
表構造解析装置、表構造解析方法および表構造解析プログラム
【課題】表データにおける項目部分と実体部分を判定する。
【解決手段】表構造解析装置100は、表データにおいて第1行のデータと第2行のデータを抽出する。これらのデータの類似度をレーベンシュタイン距離や文字数に基づいて算出する。更に、第1行と第2行全体としての類似度を求め、この類似度が所定の閾値以下であるとき、第1行と第2行の境界が、項目部分と実体部分の境界にあたると判定する。列方向についても同様に判定する。
【解決手段】表構造解析装置100は、表データにおいて第1行のデータと第2行のデータを抽出する。これらのデータの類似度をレーベンシュタイン距離や文字数に基づいて算出する。更に、第1行と第2行全体としての類似度を求め、この類似度が所定の閾値以下であるとき、第1行と第2行の境界が、項目部分と実体部分の境界にあたると判定する。列方向についても同様に判定する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、文書処理技術に関し、特に、表データの構造を解析するための技術、に関する。
【背景技術】
【0002】
「表データ」は、人間にとってわかりやすいだけではなく、コンピュータにとっても情報処理しやすいデータ保持形式である。表データは、通常、項目部分と実体部分を含む。項目部分は、表の項目を示すデータ(以下、「項目データ」とよぶ)が位置する領域であり、実体部分は、表の実体的な内容を示すデータ(以下、「実体データ」とよぶ)が位置する領域である。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2001−134605号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
表データを正しく処理するためには、項目部分と実体部分、いいかえれば、項目データと実体データを判別する必要がある。表データを処理する前に、項目部分や実体部分を手動により明示的に指定してもよいが、こういったやり方は煩雑である。あるいは、項目部分と実体部分を特定するためのメタ情報をあらかじめ表データに設定しておいてもよいが、すべての表作成者にメタ情報の設定を義務づけることは現実的ではない。
【0005】
本発明は、上記課題に鑑みて完成された発明であり、その主たる目的は、表データにおける項目部分と実体部分を効率的に判別するための技術を提供することである。
【課題を解決するための手段】
【0006】
本発明のある態様は、表構造解析装置に関する。
この装置は、表データにおける第1のデータ系列と第2のデータ系列からそれぞれデータを抽出する。「データ系列」とは、表データの「行」あるいは「列」であってもよい。それらのデータが類似していなければ、第1のデータ系列と第2のデータ系列の境界が、表データにおける項目部分と実体部分の境界にあたると判定する。
類似度は、第1のデータに所定の加工操作を施して第2のデータを生成するときの加工操作回数に基づいて算出される。
【0007】
なお、以上の構成要素の任意の組み合わせ、本発明の表現を方法、システム、プログラム、記録媒体などの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0008】
本発明によれば、表データにおける項目部分と実体部分を効率的に判別できる。
【図面の簡単な説明】
【0009】
【図1(a)】項目部分と実体部分が判別される前の表データを示す図である。
【図1(b)】項目部分と実体部分が判別された後の図1(a)の表データを示す図である。
【図2】表構造解析装置の機能ブロック図である。
【図3】一部のセルが結合している表データの一例を示す図である。
【図4】一部のセルが結合している表データの別例を示す図である。
【図5】境界判定の処理過程を示すフローチャートである。
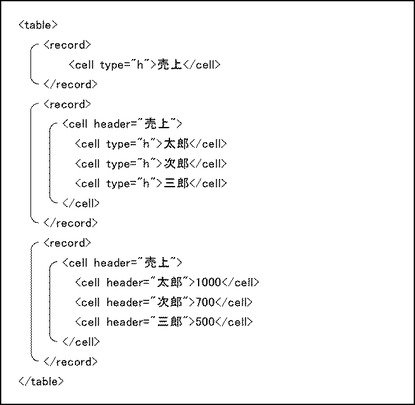
【図6】図1(a)の表データに基づくXML文書を示す図である。
【図7】第1行だけが項目部分を形成する表データを示す図である。
【図8】図7の表データに基づくXML文書を示す図である。
【図9】第1列だけが項目部分を形成する表データを示す図である。
【図10】図9の表データに基づくXML文書を示す図である。
【図11】第1列と第2列が項目部分を形成する表データを示す図である。
【図12】図11の表データに基づくXML文書を示す図である。
【図13】第1行と第2行が項目部分を形成する表データを示す図である。
【図14】図13の表データに基づくXML文書を示す図である。
【図15】第2の実施の形態に係る表構造解析装置の機能ブロック図である。
【図16】図1(a)に示した表データを、スプレッドシート形式で表示した画面の例を示す図である。
【図17】表の構造に関する情報をユーザから受け付けるためのユーザインタフェース画面の例を示す図である。
【図18】図1(a)に示した表データを、スプレッドシート形式で表示した画面の例を示す図である。
【図19】表の構造に関する情報をユーザから受け付けるためのユーザインタフェース画面の例を示す図である。
【図20】図1(a)に示した表データを、スプレッドシート形式で表示した画面の例を示す図である。
【図21】表の構造に関する情報をユーザから受け付けるためのユーザインタフェース画面の例を示す図である。
【図22】図1(a)に示した表データを、スプレッドシート形式で表示した画面の例を示す図である。
【発明を実施するための形態】
【0010】
(第1の実施の形態)
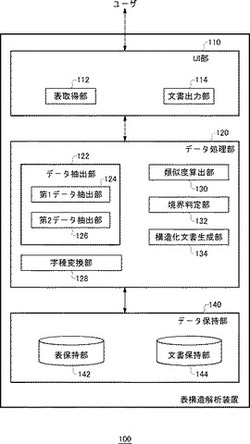
図1(a)は、項目部分と実体部分が判別される前の表データの一例である。
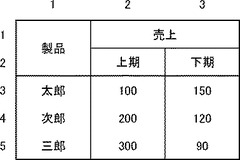
図1(a)に示す表データは、4行×3列により12個のデータを含む。第1行第2列のデータ(以下、「データ(1・2)」のように表記する)である「売上」は、第2列の項目名、すなわち、「列項目」を示す。同様に、「本数(1・3)」は、第3列の列項目である。「太郎(2・1)」は、第2行の項目名、すなわち、「行項目」を示す。
【0011】
したがって、第2行第2列のデータ「10000」は、「太郎(2・1)」という「製品(1・1)」の「売上(1・2)」が「10000」であることを示している。以下、行や列として示される一連のデータ群のことを、「データ系列」とよぶ。
【0012】
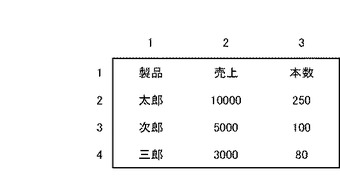
図1(b)は、項目部分と実体部分が判別された後の図1(a)の表データである。
第1行の「製品」、「売上」、「本数」は、いずれも列項目を示す項目データである。以下、第1行のように項目データのみを含む行を「項目行」とよぶ。第2行の「太郎」は行項目を示す項目データであるが、「10000」と「250」は、実体データである。第2行のように実体データを含む行を「実体行」とよぶ。第3行、第4行も実体行である。
【0013】
第1列の「製品」、「太郎」、「次郎」、「三郎」は、いずれも行項目を示す項目データである。以下、第1列のように項目データのみを含む列を「項目列」とよぶ。第2列の「売上」は列項目を示す項目データであるが、「10000」、「5000」、「3000」は実体データである。第2列のように実体データを含む列を「実体列」とよぶ。第3列も実体列である。
【0014】
項目行および項目列は「項目部分」を形成し、それ以外の部分は「実体部分」を形成する。図1(b)においては、項目部分を斜線にて示している。以降に示す図においても同様である。
本実施例の表構造解析装置100は、図1(a)に示したような行列形式の表データを取得し、項目部分と実体部分を自動的に判別する装置である。
【0015】
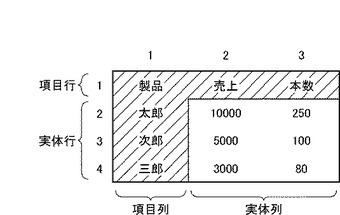
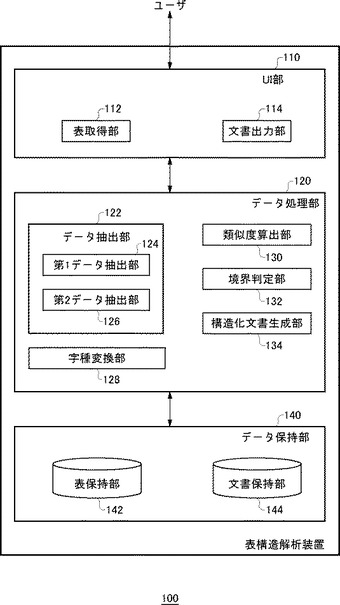
図2は、表構造解析装置100の機能ブロック図である。
ここに示す各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組み合わせによっていろいろなかたちで実現できることは、当業者には理解されるところである。
【0016】
表構造解析装置100は、UI(ユーザ・インタフェース)部110、データ処理部120およびデータ保持部140を含む。
UI部110は、ユーザインタフェース全般に関する処理を担当する。
データ処理部120は、UI部110やデータ保持部140から取得されたデータをもとにして各種のデータ処理を実行する。データ処理部120は、UI部110とデータ保持部140の間のインタフェースの役割も果たす。
データ保持部140は、あらかじめ用意された各種の設定データや、データ処理部120から受け取ったデータを格納する。
【0017】
UI部110:
UI部110は、表取得部112および文書出力部114を含む。表取得部112は、表データを取得する。表データは、表計算アプリケーションにより生成されてもよい。表取得部112は、HTML(HyperText Markup Language)に含まれるtableタグに基づいて、HTML文書中から表データを抽出してもよい。表データは後述する構造化文書生成部134によりXML(eXtensible Markup Language)文書に変換される。XML文書以外にも、HTML文書やXHTML(eXtensible HyperText Markup Language)文書などの他形式の構造化文書ファイルに変換してもよい。文書出力部114は、生成されたXML文書を画面表示させる。あるいは、外部装置に送信する。
【0018】
データ保持部140:
データ保持部140は、表保持部142と文書保持部144を含む。表保持部142は、表取得部112が取得した表データを保持する。文書保持部144は、表データから生成されたXML文書を保持する。
【0019】
データ処理部120:
データ処理部120は、データ抽出部122、字種変換部128、類似度算出部130、境界判定部132および構造化文書生成部134を含む。データ抽出部122は、表データからデータを抽出する。データ抽出部122は、第1データ抽出部124と第2データ抽出部126を含む。第1データ抽出部124は、表データにおける第1のデータ系列からデータを抽出し、第2データ抽出部126は、第1のデータ系列に隣接する第2のデータ系列からデータを抽出する。たとえば、第1データ抽出部124が第1行からデータ(1・m)を抽出するとき、第2データ抽出部126は第2行からデータ(2・m)を抽出する。第1データ抽出部124が第1列からデータ(n・1)を抽出するとき、第2データ抽出部126は第2行からデータ(n・2)を抽出する。
【0020】
字種変換部128は、抽出されたデータに含まれる文字を、字種に応じた所定文字(以下、「字種文字」とよぶ)に変換する。字種文字への変換(以下、単に「字種変換」とよぶ)については後に詳述する。
【0021】
類似度算出部130は、類似度を算出する。本実施例における「類似度」は、「データ類似度」と「系列類似度」を総称した概念である。また、「データ類似度」は「文字類似度」、「字種類似度」および「総合類似度」を総称した概念である。境界判定部132は表データにおける項目部分と実体部分の境界を類似度、より具体的には、系列類似度に基づいて判定する(以下、このような判定を「境界判定」とよぶ)。以下、類似度について説明する。
【0022】
(1)データ類似度
(1−1)文字類似度
比較対象となる2つのデータについて、文字自体に基づく類似度を示す。文字類似度の計算式は、以下の通りである。
【0023】
【数1】

【0024】
レーベンシュタイン距離(編集距離)とは、情報理論分野において2つの文字列がどの程度異なっているかを示す指標値である。具体的には、第1の文字列に対して、文字の挿入・置換・削除・追加といった加工操作を施し、第2の文字列を生成するときの加工操作の回数を示す。加工操作が少ないほど、いいかえれば、レーベンシュタイン距離が短いほど、第1の文字列と第2の文字列は類似していることになる。
【0025】
たとえば、文字列「kitten」に加工操作を施して文字列「sitting」を生成する場合、
1回目.sitten(「kitten」の先頭文字「k」を「s」に置換)
2回目.sittin(「sitten」の5番目の文字「e」を「i」に置換)
3回目.sitting(文字「g」を追加)
という3回の加工操作が必要である。したがって、文字列「kitten」と文字列「sitting」のレーベンシュタイン距離は「3」となる。Distance(A,B)は、レーベンシュタイン距離に限らず、文字列としての違いを示す上で適切な指標値であればよい。
【0026】
文字列「kitten」は6文字、文字列「sitting」は7文字であるため、Max("kitten","sitting")は、「7」となる。したがって、Sim("kitten","sitting")=(7−3)÷7=約0.57となる。上記からも明らかなように、文字列類似度は、レーベンシュタイン距離が一定であれば文字列が長いほど、また、文字列長が一定であればレーベンシュタイン距離が短いほど大きな値となる。
【0027】
同様にして、図1(a)において第1行の「売上(1・2)」と第2行の「10000(2・2)」を比較してみる。「売上」は2文字、「10000」は5文字であるため、Max("売上","10000")=5である。Distance("売上","10000")=5である。したがって、Sim("売上","10000")=(5−5)÷5=0となる。
第2行の「10000(2・2)」と第3行の「5000(3・2)」を比較してみる。Max("10000","5000")=5、Distance("10000","5000")=2であるから、Sim("10000","5000")=(5−2)÷5=0.6となる。
【0028】
第1データ抽出部124は、第1行から「製品」、「売上」、「本数」を順次抽出する。第2データ抽出部126は、第2行から「太郎」、「10000」、「250」を順次抽出する。類似度算出部130は、「製品」と「太郎」、「売上」と「10000」、「本数」と「250」のそれぞれに組み合わせについて文字類似度を算出する。
【0029】
(1−2)字種類似度
比較対象となる2つのデータについて、字種に基づく類似度を示す。字種類似度の計算式も、文字類似度の計算式と同じである。ただし、字種類似度を計算する前に、比較対象となる各文字列に含まれる各文字を、
数字・記号 →0
英文字 →A
全角文字 →ZZ
半角カタカナ →Y
全角区切り文字→//
その他の文字 →*
のように字種変換する。「0」、「A」、「ZZ」、「Y」、「//」、「*」は字種文字である。
【0030】
たとえば、文字列「kitten」を字種変換すると「AAAAAA」、文字列「sitting」を字種変換すると「AAAAAAA」となる。字種変換後の文字列「kitten」と字種変換後の文字列「sitting」のレーベンシュタイン距離とは、文字列「AAAAAA」と文字列「AAAAAAA」のレーベンシュタイン距離であり、「1」となる。したがって、字種類似度Sim("kitten","sitting")=(7−1)÷7=約0.86となる。字種類似度も、比較対象となる文字列が長いほど、また、レーベンシュタイン距離が短いほど大きな値となる。字種の相違による影響は、文字類似度に対してよりも字種類似度に対しての方が大きい。
【0031】
同様にして、図1(a)において第1行の「売上(1・2)」と第2行の「10000(2・2)」の字種類似度を求めてみる。「売上」→「ZZZZ」、「10000」→「00000」であるため、Distance("売上","10000")=5となり、字種類似度Sim("売上","10000")=(5−5)÷5=0となる。
第2行の「10000(2・2)」と第3行の「5000(3・2)」を比較してみる。「10000」→「00000」、「5000」→「0000」であるため、Distance("10000","5000")=1となり、字種類似度Sim("10000","5000")=(5−1)÷5=0.8となる。
【0032】
字種変換部128は、第1データ抽出部124や第2データ抽出部126が抽出するデータをそれぞれ字種変換し、類似度算出部130は、字種変換後の文字列それぞれについて字種類似度を計算する。
【0033】
(1−3)総合類似度
文字類似度と字種類似度に基づく類似度である。総合類似度の計算式は、以下の通りである。
【0034】
【数2】
【0035】
第1データ抽出部124が第1行からデータを抽出し、第2データ抽出部126が第2行からデータを抽出するとき、類似度算出部130は、「製品」と「太郎」、「売上」と「10000」、「本数」と「250」のそれぞれに組み合わせについて文字類似度、字種類似度および総合類似度を算出する。本実施例においては、a=0.3、b=0.7に設定し、文字類似度よりも字種類似度の影響が大きくなるように総合類似度の計算式を設定する。
【0036】
(2)系列類似度
系列類似度は、比較対象となる2つのデータ系列についての類似度を示す。類似度算出部130は、データ類似度、すなわち、文字類似度、字種類似度あるいは総合類似度に基づいて、系列類似度を算出する。本実施例においては、総合類似度に基づいて系列類似度を算出する。より具体的には、類似度算出部130は、総合類似度の平均値を系列類似度として算出する。
たとえば、第1行と第2行を比較する場合、「製品」と「太郎」の総合類似度をA1、「売上」と「10000」の総合類似度をA2、「本数」と「250」の総合類似度をA3とすると、A1〜A3の平均値が、第1行と第2行の系列類似度となる。系列類似度が所定の閾値(以下、「境界閾値」とよぶ)以下、たとえば、0.32以下であれば、第1行と第2行の境界が項目部分と実体部分の境界であると判定する。
【0037】
表データにおける項目データと実体データを見比べると、通常、データの種別や長さに顕著な差異が表れることが多い。表構造解析装置100は、このような知見を反映したアルゴリズムによる境界判定を実現している。a=0.3、b=0.7、境界閾値=0.32として、本発明者が実験したところ、約90%の精度にて、正しく境界を判定することができた。
【0038】
なお、A1〜A3の単純平均ではなく、たとえば、加重平均により系列類似度を求めてもよい。構造化文書生成部134は、境界判定の結果にしたがって、表データを構造化し、XML文書を生成する。XML文書の生成については、図6以降に関連して詳述する。
【0039】
図3は、一部のセルが結合している表データの一例である。
図3に示す5行×3列の表データにおいて、第1行と第2行は「製品(1・1)(2・1)」を共用している。このような構造の表データの場合、通常、第1行と第2行の境界は、項目部分と実体部分の境界とはならない。そこで、比較対象となるデータ系列が1つでもデータを共用しているときには、境界判定部132は、系列類似度の計算をすることなく、境界ではないと判定する。代わりに、境界判定部132は、第2行と第3行を対象として境界判定を実行する。
以下、図3のように比較対象となるデータ系列において、データが共用される表構造のことを「第1パターン構造」とよぶ。
【0040】
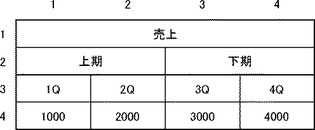
図4は、一部のセルが結合している表データの別例である。
図4に示す4行×4列の表データにおいて、第1行には1つのデータだけが含まれているが、第2行には2つのデータが含まれている。すなわち、「売上(1・1〜4)」に対しては、「上期(2・1〜2)」と「下期(2・3〜4)」の2つが対応している。このような構造の表データの場合、通常、第1行と第2行の境界が項目部分と実体部分の境界となる可能性は低い。そこで、まず、第1行と第2行を比較するに際しては、「売上」と「上期」、「売上」と「下期」のそれぞれの組み合わせについて総合類似度A1、A2を算出する。更に、類似度算出部130は総合類似度A1、A2に所定の補正値、たとえば、0.07を加算する。このような補正により、図4に示す表データにおいて、第1行と第2行の境界が項目部分と実体部分の境界として判定されにくくなるように処置している。第1行と第2行の境界が項目部分と実体部分の境界として判定されなければ、境界判定部132は第2行と第3行について境界判定を実行する。
以下、図4のように比較対象となるデータ系列において、比較対象となるデータが1対多対応する表構造のことを「第2パターン構造」とよぶ。
【0041】
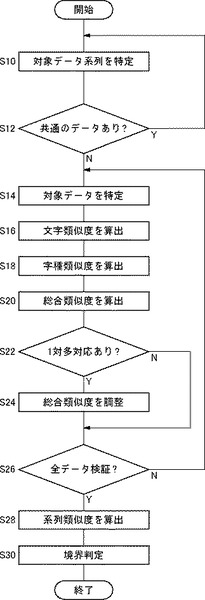
図5は、境界判定の処理過程を示すフローチャートである。
まず、データ抽出部122は、比較対象となるデータ系列を特定する(S10)。たとえば、第1行と第2行を特定する。ここで、第1行と第2行が1つのデータを共有していれば(S12のY)、いいかえれば、第1パターン構造であれば、別のデータ系列が比較対象として選択される。第1行と第2行の関係において第1パターン構造となっているときには、第2行と第3行が比較対象となる。第1パターン構造となっていなければ(S12のN)、第1データ抽出部124と第2データ抽出部126は、順次、比較対象となるデータを抽出する(S14)。図1(a)の表データの場合、第1行と第2行が比較対象となり、まず、第1データ抽出部124が「製品(1・1)」、第2データ抽出部126が「太郎(2・1)」を抽出する。類似度算出部130は、文字類似度Sim1を算出する(S16)。「製品(1・1)」と「太郎(2・1)」の場合、文字類似度Sim1は「0」となる。
【0042】
次に、字種変換部128が比較対象となるデータを字種変換し、類似度算出部130は字種類似度Sim2を算出する(S18)。「製品(1・1)」と「太郎(2・1)」の場合、「製品(1・1)」→「ZZZZ」、「太郎(2・1)」→「ZZZZ」に字種変換され、字種類似度Sim2は「1」となる。
【0043】
類似度算出部130は、次に、総合類似度Sim3を算出する(S20)。「製品(1・1)」と「太郎(2・1)」であれば、Sim3=0.3×Sim1+0.7×Sim2=0.7となる。
【0044】
ここで、比較対象となるデータが、第2パターンのように1対多対応となる場合には(S22のY)、いいかえれば、第2パターン構造であれば、補正値の加算により総合類似度を調整する(S24)。1対多対応でなければ(S22のN)、S24はスキップされる。比較対象となるデータ系列において、未検証のデータがあれば(S26のN)、処理はS14に戻る。図1(a)の表データの場合、「売上(1・2)」と「10000(2・2)」を次の比較対象として、「売上(1・2)」と「10000(2・2)」の総合類似度を求める。図1(a)の表データにおける第1行と第2行の場合、
Sim3("製品","太郎")=0.7
Sim3("売上","10000")=0
Sim3("本数","250")=0
となる。
【0045】
すべてのデータについて総合類似度を算出すると(S26のY)、類似度算出部130は、各総合類似度Sim3の平均値として系列類似度Sim4を算出する(S28)。上記例の場合、Sim4=(0.7+0+0)/3=0.23となる。境界判定部132は、系列類似度が境界閾値0.32以下であるか否かに基づいて境界判定を実行する(S30)。上記例の場合、第1行と第2行についての系列類似度Sim4は境界閾値0.32以下なので、第1行と第2行の境界は、項目部分と実体部分の境界であると判定される。
【0046】
同様にして、各列についても類似度を算出し、項目列が存在するか否かについて境界判定が実行される。こうして、表データの項目部分と実体部分が自動的に特定される。構造化文書生成部134は、境界判定の結果に基づいて、表データに含まれる各データを構造化し、XML文書を生成する。
【0047】
図6は、図1(a)の表データに基づくXML文書を示す図である。
表自体は、tableタグにより示される。recordタグは、各行を示す。図1(a)の表データは、4行なので、record要素は4つである。
【0048】
recordタグのheader属性は、対象行の行項目を示す。行項目がなければ、いいかれば、項目列がなければheader属性は設定されない。たとえば、図1(a)の表データの場合、各行の行項目は「製品」、「太郎」、「次郎」、「三郎」であるため、各行に対応するrecordタグのheader属性は、それぞれ、「製品」、「太郎」、「次郎」、「三郎」となる。
【0049】
cell要素は、対象行に含まれるデータを示す。3列なので、各record要素におけるcell要素の数は3つである。
【0050】
cellタグのheader属性は、対象データの列項目を示す。列項目がなければ、いいかえれば、項目行がなければheader属性は設定されない。対象データ自体が列項目である場合にはcellタグのtype属性として「h」が設定される。図1(a)の表データの場合、各列の列項目は「製品」、「売上」、「本数」であるため、cellタグのheader属性は、それぞれ、「製品」、「売上」、「本数」となる。ただし、第1行に含まれるデータは列項目であるため、header属性の代わりにtype属性として「h」が設定されている。
【0051】
XML文書による構造化により、XPath式によるデータ検索が可能となる。たとえば、
//record[@header="太郎"]
という検索式により、行項目名=「太郎」に該当する行のデータを検索できる。
【0052】
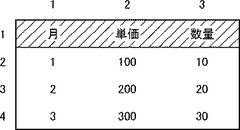
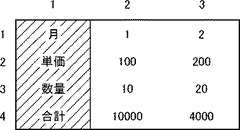
図7は、第1行だけが項目部分を形成する表データである。
図7に示す表データは、4行×3列により12個のデータを含む。第1行は項目行であり、第2行〜第4行は実体行である。また、第1列〜第3列はいずれも実体列である。
【0053】
図8は、図7の表データに基づくXML文書を示す図である。
図7の表データは、4行なので、record要素は4つである。項目列は存在しないため、いいかえれば、行項目が存在しないため、各recordタグにはheader属性が設定されない。3列なので、各record要素におけるcell要素の数は3つである。
【0054】
図7の表データの場合、各列の列項目は「月」、「単価」、「数量」である。第1行は項目行であるため、cell要素のtype属性として「h」が設定される。第2行から第4行のcell要素については、header=列項目が設定される。
【0055】
図9は、第1列だけが項目部分を形成する表データである。
図9に示す表データは、4行×3列により12個のデータを含む。第1列は項目列であり、第2列と第3列は実体列である。また、第1行〜第4行はいずれも実体行である。
【0056】
図10は、図9の表データに基づくXML文書を示す図である。
図9の表データは4行なので、record要素は4つである。また、第1列が項目列であるため、各recordタグのheader属性には行項目が設定される。3列なので、各record要素におけるcell要素の数は3つである。項目行が存在しないため、いいかえれば、列項目が存在しないため、各cellタグにはheader属性やtype属性が設定されない。
【0057】
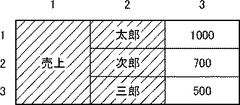
図11は、第1列と第2列が項目部分を形成する表データである。
図11に示す表データは、3行×3列であるが、第1列には1つのデータだけが含まれるため、計7個のデータが含まれている。第1列と第2列は項目列であり、第3列は実体列である。第1行〜第3行はいずれも実体行である。第1列のデータ「売上」と第2列のデータ「太郎」、「次郎」、「三郎」は、1対3の対応関係にある。したがって、第2パターン構造が形成されている。
【0058】
図12は、図11の表データに基づくXML文書を示す図である。
図11の表データは、「売上」行に「太郎」、「次郎」、「三郎」という3行が包含される構造となっている。そこで、「売上」行に対応するrecord要素に、「太郎」行に対応するrecord要素、「次郎」行に対応するrecord要素、「三郎」行に対応するrecord要素が包含されるタグ構造となっている。
「売上」行に対応するrecord要素のheader属性には、行項目である「売上」が設定される。また、「太郎」行、「次郎」行、「三郎」行にそれぞれ対応するrecord要素のheader属性には、それぞれ、行項目である「太郎」、「次郎」、「三郎」が設定される。列項目はないので、cell要素にはtype属性もheader属性も設定されない。
【0059】
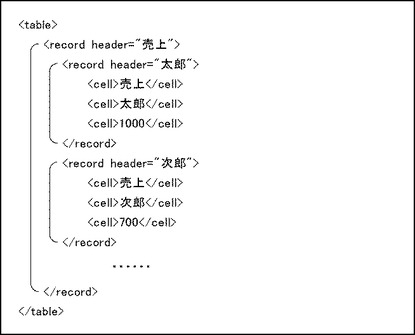
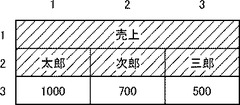
図13は、第1行と第2行が項目部分を形成する表データである。
図13に示す表データは、3行×3列であるが、第1行には1つのデータだけが含まれるため、計7個のデータが含まれている。第1行と第2行は項目行であり、第3行は実体列である。第1列〜第3列はいずれも実体列である。第1行のデータ「売上」と第2行のデータ「太郎」、「次郎」、「三郎」は、1対3の対応関係にある。したがって、第2パターン構造が形成されている。
【0060】
図14は、図13の表データに基づくXML文書を示す図である。
図13に示す表データは、3行が分離されているため、record要素は3つである。行項目は存在しないため、各record要素にheader属性は設定されない。第1行には項目データ「売上」だけが含まれるため、第1行に対応するrecord要素は、cell要素を1つしか含まない。また、第1行は項目行であるため、type属性として「h」が設定される。
【0061】
第2行は「太郎」、「次郎」、「三郎」という3つのデータを含むため、cell要素も3つである。第2行も項目行であるため、type属性として「h」が設定される。更に、第2行の各項目データは、第1行の項目データ「売上」に属しているため、3つのcell要素を包含するcell要素のheader属性として「売上」が設定される。
【0062】
第3行は「1000」、「700」、「500」という3つのデータを含むため、cell要素も3つである。第3行は実体行であるため、type属性は設定されない。更に、第3行の各項目データは、第2行の項目データ「太郎」、「次郎」、「三郎」にそれぞれ属し、更に、第1行の項目データ「売上」に属している。
【0063】
以上、実施例に基づいて表構造解析装置100を説明した。
表構造解析装置100によれば、複数のデータから構成される表データを取得したとき、項目部分と実体部分を自動的に、かつ、高い精度にて判定できる。通常、表データにおいて、項目部分と実体部分は字種が異なることが多い。このため、文字類似度ではなく、字種類似度、あるいは、総合類似度に基づいて境界判定を実行することにより、境界判定の精度をいっそう高めやすくなる。また、総合類似度を算出する際に、文字類似度よりも字種類似度に重み付け設定すれば、いっそう精度が高くなる。
【0064】
また、実施例において説明した第1パターン構造や第2パターン構造という表データの構造的な特徴を考慮することにより、境界判定の精度を更に高めることができる。境界判定の結果として特定された表構造に基づいてXML文書を作成することにより、表データをXPathなどの汎用技術により取り扱いやすくなる。
【0065】
(第2の実施の形態)
第1の実施の形態では、表構造解析装置100が表の項目部分と実体部分を自動的に判別する例について説明したが、第2の実施の形態では、表構造解析装置100が表の項目データの指定をユーザから受け付ける例について説明する。
【0066】
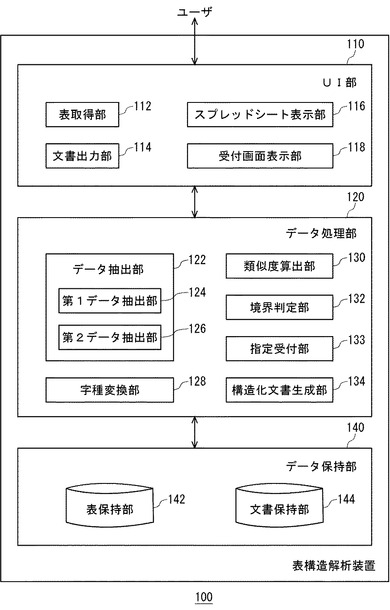
図15は、第2の実施の形態に係る表構造解析装置100の機能ブロック図である。本実施の形態の表構造解析装置100は、図2に示した第1の実施の形態の表構造解析装置100の構成に加えて、スプレッドシート表示部116、受付画面表示部118、及び指定受付部133を更に備える。
【0067】
指定受付部133は、表取得部112が取得して表保持部142に保持されている表データのうち、表全体の範囲の指定や、項目部分と実体部分の境界の指定などをユーザから受け付ける。指定受付部133は、ユーザから表の構造に関する情報を受け付けるためのユーザインタフェースとなる受付画面を受付画面表示部118に表示させ、受付画面を介してユーザから指定を受け付ける。このとき、スプレッドシート表示部116は、表全体の範囲、項目行の範囲、項目列の範囲などを受け付けるためのユーザインタフェースとして、表保持部142に保持された表データをスプレッドシート形式で表示する。指定受付部133は、スプレッドシート表示部116が表示したスプレッドシート画面において、ユーザからマウスのドラッグ操作などによる範囲の指定を受け付ける。
【0068】
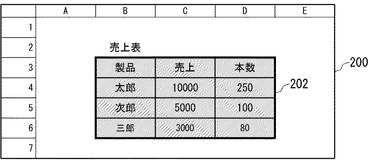
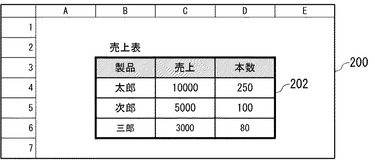
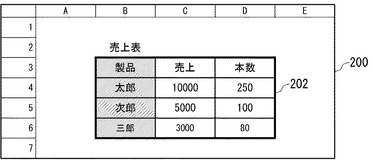
図16は、図1(a)に示した表データを、スプレッドシート形式で表示した画面の例を示す。画面200には、表取得部112が取得し、表保持部142に保持されている表データ202が表示されている。
【0069】
図17は、表の構造に関する情報をユーザから受け付けるためのユーザインタフェース画面の例を示す。図17に示したユーザインタフェース画面204では、表全体の範囲と、項目行又は項目列(見出し)の有無の設定をユーザから受け付ける。ユーザは、表の開始セル位置を入力するためのテキストボックス206と、表の終了セル位置を入力するためのテキストボックス210に、それぞれ表の開始セル位置と終了セル位置を直接入力することにより、表全体の範囲を指定することができる。また、ボタン208又はボタン212をクリックすることにより、図18に示すように、表データをスプレッドシート形式で表示した画面200において、開始セル位置から終了セル位置までマウスをドラッグするなどの操作により、表全体の範囲を指定することもできる。スプレッドシート形式の表データにおいて、複数行をセル結合して1行に見せている場合や、規則的に行間をあけて表データが記述されている場合などには、除外する行を入力するためのテキストボックス214にスキップする行数を入力することにより、指定した行数おきに表の行とするように指定することもできる。
【0070】
表データに項目行が存在する場合は、項目行(見出し行)があることを指定するためのチェックボックス216をチェックすることにより、項目行を指定することができる。この場合、指定受付部133は、指定された表データの範囲のうち、開始セル位置を含む行、すなわち、最も上に位置する最初の行を項目行として設定する。同様に、表データに項目列が存在する場合は、項目列(見出し列)があることを指定するためのチェックボックス218をチェックすることにより、項目列を指定することができる。この場合、指定受付部133は、指定された表データの範囲のうち、開始セル位置を含む列、すなわち、最も左に位置する最初の列を項目列として設定する。
【0071】
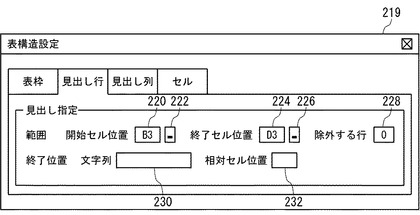
図19は、表の構造に関する情報をユーザから受け付けるためのユーザインタフェース画面の例を示す。図19に示したユーザインタフェース画面219では、項目行(見出し行)の範囲と、表全体の終了位置の設定をユーザから受け付ける。ユーザは、項目行の開始セル位置を入力するためのテキストボックス220と、項目行の終了セル位置を入力するためのテキストボックス224に、それぞれ項目行の開始セル位置と終了セル位置を直接入力することにより、項目行の範囲を指定することができる。また、ボタン222又はボタン226をクリックすることにより、図20に示すように、表データをスプレッドシート形式で表示した画面200において、開始セル位置から終了セル位置までマウスをドラッグするなどの操作により、項目行の範囲を指定することもできる。スプレッドシート形式の表データにおいて、複数行をセル結合して1行に見せている場合や、規則的に行間をあけて表データが記述されている場合などには、除外する行を入力するためのテキストボックス228にスキップする行数を入力することにより、指定した行数おきに表の行とするように指定することもできる。
【0072】
項目行の範囲が指定されると、指定受付部133は、項目行の開始セル位置を、表全体の開始セル位置とする。表の終了位置が指定されない場合は、指定受付部133は、項目行から下方へ探索し、最初に空白行が出現する直前の行までを表データとする。ユーザは、表の終了条件として、特定の文字列が出現するセルの位置を基準として、その位置からの相対セル位置を指定することもできる。例えば、文字列を入力するためのテキストボックス230に「売上表」を入力し、相対セル位置を入力するためのテキストボックス232に「(+2,+4)」を入力することにより、「売上表」という文字列が出現するセル(B,2)から(+2,+4)の位置にあるセル(D,6)を終了セル位置として指定することができる。
【0073】
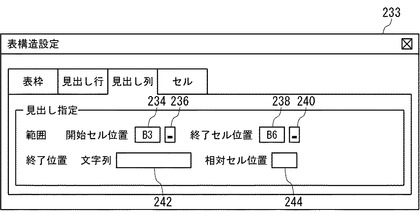
図21は、表の構造に関する情報をユーザから受け付けるためのユーザインタフェース画面の例を示す。図21に示したユーザインタフェース画面233では、項目列(見出し列)の範囲と、表全体の終了位置の設定をユーザから受け付ける。ユーザは、項目列の開始セル位置を入力するためのテキストボックス234と、項目列の終了セル位置を入力するためのテキストボックス238に、それぞれ項目列の開始セル位置と終了セル位置を直接入力することにより、項目列の範囲を指定することができる。また、ボタン236又はボタン240をクリックすることにより、図22に示すように、表データをスプレッドシート形式で表示した画面200において、開始セル位置から終了セル位置までマウスをドラッグするなどの操作により、項目列の範囲を指定することもできる。
【0074】
項目列の範囲が指定されると、指定受付部133は、項目列の開始セル位置を、表全体の開始セル位置とする。表の終了位置が指定されない場合は、指定受付部133は、項目列から右方へ探索し、最初に空白列が出現する直前の列までを表データとする。ユーザは、表の終了条件として、特定の文字列が出現するセルの位置を基準として、その位置からの相対セル位置を指定することもできる。例えば、文字列を入力するためのテキストボックス242に「売上表」を入力し、相対セル位置を入力するためのテキストボックス244に「(+2,+4)」を入力することにより、「売上表」という文字列が出現するセル(B,2)から(+2,+4)の位置にあるセル(D,6)を終了セル位置として指定することができる。
【0075】
以上のように、指定受付部133がユーザから表の構造に関する情報を受け付けると、第1の実施の形態と同様に、構造化文書生成部134は、受け付けた情報に基づいて、構造化文書を生成することができる。
【0076】
表構造解析装置100は、境界判定部132が境界を判定できないときに、指定受付部133によりユーザから指定を受け付けてもよい。また、指定受付部133がユーザから指定を受け付ける際に、境界判定部132により自動的に判定された情報を、受付画面に予めデフォルト値として入力しておいてもよい。これにより、ユーザの利便性を向上させることができる。
【0077】
以上、本発明を実施の形態をもとに説明した。この実施の形態は例示であり、それらの各構成要素や各処理プロセスの組み合わせにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【符号の説明】
【0078】
100 表構造解析装置、 110 UI部、 112 表取得部、 114 文書出力部、 116 スプレッドシート表示部、 118 受付画面表示部、 120 データ処理部、 122 データ抽出部、 124 第1データ抽出部、 126 第2データ抽出部、 128 字種変換部、 130 類似度算出部、 132 境界判定部、 133 指定受付部、 134 構造化文書生成部、 140 データ保持部、 142 表保持部。
【技術分野】
【0001】
本発明は、文書処理技術に関し、特に、表データの構造を解析するための技術、に関する。
【背景技術】
【0002】
「表データ」は、人間にとってわかりやすいだけではなく、コンピュータにとっても情報処理しやすいデータ保持形式である。表データは、通常、項目部分と実体部分を含む。項目部分は、表の項目を示すデータ(以下、「項目データ」とよぶ)が位置する領域であり、実体部分は、表の実体的な内容を示すデータ(以下、「実体データ」とよぶ)が位置する領域である。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2001−134605号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
表データを正しく処理するためには、項目部分と実体部分、いいかえれば、項目データと実体データを判別する必要がある。表データを処理する前に、項目部分や実体部分を手動により明示的に指定してもよいが、こういったやり方は煩雑である。あるいは、項目部分と実体部分を特定するためのメタ情報をあらかじめ表データに設定しておいてもよいが、すべての表作成者にメタ情報の設定を義務づけることは現実的ではない。
【0005】
本発明は、上記課題に鑑みて完成された発明であり、その主たる目的は、表データにおける項目部分と実体部分を効率的に判別するための技術を提供することである。
【課題を解決するための手段】
【0006】
本発明のある態様は、表構造解析装置に関する。
この装置は、表データにおける第1のデータ系列と第2のデータ系列からそれぞれデータを抽出する。「データ系列」とは、表データの「行」あるいは「列」であってもよい。それらのデータが類似していなければ、第1のデータ系列と第2のデータ系列の境界が、表データにおける項目部分と実体部分の境界にあたると判定する。
類似度は、第1のデータに所定の加工操作を施して第2のデータを生成するときの加工操作回数に基づいて算出される。
【0007】
なお、以上の構成要素の任意の組み合わせ、本発明の表現を方法、システム、プログラム、記録媒体などの間で変換したものもまた、本発明の態様として有効である。
【発明の効果】
【0008】
本発明によれば、表データにおける項目部分と実体部分を効率的に判別できる。
【図面の簡単な説明】
【0009】
【図1(a)】項目部分と実体部分が判別される前の表データを示す図である。
【図1(b)】項目部分と実体部分が判別された後の図1(a)の表データを示す図である。
【図2】表構造解析装置の機能ブロック図である。
【図3】一部のセルが結合している表データの一例を示す図である。
【図4】一部のセルが結合している表データの別例を示す図である。
【図5】境界判定の処理過程を示すフローチャートである。
【図6】図1(a)の表データに基づくXML文書を示す図である。
【図7】第1行だけが項目部分を形成する表データを示す図である。
【図8】図7の表データに基づくXML文書を示す図である。
【図9】第1列だけが項目部分を形成する表データを示す図である。
【図10】図9の表データに基づくXML文書を示す図である。
【図11】第1列と第2列が項目部分を形成する表データを示す図である。
【図12】図11の表データに基づくXML文書を示す図である。
【図13】第1行と第2行が項目部分を形成する表データを示す図である。
【図14】図13の表データに基づくXML文書を示す図である。
【図15】第2の実施の形態に係る表構造解析装置の機能ブロック図である。
【図16】図1(a)に示した表データを、スプレッドシート形式で表示した画面の例を示す図である。
【図17】表の構造に関する情報をユーザから受け付けるためのユーザインタフェース画面の例を示す図である。
【図18】図1(a)に示した表データを、スプレッドシート形式で表示した画面の例を示す図である。
【図19】表の構造に関する情報をユーザから受け付けるためのユーザインタフェース画面の例を示す図である。
【図20】図1(a)に示した表データを、スプレッドシート形式で表示した画面の例を示す図である。
【図21】表の構造に関する情報をユーザから受け付けるためのユーザインタフェース画面の例を示す図である。
【図22】図1(a)に示した表データを、スプレッドシート形式で表示した画面の例を示す図である。
【発明を実施するための形態】
【0010】
(第1の実施の形態)
図1(a)は、項目部分と実体部分が判別される前の表データの一例である。
図1(a)に示す表データは、4行×3列により12個のデータを含む。第1行第2列のデータ(以下、「データ(1・2)」のように表記する)である「売上」は、第2列の項目名、すなわち、「列項目」を示す。同様に、「本数(1・3)」は、第3列の列項目である。「太郎(2・1)」は、第2行の項目名、すなわち、「行項目」を示す。
【0011】
したがって、第2行第2列のデータ「10000」は、「太郎(2・1)」という「製品(1・1)」の「売上(1・2)」が「10000」であることを示している。以下、行や列として示される一連のデータ群のことを、「データ系列」とよぶ。
【0012】
図1(b)は、項目部分と実体部分が判別された後の図1(a)の表データである。
第1行の「製品」、「売上」、「本数」は、いずれも列項目を示す項目データである。以下、第1行のように項目データのみを含む行を「項目行」とよぶ。第2行の「太郎」は行項目を示す項目データであるが、「10000」と「250」は、実体データである。第2行のように実体データを含む行を「実体行」とよぶ。第3行、第4行も実体行である。
【0013】
第1列の「製品」、「太郎」、「次郎」、「三郎」は、いずれも行項目を示す項目データである。以下、第1列のように項目データのみを含む列を「項目列」とよぶ。第2列の「売上」は列項目を示す項目データであるが、「10000」、「5000」、「3000」は実体データである。第2列のように実体データを含む列を「実体列」とよぶ。第3列も実体列である。
【0014】
項目行および項目列は「項目部分」を形成し、それ以外の部分は「実体部分」を形成する。図1(b)においては、項目部分を斜線にて示している。以降に示す図においても同様である。
本実施例の表構造解析装置100は、図1(a)に示したような行列形式の表データを取得し、項目部分と実体部分を自動的に判別する装置である。
【0015】
図2は、表構造解析装置100の機能ブロック図である。
ここに示す各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組み合わせによっていろいろなかたちで実現できることは、当業者には理解されるところである。
【0016】
表構造解析装置100は、UI(ユーザ・インタフェース)部110、データ処理部120およびデータ保持部140を含む。
UI部110は、ユーザインタフェース全般に関する処理を担当する。
データ処理部120は、UI部110やデータ保持部140から取得されたデータをもとにして各種のデータ処理を実行する。データ処理部120は、UI部110とデータ保持部140の間のインタフェースの役割も果たす。
データ保持部140は、あらかじめ用意された各種の設定データや、データ処理部120から受け取ったデータを格納する。
【0017】
UI部110:
UI部110は、表取得部112および文書出力部114を含む。表取得部112は、表データを取得する。表データは、表計算アプリケーションにより生成されてもよい。表取得部112は、HTML(HyperText Markup Language)に含まれるtableタグに基づいて、HTML文書中から表データを抽出してもよい。表データは後述する構造化文書生成部134によりXML(eXtensible Markup Language)文書に変換される。XML文書以外にも、HTML文書やXHTML(eXtensible HyperText Markup Language)文書などの他形式の構造化文書ファイルに変換してもよい。文書出力部114は、生成されたXML文書を画面表示させる。あるいは、外部装置に送信する。
【0018】
データ保持部140:
データ保持部140は、表保持部142と文書保持部144を含む。表保持部142は、表取得部112が取得した表データを保持する。文書保持部144は、表データから生成されたXML文書を保持する。
【0019】
データ処理部120:
データ処理部120は、データ抽出部122、字種変換部128、類似度算出部130、境界判定部132および構造化文書生成部134を含む。データ抽出部122は、表データからデータを抽出する。データ抽出部122は、第1データ抽出部124と第2データ抽出部126を含む。第1データ抽出部124は、表データにおける第1のデータ系列からデータを抽出し、第2データ抽出部126は、第1のデータ系列に隣接する第2のデータ系列からデータを抽出する。たとえば、第1データ抽出部124が第1行からデータ(1・m)を抽出するとき、第2データ抽出部126は第2行からデータ(2・m)を抽出する。第1データ抽出部124が第1列からデータ(n・1)を抽出するとき、第2データ抽出部126は第2行からデータ(n・2)を抽出する。
【0020】
字種変換部128は、抽出されたデータに含まれる文字を、字種に応じた所定文字(以下、「字種文字」とよぶ)に変換する。字種文字への変換(以下、単に「字種変換」とよぶ)については後に詳述する。
【0021】
類似度算出部130は、類似度を算出する。本実施例における「類似度」は、「データ類似度」と「系列類似度」を総称した概念である。また、「データ類似度」は「文字類似度」、「字種類似度」および「総合類似度」を総称した概念である。境界判定部132は表データにおける項目部分と実体部分の境界を類似度、より具体的には、系列類似度に基づいて判定する(以下、このような判定を「境界判定」とよぶ)。以下、類似度について説明する。
【0022】
(1)データ類似度
(1−1)文字類似度
比較対象となる2つのデータについて、文字自体に基づく類似度を示す。文字類似度の計算式は、以下の通りである。
【0023】
【数1】
【0024】
レーベンシュタイン距離(編集距離)とは、情報理論分野において2つの文字列がどの程度異なっているかを示す指標値である。具体的には、第1の文字列に対して、文字の挿入・置換・削除・追加といった加工操作を施し、第2の文字列を生成するときの加工操作の回数を示す。加工操作が少ないほど、いいかえれば、レーベンシュタイン距離が短いほど、第1の文字列と第2の文字列は類似していることになる。
【0025】
たとえば、文字列「kitten」に加工操作を施して文字列「sitting」を生成する場合、
1回目.sitten(「kitten」の先頭文字「k」を「s」に置換)
2回目.sittin(「sitten」の5番目の文字「e」を「i」に置換)
3回目.sitting(文字「g」を追加)
という3回の加工操作が必要である。したがって、文字列「kitten」と文字列「sitting」のレーベンシュタイン距離は「3」となる。Distance(A,B)は、レーベンシュタイン距離に限らず、文字列としての違いを示す上で適切な指標値であればよい。
【0026】
文字列「kitten」は6文字、文字列「sitting」は7文字であるため、Max("kitten","sitting")は、「7」となる。したがって、Sim("kitten","sitting")=(7−3)÷7=約0.57となる。上記からも明らかなように、文字列類似度は、レーベンシュタイン距離が一定であれば文字列が長いほど、また、文字列長が一定であればレーベンシュタイン距離が短いほど大きな値となる。
【0027】
同様にして、図1(a)において第1行の「売上(1・2)」と第2行の「10000(2・2)」を比較してみる。「売上」は2文字、「10000」は5文字であるため、Max("売上","10000")=5である。Distance("売上","10000")=5である。したがって、Sim("売上","10000")=(5−5)÷5=0となる。
第2行の「10000(2・2)」と第3行の「5000(3・2)」を比較してみる。Max("10000","5000")=5、Distance("10000","5000")=2であるから、Sim("10000","5000")=(5−2)÷5=0.6となる。
【0028】
第1データ抽出部124は、第1行から「製品」、「売上」、「本数」を順次抽出する。第2データ抽出部126は、第2行から「太郎」、「10000」、「250」を順次抽出する。類似度算出部130は、「製品」と「太郎」、「売上」と「10000」、「本数」と「250」のそれぞれに組み合わせについて文字類似度を算出する。
【0029】
(1−2)字種類似度
比較対象となる2つのデータについて、字種に基づく類似度を示す。字種類似度の計算式も、文字類似度の計算式と同じである。ただし、字種類似度を計算する前に、比較対象となる各文字列に含まれる各文字を、
数字・記号 →0
英文字 →A
全角文字 →ZZ
半角カタカナ →Y
全角区切り文字→//
その他の文字 →*
のように字種変換する。「0」、「A」、「ZZ」、「Y」、「//」、「*」は字種文字である。
【0030】
たとえば、文字列「kitten」を字種変換すると「AAAAAA」、文字列「sitting」を字種変換すると「AAAAAAA」となる。字種変換後の文字列「kitten」と字種変換後の文字列「sitting」のレーベンシュタイン距離とは、文字列「AAAAAA」と文字列「AAAAAAA」のレーベンシュタイン距離であり、「1」となる。したがって、字種類似度Sim("kitten","sitting")=(7−1)÷7=約0.86となる。字種類似度も、比較対象となる文字列が長いほど、また、レーベンシュタイン距離が短いほど大きな値となる。字種の相違による影響は、文字類似度に対してよりも字種類似度に対しての方が大きい。
【0031】
同様にして、図1(a)において第1行の「売上(1・2)」と第2行の「10000(2・2)」の字種類似度を求めてみる。「売上」→「ZZZZ」、「10000」→「00000」であるため、Distance("売上","10000")=5となり、字種類似度Sim("売上","10000")=(5−5)÷5=0となる。
第2行の「10000(2・2)」と第3行の「5000(3・2)」を比較してみる。「10000」→「00000」、「5000」→「0000」であるため、Distance("10000","5000")=1となり、字種類似度Sim("10000","5000")=(5−1)÷5=0.8となる。
【0032】
字種変換部128は、第1データ抽出部124や第2データ抽出部126が抽出するデータをそれぞれ字種変換し、類似度算出部130は、字種変換後の文字列それぞれについて字種類似度を計算する。
【0033】
(1−3)総合類似度
文字類似度と字種類似度に基づく類似度である。総合類似度の計算式は、以下の通りである。
【0034】
【数2】
【0035】
第1データ抽出部124が第1行からデータを抽出し、第2データ抽出部126が第2行からデータを抽出するとき、類似度算出部130は、「製品」と「太郎」、「売上」と「10000」、「本数」と「250」のそれぞれに組み合わせについて文字類似度、字種類似度および総合類似度を算出する。本実施例においては、a=0.3、b=0.7に設定し、文字類似度よりも字種類似度の影響が大きくなるように総合類似度の計算式を設定する。
【0036】
(2)系列類似度
系列類似度は、比較対象となる2つのデータ系列についての類似度を示す。類似度算出部130は、データ類似度、すなわち、文字類似度、字種類似度あるいは総合類似度に基づいて、系列類似度を算出する。本実施例においては、総合類似度に基づいて系列類似度を算出する。より具体的には、類似度算出部130は、総合類似度の平均値を系列類似度として算出する。
たとえば、第1行と第2行を比較する場合、「製品」と「太郎」の総合類似度をA1、「売上」と「10000」の総合類似度をA2、「本数」と「250」の総合類似度をA3とすると、A1〜A3の平均値が、第1行と第2行の系列類似度となる。系列類似度が所定の閾値(以下、「境界閾値」とよぶ)以下、たとえば、0.32以下であれば、第1行と第2行の境界が項目部分と実体部分の境界であると判定する。
【0037】
表データにおける項目データと実体データを見比べると、通常、データの種別や長さに顕著な差異が表れることが多い。表構造解析装置100は、このような知見を反映したアルゴリズムによる境界判定を実現している。a=0.3、b=0.7、境界閾値=0.32として、本発明者が実験したところ、約90%の精度にて、正しく境界を判定することができた。
【0038】
なお、A1〜A3の単純平均ではなく、たとえば、加重平均により系列類似度を求めてもよい。構造化文書生成部134は、境界判定の結果にしたがって、表データを構造化し、XML文書を生成する。XML文書の生成については、図6以降に関連して詳述する。
【0039】
図3は、一部のセルが結合している表データの一例である。
図3に示す5行×3列の表データにおいて、第1行と第2行は「製品(1・1)(2・1)」を共用している。このような構造の表データの場合、通常、第1行と第2行の境界は、項目部分と実体部分の境界とはならない。そこで、比較対象となるデータ系列が1つでもデータを共用しているときには、境界判定部132は、系列類似度の計算をすることなく、境界ではないと判定する。代わりに、境界判定部132は、第2行と第3行を対象として境界判定を実行する。
以下、図3のように比較対象となるデータ系列において、データが共用される表構造のことを「第1パターン構造」とよぶ。
【0040】
図4は、一部のセルが結合している表データの別例である。
図4に示す4行×4列の表データにおいて、第1行には1つのデータだけが含まれているが、第2行には2つのデータが含まれている。すなわち、「売上(1・1〜4)」に対しては、「上期(2・1〜2)」と「下期(2・3〜4)」の2つが対応している。このような構造の表データの場合、通常、第1行と第2行の境界が項目部分と実体部分の境界となる可能性は低い。そこで、まず、第1行と第2行を比較するに際しては、「売上」と「上期」、「売上」と「下期」のそれぞれの組み合わせについて総合類似度A1、A2を算出する。更に、類似度算出部130は総合類似度A1、A2に所定の補正値、たとえば、0.07を加算する。このような補正により、図4に示す表データにおいて、第1行と第2行の境界が項目部分と実体部分の境界として判定されにくくなるように処置している。第1行と第2行の境界が項目部分と実体部分の境界として判定されなければ、境界判定部132は第2行と第3行について境界判定を実行する。
以下、図4のように比較対象となるデータ系列において、比較対象となるデータが1対多対応する表構造のことを「第2パターン構造」とよぶ。
【0041】
図5は、境界判定の処理過程を示すフローチャートである。
まず、データ抽出部122は、比較対象となるデータ系列を特定する(S10)。たとえば、第1行と第2行を特定する。ここで、第1行と第2行が1つのデータを共有していれば(S12のY)、いいかえれば、第1パターン構造であれば、別のデータ系列が比較対象として選択される。第1行と第2行の関係において第1パターン構造となっているときには、第2行と第3行が比較対象となる。第1パターン構造となっていなければ(S12のN)、第1データ抽出部124と第2データ抽出部126は、順次、比較対象となるデータを抽出する(S14)。図1(a)の表データの場合、第1行と第2行が比較対象となり、まず、第1データ抽出部124が「製品(1・1)」、第2データ抽出部126が「太郎(2・1)」を抽出する。類似度算出部130は、文字類似度Sim1を算出する(S16)。「製品(1・1)」と「太郎(2・1)」の場合、文字類似度Sim1は「0」となる。
【0042】
次に、字種変換部128が比較対象となるデータを字種変換し、類似度算出部130は字種類似度Sim2を算出する(S18)。「製品(1・1)」と「太郎(2・1)」の場合、「製品(1・1)」→「ZZZZ」、「太郎(2・1)」→「ZZZZ」に字種変換され、字種類似度Sim2は「1」となる。
【0043】
類似度算出部130は、次に、総合類似度Sim3を算出する(S20)。「製品(1・1)」と「太郎(2・1)」であれば、Sim3=0.3×Sim1+0.7×Sim2=0.7となる。
【0044】
ここで、比較対象となるデータが、第2パターンのように1対多対応となる場合には(S22のY)、いいかえれば、第2パターン構造であれば、補正値の加算により総合類似度を調整する(S24)。1対多対応でなければ(S22のN)、S24はスキップされる。比較対象となるデータ系列において、未検証のデータがあれば(S26のN)、処理はS14に戻る。図1(a)の表データの場合、「売上(1・2)」と「10000(2・2)」を次の比較対象として、「売上(1・2)」と「10000(2・2)」の総合類似度を求める。図1(a)の表データにおける第1行と第2行の場合、
Sim3("製品","太郎")=0.7
Sim3("売上","10000")=0
Sim3("本数","250")=0
となる。
【0045】
すべてのデータについて総合類似度を算出すると(S26のY)、類似度算出部130は、各総合類似度Sim3の平均値として系列類似度Sim4を算出する(S28)。上記例の場合、Sim4=(0.7+0+0)/3=0.23となる。境界判定部132は、系列類似度が境界閾値0.32以下であるか否かに基づいて境界判定を実行する(S30)。上記例の場合、第1行と第2行についての系列類似度Sim4は境界閾値0.32以下なので、第1行と第2行の境界は、項目部分と実体部分の境界であると判定される。
【0046】
同様にして、各列についても類似度を算出し、項目列が存在するか否かについて境界判定が実行される。こうして、表データの項目部分と実体部分が自動的に特定される。構造化文書生成部134は、境界判定の結果に基づいて、表データに含まれる各データを構造化し、XML文書を生成する。
【0047】
図6は、図1(a)の表データに基づくXML文書を示す図である。
表自体は、tableタグにより示される。recordタグは、各行を示す。図1(a)の表データは、4行なので、record要素は4つである。
【0048】
recordタグのheader属性は、対象行の行項目を示す。行項目がなければ、いいかれば、項目列がなければheader属性は設定されない。たとえば、図1(a)の表データの場合、各行の行項目は「製品」、「太郎」、「次郎」、「三郎」であるため、各行に対応するrecordタグのheader属性は、それぞれ、「製品」、「太郎」、「次郎」、「三郎」となる。
【0049】
cell要素は、対象行に含まれるデータを示す。3列なので、各record要素におけるcell要素の数は3つである。
【0050】
cellタグのheader属性は、対象データの列項目を示す。列項目がなければ、いいかえれば、項目行がなければheader属性は設定されない。対象データ自体が列項目である場合にはcellタグのtype属性として「h」が設定される。図1(a)の表データの場合、各列の列項目は「製品」、「売上」、「本数」であるため、cellタグのheader属性は、それぞれ、「製品」、「売上」、「本数」となる。ただし、第1行に含まれるデータは列項目であるため、header属性の代わりにtype属性として「h」が設定されている。
【0051】
XML文書による構造化により、XPath式によるデータ検索が可能となる。たとえば、
//record[@header="太郎"]
という検索式により、行項目名=「太郎」に該当する行のデータを検索できる。
【0052】
図7は、第1行だけが項目部分を形成する表データである。
図7に示す表データは、4行×3列により12個のデータを含む。第1行は項目行であり、第2行〜第4行は実体行である。また、第1列〜第3列はいずれも実体列である。
【0053】
図8は、図7の表データに基づくXML文書を示す図である。
図7の表データは、4行なので、record要素は4つである。項目列は存在しないため、いいかえれば、行項目が存在しないため、各recordタグにはheader属性が設定されない。3列なので、各record要素におけるcell要素の数は3つである。
【0054】
図7の表データの場合、各列の列項目は「月」、「単価」、「数量」である。第1行は項目行であるため、cell要素のtype属性として「h」が設定される。第2行から第4行のcell要素については、header=列項目が設定される。
【0055】
図9は、第1列だけが項目部分を形成する表データである。
図9に示す表データは、4行×3列により12個のデータを含む。第1列は項目列であり、第2列と第3列は実体列である。また、第1行〜第4行はいずれも実体行である。
【0056】
図10は、図9の表データに基づくXML文書を示す図である。
図9の表データは4行なので、record要素は4つである。また、第1列が項目列であるため、各recordタグのheader属性には行項目が設定される。3列なので、各record要素におけるcell要素の数は3つである。項目行が存在しないため、いいかえれば、列項目が存在しないため、各cellタグにはheader属性やtype属性が設定されない。
【0057】
図11は、第1列と第2列が項目部分を形成する表データである。
図11に示す表データは、3行×3列であるが、第1列には1つのデータだけが含まれるため、計7個のデータが含まれている。第1列と第2列は項目列であり、第3列は実体列である。第1行〜第3行はいずれも実体行である。第1列のデータ「売上」と第2列のデータ「太郎」、「次郎」、「三郎」は、1対3の対応関係にある。したがって、第2パターン構造が形成されている。
【0058】
図12は、図11の表データに基づくXML文書を示す図である。
図11の表データは、「売上」行に「太郎」、「次郎」、「三郎」という3行が包含される構造となっている。そこで、「売上」行に対応するrecord要素に、「太郎」行に対応するrecord要素、「次郎」行に対応するrecord要素、「三郎」行に対応するrecord要素が包含されるタグ構造となっている。
「売上」行に対応するrecord要素のheader属性には、行項目である「売上」が設定される。また、「太郎」行、「次郎」行、「三郎」行にそれぞれ対応するrecord要素のheader属性には、それぞれ、行項目である「太郎」、「次郎」、「三郎」が設定される。列項目はないので、cell要素にはtype属性もheader属性も設定されない。
【0059】
図13は、第1行と第2行が項目部分を形成する表データである。
図13に示す表データは、3行×3列であるが、第1行には1つのデータだけが含まれるため、計7個のデータが含まれている。第1行と第2行は項目行であり、第3行は実体列である。第1列〜第3列はいずれも実体列である。第1行のデータ「売上」と第2行のデータ「太郎」、「次郎」、「三郎」は、1対3の対応関係にある。したがって、第2パターン構造が形成されている。
【0060】
図14は、図13の表データに基づくXML文書を示す図である。
図13に示す表データは、3行が分離されているため、record要素は3つである。行項目は存在しないため、各record要素にheader属性は設定されない。第1行には項目データ「売上」だけが含まれるため、第1行に対応するrecord要素は、cell要素を1つしか含まない。また、第1行は項目行であるため、type属性として「h」が設定される。
【0061】
第2行は「太郎」、「次郎」、「三郎」という3つのデータを含むため、cell要素も3つである。第2行も項目行であるため、type属性として「h」が設定される。更に、第2行の各項目データは、第1行の項目データ「売上」に属しているため、3つのcell要素を包含するcell要素のheader属性として「売上」が設定される。
【0062】
第3行は「1000」、「700」、「500」という3つのデータを含むため、cell要素も3つである。第3行は実体行であるため、type属性は設定されない。更に、第3行の各項目データは、第2行の項目データ「太郎」、「次郎」、「三郎」にそれぞれ属し、更に、第1行の項目データ「売上」に属している。
【0063】
以上、実施例に基づいて表構造解析装置100を説明した。
表構造解析装置100によれば、複数のデータから構成される表データを取得したとき、項目部分と実体部分を自動的に、かつ、高い精度にて判定できる。通常、表データにおいて、項目部分と実体部分は字種が異なることが多い。このため、文字類似度ではなく、字種類似度、あるいは、総合類似度に基づいて境界判定を実行することにより、境界判定の精度をいっそう高めやすくなる。また、総合類似度を算出する際に、文字類似度よりも字種類似度に重み付け設定すれば、いっそう精度が高くなる。
【0064】
また、実施例において説明した第1パターン構造や第2パターン構造という表データの構造的な特徴を考慮することにより、境界判定の精度を更に高めることができる。境界判定の結果として特定された表構造に基づいてXML文書を作成することにより、表データをXPathなどの汎用技術により取り扱いやすくなる。
【0065】
(第2の実施の形態)
第1の実施の形態では、表構造解析装置100が表の項目部分と実体部分を自動的に判別する例について説明したが、第2の実施の形態では、表構造解析装置100が表の項目データの指定をユーザから受け付ける例について説明する。
【0066】
図15は、第2の実施の形態に係る表構造解析装置100の機能ブロック図である。本実施の形態の表構造解析装置100は、図2に示した第1の実施の形態の表構造解析装置100の構成に加えて、スプレッドシート表示部116、受付画面表示部118、及び指定受付部133を更に備える。
【0067】
指定受付部133は、表取得部112が取得して表保持部142に保持されている表データのうち、表全体の範囲の指定や、項目部分と実体部分の境界の指定などをユーザから受け付ける。指定受付部133は、ユーザから表の構造に関する情報を受け付けるためのユーザインタフェースとなる受付画面を受付画面表示部118に表示させ、受付画面を介してユーザから指定を受け付ける。このとき、スプレッドシート表示部116は、表全体の範囲、項目行の範囲、項目列の範囲などを受け付けるためのユーザインタフェースとして、表保持部142に保持された表データをスプレッドシート形式で表示する。指定受付部133は、スプレッドシート表示部116が表示したスプレッドシート画面において、ユーザからマウスのドラッグ操作などによる範囲の指定を受け付ける。
【0068】
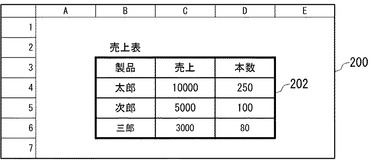
図16は、図1(a)に示した表データを、スプレッドシート形式で表示した画面の例を示す。画面200には、表取得部112が取得し、表保持部142に保持されている表データ202が表示されている。
【0069】
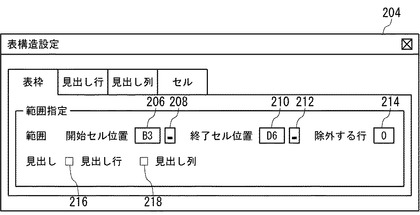
図17は、表の構造に関する情報をユーザから受け付けるためのユーザインタフェース画面の例を示す。図17に示したユーザインタフェース画面204では、表全体の範囲と、項目行又は項目列(見出し)の有無の設定をユーザから受け付ける。ユーザは、表の開始セル位置を入力するためのテキストボックス206と、表の終了セル位置を入力するためのテキストボックス210に、それぞれ表の開始セル位置と終了セル位置を直接入力することにより、表全体の範囲を指定することができる。また、ボタン208又はボタン212をクリックすることにより、図18に示すように、表データをスプレッドシート形式で表示した画面200において、開始セル位置から終了セル位置までマウスをドラッグするなどの操作により、表全体の範囲を指定することもできる。スプレッドシート形式の表データにおいて、複数行をセル結合して1行に見せている場合や、規則的に行間をあけて表データが記述されている場合などには、除外する行を入力するためのテキストボックス214にスキップする行数を入力することにより、指定した行数おきに表の行とするように指定することもできる。
【0070】
表データに項目行が存在する場合は、項目行(見出し行)があることを指定するためのチェックボックス216をチェックすることにより、項目行を指定することができる。この場合、指定受付部133は、指定された表データの範囲のうち、開始セル位置を含む行、すなわち、最も上に位置する最初の行を項目行として設定する。同様に、表データに項目列が存在する場合は、項目列(見出し列)があることを指定するためのチェックボックス218をチェックすることにより、項目列を指定することができる。この場合、指定受付部133は、指定された表データの範囲のうち、開始セル位置を含む列、すなわち、最も左に位置する最初の列を項目列として設定する。
【0071】
図19は、表の構造に関する情報をユーザから受け付けるためのユーザインタフェース画面の例を示す。図19に示したユーザインタフェース画面219では、項目行(見出し行)の範囲と、表全体の終了位置の設定をユーザから受け付ける。ユーザは、項目行の開始セル位置を入力するためのテキストボックス220と、項目行の終了セル位置を入力するためのテキストボックス224に、それぞれ項目行の開始セル位置と終了セル位置を直接入力することにより、項目行の範囲を指定することができる。また、ボタン222又はボタン226をクリックすることにより、図20に示すように、表データをスプレッドシート形式で表示した画面200において、開始セル位置から終了セル位置までマウスをドラッグするなどの操作により、項目行の範囲を指定することもできる。スプレッドシート形式の表データにおいて、複数行をセル結合して1行に見せている場合や、規則的に行間をあけて表データが記述されている場合などには、除外する行を入力するためのテキストボックス228にスキップする行数を入力することにより、指定した行数おきに表の行とするように指定することもできる。
【0072】
項目行の範囲が指定されると、指定受付部133は、項目行の開始セル位置を、表全体の開始セル位置とする。表の終了位置が指定されない場合は、指定受付部133は、項目行から下方へ探索し、最初に空白行が出現する直前の行までを表データとする。ユーザは、表の終了条件として、特定の文字列が出現するセルの位置を基準として、その位置からの相対セル位置を指定することもできる。例えば、文字列を入力するためのテキストボックス230に「売上表」を入力し、相対セル位置を入力するためのテキストボックス232に「(+2,+4)」を入力することにより、「売上表」という文字列が出現するセル(B,2)から(+2,+4)の位置にあるセル(D,6)を終了セル位置として指定することができる。
【0073】
図21は、表の構造に関する情報をユーザから受け付けるためのユーザインタフェース画面の例を示す。図21に示したユーザインタフェース画面233では、項目列(見出し列)の範囲と、表全体の終了位置の設定をユーザから受け付ける。ユーザは、項目列の開始セル位置を入力するためのテキストボックス234と、項目列の終了セル位置を入力するためのテキストボックス238に、それぞれ項目列の開始セル位置と終了セル位置を直接入力することにより、項目列の範囲を指定することができる。また、ボタン236又はボタン240をクリックすることにより、図22に示すように、表データをスプレッドシート形式で表示した画面200において、開始セル位置から終了セル位置までマウスをドラッグするなどの操作により、項目列の範囲を指定することもできる。
【0074】
項目列の範囲が指定されると、指定受付部133は、項目列の開始セル位置を、表全体の開始セル位置とする。表の終了位置が指定されない場合は、指定受付部133は、項目列から右方へ探索し、最初に空白列が出現する直前の列までを表データとする。ユーザは、表の終了条件として、特定の文字列が出現するセルの位置を基準として、その位置からの相対セル位置を指定することもできる。例えば、文字列を入力するためのテキストボックス242に「売上表」を入力し、相対セル位置を入力するためのテキストボックス244に「(+2,+4)」を入力することにより、「売上表」という文字列が出現するセル(B,2)から(+2,+4)の位置にあるセル(D,6)を終了セル位置として指定することができる。
【0075】
以上のように、指定受付部133がユーザから表の構造に関する情報を受け付けると、第1の実施の形態と同様に、構造化文書生成部134は、受け付けた情報に基づいて、構造化文書を生成することができる。
【0076】
表構造解析装置100は、境界判定部132が境界を判定できないときに、指定受付部133によりユーザから指定を受け付けてもよい。また、指定受付部133がユーザから指定を受け付ける際に、境界判定部132により自動的に判定された情報を、受付画面に予めデフォルト値として入力しておいてもよい。これにより、ユーザの利便性を向上させることができる。
【0077】
以上、本発明を実施の形態をもとに説明した。この実施の形態は例示であり、それらの各構成要素や各処理プロセスの組み合わせにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
【符号の説明】
【0078】
100 表構造解析装置、 110 UI部、 112 表取得部、 114 文書出力部、 116 スプレッドシート表示部、 118 受付画面表示部、 120 データ処理部、 122 データ抽出部、 124 第1データ抽出部、 126 第2データ抽出部、 128 字種変換部、 130 類似度算出部、 132 境界判定部、 133 指定受付部、 134 構造化文書生成部、 140 データ保持部、 142 表保持部。
【特許請求の範囲】
【請求項1】
表データを取得する表取得部と、
前記表データにおける第1のデータ系列から、第1のデータを抽出する第1データ抽出部と、
前記第1のデータ系列と隣接する第2のデータ系列から、第2のデータを抽出する第2データ抽出部と、
前記第1のデータと前記第2のデータの類似度を算出する類似度算出部と、
前記類似度が所定の閾値よりも小さいとき、前記第1のデータ系列と前記第2のデータ系列の境界が、表データにおける項目部分と実体部分の境界にあたると判定する境界判定部と、を備え、
前記類似度算出部は、前記第1のデータに所定の加工操作を施して前記第2のデータを生成するときの加工操作回数が少ないほど高い類似度を算出することを特徴とする表構造解析装置。
【請求項2】
前記類似度算出部は、前記第1のデータと前記第2のデータのレーベンシュタイン距離(Levenshtein Distance)が小さいほど高い類似度を算出することを特徴とする請求項1に記載の表構造解析装置。
【請求項3】
前記類似度算出部は、更に、前記第1のデータの文字数または前記第2のデータの文字数が多いほど高い類似度を算出することを特徴とする請求項1または2に記載の表構造解析装置。
【請求項4】
データに含まれる文字を、その字種を示す字種文字に変換する字種変換部、を更に備え、
前記類似度算出部は、変換後の前記第1のデータおよび変換後の前記第2のデータを対象として類似度を算出することを特徴とする請求項1から3のいずれかに記載の表構造解析装置。
【請求項5】
前記類似度算出部は、変換前の前記第1のデータおよび変換前の前記第2のデータを対象とする類似度を文字類似度、変換後の前記第1のデータおよび変換後の前記第2のデータを対象とする類似度を字種類似度としてそれぞれ算出し、文字類似度と字種類似度の加算値を境界判定のための類似度として算出することを特徴とする請求項4に記載の表構造解析装置。
【請求項6】
前記類似度算出部は、文字類似度および字種類似度の双方または一方を重み付けした上で、加算することを特徴とする請求項5に記載の表構造解析装置。
【請求項7】
前記類似度算出部は、文字類似度よりも字種類似度の重みが大きくなるように重み付け設定することを特徴とする請求項6に記載の表構造解析装置。
【請求項8】
前記類似度算出部は、前記第1のデータ系列と前記第2のデータ系列において互いに対応関係にある第1のデータと第2のデータを一セットとして、複数セットそれぞれについての類似度をデータ類似度として算出し、複数セットについての各データ類似度から前記第1のデータ系列と前記第2のデータ系列のデータ系列としての類似度を系列類似度として算出し、
前記境界判定部は、系列類似度が所定の閾値よりも小さいとき、前記第1のデータ系列および前記第2のデータ系列の境界が、項目部分と実体部分の境界にあたると判定することを特徴とする請求項1から7のいずれかに記載の表構造解析装置。
【請求項9】
前記境界判定部は、前記第1のデータ系列と前記第2のデータ系列に共用されるデータが存在するときには、前記第1のデータ系列および前記第2のデータ系列の境界は項目部分と実体部分の境界ではないと判定することを特徴とする請求項1から8のいずれかに記載の表構造解析装置。
【請求項10】
前記類似度算出部は、前記第1のデータ系列における一のデータに対し、前記第2のデータ系列において複数のデータが対応付けられているときには、類似度が高くなるように調整することを特徴とする請求項1から9のいずれかに記載の表構造解析装置。
【請求項11】
前記第1のデータ系列が項目部分を示すデータ系列であり、前記第2のデータ系列が実体部分を示すデータ系列であるとき、前記第1のデータ系列に含まれるデータに対しては項目を示す属性情報を付与し、前記第2のデータ系列に含まれるデータに対しては内容を示す属性情報を付与することにより、前記表データの構造を反映した構造化文書ファイルを生成する構造化文書生成部、を更に備えることを特徴とする請求項1から10のいずれかに記載の表構造解析装置。
【請求項12】
項目部分と実体部分の境界の指定をユーザから受け付ける指定受付部を更に備えることを特徴とする請求項1から11のいずれかに記載の表構造解析装置。
【請求項13】
表データを取得するステップと、
前記表データにおける第1のデータ系列から、第1のデータを抽出するステップと、
前記第1のデータ系列と隣接する第2のデータ系列から、第2のデータを抽出するステップと、
前記第1のデータと前記第2のデータの類似度を算出するステップと、
前記類似度が所定の閾値よりも小さいとき、前記第1のデータ系列と前記第2のデータ系列の境界が、表データにおける項目部分と実体部分の境界にあたると判定するステップと、を含み、
前記第1のデータに所定の加工操作を施して前記第2のデータを生成するときの加工操作回数が少ないほど高い類似度を算出することを特徴とする表構造解析方法。
【請求項14】
表データを取得する処理と、
前記表データにおける第1のデータ系列から、第1のデータを抽出する処理と、
前記第1のデータ系列と隣接する第2のデータ系列から、第2のデータを抽出する処理と、
前記第1のデータと前記第2のデータの類似度を算出する処理と、
前記類似度が所定の閾値よりも小さいとき、前記第1のデータ系列と前記第2のデータ系列の境界が、表データにおける項目部分と実体部分の境界にあたると判定する処理と、をコンピュータに実行させ、
前記第1のデータに所定の加工操作を施して前記第2のデータを生成するときの加工操作回数が少ないほど高い類似度を算出することを特徴とする表構造解析プログラム。
【請求項1】
表データを取得する表取得部と、
前記表データにおける第1のデータ系列から、第1のデータを抽出する第1データ抽出部と、
前記第1のデータ系列と隣接する第2のデータ系列から、第2のデータを抽出する第2データ抽出部と、
前記第1のデータと前記第2のデータの類似度を算出する類似度算出部と、
前記類似度が所定の閾値よりも小さいとき、前記第1のデータ系列と前記第2のデータ系列の境界が、表データにおける項目部分と実体部分の境界にあたると判定する境界判定部と、を備え、
前記類似度算出部は、前記第1のデータに所定の加工操作を施して前記第2のデータを生成するときの加工操作回数が少ないほど高い類似度を算出することを特徴とする表構造解析装置。
【請求項2】
前記類似度算出部は、前記第1のデータと前記第2のデータのレーベンシュタイン距離(Levenshtein Distance)が小さいほど高い類似度を算出することを特徴とする請求項1に記載の表構造解析装置。
【請求項3】
前記類似度算出部は、更に、前記第1のデータの文字数または前記第2のデータの文字数が多いほど高い類似度を算出することを特徴とする請求項1または2に記載の表構造解析装置。
【請求項4】
データに含まれる文字を、その字種を示す字種文字に変換する字種変換部、を更に備え、
前記類似度算出部は、変換後の前記第1のデータおよび変換後の前記第2のデータを対象として類似度を算出することを特徴とする請求項1から3のいずれかに記載の表構造解析装置。
【請求項5】
前記類似度算出部は、変換前の前記第1のデータおよび変換前の前記第2のデータを対象とする類似度を文字類似度、変換後の前記第1のデータおよび変換後の前記第2のデータを対象とする類似度を字種類似度としてそれぞれ算出し、文字類似度と字種類似度の加算値を境界判定のための類似度として算出することを特徴とする請求項4に記載の表構造解析装置。
【請求項6】
前記類似度算出部は、文字類似度および字種類似度の双方または一方を重み付けした上で、加算することを特徴とする請求項5に記載の表構造解析装置。
【請求項7】
前記類似度算出部は、文字類似度よりも字種類似度の重みが大きくなるように重み付け設定することを特徴とする請求項6に記載の表構造解析装置。
【請求項8】
前記類似度算出部は、前記第1のデータ系列と前記第2のデータ系列において互いに対応関係にある第1のデータと第2のデータを一セットとして、複数セットそれぞれについての類似度をデータ類似度として算出し、複数セットについての各データ類似度から前記第1のデータ系列と前記第2のデータ系列のデータ系列としての類似度を系列類似度として算出し、
前記境界判定部は、系列類似度が所定の閾値よりも小さいとき、前記第1のデータ系列および前記第2のデータ系列の境界が、項目部分と実体部分の境界にあたると判定することを特徴とする請求項1から7のいずれかに記載の表構造解析装置。
【請求項9】
前記境界判定部は、前記第1のデータ系列と前記第2のデータ系列に共用されるデータが存在するときには、前記第1のデータ系列および前記第2のデータ系列の境界は項目部分と実体部分の境界ではないと判定することを特徴とする請求項1から8のいずれかに記載の表構造解析装置。
【請求項10】
前記類似度算出部は、前記第1のデータ系列における一のデータに対し、前記第2のデータ系列において複数のデータが対応付けられているときには、類似度が高くなるように調整することを特徴とする請求項1から9のいずれかに記載の表構造解析装置。
【請求項11】
前記第1のデータ系列が項目部分を示すデータ系列であり、前記第2のデータ系列が実体部分を示すデータ系列であるとき、前記第1のデータ系列に含まれるデータに対しては項目を示す属性情報を付与し、前記第2のデータ系列に含まれるデータに対しては内容を示す属性情報を付与することにより、前記表データの構造を反映した構造化文書ファイルを生成する構造化文書生成部、を更に備えることを特徴とする請求項1から10のいずれかに記載の表構造解析装置。
【請求項12】
項目部分と実体部分の境界の指定をユーザから受け付ける指定受付部を更に備えることを特徴とする請求項1から11のいずれかに記載の表構造解析装置。
【請求項13】
表データを取得するステップと、
前記表データにおける第1のデータ系列から、第1のデータを抽出するステップと、
前記第1のデータ系列と隣接する第2のデータ系列から、第2のデータを抽出するステップと、
前記第1のデータと前記第2のデータの類似度を算出するステップと、
前記類似度が所定の閾値よりも小さいとき、前記第1のデータ系列と前記第2のデータ系列の境界が、表データにおける項目部分と実体部分の境界にあたると判定するステップと、を含み、
前記第1のデータに所定の加工操作を施して前記第2のデータを生成するときの加工操作回数が少ないほど高い類似度を算出することを特徴とする表構造解析方法。
【請求項14】
表データを取得する処理と、
前記表データにおける第1のデータ系列から、第1のデータを抽出する処理と、
前記第1のデータ系列と隣接する第2のデータ系列から、第2のデータを抽出する処理と、
前記第1のデータと前記第2のデータの類似度を算出する処理と、
前記類似度が所定の閾値よりも小さいとき、前記第1のデータ系列と前記第2のデータ系列の境界が、表データにおける項目部分と実体部分の境界にあたると判定する処理と、をコンピュータに実行させ、
前記第1のデータに所定の加工操作を施して前記第2のデータを生成するときの加工操作回数が少ないほど高い類似度を算出することを特徴とする表構造解析プログラム。
【図1(a)】

【図1(b)】
【図2】
【図3】
【図4】
【図5】
【図6】

【図7】
【図8】

【図9】
【図10】

【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図1(b)】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【公開番号】特開2010−15554(P2010−15554A)
【公開日】平成22年1月21日(2010.1.21)
【国際特許分類】
【出願番号】特願2009−134418(P2009−134418)
【出願日】平成21年6月3日(2009.6.3)
【出願人】(390024350)株式会社ジャストシステム (123)
【Fターム(参考)】
【公開日】平成22年1月21日(2010.1.21)
【国際特許分類】
【出願日】平成21年6月3日(2009.6.3)
【出願人】(390024350)株式会社ジャストシステム (123)
【Fターム(参考)】
[ Back to top ]