
細胞識別装置及びプログラム
【課題】株レベルでの細胞識別を高精度且つ迅速に行うことのできる細胞識別装置を提供する。
【解決手段】被検細胞を質量分析して得られた結果に基づいて該被検細胞の種類を識別する装置において、既知細胞の構成成分のイオン質量が記載された質量リストを収録した上位DB21と、前記イオン質量のうち各株に特異的なものだけを記載した部分質量リストを収録した下位DB22とを設け、まず、被検細胞の質量分析結果から作成された被検質量リストを用いて上位DB21を検索し、その検索に基づいて以降の検索で対象とする生物種を決定した後、前記被検細胞の質量リストから前記生物種に共通する質量を削除し、削除後の質量リストを用いて下位DB22に対する検索を行う構成とする。これにより、遺伝的に近縁な複数の既知細胞の中から被検細胞により近いものを高い精度で抽出することが可能となる。
【解決手段】被検細胞を質量分析して得られた結果に基づいて該被検細胞の種類を識別する装置において、既知細胞の構成成分のイオン質量が記載された質量リストを収録した上位DB21と、前記イオン質量のうち各株に特異的なものだけを記載した部分質量リストを収録した下位DB22とを設け、まず、被検細胞の質量分析結果から作成された被検質量リストを用いて上位DB21を検索し、その検索に基づいて以降の検索で対象とする生物種を決定した後、前記被検細胞の質量リストから前記生物種に共通する質量を削除し、削除後の質量リストを用いて下位DB22に対する検索を行う構成とする。これにより、遺伝的に近縁な複数の既知細胞の中から被検細胞により近いものを高い精度で抽出することが可能となる。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、細胞由来の成分を質量分析した結果に基づいて該細胞の種類を識別するための装置、及びプログラムに関する。
【背景技術】
【0002】
従来、細胞の種類を識別する手法の1つとしてDNA塩基配列に基づく相同性解析が知られており、微生物の分類・同定等に広く用いられている(例えば、特許文献1を参照)。この手法では、まず、被検細胞からDNAを抽出してrRNA遺伝子等の全生物に高い保存性で存在している領域のDNA塩基配列を決定する。次に、このDNA塩基配列を用いて、既知細胞のDNA塩基配列データを多数収録したデータベースを検索し、前記被検細胞のDNA塩基配列と高い類似性を示す塩基配列を選出する。そして、該塩基配列が由来する生物種を、前記被検細胞と同一種又は近縁種であると判定する。
【0003】
しかしながら、こうしたDNA塩基配列を利用した手法では、被検細胞からのDNA抽出やDNA塩基配列の決定などに比較的長い時間を要するため、迅速な細胞識別を行うのが困難であるという問題があった。
【0004】
そこで、近年では被検細胞を質量分析して得られた質量スペクトルパターンに基づいて細胞識別を行う手法が用いられるようになりつつある(例えば、特許文献2を参照)。この手法では、まず、被検細胞から抽出したタンパク質を含む溶液や被検細胞の懸濁液等をMALDI−MS(マトリックス支援レーザ脱離イオン化質量分析)等のソフトなイオン化法を用いた質量分析装置によって分析する。そして、得られた質量スペクトルパターンを、データベースに収録された既知細胞の質量スペクトルパターンと照合することにより、被検細胞の同定を行う。質量分析では、ごく微量の細胞試料を用いて短時間で分析結果を得ることができ、且つ多検体の連続分析も容易である。そのため、こうした質量分析を利用した細胞識別手法によれば、簡便且つ迅速な細胞識別が可能となる。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2006-191922号公報
【特許文献2】特開2007-316063号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
上記の質量分析を利用した細胞識別手法では、一般に、リボソームタンパク質群の質量情報に着目して細胞の識別が行われる。しかしながら、リボソームタンパク質群はアミノ酸配列の保存性が高いため、同一の生物種に属する細胞同士では、質量スペクトル上に現れるピークの大部分が同一質量となる。そのため、こうした質量分析を利用した細胞識別方法では、細胞の種(species)レベルでの違いを識別することはできても、その下位の分類である株(strain)レベルでの違いを識別するのは困難な場合があった。
【0007】
本発明は上記課題を解決するために成されたものであり、その目的とするところは、株レベルでの細胞識別を高精度且つ迅速に行うことのできる細胞識別装置を提供することにある。
【課題を解決するための手段】
【0008】
上記課題を解決するために成された本発明の第1の態様に係る細胞識別装置は、記憶装置及び演算装置を有し、被検細胞を質量分析して得られた結果に基づいて該被検細胞の種類を識別する装置であって、
前記記憶装置が、既知細胞の構成成分のイオン質量又は分子量が記載された質量リストを複数の既知細胞について収録した第1データベースと、既知細胞の構成成分のイオン質量又は分子量のうち、該既知細胞が属する予め定められた階級の分類群に共通するイオン質量又は分子量以外を記載した部分質量リストを複数の既知細胞について収録した第2データベースと、を記憶しており、
前記演算装置が、
a)前記質量分析の結果に基づいて作成された前記被検細胞の構成成分のイオン質量又は分子量を記載した被検質量リストを用いて前記第1データベースを検索する第1検索手段と、
b)前記第1検索手段による検索結果に基づいて、前記階級に位置する分類群のいずれかを以降の検索で対象とする分類群として決定する分類群決定手段と、
c)前記被検質量リストから前記分類群決定手段で決定された分類群に共通するイオン質量又は分子量を削除した被検部分質量リストを作成する被検部分質量リスト作成手段と、
d)前記被検部分質量リスト作成手段により作成された被検部分質量リストを用いて前記第2データベースを検索する第2検索手段と、
を有することを特徴としている。
【0009】
なお、上記の分類群決定手段は、例えば、第1検索手段による検索の結果、被検質量リストとの一致度が高かったものを自動的に以降の検索で対象とする分類群を決定するものとしてもよく、あるいは第1検索手段による検索結果をモニタ等の表示装置に表示させると共に、ユーザからの分類群の指定を受け付け、前記検索結果に基づいてユーザがキーボード等の入力装置から指定した分類群を以降の検索で対象とする分類群として決定するものとしてもよい。
【0010】
本願発明に係る細胞識別装置による細胞識別の原理について図6、7を用いて説明する。本発明の細胞識別装置は、第1データベース(第1DB)と第2データベース(第2DB)を備えており、それぞれ、例えば図6に示すような複数の既知細胞に関する質量リスト、及び図7に示すような複数の既知細胞に関する部分質量リストが登録されている。ここで、質量リストとは、ある細胞の構成成分のイオン質量又は分子量を記載したリストであり、例えば、ある細胞を質量分析し、得られた質量スペクトル上の各ピークの質量(厳密にはm/z)をリスト化することによって作成することができる。一方、部分質量リストとは、ある細胞の構成成分のイオン質量又は分子量のうち、該細胞が属する、所定の分類階級(生物分類の階層)の分類群に共通するイオン質量又は分子量以外を記載したものであり、例えば、ある細胞について作成された前記質量リストから、該細胞が属する種において共通に含まれるものを削除することにより作成することができる。なお、図6、7では、各質量リスト及び部分質量リストを質量スペクトル上に現れるピークの質量及び高さの情報を含んだものとしているが、本発明における質量リストには必ずしもピークの高さ(即ち、各構成成分の存在量比)の情報を含める必要はない。
【0011】
本発明における細胞識別装置では、まず、被検細胞を質量分析した結果から作成された質量リスト(被検質量リスト)を用いて第1データベースを検索する。このとき、図6に示すように、前記被検質量リスト及び第1データベース中の各質量リストには、いずれも多数の質量が列挙されているが、遺伝的に近縁の細胞(例えば、同一種に属する生物の細胞)同士では、その大部分が一致する。例えば、図6の例の場合、既知細胞Aの質量リストには被検質量リストに列挙された20個の質量の内の19個が含まれており、既知細胞Bの質量リストには前記20個の内18個が、既知細胞Cの質量リストには17個が含まれている。そのため、被検質量リストに挙げられた質量の内、各既知細胞の質量リストに含まれているものの割合は、既知細胞Aで19/20=0.95、既知細胞Bで18/20=0.9、既知細胞Cで17/20=0.85のように、相互に近い値となる(なお、図6では簡略化のため各質量リストに含まれる質量の数を少なくしているが、実際の質量リストには、より多くの質量が列挙されるため、遺伝的に近縁の細胞間における前記割合の違いは一層小さくなる)。
【0012】
このように第1データベースによる検索では、遺伝的に近縁の既知細胞同士では被検細胞との照合結果の差が小さくなる。しかし、従来の細胞識別装置では、こうした第1データベースの検索に相当する検索のみを行っているため、種レベルでの細胞識別は可能であっても、株レベルでの高精度な細胞識別を行うのは一般的に困難であった。
【0013】
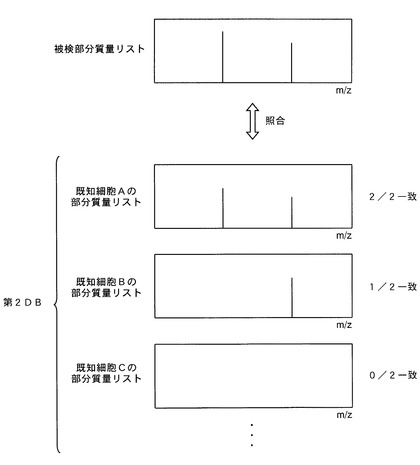
これに対し、本発明の細胞識別装置では、第1データベースを検索した結果に基づいて被検細胞が属する分類群(例えば種)を決定した後、該分類群に共通して存在する質量を前記被検質量リストから削除する。これにより、例えば、図7の上段に示すような被検細胞の部分質量リスト(被検部分質量リスト)が作成される。そして、この被検部分質量リストを用いて第2データベースを対象とした検索を行う。上述の通り、第2データベースに収録された部分質量リストでは、各既知細胞の構成成分のイオン質量(又は分子量)のうち、該既知細胞が属する所定階級の分類群に共通するものが除かれている。そのため、第2データベース中の各部分質量リストには、その細胞が属する分類群(分類群決定手段で決定された分類群の1つ下の階級の分類群、例えば株)に特異的な質量のみが記載されており、記載されている質量の総数も前記質量リストに比べて大幅に少なくなっている。このため、第2データベースを対象とした検索では、遺伝的に近縁の細胞同士であっても被検細胞との照合結果の違いが大きくなる。例えば、図7の例では、被検部分質量リストに記載された質量の内、各既知細胞の部分質量リストに含まれているものの割合は、既知細胞Aで2/2=1、既知細胞Bで1/2=0.5、既知細胞Cで0/2=0となり、図6の例に比べて既知細胞間での結果の違いが大きくなっている。このため、第2データベースを対象とした検索では、遺伝的に近縁な複数の既知細胞の中から被検細胞により近いものを高い精度で抽出することが可能となり、その結果、従来困難であった株レベルでの高精度な細胞識別が可能となる。
【0014】
なお、本発明に係る細胞識別装置は、上記のように第1データベースと第2データベースを対象として2段階検索を行う構成とするほか、1つのデータベースを対象として2段階の検索を行う構成とすることもできる。
【0015】
即ち、上記課題を解決するために成された本発明の第2の態様に係る細胞識別装置は、記憶装置及び演算装置を有し、被検細胞を質量分析して得られた結果に基づいて該被検細胞の種類を識別する装置であって、
前記記憶装置が、既知細胞の構成成分のイオン質量又は分子量が記載された質量リストを複数の既知細胞について収録したデータベースを記憶しており、
前記演算装置が、
a)前記質量分析の結果に基づいて作成された前記被検細胞の構成成分のイオン質量又は分子量が記載された被検質量リストを用いて前記データベースを検索する第1検索手段と、
b)前記第1検索手段による検索結果に基づいて以降の検索で対象とする分類群を決定する分類群決定手段と、
c)前記被検質量リストから前記分類群決定手段で決定された分類群に共通するイオン質量又は分子量を削除した被検部分質量リストを作成する被検部分質量リスト作成手段と、
d) 前記データベースに収録された質量リストの内、前記分類群決定手段で決定された分類群に属する既知細胞の質量リストを検索対象として前記被検部分質量リストを用いた検索を行う第2検索手段と、
を有し、
前記第2検索手段が、検索対象とする質量リストから前記分類群決定手段で決定された分類群に共通するイオン質量又は分子量を削除し、該削除後の質量リストに対して前記被検部分質量リストを用いた検索を行うものであることを特徴としている。
【発明の効果】
【0016】
以上説明した通り、本発明に係る細胞識別装置によれば、遺伝的に近縁な複数の既知細胞の中から被検細胞により近いものを高い精度で抽出することができる。そのため、本発明に係る細胞識別装置によれば、従来困難であった株レベルでの高精度な細胞識別を簡便且つ迅速に行うことが可能となる。
【図面の簡単な説明】
【0017】
【図1】本発明の実施例1に係る細胞識別システムの要部を示す構成図。
【図2】同システムの動作を示すフローチャート。
【図3】本発明の実施例2に係る細胞識別システムの要部を示す構成図。
【図4】同システムの動作を示すフローチャート。
【図5】本発明の実施例3に係る細胞識別システムの要部を示す構成図。
【図6】第1データベースに対する検索を説明するための概念図。
【図7】第2データベースに対する検索を説明するための概念図。
【発明を実施するための形態】
【0018】
以下、本発明に係る細胞識別装置を実施するための形態について実施例を挙げて説明する。
【実施例1】
【0019】
図1は本実施例に係る細胞識別装置を備えた細胞識別システムの全体図であり、図2は本システムを用いた細胞識別の手順を示すフローチャートである。
【0020】
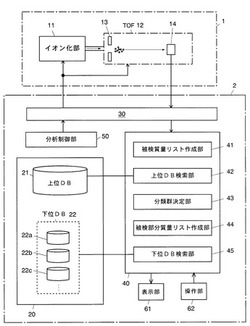
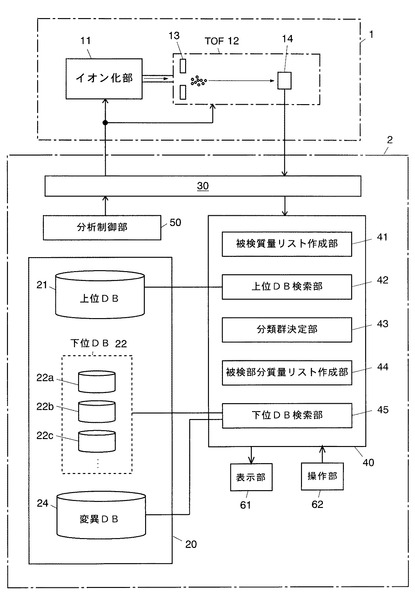
本実施例の細胞識別装置は、大別して、質量分析部1と細胞識別部2と、から成る。質量分析部1は、マトリックス支援レーザ脱離イオン化法(MALDI)によって試料中の分子や原子をイオン化するイオン化部11と、イオン化部11から出射された各種イオンを質量に応じて分離する飛行時間型質量分離器(TOF)12を備える。
【0021】
TOF12は、イオン化部11からイオンを引き出してTOF12内のイオン飛行空間に導くための引き出し電極13と、イオン飛行空間で質量分離されたイオンを検出する検出器14とを備える。
【0022】
細胞識別部2は、検索用のデータベースを格納した記憶部20と、通信線を介して前記質量分析部1との情報のやり取りを行うインターフェース部30と、質量分析部1の検出器14から出力された検出信号に基づいて前記データベースの検索を行う演算部40と、質量分析部1の動作を制御する分析制御部50とを備えている。
【0023】
記憶部20はハードディスク装置等の大容量記憶装置から成り、上位データベース21と下位データベース22の2種類のデータベースを格納している。これらの上位データベース21及び下位データベース22は、それぞれ本発明における第1データベース及び第2データベースに相当する。
【0024】
上位データベース21には、既知微生物に関する質量リストが多数登録されている。本実施例における質量リストは、ある微生物細胞を質量分析した際に検出されるイオンの質量を列挙したものであり、該イオン質量の情報に加えて、少なくとも、前記微生物細胞が属する分類群(属、種、及び株)の情報(分類情報)を含んでいる。こうした質量リストは、予め各種の微生物細胞を前記質量分析部1によるものと同様のイオン化法及び質量分離法によって実際に質量分析して得られたデータ(実測データ)に基づいて作成することが望ましい。
【0025】
前記実測データから質量リストを作成する際には、まず、前記実測データとして取得された質量スペクトルから所定の質量範囲に現れるピークを抽出する。このとき、前記質量範囲を4,000〜15,000程度とすることにより、主にタンパク質由来のピークを抽出することができる。また、ピークの高さ(相対強度)が所定の閾値以上のものだけを抽出することにより、不所望のピーク(ノイズ)を除外することができる。なお、リボソームタンパク質群は細胞内で大量に発現しているため、前記閾値を適切に設定することにより、質量リストに記載される質量の大部分をリボソームタンパク質由来のものとすることができる。そして、以上により抽出されたピークの質量(m/z)を細胞毎にリスト化し、前記分類情報等を付加した上で上位データベース21に登録する。なお、培養条件による遺伝子発現のばらつきを抑えるため、実測データの採取に用いる各微生物細胞は、予め培養環境を規格化しておくことが望ましい。
【0026】
なお、膨大な既知微生物の全てについて、上記のような実測データを取得するのは困難である。そこで、少なくとも一部の微生物については、上記のような実測データに基づく質量リストの代わりに、計算により求められた分子量(計算分子量)に基づく質量リストを上位データベース21に登録するようにしてもよい。この場合、各質量リストには、それが実測データ及び計算分子量のいずれに基づいて作成されたものであるかを示す情報を付与しておくことが望ましい。
【0027】
前記計算分子量に基づく質量リストは、例えば、以下のようにして作成される。
【0028】
(1)既存のデータベース(例えばDDBJ、EMBL、GenBank等の公共データベース)から既知微生物の遺伝子(例えば、リボソームタンパク質群の遺伝子)のDNA塩基配列を入手し、それをアミノ酸配列に翻訳することによって該微生物の細胞に含まれる各種タンパク質の計算分子量を導出する。このとき、更に、前記計算分子量に、N−末端開始メチオニン残基の切断、翻訳後修飾、又は生物情報工学的な相同性解析に基づいて行われるアミノ酸配列の修正を加味した補正を施し、これを補正前の計算分子量に加えて又は代えて質量リストの作成に使用するようにしてもよい。なお、前記「生物情報工学的な相同性解析に基づいて行われるアミノ酸配列の修正」は次のようなものである。まず、BLAST等の相同性解析を利用して対象微生物の遺伝子配列と相同性の高い遺伝子配列を既存のデータベース等で検索する。次に、それらの中でアノテーションされているものを参照して正しい翻訳領域を推測する。次に、それに基づいてアミノ酸配列を修正し、補正後のアミノ酸配列から計算分子量を算出する。
【0029】
また、上記既存のデータベースに各種微生物細胞に含まれるタンパク質の計算分子量が収録されている場合は、これを入手して質量リストの作成に用いるようにしてもよい。この場合も、必要に応じてN−末端開始メチオニン残基の切断、翻訳後修飾、又は生物情報工学的な相同性解析に基づいて行われるアミノ酸配列の修正を加味した計算分子量の補正を行う。
【0030】
なお、上述のように、実測データに基づいて質量リストを作成した場合も、上記同様の手法により計算分子量を算出し、質量リスト上の各質量を前記計算分子量と比較してその妥当性を検証した上で上位データベースに登録することが望ましい。これにより、上位データベース21中のデータの信頼性を高めることができる。なお、計算分子量との比較の結果、妥当でないと判断された質量リストについては、計算分子量に基づいて質量を修正したり、質量分析をやり直して質量リストを再作成したりすることが望ましい。
【0031】
(2)上記(1)の工程で求められた計算分子量をイオン質量に変換し、該イオン質量をリスト化することで質量リストを作成する。なお、生体試料をMALDI−TOFMSで分析した際には、主に[M+H]+(Mは分子、Hは水素原子)、[M−H]−、又は[M+Na]+(Naはナトリウム原子)等の分子量関連イオンが検出されることが知られている。従って、質量分析条件が明らかであれば、前記計算分子量からイオン質量への変換は容易に行うことができる。例えば、シナピン酸をマトリックス剤として調製された生体試料をMALDI−TOFMSで分析すると、主にプロトン化分子([M+H]+)のピークが観測される。従って、この場合には上記(1)の工程で求められた計算分子量にプロトンの質量を加算することでイオン質量への変換が可能である。
【0032】
下位データベース22は、微生物の種(species)ごとに分けられた複数のサブデータベース22a、22b、22c…を含んでいる。サブデータベース22a、22b、22c…には、それぞれ1つの種に属する一又は複数の微生物細胞に関する部分質量リストが収録されている。本実施例における部分質量リストとは、ある微生物細胞を質量分析した際に検出されるイオンの質量を列挙したリストから該微生物が属する種において共通に検出される質量を除いたものである。このような部分質量リストは、上述の方法で作成された既知微生物に関する多数の質量リストから、同一種に属する微生物の質量リストを抽出し、これらの質量リストに共通に含まれている質量を各質量リストから削除することにより作成することができる。従って、仮にある1つの種に属する微生物の質量リストが上位データベースに1つしか登録されていない場合は、該微生物について上位データベース21に登録される質量リストと下位データベース22に登録される部分質量リストは同一の内容となる。
【0033】
演算部40は、被検細胞の構成成分を含む試料を質量分析部1で分析した結果に基づいて前記上位データベース21及び下位データベース22を対象とした検索を実行するものであり、被検質量リスト作成部41、上位DB検索部42、分類群決定部43、被検部分質量リスト作成部44、及び下位DB検索部45を機能ブロックとして含んでいる(各部の機能は後述する)。なお、前記上位DB検索部42が本発明における第1検索手段に相当し、下位DB検索部45が本発明における第2検索手段に相当する。本実施例における細胞識別部2の実体はCPUやメモリ等を含んだコンピュータであって、CPUが該コンピュータにインストールされた所定の制御・処理プログラムを実行することにより、前記各機能ブロックの機能がソフトウェア的に達成される。演算部40は、インターフェース部30を介して質量分析部1に接続されており、更に、キーボードやマウスなどのポインティングデバイス等である操作部62と、液晶ディスプレイなどの表示部61とも接続されている。
【0034】
次に、本実施例の細胞識別システムを用いて微生物の種及び株を識別する際の手順について、図2により説明する。
【0035】
まず、ユーザは被検細胞の構成成分を含む試料を調製し、質量分析部1にセットして質量分析を実行させる。このとき、前記試料としては、細胞抽出物、又は細胞抽出物からリボソームタンパク質等の細胞構成成分を精製したものの他、菌体や細胞懸濁液をそのまま使用することもできるが、上位データベース21中の実測データに基づく質量リストが作成された時の条件と同一とすることが望ましい。
【0036】
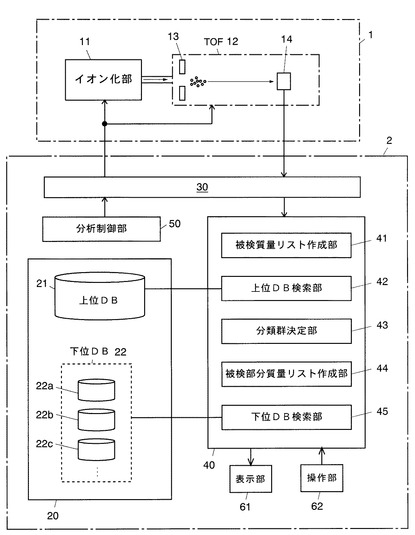
被検質量リスト作成部41は、質量分析部1の検出器14から得られる検出信号をインターフェース部30を介して取得する(ステップS11)。そして、該検出信号に基づいて質量スペクトルを作成し、該質量スペクトル中に現れているピークを抽出して各ピークの質量(厳密にはm/z)の情報を含む質量リスト(以下これを「被検質量リスト」と呼ぶ)を作成する(ステップS12)。なお、このときのピーク抽出条件(抽出する質量範囲、及びピーク強度の閾値など)についても、上位データベース21中の実測データに基づく質量リストが作成された時の条件と同一とすることが望ましい。
【0037】
次に、上位DB検索部42が、前記被検質量リストを用いて上位データベース21を検索し、該被検質量リストに類似した質量パターンを有する既知微生物の質量リスト、例えば被検質量リスト中の各質量と所定の誤差範囲で一致する質量が多く含まれている質量リストを抽出する(ステップS13)。
【0038】
続いて、分類群決定部43が、ステップS13で抽出された質量リストに記載された分類群の情報を参照することで該質量リストに対応した既知微生物が属する生物種を特定する。そして、この生物種を前記被検細胞が属する生物種と推定し、これを以降で検索対象とする分類群して決定する(ステップS14)。
【0039】
以上により被検細胞が属する生物種が決定されると、被検部分質量リスト作成部44が、前記生物種において共通して検出される質量(種共通質量)を前記被検質量リストから削除する(ステップS15)。これにより得られる質量リストを「被検部分質量リスト」と呼ぶ。なお、前記種共通質量は、予め生物種毎に導出して記憶部20に記憶させておくことが望ましい。あるいは、被検細胞が属する生物種が決定された時点で、被検部分質量リスト作成部44が該生物種に属する既知微生物の質量リストを上位データベースから取得し、これらを比較することによって種共通質量を決定して前記被検部分質量リストの作成に使用するようにしてもよい。
【0040】
その後、下位DB検索部45が、前記分類群決定部43で決定された生物種に対応したサブデータベース(例えばサブデータベース22a)を検索対象として選択する。そして、該サブデータベース22aを対象に前記被検部分質量リストを用いた検索を実行し(ステップS16)、前記被検部分質量リストとの一致度が高い部分質量リストを該サブデータベースから抽出する。このとき、前記一致度が最も高かったものを1つだけ抽出するようにしてもよいが、一致度が予め定めた閾値を超えるもの、又は、前記一致度が高い順に予め決められた数のものを抽出するようにしてもよい。
【0041】
続いて、下位DB検索部45は、上記検索により抽出された部分質量リストの情報を検索結果として表示部61に表示させる(ステップS17)。ここで表示させる情報には、少なくとも前記部分質量リストに記載された既知微生物の株名及び被検部分質量リストとの一致度とを含む。これにより、ユーザが、被検細胞に類似した質量パターンを生じる既知微生物の株名を知ることができ、被検細胞をその株と同一又は遺伝的に近縁の株と推定することができる。
【0042】
なお、ステップS17で表示する部分質量リストの情報には更に、該部分質量リストが実測データに基づいて作成されたものであるか、計算分子量に基づいて作成されたものであるかを示す情報を含めることが望ましい。一般に、実測データに基づいて作成された質量リストの方がより正確であるため、検索結果として複数の部分質量リストが表示された場合に、ユーザが前記情報を参照することにより、いずれの部分質量リストが検索結果としてより適切であるかを判断することが可能となる。
【実施例2】
【0043】
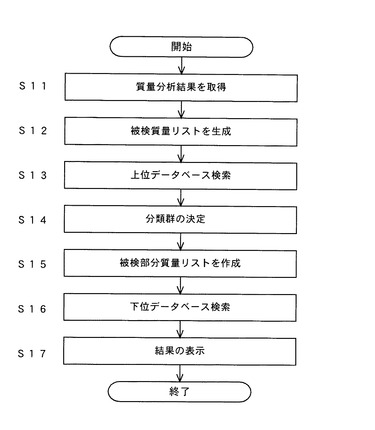
上記の実施例1では上位データベース21と下位データベース22の2つのデータベースを備えた細胞識別装置を示したが、本発明に係る細胞識別装置は、1つのデータベースのみを備えた構成とすることもできる。以下、このような構成を備えた細胞識別装置の実施例について、図3、4を参照して説明する。図3は本実施例に係る細胞識別装置を備えた細胞識別システムの全体図、図4は本システムを用いた細胞識別の手順を示すフローチャートである。
【0044】
本実施例に係る細胞識別システムは、上位データベース21及び下位データベース22に代わって1つのデータベース23を有している点、並びに上位DB検索部42及び下位DB検索部45に代わって第1検索部46及び第2検索部47を有している点以外は実施例1と同様の構成を有している。
【0045】
本実施例におけるデータベース23は、実施例1における上位データベース21に相当するものであり、前記上位データベース21と同様に既知微生物に関する質量リストが多数収録されている
【0046】
第1検索部46は、実施例1における上位DB検索部42と同様の役割を果たすものであり、被検質量リスト作成部41で作成された被検質量リストを用いてデータベース23を検索する。第2検索部47は被検部分質量リスト作成部44で作成された被検部分質量リストを用いてデータベース23を検索するものであり、このとき、分類群決定部43で決定された分類群に属する微生物に関するものだけを検索対象とする。更に、データベース23内の各質量リストに記載された質量の内、前記分類群において共通するもの以外を被検部分質量リストとの照合に使用する。
【0047】
本実施例の細胞識別システムを用いて微生物の種及び株を識別する際の手順について、図4により説明する。
【0048】
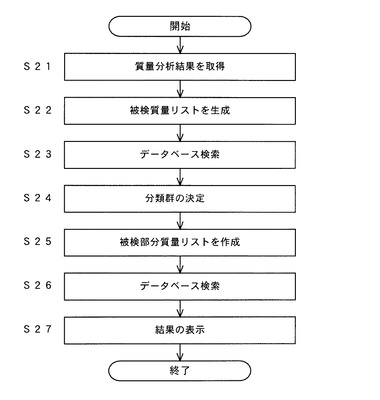
まず、ユーザが被検細胞の構成成分を含む試料を質量分析部1にセットして質量分析を行った後、被検質量リスト作成部41が該質量分析の結果を取得し(ステップS21)、被検質量リストの作成(ステップS22)を行う。なお、これらの工程は、図2のステップS11及びS12と同様であるため詳細は省略する。
【0049】
次に、第1検索部46が、前記被検質量リストを用いてデータベース23を検索し、該被検質量リストに類似した質量パターンを有する既知微生物の質量リストを抽出する(ステップS23)。
【0050】
続いて、分類群決定部43が、ステップS23で抽出された質量リストに記載された分類情報を参照することにより該質量リストに対応した既知微生物が属する生物種を特定する。そして、この生物種を前記被検細胞が属する生物種と推定し、これを以降の検索で対象とする分類群として決定する(ステップS24)。
【0051】
以上により被検細胞が属する生物種が決定されると、被検部分質量リスト作成部44が、前記生物種に共通する質量を前記被検質量リストから削除することにより被検部分質量リストを作成する(ステップS25)。この工程は、図2のステップS15と同様であるため詳細は省略する。
【0052】
その後、第2検索部47が、ステップS25で作成された被検部分質量リストを用いてデータベース23を検索する(ステップS26)。このとき、第2検索部47は、データベース23に収録された多数の質量リストのうち、ステップS24で決定された生物種に属する微生物に関するものを検索対象として選択する。更に、選択した各質量リストに記載された質量のうち、各株に特異的な質量のみを被検部分質量リストとの照合に使用する。具体的には、まず、検索対象として選択した各質量リスト中に共通に含まれる質量(種共通質量)を第2検索部47が特定し、各質量リストから種共通質量を除いたものと、前記被検部分質量リスト中の各質量とを照合して一致度を算出する。その結果、被検部分質量リストとの一致度が高かった質量リストをデータベース23から抽出する。なお、上記のように第2検索部47が種共通質量を特定する代わりに、予め微生物種毎に種共通質量を特定し、記憶部20に記憶しておくようにしてもよい。
【0053】
続いて、第2検索部47が、上記検索により抽出された部分質量リストの情報を検索結果として表示部61に表示させる(ステップS27)。このとき表示させる情報には、少なくとも該質量リストに記載された既知微生物の株名及び該被検部分質量リストとの一致度とを含む。以上により、ユーザが被検細胞に類似した質量パターンを生じる既知微生物の株名を知ることができ、被検細胞を前記の株と同一又は遺伝的に近縁の株と推定することができる。
【実施例3】
【0054】
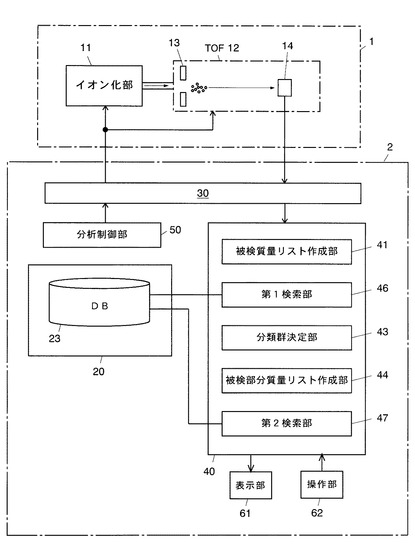
本発明に係る細胞識別装置の第3の実施例について図5を用いて説明する。本実施例のシステムは、塩基配列又はアミノ酸配列に起こり得る変異に関する情報(以下、「変異情報」と呼ぶ)を収録した変異データベース24を備え、下位DB検索部45において前記変異を考慮した検索を行う構成となっている。
【0055】
変異データベース24には、上記の変異情報、即ち、変異の名称、変化するアミノ酸又は塩基の種類や変化する部位、該変異によるイオン質量の変化量(m/z)などが予め登録される。
【0056】
本システムにおいて下位データベース22に登録される部分質量リストには、上述の質量情報及び分類情報のほかに、該リスト中の各質量に対応するタンパク質のアミノ酸配列及び/又は前記タンパク質をコードする遺伝子の塩基配列に関する情報(以下、「配列情報」と呼ぶ)が含まれている。
【0057】
本実施例の細胞識別システムを用いた細胞識別の手順は、図2のフローチャートで示したものとほぼ同様である。但し、ステップS16では、下位DB検索部45において、上記実施例1と同様の検索(変異を考慮しない検索)に加え、更にアミノ酸配列又は塩基配列に起こり得る変異を考慮した検索が実行される。
【0058】
前記変異を考慮した検索では、まず、下位DB検索部45が前記変異データベース24から変異情報を取得する。なお、変異データベース24には様々な変異に関する情報が登録されているが、ここでは、まず1種類の変異に関する情報を取得する。そして、検索対象とするサブデータベース(例えばサブデータベース22a)中の部分質量リストを、前記変異情報に基づいて改変することにより該変異を適用した部分質量リスト(以下、これを「改変質量リスト」と呼ぶ)を作成する。具体的には、各部分質量リスト中の前記配列情報を参照することにより該部分質量リストに列挙された各質量に対応するタンパク質のアミノ酸配列(又は該タンパク質をコードする遺伝子の塩基配列)の中に、前記変異を生じ得る領域が含まれているか否かを判定し、含まれていた場合には、該質量を前記変異が生じた場合の質量に変更する。
【0059】
続いて、以上により得られた改変質量リストを前記被検部分質量リストと照合し、質量パターンの一致度を算出して記憶部20に一旦記憶させる。そして、変異データベース24に登録された全ての変異について、上記のような改変質量リストの作成及び一致度の算出を繰り返す。全ての変異を考慮した検索が終了すると、下位DB検索部45は、全ての検索結果を記憶部20から読み出し、一致度などを参考にした結果の妥当性の評価を行う。例えば一定以上の一致度を有する結果、あるいは、一致度の高い順に所定数の結果を抽出する。そして、抽出した結果を表示部61の画面上に表示する(ステップS17)。
【0060】
このように、変異を考慮した検索を行うことにより、被検細胞が既知の微生物株からの変異によって生じたものであった場合にも精度の高い検索結果を得ることができる。
【0061】
なお、上記実施例では、変異データベース24に登録されている全ての変異を考慮した検索を行うものとしたが、変異データベース24に登録された変異の中には実際には非常に低い確率でしか起こらない変異も数多く含まれる。そこで、起こる可能性の高さに基づく優先度や重要度などを各変異について変異データベース24に登録しておき、例えば、この優先度の高い順に予めユーザが指定した所定の個数の変異を選択して検索に適用するようにしてもよい。あるいは、下位データベース22の検索に先立ち、変異データベース24に登録されている変異の一覧を表示部61に表示して該一覧の中から検索に適用する変異をユーザに選択させるようにしてもよい。また、下位データベース22の検索中に一致度が相当に高いものがヒットしたらその時点で検索を終了するようにしてもよい。この場合、下位DB検索部45は、被検部分質量リストとの一致度が予め定められた閾値以上である部分質量リスト又は改変質量リストが探索された時点でデータベース検索の繰り返しを打ち切るものとする。これにより検索時間の大幅な短縮が見込める。
【0062】
更に、本実施例では、実施例1のような、上位データベース21に対する検索と下位データベース22に対する検索とを行う装置において、変異を考慮した検索を行う場合を説明したが、実施例2の装置のように、1つのデータベース23に対して2段階の検索を行う装置においても記憶部20に上記同様の変異データベースを設けることにより、変異を考慮した検索を行うことが可能となる。この場合、前記データベース23中の質量リストに記載された質量のうち、少なくとも株特異的な質量に関して上記のような配列情報を記載しておく。そして、第2検索部47による検索の実行時に、前記変異データベースに登録された変異を考慮した検索を行うようにする。
【0063】
以上、本発明を実施するための形態について実施例を挙げて説明を行ったが、本発明は上記実施例に限定されるものではなく、本発明の趣旨の範囲で適宜変更が許容される。例えば、上記実施例ではマトリックス支援レーザ脱離イオン化法(MALDI)によるイオン化部と飛行時間型の質量分離器(TOF)とを組合せて成る質量分析部を備えた細胞識別システムを例示したが、質量分析部は、1,000〜25,000程度の質量範囲の分子をイオン化し、検出できるものであれば前記構成に限定されるものではない。例えば、イオン化部として、エレクトロスプレーイオン化法(ESI)、レーザ脱離エレクトロスプレーイオン化(LDESI)、マトリックス支援レーザ脱離エレクトロスプレーイオン化(MALDESI)、短針スプレーイオン化(PSI)、大気圧化学イオン化(APCI)、又は電気衝突イオン化(EI)によるものなどを利用することもできる。
【0064】
また、上記実施例では上位DB検索部42又は第1検索部46による1回目の検索で種レベルの細胞識別を行い、下位DB検索部45又は第2検索部47による2回目の検索で株レベルの細胞識別を行うものとしたが、これに限らず、例えば、1回目の検索で属レベルの細胞識別を行い、2回目の検索で種レベルの識別を行うものとしてもよい。
【0065】
また更に、上記実施例では各データベースに登録する質量リスト又は部分質量リストに細胞構成成分のイオン質量を記載するものとしたが、これに限らず細胞構成成分の分子量を記載するようにしてもよい。この場合には、被検質量リスト作成部41において被検質量リストを作成する際に、質量分析で検出された各イオンの質量を分子量に換算するか、あるいは上位DB検索部42、下位DB検索部45、第1検索部46、及び第2検索部47によるデータベース検索を行う際に、データベース中の各質量リスト(又は部分質量リスト)に記載された分子量をイオン質量に換算した上で被検質量リスト(又は被検部分質量リスト)との照合を行う構成とする。
【符号の説明】
【0066】
1…質量分析部
11…イオン化部
12…TOF
2…細胞識別部
20…記憶部
21…上位データベース
22…下位データベース
22a、22b、22c…サブデータベース
23…データベース
24…変異データベース
30…インターフェース部
40…演算部
41…被検質量リスト作成部
42…上位DB検索部
43…分類群決定部
44…被検部分質量リスト作成部
45…下位DB検索部
46…第1検索部
47…第2検索部
50…分析制御部
61…表示部
62…操作部
【技術分野】
【0001】
本発明は、細胞由来の成分を質量分析した結果に基づいて該細胞の種類を識別するための装置、及びプログラムに関する。
【背景技術】
【0002】
従来、細胞の種類を識別する手法の1つとしてDNA塩基配列に基づく相同性解析が知られており、微生物の分類・同定等に広く用いられている(例えば、特許文献1を参照)。この手法では、まず、被検細胞からDNAを抽出してrRNA遺伝子等の全生物に高い保存性で存在している領域のDNA塩基配列を決定する。次に、このDNA塩基配列を用いて、既知細胞のDNA塩基配列データを多数収録したデータベースを検索し、前記被検細胞のDNA塩基配列と高い類似性を示す塩基配列を選出する。そして、該塩基配列が由来する生物種を、前記被検細胞と同一種又は近縁種であると判定する。
【0003】
しかしながら、こうしたDNA塩基配列を利用した手法では、被検細胞からのDNA抽出やDNA塩基配列の決定などに比較的長い時間を要するため、迅速な細胞識別を行うのが困難であるという問題があった。
【0004】
そこで、近年では被検細胞を質量分析して得られた質量スペクトルパターンに基づいて細胞識別を行う手法が用いられるようになりつつある(例えば、特許文献2を参照)。この手法では、まず、被検細胞から抽出したタンパク質を含む溶液や被検細胞の懸濁液等をMALDI−MS(マトリックス支援レーザ脱離イオン化質量分析)等のソフトなイオン化法を用いた質量分析装置によって分析する。そして、得られた質量スペクトルパターンを、データベースに収録された既知細胞の質量スペクトルパターンと照合することにより、被検細胞の同定を行う。質量分析では、ごく微量の細胞試料を用いて短時間で分析結果を得ることができ、且つ多検体の連続分析も容易である。そのため、こうした質量分析を利用した細胞識別手法によれば、簡便且つ迅速な細胞識別が可能となる。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2006-191922号公報
【特許文献2】特開2007-316063号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
上記の質量分析を利用した細胞識別手法では、一般に、リボソームタンパク質群の質量情報に着目して細胞の識別が行われる。しかしながら、リボソームタンパク質群はアミノ酸配列の保存性が高いため、同一の生物種に属する細胞同士では、質量スペクトル上に現れるピークの大部分が同一質量となる。そのため、こうした質量分析を利用した細胞識別方法では、細胞の種(species)レベルでの違いを識別することはできても、その下位の分類である株(strain)レベルでの違いを識別するのは困難な場合があった。
【0007】
本発明は上記課題を解決するために成されたものであり、その目的とするところは、株レベルでの細胞識別を高精度且つ迅速に行うことのできる細胞識別装置を提供することにある。
【課題を解決するための手段】
【0008】
上記課題を解決するために成された本発明の第1の態様に係る細胞識別装置は、記憶装置及び演算装置を有し、被検細胞を質量分析して得られた結果に基づいて該被検細胞の種類を識別する装置であって、
前記記憶装置が、既知細胞の構成成分のイオン質量又は分子量が記載された質量リストを複数の既知細胞について収録した第1データベースと、既知細胞の構成成分のイオン質量又は分子量のうち、該既知細胞が属する予め定められた階級の分類群に共通するイオン質量又は分子量以外を記載した部分質量リストを複数の既知細胞について収録した第2データベースと、を記憶しており、
前記演算装置が、
a)前記質量分析の結果に基づいて作成された前記被検細胞の構成成分のイオン質量又は分子量を記載した被検質量リストを用いて前記第1データベースを検索する第1検索手段と、
b)前記第1検索手段による検索結果に基づいて、前記階級に位置する分類群のいずれかを以降の検索で対象とする分類群として決定する分類群決定手段と、
c)前記被検質量リストから前記分類群決定手段で決定された分類群に共通するイオン質量又は分子量を削除した被検部分質量リストを作成する被検部分質量リスト作成手段と、
d)前記被検部分質量リスト作成手段により作成された被検部分質量リストを用いて前記第2データベースを検索する第2検索手段と、
を有することを特徴としている。
【0009】
なお、上記の分類群決定手段は、例えば、第1検索手段による検索の結果、被検質量リストとの一致度が高かったものを自動的に以降の検索で対象とする分類群を決定するものとしてもよく、あるいは第1検索手段による検索結果をモニタ等の表示装置に表示させると共に、ユーザからの分類群の指定を受け付け、前記検索結果に基づいてユーザがキーボード等の入力装置から指定した分類群を以降の検索で対象とする分類群として決定するものとしてもよい。
【0010】
本願発明に係る細胞識別装置による細胞識別の原理について図6、7を用いて説明する。本発明の細胞識別装置は、第1データベース(第1DB)と第2データベース(第2DB)を備えており、それぞれ、例えば図6に示すような複数の既知細胞に関する質量リスト、及び図7に示すような複数の既知細胞に関する部分質量リストが登録されている。ここで、質量リストとは、ある細胞の構成成分のイオン質量又は分子量を記載したリストであり、例えば、ある細胞を質量分析し、得られた質量スペクトル上の各ピークの質量(厳密にはm/z)をリスト化することによって作成することができる。一方、部分質量リストとは、ある細胞の構成成分のイオン質量又は分子量のうち、該細胞が属する、所定の分類階級(生物分類の階層)の分類群に共通するイオン質量又は分子量以外を記載したものであり、例えば、ある細胞について作成された前記質量リストから、該細胞が属する種において共通に含まれるものを削除することにより作成することができる。なお、図6、7では、各質量リスト及び部分質量リストを質量スペクトル上に現れるピークの質量及び高さの情報を含んだものとしているが、本発明における質量リストには必ずしもピークの高さ(即ち、各構成成分の存在量比)の情報を含める必要はない。
【0011】
本発明における細胞識別装置では、まず、被検細胞を質量分析した結果から作成された質量リスト(被検質量リスト)を用いて第1データベースを検索する。このとき、図6に示すように、前記被検質量リスト及び第1データベース中の各質量リストには、いずれも多数の質量が列挙されているが、遺伝的に近縁の細胞(例えば、同一種に属する生物の細胞)同士では、その大部分が一致する。例えば、図6の例の場合、既知細胞Aの質量リストには被検質量リストに列挙された20個の質量の内の19個が含まれており、既知細胞Bの質量リストには前記20個の内18個が、既知細胞Cの質量リストには17個が含まれている。そのため、被検質量リストに挙げられた質量の内、各既知細胞の質量リストに含まれているものの割合は、既知細胞Aで19/20=0.95、既知細胞Bで18/20=0.9、既知細胞Cで17/20=0.85のように、相互に近い値となる(なお、図6では簡略化のため各質量リストに含まれる質量の数を少なくしているが、実際の質量リストには、より多くの質量が列挙されるため、遺伝的に近縁の細胞間における前記割合の違いは一層小さくなる)。
【0012】
このように第1データベースによる検索では、遺伝的に近縁の既知細胞同士では被検細胞との照合結果の差が小さくなる。しかし、従来の細胞識別装置では、こうした第1データベースの検索に相当する検索のみを行っているため、種レベルでの細胞識別は可能であっても、株レベルでの高精度な細胞識別を行うのは一般的に困難であった。
【0013】
これに対し、本発明の細胞識別装置では、第1データベースを検索した結果に基づいて被検細胞が属する分類群(例えば種)を決定した後、該分類群に共通して存在する質量を前記被検質量リストから削除する。これにより、例えば、図7の上段に示すような被検細胞の部分質量リスト(被検部分質量リスト)が作成される。そして、この被検部分質量リストを用いて第2データベースを対象とした検索を行う。上述の通り、第2データベースに収録された部分質量リストでは、各既知細胞の構成成分のイオン質量(又は分子量)のうち、該既知細胞が属する所定階級の分類群に共通するものが除かれている。そのため、第2データベース中の各部分質量リストには、その細胞が属する分類群(分類群決定手段で決定された分類群の1つ下の階級の分類群、例えば株)に特異的な質量のみが記載されており、記載されている質量の総数も前記質量リストに比べて大幅に少なくなっている。このため、第2データベースを対象とした検索では、遺伝的に近縁の細胞同士であっても被検細胞との照合結果の違いが大きくなる。例えば、図7の例では、被検部分質量リストに記載された質量の内、各既知細胞の部分質量リストに含まれているものの割合は、既知細胞Aで2/2=1、既知細胞Bで1/2=0.5、既知細胞Cで0/2=0となり、図6の例に比べて既知細胞間での結果の違いが大きくなっている。このため、第2データベースを対象とした検索では、遺伝的に近縁な複数の既知細胞の中から被検細胞により近いものを高い精度で抽出することが可能となり、その結果、従来困難であった株レベルでの高精度な細胞識別が可能となる。
【0014】
なお、本発明に係る細胞識別装置は、上記のように第1データベースと第2データベースを対象として2段階検索を行う構成とするほか、1つのデータベースを対象として2段階の検索を行う構成とすることもできる。
【0015】
即ち、上記課題を解決するために成された本発明の第2の態様に係る細胞識別装置は、記憶装置及び演算装置を有し、被検細胞を質量分析して得られた結果に基づいて該被検細胞の種類を識別する装置であって、
前記記憶装置が、既知細胞の構成成分のイオン質量又は分子量が記載された質量リストを複数の既知細胞について収録したデータベースを記憶しており、
前記演算装置が、
a)前記質量分析の結果に基づいて作成された前記被検細胞の構成成分のイオン質量又は分子量が記載された被検質量リストを用いて前記データベースを検索する第1検索手段と、
b)前記第1検索手段による検索結果に基づいて以降の検索で対象とする分類群を決定する分類群決定手段と、
c)前記被検質量リストから前記分類群決定手段で決定された分類群に共通するイオン質量又は分子量を削除した被検部分質量リストを作成する被検部分質量リスト作成手段と、
d) 前記データベースに収録された質量リストの内、前記分類群決定手段で決定された分類群に属する既知細胞の質量リストを検索対象として前記被検部分質量リストを用いた検索を行う第2検索手段と、
を有し、
前記第2検索手段が、検索対象とする質量リストから前記分類群決定手段で決定された分類群に共通するイオン質量又は分子量を削除し、該削除後の質量リストに対して前記被検部分質量リストを用いた検索を行うものであることを特徴としている。
【発明の効果】
【0016】
以上説明した通り、本発明に係る細胞識別装置によれば、遺伝的に近縁な複数の既知細胞の中から被検細胞により近いものを高い精度で抽出することができる。そのため、本発明に係る細胞識別装置によれば、従来困難であった株レベルでの高精度な細胞識別を簡便且つ迅速に行うことが可能となる。
【図面の簡単な説明】
【0017】
【図1】本発明の実施例1に係る細胞識別システムの要部を示す構成図。
【図2】同システムの動作を示すフローチャート。
【図3】本発明の実施例2に係る細胞識別システムの要部を示す構成図。
【図4】同システムの動作を示すフローチャート。
【図5】本発明の実施例3に係る細胞識別システムの要部を示す構成図。
【図6】第1データベースに対する検索を説明するための概念図。
【図7】第2データベースに対する検索を説明するための概念図。
【発明を実施するための形態】
【0018】
以下、本発明に係る細胞識別装置を実施するための形態について実施例を挙げて説明する。
【実施例1】
【0019】
図1は本実施例に係る細胞識別装置を備えた細胞識別システムの全体図であり、図2は本システムを用いた細胞識別の手順を示すフローチャートである。
【0020】
本実施例の細胞識別装置は、大別して、質量分析部1と細胞識別部2と、から成る。質量分析部1は、マトリックス支援レーザ脱離イオン化法(MALDI)によって試料中の分子や原子をイオン化するイオン化部11と、イオン化部11から出射された各種イオンを質量に応じて分離する飛行時間型質量分離器(TOF)12を備える。
【0021】
TOF12は、イオン化部11からイオンを引き出してTOF12内のイオン飛行空間に導くための引き出し電極13と、イオン飛行空間で質量分離されたイオンを検出する検出器14とを備える。
【0022】
細胞識別部2は、検索用のデータベースを格納した記憶部20と、通信線を介して前記質量分析部1との情報のやり取りを行うインターフェース部30と、質量分析部1の検出器14から出力された検出信号に基づいて前記データベースの検索を行う演算部40と、質量分析部1の動作を制御する分析制御部50とを備えている。
【0023】
記憶部20はハードディスク装置等の大容量記憶装置から成り、上位データベース21と下位データベース22の2種類のデータベースを格納している。これらの上位データベース21及び下位データベース22は、それぞれ本発明における第1データベース及び第2データベースに相当する。
【0024】
上位データベース21には、既知微生物に関する質量リストが多数登録されている。本実施例における質量リストは、ある微生物細胞を質量分析した際に検出されるイオンの質量を列挙したものであり、該イオン質量の情報に加えて、少なくとも、前記微生物細胞が属する分類群(属、種、及び株)の情報(分類情報)を含んでいる。こうした質量リストは、予め各種の微生物細胞を前記質量分析部1によるものと同様のイオン化法及び質量分離法によって実際に質量分析して得られたデータ(実測データ)に基づいて作成することが望ましい。
【0025】
前記実測データから質量リストを作成する際には、まず、前記実測データとして取得された質量スペクトルから所定の質量範囲に現れるピークを抽出する。このとき、前記質量範囲を4,000〜15,000程度とすることにより、主にタンパク質由来のピークを抽出することができる。また、ピークの高さ(相対強度)が所定の閾値以上のものだけを抽出することにより、不所望のピーク(ノイズ)を除外することができる。なお、リボソームタンパク質群は細胞内で大量に発現しているため、前記閾値を適切に設定することにより、質量リストに記載される質量の大部分をリボソームタンパク質由来のものとすることができる。そして、以上により抽出されたピークの質量(m/z)を細胞毎にリスト化し、前記分類情報等を付加した上で上位データベース21に登録する。なお、培養条件による遺伝子発現のばらつきを抑えるため、実測データの採取に用いる各微生物細胞は、予め培養環境を規格化しておくことが望ましい。
【0026】
なお、膨大な既知微生物の全てについて、上記のような実測データを取得するのは困難である。そこで、少なくとも一部の微生物については、上記のような実測データに基づく質量リストの代わりに、計算により求められた分子量(計算分子量)に基づく質量リストを上位データベース21に登録するようにしてもよい。この場合、各質量リストには、それが実測データ及び計算分子量のいずれに基づいて作成されたものであるかを示す情報を付与しておくことが望ましい。
【0027】
前記計算分子量に基づく質量リストは、例えば、以下のようにして作成される。
【0028】
(1)既存のデータベース(例えばDDBJ、EMBL、GenBank等の公共データベース)から既知微生物の遺伝子(例えば、リボソームタンパク質群の遺伝子)のDNA塩基配列を入手し、それをアミノ酸配列に翻訳することによって該微生物の細胞に含まれる各種タンパク質の計算分子量を導出する。このとき、更に、前記計算分子量に、N−末端開始メチオニン残基の切断、翻訳後修飾、又は生物情報工学的な相同性解析に基づいて行われるアミノ酸配列の修正を加味した補正を施し、これを補正前の計算分子量に加えて又は代えて質量リストの作成に使用するようにしてもよい。なお、前記「生物情報工学的な相同性解析に基づいて行われるアミノ酸配列の修正」は次のようなものである。まず、BLAST等の相同性解析を利用して対象微生物の遺伝子配列と相同性の高い遺伝子配列を既存のデータベース等で検索する。次に、それらの中でアノテーションされているものを参照して正しい翻訳領域を推測する。次に、それに基づいてアミノ酸配列を修正し、補正後のアミノ酸配列から計算分子量を算出する。
【0029】
また、上記既存のデータベースに各種微生物細胞に含まれるタンパク質の計算分子量が収録されている場合は、これを入手して質量リストの作成に用いるようにしてもよい。この場合も、必要に応じてN−末端開始メチオニン残基の切断、翻訳後修飾、又は生物情報工学的な相同性解析に基づいて行われるアミノ酸配列の修正を加味した計算分子量の補正を行う。
【0030】
なお、上述のように、実測データに基づいて質量リストを作成した場合も、上記同様の手法により計算分子量を算出し、質量リスト上の各質量を前記計算分子量と比較してその妥当性を検証した上で上位データベースに登録することが望ましい。これにより、上位データベース21中のデータの信頼性を高めることができる。なお、計算分子量との比較の結果、妥当でないと判断された質量リストについては、計算分子量に基づいて質量を修正したり、質量分析をやり直して質量リストを再作成したりすることが望ましい。
【0031】
(2)上記(1)の工程で求められた計算分子量をイオン質量に変換し、該イオン質量をリスト化することで質量リストを作成する。なお、生体試料をMALDI−TOFMSで分析した際には、主に[M+H]+(Mは分子、Hは水素原子)、[M−H]−、又は[M+Na]+(Naはナトリウム原子)等の分子量関連イオンが検出されることが知られている。従って、質量分析条件が明らかであれば、前記計算分子量からイオン質量への変換は容易に行うことができる。例えば、シナピン酸をマトリックス剤として調製された生体試料をMALDI−TOFMSで分析すると、主にプロトン化分子([M+H]+)のピークが観測される。従って、この場合には上記(1)の工程で求められた計算分子量にプロトンの質量を加算することでイオン質量への変換が可能である。
【0032】
下位データベース22は、微生物の種(species)ごとに分けられた複数のサブデータベース22a、22b、22c…を含んでいる。サブデータベース22a、22b、22c…には、それぞれ1つの種に属する一又は複数の微生物細胞に関する部分質量リストが収録されている。本実施例における部分質量リストとは、ある微生物細胞を質量分析した際に検出されるイオンの質量を列挙したリストから該微生物が属する種において共通に検出される質量を除いたものである。このような部分質量リストは、上述の方法で作成された既知微生物に関する多数の質量リストから、同一種に属する微生物の質量リストを抽出し、これらの質量リストに共通に含まれている質量を各質量リストから削除することにより作成することができる。従って、仮にある1つの種に属する微生物の質量リストが上位データベースに1つしか登録されていない場合は、該微生物について上位データベース21に登録される質量リストと下位データベース22に登録される部分質量リストは同一の内容となる。
【0033】
演算部40は、被検細胞の構成成分を含む試料を質量分析部1で分析した結果に基づいて前記上位データベース21及び下位データベース22を対象とした検索を実行するものであり、被検質量リスト作成部41、上位DB検索部42、分類群決定部43、被検部分質量リスト作成部44、及び下位DB検索部45を機能ブロックとして含んでいる(各部の機能は後述する)。なお、前記上位DB検索部42が本発明における第1検索手段に相当し、下位DB検索部45が本発明における第2検索手段に相当する。本実施例における細胞識別部2の実体はCPUやメモリ等を含んだコンピュータであって、CPUが該コンピュータにインストールされた所定の制御・処理プログラムを実行することにより、前記各機能ブロックの機能がソフトウェア的に達成される。演算部40は、インターフェース部30を介して質量分析部1に接続されており、更に、キーボードやマウスなどのポインティングデバイス等である操作部62と、液晶ディスプレイなどの表示部61とも接続されている。
【0034】
次に、本実施例の細胞識別システムを用いて微生物の種及び株を識別する際の手順について、図2により説明する。
【0035】
まず、ユーザは被検細胞の構成成分を含む試料を調製し、質量分析部1にセットして質量分析を実行させる。このとき、前記試料としては、細胞抽出物、又は細胞抽出物からリボソームタンパク質等の細胞構成成分を精製したものの他、菌体や細胞懸濁液をそのまま使用することもできるが、上位データベース21中の実測データに基づく質量リストが作成された時の条件と同一とすることが望ましい。
【0036】
被検質量リスト作成部41は、質量分析部1の検出器14から得られる検出信号をインターフェース部30を介して取得する(ステップS11)。そして、該検出信号に基づいて質量スペクトルを作成し、該質量スペクトル中に現れているピークを抽出して各ピークの質量(厳密にはm/z)の情報を含む質量リスト(以下これを「被検質量リスト」と呼ぶ)を作成する(ステップS12)。なお、このときのピーク抽出条件(抽出する質量範囲、及びピーク強度の閾値など)についても、上位データベース21中の実測データに基づく質量リストが作成された時の条件と同一とすることが望ましい。
【0037】
次に、上位DB検索部42が、前記被検質量リストを用いて上位データベース21を検索し、該被検質量リストに類似した質量パターンを有する既知微生物の質量リスト、例えば被検質量リスト中の各質量と所定の誤差範囲で一致する質量が多く含まれている質量リストを抽出する(ステップS13)。
【0038】
続いて、分類群決定部43が、ステップS13で抽出された質量リストに記載された分類群の情報を参照することで該質量リストに対応した既知微生物が属する生物種を特定する。そして、この生物種を前記被検細胞が属する生物種と推定し、これを以降で検索対象とする分類群して決定する(ステップS14)。
【0039】
以上により被検細胞が属する生物種が決定されると、被検部分質量リスト作成部44が、前記生物種において共通して検出される質量(種共通質量)を前記被検質量リストから削除する(ステップS15)。これにより得られる質量リストを「被検部分質量リスト」と呼ぶ。なお、前記種共通質量は、予め生物種毎に導出して記憶部20に記憶させておくことが望ましい。あるいは、被検細胞が属する生物種が決定された時点で、被検部分質量リスト作成部44が該生物種に属する既知微生物の質量リストを上位データベースから取得し、これらを比較することによって種共通質量を決定して前記被検部分質量リストの作成に使用するようにしてもよい。
【0040】
その後、下位DB検索部45が、前記分類群決定部43で決定された生物種に対応したサブデータベース(例えばサブデータベース22a)を検索対象として選択する。そして、該サブデータベース22aを対象に前記被検部分質量リストを用いた検索を実行し(ステップS16)、前記被検部分質量リストとの一致度が高い部分質量リストを該サブデータベースから抽出する。このとき、前記一致度が最も高かったものを1つだけ抽出するようにしてもよいが、一致度が予め定めた閾値を超えるもの、又は、前記一致度が高い順に予め決められた数のものを抽出するようにしてもよい。
【0041】
続いて、下位DB検索部45は、上記検索により抽出された部分質量リストの情報を検索結果として表示部61に表示させる(ステップS17)。ここで表示させる情報には、少なくとも前記部分質量リストに記載された既知微生物の株名及び被検部分質量リストとの一致度とを含む。これにより、ユーザが、被検細胞に類似した質量パターンを生じる既知微生物の株名を知ることができ、被検細胞をその株と同一又は遺伝的に近縁の株と推定することができる。
【0042】
なお、ステップS17で表示する部分質量リストの情報には更に、該部分質量リストが実測データに基づいて作成されたものであるか、計算分子量に基づいて作成されたものであるかを示す情報を含めることが望ましい。一般に、実測データに基づいて作成された質量リストの方がより正確であるため、検索結果として複数の部分質量リストが表示された場合に、ユーザが前記情報を参照することにより、いずれの部分質量リストが検索結果としてより適切であるかを判断することが可能となる。
【実施例2】
【0043】
上記の実施例1では上位データベース21と下位データベース22の2つのデータベースを備えた細胞識別装置を示したが、本発明に係る細胞識別装置は、1つのデータベースのみを備えた構成とすることもできる。以下、このような構成を備えた細胞識別装置の実施例について、図3、4を参照して説明する。図3は本実施例に係る細胞識別装置を備えた細胞識別システムの全体図、図4は本システムを用いた細胞識別の手順を示すフローチャートである。
【0044】
本実施例に係る細胞識別システムは、上位データベース21及び下位データベース22に代わって1つのデータベース23を有している点、並びに上位DB検索部42及び下位DB検索部45に代わって第1検索部46及び第2検索部47を有している点以外は実施例1と同様の構成を有している。
【0045】
本実施例におけるデータベース23は、実施例1における上位データベース21に相当するものであり、前記上位データベース21と同様に既知微生物に関する質量リストが多数収録されている
【0046】
第1検索部46は、実施例1における上位DB検索部42と同様の役割を果たすものであり、被検質量リスト作成部41で作成された被検質量リストを用いてデータベース23を検索する。第2検索部47は被検部分質量リスト作成部44で作成された被検部分質量リストを用いてデータベース23を検索するものであり、このとき、分類群決定部43で決定された分類群に属する微生物に関するものだけを検索対象とする。更に、データベース23内の各質量リストに記載された質量の内、前記分類群において共通するもの以外を被検部分質量リストとの照合に使用する。
【0047】
本実施例の細胞識別システムを用いて微生物の種及び株を識別する際の手順について、図4により説明する。
【0048】
まず、ユーザが被検細胞の構成成分を含む試料を質量分析部1にセットして質量分析を行った後、被検質量リスト作成部41が該質量分析の結果を取得し(ステップS21)、被検質量リストの作成(ステップS22)を行う。なお、これらの工程は、図2のステップS11及びS12と同様であるため詳細は省略する。
【0049】
次に、第1検索部46が、前記被検質量リストを用いてデータベース23を検索し、該被検質量リストに類似した質量パターンを有する既知微生物の質量リストを抽出する(ステップS23)。
【0050】
続いて、分類群決定部43が、ステップS23で抽出された質量リストに記載された分類情報を参照することにより該質量リストに対応した既知微生物が属する生物種を特定する。そして、この生物種を前記被検細胞が属する生物種と推定し、これを以降の検索で対象とする分類群として決定する(ステップS24)。
【0051】
以上により被検細胞が属する生物種が決定されると、被検部分質量リスト作成部44が、前記生物種に共通する質量を前記被検質量リストから削除することにより被検部分質量リストを作成する(ステップS25)。この工程は、図2のステップS15と同様であるため詳細は省略する。
【0052】
その後、第2検索部47が、ステップS25で作成された被検部分質量リストを用いてデータベース23を検索する(ステップS26)。このとき、第2検索部47は、データベース23に収録された多数の質量リストのうち、ステップS24で決定された生物種に属する微生物に関するものを検索対象として選択する。更に、選択した各質量リストに記載された質量のうち、各株に特異的な質量のみを被検部分質量リストとの照合に使用する。具体的には、まず、検索対象として選択した各質量リスト中に共通に含まれる質量(種共通質量)を第2検索部47が特定し、各質量リストから種共通質量を除いたものと、前記被検部分質量リスト中の各質量とを照合して一致度を算出する。その結果、被検部分質量リストとの一致度が高かった質量リストをデータベース23から抽出する。なお、上記のように第2検索部47が種共通質量を特定する代わりに、予め微生物種毎に種共通質量を特定し、記憶部20に記憶しておくようにしてもよい。
【0053】
続いて、第2検索部47が、上記検索により抽出された部分質量リストの情報を検索結果として表示部61に表示させる(ステップS27)。このとき表示させる情報には、少なくとも該質量リストに記載された既知微生物の株名及び該被検部分質量リストとの一致度とを含む。以上により、ユーザが被検細胞に類似した質量パターンを生じる既知微生物の株名を知ることができ、被検細胞を前記の株と同一又は遺伝的に近縁の株と推定することができる。
【実施例3】
【0054】
本発明に係る細胞識別装置の第3の実施例について図5を用いて説明する。本実施例のシステムは、塩基配列又はアミノ酸配列に起こり得る変異に関する情報(以下、「変異情報」と呼ぶ)を収録した変異データベース24を備え、下位DB検索部45において前記変異を考慮した検索を行う構成となっている。
【0055】
変異データベース24には、上記の変異情報、即ち、変異の名称、変化するアミノ酸又は塩基の種類や変化する部位、該変異によるイオン質量の変化量(m/z)などが予め登録される。
【0056】
本システムにおいて下位データベース22に登録される部分質量リストには、上述の質量情報及び分類情報のほかに、該リスト中の各質量に対応するタンパク質のアミノ酸配列及び/又は前記タンパク質をコードする遺伝子の塩基配列に関する情報(以下、「配列情報」と呼ぶ)が含まれている。
【0057】
本実施例の細胞識別システムを用いた細胞識別の手順は、図2のフローチャートで示したものとほぼ同様である。但し、ステップS16では、下位DB検索部45において、上記実施例1と同様の検索(変異を考慮しない検索)に加え、更にアミノ酸配列又は塩基配列に起こり得る変異を考慮した検索が実行される。
【0058】
前記変異を考慮した検索では、まず、下位DB検索部45が前記変異データベース24から変異情報を取得する。なお、変異データベース24には様々な変異に関する情報が登録されているが、ここでは、まず1種類の変異に関する情報を取得する。そして、検索対象とするサブデータベース(例えばサブデータベース22a)中の部分質量リストを、前記変異情報に基づいて改変することにより該変異を適用した部分質量リスト(以下、これを「改変質量リスト」と呼ぶ)を作成する。具体的には、各部分質量リスト中の前記配列情報を参照することにより該部分質量リストに列挙された各質量に対応するタンパク質のアミノ酸配列(又は該タンパク質をコードする遺伝子の塩基配列)の中に、前記変異を生じ得る領域が含まれているか否かを判定し、含まれていた場合には、該質量を前記変異が生じた場合の質量に変更する。
【0059】
続いて、以上により得られた改変質量リストを前記被検部分質量リストと照合し、質量パターンの一致度を算出して記憶部20に一旦記憶させる。そして、変異データベース24に登録された全ての変異について、上記のような改変質量リストの作成及び一致度の算出を繰り返す。全ての変異を考慮した検索が終了すると、下位DB検索部45は、全ての検索結果を記憶部20から読み出し、一致度などを参考にした結果の妥当性の評価を行う。例えば一定以上の一致度を有する結果、あるいは、一致度の高い順に所定数の結果を抽出する。そして、抽出した結果を表示部61の画面上に表示する(ステップS17)。
【0060】
このように、変異を考慮した検索を行うことにより、被検細胞が既知の微生物株からの変異によって生じたものであった場合にも精度の高い検索結果を得ることができる。
【0061】
なお、上記実施例では、変異データベース24に登録されている全ての変異を考慮した検索を行うものとしたが、変異データベース24に登録された変異の中には実際には非常に低い確率でしか起こらない変異も数多く含まれる。そこで、起こる可能性の高さに基づく優先度や重要度などを各変異について変異データベース24に登録しておき、例えば、この優先度の高い順に予めユーザが指定した所定の個数の変異を選択して検索に適用するようにしてもよい。あるいは、下位データベース22の検索に先立ち、変異データベース24に登録されている変異の一覧を表示部61に表示して該一覧の中から検索に適用する変異をユーザに選択させるようにしてもよい。また、下位データベース22の検索中に一致度が相当に高いものがヒットしたらその時点で検索を終了するようにしてもよい。この場合、下位DB検索部45は、被検部分質量リストとの一致度が予め定められた閾値以上である部分質量リスト又は改変質量リストが探索された時点でデータベース検索の繰り返しを打ち切るものとする。これにより検索時間の大幅な短縮が見込める。
【0062】
更に、本実施例では、実施例1のような、上位データベース21に対する検索と下位データベース22に対する検索とを行う装置において、変異を考慮した検索を行う場合を説明したが、実施例2の装置のように、1つのデータベース23に対して2段階の検索を行う装置においても記憶部20に上記同様の変異データベースを設けることにより、変異を考慮した検索を行うことが可能となる。この場合、前記データベース23中の質量リストに記載された質量のうち、少なくとも株特異的な質量に関して上記のような配列情報を記載しておく。そして、第2検索部47による検索の実行時に、前記変異データベースに登録された変異を考慮した検索を行うようにする。
【0063】
以上、本発明を実施するための形態について実施例を挙げて説明を行ったが、本発明は上記実施例に限定されるものではなく、本発明の趣旨の範囲で適宜変更が許容される。例えば、上記実施例ではマトリックス支援レーザ脱離イオン化法(MALDI)によるイオン化部と飛行時間型の質量分離器(TOF)とを組合せて成る質量分析部を備えた細胞識別システムを例示したが、質量分析部は、1,000〜25,000程度の質量範囲の分子をイオン化し、検出できるものであれば前記構成に限定されるものではない。例えば、イオン化部として、エレクトロスプレーイオン化法(ESI)、レーザ脱離エレクトロスプレーイオン化(LDESI)、マトリックス支援レーザ脱離エレクトロスプレーイオン化(MALDESI)、短針スプレーイオン化(PSI)、大気圧化学イオン化(APCI)、又は電気衝突イオン化(EI)によるものなどを利用することもできる。
【0064】
また、上記実施例では上位DB検索部42又は第1検索部46による1回目の検索で種レベルの細胞識別を行い、下位DB検索部45又は第2検索部47による2回目の検索で株レベルの細胞識別を行うものとしたが、これに限らず、例えば、1回目の検索で属レベルの細胞識別を行い、2回目の検索で種レベルの識別を行うものとしてもよい。
【0065】
また更に、上記実施例では各データベースに登録する質量リスト又は部分質量リストに細胞構成成分のイオン質量を記載するものとしたが、これに限らず細胞構成成分の分子量を記載するようにしてもよい。この場合には、被検質量リスト作成部41において被検質量リストを作成する際に、質量分析で検出された各イオンの質量を分子量に換算するか、あるいは上位DB検索部42、下位DB検索部45、第1検索部46、及び第2検索部47によるデータベース検索を行う際に、データベース中の各質量リスト(又は部分質量リスト)に記載された分子量をイオン質量に換算した上で被検質量リスト(又は被検部分質量リスト)との照合を行う構成とする。
【符号の説明】
【0066】
1…質量分析部
11…イオン化部
12…TOF
2…細胞識別部
20…記憶部
21…上位データベース
22…下位データベース
22a、22b、22c…サブデータベース
23…データベース
24…変異データベース
30…インターフェース部
40…演算部
41…被検質量リスト作成部
42…上位DB検索部
43…分類群決定部
44…被検部分質量リスト作成部
45…下位DB検索部
46…第1検索部
47…第2検索部
50…分析制御部
61…表示部
62…操作部
【特許請求の範囲】
【請求項1】
記憶装置及び演算装置を有し、被検細胞を質量分析して得られた結果に基づいて該被検細胞の種類を識別する装置であって、
前記記憶装置が、既知細胞の構成成分のイオン質量又は分子量が記載された質量リストを複数の既知細胞について収録した第1データベースと、既知細胞の構成成分のイオン質量又は分子量のうち、該既知細胞が属する予め定められた階級の分類群に共通するイオン質量又は分子量以外を記載した部分質量リストを複数の既知細胞について収録した第2データベースと、を記憶しており、
前記演算装置が、
a)前記質量分析の結果に基づいて作成された前記被検細胞の構成成分のイオン質量又は分子量を記載した被検質量リストを用いて前記第1データベースを検索する第1検索手段と、
b)前記第1検索手段による検索結果に基づいて、前記階級に位置する分類群のいずれかを以降の検索で対象とする分類群として決定する分類群決定手段と、
c)前記被検質量リストから前記分類群決定手段で決定された分類群に共通するイオン質量又は分子量を削除した被検部分質量リストを作成する被検部分質量リスト作成手段と、
d)前記被検部分質量リスト作成手段により作成された被検部分質量リストを用いて前記第2データベースを検索する第2検索手段と、
を有することを特徴とする細胞識別装置。
【請求項2】
記憶装置及び演算装置を有し、被検細胞を質量分析して得られた結果に基づいて該被検細胞の種類を識別する装置であって、
前記記憶装置が、既知細胞の構成成分のイオン質量又は分子量が記載された質量リストを複数の既知細胞について収録したデータベースを記憶しており、
前記演算装置が、
a)前記質量分析の結果に基づいて作成された前記被検細胞の構成成分のイオン質量又は分子量が記載された被検質量リストを用いて前記データベースを検索する第1検索手段と、
b)前記第1検索手段による検索結果に基づいて以降の検索で対象とする分類群を決定する分類群決定手段と、
c)前記被検質量リストから前記分類群決定手段で決定された分類群に共通するイオン質量又は分子量を削除した被検部分質量リストを作成する被検部分質量リスト作成手段と、
d) 前記データベースに収録された質量リストの内、前記分類群決定手段で決定された分類群に属する既知細胞の質量リストを検索対象として前記被検部分質量リストを用いた検索を行う第2検索手段と、
を有し、
前記第2検索手段が、検索対象とする質量リストから前記分類群決定手段で決定された分類群に共通するイオン質量又は分子量を削除し、該削除後の質量リストに対して前記被検部分質量リストを用いた検索を行うものであることを特徴とする細胞識別装置。
【請求項3】
更に、塩基配列又はアミノ酸配列に起こり得る変異に関する情報を収録した変異データベースを備え、
前記第2検索手段が、前記変異データベースから変異に関する情報を取得し、該情報に基づいて前記第2データベース中の部分質量リストに含まれるイオン質量又は分子量を前記変異が起きた場合のイオン質量又は分子量に変更したものを対象として前記被検部分質量リストを用いた検索を行うことを特徴とする請求項1に記載の細胞識別装置。
【請求項4】
更に、塩基配列又はアミノ酸配列に起こり得る変異に関する情報を収録した変異データベースを備え、
前記第2検索手段が、前記変異データベースから変異に関する情報を取得し、該情報に基づいて前記削除後の質量リストに含まれるイオン質量又は分子量を前記変異が起きた場合のイオン質量又は分子量に変更し、該変更後の質量リストを対象として前記被検部分質量リストを用いた検索を行うことを特徴とする請求項2に記載の細胞識別装置。
【請求項5】
コンピュータを請求項1に記載の第1検索手段、分類群決定手段、被検部分質量リスト作成手段、及び第2検索手段として機能させるためのプログラム。
【請求項6】
コンピュータを請求項2に記載の第1検索手段、分類群決定手段、被検部分質量リスト作成手段、及び第2検索手段として機能させるためのプログラム。
【請求項1】
記憶装置及び演算装置を有し、被検細胞を質量分析して得られた結果に基づいて該被検細胞の種類を識別する装置であって、
前記記憶装置が、既知細胞の構成成分のイオン質量又は分子量が記載された質量リストを複数の既知細胞について収録した第1データベースと、既知細胞の構成成分のイオン質量又は分子量のうち、該既知細胞が属する予め定められた階級の分類群に共通するイオン質量又は分子量以外を記載した部分質量リストを複数の既知細胞について収録した第2データベースと、を記憶しており、
前記演算装置が、
a)前記質量分析の結果に基づいて作成された前記被検細胞の構成成分のイオン質量又は分子量を記載した被検質量リストを用いて前記第1データベースを検索する第1検索手段と、
b)前記第1検索手段による検索結果に基づいて、前記階級に位置する分類群のいずれかを以降の検索で対象とする分類群として決定する分類群決定手段と、
c)前記被検質量リストから前記分類群決定手段で決定された分類群に共通するイオン質量又は分子量を削除した被検部分質量リストを作成する被検部分質量リスト作成手段と、
d)前記被検部分質量リスト作成手段により作成された被検部分質量リストを用いて前記第2データベースを検索する第2検索手段と、
を有することを特徴とする細胞識別装置。
【請求項2】
記憶装置及び演算装置を有し、被検細胞を質量分析して得られた結果に基づいて該被検細胞の種類を識別する装置であって、
前記記憶装置が、既知細胞の構成成分のイオン質量又は分子量が記載された質量リストを複数の既知細胞について収録したデータベースを記憶しており、
前記演算装置が、
a)前記質量分析の結果に基づいて作成された前記被検細胞の構成成分のイオン質量又は分子量が記載された被検質量リストを用いて前記データベースを検索する第1検索手段と、
b)前記第1検索手段による検索結果に基づいて以降の検索で対象とする分類群を決定する分類群決定手段と、
c)前記被検質量リストから前記分類群決定手段で決定された分類群に共通するイオン質量又は分子量を削除した被検部分質量リストを作成する被検部分質量リスト作成手段と、
d) 前記データベースに収録された質量リストの内、前記分類群決定手段で決定された分類群に属する既知細胞の質量リストを検索対象として前記被検部分質量リストを用いた検索を行う第2検索手段と、
を有し、
前記第2検索手段が、検索対象とする質量リストから前記分類群決定手段で決定された分類群に共通するイオン質量又は分子量を削除し、該削除後の質量リストに対して前記被検部分質量リストを用いた検索を行うものであることを特徴とする細胞識別装置。
【請求項3】
更に、塩基配列又はアミノ酸配列に起こり得る変異に関する情報を収録した変異データベースを備え、
前記第2検索手段が、前記変異データベースから変異に関する情報を取得し、該情報に基づいて前記第2データベース中の部分質量リストに含まれるイオン質量又は分子量を前記変異が起きた場合のイオン質量又は分子量に変更したものを対象として前記被検部分質量リストを用いた検索を行うことを特徴とする請求項1に記載の細胞識別装置。
【請求項4】
更に、塩基配列又はアミノ酸配列に起こり得る変異に関する情報を収録した変異データベースを備え、
前記第2検索手段が、前記変異データベースから変異に関する情報を取得し、該情報に基づいて前記削除後の質量リストに含まれるイオン質量又は分子量を前記変異が起きた場合のイオン質量又は分子量に変更し、該変更後の質量リストを対象として前記被検部分質量リストを用いた検索を行うことを特徴とする請求項2に記載の細胞識別装置。
【請求項5】
コンピュータを請求項1に記載の第1検索手段、分類群決定手段、被検部分質量リスト作成手段、及び第2検索手段として機能させるためのプログラム。
【請求項6】
コンピュータを請求項2に記載の第1検索手段、分類群決定手段、被検部分質量リスト作成手段、及び第2検索手段として機能させるためのプログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】

【図7】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【公開番号】特開2013−85517(P2013−85517A)
【公開日】平成25年5月13日(2013.5.13)
【国際特許分類】
【出願番号】特願2011−229226(P2011−229226)
【出願日】平成23年10月18日(2011.10.18)
【出願人】(000001993)株式会社島津製作所 (3,708)
【出願人】(599002043)学校法人 名城大学 (142)
【Fターム(参考)】
【公開日】平成25年5月13日(2013.5.13)
【国際特許分類】
【出願日】平成23年10月18日(2011.10.18)
【出願人】(000001993)株式会社島津製作所 (3,708)
【出願人】(599002043)学校法人 名城大学 (142)
【Fターム(参考)】
[ Back to top ]