
画像処理装置
【課題】画像処理ユニットから送られてくるデータ等の情報の取りこぼしを防止することができる画像処理装置を提供すること。
【解決手段】本発明の画像処理装置は、所定の画像データの処理を行うための少なくとも1つの画像処理ユニット1と、画像処理ユニット1から出力されるデータを一時的に記憶するデータ一時記憶装置2と、画像処理ユニット1から出力されるデータをデータ一時記憶装置2を介して受けるホスト処理装置3と、を具備する。画像処理ユニット1は、配線基板の上にマイクロプロセッサ、ロジックアレイ、メモリ装置及びこれらを接続する接続手段と外部信号入出力のための少なくとも1つの外部接続端子とを有し、前記マイクロプロセッサ及び前記ロジックアレイに組み込まれるソフトウェアによりデータの処理内容が決定される少なくとも1つのセル基板11を具備する。
【解決手段】本発明の画像処理装置は、所定の画像データの処理を行うための少なくとも1つの画像処理ユニット1と、画像処理ユニット1から出力されるデータを一時的に記憶するデータ一時記憶装置2と、画像処理ユニット1から出力されるデータをデータ一時記憶装置2を介して受けるホスト処理装置3と、を具備する。画像処理ユニット1は、配線基板の上にマイクロプロセッサ、ロジックアレイ、メモリ装置及びこれらを接続する接続手段と外部信号入出力のための少なくとも1つの外部接続端子とを有し、前記マイクロプロセッサ及び前記ロジックアレイに組み込まれるソフトウェアによりデータの処理内容が決定される少なくとも1つのセル基板11を具備する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、所定の画像データの処理を行う画像処理装置に関するものである。
【背景技術】
【0002】
現在、画像データ処理を応用した画像処理装置は多種多様な分野で使用されており、製造分野では欠かすことができないものとなりつつある。画像処理装置は、多種多様であり、撮像対象、処理基準及び処理手法もそれぞれ多様である。
【0003】
画像処理装置及びそこで使われる画像データ処理用回路基板の開発フローとしては、処理すべき対象とその処理基準を最初に決め、それに見合った画像処理手法の確立、それを実現するためのハードウェア並びにソフトウェアの設計、製造、テスト、導入といった順に開発を進めるのが一般的である。
【0004】
この開発フローの中で特にハードウェアの部分は、撮像対象、処理基準、処理手法などが、明確化かつ最適化されていないと着手できないことが多い。最適化が不十分であると、実現困難、あるいは実現するのに多大なコストがかかるという開発の根幹に関わる問題が発生することがある。また、明確化が不十分であると、ハードウェアの変更が必要になることがあるが、それには多大な労力がかかることが多い。
【0005】
元来、ハードウェアは製造コストと比較してイニシャルコストの方が圧倒的に大きいため、再開発をすることはあまり現実的ではないものである。回路基板などのハードウェア製作では、プロセッサのパフォーマンス、メモリ装置の容量や速度、周辺回路構成などの基本的なハードウェア構成情報は確度の高いものにしておかなければならない。
【0006】
それでも仕様変更などが発生した場合、ハードウェアの全面的な再開発までは至らずに一定の範囲内で仕様変更を吸収できるようにするために、ハードウェアの一部をFPGA(Field Programmable Gate Array)及びCPLD(Complex Programmable Logic Device)などのプログラマブルにハードウェアを構築できるロジックアレイを使用して実現する手法を採ることが多い。この手法により、ロジックアレイの有する容量の範囲でプログラマブルに任意の論理回路を実現することができる。
【0007】
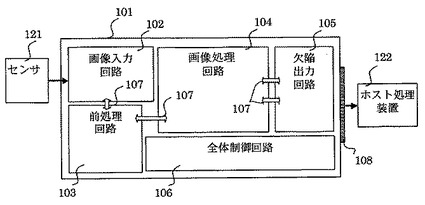
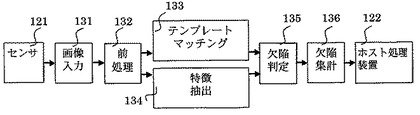
前述の理由により、ロジックアレイを使用して回路基板(以下、セル基板と呼ぶ)を製作することが一般的になっている。ただし、ロジックアレイの有する容量は有限であり、そのロジックアレイの有するボリュームが目的とする処理のボリュームより小さい場合、ロジックアレイを複数個使用することになる。年々処理が複雑化、かつ、高速化している状況では、むしろこのようなケースのほうが多くなってきている(非特許文献1参照)。このようなセル基板の製作方法は、コスト面、性能面、自由度の面でも優位性が高く、現在のセル基板の主流を占めている。このケースに相当するセル基板を具備する従来の画像処理装置のブロック図が図8及び図10に示されている。
【0008】
図8に示す従来の画像処理装置は、ベース基板101に実装されている画像入力回路102、前処理回路103、画像処理回路104、欠陥出力回路105及び全体制御回路106を具備している。
【0009】
図8に示す従来の画像処理装置は、各回路102〜106をそれぞれプロセッサ、メモリ装置、処理手順を示すソフトウェアを搭載したロジックアレイなどで構成して各回路が行うべき処理を実現するようにして、ベース基板101の上に直接実装するかまたはサブボード化して接続している。各回路102〜106の間のデータのやり取りは配線板上に固定的に配置されたローカルバス107で行う。画像入力回路102は、センサ121からの画像データを受ける。欠陥出力回路105からのデータは、外部インターフェイス108を介してホスト処理装置122に与えられる。
【0010】
図8に示す従来の画像処理装置は、図9に示すように、処理をいくつかのブロック131〜136に分割し、それぞれをベース基板101の上に収まるように配置・実装することで実現している。各ブロックは、ベース基板101の上に直接実装する場合と、サブボード化しておきベース基板101に接続する場合の双方があるが、どちらでもベース基板101の上のローカルバス107のパターンは同じになる。なお、各ブロックを統括して制御するための全体制御回路106も必要になる。
【0011】
各ブロック間のデータのやり取りは、ベース基板101上にパターン形成されたローカルバス107により行われる。ローカルバス107は、汎用性を高める場合は各ブロック共通でバス接続することが多い。逆にリアルタイム性が高い場合はブロック間でデータのやり取りが必要となる部分をピアツーピアの接続にすることが多くなるが、この場合、他の経路間でのデータのやり取りできなくなるという制約が生じる。回路基板を製作する目的としては、処理を高速化するケースが圧倒的に多い(後者のケースに相当する)。
【0012】
処理を高速化すればするほど、回路基板は使用目的を絞り込まなければならなくなってくる。従来の画像処理装置では、「ローカルバス107を固定パターン化する」ことが目的の絞り込みに相当する。
【0013】
また、各処理ブロックのハードウエアは、実装可能な処理のボリュームの上限をあらかじめ、ある値N(一定値であり、これを変更することは回路基板を再設計することを意味する)として決めておかないと製作できない。上記の値Nより、実装する処理のボリュームが十分小さい場合はハードウエアの使用効率が低く、コスト面からも余剰なコストが生じていることになる。逆に、実装する処理のボリュームが大きい場合は、実装不可能ということになる。
【0014】
図10に示す従来の画像処理装置は、ベース基板141に実装されている画像入力回路142、前処理回路143、欠陥判定回路144、欠陥出力回路145及び全体制御回路146を具備している。図10に示す従来の画像処理装置においても、図8に示す従来の画像処理装置と同じ問題を有している。
【0015】
実施すべき画像処理の処理ボリュームが1枚の回路基板で収まりきれない場合は、複数のセル基板を組み合わせて所望の処理を実現する。複数のセル基板を組み合わせて、まとまった一連の処理を実現する単位を画像処理ユニットと称する。
【0016】
生産ライン上の画像検査装置のように複数台のラインカメラを撮像装置として用いるような場合、カメラ1台ごとに同じ画像処理を実施しなければならない。複数台のラインカメラからの画像の処理を1台の画像処理ユニットでシリアルに実行していたのでは処理タクトが膨大になる。そこでラインカメラの台数分の画像処理ユニットを用意し、パラレルに実行することで高速な画像処理が可能になる。
【0017】
画像処理ユニットの数が増えれば処理は高速になるが、出力される画像処理結果のデータ量も膨大になる。画像処理ユニットからの出力を収集し、データ解析を行うホスト処理装置(ワークステーション、デスクトップパソコンなど)は全ての画像処理ユニットから出力されてくる結果データを取りこぼさずに収集可能でなければならない。
【0018】
しかし、FPGAやCPLDなどの高速ハードウェアを備えた画像処理ユニットのデータ出力能力と、ホスト処理装置のCPUのソフトウェア処理能力には大きなギャップがあるため、複数の画像処理ユニットから出力されるデータを直接ホスト処理装置が受信させようとするとデータの取りこぼしが発生する恐れがある。
【0019】
【非特許文献1】株式会社ソリトンシステムズ、”画像処理FPGAボード”、[online]、2007年、株式会社ソリトンシステムズ、[平成19年7月30日検索]、<URL: http://www.soliton.co.jp/products/fpga_board/index.html>
【発明の開示】
【発明が解決しようとする課題】
【0020】
本発明の目的は、画像処理ユニットから送られてくるデータ等の情報の取りこぼしを防止することができる画像処理装置を提供することにある。また、本発明の他の目的は、画像データサイズ、画像データ数及び処理方法(処理アルゴリズム)などにより、処理負荷が多様な画像処理装置において、処理の負荷に応じてハードウエアを新規に開発することなく、画像処理をフレキシブルに実現することできる画像処理装置を提供することにある。
【課題を解決するための手段】
【0021】
請求項1の発明に係る画像処理装置は、所定の画像データの処理を行うための少なくとも1つの画像処理ユニットと、前記画像処理ユニットから出力されるデータを一時的に記憶するデータ一時記憶装置と、前記画像処理ユニットから出力されるデータを前記データ一時記憶装置を介して受けるホスト処理装置と、を具備することを特徴とする。
【0022】
請求項2の発明に係る画像処理装置は、請求項1に記載の画像処理装置において、前記画像処理ユニットが、配線基板の上にマイクロプロセッサ、ロジックアレイ、メモリ装置及びこれらを接続する接続手段と外部信号入出力のための少なくとも1つの外部接続端子とを有し、前記マイクロプロセッサ及び前記ロジックアレイに組み込まれるソフトウェアによりデータの処理内容が決定される少なくとも1つのセル基板を具備し、前記セル基板の外部接続端子と前記他のセル基板の外部接続端子とをセル基板間接続手段により接続して、前記複数のセル基板を所定の配置で接続することにより、前記画像処理ユニットで実施すべきデータの処理内容を実行することを特徴とする。
【0023】
請求項3の発明に係る画像処理装置は、請求項1及び請求項2のいずれか1つに記載の画像処理装置において、前記セル基板を構成する配線板は、同一形状のものであることを特徴とする。
【0024】
請求項4の発明に係る画像処理装置は、請求項1及び請求項3のいずれか1つに記載の画像処理装置において、前記データ一時記憶装置は、前記ホスト処理装置がデータを読み出すリード専用領域と、前記ホスト処理装置がコマンドを書込むライト専用領域と、を具備することを特徴とする。
【0025】
請求項5の発明に係る画像処理装置は、請求項1請求項4のいずれか1つに記載の画像処理装置において、前記データ一時記憶領装置がFIFO(First In First Out)で構成されていることを特徴とする。
【0026】
請求項6の発明に係る画像処理装置は、請求項1請求項5のいずれか1つに記載の画像処理装置において、前記画像処理装置の前記画像処理ユニットと前記データ一時記憶装置との間に接続されている画像検査ユニットと、をさらに具備し、前記画像検査ユニットが、
前記画像処理ユニットから受ける画像データを検査して検査結果を前記データ一時記憶装置を介して前記ホスト処理装置に与えることを特徴とする。
【発明の効果】
【0027】
本発明によれば、データ一時記憶装置を具備するため画像処理ユニットよりホスト処理装置のほうがデータの処理速度が遅くてもデータ一時記憶装置がデータの処理速度を調整することができるから、画像処理ユニットから送られてくるデータ等の情報の取りこぼしを防止することができる。また、本発明によれば、データ一時記憶装置を具備するため画像処理ユニットよりホスト処理装置のほうがデータの処理速度が遅くてもデータ一時記憶装置がデータの処理速度を調整することができるから、画像データサイズ、画像データ数及び処理方法(処理アルゴリズム)などにより、処理負荷が多様な画像処理装置において、処理の負荷に応じてハードウエアを新規に開発することなく、画像処理をフレキシブルに実現することできる。
【発明を実施するための最良の形態】
【0028】
次に、本発明の実施の形態について。図面を参照して詳細に説明する。
(実施の形態1)
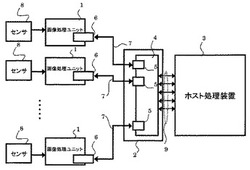
図1は、本発明の実施の形態1に係る画像処理装置を示すブロック図である。図2は、本発明の実施の形態1に係る画像処理装置の画像処理ユニットを示すブロック図である。図3は、本発明の実施の形態1に係る画像処理装置のデータ一時記憶装置を示すブロック図である。
【0029】
図1に示すように、本発明の実施の形態1に係る画像処理装置は、複数の画像処理ユニット1、データ一時記憶装置2及びホスト処理装置3を具備している。データ一時記憶装置2は、インタフェース基板4と、このインタフェース基板4に搭載されている複数の一時記憶領域5と、を具備している。複数の画像処理ユニット1の外部入出力端子6は、複数の一時記憶領域5にシリアルインタフェース7によって接続されている。複数の画像処理ユニット1の入力端子には、センサ(例えば、カメラなどの撮像装置)8が接続されている。インタフェース基板4は、ホスト処理装置3にバスコネクタ(PCIバス)9などによって接続されている。なお、本発明の実施の形態1に係る画像処理装置は、1つの画像処理ユニット1を具備する構成であってもよい。
【0030】
画像処理ユニット1は、センサ8からの画像データを受けて所定の画像データの処理を行う。データ一時記憶装置2は、画像処理ユニット1から出力されるデータを一時的に記憶してホスト処理装置3に与える。
【0031】
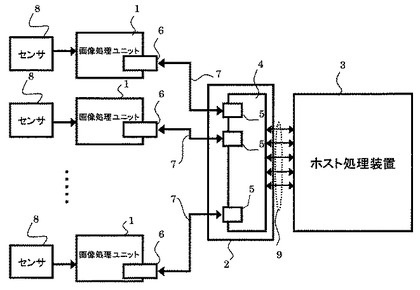
図2に示すように、画像処理ユニット1は、複数のセル基板11を具備している。各画像処理ユニット1は、センサ8から画像データを受けて処理して結果出力まで一連の画像処理を行うことができる。各画像処理ユニット1のハードウェアは実質的に同じ構成である。セル基板11に搭載されているペリフェラルの構成及びソフトウェアロジックは、当該画像処理ユニット1で実施すべき処理内容によって異なる構成にすることも可能である。
なお、画像処理ユニット1は、1つのセル基板11を具備する構成であってもよい。
【0032】
セル基板11は、配線基板の上にマイクロプロセッサ、ロジックアレイ、メモリ装置及びこれらを接続する接続手段と外部信号入出力のための少なくとも1つの外部接続端子とを有し、前記マイクロプロセッサ及び前記ロジックアレイに組み込まれるソフトウェアによりデータの処理内容が決定される。
【0033】
また、画像処理ユニット1は、セル基板11の外部接続端子と他のセル基板11の外部接続端子とを接続手段により接続して、複数のセル基板11を所定の配置で接続することにより、画像処理ユニット1で実施すべきデータの処理内容を実行する。
【0034】
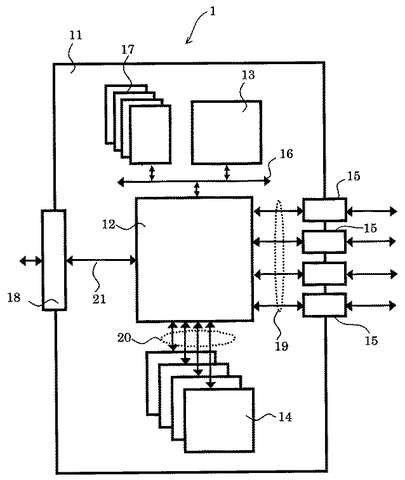
次に、セル基板11について、より具体的に説明する。セル基板11は、画像処理ユニット1を構成するハードウェアの基本単位である。セル基板11は、主にロジックアレイ12、CPU13、メモリ装置14及びペリフェラルデバイス17などを搭載している。また、セル基板11は、外部との信号のやり取りをするための接合手15及び全体制御信号用コネクタ18を具備している。ロジックアレイ12は、CPU13及びペリフェラルデバイス17とローカルバス16により接続されている。また、ロジックアレイ12は、接合手15とシリアルインターフェース19により接続されている。また、ロジックアレイ12は、メモリ装置14とメモリインターフェース20により接続されている。ロジックアレイ12は、全体制御信号用コネクタ18と全体制御インターフェイス21により接続されている。
【0035】
セル基板11においては、搭載するロジックアレイ12の容量やデータ入出力経路及び搭載するCPU13、メモリ装置14及びペリフェラルデバイス17の数や容量などを決定するだけでよい。実装させたい処理手順は、当該画像処理方式に応じたソフトウェアとしてロジックアレイ12に実装していく。このようにセル基板11は、ハードウェア単体としては使用目的を持たせないことを特徴としており、換言すれば、ハードウェアと使用目的の依存関係を切り離すことを特徴としている。以上で説明したようなセル基板11のロジックアレイ12に各種の処理ソフトウェアを書き込むことにより、セル基板11の形状及び形態は同一で構成されていても、処理内容が異なるセル基板11を得ることができる。
【0036】
なお、各セル基板11が受け持つ処理内容や処理ボリュームによっては、そのセル基板11が搭載するメモリ装置14及びペリフェラルデバイス17などの種類及び数が異なることもあり得る。その場合は、メモリ装置14及びペリフェラルデバイス17の抜き差しが可能なコネクタをセル基板11の上に準備しておき、各セル基板11が受け持つ処理内容及び処理ボリュームが決まった時点で、実際に使用するメモリ装置14及びペリフェラルデバイス17などを実装してもよい。
【0037】
接合手15は、他のセル基板11などと画像データ及び画像情報をやり取りするためのチャンネルで、省スペース実装が可能で、かつ、高速伝送が可能なシリアルインタフェースのほうが望ましい。接続手段15としては、特にシリアルインタフェースを限定するものではないが、インフィニバンドなどの小振幅差動信号インタフェースなどが一例として挙げられる。これらは、高速伝送(数百MHz以上)の場合はピアツーピアを基本とするが、低速伝送の場合はマルチドロップも可能である。
【0038】
接合手15のチャンネル数は特に限定する必要はないが、実用性、コスト性でバランスが取れているのは、3〜5チャンネル程度と考えられる。各チャンネルは独立して動作する。なお、昨今のシリアルインタフェースでは、チャネル数を増やして伝送帯域を稼ぐ手法が多用されているが、本発明の実施の形態1では、前記レーン数を特に規定する必要はない。この部分をパラレルバスとして、固定的に回路基板上にパターン化するのが従来技術である。
【0039】
画像処理ユニット1とデータ一時記憶装置2との接続手段(外部入出力端子6)としても、接合手15を用いる。画像処理ユニット11によってハードウェアで高速に処理された処理結果を掃きだすため、接合手15の通信速度も十分な高速性が求められる。例えば接合手15としてインフィニバンドやPCIエクスプレスを用いた場合、1チャネルあたり2.5BPSのデータ転送が可能である。
【0040】
このようなアーキテクチャを採ることにより、得られる効果は、下記(a)〜(d)のようなものである。
(a)複雑な処理内容を実現したい場合には、その各処理項目を実行するセル基板11をカスケード接続すればよい。
(b)所定の処理速度を得るためには、同じ処理を行うセル基板11の組を、必要に応じてパラレル接続すればよい。
(c)あるセル基板11に割り当てられる処理の負荷が軽い場合は、処理の前記ブロックを統合し、セル基板11の枚数を減らすことも可能である。
(d)画像処理ユニット1の開発途中で処理内容、処理順序、処理のボリューム、処理すべきデータ量などに変更が生じても、容易に対処することが可能になる。
【0041】
高速な画像処理ユニット1及び接合手15と比較して、ホスト処理装置(例えば、デスクトップPC)3のCPUのソフトウェア演算速度は遅い。そこで、画像処理ユニット1とホスト処理装置3の間にデータ一時記憶装置2が設けられている。データ一時記憶装置2は、高速に転送されてきたデータを一時的に記憶(バッファリング)する。データ一時記憶装置2は、画像処理ユニット1ごとに用意されており、各転送チャネルから転送されてきたデータを一時的に記憶(バッファリング)する。
【0042】
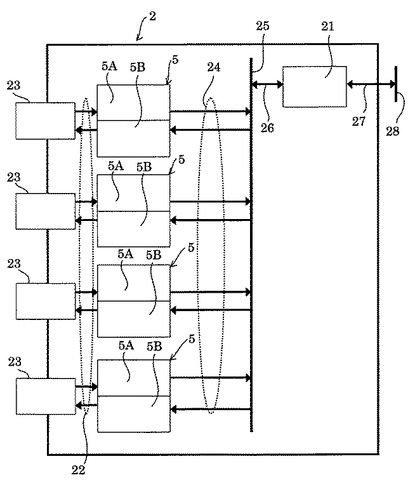
次に、データ一時記憶装置2について、詳細に説明する。図3に示すように、データ一時記憶装置2は、インタフェース基板4と、このインタフェース基板4に搭載されている複数の一時記憶領域5と、記憶装置制御部21と、を具備している。複数の一時記憶領域5の数は、画像処理ユニット1からの出力チャネルの数と同じである。複数の一時記憶領域5は、接合手22及び外部入出力端子23を介して画像処理ユニット1に接続されている。記憶装置制御部21は、接合手24、メモリバス25及び結合手26を介して複数の一時記憶領域5に接続されている。また、記憶装置制御部21は、バス27及びバスコネクタ28を介してホスト処理装置3に接続されている。
【0043】
データ一時記憶装置2は、ホスト処理装置3がデータを読み出すリード専用領域5Aと、ホスト処理装置3がコマンドを書込むライト専用領域5Bと、とを具備する。すなわち、一時記憶領域5は、リード専用領域5Aとライト専用領域5Bとに分割されている。
【0044】
データ一時記憶領装置2の一時記憶領域5は、FIFO(First In First Out)で構成されている。FIFOとは、ある場所に格納したデータを古くに格納した順番に取り出すようにするデータ構造である。リード専用領域5A及びライト専用領域5BがFIFOで構成されていることにより、書き込まれたデータ数、次に読み出すべきデータの番地(以下、リードポインタと呼ぶ)、次にデータを書き込むべきデータの番地(以下、ライトポインタと呼ぶ)の管理を容易に行うことができる。
【0045】
各画像処理ユニット1から出力される画像処理後のデータは、まずインタフェース基板4の上のリード専用領域5AのFIFOに格納される。リード専用領域5AのFIFOにデータが格納された後に、記憶装置制御部21はインタフェース基板4の上のレジスタにFIFOにデータが格納されたことを示すフラグを立てる。ホスト処理装置3は一定時間ごとに前記フラグを監視しており、前記フラグが立っていればFIFOに格納されているデータを全て読み出す。
【0046】
一方、ホスト処理装置3から画像処理ユニット1を制御するためのコマンドを発行する場合も、まずインタフェース基板4の上のライト専用領域5BのFIFOにコマンドが書き込まれる。このコマンドには送信先を示す情報が含まれている。メモリ装置制御部21は、送信先情報と一致する画像処理ユニット1のチャネルに対応したライト専用領域5BのFIFOにコマンドを書き込む。画像処理ユニット1は、一定時間ごとにライト専用領域5BのFIFOにデータが格納されていないかどうかの監視を行い、データが格納されていれば一度に全てのデータを読み出す。
【0047】
データ一時記憶装置2が十分な大きさの一時記憶領域5を備えていれば、画像処理ユニット1のハードウェアとホスト処理装置3のソフトウェアとの処理速度差を吸収し、データの取りこぼしを防ぐ効果がある。
【0048】
画像処理ユニット1からのデータがデータ量の大きな画像データである場合、画像データの全てを一度に送信せずに、複数回に分割して送信することが多い。例えばVGAサイズの画像データを1ライン毎のラインデータに分割して送信するなどである。ホスト処理ユニット1のソフトウェアは分割されて送信されてきたラインデータを再び画像データに構築しなおさなければならない。
【0049】
本発明の実施の形態1では、データ一時記憶装置2がFIFOで構成されているため、画像データの上からシーケンシャルにFIFOに書き込んでいけば、書き込み時と読み出し時でデータの順番が保障されている。そのため、ホスト処理装置3のソフトウェア上では分割されて送信されてきたラインデータを再び画像データに構築する処理が容易となる。
【0050】
(実施の形態2)
次に、本発明の実施の形態2について、図面を参照して詳細に説明する。図4は、本発明の実施の形態2に係る画像処理装置を示すブロック図である。図5は、本発明の実施の形態2に係る画像処理装置の画像検査ユニットを処理を説明するための図である。本発明の実施の形態2においては、本発明の実施の形態1と同じ構成要素には同じ参照符号を付してその説明を省略する。
【0051】
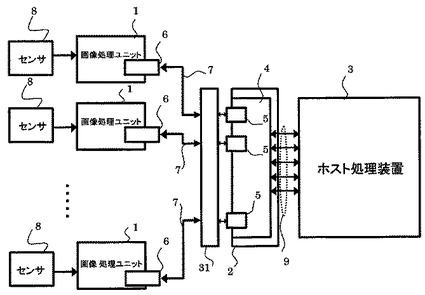
図4に示すように、本発明の実施の形態2に係る画像処理装置は、本発明の実施の形態1に係る画像処理装置において、画像処理ユニット1とデータ一時記憶装置2との間に接続されている画像検査ユニット31と、をさらに具備している。すなわち、本発明の実施の形態2に係る画像処理装置は、複数の画像処理ユニット1、画像検査ユニット31、データ一時記憶装置2及びホスト処理装置3を具備している。画像検査ユニット31は、画像処理ユニット1から受けるデータを検査して検査結果をデータ一時記憶装置2を介してホスト処理装置3に与える。
【0052】
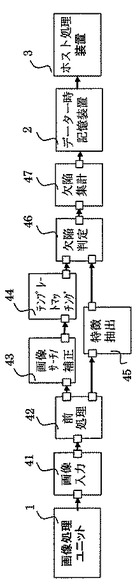
次に、本発明の実施の形態2に係る画像検査ユニット31について、図5を参照して詳細に説明する。
まず、図5に示す処理フローは、パターン検査の場合についてのものである。図5において41〜46は画像検査ユニット31が行う各種処理である。画像検査ユニット31は、画像処理ユニット1からのデータに対して各種処理41〜46を行い、検査結果の出力先であるホスト処理装置3にデータ一時記憶装置2を介して与える。パターン検査では、図5に示すように、代表的な検出手法であるテンプレートマッチング43と特徴抽出44を併用することが多い。
【0053】
テンプレートマッチング43は、テンプレート画像と検査画像の位置合わせ(画像サーチX、Y、θの3軸方向に対して位置を補正する)した後にマッチングを行うことが多い。テンプレート画像は、元画像をそのまま使用せず、マスク処理やモフォロジ処理を施す場合もある。位置合わせすべき軸数により大幅に処理のボリュームが変わるが、一般にマッチング処理より位置合わせ処理の方が処理のボリュームが大きくなることが多い。
【0054】
特徴抽出44は、端点、交点、独立点、直線、曲線などの特徴を抽出し、所定の特徴ルール則と比較する場合が多いが、その検出方法により処理のボリュームが大幅に変わるという傾向がある。上記二つの検出手法は共に、回路基板を製作する以前に決定しておくべき処理である。
【0055】
画像入力41、前処理42は、比較的ハードウエアで具現する処理が多く、ソフトウエアが介在する比率が少ない。従って定型的な処理が多くなり、処理のボリュームも予測がつけやすい。
【0056】
欠陥判定45は、テンプレートマッチング43と特徴抽出44から得られた結果から、欠陥判定(正常/異常の2値情報にする)することになるが、この部分も定型的な処理が多く、処理のボリュームも予測がつきやすい。
【0057】
処理欠陥集計46は、欠陥判定25の結果から欠陥の位置、サイズ、面積、重心などを求める処理(ラベリング処理)になるが、この部分も定型的な処理が多く、処理のボリュームは大きいものの予測がつけやすい。
【0058】
本発明の実施の形態2は、セル基板11を組み合わせて、図9の処理を実現したものが、図5の処理になる。セル基板11は、図2に示したように、同一構造のセル基板11の上で、各種の異なる処理を実現することができるという機能を持つ。
【0059】
そのため、テンプレートマッチングと特徴抽出のように、処理のボリュームが変動しやすい部分については、処理のボリューム応じたセル基板11の構成が取れる。またセル基板11の間は、各セル基板11の接合手15をコネクタで自由に接続することができるので、処理順序に沿って、所定の処理を行うセル基板11を接続していくことが可能である。
【0060】
上記接続された経路を介して、画像データ及び付随する画像情報がやり取りされる。ただし、下流(後工程)の接続経路は、より情報圧縮された画像データのやり取りになる場合もある。
【0061】
例えば、画像サーチとその補正をX、Y、θの3軸方向に対して実行する場合は、その処理のボリュームが非常に大きくなるため、テンプレートマッチング処理は、画像サーチ/補正43とテンプレートマッチング44という2つのセル基板11に分割して直列に接続する。ここでの各セル基板11の役割は、画像サーチ/補正43ではテンプレートに対してX、Y、θの3軸方向の位置合わせ済みの画像データを出力し、テンプレートマッチング44では該画像データとテンプレート画像データと比較(相関)を行う。
【0062】
画像サーチとその補正がX、Yの2軸方向だけでよい場合は、その処理ボリュームは大きく低減されるため、テンプレートマッチング処理を複数のセル基板11とする必要はなく、一枚のセル基板11で実装すればよい。なお、図5では、セル基板11を直列に接続した場合を示したが、パラレル接続することも可能である。セル基板11の間の接続形態は任意であり、処理方法により決定される。
【0063】
処理内容は全く異なるが、特徴抽出45も、テンプレートマッチング処理23に対する実装方法と考え方は同じである。すなわち、特徴抽出45の処理のボリュームに応じてセル基板11の枚数とその接続を決定すればよい。
【0064】
逆に画像入力41と前処理42の処理のボリュームが少ない場合は、2枚のボードに分割する必要はなく、1枚のセル基板11の上に実装すればよい。欠陥判定46や欠陥集計47についても同様である。このことは、無駄なハードウエアの節約となり、コストダウンにもつながる。
【0065】
このように、従来方法では不可能であった画像検査処理に対するハードウエアの最適化をセル基板11のトポロジ(ボード枚数とその接続形態)により実現している。この効果は、画像検査処理が複雑化、又は、高速化すればするほど顕著になっていく。
【0066】
(実施の形態3)
次に、本発明の実施の形態3について、図面を参照して詳細に説明する。図6は、本発明の実施の形態3に係る画像処理装置を示すブロック図である。図7は、本発明の実施の形態3に係る画像処理装置の画像検査ユニットを処理を説明するための図である。本発明の実施の形態3においては、本発明の実施の形態1と同じ構成要素には同じ参照符号を付してその説明を省略する。
【0067】
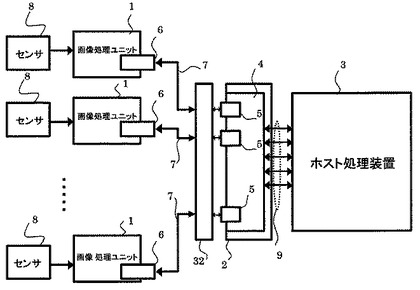
図6に示すように、本発明の実施の形態3に係る画像処理装置は、本発明の実施の形態1に係る画像処理装置において、画像処理ユニット1とデータ一時記憶装置2との間に接続されている画像検査ユニット32をさらに具備している。すなわち、本発明の実施の形態3に係る画像処理装置は、複数の画像処理ユニット1、画像検査ユニット32、データ一時記憶装置2及びホスト処理装置3を具備している。画像検査ユニット32は、画像処理ユニットから受けるデータを検査して検査結果をデータ一時記憶装置2を介してホスト処理装置3に与える。
【0068】
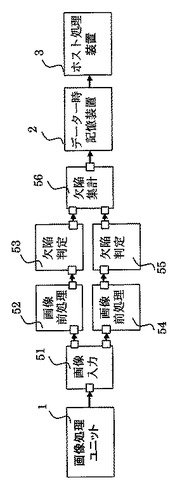
次に、本発明の実施の形態3に係る画像検査ユニットについて、図7を参照して詳細に説明する。
図7において51〜56は画像検査ユニット32が行う各種処理である。画像検査ユニット32は、画像処理ユニット1からのデータに対して各種処理51〜56を行い、検査結果の出力先であるホスト処理装置3にデータ一時記憶装置2を介して与える。
【0069】
図7に示す処理は、ウェブ検査の場合のものであるが、図5のパターン検査の場合と異なる部分についてのみ説明する。ウェブ検査は比較的検査手法は単純であるが、全面を連続検査する必要があるため、パターン検査より高速性が要求される場合が多い。高速性を満たすため、図5の処理フローにおける前処理42および欠陥判定46の部分を、2並列で検査処理を行う場合の例を示したものである。
【0070】
従来方法では、回路基板が有している処理能力は設計段階で決定されるため、後から並列化したくなることがあってもできないことが多い。逆にあらかじめ並列化していたが高速性が要求されず並列化が不必要となった場合は、冗長度が大きく割高ということになることが多い。しかし、本発明におけるボード構成では、並列にするかどうかを自由に選択できることにより、必要な処理速度に応じたハードウエア構成をとることができる。
【0071】
従来技術では、セル基板が有している処理能力は設計段階で決定されるため、後から並列化したくなることがあってもできないことが多い。逆にあらかじめ並列化していたが高速性が要求されず並列化が不必要となった場合は、冗長度が大きく割高ということになることが多い。しかし、本発明の実施の形態では、並列にするかどうかを自由に選択できることにより、必要な処理速度に応じたハードウェア構成をとることができる。
【0072】
また、本発明の実施の形態においては、ターゲットに合わせたハードウェア開発をせず、図2に示すようなメモリ装置/CPU/ロジックアレイ/データ入出力チャンネルを有するセル型のハードウェア構造(セル基板11)を基本単位とする。セル基板11を複数枚組み合わせることにより、ターゲットに適したハードウェアを構築することが可能である。ハードウェアによって演算された画像処理結果をホスト処理装置3に送信する場合、従来はハードウェアとソフトウェアの処理速度差が問題となるが、本発明の実施の形態ではハードウェアとホスト処理装置3との間にFIFOメモリ装置によるバッファリングを行うことで上記処理速度の差を吸収した。
【0073】
本発明の実施の形態においては、液晶パネル基板の生産ライン等における画像処理ユニット1において、所定の画像処理の演算をハードウェア上で高速に行い、その処理結果を取りこぼさずにホスト処理装置3に送信することが可能になる。
【図面の簡単な説明】
【0074】
【図1】本発明の実施の形態1に係る画像処理装置を示すブロック図である。
【図2】本発明の実施の形態1に係る画像処理装置の画像処理ユニットを示すブロック図である。
【図3】本発明の実施の形態1に係る画像処理装置のデータ一時記憶装置を示すブロック図である。
【図4】本発明の実施の形態2に係る画像処理装置を示すブロック図である。
【図5】本発明の実施の形態2に係る画像処理装置の画像検査ユニットを処理を説明するための図である。
【図6】本発明の実施の形態3に係る画像処理装置を示すブロック図である。
【図7】本発明の実施の形態3に係る画像処理装置の画像検査ユニットを処理を説明するための図である。
【図8】従来の画像処理装置の1例を示すブロック図である。
【図9】図8の従来の画像処理装置の処理を説明するための図である。
【図10】従来の画像処理装置の他の例を示すブロック図である。
【符号の説明】
【0075】
1 画像処理ユニット
2 データ一時記憶装置
3 ホスト処理装置
4 インタフェース基板
5 一時記憶領域
11 セル基板
12 ジックアレイ
13 CPU
14 メモリ装置
17 ペリフェラルデバイス
21 記憶装置制御部
5A リード専用領域
5B ライト専用領域
【技術分野】
【0001】
本発明は、所定の画像データの処理を行う画像処理装置に関するものである。
【背景技術】
【0002】
現在、画像データ処理を応用した画像処理装置は多種多様な分野で使用されており、製造分野では欠かすことができないものとなりつつある。画像処理装置は、多種多様であり、撮像対象、処理基準及び処理手法もそれぞれ多様である。
【0003】
画像処理装置及びそこで使われる画像データ処理用回路基板の開発フローとしては、処理すべき対象とその処理基準を最初に決め、それに見合った画像処理手法の確立、それを実現するためのハードウェア並びにソフトウェアの設計、製造、テスト、導入といった順に開発を進めるのが一般的である。
【0004】
この開発フローの中で特にハードウェアの部分は、撮像対象、処理基準、処理手法などが、明確化かつ最適化されていないと着手できないことが多い。最適化が不十分であると、実現困難、あるいは実現するのに多大なコストがかかるという開発の根幹に関わる問題が発生することがある。また、明確化が不十分であると、ハードウェアの変更が必要になることがあるが、それには多大な労力がかかることが多い。
【0005】
元来、ハードウェアは製造コストと比較してイニシャルコストの方が圧倒的に大きいため、再開発をすることはあまり現実的ではないものである。回路基板などのハードウェア製作では、プロセッサのパフォーマンス、メモリ装置の容量や速度、周辺回路構成などの基本的なハードウェア構成情報は確度の高いものにしておかなければならない。
【0006】
それでも仕様変更などが発生した場合、ハードウェアの全面的な再開発までは至らずに一定の範囲内で仕様変更を吸収できるようにするために、ハードウェアの一部をFPGA(Field Programmable Gate Array)及びCPLD(Complex Programmable Logic Device)などのプログラマブルにハードウェアを構築できるロジックアレイを使用して実現する手法を採ることが多い。この手法により、ロジックアレイの有する容量の範囲でプログラマブルに任意の論理回路を実現することができる。
【0007】
前述の理由により、ロジックアレイを使用して回路基板(以下、セル基板と呼ぶ)を製作することが一般的になっている。ただし、ロジックアレイの有する容量は有限であり、そのロジックアレイの有するボリュームが目的とする処理のボリュームより小さい場合、ロジックアレイを複数個使用することになる。年々処理が複雑化、かつ、高速化している状況では、むしろこのようなケースのほうが多くなってきている(非特許文献1参照)。このようなセル基板の製作方法は、コスト面、性能面、自由度の面でも優位性が高く、現在のセル基板の主流を占めている。このケースに相当するセル基板を具備する従来の画像処理装置のブロック図が図8及び図10に示されている。
【0008】
図8に示す従来の画像処理装置は、ベース基板101に実装されている画像入力回路102、前処理回路103、画像処理回路104、欠陥出力回路105及び全体制御回路106を具備している。
【0009】
図8に示す従来の画像処理装置は、各回路102〜106をそれぞれプロセッサ、メモリ装置、処理手順を示すソフトウェアを搭載したロジックアレイなどで構成して各回路が行うべき処理を実現するようにして、ベース基板101の上に直接実装するかまたはサブボード化して接続している。各回路102〜106の間のデータのやり取りは配線板上に固定的に配置されたローカルバス107で行う。画像入力回路102は、センサ121からの画像データを受ける。欠陥出力回路105からのデータは、外部インターフェイス108を介してホスト処理装置122に与えられる。
【0010】
図8に示す従来の画像処理装置は、図9に示すように、処理をいくつかのブロック131〜136に分割し、それぞれをベース基板101の上に収まるように配置・実装することで実現している。各ブロックは、ベース基板101の上に直接実装する場合と、サブボード化しておきベース基板101に接続する場合の双方があるが、どちらでもベース基板101の上のローカルバス107のパターンは同じになる。なお、各ブロックを統括して制御するための全体制御回路106も必要になる。
【0011】
各ブロック間のデータのやり取りは、ベース基板101上にパターン形成されたローカルバス107により行われる。ローカルバス107は、汎用性を高める場合は各ブロック共通でバス接続することが多い。逆にリアルタイム性が高い場合はブロック間でデータのやり取りが必要となる部分をピアツーピアの接続にすることが多くなるが、この場合、他の経路間でのデータのやり取りできなくなるという制約が生じる。回路基板を製作する目的としては、処理を高速化するケースが圧倒的に多い(後者のケースに相当する)。
【0012】
処理を高速化すればするほど、回路基板は使用目的を絞り込まなければならなくなってくる。従来の画像処理装置では、「ローカルバス107を固定パターン化する」ことが目的の絞り込みに相当する。
【0013】
また、各処理ブロックのハードウエアは、実装可能な処理のボリュームの上限をあらかじめ、ある値N(一定値であり、これを変更することは回路基板を再設計することを意味する)として決めておかないと製作できない。上記の値Nより、実装する処理のボリュームが十分小さい場合はハードウエアの使用効率が低く、コスト面からも余剰なコストが生じていることになる。逆に、実装する処理のボリュームが大きい場合は、実装不可能ということになる。
【0014】
図10に示す従来の画像処理装置は、ベース基板141に実装されている画像入力回路142、前処理回路143、欠陥判定回路144、欠陥出力回路145及び全体制御回路146を具備している。図10に示す従来の画像処理装置においても、図8に示す従来の画像処理装置と同じ問題を有している。
【0015】
実施すべき画像処理の処理ボリュームが1枚の回路基板で収まりきれない場合は、複数のセル基板を組み合わせて所望の処理を実現する。複数のセル基板を組み合わせて、まとまった一連の処理を実現する単位を画像処理ユニットと称する。
【0016】
生産ライン上の画像検査装置のように複数台のラインカメラを撮像装置として用いるような場合、カメラ1台ごとに同じ画像処理を実施しなければならない。複数台のラインカメラからの画像の処理を1台の画像処理ユニットでシリアルに実行していたのでは処理タクトが膨大になる。そこでラインカメラの台数分の画像処理ユニットを用意し、パラレルに実行することで高速な画像処理が可能になる。
【0017】
画像処理ユニットの数が増えれば処理は高速になるが、出力される画像処理結果のデータ量も膨大になる。画像処理ユニットからの出力を収集し、データ解析を行うホスト処理装置(ワークステーション、デスクトップパソコンなど)は全ての画像処理ユニットから出力されてくる結果データを取りこぼさずに収集可能でなければならない。
【0018】
しかし、FPGAやCPLDなどの高速ハードウェアを備えた画像処理ユニットのデータ出力能力と、ホスト処理装置のCPUのソフトウェア処理能力には大きなギャップがあるため、複数の画像処理ユニットから出力されるデータを直接ホスト処理装置が受信させようとするとデータの取りこぼしが発生する恐れがある。
【0019】
【非特許文献1】株式会社ソリトンシステムズ、”画像処理FPGAボード”、[online]、2007年、株式会社ソリトンシステムズ、[平成19年7月30日検索]、<URL: http://www.soliton.co.jp/products/fpga_board/index.html>
【発明の開示】
【発明が解決しようとする課題】
【0020】
本発明の目的は、画像処理ユニットから送られてくるデータ等の情報の取りこぼしを防止することができる画像処理装置を提供することにある。また、本発明の他の目的は、画像データサイズ、画像データ数及び処理方法(処理アルゴリズム)などにより、処理負荷が多様な画像処理装置において、処理の負荷に応じてハードウエアを新規に開発することなく、画像処理をフレキシブルに実現することできる画像処理装置を提供することにある。
【課題を解決するための手段】
【0021】
請求項1の発明に係る画像処理装置は、所定の画像データの処理を行うための少なくとも1つの画像処理ユニットと、前記画像処理ユニットから出力されるデータを一時的に記憶するデータ一時記憶装置と、前記画像処理ユニットから出力されるデータを前記データ一時記憶装置を介して受けるホスト処理装置と、を具備することを特徴とする。
【0022】
請求項2の発明に係る画像処理装置は、請求項1に記載の画像処理装置において、前記画像処理ユニットが、配線基板の上にマイクロプロセッサ、ロジックアレイ、メモリ装置及びこれらを接続する接続手段と外部信号入出力のための少なくとも1つの外部接続端子とを有し、前記マイクロプロセッサ及び前記ロジックアレイに組み込まれるソフトウェアによりデータの処理内容が決定される少なくとも1つのセル基板を具備し、前記セル基板の外部接続端子と前記他のセル基板の外部接続端子とをセル基板間接続手段により接続して、前記複数のセル基板を所定の配置で接続することにより、前記画像処理ユニットで実施すべきデータの処理内容を実行することを特徴とする。
【0023】
請求項3の発明に係る画像処理装置は、請求項1及び請求項2のいずれか1つに記載の画像処理装置において、前記セル基板を構成する配線板は、同一形状のものであることを特徴とする。
【0024】
請求項4の発明に係る画像処理装置は、請求項1及び請求項3のいずれか1つに記載の画像処理装置において、前記データ一時記憶装置は、前記ホスト処理装置がデータを読み出すリード専用領域と、前記ホスト処理装置がコマンドを書込むライト専用領域と、を具備することを特徴とする。
【0025】
請求項5の発明に係る画像処理装置は、請求項1請求項4のいずれか1つに記載の画像処理装置において、前記データ一時記憶領装置がFIFO(First In First Out)で構成されていることを特徴とする。
【0026】
請求項6の発明に係る画像処理装置は、請求項1請求項5のいずれか1つに記載の画像処理装置において、前記画像処理装置の前記画像処理ユニットと前記データ一時記憶装置との間に接続されている画像検査ユニットと、をさらに具備し、前記画像検査ユニットが、
前記画像処理ユニットから受ける画像データを検査して検査結果を前記データ一時記憶装置を介して前記ホスト処理装置に与えることを特徴とする。
【発明の効果】
【0027】
本発明によれば、データ一時記憶装置を具備するため画像処理ユニットよりホスト処理装置のほうがデータの処理速度が遅くてもデータ一時記憶装置がデータの処理速度を調整することができるから、画像処理ユニットから送られてくるデータ等の情報の取りこぼしを防止することができる。また、本発明によれば、データ一時記憶装置を具備するため画像処理ユニットよりホスト処理装置のほうがデータの処理速度が遅くてもデータ一時記憶装置がデータの処理速度を調整することができるから、画像データサイズ、画像データ数及び処理方法(処理アルゴリズム)などにより、処理負荷が多様な画像処理装置において、処理の負荷に応じてハードウエアを新規に開発することなく、画像処理をフレキシブルに実現することできる。
【発明を実施するための最良の形態】
【0028】
次に、本発明の実施の形態について。図面を参照して詳細に説明する。
(実施の形態1)
図1は、本発明の実施の形態1に係る画像処理装置を示すブロック図である。図2は、本発明の実施の形態1に係る画像処理装置の画像処理ユニットを示すブロック図である。図3は、本発明の実施の形態1に係る画像処理装置のデータ一時記憶装置を示すブロック図である。
【0029】
図1に示すように、本発明の実施の形態1に係る画像処理装置は、複数の画像処理ユニット1、データ一時記憶装置2及びホスト処理装置3を具備している。データ一時記憶装置2は、インタフェース基板4と、このインタフェース基板4に搭載されている複数の一時記憶領域5と、を具備している。複数の画像処理ユニット1の外部入出力端子6は、複数の一時記憶領域5にシリアルインタフェース7によって接続されている。複数の画像処理ユニット1の入力端子には、センサ(例えば、カメラなどの撮像装置)8が接続されている。インタフェース基板4は、ホスト処理装置3にバスコネクタ(PCIバス)9などによって接続されている。なお、本発明の実施の形態1に係る画像処理装置は、1つの画像処理ユニット1を具備する構成であってもよい。
【0030】
画像処理ユニット1は、センサ8からの画像データを受けて所定の画像データの処理を行う。データ一時記憶装置2は、画像処理ユニット1から出力されるデータを一時的に記憶してホスト処理装置3に与える。
【0031】
図2に示すように、画像処理ユニット1は、複数のセル基板11を具備している。各画像処理ユニット1は、センサ8から画像データを受けて処理して結果出力まで一連の画像処理を行うことができる。各画像処理ユニット1のハードウェアは実質的に同じ構成である。セル基板11に搭載されているペリフェラルの構成及びソフトウェアロジックは、当該画像処理ユニット1で実施すべき処理内容によって異なる構成にすることも可能である。
なお、画像処理ユニット1は、1つのセル基板11を具備する構成であってもよい。
【0032】
セル基板11は、配線基板の上にマイクロプロセッサ、ロジックアレイ、メモリ装置及びこれらを接続する接続手段と外部信号入出力のための少なくとも1つの外部接続端子とを有し、前記マイクロプロセッサ及び前記ロジックアレイに組み込まれるソフトウェアによりデータの処理内容が決定される。
【0033】
また、画像処理ユニット1は、セル基板11の外部接続端子と他のセル基板11の外部接続端子とを接続手段により接続して、複数のセル基板11を所定の配置で接続することにより、画像処理ユニット1で実施すべきデータの処理内容を実行する。
【0034】
次に、セル基板11について、より具体的に説明する。セル基板11は、画像処理ユニット1を構成するハードウェアの基本単位である。セル基板11は、主にロジックアレイ12、CPU13、メモリ装置14及びペリフェラルデバイス17などを搭載している。また、セル基板11は、外部との信号のやり取りをするための接合手15及び全体制御信号用コネクタ18を具備している。ロジックアレイ12は、CPU13及びペリフェラルデバイス17とローカルバス16により接続されている。また、ロジックアレイ12は、接合手15とシリアルインターフェース19により接続されている。また、ロジックアレイ12は、メモリ装置14とメモリインターフェース20により接続されている。ロジックアレイ12は、全体制御信号用コネクタ18と全体制御インターフェイス21により接続されている。
【0035】
セル基板11においては、搭載するロジックアレイ12の容量やデータ入出力経路及び搭載するCPU13、メモリ装置14及びペリフェラルデバイス17の数や容量などを決定するだけでよい。実装させたい処理手順は、当該画像処理方式に応じたソフトウェアとしてロジックアレイ12に実装していく。このようにセル基板11は、ハードウェア単体としては使用目的を持たせないことを特徴としており、換言すれば、ハードウェアと使用目的の依存関係を切り離すことを特徴としている。以上で説明したようなセル基板11のロジックアレイ12に各種の処理ソフトウェアを書き込むことにより、セル基板11の形状及び形態は同一で構成されていても、処理内容が異なるセル基板11を得ることができる。
【0036】
なお、各セル基板11が受け持つ処理内容や処理ボリュームによっては、そのセル基板11が搭載するメモリ装置14及びペリフェラルデバイス17などの種類及び数が異なることもあり得る。その場合は、メモリ装置14及びペリフェラルデバイス17の抜き差しが可能なコネクタをセル基板11の上に準備しておき、各セル基板11が受け持つ処理内容及び処理ボリュームが決まった時点で、実際に使用するメモリ装置14及びペリフェラルデバイス17などを実装してもよい。
【0037】
接合手15は、他のセル基板11などと画像データ及び画像情報をやり取りするためのチャンネルで、省スペース実装が可能で、かつ、高速伝送が可能なシリアルインタフェースのほうが望ましい。接続手段15としては、特にシリアルインタフェースを限定するものではないが、インフィニバンドなどの小振幅差動信号インタフェースなどが一例として挙げられる。これらは、高速伝送(数百MHz以上)の場合はピアツーピアを基本とするが、低速伝送の場合はマルチドロップも可能である。
【0038】
接合手15のチャンネル数は特に限定する必要はないが、実用性、コスト性でバランスが取れているのは、3〜5チャンネル程度と考えられる。各チャンネルは独立して動作する。なお、昨今のシリアルインタフェースでは、チャネル数を増やして伝送帯域を稼ぐ手法が多用されているが、本発明の実施の形態1では、前記レーン数を特に規定する必要はない。この部分をパラレルバスとして、固定的に回路基板上にパターン化するのが従来技術である。
【0039】
画像処理ユニット1とデータ一時記憶装置2との接続手段(外部入出力端子6)としても、接合手15を用いる。画像処理ユニット11によってハードウェアで高速に処理された処理結果を掃きだすため、接合手15の通信速度も十分な高速性が求められる。例えば接合手15としてインフィニバンドやPCIエクスプレスを用いた場合、1チャネルあたり2.5BPSのデータ転送が可能である。
【0040】
このようなアーキテクチャを採ることにより、得られる効果は、下記(a)〜(d)のようなものである。
(a)複雑な処理内容を実現したい場合には、その各処理項目を実行するセル基板11をカスケード接続すればよい。
(b)所定の処理速度を得るためには、同じ処理を行うセル基板11の組を、必要に応じてパラレル接続すればよい。
(c)あるセル基板11に割り当てられる処理の負荷が軽い場合は、処理の前記ブロックを統合し、セル基板11の枚数を減らすことも可能である。
(d)画像処理ユニット1の開発途中で処理内容、処理順序、処理のボリューム、処理すべきデータ量などに変更が生じても、容易に対処することが可能になる。
【0041】
高速な画像処理ユニット1及び接合手15と比較して、ホスト処理装置(例えば、デスクトップPC)3のCPUのソフトウェア演算速度は遅い。そこで、画像処理ユニット1とホスト処理装置3の間にデータ一時記憶装置2が設けられている。データ一時記憶装置2は、高速に転送されてきたデータを一時的に記憶(バッファリング)する。データ一時記憶装置2は、画像処理ユニット1ごとに用意されており、各転送チャネルから転送されてきたデータを一時的に記憶(バッファリング)する。
【0042】
次に、データ一時記憶装置2について、詳細に説明する。図3に示すように、データ一時記憶装置2は、インタフェース基板4と、このインタフェース基板4に搭載されている複数の一時記憶領域5と、記憶装置制御部21と、を具備している。複数の一時記憶領域5の数は、画像処理ユニット1からの出力チャネルの数と同じである。複数の一時記憶領域5は、接合手22及び外部入出力端子23を介して画像処理ユニット1に接続されている。記憶装置制御部21は、接合手24、メモリバス25及び結合手26を介して複数の一時記憶領域5に接続されている。また、記憶装置制御部21は、バス27及びバスコネクタ28を介してホスト処理装置3に接続されている。
【0043】
データ一時記憶装置2は、ホスト処理装置3がデータを読み出すリード専用領域5Aと、ホスト処理装置3がコマンドを書込むライト専用領域5Bと、とを具備する。すなわち、一時記憶領域5は、リード専用領域5Aとライト専用領域5Bとに分割されている。
【0044】
データ一時記憶領装置2の一時記憶領域5は、FIFO(First In First Out)で構成されている。FIFOとは、ある場所に格納したデータを古くに格納した順番に取り出すようにするデータ構造である。リード専用領域5A及びライト専用領域5BがFIFOで構成されていることにより、書き込まれたデータ数、次に読み出すべきデータの番地(以下、リードポインタと呼ぶ)、次にデータを書き込むべきデータの番地(以下、ライトポインタと呼ぶ)の管理を容易に行うことができる。
【0045】
各画像処理ユニット1から出力される画像処理後のデータは、まずインタフェース基板4の上のリード専用領域5AのFIFOに格納される。リード専用領域5AのFIFOにデータが格納された後に、記憶装置制御部21はインタフェース基板4の上のレジスタにFIFOにデータが格納されたことを示すフラグを立てる。ホスト処理装置3は一定時間ごとに前記フラグを監視しており、前記フラグが立っていればFIFOに格納されているデータを全て読み出す。
【0046】
一方、ホスト処理装置3から画像処理ユニット1を制御するためのコマンドを発行する場合も、まずインタフェース基板4の上のライト専用領域5BのFIFOにコマンドが書き込まれる。このコマンドには送信先を示す情報が含まれている。メモリ装置制御部21は、送信先情報と一致する画像処理ユニット1のチャネルに対応したライト専用領域5BのFIFOにコマンドを書き込む。画像処理ユニット1は、一定時間ごとにライト専用領域5BのFIFOにデータが格納されていないかどうかの監視を行い、データが格納されていれば一度に全てのデータを読み出す。
【0047】
データ一時記憶装置2が十分な大きさの一時記憶領域5を備えていれば、画像処理ユニット1のハードウェアとホスト処理装置3のソフトウェアとの処理速度差を吸収し、データの取りこぼしを防ぐ効果がある。
【0048】
画像処理ユニット1からのデータがデータ量の大きな画像データである場合、画像データの全てを一度に送信せずに、複数回に分割して送信することが多い。例えばVGAサイズの画像データを1ライン毎のラインデータに分割して送信するなどである。ホスト処理ユニット1のソフトウェアは分割されて送信されてきたラインデータを再び画像データに構築しなおさなければならない。
【0049】
本発明の実施の形態1では、データ一時記憶装置2がFIFOで構成されているため、画像データの上からシーケンシャルにFIFOに書き込んでいけば、書き込み時と読み出し時でデータの順番が保障されている。そのため、ホスト処理装置3のソフトウェア上では分割されて送信されてきたラインデータを再び画像データに構築する処理が容易となる。
【0050】
(実施の形態2)
次に、本発明の実施の形態2について、図面を参照して詳細に説明する。図4は、本発明の実施の形態2に係る画像処理装置を示すブロック図である。図5は、本発明の実施の形態2に係る画像処理装置の画像検査ユニットを処理を説明するための図である。本発明の実施の形態2においては、本発明の実施の形態1と同じ構成要素には同じ参照符号を付してその説明を省略する。
【0051】
図4に示すように、本発明の実施の形態2に係る画像処理装置は、本発明の実施の形態1に係る画像処理装置において、画像処理ユニット1とデータ一時記憶装置2との間に接続されている画像検査ユニット31と、をさらに具備している。すなわち、本発明の実施の形態2に係る画像処理装置は、複数の画像処理ユニット1、画像検査ユニット31、データ一時記憶装置2及びホスト処理装置3を具備している。画像検査ユニット31は、画像処理ユニット1から受けるデータを検査して検査結果をデータ一時記憶装置2を介してホスト処理装置3に与える。
【0052】
次に、本発明の実施の形態2に係る画像検査ユニット31について、図5を参照して詳細に説明する。
まず、図5に示す処理フローは、パターン検査の場合についてのものである。図5において41〜46は画像検査ユニット31が行う各種処理である。画像検査ユニット31は、画像処理ユニット1からのデータに対して各種処理41〜46を行い、検査結果の出力先であるホスト処理装置3にデータ一時記憶装置2を介して与える。パターン検査では、図5に示すように、代表的な検出手法であるテンプレートマッチング43と特徴抽出44を併用することが多い。
【0053】
テンプレートマッチング43は、テンプレート画像と検査画像の位置合わせ(画像サーチX、Y、θの3軸方向に対して位置を補正する)した後にマッチングを行うことが多い。テンプレート画像は、元画像をそのまま使用せず、マスク処理やモフォロジ処理を施す場合もある。位置合わせすべき軸数により大幅に処理のボリュームが変わるが、一般にマッチング処理より位置合わせ処理の方が処理のボリュームが大きくなることが多い。
【0054】
特徴抽出44は、端点、交点、独立点、直線、曲線などの特徴を抽出し、所定の特徴ルール則と比較する場合が多いが、その検出方法により処理のボリュームが大幅に変わるという傾向がある。上記二つの検出手法は共に、回路基板を製作する以前に決定しておくべき処理である。
【0055】
画像入力41、前処理42は、比較的ハードウエアで具現する処理が多く、ソフトウエアが介在する比率が少ない。従って定型的な処理が多くなり、処理のボリュームも予測がつけやすい。
【0056】
欠陥判定45は、テンプレートマッチング43と特徴抽出44から得られた結果から、欠陥判定(正常/異常の2値情報にする)することになるが、この部分も定型的な処理が多く、処理のボリュームも予測がつきやすい。
【0057】
処理欠陥集計46は、欠陥判定25の結果から欠陥の位置、サイズ、面積、重心などを求める処理(ラベリング処理)になるが、この部分も定型的な処理が多く、処理のボリュームは大きいものの予測がつけやすい。
【0058】
本発明の実施の形態2は、セル基板11を組み合わせて、図9の処理を実現したものが、図5の処理になる。セル基板11は、図2に示したように、同一構造のセル基板11の上で、各種の異なる処理を実現することができるという機能を持つ。
【0059】
そのため、テンプレートマッチングと特徴抽出のように、処理のボリュームが変動しやすい部分については、処理のボリューム応じたセル基板11の構成が取れる。またセル基板11の間は、各セル基板11の接合手15をコネクタで自由に接続することができるので、処理順序に沿って、所定の処理を行うセル基板11を接続していくことが可能である。
【0060】
上記接続された経路を介して、画像データ及び付随する画像情報がやり取りされる。ただし、下流(後工程)の接続経路は、より情報圧縮された画像データのやり取りになる場合もある。
【0061】
例えば、画像サーチとその補正をX、Y、θの3軸方向に対して実行する場合は、その処理のボリュームが非常に大きくなるため、テンプレートマッチング処理は、画像サーチ/補正43とテンプレートマッチング44という2つのセル基板11に分割して直列に接続する。ここでの各セル基板11の役割は、画像サーチ/補正43ではテンプレートに対してX、Y、θの3軸方向の位置合わせ済みの画像データを出力し、テンプレートマッチング44では該画像データとテンプレート画像データと比較(相関)を行う。
【0062】
画像サーチとその補正がX、Yの2軸方向だけでよい場合は、その処理ボリュームは大きく低減されるため、テンプレートマッチング処理を複数のセル基板11とする必要はなく、一枚のセル基板11で実装すればよい。なお、図5では、セル基板11を直列に接続した場合を示したが、パラレル接続することも可能である。セル基板11の間の接続形態は任意であり、処理方法により決定される。
【0063】
処理内容は全く異なるが、特徴抽出45も、テンプレートマッチング処理23に対する実装方法と考え方は同じである。すなわち、特徴抽出45の処理のボリュームに応じてセル基板11の枚数とその接続を決定すればよい。
【0064】
逆に画像入力41と前処理42の処理のボリュームが少ない場合は、2枚のボードに分割する必要はなく、1枚のセル基板11の上に実装すればよい。欠陥判定46や欠陥集計47についても同様である。このことは、無駄なハードウエアの節約となり、コストダウンにもつながる。
【0065】
このように、従来方法では不可能であった画像検査処理に対するハードウエアの最適化をセル基板11のトポロジ(ボード枚数とその接続形態)により実現している。この効果は、画像検査処理が複雑化、又は、高速化すればするほど顕著になっていく。
【0066】
(実施の形態3)
次に、本発明の実施の形態3について、図面を参照して詳細に説明する。図6は、本発明の実施の形態3に係る画像処理装置を示すブロック図である。図7は、本発明の実施の形態3に係る画像処理装置の画像検査ユニットを処理を説明するための図である。本発明の実施の形態3においては、本発明の実施の形態1と同じ構成要素には同じ参照符号を付してその説明を省略する。
【0067】
図6に示すように、本発明の実施の形態3に係る画像処理装置は、本発明の実施の形態1に係る画像処理装置において、画像処理ユニット1とデータ一時記憶装置2との間に接続されている画像検査ユニット32をさらに具備している。すなわち、本発明の実施の形態3に係る画像処理装置は、複数の画像処理ユニット1、画像検査ユニット32、データ一時記憶装置2及びホスト処理装置3を具備している。画像検査ユニット32は、画像処理ユニットから受けるデータを検査して検査結果をデータ一時記憶装置2を介してホスト処理装置3に与える。
【0068】
次に、本発明の実施の形態3に係る画像検査ユニットについて、図7を参照して詳細に説明する。
図7において51〜56は画像検査ユニット32が行う各種処理である。画像検査ユニット32は、画像処理ユニット1からのデータに対して各種処理51〜56を行い、検査結果の出力先であるホスト処理装置3にデータ一時記憶装置2を介して与える。
【0069】
図7に示す処理は、ウェブ検査の場合のものであるが、図5のパターン検査の場合と異なる部分についてのみ説明する。ウェブ検査は比較的検査手法は単純であるが、全面を連続検査する必要があるため、パターン検査より高速性が要求される場合が多い。高速性を満たすため、図5の処理フローにおける前処理42および欠陥判定46の部分を、2並列で検査処理を行う場合の例を示したものである。
【0070】
従来方法では、回路基板が有している処理能力は設計段階で決定されるため、後から並列化したくなることがあってもできないことが多い。逆にあらかじめ並列化していたが高速性が要求されず並列化が不必要となった場合は、冗長度が大きく割高ということになることが多い。しかし、本発明におけるボード構成では、並列にするかどうかを自由に選択できることにより、必要な処理速度に応じたハードウエア構成をとることができる。
【0071】
従来技術では、セル基板が有している処理能力は設計段階で決定されるため、後から並列化したくなることがあってもできないことが多い。逆にあらかじめ並列化していたが高速性が要求されず並列化が不必要となった場合は、冗長度が大きく割高ということになることが多い。しかし、本発明の実施の形態では、並列にするかどうかを自由に選択できることにより、必要な処理速度に応じたハードウェア構成をとることができる。
【0072】
また、本発明の実施の形態においては、ターゲットに合わせたハードウェア開発をせず、図2に示すようなメモリ装置/CPU/ロジックアレイ/データ入出力チャンネルを有するセル型のハードウェア構造(セル基板11)を基本単位とする。セル基板11を複数枚組み合わせることにより、ターゲットに適したハードウェアを構築することが可能である。ハードウェアによって演算された画像処理結果をホスト処理装置3に送信する場合、従来はハードウェアとソフトウェアの処理速度差が問題となるが、本発明の実施の形態ではハードウェアとホスト処理装置3との間にFIFOメモリ装置によるバッファリングを行うことで上記処理速度の差を吸収した。
【0073】
本発明の実施の形態においては、液晶パネル基板の生産ライン等における画像処理ユニット1において、所定の画像処理の演算をハードウェア上で高速に行い、その処理結果を取りこぼさずにホスト処理装置3に送信することが可能になる。
【図面の簡単な説明】
【0074】
【図1】本発明の実施の形態1に係る画像処理装置を示すブロック図である。
【図2】本発明の実施の形態1に係る画像処理装置の画像処理ユニットを示すブロック図である。
【図3】本発明の実施の形態1に係る画像処理装置のデータ一時記憶装置を示すブロック図である。
【図4】本発明の実施の形態2に係る画像処理装置を示すブロック図である。
【図5】本発明の実施の形態2に係る画像処理装置の画像検査ユニットを処理を説明するための図である。
【図6】本発明の実施の形態3に係る画像処理装置を示すブロック図である。
【図7】本発明の実施の形態3に係る画像処理装置の画像検査ユニットを処理を説明するための図である。
【図8】従来の画像処理装置の1例を示すブロック図である。
【図9】図8の従来の画像処理装置の処理を説明するための図である。
【図10】従来の画像処理装置の他の例を示すブロック図である。
【符号の説明】
【0075】
1 画像処理ユニット
2 データ一時記憶装置
3 ホスト処理装置
4 インタフェース基板
5 一時記憶領域
11 セル基板
12 ジックアレイ
13 CPU
14 メモリ装置
17 ペリフェラルデバイス
21 記憶装置制御部
5A リード専用領域
5B ライト専用領域
【特許請求の範囲】
【請求項1】
所定の画像データの処理を行うための少なくとも1つの画像処理ユニットと、
前記画像処理ユニットから出力されるデータを一時的に記憶するデータ一時記憶装置と、
前記画像処理ユニットから出力されるデータを前記データ一時記憶装置を介して受けるホスト処理装置と、を具備することを特徴とする画像処理装置。
【請求項2】
前記画像処理ユニットは、
配線基板の上にマイクロプロセッサ、ロジックアレイ、メモリ装置及びこれらを接続する接続手段と外部信号入出力のための少なくとも1つの外部接続端子とを有し、前記マイクロプロセッサ及び前記ロジックアレイに組み込まれるソフトウェアによりデータの処理内容が決定される少なくとも1つのセル基板を具備し、
前記セル基板の外部接続端子と前記他のセル基板の外部接続端子とを接続手段により接続して、前記複数のセル基板を所定の配置で接続することにより、前記画像処理ユニットで実施すべきデータの処理内容を実行することを特徴とする請求項1に記載の画像処理装置。
【請求項3】
前記セル基板を構成する配線板は、同一形状のものであることを特徴とする請求項1及び請求項2のいずれか1つに記載の画像処理装置。
【請求項4】
前記データ一時記憶装置は、前記ホスト処理装置がデータを読み出すリード専用領域と、前記ホスト処理装置がコマンドを書込むライト専用領域と、を具備することを特徴とする請求項1及び請求項3のいずれか1つに記載の画像処理装置。
【請求項5】
前記データ一時記憶領装置は、FIFO(First In First Out)で構成されていることを特徴とする請求項1請求項4のいずれか1つに記載の画像処理装置。
【請求項6】
前記画像処理装置の前記画像処理ユニットと前記データ一時記憶装置との間に接続されている画像検査ユニットと、をさらに具備し、
前記画像検査ユニットは、
前記画像処理ユニットから受けるデータを検査して検査結果を前記データ一時記憶装置を介して前記ホスト処理装置に与えることを特徴とする請求項1請求項5のいずれか1つに記載の画像処理装置。
【請求項1】
所定の画像データの処理を行うための少なくとも1つの画像処理ユニットと、
前記画像処理ユニットから出力されるデータを一時的に記憶するデータ一時記憶装置と、
前記画像処理ユニットから出力されるデータを前記データ一時記憶装置を介して受けるホスト処理装置と、を具備することを特徴とする画像処理装置。
【請求項2】
前記画像処理ユニットは、
配線基板の上にマイクロプロセッサ、ロジックアレイ、メモリ装置及びこれらを接続する接続手段と外部信号入出力のための少なくとも1つの外部接続端子とを有し、前記マイクロプロセッサ及び前記ロジックアレイに組み込まれるソフトウェアによりデータの処理内容が決定される少なくとも1つのセル基板を具備し、
前記セル基板の外部接続端子と前記他のセル基板の外部接続端子とを接続手段により接続して、前記複数のセル基板を所定の配置で接続することにより、前記画像処理ユニットで実施すべきデータの処理内容を実行することを特徴とする請求項1に記載の画像処理装置。
【請求項3】
前記セル基板を構成する配線板は、同一形状のものであることを特徴とする請求項1及び請求項2のいずれか1つに記載の画像処理装置。
【請求項4】
前記データ一時記憶装置は、前記ホスト処理装置がデータを読み出すリード専用領域と、前記ホスト処理装置がコマンドを書込むライト専用領域と、を具備することを特徴とする請求項1及び請求項3のいずれか1つに記載の画像処理装置。
【請求項5】
前記データ一時記憶領装置は、FIFO(First In First Out)で構成されていることを特徴とする請求項1請求項4のいずれか1つに記載の画像処理装置。
【請求項6】
前記画像処理装置の前記画像処理ユニットと前記データ一時記憶装置との間に接続されている画像検査ユニットと、をさらに具備し、
前記画像検査ユニットは、
前記画像処理ユニットから受けるデータを検査して検査結果を前記データ一時記憶装置を介して前記ホスト処理装置に与えることを特徴とする請求項1請求項5のいずれか1つに記載の画像処理装置。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【公開番号】特開2010−79708(P2010−79708A)
【公開日】平成22年4月8日(2010.4.8)
【国際特許分類】
【出願番号】特願2008−248754(P2008−248754)
【出願日】平成20年9月26日(2008.9.26)
【出願人】(000003193)凸版印刷株式会社 (10,630)
【Fターム(参考)】
【公開日】平成22年4月8日(2010.4.8)
【国際特許分類】
【出願日】平成20年9月26日(2008.9.26)
【出願人】(000003193)凸版印刷株式会社 (10,630)
【Fターム(参考)】
[ Back to top ]