
話題抽出装置及びプログラム
【課題】指定した対象期間において、話題の変遷を提示する。
【解決手段】一つの実施形態によれば、話題抽出装置は、話題抽出手段及び話題提示手段を備えている。前記話題抽出手段は、単語抽出手段及び話題語抽出手段を備えている。前記単語抽出手段は、対象文書集合から各単語を抽出し、当該各単語の出現頻度及び当該各単語が出現する文書頻度を算出する。前記話題語抽出手段は、前記抽出された各単語について、前記対象期間における出現文書の文書集合を取得し、話題語らしさを表す尺度である話題度を算出し、前記話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出された話題語について当該対象期間における出現日時に基づいて新鮮度を算出する。前記話題提示手段は、前記抽出された話題語を前記新鮮度の順に提示すると共に、当該提示した各話題語について単位期間毎の出現文書数を提示する。
【解決手段】一つの実施形態によれば、話題抽出装置は、話題抽出手段及び話題提示手段を備えている。前記話題抽出手段は、単語抽出手段及び話題語抽出手段を備えている。前記単語抽出手段は、対象文書集合から各単語を抽出し、当該各単語の出現頻度及び当該各単語が出現する文書頻度を算出する。前記話題語抽出手段は、前記抽出された各単語について、前記対象期間における出現文書の文書集合を取得し、話題語らしさを表す尺度である話題度を算出し、前記話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出された話題語について当該対象期間における出現日時に基づいて新鮮度を算出する。前記話題提示手段は、前記抽出された話題語を前記新鮮度の順に提示すると共に、当該提示した各話題語について単位期間毎の出現文書数を提示する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明の実施形態は、話題抽出装置及びプログラムに関する。
【背景技術】
【0002】
近年、計算機の高性能化や記憶媒体の大容量化、計算機ネットワークの普及などに伴い、日々、大量の電子化された文書が流通し、計算機システム上で活用することが可能となっている。ここでいう文書とは、例えば、ニュース記事、電子メール、ウェブページといった、ネットワーク上で共有されている文書などを指す。また、ここでいう文書は、個々の企業内で活用される文書(例、製品の不具合情報、顧客からの問い合わせ情報など)も指している。
【0003】
一般に、これらの文書のニュース記事やブログなどから、最近注目されている話題を知りたいというニーズがある。同様に、企業では、日々蓄積される製品の不具合情報から現在増加している問題を見つけて早期対策につなげたいニーズや、顧客からの問い合わせ情報から新たな需要を見つけて商品企画に活かしたいニーズが大きくなっている。
【0004】
これらのニーズに対し、例えば、従来の話題抽出方式では、指定期間の文書集合に含まれる単語に対して、出現頻度に基づいてスコアリングを行い、話題語の抽出と階層化を行っている。また、従来の話題抽出方式では、話題語のスコアの履歴情報を保持し、前回抽出時のスコアとの差分により、「新着」などのステータスを提示している。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特許第4234740号公報
【特許文献2】特許第4342575号公報
【非特許文献】
【0006】
【非特許文献1】藤木稔明、南野朋之、鈴木泰裕、奥村学、「document stream における burst の発見」、情報処理学会研究報告、2004−NL−160、pp.85−92、2004年
【発明の概要】
【発明が解決しようとする課題】
【0007】
以上のような従来の話題抽出方式は、通常は何の問題もないが、本発明者の検討によれば、更なる改良の余地がある。
【0008】
例えば、従来の話題抽出方式では、話題語のスコアの履歴情報に基づき、「新着」などのステータスを提示する方法を用いている。しかしながら、この方法は、定点観測的に“今”の話題を知る用途には向いているものの、1週間や1ヶ月といった一定の期間における話題の変遷を知る用途には不十分である。
【0009】
本発明が解決しようとする課題は、指定した対象期間において、話題の変遷を提示し得る話題抽出装置及びプログラムを提供することである。
【課題を解決するための手段】
【0010】
実施形態の話題抽出装置は、文書記憶手段、期間指定手段、話題抽出手段及び話題提示手段を備えている。
【0011】
前記文書記憶手段は、テキスト情報と日時情報を持つ複数の文書からなる対象文書集合を記憶する。
【0012】
前記期間指定手段は、話題抽出の対象とする対象期間の指定を受け付ける。
【0013】
前記話題抽出手段は、前記文書記憶手段に記憶された対象文書集合から、前記指定を受け付けた対象期間での話題を表す単語である話題語を抽出すると共に、各話題語について時事性を表す尺度である新鮮度を算出する。
【0014】
前記話題提示手段は、前記話題抽出手段によって抽出された話題語を前記新鮮度の順に提示すると共に、当該提示した各話題語について単位期間毎の出現文書数を提示する。
【0015】
前記話題抽出手段は、単語抽出手段及び話題語抽出手段を備えている。
【0016】
前記単語抽出手段は、前記文書記憶手段に記憶された対象文書集合から各単語を抽出し、当該各単語の出現頻度及び当該各単語が出現する文書数を示す文書頻度をそれぞれ算出する。
【0017】
前記話題語抽出手段は、前記単語抽出手段によって抽出された各単語について、前記対象期間における当該単語が出現する出現文書の文書集合を取得し、当該出現文書の出現頻度の有意性を表す値と、前記単語の出現頻度及び前記文書頻度に基づく当該単語の重み値とに基づいて、話題語らしさを表す尺度である話題度を算出し、前記話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出された話題語について当該対象期間における出現日時に基づいて新鮮度を算出する。
【図面の簡単な説明】
【0018】
【図1】第1の実施形態に係る話題抽出装置の構成を表すブロック図である。
【図2】同実施形態における文書データの例を表す模式図である。
【図3】同実施形態における指定画面の例を表す模式図である。
【図4】同実施形態における話題提示画面の例を表す模式図である。
【図5】同実施形態における単語文書テーブルの例を表す模式図である。
【図6】同実施形態における単語期間テーブルの例を表す模式図である。
【図7】同実施形態における話題語テーブルの例を表す模式図である。
【図8】同実施形態における処理の全体の流れを表すフローチャートである。
【図9】同実施形態における単語抽出処理の流れを表すフローチャートである。
【図10】同実施形態における話題抽出処理の流れを表すフローチャートである。
【図11】同実施形態における話題提示処理の流れを表すフローチャートである。
【図12】第2の実施形態に係る話題抽出装置の構成を表すブロック図である。
【図13】同実施形態における話題語テーブルの例を表す模式図である。
【図14】同実施形態における処理の全体の流れを表すフローチャートである。
【図15】同実施形態における話題語集約処理の流れを表すフローチャートである。
【図16】同実施形態における話題提示画面の例を表す模式図である。
【図17】第3の実施形態に係る話題抽出装置の構成を表すブロック図である。
【図18】同実施形態における話題語テーブルの例を表す模式図である。
【図19】同実施形態における話題語の階層の例を表す模式図である。
【図20】同実施形態における処理の全体の流れを表すフローチャートである。
【図21】同実施形態における話題語階層抽出処理の流れを表すフローチャートである。
【図22】同実施形態における話題提示処理の流れを表すフローチャートである。
【図23】同実施形態における話題提示画面の例を表す模式図である。
【図24】第4の実施形態に係る話題抽出装置の構成を表すブロック図である。
【図25】同実施形態における話題語テーブルの例を表す模式図である。
【図26】同実施形態における話題語の階層の例を表す模式図である。
【図27】同実施形態における処理の全体の流れを表すフローチャートである。
【図28】同実施形態における話題提示画面の例を表す模式図である。
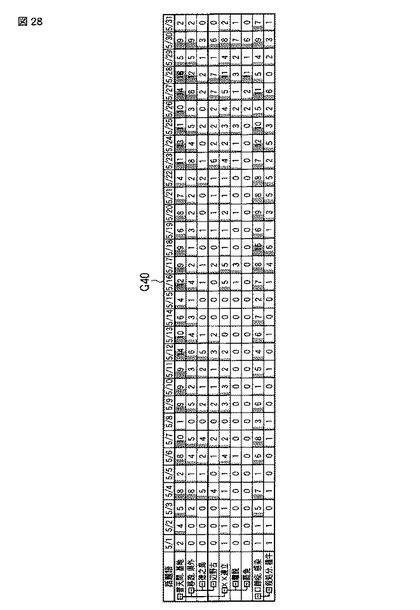
【図29】第5の実施形態に係る話題抽出装置の構成を表すブロック図である。
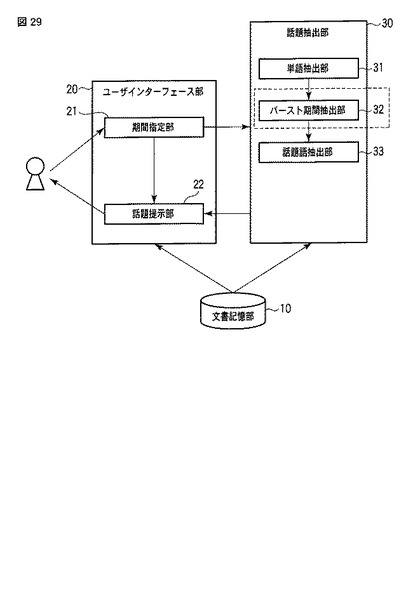
【図30】同実施形態における単語期間テーブルの例を表す模式図である。
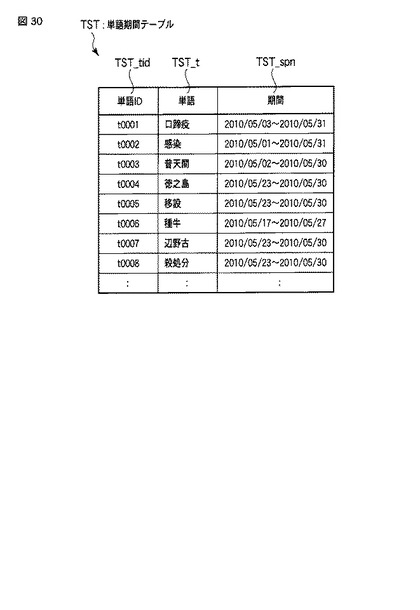
【図31】同実施形態における処理の全体の流れを表すフローチャートである。
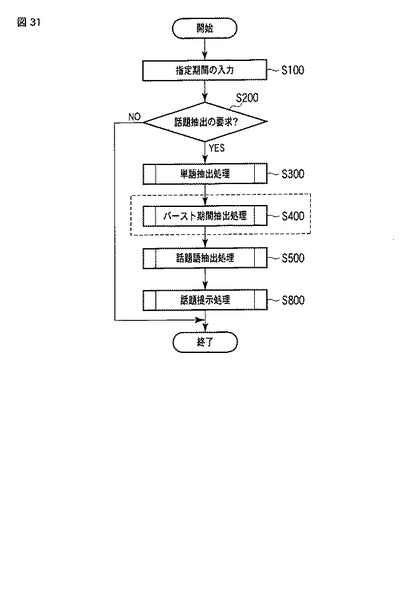
【図32】同実施形態におけるバースト期間抽出処理の流れを表すフローチャートである。
【図33】同実施形態における処理の話題提示処理の流れを表すフローチャートである。
【図34】同実施形態における話題提示画面の例を表す模式図である。
【図35】第6の実施形態に係る話題抽出装置の構成を表すブロック図である。
【図36】同実施形態における処理の全体の流れを表すフローチャートである。
【図37】同実施形態における話題提示画面の例を表す模式図である。
【図38】第7の実施形態に係る話題抽出装置の構成を表すブロック図である。
【図39】同実施形態における処理の全体の流れを表すフローチャートである。
【図40】同実施形態における処理の話題提示処理の流れを表すフローチャートである。
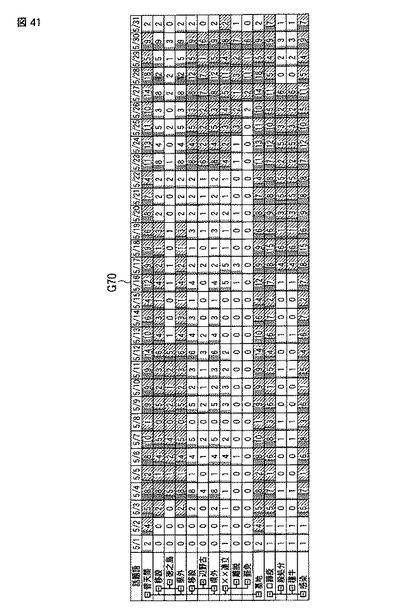
【図41】同実施形態における話題提示画面の例を表す模式図である。
【図42】第8の実施形態に係る話題抽出装置の構成を表すブロック図である。
【図43】同実施形態における処理の全体の流れを表すフローチャートである。
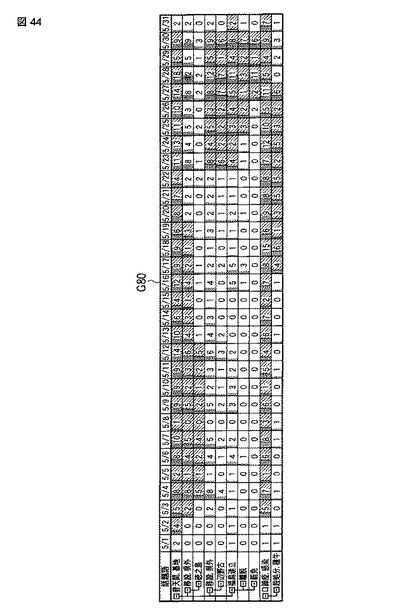
【図44】同実施形態における話題提示画面の例を表す模式図である。
【発明を実施するための形態】
【0019】
以下、各実施形態について図面を用いて説明するが、その前に、各実施形態で用いる主な記号を列挙して示す。
【0020】
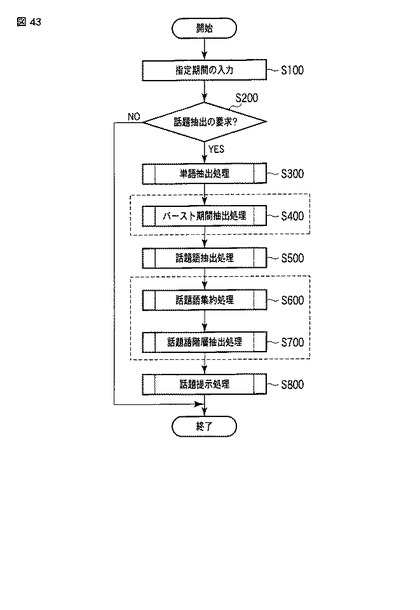
SPN:期間(開始日時from,終了日時to)。
【0021】
BST:バースト期間(第4〜第8の実施形態)。
【0022】
D:対象文書集合。
【0023】
Dspn:対象文書集合D中で、ある期間SPNに含まれる文書の集合(但し、Dspn⊂D)。なお、対象文書集合D中で、バースト期間BSTに含まれる文書の集合については、Dbstと表す(但し、Dbst⊂Dspn⊂D)。このように、バースト期間BSTを用いる場合、実施形態に記述された「SPN」又は添字の「spn」は、それぞれ「BST」又は添字の「bst」に読替え可能となっている。
【0024】
Docs:対象文書集合D中で、ある期間SPNiに含まれる文書の集合Dspniと、ある期間SPNjに含まれる文書の集合Dspnjとの和集合(Docs=Dspni∪Dspnj)。なお、バースト期間BSTi,BSTjを用いる場合、和集合Docsは、Docs=Dbsti∪Dbstjと読替え可能となっている。
【0025】
|Docs|:文書集合Docsに含まれる文書数。
【0026】
f(term,d):文書dでの、単語termの出現数。
【0027】
df(term,Docs):文書集合Docsのうち、単語termを含む文書の文書数。
【0028】
tf(term,Docs):文書集合Docsの中での、単語termの出現数。
【0029】
tc(Docs):文書集合Docsの中に含まれる単語の延べ数。
【0030】
time(d):文書dの出現日時。
【0031】
TD(term,Docs):文書集合Docsの中で、単語termを含む文書の集合。
【0032】
co(term1,term2,Docs):文書集合Docsの中で、単語term1とterm2がともに出現している文書の数。
【0033】
cospan(SPN1,SPN2):期間SPN1とSPN2で共通する期間。なお、バースト期間BST1,BST2を用いる場合、共通期間cospan(SPN1,SPN2)は、共通期間cospan(BST1,BST2)と読替え可能となっている。
【0034】
|SPN|:期間SPNの長さ。なお、バースト期間BSTの長さは、|BST|と表される。
【0035】
ITVLS:話題データをユーザに提示する際の時間間隔の集合。
【0036】
例えば、2010/05/01〜2010/05/31について、1日毎の出現数を提示する場合、時間間隔の集合ITVLSは、以下のような値を持つ。
【0037】
ITVLS ={2010/05/01 00:00〜2010/05/01 23:59,
2010/05/02 00:00〜2010/05/02 23:59,
:
2010/05/31 00:00〜2010/05/31 23:59}
また、時間間隔の集合ITVLSにより提示する期間は、期間SPNの長さと同じ場合を例に挙げて説明するが、これに限らず、期間の長さSPNより長い期間を提示してもよい。
【0038】
以上が各実施形態で用いる主な記号の説明である。これらの主な記号は、各実施形態において、種々の値の算出などに用いられる。
【0039】
また、各実施形態は、電子化された文書群から、それぞれの文書に含まれるテキスト情報と日時情報に基づいて、話題を抽出するための話題抽出装置に関連している。各実施形態の話題抽出装置は、ハードウェア構成、又はハードウェア資源とソフトウェアとの組合せ構成のいずれでも実施可能となっている。組合せ構成のソフトウェアとしては、予めネットワーク又は記憶媒体からコンピュータにインストールされ、当該コンピュータに話題抽出装置の機能を実現させるためのプログラムが用いられる。
【0040】
<第1の実施形態>
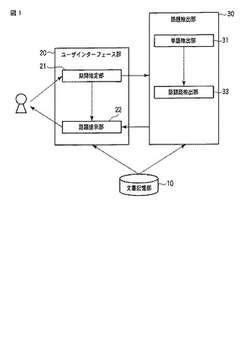
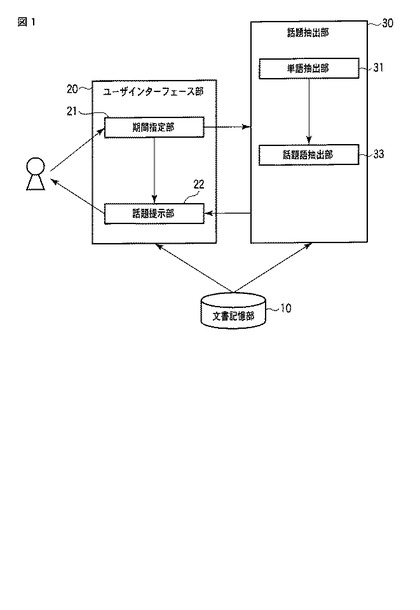
図1は第1の実施形態に係る話題抽出装置の構成を表すブロック図である。文書記憶部10は、話題抽出の対象となる文書データを格納する手段である。文書記憶部10は一般的にはファイルシステムや文書データベース等によって実現するが、例えば、計算機ネットワークによって接続した複数の記憶手段によって構成してもよい。文書記憶部10には、複数の文書が文書データとして格納される。各々の文書データは、図2に示すように、テキスト情報と、日時情報を持っている。
【0041】
文書記憶部10は、図2に示すように、テキスト情報(12,13)と日時情報(14)を持つ複数の文書(d)からなる対象文書集合Dを記憶する。各文書dは、ユニークな識別子である「文書ID」11を持つ。各文書dはテキスト、すなわち日本語や英語などの自然言語で記述されたデータとして、「見出し」12や「本文」13などのテキスト情報を持つ。さらに、各文書dは、「発信日時」14のように、1つ以上の日時属性(日時情報)を持つ。話題抽出装置では、この日時属性に基づいて、単語の新鮮度などを求める。各文書dが複数の日時属性を持つ場合は、話題抽出を実行する際に、どの日時属性を使用するかをユーザが指定するようにしてもよい。
【0042】
ユーザインターフェース部20は、話題抽出の対象とする期間の指定を受け付け、後述する話題抽出部30による話題抽出の結果を提示する手段である。ユーザインターフェース部は、期間指定部21と話題提示部22から構成される。
【0043】
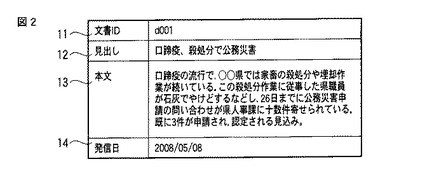
期間指定部21は、話題抽出の対象とする対象期間SPNの指定を受け付ける手段であり、例えば、当該指定を受け付けた対象期間と、話題抽出の実行要求とを話題抽出部30に送出する機能を持っている。例えば、期間指定部21では、図3に示す如き指定画面G1を介して、ユーザにより指定された対象期間の入力を受け付け、話題抽出部30に、この対象期間と、話題抽出部30の実行要求を送る。
【0044】
話題提示部22は、図4に例示する話題提示画面G10のように、話題抽出部30で抽出された話題語を新鮮度の順に提示すると共に、当該提示した各話題語について単位期間後の出現文書数を提示するものである。なお、新鮮度の順は、昇順及び降順のいずれでもよい。また、単位期間は、指定される対象期間よりも短い期間である。
【0045】
話題抽出部30は、文書記憶部10に記憶された対象文書集合Dから、期間指定部21で指定を受け付けた対象期間SPNでの話題を表す単語である話題語を抽出すると共に、各話題語について時事性を表す尺度である新鮮度を算出する手段である。この新鮮度によって、話題提示部22で、ユーザが話題語の時系列的な遷移を把握できるように、提示することを実現している。第1の実施形態では、話題抽出部30を、単語抽出部31及び話題語抽出部33で構成する。
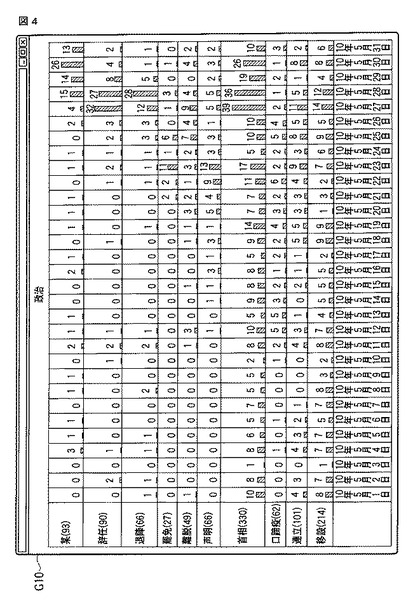
【0046】
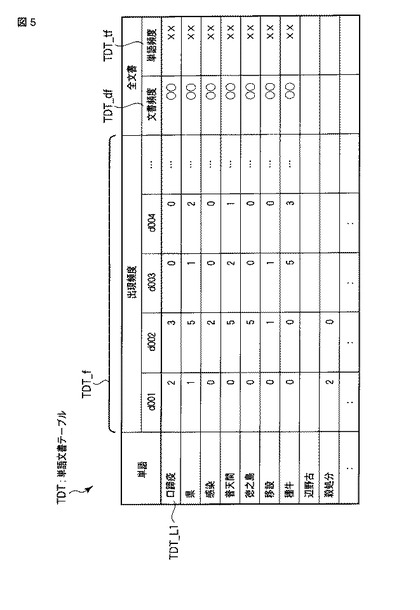
単語抽出部31は、文書記憶部10に記憶された対象文書集合Dから各単語を抽出し、当該各単語の出現頻度(tf(term,D))及び当該各単語が出現する文書数を示す文書頻度(df(term,D))をそれぞれ算出する手段である。詳しくは、単語抽出部31は、それぞれの単語について、各文書dでの出現数を算出すると共に、対象文書集合D全体での単語頻度と、文書頻度を算出し、図5に示す如き、単語文書テーブルTDTを生成する。話題語として抽出する単語の候補として、単語文書テーブルに含まれる単語を、図6に示す如き、単語期間テーブルTSTの形で出力する。単語期間テーブルTSTでは、各単語について、その対象期間を合わせて保持する。
【0047】
単語文書テーブルTDTは、図5に示すように、対象文書D中に含まれるそれぞれの単語について、各文書での出現数である「出現頻度」TDT_fを保持する。また、それぞれの単語について、対象文書集合D全体での出現する文書数である「文書頻度」TDT_dfと、出現頻度の合計である「単語頻度」TDT_tfを保持する。単語文書テーブルTDTは、話題抽出部30の内部データとして保持され、後述するバースト期間抽出部32、話題語抽出部33、話題語集約部34及び話題語階層抽出部35で使用される。
【0048】
単語期間テーブルTSTは、図6に示すように、話題語として抽出する単語の候補と、その単語が対象とする期間を保持する。各単語は、ユニークな識別子である「単語ID」TST_tidと、その単語の表記である「単語」TST_tと、その単語が対象とする期間である「期間」TST_spnを持つ。ここで、単語抽出部31では、単語文書テーブルTDTに含まれる全ての単語について、ユーザインターフェース部20から取得した対象期間をTST_spnに設定する。従って、TST_spnの値は、「2010/05/01〜2010/05/31」となる。また、単語期間テーブルTSTは、後述するバースト期間抽出部32においても生成される。バースト期間抽出部32においては、TST_spnには各単語に対して抽出されたバースト期間が保持される。なお、バースト期間抽出部32の詳細については後述する。
【0049】
話題語抽出部33は、単語抽出部31によって抽出された各単語について、対象期間SPNにおける当該単語が出現する出現文書の文書集合(TD(term,Dspn))を取得し、当該出現文書の出現頻度の有意性を表す値と、単語の出現頻度及び文書頻度に基づく当該単語の重み値とに基づいて、話題語らしさを表す尺度である話題度を算出し、話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出された話題語について当該対象期間における出現日時に基づいて新鮮度を算出する手段である。
【0050】
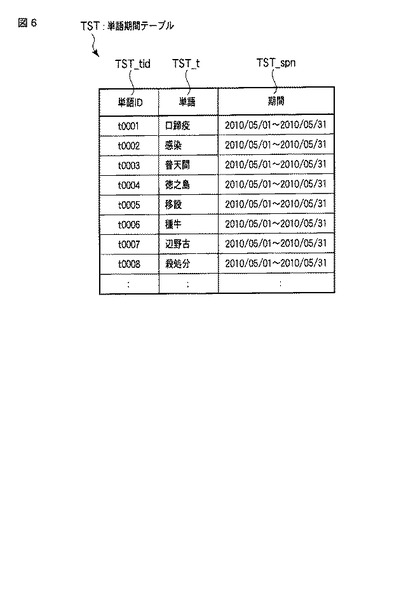
例えば、話題語抽出部33は、単語文書テーブルTDTと単語期間テーブルTSTを用いて話題語を抽出する。この場合、話題語抽出部33では、単語期間テーブルTSTに含まれるそれぞれの単語について、対応する期間での出現文書と文書頻度、単語頻度を算出し、それら頻度情報と出現文書の日時情報を用いて、話題語らしさを表す話題度を求め、この話題度に基づいて話題語を抽出する。さらに、抽出した話題語について、その出現文書の日時情報の系列に基づいて、その時事性を表す新鮮度を求める。そして、抽出した話題語について、図7に示すような話題語テーブルTWTを生成する。
【0051】
話題語テーブルTWTは、図7に示すように、話題語抽出部33で生成され、話題抽出部33の抽出結果として、話題提示部22に出力されるデータである。話題語テーブルTWTは、後述する話題集約部34と話題語階層抽出部35で更新される。話題語抽出部33では、話題語テーブルTWTの列のうち、「単語ID」TWT_tid、「単語」TWT_t、「期間」TWT_spn、「出現文書」TWT_did、「文書頻度」TWT_df、「単語頻度」TWT_tf、「話題度」TWT_score、「新鮮度」TWT_freshが格納される。「単語ID」TWT_tid、「単語」TWT_t及び「期間」TWT_spnは、単語期間テーブルTST中の「単語ID」TST_tid、「単語」TST_t、「期間」TST_spnの値である。但し、話題語単語テーブルTWTに保持される単語TWT_tは、単語期間テーブルTSTに含まれる単語TST_tの中で、話題語抽出部33で話題語と判定された単語のみである。話題語抽出部33は、それぞれの単語について、「期間」中に出現する文書集合TD(term,Dspn)である「出現文書」と、「出現文書」の文書数df(term,Dspn)である「文書頻度」、「出現文書」の文書集合での単語の出現頻度tf(term,Dspn)である「単語頻度」を取得し、「出現文書」TWT_did、「文書頻度」TWT_df及び「単語頻度」TWT_tfの各列に格納する。さらに、話題語抽出部33は、それらの情報によって算出した、話題語らしさを表す尺度である「話題度」score(term,SPN)と、その話題の時事性を表す尺度である「新鮮度」fresh(term,SPN)を算出し、「話題度」TWT_score及び「新鮮度」TWT_freshの各列に格納する。
【0052】
次に、以上のように構成された話題抽出装置の動作を図8乃至図11のフローチャートを用いて説明する。
【0053】
ユーザインターフェース部20内の期間指定部21は、図8に示すように、ユーザからの対象期間の指定を受け付けると共に(ステップS100)、話題抽出の実行要求を受け付ける(ステップS200)。対象期間の指定は、例えば図3に示す如き、指定画面G1において、ユーザが対象期間の開始日時g1と終了日時g2を設定する。そして、期間指定部21は、ユーザによる「実行」ボタンg3のクリック操作に応じて、話題抽出部30に対象期間SPN及び話題抽出の実行要求を送出する。
【0054】
指定画面G1で「実行」ボタンg3がクリック操作され、話題抽出の実行要求が送出された場合、話題抽出装置は、ステップS300〜S800の処理を行う(ステップS200−YES)。
【0055】
一方、指定画面G1で「キャンセル」ボタンg4がクリック操作された場合、話題抽出装置は、全体の処理を終了する(ステップS200−NO)。
【0056】
話題抽出の実行要求が送出された場合(ステップS200−YES)、単語抽出部31は、文書記憶部10に格納された対象文書集合Dに含まれる単語を抽出し、それぞれの単語が出現する文書や、出現頻度などの情報を求め、単語文書テーブルTWTと単語期間テーブルTSTを生成する単語抽出処理を行う(ステップS300)。なお、単語抽出処理(ステップS300)の詳細については後述する。
【0057】
次に、話題語抽出部33は、単語期間テーブルTST中のそれぞれの単語について、当該期間中に当該単語が出現する文書や、文書頻度、出現頻度などの情報に基づき、単語の話題度算出(スコアリング)を行い、話題語を抽出する話題語抽出処理を行う(ステップS500)。話題語抽出処理の詳細については後述する。また、話題語抽出処理(ステップS500)によって得られた頻度情報や話題度、新鮮度などは、話題語テーブルTWTとして話題抽出部30に保持される。
【0058】
そして、ユーザインターフェース部2の話題提示部22は、話題語テーブルTWTを話題抽出部30から受け取り、この話題語テーブルTWTに基づき、抽出結果をユーザに提示する話題提示処理を行う(ステップS800)。なお、話題提示処理(ステップS800)の詳細については後述する。
【0059】
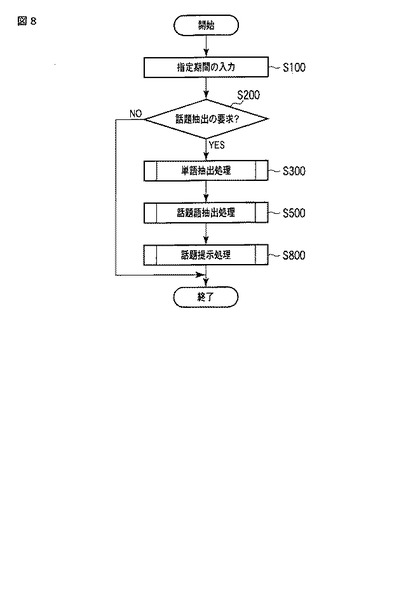
図9は単語抽出部31による単語抽出処理(ステップS300)の流れを表すフローチャートである。
【0060】
単語抽出部31は、入力として対象期間SPNを期間指定部21から受け取る(ステップS301)。続いて、単語抽出部31は、文書記憶部10から話題抽出の対象とする対象文書集合Dを取得し(ステップS302)、空の単語文書テーブルTDTを作成する(ステップS303)。
【0061】
次に、単語抽出部31は、対象文書集合Dに含まれる全ての文書のテキスト情報を形態素解析する(ステップS304)。例えば、図2に示す文書データの場合、「見出し」と「本文」の内容をテキスト情報とすると、形態素解析によって、「口蹄疫」「殺処分」「公務」「殺害」「流行」などの単語が抽出される。そして、単語抽出部31は、形態素解析結果に含まれるすべての単語termについて、ステップS306の処理を繰り返す(ステップS305)。ここで、単語抽出部31は、所定の品詞の単語であるか、あるいは、不要語ではないかによって、対象とする単語を絞り込んでもよい。例えば、品詞が名詞やサ変名詞、固有名詞などである単語は対象として、接続詞や副詞などは対象としないといった単語の選別を行う。また、例えば新聞記事を処理対象とする場合には、「政治」、「経済」といった単語は一般的な単語であり、話題を表さないので不要語として除去する。
【0062】
ステップS306では、単語抽出部31は、単語termについて、さらに文書集合Dに含まれる全ての文書dについて、単語termが文書d中での出現する回数を表す出現頻度f(term、d)を求め、単語文書テーブルTDTに格納する処理(ステップS307)を繰り返す。
【0063】
ステップS307において、例えば図2に示す文書データでは、「口蹄疫」の出現頻度f(「口蹄疫」,d001)=2となる。そして、単語抽出部31は、図5に示す単語文書テーブルTDTに対し、「口蹄疫」に対応する行TDT_L1について、文書ID=d001の出現頻度TDT_fとして“2”を格納する。
【0064】
そして、単語抽出部31は、ステップS306の繰り返し終了後、対象文書集合Dにおいて、単語termが出現する文書数である文書頻度df(term,D)と、単語termの出現頻度の合計である出現頻度tf(term、D)を求め、それぞれ、単語文書テーブルTDTの「文書頻度」TDT_dfと「単語頻度」TDT_tfに格納する(ステップS308)。
【0065】
S305の繰り返し終了後、単語抽出部31は、ステップS309〜ステップS311の処理を行う。
【0066】
始めに、単語抽出部31は、空の単語期間テーブルTSTを作成し(ステップS309)、ステップS308までの処理で作成した単語文書テーブルに含まれる全ての単語termについて、ステップS311の処理を繰り返す(ステップS310)。
【0067】
ステップS311では、単語抽出部31は、単語termと、ステップS301で取得した対象期間SPNの組である単語期間データTS={tid,term,SPN}を、単語期間テーブルTSTに格納する。ここで、tidは単語期間テーブルについてユニークな単語IDである。このステップS310〜ステップS311の処理により、単語抽出部31は、話題語抽出の対象となる単語データの集合である単語期間テーブルの初期データTSを作成する。
【0068】
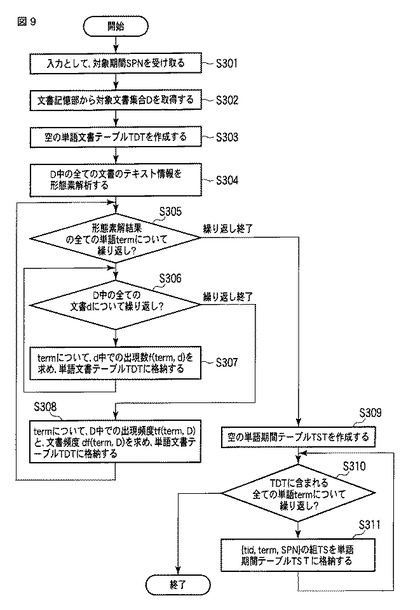
図10は話題語抽出部33による話題抽出処理(ステップS400)の流れを表すフローチャートである。
【0069】
話題語抽出部33は、単語文書テーブルTDTと単語期間テーブルTSTを取得し(ステップS501)、空の話題語テーブルTWTを作成する(ステップS502)。
【0070】
次に、話題語抽出部33は、単語期間テーブルTST中の全ての単語期間データTSについて、ステップS504〜ステップS509の処理を繰り返す(ステップS503)。ここで、単語期間データTSとは、{単語ID tid,単語term,期間SPN}の組である(TS={tid,term,SPN})。この繰り返し処理によって、話題語抽出部33は、単語期間データTS中の単語の中から、話題語に相応しい単語を抽出すると共に、その際に算出した頻度情報や話題度などの統計情報を話題語テーブルTWTとして保持する。そのために、話題語抽出部33は、当該単語期間データTSの単語termについて、単語文書テーブルTDTから対象文書集合全体Dでの、「文書頻度df(term,D)」TDT_dfの列と、「単語頻度tf(term,D)」TDT_tfの列を取得する(ステップS504)。
【0071】
次に、話題語抽出部33は、単語文書テーブルTDTから、単語termが出現する文書について文書記憶部10で日時情報を参照し、期間SPN中に単語termが出現する文書の集合TD(term,Dspn)を取得する(ステップS505)。
【0072】
次に、話題語抽出部33は、単語termについて、単語文書テーブルから、期間SPN中での文書頻度df(term,Dspn)と、単語頻度tf(term,Dspn)を算出する(ステップS506)。
【0073】
次に、話題語抽出部33は、ステップS504〜S506で算出した情報を用いて、単語termについて、その話題語らしさを表す尺度である話題度score(term,SPN)と、その話題の時事性を表す尺度である新鮮度fresh(term,SPN)を算出する(ステップS507)。
【0074】
話題度score(term,SPN)は、例えば[数1]に示す式によって算出される。
【数1】

【0075】
ここで、期間偏在値topical(term,SPN)は、全文書集合Dの中における、期間SPNでの出現頻度の有意性を表す値であり、期間SPNに偏って出現している単語ほど大きな値となる。さらに、重み値tfidf(term)は、文書分類や文書検索などで、単語の重みとして一般的に使われている指標である。話題度score(term,SPN)では、期間偏在値topical(term,SPN)に、この重み値tfidf(term)を乗算することにより、話題性があり、かつ、その話題をよく表す単語が高い話題度になるようにする。また、新鮮度fresh(term,SPN)は、例えば[数2]に示す式によって算出される。
【数2】
【0076】
新鮮度fresh(term,SPN)は、期間SPNにおける単語termの出現時間の平均を表し、0≦fresh(term,SPN)≦1の値となる。期間SPN(開始日時from、終了日時to)に対して、単語termが終了日時toに偏って出現しているほど、新鮮度fresh(term,SPN)の値は1に近づき、その単語が表す話題が新鮮であることを表す。なお、単語の話題度として、[数1]に示した話題度score(term,SPN)に、この新鮮度fresh(term,SPN)を乗算した値を使用してもよい。その場合は、期間SPNにおいて、最近に盛り上がった話題を重視して話題語を抽出することとなる。
【0077】
次に、話題語抽出部33は、score(term,SPN)>αという式によって、単語termが話題語であるか否かを判定する(ステップS508)。ここで、αとは、当該単語termが話題語として適切かどうかを判定するためのしきい値であり、話題抽出装置において、事前に設定されていてもよいし、話題抽出の処理の都度、ユーザが設定してもよい。
【0078】
話題語と判定した場合(ステップS508−YES)、話題語抽出部33は、当該単語termを話題語として、算出した統計情報を話題語テーブルTWTに追加する(ステップS509)。ここで、ある単語termを話題語として判定した場合、話題語抽出部33は、図7の話題語テーブルTWTについて、単語期間データTS中の「単語ID」TST_tid、「単語」TST_t、「期間」TST_spnの値を、それぞれ「単語ID」TWT_tid、「単語」TWT_t、「期間」TWT_spnに保持する。また、話題語抽出部33は、ステップS505〜S507によって算出された文書集合TD(term、Dspn)、文書頻度df(term,Dspn)、単語頻度tf(term,Dspn)、話題度score(term,SPN)、新鮮度(term,SPN)を、それぞれ「出現文書」TWT_did、「文書頻度」TWT_df、「単語頻度」TWT_tf、「話題度」TWT_score、「新鮮度」TWT_freshに保持する。
【0079】
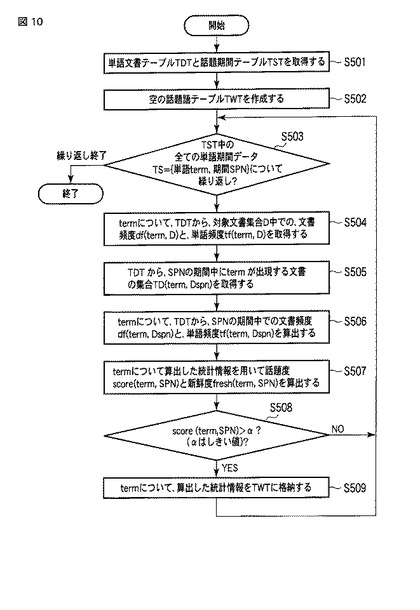
図11は話題提示部22による話題提示処理(ステップS800)の流れを表すフローチャートである。
【0080】
話題提示部22は、ユーザから表示のための時間間隔の指定を受け付け、時間間隔の集合ITVLSを作成する(ステップS801)。時間間隔の指定は、対象期間の指定(ステップS100)の際に、図3に示した指定画面G1の「表示間隔」g5でユーザが行うものとする。話題提示部22は、指定画面G1によりユーザに指定された「期間」について、「表示間隔」毎に区切った時間間隔ITVLSを作成する。例えば、指定画面G1の「期間」に「2010/05/01〜2010/05/31」が入力され、表示間隔に「日」が入力された場合、話題提示部22は、時間間隔ITVLSを次に示すように作成する。
【0081】
ITVLS=
{2010/05/01 00:00〜2010/05/01 23:59,
2010/05/02 00:00〜2010/05/02 23:59,
: :
2010/05/31 00:00〜2010/05/31 23:59}
なお、時間間隔の集合ITVLSには、ユーザが任意の時間間隔を指定してもよい。次に、話題提示部22は、時間間隔の集合ITVLSの各要素の内容を、図4に示したように、提示画面G10の最終行に表示する。図4の例では、時間間隔の集合ITVLSの各要素を「10年5月1日」、「10年5月2日」、…、「10年5月31日」のように簡略化して表示している。
【0082】
次に、話題提示部22は、話題抽出部30から話題語テーブルTWTを取得し、話題語テーブルTWT内の話題語データを要素として含む話題語データの集合をTWSとする(ステップS804)。
【0083】
次に、話題提示部22は、話題語データ集合TWSの要素を、「新鮮度」TWT_freshによってソートする(ステップS805)。これによって、話題語が時系列順にソートされる。
【0084】
次に話題提示部22は、話題語データ集合TWSが空になるまで、ステップS807〜S814の処理を繰り返す(ステップS806)。始めに、話題提示部22は、話題語データ集合TWS中の先頭にある話題語データをpとする(ステップS807)。
【0085】
次に、話題提示部22は、未表示の話題語データを、順次、話題語データ集合TWS中の先頭の話題語データpの位置に挿入する(ステップS810)。ステップS810では、話題提示部22は、話題語データ集合TWS中の表示済の話題語データpを削除した上で、pの位置にステップS805でソートした順に、話題語データの集合TWS中の話題語データを挿入する。
【0086】
そして、話題提示部22は、ステップS811〜S814の処理によって、話題語データpの情報を話題提示画面G10に表示する。そのために、話題提示部22は、話題提示画面G10に行を追加し(ステップS811)、追加した行の先頭列に話題語データpの「単語」を表示する(ステップS812)。
【0087】
次に、話題提示部22は、話題語データpの「出現文書」のそれぞれの文書dについて、文書記憶部10を参照して、出現日時time(d)を取得する(ステップS813)。話題提示部22は、取得した各文書の出現日時time(d)を、ITVLS中の各期間ITVLについてカウントすることにより、話題語データpの単語termを含む文書の出現頻度を各期間ITVLについて取得し、該当列にその出現頻度を表示する(ステップS814)。出現頻度の表示には、数値や棒グラフ、折れ線グラフなどを用いる。これによって、当該話題語データの行について、話題提示画面G10に文書dの出現頻度が表示される。
【0088】
このように、話題提示部22は、ステップS807〜S814の処理をTWSが空になるまで繰り返すことによって、話題語テーブルTWT中の全ての話題語データを新鮮度によって時系列順にソートしながら、話題語提示画面G10に表示する。
【0089】
上述したように本実施形態によれば、抽出された各単語について、話題語らしさを表す話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出された話題語について当該対象期間における出現日時に基づいて新鮮度を算出し、抽出された話題語を新鮮度の順に提示すると共に、当該提示した各話題語について単位期間毎の出現文書数を提示する構成により、対象文書集合について、指定された対象期間における話題を提示することができる。特に、新鮮度によるソートと、各話題語の単位時間毎の出現文書数の提示により、話題の時間的な遷移を、その盛り上がり具合とともに提示することができる。例えば、図4に示すように、対象期間の中で、直近で注目され始めた話題から、少し前に盛り上がった話題、長い間注目されている話題といった、話題の全体的な遷移を提示することができる。
【0090】
続いて、第1の実施形態に述べた処理(ステップS100〜S300,S500,S800)に対し、話題語集約処理(ステップS600)、話題語階層抽出処理(ステップS700)及びバースト期間抽出処理(ステップS400)のうちの1つ以上の処理を追加する場合について、以下の各実施形態により説明する。なお、各処理(ステップS400,S600,S700)は、それぞれ独立的に追加することが可能である(機能的には依存関係がない)。しかしながら、追加する場合は、ステップ番号の若い順に処理を行う必要がある(処理順序には依存関係がある)。
【0091】
以下、順次、第2〜第8の実施形態によって説明する。
【0092】
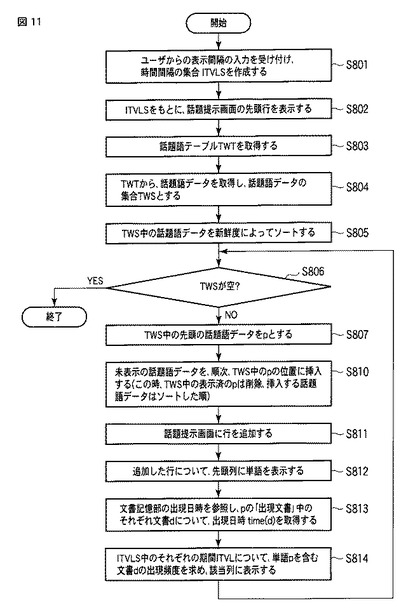
<第2の実施形態>
図12は第2の実施形態に係る話題抽出装置の構成を表すブロック図であり、図1と同様の部分については同一の符号を付して詳しい説明を省略し、ここでは変更した部分(破線で囲んだ部分)について主に述べる。以下の各実施形態も同様にして重複した部分の説明を省略する。
【0093】
本実施形態は、第1の実施形態の変形例であり、話題集約部34を更に備えている。
【0094】
ここで、話題集約部34は、話題語抽出部33によって抽出された話題語(termi,termj)について、対象期間における出現文書(Dspni,Dspnj)と当該出現文書の出現頻度(df(termi,docs),df(termj,docs))と日時情報(SPN1,SPN2)に基づいて話題語間の類似度(sim(TWi,TWj))を算出し、当該類似度によって対象期間において同一の話題を表す複数の話題語からなる話題語群を抽出し、当該話題語群について当該対象期間における出現文書の文書集合(TDm=TDi∩TDj)を取得し、当該文書集合の頻度情報(dfm,tfk)及び日時情報に基づいて、話題度と新鮮度を再計算する手段である。
【0095】
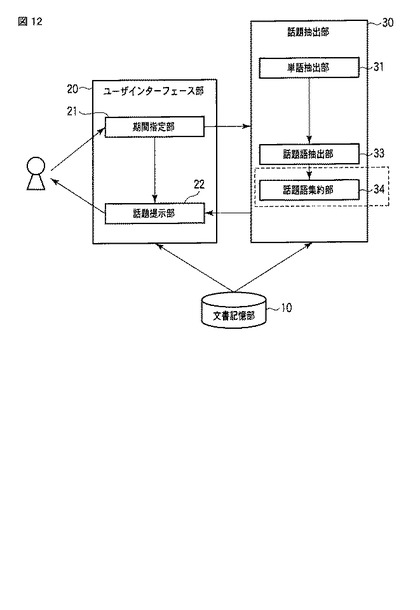
具体的には、話題語集約部34は、話題語テーブルTWTに含まれる単語について、同一の話題を表す単語同士を、一つの単語として集約する。この場合、話題語集約部34は、話題語テーブルTWT中の出現文書の情報を用いて、2つの単語間の類似度を算出し、類似度が大きい単語同士の話題語データを統合し、図13に示すように、話題語テーブルTWTを修正する。この統合において、統合する2つの単語の期間と出現文書も統合し、それに基づいて文書頻度、単語頻度、話題度、新鮮度も修正する。
【0096】
図13は、話題語集約部34によって、更新された話題語テーブルTWTのデータの例を表す模式図である。話題語集約部34は、話題語テーブルTWT中の単語について、同一の話題を表すと判定した単語同士の話題語データ(話題語テーブルTWTの行)を統合する。例えば、図7の話題語テーブルTWTについて、話題語集約部34は、1行目TWT_L1の単語TWT_tの「口蹄疫」と、2行目TWT_L2の単語TWT_tの「感染」とを同一の話題と判定した場合、図6の1行目TWT_L1’に示すように、これら2単語の話題語データを統合する。統合の際には、「出現文書」TWT_didや「文書頻度」TWT_df、「単語頻度」TWT_tf、「話題度」TWT_score、「新鮮度」TWT_freshの値を修正する。
【0097】
次に、以上のように構成された話題抽出装置の動作について図14及び図15のフローチャートを用いて説明する。
【0098】
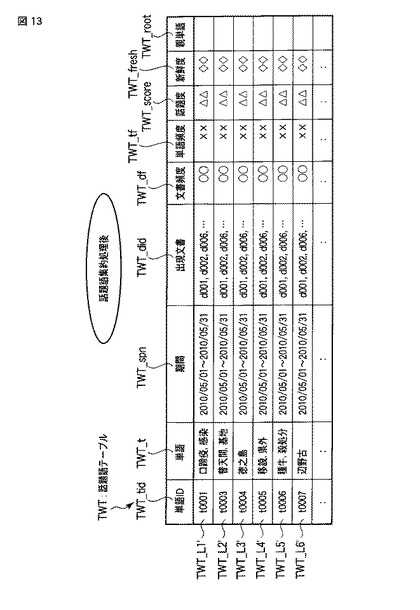
いま、図14に示すステップS100及びS300は、前述同様に実行され、話題語抽出処理によって得られた頻度情報や話題度、新鮮度などが話題語テーブルTWTとして話題抽出部30に保持される。
【0099】
次に、話題語集約部34は、話題語テーブルTWT中の単語について、同一の話題を表す単語同士を集約する話題語集約処理を行う(ステップS600)。話題語集約処理によって、同一の話題を表すと判定された単語同士の話題語データは統合される。
【0100】
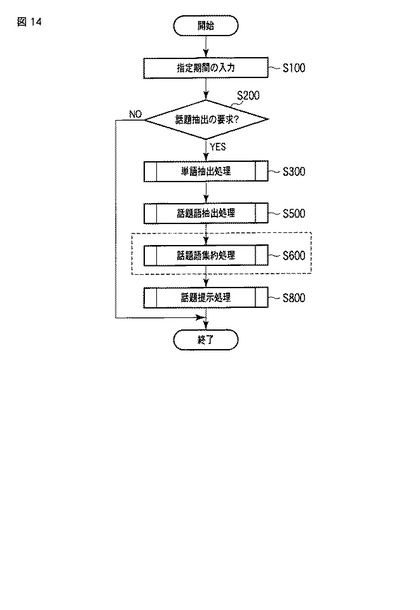
図15は話題語集約部34による話題語集約処理(ステップS600)の流れを表すフローチャートである。
【0101】
話題語集約部34は、話題語テーブルTWTを取得する(ステップS601)。そして、話題語集約部34は、話題語テーブルTWT中の全ての話題語データTWiについて、さらに、同様に話題語テーブルTWT中の全ての話題語データTWjについて、ステップS604〜ステップS606の処理を繰り返す(ステップS602、ステップS603)。但し、TWi≠TWjとする。
【0102】
このステップS602〜S603の繰り返しによって、話題語集約部34は、話題語テーブルTWTに含まれる単語間について、集約するか否かを判定する。そのために、話題語集約部34は、ステップS604において、話題語データTWiとTWjの類似度sim(TWi,TWj)を、[数3]に示す式により算出する。
【数3】
【0103】
ここで、共起類似度cosim(termi,termj,Dspni∪Dspnj)とは、2つの単語termi,termjの共起の強さを表す指標である。共起類似度としては、用語抽出や関連語抽出で一般的に使われるダイス(Dice)係数、ジャカード(Jaccard)係数などが使用可能となっている。本実施形態では、ダイス係数(dice(term1,term2,Docs))を用いる。文書の和集合Docsは、前述した和集合Dspni∪Dspnjを表す。
【0104】
共通期間割合cospanrate(SPNi,SPNj)は、TWiとTWjの「期間」で共通する期間の割合を表す指標である。そして、話題語集約部34は、類似度sim(TWi,TWj)及びしきい値βに基づき、類似度sim(TWi,TWj)>βの関係を満たすか否かに応じて、話題語データTWiとTWjが同一話題か否かを判定する(ステップS605)。ここで、しきい値βとは、当該話題語データTWiと話題語データTWjが、同一の話題を表すか否かを判定するための基準値であり、話題抽出装置において、事前に設定されていてもよいし、話題抽出の処理の都度、ユーザが設定してもよい。
【0105】
話題語データTWiと話題語データTWjとを同一話題と判定した場合(ステップS605−YES)、話題語集約部34は、話題語テーブルTWT中の当該話題語データTWi,TWjを統合した話題語データTWmを作成し、話題語テーブルTWTに格納する(ステップS606)。
【0106】
このとき、統合された話題語データTWmの各項目の値は以下の通りとする。
【0107】
すなわち、話題語データTWa={単語ID termIDa,単語terma,期間SPNa,出現文書TDa,文書頻度dfa、単語頻度tfa,話題度scorea,新鮮度fresha}(aは添え字i,jもしくはm)で表す。また、統合された話題語データの各項目について、以下のように補足して述べる。
【0108】
・単語ID:統合した話題語データの一方の単語ID。
【0109】
termIDm=termIDi
・単語:2つの話題語データの単語の集合。
【0110】
termm={termi,termj}
・期間:2つの話題語データの期間で共通する期間。
【0111】
SPNm=cospan(SPNi,SPNj)
・出現文書の集合:2つの話題語データの出現頻度で共通する文書の集合。
【0112】
TDm=TDi∩TDj
・文書頻度:TDmに含まれる文書数
dfm=|TDm|
・単語頻度:単語の集合TDm中に含まれる単語termi,termjの出現頻度の平均。
【0113】
tfk=(tf(termi,TDk)+tf(termj,TDk))/2
・話題度:上記の値を使い、[数3]に示した式によって再計算した話題度。
【0114】
scorek=score(termk,SPNk)
ここで、df(termk,Dspnk)=dfk、
tf(termk,D)=(tf(termi,D)+tf(termj,D))/2
・新鮮度:上記の値を使い、[数2]に示した式によって再計算した新鮮度。
【0115】
freshk=fresh(termk,SPNk)
以上が、統合された話題語データTWmの各項目の補足説明である。
【0116】
また、統合処理後、話題語集約部34は、話題語テーブルTWTから話題語データTWi,TWjを削除する(ステップS607)。最後に、話題語集約部34は、話題語テーブルTWTを出力する(ステップS608)。
【0117】
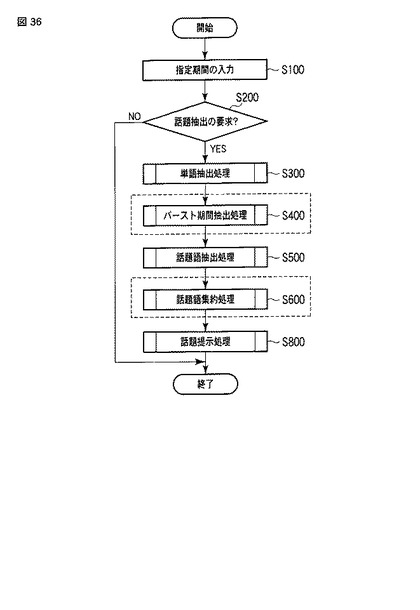
話題語集約処理の終了後、話題提示部22は、以上の処理(ステップS300、S500、S600)によって生成された話題語テーブルTWTを話題抽出部30から受け取り、この話題語テーブルTWTに基づき、図16に示すように、抽出結果を示す話題提示画面G20をユーザに提示する話題提示処理を行う(ステップS800)。話題提示画面G20では、話題語のうち、「口蹄疫、感染」、「普天間、基地」、「移設、県外」及び「殺処分、種牛」の箇所において、話題語が集約されて提示されている。
【0118】
上述したように本実施形態によれば、第1の実施形態の効果に加え、類似度及び出現日時の系列に基づいて、同一話題を表す単語を適切に集約する構成により、話題語を精度良く抽出することができる。また、話題を単語の集まりとして提示することで、ユーザは話題の内容をより的確に把握することができる。
【0119】
<第3の実施形態>
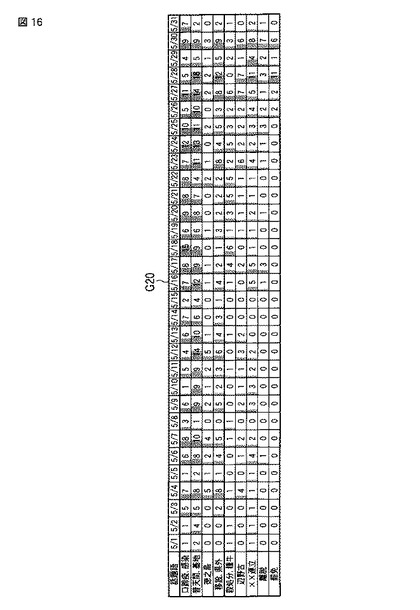
図17は第3の実施形態に係る話題抽出装置の構成を表すブロック図である。
【0120】
本実施形態は、第1の実施形態の変形例であり、図1に示した話題抽出部30において、話題語階層抽出部35を更に備えている。
【0121】
ここで、話題語階層抽出部35は、話題語抽出部33によって抽出された話題語(termi,termj)について、対象期間における出現文書の出現頻度(df(term1,Docs),df(term2,Docs))と日時情報(SPNi,SPNj)に基づいて話題語間の関連度を算出し、当該関連度によって話題語間の階層関係を抽出する手段である。
【0122】
具体的には、話題語階層抽出部35は、話題語テーブルTWTに基づいて、話題語間の階層を抽出する。話題語階層抽出部35では、話題語テーブルTWT中の出現文書の情報を用いて、2つの単語間の関連度を算出し、その関連度に基づいて、単語間の階層関係を判定する。そして、判定した結果を、話題語テーブルTWTに付与する。
【0123】
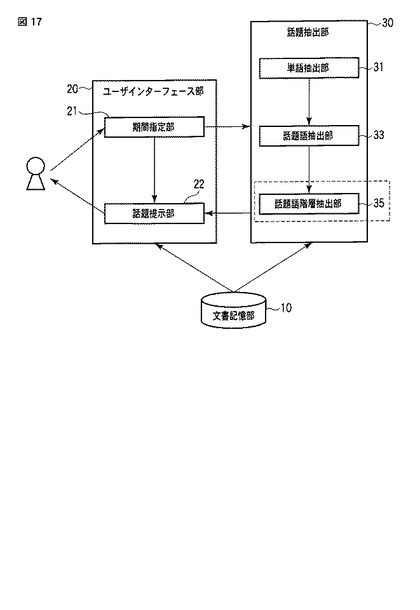
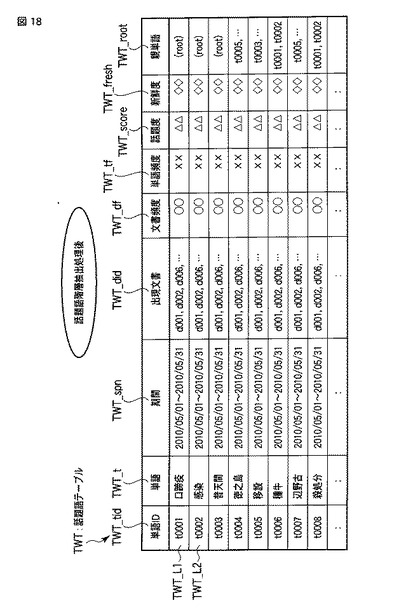
図18は、話題語階層抽出部35によって、更新された話題語テーブルTWTのデータの例を表す模式図である。話題語階層抽出部35は、話題語テーブルTWT中の単語について、単語間の親子関係を判定し、その親子関係を表すために、話題語テーブルTWTの「親単語」709の列に、その単語の親単語の単語IDを格納する。例えば、図7に示した話題語テーブルTWTの単語TWT_tの「口蹄疫」、「感染」、「普天間」、「基地」、「移設」、「県外」、「徳之島」、「種牛」、「殺処分」及び「辺野古」について、話題語階層抽出部35は、図19(a)及び図19(b)に示す如き、階層関係を抽出した場合、それぞれの話題語データについて、図18の「親単語」TWT_rootのような値を格納する。ここで、「親単語」は、その単語の親単語の単語IDを表す。但し、最上位の単語(上述の例では、「普天間」、「基地」、「口蹄疫」、「感染」)に対する親単語としては(root)という値が格納される。
【0124】
また、話題抽出装置においては、話題語階層抽出部35を更に備えたことに伴い、話題提示部22が、話題語階層抽出部35によって抽出された話題語の階層関係に従い、話題語間の親子関係を提示すると共に、兄弟関係にある話題語を新鮮度の順に提示する機能を有している。
【0125】
次に、以上のように構成された話題抽出装置の動作について図20乃至図22のフローチャートを用いて説明する。
【0126】
いま、図20に示すステップS100〜S300及びS500は、前述同様に実行され、話題語抽出処理によって得られた頻度情報や話題度、新鮮度などが話題語テーブルTWTとして話題抽出部30に保持される。
【0127】
次に、話題語階層抽出部35は、話題語テーブルTWT中の単語について、単語間の階層関係を抽出し、その階層構造の情報を話題語テーブルTWTに付与する話題語階層抽出処理を行う(ステップS700)。なお、話題語階層抽出処理の詳細については後述する。
【0128】
話題語階層処理の終了後、話題提示部22は、以上の処理(ステップS300、S500、S700)によって生成された話題語テーブルTWTを話題抽出部30から受け取り、この話題語テーブルTWTに基づき、抽出結果をユーザに提示する話題提示処理を行う(ステップS800)。なお、話題提示処理の詳細については後述する。
【0129】
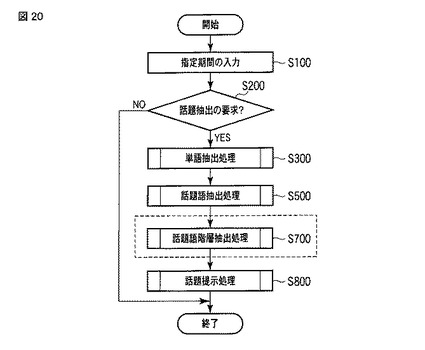
図21は話題語階層抽出部35による話題語階層抽出処理(ステップS700)の流れを表すフローチャートである。
【0130】
話題語階層抽出部35は、話題語テーブルTWTを取得する(ステップS701)。そして、話題語階層抽出部35は、話題語テーブルTWT中の全ての話題語データTWiについて、さらに、同様に話題語テーブルTWT中の全ての話題語データTWjについて、ステップS704〜ステップS706の処理を繰り返す(ステップS702,S703)。但し、TWi≠TWjとする。
【0131】
このステップS702,S703の繰り返しによって、話題語階層抽出部35は、話題語テーブルTWTに含まれる全ての単語間について親子関係を判定する。そのために、話題語階層抽出部35は、ステップS704において、話題語データTWiとTWjの関連度rel(TWi,TWj)を、[数4]に示す式により算出する。
【数4】
【0132】
ここで、mi(termi,termj,Dspni∪Dspnj)は、話題語データTWi,TWjの出現文書の和集合において、一方の単語termiから見たときの他方の単語termjの関係の強さを相互情報量に基づいて、算出する式である。また、共通期間割合cospanrate(SPNi,SPNj)は、[数3]に示した式と同様の式で、期間の共通性を考慮するための指標である。次に、関連度rel(TWi,TWj)>γという式によって、話題語データTWiとTWjが親子関係を判定する(ステップS705)。ここで、しきい値γは、当該話題語データTWiが話題語データTWjの親にすべきかを判定するための基準値であり、話題抽出装置において、事前に設定されていてもよいし、話題抽出の処理の都度、ユーザが設定してもよい。
【0133】
そして、話題語データTWiと話題語データTWjに親子関係があると判定した場合(ステップS705−YES)、話題語階層抽出部35は、当該TWiを親、TWjを子として、話題語データTWjの「親単語」(図7に示すTWT_root)に、話題語データTWiの「単語ID」(図7に示すTWT_tid)の値を格納する(ステップS706)「親単語」に格納される値については、図18の説明を参照されたい。
【0134】
話題語階層抽出部35は、このステップS702〜S703の繰り返しによる話題語テーブルTWT中の単語間の親子関係の判定を、親子関係が抽出されなくなるまで繰り返す(ステップS707)。
【0135】
そして、このステップS702、ステップS703の繰り返しにおいて、1度も親子関係が抽出されなかった場合(ステップS707−YES)、話題語階層抽出部35は、話題語テーブルTWTを出力する(ステップS708)。ステップS707の繰り返しによって、話題語階層抽出部35は、話題語テーブルTWT中の単語の親子関係を多階層的に抽出する。また、抽出する階層関係について、何階層まで抽出するかをユーザが指定するとしてもよい。
【0136】
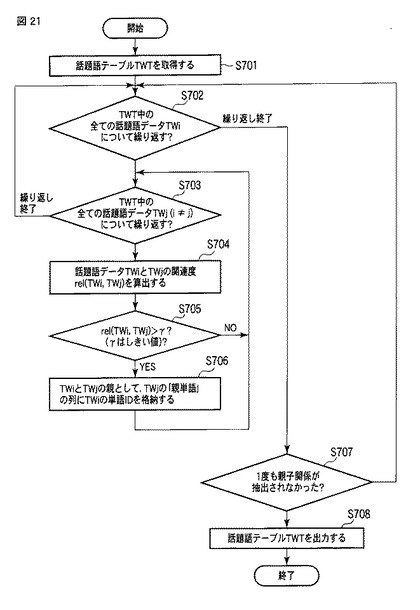
図22は話題提示部22による話題提示処理(ステップS800)の流れを表すフローチャートである。
【0137】
いま、ステップS801〜S803は、前述同様に実行される。
【0138】
次に、話題提示部22は、話題抽出部30から話題語テーブルTWTを取得し、話題語テーブルTWT中から「親単語」が「(root)」である(つまり、階層的に最上位の)話題語データを取得し、それらの話題語データを要素として含む話題語データの集合をTWSとする(ステップS804’)。例えば、図7の例では、TWS={「普天間」,「基地」,「口蹄疫」,「感染」}となる。
【0139】
次に、話題提示部22は、話題語データ集合TWSの要素を、「新鮮度」TWT_freshによってソートする(ステップS805)。これによって、階層的に兄弟の関係にある話題が時系列順にソートされる。これは、後述するステップS809の処理も同様である。
【0140】
次に話題提示部22は、話題語データ集合TWSが空になるまで、ステップS807〜S814の処理を繰り返す(ステップS806)。
【0141】
始めに、話題提示部22は、話題語データ集合TWS中の先頭にある話題語データをpとする(ステップS807)。例えば、上述した例では、TWS={「普天間」,「基地」,「口蹄疫」,「感染」}の先頭の話題語データなので、p=「普天間」となる。
【0142】
次に、話題提示部22は、話題語テーブルTWTからpを親とする話題語データの集合CTSを取得する。上述の例では、p=「普天間」なので、CTS={「移設」、「県外」、「×× 連立」}となる。
【0143】
次に、話題提示部22は、先頭の話題語データpを親とする話題語データの集合CTS中の要素を「新鮮度」によってソートする(ステップS809)。
【0144】
次に、話題提示部22は、当該話題語データの集合CTS中の全ての話題語データを、話題語データ集合TWS中の先頭の話題語データpの位置に挿入する(ステップS810’)。このとき、話題提示部22は、話題語データ集合TWS中の先頭の話題語データpを削除した上で、pの位置にステップS809でソートした順に、pを親とする話題語データの集合CTS中の話題語データを挿入する。
【0145】
例えば、上述の例では、TWS={「普天間」,「基地」,「口蹄疫」,「感染」}、p=「普天間」、CTS={「移設」,「県外」,「×× 連立」}に対して、ステップS810の処理によって、TWS={「移設」,「県外」,「×× 連立」,「基地」,「口蹄疫」,「感染」}となる。
【0146】
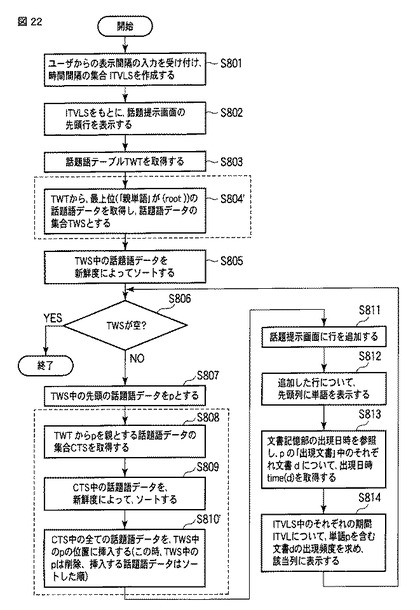
そして、話題提示部22は、前述したステップS811〜S814の処理によって、図23に示すように、話題語データpの情報を話題提示画面に表示する。
【0147】
このように、話題提示部22は、ステップS807〜S814の処理をTWSが空になるまで繰り返すことによって、話題語テーブルTWT中の全ての話題語データを、その階層構造に従い、かつ、兄弟関係にある話題語データについては新鮮度によって時系列順にソートしながら、図23に示すように、話題語提示画面G30に表示する。
【0148】
上述したように本実施形態によれば、第1の実施形態の効果に加え、関連度及び出現日時の系列に基づいて話題語を階層化する構成により、文書数の規模だけでなく、話題の期間的な規模に応じて話題語を階層化することができる。ユーザにとっては、上位下位層の話題語を概観することにより対象期間における大きな話題の潮流を俯瞰でき、さらに着目する話題については深堀しながら、話題の詳細を知ることができる。さらに、同一階層の話題を新鮮度でソートするため、話題の遷移を様々な粒度で提示することができる。
【0149】
<第4の実施形態>
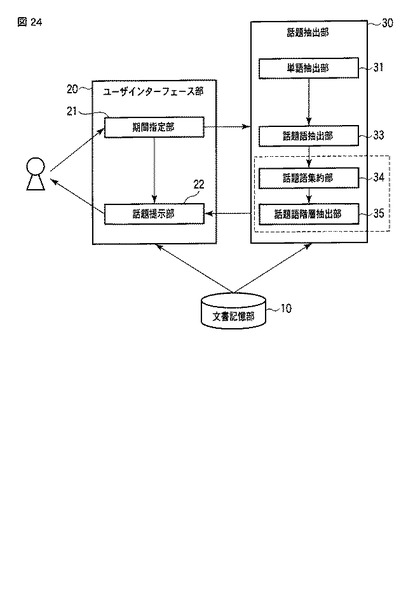
図24は第4の実施形態に係る話題抽出装置の構成を表すブロック図である。
【0150】
本実施形態は、第1の実施形態に第2及び第3の実施形態を組合せた例であり、図1に示した話題抽出部30において、図12に示した話題語集約部34と、図17に示した話題語階層抽出部35とを更に備えている。
【0151】
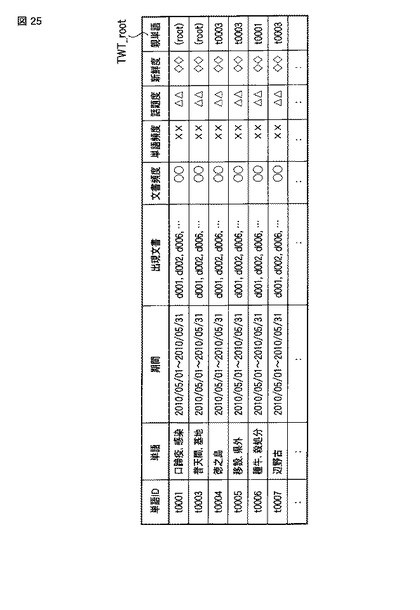
これに伴い、話題語テーブルTWT及び階層構造は、図25、図26(a)及び図26(b)に示すように、集約された話題語に対しても、階層構造を示すものとなる。
【0152】
以上のような構成によれば、図27に示すように、前述した話題語抽出処理(ステップS500)の後に、前述した話題語集約処理(ステップS600)及び話題語階層抽出処理(ステップS700)が実行される。
【0153】
その結果、図28に示すように、話題語が集約され、且つ、話題語の階層構造が明示された話題提示画面G40が提示される。
【0154】
上述したように本実施形態によれば、第1、第2及び第3の実施形態の効果を同時に得ることができる。
【0155】
<第5の実施形態>
図29は第5の実施形態に係る話題抽出装置の構成を表すブロック図である。
【0156】
本実施形態は、第1の実施形態の変形例であり、図1に示した話題抽出部30において、バースト期間抽出部32を更に備えている。
【0157】
ここで、バースト期間抽出部32は、単語抽出部31によって抽出された各単語について、出現文書の文書集合(TD(term,Dspn))における出現日時の系列(TIMES)を取得し、当該出現日時の系列を用いて当該単語(term)が集中的に出現している複数のバースト期間(BST)をそれぞれ抽出し、当該単語とそれぞれのバースト期間との組(TS={term,BST})を異なる単語として保持する手段である。
【0158】
具体的には、バースト期間抽出部32は、単語文書テーブルTDTに含まれるそれぞれの単語について、その単語が出現する文書の日時の系列を用いて、その単語が集中しているバースト期間BSTを抽出し、そのバースト期間BSTを単語期間テーブルTSTの「期間」TST_spnに書き込む。ここで、1つの単語が複数のバースト期間BSTi,BSTj,…を持つ場合は、抽出したバースト期間BSTi,BSTj,…の数だけ、{単語,期間}の組(単語期間データ)を生成し、それぞれ異なる「単語ID」を付与する。すなわち、表記上、同じ単語であっても、異なるバースト期間BSTi,BSTj,…を持つものは、別の単語として扱う。これによって、例えば図30に示す単語期間テーブルTSTが生成される。ここで生成した単語期間テーブルTSTは、話題語抽出部33の入力として使用する。バースト期間抽出部32を含む構成(第5の実施形態〜第8の実施形態)においては、バースト期間抽出部32によって、生成された単語期間テーブルTSTに基づいて、話題語テーブルTWTが生成される。
【0159】
なお、この単語期間テーブルTSTに対応させて、バースト期間抽出部32を組み込んだ場合の話題語テーブルTWTについては、それぞれ図7、図13、図18、図25において、TWT_spnの期間を図30のTST_spnの期間に置き換えることで得られる。
【0160】
また、話題抽出装置は、バースト期間抽出部32を更に備えたことに伴い、話題語抽出部33及び話題提示部22が以下の機能を有するものとなっている。
【0161】
すなわち、話題語抽出部33は、単語抽出部31により抽出された各単語のうちでバースト期間抽出部32によっても抽出された単語については対象期間における当該単語が出現する出現文書の文書集合の取得に代えて、バースト期間抽出部32によって抽出された単語とそれぞれのバースト期間との組(TS={term,BST})に基づいて、当該単語が当該バースト期間において出現する出現文書の文書集合(TD(term,Dbst))を取得し、当該出現文書の出現頻度の有意性を表す値(topical(term,BST))と、重み値(tfidf(term))とに基づいて話題度(score(term,BST))を算出し、当該話題度が所定の値(α)以上の単語を話題語として抽出すると共に、当該抽出した各話題語について、バースト期間における出現日時の系列に基づいて新鮮度(fresh(term,BST))を算出する機能をもっている。
【0162】
話題提示部22は、提示した各話題語について、バースト期間抽出部32によって抽出したバースト期間に該当する箇所を強調表示する機能をもっている。
【0163】
次に、以上のように構成された話題抽出装置の動作について図31乃至図33のフローチャートを用いて説明する。
【0164】
いま、図31に示すステップS100〜S300は、前述同様に実行され、単語抽出処理によって得られた単語文書テーブルTDTが話題抽出部30に保持される。
【0165】
次に、バースト期間抽出部32は、単語文書テーブルTDTに含まれるそれぞれの単語についてバースト期間BSTを抽出し、単語期間データの集合である単語期間テーブルTSTを生成する処理(以下、バースト期間抽出処理)を行う(ステップS400)。なお、バースト期間抽出処理の詳細については後述する。
【0166】
次に、話題語抽出部33は、バースト期間抽出処理(ステップS400)によって生成された単語期間テーブルTST中のそれぞれの単語について、当該期間中に当該単語が出現する文書や、文書頻度、出現頻度などの情報に基づき、単語の話題度算出(スコアリング)を行い、話題語を抽出する話題語抽出処理を行う(ステップS500)。話題語抽出処理の詳細については後述する。また、この話題語抽出処理によって得られた頻度情報や話題度、新鮮度などは、話題語テーブルTWTとして話題抽出部30に保持する。
【0167】
そして、話題提示部22は、以上の処理(ステップS300〜ステップS700)によって生成された話題語テーブルTWTを話題抽出部30から受け取り、この話題語テーブルTWTに基づき、抽出結果をユーザに提示する話題提示処理を行う(ステップS800)。なお、話題提示処理の詳細については後述する。
【0168】
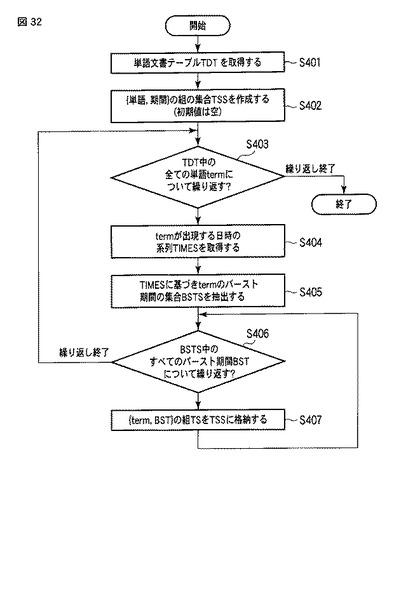
図32はバースト期間抽出部32によるバースト期間抽出処理(ステップS400)の流れを表すフローチャートである。
【0169】
バースト期間抽出部32は、単語文書テーブルTDTを取得し(ステップS401)、{単語,期間}の組の集合TSSを作成する(ステップS402)。ここで、組の集合TSSの初期値は空とする。
【0170】
次に、バースト期間抽出部32は、単語文書テーブルTDTに含まれる全ての単語termについて、ステップS404〜S407の処理を繰り返す(ステップS403)。
【0171】
ステップS404では、バースト期間抽出部32は、単語文書テーブルTDTから単語termの出現文書(「出現頻度」が1以上の文書)を取得し、その出現文書の日時情報を、単語termの出現日時の系列TIMESとして取得する。
【0172】
次に、バースト期間抽出部32は、単語termの出現日時の系列TIMESに基づいて、単語termのバースト期間の集合BSTSを抽出する(ステップS405)。ここで、バースト期間の抽出手法としては、例えば、非特許文献1に記載の手法が使用可能となっている。この抽出手法では、単語の出現日時の系列(ここでは、TIMES)に基づいて、その単語が密集して出現する複数の期間を取得する。補足すると、一様に出現するような単語については、バースト期間BSTは抽出されない。
【0173】
ステップS405の後、バースト期間抽出部32は、バースト期間の集合BSTS中の全てのバースト期間BSTについて、ステップS407を繰り返し(ステップS406)、{term,BST}の組TSを当該組の集合TSSに追加する。以上のバースト期間抽出処理によって、単語文書テーブルTDT中の単語は、バースト期間BSTによって分割され、以降の処理でそれぞれ異なる単語として処理される。
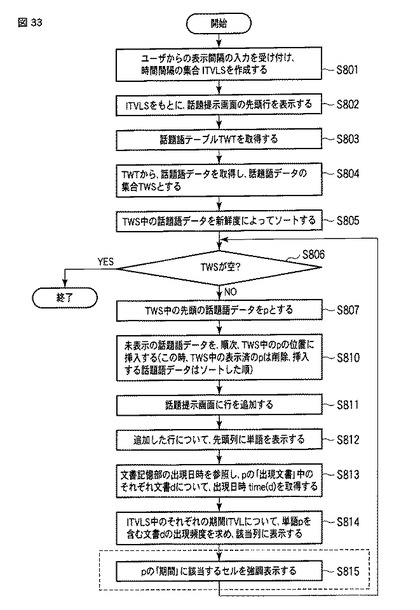
【0174】
図33は話題提示部22による話題提示処理(ステップS800)の流れを表すフローチャートである。
【0175】
ここで、ステップS801〜S814は、前述した図11と同様に実行される。但し、前述した話題度score(term,SPN)は、期間SPNに代えてバースト期間BSTに基づく話題度score(term,BST)として算出されている(Dspnに基づくtopical(term,SPN)が、Dbstに基づくtopical(term,BST)として算出されている)。同様に、前述した新鮮度fresh(term,SPN)は、期間SPNに代えてバースト期間BSTに基づく新鮮度fresh(term,BST)として算出されている。
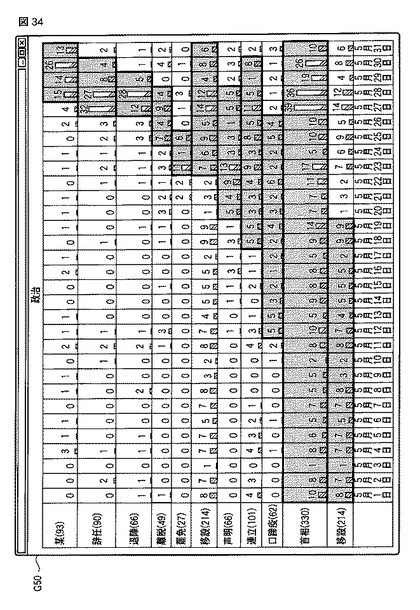
【0176】
また、ステップS814の後、話題提示部22は、ステップS811で追加した行について、話題語データpの「期間」に該当する列のセルを強調表示する(ステップS815)。この処理によって、図34に示すように、話題提示画面G50中で当該話題が盛り上がっている時期(バースト期間BST)を強調表示する。
【0177】
上述したように本実施形態によれば、第1の実施形態の効果に加え、単語をバースト期間によって分割した上で、話題語を抽出する構成により、同じ話題語でも盛り上がった時期毎に提示することで、時期によって異なる話題間の関連を提示することができる。
【0178】
補足すると、背景技術に述べた従来の話題抽出方式とは異なった従来の他の話題抽出方式として、文書クラスタリングを階層的に繰り返すことにより、話題を文書の集合(話題クラスタ)とし、話題クラスタ・サブ話題クラスタという話題の階層を抽出するものがある。当該他の話題抽出方式では、それぞれの話題クラスタ毎に、出現頻度に基づいて話題語を抽出し、日時情報に基づいて提示する。
【0179】
しかしながら、当該他の話題抽出方式は、本発明者の検討によれば、話題を文書集合として細分化するため、話題を掘り下げて詳細を知る用途には向いているものの、話題の変遷を知る用途には不向きである。
【0180】
また、ニュースやブログなどにおいて、同一の話題を表す単語や、話題に関連する単語は、時間の経過と共に変化するものである。このため、単語間の関連を求める場合、単語が出現する期間を考慮する必要がある。また、一つの単語に着目して話題を表す際にも、一つの単語が出現時期によって異なる話題を表す場合があることから、単語の出現時期を考慮する必要がある。
【0181】
例えば沖縄県の普天間基地に対する「移設」という単語は、ある時期には「徳之島への移設」の話題を表し、他の時期には「辺野古への移設」の話題を表している。このように、一つの単語は、時期によって異なる話題を表す場合がある。
【0182】
しかし、背景技術で述べた従来の話題抽出方式では、単語の出現時期を考慮していないことから、単語の出現時期によっては、異なる話題を同じ話題と混同してしまう可能性がある。
【0183】
従来の他の話題抽出方式では、話題を話題クラスタとして抽出することにより、話題の混同を吸収している。しかし、従来の他の話題抽出方式では、話題語を抽出する際に、同様の混同を生じる可能性がある。
【0184】
これに対し、本実施形態によれば、前述した通り、単語をバースト期間によって分割した上で、話題語の抽出を行う構成により、話題の混同を防ぐことができる。
【0185】
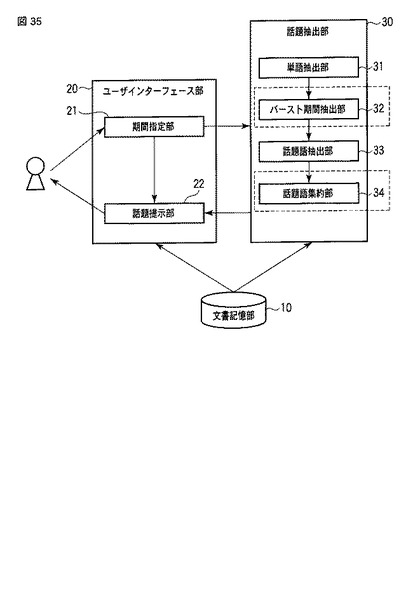
<第6の実施形態>
図35は第6の実施形態に係る話題抽出装置の構成を表すブロック図である。
【0186】
本実施形態は、第1の実施形態に第2及び第5の実施形態を組合せた例であり、図1に示した話題抽出部30において、図12に示した話題語集約部34と、図29に示したバースト期間抽出部32とを更に備えている。
【0187】
以上のような構成によれば、図36に示すように、前述したバースト期間抽出処理(ステップS400)の後に、前述した話題語集約処理(ステップS600)が実行される。このため、話題語集約処理(ステップS600)において、期間SPNに基づく類似度sim(TWi,TWj)は、期間SPNに代えてバースト期間BSTに基づく類似度sim(TWi,TWj)として算出される。補足すると、期間SPNに基づく共起類似度co(termi,termj,Dspni∪Dspnj)は、期間SPNに代えてバースト期間BSTに基づく共起類似度co(termi,termj,Dbsti∪Dbstj)として算出される。同様に、期間SPNに基づく共通期間割合cospanrate(SPNi,SPNj)は、期間SPNに代えてバースト期間BSTに基づく共通期間割合cospanrate(BSTi,BSTj)として算出される。
【0188】
その結果、図37に示すように、話題語が集約され、バースト期間が強調された話題提示画面G60が提示される。
【0189】
上述したように本実施形態によれば、第1、第2及び第5の実施形態の効果を同時に得ることができる。
【0190】
<第7の実施形態>
図38は第7の実施形態に係る話題抽出装置の構成を表すブロック図である。
【0191】
本実施形態は、第1の実施形態に第3及び第5の実施形態を組合せた例であり、図1に示した話題抽出部30において、図17に示した話題語階層抽出部35と、図29に示したバースト期間抽出部32とを更に備えている。
【0192】
以上のような構成によれば、図39に示すように、前述したバースト期間抽出処理(ステップS400)の後に、前述した話題語階層抽出処理(ステップS700)が実行される。このため、話題語階層抽出処理(ステップS700)において、期間SPNに基づく関連度rel(TWi,TWj)は、期間SPNに代えてバースト期間BSTに基づく関連度rel(TWi,TWj)として算出される。補足すると、期間SPNに基づく相互情報量mi(termi,termj,Dspni∪Dspnj)は、期間SPNに代えてバースト期間BSTに基づく相互情報量mi(termi,termj,Dbsti∪Dbstj)として算出される。同様に、期間SPNに基づく共通期間割合cospanrate(SPNi,SPNj)は、期間SPNに代えてバースト期間BSTに基づく共通期間割合cospanrate(BSTi,BSTj)として算出される。
【0193】
また、話題提示処理は、図40に示すように、バースト期間BSTを強調表示するステップS815を有して実行される。
【0194】
その結果、図41に示すように、話題語の階層構造が明示され、バースト期間が強調された話題提示画面G70が提示される。
【0195】
上述したように本実施形態によれば、第1、第3及び第5の実施形態の効果を同時に得ることができる。
【0196】
<第8の実施形態>
図42は第8の実施形態に係る話題抽出装置の構成を表すブロック図である。
【0197】
本実施形態は、第1の実施形態に第4及び第5の実施形態を組合せた例であり、図1に示した話題抽出部30において、図24に示した話題語集約部34及び話題語階層抽出部35と、図29に示したバースト期間抽出部32とを更に備えている。
【0198】
以上のような構成によれば、図43に示すように、前述したバースト期間抽出処理(ステップS400)の後に、前述した話題語集約処理(ステップS600)及び話題語階層抽出処理(ステップS700)が実行される。すなわち、各処理(ステップS600,S700)では、第6及び第7の実施形態と同様に、期間SPNに代えてバースト期間BSTに基づき、類似度sim(TWi,TWj)、共起類似度co(termi,termj,Dbsti∪Dbstj)共通期間割合cospanrate(BSTi,BSTj)、関連度rel(TWi,TWj)、相互情報量mi(termi,termj,Dbsti∪Dbstj)が算出される。
【0199】
その結果、図44に示すように、話題語が集約され、話題語の階層構造が明示され、且つバースト期間が強調された話題提示画面G80が提示される。
【0200】
上述したように本実施形態によれば、第1、第4及び第5の実施形態の効果を同時に得ることができる。
【0201】
補足すると、話題を表す単語を話題語として抽出し、同一の話題に関連する話題語を集約すると共に、文書数や時間的な規模に応じて、階層化する構成により、話題の全体像や詳細を、その時間的な遷移と共に的確に把握できる。また、同じ話題でも盛り上がった時期毎に階層化することで、時期によって異なる話題間の関連を提示できる。
【0202】
以上説明した少なくとも一つの実施形態によれば、指定した対象期間において、話題の変遷を提示することができる。
【0203】
なお、上記の各実施形態に記載した手法は、コンピュータに実行させることのできるプログラムとして、磁気ディスク(フロッピー(登録商標)ディスク、ハードディスクなど)、光ディスク(CD−ROM、DVDなど)、光磁気ディスク(MO)、半導体メモリなどの記憶媒体に格納して頒布することもできる。
【0204】
また、この記憶媒体としては、プログラムを記憶でき、かつコンピュータが読み取り可能な記憶媒体であれば、その記憶形式は何れの形態であってもよい。
【0205】
また、記憶媒体からコンピュータにインストールされたプログラムの指示に基づきコンピュータ上で稼働しているOS(オペレーティングシステム)や、データベース管理ソフト、ネットワークソフト等のMW(ミドルウェア)等が上記実施形態を実現するための各処理の一部を実行してもよい。
【0206】
さらに、各実施形態における記憶媒体は、コンピュータと独立した媒体に限らず、LANやインターネット等により伝送されたプログラムをダウンロードして記憶または一時記憶した記憶媒体も含まれる。
【0207】
また、記憶媒体は1つに限らず、複数の媒体から上記の各実施形態における処理が実行される場合も本発明における記憶媒体に含まれ、媒体構成は何れの構成であってもよい。
【0208】
なお、各実施形態におけるコンピュータは、記憶媒体に記憶されたプログラムに基づき、上記の各実施形態における各処理を実行するものであって、パソコン等の1つからなる装置、複数の装置がネットワーク接続されたシステム等の何れの構成であってもよい。
【0209】
また、各実施形態におけるコンピュータとは、パソコンに限らず、情報処理機器に含まれる演算処理装置、マイコン等も含み、プログラムによって本発明の機能を実現することが可能な機器、装置を総称している。
【0210】
なお、本発明のいくつかの実施形態を説明したが、これらの実施形態は、例として提示したものであり、発明の範囲を限定することは意図していない。これら新規な実施形態は、その他の様々な形態で実施されることが可能であり、発明の要旨を逸脱しない範囲で、種々の省略、置き換え、変更を行うことができる。これら実施形態やその変形は、発明の範囲や要旨に含まれるとともに、特許請求の範囲に記載された発明とその均等の範囲に含まれる。
【符号の説明】
【0211】
10…文書記憶部、20…ユーザインターフェース部、21…期間指定部、22…話題提示部、30…話題抽出部、31…単語抽出部、32…バースト期間抽出部、33…話題語抽出部、34…話題語集約部、35…話題語階層抽出部、G1…指定画面、g1…開始日時、g2…終了日時、g3…実行ボタン、g4…キャンセルボタン、g5…表示間隔、G10〜G80…話題提示画面。
【技術分野】
【0001】
本発明の実施形態は、話題抽出装置及びプログラムに関する。
【背景技術】
【0002】
近年、計算機の高性能化や記憶媒体の大容量化、計算機ネットワークの普及などに伴い、日々、大量の電子化された文書が流通し、計算機システム上で活用することが可能となっている。ここでいう文書とは、例えば、ニュース記事、電子メール、ウェブページといった、ネットワーク上で共有されている文書などを指す。また、ここでいう文書は、個々の企業内で活用される文書(例、製品の不具合情報、顧客からの問い合わせ情報など)も指している。
【0003】
一般に、これらの文書のニュース記事やブログなどから、最近注目されている話題を知りたいというニーズがある。同様に、企業では、日々蓄積される製品の不具合情報から現在増加している問題を見つけて早期対策につなげたいニーズや、顧客からの問い合わせ情報から新たな需要を見つけて商品企画に活かしたいニーズが大きくなっている。
【0004】
これらのニーズに対し、例えば、従来の話題抽出方式では、指定期間の文書集合に含まれる単語に対して、出現頻度に基づいてスコアリングを行い、話題語の抽出と階層化を行っている。また、従来の話題抽出方式では、話題語のスコアの履歴情報を保持し、前回抽出時のスコアとの差分により、「新着」などのステータスを提示している。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特許第4234740号公報
【特許文献2】特許第4342575号公報
【非特許文献】
【0006】
【非特許文献1】藤木稔明、南野朋之、鈴木泰裕、奥村学、「document stream における burst の発見」、情報処理学会研究報告、2004−NL−160、pp.85−92、2004年
【発明の概要】
【発明が解決しようとする課題】
【0007】
以上のような従来の話題抽出方式は、通常は何の問題もないが、本発明者の検討によれば、更なる改良の余地がある。
【0008】
例えば、従来の話題抽出方式では、話題語のスコアの履歴情報に基づき、「新着」などのステータスを提示する方法を用いている。しかしながら、この方法は、定点観測的に“今”の話題を知る用途には向いているものの、1週間や1ヶ月といった一定の期間における話題の変遷を知る用途には不十分である。
【0009】
本発明が解決しようとする課題は、指定した対象期間において、話題の変遷を提示し得る話題抽出装置及びプログラムを提供することである。
【課題を解決するための手段】
【0010】
実施形態の話題抽出装置は、文書記憶手段、期間指定手段、話題抽出手段及び話題提示手段を備えている。
【0011】
前記文書記憶手段は、テキスト情報と日時情報を持つ複数の文書からなる対象文書集合を記憶する。
【0012】
前記期間指定手段は、話題抽出の対象とする対象期間の指定を受け付ける。
【0013】
前記話題抽出手段は、前記文書記憶手段に記憶された対象文書集合から、前記指定を受け付けた対象期間での話題を表す単語である話題語を抽出すると共に、各話題語について時事性を表す尺度である新鮮度を算出する。
【0014】
前記話題提示手段は、前記話題抽出手段によって抽出された話題語を前記新鮮度の順に提示すると共に、当該提示した各話題語について単位期間毎の出現文書数を提示する。
【0015】
前記話題抽出手段は、単語抽出手段及び話題語抽出手段を備えている。
【0016】
前記単語抽出手段は、前記文書記憶手段に記憶された対象文書集合から各単語を抽出し、当該各単語の出現頻度及び当該各単語が出現する文書数を示す文書頻度をそれぞれ算出する。
【0017】
前記話題語抽出手段は、前記単語抽出手段によって抽出された各単語について、前記対象期間における当該単語が出現する出現文書の文書集合を取得し、当該出現文書の出現頻度の有意性を表す値と、前記単語の出現頻度及び前記文書頻度に基づく当該単語の重み値とに基づいて、話題語らしさを表す尺度である話題度を算出し、前記話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出された話題語について当該対象期間における出現日時に基づいて新鮮度を算出する。
【図面の簡単な説明】
【0018】
【図1】第1の実施形態に係る話題抽出装置の構成を表すブロック図である。
【図2】同実施形態における文書データの例を表す模式図である。
【図3】同実施形態における指定画面の例を表す模式図である。
【図4】同実施形態における話題提示画面の例を表す模式図である。
【図5】同実施形態における単語文書テーブルの例を表す模式図である。
【図6】同実施形態における単語期間テーブルの例を表す模式図である。
【図7】同実施形態における話題語テーブルの例を表す模式図である。
【図8】同実施形態における処理の全体の流れを表すフローチャートである。
【図9】同実施形態における単語抽出処理の流れを表すフローチャートである。
【図10】同実施形態における話題抽出処理の流れを表すフローチャートである。
【図11】同実施形態における話題提示処理の流れを表すフローチャートである。
【図12】第2の実施形態に係る話題抽出装置の構成を表すブロック図である。
【図13】同実施形態における話題語テーブルの例を表す模式図である。
【図14】同実施形態における処理の全体の流れを表すフローチャートである。
【図15】同実施形態における話題語集約処理の流れを表すフローチャートである。
【図16】同実施形態における話題提示画面の例を表す模式図である。
【図17】第3の実施形態に係る話題抽出装置の構成を表すブロック図である。
【図18】同実施形態における話題語テーブルの例を表す模式図である。
【図19】同実施形態における話題語の階層の例を表す模式図である。
【図20】同実施形態における処理の全体の流れを表すフローチャートである。
【図21】同実施形態における話題語階層抽出処理の流れを表すフローチャートである。
【図22】同実施形態における話題提示処理の流れを表すフローチャートである。
【図23】同実施形態における話題提示画面の例を表す模式図である。
【図24】第4の実施形態に係る話題抽出装置の構成を表すブロック図である。
【図25】同実施形態における話題語テーブルの例を表す模式図である。
【図26】同実施形態における話題語の階層の例を表す模式図である。
【図27】同実施形態における処理の全体の流れを表すフローチャートである。
【図28】同実施形態における話題提示画面の例を表す模式図である。
【図29】第5の実施形態に係る話題抽出装置の構成を表すブロック図である。
【図30】同実施形態における単語期間テーブルの例を表す模式図である。
【図31】同実施形態における処理の全体の流れを表すフローチャートである。
【図32】同実施形態におけるバースト期間抽出処理の流れを表すフローチャートである。
【図33】同実施形態における処理の話題提示処理の流れを表すフローチャートである。
【図34】同実施形態における話題提示画面の例を表す模式図である。
【図35】第6の実施形態に係る話題抽出装置の構成を表すブロック図である。
【図36】同実施形態における処理の全体の流れを表すフローチャートである。
【図37】同実施形態における話題提示画面の例を表す模式図である。
【図38】第7の実施形態に係る話題抽出装置の構成を表すブロック図である。
【図39】同実施形態における処理の全体の流れを表すフローチャートである。
【図40】同実施形態における処理の話題提示処理の流れを表すフローチャートである。
【図41】同実施形態における話題提示画面の例を表す模式図である。
【図42】第8の実施形態に係る話題抽出装置の構成を表すブロック図である。
【図43】同実施形態における処理の全体の流れを表すフローチャートである。
【図44】同実施形態における話題提示画面の例を表す模式図である。
【発明を実施するための形態】
【0019】
以下、各実施形態について図面を用いて説明するが、その前に、各実施形態で用いる主な記号を列挙して示す。
【0020】
SPN:期間(開始日時from,終了日時to)。
【0021】
BST:バースト期間(第4〜第8の実施形態)。
【0022】
D:対象文書集合。
【0023】
Dspn:対象文書集合D中で、ある期間SPNに含まれる文書の集合(但し、Dspn⊂D)。なお、対象文書集合D中で、バースト期間BSTに含まれる文書の集合については、Dbstと表す(但し、Dbst⊂Dspn⊂D)。このように、バースト期間BSTを用いる場合、実施形態に記述された「SPN」又は添字の「spn」は、それぞれ「BST」又は添字の「bst」に読替え可能となっている。
【0024】
Docs:対象文書集合D中で、ある期間SPNiに含まれる文書の集合Dspniと、ある期間SPNjに含まれる文書の集合Dspnjとの和集合(Docs=Dspni∪Dspnj)。なお、バースト期間BSTi,BSTjを用いる場合、和集合Docsは、Docs=Dbsti∪Dbstjと読替え可能となっている。
【0025】
|Docs|:文書集合Docsに含まれる文書数。
【0026】
f(term,d):文書dでの、単語termの出現数。
【0027】
df(term,Docs):文書集合Docsのうち、単語termを含む文書の文書数。
【0028】
tf(term,Docs):文書集合Docsの中での、単語termの出現数。
【0029】
tc(Docs):文書集合Docsの中に含まれる単語の延べ数。
【0030】
time(d):文書dの出現日時。
【0031】
TD(term,Docs):文書集合Docsの中で、単語termを含む文書の集合。
【0032】
co(term1,term2,Docs):文書集合Docsの中で、単語term1とterm2がともに出現している文書の数。
【0033】
cospan(SPN1,SPN2):期間SPN1とSPN2で共通する期間。なお、バースト期間BST1,BST2を用いる場合、共通期間cospan(SPN1,SPN2)は、共通期間cospan(BST1,BST2)と読替え可能となっている。
【0034】
|SPN|:期間SPNの長さ。なお、バースト期間BSTの長さは、|BST|と表される。
【0035】
ITVLS:話題データをユーザに提示する際の時間間隔の集合。
【0036】
例えば、2010/05/01〜2010/05/31について、1日毎の出現数を提示する場合、時間間隔の集合ITVLSは、以下のような値を持つ。
【0037】
ITVLS ={2010/05/01 00:00〜2010/05/01 23:59,
2010/05/02 00:00〜2010/05/02 23:59,
:
2010/05/31 00:00〜2010/05/31 23:59}
また、時間間隔の集合ITVLSにより提示する期間は、期間SPNの長さと同じ場合を例に挙げて説明するが、これに限らず、期間の長さSPNより長い期間を提示してもよい。
【0038】
以上が各実施形態で用いる主な記号の説明である。これらの主な記号は、各実施形態において、種々の値の算出などに用いられる。
【0039】
また、各実施形態は、電子化された文書群から、それぞれの文書に含まれるテキスト情報と日時情報に基づいて、話題を抽出するための話題抽出装置に関連している。各実施形態の話題抽出装置は、ハードウェア構成、又はハードウェア資源とソフトウェアとの組合せ構成のいずれでも実施可能となっている。組合せ構成のソフトウェアとしては、予めネットワーク又は記憶媒体からコンピュータにインストールされ、当該コンピュータに話題抽出装置の機能を実現させるためのプログラムが用いられる。
【0040】
<第1の実施形態>
図1は第1の実施形態に係る話題抽出装置の構成を表すブロック図である。文書記憶部10は、話題抽出の対象となる文書データを格納する手段である。文書記憶部10は一般的にはファイルシステムや文書データベース等によって実現するが、例えば、計算機ネットワークによって接続した複数の記憶手段によって構成してもよい。文書記憶部10には、複数の文書が文書データとして格納される。各々の文書データは、図2に示すように、テキスト情報と、日時情報を持っている。
【0041】
文書記憶部10は、図2に示すように、テキスト情報(12,13)と日時情報(14)を持つ複数の文書(d)からなる対象文書集合Dを記憶する。各文書dは、ユニークな識別子である「文書ID」11を持つ。各文書dはテキスト、すなわち日本語や英語などの自然言語で記述されたデータとして、「見出し」12や「本文」13などのテキスト情報を持つ。さらに、各文書dは、「発信日時」14のように、1つ以上の日時属性(日時情報)を持つ。話題抽出装置では、この日時属性に基づいて、単語の新鮮度などを求める。各文書dが複数の日時属性を持つ場合は、話題抽出を実行する際に、どの日時属性を使用するかをユーザが指定するようにしてもよい。
【0042】
ユーザインターフェース部20は、話題抽出の対象とする期間の指定を受け付け、後述する話題抽出部30による話題抽出の結果を提示する手段である。ユーザインターフェース部は、期間指定部21と話題提示部22から構成される。
【0043】
期間指定部21は、話題抽出の対象とする対象期間SPNの指定を受け付ける手段であり、例えば、当該指定を受け付けた対象期間と、話題抽出の実行要求とを話題抽出部30に送出する機能を持っている。例えば、期間指定部21では、図3に示す如き指定画面G1を介して、ユーザにより指定された対象期間の入力を受け付け、話題抽出部30に、この対象期間と、話題抽出部30の実行要求を送る。
【0044】
話題提示部22は、図4に例示する話題提示画面G10のように、話題抽出部30で抽出された話題語を新鮮度の順に提示すると共に、当該提示した各話題語について単位期間後の出現文書数を提示するものである。なお、新鮮度の順は、昇順及び降順のいずれでもよい。また、単位期間は、指定される対象期間よりも短い期間である。
【0045】
話題抽出部30は、文書記憶部10に記憶された対象文書集合Dから、期間指定部21で指定を受け付けた対象期間SPNでの話題を表す単語である話題語を抽出すると共に、各話題語について時事性を表す尺度である新鮮度を算出する手段である。この新鮮度によって、話題提示部22で、ユーザが話題語の時系列的な遷移を把握できるように、提示することを実現している。第1の実施形態では、話題抽出部30を、単語抽出部31及び話題語抽出部33で構成する。
【0046】
単語抽出部31は、文書記憶部10に記憶された対象文書集合Dから各単語を抽出し、当該各単語の出現頻度(tf(term,D))及び当該各単語が出現する文書数を示す文書頻度(df(term,D))をそれぞれ算出する手段である。詳しくは、単語抽出部31は、それぞれの単語について、各文書dでの出現数を算出すると共に、対象文書集合D全体での単語頻度と、文書頻度を算出し、図5に示す如き、単語文書テーブルTDTを生成する。話題語として抽出する単語の候補として、単語文書テーブルに含まれる単語を、図6に示す如き、単語期間テーブルTSTの形で出力する。単語期間テーブルTSTでは、各単語について、その対象期間を合わせて保持する。
【0047】
単語文書テーブルTDTは、図5に示すように、対象文書D中に含まれるそれぞれの単語について、各文書での出現数である「出現頻度」TDT_fを保持する。また、それぞれの単語について、対象文書集合D全体での出現する文書数である「文書頻度」TDT_dfと、出現頻度の合計である「単語頻度」TDT_tfを保持する。単語文書テーブルTDTは、話題抽出部30の内部データとして保持され、後述するバースト期間抽出部32、話題語抽出部33、話題語集約部34及び話題語階層抽出部35で使用される。
【0048】
単語期間テーブルTSTは、図6に示すように、話題語として抽出する単語の候補と、その単語が対象とする期間を保持する。各単語は、ユニークな識別子である「単語ID」TST_tidと、その単語の表記である「単語」TST_tと、その単語が対象とする期間である「期間」TST_spnを持つ。ここで、単語抽出部31では、単語文書テーブルTDTに含まれる全ての単語について、ユーザインターフェース部20から取得した対象期間をTST_spnに設定する。従って、TST_spnの値は、「2010/05/01〜2010/05/31」となる。また、単語期間テーブルTSTは、後述するバースト期間抽出部32においても生成される。バースト期間抽出部32においては、TST_spnには各単語に対して抽出されたバースト期間が保持される。なお、バースト期間抽出部32の詳細については後述する。
【0049】
話題語抽出部33は、単語抽出部31によって抽出された各単語について、対象期間SPNにおける当該単語が出現する出現文書の文書集合(TD(term,Dspn))を取得し、当該出現文書の出現頻度の有意性を表す値と、単語の出現頻度及び文書頻度に基づく当該単語の重み値とに基づいて、話題語らしさを表す尺度である話題度を算出し、話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出された話題語について当該対象期間における出現日時に基づいて新鮮度を算出する手段である。
【0050】
例えば、話題語抽出部33は、単語文書テーブルTDTと単語期間テーブルTSTを用いて話題語を抽出する。この場合、話題語抽出部33では、単語期間テーブルTSTに含まれるそれぞれの単語について、対応する期間での出現文書と文書頻度、単語頻度を算出し、それら頻度情報と出現文書の日時情報を用いて、話題語らしさを表す話題度を求め、この話題度に基づいて話題語を抽出する。さらに、抽出した話題語について、その出現文書の日時情報の系列に基づいて、その時事性を表す新鮮度を求める。そして、抽出した話題語について、図7に示すような話題語テーブルTWTを生成する。
【0051】
話題語テーブルTWTは、図7に示すように、話題語抽出部33で生成され、話題抽出部33の抽出結果として、話題提示部22に出力されるデータである。話題語テーブルTWTは、後述する話題集約部34と話題語階層抽出部35で更新される。話題語抽出部33では、話題語テーブルTWTの列のうち、「単語ID」TWT_tid、「単語」TWT_t、「期間」TWT_spn、「出現文書」TWT_did、「文書頻度」TWT_df、「単語頻度」TWT_tf、「話題度」TWT_score、「新鮮度」TWT_freshが格納される。「単語ID」TWT_tid、「単語」TWT_t及び「期間」TWT_spnは、単語期間テーブルTST中の「単語ID」TST_tid、「単語」TST_t、「期間」TST_spnの値である。但し、話題語単語テーブルTWTに保持される単語TWT_tは、単語期間テーブルTSTに含まれる単語TST_tの中で、話題語抽出部33で話題語と判定された単語のみである。話題語抽出部33は、それぞれの単語について、「期間」中に出現する文書集合TD(term,Dspn)である「出現文書」と、「出現文書」の文書数df(term,Dspn)である「文書頻度」、「出現文書」の文書集合での単語の出現頻度tf(term,Dspn)である「単語頻度」を取得し、「出現文書」TWT_did、「文書頻度」TWT_df及び「単語頻度」TWT_tfの各列に格納する。さらに、話題語抽出部33は、それらの情報によって算出した、話題語らしさを表す尺度である「話題度」score(term,SPN)と、その話題の時事性を表す尺度である「新鮮度」fresh(term,SPN)を算出し、「話題度」TWT_score及び「新鮮度」TWT_freshの各列に格納する。
【0052】
次に、以上のように構成された話題抽出装置の動作を図8乃至図11のフローチャートを用いて説明する。
【0053】
ユーザインターフェース部20内の期間指定部21は、図8に示すように、ユーザからの対象期間の指定を受け付けると共に(ステップS100)、話題抽出の実行要求を受け付ける(ステップS200)。対象期間の指定は、例えば図3に示す如き、指定画面G1において、ユーザが対象期間の開始日時g1と終了日時g2を設定する。そして、期間指定部21は、ユーザによる「実行」ボタンg3のクリック操作に応じて、話題抽出部30に対象期間SPN及び話題抽出の実行要求を送出する。
【0054】
指定画面G1で「実行」ボタンg3がクリック操作され、話題抽出の実行要求が送出された場合、話題抽出装置は、ステップS300〜S800の処理を行う(ステップS200−YES)。
【0055】
一方、指定画面G1で「キャンセル」ボタンg4がクリック操作された場合、話題抽出装置は、全体の処理を終了する(ステップS200−NO)。
【0056】
話題抽出の実行要求が送出された場合(ステップS200−YES)、単語抽出部31は、文書記憶部10に格納された対象文書集合Dに含まれる単語を抽出し、それぞれの単語が出現する文書や、出現頻度などの情報を求め、単語文書テーブルTWTと単語期間テーブルTSTを生成する単語抽出処理を行う(ステップS300)。なお、単語抽出処理(ステップS300)の詳細については後述する。
【0057】
次に、話題語抽出部33は、単語期間テーブルTST中のそれぞれの単語について、当該期間中に当該単語が出現する文書や、文書頻度、出現頻度などの情報に基づき、単語の話題度算出(スコアリング)を行い、話題語を抽出する話題語抽出処理を行う(ステップS500)。話題語抽出処理の詳細については後述する。また、話題語抽出処理(ステップS500)によって得られた頻度情報や話題度、新鮮度などは、話題語テーブルTWTとして話題抽出部30に保持される。
【0058】
そして、ユーザインターフェース部2の話題提示部22は、話題語テーブルTWTを話題抽出部30から受け取り、この話題語テーブルTWTに基づき、抽出結果をユーザに提示する話題提示処理を行う(ステップS800)。なお、話題提示処理(ステップS800)の詳細については後述する。
【0059】
図9は単語抽出部31による単語抽出処理(ステップS300)の流れを表すフローチャートである。
【0060】
単語抽出部31は、入力として対象期間SPNを期間指定部21から受け取る(ステップS301)。続いて、単語抽出部31は、文書記憶部10から話題抽出の対象とする対象文書集合Dを取得し(ステップS302)、空の単語文書テーブルTDTを作成する(ステップS303)。
【0061】
次に、単語抽出部31は、対象文書集合Dに含まれる全ての文書のテキスト情報を形態素解析する(ステップS304)。例えば、図2に示す文書データの場合、「見出し」と「本文」の内容をテキスト情報とすると、形態素解析によって、「口蹄疫」「殺処分」「公務」「殺害」「流行」などの単語が抽出される。そして、単語抽出部31は、形態素解析結果に含まれるすべての単語termについて、ステップS306の処理を繰り返す(ステップS305)。ここで、単語抽出部31は、所定の品詞の単語であるか、あるいは、不要語ではないかによって、対象とする単語を絞り込んでもよい。例えば、品詞が名詞やサ変名詞、固有名詞などである単語は対象として、接続詞や副詞などは対象としないといった単語の選別を行う。また、例えば新聞記事を処理対象とする場合には、「政治」、「経済」といった単語は一般的な単語であり、話題を表さないので不要語として除去する。
【0062】
ステップS306では、単語抽出部31は、単語termについて、さらに文書集合Dに含まれる全ての文書dについて、単語termが文書d中での出現する回数を表す出現頻度f(term、d)を求め、単語文書テーブルTDTに格納する処理(ステップS307)を繰り返す。
【0063】
ステップS307において、例えば図2に示す文書データでは、「口蹄疫」の出現頻度f(「口蹄疫」,d001)=2となる。そして、単語抽出部31は、図5に示す単語文書テーブルTDTに対し、「口蹄疫」に対応する行TDT_L1について、文書ID=d001の出現頻度TDT_fとして“2”を格納する。
【0064】
そして、単語抽出部31は、ステップS306の繰り返し終了後、対象文書集合Dにおいて、単語termが出現する文書数である文書頻度df(term,D)と、単語termの出現頻度の合計である出現頻度tf(term、D)を求め、それぞれ、単語文書テーブルTDTの「文書頻度」TDT_dfと「単語頻度」TDT_tfに格納する(ステップS308)。
【0065】
S305の繰り返し終了後、単語抽出部31は、ステップS309〜ステップS311の処理を行う。
【0066】
始めに、単語抽出部31は、空の単語期間テーブルTSTを作成し(ステップS309)、ステップS308までの処理で作成した単語文書テーブルに含まれる全ての単語termについて、ステップS311の処理を繰り返す(ステップS310)。
【0067】
ステップS311では、単語抽出部31は、単語termと、ステップS301で取得した対象期間SPNの組である単語期間データTS={tid,term,SPN}を、単語期間テーブルTSTに格納する。ここで、tidは単語期間テーブルについてユニークな単語IDである。このステップS310〜ステップS311の処理により、単語抽出部31は、話題語抽出の対象となる単語データの集合である単語期間テーブルの初期データTSを作成する。
【0068】
図10は話題語抽出部33による話題抽出処理(ステップS400)の流れを表すフローチャートである。
【0069】
話題語抽出部33は、単語文書テーブルTDTと単語期間テーブルTSTを取得し(ステップS501)、空の話題語テーブルTWTを作成する(ステップS502)。
【0070】
次に、話題語抽出部33は、単語期間テーブルTST中の全ての単語期間データTSについて、ステップS504〜ステップS509の処理を繰り返す(ステップS503)。ここで、単語期間データTSとは、{単語ID tid,単語term,期間SPN}の組である(TS={tid,term,SPN})。この繰り返し処理によって、話題語抽出部33は、単語期間データTS中の単語の中から、話題語に相応しい単語を抽出すると共に、その際に算出した頻度情報や話題度などの統計情報を話題語テーブルTWTとして保持する。そのために、話題語抽出部33は、当該単語期間データTSの単語termについて、単語文書テーブルTDTから対象文書集合全体Dでの、「文書頻度df(term,D)」TDT_dfの列と、「単語頻度tf(term,D)」TDT_tfの列を取得する(ステップS504)。
【0071】
次に、話題語抽出部33は、単語文書テーブルTDTから、単語termが出現する文書について文書記憶部10で日時情報を参照し、期間SPN中に単語termが出現する文書の集合TD(term,Dspn)を取得する(ステップS505)。
【0072】
次に、話題語抽出部33は、単語termについて、単語文書テーブルから、期間SPN中での文書頻度df(term,Dspn)と、単語頻度tf(term,Dspn)を算出する(ステップS506)。
【0073】
次に、話題語抽出部33は、ステップS504〜S506で算出した情報を用いて、単語termについて、その話題語らしさを表す尺度である話題度score(term,SPN)と、その話題の時事性を表す尺度である新鮮度fresh(term,SPN)を算出する(ステップS507)。
【0074】
話題度score(term,SPN)は、例えば[数1]に示す式によって算出される。
【数1】
【0075】
ここで、期間偏在値topical(term,SPN)は、全文書集合Dの中における、期間SPNでの出現頻度の有意性を表す値であり、期間SPNに偏って出現している単語ほど大きな値となる。さらに、重み値tfidf(term)は、文書分類や文書検索などで、単語の重みとして一般的に使われている指標である。話題度score(term,SPN)では、期間偏在値topical(term,SPN)に、この重み値tfidf(term)を乗算することにより、話題性があり、かつ、その話題をよく表す単語が高い話題度になるようにする。また、新鮮度fresh(term,SPN)は、例えば[数2]に示す式によって算出される。
【数2】
【0076】
新鮮度fresh(term,SPN)は、期間SPNにおける単語termの出現時間の平均を表し、0≦fresh(term,SPN)≦1の値となる。期間SPN(開始日時from、終了日時to)に対して、単語termが終了日時toに偏って出現しているほど、新鮮度fresh(term,SPN)の値は1に近づき、その単語が表す話題が新鮮であることを表す。なお、単語の話題度として、[数1]に示した話題度score(term,SPN)に、この新鮮度fresh(term,SPN)を乗算した値を使用してもよい。その場合は、期間SPNにおいて、最近に盛り上がった話題を重視して話題語を抽出することとなる。
【0077】
次に、話題語抽出部33は、score(term,SPN)>αという式によって、単語termが話題語であるか否かを判定する(ステップS508)。ここで、αとは、当該単語termが話題語として適切かどうかを判定するためのしきい値であり、話題抽出装置において、事前に設定されていてもよいし、話題抽出の処理の都度、ユーザが設定してもよい。
【0078】
話題語と判定した場合(ステップS508−YES)、話題語抽出部33は、当該単語termを話題語として、算出した統計情報を話題語テーブルTWTに追加する(ステップS509)。ここで、ある単語termを話題語として判定した場合、話題語抽出部33は、図7の話題語テーブルTWTについて、単語期間データTS中の「単語ID」TST_tid、「単語」TST_t、「期間」TST_spnの値を、それぞれ「単語ID」TWT_tid、「単語」TWT_t、「期間」TWT_spnに保持する。また、話題語抽出部33は、ステップS505〜S507によって算出された文書集合TD(term、Dspn)、文書頻度df(term,Dspn)、単語頻度tf(term,Dspn)、話題度score(term,SPN)、新鮮度(term,SPN)を、それぞれ「出現文書」TWT_did、「文書頻度」TWT_df、「単語頻度」TWT_tf、「話題度」TWT_score、「新鮮度」TWT_freshに保持する。
【0079】
図11は話題提示部22による話題提示処理(ステップS800)の流れを表すフローチャートである。
【0080】
話題提示部22は、ユーザから表示のための時間間隔の指定を受け付け、時間間隔の集合ITVLSを作成する(ステップS801)。時間間隔の指定は、対象期間の指定(ステップS100)の際に、図3に示した指定画面G1の「表示間隔」g5でユーザが行うものとする。話題提示部22は、指定画面G1によりユーザに指定された「期間」について、「表示間隔」毎に区切った時間間隔ITVLSを作成する。例えば、指定画面G1の「期間」に「2010/05/01〜2010/05/31」が入力され、表示間隔に「日」が入力された場合、話題提示部22は、時間間隔ITVLSを次に示すように作成する。
【0081】
ITVLS=
{2010/05/01 00:00〜2010/05/01 23:59,
2010/05/02 00:00〜2010/05/02 23:59,
: :
2010/05/31 00:00〜2010/05/31 23:59}
なお、時間間隔の集合ITVLSには、ユーザが任意の時間間隔を指定してもよい。次に、話題提示部22は、時間間隔の集合ITVLSの各要素の内容を、図4に示したように、提示画面G10の最終行に表示する。図4の例では、時間間隔の集合ITVLSの各要素を「10年5月1日」、「10年5月2日」、…、「10年5月31日」のように簡略化して表示している。
【0082】
次に、話題提示部22は、話題抽出部30から話題語テーブルTWTを取得し、話題語テーブルTWT内の話題語データを要素として含む話題語データの集合をTWSとする(ステップS804)。
【0083】
次に、話題提示部22は、話題語データ集合TWSの要素を、「新鮮度」TWT_freshによってソートする(ステップS805)。これによって、話題語が時系列順にソートされる。
【0084】
次に話題提示部22は、話題語データ集合TWSが空になるまで、ステップS807〜S814の処理を繰り返す(ステップS806)。始めに、話題提示部22は、話題語データ集合TWS中の先頭にある話題語データをpとする(ステップS807)。
【0085】
次に、話題提示部22は、未表示の話題語データを、順次、話題語データ集合TWS中の先頭の話題語データpの位置に挿入する(ステップS810)。ステップS810では、話題提示部22は、話題語データ集合TWS中の表示済の話題語データpを削除した上で、pの位置にステップS805でソートした順に、話題語データの集合TWS中の話題語データを挿入する。
【0086】
そして、話題提示部22は、ステップS811〜S814の処理によって、話題語データpの情報を話題提示画面G10に表示する。そのために、話題提示部22は、話題提示画面G10に行を追加し(ステップS811)、追加した行の先頭列に話題語データpの「単語」を表示する(ステップS812)。
【0087】
次に、話題提示部22は、話題語データpの「出現文書」のそれぞれの文書dについて、文書記憶部10を参照して、出現日時time(d)を取得する(ステップS813)。話題提示部22は、取得した各文書の出現日時time(d)を、ITVLS中の各期間ITVLについてカウントすることにより、話題語データpの単語termを含む文書の出現頻度を各期間ITVLについて取得し、該当列にその出現頻度を表示する(ステップS814)。出現頻度の表示には、数値や棒グラフ、折れ線グラフなどを用いる。これによって、当該話題語データの行について、話題提示画面G10に文書dの出現頻度が表示される。
【0088】
このように、話題提示部22は、ステップS807〜S814の処理をTWSが空になるまで繰り返すことによって、話題語テーブルTWT中の全ての話題語データを新鮮度によって時系列順にソートしながら、話題語提示画面G10に表示する。
【0089】
上述したように本実施形態によれば、抽出された各単語について、話題語らしさを表す話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出された話題語について当該対象期間における出現日時に基づいて新鮮度を算出し、抽出された話題語を新鮮度の順に提示すると共に、当該提示した各話題語について単位期間毎の出現文書数を提示する構成により、対象文書集合について、指定された対象期間における話題を提示することができる。特に、新鮮度によるソートと、各話題語の単位時間毎の出現文書数の提示により、話題の時間的な遷移を、その盛り上がり具合とともに提示することができる。例えば、図4に示すように、対象期間の中で、直近で注目され始めた話題から、少し前に盛り上がった話題、長い間注目されている話題といった、話題の全体的な遷移を提示することができる。
【0090】
続いて、第1の実施形態に述べた処理(ステップS100〜S300,S500,S800)に対し、話題語集約処理(ステップS600)、話題語階層抽出処理(ステップS700)及びバースト期間抽出処理(ステップS400)のうちの1つ以上の処理を追加する場合について、以下の各実施形態により説明する。なお、各処理(ステップS400,S600,S700)は、それぞれ独立的に追加することが可能である(機能的には依存関係がない)。しかしながら、追加する場合は、ステップ番号の若い順に処理を行う必要がある(処理順序には依存関係がある)。
【0091】
以下、順次、第2〜第8の実施形態によって説明する。
【0092】
<第2の実施形態>
図12は第2の実施形態に係る話題抽出装置の構成を表すブロック図であり、図1と同様の部分については同一の符号を付して詳しい説明を省略し、ここでは変更した部分(破線で囲んだ部分)について主に述べる。以下の各実施形態も同様にして重複した部分の説明を省略する。
【0093】
本実施形態は、第1の実施形態の変形例であり、話題集約部34を更に備えている。
【0094】
ここで、話題集約部34は、話題語抽出部33によって抽出された話題語(termi,termj)について、対象期間における出現文書(Dspni,Dspnj)と当該出現文書の出現頻度(df(termi,docs),df(termj,docs))と日時情報(SPN1,SPN2)に基づいて話題語間の類似度(sim(TWi,TWj))を算出し、当該類似度によって対象期間において同一の話題を表す複数の話題語からなる話題語群を抽出し、当該話題語群について当該対象期間における出現文書の文書集合(TDm=TDi∩TDj)を取得し、当該文書集合の頻度情報(dfm,tfk)及び日時情報に基づいて、話題度と新鮮度を再計算する手段である。
【0095】
具体的には、話題語集約部34は、話題語テーブルTWTに含まれる単語について、同一の話題を表す単語同士を、一つの単語として集約する。この場合、話題語集約部34は、話題語テーブルTWT中の出現文書の情報を用いて、2つの単語間の類似度を算出し、類似度が大きい単語同士の話題語データを統合し、図13に示すように、話題語テーブルTWTを修正する。この統合において、統合する2つの単語の期間と出現文書も統合し、それに基づいて文書頻度、単語頻度、話題度、新鮮度も修正する。
【0096】
図13は、話題語集約部34によって、更新された話題語テーブルTWTのデータの例を表す模式図である。話題語集約部34は、話題語テーブルTWT中の単語について、同一の話題を表すと判定した単語同士の話題語データ(話題語テーブルTWTの行)を統合する。例えば、図7の話題語テーブルTWTについて、話題語集約部34は、1行目TWT_L1の単語TWT_tの「口蹄疫」と、2行目TWT_L2の単語TWT_tの「感染」とを同一の話題と判定した場合、図6の1行目TWT_L1’に示すように、これら2単語の話題語データを統合する。統合の際には、「出現文書」TWT_didや「文書頻度」TWT_df、「単語頻度」TWT_tf、「話題度」TWT_score、「新鮮度」TWT_freshの値を修正する。
【0097】
次に、以上のように構成された話題抽出装置の動作について図14及び図15のフローチャートを用いて説明する。
【0098】
いま、図14に示すステップS100及びS300は、前述同様に実行され、話題語抽出処理によって得られた頻度情報や話題度、新鮮度などが話題語テーブルTWTとして話題抽出部30に保持される。
【0099】
次に、話題語集約部34は、話題語テーブルTWT中の単語について、同一の話題を表す単語同士を集約する話題語集約処理を行う(ステップS600)。話題語集約処理によって、同一の話題を表すと判定された単語同士の話題語データは統合される。
【0100】
図15は話題語集約部34による話題語集約処理(ステップS600)の流れを表すフローチャートである。
【0101】
話題語集約部34は、話題語テーブルTWTを取得する(ステップS601)。そして、話題語集約部34は、話題語テーブルTWT中の全ての話題語データTWiについて、さらに、同様に話題語テーブルTWT中の全ての話題語データTWjについて、ステップS604〜ステップS606の処理を繰り返す(ステップS602、ステップS603)。但し、TWi≠TWjとする。
【0102】
このステップS602〜S603の繰り返しによって、話題語集約部34は、話題語テーブルTWTに含まれる単語間について、集約するか否かを判定する。そのために、話題語集約部34は、ステップS604において、話題語データTWiとTWjの類似度sim(TWi,TWj)を、[数3]に示す式により算出する。
【数3】
【0103】
ここで、共起類似度cosim(termi,termj,Dspni∪Dspnj)とは、2つの単語termi,termjの共起の強さを表す指標である。共起類似度としては、用語抽出や関連語抽出で一般的に使われるダイス(Dice)係数、ジャカード(Jaccard)係数などが使用可能となっている。本実施形態では、ダイス係数(dice(term1,term2,Docs))を用いる。文書の和集合Docsは、前述した和集合Dspni∪Dspnjを表す。
【0104】
共通期間割合cospanrate(SPNi,SPNj)は、TWiとTWjの「期間」で共通する期間の割合を表す指標である。そして、話題語集約部34は、類似度sim(TWi,TWj)及びしきい値βに基づき、類似度sim(TWi,TWj)>βの関係を満たすか否かに応じて、話題語データTWiとTWjが同一話題か否かを判定する(ステップS605)。ここで、しきい値βとは、当該話題語データTWiと話題語データTWjが、同一の話題を表すか否かを判定するための基準値であり、話題抽出装置において、事前に設定されていてもよいし、話題抽出の処理の都度、ユーザが設定してもよい。
【0105】
話題語データTWiと話題語データTWjとを同一話題と判定した場合(ステップS605−YES)、話題語集約部34は、話題語テーブルTWT中の当該話題語データTWi,TWjを統合した話題語データTWmを作成し、話題語テーブルTWTに格納する(ステップS606)。
【0106】
このとき、統合された話題語データTWmの各項目の値は以下の通りとする。
【0107】
すなわち、話題語データTWa={単語ID termIDa,単語terma,期間SPNa,出現文書TDa,文書頻度dfa、単語頻度tfa,話題度scorea,新鮮度fresha}(aは添え字i,jもしくはm)で表す。また、統合された話題語データの各項目について、以下のように補足して述べる。
【0108】
・単語ID:統合した話題語データの一方の単語ID。
【0109】
termIDm=termIDi
・単語:2つの話題語データの単語の集合。
【0110】
termm={termi,termj}
・期間:2つの話題語データの期間で共通する期間。
【0111】
SPNm=cospan(SPNi,SPNj)
・出現文書の集合:2つの話題語データの出現頻度で共通する文書の集合。
【0112】
TDm=TDi∩TDj
・文書頻度:TDmに含まれる文書数
dfm=|TDm|
・単語頻度:単語の集合TDm中に含まれる単語termi,termjの出現頻度の平均。
【0113】
tfk=(tf(termi,TDk)+tf(termj,TDk))/2
・話題度:上記の値を使い、[数3]に示した式によって再計算した話題度。
【0114】
scorek=score(termk,SPNk)
ここで、df(termk,Dspnk)=dfk、
tf(termk,D)=(tf(termi,D)+tf(termj,D))/2
・新鮮度:上記の値を使い、[数2]に示した式によって再計算した新鮮度。
【0115】
freshk=fresh(termk,SPNk)
以上が、統合された話題語データTWmの各項目の補足説明である。
【0116】
また、統合処理後、話題語集約部34は、話題語テーブルTWTから話題語データTWi,TWjを削除する(ステップS607)。最後に、話題語集約部34は、話題語テーブルTWTを出力する(ステップS608)。
【0117】
話題語集約処理の終了後、話題提示部22は、以上の処理(ステップS300、S500、S600)によって生成された話題語テーブルTWTを話題抽出部30から受け取り、この話題語テーブルTWTに基づき、図16に示すように、抽出結果を示す話題提示画面G20をユーザに提示する話題提示処理を行う(ステップS800)。話題提示画面G20では、話題語のうち、「口蹄疫、感染」、「普天間、基地」、「移設、県外」及び「殺処分、種牛」の箇所において、話題語が集約されて提示されている。
【0118】
上述したように本実施形態によれば、第1の実施形態の効果に加え、類似度及び出現日時の系列に基づいて、同一話題を表す単語を適切に集約する構成により、話題語を精度良く抽出することができる。また、話題を単語の集まりとして提示することで、ユーザは話題の内容をより的確に把握することができる。
【0119】
<第3の実施形態>
図17は第3の実施形態に係る話題抽出装置の構成を表すブロック図である。
【0120】
本実施形態は、第1の実施形態の変形例であり、図1に示した話題抽出部30において、話題語階層抽出部35を更に備えている。
【0121】
ここで、話題語階層抽出部35は、話題語抽出部33によって抽出された話題語(termi,termj)について、対象期間における出現文書の出現頻度(df(term1,Docs),df(term2,Docs))と日時情報(SPNi,SPNj)に基づいて話題語間の関連度を算出し、当該関連度によって話題語間の階層関係を抽出する手段である。
【0122】
具体的には、話題語階層抽出部35は、話題語テーブルTWTに基づいて、話題語間の階層を抽出する。話題語階層抽出部35では、話題語テーブルTWT中の出現文書の情報を用いて、2つの単語間の関連度を算出し、その関連度に基づいて、単語間の階層関係を判定する。そして、判定した結果を、話題語テーブルTWTに付与する。
【0123】
図18は、話題語階層抽出部35によって、更新された話題語テーブルTWTのデータの例を表す模式図である。話題語階層抽出部35は、話題語テーブルTWT中の単語について、単語間の親子関係を判定し、その親子関係を表すために、話題語テーブルTWTの「親単語」709の列に、その単語の親単語の単語IDを格納する。例えば、図7に示した話題語テーブルTWTの単語TWT_tの「口蹄疫」、「感染」、「普天間」、「基地」、「移設」、「県外」、「徳之島」、「種牛」、「殺処分」及び「辺野古」について、話題語階層抽出部35は、図19(a)及び図19(b)に示す如き、階層関係を抽出した場合、それぞれの話題語データについて、図18の「親単語」TWT_rootのような値を格納する。ここで、「親単語」は、その単語の親単語の単語IDを表す。但し、最上位の単語(上述の例では、「普天間」、「基地」、「口蹄疫」、「感染」)に対する親単語としては(root)という値が格納される。
【0124】
また、話題抽出装置においては、話題語階層抽出部35を更に備えたことに伴い、話題提示部22が、話題語階層抽出部35によって抽出された話題語の階層関係に従い、話題語間の親子関係を提示すると共に、兄弟関係にある話題語を新鮮度の順に提示する機能を有している。
【0125】
次に、以上のように構成された話題抽出装置の動作について図20乃至図22のフローチャートを用いて説明する。
【0126】
いま、図20に示すステップS100〜S300及びS500は、前述同様に実行され、話題語抽出処理によって得られた頻度情報や話題度、新鮮度などが話題語テーブルTWTとして話題抽出部30に保持される。
【0127】
次に、話題語階層抽出部35は、話題語テーブルTWT中の単語について、単語間の階層関係を抽出し、その階層構造の情報を話題語テーブルTWTに付与する話題語階層抽出処理を行う(ステップS700)。なお、話題語階層抽出処理の詳細については後述する。
【0128】
話題語階層処理の終了後、話題提示部22は、以上の処理(ステップS300、S500、S700)によって生成された話題語テーブルTWTを話題抽出部30から受け取り、この話題語テーブルTWTに基づき、抽出結果をユーザに提示する話題提示処理を行う(ステップS800)。なお、話題提示処理の詳細については後述する。
【0129】
図21は話題語階層抽出部35による話題語階層抽出処理(ステップS700)の流れを表すフローチャートである。
【0130】
話題語階層抽出部35は、話題語テーブルTWTを取得する(ステップS701)。そして、話題語階層抽出部35は、話題語テーブルTWT中の全ての話題語データTWiについて、さらに、同様に話題語テーブルTWT中の全ての話題語データTWjについて、ステップS704〜ステップS706の処理を繰り返す(ステップS702,S703)。但し、TWi≠TWjとする。
【0131】
このステップS702,S703の繰り返しによって、話題語階層抽出部35は、話題語テーブルTWTに含まれる全ての単語間について親子関係を判定する。そのために、話題語階層抽出部35は、ステップS704において、話題語データTWiとTWjの関連度rel(TWi,TWj)を、[数4]に示す式により算出する。
【数4】
【0132】
ここで、mi(termi,termj,Dspni∪Dspnj)は、話題語データTWi,TWjの出現文書の和集合において、一方の単語termiから見たときの他方の単語termjの関係の強さを相互情報量に基づいて、算出する式である。また、共通期間割合cospanrate(SPNi,SPNj)は、[数3]に示した式と同様の式で、期間の共通性を考慮するための指標である。次に、関連度rel(TWi,TWj)>γという式によって、話題語データTWiとTWjが親子関係を判定する(ステップS705)。ここで、しきい値γは、当該話題語データTWiが話題語データTWjの親にすべきかを判定するための基準値であり、話題抽出装置において、事前に設定されていてもよいし、話題抽出の処理の都度、ユーザが設定してもよい。
【0133】
そして、話題語データTWiと話題語データTWjに親子関係があると判定した場合(ステップS705−YES)、話題語階層抽出部35は、当該TWiを親、TWjを子として、話題語データTWjの「親単語」(図7に示すTWT_root)に、話題語データTWiの「単語ID」(図7に示すTWT_tid)の値を格納する(ステップS706)「親単語」に格納される値については、図18の説明を参照されたい。
【0134】
話題語階層抽出部35は、このステップS702〜S703の繰り返しによる話題語テーブルTWT中の単語間の親子関係の判定を、親子関係が抽出されなくなるまで繰り返す(ステップS707)。
【0135】
そして、このステップS702、ステップS703の繰り返しにおいて、1度も親子関係が抽出されなかった場合(ステップS707−YES)、話題語階層抽出部35は、話題語テーブルTWTを出力する(ステップS708)。ステップS707の繰り返しによって、話題語階層抽出部35は、話題語テーブルTWT中の単語の親子関係を多階層的に抽出する。また、抽出する階層関係について、何階層まで抽出するかをユーザが指定するとしてもよい。
【0136】
図22は話題提示部22による話題提示処理(ステップS800)の流れを表すフローチャートである。
【0137】
いま、ステップS801〜S803は、前述同様に実行される。
【0138】
次に、話題提示部22は、話題抽出部30から話題語テーブルTWTを取得し、話題語テーブルTWT中から「親単語」が「(root)」である(つまり、階層的に最上位の)話題語データを取得し、それらの話題語データを要素として含む話題語データの集合をTWSとする(ステップS804’)。例えば、図7の例では、TWS={「普天間」,「基地」,「口蹄疫」,「感染」}となる。
【0139】
次に、話題提示部22は、話題語データ集合TWSの要素を、「新鮮度」TWT_freshによってソートする(ステップS805)。これによって、階層的に兄弟の関係にある話題が時系列順にソートされる。これは、後述するステップS809の処理も同様である。
【0140】
次に話題提示部22は、話題語データ集合TWSが空になるまで、ステップS807〜S814の処理を繰り返す(ステップS806)。
【0141】
始めに、話題提示部22は、話題語データ集合TWS中の先頭にある話題語データをpとする(ステップS807)。例えば、上述した例では、TWS={「普天間」,「基地」,「口蹄疫」,「感染」}の先頭の話題語データなので、p=「普天間」となる。
【0142】
次に、話題提示部22は、話題語テーブルTWTからpを親とする話題語データの集合CTSを取得する。上述の例では、p=「普天間」なので、CTS={「移設」、「県外」、「×× 連立」}となる。
【0143】
次に、話題提示部22は、先頭の話題語データpを親とする話題語データの集合CTS中の要素を「新鮮度」によってソートする(ステップS809)。
【0144】
次に、話題提示部22は、当該話題語データの集合CTS中の全ての話題語データを、話題語データ集合TWS中の先頭の話題語データpの位置に挿入する(ステップS810’)。このとき、話題提示部22は、話題語データ集合TWS中の先頭の話題語データpを削除した上で、pの位置にステップS809でソートした順に、pを親とする話題語データの集合CTS中の話題語データを挿入する。
【0145】
例えば、上述の例では、TWS={「普天間」,「基地」,「口蹄疫」,「感染」}、p=「普天間」、CTS={「移設」,「県外」,「×× 連立」}に対して、ステップS810の処理によって、TWS={「移設」,「県外」,「×× 連立」,「基地」,「口蹄疫」,「感染」}となる。
【0146】
そして、話題提示部22は、前述したステップS811〜S814の処理によって、図23に示すように、話題語データpの情報を話題提示画面に表示する。
【0147】
このように、話題提示部22は、ステップS807〜S814の処理をTWSが空になるまで繰り返すことによって、話題語テーブルTWT中の全ての話題語データを、その階層構造に従い、かつ、兄弟関係にある話題語データについては新鮮度によって時系列順にソートしながら、図23に示すように、話題語提示画面G30に表示する。
【0148】
上述したように本実施形態によれば、第1の実施形態の効果に加え、関連度及び出現日時の系列に基づいて話題語を階層化する構成により、文書数の規模だけでなく、話題の期間的な規模に応じて話題語を階層化することができる。ユーザにとっては、上位下位層の話題語を概観することにより対象期間における大きな話題の潮流を俯瞰でき、さらに着目する話題については深堀しながら、話題の詳細を知ることができる。さらに、同一階層の話題を新鮮度でソートするため、話題の遷移を様々な粒度で提示することができる。
【0149】
<第4の実施形態>
図24は第4の実施形態に係る話題抽出装置の構成を表すブロック図である。
【0150】
本実施形態は、第1の実施形態に第2及び第3の実施形態を組合せた例であり、図1に示した話題抽出部30において、図12に示した話題語集約部34と、図17に示した話題語階層抽出部35とを更に備えている。
【0151】
これに伴い、話題語テーブルTWT及び階層構造は、図25、図26(a)及び図26(b)に示すように、集約された話題語に対しても、階層構造を示すものとなる。
【0152】
以上のような構成によれば、図27に示すように、前述した話題語抽出処理(ステップS500)の後に、前述した話題語集約処理(ステップS600)及び話題語階層抽出処理(ステップS700)が実行される。
【0153】
その結果、図28に示すように、話題語が集約され、且つ、話題語の階層構造が明示された話題提示画面G40が提示される。
【0154】
上述したように本実施形態によれば、第1、第2及び第3の実施形態の効果を同時に得ることができる。
【0155】
<第5の実施形態>
図29は第5の実施形態に係る話題抽出装置の構成を表すブロック図である。
【0156】
本実施形態は、第1の実施形態の変形例であり、図1に示した話題抽出部30において、バースト期間抽出部32を更に備えている。
【0157】
ここで、バースト期間抽出部32は、単語抽出部31によって抽出された各単語について、出現文書の文書集合(TD(term,Dspn))における出現日時の系列(TIMES)を取得し、当該出現日時の系列を用いて当該単語(term)が集中的に出現している複数のバースト期間(BST)をそれぞれ抽出し、当該単語とそれぞれのバースト期間との組(TS={term,BST})を異なる単語として保持する手段である。
【0158】
具体的には、バースト期間抽出部32は、単語文書テーブルTDTに含まれるそれぞれの単語について、その単語が出現する文書の日時の系列を用いて、その単語が集中しているバースト期間BSTを抽出し、そのバースト期間BSTを単語期間テーブルTSTの「期間」TST_spnに書き込む。ここで、1つの単語が複数のバースト期間BSTi,BSTj,…を持つ場合は、抽出したバースト期間BSTi,BSTj,…の数だけ、{単語,期間}の組(単語期間データ)を生成し、それぞれ異なる「単語ID」を付与する。すなわち、表記上、同じ単語であっても、異なるバースト期間BSTi,BSTj,…を持つものは、別の単語として扱う。これによって、例えば図30に示す単語期間テーブルTSTが生成される。ここで生成した単語期間テーブルTSTは、話題語抽出部33の入力として使用する。バースト期間抽出部32を含む構成(第5の実施形態〜第8の実施形態)においては、バースト期間抽出部32によって、生成された単語期間テーブルTSTに基づいて、話題語テーブルTWTが生成される。
【0159】
なお、この単語期間テーブルTSTに対応させて、バースト期間抽出部32を組み込んだ場合の話題語テーブルTWTについては、それぞれ図7、図13、図18、図25において、TWT_spnの期間を図30のTST_spnの期間に置き換えることで得られる。
【0160】
また、話題抽出装置は、バースト期間抽出部32を更に備えたことに伴い、話題語抽出部33及び話題提示部22が以下の機能を有するものとなっている。
【0161】
すなわち、話題語抽出部33は、単語抽出部31により抽出された各単語のうちでバースト期間抽出部32によっても抽出された単語については対象期間における当該単語が出現する出現文書の文書集合の取得に代えて、バースト期間抽出部32によって抽出された単語とそれぞれのバースト期間との組(TS={term,BST})に基づいて、当該単語が当該バースト期間において出現する出現文書の文書集合(TD(term,Dbst))を取得し、当該出現文書の出現頻度の有意性を表す値(topical(term,BST))と、重み値(tfidf(term))とに基づいて話題度(score(term,BST))を算出し、当該話題度が所定の値(α)以上の単語を話題語として抽出すると共に、当該抽出した各話題語について、バースト期間における出現日時の系列に基づいて新鮮度(fresh(term,BST))を算出する機能をもっている。
【0162】
話題提示部22は、提示した各話題語について、バースト期間抽出部32によって抽出したバースト期間に該当する箇所を強調表示する機能をもっている。
【0163】
次に、以上のように構成された話題抽出装置の動作について図31乃至図33のフローチャートを用いて説明する。
【0164】
いま、図31に示すステップS100〜S300は、前述同様に実行され、単語抽出処理によって得られた単語文書テーブルTDTが話題抽出部30に保持される。
【0165】
次に、バースト期間抽出部32は、単語文書テーブルTDTに含まれるそれぞれの単語についてバースト期間BSTを抽出し、単語期間データの集合である単語期間テーブルTSTを生成する処理(以下、バースト期間抽出処理)を行う(ステップS400)。なお、バースト期間抽出処理の詳細については後述する。
【0166】
次に、話題語抽出部33は、バースト期間抽出処理(ステップS400)によって生成された単語期間テーブルTST中のそれぞれの単語について、当該期間中に当該単語が出現する文書や、文書頻度、出現頻度などの情報に基づき、単語の話題度算出(スコアリング)を行い、話題語を抽出する話題語抽出処理を行う(ステップS500)。話題語抽出処理の詳細については後述する。また、この話題語抽出処理によって得られた頻度情報や話題度、新鮮度などは、話題語テーブルTWTとして話題抽出部30に保持する。
【0167】
そして、話題提示部22は、以上の処理(ステップS300〜ステップS700)によって生成された話題語テーブルTWTを話題抽出部30から受け取り、この話題語テーブルTWTに基づき、抽出結果をユーザに提示する話題提示処理を行う(ステップS800)。なお、話題提示処理の詳細については後述する。
【0168】
図32はバースト期間抽出部32によるバースト期間抽出処理(ステップS400)の流れを表すフローチャートである。
【0169】
バースト期間抽出部32は、単語文書テーブルTDTを取得し(ステップS401)、{単語,期間}の組の集合TSSを作成する(ステップS402)。ここで、組の集合TSSの初期値は空とする。
【0170】
次に、バースト期間抽出部32は、単語文書テーブルTDTに含まれる全ての単語termについて、ステップS404〜S407の処理を繰り返す(ステップS403)。
【0171】
ステップS404では、バースト期間抽出部32は、単語文書テーブルTDTから単語termの出現文書(「出現頻度」が1以上の文書)を取得し、その出現文書の日時情報を、単語termの出現日時の系列TIMESとして取得する。
【0172】
次に、バースト期間抽出部32は、単語termの出現日時の系列TIMESに基づいて、単語termのバースト期間の集合BSTSを抽出する(ステップS405)。ここで、バースト期間の抽出手法としては、例えば、非特許文献1に記載の手法が使用可能となっている。この抽出手法では、単語の出現日時の系列(ここでは、TIMES)に基づいて、その単語が密集して出現する複数の期間を取得する。補足すると、一様に出現するような単語については、バースト期間BSTは抽出されない。
【0173】
ステップS405の後、バースト期間抽出部32は、バースト期間の集合BSTS中の全てのバースト期間BSTについて、ステップS407を繰り返し(ステップS406)、{term,BST}の組TSを当該組の集合TSSに追加する。以上のバースト期間抽出処理によって、単語文書テーブルTDT中の単語は、バースト期間BSTによって分割され、以降の処理でそれぞれ異なる単語として処理される。
【0174】
図33は話題提示部22による話題提示処理(ステップS800)の流れを表すフローチャートである。
【0175】
ここで、ステップS801〜S814は、前述した図11と同様に実行される。但し、前述した話題度score(term,SPN)は、期間SPNに代えてバースト期間BSTに基づく話題度score(term,BST)として算出されている(Dspnに基づくtopical(term,SPN)が、Dbstに基づくtopical(term,BST)として算出されている)。同様に、前述した新鮮度fresh(term,SPN)は、期間SPNに代えてバースト期間BSTに基づく新鮮度fresh(term,BST)として算出されている。
【0176】
また、ステップS814の後、話題提示部22は、ステップS811で追加した行について、話題語データpの「期間」に該当する列のセルを強調表示する(ステップS815)。この処理によって、図34に示すように、話題提示画面G50中で当該話題が盛り上がっている時期(バースト期間BST)を強調表示する。
【0177】
上述したように本実施形態によれば、第1の実施形態の効果に加え、単語をバースト期間によって分割した上で、話題語を抽出する構成により、同じ話題語でも盛り上がった時期毎に提示することで、時期によって異なる話題間の関連を提示することができる。
【0178】
補足すると、背景技術に述べた従来の話題抽出方式とは異なった従来の他の話題抽出方式として、文書クラスタリングを階層的に繰り返すことにより、話題を文書の集合(話題クラスタ)とし、話題クラスタ・サブ話題クラスタという話題の階層を抽出するものがある。当該他の話題抽出方式では、それぞれの話題クラスタ毎に、出現頻度に基づいて話題語を抽出し、日時情報に基づいて提示する。
【0179】
しかしながら、当該他の話題抽出方式は、本発明者の検討によれば、話題を文書集合として細分化するため、話題を掘り下げて詳細を知る用途には向いているものの、話題の変遷を知る用途には不向きである。
【0180】
また、ニュースやブログなどにおいて、同一の話題を表す単語や、話題に関連する単語は、時間の経過と共に変化するものである。このため、単語間の関連を求める場合、単語が出現する期間を考慮する必要がある。また、一つの単語に着目して話題を表す際にも、一つの単語が出現時期によって異なる話題を表す場合があることから、単語の出現時期を考慮する必要がある。
【0181】
例えば沖縄県の普天間基地に対する「移設」という単語は、ある時期には「徳之島への移設」の話題を表し、他の時期には「辺野古への移設」の話題を表している。このように、一つの単語は、時期によって異なる話題を表す場合がある。
【0182】
しかし、背景技術で述べた従来の話題抽出方式では、単語の出現時期を考慮していないことから、単語の出現時期によっては、異なる話題を同じ話題と混同してしまう可能性がある。
【0183】
従来の他の話題抽出方式では、話題を話題クラスタとして抽出することにより、話題の混同を吸収している。しかし、従来の他の話題抽出方式では、話題語を抽出する際に、同様の混同を生じる可能性がある。
【0184】
これに対し、本実施形態によれば、前述した通り、単語をバースト期間によって分割した上で、話題語の抽出を行う構成により、話題の混同を防ぐことができる。
【0185】
<第6の実施形態>
図35は第6の実施形態に係る話題抽出装置の構成を表すブロック図である。
【0186】
本実施形態は、第1の実施形態に第2及び第5の実施形態を組合せた例であり、図1に示した話題抽出部30において、図12に示した話題語集約部34と、図29に示したバースト期間抽出部32とを更に備えている。
【0187】
以上のような構成によれば、図36に示すように、前述したバースト期間抽出処理(ステップS400)の後に、前述した話題語集約処理(ステップS600)が実行される。このため、話題語集約処理(ステップS600)において、期間SPNに基づく類似度sim(TWi,TWj)は、期間SPNに代えてバースト期間BSTに基づく類似度sim(TWi,TWj)として算出される。補足すると、期間SPNに基づく共起類似度co(termi,termj,Dspni∪Dspnj)は、期間SPNに代えてバースト期間BSTに基づく共起類似度co(termi,termj,Dbsti∪Dbstj)として算出される。同様に、期間SPNに基づく共通期間割合cospanrate(SPNi,SPNj)は、期間SPNに代えてバースト期間BSTに基づく共通期間割合cospanrate(BSTi,BSTj)として算出される。
【0188】
その結果、図37に示すように、話題語が集約され、バースト期間が強調された話題提示画面G60が提示される。
【0189】
上述したように本実施形態によれば、第1、第2及び第5の実施形態の効果を同時に得ることができる。
【0190】
<第7の実施形態>
図38は第7の実施形態に係る話題抽出装置の構成を表すブロック図である。
【0191】
本実施形態は、第1の実施形態に第3及び第5の実施形態を組合せた例であり、図1に示した話題抽出部30において、図17に示した話題語階層抽出部35と、図29に示したバースト期間抽出部32とを更に備えている。
【0192】
以上のような構成によれば、図39に示すように、前述したバースト期間抽出処理(ステップS400)の後に、前述した話題語階層抽出処理(ステップS700)が実行される。このため、話題語階層抽出処理(ステップS700)において、期間SPNに基づく関連度rel(TWi,TWj)は、期間SPNに代えてバースト期間BSTに基づく関連度rel(TWi,TWj)として算出される。補足すると、期間SPNに基づく相互情報量mi(termi,termj,Dspni∪Dspnj)は、期間SPNに代えてバースト期間BSTに基づく相互情報量mi(termi,termj,Dbsti∪Dbstj)として算出される。同様に、期間SPNに基づく共通期間割合cospanrate(SPNi,SPNj)は、期間SPNに代えてバースト期間BSTに基づく共通期間割合cospanrate(BSTi,BSTj)として算出される。
【0193】
また、話題提示処理は、図40に示すように、バースト期間BSTを強調表示するステップS815を有して実行される。
【0194】
その結果、図41に示すように、話題語の階層構造が明示され、バースト期間が強調された話題提示画面G70が提示される。
【0195】
上述したように本実施形態によれば、第1、第3及び第5の実施形態の効果を同時に得ることができる。
【0196】
<第8の実施形態>
図42は第8の実施形態に係る話題抽出装置の構成を表すブロック図である。
【0197】
本実施形態は、第1の実施形態に第4及び第5の実施形態を組合せた例であり、図1に示した話題抽出部30において、図24に示した話題語集約部34及び話題語階層抽出部35と、図29に示したバースト期間抽出部32とを更に備えている。
【0198】
以上のような構成によれば、図43に示すように、前述したバースト期間抽出処理(ステップS400)の後に、前述した話題語集約処理(ステップS600)及び話題語階層抽出処理(ステップS700)が実行される。すなわち、各処理(ステップS600,S700)では、第6及び第7の実施形態と同様に、期間SPNに代えてバースト期間BSTに基づき、類似度sim(TWi,TWj)、共起類似度co(termi,termj,Dbsti∪Dbstj)共通期間割合cospanrate(BSTi,BSTj)、関連度rel(TWi,TWj)、相互情報量mi(termi,termj,Dbsti∪Dbstj)が算出される。
【0199】
その結果、図44に示すように、話題語が集約され、話題語の階層構造が明示され、且つバースト期間が強調された話題提示画面G80が提示される。
【0200】
上述したように本実施形態によれば、第1、第4及び第5の実施形態の効果を同時に得ることができる。
【0201】
補足すると、話題を表す単語を話題語として抽出し、同一の話題に関連する話題語を集約すると共に、文書数や時間的な規模に応じて、階層化する構成により、話題の全体像や詳細を、その時間的な遷移と共に的確に把握できる。また、同じ話題でも盛り上がった時期毎に階層化することで、時期によって異なる話題間の関連を提示できる。
【0202】
以上説明した少なくとも一つの実施形態によれば、指定した対象期間において、話題の変遷を提示することができる。
【0203】
なお、上記の各実施形態に記載した手法は、コンピュータに実行させることのできるプログラムとして、磁気ディスク(フロッピー(登録商標)ディスク、ハードディスクなど)、光ディスク(CD−ROM、DVDなど)、光磁気ディスク(MO)、半導体メモリなどの記憶媒体に格納して頒布することもできる。
【0204】
また、この記憶媒体としては、プログラムを記憶でき、かつコンピュータが読み取り可能な記憶媒体であれば、その記憶形式は何れの形態であってもよい。
【0205】
また、記憶媒体からコンピュータにインストールされたプログラムの指示に基づきコンピュータ上で稼働しているOS(オペレーティングシステム)や、データベース管理ソフト、ネットワークソフト等のMW(ミドルウェア)等が上記実施形態を実現するための各処理の一部を実行してもよい。
【0206】
さらに、各実施形態における記憶媒体は、コンピュータと独立した媒体に限らず、LANやインターネット等により伝送されたプログラムをダウンロードして記憶または一時記憶した記憶媒体も含まれる。
【0207】
また、記憶媒体は1つに限らず、複数の媒体から上記の各実施形態における処理が実行される場合も本発明における記憶媒体に含まれ、媒体構成は何れの構成であってもよい。
【0208】
なお、各実施形態におけるコンピュータは、記憶媒体に記憶されたプログラムに基づき、上記の各実施形態における各処理を実行するものであって、パソコン等の1つからなる装置、複数の装置がネットワーク接続されたシステム等の何れの構成であってもよい。
【0209】
また、各実施形態におけるコンピュータとは、パソコンに限らず、情報処理機器に含まれる演算処理装置、マイコン等も含み、プログラムによって本発明の機能を実現することが可能な機器、装置を総称している。
【0210】
なお、本発明のいくつかの実施形態を説明したが、これらの実施形態は、例として提示したものであり、発明の範囲を限定することは意図していない。これら新規な実施形態は、その他の様々な形態で実施されることが可能であり、発明の要旨を逸脱しない範囲で、種々の省略、置き換え、変更を行うことができる。これら実施形態やその変形は、発明の範囲や要旨に含まれるとともに、特許請求の範囲に記載された発明とその均等の範囲に含まれる。
【符号の説明】
【0211】
10…文書記憶部、20…ユーザインターフェース部、21…期間指定部、22…話題提示部、30…話題抽出部、31…単語抽出部、32…バースト期間抽出部、33…話題語抽出部、34…話題語集約部、35…話題語階層抽出部、G1…指定画面、g1…開始日時、g2…終了日時、g3…実行ボタン、g4…キャンセルボタン、g5…表示間隔、G10〜G80…話題提示画面。
【特許請求の範囲】
【請求項1】
テキスト情報と日時情報を持つ複数の文書からなる対象文書集合を記憶する文書記憶手段と、
話題抽出の対象とする対象期間の指定を受け付ける期間指定手段と、
前記文書記憶手段に記憶された対象文書集合から、前記指定を受け付けた対象期間での話題を表す単語である話題語を抽出すると共に、各話題語について時事性を表す尺度である新鮮度を算出する話題抽出手段と、
前記話題抽出手段によって抽出された話題語を前記新鮮度の順に提示すると共に、当該提示した各話題語について単位期間毎の出現文書数を提示する話題提示手段を備えた話題抽出装置であって、
前記話題抽出手段は、
前記文書記憶手段に記憶された対象文書集合から各単語を抽出し、当該各単語の出現頻度及び当該各単語が出現する文書数を示す文書頻度をそれぞれ算出する単語抽出手段と、
前記単語抽出手段によって抽出された各単語について、前記対象期間における当該単語が出現する出現文書の文書集合を取得し、当該出現文書の出現頻度の有意性を表す値と、前記単語の出現頻度及び前記文書頻度に基づく当該単語の重み値とに基づいて、話題語らしさを表す尺度である話題度を算出し、前記話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出された話題語について当該対象期間における出現日時に基づいて新鮮度を算出する話題語抽出手段と、
を備えたことを特徴とする話題抽出装置。
【請求項2】
請求項1に記載の話題抽出装置において、
前記話題抽出手段は、
前記話題語抽出手段によって抽出された話題語について、前記対象期間における出現文書と当該出現文書の出現頻度と日時情報に基づいて話題語間の類似度を算出し、当該類似度によって対象期間において同一の話題を表す複数の話題語からなる話題語群を抽出し、当該話題語群について当該対象期間における出現文書の文書集合を取得し、当該文書集合の頻度情報及び日時情報に基づいて、前記話題度と前記新鮮度を再計算する話題語集約手段、
を更に備えたことを特徴とする話題抽出装置。
【請求項3】
請求項1又は請求項2に記載の話題抽出装置において、
前記話題抽出手段は、
前記話題語抽出手段によって抽出された話題語について、前記対象期間における出現文書の出現頻度と日時情報に基づいて話題語間の関連度を算出し、当該関連度によって話題語間の階層関係を抽出する話題語階層抽出手段を更に備え、
前記話題提示手段は、
前記話題語階層抽出手段によって抽出された話題語の階層関係に従い、話題語間の親子関係を提示すると共に、兄弟関係にある話題語を前記新鮮度の順に提示することを特徴とする話題抽出装置。
【請求項4】
請求項1乃至請求項3のいずれか1項に記載の話題抽出装置において、
前記話題抽出手段は、
前記単語抽出手段によって抽出された各単語について、前記出現文書の文書集合における出現日時の系列を取得し、当該出現日時の系列を用いて当該単語が集中的に出現している複数のバースト期間をそれぞれ抽出し、当該単語とそれぞれのバースト期間との組を異なる単語として保持するバースト期間抽出手段を更に備え、
前記話題語抽出手段は、
前記単語抽出手段により抽出された各単語のうちで前記バースト期間抽出手段によっても抽出された単語については前記対象期間における当該単語が出現する出現文書の文書集合の取得に代えて、前記バースト期間抽出手段によって抽出された単語とそれぞれのバースト期間との組に基づいて、当該単語が当該バースト期間において出現する出現文書の文書集合を取得し、当該出現文書の出現頻度の有意性を表す値と、前記重み値とに基づいて話題度を算出し、当該話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出した各話題語について、バースト期間における出現日時の系列に基づいて新鮮度を算出し、
前記話題提示手段は、
前記提示した各話題語について、前記バースト期間抽出手段によって抽出したバースト期間に該当する箇所を強調表示することを特徴とする話題抽出装置。
【請求項5】
テキスト情報と日時情報を持つ複数の文書からなる対象文書集合を記憶する文書記憶手段を備えた話題抽出装置に用いられるプログラムであって、
前記話題抽出装置を、
話題抽出の対象とする対象期間の指定を受け付ける期間指定手段、
前記文書記憶手段に記憶された対象文書集合から、前記指定を受け付けた対象期間での話題を表す単語である話題語を抽出すると共に、各話題語について時事性を表す尺度である新鮮度を算出する話題抽出手段、
前記話題抽出手段によって抽出された話題語を前記新鮮度の順に提示すると共に、当該提示した各話題語について単位期間毎の出現文書数を提示する話題提示手段、
として機能させ、
前記話題抽出手段は、
前記文書記憶手段に記憶された対象文書集合から各単語を抽出し、当該各単語の出現頻度及び当該各単語が出現する文書数を示す文書頻度をそれぞれ算出する単語抽出手段と、
前記単語抽出手段によって抽出された各単語について、前記対象期間における当該単語が出現する出現文書の文書集合を取得し、当該出現文書の出現頻度の有意性を表す値と、前記単語の出現頻度及び前記文書頻度に基づく当該単語の重み値とに基づいて、話題語らしさを表す尺度である話題度を算出し、前記話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出された話題語について当該対象期間における出現日時に基づいて新鮮度を算出する話題語抽出手段と、
を含んでいるプログラム。
【請求項1】
テキスト情報と日時情報を持つ複数の文書からなる対象文書集合を記憶する文書記憶手段と、
話題抽出の対象とする対象期間の指定を受け付ける期間指定手段と、
前記文書記憶手段に記憶された対象文書集合から、前記指定を受け付けた対象期間での話題を表す単語である話題語を抽出すると共に、各話題語について時事性を表す尺度である新鮮度を算出する話題抽出手段と、
前記話題抽出手段によって抽出された話題語を前記新鮮度の順に提示すると共に、当該提示した各話題語について単位期間毎の出現文書数を提示する話題提示手段を備えた話題抽出装置であって、
前記話題抽出手段は、
前記文書記憶手段に記憶された対象文書集合から各単語を抽出し、当該各単語の出現頻度及び当該各単語が出現する文書数を示す文書頻度をそれぞれ算出する単語抽出手段と、
前記単語抽出手段によって抽出された各単語について、前記対象期間における当該単語が出現する出現文書の文書集合を取得し、当該出現文書の出現頻度の有意性を表す値と、前記単語の出現頻度及び前記文書頻度に基づく当該単語の重み値とに基づいて、話題語らしさを表す尺度である話題度を算出し、前記話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出された話題語について当該対象期間における出現日時に基づいて新鮮度を算出する話題語抽出手段と、
を備えたことを特徴とする話題抽出装置。
【請求項2】
請求項1に記載の話題抽出装置において、
前記話題抽出手段は、
前記話題語抽出手段によって抽出された話題語について、前記対象期間における出現文書と当該出現文書の出現頻度と日時情報に基づいて話題語間の類似度を算出し、当該類似度によって対象期間において同一の話題を表す複数の話題語からなる話題語群を抽出し、当該話題語群について当該対象期間における出現文書の文書集合を取得し、当該文書集合の頻度情報及び日時情報に基づいて、前記話題度と前記新鮮度を再計算する話題語集約手段、
を更に備えたことを特徴とする話題抽出装置。
【請求項3】
請求項1又は請求項2に記載の話題抽出装置において、
前記話題抽出手段は、
前記話題語抽出手段によって抽出された話題語について、前記対象期間における出現文書の出現頻度と日時情報に基づいて話題語間の関連度を算出し、当該関連度によって話題語間の階層関係を抽出する話題語階層抽出手段を更に備え、
前記話題提示手段は、
前記話題語階層抽出手段によって抽出された話題語の階層関係に従い、話題語間の親子関係を提示すると共に、兄弟関係にある話題語を前記新鮮度の順に提示することを特徴とする話題抽出装置。
【請求項4】
請求項1乃至請求項3のいずれか1項に記載の話題抽出装置において、
前記話題抽出手段は、
前記単語抽出手段によって抽出された各単語について、前記出現文書の文書集合における出現日時の系列を取得し、当該出現日時の系列を用いて当該単語が集中的に出現している複数のバースト期間をそれぞれ抽出し、当該単語とそれぞれのバースト期間との組を異なる単語として保持するバースト期間抽出手段を更に備え、
前記話題語抽出手段は、
前記単語抽出手段により抽出された各単語のうちで前記バースト期間抽出手段によっても抽出された単語については前記対象期間における当該単語が出現する出現文書の文書集合の取得に代えて、前記バースト期間抽出手段によって抽出された単語とそれぞれのバースト期間との組に基づいて、当該単語が当該バースト期間において出現する出現文書の文書集合を取得し、当該出現文書の出現頻度の有意性を表す値と、前記重み値とに基づいて話題度を算出し、当該話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出した各話題語について、バースト期間における出現日時の系列に基づいて新鮮度を算出し、
前記話題提示手段は、
前記提示した各話題語について、前記バースト期間抽出手段によって抽出したバースト期間に該当する箇所を強調表示することを特徴とする話題抽出装置。
【請求項5】
テキスト情報と日時情報を持つ複数の文書からなる対象文書集合を記憶する文書記憶手段を備えた話題抽出装置に用いられるプログラムであって、
前記話題抽出装置を、
話題抽出の対象とする対象期間の指定を受け付ける期間指定手段、
前記文書記憶手段に記憶された対象文書集合から、前記指定を受け付けた対象期間での話題を表す単語である話題語を抽出すると共に、各話題語について時事性を表す尺度である新鮮度を算出する話題抽出手段、
前記話題抽出手段によって抽出された話題語を前記新鮮度の順に提示すると共に、当該提示した各話題語について単位期間毎の出現文書数を提示する話題提示手段、
として機能させ、
前記話題抽出手段は、
前記文書記憶手段に記憶された対象文書集合から各単語を抽出し、当該各単語の出現頻度及び当該各単語が出現する文書数を示す文書頻度をそれぞれ算出する単語抽出手段と、
前記単語抽出手段によって抽出された各単語について、前記対象期間における当該単語が出現する出現文書の文書集合を取得し、当該出現文書の出現頻度の有意性を表す値と、前記単語の出現頻度及び前記文書頻度に基づく当該単語の重み値とに基づいて、話題語らしさを表す尺度である話題度を算出し、前記話題度が所定の値以上の単語を話題語として抽出すると共に、当該抽出された話題語について当該対象期間における出現日時に基づいて新鮮度を算出する話題語抽出手段と、
を含んでいるプログラム。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【図30】
【図31】
【図32】
【図33】
【図34】
【図35】
【図36】
【図37】
【図38】
【図39】
【図40】
【図41】
【図42】
【図43】
【図44】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図19】
【図20】
【図21】
【図22】
【図23】
【図24】
【図25】
【図26】
【図27】
【図28】
【図29】
【図30】
【図31】
【図32】
【図33】
【図34】
【図35】
【図36】
【図37】
【図38】
【図39】
【図40】
【図41】
【図42】
【図43】
【図44】
【公開番号】特開2012−190340(P2012−190340A)
【公開日】平成24年10月4日(2012.10.4)
【国際特許分類】
【出願番号】特願2011−54497(P2011−54497)
【出願日】平成23年3月11日(2011.3.11)
【出願人】(000003078)株式会社東芝 (54,554)
【出願人】(301063496)東芝ソリューション株式会社 (1,478)
【Fターム(参考)】
【公開日】平成24年10月4日(2012.10.4)
【国際特許分類】
【出願日】平成23年3月11日(2011.3.11)
【出願人】(000003078)株式会社東芝 (54,554)
【出願人】(301063496)東芝ソリューション株式会社 (1,478)
【Fターム(参考)】
[ Back to top ]