
発症確率算出装置、および、プログラム
【課題】 疾患等の発症予測をより正確におこなう。
【解決手段】
記憶部160には、複数人の医療データがコホートデータとして蓄積されている。データ分類部111は、指定された疾患についてのコホートデータを記憶部160から取得し、体質タイプ別に分類する。発症確率算出部114が、指定された疾患の発症確率を体質タイプ別に算出するとともに、特徴量算出部112が、体質タイプ毎の特徴量を算出する。発症確率算出部114は、指定された被評価者についてのコホートデータを記憶部160から取得し、各体質タイプの特徴量との類似度を算出する。発症確率算出部114は、体質タイプ別に算出した発症確率を、算出した類似度で重み付けすることで、被評価者についての発症確率を算出し、出力制御部140を介して出力する。
【解決手段】
記憶部160には、複数人の医療データがコホートデータとして蓄積されている。データ分類部111は、指定された疾患についてのコホートデータを記憶部160から取得し、体質タイプ別に分類する。発症確率算出部114が、指定された疾患の発症確率を体質タイプ別に算出するとともに、特徴量算出部112が、体質タイプ毎の特徴量を算出する。発症確率算出部114は、指定された被評価者についてのコホートデータを記憶部160から取得し、各体質タイプの特徴量との類似度を算出する。発症確率算出部114は、体質タイプ別に算出した発症確率を、算出した類似度で重み付けすることで、被評価者についての発症確率を算出し、出力制御部140を介して出力する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、発症確率算出装置、および、プログラムに関し、特に、疾患の発症予測に好適な発症確率算出装置、および、プログラムに関する。
【背景技術】
【0002】
近時の疫学の進展により、種々の疾患(疾病)が発症する際の因果関係などが解明されており、疾患の予防や健康増進のために活用されている。一方で、医療機関などにおける情報化が進み、健康診断の結果や被験者のカルテ情報などが電子的に蓄積・管理され、各個人の健康管理等に用いられている。
【0003】
こうした情報をデータベース化し、情報処理装置によって処理することで、個人の健康状態を指標化し、健康度を評価する手法が提案されている(例えば、特許文献1)。
【0004】
このような手法において、被評価者の健康診断データ(健診データ)を用いて疾患の発症予測をおこなう場合、健診データを指標化した値(健康度)について、健常者の健康標準モデルと非健常者(擬似被験者)の疾患モデルとを比較解析し、その類似度によって将来の健康度を予測している。
【0005】
ここで、疾患によっては、発症の因果関係として体質が深く影響する場合も多い。例えば、糖尿病において、コレステロールがいくら高くても発症しないが血圧が高くなると発症しやすい体質や、逆に、血圧がいくら高くても発症しないがコレステロールが高くなると発症しやすい体質などがあることが知られている。このような、体質が発症に影響を与える疾患については、単に健常者の健康標準モデルと非健常者の疾患モデルとを比較解析しただけでは、正確な発症予測をおこなうことができない。すなわち、従来の手法では、疾患の発症予測などを正確におこなうことができなかった。
【特許文献1】特開2002−63278号公報
【発明の開示】
【発明が解決しようとする課題】
【0006】
本発明は上記実状に鑑みてなされたもので、疾患の発症予測をより正確におこなうことができる発症確率算出装置、および、プログラムを提供することを目的とする。
【課題を解決するための手段】
【0007】
上記目的を達成するため、本発明の第1の観点にかかる発症確率算出装置は、
所定の医療データをコホートデータとして取得して蓄積するコホートデータ蓄積手段と、
前記コホートデータ蓄積手段が取得したコホートデータを、疾患毎の所定のタイプ別に分類するデータ分類手段と、
指定された被評価者に関するコホートデータを前記コホートデータ蓄積手段から取得し、指定された疾患に関するコホートデータを前記データ分類手段による分類に応じて前記コホートデータ蓄積手段から取得する対象データ取得手段と、
前記指定された疾患の発症確率を分類毎に算出し、前記対象データ取得手段が取得したコホートデータに基づいて重み付けして演算することで、被評価者の発症確率を算出する発症確率算出手段と、
前記発症確率算出手段による算出結果を示す情報を出力する出力手段と、を備える、
ことを特徴とする。
【0008】
上記発症確率算出装置において、
前記データ分類手段は、コホートデータを疾患毎の体質タイプ別に分類し、
前記発症確率算出手段は、
前記指定された疾患に関するコホートデータに基づいて、前記データ分類手段が分類した該疾患についての体質タイプ別の特徴量を算出する特徴量算出手段と、
前記特徴量算出手段が算出した特徴量と、前記被評価者に関するコホートデータとの類似度を算出する類似度算出手段と、をさらに備えていることが望ましく、この場合、
前記類似度算出手段が算出した類似度を重み付け係数として重み付けすることが望ましい。
【0009】
上記発症確率算出装置は、
所定の疾患を示す情報と対象となるデータ項目を示す情報とを対応付けた疾患情報を予め記憶する疾患情報記憶手段をさらに備えていることが望ましく、この場合、
前記対象データ取得手段は、前記疾患情報記憶手段が記憶する疾患情報に基づいて、前記コホートデータから対象となるデータ項目を抽出することが望ましい。
【0010】
上記目的を達成するため、本発明の第2の観点にかかるプログラムは、
コンピュータに、
所定の医療データをコホートデータとして取得して蓄積する機能と、
指定された疾患を示す情報に基づいて、蓄積されているコホートデータから該疾患に関するコホートデータを取得する機能と、
指定された疾患のコホートデータを体質タイプ別に分類し、体質タイプ別の発症確率を算出する機能と、
指定された被評価者を示す情報に基づいて、蓄積されているコホートデータから、該被評価者に関するコホートデータを取得する機能と、
前記指定された疾患の体質タイプ別の特徴量を算出し、前記取得した被評価者に関するコホートデータとの類似度を算出する機能と、
前記算出した体質タイプ別の発症確率を、前記算出した類似度で重み付けすることで前記被評価者の発症確率として算出する機能と、
算出した前記被評価者の発症確率を示す情報を出力する機能と、
を実現させることを特徴とする。
【発明の効果】
【0011】
本発明によれば、予測対象として指定された疾患についてのコホートデータを、例えば、体質タイプに応じて分類し、各体質タイプ毎の発症確率を算出するとともに、各体質タイプ毎の特徴量を算出する。そして、指定された被評価者についてのコホートデータと、各体質タイプの特徴量との類似度を算出し、算出した類似度で各体質タイプ毎に算出した発症確率を重み付けすることで、被評価者が当該疾患を発症する確率を算出ので、体質を考慮した発症予測をおこなうことができる。この結果、体質が発症に影響する疾患についても、正確な発症予測をおこなうことができる。
【発明を実施するための最良の形態】
【0012】
本発明にかかる実施の形態を、以下図面を参照して説明する。
【0013】
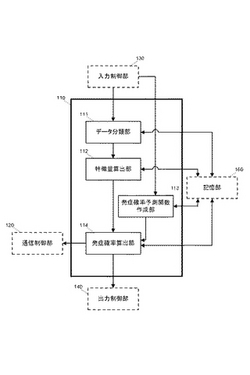
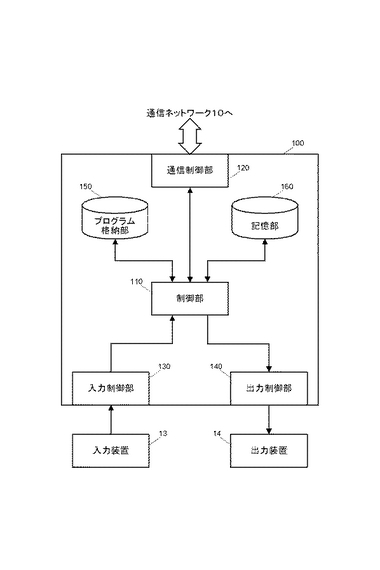
図1は、本実施の形態にかかる医療情報処理装置100の構成を模式的に示す図である。本実施の形態にかかる医療情報処理装置100は、例えば、医療機関などで運用されるワークステーションやパーソナルコンピュータなどといった情報処理装置から構成され、疾患や患者等についての種々情報を出力する。本実施形態では、特に、所定の疾患についての発症確率を算出して出力する発症確率算出装置として機能する。このような医療情報処理装置100の構成を図1を参照して説明する。図1は、医療情報処理装置100の構成を示すブロック図である。
【0014】
図示するように、本実施形態にかかる医療情報処理装置100は、制御部110、通信制御部120、入力制御部130、出力制御部140、プログラム格納部150、記憶部160、などから構成されている。
【0015】
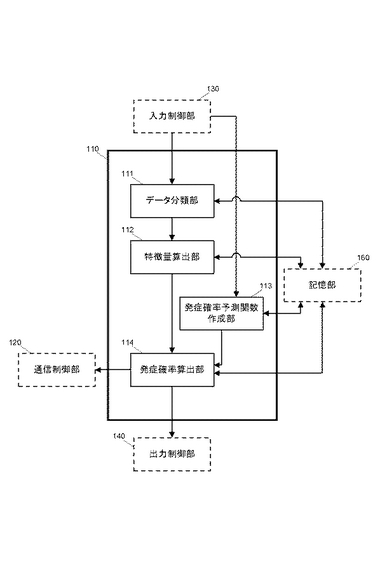
制御部110は、例えば、CPU(Central Processing Unit:中央演算処理装置)などから構成され、医療情報処理装置100の各部を制御するとともに、プログラム格納部150に格納されているプログラムの実行により、通信制御部120、入力制御部130、出力制御部140、記憶部160と協働して、後述する各処理を実現する。
【0016】
より詳細には、プログラム格納部150に格納されているプログラムを実行することで、制御部110は、図2に示す各構成として機能する。すなわち、制御部110は、プログラムの実行により、データ分類部111、特徴量算出部112、発症確率予測関数作成部113、発症確率算出部114、として機能する。
【0017】
データ分類部111は、記憶部160のデータベースに蓄積されるコホートデータ(詳細後述)に基づいて、各疾患を所定のタイプに応じて分類する。本実施形態では、コホートデータを体質タイプに応じた複数の体質タイプ群に分類する。
【0018】
特徴量算出部112は、データ分類部111により分類された体質タイプ群毎の特徴量を算出する。
【0019】
発症確率予測関数作成部113は、疾患毎の発症確率を算出するための発症確率予測関数を、データ分類部111が分類した体質タイプ群毎に作成する。
【0020】
発症確率算出部114は、指定された発症予測対象となる疾患および被評価者についてのコホートデータを記憶部160から取得し、当該対象疾患について特徴量算出部112が算出した特徴量、発症確率予測関数作成部113が作成した発症確率予測関数、および、取得したコホートデータを用いて、指定された疾患の発症確率を被評価者の体質に応じて算出する。
【0021】
本実施形態では、制御部110がプログラムを実行することで、ソフトウェア処理により上記各構成として機能するものとするが、これらの構成を、例えば、ASIC(Application Specific Integrated Circuit:特定用途向け集積回路)などで構成し、ハードウェア処理により実現してもよい。
【0022】
通信制御部120は、例えば、NIC(Network Interface Card)やモデムなどといった通信装置から構成され、医療情報処理装置100と所定の通信ネットワーク10(不図示)とを接続して通信をおこなう。通信ネットワーク10は、例えば、LAN(Local Area Network:構内通信網)、もしくは、インターネットなどのWAN(Wide Area Network:広域通信網)などとすることができる。本実施形態では、通信制御部120によって、記憶部160のデータベースに蓄積するデータを、必要に応じて外部の装置から通信ネットワーク10を介して取得する。
【0023】
入力制御部130は、例えば、キーボードやポインティングデバイスなどの入力装置13を接続し、ユーザの操作に応じた入力信号を制御部110に入力する。
【0024】
出力制御部140は、例えば、ディスプレイやプリンタなどの出力装置14を接続し、制御部110の処理結果などを出力装置14に出力する。
【0025】
プログラム格納部150は、例えば、ハードディスク装置などの記憶装置から構成され、制御部110が実行するプログラムを格納する。プログラム格納部150には、制御部110を、上述したデータ分類部111、特徴量算出部112、発症確率予測関数作成部113、発症確率算出部114、として機能させるためのプログラムが格納される。また、制御部110が、通信制御部120、入力制御部130、出力制御部140、記憶部160を制御するためのプログラムも格納される。すなわち、制御部110がプログラム格納部150に格納されている各プログラムを実行することにより、医療情報処理装置100全体として後述する各処理が実現される。
【0026】
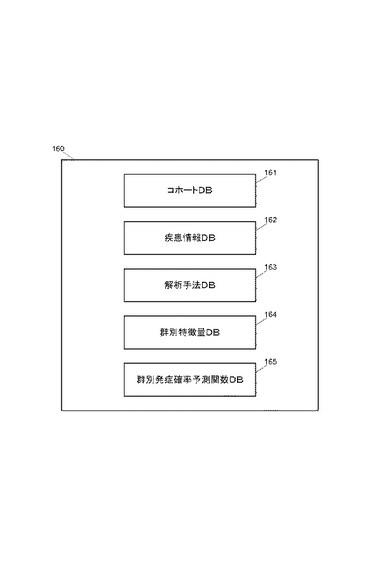
記憶部160は、例えば、ハードディスク装置などの記憶装置から構成され、本実施の形態にかかる各処理を実現するために必要な種々の情報が記録される。本実施の形態では、図3に示すようなデータベースが記憶部160に構成される。図示するように、記憶部160には、コホートDB161、疾患情報DB162、解析手法DB163、群別特徴量DB164、群別発症確率予測関数DB165、などのデータベースが構成される。各データベースについて以下説明する。
【0027】
コホートDB161は、医療情報処理装置100により疾患の発症予測を行う際に必要となる「コホートデータ」(母集団データ)を蓄積する。ここでは、所定の医療データがコホートデータとして蓄積される。本実施形態では、医療機関などにおいて、診察や治療、あるいは、健康診断などを受けた複数の者(以下、「被験者」とする)を対象とし、これらの被験者についての医療データをコホートデータとして蓄積するものとする。「医療データ」とは、例えば、種々の疾患(疾病)に関する情報の他、被験者の身体や健康状態に関する情報などである。被験者に関する医療データには、例えば、診察や治療、あるいは、健康診断などの結果を示す情報(健診データ)の他、被験者の体質や身体的特徴を示す情報(遺伝子タイプや血液型、身長・体重など)、その他年齢や性別などの属性情報などが含まれる。
【0028】
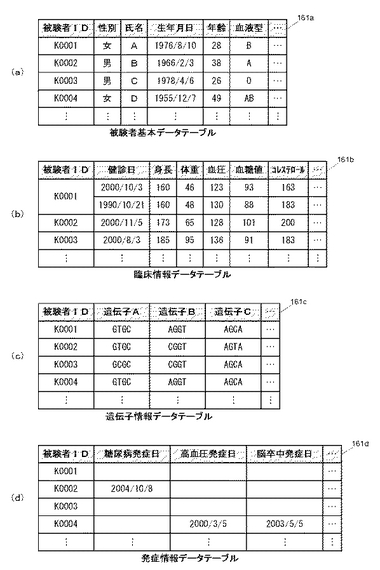
このようなコホートデータを管理するため、コホートDB161には、図4に示すように、被験者基本データテーブル161a、臨床情報データテーブル161b、遺伝子情報データテーブル161c、発症情報データテーブル161d、などのテーブルが作成され、各種コホートデータが記録される。
【0029】
被験者基本データテーブル161aに記録される情報の例を図4(a)に示す。図示するように、被験者基本データテーブル161aには、対象となる被験者毎に一意に割り当てられている被験者IDをキーとしたレコードが作成されており、各レコードには、例えば、当該被験者についての属性情報(例えば、性別、氏名、生年月日、年齢、血液型、など)が記録されている。すなわち、被験者基本データテーブル161aには、対象となる被験者についての基本情報が記録される。
【0030】
臨床情報データテーブル161bに記録される情報の例を図4(b)に示す。図示するように、臨床情報データテーブル161bには、被験者IDをキーとしたレコードが作成されており、各レコードには、例えば、当該被験者についての健康診断データ(以下、「健診データ」とする)などが記録される。健診データは、健診日毎の健診結果(例えば、身長、体重、血圧、血糖値、コレステロール、などの計測結果)を示すものである。すなわち、臨床情報データテーブル161bには、各被験者毎の複数回の健診結果によって示される、被験者毎の体質を示す情報が記録される。
【0031】
遺伝子情報データテーブル161cに記録される情報の例を図4(c)に示す。図示するように、遺伝子情報データテーブル161cには、被験者IDをキーとしたレコードが作成されており、各レコードには、当該被験者の遺伝子タイプを示す情報などが記録される。ここでは、例えば、個体毎に異なる体質に影響する遺伝子について記録されるものとする。すなわち、遺伝子情報データテーブル161cには、被験者毎の体質を示す情報が記録されることになる。
【0032】
発症情報データテーブル161dに記録される情報の例を図4(d)に示す。図示するように、発症情報データテーブル161dには、被験者IDをキーとしたレコードが作成されており、各レコードには、当該被験者について、所定の疾患(疾病)の発症履歴を示す情報などが記録される。ここでは、少なくとも、発症予測の対象となる疾患についての発症履歴が記録されるものとする。すなわち、所定の疾患の発症日などを示す情報が、発症した被験者の被験者IDに対応付けて記録される。この発症情報データテーブル161dに記録される情報は、例えば、各被験者についてのカルテ情報などに基づいて記録される。
【0033】
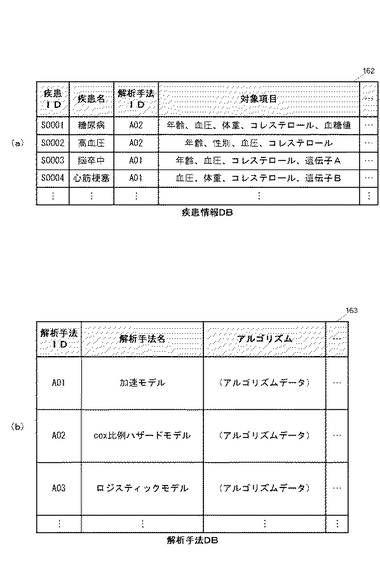
疾患情報DB162には、対象となる疾患(疾病)についての情報が記録される。疾患情報DB162に記録される情報の例を図5(a)に示す。図示するように、疾患情報DB162には、対象となる疾患毎に一意に付与されている疾患IDをキーとしたレコードが作成されており、各レコードには、当該IDに対応する疾患名を示す情報の他、当該疾患についての発症予測をおこなう際の解析手法を示す情報(解析手法ID)や、当該疾患についての発症予測をおこなう際に必要となるコホートデータの項目(対象項目)などが記録されている。「対象項目」とは、当該疾患の発症確率を算出する際に必要となるデータ項目を指定する情報である。ここで指定されるデータ項目とは、コホートDB161に記録される各コホートデータ中のデータ項目である。
【0034】
解析手法DB163には、疾患の発症予測をおこなうための発症確率算出に用いられる解析手法を示す情報が記録される。解析手法DB163に記録される情報の例を図5(b)に示す。図示するように、解析手法DB163には、各解析手法毎に一意に割り当てられている解析手法IDをキーとしたレコードが作成されており、各レコードには、当該IDに対応する解析手法名を示す情報の他、当該解析手法のアルゴリズムデータなどが記録される。ここには、例えば、cox比例ハザードモデルやロジスティックモデルなどといった生存時間解析方法に基づくアルゴリズムデータなどが記録される。
【0035】
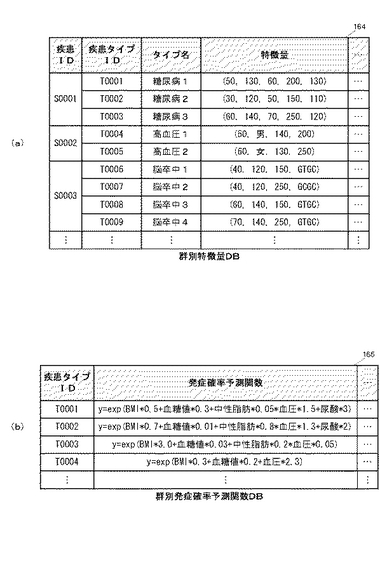
群別特徴量DB164には、特徴量算出部112が算出したタイプ群別の特徴量を示す情報が記録される。群別特徴量DB164に記録される情報の例を図6(a)に示す。図示するように、群別特徴量DB164には、疾患IDをキーとしたレコードが作成されており、各レコードには、当該疾患を体質タイプに応じて分類したタイプ毎に一意に割り当てられている疾患タイプIDや当該疾患タイプIDに対応する疾患タイプ名を示す情報の他、当該疾患タイプについて算出された特徴量を示す情報などが記録される。ここでの「特徴量」とは、例えば、当該疾患タイプに属するデータの対象項目毎の平均値を示す。
【0036】
群別発症確率予測関数DB165には、発症確率予測関数作成部113により作成された、疾患タイプ毎の発症確率予測関数が記録される。群別発症確率予測関数DB165に記録される情報の例を図6(b)に示す。図示するように、群別発症確率予測関数DB165には、疾患タイプIDをキーとしたレコードが作成されており、各レコードには、当該疾患タイプについて作成された発症確率予測関数が記録される。
【0037】
記憶部160には、以上のような各種データベースが構成されるが、これらのデータベースに記録される情報は、例えば、オペレータが入力装置13を操作することで入力される他、例えば、制御部110の制御により、通信ネットワーク10に接続されている他の装置等から取得して入力されてもよい。この場合、例えば、医療機関において患者情報を管理している装置など(例えば、電子カルテシステムなど)から各種情報を取得可能であることはもとより、例えば、診察や治療に用いられる医療用装置(診断装置や計測装置など)から測定結果等を示す情報を取得するようにしてもよい。あるいは、例えば、CD−ROMなどの記録媒体に記録されている情報を取得するようにしてもよい。この場合、記憶部160には、例えば、CD−ROMドライブなどの読取装置等が含まれるものとする。
【0038】
このようにして、医療情報処理装置100は、コホートデータを随時取得し、コホートDB161に蓄積する。例えば、医療活動(診察、診断、治療、健康診断など)において発生するデータを随時取得したり、夜間のバッチ処理などによって定期的に取得することでコホートデータが蓄積される。
【0039】
また、記憶部160は、上記データベースとして用いられる他、例えば、取得した情報や処理中の演算結果などを一時的に記憶しておく記憶領域としても用いられる。なお、プログラム格納部150および記憶部160を構成する記憶装置はハードディスク装置に限られず、例えば、RAM(Random Access Memory)、ROM(Read Only Memory)、EEPROM(Electrically Erasable Programmable ROM)などを含んでいてもよい。
【0040】
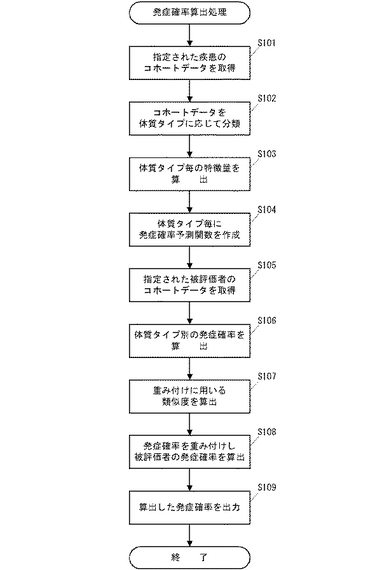
以上のように構成された医療情報処理装置100の動作を以下説明する。医療情報処理装置100は、被評価者が所定の疾患を発症する確率を算出して発症予測をおこなうための「発症確率算出処理」を実行する。この発症確率算出処理は、オペレータによる操作などにより処理開始が指示されたことを契機に開始される。
【0041】
図7に示すフローチャートを参照して発症確率算出処理における医療情報処理装置100の動作を説明する。ここでは、プログラム格納部150に格納されているプログラムを実行することにより、制御部110が、データ分類部111、特徴量算出部112、発症確率予測関数作成部113、発症確率算出部114として機能し、記憶部160に構成されている各データベースとの協働により処理が実行される。
【0042】
発症確率算出処理においては、被評価者が所定の疾患を発症する確率を予測するため、対象となる疾患および被評価者を特定する情報を入力して指定する。ここでは、例えば、オペレータなどが入力装置13を操作することにより、対象とする疾患を特定する情報(例えば、疾患名)、および、被評価者を特定する情報(例えば、被評価者の氏名)を医療情報処理装置100に入力して指定する。この場合、発症確率算出処理の開始に応じて、例えば、これらの情報を入力するための入力画面が出力装置14(ディスプレイ)に表示され、この入力画面から疾患名や被評価者氏名などを入力するものとする。
【0043】
疾患名が制御部110に入力されると、データ分類部111は、記憶部160に構成されている疾患情報DB162にアクセスし、指定された疾患名に対応する疾患IDを取得するとともに、コホートDB161から、指定された疾患名に対応するコホートデータを取得する(ステップS101)。
【0044】
ここでは、データ分類部111が発症情報データテーブル161dにアクセスし、対象とする疾患を発症した被験者(以下、「患者」とする)を特定する。例えば、入力された疾患名が「糖尿病」である場合、発症情報データテーブル161d内で糖尿病の発症履歴が記録されているレコードを特定し、当該レコードのキー項目となっている被験者IDを特定する。
【0045】
次にデータ分類部111は、被験者基本データテーブル161a、臨床情報データテーブル161b、遺伝子情報データテーブル161cにアクセスし、特定した被験者IDがキーとなっているレコードを各テーブル上で特定し、特定したレコードを抽出することでコホートデータを取得する。
【0046】
すなわち、入力された疾患を発症したことのある患者について、被験者基本データテーブル161aから基本情報が取得され、臨床情報データテーブル161bから健診データが取得され、遺伝子情報データテーブル161cから遺伝子情報が取得される。ここで、対象とする疾患の患者が複数人いる場合、当該疾患について、複数人の医療データが取得されることになる。すなわち、当該疾患の発症確率の算出に用いられるデータとしてコホートデータが取得される。
【0047】
データ分類部111は、取得したコホートデータのうち、疾患情報DB162に記録されている対象項目が示す項目のデータを抽出する。例えば、当該疾患についての対象項目が、「年齢」、「血圧」、「体重」、「コレステロール」、「血糖値」である場合には、年齢を示す情報を被験者基本データテーブル161aから抽出し、血圧、体重、コレステロール、血糖値を示す情報を臨床情報データテーブル161bから抽出する。すなわち、発症確率の算出において対象となるデータを、コホートDB161から選択的に取得する。
【0048】
ここで、例えば、ある患者が複数回の健診を受けている場合などには、対象項目のそれぞれについて複数のデータが臨床情報データテーブル161bに記録されていることがある。このような場合には、例えば、データ分類部111が各対象項目毎に平均値を算出するか、最新のデータを取得するものとする。
【0049】
次にデータ分類部111は、ステップS101で取得したコホートデータを体質タイプに応じた複数のタイプ群に分類する(ステップS102)。ここでは、取得したコホートデータを、例えば、体質タイプ別にn個の群G1,G2, . . . ,Gnに分類する。データ分類部111は、例えば、k-平均法(k-means method)などといったクラスタリング手法でクラスタ分析を実行することで、コホートデータを自動的に体質タイプ別に分類する。すなわち、コホートデータを構成する複数のデータ項目を多次元空間上にプロットし、ある一定の特徴を持つクラスタに収束させることで、コホートデータを分類する。
【0050】
ここでは、例えば、当該疾患を発症した者の体質タイプに応じて複数の群に分類する。例えば、糖尿病の場合、「血圧は高くなくてもコレステロールが高い」、「コレステロールは高くなくても血圧が高い」、「血圧、コレステロールのいずれも高い」、などといった体質タイプに分類する。
【0051】
データ分類部111は、このようにして、対象となる疾患を複数のタイプ群に分類すると、各分類毎に一意の疾患タイプIDを割り当て、群別特徴量DB164にレコードを作成する。
【0052】
データ分類部111は、対象とする疾患についてのデータが体質タイプ別に分類すると、ステップS101で取得したコホートデータを特徴量算出部112に提供する。特徴量算出部112は、データ分類部111から提供されたコホートデータを用いて、各体質タイプ毎の特徴量を算出する(ステップS103)。上述したように、「特徴量」とは、例えば、各タイプ群に属するデータの項目毎の平均値を示すものである。したがって、特徴量算出部112は、取得したコホートデータが示す数値の平均値を項目毎に算出する。
【0053】
例えば、対象としている疾患の対象項目が、年齢(項目1)、血圧(項目2)、体重(項目3)、コレステロール(項目4)、血糖値(項目5)の5項目であり、分類された体質タイプ群が、群1(G1)、群2(G2)、群3(G3)の3群であった場合、データ分類部111が各項目についてコホートDB161から取得したデータの項目毎の平均値を算出し、群別特徴量DB164に記録する。ここでは、対応するタイプ群のレコードに算出した特徴量を記録する。
【0054】
以下、本実施形態では、発症予測対象としている疾患を疾患TDとし、疾患TDについての対象項目が上記5項目、分類された体質タイプ群が上記3群である場合を例に説明することとする。
【0055】
対象となる疾患についてのコホートデータが体質タイプに応じて分類され、分類毎に特徴量が算出されると、発症確率予測関数作成部113が、各体質タイプ(群)毎に発症確率予測関数(群別発症確率予測関数)を作成し、群別発症確率予測関数DB165に記録する(ステップS104)。ここではまず、発症確率予測関数作成部113が疾患情報DB162にアクセスし、疾患TDに対応する解析手法を特定する。そして、解析手法DB163にアクセスし、特定した解析手法のアルゴリズムを取得し、当該アルゴリズムにしたがった演算をおこなうことで、疾患TDの各体質タイプ別(G1〜G3)に発症確率予測関数を作成する。
【0056】
ここでは、例えば、cox比例ハザードモデルやロジスティックモデルなどの生存時間解析方法を用いて、発症確率予測関数を体質タイプ別に作成する。発症確率予測関数作成部113は、各体質タイプを示す疾患タイプIDをキーとしたレコードを群別発症確率予測関数DB165に作成し、作成した発症確率予測関数を各レコードに記録する。
【0057】
このようにして、対象とする疾患について体質タイプ別の発症確率予測関数が作成されると、発症確率算出部114が、作成された発症確率予測関数を用いて、被評価者が当該疾患を発症する確率を算出するための処理を開始する。
【0058】
まず、発症確率算出部114は、被験者基本データテーブル161aにアクセスし、本処理の開始時に指定された被評価者の氏名に対応する被験者IDを特定する。そして、コホートDB161の各テーブルにおいて、当該被験者IDに対応するレコードを特定し、当該レコードに記録されている情報を、被評価者のコホートデータ(以下、「被評価者データ」とする)として取得する(ステップS105)。
【0059】
発症確率算出部114は、さらに、取得した被評価者データから、疾患TDの対象項目に対応するデータ(すなわち、年齢(項目1)、血圧(項目2)、体重(項目3)、コレステロール(項目4)、血糖値(項目5)、についてのデータ)を抽出する。すなわち、疾患情報DB162に記録されている対象項目が示す項目のデータを抽出することで、発症確率の算出において対象となるデータを、コホートDB161から選択的に取得する。
【0060】
ここで、ある対象項目について複数のデータが記録されている場合には、例えば、発症確率算出部114が各対象項目毎に平均値を算出するか最新のデータを取得することで、被評価者データとして取得する。
【0061】
被評価者データを取得すると、発症確率算出部114は、当該被評価者データと、疾患TDについての体質タイプ毎の特徴量とに基づき、被評価者が疾患TDを発症する確率を算出する。
【0062】
この場合、発症確率算出部114は、疾患TDについて体質タイプ別に算出される発症確率に、被評価者のコホートデータに基づく重み付けをおこなうことで、当該被評価者の体質に応じた発症確率を算出する。発症確率算出部114による発症確率の算出手法を以下説明する。
【0063】
まず、発症確率算出部114は、疾患TDについて、体質タイプ別の発症確率を算出する(ステップS106)。体質タイプ別の発症確率は、ステップS104で作成した群別発症確率予測関数を用いて算出される。ここでは、ステップS102での分類に応じて取得されたコホートデータを用いて、発症確率算出部114が群別発症確率予測関数を演算することで、体質タイプ別に疾患TDの発症確率を算出する。ここで、疾患TDについての体質タイプ群の番号をiとした場合、群別発症確率予測関数は、例えば、各項目のデータをxとした、数1に示すようなベクトル関数で表される。
【0064】
(数1)
Fi(x)=βi1xi1+βi2xi2+…+βinxin (nは対象項目数)
【0065】
このような群別発症確率予測関数を演算することで、疾患TDの発症確率が体質タイプ別に算出される。すなわち、群1についての発症確率は関数F1(x)で求められ、群2についての発症確率は関数F2(x)で求められ、群3についての発症確率は関数F3(x)で求められる。
【0066】
次に発症確率算出部114は、算出した体質タイプ別の発症確率を被評価者の体質に応じて重み付けするための重み付け係数を算出する。本実施形態では、重み付け係数をαとし、体質タイプ群別の重み付け係数は「αi」で表すものとする。本実施形態では、体質タイプ群がG1〜G3の3群であるため、αiは、α1、α2、α3のいずれかとなる。
【0067】
ここで、重み付け係数αは、例えば、被評価者データと、疾患TDについての体質タイプ群毎の特徴量(平均値)との「類似度」を算出することで求める。すなわち、発症確率算出部114は、疾患TDについてのコホートデータから算出した体質タイプ別の特徴量と、被評価者のコホートデータとの類似度を算出することで重み付け係数を算出する(ステップS107)。
【0068】
類似度の算出には、例えば、クラスタ分析における類似度の判定に用いられる「ユークリッド距離」を用いる。すなわち、k-平均法などのクラスタ分析により体質タイプ別に分類されたコホートデータのクラスタと、被評価者データとの多次元空間上での距離を求めることにより、被評価者データがどの体質タイプに近いかを示す類似度として算出する。ユークリッド距離を用いた類似度の算出方法の例を以下説明する。
【0069】
ここでは、対象項目の項目番号をjとし、各体質タイプ群に属するデータを「zij」、被評価者データ中の各対象項目のデータを「yj」で表すこととする。例えば、群1における項目1(年齢)のデータは「z11」、群3における項目5(血糖値)のデータは「z35」と表し、被評価者についての項目3(体重)のデータは「y3」と表す。
【0070】
そして、例えば、i番目の体質タイプ群における、被評価者データと当該体質タイプ群に属するデータとのユークリッド距離の逆数(以下、ユークリッド逆数Diとする)を用いて重み付け係数となる類似度を求める。この場合、発症確率算出部114が以下の数2を演算することによりユークリッド逆数Diを求める。なお、数2において、SQRD(a)は、aの平方根を示す。
【0071】
(数2)
Di=1/SQRD ((y1−zi1)2+(y2−zi2)2+…+(yn−zin)2 (nは対象項目数)
【0072】
このようにして求められたユークリッド逆数Diを用いて、各体質タイプ群別の重み付け係数αiを求める。この場合、発症確率算出部114が以下の数3を演算することより重み付け係数αiが求められる。
【0073】
(数3)
αi=Di/(D1+D2+…+Dm) (mはタイプ群数)
【0074】
そして、各体質タイプ群毎の発症確率はそれぞれ、F1(x)、F2(x)、F3(x)であるので、これらと被評価者について算出された体質タイプ群別の重み付け係数αとを乗じることで、当該被評価者が疾患TDを発症する確率(F(x))を算出する。ここでは、発症確率算出部114が以下の数4を演算することで、被評価者の発症確率を算出する。
【0075】
(数4)
F(x)=(α1×F1(x))+(α2×F2(x))+…+(αm×Fm(x)) (mはタイプ群数)
【0076】
すなわち、発症確率算出部114は、指定された疾患について算出された体質タイプ別の発症確率を、被評価者データと当該疾患についての体質タイプ別の特徴量との類似度で重み付けすることで、被評価者が疾患TDを発症する確率を算出する(ステップS108)。
【0077】
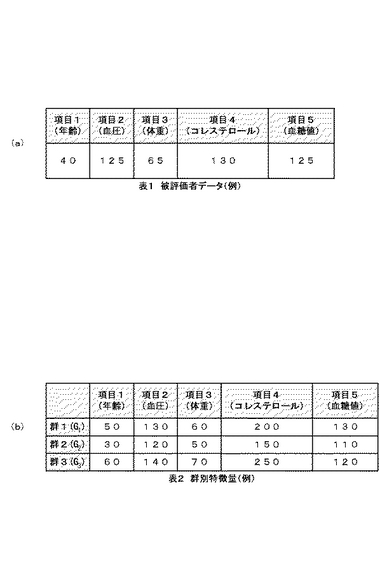
上記ステップS106〜S108における発症確率算出部114の動作、具体的な数値例を用いて以下説明する。ここでは、被評価者について取得したコホートデータ(被評価者データ)の例を図8(a)の表1に示し、予測対象となっている疾患についての群別の特徴量の例を図8(b)の表2に示す。
【0078】
発症確率算出部114は、重み付け係数αi(すなわち、α1、α2、α3)のそれぞれを算出するにあたり、各体質タイプ群に対応するユークリッド逆数Di(すなわち、D1、D2、D3)を算出する。
【0079】
ここで、図8(a)の表1示す被評価者データによれば、被評価者についての各対象項目のデータ(数値)は、「項目1(年齢):40」、「項目2(血圧):125」、「項目3(体重):65」、「項目4(コレステロール):130」、「項目5(血糖値):125」となる。
【0080】
一方、図8(b)の表2に示すように、群1(G1)の各対象項目のデータ(平均値)は、「項目1(年齢):50」、「項目2(血圧):130」、「項目3(体重):60」、「項目4(コレステロール):200」、「項目5(血糖値):130」となる。
【0081】
この場合、発症確率算出部114は、被評価者の各データをy1〜y5、群1の各データをz11〜z15として数2を演算することで、まず、群1についての被評価者とのユークリッド距離の逆数であるユークリッド逆数D1を算出する。この場合、上記各数値を数2に代入することにより、発症確率算出部114は、「D1=1/SQRT((40−50)2+(125−130)2+(65−60)2+(130−200)2+(125−130)2) (SQRT(a)はaの平方根を示す)」を演算する。この結果、群1における被評価者データとのユークリッド距離の逆数として「D1=0.014」が算出される。
【0082】
同様にして、発症確率算出部114は、群2および群3について、それぞれ被評価者データとのユークリッド距離の逆数を求める。ここでは、図8(b)の表2に示すように、群2(G2)のデータ(平均値)が、「項目1(年齢):30」、「項目2(血圧):120」、「項目3(体重):50」、「項目4(コレステロール):150」、「項目5(血糖値):110」であり、群3(G3)のデータ(平均値)が、「項目1(年齢):60」、「項目2(血圧):140」、「項目3(体重):70」、「項目4(コレステロール):250」、「項目5(血糖値):120」であるので、発症確率算出部114は、これらの各データと被評価者データを数2に代入して演算する。この結果、群2と群3については、それぞれ「D2=0.032」、「D3=0.008」が算出される。
【0083】
このようにして、各体質タイプ群毎にユークリッド逆数Diを算出すると、発症確率算出部114は、算出したユークリッド逆数Diを用いて数3を演算することにより、重み付け係数αi(α1、α2、α3)を算出する。ここで、D1=0.014、D2=0.032、D3=0.008であるので、発症確率算出部114は、「α1=0.014/(0.014+0.032+0.008)」を演算することで、群1についての重み付け係数を求める。この結果、群1についての重み付け係数は「α1=0.26」となる。同様にして、群2および群3についての重み付け係数を求めると、それぞれ「α2=0.59」、「α3=0.15」となる。
【0084】
ここで、例えば、群1についての発症確率が「F1(x)=30%」、群2についての発症確率が「F2(x)=20%」、群3についての発症確率が「F3(x)=10%」であるとする。これらは、ステップS106において、発症確率算出部114が、各タイプ群毎のコホートデータを用いて、当該タイプ群について作成された発症確率予測関数を演算することで求められたものである。
【0085】
そして、発症確率算出部114は、このような各タイプ群毎の発症確率と算出した重み付け係数αを用いて数4を演算することで、被評価者が疾患TDを発症する確率を算出する。ここでは、α1=0.26、α2=0.59、α3=0.15であり、F1(x)=30%、F2(x)=20%、F3(x)=10%であるので、発症確率算出部114は、各値を数4に代入し、「F(x)=0.26×30+0.59×20+0.15×10」を演算する。この結果、被評価者が疾患TDを発症する確率として「F(x)=21.1%」が算出される。
【0086】
このようにして、被評価者の発症確率を算出すると、発症確率算出部114は、算出結果を出力装置14が出力して(ステップS109)、処理を終了する。ここでは、発症確率算出部114(制御部110)が、算出結果を出力制御部140に送出することで、被評価者が疾患TDを発症する確率を示す情報(以下、「発症予測情報」とする)が出力装置14により出力される。
【0087】
ここでは、例えば、ディスプレイなどの表示装置によって表示出力されたり、プリンタなどの印刷装置により帳票に印字出力等される他、例えば、所定の記憶装置(記憶部160など)や記憶媒体などに算出結果を出力することで、発症予測情報をこれらに電子的に記録するようにしてもよい。あるいは、算出結果を通信制御部120に出力することで、発症予測情報を通信ネットワーク10を介して他の装置等に送信(出力)するようにしてもよい。
【0088】
以上説明したように、上記実施の形態によれば、予測対象として指定された疾患についてのコホートデータを体質タイプに応じて分類し、各体質タイプ毎の発症確率を算出するとともに、各体質タイプ毎の特徴量を算出する。そして、指定された被評価者についてのコホートデータと、各体質タイプの特徴量との類似度を算出し、算出した類似度で各体質タイプ毎に算出した発症確率を重み付けすることで、被評価者が当該疾患を発症する確率を算出する。これにより、体質を考慮した発症予測をおこなうことができるので、体質が発症に影響する疾患についても、正確な発症予測をおこなうことができる。
【0089】
上記実施の形態は一例であり、本発明の適用範囲はこれに限られない。すなわち、種々の応用が可能であり、あらゆる実施の形態が本発明の範囲に含まれる。
【0090】
例えば、上記実施の形態では、発症予測対象とする疾患が指定されたことに応じて、当該疾患についての体質タイプ別の発症確率予測関数を作成したが、発症確率予測関数は予め生成して群別発症確率予測関数DB165に蓄積しておいてもよい。また、特徴量についても同様であり、種々の疾患について予め体質タイプ別に分類して特徴量を算出し、群別特徴量DB164に蓄積しておいてもよい。
【0091】
また、上記実施の形態では、被評価者についてのデータを、コホートデータから取得するものとしたが、対象項目についてのデータ(数値)をその都度入力するようにしてもよい。このような構成によれば、例えば、診察や健康診断等を受診していない者についての発症予測をおこなうことができる。
【0092】
また、このような構成によれば、例えば、インターネットなどの通信ネットワークを介したウェブサービスなどによって、任意の被評価者について疾患の発症予測情報を提供するサービスを実現することもできる。すなわち、上記実施の形態にかかる医療情報処理装置100と同様の構成を有するウェブサーバを構成する。被評価者は、例えば、パーソナルコンピュータなど端末装置を用い、インターネットなどの通信ネットワークを介して上記ウェブサーバが提供するウェブサイトにアクセスする。ウェブサーバは、アクセスに応じて、発症予測対象とする疾患を指定する情報を入力するためのウェブページをアクセス元の端末装置に送信する。端末装置から疾患を指定する情報がウェブサーバに送信されると、ウェブサーバは、当該疾患についての対象項目を抽出し、各項目のデータを入力するためのウェブページをアクセス元の端末装置に送信する。端末装置から各対象項目のデータがウェブサーバに送信されると、ウェブサーバは、上記「発症確率算出処理」と同様の処理をおこなうことで、当該被評価者の発症確率を算出し、算出結果を示すウェブページをアクセス元の端末装置に送信する。
【0093】
このような構成によれば、例えば、被評価者の自宅などといった、医療機関などとは異なる場所からでも、任意の疾患についての発症確率を知ることができ、容易に自己の健康管理等に利用することができる。
【0094】
また、上記実施の形態では、コホートデータを体質タイプに応じて分類したが、分類の形態は任意であり、体質以外の要素に基づいて分類してもよい。
【0095】
上記実施の形態にかかる医療情報処理装置100は、専用装置から構成可能であることはもとより、汎用のコンピュータ装置などを用いて構成することもできる。すなわち、このような汎用装置に上述したプログラムをインストールして実行させることで、上記実施の形態にかかる医療情報処理装置100として機能させることができる。
【0096】
このようなプログラムの提供方法は任意であり、例えば、CD−ROMなどの記憶媒体に格納して配布可能であることはもとより、プログラムデータを搬送波に重畳することで、所定の通信媒体(例えば、インターネットなど)を介して配布することもできる。
【図面の簡単な説明】
【0097】
【図1】本発明の実施の形態にかかる医療情報処理装置の構成を示すブロック図である。
【図2】図1に示す制御部が実現する機能を示す機能ブロック図である。
【図3】図1に示す記憶部に構成されるデータベースの例を示す図である。
【図4】図3に示すコホートDBに蓄積される情報の例を示す図であり、(a)は被験者基本データテーブルに記録される情報の例を示し、(b)は臨床情報データテーブルに記録される情報の例を示し、(c)は遺伝子情報データテーブルに記録される情報の例を示し、(d)は発症情報データテーブルに記録される情報の例を示す。
【図5】図3に示すデータベースに蓄積される情報の例を示す図であり、(a)は疾患情報DBに記録される情報の例を示し、(b)は解析手法DBに記録される情報の例を示す。
【図6】図3に示すデータベースに蓄積される情報の例を示す図であり、(a)は群別特徴量DBに記録される情報の例を示し、(b)は群別発症確率予測関数DBに記録される情報の例を示す。
【図7】本発明の実施の形態にかかる発症確率算出処理を説明するためのフローチャートである。
【図8】図7に示す発症確率算出処理の具体例に用いるデータ例を示す図であり、(a)は被評価者データの例を示し、(b)は群別特徴量の例を示す。
【符号の説明】
【0098】
10 通信ネットワーク
100 医療情報処理装置
111 データ分類部
112 特徴量算出部
113 発症確率予測関数作成部
114 発症確率算出部
161 コホートDB
162 疾患情報DB
163 解析手法DB
164 群別特徴量DB
165 群別発症確率予測関数DB
【技術分野】
【0001】
本発明は、発症確率算出装置、および、プログラムに関し、特に、疾患の発症予測に好適な発症確率算出装置、および、プログラムに関する。
【背景技術】
【0002】
近時の疫学の進展により、種々の疾患(疾病)が発症する際の因果関係などが解明されており、疾患の予防や健康増進のために活用されている。一方で、医療機関などにおける情報化が進み、健康診断の結果や被験者のカルテ情報などが電子的に蓄積・管理され、各個人の健康管理等に用いられている。
【0003】
こうした情報をデータベース化し、情報処理装置によって処理することで、個人の健康状態を指標化し、健康度を評価する手法が提案されている(例えば、特許文献1)。
【0004】
このような手法において、被評価者の健康診断データ(健診データ)を用いて疾患の発症予測をおこなう場合、健診データを指標化した値(健康度)について、健常者の健康標準モデルと非健常者(擬似被験者)の疾患モデルとを比較解析し、その類似度によって将来の健康度を予測している。
【0005】
ここで、疾患によっては、発症の因果関係として体質が深く影響する場合も多い。例えば、糖尿病において、コレステロールがいくら高くても発症しないが血圧が高くなると発症しやすい体質や、逆に、血圧がいくら高くても発症しないがコレステロールが高くなると発症しやすい体質などがあることが知られている。このような、体質が発症に影響を与える疾患については、単に健常者の健康標準モデルと非健常者の疾患モデルとを比較解析しただけでは、正確な発症予測をおこなうことができない。すなわち、従来の手法では、疾患の発症予測などを正確におこなうことができなかった。
【特許文献1】特開2002−63278号公報
【発明の開示】
【発明が解決しようとする課題】
【0006】
本発明は上記実状に鑑みてなされたもので、疾患の発症予測をより正確におこなうことができる発症確率算出装置、および、プログラムを提供することを目的とする。
【課題を解決するための手段】
【0007】
上記目的を達成するため、本発明の第1の観点にかかる発症確率算出装置は、
所定の医療データをコホートデータとして取得して蓄積するコホートデータ蓄積手段と、
前記コホートデータ蓄積手段が取得したコホートデータを、疾患毎の所定のタイプ別に分類するデータ分類手段と、
指定された被評価者に関するコホートデータを前記コホートデータ蓄積手段から取得し、指定された疾患に関するコホートデータを前記データ分類手段による分類に応じて前記コホートデータ蓄積手段から取得する対象データ取得手段と、
前記指定された疾患の発症確率を分類毎に算出し、前記対象データ取得手段が取得したコホートデータに基づいて重み付けして演算することで、被評価者の発症確率を算出する発症確率算出手段と、
前記発症確率算出手段による算出結果を示す情報を出力する出力手段と、を備える、
ことを特徴とする。
【0008】
上記発症確率算出装置において、
前記データ分類手段は、コホートデータを疾患毎の体質タイプ別に分類し、
前記発症確率算出手段は、
前記指定された疾患に関するコホートデータに基づいて、前記データ分類手段が分類した該疾患についての体質タイプ別の特徴量を算出する特徴量算出手段と、
前記特徴量算出手段が算出した特徴量と、前記被評価者に関するコホートデータとの類似度を算出する類似度算出手段と、をさらに備えていることが望ましく、この場合、
前記類似度算出手段が算出した類似度を重み付け係数として重み付けすることが望ましい。
【0009】
上記発症確率算出装置は、
所定の疾患を示す情報と対象となるデータ項目を示す情報とを対応付けた疾患情報を予め記憶する疾患情報記憶手段をさらに備えていることが望ましく、この場合、
前記対象データ取得手段は、前記疾患情報記憶手段が記憶する疾患情報に基づいて、前記コホートデータから対象となるデータ項目を抽出することが望ましい。
【0010】
上記目的を達成するため、本発明の第2の観点にかかるプログラムは、
コンピュータに、
所定の医療データをコホートデータとして取得して蓄積する機能と、
指定された疾患を示す情報に基づいて、蓄積されているコホートデータから該疾患に関するコホートデータを取得する機能と、
指定された疾患のコホートデータを体質タイプ別に分類し、体質タイプ別の発症確率を算出する機能と、
指定された被評価者を示す情報に基づいて、蓄積されているコホートデータから、該被評価者に関するコホートデータを取得する機能と、
前記指定された疾患の体質タイプ別の特徴量を算出し、前記取得した被評価者に関するコホートデータとの類似度を算出する機能と、
前記算出した体質タイプ別の発症確率を、前記算出した類似度で重み付けすることで前記被評価者の発症確率として算出する機能と、
算出した前記被評価者の発症確率を示す情報を出力する機能と、
を実現させることを特徴とする。
【発明の効果】
【0011】
本発明によれば、予測対象として指定された疾患についてのコホートデータを、例えば、体質タイプに応じて分類し、各体質タイプ毎の発症確率を算出するとともに、各体質タイプ毎の特徴量を算出する。そして、指定された被評価者についてのコホートデータと、各体質タイプの特徴量との類似度を算出し、算出した類似度で各体質タイプ毎に算出した発症確率を重み付けすることで、被評価者が当該疾患を発症する確率を算出ので、体質を考慮した発症予測をおこなうことができる。この結果、体質が発症に影響する疾患についても、正確な発症予測をおこなうことができる。
【発明を実施するための最良の形態】
【0012】
本発明にかかる実施の形態を、以下図面を参照して説明する。
【0013】
図1は、本実施の形態にかかる医療情報処理装置100の構成を模式的に示す図である。本実施の形態にかかる医療情報処理装置100は、例えば、医療機関などで運用されるワークステーションやパーソナルコンピュータなどといった情報処理装置から構成され、疾患や患者等についての種々情報を出力する。本実施形態では、特に、所定の疾患についての発症確率を算出して出力する発症確率算出装置として機能する。このような医療情報処理装置100の構成を図1を参照して説明する。図1は、医療情報処理装置100の構成を示すブロック図である。
【0014】
図示するように、本実施形態にかかる医療情報処理装置100は、制御部110、通信制御部120、入力制御部130、出力制御部140、プログラム格納部150、記憶部160、などから構成されている。
【0015】
制御部110は、例えば、CPU(Central Processing Unit:中央演算処理装置)などから構成され、医療情報処理装置100の各部を制御するとともに、プログラム格納部150に格納されているプログラムの実行により、通信制御部120、入力制御部130、出力制御部140、記憶部160と協働して、後述する各処理を実現する。
【0016】
より詳細には、プログラム格納部150に格納されているプログラムを実行することで、制御部110は、図2に示す各構成として機能する。すなわち、制御部110は、プログラムの実行により、データ分類部111、特徴量算出部112、発症確率予測関数作成部113、発症確率算出部114、として機能する。
【0017】
データ分類部111は、記憶部160のデータベースに蓄積されるコホートデータ(詳細後述)に基づいて、各疾患を所定のタイプに応じて分類する。本実施形態では、コホートデータを体質タイプに応じた複数の体質タイプ群に分類する。
【0018】
特徴量算出部112は、データ分類部111により分類された体質タイプ群毎の特徴量を算出する。
【0019】
発症確率予測関数作成部113は、疾患毎の発症確率を算出するための発症確率予測関数を、データ分類部111が分類した体質タイプ群毎に作成する。
【0020】
発症確率算出部114は、指定された発症予測対象となる疾患および被評価者についてのコホートデータを記憶部160から取得し、当該対象疾患について特徴量算出部112が算出した特徴量、発症確率予測関数作成部113が作成した発症確率予測関数、および、取得したコホートデータを用いて、指定された疾患の発症確率を被評価者の体質に応じて算出する。
【0021】
本実施形態では、制御部110がプログラムを実行することで、ソフトウェア処理により上記各構成として機能するものとするが、これらの構成を、例えば、ASIC(Application Specific Integrated Circuit:特定用途向け集積回路)などで構成し、ハードウェア処理により実現してもよい。
【0022】
通信制御部120は、例えば、NIC(Network Interface Card)やモデムなどといった通信装置から構成され、医療情報処理装置100と所定の通信ネットワーク10(不図示)とを接続して通信をおこなう。通信ネットワーク10は、例えば、LAN(Local Area Network:構内通信網)、もしくは、インターネットなどのWAN(Wide Area Network:広域通信網)などとすることができる。本実施形態では、通信制御部120によって、記憶部160のデータベースに蓄積するデータを、必要に応じて外部の装置から通信ネットワーク10を介して取得する。
【0023】
入力制御部130は、例えば、キーボードやポインティングデバイスなどの入力装置13を接続し、ユーザの操作に応じた入力信号を制御部110に入力する。
【0024】
出力制御部140は、例えば、ディスプレイやプリンタなどの出力装置14を接続し、制御部110の処理結果などを出力装置14に出力する。
【0025】
プログラム格納部150は、例えば、ハードディスク装置などの記憶装置から構成され、制御部110が実行するプログラムを格納する。プログラム格納部150には、制御部110を、上述したデータ分類部111、特徴量算出部112、発症確率予測関数作成部113、発症確率算出部114、として機能させるためのプログラムが格納される。また、制御部110が、通信制御部120、入力制御部130、出力制御部140、記憶部160を制御するためのプログラムも格納される。すなわち、制御部110がプログラム格納部150に格納されている各プログラムを実行することにより、医療情報処理装置100全体として後述する各処理が実現される。
【0026】
記憶部160は、例えば、ハードディスク装置などの記憶装置から構成され、本実施の形態にかかる各処理を実現するために必要な種々の情報が記録される。本実施の形態では、図3に示すようなデータベースが記憶部160に構成される。図示するように、記憶部160には、コホートDB161、疾患情報DB162、解析手法DB163、群別特徴量DB164、群別発症確率予測関数DB165、などのデータベースが構成される。各データベースについて以下説明する。
【0027】
コホートDB161は、医療情報処理装置100により疾患の発症予測を行う際に必要となる「コホートデータ」(母集団データ)を蓄積する。ここでは、所定の医療データがコホートデータとして蓄積される。本実施形態では、医療機関などにおいて、診察や治療、あるいは、健康診断などを受けた複数の者(以下、「被験者」とする)を対象とし、これらの被験者についての医療データをコホートデータとして蓄積するものとする。「医療データ」とは、例えば、種々の疾患(疾病)に関する情報の他、被験者の身体や健康状態に関する情報などである。被験者に関する医療データには、例えば、診察や治療、あるいは、健康診断などの結果を示す情報(健診データ)の他、被験者の体質や身体的特徴を示す情報(遺伝子タイプや血液型、身長・体重など)、その他年齢や性別などの属性情報などが含まれる。
【0028】
このようなコホートデータを管理するため、コホートDB161には、図4に示すように、被験者基本データテーブル161a、臨床情報データテーブル161b、遺伝子情報データテーブル161c、発症情報データテーブル161d、などのテーブルが作成され、各種コホートデータが記録される。
【0029】
被験者基本データテーブル161aに記録される情報の例を図4(a)に示す。図示するように、被験者基本データテーブル161aには、対象となる被験者毎に一意に割り当てられている被験者IDをキーとしたレコードが作成されており、各レコードには、例えば、当該被験者についての属性情報(例えば、性別、氏名、生年月日、年齢、血液型、など)が記録されている。すなわち、被験者基本データテーブル161aには、対象となる被験者についての基本情報が記録される。
【0030】
臨床情報データテーブル161bに記録される情報の例を図4(b)に示す。図示するように、臨床情報データテーブル161bには、被験者IDをキーとしたレコードが作成されており、各レコードには、例えば、当該被験者についての健康診断データ(以下、「健診データ」とする)などが記録される。健診データは、健診日毎の健診結果(例えば、身長、体重、血圧、血糖値、コレステロール、などの計測結果)を示すものである。すなわち、臨床情報データテーブル161bには、各被験者毎の複数回の健診結果によって示される、被験者毎の体質を示す情報が記録される。
【0031】
遺伝子情報データテーブル161cに記録される情報の例を図4(c)に示す。図示するように、遺伝子情報データテーブル161cには、被験者IDをキーとしたレコードが作成されており、各レコードには、当該被験者の遺伝子タイプを示す情報などが記録される。ここでは、例えば、個体毎に異なる体質に影響する遺伝子について記録されるものとする。すなわち、遺伝子情報データテーブル161cには、被験者毎の体質を示す情報が記録されることになる。
【0032】
発症情報データテーブル161dに記録される情報の例を図4(d)に示す。図示するように、発症情報データテーブル161dには、被験者IDをキーとしたレコードが作成されており、各レコードには、当該被験者について、所定の疾患(疾病)の発症履歴を示す情報などが記録される。ここでは、少なくとも、発症予測の対象となる疾患についての発症履歴が記録されるものとする。すなわち、所定の疾患の発症日などを示す情報が、発症した被験者の被験者IDに対応付けて記録される。この発症情報データテーブル161dに記録される情報は、例えば、各被験者についてのカルテ情報などに基づいて記録される。
【0033】
疾患情報DB162には、対象となる疾患(疾病)についての情報が記録される。疾患情報DB162に記録される情報の例を図5(a)に示す。図示するように、疾患情報DB162には、対象となる疾患毎に一意に付与されている疾患IDをキーとしたレコードが作成されており、各レコードには、当該IDに対応する疾患名を示す情報の他、当該疾患についての発症予測をおこなう際の解析手法を示す情報(解析手法ID)や、当該疾患についての発症予測をおこなう際に必要となるコホートデータの項目(対象項目)などが記録されている。「対象項目」とは、当該疾患の発症確率を算出する際に必要となるデータ項目を指定する情報である。ここで指定されるデータ項目とは、コホートDB161に記録される各コホートデータ中のデータ項目である。
【0034】
解析手法DB163には、疾患の発症予測をおこなうための発症確率算出に用いられる解析手法を示す情報が記録される。解析手法DB163に記録される情報の例を図5(b)に示す。図示するように、解析手法DB163には、各解析手法毎に一意に割り当てられている解析手法IDをキーとしたレコードが作成されており、各レコードには、当該IDに対応する解析手法名を示す情報の他、当該解析手法のアルゴリズムデータなどが記録される。ここには、例えば、cox比例ハザードモデルやロジスティックモデルなどといった生存時間解析方法に基づくアルゴリズムデータなどが記録される。
【0035】
群別特徴量DB164には、特徴量算出部112が算出したタイプ群別の特徴量を示す情報が記録される。群別特徴量DB164に記録される情報の例を図6(a)に示す。図示するように、群別特徴量DB164には、疾患IDをキーとしたレコードが作成されており、各レコードには、当該疾患を体質タイプに応じて分類したタイプ毎に一意に割り当てられている疾患タイプIDや当該疾患タイプIDに対応する疾患タイプ名を示す情報の他、当該疾患タイプについて算出された特徴量を示す情報などが記録される。ここでの「特徴量」とは、例えば、当該疾患タイプに属するデータの対象項目毎の平均値を示す。
【0036】
群別発症確率予測関数DB165には、発症確率予測関数作成部113により作成された、疾患タイプ毎の発症確率予測関数が記録される。群別発症確率予測関数DB165に記録される情報の例を図6(b)に示す。図示するように、群別発症確率予測関数DB165には、疾患タイプIDをキーとしたレコードが作成されており、各レコードには、当該疾患タイプについて作成された発症確率予測関数が記録される。
【0037】
記憶部160には、以上のような各種データベースが構成されるが、これらのデータベースに記録される情報は、例えば、オペレータが入力装置13を操作することで入力される他、例えば、制御部110の制御により、通信ネットワーク10に接続されている他の装置等から取得して入力されてもよい。この場合、例えば、医療機関において患者情報を管理している装置など(例えば、電子カルテシステムなど)から各種情報を取得可能であることはもとより、例えば、診察や治療に用いられる医療用装置(診断装置や計測装置など)から測定結果等を示す情報を取得するようにしてもよい。あるいは、例えば、CD−ROMなどの記録媒体に記録されている情報を取得するようにしてもよい。この場合、記憶部160には、例えば、CD−ROMドライブなどの読取装置等が含まれるものとする。
【0038】
このようにして、医療情報処理装置100は、コホートデータを随時取得し、コホートDB161に蓄積する。例えば、医療活動(診察、診断、治療、健康診断など)において発生するデータを随時取得したり、夜間のバッチ処理などによって定期的に取得することでコホートデータが蓄積される。
【0039】
また、記憶部160は、上記データベースとして用いられる他、例えば、取得した情報や処理中の演算結果などを一時的に記憶しておく記憶領域としても用いられる。なお、プログラム格納部150および記憶部160を構成する記憶装置はハードディスク装置に限られず、例えば、RAM(Random Access Memory)、ROM(Read Only Memory)、EEPROM(Electrically Erasable Programmable ROM)などを含んでいてもよい。
【0040】
以上のように構成された医療情報処理装置100の動作を以下説明する。医療情報処理装置100は、被評価者が所定の疾患を発症する確率を算出して発症予測をおこなうための「発症確率算出処理」を実行する。この発症確率算出処理は、オペレータによる操作などにより処理開始が指示されたことを契機に開始される。
【0041】
図7に示すフローチャートを参照して発症確率算出処理における医療情報処理装置100の動作を説明する。ここでは、プログラム格納部150に格納されているプログラムを実行することにより、制御部110が、データ分類部111、特徴量算出部112、発症確率予測関数作成部113、発症確率算出部114として機能し、記憶部160に構成されている各データベースとの協働により処理が実行される。
【0042】
発症確率算出処理においては、被評価者が所定の疾患を発症する確率を予測するため、対象となる疾患および被評価者を特定する情報を入力して指定する。ここでは、例えば、オペレータなどが入力装置13を操作することにより、対象とする疾患を特定する情報(例えば、疾患名)、および、被評価者を特定する情報(例えば、被評価者の氏名)を医療情報処理装置100に入力して指定する。この場合、発症確率算出処理の開始に応じて、例えば、これらの情報を入力するための入力画面が出力装置14(ディスプレイ)に表示され、この入力画面から疾患名や被評価者氏名などを入力するものとする。
【0043】
疾患名が制御部110に入力されると、データ分類部111は、記憶部160に構成されている疾患情報DB162にアクセスし、指定された疾患名に対応する疾患IDを取得するとともに、コホートDB161から、指定された疾患名に対応するコホートデータを取得する(ステップS101)。
【0044】
ここでは、データ分類部111が発症情報データテーブル161dにアクセスし、対象とする疾患を発症した被験者(以下、「患者」とする)を特定する。例えば、入力された疾患名が「糖尿病」である場合、発症情報データテーブル161d内で糖尿病の発症履歴が記録されているレコードを特定し、当該レコードのキー項目となっている被験者IDを特定する。
【0045】
次にデータ分類部111は、被験者基本データテーブル161a、臨床情報データテーブル161b、遺伝子情報データテーブル161cにアクセスし、特定した被験者IDがキーとなっているレコードを各テーブル上で特定し、特定したレコードを抽出することでコホートデータを取得する。
【0046】
すなわち、入力された疾患を発症したことのある患者について、被験者基本データテーブル161aから基本情報が取得され、臨床情報データテーブル161bから健診データが取得され、遺伝子情報データテーブル161cから遺伝子情報が取得される。ここで、対象とする疾患の患者が複数人いる場合、当該疾患について、複数人の医療データが取得されることになる。すなわち、当該疾患の発症確率の算出に用いられるデータとしてコホートデータが取得される。
【0047】
データ分類部111は、取得したコホートデータのうち、疾患情報DB162に記録されている対象項目が示す項目のデータを抽出する。例えば、当該疾患についての対象項目が、「年齢」、「血圧」、「体重」、「コレステロール」、「血糖値」である場合には、年齢を示す情報を被験者基本データテーブル161aから抽出し、血圧、体重、コレステロール、血糖値を示す情報を臨床情報データテーブル161bから抽出する。すなわち、発症確率の算出において対象となるデータを、コホートDB161から選択的に取得する。
【0048】
ここで、例えば、ある患者が複数回の健診を受けている場合などには、対象項目のそれぞれについて複数のデータが臨床情報データテーブル161bに記録されていることがある。このような場合には、例えば、データ分類部111が各対象項目毎に平均値を算出するか、最新のデータを取得するものとする。
【0049】
次にデータ分類部111は、ステップS101で取得したコホートデータを体質タイプに応じた複数のタイプ群に分類する(ステップS102)。ここでは、取得したコホートデータを、例えば、体質タイプ別にn個の群G1,G2, . . . ,Gnに分類する。データ分類部111は、例えば、k-平均法(k-means method)などといったクラスタリング手法でクラスタ分析を実行することで、コホートデータを自動的に体質タイプ別に分類する。すなわち、コホートデータを構成する複数のデータ項目を多次元空間上にプロットし、ある一定の特徴を持つクラスタに収束させることで、コホートデータを分類する。
【0050】
ここでは、例えば、当該疾患を発症した者の体質タイプに応じて複数の群に分類する。例えば、糖尿病の場合、「血圧は高くなくてもコレステロールが高い」、「コレステロールは高くなくても血圧が高い」、「血圧、コレステロールのいずれも高い」、などといった体質タイプに分類する。
【0051】
データ分類部111は、このようにして、対象となる疾患を複数のタイプ群に分類すると、各分類毎に一意の疾患タイプIDを割り当て、群別特徴量DB164にレコードを作成する。
【0052】
データ分類部111は、対象とする疾患についてのデータが体質タイプ別に分類すると、ステップS101で取得したコホートデータを特徴量算出部112に提供する。特徴量算出部112は、データ分類部111から提供されたコホートデータを用いて、各体質タイプ毎の特徴量を算出する(ステップS103)。上述したように、「特徴量」とは、例えば、各タイプ群に属するデータの項目毎の平均値を示すものである。したがって、特徴量算出部112は、取得したコホートデータが示す数値の平均値を項目毎に算出する。
【0053】
例えば、対象としている疾患の対象項目が、年齢(項目1)、血圧(項目2)、体重(項目3)、コレステロール(項目4)、血糖値(項目5)の5項目であり、分類された体質タイプ群が、群1(G1)、群2(G2)、群3(G3)の3群であった場合、データ分類部111が各項目についてコホートDB161から取得したデータの項目毎の平均値を算出し、群別特徴量DB164に記録する。ここでは、対応するタイプ群のレコードに算出した特徴量を記録する。
【0054】
以下、本実施形態では、発症予測対象としている疾患を疾患TDとし、疾患TDについての対象項目が上記5項目、分類された体質タイプ群が上記3群である場合を例に説明することとする。
【0055】
対象となる疾患についてのコホートデータが体質タイプに応じて分類され、分類毎に特徴量が算出されると、発症確率予測関数作成部113が、各体質タイプ(群)毎に発症確率予測関数(群別発症確率予測関数)を作成し、群別発症確率予測関数DB165に記録する(ステップS104)。ここではまず、発症確率予測関数作成部113が疾患情報DB162にアクセスし、疾患TDに対応する解析手法を特定する。そして、解析手法DB163にアクセスし、特定した解析手法のアルゴリズムを取得し、当該アルゴリズムにしたがった演算をおこなうことで、疾患TDの各体質タイプ別(G1〜G3)に発症確率予測関数を作成する。
【0056】
ここでは、例えば、cox比例ハザードモデルやロジスティックモデルなどの生存時間解析方法を用いて、発症確率予測関数を体質タイプ別に作成する。発症確率予測関数作成部113は、各体質タイプを示す疾患タイプIDをキーとしたレコードを群別発症確率予測関数DB165に作成し、作成した発症確率予測関数を各レコードに記録する。
【0057】
このようにして、対象とする疾患について体質タイプ別の発症確率予測関数が作成されると、発症確率算出部114が、作成された発症確率予測関数を用いて、被評価者が当該疾患を発症する確率を算出するための処理を開始する。
【0058】
まず、発症確率算出部114は、被験者基本データテーブル161aにアクセスし、本処理の開始時に指定された被評価者の氏名に対応する被験者IDを特定する。そして、コホートDB161の各テーブルにおいて、当該被験者IDに対応するレコードを特定し、当該レコードに記録されている情報を、被評価者のコホートデータ(以下、「被評価者データ」とする)として取得する(ステップS105)。
【0059】
発症確率算出部114は、さらに、取得した被評価者データから、疾患TDの対象項目に対応するデータ(すなわち、年齢(項目1)、血圧(項目2)、体重(項目3)、コレステロール(項目4)、血糖値(項目5)、についてのデータ)を抽出する。すなわち、疾患情報DB162に記録されている対象項目が示す項目のデータを抽出することで、発症確率の算出において対象となるデータを、コホートDB161から選択的に取得する。
【0060】
ここで、ある対象項目について複数のデータが記録されている場合には、例えば、発症確率算出部114が各対象項目毎に平均値を算出するか最新のデータを取得することで、被評価者データとして取得する。
【0061】
被評価者データを取得すると、発症確率算出部114は、当該被評価者データと、疾患TDについての体質タイプ毎の特徴量とに基づき、被評価者が疾患TDを発症する確率を算出する。
【0062】
この場合、発症確率算出部114は、疾患TDについて体質タイプ別に算出される発症確率に、被評価者のコホートデータに基づく重み付けをおこなうことで、当該被評価者の体質に応じた発症確率を算出する。発症確率算出部114による発症確率の算出手法を以下説明する。
【0063】
まず、発症確率算出部114は、疾患TDについて、体質タイプ別の発症確率を算出する(ステップS106)。体質タイプ別の発症確率は、ステップS104で作成した群別発症確率予測関数を用いて算出される。ここでは、ステップS102での分類に応じて取得されたコホートデータを用いて、発症確率算出部114が群別発症確率予測関数を演算することで、体質タイプ別に疾患TDの発症確率を算出する。ここで、疾患TDについての体質タイプ群の番号をiとした場合、群別発症確率予測関数は、例えば、各項目のデータをxとした、数1に示すようなベクトル関数で表される。
【0064】
(数1)
Fi(x)=βi1xi1+βi2xi2+…+βinxin (nは対象項目数)
【0065】
このような群別発症確率予測関数を演算することで、疾患TDの発症確率が体質タイプ別に算出される。すなわち、群1についての発症確率は関数F1(x)で求められ、群2についての発症確率は関数F2(x)で求められ、群3についての発症確率は関数F3(x)で求められる。
【0066】
次に発症確率算出部114は、算出した体質タイプ別の発症確率を被評価者の体質に応じて重み付けするための重み付け係数を算出する。本実施形態では、重み付け係数をαとし、体質タイプ群別の重み付け係数は「αi」で表すものとする。本実施形態では、体質タイプ群がG1〜G3の3群であるため、αiは、α1、α2、α3のいずれかとなる。
【0067】
ここで、重み付け係数αは、例えば、被評価者データと、疾患TDについての体質タイプ群毎の特徴量(平均値)との「類似度」を算出することで求める。すなわち、発症確率算出部114は、疾患TDについてのコホートデータから算出した体質タイプ別の特徴量と、被評価者のコホートデータとの類似度を算出することで重み付け係数を算出する(ステップS107)。
【0068】
類似度の算出には、例えば、クラスタ分析における類似度の判定に用いられる「ユークリッド距離」を用いる。すなわち、k-平均法などのクラスタ分析により体質タイプ別に分類されたコホートデータのクラスタと、被評価者データとの多次元空間上での距離を求めることにより、被評価者データがどの体質タイプに近いかを示す類似度として算出する。ユークリッド距離を用いた類似度の算出方法の例を以下説明する。
【0069】
ここでは、対象項目の項目番号をjとし、各体質タイプ群に属するデータを「zij」、被評価者データ中の各対象項目のデータを「yj」で表すこととする。例えば、群1における項目1(年齢)のデータは「z11」、群3における項目5(血糖値)のデータは「z35」と表し、被評価者についての項目3(体重)のデータは「y3」と表す。
【0070】
そして、例えば、i番目の体質タイプ群における、被評価者データと当該体質タイプ群に属するデータとのユークリッド距離の逆数(以下、ユークリッド逆数Diとする)を用いて重み付け係数となる類似度を求める。この場合、発症確率算出部114が以下の数2を演算することによりユークリッド逆数Diを求める。なお、数2において、SQRD(a)は、aの平方根を示す。
【0071】
(数2)
Di=1/SQRD ((y1−zi1)2+(y2−zi2)2+…+(yn−zin)2 (nは対象項目数)
【0072】
このようにして求められたユークリッド逆数Diを用いて、各体質タイプ群別の重み付け係数αiを求める。この場合、発症確率算出部114が以下の数3を演算することより重み付け係数αiが求められる。
【0073】
(数3)
αi=Di/(D1+D2+…+Dm) (mはタイプ群数)
【0074】
そして、各体質タイプ群毎の発症確率はそれぞれ、F1(x)、F2(x)、F3(x)であるので、これらと被評価者について算出された体質タイプ群別の重み付け係数αとを乗じることで、当該被評価者が疾患TDを発症する確率(F(x))を算出する。ここでは、発症確率算出部114が以下の数4を演算することで、被評価者の発症確率を算出する。
【0075】
(数4)
F(x)=(α1×F1(x))+(α2×F2(x))+…+(αm×Fm(x)) (mはタイプ群数)
【0076】
すなわち、発症確率算出部114は、指定された疾患について算出された体質タイプ別の発症確率を、被評価者データと当該疾患についての体質タイプ別の特徴量との類似度で重み付けすることで、被評価者が疾患TDを発症する確率を算出する(ステップS108)。
【0077】
上記ステップS106〜S108における発症確率算出部114の動作、具体的な数値例を用いて以下説明する。ここでは、被評価者について取得したコホートデータ(被評価者データ)の例を図8(a)の表1に示し、予測対象となっている疾患についての群別の特徴量の例を図8(b)の表2に示す。
【0078】
発症確率算出部114は、重み付け係数αi(すなわち、α1、α2、α3)のそれぞれを算出するにあたり、各体質タイプ群に対応するユークリッド逆数Di(すなわち、D1、D2、D3)を算出する。
【0079】
ここで、図8(a)の表1示す被評価者データによれば、被評価者についての各対象項目のデータ(数値)は、「項目1(年齢):40」、「項目2(血圧):125」、「項目3(体重):65」、「項目4(コレステロール):130」、「項目5(血糖値):125」となる。
【0080】
一方、図8(b)の表2に示すように、群1(G1)の各対象項目のデータ(平均値)は、「項目1(年齢):50」、「項目2(血圧):130」、「項目3(体重):60」、「項目4(コレステロール):200」、「項目5(血糖値):130」となる。
【0081】
この場合、発症確率算出部114は、被評価者の各データをy1〜y5、群1の各データをz11〜z15として数2を演算することで、まず、群1についての被評価者とのユークリッド距離の逆数であるユークリッド逆数D1を算出する。この場合、上記各数値を数2に代入することにより、発症確率算出部114は、「D1=1/SQRT((40−50)2+(125−130)2+(65−60)2+(130−200)2+(125−130)2) (SQRT(a)はaの平方根を示す)」を演算する。この結果、群1における被評価者データとのユークリッド距離の逆数として「D1=0.014」が算出される。
【0082】
同様にして、発症確率算出部114は、群2および群3について、それぞれ被評価者データとのユークリッド距離の逆数を求める。ここでは、図8(b)の表2に示すように、群2(G2)のデータ(平均値)が、「項目1(年齢):30」、「項目2(血圧):120」、「項目3(体重):50」、「項目4(コレステロール):150」、「項目5(血糖値):110」であり、群3(G3)のデータ(平均値)が、「項目1(年齢):60」、「項目2(血圧):140」、「項目3(体重):70」、「項目4(コレステロール):250」、「項目5(血糖値):120」であるので、発症確率算出部114は、これらの各データと被評価者データを数2に代入して演算する。この結果、群2と群3については、それぞれ「D2=0.032」、「D3=0.008」が算出される。
【0083】
このようにして、各体質タイプ群毎にユークリッド逆数Diを算出すると、発症確率算出部114は、算出したユークリッド逆数Diを用いて数3を演算することにより、重み付け係数αi(α1、α2、α3)を算出する。ここで、D1=0.014、D2=0.032、D3=0.008であるので、発症確率算出部114は、「α1=0.014/(0.014+0.032+0.008)」を演算することで、群1についての重み付け係数を求める。この結果、群1についての重み付け係数は「α1=0.26」となる。同様にして、群2および群3についての重み付け係数を求めると、それぞれ「α2=0.59」、「α3=0.15」となる。
【0084】
ここで、例えば、群1についての発症確率が「F1(x)=30%」、群2についての発症確率が「F2(x)=20%」、群3についての発症確率が「F3(x)=10%」であるとする。これらは、ステップS106において、発症確率算出部114が、各タイプ群毎のコホートデータを用いて、当該タイプ群について作成された発症確率予測関数を演算することで求められたものである。
【0085】
そして、発症確率算出部114は、このような各タイプ群毎の発症確率と算出した重み付け係数αを用いて数4を演算することで、被評価者が疾患TDを発症する確率を算出する。ここでは、α1=0.26、α2=0.59、α3=0.15であり、F1(x)=30%、F2(x)=20%、F3(x)=10%であるので、発症確率算出部114は、各値を数4に代入し、「F(x)=0.26×30+0.59×20+0.15×10」を演算する。この結果、被評価者が疾患TDを発症する確率として「F(x)=21.1%」が算出される。
【0086】
このようにして、被評価者の発症確率を算出すると、発症確率算出部114は、算出結果を出力装置14が出力して(ステップS109)、処理を終了する。ここでは、発症確率算出部114(制御部110)が、算出結果を出力制御部140に送出することで、被評価者が疾患TDを発症する確率を示す情報(以下、「発症予測情報」とする)が出力装置14により出力される。
【0087】
ここでは、例えば、ディスプレイなどの表示装置によって表示出力されたり、プリンタなどの印刷装置により帳票に印字出力等される他、例えば、所定の記憶装置(記憶部160など)や記憶媒体などに算出結果を出力することで、発症予測情報をこれらに電子的に記録するようにしてもよい。あるいは、算出結果を通信制御部120に出力することで、発症予測情報を通信ネットワーク10を介して他の装置等に送信(出力)するようにしてもよい。
【0088】
以上説明したように、上記実施の形態によれば、予測対象として指定された疾患についてのコホートデータを体質タイプに応じて分類し、各体質タイプ毎の発症確率を算出するとともに、各体質タイプ毎の特徴量を算出する。そして、指定された被評価者についてのコホートデータと、各体質タイプの特徴量との類似度を算出し、算出した類似度で各体質タイプ毎に算出した発症確率を重み付けすることで、被評価者が当該疾患を発症する確率を算出する。これにより、体質を考慮した発症予測をおこなうことができるので、体質が発症に影響する疾患についても、正確な発症予測をおこなうことができる。
【0089】
上記実施の形態は一例であり、本発明の適用範囲はこれに限られない。すなわち、種々の応用が可能であり、あらゆる実施の形態が本発明の範囲に含まれる。
【0090】
例えば、上記実施の形態では、発症予測対象とする疾患が指定されたことに応じて、当該疾患についての体質タイプ別の発症確率予測関数を作成したが、発症確率予測関数は予め生成して群別発症確率予測関数DB165に蓄積しておいてもよい。また、特徴量についても同様であり、種々の疾患について予め体質タイプ別に分類して特徴量を算出し、群別特徴量DB164に蓄積しておいてもよい。
【0091】
また、上記実施の形態では、被評価者についてのデータを、コホートデータから取得するものとしたが、対象項目についてのデータ(数値)をその都度入力するようにしてもよい。このような構成によれば、例えば、診察や健康診断等を受診していない者についての発症予測をおこなうことができる。
【0092】
また、このような構成によれば、例えば、インターネットなどの通信ネットワークを介したウェブサービスなどによって、任意の被評価者について疾患の発症予測情報を提供するサービスを実現することもできる。すなわち、上記実施の形態にかかる医療情報処理装置100と同様の構成を有するウェブサーバを構成する。被評価者は、例えば、パーソナルコンピュータなど端末装置を用い、インターネットなどの通信ネットワークを介して上記ウェブサーバが提供するウェブサイトにアクセスする。ウェブサーバは、アクセスに応じて、発症予測対象とする疾患を指定する情報を入力するためのウェブページをアクセス元の端末装置に送信する。端末装置から疾患を指定する情報がウェブサーバに送信されると、ウェブサーバは、当該疾患についての対象項目を抽出し、各項目のデータを入力するためのウェブページをアクセス元の端末装置に送信する。端末装置から各対象項目のデータがウェブサーバに送信されると、ウェブサーバは、上記「発症確率算出処理」と同様の処理をおこなうことで、当該被評価者の発症確率を算出し、算出結果を示すウェブページをアクセス元の端末装置に送信する。
【0093】
このような構成によれば、例えば、被評価者の自宅などといった、医療機関などとは異なる場所からでも、任意の疾患についての発症確率を知ることができ、容易に自己の健康管理等に利用することができる。
【0094】
また、上記実施の形態では、コホートデータを体質タイプに応じて分類したが、分類の形態は任意であり、体質以外の要素に基づいて分類してもよい。
【0095】
上記実施の形態にかかる医療情報処理装置100は、専用装置から構成可能であることはもとより、汎用のコンピュータ装置などを用いて構成することもできる。すなわち、このような汎用装置に上述したプログラムをインストールして実行させることで、上記実施の形態にかかる医療情報処理装置100として機能させることができる。
【0096】
このようなプログラムの提供方法は任意であり、例えば、CD−ROMなどの記憶媒体に格納して配布可能であることはもとより、プログラムデータを搬送波に重畳することで、所定の通信媒体(例えば、インターネットなど)を介して配布することもできる。
【図面の簡単な説明】
【0097】
【図1】本発明の実施の形態にかかる医療情報処理装置の構成を示すブロック図である。
【図2】図1に示す制御部が実現する機能を示す機能ブロック図である。
【図3】図1に示す記憶部に構成されるデータベースの例を示す図である。
【図4】図3に示すコホートDBに蓄積される情報の例を示す図であり、(a)は被験者基本データテーブルに記録される情報の例を示し、(b)は臨床情報データテーブルに記録される情報の例を示し、(c)は遺伝子情報データテーブルに記録される情報の例を示し、(d)は発症情報データテーブルに記録される情報の例を示す。
【図5】図3に示すデータベースに蓄積される情報の例を示す図であり、(a)は疾患情報DBに記録される情報の例を示し、(b)は解析手法DBに記録される情報の例を示す。
【図6】図3に示すデータベースに蓄積される情報の例を示す図であり、(a)は群別特徴量DBに記録される情報の例を示し、(b)は群別発症確率予測関数DBに記録される情報の例を示す。
【図7】本発明の実施の形態にかかる発症確率算出処理を説明するためのフローチャートである。
【図8】図7に示す発症確率算出処理の具体例に用いるデータ例を示す図であり、(a)は被評価者データの例を示し、(b)は群別特徴量の例を示す。
【符号の説明】
【0098】
10 通信ネットワーク
100 医療情報処理装置
111 データ分類部
112 特徴量算出部
113 発症確率予測関数作成部
114 発症確率算出部
161 コホートDB
162 疾患情報DB
163 解析手法DB
164 群別特徴量DB
165 群別発症確率予測関数DB
【特許請求の範囲】
【請求項1】
所定の医療データをコホートデータとして取得して蓄積するコホートデータ蓄積手段と、
前記コホートデータ蓄積手段が取得したコホートデータを、疾患毎の所定のタイプ別に分類するデータ分類手段と、
指定された被評価者に関するコホートデータを前記コホートデータ蓄積手段から取得し、指定された疾患に関するコホートデータを前記データ分類手段による分類に応じて前記コホートデータ蓄積手段から取得する対象データ取得手段と、
前記指定された疾患の発症確率を分類毎に算出し、前記対象データ取得手段が取得したコホートデータに基づいて重み付けして演算することで、被評価者の発症確率を算出する発症確率算出手段と、
前記発症確率算出手段による算出結果を示す情報を出力する出力手段と、を備える、
ことを特徴とする発症確率算出装置。
【請求項2】
前記データ分類手段は、コホートデータを疾患毎の体質タイプ別に分類し、
前記発症確率算出手段は、
前記指定された疾患に関するコホートデータに基づいて、前記データ分類手段が分類した該疾患についての体質タイプ別の特徴量を算出する特徴量算出手段と、
前記特徴量算出手段が算出した特徴量と、前記被評価者に関するコホートデータとの類似度を算出する類似度算出手段と、をさらに備え、
前記類似度算出手段が算出した類似度を重み付け係数として重み付けする、
ことを特徴とする請求項1に記載の発症確率算出装置。
【請求項3】
所定の疾患を示す情報と対象となるデータ項目を示す情報とを対応付けた疾患情報を予め記憶する疾患情報記憶手段をさらに備え、
前記対象データ取得手段は、前記疾患情報記憶手段が記憶する疾患情報に基づいて、前記コホートデータから対象となるデータ項目を抽出する、
ことを特徴とする請求項1または2に記載の発症確率算出装置。
【請求項4】
コンピュータに、
所定の医療データをコホートデータとして取得して蓄積する機能と、
指定された疾患を示す情報に基づいて、蓄積されているコホートデータから該疾患に関するコホートデータを取得する機能と、
指定された疾患のコホートデータを体質タイプ別に分類し、体質タイプ別の発症確率を算出する機能と、
指定された被評価者を示す情報に基づいて、蓄積されているコホートデータから、該被評価者に関するコホートデータを取得する機能と、
前記指定された疾患の体質タイプ別の特徴量を算出し、前記取得した被評価者に関するコホートデータとの類似度を算出する機能と、
前記算出した体質タイプ別の発症確率を、前記算出した類似度で重み付けすることで前記被評価者の発症確率として算出する機能と、
算出した前記被評価者の発症確率を示す情報を出力する機能と、
を実現させることを特徴とするプログラム。
【請求項1】
所定の医療データをコホートデータとして取得して蓄積するコホートデータ蓄積手段と、
前記コホートデータ蓄積手段が取得したコホートデータを、疾患毎の所定のタイプ別に分類するデータ分類手段と、
指定された被評価者に関するコホートデータを前記コホートデータ蓄積手段から取得し、指定された疾患に関するコホートデータを前記データ分類手段による分類に応じて前記コホートデータ蓄積手段から取得する対象データ取得手段と、
前記指定された疾患の発症確率を分類毎に算出し、前記対象データ取得手段が取得したコホートデータに基づいて重み付けして演算することで、被評価者の発症確率を算出する発症確率算出手段と、
前記発症確率算出手段による算出結果を示す情報を出力する出力手段と、を備える、
ことを特徴とする発症確率算出装置。
【請求項2】
前記データ分類手段は、コホートデータを疾患毎の体質タイプ別に分類し、
前記発症確率算出手段は、
前記指定された疾患に関するコホートデータに基づいて、前記データ分類手段が分類した該疾患についての体質タイプ別の特徴量を算出する特徴量算出手段と、
前記特徴量算出手段が算出した特徴量と、前記被評価者に関するコホートデータとの類似度を算出する類似度算出手段と、をさらに備え、
前記類似度算出手段が算出した類似度を重み付け係数として重み付けする、
ことを特徴とする請求項1に記載の発症確率算出装置。
【請求項3】
所定の疾患を示す情報と対象となるデータ項目を示す情報とを対応付けた疾患情報を予め記憶する疾患情報記憶手段をさらに備え、
前記対象データ取得手段は、前記疾患情報記憶手段が記憶する疾患情報に基づいて、前記コホートデータから対象となるデータ項目を抽出する、
ことを特徴とする請求項1または2に記載の発症確率算出装置。
【請求項4】
コンピュータに、
所定の医療データをコホートデータとして取得して蓄積する機能と、
指定された疾患を示す情報に基づいて、蓄積されているコホートデータから該疾患に関するコホートデータを取得する機能と、
指定された疾患のコホートデータを体質タイプ別に分類し、体質タイプ別の発症確率を算出する機能と、
指定された被評価者を示す情報に基づいて、蓄積されているコホートデータから、該被評価者に関するコホートデータを取得する機能と、
前記指定された疾患の体質タイプ別の特徴量を算出し、前記取得した被評価者に関するコホートデータとの類似度を算出する機能と、
前記算出した体質タイプ別の発症確率を、前記算出した類似度で重み付けすることで前記被評価者の発症確率として算出する機能と、
算出した前記被評価者の発症確率を示す情報を出力する機能と、
を実現させることを特徴とするプログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【公開番号】特開2006−163489(P2006−163489A)
【公開日】平成18年6月22日(2006.6.22)
【国際特許分類】
【出願番号】特願2004−349777(P2004−349777)
【出願日】平成16年12月2日(2004.12.2)
【出願人】(000102728)株式会社エヌ・ティ・ティ・データ (438)
【公開日】平成18年6月22日(2006.6.22)
【国際特許分類】
【出願日】平成16年12月2日(2004.12.2)
【出願人】(000102728)株式会社エヌ・ティ・ティ・データ (438)
[ Back to top ]