
知識作成装置および知識作成方法
【課題】 知識作成に用いるデータを適宜に減らすことによって、パラメータ調整結果の最適性を損なうことなくパラメータ調整に要する時間を削減することができる知識作成装置を提供すること
【解決手段】 波形データベース21に格納された同一種類(良品)に属する複数の波形データの中から所定の波形データを選択するデータ選択部23と、そのデータ選択部が選択した波形データである選択データを少なくとも用いて、前記良否判定知識を作成する知識作成手段(パラメータ最適化部24,ルール作成部25)とを備える。データ選択部は、複数の良品の波形データから、その境界領域に属する所定数の境界データを選択する機能と、境界領域に属さない波形データの中から一部の波形データを代表データとして選択する機能とを有し、それら選択された境界データと代表データを併せて選択データとするようにした。
【解決手段】 波形データベース21に格納された同一種類(良品)に属する複数の波形データの中から所定の波形データを選択するデータ選択部23と、そのデータ選択部が選択した波形データである選択データを少なくとも用いて、前記良否判定知識を作成する知識作成手段(パラメータ最適化部24,ルール作成部25)とを備える。データ選択部は、複数の良品の波形データから、その境界領域に属する所定数の境界データを選択する機能と、境界領域に属さない波形データの中から一部の波形データを代表データとして選択する機能とを有し、それら選択された境界データと代表データを併せて選択データとするようにした。
【発明の詳細な説明】
【技術分野】
【0001】
この発明は、知識作成装置および知識作成方法に関するもので、より具体的には、入力された検査対象の計測データに対して特徴量を抽出し、抽出した特徴量に基づいて状態を判定する検査装置における検査ロジック(有効特徴量,特徴量のパラメータ調整等)の生成を行なう技術に関する。
【背景技術】
【0002】
自動車や家電製品などには、モータ等の駆動系部品が組み込まれた回転機器が非常に多く用いられている。例えば自動車を例にとってみると、エンジン,パワーステアリング,パワーシート,ミッションその他の至る所に回転機器が実装されている。また、家電製品では、冷蔵庫,エアコン,洗濯機その他各種の製品がある。そして、係る回転機器が実際に稼働すると、モータ等の回転に伴って音が発生する。
【0003】
係る音は、正常な動作に伴い必然的に発生するものもあれば、不良(故障)に伴い発生する音もある。その不良に伴う異常音の一例としては、ベアリングの異常,内部の異常接触,アンバランス,異物混入などがある。より具体的には、ギヤ1回転について1度の頻度で発生するギヤ欠け,異物かみ込み,スポット傷,モータ内部の回転部と固定部が回転中の一瞬だけこすれ合うような異常音がある。また、人が不快と感じる音としては、例えば人間が聞こえる20Hzから20kHzの中で様々な音があり、例えば約15kHz程度のものがある。そして、係る所定の周波数成分の音が発生している場合も異常音となる。もちろん、異常音はこの周波数に限られない。
【0004】
係る不良に伴う音は、不快であるばかりでなく、さらなる故障を発生させるおそれもある。そこで、それら各製品に対する品質保証を目的とし、生産工場においては、通常検査員による聴覚や触覚などの五感に頼った「官能検査」を行ない、異常音の有無の判断を行っている。具体的には、耳で聞いたり、手で触って振動を確認したりすることによって行っている。なお、官能検査は、官能検査用語 JIS Z8144により定義されている。
【0005】
ところで、係る検査員の五感に頼った官能検査では、熟練した技術を要するばかりでなく、判定結果に個人差や時間による変化などのばらつきが大きい。さらには、判定結果のデータ化,数値化が難しく管理も困難となるという問題がある。そこで、係る問題を解決するため、駆動系部品を含む製品の異常を検査する検査装置として、定量的かつ明確な基準による安定した検査を目的とした異音検査装置がある。
【0006】
このように検査対象から得られた振動波形から正常/異常を判別する検査(いわゆる異音検査)を自動的に行なう異音検査装置としては、従来、特許文献1に開示されたものがある。この特許文献1に開示された発明は、時間軸波形から得られた特徴量と周波数波形から得られた特徴量とを用いて検査対象の正常/異常を総合的に判別するものである。
【0007】
このように時間軸波形と周波数軸波形のように異なる軸から得られる波形に基づいて総合的に異音検査をするのは以下の理由からである。すなわち、それ以前に開発されていた時間軸波形から得られた特徴量だけの異音検査や、周波数軸波形から得られた特徴量だけの異音検査ではすべての異音を検出することが難しい。それは、それぞれの特徴量には得意・不得意があるからである。複数の特徴量を用いる異音検査は、単一の特徴量を用いる異音検査に比べて高い判別能力を有する。
【0008】
つまり、そもそも駆動系部品は、回転や往復運動を繰り返す機構で成り立っており、その機構にわずかな機械的異常があれば、それに起因した異常成分(良品から発せられる正常成分とは何かが違う成分)が必ず振動や音として周囲に伝達される。ところが、異音検査における異常成分は、正常成分と比較しても振動や音の波形に含まれる、わずかな違いでしかなく、熟練した人の耳であれば聞き分けられるような違いがあっても、波形解析してみるとノイズに埋もれてうまく検知することができないことがあった。これは、従前の異音検査が時間軸波形から得られた特徴量だけや、周波数軸波形から得られた特徴量だけの判別、しかも単一の特徴量のみに基づいて行われる判別であったからである。そこで、上記の特許文献1では、複数の軸から得られる複数の特徴量に基づいて総合的に正常/異常を判断するようにしている。そして、この特許文献1に開示された発明では、判別ルールとして、ファジィルールを用い、ファジィ推論により複数の特徴量に基づく正常/異常の判断を行なうようにしている。
【0009】
ところで、特許文献1に開示された異音検査に判別ルールとして用いるファジィ推論は、ニューラルネットなど、その他の判別モデルと比較して、人が判別ルールを理解しやすいという利点がある。例えばニューラルネットとは、ニューロンモデルを互いに多数結合させて接続しネットワーク状にしたものであり、どのような判別をしてそのような結果に至ったのか、その根拠が難解で感覚的に理解しがたい。感覚的に理解できないものを人は信用しにくい。それが品質の要となる検査装置であるならなおさらである。
【0010】
これに対して、ファジィ推論は、あいまいさを表現するメンバシップ関数を用いており、ファジィ推論を用いた判別ルールは、判別の根拠と判別結果を対応づけて「IF 特徴量A=大 THEN 異常」のように人に理解しやすい表現で示すことが出来る。このように感覚的に理解できるものは説明もしやすく、品質ソリューションを事業とする場合に、検査装置の検査ロジックとして判別ルールを説明しやすいため、その説明を受けた顧客にとっても納得する度合いが高いので安心して採用できるという利点がある。
【0011】
また、新規に異音検査装置を導入しようとする顧客は、それまで熟練者(官能検査員)の耳による官能検査を行っていることも多く、官能検査員は「異音なきこと」などの記述が一般的な検査基準に対して独自の判定基準やノウハウ、知見をすでに有している。このような場合には、異音検査装置は官能検査員がこれまで行っていた官能検査の置き換えとなるので、官能検査員の持つ判定基準やノウハウ、知見との整合性が自ずと求められるのが現状である。係る場合にも、作成した判別ルールと、それまでの官能検査員がもっていた知識(検査基準)との整合性を説明しやすいということは、顧客に対して説明責任を負うソリューション提供者にとってファジィ推論による説明のしやすさは事業を進める上で大きな利点となっている。
【0012】
ところで、使用する特徴量の数が増加するほど、良否判定をするための判別ルールも複雑になったり、多数必要になったりする。そのため、精度の高い異音検査を行なうためには、判別ルールを精度良く作成する必要がある。異音検査における判別ルールを作成する工数を削減する技術として、非特許文献1に開示された技術がある。この非特許文献1には、判別ルール(検査ロジック)の自動生成において判別ルールに用いる特徴量選択とパラメータ探索に遺伝子アルゴリズムを用いる技術が開示されている。つまり、判別ルールに用いる特徴量選択とパラメータ探索とに、遺伝子アルゴリズムを用いることによって、それまで、人の勘と経験による試行錯誤でしか出来ないとされてきた判別ルールの作成処理を自動化/半自動化できるようにした。
【0013】
また、異音検査における判別ルールを自動作成する技術としては、非特許文献2に開示された発明もある。この非特許文献2には、判別ルールの自動生成において、判別ルール生成のために収集した正常データと異常データから適切な数の正常データと異常データを選択し、選択したデータから遺伝子アルゴリズムを用いて判別ルールに用いる特徴量選択とパラメータ調整をし、選択した特徴量と調整したパラメータからファジィ推論を用いて判別ルールを生成する技術が開示されている。このように正常データと異常データからそれらを最も分離する判別ルールを生成する技術は一般に不良識別と呼ばれている。
【0014】
しかしながら、不良識別では、正常/異常を判別するにはサンプルデータとして正常データと異常データがあらかじめ必要であり、異常データは正常データに比べて取得しにくいことから異常データがなければ判別ルールが生成できないという問題点がある。
【特許文献1】特許第3484665号
【非特許文献1】オムロンテクニクスVol.43 No.1 pp.99−105(2003)
【非特許文献2】オムロンテクニクスVol.44 No.1 pp.48−53(2004)
【発明の開示】
【発明が解決しようとする課題】
【0015】
上述した通り、これまでにも各種の異音検査装置の開発が試みられてきている。しかし、いずれも、不良品(異常品)を良品(正常品)と誤判定してしまう見逃し率の発生をなくしつつ(不良品を出荷することになるため確実に阻止する必要がある)、良品を不良品と誤判定してしまう過検出率の低減を図る(良品が出荷されず、廃棄処理等されてしまう無駄・歩留まり低下の防止をする)ことを目的とし、高性能な良否判定アルゴリズムの作成・改良が行なわれている。そのため、使用する特徴量の数が増加したり、よりよい判定ルールを作成するために要求されるサンプル数が増加したりするのが現状であった。
【0016】
たとえば検査対象データごとに最適な特徴量値を出力できるようにパラメータを調整することで、正常か異常かの微妙なところも判定できる。ここで、パラメータは、たとえば特徴量Aがある値(しきい値)以上となると、不良品であるというような場合、特徴量Aについての係るしきい値がパラメータとなり、そのしきい値をいくつにするかの調整がパラメータの調整(学習)となる。しかし、パラメータの調整が不十分だったり、未調整のままだったりすると、正しい検査ができない可能性がある。
【0017】
従って、上述したように、特徴量の増加並びにサンプル数の増加に伴い、学習に伴い生成・確認(ルールの適否判断)される判定ルールも多岐にわたり、学習が収束して最終的に最適な判定ルールを作成するのに時間がかかる。
【0018】
また、非特許文献2には、適切な数の正常データと異常データを選択することが開示されており、具体的には「パラメータ調整に使用するデータセットを選択する。40種類の特徴量を使ってOKデータを元に基準空間を求め、各データに対してマハラノビス距離を計算する。すべてのデータの中から、指定された件数のOKデータおよびNGデータを全体の分布と照らし合わせて、バランスを考慮して選択する。」と記載されている。つまり、OKデータ(正常データ)とNGデータ(異常データ)の数のバランスが悪いと、適切かつ効率のよい学習が行なえないおそれがある。
【0019】
ところで、実際の判定処理の際に発生する不良品に基づく異常データをあらかじめ用意するのは困難で、学習時に用意できるサンプルデータのほとんどは良品に基づく正常データとなり、正常データと異常データのサンプル数に大きなばらつきが生じる。そこで、適切な数の正常/異常データに基づいて学習を行なうためには、正常データの削除(データの間引き)を行なうことになる。しかし、闇雲に削除するとパラメータ調整の演算時間が短縮できても過検出が多くなり、検査装置としての性能が出ないおそれがある。
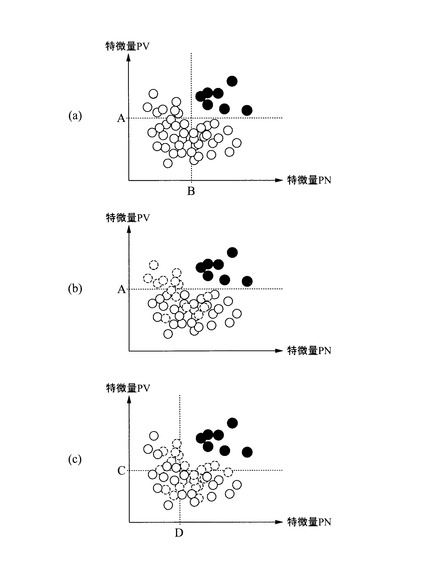
【0020】
一例を示すと、正常データと異常データにおける2つの特徴量PV,PNを軸とした散布図が、図1(a)に示すようになっていたとする。ここで、散布図は、データの特性を定量的に表す指標を複数定め、それら指標を軸にして構成される空間上に、各データをその指標値にしたがって配置した図である。ここでは2種類の特徴量を軸にした場合の散布図の例である。
【0021】
この散布図において、白丸が正常データで、黒丸が異常データである。すべてのデータを考慮して判定ルールを作成すると、各特徴量の閾値が図中波線で示すような境界線に基づき分離することになり、ルールの一例を示すと、下記のようになる。
IF PV>A AND PN>B Then 異常データ
【0022】
この図1(a)に示すデータから、正常データの一部を削除し、残った正常データ(代表データ)と異常データに基づいて学習を行い判定ルールを作成する。このとき、たとえば図1(b)に示すように偏った選択をする(点線の白丸は削除され、実線の白丸の正常データと、黒丸の異常データに基づいて学習する)と、本来は2つの特徴量を使わないと分離できないものを、1つの特徴量PVだけで分離しようとする誤った検査知識が作られる可能性がある。このときのルールの一例を示すと、下記のようになる。
IF PV>A Then 異常データ
【0023】
同様に、図1(c)に示すように偏った選択をする(点線の白丸は削除され、実線の白丸の正常データと、黒丸の異常データに基づいて学習する)と、正常データと異常データとの境界線(検査時のしきい値)をうまく設定できない可能性がある。このときのルールの一例を示すと、下記のようになる。
IF PV>C AND PN>D Then 異常データ
【0024】
上述したように適切でないルールが生成されてしまうと、点線の白丸である正常データが異常データと誤判定されてしまい、過検出が増える。なお、検査装置であるため、異常データを良品と誤判定(見逃し)して出荷してしまうことはさけなければいけない。よって、適切なデータが選択されないと、上述したように過検出が増え、無駄に廃棄されるものが多くなるという問題を有する。
【0025】
この発明は、知識作成に用いるデータを適宜に減らすことによって、パラメータ調整結果の最適性を損なうことなくパラメータ調整に要する時間を削減することができる知識作成装置および知識作成方法を提供することを目的とする。
【課題を解決するための手段】
【0026】
上記した目的を達成するため、本発明の知識作成装置は、入力された検査対象の計測データに対して特徴量を抽出し、抽出した特徴量に基づいて前記検査対象の良否判定をする検査装置における前記良否判定を行う際に使用する良否判定知識を作成する知識作成装置であって、取得した同一種類に属する複数の波形データの中から所定の波形データを選択するデータ選択手段と、そのデータ選択手段が選択した波形データである選択データを少なくとも用いて、前記良否判定知識を作成する知識作成手段とを備え、前記データ選択手段は、前記選択対象の複数の波形データが属するグループの境界領域に属する所定数の境界データを選択する機能と、前記境界領域に属さない波形データの中から一部の波形データを代表データとして選択する機能とを有し、それら選択された前記境界データと前記代表データを併せて前記選択データとするように構成した。
【0027】
知識作成手段は、実施の形態では、「パラメータ最適化部」と「ルール作成部」により実現されているが、選択された選択データに基づいて良否判定知識を作成するものであれば、実施の形態に示したものに限られないのはもちろんである。
【0028】
前記データ選択手段は、前記同一種類に属する全ての波形データに対して仮の特徴量演算を行なう機能と、その仮の特徴量演算を実行して得られた特徴量演算結果と、その特徴量演算結果の分布に基づいて前記境界データと前記代表データを選択することができる。係る発明を前提として、前記データ選択手段は、前記特徴量演算結果に基づき、各波形データについてそれぞれ求めた複数の特徴量値を基準化するとともに、マハラノビス距離を求め、そのマハラノビス距離が大きいグループから前記境界データを選択し、そのマハラノビス距離が小さいグループから前記代表データを選択するように構成するとよい。
【0029】
さらに、前記データ選択手段における選択手法としては、前記マハラノビス距離が設定されたしきい値以上に該当するものを前記境界データと選択するようにしたり、前記マハラノビス距離が大きいものから所定量(具体的な数/割合等)を前記境界データと選択するようにしたり、各波形データをマハラノビス距離の順にソートし、所定数おきに波形データを選択することで、前記代表データを選択するようにしたり、各波形データをマハラノビス距離の順にソートし、所定距離間隔で波形データを選択することで、前記代表データを選択するようにすることができる。もちろん、それ以外の手法によって選択するのを妨げない。
【0030】
さらに、上述した各種の発明を前提とし、前記知識作成手段が作成した良否判定知識を用いて実行された良否判断の結果が、判別性能の目標値に達しているか否かを判断する判断手段(実施の形態ではデータ選択部が兼用しているが、別に構成してももちろんよい)と、その判断手段の判断結果が、目標値に達しない場合には、前記データ選択手段で選択するデータを増やし、再度データ選択を行なう機能を備えるとよい。この発明は、第2の実施の形態により実現されている。
【0031】
前記データ選択手段で選択するデータを増やす処理は、下記の(1)から(3)のうち少なくとも1つを含むとよい。もちろん、これ以外の手法をとることも妨げない。(1)前記同一種類に属する波形データを異なるグループと誤判断した場合に、その誤判断した波形データを境界データとして追加する。(2)前記同一種類に属さない波形データを前記同一種類に属すると誤判断した場合には、データ選択する総数を増やす。(3)前記同一種類に属さない波形データを前記同一種類に属すると誤判断するとともに、前記同一種類に属する波形データを異なるグループと誤判断した場合には、境界データとして選択する量を増やす。
【0032】
一方、本発明に係る知識作成法は、入力された検査対象の計測データに対して特徴量を抽出し、抽出した特徴量に基づいて前記検査対象の良否判定をする検査装置における前記良否判定を行う際に使用する良否判定知識を作成する知識作成装置における知識作成法であって、取得した同一種類に属する複数の波形データの中から所定の波形データを選択するデータ選択処理と、そのデータ選択処理を実行して選択された波形データである選択データを少なくとも用いて、前記良否判定知識を作成する知識作成する処理とを含む。そして、前記データ選択処理は、前記選択対象の複数の波形データが属するグループの境界領域に属する所定数の境界データを選択する機能と、前記境界領域に属さない波形データの中から一部の波形データを代表データとして選択するとともに、それら選択された前記境界データと前記代表データを併せて前記選択データとするようにした。
【発明の効果】
【0033】
本発明では、知識作成に用いるデータをうまく減らすことによって、パラメータ調整結果の最適性を損なうことなくパラメータ調整に要する時間を削減することができる。
【発明を実施するための最良の形態】
【0034】
本発明の一実施の形態の装置を説明するに先立ち、本装置により設定される判定ルールを用いて良否判定(官能検査)を行う検査システムを説明する。図2に示すように、検査対象物1に接触・近接配置するマイク2および加速度ピックアップ3からの信号をアンプ4で増幅し、AD変換器5にてデジタルデータに変更後、検査装置10に与えるようになっている。そして、検査装置10は、マイク2で収集した音データや、加速度ピックアップ3で収集した振動データに基づく波形データを取得し、特徴量を抽出するとともに、異常判定を行なう。図2から明らかなように、検査装置10は、コンピュータから構成され、CPU本体10aと、キーボード,マウス等の入力装置10bと、ディスプレイ10cとを備えている。また、必要に応じて外部記憶装置を備えたり、通信機能を備えて外部のデータベースと通信し、必要な情報を取得することが出来る。
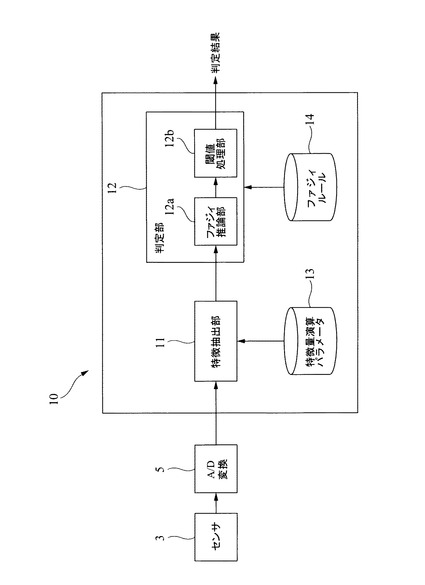
【0035】
図3に示すように、検査装置10は、A/D変換器5を介して取得した波形データから特徴量を抽出する特徴量抽出部11と、その特徴量抽出部11で抽出した特徴量の値に基づいて、正常データか異常データかの良否判定を行う判定部12と、特徴量抽出部11にて特徴量抽出する特徴量とそのパラメータ等を記憶する特徴量演算パラメータ記憶部13と、判定部12にて良否判定処理を行う際に使用するファジィルールを記憶するファジィルール記憶部14とを備えている。判定部12は、ファジィルール記憶部14に格納されたルールに従い、与えられた特徴量に対しファジィ推論部12aにてファジィ推論を行う。そして、求められた適合度を閾値処理部12bに与え、そこにおいて閾値処理をし、良否判定を行う。この判定部12の判定結果は、例えばディスプレイ10cにリアルタイムで表示したり、記憶装置に格納したりすることができる。
【0036】
上述した検査装置10の具体的な構成(各処理部の詳細な構成)は、従来公知の各種のものを適用できるため、詳細な説明を省略する。本発明に係る知識作成装置の実施の形態では、上述した特徴量演算パラメータ記憶部13に格納する特徴量や、その特徴量のパラメータを作成したり、ファジィルール記憶部14に格納するルールを作成するものである。図4は、本発明に係る知識作成装置の一実施の形態の概略構成を示している。
【0037】
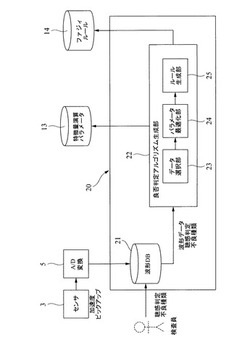
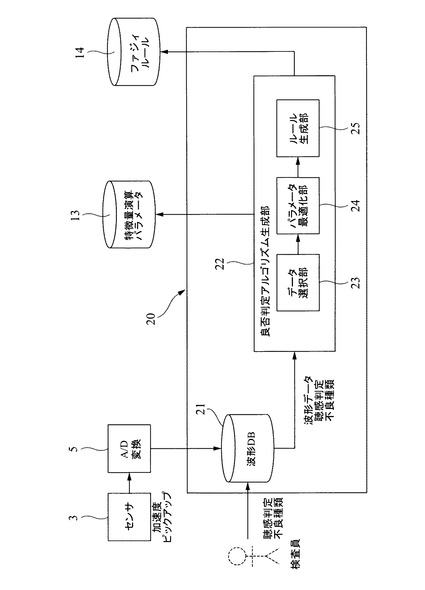
図4に示すように、知識作成装置20は、サンプルデータを格納する波形データベース21と、その波形データベースに格納されたサンプルデータ(正常データと異常データの波形データ)に基づき、検査装置10が良否判定を行なう際に使用する上述した特徴量やルール等を生成する良否判定アルゴリズム生成部22とを備えている。
【0038】
波形データベース21に格納する波形データは、例えば、実際の官能検査を行なうのと同様に、サンプル品等を動作させた時に生じる音や振動をセンサ3で取得した(図示省略するが、必要に応じて増幅する)ものを記憶しても良いし、別途用意した別のデータベースからダウンロードして格納しても良い。また、この波形データベース21には、実際の波形データと、その種類(正常データと異常データの区別)が分かるように格納されている。すなわち、各波形データと、種類を関係づけて格納しても良いし、正常データのホルダと、異常データのホルダを分け、各ホルダ毎に対応する波形データを格納するようにしても良い。要は、格納された波形データの種類が分かるようになっていればよい。尚、上記の種類は、例えば、検査員が実際にセンサ3でデータ取得した際に検査員が同時に検査対象物(サンプル品)から発生する音等を聴いて判断したり、一旦格納した波形データを再生し、その再生した音を検査員が聴いて判断した結果を格納するようにしても良いし、サンプルデータを取得するための検査対象物が、予め良品か不良品かの区別が付いているものの場合には、予め種類を指定して波形データを取り込むことにより自動的に種類と波形データの関連づけを行なうようにしても良い。
【0039】
良否判定アルゴリズム生成部22は、データ選択部23と、パラメータ最適化部24と、ルール作成部25とを備えている。データ選択部23が本発明の要部となるところで、波形データベース21に格納されたサンプルデータのうち、良否判定アルゴリズムを生成する際に使用するデータを選択するものである。波形データベース21に格納されたサンプルデータ、換言すると、用意できるサンプルデータの数は、正常データのサンプル数が圧倒的に多いのが通常である。そして、基本的には、サンプル数が多いほどより高精度の判定を行なうことのできる良否判定アルゴリズムを生成することができる。但し、サンプル数が多いと、たとえば、後段のパラメータ最適化部24にて行われる最適化処理を実行し特徴量やその特徴量のパラメータを決定するまでに要する処理時間が長くなる。そこで、データ選択部23は、波形データベース21に格納されたサンプルデータのうち、特にデータ数が多くなることが予測できる正常データを間引いて選択する。これにより、良否判定アルゴリズムの生成には使用されない(反映されない)正常データのサンプルデータも存在するため、後段のパラメータ最適化部24にて行われる最適化処理時間が短くすることができる。そして、後述するように、正常データのサンプルデータを選択する際に、一定の条件の下で抽出するため、選択する前のすべてのサンプルデータを用いて求めた良否判定アルゴリズムとほぼ同様の高精度のものを得ることができる。
【0040】
パラメータ最適化部24は、良否判定を行なう際に使用する特徴量(有効特徴量)と、その特徴量についてのパラメータを決定するものである。すなわち、特徴量の一例を示すと、周波数成分や、平均値,分散,最大値,最小値,閾値越えのピーク数や、N番目のピークの値などがある。周波数成分については、ローパスフィルタや、バンドパスフィルタその他各種のフィルタを用いたり、FFT処理などの波形変換を行なうことなどがある。そのときの特徴量のパラメータは、ローパスフィルタについては、カットオフ周波数の値であったり、バンドパスフィルタの場合には、通過帯域を区切る値等となる。FFT処理の場合には、周波数軸に変換されたため、任意の周波数帯における成分を特徴量とすることで、異常成分の含まれている状態を定量化することが可能なる。つまり、FFT処理後に抽出すべき周波数帯域がパラメータとなる。平均値、最大値等の特徴量は、通常、フィルタ処理した後の波形データに基づいて求める。閾値越えのピーク数を特徴量とした場合のパラメータは、当該閾値の値となる。また、特徴量が、各ピーク値の上からN番目の場合は、Nの値(単数,複数)がパラメータとなる。さらに、ピーク数やピーク値の場合、検出対象の時間をパラメータとして設定したり、閾値も1つのみでなく、下限値と上限値というように2つの閾値を設定し、一定の範囲内或いは範囲外をパラメータとして設定することができる。もちろん、特徴量は上述したものに限られないのは言うまでもなく、また、例示列挙した特徴量に対するパラメータも、これに限られないのはもちろんである。
【0041】
このパラメータ最適化部24は、良品(正常データ)と不良品(異常データ)を最もよく分離できる特徴量演算用の諸パラメータ(特徴量演算パラメータや各特徴量の評価値の重み)を探索するものであり、本実施の形態では、例えば特開2004−079211号公報に開示された発明のように、GA(遺伝的アルゴリズム)を用いて有効特徴量と、そのパラメータを決定することができる。すなわち、パラメータ探索のアルゴリズムとして遺伝的アルゴリズムが用いられた場合、個別のパラメータを遺伝子,全パラメータの組合せを個体とみなす。そこで、個体の交叉・突然変異によって新たな個体を創り出し(世代交代し)、評価の低い個体を新個体で置き換える。このようにして、評価の高いより優れた個体を残していくことにより最適に近い個体(パラメータ設定)を得る。
【0042】
そして、最終的に求められたパラメータ等が、特徴量演算パラメータ記憶部13に格納される。なお、図示の例では、良否判定アルゴリズム生成部22(パラメータ最適化部24)が、検査装置10の特徴量演算パラメータ記憶部13に直接アクセスして格納するようにしているが、必ずしも直接格納する必要はなく、図示省略する知識作成装置20の記憶装置内にパラメータ最適化部24で生成した特徴量,パラメータ等を格納し、所定の方法(オンライン,通信,記録メディアを介する)でデータを格納すればよい。
【0043】
なお、パラメータ最適化部24における最適化処理、つまり、パラメータ等の探索方法は、上述したGA(遺伝的アルゴリズム)に限ることはなく、例えば、NN(ニューラルネットワーク),SVM(サポートベクターマシン),総当りなどの各種の手法をとることができる。
【0044】
また、パラメータ最適化部24で求めた検査装置10で使用すべき特徴量とそのパラメータは、ルール作成部25に与えられる。ルール作成部25は、与えられた特徴量とそのパラメータに基づいてファジィルールを作成する。使用すべき特徴量と、良否判定する場合のパラメータが分かっているため、公知の手法により“IF THEN方式”のルールを簡単に作成することができるし、それに基づいてメンバシップ関数も作成できる。そして、それら作成したルール等をファジィルール記憶部14に格納する。なお、図示の例では、良否判定アルゴリズム生成部22(ルール作成部25)が、検査装置10のファジィルール記憶部14に直接アクセスして格納するようにしているが、必ずしも直接格納する必要はなく、図示省略する知識作成装置20の記憶装置内にルール記憶部14で生成したファジィルール等を格納し、所定の方法(オンライン,通信,記録メディアを介する)でデータを格納すればよい。
【0045】
ここで、本発明の要部となるデータ選択部23の機能を説明する。上述したように、遺伝的アルゴリズムによるパラメータ探索を用いた場合、個別のパラメータを遺伝子,全パラメータの組合せを個体とみなして,個体の交叉・突然変異によって新たな個体を創りだしながら、より優れた個体を残していくことにより最適に近い個体(パラメータ設定)を獲得することができる。遺伝的アルゴリズムを使ったとしても、パラメータ探索に用いるデータの数や探索の繰り返し回数が増えると探索にかかる時間が膨大になる。もちろん、基本的にはデータの数が多いほど、探索の繰り返し回数が多いほど、最適なパラメータ設定が得られやすくなるが、本実施の形態のデータ選択部23では、探索に用いるデータを適宜に減らすことによって、パラメータ調整結果の最適性を損なうことなくパラメータ調整に要する時間を削減することができるようにする。つまり、データ選択を行わない場合の特徴量演算パラメータ調整結果とほぼ同等のパラメータ調整結果が得られるようにする。
【0046】
ここで、パラメータ調整結果が「良い」とは、そのパラメータ設定条件で演算した特徴量を用いることによって、よい判定性能(過検出率・見逃し率がともに0%に近いほどよい)が得られることである。ただし、判定性能の値は、最終的な検査ルールが確定しないと得られないことから、パラメータ調整の過程および結果の時点では、分離度を用いて特徴量およびその演算パラメータの良し悪しを評価する。
【0047】
ここで、分離度が低いとは、データの散布図が例えば図5(a)に示すように、軸となっている特徴量にそれぞれどのように閾値を設定しても良品データ群と不良品データ群の領域を分割することはできないような状態をいう。つまり、このままの特徴量の演算結果では良品と不良品の判別が難しいことを示している。なお、この散布図において、白丸が正常データで、黒丸が異常データである。
【0048】
逆に、分離度が高い場合には、図5(b)に示すように、軸となっている特徴量にそれぞれ適切に閾値を設定することによって良品データ群と不良品データ群のそれぞれが存在する領域を分割することができるような状態を言う。この特徴量演算結果で良品と不良品の判別ができる可能性が高いことを示している。
【0049】
使用する特徴量を変えたり、仮に同じ特徴量であってもパラメータを調整することで、図5(a)の状態から図5(b)に示す状態に変更することができる可能性がある。もちろん、どのように調整しても分離度が低いものもあるが、それは、解析に適さない特徴量・パラメータ等であることになる。ここで、データ選択部23は、データを選択した結果分離度が悪くなったり、図1に示したように、本来の全てのデータを用いて設定した閾値(パラメータ)と異なり、誤検出を生じるようになることを避ける必要がある。
【0050】
上記の条件の下で、本実施の形態では、以下のようにデータ選択をするようにした。すなわち、概念図として示すと、特徴量PV,PNを軸とした散布図が、図6(a)に示すように良品に基づく全ての正常データが白丸で示すようになっており、不良品に基づく異常データが黒丸で示すようになっているとする。図から明らかなように、異常データ(黒丸)に比べて、正常データ(白丸)のサンプル数が多く、バランスを欠いているとともに、正常データについては、似ている(散布図上での位置(座標値)が近い)ものが多く、サンプル数が多く、最終的な良否判定アルゴリズムを生成するのに時間がかかる割に、無駄な正常データのサンプルの存在も否定できず、無駄に学習を繰り返し行なっているといえる。
【0051】
係る場合に、データ選択部23は、正常データについて、図6(b)に示すように、中心部分に位置する代表的な正常データ(白丸)と、正常データの境界域に存在する正常データ(ハッチング丸)を選択し、その選択された正常データ(代表データ)と、全ての異常データを次段のパラメータ最適化部24に送り、学習を行うようにする。このように、境界部分の正常データを残すことにより、図6(b)に示すように、正常データと異常データを区別する閾値を、図6(a)の場合と同様にすることができる。そして、正常データのうち、波線の丸で示したものは学習に使用しないため、サンプル数が少なくなり、短時間で同程度の品質の良否判定アルゴリズムを生成することが可能となる。
【0052】
そして、境界部分の正常データを選択するに際し、本実施の形態では、マハラノビス距離によるデータ選択を行うようにした。すなわち、図7に示す例によれば、点Aは点Bよりもユークリッド距離は遠くなるが、楕円で囲むデータの分布領域はA方向に分散が大きいため、Bの方がマハラノビス距離は大きくなる。そこで、正常データは、マハラノビス距離の大きい方(図7中ハッチング部分)に存在するものを順番に選択するようにした。この部分が境界部分の正常データとなる。また、白抜きの中央領域(ここでは、境界部分以外領域)は、均等になるように選択するようにした。この部分が、代表的な正常データとなる。
【0053】
ここで、マハラノビス距離は、データのばらつきを考慮した距離尺度であり、散布図上のユークリッド距離では等距離でも、分散が大きい方向ではマハラノビス距離は小さく、分散が小さい方向ではマハラノビス距離は大きくなる。換言すると、マハラノビス距離とは、データの母集団と各データとの距離を表す尺度となる。
たとえば、特徴量PV、PNの平均をμPV、μPNとし、特徴量PV、PNの母集団をXPV,XPNとする。そして、
【数1】

【0054】
とおき、特徴量PV,PNの演算値の分散共分散行列をΣ,その逆行列をΣ−1とすると、母集団と各データとのマハラノビス距離dは、
【数2】
で求められる。
【0055】
なお、実際には、各特徴量で、スパンが異なることから、正規化(基準化)をする必要がある。つまり、まず、各変量の単位を合わせるため、例えば、平均=0、分散を=1に基準化する。その後、上述した式に基づいてデータの中心からマハラノビス距離を求める。そして、マハラノビス距離の遠い方から一定数選択する。これにより、境界部分の正常データが抽出される。そして、残ったデータの中から、所定の条件に従い所定数の正常データ(代表データ)を抽出する。係る処理の具体的な一例を示すと、図8に示すフローチャートを実行する。
【0056】
まず、データのクラス分けを行ない、必要なデータを取得する(S1)。ここでは、良品(正常データ)と不良品(異常データ)に分類分けを行なう。実際には、波形データベース21にサンプルデータを格納する際に、その種類が関連づけられて登録されているため、ここでは、そのサンプルデータに登録される際の種類に基づき、必要なデータを取得する。本実施の形態では、所定データの中から所定数選択する(正常データを所定数間引く)。
【0057】
次に、データ選択数の設定数の設定を受け付ける(S2)。すなわち、ユーザが入力装置等を操作して境界部分の正常データの数と、代表的な正常データの数を入力する。そこで、データ選択部23は、入力装置等を介して受け付けた選択すべきデータ数を取得する。この時指定するデータの数は、絶対的な数値でも良いし、全体の何%のように相対的な値でもよい。また、境界部分の正常データの指定方法と、代表的な正常データの指定方法とは、同じ方法でも良いし、異なる方法でも良い。
【0058】
波形データベース21に格納された全てのデータに対して、特徴量演算を行なう(S3)この特徴量演算する対象の波形データは、少なくともデータ選択する対象(種類)のサンプルデータであり、本実施形態では、全ての正常データとなる。なお、すでに特徴量が求められている場合には、それを利用することができる。
【0059】
次に、処理ステップS3で求めたクラス内(本実施の形態では、良品)の全データの特徴量演算結果を基準化する(S4)。この基準化は、具体的には、各特徴量の値が、平均が0で分散が1になるように変換する。ついで、係る処理ステップS4を実行して得られたクラス内の全データの基準化特徴量データから、マハラノビス距離を算出する(S5)。ここで算出するマハラノビス距離は、クラス内(ここでは正常データのクラス)の全データの基準化特徴量データから算出される「基準空間」と、クラス内の個別データ(の基準化特徴量データ)と、の距離である。
【0060】
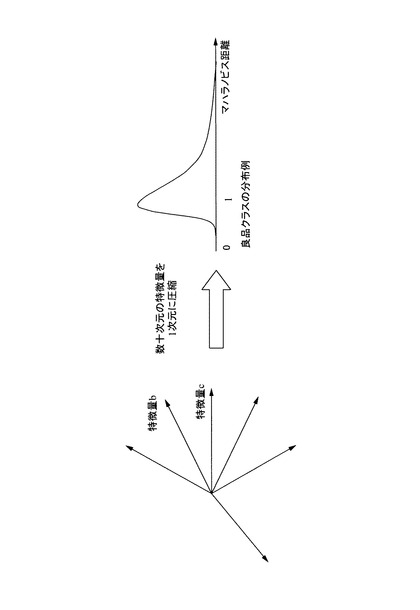
これにより、図9に示すように、数十次元の特徴量データから1次元に集約された距離を求めることができる。そのクラス(良品)に近いほど、算出したマハラノビス距離は1に近く、良品の特徴から遠いほどマハラノビスの距離は大きな値となる。従って、今回の場合すべてが良品に基づく正常データであるため、マハラノビスの距離が大きなものほど、領域部分に存在するデータといえる。
【0061】
次いで、マハラノビス距離に基づいてクラス中心から遠いものを選択する(S6)。具体的には、マハラノビス距離の大きい順に良品データをソートし、ソートされた良品データの上位から、予め定めた比率もしくは件数を選択する。これにより、いわゆる境界領域に位置するデータ(正常データ)が選択される。本実施の形態では、処理ステップS2で指定された上位N個(あるいはX%)分を全て選択するようにした。このように、本実施の形態では、境界領域に属する正常データを上位(もっともマハラノビス距離の大きい)から所定量を連続して抽出するようにしたが、抽出のルールはこれに限るものではない。ただし、マハラノビス距離の大きい正常データをある程度の個数抽出することで、たとえば図6(b)に示すように、正常データの存在領域の境界領域に存在する正常データを確実に抽出することができる。
【0062】
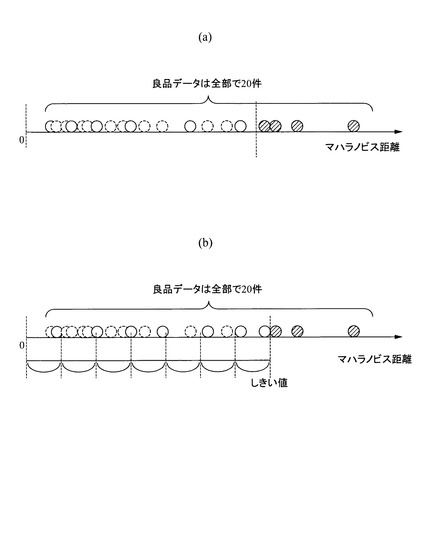
特に、この境界領域付近のデータの良否判定の適否が性能にシビアに効いてくるので、境界領域の正常データを確実に選択し、学習に使用することで、異常データと正常データを弁別するためのルール・閾値等を精度よく作成することができる。
【0063】
次に、マハラノビス距離に基づいて残りの正常データから所定の条件(たとえば、等距離間隔や、所定数置き等)に合致する正常データを選択する(S7)。すなわち、異常データ(不良品)と正常データ(良品)を精度よく弁別するための良否判定アルゴリズムを生成するためには、上述するように境界領域のデータも必要であるが、各領域に属するデータを代表する、境界領域以外に点在するデータも偏ることなく適度に選択する必要がある。そこで、偏りを生じないような所定の条件に合致する正常データを選択する。このように偏りなく正常データを選択することで、選択された代表データは、そのクラス全体の分布特性をより少ない件数で表すことができるデータとなる。所定の条件については、後述する。
【0064】
このように代表するデータも適度に抽出することにより、クラス同士、つまり、正常データ(良品)の領域と異常データ(不良品)の領域同士の分布の距離をみて分離度を求めることで、パラメータ調整の良し悪しを評価することができる。
【0065】
そして、上述した各処理を実行して得られた結果を次段のパラメータ最適化部24に出力する(S8)。なお、上述した実施の形態では、正常データのみをデータ選択の対象としたが、異常データのみをデータ選択の対象としても良い。その場合には、処理ステップS1におい取得するデータが異常データとなる。また、汎用性を持たせるためには、処理ステップS1では、正常データと異常データを分離して抽出し、処理ステップS2では、正常データと異常データのそれぞれに対して選択する数等を設定することになる。
【0066】
代表データを選択するための具体的な方法としては、たとえば図10(a)に示すように、距離の順位をベースにした選択方法と、図10(b)に示すように、距離そのものをベースにした選択方法とがある。もちろん、これ以外の方法を用いてもよい。
【0067】
図10(a)に示す距離の順位をベースにする選択方法は、以下のように行なう。まず、前提として処理ステップS2で設定する各値が、良品データ全20件から10件の選択を想定し、選択データに占める境界データ比率を40%とする。従って、境界領域として選択される正常データは、4個となり、残りの16個のデータの中から6個のデータを代表データとして選択することになる。
【0068】
処理ステップS3〜S5を実行後、算出したマハラノビス距離に基づいて正常データをソートする。これにより、図10(a)に示すように、各データがマハラノビス距離を横軸にした一軸上に配置される。この状態で、距離の大きいものから4個(図中、ハッチングで示す円)を境界領域の正常データ(境界データ)として選択する。これが処理ステップS6の実行の具体例である。次いで、上述した境界データを除いた良品から等間隔個数ごと(この例では2つおき)に正常データを選択する。
【0069】
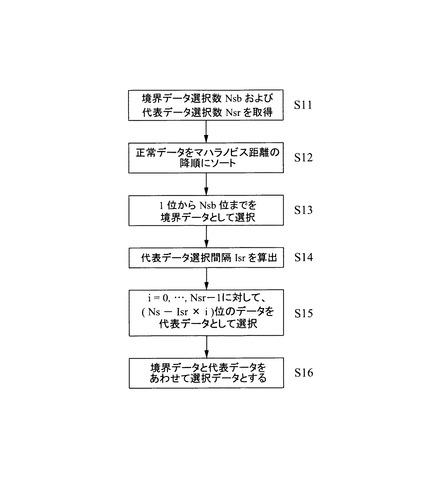
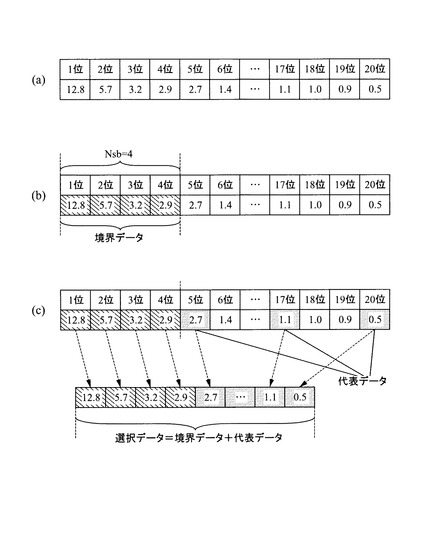
より具体的には、図11に示すフローチャートを実行することになる。すなわち、まず、境界データ選択数Nsbおよび代表データ選択数Nsrを取得する(S11)。この取得処理は、例えば、上述した処理ステップ2において設定された各値が具体的な数値の場合には、係る値を取得すればよいが、相対的な値の場合には、現在の全データ数Nから演算により求める必要がある。例えば、上述したように、データ選択数Nsと、境界データ比率rbのように設定された場合には、境界データ選択数Nsbおよび代表データ選択数Nsrは、それぞれ下記式に基づいて算出する。
Nsb=Ns×rb/100
Nsr=Ns−Nsb
【0070】
従って、仮に上述したようにNs=10,rb=40%とすると、
境界データ選択数Nsb=10×40/100=4個,
代表データ選択数Nsr=10−4=6個
となる。
【0071】
次いで、正常データをマハラノビス距離の降順にソートする(S12)。これにより、例えば図12(a)に示すように、マハラノビス距離が大きい順に各データの順位付けがなされる。なお、この処理ステップS12と、上述した処理ステップS11の実行順序は、逆にしてももちろんよい。
【0072】
そして、1位からNsb位までを境界データとして選択する(S13)。これにより、上記した具体例の場合には、1位から4位までの4つのデータが選択される(図12(b)参照)。
【0073】
次に、代表データ選択間隔Isrを算出する(S14)。本実施の形態では、下記式
Isr=f[(Ns−Nsb)/Nsr]
に基づいて算出する。ここで、関数f[X]は、例えば、Xを超えない最大整数としたり、小数点以下1位を四捨五入した整数とすることができる。いずれの場合も、データ選択は等間隔順位(Y個ずつ)となるが、関数f[X]が四捨五入した結果、切り上がった場合を想定すると、どちらかというと前者のXを超えない最大整数とした場合には、マハラノビス距離が小さい方が代表データとして選択され、後者の四捨五入(結果として切り上げ)の場合には、マハラノビス距離が大きい方まで代表データとして選択されることになる。
【0074】
一例を示すと、上述した具体例の場合、
代表データ選択間隔Isr=(20−4)/6=2.666……
となるため、前者の方式を採るとIsr=2となり、後者の方式を採るIsr=3となり、値が異なる。
【0075】
次いで、i=0,1,……,Nsr−1に対して、
(Ns−Isr×i)位
のデータを代表データとして選択する(S15)。このように、i=0の順位を選択することで、マハラノビス距離が最も短く、正常データの特徴を最も良く表していると言える正常データの領域の中心(中心付近)に存在する最大順位の正常データが選択される。上述した具体例の場合、Isr=2とすると、20位,18位,16位,14位,12位,10位の6つのデータが代表データとして選択され、Isr=3とすると、20位,17位,14位,11位,8位,5位の6つのデータが代表データとして選択される(図12(c)参照)。
【0076】
このようにして、上述した処理ステップS13,S15を実行してそれぞれ選択された境界データと代表データをあわせて選択データとして確定する(S16)(図12(c)参照)。
【0077】
なお、上述した具体例では、図10(a)に合わせて境界データを4個選択する場合を例に挙げて説明したが、例えば、境界データを2個とすると、境界データ選択数Nsbと代表データ選択数Nsrとは、それぞれ、
Nsb=10×20/100=2個
Nsr=10−2=8個
となる。
【0078】
従って、処理ステップS12を実行することで、図13(a)のようになり、処理ステップ13を実行することで、上位2個の正常データが境界データとして選択される(図13(b)参照)。
【0079】
代表データ選択間隔Isrは、
(20−2)/8=2
より、上述したどちらのルールによってもIsr=2となる(S14の実行)。
【0080】
従って、処理ステップS15を実行すると、i=0,1,2,……,(Nsr−1)に対して、(20−2×i)位を代表データとして選択することになる。上述した具体例によれば、0,1,2,……,7に対応する順位、すなわち、20位,18位,……,6位を代表データとする(図13(c)参照)。
【0081】
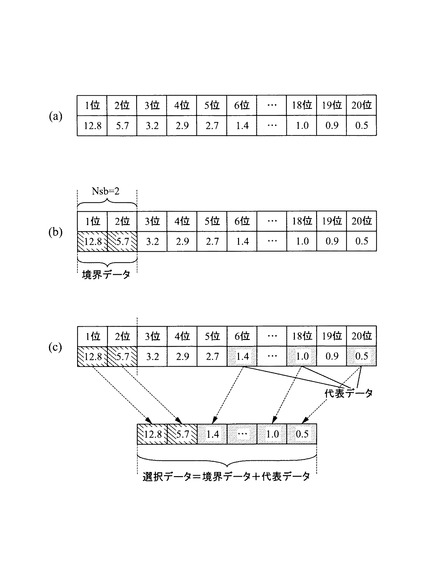
次に、図10(b)に概念図を示した距離そのものをベースにした選択方法について説明する。1つの方法としては、上述したように、マハラノビス距離を算出し、それに基づいて正常データをソートする。そして、マハラノビス距離がしきい値を超えるものを境界データとして選択し、残ったデータに対し等間隔に区切って代表データを選択する。
【0082】
具体的には、図14に示すフローチャートを実行する。すなわち、まず、選択数Nsと境界距離閾値thを取得する(S11)。この取得処理は、例えば、上述した処理ステップ2において設定された情報に基づいて設定してもよいし、不足している情報(たとえば境界距離閾値)がある場合には、係る不足している情報の入力を促し、ユーザからの入力を待つ。また、境界距離閾値は、このようにユーザからの入力に基づくものに限らず、初期値として装置側に設定しておき、それを利用してもよい。
【0083】
次いで、正常データをマハラノビス距離の降順にソートする(S22)。なお、この処理ステップS22と、上述した処理ステップS21の実行順序は、逆にしてももちろんよい。また、先に処理ステップS22を実行した場合、マハラノビス距離の最大値や、平均・分散などがわかるので、それに基づいて境界距離閾値を算出するようにしてもよい。
【0084】
そして、マハラノビス距離が境界距離閾値thを超える正常データを、境界データとして選択し、選択された正常データの数をNsbに設定する(S23)。これにより、図10(b)でいうと、ハッチングで示された3つの正常データが境界データとして選択される。たとえば、正常データが図12(a)に示すものとし、境界距離閾値thが3.0とすると、1位から3位の3つの正常データが境界データとして選択される。
【0085】
次に、境界データとして選択されたデータを除く正常データの中で、マハラノビス距離の最大値Dmaxと最小値Dminを求める(S24)。一例を示すと、正常データが図12(a)に示すようになっており、上述したように境界距離閾値thが3.0とすると、境界データとして選択されずに残った正常データは、4位以下のデータであるので、最大値Dmax=2.9となり、最小値Dmin=0.5となる。
【0086】
そして、代表データ選択数Nsrと、代表データ間隔距離Dsrを、
Nsr=Ns−Nsb
Dsr=(Dmax−Dmin)/Nsr
に基づいて算出する(S25)。
【0087】
次いで、i=0,1,……,Nsr−1に対して、それぞれ(Dmin+i×Dsr)を求める。これにより、残った正常で他を等距離に分割する位置が設定される。そして、各分割位置に最も近い正常データをそれぞれ代表データとして選択する(S26)。上記の演算式を用いることにより、i=0の時の分割位置は、Dminの位置となるので、マハラノビス距離が最も短く、正常データの特徴を最も良く表していると言える正常データの領域の中心(中心付近)に存在する最大順位の正常データが選択される。そして、上述した処理ステップS23,S26を実行してそれぞれ選択された境界データと代表データをあわせて選択データとして確定する(S27)。
【0088】
もちろん、本発明では、代表データ間隔距離Dsrを求める際に、上述したように最小値Dminを必ずしも用いる必要はなく、たとえば、
Dsr=Dmax/Nsr
に基づいて算出するほか、各種の演算により求めることができる。
【0089】
また、距離そのものをベースにした選択方法としては、上述した方法(境界データを閾値に基づいて決定する)ものに限ることはない。一例を示すと、例えば、まず、絶対値か相対的な値かは問わないが、境界データとして選択すべき量を決定し、マハラノビス距離の大きいものから順に上位の正常データを境界データとして選択する。そして、残ったデータの最大値(必要に応じて最小値も利用)と選択すべき数に基づいて等間隔で分割する距離を算出し、それに基づいて各分割する位置に近いデータを代表データとして選択するようにしてもよい。
【0090】
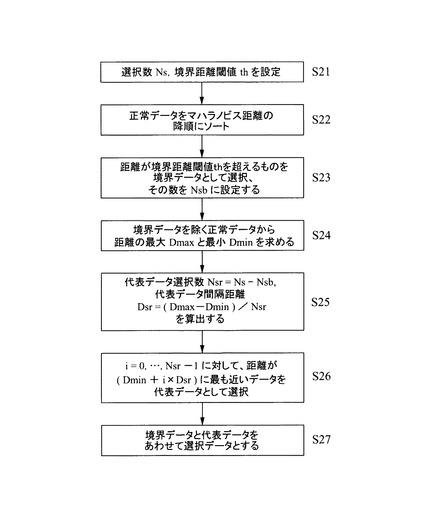
図15は、本発明の第2の実施の形態の要部を示している。すなわち、上述した第1の実施の形態の装置を用いて作成した良否判定アルゴリズムが、ユーザにとって必ずしも十分満足の行く性能が得られるとは限らない。そこで、本実施の形態では、十分な性能が得られなかった場合に再選択を行う機能を持たせている。
【0091】
まず、本装置で作成した良否判定アルゴリズムに基づいて実際に良否判定を行ない、見逃し率と過検出率を求め、判別性能の目標を達成したか否かを判断する(S31)。ここで、「見逃し」とは、本来「不良品」と判断し廃棄等して出荷しないようにする必要があるところ、良品と誤判断してしまうものである。係る事態は避けなければならないため、見逃し率は0%にする必要がある(0%が好ましい)。「過検出」とは、本来「良品」と判断し、そのまま出荷等できるものを「不良品」と判断してしまうことである。この「過検出」の発生率が多いと、意味のない歩留まりの低下を招き、商品のコストアップ等に結びつくとともに、利益を圧迫するおそれがある。従って、この過検出率もできるだけ小さい方が好ましい。ただし、通常「見逃し率」と「過検出率」をともに0%にするのは、事実上困難であるため、過検出はある程度生じることを許容するのが一般的である。よって、本実施の形態では、見逃し率は0%で過検出率を5%とした。なお、この数値は任意である。
【0092】
この判別性能が目標に達成したか否かは、例えば、波形データベース21に格納されたサンプルデータ(良否結果が分かっているもの)に基づいて良否判定を行ない、良否判定アルゴリズムに基づいて判定された結果が正しいか否かを求め、それに基づいて過検出率と見逃し率を算出する。また、この判断は、本実施の経緯では、データ選択部が行なうようにしているが、別途判定手段を設けてももちろん良い。
【0093】
また、実際の良否判定結果は、図2に示す検査装置10の出力を取得することになるが、具体的な処理手順の一例を示すと、波形データベース21に核に脳されたすべてのサンプルデータを検査装置10に渡す。検査装置10は、取得したサンプルデータについて良否判定を行ない、その判定結果を知識作成装置に渡す。サンプルデータには、サンプルデータを識別するコードが付与されているため、検査装置10は、係るコードと判定結果を関連づけて知識作成装置20に渡す。これにより、知識作成装置20は、そのコードに基づき、波形データベース21に格納された対応するサンプルデータの種類(良品/不良品)を知ることができるため、検査装置の判定結果の適否がわかる。
【0094】
なお、検査装置10と知識作成装置20の間におけるデータの送受は、通信で行なっても良いし、所定の記録媒体を用いてオフラインで行なっても良い。また、同一のパソコンなどに組み込まれている場合には、そのパソコンの記憶装置に互いにアクセスすることで簡単にデータの送受が行える。
【0095】
そして、性能が目標を達成している場合(処理ステップS31の分岐判断でYes)には、処理を終了するが、性能が目標を達成していない場合(処理ステップS31の分岐判断でNo)には、過検出・見逃し率がともに収束しているか否かを判断する(S32)。すなわち、処理ステップ31の分岐判断でNoとなった場合には、各回毎に求めた過検出率と見逃し率をメモリ(一時記憶手段)に記憶する。そして、過去の履歴から収束方向にあるか否かを判断する。つまり、過検出率並びに見逃し率が徐々に小さくなっている場合にも収束していると判断する(多少の変動はあっても全体的に小さくなる場合には収束していると判断する)。
【0096】
収束している場合には、そのまま学習を継続することで判別性能目標を達成する可能性が高いので、世代数を増やして判別ルール作成を再実行する(S32)。つまり、第1の実施の形態で説明したように、データ選択部23で選択された代表データは、次段のパラメータ最適化部24に送られ、そこにおいてGAを用いてパラメータの最適化を行なうため、係るGAを継続して続行(学習の再実行)し、適当なタイミングで判別性能が目標に達したか否かの判断を行なう(S31)。
【0097】
一方、過検出率及びまたは見逃し率が収束していない場合(処理ステップS32の分岐判断でNo)には、データ選択部23で選択した代表データが適切でなかったおそれがあるので、データ選択部23は、再度データ選択を行う。具体的には、まず、見逃し率が目標より大きいか否かを判断する(S34)。そして、見逃し率が目標に達している(目標以下の)場合(処理ステップS34の分岐判断はNo)には、過検出率を抑制する必要があるため、過検出されたデータを追加するデータ選択の再実行処理を行う(S35)。
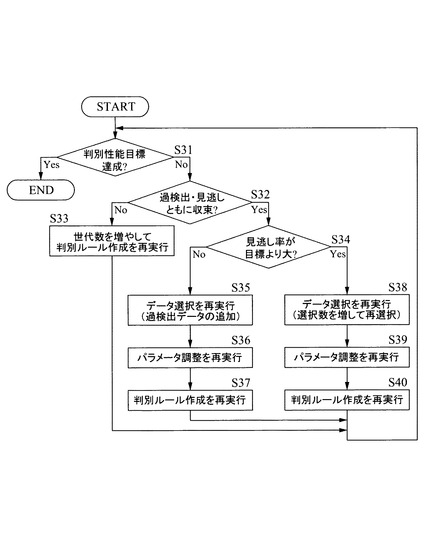
【0098】
具体的には、図16に示すフローチャートのように、まず、前回のデータ選択結果を読込み(S41)、検査結果を参照して過検出された良品データを抽出する(S42)。係る抽出処理は、たとえば、良否判定アルゴリズムに基づく検査装置の判定結果が「不良品」(全ての検査装置の判定結果と対応する波形データ(波形データのサンプルデータを特定する情報でも可)を記憶保持しておくか、少なくとも不良品と判定された波形データのサンプルデータを特定する情報を記憶保持しておくことで自動抽出できる)で、波形データベース21に登録された判定結果が「良品」のものをピックアップすることで自動的に行うことができる。
【0099】
抽出した良品データを前回のデータ選択結果(処理ステップS41の実行により取得)に追加し(S43)、追加後のデータ選択結果を新たな代表データとして出力する(S44)。つまり、次段のパラメータ最適化部24に渡す。
【0100】
上述した処理ステップS41からS44を実行して、データ選択部23が新たな代表データを選択すると、図15の処理ステップS36に進み、パラメータ最適化部24がパラメータ調整を再実行し、続いて、ルール作成部25が判別ルール作成を再実行する(S37)。これらの処理を経て、新たな代表データに基づく良否判定アルゴリズムが生成され、それぞれのデータベースに格納される。そして、処理ステップ31に戻り、その新たな代表データに基づく良否判定アルゴリズムを用いて検査装置を実行させ、判別性能が目標に達したか否かの判断を行なう。
【0101】
一方、見逃し率が目標値を達成していない場合には、処理ステップS34の分岐判断がYesとなるので、処理ステップS38に飛び、選択数を増して再度代表データの選択を行なう(S38)。すなわち、見逃し率が目標に達しない場合は、不良品(以上データ)が良品(正常データ)の分布の範囲内、それも分布の中心付近に位置したり、不良全体の分布が広範囲にわたる場合等、そもそも特徴量の段階で分離できていない状態にあることが多い。つまり、データ選択が適切ではなかったことを意味し、より多くのサンプルデータに基づいて正常データと異常データを分離するべく、データ選択部23で選択する学習する際の正常データの数を増加する。
【0102】
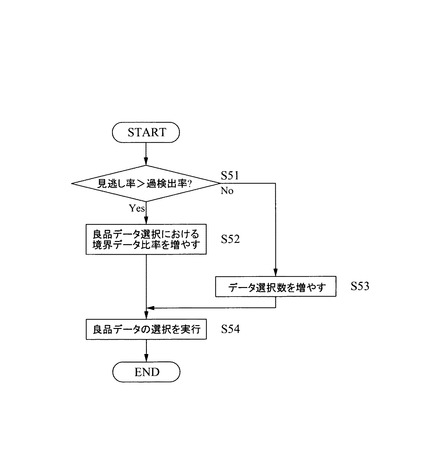
このとき、単純に増加する方法も考えられるが、単純にデータ数を増やすと、学習時間が増加するという弊害もでてくる。そこで、たとえば、図17に示すフローチャートに従って増加させることで、そのときの状況にあった適切なデータ数の増加を図り、学習結果の性能の向上を図りつつ、できるだけ少ないデータ数により短時間で学習を行なうことができるようにする。
【0103】
具体的には、まず、見逃し率と過検出率のどちらの方が悪いかを判断する(S51)。つまり、見逃し率が目標値に達していない場合、過検出率も目標値に達していない場合と過検出率は目標値に達している場合の両方が想定でき、しかも、両方とも目標値に達していない場合には、見逃し率と過検出率のいずれの方がより悪いかなどの場合分けができる。そこで、それらを一括して判断するため、本実施の形態では、
「見逃し率>過検出率?」
を判断する。
【0104】
そして、見逃し率が多い場合(処理ステップS51の分岐判断がYes)は、良品の境界データが不足していたと考えられるため、境界データ比率を増やす(S52)。あるいは、境界データの選択数を増やす。一方、過検出率の方が多い場合(処理ステップS51の分岐判断がNo)は、良品の分布を広く捉えなおすためにデータ選択数を増やす(S53)。
【0105】
そして、上述した各処理を実行した後、新たに設定された代表データとしての選択条件に従って、良品データの選択(新たな代表データの選択)を実行する(S54)。なお、図17に示したフローチャートでは、処理ステップ51の分岐判断の結果に基づいて処理ステップS52とS53のいずれか一方を実行するようにしたが、たとえば、処理ステップS52を実行した場合には、続いて処理ステップS53も実行するというように両方の処理を実行するようにしても良い。
【0106】
上述した処理ステップS51からS54を実行して、データ選択部23が新たな代表データを選択すると、図15の処理ステップS39に進み、パラメータ最適化部24がパラメータ調整を再実行し、続いて、ルール作成部25が判別ルール作成を再実行する(S40)。これらの処理を経て、新たな代表データに基づく良否判定アルゴリズムが生成され、それぞれのデータベースに格納される。そして、処理ステップ31に戻り、その新たな代表データに基づく良否判定アルゴリズムを用いて検査装置を実行させ、判別性能が目標に達したか否かの判断を行なう。
【0107】
上述した各処理ステップを、適宜のルートで繰り返し実行することで、適切なデータ数の代表データに基づいて学習が行われ、目標とする品質を備えた良否判定アルゴリズムを生成することができる。
【図面の簡単な説明】
【0108】
【図1】従来の問題点を説明する図である。
【図2】検査システムの一例を示す図である。
【図3】主に検査装置の内部構成の一例を示すブロック図である。
【図4】本発明に係る知識作成装置の一実施の形態を示すブロック図である。
【図5】分離度を説明する図である。
【図6】本実施の形態の動作原理・作用の概要を説明する図である。
【図7】本実施の形態の動作原理・作用の概要を説明する図である。
【図8】データ選択部の機能の一例を示すフローチャートである。
【図9】本実施の形態における各特徴量と、マハラノビス距離を説明する図である。
【図10】本実施の形態の動作原理・作用の概要を説明する図である。
【図11】データ選択部の機能の詳細な一例を示すフローチャートである。
【図12】本実施の形態の動作原理・作用の一例を示す図である。
【図13】本実施の形態の動作原理・作用の一例を示す図である。
【図14】データ選択部の機能の詳細な一例を示すフローチャートである。
【図15】第2の実施の形態を示すフローチャートの一例を示す図である。
【図16】処理ステップS33の具体的な処理手順の一例を示すフローチャートである。
【図17】処理ステップS35の具体的な処理手順の一例を示すフローチャートである。
【符号の説明】
【0109】
10 検査装置
20 知識作成装置
21 波形データベース
22 良否判定アルゴリズム生成部
23 データ選択部
24 パラメータ最適化部
25 ルール作成部
【技術分野】
【0001】
この発明は、知識作成装置および知識作成方法に関するもので、より具体的には、入力された検査対象の計測データに対して特徴量を抽出し、抽出した特徴量に基づいて状態を判定する検査装置における検査ロジック(有効特徴量,特徴量のパラメータ調整等)の生成を行なう技術に関する。
【背景技術】
【0002】
自動車や家電製品などには、モータ等の駆動系部品が組み込まれた回転機器が非常に多く用いられている。例えば自動車を例にとってみると、エンジン,パワーステアリング,パワーシート,ミッションその他の至る所に回転機器が実装されている。また、家電製品では、冷蔵庫,エアコン,洗濯機その他各種の製品がある。そして、係る回転機器が実際に稼働すると、モータ等の回転に伴って音が発生する。
【0003】
係る音は、正常な動作に伴い必然的に発生するものもあれば、不良(故障)に伴い発生する音もある。その不良に伴う異常音の一例としては、ベアリングの異常,内部の異常接触,アンバランス,異物混入などがある。より具体的には、ギヤ1回転について1度の頻度で発生するギヤ欠け,異物かみ込み,スポット傷,モータ内部の回転部と固定部が回転中の一瞬だけこすれ合うような異常音がある。また、人が不快と感じる音としては、例えば人間が聞こえる20Hzから20kHzの中で様々な音があり、例えば約15kHz程度のものがある。そして、係る所定の周波数成分の音が発生している場合も異常音となる。もちろん、異常音はこの周波数に限られない。
【0004】
係る不良に伴う音は、不快であるばかりでなく、さらなる故障を発生させるおそれもある。そこで、それら各製品に対する品質保証を目的とし、生産工場においては、通常検査員による聴覚や触覚などの五感に頼った「官能検査」を行ない、異常音の有無の判断を行っている。具体的には、耳で聞いたり、手で触って振動を確認したりすることによって行っている。なお、官能検査は、官能検査用語 JIS Z8144により定義されている。
【0005】
ところで、係る検査員の五感に頼った官能検査では、熟練した技術を要するばかりでなく、判定結果に個人差や時間による変化などのばらつきが大きい。さらには、判定結果のデータ化,数値化が難しく管理も困難となるという問題がある。そこで、係る問題を解決するため、駆動系部品を含む製品の異常を検査する検査装置として、定量的かつ明確な基準による安定した検査を目的とした異音検査装置がある。
【0006】
このように検査対象から得られた振動波形から正常/異常を判別する検査(いわゆる異音検査)を自動的に行なう異音検査装置としては、従来、特許文献1に開示されたものがある。この特許文献1に開示された発明は、時間軸波形から得られた特徴量と周波数波形から得られた特徴量とを用いて検査対象の正常/異常を総合的に判別するものである。
【0007】
このように時間軸波形と周波数軸波形のように異なる軸から得られる波形に基づいて総合的に異音検査をするのは以下の理由からである。すなわち、それ以前に開発されていた時間軸波形から得られた特徴量だけの異音検査や、周波数軸波形から得られた特徴量だけの異音検査ではすべての異音を検出することが難しい。それは、それぞれの特徴量には得意・不得意があるからである。複数の特徴量を用いる異音検査は、単一の特徴量を用いる異音検査に比べて高い判別能力を有する。
【0008】
つまり、そもそも駆動系部品は、回転や往復運動を繰り返す機構で成り立っており、その機構にわずかな機械的異常があれば、それに起因した異常成分(良品から発せられる正常成分とは何かが違う成分)が必ず振動や音として周囲に伝達される。ところが、異音検査における異常成分は、正常成分と比較しても振動や音の波形に含まれる、わずかな違いでしかなく、熟練した人の耳であれば聞き分けられるような違いがあっても、波形解析してみるとノイズに埋もれてうまく検知することができないことがあった。これは、従前の異音検査が時間軸波形から得られた特徴量だけや、周波数軸波形から得られた特徴量だけの判別、しかも単一の特徴量のみに基づいて行われる判別であったからである。そこで、上記の特許文献1では、複数の軸から得られる複数の特徴量に基づいて総合的に正常/異常を判断するようにしている。そして、この特許文献1に開示された発明では、判別ルールとして、ファジィルールを用い、ファジィ推論により複数の特徴量に基づく正常/異常の判断を行なうようにしている。
【0009】
ところで、特許文献1に開示された異音検査に判別ルールとして用いるファジィ推論は、ニューラルネットなど、その他の判別モデルと比較して、人が判別ルールを理解しやすいという利点がある。例えばニューラルネットとは、ニューロンモデルを互いに多数結合させて接続しネットワーク状にしたものであり、どのような判別をしてそのような結果に至ったのか、その根拠が難解で感覚的に理解しがたい。感覚的に理解できないものを人は信用しにくい。それが品質の要となる検査装置であるならなおさらである。
【0010】
これに対して、ファジィ推論は、あいまいさを表現するメンバシップ関数を用いており、ファジィ推論を用いた判別ルールは、判別の根拠と判別結果を対応づけて「IF 特徴量A=大 THEN 異常」のように人に理解しやすい表現で示すことが出来る。このように感覚的に理解できるものは説明もしやすく、品質ソリューションを事業とする場合に、検査装置の検査ロジックとして判別ルールを説明しやすいため、その説明を受けた顧客にとっても納得する度合いが高いので安心して採用できるという利点がある。
【0011】
また、新規に異音検査装置を導入しようとする顧客は、それまで熟練者(官能検査員)の耳による官能検査を行っていることも多く、官能検査員は「異音なきこと」などの記述が一般的な検査基準に対して独自の判定基準やノウハウ、知見をすでに有している。このような場合には、異音検査装置は官能検査員がこれまで行っていた官能検査の置き換えとなるので、官能検査員の持つ判定基準やノウハウ、知見との整合性が自ずと求められるのが現状である。係る場合にも、作成した判別ルールと、それまでの官能検査員がもっていた知識(検査基準)との整合性を説明しやすいということは、顧客に対して説明責任を負うソリューション提供者にとってファジィ推論による説明のしやすさは事業を進める上で大きな利点となっている。
【0012】
ところで、使用する特徴量の数が増加するほど、良否判定をするための判別ルールも複雑になったり、多数必要になったりする。そのため、精度の高い異音検査を行なうためには、判別ルールを精度良く作成する必要がある。異音検査における判別ルールを作成する工数を削減する技術として、非特許文献1に開示された技術がある。この非特許文献1には、判別ルール(検査ロジック)の自動生成において判別ルールに用いる特徴量選択とパラメータ探索に遺伝子アルゴリズムを用いる技術が開示されている。つまり、判別ルールに用いる特徴量選択とパラメータ探索とに、遺伝子アルゴリズムを用いることによって、それまで、人の勘と経験による試行錯誤でしか出来ないとされてきた判別ルールの作成処理を自動化/半自動化できるようにした。
【0013】
また、異音検査における判別ルールを自動作成する技術としては、非特許文献2に開示された発明もある。この非特許文献2には、判別ルールの自動生成において、判別ルール生成のために収集した正常データと異常データから適切な数の正常データと異常データを選択し、選択したデータから遺伝子アルゴリズムを用いて判別ルールに用いる特徴量選択とパラメータ調整をし、選択した特徴量と調整したパラメータからファジィ推論を用いて判別ルールを生成する技術が開示されている。このように正常データと異常データからそれらを最も分離する判別ルールを生成する技術は一般に不良識別と呼ばれている。
【0014】
しかしながら、不良識別では、正常/異常を判別するにはサンプルデータとして正常データと異常データがあらかじめ必要であり、異常データは正常データに比べて取得しにくいことから異常データがなければ判別ルールが生成できないという問題点がある。
【特許文献1】特許第3484665号
【非特許文献1】オムロンテクニクスVol.43 No.1 pp.99−105(2003)
【非特許文献2】オムロンテクニクスVol.44 No.1 pp.48−53(2004)
【発明の開示】
【発明が解決しようとする課題】
【0015】
上述した通り、これまでにも各種の異音検査装置の開発が試みられてきている。しかし、いずれも、不良品(異常品)を良品(正常品)と誤判定してしまう見逃し率の発生をなくしつつ(不良品を出荷することになるため確実に阻止する必要がある)、良品を不良品と誤判定してしまう過検出率の低減を図る(良品が出荷されず、廃棄処理等されてしまう無駄・歩留まり低下の防止をする)ことを目的とし、高性能な良否判定アルゴリズムの作成・改良が行なわれている。そのため、使用する特徴量の数が増加したり、よりよい判定ルールを作成するために要求されるサンプル数が増加したりするのが現状であった。
【0016】
たとえば検査対象データごとに最適な特徴量値を出力できるようにパラメータを調整することで、正常か異常かの微妙なところも判定できる。ここで、パラメータは、たとえば特徴量Aがある値(しきい値)以上となると、不良品であるというような場合、特徴量Aについての係るしきい値がパラメータとなり、そのしきい値をいくつにするかの調整がパラメータの調整(学習)となる。しかし、パラメータの調整が不十分だったり、未調整のままだったりすると、正しい検査ができない可能性がある。
【0017】
従って、上述したように、特徴量の増加並びにサンプル数の増加に伴い、学習に伴い生成・確認(ルールの適否判断)される判定ルールも多岐にわたり、学習が収束して最終的に最適な判定ルールを作成するのに時間がかかる。
【0018】
また、非特許文献2には、適切な数の正常データと異常データを選択することが開示されており、具体的には「パラメータ調整に使用するデータセットを選択する。40種類の特徴量を使ってOKデータを元に基準空間を求め、各データに対してマハラノビス距離を計算する。すべてのデータの中から、指定された件数のOKデータおよびNGデータを全体の分布と照らし合わせて、バランスを考慮して選択する。」と記載されている。つまり、OKデータ(正常データ)とNGデータ(異常データ)の数のバランスが悪いと、適切かつ効率のよい学習が行なえないおそれがある。
【0019】
ところで、実際の判定処理の際に発生する不良品に基づく異常データをあらかじめ用意するのは困難で、学習時に用意できるサンプルデータのほとんどは良品に基づく正常データとなり、正常データと異常データのサンプル数に大きなばらつきが生じる。そこで、適切な数の正常/異常データに基づいて学習を行なうためには、正常データの削除(データの間引き)を行なうことになる。しかし、闇雲に削除するとパラメータ調整の演算時間が短縮できても過検出が多くなり、検査装置としての性能が出ないおそれがある。
【0020】
一例を示すと、正常データと異常データにおける2つの特徴量PV,PNを軸とした散布図が、図1(a)に示すようになっていたとする。ここで、散布図は、データの特性を定量的に表す指標を複数定め、それら指標を軸にして構成される空間上に、各データをその指標値にしたがって配置した図である。ここでは2種類の特徴量を軸にした場合の散布図の例である。
【0021】
この散布図において、白丸が正常データで、黒丸が異常データである。すべてのデータを考慮して判定ルールを作成すると、各特徴量の閾値が図中波線で示すような境界線に基づき分離することになり、ルールの一例を示すと、下記のようになる。
IF PV>A AND PN>B Then 異常データ
【0022】
この図1(a)に示すデータから、正常データの一部を削除し、残った正常データ(代表データ)と異常データに基づいて学習を行い判定ルールを作成する。このとき、たとえば図1(b)に示すように偏った選択をする(点線の白丸は削除され、実線の白丸の正常データと、黒丸の異常データに基づいて学習する)と、本来は2つの特徴量を使わないと分離できないものを、1つの特徴量PVだけで分離しようとする誤った検査知識が作られる可能性がある。このときのルールの一例を示すと、下記のようになる。
IF PV>A Then 異常データ
【0023】
同様に、図1(c)に示すように偏った選択をする(点線の白丸は削除され、実線の白丸の正常データと、黒丸の異常データに基づいて学習する)と、正常データと異常データとの境界線(検査時のしきい値)をうまく設定できない可能性がある。このときのルールの一例を示すと、下記のようになる。
IF PV>C AND PN>D Then 異常データ
【0024】
上述したように適切でないルールが生成されてしまうと、点線の白丸である正常データが異常データと誤判定されてしまい、過検出が増える。なお、検査装置であるため、異常データを良品と誤判定(見逃し)して出荷してしまうことはさけなければいけない。よって、適切なデータが選択されないと、上述したように過検出が増え、無駄に廃棄されるものが多くなるという問題を有する。
【0025】
この発明は、知識作成に用いるデータを適宜に減らすことによって、パラメータ調整結果の最適性を損なうことなくパラメータ調整に要する時間を削減することができる知識作成装置および知識作成方法を提供することを目的とする。
【課題を解決するための手段】
【0026】
上記した目的を達成するため、本発明の知識作成装置は、入力された検査対象の計測データに対して特徴量を抽出し、抽出した特徴量に基づいて前記検査対象の良否判定をする検査装置における前記良否判定を行う際に使用する良否判定知識を作成する知識作成装置であって、取得した同一種類に属する複数の波形データの中から所定の波形データを選択するデータ選択手段と、そのデータ選択手段が選択した波形データである選択データを少なくとも用いて、前記良否判定知識を作成する知識作成手段とを備え、前記データ選択手段は、前記選択対象の複数の波形データが属するグループの境界領域に属する所定数の境界データを選択する機能と、前記境界領域に属さない波形データの中から一部の波形データを代表データとして選択する機能とを有し、それら選択された前記境界データと前記代表データを併せて前記選択データとするように構成した。
【0027】
知識作成手段は、実施の形態では、「パラメータ最適化部」と「ルール作成部」により実現されているが、選択された選択データに基づいて良否判定知識を作成するものであれば、実施の形態に示したものに限られないのはもちろんである。
【0028】
前記データ選択手段は、前記同一種類に属する全ての波形データに対して仮の特徴量演算を行なう機能と、その仮の特徴量演算を実行して得られた特徴量演算結果と、その特徴量演算結果の分布に基づいて前記境界データと前記代表データを選択することができる。係る発明を前提として、前記データ選択手段は、前記特徴量演算結果に基づき、各波形データについてそれぞれ求めた複数の特徴量値を基準化するとともに、マハラノビス距離を求め、そのマハラノビス距離が大きいグループから前記境界データを選択し、そのマハラノビス距離が小さいグループから前記代表データを選択するように構成するとよい。
【0029】
さらに、前記データ選択手段における選択手法としては、前記マハラノビス距離が設定されたしきい値以上に該当するものを前記境界データと選択するようにしたり、前記マハラノビス距離が大きいものから所定量(具体的な数/割合等)を前記境界データと選択するようにしたり、各波形データをマハラノビス距離の順にソートし、所定数おきに波形データを選択することで、前記代表データを選択するようにしたり、各波形データをマハラノビス距離の順にソートし、所定距離間隔で波形データを選択することで、前記代表データを選択するようにすることができる。もちろん、それ以外の手法によって選択するのを妨げない。
【0030】
さらに、上述した各種の発明を前提とし、前記知識作成手段が作成した良否判定知識を用いて実行された良否判断の結果が、判別性能の目標値に達しているか否かを判断する判断手段(実施の形態ではデータ選択部が兼用しているが、別に構成してももちろんよい)と、その判断手段の判断結果が、目標値に達しない場合には、前記データ選択手段で選択するデータを増やし、再度データ選択を行なう機能を備えるとよい。この発明は、第2の実施の形態により実現されている。
【0031】
前記データ選択手段で選択するデータを増やす処理は、下記の(1)から(3)のうち少なくとも1つを含むとよい。もちろん、これ以外の手法をとることも妨げない。(1)前記同一種類に属する波形データを異なるグループと誤判断した場合に、その誤判断した波形データを境界データとして追加する。(2)前記同一種類に属さない波形データを前記同一種類に属すると誤判断した場合には、データ選択する総数を増やす。(3)前記同一種類に属さない波形データを前記同一種類に属すると誤判断するとともに、前記同一種類に属する波形データを異なるグループと誤判断した場合には、境界データとして選択する量を増やす。
【0032】
一方、本発明に係る知識作成法は、入力された検査対象の計測データに対して特徴量を抽出し、抽出した特徴量に基づいて前記検査対象の良否判定をする検査装置における前記良否判定を行う際に使用する良否判定知識を作成する知識作成装置における知識作成法であって、取得した同一種類に属する複数の波形データの中から所定の波形データを選択するデータ選択処理と、そのデータ選択処理を実行して選択された波形データである選択データを少なくとも用いて、前記良否判定知識を作成する知識作成する処理とを含む。そして、前記データ選択処理は、前記選択対象の複数の波形データが属するグループの境界領域に属する所定数の境界データを選択する機能と、前記境界領域に属さない波形データの中から一部の波形データを代表データとして選択するとともに、それら選択された前記境界データと前記代表データを併せて前記選択データとするようにした。
【発明の効果】
【0033】
本発明では、知識作成に用いるデータをうまく減らすことによって、パラメータ調整結果の最適性を損なうことなくパラメータ調整に要する時間を削減することができる。
【発明を実施するための最良の形態】
【0034】
本発明の一実施の形態の装置を説明するに先立ち、本装置により設定される判定ルールを用いて良否判定(官能検査)を行う検査システムを説明する。図2に示すように、検査対象物1に接触・近接配置するマイク2および加速度ピックアップ3からの信号をアンプ4で増幅し、AD変換器5にてデジタルデータに変更後、検査装置10に与えるようになっている。そして、検査装置10は、マイク2で収集した音データや、加速度ピックアップ3で収集した振動データに基づく波形データを取得し、特徴量を抽出するとともに、異常判定を行なう。図2から明らかなように、検査装置10は、コンピュータから構成され、CPU本体10aと、キーボード,マウス等の入力装置10bと、ディスプレイ10cとを備えている。また、必要に応じて外部記憶装置を備えたり、通信機能を備えて外部のデータベースと通信し、必要な情報を取得することが出来る。
【0035】
図3に示すように、検査装置10は、A/D変換器5を介して取得した波形データから特徴量を抽出する特徴量抽出部11と、その特徴量抽出部11で抽出した特徴量の値に基づいて、正常データか異常データかの良否判定を行う判定部12と、特徴量抽出部11にて特徴量抽出する特徴量とそのパラメータ等を記憶する特徴量演算パラメータ記憶部13と、判定部12にて良否判定処理を行う際に使用するファジィルールを記憶するファジィルール記憶部14とを備えている。判定部12は、ファジィルール記憶部14に格納されたルールに従い、与えられた特徴量に対しファジィ推論部12aにてファジィ推論を行う。そして、求められた適合度を閾値処理部12bに与え、そこにおいて閾値処理をし、良否判定を行う。この判定部12の判定結果は、例えばディスプレイ10cにリアルタイムで表示したり、記憶装置に格納したりすることができる。
【0036】
上述した検査装置10の具体的な構成(各処理部の詳細な構成)は、従来公知の各種のものを適用できるため、詳細な説明を省略する。本発明に係る知識作成装置の実施の形態では、上述した特徴量演算パラメータ記憶部13に格納する特徴量や、その特徴量のパラメータを作成したり、ファジィルール記憶部14に格納するルールを作成するものである。図4は、本発明に係る知識作成装置の一実施の形態の概略構成を示している。
【0037】
図4に示すように、知識作成装置20は、サンプルデータを格納する波形データベース21と、その波形データベースに格納されたサンプルデータ(正常データと異常データの波形データ)に基づき、検査装置10が良否判定を行なう際に使用する上述した特徴量やルール等を生成する良否判定アルゴリズム生成部22とを備えている。
【0038】
波形データベース21に格納する波形データは、例えば、実際の官能検査を行なうのと同様に、サンプル品等を動作させた時に生じる音や振動をセンサ3で取得した(図示省略するが、必要に応じて増幅する)ものを記憶しても良いし、別途用意した別のデータベースからダウンロードして格納しても良い。また、この波形データベース21には、実際の波形データと、その種類(正常データと異常データの区別)が分かるように格納されている。すなわち、各波形データと、種類を関係づけて格納しても良いし、正常データのホルダと、異常データのホルダを分け、各ホルダ毎に対応する波形データを格納するようにしても良い。要は、格納された波形データの種類が分かるようになっていればよい。尚、上記の種類は、例えば、検査員が実際にセンサ3でデータ取得した際に検査員が同時に検査対象物(サンプル品)から発生する音等を聴いて判断したり、一旦格納した波形データを再生し、その再生した音を検査員が聴いて判断した結果を格納するようにしても良いし、サンプルデータを取得するための検査対象物が、予め良品か不良品かの区別が付いているものの場合には、予め種類を指定して波形データを取り込むことにより自動的に種類と波形データの関連づけを行なうようにしても良い。
【0039】
良否判定アルゴリズム生成部22は、データ選択部23と、パラメータ最適化部24と、ルール作成部25とを備えている。データ選択部23が本発明の要部となるところで、波形データベース21に格納されたサンプルデータのうち、良否判定アルゴリズムを生成する際に使用するデータを選択するものである。波形データベース21に格納されたサンプルデータ、換言すると、用意できるサンプルデータの数は、正常データのサンプル数が圧倒的に多いのが通常である。そして、基本的には、サンプル数が多いほどより高精度の判定を行なうことのできる良否判定アルゴリズムを生成することができる。但し、サンプル数が多いと、たとえば、後段のパラメータ最適化部24にて行われる最適化処理を実行し特徴量やその特徴量のパラメータを決定するまでに要する処理時間が長くなる。そこで、データ選択部23は、波形データベース21に格納されたサンプルデータのうち、特にデータ数が多くなることが予測できる正常データを間引いて選択する。これにより、良否判定アルゴリズムの生成には使用されない(反映されない)正常データのサンプルデータも存在するため、後段のパラメータ最適化部24にて行われる最適化処理時間が短くすることができる。そして、後述するように、正常データのサンプルデータを選択する際に、一定の条件の下で抽出するため、選択する前のすべてのサンプルデータを用いて求めた良否判定アルゴリズムとほぼ同様の高精度のものを得ることができる。
【0040】
パラメータ最適化部24は、良否判定を行なう際に使用する特徴量(有効特徴量)と、その特徴量についてのパラメータを決定するものである。すなわち、特徴量の一例を示すと、周波数成分や、平均値,分散,最大値,最小値,閾値越えのピーク数や、N番目のピークの値などがある。周波数成分については、ローパスフィルタや、バンドパスフィルタその他各種のフィルタを用いたり、FFT処理などの波形変換を行なうことなどがある。そのときの特徴量のパラメータは、ローパスフィルタについては、カットオフ周波数の値であったり、バンドパスフィルタの場合には、通過帯域を区切る値等となる。FFT処理の場合には、周波数軸に変換されたため、任意の周波数帯における成分を特徴量とすることで、異常成分の含まれている状態を定量化することが可能なる。つまり、FFT処理後に抽出すべき周波数帯域がパラメータとなる。平均値、最大値等の特徴量は、通常、フィルタ処理した後の波形データに基づいて求める。閾値越えのピーク数を特徴量とした場合のパラメータは、当該閾値の値となる。また、特徴量が、各ピーク値の上からN番目の場合は、Nの値(単数,複数)がパラメータとなる。さらに、ピーク数やピーク値の場合、検出対象の時間をパラメータとして設定したり、閾値も1つのみでなく、下限値と上限値というように2つの閾値を設定し、一定の範囲内或いは範囲外をパラメータとして設定することができる。もちろん、特徴量は上述したものに限られないのは言うまでもなく、また、例示列挙した特徴量に対するパラメータも、これに限られないのはもちろんである。
【0041】
このパラメータ最適化部24は、良品(正常データ)と不良品(異常データ)を最もよく分離できる特徴量演算用の諸パラメータ(特徴量演算パラメータや各特徴量の評価値の重み)を探索するものであり、本実施の形態では、例えば特開2004−079211号公報に開示された発明のように、GA(遺伝的アルゴリズム)を用いて有効特徴量と、そのパラメータを決定することができる。すなわち、パラメータ探索のアルゴリズムとして遺伝的アルゴリズムが用いられた場合、個別のパラメータを遺伝子,全パラメータの組合せを個体とみなす。そこで、個体の交叉・突然変異によって新たな個体を創り出し(世代交代し)、評価の低い個体を新個体で置き換える。このようにして、評価の高いより優れた個体を残していくことにより最適に近い個体(パラメータ設定)を得る。
【0042】
そして、最終的に求められたパラメータ等が、特徴量演算パラメータ記憶部13に格納される。なお、図示の例では、良否判定アルゴリズム生成部22(パラメータ最適化部24)が、検査装置10の特徴量演算パラメータ記憶部13に直接アクセスして格納するようにしているが、必ずしも直接格納する必要はなく、図示省略する知識作成装置20の記憶装置内にパラメータ最適化部24で生成した特徴量,パラメータ等を格納し、所定の方法(オンライン,通信,記録メディアを介する)でデータを格納すればよい。
【0043】
なお、パラメータ最適化部24における最適化処理、つまり、パラメータ等の探索方法は、上述したGA(遺伝的アルゴリズム)に限ることはなく、例えば、NN(ニューラルネットワーク),SVM(サポートベクターマシン),総当りなどの各種の手法をとることができる。
【0044】
また、パラメータ最適化部24で求めた検査装置10で使用すべき特徴量とそのパラメータは、ルール作成部25に与えられる。ルール作成部25は、与えられた特徴量とそのパラメータに基づいてファジィルールを作成する。使用すべき特徴量と、良否判定する場合のパラメータが分かっているため、公知の手法により“IF THEN方式”のルールを簡単に作成することができるし、それに基づいてメンバシップ関数も作成できる。そして、それら作成したルール等をファジィルール記憶部14に格納する。なお、図示の例では、良否判定アルゴリズム生成部22(ルール作成部25)が、検査装置10のファジィルール記憶部14に直接アクセスして格納するようにしているが、必ずしも直接格納する必要はなく、図示省略する知識作成装置20の記憶装置内にルール記憶部14で生成したファジィルール等を格納し、所定の方法(オンライン,通信,記録メディアを介する)でデータを格納すればよい。
【0045】
ここで、本発明の要部となるデータ選択部23の機能を説明する。上述したように、遺伝的アルゴリズムによるパラメータ探索を用いた場合、個別のパラメータを遺伝子,全パラメータの組合せを個体とみなして,個体の交叉・突然変異によって新たな個体を創りだしながら、より優れた個体を残していくことにより最適に近い個体(パラメータ設定)を獲得することができる。遺伝的アルゴリズムを使ったとしても、パラメータ探索に用いるデータの数や探索の繰り返し回数が増えると探索にかかる時間が膨大になる。もちろん、基本的にはデータの数が多いほど、探索の繰り返し回数が多いほど、最適なパラメータ設定が得られやすくなるが、本実施の形態のデータ選択部23では、探索に用いるデータを適宜に減らすことによって、パラメータ調整結果の最適性を損なうことなくパラメータ調整に要する時間を削減することができるようにする。つまり、データ選択を行わない場合の特徴量演算パラメータ調整結果とほぼ同等のパラメータ調整結果が得られるようにする。
【0046】
ここで、パラメータ調整結果が「良い」とは、そのパラメータ設定条件で演算した特徴量を用いることによって、よい判定性能(過検出率・見逃し率がともに0%に近いほどよい)が得られることである。ただし、判定性能の値は、最終的な検査ルールが確定しないと得られないことから、パラメータ調整の過程および結果の時点では、分離度を用いて特徴量およびその演算パラメータの良し悪しを評価する。
【0047】
ここで、分離度が低いとは、データの散布図が例えば図5(a)に示すように、軸となっている特徴量にそれぞれどのように閾値を設定しても良品データ群と不良品データ群の領域を分割することはできないような状態をいう。つまり、このままの特徴量の演算結果では良品と不良品の判別が難しいことを示している。なお、この散布図において、白丸が正常データで、黒丸が異常データである。
【0048】
逆に、分離度が高い場合には、図5(b)に示すように、軸となっている特徴量にそれぞれ適切に閾値を設定することによって良品データ群と不良品データ群のそれぞれが存在する領域を分割することができるような状態を言う。この特徴量演算結果で良品と不良品の判別ができる可能性が高いことを示している。
【0049】
使用する特徴量を変えたり、仮に同じ特徴量であってもパラメータを調整することで、図5(a)の状態から図5(b)に示す状態に変更することができる可能性がある。もちろん、どのように調整しても分離度が低いものもあるが、それは、解析に適さない特徴量・パラメータ等であることになる。ここで、データ選択部23は、データを選択した結果分離度が悪くなったり、図1に示したように、本来の全てのデータを用いて設定した閾値(パラメータ)と異なり、誤検出を生じるようになることを避ける必要がある。
【0050】
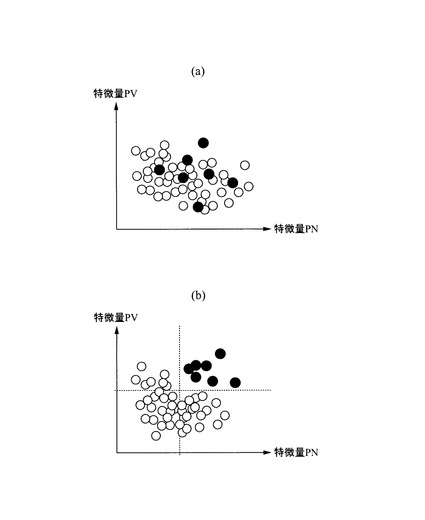
上記の条件の下で、本実施の形態では、以下のようにデータ選択をするようにした。すなわち、概念図として示すと、特徴量PV,PNを軸とした散布図が、図6(a)に示すように良品に基づく全ての正常データが白丸で示すようになっており、不良品に基づく異常データが黒丸で示すようになっているとする。図から明らかなように、異常データ(黒丸)に比べて、正常データ(白丸)のサンプル数が多く、バランスを欠いているとともに、正常データについては、似ている(散布図上での位置(座標値)が近い)ものが多く、サンプル数が多く、最終的な良否判定アルゴリズムを生成するのに時間がかかる割に、無駄な正常データのサンプルの存在も否定できず、無駄に学習を繰り返し行なっているといえる。
【0051】
係る場合に、データ選択部23は、正常データについて、図6(b)に示すように、中心部分に位置する代表的な正常データ(白丸)と、正常データの境界域に存在する正常データ(ハッチング丸)を選択し、その選択された正常データ(代表データ)と、全ての異常データを次段のパラメータ最適化部24に送り、学習を行うようにする。このように、境界部分の正常データを残すことにより、図6(b)に示すように、正常データと異常データを区別する閾値を、図6(a)の場合と同様にすることができる。そして、正常データのうち、波線の丸で示したものは学習に使用しないため、サンプル数が少なくなり、短時間で同程度の品質の良否判定アルゴリズムを生成することが可能となる。
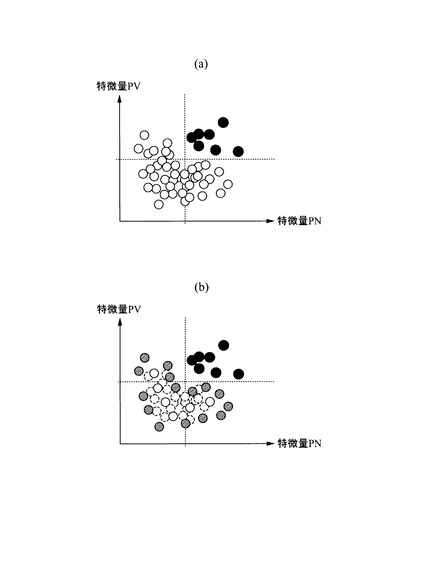
【0052】
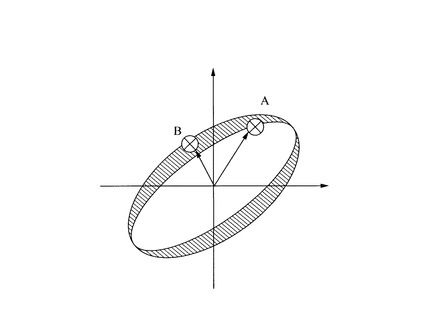
そして、境界部分の正常データを選択するに際し、本実施の形態では、マハラノビス距離によるデータ選択を行うようにした。すなわち、図7に示す例によれば、点Aは点Bよりもユークリッド距離は遠くなるが、楕円で囲むデータの分布領域はA方向に分散が大きいため、Bの方がマハラノビス距離は大きくなる。そこで、正常データは、マハラノビス距離の大きい方(図7中ハッチング部分)に存在するものを順番に選択するようにした。この部分が境界部分の正常データとなる。また、白抜きの中央領域(ここでは、境界部分以外領域)は、均等になるように選択するようにした。この部分が、代表的な正常データとなる。
【0053】
ここで、マハラノビス距離は、データのばらつきを考慮した距離尺度であり、散布図上のユークリッド距離では等距離でも、分散が大きい方向ではマハラノビス距離は小さく、分散が小さい方向ではマハラノビス距離は大きくなる。換言すると、マハラノビス距離とは、データの母集団と各データとの距離を表す尺度となる。
たとえば、特徴量PV、PNの平均をμPV、μPNとし、特徴量PV、PNの母集団をXPV,XPNとする。そして、
【数1】
【0054】
とおき、特徴量PV,PNの演算値の分散共分散行列をΣ,その逆行列をΣ−1とすると、母集団と各データとのマハラノビス距離dは、
【数2】
で求められる。
【0055】
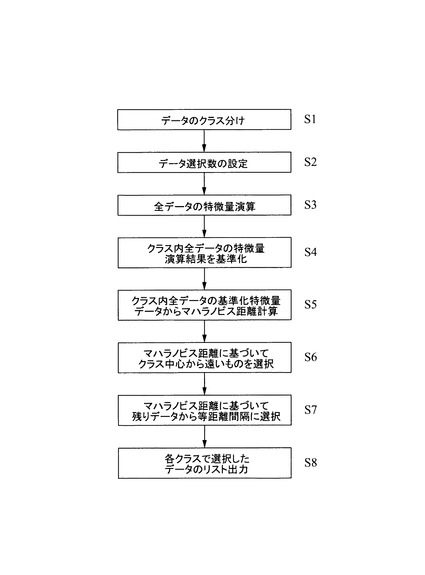
なお、実際には、各特徴量で、スパンが異なることから、正規化(基準化)をする必要がある。つまり、まず、各変量の単位を合わせるため、例えば、平均=0、分散を=1に基準化する。その後、上述した式に基づいてデータの中心からマハラノビス距離を求める。そして、マハラノビス距離の遠い方から一定数選択する。これにより、境界部分の正常データが抽出される。そして、残ったデータの中から、所定の条件に従い所定数の正常データ(代表データ)を抽出する。係る処理の具体的な一例を示すと、図8に示すフローチャートを実行する。
【0056】
まず、データのクラス分けを行ない、必要なデータを取得する(S1)。ここでは、良品(正常データ)と不良品(異常データ)に分類分けを行なう。実際には、波形データベース21にサンプルデータを格納する際に、その種類が関連づけられて登録されているため、ここでは、そのサンプルデータに登録される際の種類に基づき、必要なデータを取得する。本実施の形態では、所定データの中から所定数選択する(正常データを所定数間引く)。
【0057】
次に、データ選択数の設定数の設定を受け付ける(S2)。すなわち、ユーザが入力装置等を操作して境界部分の正常データの数と、代表的な正常データの数を入力する。そこで、データ選択部23は、入力装置等を介して受け付けた選択すべきデータ数を取得する。この時指定するデータの数は、絶対的な数値でも良いし、全体の何%のように相対的な値でもよい。また、境界部分の正常データの指定方法と、代表的な正常データの指定方法とは、同じ方法でも良いし、異なる方法でも良い。
【0058】
波形データベース21に格納された全てのデータに対して、特徴量演算を行なう(S3)この特徴量演算する対象の波形データは、少なくともデータ選択する対象(種類)のサンプルデータであり、本実施形態では、全ての正常データとなる。なお、すでに特徴量が求められている場合には、それを利用することができる。
【0059】
次に、処理ステップS3で求めたクラス内(本実施の形態では、良品)の全データの特徴量演算結果を基準化する(S4)。この基準化は、具体的には、各特徴量の値が、平均が0で分散が1になるように変換する。ついで、係る処理ステップS4を実行して得られたクラス内の全データの基準化特徴量データから、マハラノビス距離を算出する(S5)。ここで算出するマハラノビス距離は、クラス内(ここでは正常データのクラス)の全データの基準化特徴量データから算出される「基準空間」と、クラス内の個別データ(の基準化特徴量データ)と、の距離である。
【0060】
これにより、図9に示すように、数十次元の特徴量データから1次元に集約された距離を求めることができる。そのクラス(良品)に近いほど、算出したマハラノビス距離は1に近く、良品の特徴から遠いほどマハラノビスの距離は大きな値となる。従って、今回の場合すべてが良品に基づく正常データであるため、マハラノビスの距離が大きなものほど、領域部分に存在するデータといえる。
【0061】
次いで、マハラノビス距離に基づいてクラス中心から遠いものを選択する(S6)。具体的には、マハラノビス距離の大きい順に良品データをソートし、ソートされた良品データの上位から、予め定めた比率もしくは件数を選択する。これにより、いわゆる境界領域に位置するデータ(正常データ)が選択される。本実施の形態では、処理ステップS2で指定された上位N個(あるいはX%)分を全て選択するようにした。このように、本実施の形態では、境界領域に属する正常データを上位(もっともマハラノビス距離の大きい)から所定量を連続して抽出するようにしたが、抽出のルールはこれに限るものではない。ただし、マハラノビス距離の大きい正常データをある程度の個数抽出することで、たとえば図6(b)に示すように、正常データの存在領域の境界領域に存在する正常データを確実に抽出することができる。
【0062】
特に、この境界領域付近のデータの良否判定の適否が性能にシビアに効いてくるので、境界領域の正常データを確実に選択し、学習に使用することで、異常データと正常データを弁別するためのルール・閾値等を精度よく作成することができる。
【0063】
次に、マハラノビス距離に基づいて残りの正常データから所定の条件(たとえば、等距離間隔や、所定数置き等)に合致する正常データを選択する(S7)。すなわち、異常データ(不良品)と正常データ(良品)を精度よく弁別するための良否判定アルゴリズムを生成するためには、上述するように境界領域のデータも必要であるが、各領域に属するデータを代表する、境界領域以外に点在するデータも偏ることなく適度に選択する必要がある。そこで、偏りを生じないような所定の条件に合致する正常データを選択する。このように偏りなく正常データを選択することで、選択された代表データは、そのクラス全体の分布特性をより少ない件数で表すことができるデータとなる。所定の条件については、後述する。
【0064】
このように代表するデータも適度に抽出することにより、クラス同士、つまり、正常データ(良品)の領域と異常データ(不良品)の領域同士の分布の距離をみて分離度を求めることで、パラメータ調整の良し悪しを評価することができる。
【0065】
そして、上述した各処理を実行して得られた結果を次段のパラメータ最適化部24に出力する(S8)。なお、上述した実施の形態では、正常データのみをデータ選択の対象としたが、異常データのみをデータ選択の対象としても良い。その場合には、処理ステップS1におい取得するデータが異常データとなる。また、汎用性を持たせるためには、処理ステップS1では、正常データと異常データを分離して抽出し、処理ステップS2では、正常データと異常データのそれぞれに対して選択する数等を設定することになる。
【0066】
代表データを選択するための具体的な方法としては、たとえば図10(a)に示すように、距離の順位をベースにした選択方法と、図10(b)に示すように、距離そのものをベースにした選択方法とがある。もちろん、これ以外の方法を用いてもよい。
【0067】
図10(a)に示す距離の順位をベースにする選択方法は、以下のように行なう。まず、前提として処理ステップS2で設定する各値が、良品データ全20件から10件の選択を想定し、選択データに占める境界データ比率を40%とする。従って、境界領域として選択される正常データは、4個となり、残りの16個のデータの中から6個のデータを代表データとして選択することになる。
【0068】
処理ステップS3〜S5を実行後、算出したマハラノビス距離に基づいて正常データをソートする。これにより、図10(a)に示すように、各データがマハラノビス距離を横軸にした一軸上に配置される。この状態で、距離の大きいものから4個(図中、ハッチングで示す円)を境界領域の正常データ(境界データ)として選択する。これが処理ステップS6の実行の具体例である。次いで、上述した境界データを除いた良品から等間隔個数ごと(この例では2つおき)に正常データを選択する。
【0069】
より具体的には、図11に示すフローチャートを実行することになる。すなわち、まず、境界データ選択数Nsbおよび代表データ選択数Nsrを取得する(S11)。この取得処理は、例えば、上述した処理ステップ2において設定された各値が具体的な数値の場合には、係る値を取得すればよいが、相対的な値の場合には、現在の全データ数Nから演算により求める必要がある。例えば、上述したように、データ選択数Nsと、境界データ比率rbのように設定された場合には、境界データ選択数Nsbおよび代表データ選択数Nsrは、それぞれ下記式に基づいて算出する。
Nsb=Ns×rb/100
Nsr=Ns−Nsb
【0070】
従って、仮に上述したようにNs=10,rb=40%とすると、
境界データ選択数Nsb=10×40/100=4個,
代表データ選択数Nsr=10−4=6個
となる。
【0071】
次いで、正常データをマハラノビス距離の降順にソートする(S12)。これにより、例えば図12(a)に示すように、マハラノビス距離が大きい順に各データの順位付けがなされる。なお、この処理ステップS12と、上述した処理ステップS11の実行順序は、逆にしてももちろんよい。
【0072】
そして、1位からNsb位までを境界データとして選択する(S13)。これにより、上記した具体例の場合には、1位から4位までの4つのデータが選択される(図12(b)参照)。
【0073】
次に、代表データ選択間隔Isrを算出する(S14)。本実施の形態では、下記式
Isr=f[(Ns−Nsb)/Nsr]
に基づいて算出する。ここで、関数f[X]は、例えば、Xを超えない最大整数としたり、小数点以下1位を四捨五入した整数とすることができる。いずれの場合も、データ選択は等間隔順位(Y個ずつ)となるが、関数f[X]が四捨五入した結果、切り上がった場合を想定すると、どちらかというと前者のXを超えない最大整数とした場合には、マハラノビス距離が小さい方が代表データとして選択され、後者の四捨五入(結果として切り上げ)の場合には、マハラノビス距離が大きい方まで代表データとして選択されることになる。
【0074】
一例を示すと、上述した具体例の場合、
代表データ選択間隔Isr=(20−4)/6=2.666……
となるため、前者の方式を採るとIsr=2となり、後者の方式を採るIsr=3となり、値が異なる。
【0075】
次いで、i=0,1,……,Nsr−1に対して、
(Ns−Isr×i)位
のデータを代表データとして選択する(S15)。このように、i=0の順位を選択することで、マハラノビス距離が最も短く、正常データの特徴を最も良く表していると言える正常データの領域の中心(中心付近)に存在する最大順位の正常データが選択される。上述した具体例の場合、Isr=2とすると、20位,18位,16位,14位,12位,10位の6つのデータが代表データとして選択され、Isr=3とすると、20位,17位,14位,11位,8位,5位の6つのデータが代表データとして選択される(図12(c)参照)。
【0076】
このようにして、上述した処理ステップS13,S15を実行してそれぞれ選択された境界データと代表データをあわせて選択データとして確定する(S16)(図12(c)参照)。
【0077】
なお、上述した具体例では、図10(a)に合わせて境界データを4個選択する場合を例に挙げて説明したが、例えば、境界データを2個とすると、境界データ選択数Nsbと代表データ選択数Nsrとは、それぞれ、
Nsb=10×20/100=2個
Nsr=10−2=8個
となる。
【0078】
従って、処理ステップS12を実行することで、図13(a)のようになり、処理ステップ13を実行することで、上位2個の正常データが境界データとして選択される(図13(b)参照)。
【0079】
代表データ選択間隔Isrは、
(20−2)/8=2
より、上述したどちらのルールによってもIsr=2となる(S14の実行)。
【0080】
従って、処理ステップS15を実行すると、i=0,1,2,……,(Nsr−1)に対して、(20−2×i)位を代表データとして選択することになる。上述した具体例によれば、0,1,2,……,7に対応する順位、すなわち、20位,18位,……,6位を代表データとする(図13(c)参照)。
【0081】
次に、図10(b)に概念図を示した距離そのものをベースにした選択方法について説明する。1つの方法としては、上述したように、マハラノビス距離を算出し、それに基づいて正常データをソートする。そして、マハラノビス距離がしきい値を超えるものを境界データとして選択し、残ったデータに対し等間隔に区切って代表データを選択する。
【0082】
具体的には、図14に示すフローチャートを実行する。すなわち、まず、選択数Nsと境界距離閾値thを取得する(S11)。この取得処理は、例えば、上述した処理ステップ2において設定された情報に基づいて設定してもよいし、不足している情報(たとえば境界距離閾値)がある場合には、係る不足している情報の入力を促し、ユーザからの入力を待つ。また、境界距離閾値は、このようにユーザからの入力に基づくものに限らず、初期値として装置側に設定しておき、それを利用してもよい。
【0083】
次いで、正常データをマハラノビス距離の降順にソートする(S22)。なお、この処理ステップS22と、上述した処理ステップS21の実行順序は、逆にしてももちろんよい。また、先に処理ステップS22を実行した場合、マハラノビス距離の最大値や、平均・分散などがわかるので、それに基づいて境界距離閾値を算出するようにしてもよい。
【0084】
そして、マハラノビス距離が境界距離閾値thを超える正常データを、境界データとして選択し、選択された正常データの数をNsbに設定する(S23)。これにより、図10(b)でいうと、ハッチングで示された3つの正常データが境界データとして選択される。たとえば、正常データが図12(a)に示すものとし、境界距離閾値thが3.0とすると、1位から3位の3つの正常データが境界データとして選択される。
【0085】
次に、境界データとして選択されたデータを除く正常データの中で、マハラノビス距離の最大値Dmaxと最小値Dminを求める(S24)。一例を示すと、正常データが図12(a)に示すようになっており、上述したように境界距離閾値thが3.0とすると、境界データとして選択されずに残った正常データは、4位以下のデータであるので、最大値Dmax=2.9となり、最小値Dmin=0.5となる。
【0086】
そして、代表データ選択数Nsrと、代表データ間隔距離Dsrを、
Nsr=Ns−Nsb
Dsr=(Dmax−Dmin)/Nsr
に基づいて算出する(S25)。
【0087】
次いで、i=0,1,……,Nsr−1に対して、それぞれ(Dmin+i×Dsr)を求める。これにより、残った正常で他を等距離に分割する位置が設定される。そして、各分割位置に最も近い正常データをそれぞれ代表データとして選択する(S26)。上記の演算式を用いることにより、i=0の時の分割位置は、Dminの位置となるので、マハラノビス距離が最も短く、正常データの特徴を最も良く表していると言える正常データの領域の中心(中心付近)に存在する最大順位の正常データが選択される。そして、上述した処理ステップS23,S26を実行してそれぞれ選択された境界データと代表データをあわせて選択データとして確定する(S27)。
【0088】
もちろん、本発明では、代表データ間隔距離Dsrを求める際に、上述したように最小値Dminを必ずしも用いる必要はなく、たとえば、
Dsr=Dmax/Nsr
に基づいて算出するほか、各種の演算により求めることができる。
【0089】
また、距離そのものをベースにした選択方法としては、上述した方法(境界データを閾値に基づいて決定する)ものに限ることはない。一例を示すと、例えば、まず、絶対値か相対的な値かは問わないが、境界データとして選択すべき量を決定し、マハラノビス距離の大きいものから順に上位の正常データを境界データとして選択する。そして、残ったデータの最大値(必要に応じて最小値も利用)と選択すべき数に基づいて等間隔で分割する距離を算出し、それに基づいて各分割する位置に近いデータを代表データとして選択するようにしてもよい。
【0090】
図15は、本発明の第2の実施の形態の要部を示している。すなわち、上述した第1の実施の形態の装置を用いて作成した良否判定アルゴリズムが、ユーザにとって必ずしも十分満足の行く性能が得られるとは限らない。そこで、本実施の形態では、十分な性能が得られなかった場合に再選択を行う機能を持たせている。
【0091】
まず、本装置で作成した良否判定アルゴリズムに基づいて実際に良否判定を行ない、見逃し率と過検出率を求め、判別性能の目標を達成したか否かを判断する(S31)。ここで、「見逃し」とは、本来「不良品」と判断し廃棄等して出荷しないようにする必要があるところ、良品と誤判断してしまうものである。係る事態は避けなければならないため、見逃し率は0%にする必要がある(0%が好ましい)。「過検出」とは、本来「良品」と判断し、そのまま出荷等できるものを「不良品」と判断してしまうことである。この「過検出」の発生率が多いと、意味のない歩留まりの低下を招き、商品のコストアップ等に結びつくとともに、利益を圧迫するおそれがある。従って、この過検出率もできるだけ小さい方が好ましい。ただし、通常「見逃し率」と「過検出率」をともに0%にするのは、事実上困難であるため、過検出はある程度生じることを許容するのが一般的である。よって、本実施の形態では、見逃し率は0%で過検出率を5%とした。なお、この数値は任意である。
【0092】
この判別性能が目標に達成したか否かは、例えば、波形データベース21に格納されたサンプルデータ(良否結果が分かっているもの)に基づいて良否判定を行ない、良否判定アルゴリズムに基づいて判定された結果が正しいか否かを求め、それに基づいて過検出率と見逃し率を算出する。また、この判断は、本実施の経緯では、データ選択部が行なうようにしているが、別途判定手段を設けてももちろん良い。
【0093】
また、実際の良否判定結果は、図2に示す検査装置10の出力を取得することになるが、具体的な処理手順の一例を示すと、波形データベース21に核に脳されたすべてのサンプルデータを検査装置10に渡す。検査装置10は、取得したサンプルデータについて良否判定を行ない、その判定結果を知識作成装置に渡す。サンプルデータには、サンプルデータを識別するコードが付与されているため、検査装置10は、係るコードと判定結果を関連づけて知識作成装置20に渡す。これにより、知識作成装置20は、そのコードに基づき、波形データベース21に格納された対応するサンプルデータの種類(良品/不良品)を知ることができるため、検査装置の判定結果の適否がわかる。
【0094】
なお、検査装置10と知識作成装置20の間におけるデータの送受は、通信で行なっても良いし、所定の記録媒体を用いてオフラインで行なっても良い。また、同一のパソコンなどに組み込まれている場合には、そのパソコンの記憶装置に互いにアクセスすることで簡単にデータの送受が行える。
【0095】
そして、性能が目標を達成している場合(処理ステップS31の分岐判断でYes)には、処理を終了するが、性能が目標を達成していない場合(処理ステップS31の分岐判断でNo)には、過検出・見逃し率がともに収束しているか否かを判断する(S32)。すなわち、処理ステップ31の分岐判断でNoとなった場合には、各回毎に求めた過検出率と見逃し率をメモリ(一時記憶手段)に記憶する。そして、過去の履歴から収束方向にあるか否かを判断する。つまり、過検出率並びに見逃し率が徐々に小さくなっている場合にも収束していると判断する(多少の変動はあっても全体的に小さくなる場合には収束していると判断する)。
【0096】
収束している場合には、そのまま学習を継続することで判別性能目標を達成する可能性が高いので、世代数を増やして判別ルール作成を再実行する(S32)。つまり、第1の実施の形態で説明したように、データ選択部23で選択された代表データは、次段のパラメータ最適化部24に送られ、そこにおいてGAを用いてパラメータの最適化を行なうため、係るGAを継続して続行(学習の再実行)し、適当なタイミングで判別性能が目標に達したか否かの判断を行なう(S31)。
【0097】
一方、過検出率及びまたは見逃し率が収束していない場合(処理ステップS32の分岐判断でNo)には、データ選択部23で選択した代表データが適切でなかったおそれがあるので、データ選択部23は、再度データ選択を行う。具体的には、まず、見逃し率が目標より大きいか否かを判断する(S34)。そして、見逃し率が目標に達している(目標以下の)場合(処理ステップS34の分岐判断はNo)には、過検出率を抑制する必要があるため、過検出されたデータを追加するデータ選択の再実行処理を行う(S35)。
【0098】
具体的には、図16に示すフローチャートのように、まず、前回のデータ選択結果を読込み(S41)、検査結果を参照して過検出された良品データを抽出する(S42)。係る抽出処理は、たとえば、良否判定アルゴリズムに基づく検査装置の判定結果が「不良品」(全ての検査装置の判定結果と対応する波形データ(波形データのサンプルデータを特定する情報でも可)を記憶保持しておくか、少なくとも不良品と判定された波形データのサンプルデータを特定する情報を記憶保持しておくことで自動抽出できる)で、波形データベース21に登録された判定結果が「良品」のものをピックアップすることで自動的に行うことができる。
【0099】
抽出した良品データを前回のデータ選択結果(処理ステップS41の実行により取得)に追加し(S43)、追加後のデータ選択結果を新たな代表データとして出力する(S44)。つまり、次段のパラメータ最適化部24に渡す。
【0100】
上述した処理ステップS41からS44を実行して、データ選択部23が新たな代表データを選択すると、図15の処理ステップS36に進み、パラメータ最適化部24がパラメータ調整を再実行し、続いて、ルール作成部25が判別ルール作成を再実行する(S37)。これらの処理を経て、新たな代表データに基づく良否判定アルゴリズムが生成され、それぞれのデータベースに格納される。そして、処理ステップ31に戻り、その新たな代表データに基づく良否判定アルゴリズムを用いて検査装置を実行させ、判別性能が目標に達したか否かの判断を行なう。
【0101】
一方、見逃し率が目標値を達成していない場合には、処理ステップS34の分岐判断がYesとなるので、処理ステップS38に飛び、選択数を増して再度代表データの選択を行なう(S38)。すなわち、見逃し率が目標に達しない場合は、不良品(以上データ)が良品(正常データ)の分布の範囲内、それも分布の中心付近に位置したり、不良全体の分布が広範囲にわたる場合等、そもそも特徴量の段階で分離できていない状態にあることが多い。つまり、データ選択が適切ではなかったことを意味し、より多くのサンプルデータに基づいて正常データと異常データを分離するべく、データ選択部23で選択する学習する際の正常データの数を増加する。
【0102】
このとき、単純に増加する方法も考えられるが、単純にデータ数を増やすと、学習時間が増加するという弊害もでてくる。そこで、たとえば、図17に示すフローチャートに従って増加させることで、そのときの状況にあった適切なデータ数の増加を図り、学習結果の性能の向上を図りつつ、できるだけ少ないデータ数により短時間で学習を行なうことができるようにする。
【0103】
具体的には、まず、見逃し率と過検出率のどちらの方が悪いかを判断する(S51)。つまり、見逃し率が目標値に達していない場合、過検出率も目標値に達していない場合と過検出率は目標値に達している場合の両方が想定でき、しかも、両方とも目標値に達していない場合には、見逃し率と過検出率のいずれの方がより悪いかなどの場合分けができる。そこで、それらを一括して判断するため、本実施の形態では、
「見逃し率>過検出率?」
を判断する。
【0104】
そして、見逃し率が多い場合(処理ステップS51の分岐判断がYes)は、良品の境界データが不足していたと考えられるため、境界データ比率を増やす(S52)。あるいは、境界データの選択数を増やす。一方、過検出率の方が多い場合(処理ステップS51の分岐判断がNo)は、良品の分布を広く捉えなおすためにデータ選択数を増やす(S53)。
【0105】
そして、上述した各処理を実行した後、新たに設定された代表データとしての選択条件に従って、良品データの選択(新たな代表データの選択)を実行する(S54)。なお、図17に示したフローチャートでは、処理ステップ51の分岐判断の結果に基づいて処理ステップS52とS53のいずれか一方を実行するようにしたが、たとえば、処理ステップS52を実行した場合には、続いて処理ステップS53も実行するというように両方の処理を実行するようにしても良い。
【0106】
上述した処理ステップS51からS54を実行して、データ選択部23が新たな代表データを選択すると、図15の処理ステップS39に進み、パラメータ最適化部24がパラメータ調整を再実行し、続いて、ルール作成部25が判別ルール作成を再実行する(S40)。これらの処理を経て、新たな代表データに基づく良否判定アルゴリズムが生成され、それぞれのデータベースに格納される。そして、処理ステップ31に戻り、その新たな代表データに基づく良否判定アルゴリズムを用いて検査装置を実行させ、判別性能が目標に達したか否かの判断を行なう。
【0107】
上述した各処理ステップを、適宜のルートで繰り返し実行することで、適切なデータ数の代表データに基づいて学習が行われ、目標とする品質を備えた良否判定アルゴリズムを生成することができる。
【図面の簡単な説明】
【0108】
【図1】従来の問題点を説明する図である。
【図2】検査システムの一例を示す図である。
【図3】主に検査装置の内部構成の一例を示すブロック図である。
【図4】本発明に係る知識作成装置の一実施の形態を示すブロック図である。
【図5】分離度を説明する図である。
【図6】本実施の形態の動作原理・作用の概要を説明する図である。
【図7】本実施の形態の動作原理・作用の概要を説明する図である。
【図8】データ選択部の機能の一例を示すフローチャートである。
【図9】本実施の形態における各特徴量と、マハラノビス距離を説明する図である。
【図10】本実施の形態の動作原理・作用の概要を説明する図である。
【図11】データ選択部の機能の詳細な一例を示すフローチャートである。
【図12】本実施の形態の動作原理・作用の一例を示す図である。
【図13】本実施の形態の動作原理・作用の一例を示す図である。
【図14】データ選択部の機能の詳細な一例を示すフローチャートである。
【図15】第2の実施の形態を示すフローチャートの一例を示す図である。
【図16】処理ステップS33の具体的な処理手順の一例を示すフローチャートである。
【図17】処理ステップS35の具体的な処理手順の一例を示すフローチャートである。
【符号の説明】
【0109】
10 検査装置
20 知識作成装置
21 波形データベース
22 良否判定アルゴリズム生成部
23 データ選択部
24 パラメータ最適化部
25 ルール作成部
【特許請求の範囲】
【請求項1】
入力された検査対象の計測データに対して特徴量を抽出し、抽出した特徴量に基づいて前記検査対象の良否判定をする検査装置における前記良否判定を行う際に使用する良否判定知識を作成する知識作成装置であって、
取得した同一種類に属する複数の波形データの中から所定の波形データを選択するデータ選択手段と、
そのデータ選択手段が選択した波形データである選択データを少なくとも用いて、前記良否判定知識を作成する知識作成手段とを備え、
前記データ選択手段は、
前記選択対象の複数の波形データが属するグループの境界領域に属する所定数の境界データを選択する機能と、前記境界領域に属さない波形データの中から一部の波形データを代表データとして選択する機能とを有し、
それら選択された前記境界データと前記代表データを併せて前記選択データとすることを特徴とする知識作成装置。
【請求項2】
前記データ選択手段は、前記同一種類に属する全ての波形データに対して仮の特徴量演算を行なう機能と、その仮の特徴量演算を実行して得られた特徴量演算結果と、その特徴量演算結果の分布に基づいて前記境界データと前記代表データを選択するものであることを特徴とする請求項1に記載の知識作成装置。
【請求項3】
前記データ選択手段は、前記特徴量演算結果に基づき、各波形データについてそれぞれ求めた複数の特徴量値を基準化するとともに、マハラノビス距離を求め、そのマハラノビス距離が大きいグループから前記境界データを選択し、そのマハラノビス距離が小さいグループから前記代表データを選択するように構成したことを特徴とする請求項2に記載の知識作成装置。
【請求項4】
前記データ選択手段は、前記マハラノビス距離が設定されたしきい値以上に該当するものを前記境界データと選択するものであることを特徴とする請求項3に記載の知識作成装置。
【請求項5】
前記データ選択手段は、前記マハラノビス距離が大きいものから所定量を前記境界データと選択するものであることを特徴とする請求項3に記載の知識作成装置。
【請求項6】
前記データ選択手段は、各波形データをマハラノビス距離の順にソートし、所定数おきに波形データを選択することで、前記代表データを選択するものであることを特徴とする請求項3から5のいずれか1項に記載の知識作成装置。
【請求項7】
前記データ選択手段は、各波形データをマハラノビス距離の順にソートし、所定距離間隔で波形データを選択することで、前記代表データを選択するものであることを特徴とする請求項3から5のいずれか1項に記載の知識作成装置。
【請求項8】
前記知識作成手段が作成した良否判定知識を用いて実行された良否判断の結果が、判別性能の目標値に達しているか否かを判断する判断手段(実施の形態ではデータ選択部に兼用)と、
その判断手段の判断結果が、目標値に達しない場合には、前記データ選択手段で選択するデータを増やし、再度データ選択を行なう機能を備えたことを特徴とする請求項1から7のいずれか1項に記載の知識作成装置。
【請求項9】
前記データ選択手段で選択するデータを増やす処理は、下記の(1)から(3)のうち少なくとも1つを含むものであることを特徴とする請求項8に記載の知識作成装置。
(1)前記同一種類に属する波形データを異なるグループと誤判断した場合に、その誤判断した波形データを境界データとして追加する。
(2)前記同一種類に属さない波形データを前記同一種類に属すると誤判断した場合には、データ選択する総数を増やす。
(3)前記同一種類に属さない波形データを前記同一種類に属すると誤判断するとともに、前記同一種類に属する波形データを異なるグループと誤判断した場合には、境界データとして選択する量を増やす。
【請求項10】
入力された検査対象の計測データに対して特徴量を抽出し、抽出した特徴量に基づいて前記検査対象の良否判定をする検査装置における前記良否判定を行う際に使用する良否判定知識を作成する知識作成装置における知識作成法であって、
取得した同一種類に属する複数の波形データの中から所定の波形データを選択するデータ選択処理と、
そのデータ選択処理を実行して選択された波形データである選択データを少なくとも用いて、前記良否判定知識を作成する知識作成する処理とを含み、
前記データ選択処理は、
前記選択対象の複数の波形データが属するグループの境界領域に属する所定数の境界データを選択する機能と、前記境界領域に属さない波形データの中から一部の波形データを代表データとして選択するとともに、それら選択された前記境界データと前記代表データを併せて前記選択データとすることを特徴とする知識作成方法。
【請求項1】
入力された検査対象の計測データに対して特徴量を抽出し、抽出した特徴量に基づいて前記検査対象の良否判定をする検査装置における前記良否判定を行う際に使用する良否判定知識を作成する知識作成装置であって、
取得した同一種類に属する複数の波形データの中から所定の波形データを選択するデータ選択手段と、
そのデータ選択手段が選択した波形データである選択データを少なくとも用いて、前記良否判定知識を作成する知識作成手段とを備え、
前記データ選択手段は、
前記選択対象の複数の波形データが属するグループの境界領域に属する所定数の境界データを選択する機能と、前記境界領域に属さない波形データの中から一部の波形データを代表データとして選択する機能とを有し、
それら選択された前記境界データと前記代表データを併せて前記選択データとすることを特徴とする知識作成装置。
【請求項2】
前記データ選択手段は、前記同一種類に属する全ての波形データに対して仮の特徴量演算を行なう機能と、その仮の特徴量演算を実行して得られた特徴量演算結果と、その特徴量演算結果の分布に基づいて前記境界データと前記代表データを選択するものであることを特徴とする請求項1に記載の知識作成装置。
【請求項3】
前記データ選択手段は、前記特徴量演算結果に基づき、各波形データについてそれぞれ求めた複数の特徴量値を基準化するとともに、マハラノビス距離を求め、そのマハラノビス距離が大きいグループから前記境界データを選択し、そのマハラノビス距離が小さいグループから前記代表データを選択するように構成したことを特徴とする請求項2に記載の知識作成装置。
【請求項4】
前記データ選択手段は、前記マハラノビス距離が設定されたしきい値以上に該当するものを前記境界データと選択するものであることを特徴とする請求項3に記載の知識作成装置。
【請求項5】
前記データ選択手段は、前記マハラノビス距離が大きいものから所定量を前記境界データと選択するものであることを特徴とする請求項3に記載の知識作成装置。
【請求項6】
前記データ選択手段は、各波形データをマハラノビス距離の順にソートし、所定数おきに波形データを選択することで、前記代表データを選択するものであることを特徴とする請求項3から5のいずれか1項に記載の知識作成装置。
【請求項7】
前記データ選択手段は、各波形データをマハラノビス距離の順にソートし、所定距離間隔で波形データを選択することで、前記代表データを選択するものであることを特徴とする請求項3から5のいずれか1項に記載の知識作成装置。
【請求項8】
前記知識作成手段が作成した良否判定知識を用いて実行された良否判断の結果が、判別性能の目標値に達しているか否かを判断する判断手段(実施の形態ではデータ選択部に兼用)と、
その判断手段の判断結果が、目標値に達しない場合には、前記データ選択手段で選択するデータを増やし、再度データ選択を行なう機能を備えたことを特徴とする請求項1から7のいずれか1項に記載の知識作成装置。
【請求項9】
前記データ選択手段で選択するデータを増やす処理は、下記の(1)から(3)のうち少なくとも1つを含むものであることを特徴とする請求項8に記載の知識作成装置。
(1)前記同一種類に属する波形データを異なるグループと誤判断した場合に、その誤判断した波形データを境界データとして追加する。
(2)前記同一種類に属さない波形データを前記同一種類に属すると誤判断した場合には、データ選択する総数を増やす。
(3)前記同一種類に属さない波形データを前記同一種類に属すると誤判断するとともに、前記同一種類に属する波形データを異なるグループと誤判断した場合には、境界データとして選択する量を増やす。
【請求項10】
入力された検査対象の計測データに対して特徴量を抽出し、抽出した特徴量に基づいて前記検査対象の良否判定をする検査装置における前記良否判定を行う際に使用する良否判定知識を作成する知識作成装置における知識作成法であって、
取得した同一種類に属する複数の波形データの中から所定の波形データを選択するデータ選択処理と、
そのデータ選択処理を実行して選択された波形データである選択データを少なくとも用いて、前記良否判定知識を作成する知識作成する処理とを含み、
前記データ選択処理は、
前記選択対象の複数の波形データが属するグループの境界領域に属する所定数の境界データを選択する機能と、前記境界領域に属さない波形データの中から一部の波形データを代表データとして選択するとともに、それら選択された前記境界データと前記代表データを併せて前記選択データとすることを特徴とする知識作成方法。
【図1】

【図2】

【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【公開番号】特開2007−24697(P2007−24697A)
【公開日】平成19年2月1日(2007.2.1)
【国際特許分類】
【出願番号】特願2005−207910(P2005−207910)
【出願日】平成17年7月15日(2005.7.15)
【出願人】(000002945)オムロン株式会社 (3,542)
【Fターム(参考)】
【公開日】平成19年2月1日(2007.2.1)
【国際特許分類】
【出願日】平成17年7月15日(2005.7.15)
【出願人】(000002945)オムロン株式会社 (3,542)
【Fターム(参考)】
[ Back to top ]