
複数信号区間推定装置、複数信号区間推定方法、そのプログラムおよび記録媒体

【課題】音声の収録中に話者位置の移動が生じても、同一話者には同一インデックスを付与することを可能とする。
【解決手段】周波数領域変換部110が観測信号を所定長のフレームに順次切り出して当該フレームごとに周波数領域に変換し、音声区間推定部120が周波数領域の観測信号に基づき、各フレームが音声区間に該当するか否かを推定し、到来方向推定部130が周波数領域の観測信号に基づき、当該周波数領域の観測信号の到来方向を各フレームごとに推定し、到来方向分類部140が音声区間に該当すると推定された各フレームを、到来方向の類似性に基づき話者ごとのクラスタに分類する。そして、話者同定部250が所定の時刻までに同一クラスタに分類された各フレームの周波数領域の観測信号に基づき、当該クラスタに係る話者のモデルをクラスタごとに作成し、当該所定の時刻以降の観測信号の話者を各話者のモデルに基づき推定する。
【解決手段】周波数領域変換部110が観測信号を所定長のフレームに順次切り出して当該フレームごとに周波数領域に変換し、音声区間推定部120が周波数領域の観測信号に基づき、各フレームが音声区間に該当するか否かを推定し、到来方向推定部130が周波数領域の観測信号に基づき、当該周波数領域の観測信号の到来方向を各フレームごとに推定し、到来方向分類部140が音声区間に該当すると推定された各フレームを、到来方向の類似性に基づき話者ごとのクラスタに分類する。そして、話者同定部250が所定の時刻までに同一クラスタに分類された各フレームの周波数領域の観測信号に基づき、当該クラスタに係る話者のモデルをクラスタごとに作成し、当該所定の時刻以降の観測信号の話者を各話者のモデルに基づき推定する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、信号処理の技術分野に属する。特に、複数人の音声信号が混在している音響データについて、各人の音声信号が発せられている区間を推定する複数信号区間推定装置、複数信号区間推定方法、そのプログラムおよび記録媒体に関する。
【背景技術】
【0002】
複数人による会話などを複数のマイクで収録し、「いつ、誰が話したか」を推定する音声区間検出技術は、例えば会議録自動作成において、各発言に発話者を自動的に付与したり、会議収録データに話者情報を付与して録音データの検索や頭出しを容易にしたりする際に有用である。
【0003】
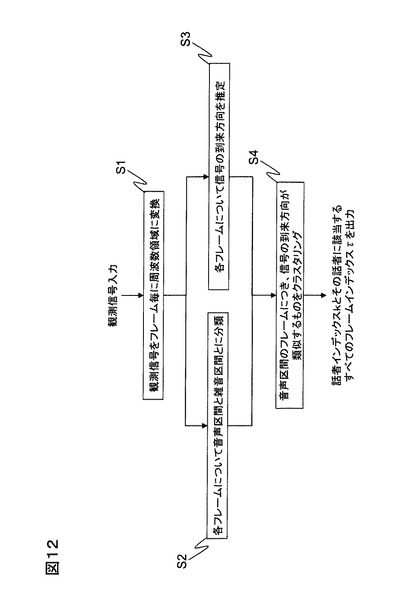
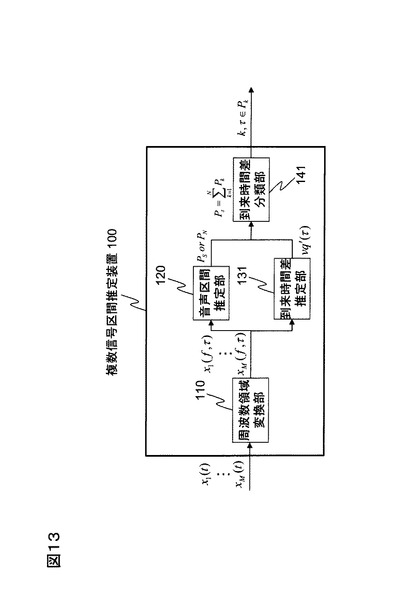
従来の音声区間検出技術としては、例えば特許文献1や非特許文献1などで開示されている方法が挙げられる。図11に従来技術による複数信号区間推定装置100の機能構成例を、図12にその処理フロー例を示す。複数信号区間推定装置100は、周波数領域変換部110と音声区間推定部120と到来方向推定部130と到来方向分類部140とから構成される。
【0004】
周波数領域変換部110は、M本のマイクによりそれぞれ収録した時間領域の観測信号xj(t)(j=1、・・・、M)を、例えば32msごとに窓関数で切り出して(切り出した1区間を以下、「フレーム」という)、切り出した各フレーム(インデックスをτとする)についてフーリエ変換等によりそれぞれ周波数領域の観測信号xj(f,τ) (f=1、・・・、L)に変換する(S1)。
【0005】
音声区間推定部120は、周波数領域変換部110で周波数領域に変換された観測信号の各フレームに音声が存在するか否かを、音声存在確率を計算することにより推定する(S2)。音声存在確率の計算に際しては、例えば非特許文献2、非特許文献3に記載された方法が利用できる。前者で説明すると、該当フレームにおける音声存在確率pV(τ)を次式により求める。
【数1】

ここで、λN(f)は周波数fにおけるノイズの平均パワー(音声が明らかに存在しない録音ファイルの冒頭区間などで求める)、x(f,τ)はM本のマイクにおける周波数領域の観測信号x1(f,τ)〜xM(f,τ)の中から任意に選んだいずれか1本についての周波数領域の観測信号である。なお、x(f,τ)はすべてのマイクの振幅の平均値として次のように求めても構わない。
【数2】
音声区間推定部120は、式(1)により求めた音声存在確率pV(τ)をそのまま出力してもよいし、pV(τ)がある閾値より大きければそのフレームは音声区間PSであると判定し、小さければ非音声(ノイズ)区間PNと判定して結果を出力してもよい。
【0006】
到来方向推定部130は、周波数領域変換部110で周波数領域に変換された観測信号の到来方向を各フレームごと又は各フレームの各周波数成分ごとにを推定する(S3)。具体的には、観測信号のマイクjとマイクj´とからの到来時間差q´jj′を全てのマイクペアについて求め、それらを並べた縦ベクトルとマイクの座標系とから音声到来方向ベクトルを推定する。
【0007】
各フレームごとに到来時間差q´jj′を計算する手法として、非特許文献4にて開示されているGCC−PHATと呼ばれる手法がある。この手法においては到来時間差q´jj′(τ)を次式に従い算出する。
【数3】
これをすべてのマイクペアjj´について求めて、それらを並べた縦ベクトルをvq´(τ)とする。なお、すべてのマイクペアを用いる代わりに、ある基準マイクを決め、基準マイクとその他のマイクに関するすべてのペアを用いてもよい。音声到来方向ベクトルvq(τ)は、vq´(τ)と音速cとマイクの座標系VDとから次式により推定する。
vq(τ)=c・VD+・vq´(τ) (4)
ここで、+はMoore-Penroseの疑似逆行列を表し、vdjがマイクjの座標を[x,y,z]と並べたベクトルであるとき、VD=[vd1−vdj,・・・,vdM−vdj]Tである。このように求めた音声到来方向ベクトルvq(τ)は、到来方向の水平角がθ、仰角がφとすると、次式のように表すことができる。
vq(τ)=[cosθ・cosφ,sinθ・cosφ,sinφ]T (5)
【0008】
各フレームの各周波数成分ごとに到来時間差q´jj′を計算する場合は、マイクjとマイクj´との到来時間差q´jj′(f,τ)を次式に従い算出する。
【数4】
これをすべてのマイクペアjj´について求めて(又は上記のように基準マイクに対して求めて)、それらを並べた縦ベクトルをvq´(f,τ)とし、式(4)と同様にして音声到来方向ベクトルvq (f,τ)を推定する。
【0009】
なお、音声区間推定部120の処理と到来方向推定部130の処理とは並行して行ってもよいし、音声区間推定部120の処理により音声区間を推定した上で、その音声区間に該当するフレームに絞って到来方向推定部130の処理を行うこととしてもよい。
【0010】
到来方向分類部140は、音声区間PSに該当する各フレームについて、音声到来方向(ベクトルvq(τ) 又はvq(f,τ))が類似するものを各話者区間Pk(k=1、・・・、N)としてクラスタリングを行い、すべてのクラスタについて、クラスタのインデックスkとそのクラスタに属するすべてのフレームのインデックスτとの組を出力する(S4)。
【数5】
【0011】
クラスタリング手法としては、公知のk−means法や階層的クラスタリングを用いてもよいし、オンラインクラスタリングを用いてもよい(非特許文献5参照)。このクラスタリング処理で分類されたクラスタCkが、そのクラスタを形成しているクラスタメンバ(ベクトルvq(τ) 又はvq(f,τ))から求められるセントロイドで示される角度方向にいる話者kに相当し、このクラスタメンバに該当する各フレームτが話者kによる話者区間Pkを構成する。
【0012】
なお、上記の説明では、到来方向推定部130はマイク間の到達時間差ベクトルvq´(τ)又はvq´(f,τ)を推定した上で、更に音声到来方向ベクトルvq (τ)又はvq (f,τ)を推定しているが、単に到達時間差ベクトルを推定するだけでも構わない。従って、この場合は図13に示すように、到来方向推定部130が到来時間差推定部131として構成され、到来方向分類部140が到来時間差分類部141としてvq (τ)又はvq (f,τ)の代わりにvq´(τ)又はvq´(f,τ)を分類するように構成すればよい。
【特許文献1】特表2000−512108号公報
【非特許文献1】S.Araki, M.Fujimoto, K.Ishizuka, H.Sawada and S.Makino, "Speaker indexing and speech enhancement in real meetings/conversations," IEEE International Conference on Acoustics, Speech, and Signal Processing(ICASSP-2008), 2008, p.93-96
【非特許文献2】J.Sohn, N.S.Kim and W.Sung,"A Statistical Model-Based Voice Activity Detection," IEEE Signal Processing letters, 1999, vol.6, no.1, p.1-3
【非特許文献3】藤本、石塚、中谷、「複数の音声区間検出法の適応的統合の検討と考察」、電子情報通信学会 音声研究会、2007、SP2007-97、p.7-12
【非特許文献4】C.H.Knapp and G.C.Carter,"The generalized correlation method for estimation of time delay," IEEE Trans. Acoust. Speech and Signal Processing, 1976, vol.24, no.4, p.320-327
【非特許文献5】R.O.Duda, P.E.Hart and D.G.Stork,"Pattern Classification," 2nd edition, Wiley Interscience, 2000
【発明の開示】
【発明が解決しようとする課題】
【0013】
従来技術では、音声の到来方向情報のみにより話者識別を行っていたため、ある位置に居た話者が他の位置に移動してしまった場合に、同じ話者であるにもかかわらず新しい話者と識別したり、新しい話者であるにもかかわらず以前にその位置にいた別の話者として誤識別したりする問題があった。
本発明の目的は、音声の収録中に話者位置の移動が生じても、移動前と移動後において、同一話者には同一インデックスを付与することのできる、複数信号区間推定装置、複数信号区間推定方法、そのプログラムおよび記録媒体を提供することにある。
【課題を解決するための手段】
【0014】
本発明の複数信号区間推定装置は、複数のマイクによりそれぞれ収録された、複数の話者による発話音声が含まれる観測信号から、それぞれの話者の発話区間を推定するものであり、周波数領域変換部と音声区間推定部と到来方向推定部と到来方向分類部と話者同定部とを備える。
【0015】
周波数領域変換部は、観測信号を所定長のフレームに順次切り出し、当該フレームごとに周波数領域に変換する。
音声区間推定部は、周波数領域に変換された観測信号に基づき、各フレームが音声区間に該当するか否かを推定する。
到来方向推定部は、周波数領域に変換された観測信号に基づき、当該観測信号の到来方向を各フレームごとに推定する。
【0016】
到来方向分類部は、音声区間に該当すると推定された各フレームを、到来方向の類似性に基づき話者ごとのクラスタに分類する。
そして話者同定部は、所定の時刻までに同一クラスタに分類された各フレームの周波数領域に変換された観測信号に基づき、当該クラスタに係る話者のモデルをクラスタごとに作成し、当該所定の時刻以降の観測信号の話者を、各話者のモデルに基づき推定する。
【発明の効果】
【0017】
本発明の複数信号区間推定装置によれば、複数の話者に対する話者区間の推定にあたり、音声の到来方向の推定と分類に加え、話者の同一性の判定が可能となる。そのため、音声の収録中に話者位置の移動が生じても、移動前と移動後において、同一話者には同一のインデックスを付与することができる。
【発明を実施するための最良の形態】
【0018】
〔第1実施形態〕
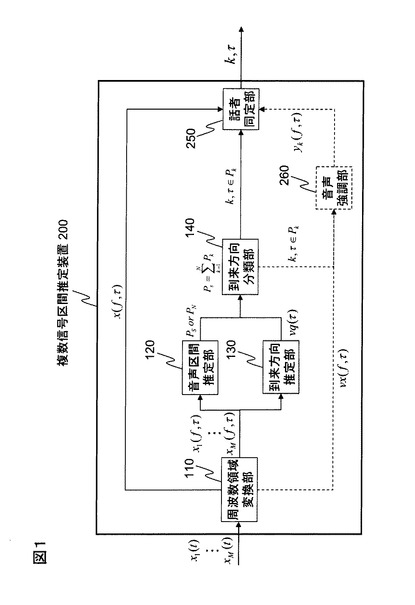
図1(実線部分)に本発明の複数信号区間推定装置200の機能構成例を、図2(実線部分)にその処理フロー例を示す。複数信号区間推定装置200は、背景技術にて説明した周波数領域変換部110、音声区間推定部120、到来方向推定部130、及び到来方向分類部140と、話者同定部250とから構成される。また、話者同定部250の処理は図11に示したフローのS4に続いて行われる。従って、ここでは背景技術として説明した内容の説明は必要最小限とし、話者同定部250での処理に重点を置いて説明する。
図3(実線部分)に話者同定部250の機能構成例を示す。話者同定部250は、特徴抽出手段251とモデル学習手段252と尤度計算手段253とから構成される。
【0019】
話者同定部250の処理においては、観測信号の収録開始から所定の時刻ttrainまでは話者の位置の移動が無かったと仮定し、その間に作成されたクラスタから、各話者のモデルMkを作成することとする。そして、時刻ttrain以降は話者の位置の移動があり得たと仮定し、時刻ttrain以降のすべての音声セグメント(同一クラスタに分類された連続フレーム)について、その発話者が時刻ttrain以前に発話したどの話者であるかを、観測信号の当初部分(収録開始から時刻ttrainまで)で作成した各話者のモデルに基づき判定する。このように各話者のモデルを観測信号の当初部分で作成することで、時刻ttrain以降については、事前に話者のモデルを用意することなく話者の同定を行うことができる。なお、ttrainは同定の対象となる話者全員が少なくとも一度発話した時点以降の時刻に設定する。
【0020】
特徴抽出手段251は、M本のマイクにおける周波数領域の観測信号x1(f,τ)〜xM(f,τ)の中から任意に選んだいずれか1本の観測信号x(f,τ)の音声特徴量ベクトルvf(τ)を、各フレームごとに計算する(S5)。音声特徴量ベクトルvf(τ)としては、たとえば12次元のMFCC(Mel-Frequency Cepstrum Coefficient)を利用できる。また、自己相関法などで推定した基本周波数F0(τ)を併用し、音声特徴量ベクトルvf(τ)の一成分として含ませてもよい。
【0021】
モデル学習手段252は、到来方向分類部140にて同一クラスタCk(話者数Nのとき、k=1、・・・、N)に分類されたフレームのうち、観測信号の収録開始から所定の時刻ttrainまでの各フレームに係る音声特徴量ベクトルvf(τ)を用いて、話者kのモデル、すなわちモデルパラメータφkを作成して出力するとともに、所定の時刻ttrainまでの各フレームのインデックスτとそれらがそれぞれ属するクラスタに係る話者のインデックスkとの組を出力する(S6)。なお、同一話者のフレームが連続する場合は、各フレームのインデックスを出力する代わりに、連続フレームの始点と終点の時刻を出力してもよい。
【0022】
話者のモデルとしては、ここでは混合正規分布(GMM: Gaussian Mixture Model)を用いる場合を例示するが、他の話者同定や話者認識の方法(隠れマルコフモデルやベクトル量子化等)を用いてもよい。GMMのガウシアンの数をMgとした時、モデルMkのモデルパラメータをφk=(平均μk,m、共分散行列Σk,m、ガウシアン重みwk,m)と置くと、GMMは次式のように表すことができる。
【数6】
ここで、pk,m(vf(τ))は話者kのm番目の多次元(次元数dは音声特徴量ベクトルの次元と同じ)ガウシアンを表している。Mgは例えば10とする。モデルパラメータφkは、EMアルゴリズムなどを用いて、所定の時刻ttrainまでのクラスタCkに属する全てのフレームに基づき、次式によって求められる対数尤度Lが最大となるφkの値として計算することができる。
【数7】
ここで、EMアルゴリズムは、「汪他、”計算統計I〜確率計算の新しい手法〜”、岩波書店、2003、p158-162」等にて公知の技術である。
【0023】
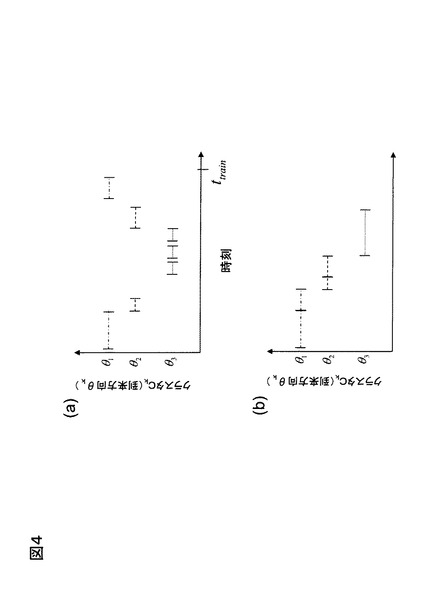
なお、モデル学習部では、モデルパラメータφkの推定精度を高める上で、各フレームτは互いに接続されていることが望ましい。そこで、接続されていない場合の処理方法の一例を説明する。図4(a)は観測信号の到来方向の時系列の例である。この例は、収録開始から時刻ttrainまでの間に到来方向がθ1→θ2→θ3→θ2→θ1の順に推移しており、つまり話者1→話者2→話者3→話者2→話者1の順に発話している場合である。このうち、話者3は短時間の隙間を挟んで計3回発話している。このように短時間(例えば300ms以下)の隙間があるような場合には、図4(b)に示すように音声区間が連続しているとみなしてモデルを学習するのが望ましい。また、話者1と話者2については、共に1回目の発話と2回目の発話との間が広くなっている。このような場合には、図4(b)に示すように1回目の発話と2回目の発話が一体的にされたものとみなしてモデルを学習する。なお、モデル学習手段252が出力するインデックスτは接続前のτであることに注意が必要である。
【0024】
尤度計算手段253は、所定の時刻ttrain以降に同一クラスタに分類された互いに接続されたフレーム(以下、「セグメント」という)の音声特徴量について、モデル学習手段252において作成した全ての話者のモデルに対する尤度を計算して、最大尤度をとるモデルに係る話者のインデックスkと当該セグメントに含まれる全てのフレームのインデックスτとを出力する(S7)。なお、同一話者のフレームが連続する場合は、各フレームのインデックスを出力する代わりに、連続フレームの始点と終点の時刻を出力してもよい。
【0025】
話者のモデルとしてGMMを用いた場合、各話者のモデルに当該セグメントに含まれる全てのフレームτの音声特徴量ベクトルvf(τ)を代入して、式(10)により対数尤度を計算し、最も大きな対数尤度をとるモデルのインデックスkを当該セグメントの話者インデックスとして付与する。なお、話者の同定は必ずしもセグメントごとに行う必要はなく、フレームごとに行っても構わない。この場合、対数尤度の計算は式(10)のΣを外した式により行う。
【0026】
以上のように本発明においては、複数の話者に対する話者区間の推定にあたり、音声の到来方向の推定と分類に加え、話者の同定を行う。そのため、音声の収録中に話者位置の移動が生じても、移動前と移動後において、同一話者には同一のインデックスを付与することができる。
【0027】
〔第2実施形態〕
第1実施形態においては、特徴抽出手段251における処理に際し、周波数領域変換部110から出力された周波数領域の観測信号x(f,τ)をそのまま使用していた。しかし、実際の会議の場では複数の発話者がしばしば同時に発話するが、各フレームではいずれかの1名の話者の発話として識別する必要があり、その他の話者の発話は雑音成分となるため、同時発話されたフレームτにおける観測信号x(f,τ)をそのまま使用すると、SN比の小ささにより特徴抽出を適切に行えずに話者モデルの推定精度が劣化する場合がある。そこで第2実施形態では、このSN比を向上させるための機能構成・処理方法を示す。
【0028】
第1実施形態との機能構成上の相違は図1において、更に点線部分の構成、つまり音声強調部260が加わる点にあり、処理フロー上の相違は、図2において更に点線部分の処理が加わる点にある。
【0029】
音声強調部260においては、それぞれの話者kの発話信号成分を強調する。ここでは、複数のマイクにおける観測信号を用いた公知のビームフォーミング的手法(例えば、参考文献1参照)を用いてもよいし、1本のマイクにおける観測信号に対して処理をする方法(例えば、Wiener Filter)による雑音除去的な手法を用いてもよい。
〔参考文献1〕S. Araki, H. Sawada and S. Makino, "Blind Speech Separation in a MeetingSituation with Maximum SNR beamformers," proc. of ICASSP2007, 2007, vol.I, p.41-45
【0030】
参考文献1のSN比最大化型ビームフォーマの場合には、周波数領域変換部110からのM本のマイクにおける周波数領域の観測信号による観測信号ベクトルvx(f,τ)=[x1(f,τ)、・・・、xM(f,τ)]Tと、到来方向分類部140からの各クラスタCkに属するフレームτの情報とから、各フレームτが属するクラスタCkに係る話者kの発話信号成分を強調した周波数領域信号yk(f,τ)を生成し(S8)、これをx(f,τ)の代わりに特徴抽出手段251での処理に用いる。
【0031】
このように第1実施形態の構成に音声強調部260による処理を加えることで、特徴抽出手段251に入力する各話者kの発話信号成分のSN比を向上することができ、話者モデルの推定精度を高めることができる。
【0032】
〔第3実施形態〕
上記の実施形態では、モデルパラメータφkを時刻ttrainまでの観測信号により求めて、それを時刻ttrain以降の話者同定処理に固定的に適用する。しかし、会話が収録される音響環境は通常、経時的に変化するものであり、求めたモデルパラメータφkが経時的にその環境に相応しくなくなる場合がある。
【0033】
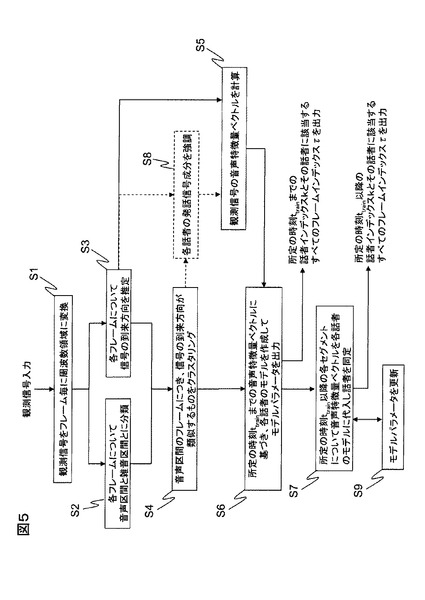
第3実施形態はそのような事態を回避するための構成であり、処理フロー例を図5に示す。S7にて時刻ttrain以降のセグメントに対して話者インデックスkを付与した後、そのセグメントに属する各フレームの音声特徴量ベクトルvf(τ)を、図3の一点鎖線に示すように尤度計算手段254からモデル学習手段253にフィードバックし、これらの音声特徴量ベクトルvf(τ)を用いて、式(10)により改めてφkを計算してモデルパラメータを更新する(S9)。更新は逐次行っても、所定の更新間隔を置いて行っても構わない。
【0034】
このように構成することで、会話が収録される音響環境が経時的に変化しても、適切なモデルパラメータにより話者の同定処理を行うことができる。
【0035】
〔第4実施形態〕
上記の各実施形態では、尤度計算手段253における話者の同定を、各話者のモデルMkに同定対象セグメントに含まれる全てのフレームτの音声特徴量ベクトルvf(τ)を代入して対数尤度を計算し、対数尤度が最大となるモデルのインデックスkを当該セグメントの話者インデックスとするというルールの下で行う。しかし、このようなルールの下では、新たに参加した話者による発話があった場合においても、当初から参加している話者のモデルのいずれかが最大対数尤度をとることになるため、そのモデルの話者であると同定されてしまう。
【0036】
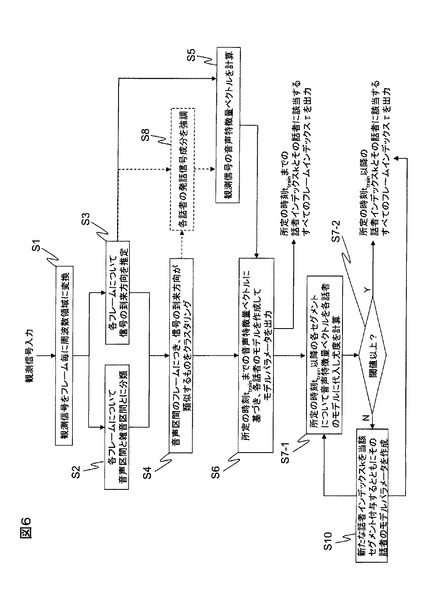
第4実施形態はそのような事態を回避するための構成である。処理フロー例を図6に示す。尤度計算手段253において、所定の時刻ttrain以降の各セグメントについて音声特徴量ベクトルを各話者のモデルに代入して対数尤度を計算し(S7−1)、最大の対数尤度が所定の閾値より小さいか否かを判断し、閾値より大きい場合には、最大尤度をとるモデルに係る話者のインデックスkと当該セグメントに含まれる全てのフレームのインデックスτとを出力し(S7−2)、閾値より小さい場合には、新たな話者が参加したと判断して新たな話者インデックスを当該セグメントに付与するとともに、そのセグメントに属する各フレームの音声特徴量ベクトルvf(τ)を、図3の一点鎖線に示すように尤度計算手段254からモデル学習手段253にフィードバックし、これらの音声特徴量ベクトルvf(τ)を用いて、式(10)によりφkを計算して新たな話者のモデルパラメータとして追加する(S10)。
【0037】
このように構成することで、新たな話者が参加した場合においても、それを検知してその話者のモデルを生成することにより、以降、その話者についても同定処理を行うことができる。
【0038】
〔第5実施形態〕
上記の各実施形態は、モデルパラメータを時刻ttrainまでの観測信号により求めて、それを用いて時刻ttrain以降の話者同定処理を行う構成である。しかし、発話が想定される複数の話者音声を予め入手できる場合には、それに基づき事前に各話者のモデルを準備しておき、この事前に準備したモデルを用いて話者同定処理を行うことが可能である。
第5実施形態はそのような場合の構成であり、話者同定部250を例えば図7のように構成することにより実現できる。上記の各実施形態との機能構成上の相違は、図3におけるモデル学習手段252が、予め準備した話者のモデルパラメータが記憶された話者モデルDB264に置き換わる点にある。
【0039】
このように構成することで、モデルパラメータを学習により求める必要が無くなるため、音声の収録当初から尤度計算手段253において話者同定が可能になる。また、話者のモデルパラメータに話者の氏名情報を関連付けてDBに記憶させておくことで、話者インデックスkに方向情報に加え話者の氏名情報も持たせることができる。
上記の各実施形態の複数信号区間推定装置の構成をコンピュータによって実現する場合、各装置が有すべき機能の処理内容はプログラムによって記述される。そして、このプログラムをコンピュータで実行することにより、上記処理機能がコンピュータ上で実現される。
【0040】
この処理内容を記述したプログラムは、コンピュータで読み取り可能な記録媒体に記録しておくことができる。コンピュータで読み取り可能な記録媒体としては、例えば、磁気記録装置、光ディスク、光磁気記録媒体、半導体メモリ等どのようなものでもよいが、具体的には、例えば、磁気記録装置として、ハードディスク装置、フレキシブルディスク、磁気テープ等を、光ディスクとして、DVD(Digital Versatile Disc)、DVD−RAM(Random Access Memory)、CD−ROM(Compact Disc Read Only Memory)、CD−R(Recordable)/RW(ReWritable)等を、光磁気記録媒体として、MO(Magneto-Optical disc)等を、半導体メモリとしてEEP−ROM(Electronically Erasable and Programmable-Read Only Memory)等を用いることができる。
【0041】
また、このプログラムの流通は、例えば、そのプログラムを記録したDVD、CD−ROM等の可搬型記録媒体を販売、譲渡、貸与等することによって行う。さらに、このプログラムをサーバコンピュータの記憶装置に格納しておき、ネットワークを介して、サーバコンピュータから他のコンピュータにそのプログラムを転送することにより、このプログラムを流通させる構成としてもよい。
【0042】
また、上述した実施形態とは別の実行形態として、コンピュータが可搬型記録媒体から直接このプログラムを読み取り、そのプログラムに従った処理を実行することとしてもよく、さらに、このコンピュータにサーバコンピュータからプログラムが転送されるたびに、逐次、受け取ったプログラムに従った処理を実行することとしてもよい。また、サーバコンピュータから、このコンピュータへのプログラムの転送は行わず、その実行指示と結果取得のみによって処理機能を実現する、いわゆるASP(Application Service Provider)型のサービスによって、上述の処理を実行する構成としてもよい。なお、本形態におけるプログラムには、電子計算機による処理の用に供する情報であってプログラムに準ずるもの(コンピュータに対する直接の指令ではないがコンピュータの処理を規定する性質を有するデータ等)を含むものとする。
【0043】
また、この形態では、コンピュータ上で所定のプログラムを実行させることにより、本装置を構成することとしたが、これらの処理内容の少なくとも一部をハードウェア的に実現することとしてもよい。
また、上述の各種処理は、記載に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されてもよい。その他、本発明の趣旨を逸脱しない範囲で適宜変更が可能である。
【0044】
〔効果の確認〕
発明の効果を確認するため、図8で示すような3本のマイクを用いた測定環境において、4名参加による5分間の会議データについての話者区間推定実験を行った。会議においては、まず男女各2名の話者がそれぞれ男1、女1、男2、女2の位置に着席して始めに自己紹介をし、その後、各話者が順番に位置PPに移動して発言を行った。自己紹介は収録開始から120秒までの間に行われたものとし、ttrainを120秒として収録開始から120秒までの観測信号を話者同定モデルの作成に用い、120秒以降について話者同定を行った。なお、短時間フーリエ変換のフレーム長は64ms、フレームシフト長は32msとした。
【0045】
評価指標としては、diarization error rate(DER)を利用した。
【数8】
ここで、DERは誤棄却(missed speaker time: MST、誰かが話しているにもかかわらず話していないと判定した時間長)、誤受理(false alarm speaker time:FAT、誰も話していないにもかかわらず誰かが話していると判定した時間長)、話者誤り(speaker error time: SET、話者を誤って判定した時間長)の3つの誤検出を含む指標となっている。つまりこの指標においては、DER値が小さい方が話者区間推定の精度が高いことを示しており、特に本発明においては話者を正しく判定できているかが問題となるため、効果の程度はSETに顕著に現れるはずである。
【0046】
図9(a)に確認結果を示す。図10は結果を図解したものであり、(a)は正解を示したもの、(b)は従来の方法による推定結果、 (c)は本発明の方法による推定結果である。なお、男1、女1、男2、女2の到来方向はそれぞれ100°、50°、−50°、−100°であり、位置PPは−160°の到来方向にあり、また、男1が話者1に、女1が話者2に、男2が話者3に、女2が話者4にそれぞれ対応する。図10(b)からわかるように、従来の方法では位置PPの話者を話者1〜4以外の別の話者5と推定しており、図9(a)に示すとおりSETが大きくなっている。これに対し、本発明の方法ではほぼ全ての時間区間で−160°方向の話者の区別を図10(a)と同様にできており、図9(a)に示すとおりSETが改善し、全体の性能であるDER値も改善していることがわかる。
【0047】
また、10組の話者組み合わせにおける会議シミュレーションを行った結果を図9(b)に示す。これは、音声信号と図8の測定環境で測定したインパルス応答とを用いて作成した会議シミュレーションデータを用いたものである。図9(b)においてシミュレーション1は各話者の音声間の重なりが無い場合であり、シミュレーション2は各話者の音声間の重なりがある場合の結果であるが、いずれの場合においてもDER、SETに関し本発明の方法が従来方法より優れた結果を示すことがわかる。
【産業上の利用可能性】
【0048】
本発明は、複数話者の音声信号が混在している音響データから各話者の音声区間を推定する必要があるシステムや装置等に利用することができ、特に音声の収録中に話者位置の移動が生じる場合に有効である。
【図面の簡単な説明】
【0049】
【図1】第1、2実施形態の複数信号区間推定装置の機能構成例を示す図
【図2】第1、2実施形態の複数信号区間推定装置の処理フロー例を示す図
【図3】第1〜4実施形態の複数信号区間推定装置の話者同定部の機能構成例を示す図
【図4】フレームが接続されていない場合に接続して処理をする方法を説明する図
【図5】第3実施形態の複数信号区間推定装置の処理フロー例を示す図
【図6】第4実施形態の複数信号区間推定装置の処理フロー例を示す図
【図7】第5実施形態の複数信号区間推定装置の機能構成例を示す図
【図8】効果の確認に用いた測定環境を示す図
【図9】効果の確認結果を示す表
【図10】効果の確認結果の根拠データを示す図
【図11】従来技術の複数信号区間推定装置の機能構成例を示す図
【図12】従来技術の複数信号区間推定装置の処理フロー例を示す図
【図13】従来技術の複数信号区間推定装置の別の機能構成例を示す図
【技術分野】
【0001】
本発明は、信号処理の技術分野に属する。特に、複数人の音声信号が混在している音響データについて、各人の音声信号が発せられている区間を推定する複数信号区間推定装置、複数信号区間推定方法、そのプログラムおよび記録媒体に関する。
【背景技術】
【0002】
複数人による会話などを複数のマイクで収録し、「いつ、誰が話したか」を推定する音声区間検出技術は、例えば会議録自動作成において、各発言に発話者を自動的に付与したり、会議収録データに話者情報を付与して録音データの検索や頭出しを容易にしたりする際に有用である。
【0003】
従来の音声区間検出技術としては、例えば特許文献1や非特許文献1などで開示されている方法が挙げられる。図11に従来技術による複数信号区間推定装置100の機能構成例を、図12にその処理フロー例を示す。複数信号区間推定装置100は、周波数領域変換部110と音声区間推定部120と到来方向推定部130と到来方向分類部140とから構成される。
【0004】
周波数領域変換部110は、M本のマイクによりそれぞれ収録した時間領域の観測信号xj(t)(j=1、・・・、M)を、例えば32msごとに窓関数で切り出して(切り出した1区間を以下、「フレーム」という)、切り出した各フレーム(インデックスをτとする)についてフーリエ変換等によりそれぞれ周波数領域の観測信号xj(f,τ) (f=1、・・・、L)に変換する(S1)。
【0005】
音声区間推定部120は、周波数領域変換部110で周波数領域に変換された観測信号の各フレームに音声が存在するか否かを、音声存在確率を計算することにより推定する(S2)。音声存在確率の計算に際しては、例えば非特許文献2、非特許文献3に記載された方法が利用できる。前者で説明すると、該当フレームにおける音声存在確率pV(τ)を次式により求める。
【数1】
ここで、λN(f)は周波数fにおけるノイズの平均パワー(音声が明らかに存在しない録音ファイルの冒頭区間などで求める)、x(f,τ)はM本のマイクにおける周波数領域の観測信号x1(f,τ)〜xM(f,τ)の中から任意に選んだいずれか1本についての周波数領域の観測信号である。なお、x(f,τ)はすべてのマイクの振幅の平均値として次のように求めても構わない。
【数2】
音声区間推定部120は、式(1)により求めた音声存在確率pV(τ)をそのまま出力してもよいし、pV(τ)がある閾値より大きければそのフレームは音声区間PSであると判定し、小さければ非音声(ノイズ)区間PNと判定して結果を出力してもよい。
【0006】
到来方向推定部130は、周波数領域変換部110で周波数領域に変換された観測信号の到来方向を各フレームごと又は各フレームの各周波数成分ごとにを推定する(S3)。具体的には、観測信号のマイクjとマイクj´とからの到来時間差q´jj′を全てのマイクペアについて求め、それらを並べた縦ベクトルとマイクの座標系とから音声到来方向ベクトルを推定する。
【0007】
各フレームごとに到来時間差q´jj′を計算する手法として、非特許文献4にて開示されているGCC−PHATと呼ばれる手法がある。この手法においては到来時間差q´jj′(τ)を次式に従い算出する。
【数3】
これをすべてのマイクペアjj´について求めて、それらを並べた縦ベクトルをvq´(τ)とする。なお、すべてのマイクペアを用いる代わりに、ある基準マイクを決め、基準マイクとその他のマイクに関するすべてのペアを用いてもよい。音声到来方向ベクトルvq(τ)は、vq´(τ)と音速cとマイクの座標系VDとから次式により推定する。
vq(τ)=c・VD+・vq´(τ) (4)
ここで、+はMoore-Penroseの疑似逆行列を表し、vdjがマイクjの座標を[x,y,z]と並べたベクトルであるとき、VD=[vd1−vdj,・・・,vdM−vdj]Tである。このように求めた音声到来方向ベクトルvq(τ)は、到来方向の水平角がθ、仰角がφとすると、次式のように表すことができる。
vq(τ)=[cosθ・cosφ,sinθ・cosφ,sinφ]T (5)
【0008】
各フレームの各周波数成分ごとに到来時間差q´jj′を計算する場合は、マイクjとマイクj´との到来時間差q´jj′(f,τ)を次式に従い算出する。
【数4】
これをすべてのマイクペアjj´について求めて(又は上記のように基準マイクに対して求めて)、それらを並べた縦ベクトルをvq´(f,τ)とし、式(4)と同様にして音声到来方向ベクトルvq (f,τ)を推定する。
【0009】
なお、音声区間推定部120の処理と到来方向推定部130の処理とは並行して行ってもよいし、音声区間推定部120の処理により音声区間を推定した上で、その音声区間に該当するフレームに絞って到来方向推定部130の処理を行うこととしてもよい。
【0010】
到来方向分類部140は、音声区間PSに該当する各フレームについて、音声到来方向(ベクトルvq(τ) 又はvq(f,τ))が類似するものを各話者区間Pk(k=1、・・・、N)としてクラスタリングを行い、すべてのクラスタについて、クラスタのインデックスkとそのクラスタに属するすべてのフレームのインデックスτとの組を出力する(S4)。
【数5】
【0011】
クラスタリング手法としては、公知のk−means法や階層的クラスタリングを用いてもよいし、オンラインクラスタリングを用いてもよい(非特許文献5参照)。このクラスタリング処理で分類されたクラスタCkが、そのクラスタを形成しているクラスタメンバ(ベクトルvq(τ) 又はvq(f,τ))から求められるセントロイドで示される角度方向にいる話者kに相当し、このクラスタメンバに該当する各フレームτが話者kによる話者区間Pkを構成する。
【0012】
なお、上記の説明では、到来方向推定部130はマイク間の到達時間差ベクトルvq´(τ)又はvq´(f,τ)を推定した上で、更に音声到来方向ベクトルvq (τ)又はvq (f,τ)を推定しているが、単に到達時間差ベクトルを推定するだけでも構わない。従って、この場合は図13に示すように、到来方向推定部130が到来時間差推定部131として構成され、到来方向分類部140が到来時間差分類部141としてvq (τ)又はvq (f,τ)の代わりにvq´(τ)又はvq´(f,τ)を分類するように構成すればよい。
【特許文献1】特表2000−512108号公報
【非特許文献1】S.Araki, M.Fujimoto, K.Ishizuka, H.Sawada and S.Makino, "Speaker indexing and speech enhancement in real meetings/conversations," IEEE International Conference on Acoustics, Speech, and Signal Processing(ICASSP-2008), 2008, p.93-96
【非特許文献2】J.Sohn, N.S.Kim and W.Sung,"A Statistical Model-Based Voice Activity Detection," IEEE Signal Processing letters, 1999, vol.6, no.1, p.1-3
【非特許文献3】藤本、石塚、中谷、「複数の音声区間検出法の適応的統合の検討と考察」、電子情報通信学会 音声研究会、2007、SP2007-97、p.7-12
【非特許文献4】C.H.Knapp and G.C.Carter,"The generalized correlation method for estimation of time delay," IEEE Trans. Acoust. Speech and Signal Processing, 1976, vol.24, no.4, p.320-327
【非特許文献5】R.O.Duda, P.E.Hart and D.G.Stork,"Pattern Classification," 2nd edition, Wiley Interscience, 2000
【発明の開示】
【発明が解決しようとする課題】
【0013】
従来技術では、音声の到来方向情報のみにより話者識別を行っていたため、ある位置に居た話者が他の位置に移動してしまった場合に、同じ話者であるにもかかわらず新しい話者と識別したり、新しい話者であるにもかかわらず以前にその位置にいた別の話者として誤識別したりする問題があった。
本発明の目的は、音声の収録中に話者位置の移動が生じても、移動前と移動後において、同一話者には同一インデックスを付与することのできる、複数信号区間推定装置、複数信号区間推定方法、そのプログラムおよび記録媒体を提供することにある。
【課題を解決するための手段】
【0014】
本発明の複数信号区間推定装置は、複数のマイクによりそれぞれ収録された、複数の話者による発話音声が含まれる観測信号から、それぞれの話者の発話区間を推定するものであり、周波数領域変換部と音声区間推定部と到来方向推定部と到来方向分類部と話者同定部とを備える。
【0015】
周波数領域変換部は、観測信号を所定長のフレームに順次切り出し、当該フレームごとに周波数領域に変換する。
音声区間推定部は、周波数領域に変換された観測信号に基づき、各フレームが音声区間に該当するか否かを推定する。
到来方向推定部は、周波数領域に変換された観測信号に基づき、当該観測信号の到来方向を各フレームごとに推定する。
【0016】
到来方向分類部は、音声区間に該当すると推定された各フレームを、到来方向の類似性に基づき話者ごとのクラスタに分類する。
そして話者同定部は、所定の時刻までに同一クラスタに分類された各フレームの周波数領域に変換された観測信号に基づき、当該クラスタに係る話者のモデルをクラスタごとに作成し、当該所定の時刻以降の観測信号の話者を、各話者のモデルに基づき推定する。
【発明の効果】
【0017】
本発明の複数信号区間推定装置によれば、複数の話者に対する話者区間の推定にあたり、音声の到来方向の推定と分類に加え、話者の同一性の判定が可能となる。そのため、音声の収録中に話者位置の移動が生じても、移動前と移動後において、同一話者には同一のインデックスを付与することができる。
【発明を実施するための最良の形態】
【0018】
〔第1実施形態〕
図1(実線部分)に本発明の複数信号区間推定装置200の機能構成例を、図2(実線部分)にその処理フロー例を示す。複数信号区間推定装置200は、背景技術にて説明した周波数領域変換部110、音声区間推定部120、到来方向推定部130、及び到来方向分類部140と、話者同定部250とから構成される。また、話者同定部250の処理は図11に示したフローのS4に続いて行われる。従って、ここでは背景技術として説明した内容の説明は必要最小限とし、話者同定部250での処理に重点を置いて説明する。
図3(実線部分)に話者同定部250の機能構成例を示す。話者同定部250は、特徴抽出手段251とモデル学習手段252と尤度計算手段253とから構成される。
【0019】
話者同定部250の処理においては、観測信号の収録開始から所定の時刻ttrainまでは話者の位置の移動が無かったと仮定し、その間に作成されたクラスタから、各話者のモデルMkを作成することとする。そして、時刻ttrain以降は話者の位置の移動があり得たと仮定し、時刻ttrain以降のすべての音声セグメント(同一クラスタに分類された連続フレーム)について、その発話者が時刻ttrain以前に発話したどの話者であるかを、観測信号の当初部分(収録開始から時刻ttrainまで)で作成した各話者のモデルに基づき判定する。このように各話者のモデルを観測信号の当初部分で作成することで、時刻ttrain以降については、事前に話者のモデルを用意することなく話者の同定を行うことができる。なお、ttrainは同定の対象となる話者全員が少なくとも一度発話した時点以降の時刻に設定する。
【0020】
特徴抽出手段251は、M本のマイクにおける周波数領域の観測信号x1(f,τ)〜xM(f,τ)の中から任意に選んだいずれか1本の観測信号x(f,τ)の音声特徴量ベクトルvf(τ)を、各フレームごとに計算する(S5)。音声特徴量ベクトルvf(τ)としては、たとえば12次元のMFCC(Mel-Frequency Cepstrum Coefficient)を利用できる。また、自己相関法などで推定した基本周波数F0(τ)を併用し、音声特徴量ベクトルvf(τ)の一成分として含ませてもよい。
【0021】
モデル学習手段252は、到来方向分類部140にて同一クラスタCk(話者数Nのとき、k=1、・・・、N)に分類されたフレームのうち、観測信号の収録開始から所定の時刻ttrainまでの各フレームに係る音声特徴量ベクトルvf(τ)を用いて、話者kのモデル、すなわちモデルパラメータφkを作成して出力するとともに、所定の時刻ttrainまでの各フレームのインデックスτとそれらがそれぞれ属するクラスタに係る話者のインデックスkとの組を出力する(S6)。なお、同一話者のフレームが連続する場合は、各フレームのインデックスを出力する代わりに、連続フレームの始点と終点の時刻を出力してもよい。
【0022】
話者のモデルとしては、ここでは混合正規分布(GMM: Gaussian Mixture Model)を用いる場合を例示するが、他の話者同定や話者認識の方法(隠れマルコフモデルやベクトル量子化等)を用いてもよい。GMMのガウシアンの数をMgとした時、モデルMkのモデルパラメータをφk=(平均μk,m、共分散行列Σk,m、ガウシアン重みwk,m)と置くと、GMMは次式のように表すことができる。
【数6】
ここで、pk,m(vf(τ))は話者kのm番目の多次元(次元数dは音声特徴量ベクトルの次元と同じ)ガウシアンを表している。Mgは例えば10とする。モデルパラメータφkは、EMアルゴリズムなどを用いて、所定の時刻ttrainまでのクラスタCkに属する全てのフレームに基づき、次式によって求められる対数尤度Lが最大となるφkの値として計算することができる。
【数7】
ここで、EMアルゴリズムは、「汪他、”計算統計I〜確率計算の新しい手法〜”、岩波書店、2003、p158-162」等にて公知の技術である。
【0023】
なお、モデル学習部では、モデルパラメータφkの推定精度を高める上で、各フレームτは互いに接続されていることが望ましい。そこで、接続されていない場合の処理方法の一例を説明する。図4(a)は観測信号の到来方向の時系列の例である。この例は、収録開始から時刻ttrainまでの間に到来方向がθ1→θ2→θ3→θ2→θ1の順に推移しており、つまり話者1→話者2→話者3→話者2→話者1の順に発話している場合である。このうち、話者3は短時間の隙間を挟んで計3回発話している。このように短時間(例えば300ms以下)の隙間があるような場合には、図4(b)に示すように音声区間が連続しているとみなしてモデルを学習するのが望ましい。また、話者1と話者2については、共に1回目の発話と2回目の発話との間が広くなっている。このような場合には、図4(b)に示すように1回目の発話と2回目の発話が一体的にされたものとみなしてモデルを学習する。なお、モデル学習手段252が出力するインデックスτは接続前のτであることに注意が必要である。
【0024】
尤度計算手段253は、所定の時刻ttrain以降に同一クラスタに分類された互いに接続されたフレーム(以下、「セグメント」という)の音声特徴量について、モデル学習手段252において作成した全ての話者のモデルに対する尤度を計算して、最大尤度をとるモデルに係る話者のインデックスkと当該セグメントに含まれる全てのフレームのインデックスτとを出力する(S7)。なお、同一話者のフレームが連続する場合は、各フレームのインデックスを出力する代わりに、連続フレームの始点と終点の時刻を出力してもよい。
【0025】
話者のモデルとしてGMMを用いた場合、各話者のモデルに当該セグメントに含まれる全てのフレームτの音声特徴量ベクトルvf(τ)を代入して、式(10)により対数尤度を計算し、最も大きな対数尤度をとるモデルのインデックスkを当該セグメントの話者インデックスとして付与する。なお、話者の同定は必ずしもセグメントごとに行う必要はなく、フレームごとに行っても構わない。この場合、対数尤度の計算は式(10)のΣを外した式により行う。
【0026】
以上のように本発明においては、複数の話者に対する話者区間の推定にあたり、音声の到来方向の推定と分類に加え、話者の同定を行う。そのため、音声の収録中に話者位置の移動が生じても、移動前と移動後において、同一話者には同一のインデックスを付与することができる。
【0027】
〔第2実施形態〕
第1実施形態においては、特徴抽出手段251における処理に際し、周波数領域変換部110から出力された周波数領域の観測信号x(f,τ)をそのまま使用していた。しかし、実際の会議の場では複数の発話者がしばしば同時に発話するが、各フレームではいずれかの1名の話者の発話として識別する必要があり、その他の話者の発話は雑音成分となるため、同時発話されたフレームτにおける観測信号x(f,τ)をそのまま使用すると、SN比の小ささにより特徴抽出を適切に行えずに話者モデルの推定精度が劣化する場合がある。そこで第2実施形態では、このSN比を向上させるための機能構成・処理方法を示す。
【0028】
第1実施形態との機能構成上の相違は図1において、更に点線部分の構成、つまり音声強調部260が加わる点にあり、処理フロー上の相違は、図2において更に点線部分の処理が加わる点にある。
【0029】
音声強調部260においては、それぞれの話者kの発話信号成分を強調する。ここでは、複数のマイクにおける観測信号を用いた公知のビームフォーミング的手法(例えば、参考文献1参照)を用いてもよいし、1本のマイクにおける観測信号に対して処理をする方法(例えば、Wiener Filter)による雑音除去的な手法を用いてもよい。
〔参考文献1〕S. Araki, H. Sawada and S. Makino, "Blind Speech Separation in a MeetingSituation with Maximum SNR beamformers," proc. of ICASSP2007, 2007, vol.I, p.41-45
【0030】
参考文献1のSN比最大化型ビームフォーマの場合には、周波数領域変換部110からのM本のマイクにおける周波数領域の観測信号による観測信号ベクトルvx(f,τ)=[x1(f,τ)、・・・、xM(f,τ)]Tと、到来方向分類部140からの各クラスタCkに属するフレームτの情報とから、各フレームτが属するクラスタCkに係る話者kの発話信号成分を強調した周波数領域信号yk(f,τ)を生成し(S8)、これをx(f,τ)の代わりに特徴抽出手段251での処理に用いる。
【0031】
このように第1実施形態の構成に音声強調部260による処理を加えることで、特徴抽出手段251に入力する各話者kの発話信号成分のSN比を向上することができ、話者モデルの推定精度を高めることができる。
【0032】
〔第3実施形態〕
上記の実施形態では、モデルパラメータφkを時刻ttrainまでの観測信号により求めて、それを時刻ttrain以降の話者同定処理に固定的に適用する。しかし、会話が収録される音響環境は通常、経時的に変化するものであり、求めたモデルパラメータφkが経時的にその環境に相応しくなくなる場合がある。
【0033】
第3実施形態はそのような事態を回避するための構成であり、処理フロー例を図5に示す。S7にて時刻ttrain以降のセグメントに対して話者インデックスkを付与した後、そのセグメントに属する各フレームの音声特徴量ベクトルvf(τ)を、図3の一点鎖線に示すように尤度計算手段254からモデル学習手段253にフィードバックし、これらの音声特徴量ベクトルvf(τ)を用いて、式(10)により改めてφkを計算してモデルパラメータを更新する(S9)。更新は逐次行っても、所定の更新間隔を置いて行っても構わない。
【0034】
このように構成することで、会話が収録される音響環境が経時的に変化しても、適切なモデルパラメータにより話者の同定処理を行うことができる。
【0035】
〔第4実施形態〕
上記の各実施形態では、尤度計算手段253における話者の同定を、各話者のモデルMkに同定対象セグメントに含まれる全てのフレームτの音声特徴量ベクトルvf(τ)を代入して対数尤度を計算し、対数尤度が最大となるモデルのインデックスkを当該セグメントの話者インデックスとするというルールの下で行う。しかし、このようなルールの下では、新たに参加した話者による発話があった場合においても、当初から参加している話者のモデルのいずれかが最大対数尤度をとることになるため、そのモデルの話者であると同定されてしまう。
【0036】
第4実施形態はそのような事態を回避するための構成である。処理フロー例を図6に示す。尤度計算手段253において、所定の時刻ttrain以降の各セグメントについて音声特徴量ベクトルを各話者のモデルに代入して対数尤度を計算し(S7−1)、最大の対数尤度が所定の閾値より小さいか否かを判断し、閾値より大きい場合には、最大尤度をとるモデルに係る話者のインデックスkと当該セグメントに含まれる全てのフレームのインデックスτとを出力し(S7−2)、閾値より小さい場合には、新たな話者が参加したと判断して新たな話者インデックスを当該セグメントに付与するとともに、そのセグメントに属する各フレームの音声特徴量ベクトルvf(τ)を、図3の一点鎖線に示すように尤度計算手段254からモデル学習手段253にフィードバックし、これらの音声特徴量ベクトルvf(τ)を用いて、式(10)によりφkを計算して新たな話者のモデルパラメータとして追加する(S10)。
【0037】
このように構成することで、新たな話者が参加した場合においても、それを検知してその話者のモデルを生成することにより、以降、その話者についても同定処理を行うことができる。
【0038】
〔第5実施形態〕
上記の各実施形態は、モデルパラメータを時刻ttrainまでの観測信号により求めて、それを用いて時刻ttrain以降の話者同定処理を行う構成である。しかし、発話が想定される複数の話者音声を予め入手できる場合には、それに基づき事前に各話者のモデルを準備しておき、この事前に準備したモデルを用いて話者同定処理を行うことが可能である。
第5実施形態はそのような場合の構成であり、話者同定部250を例えば図7のように構成することにより実現できる。上記の各実施形態との機能構成上の相違は、図3におけるモデル学習手段252が、予め準備した話者のモデルパラメータが記憶された話者モデルDB264に置き換わる点にある。
【0039】
このように構成することで、モデルパラメータを学習により求める必要が無くなるため、音声の収録当初から尤度計算手段253において話者同定が可能になる。また、話者のモデルパラメータに話者の氏名情報を関連付けてDBに記憶させておくことで、話者インデックスkに方向情報に加え話者の氏名情報も持たせることができる。
上記の各実施形態の複数信号区間推定装置の構成をコンピュータによって実現する場合、各装置が有すべき機能の処理内容はプログラムによって記述される。そして、このプログラムをコンピュータで実行することにより、上記処理機能がコンピュータ上で実現される。
【0040】
この処理内容を記述したプログラムは、コンピュータで読み取り可能な記録媒体に記録しておくことができる。コンピュータで読み取り可能な記録媒体としては、例えば、磁気記録装置、光ディスク、光磁気記録媒体、半導体メモリ等どのようなものでもよいが、具体的には、例えば、磁気記録装置として、ハードディスク装置、フレキシブルディスク、磁気テープ等を、光ディスクとして、DVD(Digital Versatile Disc)、DVD−RAM(Random Access Memory)、CD−ROM(Compact Disc Read Only Memory)、CD−R(Recordable)/RW(ReWritable)等を、光磁気記録媒体として、MO(Magneto-Optical disc)等を、半導体メモリとしてEEP−ROM(Electronically Erasable and Programmable-Read Only Memory)等を用いることができる。
【0041】
また、このプログラムの流通は、例えば、そのプログラムを記録したDVD、CD−ROM等の可搬型記録媒体を販売、譲渡、貸与等することによって行う。さらに、このプログラムをサーバコンピュータの記憶装置に格納しておき、ネットワークを介して、サーバコンピュータから他のコンピュータにそのプログラムを転送することにより、このプログラムを流通させる構成としてもよい。
【0042】
また、上述した実施形態とは別の実行形態として、コンピュータが可搬型記録媒体から直接このプログラムを読み取り、そのプログラムに従った処理を実行することとしてもよく、さらに、このコンピュータにサーバコンピュータからプログラムが転送されるたびに、逐次、受け取ったプログラムに従った処理を実行することとしてもよい。また、サーバコンピュータから、このコンピュータへのプログラムの転送は行わず、その実行指示と結果取得のみによって処理機能を実現する、いわゆるASP(Application Service Provider)型のサービスによって、上述の処理を実行する構成としてもよい。なお、本形態におけるプログラムには、電子計算機による処理の用に供する情報であってプログラムに準ずるもの(コンピュータに対する直接の指令ではないがコンピュータの処理を規定する性質を有するデータ等)を含むものとする。
【0043】
また、この形態では、コンピュータ上で所定のプログラムを実行させることにより、本装置を構成することとしたが、これらの処理内容の少なくとも一部をハードウェア的に実現することとしてもよい。
また、上述の各種処理は、記載に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されてもよい。その他、本発明の趣旨を逸脱しない範囲で適宜変更が可能である。
【0044】
〔効果の確認〕
発明の効果を確認するため、図8で示すような3本のマイクを用いた測定環境において、4名参加による5分間の会議データについての話者区間推定実験を行った。会議においては、まず男女各2名の話者がそれぞれ男1、女1、男2、女2の位置に着席して始めに自己紹介をし、その後、各話者が順番に位置PPに移動して発言を行った。自己紹介は収録開始から120秒までの間に行われたものとし、ttrainを120秒として収録開始から120秒までの観測信号を話者同定モデルの作成に用い、120秒以降について話者同定を行った。なお、短時間フーリエ変換のフレーム長は64ms、フレームシフト長は32msとした。
【0045】
評価指標としては、diarization error rate(DER)を利用した。
【数8】
ここで、DERは誤棄却(missed speaker time: MST、誰かが話しているにもかかわらず話していないと判定した時間長)、誤受理(false alarm speaker time:FAT、誰も話していないにもかかわらず誰かが話していると判定した時間長)、話者誤り(speaker error time: SET、話者を誤って判定した時間長)の3つの誤検出を含む指標となっている。つまりこの指標においては、DER値が小さい方が話者区間推定の精度が高いことを示しており、特に本発明においては話者を正しく判定できているかが問題となるため、効果の程度はSETに顕著に現れるはずである。
【0046】
図9(a)に確認結果を示す。図10は結果を図解したものであり、(a)は正解を示したもの、(b)は従来の方法による推定結果、 (c)は本発明の方法による推定結果である。なお、男1、女1、男2、女2の到来方向はそれぞれ100°、50°、−50°、−100°であり、位置PPは−160°の到来方向にあり、また、男1が話者1に、女1が話者2に、男2が話者3に、女2が話者4にそれぞれ対応する。図10(b)からわかるように、従来の方法では位置PPの話者を話者1〜4以外の別の話者5と推定しており、図9(a)に示すとおりSETが大きくなっている。これに対し、本発明の方法ではほぼ全ての時間区間で−160°方向の話者の区別を図10(a)と同様にできており、図9(a)に示すとおりSETが改善し、全体の性能であるDER値も改善していることがわかる。
【0047】
また、10組の話者組み合わせにおける会議シミュレーションを行った結果を図9(b)に示す。これは、音声信号と図8の測定環境で測定したインパルス応答とを用いて作成した会議シミュレーションデータを用いたものである。図9(b)においてシミュレーション1は各話者の音声間の重なりが無い場合であり、シミュレーション2は各話者の音声間の重なりがある場合の結果であるが、いずれの場合においてもDER、SETに関し本発明の方法が従来方法より優れた結果を示すことがわかる。
【産業上の利用可能性】
【0048】
本発明は、複数話者の音声信号が混在している音響データから各話者の音声区間を推定する必要があるシステムや装置等に利用することができ、特に音声の収録中に話者位置の移動が生じる場合に有効である。
【図面の簡単な説明】
【0049】
【図1】第1、2実施形態の複数信号区間推定装置の機能構成例を示す図
【図2】第1、2実施形態の複数信号区間推定装置の処理フロー例を示す図
【図3】第1〜4実施形態の複数信号区間推定装置の話者同定部の機能構成例を示す図
【図4】フレームが接続されていない場合に接続して処理をする方法を説明する図
【図5】第3実施形態の複数信号区間推定装置の処理フロー例を示す図
【図6】第4実施形態の複数信号区間推定装置の処理フロー例を示す図
【図7】第5実施形態の複数信号区間推定装置の機能構成例を示す図
【図8】効果の確認に用いた測定環境を示す図
【図9】効果の確認結果を示す表
【図10】効果の確認結果の根拠データを示す図
【図11】従来技術の複数信号区間推定装置の機能構成例を示す図
【図12】従来技術の複数信号区間推定装置の処理フロー例を示す図
【図13】従来技術の複数信号区間推定装置の別の機能構成例を示す図
【特許請求の範囲】
【請求項1】
複数のマイクによりそれぞれ収録された、複数の話者による発話音声が含まれる観測信号から、それぞれの話者の発話区間を推定する複数信号区間推定装置であって、
上記観測信号を所定長のフレームに順次切り出し、当該フレームごとに周波数領域に変換する周波数領域変換部と、
周波数領域に変換された上記観測信号(以下、「周波数領域観測信号」という)に基づき、各フレームが音声区間に該当するか否かを推定する音声区間推定部と、
上記周波数領域観測信号に基づき、当該周波数領域観測信号の到来方向を各フレームごとに推定する到来方向推定部と、
上記音声区間に該当すると推定された各フレームを、上記到来方向の類似性に基づき上記話者ごとのクラスタに分類する到来方向分類部と、
所定の時刻までに同一クラスタに分類された各フレームの上記周波数領域観測信号に基づき、当該クラスタに係る上記話者のモデルをクラスタごとに作成し、当該所定の時刻以降の上記観測信号の話者を、各話者のモデルに基づき推定する話者同定部と、
を備えることを特徴とする複数信号区間推定装置。
【請求項2】
請求項1に記載の複数信号区間推定装置において、
上記話者同定部は、
上記周波数領域観測信号の各フレームの音声特徴量を計算する特徴抽出手段と、
上記所定の時刻までに同一クラスタに分類された各フレームの音声特徴量を用いて、当該クラスタに係る上記話者のモデルを各クラスタごとに作成して出力するとともに、上記所定の時刻までの各フレームのインデックスと当該各フレームが属するクラスタに係る話者のインデックスとの組を出力するモデル学習手段と、
上記所定の時刻以降に同一クラスタに分類された互いに接続された フレーム(以下、「セグメント」という)の音声特徴量について、上記話者のモデルに対する尤度を各モデルごとに計算し、最大尤度をとるモデルに係る話者のインデックスを当該セグメントに付与して、当該セグメントに含まれる各フレームのインデックスとともに出力する尤度計算手段と、
を備えることを特徴とする複数信号区間推定装置。
【請求項3】
複数のマイクによりそれぞれ収録された、複数の話者による発話音声が含まれる観測信号から、それぞれの話者の発話区間を推定する複数信号区間推定装置であって、
上記観測信号を所定長のフレームに順次切り出し、当該フレームごとに周波数領域に変換する周波数領域変換部と、
周波数領域に変換された上記観測信号(以下、「周波数領域観測信号」という)に基づき、各フレームが音声区間に該当するか否かを推定する音声区間推定部と、
上記周波数領域観測信号に基づき、当該周波数領域観測信号の到来方向を各フレームごとに推定する到来方向推定部と、
上記音声区間に該当すると推定された各フレームを、上記到来方向の類似性に基づき上記話者ごとのクラスタに分類する到来方向分類部と、
上記周波数領域観測信号に基づき、上記クラスタに係る上記話者ごとに強調した信号(以下、「強調信号」という)を生成する音声強調部と、
所定の時刻までの上記強調信号に基づき、上記話者のモデルを話者ごとに作成し、当該所定の時刻以降の上記観測信号の話者を、各話者のモデルに基づき推定する話者同定部と、
を備えることを特徴とする複数信号区間推定装置。
【請求項4】
請求項3に記載の複数信号区間推定装置において、
上記話者同定部は、
上記強調信号の各フレームの音声特徴量を計算する特徴抽出手段と、
上記所定の時刻までの上記強調信号の各フレームの音声特徴量を用いて、上記話者のモデルを各話者ごとに作成して出力するとともに、上記所定の時刻までの各フレームのインデックスと当該各フレームが属するクラスタに係る話者のインデックスとの組を出力するモデル学習手段と、
上記所定の時刻以降に同一クラスタに分類された互いに接続されたフレーム(以下、「セグメント」という)の音声特徴量について、上記話者のモデルに対する尤度を各モデルごとに計算し、最大尤度をとるモデルに係る話者のインデックスを当該セグメントに付与して、当該セグメントに含まれる各フレームのインデックスとともに出力する尤度計算手段と、
を備えることを特徴とする複数信号区間推定装置。
【請求項5】
複数のマイクによりそれぞれ収録された、複数の話者による発話音声が含まれる観測信号から、それぞれの話者の発話区間を推定する複数信号区間推定方法であって、
上記観測信号を所定長のフレームに順次切り出し、当該フレームごとに周波数領域に変換する周波数領域変換ステップと、
周波数領域に変換された上記観測信号(以下、「周波数領域観測信号」という)に基づき、各フレームが音声区間に該当するか否かを推定する音声区間推定ステップと、
上記周波数領域観測信号に基づき、当該周波数領域観測信号の到来方向を各フレームごとに推定する到来方向推定ステップと、
上記音声区間に該当すると推定された各フレームを、上記到来方向の類似性に基づき上記話者ごとのクラスタに分類する到来方向分類ステップと、
所定の時刻までに同一クラスタに分類された各フレームの上記周波数領域観測信号に基づき、当該クラスタに係る上記話者のモデルをクラスタごとに作成し、当該所定の時刻以降の上記観測信号の話者を、各話者のモデルに基づき推定する話者同定ステップと、
を実行することを特徴とする複数信号区間推定方法。
【請求項6】
請求項5に記載の複数信号区間推定装置において、
上記話者同定ステップは、
上記周波数領域観測信号の各フレームの音声特徴量を計算する特徴抽出サブステップと、
上記所定の時刻までに同一クラスタに分類された各フレームの音声特徴量を用いて、当該クラスタに係る上記話者のモデルを各クラスタごとに作成して出力するとともに、上記所定の時刻までの各フレームのインデックスと当該各フレームが属するクラスタに係る話者のインデックスとの組を出力するモデル学習サブステップと、
上記所定の時刻以降に同一クラスタに分類された互いに接続されたフレーム(以下、「セグメント」という)の音声特徴量について、上記話者のモデルに対する尤度を各モデルごとに計算し、最大尤度をとるモデルに係る話者のインデックスを当該セグメントに付与して、当該セグメントに含まれる各フレームのインデックスとともに出力する尤度計算サブステップと、
を実行することを特徴とする複数信号区間推定方法。
【請求項7】
複数のマイクによりそれぞれ収録された、複数の話者による発話音声が含まれる観測信号から、それぞれの話者の発話区間を推定する複数信号区間推定方法であって、
上記観測信号を所定長のフレームに順次切り出し、当該フレームごとに周波数領域に変換する周波数領域変換ステップと、
周波数領域に変換された上記観測信号(以下、「周波数領域観測信号」という)に基づき、各フレームが音声区間に該当するか否かを推定する音声区間推定ステップと、
上記周波数領域観測信号に基づき、当該周波数領域観測信号の到来方向を各フレームごとに推定する到来方向推定ステップと、
上記音声区間に該当すると推定された各フレームを、上記到来方向の類似性に基づき上記話者ごとのクラスタに分類する到来方向分類ステップと、
上記周波数領域観測信号に基づき、上記話者ごとに強調した信号(以下、「強調信号」という)を生成する音声強調ステップと、
所定の時刻までの上記強調信号に基づき、上記話者のモデルを話者ごとに作成し、当該所定の時刻以降の上記観測信号の話者を、各話者のモデルに基づき推定する話者同定ステップと、
を実行することを特徴とする複数信号区間推定方法。
【請求項8】
請求項7に記載の複数信号区間推定方法において、
上記話者同定ステップは、
上記強調信号の各フレームの音声特徴量を計算する特徴抽出サブステップと、
上記所定の時刻までの上記強調信号の各フレームの音声特徴量を用いて、上記話者のモデルを話者ごとに作成して出力するとともに、上記所定の時刻までの各フレームのインデックスと当該各フレームが属するクラスタに係る話者のインデックスとの組を出力するモデル学習サブステップと、
上記所定の時刻以降に同一クラスタに分類された互いに接続されたフレーム(以下、「セグメント」という)の音声特徴量について、上記話者のモデルに対する尤度を各モデルごとに計算し、最大尤度をとるモデルに係る話者のインデックスを当該セグメントに付与して、当該セグメントに含まれる各フレームのインデックスとともに出力する尤度計算サブステップと、
を実行することを特徴とする複数信号区間推定方法。
【請求項9】
請求項6又は8のいずれかに記載の複数信号区間推定方法において、
更に、上記尤度計算サブステップにて上記セグメントに話者のインデックスを付与した後、そのセグメントに属する各フレームの音声特徴量に基づき改めて当該話者のモデルを作成して、当該話者のモデルを更新するモデル更新ステップ
を実行することを特徴とする複数信号区間推定方法。
【請求項10】
請求項6、8又は9のいずれかに記載の複数信号区間推定方法において、
更に、計算した上記最大尤度が所定の閾値より小さい場合に、新たな話者が参加したと判断し、当該新たな話者のインデックスを上記セグメントに付与するとともに、そのセグメントに属する各フレームの音声特徴量に基づき当該新たな話者のモデルを作成するモデル追加ステップ
を実行することを特徴とする複数信号区間推定方法。
【請求項11】
請求項1〜4のいずれかに記載した装置としてコンピュータを機能させるためのプログラム。
【請求項12】
請求項11に記載したプログラムを記録したコンピュータが読み取り可能な記録媒体。
【請求項1】
複数のマイクによりそれぞれ収録された、複数の話者による発話音声が含まれる観測信号から、それぞれの話者の発話区間を推定する複数信号区間推定装置であって、
上記観測信号を所定長のフレームに順次切り出し、当該フレームごとに周波数領域に変換する周波数領域変換部と、
周波数領域に変換された上記観測信号(以下、「周波数領域観測信号」という)に基づき、各フレームが音声区間に該当するか否かを推定する音声区間推定部と、
上記周波数領域観測信号に基づき、当該周波数領域観測信号の到来方向を各フレームごとに推定する到来方向推定部と、
上記音声区間に該当すると推定された各フレームを、上記到来方向の類似性に基づき上記話者ごとのクラスタに分類する到来方向分類部と、
所定の時刻までに同一クラスタに分類された各フレームの上記周波数領域観測信号に基づき、当該クラスタに係る上記話者のモデルをクラスタごとに作成し、当該所定の時刻以降の上記観測信号の話者を、各話者のモデルに基づき推定する話者同定部と、
を備えることを特徴とする複数信号区間推定装置。
【請求項2】
請求項1に記載の複数信号区間推定装置において、
上記話者同定部は、
上記周波数領域観測信号の各フレームの音声特徴量を計算する特徴抽出手段と、
上記所定の時刻までに同一クラスタに分類された各フレームの音声特徴量を用いて、当該クラスタに係る上記話者のモデルを各クラスタごとに作成して出力するとともに、上記所定の時刻までの各フレームのインデックスと当該各フレームが属するクラスタに係る話者のインデックスとの組を出力するモデル学習手段と、
上記所定の時刻以降に同一クラスタに分類された互いに接続された フレーム(以下、「セグメント」という)の音声特徴量について、上記話者のモデルに対する尤度を各モデルごとに計算し、最大尤度をとるモデルに係る話者のインデックスを当該セグメントに付与して、当該セグメントに含まれる各フレームのインデックスとともに出力する尤度計算手段と、
を備えることを特徴とする複数信号区間推定装置。
【請求項3】
複数のマイクによりそれぞれ収録された、複数の話者による発話音声が含まれる観測信号から、それぞれの話者の発話区間を推定する複数信号区間推定装置であって、
上記観測信号を所定長のフレームに順次切り出し、当該フレームごとに周波数領域に変換する周波数領域変換部と、
周波数領域に変換された上記観測信号(以下、「周波数領域観測信号」という)に基づき、各フレームが音声区間に該当するか否かを推定する音声区間推定部と、
上記周波数領域観測信号に基づき、当該周波数領域観測信号の到来方向を各フレームごとに推定する到来方向推定部と、
上記音声区間に該当すると推定された各フレームを、上記到来方向の類似性に基づき上記話者ごとのクラスタに分類する到来方向分類部と、
上記周波数領域観測信号に基づき、上記クラスタに係る上記話者ごとに強調した信号(以下、「強調信号」という)を生成する音声強調部と、
所定の時刻までの上記強調信号に基づき、上記話者のモデルを話者ごとに作成し、当該所定の時刻以降の上記観測信号の話者を、各話者のモデルに基づき推定する話者同定部と、
を備えることを特徴とする複数信号区間推定装置。
【請求項4】
請求項3に記載の複数信号区間推定装置において、
上記話者同定部は、
上記強調信号の各フレームの音声特徴量を計算する特徴抽出手段と、
上記所定の時刻までの上記強調信号の各フレームの音声特徴量を用いて、上記話者のモデルを各話者ごとに作成して出力するとともに、上記所定の時刻までの各フレームのインデックスと当該各フレームが属するクラスタに係る話者のインデックスとの組を出力するモデル学習手段と、
上記所定の時刻以降に同一クラスタに分類された互いに接続されたフレーム(以下、「セグメント」という)の音声特徴量について、上記話者のモデルに対する尤度を各モデルごとに計算し、最大尤度をとるモデルに係る話者のインデックスを当該セグメントに付与して、当該セグメントに含まれる各フレームのインデックスとともに出力する尤度計算手段と、
を備えることを特徴とする複数信号区間推定装置。
【請求項5】
複数のマイクによりそれぞれ収録された、複数の話者による発話音声が含まれる観測信号から、それぞれの話者の発話区間を推定する複数信号区間推定方法であって、
上記観測信号を所定長のフレームに順次切り出し、当該フレームごとに周波数領域に変換する周波数領域変換ステップと、
周波数領域に変換された上記観測信号(以下、「周波数領域観測信号」という)に基づき、各フレームが音声区間に該当するか否かを推定する音声区間推定ステップと、
上記周波数領域観測信号に基づき、当該周波数領域観測信号の到来方向を各フレームごとに推定する到来方向推定ステップと、
上記音声区間に該当すると推定された各フレームを、上記到来方向の類似性に基づき上記話者ごとのクラスタに分類する到来方向分類ステップと、
所定の時刻までに同一クラスタに分類された各フレームの上記周波数領域観測信号に基づき、当該クラスタに係る上記話者のモデルをクラスタごとに作成し、当該所定の時刻以降の上記観測信号の話者を、各話者のモデルに基づき推定する話者同定ステップと、
を実行することを特徴とする複数信号区間推定方法。
【請求項6】
請求項5に記載の複数信号区間推定装置において、
上記話者同定ステップは、
上記周波数領域観測信号の各フレームの音声特徴量を計算する特徴抽出サブステップと、
上記所定の時刻までに同一クラスタに分類された各フレームの音声特徴量を用いて、当該クラスタに係る上記話者のモデルを各クラスタごとに作成して出力するとともに、上記所定の時刻までの各フレームのインデックスと当該各フレームが属するクラスタに係る話者のインデックスとの組を出力するモデル学習サブステップと、
上記所定の時刻以降に同一クラスタに分類された互いに接続されたフレーム(以下、「セグメント」という)の音声特徴量について、上記話者のモデルに対する尤度を各モデルごとに計算し、最大尤度をとるモデルに係る話者のインデックスを当該セグメントに付与して、当該セグメントに含まれる各フレームのインデックスとともに出力する尤度計算サブステップと、
を実行することを特徴とする複数信号区間推定方法。
【請求項7】
複数のマイクによりそれぞれ収録された、複数の話者による発話音声が含まれる観測信号から、それぞれの話者の発話区間を推定する複数信号区間推定方法であって、
上記観測信号を所定長のフレームに順次切り出し、当該フレームごとに周波数領域に変換する周波数領域変換ステップと、
周波数領域に変換された上記観測信号(以下、「周波数領域観測信号」という)に基づき、各フレームが音声区間に該当するか否かを推定する音声区間推定ステップと、
上記周波数領域観測信号に基づき、当該周波数領域観測信号の到来方向を各フレームごとに推定する到来方向推定ステップと、
上記音声区間に該当すると推定された各フレームを、上記到来方向の類似性に基づき上記話者ごとのクラスタに分類する到来方向分類ステップと、
上記周波数領域観測信号に基づき、上記話者ごとに強調した信号(以下、「強調信号」という)を生成する音声強調ステップと、
所定の時刻までの上記強調信号に基づき、上記話者のモデルを話者ごとに作成し、当該所定の時刻以降の上記観測信号の話者を、各話者のモデルに基づき推定する話者同定ステップと、
を実行することを特徴とする複数信号区間推定方法。
【請求項8】
請求項7に記載の複数信号区間推定方法において、
上記話者同定ステップは、
上記強調信号の各フレームの音声特徴量を計算する特徴抽出サブステップと、
上記所定の時刻までの上記強調信号の各フレームの音声特徴量を用いて、上記話者のモデルを話者ごとに作成して出力するとともに、上記所定の時刻までの各フレームのインデックスと当該各フレームが属するクラスタに係る話者のインデックスとの組を出力するモデル学習サブステップと、
上記所定の時刻以降に同一クラスタに分類された互いに接続されたフレーム(以下、「セグメント」という)の音声特徴量について、上記話者のモデルに対する尤度を各モデルごとに計算し、最大尤度をとるモデルに係る話者のインデックスを当該セグメントに付与して、当該セグメントに含まれる各フレームのインデックスとともに出力する尤度計算サブステップと、
を実行することを特徴とする複数信号区間推定方法。
【請求項9】
請求項6又は8のいずれかに記載の複数信号区間推定方法において、
更に、上記尤度計算サブステップにて上記セグメントに話者のインデックスを付与した後、そのセグメントに属する各フレームの音声特徴量に基づき改めて当該話者のモデルを作成して、当該話者のモデルを更新するモデル更新ステップ
を実行することを特徴とする複数信号区間推定方法。
【請求項10】
請求項6、8又は9のいずれかに記載の複数信号区間推定方法において、
更に、計算した上記最大尤度が所定の閾値より小さい場合に、新たな話者が参加したと判断し、当該新たな話者のインデックスを上記セグメントに付与するとともに、そのセグメントに属する各フレームの音声特徴量に基づき当該新たな話者のモデルを作成するモデル追加ステップ
を実行することを特徴とする複数信号区間推定方法。
【請求項11】
請求項1〜4のいずれかに記載した装置としてコンピュータを機能させるためのプログラム。
【請求項12】
請求項11に記載したプログラムを記録したコンピュータが読み取り可能な記録媒体。
【図1】

【図2】

【図3】

【図4】
【図5】
【図6】
【図7】

【図8】

【図9】

【図10】

【図11】

【図12】
【図13】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【公開番号】特開2010−54733(P2010−54733A)
【公開日】平成22年3月11日(2010.3.11)
【国際特許分類】
【出願番号】特願2008−218677(P2008−218677)
【出願日】平成20年8月27日(2008.8.27)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【Fターム(参考)】
【公開日】平成22年3月11日(2010.3.11)
【国際特許分類】
【出願日】平成20年8月27日(2008.8.27)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【Fターム(参考)】
[ Back to top ]