
置換符号による特にベクトル量子化におけるディジタル信号の符号化/復号化の改善
【課題】ディジタル信号の符号化/復号化において、置換符号の符号化および復号化が引起す問題を改善する。
【解決手段】本発明は、ディジタル信号の符号化/復号化に関するものであり、特に、結合表現の計算にかかわる置換符号を使用するものに関するものである。本発明によれば、前記結合表現は、素因数累乗分解によって表されるとともに、選択された整数の事前記録表現を事前に読み出すことによって判断される。
【解決手段】本発明は、ディジタル信号の符号化/復号化に関するものであり、特に、結合表現の計算にかかわる置換符号を使用するものに関するものである。本発明によれば、前記結合表現は、素因数累乗分解によって表されるとともに、選択された整数の事前記録表現を事前に読み出すことによって判断される。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、音声、ビデオおよびより一般的にマルチメディア信号などのディジタル信号のその蓄積または伝送のための符号化/復号化に関する。本発明は、特に置換符号の符号化および復号化が引起す問題への解決法を提案する。
典型的に、本発明をまたソース符号化と同等な、チャネル符号化または「変調」に適用する。
本発明の意味するディジタル信号の圧縮符号化/復号化は通話および/または音響信号周波数符号化器が持つ変換係数の量子化に極めて有用である。
【背景技術】
【0002】
ベクトル量子化
【0003】
1つの非常に広く使用されるディジタル信号圧縮の解決法はベクトル量子化である。ベクトル量子化は有限セットから選択する同じ次元のベクトルにより入力ベクトルを表す。Mレベルを持つ量子化器(または「符号ベクトル」)は入力ベクトルセットに関する非全単射適用、一般にn次元実ユークリッド空間RnまたはM個別要素:Y={y0、y1、...yM−1}を持つRnの有限サブセットYにおけるRnのサブセットである。
Yは再生成アルファベットまたは「辞書」または「ディレクトリ」とも呼ばれ、その符号ベクトル要素は「符号語」(または「出力点」または「標本」とも)呼ばれる。
量子化器の各次元rのビット速度(またはその「リゾリューション」)を次関係式により定義する。
【0004】
【数1】

【0005】
ベクトル量子化では、nサンプルブロックをn次元ベクトルとして扱う。次元が非常に大きくなる場合ソース符号化理論により、ベクトル量子化性能はソース歪みビット速度限界に近づく。量子化器の最適性に関する必要条件に基づき、汎用ロイドアルゴリズム(Generalized Lloyd Algorithm、GLA)などの統計的方法を使用して、ベクトル量子化器辞書を設計することができる。当然得られる統計的ベクトル量子化器は構造を持たず、符号化および蓄積双方の複雑度はn2nrに比例するので、これにより計算および蓄積リソースに関してその探索は経費を要する。
図1Aを参照すると、3つの主な演算、即ち符号化の2つおよび復号化の1つがベクトル量子化器を使用する。まず辞書からの符号ベクトルの選択により、入力ベクトルを符号化する(ステップCOD)。これは、入力ベクトルに最も類似する符号ベクトルである(図1Aにおける演算OP1)。次いで、この符号ベクトル指標を判断し(ステップIND)、送信または蓄積する(図1Aにおける演算OP2)。復号化器(ステップDEC)では、符号ベクトルをその指標から判断する(図1Aにおける演算OP3)。
【0006】
変調では、図1Aの3つの演算OP1、OP2およびOP3を適用するが、順序は異なる。この変調/量子化の双対性を示す図1Bを参照して、指標から符号ベクトルへの遷移の配備を行う(図1Aの演算OP3に対応する図1BのCOD’ステップ)。次いで雑音の影響を受けるチャンネルを経る送信後に、受信ベクトルに最も近い符号ベクトルの検索を行う(図1Aの演算OP1に対応する図1BのDEC’ステップ)。最後に、符号ベクトル指標の復号化が第3のステップである(図1Aの演算OP2に対応する図1BのIND’ステップ)。
【0007】
次元、ベクトルおよびビット速度により複雑度は指数関数的に増大し、非構造化ベクトル量子化器の使用は実時間においてその使用が可能である小さな次元および/または低ビット速度に制限される。非構造化ベクトル量子化器にとり、最も近い近隣の検索(演算OP1)は、最も近い近隣と入力ベクトルとの間の距離の測定を最少にする辞書要素を選択する全辞書要素の全検索を必要とする。後者の2つの演算(指標指定OP2および逆演算OP3)は一般に表の簡単な読出しにより実行するが、それにもかかわらずこれはメモリ空間が高くつく。サイズおよび次元の制約を克服するために、基本ベクトル量子化の幾つかの変形が検討された。変形は辞書構造の欠落を修正し、従って複雑度の削減を試行するが、品質の代価を伴う。一方、性能/複雑度のトレードオフは高度化し、ベクトル量子化を効果的経費により適用することができるリゾリューションおよび/または次元の範囲を増すことを可能にする。多くの構造化ベクトル量子化器方式が提案されており、特に「置換符号」を実施するベクトル量子化器を以下に説明する。
【0008】
置換符号
「置換符号」ベクトル量子化器では、「先導」と(または「先導ベクトル」とも)呼ぶ第1の符号ベクトル構成要素の(辞書編集順序への)置換により、符号ベクトルを得る。これらの構成要素はサイズq(i≠jの場合にai≠ajであるようなqのアルファベットA)のアルファベットA={a0、a1...、aq−1}からその値を採用する。構成要素aiは実数(または完全整数)である。重みwi(iは0乃至q−1の範囲の指標である)はアルファベット文字aiの反復回数である。重みwiは
【0009】
【数2】
【0010】
であるような正整数である。規定により、アルファベットの値はa0>a1>...>aq−1を満たす。先導構成要素nは位置0から位置(n−1)へ降順に進む。それ故先導ベクトルy0は次形式の次元nのベクトルである。
【0011】
【数3】
【0012】
異なる構成要素の順序、例えば
a0<a1<...<aq−1
を選択できるであろうことは理解されるであろう。
先導ベクトルを「符号付先導」と呼び、置換符号を「タイプIに関するもの」であると言う。その他の符号ベクトルをy0の構成要素の置換により得る。置換の総数Mは次式の通りである。
【0013】
【数4】
【0014】
別のタイプの置換符号(タイプII)が存在する。再度、先導ベクトルは以前と同じ形式を有するが、その構成要素は正でなければならない(a0>a1>...>aq−1≧0)。y0の構成要素への全ての可能な符号結合の割当てによるy0の構成要素の置換により、その他の符号ベクトルをまた得る。置換の総数Mは次式の通りである。
【0015】
【数5】
【0016】
ここで、aq−1>0であればh=nであり、その他の場合h=n−wq−1である。この場合、先導ベクトルをまた絶対先導と呼ぶ。
【0017】
「置換符号」ベクトル量子化器を拡張して置換符号の合成(即ち結合)とし、最近この置換符号結合構造を次元およびリゾリューション可変ベクトル量子化に(出願者名がWO−04/00219の書類において)一般化した。置換符号は統計的ベクトル量子化において使用するだけではない。置換符号はまた代数ベクトル量子化に見られ、代数ベクトル量子化は正規ドット配列または誤り訂正符号から導出する高度構造化辞書を使用する。置換符号はまた変調において使用する。
【0018】
置換符号構造の使用により最適、高速最近近隣検索アルゴリズムの開発を可能にする(図1Aの演算OP1)。一方、符号ベクトルの指標指定(または番号指定)(図1Aの演算OP2)および逆復号化演算(図1Aの演算OP3)は非構造化ベクトル量子化器の場合におけるよりより多くの計算を必要とする。
置換を計数する幾つかの方法が存在する。シャルクビック(Schalkwijk)アルゴリズムはこれらの方法の1つである:
シャルクビックJ.P.M(Schalkwijk J.P.M)著「ソース符号化アルゴリズム(An Algorithm for source coding)」、情報理論に関するIEEE論文誌、IT18巻3号、ページ395−399、1972年5月
結合分析を使用して、これらの技術は置換符号の符号ベクトルの指標指定(演算OP2)およびまた逆指標復号化演算(OP3)の実行を可能にする。置換指標指定アルゴリズムの中では、一般に使用するシャルクビックアルゴリズムを以下に例えば次の規格において検討している。
−[3GPP TS26.273](固定点拡張AMR−広帯域(AMR−WB+)コーデック;V6.1.0(2005−06)(レリース6))および
−[3GPP TS26.304](拡張適応型多元速度−広帯域(AMR−WB+)コーデック;浮動点ANSI−C符号;V6.3.0(2005−06)(レリース6)、2005年6月)。
【0019】
符号化における置換ランクの計算(図1Aの演算OP2)
【0020】
これはベクトルy=(y0、y1...、yn‐1)の構成要素に関する全ての可能な置換の順序化および指標指定を含む。順序は辞書編集式であり、指標をここでは「ランク」と呼ぶ。ベクトルyのランクの計算は、yに関連し、yk=adであり、その場合にのみdkが指標値dを有するようなベクトルD=(d0、d1...、dn‐1)のランクの計算を含む。
例えば、次元n=8のベクトルは以下の構成要素を有する。
y=(4、2、4、0、0、4、4、2)
q=3の文字(異なる値の構成要素)を持つアルファベットをa0=4、a1=2およびa2=0であるA={4、2、0}により示す。
次いで、ベクトルyはベクトルyとベクトルD=(0、1、0、2、2、0、0、1)を関連させ、その構成要素は単にアルファベットAのq文字の指標である。
yおよびDのランクは同じであるが、ベクトルDの定義は(アルファベット{a0、a1、...、aq−1}と同じ数の要素を含む)セット{0、1、...、q−1}にその値を有するシーケンスDのランクの計算に演算を削減する。
ベクトルyおよびDの重みが同じであるのはそのそれぞれの構成要素の発生が同じであるからである。中間重み(wk0、wk1、...、wkq−1)をまた構成要素ベクトル(yk、yk+1、...、yn−1)の重みとして定義し、それ故この重みは位置k乃至n−1を残すために端を切取るベクトルyに対応する。従って、
【0021】
【数6】
【0022】
であり、δ(x、y)はクロネッカ(Kronecker)演算子(x=yであればδ(x、y)=1であり、他の場合0)である。
次式を適用する。
【0023】
【数7】
【0024】
ベクトルyのランクtを下記の公式により結合分析により計算することができる。
【0025】
【数8】
【0026】
この公式は以下のように単純化することができる。
【0027】
【数9】
【0028】
使用することが多く、それ故ここで採用することにするのはこの後者の公式である。以後、Ikdkを「順序kの部分ランク」と呼び、以下の通りとする。
【0029】
【数10】
【0030】
ランクの復号化(演算OP3):置換のその指標からの判断
【0031】
ランクtの復号化はyに関連するベクトルD=(d0、d1、...、dn−1)の回復を伴う。dkの連続検索の一方法を以下に説明する。構成要素d0をまず判断し、構成要素d1乃至構成要素dn−1により継続する。
【0032】
*d0の判断:
d0を以下の不等式を含む公式の使用により見つける。
【0033】
【数11】
【0034】
項(n−1)!、t、
【0035】
【数12】
【0036】
およびd=0、...、q−1に対する値w0dは既知である。d0の値を見つけるために、出発点としてd0=0を使用し、上記の数11に示す公式(8)を満たすまでd0を連続して1だけ増やす。部分ランクにより上記の数11に示す公式(8)を書くことにより、値d0は次のようになる。
【0037】
【数13】
【0038】
*d1の判断:
d1を見つけるために、以下の関係を使用する。
【0039】
【数14】
【0040】
d=0、...、q−1に対するw1dの値は以下のようにw0dの値から推論する。
−d=d0であれば、w1d=w0d−1および
−d≠d0であれば、w1d=w0d(次いでdがd0と異なる限りw0dを反復する)。
構成要素d0の判断と同じ問題に戻る。d1の値を見つけるために、出発点としてd1=0を使用し、不等式(9)を満たすまでd1を連続して1だけ増やす
(I1d1≦t−I0d0<I1d1+1)。
【0041】
*その他のdkの判断:
【0042】
後続するdkの計算は上記の場合から推論する。dkの値を見つけるために、出発点としてdk=0を使用し、不等式
【0043】
【数15】
【0044】
を満たすまでdkを連続して1だけ増やす。
一度ベクトルD=(d0、d1、...、dn−1)を復号化すると、単なるアルファベットの転位によりベクトルDからベクトルyを推論する。
【先行技術文献】
【特許文献】
【0045】
【特許文献1】WO−04/00219
【非特許文献】
【0046】
【非特許文献1】シャルクビックJ.P.M(Schalkwijk J.P.M)著「ソース符号化アルゴリズム(An Algorithm for source coding)」、情報理論に関するIEEE論文誌、IT18巻3号、ページ395−399、1972年5月
【非特許文献2】[3GPP TS26.273](固定点拡張AMR−広帯域(AMR−WB+)コーデック;V6.1.0(2005−06)(レリース6))
【非特許文献3】[3GPP TS26.304](拡張適応型多元速度−広帯域(AMR−WB+)コーデック;浮動点ANSI−C符号;V6.3.0(2005−06)(レリース6)、2005年6月)
【非特許文献4】ラゴット S、べセット B、ルフェーブル R著「32kビット/秒における広帯域TCX通話符号化に適用する低複雑度多元速度格子ベクトル量子化」ICASSP論文集、1巻、PP.501−4、2004年5月
【発明の概要】
【発明が解決しようとする課題】
【0047】
置換符号の指標指定および逆演算は複雑な演算である。使用するアルゴリズムは結合分析を適用する。結合の指標指定および逆演算は階乗積の除算を必要とする。
【0048】
除算の複雑度
集積回路および信号処理プロセッサにおいてなされた進歩にもかかわらず、除算は複雑な演算に留まる。典型的に、16ビットで表す整数の16ビットで表す整数による除算はそれらの乗算より18倍のコストを要する。32ビットの整数の16ビットの整数による除算の重みは32であり、それらの乗算の重みは5である。
【0049】
変数のフレーム化
除算コストは問題であるだけではない。以下の表1が示すように、変数のフレーム化は別の問題である。
8以下の整数の階乗のみを全16ビットワードで表すことができる。12より大きな数の場合、全32ビットワードにおける階乗の表現は最早可能ではない。
さらに演算の複雑度は、また変数を表すのに使用するビット数と共に増大する。従って、32ビットの整数の16のビット整数による除算は16ビットの整数の除算(重み18)の殆ど2倍複雑(重み32)である。
【0050】
【表1】
【0051】
演算OP1の複雑度を削減する解決法が提案されている。演算OP2およびOP3の複雑度の問題は極めて適切には扱われていない。一方、特に出願者のTDAC符号化器/復号化器では、または3GPP−ANR−WB+符号化器では、シャルクビック公式に基づき符号化および復号化に対し単純化が行われている。
【0052】
置換および逆演算(演算OP2およびOP3)の計数の単純化
【0053】
n項Ikdkの計算に対して行った下記の単純化により、置換ランクtおよび逆演算の計算は加速され、その定義を以下で検討する。
【0054】
【数16】
【0055】
最初の2つの項を使用して、符号化および復号化双方における複雑度を削減する。第3の項を符号化に使用し、最後に残る2つの項を復号化に使用する。
【0056】
符号化技術を図2および図3により説明する。特に、図3は従来技術の意味するシャルクビック公式によるランクの計算を扱い、一方図2は予備ステップ(「EP−nと参照し、図2のn番目の予備ステップを示す)を説明する。
【0057】
図2を参照すると、処理はステップEP−1で始まり、ベクトルy=(y0、y1...、yn‐1)の構成要素を回復する。後続の一般的ステップEP−2はこのベクトルA=(a0、a1、...、aq−1)に使用するアルファベット要素の計算、および最大指標qの判断を扱う。これを行うためにq=1、a0=y0を設定する初期化ステップEP−21の後に、1とn−1との間の指標kに関してループを実行し(検査終了EP−26およびその他の場合増分EP−27)、以下のように要素aqを検索する。
−現指標kの構成要素ykが要素{a0、a1、...、aq−1}の中に既になければ(検査EP−22)、セット{a0、a1、...、aq−1}に対してak=yk(ステップEP−22)であるように新要素aqを割り当てねばならず、qを1だけ増分しなければならない(ステップEP−25)。
【0058】
後続の一般的、予備ステップEP−3は以下のようにベクトルD=(d0、d1、...、dn−1)の計算である。
−0乃至n−1の範囲のkに対して(kを0に初期化するステップEP−31、kに関する検査終了EP−31、その他の場合増分EP−38)、yk=akであるような値dを指標セット(0、...、q−1)において見つける(ループにおけるdに関する検査EP−33、その他の場合d=d+1による増分EP−36)。
【0059】
図3を参照して次に、図2に示す予備処理に続くランクtの計算ステップの説明に進む。図3に示すステップは「CA−n」と参照し、従来技術の意味するn番目の符号化を意図する。
【0060】
ステップCA−1はランクtの0、変数Pの1(ステップCA−13におけるランクの計算に使用する分母)およびqの重みw0、w1、...、wq−1の0への初期化である。
【0061】
ここで、kの値をn−1から0へ減分する(kをn−1に初期化するステップCA−2、検査終了CA−14およびその他の場合減分CA−15)。このような選択の利益を後に説明する。予備ステップEP−3において得るベクトルDの構成要素dkを次いで使用し、現行kに対しd=dkを設定する(ステップCA−3)。関連する重みwdを更新し(ステップCA−4においてwd=wd+1)、項Pを推定する(ステップCA−5においてP=Pxwd)。ステップCA−13に対応するランクの計算における分子に関して使用する総計Sを0に初期化し(ステップCA−6)、次いで重みwiの指標iに関してループを実行し(検査終了CA−9およびその他の場合d−1へ増分CA−10)、総計Sを更新する(ステップCA−8においてS=S+wi)。ステップCA−13におけるランクtの計算の前に調査を行い、総計Sがゼロでないことを確認する(検査CA−11)。この実施の利益を後に説明する。
【0062】
ランクtの計算(ステップCA−13)は以下のような階乗項(n−k−1)!を含む。
t=t+(S/P)(n−k−1)!
【0063】
ランクtの各更新に関する項(n−k−1)!の計算に代わって、これらの値をメモリに事前記録し、簡単なメモリアクセスを使用して(ステップCA−12)、(n−k−1)!の現行値を得ることを優先する。
【0064】
従って、図3に示す処理の幾つかの利点を再び本発明の実施において取り上げることにする。これらの利点を以下に詳記する。
【0065】
*階乗の蓄積
【0066】
項(n−k−1)!およびwki!を実時間で計算することを避けるために、n+1の階乗(0!、1!、...、n!)の値を事前に計算し、蓄積する。次元nが限定的に変化すれば(n≦nmax)、値0!、1!、...、nmax!を事前に計算し、蓄積する。
【0067】
*除算を避ける中間重みの累積に関する検査
【0068】
項Sk
【0069】
【数17】
【0070】
がゼロであれば、
【0071】
【数18】
【0072】
の計算に意味がない。次にこの項は、最終位置(n−1に近いk)の場合特にゼロであることが多い。この項がゼロである性質に関する検査(図3の検査CA−11)の追加により、除算(および乗算)を避けることができる。除算の計算は検査よりかなり複雑であるので、複雑度の除外は大きい。
【0073】
*符号化における位置に関するループの反転
【0074】
1だけwk+1dを増分し、d≠dkに対してその他の値wk+1dを反復することにより、重みwk+1dから(d=0、1、...、q−1である)重みwkdを推論する。その場合、ベクトルの最終位置(k=n−1)から最初の位置(k=0)へ動作するループ(図3のステップCA−2、CA−14、CA−15)を作成することが可能である。この「逆」ループは、1に初期化後項Pkを以下のように、
【0075】
【数19】
【0076】
各反復に対して、増分および乗算のみ、即ち
【0077】
【数20】
【0078】
により計算することを可能にする。
最後の2つの位置(k=n−1およびk=n−2)を個別に処理することがまた可能である。要するに、
・最後の位置(k=n−1)について、
【0079】
【数21】
【0080】
それ故
【0081】
【数22】
【0082】
・最後から2番目の位置(k=n−2)について、
dn−2>dn−1であれば、
【0083】
【数23】
【0084】
それ故
【0085】
【数24】
【0086】
その他の場合
【0087】
【数25】
【0088】
それ故
【0089】
【数26】
【0090】
であり、dn−2=dn−1であれば、Pnー2=2、その他の場合
Pnー2=1である。
【0091】
下記のその他の有利な実施の詳細をまた提供することができる。
【0092】
*復号化における除算の除去
【0093】
d0を検索する場合に復号化における除算を避けるために、数11に示した不等式(8)を以下の形式に再公式化することができる。
【0094】
【数27】
【0095】
同様に、数14に示した不等式(9)を以下の形式に再公式化することにより、d1の検索から除算を除去する。
【0096】
【数28】
【0097】
またはさらに、
【0098】
【数29】
【0099】
従ってdk(0≦k≦n−1)の検索における除算の削除は可能であるが、Ikdk(0≦k≦n−3)の計算に(n−1)除算の実行がなお必要である。
【0100】
*復号化における重みに関する検査
【0101】
dのある値に対する最後の位置では、(位置kに先行する位置を占める値dのw0dの構成要素に対して)wkd=0である。dのこれらの値に対し不等式(8)および(9)の項を計算するのはそれ故意味がない。
【0102】
従来技術のその他の問題:変数のフレーム化
【0103】
変数フレーム化の問題は出願者のTDAC符号化器において取組んでいる。
第1の解決法は12より大きな次元の処理演算をより小さな次元の演算と区別することであった。小さな次元(n<12)の場合、32ビットの符号のない整数に関して計算を実行する。より大きな次元の場合、計算複雑度および必要なメモリ容量の増大を犠牲にして、倍精度浮動変数を使用する(浮動倍精度演算はその整数精度に等価な演算よりより経費が掛かる)。
【0104】
さらに最大精度を符号のない32ビットの整数(固定点プロセッサによる実施)に限定すれば、12より大きな整数階乗を直接事前蓄積することはできず、12より大きな次元のベクトルを個別に符号化しなければならない。この問題を解決するために、さらに高度な解決法は2j×rの形式の階乗n!の仮数および指数による擬似浮動点表現を使用する。この分解を以下の表2に詳しく示す。n!の蓄積(16以下のnの場合)を最大30ビットの精度を持つr並びに簡単なビットオフセットに対応する指数jの蓄積に削減する。
【0105】
【表2】
【0106】
従って、大部分の場合従来技術は特に固定点における限定精度の変数フレーム化の問題を解決しない。TDAC符号化器における実施は、フレーム化問題を解決するが、2つの整数の経費の掛かる除算を回避しない。
【0107】
さらに大きな次元の場合、中間計算(例えば、部分ランクIkdkの分子および分母)は限界状態に近づきうる。この場合、上記の単純化を復号化処理に使用することができず、数11および数14に示した不等式(8)および(9)の公式化への逆戻りが必要であり、それ故多くの除算を再び持ち込まねばならない。
【0108】
シャルクビック技術以外の計数技術は同じ問題に苦しむ。計数技術がまた結合分析を使用する場合、計数技術は階乗積とその除算の計算を伴う。
【0109】
本発明はこの状況の改善を目的とする。
【課題を解決するための手段】
【0110】
このため、本発明はまず結合表現の計算を含む置換符号を使用するディジタル信号の符号化/復号化法を提案し、本方法ではこれらの結合表現を素因数累乗分解により表し、選択する整数の事前記録分解表現をメモリから読出すことにより判断する。
【0111】
次いで本発明は置換符号の指標指定および逆演算双方に関連する問題への効果的な解決法を提供する。同時に本発明は変数フレーム化および除算である2つの問題を解決する。
要するに有利な実施では、事前記録表現は前記選択する整数のそれぞれの連続する素数を表す値と相関してそれぞれ蓄積する指数を表す値を含む。
従来技術における変数フレーム化に関連する問題を従って既に解決する。
変数フレーム化の問題は階乗項を操作する場合、益々重大である。
有利な実施では、結合表現が整数の階乗値を含む場合結合表現を操作するために、事前記録表現は少なくとも階乗値の分解表現を含む。
次いでこの実施は変数フレーム化の制約を取除き、そのことから関係する置換符号の次元nに関して通常設定する制限を緩和することを可能にする。
【0112】
別の有利な特徴によれば、前記結合表現の少なくとも1つは整数の分子の整数の分母による商を含み、この商を素因数累乗分解により表し、素因数累乗分解の各累乗は分子および分母とそれぞれ関連し、1つのかつ同じ素数に割当てる指数の差分である。
従来技術の除算の計算に関連する問題は従って単純な減算計算によりこの計算を置換することにより解決する。
【0113】
第1の実施形態では、上述の選択する整数の1つの事前記録分解を取出すためにアドレス指定するメモリの配備を行う。
このため、選択する整数の事前記録表現をアドレス可能なメモリに蓄積し、前記メモリのアドレス指定はそれぞれの素数に割当てる連続する指数を示し、選択する整数を再構成する。
好ましくは、選択する整数の事前記録表現を素数に対し連続するアドレス形式で蓄積することとし、各アドレスはこの素数に割当てる指数を示し、選択する整数を再構成する。
第1の実施形態によるこの実施を以後「分解の分解による相互関係表現」と名付けることにする。
【0114】
変形として第2の実施形態では、連続するビットグループを含むワード形式で、事前記録表現を蓄積し、各グループは:
−素数に応じる重み、および
−この素数に関連する指数に応じる値を
有する。
好ましくは次いで、少なくとも1つの部分マスクをビットワードに連続的に適用することにより、ビットの重みによる連続オフセットおよび残るビットの読出しにより、素因数累乗を判断する。
第2の実施形態によるこの実施を以後「分解のコンパクトな表現」と名付けることにする。
【0115】
結合表現の計算の同じ方法の処理を、一般に次の:
−前記結合表現を形成する積および/または商に現れる項を前記選択する整数から特定するステップと、
−前記項の素因数分解に含む指数をメモリにおいて読出すステップと、
−読出した指数を加算および/または対応して減算し、前記結合表現の素因数累乗分解に含む指数を判断し、そのことからその素因数累乗分解から前記結合表現を計算するステップと、
により実行することができる。
【0116】
再起的に実行する積の計算および各再起に新しい項を含むことに関し、以前の再起に対して実行した積の計算の分解を一時的に蓄積するのは有利でありうる。従って、本方法が以前の再起において判断した積を乗算する項を各再起に含む積の計算に再起ステップを含めば、
−以前の再起において判断した前記積を有利には素因数累乗分解の形式でメモリに保持し、
−積を乗算する前記項が好ましくは分解を事前記録する選択する整数の1つであり、
−現再起における前記積を判断するために、以前の再起において判断した前記積および前記積を乗算する前記項のそれぞれの分解から導出する指数を共に1つずつ各素数に対し加算すれば十分である。
【0117】
同様に、本方法が以前の再起において判断した商を除算する項を各再起において含む除算の計算に再起ステップ含めば、
−以前の再起において判断した前記商を有利には素因数累乗分解の形式でメモリに保持し、
−商を除算する前記項が好ましくは分解を事前記録する選択する整数の1つであり、
−現再起における前記除算を判断するために、前記項の分解から導出する指数を以前の再起において判断した前記商の分解から導出する指数から1つずつ各素数に対し減算する。
再起的に計算する積および/または商に関する中間分解のこの一時的蓄積は再起部分ランクの判断に特に有利であり、再起部分ランクの累積は置換ランクを表す。
【0118】
従って本発明の有利な実施では、置換符号は各部分ランクが次いで前記結合表現の1つに対応する部分ランクの累積を含む置換ランクを表す量の計算を含む。
ベクトル量子化ディジタル信号を符号化する場合、次いで置換ランクの計算を使用し、入力ベクトルに最も近い符号ベクトルを判断するために以前のステップ(演算OP1)において実行した先導ベクトルの構成要素の置換を指標指定することができる(図1Aの演算OP2)。
【0119】
同様にベクトル量子化ディジタル信号を復号化する場合に、置換ランクの所与の値から
−構成する符号ベクトルの少なくとも1つの仮定する構成要素に従い前記所与の値に近い置換ランクを表す少なくとも1つの量を計算し(図1Aの演算OP3)、
−この量が所与のランク値との近接条件を満たせば仮定する構成要素の選択が妥当である
として置換ランクの推定が行われる。
実施例では、一方で仮定する構成要素に関連する部分ランクへおよび他方で仮定する構成要素の増分に対応する構成要素に関連する部分ランクへの部分ランクの累積により所与のランク値を纏めて扱うことができれば、この近接条件を満たす。
それ故、この近接条件はシャルクビック計数の場合の上記の不等式(8)の一般的公式化に対応しうる。
従って、本発明を有利には図1Aの意味するベクトル量子化によるソース符号化/復号化に適用することができる。
一方、符号化/復号化が、
−送信前における置換ランクからの符号ベクトルの判断(図1Aおよび図1Bの同じ演算OP3)および
−受信時における受信ベクトルに対応する符号ベクトルからの置換ランクの計算(図1Aおよび図1Bの同じ演算OP2)
を含めば、符号化/復号化はまた図1Bの意味するチャネル変調符号化/復号化タイプに関するものでありうる。
【0120】
部分ランクの計算は、後に見られるであろうように一般的規則として置換符号の最大次元n以下に留まる(積または商における)項を含む。従って有利な実施では、事前記録分解を伴う選択する整数は少なくとも、
−1と前記最大次元nとの間の整数と、
−整数0の階乗値と、
−好ましくは1と最大次元nとの間の整数の階乗値
を含む。
特定の選択可能な実施では、選択する整数はまた値0を含むことができる。
【0121】
従って、置換符号がシャルクビック計数を使用すれば、符号ベクトル(y0、...、yn‐1)の切取り(yk、...、yn−1)に関連する部分ランクIkdkを、
【0122】
【数30】
【0123】
により表し、上式で、
−記法
【0124】
【数31】
【0125】
は0乃至mの範囲の整数指標iに対する積を表し、
−記法
【0126】
【数32】
【0127】
は0乃至mの範囲の指標iに対する総和を表し、
−記法l!はl>0の場合l!=1×2×3×...×(l−1)×lであり、0!=1である整数lの階乗値であり、
−整数nは符号ベクトルが含む構成要素の総数に対応する置換符号の次元であり、
−0とn−1との間の整数kは、ソース復号化における(対応してチャネル符号化における)ランク値から検索するかまたは置換をソース符号化において(対応してチャネル復号化において)指標指定する符号ベクトルのk番目の構成要素ykの指標であり、
−整数qは符号ベクトルが含む個別構成要素数であり、
−項wkd(「中間重み」と名付ける)はkとk−1との間の指標を有し、1つのかつ同じ指標構成要素dの数に等しい値を有する構成要素の数を表す。
【0128】
この場合、事前記録分解を有し、次いで部分ランクIkdkの表現において、積および/または商において特定する、選択する整数は好ましくは、
−0とn−1との間の全ての整数kに対する階乗項(n−1−k)!(即ち、0と(n−1)との間の全ての整数に対する階乗値)であり、
−各項wkiの値および/または各項wkiが0とnとの間にある積
【0129】
【数33】
【0130】
に含むその階乗値であり、
−0とn−1との間の全ての整数kに対して、各項が1とn−1との間にある項
【0131】
【数34】
【0132】
である。
【0133】
さらにシャルクビック計数の特定の場合では、中間分解の一時蓄積を有利に以下のように適用する:先行指標kに対する項
【0134】
【数35】
【0135】
の分解における指数の総和を一時的にメモリに蓄積し、指数の総和にまたは指数の総和から現指標kに対する項wkiの分解指数を加算または減算する。
【0136】
本発明のその他の特徴および利点は、以下の「発明を実施するための最良の形態」および上記の図1A、図1B、図2および図3に加えて図4乃至図9の添付する図面を考察することにより明らかになるであろう。
【0137】
思い出す契機として、特に以下の図4乃至図8を参照して、下記のことを強調すべきである。
−用語「符号化する」は置換ランクtの計算を指示し(図1Aおよび図1Bの演算OP2)、
−用語「復号化する」はこのランクtからの置換の判断を指示する(図1Aおよび図1Bの演算OP3)。
従って、これらの演算をベクトル量子化によるソース符号化/復号化の参照により指定する。これらの演算をまたチャネル符号化/復号化、変調において実行することができることを思い出すべきである。
【0138】
本発明の原理を単刀直入に示すために、素数累乗の階乗化を以下に説明する。
ゼロでない正整数Kの素数累乗への分解を以下のように表す。
【0139】
【数36】
【0140】
上式で、piはi番目の素数である(p0=1、p1=2、p2=3、p3=5、p4=7、p5=11、p6=13、p7=17、など)。
piの指数を整数Kの分解ではeKiと表示し、mKはゼロでない指数を持つKの分解に含む最大の素因数の指標を表示する。
例えば、数K=120(または5!)を次のように表す。
120=1.23.31.51であり、最大の素因数「5」が指標3を有するので(p3=5)、ここではmK=3である。それ故、以下が当てはまる:e5!0=1、e5!1=3、e5!2=1およびe5!3=1。
実際には、数「1」は乗算の中立の要素であり、p0は分解から除くことができる、即ち、以下の通りである。
【0141】
【数37】
【0142】
勿論、K=0は素因数の累乗には分解することはできない。
【0143】
16以下の正整数の素数累乗積への分解を表3aに示し、その階乗分解を表3bに示す。この分解は6つの素数を含む(2、3、5、7、11および13)。列を素数piにより指標指定し、行をnにより指標指定するので、列piと行nの交点における表3a(対応して表3b)のセルは数n(対応してn!)の素数の累乗積分解における素数piの指数eni(対応してen!i)である。
n>1の任意の正整数の場合、n!の素因数の数mn!は次の通りである:pmn!≦n<pmn!+1。数mn!(対応して数mn)を表3b(対応して表3a)の最終(対応して最後から2番目の)列に示した。次の不等式に留意すべきである:mn≦mn!。
表3aが示すように、数nの多くの分解指数はゼロである。表3aの最終列に、nの分解におけるゼロでない指数mn1を注記した。n=0の場合分解の(それ故指数の)ないことを表3aの行n=0に記号「−」により示す。
【0144】
【表3a】
【0145】
【表3b】
【0146】
最初にシャルクビック公式の場合、次いで一般の場合の置換符号に関する部分ランクの計算へのこのような分解の適用に関する説明に進む。
Ikdkと表示する部分ランクが本明細書の上記の数10に示した関係式(7)により示されることを思い出すべきである。
【0147】
【数38】
【0148】
本式では、3つの項を素数累乗に分解することができる。これらは次の項である。
【0149】
【数39】
【0150】
(n−1−k)!、PkおよびSkの分解指数から、Ikdkの分解指数を簡単な加算および減算により計算する。
要するに、Ikdkの分解における素因数piの指数
【0151】
【数40】
【0152】
を3つの項(n−1−k)!、SkおよびPkの分解におけるpiの3つの指数から計算する。指数
【0153】
【数41】
【0154】
は最初の2つの項(Ikdkの分子)のpiの指数の総和に等しく、指数の総和から最後の項(Ikdkの分母)のpiの指数を減算する。一度公式化し、この結果を次のように表す。
【0155】
【数42】
【図面の簡単な説明】
【0156】
【図1A】ベクトル量子化によるソース符号化/復号化を示す。
【図1B】変調/量子化の双対性を示す。
【図2】符号化技術を説明するための図である。
【図3】符号化技術を説明するための図である。
【図4】本発明の使用による置換ランクの符号化/復号化原理を示す。
【図5】第1の実施形態に従う本発明の使用による置換ランクの符号化のための処理演算を示し、この演算ではこの計算に使用する項の素数累乗分解指数の分解相互関係表現を提供する。
【図6】第2の実施形態により本発明を使用する置換ランクの符号化のための処理演算を示し、この演算では分解指数のコンパクトな表現を提供する。
【図7】第1の実施形態により本発明を使用する置換ランクの復号化のための処理演算を示し、この演算では分解指数の分解相互関係表現を提供する。
【図8】第2の実施形態により本発明を使用する置換ランクの復号化のための処理演算を示し、この演算では分解指数のコンパクトな表現を提供する。
【図9】本発明を実施する符号化/復号化デバイスを図的に表す。
【発明を実施するための形態】
【0157】
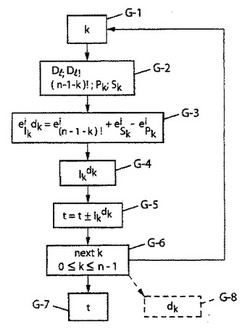
図4は、符号化および復号化のために共に本発明の意味する処理演算に含むことができる(n番目の一般的ステップを表すために「G−n」と参照する)一般的ステップを示す。
【0158】
従って図4を参照して、現指標kから(ステップG−1)および後に詳細に説明することにする幾つかの中間ステップにより、(図4に例示するステップG−2においてDlおよびDl!と表示する)事前記録表を参照する配備を行い、本明細書の以上の式(10)により、素因数累乗における中間ランクIkdkの分解に特定のグローバル指数
【0159】
【数43】
【0160】
を計算する(ステップG−3)ことを就中思い出すべきである。素因数に特定の指標iに関するループを実行することにより恐らくこれ(ステップG−4)から、中間ランクIkdkの値を次いで推論する。次いでこの中間ランクの計算は置換の全ランクtの更新を、
−指標kの減分によるランクの符号化のためのタイプの関係式t=t+Ikdk(ステップG−6)によるかまたは
−後述のように、指標kの増分によるランクの復号化のためのタイプの関係式t=t−Ikdk(ステップG−6)により、
継続することができる(ステップG−5)。
【0161】
最後に、ステップG−7の符号化または復号化(図4の破線)において置換のランクtを得、ベクトルDの構成要素dkをステップG−8における以上の公式(8)の不等式および本明細書の以上の式yk=adによるベクトルYに関する不等式から推論する。
【0162】
一般の場合およびシャルクビック計数とは独立に、置換の部分ランクt’(t’>0)が以下のようにNt’の項vj(1≦j≦Nt’)を有する分子およびDt’の項ρj(1≦j≦Dt’)を有する分母の形式であれば、
【0163】
【数44】
【0164】
その場合、部分ランクt’の分解指数et’iをNt’vjおよびDtρjの分解である中間分解から判断し、et’iを以下のように表す。
【0165】
【数45】
【0166】
素因数への分解をまた本明細書で後に部分ランクt’の整数の商の積への公式化に使用することにする。
また一般的規則として、
【0167】
【数46】
【0168】
であれば、その場合
【0169】
【数47】
【0170】
である。
【0171】
シャルクビック計数の特定の場合に戻り、次いで一度この分解を判断し、その分解から部分ランクIkdkを計算するために、計算を次のように実行することができる。
式
【0172】
【数48】
【0173】
の精神を守り、単に対応する累乗の乗算により部分ランクIkdkを以下のように計算する。
【0174】
【数49】
【0175】
ここで、項(n−1−k)!およびPkは厳密に正整数であるが、項Skはゼロでありえ、それ故分解可能でないことがありうることを示すべきである。この場合、部分ランクIkdkはゼロである。次いで、項Sk(Sk=0?)の値に関する検査を行い、本明細書の以上の説明(図3のステップCA−11)のようにSk≠0の場合にのみ部分ランクIkdkを計算する。
【0176】
より一般的には、
【0177】
【数50】
【0178】
であれば、その場合
【0179】
【数51】
【0180】
であり、
【0181】
【数52】
【0182】
であれば、その場合
【0183】
【数53】
【0184】
である。
【0185】
次いで、素因数累乗の乗算により、特にこれらの素数に関連する指数の簡単な加算および減算により除算を置換することにより、部分ランクを構成する項の素因数階乗化が除算の排除を可能にすることを思い出すであろう。
【0186】
従って、本発明の意味するメモリに蓄積する整数の素因数分解(以後「基本分解」と呼ぶ)の限られた数から、
−図4のステップG−2の意味する置換ランクに現れる
【0187】
【数54】
【0188】
のような項の素因数分解(本明細書で以後「中間分解」と呼ぶ)を判断し、
−図4のステップG−3の意味する特にこの部分ランクの分解に含む指数の(例えば、
【0189】
【数55】
【0190】
タイプの式による)計算により、これらの中間分解から置換の部分ランクt’(Ikdk)の素因数分解を判断し、
−図4のステップG−4の意味する部分ランクt’(Ikdk)をその分解から(例えば、
【0191】
【数56】
【0192】
タイプの式を使用して)計算する、
以上のステップを配備する。
【0193】
勿論、蓄積する基本分解は好ましくは有利な選択の対象である。好ましいが、限定しない実施では、関係する置換符号の最大次元(この最大次元をnと表示する)により、蓄積する基本分解を選択することにする。従って、基本分解は好ましくは:
−整数lの階乗(l!と表示する)の分解であり、整数lは0≦l≦nであり、
−整数l自体の分解であり、この場合0≦l≦nであり、
nは関係する置換符号の最大次元であることを思い出すであろう。
【0194】
次いで、
−考察する素因数の数m、
−これらmの素因数自体および
−そのそれぞれの指数
を付与する数mにより基本分解を特定することが可能である。
分解の所謂「分解相互関係」表現のコンテキストにおいて表4a乃至表4dを参照して、この実施例を後に説明することにする。後に詳しく説明する所謂「コンパクトな」表現は単一のワードの蓄積にあり、ワードのビットは分解に含む全ての指数を付与することを指摘すべきである。
次いで種々の基本分解セットおよびこれら基本分解の表現および蓄積手順の定義が可能である。
【0195】
その上、中間分解を判断する項の選択およびこれら中間分解の判断そのものは後述することにする有利な実施の対象である。部分ランクの分解およびその分解からの部分ランクの計算はまた後述する有利な実施の対象である。
【0196】
次に蓄積する基本分解の選択に関する説明に進む。
一般に、次元nの置換符号に関する計数技術とは独立に、置換ランクの計算は整数l(0≦l≦n)および就中その階乗l!(0≦l≦n)を使用する。好ましい実施では、基本分解は階乗l!(0≦l≦n)およびl(0≦l≦n)の階乗分解であり、ここでnは本明細書で以上に示したように関係する置換符号の最大次元である。(2n+1)の基本分解をそれ故この好ましい実施において配備する。
にもかかわらず、その他の実施が可能である。
例えば、(n+1)の基本分解のみ、即ちl(0≦l≦n)および0!の基本分解を配備する必要がある。従って、l!(l>0)の分解が部分ランクの計算に必要であれば、
【0197】
【数57】
【0198】
であるj(0≦j≦l)のlの基本分解から中間分解を判断するステップにおいて、l!(l>0)の分解を計算する。
逆に、l!(0≦l≦n)の(n+1)の分解のみを配備する必要がある。l(l>0)の分解が部分ランクの計算に必要であれば、l!および(l−1)!の底を持つ2つの基本分解からおよび以下の式
【0199】
【数58】
【0200】
から中間分解を判断するステップにおいて、l(l>0)の分解を計算する。
それ故、基本分解セットの選択が有利にはこれら基本分解表現の蓄積に必要なメモリの最少化と中間分解を判断するステップの複雑度の最小化との間のトレードオフになりうることが理解されるであろう。
【0201】
以下で、本発明の意味する分解表現を説明する。
以上に示したように、分解(部分ランク、中間または基本のいずれであれ)を数mにより定義し、数mは考察する素因数の数、これらmの素因数およびそのそれぞれの指数を付与する。以下では、分解を表し、基本分解データを蓄積する種々の解決法を提案する。
【0202】
指数の分解相互関係表現
【0203】
*階乗l!(0≦l≦n)の表現
【0204】
値l!の分解に含む素因数の数ml!は数lと共に増加する。l!(0≦l≦n)の分解を表す第1の解決法は、l(0≦l≦n)の各値に対する数ml!およびpi(0≦i≦ml!)のml!の累乗指数の蓄積にある。l!のml!の指数がゼロでないことを注記することにする。
より有利な変形では、基本分解セットは同じ数mn!の素因数を共有し、各基本分解に対しmn!の指数を蓄積し、ml!より大きな指標のl!の基本分解指数はゼロである。この解決法は表の正規アドレス指定を提供することによりこの指数表の使用を可能にする。一方このような実施は、かなりのメモリサイズを必要とする。この表はmn!×(n+1)の値を含み、指数
【0205】
【数59】
【0206】
をこの表のアドレス(mn!、l+(i−1))に蓄積し、ここで記法(x、y)は行xおよび列yにおけるこの表のセルを目標にする。勿論、その他の規定を考慮することができることは理解されるであろう。従って、m列およびN行を有し、それ故m×Nセル(または要素)を含む2次元の表を考察する代わりに、m×Nセルを有する1次元の表を考察することが可能であり、2次元テーブルのアドレス(x、y)におけるセルはその場合1次元テーブルのアドレスm×x+yに位置する。2次元テーブルのアドレス(l、(i−1))に蓄積する指数
【0207】
【数60】
【0208】
をその場合1次元テーブルのアドレス(mn!×l+(i−1))に蓄積する。例えば、構成上表3bの4つの列(列pi=2、3、5、7)および9つの行(行n=0、..8)を含む36のセルを有する2次元テーブルに、数0乃至8の階乗分解指数を蓄積することができる。本明細書で以下に提示する(付録A−11)36セルを持つ単一次元のテーブルDl!に、これらの同じ指数を蓄積することができる。第1のテーブルのアドレス(x、y)におけるセルはアドレスDl!:4x+yにおけるセルに等しい。
加えて、ml!の(n+1)の値を蓄積し、l!の基本分解を使用して、中間分解の計算を削減することができる配備を行うことができる。
【0209】
*整数l(0≦l≦n)の表現
【0210】
基本分解l(0≦l≦n)を表現するために、幾つかの解決法をまた提供することができる。第1の解決法は各値lに対し、数mlおよびlのpi(0≦i≦ml)のmlの累乗指数を蓄積することである。変形では、l!(ml!またはmnl)の指数に対するのと同様に多くの指数を蓄積するのが好ましいであろう。lおよびl!の基本分解はその場合同じ数mを共有する。
別の変形では、lのゼロでない分解指数の数m’lが小さいことを活用することができる。例えば、この数m’lが最大で2(l=16の場合)であることは表3aにおいて明らかであった。従って、この数および対応する値piまたは指標iのみを蓄積することが可能である。
一方、またゼロでないこれらの累乗素因数の指標iを蓄積する配備が必要であるが、これは表における対応する指数のアドレスにより指標iは最早暗黙には認識されないからである。
【0211】
*基本分解以外の分解表現
【0212】
中間分解表現は中間分解を判断する基本分解表現に依存する。同様に、部分ランクの分解表現は部分ランクの分解表現を判断する中間分解の表現に依存する。
【0213】
*基本分解の蓄積
【0214】
典型的に、次元8(n=8)の置換符号のための本明細書の以下の表4a乃至表4dによる例示により、4つの可能な蓄積の解決法を示すことができ、この解決法では4つの(m8!=4)素数(2、3、5および7)を考慮する。これらの例を3GPP AMR−WB+符号化器(規格[3GPPTS26.273]および[3GPPTS26.304])に適用することができる。この符号化器は代数ベクトル量子化を使用し、代数ベクトル量子化辞書は次元8のゴセット(Gosset)配列RE8の置換符号結合である。
最初の3つの解決法(表4a乃至表4c)は同じ方法でl!の基本分解を表し、蓄積する。要するに、ml!およびl!のpi(0≦i≦ml!)のml!の累乗指数の蓄積を配備する。以上の解決法はlの基本分解表現および蓄積において異なる。表4aはmlおよびlのpi(0≦i≦ml!)のml!の累乗指数の蓄積を目的とする第1の解決法を示す。表4bはlのpi(0≦i≦ml!)のml!の累乗指数の蓄積を目的とする第2の解決法を示す。
【0215】
【表4a】
【表4b】
【0216】
表4cはlのpiのゼロでないが累乗指数の数m’l、対応する指数i、およびその指数の蓄積を目的とする第3の解決法を示す。明瞭さを増すため提示する表で示すのは、素数piである。
【0217】
【表4c】
【0218】
第4の解決法(以下の表4dにより示す)では、基本分解セットを数mnlにより表し、各基本分解(lまたはl!)に対し、mnlの指数を蓄積する。以前に提示した表3aおよび表3bの4つの列(pi=2、3、5および7)および9つの行(n=0乃至8)から表4dを抽出する。
【0219】
【表4d】
【0220】
可変次元およびリゾリューションを持つ統計的ベクトル量子化を使用する最大次元15のTDAC符号化器では、6つの(m151=6)素数:2、3、5、7、11および13を考慮する。次いで、表3aおよび表3bの6つの列(pi=2、3、5、7、11および13)および16の行(n=0乃至15)は第4の解決法に対する基本分解セットの蓄積を示すことができる。
【0221】
指数のコンパクトな表現
【0222】
蓄積を最少にし、限定数のワードに関する基本分解指数をコンパクトに表すことにある別の有利な解決法に関する説明に進む。基本分解表現のこの変形では、中間分解および部分ランクの中間分解をまたコンパクトに表す。有利には、この解決法はまた分かるであろうようにこれらの分解に関する判断の複雑度を最少にする。
【0223】
*分解のコンパクトな表現
【0224】
各素因数piに対する部分ランクの分子におけるその指数が持つ最大値の上限βiを判断するために検索を行う。この限界はpiの指数に関する可能な値の最大数、即ちβi+1を与える。バイナリにより値(βi+1)を表現する整数ビット数の表示にbniを使用することにより、次式をえ、
【0225】
【数61】
【0226】
上式で、
【0227】
【数62】
【0228】
はx以上の直近の整数を表示する。
【0229】
【数63】
【0230】
部分ランクt’に含む項Kの累乗因数分解指数をBnビットのワードeKによりコンパクトに表現することができ、
【0231】
【数64】
【0232】
このワードeKは以下の通りである。
【0233】
【数65】
【0234】
記法「≪B」はBビットの左シフトを表す。
【0235】
数nが大きければ、整数の表現に使用するビット数B0(16、32または40ビット)よりBnが大きいであろうことを注記することにする。この場合、t’に含む整数Kの素因数分解指数をMの完全整数eK(m)、0≦m<M(勿論、M>1である)の形式で表す。
【0236】
有利には、Mワードを以下のように形成することができる。
・eK(0)はi0の第1の指数(p1乃至pi0の指数)を含む:
【0237】
【数66】
【0238】
上式で
【0239】
【数67】
【0240】
である。
・eK(1)はpi0+1乃至pi1の指数を含む:
【0241】
【数68】
【0242】
上式で
【0243】
【数69】
【0244】
である。
・pmn!の指数を含む最終ワードを構成するまで、後者の関係式を任意のmについて一般化することができる。
勿論、その他の変形を提供することができる。例えば、1つの変形はp1の指数を個別に蓄積し、p2の指数から以上の処理演算を適用することにある。
【0245】
*上限の判断
【0246】
限界βiを幾つかの方法で判断することができる。置換符号に関する情報(アルファベットのサイズq、重みwi、0≦i<q)を使用して、部分ランクの分子が持つ各指数の最大値を明確に判断することができる。幾つかの(恐らく異なる次元の)置換符号を使用すれば、好ましくは最大の最大値を各指数に対して選択する。
本発明は有利にはシャルクビック計数のコンテキストにおける上限を判断する汎用処理演算を提案する。処理演算は使用する置換符号に関して最大次元以外の事前情報を使用しない。処理演算は単に、
【0247】
【数70】
【0248】
を使用し、次いで
【0249】
【数71】
【0250】
を選択する。
非常に多様な置換符号を使用する場合、この非常に汎用的処理は特に適する。
表5aは次元が8乃至15の場合のIkdkの分子における最大指数値に関する上限を示す。表5bは次元が8乃至15の場合のこれらの指数を表すビット数bniおよびその総和Bn(最終列)を示す。次元8では、素因数2の指数を3ビットで表し、その他の素因数(3、5および7)の指数を2ビットで表す。次元15では、素因数2の指数を4ビットで表し、素因数3の指数は3ビットで、その他の素因数(5、7、11および13)の指数は2ビットで表す。
【0251】
【表5a】
【表5b】
【0252】
表6a(対応して表6b)は8(対応して15)に等しい次元nに対するlおよびl!の指数のコンパクトな表現を示す。
【0253】
【表6a】
【表6b】
【0254】
純粋な例示として、表6bを使用して整数l=12の分解の判断を試行しよう。
好ましくは表6bで、符号の最大次元がn=15であるので、「2」の指数を4ビットで表し、「3」の指数を3ビットで、その他の素因数5、7、11、13を2ビットで表す。表では列l=12において、そのコンパクトな指数e12=18を読むことができる。
【0255】
以下の表の読出しを信頼すると、B15=15ビットにおける18(=16+2)のバイナリ表現は、1つのかつ同じ素数に関連するビットを共にグループ化することにより:
000 0000 0001 0010、即ち00 00 〇〇 00 001 0010となる。
【0256】
【表6c】
【0257】
4つの低順位ビット(重みi=0乃至3)は素因数2の指数、即ち0010=2であり、これは2が素数2に割当てるべき指数であることを意味する。
次の3ビット(重みi=4乃至6)は素因数3の指数、即ち001=1であり、これは1が素数3に割当てるべき指数であることを意味する。
次の2ビット(重みi=7乃至8)は素因数5の指数、即ち00=0である。
次の2ビット(重みi=9乃至10)は素因数7の指数、即ち00=0である。
次の2ビット(重みi=11乃至12)は素因数11の指数、即ち00=0である。
次の2ビット(重みi=13乃至14)は素因数13の指数、即ち00=0である。
抽出手順は高順位ビットをマスクし、低順位ビットに含む素因数指数を回復し、次いで回復したビット数のコンパクトな指数をシフトし、次の素因数指数への切り替えを伴う。
従って次元15では、2の指数を始めとして6つの抽出すべき指数がある。
【0258】
2の指数のバイナリ表現は18の4つの低順位ビット、即ち0010に対応し、これは2に相当する。これらを回復するために、18の高順位ビットを15によりマスク(18&15と表示)し、これは:24−1=1111に等価である。
得られる結果はe12=18&(2≪4−1)=2であり、これは2が素数2に割当てるべき指数であることを意味する。
次いで、18を右に4ビットシフトし、000 0000 0001=1を与える。
3の指数のバイナリ表現は1の3つの低順位ビット、即ち001(=1)に対応する。これらを回復するために、1の高順位ビットを7によりマスクする(1&7と表示し、値
23−1=111をうる)。
得られる結果はe121=1&(2≪3−1)=1であり、これは1が素数3に割当てるべき指数であることを意味する。
次いで、1を右に2ビットシフトし、そうするとこれは全てのその他の高順位ビットに対し0000 0000=0を示す。
それ故l=12の累乗が
−素数2に対して2、および
−素数3に対して1、
即ちl=12=22×31であることを思い出すであろう。
【0259】
*分解の上限
【0260】
ここで各素因数に対し、部分ランクt’の分母におけるその指数がt’の分子におけるその指数以下であることを仮定する。
【0261】
【数72】
【0262】
であるので、t’が厳密に正であればこれは当てはまり、それ故
【0263】
【数73】
【0264】
である。
実際には、シャルクビック公式により、およびq>1であれば、値
【0265】
【数74】
【0266】
は分母Pk(q>1であればPk≦(n−1)!)の指数の最大値β’iの上限である。
【0267】
それ故、不等式
【0268】
【数75】
【0269】
を調べれば十分であり、これは以上で説明したβiの値を判断する処理演算により既に実行している。その他の場合、β’iを明確に検索し、最大のβiおよびβ’iを使用してbniを計算することが可能である。
q=1の場合、既知ランク(t=0)の単一符号ワードを置換符号に含むことは理解されるであろうし、それ故事前にランクの計算および対応する逆演算を実行することは無用である。一方この特定の場合を個別に扱うことを望まない場合でも最大のβiおよびen!iにより、なお値bniを計算する配備をなしうる。以下の表7はn=16のこの場合を示す。
【0270】
【表7】
【0271】
次に、基本分解を蓄積するのに必要なメモリ容量の簡潔な説明に進む。
基本分解の表現に選択する解決法とは独立に、基本分解をテーブルに蓄積し、次いでランクの符号化および復号化演算においてこれらのテーブルのアドレス指定に使用することができる。0の分解は可能ではない(そして、その上使用しない)が、0の分解に対し「ダミー」指数(例えば複数の0または複数の1)を蓄積し、アドレス計算を簡単にすることは好ましいであろう。
以下の表8は、これら2つ(0のダミー分解の蓄積の有無)の場合を説明する5つの解決法の基本分解に関係するデータを蓄積するのに必要なメモリサイズを要約する。
【0272】
【表8】
【0273】
第5の解決法では、ビット数bniの蓄積(+mn!)を考慮する。一方実際にはビット数をメモリから読出すよりむしろ、以下の実施形態に見るであろうように、ビット数のメモリからの読出しは「ハードにより布線」する(その値を変数として宣言することなく計算プログラムに設定する)。それ故、ビット数を実際に蓄積するのは無意味に思われた。
表9は、nmax=8および15(0のダミー蓄積を伴う)の場合のこれら5つの解決法の分解指数に関係するデータを蓄積するのに必要なメモリを示す。
【0274】
【表9】
【0275】
次に、素因数累乗の蓄積に関する説明に進む。
基本分解以外に、本発明は素因数累乗を使用し、その分解から部分ランクを計算する。これら素因数テーブルからその累乗を実時間(「オンライン」)で計算することが可能である。好ましくは、2以外の素数の累乗を事前計算して蓄積し、2の累乗のみを実時間で計算する。以下の表10aは(AMR−WB+符号化器で使用するもののような)次元8の置換符号に必要な3、5および7の累乗を示す。表10bは(TDAC符号化器で使用するもののような)最大次元15の置換符号に必要な3、5、7,11および13の累乗を示す。
【0276】
【表10a】
【表10b】
【0277】
ここで再び、各素因数に必要な累乗数のみを蓄積することが可能である。変数として規則的にアドレス可能な単一の累乗テーブルのみを有することが好ましければ、各素因数に対し必要なp2(p2=3)の累乗数と同様に多くの値を蓄積する配備を行うことができる。使用しない累乗については、勿論複数の1または複数の0などのダミー値の蓄積を使用することが可能である。
【0278】
次に、本発明を使用して符号化を実行する置換ランクの計算に関する説明に進む。
選択する基本分解セットおよびその表現に応じて幾つかの変形が存在する。簡明さのため、l!およびlの階乗分解を伴う基本分解セットに好ましい実施形態の場合に、以下の可能な実施の説明を限定する。
以下では、最も一般的な場合である各基本分解のmn!の指数を持つ指数の分解相互関係表現に関する解決法をまず説明する。指数に関する分解相互関係表現の変形を次いで記述する。最後に、基本分解指数のコンパクトな表現に関する解決法を幾つかの変形と共に説明する。その上で、本発明が置換ランクの符号化の処理演算に完全に適用できることが明らかになるであろう。
【0279】
計数処理の例として、シャルクビックアルゴリズムを以下で考察する。
【0280】
分解指数の分解相互関係表現
【0281】
nを使用する置換符号の最大次元であるとし、mn!を量n!の分解に含む素因数の数とする。
分解指数の分解相互関係表現を使用する符号化に関する第1の実施形態の説明を以下に提示する。
【0282】
第1の実施形態による符号化
【0283】
ここで、l!およびlの基本分解指数をl=0に対するダミー蓄積と共に本明細書の以上の表4dの「第4の」解決法により、mn!×(n+1)セルを有するそれぞれDlおよびDl!と表示する2つの単一次元テーブルに好ましくは蓄積する。本明細書で以上に記述したように、mn!の列および(n+1)の行を有する2次元テーブルを考慮することもまた可能であろう。l(対応してl!)の指数を規則的に(mn!の値毎に)蓄積するので、基本分解指数を読出す演算はテーブルDl(対応してDl!)におけるアドレス計算を必要とする。l!(対応してl)の分解指数を読出すために、テーブルDl!(対応してDl)のアドレス(l×mn!)を指示し、従って指数
【0284】
【数76】
【0285】
(対応してel1)、次アドレス(l×mn!+1)にある指数
【0286】
【数77】
【0287】
(対応してel2)、より一般的にはアドレス(l×mn!+i−1)にある指数
【0288】
【数78】
【0289】
(対応してeli)を目標とすることが必要である。本明細書で以上に記述したように2次元テーブルでは、指数
【0290】
【数79】
【0291】
(またはeli)はアドレス((l;(i−1))(列(i−1)および行l)にある。
l=0に対するダミー蓄積の配備がなされなければ、l(l>0)のnの基本分解テーブルDlにおけるアドレス計算は(l−1)×mn!であることに留意すべきである。
【0292】
初期化
【0293】
・Pkのmn!の中間分解指数(以下のステップC−3を参照して分かるであろうように好ましくは各位置で更新するmn!のセルを有するテーブルPに蓄積する)をゼロに初期化する。従って、命令は以下の通りである。
【0294】
【数80】
【0295】
・ランクtおよびqの重みwkd(各位置で更新するであろうqセルを有するテーブルwに蓄積する(本明細書の以下のステップC−2))をまたゼロに初期化する。命令は以下の通りである。
【0296】
【数81】
【0297】
指標kに関する反復
【0298】
図5を参照して、nの位置に関する反復(変数kに関するループにより)に進む。図5のステップC−nの記法における文字「C」は用語「符号化」を示す。
ステップC−1で、変数dkを読む。ステップC−2は構成上テーブルwのセルdkの更新を含む:w[dk]=w[dk]+1
ステップC−3はPkの分解指数(テーブルP)の更新であり、特に
−アドレスmn!×w[dk]からテーブルDlの基本分解w[dk]のmn!の指数
【0299】
【数82】
【0300】
の読出し(ステップC−31)および
−更新:1≦i≦mn!に対し、
【0301】
【数83】
【0302】
(ステップC−32)を伴う。
【0303】
従ってステップC−31を実施するには、
【0304】
【数84】
【0305】
と表示するテーブルDlの基本分解w[dk]の第1の指数がアドレスmn!×w[dk]にあり、
【0306】
【数85】
【0307】
と表示する第2の指数がアドレス(mn!×w[dk]+1)にあるなどである。より一般的には、指数
【0308】
【数86】
【0309】
はアドレスmn!×w[dk]+i−1にある。
平行してステップC−4で、通常の関係式
【0310】
【数87】
【0311】
からSkを計算する。
ステップC−5はSk値に関する検査である。部分ランクIkdkがゼロであり(本明細書の以上の公式(7))、ランクtが不変であることを意味するSkがゼロ(矢印Y)であれば、処理はステップC−11により後に続く。その他の場合(Sk≠0である矢印N)、処理はステップC−6により継続し、ステップC−6で基本分解Skのmn!の指数
eSkiをテーブルDlのアドレスmn!×Skにおいて読出す。
平行して、ステップC−7はテーブルDl!のアドレスmn!×(n−1−k)において基本分解(n−1−k)!のmn!の指数
【0312】
【数88】
【0313】
を読むことにある。総和Skがゼロでなければ(検査C−5のNの出口)、ステップC−7を実行し、何れにしろ部分ランクIkdkがゼロであれば、テーブルDl!における不要な読出しを回避するようにすることを注記することにする。
ステップC−8で、種々のテーブルの読出し結果を共にグループ化し、1≦i≦mn!の場合の関係式
【0314】
【数89】
【0315】
により、まず部分ランクIkdkのmn!の分解指数を計算することができる。
最後にステップC−9で、部分ランクIkdk自体を次式により計算する。
【0316】
【数90】
【0317】
項w[dk]が関係する置換符号の必ず最大次元n以下である重みであることを思い出すであろう。同様にこのような重みの総和Skは最大次元nより小さく留まり、同じことが勿論(n−1−k)に対しても当てはまる。w[dk]、Skおよび(n−1−k)!の分解を、実際、表4dなどの整数分解または最大次元nに至る範囲の整数階乗のテーブルにリストする。テーブルにリストする分解w[dk]および先行ループ(k−1)で判断し、メモリに保持するPk−1の分解から、Pkの分解を判断する。
【0318】
図5の部分ランク計算ステップの純粋な例示として、次元n=8およびq=4の置換符号を考察する。この例では、4つの列および9つの行を持ち、それ故36のセルを含む2次元テーブルに指数を蓄積する。それ故、列がpi=2、3、5、7および行がl=0、...、8の本明細書で以上に提示した表4dから指数を抽出することができる。
この例では先行位置k=3において、重みwのテーブルが{1、1、0、3}であり、それ故P3=1!10!3!=6であると仮定する。P3(=21×31×50×70)の分解指数テーブルPはそれ故{1、1、0、0}である。ステップC−1の位置k=2では、d2=2を読出したと仮定する。この例のステップC−2では、セルw[2]を1(w[2]=0+1=1)だけ増分することによりセルw[2]を更新する。
ステップC−31で、1(=w[2])の4つの分解指数、即ち0、0、0、0を読む(表4dの6番目乃至9番目の列および3番目の行l=1を参照)。
次いで(ステップC−32で)、テーブルPを更新し、従ってP={1、1、0、0}を得る。
ステップC−4で、Skを:Sk=w[0]+w[1]=1+1=2と計算する。それ故、Skはゼロではない(検査C−5)。
・Skの4つの分解指数を読み(表4dの6番目乃至9番目の列であるが、4番目の行l=2をさらに参照して)(ステップC−6)、p1=2(6番目の列)の場合、指数は1、pi=3、5、7(7番目乃至9番目の列)の場合、指数は0である。
・表4dであるが、今回は2番目乃至5番目の列および7番目の行l=5をさらに参照して、5!((n−1−k)!に相当)の4つの分解指数を読む(ステップC−7)。p1=2(2番目の列)の場合、指数は3である。p2=3(3番目の列)の場合、指数は1であり、p3=5(4番目の列)の場合、指数はまた1である。他方、p4=7(5番目の列)の場合、指数は0である。
・ステップC−8で、部分ランクIkdkの4つの分解指数を計算する。
【0319】
【数91】
【0320】
ステップC−9で、部分ランクIkdkをその23×30×51×70=40の分解指数から計算する。
【0321】
再び図5を参照して、ステップC−10で関係式t=t+Ikdkに従う(ステップC−9に見出す部分ランクIkdkの加算により)更新により、置換のグローバルランクtを自ら判断する。
次いで、ステップC−11は変数k(k=k−1)を減分することを目的とし、ステップC−12は処理を継続するかを決めるkの値に関する検査である。従って、k≧0(検査C−12の出口のYの矢印)であれば、処理演算のステップはkの値を1ユニットだけ減分して最初のステップC−1から再反復する。その他の場合(検査C−12の出口のNの矢印)処理はステップC−13の終わり(「終了」)で終了する。
【0322】
従って、ステップC−9より上で、ステップC−8で判断するその分解から部分ランクを計算し、以下の3つの中間分解から部分ランク自体を判断することが理解されるであろう:
−(n−1−k)!
−Sk、および
−Pk。
ステップC−6およびC−7において実行する3つの中間分解の内の2つ(n−1−k)!およびSkの判断は基本分解のそれぞれのテーブルDlおよびDl!における簡単な読出しを含む。また以下のタイプの関係式によりテーブルDl!において読出すw[d]!のqの基本分解から、第3の中間分解(Pkの中間分解)の判断を簡単に実行することができる。
【0323】
【数92】
【0324】
直接的変形
【0325】
ステップC−3はこの中間分解の判断に関するより有利な変形を提示する。テーブルDlにおいて読出す基本分解および別の部分ランク(Ik+1dk)、例えばkの反復における先行部分ランクIk+1dkについて計算する別の中間分解(Pk+1の中間分解)から、Pkの中間分解を要するに判断することができる。
本発明の変形ではより一般的に、少なくとも1つの他の部分ランクについて以前に判断した少なくとも1つの中間分解から、中間分解をまた推論することができる。
【0326】
本明細書の以上で、最後の位置(k=n−1)から最初の位置(k=0)へのループによりランクの計算を実行した。一方、本発明はまた勿論最初から最後の位置へのループにも適合する。全て必要なことは、初期化フェーズを変更し、ステップC−2およびC−3およびその順序に適合することである。
このために、重みのテーブルwをqの重みw0dにより初期化することができる。次いで0乃至q−1の範囲のdに対して、w[d]!のmn!の分解指数をテーブルDl!において読出し、中間分解テーブルのmn!の値(P0の分解指数)を累積加算により計算する。
次いで、ステップC−10の後、ステップC−2の前で、ステップC−3を実行する。w[dk]の基本分解指数
【0327】
【数93】
【0328】
をP[i]から減算する
【0329】
【数94】
【0330】
ことにより、Pの中間分解を更新する。次いでw[dk]の値を1だけ減算する(w[dk]=w[dk]−1)ことにより、ステップC−2を実行することができる。ステップC−11は変数kの1の増分を目的とし、ステップC−12はk=nであるかを単に検査する。
【0331】
可変次元nの置換符号に対して
【0332】
【数95】
【0333】
の演算を実行するよりむしろ、初期化においてmn!を読み、演算をただmn!回のみ実行するのが好ましいであろうことは簡単に注記する価値がある。
【0334】
第1の実施形態に関する一般的な変形
【0335】
より一般的には、本発明の意味する符号化に対し図5で表す実施は多数の変形を可能にする。
従って第1の変形では、(lまたはl!の)各基本分解はまたテーブルml!を含む。数ml!(1≦l≦n)を読出すのは利点をもたらす。要するに、ステップC−3およびC−6乃至C−10を最早それぞれmn!回実行せず、ただ:
・ステップC−3について
【0336】
【数96】
【0337】
回、
・ステップC−6およびステップC−8の加算
【0338】
【数97】
【0339】
について
【0340】
【数98】
【0341】
回、および
・ステップC−7およびC−9についておよびステップC−8の減算
【0342】
【数99】
【0343】
についてm(n−1−k)!回実行する。
さらに値mlを蓄積していれば、その場合全て必要なことは:
・ステップC−3を
【0344】
【数100】
【0345】
回、および
・ステップC−6を
【0346】
【数101】
【0347】
回およびステップC−8の加算を実行することである。
【0348】
符号化の別の変形で、加算にlの基本分解指数の蓄積を第3の解決法(本明細書の以上の表4c)により使用すれば、ステップC−3を
【0349】
【数102】
【0350】
の値について実行することができる。同様に、ステップC−6を
【0351】
【数103】
【0352】
の値について実行する。ステップC−8においてm(n−1−k)!の加算およびm(n−1−k)!の減算を配備する代わりに、実行する減算の数はm(n−1−k)!に留まるが、
【0353】
【数104】
【0354】
の加算のみが必要である。特に以下の通りである。
【0355】
【数105】
【0356】
第3の変形で部分ランクの3つの項(分子の2つおよび分母の1つ)への分解に代わり、部分ランクを2つの項へ分解し、その1つは商である。従って、部分ランクIkdkを次の2つの項に分解する。
−総和Skおよび
−商
【0357】
【数106】
【0358】
この商を次の関係式により更新することができる。
【0359】
【数107】
【0360】
従ってq+1の基本分解((n−1−k)!およびテーブルDl!において読出すqw[dk]!の基本分解)からのRkの分解の判断よりむしろ、
【0361】
【数108】
【0362】
と表すRk+1の中間分解および(n−1−k)およびw[dk]の基本分解(これら2つの基本分解をテーブルDlにおいて読出す)から、Rkの中間分解を判断する。
先の変形と比較して
【0363】
【数109】
【0364】
の分母に関する中間分解の判断および蓄積(テーブルP)に代わり、商Rkの中間分解を判断し、次いで蓄積する(このためにテーブルRを配備する)。テーブルPのゼロへの初期化をこの比の指数に関するテーブルRのゼロへの初期化により置換する。ステップC−3はテーブルRを更新する((n−1−k)およびw[dk]の基本分解指数を読むことにより)簡単なステップとなり、これを次式で表す。
【0365】
【数110】
【0366】
蓄積の選択肢により、ml!の加算と減算またはm(n−1−k)!の加算(対応して
【0367】
【数111】
【0368】
の減算)またはm(n−1−k)の加算(対応して
【0369】
【数112】
【0370】
の減算)すら、またはw[dk]および(n−1−k)のゼロでない指数についてのみ:m’(n−1−k)の加算および
【0371】
【数113】
【0372】
の減算により、この更新を行うことができる。この場合、ステップC−8は以下のタイプの加算のみを含む。
【0373】
【数114】
【0374】
蓄積の選択肢により、mn!の加算または
【0375】
【数115】
【0376】
の加算、または
【0377】
【数116】
【0378】
の加算すら、またはSkのゼロでない指数についてのみ:
【0379】
【数117】
【0380】
の加算を次いで計数する。
この比Rkは必ずしも整数ではなく、これは指数R[i]が負でありうることを意味することを注記することにする。この変形では、符号化における階乗分解(それ故テーブルDl!)は最早有用ではなく、ただテーブルDlのみの蓄積により整数l(l≦n)の簡単な(n+1)の基本分解セットを使用することができる。
【0381】
分解指数のコンパクトな表現
【0382】
次に、分解指数のコンパクトな表現に基づく符号化の第2の実施形態の説明に進む。
基本分解指数はコンパクトに表現され、第1の実施形態を参照して本明細書で以上に説明したような分解相互関係形式では最早ない。簡明さのため、単一ワードに指数のコンパクトな表現を含む場合のみを説明する。それ故本明細書で以上に説明したように(n+1)セルを持つそれぞれD’lおよびD’l!と表示する2つのテーブルにl=0に対するダミーワードの蓄積と共にこれらのワードを蓄積する。l!(対応してl)の分解ワードを読むために全て必要なことは、テーブルD’l!(対応してD’l)のアドレスlを指示することであるので、基本分解指数を含むこれら2つのワードテーブルにおけるアドレス計算は直接的である。
l=0に対するダミーワードの蓄積のない、基本分解l(l>0である)に対応するワードはテーブルD’lのアドレス(l−1)にあることを注記することにする。
【0383】
第2の実施形態による符号化
【0384】
初期化
【0385】
・Pkのmn!の中間分解指数のコンパクトな表現を含むワードePをゼロに初期
化する:eP=0
ワードePを各位置に関して更新することにする(以下のステップCC−3)。
・以前のように、各位置において更新することにする(本明細書の以下のステップCC
−2)qセルを有するテーブルwに蓄積するランクtおよびqの重みwkdをまた値ゼ
ロに初期化する。対応する命令は以下の通りである:
・t=0
・w[i]=0、0≦i<q
・k=n−1
【0386】
n位置に関する反復(kに関するループ)
【0387】
次に、図6を参照して、この第2の実施形態における符号化の主ステップに進む。図6のステップCC−nの記法の文字「CC」は「コンパクトな表現」による「符号化」を示す。
ステップCC−1で、変数dkを読む。ステップCC−2は構成上変数wの更新を含む:w[dk]=w[dk]+1
ステップCC−3はワードePの特に以下による更新である:
−ステップCC−31のテーブルD’lにおけるw[dk]の分解指数のコンパクトな表現を含むワード
【0388】
【数118】
【0389】
の読み取り、次いで
−ステップCC−32におけるワードeP自体の更新
【0390】
【数119】
【0391】
平行してステップCC−4で、総和Skを計算する。
【0392】
【数120】
【0393】
次ステップCC−5はSk値に関する検査である。総和Skがゼロであれば(矢印N)、指標kを直ちに減分する。その他の場合(検査CC−5の出口の矢印Y)、ステップCC−6のテーブルD’lにおけるSkの分解指数のコンパクトな表現を含むワード
【0394】
【数121】
【0395】
の読出しにより、処理は継続する。
平行して(有利には検査CC−5の結果に応じて)、(n−1−k)!の指数のコンパクトな表現を含むワードe(n−1−k)!をステップCC−7でテーブルD’l!において読む。
ステップCC−8で、種々のステップCC−3、CC−6、CC−7から得る結果を共にグループ化し、以下の2つの簡単な演算(好ましくは加算続いて減算)により部分ランク
【0396】
【数122】
【0397】
の分解のコンパクトな表現を含むワード
【0398】
【数123】
【0399】
を計算する。
【0400】
【数124】
【0401】
以前に説明したようにワードビットの適するオフセットにより、ステップCC−9は部分ランク
【0402】
【数125】
【0403】
の、ワード
【0404】
【数126】
【0405】
に含むmn!の分解指数
【0406】
【数127】
【0407】
の抽出を目的とする。このため、1乃至mn!の範囲の指標iに関するループを配備する(1へのiの初期化CC−91、iの値の検査CC−93およびiがmn!の値に達するまでの増分CC−94)。次いで、iの各ループは自らに以下のタイプの命令CC−92を適用した。
【0408】
【数128】
【0409】
記法「≪b」および「≫b」はそれぞれbビットの左シフトおよび右シフトを示すことが思い出されるであろう。その上、記法「&」はビット毎の「AND」論理演算を示す。命令i’1)は
【0410】
【数129】
【0411】
のbniの低順位ビットを回復することにある。実際には、命令「((1≪bni)−1)」に対応するマスクをハードにより布線する。
換言すれば、高順位ビットのマスク((1≪bni)−1)を初めに(1に等しいループ指標iに対して)適用し、まず第1の素因数p1に関連する
【0412】
【数130】
【0413】
の指数を付与する
【0414】
【数131】
【0415】
のbn1の低位順位ビットのみを回復する。
次いで、
−
【0416】
【数132】
【0417】
のビットをbn1だけ「右に」シフトし、高順位ビットの次の素因数p2に関連する指数を付与する(マスク((1≪bni)−1))最高順位ビットを回復し、
−次いで、指数
【0418】
【数133】
【0419】
を抽出し、
−次いで、bn2ビットの右シフトを適用し、
−i=mn!まで継続する。
次のステップCC−10は以下のように部分ランクIkdkを計算することにある。
【0420】
【数134】
【0421】
次いで、部分ランクIkdkを全ランクtに加える(ステップCC−11のt=t+Ikdk)。
指標kの値を次ステップCC−12において減分し(k=k−1)、この減分した値によりステップCC−4、CC−1、CC−7および後続のステップを再開する前に、kの値が−1に達していないか(k<0)を確かめるために検査CC−13において調査を実行し、−1になっている場合は処理を終了する(ステップCC−14)。
【0422】
このように分解表現とは独立に、本発明は部分ランクを効果的に計算することを可能にする。ステップCC−10は先行ステップCC−8およびCC−9において判断したその分解からの部分ランクの計算を目的とする。3つの(項(n−1−k)!、SkおよびPkの)中間分解を使用する。ステップCC−6およびCC−7で実行するその内の2つ((n−1−k)!およびSk)の判断はテーブルD’l!およびテーブルD’lにおけるそのコンパクトな表現の簡単な読出しにある。ステップCC−3で実行する第3の中間分解(Pk)の判断は、またテーブルDlの読出しに続く、読出した基本分解のコンパクトな表現の加算によるこの中間分解のコンパクトな表現の更新を必要とする。
以前に示したように第1の実施形態を参照して、値mn!(0≦l≦n)の蓄積はステップCC−9およびCC−10の複雑度の削減を可能にする。部分ランクIkdkに関する分解指数の抽出ループをmn!回に代わってm(n−1−k)!回実行する。同様に、ステップCC−10は最早乗算mn!ではなく、乗算m(n−1−k)!を含む。
【0423】
次に、本発明を使用する置換ランクの復号化に関する説明に進む。
ここで再び、基本分解表現の解決法に応じる幾つかの(分解相互関係またはコンパクトな)変形がある。復号化の第1の実施形態に関する説明に進み、これは分解相互関係分解表現を使用する符号化および以上に提示した表4dに関係する第4の解決法によるその蓄積について本明細書で以上に説明した第1の実施形態に似る。例としてシャルクビックアルゴリズムを採用する置換ランクの復号化に本発明が完全に適用できることが明らかになるであろう。
【0424】
第1の実施形態による復号化
【0425】
分解指数の分解相互関係表現を使用する復号化は好ましくは以下のようにデータの初期化により始まる。
【0426】
初期化
【0427】
・値wのテーブルをqの重みw0dにより初期化する(以下で説明することにするステ
ップD−19の各位置に関するループの終わりでwを更新する)。適する命令は以下の
タイプでありうる:
・w[i]=w0i、0≦i<q
・項P0のmn!の分解指数を計算する(下記ステップD−18の各位置に関するルー
プの終わりの各位置でまた更新するmn!のセルを有するテーブルPに蓄積する)。適
する命令は以下のタイプでありうる:
・1≦i≦mn!についてP[i]=0
・d=0乃至q−1のループ
・テーブルDl!における
【0428】
【数135】
【0429】
のmn!の分解指数
【0430】
【数136】
【0431】
の読出し、次いで
【0432】
【数137】
【0433】
・最後に、k=0に初期化する。
次に図7を参照して、第1の実施形態による復号化の主ステップに進む。図7のステップD−nの記法における文字「D」は「復号化」を表す。
【0434】
n位置に関する反復(指標kに関するループ)
【0435】
第1のステップD−1はテーブルDl!における(n−1−k)!のmn!の分解指数
【0436】
【数138】
【0437】
を読出すことにある。
次ステップD−2は値dk=0およびIkdk=0を設定する。
次いで、w[dk]≠0であるようなアルファベットのdkに関する第1の値の検索に進む。このため、w[dk]=0であるかを調べる検査D−3を配備し、該当する場合(矢印Y)、dkの値を増分し(dk=dk+1)、ゼロでないw[dk]の値を見つけるまで検査D−3を反復する。この値が見つかれば(w[dk]≠0の場合矢印N)、次ステップはランクtの値に関する検査D−5である。ランクがゼロであれば(検査D−5の出口の矢印Y)、Pkの指数を更新する(ステップD−18)まで以下のステップを適用するのは無意味である。ランクがゼロでなければ(検査D−5の出口の矢印N)、処理を後続のステップD−6およびD−7により継続し、これらのステップでそれぞれSk=0および中間値IkをIk=Ikdkに設定する。
【0438】
次ステップD−8は総和Sk=Sk+w[dk]を更新する計算である。Skであることが判明する総和のmn!の分解指数
【0439】
【数139】
【0440】
に関するテーブルDlの読出し(ステップD−9)が次ステップD−8に続く。
ステップD−10は、1≦i≦mn!である関係式
【0441】
【数140】
【0442】
の部分ランク分解指数
【0443】
【数141】
【0444】
の計算を目的とする。現ループの終わりで、および次ループに対して後に説明することにするステップD−18で、上記のように初期化する指数P[i]を更新する。
ステップD−11は部分ランクの計算
【0445】
【数142】
【0446】
を目的とする。
次の3ステップは、全ランクtの値の部分ランクの値との比較による全ランクtの値に関する検査を目的とする。これを行うためにステップD−12で、dkの値を増分し(dk=dk+1)、検査D−13は次の通りである:t−Ikdk≧0?。
不等式を満たせば(矢印Y)、ステップD−7乃至D−13を新しく増分したdkの値により反復する。その他の場合(矢印N)、ステップD−12の前のdkの値に戻るために、dkの値を減分する(dk=dk−1)ステップD−14により処理を継続する。このdkの値に対し、部分ランクIkdkは上述の中間値Ikを取る(ステップD−15で、Ikdk=Ik)。
次いで、ランクtを更新し、ランクtはt=t−Ikdkとなり(ステップD−16)、テーブルDlにおけるw[dk]のmn!の分解指数
【0447】
【数143】
【0448】
の読出し(ステップD−17)から、Pkの指数を(テーブルPにおいて)更新し、続けて1≦i≦mn!に対し指数自体を
【0449】
【数144】
【0450】
により更新する(ステップD−18)。次いで、w[dk]の値を減分し(w[dk]=w[dk]−1:ステップD−19)、指標kの値を増分(k=k+1:ステップ20)し、次のループに備える。
第1のステップD−1にループにより戻る前に、n構成要素を全て処理していないことを確認するために調査を実行する。このために、kの値のnとの比較(k<n)によるkの値に関する検査D−21を配備する。指標kが値nに達しない限り(検査D−21の出口の矢印Y)、kの次の値についてステップD−1において処理を再開する。その他の場合(検査D−21の出口の矢印N)、ステップD−22の終わりで処理を終了する。
【0451】
ステップ11はそれぞれの項(n−1−k)!、SkおよびPkの3つの中間分解からステップ10で判断したその分解の使用による部分ランクの計算を目的とすることを思い出すべきである。ステップD−1およびD−9で実行するそのうちの2つ((n−1−k)!およびSk)の判断は構成上それぞれのテーブルDl!およびDlにおける簡単な読出しを含む。テーブルDlの読出し(ステップD−17)に続く読出した(ステップD−18)基本分解指数の減算によるこの中間分解指数による更新により、またステップD−18で実行した第3の中間分解(Pk)の判断を実行する。この中間分解の本明細書で以上に説明した初期化はテーブルDl!のqの読出しに続く読出したqの基本分解指数の加算によるこの中間分解指数による更新を必要とする。
【0452】
本明細書で以上に説明した符号化に関しては、図7の処理は、適する場合一定のステップの複雑度を削減する変形を可能にする。
比Rkの指数の使用(前記のように)を含む変形には特に関心を持てる。要するに、図7を参照して本明細書で以上に説明した復号化処理演算では、所与の位置kについてdの幾つかの値に対する指数
【0453】
【数145】
【0454】
を計算する。検査するdの各値について、その他の変形は各指数に対する減算および加算を必要とする。
【0455】
【数146】
【0456】
一方、総和Skおよびその指数
【0457】
【数147】
【0458】
のみが所与の位置kに関してdにより変化するので、比Rkの指数を使用する変形は加算
【0459】
【数148】
【0460】
のみを必要とする。
【0461】
第2の実施形態による復号化
【0462】
次に、図8を参照して分解のコンパクトな表現を使用する復号化の実施例の説明に進む。
まず、データを以下のように初期化する。
【0463】
初期化
【0464】
・まず、qのセルを有するテーブルを参照して、0≦i<qに対する項w[i]=w0
iを判断するべきである。
・Pkのmn!の分解指数のコンパクトな表現を含むワードePを計算する。このため:
・eP=0を設定し、
・d=0乃至q−1に対するループを配備し:
・ループはテーブルD’l!にw0d!の指数mn!のコンパクトな表現を含むワー
ド
【0465】
【数149】
【0466】
の読取り、および
【0467】
【数150】
【0468】
・の更新を伴い、
・次いで、k=0に設定する。
【0469】
n位置に関する反復(kに関するループ)
【0470】
図8のステップDC−nの記法における文字「DC」は「コンパクトな表現」による「復号化」を示す。
ステップDC−1はテーブルD’l!において項(n−1−k)!の指数mn!のコンパクトな表現を含むワードe(n−1−k)!の読出しにある。
ステップDC−2乃至DC−8は図7を参照して本明細書で以上に説明したステップD−2乃至D−8に類似である。
他方ステップDC−9では、テーブルD’lに総和Skのmn!の指数のコンパクトな表現を含むワード
【0471】
【数151】
【0472】
を読む。
次いでステップDC−10で、部分ランクIkdkの指数のコンパクトな表現を含むワードを好ましくは以下のように計算する。
【0473】
【数152】
【0474】
汎用ステップDC−11はグローバルに部分ランクIkdkの指数の抽出にある。このため、次の配備を行う。
−i(1≦i≦ml!)に関するループ(DC−111におけるi=1の初期化、本明細書で以下に説明する指数
【0475】
【数153】
【0476】
の抽出(ステップDC−112)後、値mn!に達するまで指標iを増分して(ステップDC−114)ループ指標iを値mn!と比較する(ステップDC−113))。
−指数
【0477】
【数154】
【0478】
の抽出(ステップDC−112)を:
マスク((1≪bni)−1)による
【0479】
【数155】
【0480】
の高順位ビットのマスク化によるコンパクトな指数
【0481】
【数156】
【0482】
の低順位ビットにおいて以下のように表し:
【0483】
【数157】
【0484】
このマスク化に以下のコンパクトな指数
【0485】
【数158】
【0486】
のbn1の「右」シフトが続く。
【0487】
【数159】
【0488】
この汎用ステップDC−11は符号化のための図6の汎用ステップCC−9に類似である。
ステップDC−12乃至DC−17は、それ自体分解相互関係表現における復号化に特定の図7を参照する本明細書で以上に説明したステップD−11乃至D−16に類似である。
他方、テーブルD’l!にw[dk]のmn!の指数のコンパクトな表現を含むワード
【0489】
【数160】
【0490】
の読出しにより、汎用ステップDC−18におけるPkの指数(テーブルP)の更新をステップDC−181で行い、次いでPkの指数の更新自体
【0491】
【数161】
【0492】
をステップDC−182で実行する。
次いで、ステップDC−19乃至DC22は、分解相互関係分解を使用する復号化に特定の図7のステップD−19乃至D−22に類似である。
【0493】
次に、本明細書で以上に説明した変形により提供する種々の利点の説明に進む。
mn!(および/またはmlまたはm’l)のテーブルを使用する分解相互関係表現による第1の実施形態の変形は、値mn!のテーブルのみを使用する主実施形態よりさらに少ない加算/減算演算を含む。
この場合、複雑度の削減は何にもまして最後の位置(即ち、m(n−k)!、m’lまたはmlがmn!より小さい場合)において大きい。にもかかわらず、複雑度のこの削減はメモリ読出しステップ(ステップC−31、C−6およびC−7)の複雑度の増加を伴う。読み出すべき値は少ないが、他方でアドレス計算がより複雑である。
この場合、関心の持てるトレードオフは(mn!の指数を持つ)基本分解の規則的な蓄積を含み、テーブルDlおよびDl!のアドレス指定を容易にし、次いで(n+1)セルを持つテーブルDmに値ml!を蓄積する。次いで、値mlを蓄積し、加算/減算の数を効果的に削減するべきである。とはいえ、この測定はステップC−6およびD−9(対応してC−3およびD−19)の前に値mSk(対応してmw[dk])の読出しを必ず伴うが、一方値m(n−k)!はkに関する各反復の開始時にのみ読まねばならない。
【0494】
その上、分解相互関係表現に比しコンパクトな表現が提供する利益は以下の通りである。
−次に、テーブルPを更新するステップは符号化(対応して復号化)では単一の加算(対応して減算)以上を含まない。
−指数
【0495】
【数162】
【0496】
の計算は、また単一の加算および単一の減算のみを必要とする。
−ワードeKを読むアドレス計算は直接的であり、各値Kに対し単一のメモリアクセスおよび読出しのみを必要とする。
一方、コンパクトな表現はワード
【0497】
【数163】
【0498】
に含む部分ランクIkdkの指数の抽出(ステップCC−9およびDC−11)を必要とする。
一方、本明細書の以下で分かるように、部分ランクの素因数分解からの計算に取り、この演算は必ずしも欠点ではない。
【0499】
次に、素因数分解からの部分ランクの計算のこのような変形の利点に関する説明に進む。
符号化における(対応して復号化における)ステップC−9およびCC−10(対応してD−11およびDC−12)の意味する素因数累乗積の計算ステップの複雑度は、従来技術の意味する除算より遥かに小さい複雑度に留まるとはいえ、因数の数と共に大きく増加する。次に、部分ランクの多くの分解指数は実際にはゼロであり、それ故対応する累乗はまた1にある。多くの場合、全指数がゼロであるかまたは第1の指数のみがゼロでない。それ故、ゼロでない指数の累乗のみを検出し、維持することが有用である。詳細な表現では、この検出を検査mn!または検査m(n−1−k)!(各素因数に対し1回)のみにより実行することができる。
【0500】
有利には、コンパクトな表現は単一の検査により全指数がゼロであるか
【0501】
【数164】
【0502】
の検査を可能にし、該当する場合ランクt’=1である。さらに、et’の高順位ビットの検出はランクt’における最大のゼロでない指数の素因数指標の獲得、および符号化における(対応して復号化における)ステップC−9(対応してDC−11)のループ反復数の削減を可能にする。
にもかかわらず、コンパクトな表現におけるように詳細な表現では、ゼロでない指数の検出は複雑度を増すことに留意すべきである。全指数がゼロでなければ、素因数の累乗乗算の複雑度は同じに留まり、この複雑度はその場合ゼロでない指数の検出手順の複雑度により倍加する。
従って第1の変形では、素因数の可能な数が大きくなり(kがnより遥かに小さい)、その累乗乗算の複雑度が検出手順の複雑度より大きい場合にのみ、ゼロでない指数の検出を行うことができる。このため、命令行の増加の犠牲においてこの実施を適用するとしても、位置により異なるループを配備することが出来る。
分解相互関係表現およびコンパクトな表現を結合することがまた可能である。最終位置(小さい値ml!)に対する中間分解の計算は演算を殆ど伴わない。その場合、分解相互関係表現の使用が好都合であり、この表現は部分ランク指数の抽出を必要としない。他方第1の位置の場合、コンパクトな表現の使用がより好都合である。
【0503】
次に、既存の符号化/復号化における幾つかの実施例の説明に進む。
【0504】
3GPP AMR−WB+符号化器
3GPP AMR−WB+符号化器(規格[3GPPTS26.304])は代数ベクトル量子化を使用し、その辞書は次元8を有するゴセットネットワークRE8の置換符号結合である。
TCX技術は変換による予測符号化に対応する。より詳細には、TCX技術は知覚重みフィルタリングの後に適用するFFT変換符号化法を含む。規格[3GPPTS26.304]では、得られるFFTスペクトラムを次元n=8の下位帯域(または補助ベクトル)に細分化し、これらの補助ベクトルを個別に符号化する。補助ベクトルの量子化にはポイントの正規ネットワークRE8を使用する。次元8の量子化辞書は構成上ポイントのネットワークRE8から得るタイプIの置換符号結合を含む。
規格[3GPPTS26.304]によるTCX符号化器では、各置換符号は次元n=8における所与の符号付先導ベクトルに対応する。ネットワークRE8のポイントの量子化指標を以下のタイプの公式により計算する:
指標=基本オフセット+置換ランク
基本オフセットはテーブル化されているが、ランクはシャルクビック公式により計算する。にもかかわらず、これら符号付先導をその絶対先導により表し、置換符号における蓄積および検索を最適化する。関連する絶対先導リストは以下の参考文献に見ることができる。
ラゴット S、べセット B、ルフェーブル R著「32kビット/秒における広帯域TCX通話符号化に適用する低複雑度多元速度格子ベクトル量子化」ICASSP論文集、1巻、PP.501−4、2004年5月
【0505】
本発明の種々の変形を示すために、3つの実施例を以下で説明する。最初の2つの実施例は置換ランクの計算(符号化)に関係し、一方は分解相互関係分解表現を使用し、他方はコンパクトな表現を使用する。
本明細書の以下のおよび対応する付録のこれらの実施例では、テーブルRおよびPをR[0]からR[mn!−1]へおよびP[0]からP[mn!−1]へ指標指定するが(本明細書の以上の例により説明するように1からmn!へではなく)、ランク計算処理には特定の影響はない。
【0506】
第1の実施例(符号化)
【0507】
この実施形態では、分解相互関係基本分解表現を使用する。
その指数を36セル(=(8+1)×4)を持つ2つのテーブルに蓄積する。これらは付録A−11に提示し、Dl[36](それ故0のダミー分解の蓄積を伴う整数l(0≦l≦8)の分解指数を含む)およびDlと表示するテーブルである。
3、5および7の累乗の3つのテーブルをまた以下のように蓄積する:
Pow3[4]={1、3、9、27};Pow5[3]={1、5、25};
Pow7[3]={1、7、49}
【0508】
この実施形態では、一方が整数の基本分解Skであり、他方が商の中間分解である2つの中間分解から、部分ランク分解を判断する。
【0509】
【数165】
【0510】
以上に示すように、(7−k)!および
【0511】
【数166】
【0512】
の基本分解(q+1)に対応する基本分解からRkの中間分解を判断するよりむしろ、Rk+1の中間分解および(7−k)および
【0513】
【数167】
【0514】
の2つの基本分解から、この中間分解を判断する。
【0515】
【表11】
【0516】
本発明は以上の表11において各位置に対して示すm(7−k)!および
【0517】
【数168】
【0518】
の最大値に関する知見を適用し、これらの限界より大きな指標を持つ素因数指数を計算しないようにする。
【0519】
対応する処理を付録A−12に提示する。位置に関するループを分解して相互関係を表示することを注記することにする。また、商の素因数指数piを4セルを持つテーブルRが有するセルR[i−1]に蓄積することを注記することにする。
【0520】
第2の実施例(符号化)
【0521】
3GPP AMR−WB+符号化器による変形では、基本分解をコンパクトに表現する。その指数を含むワードを9セル(=(8+1))を持つ2つのテーブルに蓄積する。付録A−21を参照すると、テーブルD’lは整数l(0≦l≦8)の分解のためのワードを含み(それ故l=0の分解のダミー蓄積を伴い)、テーブルD’l!はその階乗分解のためのワードを含む。
3、5、および7の累乗をまた(使用しない累乗の0のダミー蓄積を伴う)12セルを持つテーブルPow[12]に蓄積する。
2つが整数Skおよび階乗(7−k)!の基本分解であり、第3の中間分解が部分ランクの分母の中間分解である3つの中間分解から、部分ランクの分解を判断する。
【0522】
【数169】
【0523】
以前に示したように
【0524】
【数170】
【0525】
の基本分解qからPkの中間分解を判断するよりむしろ、Pk+1の中間分解からおよび
【0526】
【数171】
【0527】
の基本分解から、この分解を判断する。4つのこの中間分解指数を含むコンパクトなワードを付録A−22で「eP」と表示する。また、「el」は4つの部分ランク分解指数を含むコンパクトなワードを表示する。
ここで再び、m(7−k)!に関する知見を適用し、部分ランク分解を表現するコンパクトなワード指数m(7−k)!のみを抽出する。
【0528】
対応する処理は付録A−22の主題である。ここで再び、位置に関するループを分解して相互関係を表示する。
【0529】
第3の実施例(復号化)
【0530】
第3の実施例は3GPP AMR−WB+符号化における置換ランクの復号化を扱う。
第1の実施例におけるように基本分解の分解相互関係表現を好ましくは使用し、第2の実施例におけるように3つの項の部分ランク分解を好ましくは使用する。しかしながら位置に関するループは分解相互関係表示しない。
以前に示したように基本分解からPkの中間分解を判断するよりむしろ、Pkー1の中間分解からおよび
【0531】
【数172】
【0532】
の基本分解から、Pkの中間分解を判断する。4つのこの中間分解指数をテーブルPに蓄積する。同様にPkの中間分解からおよび(7−k)!の基本分解から、別の中間分解(商の中間分解)を計算し、その指数をテーブルRに蓄積する。
対応する処理は付録A−3の主題である。商の(対応して積の)素因数指数piの指数を4セルを持つテーブルR(対応してP)のセルR[i−1](対応してP[i−1])に蓄積する。
【0533】
従って、本明細書の以上の第1の例は(商を含む)2つの項の部分ランク分解を使用し、他の2つの例は3つの項(分子の2つおよび分母の1つ)の分解を使用する。2つの符号化モードは個別の位置処理を使用し、ゴセットネットワークのポイントの8つの位置に関するループの分解相互関係表示によるアルゴリズムにおいて読出さず、ハードウェアにより布線するml!またはmlの項を使用するが、復号化モードはm8!(=4)の項のみを使用する。
【0534】
TDAC符号化器の実施例
【0535】
最後の実施例は、16kHz(広帯域)でサンプル化するディジタルオーディオ信号の符号化に使用する出願者のTDAC知覚周波数符号化器に関係し、その原理を本明細書で以下に説明する。
【0536】
TDAC符号化器は可変次元およびリゾリューション並びに最大次元15を持つ統計的ベクトル量子化を使用する。
次元8を持つポイントの正規ネットワークRE8の置換符号の場合、本発明は本質的に複雑度の削減を可能にする。一方12より大きな次元の置換符号を使用するTDAC符号化器の場合、本発明は非常に有利であることを証明するが、これは本発明が複雑度の削減のみならず、また固定点プロセッサに関する符号化器の実施を可能にし、その最大精度を符号のない32ビットの整数に限定するからである。本発明がなければ、このような実施は極めて複雑であろう。
【0537】
この符号化器の原理は以下の通りである。
帯域幅を7kHzに制限し、16kHzでサンプル化するオーディオ信号を320サンプル(20ms)のフレームに細分化する。50%の重複を持つ640サンプルの入力信号ブロック(20ms毎のMDCT分析のリフレッシュに相当する)に、修正離散コサイン変換(modified discrete cosine transform、「MDCT」)を適用する。最後の31の係数をゼロに設定する(その場合、最初の289の係数のみが0と異なる)ことにより、スペクトラムを7225Hzに制限する。マスク化曲線をこのスペクトラムから判断し、全マスク係数をゼロに設定する。スペクトラムを不等幅の32帯域に分割する。信号の変換係数により任意のマスク帯域を判断する。各帯域のスペクトラムに対し、MDCT係数のエネルギを(測定尺度要因を推定するために)計算する。32の測定尺度要因は信号スペクトル包絡線を構成し、信号スペクトル包絡線を次いで量子化、符号化し、フレームで送信する。ビットの動的割当はスペクトル包絡線の量子化解除バージョンから計算する各帯域のマスク化曲線に基づき、符号化器および復号化器のバイナリ割当間の両立性を得るようにする。タイプII置換符号結合を構成上含む辞書である、サイズに応じてネスト化する辞書を使用するベクトル量子化器により、各帯域にける規格化MDCT係数を次いで量子化する。最後に、トーンおよび音声情報、スペクトル包絡線並びに符号化係数を多重化し、フレームで送信する。
【0538】
置換ランク(符号化)に関する計算の実施例はここでコンパクトな分解表現を使用する。使用する置換符号の次元は可変であり、位置に関するループは分解相互関係を表示しない。この実施形態は部分ランク分解のゼロでない指数の検出法を示す。
ここで、基本分解をコンパクトに表現する。その指数を含むワードを16セル(=(15+1))を持つ2つのテーブルに蓄積する。付録B−1で、テーブルD’lは整数l(0≦l≦15)の分解のためのワードを含み、テーブルD’l!はその階乗分解のためのワードを含む。
3の累乗をまた8セルを持つテーブル(Pow3と表示)に蓄積し、5、7、11、および13の累乗を20セル(使用しない累乗のための0のダミー蓄積を伴う)を持つテーブル(Powと表示)に蓄積する。
【0539】
対応する処理を付録B−2において再度書き換える。
【0540】
勿論、本発明は例により本明細書で以上に説明した実施形態に限定しない。本発明は他の変形を包含する。
【0541】
出願者の知見では、本発明は置換符号における素因数累乗分解の最初の使用を含む。一方置換符号によるベクトル量子化におけるように結合表現の計算を配備する場合、この使用は特に有利である。従って一般に、本発明は置換ランクとは異なるが1つまたは複数の置換符号による符号化/復号化における任意の結合表現にこの素因数累乗分解を使用することを目的とする。
【0542】
本発明は、通話信号の符号化/復号化、例えば電話端末、特にセルラーにおいて有利に適用可能である。とはいえ、本発明はあらゆるタイプの信号、特にイメージまたはビデオ信号の符号化/復号化および符号化変調に適合する。
【0543】
本発明はまた置換符号を使用するディジタル信号の符号化/復号化デバイスのメモリに蓄積するように設計するコンピュータプログラムを目的にする。その場合、このプログラムは本発明の意味する方法のステップを実施する命令を含む。典型的に、本明細書で以上に説明した図4乃至図8はこのようなプログラムが含むことのできるアルゴリズムのフローチャートに相当することができる。
【0544】
本発明はまた置換符号を使用するディジタル信号の符号化/復号化デバイスを目的にし、図9を参照して、
−上述のタイプのコンピュータプログラム命令および選択する整数の事前記録分解表現を蓄積するメモリユニットMEMおよび、
−本発明の意味する方法を実施するこのメモリユニットMEMにアクセスする計算モジュールPROC
を含む。
【0545】
これらの手段MEM、PROCを設計し、
・ソース符号化器の指標指定モジュールにおいて、または
・チャネル復号化器の指標指定モジュールにおいて
・選択する符号ベクトルyから置換ランクtを供給し(図9の実線の矢印)、
・ソース復号化器の復号化モジュールの、または
・チャネル符号化器の符号化モジュールの
・置換ランクtから再構築する符号ベクトルyを供給することができる(図9の破線の矢印)。
【0546】
勿論、メモリMEMに事前記録する表現はアドレスの内容形式(分解相互関係表現)またはビットワード形式(コンパクトな表現)でありうる。
【0547】
付録
【0548】
【数173】
【数174】
【数175】
【数176】
【数177】
【数178】
【数179】
【数180】
【数181】
【数182】
【数183】
【数184】
【数185】
【数186】
【数187】
【符号の説明】
【0549】
MEM メモリユニット
PROC 計算モジュール
【技術分野】
【0001】
本発明は、音声、ビデオおよびより一般的にマルチメディア信号などのディジタル信号のその蓄積または伝送のための符号化/復号化に関する。本発明は、特に置換符号の符号化および復号化が引起す問題への解決法を提案する。
典型的に、本発明をまたソース符号化と同等な、チャネル符号化または「変調」に適用する。
本発明の意味するディジタル信号の圧縮符号化/復号化は通話および/または音響信号周波数符号化器が持つ変換係数の量子化に極めて有用である。
【背景技術】
【0002】
ベクトル量子化
【0003】
1つの非常に広く使用されるディジタル信号圧縮の解決法はベクトル量子化である。ベクトル量子化は有限セットから選択する同じ次元のベクトルにより入力ベクトルを表す。Mレベルを持つ量子化器(または「符号ベクトル」)は入力ベクトルセットに関する非全単射適用、一般にn次元実ユークリッド空間RnまたはM個別要素:Y={y0、y1、...yM−1}を持つRnの有限サブセットYにおけるRnのサブセットである。
Yは再生成アルファベットまたは「辞書」または「ディレクトリ」とも呼ばれ、その符号ベクトル要素は「符号語」(または「出力点」または「標本」とも)呼ばれる。
量子化器の各次元rのビット速度(またはその「リゾリューション」)を次関係式により定義する。
【0004】
【数1】
【0005】
ベクトル量子化では、nサンプルブロックをn次元ベクトルとして扱う。次元が非常に大きくなる場合ソース符号化理論により、ベクトル量子化性能はソース歪みビット速度限界に近づく。量子化器の最適性に関する必要条件に基づき、汎用ロイドアルゴリズム(Generalized Lloyd Algorithm、GLA)などの統計的方法を使用して、ベクトル量子化器辞書を設計することができる。当然得られる統計的ベクトル量子化器は構造を持たず、符号化および蓄積双方の複雑度はn2nrに比例するので、これにより計算および蓄積リソースに関してその探索は経費を要する。
図1Aを参照すると、3つの主な演算、即ち符号化の2つおよび復号化の1つがベクトル量子化器を使用する。まず辞書からの符号ベクトルの選択により、入力ベクトルを符号化する(ステップCOD)。これは、入力ベクトルに最も類似する符号ベクトルである(図1Aにおける演算OP1)。次いで、この符号ベクトル指標を判断し(ステップIND)、送信または蓄積する(図1Aにおける演算OP2)。復号化器(ステップDEC)では、符号ベクトルをその指標から判断する(図1Aにおける演算OP3)。
【0006】
変調では、図1Aの3つの演算OP1、OP2およびOP3を適用するが、順序は異なる。この変調/量子化の双対性を示す図1Bを参照して、指標から符号ベクトルへの遷移の配備を行う(図1Aの演算OP3に対応する図1BのCOD’ステップ)。次いで雑音の影響を受けるチャンネルを経る送信後に、受信ベクトルに最も近い符号ベクトルの検索を行う(図1Aの演算OP1に対応する図1BのDEC’ステップ)。最後に、符号ベクトル指標の復号化が第3のステップである(図1Aの演算OP2に対応する図1BのIND’ステップ)。
【0007】
次元、ベクトルおよびビット速度により複雑度は指数関数的に増大し、非構造化ベクトル量子化器の使用は実時間においてその使用が可能である小さな次元および/または低ビット速度に制限される。非構造化ベクトル量子化器にとり、最も近い近隣の検索(演算OP1)は、最も近い近隣と入力ベクトルとの間の距離の測定を最少にする辞書要素を選択する全辞書要素の全検索を必要とする。後者の2つの演算(指標指定OP2および逆演算OP3)は一般に表の簡単な読出しにより実行するが、それにもかかわらずこれはメモリ空間が高くつく。サイズおよび次元の制約を克服するために、基本ベクトル量子化の幾つかの変形が検討された。変形は辞書構造の欠落を修正し、従って複雑度の削減を試行するが、品質の代価を伴う。一方、性能/複雑度のトレードオフは高度化し、ベクトル量子化を効果的経費により適用することができるリゾリューションおよび/または次元の範囲を増すことを可能にする。多くの構造化ベクトル量子化器方式が提案されており、特に「置換符号」を実施するベクトル量子化器を以下に説明する。
【0008】
置換符号
「置換符号」ベクトル量子化器では、「先導」と(または「先導ベクトル」とも)呼ぶ第1の符号ベクトル構成要素の(辞書編集順序への)置換により、符号ベクトルを得る。これらの構成要素はサイズq(i≠jの場合にai≠ajであるようなqのアルファベットA)のアルファベットA={a0、a1...、aq−1}からその値を採用する。構成要素aiは実数(または完全整数)である。重みwi(iは0乃至q−1の範囲の指標である)はアルファベット文字aiの反復回数である。重みwiは
【0009】
【数2】
【0010】
であるような正整数である。規定により、アルファベットの値はa0>a1>...>aq−1を満たす。先導構成要素nは位置0から位置(n−1)へ降順に進む。それ故先導ベクトルy0は次形式の次元nのベクトルである。
【0011】
【数3】
【0012】
異なる構成要素の順序、例えば
a0<a1<...<aq−1
を選択できるであろうことは理解されるであろう。
先導ベクトルを「符号付先導」と呼び、置換符号を「タイプIに関するもの」であると言う。その他の符号ベクトルをy0の構成要素の置換により得る。置換の総数Mは次式の通りである。
【0013】
【数4】
【0014】
別のタイプの置換符号(タイプII)が存在する。再度、先導ベクトルは以前と同じ形式を有するが、その構成要素は正でなければならない(a0>a1>...>aq−1≧0)。y0の構成要素への全ての可能な符号結合の割当てによるy0の構成要素の置換により、その他の符号ベクトルをまた得る。置換の総数Mは次式の通りである。
【0015】
【数5】
【0016】
ここで、aq−1>0であればh=nであり、その他の場合h=n−wq−1である。この場合、先導ベクトルをまた絶対先導と呼ぶ。
【0017】
「置換符号」ベクトル量子化器を拡張して置換符号の合成(即ち結合)とし、最近この置換符号結合構造を次元およびリゾリューション可変ベクトル量子化に(出願者名がWO−04/00219の書類において)一般化した。置換符号は統計的ベクトル量子化において使用するだけではない。置換符号はまた代数ベクトル量子化に見られ、代数ベクトル量子化は正規ドット配列または誤り訂正符号から導出する高度構造化辞書を使用する。置換符号はまた変調において使用する。
【0018】
置換符号構造の使用により最適、高速最近近隣検索アルゴリズムの開発を可能にする(図1Aの演算OP1)。一方、符号ベクトルの指標指定(または番号指定)(図1Aの演算OP2)および逆復号化演算(図1Aの演算OP3)は非構造化ベクトル量子化器の場合におけるよりより多くの計算を必要とする。
置換を計数する幾つかの方法が存在する。シャルクビック(Schalkwijk)アルゴリズムはこれらの方法の1つである:
シャルクビックJ.P.M(Schalkwijk J.P.M)著「ソース符号化アルゴリズム(An Algorithm for source coding)」、情報理論に関するIEEE論文誌、IT18巻3号、ページ395−399、1972年5月
結合分析を使用して、これらの技術は置換符号の符号ベクトルの指標指定(演算OP2)およびまた逆指標復号化演算(OP3)の実行を可能にする。置換指標指定アルゴリズムの中では、一般に使用するシャルクビックアルゴリズムを以下に例えば次の規格において検討している。
−[3GPP TS26.273](固定点拡張AMR−広帯域(AMR−WB+)コーデック;V6.1.0(2005−06)(レリース6))および
−[3GPP TS26.304](拡張適応型多元速度−広帯域(AMR−WB+)コーデック;浮動点ANSI−C符号;V6.3.0(2005−06)(レリース6)、2005年6月)。
【0019】
符号化における置換ランクの計算(図1Aの演算OP2)
【0020】
これはベクトルy=(y0、y1...、yn‐1)の構成要素に関する全ての可能な置換の順序化および指標指定を含む。順序は辞書編集式であり、指標をここでは「ランク」と呼ぶ。ベクトルyのランクの計算は、yに関連し、yk=adであり、その場合にのみdkが指標値dを有するようなベクトルD=(d0、d1...、dn‐1)のランクの計算を含む。
例えば、次元n=8のベクトルは以下の構成要素を有する。
y=(4、2、4、0、0、4、4、2)
q=3の文字(異なる値の構成要素)を持つアルファベットをa0=4、a1=2およびa2=0であるA={4、2、0}により示す。
次いで、ベクトルyはベクトルyとベクトルD=(0、1、0、2、2、0、0、1)を関連させ、その構成要素は単にアルファベットAのq文字の指標である。
yおよびDのランクは同じであるが、ベクトルDの定義は(アルファベット{a0、a1、...、aq−1}と同じ数の要素を含む)セット{0、1、...、q−1}にその値を有するシーケンスDのランクの計算に演算を削減する。
ベクトルyおよびDの重みが同じであるのはそのそれぞれの構成要素の発生が同じであるからである。中間重み(wk0、wk1、...、wkq−1)をまた構成要素ベクトル(yk、yk+1、...、yn−1)の重みとして定義し、それ故この重みは位置k乃至n−1を残すために端を切取るベクトルyに対応する。従って、
【0021】
【数6】
【0022】
であり、δ(x、y)はクロネッカ(Kronecker)演算子(x=yであればδ(x、y)=1であり、他の場合0)である。
次式を適用する。
【0023】
【数7】
【0024】
ベクトルyのランクtを下記の公式により結合分析により計算することができる。
【0025】
【数8】
【0026】
この公式は以下のように単純化することができる。
【0027】
【数9】
【0028】
使用することが多く、それ故ここで採用することにするのはこの後者の公式である。以後、Ikdkを「順序kの部分ランク」と呼び、以下の通りとする。
【0029】
【数10】
【0030】
ランクの復号化(演算OP3):置換のその指標からの判断
【0031】
ランクtの復号化はyに関連するベクトルD=(d0、d1、...、dn−1)の回復を伴う。dkの連続検索の一方法を以下に説明する。構成要素d0をまず判断し、構成要素d1乃至構成要素dn−1により継続する。
【0032】
*d0の判断:
d0を以下の不等式を含む公式の使用により見つける。
【0033】
【数11】
【0034】
項(n−1)!、t、
【0035】
【数12】
【0036】
およびd=0、...、q−1に対する値w0dは既知である。d0の値を見つけるために、出発点としてd0=0を使用し、上記の数11に示す公式(8)を満たすまでd0を連続して1だけ増やす。部分ランクにより上記の数11に示す公式(8)を書くことにより、値d0は次のようになる。
【0037】
【数13】
【0038】
*d1の判断:
d1を見つけるために、以下の関係を使用する。
【0039】
【数14】
【0040】
d=0、...、q−1に対するw1dの値は以下のようにw0dの値から推論する。
−d=d0であれば、w1d=w0d−1および
−d≠d0であれば、w1d=w0d(次いでdがd0と異なる限りw0dを反復する)。
構成要素d0の判断と同じ問題に戻る。d1の値を見つけるために、出発点としてd1=0を使用し、不等式(9)を満たすまでd1を連続して1だけ増やす
(I1d1≦t−I0d0<I1d1+1)。
【0041】
*その他のdkの判断:
【0042】
後続するdkの計算は上記の場合から推論する。dkの値を見つけるために、出発点としてdk=0を使用し、不等式
【0043】
【数15】
【0044】
を満たすまでdkを連続して1だけ増やす。
一度ベクトルD=(d0、d1、...、dn−1)を復号化すると、単なるアルファベットの転位によりベクトルDからベクトルyを推論する。
【先行技術文献】
【特許文献】
【0045】
【特許文献1】WO−04/00219
【非特許文献】
【0046】
【非特許文献1】シャルクビックJ.P.M(Schalkwijk J.P.M)著「ソース符号化アルゴリズム(An Algorithm for source coding)」、情報理論に関するIEEE論文誌、IT18巻3号、ページ395−399、1972年5月
【非特許文献2】[3GPP TS26.273](固定点拡張AMR−広帯域(AMR−WB+)コーデック;V6.1.0(2005−06)(レリース6))
【非特許文献3】[3GPP TS26.304](拡張適応型多元速度−広帯域(AMR−WB+)コーデック;浮動点ANSI−C符号;V6.3.0(2005−06)(レリース6)、2005年6月)
【非特許文献4】ラゴット S、べセット B、ルフェーブル R著「32kビット/秒における広帯域TCX通話符号化に適用する低複雑度多元速度格子ベクトル量子化」ICASSP論文集、1巻、PP.501−4、2004年5月
【発明の概要】
【発明が解決しようとする課題】
【0047】
置換符号の指標指定および逆演算は複雑な演算である。使用するアルゴリズムは結合分析を適用する。結合の指標指定および逆演算は階乗積の除算を必要とする。
【0048】
除算の複雑度
集積回路および信号処理プロセッサにおいてなされた進歩にもかかわらず、除算は複雑な演算に留まる。典型的に、16ビットで表す整数の16ビットで表す整数による除算はそれらの乗算より18倍のコストを要する。32ビットの整数の16ビットの整数による除算の重みは32であり、それらの乗算の重みは5である。
【0049】
変数のフレーム化
除算コストは問題であるだけではない。以下の表1が示すように、変数のフレーム化は別の問題である。
8以下の整数の階乗のみを全16ビットワードで表すことができる。12より大きな数の場合、全32ビットワードにおける階乗の表現は最早可能ではない。
さらに演算の複雑度は、また変数を表すのに使用するビット数と共に増大する。従って、32ビットの整数の16のビット整数による除算は16ビットの整数の除算(重み18)の殆ど2倍複雑(重み32)である。
【0050】
【表1】
【0051】
演算OP1の複雑度を削減する解決法が提案されている。演算OP2およびOP3の複雑度の問題は極めて適切には扱われていない。一方、特に出願者のTDAC符号化器/復号化器では、または3GPP−ANR−WB+符号化器では、シャルクビック公式に基づき符号化および復号化に対し単純化が行われている。
【0052】
置換および逆演算(演算OP2およびOP3)の計数の単純化
【0053】
n項Ikdkの計算に対して行った下記の単純化により、置換ランクtおよび逆演算の計算は加速され、その定義を以下で検討する。
【0054】
【数16】
【0055】
最初の2つの項を使用して、符号化および復号化双方における複雑度を削減する。第3の項を符号化に使用し、最後に残る2つの項を復号化に使用する。
【0056】
符号化技術を図2および図3により説明する。特に、図3は従来技術の意味するシャルクビック公式によるランクの計算を扱い、一方図2は予備ステップ(「EP−nと参照し、図2のn番目の予備ステップを示す)を説明する。
【0057】
図2を参照すると、処理はステップEP−1で始まり、ベクトルy=(y0、y1...、yn‐1)の構成要素を回復する。後続の一般的ステップEP−2はこのベクトルA=(a0、a1、...、aq−1)に使用するアルファベット要素の計算、および最大指標qの判断を扱う。これを行うためにq=1、a0=y0を設定する初期化ステップEP−21の後に、1とn−1との間の指標kに関してループを実行し(検査終了EP−26およびその他の場合増分EP−27)、以下のように要素aqを検索する。
−現指標kの構成要素ykが要素{a0、a1、...、aq−1}の中に既になければ(検査EP−22)、セット{a0、a1、...、aq−1}に対してak=yk(ステップEP−22)であるように新要素aqを割り当てねばならず、qを1だけ増分しなければならない(ステップEP−25)。
【0058】
後続の一般的、予備ステップEP−3は以下のようにベクトルD=(d0、d1、...、dn−1)の計算である。
−0乃至n−1の範囲のkに対して(kを0に初期化するステップEP−31、kに関する検査終了EP−31、その他の場合増分EP−38)、yk=akであるような値dを指標セット(0、...、q−1)において見つける(ループにおけるdに関する検査EP−33、その他の場合d=d+1による増分EP−36)。
【0059】
図3を参照して次に、図2に示す予備処理に続くランクtの計算ステップの説明に進む。図3に示すステップは「CA−n」と参照し、従来技術の意味するn番目の符号化を意図する。
【0060】
ステップCA−1はランクtの0、変数Pの1(ステップCA−13におけるランクの計算に使用する分母)およびqの重みw0、w1、...、wq−1の0への初期化である。
【0061】
ここで、kの値をn−1から0へ減分する(kをn−1に初期化するステップCA−2、検査終了CA−14およびその他の場合減分CA−15)。このような選択の利益を後に説明する。予備ステップEP−3において得るベクトルDの構成要素dkを次いで使用し、現行kに対しd=dkを設定する(ステップCA−3)。関連する重みwdを更新し(ステップCA−4においてwd=wd+1)、項Pを推定する(ステップCA−5においてP=Pxwd)。ステップCA−13に対応するランクの計算における分子に関して使用する総計Sを0に初期化し(ステップCA−6)、次いで重みwiの指標iに関してループを実行し(検査終了CA−9およびその他の場合d−1へ増分CA−10)、総計Sを更新する(ステップCA−8においてS=S+wi)。ステップCA−13におけるランクtの計算の前に調査を行い、総計Sがゼロでないことを確認する(検査CA−11)。この実施の利益を後に説明する。
【0062】
ランクtの計算(ステップCA−13)は以下のような階乗項(n−k−1)!を含む。
t=t+(S/P)(n−k−1)!
【0063】
ランクtの各更新に関する項(n−k−1)!の計算に代わって、これらの値をメモリに事前記録し、簡単なメモリアクセスを使用して(ステップCA−12)、(n−k−1)!の現行値を得ることを優先する。
【0064】
従って、図3に示す処理の幾つかの利点を再び本発明の実施において取り上げることにする。これらの利点を以下に詳記する。
【0065】
*階乗の蓄積
【0066】
項(n−k−1)!およびwki!を実時間で計算することを避けるために、n+1の階乗(0!、1!、...、n!)の値を事前に計算し、蓄積する。次元nが限定的に変化すれば(n≦nmax)、値0!、1!、...、nmax!を事前に計算し、蓄積する。
【0067】
*除算を避ける中間重みの累積に関する検査
【0068】
項Sk
【0069】
【数17】
【0070】
がゼロであれば、
【0071】
【数18】
【0072】
の計算に意味がない。次にこの項は、最終位置(n−1に近いk)の場合特にゼロであることが多い。この項がゼロである性質に関する検査(図3の検査CA−11)の追加により、除算(および乗算)を避けることができる。除算の計算は検査よりかなり複雑であるので、複雑度の除外は大きい。
【0073】
*符号化における位置に関するループの反転
【0074】
1だけwk+1dを増分し、d≠dkに対してその他の値wk+1dを反復することにより、重みwk+1dから(d=0、1、...、q−1である)重みwkdを推論する。その場合、ベクトルの最終位置(k=n−1)から最初の位置(k=0)へ動作するループ(図3のステップCA−2、CA−14、CA−15)を作成することが可能である。この「逆」ループは、1に初期化後項Pkを以下のように、
【0075】
【数19】
【0076】
各反復に対して、増分および乗算のみ、即ち
【0077】
【数20】
【0078】
により計算することを可能にする。
最後の2つの位置(k=n−1およびk=n−2)を個別に処理することがまた可能である。要するに、
・最後の位置(k=n−1)について、
【0079】
【数21】
【0080】
それ故
【0081】
【数22】
【0082】
・最後から2番目の位置(k=n−2)について、
dn−2>dn−1であれば、
【0083】
【数23】
【0084】
それ故
【0085】
【数24】
【0086】
その他の場合
【0087】
【数25】
【0088】
それ故
【0089】
【数26】
【0090】
であり、dn−2=dn−1であれば、Pnー2=2、その他の場合
Pnー2=1である。
【0091】
下記のその他の有利な実施の詳細をまた提供することができる。
【0092】
*復号化における除算の除去
【0093】
d0を検索する場合に復号化における除算を避けるために、数11に示した不等式(8)を以下の形式に再公式化することができる。
【0094】
【数27】
【0095】
同様に、数14に示した不等式(9)を以下の形式に再公式化することにより、d1の検索から除算を除去する。
【0096】
【数28】
【0097】
またはさらに、
【0098】
【数29】
【0099】
従ってdk(0≦k≦n−1)の検索における除算の削除は可能であるが、Ikdk(0≦k≦n−3)の計算に(n−1)除算の実行がなお必要である。
【0100】
*復号化における重みに関する検査
【0101】
dのある値に対する最後の位置では、(位置kに先行する位置を占める値dのw0dの構成要素に対して)wkd=0である。dのこれらの値に対し不等式(8)および(9)の項を計算するのはそれ故意味がない。
【0102】
従来技術のその他の問題:変数のフレーム化
【0103】
変数フレーム化の問題は出願者のTDAC符号化器において取組んでいる。
第1の解決法は12より大きな次元の処理演算をより小さな次元の演算と区別することであった。小さな次元(n<12)の場合、32ビットの符号のない整数に関して計算を実行する。より大きな次元の場合、計算複雑度および必要なメモリ容量の増大を犠牲にして、倍精度浮動変数を使用する(浮動倍精度演算はその整数精度に等価な演算よりより経費が掛かる)。
【0104】
さらに最大精度を符号のない32ビットの整数(固定点プロセッサによる実施)に限定すれば、12より大きな整数階乗を直接事前蓄積することはできず、12より大きな次元のベクトルを個別に符号化しなければならない。この問題を解決するために、さらに高度な解決法は2j×rの形式の階乗n!の仮数および指数による擬似浮動点表現を使用する。この分解を以下の表2に詳しく示す。n!の蓄積(16以下のnの場合)を最大30ビットの精度を持つr並びに簡単なビットオフセットに対応する指数jの蓄積に削減する。
【0105】
【表2】
【0106】
従って、大部分の場合従来技術は特に固定点における限定精度の変数フレーム化の問題を解決しない。TDAC符号化器における実施は、フレーム化問題を解決するが、2つの整数の経費の掛かる除算を回避しない。
【0107】
さらに大きな次元の場合、中間計算(例えば、部分ランクIkdkの分子および分母)は限界状態に近づきうる。この場合、上記の単純化を復号化処理に使用することができず、数11および数14に示した不等式(8)および(9)の公式化への逆戻りが必要であり、それ故多くの除算を再び持ち込まねばならない。
【0108】
シャルクビック技術以外の計数技術は同じ問題に苦しむ。計数技術がまた結合分析を使用する場合、計数技術は階乗積とその除算の計算を伴う。
【0109】
本発明はこの状況の改善を目的とする。
【課題を解決するための手段】
【0110】
このため、本発明はまず結合表現の計算を含む置換符号を使用するディジタル信号の符号化/復号化法を提案し、本方法ではこれらの結合表現を素因数累乗分解により表し、選択する整数の事前記録分解表現をメモリから読出すことにより判断する。
【0111】
次いで本発明は置換符号の指標指定および逆演算双方に関連する問題への効果的な解決法を提供する。同時に本発明は変数フレーム化および除算である2つの問題を解決する。
要するに有利な実施では、事前記録表現は前記選択する整数のそれぞれの連続する素数を表す値と相関してそれぞれ蓄積する指数を表す値を含む。
従来技術における変数フレーム化に関連する問題を従って既に解決する。
変数フレーム化の問題は階乗項を操作する場合、益々重大である。
有利な実施では、結合表現が整数の階乗値を含む場合結合表現を操作するために、事前記録表現は少なくとも階乗値の分解表現を含む。
次いでこの実施は変数フレーム化の制約を取除き、そのことから関係する置換符号の次元nに関して通常設定する制限を緩和することを可能にする。
【0112】
別の有利な特徴によれば、前記結合表現の少なくとも1つは整数の分子の整数の分母による商を含み、この商を素因数累乗分解により表し、素因数累乗分解の各累乗は分子および分母とそれぞれ関連し、1つのかつ同じ素数に割当てる指数の差分である。
従来技術の除算の計算に関連する問題は従って単純な減算計算によりこの計算を置換することにより解決する。
【0113】
第1の実施形態では、上述の選択する整数の1つの事前記録分解を取出すためにアドレス指定するメモリの配備を行う。
このため、選択する整数の事前記録表現をアドレス可能なメモリに蓄積し、前記メモリのアドレス指定はそれぞれの素数に割当てる連続する指数を示し、選択する整数を再構成する。
好ましくは、選択する整数の事前記録表現を素数に対し連続するアドレス形式で蓄積することとし、各アドレスはこの素数に割当てる指数を示し、選択する整数を再構成する。
第1の実施形態によるこの実施を以後「分解の分解による相互関係表現」と名付けることにする。
【0114】
変形として第2の実施形態では、連続するビットグループを含むワード形式で、事前記録表現を蓄積し、各グループは:
−素数に応じる重み、および
−この素数に関連する指数に応じる値を
有する。
好ましくは次いで、少なくとも1つの部分マスクをビットワードに連続的に適用することにより、ビットの重みによる連続オフセットおよび残るビットの読出しにより、素因数累乗を判断する。
第2の実施形態によるこの実施を以後「分解のコンパクトな表現」と名付けることにする。
【0115】
結合表現の計算の同じ方法の処理を、一般に次の:
−前記結合表現を形成する積および/または商に現れる項を前記選択する整数から特定するステップと、
−前記項の素因数分解に含む指数をメモリにおいて読出すステップと、
−読出した指数を加算および/または対応して減算し、前記結合表現の素因数累乗分解に含む指数を判断し、そのことからその素因数累乗分解から前記結合表現を計算するステップと、
により実行することができる。
【0116】
再起的に実行する積の計算および各再起に新しい項を含むことに関し、以前の再起に対して実行した積の計算の分解を一時的に蓄積するのは有利でありうる。従って、本方法が以前の再起において判断した積を乗算する項を各再起に含む積の計算に再起ステップを含めば、
−以前の再起において判断した前記積を有利には素因数累乗分解の形式でメモリに保持し、
−積を乗算する前記項が好ましくは分解を事前記録する選択する整数の1つであり、
−現再起における前記積を判断するために、以前の再起において判断した前記積および前記積を乗算する前記項のそれぞれの分解から導出する指数を共に1つずつ各素数に対し加算すれば十分である。
【0117】
同様に、本方法が以前の再起において判断した商を除算する項を各再起において含む除算の計算に再起ステップ含めば、
−以前の再起において判断した前記商を有利には素因数累乗分解の形式でメモリに保持し、
−商を除算する前記項が好ましくは分解を事前記録する選択する整数の1つであり、
−現再起における前記除算を判断するために、前記項の分解から導出する指数を以前の再起において判断した前記商の分解から導出する指数から1つずつ各素数に対し減算する。
再起的に計算する積および/または商に関する中間分解のこの一時的蓄積は再起部分ランクの判断に特に有利であり、再起部分ランクの累積は置換ランクを表す。
【0118】
従って本発明の有利な実施では、置換符号は各部分ランクが次いで前記結合表現の1つに対応する部分ランクの累積を含む置換ランクを表す量の計算を含む。
ベクトル量子化ディジタル信号を符号化する場合、次いで置換ランクの計算を使用し、入力ベクトルに最も近い符号ベクトルを判断するために以前のステップ(演算OP1)において実行した先導ベクトルの構成要素の置換を指標指定することができる(図1Aの演算OP2)。
【0119】
同様にベクトル量子化ディジタル信号を復号化する場合に、置換ランクの所与の値から
−構成する符号ベクトルの少なくとも1つの仮定する構成要素に従い前記所与の値に近い置換ランクを表す少なくとも1つの量を計算し(図1Aの演算OP3)、
−この量が所与のランク値との近接条件を満たせば仮定する構成要素の選択が妥当である
として置換ランクの推定が行われる。
実施例では、一方で仮定する構成要素に関連する部分ランクへおよび他方で仮定する構成要素の増分に対応する構成要素に関連する部分ランクへの部分ランクの累積により所与のランク値を纏めて扱うことができれば、この近接条件を満たす。
それ故、この近接条件はシャルクビック計数の場合の上記の不等式(8)の一般的公式化に対応しうる。
従って、本発明を有利には図1Aの意味するベクトル量子化によるソース符号化/復号化に適用することができる。
一方、符号化/復号化が、
−送信前における置換ランクからの符号ベクトルの判断(図1Aおよび図1Bの同じ演算OP3)および
−受信時における受信ベクトルに対応する符号ベクトルからの置換ランクの計算(図1Aおよび図1Bの同じ演算OP2)
を含めば、符号化/復号化はまた図1Bの意味するチャネル変調符号化/復号化タイプに関するものでありうる。
【0120】
部分ランクの計算は、後に見られるであろうように一般的規則として置換符号の最大次元n以下に留まる(積または商における)項を含む。従って有利な実施では、事前記録分解を伴う選択する整数は少なくとも、
−1と前記最大次元nとの間の整数と、
−整数0の階乗値と、
−好ましくは1と最大次元nとの間の整数の階乗値
を含む。
特定の選択可能な実施では、選択する整数はまた値0を含むことができる。
【0121】
従って、置換符号がシャルクビック計数を使用すれば、符号ベクトル(y0、...、yn‐1)の切取り(yk、...、yn−1)に関連する部分ランクIkdkを、
【0122】
【数30】
【0123】
により表し、上式で、
−記法
【0124】
【数31】
【0125】
は0乃至mの範囲の整数指標iに対する積を表し、
−記法
【0126】
【数32】
【0127】
は0乃至mの範囲の指標iに対する総和を表し、
−記法l!はl>0の場合l!=1×2×3×...×(l−1)×lであり、0!=1である整数lの階乗値であり、
−整数nは符号ベクトルが含む構成要素の総数に対応する置換符号の次元であり、
−0とn−1との間の整数kは、ソース復号化における(対応してチャネル符号化における)ランク値から検索するかまたは置換をソース符号化において(対応してチャネル復号化において)指標指定する符号ベクトルのk番目の構成要素ykの指標であり、
−整数qは符号ベクトルが含む個別構成要素数であり、
−項wkd(「中間重み」と名付ける)はkとk−1との間の指標を有し、1つのかつ同じ指標構成要素dの数に等しい値を有する構成要素の数を表す。
【0128】
この場合、事前記録分解を有し、次いで部分ランクIkdkの表現において、積および/または商において特定する、選択する整数は好ましくは、
−0とn−1との間の全ての整数kに対する階乗項(n−1−k)!(即ち、0と(n−1)との間の全ての整数に対する階乗値)であり、
−各項wkiの値および/または各項wkiが0とnとの間にある積
【0129】
【数33】
【0130】
に含むその階乗値であり、
−0とn−1との間の全ての整数kに対して、各項が1とn−1との間にある項
【0131】
【数34】
【0132】
である。
【0133】
さらにシャルクビック計数の特定の場合では、中間分解の一時蓄積を有利に以下のように適用する:先行指標kに対する項
【0134】
【数35】
【0135】
の分解における指数の総和を一時的にメモリに蓄積し、指数の総和にまたは指数の総和から現指標kに対する項wkiの分解指数を加算または減算する。
【0136】
本発明のその他の特徴および利点は、以下の「発明を実施するための最良の形態」および上記の図1A、図1B、図2および図3に加えて図4乃至図9の添付する図面を考察することにより明らかになるであろう。
【0137】
思い出す契機として、特に以下の図4乃至図8を参照して、下記のことを強調すべきである。
−用語「符号化する」は置換ランクtの計算を指示し(図1Aおよび図1Bの演算OP2)、
−用語「復号化する」はこのランクtからの置換の判断を指示する(図1Aおよび図1Bの演算OP3)。
従って、これらの演算をベクトル量子化によるソース符号化/復号化の参照により指定する。これらの演算をまたチャネル符号化/復号化、変調において実行することができることを思い出すべきである。
【0138】
本発明の原理を単刀直入に示すために、素数累乗の階乗化を以下に説明する。
ゼロでない正整数Kの素数累乗への分解を以下のように表す。
【0139】
【数36】
【0140】
上式で、piはi番目の素数である(p0=1、p1=2、p2=3、p3=5、p4=7、p5=11、p6=13、p7=17、など)。
piの指数を整数Kの分解ではeKiと表示し、mKはゼロでない指数を持つKの分解に含む最大の素因数の指標を表示する。
例えば、数K=120(または5!)を次のように表す。
120=1.23.31.51であり、最大の素因数「5」が指標3を有するので(p3=5)、ここではmK=3である。それ故、以下が当てはまる:e5!0=1、e5!1=3、e5!2=1およびe5!3=1。
実際には、数「1」は乗算の中立の要素であり、p0は分解から除くことができる、即ち、以下の通りである。
【0141】
【数37】
【0142】
勿論、K=0は素因数の累乗には分解することはできない。
【0143】
16以下の正整数の素数累乗積への分解を表3aに示し、その階乗分解を表3bに示す。この分解は6つの素数を含む(2、3、5、7、11および13)。列を素数piにより指標指定し、行をnにより指標指定するので、列piと行nの交点における表3a(対応して表3b)のセルは数n(対応してn!)の素数の累乗積分解における素数piの指数eni(対応してen!i)である。
n>1の任意の正整数の場合、n!の素因数の数mn!は次の通りである:pmn!≦n<pmn!+1。数mn!(対応して数mn)を表3b(対応して表3a)の最終(対応して最後から2番目の)列に示した。次の不等式に留意すべきである:mn≦mn!。
表3aが示すように、数nの多くの分解指数はゼロである。表3aの最終列に、nの分解におけるゼロでない指数mn1を注記した。n=0の場合分解の(それ故指数の)ないことを表3aの行n=0に記号「−」により示す。
【0144】
【表3a】
【0145】
【表3b】
【0146】
最初にシャルクビック公式の場合、次いで一般の場合の置換符号に関する部分ランクの計算へのこのような分解の適用に関する説明に進む。
Ikdkと表示する部分ランクが本明細書の上記の数10に示した関係式(7)により示されることを思い出すべきである。
【0147】
【数38】
【0148】
本式では、3つの項を素数累乗に分解することができる。これらは次の項である。
【0149】
【数39】
【0150】
(n−1−k)!、PkおよびSkの分解指数から、Ikdkの分解指数を簡単な加算および減算により計算する。
要するに、Ikdkの分解における素因数piの指数
【0151】
【数40】
【0152】
を3つの項(n−1−k)!、SkおよびPkの分解におけるpiの3つの指数から計算する。指数
【0153】
【数41】
【0154】
は最初の2つの項(Ikdkの分子)のpiの指数の総和に等しく、指数の総和から最後の項(Ikdkの分母)のpiの指数を減算する。一度公式化し、この結果を次のように表す。
【0155】
【数42】
【図面の簡単な説明】
【0156】
【図1A】ベクトル量子化によるソース符号化/復号化を示す。
【図1B】変調/量子化の双対性を示す。
【図2】符号化技術を説明するための図である。
【図3】符号化技術を説明するための図である。
【図4】本発明の使用による置換ランクの符号化/復号化原理を示す。
【図5】第1の実施形態に従う本発明の使用による置換ランクの符号化のための処理演算を示し、この演算ではこの計算に使用する項の素数累乗分解指数の分解相互関係表現を提供する。
【図6】第2の実施形態により本発明を使用する置換ランクの符号化のための処理演算を示し、この演算では分解指数のコンパクトな表現を提供する。
【図7】第1の実施形態により本発明を使用する置換ランクの復号化のための処理演算を示し、この演算では分解指数の分解相互関係表現を提供する。
【図8】第2の実施形態により本発明を使用する置換ランクの復号化のための処理演算を示し、この演算では分解指数のコンパクトな表現を提供する。
【図9】本発明を実施する符号化/復号化デバイスを図的に表す。
【発明を実施するための形態】
【0157】
図4は、符号化および復号化のために共に本発明の意味する処理演算に含むことができる(n番目の一般的ステップを表すために「G−n」と参照する)一般的ステップを示す。
【0158】
従って図4を参照して、現指標kから(ステップG−1)および後に詳細に説明することにする幾つかの中間ステップにより、(図4に例示するステップG−2においてDlおよびDl!と表示する)事前記録表を参照する配備を行い、本明細書の以上の式(10)により、素因数累乗における中間ランクIkdkの分解に特定のグローバル指数
【0159】
【数43】
【0160】
を計算する(ステップG−3)ことを就中思い出すべきである。素因数に特定の指標iに関するループを実行することにより恐らくこれ(ステップG−4)から、中間ランクIkdkの値を次いで推論する。次いでこの中間ランクの計算は置換の全ランクtの更新を、
−指標kの減分によるランクの符号化のためのタイプの関係式t=t+Ikdk(ステップG−6)によるかまたは
−後述のように、指標kの増分によるランクの復号化のためのタイプの関係式t=t−Ikdk(ステップG−6)により、
継続することができる(ステップG−5)。
【0161】
最後に、ステップG−7の符号化または復号化(図4の破線)において置換のランクtを得、ベクトルDの構成要素dkをステップG−8における以上の公式(8)の不等式および本明細書の以上の式yk=adによるベクトルYに関する不等式から推論する。
【0162】
一般の場合およびシャルクビック計数とは独立に、置換の部分ランクt’(t’>0)が以下のようにNt’の項vj(1≦j≦Nt’)を有する分子およびDt’の項ρj(1≦j≦Dt’)を有する分母の形式であれば、
【0163】
【数44】
【0164】
その場合、部分ランクt’の分解指数et’iをNt’vjおよびDtρjの分解である中間分解から判断し、et’iを以下のように表す。
【0165】
【数45】
【0166】
素因数への分解をまた本明細書で後に部分ランクt’の整数の商の積への公式化に使用することにする。
また一般的規則として、
【0167】
【数46】
【0168】
であれば、その場合
【0169】
【数47】
【0170】
である。
【0171】
シャルクビック計数の特定の場合に戻り、次いで一度この分解を判断し、その分解から部分ランクIkdkを計算するために、計算を次のように実行することができる。
式
【0172】
【数48】
【0173】
の精神を守り、単に対応する累乗の乗算により部分ランクIkdkを以下のように計算する。
【0174】
【数49】
【0175】
ここで、項(n−1−k)!およびPkは厳密に正整数であるが、項Skはゼロでありえ、それ故分解可能でないことがありうることを示すべきである。この場合、部分ランクIkdkはゼロである。次いで、項Sk(Sk=0?)の値に関する検査を行い、本明細書の以上の説明(図3のステップCA−11)のようにSk≠0の場合にのみ部分ランクIkdkを計算する。
【0176】
より一般的には、
【0177】
【数50】
【0178】
であれば、その場合
【0179】
【数51】
【0180】
であり、
【0181】
【数52】
【0182】
であれば、その場合
【0183】
【数53】
【0184】
である。
【0185】
次いで、素因数累乗の乗算により、特にこれらの素数に関連する指数の簡単な加算および減算により除算を置換することにより、部分ランクを構成する項の素因数階乗化が除算の排除を可能にすることを思い出すであろう。
【0186】
従って、本発明の意味するメモリに蓄積する整数の素因数分解(以後「基本分解」と呼ぶ)の限られた数から、
−図4のステップG−2の意味する置換ランクに現れる
【0187】
【数54】
【0188】
のような項の素因数分解(本明細書で以後「中間分解」と呼ぶ)を判断し、
−図4のステップG−3の意味する特にこの部分ランクの分解に含む指数の(例えば、
【0189】
【数55】
【0190】
タイプの式による)計算により、これらの中間分解から置換の部分ランクt’(Ikdk)の素因数分解を判断し、
−図4のステップG−4の意味する部分ランクt’(Ikdk)をその分解から(例えば、
【0191】
【数56】
【0192】
タイプの式を使用して)計算する、
以上のステップを配備する。
【0193】
勿論、蓄積する基本分解は好ましくは有利な選択の対象である。好ましいが、限定しない実施では、関係する置換符号の最大次元(この最大次元をnと表示する)により、蓄積する基本分解を選択することにする。従って、基本分解は好ましくは:
−整数lの階乗(l!と表示する)の分解であり、整数lは0≦l≦nであり、
−整数l自体の分解であり、この場合0≦l≦nであり、
nは関係する置換符号の最大次元であることを思い出すであろう。
【0194】
次いで、
−考察する素因数の数m、
−これらmの素因数自体および
−そのそれぞれの指数
を付与する数mにより基本分解を特定することが可能である。
分解の所謂「分解相互関係」表現のコンテキストにおいて表4a乃至表4dを参照して、この実施例を後に説明することにする。後に詳しく説明する所謂「コンパクトな」表現は単一のワードの蓄積にあり、ワードのビットは分解に含む全ての指数を付与することを指摘すべきである。
次いで種々の基本分解セットおよびこれら基本分解の表現および蓄積手順の定義が可能である。
【0195】
その上、中間分解を判断する項の選択およびこれら中間分解の判断そのものは後述することにする有利な実施の対象である。部分ランクの分解およびその分解からの部分ランクの計算はまた後述する有利な実施の対象である。
【0196】
次に蓄積する基本分解の選択に関する説明に進む。
一般に、次元nの置換符号に関する計数技術とは独立に、置換ランクの計算は整数l(0≦l≦n)および就中その階乗l!(0≦l≦n)を使用する。好ましい実施では、基本分解は階乗l!(0≦l≦n)およびl(0≦l≦n)の階乗分解であり、ここでnは本明細書で以上に示したように関係する置換符号の最大次元である。(2n+1)の基本分解をそれ故この好ましい実施において配備する。
にもかかわらず、その他の実施が可能である。
例えば、(n+1)の基本分解のみ、即ちl(0≦l≦n)および0!の基本分解を配備する必要がある。従って、l!(l>0)の分解が部分ランクの計算に必要であれば、
【0197】
【数57】
【0198】
であるj(0≦j≦l)のlの基本分解から中間分解を判断するステップにおいて、l!(l>0)の分解を計算する。
逆に、l!(0≦l≦n)の(n+1)の分解のみを配備する必要がある。l(l>0)の分解が部分ランクの計算に必要であれば、l!および(l−1)!の底を持つ2つの基本分解からおよび以下の式
【0199】
【数58】
【0200】
から中間分解を判断するステップにおいて、l(l>0)の分解を計算する。
それ故、基本分解セットの選択が有利にはこれら基本分解表現の蓄積に必要なメモリの最少化と中間分解を判断するステップの複雑度の最小化との間のトレードオフになりうることが理解されるであろう。
【0201】
以下で、本発明の意味する分解表現を説明する。
以上に示したように、分解(部分ランク、中間または基本のいずれであれ)を数mにより定義し、数mは考察する素因数の数、これらmの素因数およびそのそれぞれの指数を付与する。以下では、分解を表し、基本分解データを蓄積する種々の解決法を提案する。
【0202】
指数の分解相互関係表現
【0203】
*階乗l!(0≦l≦n)の表現
【0204】
値l!の分解に含む素因数の数ml!は数lと共に増加する。l!(0≦l≦n)の分解を表す第1の解決法は、l(0≦l≦n)の各値に対する数ml!およびpi(0≦i≦ml!)のml!の累乗指数の蓄積にある。l!のml!の指数がゼロでないことを注記することにする。
より有利な変形では、基本分解セットは同じ数mn!の素因数を共有し、各基本分解に対しmn!の指数を蓄積し、ml!より大きな指標のl!の基本分解指数はゼロである。この解決法は表の正規アドレス指定を提供することによりこの指数表の使用を可能にする。一方このような実施は、かなりのメモリサイズを必要とする。この表はmn!×(n+1)の値を含み、指数
【0205】
【数59】
【0206】
をこの表のアドレス(mn!、l+(i−1))に蓄積し、ここで記法(x、y)は行xおよび列yにおけるこの表のセルを目標にする。勿論、その他の規定を考慮することができることは理解されるであろう。従って、m列およびN行を有し、それ故m×Nセル(または要素)を含む2次元の表を考察する代わりに、m×Nセルを有する1次元の表を考察することが可能であり、2次元テーブルのアドレス(x、y)におけるセルはその場合1次元テーブルのアドレスm×x+yに位置する。2次元テーブルのアドレス(l、(i−1))に蓄積する指数
【0207】
【数60】
【0208】
をその場合1次元テーブルのアドレス(mn!×l+(i−1))に蓄積する。例えば、構成上表3bの4つの列(列pi=2、3、5、7)および9つの行(行n=0、..8)を含む36のセルを有する2次元テーブルに、数0乃至8の階乗分解指数を蓄積することができる。本明細書で以下に提示する(付録A−11)36セルを持つ単一次元のテーブルDl!に、これらの同じ指数を蓄積することができる。第1のテーブルのアドレス(x、y)におけるセルはアドレスDl!:4x+yにおけるセルに等しい。
加えて、ml!の(n+1)の値を蓄積し、l!の基本分解を使用して、中間分解の計算を削減することができる配備を行うことができる。
【0209】
*整数l(0≦l≦n)の表現
【0210】
基本分解l(0≦l≦n)を表現するために、幾つかの解決法をまた提供することができる。第1の解決法は各値lに対し、数mlおよびlのpi(0≦i≦ml)のmlの累乗指数を蓄積することである。変形では、l!(ml!またはmnl)の指数に対するのと同様に多くの指数を蓄積するのが好ましいであろう。lおよびl!の基本分解はその場合同じ数mを共有する。
別の変形では、lのゼロでない分解指数の数m’lが小さいことを活用することができる。例えば、この数m’lが最大で2(l=16の場合)であることは表3aにおいて明らかであった。従って、この数および対応する値piまたは指標iのみを蓄積することが可能である。
一方、またゼロでないこれらの累乗素因数の指標iを蓄積する配備が必要であるが、これは表における対応する指数のアドレスにより指標iは最早暗黙には認識されないからである。
【0211】
*基本分解以外の分解表現
【0212】
中間分解表現は中間分解を判断する基本分解表現に依存する。同様に、部分ランクの分解表現は部分ランクの分解表現を判断する中間分解の表現に依存する。
【0213】
*基本分解の蓄積
【0214】
典型的に、次元8(n=8)の置換符号のための本明細書の以下の表4a乃至表4dによる例示により、4つの可能な蓄積の解決法を示すことができ、この解決法では4つの(m8!=4)素数(2、3、5および7)を考慮する。これらの例を3GPP AMR−WB+符号化器(規格[3GPPTS26.273]および[3GPPTS26.304])に適用することができる。この符号化器は代数ベクトル量子化を使用し、代数ベクトル量子化辞書は次元8のゴセット(Gosset)配列RE8の置換符号結合である。
最初の3つの解決法(表4a乃至表4c)は同じ方法でl!の基本分解を表し、蓄積する。要するに、ml!およびl!のpi(0≦i≦ml!)のml!の累乗指数の蓄積を配備する。以上の解決法はlの基本分解表現および蓄積において異なる。表4aはmlおよびlのpi(0≦i≦ml!)のml!の累乗指数の蓄積を目的とする第1の解決法を示す。表4bはlのpi(0≦i≦ml!)のml!の累乗指数の蓄積を目的とする第2の解決法を示す。
【0215】
【表4a】
【表4b】
【0216】
表4cはlのpiのゼロでないが累乗指数の数m’l、対応する指数i、およびその指数の蓄積を目的とする第3の解決法を示す。明瞭さを増すため提示する表で示すのは、素数piである。
【0217】
【表4c】
【0218】
第4の解決法(以下の表4dにより示す)では、基本分解セットを数mnlにより表し、各基本分解(lまたはl!)に対し、mnlの指数を蓄積する。以前に提示した表3aおよび表3bの4つの列(pi=2、3、5および7)および9つの行(n=0乃至8)から表4dを抽出する。
【0219】
【表4d】
【0220】
可変次元およびリゾリューションを持つ統計的ベクトル量子化を使用する最大次元15のTDAC符号化器では、6つの(m151=6)素数:2、3、5、7、11および13を考慮する。次いで、表3aおよび表3bの6つの列(pi=2、3、5、7、11および13)および16の行(n=0乃至15)は第4の解決法に対する基本分解セットの蓄積を示すことができる。
【0221】
指数のコンパクトな表現
【0222】
蓄積を最少にし、限定数のワードに関する基本分解指数をコンパクトに表すことにある別の有利な解決法に関する説明に進む。基本分解表現のこの変形では、中間分解および部分ランクの中間分解をまたコンパクトに表す。有利には、この解決法はまた分かるであろうようにこれらの分解に関する判断の複雑度を最少にする。
【0223】
*分解のコンパクトな表現
【0224】
各素因数piに対する部分ランクの分子におけるその指数が持つ最大値の上限βiを判断するために検索を行う。この限界はpiの指数に関する可能な値の最大数、即ちβi+1を与える。バイナリにより値(βi+1)を表現する整数ビット数の表示にbniを使用することにより、次式をえ、
【0225】
【数61】
【0226】
上式で、
【0227】
【数62】
【0228】
はx以上の直近の整数を表示する。
【0229】
【数63】
【0230】
部分ランクt’に含む項Kの累乗因数分解指数をBnビットのワードeKによりコンパクトに表現することができ、
【0231】
【数64】
【0232】
このワードeKは以下の通りである。
【0233】
【数65】
【0234】
記法「≪B」はBビットの左シフトを表す。
【0235】
数nが大きければ、整数の表現に使用するビット数B0(16、32または40ビット)よりBnが大きいであろうことを注記することにする。この場合、t’に含む整数Kの素因数分解指数をMの完全整数eK(m)、0≦m<M(勿論、M>1である)の形式で表す。
【0236】
有利には、Mワードを以下のように形成することができる。
・eK(0)はi0の第1の指数(p1乃至pi0の指数)を含む:
【0237】
【数66】
【0238】
上式で
【0239】
【数67】
【0240】
である。
・eK(1)はpi0+1乃至pi1の指数を含む:
【0241】
【数68】
【0242】
上式で
【0243】
【数69】
【0244】
である。
・pmn!の指数を含む最終ワードを構成するまで、後者の関係式を任意のmについて一般化することができる。
勿論、その他の変形を提供することができる。例えば、1つの変形はp1の指数を個別に蓄積し、p2の指数から以上の処理演算を適用することにある。
【0245】
*上限の判断
【0246】
限界βiを幾つかの方法で判断することができる。置換符号に関する情報(アルファベットのサイズq、重みwi、0≦i<q)を使用して、部分ランクの分子が持つ各指数の最大値を明確に判断することができる。幾つかの(恐らく異なる次元の)置換符号を使用すれば、好ましくは最大の最大値を各指数に対して選択する。
本発明は有利にはシャルクビック計数のコンテキストにおける上限を判断する汎用処理演算を提案する。処理演算は使用する置換符号に関して最大次元以外の事前情報を使用しない。処理演算は単に、
【0247】
【数70】
【0248】
を使用し、次いで
【0249】
【数71】
【0250】
を選択する。
非常に多様な置換符号を使用する場合、この非常に汎用的処理は特に適する。
表5aは次元が8乃至15の場合のIkdkの分子における最大指数値に関する上限を示す。表5bは次元が8乃至15の場合のこれらの指数を表すビット数bniおよびその総和Bn(最終列)を示す。次元8では、素因数2の指数を3ビットで表し、その他の素因数(3、5および7)の指数を2ビットで表す。次元15では、素因数2の指数を4ビットで表し、素因数3の指数は3ビットで、その他の素因数(5、7、11および13)の指数は2ビットで表す。
【0251】
【表5a】
【表5b】
【0252】
表6a(対応して表6b)は8(対応して15)に等しい次元nに対するlおよびl!の指数のコンパクトな表現を示す。
【0253】
【表6a】
【表6b】
【0254】
純粋な例示として、表6bを使用して整数l=12の分解の判断を試行しよう。
好ましくは表6bで、符号の最大次元がn=15であるので、「2」の指数を4ビットで表し、「3」の指数を3ビットで、その他の素因数5、7、11、13を2ビットで表す。表では列l=12において、そのコンパクトな指数e12=18を読むことができる。
【0255】
以下の表の読出しを信頼すると、B15=15ビットにおける18(=16+2)のバイナリ表現は、1つのかつ同じ素数に関連するビットを共にグループ化することにより:
000 0000 0001 0010、即ち00 00 〇〇 00 001 0010となる。
【0256】
【表6c】
【0257】
4つの低順位ビット(重みi=0乃至3)は素因数2の指数、即ち0010=2であり、これは2が素数2に割当てるべき指数であることを意味する。
次の3ビット(重みi=4乃至6)は素因数3の指数、即ち001=1であり、これは1が素数3に割当てるべき指数であることを意味する。
次の2ビット(重みi=7乃至8)は素因数5の指数、即ち00=0である。
次の2ビット(重みi=9乃至10)は素因数7の指数、即ち00=0である。
次の2ビット(重みi=11乃至12)は素因数11の指数、即ち00=0である。
次の2ビット(重みi=13乃至14)は素因数13の指数、即ち00=0である。
抽出手順は高順位ビットをマスクし、低順位ビットに含む素因数指数を回復し、次いで回復したビット数のコンパクトな指数をシフトし、次の素因数指数への切り替えを伴う。
従って次元15では、2の指数を始めとして6つの抽出すべき指数がある。
【0258】
2の指数のバイナリ表現は18の4つの低順位ビット、即ち0010に対応し、これは2に相当する。これらを回復するために、18の高順位ビットを15によりマスク(18&15と表示)し、これは:24−1=1111に等価である。
得られる結果はe12=18&(2≪4−1)=2であり、これは2が素数2に割当てるべき指数であることを意味する。
次いで、18を右に4ビットシフトし、000 0000 0001=1を与える。
3の指数のバイナリ表現は1の3つの低順位ビット、即ち001(=1)に対応する。これらを回復するために、1の高順位ビットを7によりマスクする(1&7と表示し、値
23−1=111をうる)。
得られる結果はe121=1&(2≪3−1)=1であり、これは1が素数3に割当てるべき指数であることを意味する。
次いで、1を右に2ビットシフトし、そうするとこれは全てのその他の高順位ビットに対し0000 0000=0を示す。
それ故l=12の累乗が
−素数2に対して2、および
−素数3に対して1、
即ちl=12=22×31であることを思い出すであろう。
【0259】
*分解の上限
【0260】
ここで各素因数に対し、部分ランクt’の分母におけるその指数がt’の分子におけるその指数以下であることを仮定する。
【0261】
【数72】
【0262】
であるので、t’が厳密に正であればこれは当てはまり、それ故
【0263】
【数73】
【0264】
である。
実際には、シャルクビック公式により、およびq>1であれば、値
【0265】
【数74】
【0266】
は分母Pk(q>1であればPk≦(n−1)!)の指数の最大値β’iの上限である。
【0267】
それ故、不等式
【0268】
【数75】
【0269】
を調べれば十分であり、これは以上で説明したβiの値を判断する処理演算により既に実行している。その他の場合、β’iを明確に検索し、最大のβiおよびβ’iを使用してbniを計算することが可能である。
q=1の場合、既知ランク(t=0)の単一符号ワードを置換符号に含むことは理解されるであろうし、それ故事前にランクの計算および対応する逆演算を実行することは無用である。一方この特定の場合を個別に扱うことを望まない場合でも最大のβiおよびen!iにより、なお値bniを計算する配備をなしうる。以下の表7はn=16のこの場合を示す。
【0270】
【表7】
【0271】
次に、基本分解を蓄積するのに必要なメモリ容量の簡潔な説明に進む。
基本分解の表現に選択する解決法とは独立に、基本分解をテーブルに蓄積し、次いでランクの符号化および復号化演算においてこれらのテーブルのアドレス指定に使用することができる。0の分解は可能ではない(そして、その上使用しない)が、0の分解に対し「ダミー」指数(例えば複数の0または複数の1)を蓄積し、アドレス計算を簡単にすることは好ましいであろう。
以下の表8は、これら2つ(0のダミー分解の蓄積の有無)の場合を説明する5つの解決法の基本分解に関係するデータを蓄積するのに必要なメモリサイズを要約する。
【0272】
【表8】
【0273】
第5の解決法では、ビット数bniの蓄積(+mn!)を考慮する。一方実際にはビット数をメモリから読出すよりむしろ、以下の実施形態に見るであろうように、ビット数のメモリからの読出しは「ハードにより布線」する(その値を変数として宣言することなく計算プログラムに設定する)。それ故、ビット数を実際に蓄積するのは無意味に思われた。
表9は、nmax=8および15(0のダミー蓄積を伴う)の場合のこれら5つの解決法の分解指数に関係するデータを蓄積するのに必要なメモリを示す。
【0274】
【表9】
【0275】
次に、素因数累乗の蓄積に関する説明に進む。
基本分解以外に、本発明は素因数累乗を使用し、その分解から部分ランクを計算する。これら素因数テーブルからその累乗を実時間(「オンライン」)で計算することが可能である。好ましくは、2以外の素数の累乗を事前計算して蓄積し、2の累乗のみを実時間で計算する。以下の表10aは(AMR−WB+符号化器で使用するもののような)次元8の置換符号に必要な3、5および7の累乗を示す。表10bは(TDAC符号化器で使用するもののような)最大次元15の置換符号に必要な3、5、7,11および13の累乗を示す。
【0276】
【表10a】
【表10b】
【0277】
ここで再び、各素因数に必要な累乗数のみを蓄積することが可能である。変数として規則的にアドレス可能な単一の累乗テーブルのみを有することが好ましければ、各素因数に対し必要なp2(p2=3)の累乗数と同様に多くの値を蓄積する配備を行うことができる。使用しない累乗については、勿論複数の1または複数の0などのダミー値の蓄積を使用することが可能である。
【0278】
次に、本発明を使用して符号化を実行する置換ランクの計算に関する説明に進む。
選択する基本分解セットおよびその表現に応じて幾つかの変形が存在する。簡明さのため、l!およびlの階乗分解を伴う基本分解セットに好ましい実施形態の場合に、以下の可能な実施の説明を限定する。
以下では、最も一般的な場合である各基本分解のmn!の指数を持つ指数の分解相互関係表現に関する解決法をまず説明する。指数に関する分解相互関係表現の変形を次いで記述する。最後に、基本分解指数のコンパクトな表現に関する解決法を幾つかの変形と共に説明する。その上で、本発明が置換ランクの符号化の処理演算に完全に適用できることが明らかになるであろう。
【0279】
計数処理の例として、シャルクビックアルゴリズムを以下で考察する。
【0280】
分解指数の分解相互関係表現
【0281】
nを使用する置換符号の最大次元であるとし、mn!を量n!の分解に含む素因数の数とする。
分解指数の分解相互関係表現を使用する符号化に関する第1の実施形態の説明を以下に提示する。
【0282】
第1の実施形態による符号化
【0283】
ここで、l!およびlの基本分解指数をl=0に対するダミー蓄積と共に本明細書の以上の表4dの「第4の」解決法により、mn!×(n+1)セルを有するそれぞれDlおよびDl!と表示する2つの単一次元テーブルに好ましくは蓄積する。本明細書で以上に記述したように、mn!の列および(n+1)の行を有する2次元テーブルを考慮することもまた可能であろう。l(対応してl!)の指数を規則的に(mn!の値毎に)蓄積するので、基本分解指数を読出す演算はテーブルDl(対応してDl!)におけるアドレス計算を必要とする。l!(対応してl)の分解指数を読出すために、テーブルDl!(対応してDl)のアドレス(l×mn!)を指示し、従って指数
【0284】
【数76】
【0285】
(対応してel1)、次アドレス(l×mn!+1)にある指数
【0286】
【数77】
【0287】
(対応してel2)、より一般的にはアドレス(l×mn!+i−1)にある指数
【0288】
【数78】
【0289】
(対応してeli)を目標とすることが必要である。本明細書で以上に記述したように2次元テーブルでは、指数
【0290】
【数79】
【0291】
(またはeli)はアドレス((l;(i−1))(列(i−1)および行l)にある。
l=0に対するダミー蓄積の配備がなされなければ、l(l>0)のnの基本分解テーブルDlにおけるアドレス計算は(l−1)×mn!であることに留意すべきである。
【0292】
初期化
【0293】
・Pkのmn!の中間分解指数(以下のステップC−3を参照して分かるであろうように好ましくは各位置で更新するmn!のセルを有するテーブルPに蓄積する)をゼロに初期化する。従って、命令は以下の通りである。
【0294】
【数80】
【0295】
・ランクtおよびqの重みwkd(各位置で更新するであろうqセルを有するテーブルwに蓄積する(本明細書の以下のステップC−2))をまたゼロに初期化する。命令は以下の通りである。
【0296】
【数81】
【0297】
指標kに関する反復
【0298】
図5を参照して、nの位置に関する反復(変数kに関するループにより)に進む。図5のステップC−nの記法における文字「C」は用語「符号化」を示す。
ステップC−1で、変数dkを読む。ステップC−2は構成上テーブルwのセルdkの更新を含む:w[dk]=w[dk]+1
ステップC−3はPkの分解指数(テーブルP)の更新であり、特に
−アドレスmn!×w[dk]からテーブルDlの基本分解w[dk]のmn!の指数
【0299】
【数82】
【0300】
の読出し(ステップC−31)および
−更新:1≦i≦mn!に対し、
【0301】
【数83】
【0302】
(ステップC−32)を伴う。
【0303】
従ってステップC−31を実施するには、
【0304】
【数84】
【0305】
と表示するテーブルDlの基本分解w[dk]の第1の指数がアドレスmn!×w[dk]にあり、
【0306】
【数85】
【0307】
と表示する第2の指数がアドレス(mn!×w[dk]+1)にあるなどである。より一般的には、指数
【0308】
【数86】
【0309】
はアドレスmn!×w[dk]+i−1にある。
平行してステップC−4で、通常の関係式
【0310】
【数87】
【0311】
からSkを計算する。
ステップC−5はSk値に関する検査である。部分ランクIkdkがゼロであり(本明細書の以上の公式(7))、ランクtが不変であることを意味するSkがゼロ(矢印Y)であれば、処理はステップC−11により後に続く。その他の場合(Sk≠0である矢印N)、処理はステップC−6により継続し、ステップC−6で基本分解Skのmn!の指数
eSkiをテーブルDlのアドレスmn!×Skにおいて読出す。
平行して、ステップC−7はテーブルDl!のアドレスmn!×(n−1−k)において基本分解(n−1−k)!のmn!の指数
【0312】
【数88】
【0313】
を読むことにある。総和Skがゼロでなければ(検査C−5のNの出口)、ステップC−7を実行し、何れにしろ部分ランクIkdkがゼロであれば、テーブルDl!における不要な読出しを回避するようにすることを注記することにする。
ステップC−8で、種々のテーブルの読出し結果を共にグループ化し、1≦i≦mn!の場合の関係式
【0314】
【数89】
【0315】
により、まず部分ランクIkdkのmn!の分解指数を計算することができる。
最後にステップC−9で、部分ランクIkdk自体を次式により計算する。
【0316】
【数90】
【0317】
項w[dk]が関係する置換符号の必ず最大次元n以下である重みであることを思い出すであろう。同様にこのような重みの総和Skは最大次元nより小さく留まり、同じことが勿論(n−1−k)に対しても当てはまる。w[dk]、Skおよび(n−1−k)!の分解を、実際、表4dなどの整数分解または最大次元nに至る範囲の整数階乗のテーブルにリストする。テーブルにリストする分解w[dk]および先行ループ(k−1)で判断し、メモリに保持するPk−1の分解から、Pkの分解を判断する。
【0318】
図5の部分ランク計算ステップの純粋な例示として、次元n=8およびq=4の置換符号を考察する。この例では、4つの列および9つの行を持ち、それ故36のセルを含む2次元テーブルに指数を蓄積する。それ故、列がpi=2、3、5、7および行がl=0、...、8の本明細書で以上に提示した表4dから指数を抽出することができる。
この例では先行位置k=3において、重みwのテーブルが{1、1、0、3}であり、それ故P3=1!10!3!=6であると仮定する。P3(=21×31×50×70)の分解指数テーブルPはそれ故{1、1、0、0}である。ステップC−1の位置k=2では、d2=2を読出したと仮定する。この例のステップC−2では、セルw[2]を1(w[2]=0+1=1)だけ増分することによりセルw[2]を更新する。
ステップC−31で、1(=w[2])の4つの分解指数、即ち0、0、0、0を読む(表4dの6番目乃至9番目の列および3番目の行l=1を参照)。
次いで(ステップC−32で)、テーブルPを更新し、従ってP={1、1、0、0}を得る。
ステップC−4で、Skを:Sk=w[0]+w[1]=1+1=2と計算する。それ故、Skはゼロではない(検査C−5)。
・Skの4つの分解指数を読み(表4dの6番目乃至9番目の列であるが、4番目の行l=2をさらに参照して)(ステップC−6)、p1=2(6番目の列)の場合、指数は1、pi=3、5、7(7番目乃至9番目の列)の場合、指数は0である。
・表4dであるが、今回は2番目乃至5番目の列および7番目の行l=5をさらに参照して、5!((n−1−k)!に相当)の4つの分解指数を読む(ステップC−7)。p1=2(2番目の列)の場合、指数は3である。p2=3(3番目の列)の場合、指数は1であり、p3=5(4番目の列)の場合、指数はまた1である。他方、p4=7(5番目の列)の場合、指数は0である。
・ステップC−8で、部分ランクIkdkの4つの分解指数を計算する。
【0319】
【数91】
【0320】
ステップC−9で、部分ランクIkdkをその23×30×51×70=40の分解指数から計算する。
【0321】
再び図5を参照して、ステップC−10で関係式t=t+Ikdkに従う(ステップC−9に見出す部分ランクIkdkの加算により)更新により、置換のグローバルランクtを自ら判断する。
次いで、ステップC−11は変数k(k=k−1)を減分することを目的とし、ステップC−12は処理を継続するかを決めるkの値に関する検査である。従って、k≧0(検査C−12の出口のYの矢印)であれば、処理演算のステップはkの値を1ユニットだけ減分して最初のステップC−1から再反復する。その他の場合(検査C−12の出口のNの矢印)処理はステップC−13の終わり(「終了」)で終了する。
【0322】
従って、ステップC−9より上で、ステップC−8で判断するその分解から部分ランクを計算し、以下の3つの中間分解から部分ランク自体を判断することが理解されるであろう:
−(n−1−k)!
−Sk、および
−Pk。
ステップC−6およびC−7において実行する3つの中間分解の内の2つ(n−1−k)!およびSkの判断は基本分解のそれぞれのテーブルDlおよびDl!における簡単な読出しを含む。また以下のタイプの関係式によりテーブルDl!において読出すw[d]!のqの基本分解から、第3の中間分解(Pkの中間分解)の判断を簡単に実行することができる。
【0323】
【数92】
【0324】
直接的変形
【0325】
ステップC−3はこの中間分解の判断に関するより有利な変形を提示する。テーブルDlにおいて読出す基本分解および別の部分ランク(Ik+1dk)、例えばkの反復における先行部分ランクIk+1dkについて計算する別の中間分解(Pk+1の中間分解)から、Pkの中間分解を要するに判断することができる。
本発明の変形ではより一般的に、少なくとも1つの他の部分ランクについて以前に判断した少なくとも1つの中間分解から、中間分解をまた推論することができる。
【0326】
本明細書の以上で、最後の位置(k=n−1)から最初の位置(k=0)へのループによりランクの計算を実行した。一方、本発明はまた勿論最初から最後の位置へのループにも適合する。全て必要なことは、初期化フェーズを変更し、ステップC−2およびC−3およびその順序に適合することである。
このために、重みのテーブルwをqの重みw0dにより初期化することができる。次いで0乃至q−1の範囲のdに対して、w[d]!のmn!の分解指数をテーブルDl!において読出し、中間分解テーブルのmn!の値(P0の分解指数)を累積加算により計算する。
次いで、ステップC−10の後、ステップC−2の前で、ステップC−3を実行する。w[dk]の基本分解指数
【0327】
【数93】
【0328】
をP[i]から減算する
【0329】
【数94】
【0330】
ことにより、Pの中間分解を更新する。次いでw[dk]の値を1だけ減算する(w[dk]=w[dk]−1)ことにより、ステップC−2を実行することができる。ステップC−11は変数kの1の増分を目的とし、ステップC−12はk=nであるかを単に検査する。
【0331】
可変次元nの置換符号に対して
【0332】
【数95】
【0333】
の演算を実行するよりむしろ、初期化においてmn!を読み、演算をただmn!回のみ実行するのが好ましいであろうことは簡単に注記する価値がある。
【0334】
第1の実施形態に関する一般的な変形
【0335】
より一般的には、本発明の意味する符号化に対し図5で表す実施は多数の変形を可能にする。
従って第1の変形では、(lまたはl!の)各基本分解はまたテーブルml!を含む。数ml!(1≦l≦n)を読出すのは利点をもたらす。要するに、ステップC−3およびC−6乃至C−10を最早それぞれmn!回実行せず、ただ:
・ステップC−3について
【0336】
【数96】
【0337】
回、
・ステップC−6およびステップC−8の加算
【0338】
【数97】
【0339】
について
【0340】
【数98】
【0341】
回、および
・ステップC−7およびC−9についておよびステップC−8の減算
【0342】
【数99】
【0343】
についてm(n−1−k)!回実行する。
さらに値mlを蓄積していれば、その場合全て必要なことは:
・ステップC−3を
【0344】
【数100】
【0345】
回、および
・ステップC−6を
【0346】
【数101】
【0347】
回およびステップC−8の加算を実行することである。
【0348】
符号化の別の変形で、加算にlの基本分解指数の蓄積を第3の解決法(本明細書の以上の表4c)により使用すれば、ステップC−3を
【0349】
【数102】
【0350】
の値について実行することができる。同様に、ステップC−6を
【0351】
【数103】
【0352】
の値について実行する。ステップC−8においてm(n−1−k)!の加算およびm(n−1−k)!の減算を配備する代わりに、実行する減算の数はm(n−1−k)!に留まるが、
【0353】
【数104】
【0354】
の加算のみが必要である。特に以下の通りである。
【0355】
【数105】
【0356】
第3の変形で部分ランクの3つの項(分子の2つおよび分母の1つ)への分解に代わり、部分ランクを2つの項へ分解し、その1つは商である。従って、部分ランクIkdkを次の2つの項に分解する。
−総和Skおよび
−商
【0357】
【数106】
【0358】
この商を次の関係式により更新することができる。
【0359】
【数107】
【0360】
従ってq+1の基本分解((n−1−k)!およびテーブルDl!において読出すqw[dk]!の基本分解)からのRkの分解の判断よりむしろ、
【0361】
【数108】
【0362】
と表すRk+1の中間分解および(n−1−k)およびw[dk]の基本分解(これら2つの基本分解をテーブルDlにおいて読出す)から、Rkの中間分解を判断する。
先の変形と比較して
【0363】
【数109】
【0364】
の分母に関する中間分解の判断および蓄積(テーブルP)に代わり、商Rkの中間分解を判断し、次いで蓄積する(このためにテーブルRを配備する)。テーブルPのゼロへの初期化をこの比の指数に関するテーブルRのゼロへの初期化により置換する。ステップC−3はテーブルRを更新する((n−1−k)およびw[dk]の基本分解指数を読むことにより)簡単なステップとなり、これを次式で表す。
【0365】
【数110】
【0366】
蓄積の選択肢により、ml!の加算と減算またはm(n−1−k)!の加算(対応して
【0367】
【数111】
【0368】
の減算)またはm(n−1−k)の加算(対応して
【0369】
【数112】
【0370】
の減算)すら、またはw[dk]および(n−1−k)のゼロでない指数についてのみ:m’(n−1−k)の加算および
【0371】
【数113】
【0372】
の減算により、この更新を行うことができる。この場合、ステップC−8は以下のタイプの加算のみを含む。
【0373】
【数114】
【0374】
蓄積の選択肢により、mn!の加算または
【0375】
【数115】
【0376】
の加算、または
【0377】
【数116】
【0378】
の加算すら、またはSkのゼロでない指数についてのみ:
【0379】
【数117】
【0380】
の加算を次いで計数する。
この比Rkは必ずしも整数ではなく、これは指数R[i]が負でありうることを意味することを注記することにする。この変形では、符号化における階乗分解(それ故テーブルDl!)は最早有用ではなく、ただテーブルDlのみの蓄積により整数l(l≦n)の簡単な(n+1)の基本分解セットを使用することができる。
【0381】
分解指数のコンパクトな表現
【0382】
次に、分解指数のコンパクトな表現に基づく符号化の第2の実施形態の説明に進む。
基本分解指数はコンパクトに表現され、第1の実施形態を参照して本明細書で以上に説明したような分解相互関係形式では最早ない。簡明さのため、単一ワードに指数のコンパクトな表現を含む場合のみを説明する。それ故本明細書で以上に説明したように(n+1)セルを持つそれぞれD’lおよびD’l!と表示する2つのテーブルにl=0に対するダミーワードの蓄積と共にこれらのワードを蓄積する。l!(対応してl)の分解ワードを読むために全て必要なことは、テーブルD’l!(対応してD’l)のアドレスlを指示することであるので、基本分解指数を含むこれら2つのワードテーブルにおけるアドレス計算は直接的である。
l=0に対するダミーワードの蓄積のない、基本分解l(l>0である)に対応するワードはテーブルD’lのアドレス(l−1)にあることを注記することにする。
【0383】
第2の実施形態による符号化
【0384】
初期化
【0385】
・Pkのmn!の中間分解指数のコンパクトな表現を含むワードePをゼロに初期
化する:eP=0
ワードePを各位置に関して更新することにする(以下のステップCC−3)。
・以前のように、各位置において更新することにする(本明細書の以下のステップCC
−2)qセルを有するテーブルwに蓄積するランクtおよびqの重みwkdをまた値ゼ
ロに初期化する。対応する命令は以下の通りである:
・t=0
・w[i]=0、0≦i<q
・k=n−1
【0386】
n位置に関する反復(kに関するループ)
【0387】
次に、図6を参照して、この第2の実施形態における符号化の主ステップに進む。図6のステップCC−nの記法の文字「CC」は「コンパクトな表現」による「符号化」を示す。
ステップCC−1で、変数dkを読む。ステップCC−2は構成上変数wの更新を含む:w[dk]=w[dk]+1
ステップCC−3はワードePの特に以下による更新である:
−ステップCC−31のテーブルD’lにおけるw[dk]の分解指数のコンパクトな表現を含むワード
【0388】
【数118】
【0389】
の読み取り、次いで
−ステップCC−32におけるワードeP自体の更新
【0390】
【数119】
【0391】
平行してステップCC−4で、総和Skを計算する。
【0392】
【数120】
【0393】
次ステップCC−5はSk値に関する検査である。総和Skがゼロであれば(矢印N)、指標kを直ちに減分する。その他の場合(検査CC−5の出口の矢印Y)、ステップCC−6のテーブルD’lにおけるSkの分解指数のコンパクトな表現を含むワード
【0394】
【数121】
【0395】
の読出しにより、処理は継続する。
平行して(有利には検査CC−5の結果に応じて)、(n−1−k)!の指数のコンパクトな表現を含むワードe(n−1−k)!をステップCC−7でテーブルD’l!において読む。
ステップCC−8で、種々のステップCC−3、CC−6、CC−7から得る結果を共にグループ化し、以下の2つの簡単な演算(好ましくは加算続いて減算)により部分ランク
【0396】
【数122】
【0397】
の分解のコンパクトな表現を含むワード
【0398】
【数123】
【0399】
を計算する。
【0400】
【数124】
【0401】
以前に説明したようにワードビットの適するオフセットにより、ステップCC−9は部分ランク
【0402】
【数125】
【0403】
の、ワード
【0404】
【数126】
【0405】
に含むmn!の分解指数
【0406】
【数127】
【0407】
の抽出を目的とする。このため、1乃至mn!の範囲の指標iに関するループを配備する(1へのiの初期化CC−91、iの値の検査CC−93およびiがmn!の値に達するまでの増分CC−94)。次いで、iの各ループは自らに以下のタイプの命令CC−92を適用した。
【0408】
【数128】
【0409】
記法「≪b」および「≫b」はそれぞれbビットの左シフトおよび右シフトを示すことが思い出されるであろう。その上、記法「&」はビット毎の「AND」論理演算を示す。命令i’1)は
【0410】
【数129】
【0411】
のbniの低順位ビットを回復することにある。実際には、命令「((1≪bni)−1)」に対応するマスクをハードにより布線する。
換言すれば、高順位ビットのマスク((1≪bni)−1)を初めに(1に等しいループ指標iに対して)適用し、まず第1の素因数p1に関連する
【0412】
【数130】
【0413】
の指数を付与する
【0414】
【数131】
【0415】
のbn1の低位順位ビットのみを回復する。
次いで、
−
【0416】
【数132】
【0417】
のビットをbn1だけ「右に」シフトし、高順位ビットの次の素因数p2に関連する指数を付与する(マスク((1≪bni)−1))最高順位ビットを回復し、
−次いで、指数
【0418】
【数133】
【0419】
を抽出し、
−次いで、bn2ビットの右シフトを適用し、
−i=mn!まで継続する。
次のステップCC−10は以下のように部分ランクIkdkを計算することにある。
【0420】
【数134】
【0421】
次いで、部分ランクIkdkを全ランクtに加える(ステップCC−11のt=t+Ikdk)。
指標kの値を次ステップCC−12において減分し(k=k−1)、この減分した値によりステップCC−4、CC−1、CC−7および後続のステップを再開する前に、kの値が−1に達していないか(k<0)を確かめるために検査CC−13において調査を実行し、−1になっている場合は処理を終了する(ステップCC−14)。
【0422】
このように分解表現とは独立に、本発明は部分ランクを効果的に計算することを可能にする。ステップCC−10は先行ステップCC−8およびCC−9において判断したその分解からの部分ランクの計算を目的とする。3つの(項(n−1−k)!、SkおよびPkの)中間分解を使用する。ステップCC−6およびCC−7で実行するその内の2つ((n−1−k)!およびSk)の判断はテーブルD’l!およびテーブルD’lにおけるそのコンパクトな表現の簡単な読出しにある。ステップCC−3で実行する第3の中間分解(Pk)の判断は、またテーブルDlの読出しに続く、読出した基本分解のコンパクトな表現の加算によるこの中間分解のコンパクトな表現の更新を必要とする。
以前に示したように第1の実施形態を参照して、値mn!(0≦l≦n)の蓄積はステップCC−9およびCC−10の複雑度の削減を可能にする。部分ランクIkdkに関する分解指数の抽出ループをmn!回に代わってm(n−1−k)!回実行する。同様に、ステップCC−10は最早乗算mn!ではなく、乗算m(n−1−k)!を含む。
【0423】
次に、本発明を使用する置換ランクの復号化に関する説明に進む。
ここで再び、基本分解表現の解決法に応じる幾つかの(分解相互関係またはコンパクトな)変形がある。復号化の第1の実施形態に関する説明に進み、これは分解相互関係分解表現を使用する符号化および以上に提示した表4dに関係する第4の解決法によるその蓄積について本明細書で以上に説明した第1の実施形態に似る。例としてシャルクビックアルゴリズムを採用する置換ランクの復号化に本発明が完全に適用できることが明らかになるであろう。
【0424】
第1の実施形態による復号化
【0425】
分解指数の分解相互関係表現を使用する復号化は好ましくは以下のようにデータの初期化により始まる。
【0426】
初期化
【0427】
・値wのテーブルをqの重みw0dにより初期化する(以下で説明することにするステ
ップD−19の各位置に関するループの終わりでwを更新する)。適する命令は以下の
タイプでありうる:
・w[i]=w0i、0≦i<q
・項P0のmn!の分解指数を計算する(下記ステップD−18の各位置に関するルー
プの終わりの各位置でまた更新するmn!のセルを有するテーブルPに蓄積する)。適
する命令は以下のタイプでありうる:
・1≦i≦mn!についてP[i]=0
・d=0乃至q−1のループ
・テーブルDl!における
【0428】
【数135】
【0429】
のmn!の分解指数
【0430】
【数136】
【0431】
の読出し、次いで
【0432】
【数137】
【0433】
・最後に、k=0に初期化する。
次に図7を参照して、第1の実施形態による復号化の主ステップに進む。図7のステップD−nの記法における文字「D」は「復号化」を表す。
【0434】
n位置に関する反復(指標kに関するループ)
【0435】
第1のステップD−1はテーブルDl!における(n−1−k)!のmn!の分解指数
【0436】
【数138】
【0437】
を読出すことにある。
次ステップD−2は値dk=0およびIkdk=0を設定する。
次いで、w[dk]≠0であるようなアルファベットのdkに関する第1の値の検索に進む。このため、w[dk]=0であるかを調べる検査D−3を配備し、該当する場合(矢印Y)、dkの値を増分し(dk=dk+1)、ゼロでないw[dk]の値を見つけるまで検査D−3を反復する。この値が見つかれば(w[dk]≠0の場合矢印N)、次ステップはランクtの値に関する検査D−5である。ランクがゼロであれば(検査D−5の出口の矢印Y)、Pkの指数を更新する(ステップD−18)まで以下のステップを適用するのは無意味である。ランクがゼロでなければ(検査D−5の出口の矢印N)、処理を後続のステップD−6およびD−7により継続し、これらのステップでそれぞれSk=0および中間値IkをIk=Ikdkに設定する。
【0438】
次ステップD−8は総和Sk=Sk+w[dk]を更新する計算である。Skであることが判明する総和のmn!の分解指数
【0439】
【数139】
【0440】
に関するテーブルDlの読出し(ステップD−9)が次ステップD−8に続く。
ステップD−10は、1≦i≦mn!である関係式
【0441】
【数140】
【0442】
の部分ランク分解指数
【0443】
【数141】
【0444】
の計算を目的とする。現ループの終わりで、および次ループに対して後に説明することにするステップD−18で、上記のように初期化する指数P[i]を更新する。
ステップD−11は部分ランクの計算
【0445】
【数142】
【0446】
を目的とする。
次の3ステップは、全ランクtの値の部分ランクの値との比較による全ランクtの値に関する検査を目的とする。これを行うためにステップD−12で、dkの値を増分し(dk=dk+1)、検査D−13は次の通りである:t−Ikdk≧0?。
不等式を満たせば(矢印Y)、ステップD−7乃至D−13を新しく増分したdkの値により反復する。その他の場合(矢印N)、ステップD−12の前のdkの値に戻るために、dkの値を減分する(dk=dk−1)ステップD−14により処理を継続する。このdkの値に対し、部分ランクIkdkは上述の中間値Ikを取る(ステップD−15で、Ikdk=Ik)。
次いで、ランクtを更新し、ランクtはt=t−Ikdkとなり(ステップD−16)、テーブルDlにおけるw[dk]のmn!の分解指数
【0447】
【数143】
【0448】
の読出し(ステップD−17)から、Pkの指数を(テーブルPにおいて)更新し、続けて1≦i≦mn!に対し指数自体を
【0449】
【数144】
【0450】
により更新する(ステップD−18)。次いで、w[dk]の値を減分し(w[dk]=w[dk]−1:ステップD−19)、指標kの値を増分(k=k+1:ステップ20)し、次のループに備える。
第1のステップD−1にループにより戻る前に、n構成要素を全て処理していないことを確認するために調査を実行する。このために、kの値のnとの比較(k<n)によるkの値に関する検査D−21を配備する。指標kが値nに達しない限り(検査D−21の出口の矢印Y)、kの次の値についてステップD−1において処理を再開する。その他の場合(検査D−21の出口の矢印N)、ステップD−22の終わりで処理を終了する。
【0451】
ステップ11はそれぞれの項(n−1−k)!、SkおよびPkの3つの中間分解からステップ10で判断したその分解の使用による部分ランクの計算を目的とすることを思い出すべきである。ステップD−1およびD−9で実行するそのうちの2つ((n−1−k)!およびSk)の判断は構成上それぞれのテーブルDl!およびDlにおける簡単な読出しを含む。テーブルDlの読出し(ステップD−17)に続く読出した(ステップD−18)基本分解指数の減算によるこの中間分解指数による更新により、またステップD−18で実行した第3の中間分解(Pk)の判断を実行する。この中間分解の本明細書で以上に説明した初期化はテーブルDl!のqの読出しに続く読出したqの基本分解指数の加算によるこの中間分解指数による更新を必要とする。
【0452】
本明細書で以上に説明した符号化に関しては、図7の処理は、適する場合一定のステップの複雑度を削減する変形を可能にする。
比Rkの指数の使用(前記のように)を含む変形には特に関心を持てる。要するに、図7を参照して本明細書で以上に説明した復号化処理演算では、所与の位置kについてdの幾つかの値に対する指数
【0453】
【数145】
【0454】
を計算する。検査するdの各値について、その他の変形は各指数に対する減算および加算を必要とする。
【0455】
【数146】
【0456】
一方、総和Skおよびその指数
【0457】
【数147】
【0458】
のみが所与の位置kに関してdにより変化するので、比Rkの指数を使用する変形は加算
【0459】
【数148】
【0460】
のみを必要とする。
【0461】
第2の実施形態による復号化
【0462】
次に、図8を参照して分解のコンパクトな表現を使用する復号化の実施例の説明に進む。
まず、データを以下のように初期化する。
【0463】
初期化
【0464】
・まず、qのセルを有するテーブルを参照して、0≦i<qに対する項w[i]=w0
iを判断するべきである。
・Pkのmn!の分解指数のコンパクトな表現を含むワードePを計算する。このため:
・eP=0を設定し、
・d=0乃至q−1に対するループを配備し:
・ループはテーブルD’l!にw0d!の指数mn!のコンパクトな表現を含むワー
ド
【0465】
【数149】
【0466】
の読取り、および
【0467】
【数150】
【0468】
・の更新を伴い、
・次いで、k=0に設定する。
【0469】
n位置に関する反復(kに関するループ)
【0470】
図8のステップDC−nの記法における文字「DC」は「コンパクトな表現」による「復号化」を示す。
ステップDC−1はテーブルD’l!において項(n−1−k)!の指数mn!のコンパクトな表現を含むワードe(n−1−k)!の読出しにある。
ステップDC−2乃至DC−8は図7を参照して本明細書で以上に説明したステップD−2乃至D−8に類似である。
他方ステップDC−9では、テーブルD’lに総和Skのmn!の指数のコンパクトな表現を含むワード
【0471】
【数151】
【0472】
を読む。
次いでステップDC−10で、部分ランクIkdkの指数のコンパクトな表現を含むワードを好ましくは以下のように計算する。
【0473】
【数152】
【0474】
汎用ステップDC−11はグローバルに部分ランクIkdkの指数の抽出にある。このため、次の配備を行う。
−i(1≦i≦ml!)に関するループ(DC−111におけるi=1の初期化、本明細書で以下に説明する指数
【0475】
【数153】
【0476】
の抽出(ステップDC−112)後、値mn!に達するまで指標iを増分して(ステップDC−114)ループ指標iを値mn!と比較する(ステップDC−113))。
−指数
【0477】
【数154】
【0478】
の抽出(ステップDC−112)を:
マスク((1≪bni)−1)による
【0479】
【数155】
【0480】
の高順位ビットのマスク化によるコンパクトな指数
【0481】
【数156】
【0482】
の低順位ビットにおいて以下のように表し:
【0483】
【数157】
【0484】
このマスク化に以下のコンパクトな指数
【0485】
【数158】
【0486】
のbn1の「右」シフトが続く。
【0487】
【数159】
【0488】
この汎用ステップDC−11は符号化のための図6の汎用ステップCC−9に類似である。
ステップDC−12乃至DC−17は、それ自体分解相互関係表現における復号化に特定の図7を参照する本明細書で以上に説明したステップD−11乃至D−16に類似である。
他方、テーブルD’l!にw[dk]のmn!の指数のコンパクトな表現を含むワード
【0489】
【数160】
【0490】
の読出しにより、汎用ステップDC−18におけるPkの指数(テーブルP)の更新をステップDC−181で行い、次いでPkの指数の更新自体
【0491】
【数161】
【0492】
をステップDC−182で実行する。
次いで、ステップDC−19乃至DC22は、分解相互関係分解を使用する復号化に特定の図7のステップD−19乃至D−22に類似である。
【0493】
次に、本明細書で以上に説明した変形により提供する種々の利点の説明に進む。
mn!(および/またはmlまたはm’l)のテーブルを使用する分解相互関係表現による第1の実施形態の変形は、値mn!のテーブルのみを使用する主実施形態よりさらに少ない加算/減算演算を含む。
この場合、複雑度の削減は何にもまして最後の位置(即ち、m(n−k)!、m’lまたはmlがmn!より小さい場合)において大きい。にもかかわらず、複雑度のこの削減はメモリ読出しステップ(ステップC−31、C−6およびC−7)の複雑度の増加を伴う。読み出すべき値は少ないが、他方でアドレス計算がより複雑である。
この場合、関心の持てるトレードオフは(mn!の指数を持つ)基本分解の規則的な蓄積を含み、テーブルDlおよびDl!のアドレス指定を容易にし、次いで(n+1)セルを持つテーブルDmに値ml!を蓄積する。次いで、値mlを蓄積し、加算/減算の数を効果的に削減するべきである。とはいえ、この測定はステップC−6およびD−9(対応してC−3およびD−19)の前に値mSk(対応してmw[dk])の読出しを必ず伴うが、一方値m(n−k)!はkに関する各反復の開始時にのみ読まねばならない。
【0494】
その上、分解相互関係表現に比しコンパクトな表現が提供する利益は以下の通りである。
−次に、テーブルPを更新するステップは符号化(対応して復号化)では単一の加算(対応して減算)以上を含まない。
−指数
【0495】
【数162】
【0496】
の計算は、また単一の加算および単一の減算のみを必要とする。
−ワードeKを読むアドレス計算は直接的であり、各値Kに対し単一のメモリアクセスおよび読出しのみを必要とする。
一方、コンパクトな表現はワード
【0497】
【数163】
【0498】
に含む部分ランクIkdkの指数の抽出(ステップCC−9およびDC−11)を必要とする。
一方、本明細書の以下で分かるように、部分ランクの素因数分解からの計算に取り、この演算は必ずしも欠点ではない。
【0499】
次に、素因数分解からの部分ランクの計算のこのような変形の利点に関する説明に進む。
符号化における(対応して復号化における)ステップC−9およびCC−10(対応してD−11およびDC−12)の意味する素因数累乗積の計算ステップの複雑度は、従来技術の意味する除算より遥かに小さい複雑度に留まるとはいえ、因数の数と共に大きく増加する。次に、部分ランクの多くの分解指数は実際にはゼロであり、それ故対応する累乗はまた1にある。多くの場合、全指数がゼロであるかまたは第1の指数のみがゼロでない。それ故、ゼロでない指数の累乗のみを検出し、維持することが有用である。詳細な表現では、この検出を検査mn!または検査m(n−1−k)!(各素因数に対し1回)のみにより実行することができる。
【0500】
有利には、コンパクトな表現は単一の検査により全指数がゼロであるか
【0501】
【数164】
【0502】
の検査を可能にし、該当する場合ランクt’=1である。さらに、et’の高順位ビットの検出はランクt’における最大のゼロでない指数の素因数指標の獲得、および符号化における(対応して復号化における)ステップC−9(対応してDC−11)のループ反復数の削減を可能にする。
にもかかわらず、コンパクトな表現におけるように詳細な表現では、ゼロでない指数の検出は複雑度を増すことに留意すべきである。全指数がゼロでなければ、素因数の累乗乗算の複雑度は同じに留まり、この複雑度はその場合ゼロでない指数の検出手順の複雑度により倍加する。
従って第1の変形では、素因数の可能な数が大きくなり(kがnより遥かに小さい)、その累乗乗算の複雑度が検出手順の複雑度より大きい場合にのみ、ゼロでない指数の検出を行うことができる。このため、命令行の増加の犠牲においてこの実施を適用するとしても、位置により異なるループを配備することが出来る。
分解相互関係表現およびコンパクトな表現を結合することがまた可能である。最終位置(小さい値ml!)に対する中間分解の計算は演算を殆ど伴わない。その場合、分解相互関係表現の使用が好都合であり、この表現は部分ランク指数の抽出を必要としない。他方第1の位置の場合、コンパクトな表現の使用がより好都合である。
【0503】
次に、既存の符号化/復号化における幾つかの実施例の説明に進む。
【0504】
3GPP AMR−WB+符号化器
3GPP AMR−WB+符号化器(規格[3GPPTS26.304])は代数ベクトル量子化を使用し、その辞書は次元8を有するゴセットネットワークRE8の置換符号結合である。
TCX技術は変換による予測符号化に対応する。より詳細には、TCX技術は知覚重みフィルタリングの後に適用するFFT変換符号化法を含む。規格[3GPPTS26.304]では、得られるFFTスペクトラムを次元n=8の下位帯域(または補助ベクトル)に細分化し、これらの補助ベクトルを個別に符号化する。補助ベクトルの量子化にはポイントの正規ネットワークRE8を使用する。次元8の量子化辞書は構成上ポイントのネットワークRE8から得るタイプIの置換符号結合を含む。
規格[3GPPTS26.304]によるTCX符号化器では、各置換符号は次元n=8における所与の符号付先導ベクトルに対応する。ネットワークRE8のポイントの量子化指標を以下のタイプの公式により計算する:
指標=基本オフセット+置換ランク
基本オフセットはテーブル化されているが、ランクはシャルクビック公式により計算する。にもかかわらず、これら符号付先導をその絶対先導により表し、置換符号における蓄積および検索を最適化する。関連する絶対先導リストは以下の参考文献に見ることができる。
ラゴット S、べセット B、ルフェーブル R著「32kビット/秒における広帯域TCX通話符号化に適用する低複雑度多元速度格子ベクトル量子化」ICASSP論文集、1巻、PP.501−4、2004年5月
【0505】
本発明の種々の変形を示すために、3つの実施例を以下で説明する。最初の2つの実施例は置換ランクの計算(符号化)に関係し、一方は分解相互関係分解表現を使用し、他方はコンパクトな表現を使用する。
本明細書の以下のおよび対応する付録のこれらの実施例では、テーブルRおよびPをR[0]からR[mn!−1]へおよびP[0]からP[mn!−1]へ指標指定するが(本明細書の以上の例により説明するように1からmn!へではなく)、ランク計算処理には特定の影響はない。
【0506】
第1の実施例(符号化)
【0507】
この実施形態では、分解相互関係基本分解表現を使用する。
その指数を36セル(=(8+1)×4)を持つ2つのテーブルに蓄積する。これらは付録A−11に提示し、Dl[36](それ故0のダミー分解の蓄積を伴う整数l(0≦l≦8)の分解指数を含む)およびDlと表示するテーブルである。
3、5および7の累乗の3つのテーブルをまた以下のように蓄積する:
Pow3[4]={1、3、9、27};Pow5[3]={1、5、25};
Pow7[3]={1、7、49}
【0508】
この実施形態では、一方が整数の基本分解Skであり、他方が商の中間分解である2つの中間分解から、部分ランク分解を判断する。
【0509】
【数165】
【0510】
以上に示すように、(7−k)!および
【0511】
【数166】
【0512】
の基本分解(q+1)に対応する基本分解からRkの中間分解を判断するよりむしろ、Rk+1の中間分解および(7−k)および
【0513】
【数167】
【0514】
の2つの基本分解から、この中間分解を判断する。
【0515】
【表11】
【0516】
本発明は以上の表11において各位置に対して示すm(7−k)!および
【0517】
【数168】
【0518】
の最大値に関する知見を適用し、これらの限界より大きな指標を持つ素因数指数を計算しないようにする。
【0519】
対応する処理を付録A−12に提示する。位置に関するループを分解して相互関係を表示することを注記することにする。また、商の素因数指数piを4セルを持つテーブルRが有するセルR[i−1]に蓄積することを注記することにする。
【0520】
第2の実施例(符号化)
【0521】
3GPP AMR−WB+符号化器による変形では、基本分解をコンパクトに表現する。その指数を含むワードを9セル(=(8+1))を持つ2つのテーブルに蓄積する。付録A−21を参照すると、テーブルD’lは整数l(0≦l≦8)の分解のためのワードを含み(それ故l=0の分解のダミー蓄積を伴い)、テーブルD’l!はその階乗分解のためのワードを含む。
3、5、および7の累乗をまた(使用しない累乗の0のダミー蓄積を伴う)12セルを持つテーブルPow[12]に蓄積する。
2つが整数Skおよび階乗(7−k)!の基本分解であり、第3の中間分解が部分ランクの分母の中間分解である3つの中間分解から、部分ランクの分解を判断する。
【0522】
【数169】
【0523】
以前に示したように
【0524】
【数170】
【0525】
の基本分解qからPkの中間分解を判断するよりむしろ、Pk+1の中間分解からおよび
【0526】
【数171】
【0527】
の基本分解から、この分解を判断する。4つのこの中間分解指数を含むコンパクトなワードを付録A−22で「eP」と表示する。また、「el」は4つの部分ランク分解指数を含むコンパクトなワードを表示する。
ここで再び、m(7−k)!に関する知見を適用し、部分ランク分解を表現するコンパクトなワード指数m(7−k)!のみを抽出する。
【0528】
対応する処理は付録A−22の主題である。ここで再び、位置に関するループを分解して相互関係を表示する。
【0529】
第3の実施例(復号化)
【0530】
第3の実施例は3GPP AMR−WB+符号化における置換ランクの復号化を扱う。
第1の実施例におけるように基本分解の分解相互関係表現を好ましくは使用し、第2の実施例におけるように3つの項の部分ランク分解を好ましくは使用する。しかしながら位置に関するループは分解相互関係表示しない。
以前に示したように基本分解からPkの中間分解を判断するよりむしろ、Pkー1の中間分解からおよび
【0531】
【数172】
【0532】
の基本分解から、Pkの中間分解を判断する。4つのこの中間分解指数をテーブルPに蓄積する。同様にPkの中間分解からおよび(7−k)!の基本分解から、別の中間分解(商の中間分解)を計算し、その指数をテーブルRに蓄積する。
対応する処理は付録A−3の主題である。商の(対応して積の)素因数指数piの指数を4セルを持つテーブルR(対応してP)のセルR[i−1](対応してP[i−1])に蓄積する。
【0533】
従って、本明細書の以上の第1の例は(商を含む)2つの項の部分ランク分解を使用し、他の2つの例は3つの項(分子の2つおよび分母の1つ)の分解を使用する。2つの符号化モードは個別の位置処理を使用し、ゴセットネットワークのポイントの8つの位置に関するループの分解相互関係表示によるアルゴリズムにおいて読出さず、ハードウェアにより布線するml!またはmlの項を使用するが、復号化モードはm8!(=4)の項のみを使用する。
【0534】
TDAC符号化器の実施例
【0535】
最後の実施例は、16kHz(広帯域)でサンプル化するディジタルオーディオ信号の符号化に使用する出願者のTDAC知覚周波数符号化器に関係し、その原理を本明細書で以下に説明する。
【0536】
TDAC符号化器は可変次元およびリゾリューション並びに最大次元15を持つ統計的ベクトル量子化を使用する。
次元8を持つポイントの正規ネットワークRE8の置換符号の場合、本発明は本質的に複雑度の削減を可能にする。一方12より大きな次元の置換符号を使用するTDAC符号化器の場合、本発明は非常に有利であることを証明するが、これは本発明が複雑度の削減のみならず、また固定点プロセッサに関する符号化器の実施を可能にし、その最大精度を符号のない32ビットの整数に限定するからである。本発明がなければ、このような実施は極めて複雑であろう。
【0537】
この符号化器の原理は以下の通りである。
帯域幅を7kHzに制限し、16kHzでサンプル化するオーディオ信号を320サンプル(20ms)のフレームに細分化する。50%の重複を持つ640サンプルの入力信号ブロック(20ms毎のMDCT分析のリフレッシュに相当する)に、修正離散コサイン変換(modified discrete cosine transform、「MDCT」)を適用する。最後の31の係数をゼロに設定する(その場合、最初の289の係数のみが0と異なる)ことにより、スペクトラムを7225Hzに制限する。マスク化曲線をこのスペクトラムから判断し、全マスク係数をゼロに設定する。スペクトラムを不等幅の32帯域に分割する。信号の変換係数により任意のマスク帯域を判断する。各帯域のスペクトラムに対し、MDCT係数のエネルギを(測定尺度要因を推定するために)計算する。32の測定尺度要因は信号スペクトル包絡線を構成し、信号スペクトル包絡線を次いで量子化、符号化し、フレームで送信する。ビットの動的割当はスペクトル包絡線の量子化解除バージョンから計算する各帯域のマスク化曲線に基づき、符号化器および復号化器のバイナリ割当間の両立性を得るようにする。タイプII置換符号結合を構成上含む辞書である、サイズに応じてネスト化する辞書を使用するベクトル量子化器により、各帯域にける規格化MDCT係数を次いで量子化する。最後に、トーンおよび音声情報、スペクトル包絡線並びに符号化係数を多重化し、フレームで送信する。
【0538】
置換ランク(符号化)に関する計算の実施例はここでコンパクトな分解表現を使用する。使用する置換符号の次元は可変であり、位置に関するループは分解相互関係を表示しない。この実施形態は部分ランク分解のゼロでない指数の検出法を示す。
ここで、基本分解をコンパクトに表現する。その指数を含むワードを16セル(=(15+1))を持つ2つのテーブルに蓄積する。付録B−1で、テーブルD’lは整数l(0≦l≦15)の分解のためのワードを含み、テーブルD’l!はその階乗分解のためのワードを含む。
3の累乗をまた8セルを持つテーブル(Pow3と表示)に蓄積し、5、7、11、および13の累乗を20セル(使用しない累乗のための0のダミー蓄積を伴う)を持つテーブル(Powと表示)に蓄積する。
【0539】
対応する処理を付録B−2において再度書き換える。
【0540】
勿論、本発明は例により本明細書で以上に説明した実施形態に限定しない。本発明は他の変形を包含する。
【0541】
出願者の知見では、本発明は置換符号における素因数累乗分解の最初の使用を含む。一方置換符号によるベクトル量子化におけるように結合表現の計算を配備する場合、この使用は特に有利である。従って一般に、本発明は置換ランクとは異なるが1つまたは複数の置換符号による符号化/復号化における任意の結合表現にこの素因数累乗分解を使用することを目的とする。
【0542】
本発明は、通話信号の符号化/復号化、例えば電話端末、特にセルラーにおいて有利に適用可能である。とはいえ、本発明はあらゆるタイプの信号、特にイメージまたはビデオ信号の符号化/復号化および符号化変調に適合する。
【0543】
本発明はまた置換符号を使用するディジタル信号の符号化/復号化デバイスのメモリに蓄積するように設計するコンピュータプログラムを目的にする。その場合、このプログラムは本発明の意味する方法のステップを実施する命令を含む。典型的に、本明細書で以上に説明した図4乃至図8はこのようなプログラムが含むことのできるアルゴリズムのフローチャートに相当することができる。
【0544】
本発明はまた置換符号を使用するディジタル信号の符号化/復号化デバイスを目的にし、図9を参照して、
−上述のタイプのコンピュータプログラム命令および選択する整数の事前記録分解表現を蓄積するメモリユニットMEMおよび、
−本発明の意味する方法を実施するこのメモリユニットMEMにアクセスする計算モジュールPROC
を含む。
【0545】
これらの手段MEM、PROCを設計し、
・ソース符号化器の指標指定モジュールにおいて、または
・チャネル復号化器の指標指定モジュールにおいて
・選択する符号ベクトルyから置換ランクtを供給し(図9の実線の矢印)、
・ソース復号化器の復号化モジュールの、または
・チャネル符号化器の符号化モジュールの
・置換ランクtから再構築する符号ベクトルyを供給することができる(図9の破線の矢印)。
【0546】
勿論、メモリMEMに事前記録する表現はアドレスの内容形式(分解相互関係表現)またはビットワード形式(コンパクトな表現)でありうる。
【0547】
付録
【0548】
【数173】
【数174】
【数175】
【数176】
【数177】
【数178】
【数179】
【数180】
【数181】
【数182】
【数183】
【数184】
【数185】
【数186】
【数187】
【符号の説明】
【0549】
MEM メモリユニット
PROC 計算モジュール
【特許請求の範囲】
【請求項1】
結合表現の計算を含む置換符号を使用するディジタル信号の符号化/復号化方法であって、
前記結合表現を素因数累乗分解により表し、選択する整数の事前記録分解表現をメモリから読出すことにより判断し、
前記結合表現の少なくとも1つが整数の分子の整数の分母による商を含み、前記商を素因数累乗分解により表し、該素因数累乗分解の各累乗が前記分子および前記分母とそれぞれ関連し、1つのかつ同じ素数に割当てられる指数の差分であることを特徴とする方法。
【請求項2】
請求項1に記載の方法において、本方法が、結合表現の前記計算に対し、
−前記結合表現を形成する積および/または商に現れる項を前記選択する整数から特定するステップと、
−前記項の前記素因数分解に含む指数をメモリにおいて読出すステップと、
−前記読出した指数を加算および/または対応して減算し、前記結合表現の前記素因数累乗分解に含む前記指数を判断し、そのことからその素因数累乗分解から前記結合表現を計算するステップ
を含むことを特徴とする方法。
【請求項3】
請求項2に記載の方法において、以前の再起で判断した積を乗算する項を各再起に含む積の計算の再起ステップ含み、
−以前の再起で判断した前記積を素因数累乗分解の前記形式でメモリに保持し、
−前記積を乗算する前記項が前記分解を事前記録する前記選択する整数の1つであり、
−以前の再起で判断した前記積および前記積を乗算する前記項の前記それぞれの分解から導出する前記指数を共に各素数について1つずつ加算し、現再起の前記積を判断する、
ことを特徴とする方法。
【請求項4】
請求項2に記載の方法において、以前の再起で判断した商を除算する項を各再起に含む除算の計算の再起ステップ含み、
−以前の再起で判断した前記商を素因数累乗分解の前記形式でメモリに保持し、
−前記商を除算する前記項が前記分解を事前記録する前記選択する整数の1つであり、
−前記項の前記分解から導出する前記指数を以前の再起で判断した前記商の前記分解から導出する前記指数から各素数について1つずつ減算し、現再起の前記除算を判断する、
ことを特徴とする方法。
【請求項5】
請求項1に記載の方法において、前記置換符号が、各部分ランクが前記結合表現の1つに対応する部分ランクの累積を含む置換ランクを表す量の前記計算を含み、
前記置換符号がシャルクビック計数を使用し、符号ベクトル(y0、...、yn−1)の切取り(yk、...、yn−1)に関連する部分ランク
【数1】
が、
【数2】
により表され、上式で
【数3】
−が0乃至mの範囲の整数指標iに対する積を表し、
【数4】
−が0乃至mの範囲の指標iに対する総和を表し、
−l!がl>0の場合 l!=1×2×3×...×(l−1)×lであり、0!=1である前記整数lの前記階乗値であり、
−前記整数nが、符号ベクトルが含む構成要素の前記総数に対応する前記置換符号の前記次元であり、
−0とn−1との間の前記整数kが前記符号ベクトルのk番目の構成要素ykの前記指標であり、
−前記整数qが、前記符号ベクトルが含む個別構成要素の前記数であり、
−項wkdがkとk−1との間の指標構成要素の前記数を表し、1つのかつ同じ指標構成要素dの数に等しい値を有し、
結合表現として前記部分ランク
【数5】
を形成する積および/または商において特定し、現れる前記整数が、
−0とn−1との間の全ての前記整数kに対し前記階乗項(n−1−k)!であり、
−各項wkiの前記値および/または各項wkiが0とnとの間にある前記積Pk
【数6】
に含まれるその階乗値であり、
−0とn−1との間の全ての前記整数kに対し、各項が、1とn−1との間にある前記項Sk
【数7】
である
ことを特徴とする方法。
【請求項6】
請求項5に記載の方法において、前指標kに対する前記項Pk
【数8】
の前記分解における前記指数の前記総和を一時的にメモリに蓄積し、現指標kに対する項wkiの前記分解指数に、またはから加算または減算することを特徴とする方法。
【請求項7】
デバイスのメモリに蓄積する置換符号を使用するディジタル信号の符号化/復号化のためのコンピュータプログラムであって、コンピュータプログラムが請求項1に記載する方法の各ステップを実施する命令を含むことを特徴とするコンピュータプログラム。
【請求項8】
置換符号を使用するディジタル信号の符号化/復号化デバイスであって、本デバイスが、
−請求項7に記載するコンピュータプログラムの前記命令および選択する整数の事前記録分解表現を蓄積するメモリユニットと、
−前記メモリユニットにアクセスし、請求項1に記載する方法を実施する計算モジュール
を含むことを特徴とするデバイス。
【請求項1】
結合表現の計算を含む置換符号を使用するディジタル信号の符号化/復号化方法であって、
前記結合表現を素因数累乗分解により表し、選択する整数の事前記録分解表現をメモリから読出すことにより判断し、
前記結合表現の少なくとも1つが整数の分子の整数の分母による商を含み、前記商を素因数累乗分解により表し、該素因数累乗分解の各累乗が前記分子および前記分母とそれぞれ関連し、1つのかつ同じ素数に割当てられる指数の差分であることを特徴とする方法。
【請求項2】
請求項1に記載の方法において、本方法が、結合表現の前記計算に対し、
−前記結合表現を形成する積および/または商に現れる項を前記選択する整数から特定するステップと、
−前記項の前記素因数分解に含む指数をメモリにおいて読出すステップと、
−前記読出した指数を加算および/または対応して減算し、前記結合表現の前記素因数累乗分解に含む前記指数を判断し、そのことからその素因数累乗分解から前記結合表現を計算するステップ
を含むことを特徴とする方法。
【請求項3】
請求項2に記載の方法において、以前の再起で判断した積を乗算する項を各再起に含む積の計算の再起ステップ含み、
−以前の再起で判断した前記積を素因数累乗分解の前記形式でメモリに保持し、
−前記積を乗算する前記項が前記分解を事前記録する前記選択する整数の1つであり、
−以前の再起で判断した前記積および前記積を乗算する前記項の前記それぞれの分解から導出する前記指数を共に各素数について1つずつ加算し、現再起の前記積を判断する、
ことを特徴とする方法。
【請求項4】
請求項2に記載の方法において、以前の再起で判断した商を除算する項を各再起に含む除算の計算の再起ステップ含み、
−以前の再起で判断した前記商を素因数累乗分解の前記形式でメモリに保持し、
−前記商を除算する前記項が前記分解を事前記録する前記選択する整数の1つであり、
−前記項の前記分解から導出する前記指数を以前の再起で判断した前記商の前記分解から導出する前記指数から各素数について1つずつ減算し、現再起の前記除算を判断する、
ことを特徴とする方法。
【請求項5】
請求項1に記載の方法において、前記置換符号が、各部分ランクが前記結合表現の1つに対応する部分ランクの累積を含む置換ランクを表す量の前記計算を含み、
前記置換符号がシャルクビック計数を使用し、符号ベクトル(y0、...、yn−1)の切取り(yk、...、yn−1)に関連する部分ランク
【数1】
が、
【数2】
により表され、上式で
【数3】
−が0乃至mの範囲の整数指標iに対する積を表し、
【数4】
−が0乃至mの範囲の指標iに対する総和を表し、
−l!がl>0の場合 l!=1×2×3×...×(l−1)×lであり、0!=1である前記整数lの前記階乗値であり、
−前記整数nが、符号ベクトルが含む構成要素の前記総数に対応する前記置換符号の前記次元であり、
−0とn−1との間の前記整数kが前記符号ベクトルのk番目の構成要素ykの前記指標であり、
−前記整数qが、前記符号ベクトルが含む個別構成要素の前記数であり、
−項wkdがkとk−1との間の指標構成要素の前記数を表し、1つのかつ同じ指標構成要素dの数に等しい値を有し、
結合表現として前記部分ランク
【数5】
を形成する積および/または商において特定し、現れる前記整数が、
−0とn−1との間の全ての前記整数kに対し前記階乗項(n−1−k)!であり、
−各項wkiの前記値および/または各項wkiが0とnとの間にある前記積Pk
【数6】
に含まれるその階乗値であり、
−0とn−1との間の全ての前記整数kに対し、各項が、1とn−1との間にある前記項Sk
【数7】
である
ことを特徴とする方法。
【請求項6】
請求項5に記載の方法において、前指標kに対する前記項Pk
【数8】
の前記分解における前記指数の前記総和を一時的にメモリに蓄積し、現指標kに対する項wkiの前記分解指数に、またはから加算または減算することを特徴とする方法。
【請求項7】
デバイスのメモリに蓄積する置換符号を使用するディジタル信号の符号化/復号化のためのコンピュータプログラムであって、コンピュータプログラムが請求項1に記載する方法の各ステップを実施する命令を含むことを特徴とするコンピュータプログラム。
【請求項8】
置換符号を使用するディジタル信号の符号化/復号化デバイスであって、本デバイスが、
−請求項7に記載するコンピュータプログラムの前記命令および選択する整数の事前記録分解表現を蓄積するメモリユニットと、
−前記メモリユニットにアクセスし、請求項1に記載する方法を実施する計算モジュール
を含むことを特徴とするデバイス。
【図1A】

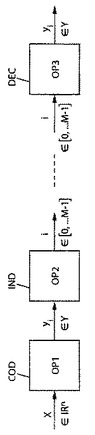
【図1B】
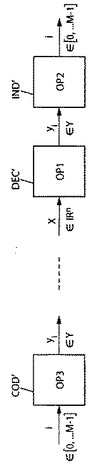
【図2】
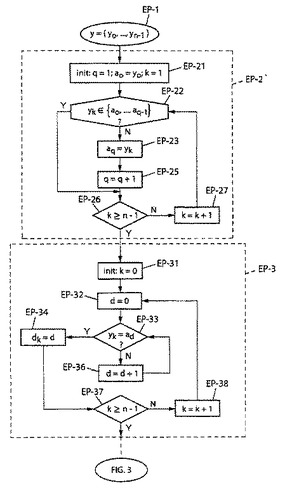
【図3】
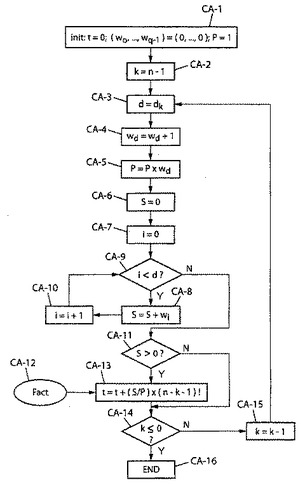
【図4】
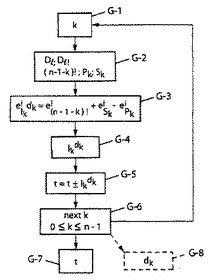
【図5】
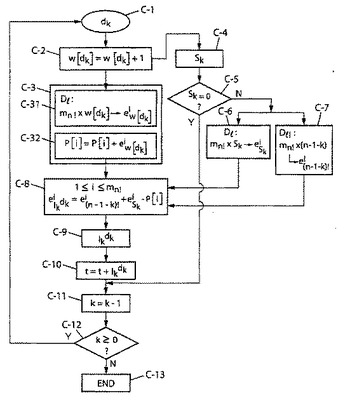
【図6】
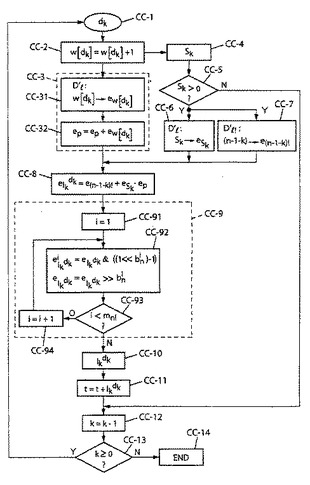
【図7】
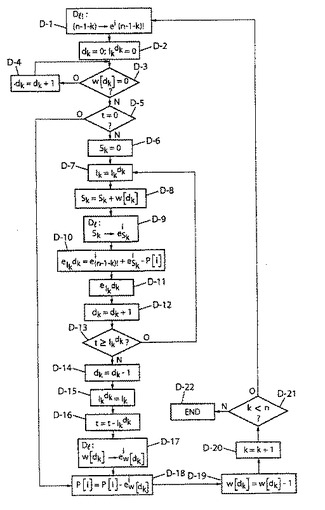
【図8】
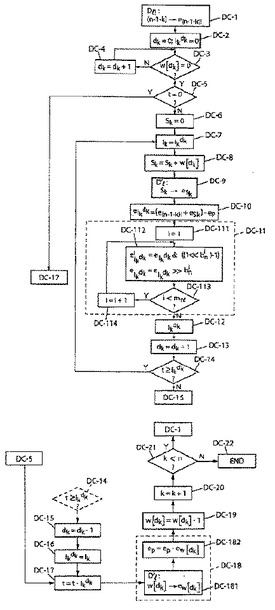
【図9】
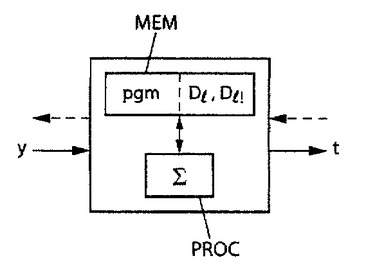
【図1B】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【公開番号】特開2009−153157(P2009−153157A)
【公開日】平成21年7月9日(2009.7.9)
【国際特許分類】
【出願番号】特願2009−11437(P2009−11437)
【出願日】平成21年1月21日(2009.1.21)
【分割の表示】特願2008−554820(P2008−554820)の分割
【原出願日】平成19年2月13日(2007.2.13)
【出願人】(591034154)フランス テレコム (290)
【Fターム(参考)】
【公開日】平成21年7月9日(2009.7.9)
【国際特許分類】
【出願日】平成21年1月21日(2009.1.21)
【分割の表示】特願2008−554820(P2008−554820)の分割
【原出願日】平成19年2月13日(2007.2.13)
【出願人】(591034154)フランス テレコム (290)
【Fターム(参考)】
[ Back to top ]