
符号化装置、復号化装置および誤り訂正装置
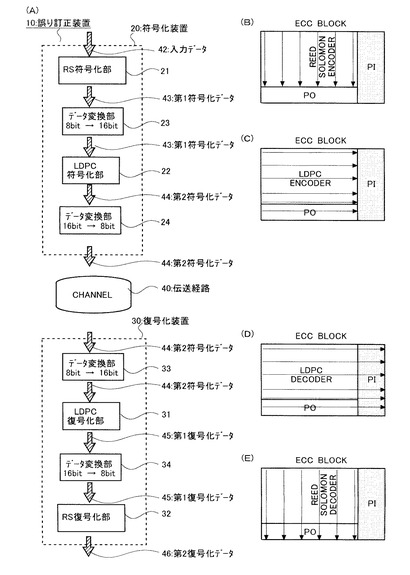
【課題】符号化訂正能力が飛躍的に向上された復号化装置を提供する。
【解決手段】本発明の符号化装置は符号化された符号化データを復号するものであり、入力された符号化データに対してLDPC復号化を行うLDPC符号化部31と、LDPC復号化部31により復号されたデータに対してリードソロモン復号化を行うRS復号化部32とを具備する。従って、データブロックを構成するページの内部に於いてはLDPC符号化を行い、ページ間に於いてはリードソロモン符号化を行うことができる。従って、両復号方法を組み合わせることにより、復号化装置の符号訂正能力を向上させることができる。
【解決手段】本発明の符号化装置は符号化された符号化データを復号するものであり、入力された符号化データに対してLDPC復号化を行うLDPC符号化部31と、LDPC復号化部31により復号されたデータに対してリードソロモン復号化を行うRS復号化部32とを具備する。従って、データブロックを構成するページの内部に於いてはLDPC符号化を行い、ページ間に於いてはリードソロモン符号化を行うことができる。従って、両復号方法を組み合わせることにより、復号化装置の符号訂正能力を向上させることができる。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は符号化装置、復号化装置および誤り訂正装置に関し、特に、LDPC(Low Density Parity Check)符号を用いた符号化装置、復号化装置および誤り訂正装置に関する。
【背景技術】
【0002】
デジタルデータの通信や記録を行う際には、外部のノイズ等によりデジタルデータに誤りが発生している。従来から、このような誤りを検出・訂正するための技術として、誤り訂正符号を用いる技術が知られている。誤り訂正符号では、符号化の際にデータに対して冗長データを付加し、復号化の際にはこの冗長データを基にデータの誤りを訂正する。通信や記録されるのは、冗長データが付加されたデータである。
【0003】
この誤り訂正符号としては、リードソロモン符号やLDPC符号がある。誤りを含むデータに対して、訂正符号を用いた誤り訂正処理を施すことで、データに含まれる誤りの値が一定以下であれば、その誤りを訂正することができる。
【0004】
リードソロモン符号は、複数個の連続したビット単位(シンボル)の誤りを訂正する符号であり、数ある訂正符号化の中でも高度な訂正能力を具備すると考えられている。具体的には、リードソロモン符号の訂正処理は、シンドロームを生成して消失位置を検出するステップと、誤り位置および誤り値の算出・訂正と訂正結果をチェックするステップと、訂正結果の出力ステップとを主要に具備している(例えば下記特許文献1を参照)。
【0005】
LDPC符号とは、疎な検査行列によって定義されるブロック符号であり、反復号処理によって復号されるものである。LDPC符号の利点を列挙すると、例えば、検査行列が低密度であり、優れた最尤復号性能を持ち、ランダム性を有し、復号に適した構造を持ち、シャノン限界に近い復号性能を備えることである。更に、LDPC符号は、様々な符号長、符号化率の符号を容易に構成できる柔軟性を持っており、エラーフロア現象が殆ど生じない利点もある(例えば下記特許文献2を参照)。
【特許文献1】特開平5−315974号公報
【特許文献2】特開2006−13714号公報
【発明の開示】
【発明が解決しようとする課題】
【0006】
しかしながら、最近の記録媒体に記録されるデータの情報量は極めて増加しており、例えば1テラバイト以上のデータが書き込み可能な情報記録ディスクが出現しつつある。このような状況を鑑みると、上記したリードソロモン符号を用いても、符号化能力が必ずしも充分とは言えない問題があった。
【0007】
更に、LDPC符号を用いると符号訂正能力を格段に向上させることができるが、符号訂正能力が高いLDPC符号を実現するためには、大規模な電気回路が必要とされる問題があった。
【0008】
この問題の対処方法として、例えば、リードソロモン符号を2重に組み合わせて符号化処理を行う手法も存在し、この方法によると符号訂正能力を向上させることができる。しかしながら、この組み合わせによる方法によっても符号訂正能力が不十分である問題があった。更にまた、他の誤り訂正方法を2重以上に組み合わせることによっても、符号訂正能力の向上は図れるが、この方法によると回路規模が巨大なものになってしまい、誤り訂正にかかるコストが高くなってしまう問題も予測される。
【0009】
本発明は上述した問題点を鑑みて成されたものである。本発明の主な目的は、符号化訂正能力が飛躍的に向上された符号化装置、復号化装置および誤り訂正装置を提供することにある。
【課題を解決するための手段】
【0010】
本発明の符号化装置は、入力された入力データを符号化する符号化装置であり、前記入力データに対してRS符号化を行って第1符号化データを生成するRS符号部と、前記第1符号化データに対してLDPC符号化を行って第2符号化データを生成するLDPC符号部と、を具備することを特徴とする。
【0011】
本発明の復号化装置は、符号化データを復号化して復号化データを生成する復号化装置であり、前記符号化データに対してLDPC復号化を行って第1復号化データを生成するLPDC復号部と、前記第1復号化データに対してRS復号化を行って第2復号化データを生成するRS復号部と、を備えることを特徴とする。
【0012】
本発明の誤り訂正装置は、入力されたデータを符号化して符号化データを生成する符号化装置と、前記符号化データを復号化して復号化データを生成する復号化装置と、を具備し、前記符号化装置は、前記入力データに対してRS符号化を行って第1符号化データを生成するRS符号部と、前記第1符号化データに対してLDPC符号化を行って第2符号化データを生成するLDPC符号部と、を備え、前記復号化装置は、前記第2復号化データに対してLDPC復号化を行って第1復号化データを生成するLDPC復号部と、前記第1復号化データに対してRS復号化を行って第2復号化データを生成するRS復号部と、を備えることを特徴とする。
【0013】
本発明の符号化装置は、多数のシンボルから構成される入力データを符号化する符号化装置であり、前記入力データに含まれる前記シンボルのビット数を多くするデータ変換部と、前記入力データに対してLDPC符号化を行って符号化データを生成するLDPC符号化部と、を具備することを特徴とする。
【0014】
本発明の復号化装置は、符号化データを復号化して復号化データを生成する復号化装置であり、前記符号化データに対してLDPC復号化を行って前記復号化データを生成するLDPC復号部と、前記復号化データに含まれるシンボルのビット数を少なくするデータ変換部と、を具備することを特徴とする。
【0015】
本発明の誤り訂正装置は、入力された入力データを符号化して符号化データを生成する符号化装置と、前記符号化データを復号化して復号化データを生成する復号化装置、と具備し、前記符号化装置は、前記入力データに含まれるシンボルのビット数を多くする符号側データ変換部と、前記入力データに対してLDPC符号化を行って符号化データを生成するLDPC符号部と、を備え、前記復号化装置は、前記符号化データに対してLDPC復号化を行って復号化データを生成するLDPC復号部と、前記復号化データに含まれるシンボルのビット数を少なくする復号側データ変換部と、を備えることを特徴とする。
【0016】
本発明の復号化装置は、アルファ係数とベータ係数とを用いるSum−procuctアルゴリズムを含む復号化を演算部により行う復号化装置に於いて、前記アルファ係数を算出する演算部と、前記ベータ係数を算出する演算部とを、少なくとも一部共用することを特徴とする。
【0017】
本発明の誤り訂正装置は、入力された入力データをLDPC符号により符号化して符号化データを生成する符号化装置と、前記符号化データを復号化して復号化データを生成する復号化装置と、を具備し、前記復号化装置は、アルファ係数とベータ係数とを用いるSum−Productアルゴリズムを含む復号化を演算部により行い、前記アルファ係数を算出する演算部と、前記ベータ係数を算出する演算部とを、少なくとも一部共有することを特徴とする。
【発明の効果】
【0018】
本発明の復号化装置では、LDPC復号部とリードソロモン復号部の2つの復号部を具備しているので、復号化性能を極めて高くすることができる。具体的には、データブロック内部のページ全体が破損するページ抜け(Page Fall)が発生しても、ページ間の符号化を行うリードソロモン復号部により、破損したページを正しく復号することができる。更に、LDPC符号部を用いることにより、復号に失敗した情報を特定した後に、正しくデータを復号することができる。
【0019】
また、本発明の復号化装置では、LDPC復号化に失敗したシンボルを無効シンボルとした後に、このシンボルの位置を示すイレージャー信号を生成して、これらを用いてリードソロモン符号の復号化を行っている。従って、後段の処理であるリードソロモン符号の誤り訂正能力を向上させることができる。
【0020】
更にまた、本発明の符号化装置に依れば、LDPC符号化を行う前に、符号化の対象となるデータに含まれるシンボルのサイズを大きくしている。従って、LDPC符号化の誤り訂正性能を向上させることができる。
【0021】
更にまた、本発明の復号化装置に依れば、共通の計算セル(演算部)で、Sum−productに使用されるアルファ係数とベータ係数とを演算している。従って、Sum−productアルゴリズムを構成するのに必要とされる回路の規模を縮小することができる。
【発明を実施するための最良の形態】
【0022】
<第1の実施の形態:誤り訂正装置の概要>
本形態では、本発明の一実施形態に係る符号化装置および復号化装置を具備する誤り訂正装置の構成および符号訂正方法を説明する。なお、以下の説明では、符号化装置または復号化装置の内部にてデータを構成する単位要素をシンボルと称し、これらの装置の外部にて伝送、書き込み、保存または読み出しされる情報を構成する単位要素をデータと称する場合もある。
【0023】
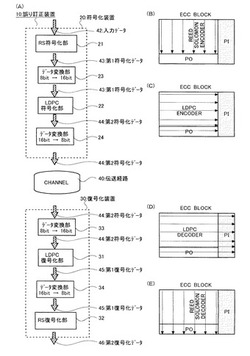
図1を参照して、先ず、本形態の誤り訂正装置10の概略的構成を説明する。図1(A)は誤り訂正装置10の概略的構成を示すブロック図であり、図1(B)〜図1(E)はError Correcting Codeブロック(ECCブロック)の構成を示す平面図である。
【0024】
図1(A)を参照して、本形態の誤り訂正装置10は、入力された入力データを符号化する符号化装置20と、伝送経路40を経由して入力された符号化データを復号する復号化装置30とを具備している。
【0025】
ここで、伝送経路40とは、有線または無線を経由した経路が考えられ、例えばデジタル放送や移動体通信がある。また、伝送経路40の代替として記録媒体が用いられても良い。例えば、符号化装置20により生成された符号化データを記録媒体(磁気ディスクや光学ディスク)に記録して、記録媒体から読み出した符号化データを復号化装置30により復号しても良い。ここで、記録媒体としては、例えばDVD(Digital Versatile Disc)やCD(Compact Disc)等のように脱着式のディスクで良いし、HDD(Hard Disk Drive)等のように固定式のディスクでも良い。更に、上記記憶媒体として、フラッシュメモリ等の半導体記憶装置も採用できる。また、HDV(High−Definition Digital Video)で使用されるフォログラムディスクが記憶媒体として採用されても良い。更にまた、記憶媒体としては、ブルーレイディスク(Blu−ray Disc:BD)やHD DVD(High−Definition Digital Versatile Disc)を採用することもできる。
【0026】
さらに、符号化装置20のみが個別に使用者に利用されても良いし、復号化装置30のみが個別に使用者に利用されても良い。また、本形態の誤り訂正装置10、符号化装置20または復号化装置30は、ハードウェアとして構成されても良いし、ソフトウェアとしてプログラムにより実現されても良い。更には、これらは一部がハードウェアにより構成され、残りの部分がソフトウェアにより実現されても良い。
【0027】
符号化装置20は、RS符号化部21と、データ変換部23と、LDPC符号化部22と、データ変換部24とを主要に具備している。
【0028】
RS(Reed Solomon)符号化部21では、入力されるデジタルデータである入力データ42に対してリードソロモン(RS)符号化が施され、結果として第1符号化データ43が生成される。具体的には、図1(B)を参照して、入力データ42を構成する一単位要素であるECCブロックは、不図示の複数のページから成り、異なるページに含まれるシンボルに対して、RS符号化が施され、ページ間冗長データが生成される。図では、ページ間冗長データをPOが付された領域で示している。そして、符号化を行う方向は図中で矢印にて示されている。ここで生成される第1符号化データ43は、実質的な意味を持ち複数のページから成る情報と、この情報から生成されたページ間冗長データ(PO)から成る。この第1符号化データ43は、データ変換部23に転送される。なお、ECCブロックの詳細は、図2等を参照して後述する。
【0029】
データ変換部23では、所定の規則に従って、ECCブロックに含まれる各シンボルのビット数を増大させる。ここでは、シンボルの情報量が8ビット(bit)から16ビットに変換されている。シンボルをこのように変換することは本発明の特徴の一つであり、このことによりLDPC符号化の誤り訂正率を向上させることができる。ここで、シンボルは必ずしも16ビットに変換される必要は無く、例えば9ビット〜15ビット程度でも良く、変換前よりも大きいビット数であればよい。しかしながら、後述するパターンマッチングの工程を考慮すると、シンボルは16ビットに変換されることが望ましい。ここで、シンボルとは、ECCブロックに含まれるページを構成する単位要素であり、後述するパターンマッチング等はシンボル毎に行われる。各シンボルのビット数が増大された第1符号化データ43は、LDPC符号化部22に転送される。
【0030】
LDPC符号化部22は、RS符号化が施された第1符号化データ43に対してLDPC符号化を施す部位である。上記したRS符号化部21がページ間の符号化を行ったのに対して、LDPC符号化部22はページ内の符号化を行う。具体的には、図1(C)を参照して、ECCブロックに含まれる全てのページに対して、LDPC符号化が施される。図では、LDPC符号化を行う方向が矢印にて示されている。LDPC符号化によって生成されたページ内冗長データは実質的な情報に付加される。図では、付加されるページ内冗長データをPIが付された領域で示している。ここで、生成される第2符号化データは、実質的な意味を有し複数のページから成る情報と、ページ間冗長データ(P0)と、ページ内冗長データ(PI)から成る。生成された第2符号化データ44は、データ変換部24に転送される。
【0031】
データ変換部24では、ECCブロックを構成する各シンボルの情報量を変換して、情報量を少なくする。例えば、上述したデータ変換部23にてシンボルが8ビットから16ビットに変換された場合は、この部位にて16ビットから8ビットに戻す。更に、戻すための変換を行う際には、データ変換部23で適用された規則とは逆の規則を用いることもできる。データを元に戻す変換を行わずに符号化装置20から復号化データを出力することも可能であるが、そうすると伝送するべき情報量が増大してしまう等の問題が発生する。従って、シンボルの情報量を元に戻してから出力することが好適である。シンボルの情報量が元に変換された第2符号化データ44は、符号化装置20から出力される。また、この部位の主たる役割は情報量の削減であるので、一般的な情報圧縮技術(即ち、上記した情報変換方法とは異なる方法)により符号化データを圧縮して、各シンボルのビット数を減少させても良い。
【0032】
第2符号化装置20から出力された第2符号化データ44は、伝送経路40を経由して復号化装置30に伝送され、後述する復号化装置30に入力される。ここで、第2符号化データ44を転送する際には、外部のノイズ等に起因して誤りが発生する。即ち、復号化装置30に入力される第2符号化データ44は、符号化装置20から出力されたものとは異なっている。復号化装置30では、この誤りを訂正して正しい情報を得る。
【0033】
復号化装置30は、データ変換部33と、LDPC復号化部31と、データ変換部34と、RS復号化部32とを主要に具備している。
【0034】
データ変換部33では、復号化装置に入力された復号化データ(符号化装置20により生成された第2符号化データ44)に含まれるシンボルの情報量を変換する。ここでは、シンボルの情報量を8ビットから16ビットに変換している。ここでの変換は、符号化装置20のデータ変換部24に於ける変換と等価(即ち、真逆の変換規則あるいは、可逆変換)である必要がある。
【0035】
LDPC復号化部31では、16ビットのシンボルから構成される第2符号化データ44に対してLDPC復号化を行い、第1復号化データを生成する。具体的には、図1(D)を参照して、ECCブロックを構成する各ページに対してページ内の復号化を行う。同図では、復号化を行う方向を矢印にて示している。ここでは、各ページ内に含まれるページ内冗長データを用いて、そのページを復号している。また、ページ間冗長データ(PO)に対しても、LDPC復号化が行われる。生成された第1復号化データ45は、データ変換部34に伝送される。
【0036】
データ変換部34では、ECCブロックを構成する各シンボルのデータを、16ビットから8ビットに変換する。この変換は、詳細を後述するパターンマッチングにより行い、マッチングしたシンボルには、対応する8ビットのシンボルが割り当てられる。一方、マッチングしないシンボルには、エラーであることを示す8ビットのシンボルが割り当てられ、更に、このシンボルの位置を指し示す別のデータ(Erasure Flag:イレージャー・フラッグ)が生成される。このイレージャー・フラッグ(イレージャー信号)は、データ変換された第1復号化データ45と共に、RS復号化部32に伝送される。
【0037】
RS復号化部32では、データ変換された第1復号化データ45に対して、リードソロモン復号化(RS復号化)を行い、復号化された第2復号化データ46を生成する。ここで生成される第2復号化データ46は、入力データ42と等価である。図1(E)を参照すると、RS復号化はページ間のシンボルに対して行われ、RS復号の方向は矢印にて示されている。
【0038】
上述したように、本発明では、ページ内の誤り訂正にLDPC符号を用いて、ページ間の誤り訂正にリードソロモン符号(RS符号)を用いている。この組み合わせにより、訂正能力を極めて高くすることができる。LDPC符号とRS符号とを組み合わせた本実施の形態の誤り訂正方法は、RS符号を2重に組み合わせた誤り訂正方法よりも訂正能力が高くなると共に、回路規模を小さく留められる。
【0039】
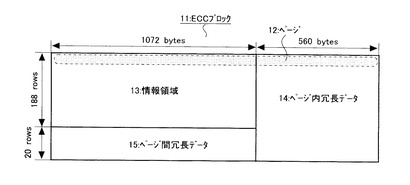
図2を参照して、次に、本発明で用いられるECCブロックの一例を説明する。図2はECCブロックの概要を示す図である。
【0040】
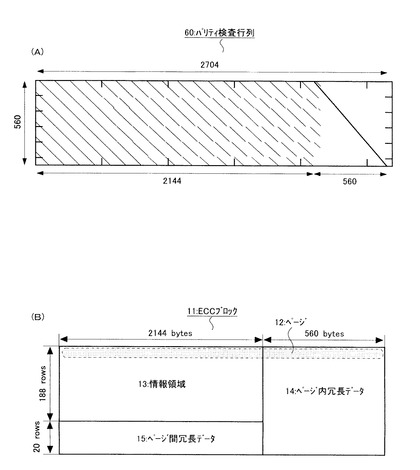
図2を参照して、ECCブロック11は、実質的な意味を有するデータ(使用者が使用するデータであり、例えば画像データや文書データ)である情報領域13と、ページ12内の誤り訂正を行うために用いられるページ内冗長データ14と、ページ12の間の誤り訂正を行うために用いられるページ間冗長データ15とから成る。1つのECCブロック11は、トータルで208個(row)のページ12から成る。また、1つのページ12は、実質的な意味を有する情報である1072バイトと、その情報の冗長データである560バイトから成る。更に、最後の20個(row)のページでは、1072バイトのページ間冗長データ15に、560バイトのページ内冗長データが付加されている。本発明では、ページ内冗長データ14はLDPC符号であり、ページ間冗長データ15はRS符号である。
【0041】
ここで、ページ12の先頭の数バイト(例えば4バイト)がページ数を示す場合があり、この場合は各ページの先頭の数バイトについては、RS符号化は行われずにページ間冗長データ15が生成されなくても良いし、この部分も含めた全体に対してページ間冗長データ15が生成されても良い。一方、ページ数がページ12の先頭に挿入されない場合は、ページ12全体に渡ってRS符号化が行われて、ページ間冗長データ15が生成される。
【0042】
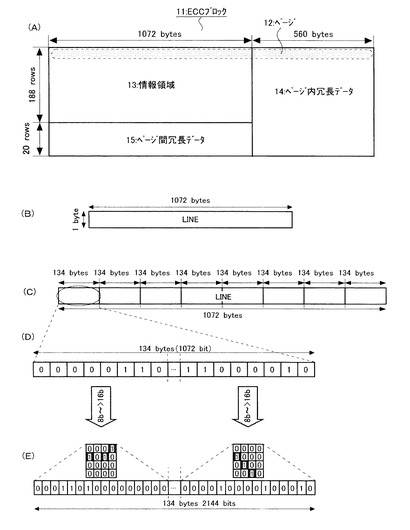
図3および図4を参照して、図1に示した符号化装置20に於けるデータの詳細を説明する。図3および図4の各図は、符号化装置20の内部に於けるデータの変遷を示す概念図である。
【0043】
図3(A)を参照して、上述したように、符号化装置20(図1参照)にて生成されるECCブロック11は複数のページから成り、情報領域13と、ページ内冗長データ14と、ページ間冗長データ15とから成る。符号化装置20では、ユーザーデータである情報領域13に、ページ内冗長データ14とページ間冗長データ15とを付加する。従って、符号化装置20に入力されるデータ(符号化処理が行われる前のデータ)は、情報領域13のみから成る。ここで、ページ間冗長データ15は、LDPC符号化に先行して生成して付与されている。ページ間冗長データ15はリードソロモン符号化により生成される。
【0044】
図3(B)を参照して、情報領域13の内部の1つのページ12は、1072バイトの情報量を有する。本発明では、先ず、1つのページ12を8個のデータブロックに分割している。ここで、1つのブロックの情報量は134バイト(1072ビット)である(図3(C)および図3(D)参照)。
【0045】
図3(E)を参照して、次に、各データブロックに含まれる8ビットのシンボルを16ビットに変換する。ここでは、予め用意されたテーブル(表)を用いて、シンボルのビット数を変換する。この変換は、ただ単にシンボルの前後に0000等のデータを付加するのではなく、LDPC符号の誤り訂正能力が向上されるように、ハミング距離が考慮される。この変換により、1つのデータブロックの情報量は、134バイト(1072ビット)から、268バイト(2144ビット)に変換される。
【0046】
図4(A)を参照して、次に、各々のデータブロックに対してLDPC符号化を施し、ページ内冗長データ14(Redundancy Block)を生成する。本発明では、1つの処理単位であるシンボルを8ビットから16ビットに変換した後に、LDPC符号化を行っているので、より高度な誤り訂正を行うことができる。
【0047】
LDPC符号化が終了した後は、データブロックに含まれるシンボルを16ビットから8ビットに再び変換する。この変換も上述したテーブルを逆に用いて(即ち、所定の規則に従って)行われる。この変換を終えた後のページを図4(B)に示す。ここでは、134バイトのデータブロックに、70バイトのページ内冗長データ(Redundanncy)が付与されている。
【0048】
図4(C)を参照して、ここでは、各々が134バイトである8個のデータブロックM1〜M8のそれぞれに対して、70バイトのページ内冗長データR1〜R8が生成される。従って、ここでは、1つのページの情報量は、これらのデータを積算して1632バイトとなる。
【0049】
上記した行程により、図3(A)に示すページ内冗長データ14が生成され、ECCブロック11が完成する。ECCブロック11は、伝送路等を介して復号化装置に伝送される。または、CD等の記録媒体にECCブロック11は書き込まれる。
【0050】
図5および図6を参照して次に、復号化装置を用いて、符号化された情報を復号化する際のデータの変遷を説明する。
【0051】
図5(A)を参照して、復号化装置に入力される情報は冗長データが付加されたものであり、具体的には、情報領域13と、ページ内冗長データ14と、ページ間冗長データ15とから成る。このECCブロック11は、伝送路等を経て復号装置に入力されるので、エラーが発生し、符号化装置により生成されたものとは異なる場合がある。そこで、復号化装置では、ページ内冗長データ14とページ間冗長データ15を用いて、このエラーを訂正する。
【0052】
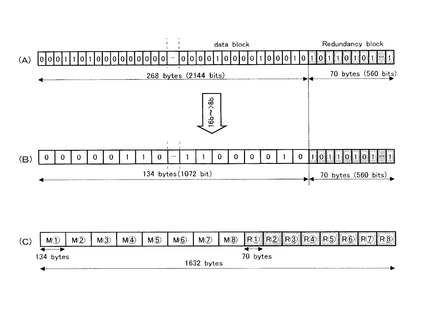
図5(B)および図5(C)を参照して、ページ内冗長データ14を含む1ページの情報量は、1632バイトであり、各々が204バイトである8個のデータブロックに1つのページは分割することができる。
【0053】
図5(D)を参照して、1つのデータブロックは、134バイトの情報領域と、70バイトのページ間冗長データから成る。このページ間冗長データは、LDPC符号化により生成されたものである。
【0054】
図5(E)および図5(F)を参照して、1つのページに含まれるデータ(実質的に意味を有している情報)は134個のシンボルから成り、各々のシンボルは8ビットの情報量を具備している。
【0055】
ここで、図5(B)に示すページ12の構成は、図4(C)に示すとおりであり、最初の1072バイト(134バイト×8個)がユーザーデータであり、その後の560バイト(70バイト×8個)が冗長データである。そしてユーザーデータと冗長データとは、各々が集合して配置されている。図5(C)および図5(D)を参照して、ページ内のデータは並べ替えられ、各ユーザーデータにその冗長データが隣接する。即ち、ユーザーデータ(134バイト)とそれに隣接した冗長データ(70バイト)から成るセットが、8個集合して1つのページが構成される。
【0056】
本発明では、各々のシンボルを8ビットから16ビットに変換している。この変換は、上述した復号化と同様に、変換のためのテーブルを用いて行われる。従って、各々のデータブロックに含まれる情報量は、1072ビットから2144ビットとなる。
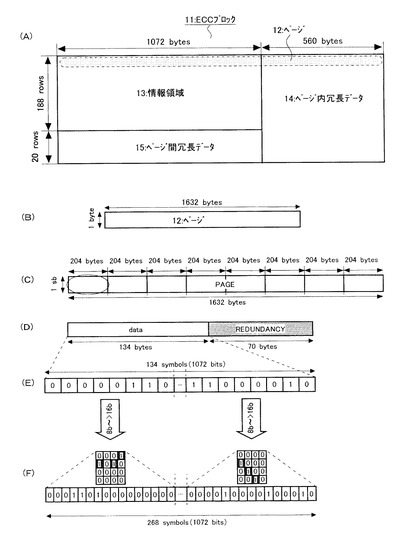
【0057】
図6(A)および図6(B)を参照して、560ビットのページ間冗長データを用いて、2144ビットの情報に対してLDPC復号化を行い、2144ビットの復号化データを得る。ここで、LDPC符号が行われても、元の情報に完全に復号されるのではなく、復号化に失敗しているシンボルも存在すると考えられる。そこで、本発明では、後に詳述するパターンマッチングを行って、伝送経路にてデータの欠損が発生したか否かを判断している。更にこの作業は、シンボルのビット数の変換も兼ねている。
【0058】
図6(C)に変換された後の8ビットの復号化データを示す。この図を参照して、上記パターンマッチングの結果、正しくマッチングしたものは、テーブル中にて対応する8ビットのシンボルに変換される。一方、正しくマッチングしないシンボルは、正しくマッチングしなかったものに割り当てられるべき8ビットのシンボルが割り当てられる。ここでは、マッチングしなかったシンボルに、「0」を指し示す8ビットのシンボルが割り当てられる。更に、図6(D)を参照して、イレージャー信号(Erasure Pattern)が生成される。このイレージャー信号は、上記したマッチングの結果、マッチングしなかった(即ち、伝送経路にてデータが破損した)シンボルの位置を指し示す信号である。
【0059】
上記した復号化データとイレージャー信号を用いて、RS復号化が行われて、完全な復号化が行われた情報が得られる。イレージャー信号を利用することにより、誤りが生じたシンボルの位置を容易に知ることができるので、RS復号化により誤り訂正の性能を向上させることができる。
【0060】
<第2の実施の形態:符号化方法>
本形態では、リードソロモン符号化およびLDPC符号化を組み合わせた符号化方法を詳述する。
【0061】
図7のフローチャートを参照して、本形態の復号化方法は、入力された入力データに対してリードソロモン符号化を行って第1符号化データを生成する第1ステップS1と、第1符号化データのビット数を変換する第2ステップS2と、第1符号化データに対してLDPC変換を行って第2符号化データを生成する第3ステップS3と、第2符号化データのビット数を変換する第4ステップS4とを主要に具備する。
【0062】
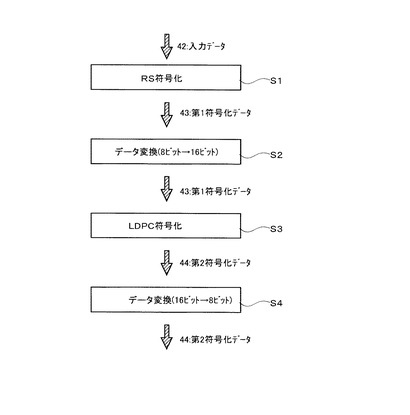
第1ステップ:RS符号化を行うステップ
図8を参照して、入力されたデータに対してリードソロモン符号化を行うステップを説明する。図8(A)は本ステップで生成されるECCブロック11を示す図であり、図8(B)はECCブロックの一部を示す図である。
【0063】
図8(A)を参照して、実質的な意味を有するユーザーデータである情報領域13は、188個(row)のページ12から成り、1つのページ12は、1072個のシンボル(1つのシンボルは8ビット)から成る。本ステップでは、異なるページに含まれるシンボルに対してリードソロモン符号化を行い、ページ間冗長データを生成する。従って、本工程で生成されるECCブロックは、ユーザーデータである情報領域13と、情報領域に含まれるページ間の冗長であるページ間冗長データ15から成る。
【0064】
図8(B)を参照して、各ページに含まれるシンボルを最上段から、B[0、j]、B[1、j]、B[2、j]、・・・・B[187、j]とした場合、多項式(Remainder Polynomial)Rjは以下の式(1)により計算される。更にここでは、188列の実質的な情報に、47列分のゼロ成分を加えて演算を行い、合計で235列としている。この様にゼロの列を加算するのは、リードソロモンコアに、処理されるデータのフォーマットを一致させるためである。この様な処理はパディングと称される。
【0065】
【数1】

また、上記式(1)は下記式(2)により表現することもできる。
【0066】
【数2】
更に、上記式(2)中のαは、下記式(3)に示す原始多項式の原始根である。
【0067】
【数3】
上記計算を、ページ12間の各々のシンボルに対して行い、ページ間冗長データ15が生成され、第1符号化データが生成される。
【0068】
第2ステップ:第1符号化データのビット数を変換するステップ
本ステップでは、ステップ1にて生成された第1符号化データに含まれるシンボルのビット数を変換する。第1ステップにて生成されるデータでは、1つのシンボルのビット数は8ビットである。本工程では、データの含まれるシンボルのビット数を8ビットから16ビットに変換する。
【0069】
本ステップでは、シンボルのビット数を8ビットから16ビットに変換するが、この変換はただ単に変換前のシンボルの前または後に「00000000」等の情報を付与するのではなく、LDPC符号化の効率が高くなるような変換が行われる。即ち、シンボル内部で情報が分散された疎な状態になるように、シンボルの情報量が16ビットに変換される。このように疎なシンボルを生成することで、LDPC符号の符号訂正能力を向上させることができる。また、ここで、ビット数を16ビットに変換しても、シンボルが取り得る値のバリエーションは256通りであり8ビットの場合と変わらない。従って、シンボルを増加させることによる計算量の増加は抑制されている。
【0070】
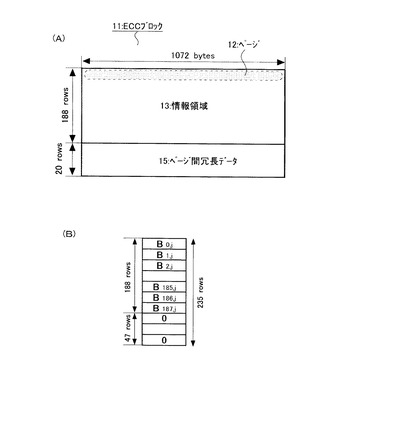
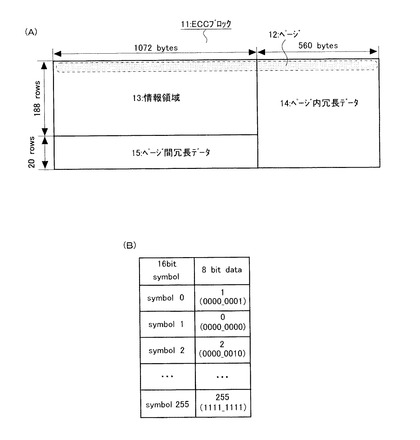
図9に、本工程で使用されるマッピングテーブルを示す。ここでは、左側の列に16ビットのシンボルが示され、右側の列にそれに対応する8ビットシンボルが示されている。このテーブルを使用して、ECCブロックに含まれる全てのシンボルは8ビットから16ビットに変換される。例えば、16ビットのシンボルに於ける最下段のシンボル255は、それに対応する8ビットシンボル255(1111_1111)に変換する(割り当てられる)。
【0071】
次に、図10および図11を参照して、上記したテーブル(マッピングテーブル)の生成方法を説明する。図10(A)は確率分布を示すグラフであり、図10(B)はそのグラフを数値化した表であり、図10(C)は8ビットシンボルのハミング距離を示す表であり、図10(D)はマッピングテーブルである。
【0072】
先ず、LDPCアルゴリズムはRaw Data Format(16ビット)を使用することで実現される。この変換テーブルの主たる目的は、8ビットデータを適切な(即ち、変換前よりも疎な状態な)16ビットデータのシンボルに割り当てることにある。
【0073】
以下に、上記マッピングテーブルを構築する方法を説明する。最初に、顧客から提供されたデータを利用して、伝送路のノイズを解析する。図10(A)は、このノイズの性質を可視化したものである。紙面上にて手前側の横軸は伝送路にインプットされるデータを示し、奥行き側に伸びる軸は伝送路から出力されるデータを示し、縦方向の軸はインプット情報とアウトプット情報にエラーが生じる確率であるエラー確率を示している。この解析は、16ビットシンボル(合計で256個)を使用したエラー確率マトリックスを構築することを可能とする。
【0074】
図10(C)を参照して、8ビットバイナリデータのハミング距離が構築される。バイナリAdataとバイナリBdataとのハミング距離は、AdataとBdataとのバイナリ値を比較することにより、簡単に計算できる。例えば、以下の2つの値が有ると仮定した場合、
第1の値:1000_0000
第2の値:0001_1011
第1の値と第2の値とのハミング距離Hdは5である。
【0075】
図10(C)には、8ビットデータの、全ての組合せのハミング距離が示されている。そして、上記した2つのマトリックスは、8ビットデータを16ビットシンボル(4×4)に割り当てるマッピングテーブルによりリンクされる。
【0076】
上記した各表(テーブル)を基に、図10(D)に示すマッピングテーブルが生成される。このテーブルは、8ビットシンボルを16ビットシンボルに変換されるときに使用されると共に、逆に、16ビットシンボルを8ビットシンボルに変換(逆変換)する際にも同じように適用される。
【0077】
更に、上記マッピングテーブルは、次のような理念に基づいて、生成される。即ち、「インプットされた16ビットシンボルが、出力されるシンボルよりも高い確率を有している場合は、対応するハミング距離Hd(A、B)が可能な限り低くなる。」という基本的考えの基にマッピングテーブルは生成される。
【0078】
図11を参照して、次に、効率的にマッピングテーブルを構築する為のアルゴリズムを説明する。図11(A)はマッチングテーブルの生成方法を示すフローチャートであり、図11(B)は最適化を行う前のマッピングテーブルであり、図11(C)は最適化を行った後のマッピングテーブルである。このアルゴリズムの主たる目的は、下記式(5)に示される式に示されるハミング比を可能な限り小さくすることにある。
【0079】
【数5】
図11(A)に示された各フローチャートの各ステップの具体的処理は以下の通りである。
【0080】
先ず、ステップS1では、8ビットを16ビットに変換するテーブルを初期化する。8ビットデータと16ビットデータとは、両方とも昇順にソートされる。そして、上記式(5)に示された式によりハミング平均値を計算する。この式により算出された値を以後、H参照値と称する。
【0081】
ステップS2では、マッピングテーブルを2つの列になるように置換する。この置換の一例を図11(B)および図11(C)に示す。置換が終了すると、16ビットシンボルの0は8ビットデータの1に対応し、16ビットシンボルの1は、8ビットデータの0に対応する(図11(C)参照)。
【0082】
ステップS3では、次に、アップデートされた(置換された)マッピングテーブルを使用して、ハミング平均値を上記式(5)に示された式を使用して計算する。この値をHup値と称する。
【0083】
ステップS4では、続いて、Hup値とH参照値(Href値と以下にて称する場合もある)とを比較する。
【0084】
上記ステップS4にて、Hup値がHref値よりも低い場合、(換言すると、この状態のマッピングテーブルが参照のマッピングテーブルよりも適している場合)は、ステップS5に移行して、次のような処置をする。即ち、ステップS2における置換が記憶されると共に、参照ハミング平均値比がHup値としてセットされる(Href値をHup値に割り当てる)。
【0085】
一方、上記ステップS4にて、Hup値がHref値よりも大きい場合、(換言すると、この状態のマッピングテーブルが参照のマッピングテーブルよりも適切でない場合)は、ステップS6に移行して、次のような処置をする。即ち、ステップS3での置換は記憶されずに、参照のマッピングテーブルを復帰させる(即ち、そのままの状態にしておく)。
【0086】
上記プロセスは、マッピングテーブルの全ての2列置換に対して行われる。このことによって、本実施の形態の目的に沿った最適なマッピングテーブルが生成される。
【0087】
第3ステップ:第1符号化データに対してLDPC変換を行うステップ
本ステップでは、上記工程により個々のシンボルが8ビットから16ビットに変換された第1符号化データに対してLDPC符号化を行い、ページ内の冗長データを生成して、第2符号化データを生成する。
【0088】
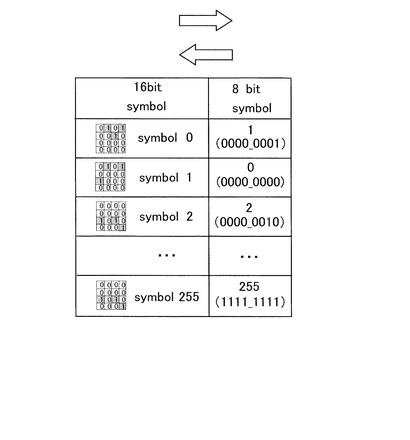
図12(A)に本ステップで用いるパリティ検査行列60を示し、図12(B)に本ステップにて生成される第2符号化データを構成するECCブロック11を示す。
【0089】
図12(A)に示すパリティ検査行列60は、例えば、560行・2704列の構成となっている。本形態では、符号化単位となる1ページ分の情報は2144ビットであり、560個のパリティビットを生成するために更に560ビットが付け加えられ、パリティ検査行列60の列数は2704列となる。また、検査行列の右端部には正方形の領域が必要となるので、パリティ検査行列60の行数は560行と成っている。なお、この正方形領域では、対角線の沿った成分は全てが1となっており、対角線より右側は0となっている。更に、この対角線より左側の領域は1が疎に配置されている。
【0090】
次に、上記したパリティ検査行列60を各々のページを構成する各ビットと演算して、パリティビットを算出する。このことを換言すれば、各ページについて560元の連立方程式を解くことで、各ページに付加されるページ内冗長データが生成される。
【0091】
このようなパリティ検査行列を用いたページ間冗長データの生成は、ECCブロックを構成する各ページについて行われる。また、RS符号化により生成されたページ間冗長データ15に関しても、LDPC符号化によるページ内冗長データ14が生成される。
【0092】
上記ステップにより、図12(B)に示す構成のECCブロック11が生成される。ECCブロック11の構成の詳細は、第1の実施の形態にて上記した。ここでは、ページ12毎にページ内冗長データ14が生成され、1つのページに560バイトのページ内冗長データ14が付加される。
【0093】
本発明の特徴の一つは、ハミング距離が考慮されてビット数が変換された情報に対して、LDPC符号変換を行う点にある。このことにより、冗長データおよび計算量の増大を抑制しつつ、LDPC符号化の誤り訂正能力を向上させることができる。一般的に、誤り訂正のための符号化技術では、符号化の為の冗長データを長くするほど、誤り訂正能力を高めることができる。しかしながら、冗長データを長くすると、伝送又は記録されるべきトータルな情報量が増大してしまい、誤り訂正の為の計算量(計算時間)も長くなってしまう等の問題もある。そこで本形態では、シンボルの情報量を8ビットから16ビットに変換した後に、このシンボルに対してLDPC符号化を行っている。このことにより、シンボルが疎な状態になるので、LDPC符号化の誤り訂正能力が向上される。更に、8ビットのシンボルに適用されるテーブルを用いることができるので、シンボルの情報量が増加することに依る符号化の計算量の増大が抑制される。
【0094】
第4ステップ:第2符号化データのビット数を変換するステップ
図13(A)を参照して、本ステップでは、LDPC符号化が行われた第2符号化データの構成するシンボルを、16ビットから8ビットに変換して、全体の情報量を削減する。具体的には、ECCブロック11の中の情報領域13とページ間冗長データ15に含まれるシンボルの情報量が、16ビットから8ビットに変換される。本ステップの情報量の変換が行われた結果、1ページに含まれる情報領域13の情報量は、2144ビットから1072ビットに変換される。また、この変換は、ページ間冗長データ15に対しても行われる。ここでは、各ページに含まれるシンボルの情報量を16ビットから8ビットに変換しているが、8ビットに以外の情報量(例えば9ビット〜15ビット)にシンボルが変換されても良い。しかしながら、電気信号が伝送される一般的な伝送路では、8ビットまたは16ビットの情報が通過することを前提として設計されている場合が多いので、このステップで生成されるシンボルの情報量は8ビットが好適である。
【0095】
本ステップで、シンボルの情報量を削減することにより、伝送または記録されるべき情報の全体的な量が小さくなる。従って、本形態の符号化装置により生成された符号化データを伝送する場合は、本ステップにてトータルな情報量が削減された結果、伝送路に与える負荷が軽減される。また、生成された符号化データが記憶媒体に記録される場合は、記憶媒体に記録可能な実質的な情報量を増大させることができる。
【0096】
本ステップの情報量の変換は、上述した第2ステップの情報量の変換とは性質が異なる。上記第2ステップでは、LDPC符号化の誤り訂正能力を向上させるために、シンボルの情報量を8ビットから16ビットにして疎な状態にした。本ステップでは、情報量の削減が目的であるので、ビット数を変換する表を用意して、この表に従ってシンボルの8ビットを16ビットに変換すればよい。図11(B)にこの変換に用いられる表の一例を示す。
【0097】
<第3の実施の形態:復号化方法>
本形態では、上記第2の実施の形態にて説明した方法により生成された符号化データを復号化して基のデータを得る方法を説明する。
【0098】
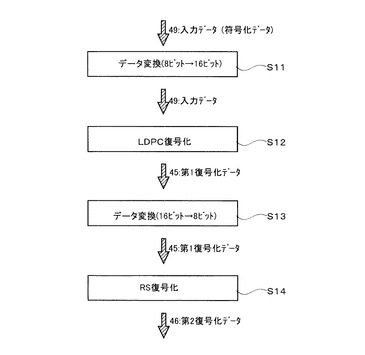
本形態の復号化方法は、図14に示すフローチャートを参照して、入力された入力データ(符号化データ)を構成するシンボルの情報量を変換する第1ステップS11と、変換されたデータに対してLDPC変換を行って第1復号化データを生成する第2ステップS12と、第1復号化データに含まれるシンボルの情報量を変換する第3ステップS13と、第1復号化データに対してRS復号化を行って第2復号化データを生成する第4ステップS14とを具備している。
【0099】
第1ステップ:入力されたデータのビット数を変換するステップ
本ステップでは、入力された入力データ49を構成するシンボルのデータ量を変換する。ここで、入力データとは、上述した第2の実施の形態で説明した方法により符号化されたデータである。
【0100】
本ステップのデータ変換は、上述した第2の実施の形態に於ける第4ステップで行われたデータ変換の逆である。従って、上述した第4ステップのデータ変換がシンボルのデータ量を8ビットから16ビットに変換するものであった場合は、本ステップではシンボルのデータ量を16ビットから8ビットに変換する。また、変換に用いるテーブルも、上述した第4ステップと同じものを用いる。図15に、本ステップのデータ変換に用いるテーブルの一例を示す。
【0101】
第2ステップ:LDPC復号化を行うステップ
本ステップでは、上述ステップによりシンボルのビット数が変換された符号化データに対して、LDPC復号化を行い、第1復号化データ45を生成する。具体的には、Sum−Productアルゴリズムに基づく繰り返し復号を行い、推定結果である復号化データを得る。
【0102】
本ステップでは対数尤度比(log likelihood ratio)に基づくSum−Product復号法を行うので、Sum−Productアルゴリズムに入力される入力情報は、入力データ49自身ではない。
【0103】
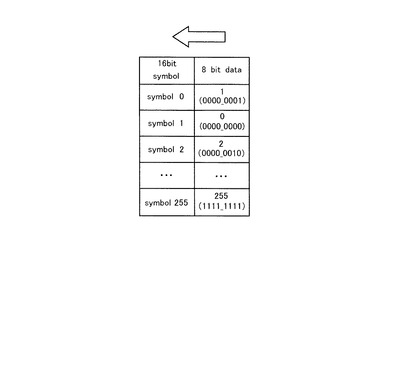
ここで、図16(A)に示すようなデータの伝送路(Channel)を想定し、伝送路に入力されるデータをXnとし、伝送路を経由して受信されるデータをYnとする。このように仮定した場合、本ステップでは、以下に示す式(4)により算出されるλnがSum−Productアルゴリズムに入力される。
【0104】
【数4】
上記λnの値は伝送路の統計学的性質による。即ち、伝送路の種類や状況によってエラーの発生する状況は様々であり、このことがλnの値に影響するので、その値を求めることは容易ではない。そこで、本発明では、伝送路に発生するエラーの統計学的性質を予め解析し、この解析の結果に基づいて対数尤度比を求めている。
【0105】
図16(B)に上記解析に基づく結果の一例を示す。この表では、00〜11の入力に対応して、00〜11が出力される確率を示している。例えば、00が入力されたときに、00が出力される確率は0.8(80%)であり、00が入力されたときに11が出力される確率は0.0(0%)である。
【0106】
上記解析結果に基づく対数尤度比の算出方法は次の通りである。先ず、それぞれの出力値に関して、入力値が0である確率(P0)と、入力値が1である確率(P1)を算出する。次に、P1/P0を算出した後に、log(P1/P0)を算出してλを求める。ここで、P1がP0よりも大きかったらλの値は正となり、P1がP0よりも小さかったらλの値は負となる。
【0107】
更に図16(B)を参照して、上記算出方法の一例を説明すると、例えば出力値が10であった場合、入力値が1である確率P1は、P1=0.6+0.1=0.7と算出される。また、入力値が0である確率P0は、P0=0.2+0.1=0.3と算出される。従って、λ=log(0.7/0.3)=0.36となる。
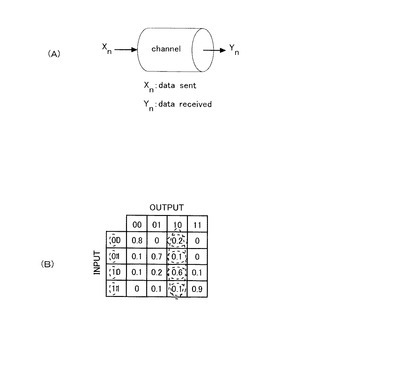
【0108】
またLDPC復号処理では、図17に示すようなGallager Function を用いて計算をしている。ここで、RTL(Register Transfer Level)等で復号化装置を構成した場合は、対数の計算にかかるコストは大きくなり、計算時間も長くなる。そこで本形態では、この対数の計算を予め行い、計算結果に基づくルックアップテーブルを生成し、このルックアップテーブルを参照することにより対数を計算している。ルックアップテーブルを用いることにより、復号化に必要とされる計算量を低減させ、計算速度を高速にすると共に回路規模を削減することができる。
【0109】
上記方法によりLDPC復号化が行われる。係る復号化の他の部分の詳細は、例えば、「低密度パリティ検査符号とその復号法:和田山正著:トリケップス」に記載されている。
【0110】
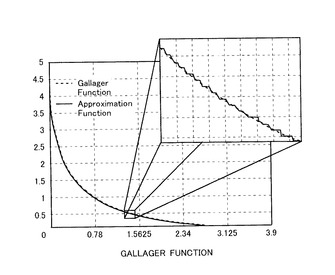
第3ステップ:第1復号化データを変換するステップ
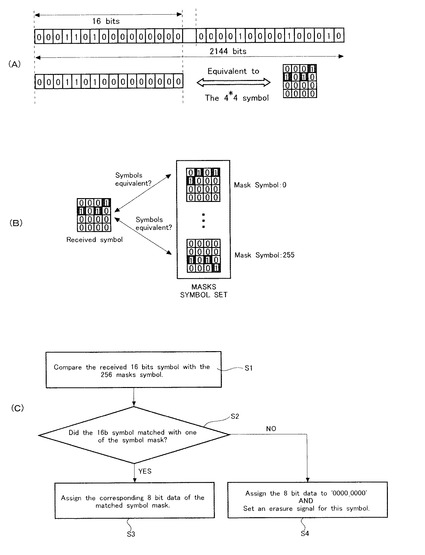
本ステップでは、図18を参照して、先ステップにて復号された第1復号化データを変換する。図18(A)は、本ステップに手処理される第1復号化データの一部を示す図であり、図18(B)はデータ変換のためのパターンマッチングを示す図であり、図18(C)は本ステップの手順を示すフローチャートである。
【0111】
本ステップでは、先ステップにて復号化処理されたデータに含まれるシンボルのビット数を変化させる。具体的には、シンボルのビット数を16ビットから8ビットに変換させる。この処理は、次ステップであるRS復号化のために必要とされる処理である。更に、本ステップでは、先ステップであるLDPCアルゴリズムにてエラーが発生したエラーを検出している。即ち、ここでは、パターンマッチングを行うことにより、これらの2つの処理を行っている。
【0112】
図18(A)を参照して、LDPC復号化が施されたデータは、1ページが2144ビットの情報量を有し、このページに含まれる1シンボルのビット数は16ビットである。16ビットの1シンボルは、4×4のマスクシンボルと等価である。このマスクシンボルは、先実施の形態にて、LDPC符号化の前に行われるデータ変換の際に用いられたものと同様なものである。
【0113】
図18(B)を参照して、本ステップでは、LDPC復号化により得られた第1復号化データに含まれるシンボルと、マスクシンボルとを逐次比較している。即ち、両シンボルのパターンが一致するか否かを確認しており、この作業はパターンマッチングと称されている。このパターンマッチングは、第1復号化データに含まれる全てのシンボルに対して行われる。このマスクシンボルは、8ビットのデータに対応して設けられているので、全部で256個存在する。
【0114】
図18(C)を参照して、上記パターンマッチングの詳細を説明する。本ステップのパターンマッチングでは、先ず、LDPC復号化された第1復号化データに含まれる16ビットのシンボルを、256個存在するマスクシンボルと順次比較する(S1)。この図に示すパターンマッチングは、第1復号化データを構成する全てのシンボルに対して順次行われる。
【0115】
次に、シンボルが多数存在するマスクシンボルの中の一つとマッチするか否かが判断される(S2)。即ち、S2では、LDPC復号化により生成された第1復号化データに含まれるシンボルと同一のものが、256個存在するマスクシンボルセットの中に存在するか否かが調べられる。
【0116】
そして、一致するマスクシンボルが存在したら(S2のYES)、一致したマスクシンボルに対応する8ビットデータが、そのシンボルに割り当てられる(S3)。このステップを踏むことにより、先工程のLDPC復号化にてエラーが発生していないことが確認されると共に、第1復号化データを構成するシンボルのビット数が、16ビットから8ビットに変換される。
【0117】
一方、一致するマスクシンボルが存在しなければ(S2のNO)、その旨を示す8ビットデータが割り当てられる(S4)。例えば、「00000000」が処理対象の16ビットのシンボルに割り当てられる。LDPC復号化が正常に行われたら(即ち、誤り訂正が正しく行われたら)、256個存在するマスクシンボルのいずれか一つとマッチするはずである。従って、処理対象のシンボルとマッチングする(一致する)マスクシンボルが存在しないと云うことは、LDPC復号化が失敗していることを意味している。このことから、ステップS4では、復号化に失敗したシンボルの存在および位置を指し示す信号であるイレージャー信号を発生させて、次ステップにてこの信号を利用する。
【0118】
以上述べたように、本ステップは、LDPC復号化が施されたデータに対してパターンマッチングを行うことにより、第1復号化データを構成する16ビットのシンボルが8ビットに変換される。更に、復号化に失敗したシンボルにはその旨を示す8ビットのシンボルが割り当てられ、更に、このシンボルの存在とその位置を示すイレージャー信号が生成される。そして、これらのデータおよび信号は、次ステップにて活用される。
【0119】
本ステップのマッチングにより、シンボルのビット数が変換されると共に、復号化の妥当さの是非も判断される。従って、1つの処理によりデータ数変換と復号化の検証が行われるので、処理の複雑化を回避しつつ高度な誤り訂正を行うことができる。
【0120】
第4ステップ:第1復号化データをRS復号化するステップ
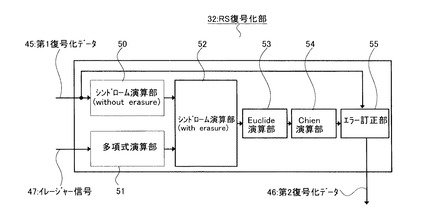
図19を参照して、RS復号化を行うステップを、RS復号化部32の構成と共に説明する。このステップの原理と使用される数式は、第1の実施の形態にて説明したので、重複する部分は割愛する。なお、本実施の形態のRS復号方法およりRS復号装置は、通常使用されるものと基本的には同様である。
【0121】
本ステップにて用いられるRS復号装置32は、シンドローム演算部50と、多項式演算部51と、シンドローム演算部52と、Eucide演算部53と、Chien演算部54と、エラー訂正部55とを主要に具備している。
【0122】
先ステップにて生成された第1復号化データ45は、シンドローム演算部50に入力され、シンドローム演算部50にてシンドロームが算出される。ここで、シンドロームとは、第1復号化データ45に、パリティ検査行列を乗じたものである。更に、多項式演算部51では、入力されたイレージャー信号47を基に、消失位置を演算する。シンドローム演算部50および多項式演算部51の算出結果は、シンドローム演算部52に伝達される。
【0123】
そして、これらの出力結果を利用して、シンドローム演算部52にて演算を行うことにより、誤りが発生したシンボルの位置とが算出される。
【0124】
更に、Euclide演算部53およびChien演算部54では、シンドローム演算部52の出力結果を利用して、誤り値が演算されると共に演算値がチェックされる。
【0125】
最後に、エラー訂正部55では、前段で算出した値を、誤りが発生している箇所の第1復号化45に加える。このことにより、誤りが訂正された第2復号化データ46が生成されて、RS復号化部32から外部に出力される。
【0126】
<第4の実施の形態:Sum−productアルゴリズムの詳細>
本実施の形態では、LDPC復号化装置の一部であるSum−productアルゴリズムの詳細を説明する。通常のSum−productアルゴリズムと本実施の形態との大きな相違点は、本実施の形態では、Sum−productアルゴリズムで使用されるα係数の演算処理と、β計数の演算処理とを合成して行っている点にある。ここで、α係数およびβ係数は、復元されたデータの確かさを示す係数である。
【0127】
Sum−productアルゴリズムを図20乃至図23を参照しつつ説明する。ここで、図20はSum−productアルゴリズムの為の回路を示すブロック図であり、図21はCMPフォーマットおよびABSフォーマットの詳細を示す表であり、図22(A)および図22(B)はSUM GALLAGERの算出プロセスを示す図であり、図22(C)はαmn係数の算出方法を示す図であり、図23はβ係数の算出方法を示す図である。
【0128】
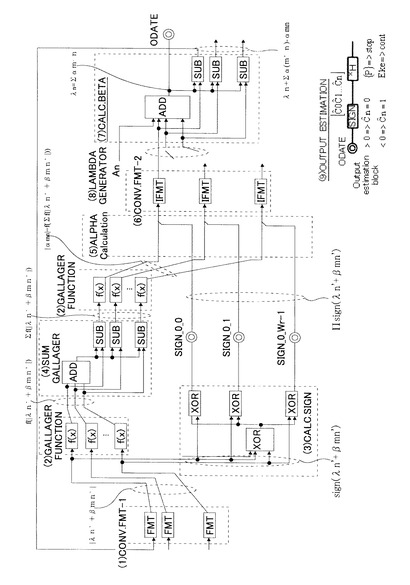
図20を参照して、Sum−productアルゴリズムを実現する回路図は、以下の各ブロックから構成されている。
(1)COV.FMT−1
(2)GALLAGER FUNCTION
(3)CALC.SIGN
(4)SUM GALLAGER
(5)ALPHA CALCULATION
(6)CONV.FMT−2
(7)CALC.BETA
(8)LAMDA GENERATOR
(9)OUTPUT ESTIMATION
上記各ブロックの機能を以下にて詳述する。
【0129】
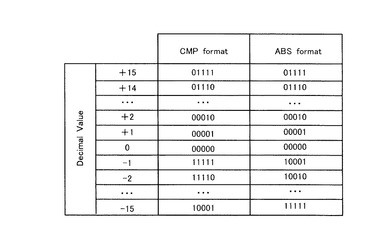
(1)COV.FMT−1
このブロックは、データのフォーマットの変換装置である。入力されるデータ(Two’S Complement Format(以降CMPと称する)は、Sign−And−Magnitude Format(以降、ABSと略称する)に変換される。
【0130】
ここで、Sign−And−Magnitude Formatとは、次の通りである。先ず、MSB(Most Significant Bit(最上位のビット))は記号であり、この記号が0の場合は正であり、この記号が負の場合は負である。そして、残りのビット群は大きさを示している。
【0131】
一例として、CMPフォーマットからABSフォーマットに変換された5ビットデータのテーブルを、図21に示す。
【0132】
このブロックは、Sum−Product Algorithmに適用され、パリティチェックマトリックスの各ラインに於いて、(λn’+βmn’)の値をABSフォーマットへの変換に使用される。
【0133】
(2)GALLAGER FUNCTION
このブロックでは、当該ブロックに入力された情報に対応するGallager Functionの値を算出する。Gallager Functionの詳細は、下記式(6)に示されている。
【0134】
【数6】
このブロックは、LDPCデコーダの一部として実施され、Sum−Productアルゴリズムに含まれる以下の2つのステップを逐次実行している。
【0135】
第1に、アルファ計数の算出プロセスの間、パリティチェックマトリックスHの各ラインに於いて、f(|λn’+βmn’|)の値を算出する。
【0136】
第2に、パリティチェックマトリックスHに含まれるアルファ係数の絶対値を算出する。
【0137】
(3)CALC.SIGN
このブロックに入力される情報は、パリティチェックマトリックスHを構成する各ラインに含まれる(λn’+βmn’)の値のサイン(符号)である。そして、このブロックの主たる機能は、下記式(7)を計算することにある。
【0138】
【数7】
(4)SUM GALLAGER
このブロックの構成は、基本的には下記する「(7)CALC.BETA」と類似している。
【0139】
パリティチェックマトリックスHに含まれる各々のラインに関して、下記式(8)を実行する。
【0140】
【数8】
例えば、パリティチェックマトリックスのある列の重みが3の場合、Sum gallagerの計算プロセスは図22(A)および図22(B)に示すようになる。
【0141】
(5)ALPHA CALCULATION
このブロックでは、(3)CALC.SIGNブロックにより算出されたアルファ係数のサインと、それらの絶対値が、第2のGallager Function Blockから算出される。
【0142】
このブロックの主たる目的は、アルファ係数の各々のサインと絶対値とを集めることにある。5ビット幅のデータの場合の処理方法の一例を、図22(C)に示す。
【0143】
図22(C)を参照すると、ALPHA CALCULATIONブロックにより、1ビットのサイン(アルファ係数がプラスかマイナスかを示している)と、4ビットの絶対値(アルファ係数の大きさを示している)とが結合されて、アルファ係数が生成されている。
【0144】
(6)CONV.FMT−2
このブロックは、基本的にはデータフォーマットを変換する部位である。sign−and−magnitudeフォーマットの入力情報は、two’s complement format(CMP)に変換される。
【0145】
このブロックは、Sum−Product algorithmに於いて、パリティチェックマトリックスHの各columnに関して、アルファ係数をCMPフォーマットに変換する。
【0146】
(7)CALC.BETA
このブロックでは、パリティチェックマトリックスHの各columnに関して、β係数を算出すると共に、Sum−product algorithmの推定出力値を生成する。
【0147】
パリティチェックマトリックスの各columnに関して、基本的にこのブロックでは、λ係数とアルファ係数とを加算している。そして、それぞれの(λk+βmn)係数は、これらの値から計算される。
【0148】
例えば、図23には、column重みが4(4つのアルファ係数のみ)の場合のベータ係数の算出プロセスが示されている。
【0149】
(8)LAMDA GENERATOR
このブロックの機能は、Sum−product algorithmの入力値から、λ=〔λ1・・・・・・λN〕の値を算出する部位である。この値は、Log−Likehood Ratio(LLR)の名称で知られている。
【0150】
(9)OUTPUT ESTIMATION
先ず、C=(C1、・・・・、CN)とSum−Product Algorithmの出力推定値を定義する。この出力推定値は、下記式(9)により実現される。
【0151】
【数9】
最後に、出力推定値の吟味が行われる。パリティチェックマトリックスHを置換した出力であるC=(C1、・・・・、CN)のマトリックス乗算を含む。
【0152】
この結果がゼロマトリックスであれば、上記推定は正しいことになる。一方、一つでもゼロでないデータがマトリックスに含まれれば、推定出力値は正しくないことを示している。
【0153】
上記した各部位の中でも、アルファ係数の算出に寄与する部位は、(1)、(2)、(3)、(4)および(5)であり、ベータ係数の算出に寄与する部位は(6)および(7)である。
【0154】
本実施の形態では、演算部(例えば、LSIの上面に組み込まれた電気回路からなる)により、上記したSum−Productアルゴリズムを実行している。上記したアルファ係数を演算する演算部と、ベータ係数を演算する演算部とは一部が共用されている。
【0155】
具体的には、上記演算部は、入力された入力データに対して加算処理を行う加算部と、加算部から入力されたデータに対して減算処理を行う減算部と、CMPフォーマットとABSフォーマットとの変換を行う変換部と、Gallager Functiuonを演算する変数演算部とを含む。そして、これらの中でも演算部と変数演算部が、ベータ係数算出およびアルファ係数算出に共用される。
【0156】
即ち、ベータ係数を算出する際には、加算部、減算部、変換部、変数算出部の順番でデータ処理が行われる。一方、アルファ係数を算出する際には、加算部、減算部、変数算出部、変換部の順番でデータ処理が行われる。
【0157】
上記のように、ベータ係数算出およびアルファ係数算出に使用される演算部を共用することにより、個別に演算部を構成した場合と比較して、Sum−Productアルゴリズムに必要とされる回路の規模を小さくすることができる。従って、復号化装置や誤り訂正装置の大きさ(即ち、これらの装置が構成されたLSIの大きさ)を小さくすることができる。
【図面の簡単な説明】
【0158】
【図1】本発明の符号化装置および復号化装置を説明するための図であり、(A)はブロック図であり、(B)−(E)はECCブロックの概要を示す図である。
【図2】本発明に用いられるECCブロックの構成を示す図である。
【図3】(A)−(E)は本発明の符号化の際のデータの構成を示す図である。
【図4】(A)−(C)は本発明の符号化の際のデータの構成を示す図である。
【図5】(A)−(F)は本発明の復号化の際のデータの構成を示す図である。
【図6】(A)−(D)は本発明の復号化の際のデータの構成を示す図である。
【図7】本発明の符号化方法を示すフローチャートである。
【図8】(A)および(B)は、本発明のRS符号化が施された後のECCブロックの構成を示す図である。
【図9】本発明のマッピングテーブルを示す表(テーブル)である。
【図10】本発明の上記マッピングテーブルの生成方法を示す図であり、(A)は確率分布を示す3次元のグラフであり、(B)はエラーが発生する確率を示す表であり、(C)はハミング距離を示す表であり、(D)はマッピングテーブルである。
【図11】本発明の上記マッピングテーブルの生成方法を示す図であり、(A)はフローチャートであり、(B)は置換前のマッピングテーブルであり、(C)は置換後のマッピングテーブルである。
【図12】本発明のLDPC符号化を示す図であり、(A)はパリティ検査行列を示す図であり、(B)はECCブロックの構成を示す図である。
【図13】(A)はECCブロックの構成を示す図であり、(B)はマッピングテーブルを示す表である。
【図14】本発明の復号化方法を示すフローチャートである。
【図15】本発明のマッピングテーブルを示す表である。
【図16】本発明のLDPC復号化方法を示す図であり、(A)は概念図であり、(B)は解析結果を示す表である。
【図17】LDPC復号処理に用いられるGallager Functionを示すグラフである。
【図18】(A)および(B)はパターンマッチングを示す図であり、(C)はこのプロセスを示すフローチャートである。
【図19】RS復号化を示すブロック図である。
【図20】Sum−productに用いられる回路を示すブロック図である。
【図21】CMP formatとABS formatとの関連を示す表である。
【図22】Sum−productの詳細を示す図であり、(A)はパリティチェックマトリックスを示す図であり、(B)および(C)はフローチャートである。
【図23】Sum−productの詳細を示す図であり、(A)はパリティチェックマトリックスを示す図であり、(B)および(C)はフローチャートである。
【符号の説明】
【0159】
10 誤り訂正装置
11 ECCブロック
12 ページ
13 情報領域
14 ページ内冗長データ
15 ページ間冗長データ
20 符号化装置
21 RS符号化部
22 LDPC符号化部
23 データ変換部
24 データ変換部
30 復号化装置
31 LDPC復号化部
32 RS復号化部
33 データ変換部
34 データ変換部
40 伝送経路
42 入力データ
43 第1符号化データ
44 第2符号化データ
45 第1復号化データ
46 第2復号化データ
47 イレージャー信号
48 出力データ
49 入力データ
50 シンドローム演算部
51 多項式演算部
52 シンドローム演算部
53 Euclide演算部
54 Chein演算部
55 エラー訂正部
60 パリティ検査行列
【技術分野】
【0001】
本発明は符号化装置、復号化装置および誤り訂正装置に関し、特に、LDPC(Low Density Parity Check)符号を用いた符号化装置、復号化装置および誤り訂正装置に関する。
【背景技術】
【0002】
デジタルデータの通信や記録を行う際には、外部のノイズ等によりデジタルデータに誤りが発生している。従来から、このような誤りを検出・訂正するための技術として、誤り訂正符号を用いる技術が知られている。誤り訂正符号では、符号化の際にデータに対して冗長データを付加し、復号化の際にはこの冗長データを基にデータの誤りを訂正する。通信や記録されるのは、冗長データが付加されたデータである。
【0003】
この誤り訂正符号としては、リードソロモン符号やLDPC符号がある。誤りを含むデータに対して、訂正符号を用いた誤り訂正処理を施すことで、データに含まれる誤りの値が一定以下であれば、その誤りを訂正することができる。
【0004】
リードソロモン符号は、複数個の連続したビット単位(シンボル)の誤りを訂正する符号であり、数ある訂正符号化の中でも高度な訂正能力を具備すると考えられている。具体的には、リードソロモン符号の訂正処理は、シンドロームを生成して消失位置を検出するステップと、誤り位置および誤り値の算出・訂正と訂正結果をチェックするステップと、訂正結果の出力ステップとを主要に具備している(例えば下記特許文献1を参照)。
【0005】
LDPC符号とは、疎な検査行列によって定義されるブロック符号であり、反復号処理によって復号されるものである。LDPC符号の利点を列挙すると、例えば、検査行列が低密度であり、優れた最尤復号性能を持ち、ランダム性を有し、復号に適した構造を持ち、シャノン限界に近い復号性能を備えることである。更に、LDPC符号は、様々な符号長、符号化率の符号を容易に構成できる柔軟性を持っており、エラーフロア現象が殆ど生じない利点もある(例えば下記特許文献2を参照)。
【特許文献1】特開平5−315974号公報
【特許文献2】特開2006−13714号公報
【発明の開示】
【発明が解決しようとする課題】
【0006】
しかしながら、最近の記録媒体に記録されるデータの情報量は極めて増加しており、例えば1テラバイト以上のデータが書き込み可能な情報記録ディスクが出現しつつある。このような状況を鑑みると、上記したリードソロモン符号を用いても、符号化能力が必ずしも充分とは言えない問題があった。
【0007】
更に、LDPC符号を用いると符号訂正能力を格段に向上させることができるが、符号訂正能力が高いLDPC符号を実現するためには、大規模な電気回路が必要とされる問題があった。
【0008】
この問題の対処方法として、例えば、リードソロモン符号を2重に組み合わせて符号化処理を行う手法も存在し、この方法によると符号訂正能力を向上させることができる。しかしながら、この組み合わせによる方法によっても符号訂正能力が不十分である問題があった。更にまた、他の誤り訂正方法を2重以上に組み合わせることによっても、符号訂正能力の向上は図れるが、この方法によると回路規模が巨大なものになってしまい、誤り訂正にかかるコストが高くなってしまう問題も予測される。
【0009】
本発明は上述した問題点を鑑みて成されたものである。本発明の主な目的は、符号化訂正能力が飛躍的に向上された符号化装置、復号化装置および誤り訂正装置を提供することにある。
【課題を解決するための手段】
【0010】
本発明の符号化装置は、入力された入力データを符号化する符号化装置であり、前記入力データに対してRS符号化を行って第1符号化データを生成するRS符号部と、前記第1符号化データに対してLDPC符号化を行って第2符号化データを生成するLDPC符号部と、を具備することを特徴とする。
【0011】
本発明の復号化装置は、符号化データを復号化して復号化データを生成する復号化装置であり、前記符号化データに対してLDPC復号化を行って第1復号化データを生成するLPDC復号部と、前記第1復号化データに対してRS復号化を行って第2復号化データを生成するRS復号部と、を備えることを特徴とする。
【0012】
本発明の誤り訂正装置は、入力されたデータを符号化して符号化データを生成する符号化装置と、前記符号化データを復号化して復号化データを生成する復号化装置と、を具備し、前記符号化装置は、前記入力データに対してRS符号化を行って第1符号化データを生成するRS符号部と、前記第1符号化データに対してLDPC符号化を行って第2符号化データを生成するLDPC符号部と、を備え、前記復号化装置は、前記第2復号化データに対してLDPC復号化を行って第1復号化データを生成するLDPC復号部と、前記第1復号化データに対してRS復号化を行って第2復号化データを生成するRS復号部と、を備えることを特徴とする。
【0013】
本発明の符号化装置は、多数のシンボルから構成される入力データを符号化する符号化装置であり、前記入力データに含まれる前記シンボルのビット数を多くするデータ変換部と、前記入力データに対してLDPC符号化を行って符号化データを生成するLDPC符号化部と、を具備することを特徴とする。
【0014】
本発明の復号化装置は、符号化データを復号化して復号化データを生成する復号化装置であり、前記符号化データに対してLDPC復号化を行って前記復号化データを生成するLDPC復号部と、前記復号化データに含まれるシンボルのビット数を少なくするデータ変換部と、を具備することを特徴とする。
【0015】
本発明の誤り訂正装置は、入力された入力データを符号化して符号化データを生成する符号化装置と、前記符号化データを復号化して復号化データを生成する復号化装置、と具備し、前記符号化装置は、前記入力データに含まれるシンボルのビット数を多くする符号側データ変換部と、前記入力データに対してLDPC符号化を行って符号化データを生成するLDPC符号部と、を備え、前記復号化装置は、前記符号化データに対してLDPC復号化を行って復号化データを生成するLDPC復号部と、前記復号化データに含まれるシンボルのビット数を少なくする復号側データ変換部と、を備えることを特徴とする。
【0016】
本発明の復号化装置は、アルファ係数とベータ係数とを用いるSum−procuctアルゴリズムを含む復号化を演算部により行う復号化装置に於いて、前記アルファ係数を算出する演算部と、前記ベータ係数を算出する演算部とを、少なくとも一部共用することを特徴とする。
【0017】
本発明の誤り訂正装置は、入力された入力データをLDPC符号により符号化して符号化データを生成する符号化装置と、前記符号化データを復号化して復号化データを生成する復号化装置と、を具備し、前記復号化装置は、アルファ係数とベータ係数とを用いるSum−Productアルゴリズムを含む復号化を演算部により行い、前記アルファ係数を算出する演算部と、前記ベータ係数を算出する演算部とを、少なくとも一部共有することを特徴とする。
【発明の効果】
【0018】
本発明の復号化装置では、LDPC復号部とリードソロモン復号部の2つの復号部を具備しているので、復号化性能を極めて高くすることができる。具体的には、データブロック内部のページ全体が破損するページ抜け(Page Fall)が発生しても、ページ間の符号化を行うリードソロモン復号部により、破損したページを正しく復号することができる。更に、LDPC符号部を用いることにより、復号に失敗した情報を特定した後に、正しくデータを復号することができる。
【0019】
また、本発明の復号化装置では、LDPC復号化に失敗したシンボルを無効シンボルとした後に、このシンボルの位置を示すイレージャー信号を生成して、これらを用いてリードソロモン符号の復号化を行っている。従って、後段の処理であるリードソロモン符号の誤り訂正能力を向上させることができる。
【0020】
更にまた、本発明の符号化装置に依れば、LDPC符号化を行う前に、符号化の対象となるデータに含まれるシンボルのサイズを大きくしている。従って、LDPC符号化の誤り訂正性能を向上させることができる。
【0021】
更にまた、本発明の復号化装置に依れば、共通の計算セル(演算部)で、Sum−productに使用されるアルファ係数とベータ係数とを演算している。従って、Sum−productアルゴリズムを構成するのに必要とされる回路の規模を縮小することができる。
【発明を実施するための最良の形態】
【0022】
<第1の実施の形態:誤り訂正装置の概要>
本形態では、本発明の一実施形態に係る符号化装置および復号化装置を具備する誤り訂正装置の構成および符号訂正方法を説明する。なお、以下の説明では、符号化装置または復号化装置の内部にてデータを構成する単位要素をシンボルと称し、これらの装置の外部にて伝送、書き込み、保存または読み出しされる情報を構成する単位要素をデータと称する場合もある。
【0023】
図1を参照して、先ず、本形態の誤り訂正装置10の概略的構成を説明する。図1(A)は誤り訂正装置10の概略的構成を示すブロック図であり、図1(B)〜図1(E)はError Correcting Codeブロック(ECCブロック)の構成を示す平面図である。
【0024】
図1(A)を参照して、本形態の誤り訂正装置10は、入力された入力データを符号化する符号化装置20と、伝送経路40を経由して入力された符号化データを復号する復号化装置30とを具備している。
【0025】
ここで、伝送経路40とは、有線または無線を経由した経路が考えられ、例えばデジタル放送や移動体通信がある。また、伝送経路40の代替として記録媒体が用いられても良い。例えば、符号化装置20により生成された符号化データを記録媒体(磁気ディスクや光学ディスク)に記録して、記録媒体から読み出した符号化データを復号化装置30により復号しても良い。ここで、記録媒体としては、例えばDVD(Digital Versatile Disc)やCD(Compact Disc)等のように脱着式のディスクで良いし、HDD(Hard Disk Drive)等のように固定式のディスクでも良い。更に、上記記憶媒体として、フラッシュメモリ等の半導体記憶装置も採用できる。また、HDV(High−Definition Digital Video)で使用されるフォログラムディスクが記憶媒体として採用されても良い。更にまた、記憶媒体としては、ブルーレイディスク(Blu−ray Disc:BD)やHD DVD(High−Definition Digital Versatile Disc)を採用することもできる。
【0026】
さらに、符号化装置20のみが個別に使用者に利用されても良いし、復号化装置30のみが個別に使用者に利用されても良い。また、本形態の誤り訂正装置10、符号化装置20または復号化装置30は、ハードウェアとして構成されても良いし、ソフトウェアとしてプログラムにより実現されても良い。更には、これらは一部がハードウェアにより構成され、残りの部分がソフトウェアにより実現されても良い。
【0027】
符号化装置20は、RS符号化部21と、データ変換部23と、LDPC符号化部22と、データ変換部24とを主要に具備している。
【0028】
RS(Reed Solomon)符号化部21では、入力されるデジタルデータである入力データ42に対してリードソロモン(RS)符号化が施され、結果として第1符号化データ43が生成される。具体的には、図1(B)を参照して、入力データ42を構成する一単位要素であるECCブロックは、不図示の複数のページから成り、異なるページに含まれるシンボルに対して、RS符号化が施され、ページ間冗長データが生成される。図では、ページ間冗長データをPOが付された領域で示している。そして、符号化を行う方向は図中で矢印にて示されている。ここで生成される第1符号化データ43は、実質的な意味を持ち複数のページから成る情報と、この情報から生成されたページ間冗長データ(PO)から成る。この第1符号化データ43は、データ変換部23に転送される。なお、ECCブロックの詳細は、図2等を参照して後述する。
【0029】
データ変換部23では、所定の規則に従って、ECCブロックに含まれる各シンボルのビット数を増大させる。ここでは、シンボルの情報量が8ビット(bit)から16ビットに変換されている。シンボルをこのように変換することは本発明の特徴の一つであり、このことによりLDPC符号化の誤り訂正率を向上させることができる。ここで、シンボルは必ずしも16ビットに変換される必要は無く、例えば9ビット〜15ビット程度でも良く、変換前よりも大きいビット数であればよい。しかしながら、後述するパターンマッチングの工程を考慮すると、シンボルは16ビットに変換されることが望ましい。ここで、シンボルとは、ECCブロックに含まれるページを構成する単位要素であり、後述するパターンマッチング等はシンボル毎に行われる。各シンボルのビット数が増大された第1符号化データ43は、LDPC符号化部22に転送される。
【0030】
LDPC符号化部22は、RS符号化が施された第1符号化データ43に対してLDPC符号化を施す部位である。上記したRS符号化部21がページ間の符号化を行ったのに対して、LDPC符号化部22はページ内の符号化を行う。具体的には、図1(C)を参照して、ECCブロックに含まれる全てのページに対して、LDPC符号化が施される。図では、LDPC符号化を行う方向が矢印にて示されている。LDPC符号化によって生成されたページ内冗長データは実質的な情報に付加される。図では、付加されるページ内冗長データをPIが付された領域で示している。ここで、生成される第2符号化データは、実質的な意味を有し複数のページから成る情報と、ページ間冗長データ(P0)と、ページ内冗長データ(PI)から成る。生成された第2符号化データ44は、データ変換部24に転送される。
【0031】
データ変換部24では、ECCブロックを構成する各シンボルの情報量を変換して、情報量を少なくする。例えば、上述したデータ変換部23にてシンボルが8ビットから16ビットに変換された場合は、この部位にて16ビットから8ビットに戻す。更に、戻すための変換を行う際には、データ変換部23で適用された規則とは逆の規則を用いることもできる。データを元に戻す変換を行わずに符号化装置20から復号化データを出力することも可能であるが、そうすると伝送するべき情報量が増大してしまう等の問題が発生する。従って、シンボルの情報量を元に戻してから出力することが好適である。シンボルの情報量が元に変換された第2符号化データ44は、符号化装置20から出力される。また、この部位の主たる役割は情報量の削減であるので、一般的な情報圧縮技術(即ち、上記した情報変換方法とは異なる方法)により符号化データを圧縮して、各シンボルのビット数を減少させても良い。
【0032】
第2符号化装置20から出力された第2符号化データ44は、伝送経路40を経由して復号化装置30に伝送され、後述する復号化装置30に入力される。ここで、第2符号化データ44を転送する際には、外部のノイズ等に起因して誤りが発生する。即ち、復号化装置30に入力される第2符号化データ44は、符号化装置20から出力されたものとは異なっている。復号化装置30では、この誤りを訂正して正しい情報を得る。
【0033】
復号化装置30は、データ変換部33と、LDPC復号化部31と、データ変換部34と、RS復号化部32とを主要に具備している。
【0034】
データ変換部33では、復号化装置に入力された復号化データ(符号化装置20により生成された第2符号化データ44)に含まれるシンボルの情報量を変換する。ここでは、シンボルの情報量を8ビットから16ビットに変換している。ここでの変換は、符号化装置20のデータ変換部24に於ける変換と等価(即ち、真逆の変換規則あるいは、可逆変換)である必要がある。
【0035】
LDPC復号化部31では、16ビットのシンボルから構成される第2符号化データ44に対してLDPC復号化を行い、第1復号化データを生成する。具体的には、図1(D)を参照して、ECCブロックを構成する各ページに対してページ内の復号化を行う。同図では、復号化を行う方向を矢印にて示している。ここでは、各ページ内に含まれるページ内冗長データを用いて、そのページを復号している。また、ページ間冗長データ(PO)に対しても、LDPC復号化が行われる。生成された第1復号化データ45は、データ変換部34に伝送される。
【0036】
データ変換部34では、ECCブロックを構成する各シンボルのデータを、16ビットから8ビットに変換する。この変換は、詳細を後述するパターンマッチングにより行い、マッチングしたシンボルには、対応する8ビットのシンボルが割り当てられる。一方、マッチングしないシンボルには、エラーであることを示す8ビットのシンボルが割り当てられ、更に、このシンボルの位置を指し示す別のデータ(Erasure Flag:イレージャー・フラッグ)が生成される。このイレージャー・フラッグ(イレージャー信号)は、データ変換された第1復号化データ45と共に、RS復号化部32に伝送される。
【0037】
RS復号化部32では、データ変換された第1復号化データ45に対して、リードソロモン復号化(RS復号化)を行い、復号化された第2復号化データ46を生成する。ここで生成される第2復号化データ46は、入力データ42と等価である。図1(E)を参照すると、RS復号化はページ間のシンボルに対して行われ、RS復号の方向は矢印にて示されている。
【0038】
上述したように、本発明では、ページ内の誤り訂正にLDPC符号を用いて、ページ間の誤り訂正にリードソロモン符号(RS符号)を用いている。この組み合わせにより、訂正能力を極めて高くすることができる。LDPC符号とRS符号とを組み合わせた本実施の形態の誤り訂正方法は、RS符号を2重に組み合わせた誤り訂正方法よりも訂正能力が高くなると共に、回路規模を小さく留められる。
【0039】
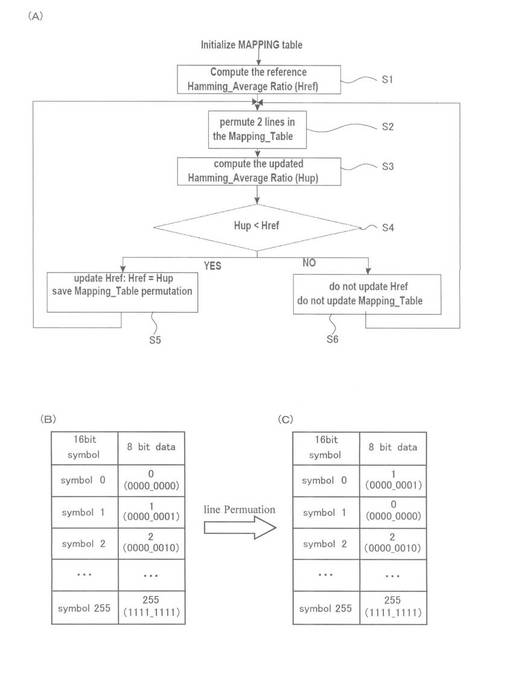
図2を参照して、次に、本発明で用いられるECCブロックの一例を説明する。図2はECCブロックの概要を示す図である。
【0040】
図2を参照して、ECCブロック11は、実質的な意味を有するデータ(使用者が使用するデータであり、例えば画像データや文書データ)である情報領域13と、ページ12内の誤り訂正を行うために用いられるページ内冗長データ14と、ページ12の間の誤り訂正を行うために用いられるページ間冗長データ15とから成る。1つのECCブロック11は、トータルで208個(row)のページ12から成る。また、1つのページ12は、実質的な意味を有する情報である1072バイトと、その情報の冗長データである560バイトから成る。更に、最後の20個(row)のページでは、1072バイトのページ間冗長データ15に、560バイトのページ内冗長データが付加されている。本発明では、ページ内冗長データ14はLDPC符号であり、ページ間冗長データ15はRS符号である。
【0041】
ここで、ページ12の先頭の数バイト(例えば4バイト)がページ数を示す場合があり、この場合は各ページの先頭の数バイトについては、RS符号化は行われずにページ間冗長データ15が生成されなくても良いし、この部分も含めた全体に対してページ間冗長データ15が生成されても良い。一方、ページ数がページ12の先頭に挿入されない場合は、ページ12全体に渡ってRS符号化が行われて、ページ間冗長データ15が生成される。
【0042】
図3および図4を参照して、図1に示した符号化装置20に於けるデータの詳細を説明する。図3および図4の各図は、符号化装置20の内部に於けるデータの変遷を示す概念図である。
【0043】
図3(A)を参照して、上述したように、符号化装置20(図1参照)にて生成されるECCブロック11は複数のページから成り、情報領域13と、ページ内冗長データ14と、ページ間冗長データ15とから成る。符号化装置20では、ユーザーデータである情報領域13に、ページ内冗長データ14とページ間冗長データ15とを付加する。従って、符号化装置20に入力されるデータ(符号化処理が行われる前のデータ)は、情報領域13のみから成る。ここで、ページ間冗長データ15は、LDPC符号化に先行して生成して付与されている。ページ間冗長データ15はリードソロモン符号化により生成される。
【0044】
図3(B)を参照して、情報領域13の内部の1つのページ12は、1072バイトの情報量を有する。本発明では、先ず、1つのページ12を8個のデータブロックに分割している。ここで、1つのブロックの情報量は134バイト(1072ビット)である(図3(C)および図3(D)参照)。
【0045】
図3(E)を参照して、次に、各データブロックに含まれる8ビットのシンボルを16ビットに変換する。ここでは、予め用意されたテーブル(表)を用いて、シンボルのビット数を変換する。この変換は、ただ単にシンボルの前後に0000等のデータを付加するのではなく、LDPC符号の誤り訂正能力が向上されるように、ハミング距離が考慮される。この変換により、1つのデータブロックの情報量は、134バイト(1072ビット)から、268バイト(2144ビット)に変換される。
【0046】
図4(A)を参照して、次に、各々のデータブロックに対してLDPC符号化を施し、ページ内冗長データ14(Redundancy Block)を生成する。本発明では、1つの処理単位であるシンボルを8ビットから16ビットに変換した後に、LDPC符号化を行っているので、より高度な誤り訂正を行うことができる。
【0047】
LDPC符号化が終了した後は、データブロックに含まれるシンボルを16ビットから8ビットに再び変換する。この変換も上述したテーブルを逆に用いて(即ち、所定の規則に従って)行われる。この変換を終えた後のページを図4(B)に示す。ここでは、134バイトのデータブロックに、70バイトのページ内冗長データ(Redundanncy)が付与されている。
【0048】
図4(C)を参照して、ここでは、各々が134バイトである8個のデータブロックM1〜M8のそれぞれに対して、70バイトのページ内冗長データR1〜R8が生成される。従って、ここでは、1つのページの情報量は、これらのデータを積算して1632バイトとなる。
【0049】
上記した行程により、図3(A)に示すページ内冗長データ14が生成され、ECCブロック11が完成する。ECCブロック11は、伝送路等を介して復号化装置に伝送される。または、CD等の記録媒体にECCブロック11は書き込まれる。
【0050】
図5および図6を参照して次に、復号化装置を用いて、符号化された情報を復号化する際のデータの変遷を説明する。
【0051】
図5(A)を参照して、復号化装置に入力される情報は冗長データが付加されたものであり、具体的には、情報領域13と、ページ内冗長データ14と、ページ間冗長データ15とから成る。このECCブロック11は、伝送路等を経て復号装置に入力されるので、エラーが発生し、符号化装置により生成されたものとは異なる場合がある。そこで、復号化装置では、ページ内冗長データ14とページ間冗長データ15を用いて、このエラーを訂正する。
【0052】
図5(B)および図5(C)を参照して、ページ内冗長データ14を含む1ページの情報量は、1632バイトであり、各々が204バイトである8個のデータブロックに1つのページは分割することができる。
【0053】
図5(D)を参照して、1つのデータブロックは、134バイトの情報領域と、70バイトのページ間冗長データから成る。このページ間冗長データは、LDPC符号化により生成されたものである。
【0054】
図5(E)および図5(F)を参照して、1つのページに含まれるデータ(実質的に意味を有している情報)は134個のシンボルから成り、各々のシンボルは8ビットの情報量を具備している。
【0055】
ここで、図5(B)に示すページ12の構成は、図4(C)に示すとおりであり、最初の1072バイト(134バイト×8個)がユーザーデータであり、その後の560バイト(70バイト×8個)が冗長データである。そしてユーザーデータと冗長データとは、各々が集合して配置されている。図5(C)および図5(D)を参照して、ページ内のデータは並べ替えられ、各ユーザーデータにその冗長データが隣接する。即ち、ユーザーデータ(134バイト)とそれに隣接した冗長データ(70バイト)から成るセットが、8個集合して1つのページが構成される。
【0056】
本発明では、各々のシンボルを8ビットから16ビットに変換している。この変換は、上述した復号化と同様に、変換のためのテーブルを用いて行われる。従って、各々のデータブロックに含まれる情報量は、1072ビットから2144ビットとなる。
【0057】
図6(A)および図6(B)を参照して、560ビットのページ間冗長データを用いて、2144ビットの情報に対してLDPC復号化を行い、2144ビットの復号化データを得る。ここで、LDPC符号が行われても、元の情報に完全に復号されるのではなく、復号化に失敗しているシンボルも存在すると考えられる。そこで、本発明では、後に詳述するパターンマッチングを行って、伝送経路にてデータの欠損が発生したか否かを判断している。更にこの作業は、シンボルのビット数の変換も兼ねている。
【0058】
図6(C)に変換された後の8ビットの復号化データを示す。この図を参照して、上記パターンマッチングの結果、正しくマッチングしたものは、テーブル中にて対応する8ビットのシンボルに変換される。一方、正しくマッチングしないシンボルは、正しくマッチングしなかったものに割り当てられるべき8ビットのシンボルが割り当てられる。ここでは、マッチングしなかったシンボルに、「0」を指し示す8ビットのシンボルが割り当てられる。更に、図6(D)を参照して、イレージャー信号(Erasure Pattern)が生成される。このイレージャー信号は、上記したマッチングの結果、マッチングしなかった(即ち、伝送経路にてデータが破損した)シンボルの位置を指し示す信号である。
【0059】
上記した復号化データとイレージャー信号を用いて、RS復号化が行われて、完全な復号化が行われた情報が得られる。イレージャー信号を利用することにより、誤りが生じたシンボルの位置を容易に知ることができるので、RS復号化により誤り訂正の性能を向上させることができる。
【0060】
<第2の実施の形態:符号化方法>
本形態では、リードソロモン符号化およびLDPC符号化を組み合わせた符号化方法を詳述する。
【0061】
図7のフローチャートを参照して、本形態の復号化方法は、入力された入力データに対してリードソロモン符号化を行って第1符号化データを生成する第1ステップS1と、第1符号化データのビット数を変換する第2ステップS2と、第1符号化データに対してLDPC変換を行って第2符号化データを生成する第3ステップS3と、第2符号化データのビット数を変換する第4ステップS4とを主要に具備する。
【0062】
第1ステップ:RS符号化を行うステップ
図8を参照して、入力されたデータに対してリードソロモン符号化を行うステップを説明する。図8(A)は本ステップで生成されるECCブロック11を示す図であり、図8(B)はECCブロックの一部を示す図である。
【0063】
図8(A)を参照して、実質的な意味を有するユーザーデータである情報領域13は、188個(row)のページ12から成り、1つのページ12は、1072個のシンボル(1つのシンボルは8ビット)から成る。本ステップでは、異なるページに含まれるシンボルに対してリードソロモン符号化を行い、ページ間冗長データを生成する。従って、本工程で生成されるECCブロックは、ユーザーデータである情報領域13と、情報領域に含まれるページ間の冗長であるページ間冗長データ15から成る。
【0064】
図8(B)を参照して、各ページに含まれるシンボルを最上段から、B[0、j]、B[1、j]、B[2、j]、・・・・B[187、j]とした場合、多項式(Remainder Polynomial)Rjは以下の式(1)により計算される。更にここでは、188列の実質的な情報に、47列分のゼロ成分を加えて演算を行い、合計で235列としている。この様にゼロの列を加算するのは、リードソロモンコアに、処理されるデータのフォーマットを一致させるためである。この様な処理はパディングと称される。
【0065】
【数1】
また、上記式(1)は下記式(2)により表現することもできる。
【0066】
【数2】
更に、上記式(2)中のαは、下記式(3)に示す原始多項式の原始根である。
【0067】
【数3】
上記計算を、ページ12間の各々のシンボルに対して行い、ページ間冗長データ15が生成され、第1符号化データが生成される。
【0068】
第2ステップ:第1符号化データのビット数を変換するステップ
本ステップでは、ステップ1にて生成された第1符号化データに含まれるシンボルのビット数を変換する。第1ステップにて生成されるデータでは、1つのシンボルのビット数は8ビットである。本工程では、データの含まれるシンボルのビット数を8ビットから16ビットに変換する。
【0069】
本ステップでは、シンボルのビット数を8ビットから16ビットに変換するが、この変換はただ単に変換前のシンボルの前または後に「00000000」等の情報を付与するのではなく、LDPC符号化の効率が高くなるような変換が行われる。即ち、シンボル内部で情報が分散された疎な状態になるように、シンボルの情報量が16ビットに変換される。このように疎なシンボルを生成することで、LDPC符号の符号訂正能力を向上させることができる。また、ここで、ビット数を16ビットに変換しても、シンボルが取り得る値のバリエーションは256通りであり8ビットの場合と変わらない。従って、シンボルを増加させることによる計算量の増加は抑制されている。
【0070】
図9に、本工程で使用されるマッピングテーブルを示す。ここでは、左側の列に16ビットのシンボルが示され、右側の列にそれに対応する8ビットシンボルが示されている。このテーブルを使用して、ECCブロックに含まれる全てのシンボルは8ビットから16ビットに変換される。例えば、16ビットのシンボルに於ける最下段のシンボル255は、それに対応する8ビットシンボル255(1111_1111)に変換する(割り当てられる)。
【0071】
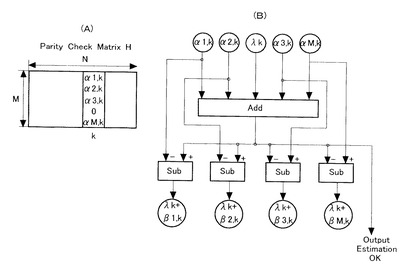
次に、図10および図11を参照して、上記したテーブル(マッピングテーブル)の生成方法を説明する。図10(A)は確率分布を示すグラフであり、図10(B)はそのグラフを数値化した表であり、図10(C)は8ビットシンボルのハミング距離を示す表であり、図10(D)はマッピングテーブルである。
【0072】
先ず、LDPCアルゴリズムはRaw Data Format(16ビット)を使用することで実現される。この変換テーブルの主たる目的は、8ビットデータを適切な(即ち、変換前よりも疎な状態な)16ビットデータのシンボルに割り当てることにある。
【0073】
以下に、上記マッピングテーブルを構築する方法を説明する。最初に、顧客から提供されたデータを利用して、伝送路のノイズを解析する。図10(A)は、このノイズの性質を可視化したものである。紙面上にて手前側の横軸は伝送路にインプットされるデータを示し、奥行き側に伸びる軸は伝送路から出力されるデータを示し、縦方向の軸はインプット情報とアウトプット情報にエラーが生じる確率であるエラー確率を示している。この解析は、16ビットシンボル(合計で256個)を使用したエラー確率マトリックスを構築することを可能とする。
【0074】
図10(C)を参照して、8ビットバイナリデータのハミング距離が構築される。バイナリAdataとバイナリBdataとのハミング距離は、AdataとBdataとのバイナリ値を比較することにより、簡単に計算できる。例えば、以下の2つの値が有ると仮定した場合、
第1の値:1000_0000
第2の値:0001_1011
第1の値と第2の値とのハミング距離Hdは5である。
【0075】
図10(C)には、8ビットデータの、全ての組合せのハミング距離が示されている。そして、上記した2つのマトリックスは、8ビットデータを16ビットシンボル(4×4)に割り当てるマッピングテーブルによりリンクされる。
【0076】
上記した各表(テーブル)を基に、図10(D)に示すマッピングテーブルが生成される。このテーブルは、8ビットシンボルを16ビットシンボルに変換されるときに使用されると共に、逆に、16ビットシンボルを8ビットシンボルに変換(逆変換)する際にも同じように適用される。
【0077】
更に、上記マッピングテーブルは、次のような理念に基づいて、生成される。即ち、「インプットされた16ビットシンボルが、出力されるシンボルよりも高い確率を有している場合は、対応するハミング距離Hd(A、B)が可能な限り低くなる。」という基本的考えの基にマッピングテーブルは生成される。
【0078】
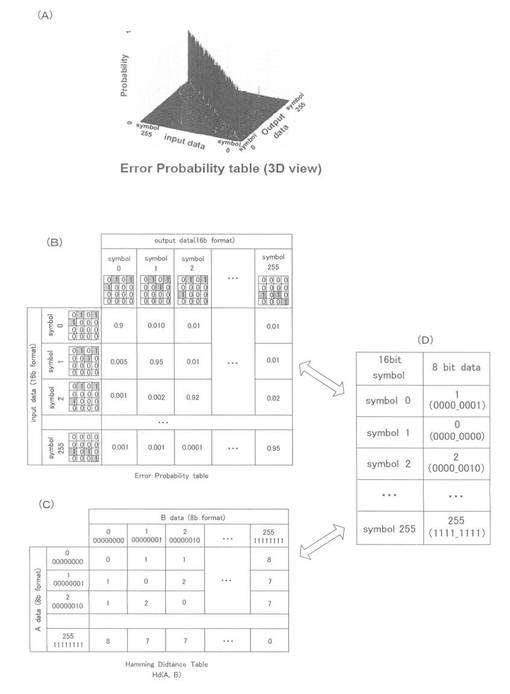
図11を参照して、次に、効率的にマッピングテーブルを構築する為のアルゴリズムを説明する。図11(A)はマッチングテーブルの生成方法を示すフローチャートであり、図11(B)は最適化を行う前のマッピングテーブルであり、図11(C)は最適化を行った後のマッピングテーブルである。このアルゴリズムの主たる目的は、下記式(5)に示される式に示されるハミング比を可能な限り小さくすることにある。
【0079】
【数5】
図11(A)に示された各フローチャートの各ステップの具体的処理は以下の通りである。
【0080】
先ず、ステップS1では、8ビットを16ビットに変換するテーブルを初期化する。8ビットデータと16ビットデータとは、両方とも昇順にソートされる。そして、上記式(5)に示された式によりハミング平均値を計算する。この式により算出された値を以後、H参照値と称する。
【0081】
ステップS2では、マッピングテーブルを2つの列になるように置換する。この置換の一例を図11(B)および図11(C)に示す。置換が終了すると、16ビットシンボルの0は8ビットデータの1に対応し、16ビットシンボルの1は、8ビットデータの0に対応する(図11(C)参照)。
【0082】
ステップS3では、次に、アップデートされた(置換された)マッピングテーブルを使用して、ハミング平均値を上記式(5)に示された式を使用して計算する。この値をHup値と称する。
【0083】
ステップS4では、続いて、Hup値とH参照値(Href値と以下にて称する場合もある)とを比較する。
【0084】
上記ステップS4にて、Hup値がHref値よりも低い場合、(換言すると、この状態のマッピングテーブルが参照のマッピングテーブルよりも適している場合)は、ステップS5に移行して、次のような処置をする。即ち、ステップS2における置換が記憶されると共に、参照ハミング平均値比がHup値としてセットされる(Href値をHup値に割り当てる)。
【0085】
一方、上記ステップS4にて、Hup値がHref値よりも大きい場合、(換言すると、この状態のマッピングテーブルが参照のマッピングテーブルよりも適切でない場合)は、ステップS6に移行して、次のような処置をする。即ち、ステップS3での置換は記憶されずに、参照のマッピングテーブルを復帰させる(即ち、そのままの状態にしておく)。
【0086】
上記プロセスは、マッピングテーブルの全ての2列置換に対して行われる。このことによって、本実施の形態の目的に沿った最適なマッピングテーブルが生成される。
【0087】
第3ステップ:第1符号化データに対してLDPC変換を行うステップ
本ステップでは、上記工程により個々のシンボルが8ビットから16ビットに変換された第1符号化データに対してLDPC符号化を行い、ページ内の冗長データを生成して、第2符号化データを生成する。
【0088】
図12(A)に本ステップで用いるパリティ検査行列60を示し、図12(B)に本ステップにて生成される第2符号化データを構成するECCブロック11を示す。
【0089】
図12(A)に示すパリティ検査行列60は、例えば、560行・2704列の構成となっている。本形態では、符号化単位となる1ページ分の情報は2144ビットであり、560個のパリティビットを生成するために更に560ビットが付け加えられ、パリティ検査行列60の列数は2704列となる。また、検査行列の右端部には正方形の領域が必要となるので、パリティ検査行列60の行数は560行と成っている。なお、この正方形領域では、対角線の沿った成分は全てが1となっており、対角線より右側は0となっている。更に、この対角線より左側の領域は1が疎に配置されている。
【0090】
次に、上記したパリティ検査行列60を各々のページを構成する各ビットと演算して、パリティビットを算出する。このことを換言すれば、各ページについて560元の連立方程式を解くことで、各ページに付加されるページ内冗長データが生成される。
【0091】
このようなパリティ検査行列を用いたページ間冗長データの生成は、ECCブロックを構成する各ページについて行われる。また、RS符号化により生成されたページ間冗長データ15に関しても、LDPC符号化によるページ内冗長データ14が生成される。
【0092】
上記ステップにより、図12(B)に示す構成のECCブロック11が生成される。ECCブロック11の構成の詳細は、第1の実施の形態にて上記した。ここでは、ページ12毎にページ内冗長データ14が生成され、1つのページに560バイトのページ内冗長データ14が付加される。
【0093】
本発明の特徴の一つは、ハミング距離が考慮されてビット数が変換された情報に対して、LDPC符号変換を行う点にある。このことにより、冗長データおよび計算量の増大を抑制しつつ、LDPC符号化の誤り訂正能力を向上させることができる。一般的に、誤り訂正のための符号化技術では、符号化の為の冗長データを長くするほど、誤り訂正能力を高めることができる。しかしながら、冗長データを長くすると、伝送又は記録されるべきトータルな情報量が増大してしまい、誤り訂正の為の計算量(計算時間)も長くなってしまう等の問題もある。そこで本形態では、シンボルの情報量を8ビットから16ビットに変換した後に、このシンボルに対してLDPC符号化を行っている。このことにより、シンボルが疎な状態になるので、LDPC符号化の誤り訂正能力が向上される。更に、8ビットのシンボルに適用されるテーブルを用いることができるので、シンボルの情報量が増加することに依る符号化の計算量の増大が抑制される。
【0094】
第4ステップ:第2符号化データのビット数を変換するステップ
図13(A)を参照して、本ステップでは、LDPC符号化が行われた第2符号化データの構成するシンボルを、16ビットから8ビットに変換して、全体の情報量を削減する。具体的には、ECCブロック11の中の情報領域13とページ間冗長データ15に含まれるシンボルの情報量が、16ビットから8ビットに変換される。本ステップの情報量の変換が行われた結果、1ページに含まれる情報領域13の情報量は、2144ビットから1072ビットに変換される。また、この変換は、ページ間冗長データ15に対しても行われる。ここでは、各ページに含まれるシンボルの情報量を16ビットから8ビットに変換しているが、8ビットに以外の情報量(例えば9ビット〜15ビット)にシンボルが変換されても良い。しかしながら、電気信号が伝送される一般的な伝送路では、8ビットまたは16ビットの情報が通過することを前提として設計されている場合が多いので、このステップで生成されるシンボルの情報量は8ビットが好適である。
【0095】
本ステップで、シンボルの情報量を削減することにより、伝送または記録されるべき情報の全体的な量が小さくなる。従って、本形態の符号化装置により生成された符号化データを伝送する場合は、本ステップにてトータルな情報量が削減された結果、伝送路に与える負荷が軽減される。また、生成された符号化データが記憶媒体に記録される場合は、記憶媒体に記録可能な実質的な情報量を増大させることができる。
【0096】
本ステップの情報量の変換は、上述した第2ステップの情報量の変換とは性質が異なる。上記第2ステップでは、LDPC符号化の誤り訂正能力を向上させるために、シンボルの情報量を8ビットから16ビットにして疎な状態にした。本ステップでは、情報量の削減が目的であるので、ビット数を変換する表を用意して、この表に従ってシンボルの8ビットを16ビットに変換すればよい。図11(B)にこの変換に用いられる表の一例を示す。
【0097】
<第3の実施の形態:復号化方法>
本形態では、上記第2の実施の形態にて説明した方法により生成された符号化データを復号化して基のデータを得る方法を説明する。
【0098】
本形態の復号化方法は、図14に示すフローチャートを参照して、入力された入力データ(符号化データ)を構成するシンボルの情報量を変換する第1ステップS11と、変換されたデータに対してLDPC変換を行って第1復号化データを生成する第2ステップS12と、第1復号化データに含まれるシンボルの情報量を変換する第3ステップS13と、第1復号化データに対してRS復号化を行って第2復号化データを生成する第4ステップS14とを具備している。
【0099】
第1ステップ:入力されたデータのビット数を変換するステップ
本ステップでは、入力された入力データ49を構成するシンボルのデータ量を変換する。ここで、入力データとは、上述した第2の実施の形態で説明した方法により符号化されたデータである。
【0100】
本ステップのデータ変換は、上述した第2の実施の形態に於ける第4ステップで行われたデータ変換の逆である。従って、上述した第4ステップのデータ変換がシンボルのデータ量を8ビットから16ビットに変換するものであった場合は、本ステップではシンボルのデータ量を16ビットから8ビットに変換する。また、変換に用いるテーブルも、上述した第4ステップと同じものを用いる。図15に、本ステップのデータ変換に用いるテーブルの一例を示す。
【0101】
第2ステップ:LDPC復号化を行うステップ
本ステップでは、上述ステップによりシンボルのビット数が変換された符号化データに対して、LDPC復号化を行い、第1復号化データ45を生成する。具体的には、Sum−Productアルゴリズムに基づく繰り返し復号を行い、推定結果である復号化データを得る。
【0102】
本ステップでは対数尤度比(log likelihood ratio)に基づくSum−Product復号法を行うので、Sum−Productアルゴリズムに入力される入力情報は、入力データ49自身ではない。
【0103】
ここで、図16(A)に示すようなデータの伝送路(Channel)を想定し、伝送路に入力されるデータをXnとし、伝送路を経由して受信されるデータをYnとする。このように仮定した場合、本ステップでは、以下に示す式(4)により算出されるλnがSum−Productアルゴリズムに入力される。
【0104】
【数4】
上記λnの値は伝送路の統計学的性質による。即ち、伝送路の種類や状況によってエラーの発生する状況は様々であり、このことがλnの値に影響するので、その値を求めることは容易ではない。そこで、本発明では、伝送路に発生するエラーの統計学的性質を予め解析し、この解析の結果に基づいて対数尤度比を求めている。
【0105】
図16(B)に上記解析に基づく結果の一例を示す。この表では、00〜11の入力に対応して、00〜11が出力される確率を示している。例えば、00が入力されたときに、00が出力される確率は0.8(80%)であり、00が入力されたときに11が出力される確率は0.0(0%)である。
【0106】
上記解析結果に基づく対数尤度比の算出方法は次の通りである。先ず、それぞれの出力値に関して、入力値が0である確率(P0)と、入力値が1である確率(P1)を算出する。次に、P1/P0を算出した後に、log(P1/P0)を算出してλを求める。ここで、P1がP0よりも大きかったらλの値は正となり、P1がP0よりも小さかったらλの値は負となる。
【0107】
更に図16(B)を参照して、上記算出方法の一例を説明すると、例えば出力値が10であった場合、入力値が1である確率P1は、P1=0.6+0.1=0.7と算出される。また、入力値が0である確率P0は、P0=0.2+0.1=0.3と算出される。従って、λ=log(0.7/0.3)=0.36となる。
【0108】
またLDPC復号処理では、図17に示すようなGallager Function を用いて計算をしている。ここで、RTL(Register Transfer Level)等で復号化装置を構成した場合は、対数の計算にかかるコストは大きくなり、計算時間も長くなる。そこで本形態では、この対数の計算を予め行い、計算結果に基づくルックアップテーブルを生成し、このルックアップテーブルを参照することにより対数を計算している。ルックアップテーブルを用いることにより、復号化に必要とされる計算量を低減させ、計算速度を高速にすると共に回路規模を削減することができる。
【0109】
上記方法によりLDPC復号化が行われる。係る復号化の他の部分の詳細は、例えば、「低密度パリティ検査符号とその復号法:和田山正著:トリケップス」に記載されている。
【0110】
第3ステップ:第1復号化データを変換するステップ
本ステップでは、図18を参照して、先ステップにて復号された第1復号化データを変換する。図18(A)は、本ステップに手処理される第1復号化データの一部を示す図であり、図18(B)はデータ変換のためのパターンマッチングを示す図であり、図18(C)は本ステップの手順を示すフローチャートである。
【0111】
本ステップでは、先ステップにて復号化処理されたデータに含まれるシンボルのビット数を変化させる。具体的には、シンボルのビット数を16ビットから8ビットに変換させる。この処理は、次ステップであるRS復号化のために必要とされる処理である。更に、本ステップでは、先ステップであるLDPCアルゴリズムにてエラーが発生したエラーを検出している。即ち、ここでは、パターンマッチングを行うことにより、これらの2つの処理を行っている。
【0112】
図18(A)を参照して、LDPC復号化が施されたデータは、1ページが2144ビットの情報量を有し、このページに含まれる1シンボルのビット数は16ビットである。16ビットの1シンボルは、4×4のマスクシンボルと等価である。このマスクシンボルは、先実施の形態にて、LDPC符号化の前に行われるデータ変換の際に用いられたものと同様なものである。
【0113】
図18(B)を参照して、本ステップでは、LDPC復号化により得られた第1復号化データに含まれるシンボルと、マスクシンボルとを逐次比較している。即ち、両シンボルのパターンが一致するか否かを確認しており、この作業はパターンマッチングと称されている。このパターンマッチングは、第1復号化データに含まれる全てのシンボルに対して行われる。このマスクシンボルは、8ビットのデータに対応して設けられているので、全部で256個存在する。
【0114】
図18(C)を参照して、上記パターンマッチングの詳細を説明する。本ステップのパターンマッチングでは、先ず、LDPC復号化された第1復号化データに含まれる16ビットのシンボルを、256個存在するマスクシンボルと順次比較する(S1)。この図に示すパターンマッチングは、第1復号化データを構成する全てのシンボルに対して順次行われる。
【0115】
次に、シンボルが多数存在するマスクシンボルの中の一つとマッチするか否かが判断される(S2)。即ち、S2では、LDPC復号化により生成された第1復号化データに含まれるシンボルと同一のものが、256個存在するマスクシンボルセットの中に存在するか否かが調べられる。
【0116】
そして、一致するマスクシンボルが存在したら(S2のYES)、一致したマスクシンボルに対応する8ビットデータが、そのシンボルに割り当てられる(S3)。このステップを踏むことにより、先工程のLDPC復号化にてエラーが発生していないことが確認されると共に、第1復号化データを構成するシンボルのビット数が、16ビットから8ビットに変換される。
【0117】
一方、一致するマスクシンボルが存在しなければ(S2のNO)、その旨を示す8ビットデータが割り当てられる(S4)。例えば、「00000000」が処理対象の16ビットのシンボルに割り当てられる。LDPC復号化が正常に行われたら(即ち、誤り訂正が正しく行われたら)、256個存在するマスクシンボルのいずれか一つとマッチするはずである。従って、処理対象のシンボルとマッチングする(一致する)マスクシンボルが存在しないと云うことは、LDPC復号化が失敗していることを意味している。このことから、ステップS4では、復号化に失敗したシンボルの存在および位置を指し示す信号であるイレージャー信号を発生させて、次ステップにてこの信号を利用する。
【0118】
以上述べたように、本ステップは、LDPC復号化が施されたデータに対してパターンマッチングを行うことにより、第1復号化データを構成する16ビットのシンボルが8ビットに変換される。更に、復号化に失敗したシンボルにはその旨を示す8ビットのシンボルが割り当てられ、更に、このシンボルの存在とその位置を示すイレージャー信号が生成される。そして、これらのデータおよび信号は、次ステップにて活用される。
【0119】
本ステップのマッチングにより、シンボルのビット数が変換されると共に、復号化の妥当さの是非も判断される。従って、1つの処理によりデータ数変換と復号化の検証が行われるので、処理の複雑化を回避しつつ高度な誤り訂正を行うことができる。
【0120】
第4ステップ:第1復号化データをRS復号化するステップ
図19を参照して、RS復号化を行うステップを、RS復号化部32の構成と共に説明する。このステップの原理と使用される数式は、第1の実施の形態にて説明したので、重複する部分は割愛する。なお、本実施の形態のRS復号方法およりRS復号装置は、通常使用されるものと基本的には同様である。
【0121】
本ステップにて用いられるRS復号装置32は、シンドローム演算部50と、多項式演算部51と、シンドローム演算部52と、Eucide演算部53と、Chien演算部54と、エラー訂正部55とを主要に具備している。
【0122】
先ステップにて生成された第1復号化データ45は、シンドローム演算部50に入力され、シンドローム演算部50にてシンドロームが算出される。ここで、シンドロームとは、第1復号化データ45に、パリティ検査行列を乗じたものである。更に、多項式演算部51では、入力されたイレージャー信号47を基に、消失位置を演算する。シンドローム演算部50および多項式演算部51の算出結果は、シンドローム演算部52に伝達される。
【0123】
そして、これらの出力結果を利用して、シンドローム演算部52にて演算を行うことにより、誤りが発生したシンボルの位置とが算出される。
【0124】
更に、Euclide演算部53およびChien演算部54では、シンドローム演算部52の出力結果を利用して、誤り値が演算されると共に演算値がチェックされる。
【0125】
最後に、エラー訂正部55では、前段で算出した値を、誤りが発生している箇所の第1復号化45に加える。このことにより、誤りが訂正された第2復号化データ46が生成されて、RS復号化部32から外部に出力される。
【0126】
<第4の実施の形態:Sum−productアルゴリズムの詳細>
本実施の形態では、LDPC復号化装置の一部であるSum−productアルゴリズムの詳細を説明する。通常のSum−productアルゴリズムと本実施の形態との大きな相違点は、本実施の形態では、Sum−productアルゴリズムで使用されるα係数の演算処理と、β計数の演算処理とを合成して行っている点にある。ここで、α係数およびβ係数は、復元されたデータの確かさを示す係数である。
【0127】
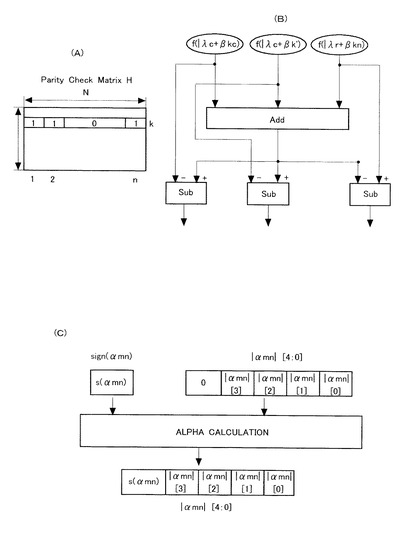
Sum−productアルゴリズムを図20乃至図23を参照しつつ説明する。ここで、図20はSum−productアルゴリズムの為の回路を示すブロック図であり、図21はCMPフォーマットおよびABSフォーマットの詳細を示す表であり、図22(A)および図22(B)はSUM GALLAGERの算出プロセスを示す図であり、図22(C)はαmn係数の算出方法を示す図であり、図23はβ係数の算出方法を示す図である。
【0128】
図20を参照して、Sum−productアルゴリズムを実現する回路図は、以下の各ブロックから構成されている。
(1)COV.FMT−1
(2)GALLAGER FUNCTION
(3)CALC.SIGN
(4)SUM GALLAGER
(5)ALPHA CALCULATION
(6)CONV.FMT−2
(7)CALC.BETA
(8)LAMDA GENERATOR
(9)OUTPUT ESTIMATION
上記各ブロックの機能を以下にて詳述する。
【0129】
(1)COV.FMT−1
このブロックは、データのフォーマットの変換装置である。入力されるデータ(Two’S Complement Format(以降CMPと称する)は、Sign−And−Magnitude Format(以降、ABSと略称する)に変換される。
【0130】
ここで、Sign−And−Magnitude Formatとは、次の通りである。先ず、MSB(Most Significant Bit(最上位のビット))は記号であり、この記号が0の場合は正であり、この記号が負の場合は負である。そして、残りのビット群は大きさを示している。
【0131】
一例として、CMPフォーマットからABSフォーマットに変換された5ビットデータのテーブルを、図21に示す。
【0132】
このブロックは、Sum−Product Algorithmに適用され、パリティチェックマトリックスの各ラインに於いて、(λn’+βmn’)の値をABSフォーマットへの変換に使用される。
【0133】
(2)GALLAGER FUNCTION
このブロックでは、当該ブロックに入力された情報に対応するGallager Functionの値を算出する。Gallager Functionの詳細は、下記式(6)に示されている。
【0134】
【数6】
このブロックは、LDPCデコーダの一部として実施され、Sum−Productアルゴリズムに含まれる以下の2つのステップを逐次実行している。
【0135】
第1に、アルファ計数の算出プロセスの間、パリティチェックマトリックスHの各ラインに於いて、f(|λn’+βmn’|)の値を算出する。
【0136】
第2に、パリティチェックマトリックスHに含まれるアルファ係数の絶対値を算出する。
【0137】
(3)CALC.SIGN
このブロックに入力される情報は、パリティチェックマトリックスHを構成する各ラインに含まれる(λn’+βmn’)の値のサイン(符号)である。そして、このブロックの主たる機能は、下記式(7)を計算することにある。
【0138】
【数7】
(4)SUM GALLAGER
このブロックの構成は、基本的には下記する「(7)CALC.BETA」と類似している。
【0139】
パリティチェックマトリックスHに含まれる各々のラインに関して、下記式(8)を実行する。
【0140】
【数8】
例えば、パリティチェックマトリックスのある列の重みが3の場合、Sum gallagerの計算プロセスは図22(A)および図22(B)に示すようになる。
【0141】
(5)ALPHA CALCULATION
このブロックでは、(3)CALC.SIGNブロックにより算出されたアルファ係数のサインと、それらの絶対値が、第2のGallager Function Blockから算出される。
【0142】
このブロックの主たる目的は、アルファ係数の各々のサインと絶対値とを集めることにある。5ビット幅のデータの場合の処理方法の一例を、図22(C)に示す。
【0143】
図22(C)を参照すると、ALPHA CALCULATIONブロックにより、1ビットのサイン(アルファ係数がプラスかマイナスかを示している)と、4ビットの絶対値(アルファ係数の大きさを示している)とが結合されて、アルファ係数が生成されている。
【0144】
(6)CONV.FMT−2
このブロックは、基本的にはデータフォーマットを変換する部位である。sign−and−magnitudeフォーマットの入力情報は、two’s complement format(CMP)に変換される。
【0145】
このブロックは、Sum−Product algorithmに於いて、パリティチェックマトリックスHの各columnに関して、アルファ係数をCMPフォーマットに変換する。
【0146】
(7)CALC.BETA
このブロックでは、パリティチェックマトリックスHの各columnに関して、β係数を算出すると共に、Sum−product algorithmの推定出力値を生成する。
【0147】
パリティチェックマトリックスの各columnに関して、基本的にこのブロックでは、λ係数とアルファ係数とを加算している。そして、それぞれの(λk+βmn)係数は、これらの値から計算される。
【0148】
例えば、図23には、column重みが4(4つのアルファ係数のみ)の場合のベータ係数の算出プロセスが示されている。
【0149】
(8)LAMDA GENERATOR
このブロックの機能は、Sum−product algorithmの入力値から、λ=〔λ1・・・・・・λN〕の値を算出する部位である。この値は、Log−Likehood Ratio(LLR)の名称で知られている。
【0150】
(9)OUTPUT ESTIMATION
先ず、C=(C1、・・・・、CN)とSum−Product Algorithmの出力推定値を定義する。この出力推定値は、下記式(9)により実現される。
【0151】
【数9】
最後に、出力推定値の吟味が行われる。パリティチェックマトリックスHを置換した出力であるC=(C1、・・・・、CN)のマトリックス乗算を含む。
【0152】
この結果がゼロマトリックスであれば、上記推定は正しいことになる。一方、一つでもゼロでないデータがマトリックスに含まれれば、推定出力値は正しくないことを示している。
【0153】
上記した各部位の中でも、アルファ係数の算出に寄与する部位は、(1)、(2)、(3)、(4)および(5)であり、ベータ係数の算出に寄与する部位は(6)および(7)である。
【0154】
本実施の形態では、演算部(例えば、LSIの上面に組み込まれた電気回路からなる)により、上記したSum−Productアルゴリズムを実行している。上記したアルファ係数を演算する演算部と、ベータ係数を演算する演算部とは一部が共用されている。
【0155】
具体的には、上記演算部は、入力された入力データに対して加算処理を行う加算部と、加算部から入力されたデータに対して減算処理を行う減算部と、CMPフォーマットとABSフォーマットとの変換を行う変換部と、Gallager Functiuonを演算する変数演算部とを含む。そして、これらの中でも演算部と変数演算部が、ベータ係数算出およびアルファ係数算出に共用される。
【0156】
即ち、ベータ係数を算出する際には、加算部、減算部、変換部、変数算出部の順番でデータ処理が行われる。一方、アルファ係数を算出する際には、加算部、減算部、変数算出部、変換部の順番でデータ処理が行われる。
【0157】
上記のように、ベータ係数算出およびアルファ係数算出に使用される演算部を共用することにより、個別に演算部を構成した場合と比較して、Sum−Productアルゴリズムに必要とされる回路の規模を小さくすることができる。従って、復号化装置や誤り訂正装置の大きさ(即ち、これらの装置が構成されたLSIの大きさ)を小さくすることができる。
【図面の簡単な説明】
【0158】
【図1】本発明の符号化装置および復号化装置を説明するための図であり、(A)はブロック図であり、(B)−(E)はECCブロックの概要を示す図である。
【図2】本発明に用いられるECCブロックの構成を示す図である。
【図3】(A)−(E)は本発明の符号化の際のデータの構成を示す図である。
【図4】(A)−(C)は本発明の符号化の際のデータの構成を示す図である。
【図5】(A)−(F)は本発明の復号化の際のデータの構成を示す図である。
【図6】(A)−(D)は本発明の復号化の際のデータの構成を示す図である。
【図7】本発明の符号化方法を示すフローチャートである。
【図8】(A)および(B)は、本発明のRS符号化が施された後のECCブロックの構成を示す図である。
【図9】本発明のマッピングテーブルを示す表(テーブル)である。
【図10】本発明の上記マッピングテーブルの生成方法を示す図であり、(A)は確率分布を示す3次元のグラフであり、(B)はエラーが発生する確率を示す表であり、(C)はハミング距離を示す表であり、(D)はマッピングテーブルである。
【図11】本発明の上記マッピングテーブルの生成方法を示す図であり、(A)はフローチャートであり、(B)は置換前のマッピングテーブルであり、(C)は置換後のマッピングテーブルである。
【図12】本発明のLDPC符号化を示す図であり、(A)はパリティ検査行列を示す図であり、(B)はECCブロックの構成を示す図である。
【図13】(A)はECCブロックの構成を示す図であり、(B)はマッピングテーブルを示す表である。
【図14】本発明の復号化方法を示すフローチャートである。
【図15】本発明のマッピングテーブルを示す表である。
【図16】本発明のLDPC復号化方法を示す図であり、(A)は概念図であり、(B)は解析結果を示す表である。
【図17】LDPC復号処理に用いられるGallager Functionを示すグラフである。
【図18】(A)および(B)はパターンマッチングを示す図であり、(C)はこのプロセスを示すフローチャートである。
【図19】RS復号化を示すブロック図である。
【図20】Sum−productに用いられる回路を示すブロック図である。
【図21】CMP formatとABS formatとの関連を示す表である。
【図22】Sum−productの詳細を示す図であり、(A)はパリティチェックマトリックスを示す図であり、(B)および(C)はフローチャートである。
【図23】Sum−productの詳細を示す図であり、(A)はパリティチェックマトリックスを示す図であり、(B)および(C)はフローチャートである。
【符号の説明】
【0159】
10 誤り訂正装置
11 ECCブロック
12 ページ
13 情報領域
14 ページ内冗長データ
15 ページ間冗長データ
20 符号化装置
21 RS符号化部
22 LDPC符号化部
23 データ変換部
24 データ変換部
30 復号化装置
31 LDPC復号化部
32 RS復号化部
33 データ変換部
34 データ変換部
40 伝送経路
42 入力データ
43 第1符号化データ
44 第2符号化データ
45 第1復号化データ
46 第2復号化データ
47 イレージャー信号
48 出力データ
49 入力データ
50 シンドローム演算部
51 多項式演算部
52 シンドローム演算部
53 Euclide演算部
54 Chein演算部
55 エラー訂正部
60 パリティ検査行列
【特許請求の範囲】
【請求項1】
入力された入力データを符号化する符号化装置であり、
前記入力データに対してRS符号化を行って第1符号化データを生成するRS符号部と、
前記第1符号化データに対してLDPC符号化を行って第2符号化データを生成するLDPC符号部と、を具備することを特徴とする符号化装置。
【請求項2】
前記入力データは複数のページからなり、
前記RS符号部では、ページ間冗長データを生成し、
前記LDPC符号部では、ページ内冗長データを生成することを特徴とする請求項1記載の符号化装置。
【請求項3】
前記RS符号部と、前記LDPC符号部との間に、前記第1符号化データを構成するシンボルのビット数を多くするデータ変換部を有することを特徴とする請求項1記載の符号化装置。
【請求項4】
符号化データを復号化して復号化データを生成する復号化装置であり、
前記符号化データに対してLDPC復号化を行って第1復号化データを生成するLDPC復号部と、
前記第1復号化データに対してRS復号化を行って第2復号化データを生成するRS復号部と、を備えることを特徴とする復号化装置。
【請求項5】
前記LDPC復号部は、誤り訂正が不可であった前記第1復号化データが属するシンボルを無効シンボルとし、前記無効シンボルの位置を示すイレージャー信号を発生させ、
前記RS復号部では、前記イレージャー信号を用いて前記第1復号化データを復号して前記第2復号化データを生成することを特徴とする請求項4記載の復号化装置。
【請求項6】
入力されたデータを符号化して符号化データを生成する符号化装置と、前記符号化データを復号化して復号化データを生成する復号化装置と、を具備し、
前記符号化装置は、前記入力データに対してRS符号化を行って第1符号化データを生成するRS符号部と、前記第1符号化データに対してLDPC符号化を行って第2符号化データを生成するLDPC符号部と、を備え、
前記復号化装置は、前記第2復号化データに対してLDPC復号化を行って第1復号化データを生成するLDPC復号部と、前記第1復号化データに対してRS復号化を行って第2復号化データを生成するRS復号部と、を備えることを特徴とする誤り訂正装置。
【請求項7】
多数のシンボルから構成される入力データを符号化する符号化装置であり、
前記入力データに含まれる前記シンボルのビット数を多くするデータ変換部と、
前記入力データに対してLDPC符号化を行って符号化データを生成するLDPC符号化部と、を具備することを特徴とする符号化装置。
【請求項8】
前記データ変換部では、前記入力データに含まれるシンボルのビット数を8ビットから16ビットに変換することを特徴とする請求項7記載の符号化装置。
【請求項9】
前記入力データは、RS符号化が施されたデータであることを特徴とする請求項7記載の符号化装置。
【請求項10】
前記LDPC符号部の後段に、前記符号化データに含まれるシンボルのビット数を少なくする他のデータ変換部を更に具備することを特徴とする請求項7記載の符号化装置。
【請求項11】
前記他のデータ変換部が前記シンボルを変換する規則は、前記変換部が前記シンボルを変換する規則と逆であることを特徴とする請求項10記載の符号化装置。
【請求項12】
符号化データを復号化して復号化データを生成する復号化装置であり、
前記符号化データに対してLDPC復号化を行って前記復号化データを生成するLDPC復号部と、
前記復号化データに含まれるシンボルのビット数を少なくするデータ変換部と、を具備することを特徴とする復号化装置。
【請求項13】
入力された入力データを符号化して符号化データを生成する符号化装置と、前記符号化データを復号化して復号化データを生成する復号化装置、と具備し、
前記符号化装置は、前記入力データに含まれるシンボルのビット数を多くする符号側データ変換部と、前記入力データに対してLDPC符号化を行って符号化データを生成するLDPC符号部と、を備え、
前記復号化装置は、前記符号化データに対してLDPC復号化を行って復号化データを生成するLDPC復号部と、前記復号化データに含まれるシンボルのビット数を少なくする復号側データ変換部と、を備えることを特徴とする誤り訂正装置。
【請求項14】
アルファ係数とベータ係数とを用いるSum−procuctアルゴリズムを含む復号化を演算部により行う復号化装置に於いて、
前記アルファ係数を算出する演算部と、前記ベータ係数を算出する演算部とを、少なくとも一部共用することを特徴とする復号化装置。
【請求項15】
前記アルファ係数及び前記ベータ係数は、記憶部に一時的に記憶されることなく演算されることを特徴とする請求項14の復号化装置。
【請求項16】
前記演算部は、入力されたデータに対して加算処理を行う加算部と、前記加算部から入力されたデータに対して減算処理を行う減算部と、前記減算部にて処理されたデータのフォーマットを変換する変換部と、Gallager Functionを算出する変数算出部とを含み、
前記変換部および前記変数算出部は、前記アルファ係数の算出および、前記ベータ係数算出部の算出の両方に用いられることを特徴とする請求項14記載の復号化装置。
【請求項17】
入力された入力データをLDPC符号により符号化して符号化データを生成する符号化装置と、前記符号化データを復号化して復号化データを生成する復号化装置と、を具備し、
前記復号化装置は、アルファ係数とベータ係数とを用いるSum−Productアルゴリズムを含む復号化を演算部により行い、
前記アルファ係数を算出する演算部と、前記ベータ係数を算出する演算部とを、少なくとも一部共有することを特徴とする誤り訂正装置。
【請求項1】
入力された入力データを符号化する符号化装置であり、
前記入力データに対してRS符号化を行って第1符号化データを生成するRS符号部と、
前記第1符号化データに対してLDPC符号化を行って第2符号化データを生成するLDPC符号部と、を具備することを特徴とする符号化装置。
【請求項2】
前記入力データは複数のページからなり、
前記RS符号部では、ページ間冗長データを生成し、
前記LDPC符号部では、ページ内冗長データを生成することを特徴とする請求項1記載の符号化装置。
【請求項3】
前記RS符号部と、前記LDPC符号部との間に、前記第1符号化データを構成するシンボルのビット数を多くするデータ変換部を有することを特徴とする請求項1記載の符号化装置。
【請求項4】
符号化データを復号化して復号化データを生成する復号化装置であり、
前記符号化データに対してLDPC復号化を行って第1復号化データを生成するLDPC復号部と、
前記第1復号化データに対してRS復号化を行って第2復号化データを生成するRS復号部と、を備えることを特徴とする復号化装置。
【請求項5】
前記LDPC復号部は、誤り訂正が不可であった前記第1復号化データが属するシンボルを無効シンボルとし、前記無効シンボルの位置を示すイレージャー信号を発生させ、
前記RS復号部では、前記イレージャー信号を用いて前記第1復号化データを復号して前記第2復号化データを生成することを特徴とする請求項4記載の復号化装置。
【請求項6】
入力されたデータを符号化して符号化データを生成する符号化装置と、前記符号化データを復号化して復号化データを生成する復号化装置と、を具備し、
前記符号化装置は、前記入力データに対してRS符号化を行って第1符号化データを生成するRS符号部と、前記第1符号化データに対してLDPC符号化を行って第2符号化データを生成するLDPC符号部と、を備え、
前記復号化装置は、前記第2復号化データに対してLDPC復号化を行って第1復号化データを生成するLDPC復号部と、前記第1復号化データに対してRS復号化を行って第2復号化データを生成するRS復号部と、を備えることを特徴とする誤り訂正装置。
【請求項7】
多数のシンボルから構成される入力データを符号化する符号化装置であり、
前記入力データに含まれる前記シンボルのビット数を多くするデータ変換部と、
前記入力データに対してLDPC符号化を行って符号化データを生成するLDPC符号化部と、を具備することを特徴とする符号化装置。
【請求項8】
前記データ変換部では、前記入力データに含まれるシンボルのビット数を8ビットから16ビットに変換することを特徴とする請求項7記載の符号化装置。
【請求項9】
前記入力データは、RS符号化が施されたデータであることを特徴とする請求項7記載の符号化装置。
【請求項10】
前記LDPC符号部の後段に、前記符号化データに含まれるシンボルのビット数を少なくする他のデータ変換部を更に具備することを特徴とする請求項7記載の符号化装置。
【請求項11】
前記他のデータ変換部が前記シンボルを変換する規則は、前記変換部が前記シンボルを変換する規則と逆であることを特徴とする請求項10記載の符号化装置。
【請求項12】
符号化データを復号化して復号化データを生成する復号化装置であり、
前記符号化データに対してLDPC復号化を行って前記復号化データを生成するLDPC復号部と、
前記復号化データに含まれるシンボルのビット数を少なくするデータ変換部と、を具備することを特徴とする復号化装置。
【請求項13】
入力された入力データを符号化して符号化データを生成する符号化装置と、前記符号化データを復号化して復号化データを生成する復号化装置、と具備し、
前記符号化装置は、前記入力データに含まれるシンボルのビット数を多くする符号側データ変換部と、前記入力データに対してLDPC符号化を行って符号化データを生成するLDPC符号部と、を備え、
前記復号化装置は、前記符号化データに対してLDPC復号化を行って復号化データを生成するLDPC復号部と、前記復号化データに含まれるシンボルのビット数を少なくする復号側データ変換部と、を備えることを特徴とする誤り訂正装置。
【請求項14】
アルファ係数とベータ係数とを用いるSum−procuctアルゴリズムを含む復号化を演算部により行う復号化装置に於いて、
前記アルファ係数を算出する演算部と、前記ベータ係数を算出する演算部とを、少なくとも一部共用することを特徴とする復号化装置。
【請求項15】
前記アルファ係数及び前記ベータ係数は、記憶部に一時的に記憶されることなく演算されることを特徴とする請求項14の復号化装置。
【請求項16】
前記演算部は、入力されたデータに対して加算処理を行う加算部と、前記加算部から入力されたデータに対して減算処理を行う減算部と、前記減算部にて処理されたデータのフォーマットを変換する変換部と、Gallager Functionを算出する変数算出部とを含み、
前記変換部および前記変数算出部は、前記アルファ係数の算出および、前記ベータ係数算出部の算出の両方に用いられることを特徴とする請求項14記載の復号化装置。
【請求項17】
入力された入力データをLDPC符号により符号化して符号化データを生成する符号化装置と、前記符号化データを復号化して復号化データを生成する復号化装置と、を具備し、
前記復号化装置は、アルファ係数とベータ係数とを用いるSum−Productアルゴリズムを含む復号化を演算部により行い、
前記アルファ係数を算出する演算部と、前記ベータ係数を算出する演算部とを、少なくとも一部共有することを特徴とする誤り訂正装置。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図10】
【図11】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図10】
【図11】
【公開番号】特開2007−336529(P2007−336529A)
【公開日】平成19年12月27日(2007.12.27)
【国際特許分類】
【出願番号】特願2007−130727(P2007−130727)
【出願日】平成19年5月16日(2007.5.16)
【出願人】(301016159)システムエルエスアイ株式会社 (5)
【Fターム(参考)】
【公開日】平成19年12月27日(2007.12.27)
【国際特許分類】
【出願日】平成19年5月16日(2007.5.16)
【出願人】(301016159)システムエルエスアイ株式会社 (5)
【Fターム(参考)】
[ Back to top ]