
自動演習システム及び自動演習プログラム
【目的】コンテンツに依存することなく、工場やオフィスにおける日常業務の知識・ノウハウの継承を可能とする自動演習システム及び自動演習プログラムを提供すること。
【解決手段】自動演習システムは、ランキングリストにおいて、閾値α以上の類似度Rαの質問フィールドを問題作成テンプレートに適用して問題文を作成するとともに、類似度Rαに対応する回答フィールドを正解選択肢とするQ-A対作成手段と、同リストにおいて、閾値β未満の類似度Rβに対応する回答フィールドのベクトル空間と、正解選択肢のベクトル空間及び/又は他の不正解選択肢のベクトル空間とを用いて、回答フィールドと正解選択肢及び/又は他の不正解選択肢との類似度Rγを求め、類似度Rγが閾値γ未満である場合に、類似度Rβに対応する回答フィールドを不正解選択肢とする不正解作成手段を備える。
【解決手段】自動演習システムは、ランキングリストにおいて、閾値α以上の類似度Rαの質問フィールドを問題作成テンプレートに適用して問題文を作成するとともに、類似度Rαに対応する回答フィールドを正解選択肢とするQ-A対作成手段と、同リストにおいて、閾値β未満の類似度Rβに対応する回答フィールドのベクトル空間と、正解選択肢のベクトル空間及び/又は他の不正解選択肢のベクトル空間とを用いて、回答フィールドと正解選択肢及び/又は他の不正解選択肢との類似度Rγを求め、類似度Rγが閾値γ未満である場合に、類似度Rβに対応する回答フィールドを不正解選択肢とする不正解作成手段を備える。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、自動演習システム及び自動演習プログラムに関し、更に詳しくは、工場やオフィスにおける日常業務に関する知識・ノウハウの継承を目的として幅広い分野に適用しうるコンテンツに依存しない自動演習システム及び自動演習プログラムに関する。
【背景技術】
【0002】
近年の工場やオフィスにおける日常業務は、設備保全のスタイルが事後保全(BM:Breakdown Maintenance 若しくは FBM:Failure Based Maintenance)から時間基準予防保全(TBM:Time Based Preventive Maintenance)へと移行した結果、事後の保守にかかる頻度が低下し、設備の安定稼働率が大きく向上している。そのため、設備の安定稼働率向上によるトラブル遭遇機会が減少する一方で、設備保全担当者の経験が不足し、トラブルに対する知識・ノウハウの継承が十分に行われないという問題が生じている。特に、熟練知識・熟練ノウハウを備えた団塊世代の大量退職(2007年問題)は、この問題を浮き彫りにする。従って、突発的トラブルや低頻度トラブルに対応する際の時間的・作業的コストは従来よりむしろ大きくなる場合がある。
【0003】
このような問題に対処すべく、データベースに工場やオフィスの実績情報が蓄積されているが、これは、実際に活用されてこそ意味をなし、更には、熟練知識・熟練ノウハウを備えた担当者の在籍の有無を問わず活用され得るべきである。そのため、熟練知識・熟練ノウハウを備えた担当者が不在であっても、工場やオフィスで蓄積された知識・ノウハウの継承を可能にしうる技術の構築が望まれている。
【0004】
そこで、この種の従来技術に目を向けると、例えば、特許文献1の試験問題データベース生成システム及び試験問題作成システム、特許文献2の研修システム装置、特許文献3の教育装置等の他、非特許文献1〜2の大規模文書集合(WWW上)を知識源とする問題の自動生成等の従来技術が知られている。そのほかにも、非特許文献3では、文書中のデータを解析して取り出した情報に基づいて選択形式、穴埋め形式、誤り訂正形式の教育用練習問題を自動的に生成・出題する練習問題自動生成システムAEGISが報告され、非特許文献4では、技術文書を対象として形態素解析や係り受け解析を行うことで校正学習のための問題を自動生成するシステムが報告されている。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2003−167506
【特許文献2】特開2000−338849
【特許文献3】特開2007−233159
【非特許文献】
【0006】
【非特許文献1】J Sheard and A Carbone. Cadal quiz : Providing support for self-managed learning? In Proc. World Conference on the WWW and Internet, 2000, pp. 482-488, 2000.
【非特許文献2】Etsuo Kobayashi, Shinobu Nagashima, and Mitsuaki Hayase. Programming-free web-based automatic online drill/quiz creator. In Proc. World Conference on Educational Multimedia, Hypermedia and Telecommunications, 2001, pp.990-991, 2001.
【非特許文献3】菅沼等,情報処理学会論文誌,Vol.46,No.7,pp.1810-1818,2005
【非特許文献4】大野等,電気情報通信学会技術研究報告,pp.39-44,2007
【発明の概要】
【発明が解決しようとする課題】
【0007】
工場やオフィスにおける日常業務の知識・ノウハウの継承を考えた場合、その知識源として対象とするのは、例えば、日報情報データベース、具体的には、自動車組立工場で運用されているトラブル管理日報情報の類、すなわち、「特定のコンテンツに依存しない自然言語文データの集合」である。
しかしながら、特許文献1〜3等に開示された技術はいずれも、特定のコンテンツに依存する。ユーザに対するインタラクションやインタフェースの提供や、教師が教材や問題を作成する際の作業量の低減を目的としているため、その適用場面が語学学習・プログラミング学習等の特定の場面に限定されているためである。従って、特許文献1〜3等に開示された技術は、工場やオフィスにおける知識・ノウハウの継承には応用が難しい。また、工場やオフィスにおける日常業務に関する知識・ノウハウは、一般性が低い。従って、非特許文献1〜2のようなWWWを利用した手法は、専門用語が多用される工場やオフィスにおける日常業務における知識・ノウハウの継承には余り役に立たない。
【0008】
また、上記の日報情報データベース(トラブル管理日報情報の類、すなわち、「特定のコンテンツに依存しない自然言語文データの集合」)は、膨大な量(例えば、8年分の日報情報だと約60000件)に上る。このような膨大な量のデータを非特許文献3のシステムで扱う場合には、同文献が専用のXMLタグ付きコーパスを解析対象としているため人手でタグ付けなどの事前準備を行う必要がある。この事前準備は、人手によるため看過できないコストが発生する。従って、非特許文献3のシステムによる実際の運用は、コスト面から現実的ではない。
【0009】
更に、上記の日報情報データベース(トラブル管理日報情報の類、すなわち、「特定のコンテンツに依存しない自然言語文データの集合」)のような工場やオフィス等の特定の環境で運用されるデータベースは、専門用語が多用されていることや、文自体が句読点や助詞、助動詞の省略、体言止めなどが多用された状態で記述されていること、データベース入力者である複数のオペレータ毎の表記ゆれがあること等の事情がある。よって、非特許文献4のような既存の汎用的な知識辞書や形態素解析を用いた手法では、記述文を正確に解析することができず、対象文書によって問題の生成能力にばらつきが生じてしまう。
【0010】
従って、知識源の種類を問わず、工場やオフィスにおける日常業務の知識・ノウハウの継承に汎用的に活用可能であり、人手によるタグ付けや特定コンテンツの別途構築等の事前準備を行うことなく、しかも、日報情報データベースのような膨大な量に上る自然言語文データを処理可能な「工場やオフィスにおける日常業務の知識・ノウハウを継承させ得る自動演習システム」の構築が望まれている。
【0011】
本発明は、上記事情に鑑みてなされたものであり、工場やオフィスにおける日常業務の知識・ノウハウとしてデータベースに蓄積された自然言語文データから重要語及び因果関係(例えば、事象・原因・処置・対策・発生箇所)を抽出し、これに基づいて、問題の自動作成処理、ユーザ回答の自動採点処理、演習結果の自動集計処理を行うことができる自動演習システム及び自動演習プログラムを提供することを目的とする。すなわち、本発明は、コンテンツに依存することなく、工場やオフィスにおける日常業務の知識・ノウハウの継承を可能とする自動演習システム及び自動演習プログラムを提供することを目的とする。
【課題を解決するための手段】
【0012】
上記課題を解決するために、本発明に係る自動演習システムは、
因果関係を有する複数の有意フィールドからなる自然言語文データベースから、前記有意フィールド毎に、カラムの位置情報フィールドと、ベクトル空間フィールドとを備えたベクトル空間テーブルと、前記有意フィールド毎に、索引語フィールドと、重要度フィールドと、索引語の位置情報フィールドとを備えた重要度テーブルとを備えた知識データベースを構築する知識収集手段と、
前記重要度テーブルからクエリに含まれる索引語を重要語としてクエリベクトル空間の要素として抽出し、当該クエリベクトル空間と、前記有意フィールドから選ばれた質問フィールドの全各カラムのベクトル空間とを用いて前記クエリと前記質問フィールドの全各カラムとの類似度を求め、当該類似度に基づいて(又は、当該類似度順に)前記質問フィールドの全各カラムをランキングしたランキングリストを作成するランキングリスト作成手段と、
前記ランキングリストにおいて、閾値α以上の類似度Rαの質問フィールドを問題作成テンプレートに適用して問題文を作成するとともに、前記類似度Rαに対応する前記有意フィールドから選ばれた回答フィールドを正解選択肢とするQ-A対作成手段とを備えたことを要旨とする。
【0013】
「因果関係」とは、データベースを構成する各フィールドが事象・原因・処置・対策・発生箇所というように相互に関連性を備えることをいうが、これらに限定されない。
「有意フィールド」とは、データベースを構成する各フィールドが事象・原因・処置・対策・発生箇所というように意味があるフィールド、換言すれば、自然言語文データからなるフィールドをいうが、これらに限定されない。
「自然言語文データベース」とは、工場やオフィスにおける日報情報データベース、トラブル情報データベースの類をいうが、自然言語文データを含む限り、これらに限定されない。
【0014】
「知識データベース」とは、自然言語文データベースから知識を収集することにより作成されるデータベースをいい、本発明においては、そのように知識を収集することにより得られたものとして、各有意フィールド毎に、「ベクトル空間テーブル」及び「重要度テーブル」を備える。
そして、「ベクトル空間テーブル」は、「カラムの位置情報フィールド」と、「ベクトル空間フィールド」とを備える。ここで、「カラムの位置情報」とは、自然言語文データが格納されているカラムの自然言語文データベースのレコード番号を特定しうる位置情報をいう。従って、「レコード番号を特定しうる位置」であればよいため、例えば、知識源テーブル(自然言語文データベースを各有意フィールド毎にコピーして得たテーブル、以下同じ)における位置情報をも含む。また、「ベクトル空間」とは、自然言語文データが格納されているカラムに含まれる索引語を重要語として抽出して要素としたものである。
【0015】
また、「重要度テーブル」は、有意フィールド毎に、「索引語フィールド」と、「重要度フィールド」と、「索引語の位置情報フィールド」とを備える。ここで、「索引語」とは、知識収集手段に含まれる後述する文字列クラス群生成手段、索引語候補群生成手段、索引語抽出手段により、各有意フィールド毎に抽出された索引語をいう。「重要度」とは、索引語の重要度を数値で表したものをいい、例えば、後述する式2により求めることができる。「索引語の位置情報」とは、索引語の出現する全てのカラムの自然言語文データベースのレコード番号を特定しうる位置情報をいう。従って、「レコード番号を特定しうる位置」であればよいため、例えば、知識源テーブル(自然言語文データベースを各有意フィールド毎にコピーして得たテーブル、以下同じ)における位置情報をも含む。
【0016】
「クエリ」とは、問題を自動作成させる場合に、ユーザによって入力される自然言語文データ又は自然言語文データベースから無作為に選択又は抽出した自然言語文データをいう。ユーザから見れば、「クエリ」としての自然言語文データは、ユーザが作成したいと考える問題に近い質問文やその質問文に含まれる単語等となる。
【0017】
「質問フィールド」とは、自然言語文データベースの複数の有意フィールドから問題作成用のフィールドとして選択された有意フィールドをいうが、知識源テーブルの同一有意フィールドをも含む。本発明においては、事象フィールド・原因フィールド・処置フィールド・対策フィールド・発生箇所フィールドのいずれかを質問フィールドとすることができるが、事象フィールドを質問フィールドと予め指定してもよい。
「類似度」とは、対比する自然言語文データが類似する程度をそれらのベクトル空間を用いて演算することにより数値によって表したものであり、例えば、後述する式3により求めることができる。
「回答フィールド」とは、自然言語文データベースの複数の有意フィールドから問題(回答)作成用のフィールドとして選択された有意フィールドをいうが、知識源テーブルの同一有意フィールドをも含む。本発明においては、事象フィールド・原因フィールド・処置フィールド・対策フィールド・発生箇所フィールドのいずれかを回答フィールドとすることができるが、原因フィールドを回答フィールドと予め指定してもよい。
「問題作成テンプレート」とは、質問フィールド及び/又は事象・原因・処置・対策・発生箇所等のフィールドの内容を埋め込む埋込フィールドが設けられたテンプレートをいう。
【0018】
上記構成を備えた本発明に係る自動演習システムによれば、知識収集手段によって、自然言語文データベースから有意フィールド毎にベクトル空間テーブルと重要度テーブルとが作成される。そして、ランキングリスト作成手段により、重要度テーブルからクエリに含まれる索引語が重要語としてクエリベクトル空間の要素として抽出され、当該クエリベクトル空間と、質問フィールドの全各カラムのベクトル空間とを用いて前記クエリと前記質問フィールドの全各カラムとの類似度が求められた後、当該類似度に基づいて(又は、当該類似度順に)前記質問フィールドの全各カラムをランキングしたランキングリストが作成される。その後、Q-A対作成手段により、前記ランキングリストにおいて、閾値α以上の類似度Rαの質問フィールドが問題作成テンプレートに適用され問題文が作成されるとともに、前記類似度Rαに対応する回答フィールドが正解選択肢とされる。
従って、本発明によれば、コンテンツに依存することなく、問題(問題文Q及び正解A)が自動作成される。閾値α以上の類似度Rαの質問フィールドを問題作成テンプレートに適用するため、ユーザの要望に応じた問題が作成される。
【0019】
本発明に係る自動演習システムは、更に、
前記ランキングリストにおいて、閾値β未満の類似度Rβに対応する回答フィールドのベクトル空間と、前記正解選択肢のベクトル空間及び/又は他の不正解選択肢のベクトル空間とを用いて前記回答フィールドと前記正解選択肢及び/又は前記他の不正解選択肢との類似度Rγを求め、当該類似度Rγが閾値γ未満である場合に、前記類似度Rβに対応する回答フィールドを不正解選択肢とする不正解作成手段を備えてもよい。
【0020】
上記構成を備えた自動演習システムによれば、不正解作成手段により、前記ランキングリストにおいて、閾値β未満の類似度Rβに対応する回答フィールドのベクトル空間と、前記正解選択肢のベクトル空間及び/又は他の不正解選択肢のベクトル空間とを用いて前記回答フィールドと前記正解選択肢及び/又は前記他の不正解選択肢との類似度Rγが求められ、当該類似度Rγが閾値γ未満である場合に、前記類似度Rβに対応する回答フィールドが不正解選択肢とされる。従って、本発明によれば、コンテンツに依存することなく、問題が自動作成される。閾値β未満の類似度Rβに対応する回答フィールドが不正解選択肢とされるため、正解選択肢とは十分に遠い不正解選択肢が得られるとともに、そのうち、正解選択肢及び/又は他の不正解選択肢との類似度γが閾値γ未満である回答フィールドが不正解選択肢とされるため、正解選択肢や他の不正解選択肢と同じ内容になることが回避される。
【0021】
本発明に係る自動演習システムは、例えば、前記類似度Rαは、前記ランキングリストにおいて最も高い類似度とすればよく、前記類似度Rβは、前記ランキングリストにおいて不正解選択肢として未選択のもののうち最も低い類似度(ただし、0超)とすればよい。
【0022】
上記課題を解決するために、本発明に係る自動演習システムは、更に、
ユーザ情報データベースに基づいて問題データベースから出題すべき問題を取得する準備手段と、
前記問題をインタフェース画面に表示するとともに、前記問題に対するユーザ回答を採点し、結果を正解情報とともに前記インタフェース画面に表示する出題採点手段と、
前記結果に基づいて前記ユーザ情報データベース及び前記問題データベースを更新する管理手段とを備えてもよい。
【0023】
上記構成を備えた自動演習システムによれば、準備手段により、ユーザ情報データベースに基づいて問題データベースから出題すべき問題が取得され、出題採点手段により、前記問題がインタフェース画面に表示されるとともに、前記問題に対するユーザ回答が採点され、結果が正解情報とともに前記インタフェース画面に表示される。そして、管理手段により、前記結果に基づいて前記ユーザ情報データベース及び前記問題データベースが更新される。従って、本発明によれば、問題の自動作成の他、ユーザ回答の自動採点処理、演習結果の自動集計処理を行うことができる。ユーザが本発明に係る自動演習システムを活用すれば、専用辞書等がなくても工場やオフィスにおける日常業務の知識・ノウハウの継承が可能となる。
【0024】
本発明に係る自動演習手段は、更に、
前記重要度テーブルから前記正解情報に含まれる索引語を重要語として正解情報ベクトル空間の要素として抽出し、当該正解情報ベクトル空間と、前記質問フィールドの全各カラムのベクトル空間とを用いて前記正解情報と前記質問フィールドの全各カラムとの類似度を求め、当該類似度に基づいて(又は、当該類似度順に)前記質問フィールドの全各カラムをランキングしたランキングリストを作成し、その内容を表示する復習手段を備えてもよい。
【0025】
本発明に係る自動演習手段によれば、復習手段により、前記重要度テーブルから前記正解情報に含まれる索引語が重要語として正解情報ベクトル空間の要素として抽出され、当該正解情報ベクトル空間と、前記質問フィールドの全各カラムのベクトル空間とを用いて前記正解情報と前記質問フィールドの全各カラムとの類似度が求められ、当該類似度に基づいて(又は、当該類似度順に)前記質問フィールドの全各カラムをランキングしたランキングリストが作成され、その内容が表示される。従って、ユーザは間違えた問題と類似するケースをチェックすることができ、知識・ノウハウの定着に役立てることができる。
【0026】
本発明に係る自動演習システムにおける知識収集手段は、特に限定されないが、例えば、以下の構成を備えるものが好ましい。すなわち、前記知識収集手段は、
前記有意フィールド毎に、サフィックス群及び/又はプレフィックス群を文字列クラスとして辞書順にソートして生成し、前後の文字列クラスの一致部分の切り出し、出現頻度が閾値T1未満の文字列クラスの除外、同一の文字列クラスの統合、及び、包含関係にある上位文字列クラスが下位文字列クラスより優先されるようにソートする文字列クラス群生成手段と、
前記有意フィールド毎に、文字列クラスの一つ前の文字列クラスと包含関係にない場合には、当該文字列クラスを索引語候補として記憶するとともに、包含関係にある場合には、頻度比を求め、前記頻度比が閾値T2以上の場合には下位文字列クラスを索引語候補として記憶する一方、頻度比が閾値T2未満の場合には下位文字列クラスを上位文字列クラスとみなして索引語候補として記憶する索引語候補群生成手段と、
前記各群の索引語候補のうち当該各群にわたって重複する索引語候補を索引語として抽出する索引語抽出手段と、
前記有意フィールド毎に、全各カラムに含まれる前記索引語を重要語として抽出し、当該重要語を要素とするベクトル空間を当該全各カラムについて生成して、当該全各カラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドと、ベクトル空間フィールドとを備えたベクトル空間テーブルを作成するベクトル空間テーブル作成手段と、
前記有意フィールド毎に、前記索引語の重要度を求め、前記有意フィールド毎に、索引語フィールドと、重要度フィールドと、当該索引語の出現する全てのカラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドと、を備えた重要度テーブルを作成する重要度テーブル作成手段とを備えるとよい。
【0027】
「包含関係」とは、一方の文字列クラスが他方の文字列クラスを包含する関係をいう。また、「上位文字列クラス」と「下位文字列クラス」とは、包含する方の文字列クラスが上位文字列クラスで、包含される方の文字列クラスが下位文字列クラスである。例えば、「チェーン」が上位文字列クラスで「チェー」が下位文字列クラスである。
【0028】
本発明に係る自動演習システムの知識収集手段によれば、文字列クラス群生成手段により、前記有意フィールド毎に、サフィックス群及び/又はプレフィックス群が文字列クラスとして辞書順にソートして生成され、前後の文字列クラスから一致部分の切り出し、出現頻度が閾値T1未満の文字列クラスの除外、同一の文字列クラスの統合がなされ、更に、包含関係にある上位文字列クラスが下位文字列クラスより優先されるようにソートされる。そして、索引語候補群生成手段により、前記有意フィールド毎に、文字列クラスの一つ前の文字列クラスと包含関係にない場合には、当該文字列クラスが索引語候補として記憶されるとともに、包含関係にある場合には、頻度比が求められ、前記頻度比が閾値T2以上の場合には下位文字列クラスが索引語候補として記憶される一方、頻度比が閾値T2未満の場合には下位文字列クラスが上位文字列クラスとみなされ索引語候補として記憶される。そして、索引語抽出手段により、前記各群の索引語候補のうち当該各群にわたって重複する索引語候補が索引語として抽出される。
【0029】
そして、ベクトル空間テーブル作成手段により、前記有意フィールド毎に、全各カラムに含まれる前記索引語が重要語として抽出され、当該重要語を要素とするベクトル空間が当該全各カラムについて生成され、当該全各カラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドと、ベクトル空間フィールドとを備えたベクトル空間テーブルが作成される。また、重要度テーブル作成手段により、前記有意フィールド毎に、前記索引語の重要度が求められ、前記有意フィールド毎に、索引語フィールドと、重要度フィールドと、当該索引語の出現する全てのカラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドとを備えた重要度テーブルが作成される。
従って、本発明に係る自動演習システムは、日報情報やトラブル情報等を自然言語文データで記録したデータベースさえ有していれば、その種類を問わずに知識収集を行うことができる。
【0030】
この場合に、
前記頻度比は、
Gap(C(n-1),Cn)=|log(Ti(n-1)/Tin)| …(式1)
(ここで、C(n-1):Cnと包含関係にある上位文字列クラス、Cn:C(n-1)と包含関係にある下位文字列クラス、Gap(C(n-1),Cn):C(n-1),Cnの頻度比、Ti(n-1):上位文字列クラスの出現頻度、Tin:下位文字列クラスの出現頻度)、により求めることができるが、これに限定されない。
【0031】
また、本発明に係る自動演習システムにおいて、前記重要度は、
Swj=log{(Fj/Dj)+1} …(式2)
(ここで、Swj:重要度、Fj:出現頻度、Dj:共起頻度)、により求めることができるが、これに限定されない。
【0032】
更に、本発明に係る自動演習システムにおいて、前記類似度は、
【数1】

…(式3)、により求めることができるが、これに限定されない。
【0033】
本発明に係る自動演習プログラムについての構成作用効果の説明は、本発明に係る自動演習システムについての上記の構成作用効果の説明をもってこれに代える。
【発明の効果】
【0034】
本発明は、上記構成を備えたため、工場やオフィスにおける日常業務の知識・ノウハウとしてデータベースに蓄積された自然言語文データから重要語及び因果関係(例えば、事象・原因・処置・対策・発生箇所)を抽出し、これに基づいて、問題の自動作成処理、ユーザ回答の自動採点処理、演習結果の自動集計処理を行うことができるという効果がある。
本発明は、上記構成を備えたため、コンテンツに依存することなく、工場やオフィスにおける日常業務に関する知識・ノウハウの継承を可能とするという効果がある。
【図面の簡単な説明】
【0035】
【図1】本発明の一実施形態に係る自動演習システム1のシステム構成概略図であり、同図(a)がサーバークライアント方式の場合の例、同図(b)がスタンドアローン方式の場合の例である。
【図2】本発明の一実施形態に係る自動演習システム1のハードウエア構成及びソフトウエア構成を示すブロック図である。
【図3】本発明の一実施形態に係る自動演習プログラムA00の処理手順を示すフローチャートである。
【図4】本発明の一実施形態に係るユーザ管理プログラムB00の処理手順を示すフローチャートである。
【図5A】本発明の一実施形態に係る知識収集プログラムC00のの処理手順を示すフローチャートである。
【図5B】文字列クラス群生成プログラムC100の処理手順を示すフローチャートである。
【図5C】索引語候補群生成プログラムC200の処理手順を示すフローチャートである。
【図5D】重要度テーブル作成プログラムC500の処理手順を示すフローチャートである。
【図6】本発明の一実施形態に係る問題作成プログラムD00の処理手順を示すフローチャートである。
【図7】本発明の一実施形態に係る演習プログラムE00の処理手順を示すフローチャートである。
【図8】本発明を適用しうる日報DB5の一例を示す図である。
【図9A】知識DB9のうちベクトル空間テーブルTb9Aの一例を示す図である。
【図9B】知識DB9のうち重要度テーブルTb9Bの一例を示す図である。
【図10】本発明で作成される問題DB10の一例を示す図である。
【図11】本発明で用いられるユーザ情報DB11の一例を示す図である。
【図12】同図(a)〜(f)は、自動演習プログラムA00の実行中(A01〜A03)に表示される画面の一例を示す図である。
【図13A】日報DB5の各有意フィールド毎に作成される知識源テーブルTb13Aの一例を示す。
【図13B】サフィックス生成(ソート前)を説明する図である。
【図13C】サフィックス生成(ソート後)を説明する図である。
【図14A】索引語候補テーブルTb14Aの一例を示す図である。
【図14B】索引語候補群生成プログラムC200を説明するための図である。
【図15】D09で表示されているクエリ指定画面G15の一例を示す図である。
【図16】D11cで作成されるランキングリストRLの一例を示す図である。
【図17A】D12〜D14でランキングリストRLに基づいてQ-A対(問題文Q及び正解Aの対)を選択するときに閾値αと比較する処理の説明図である。
【図17B】図17Aと同様、閾値αと比較する処理の説明図である。
【図18】問題作成テンプレートTPの一例を示す図である。
【図19】回答フィールドから正解Aを選択してQ-A対を登録した例を示す図である。
【図20A】回答フィールドから不正解Bを選択して不正解選択肢を登録した例を示す図である。
【図20B】選択した不正解選択肢と既選択の不正解選択肢との類似度が閾値γを超えるか否かの判断処理を説明するための説明図である。
【図21】問題が完成した一例を示す説明図である。
【図22】回答フィールドから不正解Bを選択して不正解選択肢を登録した例を示す(指定類似度による変形例)。
【図23】問題表示画面G23の一例を示す図である。
【図24】結果表示画面G24の一例を示す図である。
【図25】結果表示画面G25の一例を示す図である。
【図26】復習画面G26の一例を示す図である。
【図27】終了画面G27の一例を示す図である。
【図28】回答エラー警告画面G28の一例を示す図である。
【発明を実施するための形態】
【0036】
以下に図面を参照して、本発明の一実施形態に係る自動演習システム及び自動演習プログラムについて詳細に説明する。
【0037】
[自動演習システム1]
図1は自動演習システム1のハードウエア構成を概略的に示すシステム構成図であり、図2は自動演習システム1のハードウエア・ソフトウエア構成を示すブロック図である。これらの図において、自動演習システム1は、工場やオフィスにおける任意のデータベース(例えば、日報情報データベース)の自然言語文データを解析して因果関係を有する複数の有意フィールド(例えば、事象・原因・処置・対策・発生箇所という因果関係を有する意味のあるフィールド)等から位置情報L・索引語・重要度・ベクトル空間等の知識情報を収集する知識収集処理(図5A参照)、収集した知識情報を用いて問題を作成する問題作成処理(図6参照)、ユーザーに演習インタフェースを提供し、そのユーザ回答入力を採点管理する演習処理(図7参照)等を行うシステムである。
【0038】
自動演習システム1は、図3〜図7に示すフローチャートを実行させるための自動演習プログラムA00等をサーバー2(自動演習装置2)(図1(a)参照)やパーソナルコンピュータ3(自動演習装置3)(図1(b)参照)に搭載することにより、サーバークライアント方式、スタンドアローン方式のいずれによっても構築できる。また、サーバー2又はパーソナルコンピュータ3は、工場やオフィスのDBシステム4(「DB」とはデータベースをいう、以下同じ)によって蓄積された日報DB5と電話回線7及び/又はLAN8等により有線通信又は無線通信ができるように接続されている。これにより、サーバー2やパーソナルコンピュータ3は、日報DB5からデータの受信や読み出しができるとともに、日報DB5へデータの送信・書き込みができる。日報DB5の詳細は後述する。
【0039】
サーバークライアント方式による場合(図1(a)参照)には、図2に示すように、自動演習システム1は、サーバー2と、クライアント6とから構成される。サーバー2は、記憶部2a(ROM2a、RAM2aともいう)、制御部2b、入力部2c(キーボード2c、マウス2cともいう)、出力部2d(画面2d、スピーカ2dともいう)、各種デバイスを備える。記憶部2aは、ROMやRAMによって構成され、RAMは図3〜図7のフローチャートを実行する手順が記述された自動演習プログラムA00(図3参照)、ユーザ管理プログラムB00(図4参照)、知識収集プログラムC00(図5A〜図5D参照)、問題作成プログラムD00(図6参照)、演習プログラムE00(図7参照)が搭載されるほか、その実行に際して使用する知識DB9(図9参照)、問題DB10(図10参照)、ユーザ情報DB11(図11参照)並びにその他の各種のプログラムやデータを記憶する。ROMは当該サーバー2及び各種デバイスを制御するためのプログラムや各種データを記憶する。尚、知識DB9、問題DB10、ユーザ情報DB11の詳細は後述する。
【0040】
制御部2bは、CPU(中央処理装置)やOS(オペレーティングシステム)を備え、上記プログラムA00〜E00を呼び出して装置各部に制御命令を送出しそのプログラムに記述された処理手順を実行することにより、自動演習手段(すなわち、ユーザ管理手段、問題作成手段、演習手段)として機能する。これらの処理手順の詳細は後述する。また、制御部2bは、ユーザ入力に基づいて各種プログラムを実行したり、各種命令を装置各部に送出し実行させたり、その他の各種プログラムの実行、各種データの授受、オペレーティングシステムとしての制御・通信機能の制御、その他の装置各部の制御を行う。
【0041】
入力部2cは、データ入力に用いられるものであれば特に限定されず、入力手段としてのキーボード・マウス・ポインティングデバイス等により構成される。出力部2dは、画像、印字又は音声によってデータを提示するものであれば特に限定されず、出力手段としての画面・スピーカ・プリンター等により構成される。
【0042】
クライアント6は、記憶部6a(ROM6a、RAM6aともいう)、制御部6b、入力部6c(キーボード6c、マウス6cともいう)、出力部6d(インタフェース画面6dともいう)、各種デバイスを備える。記憶部6aは、ROMやRAMによって構成され、RAMは各種のプログラムやデータを記憶し、ROMは当該クライアント6及び各種デバイスを制御するためのプログラムや各種データを記憶する。制御部6bは、CPU(中央処理装置)やOS(オペレーティングシステム)を備え、サーバーに接続して自動演習プログラムA00を活用するための手順を実行する他、ユーザ入力に基づいて各種プログラムを実行したり、各種命令を装置各部に送出し実行させたり、その他の各種プログラムの実行、各種データの授受、オペレーティングシステムとしての制御・通信機能の制御、その他の装置各部の制御を行う。
【0043】
入力部6cは、サーバークライアント方式で自動演習システム1を利用する場合にはそのデータ入力に用いられるものであれば特に限定されず、入力手段としてのキーボード・マウス・ポインティングデバイス等により構成される。出力部6dは、サーバークライアント方式で自動演習システム1を利用する場合にはそのデータ提示手段(例えば、表示手段、印字手段、通知手段)となり、画像、印字又は音声によってデータを提示するものであれば特に限定されず、インタフェース画面・スピーカ・プリンター等により構成される。
【0044】
尚、スタンドアロン方式による場合(図1(b)参照)には、同図のパーソナルコンピュータ3は、図2の符号2a〜2dを符号3a〜3dに置き換えたものに相当するものであればよいため図示を省略するが、記憶部3a(ROM3a、RAM3aともいう)、制御部3b、入力部3c(キーボード3c、マウス3cともいう)、出力部3d(画面3d、スピーカ3dともいう)、各種デバイスを備える。このうち、記憶部3a及び制御部3bは、それぞれ、上記サーバー2の記憶部2a及び制御部2bに相当する構成を備え、入力部3c及び出力部3dは、それぞれ、上記クライアント6の入力部6c、出力部6dに相当する構成を備える。尚、記憶部3aを共有し、数台のパーソナルコンピュータ3それぞれに自動演習プログラムA00を搭載してもよい。
【0045】
[日報DB5]
図8は、日報DB5の一例を示す。日報DB5は、自動演習システム1による問題作成の知識源となるデータベースであり、工場やオフィスにおける日常業務に関する知識・ノウハウを自然言語文データで表されたデータが蓄積されたものである。すなわち、日報DB5は、同図に例示するように、日常的に現場担当者から報告される作業日報(ここでは、工場のトラブル管理業務日報)を自然言語文データで記述して蓄積した「自然言語文データベース」であるが、自然言語文データを含む限り、これに限定されない。
【0046】
日報DB5は、図8に示すように、因果関係を有する複数の有意フィールド、事象フィールド(事象有意フィールド)・原因フィールド(原因有意フィールド)・処置フィールド(処置有意フィールド)・対策フィールド(対策有意フィールド)・発生箇所フィールド(発生箇所有意フィールド)からなるレコードを単位とし、各フィールドを構成するデータが自然言語文データ又はこれを一部に含むデータによって構成されるものであれば、有意フィールドの種類や内容は特に限定されない。
ここで、「因果関係」とは、事象・原因・処置・対策・発生箇所というように相互に関連性を備えることを意味するが、これらに限定されない。また、上記のことから、「有意フィールド」とは、日報DB5を構成する事象フィールド・原因フィールド・処置フィールド・対策フィールド・発生箇所フィールドを意味するが、意味のあるフィールド、換言すれば、自然言語文データからなるフィールドであればこれらに限定されない。
以上のように、自動演習システム1は、問題作成の知識源としてこのような日報DBを利用できるためコンテンツに依存せず、業種にとらわれず種々の工場やオフィスに適用でき、予め特定のデータベースを必要としない。
【0047】
[知識DB9]
図9A及び図9Bは、知識収集プログラム(図5AのC00参照)の実行により、日報DB5(自然言語文データベース)から知識を収集することにより作成される知識DB9の一例を示す。そのように知識を収集することにより得られた具体例として、図9Aがベクトル空間テーブルTb9Aの一例を示し、図9Bが重要度テーブルTb9Bの一例を示す。これらのテーブルは、各有意フィールド毎に作成され、日報DB5の全ての有意フィールド(事象フィールド・原因フィールド・処置フィールド・対策フィールド・発生箇所フィールド)についてベクトル空間テーブルTb9A1〜Tb9A5及び重要度テーブルTb9B1〜Tb9B5を備える。尚、知識収集プログラムC00の処理手順は後述する。
【0048】
ベクトル空間テーブルTb9Aは、日報DB5の各有意フィールド(事象・原因・処置・対策・発生箇所)毎に作成され、
(1)位置情報L(自然言語文データベース(日報DB5)で索引語が出現する全てのカラムのレコード番号を特定しうる位置情報、知識源テーブルTb13Aのレコード番号でもよい、以下同じ)のフィールド(位置情報フィールド)と、
(2)当該各有意フィールドの各カラムに含まれる全ての重要語を要素とするベクトル空間のフィールド(ベクトル空間フィールド)と、を備える。
【0049】
また、重要度テーブルTb9Bは、日報DB5の各有意フィールド(事象・原因・処置・対策・発生箇所)毎に作成され、
(1)当該各有意フィールドに含まれる索引語のフィールド(索引語フィールド)と、
(2)後述する式2により求めたその索引語の重要度のフィールド(重要度フィールド)と、
(3)その索引語が出現する位置情報Lのフィールド(位置情報フィールド)とを備える。
ここで、「索引語」とは、知識収集プログラム(C00参照)から呼び出される後述する文字列クラス群生成プログラム(C01参照)、索引語候補群生成プログラム(C02参照)、索引語抽出プログラム(C03参照)の実行により、各有意フィールド毎に抽出された索引語をいう。また、「重要度」とは、索引語の重要度を数値で表したものをいい、例えば、後述する式2により求めることができる。
【0050】
[問題DB10]
図10は、問題DB10の一例を示す。問題DB10は、問題生成プログラムD00の実行により作成されるとともに、演習プログラムE00の実行によりその一部が更新される。問題DB10は、(1)問題番号、(2)問題文Q、(3)難易度、(4)総出題数、(5)総正解数、(6)正解A、(7)不正解B(B1〜B4)及び回答スコア等のフィールドからなるデータベースである。
【0051】
[ユーザ情報DB11]
図11は、ユーザ情報DB11の一例を示す。ユーザ情報DB11は、後述するユーザ管理プログラムB00の実行により作成されるとともに、演習プログラムE00の実行によりその一部が更新される。ユーザ情報DB11は、ユーザ認識情報及びユーザ成績情報によって構成され、(1)番号、(2)ユーザ名、(3)ユーザID、(4)パスワード(図示省略)、(5)試行数(演習総試行回数)、(6)正解数(総正解数)、(7)演習試行毎の累積スコア1〜n等のフィールドからなるデータベースである。
【0052】
[自動演習システム1の動作及び自動演習プログラムA00の処理手順]
本発明の一実施形態に係る自動演習システム1の動作及び自動演習プログラムA00の処理手順についてフローチャート等を参照して説明する。
【0053】
[自動演習プログラムA00]
図3の自動演習プログラムA00において、制御部2bは、ユーザからの開始入力を検出すると(A01)、A02へ進んで、ユーザ管理プログラムB00を呼び出して実行し、ユーザ管理手段として機能する。すなわち、制御部2bは、図12(a)のユーザ認証画面G12Aを表示してユーザ管理処理(ユーザ認証やユーザ登録)を行う(A02)。制御部2bは、ユーザ認証に成功すると、A03に進み、図12(b)のユーザ処理選択画面G12Bを表示してユーザ入力を待機する(A03)。
【0054】
制御部2bは、A03において知識収集ボタンB12B1の押下を検知すると、知識収集プログラムC00を呼び出して実行することにより知識収集手段として機能して、各有意フィールド毎に、ベクトル空間テーブルTb9Aと、重要度テーブルTb9Bとを作成し、これを知識DB9に記憶させる(A04)。尚、知識収集処理の詳細は後述する。
また、制御部2bは、A03において問題作成ボタンB12B2の押下を検知すると、問題作成プログラムD00を呼び出して実行することにより問題作成手段として機能して、図10に例示する問題を作成し、これを問題DB10に記憶させる(A05)。尚、問題作成処理の詳細は後述する。
更に、制御部2bは、A03において演習ボタンB12B3の押下を検知すると、演習プログラムE00を呼び出して実行することにより演習手段として機能して、問題DB10から問題を読み出して所定数の問題の出題処理が終了するまで出題し、ユーザ回答の正誤判定及びその判定結果解析を実行する(A06)。制御部2bは、知識収集処理(A03)、問題作成処理(A04)又は演習処理(A06)が終了すれば、ユーザ処理選択画面G12Bを表示してユーザ入力を待機する(A03)。制御部2bは以上の手順によって自動演習プログラムA00を実行する。
【0055】
ユーザは、自動演習システム1又は自動演習プログラムA00を使用することによって、工場やオフィスにおける日常業務に関する知識・ノウハウを身につけることができる。そして、自動演習システム1や自動演習プログラムA00は、分野や業種を問わないため、現場特有の専門用語が多用される現場ノウハウや特殊技能に関する知識を得るのに役立つ。
【0056】
[ユーザ管理プログラムB00]
制御部2bが図3のA01を実行してA02に進み、図4のユーザ管理プログラムB00を呼び出し、B01に進むと、制御部2bは、ユーザ管理手段として機能する。制御部2bは、B01においてユーザ認証画面G12Aに示すようにユーザID「ise」及びPassword「******」が入力された状態で認証ボタンB12A1の押下を検知すると(B01→B01a:no)、ユーザ情報DB11を参照する(B02)。そして、制御部2bは、該当ユーザの登録済の有無を判断し、登録済と判断すると(B03:yes)、ユーザ理解度情報としてユーザ情報DB11の試行数と正解数とを参照する(B04)。そして、制御部2bは、ユーザ処理選択画面G12Bを表示して、知識収集ボタンB12B1、問題作成ボタンB12B2、演習ボタンB12B3、終了ボタンB12B4のいずれかのボタンのユーザ入力を待機する(B05(A03))。
【0057】
一方、B01においてユーザ認証画面G12Aに示すユーザID入力ボックス及びPassword入力ボックスに正確に入力されていない状態で認証ボタンB12A1の押下を検知すると(B01→B01a:no)、B02でユーザ情報DB11を参照した後、該当ユーザが未登録であると判断し(B03:no)、図12(c)の認証エラー警告画面G12Cを表示して(B06)、ユーザ入力を受け付ける(B07)。制御部2bは、新規登録ボタンB12C1の押下を検知すると、B08に進む(尚、制御部2bは、B01aにおいて新規登録ボタンB12A2の押下を検知したときもB08に進む)。
【0058】
制御部2bは、B08において図12(d)の新規ユーザ登録画面G12Dを表示し、ユーザ入力を受け付け、同図の入力ボックスBXにユーザ情報が入力された状態で登録ボタンB12D1の押下を検知すると(B09)、入力されたユーザ情報が規定の条件を満たすか否かを判定し(B10)、条件を満たしている(正常入力である)と判断すると(B10:yes)、B11に進み、入力されたユーザ情報をユーザ情報DB11へ記憶させることにより、新規登録し(B11)、その結果として、図12(e)の新規ユーザ登録画面G12Eを表示し、同図の戻るボタンB12E3の押下を検知するとB03に戻る。
【0059】
尚、制御部2bは、B07において、認証エラー警告画面G12Cの戻るボタンB12C2の押下を検知すると、B01に戻る。また、制御部2bは、B10において、新規ユーザ登録画面G12Dにおけるユーザ入力が正常入力ではないと判断すると、図12(f)の登録エラー警告画面G12Fを表示する(B13)。制御部2bは、B13において、戻るボタンG12F1の押下を検知すると、エラー処理(B14)を行って、入力されたユーザ情報を削除した後、B07に戻る。
制御部2bは以上の手順によってユーザ管理プログラムB00を実行し、ユーザ認証に成功すると(B03:yes)、B04を経て、B05(すなわち、A03)に進んで、ユーザ入力を待機し、ユーザ入力に応じて、以下の知識収集プログラムC00、問題作成プログラムD00、演習プログラムE00等を実行する。
【0060】
[知識収集プログラムC00]
知識収集プログラムC00は、文字列クラス群生成処理(C01)、索引語候補群生成処理(C02)、索引語抽出処理(C03)、ベクトル空間テーブル作成処理(C04)、重要度テーブル作成処理(C05)を制御部2bに実行させるための手順を備える。これらの処理を総称して、知識収集処理(C01〜C05)という。そして、制御部2bは各処理を行うときは、それぞれ、文字列クラス群生成手段、索引語候補群生成手段、索引語抽出手段、ベクトル空間テーブル作成手段、重要度テーブル作成手段として機能する。これらの各処理を行うように機能する場合を総称して、知識収集手段という。
【0061】
以下フローチャートに従って説明する。制御部2bが図3のA01及びA02等を実行してA03に進み、A03において知識収集ボタンB12B1の押下を検知するとA04を実行、すなわち、知識収集プログラムC00を呼び出して、図5AのC01に進み、知識収集手段として機能する。これにより、制御部2bは、知識収集処理として、因果関係を有する複数の有意フィールドからなる自然言語文データベースから、有意フィールド毎に、図9に例示する重要度テーブルTb9Aとベクトル空間テーブルTb9Bとを備えた知識DB9を構築する処理を行う。
【0062】
制御部2bは、C01においては、図5Bの文字列クラス群生成プログラムC100を呼び出して実行することにより文字列クラス群生成手段として機能し、文字列クラス群生成処理として、有意フィールド毎に、サフィックス群及び/又はプレフィックス群を文字列クラスとして辞書順にソートして生成し、前後の文字列クラスの一致部分の切り出し、出現頻度が閾値T1未満の文字列クラスの除外、同一の文字列クラスの統合、及び、包含関係にある上位文字列クラスが下位文字列クラスより優先されるようにソートする処理を行う。尚、以下の説明ではサフィックス群を取り上げて説明するが、制御部2bは、プレフィックス群についてもサフィックス群と同様の処理を行う。
【0063】
制御部2bは、C01を介して文字列クラス群生成プログラムC100のC101に進むと、日報DB5から、各有意フィールド毎に、位置情報Lと、各有意フィールドの全各カラムの自然言語文データを配列順に一度に読み出し、図13Aに例示する知識源テーブルTb13A(事象知識源テーブル、原因知識源テーブル、処置知識源テーブル、対策知識源テーブル、発生箇所知識源テーブルを含む)を作成し、記憶部2aに記憶させる処理を行う(C101)。
【0064】
制御部2bは、C102においては、各知識源テーブルTb13Aについて、図13BのテーブルTb13Bに例示するように、読み出した自然言語文データを構成するテキストをそのテキスト中に存在する全ての文字からテキストの終端までの部分文字列(サフィックス:接頭辞)の集合(n-gram集合)であると認識し、位置情報L毎に、その集合(サフィックス)を機械的に並べたテーブルを作成する。制御部2bは、C103においては、各知識源テーブルTb13Aについて、位置情報Lが同じ自然言語文データ毎に、各サフィックスを辞書順にソートする。制御部2bは、C104においては、図13CのテーブルテーブルTb13Cに例示するように、各有意フィールド毎に、当該各有意フィールド単位で、全サフィックスを統合し全体を辞書順にソートしたテーブルを作成する。
【0065】
制御部2bは、C105においては、カウンタiと、サフィックス総数jとに所定の値を設定する。カウンタiには初期値として0を設定し、サフィックス総数jにはC104で「ソート及び統合」した全サフィックス数を設定する。制御部2bは、C106においては、「i番目のサフィックス」と「(i-1)番目のサフィックス」とを比較し、一致部分の有無を判断する。制御部2bは、一致部分有りと判断すると(C106:yes)、C107へ進み一致部分を文字列クラスCiとして切り出し、切り出した文字列クラスCiを位置情報Lと対応させて記憶する。ちなみに、上述のことからも明らかであるが、「位置情報L」は、切り出した文字列クラスCiの元となった知識源テーブルTb13Aのレコード番号、すなわち、日報DB5のレコード番号を特定する。尚、ここでは一文字でも同じ文字列があれば文字列クラスCiとして切り出される。
【0066】
例えば、(i-1)番目のサフィックスが「空DPチェーン断」、i番目のサフィックスが「空DPチェーン」である場合には、重複する「空DPチェーン」がi番目の文字列クラスCiとして切り出される。ただし、重複部分があっても、(i-1)番目のサフィックスが「空DPチェーン断」、i番目のサフィックスが「DPチェーン」である場合には、文頭文字から一致するわけではないため、こういう場合には、一致部分無しと判断される。
【0067】
そして、制御部2bは、C107を行った後又はC106で一致部分無しと判断した後は、C108で処理対象を次のサフィックスにすべくiをインクリメントするとともに、C109で全サフィックスについて処理したか否かの判断をした後、途中であれば、C106に戻り、次の「(i+1)番目のサフィックス」についての処理を行う。制御部2bは、C105〜C109を実行することにより、位置情報Lと切り出した文字列クラスとからなるテーブルを作成して、記憶部2aに記憶させる。尚、処理対象となるサフィックスのソート手法は特に限定されないため、そのソート手法に応じて、i番目と(i+1)番目とを比較してもよいし、i番目と(i-1)番目及び(i+1)番目とを一度に比較するようにしてもよい。
【0068】
制御部2bは、C110においては、サフィックスから切り出した文字列クラスの出現頻度Tiを計算し、その切り出した文字列クラスのフィールドと、位置情報Lのフィールドと、出現頻度Tiのフィールドとからなるテーブルを作成し、記憶部2aに記憶させる。ここで、「出現頻度Ti」は、各有意フィールド毎に、切り出されなかった文字列クラスCも含めて、カウントされる。そして、制御部2bは、C111に進む。
【0069】
制御部2bは、C111においては、切り出した文字列クラスを辞書順にソートする。このとき、制御部2bは、先頭文字が同一のものについては、先の配列に上位文字列クラスが、後の配列に下位文字列クラスがくるようにソートする。例えば、制御部2bは、先の配列が「チェーン」、後の配列が「チェー」となるようにソートする。
制御部2bは、C111においては、更に、同一文字列クラスを統合する。例えば、「チェーン」が複数ある場合には、出現頻度Tiや位置情報Lは残したまま、これらを一つにまとめる。そして、制御部2は、統合した文字列クラスのフィールドと、位置情報Lのフィールド(切り出された文字列クラスが出現する全ての知識源テーブルTb13Aのレコード番号、すなわち、日報DB5のレコード番号を特定するための位置情報)と、出現頻度Tiのフィールドと、除外フラグのフィールドを備えたテーブルを作成して、記憶部2aに記憶させる。
【0070】
次に、制御部2bは、C112においては、文字列クラスの出現頻度Tiが所定の閾値T1未満か否かを判断し、出現頻度Tiが閾値T1未満であるときは、その文字列クラスを除外する。ここで、閾値T1は、任意に設定することができるが、定数としてもよいし、全文字列クラスの出現頻度の総数に対する割合とすることもできる。このように一定閾値に満たない出現頻度Tiが少ない文字列クラスを除外するのは、このような文字列クラスは無意味な場合が多いことが統計的に判明していることに基づく。具体的には、文字列クラスの除外は、上記の除外フラグのフィールドの該当カラムにフラグを立てることにより行う。例えば、「T1=5」としたときは、出現頻度が5未満のものの除外フィールドにフラグが立てられる。尚、フラグを立てずに、除外する同一文字列クラスを除いて上記テーブルを作成しなおしてもよい。
【0071】
以上の手順により、制御部2bは、文字列クラス群生成処理を行う。尚、制御部2bは、プレフィックス群を生成することによっても同様にして文字列クラス群生成処理を行う。プレフィックス群の処理については、制御部2bは、読み出した自然言語文データを構成するテキストをテキストの先端からそのテキスト中に存在する全ての文字までの部分文字列(プレフィックス:接尾辞)の集合(n-gram集合)であると認識する以外は、上記と同様の処理である。そのため、サフィックス群についての説明をもって、プレフィックス群についての説明に代える。
【0072】
制御部2bは、図5AのC02に進むと、索引語候補群生成プログラムC200を呼び出して実行して、索引語候補群生成手段として機能し、索引語候補群生成処理として、有意フィールド毎に、そして、各群(サフィックス群、プレフィックス群)毎に、上記C01において生成した文字列クラスCiの一つ前の文字列クラスC(i-1)と包含関係(一方の文字列クラスが他方の文字列クラスを包含する関係をいう。例えば、「チェーン」が上位文字列クラスで「チェー」が下位文字列クラスである)にない場合には、当該文字列クラスCiを索引語候補として記憶するとともに、包含関係にある場合には、頻度比を、
Gap(C(n-1),Cn)=|log(Ti(n-1)/Tin)| …(式4)
(ここで、C(n-1):Cnと包含関係にある上位文字列クラス、Cn:C(n-1)と包含関係にある下位文字列クラス、Gap(C(n-1),Cn):C(n-1),Cnの頻度比、Ti(n-1):上位文字列クラスの出現頻度、Tin:下位文字列クラスの出現頻度)、により求め、前記頻度比が閾値T2以上の場合には下位文字列クラスを索引語候補として記憶する一方、頻度比が閾値T2未満の場合には最長一致法により下位文字列クラスを上位文字列クラスとみなして索引語候補として記憶させる処理を行う。前者の場合、下位文字列クラス「チェー」は索引語候補としてそのまま記憶されるが、後者の場合、下位文字列クラス「チェー」は上位文字列クラス「チェーン」として記憶される。尚、以下の説明ではサフィックス群を取り上げて説明するが、プレフィックス群についてもサフィックス群と同様の処理がなされる。
【0073】
制御部2bは、C02で図5Cの索引語候補群生成プログラムC200を呼び出して、C201に進むと、カウンタiを0に設定し、文字列クラスの総数jを設定する。このとき、除外フラグが立てられた文字列クラスが除外された総数jが設定される。
【0074】
制御部2bは、C202においては、「処理対象となる文字列クラスCi(i番目の文字列クラス)」が「一つ前に処理対象とされた前回読み込んだ文字列クラスC(i-1)((i-1)番目の文字列クラス)」と包含関係にあるか否かを判断する。
制御部2bが包含関係にないと判断すると(C202:no)、制御部2bは、C205に進み、i番目の文字列クラスCiを索引語候補として位置情報Lとともに、記憶部2aに記憶させる。具体的には、制御部2bは、例えば、有意フィールド毎に、図14Aに例示する索引語候補のフィールドと、位置情報Lのフィールドとを備えた索引語候補テーブルTb14Aを作成することにより行う。
【0075】
一方、制御部2bは、包含関係にあると判断すると(C202:yes)、C203において包含関係にある文字列クラスCi(i番目)の出現頻度Ti(i)と文字列クラスC(i-1)((i-1)番目)の出現頻度Ti(i-1)とを用いて上記式1により頻度比Gapを求め、頻度比Gapが閾値T2未満か否かを判断する。既述の通り、文字列クラスは、先頭文字が同一のものについては上位文字列クラスが先に下位文字列クラスが後の配列となるようにソートされているため、(i-1)番目の文字列クラスC(i-1)が上位文字列クラス、i番目の文字列クラスCiが下位文字列クラスとなる。
【0076】
さて、制御部2bは、頻度比Gapが閾値T2以上と判断すると(C203:no)、下位文字列クラスCiを索引語候補として位置情報Lとともに、索引語候補のフィールドと、位置情報Lのフィールドとからなる索引語候補テーブルTb14Aに記憶させる。
一方、制御部2bは、頻度比Gapが閾値T2未満と判断すると(C203:yes)、最長一致法に基づき上位文字列クラスC(i-1)に下位文字列クラスCiを圧縮し(C204)、下位文字列クラスCiを上位文字列クラスC(i-1)と見なして索引語候補テーブルTb14Aへ記憶させる(C205)。すなわち、「上位文字列クラスC(i-1)」を(下位)文字列クラスCiの索引語候補として(下位)文字列クラスCiの位置情報Lとともに、索引語候補のフィールドと、位置情報Lのフィールドとからなる索引語候補テーブルTb14Aに記憶させる。従って、後述するベクトル空間の生成の際には、下位文字列クラスが該当フィールドの自然言語文データに含まれていたとしても、その下位文字列クラスは、上位文字列クラスとみなされ、その上位文字列クラスがベクトル空間を構成する要素として抽出される。制御部2bは、C205を終了すると、C206及びC207を介してC202に戻り、次の「(i+1)番目の文字列クラス」についての処理を行う。iがサフィックス総数Jに等しくなるまでC202からC207が繰り返される。
【0077】
ここで、C200の索引語候補群生成処理について図14Bを参照して説明する。同図は、索引語候補がどのように生成されるのかを概念的に示したものである。まず閾値T1を「T1=5」とし、閾値T2を「T2=2.0」とする。例えば、文字列クラスC1「13ランバス加熱」とC2「13ランバス」とを比較すると、これらは包含関係にあるため上記式1により計算すると、「Gap(C1,C2)=|log8/8|=0<閾値T2」となるため、「13ランバス」は「13ランバス加熱」に圧縮されて、換言すれば、「13ランバス加熱」と見なして索引語候補テーブルTb14Aに登録、すなわち、「13ランバス」は「13ランバス加熱」として登録される。また、例えば、文字列クラスC2「13ランバス」と文字列クラスC3「CL13ランバス加熱」とを比較すると、これらはC2がC3を包含する包含関係にないため文字列クラスC3はそのまま独立クラスと見なされて索引語候補テーブルTb14Aに登録される。また、例えば、文字列クラスC4「ランバス加熱フリーズ」とC5「ランバス」とを比較すると、これらは包含関係にあるため上記式1により計算すると、「Gap(C20,C21)=|log8/1000|=2.096>閾値T2」となるため、文字列クラスC5は独立クラスとして索引語候補テーブルTb14Aへ登録される。
【0078】
制御部2bは、索引語候補群生成処理(C02)を終了すると、図5AのC03に進む。制御部2bは、C03においては、索引語抽出手段として機能し、索引語抽出処理として、有意フィールド毎に、各群(サフィックス群、プレフィックス群)の索引語候補のうち当該各群にわたって重複する索引語候補を索引語として抽出する処理を行う。この処理は、例えば、索引語候補テーブルTb14Aと同様のデータ構造の索引語テーブル(図示省略、索引語候補テーブルTb14A参照)を作成することによってなされる。索引語テーブルは、生成した索引語からなる索引語のフィールドと、その索引語が出現する全ての位置情報Lからなる位置情報Lのフィールドとからなるものであればよいからである。
【0079】
制御部2bは、索引語抽出処理(C03)を終了すると、図5AのC04に進む。制御部2bは、C04においては、ベクトル空間テーブル作成手段として機能し、ベクトル空間テーブル作成処理として、日報DB(又は知識源テーブルTb13A)から、有意フィールド毎に、全各カラムに含まれる索引語(C03の実行により生成した索引語、又は、C02の実行により生成した索引語候補でもよい)を重要語として抽出し、当該重要語を要素とするベクトル空間を当該全各カラムについて生成して、当該全各カラムの位置情報L(すなわち、日報DB5のレコード番号、又は、知識源テーブルTb13Aのレコード番号)のフィールドと、ベクトル空間フィールド(抽出された重要語が格納される)とを備えたベクトル空間テーブルTb9Aを作成する。すなわち、制御部2bは、C04においては、索引語テーブル(図示省略、索引語候補群テーブルTb14A参照)を参照して、日報DB(又は知識源テーブルTb13A)の位置情報Lで表示されるカラムに含まれる索引語を全て検索して、位置情報Lをキーフィールドとし、その位置情報Lで表される各有意フィールドの全各カラムに含まれる索引語を重要語としてベクトル空間の要素として抽出し、位置情報L(レコード番号)の順番にソートしてベクトル空間テーブルTb9Aを作成する。
【0080】
制御部2bは、C04のベクトル空間テーブル作成処理を終了すると、図5AのC05に進む。制御部2bは、C05においては、重要度テーブル作成プログラムC500を読み出して実行することにより、重要度テーブル作成手段として機能し、重要度テーブル作成処理として、
有意フィールド毎に、索引語の重要度を、
Swj=log{(Fj/Dj)+1} …(式2)
(ここで、Swj:重要度、Fj:出現頻度、Dj:共起頻度)、
により求め、有意フィールド毎に、索引語のフィールドと、重要度のフィールドと、当該索引語が出現する各カラムの自然言語文データベース(すなわち、日報DB5、ここでは、知識源テーブルTb13Aでもよい)のレコード番号を特定する位置情報Lのフィールドと、を備えた重要度テーブルTb9Bを作成する処理を行う。
ここで、「出現頻度Fj」とは、各有意フィールドにおける索引語の出現頻度を意味する。「共起頻度Dj」とは、各有意フィールドにおいて重要語と共起する重要語の種類情報(異なり数)を意味する。
【0081】
さて、制御部2bは、C501においては、カウンタiに初期値0を設定するとともに、全データ数jに各有意フィールド毎に索引語の総数を設定する。制御部2bは、C502においては、共起頻度Ciを求める。制御部2bは、索引語フィールドと位置情報フィールドとを備えた索引語テーブル(図示省略、索引語候補テーブルTb14A参照)を参照して、ある索引語が出現する位置情報Lを得た後、ベクトル空間テーブルTb9Aを参照することにより、これらの位置情報Lで示されるカラムに含まれる他の索引語の種類の総数を数え、これを共起頻度Ciとして求める。従って、共起するパターンが何度出てきてもそれは1通りとしてカウントされる。
【0082】
制御部2bは、C503においては、出現頻度Tiを求める。制御部2bは、索引語のフィールドと位置情報Lのフィールドとを備えた索引語テーブル(図示省略、索引語候補テーブルTb14A参照)を参照して、ある索引語が出現する位置情報Lがいくつあるかをカウントすることにより各有意フィールド毎に(すなわち、各有意フィールド単位で)、出現頻度Tiを求める。
【0083】
制御部2bは、C504において、各索引語の重要度を上記式2により求める。制御部2bは、上記式2により重要度を求めると、C505においては、索引語を要素とする索引語フィールドと、上記式2により求めた当該索引語の重要度を要素とする重要度フィールドと、当該索引語の出現する全てのカラムの位置情報Lのフィールドとを備えた重要度テーブルTb9Bを有意フィールド毎に作成する。
【0084】
従って、制御部2bは、知識収集プログラムC00のC01〜C05の処理を実行することにより、図9A及び図9Bに例示する事象ベクトル空間テーブルTb9A1・事象重要度テーブルTb9B1、原因ベクトル空間テーブルTb9A2・原因重要度テーブルTb9B2、処置ベクトル空間テーブルTb9A3・処置重要度テーブルTb9B3、対策ベクトル空間テーブルTb9A4・対策重要度テーブルTb9B4、発生箇所ベクトル空間テーブルTb9A5・発生箇所重要度テーブルTb9B5を作成する。
制御部2bは、以上の知識収集処理を終了すると、A07を介してA03の処理選択(図12B参照)に戻る。
【0085】
以上、知識収集処理について説明したが、制御部2bが上記のようにして知識収集処理を行うため、自動演習システム1は、コンテンツに依存することなく、問題を自動作成するために必要な知識を収集することができる。
【0086】
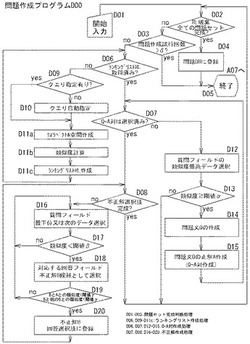
[問題作成プログラムD00]
問題作成プログラムD00は、問題セット完成判断処理(D02〜D03)、ランキングリスト作成処理(D06,D09〜D11c)、Q-A対作成処理(D06,D07,D12〜D15)、不正解作成処理(D07,D08,D16〜D20)、問題統合処理(D04)を制御部2bに実行させるための手順を備える。これらの処理を総称して、問題作成処理(D01〜D20)という。そして、制御部2bは、各処理を行うときは、それぞれ、問題セット完成判断手段、ランキングリスト作成手段、Q-A対作成手段、不正解作成手段、問題統合手段として機能する。これらの各処理を行うように機能する場合を総称して、問題作成手段という。以下各処理について説明する。
【0087】
[問題作成プログラムD00−問題セット完成判断処理:D02〜D03]
制御部2bは、図3のA03(図12B参照)において、問題作成ボタンB12B2の押下を検知すると、A05を実行、すなわち、図6のD01に進む。制御部2bは、D01において問題作成プログラムD00を呼び出して実行することにより問題作成手段として機能し、D02に進む。
【0088】
制御部2bは、D02においては、後述する図16に例示するランキングリストRLが取得されている場合にはこれを破棄するとともに、全ての問題セット(例えば、1セット10問を1000組(合計10000問)、1セット30問を500組(合計15000問)等であり、1セットの問題数及び組数は管理画面(説明省略)にて設定可能)の完成の有無を判断し、完成していないと判断すると(D02:no)、D03へ進む。制御部2bは、D03においては、問題作成試行回数(全ての問題セットの累計)がδを超過していないか判断する。ここで、δは、予め設定した問題作成試行回数の上限値である。制御部2bがD03を行うようにしたのは、不測の状況(ユーザにより設定された1セットの問題数及び組数がイリーガルである等)が生じて無限にD06以降の問題作成処理が継続されるのを防止するためである。
制御部2bは、D03において問題作成試行回数がδを超えていないと判断すると(D03:no)、次の問題作成を行うため、D06に進む。すなわち、制御部2bは、全ての問題セット(所定の問題数からなる所定の組数の問題)が作成されるまでは、問題作成試行回数がδを超過しない限り、D06に進む。
【0089】
[問題作成プログラムD00−ランキングリスト作成処理:D06,D09〜D11c]
制御部2bは、ランキングリスト作成処理(D06,D09〜D11c)では、ランキングリスト作成手段として機能し、重要度テーブルTb9BからクエリQyに含まれる索引語を重要語としてクエリベクトル空間の要素として抽出し、当該クエリベクトル空間と、複数の有意フィールドから問題文作成用の質問フィールドとして選択された有意フィールド(以下単に「質問フィールド」ともいう)のベクトル空間テーブルに含まれるベクトル空間とを用いてクエリQと質問フィールドの全各カラムとの類似度を、
【数2】
…(式3)、
により求め、当該類似度順に質問フィールドの各カラムをランキングしたランキングリストRLを作成する処理を行う。図16にランキングリストRLを例示する。尚、「類似度」とは、対比する自然言語文データが類似する程度をそのベクトル空間を用いて演算することにより数値によって表したものであり、例えば、上記式3により求めることができる。
【0090】
まず、制御部2bは、新たな問題作成を行うとき(すなわち、第n問目作成開始のとき)は、D06においてランキングリストRLを取得していないと判断し(D06:no)、D09に進む。制御部2bは、D09において図15のクエリ指定画面G15を表示する。
ここで、「クエリQy」とは、問題を自動作成させる場合に、ユーザによってクエリ指定画面G15の入力ボックスBX151に入力される自然言語文データをいい、具体的には、この自然言語文データは、ユーザが作成したいと考える問題に近い質問文やその質問文に含まれる単語等となる。また、クエリQyは、自動生成させることもでき、この場合には、クエリQyは、自然言語文データベース(例えば、日報DB5をいうが、広義には、知識源テーブルTb13Aを含む)から無作為に抽出させる自然言語文データをいう。クエリQyは、問題を作成するために用いられる。ちなみに、問題は、質問文Qと1つの正解A選択肢、複数(4つ)の不正解B(B1〜B4)選択肢からなる。
【0091】
また、「チェックボックスCB151」は、日報DB5の1レコードを構成する各フィールド、すなわち、事象フィールド、原因フィールド、処置フィールド、対策フィールド、発生箇所フィールドのうち、どのフィールドを質問フィールドとするかを指定するボックスである。すなわち、「質問フィールド」とは、その自然言語文データが問題の質問文Qとなるフィールドを意味し、自然言語文データベースの複数の有意フィールドから問題文作成用のフィールドとして選択された有意フィールドをいうが、知識源テーブルTb13Aの同一有意フィールドをも含む概念である。本実施形態においては、事象フィールド・原因フィールド・処置フィールド・対策フィールド・発生箇所フィールドのいずれかを質問フィールドとすることができる。本実施形態においては、クエリ自動生成ボタンB152の押下が検知された場合には、事象フィールドが質問フィールドとされるが、無作為に選択させてもよい。
【0092】
「チェックボックスCB152」は、日報DB5の1レコードを構成する各フィールド、すなわち、事象フィールド・原因フィールド・処置フィールド・対策フィールド・発生箇所フィールドのうち、どのフィールドを回答フィールドとするかを指定するボックスである。すなわち、「回答フィールド」とは、その自然言語文データが問題の回答選択肢(正解A・不正解Bを含む)となるフィールドを意味し、自然言語文データベースの複数の有意フィールドから回答作成用のフィールドとして選択された有意フィールドをいうが、知識源テーブルTb13Aの同一有意フィールドをも含む概念である。本実施形態においては、事象フィールド・原因フィールド・処置フィールド・対策フィールド・発生箇所フィールドのいずれかを回答フィールドとすることができる。本実施形態においては、クエリ自動生成ボタンB152の押下が検知された場合には、原因フィールドが回答フィールドとされるが、無作為に選択させてもよい。
【0093】
さて、制御部2bは、D09においては、ユーザ入力を待機し、クエリ指定画面G15のように、クエリQyとして自然言語文データが入力され、質問フィールド及び回答フィールドが指定された状態(デフォルトの状態はチェックボックスCB151が事象に、チェックボックスCB152が原因にチェックされた状態)で、指定ボタンB151の押下を検知すると、D11aに進む。
一方、制御部2bは、D09において、クエリ自動生成ボタンB152の押下を検知すると、D10に進む。制御部2bは、D10においては、有意フィールド(事象・原因・処置・対策・発生箇所)のうち、事象フィールドを質問フィールドとし、回答フィールドを原因フィールドに指定し、質問フィールドから無作為にカラムを選択してその自然言語文データをクエリQyとして、D11aに進む。
【0094】
制御部2bは、D11aにおいては、
(1)図9Bに例示する重要度テーブルTB9bからクエリQyに含まれる索引語を重要語として抽出することによりクエリベクトル空間を生成し、D11bに進んで、
(2)クエリベクトル空間と、図9Aに例示する全てのカラムの質問ベクトル空間(事象質問ベクトル空間、原因質問ベクトル空間、処置質問ベクトル空間、対策質問ベクトル空間、発生箇所質問ベクトル空間のいずれか)を用いて、クエリQyと質問フィールドの全各カラムとの類似度を上記式3により求め、D11cに進んで、
(3)その類似度順に質問フィールドの全各カラムの内容をソートしたランキングリストRL(図16参照)を作成する処理を行う。そして、制御部2bは、D06に戻る。尚、制御部2bは、クエリ指定画面G15におけるクエリQyの入力がない状態で指定ボタンB151の押下を検知すると、エラーメッセージ表示(図示省略)等を行った上で、再度クエリ指定画面G15を表示して、ユーザ入力を待機する(D09)。
【0095】
[問題作成プログラムD00−Q-A対作成処理:D06,D07,D12〜D15]
制御部2bは、上記のようにランキングリストRLを作成すると、D06においては、ランキングリストRLの取得済みであると判断して(D06:yes)、D07に進む。制御部2bがランキングリストRLを取得した直後に最初にD07を実行するときは、未だ問題文Q及び正解Aが未作成の状態であるため、制御部2bは、D07において、Q-A対(問題文Q及び正解Aの対、以下同じ)を作成していないと判断し(D07:no)、D12に進む。
【0096】
制御部2bは、D12〜D15においては、Q-A対作成手段として機能し、Q-A対作成処理として、ランキングリストRLにおいて、閾値α以上の類似度Rαの質問フィールドを図18に例示する問題作成テンプレートTPに適用して問題文Qを作成するとともに、複数の有意フィールドから正解作成用の回答フィールドとして選択された有意フィールド(すなわち、上記した回答フィールド)であって当該類似度Rαに対応する回答フィールドを正解選択肢とする処理を行う。換言すれば、制御部2bは、D12〜D15においては、クエリQyに対応する質問フィールドの内容に基づいて問題文Qを作成し、クエリQyに対応する回答フィールドの内容に基づいて正解Aを作成する。ここで、「問題作成テンプレートTP」とは、図18に例示するように、自然言語文データベースの質問フィールド及び/又は事象・原因・処置・対策・発生箇所等のフィールドの内容を埋め込む埋込フィールドが設けられたテンプレートをいう。
【0097】
以下これらの処理について説明する。制御部は、D12においては、ランキングリストRLを参照し、最も類似度が高い最上位の類似度最高データQmaxを選択し、D13に進み、D13においては、類似度最高データQmaxの類似度が閾値α以上か否かを判断する。ここで、「閾値α」は、Q-A対としてクエリQyと十分近いものを選択するため、換言すれば、ユーザの意図とはかけ離れたQ-A対が作成されないようにするために用いられる。閾値αとしては、0超1以下の任意の数値が設定されるが、0.9以上が好ましく、0.95以上がより好ましい。制御部2bは、「最高データQmaxの類似度が閾値α以上である」と判断すると(D13:yes)、D14に進む。一方、制御部2bは、「類似度がα未満である」と判断した場合には(D13:no)、選択した類似度最高データQmaxを破棄して、D02に戻る。尚、D12において選択するデータは、類似度最高データに限定されるものではなく、指定された順位のもの、指定された範囲のもの等任意に設定することができる。
【0098】
制御部2bは、D14においては、類似度最高データQmaxの質問フィールドのデータ(及び必要に応じて、他の有意フィールドのデータ)を問題作成テンプレートTPに適用して問題文Qを作成する。すなわち、制御部2bは、D14において、質問フィールド及び回答フィールドとしてどの有意フィールドが選択されているかを判断し、問題作成テンプレートTPのなかでいずれを用いるかを決定する。例えば、クエリ指定画面G15の例示のように「質問フィールドとして事象フィールドが指定され、回答フィールドとして原因フィールドが指定されている場合」には、問題作成テンプレートTPa(又はTPb)が適用される。
図19は、問題作成テンプレートTPaの適用例を示す。これは、類似度最高データQmaxのレコード番号100001の質問フィールド(事象質問フィールド)から「空DPチェーン断にて停止」が、発生箇所フィールドから「サブ1F装置5A」が読み出されて、問題作成テンプレートTPaの[事象埋込フィールド]、[発生箇所埋込フィールド]に埋め込まれた例を示す。このようにして、制御部2bは、問題文Qを作成し、記憶部2aに記憶させる(D14)。
【0099】
制御部2bは、D15においては、正解作成処理として、類似度最高データQmaxに対応する回答フィールド、すなわち、「類似度最高データQmaxのレコード番号に対応する日報DB5(又は知識源テーブルTb13A)のレコード番号の回答フィールド」の自然言語文データを正解Aとして抽出し、回答選択肢の一つとして、記憶部2aに記憶させる。例えば、制御部2bは、図19に例示するように、類似度最高データQmaxのレコード番号100001に対応する日報DB5(又は知識源テーブルTb13A)のレコード番号100001の回答フィールド(すなわち、チェックボックスCB152でチェックした原因フィールド)から「サイドカムフォロアー破損」を正解Aとして抽出し、回答選択肢の一つとして、記憶部2aに記憶させる。制御部2bは、D07に戻る。
【0100】
[問題作成プログラムD00−不正解作成処理:D07,D08,D16〜D20]
制御部2bは、不正解作成処理(D07,D08,D16〜D20)においては、関係データ間の類似度に基づいて、問題の回答選択肢を作成する。制御部2bは、回答選択肢中の不正解Bについては、類似した関係データ集合のランキングリストRLの類似度が最下位のものから昇順に4つの要素(又は任意数の残りの(n-1)枝の要素)を選択し、対応する回答フィールドの自然言語文データを抽出する。制御部2bは、作成した質問文Qと回答選択肢を列挙し(回答選択肢の列挙は、乱数発生アルゴリズムを用いて順不同となるようにする)、5択(n択)形式の問題を作成する。制御部2bは、上記の処理を繰り返して問題セットを作成する。以下、これらの処理について説明する。
【0101】
制御部2bは、正解Aを作成して(D07,D12〜D15)、D07に戻ると「Q-A対を選択済み」と判断するため(D07:yes)、D08に進み、残りの不正解の回答選択肢が完成するまで、D16〜D20の処理を繰り返して行う。例えば、5択(n択)問題であれば、正解がD12〜D15で作成済みであるから、制御部2bは、不正解の選択肢が4枝(n枝)できるようにD17〜D20の処理を少なくとも4回(n-1回)は繰り返して行う。
【0102】
制御部2bは、D16においては、ランキングリストRLを参照して「質問フィールドの類似度」が最下位又は前回選択したデータより「質問フィールドの類似度」の順位が1位高い順位のレコード(すなわち、これに対応する日報DB5又は知識源テーブルTb13Aのレコード)を選択する(図20A参照)。従って、制御部2bは、n問目最初の不正解選択肢の作成時はランキングリストRLの「質問フィールドの類似度」が最下位のレコード(すなわち、これに対応する日報DB5又は知識源テーブルTb13Aのレコード)を選択し、n問目の2つ目以降の不正解選択肢作成時は前回選択したデータより「質問フィールドの類似度」が1位高い順位のレコード(すなわち、これに対応する日報DB5又は知識源テーブルTb13Aのレコード)を選択する。ここで、「1位高い順位」は、「任意の一定若しくは可変間隔位」としてもよく、どの順位を選択するかは特に限定されない。
【0103】
例えば、図20Aの例によれば、制御部2bは、n問目最初の不正解選択肢の作成時においては、類似度が最下位である0.053のレコードを選択し、n問目2回目の不正解選択肢の作成時においては、その類似度が1位高い0.059のレコードを選択する。制御部2bは、D16において、このようにして、不正解選択肢となりうる回答フィールドを含むレコードを選択すると、D17に進む。
【0104】
制御部2bは、D17においては、選択されたレコードの質問フィールドの類似度が閾値β未満か否かを判断する。これは、制御部2bに不正解選択肢として問題の正解Aとは十分遠いものを選択させるためである。質問フィールドの類似度を比較するのは、質問フィールドの類似度が低ければ低い程、それに対応する回答フィールドの内容も遠い内容になると判断できるからである。「閾値β」としては、0.6以下が好ましく、通常、0.5が設定されるが、0超1未満の範囲で任意に設定できる。制御部2bは、D17を終えると、D18に進む。
【0105】
制御部2bは、D18においては、選択されたレコードの回答フィールドの自然言語文データを不正解選択肢として、記憶部2aに記憶させる。制御部2bは、D18を終えると、D19に進む。
【0106】
制御部2bは、D19においては、
(1)n問目最初の不正解選択肢作成時は、選択された不正解選択肢の回答フィールドと正解選択肢の回答フィールドとの類似度を、不正解選択肢の回答フィールドのベクトル空間と、正解選択肢の回答フィールドのベクトル空間とを用いて上記式3により求め、
(2)n問目の2つ目以降の不正解選択肢作成時は、選択された不正解選択肢の回答フィールドと正解選択肢の回答フィールドとの類似度に加えて、選択された不正解選択肢の回答フィールドと他の不正解選択肢全ての回答フィールドとの類似度を、選択された不正解選択肢の回答フィールドのベクトル空間と、正解選択肢の回答フィールドのベクトル空間と、他の不正解選択肢の回答フィールドのベクトル空間とを用いて上記式3により求める。
【0107】
そして、制御部2bは、求めた類似度が閾値γ未満か否かを判断する。「閾値γ」としては、通常、0.90が設定されるが、0超1未満の範囲で任意に設定できる。制御部2bに、類似度が閾値γ未満か否かを判断させるのは、不正解選択肢として問題の正解A及び他の不正解Bとは十分遠いものを選択させるためである。回答フィールドの類似度を比較するのは、回答として直接類似する選択肢を除外するためである。図20Bの例によれば、制御部2bは、質問フィールドの類似度0.076に対応する回答フィールドを不正解選択肢として選択し、登録の是非を判断するところである。この場合には、その回答フィールドの自然言語文データ「チェーン伸び」と、他の回答選択肢の回答フィールドの自然言語文データ「チェーンのび」との類似度が0.954となり閾値γより大きいため、類似度0.076のレコードは、不正解選択肢から除外される(D19:no)。これは正解選択肢と、全ての他の不正解選択肢との関係で判断される。このようにして、正解選択肢との類似、並びに、不正解選択肢どうしの類似が回避できる。制御部2bは、D19において、類似度が閾値γ未満であると判断すると(D19:yes)、D20に進む。
【0108】
制御部2bは、D20においては、選択されたレコードの回答フィールドの自然言語文データを不正解選択肢として登録する。そして、制御部2bは、D08に戻り、以降、残りの不正解選択肢が全て完成するまでD16〜D20までの処理を行う。すなわち、制御部2bが不正解選択肢が完成したと判断すると(D08:yes)、この時点で問題一問が完成する。図21は、完成した問題一問を例示する。そして、制御部2bは、D02の処理に戻り、以上説明した処理を問題セットが完成するまで実行し、D02において問題セットが完成したと判断すると(D02:yes)、D04に進む。
【0109】
[問題作成プログラムD00−問題統合処理:D04]
制御部2bは、D04においては、一問毎に、問題文Q、正解Aと不正解B1〜B4の回答選択肢(回答選択肢が全n択の場合には、不正解選択肢は、(n-1)択)とを、新たな問題番号を付して、問題DB10の問題番号、問題文Q、(難易度)、(総出題数)、(総正解数)、正解A、不正解B1〜B4の各フィールドに登録し、処理を終了する。
尚、同図のスコアは正解Aと不正解B1〜B4との類似度に基づいて設定される。
【0110】
[問題作成プログラムD00−変形例]
制御部2bは、D16においては、図22に例示するように、ランキングリストRLを参照して「質問フィールドの類似度」が指定した値又は条件を満たす類似度であるデータ(に対応する日報DB5又は知識源テーブルTb13Aのレコード)を選択するようにしてもよい。この場合には、制御部2bは、n問目最初並びに2つ目以降の不正解選択肢作成時はランキングリストRLの「質問フィールドの類似度」が指定した値又は条件を満たす類似度であるデータ(に対応する日報DB5又は知識源テーブルTb13A)のレコードを選択する。
【0111】
以上、問題作成処理について説明したが、上記説明したように、閾値α以上の類似度Rαの質問フィールドが問題作成テンプレートに適用されるため、ユーザの要望に応じた問題が作成される。また、閾値β未満の類似度Rβに対応する回答フィールドが不正解選択肢とされるため、正解とは十分に遠い不正解が得られる。更に、正解選択肢及び/又は他の不正解選択肢との類似度γが閾値γ未満である回答フィールドが不正解選択肢とされるため、正解選択肢や他の不正解選択肢と同じ内容になることが回避される。
【0112】
[演習プログラムE00]
演習プログラムE00は、準備処理(E01〜E04)、出題採点処理(E05〜E14)、管理処理(E15〜E20)を制御部2bに実行させるための手順を備える。これらの処理を総称して、演習処理(E1〜E20)という。そして、制御部2bは、各処理を行うときは、それぞれ、準備手段、出題採点手段、管理手段として機能する。これらの手段を総称して演習手段という。演習手段は、ユーザ情報DB11からユーザの習熟度や問題難易度を読み出して、これに基づいて問題DB10から逐次最適な問題セットを選択し、インタフェース画面6dを通じて問題をランダムにユーザーに提示し(図23参照)、ユーザの回答を採点し、採点結果の集計と採点結果に基づいて演算を行い、ユーザ情報DB11の当該ユーザの習熟度情報や問題難易度情報を更新する。以下これらの処理について説明する。
【0113】
[準備処理:E01〜E04]
準備処理(E01〜E04)は、RAM2aの一時記憶領域の初期化処理を行った後、問題DB10に登録された問題セットからユーザ毎に適切な問題を取得する処理である。制御部2bが図3のA03において演習ボタンB12B3の押下を検知すると、A05を実行、すなわち、図7のE01に進む。制御部2bは、E01において演習プログラムE00を呼び出して実行することにより演習手段として機能し、E02に進む。
制御部2bは、E02においては、演習処理に必要なRAM2aの一時記憶領域を初期化した後、E03に進む。制御部2bは、E03においては、ユーザ情報DB11を参照し、該当ユーザの習熟度を取得し、E04に進む。制御部2bは、E04においては、問題DB10を参照し、取得した習熟度に基づいて該当ユーザの習熟度向上の効果が最も高い1組の問題セットを選択して、これを構成する正解A・不正解B・スコア等を出題データとしてRAM2aに一時記憶し、問題セット全問についての回答制限時間をカウントするタイマーを作動させ、E05に進む。ここで、「習熟度」とは、過去の正解・不正解の記録、出題・既出題の記録をいい、問題セットの選択は、該当ユーザが過去正解だった問題をX問(X%)含め、過去不正解だった問題をY問(Y%)含め、未出題の問題をZ問(Z%)含めるという規則に基づいて行わせることができる(X,Y,Zは任意の数)。
【0114】
[出題採点処理:E05〜E14]
出題採点処理(E05〜E14)は、問題をインタフェース画面6dに表示するとともに、その問題に対するユーザ回答を採点し、その結果を表示し、RAM2aに一時記憶させる処理である。取得された問題セットの出題が終了するまで、E05〜E14の処理が繰り返される。
制御部2bは、E05においては、問題セットを参照して「問題セットのうち、この演習における未出題問題」の有無を判断し、未出題問題がある場合(E05:yes)は、E06へ進む。制御部2bはE06において、未出題問題の中から出題問題(以下、「出題問題E06」という)を一つ選択した後、E07へ進み、図23の問題表示画面G23に例示するように、インタフェース画面6dへ出題問題E06を表示する処理を行う。そして、制御部2bは、E08の処理へ進む。
【0115】
制御部2bは、E08においては、制限時間内にユーザ回答入力があった場合(E08:yes)は、E09に進む。制御部2bは、E09においては、ユーザからの回答入力を受け付け、E10に進み、E10においては、ユーザからの回答入力が正常入力であるか否かを判断する。制御部2bは、E10においては、問題表示画面G23の回答選択肢CB231にマウス等により印が付けられた状態で回答ボタンB231の押下を検知すると、正常入力であると判断して(E10:yes)、E11に進む。また、上記E08において、制御部2bが制限時間内に達したと判断した場合(E08:no)も、E11に進む。
【0116】
制御部2bは、E11においては、図24の結果表示画面G24に例示するように、出題問題E06に対するユーザ回答UAを表示するとともに、RAM2aに一時記憶した問題セットを参照し、ユーザ回答UAがどの選択肢(正解A・不正解B)と一致するかを判断する。制御部2bは、ユーザ回答UAが正解Aと一致する場合には、E12において、結果表示画面G24の例のように、ユーザ回答UAとともに、採点結果SRとして、
(1)正解/不正解の別、
(2)正解率(正解問題数/問題セットにおける出題問題累積数)、及び、
(3)獲得スコア・累積スコア等、を表示するとともに、RAM2aに一時記憶する。
【0117】
一方、制御部2bは、ユーザ回答UAが問題セットの不正解Bと一致する場合には、E12において、図25の結果表示画面G25に例示するように、ユーザ回答UAとともに、採点結果SRとして、
(1)正解/不正解の別、
(2)正解率(正解問題数/当該問題セットにおける出題問題累積数)、及び、
(3)獲得スコア・累積スコア、
(4)正解情報(知識収集プログラムC00を呼び出すポインタ情報が付与されている正解情報)等、を表示するとともに、RAM2aに一時記憶する。
【0118】
制御部2bは、E12において結果表示を行った後、E13に進み、「ユーザ回答UAがE11で正解Aと一致した場合」には、次へボタンB243の押下を待機し、「ユーザ回答UAがE11で不正解と一致した場合」には、次へボタンB253又はポインタ情報付き正解情報ボタンB254の押下を待機する。制御部2bは、正解情報ボタンB254の押下を検知すると(E13:yes)、E14へ進む。
【0119】
制御部2bは、E14においては、出題問題E06の質問フィールド(又は質問埋込フィールド)の自然言語文データをクエリQyとしてD09に渡して、D09〜D11cの処理を行った後、類似度が高いデータから順番に対応する日報DB5(又は知識源テーブル)の質問フィールドの自然言語文データを、図26の復習画面G26に例示するように、インタフェース画面6dに表示する。
【0120】
例えば、復習画面G26の場合、制御部2bは、質問フィールド(事象フィールド)の「台車オーバーランにて停止」をクエリQyとしてD09に渡す。そして、制御部2bは、D11aにおいて「台車オーバーランにて停止」に含まれる索引語を重要語として、質問フィールドの重要度テーブルTb9B(事象重要度テーブルTb9B1)を検索して抽出し、クエリベクトル空間(例えば、(台車、オーバーラン、停止)等)を生成する。制御部2bは、D11bにおいて、クエリベクトル空間と、質問ベクトル空間とを用いて、出題問題E06の問題文Qと、質問フィールドの全各カラムのデータとの類似度を上記式3により求める。そして、制御部2bは、D11cにおいて、類似度の高いものからランキングリストRLを作成する。制御部2bは、これらの処理を行った後、類似度が高いデータから順番に対応する日報DB5(又は知識源テーブルTb13A)の質問フィールドの自然言語文データをインタフェース画面6dに表示する。更に、制御部2bは、画面表示されているもののうちランキングが最も高いものから降順(又は、マウス等で指定されている質問フィールドから降順)に、画面サイズに応じて他フィールドの内容も表示する(図26参照)。尚、制御部2bは、戻るボタンB261の押下を検知すると、E13に戻る。
【0121】
制御部2bは、E13において、次へボタンB243(又はB253)の押下を検知すると、E05に戻る。制御部2bは、E05において、問題セット中の所定問題数(10問等)を完了するまで、E05〜E14の処理を繰り返す。制御部2bは、問題セットにおいて所定数の問題が終了した、すなわち、未出題問題はないと判断すると(E05:no)、E15に進む。
【0122】
[管理処理:E15〜E20]
制御部2bは、E15においては、集計処理として、RAM2aに一時記憶した問題セット及びユーザ回答UAを参照し、正解数、試行数、獲得スコア、累積スコア、現在のレベルを参照又は演算し、E16に進む。
【0123】
制御部2bは、E16においては、習熟度更新処理として、E15で参照又は演算したデータを用いてユーザ情報DB11に書き込みこれを更新する処理を行う。すなわち、制御部2bは、E16においては、試行数及び正解数を今回の結果を加算したものに更新するとともに、「図11に示す累積スコア1の累積スコアに今回のスコアを加算したもの」を新たな累積スコア1とし、従前の累積スコアの番号を1ずつ増加させて更新する処理を行う。尚、制御部2bは、累積スコアが規定された上限に到達していると判断すると、累積スコアの最後尾データを消去した上で既存のデータの累積スコア番号を1ずつ増加させて累積スコアを追加する。その後、制御部2bは、E17に進む。
【0124】
制御部2bは、E17においては、問題難易度更新処理として、問題セットに対する集計結果に基づいて問題毎の難易度レベルをユーザや演習日時に係わらず、「難易度=当該問題の総正解数/総出題数」を演算することにより求め、その結果を問題DB10の各問題の難易度、総出題数、総正解数の各フィールドに書き込むことにより更新する処理を行う。そして、制御部2bは、E18に進む。
【0125】
制御部2bは、E18においては、問題セットに対する演習結果として、ユーザ名、現在のレベル、累積スコア、正解率(今回の正解数/今回の出題数)、今回の獲得スコア等を、図27の演習終了画面G27に例示するように、インタフェース画面6dに表示する。
【0126】
制御部2bは、E19においては、ユーザ入力を待機し、再挑戦ボタンB271の押下を検知すると、E02に戻って演習処理を行い、復習ボタンB272の押下を検知すると問題セットを全て未出題とした上でE05に戻って同一問題による演習処理を行い、戻るボタンB273の押下を検知すると、自動演習プログラムA00を呼び出し、A03にジャンプし、ユーザ処理選択画面G12Bを表示してユーザ入力待ち状態となる。また、制御部2bは、上記処理過程のうちE10において、正常入力ではないと判断すると(E10:no)、図28の回答エラー警告画面G28に例示するように、エラーメッセージ表示を行った上で(E21)、E22へ進み、エラー処理として、自動演習プログラムA00を呼び出し、A03にジャンプし、ユーザ処理選択画面G12Bを表示してユーザ入力待ち状態となる。
【0127】
[演習プログラムE00−変形例]
問題の難易度とユーザ理解度の計算と更新処理は、次の仕組みによって実装することも可能である。
質問フィールドのデータQ_i と選択肢データのD_i,jの類似度sim(Q_i, D_i,j)を計算する(ここで、i = 1,2,3,...nであり,j=1,2,3,4である)。
このときに、ユーザの回答スコアはsim(Q_i,D_i,j)の総和で表現される。
score(U_k) = Σi=1...n {sim(Q_i, D_i,j)}
ユーザの学習進度は回答スコアで表現される。
prog(U_k) = score(U_k)
ユーザの理解度は回答スコアの平均値の分布に基づく偏差値で表現できる。
U-level(U_k) = zscore(U_k) * 10 + 50
zscore(U_k) = {score(U_k) - mean(score(U_k))} /σ(score(U_k))
mean(score(U_k)) = Σk=1...m{score(U_k)} / m
σ(score(U_k)) = sqrt{ ( score(U_k) - mean(score(U_k)) )^2 / m }
従って、図11のユーザ情報DB11のユーザ理解度として、偏差値のフィールドを儲けてをユーザ情報DB11に記憶させるようにしてもよい。
【0128】
問題難易度はその問題に回答したユーザ理解度の分布に基づく偏差値で表現できる。
Q-level(Q_i) = zscore(Q_i, U-level(U_k)) * 10 + 50
Ul_k = U-level(U_k) とおくと、
zscore(Q_i) = {score(Q_i,Ul_k) - mean(score(Q_i,Ul_k))} /
σ(score(Q_i,Ul_k))
mean(score(Q_i,Ul_k)) = Σi=1...{score(Q_i, Ul_k)} / n
σ(score(Q_i,Ul_k)) = sqrt{ ( score(Q_i,Ul_k) -
mean(score(Q_i,Ul_k)) )^2 / n }
従って、図10の問題DB10の難易度として、ユーザ理解度の分布に基づく偏差値を記憶させるようにしてもよい。
【0129】
問題難易度は次回出題時に回答スコアに重みとして反映される。
具体的には、1- Q-level(Q_i) / 100 を計算し、回答スコアに加算される。
初期状態は Q-level(Q_i) = 0 である。
従って、図10の問題DB10の各回答選択肢のスコアとして、この問題難易度による重み付けをしたものを記憶させるようにしてもよい。
【0130】
上記計算を用いて、一定間隔(更新期間は問題作成者の設定によって決定される)でユーザ理解度と問題難易度を再計算して更新することができる。これにより、ユーザ理解度と問題難易度を常に最新の値に保持することができる。
【0131】
以上、演習処理について説明したが、上記説明したように、自動演習システム1は、問題の自動作成の他、ユーザ回答の自動採点処理、演習結果の自動集計処理を行うことができるため、ユーザが自動演習システム1を活用すれば、専用辞書等がなくても工場やオフィスにおける日常業務の知識・ノウハウの継承が可能となる。
【0132】
以上本発明の一実施形態について説明したが、本発明は上記実施形態に何ら限定されるものではない。重要度や類似度の演算手法は、上記実施形態で採用したもの以外の演算手法を採用することができる。
更に、上記実施形態においては、工場における日報情報を知識源として用いる場合を例示したが、自然言語文データからなるデータベースを備えた工場・オフィスであれば、本発明を適用することができる。
更に、クエリQyは、質問文の作成にまず用いる例を示したが、回答の作成にまず用い、それから、質問文を作成するという利用の仕方も可能である。
【産業上の利用可能性】
【0133】
本発明に係る自動演習システムは、工場やオフィス等の日常業務に関する知識・ノウハウの継承を目的とした能動的学習を支援することができるため、退職等に伴う熟練者不在の状況にあっても熟練ノウハウ・熟練知識の継承が可能となり、工場やオフィス等の業務内容の質向上に寄与することができ、産業上極めて有益である。
【符号の説明】
【0134】
1…自動演習システム
2…サーバー(2a…記憶部、2b…制御部、2c…入力部、2d…出力部)
6…クライアント(6d…インタフェース画面)
5…日報DB
Tb13A…知識源テーブル
9…知識DB
Tb9A…ベクトル空間テーブル
Tb9B…重要度テーブル
10…問題DB
11…ユーザ情報DB
A00…自動演習プログラム
B00…ユーザ管理プログラム
C00…知識収集プログラム
D00…問題作成プログラム
E00…演習プログラム
【技術分野】
【0001】
本発明は、自動演習システム及び自動演習プログラムに関し、更に詳しくは、工場やオフィスにおける日常業務に関する知識・ノウハウの継承を目的として幅広い分野に適用しうるコンテンツに依存しない自動演習システム及び自動演習プログラムに関する。
【背景技術】
【0002】
近年の工場やオフィスにおける日常業務は、設備保全のスタイルが事後保全(BM:Breakdown Maintenance 若しくは FBM:Failure Based Maintenance)から時間基準予防保全(TBM:Time Based Preventive Maintenance)へと移行した結果、事後の保守にかかる頻度が低下し、設備の安定稼働率が大きく向上している。そのため、設備の安定稼働率向上によるトラブル遭遇機会が減少する一方で、設備保全担当者の経験が不足し、トラブルに対する知識・ノウハウの継承が十分に行われないという問題が生じている。特に、熟練知識・熟練ノウハウを備えた団塊世代の大量退職(2007年問題)は、この問題を浮き彫りにする。従って、突発的トラブルや低頻度トラブルに対応する際の時間的・作業的コストは従来よりむしろ大きくなる場合がある。
【0003】
このような問題に対処すべく、データベースに工場やオフィスの実績情報が蓄積されているが、これは、実際に活用されてこそ意味をなし、更には、熟練知識・熟練ノウハウを備えた担当者の在籍の有無を問わず活用され得るべきである。そのため、熟練知識・熟練ノウハウを備えた担当者が不在であっても、工場やオフィスで蓄積された知識・ノウハウの継承を可能にしうる技術の構築が望まれている。
【0004】
そこで、この種の従来技術に目を向けると、例えば、特許文献1の試験問題データベース生成システム及び試験問題作成システム、特許文献2の研修システム装置、特許文献3の教育装置等の他、非特許文献1〜2の大規模文書集合(WWW上)を知識源とする問題の自動生成等の従来技術が知られている。そのほかにも、非特許文献3では、文書中のデータを解析して取り出した情報に基づいて選択形式、穴埋め形式、誤り訂正形式の教育用練習問題を自動的に生成・出題する練習問題自動生成システムAEGISが報告され、非特許文献4では、技術文書を対象として形態素解析や係り受け解析を行うことで校正学習のための問題を自動生成するシステムが報告されている。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2003−167506
【特許文献2】特開2000−338849
【特許文献3】特開2007−233159
【非特許文献】
【0006】
【非特許文献1】J Sheard and A Carbone. Cadal quiz : Providing support for self-managed learning? In Proc. World Conference on the WWW and Internet, 2000, pp. 482-488, 2000.
【非特許文献2】Etsuo Kobayashi, Shinobu Nagashima, and Mitsuaki Hayase. Programming-free web-based automatic online drill/quiz creator. In Proc. World Conference on Educational Multimedia, Hypermedia and Telecommunications, 2001, pp.990-991, 2001.
【非特許文献3】菅沼等,情報処理学会論文誌,Vol.46,No.7,pp.1810-1818,2005
【非特許文献4】大野等,電気情報通信学会技術研究報告,pp.39-44,2007
【発明の概要】
【発明が解決しようとする課題】
【0007】
工場やオフィスにおける日常業務の知識・ノウハウの継承を考えた場合、その知識源として対象とするのは、例えば、日報情報データベース、具体的には、自動車組立工場で運用されているトラブル管理日報情報の類、すなわち、「特定のコンテンツに依存しない自然言語文データの集合」である。
しかしながら、特許文献1〜3等に開示された技術はいずれも、特定のコンテンツに依存する。ユーザに対するインタラクションやインタフェースの提供や、教師が教材や問題を作成する際の作業量の低減を目的としているため、その適用場面が語学学習・プログラミング学習等の特定の場面に限定されているためである。従って、特許文献1〜3等に開示された技術は、工場やオフィスにおける知識・ノウハウの継承には応用が難しい。また、工場やオフィスにおける日常業務に関する知識・ノウハウは、一般性が低い。従って、非特許文献1〜2のようなWWWを利用した手法は、専門用語が多用される工場やオフィスにおける日常業務における知識・ノウハウの継承には余り役に立たない。
【0008】
また、上記の日報情報データベース(トラブル管理日報情報の類、すなわち、「特定のコンテンツに依存しない自然言語文データの集合」)は、膨大な量(例えば、8年分の日報情報だと約60000件)に上る。このような膨大な量のデータを非特許文献3のシステムで扱う場合には、同文献が専用のXMLタグ付きコーパスを解析対象としているため人手でタグ付けなどの事前準備を行う必要がある。この事前準備は、人手によるため看過できないコストが発生する。従って、非特許文献3のシステムによる実際の運用は、コスト面から現実的ではない。
【0009】
更に、上記の日報情報データベース(トラブル管理日報情報の類、すなわち、「特定のコンテンツに依存しない自然言語文データの集合」)のような工場やオフィス等の特定の環境で運用されるデータベースは、専門用語が多用されていることや、文自体が句読点や助詞、助動詞の省略、体言止めなどが多用された状態で記述されていること、データベース入力者である複数のオペレータ毎の表記ゆれがあること等の事情がある。よって、非特許文献4のような既存の汎用的な知識辞書や形態素解析を用いた手法では、記述文を正確に解析することができず、対象文書によって問題の生成能力にばらつきが生じてしまう。
【0010】
従って、知識源の種類を問わず、工場やオフィスにおける日常業務の知識・ノウハウの継承に汎用的に活用可能であり、人手によるタグ付けや特定コンテンツの別途構築等の事前準備を行うことなく、しかも、日報情報データベースのような膨大な量に上る自然言語文データを処理可能な「工場やオフィスにおける日常業務の知識・ノウハウを継承させ得る自動演習システム」の構築が望まれている。
【0011】
本発明は、上記事情に鑑みてなされたものであり、工場やオフィスにおける日常業務の知識・ノウハウとしてデータベースに蓄積された自然言語文データから重要語及び因果関係(例えば、事象・原因・処置・対策・発生箇所)を抽出し、これに基づいて、問題の自動作成処理、ユーザ回答の自動採点処理、演習結果の自動集計処理を行うことができる自動演習システム及び自動演習プログラムを提供することを目的とする。すなわち、本発明は、コンテンツに依存することなく、工場やオフィスにおける日常業務の知識・ノウハウの継承を可能とする自動演習システム及び自動演習プログラムを提供することを目的とする。
【課題を解決するための手段】
【0012】
上記課題を解決するために、本発明に係る自動演習システムは、
因果関係を有する複数の有意フィールドからなる自然言語文データベースから、前記有意フィールド毎に、カラムの位置情報フィールドと、ベクトル空間フィールドとを備えたベクトル空間テーブルと、前記有意フィールド毎に、索引語フィールドと、重要度フィールドと、索引語の位置情報フィールドとを備えた重要度テーブルとを備えた知識データベースを構築する知識収集手段と、
前記重要度テーブルからクエリに含まれる索引語を重要語としてクエリベクトル空間の要素として抽出し、当該クエリベクトル空間と、前記有意フィールドから選ばれた質問フィールドの全各カラムのベクトル空間とを用いて前記クエリと前記質問フィールドの全各カラムとの類似度を求め、当該類似度に基づいて(又は、当該類似度順に)前記質問フィールドの全各カラムをランキングしたランキングリストを作成するランキングリスト作成手段と、
前記ランキングリストにおいて、閾値α以上の類似度Rαの質問フィールドを問題作成テンプレートに適用して問題文を作成するとともに、前記類似度Rαに対応する前記有意フィールドから選ばれた回答フィールドを正解選択肢とするQ-A対作成手段とを備えたことを要旨とする。
【0013】
「因果関係」とは、データベースを構成する各フィールドが事象・原因・処置・対策・発生箇所というように相互に関連性を備えることをいうが、これらに限定されない。
「有意フィールド」とは、データベースを構成する各フィールドが事象・原因・処置・対策・発生箇所というように意味があるフィールド、換言すれば、自然言語文データからなるフィールドをいうが、これらに限定されない。
「自然言語文データベース」とは、工場やオフィスにおける日報情報データベース、トラブル情報データベースの類をいうが、自然言語文データを含む限り、これらに限定されない。
【0014】
「知識データベース」とは、自然言語文データベースから知識を収集することにより作成されるデータベースをいい、本発明においては、そのように知識を収集することにより得られたものとして、各有意フィールド毎に、「ベクトル空間テーブル」及び「重要度テーブル」を備える。
そして、「ベクトル空間テーブル」は、「カラムの位置情報フィールド」と、「ベクトル空間フィールド」とを備える。ここで、「カラムの位置情報」とは、自然言語文データが格納されているカラムの自然言語文データベースのレコード番号を特定しうる位置情報をいう。従って、「レコード番号を特定しうる位置」であればよいため、例えば、知識源テーブル(自然言語文データベースを各有意フィールド毎にコピーして得たテーブル、以下同じ)における位置情報をも含む。また、「ベクトル空間」とは、自然言語文データが格納されているカラムに含まれる索引語を重要語として抽出して要素としたものである。
【0015】
また、「重要度テーブル」は、有意フィールド毎に、「索引語フィールド」と、「重要度フィールド」と、「索引語の位置情報フィールド」とを備える。ここで、「索引語」とは、知識収集手段に含まれる後述する文字列クラス群生成手段、索引語候補群生成手段、索引語抽出手段により、各有意フィールド毎に抽出された索引語をいう。「重要度」とは、索引語の重要度を数値で表したものをいい、例えば、後述する式2により求めることができる。「索引語の位置情報」とは、索引語の出現する全てのカラムの自然言語文データベースのレコード番号を特定しうる位置情報をいう。従って、「レコード番号を特定しうる位置」であればよいため、例えば、知識源テーブル(自然言語文データベースを各有意フィールド毎にコピーして得たテーブル、以下同じ)における位置情報をも含む。
【0016】
「クエリ」とは、問題を自動作成させる場合に、ユーザによって入力される自然言語文データ又は自然言語文データベースから無作為に選択又は抽出した自然言語文データをいう。ユーザから見れば、「クエリ」としての自然言語文データは、ユーザが作成したいと考える問題に近い質問文やその質問文に含まれる単語等となる。
【0017】
「質問フィールド」とは、自然言語文データベースの複数の有意フィールドから問題作成用のフィールドとして選択された有意フィールドをいうが、知識源テーブルの同一有意フィールドをも含む。本発明においては、事象フィールド・原因フィールド・処置フィールド・対策フィールド・発生箇所フィールドのいずれかを質問フィールドとすることができるが、事象フィールドを質問フィールドと予め指定してもよい。
「類似度」とは、対比する自然言語文データが類似する程度をそれらのベクトル空間を用いて演算することにより数値によって表したものであり、例えば、後述する式3により求めることができる。
「回答フィールド」とは、自然言語文データベースの複数の有意フィールドから問題(回答)作成用のフィールドとして選択された有意フィールドをいうが、知識源テーブルの同一有意フィールドをも含む。本発明においては、事象フィールド・原因フィールド・処置フィールド・対策フィールド・発生箇所フィールドのいずれかを回答フィールドとすることができるが、原因フィールドを回答フィールドと予め指定してもよい。
「問題作成テンプレート」とは、質問フィールド及び/又は事象・原因・処置・対策・発生箇所等のフィールドの内容を埋め込む埋込フィールドが設けられたテンプレートをいう。
【0018】
上記構成を備えた本発明に係る自動演習システムによれば、知識収集手段によって、自然言語文データベースから有意フィールド毎にベクトル空間テーブルと重要度テーブルとが作成される。そして、ランキングリスト作成手段により、重要度テーブルからクエリに含まれる索引語が重要語としてクエリベクトル空間の要素として抽出され、当該クエリベクトル空間と、質問フィールドの全各カラムのベクトル空間とを用いて前記クエリと前記質問フィールドの全各カラムとの類似度が求められた後、当該類似度に基づいて(又は、当該類似度順に)前記質問フィールドの全各カラムをランキングしたランキングリストが作成される。その後、Q-A対作成手段により、前記ランキングリストにおいて、閾値α以上の類似度Rαの質問フィールドが問題作成テンプレートに適用され問題文が作成されるとともに、前記類似度Rαに対応する回答フィールドが正解選択肢とされる。
従って、本発明によれば、コンテンツに依存することなく、問題(問題文Q及び正解A)が自動作成される。閾値α以上の類似度Rαの質問フィールドを問題作成テンプレートに適用するため、ユーザの要望に応じた問題が作成される。
【0019】
本発明に係る自動演習システムは、更に、
前記ランキングリストにおいて、閾値β未満の類似度Rβに対応する回答フィールドのベクトル空間と、前記正解選択肢のベクトル空間及び/又は他の不正解選択肢のベクトル空間とを用いて前記回答フィールドと前記正解選択肢及び/又は前記他の不正解選択肢との類似度Rγを求め、当該類似度Rγが閾値γ未満である場合に、前記類似度Rβに対応する回答フィールドを不正解選択肢とする不正解作成手段を備えてもよい。
【0020】
上記構成を備えた自動演習システムによれば、不正解作成手段により、前記ランキングリストにおいて、閾値β未満の類似度Rβに対応する回答フィールドのベクトル空間と、前記正解選択肢のベクトル空間及び/又は他の不正解選択肢のベクトル空間とを用いて前記回答フィールドと前記正解選択肢及び/又は前記他の不正解選択肢との類似度Rγが求められ、当該類似度Rγが閾値γ未満である場合に、前記類似度Rβに対応する回答フィールドが不正解選択肢とされる。従って、本発明によれば、コンテンツに依存することなく、問題が自動作成される。閾値β未満の類似度Rβに対応する回答フィールドが不正解選択肢とされるため、正解選択肢とは十分に遠い不正解選択肢が得られるとともに、そのうち、正解選択肢及び/又は他の不正解選択肢との類似度γが閾値γ未満である回答フィールドが不正解選択肢とされるため、正解選択肢や他の不正解選択肢と同じ内容になることが回避される。
【0021】
本発明に係る自動演習システムは、例えば、前記類似度Rαは、前記ランキングリストにおいて最も高い類似度とすればよく、前記類似度Rβは、前記ランキングリストにおいて不正解選択肢として未選択のもののうち最も低い類似度(ただし、0超)とすればよい。
【0022】
上記課題を解決するために、本発明に係る自動演習システムは、更に、
ユーザ情報データベースに基づいて問題データベースから出題すべき問題を取得する準備手段と、
前記問題をインタフェース画面に表示するとともに、前記問題に対するユーザ回答を採点し、結果を正解情報とともに前記インタフェース画面に表示する出題採点手段と、
前記結果に基づいて前記ユーザ情報データベース及び前記問題データベースを更新する管理手段とを備えてもよい。
【0023】
上記構成を備えた自動演習システムによれば、準備手段により、ユーザ情報データベースに基づいて問題データベースから出題すべき問題が取得され、出題採点手段により、前記問題がインタフェース画面に表示されるとともに、前記問題に対するユーザ回答が採点され、結果が正解情報とともに前記インタフェース画面に表示される。そして、管理手段により、前記結果に基づいて前記ユーザ情報データベース及び前記問題データベースが更新される。従って、本発明によれば、問題の自動作成の他、ユーザ回答の自動採点処理、演習結果の自動集計処理を行うことができる。ユーザが本発明に係る自動演習システムを活用すれば、専用辞書等がなくても工場やオフィスにおける日常業務の知識・ノウハウの継承が可能となる。
【0024】
本発明に係る自動演習手段は、更に、
前記重要度テーブルから前記正解情報に含まれる索引語を重要語として正解情報ベクトル空間の要素として抽出し、当該正解情報ベクトル空間と、前記質問フィールドの全各カラムのベクトル空間とを用いて前記正解情報と前記質問フィールドの全各カラムとの類似度を求め、当該類似度に基づいて(又は、当該類似度順に)前記質問フィールドの全各カラムをランキングしたランキングリストを作成し、その内容を表示する復習手段を備えてもよい。
【0025】
本発明に係る自動演習手段によれば、復習手段により、前記重要度テーブルから前記正解情報に含まれる索引語が重要語として正解情報ベクトル空間の要素として抽出され、当該正解情報ベクトル空間と、前記質問フィールドの全各カラムのベクトル空間とを用いて前記正解情報と前記質問フィールドの全各カラムとの類似度が求められ、当該類似度に基づいて(又は、当該類似度順に)前記質問フィールドの全各カラムをランキングしたランキングリストが作成され、その内容が表示される。従って、ユーザは間違えた問題と類似するケースをチェックすることができ、知識・ノウハウの定着に役立てることができる。
【0026】
本発明に係る自動演習システムにおける知識収集手段は、特に限定されないが、例えば、以下の構成を備えるものが好ましい。すなわち、前記知識収集手段は、
前記有意フィールド毎に、サフィックス群及び/又はプレフィックス群を文字列クラスとして辞書順にソートして生成し、前後の文字列クラスの一致部分の切り出し、出現頻度が閾値T1未満の文字列クラスの除外、同一の文字列クラスの統合、及び、包含関係にある上位文字列クラスが下位文字列クラスより優先されるようにソートする文字列クラス群生成手段と、
前記有意フィールド毎に、文字列クラスの一つ前の文字列クラスと包含関係にない場合には、当該文字列クラスを索引語候補として記憶するとともに、包含関係にある場合には、頻度比を求め、前記頻度比が閾値T2以上の場合には下位文字列クラスを索引語候補として記憶する一方、頻度比が閾値T2未満の場合には下位文字列クラスを上位文字列クラスとみなして索引語候補として記憶する索引語候補群生成手段と、
前記各群の索引語候補のうち当該各群にわたって重複する索引語候補を索引語として抽出する索引語抽出手段と、
前記有意フィールド毎に、全各カラムに含まれる前記索引語を重要語として抽出し、当該重要語を要素とするベクトル空間を当該全各カラムについて生成して、当該全各カラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドと、ベクトル空間フィールドとを備えたベクトル空間テーブルを作成するベクトル空間テーブル作成手段と、
前記有意フィールド毎に、前記索引語の重要度を求め、前記有意フィールド毎に、索引語フィールドと、重要度フィールドと、当該索引語の出現する全てのカラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドと、を備えた重要度テーブルを作成する重要度テーブル作成手段とを備えるとよい。
【0027】
「包含関係」とは、一方の文字列クラスが他方の文字列クラスを包含する関係をいう。また、「上位文字列クラス」と「下位文字列クラス」とは、包含する方の文字列クラスが上位文字列クラスで、包含される方の文字列クラスが下位文字列クラスである。例えば、「チェーン」が上位文字列クラスで「チェー」が下位文字列クラスである。
【0028】
本発明に係る自動演習システムの知識収集手段によれば、文字列クラス群生成手段により、前記有意フィールド毎に、サフィックス群及び/又はプレフィックス群が文字列クラスとして辞書順にソートして生成され、前後の文字列クラスから一致部分の切り出し、出現頻度が閾値T1未満の文字列クラスの除外、同一の文字列クラスの統合がなされ、更に、包含関係にある上位文字列クラスが下位文字列クラスより優先されるようにソートされる。そして、索引語候補群生成手段により、前記有意フィールド毎に、文字列クラスの一つ前の文字列クラスと包含関係にない場合には、当該文字列クラスが索引語候補として記憶されるとともに、包含関係にある場合には、頻度比が求められ、前記頻度比が閾値T2以上の場合には下位文字列クラスが索引語候補として記憶される一方、頻度比が閾値T2未満の場合には下位文字列クラスが上位文字列クラスとみなされ索引語候補として記憶される。そして、索引語抽出手段により、前記各群の索引語候補のうち当該各群にわたって重複する索引語候補が索引語として抽出される。
【0029】
そして、ベクトル空間テーブル作成手段により、前記有意フィールド毎に、全各カラムに含まれる前記索引語が重要語として抽出され、当該重要語を要素とするベクトル空間が当該全各カラムについて生成され、当該全各カラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドと、ベクトル空間フィールドとを備えたベクトル空間テーブルが作成される。また、重要度テーブル作成手段により、前記有意フィールド毎に、前記索引語の重要度が求められ、前記有意フィールド毎に、索引語フィールドと、重要度フィールドと、当該索引語の出現する全てのカラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドとを備えた重要度テーブルが作成される。
従って、本発明に係る自動演習システムは、日報情報やトラブル情報等を自然言語文データで記録したデータベースさえ有していれば、その種類を問わずに知識収集を行うことができる。
【0030】
この場合に、
前記頻度比は、
Gap(C(n-1),Cn)=|log(Ti(n-1)/Tin)| …(式1)
(ここで、C(n-1):Cnと包含関係にある上位文字列クラス、Cn:C(n-1)と包含関係にある下位文字列クラス、Gap(C(n-1),Cn):C(n-1),Cnの頻度比、Ti(n-1):上位文字列クラスの出現頻度、Tin:下位文字列クラスの出現頻度)、により求めることができるが、これに限定されない。
【0031】
また、本発明に係る自動演習システムにおいて、前記重要度は、
Swj=log{(Fj/Dj)+1} …(式2)
(ここで、Swj:重要度、Fj:出現頻度、Dj:共起頻度)、により求めることができるが、これに限定されない。
【0032】
更に、本発明に係る自動演習システムにおいて、前記類似度は、
【数1】
…(式3)、により求めることができるが、これに限定されない。
【0033】
本発明に係る自動演習プログラムについての構成作用効果の説明は、本発明に係る自動演習システムについての上記の構成作用効果の説明をもってこれに代える。
【発明の効果】
【0034】
本発明は、上記構成を備えたため、工場やオフィスにおける日常業務の知識・ノウハウとしてデータベースに蓄積された自然言語文データから重要語及び因果関係(例えば、事象・原因・処置・対策・発生箇所)を抽出し、これに基づいて、問題の自動作成処理、ユーザ回答の自動採点処理、演習結果の自動集計処理を行うことができるという効果がある。
本発明は、上記構成を備えたため、コンテンツに依存することなく、工場やオフィスにおける日常業務に関する知識・ノウハウの継承を可能とするという効果がある。
【図面の簡単な説明】
【0035】
【図1】本発明の一実施形態に係る自動演習システム1のシステム構成概略図であり、同図(a)がサーバークライアント方式の場合の例、同図(b)がスタンドアローン方式の場合の例である。
【図2】本発明の一実施形態に係る自動演習システム1のハードウエア構成及びソフトウエア構成を示すブロック図である。
【図3】本発明の一実施形態に係る自動演習プログラムA00の処理手順を示すフローチャートである。
【図4】本発明の一実施形態に係るユーザ管理プログラムB00の処理手順を示すフローチャートである。
【図5A】本発明の一実施形態に係る知識収集プログラムC00のの処理手順を示すフローチャートである。
【図5B】文字列クラス群生成プログラムC100の処理手順を示すフローチャートである。
【図5C】索引語候補群生成プログラムC200の処理手順を示すフローチャートである。
【図5D】重要度テーブル作成プログラムC500の処理手順を示すフローチャートである。
【図6】本発明の一実施形態に係る問題作成プログラムD00の処理手順を示すフローチャートである。
【図7】本発明の一実施形態に係る演習プログラムE00の処理手順を示すフローチャートである。
【図8】本発明を適用しうる日報DB5の一例を示す図である。
【図9A】知識DB9のうちベクトル空間テーブルTb9Aの一例を示す図である。
【図9B】知識DB9のうち重要度テーブルTb9Bの一例を示す図である。
【図10】本発明で作成される問題DB10の一例を示す図である。
【図11】本発明で用いられるユーザ情報DB11の一例を示す図である。
【図12】同図(a)〜(f)は、自動演習プログラムA00の実行中(A01〜A03)に表示される画面の一例を示す図である。
【図13A】日報DB5の各有意フィールド毎に作成される知識源テーブルTb13Aの一例を示す。
【図13B】サフィックス生成(ソート前)を説明する図である。
【図13C】サフィックス生成(ソート後)を説明する図である。
【図14A】索引語候補テーブルTb14Aの一例を示す図である。
【図14B】索引語候補群生成プログラムC200を説明するための図である。
【図15】D09で表示されているクエリ指定画面G15の一例を示す図である。
【図16】D11cで作成されるランキングリストRLの一例を示す図である。
【図17A】D12〜D14でランキングリストRLに基づいてQ-A対(問題文Q及び正解Aの対)を選択するときに閾値αと比較する処理の説明図である。
【図17B】図17Aと同様、閾値αと比較する処理の説明図である。
【図18】問題作成テンプレートTPの一例を示す図である。
【図19】回答フィールドから正解Aを選択してQ-A対を登録した例を示す図である。
【図20A】回答フィールドから不正解Bを選択して不正解選択肢を登録した例を示す図である。
【図20B】選択した不正解選択肢と既選択の不正解選択肢との類似度が閾値γを超えるか否かの判断処理を説明するための説明図である。
【図21】問題が完成した一例を示す説明図である。
【図22】回答フィールドから不正解Bを選択して不正解選択肢を登録した例を示す(指定類似度による変形例)。
【図23】問題表示画面G23の一例を示す図である。
【図24】結果表示画面G24の一例を示す図である。
【図25】結果表示画面G25の一例を示す図である。
【図26】復習画面G26の一例を示す図である。
【図27】終了画面G27の一例を示す図である。
【図28】回答エラー警告画面G28の一例を示す図である。
【発明を実施するための形態】
【0036】
以下に図面を参照して、本発明の一実施形態に係る自動演習システム及び自動演習プログラムについて詳細に説明する。
【0037】
[自動演習システム1]
図1は自動演習システム1のハードウエア構成を概略的に示すシステム構成図であり、図2は自動演習システム1のハードウエア・ソフトウエア構成を示すブロック図である。これらの図において、自動演習システム1は、工場やオフィスにおける任意のデータベース(例えば、日報情報データベース)の自然言語文データを解析して因果関係を有する複数の有意フィールド(例えば、事象・原因・処置・対策・発生箇所という因果関係を有する意味のあるフィールド)等から位置情報L・索引語・重要度・ベクトル空間等の知識情報を収集する知識収集処理(図5A参照)、収集した知識情報を用いて問題を作成する問題作成処理(図6参照)、ユーザーに演習インタフェースを提供し、そのユーザ回答入力を採点管理する演習処理(図7参照)等を行うシステムである。
【0038】
自動演習システム1は、図3〜図7に示すフローチャートを実行させるための自動演習プログラムA00等をサーバー2(自動演習装置2)(図1(a)参照)やパーソナルコンピュータ3(自動演習装置3)(図1(b)参照)に搭載することにより、サーバークライアント方式、スタンドアローン方式のいずれによっても構築できる。また、サーバー2又はパーソナルコンピュータ3は、工場やオフィスのDBシステム4(「DB」とはデータベースをいう、以下同じ)によって蓄積された日報DB5と電話回線7及び/又はLAN8等により有線通信又は無線通信ができるように接続されている。これにより、サーバー2やパーソナルコンピュータ3は、日報DB5からデータの受信や読み出しができるとともに、日報DB5へデータの送信・書き込みができる。日報DB5の詳細は後述する。
【0039】
サーバークライアント方式による場合(図1(a)参照)には、図2に示すように、自動演習システム1は、サーバー2と、クライアント6とから構成される。サーバー2は、記憶部2a(ROM2a、RAM2aともいう)、制御部2b、入力部2c(キーボード2c、マウス2cともいう)、出力部2d(画面2d、スピーカ2dともいう)、各種デバイスを備える。記憶部2aは、ROMやRAMによって構成され、RAMは図3〜図7のフローチャートを実行する手順が記述された自動演習プログラムA00(図3参照)、ユーザ管理プログラムB00(図4参照)、知識収集プログラムC00(図5A〜図5D参照)、問題作成プログラムD00(図6参照)、演習プログラムE00(図7参照)が搭載されるほか、その実行に際して使用する知識DB9(図9参照)、問題DB10(図10参照)、ユーザ情報DB11(図11参照)並びにその他の各種のプログラムやデータを記憶する。ROMは当該サーバー2及び各種デバイスを制御するためのプログラムや各種データを記憶する。尚、知識DB9、問題DB10、ユーザ情報DB11の詳細は後述する。
【0040】
制御部2bは、CPU(中央処理装置)やOS(オペレーティングシステム)を備え、上記プログラムA00〜E00を呼び出して装置各部に制御命令を送出しそのプログラムに記述された処理手順を実行することにより、自動演習手段(すなわち、ユーザ管理手段、問題作成手段、演習手段)として機能する。これらの処理手順の詳細は後述する。また、制御部2bは、ユーザ入力に基づいて各種プログラムを実行したり、各種命令を装置各部に送出し実行させたり、その他の各種プログラムの実行、各種データの授受、オペレーティングシステムとしての制御・通信機能の制御、その他の装置各部の制御を行う。
【0041】
入力部2cは、データ入力に用いられるものであれば特に限定されず、入力手段としてのキーボード・マウス・ポインティングデバイス等により構成される。出力部2dは、画像、印字又は音声によってデータを提示するものであれば特に限定されず、出力手段としての画面・スピーカ・プリンター等により構成される。
【0042】
クライアント6は、記憶部6a(ROM6a、RAM6aともいう)、制御部6b、入力部6c(キーボード6c、マウス6cともいう)、出力部6d(インタフェース画面6dともいう)、各種デバイスを備える。記憶部6aは、ROMやRAMによって構成され、RAMは各種のプログラムやデータを記憶し、ROMは当該クライアント6及び各種デバイスを制御するためのプログラムや各種データを記憶する。制御部6bは、CPU(中央処理装置)やOS(オペレーティングシステム)を備え、サーバーに接続して自動演習プログラムA00を活用するための手順を実行する他、ユーザ入力に基づいて各種プログラムを実行したり、各種命令を装置各部に送出し実行させたり、その他の各種プログラムの実行、各種データの授受、オペレーティングシステムとしての制御・通信機能の制御、その他の装置各部の制御を行う。
【0043】
入力部6cは、サーバークライアント方式で自動演習システム1を利用する場合にはそのデータ入力に用いられるものであれば特に限定されず、入力手段としてのキーボード・マウス・ポインティングデバイス等により構成される。出力部6dは、サーバークライアント方式で自動演習システム1を利用する場合にはそのデータ提示手段(例えば、表示手段、印字手段、通知手段)となり、画像、印字又は音声によってデータを提示するものであれば特に限定されず、インタフェース画面・スピーカ・プリンター等により構成される。
【0044】
尚、スタンドアロン方式による場合(図1(b)参照)には、同図のパーソナルコンピュータ3は、図2の符号2a〜2dを符号3a〜3dに置き換えたものに相当するものであればよいため図示を省略するが、記憶部3a(ROM3a、RAM3aともいう)、制御部3b、入力部3c(キーボード3c、マウス3cともいう)、出力部3d(画面3d、スピーカ3dともいう)、各種デバイスを備える。このうち、記憶部3a及び制御部3bは、それぞれ、上記サーバー2の記憶部2a及び制御部2bに相当する構成を備え、入力部3c及び出力部3dは、それぞれ、上記クライアント6の入力部6c、出力部6dに相当する構成を備える。尚、記憶部3aを共有し、数台のパーソナルコンピュータ3それぞれに自動演習プログラムA00を搭載してもよい。
【0045】
[日報DB5]
図8は、日報DB5の一例を示す。日報DB5は、自動演習システム1による問題作成の知識源となるデータベースであり、工場やオフィスにおける日常業務に関する知識・ノウハウを自然言語文データで表されたデータが蓄積されたものである。すなわち、日報DB5は、同図に例示するように、日常的に現場担当者から報告される作業日報(ここでは、工場のトラブル管理業務日報)を自然言語文データで記述して蓄積した「自然言語文データベース」であるが、自然言語文データを含む限り、これに限定されない。
【0046】
日報DB5は、図8に示すように、因果関係を有する複数の有意フィールド、事象フィールド(事象有意フィールド)・原因フィールド(原因有意フィールド)・処置フィールド(処置有意フィールド)・対策フィールド(対策有意フィールド)・発生箇所フィールド(発生箇所有意フィールド)からなるレコードを単位とし、各フィールドを構成するデータが自然言語文データ又はこれを一部に含むデータによって構成されるものであれば、有意フィールドの種類や内容は特に限定されない。
ここで、「因果関係」とは、事象・原因・処置・対策・発生箇所というように相互に関連性を備えることを意味するが、これらに限定されない。また、上記のことから、「有意フィールド」とは、日報DB5を構成する事象フィールド・原因フィールド・処置フィールド・対策フィールド・発生箇所フィールドを意味するが、意味のあるフィールド、換言すれば、自然言語文データからなるフィールドであればこれらに限定されない。
以上のように、自動演習システム1は、問題作成の知識源としてこのような日報DBを利用できるためコンテンツに依存せず、業種にとらわれず種々の工場やオフィスに適用でき、予め特定のデータベースを必要としない。
【0047】
[知識DB9]
図9A及び図9Bは、知識収集プログラム(図5AのC00参照)の実行により、日報DB5(自然言語文データベース)から知識を収集することにより作成される知識DB9の一例を示す。そのように知識を収集することにより得られた具体例として、図9Aがベクトル空間テーブルTb9Aの一例を示し、図9Bが重要度テーブルTb9Bの一例を示す。これらのテーブルは、各有意フィールド毎に作成され、日報DB5の全ての有意フィールド(事象フィールド・原因フィールド・処置フィールド・対策フィールド・発生箇所フィールド)についてベクトル空間テーブルTb9A1〜Tb9A5及び重要度テーブルTb9B1〜Tb9B5を備える。尚、知識収集プログラムC00の処理手順は後述する。
【0048】
ベクトル空間テーブルTb9Aは、日報DB5の各有意フィールド(事象・原因・処置・対策・発生箇所)毎に作成され、
(1)位置情報L(自然言語文データベース(日報DB5)で索引語が出現する全てのカラムのレコード番号を特定しうる位置情報、知識源テーブルTb13Aのレコード番号でもよい、以下同じ)のフィールド(位置情報フィールド)と、
(2)当該各有意フィールドの各カラムに含まれる全ての重要語を要素とするベクトル空間のフィールド(ベクトル空間フィールド)と、を備える。
【0049】
また、重要度テーブルTb9Bは、日報DB5の各有意フィールド(事象・原因・処置・対策・発生箇所)毎に作成され、
(1)当該各有意フィールドに含まれる索引語のフィールド(索引語フィールド)と、
(2)後述する式2により求めたその索引語の重要度のフィールド(重要度フィールド)と、
(3)その索引語が出現する位置情報Lのフィールド(位置情報フィールド)とを備える。
ここで、「索引語」とは、知識収集プログラム(C00参照)から呼び出される後述する文字列クラス群生成プログラム(C01参照)、索引語候補群生成プログラム(C02参照)、索引語抽出プログラム(C03参照)の実行により、各有意フィールド毎に抽出された索引語をいう。また、「重要度」とは、索引語の重要度を数値で表したものをいい、例えば、後述する式2により求めることができる。
【0050】
[問題DB10]
図10は、問題DB10の一例を示す。問題DB10は、問題生成プログラムD00の実行により作成されるとともに、演習プログラムE00の実行によりその一部が更新される。問題DB10は、(1)問題番号、(2)問題文Q、(3)難易度、(4)総出題数、(5)総正解数、(6)正解A、(7)不正解B(B1〜B4)及び回答スコア等のフィールドからなるデータベースである。
【0051】
[ユーザ情報DB11]
図11は、ユーザ情報DB11の一例を示す。ユーザ情報DB11は、後述するユーザ管理プログラムB00の実行により作成されるとともに、演習プログラムE00の実行によりその一部が更新される。ユーザ情報DB11は、ユーザ認識情報及びユーザ成績情報によって構成され、(1)番号、(2)ユーザ名、(3)ユーザID、(4)パスワード(図示省略)、(5)試行数(演習総試行回数)、(6)正解数(総正解数)、(7)演習試行毎の累積スコア1〜n等のフィールドからなるデータベースである。
【0052】
[自動演習システム1の動作及び自動演習プログラムA00の処理手順]
本発明の一実施形態に係る自動演習システム1の動作及び自動演習プログラムA00の処理手順についてフローチャート等を参照して説明する。
【0053】
[自動演習プログラムA00]
図3の自動演習プログラムA00において、制御部2bは、ユーザからの開始入力を検出すると(A01)、A02へ進んで、ユーザ管理プログラムB00を呼び出して実行し、ユーザ管理手段として機能する。すなわち、制御部2bは、図12(a)のユーザ認証画面G12Aを表示してユーザ管理処理(ユーザ認証やユーザ登録)を行う(A02)。制御部2bは、ユーザ認証に成功すると、A03に進み、図12(b)のユーザ処理選択画面G12Bを表示してユーザ入力を待機する(A03)。
【0054】
制御部2bは、A03において知識収集ボタンB12B1の押下を検知すると、知識収集プログラムC00を呼び出して実行することにより知識収集手段として機能して、各有意フィールド毎に、ベクトル空間テーブルTb9Aと、重要度テーブルTb9Bとを作成し、これを知識DB9に記憶させる(A04)。尚、知識収集処理の詳細は後述する。
また、制御部2bは、A03において問題作成ボタンB12B2の押下を検知すると、問題作成プログラムD00を呼び出して実行することにより問題作成手段として機能して、図10に例示する問題を作成し、これを問題DB10に記憶させる(A05)。尚、問題作成処理の詳細は後述する。
更に、制御部2bは、A03において演習ボタンB12B3の押下を検知すると、演習プログラムE00を呼び出して実行することにより演習手段として機能して、問題DB10から問題を読み出して所定数の問題の出題処理が終了するまで出題し、ユーザ回答の正誤判定及びその判定結果解析を実行する(A06)。制御部2bは、知識収集処理(A03)、問題作成処理(A04)又は演習処理(A06)が終了すれば、ユーザ処理選択画面G12Bを表示してユーザ入力を待機する(A03)。制御部2bは以上の手順によって自動演習プログラムA00を実行する。
【0055】
ユーザは、自動演習システム1又は自動演習プログラムA00を使用することによって、工場やオフィスにおける日常業務に関する知識・ノウハウを身につけることができる。そして、自動演習システム1や自動演習プログラムA00は、分野や業種を問わないため、現場特有の専門用語が多用される現場ノウハウや特殊技能に関する知識を得るのに役立つ。
【0056】
[ユーザ管理プログラムB00]
制御部2bが図3のA01を実行してA02に進み、図4のユーザ管理プログラムB00を呼び出し、B01に進むと、制御部2bは、ユーザ管理手段として機能する。制御部2bは、B01においてユーザ認証画面G12Aに示すようにユーザID「ise」及びPassword「******」が入力された状態で認証ボタンB12A1の押下を検知すると(B01→B01a:no)、ユーザ情報DB11を参照する(B02)。そして、制御部2bは、該当ユーザの登録済の有無を判断し、登録済と判断すると(B03:yes)、ユーザ理解度情報としてユーザ情報DB11の試行数と正解数とを参照する(B04)。そして、制御部2bは、ユーザ処理選択画面G12Bを表示して、知識収集ボタンB12B1、問題作成ボタンB12B2、演習ボタンB12B3、終了ボタンB12B4のいずれかのボタンのユーザ入力を待機する(B05(A03))。
【0057】
一方、B01においてユーザ認証画面G12Aに示すユーザID入力ボックス及びPassword入力ボックスに正確に入力されていない状態で認証ボタンB12A1の押下を検知すると(B01→B01a:no)、B02でユーザ情報DB11を参照した後、該当ユーザが未登録であると判断し(B03:no)、図12(c)の認証エラー警告画面G12Cを表示して(B06)、ユーザ入力を受け付ける(B07)。制御部2bは、新規登録ボタンB12C1の押下を検知すると、B08に進む(尚、制御部2bは、B01aにおいて新規登録ボタンB12A2の押下を検知したときもB08に進む)。
【0058】
制御部2bは、B08において図12(d)の新規ユーザ登録画面G12Dを表示し、ユーザ入力を受け付け、同図の入力ボックスBXにユーザ情報が入力された状態で登録ボタンB12D1の押下を検知すると(B09)、入力されたユーザ情報が規定の条件を満たすか否かを判定し(B10)、条件を満たしている(正常入力である)と判断すると(B10:yes)、B11に進み、入力されたユーザ情報をユーザ情報DB11へ記憶させることにより、新規登録し(B11)、その結果として、図12(e)の新規ユーザ登録画面G12Eを表示し、同図の戻るボタンB12E3の押下を検知するとB03に戻る。
【0059】
尚、制御部2bは、B07において、認証エラー警告画面G12Cの戻るボタンB12C2の押下を検知すると、B01に戻る。また、制御部2bは、B10において、新規ユーザ登録画面G12Dにおけるユーザ入力が正常入力ではないと判断すると、図12(f)の登録エラー警告画面G12Fを表示する(B13)。制御部2bは、B13において、戻るボタンG12F1の押下を検知すると、エラー処理(B14)を行って、入力されたユーザ情報を削除した後、B07に戻る。
制御部2bは以上の手順によってユーザ管理プログラムB00を実行し、ユーザ認証に成功すると(B03:yes)、B04を経て、B05(すなわち、A03)に進んで、ユーザ入力を待機し、ユーザ入力に応じて、以下の知識収集プログラムC00、問題作成プログラムD00、演習プログラムE00等を実行する。
【0060】
[知識収集プログラムC00]
知識収集プログラムC00は、文字列クラス群生成処理(C01)、索引語候補群生成処理(C02)、索引語抽出処理(C03)、ベクトル空間テーブル作成処理(C04)、重要度テーブル作成処理(C05)を制御部2bに実行させるための手順を備える。これらの処理を総称して、知識収集処理(C01〜C05)という。そして、制御部2bは各処理を行うときは、それぞれ、文字列クラス群生成手段、索引語候補群生成手段、索引語抽出手段、ベクトル空間テーブル作成手段、重要度テーブル作成手段として機能する。これらの各処理を行うように機能する場合を総称して、知識収集手段という。
【0061】
以下フローチャートに従って説明する。制御部2bが図3のA01及びA02等を実行してA03に進み、A03において知識収集ボタンB12B1の押下を検知するとA04を実行、すなわち、知識収集プログラムC00を呼び出して、図5AのC01に進み、知識収集手段として機能する。これにより、制御部2bは、知識収集処理として、因果関係を有する複数の有意フィールドからなる自然言語文データベースから、有意フィールド毎に、図9に例示する重要度テーブルTb9Aとベクトル空間テーブルTb9Bとを備えた知識DB9を構築する処理を行う。
【0062】
制御部2bは、C01においては、図5Bの文字列クラス群生成プログラムC100を呼び出して実行することにより文字列クラス群生成手段として機能し、文字列クラス群生成処理として、有意フィールド毎に、サフィックス群及び/又はプレフィックス群を文字列クラスとして辞書順にソートして生成し、前後の文字列クラスの一致部分の切り出し、出現頻度が閾値T1未満の文字列クラスの除外、同一の文字列クラスの統合、及び、包含関係にある上位文字列クラスが下位文字列クラスより優先されるようにソートする処理を行う。尚、以下の説明ではサフィックス群を取り上げて説明するが、制御部2bは、プレフィックス群についてもサフィックス群と同様の処理を行う。
【0063】
制御部2bは、C01を介して文字列クラス群生成プログラムC100のC101に進むと、日報DB5から、各有意フィールド毎に、位置情報Lと、各有意フィールドの全各カラムの自然言語文データを配列順に一度に読み出し、図13Aに例示する知識源テーブルTb13A(事象知識源テーブル、原因知識源テーブル、処置知識源テーブル、対策知識源テーブル、発生箇所知識源テーブルを含む)を作成し、記憶部2aに記憶させる処理を行う(C101)。
【0064】
制御部2bは、C102においては、各知識源テーブルTb13Aについて、図13BのテーブルTb13Bに例示するように、読み出した自然言語文データを構成するテキストをそのテキスト中に存在する全ての文字からテキストの終端までの部分文字列(サフィックス:接頭辞)の集合(n-gram集合)であると認識し、位置情報L毎に、その集合(サフィックス)を機械的に並べたテーブルを作成する。制御部2bは、C103においては、各知識源テーブルTb13Aについて、位置情報Lが同じ自然言語文データ毎に、各サフィックスを辞書順にソートする。制御部2bは、C104においては、図13CのテーブルテーブルTb13Cに例示するように、各有意フィールド毎に、当該各有意フィールド単位で、全サフィックスを統合し全体を辞書順にソートしたテーブルを作成する。
【0065】
制御部2bは、C105においては、カウンタiと、サフィックス総数jとに所定の値を設定する。カウンタiには初期値として0を設定し、サフィックス総数jにはC104で「ソート及び統合」した全サフィックス数を設定する。制御部2bは、C106においては、「i番目のサフィックス」と「(i-1)番目のサフィックス」とを比較し、一致部分の有無を判断する。制御部2bは、一致部分有りと判断すると(C106:yes)、C107へ進み一致部分を文字列クラスCiとして切り出し、切り出した文字列クラスCiを位置情報Lと対応させて記憶する。ちなみに、上述のことからも明らかであるが、「位置情報L」は、切り出した文字列クラスCiの元となった知識源テーブルTb13Aのレコード番号、すなわち、日報DB5のレコード番号を特定する。尚、ここでは一文字でも同じ文字列があれば文字列クラスCiとして切り出される。
【0066】
例えば、(i-1)番目のサフィックスが「空DPチェーン断」、i番目のサフィックスが「空DPチェーン」である場合には、重複する「空DPチェーン」がi番目の文字列クラスCiとして切り出される。ただし、重複部分があっても、(i-1)番目のサフィックスが「空DPチェーン断」、i番目のサフィックスが「DPチェーン」である場合には、文頭文字から一致するわけではないため、こういう場合には、一致部分無しと判断される。
【0067】
そして、制御部2bは、C107を行った後又はC106で一致部分無しと判断した後は、C108で処理対象を次のサフィックスにすべくiをインクリメントするとともに、C109で全サフィックスについて処理したか否かの判断をした後、途中であれば、C106に戻り、次の「(i+1)番目のサフィックス」についての処理を行う。制御部2bは、C105〜C109を実行することにより、位置情報Lと切り出した文字列クラスとからなるテーブルを作成して、記憶部2aに記憶させる。尚、処理対象となるサフィックスのソート手法は特に限定されないため、そのソート手法に応じて、i番目と(i+1)番目とを比較してもよいし、i番目と(i-1)番目及び(i+1)番目とを一度に比較するようにしてもよい。
【0068】
制御部2bは、C110においては、サフィックスから切り出した文字列クラスの出現頻度Tiを計算し、その切り出した文字列クラスのフィールドと、位置情報Lのフィールドと、出現頻度Tiのフィールドとからなるテーブルを作成し、記憶部2aに記憶させる。ここで、「出現頻度Ti」は、各有意フィールド毎に、切り出されなかった文字列クラスCも含めて、カウントされる。そして、制御部2bは、C111に進む。
【0069】
制御部2bは、C111においては、切り出した文字列クラスを辞書順にソートする。このとき、制御部2bは、先頭文字が同一のものについては、先の配列に上位文字列クラスが、後の配列に下位文字列クラスがくるようにソートする。例えば、制御部2bは、先の配列が「チェーン」、後の配列が「チェー」となるようにソートする。
制御部2bは、C111においては、更に、同一文字列クラスを統合する。例えば、「チェーン」が複数ある場合には、出現頻度Tiや位置情報Lは残したまま、これらを一つにまとめる。そして、制御部2は、統合した文字列クラスのフィールドと、位置情報Lのフィールド(切り出された文字列クラスが出現する全ての知識源テーブルTb13Aのレコード番号、すなわち、日報DB5のレコード番号を特定するための位置情報)と、出現頻度Tiのフィールドと、除外フラグのフィールドを備えたテーブルを作成して、記憶部2aに記憶させる。
【0070】
次に、制御部2bは、C112においては、文字列クラスの出現頻度Tiが所定の閾値T1未満か否かを判断し、出現頻度Tiが閾値T1未満であるときは、その文字列クラスを除外する。ここで、閾値T1は、任意に設定することができるが、定数としてもよいし、全文字列クラスの出現頻度の総数に対する割合とすることもできる。このように一定閾値に満たない出現頻度Tiが少ない文字列クラスを除外するのは、このような文字列クラスは無意味な場合が多いことが統計的に判明していることに基づく。具体的には、文字列クラスの除外は、上記の除外フラグのフィールドの該当カラムにフラグを立てることにより行う。例えば、「T1=5」としたときは、出現頻度が5未満のものの除外フィールドにフラグが立てられる。尚、フラグを立てずに、除外する同一文字列クラスを除いて上記テーブルを作成しなおしてもよい。
【0071】
以上の手順により、制御部2bは、文字列クラス群生成処理を行う。尚、制御部2bは、プレフィックス群を生成することによっても同様にして文字列クラス群生成処理を行う。プレフィックス群の処理については、制御部2bは、読み出した自然言語文データを構成するテキストをテキストの先端からそのテキスト中に存在する全ての文字までの部分文字列(プレフィックス:接尾辞)の集合(n-gram集合)であると認識する以外は、上記と同様の処理である。そのため、サフィックス群についての説明をもって、プレフィックス群についての説明に代える。
【0072】
制御部2bは、図5AのC02に進むと、索引語候補群生成プログラムC200を呼び出して実行して、索引語候補群生成手段として機能し、索引語候補群生成処理として、有意フィールド毎に、そして、各群(サフィックス群、プレフィックス群)毎に、上記C01において生成した文字列クラスCiの一つ前の文字列クラスC(i-1)と包含関係(一方の文字列クラスが他方の文字列クラスを包含する関係をいう。例えば、「チェーン」が上位文字列クラスで「チェー」が下位文字列クラスである)にない場合には、当該文字列クラスCiを索引語候補として記憶するとともに、包含関係にある場合には、頻度比を、
Gap(C(n-1),Cn)=|log(Ti(n-1)/Tin)| …(式4)
(ここで、C(n-1):Cnと包含関係にある上位文字列クラス、Cn:C(n-1)と包含関係にある下位文字列クラス、Gap(C(n-1),Cn):C(n-1),Cnの頻度比、Ti(n-1):上位文字列クラスの出現頻度、Tin:下位文字列クラスの出現頻度)、により求め、前記頻度比が閾値T2以上の場合には下位文字列クラスを索引語候補として記憶する一方、頻度比が閾値T2未満の場合には最長一致法により下位文字列クラスを上位文字列クラスとみなして索引語候補として記憶させる処理を行う。前者の場合、下位文字列クラス「チェー」は索引語候補としてそのまま記憶されるが、後者の場合、下位文字列クラス「チェー」は上位文字列クラス「チェーン」として記憶される。尚、以下の説明ではサフィックス群を取り上げて説明するが、プレフィックス群についてもサフィックス群と同様の処理がなされる。
【0073】
制御部2bは、C02で図5Cの索引語候補群生成プログラムC200を呼び出して、C201に進むと、カウンタiを0に設定し、文字列クラスの総数jを設定する。このとき、除外フラグが立てられた文字列クラスが除外された総数jが設定される。
【0074】
制御部2bは、C202においては、「処理対象となる文字列クラスCi(i番目の文字列クラス)」が「一つ前に処理対象とされた前回読み込んだ文字列クラスC(i-1)((i-1)番目の文字列クラス)」と包含関係にあるか否かを判断する。
制御部2bが包含関係にないと判断すると(C202:no)、制御部2bは、C205に進み、i番目の文字列クラスCiを索引語候補として位置情報Lとともに、記憶部2aに記憶させる。具体的には、制御部2bは、例えば、有意フィールド毎に、図14Aに例示する索引語候補のフィールドと、位置情報Lのフィールドとを備えた索引語候補テーブルTb14Aを作成することにより行う。
【0075】
一方、制御部2bは、包含関係にあると判断すると(C202:yes)、C203において包含関係にある文字列クラスCi(i番目)の出現頻度Ti(i)と文字列クラスC(i-1)((i-1)番目)の出現頻度Ti(i-1)とを用いて上記式1により頻度比Gapを求め、頻度比Gapが閾値T2未満か否かを判断する。既述の通り、文字列クラスは、先頭文字が同一のものについては上位文字列クラスが先に下位文字列クラスが後の配列となるようにソートされているため、(i-1)番目の文字列クラスC(i-1)が上位文字列クラス、i番目の文字列クラスCiが下位文字列クラスとなる。
【0076】
さて、制御部2bは、頻度比Gapが閾値T2以上と判断すると(C203:no)、下位文字列クラスCiを索引語候補として位置情報Lとともに、索引語候補のフィールドと、位置情報Lのフィールドとからなる索引語候補テーブルTb14Aに記憶させる。
一方、制御部2bは、頻度比Gapが閾値T2未満と判断すると(C203:yes)、最長一致法に基づき上位文字列クラスC(i-1)に下位文字列クラスCiを圧縮し(C204)、下位文字列クラスCiを上位文字列クラスC(i-1)と見なして索引語候補テーブルTb14Aへ記憶させる(C205)。すなわち、「上位文字列クラスC(i-1)」を(下位)文字列クラスCiの索引語候補として(下位)文字列クラスCiの位置情報Lとともに、索引語候補のフィールドと、位置情報Lのフィールドとからなる索引語候補テーブルTb14Aに記憶させる。従って、後述するベクトル空間の生成の際には、下位文字列クラスが該当フィールドの自然言語文データに含まれていたとしても、その下位文字列クラスは、上位文字列クラスとみなされ、その上位文字列クラスがベクトル空間を構成する要素として抽出される。制御部2bは、C205を終了すると、C206及びC207を介してC202に戻り、次の「(i+1)番目の文字列クラス」についての処理を行う。iがサフィックス総数Jに等しくなるまでC202からC207が繰り返される。
【0077】
ここで、C200の索引語候補群生成処理について図14Bを参照して説明する。同図は、索引語候補がどのように生成されるのかを概念的に示したものである。まず閾値T1を「T1=5」とし、閾値T2を「T2=2.0」とする。例えば、文字列クラスC1「13ランバス加熱」とC2「13ランバス」とを比較すると、これらは包含関係にあるため上記式1により計算すると、「Gap(C1,C2)=|log8/8|=0<閾値T2」となるため、「13ランバス」は「13ランバス加熱」に圧縮されて、換言すれば、「13ランバス加熱」と見なして索引語候補テーブルTb14Aに登録、すなわち、「13ランバス」は「13ランバス加熱」として登録される。また、例えば、文字列クラスC2「13ランバス」と文字列クラスC3「CL13ランバス加熱」とを比較すると、これらはC2がC3を包含する包含関係にないため文字列クラスC3はそのまま独立クラスと見なされて索引語候補テーブルTb14Aに登録される。また、例えば、文字列クラスC4「ランバス加熱フリーズ」とC5「ランバス」とを比較すると、これらは包含関係にあるため上記式1により計算すると、「Gap(C20,C21)=|log8/1000|=2.096>閾値T2」となるため、文字列クラスC5は独立クラスとして索引語候補テーブルTb14Aへ登録される。
【0078】
制御部2bは、索引語候補群生成処理(C02)を終了すると、図5AのC03に進む。制御部2bは、C03においては、索引語抽出手段として機能し、索引語抽出処理として、有意フィールド毎に、各群(サフィックス群、プレフィックス群)の索引語候補のうち当該各群にわたって重複する索引語候補を索引語として抽出する処理を行う。この処理は、例えば、索引語候補テーブルTb14Aと同様のデータ構造の索引語テーブル(図示省略、索引語候補テーブルTb14A参照)を作成することによってなされる。索引語テーブルは、生成した索引語からなる索引語のフィールドと、その索引語が出現する全ての位置情報Lからなる位置情報Lのフィールドとからなるものであればよいからである。
【0079】
制御部2bは、索引語抽出処理(C03)を終了すると、図5AのC04に進む。制御部2bは、C04においては、ベクトル空間テーブル作成手段として機能し、ベクトル空間テーブル作成処理として、日報DB(又は知識源テーブルTb13A)から、有意フィールド毎に、全各カラムに含まれる索引語(C03の実行により生成した索引語、又は、C02の実行により生成した索引語候補でもよい)を重要語として抽出し、当該重要語を要素とするベクトル空間を当該全各カラムについて生成して、当該全各カラムの位置情報L(すなわち、日報DB5のレコード番号、又は、知識源テーブルTb13Aのレコード番号)のフィールドと、ベクトル空間フィールド(抽出された重要語が格納される)とを備えたベクトル空間テーブルTb9Aを作成する。すなわち、制御部2bは、C04においては、索引語テーブル(図示省略、索引語候補群テーブルTb14A参照)を参照して、日報DB(又は知識源テーブルTb13A)の位置情報Lで表示されるカラムに含まれる索引語を全て検索して、位置情報Lをキーフィールドとし、その位置情報Lで表される各有意フィールドの全各カラムに含まれる索引語を重要語としてベクトル空間の要素として抽出し、位置情報L(レコード番号)の順番にソートしてベクトル空間テーブルTb9Aを作成する。
【0080】
制御部2bは、C04のベクトル空間テーブル作成処理を終了すると、図5AのC05に進む。制御部2bは、C05においては、重要度テーブル作成プログラムC500を読み出して実行することにより、重要度テーブル作成手段として機能し、重要度テーブル作成処理として、
有意フィールド毎に、索引語の重要度を、
Swj=log{(Fj/Dj)+1} …(式2)
(ここで、Swj:重要度、Fj:出現頻度、Dj:共起頻度)、
により求め、有意フィールド毎に、索引語のフィールドと、重要度のフィールドと、当該索引語が出現する各カラムの自然言語文データベース(すなわち、日報DB5、ここでは、知識源テーブルTb13Aでもよい)のレコード番号を特定する位置情報Lのフィールドと、を備えた重要度テーブルTb9Bを作成する処理を行う。
ここで、「出現頻度Fj」とは、各有意フィールドにおける索引語の出現頻度を意味する。「共起頻度Dj」とは、各有意フィールドにおいて重要語と共起する重要語の種類情報(異なり数)を意味する。
【0081】
さて、制御部2bは、C501においては、カウンタiに初期値0を設定するとともに、全データ数jに各有意フィールド毎に索引語の総数を設定する。制御部2bは、C502においては、共起頻度Ciを求める。制御部2bは、索引語フィールドと位置情報フィールドとを備えた索引語テーブル(図示省略、索引語候補テーブルTb14A参照)を参照して、ある索引語が出現する位置情報Lを得た後、ベクトル空間テーブルTb9Aを参照することにより、これらの位置情報Lで示されるカラムに含まれる他の索引語の種類の総数を数え、これを共起頻度Ciとして求める。従って、共起するパターンが何度出てきてもそれは1通りとしてカウントされる。
【0082】
制御部2bは、C503においては、出現頻度Tiを求める。制御部2bは、索引語のフィールドと位置情報Lのフィールドとを備えた索引語テーブル(図示省略、索引語候補テーブルTb14A参照)を参照して、ある索引語が出現する位置情報Lがいくつあるかをカウントすることにより各有意フィールド毎に(すなわち、各有意フィールド単位で)、出現頻度Tiを求める。
【0083】
制御部2bは、C504において、各索引語の重要度を上記式2により求める。制御部2bは、上記式2により重要度を求めると、C505においては、索引語を要素とする索引語フィールドと、上記式2により求めた当該索引語の重要度を要素とする重要度フィールドと、当該索引語の出現する全てのカラムの位置情報Lのフィールドとを備えた重要度テーブルTb9Bを有意フィールド毎に作成する。
【0084】
従って、制御部2bは、知識収集プログラムC00のC01〜C05の処理を実行することにより、図9A及び図9Bに例示する事象ベクトル空間テーブルTb9A1・事象重要度テーブルTb9B1、原因ベクトル空間テーブルTb9A2・原因重要度テーブルTb9B2、処置ベクトル空間テーブルTb9A3・処置重要度テーブルTb9B3、対策ベクトル空間テーブルTb9A4・対策重要度テーブルTb9B4、発生箇所ベクトル空間テーブルTb9A5・発生箇所重要度テーブルTb9B5を作成する。
制御部2bは、以上の知識収集処理を終了すると、A07を介してA03の処理選択(図12B参照)に戻る。
【0085】
以上、知識収集処理について説明したが、制御部2bが上記のようにして知識収集処理を行うため、自動演習システム1は、コンテンツに依存することなく、問題を自動作成するために必要な知識を収集することができる。
【0086】
[問題作成プログラムD00]
問題作成プログラムD00は、問題セット完成判断処理(D02〜D03)、ランキングリスト作成処理(D06,D09〜D11c)、Q-A対作成処理(D06,D07,D12〜D15)、不正解作成処理(D07,D08,D16〜D20)、問題統合処理(D04)を制御部2bに実行させるための手順を備える。これらの処理を総称して、問題作成処理(D01〜D20)という。そして、制御部2bは、各処理を行うときは、それぞれ、問題セット完成判断手段、ランキングリスト作成手段、Q-A対作成手段、不正解作成手段、問題統合手段として機能する。これらの各処理を行うように機能する場合を総称して、問題作成手段という。以下各処理について説明する。
【0087】
[問題作成プログラムD00−問題セット完成判断処理:D02〜D03]
制御部2bは、図3のA03(図12B参照)において、問題作成ボタンB12B2の押下を検知すると、A05を実行、すなわち、図6のD01に進む。制御部2bは、D01において問題作成プログラムD00を呼び出して実行することにより問題作成手段として機能し、D02に進む。
【0088】
制御部2bは、D02においては、後述する図16に例示するランキングリストRLが取得されている場合にはこれを破棄するとともに、全ての問題セット(例えば、1セット10問を1000組(合計10000問)、1セット30問を500組(合計15000問)等であり、1セットの問題数及び組数は管理画面(説明省略)にて設定可能)の完成の有無を判断し、完成していないと判断すると(D02:no)、D03へ進む。制御部2bは、D03においては、問題作成試行回数(全ての問題セットの累計)がδを超過していないか判断する。ここで、δは、予め設定した問題作成試行回数の上限値である。制御部2bがD03を行うようにしたのは、不測の状況(ユーザにより設定された1セットの問題数及び組数がイリーガルである等)が生じて無限にD06以降の問題作成処理が継続されるのを防止するためである。
制御部2bは、D03において問題作成試行回数がδを超えていないと判断すると(D03:no)、次の問題作成を行うため、D06に進む。すなわち、制御部2bは、全ての問題セット(所定の問題数からなる所定の組数の問題)が作成されるまでは、問題作成試行回数がδを超過しない限り、D06に進む。
【0089】
[問題作成プログラムD00−ランキングリスト作成処理:D06,D09〜D11c]
制御部2bは、ランキングリスト作成処理(D06,D09〜D11c)では、ランキングリスト作成手段として機能し、重要度テーブルTb9BからクエリQyに含まれる索引語を重要語としてクエリベクトル空間の要素として抽出し、当該クエリベクトル空間と、複数の有意フィールドから問題文作成用の質問フィールドとして選択された有意フィールド(以下単に「質問フィールド」ともいう)のベクトル空間テーブルに含まれるベクトル空間とを用いてクエリQと質問フィールドの全各カラムとの類似度を、
【数2】
…(式3)、
により求め、当該類似度順に質問フィールドの各カラムをランキングしたランキングリストRLを作成する処理を行う。図16にランキングリストRLを例示する。尚、「類似度」とは、対比する自然言語文データが類似する程度をそのベクトル空間を用いて演算することにより数値によって表したものであり、例えば、上記式3により求めることができる。
【0090】
まず、制御部2bは、新たな問題作成を行うとき(すなわち、第n問目作成開始のとき)は、D06においてランキングリストRLを取得していないと判断し(D06:no)、D09に進む。制御部2bは、D09において図15のクエリ指定画面G15を表示する。
ここで、「クエリQy」とは、問題を自動作成させる場合に、ユーザによってクエリ指定画面G15の入力ボックスBX151に入力される自然言語文データをいい、具体的には、この自然言語文データは、ユーザが作成したいと考える問題に近い質問文やその質問文に含まれる単語等となる。また、クエリQyは、自動生成させることもでき、この場合には、クエリQyは、自然言語文データベース(例えば、日報DB5をいうが、広義には、知識源テーブルTb13Aを含む)から無作為に抽出させる自然言語文データをいう。クエリQyは、問題を作成するために用いられる。ちなみに、問題は、質問文Qと1つの正解A選択肢、複数(4つ)の不正解B(B1〜B4)選択肢からなる。
【0091】
また、「チェックボックスCB151」は、日報DB5の1レコードを構成する各フィールド、すなわち、事象フィールド、原因フィールド、処置フィールド、対策フィールド、発生箇所フィールドのうち、どのフィールドを質問フィールドとするかを指定するボックスである。すなわち、「質問フィールド」とは、その自然言語文データが問題の質問文Qとなるフィールドを意味し、自然言語文データベースの複数の有意フィールドから問題文作成用のフィールドとして選択された有意フィールドをいうが、知識源テーブルTb13Aの同一有意フィールドをも含む概念である。本実施形態においては、事象フィールド・原因フィールド・処置フィールド・対策フィールド・発生箇所フィールドのいずれかを質問フィールドとすることができる。本実施形態においては、クエリ自動生成ボタンB152の押下が検知された場合には、事象フィールドが質問フィールドとされるが、無作為に選択させてもよい。
【0092】
「チェックボックスCB152」は、日報DB5の1レコードを構成する各フィールド、すなわち、事象フィールド・原因フィールド・処置フィールド・対策フィールド・発生箇所フィールドのうち、どのフィールドを回答フィールドとするかを指定するボックスである。すなわち、「回答フィールド」とは、その自然言語文データが問題の回答選択肢(正解A・不正解Bを含む)となるフィールドを意味し、自然言語文データベースの複数の有意フィールドから回答作成用のフィールドとして選択された有意フィールドをいうが、知識源テーブルTb13Aの同一有意フィールドをも含む概念である。本実施形態においては、事象フィールド・原因フィールド・処置フィールド・対策フィールド・発生箇所フィールドのいずれかを回答フィールドとすることができる。本実施形態においては、クエリ自動生成ボタンB152の押下が検知された場合には、原因フィールドが回答フィールドとされるが、無作為に選択させてもよい。
【0093】
さて、制御部2bは、D09においては、ユーザ入力を待機し、クエリ指定画面G15のように、クエリQyとして自然言語文データが入力され、質問フィールド及び回答フィールドが指定された状態(デフォルトの状態はチェックボックスCB151が事象に、チェックボックスCB152が原因にチェックされた状態)で、指定ボタンB151の押下を検知すると、D11aに進む。
一方、制御部2bは、D09において、クエリ自動生成ボタンB152の押下を検知すると、D10に進む。制御部2bは、D10においては、有意フィールド(事象・原因・処置・対策・発生箇所)のうち、事象フィールドを質問フィールドとし、回答フィールドを原因フィールドに指定し、質問フィールドから無作為にカラムを選択してその自然言語文データをクエリQyとして、D11aに進む。
【0094】
制御部2bは、D11aにおいては、
(1)図9Bに例示する重要度テーブルTB9bからクエリQyに含まれる索引語を重要語として抽出することによりクエリベクトル空間を生成し、D11bに進んで、
(2)クエリベクトル空間と、図9Aに例示する全てのカラムの質問ベクトル空間(事象質問ベクトル空間、原因質問ベクトル空間、処置質問ベクトル空間、対策質問ベクトル空間、発生箇所質問ベクトル空間のいずれか)を用いて、クエリQyと質問フィールドの全各カラムとの類似度を上記式3により求め、D11cに進んで、
(3)その類似度順に質問フィールドの全各カラムの内容をソートしたランキングリストRL(図16参照)を作成する処理を行う。そして、制御部2bは、D06に戻る。尚、制御部2bは、クエリ指定画面G15におけるクエリQyの入力がない状態で指定ボタンB151の押下を検知すると、エラーメッセージ表示(図示省略)等を行った上で、再度クエリ指定画面G15を表示して、ユーザ入力を待機する(D09)。
【0095】
[問題作成プログラムD00−Q-A対作成処理:D06,D07,D12〜D15]
制御部2bは、上記のようにランキングリストRLを作成すると、D06においては、ランキングリストRLの取得済みであると判断して(D06:yes)、D07に進む。制御部2bがランキングリストRLを取得した直後に最初にD07を実行するときは、未だ問題文Q及び正解Aが未作成の状態であるため、制御部2bは、D07において、Q-A対(問題文Q及び正解Aの対、以下同じ)を作成していないと判断し(D07:no)、D12に進む。
【0096】
制御部2bは、D12〜D15においては、Q-A対作成手段として機能し、Q-A対作成処理として、ランキングリストRLにおいて、閾値α以上の類似度Rαの質問フィールドを図18に例示する問題作成テンプレートTPに適用して問題文Qを作成するとともに、複数の有意フィールドから正解作成用の回答フィールドとして選択された有意フィールド(すなわち、上記した回答フィールド)であって当該類似度Rαに対応する回答フィールドを正解選択肢とする処理を行う。換言すれば、制御部2bは、D12〜D15においては、クエリQyに対応する質問フィールドの内容に基づいて問題文Qを作成し、クエリQyに対応する回答フィールドの内容に基づいて正解Aを作成する。ここで、「問題作成テンプレートTP」とは、図18に例示するように、自然言語文データベースの質問フィールド及び/又は事象・原因・処置・対策・発生箇所等のフィールドの内容を埋め込む埋込フィールドが設けられたテンプレートをいう。
【0097】
以下これらの処理について説明する。制御部は、D12においては、ランキングリストRLを参照し、最も類似度が高い最上位の類似度最高データQmaxを選択し、D13に進み、D13においては、類似度最高データQmaxの類似度が閾値α以上か否かを判断する。ここで、「閾値α」は、Q-A対としてクエリQyと十分近いものを選択するため、換言すれば、ユーザの意図とはかけ離れたQ-A対が作成されないようにするために用いられる。閾値αとしては、0超1以下の任意の数値が設定されるが、0.9以上が好ましく、0.95以上がより好ましい。制御部2bは、「最高データQmaxの類似度が閾値α以上である」と判断すると(D13:yes)、D14に進む。一方、制御部2bは、「類似度がα未満である」と判断した場合には(D13:no)、選択した類似度最高データQmaxを破棄して、D02に戻る。尚、D12において選択するデータは、類似度最高データに限定されるものではなく、指定された順位のもの、指定された範囲のもの等任意に設定することができる。
【0098】
制御部2bは、D14においては、類似度最高データQmaxの質問フィールドのデータ(及び必要に応じて、他の有意フィールドのデータ)を問題作成テンプレートTPに適用して問題文Qを作成する。すなわち、制御部2bは、D14において、質問フィールド及び回答フィールドとしてどの有意フィールドが選択されているかを判断し、問題作成テンプレートTPのなかでいずれを用いるかを決定する。例えば、クエリ指定画面G15の例示のように「質問フィールドとして事象フィールドが指定され、回答フィールドとして原因フィールドが指定されている場合」には、問題作成テンプレートTPa(又はTPb)が適用される。
図19は、問題作成テンプレートTPaの適用例を示す。これは、類似度最高データQmaxのレコード番号100001の質問フィールド(事象質問フィールド)から「空DPチェーン断にて停止」が、発生箇所フィールドから「サブ1F装置5A」が読み出されて、問題作成テンプレートTPaの[事象埋込フィールド]、[発生箇所埋込フィールド]に埋め込まれた例を示す。このようにして、制御部2bは、問題文Qを作成し、記憶部2aに記憶させる(D14)。
【0099】
制御部2bは、D15においては、正解作成処理として、類似度最高データQmaxに対応する回答フィールド、すなわち、「類似度最高データQmaxのレコード番号に対応する日報DB5(又は知識源テーブルTb13A)のレコード番号の回答フィールド」の自然言語文データを正解Aとして抽出し、回答選択肢の一つとして、記憶部2aに記憶させる。例えば、制御部2bは、図19に例示するように、類似度最高データQmaxのレコード番号100001に対応する日報DB5(又は知識源テーブルTb13A)のレコード番号100001の回答フィールド(すなわち、チェックボックスCB152でチェックした原因フィールド)から「サイドカムフォロアー破損」を正解Aとして抽出し、回答選択肢の一つとして、記憶部2aに記憶させる。制御部2bは、D07に戻る。
【0100】
[問題作成プログラムD00−不正解作成処理:D07,D08,D16〜D20]
制御部2bは、不正解作成処理(D07,D08,D16〜D20)においては、関係データ間の類似度に基づいて、問題の回答選択肢を作成する。制御部2bは、回答選択肢中の不正解Bについては、類似した関係データ集合のランキングリストRLの類似度が最下位のものから昇順に4つの要素(又は任意数の残りの(n-1)枝の要素)を選択し、対応する回答フィールドの自然言語文データを抽出する。制御部2bは、作成した質問文Qと回答選択肢を列挙し(回答選択肢の列挙は、乱数発生アルゴリズムを用いて順不同となるようにする)、5択(n択)形式の問題を作成する。制御部2bは、上記の処理を繰り返して問題セットを作成する。以下、これらの処理について説明する。
【0101】
制御部2bは、正解Aを作成して(D07,D12〜D15)、D07に戻ると「Q-A対を選択済み」と判断するため(D07:yes)、D08に進み、残りの不正解の回答選択肢が完成するまで、D16〜D20の処理を繰り返して行う。例えば、5択(n択)問題であれば、正解がD12〜D15で作成済みであるから、制御部2bは、不正解の選択肢が4枝(n枝)できるようにD17〜D20の処理を少なくとも4回(n-1回)は繰り返して行う。
【0102】
制御部2bは、D16においては、ランキングリストRLを参照して「質問フィールドの類似度」が最下位又は前回選択したデータより「質問フィールドの類似度」の順位が1位高い順位のレコード(すなわち、これに対応する日報DB5又は知識源テーブルTb13Aのレコード)を選択する(図20A参照)。従って、制御部2bは、n問目最初の不正解選択肢の作成時はランキングリストRLの「質問フィールドの類似度」が最下位のレコード(すなわち、これに対応する日報DB5又は知識源テーブルTb13Aのレコード)を選択し、n問目の2つ目以降の不正解選択肢作成時は前回選択したデータより「質問フィールドの類似度」が1位高い順位のレコード(すなわち、これに対応する日報DB5又は知識源テーブルTb13Aのレコード)を選択する。ここで、「1位高い順位」は、「任意の一定若しくは可変間隔位」としてもよく、どの順位を選択するかは特に限定されない。
【0103】
例えば、図20Aの例によれば、制御部2bは、n問目最初の不正解選択肢の作成時においては、類似度が最下位である0.053のレコードを選択し、n問目2回目の不正解選択肢の作成時においては、その類似度が1位高い0.059のレコードを選択する。制御部2bは、D16において、このようにして、不正解選択肢となりうる回答フィールドを含むレコードを選択すると、D17に進む。
【0104】
制御部2bは、D17においては、選択されたレコードの質問フィールドの類似度が閾値β未満か否かを判断する。これは、制御部2bに不正解選択肢として問題の正解Aとは十分遠いものを選択させるためである。質問フィールドの類似度を比較するのは、質問フィールドの類似度が低ければ低い程、それに対応する回答フィールドの内容も遠い内容になると判断できるからである。「閾値β」としては、0.6以下が好ましく、通常、0.5が設定されるが、0超1未満の範囲で任意に設定できる。制御部2bは、D17を終えると、D18に進む。
【0105】
制御部2bは、D18においては、選択されたレコードの回答フィールドの自然言語文データを不正解選択肢として、記憶部2aに記憶させる。制御部2bは、D18を終えると、D19に進む。
【0106】
制御部2bは、D19においては、
(1)n問目最初の不正解選択肢作成時は、選択された不正解選択肢の回答フィールドと正解選択肢の回答フィールドとの類似度を、不正解選択肢の回答フィールドのベクトル空間と、正解選択肢の回答フィールドのベクトル空間とを用いて上記式3により求め、
(2)n問目の2つ目以降の不正解選択肢作成時は、選択された不正解選択肢の回答フィールドと正解選択肢の回答フィールドとの類似度に加えて、選択された不正解選択肢の回答フィールドと他の不正解選択肢全ての回答フィールドとの類似度を、選択された不正解選択肢の回答フィールドのベクトル空間と、正解選択肢の回答フィールドのベクトル空間と、他の不正解選択肢の回答フィールドのベクトル空間とを用いて上記式3により求める。
【0107】
そして、制御部2bは、求めた類似度が閾値γ未満か否かを判断する。「閾値γ」としては、通常、0.90が設定されるが、0超1未満の範囲で任意に設定できる。制御部2bに、類似度が閾値γ未満か否かを判断させるのは、不正解選択肢として問題の正解A及び他の不正解Bとは十分遠いものを選択させるためである。回答フィールドの類似度を比較するのは、回答として直接類似する選択肢を除外するためである。図20Bの例によれば、制御部2bは、質問フィールドの類似度0.076に対応する回答フィールドを不正解選択肢として選択し、登録の是非を判断するところである。この場合には、その回答フィールドの自然言語文データ「チェーン伸び」と、他の回答選択肢の回答フィールドの自然言語文データ「チェーンのび」との類似度が0.954となり閾値γより大きいため、類似度0.076のレコードは、不正解選択肢から除外される(D19:no)。これは正解選択肢と、全ての他の不正解選択肢との関係で判断される。このようにして、正解選択肢との類似、並びに、不正解選択肢どうしの類似が回避できる。制御部2bは、D19において、類似度が閾値γ未満であると判断すると(D19:yes)、D20に進む。
【0108】
制御部2bは、D20においては、選択されたレコードの回答フィールドの自然言語文データを不正解選択肢として登録する。そして、制御部2bは、D08に戻り、以降、残りの不正解選択肢が全て完成するまでD16〜D20までの処理を行う。すなわち、制御部2bが不正解選択肢が完成したと判断すると(D08:yes)、この時点で問題一問が完成する。図21は、完成した問題一問を例示する。そして、制御部2bは、D02の処理に戻り、以上説明した処理を問題セットが完成するまで実行し、D02において問題セットが完成したと判断すると(D02:yes)、D04に進む。
【0109】
[問題作成プログラムD00−問題統合処理:D04]
制御部2bは、D04においては、一問毎に、問題文Q、正解Aと不正解B1〜B4の回答選択肢(回答選択肢が全n択の場合には、不正解選択肢は、(n-1)択)とを、新たな問題番号を付して、問題DB10の問題番号、問題文Q、(難易度)、(総出題数)、(総正解数)、正解A、不正解B1〜B4の各フィールドに登録し、処理を終了する。
尚、同図のスコアは正解Aと不正解B1〜B4との類似度に基づいて設定される。
【0110】
[問題作成プログラムD00−変形例]
制御部2bは、D16においては、図22に例示するように、ランキングリストRLを参照して「質問フィールドの類似度」が指定した値又は条件を満たす類似度であるデータ(に対応する日報DB5又は知識源テーブルTb13Aのレコード)を選択するようにしてもよい。この場合には、制御部2bは、n問目最初並びに2つ目以降の不正解選択肢作成時はランキングリストRLの「質問フィールドの類似度」が指定した値又は条件を満たす類似度であるデータ(に対応する日報DB5又は知識源テーブルTb13A)のレコードを選択する。
【0111】
以上、問題作成処理について説明したが、上記説明したように、閾値α以上の類似度Rαの質問フィールドが問題作成テンプレートに適用されるため、ユーザの要望に応じた問題が作成される。また、閾値β未満の類似度Rβに対応する回答フィールドが不正解選択肢とされるため、正解とは十分に遠い不正解が得られる。更に、正解選択肢及び/又は他の不正解選択肢との類似度γが閾値γ未満である回答フィールドが不正解選択肢とされるため、正解選択肢や他の不正解選択肢と同じ内容になることが回避される。
【0112】
[演習プログラムE00]
演習プログラムE00は、準備処理(E01〜E04)、出題採点処理(E05〜E14)、管理処理(E15〜E20)を制御部2bに実行させるための手順を備える。これらの処理を総称して、演習処理(E1〜E20)という。そして、制御部2bは、各処理を行うときは、それぞれ、準備手段、出題採点手段、管理手段として機能する。これらの手段を総称して演習手段という。演習手段は、ユーザ情報DB11からユーザの習熟度や問題難易度を読み出して、これに基づいて問題DB10から逐次最適な問題セットを選択し、インタフェース画面6dを通じて問題をランダムにユーザーに提示し(図23参照)、ユーザの回答を採点し、採点結果の集計と採点結果に基づいて演算を行い、ユーザ情報DB11の当該ユーザの習熟度情報や問題難易度情報を更新する。以下これらの処理について説明する。
【0113】
[準備処理:E01〜E04]
準備処理(E01〜E04)は、RAM2aの一時記憶領域の初期化処理を行った後、問題DB10に登録された問題セットからユーザ毎に適切な問題を取得する処理である。制御部2bが図3のA03において演習ボタンB12B3の押下を検知すると、A05を実行、すなわち、図7のE01に進む。制御部2bは、E01において演習プログラムE00を呼び出して実行することにより演習手段として機能し、E02に進む。
制御部2bは、E02においては、演習処理に必要なRAM2aの一時記憶領域を初期化した後、E03に進む。制御部2bは、E03においては、ユーザ情報DB11を参照し、該当ユーザの習熟度を取得し、E04に進む。制御部2bは、E04においては、問題DB10を参照し、取得した習熟度に基づいて該当ユーザの習熟度向上の効果が最も高い1組の問題セットを選択して、これを構成する正解A・不正解B・スコア等を出題データとしてRAM2aに一時記憶し、問題セット全問についての回答制限時間をカウントするタイマーを作動させ、E05に進む。ここで、「習熟度」とは、過去の正解・不正解の記録、出題・既出題の記録をいい、問題セットの選択は、該当ユーザが過去正解だった問題をX問(X%)含め、過去不正解だった問題をY問(Y%)含め、未出題の問題をZ問(Z%)含めるという規則に基づいて行わせることができる(X,Y,Zは任意の数)。
【0114】
[出題採点処理:E05〜E14]
出題採点処理(E05〜E14)は、問題をインタフェース画面6dに表示するとともに、その問題に対するユーザ回答を採点し、その結果を表示し、RAM2aに一時記憶させる処理である。取得された問題セットの出題が終了するまで、E05〜E14の処理が繰り返される。
制御部2bは、E05においては、問題セットを参照して「問題セットのうち、この演習における未出題問題」の有無を判断し、未出題問題がある場合(E05:yes)は、E06へ進む。制御部2bはE06において、未出題問題の中から出題問題(以下、「出題問題E06」という)を一つ選択した後、E07へ進み、図23の問題表示画面G23に例示するように、インタフェース画面6dへ出題問題E06を表示する処理を行う。そして、制御部2bは、E08の処理へ進む。
【0115】
制御部2bは、E08においては、制限時間内にユーザ回答入力があった場合(E08:yes)は、E09に進む。制御部2bは、E09においては、ユーザからの回答入力を受け付け、E10に進み、E10においては、ユーザからの回答入力が正常入力であるか否かを判断する。制御部2bは、E10においては、問題表示画面G23の回答選択肢CB231にマウス等により印が付けられた状態で回答ボタンB231の押下を検知すると、正常入力であると判断して(E10:yes)、E11に進む。また、上記E08において、制御部2bが制限時間内に達したと判断した場合(E08:no)も、E11に進む。
【0116】
制御部2bは、E11においては、図24の結果表示画面G24に例示するように、出題問題E06に対するユーザ回答UAを表示するとともに、RAM2aに一時記憶した問題セットを参照し、ユーザ回答UAがどの選択肢(正解A・不正解B)と一致するかを判断する。制御部2bは、ユーザ回答UAが正解Aと一致する場合には、E12において、結果表示画面G24の例のように、ユーザ回答UAとともに、採点結果SRとして、
(1)正解/不正解の別、
(2)正解率(正解問題数/問題セットにおける出題問題累積数)、及び、
(3)獲得スコア・累積スコア等、を表示するとともに、RAM2aに一時記憶する。
【0117】
一方、制御部2bは、ユーザ回答UAが問題セットの不正解Bと一致する場合には、E12において、図25の結果表示画面G25に例示するように、ユーザ回答UAとともに、採点結果SRとして、
(1)正解/不正解の別、
(2)正解率(正解問題数/当該問題セットにおける出題問題累積数)、及び、
(3)獲得スコア・累積スコア、
(4)正解情報(知識収集プログラムC00を呼び出すポインタ情報が付与されている正解情報)等、を表示するとともに、RAM2aに一時記憶する。
【0118】
制御部2bは、E12において結果表示を行った後、E13に進み、「ユーザ回答UAがE11で正解Aと一致した場合」には、次へボタンB243の押下を待機し、「ユーザ回答UAがE11で不正解と一致した場合」には、次へボタンB253又はポインタ情報付き正解情報ボタンB254の押下を待機する。制御部2bは、正解情報ボタンB254の押下を検知すると(E13:yes)、E14へ進む。
【0119】
制御部2bは、E14においては、出題問題E06の質問フィールド(又は質問埋込フィールド)の自然言語文データをクエリQyとしてD09に渡して、D09〜D11cの処理を行った後、類似度が高いデータから順番に対応する日報DB5(又は知識源テーブル)の質問フィールドの自然言語文データを、図26の復習画面G26に例示するように、インタフェース画面6dに表示する。
【0120】
例えば、復習画面G26の場合、制御部2bは、質問フィールド(事象フィールド)の「台車オーバーランにて停止」をクエリQyとしてD09に渡す。そして、制御部2bは、D11aにおいて「台車オーバーランにて停止」に含まれる索引語を重要語として、質問フィールドの重要度テーブルTb9B(事象重要度テーブルTb9B1)を検索して抽出し、クエリベクトル空間(例えば、(台車、オーバーラン、停止)等)を生成する。制御部2bは、D11bにおいて、クエリベクトル空間と、質問ベクトル空間とを用いて、出題問題E06の問題文Qと、質問フィールドの全各カラムのデータとの類似度を上記式3により求める。そして、制御部2bは、D11cにおいて、類似度の高いものからランキングリストRLを作成する。制御部2bは、これらの処理を行った後、類似度が高いデータから順番に対応する日報DB5(又は知識源テーブルTb13A)の質問フィールドの自然言語文データをインタフェース画面6dに表示する。更に、制御部2bは、画面表示されているもののうちランキングが最も高いものから降順(又は、マウス等で指定されている質問フィールドから降順)に、画面サイズに応じて他フィールドの内容も表示する(図26参照)。尚、制御部2bは、戻るボタンB261の押下を検知すると、E13に戻る。
【0121】
制御部2bは、E13において、次へボタンB243(又はB253)の押下を検知すると、E05に戻る。制御部2bは、E05において、問題セット中の所定問題数(10問等)を完了するまで、E05〜E14の処理を繰り返す。制御部2bは、問題セットにおいて所定数の問題が終了した、すなわち、未出題問題はないと判断すると(E05:no)、E15に進む。
【0122】
[管理処理:E15〜E20]
制御部2bは、E15においては、集計処理として、RAM2aに一時記憶した問題セット及びユーザ回答UAを参照し、正解数、試行数、獲得スコア、累積スコア、現在のレベルを参照又は演算し、E16に進む。
【0123】
制御部2bは、E16においては、習熟度更新処理として、E15で参照又は演算したデータを用いてユーザ情報DB11に書き込みこれを更新する処理を行う。すなわち、制御部2bは、E16においては、試行数及び正解数を今回の結果を加算したものに更新するとともに、「図11に示す累積スコア1の累積スコアに今回のスコアを加算したもの」を新たな累積スコア1とし、従前の累積スコアの番号を1ずつ増加させて更新する処理を行う。尚、制御部2bは、累積スコアが規定された上限に到達していると判断すると、累積スコアの最後尾データを消去した上で既存のデータの累積スコア番号を1ずつ増加させて累積スコアを追加する。その後、制御部2bは、E17に進む。
【0124】
制御部2bは、E17においては、問題難易度更新処理として、問題セットに対する集計結果に基づいて問題毎の難易度レベルをユーザや演習日時に係わらず、「難易度=当該問題の総正解数/総出題数」を演算することにより求め、その結果を問題DB10の各問題の難易度、総出題数、総正解数の各フィールドに書き込むことにより更新する処理を行う。そして、制御部2bは、E18に進む。
【0125】
制御部2bは、E18においては、問題セットに対する演習結果として、ユーザ名、現在のレベル、累積スコア、正解率(今回の正解数/今回の出題数)、今回の獲得スコア等を、図27の演習終了画面G27に例示するように、インタフェース画面6dに表示する。
【0126】
制御部2bは、E19においては、ユーザ入力を待機し、再挑戦ボタンB271の押下を検知すると、E02に戻って演習処理を行い、復習ボタンB272の押下を検知すると問題セットを全て未出題とした上でE05に戻って同一問題による演習処理を行い、戻るボタンB273の押下を検知すると、自動演習プログラムA00を呼び出し、A03にジャンプし、ユーザ処理選択画面G12Bを表示してユーザ入力待ち状態となる。また、制御部2bは、上記処理過程のうちE10において、正常入力ではないと判断すると(E10:no)、図28の回答エラー警告画面G28に例示するように、エラーメッセージ表示を行った上で(E21)、E22へ進み、エラー処理として、自動演習プログラムA00を呼び出し、A03にジャンプし、ユーザ処理選択画面G12Bを表示してユーザ入力待ち状態となる。
【0127】
[演習プログラムE00−変形例]
問題の難易度とユーザ理解度の計算と更新処理は、次の仕組みによって実装することも可能である。
質問フィールドのデータQ_i と選択肢データのD_i,jの類似度sim(Q_i, D_i,j)を計算する(ここで、i = 1,2,3,...nであり,j=1,2,3,4である)。
このときに、ユーザの回答スコアはsim(Q_i,D_i,j)の総和で表現される。
score(U_k) = Σi=1...n {sim(Q_i, D_i,j)}
ユーザの学習進度は回答スコアで表現される。
prog(U_k) = score(U_k)
ユーザの理解度は回答スコアの平均値の分布に基づく偏差値で表現できる。
U-level(U_k) = zscore(U_k) * 10 + 50
zscore(U_k) = {score(U_k) - mean(score(U_k))} /σ(score(U_k))
mean(score(U_k)) = Σk=1...m{score(U_k)} / m
σ(score(U_k)) = sqrt{ ( score(U_k) - mean(score(U_k)) )^2 / m }
従って、図11のユーザ情報DB11のユーザ理解度として、偏差値のフィールドを儲けてをユーザ情報DB11に記憶させるようにしてもよい。
【0128】
問題難易度はその問題に回答したユーザ理解度の分布に基づく偏差値で表現できる。
Q-level(Q_i) = zscore(Q_i, U-level(U_k)) * 10 + 50
Ul_k = U-level(U_k) とおくと、
zscore(Q_i) = {score(Q_i,Ul_k) - mean(score(Q_i,Ul_k))} /
σ(score(Q_i,Ul_k))
mean(score(Q_i,Ul_k)) = Σi=1...{score(Q_i, Ul_k)} / n
σ(score(Q_i,Ul_k)) = sqrt{ ( score(Q_i,Ul_k) -
mean(score(Q_i,Ul_k)) )^2 / n }
従って、図10の問題DB10の難易度として、ユーザ理解度の分布に基づく偏差値を記憶させるようにしてもよい。
【0129】
問題難易度は次回出題時に回答スコアに重みとして反映される。
具体的には、1- Q-level(Q_i) / 100 を計算し、回答スコアに加算される。
初期状態は Q-level(Q_i) = 0 である。
従って、図10の問題DB10の各回答選択肢のスコアとして、この問題難易度による重み付けをしたものを記憶させるようにしてもよい。
【0130】
上記計算を用いて、一定間隔(更新期間は問題作成者の設定によって決定される)でユーザ理解度と問題難易度を再計算して更新することができる。これにより、ユーザ理解度と問題難易度を常に最新の値に保持することができる。
【0131】
以上、演習処理について説明したが、上記説明したように、自動演習システム1は、問題の自動作成の他、ユーザ回答の自動採点処理、演習結果の自動集計処理を行うことができるため、ユーザが自動演習システム1を活用すれば、専用辞書等がなくても工場やオフィスにおける日常業務の知識・ノウハウの継承が可能となる。
【0132】
以上本発明の一実施形態について説明したが、本発明は上記実施形態に何ら限定されるものではない。重要度や類似度の演算手法は、上記実施形態で採用したもの以外の演算手法を採用することができる。
更に、上記実施形態においては、工場における日報情報を知識源として用いる場合を例示したが、自然言語文データからなるデータベースを備えた工場・オフィスであれば、本発明を適用することができる。
更に、クエリQyは、質問文の作成にまず用いる例を示したが、回答の作成にまず用い、それから、質問文を作成するという利用の仕方も可能である。
【産業上の利用可能性】
【0133】
本発明に係る自動演習システムは、工場やオフィス等の日常業務に関する知識・ノウハウの継承を目的とした能動的学習を支援することができるため、退職等に伴う熟練者不在の状況にあっても熟練ノウハウ・熟練知識の継承が可能となり、工場やオフィス等の業務内容の質向上に寄与することができ、産業上極めて有益である。
【符号の説明】
【0134】
1…自動演習システム
2…サーバー(2a…記憶部、2b…制御部、2c…入力部、2d…出力部)
6…クライアント(6d…インタフェース画面)
5…日報DB
Tb13A…知識源テーブル
9…知識DB
Tb9A…ベクトル空間テーブル
Tb9B…重要度テーブル
10…問題DB
11…ユーザ情報DB
A00…自動演習プログラム
B00…ユーザ管理プログラム
C00…知識収集プログラム
D00…問題作成プログラム
E00…演習プログラム
【特許請求の範囲】
【請求項1】
因果関係を有する複数の有意フィールドからなる自然言語文データベースから、前記有意フィールド毎に、カラムの位置情報フィールドと、ベクトル空間フィールドとを備えたベクトル空間テーブルと、前記有意フィールド毎に、索引語フィールドと、重要度フィールドと、索引語の位置情報フィールドとを備えた重要度テーブルとを備えた知識データベースを構築する知識収集手段と、
前記重要度テーブルからクエリに含まれる索引語を重要語としてクエリベクトル空間の要素として抽出し、当該クエリベクトル空間と、前記有意フィールドから選ばれた質問フィールドの全各カラムのベクトル空間とを用いて前記クエリと前記質問フィールドの全各カラムとの類似度を求め、当該類似度に基づいて前記質問フィールドの全各カラムをランキングしたランキングリストを作成するランキングリスト作成手段と、
前記ランキングリストにおいて、閾値α以上の類似度Rαの質問フィールドを問題作成テンプレートに適用して問題文を作成するとともに、前記類似度Rαに対応する前記有意フィールドから選ばれた回答フィールドを正解選択肢とするQ-A対作成手段とを備えたことを特徴とする自動演習システム。
【請求項2】
更に、
前記ランキングリストにおいて、閾値β未満の類似度Rβに対応する回答フィールドのベクトル空間と、前記正解選択肢のベクトル空間及び/又は他の不正解選択肢のベクトル空間とを用いて前記回答フィールドと前記正解選択肢及び/又は前記他の不正解選択肢との類似度Rγを求め、当該類似度Rγが閾値γ未満である場合に、前記類似度Rβに対応する回答フィールドを不正解選択肢とする不正解作成手段を備えたことを特徴とする請求項1に記載の自動演習システム。
【請求項3】
前記類似度Rαは、前記ランキングリストにおいて最も高い類似度であることを特徴とする請求項1又は2に記載の自動演習システム。
【請求項4】
前記類似度Rβは、前記ランキングリストにおいて不正解選択肢として未選択のもののうち最も低い類似度(ただし、0超)であることを特徴とする請求項2又は3に記載の自動演習システム。
【請求項5】
更に、
ユーザ情報データベースに基づいて問題データベースから出題すべき問題を取得する準備手段と、
前記問題をインタフェース画面に表示するとともに、前記問題に対するユーザ回答を採点し、結果を正解情報とともに前記インタフェース画面に表示する出題採点手段と、
前記結果に基づいて前記ユーザ情報データベース及び前記問題データベースを更新する管理手段とを備えたことを特徴とする請求項1〜4のいずれかに記載の自動演習システム。
【請求項6】
更に、
前記重要度テーブルから前記正解情報に含まれる索引語を重要語として正解情報ベクトル空間の要素として抽出し、当該正解情報ベクトル空間と、前記質問フィールドの全各カラムのベクトル空間とを用いて前記正解情報と前記質問フィールドの全各カラムとの類似度を求め、当該類似度に基づいて前記質問フィールドの全各カラムをランキングしたランキングリストを作成し、その内容を表示する復習手段を備えたことを特徴とする請求項5に記載の自動演習システム。
【請求項7】
前記知識収集手段は、
前記有意フィールド毎に、サフィックス群及び/又はプレフィックス群を文字列クラスとして辞書順にソートして生成し、前後の文字列クラスの一致部分の切り出し、出現頻度が閾値T1未満の文字列クラスの除外、同一の文字列クラスの統合、及び、包含関係にある上位文字列クラスが下位文字列クラスより優先されるようにソートする文字列クラス群生成手段と、
前記有意フィールド毎に、文字列クラスの一つ前の文字列クラスと包含関係にない場合には、当該文字列クラスを索引語候補として記憶するとともに、包含関係にある場合には、頻度比を求め、前記頻度比が閾値T2以上の場合には下位文字列クラスを索引語候補として記憶する一方、頻度比が閾値T2未満の場合には下位文字列クラスを上位文字列クラスとみなして索引語候補として記憶する索引語候補群生成手段と、
前記各群の索引語候補のうち当該各群にわたって重複する索引語候補を索引語として抽出する索引語抽出手段と、
前記有意フィールド毎に、全各カラムに含まれる前記索引語を重要語として抽出し、当該重要語を要素とするベクトル空間を当該全各カラムについて生成して、当該全各カラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドと、ベクトル空間フィールドとを備えたベクトル空間テーブルを作成するベクトル空間テーブル作成手段と、
前記有意フィールド毎に、前記索引語の重要度を求め、前記有意フィールド毎に、索引語フィールドと、重要度フィールドと、当該索引語の出現する全てのカラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドと、を備えた重要度テーブルを作成する重要度テーブル作成手段とを備えることを特徴とする請求項1〜6のいずれかに記載の自動演習システム。
【請求項8】
前記頻度比は、
Gap(C(n-1),Cn)=|log(Ti(n-1)/Tin)| …(式1)
(ここで、C(n-1):Cnと包含関係にある上位文字列クラス、Cn:C(n-1)と包含関係にある下位文字列クラス、Gap(C(n-1),Cn):C(n-1),Cnの頻度比、Ti(n-1):上位文字列クラスの出現頻度、Tin:下位文字列クラスの出現頻度)、により求めることを特徴とする請求項7に記載の自動演習システム。
【請求項9】
前記重要度は、
Swj=log{(Fj/Dj)+1} …(式2)
(ここで、Swj:重要度、Fj:出現頻度、Dj:共起頻度)、により求めることを特徴とする請求項7又は8に記載の自動演習システム。
【請求項10】
前記類似度は、
【数1】
…(式3)、により求めることを特徴とする請求項1〜9のいずれかに記載の自動演習システム。
【請求項11】
問題を自動作成するためにコンピュータを、
因果関係を有する複数の有意フィールドからなる自然言語文データベースから、前記有意フィールド毎に、カラムの位置情報フィールドと、ベクトル空間フィールドとを備えたベクトル空間テーブルと、前記有意フィールド毎に、索引語フィールドと、重要度フィールドと、索引語の位置情報フィールドとを備えた重要度テーブルとを備えた知識データベースを構築する知識収集手段、
前記重要度テーブルからクエリに含まれる索引語を重要語としてクエリベクトル空間の要素として抽出し、当該クエリベクトル空間と、前記有意フィールドから選ばれた質問フィールドの全各カラムのベクトル空間とを用いて前記クエリと前記質問フィールドの全各カラムとの類似度を求め、当該類似度に基づいて前記質問フィールドの全各カラムをランキングしたランキングリストを作成するランキングリスト作成手段、
前記ランキングリストにおいて、閾値α以上の類似度Rαの質問フィールドを問題作成テンプレートに適用して問題文を作成するとともに、前記類似度Rαに対応する前記有意フィールドから選ばれた回答フィールドを正解選択肢とするQ-A対作成手段、として機能させるための自動演習プログラム。
【請求項12】
前記コンピュータを、更に、
前記ランキングリストにおいて、閾値β未満の類似度Rβに対応する回答フィールドのベクトル空間と、前記正解選択肢のベクトル空間及び/又は他の不正解選択肢のベクトル空間とを用いて前記回答フィールドと前記正解選択肢及び/又は前記他の不正解選択肢との類似度Rγを求め、当該類似度Rγが閾値γ未満である場合に、前記類似度Rβに対応する回答フィールドを不正解選択肢とする不正解作成手段として機能させるための請求項11に記載の自動演習プログラム。
【請求項13】
前記類似度Rαは、前記ランキングリストにおいて最も高い類似度であることを特徴とする請求項11又は12に記載の自動演習プログラム。
【請求項14】
前記類似度Rβは、前記ランキングリストにおいて不正解選択肢として未選択のもののうち最も低い類似度(ただし、0超)であることを特徴とする請求項12又は13に記載の自動演習プログラム。
【請求項15】
問題演習をするために前記コンピュータを、更に、
ユーザ情報データベースに基づいて問題データベースから出題すべき問題を取得する準備手段、
前記問題をインタフェース画面に表示するとともに、前記問題に対するユーザ回答を採点し、結果を正解情報とともに前記インタフェース画面に表示する出題採点手段、
前記結果に基づいて前記ユーザ情報データベース及び前記問題データベースを更新する管理手段として機能させるための請求項11〜14のいずれかに記載の自動演習プログラム。
【請求項16】
前記コンピュータを、更に、
前記重要度テーブルから前記正解情報に含まれる索引語を重要語として正解情報ベクトル空間の要素として抽出し、当該正解情報ベクトル空間と、前記質問フィールドの全各カラムのベクトル空間とを用いて前記正解情報と前記質問フィールドの全各カラムとの類似度を求め、当該類似度に基づいて前記質問フィールドの全各カラムをランキングしたランキングリストを作成し、その内容を表示する復習手段として機能させるための請求項15に記載の自動演習プログラム。
【請求項17】
前記知識収集手段として機能させるために、前記コンピュータを、
前記有意フィールド毎に、サフィックス群及び/又はプレフィックス群を文字列クラスとして辞書順にソートして生成し、前後の文字列クラスの一致部分の切り出し、出現頻度が閾値T1未満の文字列クラスの除外、同一の文字列クラスの統合、及び、包含関係にある上位文字列クラスが下位文字列クラスより優先されるようにソートする文字列クラス群生成手段、
前記有意フィールド毎に、文字列クラスの一つ前の文字列クラスと包含関係にない場合には、当該文字列クラスを索引語候補として記憶するとともに、包含関係にある場合には、頻度比を求め、前記頻度比が閾値T2以上の場合には下位文字列クラスを索引語候補として記憶する一方、頻度比が閾値T2未満の場合には下位文字列クラスを上位文字列クラスとみなして索引語候補として記憶する索引語候補群生成手段、
前記各群の索引語候補のうち当該各群にわたって重複する索引語候補を索引語として抽出する索引語抽出手段、
前記有意フィールド毎に、全各カラムに含まれる前記索引語を重要語として抽出し、当該重要語を要素とするベクトル空間を当該全各カラムについて生成して、当該全各カラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドと、ベクトル空間フィールドとを備えたベクトル空間テーブルを作成するベクトル空間テーブル作成手段、
前記有意フィールド毎に、前記索引語の重要度を求め、前記有意フィールド毎に、索引語フィールドと、重要度フィールドと、当該索引語の出現する全てのカラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドと、を備えた重要度テーブルを作成する重要度テーブル作成手段、として機能させるための請求項11〜16のいずれかに記載の自動演習プログラム。
【請求項18】
前記頻度比は、
Gap(C(n-1),Cn)=|log(Ti(n-1)/Tin)| …(式1)
(ここで、C(n-1):Cnと包含関係にある上位文字列クラス、Cn:C(n-1)と包含関係にある下位文字列クラス、Gap(C(n-1),Cn):C(n-1),Cnの頻度比、Ti(n-1):上位文字列クラスの出現頻度、Tin:下位文字列クラスの出現頻度)、により求めることを特徴とする請求項17に記載の自動演習プログラム。
【請求項19】
前記重要度は、
Swj=log{(Fj/Dj)+1} …(式2)
(ここで、Swj:重要度、Fj:出現頻度、Dj:共起頻度)、により求めることを特徴とする請求項17又は18に記載の自動演習プログラム。
【請求項20】
前記類似度は、
【数2】
…(式3)、により求めることを特徴とする請求項11〜19のいずれかに記載の自動演習プログラム。
【請求項1】
因果関係を有する複数の有意フィールドからなる自然言語文データベースから、前記有意フィールド毎に、カラムの位置情報フィールドと、ベクトル空間フィールドとを備えたベクトル空間テーブルと、前記有意フィールド毎に、索引語フィールドと、重要度フィールドと、索引語の位置情報フィールドとを備えた重要度テーブルとを備えた知識データベースを構築する知識収集手段と、
前記重要度テーブルからクエリに含まれる索引語を重要語としてクエリベクトル空間の要素として抽出し、当該クエリベクトル空間と、前記有意フィールドから選ばれた質問フィールドの全各カラムのベクトル空間とを用いて前記クエリと前記質問フィールドの全各カラムとの類似度を求め、当該類似度に基づいて前記質問フィールドの全各カラムをランキングしたランキングリストを作成するランキングリスト作成手段と、
前記ランキングリストにおいて、閾値α以上の類似度Rαの質問フィールドを問題作成テンプレートに適用して問題文を作成するとともに、前記類似度Rαに対応する前記有意フィールドから選ばれた回答フィールドを正解選択肢とするQ-A対作成手段とを備えたことを特徴とする自動演習システム。
【請求項2】
更に、
前記ランキングリストにおいて、閾値β未満の類似度Rβに対応する回答フィールドのベクトル空間と、前記正解選択肢のベクトル空間及び/又は他の不正解選択肢のベクトル空間とを用いて前記回答フィールドと前記正解選択肢及び/又は前記他の不正解選択肢との類似度Rγを求め、当該類似度Rγが閾値γ未満である場合に、前記類似度Rβに対応する回答フィールドを不正解選択肢とする不正解作成手段を備えたことを特徴とする請求項1に記載の自動演習システム。
【請求項3】
前記類似度Rαは、前記ランキングリストにおいて最も高い類似度であることを特徴とする請求項1又は2に記載の自動演習システム。
【請求項4】
前記類似度Rβは、前記ランキングリストにおいて不正解選択肢として未選択のもののうち最も低い類似度(ただし、0超)であることを特徴とする請求項2又は3に記載の自動演習システム。
【請求項5】
更に、
ユーザ情報データベースに基づいて問題データベースから出題すべき問題を取得する準備手段と、
前記問題をインタフェース画面に表示するとともに、前記問題に対するユーザ回答を採点し、結果を正解情報とともに前記インタフェース画面に表示する出題採点手段と、
前記結果に基づいて前記ユーザ情報データベース及び前記問題データベースを更新する管理手段とを備えたことを特徴とする請求項1〜4のいずれかに記載の自動演習システム。
【請求項6】
更に、
前記重要度テーブルから前記正解情報に含まれる索引語を重要語として正解情報ベクトル空間の要素として抽出し、当該正解情報ベクトル空間と、前記質問フィールドの全各カラムのベクトル空間とを用いて前記正解情報と前記質問フィールドの全各カラムとの類似度を求め、当該類似度に基づいて前記質問フィールドの全各カラムをランキングしたランキングリストを作成し、その内容を表示する復習手段を備えたことを特徴とする請求項5に記載の自動演習システム。
【請求項7】
前記知識収集手段は、
前記有意フィールド毎に、サフィックス群及び/又はプレフィックス群を文字列クラスとして辞書順にソートして生成し、前後の文字列クラスの一致部分の切り出し、出現頻度が閾値T1未満の文字列クラスの除外、同一の文字列クラスの統合、及び、包含関係にある上位文字列クラスが下位文字列クラスより優先されるようにソートする文字列クラス群生成手段と、
前記有意フィールド毎に、文字列クラスの一つ前の文字列クラスと包含関係にない場合には、当該文字列クラスを索引語候補として記憶するとともに、包含関係にある場合には、頻度比を求め、前記頻度比が閾値T2以上の場合には下位文字列クラスを索引語候補として記憶する一方、頻度比が閾値T2未満の場合には下位文字列クラスを上位文字列クラスとみなして索引語候補として記憶する索引語候補群生成手段と、
前記各群の索引語候補のうち当該各群にわたって重複する索引語候補を索引語として抽出する索引語抽出手段と、
前記有意フィールド毎に、全各カラムに含まれる前記索引語を重要語として抽出し、当該重要語を要素とするベクトル空間を当該全各カラムについて生成して、当該全各カラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドと、ベクトル空間フィールドとを備えたベクトル空間テーブルを作成するベクトル空間テーブル作成手段と、
前記有意フィールド毎に、前記索引語の重要度を求め、前記有意フィールド毎に、索引語フィールドと、重要度フィールドと、当該索引語の出現する全てのカラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドと、を備えた重要度テーブルを作成する重要度テーブル作成手段とを備えることを特徴とする請求項1〜6のいずれかに記載の自動演習システム。
【請求項8】
前記頻度比は、
Gap(C(n-1),Cn)=|log(Ti(n-1)/Tin)| …(式1)
(ここで、C(n-1):Cnと包含関係にある上位文字列クラス、Cn:C(n-1)と包含関係にある下位文字列クラス、Gap(C(n-1),Cn):C(n-1),Cnの頻度比、Ti(n-1):上位文字列クラスの出現頻度、Tin:下位文字列クラスの出現頻度)、により求めることを特徴とする請求項7に記載の自動演習システム。
【請求項9】
前記重要度は、
Swj=log{(Fj/Dj)+1} …(式2)
(ここで、Swj:重要度、Fj:出現頻度、Dj:共起頻度)、により求めることを特徴とする請求項7又は8に記載の自動演習システム。
【請求項10】
前記類似度は、
【数1】
…(式3)、により求めることを特徴とする請求項1〜9のいずれかに記載の自動演習システム。
【請求項11】
問題を自動作成するためにコンピュータを、
因果関係を有する複数の有意フィールドからなる自然言語文データベースから、前記有意フィールド毎に、カラムの位置情報フィールドと、ベクトル空間フィールドとを備えたベクトル空間テーブルと、前記有意フィールド毎に、索引語フィールドと、重要度フィールドと、索引語の位置情報フィールドとを備えた重要度テーブルとを備えた知識データベースを構築する知識収集手段、
前記重要度テーブルからクエリに含まれる索引語を重要語としてクエリベクトル空間の要素として抽出し、当該クエリベクトル空間と、前記有意フィールドから選ばれた質問フィールドの全各カラムのベクトル空間とを用いて前記クエリと前記質問フィールドの全各カラムとの類似度を求め、当該類似度に基づいて前記質問フィールドの全各カラムをランキングしたランキングリストを作成するランキングリスト作成手段、
前記ランキングリストにおいて、閾値α以上の類似度Rαの質問フィールドを問題作成テンプレートに適用して問題文を作成するとともに、前記類似度Rαに対応する前記有意フィールドから選ばれた回答フィールドを正解選択肢とするQ-A対作成手段、として機能させるための自動演習プログラム。
【請求項12】
前記コンピュータを、更に、
前記ランキングリストにおいて、閾値β未満の類似度Rβに対応する回答フィールドのベクトル空間と、前記正解選択肢のベクトル空間及び/又は他の不正解選択肢のベクトル空間とを用いて前記回答フィールドと前記正解選択肢及び/又は前記他の不正解選択肢との類似度Rγを求め、当該類似度Rγが閾値γ未満である場合に、前記類似度Rβに対応する回答フィールドを不正解選択肢とする不正解作成手段として機能させるための請求項11に記載の自動演習プログラム。
【請求項13】
前記類似度Rαは、前記ランキングリストにおいて最も高い類似度であることを特徴とする請求項11又は12に記載の自動演習プログラム。
【請求項14】
前記類似度Rβは、前記ランキングリストにおいて不正解選択肢として未選択のもののうち最も低い類似度(ただし、0超)であることを特徴とする請求項12又は13に記載の自動演習プログラム。
【請求項15】
問題演習をするために前記コンピュータを、更に、
ユーザ情報データベースに基づいて問題データベースから出題すべき問題を取得する準備手段、
前記問題をインタフェース画面に表示するとともに、前記問題に対するユーザ回答を採点し、結果を正解情報とともに前記インタフェース画面に表示する出題採点手段、
前記結果に基づいて前記ユーザ情報データベース及び前記問題データベースを更新する管理手段として機能させるための請求項11〜14のいずれかに記載の自動演習プログラム。
【請求項16】
前記コンピュータを、更に、
前記重要度テーブルから前記正解情報に含まれる索引語を重要語として正解情報ベクトル空間の要素として抽出し、当該正解情報ベクトル空間と、前記質問フィールドの全各カラムのベクトル空間とを用いて前記正解情報と前記質問フィールドの全各カラムとの類似度を求め、当該類似度に基づいて前記質問フィールドの全各カラムをランキングしたランキングリストを作成し、その内容を表示する復習手段として機能させるための請求項15に記載の自動演習プログラム。
【請求項17】
前記知識収集手段として機能させるために、前記コンピュータを、
前記有意フィールド毎に、サフィックス群及び/又はプレフィックス群を文字列クラスとして辞書順にソートして生成し、前後の文字列クラスの一致部分の切り出し、出現頻度が閾値T1未満の文字列クラスの除外、同一の文字列クラスの統合、及び、包含関係にある上位文字列クラスが下位文字列クラスより優先されるようにソートする文字列クラス群生成手段、
前記有意フィールド毎に、文字列クラスの一つ前の文字列クラスと包含関係にない場合には、当該文字列クラスを索引語候補として記憶するとともに、包含関係にある場合には、頻度比を求め、前記頻度比が閾値T2以上の場合には下位文字列クラスを索引語候補として記憶する一方、頻度比が閾値T2未満の場合には下位文字列クラスを上位文字列クラスとみなして索引語候補として記憶する索引語候補群生成手段、
前記各群の索引語候補のうち当該各群にわたって重複する索引語候補を索引語として抽出する索引語抽出手段、
前記有意フィールド毎に、全各カラムに含まれる前記索引語を重要語として抽出し、当該重要語を要素とするベクトル空間を当該全各カラムについて生成して、当該全各カラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドと、ベクトル空間フィールドとを備えたベクトル空間テーブルを作成するベクトル空間テーブル作成手段、
前記有意フィールド毎に、前記索引語の重要度を求め、前記有意フィールド毎に、索引語フィールドと、重要度フィールドと、当該索引語の出現する全てのカラムの前記自然言語文データベースのレコード番号を特定しうる位置情報フィールドと、を備えた重要度テーブルを作成する重要度テーブル作成手段、として機能させるための請求項11〜16のいずれかに記載の自動演習プログラム。
【請求項18】
前記頻度比は、
Gap(C(n-1),Cn)=|log(Ti(n-1)/Tin)| …(式1)
(ここで、C(n-1):Cnと包含関係にある上位文字列クラス、Cn:C(n-1)と包含関係にある下位文字列クラス、Gap(C(n-1),Cn):C(n-1),Cnの頻度比、Ti(n-1):上位文字列クラスの出現頻度、Tin:下位文字列クラスの出現頻度)、により求めることを特徴とする請求項17に記載の自動演習プログラム。
【請求項19】
前記重要度は、
Swj=log{(Fj/Dj)+1} …(式2)
(ここで、Swj:重要度、Fj:出現頻度、Dj:共起頻度)、により求めることを特徴とする請求項17又は18に記載の自動演習プログラム。
【請求項20】
前記類似度は、
【数2】
…(式3)、により求めることを特徴とする請求項11〜19のいずれかに記載の自動演習プログラム。
【図1】

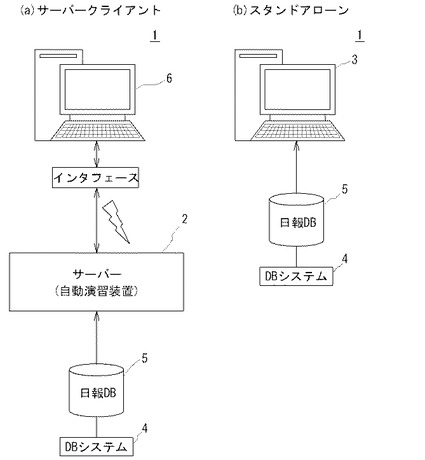
【図2】
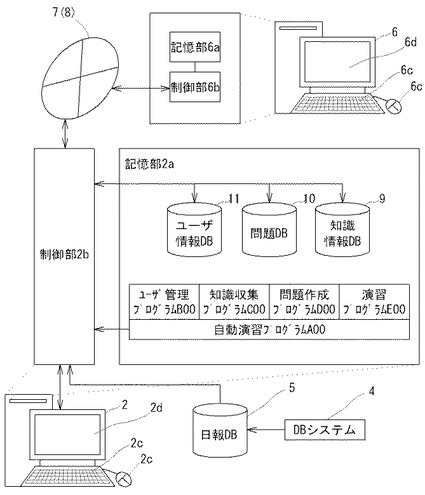
【図3】
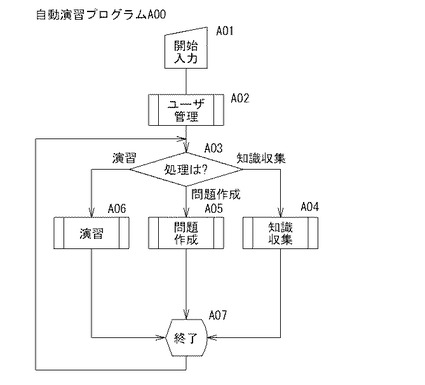
【図4】
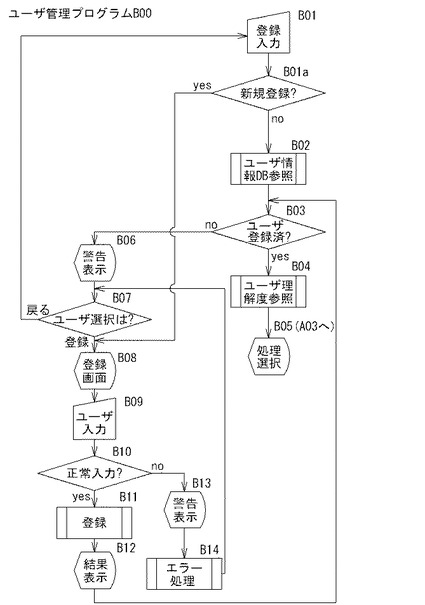
【図5A】
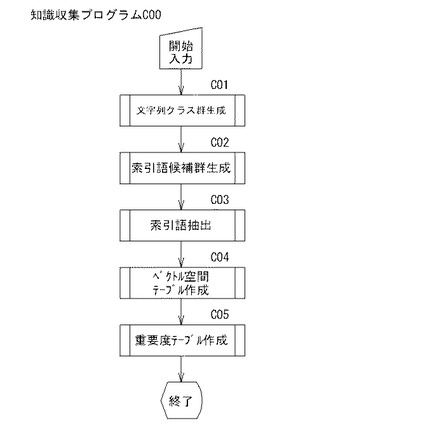
【図5B】
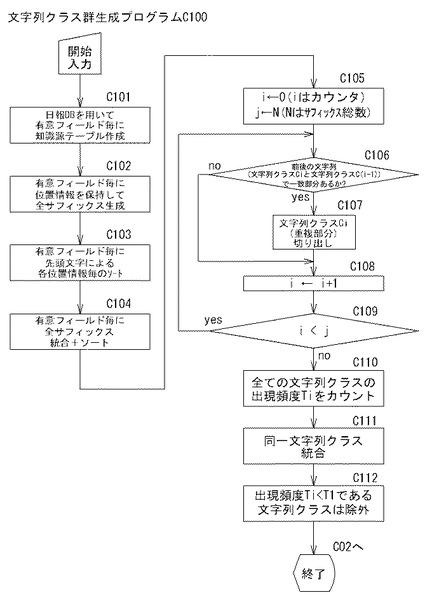
【図5C】
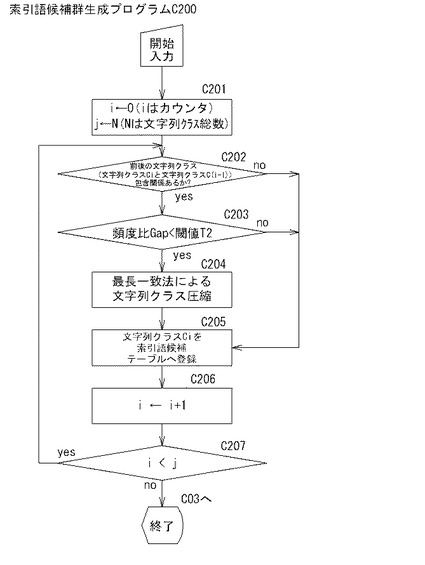
【図5D】
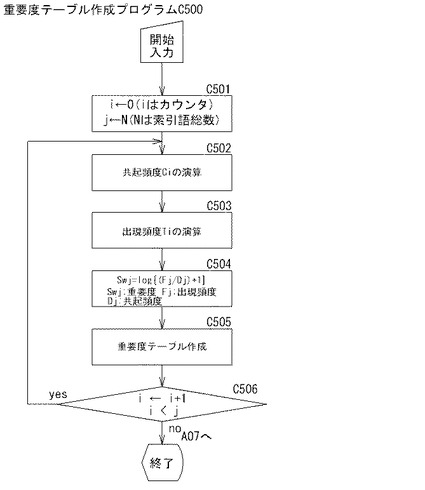
【図6】
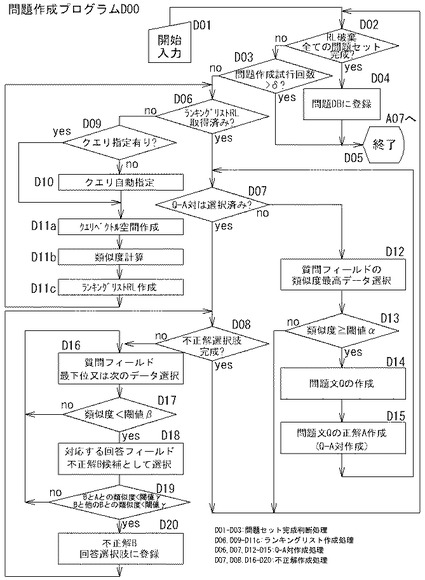
【図7】
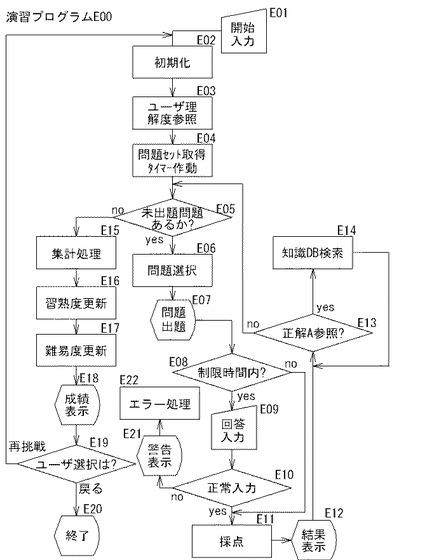
【図8】
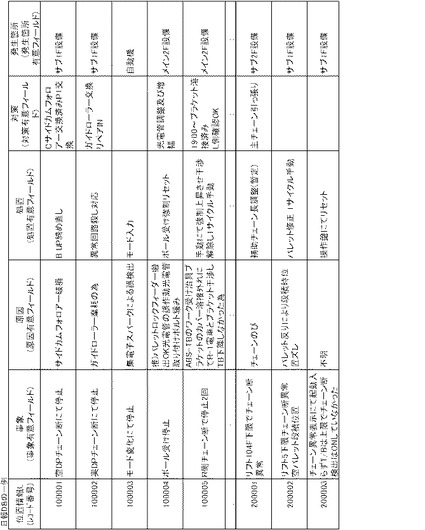
【図9A】

【図9B】
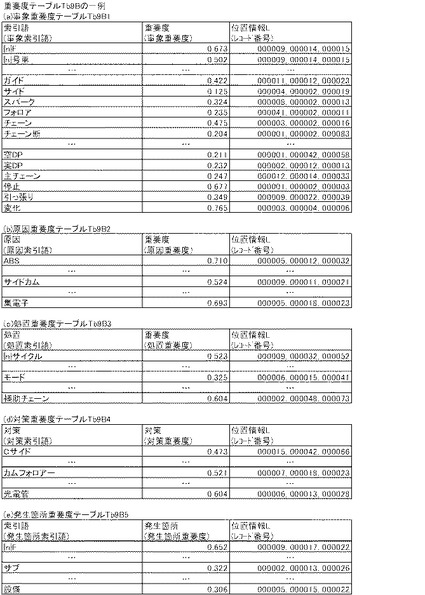
【図10】
【図11】
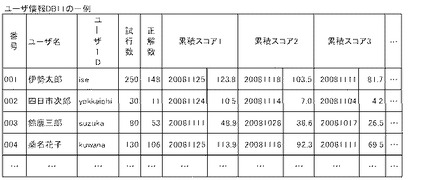
【図12】

【図13A】
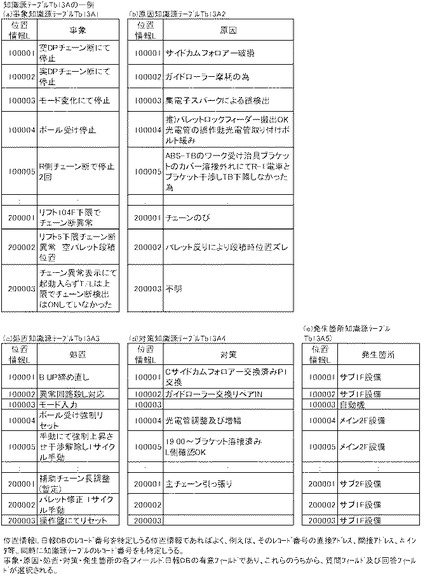
【図13B】
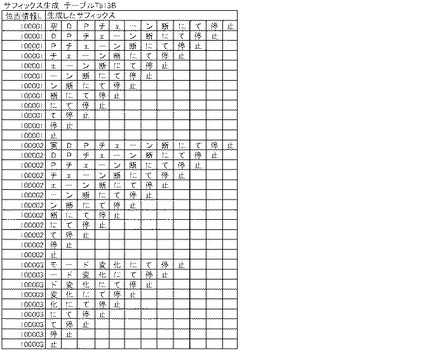
【図13C】
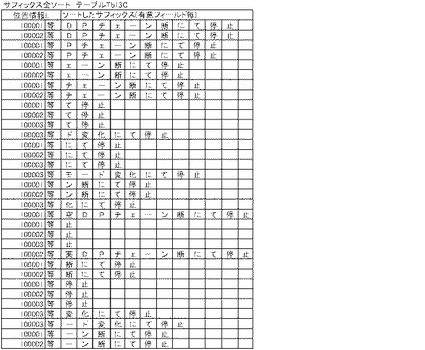
【図14A】
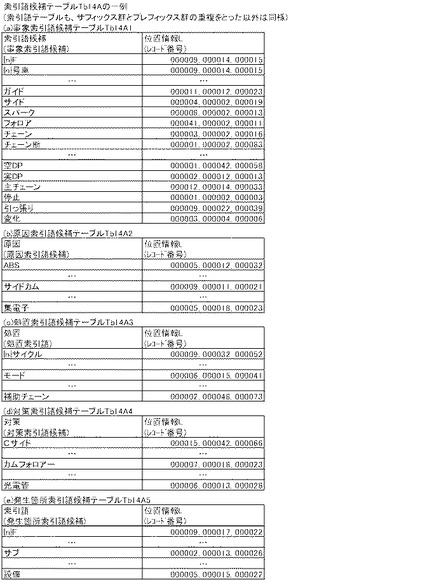
【図14B】
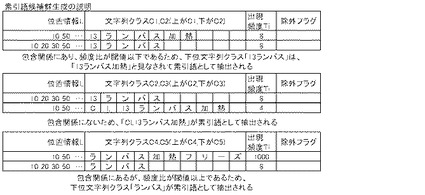
【図15】
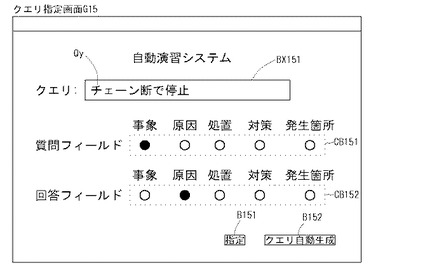
【図16】
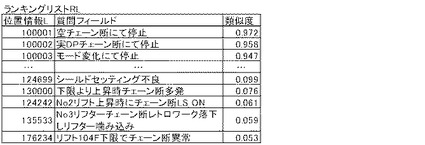
【図17A】
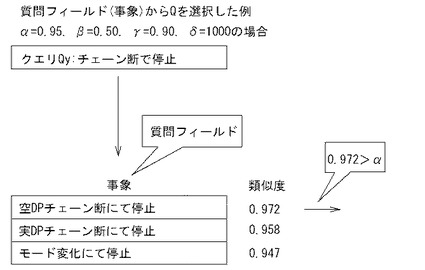
【図17B】
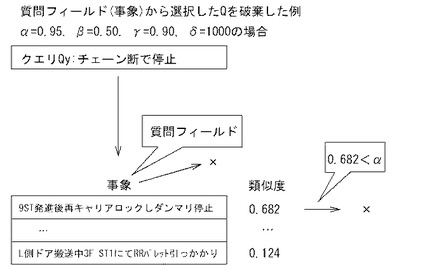
【図18】
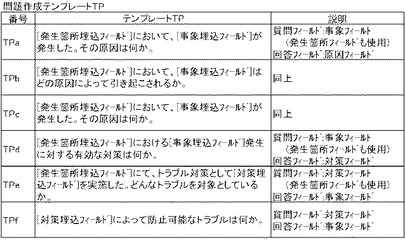
【図19】
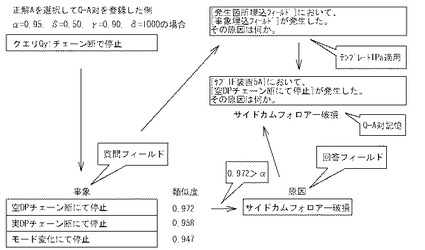
【図20A】
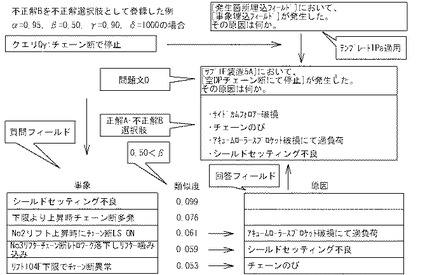
【図20B】
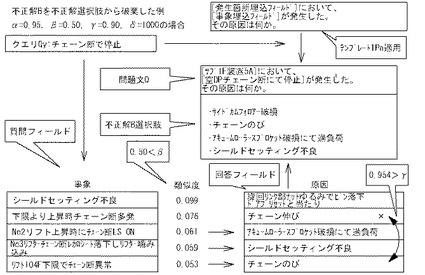
【図21】
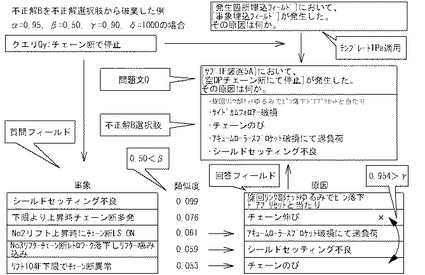
【図22】
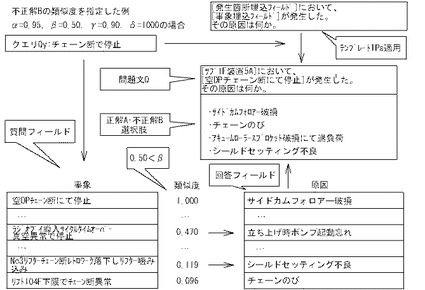
【図23】
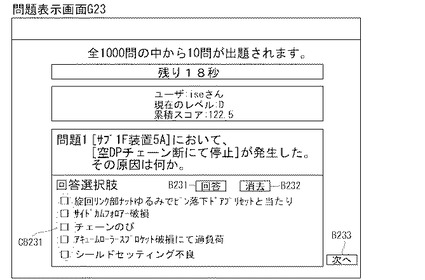
【図24】
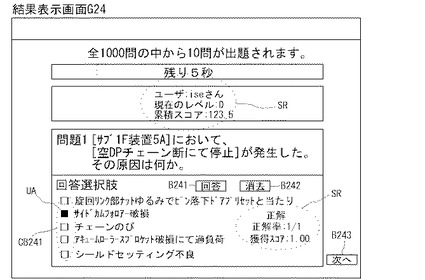
【図25】
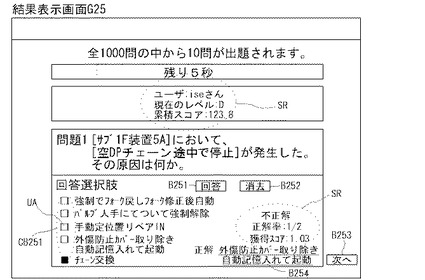
【図26】
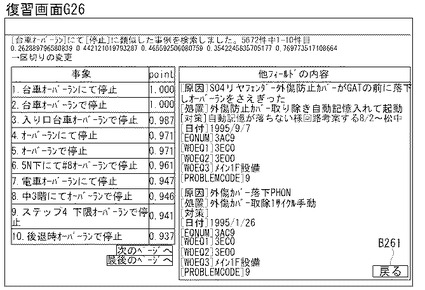
【図27】
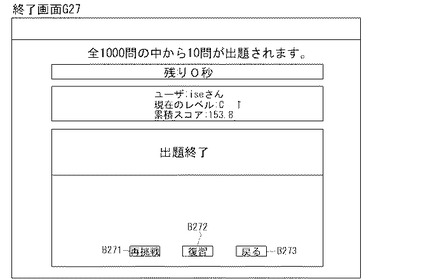
【図28】
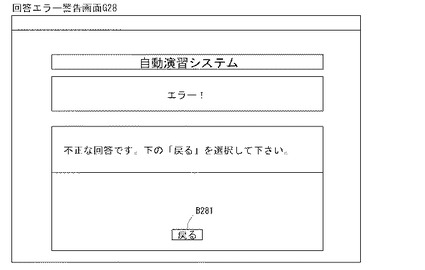
【図2】
【図3】
【図4】
【図5A】
【図5B】
【図5C】
【図5D】
【図6】
【図7】
【図8】
【図9A】
【図9B】
【図10】
【図11】
【図12】
【図13A】
【図13B】
【図13C】
【図14A】
【図14B】
【図15】
【図16】
【図17A】
【図17B】
【図18】
【図19】
【図20A】
【図20B】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【公開番号】特開2010−157199(P2010−157199A)
【公開日】平成22年7月15日(2010.7.15)
【国際特許分類】
【出願番号】特願2009−69136(P2009−69136)
【出願日】平成21年3月19日(2009.3.19)
【出願人】(304026696)国立大学法人三重大学 (270)
【Fターム(参考)】
【公開日】平成22年7月15日(2010.7.15)
【国際特許分類】
【出願日】平成21年3月19日(2009.3.19)
【出願人】(304026696)国立大学法人三重大学 (270)
【Fターム(参考)】
[ Back to top ]