Ysは2のべき乗であることが好ましい。2のべき乗による割り算はビットシフト処理により置き換えられる。
【0034】
ステップS505において、キャッシュ制御部104は、要求アドレスがキャッシュ2_106の重複部分内であるかどうかを判断する。上記アドレスがキャッシュ2_106の重複部分内であることの条件式を以下に示す。
【0035】
Xs−Xd≦u<Xs+Xe
ステップS505の判別の結果、要求アドレスがキャッシュ2_106の重複部分内であると判断されたときは(ステップS505でYES)、ステップS510に進む。
【0036】
ステップS510において、(m,n)で指定される矩形の右辺重複部のキャッシュ情報(キャッシュのタグとフラグの情報)をキャッシュ1_105からリードする。キャッシュ1_105上のキャッシュ情報が格納されているアドレスは以下の式により与えられる。
【0037】
n(Yd+Ye)P+Xs(m+1)
次に、ステップS511において、右辺重複部のキャッシュフラグが有効であれば(ステップS511でYES)、ステップS512にて、キャッシュ制御部104は、キャッシュ2_106からデータをリードする。キャッシュ2_106上のデータが格納されているアドレスは以下の式により与えられる。
【0038】
y(Xd+Xe)P/Xs+m(Xd+Xe)+u−Xs+Xd+Xe
ステップS511において、右辺重複部のキャッシュフラグが無効であれば(ステップS511でNO)、ステップS513にて、キャッシュ制御部104は、主メモリ102からデータをリードし、さらにキャッシュの相当するアドレスにデータを格納する。そのアドレスは上記の式で与えられる。
【0039】
次に、ステップS514にて、キャッシュ制御部104は、辺の最後のアクセスであるか否かを判定し、Yesのときのみキャッシュ情報(キャッシュのタグとフラグの情報)をキャッシュ1_105の該当個所に格納して更新する(ステップS515)。アドレスは先に述べた式で与えられる。
【0040】
ステップS505の判別の結果、要求アドレスがキャッシュ2_106の重複部分内でないと判断されたときは(ステップS505でNO)、ステップS506へ分岐する。さらに、要求アドレスがキャッシュ1_105の重複部分内であるかどうか、次式によって判断する。次式が成立したときは、キャッシュ1_105の重複部分であることを意味する。
【0041】
Ys−Yd≦v<Ys+Ye
ステップS506の判別の結果、重複部分外であれば(ステップS506でNO)、キャッシュ制御部104は、主メモリ102からデータをリードする(ステップS516)。一方、要求アドレスがキャッシュ1_105の重複部分内であると判断されたときは(ステップS506でYES)、ステップS507にて、キャッシュ制御部104は、キャッシュ1_105からデータをリードする。キャッシュ1_105のデータが格納されているアドレスは以下の式により与えられる。
【0042】
P{n(Yd+Ye)+v−Ys+Yd+Ye}+x
ステップS508において、右辺重複部のキャッシュフラグが無効であれば(ステップS508でNO)、ステップS513へ進む。一方、右辺重複部のキャッシュフラグが有効であれば(ステップS508でYES)、ステップS509にて、キャッシュ制御部104は、キャッシュ1_105からデータをリードする。
【0043】
以上が1回のデータ転送要求に対するキャッシュ制御部104の制御フローであり、それらはステップS516によって全データの処理終了が判断されるまで繰り返される。例えば、Xs=Ys=0x40(64)、Xe=Ye=Xd=Yd=4、P=0x2000(8192)、ページの副走査方向のサイズ=0x2000(8192)とする。そうすると、主メモリ102のアドレスとキャッシュ1_105のアドレスとの対応関係と主メモリ102のアドレスとキャッシュ2_106のアドレスとの関係は図7(a)、図7(b)のようになる。ただし、ここで記載されるアドレスは、画素の単位で表現している。つまり、1画素につき1バイトであれば表のとおりであるが、例えば1画素が4バイトの領域をとるシステムであれば、アドレスは4を乗じた値になる。
【0044】
図8は、画像処理部A107に実装されるスムージング回路の概略構成を示す図である。なお、図示例では、画像処理部B108は、画像処理部A107と同一の構成を有することから、その記載を省略する。
【0045】
画像処理部A107,B108は、それぞれスムージング機能を有する。2つの画像処理部A107,B108を並列に動作させることにより、全体の処理のパフォーマンスを向上することが可能である。
【0046】
画像処理部A107,B108は、バスインターフェースであるインターフェース部10が必要な画像データ、つまり矩形領域の周囲の重複部分を含むエリアの画像データを主メモリ102から読み取る。そして、内部で処理した後に、矩形領域のエリアのみの画像データを出力部103へ渡す。
【0047】
インターフェース部10は、受信したデータをシリアルデータに変換して記憶部17へVCLKに同期させて転送する。記憶部17は、インターフェース部10より送られてくる画像信号を受け、記憶部17が主走査7ラインを記憶し、スムージング部18がそれをウィンドウ状に主走査7ドットに展開してスムージング処理を行って出力する。
【0048】
画像処理部A107,B108がエッジ強調などのフィルタリングを行う画像処理であった場合においても、注目画素(矩形領域)の周辺画素(参照領域)を参照する点で同様な回路構成になる。つまり、画像データバスとのインターフェースと周辺画素を記憶するための記憶部が記憶部17であり、周辺画素から注目画素のデータを決定する論理決定部がスムージング部18に相当する。
【0049】
図9は、画像処理部A107がキャッシュ制御部104へ画像データリード要求を出力する際に実行する処理のフローチャートである。なお、画像処理部B108についても同様の処理を実行するものである。
【0050】
まず、ステップS801では、画像処理部A107は、不図示のアドレスレジスタに初期アドレスの設定を行う。このアドレスレジスタの値は、画像データリード要求コマンド送信時に使用される。また、このアドレスは、重複部分を含む矩形領域のアドレスである。
【0051】
ステップS802において、画像処理部A107は、画像データが受信可能かどうかを判断する。この結果、NOであれば、YESになるまでステップS806において待機(Wait)する。画像データが受信可能であれば、ステップS803において、アドレスを含む画像データリード要求コマンドをキャッシュ制御部104へ送信する。
【0052】
次に、ステップS804において、画像処理部A107は、アドレスの値をチェックして、重複部分を含む画像読み取り領域の右端でなければ、ステップS807へ遷移する。そして、主走査方向の次のアクセスアドレスを上記アドレスレジスタへセットし、ステップS802へ戻る。一方、カレントのアドレスが画像読み取り領域の右端であれば、ステップS805において、カレントのラインが最終ラインであるかどうかの検査がなされ、Yesであれば本処理を終了する。一方、Noであれば、ステップS808において、次ラインの左端のアドレスが上記アドレスレジスタへセットされ、ステップS802へ戻る。
【0053】
図10は、画像処理部A107の詳細構成を示すブロック図である。
【0054】
同図に示した画像処理部A107には、図8のインターフェース部10から画像転送クロックVCLKと画像クロックVCLKと同位相で8倍の周波数のシステムクロックSCLK、そして画像クロックVCLKに同期してシリアル画像信号が送られてくる。シリアル画像信号は、3ステートラッチバッファ24の入力端の1つであるD0端子に入力され、D0に対応する3ステートラッチバッファ24の出力Q0は、シフトレジスタ29に入力されると共に、SRAM21のデータ端子であるI/O1にも入力される。また、SRAM21のアドレスAD0〜AD6は、アドレスカウンタ22より供給される7本のアドレスラインと接続されている。なお、これら7本のアドレスラインにて展開されるアドレス長は、矩形の1ラインと周辺の画像データを記憶するのに十分である。
【0055】
また、SRAM21への読み出し信号OE、書き込み信号WE、3ステートラッチバッファ24のラッチ信号CLK、出力イネーブル信号OC、及びアドレスカウンタ22のクリア信号RESETは、制御回路23にて生成される。
【0056】
制御回路23は、画像クロックVCLKの1周期間にシステムクロックSCLKにより複数のステートを作り出している。SCLKはVCLKの8倍の周波数なので、画像クロックVLCKの1周期の間に最大8つのステップを実行することができる。なお、3ステートラッチバッファ24の各バッファは、図11に示すように、ラッチ回路24aとバッファ回路24bとから構成されている。
【0057】
次に、図10におけるSRAM21の周辺回路の動作を図12を参照して説明する。なお、以下の説明では、第n番目の画素のデータをdata(n)、そのデータが格納されるアドレスをadr(n)と記す。
【0058】
図12において、画像クロックVLCK(2)が論理ローレベルになってから第1番目のクロックが入る(時刻t1)。そのとき、3ステートラッチバッファ24の出力イネーブル信号OC(9)がFALSE状態になり、3ステートラッチバッファ24内部のバッファ回路はハイインピーダンス状態となる。すると、今まで出力されていたデータdata(n−1)((10)バッファ出力参照)の出力が止まり、SRAM21のデータバスには何も入力されない状態となる。
【0059】
第2番目のクロックが入ると(時刻t2)、OE信号(5)がTRUE状態となる。同時にSRAM21はリード状態となって((12)メモリ状態参照)、アドレスadr(n)に格納されていたデータdata(n)がデータバス上に出力される((6)メモリ出力データ参照)。
【0060】
第3番目のクロックにて(時刻t3)、ラッチクロック(7)が立ち上がるので、データバス上に出力されていたデータdata(n)が3ステートラッチバッファ24の内部でラッチされる。しかし、このときは、出力イネーブル信号OC(9)がFALSE状態のままなので、データは3ステートラッチバッファ24の外部には出力されない。そのため、バスの衝突は起こらない。
【0061】
第4番目のクロックが入ると(時刻t4)、SRAM21の出力イネーブル信号OE(5)がFALSE状態になり、SRAM21はフローテイング状態となる。そして、第5番目のクロックが入ると(時刻t5)、3ステートラッチバッファ24の出力イネーブル信号OC(9)がTRUE状態に変化し、ラッチされていたデータdata(n)が出力されてSRAM21に送られる。しかし、SRAM21は、ライトイネーブル信号WE(11)がFALSE状態であるため、書き込みは行われない。
【0062】
第6番目のクロックにて(時刻t6)、SRAM21のライトイネーブル信号WE(11)がTRUE状態となり、SRAM21にdata(n)が書き込まれる。そして、第7番目のクロックが入力されると(時刻t7)、ライトイネーブル信号WEがFALSE状態となって書き込み動作が完了する。第8番目のクロックが入力されると(時刻t8)、アドレスがadr(n)からadr(n+1)に更新され、一画素のデータに関しての一連の動作が完了する。
【0063】
以上の動作が3ステートラッチバッファ24及びSRAM21にて行なわれることで、画像クロックVCLKの1サイクルの間にSRAM21の端子から出力されたデータが同じアドレスの別端子に入力される。さらに、順次データが送られることによって、常に7ラインの画像データが記憶される。同時に、シフトレジスタ29〜35に対しても画像データが供給される。
【0064】
シフトレジスタ29〜35は、それぞれ7ビットのビット長を有する。それらは、3ステートラッチバッファ24から送られてくる7ラインの画像データに対して直列−並列変換を施すことで主走査方向7ドットずつに展開して、論理回路41に対しては、計49ドットの画像データを送出する。論理回路41では、送出された49ビットの画像データを、図13に示すような7×7のウィンドウにあてはめ、以下に説明する定められた論理に従って注目画素D4を主走査方向に1/4の大きさの4ドットa,b,c,dに分割する。さらに、レーザ光量の大小を指定する信号LPを決定する。なお、ここでは、レーザ光量指定信号Pは、画像クロックVCLK単位に変化するものとする。
【0065】
論理回路41は、ANDロジツク回路にて構成され、シフトレジスタ29〜35からの計49個のデータの論理積をとり、その結果に応じて、1画素を4分割したa,b,c,d区画の印字、非印字を表わすVDO信号とレーザ光量指定信号LPを出力する。このレーザ光量指定信号LPは、1ドット単位で変化し、VDO信号は、1/4ドット単位に変化する。
【0066】
図14〜図16は、図10の論理回路41にて行われるスムージング処理を説明するための図である。
【0067】
図14において、図の右上に示す論理が成立する。つまり、3C,3D,3E,3F,3G,4A,4B,4Cが0(白)、4D,4E,4F,4G,5A,5B,5C,5D,5E,5F,5Gが1(黒)の場合は、注目画素4DのVDOをa=0,b=1,c=1,d=0とする。同様に、図15の場合、注目画素4DのVDOをa=0,b=1,c=1,d=0とする。また、図16の場合、注目画素4DのVDOをa=0,b=0,c=1,d=0とする。以上のスムージング処理により得られる画像の一例を図17に示す。図17(a)は、スムージング処理前の画像を示す図であり、図17(b)はスムージング処理後の画像を示す図である。図17(a)において、ドットで示される画素は、図14〜図16における黒ドットデータに相当する。また、図17(b)において、ドットで示される画素は1画素の全区画を印字することを示す。また、図17(b)において、1画素内の一部が黒で埋められている画素は1画素の一部の区画(黒色)を印字し他の区画(白色)を非印字とすることを示す。
【0068】
図17(a)及び図17(b)では、画像処理部が出力する矩形の単位を64×64であるときの例を示している。画像処理部としては重複部を含む70×70の画像領域を処理する。上述のように、1画素を1/4分割し、各区画を印字または非印字にすることで、エッジや文字の輪郭を滑らかにすることができる。これは、この処理にて感光ドラム上の潜像電位を滑らかにすることができるためであり、電子写真特有の現象である。なお、本実施形態では、水平に近いラインのスムージング処理について説明したが、垂直に近いライン、斜め線、文字の輪郭という部分も、49画素の論理のデータの論理積をとることで検出できる。いずれの場合も感光ドラム上の潜像電位を滑らかにつなぎ、印字結果を滑らかにするよう注目画素の印字面積及びレーザ光量が決定される。また、論理回路41の出力であるa,b,c,dは、インターフェース部10にてデータバスのプロトコルに変換され出力される。
【0069】
上記第1の実施形態によれば、主メモリ102上に展開された画像データに対して、注目画素としての各矩形領域を順番通りに画像処理することなく、メモリの帯域の無駄な消費を抑制すると共に、主メモリへの重複アクセスを抑制することができる。
【0070】
また、上記第1の実施形態によれば、画像処理の速度的なパフォーマンスの向上が可能となる。なぜなら、画像処理部とキャッシュメモリ間のアクセスレイテンシは、画像処理部と主メモリのアクセスレイテンシよりも短いためである。これは主メモリとしてはコストは安いが制御が煩雑であるDRAMを使用すること、主メモリは他のデバイスからのアクセスが可能な構成でそれらとの調停のためレイテンシは増えることによる。キャッシュメモリとしてはSRAMが使用されるので画像処理部がデータを要求してからそれを得るまでのレインテンシは短い。例えば、一つの矩形のサイズを64×64、参照エリアのサイズが74×74とする。そのとき、従来は、重複するアクセスの全体に対する割合が下記となる。この分の主メモリの帯域が無駄に消費されるわけであり、本発明によれば、この無駄をなくすことが可能となる。
【0071】
(70^2−64^2)/64^2×100=20(パーセント)
[第2の実施形態]
本発明の第2の実施形態は、図18に示すように、格子状の重複部分が交差する領域の主走査方向の辺の延長領域を含む点で、上記第1の実施形態と異なる。以下に、上記第1の実施の形態と異なる点のみを説明する。
【0072】
図18は、本発明の第2の実施形態において使用する定数の定義を説明するための図である。
【0073】
図18において、例えば、図3におけるC1(1,2)に対して、Ca1(1,2)が横の辺の延長領域(T1(1,2)、T2(1,2))を含むようになっている。そして、図3におけるC2(1,2)に対して、Ca2(1,2)が縦の辺の延長領域T1(1,2)、T2(1,2)分短くなっている。
【0074】
図19は、第2の実施形態における主メモリ上の画像データとキャッシュ1上の記憶領域との対応関係を示す図である。図20は、第2の実施形態において主メモリ上の画像データとキャッシュ2上の記憶領域との対応関係を示す図である。なお、図3、図4と同一の構成要素については同一の符号を付して、その説明を省略する。
【0075】
図19において、画像410内の任意の重複部分Ca1(m、n)は、キャッシュ1_105上の一つの記憶領域に対応する。本実施形態において、キャッシュ1_105は、主走査方向は全範囲、副走査方向は矩形単位で4個分の領域内の重複部分に相当する容量を保持している。例えば、画像410内のCa1(1,2)、Ca1(2,2)、Ca1(3,2)の領域は、キャッシュ1_105内のCa1(1,2)、Ca1(2,2)、Ca1(3,2)の領域に対応する。また、画像410内のCa1(1,6)、Ca1(2,6)、Ca1(3,6)も、キャッシュ1_105内のCa1(1,2)、Ca1(2,2)、Ca1(3,2)の領域に対応する。つまり、Ca1(1,2)のデータがキャッシュされた後に、Ca1(1,6)がアクセスされたならば、キャッシュ1_105内のデータは上書きされることになる。
【0076】
図20において、画像410内の任意の重複部分Ca2(m、n)は、キャッシュ2_106の一つの記憶領域に対応する。本実施形態においては、キャッシュ2_106は、主走査方向は全範囲、副走査方向は矩形単位で4個分の領域内の重複部分に相当する容量を保持している。例えば、画像410内のCa2(1,1)、Ca2(1,2)、Ca2(1,3)の領域は、キャッシュ2_106内のCa2(1,1)、Ca2(1,2)、Ca2(1,3)の領域に対応する。また、画像410内のCa2(1,5)、Ca2(1,6)、Ca2(1,7)も、キャッシュ2_106内のCa2(1,1)、Ca2(1,2)、Ca2(1,3)の領域に対応する。つまり、Ca2(1,1)のデータがキャッシュされた後に、Ca2(1、5)がアクセスされたならば、キャッシュ2_106内のデータは上書きされることになる。
【0077】
キャッシュ制御部104は、副走査方向の矩形4個分のアドレス領域内でデコードを行い、キャッシュメモリのアドレスを算出する。そのアドレス領域を他と区別する上位アドレスは、タグ情報としてキャッシュに保持される必要がある。また、キャッシュ内のデータが有効であるか否かを決定するためのフラグ情報も必要である。
【0078】
上述したタグ情報とフラグ情報は、一般的なキャッシュにおいてはキャッシュの各データ単位ごとに用意される。しかし、本実施形態におけるシステムでは、キャッシュメモリへの更新の単位が必ず矩形の各辺に当たる領域であるので、それら各辺に属する領域に一組のタグ情報とフラグ情報を格納することが可能である。つまり、タグ情報とフラグ情報のための格納領域を一般のキャッシュシステムに比べて削減することが可能である。なお、キャッシュとタグの情報を格納するために、別のSRAMを用意してもよい。ただし、SRAMのデバイスとしての個数増加は、半導体上の使用面積として影響が大きいので、より好適な実装形態としてはキャッシュ2の空き領域に格納する方法がある。
【0079】
上記空き領域は、重複部分が格子状に交差する領域である。この格子状の領域は、キャッシュ1に割り当てられているので、キャッシュメモリとしてはデータのために使用されない領域になっている。格子状の重複部分の交点に当たる領域は、キャッシュ1に含める実装形態も当然可能である(第1の実施形態)。
【0080】
図21は、第2の実施形態におけるキャッシュ制御部の制御処理を示すフローチャートである。なお、図6の処理を同一のステップについては同一のステップ番号を付して、その説明は省略する。
【0081】
図21において、ステップS705では、キャッシュ制御部104は、要求アドレスがキャッシュ1_105の重複部分内であるかどうかを判断する。上記アドレスがキャッシュ1_105の重複部分内であることの条件式を以下に示す。
【0082】
Ys−Yd≦v<Ys+Ye
ステップS705の判別の結果、要求アドレスがキャッシュ1_105の重複部分内であると判断されたときは(ステップS705でYES)、ステップS710に進む。
【0083】
ステップS710において、(m,n)で指定される矩形の右辺重複部のキャッシュ情報(キャッシュのタグとフラグの情報)をキャッシュ2_106からリードする。キャッシュ2_106上のキャッシュ情報が格納されているアドレスは以下の式により与えられる。
【0084】
(Ys+1)(Xd+Xe)P/Xs+m(Xd+Xe)
次に、ステップS511において、右辺重複部のキャッシュフラグが有効であれば(ステップS511でYES)、ステップS712にて、キャッシュ制御部104は、キャッシュ1_105からデータをリードする。キャッシュ1_105上のデータが格納されているアドレスは以下の式により与えられる。
【0085】
P{n(Yd+Ye)+v−Ys+Yd+Ye}+x
ステップS705の判別の結果、要求アドレスがキャッシュ1_105の重複部分内でないと判断されたときは(ステップS705でNO)、ステップS706へ分岐する。そして、さらに要求アドレスがキャッシュ2_106の重複部分内であるかどうか、次式によって判断する。次式が成立したときは、キャッシュ2_106の重複部分であることを意味する。
【0086】
Xs−Xd≦u<Xs+Xe
ステップS706の判別の結果、重複部分外であれば(ステップS706でNO)、ステップS516へ進む。一方、要求アドレスがキャッシュ2_106の重複部分内であると判断されたときは(ステップS706でYES)、ステップS707にて、キャッシュ制御部104は、キャッシュ2_106からデータをリードする。キャッシュ2_106のデータが格納されているアドレスは以下の式により与えられる。
【0087】
y(Xd+Xe)P/Xs+m(Xd+Xe)+u−Xs+Xd+Xe
ステップS508において、右辺重複部のキャッシュフラグが無効であれば(ステップS508でNO)、ステップS513へ進む。一方、右辺重複部のキャッシュフラグが有効であれば(ステップS508でYES)、ステップS709にて、キャッシュ制御部104は、キャッシュ2_106からデータをリードする。
【0088】
以上、第2の実施形態によれば、上記第1の実施形態による効果を奏することができる。
【0089】
また、本発明の目的は、以下の処理を実行することによっても達成される。即ち、上述した実施形態の機能を実現するソフトウェアのプログラムコードを記録した記憶媒体を、システム或いは装置に供給し、そのシステム或いは装置のコンピュータ(またはCPUやMPU等)が記憶媒体に格納されたプログラムコードを読み出す処理である。この場合、記憶媒体から読み出されたプログラムコード自体が前述した実施の形態の機能を実現することになり、そのプログラムコード及び該プログラムコードを記憶した記憶媒体は本発明を構成することになる。
【符号の説明】
【0090】
100 画像処理装置
101 描画部
102 主メモリ
103 出力部
104 キャッシュ制御部
105 キャッシュ1
106 キャッシュ2
107 画像処理部A
108 画像処理部B
【特許請求の範囲】
【請求項1】
画像データを記憶する第1記憶手段と、
前記第1記憶手段に記憶された画像データを所定サイズの複数の矩形画像データに分割して読み出す読み出し手段と、
前記複数の矩形画像データを囲む参照領域の画像データであって、隣り合う2つの矩形画像データ間の境界を含むように互いに重複する部分を有する参照領域の画像データを記憶する第2記憶手段と、
前記読み出し手段により読み出された前記複数の矩形画像データと、前記第2記憶手段に記憶された前記参照領域の画像データに基づいて画像処理を行う画像処理手段と、
前記画像処理手段からの要求に応じて前記参照領域の画像データを前記第2記憶手段から前記画像処理手段へ転送するよう制御するキャッシュ制御手段とを備えることを特徴とする画像処理装置。
【請求項2】
前記第2記憶手段は、
前記重複する部分のうち、主方向の重複部分と副方向の重複部分とが交差する格子状の領域を除いた前記主方向の重複部分を記憶する第1のキャッシュと、
前記重複する部分のうち、前記格子状の領域を含む前記副方向の重複部分を記憶する第2のキャッシュを有することを特徴とする請求項1記載の画像処理装置。
【請求項3】
前記第2記憶手段は、
前記重複する部分のうち、主方向の重複部分と副方向の重複部分とが交差する格子状の領域を除いた前記副方向の重複部分を記憶する第2のキャッシュと、
前記重複する部分のうち、前記格子状の領域を含む前記主方向の重複部分を記憶する第1のキャッシュを有することを特徴とする請求項1記載の画像処理装置。
【請求項4】
画像データを記憶する第1記憶手段に記憶する第1記憶工程と、
前記第1記憶手段に記憶された画像データを所定サイズの複数の矩形画像データに分割して読み出す読み出し工程と、
前記複数の矩形画像データを囲む参照領域の画像データであって、隣り合う2つの矩形画像データ間の境界を含むように互い重複する部分を有する参照領域の画像データを第2記憶手段に記憶する第2記憶工程と、
前記読み出し工程にて読み出された前記複数の矩形画像データと、前記第2記憶手段に記憶された前記参照領域の画像データに基づいて画像処理手段により画像処理を行う画像処理工程と、
前記画像処理手段からの要求に応じて前記参照領域の画像データを前記第2記憶手段から前記画像処理手段へ転送するよう制御するキャッシュ制御工程とを備えることを特徴とする画像処理方法。
【請求項5】
請求項4記載の画像処理方法をコンピュータに実行させるためのコンピュータに読み取り可能なプログラム。
【請求項1】
画像データを記憶する第1記憶手段と、
前記第1記憶手段に記憶された画像データを所定サイズの複数の矩形画像データに分割して読み出す読み出し手段と、
前記複数の矩形画像データを囲む参照領域の画像データであって、隣り合う2つの矩形画像データ間の境界を含むように互いに重複する部分を有する参照領域の画像データを記憶する第2記憶手段と、
前記読み出し手段により読み出された前記複数の矩形画像データと、前記第2記憶手段に記憶された前記参照領域の画像データに基づいて画像処理を行う画像処理手段と、
前記画像処理手段からの要求に応じて前記参照領域の画像データを前記第2記憶手段から前記画像処理手段へ転送するよう制御するキャッシュ制御手段とを備えることを特徴とする画像処理装置。
【請求項2】
前記第2記憶手段は、
前記重複する部分のうち、主方向の重複部分と副方向の重複部分とが交差する格子状の領域を除いた前記主方向の重複部分を記憶する第1のキャッシュと、
前記重複する部分のうち、前記格子状の領域を含む前記副方向の重複部分を記憶する第2のキャッシュを有することを特徴とする請求項1記載の画像処理装置。
【請求項3】
前記第2記憶手段は、
前記重複する部分のうち、主方向の重複部分と副方向の重複部分とが交差する格子状の領域を除いた前記副方向の重複部分を記憶する第2のキャッシュと、
前記重複する部分のうち、前記格子状の領域を含む前記主方向の重複部分を記憶する第1のキャッシュを有することを特徴とする請求項1記載の画像処理装置。
【請求項4】
画像データを記憶する第1記憶手段に記憶する第1記憶工程と、
前記第1記憶手段に記憶された画像データを所定サイズの複数の矩形画像データに分割して読み出す読み出し工程と、
前記複数の矩形画像データを囲む参照領域の画像データであって、隣り合う2つの矩形画像データ間の境界を含むように互い重複する部分を有する参照領域の画像データを第2記憶手段に記憶する第2記憶工程と、
前記読み出し工程にて読み出された前記複数の矩形画像データと、前記第2記憶手段に記憶された前記参照領域の画像データに基づいて画像処理手段により画像処理を行う画像処理工程と、
前記画像処理手段からの要求に応じて前記参照領域の画像データを前記第2記憶手段から前記画像処理手段へ転送するよう制御するキャッシュ制御工程とを備えることを特徴とする画像処理方法。
【請求項5】
請求項4記載の画像処理方法をコンピュータに実行させるためのコンピュータに読み取り可能なプログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【公開番号】特開2010−244113(P2010−244113A)
【公開日】平成22年10月28日(2010.10.28)
【国際特許分類】
【出願番号】特願2009−89065(P2009−89065)
【出願日】平成21年4月1日(2009.4.1)
【出願人】(000001007)キヤノン株式会社 (59,756)
【Fターム(参考)】
【公開日】平成22年10月28日(2010.10.28)
【国際特許分類】
【出願日】平成21年4月1日(2009.4.1)
【出願人】(000001007)キヤノン株式会社 (59,756)
【Fターム(参考)】
[ Back to top ]