
筆跡入力のスタイルを意識した使用
ユーザの筆跡スタイルに基づいて筆跡入力を処理するための技術。いくつかの技術はユーザが単一の文字を書くスタイルを使用するが、代替的に又は追加的に、他の技術は筆跡スタイルを形成する一群の異書体を使用する。筆跡スタイル分析ツールによって実施されるような、これらの技術のいくつかの実施は、ユーザによって書かれた1つ又は複数の文字を分析して、ユーザの筆跡スタイルが属する地理的領域又は文化的集団などのコミュニティを特定する。他の実施は、代替的に又は追加的に、ユーザの筆跡を特定の筆跡スタイルに分類するためにユーザの筆跡の1つ又は複数の文字を分析する。次いで、筆跡スタイル分析ツールは、そのユーザの個人的な筆跡スタイルのために特に構成された筆跡認識アプリケーションをユーザに提供する。

【発明の詳細な説明】
【技術分野】
【0001】
背景技術
コンピュータは、世界中で様々な目的のために日常的に使用されている。コンピュータが一般的になってきたのにつれて、コンピュータの製造業者は、それらのコンピュータをより利用しやすく、ユーザフレンドリにしようとし続けてきた。1つのそのような取り組みは自然な入力方法の開発であった。例えば、音声認識は、声を出して単にデータを話すことによってユーザがデータをコンピュータに入力することを可能にする。そのとき、ユーザの発話の音素をタイプされたテキストに変換するために、そのユーザの発話の音素が分析される。或いは、筆跡認識は、ユーザがスタイラスを用いてデジタイザ上に書くことによってデータを入力して電子インクを生成することを可能にする。コンピュータは、インクの形状を分析し、その形状をタイプされたテキストに変換する。
【0002】
筆跡入力技術の登場は、多くのコンピュータユーザにとって特に有益であった。一部のユーザは、それらのユーザがキーボードを使用して文字をタイプすることができるよりも速く、手で同じ文字を書くことができる。したがって、これらのユーザは、キーボード入力よりも迅速に筆跡入力を作成することができる。また、たいていの東アジアの言語のユーザは、筆跡入力の筆跡の方がキーボード入力よりも効率的であることを知る。典型的には、東アジアの言語は、何千もの文字を有する象形文字の組を使用して書かれる。大きなキーボードであっても、ユーザが東アジアの言語で書くのに十分なキーを含むことはできない。したがって、キーボードのユーザは、キーボード上に示された表音文字を所望の象形文字に回りくどく変換するように要求される。筆跡入力を受け取り、認識するコンピュータを用いて、今や東アジアの言語のユーザは、電子インクで所望の象形文字を直接簡単に書くことができる。その上、一部のユーザは、キーボードの使用を許さない環境でコンピュータを使用する。例えば、病院内を歩き回る医師はキーボードの使用が実用的でない場所で筆跡入力を作成する。
【発明の開示】
【発明が解決しようとする課題】
【0003】
筆跡入力技術は様々なユーザにとって非常に便利である可能性があるが、これらの技術の有用性はそれらの技術の認識精度に大きく依存する。しかし、異なるユーザは多種多様な異なる形状を使用して同じ文字を書くので、一貫して精度の高い筆跡認識は得ることが難しい。
【0004】
筆跡認識の問題に対処するために、一部のソフトウェア開発者が、多種多様なユーザの全てに当てはまる筆跡認識ソフトウェアアプリケーションを作成した。これらのソフトウェアアプリケーションは、言語に関する筆跡の全ての形態に共通する1つ又は複数の筆跡認識技術を使用する。例えば、これらの技術の一部は、筆跡文字を1組の文字の基本形と比較して筆跡文字がどの基本形に最もよく似ているかを決定することができる。そのとき、1組の基本形は、ユーザの文字体系内の各文字に対する1つ又は複数の通常の異書体を含む。これらの汎用的な認識技術は多種多様なユーザに対して「追加設定なしで」筆跡を認識するが、典型的には、それらの技術は任意の特定のユーザに関して高い認識率を提供しない。更に、通常、これらの種類の認識技術の精度は時間の経過と共に向上しない。
【0005】
その代わりに、一部のソフトウェア開発者は、特定の個人の筆跡を認識することを学習する個人化筆跡認識ソフトウェアアプリケーションを提供する。しかし、典型的に、これらのアプリケーションは、学習プロセスの間に多量の筆跡データを入力するようにユーザに要求する。結果として、これらの筆跡認識ソフトウェアアプリケーションの一部は、「追加設定なしで」はそれほど精度が高くない。更に、多くのユーザは、ユーザの筆跡を認識するようにこの種のソフトウェアを適切に訓練するために必要とされる時間をつぎ込むことに消極的である。更に、これらの個人化筆跡認識ソフトウェアアプリケーションは過学習に陥りやすい。ソフトウェアは時間の経過と共にそのソフトウェアの認識プロセスを改良し続けるので、そのソフトウェアは、そのソフトウェアの訓練データ内にユーザによって書かれた異常な文字形状を含む可能性がある。ユーザの典型的な筆跡には通常見られないこれらのときとして異常な文字形状は、時間の経過と共にアプリケーションの認識精度を実際に低下させ得る。
【課題を解決するための手段】
【0006】
本発明の種々の態様は、ユーザの筆跡スタイルに基づいて筆跡入力を処理するための技術に関する。本発明のいくつかの態様は、ユーザが単一の文字を書くスタイルを使用する。代替的に又は追加的に、本発明の他の態様は、筆跡スタイルを形成する一群の異書体を使用する。
【0007】
例えば、本発明のいくつかの実現形態は、ユーザによって書かれた1つ又は複数の文字を分析して、ユーザの筆跡スタイルが属する地理的領域又は文化的集団などのコミュニティを特定する。これらの実現形態によれば、ユーザには、コミュニティによって使用される筆跡スタイルを認識するように調整された筆跡認識アプリケーションが提供される。本発明の他の実現形態は、代替的に又は追加的に、ユーザの筆跡を特定の筆跡スタイルに分類するためにユーザの筆跡の1つ又は複数の文字を分析する。そこで、ユーザには、ユーザの個人的な筆跡スタイルのために特に構成された筆跡認識アプリケーションが提供される。有利なことに、両方の種類の筆跡認識アプリケーションは、ユーザに大量の訓練データを提出するように要求することなしに、汎用筆跡認識アプリケーションよりも高い認識精度を提供する。
【0008】
本発明の更に他の実現形態によれば、代替的に又は追加的に、ユーザの筆跡スタイルが、筆跡認識アプリケーションが異常な形で書かれた文字を認識プロセスを向上するための訓練データとして使用することを防止するために使用されることができる。そこで、代替的に又は追加的に、本発明のいくつかの例は、ユーザの異書体のうちの1つ又は複数を分析して、ユーザが他の文字をどのように書くかを予測する。ユーザにそれらの文字のそれぞれに対応する訓練データを提出するように要求するのではなく、例えば、これらの実現形態は、代わりに、それらの他の文字をどのように書くかを確認するようにユーザに促す。これらの実現形態は、例えば、分析された異書体と同じ筆跡スタイルに属する異書体をユーザに選択させるだけである。
【0009】
代替的に又は追加的に、本発明の更に他の実現形態は、ユーザの筆跡スタイルを分析して、ユーザが右手で書くか、左手で書くかを決定する。次いで、これらの実現形態は、例えば、ユーザの「利き手」に対応するようにコンピュータの1つ又は複数のユーザインターフェースを構成する。
【0010】
本発明の異なる実現形態のこれらの及び他の特徴及び利点を、以下で一層詳細に説明する。本特許又は出願書類は、カラーで作成された少なくとも1つの図面を含む。カラー図面を伴う本特許又は特許出願公開のコピーは、請求と必要な手数料の支払いとに応じて特許庁によって提供される。
【発明を実施するための最良の形態】
【0011】
筆跡スタイル
本発明の種々の態様は、ユーザの筆跡スタイルを使用しての筆跡入力技術の向上に関する。本発明のいくつかの例は、ユーザが、以降「異書体」と呼ばれる単一の文字を書くスタイルを使用する。以降で使用される用語「文字」は、個々の文字、数字又はその他の記号と、合字(すなわち、2つ以上の基礎的な文字、数字又はその他の記号を表す単一の形状又は象形文字)とを総称的に示す。文字の異書体は、例えば、ユーザが文字を書くために行うストローク数と、それぞれのストロークが書かれる順番と、それぞれのストロークが書かれる方向とによって決定されることができる。
【0012】
代替的に又は追加的に、本発明の他の態様は、筆跡スタイルを形成する一群の異書体を使用することができる。例えば、図1Aは模範的なモダン筆記体(Modern Cursive)筆跡スタイルを示すが、図1Bは模範的なシンプル筆記体(Simple Cursive)筆跡スタイルを示す。これらの図から分かるように、両方の模範的筆跡スタイルは、(シンプル筆記体筆跡スタイルにおける異書体はモダン筆記体筆跡スタイルにおける異書体よりも若干角度が付けられているが)大文字「T」に関して類似した異書体を共有する。しかし、これらの筆跡スタイルは、小文字「p」に関して大きく異なる異書体を有する。本明細書において使用される用語「筆跡スタイル」は、単一の異書体、一群の異書体又は複数の異書体によって構成される筆跡スタイルを総称的に示す。
【0013】
図1A及び1Bに示された筆跡スタイルは、典型的には、学校で新しい書き手に筆跡を教えるために使用される模範的筆跡スタイルである。しかし、より熟達した書き手は、ブロック体の筆跡及び筆記体の筆跡を含む、その書き手自身の特有の筆跡スタイルを開発している。典型的には、この特有の筆跡スタイルは、様々な異なる模範的筆跡スタイルからの異書体の特徴を、いかなる特定の模範的筆跡スタイルにも属さない普通でない異書体の特徴と組み合わせる。書き手が個人的な筆跡スタイルを発達させると、その個人的な筆跡スタイルは通常は時間が経過しても変化しない。したがって、ユーザの特有の筆跡スタイルは、独自の特徴と、1人又は複数のその他の書き手と共有されるいくつかの特徴とを有する。独自の特徴の組は個人的特徴の集合と呼ばれ、共有される特徴は「スタイルの」特徴の集合と呼ばれる。したがって、以下でより詳細に説明するように、2つ以上の特有の筆跡スタイルは、1つ又は複数の共有される「スタイルの」特徴に基づいて一層包括的な筆跡スタイルにまとめられることができる。
【0014】
実施環境
当業者によって理解されるように、本発明の様々な例はアナログ回路を使用して実施されることができる。しかし、更に普通には、本発明の態様は、プログラミング又は「ソフトウェア」命令を実行するプログラム可能なコンピューティング装置を使用して実施される。したがって、本発明の様々な例を実施するために使用されることができるコンピューティング装置環境の包括的な例を、図2及び図3に関してここで説明する。
【0015】
より具体的には、図2は、本発明の様々な例を実施するために使用されることができる汎用デジタルコンピューティング環境の一例を示す。特に、図2はコンピュータ200の概略図を示す。典型的には、コンピュータ200は少なくとも何らかの形態のコンピュータ読み取り可能媒体を含む。コンピュータ読み取り可能媒体は、コンピュータ200によってアクセスされることができる任意の利用可能な媒体であり得る。例えば、コンピュータ読み取り可能媒体は、コンピュータ記憶媒体及び通信媒体を含むことができるが、これらに限定されない。コンピュータ記憶媒体は、コンピュータ読み取り可能命令、データ構造、プログラムモジュール又はその他のデータなどの情報を記憶するための任意の方法又は技術で実現された揮発性及び不揮発性の取り外し可能及び取り外し不可能な媒体を含む。コンピュータ記憶媒体は、RAM、ROM、EEPROM、フラッシュメモリ又はその他のメモリ技術、CD−ROM、デジタルバーサタイルディスク(DVD)又はその他の光学式記憶装置、磁気カセット、磁気テープ、磁気ディスク記憶装置又はその他の磁気記憶装置、せん孔媒体、ホログラフィック記憶装置、或いは所望の情報を記憶するために使用されることができ、コンピュータ200によってアクセスされることができる任意のその他の媒体を含むが、これらに限定されない。
【0016】
典型的には、通信媒体は、コンピュータ読み取り可能命令、データ構造、プログラムモジュール、又は、搬送波などの変調されたデータ信号又はその他の搬送メカニズムにおける他のデータを具体化するもので、任意の情報配信媒体を含む。用語「変調されたデータ信号」は、その信号の特徴のうちの1つ又は複数が、情報を符号化するように設定又は変更された信号を意味する。例えば、通信媒体は、有線ネットワーク又は直接有線接続などの有線媒体や、音響、RF、赤外線及びその他の無線媒体などの無線媒体を含むが、これらに限定されない。上記の媒体のうちの任意のものの組合せもコンピュータ読み取り可能媒体の範囲内に含まれるべきである。
【0017】
図2に示されるように、コンピュータ200は、処理ユニット210と、システムメモリ220と、システムメモリ220を含む種々のシステムコンポーネントを処理ユニット210に結合するシステムバス230とを含む。システムバス230は、各種のバスアーキテクチャのいずれかを使用したメモリバス又はメモリコントローラ、周辺バス及びローカルバスを含む数種のバス構造のいずれであってもよい。システムメモリ220は、読み出し専用メモリ(ROM)240及びランダムアクセスメモリ(RAM)250を含むことができる。
【0018】
基本入出力システム(BIOS)260は、起動期間などにコンピュータ200内の要素間で情報を転送することに役立つ基礎的なルーチンを含み、ROM240に記憶される。また、コンピュータ200は、ハードディスク(図示せず)との間の読み出し、書き込みのためのハードディスクドライブ270と、リムーバブル磁気ディスク281との間の読み出し、書き込みのための磁気ディスクドライブ280と、CD ROM、DVD ROM又はその他の光媒体などの取り外し可能光ディスク291との間の読み出し、書き込みのための光ディスクドライブ290とを更に含むことができる。ハードディスクドライブ270、磁気ディスクドライブ280及び光ディスクドライブ290は、それぞれ、ハードディスクドライブインターフェース292、磁気ディスクドライブインターフェース293及び光ディスクドライブインタ―フェース294によってシステムバス230に接続される。これらのドライブ及びこれらのドライブに関連するコンピュータ読み取り可能媒体は、パーソナルコンピュータ200のためのコンピュータ読み取り可能命令、データ構造、プログラムモジュール及びその他のデータの不揮発性の記憶を提供する。当業者によって理解されるように、磁気カセット、フラッシュメモリカード、デジタルビデオディスク、ベルヌーイカートリッジ、ランダムアクセスメモリ(RAM)、読み出し専用メモリ(ROM)などの、コンピュータによってアクセス可能なデータを記憶することができるその他の種類のコンピュータ読み取り可能媒体も、例示の動作環境の例において使用され得る。
【0019】
オペレーティングシステム295、1つ又は複数のアプリケーションプログラム296、その他のプログラムモジュール297及びプログラムデータ298を含む複数のプログラムモジュールが、ハードディスクドライブ270、磁気ディスク281、光ディスク291、ROM240又はRAM250に記憶されることができる。ユーザは、キーボード201及び(マウスなどの)ポインティングデバイス202などの入力デバイスを介してコンピュータ200に命令及び情報を入力することができる。その他の入力デバイス(図示せず)は、マイクロホン、ジョイスティック、ゲームパッド、衛星通信用パラボラアンテナ、スキャナなどを含み得る。これらの及びその他の入力デバイスは、しばしば、システムバス230に結合されたシリアルポートインターフェース206を介して処理ユニット210に接続されるが、パラレルポート、ゲームポート又はユニバーサルシリアルバス(USB)などの他のインターフェースによって接続されることもできる。その上、これらのデバイスは、適切なインターフェース(図示せず)を介してシステムバス230に直結されることができる。
【0020】
モニタ207又はその他の種類のディスプレイ装置も、ビデオアダプタ208などのインターフェースを介してシステムバス230に接続されることができる。モニタ207に加えて、典型的には、パーソナルコンピュータは、スピーカ及びプリンタなどのその他の周辺出力装置(図示せず)を備える。一例において、ペンデジタイザ265及び付属のペン又はスタイラス266が、フリーハンド入力をデジタル式に取り込むために提供される。ペンデジタイザ265とシリアルポートインターフェース206との間の接続が図2に示されるが、実際は、ペンデジタイザ265は、処理ユニット210に直接結合されることができ、又は、ペンデジタイザ265は、当技術分野で知られているように、パラレルポート又は別のインターフェースとシステムバス230とを介するなどの任意の好適なやり方で処理ユニット210に結合されることができる。更に、デジタイザ265は図2においてモニタ207と別個に図示されているが、デジタイザ265の使用可能な入力領域は、モニタ207の表示領域と同じ空間的広がりを持つことができる。その上、デジタイザ265は、モニタ207に統合されることができ、又は、モニタ207に重なる若しくは取り付けられる別個の装置として存在することができる。
【0021】
コンピュータ200は、リモートコンピュータ209などの1つ又は複数のリモートコンピュータへの論理接続を使用したネットワーク環境で動作することができる。リモートコンピュータ209はサーバ、ルータ、ネットワークPC、ピア機器又はその他の一般的なネットワークノードであることができ、簡単にするために、図2においてはメモリ記憶装置211のみが示されたが、典型的には、リモートコンピュータ209は、コンピュータ200に関して上述された要素の多く又は全てを含む。図2に示された論理接続は、ローカルエリアネットワーク(LAN)212及び広域ネットワーク(WAN)213を含む。そのようなネットワーキング環境は、有線接続及び無線接続を使用するオフィス、企業規模のコンピュータネットワーク、イントラネット及びインターネットにおいて一般的である。
【0022】
LANネットワーキング環境において使用されるとき、コンピュータ200は、ネットワークインターフェース又はアダプタ214を介してローカルエリアネットワーク212に接続される。WANネットワーキング環境において使用されるとき、典型的には、パーソナルコンピュータ200は、モデム215や、インターネットなどの広域ネットワーク213を介して通信リンクを確立するためのその他の手段を備える。コンピュータ200に内蔵されても、外付されてもよいモデム215は、シリアルポートインターフェース206を介してシステムバス230に接続される。ネットワーク環境において、パーソナルコンピュータ200に関連して示されたプログラムモジュール又はその一部は、リモートのメモリ記憶装置に記憶されることができる。
【0023】
理解されるように、図示されたネットワーク接続は例であり、コンピュータ間の通信リンクを確立するために他の技術を使用することができる。TCP/IP、イーサネット(登録商標) 、FTP、HTTP、UDPなどの様々な周知のプロトコルのうちのいずれかの存在が想定され、システムは、ユーザがウェブベースのサーバからウェブページを検索することを許容するユーザ−サーバ構成において動作する。様々な通常のウェブブラウザのうちの任意のものを、ウェブページ上のデータの表示及び操作のために使用され得る。
【0024】
図2の環境は本発明の種々の実施の形態に対する動作環境の一例を示すが、理解されるように、他のコンピューティング環境を使用することもできる。例えば、本発明の1つ又は複数の例は、図2に示され且つ上述された様々な態様の全てよりも少ない態様を有する環境を使用し得、これらの態様は、当業者には明らかな様々な組み合わせ及び準組み合わせにおいて現れる。
【0025】
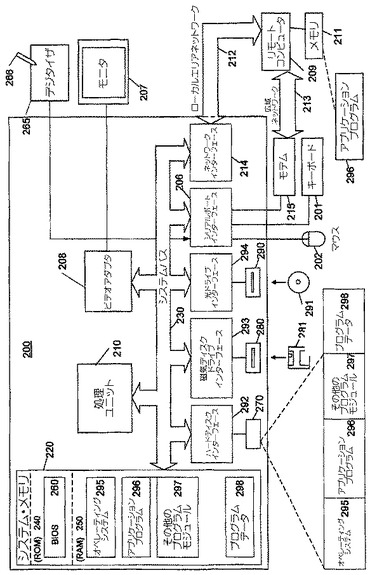
図3は、本発明の種々の態様に従って使用されることができる、ペン入力型のパーソナルコンピュータ(PC)301を示す。図2のシステムの特徴、サブシステム及び機能のうちのいずれか又は全てが、図3のコンピュータ301に含まれる。ペン入力型のパーソナルコンピュータシステム301は、大きな表示面302、例えば、ウィンドウ表示されるグラフィカル・ユーザ・インターフェースなどの複数のグラフィカル・ユーザ・インターフェース303が表示される液晶ディスプレイ(LCD)スクリーンなどのデジタル化フラットパネルディスプレイを含む。スタイラス266を使用して、ユーザは、デジタル化表示領域上で選択、ハイライト及び書き込みを行うことができる。好適なデジタル化ディスプレイパネルの例は、(現在はファインポイント・イノベーションズ社として知られる)ムトーやワコム・テクノロジー社から入手可能なペンデジタイザなどの電磁ペンデジタイザを含む。その他の種類のペンデジタイザ、例えば、光学式デジタイザ及び接触感知式デジタイザも使用されることができる。ペン入力型のコンピューティングシステム301は、スタイラス266を使用して行われたジェスチャを解釈して、データの操作、テキストの入力、表計算や文書処理プログラムなどの作成、編集、修正などの、通常のコンピュータアプリケーションタスクを実行する。
【0026】
スタイラス266は、その能力を高めるためにボタン又はその他の機能を備えることができる。一例において、スタイラス266は「鉛筆」又は「ペン」として実現され、その一端は書き込み部を構成する。スタイラス266の他端は、ディスプレイを横切って移動されるときに消されるべきディスプレイ上の電子インクの部分を示す「消しゴム」の端部を構成する。マウス、トラックボール、キーボードなどのその他の種類の入力装置が使用され得る。更に、ディスプレイが接触感知式又は接近感知式ディスプレイである場合、表示された画像の部分を選択又は指示するためにユーザ自身の指が使用され得る。したがって、本明細書において使用される用語「ユーザ入力装置」は幅広い定義を持ち、周知の入力装置の多くの変更形態を包含するものとする。
【0027】
フルパフォーマンスのペン入力型コンピューティングシステム又は「タブレットPC」(例えば、コンバーチブル型ラップトップもしくは「スレート」型タブレットPC)と共に使用することに加えて、本発明の態様は、他の種類のペン入力型コンピューティングシステム及び/又は他の装置と共に使用されることができる。ここで、他の装置は、例えば(i)手持ち式もしくはパームトップ型のコンピューティングシステム、(ii)携帯情報端末、(iii)ポケットパーソナルコンピュータ、(iv)移動式電話及び携帯電話、ページャ及びその他の通信デバイス、(v)腕時計、(vi)電化製品並びに(vii)任意の他の装置又はシステムなどの、データを電子インクとして受け取り、及び/又は、電子ペンもしくはスタイラスの入力を受け取る装置である。上記任意の他の装置又はシステムは、印刷された又はグラフィカル情報をユーザに提示し及び/又は電子ペンもしくはスタイラスを使用しての入力を可能にする、或いは、別の装置(例えば、タブレットPCによって収集された電子インクを処理することができる通常のデスクトップコンピュータ)によって収集された電子インクを処理することができる、モニタ又は他のディスプレイ装置及び/又はデジタイザを備える。
【0028】
筆跡スタイル分析ツール
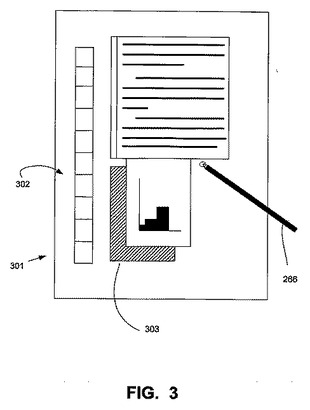
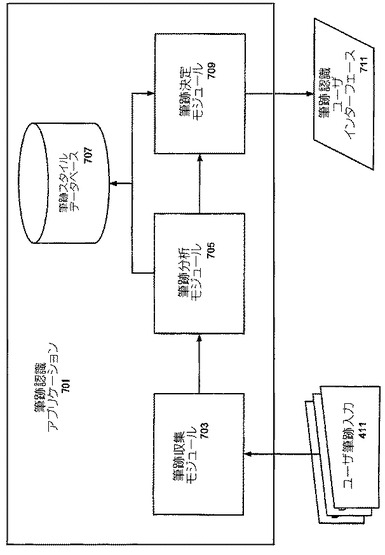
図4は、本発明の様々な例によって実施されることができる筆跡スタイル分析ツール401を示す。この図に示されるように、筆跡スタイル分析ツール401は、筆跡収集モジュール403、スタイル分析モジュール405、認識訓練データベース407及び認識訓練モジュール409を備えている。以下で詳細に説明されるように、筆跡スタイル分析ツール401は、様々なユーザから入力された筆跡データ411を受け取って、受け取り側ユーザの筆跡スタイルに対してカスタマイズされた筆跡認識アプリケーション413を1人又は複数のユーザに提供する。
【0029】
図4に示されるように、筆跡スタイル分析ツール401は様々なユーザにアクセス可能である。したがって、本発明の種々の例を用いる場合、少なくとも筆跡収集モジュール403は、インターネットなどの1つ又は複数のネットワーク上で複数のユーザにアクセス可能なサーバコンピュータ上に実装されることができる。ユーザの筆跡を収集することに加えて、筆跡収集モジュール403は、ユーザに関する追加的な個人情報をも含むことができる。例えば、筆跡収集モジュール403は、ユーザの利き手(すなわち、ユーザが右手で書くか、左手で書くか)を取得する。代替的に又は追加的に、筆跡収集モジュール403は、ユーザの地理的、宗教的及び/又は文化的情報などの、ユーザが属する1つ又は複数のコミュニティに関する情報を取得する。したがって、筆跡収集モジュール403は、ユーザが書くことを学んだ国その他の地理的領域、ユーザが宗教学校で教育を受けたかどうか、又はユーザが識別可能な文化的集団に属しているかどうかを確認することができる。
【0030】
以下で一層詳細に説明するように、スタイル分析モジュール405は、受け取った筆跡サンプル411を、それらの特徴の類似性に基づいて、関連グループ又は「クラスタ」に組織化する。上述の説明から理解されるように、各クラスタは、筆跡サンプルがクラスタに含まれる1人又は複数のユーザに共通する筆跡スタイルとして定義される。受け取った筆跡サンプル411をクラスタに組織化するために2つの別個の技術、すなわち、大雑把な下位スタイルを検出するトップダウンのアプローチ又はボトムアップのクラスタリングアプローチが、本発明の種々の例と共に使用されることができる。
【0031】
図示された例において、スタイル分析モジュール405はボトムアップのアプローチを使用する。これは、以下の検討から明らかなように、ボトムアップのアプローチを使用して得られた情報が認識訓練モジュール409によって直接使用されることができるからである。このアプローチを使用して、筆跡サンプルデータ集合X={x1、x2、...、xM}のクラスタリングCは、
【0032】
【数1】
【0033】
であるように、互いに素な集合の集合{c1、c2、...、cK}へのデータの分割を定義する。クラスタリングCは、筆跡サンプル411における全ての文字に対して独立に計算される。
【0034】
本発明の種々の例によれば、スタイル分析モジュール405は、Cm−1がCmの部分集合であるように入れ子になったクラスタリングの階層構造[C1、C2、...、CM]を生成する階層的クラスタリングアルゴリズムを使用する。この階層は、ステップmにおけるクラスタリングがステップm−1において生成されたクラスタリングから生成されるM個のステップにおいて構築される。ステップ1において、サンプル集合Xにおける全ての要素が、その要素自体のクラスタを表す。2つのクラスタの非類似性関数D(ck、ck’)を使用して、以下のアルゴリズムが適用される。初めに、C1={{x1}、{x2}、...、{xM}}と初期化する。次いで、m=2、...、Mに対して、Cm−1のクラスタckminとck’minを統合することによって、新しいクラスタリングCmを取得する。ここで(kmin、k’min)=argmin(k,k’),k≠k’D(ck、ck’)である。
【0035】
クラスタ非類似性関数D(ck、ck’)は、例えば、インクサンプル非類似性関数D(xk、xk’)に基づくものである。インクサンプル間の差を決定するために任意の所望の非類似性関数を使用することができるが、本発明の種々の例は、1つのインクサンプルが別のインクサンプルとどれだけ類似しているかを決定するために弾性マッチングアルゴリズム(動的タイミング・ワーピング・アルゴリズムとしても知られる)を使用する。
【0036】
したがって、インクサンプルk(S個のストロークからなる)及びk’(S’個のストロークからなる)に対して、S≠S’の場合、
【0037】
【数2】
【0038】
であり、
S=S’の場合
【0039】
【数3】
【0040】
となる。ただし、P及びP’はサンプルk、k’の対応する再サンプリングされた座標ベクトルであり、Nはサンプリング点の数である。ベクトルPの要素pは3つの座標(x、y、Θ)を有し、ここでx及びyは点pのデカルト座標であり、Θは同じ点における傾きの推定値である。
【0041】
この定義より理解されるように、異なるストローク数を有するインクサンプルは、プロセスの最後まで、同じクラスタに統合されない。その時点で、統合は実際に停止してしまっている。
【0042】
したがって、
【0043】
【数4】
【0044】
が成り立つ。平均値又は最小値ではなく最大値を使用し、∞までの異なるストローク数を持つ2つのインクサンプル間の距離の定義を使用する判断は、小型のクラスタにとって有利である。
【0045】
クラスタにおけるインクサンプルが、クラスタの代表として選択される。あらゆるクラスタに対して選択される代表は、例えば、クラスタのメジアン中心である。クラスタckに対するメジアン中心x〜kは、残りのクラスタ要素のインクサンプルに対して最小のメジアン距離を有するインクサンプルとして定義される。すなわち、
【0046】
【数5】
【0047】
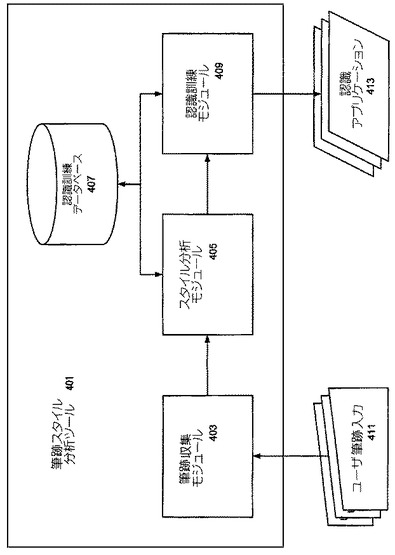
が成り立つ。あらゆる文字に対するクラスタリングの結果は2分木(「非類似性デンドログラム」とも呼ばれる)として視覚化されることができる。図5は、文字Kの様々なインクサンプルに関する結果として得られるデンドログラム501の一例を示す。この図において、ストロークは、ストロークの色すなわち(1)赤、(2)緑、(3)青及び(4)マゼンタがその書かれた順序を示すように色分けされる。また、それぞれのストロークは、その始点から終点に向かって次第に薄くなるように示される。
【0048】
本発明の種々の例によれば、あらゆる文字に対するクラスタの数が所望の閾値Dmaxとして定義され、クラスタの更なる統合は閾値Dmaxより上では行われない。その場合、統合が停止したときに残っている有効なクラスタは、対応する文字の様々な文字スタイル又は異書体として定義される。したがって、結果として得られるスタイルの数は、文字形状の多様性に依存して、文字毎に異なる。
【0049】
ユーザの利き手の決定
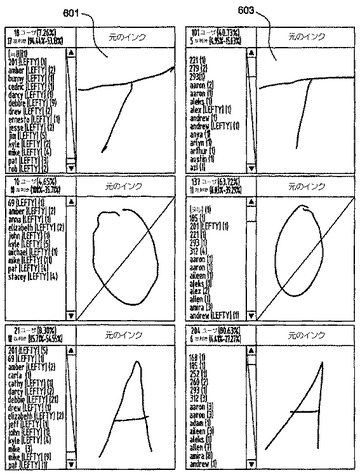
本発明のいくつかの実現形態によれば、認識訓練モジュール409は、書き手の利き手を認識する筆跡認識アプリケーションを生成するために、スタイル分析モジュール405によって生成されたデータを使用する。前述のように、文字のストロークの形状に加えて、本発明の種々の例は、異書体を定義するとき、各ストロークの方向及び各ストロークが書かれる順番をも考慮する。本発明の例を使用することによって、特定の異書体とそれらの異書体を使用する書き手の利き手との間の非常に高い相関が主観的に発見された。したがって、これらの異書体は、利き手を示す異書体として働く。図6は、これらの異書体のうちの幾つかと、それらに対応する書き手の利き手の統計とを示す。
【0050】
この図から分かるように、様々な異書体は、特定の利き手の書き手によってほぼ排他的に書かれる。例えば、文字Tを(横線が左から右ではなく右から左に向かって書かれる)スタイル601で書いた書き手の94.44%は、左手で書く。反対に、文字Tを(横線が左から右に向かって書かれる)スタイル603で書いた書き手の4.95%のみが、左手で書いている。
【0051】
したがって、認識訓練モジュール409は、利き手を示す1つ又は複数の異書体とユーザからの筆跡サンプルとを比較する、図7に示される筆跡認識ツール701などの筆跡認識アプリケーションをユーザに提供する。この図に見られるように、筆跡認識アプリケーション701は、ユーザからの筆跡入力411を受け取る筆跡収集モジュール703を備えている。また、筆跡認識アプリケーション701は、筆跡入力411の筆跡スタイルを決定する筆跡分析モジュール705を備える。そこで、利き手決定モジュール709は、ユーザの筆跡スタイルを、筆跡スタイルデータベース707における、利き手を示す筆跡スタイルと比較する。比較に基づいて、利き手決定モジュール709はユ―ザの利き手を決定する。
【0052】
本発明のいくつかの例によれば、利き手決定モジュール709は、決定された利き手をユーザが有すると結論するだけである。代りに、認識アプリケーションは、ユーザにその利き手を確認するように促すユーザインターフェース711をユーザに提供してもよい。この種のユーザインターフェースの一例が図8に図示されている。この図に見られるように、認識アプリケーション701は、ユーザが筆跡サンプルをテキスト入力パネル・ユーザインターフェース801に提出することに応答して、ユーザインターフェース711を提供する。ユーザの筆跡サンプルからの利き手の決定に基づいて、認識アプリケーション701は、例えば、ユーザの利き手に適する、コンピュータの1つ又は複数のユーザインターフェースを構成する。
【0053】
コミュニティに基づく筆跡認識
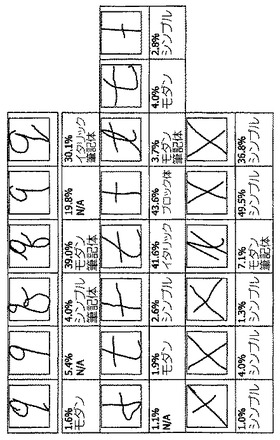
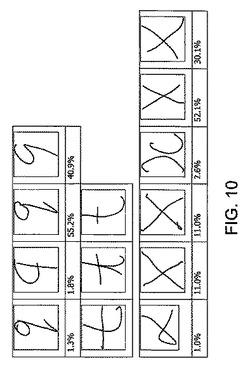
本発明の種々の例によれば、認識訓練モジュール409は、スタイル分析モジュール405によって生成されたデータを使用して、地理的領域、信仰する宗教、民族的背景、文化的集団又は任意の他の種類のコミュニティに特有の筆跡スタイル又は異書体に基づいて訓練された筆跡認識アプリケーションを生成する。例えば、前述の階層的クラスタリングアルゴリズムが、米国出身の267人の書き手によって書かれた99個の文字に対応する71,600個のインクサンプルに適用された。図9は、「ノイズのある」クラスタ(すなわち、出現頻度が極めて低いクラスタ)を取り除いた後の、文字「q」、「t」、「x」に関する結果のスタイルを、それらのスタイルの相対的頻度と共に示している。同じ実験が、英国出身の228人の書き手によって書かれた99個の文字に対応する70,000個のインクサンプルの集合に対して繰り返された。図10は、「ノイズのある」クラスタを取り除いた後の、文字「q」、「t」、「x」に対してこのデータから得られた結果のスタイルを、それらのスタイルの相対的頻度と共に示している。
【0054】
この実験から、両方の地理的コミュニティに対する主要な異書体は、異なる頻度で出現するけれども、ほとんどの文字に関してほぼ同じであるように見えると決定された。また、いくつかの二流の(すなわち、頻度の低い)異書体は、一方の地理的コミュニティに対しては存在するが、他方の地理的コミュニティに対しては存在しないように見える。その上、たとえ二流の異書体が両方の地理的コミュニティに現れるとしても、その頻度は地理的コミュニティ間で大きく異なる。
【0055】
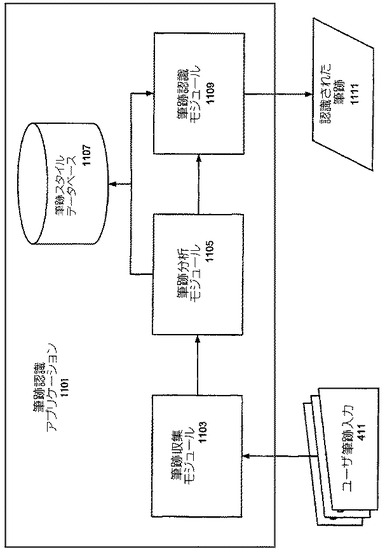
スタイル分析モジュール405によって取得された、この種のコミュニティに基づく異書体及び筆跡スタイル情報を使用して、認識訓練モジュール409は、特定のコミュニティに共通する異書体に対して特に訓練された(又は、特に訓練されるように構成された)筆跡認識アプリケーションをユーザに提供する。1つのそのような筆跡認識ツール1101が図11に図示されている。この図に見られるように、筆跡認識アプリケーション1101は、ユーザからの筆跡入力411を受け取る筆跡収集モジュール1103を備える。また、筆跡認識アプリケーション1101は、筆跡入力411の筆跡スタイルを決定する筆跡分析モジュール1105を備える。そこで、筆跡認識モジュール1109は、ユーザの筆跡スタイルと筆跡スタイルデータベース1107における1つ又は複数の筆跡スタイルとを比較して、例えば、ユーザの筆跡の1つ又は複数の異書体が特定の地理的領域に属するコミュニティなどの特定のコミュニティに関連する異書体に対応するかどうかを決定する。
【0056】
この比較に基づいて、筆跡認識モジュール1109は筆跡スタイルデータベース1107における筆跡スタイルを使用して、ユーザからの現在の及び将来の筆跡入力411を認識することができる。本発明のいくつかの例によれば、筆跡認識モジュール1109は、ユーザが特定のコミュニティに属していると結論付けるだけである。代りに、認識アプリケーション1101は、ユーザが特定のコミュニティに属していることを確認するようにユーザに促すユーザインターフェースをユーザに提供することができる。
【0057】
言うまでもなく、スタイル分析モジュール405によって取得される異書体及び筆跡スタイル情報は、信仰する宗教、民族的背景、文化的集団又はユーザの筆跡スタイルに影響を与え得る任意の他の種類のコミュニティなどの、識別可能な筆跡スタイルに関連付けられる任意の所望の種類のコミュニティに、コミュニティ特有の筆跡認識アプリケーションを提供するために使用される。
【0058】
スタイルを意識した認識の訓練
また、スタイル分析モジュール405によって得られた異書体及び筆跡スタイル情報は、通常の筆跡認識アプリケーションを含む様々な種類の筆跡認識アプリケーションの訓練動作を改善するために取得される。例えば、スタイル分析モジュール405によって得られた異書体及び筆跡スタイル情報は、筆跡認識アプリケーションの訓練プロセスの期間に異常な筆跡サンプルをフィルタリングするために使用される。
【0059】
例えば、上述の実験において、ノイズがあって不良なインクサンプルで大部分が構成されたクラスタ(すなわち異書体)が存在することが観察された。しかし、傾向として、これらのクラスタは主に濃度が低かった。これは予測されることである。ノイズ仮説(又はデータの異常値)は通常は分散しており、一定でないからである。したがって、これらのクラスタ又は異書体は、無意味な異書体とみなされることができる。
【0060】
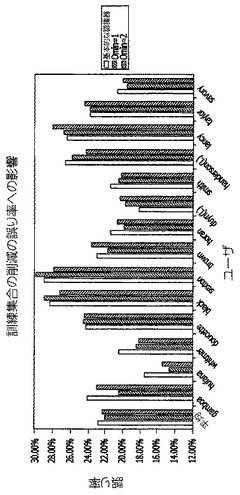
これらの無意味な異書体を筆跡認識アプリケーションの訓練から除外すること(すなわち、無意味な異書体を、筆跡認識アプリケーションの訓練のために使用される訓練文字の集合から除外すること)の影響が測定された。所望の閾値Ominを定義することができ、その閾値より下ではスタイルは無意味とみなされる。当業者によって理解されるように、この閾値のために選択される値は、筆跡訓練集合のために望まれる許容可能なノイズの量に基づく。これらの無意味な異書体を除外することの筆跡認識アプリケーションの認識精度に対する影響を測定するために、14人の書き手(うち2人は左利きである)によって書かれた18,628個のインクサンプルのデータベースが使用された。次いで、個々の誤り率及び平均誤り率が、5つの異なる筆跡認識アプリケーションに対して比較された。第1の筆跡認識アプリケーションは訓練集合全体について訓練された(すなわち100%認識器である)。第2の筆跡認識アプリケーションは、無意味な異書体を含む訓練集合全体のうちの15%について訓練された。そして、3つの残りの筆跡認識アプリケーションは、訓練集合全体のうちの15%について訓練されたが、異なる値のOminに基づいて無意味な異書体を除外した。
【0061】
図12は、異なる筆跡認識アプリケーションの間でOminの値と共に試験誤り率がどのように変化したかを示す。試験の結果に基づいて分かったのは、14人中の10人について、また平均して、対応する「削減されていない」筆跡認識アプリケーションよりも低い試験誤り率を有する筆跡認識アプリケーションを生成する「削減された」訓練集合(すなわち、無意味な異書体を除外した訓練集合)が存在することである。更に、14人の書き手のうちの5人に関しては、無意味な異書体を除外したデータのうちの15%について訓練することによって達成された試験誤り率が、訓練集合全体(すなわち、訓練集合のうちの100%)について筆跡認識アプリケーションを訓練することによって達成された誤り率よりも低かった。
【0062】
したがって、本発明の種々の例は、スタイル分析モジュール405によって識別された筆跡スタイルを使用して、どの異書体が、筆跡認識アプリケーション413によってユーザの筆跡認識を一層正確に認識するように筆跡認識アプリケーション413自身を訓練するために使用されるのかを決定することができる。当業者に理解されるように、Ominの値は、例えば筆跡認識アプリケーションが使用されるコミュニティに基づいて、訓練データの精度の高い集合を提供するよう実験的に選択されることができる。
【0063】
個人化された筆跡認識
本発明の更に他の例によれば、認識訓練モジュール409は、スタイル分析モジュール405によって得られたデータを使用して、ユーザの個人的な筆跡スタイル(すなわち、ユーザによって最もよく使用される異書体の集合)を認識するように特に調整された筆跡認識アプリケーションを生成する。
【0064】
従来の筆跡認識アプリケーションは差別的分類器モデルに基づく。これらの従来の筆跡認識アプリケーションのために使用される分類器は1文字分類器を含んでおり、典型的には、数百の書き手から収集されたデータを包含する訓練データにより訓練される。特定の書き手に対して筆跡認識アプリケーションを個人化するために、これらの分類器は、明示的な又は暗黙的な手段を介して書き手が提供する筆跡データの少量のサンプルで更に訓練される。通常、書き手に特有の訓練は、過学習を防ぐために、制限された繰り返し回数で実行される。個人化に対するこの従来のアプローチは、本明細書においては「古典的」個人化と呼ばれる。
【0065】
しかし、本発明の種々の例は、スタイル分析モジュール405によって得られたスタイル情報を使用する代替的なアプローチを使用してもよい。この代替的なアプローチは、本明細書において「スタイルに基づく」個人化と呼ばれる。より具体的には、このアプローチによれば、認識訓練モジュール409は、ユーザによって提供されたインクサンプルを使用して、ユーザによって典型的に使用される異書体の群を計算する。異書体のこの群は、ユーザの筆跡スタイル又は「スタイル・メンバシップ・ベクトル」を構成する。次いで、このベクトルは、書き手のスタイルに最も一致する訓練集合のサブセットを計算するために使用される。そこで、分類器は、訓練集合の計算されたサブセットについて訓練されることができる。
【0066】
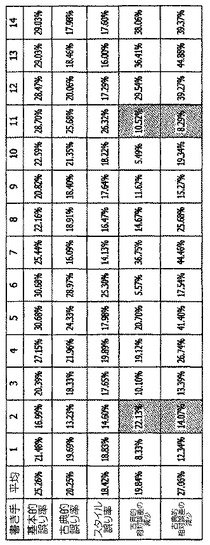
このスタイルに基づく個人化のアプローチを評価するために、このアプローチを使用して訓練された筆跡認識アプリケーションの性能を、基本的な筆跡認識アプリケーション(すなわち、汎用筆跡認識アプリケーション)及び古典的個人化によって訓練された筆跡認識アプリケーションと比較した実験が行われた。267人の書き手によって書かれた70,000個のインクサンプルからなる訓練集合が、基本的な筆跡認識アプリケーションを生成するために使用された。14人の書き手の集合(そのうちの2人は左利きであり、どの書き手も訓練集合にデータを持たない)が個人化の実験の対象とされた。これらの書き手のそれぞれは、個人化の目的のために99個のサポートされる文字のそれぞれに対して2つのインクサンプルを提供し、合計で198個のインクサンプルを作成した。また、また、それぞれの書き手は、試験の目的のための文字に対して14個のサンプルを提供した。
【0067】
筆跡認識アプリケーションは、書き手の個人化のインクサンプルによって補強された元の訓練集合について汎用筆跡認識アプリケーションを訓練することによって、書き手のそれぞれに対して個人化された。上述のように、これらの筆跡認識アプリケーションは、古典的に個人化された筆跡認識アプリケーションと呼ばれる。次いで、別の汎用筆跡認識アプリケーションが、書き手の個人化データを使用して書き手の筆跡スタイルに一致した訓練集合のサブセットを選択することにより、書き手のそれぞれに対して個人化された。すなわち、訓練集合に対してスタイル分析を実行した後、書き手の個人化インクサンプルのそれぞれが、訓練集合における各文字に対する異書体のうちの1つを有効化するために使用された。次に、筆跡認識アプリケーションは、個人化インクサンプルによって補強された訓練データのこのサブセットについて、当該書き手に対して訓練された。上述のように、これらの筆跡認識アプリケーションは、スタイル個人化された筆跡認識アプリケーションと呼ばれる。これらの3つの筆跡認識アプリケーションのそれぞれが、それぞれの書き手によって提供された試験集合に対して評価された。
【0068】
図13及び図14は、この実験において対象とされた14人の書き手のそれぞれに対する上述の3つの筆跡認識アプリケーションのそれぞれに対する試験誤り率と、それぞれのスタイル個人化された筆跡認識アプリケーションを訓練するために選択された訓練集合の百分率とを示している。これらの図から分かるように、14人の書き手のそれぞれに関して、古典的個人化筆跡認識アプリケーション及びスタイル個人化された筆跡認識アプリケーションは、基本的な認識器によってもたらされた試験誤り率から試験誤り率を低下させた。また、12人の書き手に関して、スタイル個人化された筆跡認識アプリケーションは、古典的に個人化された筆跡認識アプリケーションによってもたらされた誤りの減少よりも大きな誤りの減少をもたらした。更に、スタイル個人化された筆跡認識アプリケーションによってもたらされた平均相対誤差の減少は約27%であったが、平均相対誤差の減少は、古典的に個人化された筆跡認識アプリケーションに関しては約20%にすぎなかった。更に、スタイルに基づく個人化において選択された訓練集合の部分の平均的な大きさは、基本的な訓練集合の約68%であった。
【0069】
したがって、スタイル分析モジュール405が、ユーザから取得した筆跡サンプルを分析した後、認識訓練モジュール409は、スタイル分析モジュール405によって提供されたデータを使用して、精度の向上を達成するようユーザから一層少ない訓練を要求しながらも、ユーザに対して一層高い認識精度を提供する、スタイル個人化された筆跡認識アプリケーションを生成する。より具体的には、筆跡スタイル分析ツール401は、ユーザの筆跡スタイルに対応した異書体を含む又はその異書体に制限された訓練集合を使用する筆跡認識アプリケーション413をユーザに提供する。
【0070】
スタイル予測
筆跡認識アプリケーションの訓練集合を改善することに加えて、本発明の種々の例によれば、代替的に又は追加的に、筆跡スタイル分析ツール401はユーザの筆跡入力411からユーザの筆跡スタイルを予測する(及び/又は、ユーザの筆跡入力411からユーザの筆跡スタイルを予測する筆跡認識アプリケーションを提供する)。例えば、筆跡スタイル分析ツール401は、例えば協調フィルタリングを使用して、書き手がいくつかの文字をどのように書くかを、他の文字の収集されたインクサンプルに基づいて予測する。
【0071】
協調フィルタリングは、他のユーザのサンプル又は集団からのユーザの投票のデータベースに基づいて特定のユーザに対するアイテムの有用性を予測するために普通に使用される公知の技術である。本発明の種々の例の実施に特に関連するのは、メモリベースのアルゴリズムとして知られる協調フィルタリングの分類である。
【0072】
この種の協調フィルタリングによれば、(アイテムjについてのユーザiの投票に対応する)投票vi,jからなるユーザデータベースが用いられて、新たなユーザuに関する何らかの部分的情報とユーザデータベースから計算された1組の重みとに基づいて、有効なユーザの投票が予測される。アイテムjに関する新たなユーザuの予測される投票がPu,jであると仮定される。Pu,jは、データベースにおける他のユーザの投票の加重和である。すなわち、
【0073】
【数6】
【0074】
である。ただし、Nは協調フィルタリングのデータベースにおけるユーザ数である。重みw(u、i)は、各ユーザiとユーザuとの間の相関又は類似性を反映する。値αは、投票の合計が1になることを保証するための正規化係数である。
【0075】
重みを計算する最も単純で最も普通の方法は、ピアソンの相関係数を使用することである。この係数を使用すると、ユーザiとuとの間の相関は、
【0076】
【数7】
【0077】
によって与えられる。jについての加算は、ユーザu及びiが投票したアイテムについて行われる。
書き手の筆跡スタイルの予測において、ユーザデータベースは筆跡スタイルデータベースに対応し、ユーザの投票は書き手のスタイル・メンバシップ・ベクトルの値に対応し、部分的な投票が知られているユーザuは、入力筆跡データから部分的なスタイルメンバシップが知られている書き手であって、筆跡スタイル分析ツール401(又は筆跡認識アプリケーション413)が残りのスタイルを予測するように要求される書き手に対応する。本発明の種々の例によれば、筆跡スタイル分析ツール401(又は筆跡認識アプリケーション413)は、例えば文字a、A、I、0、1、2、9に基づいてユーザの筆跡スタイルを予測する。これは、これらの文字が特有であり、筆跡認識器の日々の使用の中で獲得されやすいからである。言うまでもなく、本発明の代替的な例は、ユーザの筆跡スタイルを予測するために文字の任意の組合せを使用する。
【0078】
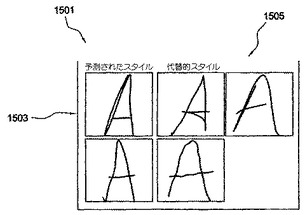
本発明のいくつかの例によれば、筆跡スタイル分析ツール401(又は筆跡認識アプリケーション413)は、ユーザが特定の筆跡スタイルを有することを予測し、このスタイルを構成する異書体を使用してユーザの筆跡を認識するだけである。代りに、筆跡スタイル分析ツール401(又は筆跡認識アプリケーション413)は、予測された筆跡スタイルに基づいて、ユーザがどのように特定の文字を書き得るかを確認するようにユーザに促すユーザインターフェースをユーザに提供する。この種のユーザインターフェースの一例が図15に示される。この図に見られるように、ユーザインターフェース1501は、ユーザの筆跡入力に最もよく対応する筆跡スタイル内の異書体の一次選択1503を提供する。また、ユーザインターフェース1501は、異書体の一次選択よりも幾分劣るユーザの筆跡入力に対応する筆跡スタイル内の異書体1505の代替的集合を提供する。ユーザの筆跡スタイルの決定に基づいて、筆跡認識アプリケーション413は、上で詳細に検討されたように、ユーザの筆跡入力を一層正確に認識することができる。
【0079】
結論
本発明について、本発明を実施する現在の好ましい形態を含む特定の例に関して説明してきたが、当業者は理解するように、特許請求の範囲に記載された本発明の精神及び範囲内に入る上述のシステム及び技術の多数の変更及び変形が存在する。
【図面の簡単な説明】
【0080】
【図1A】学校で筆跡を教えるために典型的に使用される模範的筆跡スタイルを示す図である。
【図1B】学校で筆跡を教えるために典型的に使用される模範的筆跡スタイルを示す図である。
【図2】本発明の種々の例に係る、筆跡認識技術を実施するために使用されることができる動作環境の例を示す図である。
【図3】本発明の種々の例に係る、筆跡認識技術を実施するために使用されることができる動作環境の例を示す図である。
【図4】本発明の種々の例によって実施されることができる筆跡スタイル分析ツールを示す図である。
【図5】文字Kの様々なインクサンプルに関するクラスタリングの一例を示す図である。
【図6】様々な利き手を示す異書体と、それらの異書体に対応する書き手の利き手の統計とを示す図である。
【図7】本発明の種々の例に係る、ユーザからの筆跡サンプルと利き手を示す1つ又は複数の異書体とを比較する筆跡認識ツールを示す図である。
【図8】本発明の種々の例によって使用される、利き手を確認するようにユーザに促すユーザインターフェースを示す図である。
【図9】本発明の種々の例に係る階層的クラスタリングアルゴリズムを、米国出身の267人の書き手によって書かれた99の文字に対応する71,600個のインクサンプルに対して実行することによって得られた文字「q」、「t」、「x」に関する結果のスタイルを示す図である。
【図10】本発明の種々の例に係る階層的クラスタリングアルゴリズムを英国出身の228人の書き手によって書かれた99の文字に対応する70,000個のインクサンプルに対して実行することによって得られた文字「q」、「t」、「x」に関する結果のスタイルを示す図である。
【図11】特定のコミュニティに共通の異書体に関して特に訓練された(又は特に訓練されるように構成された)筆跡認識アプリケーションを示す図である。
【図12】異なる筆跡認識アプリケーション間の様々なレベルのノイズを除外することによる試験誤り率の変化を示す図である。
【図13】異なる訓練技術を使用した3つの筆跡認識アプリケーションのそれぞれに関する試験誤り率を示す図である。
【図14】異なる訓練技術を使用した3つの筆跡認識アプリケーションのそれぞれに関する試験誤り率を示す図である。
【図15】予測された筆跡スタイルに基づいて、どのように特定の文字を書き得るかを確認するようにユーザに促すユーザインターフェースを示す図である。
【技術分野】
【0001】
背景技術
コンピュータは、世界中で様々な目的のために日常的に使用されている。コンピュータが一般的になってきたのにつれて、コンピュータの製造業者は、それらのコンピュータをより利用しやすく、ユーザフレンドリにしようとし続けてきた。1つのそのような取り組みは自然な入力方法の開発であった。例えば、音声認識は、声を出して単にデータを話すことによってユーザがデータをコンピュータに入力することを可能にする。そのとき、ユーザの発話の音素をタイプされたテキストに変換するために、そのユーザの発話の音素が分析される。或いは、筆跡認識は、ユーザがスタイラスを用いてデジタイザ上に書くことによってデータを入力して電子インクを生成することを可能にする。コンピュータは、インクの形状を分析し、その形状をタイプされたテキストに変換する。
【0002】
筆跡入力技術の登場は、多くのコンピュータユーザにとって特に有益であった。一部のユーザは、それらのユーザがキーボードを使用して文字をタイプすることができるよりも速く、手で同じ文字を書くことができる。したがって、これらのユーザは、キーボード入力よりも迅速に筆跡入力を作成することができる。また、たいていの東アジアの言語のユーザは、筆跡入力の筆跡の方がキーボード入力よりも効率的であることを知る。典型的には、東アジアの言語は、何千もの文字を有する象形文字の組を使用して書かれる。大きなキーボードであっても、ユーザが東アジアの言語で書くのに十分なキーを含むことはできない。したがって、キーボードのユーザは、キーボード上に示された表音文字を所望の象形文字に回りくどく変換するように要求される。筆跡入力を受け取り、認識するコンピュータを用いて、今や東アジアの言語のユーザは、電子インクで所望の象形文字を直接簡単に書くことができる。その上、一部のユーザは、キーボードの使用を許さない環境でコンピュータを使用する。例えば、病院内を歩き回る医師はキーボードの使用が実用的でない場所で筆跡入力を作成する。
【発明の開示】
【発明が解決しようとする課題】
【0003】
筆跡入力技術は様々なユーザにとって非常に便利である可能性があるが、これらの技術の有用性はそれらの技術の認識精度に大きく依存する。しかし、異なるユーザは多種多様な異なる形状を使用して同じ文字を書くので、一貫して精度の高い筆跡認識は得ることが難しい。
【0004】
筆跡認識の問題に対処するために、一部のソフトウェア開発者が、多種多様なユーザの全てに当てはまる筆跡認識ソフトウェアアプリケーションを作成した。これらのソフトウェアアプリケーションは、言語に関する筆跡の全ての形態に共通する1つ又は複数の筆跡認識技術を使用する。例えば、これらの技術の一部は、筆跡文字を1組の文字の基本形と比較して筆跡文字がどの基本形に最もよく似ているかを決定することができる。そのとき、1組の基本形は、ユーザの文字体系内の各文字に対する1つ又は複数の通常の異書体を含む。これらの汎用的な認識技術は多種多様なユーザに対して「追加設定なしで」筆跡を認識するが、典型的には、それらの技術は任意の特定のユーザに関して高い認識率を提供しない。更に、通常、これらの種類の認識技術の精度は時間の経過と共に向上しない。
【0005】
その代わりに、一部のソフトウェア開発者は、特定の個人の筆跡を認識することを学習する個人化筆跡認識ソフトウェアアプリケーションを提供する。しかし、典型的に、これらのアプリケーションは、学習プロセスの間に多量の筆跡データを入力するようにユーザに要求する。結果として、これらの筆跡認識ソフトウェアアプリケーションの一部は、「追加設定なしで」はそれほど精度が高くない。更に、多くのユーザは、ユーザの筆跡を認識するようにこの種のソフトウェアを適切に訓練するために必要とされる時間をつぎ込むことに消極的である。更に、これらの個人化筆跡認識ソフトウェアアプリケーションは過学習に陥りやすい。ソフトウェアは時間の経過と共にそのソフトウェアの認識プロセスを改良し続けるので、そのソフトウェアは、そのソフトウェアの訓練データ内にユーザによって書かれた異常な文字形状を含む可能性がある。ユーザの典型的な筆跡には通常見られないこれらのときとして異常な文字形状は、時間の経過と共にアプリケーションの認識精度を実際に低下させ得る。
【課題を解決するための手段】
【0006】
本発明の種々の態様は、ユーザの筆跡スタイルに基づいて筆跡入力を処理するための技術に関する。本発明のいくつかの態様は、ユーザが単一の文字を書くスタイルを使用する。代替的に又は追加的に、本発明の他の態様は、筆跡スタイルを形成する一群の異書体を使用する。
【0007】
例えば、本発明のいくつかの実現形態は、ユーザによって書かれた1つ又は複数の文字を分析して、ユーザの筆跡スタイルが属する地理的領域又は文化的集団などのコミュニティを特定する。これらの実現形態によれば、ユーザには、コミュニティによって使用される筆跡スタイルを認識するように調整された筆跡認識アプリケーションが提供される。本発明の他の実現形態は、代替的に又は追加的に、ユーザの筆跡を特定の筆跡スタイルに分類するためにユーザの筆跡の1つ又は複数の文字を分析する。そこで、ユーザには、ユーザの個人的な筆跡スタイルのために特に構成された筆跡認識アプリケーションが提供される。有利なことに、両方の種類の筆跡認識アプリケーションは、ユーザに大量の訓練データを提出するように要求することなしに、汎用筆跡認識アプリケーションよりも高い認識精度を提供する。
【0008】
本発明の更に他の実現形態によれば、代替的に又は追加的に、ユーザの筆跡スタイルが、筆跡認識アプリケーションが異常な形で書かれた文字を認識プロセスを向上するための訓練データとして使用することを防止するために使用されることができる。そこで、代替的に又は追加的に、本発明のいくつかの例は、ユーザの異書体のうちの1つ又は複数を分析して、ユーザが他の文字をどのように書くかを予測する。ユーザにそれらの文字のそれぞれに対応する訓練データを提出するように要求するのではなく、例えば、これらの実現形態は、代わりに、それらの他の文字をどのように書くかを確認するようにユーザに促す。これらの実現形態は、例えば、分析された異書体と同じ筆跡スタイルに属する異書体をユーザに選択させるだけである。
【0009】
代替的に又は追加的に、本発明の更に他の実現形態は、ユーザの筆跡スタイルを分析して、ユーザが右手で書くか、左手で書くかを決定する。次いで、これらの実現形態は、例えば、ユーザの「利き手」に対応するようにコンピュータの1つ又は複数のユーザインターフェースを構成する。
【0010】
本発明の異なる実現形態のこれらの及び他の特徴及び利点を、以下で一層詳細に説明する。本特許又は出願書類は、カラーで作成された少なくとも1つの図面を含む。カラー図面を伴う本特許又は特許出願公開のコピーは、請求と必要な手数料の支払いとに応じて特許庁によって提供される。
【発明を実施するための最良の形態】
【0011】
筆跡スタイル
本発明の種々の態様は、ユーザの筆跡スタイルを使用しての筆跡入力技術の向上に関する。本発明のいくつかの例は、ユーザが、以降「異書体」と呼ばれる単一の文字を書くスタイルを使用する。以降で使用される用語「文字」は、個々の文字、数字又はその他の記号と、合字(すなわち、2つ以上の基礎的な文字、数字又はその他の記号を表す単一の形状又は象形文字)とを総称的に示す。文字の異書体は、例えば、ユーザが文字を書くために行うストローク数と、それぞれのストロークが書かれる順番と、それぞれのストロークが書かれる方向とによって決定されることができる。
【0012】
代替的に又は追加的に、本発明の他の態様は、筆跡スタイルを形成する一群の異書体を使用することができる。例えば、図1Aは模範的なモダン筆記体(Modern Cursive)筆跡スタイルを示すが、図1Bは模範的なシンプル筆記体(Simple Cursive)筆跡スタイルを示す。これらの図から分かるように、両方の模範的筆跡スタイルは、(シンプル筆記体筆跡スタイルにおける異書体はモダン筆記体筆跡スタイルにおける異書体よりも若干角度が付けられているが)大文字「T」に関して類似した異書体を共有する。しかし、これらの筆跡スタイルは、小文字「p」に関して大きく異なる異書体を有する。本明細書において使用される用語「筆跡スタイル」は、単一の異書体、一群の異書体又は複数の異書体によって構成される筆跡スタイルを総称的に示す。
【0013】
図1A及び1Bに示された筆跡スタイルは、典型的には、学校で新しい書き手に筆跡を教えるために使用される模範的筆跡スタイルである。しかし、より熟達した書き手は、ブロック体の筆跡及び筆記体の筆跡を含む、その書き手自身の特有の筆跡スタイルを開発している。典型的には、この特有の筆跡スタイルは、様々な異なる模範的筆跡スタイルからの異書体の特徴を、いかなる特定の模範的筆跡スタイルにも属さない普通でない異書体の特徴と組み合わせる。書き手が個人的な筆跡スタイルを発達させると、その個人的な筆跡スタイルは通常は時間が経過しても変化しない。したがって、ユーザの特有の筆跡スタイルは、独自の特徴と、1人又は複数のその他の書き手と共有されるいくつかの特徴とを有する。独自の特徴の組は個人的特徴の集合と呼ばれ、共有される特徴は「スタイルの」特徴の集合と呼ばれる。したがって、以下でより詳細に説明するように、2つ以上の特有の筆跡スタイルは、1つ又は複数の共有される「スタイルの」特徴に基づいて一層包括的な筆跡スタイルにまとめられることができる。
【0014】
実施環境
当業者によって理解されるように、本発明の様々な例はアナログ回路を使用して実施されることができる。しかし、更に普通には、本発明の態様は、プログラミング又は「ソフトウェア」命令を実行するプログラム可能なコンピューティング装置を使用して実施される。したがって、本発明の様々な例を実施するために使用されることができるコンピューティング装置環境の包括的な例を、図2及び図3に関してここで説明する。
【0015】
より具体的には、図2は、本発明の様々な例を実施するために使用されることができる汎用デジタルコンピューティング環境の一例を示す。特に、図2はコンピュータ200の概略図を示す。典型的には、コンピュータ200は少なくとも何らかの形態のコンピュータ読み取り可能媒体を含む。コンピュータ読み取り可能媒体は、コンピュータ200によってアクセスされることができる任意の利用可能な媒体であり得る。例えば、コンピュータ読み取り可能媒体は、コンピュータ記憶媒体及び通信媒体を含むことができるが、これらに限定されない。コンピュータ記憶媒体は、コンピュータ読み取り可能命令、データ構造、プログラムモジュール又はその他のデータなどの情報を記憶するための任意の方法又は技術で実現された揮発性及び不揮発性の取り外し可能及び取り外し不可能な媒体を含む。コンピュータ記憶媒体は、RAM、ROM、EEPROM、フラッシュメモリ又はその他のメモリ技術、CD−ROM、デジタルバーサタイルディスク(DVD)又はその他の光学式記憶装置、磁気カセット、磁気テープ、磁気ディスク記憶装置又はその他の磁気記憶装置、せん孔媒体、ホログラフィック記憶装置、或いは所望の情報を記憶するために使用されることができ、コンピュータ200によってアクセスされることができる任意のその他の媒体を含むが、これらに限定されない。
【0016】
典型的には、通信媒体は、コンピュータ読み取り可能命令、データ構造、プログラムモジュール、又は、搬送波などの変調されたデータ信号又はその他の搬送メカニズムにおける他のデータを具体化するもので、任意の情報配信媒体を含む。用語「変調されたデータ信号」は、その信号の特徴のうちの1つ又は複数が、情報を符号化するように設定又は変更された信号を意味する。例えば、通信媒体は、有線ネットワーク又は直接有線接続などの有線媒体や、音響、RF、赤外線及びその他の無線媒体などの無線媒体を含むが、これらに限定されない。上記の媒体のうちの任意のものの組合せもコンピュータ読み取り可能媒体の範囲内に含まれるべきである。
【0017】
図2に示されるように、コンピュータ200は、処理ユニット210と、システムメモリ220と、システムメモリ220を含む種々のシステムコンポーネントを処理ユニット210に結合するシステムバス230とを含む。システムバス230は、各種のバスアーキテクチャのいずれかを使用したメモリバス又はメモリコントローラ、周辺バス及びローカルバスを含む数種のバス構造のいずれであってもよい。システムメモリ220は、読み出し専用メモリ(ROM)240及びランダムアクセスメモリ(RAM)250を含むことができる。
【0018】
基本入出力システム(BIOS)260は、起動期間などにコンピュータ200内の要素間で情報を転送することに役立つ基礎的なルーチンを含み、ROM240に記憶される。また、コンピュータ200は、ハードディスク(図示せず)との間の読み出し、書き込みのためのハードディスクドライブ270と、リムーバブル磁気ディスク281との間の読み出し、書き込みのための磁気ディスクドライブ280と、CD ROM、DVD ROM又はその他の光媒体などの取り外し可能光ディスク291との間の読み出し、書き込みのための光ディスクドライブ290とを更に含むことができる。ハードディスクドライブ270、磁気ディスクドライブ280及び光ディスクドライブ290は、それぞれ、ハードディスクドライブインターフェース292、磁気ディスクドライブインターフェース293及び光ディスクドライブインタ―フェース294によってシステムバス230に接続される。これらのドライブ及びこれらのドライブに関連するコンピュータ読み取り可能媒体は、パーソナルコンピュータ200のためのコンピュータ読み取り可能命令、データ構造、プログラムモジュール及びその他のデータの不揮発性の記憶を提供する。当業者によって理解されるように、磁気カセット、フラッシュメモリカード、デジタルビデオディスク、ベルヌーイカートリッジ、ランダムアクセスメモリ(RAM)、読み出し専用メモリ(ROM)などの、コンピュータによってアクセス可能なデータを記憶することができるその他の種類のコンピュータ読み取り可能媒体も、例示の動作環境の例において使用され得る。
【0019】
オペレーティングシステム295、1つ又は複数のアプリケーションプログラム296、その他のプログラムモジュール297及びプログラムデータ298を含む複数のプログラムモジュールが、ハードディスクドライブ270、磁気ディスク281、光ディスク291、ROM240又はRAM250に記憶されることができる。ユーザは、キーボード201及び(マウスなどの)ポインティングデバイス202などの入力デバイスを介してコンピュータ200に命令及び情報を入力することができる。その他の入力デバイス(図示せず)は、マイクロホン、ジョイスティック、ゲームパッド、衛星通信用パラボラアンテナ、スキャナなどを含み得る。これらの及びその他の入力デバイスは、しばしば、システムバス230に結合されたシリアルポートインターフェース206を介して処理ユニット210に接続されるが、パラレルポート、ゲームポート又はユニバーサルシリアルバス(USB)などの他のインターフェースによって接続されることもできる。その上、これらのデバイスは、適切なインターフェース(図示せず)を介してシステムバス230に直結されることができる。
【0020】
モニタ207又はその他の種類のディスプレイ装置も、ビデオアダプタ208などのインターフェースを介してシステムバス230に接続されることができる。モニタ207に加えて、典型的には、パーソナルコンピュータは、スピーカ及びプリンタなどのその他の周辺出力装置(図示せず)を備える。一例において、ペンデジタイザ265及び付属のペン又はスタイラス266が、フリーハンド入力をデジタル式に取り込むために提供される。ペンデジタイザ265とシリアルポートインターフェース206との間の接続が図2に示されるが、実際は、ペンデジタイザ265は、処理ユニット210に直接結合されることができ、又は、ペンデジタイザ265は、当技術分野で知られているように、パラレルポート又は別のインターフェースとシステムバス230とを介するなどの任意の好適なやり方で処理ユニット210に結合されることができる。更に、デジタイザ265は図2においてモニタ207と別個に図示されているが、デジタイザ265の使用可能な入力領域は、モニタ207の表示領域と同じ空間的広がりを持つことができる。その上、デジタイザ265は、モニタ207に統合されることができ、又は、モニタ207に重なる若しくは取り付けられる別個の装置として存在することができる。
【0021】
コンピュータ200は、リモートコンピュータ209などの1つ又は複数のリモートコンピュータへの論理接続を使用したネットワーク環境で動作することができる。リモートコンピュータ209はサーバ、ルータ、ネットワークPC、ピア機器又はその他の一般的なネットワークノードであることができ、簡単にするために、図2においてはメモリ記憶装置211のみが示されたが、典型的には、リモートコンピュータ209は、コンピュータ200に関して上述された要素の多く又は全てを含む。図2に示された論理接続は、ローカルエリアネットワーク(LAN)212及び広域ネットワーク(WAN)213を含む。そのようなネットワーキング環境は、有線接続及び無線接続を使用するオフィス、企業規模のコンピュータネットワーク、イントラネット及びインターネットにおいて一般的である。
【0022】
LANネットワーキング環境において使用されるとき、コンピュータ200は、ネットワークインターフェース又はアダプタ214を介してローカルエリアネットワーク212に接続される。WANネットワーキング環境において使用されるとき、典型的には、パーソナルコンピュータ200は、モデム215や、インターネットなどの広域ネットワーク213を介して通信リンクを確立するためのその他の手段を備える。コンピュータ200に内蔵されても、外付されてもよいモデム215は、シリアルポートインターフェース206を介してシステムバス230に接続される。ネットワーク環境において、パーソナルコンピュータ200に関連して示されたプログラムモジュール又はその一部は、リモートのメモリ記憶装置に記憶されることができる。
【0023】
理解されるように、図示されたネットワーク接続は例であり、コンピュータ間の通信リンクを確立するために他の技術を使用することができる。TCP/IP、イーサネット(登録商標) 、FTP、HTTP、UDPなどの様々な周知のプロトコルのうちのいずれかの存在が想定され、システムは、ユーザがウェブベースのサーバからウェブページを検索することを許容するユーザ−サーバ構成において動作する。様々な通常のウェブブラウザのうちの任意のものを、ウェブページ上のデータの表示及び操作のために使用され得る。
【0024】
図2の環境は本発明の種々の実施の形態に対する動作環境の一例を示すが、理解されるように、他のコンピューティング環境を使用することもできる。例えば、本発明の1つ又は複数の例は、図2に示され且つ上述された様々な態様の全てよりも少ない態様を有する環境を使用し得、これらの態様は、当業者には明らかな様々な組み合わせ及び準組み合わせにおいて現れる。
【0025】
図3は、本発明の種々の態様に従って使用されることができる、ペン入力型のパーソナルコンピュータ(PC)301を示す。図2のシステムの特徴、サブシステム及び機能のうちのいずれか又は全てが、図3のコンピュータ301に含まれる。ペン入力型のパーソナルコンピュータシステム301は、大きな表示面302、例えば、ウィンドウ表示されるグラフィカル・ユーザ・インターフェースなどの複数のグラフィカル・ユーザ・インターフェース303が表示される液晶ディスプレイ(LCD)スクリーンなどのデジタル化フラットパネルディスプレイを含む。スタイラス266を使用して、ユーザは、デジタル化表示領域上で選択、ハイライト及び書き込みを行うことができる。好適なデジタル化ディスプレイパネルの例は、(現在はファインポイント・イノベーションズ社として知られる)ムトーやワコム・テクノロジー社から入手可能なペンデジタイザなどの電磁ペンデジタイザを含む。その他の種類のペンデジタイザ、例えば、光学式デジタイザ及び接触感知式デジタイザも使用されることができる。ペン入力型のコンピューティングシステム301は、スタイラス266を使用して行われたジェスチャを解釈して、データの操作、テキストの入力、表計算や文書処理プログラムなどの作成、編集、修正などの、通常のコンピュータアプリケーションタスクを実行する。
【0026】
スタイラス266は、その能力を高めるためにボタン又はその他の機能を備えることができる。一例において、スタイラス266は「鉛筆」又は「ペン」として実現され、その一端は書き込み部を構成する。スタイラス266の他端は、ディスプレイを横切って移動されるときに消されるべきディスプレイ上の電子インクの部分を示す「消しゴム」の端部を構成する。マウス、トラックボール、キーボードなどのその他の種類の入力装置が使用され得る。更に、ディスプレイが接触感知式又は接近感知式ディスプレイである場合、表示された画像の部分を選択又は指示するためにユーザ自身の指が使用され得る。したがって、本明細書において使用される用語「ユーザ入力装置」は幅広い定義を持ち、周知の入力装置の多くの変更形態を包含するものとする。
【0027】
フルパフォーマンスのペン入力型コンピューティングシステム又は「タブレットPC」(例えば、コンバーチブル型ラップトップもしくは「スレート」型タブレットPC)と共に使用することに加えて、本発明の態様は、他の種類のペン入力型コンピューティングシステム及び/又は他の装置と共に使用されることができる。ここで、他の装置は、例えば(i)手持ち式もしくはパームトップ型のコンピューティングシステム、(ii)携帯情報端末、(iii)ポケットパーソナルコンピュータ、(iv)移動式電話及び携帯電話、ページャ及びその他の通信デバイス、(v)腕時計、(vi)電化製品並びに(vii)任意の他の装置又はシステムなどの、データを電子インクとして受け取り、及び/又は、電子ペンもしくはスタイラスの入力を受け取る装置である。上記任意の他の装置又はシステムは、印刷された又はグラフィカル情報をユーザに提示し及び/又は電子ペンもしくはスタイラスを使用しての入力を可能にする、或いは、別の装置(例えば、タブレットPCによって収集された電子インクを処理することができる通常のデスクトップコンピュータ)によって収集された電子インクを処理することができる、モニタ又は他のディスプレイ装置及び/又はデジタイザを備える。
【0028】
筆跡スタイル分析ツール
図4は、本発明の様々な例によって実施されることができる筆跡スタイル分析ツール401を示す。この図に示されるように、筆跡スタイル分析ツール401は、筆跡収集モジュール403、スタイル分析モジュール405、認識訓練データベース407及び認識訓練モジュール409を備えている。以下で詳細に説明されるように、筆跡スタイル分析ツール401は、様々なユーザから入力された筆跡データ411を受け取って、受け取り側ユーザの筆跡スタイルに対してカスタマイズされた筆跡認識アプリケーション413を1人又は複数のユーザに提供する。
【0029】
図4に示されるように、筆跡スタイル分析ツール401は様々なユーザにアクセス可能である。したがって、本発明の種々の例を用いる場合、少なくとも筆跡収集モジュール403は、インターネットなどの1つ又は複数のネットワーク上で複数のユーザにアクセス可能なサーバコンピュータ上に実装されることができる。ユーザの筆跡を収集することに加えて、筆跡収集モジュール403は、ユーザに関する追加的な個人情報をも含むことができる。例えば、筆跡収集モジュール403は、ユーザの利き手(すなわち、ユーザが右手で書くか、左手で書くか)を取得する。代替的に又は追加的に、筆跡収集モジュール403は、ユーザの地理的、宗教的及び/又は文化的情報などの、ユーザが属する1つ又は複数のコミュニティに関する情報を取得する。したがって、筆跡収集モジュール403は、ユーザが書くことを学んだ国その他の地理的領域、ユーザが宗教学校で教育を受けたかどうか、又はユーザが識別可能な文化的集団に属しているかどうかを確認することができる。
【0030】
以下で一層詳細に説明するように、スタイル分析モジュール405は、受け取った筆跡サンプル411を、それらの特徴の類似性に基づいて、関連グループ又は「クラスタ」に組織化する。上述の説明から理解されるように、各クラスタは、筆跡サンプルがクラスタに含まれる1人又は複数のユーザに共通する筆跡スタイルとして定義される。受け取った筆跡サンプル411をクラスタに組織化するために2つの別個の技術、すなわち、大雑把な下位スタイルを検出するトップダウンのアプローチ又はボトムアップのクラスタリングアプローチが、本発明の種々の例と共に使用されることができる。
【0031】
図示された例において、スタイル分析モジュール405はボトムアップのアプローチを使用する。これは、以下の検討から明らかなように、ボトムアップのアプローチを使用して得られた情報が認識訓練モジュール409によって直接使用されることができるからである。このアプローチを使用して、筆跡サンプルデータ集合X={x1、x2、...、xM}のクラスタリングCは、
【0032】
【数1】
【0033】
であるように、互いに素な集合の集合{c1、c2、...、cK}へのデータの分割を定義する。クラスタリングCは、筆跡サンプル411における全ての文字に対して独立に計算される。
【0034】
本発明の種々の例によれば、スタイル分析モジュール405は、Cm−1がCmの部分集合であるように入れ子になったクラスタリングの階層構造[C1、C2、...、CM]を生成する階層的クラスタリングアルゴリズムを使用する。この階層は、ステップmにおけるクラスタリングがステップm−1において生成されたクラスタリングから生成されるM個のステップにおいて構築される。ステップ1において、サンプル集合Xにおける全ての要素が、その要素自体のクラスタを表す。2つのクラスタの非類似性関数D(ck、ck’)を使用して、以下のアルゴリズムが適用される。初めに、C1={{x1}、{x2}、...、{xM}}と初期化する。次いで、m=2、...、Mに対して、Cm−1のクラスタckminとck’minを統合することによって、新しいクラスタリングCmを取得する。ここで(kmin、k’min)=argmin(k,k’),k≠k’D(ck、ck’)である。
【0035】
クラスタ非類似性関数D(ck、ck’)は、例えば、インクサンプル非類似性関数D(xk、xk’)に基づくものである。インクサンプル間の差を決定するために任意の所望の非類似性関数を使用することができるが、本発明の種々の例は、1つのインクサンプルが別のインクサンプルとどれだけ類似しているかを決定するために弾性マッチングアルゴリズム(動的タイミング・ワーピング・アルゴリズムとしても知られる)を使用する。
【0036】
したがって、インクサンプルk(S個のストロークからなる)及びk’(S’個のストロークからなる)に対して、S≠S’の場合、
【0037】
【数2】
【0038】
であり、
S=S’の場合
【0039】
【数3】
【0040】
となる。ただし、P及びP’はサンプルk、k’の対応する再サンプリングされた座標ベクトルであり、Nはサンプリング点の数である。ベクトルPの要素pは3つの座標(x、y、Θ)を有し、ここでx及びyは点pのデカルト座標であり、Θは同じ点における傾きの推定値である。
【0041】
この定義より理解されるように、異なるストローク数を有するインクサンプルは、プロセスの最後まで、同じクラスタに統合されない。その時点で、統合は実際に停止してしまっている。
【0042】
したがって、
【0043】
【数4】
【0044】
が成り立つ。平均値又は最小値ではなく最大値を使用し、∞までの異なるストローク数を持つ2つのインクサンプル間の距離の定義を使用する判断は、小型のクラスタにとって有利である。
【0045】
クラスタにおけるインクサンプルが、クラスタの代表として選択される。あらゆるクラスタに対して選択される代表は、例えば、クラスタのメジアン中心である。クラスタckに対するメジアン中心x〜kは、残りのクラスタ要素のインクサンプルに対して最小のメジアン距離を有するインクサンプルとして定義される。すなわち、
【0046】
【数5】
【0047】
が成り立つ。あらゆる文字に対するクラスタリングの結果は2分木(「非類似性デンドログラム」とも呼ばれる)として視覚化されることができる。図5は、文字Kの様々なインクサンプルに関する結果として得られるデンドログラム501の一例を示す。この図において、ストロークは、ストロークの色すなわち(1)赤、(2)緑、(3)青及び(4)マゼンタがその書かれた順序を示すように色分けされる。また、それぞれのストロークは、その始点から終点に向かって次第に薄くなるように示される。
【0048】
本発明の種々の例によれば、あらゆる文字に対するクラスタの数が所望の閾値Dmaxとして定義され、クラスタの更なる統合は閾値Dmaxより上では行われない。その場合、統合が停止したときに残っている有効なクラスタは、対応する文字の様々な文字スタイル又は異書体として定義される。したがって、結果として得られるスタイルの数は、文字形状の多様性に依存して、文字毎に異なる。
【0049】
ユーザの利き手の決定
本発明のいくつかの実現形態によれば、認識訓練モジュール409は、書き手の利き手を認識する筆跡認識アプリケーションを生成するために、スタイル分析モジュール405によって生成されたデータを使用する。前述のように、文字のストロークの形状に加えて、本発明の種々の例は、異書体を定義するとき、各ストロークの方向及び各ストロークが書かれる順番をも考慮する。本発明の例を使用することによって、特定の異書体とそれらの異書体を使用する書き手の利き手との間の非常に高い相関が主観的に発見された。したがって、これらの異書体は、利き手を示す異書体として働く。図6は、これらの異書体のうちの幾つかと、それらに対応する書き手の利き手の統計とを示す。
【0050】
この図から分かるように、様々な異書体は、特定の利き手の書き手によってほぼ排他的に書かれる。例えば、文字Tを(横線が左から右ではなく右から左に向かって書かれる)スタイル601で書いた書き手の94.44%は、左手で書く。反対に、文字Tを(横線が左から右に向かって書かれる)スタイル603で書いた書き手の4.95%のみが、左手で書いている。
【0051】
したがって、認識訓練モジュール409は、利き手を示す1つ又は複数の異書体とユーザからの筆跡サンプルとを比較する、図7に示される筆跡認識ツール701などの筆跡認識アプリケーションをユーザに提供する。この図に見られるように、筆跡認識アプリケーション701は、ユーザからの筆跡入力411を受け取る筆跡収集モジュール703を備えている。また、筆跡認識アプリケーション701は、筆跡入力411の筆跡スタイルを決定する筆跡分析モジュール705を備える。そこで、利き手決定モジュール709は、ユーザの筆跡スタイルを、筆跡スタイルデータベース707における、利き手を示す筆跡スタイルと比較する。比較に基づいて、利き手決定モジュール709はユ―ザの利き手を決定する。
【0052】
本発明のいくつかの例によれば、利き手決定モジュール709は、決定された利き手をユーザが有すると結論するだけである。代りに、認識アプリケーションは、ユーザにその利き手を確認するように促すユーザインターフェース711をユーザに提供してもよい。この種のユーザインターフェースの一例が図8に図示されている。この図に見られるように、認識アプリケーション701は、ユーザが筆跡サンプルをテキスト入力パネル・ユーザインターフェース801に提出することに応答して、ユーザインターフェース711を提供する。ユーザの筆跡サンプルからの利き手の決定に基づいて、認識アプリケーション701は、例えば、ユーザの利き手に適する、コンピュータの1つ又は複数のユーザインターフェースを構成する。
【0053】
コミュニティに基づく筆跡認識
本発明の種々の例によれば、認識訓練モジュール409は、スタイル分析モジュール405によって生成されたデータを使用して、地理的領域、信仰する宗教、民族的背景、文化的集団又は任意の他の種類のコミュニティに特有の筆跡スタイル又は異書体に基づいて訓練された筆跡認識アプリケーションを生成する。例えば、前述の階層的クラスタリングアルゴリズムが、米国出身の267人の書き手によって書かれた99個の文字に対応する71,600個のインクサンプルに適用された。図9は、「ノイズのある」クラスタ(すなわち、出現頻度が極めて低いクラスタ)を取り除いた後の、文字「q」、「t」、「x」に関する結果のスタイルを、それらのスタイルの相対的頻度と共に示している。同じ実験が、英国出身の228人の書き手によって書かれた99個の文字に対応する70,000個のインクサンプルの集合に対して繰り返された。図10は、「ノイズのある」クラスタを取り除いた後の、文字「q」、「t」、「x」に対してこのデータから得られた結果のスタイルを、それらのスタイルの相対的頻度と共に示している。
【0054】
この実験から、両方の地理的コミュニティに対する主要な異書体は、異なる頻度で出現するけれども、ほとんどの文字に関してほぼ同じであるように見えると決定された。また、いくつかの二流の(すなわち、頻度の低い)異書体は、一方の地理的コミュニティに対しては存在するが、他方の地理的コミュニティに対しては存在しないように見える。その上、たとえ二流の異書体が両方の地理的コミュニティに現れるとしても、その頻度は地理的コミュニティ間で大きく異なる。
【0055】
スタイル分析モジュール405によって取得された、この種のコミュニティに基づく異書体及び筆跡スタイル情報を使用して、認識訓練モジュール409は、特定のコミュニティに共通する異書体に対して特に訓練された(又は、特に訓練されるように構成された)筆跡認識アプリケーションをユーザに提供する。1つのそのような筆跡認識ツール1101が図11に図示されている。この図に見られるように、筆跡認識アプリケーション1101は、ユーザからの筆跡入力411を受け取る筆跡収集モジュール1103を備える。また、筆跡認識アプリケーション1101は、筆跡入力411の筆跡スタイルを決定する筆跡分析モジュール1105を備える。そこで、筆跡認識モジュール1109は、ユーザの筆跡スタイルと筆跡スタイルデータベース1107における1つ又は複数の筆跡スタイルとを比較して、例えば、ユーザの筆跡の1つ又は複数の異書体が特定の地理的領域に属するコミュニティなどの特定のコミュニティに関連する異書体に対応するかどうかを決定する。
【0056】
この比較に基づいて、筆跡認識モジュール1109は筆跡スタイルデータベース1107における筆跡スタイルを使用して、ユーザからの現在の及び将来の筆跡入力411を認識することができる。本発明のいくつかの例によれば、筆跡認識モジュール1109は、ユーザが特定のコミュニティに属していると結論付けるだけである。代りに、認識アプリケーション1101は、ユーザが特定のコミュニティに属していることを確認するようにユーザに促すユーザインターフェースをユーザに提供することができる。
【0057】
言うまでもなく、スタイル分析モジュール405によって取得される異書体及び筆跡スタイル情報は、信仰する宗教、民族的背景、文化的集団又はユーザの筆跡スタイルに影響を与え得る任意の他の種類のコミュニティなどの、識別可能な筆跡スタイルに関連付けられる任意の所望の種類のコミュニティに、コミュニティ特有の筆跡認識アプリケーションを提供するために使用される。
【0058】
スタイルを意識した認識の訓練
また、スタイル分析モジュール405によって得られた異書体及び筆跡スタイル情報は、通常の筆跡認識アプリケーションを含む様々な種類の筆跡認識アプリケーションの訓練動作を改善するために取得される。例えば、スタイル分析モジュール405によって得られた異書体及び筆跡スタイル情報は、筆跡認識アプリケーションの訓練プロセスの期間に異常な筆跡サンプルをフィルタリングするために使用される。
【0059】
例えば、上述の実験において、ノイズがあって不良なインクサンプルで大部分が構成されたクラスタ(すなわち異書体)が存在することが観察された。しかし、傾向として、これらのクラスタは主に濃度が低かった。これは予測されることである。ノイズ仮説(又はデータの異常値)は通常は分散しており、一定でないからである。したがって、これらのクラスタ又は異書体は、無意味な異書体とみなされることができる。
【0060】
これらの無意味な異書体を筆跡認識アプリケーションの訓練から除外すること(すなわち、無意味な異書体を、筆跡認識アプリケーションの訓練のために使用される訓練文字の集合から除外すること)の影響が測定された。所望の閾値Ominを定義することができ、その閾値より下ではスタイルは無意味とみなされる。当業者によって理解されるように、この閾値のために選択される値は、筆跡訓練集合のために望まれる許容可能なノイズの量に基づく。これらの無意味な異書体を除外することの筆跡認識アプリケーションの認識精度に対する影響を測定するために、14人の書き手(うち2人は左利きである)によって書かれた18,628個のインクサンプルのデータベースが使用された。次いで、個々の誤り率及び平均誤り率が、5つの異なる筆跡認識アプリケーションに対して比較された。第1の筆跡認識アプリケーションは訓練集合全体について訓練された(すなわち100%認識器である)。第2の筆跡認識アプリケーションは、無意味な異書体を含む訓練集合全体のうちの15%について訓練された。そして、3つの残りの筆跡認識アプリケーションは、訓練集合全体のうちの15%について訓練されたが、異なる値のOminに基づいて無意味な異書体を除外した。
【0061】
図12は、異なる筆跡認識アプリケーションの間でOminの値と共に試験誤り率がどのように変化したかを示す。試験の結果に基づいて分かったのは、14人中の10人について、また平均して、対応する「削減されていない」筆跡認識アプリケーションよりも低い試験誤り率を有する筆跡認識アプリケーションを生成する「削減された」訓練集合(すなわち、無意味な異書体を除外した訓練集合)が存在することである。更に、14人の書き手のうちの5人に関しては、無意味な異書体を除外したデータのうちの15%について訓練することによって達成された試験誤り率が、訓練集合全体(すなわち、訓練集合のうちの100%)について筆跡認識アプリケーションを訓練することによって達成された誤り率よりも低かった。
【0062】
したがって、本発明の種々の例は、スタイル分析モジュール405によって識別された筆跡スタイルを使用して、どの異書体が、筆跡認識アプリケーション413によってユーザの筆跡認識を一層正確に認識するように筆跡認識アプリケーション413自身を訓練するために使用されるのかを決定することができる。当業者に理解されるように、Ominの値は、例えば筆跡認識アプリケーションが使用されるコミュニティに基づいて、訓練データの精度の高い集合を提供するよう実験的に選択されることができる。
【0063】
個人化された筆跡認識
本発明の更に他の例によれば、認識訓練モジュール409は、スタイル分析モジュール405によって得られたデータを使用して、ユーザの個人的な筆跡スタイル(すなわち、ユーザによって最もよく使用される異書体の集合)を認識するように特に調整された筆跡認識アプリケーションを生成する。
【0064】
従来の筆跡認識アプリケーションは差別的分類器モデルに基づく。これらの従来の筆跡認識アプリケーションのために使用される分類器は1文字分類器を含んでおり、典型的には、数百の書き手から収集されたデータを包含する訓練データにより訓練される。特定の書き手に対して筆跡認識アプリケーションを個人化するために、これらの分類器は、明示的な又は暗黙的な手段を介して書き手が提供する筆跡データの少量のサンプルで更に訓練される。通常、書き手に特有の訓練は、過学習を防ぐために、制限された繰り返し回数で実行される。個人化に対するこの従来のアプローチは、本明細書においては「古典的」個人化と呼ばれる。
【0065】
しかし、本発明の種々の例は、スタイル分析モジュール405によって得られたスタイル情報を使用する代替的なアプローチを使用してもよい。この代替的なアプローチは、本明細書において「スタイルに基づく」個人化と呼ばれる。より具体的には、このアプローチによれば、認識訓練モジュール409は、ユーザによって提供されたインクサンプルを使用して、ユーザによって典型的に使用される異書体の群を計算する。異書体のこの群は、ユーザの筆跡スタイル又は「スタイル・メンバシップ・ベクトル」を構成する。次いで、このベクトルは、書き手のスタイルに最も一致する訓練集合のサブセットを計算するために使用される。そこで、分類器は、訓練集合の計算されたサブセットについて訓練されることができる。
【0066】
このスタイルに基づく個人化のアプローチを評価するために、このアプローチを使用して訓練された筆跡認識アプリケーションの性能を、基本的な筆跡認識アプリケーション(すなわち、汎用筆跡認識アプリケーション)及び古典的個人化によって訓練された筆跡認識アプリケーションと比較した実験が行われた。267人の書き手によって書かれた70,000個のインクサンプルからなる訓練集合が、基本的な筆跡認識アプリケーションを生成するために使用された。14人の書き手の集合(そのうちの2人は左利きであり、どの書き手も訓練集合にデータを持たない)が個人化の実験の対象とされた。これらの書き手のそれぞれは、個人化の目的のために99個のサポートされる文字のそれぞれに対して2つのインクサンプルを提供し、合計で198個のインクサンプルを作成した。また、また、それぞれの書き手は、試験の目的のための文字に対して14個のサンプルを提供した。
【0067】
筆跡認識アプリケーションは、書き手の個人化のインクサンプルによって補強された元の訓練集合について汎用筆跡認識アプリケーションを訓練することによって、書き手のそれぞれに対して個人化された。上述のように、これらの筆跡認識アプリケーションは、古典的に個人化された筆跡認識アプリケーションと呼ばれる。次いで、別の汎用筆跡認識アプリケーションが、書き手の個人化データを使用して書き手の筆跡スタイルに一致した訓練集合のサブセットを選択することにより、書き手のそれぞれに対して個人化された。すなわち、訓練集合に対してスタイル分析を実行した後、書き手の個人化インクサンプルのそれぞれが、訓練集合における各文字に対する異書体のうちの1つを有効化するために使用された。次に、筆跡認識アプリケーションは、個人化インクサンプルによって補強された訓練データのこのサブセットについて、当該書き手に対して訓練された。上述のように、これらの筆跡認識アプリケーションは、スタイル個人化された筆跡認識アプリケーションと呼ばれる。これらの3つの筆跡認識アプリケーションのそれぞれが、それぞれの書き手によって提供された試験集合に対して評価された。
【0068】
図13及び図14は、この実験において対象とされた14人の書き手のそれぞれに対する上述の3つの筆跡認識アプリケーションのそれぞれに対する試験誤り率と、それぞれのスタイル個人化された筆跡認識アプリケーションを訓練するために選択された訓練集合の百分率とを示している。これらの図から分かるように、14人の書き手のそれぞれに関して、古典的個人化筆跡認識アプリケーション及びスタイル個人化された筆跡認識アプリケーションは、基本的な認識器によってもたらされた試験誤り率から試験誤り率を低下させた。また、12人の書き手に関して、スタイル個人化された筆跡認識アプリケーションは、古典的に個人化された筆跡認識アプリケーションによってもたらされた誤りの減少よりも大きな誤りの減少をもたらした。更に、スタイル個人化された筆跡認識アプリケーションによってもたらされた平均相対誤差の減少は約27%であったが、平均相対誤差の減少は、古典的に個人化された筆跡認識アプリケーションに関しては約20%にすぎなかった。更に、スタイルに基づく個人化において選択された訓練集合の部分の平均的な大きさは、基本的な訓練集合の約68%であった。
【0069】
したがって、スタイル分析モジュール405が、ユーザから取得した筆跡サンプルを分析した後、認識訓練モジュール409は、スタイル分析モジュール405によって提供されたデータを使用して、精度の向上を達成するようユーザから一層少ない訓練を要求しながらも、ユーザに対して一層高い認識精度を提供する、スタイル個人化された筆跡認識アプリケーションを生成する。より具体的には、筆跡スタイル分析ツール401は、ユーザの筆跡スタイルに対応した異書体を含む又はその異書体に制限された訓練集合を使用する筆跡認識アプリケーション413をユーザに提供する。
【0070】
スタイル予測
筆跡認識アプリケーションの訓練集合を改善することに加えて、本発明の種々の例によれば、代替的に又は追加的に、筆跡スタイル分析ツール401はユーザの筆跡入力411からユーザの筆跡スタイルを予測する(及び/又は、ユーザの筆跡入力411からユーザの筆跡スタイルを予測する筆跡認識アプリケーションを提供する)。例えば、筆跡スタイル分析ツール401は、例えば協調フィルタリングを使用して、書き手がいくつかの文字をどのように書くかを、他の文字の収集されたインクサンプルに基づいて予測する。
【0071】
協調フィルタリングは、他のユーザのサンプル又は集団からのユーザの投票のデータベースに基づいて特定のユーザに対するアイテムの有用性を予測するために普通に使用される公知の技術である。本発明の種々の例の実施に特に関連するのは、メモリベースのアルゴリズムとして知られる協調フィルタリングの分類である。
【0072】
この種の協調フィルタリングによれば、(アイテムjについてのユーザiの投票に対応する)投票vi,jからなるユーザデータベースが用いられて、新たなユーザuに関する何らかの部分的情報とユーザデータベースから計算された1組の重みとに基づいて、有効なユーザの投票が予測される。アイテムjに関する新たなユーザuの予測される投票がPu,jであると仮定される。Pu,jは、データベースにおける他のユーザの投票の加重和である。すなわち、
【0073】
【数6】
【0074】
である。ただし、Nは協調フィルタリングのデータベースにおけるユーザ数である。重みw(u、i)は、各ユーザiとユーザuとの間の相関又は類似性を反映する。値αは、投票の合計が1になることを保証するための正規化係数である。
【0075】
重みを計算する最も単純で最も普通の方法は、ピアソンの相関係数を使用することである。この係数を使用すると、ユーザiとuとの間の相関は、
【0076】
【数7】
【0077】
によって与えられる。jについての加算は、ユーザu及びiが投票したアイテムについて行われる。
書き手の筆跡スタイルの予測において、ユーザデータベースは筆跡スタイルデータベースに対応し、ユーザの投票は書き手のスタイル・メンバシップ・ベクトルの値に対応し、部分的な投票が知られているユーザuは、入力筆跡データから部分的なスタイルメンバシップが知られている書き手であって、筆跡スタイル分析ツール401(又は筆跡認識アプリケーション413)が残りのスタイルを予測するように要求される書き手に対応する。本発明の種々の例によれば、筆跡スタイル分析ツール401(又は筆跡認識アプリケーション413)は、例えば文字a、A、I、0、1、2、9に基づいてユーザの筆跡スタイルを予測する。これは、これらの文字が特有であり、筆跡認識器の日々の使用の中で獲得されやすいからである。言うまでもなく、本発明の代替的な例は、ユーザの筆跡スタイルを予測するために文字の任意の組合せを使用する。
【0078】
本発明のいくつかの例によれば、筆跡スタイル分析ツール401(又は筆跡認識アプリケーション413)は、ユーザが特定の筆跡スタイルを有することを予測し、このスタイルを構成する異書体を使用してユーザの筆跡を認識するだけである。代りに、筆跡スタイル分析ツール401(又は筆跡認識アプリケーション413)は、予測された筆跡スタイルに基づいて、ユーザがどのように特定の文字を書き得るかを確認するようにユーザに促すユーザインターフェースをユーザに提供する。この種のユーザインターフェースの一例が図15に示される。この図に見られるように、ユーザインターフェース1501は、ユーザの筆跡入力に最もよく対応する筆跡スタイル内の異書体の一次選択1503を提供する。また、ユーザインターフェース1501は、異書体の一次選択よりも幾分劣るユーザの筆跡入力に対応する筆跡スタイル内の異書体1505の代替的集合を提供する。ユーザの筆跡スタイルの決定に基づいて、筆跡認識アプリケーション413は、上で詳細に検討されたように、ユーザの筆跡入力を一層正確に認識することができる。
【0079】
結論
本発明について、本発明を実施する現在の好ましい形態を含む特定の例に関して説明してきたが、当業者は理解するように、特許請求の範囲に記載された本発明の精神及び範囲内に入る上述のシステム及び技術の多数の変更及び変形が存在する。
【図面の簡単な説明】
【0080】
【図1A】学校で筆跡を教えるために典型的に使用される模範的筆跡スタイルを示す図である。
【図1B】学校で筆跡を教えるために典型的に使用される模範的筆跡スタイルを示す図である。
【図2】本発明の種々の例に係る、筆跡認識技術を実施するために使用されることができる動作環境の例を示す図である。
【図3】本発明の種々の例に係る、筆跡認識技術を実施するために使用されることができる動作環境の例を示す図である。
【図4】本発明の種々の例によって実施されることができる筆跡スタイル分析ツールを示す図である。
【図5】文字Kの様々なインクサンプルに関するクラスタリングの一例を示す図である。
【図6】様々な利き手を示す異書体と、それらの異書体に対応する書き手の利き手の統計とを示す図である。
【図7】本発明の種々の例に係る、ユーザからの筆跡サンプルと利き手を示す1つ又は複数の異書体とを比較する筆跡認識ツールを示す図である。
【図8】本発明の種々の例によって使用される、利き手を確認するようにユーザに促すユーザインターフェースを示す図である。
【図9】本発明の種々の例に係る階層的クラスタリングアルゴリズムを、米国出身の267人の書き手によって書かれた99の文字に対応する71,600個のインクサンプルに対して実行することによって得られた文字「q」、「t」、「x」に関する結果のスタイルを示す図である。
【図10】本発明の種々の例に係る階層的クラスタリングアルゴリズムを英国出身の228人の書き手によって書かれた99の文字に対応する70,000個のインクサンプルに対して実行することによって得られた文字「q」、「t」、「x」に関する結果のスタイルを示す図である。
【図11】特定のコミュニティに共通の異書体に関して特に訓練された(又は特に訓練されるように構成された)筆跡認識アプリケーションを示す図である。
【図12】異なる筆跡認識アプリケーション間の様々なレベルのノイズを除外することによる試験誤り率の変化を示す図である。
【図13】異なる訓練技術を使用した3つの筆跡認識アプリケーションのそれぞれに関する試験誤り率を示す図である。
【図14】異なる訓練技術を使用した3つの筆跡認識アプリケーションのそれぞれに関する試験誤り率を示す図である。
【図15】予測された筆跡スタイルに基づいて、どのように特定の文字を書き得るかを確認するようにユーザに促すユーザインターフェースを示す図である。
【特許請求の範囲】
【請求項1】
ユーザから筆跡を収集する筆跡収集モジュールと、
前記収集された筆跡を分析し、前記収集された筆跡のスタイルを決定するスタイル分析モジュールと、
を備える筆跡スタイル分析ツール。
【請求項2】
前記スタイル分析モジュールが、前記収集された筆跡に関連するコミュニティを更に識別する、請求項1に記載の筆跡スタイル分析ツール。
【請求項3】
前記コミュニティが、地理的領域、文化的集団又は信仰する宗教によって定義される、請求項2に記載の筆跡スタイル分析ツール。
【請求項4】
前記スタイル分析が、前記ユーザに特有のスタイルを識別する、請求項1に記載の筆跡スタイル分析ツール。
【請求項5】
ユーザから収集された筆跡を分析し、前記収集された筆跡のスタイルを決定する筆跡分析モジュールと、
利き手を示す筆跡スタイルを含む筆跡スタイルデータベースと、
前記収集された筆跡の前記スタイルを、前記利き手を示す筆跡スタイルと比較し、前記ユーザの利き手を決定する利き手決定モジュールと、
を備える筆跡認識アプリケーション。
【請求項6】
前記筆跡分析モジュールは、前記決定された利き手を確認するように前記ユーザに促すインターフェースを前記ユーザに更に提供する、請求項5に記載の筆跡認識アプリケーション。
【請求項7】
前記筆跡分析モジュールが、前記決定された利き手に基づいて動作するようにコンピュータを構成する、請求項5に記載の筆跡認識アプリケーション。
【請求項8】
筆跡認識アプリケーションを訓練する方法であって、
複数の書き手から筆跡を収集するステップと、
前記複数の書き手に関する筆跡スタイルを決定するステップと、
前記決定された筆跡スタイルのうちの少なくとも1つから選択された訓練サンプルを使用して筆跡認識アプリケーションを訓練するステップと、
を含む筆跡認識アプリケーション訓練方法。
【請求項9】
前記決定された筆跡スタイルのうちの少なくとも1つから選択された訓練サンプルのみを使用して前記筆跡認識アプリケーションを訓練するステップを更に含む、請求項8に記載の筆跡認識アプリケーション訓練方法。
【請求項10】
ユーザから収集された筆跡を分析するステップと、
前記決定されたスタイルのうちの少なくとも1つを前記ユーザに関連付けるステップと、
前記ユーザに関連付けられた前記決定された筆跡スタイルのうちの少なくとも1つから選択された訓練サンプルを使用して前記筆跡認識アプリケーションを訓練するステップと、
を更に含む、請求項8に記載の筆跡認識アプリケーション訓練方法。
【請求項11】
前記決定されたスタイルのうちの前記関連付けられた少なくとも1つが、コミュニティに共通のスタイルである、請求項10に記載の筆跡認識アプリケーション訓練方法。
【請求項12】
前記コミュニティが、地理的領域、文化的集団又は信仰する宗教によって定義される、請求項11に記載の筆跡認識アプリケーション訓練方法。
【請求項13】
前記決定されたスタイルのうちの前記関連付けられた少なくとも1つが、前記ユーザに特有のスタイルである、請求項10に記載の筆跡認識アプリケーション訓練方法。
【請求項14】
前記決定されたスタイルのうちの前記関連付けられた少なくとも1つが、利き手を示すスタイルである、請求項10に記載の筆跡認識アプリケーション訓練方法。
【請求項15】
ユーザから収集された筆跡を分析するステップと、
前記決定されたスタイルのうちの少なくとも1つを前記ユーザに関連付けるステップと、
前記ユーザによって書かれた文字に関する筆跡スタイルを予測するために前記決定されたスタイルのうちの前記関連付けられた少なくとも1つを使用するステップと、
を更に含む、請求項8に記載の筆跡認識アプリケーション訓練方法。
【請求項16】
前記予測された筆跡スタイルを確認するようにユーザに促すステップを更に含む、請求項15に記載の筆跡認識アプリケーション訓練方法。
【請求項17】
ユーザによって書かれた文字に関する筆跡スタイルを予測するためにメモリベースの協調フィルタリングを使用するステップを更に含む、請求項15に記載の筆跡認識アプリケーション訓練方法。
【請求項1】
ユーザから筆跡を収集する筆跡収集モジュールと、
前記収集された筆跡を分析し、前記収集された筆跡のスタイルを決定するスタイル分析モジュールと、
を備える筆跡スタイル分析ツール。
【請求項2】
前記スタイル分析モジュールが、前記収集された筆跡に関連するコミュニティを更に識別する、請求項1に記載の筆跡スタイル分析ツール。
【請求項3】
前記コミュニティが、地理的領域、文化的集団又は信仰する宗教によって定義される、請求項2に記載の筆跡スタイル分析ツール。
【請求項4】
前記スタイル分析が、前記ユーザに特有のスタイルを識別する、請求項1に記載の筆跡スタイル分析ツール。
【請求項5】
ユーザから収集された筆跡を分析し、前記収集された筆跡のスタイルを決定する筆跡分析モジュールと、
利き手を示す筆跡スタイルを含む筆跡スタイルデータベースと、
前記収集された筆跡の前記スタイルを、前記利き手を示す筆跡スタイルと比較し、前記ユーザの利き手を決定する利き手決定モジュールと、
を備える筆跡認識アプリケーション。
【請求項6】
前記筆跡分析モジュールは、前記決定された利き手を確認するように前記ユーザに促すインターフェースを前記ユーザに更に提供する、請求項5に記載の筆跡認識アプリケーション。
【請求項7】
前記筆跡分析モジュールが、前記決定された利き手に基づいて動作するようにコンピュータを構成する、請求項5に記載の筆跡認識アプリケーション。
【請求項8】
筆跡認識アプリケーションを訓練する方法であって、
複数の書き手から筆跡を収集するステップと、
前記複数の書き手に関する筆跡スタイルを決定するステップと、
前記決定された筆跡スタイルのうちの少なくとも1つから選択された訓練サンプルを使用して筆跡認識アプリケーションを訓練するステップと、
を含む筆跡認識アプリケーション訓練方法。
【請求項9】
前記決定された筆跡スタイルのうちの少なくとも1つから選択された訓練サンプルのみを使用して前記筆跡認識アプリケーションを訓練するステップを更に含む、請求項8に記載の筆跡認識アプリケーション訓練方法。
【請求項10】
ユーザから収集された筆跡を分析するステップと、
前記決定されたスタイルのうちの少なくとも1つを前記ユーザに関連付けるステップと、
前記ユーザに関連付けられた前記決定された筆跡スタイルのうちの少なくとも1つから選択された訓練サンプルを使用して前記筆跡認識アプリケーションを訓練するステップと、
を更に含む、請求項8に記載の筆跡認識アプリケーション訓練方法。
【請求項11】
前記決定されたスタイルのうちの前記関連付けられた少なくとも1つが、コミュニティに共通のスタイルである、請求項10に記載の筆跡認識アプリケーション訓練方法。
【請求項12】
前記コミュニティが、地理的領域、文化的集団又は信仰する宗教によって定義される、請求項11に記載の筆跡認識アプリケーション訓練方法。
【請求項13】
前記決定されたスタイルのうちの前記関連付けられた少なくとも1つが、前記ユーザに特有のスタイルである、請求項10に記載の筆跡認識アプリケーション訓練方法。
【請求項14】
前記決定されたスタイルのうちの前記関連付けられた少なくとも1つが、利き手を示すスタイルである、請求項10に記載の筆跡認識アプリケーション訓練方法。
【請求項15】
ユーザから収集された筆跡を分析するステップと、
前記決定されたスタイルのうちの少なくとも1つを前記ユーザに関連付けるステップと、
前記ユーザによって書かれた文字に関する筆跡スタイルを予測するために前記決定されたスタイルのうちの前記関連付けられた少なくとも1つを使用するステップと、
を更に含む、請求項8に記載の筆跡認識アプリケーション訓練方法。
【請求項16】
前記予測された筆跡スタイルを確認するようにユーザに促すステップを更に含む、請求項15に記載の筆跡認識アプリケーション訓練方法。
【請求項17】
ユーザによって書かれた文字に関する筆跡スタイルを予測するためにメモリベースの協調フィルタリングを使用するステップを更に含む、請求項15に記載の筆跡認識アプリケーション訓練方法。
【図1A】


【図1B】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】

【図9】
【図10】
【図11】
【図12】
【図13】
【図14】

【図15】
【図1B】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【公表番号】特表2009−506464(P2009−506464A)
【公表日】平成21年2月12日(2009.2.12)
【国際特許分類】
【出願番号】特願2008−529224(P2008−529224)
【出願日】平成18年8月29日(2006.8.29)
【国際出願番号】PCT/US2006/033824
【国際公開番号】WO2007/027747
【国際公開日】平成19年3月8日(2007.3.8)
【出願人】(500046438)マイクロソフト コーポレーション (3,165)
【Fターム(参考)】
【公表日】平成21年2月12日(2009.2.12)
【国際特許分類】
【出願日】平成18年8月29日(2006.8.29)
【国際出願番号】PCT/US2006/033824
【国際公開番号】WO2007/027747
【国際公開日】平成19年3月8日(2007.3.8)
【出願人】(500046438)マイクロソフト コーポレーション (3,165)
【Fターム(参考)】
[ Back to top ]