
緑茶の品質予測方法
【課題】緑茶の品質、特に従来困難であった製品緑茶の総合品質を、簡便にかつ精度よく予測する方法を提供すること。
【解決手段】本発明の緑茶の品質予測方法は、緑茶を前処理して分析サンプルを得る工程;該分析サンプルを機器分析に供して分析結果を得る工程;該分析結果を数値データに変換して多変量解析する工程;および得られた解析結果から、品質を予測する工程を含む。好ましくは、品質既知の複数の緑茶の機器分析結果について多変量解析としてPLS回帰分析を行うことにより品質予測モデルが作成され、品質未知の緑茶についての解析結果を品質予測モデルと照合する。
【解決手段】本発明の緑茶の品質予測方法は、緑茶を前処理して分析サンプルを得る工程;該分析サンプルを機器分析に供して分析結果を得る工程;該分析結果を数値データに変換して多変量解析する工程;および得られた解析結果から、品質を予測する工程を含む。好ましくは、品質既知の複数の緑茶の機器分析結果について多変量解析としてPLS回帰分析を行うことにより品質予測モデルが作成され、品質未知の緑茶についての解析結果を品質予測モデルと照合する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、緑茶の品質予測方法に関する。より詳細には、緑茶の代謝物または分解物の機器分析による品質予測方法に関する。
【背景技術】
【0002】
茶は最も普及している飲料であり、Camellia sinensisという植物の葉から製造される。酸化反応の長さおよび葉の加工方法に基づいて、紅茶、ウーロン茶、および緑茶の3つの種類に分類される。このうち緑茶は、まず加熱によって酸化酵素が不活性化されるので、酸化されておらず、そして発酵させていない。そのため、緑茶の味は、茶木の種類、摘採時間、栽培方法などによって決定される。
【0003】
現在、緑茶の最終品質は、熟練者による葉の外観、芳香、色、および味に基づく官能検査により決定されている。これらの技能を獲得するには経験年数がかかる。また、客観性や再現性が低いという欠点がある。そのため、製造工程管理や製品品質管理のためには、簡便な機械化された品質予測方法が必要である。これまで、緑茶の品質予測方法として、近赤外分光法を用いた方法(特許文献1および2)ならびに茶葉の性状に基づく方法(特許文献3〜5)が開示されている。
【0004】
特許文献1には、可視光および近赤外線を用いて茶葉、特に加工前の生茶葉、の品質を測定する方法が記載されている。可視光から茶葉の色を、そして近赤外線から茶葉の成分を測定すると記載されているが、近赤外線から具体的にどのような成分を測定し、どのように品質を予測するのかについては記載されていない。特許文献2には、近赤外分光法を用いて、茶葉中の遊離アミノ酸の含有率と中性デタージェント繊維の含有率とを求めることによって品質評価する方法が記載されている。しかし、これらの近赤外分光に基づく方法は、生葉の品質予測には効力を発するが、製品緑茶の品質予測の実績はほとんどない。
【0005】
特許文献3〜5には、生茶葉の含水量、含繊維量、含窒素量、外観などの性状を測定することによって、品質を評価することが記載されている。しかし、含水量などの性状に基づく方法は、簡便であるが、精度に乏しい。
【特許文献1】特開2000−346797号公報
【特許文献2】特開平8−114543号公報
【特許文献3】特開2000−228950号公報
【特許文献4】特開平11−313608号公報
【特許文献5】特開平9−224573号公報
【発明の開示】
【発明が解決しようとする課題】
【0006】
化学分析は、緑茶の品質を評価するために最も信頼性のある方法であると思われる。機器分析法と強力なコンピュータ駆動パターン認識技術との組み合わせから、複雑な材料の品質制御および特徴づけのための新たな可能性が実現されている。そこで、本発明は、緑茶の品質、特に従来困難であった製品緑茶の総合品質を、簡便に予測する方法を提供することを目的とする。
【課題を解決するための手段】
【0007】
緑茶の味は、アミノ酸、特に茶葉中の約60〜70%のアミノ酸を占める独特のテアニンに起因する。その収歛性の味は、カテキン(タンニン)によるものであり、苦味はカフェインによるものである。また、揮発性化合物は、主として茶の香りの差に寄与する。栽培品種の差、環境的効果、加工方法などにより、中間経路代謝物の見かけの定常状態の量および/または最終代謝物の末端蓄積も変動する。また、加熱処理による分解物も緑茶の味に影響を与える。したがって、茶葉中の代謝物や分解物を、空間的および時間的の両方でモニターすることは、品質の評価に重要である。
【0008】
クロマトグラフィーにおいて、パターン認識方法に基づくフィンガープリンティングは、種々の分析領域、例えば、食品および栄養分野で加工モニタリングおよび制御(生材料の等級付け、日常的なオンライン品質チェック、または製品が製造される工程の測定)、地理的起源(成分の化学組成による供与源の測定、風味および芳香成分による最終製品の起源の追跡)の分析に使用されている。
【0009】
そこで、本発明は、医用目的の抗酸化化合物、ならびに呈味および芳香用のカテキンおよび他のフェノール性化合物などの、特定の機能に重要であると考えられる特定の群の限られた数の個々の化合物の特徴づけの代わりに、代謝物や分解物に注目し、これらについての化学的フィンガープリントと多変量解析と組み合わせることによって、総合的にかつ迅速に緑茶を分析できることに基づいて完成された。
【0010】
本発明は、緑茶の品質予測方法を提供し、該方法は、
緑茶を前処理して分析サンプルを得る工程;
該分析サンプルを機器分析に供して分析結果を得る工程;
該分析結果を数値データに変換して多変量解析する工程;および
得られた解析結果から、品質を予測する工程を含む。
【0011】
本発明はまた、品質既知の複数の緑茶を前処理して個別の分析サンプルを得る工程;
該個別の分析サンプルを機器分析に供して個別の分析結果を得る工程;および
該個別の分析結果と該品質との関係を数値データに変換して多変量解析する工程;
によって得られる、緑茶の品質予測モデルを提供する。
【0012】
1つの実施態様では、上記多変量解析は、PLS回帰分析である。
【0013】
好適な実施態様では、上記前処理は、上記緑茶を熱分解処理する工程を含み、そして前記機器分析が、ガスクロマトグラフィーと質量分析との組み合わせである。より好適な実施態様では、上記解析結果は、保持時間に基づいて品質予測される。
【0014】
他の好適な実施態様では、上記前処理は、上記緑茶から親水性化合物を抽出して抽出物を得る工程を含む。
【0015】
より好適な実施態様では、上記機器分析は、ガスクロマトグラフィーと質量分析との組み合わせであり、そして上記前処理はさらに上記抽出物をシリル化する工程を含む。
【0016】
さらに好適な実施態様では、上記分析結果の中で、アラビノース、グルタミン、クエン酸、グルタミン酸、アスパラギン酸、イノシトール、シキミ酸、リン酸、フルクトース、テアニン、リンゴ酸、カフェイン、キナ酸、グルコース、マンノース、リボース、およびスクロースのデータが解析される。
【0017】
別の好適な実施態様では、上記機器分析は、液体クロマトグラフィーと質量分析との組み合わせ(特に、高速液体クロマトグラフィーと質量分析との組み合わせ、または超高速液体クロマトグラフィーと質量分析との組み合わせ)、または核磁気共鳴分析(特に、フーリエ変換核磁気共鳴分析)である。
【0018】
他の好適な実施態様では、上記前処理は、上記緑茶を粉砕して粉末を得る工程および該粉末を溶媒でペースト状にする工程を含む。
【0019】
より好適な実施態様では、上記機器分析は、赤外分光分析または近赤外分光分析(特に、フーリエ変換赤外分光分析またはフーリエ変換近赤外分光分析)である。
【0020】
さらに好適な実施態様では、上記機器分析は、フーリエ変換近赤外分光分析であり、上記多変量解析する工程において、上記分析結果の中で5500〜5200cm−1の結果についてデータ変換し、変換されたデータをさらに二次微分する。
【0021】
別の好適な実施態様では、上記分析結果は、ガスクロマトグラフィーと質量分析との組み合わせ、高速液体クロマトグラフィーと質量分析との組み合わせ、超高速液体クロマトグラフィーと質量分析との組み合わせ、フーリエ変換赤外・近赤外分光分析、およびフーリエ変換核磁気共鳴分析からなる群より選択される少なくとも2つの機器分析の分析結果である。
【0022】
本発明はさらに、緑茶の品質予測方法を提供し、該方法は
緑茶を前処理して分析サンプルを得る工程;
該分析サンプルを機器分析に供して分析結果を得る工程;
該分析結果を数値データに変換して多変量解析する工程;および
得られた解析結果を、上記のいずれか品質予測モデルと照合する工程を含む。
【発明の効果】
【0023】
本発明によれば、従来困難であった製品緑茶の総合品質を、より精度よくかつ簡便な方法で予測することが可能である。
【発明を実施するための最良の形態】
【0024】
緑茶は、生茶葉を加熱して酵素活性を失わせ、成分の酸化を防ぎ、緑色を保持させた不発酵茶である。本発明において品質予測の対象となる緑茶は、加工前の生茶葉であってもよいが、好ましくは、荒茶、仕上げ茶(すなわち、製品緑茶)のような緑茶としての加工が施された緑茶の葉である。本発明においては、より好ましくは、製品緑茶を品質予測の対象とする。
【0025】
本発明において、緑茶は、以下で述べる機器分析に応じて適切に前処理された後、種々の機器分析に供される。
【0026】
本発明において、機器分析とは、分析機器を用いる分析・測定手段をいい、ガスクロマトグラフィー(GC)、液体クロマトグラフィー(LC)(例えば、高速液体クロマトグラフィー(HPLC)、超高速液体クロマトグラフィー(UPLC))、質量分析(MS)、赤外分光分析(IR)(例えば、フーリエ変換赤外分光分析(FT−IR))、近赤外分光分析(NIR)(例えば、フーリエ変換近赤外分光分析(FT−NIR))、核磁気共鳴分析(NMR)(例えば、フーリエ変換核磁気共鳴分析(FT−NMR))などが挙げられる。これらの機器分析は組み合わせてもよく、例えば、GC/MS、LC/MS(特に、HPLC/MS、UPLC/MS)などの組み合わせが挙げられる。これらの機器分析に用いられる装置は、特に限定されず、緑茶中に含まれる代謝物(例えば、アミノ酸、有機酸、糖)を測定することが可能であれば、通常用いられている装置が用いられ得る。また、測定条件は、これらの物質の測定に適切なように当業者によって適宜設定され得る。
【0027】
前処理は、緑茶中の分析対象物質を機器分析に供するに適した形態にするために、上述のように機器分析に応じて行われる。前処理としては、乾燥、切断、粉砕、抽出などの処理が挙げられる。例えば、粉砕については、ブレンダー、ボールミルなどの適切な器具を用いて行われ得る。また、抽出については、水、有機溶媒、またはこれらの溶媒の混合液を用いて行われ得る。抽出に使用され得る有機溶媒としては、メタノール、エタノール、n−プロパノール、イソプロパノール、アセトン、クロロホルムなどが挙げられる。抽出操作としては、緑茶を水および/または有機溶媒中で加熱して、熱分解物を抽出してもよい。加熱温度は、使用される溶媒に応じて適宜決定され得、通常は、常圧下で溶媒の沸点付近の温度である。加熱時間も適宜設定される。これらの単位操作を単独でまたは組み合わせて適切な前処理条件を設定する。
【0028】
例えば、機器分析としてGCを行う場合、好ましくは、前処理は、緑茶からの抽出物をシリル化する工程をさらに含む。シリル化は、当業者が通常用いるGC用のシリル化試薬を用いて行われ得る。あるいは、前処理として、緑茶を、例えば、粉砕した後、熱分解処理のみ施したものも、分析対象試料となり得る。この場合、熱分解物を、抽出することなく直接GCに導入することができる。熱分解は、市販の熱分解装置を用いて行うことができる。
【0029】
機器分析としてIR・NIRを行う場合については、好ましくは、前処理は、緑茶の粉末を溶媒でペースト状にする工程を含む。粉末を得る工程は、上記のとおりである。ペーストにするための溶媒は、例えば、IR測定用試料の調製のために、試料に応じて通常選択される溶媒が用いられる。
【0030】
機器分析としてNMRを行う場合については、好ましくは、前処理は、緑茶から水および/または親水性溶媒で抽出して抽出物を得る工程を含む。親水性有機溶媒としては、例えば、メタノール、エタノール、n−プロパノール、イソプロパノール、アセトンなどが挙げられる。
【0031】
機器分析としてLC、特にHPLCを行う場合については、好ましくは、前処理は、緑茶から水および/または親水性溶媒で抽出して抽出物を得る工程を含む。用いるカラムとしては、例えば、アフィニティーカラム、逆相カラム、およびイオン交換カラムが挙げられる。HPLCの条件(例えば、流速、検出器、移動相など)は、試料に応じて適宜選択される。
【0032】
機器分析として超高速液体クロマトグラフィー(UPLC)を行う場合については、好ましくは、前処理は、緑茶から水および/または親水性溶媒で抽出して抽出物を得る工程を含む。UPLCは、微小なカラム粒子に高い線速度の移動相を通過させて、速い分析スピード、高い分離能、および高感度が達成される。UPLCに用いられるカラム粒子は、HPLCに用いるカラム粒子(例えば、5μmまたは3.5μm)よりも小さい直径(例えば、1.7μm)を有するカラム粒子であり、例えば、アフィニティーカラム、逆相カラム、およびイオン交換カラムが挙げられる。UPLCの条件(例えば、流速、検出器、移動相など)は、試料に応じて適宜選択される。
【0033】
上記の前処理が施された緑茶サンプルは、任意の機器分析に供され、分析結果が得られる。得られた分析結果は、緑茶サンプルのフィンガープリントであり得る。このフィンガープリントを数値データに変換して多変量解析が行われる。分析により得られる結果(変数)としては、保持時間、波長(または波数)、ならびにシグナル強度(またはイオン強度)、吸光度などのスペクトルデータが挙げられる。さらに、変数としては、緑茶サンプルのランキング(等級)も挙げられる。
【0034】
多変量解析としては、機器分析データの解析に、特にケモメトリックスにおいて通常用いられる解析ツールが採用される。例えば、PCA(主成分分析:principal component analysis)、HCA(階層クラスター分析:hierarchical cluster analysis)、PLS回帰分析(潜在的構造に対する射影:Projection to Latent Structure)、判別分析(discriminate analysis)などの種々の多変量ツールが挙げられる。さらに、部分最小二乗によるPLS(Partial least square projection to Latent Structure)を用いて、関連の変量の2群間の関係;例えば、緑茶の代謝物とその品質との間の関係、が確認される。必要に応じて、スペクトルフィルタリング法、例えば、妨害成分を取り除くための直交シグナル補正(orthogonal signal correction:OSC)と組み合わせて多変量解析が行われてもよい。これらの解析ツールは、ソフトウエアとして多数市販されており、任意のものが入手可能である。このような市販のツールは、一般的に、難しい数学・統計学の知識がなくても、多変量解析を行うことができるように操作マニュアルが備えられている。
【0035】
多変量解析は、得られた全データではなく、品質予測に重要な一定の範囲のデータを選択して行ってもよい。例えば、緑茶の粉末をペースト状にしてFT−NIRで分析する場合、5500〜5200cm−1の波数域のデータについてPCAを行うことが好ましい。
【0036】
本発明において好適に採用されるPLS回帰分析は、変数(例えば、波数、波長)間に相関を有するスペクトルデータからの検量線作成に有効な手法である。通常、変数間に相関があると、用いる変数の組み合わせによっては回帰精度が著しく低下するが、これを避けるためにPLSでは変数を互いに無相関な変数(潜在変数)に変換し、この潜在変数を用いて回帰を行う。すなわち、PLSとはデータの変数を直交変換し、その新たな変数を用いて(重)回帰分析を行う解析手法である。
【0037】
具体的には、複数の品質既知の緑茶サンプルから親水性低分子代謝物を抽出してあるいは緑茶の熱分解物についてGC/MSにより定量解析を行う場合には、得られたGC/MSクロマトグラムから保持時間インデックスを独立変数、質量分析シグナル強度を従属変数としてマトリクスデータを作成する。ランキング既知の複数の緑茶サンプルのランキング順位を説明変数として、既知サンプルをトレーニングセットとしてPLS法によりランキング予測モデルを作成できる。例えば、品質未知の緑茶サンプルから同様に機器分析して得られたデータを多変量解析し、その解析結果を予測モデルと比較・照合することによって、どのランキングに位置するかがわかるため、品質を予測することができる。
【0038】
例えば、緑茶から代謝物を抽出してGC/MSで分析した場合、得られる分析結果は、種々の代謝物の保持時間、マススペクトル、イオン強度などがある。この場合、特に、アラビノース、グルタミン、クエン酸、グルタミン酸、アスパラギン酸、イノシトール、シキミ酸、リン酸、フルクトース、テアニン、リンゴ酸、カフェイン、キナ酸、グルコース、マンノース、リボース、およびスクロースのデータは、緑茶の品質予測(等級分類)に重要な役割を果たす。本発明により、高いランキングの緑茶サンプル中には、代謝物として、アミノ酸、キナ酸、リン酸、リボース、およびアラビノースの量が比較的多く、低いランキングの緑茶サンプル中には、フルクトース、グルコース、マンノースなどの糖が主代謝物として存在する傾向があることが、明らかになっている。
【0039】
また、上記の方法によって得られる予測モデルは、データの蓄積により、精度が上昇し得る。したがって、例えば、緑茶中の代謝物の相対量の傾向がより明確になれば、品質未知の緑茶の分析結果からフィンガープリントを得、このフィンガープリントに基づいて品質予測をすることも可能となる。
【実施例】
【0040】
(実施例1:GC/MS用の分析サンプルの調製)
2005年の品評会でランキング(格付け)された53種の一番茶の加工後の乾燥葉をサンプルとして用いた。市販茶品評会に記載されたこれらの茶サンプルは、奈良県農業総合センター茶業振興センターから入手した。茶のランキングは、官能試験の総合スコアによって決定され、これは、葉の外観、入れた茶の芳香、色、および味であり、専門の茶の鑑定人によって鑑定された。なお、ランキングの高い方から順に、1番から53番まで順位をつけた。
【0041】
まず、2mL容のエッペンドルフ管中で乾燥茶葉(30mg)を凍結乾燥し、Retschボールミル(20Hz、1分間)で粉砕した。この茶葉に、メタノール、水、およびクロロホルムの混液(2.5:1:1、v/v/v)を1mL加え、さらに内部標準として60μLのリビトール(和光純薬工業株式会社:脱イオン水で0.2mg/mLの濃度まで希釈)を加えて、5分間振盪し、そして4℃にて16000×gで3分間遠心分離した。次いで、900μLの上清を、1.5mL容のエッペンドルフ管に移した。Millipore Milli-Qシステム(Berdford、MA)を用いて精製された400μLの水を添加して、ボルテックスおよび遠心分離し、次いで400μLの極性相を、穴あきキャップでキャップした他の1.5mL容のエッペンドルフ管に移した。得られた抽出物(親水性化合物)を、乾燥するまで(一晩)真空遠心分離乾燥機中で乾燥させた。
【0042】
次いで、この抽出物に50μLの塩酸メトキシアミン(Sigma)のピリジン溶液(20mg/mL)を、第1の誘導体化剤として添加した。混合物を30℃にて90分間インキュベートした。さらに、第2の誘導体化剤である100μLのN−メチル−N−(トリメチルシリル)トリフルオロアセタミド(MSTFA:GL sciences Inc.)を添加して、30℃にて30分間インキュベートすることにより抽出物を誘導体化して、分析サンプルを得た。
【0043】
(実施例2:GC/MSによる緑茶サンプルの分析)
上記実施例1で得られた1μLの分析サンプルを、スプリットモードでGC/MSに注入した(25:1、v/v)。本実施例で使用したGC/MS装置は、Pegasus III TOF質量分析器(LEGO)ならびにオートサンプラーとして7683Bシリーズインジェクター(Agilent Co.)を連結した0.25μm CP-SIL 8 CB低ブリード(Varian Inc.)でコーティングされた30m×0.25mm i.d.のフューズドシリカキャピラリーカラムを装着した689CN(Agilent Co.)であった。注入温度は230℃であった。カラムを通るヘリウムガスの流速は、1mL/分であった。カラム温度は、2分間80℃で等温に保ち、次いで15℃/分で330℃まで上昇させ、そして6分間等温に保った。搬送ラインおよびイオンソース温度は、それぞれ250℃および200℃であった。イオンを、70kV電子衝撃(EI)によって生成し、そして1秒当たり20スキャンを、85〜650m/zの質量範囲にわたって記録した。加速電圧は、250秒の溶媒遅延後に作動した。
【0044】
(実施例3:GC/MSによるデータの解析および緑茶の代謝物のフィンガープリンティング)
上記実施例2においてGC/MSにより得られたデータの前処理については、得られた生のクロマトグラフデータ(Pegasusファイル、*.peg)を、ANDIファイル(分析データ交換プロトコル、*.cdf)に変換した。ANDIフォーマットを用いると、異なるマススペクトルデータシステム間のデータの変換および転送を行うことができた。変換したファイル(ANDI)を、データ前処理手順に供し、データ点を詳細に再処理した。さらに、データ変換も、最良のクロマトグラフデータを得るために行った。次いで、トータルイオンクロマトグラフデータを抽出し、そしてフラグメントデータなしのANDIフォーマットとして保存した。これらのファイルを、保持時間のマルチプルアライメント用の市販のソフトウエアのLineUp(Informatrix, Inc.)に移行した。ミスアライメントピークを、相関最適化ワーピングアルゴリズムを用いてアライメントした。
【0045】
次いで、多変量データの群中の類似性または相違性で表される関係を把握するために、主成分分析(PCA)を行った。市販のソフトウエアであるPirouette(登録商標)(Informatrix, Inc.)をこの目的に適用した。
【0046】
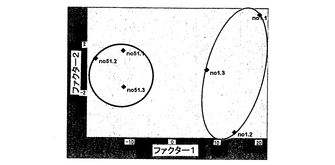
53種のランキングされた一番茶サンプルを、それらの等級に従ってランキングされた3群に分けたが、これらの3群の分類は明瞭ではなかった。各所定の群に約20サンプルがあるので各群のサンプルの変動が非常に高すぎたため、高いランキングのサンプルは、低いランキングのサンプルとは別の明らかな集団を示さなかった。次いで、低いランキング(51番)および高いランキング(1番)のサンプルについて、再度、データを変換せずに平均中央で前処理した。その結果、これらの群間で、ある程度の差があることがわかった(図1)。
【0047】
顕著な化合物を、そのマススペクトルとライブラリー(NISTライブラリーおよび認証された標準化学物質から調製された内部ライブラリー)中のスペクトルとを比較することによって同定した。さらに、the Max-Planck Institute of Molecular Plant Physiology、Germanyによって提供されたライブラリーも、この目的に用いた(http://www.mpimp-golm.mpg.de/mms-library/index-e.htlm)。高いランキングのサンプル中には、アミノ酸、キナ酸、リン酸、リボース、およびアラビノースの量が比較的多いが、低いランキングのサンプルでは、主として糖(フルクトース、グルコース、およびマンノース)であった。これは、メタボロミクス解析が、緑茶の品質測定に有用であり得ることを示した。
【0048】
次いで、部分最小二乗法による潜在的構造に対する射影(PLS)(SIMCA-P version 11.0:Umetrics)を選択して、予測モデルを作成した。PLSにより、2セットの変量(測定値および応答値)間の関係が見出される。すなわち、得られたGC/MSクロマトグラムから保持時間インデックスを独立変数、質量分析シグナル強度を従属変数としてマトリクスデータを作成し、各サンプルの品評会ランキング順位を説明変数として、既知サンプルをトレーニングセットとしてPLS法によりランキング予測モデルを作成した。
【0049】
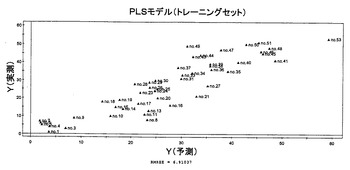
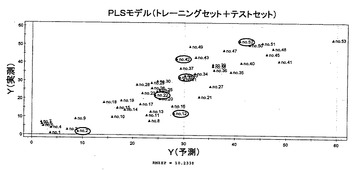
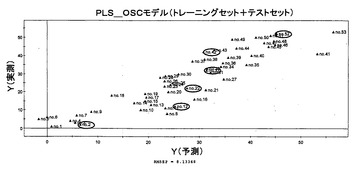
サンプルの代謝物フィンガープリント(マトリクスX)とその品質(マトリクスY)との間の関係を観察した。まず、分析サンプルを、トレーニングセットおよびテストセットの群に分けた。2番、12番、22番、32番、42番、および52番のランキングのサンプルを、モデルのバリデーション用のテストセットとして除外した。変換した変数はなかった;変数の全てを集約し、そしてパレート分散にスケールして、クロマトグラフデータノイズ効果を減少させた。モデルの完全性、すなわち、PLSモデルにおける潜在的ファクターの数は、クロスバリデーションによって決定され得、最適な数は、(モデルに対する)適合と予測能との間のバランスで見られた。さらに、PLSモデルは、テストセットでバリデートされ、予測値の平均二乗誤差(RMSEP)をコンピュータ計算した。2つの顕著な成分を抽出し、クロスバリデーションに従って、Yの80.7%の変動を記述し(R2Y=0.807)そしてYの31.3%の変動を予測した(Q2Y=0.313)(図2参照)。次いで、テストセットについて、PLSモデルで予測し、トレーニングセットサンプル(RMSEP=6.91)に基づくモデル評価に関して、テストサンプル(RMSEP=10.23)の予測精度が得られた(図3)。このPLSモデルにより、ある程度の予測が得られた。
【0050】
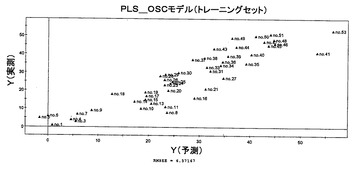
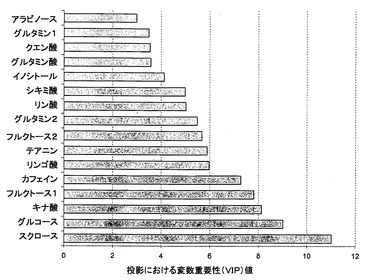
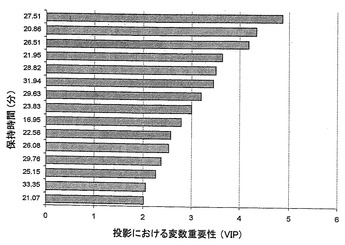
さらに、PLSモデルの予測力を増強するために、スペクトルフィルタリング技術を適用した。OSCは、PLSベースの解決手段であり、Yのモデリングに関連のないXデータ変動値を除去する。OSCでは、1つの成分を、非線形反復部分最小二乗法(NIPALS)アルゴリズムを用いるマトリクスXから1つずつ除去する。上記のPLSモデルから2つのOSC成分を除去することにより、Q2Yは、0.500まで上昇した。二乗の残余合計は41.40%であった。したがって、58.60%のXの変動値は、Yに関連せず、除去された(図4参照)。テストセットをモデルに供した後の予測値は、トレーニングサンプル(RMSEP=6.57)に基づくモデル評価とよく一致するテストサンプル(RMSEE=8.13)についての予測精度になった(図5)。さらに、高い関連を有する説明変数Yも、VIP(投影における変数重要性)値から同定した。1を超える大きなVIP値は、最も関連がある説明変数Yである。このように、キナ酸、アミノ酸(特にテアニン)、および糖類が、緑茶についての品質予測モデルを作成するために重要であることを見出した(図6)。
【0051】
(実施例4:GC/MSによる緑茶代謝プロファイリング)
高い等級の茶として受け入れられている大和茶を、奈良県農業総合センター茶業振興センターから入手した。緑茶サンプルの前処理方法およびGC/MSによる分析条件は、上記実施例1および2と同じであった。クロマトグラムの分離度は満足のいくものであるため、各代謝物のピーク面積を、総イオンカウント(TIC)により算出した。続いて、同定した代謝物の全てのピークを内部標準のリビトールに対して標準化した。この分析から、緑茶の乾燥葉は、以下の表1に示すような、多くの化合物、主として有機酸、アミノ酸 および糖類(単糖類および二糖類の両方)を含むことがわかった。最高量で検出した化合物は、糖類であり、特にスクロースおよびフルクトースが多かった。茶の独特の呈味に寄与する重要なアミノ酸であるテアニンも検出した。抽出物中にいくつかの他のアミノ酸を同定できたが、少量であった。約23の同定した代謝物は、クロマトグラムから同定した。
【0052】
【表1】

【0053】
このことから、上記実施例3で得られたケモメトリクスと組み合わせたGC/MSを用いるメタボロミクス解析が、緑茶の研究において有用な情報を提供することが証明された。
【0054】
(実施例5:1H−NMR用の分析サンプルの調製および分析)
上記実施例1と同様に、2005年の品評会でランキング(格付け)された53種の一番茶の加工後の乾燥葉をサンプルとして用いた。
【0055】
まず、1mL容のエッペンドルフ管中で乾燥茶葉(50mg)を凍結乾燥し、Retschボールミル(20Hz、1分間)で粉砕した。この茶葉に、1mLの重水(重水素原子99.9%:Cambridge Isotope Laboratories, Inc.)を加えた。この混合物を、Thermomixer comfort(Eppendorf)で60℃および1400rpmにて30分間インキュベートし、25℃および16000×gにて10分間遠心分離した(遠心分離機5415R:Eppendorf)。親水性代謝物を含む上清を、0.45μmのPTFEメンブレン(Advantec)を通して濾過した。次いで、400μLの濾液を、内部標準として3mMの3−(トリメチルシリル)−1−プロパン硫酸ナトリウム(DSS:Aldrich)を含む200μLの0.2Mリン酸緩衝液(pH7.4)に溶解した。なお、サンプル調製は、1H−NMR測定の1日前に行った。
【0056】
得られた分析サンプルを、1H−NMRによって測定した。本実施例では、750MHz Varian Inova 750スペクトロメーターを使用し、5mmの1H{13C/15N}三重共鳴間接検出プローブを用いて25℃にてスペクトルを記録した。1H−NMR測定は、64トランジエントおよび131K複合データポイントで行った。捕捉時間およびリサイクル遅延は、30°パルス角を用いて、1スキャン当たりそれぞれ6.257秒および3.743秒であった。予備飽和パルスシーケンスを適用して、残存水のシグナルを抑制した。すべてのスペクトルは、データ処理前に0.1Hz線幅広がりでフーリエ変換した。
【0057】
(実施例6:1H−NMRのデータの解析、緑茶の代謝物のフィンガープリンティング、および緑茶代謝プロファイリング)
1H−NMR測定によって得られたスペクトルは、まず、Chenomx NMR Suite4.6ソフトウエアプロフェッショナル版(Chenomx Inc., Canada)によって位相およびベースライン補正した。1.0〜8.0ppmの範囲にわたって、0.04ppmのサイズで積分した。一方、4.6〜5.0ppmの水のシグナルは削除した。すべての測定値は、DSSのメチルのピーク面積に対して標準化した。
【0058】
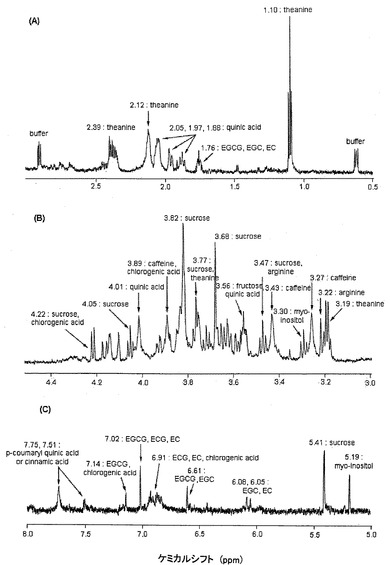
最高品質の茶から抽出した水溶性化合物の1H−NMRスペクトルを、図7に示す。代謝物由来のシグナルを、同条件下で分析した公知の標準化合物由来のシグナルならびにChenomx NMR Suite4.6の750MHz(pH4〜9)ライブラリデータベースとの比較によって帰属した。このうち、約10の主要な化合物を同定することができた。テアニン、アミノ酸、およびキナ酸が高磁場領域(δ0.5〜3.0ppm:図7A)で主として観察された。中磁場領域(δ3.0〜4.5ppm:図7B)においては、スクロースおよびフルクトース以外では、カフェイン、アルギニン、ミオイノシトール、クロロゲン酸、およびキナ酸が明確に観察された。低磁場領域(δ5.0〜8.0ppm:図7C)には、2−O−β−L−アラビノピラノシル−ミオイノシトール、p−クマリル−キナ酸またはケイ皮酸、(−)−エピガロカテキン−3−没食子酸(EGCG)、および(−)−エピカテキン−3−没食子酸(ECG)が主に観察された。(−)−エピガロカテキン(EGC)および(−)−エピカテキン(EC)は、水溶性が低いため、あまり顕著には観察されなかった。
【0059】
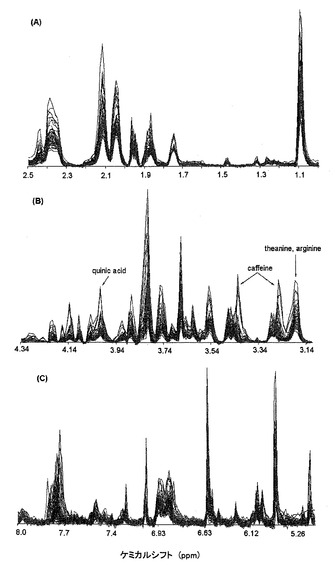
図8に、53種のランキングされた一番茶サンプルについて得られたすべての1H−NMRスペクトルを重ねて示す。高磁場領域(図8A)および低磁場領域(図8C)では顕著な差は見られなかったが、中磁場領域(図8B)では、いくつかの差が観察された。特に、δ3.27および3.43ppmのカフェインのシグナルが、高品質の茶サンプルで強かった。カフェインは、茶の苦味に寄与し、茶の品質に重要であることが知られている。したがって、NMRでの測定においても、品質予測モデルを作成するために重要な因子であることが示された。
【0060】
次に、多変量データの群中の類似性または相違性で表される関係を把握するために、Pirouette(登録商標)ソフトウエア(Informatrix, Inc.)を用いて、高磁場領域(δ1.0〜2.5ppm)、中磁場領域(δ3.12〜4.34ppm)、および低磁場領域(δ6.15〜6.35ppm)についてそれぞれ主成分分析(PCA)を行った。まず、53種のサンプルを、それらの等級に従ってランキングされた2群に分けた(高品質:1〜25番、および低品質:26〜53番)。スコアプロットにおいて、高磁場領域では、2群間の差は明瞭には見られなかったが、中磁場領域および低磁場領域では、高品質および低品質の2群に大まかに分けることが可能であった(データは示さず)。また、ローディングプロットでは、カフェイン、テアニン、EGCG、ECG、EGC、およびEC由来のシグナルが、クラスタ分離に寄与することがわかった(データは示さず)。
【0061】
さらに、部分最小二乗法による潜在的構造に対する射影(PLS)(SIMCA-P version 11.0:Umetrics)を選択して、独立(予測)変数Xから従属(応答)変数Yを予測するための回帰モデルを作成した。回帰は、システム行動に基づく数学的モデルを作成することによって行われ、トレーニングサンプルに関するモデルパラメータに最適な値を決定する。次いで、未知の独立変数の値を、得られたトレーニングモデルを用いて予測する。本実施例では、品評会ランキング順位を従属変数として用いた。分析サンプルを、トレーニングセットおよびテストセットの群に分けた。5番、15番、25番、35番、および45番のランキングのサンプルを、モデルのバリデーション用のテストセットとした。分析前に変換した変数はなく、データを集約し、そしてユニット分散にスケールした。
【0062】
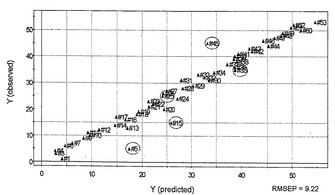
緑茶サンプルの測定値と予測値との間のPLS関係を図9に示す。なお、2番および8番のサンプルについては、ノイズが大きいため、モデル作成から除外した。PLS回帰モデルの性能を、相関係数R2およびクロスバリデートした相関係数Q2ならびに予測値の平均二乗誤差(RMSEP)という測定値と予測値との間のバリデーション誤差によって検証した。緑茶のPLS回帰モデルは、R2=0.987およびQ2=0.671(RMSEP=1.82)を示した(図9)。これは、適合および予測力に優れることを示している。緑茶のランキング順位を予測するためのモデルの予測性を、テストセットによって試験した(図11において丸で囲む)。予測結果は、理想的な対角線上から分散していた(RMSEP=9.22)。このPLSモデルにより、ある程度の予測が得られた。
【0063】
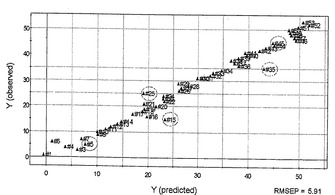
さらに、PLSモデルの予測力を、直交シグナル補正(OSC)を用いて変動を単純化することによって改善した。上記PLSモデルから2つのOSC成分を除去することにより、Q2は0.671から0.982に上昇し、予測性は31%改善した(図10)。PLS−OSC回帰モデルの予測性を、再度テストセットによって検証した(図10において丸で囲む)。RMSEP値は9.22から5.91に顕著に減少した。図10に示す回帰プロットによれば、Q2の上昇およびRMSEPの低下が、シグナル補正によって予測モデルの能力が劇的に改善されたことを示す。
【0064】
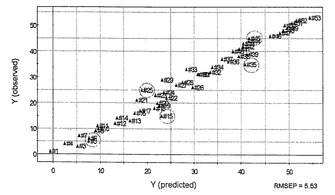
ウェーブレット変換は、複雑なシグナルを圧縮してノイズを除き、関連のある情報のみを抽出するために用いられるシグナル処理のツールである。OSCとの組み合わせにより、予測力を損なうことなく多変量検定の質を改善できることが知られている。そこで、本実施例においても、OSCとウェーブレット変換との組み合わせ(OSCW)を適用した。1成分OSCフィルタリングにより、63.42%の非関連X変数が除去された。506ウェーブレット係数を用いて、二乗の合計の99.50%を保持した。得られたPLS−OSCW回帰を図11に示す。R2およびQ2はそれぞれ0.982および0.944であった。PLS回帰モデルの予測能は、OSCWの実行により改善され、テストセットでの検証では、RMSEPが5.91から5.53に低下していた(図11において丸で囲む)。有益な変数を捕捉するためにPLSモデルで用いられたウェーブレット係数の数は非常に高く、そして0.5%の非関連変数のみが除去された。これは、ほとんどすべてのY変数がOSCフィルタリングによって捕捉され、ノイズから生じた一部の変動のみが残ったことを示す。ウェーブレット解析は、予測能を損失することなく残りの変数を除去することによって予備加工性能を増強する。
【0065】
このように、PLS、PLS−OSC、およびPLS−OSCW回帰のR2、Q2、およびRMSEP値を比較すると、R2およびQ2値は両方ともすべてのモデルについて0.9より大きく、非常に良好な適合性および優れた予測性で緑茶の品質を予測するために使用できることを示す。
【0066】
(実施例7:FT−NIR用の分析サンプルの調製および分析)
2005年の品評会でランキング(格付け)された64種の一番茶から選択された13種の加工後の乾燥葉をサンプルとして用いた。これらの茶は、4、8、14、18、24、28、34、38、44、48、54、58、および64番のランキングのサンプルである。市販茶品評会に記載されたこれらの茶サンプルは、奈良県農業総合センター茶業振興センターから入手した。茶のランキングは、官能試験の総合スコアによって決定され、これは、葉の外観、入れた茶の芳香、色、および味であり、専門の茶の鑑定人によって鑑定された。
【0067】
2mL容のエッペンドルフ管中で乾燥茶葉(200mg)を、Retschボールミル(20Hz、10分間)で粉砕し、600μLのグリセロール、ヘキサン、アセトニトリル、または鉱油を加えた。これらの各混合物を再度ボールミルで(20Hz、10分間)でホモジナイズして、ペースト状の分析サンプルを得た。これらの分析サンプルを、それぞれ2mL容のガラスバイアルに移した。
【0068】
得られたペースト状の分析サンプルを、FT−NIRによって測定した。本実施例で使用したFT−NIR測定装置は、Smart Near-IR UpDRIFT、CaF2ビームスプリッタ、および冷却InGaAs検出器を装着したNICOLET 6700 FT-IR(サーモエレクトロン株式会社)であった。FT−NIRスペクトルは、3.857cm−1の間隔で10000〜4000cm−1まで記録した。ミラー速度は1.2659cm/sであり、そして分解能は8cm−1であった。データポイントの総数は、各スペクトルにつき1557であった。各サンプルについて4回ずつ測定した。
【0069】
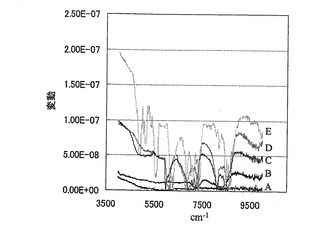
種々の溶媒を用いて調製したサンプルについてFT−NIRを測定したところ、グリセロール(B)を用いた場合に測定データの変動が最小であった(図12)。したがって、グリセロールを用いて調製したサンプルについて以下の解析を行った。
【0070】
(実施例8:FT−NIRのデータの解析、緑茶の代謝物のフィンガープリンティング、および緑茶の品質予測)
FT−NIRにより得られた各データ(すなわち、測定値)は、平均して100,000を乗じた。全データを、二次微分および標準正規変量(SNV)によって前処理して変換した。
【0071】
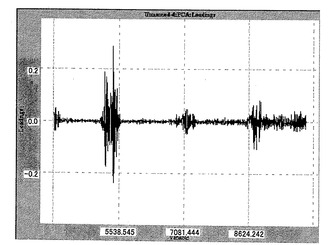
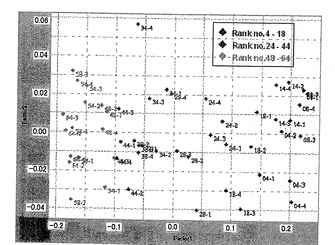
市販のソフトウエアであるPirouette(登録商標)(Informatrix, Inc.)を用いて主成分分析(PCA)を行った。PCAのファクター3において、13種の茶サンプルを、それらの等級に従ってランキングされた3群に分けることができた。ファクター3での変動は、総変動の2.38%であり、非常に低かった。このファクター3のローディングプロットから、5500〜5200cm−1の波数域が、茶の等級に関連すると予測された(図13)。そこで、5500〜5200cm−1の波数域のデータについて再度PCAを行った。その結果、ファクター1によって群分けが可能であり、この波数域が茶の等級と非常に関連することがわかった(図14)。
【0072】
次いで、部分最小二乗法による潜在的構造に対する射影(PLS)を選択して、茶サンプルの品質の予測モデルを作成した。分析サンプルを、トレーニングセットおよびテストセットの群に分けた。14番、34番、および54番のランキングのサンプルを、モデルのバリデーション用のテストセットとして除外した。5500〜5200cm−1のスペクトル域の全データについて、二次微分および標準正規変量(SNV)を行った。PLSモデルにおける潜在的ファクターの数は、クロスバリデーションによって決定した。最適な数は、トレーニングセットのモデルにおいて5であった。トレーニングセットの予測値の標準誤差(SEP)は1.59であり、テストセットのSEPは、3.05であった(図15)。トレーニングセットのスチューデント化残差は0.997であり、テストセットでは0.998であった。これらの数値は、予測モデルの精度を示す。すなわち、値が「1」に近い場合は、結果が正確であることをいう。これらの事実は、予測モデルが非常に正確であることを示唆する。テストセットの結果から、このモデルは、低品質サンプルの予測について正確であるが、高品質サンプルの予測ではあまり正確ではなかった(図15)。この結果は、茶品質が高い場合には品質の差が小さいため、予測が困難になることを示唆する。この研究は、FT−NIRを用いる代謝物フィンガープリンティングによる茶の品質予測が正確であり現実的であることを示した。
【0073】
(実施例9:GC/MS用の熱分解処理分析サンプルの調製および分析)
上記実施例1と同様に、2005年の品評会でランキング(格付け)された53種の一番茶の加工後の乾燥葉をサンプルとして用いた。これらの茶葉を、葉および葉柄を均一にするためにブレンダーを用いて粉末に粉砕し、−20℃にて保存した。
【0074】
粉砕したサンプルの1±0.005mgを秤量し、そしてEco-cup S(フロンティア・ラボ株式会社)に入れ、PY-2020iDダブルショット・パイロライザー(フロンティア・ラボ株式会社)に導入した。パイロライザーのオーブン温度を500℃に、そしてインターフェースは250℃に設定した。熱分解時間は、各サンプルについて5分に設定した。
【0075】
GC/MS装置を、GC注入口を介してパイロライザーと直接連結した。本実施例で使用したGC/MS装置は、THERMO TR-WaxMSカラム(60m×0.25mmi.d.×0.25μm)(Thermo electron Co.)を装着し、TRACE DSQマススペクトロメータ(Thermo electron Co.)と連結されたTRACE GCガスクロマトグラフ(Thermo electron Co.)であった。注入温度は230℃であった。キャリアガスとして、高純度ヘリウムガスを、流速1mL/分で用いた。GC注入口のスプリット比は20:1であった。分析は、以下のオーブン温度プログラムで行った:2分間70℃で等温に保ち、次いで7℃/分で70℃から260℃まで上昇させ、そして20分間260℃に保った。搬送ラインおよびイオンソース温度は、両方とも250℃であった。イオンを、70kV電子衝撃(EI)によって生成し、そして1秒当たり20スキャンを、50〜650m/zの質量範囲にわたって記録した。加速電圧は、すべてのGC走査時間後に作動した。
【0076】
(実施例10:熱分解処理緑茶サンプルのGC/MSのデータ解析、緑茶の代謝物のフィンガープリンティング、および緑茶代謝プロファイリング)
上記実施例9においてGC/MSにより得られたデータの前処理については、得られた生のクロマトグラフデータ(Xcaliburファイルタイプ、*.raw)を、Xcaliburソフトウエア(Thermofinnigan)のファイル変換メニューを用いてANDIファイル(分析データ交換プロトコル、*.cdf)に変換した。クロマトグラムのデータポイントを、自動的に0.01秒毎に強度をスキャンするように調節して、フラグメントデータを含まずにAIAデータとして保存した。データを、保持時間のアライメント用の市販のソフトウエアのLineUp(Informatrix, Inc.)に移行して、相関最適化ワーピングアルゴリズムを用いてアライメントした。
【0077】
サンプルの代謝物フィンガープリント(マトリクスX)とその品質(マトリクスY)との間の関係を観察した。まず、分析サンプルを、トレーニングセットおよびテストセットの群に分けた。2番、12番、22番、32番、42番、および52番のランキングのサンプルを、モデルのバリデーション用のテストセットとして除外した。部分最小二乗法による潜在的構造に対する射影(PLS)(SIMCA-P version 11.0:Umetrics)を、スペクトルフィルタリング技術である直交シグナル補正(OSC)とともに用いて回帰モデルを作成し、緑茶の代謝物プロファイル(X変数)と品質ランキング(Y変数)との関係を検討した。PLS回帰モデルの有効性および信頼性を、モデル(R2Y)、予測性パラメータ(Q2)、トレーニングセットの推定値の平均二乗誤差(RMSEE)、およびテストセットの予測値の平均二乗誤差(RMSEP)によって説明される変動割合によって評価した。PLS回帰モデルの有効性および信頼性は、トレーニングセットによって検証し、そしてテストセットでバリデートした。
【0078】
2つのOSC成分を除去して、モデル中でY変数に対して関連するX変数の52.11%を残した。PLSモデルを構築した後、クロスバリデーションに従って、Yの77.9%の変動を反映し(R2Y=0.779)そしてYの66.9%の変動を予測した(Q2=0.669)。このトレーニングセットによって作成したモデルは、7.57のRMSEE値であった。X(t1)およびY(u1)の第1のサマリー間のプロットにより、良好な相関が観察された。しかし、46番のサンプルについては、予測値が非常に大きく乖離していたので、除外した。46番を除外して再度予測モデルを構築すると、R2Y=0.876およびQ2=0.778に改善され、XとYとの間に良好な相関が見られた(図16)。RMSEEも5.36に低下していた。次いで、テストセットで検証したところ、品質のランキングに非常に良く一致していた(図16)。
【0079】
さらに、モデル構築に重要な高い関連を有する説明変数Yを、VIP(投影における変数重要性)値からコンピュータ解析により同定した。1を超える大きなVIP値は、最も関連がある説明変数Yである。分子はランダムに破壊されるので、クロマトグラムから代謝物を同定することは実行不可能であるが、VIP値から判断して、重要な代謝物を保持時間として特徴づけることができた(図17)。保持時間に対する変数は、元のクロマトグラムでは、高いランキングの緑茶と低いランキングの緑茶との間に強度差を示した。したがって、最終的なモデルに対する貢献度(例えば、保持時間)の順に予測変数をランク付けすることによって、緑茶の品質予測が可能であることがわかった。
【0080】
(実施例11:UPLC/MS用の分析サンプルの調製および分析)
2006年の品評会でランキング(格付け)された56種の一番茶の加工後の乾燥葉をサンプルとして用いた。市販茶品評会に記載されたこれらの茶サンプルは、奈良県農業総合センター茶業振興センターから入手した。茶のランキングは、官能試験の総合スコアによって決定され、これは、葉の外観、入れた茶の芳香、色、および味であり、専門の茶の鑑定人によって鑑定された。なお、ランキングの高い方から順に、1番から56番まで順位をつけた。
【0081】
まず、2mL容のエッペンドルフ管中で乾燥茶葉(10mg)を凍結乾燥し、Retschボールミル(20Hz、1分間)で粉砕した。緑茶の親水性一次代謝物を、メタノール、水、およびクロロホルムの混液(2.5:1:1、v/v/v)を用いて抽出した。得られた混合物を、サーモミキサー中で37℃にて30分間インキュベートした。その後、溶液を4℃にて16000×gで10分間遠心分離した。次いで、200μLの上清を、穴あきキャップでキャップした1.5mL容のエッペンドルフ管に移した。得られた抽出物を、乾燥するまで(一晩)真空遠心分離乾燥機中で乾燥させた。得られた乾燥物に200μLのメタノール/水(4:1、v/v)(0.1%(v/v)のギ酸を含む)を加えて、PTFEフィルターを通して濾過し、分析サンプルとした。
【0082】
分析サンプルの4μLを、UPLC/MSに供した。本実施例では、バイナリーソルベントマネージャ、カラムヒータ、およびサンプルマネージャを装着したACQUITY UPLCTMシステム(Waters)を用い、そして検出を、LCT premierTM XEマススペクトロメトリー(Waters)を用いて行った。この装置には、2.1×150mm,1.7μmのAcquity UPLC BEH C18カラムを装着し、40℃で操作した。移動相の条件としては、0.3mL/分の流速で、移動相Aとして水(0.1%(v/v)のギ酸を含む)および移動相Bとしてアセトニトリル(0.1%(v/v)のギ酸を含む)を用い、移動相Bを0%(v/v)から100%(v/v) に7分間で増加させる直線グラジエントを行い、次いで7分間維持させた。MSは、ネガティブモードでエレクトロスプレーイオン化(ESI)ソースを用いた。イオン化パラメータは、キャピラリー電圧:2.0kV、コーン電圧:0.035kV、脱溶媒和ガス流量500L/時間、脱溶媒和温度:350℃、およびソース温度:100℃であった。
【0083】
(実施例12:緑茶サンプルのUPLC/MSのデータ解析および緑茶代謝プロファイリング)
上記実施例11においてUPLC/MSにより得られたデータの前処理については、得られた生のクロマトグラフデータを、ANDIファイル(分析データ交換プロトコル、*.cdf)に変換した。変換したファイル(AIA)を、ピーク検出、アラインメント、ギャップフィルタリング、および標準化についてデータ処理ソフトウェアMZmineを用いてデータの前処理を行った。
【0084】
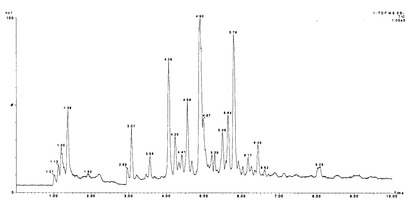
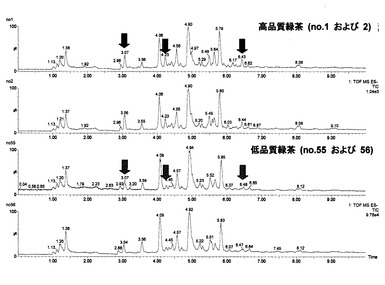
ランキングされた一番茶サンプルのうち、1番のランキングの緑茶サンプルのトータルイオンクロマトグラムを図18に示す。すべてのランクのサンプルが、同様のクロマトグラムパターンを示した。しかし、図19に示すように、茶の品質の違いによりピーク強度の差が見られた。
【0085】
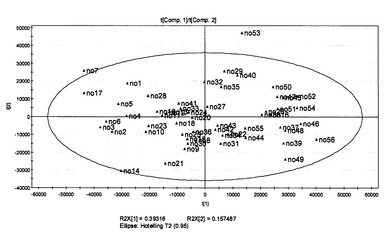
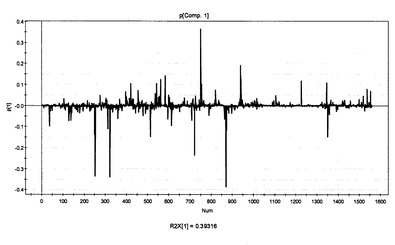
次いで、この複雑なデータから重要な化合物および情報を明らかにするために、多変量分析を行った。多変量データの群中の類似性または相違性で表される関係を把握するために、主成分分析(PCA)(SIMCA-P version 11.0:Umetrics)を選択した。全体を把握するためにUnsupervised PCAを行った。9つの主成分では、R2X=0.767およびQ2=0.508であり、低い等級の茶および高い等級の茶は、PC1軸に沿って別々に分かれた(図20)。すなわち、高品質の緑茶サンプルはPC1のネガティブ側に、そして低品質の緑茶サンプルは、PC1のポジティブ側に集まった。スコアプロットに対応するローディングプロットを図21に示す。予測品質の差によって緑茶サンプルの代謝プロファイリングの差が示された。
【0086】
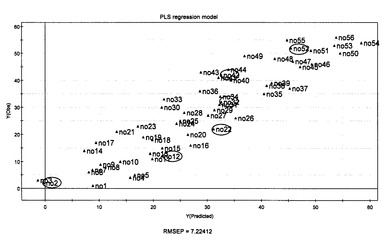
次いで、緑茶品質とそのメタボロームとの関係を検討するために、部分最小二乗法による潜在的構造に対する射影(PLS)(SIMCA-P version 11.0:Umetrics)を選択して、予測モデルを作成した。実施例11で得られた56種の分析サンプルを、トレーニングセット(50サンプル)およびテストセット(6サンプル)の群に分けた。2番、12番、22番、32番、42番、および52番のサンプルを、モデルのバリデーション用のテストセットとして除外した。すべての変数のXマトリクスを、中心にスケールした。2つの顕著な成分を抽出し、クロスバリデーションに従って、Yの83.3%の変動を記述し(R2Y=0.833)そしてYの71.4%の変動を予測した(Q2Y=0.714)(図22)。次いで、テストセットについて、PLSモデルで予測し、トレーニングセットサンプル(RMSEE=6.75)に基づくモデル評価に関して、テストサンプル(RMSEP=7.22)の予測精度が得られた(図22)。
【産業上の利用可能性】
【0087】
本発明によれば、従来困難であった製品緑茶の総合品質を簡便な方法で予測することが可能である。すなわち、緑茶を、クロマトグラフィーや分光分析などの種々の機器分析によりスクリーニングすることによって、迅速かつ有益に品質予測し得る。
【0088】
従来の緑茶の機器分析は、医用目的の抗酸化化合物、ならびに呈味および芳香用のカテキンおよび他のフェノール性化合物などの、特定の機能に重要であると考えられる特定の群の化合物に焦点が当てられていた。しかし、緑茶の特徴づけは、単一の代謝物に由来するのではなく組み合わせに由来し得る。したがって、複数の成分を一度に分析することによる本発明の方法を用いれば、より精度よい品質予測が可能であり、緑茶製造工程あるいは緑茶流通保管工程のさらなる改善が期待できる。
【図面の簡単な説明】
【0089】
【図1】PCA解析結果を示す図であり、高いおよび低いランキングの緑茶サンプルについてのスコアプロットである。
【図2】トレーニングセットとしての46種の緑茶サンプルについてのPLSモデルの実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図3】テストセット(丸で示す)およびトレーニングセットの両方の53種の全ての緑茶サンプルについてのPLSモデルの実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図4】直交シグナル補正(OSC)を用いたトレーニングセットとしての46種の緑茶サンプルについてのPLSモデルの実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図5】直交シグナル補正(OSC)を用いたテストセット(丸で示す)およびトレーニングセットの両方の53種の全ての緑茶サンプルについてのPLSモデルの実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図6】緑茶の品質予測値を生成するために用いた変数の影響を示すグラフである。
【図7】最高品質の茶から抽出したサンプルの1H−NMRスペクトル(750MHz、D2O)を示す。
【図8】53種のランキングされた一番茶サンプルのすべてについて得られた1H−NMRスペクトルを重ねて示す。
【図9】トレーニングセットおよびテストセット(丸で示す)の両方の緑茶サンプルの1H−NMRデータから算出したPLSモデルについての実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図10】トレーニングセットおよびテストセット(丸で示す)の両方の緑茶サンプルの1H−NMRデータから算出したPLS−OSCモデルについての実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図11】トレーニングセットおよびテストセット(丸で示す)の両方の緑茶サンプルの1H−NMRデータから算出したPLS−OSCWモデルについての実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図12】種々の溶媒で調製したサンプルについてのFT−NIRスペクトルであり、図中、Aはブランク、Bはグリセロール、Cは鉱油、Dはヘキサン、およびEはアセトニトリルの場合を示す。
【図13】PCA解析結果を示す図であり、ファクター3のローディングプロットである。
【図14】5500〜5200cm−1のスペクトル域のデータについてのPCA解析結果を示す図であり、高いおよび低いランキングの緑茶サンプルについてのスコアプロットである。
【図15】テストセット(丸で示す)およびトレーニングセットの両方の53種の全ての緑茶サンプルについてのPLSモデルの実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図16】46番のサンプルを除くトレーニングセットおよびテストセット(丸で示す)の緑茶サンプルの1H−NMRデータから算出したPLS−OSCモデルについての実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図17】重要な代謝を特徴づける保持時間ごとのVIP値を示すグラフである。
【図18】1番のランキングの緑茶サンプルのUPLCのトータルイオンクロマトグラムである。
【図19】高品質緑茶(No.1および2)および低品質緑茶(No.55および56)のUPLCのイオン強度を示すクロマトグラムである。
【図20】すべてのランキングの緑茶サンプルのUPLC/MS分析によるPCAスコアプロットである。
【図21】緑茶サンプルのUPLC/MS分析のPCA解析結果を示す図であり、PC1のローディングプロットである。
【図22】テストセット(丸で示す)およびトレーニングセットの両方の56種の全ての緑茶サンプルのUPLC/MS分析でのPLSモデルの実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【技術分野】
【0001】
本発明は、緑茶の品質予測方法に関する。より詳細には、緑茶の代謝物または分解物の機器分析による品質予測方法に関する。
【背景技術】
【0002】
茶は最も普及している飲料であり、Camellia sinensisという植物の葉から製造される。酸化反応の長さおよび葉の加工方法に基づいて、紅茶、ウーロン茶、および緑茶の3つの種類に分類される。このうち緑茶は、まず加熱によって酸化酵素が不活性化されるので、酸化されておらず、そして発酵させていない。そのため、緑茶の味は、茶木の種類、摘採時間、栽培方法などによって決定される。
【0003】
現在、緑茶の最終品質は、熟練者による葉の外観、芳香、色、および味に基づく官能検査により決定されている。これらの技能を獲得するには経験年数がかかる。また、客観性や再現性が低いという欠点がある。そのため、製造工程管理や製品品質管理のためには、簡便な機械化された品質予測方法が必要である。これまで、緑茶の品質予測方法として、近赤外分光法を用いた方法(特許文献1および2)ならびに茶葉の性状に基づく方法(特許文献3〜5)が開示されている。
【0004】
特許文献1には、可視光および近赤外線を用いて茶葉、特に加工前の生茶葉、の品質を測定する方法が記載されている。可視光から茶葉の色を、そして近赤外線から茶葉の成分を測定すると記載されているが、近赤外線から具体的にどのような成分を測定し、どのように品質を予測するのかについては記載されていない。特許文献2には、近赤外分光法を用いて、茶葉中の遊離アミノ酸の含有率と中性デタージェント繊維の含有率とを求めることによって品質評価する方法が記載されている。しかし、これらの近赤外分光に基づく方法は、生葉の品質予測には効力を発するが、製品緑茶の品質予測の実績はほとんどない。
【0005】
特許文献3〜5には、生茶葉の含水量、含繊維量、含窒素量、外観などの性状を測定することによって、品質を評価することが記載されている。しかし、含水量などの性状に基づく方法は、簡便であるが、精度に乏しい。
【特許文献1】特開2000−346797号公報
【特許文献2】特開平8−114543号公報
【特許文献3】特開2000−228950号公報
【特許文献4】特開平11−313608号公報
【特許文献5】特開平9−224573号公報
【発明の開示】
【発明が解決しようとする課題】
【0006】
化学分析は、緑茶の品質を評価するために最も信頼性のある方法であると思われる。機器分析法と強力なコンピュータ駆動パターン認識技術との組み合わせから、複雑な材料の品質制御および特徴づけのための新たな可能性が実現されている。そこで、本発明は、緑茶の品質、特に従来困難であった製品緑茶の総合品質を、簡便に予測する方法を提供することを目的とする。
【課題を解決するための手段】
【0007】
緑茶の味は、アミノ酸、特に茶葉中の約60〜70%のアミノ酸を占める独特のテアニンに起因する。その収歛性の味は、カテキン(タンニン)によるものであり、苦味はカフェインによるものである。また、揮発性化合物は、主として茶の香りの差に寄与する。栽培品種の差、環境的効果、加工方法などにより、中間経路代謝物の見かけの定常状態の量および/または最終代謝物の末端蓄積も変動する。また、加熱処理による分解物も緑茶の味に影響を与える。したがって、茶葉中の代謝物や分解物を、空間的および時間的の両方でモニターすることは、品質の評価に重要である。
【0008】
クロマトグラフィーにおいて、パターン認識方法に基づくフィンガープリンティングは、種々の分析領域、例えば、食品および栄養分野で加工モニタリングおよび制御(生材料の等級付け、日常的なオンライン品質チェック、または製品が製造される工程の測定)、地理的起源(成分の化学組成による供与源の測定、風味および芳香成分による最終製品の起源の追跡)の分析に使用されている。
【0009】
そこで、本発明は、医用目的の抗酸化化合物、ならびに呈味および芳香用のカテキンおよび他のフェノール性化合物などの、特定の機能に重要であると考えられる特定の群の限られた数の個々の化合物の特徴づけの代わりに、代謝物や分解物に注目し、これらについての化学的フィンガープリントと多変量解析と組み合わせることによって、総合的にかつ迅速に緑茶を分析できることに基づいて完成された。
【0010】
本発明は、緑茶の品質予測方法を提供し、該方法は、
緑茶を前処理して分析サンプルを得る工程;
該分析サンプルを機器分析に供して分析結果を得る工程;
該分析結果を数値データに変換して多変量解析する工程;および
得られた解析結果から、品質を予測する工程を含む。
【0011】
本発明はまた、品質既知の複数の緑茶を前処理して個別の分析サンプルを得る工程;
該個別の分析サンプルを機器分析に供して個別の分析結果を得る工程;および
該個別の分析結果と該品質との関係を数値データに変換して多変量解析する工程;
によって得られる、緑茶の品質予測モデルを提供する。
【0012】
1つの実施態様では、上記多変量解析は、PLS回帰分析である。
【0013】
好適な実施態様では、上記前処理は、上記緑茶を熱分解処理する工程を含み、そして前記機器分析が、ガスクロマトグラフィーと質量分析との組み合わせである。より好適な実施態様では、上記解析結果は、保持時間に基づいて品質予測される。
【0014】
他の好適な実施態様では、上記前処理は、上記緑茶から親水性化合物を抽出して抽出物を得る工程を含む。
【0015】
より好適な実施態様では、上記機器分析は、ガスクロマトグラフィーと質量分析との組み合わせであり、そして上記前処理はさらに上記抽出物をシリル化する工程を含む。
【0016】
さらに好適な実施態様では、上記分析結果の中で、アラビノース、グルタミン、クエン酸、グルタミン酸、アスパラギン酸、イノシトール、シキミ酸、リン酸、フルクトース、テアニン、リンゴ酸、カフェイン、キナ酸、グルコース、マンノース、リボース、およびスクロースのデータが解析される。
【0017】
別の好適な実施態様では、上記機器分析は、液体クロマトグラフィーと質量分析との組み合わせ(特に、高速液体クロマトグラフィーと質量分析との組み合わせ、または超高速液体クロマトグラフィーと質量分析との組み合わせ)、または核磁気共鳴分析(特に、フーリエ変換核磁気共鳴分析)である。
【0018】
他の好適な実施態様では、上記前処理は、上記緑茶を粉砕して粉末を得る工程および該粉末を溶媒でペースト状にする工程を含む。
【0019】
より好適な実施態様では、上記機器分析は、赤外分光分析または近赤外分光分析(特に、フーリエ変換赤外分光分析またはフーリエ変換近赤外分光分析)である。
【0020】
さらに好適な実施態様では、上記機器分析は、フーリエ変換近赤外分光分析であり、上記多変量解析する工程において、上記分析結果の中で5500〜5200cm−1の結果についてデータ変換し、変換されたデータをさらに二次微分する。
【0021】
別の好適な実施態様では、上記分析結果は、ガスクロマトグラフィーと質量分析との組み合わせ、高速液体クロマトグラフィーと質量分析との組み合わせ、超高速液体クロマトグラフィーと質量分析との組み合わせ、フーリエ変換赤外・近赤外分光分析、およびフーリエ変換核磁気共鳴分析からなる群より選択される少なくとも2つの機器分析の分析結果である。
【0022】
本発明はさらに、緑茶の品質予測方法を提供し、該方法は
緑茶を前処理して分析サンプルを得る工程;
該分析サンプルを機器分析に供して分析結果を得る工程;
該分析結果を数値データに変換して多変量解析する工程;および
得られた解析結果を、上記のいずれか品質予測モデルと照合する工程を含む。
【発明の効果】
【0023】
本発明によれば、従来困難であった製品緑茶の総合品質を、より精度よくかつ簡便な方法で予測することが可能である。
【発明を実施するための最良の形態】
【0024】
緑茶は、生茶葉を加熱して酵素活性を失わせ、成分の酸化を防ぎ、緑色を保持させた不発酵茶である。本発明において品質予測の対象となる緑茶は、加工前の生茶葉であってもよいが、好ましくは、荒茶、仕上げ茶(すなわち、製品緑茶)のような緑茶としての加工が施された緑茶の葉である。本発明においては、より好ましくは、製品緑茶を品質予測の対象とする。
【0025】
本発明において、緑茶は、以下で述べる機器分析に応じて適切に前処理された後、種々の機器分析に供される。
【0026】
本発明において、機器分析とは、分析機器を用いる分析・測定手段をいい、ガスクロマトグラフィー(GC)、液体クロマトグラフィー(LC)(例えば、高速液体クロマトグラフィー(HPLC)、超高速液体クロマトグラフィー(UPLC))、質量分析(MS)、赤外分光分析(IR)(例えば、フーリエ変換赤外分光分析(FT−IR))、近赤外分光分析(NIR)(例えば、フーリエ変換近赤外分光分析(FT−NIR))、核磁気共鳴分析(NMR)(例えば、フーリエ変換核磁気共鳴分析(FT−NMR))などが挙げられる。これらの機器分析は組み合わせてもよく、例えば、GC/MS、LC/MS(特に、HPLC/MS、UPLC/MS)などの組み合わせが挙げられる。これらの機器分析に用いられる装置は、特に限定されず、緑茶中に含まれる代謝物(例えば、アミノ酸、有機酸、糖)を測定することが可能であれば、通常用いられている装置が用いられ得る。また、測定条件は、これらの物質の測定に適切なように当業者によって適宜設定され得る。
【0027】
前処理は、緑茶中の分析対象物質を機器分析に供するに適した形態にするために、上述のように機器分析に応じて行われる。前処理としては、乾燥、切断、粉砕、抽出などの処理が挙げられる。例えば、粉砕については、ブレンダー、ボールミルなどの適切な器具を用いて行われ得る。また、抽出については、水、有機溶媒、またはこれらの溶媒の混合液を用いて行われ得る。抽出に使用され得る有機溶媒としては、メタノール、エタノール、n−プロパノール、イソプロパノール、アセトン、クロロホルムなどが挙げられる。抽出操作としては、緑茶を水および/または有機溶媒中で加熱して、熱分解物を抽出してもよい。加熱温度は、使用される溶媒に応じて適宜決定され得、通常は、常圧下で溶媒の沸点付近の温度である。加熱時間も適宜設定される。これらの単位操作を単独でまたは組み合わせて適切な前処理条件を設定する。
【0028】
例えば、機器分析としてGCを行う場合、好ましくは、前処理は、緑茶からの抽出物をシリル化する工程をさらに含む。シリル化は、当業者が通常用いるGC用のシリル化試薬を用いて行われ得る。あるいは、前処理として、緑茶を、例えば、粉砕した後、熱分解処理のみ施したものも、分析対象試料となり得る。この場合、熱分解物を、抽出することなく直接GCに導入することができる。熱分解は、市販の熱分解装置を用いて行うことができる。
【0029】
機器分析としてIR・NIRを行う場合については、好ましくは、前処理は、緑茶の粉末を溶媒でペースト状にする工程を含む。粉末を得る工程は、上記のとおりである。ペーストにするための溶媒は、例えば、IR測定用試料の調製のために、試料に応じて通常選択される溶媒が用いられる。
【0030】
機器分析としてNMRを行う場合については、好ましくは、前処理は、緑茶から水および/または親水性溶媒で抽出して抽出物を得る工程を含む。親水性有機溶媒としては、例えば、メタノール、エタノール、n−プロパノール、イソプロパノール、アセトンなどが挙げられる。
【0031】
機器分析としてLC、特にHPLCを行う場合については、好ましくは、前処理は、緑茶から水および/または親水性溶媒で抽出して抽出物を得る工程を含む。用いるカラムとしては、例えば、アフィニティーカラム、逆相カラム、およびイオン交換カラムが挙げられる。HPLCの条件(例えば、流速、検出器、移動相など)は、試料に応じて適宜選択される。
【0032】
機器分析として超高速液体クロマトグラフィー(UPLC)を行う場合については、好ましくは、前処理は、緑茶から水および/または親水性溶媒で抽出して抽出物を得る工程を含む。UPLCは、微小なカラム粒子に高い線速度の移動相を通過させて、速い分析スピード、高い分離能、および高感度が達成される。UPLCに用いられるカラム粒子は、HPLCに用いるカラム粒子(例えば、5μmまたは3.5μm)よりも小さい直径(例えば、1.7μm)を有するカラム粒子であり、例えば、アフィニティーカラム、逆相カラム、およびイオン交換カラムが挙げられる。UPLCの条件(例えば、流速、検出器、移動相など)は、試料に応じて適宜選択される。
【0033】
上記の前処理が施された緑茶サンプルは、任意の機器分析に供され、分析結果が得られる。得られた分析結果は、緑茶サンプルのフィンガープリントであり得る。このフィンガープリントを数値データに変換して多変量解析が行われる。分析により得られる結果(変数)としては、保持時間、波長(または波数)、ならびにシグナル強度(またはイオン強度)、吸光度などのスペクトルデータが挙げられる。さらに、変数としては、緑茶サンプルのランキング(等級)も挙げられる。
【0034】
多変量解析としては、機器分析データの解析に、特にケモメトリックスにおいて通常用いられる解析ツールが採用される。例えば、PCA(主成分分析:principal component analysis)、HCA(階層クラスター分析:hierarchical cluster analysis)、PLS回帰分析(潜在的構造に対する射影:Projection to Latent Structure)、判別分析(discriminate analysis)などの種々の多変量ツールが挙げられる。さらに、部分最小二乗によるPLS(Partial least square projection to Latent Structure)を用いて、関連の変量の2群間の関係;例えば、緑茶の代謝物とその品質との間の関係、が確認される。必要に応じて、スペクトルフィルタリング法、例えば、妨害成分を取り除くための直交シグナル補正(orthogonal signal correction:OSC)と組み合わせて多変量解析が行われてもよい。これらの解析ツールは、ソフトウエアとして多数市販されており、任意のものが入手可能である。このような市販のツールは、一般的に、難しい数学・統計学の知識がなくても、多変量解析を行うことができるように操作マニュアルが備えられている。
【0035】
多変量解析は、得られた全データではなく、品質予測に重要な一定の範囲のデータを選択して行ってもよい。例えば、緑茶の粉末をペースト状にしてFT−NIRで分析する場合、5500〜5200cm−1の波数域のデータについてPCAを行うことが好ましい。
【0036】
本発明において好適に採用されるPLS回帰分析は、変数(例えば、波数、波長)間に相関を有するスペクトルデータからの検量線作成に有効な手法である。通常、変数間に相関があると、用いる変数の組み合わせによっては回帰精度が著しく低下するが、これを避けるためにPLSでは変数を互いに無相関な変数(潜在変数)に変換し、この潜在変数を用いて回帰を行う。すなわち、PLSとはデータの変数を直交変換し、その新たな変数を用いて(重)回帰分析を行う解析手法である。
【0037】
具体的には、複数の品質既知の緑茶サンプルから親水性低分子代謝物を抽出してあるいは緑茶の熱分解物についてGC/MSにより定量解析を行う場合には、得られたGC/MSクロマトグラムから保持時間インデックスを独立変数、質量分析シグナル強度を従属変数としてマトリクスデータを作成する。ランキング既知の複数の緑茶サンプルのランキング順位を説明変数として、既知サンプルをトレーニングセットとしてPLS法によりランキング予測モデルを作成できる。例えば、品質未知の緑茶サンプルから同様に機器分析して得られたデータを多変量解析し、その解析結果を予測モデルと比較・照合することによって、どのランキングに位置するかがわかるため、品質を予測することができる。
【0038】
例えば、緑茶から代謝物を抽出してGC/MSで分析した場合、得られる分析結果は、種々の代謝物の保持時間、マススペクトル、イオン強度などがある。この場合、特に、アラビノース、グルタミン、クエン酸、グルタミン酸、アスパラギン酸、イノシトール、シキミ酸、リン酸、フルクトース、テアニン、リンゴ酸、カフェイン、キナ酸、グルコース、マンノース、リボース、およびスクロースのデータは、緑茶の品質予測(等級分類)に重要な役割を果たす。本発明により、高いランキングの緑茶サンプル中には、代謝物として、アミノ酸、キナ酸、リン酸、リボース、およびアラビノースの量が比較的多く、低いランキングの緑茶サンプル中には、フルクトース、グルコース、マンノースなどの糖が主代謝物として存在する傾向があることが、明らかになっている。
【0039】
また、上記の方法によって得られる予測モデルは、データの蓄積により、精度が上昇し得る。したがって、例えば、緑茶中の代謝物の相対量の傾向がより明確になれば、品質未知の緑茶の分析結果からフィンガープリントを得、このフィンガープリントに基づいて品質予測をすることも可能となる。
【実施例】
【0040】
(実施例1:GC/MS用の分析サンプルの調製)
2005年の品評会でランキング(格付け)された53種の一番茶の加工後の乾燥葉をサンプルとして用いた。市販茶品評会に記載されたこれらの茶サンプルは、奈良県農業総合センター茶業振興センターから入手した。茶のランキングは、官能試験の総合スコアによって決定され、これは、葉の外観、入れた茶の芳香、色、および味であり、専門の茶の鑑定人によって鑑定された。なお、ランキングの高い方から順に、1番から53番まで順位をつけた。
【0041】
まず、2mL容のエッペンドルフ管中で乾燥茶葉(30mg)を凍結乾燥し、Retschボールミル(20Hz、1分間)で粉砕した。この茶葉に、メタノール、水、およびクロロホルムの混液(2.5:1:1、v/v/v)を1mL加え、さらに内部標準として60μLのリビトール(和光純薬工業株式会社:脱イオン水で0.2mg/mLの濃度まで希釈)を加えて、5分間振盪し、そして4℃にて16000×gで3分間遠心分離した。次いで、900μLの上清を、1.5mL容のエッペンドルフ管に移した。Millipore Milli-Qシステム(Berdford、MA)を用いて精製された400μLの水を添加して、ボルテックスおよび遠心分離し、次いで400μLの極性相を、穴あきキャップでキャップした他の1.5mL容のエッペンドルフ管に移した。得られた抽出物(親水性化合物)を、乾燥するまで(一晩)真空遠心分離乾燥機中で乾燥させた。
【0042】
次いで、この抽出物に50μLの塩酸メトキシアミン(Sigma)のピリジン溶液(20mg/mL)を、第1の誘導体化剤として添加した。混合物を30℃にて90分間インキュベートした。さらに、第2の誘導体化剤である100μLのN−メチル−N−(トリメチルシリル)トリフルオロアセタミド(MSTFA:GL sciences Inc.)を添加して、30℃にて30分間インキュベートすることにより抽出物を誘導体化して、分析サンプルを得た。
【0043】
(実施例2:GC/MSによる緑茶サンプルの分析)
上記実施例1で得られた1μLの分析サンプルを、スプリットモードでGC/MSに注入した(25:1、v/v)。本実施例で使用したGC/MS装置は、Pegasus III TOF質量分析器(LEGO)ならびにオートサンプラーとして7683Bシリーズインジェクター(Agilent Co.)を連結した0.25μm CP-SIL 8 CB低ブリード(Varian Inc.)でコーティングされた30m×0.25mm i.d.のフューズドシリカキャピラリーカラムを装着した689CN(Agilent Co.)であった。注入温度は230℃であった。カラムを通るヘリウムガスの流速は、1mL/分であった。カラム温度は、2分間80℃で等温に保ち、次いで15℃/分で330℃まで上昇させ、そして6分間等温に保った。搬送ラインおよびイオンソース温度は、それぞれ250℃および200℃であった。イオンを、70kV電子衝撃(EI)によって生成し、そして1秒当たり20スキャンを、85〜650m/zの質量範囲にわたって記録した。加速電圧は、250秒の溶媒遅延後に作動した。
【0044】
(実施例3:GC/MSによるデータの解析および緑茶の代謝物のフィンガープリンティング)
上記実施例2においてGC/MSにより得られたデータの前処理については、得られた生のクロマトグラフデータ(Pegasusファイル、*.peg)を、ANDIファイル(分析データ交換プロトコル、*.cdf)に変換した。ANDIフォーマットを用いると、異なるマススペクトルデータシステム間のデータの変換および転送を行うことができた。変換したファイル(ANDI)を、データ前処理手順に供し、データ点を詳細に再処理した。さらに、データ変換も、最良のクロマトグラフデータを得るために行った。次いで、トータルイオンクロマトグラフデータを抽出し、そしてフラグメントデータなしのANDIフォーマットとして保存した。これらのファイルを、保持時間のマルチプルアライメント用の市販のソフトウエアのLineUp(Informatrix, Inc.)に移行した。ミスアライメントピークを、相関最適化ワーピングアルゴリズムを用いてアライメントした。
【0045】
次いで、多変量データの群中の類似性または相違性で表される関係を把握するために、主成分分析(PCA)を行った。市販のソフトウエアであるPirouette(登録商標)(Informatrix, Inc.)をこの目的に適用した。
【0046】
53種のランキングされた一番茶サンプルを、それらの等級に従ってランキングされた3群に分けたが、これらの3群の分類は明瞭ではなかった。各所定の群に約20サンプルがあるので各群のサンプルの変動が非常に高すぎたため、高いランキングのサンプルは、低いランキングのサンプルとは別の明らかな集団を示さなかった。次いで、低いランキング(51番)および高いランキング(1番)のサンプルについて、再度、データを変換せずに平均中央で前処理した。その結果、これらの群間で、ある程度の差があることがわかった(図1)。
【0047】
顕著な化合物を、そのマススペクトルとライブラリー(NISTライブラリーおよび認証された標準化学物質から調製された内部ライブラリー)中のスペクトルとを比較することによって同定した。さらに、the Max-Planck Institute of Molecular Plant Physiology、Germanyによって提供されたライブラリーも、この目的に用いた(http://www.mpimp-golm.mpg.de/mms-library/index-e.htlm)。高いランキングのサンプル中には、アミノ酸、キナ酸、リン酸、リボース、およびアラビノースの量が比較的多いが、低いランキングのサンプルでは、主として糖(フルクトース、グルコース、およびマンノース)であった。これは、メタボロミクス解析が、緑茶の品質測定に有用であり得ることを示した。
【0048】
次いで、部分最小二乗法による潜在的構造に対する射影(PLS)(SIMCA-P version 11.0:Umetrics)を選択して、予測モデルを作成した。PLSにより、2セットの変量(測定値および応答値)間の関係が見出される。すなわち、得られたGC/MSクロマトグラムから保持時間インデックスを独立変数、質量分析シグナル強度を従属変数としてマトリクスデータを作成し、各サンプルの品評会ランキング順位を説明変数として、既知サンプルをトレーニングセットとしてPLS法によりランキング予測モデルを作成した。
【0049】
サンプルの代謝物フィンガープリント(マトリクスX)とその品質(マトリクスY)との間の関係を観察した。まず、分析サンプルを、トレーニングセットおよびテストセットの群に分けた。2番、12番、22番、32番、42番、および52番のランキングのサンプルを、モデルのバリデーション用のテストセットとして除外した。変換した変数はなかった;変数の全てを集約し、そしてパレート分散にスケールして、クロマトグラフデータノイズ効果を減少させた。モデルの完全性、すなわち、PLSモデルにおける潜在的ファクターの数は、クロスバリデーションによって決定され得、最適な数は、(モデルに対する)適合と予測能との間のバランスで見られた。さらに、PLSモデルは、テストセットでバリデートされ、予測値の平均二乗誤差(RMSEP)をコンピュータ計算した。2つの顕著な成分を抽出し、クロスバリデーションに従って、Yの80.7%の変動を記述し(R2Y=0.807)そしてYの31.3%の変動を予測した(Q2Y=0.313)(図2参照)。次いで、テストセットについて、PLSモデルで予測し、トレーニングセットサンプル(RMSEP=6.91)に基づくモデル評価に関して、テストサンプル(RMSEP=10.23)の予測精度が得られた(図3)。このPLSモデルにより、ある程度の予測が得られた。
【0050】
さらに、PLSモデルの予測力を増強するために、スペクトルフィルタリング技術を適用した。OSCは、PLSベースの解決手段であり、Yのモデリングに関連のないXデータ変動値を除去する。OSCでは、1つの成分を、非線形反復部分最小二乗法(NIPALS)アルゴリズムを用いるマトリクスXから1つずつ除去する。上記のPLSモデルから2つのOSC成分を除去することにより、Q2Yは、0.500まで上昇した。二乗の残余合計は41.40%であった。したがって、58.60%のXの変動値は、Yに関連せず、除去された(図4参照)。テストセットをモデルに供した後の予測値は、トレーニングサンプル(RMSEP=6.57)に基づくモデル評価とよく一致するテストサンプル(RMSEE=8.13)についての予測精度になった(図5)。さらに、高い関連を有する説明変数Yも、VIP(投影における変数重要性)値から同定した。1を超える大きなVIP値は、最も関連がある説明変数Yである。このように、キナ酸、アミノ酸(特にテアニン)、および糖類が、緑茶についての品質予測モデルを作成するために重要であることを見出した(図6)。
【0051】
(実施例4:GC/MSによる緑茶代謝プロファイリング)
高い等級の茶として受け入れられている大和茶を、奈良県農業総合センター茶業振興センターから入手した。緑茶サンプルの前処理方法およびGC/MSによる分析条件は、上記実施例1および2と同じであった。クロマトグラムの分離度は満足のいくものであるため、各代謝物のピーク面積を、総イオンカウント(TIC)により算出した。続いて、同定した代謝物の全てのピークを内部標準のリビトールに対して標準化した。この分析から、緑茶の乾燥葉は、以下の表1に示すような、多くの化合物、主として有機酸、アミノ酸 および糖類(単糖類および二糖類の両方)を含むことがわかった。最高量で検出した化合物は、糖類であり、特にスクロースおよびフルクトースが多かった。茶の独特の呈味に寄与する重要なアミノ酸であるテアニンも検出した。抽出物中にいくつかの他のアミノ酸を同定できたが、少量であった。約23の同定した代謝物は、クロマトグラムから同定した。
【0052】
【表1】
【0053】
このことから、上記実施例3で得られたケモメトリクスと組み合わせたGC/MSを用いるメタボロミクス解析が、緑茶の研究において有用な情報を提供することが証明された。
【0054】
(実施例5:1H−NMR用の分析サンプルの調製および分析)
上記実施例1と同様に、2005年の品評会でランキング(格付け)された53種の一番茶の加工後の乾燥葉をサンプルとして用いた。
【0055】
まず、1mL容のエッペンドルフ管中で乾燥茶葉(50mg)を凍結乾燥し、Retschボールミル(20Hz、1分間)で粉砕した。この茶葉に、1mLの重水(重水素原子99.9%:Cambridge Isotope Laboratories, Inc.)を加えた。この混合物を、Thermomixer comfort(Eppendorf)で60℃および1400rpmにて30分間インキュベートし、25℃および16000×gにて10分間遠心分離した(遠心分離機5415R:Eppendorf)。親水性代謝物を含む上清を、0.45μmのPTFEメンブレン(Advantec)を通して濾過した。次いで、400μLの濾液を、内部標準として3mMの3−(トリメチルシリル)−1−プロパン硫酸ナトリウム(DSS:Aldrich)を含む200μLの0.2Mリン酸緩衝液(pH7.4)に溶解した。なお、サンプル調製は、1H−NMR測定の1日前に行った。
【0056】
得られた分析サンプルを、1H−NMRによって測定した。本実施例では、750MHz Varian Inova 750スペクトロメーターを使用し、5mmの1H{13C/15N}三重共鳴間接検出プローブを用いて25℃にてスペクトルを記録した。1H−NMR測定は、64トランジエントおよび131K複合データポイントで行った。捕捉時間およびリサイクル遅延は、30°パルス角を用いて、1スキャン当たりそれぞれ6.257秒および3.743秒であった。予備飽和パルスシーケンスを適用して、残存水のシグナルを抑制した。すべてのスペクトルは、データ処理前に0.1Hz線幅広がりでフーリエ変換した。
【0057】
(実施例6:1H−NMRのデータの解析、緑茶の代謝物のフィンガープリンティング、および緑茶代謝プロファイリング)
1H−NMR測定によって得られたスペクトルは、まず、Chenomx NMR Suite4.6ソフトウエアプロフェッショナル版(Chenomx Inc., Canada)によって位相およびベースライン補正した。1.0〜8.0ppmの範囲にわたって、0.04ppmのサイズで積分した。一方、4.6〜5.0ppmの水のシグナルは削除した。すべての測定値は、DSSのメチルのピーク面積に対して標準化した。
【0058】
最高品質の茶から抽出した水溶性化合物の1H−NMRスペクトルを、図7に示す。代謝物由来のシグナルを、同条件下で分析した公知の標準化合物由来のシグナルならびにChenomx NMR Suite4.6の750MHz(pH4〜9)ライブラリデータベースとの比較によって帰属した。このうち、約10の主要な化合物を同定することができた。テアニン、アミノ酸、およびキナ酸が高磁場領域(δ0.5〜3.0ppm:図7A)で主として観察された。中磁場領域(δ3.0〜4.5ppm:図7B)においては、スクロースおよびフルクトース以外では、カフェイン、アルギニン、ミオイノシトール、クロロゲン酸、およびキナ酸が明確に観察された。低磁場領域(δ5.0〜8.0ppm:図7C)には、2−O−β−L−アラビノピラノシル−ミオイノシトール、p−クマリル−キナ酸またはケイ皮酸、(−)−エピガロカテキン−3−没食子酸(EGCG)、および(−)−エピカテキン−3−没食子酸(ECG)が主に観察された。(−)−エピガロカテキン(EGC)および(−)−エピカテキン(EC)は、水溶性が低いため、あまり顕著には観察されなかった。
【0059】
図8に、53種のランキングされた一番茶サンプルについて得られたすべての1H−NMRスペクトルを重ねて示す。高磁場領域(図8A)および低磁場領域(図8C)では顕著な差は見られなかったが、中磁場領域(図8B)では、いくつかの差が観察された。特に、δ3.27および3.43ppmのカフェインのシグナルが、高品質の茶サンプルで強かった。カフェインは、茶の苦味に寄与し、茶の品質に重要であることが知られている。したがって、NMRでの測定においても、品質予測モデルを作成するために重要な因子であることが示された。
【0060】
次に、多変量データの群中の類似性または相違性で表される関係を把握するために、Pirouette(登録商標)ソフトウエア(Informatrix, Inc.)を用いて、高磁場領域(δ1.0〜2.5ppm)、中磁場領域(δ3.12〜4.34ppm)、および低磁場領域(δ6.15〜6.35ppm)についてそれぞれ主成分分析(PCA)を行った。まず、53種のサンプルを、それらの等級に従ってランキングされた2群に分けた(高品質:1〜25番、および低品質:26〜53番)。スコアプロットにおいて、高磁場領域では、2群間の差は明瞭には見られなかったが、中磁場領域および低磁場領域では、高品質および低品質の2群に大まかに分けることが可能であった(データは示さず)。また、ローディングプロットでは、カフェイン、テアニン、EGCG、ECG、EGC、およびEC由来のシグナルが、クラスタ分離に寄与することがわかった(データは示さず)。
【0061】
さらに、部分最小二乗法による潜在的構造に対する射影(PLS)(SIMCA-P version 11.0:Umetrics)を選択して、独立(予測)変数Xから従属(応答)変数Yを予測するための回帰モデルを作成した。回帰は、システム行動に基づく数学的モデルを作成することによって行われ、トレーニングサンプルに関するモデルパラメータに最適な値を決定する。次いで、未知の独立変数の値を、得られたトレーニングモデルを用いて予測する。本実施例では、品評会ランキング順位を従属変数として用いた。分析サンプルを、トレーニングセットおよびテストセットの群に分けた。5番、15番、25番、35番、および45番のランキングのサンプルを、モデルのバリデーション用のテストセットとした。分析前に変換した変数はなく、データを集約し、そしてユニット分散にスケールした。
【0062】
緑茶サンプルの測定値と予測値との間のPLS関係を図9に示す。なお、2番および8番のサンプルについては、ノイズが大きいため、モデル作成から除外した。PLS回帰モデルの性能を、相関係数R2およびクロスバリデートした相関係数Q2ならびに予測値の平均二乗誤差(RMSEP)という測定値と予測値との間のバリデーション誤差によって検証した。緑茶のPLS回帰モデルは、R2=0.987およびQ2=0.671(RMSEP=1.82)を示した(図9)。これは、適合および予測力に優れることを示している。緑茶のランキング順位を予測するためのモデルの予測性を、テストセットによって試験した(図11において丸で囲む)。予測結果は、理想的な対角線上から分散していた(RMSEP=9.22)。このPLSモデルにより、ある程度の予測が得られた。
【0063】
さらに、PLSモデルの予測力を、直交シグナル補正(OSC)を用いて変動を単純化することによって改善した。上記PLSモデルから2つのOSC成分を除去することにより、Q2は0.671から0.982に上昇し、予測性は31%改善した(図10)。PLS−OSC回帰モデルの予測性を、再度テストセットによって検証した(図10において丸で囲む)。RMSEP値は9.22から5.91に顕著に減少した。図10に示す回帰プロットによれば、Q2の上昇およびRMSEPの低下が、シグナル補正によって予測モデルの能力が劇的に改善されたことを示す。
【0064】
ウェーブレット変換は、複雑なシグナルを圧縮してノイズを除き、関連のある情報のみを抽出するために用いられるシグナル処理のツールである。OSCとの組み合わせにより、予測力を損なうことなく多変量検定の質を改善できることが知られている。そこで、本実施例においても、OSCとウェーブレット変換との組み合わせ(OSCW)を適用した。1成分OSCフィルタリングにより、63.42%の非関連X変数が除去された。506ウェーブレット係数を用いて、二乗の合計の99.50%を保持した。得られたPLS−OSCW回帰を図11に示す。R2およびQ2はそれぞれ0.982および0.944であった。PLS回帰モデルの予測能は、OSCWの実行により改善され、テストセットでの検証では、RMSEPが5.91から5.53に低下していた(図11において丸で囲む)。有益な変数を捕捉するためにPLSモデルで用いられたウェーブレット係数の数は非常に高く、そして0.5%の非関連変数のみが除去された。これは、ほとんどすべてのY変数がOSCフィルタリングによって捕捉され、ノイズから生じた一部の変動のみが残ったことを示す。ウェーブレット解析は、予測能を損失することなく残りの変数を除去することによって予備加工性能を増強する。
【0065】
このように、PLS、PLS−OSC、およびPLS−OSCW回帰のR2、Q2、およびRMSEP値を比較すると、R2およびQ2値は両方ともすべてのモデルについて0.9より大きく、非常に良好な適合性および優れた予測性で緑茶の品質を予測するために使用できることを示す。
【0066】
(実施例7:FT−NIR用の分析サンプルの調製および分析)
2005年の品評会でランキング(格付け)された64種の一番茶から選択された13種の加工後の乾燥葉をサンプルとして用いた。これらの茶は、4、8、14、18、24、28、34、38、44、48、54、58、および64番のランキングのサンプルである。市販茶品評会に記載されたこれらの茶サンプルは、奈良県農業総合センター茶業振興センターから入手した。茶のランキングは、官能試験の総合スコアによって決定され、これは、葉の外観、入れた茶の芳香、色、および味であり、専門の茶の鑑定人によって鑑定された。
【0067】
2mL容のエッペンドルフ管中で乾燥茶葉(200mg)を、Retschボールミル(20Hz、10分間)で粉砕し、600μLのグリセロール、ヘキサン、アセトニトリル、または鉱油を加えた。これらの各混合物を再度ボールミルで(20Hz、10分間)でホモジナイズして、ペースト状の分析サンプルを得た。これらの分析サンプルを、それぞれ2mL容のガラスバイアルに移した。
【0068】
得られたペースト状の分析サンプルを、FT−NIRによって測定した。本実施例で使用したFT−NIR測定装置は、Smart Near-IR UpDRIFT、CaF2ビームスプリッタ、および冷却InGaAs検出器を装着したNICOLET 6700 FT-IR(サーモエレクトロン株式会社)であった。FT−NIRスペクトルは、3.857cm−1の間隔で10000〜4000cm−1まで記録した。ミラー速度は1.2659cm/sであり、そして分解能は8cm−1であった。データポイントの総数は、各スペクトルにつき1557であった。各サンプルについて4回ずつ測定した。
【0069】
種々の溶媒を用いて調製したサンプルについてFT−NIRを測定したところ、グリセロール(B)を用いた場合に測定データの変動が最小であった(図12)。したがって、グリセロールを用いて調製したサンプルについて以下の解析を行った。
【0070】
(実施例8:FT−NIRのデータの解析、緑茶の代謝物のフィンガープリンティング、および緑茶の品質予測)
FT−NIRにより得られた各データ(すなわち、測定値)は、平均して100,000を乗じた。全データを、二次微分および標準正規変量(SNV)によって前処理して変換した。
【0071】
市販のソフトウエアであるPirouette(登録商標)(Informatrix, Inc.)を用いて主成分分析(PCA)を行った。PCAのファクター3において、13種の茶サンプルを、それらの等級に従ってランキングされた3群に分けることができた。ファクター3での変動は、総変動の2.38%であり、非常に低かった。このファクター3のローディングプロットから、5500〜5200cm−1の波数域が、茶の等級に関連すると予測された(図13)。そこで、5500〜5200cm−1の波数域のデータについて再度PCAを行った。その結果、ファクター1によって群分けが可能であり、この波数域が茶の等級と非常に関連することがわかった(図14)。
【0072】
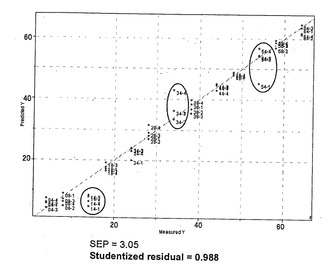
次いで、部分最小二乗法による潜在的構造に対する射影(PLS)を選択して、茶サンプルの品質の予測モデルを作成した。分析サンプルを、トレーニングセットおよびテストセットの群に分けた。14番、34番、および54番のランキングのサンプルを、モデルのバリデーション用のテストセットとして除外した。5500〜5200cm−1のスペクトル域の全データについて、二次微分および標準正規変量(SNV)を行った。PLSモデルにおける潜在的ファクターの数は、クロスバリデーションによって決定した。最適な数は、トレーニングセットのモデルにおいて5であった。トレーニングセットの予測値の標準誤差(SEP)は1.59であり、テストセットのSEPは、3.05であった(図15)。トレーニングセットのスチューデント化残差は0.997であり、テストセットでは0.998であった。これらの数値は、予測モデルの精度を示す。すなわち、値が「1」に近い場合は、結果が正確であることをいう。これらの事実は、予測モデルが非常に正確であることを示唆する。テストセットの結果から、このモデルは、低品質サンプルの予測について正確であるが、高品質サンプルの予測ではあまり正確ではなかった(図15)。この結果は、茶品質が高い場合には品質の差が小さいため、予測が困難になることを示唆する。この研究は、FT−NIRを用いる代謝物フィンガープリンティングによる茶の品質予測が正確であり現実的であることを示した。
【0073】
(実施例9:GC/MS用の熱分解処理分析サンプルの調製および分析)
上記実施例1と同様に、2005年の品評会でランキング(格付け)された53種の一番茶の加工後の乾燥葉をサンプルとして用いた。これらの茶葉を、葉および葉柄を均一にするためにブレンダーを用いて粉末に粉砕し、−20℃にて保存した。
【0074】
粉砕したサンプルの1±0.005mgを秤量し、そしてEco-cup S(フロンティア・ラボ株式会社)に入れ、PY-2020iDダブルショット・パイロライザー(フロンティア・ラボ株式会社)に導入した。パイロライザーのオーブン温度を500℃に、そしてインターフェースは250℃に設定した。熱分解時間は、各サンプルについて5分に設定した。
【0075】
GC/MS装置を、GC注入口を介してパイロライザーと直接連結した。本実施例で使用したGC/MS装置は、THERMO TR-WaxMSカラム(60m×0.25mmi.d.×0.25μm)(Thermo electron Co.)を装着し、TRACE DSQマススペクトロメータ(Thermo electron Co.)と連結されたTRACE GCガスクロマトグラフ(Thermo electron Co.)であった。注入温度は230℃であった。キャリアガスとして、高純度ヘリウムガスを、流速1mL/分で用いた。GC注入口のスプリット比は20:1であった。分析は、以下のオーブン温度プログラムで行った:2分間70℃で等温に保ち、次いで7℃/分で70℃から260℃まで上昇させ、そして20分間260℃に保った。搬送ラインおよびイオンソース温度は、両方とも250℃であった。イオンを、70kV電子衝撃(EI)によって生成し、そして1秒当たり20スキャンを、50〜650m/zの質量範囲にわたって記録した。加速電圧は、すべてのGC走査時間後に作動した。
【0076】
(実施例10:熱分解処理緑茶サンプルのGC/MSのデータ解析、緑茶の代謝物のフィンガープリンティング、および緑茶代謝プロファイリング)
上記実施例9においてGC/MSにより得られたデータの前処理については、得られた生のクロマトグラフデータ(Xcaliburファイルタイプ、*.raw)を、Xcaliburソフトウエア(Thermofinnigan)のファイル変換メニューを用いてANDIファイル(分析データ交換プロトコル、*.cdf)に変換した。クロマトグラムのデータポイントを、自動的に0.01秒毎に強度をスキャンするように調節して、フラグメントデータを含まずにAIAデータとして保存した。データを、保持時間のアライメント用の市販のソフトウエアのLineUp(Informatrix, Inc.)に移行して、相関最適化ワーピングアルゴリズムを用いてアライメントした。
【0077】
サンプルの代謝物フィンガープリント(マトリクスX)とその品質(マトリクスY)との間の関係を観察した。まず、分析サンプルを、トレーニングセットおよびテストセットの群に分けた。2番、12番、22番、32番、42番、および52番のランキングのサンプルを、モデルのバリデーション用のテストセットとして除外した。部分最小二乗法による潜在的構造に対する射影(PLS)(SIMCA-P version 11.0:Umetrics)を、スペクトルフィルタリング技術である直交シグナル補正(OSC)とともに用いて回帰モデルを作成し、緑茶の代謝物プロファイル(X変数)と品質ランキング(Y変数)との関係を検討した。PLS回帰モデルの有効性および信頼性を、モデル(R2Y)、予測性パラメータ(Q2)、トレーニングセットの推定値の平均二乗誤差(RMSEE)、およびテストセットの予測値の平均二乗誤差(RMSEP)によって説明される変動割合によって評価した。PLS回帰モデルの有効性および信頼性は、トレーニングセットによって検証し、そしてテストセットでバリデートした。
【0078】
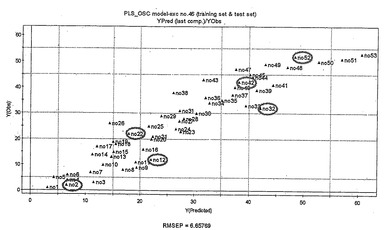
2つのOSC成分を除去して、モデル中でY変数に対して関連するX変数の52.11%を残した。PLSモデルを構築した後、クロスバリデーションに従って、Yの77.9%の変動を反映し(R2Y=0.779)そしてYの66.9%の変動を予測した(Q2=0.669)。このトレーニングセットによって作成したモデルは、7.57のRMSEE値であった。X(t1)およびY(u1)の第1のサマリー間のプロットにより、良好な相関が観察された。しかし、46番のサンプルについては、予測値が非常に大きく乖離していたので、除外した。46番を除外して再度予測モデルを構築すると、R2Y=0.876およびQ2=0.778に改善され、XとYとの間に良好な相関が見られた(図16)。RMSEEも5.36に低下していた。次いで、テストセットで検証したところ、品質のランキングに非常に良く一致していた(図16)。
【0079】
さらに、モデル構築に重要な高い関連を有する説明変数Yを、VIP(投影における変数重要性)値からコンピュータ解析により同定した。1を超える大きなVIP値は、最も関連がある説明変数Yである。分子はランダムに破壊されるので、クロマトグラムから代謝物を同定することは実行不可能であるが、VIP値から判断して、重要な代謝物を保持時間として特徴づけることができた(図17)。保持時間に対する変数は、元のクロマトグラムでは、高いランキングの緑茶と低いランキングの緑茶との間に強度差を示した。したがって、最終的なモデルに対する貢献度(例えば、保持時間)の順に予測変数をランク付けすることによって、緑茶の品質予測が可能であることがわかった。
【0080】
(実施例11:UPLC/MS用の分析サンプルの調製および分析)
2006年の品評会でランキング(格付け)された56種の一番茶の加工後の乾燥葉をサンプルとして用いた。市販茶品評会に記載されたこれらの茶サンプルは、奈良県農業総合センター茶業振興センターから入手した。茶のランキングは、官能試験の総合スコアによって決定され、これは、葉の外観、入れた茶の芳香、色、および味であり、専門の茶の鑑定人によって鑑定された。なお、ランキングの高い方から順に、1番から56番まで順位をつけた。
【0081】
まず、2mL容のエッペンドルフ管中で乾燥茶葉(10mg)を凍結乾燥し、Retschボールミル(20Hz、1分間)で粉砕した。緑茶の親水性一次代謝物を、メタノール、水、およびクロロホルムの混液(2.5:1:1、v/v/v)を用いて抽出した。得られた混合物を、サーモミキサー中で37℃にて30分間インキュベートした。その後、溶液を4℃にて16000×gで10分間遠心分離した。次いで、200μLの上清を、穴あきキャップでキャップした1.5mL容のエッペンドルフ管に移した。得られた抽出物を、乾燥するまで(一晩)真空遠心分離乾燥機中で乾燥させた。得られた乾燥物に200μLのメタノール/水(4:1、v/v)(0.1%(v/v)のギ酸を含む)を加えて、PTFEフィルターを通して濾過し、分析サンプルとした。
【0082】
分析サンプルの4μLを、UPLC/MSに供した。本実施例では、バイナリーソルベントマネージャ、カラムヒータ、およびサンプルマネージャを装着したACQUITY UPLCTMシステム(Waters)を用い、そして検出を、LCT premierTM XEマススペクトロメトリー(Waters)を用いて行った。この装置には、2.1×150mm,1.7μmのAcquity UPLC BEH C18カラムを装着し、40℃で操作した。移動相の条件としては、0.3mL/分の流速で、移動相Aとして水(0.1%(v/v)のギ酸を含む)および移動相Bとしてアセトニトリル(0.1%(v/v)のギ酸を含む)を用い、移動相Bを0%(v/v)から100%(v/v) に7分間で増加させる直線グラジエントを行い、次いで7分間維持させた。MSは、ネガティブモードでエレクトロスプレーイオン化(ESI)ソースを用いた。イオン化パラメータは、キャピラリー電圧:2.0kV、コーン電圧:0.035kV、脱溶媒和ガス流量500L/時間、脱溶媒和温度:350℃、およびソース温度:100℃であった。
【0083】
(実施例12:緑茶サンプルのUPLC/MSのデータ解析および緑茶代謝プロファイリング)
上記実施例11においてUPLC/MSにより得られたデータの前処理については、得られた生のクロマトグラフデータを、ANDIファイル(分析データ交換プロトコル、*.cdf)に変換した。変換したファイル(AIA)を、ピーク検出、アラインメント、ギャップフィルタリング、および標準化についてデータ処理ソフトウェアMZmineを用いてデータの前処理を行った。
【0084】
ランキングされた一番茶サンプルのうち、1番のランキングの緑茶サンプルのトータルイオンクロマトグラムを図18に示す。すべてのランクのサンプルが、同様のクロマトグラムパターンを示した。しかし、図19に示すように、茶の品質の違いによりピーク強度の差が見られた。
【0085】
次いで、この複雑なデータから重要な化合物および情報を明らかにするために、多変量分析を行った。多変量データの群中の類似性または相違性で表される関係を把握するために、主成分分析(PCA)(SIMCA-P version 11.0:Umetrics)を選択した。全体を把握するためにUnsupervised PCAを行った。9つの主成分では、R2X=0.767およびQ2=0.508であり、低い等級の茶および高い等級の茶は、PC1軸に沿って別々に分かれた(図20)。すなわち、高品質の緑茶サンプルはPC1のネガティブ側に、そして低品質の緑茶サンプルは、PC1のポジティブ側に集まった。スコアプロットに対応するローディングプロットを図21に示す。予測品質の差によって緑茶サンプルの代謝プロファイリングの差が示された。
【0086】
次いで、緑茶品質とそのメタボロームとの関係を検討するために、部分最小二乗法による潜在的構造に対する射影(PLS)(SIMCA-P version 11.0:Umetrics)を選択して、予測モデルを作成した。実施例11で得られた56種の分析サンプルを、トレーニングセット(50サンプル)およびテストセット(6サンプル)の群に分けた。2番、12番、22番、32番、42番、および52番のサンプルを、モデルのバリデーション用のテストセットとして除外した。すべての変数のXマトリクスを、中心にスケールした。2つの顕著な成分を抽出し、クロスバリデーションに従って、Yの83.3%の変動を記述し(R2Y=0.833)そしてYの71.4%の変動を予測した(Q2Y=0.714)(図22)。次いで、テストセットについて、PLSモデルで予測し、トレーニングセットサンプル(RMSEE=6.75)に基づくモデル評価に関して、テストサンプル(RMSEP=7.22)の予測精度が得られた(図22)。
【産業上の利用可能性】
【0087】
本発明によれば、従来困難であった製品緑茶の総合品質を簡便な方法で予測することが可能である。すなわち、緑茶を、クロマトグラフィーや分光分析などの種々の機器分析によりスクリーニングすることによって、迅速かつ有益に品質予測し得る。
【0088】
従来の緑茶の機器分析は、医用目的の抗酸化化合物、ならびに呈味および芳香用のカテキンおよび他のフェノール性化合物などの、特定の機能に重要であると考えられる特定の群の化合物に焦点が当てられていた。しかし、緑茶の特徴づけは、単一の代謝物に由来するのではなく組み合わせに由来し得る。したがって、複数の成分を一度に分析することによる本発明の方法を用いれば、より精度よい品質予測が可能であり、緑茶製造工程あるいは緑茶流通保管工程のさらなる改善が期待できる。
【図面の簡単な説明】
【0089】
【図1】PCA解析結果を示す図であり、高いおよび低いランキングの緑茶サンプルについてのスコアプロットである。
【図2】トレーニングセットとしての46種の緑茶サンプルについてのPLSモデルの実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図3】テストセット(丸で示す)およびトレーニングセットの両方の53種の全ての緑茶サンプルについてのPLSモデルの実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図4】直交シグナル補正(OSC)を用いたトレーニングセットとしての46種の緑茶サンプルについてのPLSモデルの実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図5】直交シグナル補正(OSC)を用いたテストセット(丸で示す)およびトレーニングセットの両方の53種の全ての緑茶サンプルについてのPLSモデルの実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図6】緑茶の品質予測値を生成するために用いた変数の影響を示すグラフである。
【図7】最高品質の茶から抽出したサンプルの1H−NMRスペクトル(750MHz、D2O)を示す。
【図8】53種のランキングされた一番茶サンプルのすべてについて得られた1H−NMRスペクトルを重ねて示す。
【図9】トレーニングセットおよびテストセット(丸で示す)の両方の緑茶サンプルの1H−NMRデータから算出したPLSモデルについての実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図10】トレーニングセットおよびテストセット(丸で示す)の両方の緑茶サンプルの1H−NMRデータから算出したPLS−OSCモデルについての実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図11】トレーニングセットおよびテストセット(丸で示す)の両方の緑茶サンプルの1H−NMRデータから算出したPLS−OSCWモデルについての実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図12】種々の溶媒で調製したサンプルについてのFT−NIRスペクトルであり、図中、Aはブランク、Bはグリセロール、Cは鉱油、Dはヘキサン、およびEはアセトニトリルの場合を示す。
【図13】PCA解析結果を示す図であり、ファクター3のローディングプロットである。
【図14】5500〜5200cm−1のスペクトル域のデータについてのPCA解析結果を示す図であり、高いおよび低いランキングの緑茶サンプルについてのスコアプロットである。
【図15】テストセット(丸で示す)およびトレーニングセットの両方の53種の全ての緑茶サンプルについてのPLSモデルの実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図16】46番のサンプルを除くトレーニングセットおよびテストセット(丸で示す)の緑茶サンプルの1H−NMRデータから算出したPLS−OSCモデルについての実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【図17】重要な代謝を特徴づける保持時間ごとのVIP値を示すグラフである。
【図18】1番のランキングの緑茶サンプルのUPLCのトータルイオンクロマトグラムである。
【図19】高品質緑茶(No.1および2)および低品質緑茶(No.55および56)のUPLCのイオン強度を示すクロマトグラムである。
【図20】すべてのランキングの緑茶サンプルのUPLC/MS分析によるPCAスコアプロットである。
【図21】緑茶サンプルのUPLC/MS分析のPCA解析結果を示す図であり、PC1のローディングプロットである。
【図22】テストセット(丸で示す)およびトレーニングセットの両方の56種の全ての緑茶サンプルのUPLC/MS分析でのPLSモデルの実測および予測の緑茶品質(ランキング)間の関係を示す図である。
【特許請求の範囲】
【請求項1】
緑茶の品質予測方法であって、
緑茶を前処理して分析サンプルを得る工程;
該分析サンプルを機器分析に供して分析結果を得る工程;
該分析結果を数値データに変換して多変量解析する工程;および
得られた解析結果から、品質を予測する工程;
を含む、方法。
【請求項2】
前記多変量解析が、PLS回帰分析である、請求項1に記載の方法。
【請求項3】
前記前処理が、前記緑茶を熱分解処理する工程を含み、そして前記機器分析が、ガスクロマトグラフィーと質量分析との組み合わせである、請求項1または2に記載の方法。
【請求項4】
前記解析結果が、保持時間に基づいて品質予測される、請求項3に記載の方法。
【請求項5】
前記前処理が、前記緑茶から親水性化合物を抽出して抽出物を得る工程を含む、請求項1または2に記載の方法。
【請求項6】
前記機器分析が、ガスクロマトグラフィーと質量分析との組み合わせであり、そして前記前処理がさらに前記抽出物をシリル化する工程を含む、請求項5に記載の方法。
【請求項7】
前記分析結果の中で、アラビノース、グルタミン、クエン酸、グルタミン酸、アスパラギン酸、イノシトール、シキミ酸、リン酸、フルクトース、テアニン、リンゴ酸、カフェイン、キナ酸、グルコース、マンノース、リボース、およびスクロースのデータが解析される、請求項6に記載の方法。
【請求項8】
前記機器分析が、液体クロマトグラフィーと質量分析との組み合わせ、または核磁気共鳴分析である、請求項5に記載の方法。
【請求項9】
前記前処理が、前記緑茶を粉砕して粉末を得る工程および該粉末を溶媒でペースト状にする工程を含む、請求項1または2に記載の方法。
【請求項10】
前記機器分析が、赤外分光分析または近赤外分光分析である、請求項9に記載の方法。
【請求項11】
前記機器分析が、フーリエ変換近赤外分光分析であり、そして前記多変量解析する工程において、前記分析結果の中で5500〜5200cm−1の結果についてデータ変換し、該変換されたデータをさらに二次微分する、請求項10に記載の方法。
【請求項12】
品質既知の複数の緑茶を前処理して個別の分析サンプルを得る工程;
該個別の分析サンプルを機器分析に供して個別の分析結果を得る工程;および
該個別の分析結果と該品質との関係を数値データに変換して多変量解析する工程;
によって得られる、緑茶の品質予測モデル。
【請求項13】
緑茶の品質予測方法であって、
緑茶を前処理して分析サンプルを得る工程;
該分析サンプルを機器分析に供して分析結果を得る工程;
該分析結果を数値データに変換して多変量解析する工程;および
得られた解析結果を、請求項12に記載の品質予測モデルと照合する工程;
を含む、方法。
【請求項1】
緑茶の品質予測方法であって、
緑茶を前処理して分析サンプルを得る工程;
該分析サンプルを機器分析に供して分析結果を得る工程;
該分析結果を数値データに変換して多変量解析する工程;および
得られた解析結果から、品質を予測する工程;
を含む、方法。
【請求項2】
前記多変量解析が、PLS回帰分析である、請求項1に記載の方法。
【請求項3】
前記前処理が、前記緑茶を熱分解処理する工程を含み、そして前記機器分析が、ガスクロマトグラフィーと質量分析との組み合わせである、請求項1または2に記載の方法。
【請求項4】
前記解析結果が、保持時間に基づいて品質予測される、請求項3に記載の方法。
【請求項5】
前記前処理が、前記緑茶から親水性化合物を抽出して抽出物を得る工程を含む、請求項1または2に記載の方法。
【請求項6】
前記機器分析が、ガスクロマトグラフィーと質量分析との組み合わせであり、そして前記前処理がさらに前記抽出物をシリル化する工程を含む、請求項5に記載の方法。
【請求項7】
前記分析結果の中で、アラビノース、グルタミン、クエン酸、グルタミン酸、アスパラギン酸、イノシトール、シキミ酸、リン酸、フルクトース、テアニン、リンゴ酸、カフェイン、キナ酸、グルコース、マンノース、リボース、およびスクロースのデータが解析される、請求項6に記載の方法。
【請求項8】
前記機器分析が、液体クロマトグラフィーと質量分析との組み合わせ、または核磁気共鳴分析である、請求項5に記載の方法。
【請求項9】
前記前処理が、前記緑茶を粉砕して粉末を得る工程および該粉末を溶媒でペースト状にする工程を含む、請求項1または2に記載の方法。
【請求項10】
前記機器分析が、赤外分光分析または近赤外分光分析である、請求項9に記載の方法。
【請求項11】
前記機器分析が、フーリエ変換近赤外分光分析であり、そして前記多変量解析する工程において、前記分析結果の中で5500〜5200cm−1の結果についてデータ変換し、該変換されたデータをさらに二次微分する、請求項10に記載の方法。
【請求項12】
品質既知の複数の緑茶を前処理して個別の分析サンプルを得る工程;
該個別の分析サンプルを機器分析に供して個別の分析結果を得る工程;および
該個別の分析結果と該品質との関係を数値データに変換して多変量解析する工程;
によって得られる、緑茶の品質予測モデル。
【請求項13】
緑茶の品質予測方法であって、
緑茶を前処理して分析サンプルを得る工程;
該分析サンプルを機器分析に供して分析結果を得る工程;
該分析結果を数値データに変換して多変量解析する工程;および
得られた解析結果を、請求項12に記載の品質予測モデルと照合する工程;
を含む、方法。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【公開番号】特開2009−14700(P2009−14700A)
【公開日】平成21年1月22日(2009.1.22)
【国際特許分類】
【出願番号】特願2008−20458(P2008−20458)
【出願日】平成20年1月31日(2008.1.31)
【新規性喪失の例外の表示】特許法第30条第1項適用申請有り 2006年8月3日 社団法人 日本生物工学会発行の「第58回日本生物工学会大会講演要旨集」に発表
【出願人】(504176911)国立大学法人大阪大学 (1,536)
【出願人】(000225142)奈良県 (42)
【出願人】(306023336)財団法人奈良県中小企業支援センター (18)
【Fターム(参考)】
【公開日】平成21年1月22日(2009.1.22)
【国際特許分類】
【出願日】平成20年1月31日(2008.1.31)
【新規性喪失の例外の表示】特許法第30条第1項適用申請有り 2006年8月3日 社団法人 日本生物工学会発行の「第58回日本生物工学会大会講演要旨集」に発表
【出願人】(504176911)国立大学法人大阪大学 (1,536)
【出願人】(000225142)奈良県 (42)
【出願人】(306023336)財団法人奈良県中小企業支援センター (18)
【Fターム(参考)】
[ Back to top ]