
発話区間話者分類装置とその方法と、その装置を用いた音声認識装置とその方法と、プログラムと記録媒体
【課題】事前の話者登録を無くす。
【解決手段】この発明の発話区間話者分類装置は、音量音声区間分割部と、特徴量分析部と、代表特徴量抽出部と、セグメント分類部と、セグメント統合部と、を具備する。音量音声区間分割部は、離散値化された音声信号の音声区間検出を行い音声区間セグメントを出力する。特徴量分析部は、音声区間セグメントの音響特徴量分析を行い音響特徴量を出力する。代表特徴量抽出部は、音響特徴量から音声区間セグメントの代表特徴量を抽出する。セグメント分類部は、代表特徴量のそれぞれの間の距離を計算して距離に基づいて音声区間セグメントをクラスタに分類する。セグメント統合部は、隣接する上記音声区間セグメントが同一クラスタに属する場合に、隣接する音声区間セグメントを1個のセグメントとして統合する。
【解決手段】この発明の発話区間話者分類装置は、音量音声区間分割部と、特徴量分析部と、代表特徴量抽出部と、セグメント分類部と、セグメント統合部と、を具備する。音量音声区間分割部は、離散値化された音声信号の音声区間検出を行い音声区間セグメントを出力する。特徴量分析部は、音声区間セグメントの音響特徴量分析を行い音響特徴量を出力する。代表特徴量抽出部は、音響特徴量から音声区間セグメントの代表特徴量を抽出する。セグメント分類部は、代表特徴量のそれぞれの間の距離を計算して距離に基づいて音声区間セグメントをクラスタに分類する。セグメント統合部は、隣接する上記音声区間セグメントが同一クラスタに属する場合に、隣接する音声区間セグメントを1個のセグメントとして統合する。
【発明の詳細な説明】
【技術分野】
【0001】
この発明は、入力音声信号の発話区間を話者毎に分類する発話区間話者分類装置とその方法と、その装置を用いた音声認識装置とその方法と、プログラムと記録媒体に関する。
【背景技術】
【0002】
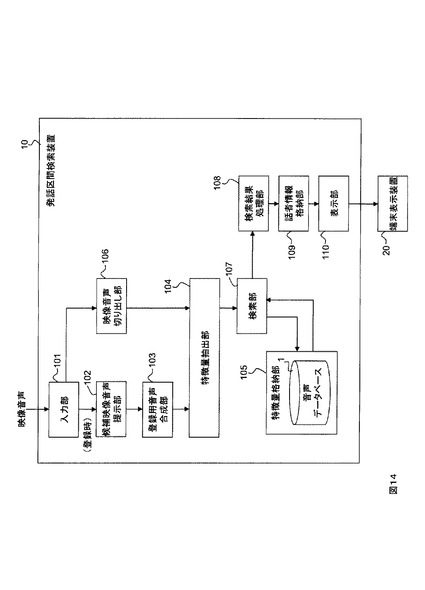
従来、複数話者による音声信号を話者毎に分類するためには、話者毎の音響特徴量を事前に登録する必要があった。図14に従来方法による発話区間検索装置の機能構成を示して簡単に説明する(特許文献1)。発話区間検索装置10は、入力部101、候補映像音声提示部102、登録用音声合成部103、特徴量抽出部104、特徴量格納部105、映像音声切り出し部106、検索部107、検索結果処理部108、話者情報格納部109、表示部110、端末表示装置20を備える。
【0003】
話者毎の音響特徴量を登録する時、候補映像音声提示部102は、入力された映像音声から一人が連続して一定時間話す区間を検出して利用者に提示する。利用者は登録する話者を選択する。登録用音声合成部103は、選択された複数人の登録話者音声から任意の組み合わせの音声を合成して特徴量抽出部104に出力する。特徴量抽出部104は、任意の組み合わせの登録話者音声の音響特徴量を抽出して、特徴量格納部105に記録する。
【0004】
話者を分類する時、映像音声切り出し部106は入力された映像音声を短時間毎に区切って切り出し、特徴量抽出部104に出力する。特徴量抽出部104は、切り出された音声の音響特徴量を抽出する。検索部107は、切り出された音声の音響特徴量と、特徴量格納部105に記録された登録話者音声の音響特徴量との類似計算を行い最も類似度が高い登録話者を話者とする。話者情報は話者情報格納部109に記録される。
【特許文献1】特開2004−145161号公報(図3)
【発明の開示】
【発明が解決しようとする課題】
【0005】
従来の発話区間検索装置では、複数の発話者の音声からなる音声信号を話者毎に分類するために事前に話者音声登録が必要であり、そのためのコストが発生していた。また必然的に特定話者に対応するので汎用性に欠ける問題点もあった。
【0006】
この発明は、このような問題点に鑑みてなされたものであり、事前の話者登録が無くても不特定話者に対応可能な発話区間話者分類装置とその方法と、また、その装置を用いた音声認識装置とその方法と、プログラムと記録媒体を提供することを目的とする。
【課題を解決するための手段】
【0007】
この発明の発話区間話者分類装置は、音量音声区間分割部と、特徴量分析部と、代表特徴量抽出部と、セグメント分類部と、セグメント統合部と、を具備する。音量音声区間分割部は、離散値化された音声信号の音声区間検出を行い音声区間セグメントを出力する。特徴量分析部は、音声区間セグメントの音響特徴量分析を行い音響特徴量を出力する。代表特徴量抽出部は、音響特徴量から音声区間セグメントの代表特徴量を抽出する。セグメント分類部は、代表特徴量のそれぞれの間の距離を計算して距離に基づいて音声区間セグメントをクラスタに分類する。セグメント統合部は、隣接する上記音声区間セグメントが同一クラスタに属する場合に、隣接する音声区間セグメントを1個のセグメントとして統合する。
【0008】
また、この発明の音声認識装置は、この発明の発話区間話者分類装置を含み、発話区間話者分類装置が出力するクラスタ毎に話者適応化処理を行う。
【発明の効果】
【0009】
この発明の発話区間話者分類装置は、音声信号を音声区間セグメントに分割し、各音声区間セグメントを代表する音響特徴量を代表特徴量として抽出する。そして、代表特徴量間の距離に基づいてクラスタに分類する。したがって、音声区間セグメントが音響特徴量に基づいて話者毎に分類される。つまり、事前に話者登録をすることなく自動的に話者分類を行うことが可能になる。
【0010】
また、この発明の音声認識装置は、事前に話者登録をしなくとも認識率の良い音声認識装置とすることが可能である。
【発明を実施するための最良の形態】
【0011】
以下、この発明の実施の形態を図面を参照して説明する。複数の図面中同一のものには同じ参照符号を付し、説明は繰り返さない。
【実施例1】
【0012】
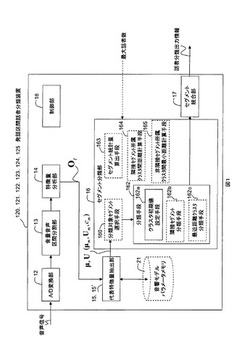
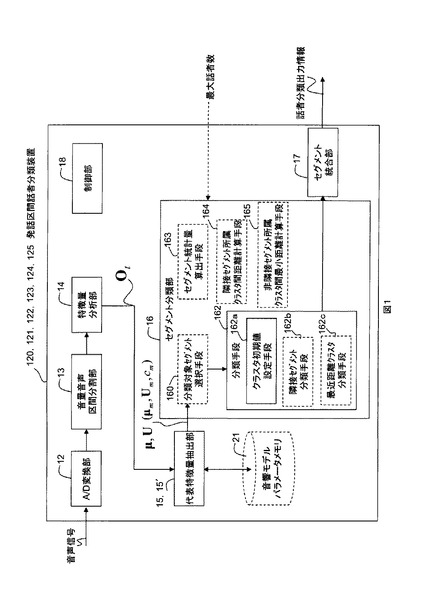
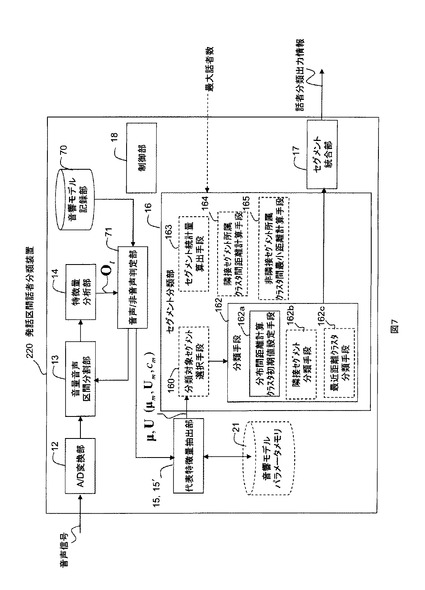
図1にこの発明の発話区間話者分類装置120の機能構成例を示す。その動作フローを図2に示す。発話区間話者分類装置120は、A/D変換部12と、音量音声区間分割部13と、特徴量分析部14と、代表特徴量抽出部15と、セグメント分類部16と、セグメント統合部17と、制御部18とを備える。発話区間話者分類装置120は、例えばROM、RAM、CPU等で構成されるコンピュータに所定のプログラムが読み込まれて、CPUがそのプログラムを実行することで実現されるものである。
【0013】
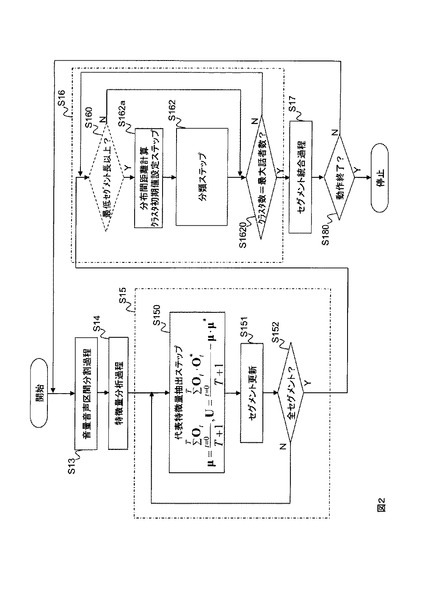
A/D変換部12は、入力されるアナログ信号の音声を、例えばサンプリング周波数16kHzで離散的なディジタル信号に変換する。音量音声区間分割部13は、ディジタル信号に変換された音声信号を、例えば320個の音声信号を1フレーム(20ms)としてフレーム毎に音量(パワー)に基づくに音声区間検出を行い、音声区間の始りと終わりに時刻情報を付した音声区間セグメントとして出力する。(ステップS13)。音量に基づく音声区間検出とは、ここでは、例えばフレームの平均パワーが閾値以上となったフレームの時刻を開始時刻、フレームの平均パワーが閾値未満となったフレーム時刻を終了時刻とした一区間を、音声区間セグメントとして出力することである。開始時刻と終了時刻をフレーム毎に判定すると、音声区間が細かくなり過ぎるのと、誤判定の原因になるので、開始時刻の前、終了時刻の後に例えば0.5秒程度の無音区間を含むようにする。
【0014】
特徴量分析部14は、音声区間セグメントのフレーム毎に、例えばメル周波数ケプストラム係数(MFCC)分析によって抽出された音響特徴量Otを出力する(ステップS14)。音響特徴量Otはベクトルであり、以降、ベクトルは式内では太字、本文中ではOt→のように変数の右肩に→を表記して表す。音響特徴量Ot→は、MFCC、POW、ΔMFCC、ΔPOW等の音声認識などに用いられる一般的なものである。
【0015】
代表特徴量抽出部15は、フレーム毎の音響特徴量から音声区間セグメントの代表特徴量を、式(1)によって抽出する(ステップS15)。
【0016】
【数1】

【0017】
ここで、Tは音声区間セグメントの時間幅、*は転置である。式(1)から明らかなように、代表特徴量は音声区間セグメントの特徴量の平均μ→と分散U→である(ステプS150)。代表特徴量は、分散U→を用いずに平均μ→だけを用いても良い。この代表特徴量(μ→,U→)は、音声区間セグメントが更新(ステップS151)され、全てのセグメントについて求められる(ステップS152のY)。
【0018】
セグメント分類部16は、全ての音声区間セグメント間の代表特徴量の距離に基づいて、音声区間セグメントをクラスタに分類する。ここで距離とは、代表特徴量を表すガウス分布(μ→,U→)の分布間の距離である。ガウス分布間の距離には、分布間の対数尤度比(差分)に基づくK-Lダイバージェンス(K-L Divergence)や、2つの分布の重なり度合いに基づく距離であるバタチャリア(Bhattacharyya)距離等の一般的な分布間距離尺度を用いる。例えばバタチャリア距離dBは、式(2)で計算できる。式(2)では、クラスタkの分散行列Ukは対角共分散行列としており、Iは次元数、第i次の平均,分散をμki,σ2kiと表記している。
【0019】
【数2】
【0020】
分布間距離尺度については、例えば参考文献、「音響モデルの分布数削減のための混合重み計数を考慮した分布間距離尺度」小川厚徳、高橋敏、電子情報通信学会論文誌 D Vol.J90-D No.10 pp.2940-2944に記載されている。
【0021】
分類手段162は、最もよく知られた分類方法の一つである例えばk-means法等を用いて、代表特徴量間の距離で音声区間セグメントをクラスタに分類する(ステップS162)k-means法については、例えば参考文献、「パターン認識と学習の統計学」甘利俊一ほか著、岩波書店、pp60にK-平均法として記載されている。
【0022】
分類手順の一例を説明する。最初に、分類手段162のクラスタ初期値設定手段162aが、全ての音声区間セグメント間の代表特徴量の距離を求め、最も距離が離れた2つの音声区間セグメントの代表特徴量を、2個の初期クラスタの中心値(セントロイド)とする(ステップS162a)。以降、全ての音声区間セグメントに対して、分類対象の音声区間セグメントの代表特徴量と、2個のクラスタの中心値との距離を計算し、近い方のクラスタに分類対象の音声区間セグメントを分類する(ステップS162)。全ての音声区間セグメントの分類が終わったら、各クラスタの代表特徴量を、各クラスタに所属する音声区間セグメントの代表特徴量とセグメント長に基づいて更新する。以上の動作をクラスタ間で音声区間セグメントの移動が無くなるまで行う。次に、2つのクラスタの中心値から最も離れた音声区間セグメントの代表特徴量を新たなクラスタの中心値として同様の分類を行い、クラスタ数を2から3へ増加させる。以上の処理をクラスタ数を増加させて、外部から与えられる最大話者数になるまで繰り返す(ステップS1620)。
【0023】
なお、外部から与えた最大話者数に基づいて分類過程(ステップS16)の分類動作を終了させる例で説明したが、音声信号内に含まれる話者数が、与えられた最大話者数よりも少ない場合には、余分なクラスタが出来てしまう。そこで、例えば、クラスタ数の増減により、各クラスタに所属する音声区間セグメントの代表特徴量と、各クラスタの中心値との距離の総和の変動が、与えられた閾値以下になった時に分類動作を終了させるようにしても良い。
【0024】
また、分類方法としては、全音声区間セグメントを初期クラスタとして距離の近いクラスタを統合してクラスタ数を減少させて行く方法もある。分類方法は、クラスタ数を増やして行くトップダウンクラスタリングでも、クラスタ数を減らして行くボトムアップクラスタリングでのどちらでも構わない。ただ、一般的な会議の場面を想定すると発話者が5人程度に限定される場合が多いので、クラスタを増加させるトップダウンクラスタリングの方が、音声区間セグメントの数が多い場合に効率的である。
【0025】
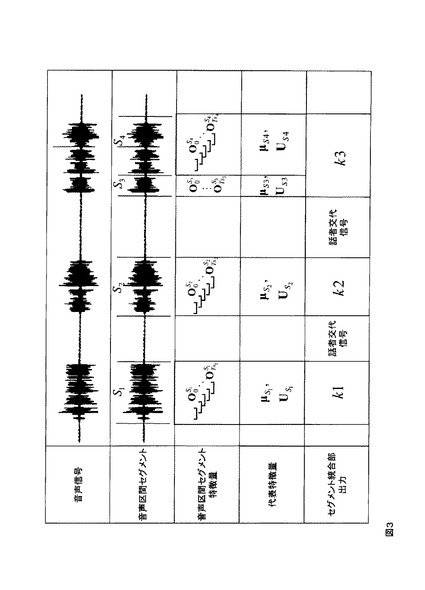
音声区間セグメントの時間幅が長いほど、音声区間セグメントを利用する例えば特に話者正規化や話者適応を行う音声認識装置の音声認識率を向上させることが出来る。そこで、セグメント統合部17は、同一クラスタに属する時刻情報が連続する音声区間セグメントを1個の音声区間セグメントとして統合(ステップS17)し、話者分類出力情報を出力する。話者分類出力情報とは、音声区間セグメントと、その開始/終了時刻情報と、クラスタ番号である。また、話者分類出力情報に話者交代信号を含めても良い。話者交代信号は、図3に示すようにクラスタ番号を出力する間のタイミングに出力しても良いし、音声区間セグメントにその情報を持たせるようにしても良い。
【0026】
以上説明した発話区間話者分類動作は、制御部18が動作終了を指示する信号を出力するまで継続される(ステップS180のN)。このように実施例1の発話区間話者分類装置120によれば、事前に話者登録をすることなく自動的に話者分類を行うことが可能である。
【0027】
図3に、以上説明した動作過程を示す。図3の横方向は経過時間であり、縦方向に上から順に、音声信号、音声区間セグメント、音声区間セグメント特徴量、代表特徴量、セグメント統合部17の出力を表す。音声信号は、経過時間軸上の3箇所に分散している。その音声信号は、音量音声区間分割部13において時刻情報が付された音声区間セグメントS1〜S4として出力される。3個目の音声信号の塊は、2つの音声区間セグメントS3とS4とからなる。各音声区間セグメントの前後には無音区間が付加されている。特徴量分析部14において、各音声区間セグメントを構成する各フレームの音響特徴量OtS1→,OtS2→,OtS3→,が求められる。
【0028】
代表特徴量抽出部15において、各音声区間セグメントの代表特徴量が式(1)で抽出される。音声区間セグメントS1の代表特徴量は(μS1→,US1→)、音声区間セグメントS2の代表特徴量は(μS2→,US2→)、音声区間セグメントS3とS4の代表特徴量は(μS3→,US3→)、(μS4→,US4→)である。音声区間セグメントS3とS4とは、同一の話者が発話を一時中断した後に再び発話した場合の例である。
【0029】
図3に示す例では、音声区間セグメントS1がクラスタC1に、音声区間セグメントS2がクラスタC2に、音声区間セグメントS3とS4がクラスタC3に分類される。クラスタは、音声区間セグメントの集合であるので、クラスタも代表特徴量を持つ。実際のクラスタは、複数の音声区間セグメントを含み、クラスタの代表特徴量の平均は、音声区間セグメントの代表特徴量の平均をセグメント長で重み付け平均した値となる。
【0030】
セグメント統合部17は、同一クラスタC3に属する音声区間セグメントS3とS4の時刻情報が連続するので1個の音声区間セグメントとして統合する。上記した例では、全ての音声区間セグメントを分類対象として説明を行ったが、時間幅の短い音声区間セグメントではフレーム数が少ないので平均や分散を安定して計算出来ない。よって、時間幅の短い音声区間セグメントから分類を始めると、その不安定性から適切な分類が行えない場合がある。そこで、初めに所定時間幅以上の音声区間セグメントについて分類を行う変形例を次に示して説明する。
【0031】
〔変形例1〕
変形例1の発話区間話者分類装置121の機能構成例を図1に示す。その動作フローを図2に示す。実施例1と異なる点は、セグメント分類部16に分類対象セグメント選択手段160を備える点である。分類対象セグメント選択手段160を図1中に破線で示す。動作フローも同じである。
【0032】
分類対象セグメント選択手段160は、予め定められた最低セグメント長以上の時間幅の音声区間セグメントを対象に分類手段162に分類させる(ステップS160のY)。最低セグメント長は、可変可能な値として外部から設定できるようにしても良いし、分類対象セグメント選択手段160に固定値として設定しておいても良い。例えば最低セグメント長を3秒に設定すると、最初に3秒以上の時間幅の音声区間セグメントがクラスタに分類されるので、クラスタの代表特徴量は話者の音響特徴量を反映した値になる。つまり、分類する音声区間セグメントの時間長が、一定幅以上あった方が、クラスタの中心値(セントロイド)が適切に設定されることになる。図2の動作フローでは省略しているが、クラスタの中心値(セントロイド)を適切に設定した後、時間幅の短い音声区間セグメントは、そのクラスタに対して分類される。
【0033】
このように所定時間幅以上の音声区間セグメントについて最初に分類することで、クラスタの中心値(セントロイド)が話者の音響特徴量に近い適切な値に設定される効果を奏する。
【0034】
〔変形例2〕
変形例1では、最低セグメント長を例えば3秒に設定した場合で説明を行ったが、その場合、例えば3秒以上連続した音声信号が無い場合は、全く分類されなくなってしまう。そこで、音量音声区間分割部13が出力する全ての音声区間セグメントの統計量を求め、その統計量から最低セグメント長を設定する方法が考えられる。その方法を変形例2として説明する。音声区間セグメントの統計量は、一般的な方法で計算できるので動作フローは省略する。
【0035】
変形例2の発話区間話者分類装置122の機能構成例を図1に示す。変形例1と異なる点は、セグメント分類部16にセグメント統計量算出手段163を備える点である。セグメント統計量算出部163は、音量音声区間分割部13が出力した音声区間セグメントの例えば平均値を算出するものである。その平均値は、分類対象セグメント選択手段160の最低セグメント長として設定される。統計量は平均値でなくても良い。例えば音声区間セグメントの時間幅の統計量の50%以上の任意の時間幅を最低セグメント長に設定しても良い。
【0036】
この変形例2によれば、実際の音声区間セグメントの時間長の統計量を基に最低セグメント長が設定されるので、クラスタの中心値(セントロイド)を適切に求めることが可能である。
【0037】
〔変形例3〕
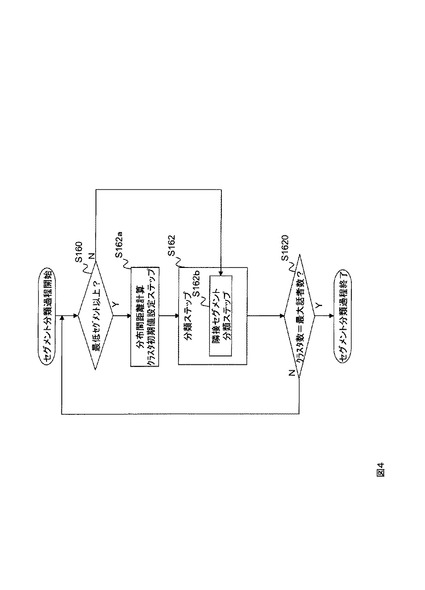
変形例3の発話区間話者分類装置123の機能構成例を図1に示す。その動作フローを図4に示す。変形例1,2と異なる点は、分類手段162が隣接セグメント分類手段162bを備える点である。変形例3の発話区間話者分類装置123は、最小セグメント長未満(ステップS160のN)の短音声区間セグメントを時刻情報が隣接する音声区間セグメントが属するクラスタに分類(ステップS162b)する点が異なる。この考えは、短音声区間セグメントは隣接する時間幅の長い音声区間セグメントに連結する可能性が高いとの前提に立って分類するものである。
【0038】
隣接セグメント分類手段162bは、時刻情報が隣接する前後の音声区間セグメントが属するクラスタのどちらに短音声区間セグメントを分類しても構わない。直前又は直後のどちらにするかは、事前に設定しておく。又は、隣接セグメント分類手段162bが、短音声区間セグメントが隣接する短音声区間セグメントで無い2つの音声区間セグメントが属するクラスタの代表特徴量と、短音声区間セグメントの代表特徴量との間の距離を比較し、近い方のクラスタに短音声区間セグメントを分類するようにしても良い。このようにすることで、短時間音声区間セグメントの発生を抑圧することが出来る。
【0039】
〔変形例4〕
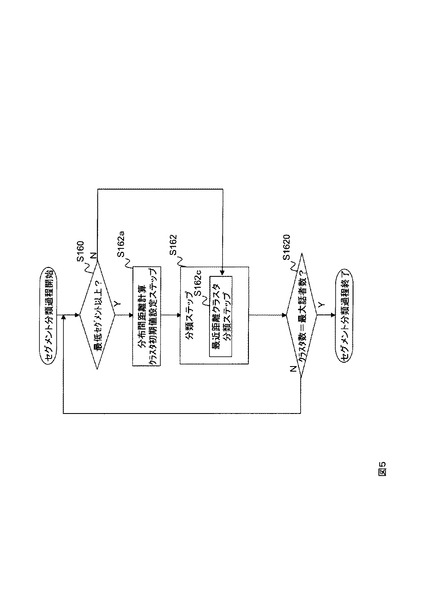
変形例4の発話区間話者分類装置124の機能構成例を図1に示す。その動作フローを図5に示す。変形例3と異なる点は、分類手段162が、隣接セグメント分類手段162aに替えて最近距離クラスタ分類手段162cを備える点である。最近距離クラスタ分類手段162cは、最小セグメント長未満(ステップS160のN)の短音声区間セグメントの代表特徴量と各クラスタの代表特徴量との距離を計算して、距離の最も近い最近距離クラスタに短音声区間セグメントを分類する。このようにすることで、変形例3よりも音響的に近いクラスタに短時間音声区間セグメントを分類することが出来る。
【0040】
〔変形例5〕
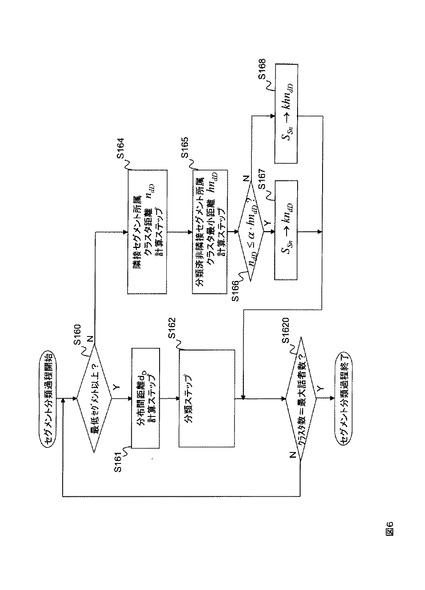
変形例5の発話区間話者分類装置125の機能構成例を図1に示す。その動作フローを図6に示す。変形例1乃至4と異なる点は、セグメント分類部16が隣接セグメント所属クラスタ間距離計算手段164と、非隣接セグメント所属クラスタ間最小距離計算手段165とを備える点である。隣接セグメント所属クラスタ間距離計算手段164は、分類対象の最低セグメント長未満の短音声区間セグメントSSnの時刻情報と時刻情報が隣接する音声区間セグメントを含むクラスタの代表特徴量との間の距離である隣接距離ndDを計算する(ステップS164)。
【0041】
非隣接セグメント所属クラスタ間最小距離計算手段165は、短音声区間セグメントの代表特徴量と全てのクラスタの代表特徴量との距離から、時刻情報が隣接しない音声区間セグメントを含むクラスタ間との最小非隣接距離hndDを計算する(ステップS165)。分類手段162は、最小非隣接距離に1より大きな重み係数を乗算した拡大非隣接距離と、上記隣接距離とを比較する(ステップS166)。隣接距離ndDが非隣接距離hndD以下の場合は、短音声区間セグメントSSnを隣接距離ndDのクラスタkndDに分類する(ステップS167)。逆に隣接距離ndDが非隣接距離hndDよりも大きい場合は、短音声区間セグメントSSnを非隣接距離hndDのクラスタkhndDに分類する(ステップS168)。つまり、時刻情報が隣接する音声区間セグメントを含むクラスタに分類し易くする。
【0042】
このようにすることで短音声区間セグメントをより適切に分類することが可能である。以上述べた実施例1と各変形例は、音声区間セグメントの代表特徴量を1個のガウス分布で表現する例で説明したが、代表特徴量を混合正規分布モデル(音声GMM)で表現しても良い。混合正規分布モデルを用いた発話区間話者分類装置126は、音響モデルパラメータメモリ21を備える。代表特徴量抽出部15′は、音響特徴量OtSn→に対する音響モデルの出力確率スコアと、各混合正規分布モデルの事後確率値γとから適応化処理によって代表特徴量を抽出する。出力確率スコアSsp(OtSn→)は式(3)、事後確率値γ(OtSn→,m)は式(4)で計算出来る。
【0043】
【数3】
【0044】
ここでmは分布番号、Mは混合分布数、cは混合分布重み係数である。適応後のセグメ
ント代表特徴量の平均ベクトルμadapt→は式(5)、分散ベクトルUadapt→は式(6)、混合重み係数cadaptは式(7)で計算出来る。*は転置である。
【0045】
【数4】
【0046】
このように混合正規分布モデルを用いて求めた代表特徴量は、1個のガウス分布から求
めた値よりも、より音響特徴量OtSn→に対応した精度の高い値にすることが出来る。その結果、話者分類の精度も向上させることが出来る。
【実施例2】
【0047】
図7に音響モデルを用いて音声区間セグメントのフレーム毎に音声/非音声判定を行うようにした発話区間話者分類装置220の機能構成例を示す。動作フローを図8に示す。発話区間話者分類装置220は、音響モデル記録部70と、音声/非音声判定部71とを備える点が実施例1と異なる。他の構成は実施例1と同じである。音声/非音声判定部71は、特徴量分析部14から入力される音響特徴量Ot→に対してフレーム毎に音響モデル記録部70に記録された音声モデルと非音声モデルとを用いて音声/非音声判定を行う。その音声/非音声判定結果に基づいて、音量音声区間分割部13は時刻情報を付した音声区間セグメントに分割する。
【0048】
音声/非音声判定部71は、フレーム毎の音響特徴量Ot→に対して音声モデルの出力確率スコアSsp(Ot→)を式(8)で計算する(ステップS710)。同様に、非音声モデルの出力確率スコアSnsp(Ot→)を式(9)で計算する(ステップS711)。
【0049】
【数5】
【0050】
ここでmは分布番号、Mは混合分布数、Jは状態数、jは状態番号、cは混合分布重み計数、N(・)は平均μと分散Uの正規分布に基づく音響特徴量Ot→から得られるスコアである。音声モデルの出力確率スコアSsp(Ot→)と、非音声モデルの出力確率スコアSnsp(Ot→)とを比較し、出力確率スコアSsp(Ot→)が大きければ音声区間と判定(ステップS712のY)し、非音声区間を計数する非音声連続時間Nstをリセット(ステップS713)して、音量音声区間分割部13に音声区間のスタートを指示する(ステップS714)。そしてフレームを更新(ステップS719)して、次フレームの出力確率スコアを計算する(ステップS710,S711)。
【0051】
音声モデルの出力確率スコアSsp(Ot→)よりも、非音声モデルの出力確率スコアSnsp(Ot→)が大きい場合は非音声区間と判定(ステップS712のN)し、非音声区間が所定時間のTNst(閾値)以上か否かを判断する(ステップS715)。TNstは例えば0.3秒程度の時間である。非音声区間がTNst未満の場合は、非音声連続時間Nstにフレーム時刻tを加算(ステップS716)して次フレームの処理を行う。非音声連続時間NstがTNst以上の場合(ステップS715のY)は、非音声連続時間Nstをリセットして音量音声区間分割部13に音声区間の終了を指示する(ステップS718)。このように音声/非音声判定部71が動作することで、非音声モデルの出力確率スコアSnsp(Ot→)の大きいフレームが非音声連続時間Nst以上の時間継続すると、1個の音声区間セグメントが出力される。つまり、非音声区間がTNst以上の時間連続して初めて音声区間セグメントが終了する。一方音声区間セグメントの開始は、この例の場合、音声モデルの出力確率スコアSsp(Ot→)が大であれば、そのフレームが直ちに音声区間セグメントのスタートとされる。
【0052】
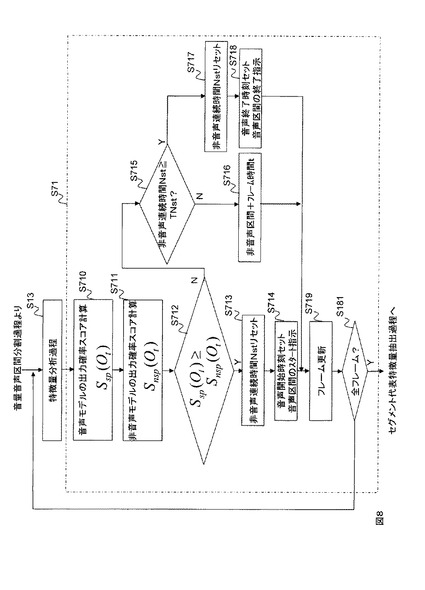
以上のように音声/非音声の判定を音響モデルを用いて行うことで、パワーの大小で音声区間セグメントを分割した実施例1よりも精度の高い音声区間セグメントを生成することが可能である。この実施例2の方法で音声区間セグメントを生成した一例を図9に示す。図9の横方向は経過時間であり、縦方向は音声信号のパワーである。音声信号がある時間内に密集している。実施例1の方法では1個の音声区間セグメントとして出力したこの音声信号も、実施例2の方法であれば例えば4個の音声区間セグメントとして出力することが可能である。図9は、経過時間順の代表特徴量が(μS1→,US1→)、(μS1→,US1→)、
(μS3→,US3→)、(μS2→,US2→)と変化する様子を例示している。
【0053】
〔音声認識装置〕
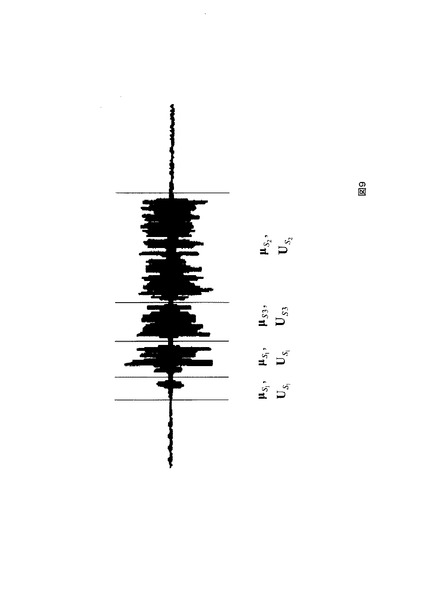
上記した発話区間話者分類装置は、音声認識装置に応用が可能である。図10に、音声区間話者分類装置120乃至125の何れか1つを用いて音声認識装置500を構成した場合の機能構成例を示す。音声認識装置500は、発話区間話者分類装置と、音声認識部90と、言語モデルパラメータメモリ91と、音響モデルパラメータメモリ92と、制御部95とを備える。音声認識装置500は、この発明の音声区間話者分類装置を用いたところに特徴があり、他の構成は一般的な音声認識装置と同じである。この発明の音声認識装置は、音響モデルの適応化処理方法に特徴がある。
【0054】
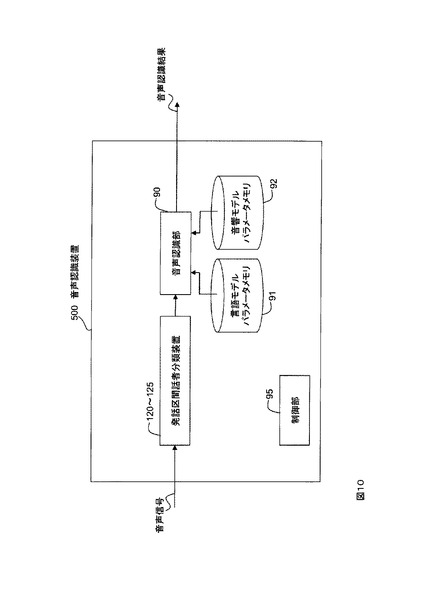
その適応化処理方法を動作フローを示して説明する。図11に発話区間話者分類装置が分類したクラスタ毎に適応化処理を行う動作フローを示す。発話区間話者分類装置で話者分類した結果のクラスタは、話者に対応しているので、そのクラスタ毎に話者正規化/適応を行って(ステップS90、図11)、音声認識(ステップS91)することで認識精度を向上させることが可能になる。
【0055】
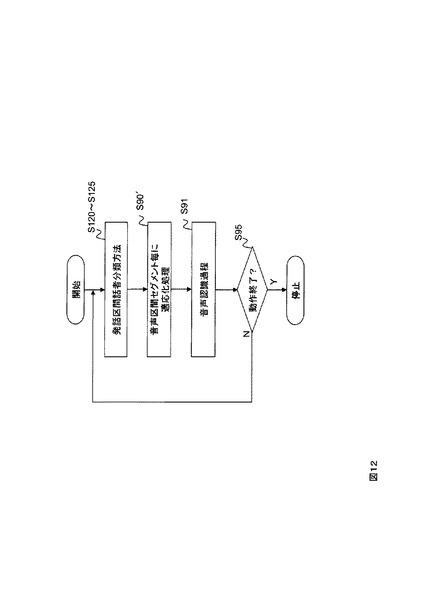
また、話者正規化/適応をクラスタ内の音声区間セグメント毎に行う方法も考えられえる。音声区間セグメント毎に適応化処理(ステップS90′、図12)行うことで異なる話者の音響データが混入する危険を減少させられる。その結果、より認識精度を向上させることが可能になる。
【0056】
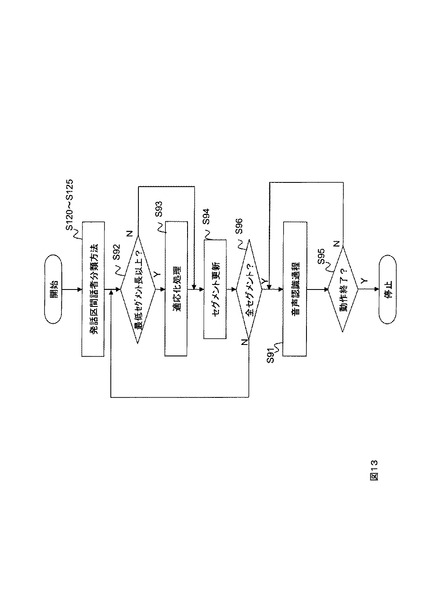
また、最低セグメント長以下の短音声区間セグメントについては、フレーム数が少ないので平均や分散を安定して計算出来ないことから分類誤りが発生し易い。そこで、短音声区間セグメントについては適応化処理を行わないようにすることで、分類誤りの影響を低減することが可能である。その考えの動作フローを図13に示す。ステップS92で最低セグメント長を確認して最低セグメント長以上(ステップS92のY)の音声区間セグメントを用いて適応化処理(ステップS93)を行う。このようにすることで、認識精度を向上させることが可能である。このようにこの発明の発話区間話者分類装置を利用することで、事前の話者登録をしなくても認識精度の高い音声認識装置を実現することが出来る。
【0057】
この発明の技術思想に基づく発話区間話者分類装置とその方法と、それを用いた音声認識装置は、上述の実施形態に限定されるものではなく、この発明の趣旨を逸脱しない範囲で適宜変更が可能である。上記した装置及び方法において説明した処理は、記載の順に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されるとしてもよい。
【0058】
また、上記装置における処理手段をコンピュータによって実現する場合、各装置が有すべき機能の処理内容はプログラムによって記述される。そして、このプログラムをコンピュータで実行することにより、各装置における処理手段がコンピュータ上で実現される。
【0059】
この処理内容を記述したプログラムは、コンピュータで読み取り可能な記録媒体に記録しておくことができる。コンピュータで読み取り可能な記録媒体としては、例えば、磁気記録装置、光ディスク、光磁気記録媒体、半導体メモリ等どのようなものでもよい。具体的には、例えば、磁気記録装置として、ハードディスク装置、フレキシブルディスク、磁気テープ等を、光ディスクとして、DVD(Digital Versatile Disc)、DVD-RAM(Random Access Memory)、CD-ROM(Compact Disc Read Only Memory)、CD-R(Recordable)/RW(ReWritable)等を、光磁気記録媒体として、MO(Magneto Optical disc)等を、半導体メモリとしてフラッシュメモリー等を用いることができる。
【0060】
また、このプログラムの流通は、例えば、そのプログラムを記録したDVD、CD−ROM等の可搬型記録媒体を販売、譲渡、貸与等することによって行う。さらに、このプログラムをサーバコンピュータの記録装置に格納しておき、ネットワークを介して、サーバコンピュータから他のコンピュータにそのプログラムを転送することにより、このプログラムを流通させる構成としてもよい。
【0061】
また、各手段は、コンピュータ上で所定のプログラムを実行させることにより構成することにしてもよいし、これらの処理内容の少なくとも一部をハードウェア的に実現することとしてもよい。
【図面の簡単な説明】
【0062】
【図1】この発明の発話区間話者分類装置120〜125の機能構成例を示す図。
【図2】発話区間話者分類装置120の動作フローを示す図。
【図3】発話区間話者分類装置120の動作過程を図形として示す図。
【図4】発話区間話者分類装置123のセグメント分類過程の動作フローを示す図。
【図5】発話区間話者分類装置124のセグメント分類過程の動作フローを示す図。
【図6】発話区間話者分類装置125のセグメント分類過程の動作フローを示す図。
【図7】この発明の発話区間話者分類装置220の機能構成例を示す図。
【図8】発話区間話者分類装置220の音声/非音声判定部71の動作フローを示す図。
【図9】実施例2の方法で音声区間セグメントを生成した一例を示す図。
【図10】音声認識装置500の機能構成例を示す図。
【図11】音声認識装置500の音響モデルの適応化処理方法の一例を示す図。
【図12】音声認識装置500の音響モデルの適応化処理方法の一例を示す図。
【図13】音声認識装置500の音響モデルの適応化処理方法の一例を示す図。
【図14】従来方法の発話区間検索装置10の機能構成を示す図。
【技術分野】
【0001】
この発明は、入力音声信号の発話区間を話者毎に分類する発話区間話者分類装置とその方法と、その装置を用いた音声認識装置とその方法と、プログラムと記録媒体に関する。
【背景技術】
【0002】
従来、複数話者による音声信号を話者毎に分類するためには、話者毎の音響特徴量を事前に登録する必要があった。図14に従来方法による発話区間検索装置の機能構成を示して簡単に説明する(特許文献1)。発話区間検索装置10は、入力部101、候補映像音声提示部102、登録用音声合成部103、特徴量抽出部104、特徴量格納部105、映像音声切り出し部106、検索部107、検索結果処理部108、話者情報格納部109、表示部110、端末表示装置20を備える。
【0003】
話者毎の音響特徴量を登録する時、候補映像音声提示部102は、入力された映像音声から一人が連続して一定時間話す区間を検出して利用者に提示する。利用者は登録する話者を選択する。登録用音声合成部103は、選択された複数人の登録話者音声から任意の組み合わせの音声を合成して特徴量抽出部104に出力する。特徴量抽出部104は、任意の組み合わせの登録話者音声の音響特徴量を抽出して、特徴量格納部105に記録する。
【0004】
話者を分類する時、映像音声切り出し部106は入力された映像音声を短時間毎に区切って切り出し、特徴量抽出部104に出力する。特徴量抽出部104は、切り出された音声の音響特徴量を抽出する。検索部107は、切り出された音声の音響特徴量と、特徴量格納部105に記録された登録話者音声の音響特徴量との類似計算を行い最も類似度が高い登録話者を話者とする。話者情報は話者情報格納部109に記録される。
【特許文献1】特開2004−145161号公報(図3)
【発明の開示】
【発明が解決しようとする課題】
【0005】
従来の発話区間検索装置では、複数の発話者の音声からなる音声信号を話者毎に分類するために事前に話者音声登録が必要であり、そのためのコストが発生していた。また必然的に特定話者に対応するので汎用性に欠ける問題点もあった。
【0006】
この発明は、このような問題点に鑑みてなされたものであり、事前の話者登録が無くても不特定話者に対応可能な発話区間話者分類装置とその方法と、また、その装置を用いた音声認識装置とその方法と、プログラムと記録媒体を提供することを目的とする。
【課題を解決するための手段】
【0007】
この発明の発話区間話者分類装置は、音量音声区間分割部と、特徴量分析部と、代表特徴量抽出部と、セグメント分類部と、セグメント統合部と、を具備する。音量音声区間分割部は、離散値化された音声信号の音声区間検出を行い音声区間セグメントを出力する。特徴量分析部は、音声区間セグメントの音響特徴量分析を行い音響特徴量を出力する。代表特徴量抽出部は、音響特徴量から音声区間セグメントの代表特徴量を抽出する。セグメント分類部は、代表特徴量のそれぞれの間の距離を計算して距離に基づいて音声区間セグメントをクラスタに分類する。セグメント統合部は、隣接する上記音声区間セグメントが同一クラスタに属する場合に、隣接する音声区間セグメントを1個のセグメントとして統合する。
【0008】
また、この発明の音声認識装置は、この発明の発話区間話者分類装置を含み、発話区間話者分類装置が出力するクラスタ毎に話者適応化処理を行う。
【発明の効果】
【0009】
この発明の発話区間話者分類装置は、音声信号を音声区間セグメントに分割し、各音声区間セグメントを代表する音響特徴量を代表特徴量として抽出する。そして、代表特徴量間の距離に基づいてクラスタに分類する。したがって、音声区間セグメントが音響特徴量に基づいて話者毎に分類される。つまり、事前に話者登録をすることなく自動的に話者分類を行うことが可能になる。
【0010】
また、この発明の音声認識装置は、事前に話者登録をしなくとも認識率の良い音声認識装置とすることが可能である。
【発明を実施するための最良の形態】
【0011】
以下、この発明の実施の形態を図面を参照して説明する。複数の図面中同一のものには同じ参照符号を付し、説明は繰り返さない。
【実施例1】
【0012】
図1にこの発明の発話区間話者分類装置120の機能構成例を示す。その動作フローを図2に示す。発話区間話者分類装置120は、A/D変換部12と、音量音声区間分割部13と、特徴量分析部14と、代表特徴量抽出部15と、セグメント分類部16と、セグメント統合部17と、制御部18とを備える。発話区間話者分類装置120は、例えばROM、RAM、CPU等で構成されるコンピュータに所定のプログラムが読み込まれて、CPUがそのプログラムを実行することで実現されるものである。
【0013】
A/D変換部12は、入力されるアナログ信号の音声を、例えばサンプリング周波数16kHzで離散的なディジタル信号に変換する。音量音声区間分割部13は、ディジタル信号に変換された音声信号を、例えば320個の音声信号を1フレーム(20ms)としてフレーム毎に音量(パワー)に基づくに音声区間検出を行い、音声区間の始りと終わりに時刻情報を付した音声区間セグメントとして出力する。(ステップS13)。音量に基づく音声区間検出とは、ここでは、例えばフレームの平均パワーが閾値以上となったフレームの時刻を開始時刻、フレームの平均パワーが閾値未満となったフレーム時刻を終了時刻とした一区間を、音声区間セグメントとして出力することである。開始時刻と終了時刻をフレーム毎に判定すると、音声区間が細かくなり過ぎるのと、誤判定の原因になるので、開始時刻の前、終了時刻の後に例えば0.5秒程度の無音区間を含むようにする。
【0014】
特徴量分析部14は、音声区間セグメントのフレーム毎に、例えばメル周波数ケプストラム係数(MFCC)分析によって抽出された音響特徴量Otを出力する(ステップS14)。音響特徴量Otはベクトルであり、以降、ベクトルは式内では太字、本文中ではOt→のように変数の右肩に→を表記して表す。音響特徴量Ot→は、MFCC、POW、ΔMFCC、ΔPOW等の音声認識などに用いられる一般的なものである。
【0015】
代表特徴量抽出部15は、フレーム毎の音響特徴量から音声区間セグメントの代表特徴量を、式(1)によって抽出する(ステップS15)。
【0016】
【数1】
【0017】
ここで、Tは音声区間セグメントの時間幅、*は転置である。式(1)から明らかなように、代表特徴量は音声区間セグメントの特徴量の平均μ→と分散U→である(ステプS150)。代表特徴量は、分散U→を用いずに平均μ→だけを用いても良い。この代表特徴量(μ→,U→)は、音声区間セグメントが更新(ステップS151)され、全てのセグメントについて求められる(ステップS152のY)。
【0018】
セグメント分類部16は、全ての音声区間セグメント間の代表特徴量の距離に基づいて、音声区間セグメントをクラスタに分類する。ここで距離とは、代表特徴量を表すガウス分布(μ→,U→)の分布間の距離である。ガウス分布間の距離には、分布間の対数尤度比(差分)に基づくK-Lダイバージェンス(K-L Divergence)や、2つの分布の重なり度合いに基づく距離であるバタチャリア(Bhattacharyya)距離等の一般的な分布間距離尺度を用いる。例えばバタチャリア距離dBは、式(2)で計算できる。式(2)では、クラスタkの分散行列Ukは対角共分散行列としており、Iは次元数、第i次の平均,分散をμki,σ2kiと表記している。
【0019】
【数2】
【0020】
分布間距離尺度については、例えば参考文献、「音響モデルの分布数削減のための混合重み計数を考慮した分布間距離尺度」小川厚徳、高橋敏、電子情報通信学会論文誌 D Vol.J90-D No.10 pp.2940-2944に記載されている。
【0021】
分類手段162は、最もよく知られた分類方法の一つである例えばk-means法等を用いて、代表特徴量間の距離で音声区間セグメントをクラスタに分類する(ステップS162)k-means法については、例えば参考文献、「パターン認識と学習の統計学」甘利俊一ほか著、岩波書店、pp60にK-平均法として記載されている。
【0022】
分類手順の一例を説明する。最初に、分類手段162のクラスタ初期値設定手段162aが、全ての音声区間セグメント間の代表特徴量の距離を求め、最も距離が離れた2つの音声区間セグメントの代表特徴量を、2個の初期クラスタの中心値(セントロイド)とする(ステップS162a)。以降、全ての音声区間セグメントに対して、分類対象の音声区間セグメントの代表特徴量と、2個のクラスタの中心値との距離を計算し、近い方のクラスタに分類対象の音声区間セグメントを分類する(ステップS162)。全ての音声区間セグメントの分類が終わったら、各クラスタの代表特徴量を、各クラスタに所属する音声区間セグメントの代表特徴量とセグメント長に基づいて更新する。以上の動作をクラスタ間で音声区間セグメントの移動が無くなるまで行う。次に、2つのクラスタの中心値から最も離れた音声区間セグメントの代表特徴量を新たなクラスタの中心値として同様の分類を行い、クラスタ数を2から3へ増加させる。以上の処理をクラスタ数を増加させて、外部から与えられる最大話者数になるまで繰り返す(ステップS1620)。
【0023】
なお、外部から与えた最大話者数に基づいて分類過程(ステップS16)の分類動作を終了させる例で説明したが、音声信号内に含まれる話者数が、与えられた最大話者数よりも少ない場合には、余分なクラスタが出来てしまう。そこで、例えば、クラスタ数の増減により、各クラスタに所属する音声区間セグメントの代表特徴量と、各クラスタの中心値との距離の総和の変動が、与えられた閾値以下になった時に分類動作を終了させるようにしても良い。
【0024】
また、分類方法としては、全音声区間セグメントを初期クラスタとして距離の近いクラスタを統合してクラスタ数を減少させて行く方法もある。分類方法は、クラスタ数を増やして行くトップダウンクラスタリングでも、クラスタ数を減らして行くボトムアップクラスタリングでのどちらでも構わない。ただ、一般的な会議の場面を想定すると発話者が5人程度に限定される場合が多いので、クラスタを増加させるトップダウンクラスタリングの方が、音声区間セグメントの数が多い場合に効率的である。
【0025】
音声区間セグメントの時間幅が長いほど、音声区間セグメントを利用する例えば特に話者正規化や話者適応を行う音声認識装置の音声認識率を向上させることが出来る。そこで、セグメント統合部17は、同一クラスタに属する時刻情報が連続する音声区間セグメントを1個の音声区間セグメントとして統合(ステップS17)し、話者分類出力情報を出力する。話者分類出力情報とは、音声区間セグメントと、その開始/終了時刻情報と、クラスタ番号である。また、話者分類出力情報に話者交代信号を含めても良い。話者交代信号は、図3に示すようにクラスタ番号を出力する間のタイミングに出力しても良いし、音声区間セグメントにその情報を持たせるようにしても良い。
【0026】
以上説明した発話区間話者分類動作は、制御部18が動作終了を指示する信号を出力するまで継続される(ステップS180のN)。このように実施例1の発話区間話者分類装置120によれば、事前に話者登録をすることなく自動的に話者分類を行うことが可能である。
【0027】
図3に、以上説明した動作過程を示す。図3の横方向は経過時間であり、縦方向に上から順に、音声信号、音声区間セグメント、音声区間セグメント特徴量、代表特徴量、セグメント統合部17の出力を表す。音声信号は、経過時間軸上の3箇所に分散している。その音声信号は、音量音声区間分割部13において時刻情報が付された音声区間セグメントS1〜S4として出力される。3個目の音声信号の塊は、2つの音声区間セグメントS3とS4とからなる。各音声区間セグメントの前後には無音区間が付加されている。特徴量分析部14において、各音声区間セグメントを構成する各フレームの音響特徴量OtS1→,OtS2→,OtS3→,が求められる。
【0028】
代表特徴量抽出部15において、各音声区間セグメントの代表特徴量が式(1)で抽出される。音声区間セグメントS1の代表特徴量は(μS1→,US1→)、音声区間セグメントS2の代表特徴量は(μS2→,US2→)、音声区間セグメントS3とS4の代表特徴量は(μS3→,US3→)、(μS4→,US4→)である。音声区間セグメントS3とS4とは、同一の話者が発話を一時中断した後に再び発話した場合の例である。
【0029】
図3に示す例では、音声区間セグメントS1がクラスタC1に、音声区間セグメントS2がクラスタC2に、音声区間セグメントS3とS4がクラスタC3に分類される。クラスタは、音声区間セグメントの集合であるので、クラスタも代表特徴量を持つ。実際のクラスタは、複数の音声区間セグメントを含み、クラスタの代表特徴量の平均は、音声区間セグメントの代表特徴量の平均をセグメント長で重み付け平均した値となる。
【0030】
セグメント統合部17は、同一クラスタC3に属する音声区間セグメントS3とS4の時刻情報が連続するので1個の音声区間セグメントとして統合する。上記した例では、全ての音声区間セグメントを分類対象として説明を行ったが、時間幅の短い音声区間セグメントではフレーム数が少ないので平均や分散を安定して計算出来ない。よって、時間幅の短い音声区間セグメントから分類を始めると、その不安定性から適切な分類が行えない場合がある。そこで、初めに所定時間幅以上の音声区間セグメントについて分類を行う変形例を次に示して説明する。
【0031】
〔変形例1〕
変形例1の発話区間話者分類装置121の機能構成例を図1に示す。その動作フローを図2に示す。実施例1と異なる点は、セグメント分類部16に分類対象セグメント選択手段160を備える点である。分類対象セグメント選択手段160を図1中に破線で示す。動作フローも同じである。
【0032】
分類対象セグメント選択手段160は、予め定められた最低セグメント長以上の時間幅の音声区間セグメントを対象に分類手段162に分類させる(ステップS160のY)。最低セグメント長は、可変可能な値として外部から設定できるようにしても良いし、分類対象セグメント選択手段160に固定値として設定しておいても良い。例えば最低セグメント長を3秒に設定すると、最初に3秒以上の時間幅の音声区間セグメントがクラスタに分類されるので、クラスタの代表特徴量は話者の音響特徴量を反映した値になる。つまり、分類する音声区間セグメントの時間長が、一定幅以上あった方が、クラスタの中心値(セントロイド)が適切に設定されることになる。図2の動作フローでは省略しているが、クラスタの中心値(セントロイド)を適切に設定した後、時間幅の短い音声区間セグメントは、そのクラスタに対して分類される。
【0033】
このように所定時間幅以上の音声区間セグメントについて最初に分類することで、クラスタの中心値(セントロイド)が話者の音響特徴量に近い適切な値に設定される効果を奏する。
【0034】
〔変形例2〕
変形例1では、最低セグメント長を例えば3秒に設定した場合で説明を行ったが、その場合、例えば3秒以上連続した音声信号が無い場合は、全く分類されなくなってしまう。そこで、音量音声区間分割部13が出力する全ての音声区間セグメントの統計量を求め、その統計量から最低セグメント長を設定する方法が考えられる。その方法を変形例2として説明する。音声区間セグメントの統計量は、一般的な方法で計算できるので動作フローは省略する。
【0035】
変形例2の発話区間話者分類装置122の機能構成例を図1に示す。変形例1と異なる点は、セグメント分類部16にセグメント統計量算出手段163を備える点である。セグメント統計量算出部163は、音量音声区間分割部13が出力した音声区間セグメントの例えば平均値を算出するものである。その平均値は、分類対象セグメント選択手段160の最低セグメント長として設定される。統計量は平均値でなくても良い。例えば音声区間セグメントの時間幅の統計量の50%以上の任意の時間幅を最低セグメント長に設定しても良い。
【0036】
この変形例2によれば、実際の音声区間セグメントの時間長の統計量を基に最低セグメント長が設定されるので、クラスタの中心値(セントロイド)を適切に求めることが可能である。
【0037】
〔変形例3〕
変形例3の発話区間話者分類装置123の機能構成例を図1に示す。その動作フローを図4に示す。変形例1,2と異なる点は、分類手段162が隣接セグメント分類手段162bを備える点である。変形例3の発話区間話者分類装置123は、最小セグメント長未満(ステップS160のN)の短音声区間セグメントを時刻情報が隣接する音声区間セグメントが属するクラスタに分類(ステップS162b)する点が異なる。この考えは、短音声区間セグメントは隣接する時間幅の長い音声区間セグメントに連結する可能性が高いとの前提に立って分類するものである。
【0038】
隣接セグメント分類手段162bは、時刻情報が隣接する前後の音声区間セグメントが属するクラスタのどちらに短音声区間セグメントを分類しても構わない。直前又は直後のどちらにするかは、事前に設定しておく。又は、隣接セグメント分類手段162bが、短音声区間セグメントが隣接する短音声区間セグメントで無い2つの音声区間セグメントが属するクラスタの代表特徴量と、短音声区間セグメントの代表特徴量との間の距離を比較し、近い方のクラスタに短音声区間セグメントを分類するようにしても良い。このようにすることで、短時間音声区間セグメントの発生を抑圧することが出来る。
【0039】
〔変形例4〕
変形例4の発話区間話者分類装置124の機能構成例を図1に示す。その動作フローを図5に示す。変形例3と異なる点は、分類手段162が、隣接セグメント分類手段162aに替えて最近距離クラスタ分類手段162cを備える点である。最近距離クラスタ分類手段162cは、最小セグメント長未満(ステップS160のN)の短音声区間セグメントの代表特徴量と各クラスタの代表特徴量との距離を計算して、距離の最も近い最近距離クラスタに短音声区間セグメントを分類する。このようにすることで、変形例3よりも音響的に近いクラスタに短時間音声区間セグメントを分類することが出来る。
【0040】
〔変形例5〕
変形例5の発話区間話者分類装置125の機能構成例を図1に示す。その動作フローを図6に示す。変形例1乃至4と異なる点は、セグメント分類部16が隣接セグメント所属クラスタ間距離計算手段164と、非隣接セグメント所属クラスタ間最小距離計算手段165とを備える点である。隣接セグメント所属クラスタ間距離計算手段164は、分類対象の最低セグメント長未満の短音声区間セグメントSSnの時刻情報と時刻情報が隣接する音声区間セグメントを含むクラスタの代表特徴量との間の距離である隣接距離ndDを計算する(ステップS164)。
【0041】
非隣接セグメント所属クラスタ間最小距離計算手段165は、短音声区間セグメントの代表特徴量と全てのクラスタの代表特徴量との距離から、時刻情報が隣接しない音声区間セグメントを含むクラスタ間との最小非隣接距離hndDを計算する(ステップS165)。分類手段162は、最小非隣接距離に1より大きな重み係数を乗算した拡大非隣接距離と、上記隣接距離とを比較する(ステップS166)。隣接距離ndDが非隣接距離hndD以下の場合は、短音声区間セグメントSSnを隣接距離ndDのクラスタkndDに分類する(ステップS167)。逆に隣接距離ndDが非隣接距離hndDよりも大きい場合は、短音声区間セグメントSSnを非隣接距離hndDのクラスタkhndDに分類する(ステップS168)。つまり、時刻情報が隣接する音声区間セグメントを含むクラスタに分類し易くする。
【0042】
このようにすることで短音声区間セグメントをより適切に分類することが可能である。以上述べた実施例1と各変形例は、音声区間セグメントの代表特徴量を1個のガウス分布で表現する例で説明したが、代表特徴量を混合正規分布モデル(音声GMM)で表現しても良い。混合正規分布モデルを用いた発話区間話者分類装置126は、音響モデルパラメータメモリ21を備える。代表特徴量抽出部15′は、音響特徴量OtSn→に対する音響モデルの出力確率スコアと、各混合正規分布モデルの事後確率値γとから適応化処理によって代表特徴量を抽出する。出力確率スコアSsp(OtSn→)は式(3)、事後確率値γ(OtSn→,m)は式(4)で計算出来る。
【0043】
【数3】
【0044】
ここでmは分布番号、Mは混合分布数、cは混合分布重み係数である。適応後のセグメ
ント代表特徴量の平均ベクトルμadapt→は式(5)、分散ベクトルUadapt→は式(6)、混合重み係数cadaptは式(7)で計算出来る。*は転置である。
【0045】
【数4】
【0046】
このように混合正規分布モデルを用いて求めた代表特徴量は、1個のガウス分布から求
めた値よりも、より音響特徴量OtSn→に対応した精度の高い値にすることが出来る。その結果、話者分類の精度も向上させることが出来る。
【実施例2】
【0047】
図7に音響モデルを用いて音声区間セグメントのフレーム毎に音声/非音声判定を行うようにした発話区間話者分類装置220の機能構成例を示す。動作フローを図8に示す。発話区間話者分類装置220は、音響モデル記録部70と、音声/非音声判定部71とを備える点が実施例1と異なる。他の構成は実施例1と同じである。音声/非音声判定部71は、特徴量分析部14から入力される音響特徴量Ot→に対してフレーム毎に音響モデル記録部70に記録された音声モデルと非音声モデルとを用いて音声/非音声判定を行う。その音声/非音声判定結果に基づいて、音量音声区間分割部13は時刻情報を付した音声区間セグメントに分割する。
【0048】
音声/非音声判定部71は、フレーム毎の音響特徴量Ot→に対して音声モデルの出力確率スコアSsp(Ot→)を式(8)で計算する(ステップS710)。同様に、非音声モデルの出力確率スコアSnsp(Ot→)を式(9)で計算する(ステップS711)。
【0049】
【数5】
【0050】
ここでmは分布番号、Mは混合分布数、Jは状態数、jは状態番号、cは混合分布重み計数、N(・)は平均μと分散Uの正規分布に基づく音響特徴量Ot→から得られるスコアである。音声モデルの出力確率スコアSsp(Ot→)と、非音声モデルの出力確率スコアSnsp(Ot→)とを比較し、出力確率スコアSsp(Ot→)が大きければ音声区間と判定(ステップS712のY)し、非音声区間を計数する非音声連続時間Nstをリセット(ステップS713)して、音量音声区間分割部13に音声区間のスタートを指示する(ステップS714)。そしてフレームを更新(ステップS719)して、次フレームの出力確率スコアを計算する(ステップS710,S711)。
【0051】
音声モデルの出力確率スコアSsp(Ot→)よりも、非音声モデルの出力確率スコアSnsp(Ot→)が大きい場合は非音声区間と判定(ステップS712のN)し、非音声区間が所定時間のTNst(閾値)以上か否かを判断する(ステップS715)。TNstは例えば0.3秒程度の時間である。非音声区間がTNst未満の場合は、非音声連続時間Nstにフレーム時刻tを加算(ステップS716)して次フレームの処理を行う。非音声連続時間NstがTNst以上の場合(ステップS715のY)は、非音声連続時間Nstをリセットして音量音声区間分割部13に音声区間の終了を指示する(ステップS718)。このように音声/非音声判定部71が動作することで、非音声モデルの出力確率スコアSnsp(Ot→)の大きいフレームが非音声連続時間Nst以上の時間継続すると、1個の音声区間セグメントが出力される。つまり、非音声区間がTNst以上の時間連続して初めて音声区間セグメントが終了する。一方音声区間セグメントの開始は、この例の場合、音声モデルの出力確率スコアSsp(Ot→)が大であれば、そのフレームが直ちに音声区間セグメントのスタートとされる。
【0052】
以上のように音声/非音声の判定を音響モデルを用いて行うことで、パワーの大小で音声区間セグメントを分割した実施例1よりも精度の高い音声区間セグメントを生成することが可能である。この実施例2の方法で音声区間セグメントを生成した一例を図9に示す。図9の横方向は経過時間であり、縦方向は音声信号のパワーである。音声信号がある時間内に密集している。実施例1の方法では1個の音声区間セグメントとして出力したこの音声信号も、実施例2の方法であれば例えば4個の音声区間セグメントとして出力することが可能である。図9は、経過時間順の代表特徴量が(μS1→,US1→)、(μS1→,US1→)、
(μS3→,US3→)、(μS2→,US2→)と変化する様子を例示している。
【0053】
〔音声認識装置〕
上記した発話区間話者分類装置は、音声認識装置に応用が可能である。図10に、音声区間話者分類装置120乃至125の何れか1つを用いて音声認識装置500を構成した場合の機能構成例を示す。音声認識装置500は、発話区間話者分類装置と、音声認識部90と、言語モデルパラメータメモリ91と、音響モデルパラメータメモリ92と、制御部95とを備える。音声認識装置500は、この発明の音声区間話者分類装置を用いたところに特徴があり、他の構成は一般的な音声認識装置と同じである。この発明の音声認識装置は、音響モデルの適応化処理方法に特徴がある。
【0054】
その適応化処理方法を動作フローを示して説明する。図11に発話区間話者分類装置が分類したクラスタ毎に適応化処理を行う動作フローを示す。発話区間話者分類装置で話者分類した結果のクラスタは、話者に対応しているので、そのクラスタ毎に話者正規化/適応を行って(ステップS90、図11)、音声認識(ステップS91)することで認識精度を向上させることが可能になる。
【0055】
また、話者正規化/適応をクラスタ内の音声区間セグメント毎に行う方法も考えられえる。音声区間セグメント毎に適応化処理(ステップS90′、図12)行うことで異なる話者の音響データが混入する危険を減少させられる。その結果、より認識精度を向上させることが可能になる。
【0056】
また、最低セグメント長以下の短音声区間セグメントについては、フレーム数が少ないので平均や分散を安定して計算出来ないことから分類誤りが発生し易い。そこで、短音声区間セグメントについては適応化処理を行わないようにすることで、分類誤りの影響を低減することが可能である。その考えの動作フローを図13に示す。ステップS92で最低セグメント長を確認して最低セグメント長以上(ステップS92のY)の音声区間セグメントを用いて適応化処理(ステップS93)を行う。このようにすることで、認識精度を向上させることが可能である。このようにこの発明の発話区間話者分類装置を利用することで、事前の話者登録をしなくても認識精度の高い音声認識装置を実現することが出来る。
【0057】
この発明の技術思想に基づく発話区間話者分類装置とその方法と、それを用いた音声認識装置は、上述の実施形態に限定されるものではなく、この発明の趣旨を逸脱しない範囲で適宜変更が可能である。上記した装置及び方法において説明した処理は、記載の順に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されるとしてもよい。
【0058】
また、上記装置における処理手段をコンピュータによって実現する場合、各装置が有すべき機能の処理内容はプログラムによって記述される。そして、このプログラムをコンピュータで実行することにより、各装置における処理手段がコンピュータ上で実現される。
【0059】
この処理内容を記述したプログラムは、コンピュータで読み取り可能な記録媒体に記録しておくことができる。コンピュータで読み取り可能な記録媒体としては、例えば、磁気記録装置、光ディスク、光磁気記録媒体、半導体メモリ等どのようなものでもよい。具体的には、例えば、磁気記録装置として、ハードディスク装置、フレキシブルディスク、磁気テープ等を、光ディスクとして、DVD(Digital Versatile Disc)、DVD-RAM(Random Access Memory)、CD-ROM(Compact Disc Read Only Memory)、CD-R(Recordable)/RW(ReWritable)等を、光磁気記録媒体として、MO(Magneto Optical disc)等を、半導体メモリとしてフラッシュメモリー等を用いることができる。
【0060】
また、このプログラムの流通は、例えば、そのプログラムを記録したDVD、CD−ROM等の可搬型記録媒体を販売、譲渡、貸与等することによって行う。さらに、このプログラムをサーバコンピュータの記録装置に格納しておき、ネットワークを介して、サーバコンピュータから他のコンピュータにそのプログラムを転送することにより、このプログラムを流通させる構成としてもよい。
【0061】
また、各手段は、コンピュータ上で所定のプログラムを実行させることにより構成することにしてもよいし、これらの処理内容の少なくとも一部をハードウェア的に実現することとしてもよい。
【図面の簡単な説明】
【0062】
【図1】この発明の発話区間話者分類装置120〜125の機能構成例を示す図。
【図2】発話区間話者分類装置120の動作フローを示す図。
【図3】発話区間話者分類装置120の動作過程を図形として示す図。
【図4】発話区間話者分類装置123のセグメント分類過程の動作フローを示す図。
【図5】発話区間話者分類装置124のセグメント分類過程の動作フローを示す図。
【図6】発話区間話者分類装置125のセグメント分類過程の動作フローを示す図。
【図7】この発明の発話区間話者分類装置220の機能構成例を示す図。
【図8】発話区間話者分類装置220の音声/非音声判定部71の動作フローを示す図。
【図9】実施例2の方法で音声区間セグメントを生成した一例を示す図。
【図10】音声認識装置500の機能構成例を示す図。
【図11】音声認識装置500の音響モデルの適応化処理方法の一例を示す図。
【図12】音声認識装置500の音響モデルの適応化処理方法の一例を示す図。
【図13】音声認識装置500の音響モデルの適応化処理方法の一例を示す図。
【図14】従来方法の発話区間検索装置10の機能構成を示す図。
【特許請求の範囲】
【請求項1】
離散値化された音声信号の音声区間検出を行い音声区間セグメントを出力する音量音声区間分割部と、
上記音声区間セグメントの音響特徴量分析を行い音響特徴量を出力する特徴量分析部と、
上記音響特徴量から上記音声区間セグメントの代表特徴量を抽出する代表特徴量抽出部と、
上記音声区間セグメントについて、それぞれの上記代表特徴量間の距離を計算して上記距離に基づいて上記音声区間セグメントをクラスタに分類するセグメント分類部と、
隣接する上記音声区間セグメントが同一クラスタに属する場合に、隣接する上記音声区間セグメントを1個の音声セグメントとして統合するセグメント統合部と、
を具備する発話区間話者分類装置。
【請求項2】
請求項1に記載した発話区間話者分類装置において、
上記セグメント分類部は、分類対象セグメント選択手段を備え、
上記分類対象セグメント選択手段が、予め定められた最低セグメント長以上の時間幅の上記音声区間セグメントを選択する、
上記セグメント分類部が、上記選択した音声区間セグメントの代表特徴量を含む上記クラスタに、上記選択した音声区間セグメントを分類することを特徴とする発話区間話者分類装置。
【請求項3】
請求項2に記載した発話区間話者分類装置において、
上記セグメント分類部は、セグメント統計量算出手段を備え、
上記セグメント統計量算出手段が、全ての上記音声区間セグメントの統計量から上記最低セグメント長を算出することを特徴とする発話区間話者分類装置。
【請求項4】
請求項2又は3に記載した発話区間話者分類装置において、
上記セグメント分類部は、隣接セグメント分類手段を備え、
上記分類対象セグメント選択手段が、予め定められた最低セグメント長未満の時間幅の短音声区間セグメントを選択し、
隣接セグメント分類手段は、上記短音声区間セグメントを、時刻情報が隣接する音声区間セグメントが属する上記クラスタに分類することを特徴とする発話区間話者分類装置。
【請求項5】
請求項2又は3に記載した発話区間話者分類装置において、
上記セグメント分類部は、
最近距離クラスタ分類手段を備え、
上記分類対象セグメント選択手段が、予め定められた最低セグメント長未満の時間幅の短音声区間セグメントを選択し、
上記最近距離クラスタ分類部は、上記短音声区間セグメントの代表特徴量と、複数の上記クラスタの代表特徴量との間の距離を比較し、上記距離の最も近い最近距離クラスタに上記短音声区間セグメントを分類することを特徴とする発話区間話者分類装置。
【請求項6】
請求項5に記載した発話区間話者分類装置において、
上記セグメント分類部は、
隣接セグメント所属クラスタ間距離計算手段と、非隣接セグメント所属クラスタ間最小距離計算手段とを備え、
上記隣接セグメント所属クラスタ間距離計算手段は、上記短音声区間セグメントと時刻情報が隣接する音声区間セグメントを含むクラスタの代表特徴量との間の距離である隣接距離を計算する、
上記非隣接セグメント所属クラスタ間最小距離計算手段は、上記短音声区間セグメントの代表特徴量と分類済みのクラスタの代表特徴量との距離から最小非隣接距離を計算する、
上記最近距離クラスタ分類手段は、上記最小非隣接距離に1より大きな重み係数を乗算した拡大非隣接距離と上記隣接距離とを比較して小さい方の音声区間セグメントが属する最近距離クラスタに、上記短音声区間セグメントを分類する、
ことを特徴とする発話区間話者分類装置。
【請求項7】
請求項1乃至6の何れかに記載した発話区間話者分類装置において、
上記セグメント代表特徴抽出部は、上記代表特徴量を混合正規分布モデルで表現することを特徴とする発話区間話者分類装置。
【請求項8】
請求項1乃至7の何れかに記載した発話区間話者分類装置において、
音声モデルと非音声モデルとを記録した音響モデル記録部と、
上記音声モデルと非音声モデルを用いて音声/非音声判定を行う音声/非音声判定部と、
を備え、
上記音量音声区間分割部は、上記音声/非音声判定部の上記音声/非音声判定結果に基づいて上記音声セグメントを更に分割するものであることを特徴とする発話区間話者分類装置。
【請求項9】
請求項1乃至8の何れかに記載した発話区間話者分類装置と、
上記発話区間話者分類装置が出力するクラスタ毎に話者適応化処理を行う音声認識部と、
を具備する音声認識装置。
【請求項10】
請求項9に記載した音声認識装置において、
上記音声認識部は、クラスタ内の上記音声区間セグメント毎に話者適応化処理を行うことを特徴とする音声認識装置。
【請求項11】
音量音声区間分割部が、離散値化された音声信号の音声区間検出を行い音声区間セグメントを出力する音量音声区間分割過程と、
特徴量分析部が、上記音声区間セグメントの音響特徴量分析を行い音響特徴量を出力する特徴量分析過程と、
代表特徴量抽出部が、上記音響特徴量から上記音声区間セグメントの代表特徴量を抽出する代表特徴量抽出過程と、
セグメント分類部が、上記音声区間セグメントについて、それぞれの上記代表特徴量間の距離を計算して上記距離に基づいて上記音声区間セグメントをクラスタに分類するセグメント分類過程と、
セグメント統合部が、隣接する上記音声セグメントが同一クラスタに属する場合に、隣接する上記音声セグメントを1個の音声セグメントとして統合するセグメント統合過程と、
を含む発話区間話者分類方法。
【請求項12】
請求項11に記載した発話区間話者分類方法において、
上記セグメント分類過程は、分類対象セグメント選択ステップを含み、
上記分類対象セグメント選択ステップが、予め定められた最低セグメント長以上の時間幅の上記音声区間セグメントを選択し、
上記セグメント分類過程が、上記選択した音声区間セグメントの代表特徴量を含む上記クラスタに、上記選択した音声区間セグメントを分類する過程であることを特徴とする発話区間話者分類方法。
【請求項13】
請求項12に記載した発話区間話者分類方法において、
上記セグメント分類過程は、セグメント統計量算出ステップを含み、
上記セグメント統計量算出ステップが、全ての上記音声区間セグメントの統計量から上記最低セグメント長を算出するステップであることを特徴とする発話区間話者分類方法。
【請求項14】
請求項12又は13に記載した発話区間話者分類方法において、
上記セグメント分類過程は、隣接セグメント分類ステップを含み、
上記分類対象セグメント選択ステップが、予め定められた最低セグメント長未満の時間幅の短音声区間セグメントを選択し、
上記隣接セグメント分類ステップは、上記短音声区間セグメントを、時刻情報が隣接する音声区間セグメントが属する上記クラスタに分類するステップであることを特徴とする発話区間話者分類方法。
【請求項15】
請求項12又は13に記載した発話区間話者分類方法において、
上記セグメント分類過程は、最近距離クラスタ分類ステップを含み、
上記分類対象セグメント選択ステップが、予め定められた最低セグメント長未満の時間幅の短音声区間セグメントを選択し、
上記最近距離クラスタ分類ステップは、上記短音声区間セグメントの代表特徴量と、複数の上記クラスタの代表特徴量との間の距離を比較し、上記距離の最も近い最近距離クラスタに上記短音声区間セグメントを分類するステップであることを特徴とする発話区間話者分類方法。
【請求項16】
請求項15に記載した発話区間話者分類方法において、
上記セグメント分類過程は、
隣接セグメント所属クラスタ距離計算ステップと、非隣接セグメント所属クラスタ間最小距離計算ステップとを含み、
上記隣接セグメント所属クラスタ間距離計算ステップは、上記短音声区間セグメントと時刻情報が隣接する音声区間セグメントを含むクラスタの代表特徴量との間の距離である隣接距離を計算するステップであり、
上記非隣接セグメント所属クラスタ間最小距離計算手段は、上記短音声区間セグメントの代表特徴量と分類済みのクラスタの代表特徴量との距離から最小非隣接距離を計算するステップであり、
上記最近距離クラスタ分類ステップは、上記最小非隣接距離に1より大きな重み係数を乗算した拡大非隣接距離と上記隣接距離とを比較して小さい方の音声区間セグメントが属する最近距離クラスタに、上記短音声区間セグメントを分類するステップであることを特徴とする発話区間話者分類方法。
【請求項17】
請求項11乃至16の何れかに記載した発話区間話者分類装置において、
上記代表特徴量抽出過程は、上記代表特徴量を混合正規分布モデルで表現する過程であることを特徴とする発話区間話者分類方法。
【請求項18】
請求項11乃至17の何れかに記載した発話区間話者分類方法と、
音声/非音声判定部が、上記音声モデルと非音声モデルを用いて音声/非音声判定を行う音声/非音声判定過程を含み、
上記音量音声区間分割過程は、上記音声/非音声判定過程の上記音声/非音声判定結果に基づいて上記音声セグメントを更に分割する過程であることを特徴とする発話区間話者分類方法。
【請求項19】
請求項11乃至18の何れかに記載した発話区間話者分類方法と、
音声認識部が、上記発話区間話者分類方法で分類したクラスタ毎に話者適応化処理を行う音声認識過程と、
を含む音声認識方法。
【請求項20】
請求項1乃至8の何れかに記載した発話区間話者分類装置としてコンピュータを機能させるための装置プログラム。
【請求項21】
請求項9又は10に記載した音声認識装置としてコンピュータを機能させるための装置プログラム。
【請求項22】
請求項20と21に記載した何れかの装置プログラムを記録したコンピュータで読み取り可能な記録媒体。
【請求項1】
離散値化された音声信号の音声区間検出を行い音声区間セグメントを出力する音量音声区間分割部と、
上記音声区間セグメントの音響特徴量分析を行い音響特徴量を出力する特徴量分析部と、
上記音響特徴量から上記音声区間セグメントの代表特徴量を抽出する代表特徴量抽出部と、
上記音声区間セグメントについて、それぞれの上記代表特徴量間の距離を計算して上記距離に基づいて上記音声区間セグメントをクラスタに分類するセグメント分類部と、
隣接する上記音声区間セグメントが同一クラスタに属する場合に、隣接する上記音声区間セグメントを1個の音声セグメントとして統合するセグメント統合部と、
を具備する発話区間話者分類装置。
【請求項2】
請求項1に記載した発話区間話者分類装置において、
上記セグメント分類部は、分類対象セグメント選択手段を備え、
上記分類対象セグメント選択手段が、予め定められた最低セグメント長以上の時間幅の上記音声区間セグメントを選択する、
上記セグメント分類部が、上記選択した音声区間セグメントの代表特徴量を含む上記クラスタに、上記選択した音声区間セグメントを分類することを特徴とする発話区間話者分類装置。
【請求項3】
請求項2に記載した発話区間話者分類装置において、
上記セグメント分類部は、セグメント統計量算出手段を備え、
上記セグメント統計量算出手段が、全ての上記音声区間セグメントの統計量から上記最低セグメント長を算出することを特徴とする発話区間話者分類装置。
【請求項4】
請求項2又は3に記載した発話区間話者分類装置において、
上記セグメント分類部は、隣接セグメント分類手段を備え、
上記分類対象セグメント選択手段が、予め定められた最低セグメント長未満の時間幅の短音声区間セグメントを選択し、
隣接セグメント分類手段は、上記短音声区間セグメントを、時刻情報が隣接する音声区間セグメントが属する上記クラスタに分類することを特徴とする発話区間話者分類装置。
【請求項5】
請求項2又は3に記載した発話区間話者分類装置において、
上記セグメント分類部は、
最近距離クラスタ分類手段を備え、
上記分類対象セグメント選択手段が、予め定められた最低セグメント長未満の時間幅の短音声区間セグメントを選択し、
上記最近距離クラスタ分類部は、上記短音声区間セグメントの代表特徴量と、複数の上記クラスタの代表特徴量との間の距離を比較し、上記距離の最も近い最近距離クラスタに上記短音声区間セグメントを分類することを特徴とする発話区間話者分類装置。
【請求項6】
請求項5に記載した発話区間話者分類装置において、
上記セグメント分類部は、
隣接セグメント所属クラスタ間距離計算手段と、非隣接セグメント所属クラスタ間最小距離計算手段とを備え、
上記隣接セグメント所属クラスタ間距離計算手段は、上記短音声区間セグメントと時刻情報が隣接する音声区間セグメントを含むクラスタの代表特徴量との間の距離である隣接距離を計算する、
上記非隣接セグメント所属クラスタ間最小距離計算手段は、上記短音声区間セグメントの代表特徴量と分類済みのクラスタの代表特徴量との距離から最小非隣接距離を計算する、
上記最近距離クラスタ分類手段は、上記最小非隣接距離に1より大きな重み係数を乗算した拡大非隣接距離と上記隣接距離とを比較して小さい方の音声区間セグメントが属する最近距離クラスタに、上記短音声区間セグメントを分類する、
ことを特徴とする発話区間話者分類装置。
【請求項7】
請求項1乃至6の何れかに記載した発話区間話者分類装置において、
上記セグメント代表特徴抽出部は、上記代表特徴量を混合正規分布モデルで表現することを特徴とする発話区間話者分類装置。
【請求項8】
請求項1乃至7の何れかに記載した発話区間話者分類装置において、
音声モデルと非音声モデルとを記録した音響モデル記録部と、
上記音声モデルと非音声モデルを用いて音声/非音声判定を行う音声/非音声判定部と、
を備え、
上記音量音声区間分割部は、上記音声/非音声判定部の上記音声/非音声判定結果に基づいて上記音声セグメントを更に分割するものであることを特徴とする発話区間話者分類装置。
【請求項9】
請求項1乃至8の何れかに記載した発話区間話者分類装置と、
上記発話区間話者分類装置が出力するクラスタ毎に話者適応化処理を行う音声認識部と、
を具備する音声認識装置。
【請求項10】
請求項9に記載した音声認識装置において、
上記音声認識部は、クラスタ内の上記音声区間セグメント毎に話者適応化処理を行うことを特徴とする音声認識装置。
【請求項11】
音量音声区間分割部が、離散値化された音声信号の音声区間検出を行い音声区間セグメントを出力する音量音声区間分割過程と、
特徴量分析部が、上記音声区間セグメントの音響特徴量分析を行い音響特徴量を出力する特徴量分析過程と、
代表特徴量抽出部が、上記音響特徴量から上記音声区間セグメントの代表特徴量を抽出する代表特徴量抽出過程と、
セグメント分類部が、上記音声区間セグメントについて、それぞれの上記代表特徴量間の距離を計算して上記距離に基づいて上記音声区間セグメントをクラスタに分類するセグメント分類過程と、
セグメント統合部が、隣接する上記音声セグメントが同一クラスタに属する場合に、隣接する上記音声セグメントを1個の音声セグメントとして統合するセグメント統合過程と、
を含む発話区間話者分類方法。
【請求項12】
請求項11に記載した発話区間話者分類方法において、
上記セグメント分類過程は、分類対象セグメント選択ステップを含み、
上記分類対象セグメント選択ステップが、予め定められた最低セグメント長以上の時間幅の上記音声区間セグメントを選択し、
上記セグメント分類過程が、上記選択した音声区間セグメントの代表特徴量を含む上記クラスタに、上記選択した音声区間セグメントを分類する過程であることを特徴とする発話区間話者分類方法。
【請求項13】
請求項12に記載した発話区間話者分類方法において、
上記セグメント分類過程は、セグメント統計量算出ステップを含み、
上記セグメント統計量算出ステップが、全ての上記音声区間セグメントの統計量から上記最低セグメント長を算出するステップであることを特徴とする発話区間話者分類方法。
【請求項14】
請求項12又は13に記載した発話区間話者分類方法において、
上記セグメント分類過程は、隣接セグメント分類ステップを含み、
上記分類対象セグメント選択ステップが、予め定められた最低セグメント長未満の時間幅の短音声区間セグメントを選択し、
上記隣接セグメント分類ステップは、上記短音声区間セグメントを、時刻情報が隣接する音声区間セグメントが属する上記クラスタに分類するステップであることを特徴とする発話区間話者分類方法。
【請求項15】
請求項12又は13に記載した発話区間話者分類方法において、
上記セグメント分類過程は、最近距離クラスタ分類ステップを含み、
上記分類対象セグメント選択ステップが、予め定められた最低セグメント長未満の時間幅の短音声区間セグメントを選択し、
上記最近距離クラスタ分類ステップは、上記短音声区間セグメントの代表特徴量と、複数の上記クラスタの代表特徴量との間の距離を比較し、上記距離の最も近い最近距離クラスタに上記短音声区間セグメントを分類するステップであることを特徴とする発話区間話者分類方法。
【請求項16】
請求項15に記載した発話区間話者分類方法において、
上記セグメント分類過程は、
隣接セグメント所属クラスタ距離計算ステップと、非隣接セグメント所属クラスタ間最小距離計算ステップとを含み、
上記隣接セグメント所属クラスタ間距離計算ステップは、上記短音声区間セグメントと時刻情報が隣接する音声区間セグメントを含むクラスタの代表特徴量との間の距離である隣接距離を計算するステップであり、
上記非隣接セグメント所属クラスタ間最小距離計算手段は、上記短音声区間セグメントの代表特徴量と分類済みのクラスタの代表特徴量との距離から最小非隣接距離を計算するステップであり、
上記最近距離クラスタ分類ステップは、上記最小非隣接距離に1より大きな重み係数を乗算した拡大非隣接距離と上記隣接距離とを比較して小さい方の音声区間セグメントが属する最近距離クラスタに、上記短音声区間セグメントを分類するステップであることを特徴とする発話区間話者分類方法。
【請求項17】
請求項11乃至16の何れかに記載した発話区間話者分類装置において、
上記代表特徴量抽出過程は、上記代表特徴量を混合正規分布モデルで表現する過程であることを特徴とする発話区間話者分類方法。
【請求項18】
請求項11乃至17の何れかに記載した発話区間話者分類方法と、
音声/非音声判定部が、上記音声モデルと非音声モデルを用いて音声/非音声判定を行う音声/非音声判定過程を含み、
上記音量音声区間分割過程は、上記音声/非音声判定過程の上記音声/非音声判定結果に基づいて上記音声セグメントを更に分割する過程であることを特徴とする発話区間話者分類方法。
【請求項19】
請求項11乃至18の何れかに記載した発話区間話者分類方法と、
音声認識部が、上記発話区間話者分類方法で分類したクラスタ毎に話者適応化処理を行う音声認識過程と、
を含む音声認識方法。
【請求項20】
請求項1乃至8の何れかに記載した発話区間話者分類装置としてコンピュータを機能させるための装置プログラム。
【請求項21】
請求項9又は10に記載した音声認識装置としてコンピュータを機能させるための装置プログラム。
【請求項22】
請求項20と21に記載した何れかの装置プログラムを記録したコンピュータで読み取り可能な記録媒体。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【公開番号】特開2010−32792(P2010−32792A)
【公開日】平成22年2月12日(2010.2.12)
【国際特許分類】
【出願番号】特願2008−195136(P2008−195136)
【出願日】平成20年7月29日(2008.7.29)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【Fターム(参考)】
【公開日】平成22年2月12日(2010.2.12)
【国際特許分類】
【出願日】平成20年7月29日(2008.7.29)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【Fターム(参考)】
[ Back to top ]