
組織内ソーシャルマップ作成システム及び組織内ソーシャルマップ作成方法
【課題】利用者の自発的な作業を行うことなく、検索をかけた利用者と業務等において関係すると思われる利用者を抽出する。
【解決手段】所定の組織内に構築されるソーシャルマップ作成システムが、利用者がアクセス先で閲覧した情報の履歴であるアクセスログを蓄積する。前記アクセスログに基づいて、各利用者を識別するための情報と、前記各利用者がアクセスしたアクセス先を特定する情報とを関連付けたテーブルである第1のテーブルを作成する。第1の利用者からの検索要求を受け付けた場合に、当該第1の利用者を識別するための情報を検索キーとして前記第1のテーブルを検索し、前記検索キーとしたアクセス先にアクセスした利用者である第2の利用者を特定し、当該特定した第2の利用者を識別するための情報を抽出する。抽出された第2の利用者を識別するための情報を前記第1の利用者に通知する。
【解決手段】所定の組織内に構築されるソーシャルマップ作成システムが、利用者がアクセス先で閲覧した情報の履歴であるアクセスログを蓄積する。前記アクセスログに基づいて、各利用者を識別するための情報と、前記各利用者がアクセスしたアクセス先を特定する情報とを関連付けたテーブルである第1のテーブルを作成する。第1の利用者からの検索要求を受け付けた場合に、当該第1の利用者を識別するための情報を検索キーとして前記第1のテーブルを検索し、前記検索キーとしたアクセス先にアクセスした利用者である第2の利用者を特定し、当該特定した第2の利用者を識別するための情報を抽出する。抽出された第2の利用者を識別するための情報を前記第1の利用者に通知する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は会社等の所定の組織内におけるソーシャルマップの作成に関する。
【背景技術】
【0002】
近年、例えばインターネットを利用したソーシャル・ネットワーキング・システムが広く普及している。また、LANやイントラネットを利用して、例えば会社等の組織内でソーシャル・ネットワーキング・システムを構築するということも行われている。
【0003】
このようなソーシャル・ネットワーキング・システムに関する技術の一例が特許文献1に記載されている。
【0004】
特許文献1に記載の技術では、利用者各人毎に、所属や、興味の対象を表すもの等をプロファイル情報として予め登録しておく。そして、利用者間でプロファイル情報が近似している利用者を抽出し、各利用者に抽出結果を通知する。これにより、利用者間での交流を促すことが可能となる。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2011−22905号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
しかしながら、上述したような一般的なソーシャル・ネットワーキング・システムには、下述のような問題があった。
【0007】
上述したような一般的な仕組みでは、ソーシャル・ネットワーキング・システムに参加している人間同士でしかつながることができず、なおかつ参加者が自発的な意思で情報発信をし続けない限り、つながりを持たない人間同士を結び付けることはできなかったという問題である。例えば、特許文献1に記載の技術であれば、予め能動的にプロファイル情報を登録しておかなければならない。
【0008】
また、情報の更新も人間の恣意的な情報出力に依存しているため、主業務以外のノウハウが可視化されにくく、多くの情報を提供するには人間が多くのコストをかけなくてはならないため、本来の業務に支障が出るという矛盾も発生していた。
【0009】
具体例として大規模な会社を挙げてこの問題点を検討する。例えば、大規模な会社では、異なる部署に所属していれば、同じオペレーティングシステムやミドルウェアを使用して仕事を行っていても、仕事上の関連がない場合、お互いの存在を知り得ることはない。
【0010】
よって、企業としての人的リソースの重複が発生することがある。一般的なソーシャル・ネットワーキング・システムによる自主的な情報公開では自発的な意思を持って活動しない限り、ソーシャルネットは機能しない。
【0011】
そこで本発明は、利用者の自発的な作業を行うことなく、検索をかけた利用者と業務等において関係すると思われる利用者を抽出することが可能な、組織内ソーシャルマップ作成システム及び組織内ソーシャルマップ作成方法を提供することを目的とする。
【課題を解決するための手段】
【0012】
本発明の第1の観点によれば、所定の組織内に構築されるソーシャルマップ作成システムにおいて、利用者がアクセス先で閲覧した情報の履歴であるアクセスログを蓄積するアクセスログ蓄積記憶手段と、前記アクセスログに基づいて、各利用者を識別するための情報と、前記各利用者がアクセスしたアクセス先を特定する情報とを関連付けたテーブルである第1のテーブルを作成するアクセスログ処理手段と、第1の利用者からの検索要求を受け付けた場合に、当該第1の利用者を識別するための情報を検索キーとして前記第1のテーブルを検索し、当該第1の利用者に関連付けられているアクセス先を特定する情報を抽出し、当該抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第2の利用者を特定し、当該特定した第2の利用者を識別するための情報を抽出する検索手段と、前記検索手段により抽出された第2の利用者を識別するための情報を前記第1の利用者に通知する手段と、を備えることを特徴とするソーシャルマップ作成システムが提供される。
【0013】
本発明の第2の観点によれば、所定の組織内に構築されるシステムが行うソーシャルマップ作成方法において、利用者がアクセス先で閲覧した情報の履歴であるアクセスログを蓄積するアクセスログ蓄積記憶ステップと、前記アクセスログに基づいて、各利用者を識別するための情報と、前記各利用者がアクセスしたアクセス先を特定する情報とを関連付けたテーブルである第1のテーブルを作成するアクセスログ処理ステップと、第1の利用者からの検索要求を受け付けた場合に、当該第1の利用者を識別するための情報を検索キーとして前記第1のテーブルを検索し、当該第1の利用者に関連付けられているアクセス先を特定する情報を抽出し、当該抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第2の利用者を特定し、当該特定した第2の利用者を識別するための情報を抽出する検索ステップと、前記検索ステップにより抽出された第2の利用者を識別するための情報を前記第1の利用者に通知するステップと、を備えることを特徴とするソーシャルマップ作成方法が提供される。
【発明の効果】
【0014】
本発明によれば、インターネットやイントラネットアクセスのアクセスログを自動的に蓄積し、蓄積した情報に基づいて検索を行うことから、利用者の自発的な作業を行うことなく、検索をかけた利用者と業務等において関係すると思われる利用者を抽出することが可能となる。
【図面の簡単な説明】
【0015】
【図1】図1は本発明の実施形態に係る各サーバの全体構成を表す図である。
【図2−1】図2−1は本発明の実施形態に係るProxyサーバの構成を表す図である。
【図2−2】図2−2は本発明の実施形態に係るProxyサーバ内で保持されるクライアントアクセスログの形式を表す図である。
【図2−3】図2−3は本発明の実施形態に係るProxyサーバ内でのhtmlファイルを一時的に保持するフォルダ構造を表す図である。
【図3−1】図3−1は本発明の実施形態に係るアクセスログ収集サーバの構成を表す図である。
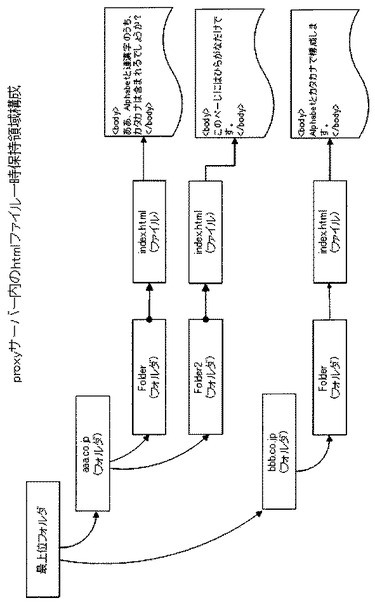
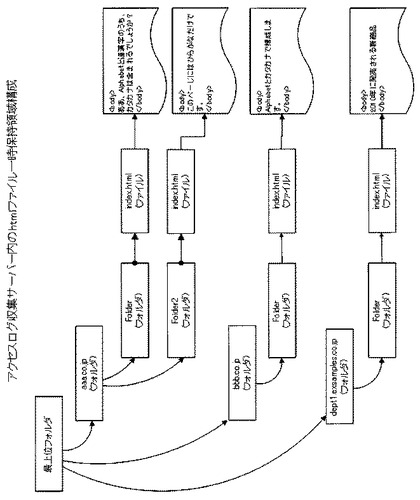
【図3−2】図3−2は本発明の実施形態に係るアクセスログ収集サーバ内でのhtmlファイルを一時的に保持するフォルダ構造を表す図である。
【図4−1】図4−1は本発明の実施形態に係る社内公開サーバの全体構成を表す図である。
【図4−2】図4−2は本発明の実施形態に係る社内公開サーバ内で保持されるアクセスログの形式を表す図である。
【図5−1】図5−1は本発明の実施形態に係るアクセスログ蓄積サーバの構成を表す図である。
【図5−2】図5−2は本発明の実施形態に係るアクセスログ蓄積サーバ内で保持される単語とURLの関連テーブルを表す図である。
【図5−3】図5−3は本発明の実施形態に係るアクセスログ蓄積サーバ内で保持されるURLと社員番号の関連を表す図である。
【図6】図6は本発明の実施形態に係る閲覧サーバの構成を表す図である。
【図7−1】図7−1は本発明の実施形態に係る認証サーバの構成を表す図である。
【図7−2】図7−2は本発明の実施形態に係る認証サーバ内で保持される社員の認証情報データベースの格納形式を表した図である。
【図8】図8は本発明の実施形態に係るクライアントが閲覧サーバにアクセスした際に表示されるユーザーインターフェースの概要を表す図である。
【図9−1】図9−1は本発明の実施形態にかかわる蓄積サーバ内でhtmlファイルから単語を抽出する処理の手順を表したフローチャート(1/2)である。
【図9−2】図9−2は本発明の実施形態にかかわる蓄積サーバ内でhtmlファイルから単語を抽出する処理の手順を表したフローチャート(2/2)である。
【発明を実施するための形態】
【0016】
次に、本発明の実施形態について図面を用いて詳細に説明する。
【0017】
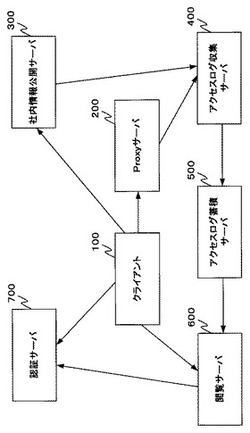
図1は、本実施形態である社外及び社内のWebサーバにアクセス可能なシステム全体の構成を表す図である。なお、本実施形態は、会社単位に限らず所定の単位での組織に適用可能であるが、今回は会社を単位として適用させた場合を想定する。
【0018】
図1を参照すると、本実施形態は、クライアント100、Proxyサーバ200、社内情報公開サーバ300、アクセスログ収集サーバ400、アクセスログ蓄積サーバ500、閲覧サーバ600及び認証サーバ700を有する。
【0019】
クライアント100は、利用者が直接利用する端末であり、一般的な汎用のパーソナルコンピューターにより実現可能である。
【0020】
また、クライアント100以外のProxyサーバ200、社内情報公開サーバ300、アクセスログ収集サーバ400、アクセスログ蓄積サーバ500、閲覧サーバ600及び認証サーバ700も、一般的な汎用のパーソナルコンピューターと同等の機能を持つ装置により実現可能である。
【0021】
すなわち、本実施形態は一般的な汎用のパーソナルコンピューターというハードウェアに本実施形態特有のプログラム(ソフトウェア)を組み込むことにより実現が可能である。また、図1では説明の便宜上、各サーバを機能毎に分類し、それぞれを1つのサーバとして図示しているが、これは、あくまで実装例のひとつに過ぎない。例えば、物理的に単一のサーバにより図1に示す複数のサーバの機能を実現させてもよい。また、物理的に複数のサーバにより図1に示す1つのサーバの機能を実現させてもよい。
【0022】
続いて、これらの各サーバ固有の機能に関して詳細に解説をする。
【0023】
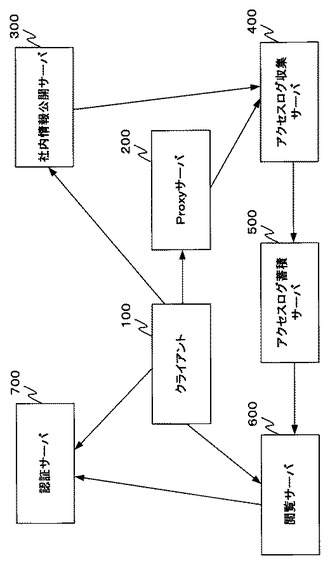
図2−1はProxyサーバ200の機能構成を示す図である。
【0024】
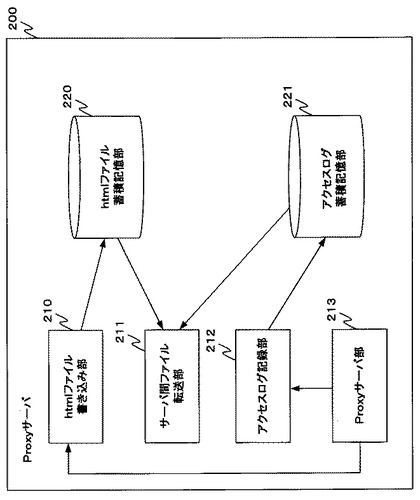
Proxyサーバ200は、htmlファイル書き込み部210、サーバ間ファイル転送部211、アクセスログ記録部212、Proxyサーバ部213、htmlファイル蓄積記憶部220及びアクセスログ蓄積記憶部221を含む。アクセスログ蓄積記憶部221は、アクセスログを記憶する。このアクセスログは任意の形式により記憶されるが、今回の説明においては図2−2に表すようにCSVテキストファイル形式でアクセスログを記憶するものとする。
【0025】
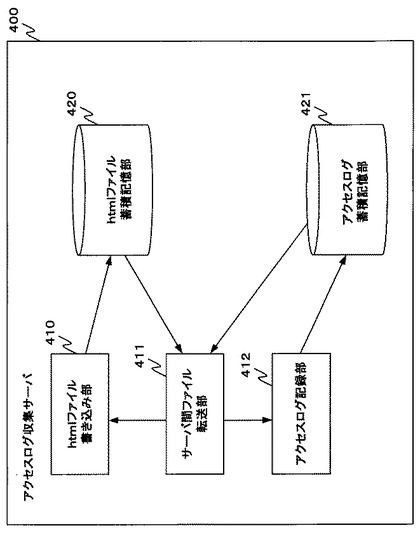
図3−1はアクセスログ収集サーバ400の機能構成を示す図である。
【0026】
アクセスログ収集サーバ400は、htmlファイル書き込み部410、サーバ間ファイル転送部411、アクセスログ記録部412、htmlファイル蓄積記憶部420及びアクセスログ蓄積記憶部421を含む。
【0027】
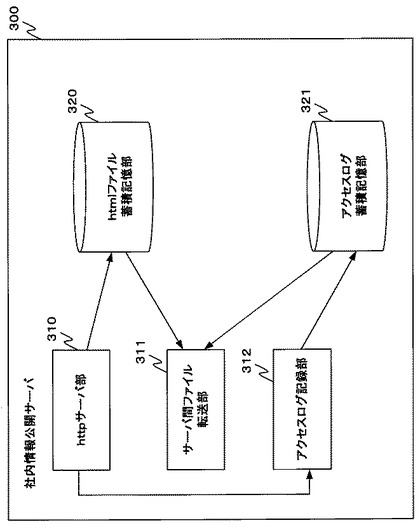
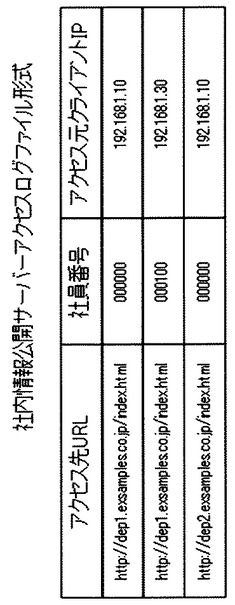
図4−1は社内情報公開サーバ300の機能構成を示す図である。
【0028】
社内情報公開サーバは、httpサーバ部310、サーバ間ファイル転送部311、アクセスログ記録部312、htmlファイル蓄積記憶部320及びアクセスログ蓄積記憶部321を含む。アクセスログ蓄積記憶部321は、アクセスログを記憶する。このアクセスログは任意の形式により記憶されるが、今回の説明においては図4−2に表すようにCSVテキストファイル形式でアクセスログを記憶するものとする。
【0029】
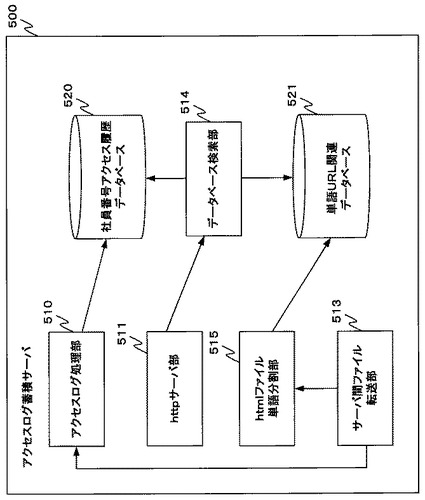
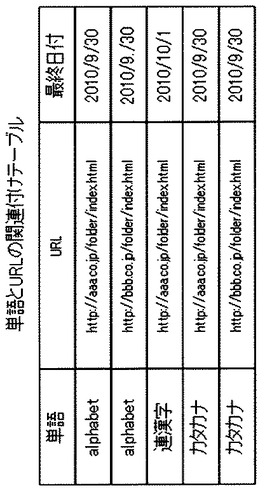
図5−1はアクセスログ蓄積サーバ500の機能構成を示す図である。
【0030】
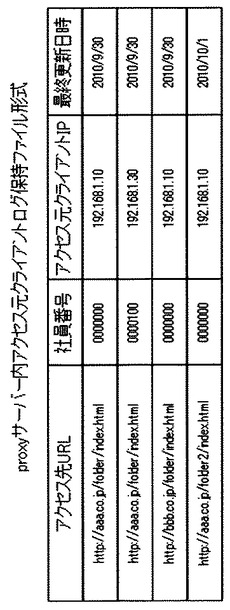
アクセスログ蓄積サーバ500はアクセスログ処理部510、httpサーバ部511、htmlファイル単語分割部512、サーバ間ファイル転送部513、データベース検索部514、社員番号アクセス履歴データベース520及び単語URL関連データベース521を含む。
【0031】
単語URL関連データベース521には図5−2示される形式のデータベーステーブルを含む。また、社員番号アクセス履歴データベース520には図5−3に示される形式のデータベーステーブルを含む。
【0032】
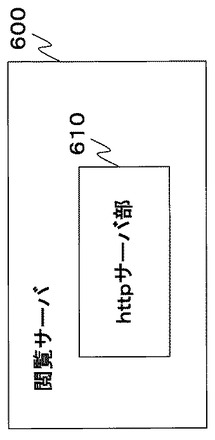
図6は閲覧サーバ600の機能構成を示す図である。
【0033】
閲覧サーバ600はhttpサーバ部610を含む。
【0034】
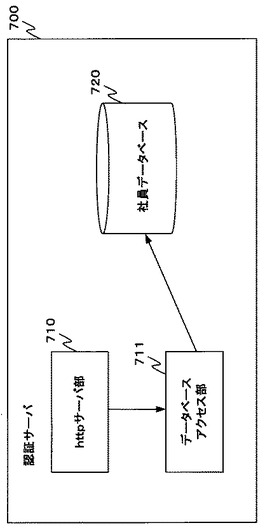
図7−1は認証サーバ700の機能構成を示す図である。
【0035】
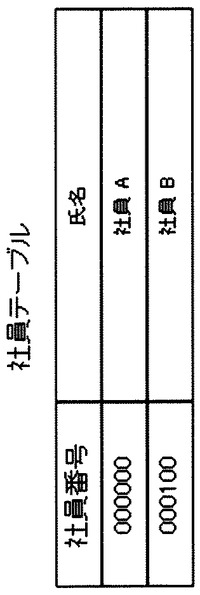
認証サーバ700はhttpサーバ部710、データベースアクセス部711及び社員データベース720を含む。社員データベースは図7−2の形式の社員テーブルを含む。
【0036】
各蓄積記憶部、蓄積フォルダ、蓄積領域及び各データベースは各サーバが利用する記憶装置により実現される。具体的には、この記憶装置は、HDD(Hard disk drive)やFlash SSD(Solid State Drive)により実現される。また、この記憶装置は各サーバにそれぞれ含まれていてもよいが、外部の記憶装置(図示を省略する)を利用するようにしてもよい。この場合記憶装置を別のコンピュータとして実現し、バスやUSB規格に準拠したケーブル、インターネット等の手段を用いて接続するようにしてもよい。更に、単一の記憶装置により実現されてもよいが、複数の記憶装置の組合せにより実現されていてもよい。
【0037】
続いて本実施形態の操作の説明を行う。まず、クライアント100によるアクセスについて説明する。
【0038】
最初に、クライアント100がProxyサーバ200を経由して、社外のWebサーバ(図示を省略する)へのアクセスを試みる場合を考える。この場合、Proxyサーバ200はクライアント100に組み込まれているWebブラウザから送信された認証情報と、アクセス先URLとを使用して、社外のWebサーバへアクセスを行う。
【0039】
アクセスが成功した場合、Proxyサーバ200は、htmlデータをクライアント100へ送り返す。また、Proxyサーバ200はアクセスが成功したタイミングで、アクセスログ蓄積記憶装置221へアクセスログを記録する。この際、アクセスログは図2−2の形式でテキストファイルとして記録される。また、クライアントに返却したhtmlデータのうち、htmlを構成するテキスト要素をhtmlファイル蓄積記憶装置220へ記録する。具体的には、htmlファイル蓄積記憶装置220内に図2−3で示されるフォルダ構成でフォルダを作成し、作成したフォルダにテキスト要素を保存する。
【0040】
一方、クライアント100がProxyサーバ200を経由せず、社内情報公開サーバ300に直接アクセスする場合も考えられる。この場合、社内情報公開サーバ300は認証サーバ700のhttpサーバ部710上で提供されるWebサービスを使用して認証情報を取得する。そして、取得した認証情報、アクセス元クライアント情報を、アクセスログ蓄積記憶部321に記憶する。この際、取得した認証情報及びアクセス元クライアント情報は、図4−2に示されるCSV形式で記憶される。
【0041】
次に、アクセスログ収集サーバ400による収集について説明する。
【0042】
アクセスログ収集サーバ400は定期的にProxyサーバ200にアクセスを行う。そして、アクセスログ収集サーバ400はサーバ間ファイル転送部411を用いて、図2−2及び図2−3の形式でProxyサーバ200に格納されているアクセスログ及びhtmlのキャッシュをそのままファイル転送する。
【0043】
アクセスログ収集サーバ400は、Proxyサーバ200からのファイル転送が終了すると、次に社内情報公開サーバ300にアクセスをする。そして、アクセスログ収集サーバ400は、サーバ間ファイル転送部411を用いて、図4−2の形式で社内情報公開サーバ300に記憶されているアクセスログを取得する。次に、htmlファイル書き込み部410を用いて、内情報公開サーバ300のアクセスログに記録されているURLにhttpプロトコルによるアクセスを行い、図3−2で示すフォルダ階層を使用して、社内及び社外のhtmlファイルを結合してhtmlファイル蓄積記憶部320に保存する。
【0044】
次に、アクセスログ蓄積サーバ500の動作について説明する。
【0045】
アクセスログ蓄積サーバ500では、一定間隔でアクセスログ蓄積サーバ400のサーバ間ファイル転送部411を呼び出し、アクセスログ収集サーバ400に複製された情報を逐次取得する。具体的には、htmlファイル蓄積記憶部420及びアクセスログ蓄積記憶部421の記憶している情報を取得する。そして、アクセスログ蓄積サーバ500は、取得した情報をもとに、以下の手順で正規化、蓄積を行う。その詳細を以下に示す。
【0046】
まず、サーバ間ファイル転送部411を用いて、htmlファイル蓄積部420からhtmlテキストを一つずつ取得する。取得したhtmlテキストを一文字ずつ読み込み、単語抽出処理を図9のフローチャートで表される手順で行う。単語抽出処理の詳細を図9を参照しながら解説する。
【0047】
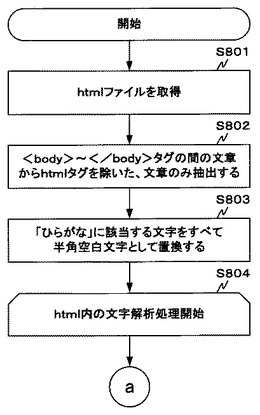
まず、htmlファイルを取得する(ステップS801)。
【0048】
続いて、取得したhtmlファイルの<body>〜</body>タグの間の文章のうちから、htmlタグを除いた、文章のみ抽出する(ステップS802)。
【0049】
抽出した文章のうち、「ひらがな」に該当する文字をすべて半角空白文字として置換する(ステップS803)。これにより、各単語の区切りが生成される。なお、半角空白文字として置換するのはあくまで一例に過ぎず、漢字、英数字、カタカナ以外の任意の文字に置換するようにしてもよい。
【0050】
次に、html内の文字解析処理を開始する(ステップS804)。なお、ステップS804及びS810は、繰り返し処理の最初と最後を表すものであり、html内の解析対象とすべき文字全てに対して解析が終了するまでは、ステップS805〜S809を繰り返すことを意味する。
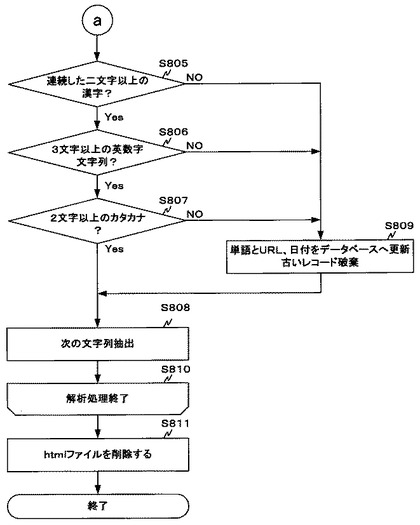
文字解析処理では、半角空白を単語の区切りとして、html内の単が「連続した二文字以上の漢字」か否かを確認する(ステップS805)。「連続した二文字以上の漢字」であれば(ステップS805においてYes)、その単語を分割してステップS809に進む。一方「連続した二文字以上の漢字」で無い場合は(ステップS805においてNo)、ステップS806に進む。
【0051】
ステップS806ではhtml内の単語が「3文字以上の英数字文字列」か否かを確認する(ステップS806)。「3文字以上の英数字文字列」であれば(ステップS806においてYes)、その単語を分割してステップS809に進む。一方「3文字以上の英数字文字列」で無い場合は(ステップS806においてNo)、ステップS807に進む。
【0052】
ステップS807ではhtml内の単語が「2文字以上のカタカナ」か否かを確認する(ステップS807)。「2文字以上のカタカナ」であれば(ステップS807においてYes)、その単語を分割してステップS809に進む。一方「2文字以上のカタカナ」で無い場合は(ステップS807においてNo)、ステップS808に進む。
【0053】
一方、ステップS809では、分割された単語を、URL及び該当URLの最終更新日と関連付けて、htmlの最終更新日付と関連付けて図5−2の形式で単語URL関連データベース521に保存する(ステップS809)。なお、保存する際に同じ単語及び、同一URLを持つレコードが既に存在していた場合、古いレコードを破棄する。
【0054】
その後、次の文字列を抽出し(ステップS808)、この手順をアクセスログ蓄積サーバ400内のhtmlファイルが存在しなくなるまで繰り返す。
【0055】
全ての文字列に関して解析が終了したhtmlファイルはアクセスログ蓄積サーバ400から削除する(ステップS811)。
【0056】
次に、アクセスログ蓄積サーバ500はアクセスログ収集サーバ400からサーバ間ファイル転送部411を使用して、アクセスログをすべて取得し、アクセスログ一行ごとに社員番号とアクセス先URL、URLの最終更新日を社員番号アクセス履歴データベース520に図5−3の形式で記録する。
【0057】
以上でアクセスログ蓄積サーバ500内での記録処理は終了する。
【0058】
次に、或る社員が社内で自分と関連のある社員を自動的に検索したい場合の処理を解説する。この或る社員の社員番号は「000000」であるものとする。また、この或る社員を以下では、「検索元社員」と呼ぶ。
【0059】
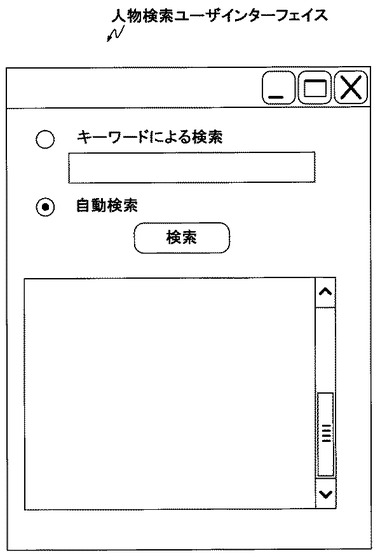
まず、検索元社員がクライアント100から、閲覧サーバ600のhttpサーバ部601を呼び出してアクセスをする。このアクセスに応じてクライアント100にユーザーインターフェースが表示される。ユーザーインターフェースは、任意のものを利用することが可能であるが、本実施形態では図8に示すユーザーインターフェースを表示する。
【0060】
続いて、検索元社員が図8に示す画面で「自動検索」を選択して、検索ボタンを押したとする。これにより閲覧サーバ600はクライアント100から送出された社員番号(000000)をキーにして、アクセスログ蓄積サーバ500のhttpサーバ部511を呼び出す。
【0061】
次に、データベース検索部514が、クライアント100から送信された社員番号をキーにして、社員番号アクセス履歴データベース520内を検索し、送信された社員番号に対応するURLを抽出する。
【0062】
更に、社員番号アクセス履歴データベース520内を検索し、抽出されたURL一つに対して同じURLにアクセスしたことのある社員をすべて抽出する。なお、抽出の際、現在クライアント100からアクセスしている検索元社員は抽出結果から除く。
【0063】
図5−3の例では、現在アクセス中の検索元社員(社員番号000000)と同じURLに、社員番号000100の社員がアクセスしている。そのため、社員番号000100が抽出される。
【0064】
抽出対象が存在した場合、閲覧サーバ600は認証サーバ700のhttpサーバ部710を呼びだす。httpサーバ部710はデータベースアクセス部711を使用して、社員番号が000100の社員の氏名を取得し、クライアント100に表示する。
【0065】
以上の動作により、検索元社員(社員番号000000)は自身が閲覧したURLと同一のURLを閲覧したことのある社員(社員番号000100)の社員番号及び氏名を検索することが可能となるという効果を奏する。
【0066】
次に、或る社員が社内で特定のキーワードに関して関心があると思われる社員を自動的に検索したい場合の処理を解説する。上述の説明と同様に、この或る社員の社員番号は「000000」であるものとする。また、この或る社員を以下では、「検索元社員」と呼ぶ。
【0067】
まず、検索元社員がクライアント100から、閲覧サーバ600のhttpサーバ部601を呼び出してアクセスをする。このアクセスに応じてクライアント100にユーザーインターフェースが表示される。ユーザーインターフェースは上述の説明と同じく図8に示すユーザーインターフェースである。
【0068】
次に、検索元社員が図8の画面において、「キーワードによる検索」を選択し、知りたいキーワードを下のテキストボックスに入力する。
【0069】
そして、更に「検索」を選択して、検索ボタンを押すと、閲覧サーバ600はクライアント100から送出された社員番号(000000)及び、キーワードを使用して、httpサーバ部511を呼び出す。
【0070】
アクセスログ蓄積サーバ500では、単語URL関連データベース521内に存在する、「単語とURLの関連付け」テーブル(図5−2参照)からクライアント100より送出されたキーワードの検索を行う。
【0071】
検索に使用したキーワード(単語)がデータベース上に存在した場合は、その単語に関連付けられているURLを抽出する。次に抽出されたURLを検索キーとして、社員番号アクセス履歴データベース520のテーブルから社員番号を検索する。
【0072】
図5−3の例では、現在アクセス中の検索元社員(社員番号000000)と同じURLに、社員番号000100の社員がアクセスしている。そのため、社員番号000100が抽出される。
【0073】
抽出対象が存在した場合、閲覧サーバ600は認証サーバ700のhttpサーバ部710を呼びだす。httpサーバ部710はデータベースアクセス部711を使用して、社員番号が000100の社員の氏名を取得し、クライアント100に表示する。
【0074】
以上の動作により、検索元社員(社員番号000000)は特定のキーワードに関して関心があると思われる社員の社員番号及び氏名を検索することが可能となるという効果を奏する。
【0075】
更に、本実施形態は、日常業務の延長で新しい人間関係を築くシステムを提供できるという効果を奏する。
【0076】
その理由は、各社員の能動的な作業を伴わないためである。
【0077】
次に、本実施形態を変形した変形例の構成について図面を参照して詳細に説明する。
【0078】
上述した実施形態においては、図2−1及び図3−1にはhtmlファイル書き込み部210及びhtmlファイル書き込み部410が存在していた。もっとも、この構成を変形して、htmlファイル書き込み部210及びhtmlファイル書き込み部410を省いた構成とすることも可能である。
【0079】
htmlファイル書き込み部210及びhtmlファイル書き込み部410を省いた場合でも、図2−1及び、図3−1のアクセスログ記録部212及びアクセスログ記録部412があれば、図5−3の社員番号アクセス履歴テーブルを検索することにより、自動検索のみの機能でソーシャルマップを作成することができる。
【0080】
また、本実施形態では自発的な行動によらず、自動的に無関係な部署同士の人間に新しいつながりを発見することが可能となる。
【0081】
また、新しいつながりを構築することにより、部署内で解決しない問題であっても新しい人間関係により、情報を持っている人間同士で解決する可能性が高くなる効果が期待できる。
【0082】
加えて、本実施形態は、一般的な技術に比べ下記の点において有利な効果を奏する。
【0083】
一般的な技術における、ユーザーコンテンツ処理手段では、発明内で管理されているユーザーコンテンツ記憶手段を用いる必要がある。例えば、ページ内のURLに発明システムがコードを挿入する必要があるため、他のシステムで管理されているURLでの分析を行うことができないと考えられる。しかし、本実施形態では、既存のユーザーコンテンツに修正、改変を行うことなく、自動的にコンテンツの解析を行い、情報を収集する仕組みを備えているため上記のような問題は生じない。
【0084】
また、本実施形態では、一般的な技術のような、能動的にコンテンツを作成及び管理するシステムを備えない。また、一般的な技術ではコンテンツ配信機能があるが、本発明ではコンテンツそのものの配信機能は備えない。すなわち本実施形態は、集積した結果のみ一時的に蓄積するだけであるため、システム構成上も一般的な技術とは異なっている。
【0085】
また、一般的な技術では明示的にコメントのカテゴリとコメント情報をユーザーが能動的に設定している。本実施形態ではユーザーが能動的にカテゴリ分類を行う必要なく、自動的にキーワードとURLの関連付けを行っている。よって、本実施形態ではカテゴリ設定に依存しない、自律的な集計が可能となる。
【0086】
なお、上記実施形態では、プログラムが、クライアント及び各サーバに予め記憶されているものとして説明した。しかし、コンピュータを、クライアント及び各サーバの全部又は一部として動作させ、あるいは、上述の処理を実行させるためのプログラムを、フレキシブルディスク、CD−ROM(Compact Disc Read-Only Memory)、DVD(Digital Versatile Disc)、MO(Magneto Optical Disk(Disc))BD(Blu-ray Disc)等のコンピュータ読み取り可能な記録媒体に格納して配布し、これを別のコンピュータにインストールし、上述の手段として動作させ、あるいは、上述の工程を実行させてもよい。
【0087】
さらに、インターネット上のサーバ装置が有するディスク装置等にプログラムを格納しておき、例えば、搬送波にプログラムを重畳させて、コンピュータにダウンロード等してプログラムを実行してもよい。
【0088】
なお、本発明の実施形態であるクライアント及び各サーバは、ハードウェアにより実現することもできるが、コンピュータをそのクライアント及び各サーバとして機能させるためのプログラムをコンピュータがコンピュータ読み取り可能な記録媒体から読み込んで実行することによっても実現することができる。
【0089】
また、本発明の実施形態による組織内ソーシャルマップ作成方法は、ハードウェアにより実現することもできるが、コンピュータにその方法を実行させるためのプログラムをコンピュータがコンピュータ読み取り可能な記録媒体から読み込んで実行することによっても実現することができる。
【0090】
また、上述した実施形態は、本発明の好適な実施形態ではあるが、上記実施形態のみに本発明の範囲を限定するものではなく、本発明の要旨を逸脱しない範囲において種々の変更を施した形態での実施が可能である。
【0091】
上記の実施形態の一部又は全部は、以下の付記のようにも記載されうるが、以下には限られない。
【0092】
(付記1) 所定の組織内に構築されるソーシャルマップ作成システムにおいて、
利用者がアクセス先で閲覧した情報の履歴であるアクセスログを蓄積するアクセスログ蓄積記憶手段と、
前記アクセスログに基づいて、各利用者を識別するための情報と、前記各利用者がアクセスしたアクセス先を特定する情報とを関連付けたテーブルである第1のテーブルを作成するアクセスログ処理手段と、
第1の利用者からの検索要求を受け付けた場合に、当該第1の利用者を識別するための情報を検索キーとして前記第1のテーブルを検索し、当該第1の利用者に関連付けられているアクセス先を特定する情報を抽出し、当該抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第2の利用者を特定し、当該特定した第2の利用者を識別するための情報を抽出する検索手段と、
前記検索手段により抽出された第2の利用者を識別するための情報を前記第1の利用者に通知する手段と、
を備えることを特徴とするソーシャルマップ作成システム。
【0093】
(付記2) 付記1に記載のソーシャルマップ作成システムにおいて、
前記アクセスログに含まれる文章を抽出し、抽出した文章を単語単位に分割し、当該分割された単語と当該単語が含まれていたアクセス先を特定する情報とを関連付けたテーブルである第2のテーブルを作成する単語分割手段と、
第3の利用者から或る単語をキーワードとした検索要求を受け付けた場合に、当該キーワードである前記或る単語を検索キーとして前記第2のテーブルを検索し、当該単語と関連付けられているアクセス先を特定する情報を抽出し、抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第4の利用者を特定し、当該特定した第4の利用者を識別するための情報を抽出する検索手段と、
前記検索手段により抽出された第4の利用者を識別するための情報を前記第3の利用者に通知する手段と、
を備えることを特徴とするソーシャルマップ作成システム。
【0094】
(付記3) 付記2に記載のソーシャルマップ作成システムにおいて、
前記単語分割手段は、
前記抽出した文章内の平仮名に該当する文字を、漢字、英数字及びカタカナ以外の任意の文字に置き換えることにより前記単語単位の分割を行うことを特徴とするソーシャルマップ作成システム。
【0095】
(付記4) 付記2又は3に記載のソーシャルマップ作成システムにおいて、
前記単語分割手段は、
前記分割後の単語が、連続した二文字以上の漢字、三文字以上の英数字及び二文字以上のカタカナ、の何れかである場合に前記第2のテーブルに格納することを特徴とするソーシャルマップ作成システム。
【0096】
(付記5) 付記1乃至4の何れか1に記載のソーシャルマップ作成システムにおいて、
前記アクセスログの収集は、当該ソーシャルマップ作成システムが自動的に行うものであり、アクセスログの収集のために利用者の操作を必要としないことを特徴とするソーシャルマップ作成システム。
【0097】
(付記6) 付記1乃至5の何れか1に記載のソーシャルマップ作成システムにおいて、
前記利用者を識別するための情報と、当該利用者を識別するための情報により識別される利用者の氏名とを関連付けたテーブルである第3のテーブルを更に有しており、
前記第3のテーブルを検索することにより前記利用者を識別するための情報ではなく、前記利用者の氏名を通知することを特徴とするソーシャルマップ作成システム。
【0098】
(付記7) 所定の組織内に構築されるシステムが行うソーシャルマップ作成方法において、
利用者がアクセス先で閲覧した情報の履歴であるアクセスログを蓄積するアクセスログ蓄積記憶ステップと、
前記アクセスログに基づいて、各利用者を識別するための情報と、前記各利用者がアクセスしたアクセス先を特定する情報とを関連付けたテーブルである第1のテーブルを作成するアクセスログ処理ステップと、
第1の利用者からの検索要求を受け付けた場合に、当該第1の利用者を識別するための情報を検索キーとして前記第1のテーブルを検索し、当該第1の利用者に関連付けられているアクセス先を特定する情報を抽出し、当該抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第2の利用者を特定し、当該特定した第2の利用者を識別するための情報を抽出する検索ステップと、
前記検索ステップにより抽出された第2の利用者を識別するための情報を前記第1の利用者に通知するステップと、
を備えることを特徴とするソーシャルマップ作成方法。
【産業上の利用可能性】
【0099】
本発明は、たとえば企業内における、部門間において連携がないが、特定のノウハウを持っていると考えられる人間を検索する場面に好適である。
【符号の説明】
【0100】
100 クライアント
200 Proxyサーバ
210 htmlファイル書き込み部
211 サーバ間ファイル転送部
212 アクセスログ記録部
213 Proxyサーバ部
220 htmlファイル蓄積記憶部
221 アクセスログ蓄積記憶部
300 社内情報公開サーバ
310 httpサーバ部
311 サーバ間ファイル転送部
312 アクセスログ記録部
320 htmlファイル蓄積記憶部
321 アクセスログ蓄積記憶部
400 アクセスログ収集サーバ
410 htmlファイル書き込み部
411 サーバ間ファイル転送部
412 アクセスログ記録部
420 htmlファイル蓄積記憶部
421 アクセスログ蓄積記憶部
500 アクセスログ蓄積サーバ
510 アクセスログ処理部
511 httpサーバ部
512 htmlファイル単語分割部
513 サーバ間ファイル転送部
514 データベース検索部
520 社員番号アクセス履歴データベース
521 単語URL関連データベース
600 閲覧サーバ
610 httpサーバ部
700 認証サーバ
710 httpサーバ部
711 データベースアクセス部
720 社員データベース
【技術分野】
【0001】
本発明は会社等の所定の組織内におけるソーシャルマップの作成に関する。
【背景技術】
【0002】
近年、例えばインターネットを利用したソーシャル・ネットワーキング・システムが広く普及している。また、LANやイントラネットを利用して、例えば会社等の組織内でソーシャル・ネットワーキング・システムを構築するということも行われている。
【0003】
このようなソーシャル・ネットワーキング・システムに関する技術の一例が特許文献1に記載されている。
【0004】
特許文献1に記載の技術では、利用者各人毎に、所属や、興味の対象を表すもの等をプロファイル情報として予め登録しておく。そして、利用者間でプロファイル情報が近似している利用者を抽出し、各利用者に抽出結果を通知する。これにより、利用者間での交流を促すことが可能となる。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2011−22905号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
しかしながら、上述したような一般的なソーシャル・ネットワーキング・システムには、下述のような問題があった。
【0007】
上述したような一般的な仕組みでは、ソーシャル・ネットワーキング・システムに参加している人間同士でしかつながることができず、なおかつ参加者が自発的な意思で情報発信をし続けない限り、つながりを持たない人間同士を結び付けることはできなかったという問題である。例えば、特許文献1に記載の技術であれば、予め能動的にプロファイル情報を登録しておかなければならない。
【0008】
また、情報の更新も人間の恣意的な情報出力に依存しているため、主業務以外のノウハウが可視化されにくく、多くの情報を提供するには人間が多くのコストをかけなくてはならないため、本来の業務に支障が出るという矛盾も発生していた。
【0009】
具体例として大規模な会社を挙げてこの問題点を検討する。例えば、大規模な会社では、異なる部署に所属していれば、同じオペレーティングシステムやミドルウェアを使用して仕事を行っていても、仕事上の関連がない場合、お互いの存在を知り得ることはない。
【0010】
よって、企業としての人的リソースの重複が発生することがある。一般的なソーシャル・ネットワーキング・システムによる自主的な情報公開では自発的な意思を持って活動しない限り、ソーシャルネットは機能しない。
【0011】
そこで本発明は、利用者の自発的な作業を行うことなく、検索をかけた利用者と業務等において関係すると思われる利用者を抽出することが可能な、組織内ソーシャルマップ作成システム及び組織内ソーシャルマップ作成方法を提供することを目的とする。
【課題を解決するための手段】
【0012】
本発明の第1の観点によれば、所定の組織内に構築されるソーシャルマップ作成システムにおいて、利用者がアクセス先で閲覧した情報の履歴であるアクセスログを蓄積するアクセスログ蓄積記憶手段と、前記アクセスログに基づいて、各利用者を識別するための情報と、前記各利用者がアクセスしたアクセス先を特定する情報とを関連付けたテーブルである第1のテーブルを作成するアクセスログ処理手段と、第1の利用者からの検索要求を受け付けた場合に、当該第1の利用者を識別するための情報を検索キーとして前記第1のテーブルを検索し、当該第1の利用者に関連付けられているアクセス先を特定する情報を抽出し、当該抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第2の利用者を特定し、当該特定した第2の利用者を識別するための情報を抽出する検索手段と、前記検索手段により抽出された第2の利用者を識別するための情報を前記第1の利用者に通知する手段と、を備えることを特徴とするソーシャルマップ作成システムが提供される。
【0013】
本発明の第2の観点によれば、所定の組織内に構築されるシステムが行うソーシャルマップ作成方法において、利用者がアクセス先で閲覧した情報の履歴であるアクセスログを蓄積するアクセスログ蓄積記憶ステップと、前記アクセスログに基づいて、各利用者を識別するための情報と、前記各利用者がアクセスしたアクセス先を特定する情報とを関連付けたテーブルである第1のテーブルを作成するアクセスログ処理ステップと、第1の利用者からの検索要求を受け付けた場合に、当該第1の利用者を識別するための情報を検索キーとして前記第1のテーブルを検索し、当該第1の利用者に関連付けられているアクセス先を特定する情報を抽出し、当該抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第2の利用者を特定し、当該特定した第2の利用者を識別するための情報を抽出する検索ステップと、前記検索ステップにより抽出された第2の利用者を識別するための情報を前記第1の利用者に通知するステップと、を備えることを特徴とするソーシャルマップ作成方法が提供される。
【発明の効果】
【0014】
本発明によれば、インターネットやイントラネットアクセスのアクセスログを自動的に蓄積し、蓄積した情報に基づいて検索を行うことから、利用者の自発的な作業を行うことなく、検索をかけた利用者と業務等において関係すると思われる利用者を抽出することが可能となる。
【図面の簡単な説明】
【0015】
【図1】図1は本発明の実施形態に係る各サーバの全体構成を表す図である。
【図2−1】図2−1は本発明の実施形態に係るProxyサーバの構成を表す図である。
【図2−2】図2−2は本発明の実施形態に係るProxyサーバ内で保持されるクライアントアクセスログの形式を表す図である。
【図2−3】図2−3は本発明の実施形態に係るProxyサーバ内でのhtmlファイルを一時的に保持するフォルダ構造を表す図である。
【図3−1】図3−1は本発明の実施形態に係るアクセスログ収集サーバの構成を表す図である。
【図3−2】図3−2は本発明の実施形態に係るアクセスログ収集サーバ内でのhtmlファイルを一時的に保持するフォルダ構造を表す図である。
【図4−1】図4−1は本発明の実施形態に係る社内公開サーバの全体構成を表す図である。
【図4−2】図4−2は本発明の実施形態に係る社内公開サーバ内で保持されるアクセスログの形式を表す図である。
【図5−1】図5−1は本発明の実施形態に係るアクセスログ蓄積サーバの構成を表す図である。
【図5−2】図5−2は本発明の実施形態に係るアクセスログ蓄積サーバ内で保持される単語とURLの関連テーブルを表す図である。
【図5−3】図5−3は本発明の実施形態に係るアクセスログ蓄積サーバ内で保持されるURLと社員番号の関連を表す図である。
【図6】図6は本発明の実施形態に係る閲覧サーバの構成を表す図である。
【図7−1】図7−1は本発明の実施形態に係る認証サーバの構成を表す図である。
【図7−2】図7−2は本発明の実施形態に係る認証サーバ内で保持される社員の認証情報データベースの格納形式を表した図である。
【図8】図8は本発明の実施形態に係るクライアントが閲覧サーバにアクセスした際に表示されるユーザーインターフェースの概要を表す図である。
【図9−1】図9−1は本発明の実施形態にかかわる蓄積サーバ内でhtmlファイルから単語を抽出する処理の手順を表したフローチャート(1/2)である。
【図9−2】図9−2は本発明の実施形態にかかわる蓄積サーバ内でhtmlファイルから単語を抽出する処理の手順を表したフローチャート(2/2)である。
【発明を実施するための形態】
【0016】
次に、本発明の実施形態について図面を用いて詳細に説明する。
【0017】
図1は、本実施形態である社外及び社内のWebサーバにアクセス可能なシステム全体の構成を表す図である。なお、本実施形態は、会社単位に限らず所定の単位での組織に適用可能であるが、今回は会社を単位として適用させた場合を想定する。
【0018】
図1を参照すると、本実施形態は、クライアント100、Proxyサーバ200、社内情報公開サーバ300、アクセスログ収集サーバ400、アクセスログ蓄積サーバ500、閲覧サーバ600及び認証サーバ700を有する。
【0019】
クライアント100は、利用者が直接利用する端末であり、一般的な汎用のパーソナルコンピューターにより実現可能である。
【0020】
また、クライアント100以外のProxyサーバ200、社内情報公開サーバ300、アクセスログ収集サーバ400、アクセスログ蓄積サーバ500、閲覧サーバ600及び認証サーバ700も、一般的な汎用のパーソナルコンピューターと同等の機能を持つ装置により実現可能である。
【0021】
すなわち、本実施形態は一般的な汎用のパーソナルコンピューターというハードウェアに本実施形態特有のプログラム(ソフトウェア)を組み込むことにより実現が可能である。また、図1では説明の便宜上、各サーバを機能毎に分類し、それぞれを1つのサーバとして図示しているが、これは、あくまで実装例のひとつに過ぎない。例えば、物理的に単一のサーバにより図1に示す複数のサーバの機能を実現させてもよい。また、物理的に複数のサーバにより図1に示す1つのサーバの機能を実現させてもよい。
【0022】
続いて、これらの各サーバ固有の機能に関して詳細に解説をする。
【0023】
図2−1はProxyサーバ200の機能構成を示す図である。
【0024】
Proxyサーバ200は、htmlファイル書き込み部210、サーバ間ファイル転送部211、アクセスログ記録部212、Proxyサーバ部213、htmlファイル蓄積記憶部220及びアクセスログ蓄積記憶部221を含む。アクセスログ蓄積記憶部221は、アクセスログを記憶する。このアクセスログは任意の形式により記憶されるが、今回の説明においては図2−2に表すようにCSVテキストファイル形式でアクセスログを記憶するものとする。
【0025】
図3−1はアクセスログ収集サーバ400の機能構成を示す図である。
【0026】
アクセスログ収集サーバ400は、htmlファイル書き込み部410、サーバ間ファイル転送部411、アクセスログ記録部412、htmlファイル蓄積記憶部420及びアクセスログ蓄積記憶部421を含む。
【0027】
図4−1は社内情報公開サーバ300の機能構成を示す図である。
【0028】
社内情報公開サーバは、httpサーバ部310、サーバ間ファイル転送部311、アクセスログ記録部312、htmlファイル蓄積記憶部320及びアクセスログ蓄積記憶部321を含む。アクセスログ蓄積記憶部321は、アクセスログを記憶する。このアクセスログは任意の形式により記憶されるが、今回の説明においては図4−2に表すようにCSVテキストファイル形式でアクセスログを記憶するものとする。
【0029】
図5−1はアクセスログ蓄積サーバ500の機能構成を示す図である。
【0030】
アクセスログ蓄積サーバ500はアクセスログ処理部510、httpサーバ部511、htmlファイル単語分割部512、サーバ間ファイル転送部513、データベース検索部514、社員番号アクセス履歴データベース520及び単語URL関連データベース521を含む。
【0031】
単語URL関連データベース521には図5−2示される形式のデータベーステーブルを含む。また、社員番号アクセス履歴データベース520には図5−3に示される形式のデータベーステーブルを含む。
【0032】
図6は閲覧サーバ600の機能構成を示す図である。
【0033】
閲覧サーバ600はhttpサーバ部610を含む。
【0034】
図7−1は認証サーバ700の機能構成を示す図である。
【0035】
認証サーバ700はhttpサーバ部710、データベースアクセス部711及び社員データベース720を含む。社員データベースは図7−2の形式の社員テーブルを含む。
【0036】
各蓄積記憶部、蓄積フォルダ、蓄積領域及び各データベースは各サーバが利用する記憶装置により実現される。具体的には、この記憶装置は、HDD(Hard disk drive)やFlash SSD(Solid State Drive)により実現される。また、この記憶装置は各サーバにそれぞれ含まれていてもよいが、外部の記憶装置(図示を省略する)を利用するようにしてもよい。この場合記憶装置を別のコンピュータとして実現し、バスやUSB規格に準拠したケーブル、インターネット等の手段を用いて接続するようにしてもよい。更に、単一の記憶装置により実現されてもよいが、複数の記憶装置の組合せにより実現されていてもよい。
【0037】
続いて本実施形態の操作の説明を行う。まず、クライアント100によるアクセスについて説明する。
【0038】
最初に、クライアント100がProxyサーバ200を経由して、社外のWebサーバ(図示を省略する)へのアクセスを試みる場合を考える。この場合、Proxyサーバ200はクライアント100に組み込まれているWebブラウザから送信された認証情報と、アクセス先URLとを使用して、社外のWebサーバへアクセスを行う。
【0039】
アクセスが成功した場合、Proxyサーバ200は、htmlデータをクライアント100へ送り返す。また、Proxyサーバ200はアクセスが成功したタイミングで、アクセスログ蓄積記憶装置221へアクセスログを記録する。この際、アクセスログは図2−2の形式でテキストファイルとして記録される。また、クライアントに返却したhtmlデータのうち、htmlを構成するテキスト要素をhtmlファイル蓄積記憶装置220へ記録する。具体的には、htmlファイル蓄積記憶装置220内に図2−3で示されるフォルダ構成でフォルダを作成し、作成したフォルダにテキスト要素を保存する。
【0040】
一方、クライアント100がProxyサーバ200を経由せず、社内情報公開サーバ300に直接アクセスする場合も考えられる。この場合、社内情報公開サーバ300は認証サーバ700のhttpサーバ部710上で提供されるWebサービスを使用して認証情報を取得する。そして、取得した認証情報、アクセス元クライアント情報を、アクセスログ蓄積記憶部321に記憶する。この際、取得した認証情報及びアクセス元クライアント情報は、図4−2に示されるCSV形式で記憶される。
【0041】
次に、アクセスログ収集サーバ400による収集について説明する。
【0042】
アクセスログ収集サーバ400は定期的にProxyサーバ200にアクセスを行う。そして、アクセスログ収集サーバ400はサーバ間ファイル転送部411を用いて、図2−2及び図2−3の形式でProxyサーバ200に格納されているアクセスログ及びhtmlのキャッシュをそのままファイル転送する。
【0043】
アクセスログ収集サーバ400は、Proxyサーバ200からのファイル転送が終了すると、次に社内情報公開サーバ300にアクセスをする。そして、アクセスログ収集サーバ400は、サーバ間ファイル転送部411を用いて、図4−2の形式で社内情報公開サーバ300に記憶されているアクセスログを取得する。次に、htmlファイル書き込み部410を用いて、内情報公開サーバ300のアクセスログに記録されているURLにhttpプロトコルによるアクセスを行い、図3−2で示すフォルダ階層を使用して、社内及び社外のhtmlファイルを結合してhtmlファイル蓄積記憶部320に保存する。
【0044】
次に、アクセスログ蓄積サーバ500の動作について説明する。
【0045】
アクセスログ蓄積サーバ500では、一定間隔でアクセスログ蓄積サーバ400のサーバ間ファイル転送部411を呼び出し、アクセスログ収集サーバ400に複製された情報を逐次取得する。具体的には、htmlファイル蓄積記憶部420及びアクセスログ蓄積記憶部421の記憶している情報を取得する。そして、アクセスログ蓄積サーバ500は、取得した情報をもとに、以下の手順で正規化、蓄積を行う。その詳細を以下に示す。
【0046】
まず、サーバ間ファイル転送部411を用いて、htmlファイル蓄積部420からhtmlテキストを一つずつ取得する。取得したhtmlテキストを一文字ずつ読み込み、単語抽出処理を図9のフローチャートで表される手順で行う。単語抽出処理の詳細を図9を参照しながら解説する。
【0047】
まず、htmlファイルを取得する(ステップS801)。
【0048】
続いて、取得したhtmlファイルの<body>〜</body>タグの間の文章のうちから、htmlタグを除いた、文章のみ抽出する(ステップS802)。
【0049】
抽出した文章のうち、「ひらがな」に該当する文字をすべて半角空白文字として置換する(ステップS803)。これにより、各単語の区切りが生成される。なお、半角空白文字として置換するのはあくまで一例に過ぎず、漢字、英数字、カタカナ以外の任意の文字に置換するようにしてもよい。
【0050】
次に、html内の文字解析処理を開始する(ステップS804)。なお、ステップS804及びS810は、繰り返し処理の最初と最後を表すものであり、html内の解析対象とすべき文字全てに対して解析が終了するまでは、ステップS805〜S809を繰り返すことを意味する。
文字解析処理では、半角空白を単語の区切りとして、html内の単が「連続した二文字以上の漢字」か否かを確認する(ステップS805)。「連続した二文字以上の漢字」であれば(ステップS805においてYes)、その単語を分割してステップS809に進む。一方「連続した二文字以上の漢字」で無い場合は(ステップS805においてNo)、ステップS806に進む。
【0051】
ステップS806ではhtml内の単語が「3文字以上の英数字文字列」か否かを確認する(ステップS806)。「3文字以上の英数字文字列」であれば(ステップS806においてYes)、その単語を分割してステップS809に進む。一方「3文字以上の英数字文字列」で無い場合は(ステップS806においてNo)、ステップS807に進む。
【0052】
ステップS807ではhtml内の単語が「2文字以上のカタカナ」か否かを確認する(ステップS807)。「2文字以上のカタカナ」であれば(ステップS807においてYes)、その単語を分割してステップS809に進む。一方「2文字以上のカタカナ」で無い場合は(ステップS807においてNo)、ステップS808に進む。
【0053】
一方、ステップS809では、分割された単語を、URL及び該当URLの最終更新日と関連付けて、htmlの最終更新日付と関連付けて図5−2の形式で単語URL関連データベース521に保存する(ステップS809)。なお、保存する際に同じ単語及び、同一URLを持つレコードが既に存在していた場合、古いレコードを破棄する。
【0054】
その後、次の文字列を抽出し(ステップS808)、この手順をアクセスログ蓄積サーバ400内のhtmlファイルが存在しなくなるまで繰り返す。
【0055】
全ての文字列に関して解析が終了したhtmlファイルはアクセスログ蓄積サーバ400から削除する(ステップS811)。
【0056】
次に、アクセスログ蓄積サーバ500はアクセスログ収集サーバ400からサーバ間ファイル転送部411を使用して、アクセスログをすべて取得し、アクセスログ一行ごとに社員番号とアクセス先URL、URLの最終更新日を社員番号アクセス履歴データベース520に図5−3の形式で記録する。
【0057】
以上でアクセスログ蓄積サーバ500内での記録処理は終了する。
【0058】
次に、或る社員が社内で自分と関連のある社員を自動的に検索したい場合の処理を解説する。この或る社員の社員番号は「000000」であるものとする。また、この或る社員を以下では、「検索元社員」と呼ぶ。
【0059】
まず、検索元社員がクライアント100から、閲覧サーバ600のhttpサーバ部601を呼び出してアクセスをする。このアクセスに応じてクライアント100にユーザーインターフェースが表示される。ユーザーインターフェースは、任意のものを利用することが可能であるが、本実施形態では図8に示すユーザーインターフェースを表示する。
【0060】
続いて、検索元社員が図8に示す画面で「自動検索」を選択して、検索ボタンを押したとする。これにより閲覧サーバ600はクライアント100から送出された社員番号(000000)をキーにして、アクセスログ蓄積サーバ500のhttpサーバ部511を呼び出す。
【0061】
次に、データベース検索部514が、クライアント100から送信された社員番号をキーにして、社員番号アクセス履歴データベース520内を検索し、送信された社員番号に対応するURLを抽出する。
【0062】
更に、社員番号アクセス履歴データベース520内を検索し、抽出されたURL一つに対して同じURLにアクセスしたことのある社員をすべて抽出する。なお、抽出の際、現在クライアント100からアクセスしている検索元社員は抽出結果から除く。
【0063】
図5−3の例では、現在アクセス中の検索元社員(社員番号000000)と同じURLに、社員番号000100の社員がアクセスしている。そのため、社員番号000100が抽出される。
【0064】
抽出対象が存在した場合、閲覧サーバ600は認証サーバ700のhttpサーバ部710を呼びだす。httpサーバ部710はデータベースアクセス部711を使用して、社員番号が000100の社員の氏名を取得し、クライアント100に表示する。
【0065】
以上の動作により、検索元社員(社員番号000000)は自身が閲覧したURLと同一のURLを閲覧したことのある社員(社員番号000100)の社員番号及び氏名を検索することが可能となるという効果を奏する。
【0066】
次に、或る社員が社内で特定のキーワードに関して関心があると思われる社員を自動的に検索したい場合の処理を解説する。上述の説明と同様に、この或る社員の社員番号は「000000」であるものとする。また、この或る社員を以下では、「検索元社員」と呼ぶ。
【0067】
まず、検索元社員がクライアント100から、閲覧サーバ600のhttpサーバ部601を呼び出してアクセスをする。このアクセスに応じてクライアント100にユーザーインターフェースが表示される。ユーザーインターフェースは上述の説明と同じく図8に示すユーザーインターフェースである。
【0068】
次に、検索元社員が図8の画面において、「キーワードによる検索」を選択し、知りたいキーワードを下のテキストボックスに入力する。
【0069】
そして、更に「検索」を選択して、検索ボタンを押すと、閲覧サーバ600はクライアント100から送出された社員番号(000000)及び、キーワードを使用して、httpサーバ部511を呼び出す。
【0070】
アクセスログ蓄積サーバ500では、単語URL関連データベース521内に存在する、「単語とURLの関連付け」テーブル(図5−2参照)からクライアント100より送出されたキーワードの検索を行う。
【0071】
検索に使用したキーワード(単語)がデータベース上に存在した場合は、その単語に関連付けられているURLを抽出する。次に抽出されたURLを検索キーとして、社員番号アクセス履歴データベース520のテーブルから社員番号を検索する。
【0072】
図5−3の例では、現在アクセス中の検索元社員(社員番号000000)と同じURLに、社員番号000100の社員がアクセスしている。そのため、社員番号000100が抽出される。
【0073】
抽出対象が存在した場合、閲覧サーバ600は認証サーバ700のhttpサーバ部710を呼びだす。httpサーバ部710はデータベースアクセス部711を使用して、社員番号が000100の社員の氏名を取得し、クライアント100に表示する。
【0074】
以上の動作により、検索元社員(社員番号000000)は特定のキーワードに関して関心があると思われる社員の社員番号及び氏名を検索することが可能となるという効果を奏する。
【0075】
更に、本実施形態は、日常業務の延長で新しい人間関係を築くシステムを提供できるという効果を奏する。
【0076】
その理由は、各社員の能動的な作業を伴わないためである。
【0077】
次に、本実施形態を変形した変形例の構成について図面を参照して詳細に説明する。
【0078】
上述した実施形態においては、図2−1及び図3−1にはhtmlファイル書き込み部210及びhtmlファイル書き込み部410が存在していた。もっとも、この構成を変形して、htmlファイル書き込み部210及びhtmlファイル書き込み部410を省いた構成とすることも可能である。
【0079】
htmlファイル書き込み部210及びhtmlファイル書き込み部410を省いた場合でも、図2−1及び、図3−1のアクセスログ記録部212及びアクセスログ記録部412があれば、図5−3の社員番号アクセス履歴テーブルを検索することにより、自動検索のみの機能でソーシャルマップを作成することができる。
【0080】
また、本実施形態では自発的な行動によらず、自動的に無関係な部署同士の人間に新しいつながりを発見することが可能となる。
【0081】
また、新しいつながりを構築することにより、部署内で解決しない問題であっても新しい人間関係により、情報を持っている人間同士で解決する可能性が高くなる効果が期待できる。
【0082】
加えて、本実施形態は、一般的な技術に比べ下記の点において有利な効果を奏する。
【0083】
一般的な技術における、ユーザーコンテンツ処理手段では、発明内で管理されているユーザーコンテンツ記憶手段を用いる必要がある。例えば、ページ内のURLに発明システムがコードを挿入する必要があるため、他のシステムで管理されているURLでの分析を行うことができないと考えられる。しかし、本実施形態では、既存のユーザーコンテンツに修正、改変を行うことなく、自動的にコンテンツの解析を行い、情報を収集する仕組みを備えているため上記のような問題は生じない。
【0084】
また、本実施形態では、一般的な技術のような、能動的にコンテンツを作成及び管理するシステムを備えない。また、一般的な技術ではコンテンツ配信機能があるが、本発明ではコンテンツそのものの配信機能は備えない。すなわち本実施形態は、集積した結果のみ一時的に蓄積するだけであるため、システム構成上も一般的な技術とは異なっている。
【0085】
また、一般的な技術では明示的にコメントのカテゴリとコメント情報をユーザーが能動的に設定している。本実施形態ではユーザーが能動的にカテゴリ分類を行う必要なく、自動的にキーワードとURLの関連付けを行っている。よって、本実施形態ではカテゴリ設定に依存しない、自律的な集計が可能となる。
【0086】
なお、上記実施形態では、プログラムが、クライアント及び各サーバに予め記憶されているものとして説明した。しかし、コンピュータを、クライアント及び各サーバの全部又は一部として動作させ、あるいは、上述の処理を実行させるためのプログラムを、フレキシブルディスク、CD−ROM(Compact Disc Read-Only Memory)、DVD(Digital Versatile Disc)、MO(Magneto Optical Disk(Disc))BD(Blu-ray Disc)等のコンピュータ読み取り可能な記録媒体に格納して配布し、これを別のコンピュータにインストールし、上述の手段として動作させ、あるいは、上述の工程を実行させてもよい。
【0087】
さらに、インターネット上のサーバ装置が有するディスク装置等にプログラムを格納しておき、例えば、搬送波にプログラムを重畳させて、コンピュータにダウンロード等してプログラムを実行してもよい。
【0088】
なお、本発明の実施形態であるクライアント及び各サーバは、ハードウェアにより実現することもできるが、コンピュータをそのクライアント及び各サーバとして機能させるためのプログラムをコンピュータがコンピュータ読み取り可能な記録媒体から読み込んで実行することによっても実現することができる。
【0089】
また、本発明の実施形態による組織内ソーシャルマップ作成方法は、ハードウェアにより実現することもできるが、コンピュータにその方法を実行させるためのプログラムをコンピュータがコンピュータ読み取り可能な記録媒体から読み込んで実行することによっても実現することができる。
【0090】
また、上述した実施形態は、本発明の好適な実施形態ではあるが、上記実施形態のみに本発明の範囲を限定するものではなく、本発明の要旨を逸脱しない範囲において種々の変更を施した形態での実施が可能である。
【0091】
上記の実施形態の一部又は全部は、以下の付記のようにも記載されうるが、以下には限られない。
【0092】
(付記1) 所定の組織内に構築されるソーシャルマップ作成システムにおいて、
利用者がアクセス先で閲覧した情報の履歴であるアクセスログを蓄積するアクセスログ蓄積記憶手段と、
前記アクセスログに基づいて、各利用者を識別するための情報と、前記各利用者がアクセスしたアクセス先を特定する情報とを関連付けたテーブルである第1のテーブルを作成するアクセスログ処理手段と、
第1の利用者からの検索要求を受け付けた場合に、当該第1の利用者を識別するための情報を検索キーとして前記第1のテーブルを検索し、当該第1の利用者に関連付けられているアクセス先を特定する情報を抽出し、当該抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第2の利用者を特定し、当該特定した第2の利用者を識別するための情報を抽出する検索手段と、
前記検索手段により抽出された第2の利用者を識別するための情報を前記第1の利用者に通知する手段と、
を備えることを特徴とするソーシャルマップ作成システム。
【0093】
(付記2) 付記1に記載のソーシャルマップ作成システムにおいて、
前記アクセスログに含まれる文章を抽出し、抽出した文章を単語単位に分割し、当該分割された単語と当該単語が含まれていたアクセス先を特定する情報とを関連付けたテーブルである第2のテーブルを作成する単語分割手段と、
第3の利用者から或る単語をキーワードとした検索要求を受け付けた場合に、当該キーワードである前記或る単語を検索キーとして前記第2のテーブルを検索し、当該単語と関連付けられているアクセス先を特定する情報を抽出し、抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第4の利用者を特定し、当該特定した第4の利用者を識別するための情報を抽出する検索手段と、
前記検索手段により抽出された第4の利用者を識別するための情報を前記第3の利用者に通知する手段と、
を備えることを特徴とするソーシャルマップ作成システム。
【0094】
(付記3) 付記2に記載のソーシャルマップ作成システムにおいて、
前記単語分割手段は、
前記抽出した文章内の平仮名に該当する文字を、漢字、英数字及びカタカナ以外の任意の文字に置き換えることにより前記単語単位の分割を行うことを特徴とするソーシャルマップ作成システム。
【0095】
(付記4) 付記2又は3に記載のソーシャルマップ作成システムにおいて、
前記単語分割手段は、
前記分割後の単語が、連続した二文字以上の漢字、三文字以上の英数字及び二文字以上のカタカナ、の何れかである場合に前記第2のテーブルに格納することを特徴とするソーシャルマップ作成システム。
【0096】
(付記5) 付記1乃至4の何れか1に記載のソーシャルマップ作成システムにおいて、
前記アクセスログの収集は、当該ソーシャルマップ作成システムが自動的に行うものであり、アクセスログの収集のために利用者の操作を必要としないことを特徴とするソーシャルマップ作成システム。
【0097】
(付記6) 付記1乃至5の何れか1に記載のソーシャルマップ作成システムにおいて、
前記利用者を識別するための情報と、当該利用者を識別するための情報により識別される利用者の氏名とを関連付けたテーブルである第3のテーブルを更に有しており、
前記第3のテーブルを検索することにより前記利用者を識別するための情報ではなく、前記利用者の氏名を通知することを特徴とするソーシャルマップ作成システム。
【0098】
(付記7) 所定の組織内に構築されるシステムが行うソーシャルマップ作成方法において、
利用者がアクセス先で閲覧した情報の履歴であるアクセスログを蓄積するアクセスログ蓄積記憶ステップと、
前記アクセスログに基づいて、各利用者を識別するための情報と、前記各利用者がアクセスしたアクセス先を特定する情報とを関連付けたテーブルである第1のテーブルを作成するアクセスログ処理ステップと、
第1の利用者からの検索要求を受け付けた場合に、当該第1の利用者を識別するための情報を検索キーとして前記第1のテーブルを検索し、当該第1の利用者に関連付けられているアクセス先を特定する情報を抽出し、当該抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第2の利用者を特定し、当該特定した第2の利用者を識別するための情報を抽出する検索ステップと、
前記検索ステップにより抽出された第2の利用者を識別するための情報を前記第1の利用者に通知するステップと、
を備えることを特徴とするソーシャルマップ作成方法。
【産業上の利用可能性】
【0099】
本発明は、たとえば企業内における、部門間において連携がないが、特定のノウハウを持っていると考えられる人間を検索する場面に好適である。
【符号の説明】
【0100】
100 クライアント
200 Proxyサーバ
210 htmlファイル書き込み部
211 サーバ間ファイル転送部
212 アクセスログ記録部
213 Proxyサーバ部
220 htmlファイル蓄積記憶部
221 アクセスログ蓄積記憶部
300 社内情報公開サーバ
310 httpサーバ部
311 サーバ間ファイル転送部
312 アクセスログ記録部
320 htmlファイル蓄積記憶部
321 アクセスログ蓄積記憶部
400 アクセスログ収集サーバ
410 htmlファイル書き込み部
411 サーバ間ファイル転送部
412 アクセスログ記録部
420 htmlファイル蓄積記憶部
421 アクセスログ蓄積記憶部
500 アクセスログ蓄積サーバ
510 アクセスログ処理部
511 httpサーバ部
512 htmlファイル単語分割部
513 サーバ間ファイル転送部
514 データベース検索部
520 社員番号アクセス履歴データベース
521 単語URL関連データベース
600 閲覧サーバ
610 httpサーバ部
700 認証サーバ
710 httpサーバ部
711 データベースアクセス部
720 社員データベース
【特許請求の範囲】
【請求項1】
所定の組織内に構築されるソーシャルマップ作成システムにおいて、
利用者がアクセス先で閲覧した情報の履歴であるアクセスログを蓄積するアクセスログ蓄積記憶手段と、
前記アクセスログに基づいて、各利用者を識別するための情報と、前記各利用者がアクセスしたアクセス先を特定する情報とを関連付けたテーブルである第1のテーブルを作成するアクセスログ処理手段と、
第1の利用者からの検索要求を受け付けた場合に、当該第1の利用者を識別するための情報を検索キーとして前記第1のテーブルを検索し、当該第1の利用者に関連付けられているアクセス先を特定する情報を抽出し、当該抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第2の利用者を特定し、当該特定した第2の利用者を識別するための情報を抽出する検索手段と、
前記検索手段により抽出された第2の利用者を識別するための情報を前記第1の利用者に通知する手段と、
を備えることを特徴とするソーシャルマップ作成システム。
【請求項2】
請求項1に記載のソーシャルマップ作成システムにおいて、
前記アクセスログに含まれる文章を抽出し、抽出した文章を単語単位に分割し、当該分割された単語と当該単語が含まれていたアクセス先を特定する情報とを関連付けたテーブルである第2のテーブルを作成する単語分割手段と、
第3の利用者から或る単語をキーワードとした検索要求を受け付けた場合に、当該キーワードである前記或る単語を検索キーとして前記第2のテーブルを検索し、当該単語と関連付けられているアクセス先を特定する情報を抽出し、抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第4の利用者を特定し、当該特定した第4の利用者を識別するための情報を抽出する検索手段と、
前記検索手段により抽出された第4の利用者を識別するための情報を前記第3の利用者に通知する手段と、
を備えることを特徴とするソーシャルマップ作成システム。
【請求項3】
請求項2に記載のソーシャルマップ作成システムにおいて、
前記単語分割手段は、
前記抽出した文章内の平仮名に該当する文字を、漢字、英数字及びカタカナ以外の任意の文字に置き換えることにより前記単語単位の分割を行うことを特徴とするソーシャルマップ作成システム。
【請求項4】
請求項2又は3に記載のソーシャルマップ作成システムにおいて、
前記単語分割手段は、
前記分割後の単語が、連続した二文字以上の漢字、三文字以上の英数字及び二文字以上のカタカナ、の何れかである場合に前記第2のテーブルに格納することを特徴とするソーシャルマップ作成システム。
【請求項5】
請求項1乃至4の何れか1項に記載のソーシャルマップ作成システムにおいて、
前記アクセスログの収集は、当該ソーシャルマップ作成システムが自動的に行うものであり、アクセスログの収集のために利用者の操作を必要としないことを特徴とするソーシャルマップ作成システム。
【請求項6】
請求項1乃至5の何れか1項に記載のソーシャルマップ作成システムにおいて、
前記利用者を識別するための情報と、当該利用者を識別するための情報により識別される利用者の氏名とを関連付けたテーブルである第3のテーブルを更に有しており、
前記第3のテーブルを検索することにより前記利用者を識別するための情報ではなく、前記利用者の氏名を通知することを特徴とするソーシャルマップ作成システム。
【請求項7】
所定の組織内に構築されるシステムが行うソーシャルマップ作成方法において、
利用者がアクセス先で閲覧した情報の履歴であるアクセスログを蓄積するアクセスログ蓄積記憶ステップと、
前記アクセスログに基づいて、各利用者を識別するための情報と、前記各利用者がアクセスしたアクセス先を特定する情報とを関連付けたテーブルである第1のテーブルを作成するアクセスログ処理ステップと、
第1の利用者からの検索要求を受け付けた場合に、当該第1の利用者を識別するための情報を検索キーとして前記第1のテーブルを検索し、当該第1の利用者に関連付けられているアクセス先を特定する情報を抽出し、当該抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第2の利用者を特定し、当該特定した第2の利用者を識別するための情報を抽出する検索ステップと、
前記検索ステップにより抽出された第2の利用者を識別するための情報を前記第1の利用者に通知するステップと、
を備えることを特徴とするソーシャルマップ作成方法。
【請求項1】
所定の組織内に構築されるソーシャルマップ作成システムにおいて、
利用者がアクセス先で閲覧した情報の履歴であるアクセスログを蓄積するアクセスログ蓄積記憶手段と、
前記アクセスログに基づいて、各利用者を識別するための情報と、前記各利用者がアクセスしたアクセス先を特定する情報とを関連付けたテーブルである第1のテーブルを作成するアクセスログ処理手段と、
第1の利用者からの検索要求を受け付けた場合に、当該第1の利用者を識別するための情報を検索キーとして前記第1のテーブルを検索し、当該第1の利用者に関連付けられているアクセス先を特定する情報を抽出し、当該抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第2の利用者を特定し、当該特定した第2の利用者を識別するための情報を抽出する検索手段と、
前記検索手段により抽出された第2の利用者を識別するための情報を前記第1の利用者に通知する手段と、
を備えることを特徴とするソーシャルマップ作成システム。
【請求項2】
請求項1に記載のソーシャルマップ作成システムにおいて、
前記アクセスログに含まれる文章を抽出し、抽出した文章を単語単位に分割し、当該分割された単語と当該単語が含まれていたアクセス先を特定する情報とを関連付けたテーブルである第2のテーブルを作成する単語分割手段と、
第3の利用者から或る単語をキーワードとした検索要求を受け付けた場合に、当該キーワードである前記或る単語を検索キーとして前記第2のテーブルを検索し、当該単語と関連付けられているアクセス先を特定する情報を抽出し、抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第4の利用者を特定し、当該特定した第4の利用者を識別するための情報を抽出する検索手段と、
前記検索手段により抽出された第4の利用者を識別するための情報を前記第3の利用者に通知する手段と、
を備えることを特徴とするソーシャルマップ作成システム。
【請求項3】
請求項2に記載のソーシャルマップ作成システムにおいて、
前記単語分割手段は、
前記抽出した文章内の平仮名に該当する文字を、漢字、英数字及びカタカナ以外の任意の文字に置き換えることにより前記単語単位の分割を行うことを特徴とするソーシャルマップ作成システム。
【請求項4】
請求項2又は3に記載のソーシャルマップ作成システムにおいて、
前記単語分割手段は、
前記分割後の単語が、連続した二文字以上の漢字、三文字以上の英数字及び二文字以上のカタカナ、の何れかである場合に前記第2のテーブルに格納することを特徴とするソーシャルマップ作成システム。
【請求項5】
請求項1乃至4の何れか1項に記載のソーシャルマップ作成システムにおいて、
前記アクセスログの収集は、当該ソーシャルマップ作成システムが自動的に行うものであり、アクセスログの収集のために利用者の操作を必要としないことを特徴とするソーシャルマップ作成システム。
【請求項6】
請求項1乃至5の何れか1項に記載のソーシャルマップ作成システムにおいて、
前記利用者を識別するための情報と、当該利用者を識別するための情報により識別される利用者の氏名とを関連付けたテーブルである第3のテーブルを更に有しており、
前記第3のテーブルを検索することにより前記利用者を識別するための情報ではなく、前記利用者の氏名を通知することを特徴とするソーシャルマップ作成システム。
【請求項7】
所定の組織内に構築されるシステムが行うソーシャルマップ作成方法において、
利用者がアクセス先で閲覧した情報の履歴であるアクセスログを蓄積するアクセスログ蓄積記憶ステップと、
前記アクセスログに基づいて、各利用者を識別するための情報と、前記各利用者がアクセスしたアクセス先を特定する情報とを関連付けたテーブルである第1のテーブルを作成するアクセスログ処理ステップと、
第1の利用者からの検索要求を受け付けた場合に、当該第1の利用者を識別するための情報を検索キーとして前記第1のテーブルを検索し、当該第1の利用者に関連付けられているアクセス先を特定する情報を抽出し、当該抽出したアクセス先を特定する情報を検索キーとして前記第1のテーブルを更なる検索をし、当該更なる検索により前記検索キーとしたアクセス先にアクセスした利用者である第2の利用者を特定し、当該特定した第2の利用者を識別するための情報を抽出する検索ステップと、
前記検索ステップにより抽出された第2の利用者を識別するための情報を前記第1の利用者に通知するステップと、
を備えることを特徴とするソーシャルマップ作成方法。
【図1】


【図2−1】
【図2−2】
【図2−3】
【図3−1】
【図3−2】
【図4−1】
【図4−2】
【図5−1】
【図5−2】
【図5−3】
【図6】
【図7−1】
【図7−2】
【図8】
【図9−1】
【図9−2】
【図2−1】
【図2−2】
【図2−3】
【図3−1】
【図3−2】
【図4−1】
【図4−2】
【図5−1】
【図5−2】
【図5−3】
【図6】
【図7−1】
【図7−2】
【図8】
【図9−1】
【図9−2】
【公開番号】特開2012−216120(P2012−216120A)
【公開日】平成24年11月8日(2012.11.8)
【国際特許分類】
【出願番号】特願2011−81721(P2011−81721)
【出願日】平成23年4月1日(2011.4.1)
【出願人】(390001395)NECシステムテクノロジー株式会社 (438)
【Fターム(参考)】
【公開日】平成24年11月8日(2012.11.8)
【国際特許分類】
【出願日】平成23年4月1日(2011.4.1)
【出願人】(390001395)NECシステムテクノロジー株式会社 (438)
【Fターム(参考)】
[ Back to top ]