
自動利得制御
【課題】複数話者オーディオにおけるオーディオ利得レベルを調整するための技術に関する。
【解決手段】1つの例として、オーディオシステムは、新たな話者の存在に対して、オーディオストリームを監視する。新たな話者を識別すると、システムは、新たな話者が初めての話者かどうかを決定する。初めての話者に対して、システムは、初めての話者に対する利得値を迅速に決定するため、高速アタック/ディケイ自動利得制御(AGC)を実行する。更に、初めての話者が会話中、初めての話者に対する利得を改善するため、標準AGC技術を実行する。初めての話者に対し、標準AGCを用いて、デシベルしきい値内の安定状態が達成されると、システムは、初めての話者に対する安定状態利得を記憶部に格納する。以前に識別された話者を識別すると、システムは、話者に対する安定状態利得を記憶部から読み出し、オーディオストリームに適用する。
【解決手段】1つの例として、オーディオシステムは、新たな話者の存在に対して、オーディオストリームを監視する。新たな話者を識別すると、システムは、新たな話者が初めての話者かどうかを決定する。初めての話者に対して、システムは、初めての話者に対する利得値を迅速に決定するため、高速アタック/ディケイ自動利得制御(AGC)を実行する。更に、初めての話者が会話中、初めての話者に対する利得を改善するため、標準AGC技術を実行する。初めての話者に対し、標準AGCを用いて、デシベルしきい値内の安定状態が達成されると、システムは、初めての話者に対する安定状態利得を記憶部に格納する。以前に識別された話者を識別すると、システムは、話者に対する安定状態利得を記憶部から読み出し、オーディオストリームに適用する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、オーディオストリームに適用される利得調整に関する。
【背景技術】
【0002】
未処理(raw)のオーディオ信号は、マイクで受信された全周波数の畳み込み(convolution)であり、オーディオ信号に変換される。複数話者(multi-talker)環境において、周波数のこの畳み込みは、話者の各々に対する音声パターンを含み、音声パターンは、オーディオシステムが、オーディオ信号を処理し、現在話者に対する関連した音声パターンを識別することにより、現在話者を識別することを可能にする。
【発明の概要】
【課題を解決するための手段】
【0003】
1つの実施例において、方法は、第1の話者を識別するため、オーディオシステムにおけるオーディオ信号を処理するステップを有する。方法は、また、オーディオシステムが第1の話者と利得との間の関連を格納しているかどうかを決定するステップ、オーディオシステムが第1の話者と利得との間の関連を格納していないとき、アタック率(attack rate)又はディケイ率(decay rate)の少なくとも1つを増加させるため、オーディオシステムにおける自動利得制御(automatic gain control: AGC)アルゴリズムを変更するステップ、第1の話者に対する利得を決定するため、変更されたAGCアルゴリズムをオーディオ信号に適用するステップを有する。方法は、また、オーディオシステムが、出力オーディオ信号を生成するため、オーディオ信号の表示(representation)に第1の話者に対する利得を適用するステップ、及びオーディオシステムから出力オーディオ信号を出力するステップを有する。
【0004】
その他の実施例において、オーディオシステムは、第1の話者を識別するため、オーディオシステムにおけるオーディオ信号を処理するための手段を有する。オーディオシステムは、また、オーディオシステムが第1の話者と利得との間の関連を格納しているかどうかを決定する話者識別モジュールを有する。オーディオシステムは、また、自動利得制御(AGC)モジュールを有し、オーディオシステムが第1の話者と利得との間の関連を格納していないとき、話者識別モジュールは、アタック率またはディケイ率の少なくとも1つを増加させるため、AGCモジュールを変更し、AGCモジュールは、第1の話者に対する利得を決定するため、変更されたAGCアルゴリズムをオーディオ信号に適用し、AGCモジュールは、出力オーディオ信号を生成するため、オーディオ信号の表示に第1の話者に対する利得を適用し、オーディオシステムは、出力オーディオ信号を出力する。
【0005】
その他の実施例において、コンピュータ読取り可能記憶媒体は、実行時において、第1の話者を識別するため、オーディオシステムにおけるオーディオ信号を処理するステップ、オーディオシステムが第1の話者と利得との間の関連を格納しているかどうかを決定するステップ、オーディオシステムが第1の話者と利得との間の関連を格納していないとき、アタック率またはディケイ率の少なくとも1つを増加させるため、オーディオシステムにおける自動利得制御(AGC)アルゴリズムを変更するステップ、第1の話者に対する利得を決定するため、変更されたAGCアルゴリズムをオーディオ信号に適用するステップを有する処理を実現する命令を有する。命令は、実行時において、オーディオシステムが、出力オーディオ信号を生成するため、オーディ信号の表示に第1の話者に対する利得を適用するステップ、オーディオシステムから出力オーディオ信号を出力するステップを有する処理を更に実現する。
【0006】
1つ以上の実施例の詳細は、添付の図面と以下の記載に説明される。その他の特徴、目的、及び利点は、記載と図面から、及び特許請求の範囲から明白となる。
【図面の簡単な説明】
【0007】
【図1】本明細書に記載される声紋(voice-print)マッチング及び高速アタック利得制御技術を用いて、電気信号に適用される利得を調整するオーディオシステムを説明するブロック図である。
【図2】図1のオーディオシステムの事例をより詳細に説明するブロック図である。
【図3】本明細書に記載の技術に従い、オーディシステムにより受信されるオーディオストリーム内の新たな話者の登場に応答して、利得を迅速に調整するためのオーディシステムの動作例を説明するフローチャートである。
【図4】記載の技術に従い、オーディシステムにより受信されるオーディオストリーム内の新たな話者の登場に応答して、結合された利得を適用するためのオーディシステムの動作の例示的なモードを説明するフローチャートである。
【発明を実施するための形態】
【0008】
複数話者環境における会話が、共通マイクから遠い話者などの穏やか(soft)な話者から、共通マイクに近い話者などの大音量の話者に推移するとき(又は、その反対)、数秒の単位で出力利得を変更する時間平均された自動化利得制御(AGC)アルゴリズムは、安定した音量(volume)を供給するために、十分な速さで適応することはできない。この結果、AGCアルゴリズムの動作中、大音量の話者は十分に減衰されず、及び/又は、穏やかな話者は十分に増幅されない。
【0009】
一般的に、複数話者オーディオにおけるオーディオ利得レベルを調整するための技術がある。1つの例において、複数話者環境において動作するオーディオシステムは、新たな話者の存在に対してオーディオストリームを継続的に監視する。新たな話者を識別すると、オーディオシステムは、新たな話者が初めての話者であり、その声紋(voice print)がシステムに未知であるかどうかを決定する。新たな話者が初めての話者である場合、オーディオシステムは、その話者に対して以前に決められたオーディオ利得レベルに関連付けられた声紋の記録を持たない。初めての話者に対して、オーディオシステムは、以下に詳細に記載するように、初めての話者に対する利得値を迅速に決定するため、高速アタック/ディケイ(fast-attack/decay)AGCアルゴリズムを実行し、この利得値をオーディオ出力に適用する。オーディオシステムは、初めての話者が話しを続ける間、初めての話者に対する利得を改善するために、標準AGC技術を更に実行する。
【0010】
初めての話者に対して標準AGCを用いることにより、デシベル範囲内の安定した状態が達成されると、オーディオシステムは、初めての話者に対する声紋に関連して、初めての話者に対する安定した状態の利得を記憶装置に格納する。以前に識別された話者を識別すると、システムは、この話者に対し以前に決定された安定状態の利得を記憶装置から読み出し、オーディオストリームに安定状態利得を適用する。この結果、オーディオシステムは、複数話者オーディオにおける利得を迅速に決定するため、複数話者に対し、それぞれの所定の利得を用い、未識別の話者に対し、高速アタックAGCアルゴリズムを用いる。
【0011】
本明細書の技術は、1つ以上の利点を提示する。例えば、本明細書の技術を用いて、オーディオシステムは、複数話者環境において、識別された話者と未識別の話者の両方に適用される利得を迅速に切り替えることができる。
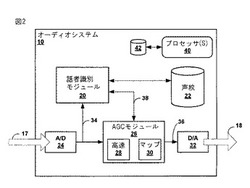
【0012】
図1は、オーディオシステム10を説明するブロック図であり、本明細書に記載される声紋マッチング及び高速アタック利得制御技術を用いて、電気信号に適用される利得を調整する利得制御システムの例である。マイク14は、連続的、及び/又は、同時(クロストーク)に声を発する複数の話者12A〜12N(集合的に「話者12」)の1人以上により発生される音声サウンドを含む、その近傍の周囲サウンドを獲得する。話者12の各々は、任意の時間だけ突発的に話しをする(例えば、数十ミリ秒程度から数時間程度の間)。マイク14は、周囲サウンドを、オーディオシステム10により受信される電気信号17に変換する。人間に対して、本明細書では記載されているが、話者12は、任意のオーディオソース又はその記録とすることができる。
【0013】
幾つかの態様において、電気信号17は、話者12のサウンド、又は記憶媒体(例えば、コンパクトディスク(CD)、ハードディスク、レコード、テープ、若しくはフラッシュメモリ)上に予め記録されたその他任意のオーディオソースにより提供されるサウンドから符号化されたデータを用いる再生装置(例えば、CDプレイヤー、コンピュータプログラム、若しくはテーププレイヤー)により再生される電気信号を表す。
【0014】
オーディオシステム10は、変更された電気信号18を出力するよう電気信号17を処理し、変更された電気信号18は、話者12が話しをしている間、より安定的な音量(例えば、許容可能なデシベル(dB)範囲内)を有するオーディオをスピーカ16に出力させる。オーディオシステム10は、例えば、携帯オーディオプレイヤー、ミキシングボード(mixing board)、スマートフォン、パブリックアドレス(PA)システム、又は電話会議やビデオ会議システムとすることができる。許容可能なdB範囲は、任意の話者12によりユーザ設定することが可能であり、あるいは、電話若しくはビデオ会議、コンサート若しくはPAなど、オーディオシステム10が動作している状況に対してオーディオシステム10を監視している、又は携帯オーディオプレイヤーで聴取しているユーザ、管理者やサウンドエンジニアによりユーザ設定することが可能である。幾つかの態様において、マイク14とスピーカ16の一方又は両方は、オーディオシステム10も含むシャーシ又はその他タイプのケース内に組み込まれ、あるいは、有線コネクタを介して、オーディオシステム10に直接的に接続することができる。幾つかの態様において、マイク14とスピーカ16の一方又は両方は、例えば、公衆交換電話網(public switched telephone network: PSTN)、公衆地上移動網(public land mobile network: PLMN)、企業仮想プライベート網(virtual private network: VPN)、インターネット、WiFi接続、又は3GPPセルラー無線網など、ネットワークを介して通信可能に接続されることで、オーディオシステム10から離すことができる。幾つかの態様において、マイク14とスピーカ16の一方又は両方は、無線とすることができる。幾つかの態様において、マイク14は、様々な組合せで、話者12の間に配置される複数のマイクとすることができる。更に、幾つかの態様において、話者12の各々は、オーディオシステム10の異なる例と関連付けることができる。
【0015】
変更された電気信号18を許容可能なdB範囲内で出力し、話者12に対するサウンド忠実度(fidelity)を維持するよう電気信号17を処理するため、オーディオシステム10は、話者12毎に自動利得制御(AGC)技術を適用する。話者12の各々により生成されるサウンド(例えば、音声、咳、叫び、歌唱など)は、話者の固有性やマイク14から話者までの距離に基づいた様々な特徴を有する。例えば、穏やかな話者やマイク14から離れている話者は、大音量の話者やマイク14に近い話者により生成されるサウンドより、マイク14において、より低い振幅(amplitude)を有するサウンドを生成する傾向にある。
【0016】
オーディオシステム10は、話者毎にAGC技術を適用するため、話者12中の個々の話者に対して、電気信号17を監視する。話者12の各々は、何時でもサウンドを発することができ、サウンドはマイク14で受信され、電気信号17に変換される。従って、会話(即ち、話者12により生成され、マイク14で受信される一体となったサウンド)に加わる新たな話者や会話から離れる現在の話者に伴い、特定時間において、話者12の異なる組合せが音を発することができる。ここで、「新たな(new)」話者は、最近会話に加わった、又は再び加わった話者12の1人にあたる。
【0017】
話者12中の新たな話者のオーディオの存在を識別するため、オーディオシステム10は、話者検出及び識別技術を用いて電気信号17を処理する。新たな話者を検出後、オーディオシステム10は、新たな話者が初めての話者かどうかを決定するため、その話者を識別することができる。様々な例において、「初めて(first-time)」または「未識別(unidentified)」の話者は、オーディオシステム10が以前に認識していないか、あるいはシステムから以前の認識の記録が削除されている話者、又は以前の認識の記録が存在するにも係わらず、オーディオシステム10がその話者をもはや認識することが出来ないほどにその音声が変更されてしまった話者12の1人にあたる。電気信号17中に検出された新たな話者が初めての話者であることを決定することに応答して、オーディオシステム10は、初めての話者に対する利得値を迅速に決定するため、高速アタック/ディケイAGCアルゴリズムを実行することができ、そしてオーディオシステム10は、変更された電気信号18を生成するため、電気信号17のこの決定された利得値を適用することができる。高速アタック/ディケイAGCアルゴリズムは、標準AGCに対し必要となる時間より少ない時間で(例えば、数百マイクロ秒またはミリ秒)、初めての話者に対する利得値に収束する(あるいは、「安定する」)。オーディオシステム10は、初めての話者が話し続けている間、初めての話者に対する利得を改善し、適用するため、同時に、及び/又は続いて、標準AGCを実行することができる。
【0018】
オーディオシステム10が、標準AGCを用いて、初めての話者に対してデシベルしきい値内の安定した状態に達したとき、オーディオシステム10は、この安定状態を実現する利得、あるいは安定状態利得と初めての話者を関連付けることができる。電気信号17で表される話者12中に以前に識別された話者を検出し、識別すると、オーディオシステム10は、以前に識別された話者に対して先に関連付けられた安定状態利得を記憶媒体から呼び出して、変更された電気信号18を生成するため、先に関連付けられた安定状態利得を電気信号17に適用することができる。以前に識別された話者により生成されたサウンドに基づいて、利得を改善し、マイク14で生成された電気信号17に利得を適用するため、オーディオシステム10が標準AGCを同時に実行する一方、様々な例において、オーディオシステム10は、以前に識別された話者に対して適用された利得により早く収束するため、先に関連付けられた安定状態利得を少なくとも初期に適用する。標準AGCは、AGCフィードバックメカニズムに基づいて、安定状態利得値に達するまで、数秒を必要とするため、以前に識別した新たな話者12に対して、それぞれの所定の利得を適用することと、未識別の新たな話者12に対して高速アタック/ディケイAGC技術を適用することの組合せは、オーディオシステム10が、変更された電気信号18を生成するため、電気信号17に適用するための適切な利得を迅速に決定することを可能にし、変更された電気信号18は、スピーカ16により変換されるとき、新たな話者である特定の話者12の存在にも係わらず、許容可能なdB範囲内のサウンドとなる。更に、以前に識別された新たな話者12に対する所定の利得を適用することは、高速アタック/ディケイAGCのみに比べ、そのような話者におけるサウンドのdB範囲の不変性を改善することができる。
【0019】
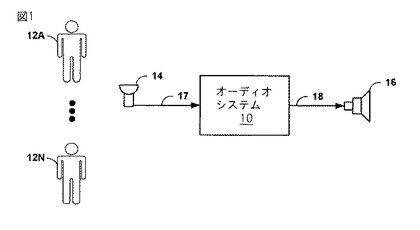
図2は、図1のオーディオシステム10の例をより詳細に説明したブロック図である。図1の同等の要素を特定するため、同等の番号が使用される。オーディオシステム10は、電気信号17を受信し、デジタル信号34を出力するアナログ−デジタル(A/D)変換器24を有し、デジタル信号34は、話者識別モジュール20及び自動利得制御(AGC)モジュール26(「AGCモジュール26」と表記)により受信される電気信号17のデジタル表記である。幾つかの例において、オーディオシステム10は、デジタル信号34として出力するため、電気信号17をパルスコード変調(PCM)符号化されたデジタルオーディオ信号などのデジタルオーディオ信号に変換するオーディオ帯域符号化/復号器(CODEC)を更に有する。幾つかの態様において、電気信号17はデジタル信号であり、このため、A/D変換器24は、オーディオシステム10から省略することができる。
【0020】
話者識別モジュール20は、デジタル信号34をサンプリングし、解析して、話者を識別するための声紋を抽出する。幾つかの態様において、話者識別モジュール20は、声紋を抽出し、新たな話者を検出、識別するため、内部または外部セグメンテーションを持つ混合ガウスモデル(Gaussian mixture model)、一般背景モデル(universal background model)(GMM−UBM)を使うことができる。その他の態様において、話者識別モジュール20は、周波数推定、パターンマッチングアルゴリズム、ベクトル量子化、決定木(decision tree)、隠れマルコフモデル、又はその他技術を使用することができる。話者識別モジュール20は、新たな話者(即ち、デジタル信号34で表される会話への1人の話者の登場または再登場)を識別するため、デジタル信号34を継続的に監視する。オーディオシステム10の声紋22は、コンピュータ読取り可能記録媒体上に格納されたデータベース又はその他データ構造を有し、これらは、話者識別モジュール20により以前に識別された各々の話者に対する1以上の声紋を格納する。各声紋は、話者の特徴的な信号パラメータ、話者の音声信号の連続するサンプル、ケプストラムまたはスペクトル特性ベクトル、又はその他の情報を含むことができ、これらは、声紋と共に、対応する話者にマッチングするため、話者識別モジュール20により使用される。話者識別モジュール20は、声紋22に格納するための声紋パラメータを習得(learn)するため、トレーニング技術を実行することができる。以下に詳細に記載されるように、デジタル信号34は、声紋に合致する話者に対するオーディオ信号を含み、声紋22の各々は、AGCモジュール26により、デジタル信号34に適用されることになる関連付けられた利得を有する。
【0021】
デジタル信号34内の新たな話者に対する声紋を抽出すると、話者識別モジュール20は、当該声紋と声紋22に格納されている声紋とを比較する。声紋22内の一致する声紋は、新たな話者が以前に識別されていることを示し、話者識別モジュール20は、制御チャネル38を用い、AGCモジュール26に一致する声紋の話者識別を提供する。声紋22が、新たに識別された声紋に対する一致を有しない場合、話者識別モジュール20は、制御チャネル38を用い、AGCモジュール26にデジタル信号34内の未識別話者の出現を示す。幾つかの態様において、話者識別モジュール20は、複数の声紋22が現在の話者に対して各々の一致確率(matching probability)を持っていることを決定できる。そのような態様において、話者識別モジュール20は、声紋22から、複数の声紋22に対する決定された各々の一致確率と同様に、関連付けられた各々の利得を受け取る。例えば、新たな話者が、声紋22の一致する声紋「A」の確率0.7及び声紋22の一致する声紋「B」の確率0.3を有することが決定されると、話者識別モジュール20は、声紋「A」と「B」に対する確率と共に、関連付けられた利得を読み出し、AGCモジュール26に提供する。声紋を用いて話者を識別するよう記載されているが、話者識別モジュール20は、複数のオーディオソースを区別するオーディオプリントを用いてオーディオソースを識別するオーディオソース識別モジュールと見なすことができる。
【0022】
AGCモジュール26は、デジタル出力信号36がスピーカ又はその他の適切な装置によりオーディオに変換されるとき、デジタル出力信号36に対する信号振幅が許容可能なdB範囲内に維持されるように、デジタル信号34を変換するための自動利得制御技術を適用する。幾つかの適切なAGCアルゴリズムのいずれかを、許容可能なdB範囲になるようデジタル信号34の振幅に適応するため、適用することができる。AGCアルゴリズムは、通常、入力量に基づいて以前に適用された利得レベルの結果を監視するフィードバックループに依存する。結果に基づき、典型的なAGCアルゴリズムは、入力量を出力量に変換するための利得レベルを変更し、出力量は、目標量により近似したその後の入力量となる。本技術において関連する量は、デジタル出力信号36に対する信号振幅である。幾つかの態様において、オーディオシステム10は、AGCモジュール26から利得信号を受信するアナログ又はデジタルの増幅器を有し、増幅器は、デジタル出力信号36又は変更された電気信号18を生成するため、電気信号17又はデジタル信号34の1つに利得信号を適用する。幾つかの態様において、利得は、変更された電気信号18を生成するため、電気信号17を増幅、減衰、又はその他変更するためのオーディオフィルタ、その他装置、又は値として、計算され、格納され、適用される。
【0023】
AGCモジュール26は、標準AGCを適用し、ほぼ一定音量で話をする話者に対して、1つの利得に数秒の単位で収束する。AGCモジュール26は、制御チャネル38を用い、話者識別モジュール20に結果の利得を提供する。話者識別モジュール20は、話者に対して関連付けられた声紋と共に、結果の利得を声紋22に格納する。幾つかの例において、話者識別モジュール20は、声紋22内で、関連付けられた声紋に対して既に格納されている利得をAGCモジュール26から受信された新たな結果の利得で置き換える。
【0024】
AGCモジュール26の高速AGCモジュール28(「高速28」として表示)及びマッピングモジュール30(「マップ30」として表示)は、AGCモジュール26がデジタル出力信号36を生成する速度を改善するため、本発明と調和した技術を実行し、デジタル出力信号36は、現在許容可能なdB範囲で音量を生成する。特に、話者識別モジュール20から、デジタル信号34の現在の話者が未識別の話者であるとの信号を受信すると、高速AGCモジュール28は、アタック率(AGC技術が大音量信号に応じて利得を減少させる速度に対応する)、及び/又はディケイ率(AGC技術が大音量信号の離脱に応じて利得を増加させる速度に対応する)を増加させるため、AGCモジュール26によりデジタル信号34に適用される標準AGCを変更する。この結果、AGCモジュール26が標準AGCに従い利得を変更する速度と比べ、AGCモジュール26は、デジタル信号34に適用される利得を迅速に変更し、これにより、許容可能な音量をもたらすデジタル出力信号36を早急に生成する。高速AGCモジュール28は、分離した集積回路またはプロセッサで実現することができ、AGCモジュール26により実行される標準AGCに代わり、合図があると、高速アタック/ディケイAGC技術を実行する。
【0025】
高速アタック/ディケイAGC技術は、利得安定性に関連して欠陥を有するため(例えば、入力振幅における一時的なわずかの変調は大きな利得適応となり得る)、マッピングモジュール30は、以前に識別された話者に対して話者識別モジュール20から受信された所定の利得値を適用する。上記のように、話者識別モジュール20が、デジタル信号34に対して、声紋22の一致する1つを識別すると、話者識別モジュール20は、一致する声紋に対する関連付けられた利得をAGCモジュール26に供給する。AGCモジュール26が関連付けられた利得を決定している間、識別された話者に対するオーディオ信号の受信の以前の発生にほぼ一致した音量で、識別された話者がサウンドを生成するとき、マッピングモジュール30は、オーディオシステム10における許容可能なdB範囲に合致するデジタル出力信号36を生成するため、デジタル信号34に関連付けられた利得を適用する。
【0026】
幾つかの態様において、オーディオシステム10は、識別された話者に対する計算された利得とその識別された話者に対する格納された関連付けられた利得との差分に基づき、マイクの移動を検出する。例えば、話者識別モジュール20は、新たな話者に関するデジタル信号34に対して、声紋22の一致する1つを識別することができ、マッピングモジュール30は初めにデジタル信号34に適用する。続いて、AGCモジュール26は、デジタル信号34の振幅の差分により、話者に対する新たな利得を計算することができる。AGCモジュール26は、制御チャネル38を介し、話者識別モジュール20に新たな利得を提供する。話者識別モジュール20は、声紋22内の話者に対し以前に格納された利得と新たな利得を比較する。差分が設定可能なしきい値を超える場合、マイクは移動したものであり、これにより、話者12の各々は、マイク移動前にマイクで生成されたサウンドから振幅で相違するサウンドをマイクで生成することになる。この結果、話者識別モジュール20は、新たな利得と以前に格納された利得との間の、例えば、相対的又は絶対的な差分を声紋22に関連付けられた利得のそれぞれに適用することができる。このように、声紋22に関連する話者のそれぞれは、その次の会話の順番に備えて調整された各々の格納された利得を有する。
【0027】
幾つかの態様において、オーディオシステム10は、スマートフォンなどの装置を表し、更に加速度計、カメラ、赤外探知機、又は装置の移動を追跡するその他の要素を含む。そのような態様において、オーディオシステム10は、追跡要素から受信された装置に対する移動情報に基づいて、利得変更を計算することができる。例えば、移動情報は、話者12の1人が共通マイクから更に移動していることを示すことができる。その結果、オーディオシステム10は、デジタル信号34に適用される利得を増加させる利得変更を計算することができる。幾つかの態様において、オーディオシステム10は、スマートフォンなどの装置を表し、カメラ又は話者12の移動を追跡するその他の装置からの位置データを含み、又は受信する。これらの態様において、オーディオシステムは、追跡要素から受信される話者に対する移動情報に基づき、話者毎の利得変更を計算することができる。
【0028】
オーディオシステム10のデジタル−オーディオ(D/A)変換器32は、デジタル出力信号36を変更された電気信号18に変換し、これは、アナログ信号を表すことができる。幾つかの例において、オーディオシステム10は、デジタル出力信号36を変更された電気信号18に変換するオーディオ帯域CODECを更に含む。幾つかの態様において、変更された電気信号18はデジタル信号であり、このため、D/A変換器32はオーディオシステム10から取り除くことができる。
【0029】
オーディオシステム10の1以上のプロセッサ40は、オーディオシステム10の様々なモジュールの機能を実行するために動作する。プロセッサ40は、マイクロプロセッサ、コントローラ、デジタル信号プロセッサ(DSP)、音声帯域オーディオプロセッサ、特定アプリケーション向け集積回路(ASIC)、フィールドプログラマブルゲートアレイ(FPGA)、又は等価な分離若しくは集積論理回路の任意の1つ以上を含むことができる。更に、本発明において、プロセッサ40に起因する機能は、ソフトウェア、ファームウェア、ハードウェア又はそれらの任意の組合せとして搭載することができる。プロセッサ40は、オーディオシステム10の記憶装置42により格納された命令を実行することができ、記憶装置42は、例えば、プロセッサ40などの1以上のプロッセサに様々な機能を実現させる命令を有するコンピュータ読取り可能、機械読取り可能、又はプロセッサ読取り可能な記憶媒体を含むことができる。記憶装置42は、ランダムアクセスメモリ(RAM)、読み出し専用メモリ(ROM)、プログラム可能読み出し専用メモリ(PROM)、消去可能PROM(EPROM)、電気的消去可能PROM(EEPROM)、フラッシュメモリ、ハードディスク、CD−ROM、フロッピーディスク、カセット、磁気媒体、光学媒体、又はその他のコンピュータ読取り可能記憶媒体など、任意の有形(trangible)又は持続的(non-transitory)コンピュータ読取り可能記憶媒体を含むことができる。声紋22は、記憶装置42により格納することができる。
【0030】
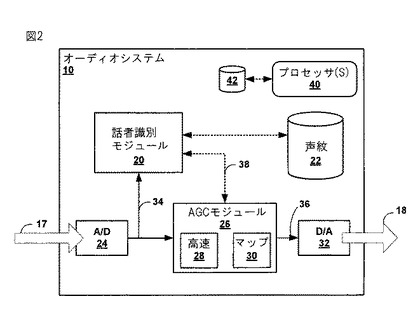
図3は、ここに記載される技術に関連して、オーディオシステムにより受信されるオーディオストリーム内の新たな話者の登場に応答して迅速に利得を調整するための、図2のオーディオシステム10の動作例を説明するフローチャートである。オーディオシステム10は、オーディオ信号波形(waveform)を含む電気信号17を受信する(100)。話者識別モジュール20は、波形内の新たな話者を識別するため、オーディオ信号波形の表示をサンプルし、解析する(102)。話者が、話者識別モジュール20が声紋22の1つと一致できない初めての話者である場合(104のYES分岐)、話者識別モジュール20は、新たな話者に対する利得を迅速に調整するため、高速AGCモジュール28を適用するようAGCモジュール26に指示する(108)。更に、AGCモジュール26は、新たな話者に対する結果の利得に収束するよう、続けて、及び/又は同時に標準AGCを適用する(110)。AGCモジュール26は、話者識別モジュール20にこの結果の利得を提供し、新たな話者に対する声紋と結果の利得を関連付け、声紋22に関連を格納する(112)。
【0031】
話者識別モジュール20が、声紋22の1つと話者を一致できる場合(即ち、話者はオーディオシステム10により以前に識別されている)(104のNO分岐)、話者識別モジュール20は、声紋22から読み出し、一致した声紋に対して関連付けられた利得をAGCモジュール26に提供する。マッピングモジュール30は、新たな話者に対する利得を迅速に調整するため、関連付けられた利得を適用する(106)。オーディオシステム10は、電気信号17のオーディオ信号波形に適用される利得により変更されたオーディオ信号波形を含む変更された電気信号18を継続して出力する(114)。マッピングモジュール30は、上記技術の適用において、更なる新たな話者が検出されると、新たな話者に対する関連を適用し続けることができる。
【0032】
この動作の幾つかの態様において、話者識別モジュール20は、声紋22の1つに対する入力オーディオ信号波形の確率を決定する。話者識別モジュール20内の設定可能又は事前プログラムされたしきい値確率は、一致する声紋に対する識別を規定する。即ち、想定される一致する声紋の確率がしきい値確率を超える場合、話者識別モジュール20は、一致した声紋に対する関連付けられた利得を適用するようAGCモジュール26に指示する。そうでなければ、話者識別モジュール20は、高速AGCモジュール28を適用するようAGCモジュール26に指示する。
【0033】
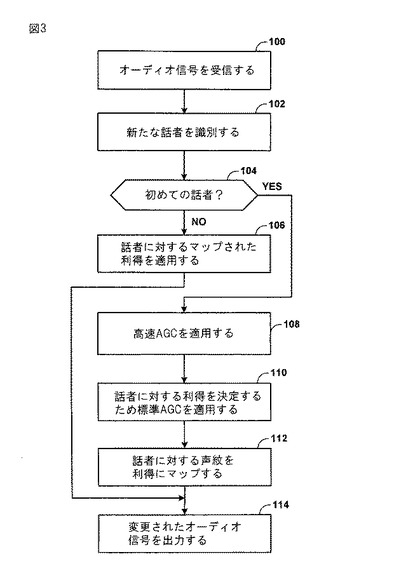
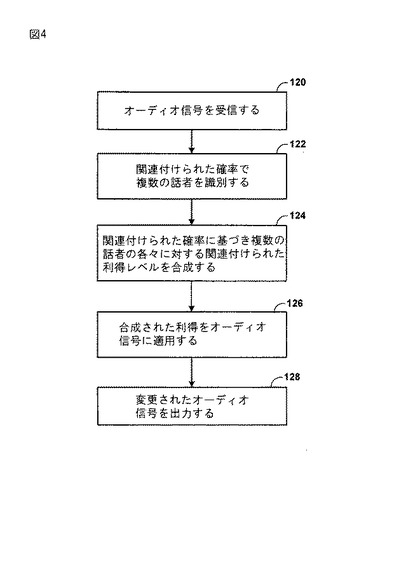
図4は、記載の技術に従い、オーディオシステムにより受信されるオーディオストリーム内の新たな話者の登場に応答して、合成された利得を提供するための、オーディオシステム10の動作のモード例を説明するフローチャートである。オーディオシステム10は、話者に対するオーディオ信号波形を含む電気信号17を受信する(120)。話者識別モジュール20は、オーディオ信号波形の表示をサンプルし、波形内で話者に対する一致確率と各々関連付けられた複数の可能な話者を伴う声紋22とマッチングする(122)。例えば、話者識別モジュール20は、一致確率0.7で第1の話者と一致することができ、更に一致確率0.3で第2の話者と一致することができる。
【0034】
可能性のある一致する話者は、合成された利得を生成するため、各々の一致確率に基づき、話者識別モジュール20が合成する各々の利得と声紋22において関連付けられる。例えば、話者識別モジュール20は、対応する声紋の一致確率により利得を重み付けし、重み付けされた利得を足し合わせて、合成された利得を生成する。話者識別モジュール20は、AGCモジュール26に合成された利得を提供し、マッピングモジュール30は、新たな話者に対する利得を迅速に調整するため、関連付けられた利得を適用する(126)。オーディオシステム10は、電気信号17のオーディオ信号波形に適用された利得により変更されたオーディオ信号波形を含む変更された電気信号18を継続して出力する(128)。
【0035】
様々な実施例が記載された。これら、及びその他の実施例は、特許請求項の範囲内となる。
【技術分野】
【0001】
本発明は、オーディオストリームに適用される利得調整に関する。
【背景技術】
【0002】
未処理(raw)のオーディオ信号は、マイクで受信された全周波数の畳み込み(convolution)であり、オーディオ信号に変換される。複数話者(multi-talker)環境において、周波数のこの畳み込みは、話者の各々に対する音声パターンを含み、音声パターンは、オーディオシステムが、オーディオ信号を処理し、現在話者に対する関連した音声パターンを識別することにより、現在話者を識別することを可能にする。
【発明の概要】
【課題を解決するための手段】
【0003】
1つの実施例において、方法は、第1の話者を識別するため、オーディオシステムにおけるオーディオ信号を処理するステップを有する。方法は、また、オーディオシステムが第1の話者と利得との間の関連を格納しているかどうかを決定するステップ、オーディオシステムが第1の話者と利得との間の関連を格納していないとき、アタック率(attack rate)又はディケイ率(decay rate)の少なくとも1つを増加させるため、オーディオシステムにおける自動利得制御(automatic gain control: AGC)アルゴリズムを変更するステップ、第1の話者に対する利得を決定するため、変更されたAGCアルゴリズムをオーディオ信号に適用するステップを有する。方法は、また、オーディオシステムが、出力オーディオ信号を生成するため、オーディオ信号の表示(representation)に第1の話者に対する利得を適用するステップ、及びオーディオシステムから出力オーディオ信号を出力するステップを有する。
【0004】
その他の実施例において、オーディオシステムは、第1の話者を識別するため、オーディオシステムにおけるオーディオ信号を処理するための手段を有する。オーディオシステムは、また、オーディオシステムが第1の話者と利得との間の関連を格納しているかどうかを決定する話者識別モジュールを有する。オーディオシステムは、また、自動利得制御(AGC)モジュールを有し、オーディオシステムが第1の話者と利得との間の関連を格納していないとき、話者識別モジュールは、アタック率またはディケイ率の少なくとも1つを増加させるため、AGCモジュールを変更し、AGCモジュールは、第1の話者に対する利得を決定するため、変更されたAGCアルゴリズムをオーディオ信号に適用し、AGCモジュールは、出力オーディオ信号を生成するため、オーディオ信号の表示に第1の話者に対する利得を適用し、オーディオシステムは、出力オーディオ信号を出力する。
【0005】
その他の実施例において、コンピュータ読取り可能記憶媒体は、実行時において、第1の話者を識別するため、オーディオシステムにおけるオーディオ信号を処理するステップ、オーディオシステムが第1の話者と利得との間の関連を格納しているかどうかを決定するステップ、オーディオシステムが第1の話者と利得との間の関連を格納していないとき、アタック率またはディケイ率の少なくとも1つを増加させるため、オーディオシステムにおける自動利得制御(AGC)アルゴリズムを変更するステップ、第1の話者に対する利得を決定するため、変更されたAGCアルゴリズムをオーディオ信号に適用するステップを有する処理を実現する命令を有する。命令は、実行時において、オーディオシステムが、出力オーディオ信号を生成するため、オーディ信号の表示に第1の話者に対する利得を適用するステップ、オーディオシステムから出力オーディオ信号を出力するステップを有する処理を更に実現する。
【0006】
1つ以上の実施例の詳細は、添付の図面と以下の記載に説明される。その他の特徴、目的、及び利点は、記載と図面から、及び特許請求の範囲から明白となる。
【図面の簡単な説明】
【0007】
【図1】本明細書に記載される声紋(voice-print)マッチング及び高速アタック利得制御技術を用いて、電気信号に適用される利得を調整するオーディオシステムを説明するブロック図である。
【図2】図1のオーディオシステムの事例をより詳細に説明するブロック図である。
【図3】本明細書に記載の技術に従い、オーディシステムにより受信されるオーディオストリーム内の新たな話者の登場に応答して、利得を迅速に調整するためのオーディシステムの動作例を説明するフローチャートである。
【図4】記載の技術に従い、オーディシステムにより受信されるオーディオストリーム内の新たな話者の登場に応答して、結合された利得を適用するためのオーディシステムの動作の例示的なモードを説明するフローチャートである。
【発明を実施するための形態】
【0008】
複数話者環境における会話が、共通マイクから遠い話者などの穏やか(soft)な話者から、共通マイクに近い話者などの大音量の話者に推移するとき(又は、その反対)、数秒の単位で出力利得を変更する時間平均された自動化利得制御(AGC)アルゴリズムは、安定した音量(volume)を供給するために、十分な速さで適応することはできない。この結果、AGCアルゴリズムの動作中、大音量の話者は十分に減衰されず、及び/又は、穏やかな話者は十分に増幅されない。
【0009】
一般的に、複数話者オーディオにおけるオーディオ利得レベルを調整するための技術がある。1つの例において、複数話者環境において動作するオーディオシステムは、新たな話者の存在に対してオーディオストリームを継続的に監視する。新たな話者を識別すると、オーディオシステムは、新たな話者が初めての話者であり、その声紋(voice print)がシステムに未知であるかどうかを決定する。新たな話者が初めての話者である場合、オーディオシステムは、その話者に対して以前に決められたオーディオ利得レベルに関連付けられた声紋の記録を持たない。初めての話者に対して、オーディオシステムは、以下に詳細に記載するように、初めての話者に対する利得値を迅速に決定するため、高速アタック/ディケイ(fast-attack/decay)AGCアルゴリズムを実行し、この利得値をオーディオ出力に適用する。オーディオシステムは、初めての話者が話しを続ける間、初めての話者に対する利得を改善するために、標準AGC技術を更に実行する。
【0010】
初めての話者に対して標準AGCを用いることにより、デシベル範囲内の安定した状態が達成されると、オーディオシステムは、初めての話者に対する声紋に関連して、初めての話者に対する安定した状態の利得を記憶装置に格納する。以前に識別された話者を識別すると、システムは、この話者に対し以前に決定された安定状態の利得を記憶装置から読み出し、オーディオストリームに安定状態利得を適用する。この結果、オーディオシステムは、複数話者オーディオにおける利得を迅速に決定するため、複数話者に対し、それぞれの所定の利得を用い、未識別の話者に対し、高速アタックAGCアルゴリズムを用いる。
【0011】
本明細書の技術は、1つ以上の利点を提示する。例えば、本明細書の技術を用いて、オーディオシステムは、複数話者環境において、識別された話者と未識別の話者の両方に適用される利得を迅速に切り替えることができる。
【0012】
図1は、オーディオシステム10を説明するブロック図であり、本明細書に記載される声紋マッチング及び高速アタック利得制御技術を用いて、電気信号に適用される利得を調整する利得制御システムの例である。マイク14は、連続的、及び/又は、同時(クロストーク)に声を発する複数の話者12A〜12N(集合的に「話者12」)の1人以上により発生される音声サウンドを含む、その近傍の周囲サウンドを獲得する。話者12の各々は、任意の時間だけ突発的に話しをする(例えば、数十ミリ秒程度から数時間程度の間)。マイク14は、周囲サウンドを、オーディオシステム10により受信される電気信号17に変換する。人間に対して、本明細書では記載されているが、話者12は、任意のオーディオソース又はその記録とすることができる。
【0013】
幾つかの態様において、電気信号17は、話者12のサウンド、又は記憶媒体(例えば、コンパクトディスク(CD)、ハードディスク、レコード、テープ、若しくはフラッシュメモリ)上に予め記録されたその他任意のオーディオソースにより提供されるサウンドから符号化されたデータを用いる再生装置(例えば、CDプレイヤー、コンピュータプログラム、若しくはテーププレイヤー)により再生される電気信号を表す。
【0014】
オーディオシステム10は、変更された電気信号18を出力するよう電気信号17を処理し、変更された電気信号18は、話者12が話しをしている間、より安定的な音量(例えば、許容可能なデシベル(dB)範囲内)を有するオーディオをスピーカ16に出力させる。オーディオシステム10は、例えば、携帯オーディオプレイヤー、ミキシングボード(mixing board)、スマートフォン、パブリックアドレス(PA)システム、又は電話会議やビデオ会議システムとすることができる。許容可能なdB範囲は、任意の話者12によりユーザ設定することが可能であり、あるいは、電話若しくはビデオ会議、コンサート若しくはPAなど、オーディオシステム10が動作している状況に対してオーディオシステム10を監視している、又は携帯オーディオプレイヤーで聴取しているユーザ、管理者やサウンドエンジニアによりユーザ設定することが可能である。幾つかの態様において、マイク14とスピーカ16の一方又は両方は、オーディオシステム10も含むシャーシ又はその他タイプのケース内に組み込まれ、あるいは、有線コネクタを介して、オーディオシステム10に直接的に接続することができる。幾つかの態様において、マイク14とスピーカ16の一方又は両方は、例えば、公衆交換電話網(public switched telephone network: PSTN)、公衆地上移動網(public land mobile network: PLMN)、企業仮想プライベート網(virtual private network: VPN)、インターネット、WiFi接続、又は3GPPセルラー無線網など、ネットワークを介して通信可能に接続されることで、オーディオシステム10から離すことができる。幾つかの態様において、マイク14とスピーカ16の一方又は両方は、無線とすることができる。幾つかの態様において、マイク14は、様々な組合せで、話者12の間に配置される複数のマイクとすることができる。更に、幾つかの態様において、話者12の各々は、オーディオシステム10の異なる例と関連付けることができる。
【0015】
変更された電気信号18を許容可能なdB範囲内で出力し、話者12に対するサウンド忠実度(fidelity)を維持するよう電気信号17を処理するため、オーディオシステム10は、話者12毎に自動利得制御(AGC)技術を適用する。話者12の各々により生成されるサウンド(例えば、音声、咳、叫び、歌唱など)は、話者の固有性やマイク14から話者までの距離に基づいた様々な特徴を有する。例えば、穏やかな話者やマイク14から離れている話者は、大音量の話者やマイク14に近い話者により生成されるサウンドより、マイク14において、より低い振幅(amplitude)を有するサウンドを生成する傾向にある。
【0016】
オーディオシステム10は、話者毎にAGC技術を適用するため、話者12中の個々の話者に対して、電気信号17を監視する。話者12の各々は、何時でもサウンドを発することができ、サウンドはマイク14で受信され、電気信号17に変換される。従って、会話(即ち、話者12により生成され、マイク14で受信される一体となったサウンド)に加わる新たな話者や会話から離れる現在の話者に伴い、特定時間において、話者12の異なる組合せが音を発することができる。ここで、「新たな(new)」話者は、最近会話に加わった、又は再び加わった話者12の1人にあたる。
【0017】
話者12中の新たな話者のオーディオの存在を識別するため、オーディオシステム10は、話者検出及び識別技術を用いて電気信号17を処理する。新たな話者を検出後、オーディオシステム10は、新たな話者が初めての話者かどうかを決定するため、その話者を識別することができる。様々な例において、「初めて(first-time)」または「未識別(unidentified)」の話者は、オーディオシステム10が以前に認識していないか、あるいはシステムから以前の認識の記録が削除されている話者、又は以前の認識の記録が存在するにも係わらず、オーディオシステム10がその話者をもはや認識することが出来ないほどにその音声が変更されてしまった話者12の1人にあたる。電気信号17中に検出された新たな話者が初めての話者であることを決定することに応答して、オーディオシステム10は、初めての話者に対する利得値を迅速に決定するため、高速アタック/ディケイAGCアルゴリズムを実行することができ、そしてオーディオシステム10は、変更された電気信号18を生成するため、電気信号17のこの決定された利得値を適用することができる。高速アタック/ディケイAGCアルゴリズムは、標準AGCに対し必要となる時間より少ない時間で(例えば、数百マイクロ秒またはミリ秒)、初めての話者に対する利得値に収束する(あるいは、「安定する」)。オーディオシステム10は、初めての話者が話し続けている間、初めての話者に対する利得を改善し、適用するため、同時に、及び/又は続いて、標準AGCを実行することができる。
【0018】
オーディオシステム10が、標準AGCを用いて、初めての話者に対してデシベルしきい値内の安定した状態に達したとき、オーディオシステム10は、この安定状態を実現する利得、あるいは安定状態利得と初めての話者を関連付けることができる。電気信号17で表される話者12中に以前に識別された話者を検出し、識別すると、オーディオシステム10は、以前に識別された話者に対して先に関連付けられた安定状態利得を記憶媒体から呼び出して、変更された電気信号18を生成するため、先に関連付けられた安定状態利得を電気信号17に適用することができる。以前に識別された話者により生成されたサウンドに基づいて、利得を改善し、マイク14で生成された電気信号17に利得を適用するため、オーディオシステム10が標準AGCを同時に実行する一方、様々な例において、オーディオシステム10は、以前に識別された話者に対して適用された利得により早く収束するため、先に関連付けられた安定状態利得を少なくとも初期に適用する。標準AGCは、AGCフィードバックメカニズムに基づいて、安定状態利得値に達するまで、数秒を必要とするため、以前に識別した新たな話者12に対して、それぞれの所定の利得を適用することと、未識別の新たな話者12に対して高速アタック/ディケイAGC技術を適用することの組合せは、オーディオシステム10が、変更された電気信号18を生成するため、電気信号17に適用するための適切な利得を迅速に決定することを可能にし、変更された電気信号18は、スピーカ16により変換されるとき、新たな話者である特定の話者12の存在にも係わらず、許容可能なdB範囲内のサウンドとなる。更に、以前に識別された新たな話者12に対する所定の利得を適用することは、高速アタック/ディケイAGCのみに比べ、そのような話者におけるサウンドのdB範囲の不変性を改善することができる。
【0019】
図2は、図1のオーディオシステム10の例をより詳細に説明したブロック図である。図1の同等の要素を特定するため、同等の番号が使用される。オーディオシステム10は、電気信号17を受信し、デジタル信号34を出力するアナログ−デジタル(A/D)変換器24を有し、デジタル信号34は、話者識別モジュール20及び自動利得制御(AGC)モジュール26(「AGCモジュール26」と表記)により受信される電気信号17のデジタル表記である。幾つかの例において、オーディオシステム10は、デジタル信号34として出力するため、電気信号17をパルスコード変調(PCM)符号化されたデジタルオーディオ信号などのデジタルオーディオ信号に変換するオーディオ帯域符号化/復号器(CODEC)を更に有する。幾つかの態様において、電気信号17はデジタル信号であり、このため、A/D変換器24は、オーディオシステム10から省略することができる。
【0020】
話者識別モジュール20は、デジタル信号34をサンプリングし、解析して、話者を識別するための声紋を抽出する。幾つかの態様において、話者識別モジュール20は、声紋を抽出し、新たな話者を検出、識別するため、内部または外部セグメンテーションを持つ混合ガウスモデル(Gaussian mixture model)、一般背景モデル(universal background model)(GMM−UBM)を使うことができる。その他の態様において、話者識別モジュール20は、周波数推定、パターンマッチングアルゴリズム、ベクトル量子化、決定木(decision tree)、隠れマルコフモデル、又はその他技術を使用することができる。話者識別モジュール20は、新たな話者(即ち、デジタル信号34で表される会話への1人の話者の登場または再登場)を識別するため、デジタル信号34を継続的に監視する。オーディオシステム10の声紋22は、コンピュータ読取り可能記録媒体上に格納されたデータベース又はその他データ構造を有し、これらは、話者識別モジュール20により以前に識別された各々の話者に対する1以上の声紋を格納する。各声紋は、話者の特徴的な信号パラメータ、話者の音声信号の連続するサンプル、ケプストラムまたはスペクトル特性ベクトル、又はその他の情報を含むことができ、これらは、声紋と共に、対応する話者にマッチングするため、話者識別モジュール20により使用される。話者識別モジュール20は、声紋22に格納するための声紋パラメータを習得(learn)するため、トレーニング技術を実行することができる。以下に詳細に記載されるように、デジタル信号34は、声紋に合致する話者に対するオーディオ信号を含み、声紋22の各々は、AGCモジュール26により、デジタル信号34に適用されることになる関連付けられた利得を有する。
【0021】
デジタル信号34内の新たな話者に対する声紋を抽出すると、話者識別モジュール20は、当該声紋と声紋22に格納されている声紋とを比較する。声紋22内の一致する声紋は、新たな話者が以前に識別されていることを示し、話者識別モジュール20は、制御チャネル38を用い、AGCモジュール26に一致する声紋の話者識別を提供する。声紋22が、新たに識別された声紋に対する一致を有しない場合、話者識別モジュール20は、制御チャネル38を用い、AGCモジュール26にデジタル信号34内の未識別話者の出現を示す。幾つかの態様において、話者識別モジュール20は、複数の声紋22が現在の話者に対して各々の一致確率(matching probability)を持っていることを決定できる。そのような態様において、話者識別モジュール20は、声紋22から、複数の声紋22に対する決定された各々の一致確率と同様に、関連付けられた各々の利得を受け取る。例えば、新たな話者が、声紋22の一致する声紋「A」の確率0.7及び声紋22の一致する声紋「B」の確率0.3を有することが決定されると、話者識別モジュール20は、声紋「A」と「B」に対する確率と共に、関連付けられた利得を読み出し、AGCモジュール26に提供する。声紋を用いて話者を識別するよう記載されているが、話者識別モジュール20は、複数のオーディオソースを区別するオーディオプリントを用いてオーディオソースを識別するオーディオソース識別モジュールと見なすことができる。
【0022】
AGCモジュール26は、デジタル出力信号36がスピーカ又はその他の適切な装置によりオーディオに変換されるとき、デジタル出力信号36に対する信号振幅が許容可能なdB範囲内に維持されるように、デジタル信号34を変換するための自動利得制御技術を適用する。幾つかの適切なAGCアルゴリズムのいずれかを、許容可能なdB範囲になるようデジタル信号34の振幅に適応するため、適用することができる。AGCアルゴリズムは、通常、入力量に基づいて以前に適用された利得レベルの結果を監視するフィードバックループに依存する。結果に基づき、典型的なAGCアルゴリズムは、入力量を出力量に変換するための利得レベルを変更し、出力量は、目標量により近似したその後の入力量となる。本技術において関連する量は、デジタル出力信号36に対する信号振幅である。幾つかの態様において、オーディオシステム10は、AGCモジュール26から利得信号を受信するアナログ又はデジタルの増幅器を有し、増幅器は、デジタル出力信号36又は変更された電気信号18を生成するため、電気信号17又はデジタル信号34の1つに利得信号を適用する。幾つかの態様において、利得は、変更された電気信号18を生成するため、電気信号17を増幅、減衰、又はその他変更するためのオーディオフィルタ、その他装置、又は値として、計算され、格納され、適用される。
【0023】
AGCモジュール26は、標準AGCを適用し、ほぼ一定音量で話をする話者に対して、1つの利得に数秒の単位で収束する。AGCモジュール26は、制御チャネル38を用い、話者識別モジュール20に結果の利得を提供する。話者識別モジュール20は、話者に対して関連付けられた声紋と共に、結果の利得を声紋22に格納する。幾つかの例において、話者識別モジュール20は、声紋22内で、関連付けられた声紋に対して既に格納されている利得をAGCモジュール26から受信された新たな結果の利得で置き換える。
【0024】
AGCモジュール26の高速AGCモジュール28(「高速28」として表示)及びマッピングモジュール30(「マップ30」として表示)は、AGCモジュール26がデジタル出力信号36を生成する速度を改善するため、本発明と調和した技術を実行し、デジタル出力信号36は、現在許容可能なdB範囲で音量を生成する。特に、話者識別モジュール20から、デジタル信号34の現在の話者が未識別の話者であるとの信号を受信すると、高速AGCモジュール28は、アタック率(AGC技術が大音量信号に応じて利得を減少させる速度に対応する)、及び/又はディケイ率(AGC技術が大音量信号の離脱に応じて利得を増加させる速度に対応する)を増加させるため、AGCモジュール26によりデジタル信号34に適用される標準AGCを変更する。この結果、AGCモジュール26が標準AGCに従い利得を変更する速度と比べ、AGCモジュール26は、デジタル信号34に適用される利得を迅速に変更し、これにより、許容可能な音量をもたらすデジタル出力信号36を早急に生成する。高速AGCモジュール28は、分離した集積回路またはプロセッサで実現することができ、AGCモジュール26により実行される標準AGCに代わり、合図があると、高速アタック/ディケイAGC技術を実行する。
【0025】
高速アタック/ディケイAGC技術は、利得安定性に関連して欠陥を有するため(例えば、入力振幅における一時的なわずかの変調は大きな利得適応となり得る)、マッピングモジュール30は、以前に識別された話者に対して話者識別モジュール20から受信された所定の利得値を適用する。上記のように、話者識別モジュール20が、デジタル信号34に対して、声紋22の一致する1つを識別すると、話者識別モジュール20は、一致する声紋に対する関連付けられた利得をAGCモジュール26に供給する。AGCモジュール26が関連付けられた利得を決定している間、識別された話者に対するオーディオ信号の受信の以前の発生にほぼ一致した音量で、識別された話者がサウンドを生成するとき、マッピングモジュール30は、オーディオシステム10における許容可能なdB範囲に合致するデジタル出力信号36を生成するため、デジタル信号34に関連付けられた利得を適用する。
【0026】
幾つかの態様において、オーディオシステム10は、識別された話者に対する計算された利得とその識別された話者に対する格納された関連付けられた利得との差分に基づき、マイクの移動を検出する。例えば、話者識別モジュール20は、新たな話者に関するデジタル信号34に対して、声紋22の一致する1つを識別することができ、マッピングモジュール30は初めにデジタル信号34に適用する。続いて、AGCモジュール26は、デジタル信号34の振幅の差分により、話者に対する新たな利得を計算することができる。AGCモジュール26は、制御チャネル38を介し、話者識別モジュール20に新たな利得を提供する。話者識別モジュール20は、声紋22内の話者に対し以前に格納された利得と新たな利得を比較する。差分が設定可能なしきい値を超える場合、マイクは移動したものであり、これにより、話者12の各々は、マイク移動前にマイクで生成されたサウンドから振幅で相違するサウンドをマイクで生成することになる。この結果、話者識別モジュール20は、新たな利得と以前に格納された利得との間の、例えば、相対的又は絶対的な差分を声紋22に関連付けられた利得のそれぞれに適用することができる。このように、声紋22に関連する話者のそれぞれは、その次の会話の順番に備えて調整された各々の格納された利得を有する。
【0027】
幾つかの態様において、オーディオシステム10は、スマートフォンなどの装置を表し、更に加速度計、カメラ、赤外探知機、又は装置の移動を追跡するその他の要素を含む。そのような態様において、オーディオシステム10は、追跡要素から受信された装置に対する移動情報に基づいて、利得変更を計算することができる。例えば、移動情報は、話者12の1人が共通マイクから更に移動していることを示すことができる。その結果、オーディオシステム10は、デジタル信号34に適用される利得を増加させる利得変更を計算することができる。幾つかの態様において、オーディオシステム10は、スマートフォンなどの装置を表し、カメラ又は話者12の移動を追跡するその他の装置からの位置データを含み、又は受信する。これらの態様において、オーディオシステムは、追跡要素から受信される話者に対する移動情報に基づき、話者毎の利得変更を計算することができる。
【0028】
オーディオシステム10のデジタル−オーディオ(D/A)変換器32は、デジタル出力信号36を変更された電気信号18に変換し、これは、アナログ信号を表すことができる。幾つかの例において、オーディオシステム10は、デジタル出力信号36を変更された電気信号18に変換するオーディオ帯域CODECを更に含む。幾つかの態様において、変更された電気信号18はデジタル信号であり、このため、D/A変換器32はオーディオシステム10から取り除くことができる。
【0029】
オーディオシステム10の1以上のプロセッサ40は、オーディオシステム10の様々なモジュールの機能を実行するために動作する。プロセッサ40は、マイクロプロセッサ、コントローラ、デジタル信号プロセッサ(DSP)、音声帯域オーディオプロセッサ、特定アプリケーション向け集積回路(ASIC)、フィールドプログラマブルゲートアレイ(FPGA)、又は等価な分離若しくは集積論理回路の任意の1つ以上を含むことができる。更に、本発明において、プロセッサ40に起因する機能は、ソフトウェア、ファームウェア、ハードウェア又はそれらの任意の組合せとして搭載することができる。プロセッサ40は、オーディオシステム10の記憶装置42により格納された命令を実行することができ、記憶装置42は、例えば、プロセッサ40などの1以上のプロッセサに様々な機能を実現させる命令を有するコンピュータ読取り可能、機械読取り可能、又はプロセッサ読取り可能な記憶媒体を含むことができる。記憶装置42は、ランダムアクセスメモリ(RAM)、読み出し専用メモリ(ROM)、プログラム可能読み出し専用メモリ(PROM)、消去可能PROM(EPROM)、電気的消去可能PROM(EEPROM)、フラッシュメモリ、ハードディスク、CD−ROM、フロッピーディスク、カセット、磁気媒体、光学媒体、又はその他のコンピュータ読取り可能記憶媒体など、任意の有形(trangible)又は持続的(non-transitory)コンピュータ読取り可能記憶媒体を含むことができる。声紋22は、記憶装置42により格納することができる。
【0030】
図3は、ここに記載される技術に関連して、オーディオシステムにより受信されるオーディオストリーム内の新たな話者の登場に応答して迅速に利得を調整するための、図2のオーディオシステム10の動作例を説明するフローチャートである。オーディオシステム10は、オーディオ信号波形(waveform)を含む電気信号17を受信する(100)。話者識別モジュール20は、波形内の新たな話者を識別するため、オーディオ信号波形の表示をサンプルし、解析する(102)。話者が、話者識別モジュール20が声紋22の1つと一致できない初めての話者である場合(104のYES分岐)、話者識別モジュール20は、新たな話者に対する利得を迅速に調整するため、高速AGCモジュール28を適用するようAGCモジュール26に指示する(108)。更に、AGCモジュール26は、新たな話者に対する結果の利得に収束するよう、続けて、及び/又は同時に標準AGCを適用する(110)。AGCモジュール26は、話者識別モジュール20にこの結果の利得を提供し、新たな話者に対する声紋と結果の利得を関連付け、声紋22に関連を格納する(112)。
【0031】
話者識別モジュール20が、声紋22の1つと話者を一致できる場合(即ち、話者はオーディオシステム10により以前に識別されている)(104のNO分岐)、話者識別モジュール20は、声紋22から読み出し、一致した声紋に対して関連付けられた利得をAGCモジュール26に提供する。マッピングモジュール30は、新たな話者に対する利得を迅速に調整するため、関連付けられた利得を適用する(106)。オーディオシステム10は、電気信号17のオーディオ信号波形に適用される利得により変更されたオーディオ信号波形を含む変更された電気信号18を継続して出力する(114)。マッピングモジュール30は、上記技術の適用において、更なる新たな話者が検出されると、新たな話者に対する関連を適用し続けることができる。
【0032】
この動作の幾つかの態様において、話者識別モジュール20は、声紋22の1つに対する入力オーディオ信号波形の確率を決定する。話者識別モジュール20内の設定可能又は事前プログラムされたしきい値確率は、一致する声紋に対する識別を規定する。即ち、想定される一致する声紋の確率がしきい値確率を超える場合、話者識別モジュール20は、一致した声紋に対する関連付けられた利得を適用するようAGCモジュール26に指示する。そうでなければ、話者識別モジュール20は、高速AGCモジュール28を適用するようAGCモジュール26に指示する。
【0033】
図4は、記載の技術に従い、オーディオシステムにより受信されるオーディオストリーム内の新たな話者の登場に応答して、合成された利得を提供するための、オーディオシステム10の動作のモード例を説明するフローチャートである。オーディオシステム10は、話者に対するオーディオ信号波形を含む電気信号17を受信する(120)。話者識別モジュール20は、オーディオ信号波形の表示をサンプルし、波形内で話者に対する一致確率と各々関連付けられた複数の可能な話者を伴う声紋22とマッチングする(122)。例えば、話者識別モジュール20は、一致確率0.7で第1の話者と一致することができ、更に一致確率0.3で第2の話者と一致することができる。
【0034】
可能性のある一致する話者は、合成された利得を生成するため、各々の一致確率に基づき、話者識別モジュール20が合成する各々の利得と声紋22において関連付けられる。例えば、話者識別モジュール20は、対応する声紋の一致確率により利得を重み付けし、重み付けされた利得を足し合わせて、合成された利得を生成する。話者識別モジュール20は、AGCモジュール26に合成された利得を提供し、マッピングモジュール30は、新たな話者に対する利得を迅速に調整するため、関連付けられた利得を適用する(126)。オーディオシステム10は、電気信号17のオーディオ信号波形に適用された利得により変更されたオーディオ信号波形を含む変更された電気信号18を継続して出力する(128)。
【0035】
様々な実施例が記載された。これら、及びその他の実施例は、特許請求項の範囲内となる。
【特許請求の範囲】
【請求項1】
第1のオーディオソースを識別するため、オーディオシステムにおけるオーディオ信号を処理するステップと、
前記オーディオシステムが、前記第1のオーディオソースと利得との間の関連を格納しているかどうかを決定するステップと、
前記オーディオシステムが、前記第1のオーディオソースと前記利得との間の前記関連を格納していない場合、アタック率又はディケイ率の少なくとも1つを増加させるため、前記オーディオシステムにおける自動利得制御アルゴリズムを変更し、前記第1のオーディオソースに対する前記利得を決定するため、前記オーディオ信号に前記変更された自動利得制御アルゴリズムを適用するステップと、
前記オーディオシステムが、出力オーディオ信号を生成するため、前記オーディオ信号の表示に前記第1のオーディオソースに対する前記利得を適用するステップと、
前記オーディオ信号の前記表示に前記利得を適用した後、前記アタック率又はディケイ率の少なくとも1つを減少させるため、前記オーディオシステムにおける前記自動利得制御アルゴリズムを元に戻すステップと、
前記オーディオシステムが、前記第1のオーディオソースに対する結果の利得を決定するため、前記オーディオ信号の前記表示に前記元に戻された自動利得制御アルゴリズムを適用するステップと、
第1の声紋を前記結果の利得と関連付けるステップと、
前記第1のオーディオソースと前記結果の利得との間の関連として、前記結果の利得と前記第1の声紋の前記関連を記憶媒体に格納するステップと、
前記オーディオシステムから前記出力オーディオ信号を出力するステップと、
を有する方法。
【請求項2】
前記出力オーディオ信号を生成するため、前記オーディオシステムが、前記オーディオ信号の前記表示に前記結果の利得を適用するステップを更に有する、請求項1に記載の方法。
【請求項3】
前記第1のオーディオソースを前記結果の利得と関連付けるステップと、
前記第1のオーディオソースと前記結果の利得との前記関連を記憶媒体に格納するステップと、
を更に有する、請求項1又は2に記載の方法。
【請求項4】
前記オーディオシステムは、前記オーディオ信号で表される1以上のオーディオソースに対する各々の声紋として格納するための各々の声紋パラメータを知るため、前記オーディオ信号の前記表示を処理する、請求項1〜3のいずれか一項に記載の方法。
【請求項5】
前記オーディオシステムが、前記第1のオーディオソースと前記利得との間の前記関連を格納しているとき、前記第1のオーディオソースに対する前記利得を読み出すステップと、
前記オーディオシステムが、前記第1のオーディオソースに対する前記利得を適用するステップと、
を更に有する、請求項1〜4のいずれか一項に記載の方法。
【請求項6】
前記オーディオシステムは、前記第1のオーディオソースと前記利得との間の前記関連を格納し、前記方法は、
前記オーディオシステムが、前記第1のオーディオソースに対する一致する声紋の確率を決定するステップと、
前記確率がしきい値確率と合致しない場合、前記アタック率又はディケイ率の少なくとも1つを増加させるため、前記オーディオシステムにおける前記自動利得制御アルゴリズムを変更し、前記第1のオーディオソースに対する前記利得を決定するため、前記オーディオ信号の前記表示に前記変更された自動利得制御アルゴリズムを適用するステップと、
を更に有する、請求項1〜5のいずれか一項に記載の方法。
【請求項7】
前記オーディオシステムは、前記第1のオーディオソースと前記利得との間の前記関連を格納し、前記方法は、
前記オーディオシステムが、前記第1のオーディオソースに対する一致する声紋の確率を決定するステップと、
前記確率がしきい値確率と合致する場合、前記第1のオーディオソースに対する前記利得を読み出すステップと、
前記オーディオシステムが、前記第1のオーディオソースに対して読み出された前記利得を適用するステップと、
を更に有する、請求項1〜5のいずれか一項に記載の方法。
【請求項8】
前記オーディオシステムが、前記第1のオーディオソースと前記利得との間の前記関連を格納しているとき、前記オーディオシステムが、前記第1のオーディオソースに対する一致する声紋の非ゼロの確率を決定するステップと、
前記オーディオシステムが、第2のオーディオソースに対する一致する声紋の非ゼロの確率を決定するステップと、
前記第1のオーディオソースに対する前記利得、及び前記第2のオーディオソースに対する利得を読み出すステップと、
前記出力オーディ信号を生成するため、前記第1のオーディオソースに対する前記利得と及び前記第2のオーディオソースに対する前記利得の組合せを前記オーディオ信号の前記表示に適用するステップと、
を更に有する、請求項1〜7のいずれか一項に記載の方法。
【請求項9】
前記第1のオーディオソースに対する前記利得を前記第1のオーディオソースに対する前記一致する声紋の前記非ゼロの確率により重み付けし、前記第2のオーディオソースに対する前記利得を前記第2のオーディオソースに対する前記一致する声紋の前記非ゼロの確率により重み付けするステップと、
前記組合せを生成するため、前記第1のオーディオソースに対する前記重み付けされた利得と前記第2のオーディオソースに対する前記重み付けされた利得を加算するステップと、
を更に有する、請求項8に記載の方法。
【請求項10】
前記オーディオシステムが、前記第1のオーディオソースから前記オーディオ信号を生成するマイクまでの距離の変化を決定するステップと、
前記距離の変化に少なくとも基づいて、利得変更を決定するステップと、
前記第1のオーディオソースに対する前記利得に前記利得変更を適用するステップと、
を更に有する、請求項1〜9のいずれか一項に記載の方法。
【請求項11】
前記オーディオシステムが、前記第1のオーディオソースと前記利得との間の前記関連を格納しているとき、前記オーディオシステムが、前記第1のオーディオソースに対する新たな利得を計算するため、前記自動利得制御アルゴリズムを適用するステップと、
前記第1のオーディオソースに対する前記利得と前記第1のオーディオソースに対する前記新たな利得との間の差分を決定するステップと、
前記オーディオシステムにより格納され、第2のオーディオソースに関連付けられた利得に前記差分を適用するステップと、
を更に有する、請求項1〜10のいずれか一項に記載の方法。
【請求項12】
前記自動利得制御アルゴリズムは、前記自動利得制御アルゴリズムの第1の例であり、前記方法は、
結果の利得を生成するため、前記変更された自動利得制御アルゴリズムを同時に適用すると共に、前記オーディオシステムが、変更されていないアタック率及びディケイ率を持つ前記自動利得制御アルゴリズムの第2の例を、前記オーディオ信号の前記表示に適用するステップと、
前記オーディオシステムが、前記出力オーディオ信号を生成するため、前記結果の利得を前記オーディオ信号の前記表示に適用するステップと、
を更に有する、請求項1〜11のいずれか一項に記載の方法。
【請求項13】
第2のオーディオソースを識別するため、前記オーディオシステムにおける前記オーディオ信号の前記表示を処理するステップと、
前記オーディオシステムが、前記第2のオーディオソースと前記第2のオーディオソースに対する利得との間の関連を格納しているかどうかを決定するステップと、
前記オーディオシステムが、前記第2のオーディオソースと前記第2のオーディオソースに対する前記利得との間の前記関連を格納していない場合、前記アタック率又はディケイ率の少なくとも1つを増加させるため、前記オーディオシステムにおける前記自動利得制御アルゴリズムを変更し、前記第2のオーディオソースに対する前記利得を決定するため、前記オーディオ信号の前記表示に前記変更された自動利得制御アルゴリズムを適用するステップと、
前記オーディオシステムが、出力オーディオ信号を生成するため、前記オーディオ信号の前記表示に前記第2のオーディオソースに対する前記利得を適用するステップと、
を更に有する、請求項1〜12のいずれか一項に記載の方法。
【請求項14】
第1のオーディオソースを識別するため、オーディオ信号を処理し、オーディオシステムが、前記第1のオーディオソースと利得との間の関連を格納しているかどうかを決定する話者識別モジュールと、
自動利得制御モジュールと、を有し、
前記オーディオシステムが、前記第1のオーディオソースと前記利得との間の前記関連を格納していない場合、前記話者識別モジュールは、アタック率又はディケイ率の少なくとも1つを増加させるため、前記自動利得制御モジュールを変更し、
前記自動利得制御モジュールは、前記第1のオーディオソースに対する前記利得を決定するため、前記オーディオ信号に前記変更された自動利得制御アルゴリズムを適用し、
前記自動利得制御モジュールは、出力オーディオ信号を生成するため、前記オーディオ信号の表示に前記第1のオーディオソースに対する前記利得を適用し、
前記オーディオ信号の前記表示に前記利得を適用した後、前記自動利得制御モジュールは、前記アタック率又はディケイ率の少なくとも1つを減少させるため、前記オーディオシステムにおける前記自動利得制御アルゴリズムを元に戻し、
前記自動利得制御モジュールは、前記第1のオーディオソースに対する結果の利得を決定するため、前記オーディオ信号の前記表示に前記元に戻された自動利得制御アルゴリズムを適用し、
前記話者識別モジュールは、第1の声紋を前記結果の利得と関連付け、
前記話者識別モジュールは、前記第1のオーディオソースと前記結果の利得との間の前記関連として、前記結果の利得と前記第1の声紋の前記関連を記憶媒体に格納し、
前記オーディオシステムは前記出力オーディオ信号を出力する、オーディオシステム。
【請求項15】
第1のオーディオソースを識別するため、オーディオシステムにおけるオーディオ信号を処理するステップと、
前記オーディオシステムが、前記第1のオーディオソースと利得との間の関連を格納しているかどうかを決定するステップと、
前記オーディオシステムが、前記第1のオーディオソースと前記利得との間の前記関連を格納していない場合、アタック率又はディケイ率の少なくとも1つを増加させるため、前記オーディオシステムにおける自動利得制御アルゴリズムを変更し、前記第1のオーディオソースに対する前記利得を決定するため、前記オーディオ信号に前記変更された自動利得制御アルゴリズムを適用するステップと、
前記オーディオシステムが、出力オーディオ信号を生成するため、前記オーディオ信号の表示に前記第1のオーディオソースに対する前記利得を適用するステップと、
前記オーディオ信号の前記表示に前記利得を適用した後、前記アタック率又はディケイ率の少なくとも1つを減少させるため、前記オーディオシステムにおける前記自動利得制御アルゴリズムを元に戻すステップと、
前記オーディオシステムが、前記第1のオーディオソースに対する結果の利得を決定するため、前記オーディオ信号の前記表示に前記元に戻された自動利得制御アルゴリズムを適用するステップと、
第1の声紋を前記結果の利得と関連付けるステップと、
前記第1のオーディオソースと前記結果の利得との間の関連として、前記結果の利得と前記第1の声紋の前記関連を記憶媒体に格納するステップと、
前記オーディオシステムから前記出力オーディオ信号を出力するステップと、
を有する処理をコンピュータに実行させる命令を記録したコンピュータ読取り可能記憶装置。
【請求項1】
第1のオーディオソースを識別するため、オーディオシステムにおけるオーディオ信号を処理するステップと、
前記オーディオシステムが、前記第1のオーディオソースと利得との間の関連を格納しているかどうかを決定するステップと、
前記オーディオシステムが、前記第1のオーディオソースと前記利得との間の前記関連を格納していない場合、アタック率又はディケイ率の少なくとも1つを増加させるため、前記オーディオシステムにおける自動利得制御アルゴリズムを変更し、前記第1のオーディオソースに対する前記利得を決定するため、前記オーディオ信号に前記変更された自動利得制御アルゴリズムを適用するステップと、
前記オーディオシステムが、出力オーディオ信号を生成するため、前記オーディオ信号の表示に前記第1のオーディオソースに対する前記利得を適用するステップと、
前記オーディオ信号の前記表示に前記利得を適用した後、前記アタック率又はディケイ率の少なくとも1つを減少させるため、前記オーディオシステムにおける前記自動利得制御アルゴリズムを元に戻すステップと、
前記オーディオシステムが、前記第1のオーディオソースに対する結果の利得を決定するため、前記オーディオ信号の前記表示に前記元に戻された自動利得制御アルゴリズムを適用するステップと、
第1の声紋を前記結果の利得と関連付けるステップと、
前記第1のオーディオソースと前記結果の利得との間の関連として、前記結果の利得と前記第1の声紋の前記関連を記憶媒体に格納するステップと、
前記オーディオシステムから前記出力オーディオ信号を出力するステップと、
を有する方法。
【請求項2】
前記出力オーディオ信号を生成するため、前記オーディオシステムが、前記オーディオ信号の前記表示に前記結果の利得を適用するステップを更に有する、請求項1に記載の方法。
【請求項3】
前記第1のオーディオソースを前記結果の利得と関連付けるステップと、
前記第1のオーディオソースと前記結果の利得との前記関連を記憶媒体に格納するステップと、
を更に有する、請求項1又は2に記載の方法。
【請求項4】
前記オーディオシステムは、前記オーディオ信号で表される1以上のオーディオソースに対する各々の声紋として格納するための各々の声紋パラメータを知るため、前記オーディオ信号の前記表示を処理する、請求項1〜3のいずれか一項に記載の方法。
【請求項5】
前記オーディオシステムが、前記第1のオーディオソースと前記利得との間の前記関連を格納しているとき、前記第1のオーディオソースに対する前記利得を読み出すステップと、
前記オーディオシステムが、前記第1のオーディオソースに対する前記利得を適用するステップと、
を更に有する、請求項1〜4のいずれか一項に記載の方法。
【請求項6】
前記オーディオシステムは、前記第1のオーディオソースと前記利得との間の前記関連を格納し、前記方法は、
前記オーディオシステムが、前記第1のオーディオソースに対する一致する声紋の確率を決定するステップと、
前記確率がしきい値確率と合致しない場合、前記アタック率又はディケイ率の少なくとも1つを増加させるため、前記オーディオシステムにおける前記自動利得制御アルゴリズムを変更し、前記第1のオーディオソースに対する前記利得を決定するため、前記オーディオ信号の前記表示に前記変更された自動利得制御アルゴリズムを適用するステップと、
を更に有する、請求項1〜5のいずれか一項に記載の方法。
【請求項7】
前記オーディオシステムは、前記第1のオーディオソースと前記利得との間の前記関連を格納し、前記方法は、
前記オーディオシステムが、前記第1のオーディオソースに対する一致する声紋の確率を決定するステップと、
前記確率がしきい値確率と合致する場合、前記第1のオーディオソースに対する前記利得を読み出すステップと、
前記オーディオシステムが、前記第1のオーディオソースに対して読み出された前記利得を適用するステップと、
を更に有する、請求項1〜5のいずれか一項に記載の方法。
【請求項8】
前記オーディオシステムが、前記第1のオーディオソースと前記利得との間の前記関連を格納しているとき、前記オーディオシステムが、前記第1のオーディオソースに対する一致する声紋の非ゼロの確率を決定するステップと、
前記オーディオシステムが、第2のオーディオソースに対する一致する声紋の非ゼロの確率を決定するステップと、
前記第1のオーディオソースに対する前記利得、及び前記第2のオーディオソースに対する利得を読み出すステップと、
前記出力オーディ信号を生成するため、前記第1のオーディオソースに対する前記利得と及び前記第2のオーディオソースに対する前記利得の組合せを前記オーディオ信号の前記表示に適用するステップと、
を更に有する、請求項1〜7のいずれか一項に記載の方法。
【請求項9】
前記第1のオーディオソースに対する前記利得を前記第1のオーディオソースに対する前記一致する声紋の前記非ゼロの確率により重み付けし、前記第2のオーディオソースに対する前記利得を前記第2のオーディオソースに対する前記一致する声紋の前記非ゼロの確率により重み付けするステップと、
前記組合せを生成するため、前記第1のオーディオソースに対する前記重み付けされた利得と前記第2のオーディオソースに対する前記重み付けされた利得を加算するステップと、
を更に有する、請求項8に記載の方法。
【請求項10】
前記オーディオシステムが、前記第1のオーディオソースから前記オーディオ信号を生成するマイクまでの距離の変化を決定するステップと、
前記距離の変化に少なくとも基づいて、利得変更を決定するステップと、
前記第1のオーディオソースに対する前記利得に前記利得変更を適用するステップと、
を更に有する、請求項1〜9のいずれか一項に記載の方法。
【請求項11】
前記オーディオシステムが、前記第1のオーディオソースと前記利得との間の前記関連を格納しているとき、前記オーディオシステムが、前記第1のオーディオソースに対する新たな利得を計算するため、前記自動利得制御アルゴリズムを適用するステップと、
前記第1のオーディオソースに対する前記利得と前記第1のオーディオソースに対する前記新たな利得との間の差分を決定するステップと、
前記オーディオシステムにより格納され、第2のオーディオソースに関連付けられた利得に前記差分を適用するステップと、
を更に有する、請求項1〜10のいずれか一項に記載の方法。
【請求項12】
前記自動利得制御アルゴリズムは、前記自動利得制御アルゴリズムの第1の例であり、前記方法は、
結果の利得を生成するため、前記変更された自動利得制御アルゴリズムを同時に適用すると共に、前記オーディオシステムが、変更されていないアタック率及びディケイ率を持つ前記自動利得制御アルゴリズムの第2の例を、前記オーディオ信号の前記表示に適用するステップと、
前記オーディオシステムが、前記出力オーディオ信号を生成するため、前記結果の利得を前記オーディオ信号の前記表示に適用するステップと、
を更に有する、請求項1〜11のいずれか一項に記載の方法。
【請求項13】
第2のオーディオソースを識別するため、前記オーディオシステムにおける前記オーディオ信号の前記表示を処理するステップと、
前記オーディオシステムが、前記第2のオーディオソースと前記第2のオーディオソースに対する利得との間の関連を格納しているかどうかを決定するステップと、
前記オーディオシステムが、前記第2のオーディオソースと前記第2のオーディオソースに対する前記利得との間の前記関連を格納していない場合、前記アタック率又はディケイ率の少なくとも1つを増加させるため、前記オーディオシステムにおける前記自動利得制御アルゴリズムを変更し、前記第2のオーディオソースに対する前記利得を決定するため、前記オーディオ信号の前記表示に前記変更された自動利得制御アルゴリズムを適用するステップと、
前記オーディオシステムが、出力オーディオ信号を生成するため、前記オーディオ信号の前記表示に前記第2のオーディオソースに対する前記利得を適用するステップと、
を更に有する、請求項1〜12のいずれか一項に記載の方法。
【請求項14】
第1のオーディオソースを識別するため、オーディオ信号を処理し、オーディオシステムが、前記第1のオーディオソースと利得との間の関連を格納しているかどうかを決定する話者識別モジュールと、
自動利得制御モジュールと、を有し、
前記オーディオシステムが、前記第1のオーディオソースと前記利得との間の前記関連を格納していない場合、前記話者識別モジュールは、アタック率又はディケイ率の少なくとも1つを増加させるため、前記自動利得制御モジュールを変更し、
前記自動利得制御モジュールは、前記第1のオーディオソースに対する前記利得を決定するため、前記オーディオ信号に前記変更された自動利得制御アルゴリズムを適用し、
前記自動利得制御モジュールは、出力オーディオ信号を生成するため、前記オーディオ信号の表示に前記第1のオーディオソースに対する前記利得を適用し、
前記オーディオ信号の前記表示に前記利得を適用した後、前記自動利得制御モジュールは、前記アタック率又はディケイ率の少なくとも1つを減少させるため、前記オーディオシステムにおける前記自動利得制御アルゴリズムを元に戻し、
前記自動利得制御モジュールは、前記第1のオーディオソースに対する結果の利得を決定するため、前記オーディオ信号の前記表示に前記元に戻された自動利得制御アルゴリズムを適用し、
前記話者識別モジュールは、第1の声紋を前記結果の利得と関連付け、
前記話者識別モジュールは、前記第1のオーディオソースと前記結果の利得との間の前記関連として、前記結果の利得と前記第1の声紋の前記関連を記憶媒体に格納し、
前記オーディオシステムは前記出力オーディオ信号を出力する、オーディオシステム。
【請求項15】
第1のオーディオソースを識別するため、オーディオシステムにおけるオーディオ信号を処理するステップと、
前記オーディオシステムが、前記第1のオーディオソースと利得との間の関連を格納しているかどうかを決定するステップと、
前記オーディオシステムが、前記第1のオーディオソースと前記利得との間の前記関連を格納していない場合、アタック率又はディケイ率の少なくとも1つを増加させるため、前記オーディオシステムにおける自動利得制御アルゴリズムを変更し、前記第1のオーディオソースに対する前記利得を決定するため、前記オーディオ信号に前記変更された自動利得制御アルゴリズムを適用するステップと、
前記オーディオシステムが、出力オーディオ信号を生成するため、前記オーディオ信号の表示に前記第1のオーディオソースに対する前記利得を適用するステップと、
前記オーディオ信号の前記表示に前記利得を適用した後、前記アタック率又はディケイ率の少なくとも1つを減少させるため、前記オーディオシステムにおける前記自動利得制御アルゴリズムを元に戻すステップと、
前記オーディオシステムが、前記第1のオーディオソースに対する結果の利得を決定するため、前記オーディオ信号の前記表示に前記元に戻された自動利得制御アルゴリズムを適用するステップと、
第1の声紋を前記結果の利得と関連付けるステップと、
前記第1のオーディオソースと前記結果の利得との間の関連として、前記結果の利得と前記第1の声紋の前記関連を記憶媒体に格納するステップと、
前記オーディオシステムから前記出力オーディオ信号を出力するステップと、
を有する処理をコンピュータに実行させる命令を記録したコンピュータ読取り可能記憶装置。
【図1】


【図2】
【図3】
【図4】
【図2】
【図3】
【図4】
【公開番号】特開2013−109346(P2013−109346A)
【公開日】平成25年6月6日(2013.6.6)
【国際特許分類】
【外国語出願】
【出願番号】特願2012−250125(P2012−250125)
【出願日】平成24年11月14日(2012.11.14)
【出願人】(511081923)グーグル インコーポレイティド (2)
【Fターム(参考)】
【公開日】平成25年6月6日(2013.6.6)
【国際特許分類】
【出願番号】特願2012−250125(P2012−250125)
【出願日】平成24年11月14日(2012.11.14)
【出願人】(511081923)グーグル インコーポレイティド (2)
【Fターム(参考)】
[ Back to top ]