
話者クラスタリング方法、話者クラスタリング装置、プログラム
【課題】同一クラスタ内の話者間の知覚的類似度を高くできる話者クラスタリング方法を提供する。
【解決手段】N名の話者による同一内容の発話の音声データのうちk番目とj番目(1≦k,j≦N)の話者の発話の音声データの知覚的類似度の主観評価値をj番目の要素として有する話者ベクトルを生成する話者ベクトル生成サブステップと、話者ベクトルのベクトル間距離に基づいて、N名の話者をクラスタ数Mにクラスタリングするクラスタリングサブステップと、話者の属するクラスタ毎に当該話者の発話の音声データから選択用モデルを学習する選択用モデル学習サブステップと、任意の話者の音声データを入力とし当該入力された任意の話者の音声データと各クラスタの選択用モデルとの尤度を計算する尤度計算サブステップと、計算された尤度が最も高いクラスタを入力された音声データの話者が属するクラスタとして選択するクラスタ選択サブステップとを有する。
【解決手段】N名の話者による同一内容の発話の音声データのうちk番目とj番目(1≦k,j≦N)の話者の発話の音声データの知覚的類似度の主観評価値をj番目の要素として有する話者ベクトルを生成する話者ベクトル生成サブステップと、話者ベクトルのベクトル間距離に基づいて、N名の話者をクラスタ数Mにクラスタリングするクラスタリングサブステップと、話者の属するクラスタ毎に当該話者の発話の音声データから選択用モデルを学習する選択用モデル学習サブステップと、任意の話者の音声データを入力とし当該入力された任意の話者の音声データと各クラスタの選択用モデルとの尤度を計算する尤度計算サブステップと、計算された尤度が最も高いクラスタを入力された音声データの話者が属するクラスタとして選択するクラスタ選択サブステップとを有する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は複数の話者を音声の特徴が類似したグループにまとめる話者クラスタリング方法、話者クラスタリング装置、プログラムに関する。
【背景技術】
【0002】
従来、あらかじめ用意した複数の話者の音声から、音声の特徴が似た話者同士をまとめてグループ化する話者クラスタリング技術の研究がおこなわれている(例えば非特許文献1)。この話者クラスタリング技術の応用先として、音声認識における話者適応技術がある。この手法では、あらかじめ話者クラスタリングにより話者を分割し、クラスタ毎に音響モデルを学習する。音声認識時には、入力された話者と音響特徴量が類似した音響モデルを選択することで音声認識の認識性能を向上させることができる。
【0003】
また音声合成において、任意話者の音声を合成するために、モデル変換に基づく話者適応手法の検討が行われている(非特許文献2)。この手法では、変換元のモデルとして、複数の話者の特徴を平均化したモデル(平均声モデル)が使用されているが、話者クラスタリングによって、あらかじめ複数の変換元モデルを用意し、変換元のモデルとして合成したい話者に類似したモデルを選択できれば、変換元モデルに平均声モデルを使用する場合に比べ、合成音声の自然性や類似性の向上が期待できる。
【先行技術文献】
【非特許文献】
【0004】
【非特許文献1】小坂、松永、嵯峨山、「話者適応のための木構造話者クラスタリング」、電子情報通信学会技術研究報告、社団法人電子情報通信学会、平成5年12月、SP, 音声, 93(364)、pp49〜54.
【非特許文献2】田村、益子、徳田、小林、「HMMに基づく音声合成におけるピッチ・スペクトルの話者適応」、電子情報通信学会論文誌、社団法人電子情報通信学会、平成14年 4月、D-II, 情報・システム, II-パターン処理, J85-D-II(4)、pp545〜553.
【発明の概要】
【発明が解決しようとする課題】
【0005】
従来の手法では、クラスタリングに使用する話者ベクトルとして、話者間の音響特徴量(ケプストラム、フォルマント周波数、声道長)や音響特徴量を用いて学習した統計モデル(HMM等)の距離等の客観尺度を使用している。しかしながら、これらの音響特徴量等の客観尺度は人間が知覚する話者間の知覚的類似度とは必ずしも一致しておらず、同一クラスタ内に存在する話者間の知覚的類似度が低くなる場合がある。そのため、音声合成に話者クラスタリングに基づく話者適応を適用する場合、最終的に合成される合成音声の自然性、類似性が低下してしまう場合がある。そこで、本発明では、同一クラスタ内に存在する話者間の知覚的類似度を高くできる話者クラスタリング装置を提供することを目的とする。
【課題を解決するための手段】
【0006】
本発明の話者クラスタリング装置は、モデル生成部と、クラスタ決定部とを備える。モデル生成部は発話記憶手段と、知覚的類似度行列記憶手段と、話者ベクトル生成手段と、クラスタリング手段と、選択用モデル学習手段と、選択用モデル記憶手段とを備える。クラスタ決定部は尤度計算手段と、クラスタ選択手段とを備える。
【0007】
発話記憶手段は、N名(Nは2以上の整数)の話者による同一内容の発話の音声データを記憶する。知覚的類似度行列記憶手段は、記憶されたN名の話者による同一内容の発話の音声データのうちi番目(iは1≦i≦Nを充たす整数)の話者の発話の音声データとj番目(jは1≦j≦Nを充たす整数)の話者の発話の音声データとの知覚的類似度の主観評価値を(i,j)要素として有するN×N行列を知覚的類似度行列として記憶する。話者ベクトル生成手段は、知覚的類似度行列の第k行ベクトル(kは1≦k≦Nを充たす整数)をk番目の話者の話者ベクトルとして生成する。クラスタリング手段は、話者ベクトルのベクトル間距離に基づいて、N名の話者をクラスタ数M(MはM<Nを充たす整数)にクラスタリングする。選択用モデル学習手段は、話者の属するクラスタ毎に、当該話者の発話の音声データから選択用モデルを学習する。選択用モデル記憶手段は、学習された選択用モデルを記憶する。
【0008】
尤度計算手段は、任意の話者の音声データを入力とし、当該入力された任意の話者の音声データと各クラスタの選択用モデルとの尤度をクラスタ毎に計算する。クラスタ選択手段は、計算された尤度が最も高いクラスタを入力された音声データの話者が属するクラスタとして選択する。
【発明の効果】
【0009】
本発明の話者クラスタリング装置によれば、同一クラスタ内に存在する話者間の知覚的類似度を高くできる。
【図面の簡単な説明】
【0010】
【図1】実施例1に係る話者クラスタリング装置の構成を示すブロック図。
【図2】実施例1に係る話者クラスタリング装置の動作を示すフローチャート。
【図3】実施例2に係る話者クラスタリング装置の構成を示すブロック図。
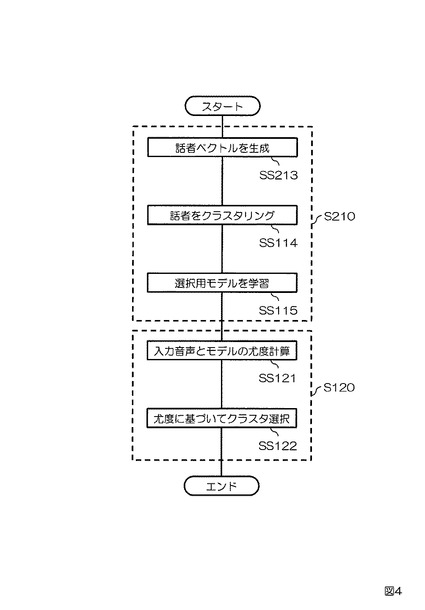
【図4】実施例2に係る話者クラスタリング装置の動作を示すフローチャート。
【図5】知覚的類似度の主観評価に使用する評価値とその表現例を示す図。
【発明を実施するための形態】
【0011】
以下、本発明の実施の形態について、詳細に説明する。なお、同じ機能を有する構成部には同じ番号を付し、重複説明を省略する。
【0012】
<発話記憶手段111>
全ての実施例の話者クラスタリング装置100、200が備える発話記憶手段111について説明する。発話記憶手段111には、N名(Nは2以上の整数)の話者の発話の音声データが予め記憶される。記憶されるN名の話者の発話内容はすべて同一文章を読み上げた音声に統一されているものとする。
【0013】
<知覚的類似度行列記憶手段112>
次に、全ての実施例の話者クラスタリング装置100、200が備える知覚的類似度行列記憶手段112について説明する。知覚的類似度行列記憶手段112には、知覚的類似度行列Sが予め記憶されている。この知覚的類似度行列Sは、前述の発話記憶手段111に保存されたN名の話者のうち任意の2名の話者の発話の知覚的類似度を、予め定めた評価者が主観評価により評価した値を要素に持つ行列である。以下、評価者が行う主観評価について説明する。まず評価者を予め用意する。個人差による主観評価の偏りを防ぐため、評価者数Lは4名以上とすることが望ましい。主観評価においては、前述の発話記憶手段111に予め記憶されたi番目の話者、およびj番目の話者(i,jは1≦i≦N、1≦j≦Nを充たす整数)が同一文章を発話した音声データをi番目の話者、j番目の話者の順番に評価者L名が聴取し、二つの音声データの類似度を評価する。主観評価には例えば図5のような主観評価尺度を用いることができる。図5は知覚的類似度の主観評価に使用する評価値とその表現例を示す図である。図5の例では主観評価尺度が3段階となっているが、評価値や表現は適宜変更することができる。例えば、3段階のかわりに5段階の主観評価尺度を用いることとしてもよい。このとき、i番目の話者、j番目の話者間の知覚的類似度S(i,j)は以下のように定義される。
【0014】
【数1】

【0015】
ここで、sl(i,j)はl番目の評価者がi番目の話者、j番目の話者の発話音声データをi番目−j番目の順番で聞いた場合の評価値であり、一つの音声データの組み合わせに対してL名の評価者全員が評価を行う。評価者は最終的にN×N通りの組み合わせの音声の評価を行う。知覚的類似度行列Sとは上述のi番目の話者、j番目の話者間の知覚的類似度S(i,j)を行列の(i,j)要素として有するN×N行列のことである。
【0016】
<話者ベクトル生成手段113>
次に、実施例1の話者クラスタリング装置100が備える話者ベクトル生成手段113について説明する。話者ベクトル生成手段113は、前述の知覚的類似度行列Sを入力とし、k番目(kは1≦k≦Nを充たす整数)の話者の話者ベクトルvkを以下のように生成する(SS113)。
【0017】
【数2】
【0018】
従って、k番目の話者の話者ベクトルとは知覚的類似度行列Sの第k行ベクトルSkを意味する。実施例における説明では、話者ベクトル生成手段113は、知覚的類似度行列Sを知覚的類似度行列記憶手段112から取得して、当該取得した知覚的類似度行列Sの第k行ベクトルSkをk番目の話者の話者ベクトルvkとして生成することとしたが、本発明の実現方法はこれに限られない。話者ベクトル生成手段113は、前述のN名の話者のうち任意の2名の発話(同一話者同士の比較含む)の音声データに対する知覚的類似度の主観評価の評価者L名による平均値の全ての組み合わせ(N×N個)を取得して、k番目の話者の発話の音声データとj番目の話者の発話の音声データとの知覚的類似度の主観評価値をj番目の要素として有するベクトル(要素数N)をk番目の話者の話者ベクトルvkとして、知覚的類似度行列Sを準備せずに、話者ベクトルを生成することも可能である。従って、前述の知覚的類似度行列記憶手段112は発明を実現するための必須の構成ではなく、何らかの方法で、話者ベクトル生成手段113に主観評価の平均値(N×N個)のデータを供給することができればよい。
【0019】
<クラスタリング手段114>
次に、全ての実施例の話者クラスタリング装置100、200が備えるクラスタリング手段114について説明する。クラスタリング手段114は、前述の話者ベクトルのベクトル間距離に基づいて、N名の話者をクラスタ数M(MはM<Nを充たす整数)にクラスタリングする(SS114)。これにより、各話者にクラスタ番号を付与する。クラスタリング手段が用いるアルゴリズムとして、例えばk−means法やLBG法など、一般的なクラスタリングアルゴリズムを使用することができる。
【0020】
<選択用モデル学習手段115、選択用モデル記憶手段116>
次に、全ての実施例の話者クラスタリング装置100、200が備える選択用モデル学習手段115、選択用モデル記憶手段116について説明する。選択用モデル学習手段115は、任意の話者の音声が入力された場合、その音声がどのクラスタに属するか選択するためのモデル(以下、選択用モデルという)を話者の属するクラスタ毎に、当該話者の発話の音声データから学習する(SS115)。クラスタの選択には、入力された音声と各クラスタ内の話者との知覚的類似度を得ることが望ましいが、クラスタ選択は人手を介さず行うため、主観評価により知覚的類似度を設定することは不可能である。そのためクラスタ選択手法として、入力話者の音声データと各クラスタに含まれる話者の音声データとの音響特徴量を利用する。例として、選択用モデル学習手段115は、各クラスタに含まれる話者の音声データから統計モデル(GMM(Gaussian Mixture Model:正規混合分布))を選択用モデルとして学習する(参考非特許文献1:D. A. Reynolds,“Speaker identification and verification using Gaussian mixture speaker models,” Speech Communication, vol.17, pp.91〜108, (1995))。モデル学習に用いる特徴量としては、例えば各クラスタの音声データから抽出したケプストラム等の音響特徴量を使用することができる。
【0021】
選択用モデル記憶手段116は、選択用モデル学習手段115が学習した選択用モデルをクラスタ毎に記憶する。
【0022】
<尤度計算手段121>
次に、全ての実施例の話者クラスタリング装置100、200が備える尤度計算手段121について説明する。尤度計算手段121は、任意の話者の音声データと前述の選択用モデル学習手段115が学習した選択用モデルとを入力とし、当該選択用モデル(例えばGMM)と入力された話者の音声とから尤度をクラスタ毎に計算する(SS121)。
【0023】
<クラスタ選択手段122>
次に、全ての実施例の話者クラスタリング装置100、200が備えるクラスタ選択手段122について説明する。クラスタ選択手段122は、入力された任意の話者の音声がM個のクラスタのうち、どのクラスタに属するか選択する。具体的には、クラスタ選択手段122は、前述の尤度計算手段121で計算された尤度が最も高いクラスタを入力話者が属するクラスタとして選択する(SS122)。
【0024】
<話者間距離行列記憶手段217>
次に、実施例2の話者クラスタリング装置200が備える話者間距離行列記憶手段217について説明する。話者間距離行列記憶手段217は、発話記憶手段111に記憶されたN名の話者の発話の音声データのうち、i番目の話者−j番目の話者間の客観尺度に基づく話者間距離値D(i,j)を行列の(i,j)要素として有するN×N行列を話者間距離行列Dとして予め記憶する。以下、客観尺度に基づく話者間距離の例として、特定話者HMM間の距離について記載する(参考非特許文献2:小坂、松永、嵯峨山、「話者適応のための木構造話者クラスタリング」、電子情報通信学会技術研究報告、社団法人電子情報通信学会、平成5年12月、SP, 音声, 93(364)、pp49〜54)。この手法ではまず、あらかじめ距離値を計算する全ての話者個別に特定話者HMMを学習する。このとき、二名の話者であるi番目の話者、j番目の話者のモデル構造が等しい場合、モデル間距離D(i,j)は以下により定義される。
【0025】
【数3】
【0026】
ここで、bs(i)はi番目の話者のモデルの状態sの出力確率分布、bs(j)はj番目の話者のモデルの状態sの出力確率分布、Sはモデルの総状態数を示す。出力確率分布が正規分布の場合、d(bs(i),bs(j))は以下により求められる。
【0027】
【数4】
【0028】
ここで、μi,Σiはそれぞれi番目の話者の発話の音声データのHMMの平均ベクトルと共分散行列を示す。同様に、μj,Σjはそれぞれj番目の話者の発話の音声データのHMMの平均ベクトルと共分散行列を示す。客観尺度による話者間距離として、これ以外にも声道特徴等の特徴量を使用してもよい(例えば、参考非特許文献4:内藤、Li、匂坂、「声道の特徴を用いた話者クラスタリング手法の検討」、情報処理学会研究報告、一般社団法人情報処理学会、平成9年12月、SLP, 音声言語情報処理97(120), pp35〜40)。
【0029】
<話者ベクトル生成手段213>
次に、実施例2の話者クラスタリング装置200が備える話者ベクトル生成手段213について説明する。話者ベクトル生成手段213は、主観評価により得られた話者間の知覚的類似度に基づく知覚的類似度行列Sの第k行ベクトル(kは1≦k≦Nを充たす整数)と、客観尺度に基づく話者間距離行列Dの第k行ベクトルとを結合した要素数2kのベクトルをk番目の話者の話者ベクトルとして生成する(SS213)。具体的には、k番目の話者の話者ベクトルは以下により与えられる。
【0030】
【数5】
【0031】
前述の話者ベクトル生成手段113と同様に、話者間距離行列Dを準備せずに、話者ベクトルを生成することも可能である。従って、前述の話者間距離行列記憶手段217は発明を実現するための必須の構成ではなく、何らかの方法で、話者ベクトル生成手段213に話者間距離値(N×N個)のデータを供給することができればよい。
【実施例1】
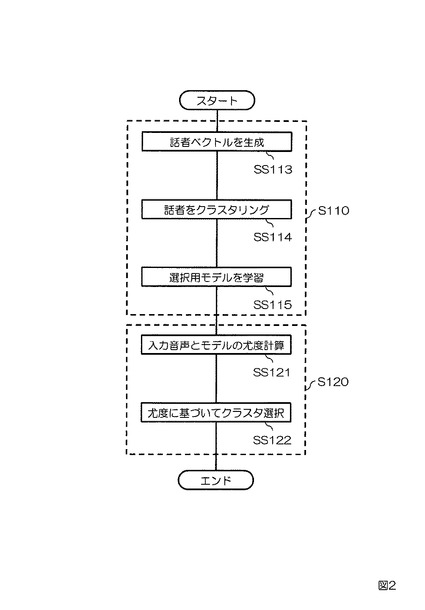
【0032】
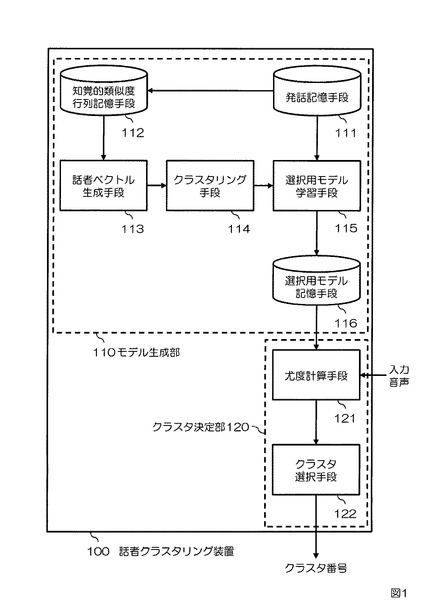
上述を前提として、実施例1に係る話者クラスタリング装置について図1、図2を参照して説明する。図1は本実施例に係る話者クラスタリング装置100の構成を示すブロック図である。図2は本実施例に係る話者クラスタリング装置100の動作を示すフローチャートである。本実施例の話者クラスタリング装置100は、モデル生成部110と、クラスタ決定部120とを備える。モデル生成部110は発話記憶手段111と、知覚的類似度行列記憶手段112と、話者ベクトル生成手段113と、クラスタリング手段114と、選択用モデル学習手段115と、選択用モデル記憶手段116とを備える。クラスタ決定部120は尤度計算手段121と、クラスタ選択手段122とを備える。
【0033】
まず、モデル生成部110について説明する。発話記憶手段111は、N名(Nは2以上の整数)の話者による同一内容の発話の音声データを予め記憶する。知覚的類似度行列記憶手段112は、記憶されたN名の話者による同一内容の発話の音声データのうちi番目(iは1≦i≦Nを充たす整数)の話者の発話の音声データとj番目(jは1≦j≦Nを充たす整数)の話者の発話の音声データとの知覚的類似度の主観評価値を(i,j)要素として有するN×N行列を知覚的類似度行列Sとして予め記憶する。話者ベクトル生成手段113は、知覚的類似度行列Sの第k行ベクトル(kは1≦k≦Nを充たす整数)をk番目の話者の話者ベクトルとして生成する(SS113)。クラスタリング手段114は、話者ベクトルのベクトル間距離に基づいて、N名の話者をクラスタ数M(MはM<Nを充たす整数)にクラスタリングする(SS114)。選択用モデル学習手段115は、話者の属するクラスタ毎に、当該話者の発話の音声データから選択用モデルを学習する(SS115)。選択用モデル記憶手段116は、学習された選択用モデルを記憶する(SS116)。
【0034】
次に、クラスタ決定部120について説明する。尤度計算手段121は、任意の話者の音声データを入力とし、当該入力された任意の話者の音声データと各クラスタの選択用モデルとの尤度をクラスタ毎に計算する(SS121)。クラスタ選択手段122は、計算された尤度が最も高いクラスタを入力された音声データの話者が属するクラスタとして選択する(SS122)。
【0035】
本実施例の話者クラスタリング装置100によれば、話者ベクトル生成手段113が、知覚的類似度の主観評価結果を要素に持つ話者ベクトルを生成し、クラスタリング手段114が、話者ベクトルのベクトル間距離に基づいてクラスタリングを行うため、話者同士の知覚的類似度の主観評価を考慮したクラスタを生成することができ、同一クラスタ内に存在する話者間の知覚的類似度を高くすることができる。
【実施例2】
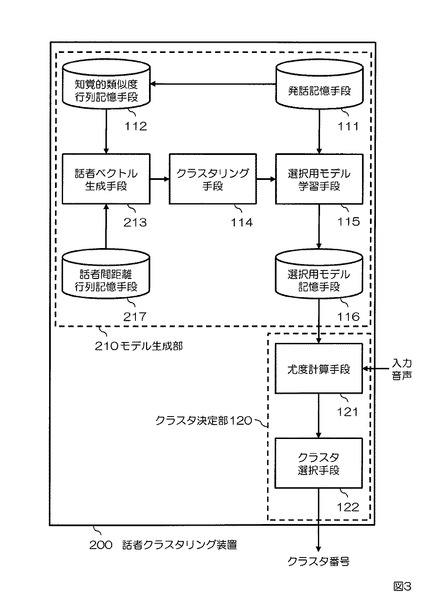
【0036】
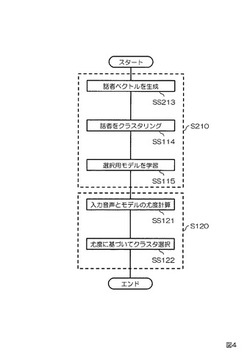
次に、実施例1の知覚的類似度の主観評価に加えて客観尺度による話者間距離を要素に持つ話者ベクトルを生成する実施例2に係る話者クラスタリング装置について図3、図4を参照して説明する。図3は本実施例に係る話者クラスタリング装置200の構成を示すブロック図である。図4は本実施例に係る話者クラスタリング装置200の動作を示すフローチャートである。本実施例の話者クラスタリング装置200は、モデル生成部210と、クラスタ決定部120とを備える。モデル生成部210は発話記憶手段111と、知覚的類似度行列記憶手段112と、話者ベクトル生成手段213と、クラスタリング手段114と、選択用モデル学習手段115と、選択用モデル記憶手段116と、話者間距離行列記憶手段217とを備える。クラスタ決定部120は尤度計算手段121と、クラスタ選択手段122とを備える。本実施例の実施例1との違いは、実施例1のモデル生成部110が本実施例ではモデル生成部210に変更されている点である。より具体的には、実施例1のモデル生成部110が備えない話者間距離行列記憶手段217を本実施例のモデル生成部210が備える点、及び実施例1の話者ベクトル生成手段113が本実施例において話者ベクトル生成手段213に変更されている点である。
【0037】
まず、モデル生成部210について説明する。発話記憶手段111は、N名(Nは2以上の整数)の話者による同一内容の発話の音声データを予め記憶する。知覚的類似度行列記憶手段112は、記憶されたN名の話者による同一内容の発話の音声データのうちi番目(iは1≦i≦Nを充たす整数)の話者の発話の音声データとj番目(jは1≦j≦Nを充たす整数)の話者の発話の音声データとの知覚的類似度の主観評価値を(i,j)要素として有するN×N行列を知覚的類似度行列Sとして予め記憶する。話者間距離行列記憶手段217は、記憶されたN名の話者による同一内容の発話の音声データのうちi番目(iは1≦i≦Nを充たす整数)の話者の発話の音声データとj番目(jは1≦j≦Nを充たす整数)の話者の発話の音声データとの話者間距離値を(i,j)要素として有するN×N行列を話者間距離行列Dとして予め記憶する。話者ベクトル生成手段213は、知覚的類似度行列Sの第k行ベクトル(kは1≦k≦Nを充たす整数)と、話者間距離行列Dの第k行ベクトルとを結合した要素数2kのベクトルをk番目の話者の話者ベクトルとして生成する(SS213)。クラスタリング手段114は、話者ベクトルのベクトル間距離に基づいて、N名の話者をクラスタ数M(MはM<Nを充たす整数)にクラスタリングする(SS114)。選択用モデル学習手段115は、話者の属するクラスタ毎に、当該話者の発話の音声データから選択用モデルを学習する(SS115)。選択用モデル記憶手段116は、学習された選択用モデルを記憶する(SS116)。
【0038】
次に、クラスタ決定部120について説明する。尤度計算手段121は、任意の話者の音声データを入力とし、当該入力された任意の話者の音声データと各クラスタの選択用モデルとの尤度をクラスタ毎に計算する(SS121)。クラスタ選択手段122は、計算された尤度が最も高いクラスタを入力された音声データの話者が属するクラスタとして選択する(SS122)。
【0039】
本実施例の話者クラスタリング装置200によれば、話者ベクトル生成手段213が、知覚的類似度の主観評価結果と、客観的指標である話者間距離値の双方を要素に持つ話者ベクトルを生成し、クラスタリング手段114が、話者ベクトルのベクトル間距離に基づいてクラスタリングを行うため、話者同士の知覚的類似度の主観評価のみならず、客観的指標である話者間距離をも考慮したクラスタを生成することができ、実施例1の効果に加えて、同一クラスタ内に存在する話者間の話者間距離が極端に大きくなることを防ぐことができる。
【0040】
また、上述の各種の処理は、記載に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されてもよい。その他、本発明の趣旨を逸脱しない範囲で適宜変更が可能であることはいうまでもない。
【0041】
また、上述の構成をコンピュータによって実現する場合、各装置が有すべき機能の処理内容はプログラムによって記述される。そして、このプログラムをコンピュータで実行することにより、上記処理機能がコンピュータ上で実現される。
【0042】
この処理内容を記述したプログラムは、コンピュータで読み取り可能な記録媒体に記録しておくことができる。コンピュータで読み取り可能な記録媒体としては、例えば、磁気記録装置、光ディスク、光磁気記録媒体、半導体メモリ等どのようなものでもよい。
【0043】
また、このプログラムの流通は、例えば、そのプログラムを記録したDVD、CD−ROM等の可搬型記録媒体を販売、譲渡、貸与等することによって行う。さらに、このプログラムをサーバコンピュータの記憶装置に格納しておき、ネットワークを介して、サーバコンピュータから他のコンピュータにそのプログラムを転送することにより、このプログラムを流通させる構成としてもよい。
【0044】
このようなプログラムを実行するコンピュータは、例えば、まず、可搬型記録媒体に記録されたプログラムもしくはサーバコンピュータから転送されたプログラムを、一旦、自己の記憶装置に格納する。そして、処理の実行時、このコンピュータは、自己の記録媒体に格納されたプログラムを読み取り、読み取ったプログラムに従った処理を実行する。また、このプログラムの別の実行形態として、コンピュータが可搬型記録媒体から直接プログラムを読み取り、そのプログラムに従った処理を実行することとしてもよく、さらに、このコンピュータにサーバコンピュータからプログラムが転送されるたびに、逐次、受け取ったプログラムに従った処理を実行することとしてもよい。また、サーバコンピュータから、このコンピュータへのプログラムの転送は行わず、その実行指示と結果取得のみによって処理機能を実現する、いわゆるASP(Application Service Provider)型のサービスによって、上述の処理を実行する構成としてもよい。なお、本形態におけるプログラムには、電子計算機による処理の用に供する情報であってプログラムに準ずるもの(コンピュータに対する直接の指令ではないがコンピュータの処理を規定する性質を有するデータ等)を含むものとする。
【0045】
また、この形態では、コンピュータ上で所定のプログラムを実行させることにより、本装置を構成することとしたが、これらの処理内容の少なくとも一部をハードウェア的に実現することとしてもよい。
【技術分野】
【0001】
本発明は複数の話者を音声の特徴が類似したグループにまとめる話者クラスタリング方法、話者クラスタリング装置、プログラムに関する。
【背景技術】
【0002】
従来、あらかじめ用意した複数の話者の音声から、音声の特徴が似た話者同士をまとめてグループ化する話者クラスタリング技術の研究がおこなわれている(例えば非特許文献1)。この話者クラスタリング技術の応用先として、音声認識における話者適応技術がある。この手法では、あらかじめ話者クラスタリングにより話者を分割し、クラスタ毎に音響モデルを学習する。音声認識時には、入力された話者と音響特徴量が類似した音響モデルを選択することで音声認識の認識性能を向上させることができる。
【0003】
また音声合成において、任意話者の音声を合成するために、モデル変換に基づく話者適応手法の検討が行われている(非特許文献2)。この手法では、変換元のモデルとして、複数の話者の特徴を平均化したモデル(平均声モデル)が使用されているが、話者クラスタリングによって、あらかじめ複数の変換元モデルを用意し、変換元のモデルとして合成したい話者に類似したモデルを選択できれば、変換元モデルに平均声モデルを使用する場合に比べ、合成音声の自然性や類似性の向上が期待できる。
【先行技術文献】
【非特許文献】
【0004】
【非特許文献1】小坂、松永、嵯峨山、「話者適応のための木構造話者クラスタリング」、電子情報通信学会技術研究報告、社団法人電子情報通信学会、平成5年12月、SP, 音声, 93(364)、pp49〜54.
【非特許文献2】田村、益子、徳田、小林、「HMMに基づく音声合成におけるピッチ・スペクトルの話者適応」、電子情報通信学会論文誌、社団法人電子情報通信学会、平成14年 4月、D-II, 情報・システム, II-パターン処理, J85-D-II(4)、pp545〜553.
【発明の概要】
【発明が解決しようとする課題】
【0005】
従来の手法では、クラスタリングに使用する話者ベクトルとして、話者間の音響特徴量(ケプストラム、フォルマント周波数、声道長)や音響特徴量を用いて学習した統計モデル(HMM等)の距離等の客観尺度を使用している。しかしながら、これらの音響特徴量等の客観尺度は人間が知覚する話者間の知覚的類似度とは必ずしも一致しておらず、同一クラスタ内に存在する話者間の知覚的類似度が低くなる場合がある。そのため、音声合成に話者クラスタリングに基づく話者適応を適用する場合、最終的に合成される合成音声の自然性、類似性が低下してしまう場合がある。そこで、本発明では、同一クラスタ内に存在する話者間の知覚的類似度を高くできる話者クラスタリング装置を提供することを目的とする。
【課題を解決するための手段】
【0006】
本発明の話者クラスタリング装置は、モデル生成部と、クラスタ決定部とを備える。モデル生成部は発話記憶手段と、知覚的類似度行列記憶手段と、話者ベクトル生成手段と、クラスタリング手段と、選択用モデル学習手段と、選択用モデル記憶手段とを備える。クラスタ決定部は尤度計算手段と、クラスタ選択手段とを備える。
【0007】
発話記憶手段は、N名(Nは2以上の整数)の話者による同一内容の発話の音声データを記憶する。知覚的類似度行列記憶手段は、記憶されたN名の話者による同一内容の発話の音声データのうちi番目(iは1≦i≦Nを充たす整数)の話者の発話の音声データとj番目(jは1≦j≦Nを充たす整数)の話者の発話の音声データとの知覚的類似度の主観評価値を(i,j)要素として有するN×N行列を知覚的類似度行列として記憶する。話者ベクトル生成手段は、知覚的類似度行列の第k行ベクトル(kは1≦k≦Nを充たす整数)をk番目の話者の話者ベクトルとして生成する。クラスタリング手段は、話者ベクトルのベクトル間距離に基づいて、N名の話者をクラスタ数M(MはM<Nを充たす整数)にクラスタリングする。選択用モデル学習手段は、話者の属するクラスタ毎に、当該話者の発話の音声データから選択用モデルを学習する。選択用モデル記憶手段は、学習された選択用モデルを記憶する。
【0008】
尤度計算手段は、任意の話者の音声データを入力とし、当該入力された任意の話者の音声データと各クラスタの選択用モデルとの尤度をクラスタ毎に計算する。クラスタ選択手段は、計算された尤度が最も高いクラスタを入力された音声データの話者が属するクラスタとして選択する。
【発明の効果】
【0009】
本発明の話者クラスタリング装置によれば、同一クラスタ内に存在する話者間の知覚的類似度を高くできる。
【図面の簡単な説明】
【0010】
【図1】実施例1に係る話者クラスタリング装置の構成を示すブロック図。
【図2】実施例1に係る話者クラスタリング装置の動作を示すフローチャート。
【図3】実施例2に係る話者クラスタリング装置の構成を示すブロック図。
【図4】実施例2に係る話者クラスタリング装置の動作を示すフローチャート。
【図5】知覚的類似度の主観評価に使用する評価値とその表現例を示す図。
【発明を実施するための形態】
【0011】
以下、本発明の実施の形態について、詳細に説明する。なお、同じ機能を有する構成部には同じ番号を付し、重複説明を省略する。
【0012】
<発話記憶手段111>
全ての実施例の話者クラスタリング装置100、200が備える発話記憶手段111について説明する。発話記憶手段111には、N名(Nは2以上の整数)の話者の発話の音声データが予め記憶される。記憶されるN名の話者の発話内容はすべて同一文章を読み上げた音声に統一されているものとする。
【0013】
<知覚的類似度行列記憶手段112>
次に、全ての実施例の話者クラスタリング装置100、200が備える知覚的類似度行列記憶手段112について説明する。知覚的類似度行列記憶手段112には、知覚的類似度行列Sが予め記憶されている。この知覚的類似度行列Sは、前述の発話記憶手段111に保存されたN名の話者のうち任意の2名の話者の発話の知覚的類似度を、予め定めた評価者が主観評価により評価した値を要素に持つ行列である。以下、評価者が行う主観評価について説明する。まず評価者を予め用意する。個人差による主観評価の偏りを防ぐため、評価者数Lは4名以上とすることが望ましい。主観評価においては、前述の発話記憶手段111に予め記憶されたi番目の話者、およびj番目の話者(i,jは1≦i≦N、1≦j≦Nを充たす整数)が同一文章を発話した音声データをi番目の話者、j番目の話者の順番に評価者L名が聴取し、二つの音声データの類似度を評価する。主観評価には例えば図5のような主観評価尺度を用いることができる。図5は知覚的類似度の主観評価に使用する評価値とその表現例を示す図である。図5の例では主観評価尺度が3段階となっているが、評価値や表現は適宜変更することができる。例えば、3段階のかわりに5段階の主観評価尺度を用いることとしてもよい。このとき、i番目の話者、j番目の話者間の知覚的類似度S(i,j)は以下のように定義される。
【0014】
【数1】
【0015】
ここで、sl(i,j)はl番目の評価者がi番目の話者、j番目の話者の発話音声データをi番目−j番目の順番で聞いた場合の評価値であり、一つの音声データの組み合わせに対してL名の評価者全員が評価を行う。評価者は最終的にN×N通りの組み合わせの音声の評価を行う。知覚的類似度行列Sとは上述のi番目の話者、j番目の話者間の知覚的類似度S(i,j)を行列の(i,j)要素として有するN×N行列のことである。
【0016】
<話者ベクトル生成手段113>
次に、実施例1の話者クラスタリング装置100が備える話者ベクトル生成手段113について説明する。話者ベクトル生成手段113は、前述の知覚的類似度行列Sを入力とし、k番目(kは1≦k≦Nを充たす整数)の話者の話者ベクトルvkを以下のように生成する(SS113)。
【0017】
【数2】
【0018】
従って、k番目の話者の話者ベクトルとは知覚的類似度行列Sの第k行ベクトルSkを意味する。実施例における説明では、話者ベクトル生成手段113は、知覚的類似度行列Sを知覚的類似度行列記憶手段112から取得して、当該取得した知覚的類似度行列Sの第k行ベクトルSkをk番目の話者の話者ベクトルvkとして生成することとしたが、本発明の実現方法はこれに限られない。話者ベクトル生成手段113は、前述のN名の話者のうち任意の2名の発話(同一話者同士の比較含む)の音声データに対する知覚的類似度の主観評価の評価者L名による平均値の全ての組み合わせ(N×N個)を取得して、k番目の話者の発話の音声データとj番目の話者の発話の音声データとの知覚的類似度の主観評価値をj番目の要素として有するベクトル(要素数N)をk番目の話者の話者ベクトルvkとして、知覚的類似度行列Sを準備せずに、話者ベクトルを生成することも可能である。従って、前述の知覚的類似度行列記憶手段112は発明を実現するための必須の構成ではなく、何らかの方法で、話者ベクトル生成手段113に主観評価の平均値(N×N個)のデータを供給することができればよい。
【0019】
<クラスタリング手段114>
次に、全ての実施例の話者クラスタリング装置100、200が備えるクラスタリング手段114について説明する。クラスタリング手段114は、前述の話者ベクトルのベクトル間距離に基づいて、N名の話者をクラスタ数M(MはM<Nを充たす整数)にクラスタリングする(SS114)。これにより、各話者にクラスタ番号を付与する。クラスタリング手段が用いるアルゴリズムとして、例えばk−means法やLBG法など、一般的なクラスタリングアルゴリズムを使用することができる。
【0020】
<選択用モデル学習手段115、選択用モデル記憶手段116>
次に、全ての実施例の話者クラスタリング装置100、200が備える選択用モデル学習手段115、選択用モデル記憶手段116について説明する。選択用モデル学習手段115は、任意の話者の音声が入力された場合、その音声がどのクラスタに属するか選択するためのモデル(以下、選択用モデルという)を話者の属するクラスタ毎に、当該話者の発話の音声データから学習する(SS115)。クラスタの選択には、入力された音声と各クラスタ内の話者との知覚的類似度を得ることが望ましいが、クラスタ選択は人手を介さず行うため、主観評価により知覚的類似度を設定することは不可能である。そのためクラスタ選択手法として、入力話者の音声データと各クラスタに含まれる話者の音声データとの音響特徴量を利用する。例として、選択用モデル学習手段115は、各クラスタに含まれる話者の音声データから統計モデル(GMM(Gaussian Mixture Model:正規混合分布))を選択用モデルとして学習する(参考非特許文献1:D. A. Reynolds,“Speaker identification and verification using Gaussian mixture speaker models,” Speech Communication, vol.17, pp.91〜108, (1995))。モデル学習に用いる特徴量としては、例えば各クラスタの音声データから抽出したケプストラム等の音響特徴量を使用することができる。
【0021】
選択用モデル記憶手段116は、選択用モデル学習手段115が学習した選択用モデルをクラスタ毎に記憶する。
【0022】
<尤度計算手段121>
次に、全ての実施例の話者クラスタリング装置100、200が備える尤度計算手段121について説明する。尤度計算手段121は、任意の話者の音声データと前述の選択用モデル学習手段115が学習した選択用モデルとを入力とし、当該選択用モデル(例えばGMM)と入力された話者の音声とから尤度をクラスタ毎に計算する(SS121)。
【0023】
<クラスタ選択手段122>
次に、全ての実施例の話者クラスタリング装置100、200が備えるクラスタ選択手段122について説明する。クラスタ選択手段122は、入力された任意の話者の音声がM個のクラスタのうち、どのクラスタに属するか選択する。具体的には、クラスタ選択手段122は、前述の尤度計算手段121で計算された尤度が最も高いクラスタを入力話者が属するクラスタとして選択する(SS122)。
【0024】
<話者間距離行列記憶手段217>
次に、実施例2の話者クラスタリング装置200が備える話者間距離行列記憶手段217について説明する。話者間距離行列記憶手段217は、発話記憶手段111に記憶されたN名の話者の発話の音声データのうち、i番目の話者−j番目の話者間の客観尺度に基づく話者間距離値D(i,j)を行列の(i,j)要素として有するN×N行列を話者間距離行列Dとして予め記憶する。以下、客観尺度に基づく話者間距離の例として、特定話者HMM間の距離について記載する(参考非特許文献2:小坂、松永、嵯峨山、「話者適応のための木構造話者クラスタリング」、電子情報通信学会技術研究報告、社団法人電子情報通信学会、平成5年12月、SP, 音声, 93(364)、pp49〜54)。この手法ではまず、あらかじめ距離値を計算する全ての話者個別に特定話者HMMを学習する。このとき、二名の話者であるi番目の話者、j番目の話者のモデル構造が等しい場合、モデル間距離D(i,j)は以下により定義される。
【0025】
【数3】
【0026】
ここで、bs(i)はi番目の話者のモデルの状態sの出力確率分布、bs(j)はj番目の話者のモデルの状態sの出力確率分布、Sはモデルの総状態数を示す。出力確率分布が正規分布の場合、d(bs(i),bs(j))は以下により求められる。
【0027】
【数4】
【0028】
ここで、μi,Σiはそれぞれi番目の話者の発話の音声データのHMMの平均ベクトルと共分散行列を示す。同様に、μj,Σjはそれぞれj番目の話者の発話の音声データのHMMの平均ベクトルと共分散行列を示す。客観尺度による話者間距離として、これ以外にも声道特徴等の特徴量を使用してもよい(例えば、参考非特許文献4:内藤、Li、匂坂、「声道の特徴を用いた話者クラスタリング手法の検討」、情報処理学会研究報告、一般社団法人情報処理学会、平成9年12月、SLP, 音声言語情報処理97(120), pp35〜40)。
【0029】
<話者ベクトル生成手段213>
次に、実施例2の話者クラスタリング装置200が備える話者ベクトル生成手段213について説明する。話者ベクトル生成手段213は、主観評価により得られた話者間の知覚的類似度に基づく知覚的類似度行列Sの第k行ベクトル(kは1≦k≦Nを充たす整数)と、客観尺度に基づく話者間距離行列Dの第k行ベクトルとを結合した要素数2kのベクトルをk番目の話者の話者ベクトルとして生成する(SS213)。具体的には、k番目の話者の話者ベクトルは以下により与えられる。
【0030】
【数5】
【0031】
前述の話者ベクトル生成手段113と同様に、話者間距離行列Dを準備せずに、話者ベクトルを生成することも可能である。従って、前述の話者間距離行列記憶手段217は発明を実現するための必須の構成ではなく、何らかの方法で、話者ベクトル生成手段213に話者間距離値(N×N個)のデータを供給することができればよい。
【実施例1】
【0032】
上述を前提として、実施例1に係る話者クラスタリング装置について図1、図2を参照して説明する。図1は本実施例に係る話者クラスタリング装置100の構成を示すブロック図である。図2は本実施例に係る話者クラスタリング装置100の動作を示すフローチャートである。本実施例の話者クラスタリング装置100は、モデル生成部110と、クラスタ決定部120とを備える。モデル生成部110は発話記憶手段111と、知覚的類似度行列記憶手段112と、話者ベクトル生成手段113と、クラスタリング手段114と、選択用モデル学習手段115と、選択用モデル記憶手段116とを備える。クラスタ決定部120は尤度計算手段121と、クラスタ選択手段122とを備える。
【0033】
まず、モデル生成部110について説明する。発話記憶手段111は、N名(Nは2以上の整数)の話者による同一内容の発話の音声データを予め記憶する。知覚的類似度行列記憶手段112は、記憶されたN名の話者による同一内容の発話の音声データのうちi番目(iは1≦i≦Nを充たす整数)の話者の発話の音声データとj番目(jは1≦j≦Nを充たす整数)の話者の発話の音声データとの知覚的類似度の主観評価値を(i,j)要素として有するN×N行列を知覚的類似度行列Sとして予め記憶する。話者ベクトル生成手段113は、知覚的類似度行列Sの第k行ベクトル(kは1≦k≦Nを充たす整数)をk番目の話者の話者ベクトルとして生成する(SS113)。クラスタリング手段114は、話者ベクトルのベクトル間距離に基づいて、N名の話者をクラスタ数M(MはM<Nを充たす整数)にクラスタリングする(SS114)。選択用モデル学習手段115は、話者の属するクラスタ毎に、当該話者の発話の音声データから選択用モデルを学習する(SS115)。選択用モデル記憶手段116は、学習された選択用モデルを記憶する(SS116)。
【0034】
次に、クラスタ決定部120について説明する。尤度計算手段121は、任意の話者の音声データを入力とし、当該入力された任意の話者の音声データと各クラスタの選択用モデルとの尤度をクラスタ毎に計算する(SS121)。クラスタ選択手段122は、計算された尤度が最も高いクラスタを入力された音声データの話者が属するクラスタとして選択する(SS122)。
【0035】
本実施例の話者クラスタリング装置100によれば、話者ベクトル生成手段113が、知覚的類似度の主観評価結果を要素に持つ話者ベクトルを生成し、クラスタリング手段114が、話者ベクトルのベクトル間距離に基づいてクラスタリングを行うため、話者同士の知覚的類似度の主観評価を考慮したクラスタを生成することができ、同一クラスタ内に存在する話者間の知覚的類似度を高くすることができる。
【実施例2】
【0036】
次に、実施例1の知覚的類似度の主観評価に加えて客観尺度による話者間距離を要素に持つ話者ベクトルを生成する実施例2に係る話者クラスタリング装置について図3、図4を参照して説明する。図3は本実施例に係る話者クラスタリング装置200の構成を示すブロック図である。図4は本実施例に係る話者クラスタリング装置200の動作を示すフローチャートである。本実施例の話者クラスタリング装置200は、モデル生成部210と、クラスタ決定部120とを備える。モデル生成部210は発話記憶手段111と、知覚的類似度行列記憶手段112と、話者ベクトル生成手段213と、クラスタリング手段114と、選択用モデル学習手段115と、選択用モデル記憶手段116と、話者間距離行列記憶手段217とを備える。クラスタ決定部120は尤度計算手段121と、クラスタ選択手段122とを備える。本実施例の実施例1との違いは、実施例1のモデル生成部110が本実施例ではモデル生成部210に変更されている点である。より具体的には、実施例1のモデル生成部110が備えない話者間距離行列記憶手段217を本実施例のモデル生成部210が備える点、及び実施例1の話者ベクトル生成手段113が本実施例において話者ベクトル生成手段213に変更されている点である。
【0037】
まず、モデル生成部210について説明する。発話記憶手段111は、N名(Nは2以上の整数)の話者による同一内容の発話の音声データを予め記憶する。知覚的類似度行列記憶手段112は、記憶されたN名の話者による同一内容の発話の音声データのうちi番目(iは1≦i≦Nを充たす整数)の話者の発話の音声データとj番目(jは1≦j≦Nを充たす整数)の話者の発話の音声データとの知覚的類似度の主観評価値を(i,j)要素として有するN×N行列を知覚的類似度行列Sとして予め記憶する。話者間距離行列記憶手段217は、記憶されたN名の話者による同一内容の発話の音声データのうちi番目(iは1≦i≦Nを充たす整数)の話者の発話の音声データとj番目(jは1≦j≦Nを充たす整数)の話者の発話の音声データとの話者間距離値を(i,j)要素として有するN×N行列を話者間距離行列Dとして予め記憶する。話者ベクトル生成手段213は、知覚的類似度行列Sの第k行ベクトル(kは1≦k≦Nを充たす整数)と、話者間距離行列Dの第k行ベクトルとを結合した要素数2kのベクトルをk番目の話者の話者ベクトルとして生成する(SS213)。クラスタリング手段114は、話者ベクトルのベクトル間距離に基づいて、N名の話者をクラスタ数M(MはM<Nを充たす整数)にクラスタリングする(SS114)。選択用モデル学習手段115は、話者の属するクラスタ毎に、当該話者の発話の音声データから選択用モデルを学習する(SS115)。選択用モデル記憶手段116は、学習された選択用モデルを記憶する(SS116)。
【0038】
次に、クラスタ決定部120について説明する。尤度計算手段121は、任意の話者の音声データを入力とし、当該入力された任意の話者の音声データと各クラスタの選択用モデルとの尤度をクラスタ毎に計算する(SS121)。クラスタ選択手段122は、計算された尤度が最も高いクラスタを入力された音声データの話者が属するクラスタとして選択する(SS122)。
【0039】
本実施例の話者クラスタリング装置200によれば、話者ベクトル生成手段213が、知覚的類似度の主観評価結果と、客観的指標である話者間距離値の双方を要素に持つ話者ベクトルを生成し、クラスタリング手段114が、話者ベクトルのベクトル間距離に基づいてクラスタリングを行うため、話者同士の知覚的類似度の主観評価のみならず、客観的指標である話者間距離をも考慮したクラスタを生成することができ、実施例1の効果に加えて、同一クラスタ内に存在する話者間の話者間距離が極端に大きくなることを防ぐことができる。
【0040】
また、上述の各種の処理は、記載に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されてもよい。その他、本発明の趣旨を逸脱しない範囲で適宜変更が可能であることはいうまでもない。
【0041】
また、上述の構成をコンピュータによって実現する場合、各装置が有すべき機能の処理内容はプログラムによって記述される。そして、このプログラムをコンピュータで実行することにより、上記処理機能がコンピュータ上で実現される。
【0042】
この処理内容を記述したプログラムは、コンピュータで読み取り可能な記録媒体に記録しておくことができる。コンピュータで読み取り可能な記録媒体としては、例えば、磁気記録装置、光ディスク、光磁気記録媒体、半導体メモリ等どのようなものでもよい。
【0043】
また、このプログラムの流通は、例えば、そのプログラムを記録したDVD、CD−ROM等の可搬型記録媒体を販売、譲渡、貸与等することによって行う。さらに、このプログラムをサーバコンピュータの記憶装置に格納しておき、ネットワークを介して、サーバコンピュータから他のコンピュータにそのプログラムを転送することにより、このプログラムを流通させる構成としてもよい。
【0044】
このようなプログラムを実行するコンピュータは、例えば、まず、可搬型記録媒体に記録されたプログラムもしくはサーバコンピュータから転送されたプログラムを、一旦、自己の記憶装置に格納する。そして、処理の実行時、このコンピュータは、自己の記録媒体に格納されたプログラムを読み取り、読み取ったプログラムに従った処理を実行する。また、このプログラムの別の実行形態として、コンピュータが可搬型記録媒体から直接プログラムを読み取り、そのプログラムに従った処理を実行することとしてもよく、さらに、このコンピュータにサーバコンピュータからプログラムが転送されるたびに、逐次、受け取ったプログラムに従った処理を実行することとしてもよい。また、サーバコンピュータから、このコンピュータへのプログラムの転送は行わず、その実行指示と結果取得のみによって処理機能を実現する、いわゆるASP(Application Service Provider)型のサービスによって、上述の処理を実行する構成としてもよい。なお、本形態におけるプログラムには、電子計算機による処理の用に供する情報であってプログラムに準ずるもの(コンピュータに対する直接の指令ではないがコンピュータの処理を規定する性質を有するデータ等)を含むものとする。
【0045】
また、この形態では、コンピュータ上で所定のプログラムを実行させることにより、本装置を構成することとしたが、これらの処理内容の少なくとも一部をハードウェア的に実現することとしてもよい。
【特許請求の範囲】
【請求項1】
モデル生成ステップと、クラスタ決定ステップとを備える話者クラスタリング方法であって、
前記モデル生成ステップは、
N名(Nは2以上の整数)の話者による同一内容の発話の音声データのうちk番目(kは1≦k≦Nを充たす整数)の話者の発話の音声データとj番目(jは1≦j≦Nを充たす整数)の話者の発話の音声データとの知覚的類似度の主観評価値をj番目の要素として有するベクトルをk番目の話者の話者ベクトルとして生成する話者ベクトル生成サブステップと、
前記話者ベクトルのベクトル間距離に基づいて、前記N名の話者をクラスタ数M(MはM<Nを充たす整数)にクラスタリングするクラスタリングサブステップと、
前記話者の属するクラスタ毎に、当該話者の発話の音声データから選択用モデルを学習する選択用モデル学習サブステップと、を有し、
前記クラスタ決定ステップは、
任意の話者の音声データを入力とし、当該入力された任意の話者の音声データと前記各クラスタの選択用モデルとの尤度をクラスタ毎に計算する尤度計算サブステップと、
前記計算された尤度が最も高いクラスタを前記入力された音声データの話者が属するクラスタとして選択するクラスタ選択サブステップと、
を有することを特徴とする話者クラスタリング方法。
【請求項2】
モデル生成ステップと、クラスタ決定ステップとを備える話者クラスタリング方法であって、
前記モデル生成ステップは、
N名(Nは2以上の整数)の話者による同一内容の発話の音声データのうちk番目(kは1≦k≦Nを充たす整数)の話者の発話の音声データとj番目(jは1≦j≦Nを充たす整数)の話者の発話の音声データとの知覚的類似度の主観評価値をj番目の要素として有し、k番目の話者の発話の音声データとj番目の話者の発話の音声データとの話者間距離値をN+j番目の要素として有するベクトルをk番目の話者の話者ベクトルとして生成する話者ベクトル生成サブステップと、
前記話者ベクトルのベクトル間距離に基づいて、前記N名の話者をクラスタ数M(MはM<Nを充たす整数)にクラスタリングするクラスタリングサブステップと、
前記話者の属するクラスタ毎に、当該話者の発話の音声データから選択用モデルを学習する選択用モデル学習サブステップと、を有し、
前記クラスタ決定ステップは、
任意の話者の音声データを入力とし、当該入力された任意の話者の音声データと前記各クラスタの選択用モデルとの尤度をクラスタ毎に計算する尤度計算サブステップと、
前記計算された尤度が最も高いクラスタを前記入力された音声データの話者が属するクラスタとして選択するクラスタ選択サブステップと、
を有することを特徴とする話者クラスタリング方法。
【請求項3】
モデル生成部と、クラスタ決定部とを備える話者クラスタリング装置であって、
前記モデル生成部は、
N名(Nは2以上の整数)の話者による同一内容の発話の音声データを記憶する発話記憶手段と、
前記記憶されたN名の話者による同一内容の発話の音声データのうちi番目(iは1≦i≦Nを充たす整数)の話者の発話の音声データとj番目(jは1≦j≦Nを充たす整数)の話者の発話の音声データとの知覚的類似度の主観評価値を(i,j)要素として有するN×N行列を知覚的類似度行列として記憶する知覚的類似度行列記憶手段と、
前記知覚的類似度行列の第k行ベクトル(kは1≦k≦Nを充たす整数)をk番目の話者の話者ベクトルとして生成する話者ベクトル生成手段と、
前記話者ベクトルのベクトル間距離に基づいて、前記N名の話者をクラスタ数M(MはM<Nを充たす整数)にクラスタリングするクラスタリング手段と、
前記話者の属するクラスタ毎に、当該話者の発話の音声データから選択用モデルを学習する選択用モデル学習手段と、
前記学習された選択用モデルを記憶する選択用モデル記憶手段と、を備え、
前記クラスタ決定部は、
任意の話者の音声データを入力とし、当該入力された任意の話者の音声データと前記各クラスタの選択用モデルとの尤度をクラスタ毎に計算する尤度計算手段と、
前記計算された尤度が最も高いクラスタを前記入力された音声データの話者が属するクラスタとして選択するクラスタ選択手段と、
を備えることを特徴とする話者クラスタリング装置。
【請求項4】
請求項1又は2に記載の話者クラスタリング方法を実行すべき指令をコンピュータに対してするプログラム。
【請求項1】
モデル生成ステップと、クラスタ決定ステップとを備える話者クラスタリング方法であって、
前記モデル生成ステップは、
N名(Nは2以上の整数)の話者による同一内容の発話の音声データのうちk番目(kは1≦k≦Nを充たす整数)の話者の発話の音声データとj番目(jは1≦j≦Nを充たす整数)の話者の発話の音声データとの知覚的類似度の主観評価値をj番目の要素として有するベクトルをk番目の話者の話者ベクトルとして生成する話者ベクトル生成サブステップと、
前記話者ベクトルのベクトル間距離に基づいて、前記N名の話者をクラスタ数M(MはM<Nを充たす整数)にクラスタリングするクラスタリングサブステップと、
前記話者の属するクラスタ毎に、当該話者の発話の音声データから選択用モデルを学習する選択用モデル学習サブステップと、を有し、
前記クラスタ決定ステップは、
任意の話者の音声データを入力とし、当該入力された任意の話者の音声データと前記各クラスタの選択用モデルとの尤度をクラスタ毎に計算する尤度計算サブステップと、
前記計算された尤度が最も高いクラスタを前記入力された音声データの話者が属するクラスタとして選択するクラスタ選択サブステップと、
を有することを特徴とする話者クラスタリング方法。
【請求項2】
モデル生成ステップと、クラスタ決定ステップとを備える話者クラスタリング方法であって、
前記モデル生成ステップは、
N名(Nは2以上の整数)の話者による同一内容の発話の音声データのうちk番目(kは1≦k≦Nを充たす整数)の話者の発話の音声データとj番目(jは1≦j≦Nを充たす整数)の話者の発話の音声データとの知覚的類似度の主観評価値をj番目の要素として有し、k番目の話者の発話の音声データとj番目の話者の発話の音声データとの話者間距離値をN+j番目の要素として有するベクトルをk番目の話者の話者ベクトルとして生成する話者ベクトル生成サブステップと、
前記話者ベクトルのベクトル間距離に基づいて、前記N名の話者をクラスタ数M(MはM<Nを充たす整数)にクラスタリングするクラスタリングサブステップと、
前記話者の属するクラスタ毎に、当該話者の発話の音声データから選択用モデルを学習する選択用モデル学習サブステップと、を有し、
前記クラスタ決定ステップは、
任意の話者の音声データを入力とし、当該入力された任意の話者の音声データと前記各クラスタの選択用モデルとの尤度をクラスタ毎に計算する尤度計算サブステップと、
前記計算された尤度が最も高いクラスタを前記入力された音声データの話者が属するクラスタとして選択するクラスタ選択サブステップと、
を有することを特徴とする話者クラスタリング方法。
【請求項3】
モデル生成部と、クラスタ決定部とを備える話者クラスタリング装置であって、
前記モデル生成部は、
N名(Nは2以上の整数)の話者による同一内容の発話の音声データを記憶する発話記憶手段と、
前記記憶されたN名の話者による同一内容の発話の音声データのうちi番目(iは1≦i≦Nを充たす整数)の話者の発話の音声データとj番目(jは1≦j≦Nを充たす整数)の話者の発話の音声データとの知覚的類似度の主観評価値を(i,j)要素として有するN×N行列を知覚的類似度行列として記憶する知覚的類似度行列記憶手段と、
前記知覚的類似度行列の第k行ベクトル(kは1≦k≦Nを充たす整数)をk番目の話者の話者ベクトルとして生成する話者ベクトル生成手段と、
前記話者ベクトルのベクトル間距離に基づいて、前記N名の話者をクラスタ数M(MはM<Nを充たす整数)にクラスタリングするクラスタリング手段と、
前記話者の属するクラスタ毎に、当該話者の発話の音声データから選択用モデルを学習する選択用モデル学習手段と、
前記学習された選択用モデルを記憶する選択用モデル記憶手段と、を備え、
前記クラスタ決定部は、
任意の話者の音声データを入力とし、当該入力された任意の話者の音声データと前記各クラスタの選択用モデルとの尤度をクラスタ毎に計算する尤度計算手段と、
前記計算された尤度が最も高いクラスタを前記入力された音声データの話者が属するクラスタとして選択するクラスタ選択手段と、
を備えることを特徴とする話者クラスタリング装置。
【請求項4】
請求項1又は2に記載の話者クラスタリング方法を実行すべき指令をコンピュータに対してするプログラム。
【図1】

【図2】
【図3】
【図4】
【図5】

【図2】
【図3】
【図4】
【図5】
【公開番号】特開2013−37108(P2013−37108A)
【公開日】平成25年2月21日(2013.2.21)
【国際特許分類】
【出願番号】特願2011−171815(P2011−171815)
【出願日】平成23年8月5日(2011.8.5)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【Fターム(参考)】
【公開日】平成25年2月21日(2013.2.21)
【国際特許分類】
【出願日】平成23年8月5日(2011.8.5)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【Fターム(参考)】
[ Back to top ]