
識別器生成装置、方法及びプログラム、並びにクラス認識器、方法及びプログラム
【課題】高速に学習、認識することができる識別器生成装置、方法及びプログラム、並びにクラス認識器、方法及びプログラムを提供する。
【解決手段】識別器生成装置10は、入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとするラベリング部11と、教師データの特徴量を重みベクトルとして抽出する特徴量抽出部12と、自己増殖型ネットワークにより、特徴量抽出部12が抽出した特徴量を学習する特徴量学習部13と、各重みベクトルが有するポジティブ又はネガティブ情報に基づき、SVMにより当該ポジティブノードとネガティブノードの分離境界を学習する分離境界学習部15とを有する。特徴量学習部は、重みベクトルを入力ノードとし、入力ノードと各ノードとの間の距離に基づき、新たなノードを挿入するか否かを決定する。SVMは、線形とし、重みの推定に確率的勾配降下法を使用する。
【解決手段】識別器生成装置10は、入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとするラベリング部11と、教師データの特徴量を重みベクトルとして抽出する特徴量抽出部12と、自己増殖型ネットワークにより、特徴量抽出部12が抽出した特徴量を学習する特徴量学習部13と、各重みベクトルが有するポジティブ又はネガティブ情報に基づき、SVMにより当該ポジティブノードとネガティブノードの分離境界を学習する分離境界学習部15とを有する。特徴量学習部は、重みベクトルを入力ノードとし、入力ノードと各ノードとの間の距離に基づき、新たなノードを挿入するか否かを決定する。SVMは、線形とし、重みの推定に確率的勾配降下法を使用する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、識別対象であるクラスをその特徴である属性により認識することで転移学習を可能とする技術に関し、クラスを認識するための識別器生成装置、方法及びプログラム、並びに、それらを利用したクラス認識器、方法及びプログラムに関する。
【背景技術】
【0002】
対象認識や対象識別についての個々の研究が、ここ10年の間に大きな発達を遂げている。顔や車両のような特定の物体を検出するタスクについては、とても強力な検出器や認識器が利用可能である。このような検出器や認識器は、対象の特徴を示す低次元の特徴量(例えば、SIFT、SURFなど)と、サポートベクトルマシーン(SVM)などの現代的な機械学習メカニズムと、の組み合わせにより得ることができる。しかしながらこのような手法では、良好な精度を得るために人手によりラベル付けされた多数の教師データを通常必要とし、各個別のクラスを学習するためには一般的に数10万枚のサンプル画像を必要とする。
【0003】
また、多くの対象を認識する必要がある場合には他の問題が発生することがある。このような多くの対象を認識するという問題を解決するためには、これまでの手法では、各対象カテゴリーに対してそれぞれ新たな検出器を作った上で、それら検出器を学習する必要がある。しかしながら、新たな各検出器を効率的に学習する場合においても、上述したのと同様にして、人手によりラベル付けされた多数の教師データを必要とし、各個別のクラスを学習するために、一般的に数10万枚のサンプル画像を必要とする。
【0004】
コンピュータの見地から見れば、例えば何らかの効率的で自動的なラベリングツールが利用可能であれば、多数の学習データセットを用意することはそれほど大変なことではないと考えられるかもしれない。インターネットを介して多数の画像の集合へは簡単にアクセスすることができ、コンピュータハードウェアのパフォーマンスは近年では劇的に向上してきた。それにもかかわらず、ロボットのような知的エージェントの利用には、このようなことは当てはまらない。知的ロボットに対しては、ロボットはインターネットへのアクセスが限定されると共にハードウェア資源も限られており、また、実用的な実世界でのタスクがあまりにも一般的なものであるために、事前に学習された検出器のみを利用するものとしてはとてもこのタスクを解決することはできそうにない。従って最近では、多くの研究者達が、対象の属性(例えば非特許文献1に例示される。)や、対象の部分を考慮することによる対象認識についてより興味を持つようになってきた。
【0005】
複数の対象同士の間には、通常、何らかの共通属性が存在する(例えば、ライオン、タイガー、ドッグ、キャットなどでは、全て4本足の動物であるという共通の属性が存在する。)。非特許文献1において提案されているように、人間は、例から学習してそれを十分に抽象化することによって、少なくとも30000の関連のある対象クラスを区別することができる(人間は、高次元の特徴記述が与えられた時には、完全に未知の対象クラスであっても検出することができる。)。このことはつまり、1つの対象クラスにおいて発見された属性の知識が、同じ属性を含む他の異なる対象クラスへの利用のために転移されているものと考えられている。コンピュータビジョンにおける多くのこれまでの貴重な成果が、転移された属性を利用することで、未知の対象クラスの検出がまさに可能となることを既に示している(例えば、非特許文献1を参照されたい。)。
【先行技術文献】
【非特許文献】
【0006】
【非特許文献1】Lampert, C., Nickisch, H., Harmeling, S.: Learning to detect unseen object classes by between-class attribute transfer. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition, (2009)
【発明の概要】
【発明が解決しようとする課題】
【0007】
共通属性の学習の可能性とそれら属性を新規クラスの検出への利用に転移させることは、現在のロボティクスでは極めて有効である。簡単に説明するため、オフィス内での移動ロボットの利用を想定する。ロボットを他の部屋へと移動させて我々のために対象Bを取ってくるようにロボットに命令したい場合に、そのような対象Bの画像をロボットに提示するために我々が用意しているという状況は、とてもありえそうなことではない。対象の画像を必要とせずにロボットに命令を与える唯一の方法は、対象の属性を言葉で説明することである。これは、対象の1つのクラスからの属性をロボットに学習させ、さらに、その学習させた属性を転移させて未知クラスに属する新たな対象の認識へ利用させることで、解決されるべきである。
【0008】
しかしながら、属性の学習及び転移によって未知対象クラスの検出が可能となることがこれまでに示されたにも関わらず、これまでに提案された属性の転移及び学習手法をロボットでの利用に応用することについては以下に述べるような課題がある。
【0009】
まず、従来手法では、学習した属性は他の対象クラスでの利用に転移可能であるものの、各属性検出器を学習する事前の学習段階に関して、完全にバッチ処理となっている。従来手法では、任意の1つの属性の検出器を学習するために、巨大な教師画像データセットを必要とする。また、ロボットで利用するためには、システムは、教師画像を取得したときにはいつでもより柔軟に学習すべきであり、さらに、必要な場合にはいつでも識別すべきである。従って、完全に追加的な、属性の学習及び転移手法が必要である。
【0010】
ここで、非特許文献1に開示された従来手法を例に課題を説明する。非特許文献1に開示された従来手法では、個別の属性それぞれについての識別器を学習する必要がある。テスト段階では、各属性識別器が各属性についての確率を予測し、ベイズ理論に基づいて最終的な確率スコアが計算される。各属性識別器はSVMによって学習され、学習には数時間を必要とする。これを全ての属性(85個の属性)について行うと、あまりにも計算負荷が高くなり、ロボティクスや他のオンラインアプリケーションには事実上利用することができない。また、全ての属性に対してSVMを再度学習することは非現実的であることから、新たな入力教師データを追加的に学習することができない。
【0011】
そこで、本願出願人は、先に、このような問題点を解決するためになされたものであり、オンラインかつ追加学習が可能な属性の学習及び転移システム、及び、学習及び転移方法にかかる発明について出願している(特願2010−204650)。
【0012】
これに対し、本発明は、さらに認識率を向上した識別器生成装置、方法及びプログラム、並びにクラス認識器、方法及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0013】
本発明に係る識別器生成装置は、ある属性を有するか否かを識別する属性識別器を、教師データの特徴量を学習することにより生成する識別器生成装置であって、入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとするラベリング部と、前記教師データの特徴量を重みベクトルとして抽出する特徴量抽出部と、自己増殖型ネットワークにより、前記特徴量抽出部が抽出した特徴量を学習する特徴量学習部と、前記各重みベクトルが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)により当該ポジティブノードとネガティブノードの分離境界を学習する分離境界学習部とを有する。
【0014】
ここで、前記特徴量学習部は、前記特徴量抽出部にて抽出された重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノード及び2番目に近いノードをそれぞれ第1勝者ノード及び第2勝者ノードとして抽出する勝者ノード抽出部と、前記入力ノードと、前記第1及び第2勝者ノードとの距離に基づき、当該入力ノードを新たなノードとして挿入するか否かを判定するノード挿入判定部と、前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードと前記第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とし、エッジがある場合はその年齢を0とし、さらに前記第1勝者ノードが有する全エッジの年齢をインクリメントし、所定の年齢に達したエッジを削除するエッジ管理部と、前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードの重みベクトルを当該入力ノードの重みベクトルに基づき更新するノード重み更新部と、所定のタイミングで、そのノード密度に応じてノードを削除するノード削除部とを有するものである。
【0015】
本発明においては、属性を有するか否かがラベル付けされた教師データを使用し、自己増殖型ネットワークにより、その特徴量を学習すると共に、属性が有するか否かの分離境界をサポートベクタマシンにより学習する。これにより、処理時間を短縮しつつ、属性を有するか否かの境界を正確に学習することができ、認識率を向上することができる。
【0016】
また、前記教師データを前記特徴量学習部に入力する毎に、前記分離境界学習部により前記分離境界を生成又は更新するものとすることができ、これにより、完全オンラインの学習が可能となる。
【0017】
さらに、複数の前記教師データを前記特徴量学習部に入力して特徴量を学習した後、前記分離境界学習部により前記分離境界を生成又は更新することができ、非オンラインでの学習も可能となる。
【0018】
さらにまた、前記ノード削除部は、前記教師データを前記特徴量学習部に入力する毎に、全ノードの年齢をインクリメントし、全ノードのうち所定の年齢に達するノードについて、所定数未満のノードとエッジで接続されているノードを削除するようにすることができ、ノードの削除処理をより正確に行うことができる。
【0019】
また、前記SVMは、線形SVMであり、重みの推定に確率的勾配降下法(stochastic gradient descent (SGD))を使用したものとすることができ、完全オンラインの学習が可能となる。
【0020】
さらに、前記特徴量学習部における自己増殖型ネットワークは、Self-Organizing and Incremental Neural Networks(SOINN)とすることができ、ノイズにロバストかつ高速演算、完全オンライン学習が可能となる。
【0021】
本発明に係る識別器生成方法は、ある属性を有するか否かを識別する属性識別器を、教師データの特徴量を学習することにより生成する識別器生成方法であって、入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとするラベリング工程と、前記教師データの特徴量を重みベクトルとして抽出する特徴量抽出工程と、自己増殖型ネットワークにより、前記特徴量抽出工程にて抽出された特徴量を学習する特徴量学習工程と、前記各重みベクトルが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)により当該ポジティブノードとネガティブノードの分離境界を学習する分離境界生成工程とを有する。
【0022】
ここで、前記特徴量学習工程は、前記特徴量抽出工程にて抽出された重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノード及び2番目に近いノードをそれぞれ第1勝者ノード及び第2勝者ノードとして抽出する勝者ノード抽出工程と、前記入力ノードと、前記第1及び第2勝者ノードとの距離に基づき、当該入力ノードを新たなノードとして挿入するか否かを判定するノード挿入判定工程と、前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードと前記第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とし、エッジがある場合はその年齢を0とし、さらに前記第1勝者ノードが有する全エッジの年齢をインクリメントし、所定の年齢に達したエッジを削除するエッジ管理工程と、前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードの重みベクトルを当該入力ノードの重みベクトルに基づき更新するノード重み更新工程と、所定のタイミングで、そのノード密度に応じてノードを削除するノード削除工程とを有するものである。
【0023】
本発明に係るプログラムは、ある属性を有するか否かを識別する属性識別器を、教師データの特徴量を学習することにより生成する処理をコンピュータに実行させるためのプログラムであって、入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとするラベリング処理と、前記教師データの特徴量を重みベクトルとして抽出する特徴量抽出処理と、自己増殖型ネットワークにより、前記特徴量抽出処理にて抽出された特徴量を学習する特徴量学習処理と、前記各重みベクトルが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)により当該ポジティブノードとネガティブノードの分離境界を学習する分離境界生成処理とを実行するものである。
【0024】
前記特徴量学習処理では、前記特徴量抽出処理にて抽出された重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノード及び2番目に近いノードをそれぞれ第1勝者ノード及び第2勝者ノードとして抽出する勝者ノード抽出処理と、前記入力ノードと、前記第1及び第2勝者ノードとの距離に基づき、当該入力ノードを新たなノードとして挿入するか否かを判定するノード挿入判定処理と、前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードと前記第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とし、エッジがある場合はその年齢を0とし、さらに前記第1勝者ノードが有する全エッジの年齢をインクリメントし、所定の年齢に達したエッジを削除するエッジ管理処理と、前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードの重みベクトルを当該入力ノードの重みベクトルに基づき更新するノード重み更新処理と、所定のタイミングで、そのノード密度に応じてノードを削除するノード削除処理とが実行されるものである。
【0025】
本発明に係るクラス識別器は、入力データから特徴量を重みベクトルとして抽出する特徴量抽出部と、前記特徴量抽出部により抽出された重みベクトルから、当該入力データがいずれの属性を有しているかを判断する、複数の属性識別器からなる属性認識部と、属性認識部で識別された属性を属性ベクトルとして出力する属性出力部とを備える。
この属性識別器は、上述の識別器生成装置で学習され生成されたものであって、属性認識部は、前記入力データに含まれる認識対象であるクラスがいずれの属性を有するか判断するものであり、当該クラスを識別するために必要な数の属性に対応する前記属性識別器を備えるものである。
【0026】
本発明においては、上述の識別器生成装置により学習された属性識別器を複数備えることで、クラスを複数の属性としてとらえることができ、転移学習により、未知のクラスであっても、その属性を識別することができる。
【0027】
この場合、前記属性認識部は、前記入力データから抽出する特徴量の種類をN種類(Nは1以上の自然数)、クラスを識別するために必要な数の属性をM個(Mは1以上の自然数)とすると、N×Mの属性識別器を有するものとすることができる。ポジティブとネガティブで異なる属性識別器を使用するのに比して、演算量を低減することができる。
【0028】
クラスと属性の関係を有するクラス−属性辞書に基づき、前記属性出力部から出力された属性ベクトルに対するクラスを検出し、検出結果として出力するクラス認識結果出力部を更に有するものとすることができ、辞書データを具備すれば、学習していない未知のクラスであっても、認識することができる。
【0029】
本発明にかかるクラス識別方法は、入力データから特徴量を重みベクトルとして抽出する特徴量抽出工程と、前記特徴量抽出工程にて抽出された重みベクトルから、複数の属性識別器により、当該入力データがいずれの属性を有しているかを判断する属性認識工程と、属性認識工程にて識別された属性を属性ベクトルとして出力する属性出力工程とを備える。
前記属性識別器は、上述の識別器生成方法で学習され生成されたものであって、前記属性認識工程では、前記入力データに含まれる認識対象であるクラスがいずれの属性を有するか判断するものであり、当該クラスを識別するために必要な数の属性に対応する前記属性識別器を使用するものである。
【0030】
本発明にかかるプログラムは、入力データから特徴量を重みベクトルとして抽出する特徴量抽出処理と、前記特徴量抽出処理にて抽出された重みベクトルから、複数の属性識別器により、当該入力データがいずれの属性を有しているかを判断する属性認識処理と、属性認識処理にて識別された属性を属性ベクトルとして出力する属性出力処理とをコンピュータに実行させるためのプログラムである。
そして、前記属性識別器は、上述の識別器生成プログラムで学習され生成されたものであり、前記属性認識処理では、前記入力データに含まれる認識対象であるクラスがいずれの属性を有するか判断するものであり、当該クラスを識別するために必要な数の属性に対応する前記属性識別器を使用するものである。
【発明の効果】
【0031】
本発明によれば、高速に学習、認識することができる識別器生成装置、方法及びプログラム、並びにクラス認識器、方法及びプログラムを提供することができる。
【図面の簡単な説明】
【0032】
【図1】属性を使用した転移学習システムの概念を示す図である。
【図2】本発明の実施の形態1にかかる属性識別器生成装置を示す図である。
【図3】本発明の実施の形態1にかかる属性識別器の学習方法を示すフローチャートである。
【図4】本発明の実施の形態1にかかる属性識別器生成装置におけるAdjusted−SOINNの動作を示すフローチャートである。
【図5】本発明の実施の形態2にかかる属性識別器の学習方法を示すフローチャートである。
【図6】本発明の実施の形態2にかかる属性識別器の学習方法を説明する図である。
【図7】本発明の実施の形態2にかかる属性識別器の学習時、SOINNにデータを入力した場合に、そのデータを新たなノードとして挿入する場合を説明する図である。
【図8】本発明の実施の形態2にかかる属性識別器の学習時、SOINNにデータを入力した場合に、ノードを挿入せず、第1勝者の重みベクトルを更新する場合を説明する図である。
【図9】本発明の実施の形態3にかかるクラス識別システムを示す図である。
【図10】画像、属性及びクラスの関係を説明する図である。
【図11】本発明の実施の形態3にかかるクラス識別方法を示す図である。
【図12】本発明の実施の形態にかかる属性識別器生成装置やクラス識別システムを実施するコンピュータの一例を示す図である。
【図13】本発明の実施例及び比較例にかかる平均認識率を示す図である。
【図14】本発明の実施例及び比較例にかかる計算時間を示す。
【図15】参考例にかかる属性識別器生成装置を説明するための図である。
【発明を実施するための形態】
【0033】
以下、本発明を適用した具体的な実施の形態について、図面を参照しながら詳細に説明する。この実施の形態は、本発明を、識別対象であるクラスをその特徴である属性により認識する転移学習に使用する属性識別器を、教師データの特徴量を学習することにより生成する識別器生成装置に適用したものである。
【0034】
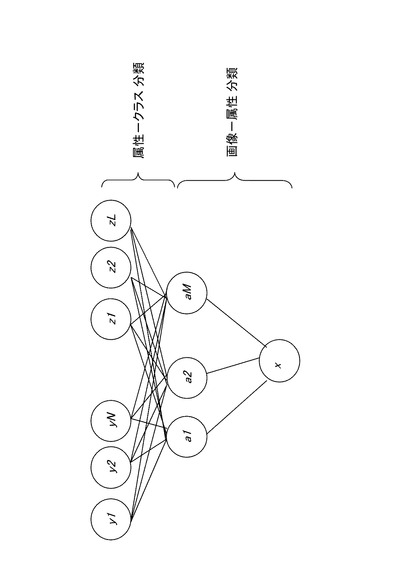
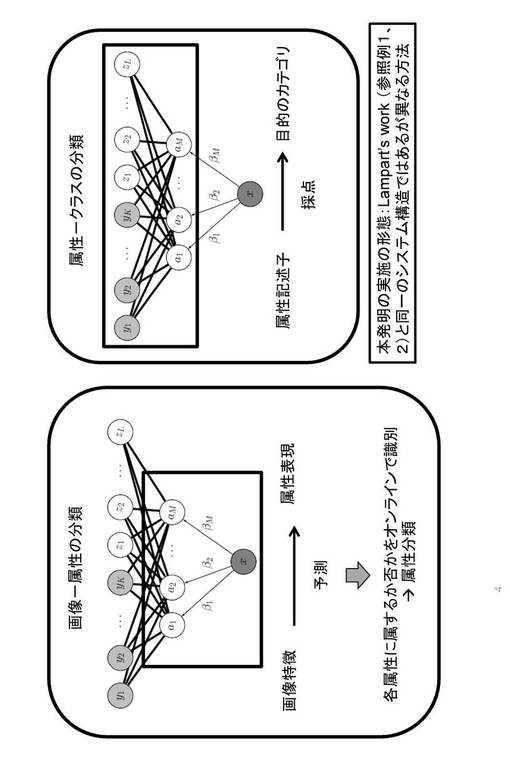
先ず、ここでは、本発明の理解を容易とするため、属性を使用した転移学習について説明する。図1は、システム構造の概念を示す図である。図1は、直接属性予測モデル(direct attribute prediction (DAP)model)を示している(非特許文献参照)。このモデルの役割は、画像の特徴量xから属性を検出することである。
【0035】
最下層にあるのが画像の特徴空間Xであり、中間層は、画像の属性ベクトルa1〜aMを示している。最上層のY(y1〜yN)は、個別のクラスラベルを示し、クラスレベルZ(z1〜zL)は、クラスレベルYと異なるクラスレベルを示す。本実施の形態においては、Yが学習クラスであり、Zが認識テストに使用する未知のクラスを示す。
【0036】
転移学習では、学習クラスYが有する属性ベクトルay∈Aを学習する。本実施の形態においては、属性ベクトルay=(ay1,...,ayM)であり、各要素は、aym∈{1,0}で示される。すなわち、各属性ベクトルの1つの要素(1つの属性)は、それを有している(ポジティブ、aym=1)か、有していない(ポジティブ、aym=0)のいずれかで表現される。各属性ベクトルの各要素毎に、学習クラスYが示されている画像の特徴量Xを学習することで、属性ベクトルaに対応する特徴量(重みベクトル)Xを学習する。すなわち、クラスYの特徴量を学習するのではなく、属性ベクトルaの各要素(1つの属性)に対応する特徴量Xを学習し、どの属性ベクトルaを有するものがどのクラスYであるかを学習する。
【0037】
これにより、新しい未知のクラスZの画像が入力された場合、その特徴量からクラスZの属性を認識することができる。すなわち、クラスZの名前は不明であっても、どのような属性を有するものであるかは認識することができる。識別器は、未知のクラスZが入力された場合に、どのような属性を有するものであるかを出力することもできるし、属性とクラスの関係を示す辞書データを備え、この辞書データを参照することで、未知のクラス名を答えることも可能とする。
【0038】
このように転移学習とは、識別対象であるクラスの特徴を学習するのではなく、クラスの属性を学習することで、未知のクラスの検出を可能とするものである。なお、以下の実施の形態においては、入力データは、クラスが表示された画像のデータとして説明するが、入力データは、画像に限らず、音声その他のデータであってもよい。
【0039】
ここで、本実施の形態においては、ある属性を具備するか否かを示す2値SVMを属性識別器として使用する。その重みの推定に確率的勾配降下法(stochastic gradient descent (SGD))を使用(以下、SGD−SVMともいう。)する。
【0040】
しかしながら、重みパラメータを、SGDを使用して更新すると、1サンプルが考慮されるため、ノイズに影響されやすい。これを解決するために、本発明においては、入力画像の特徴を直接使用する代わりに、SVMの入力データとして、後述するSOINN(Self-Organizing and Incremental Neural Networks)ノードを使用する。SOINNによってノイズを抑制することができ、ノイズ除去ステップも有するのでノイズが入力されるためにSGDの重み更新に発生するエラーを低減することができる。
【0041】
<1>本発明の実施の形態1.
<1−1>属性識別器生成装置の構成
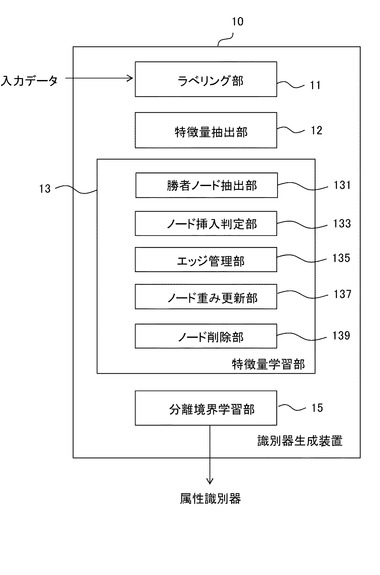
次に、本発明の実施の形態1について説明する。図2は、本実施の形態にかかる属性識別器生成装置を示す図である。図2に示すように、属性識別器生成装置10は、ラベリング部11、特徴量抽出部12、特徴量学習部13及び分離境界学習部15を有する。ここで特徴量学習部13は、後述する自己増殖型ネットワークSOINNで構成され、特徴量抽出部12により抽出された属性の特徴量が学習される。分離境界学習部15は、SVMにより分離境界を学習する。ラベリング部11は、入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとする。なお、予めラベリングしたデータを特徴量抽出部12に入力するようにしてもよい。また、特徴量を抽出した後で、ラベリングして教師データとしてもよい。
【0042】
特徴量抽出部12は、教師データから特徴量を重みベクトルとして抽出する。例えば教師データ及び入力データが画像データである場合には、SIFT、SURFなどの特徴量を抽出する。なお、SIFT、SURF以外にも、rg−SIFT特徴量、PHOG特徴量、cq特徴量、Lss−histogram特徴量など公知の特徴量のうちいずれか1つを抽出してもよいし、複数の種類の特徴量を抽出するものとしてもよい。また、教師データ及び入力データは画像データに限定されず、音声データなどであってもよい。特徴量抽出部12で抽出された重みベクトルは、ラベルと共に、入力ノードとして特徴量学習部13に入力される。分離境界学習部15は、特徴量学習部13において学習された各ノードが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)によりポジティブノードとネガティブノードの分離境界を学習する。
【0043】
ここで、本実施の形態にかかる属性識別器生成装置10では、1つの属性について、それを備えているか(ポジティブ)、備えていないか(ネガティブ)を識別する属性識別器を学習して生成する。つまり、あるクラス(例えば動物)を表現する属性が例えばM個(Mは1以上の自然数)ある場合、M個の属性識別器が学習されることになる。さらに、入力画像からN種類(Nは1以上の自然数)の特徴量を抽出する場合は、各特徴量について各属性を学習するため、N×M個の属性識別器にて、各特徴ごと、各属性毎に、その特徴量が学習される。
【0044】
ここで、特徴量学習部13は、勝者ノード抽出部131、ノード挿入部133、エッジ管理部135、ノード重み更新部137及びノード削除部139を有する。
【0045】
勝者ノード抽出部131は、特徴量抽出部12にて抽出された重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノードを第1勝者ノードとして抽出し、2番目に近いノードを第2勝者ノードとして抽出する。
【0046】
ノード挿入部133は、入力ノードと第1勝者ノードとの間の距離、及び入力ノードと第2勝者ノードとの間の距離に基づき、その入力ノードを新たなノードとして挿入するか否かを判定する。
【0047】
エッジ管理部135は、入力ノードを新たなノードとして挿入しない場合、第1勝者ノードと第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とする。エッジがある場合はその年齢を0とし、さらに第1勝者ノードに接続されている全てのエッジの年齢をインクリメントし、さらに、所定の年齢に達したエッジを削除する。
【0048】
ノード重み更新部137は、入力ノードを新たなノードとして挿入しない場合、第1勝者ノードの重みベクトルを入力ノードの重みベクトルに基づき更新する。なお、第2勝者ノードの重みベクトルも更新するようにしてもよい。
【0049】
ノード削除部139は、所定のタイミングで、そのノード密度に応じてノードを削除する。例えば、入力データ数が100の倍数となるタイミングでノードを削除することができる。又は、ノードのエッジの年齢をカウントし、年齢が100の倍数となるタイミングで、各ノード個別にノードの削除を行ってもよい。
【0050】
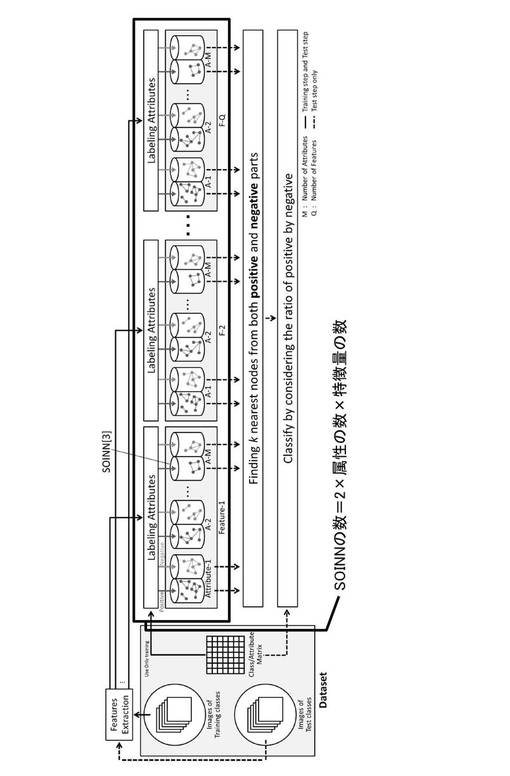
本実施の形態においては、教師画像をSOINNに全て入力し、特徴量を学習した後で、SGD−SVMにより、ポジティブとネガティブの分離境界を学習する。1つのSOINNにより、入力データがある属性を有している(ポジティブ)又は有していない(ネガティブ)を識別することができるので、ポジティブと、ネガティブと別々のSOINNを要していた先願(特願2010−204650、参考例という。)に対し、SOINNの数を2分の1にすることができる。
【0051】
すなわち、本実施の形態においては、教師画像から抽出する特徴量の数=N種類(Nは1以上の自然数)とし、認識対象のクラスを識別するのに必要な属性をM個(Mは1以上の自然数)とすると、N×M個のSOINNにより、各属性(ポジティブ、ネガティブ)に対応する特徴量が学習されることになる。
【0052】
図15は、参考例にかかる属性識別器生成装置を説明するための図である。図15に示すように、教師画像(training data)から特徴量を抽出するまでは本実施の形態と同様である。ただし、本実施の形態のように、SGD−SVMを使用してポジティブとネガティブの境界を学習するのではなく、SOINNに入力するが、各属性について、ポジティブとネガティブで別個のSOINNを用意して学習する。よって、SOINNの個数は、2×属性の数×特徴量の数となる。
【0053】
本実施の形態においては、ネガティブノードとポジティブノードとで同一のSOINNを使用するため、実施が容易となる。先願の方法であると、ネットワークにあるノードに対する最近傍法で識別を行う。この場合、空間上に近傍ノードがなければ、距離のみの識別となるため、識別結果が学習データに大きく依存してしまう。これに対して、実施の形態にかかる属性識別器生成装置10により生成された属性識別器を使用して、入力データがいずれの属性にぞくするかを識別する場合、SGD−SVMにより学習し分離境界で識別を行う。分離境界も学習データに依存するが、学習データがない空間であっても、学習データに基づいた適切な識別が可能となり、先願と比べると識別力を向上することができる。
【0054】
なお、本実施の形態においては、属性識別器生成装置10が、ラベリング部11及び特徴量抽出部12を有するものとして説明したが、入力画像から特徴量を抽出し、これにラベリングした教師データを予め用意し、特徴量学習部13に入力するようにしてもよい。この場合は、ラベリング部11及び特徴量抽出部12は、不要である。すなわち、属性識別器生成装置10に入力するまえに特徴量を抽出してもよく、又はラベリングして教師データとしてもよい。
【0055】
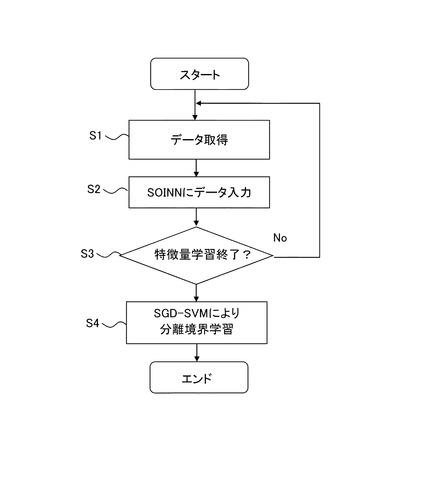
図3は、本実施の形態にかかる属性識別器の学習方法を示すフローチャートである。先ず、教師画像からSOINNの入力データとして特徴量を取得する(ステップS1)。すなわち、この場合、特徴量として、SIFT特徴量、SURF特徴量、rg−SIFT特徴量、PHOG特徴量、cq特徴量、Lss−histogram特徴量など公知の特徴量のうち、いずれか1つを抽出するものとしてもよいし、複数の種類の特徴量を抽出するものとしてもよい。属性の数=m{1〜M}とするとき、m番目のSOINNには、{xi,aym}が入力される。ここで、xiはクラスyの特徴量、aymは、m番目の属性の2値の値(1又は0)を示す。
【0056】
すなわち、教師画像がいずれの属性を有するかがラベリングされており、抽出された特徴量にも、いずれの属性を有するか否かがラベリングされている。次に、取得したデータ{xi,aym}をSOINNに入力する(ステップS2)。上述したように、SOINNは、各属性毎に設けられる。例えばあるクラス(例えば、動物)を認識するための属性が85個ある場合、85個の属性に対応したSOINNで学習が行われる。教師画像は、各85個の属性それぞれについて、当該属性を有する、有しない、の情報がラベルづけされており、このラベル付けされた情報に基づき、各属性毎に、それを有する場合、有しない場合の特徴量が学習されていく
【0057】
そして、特徴量の学習が終了するまで、このステップS1、S2を繰り返す(ステップS3:No)。そして、特徴量の学習が終了したら、SDG−SVMにより、ネガティブノードとポジティブノードの分離境界を学習する(ステップS4)。以上により、ある属性を有するか(ポジティブ)、有しないか(ネガティブ)を識別することができる属性識別器を、教師画像を使用して学習により、生成することができる。
【0058】
なお、本実施の形態においては、SOINNに教師画像の特徴量全部を入力し、特徴量の学習が終了した後、分離境界を学習するものとして説明したが、所定の枚数、例えば100枚毎に、教師画像の特徴量の学習が終了したら、分離境界を学習する、等のようにしてもよい。
【0059】
<1−2>確率的勾配降下法(stochastic gradient descent:SGD)−SVM(Support Vector Machine)
次に、SGD−SVMについて説明する。入力データ(入力ベクトル)をx、出力データ(出力ベクトル)をyとしたとき、推定関数f:x→yを、入力ベクトルxに基づき、出力ベクトルyを推定するものと定義する。損失関数l(f(x),y)は、推定関数の出力と、実際の値との間のエラーを示すものと定義される。ここで、期待リスクE(f)を最小とする関数fを推定することを目的とし、期待リスクE(f)は、下記数式(1)により求めることができる。
【0060】
【数1】

ここで、nは学習サンプル、zi=(xi,yi)で、i=1,2,...,nを示すものとする。そして、経験的リスクを最小化する関数fを下記数式(2)により求める。
【0061】
【数2】
により、線形にパラメータ化される。基準勾配降下法は、重みベクトルwの勾配の傾きを使用して経験的リスクを最小化するために提案された。この傾きを計算し、最適化パラメータwを更新するために、1つの完全な学習セットにより学習する必要がある。さらに、大域的最適を得るためには、多くの繰り返しが必要である。ここで、確率的勾配降下法は、各繰り返しでサンプルziを抽出し、下記数式(3)の時間依存因子を使用して重みベクトルwを繰り返し更新することで、経験的リスクを最小化する。
【0062】
【数3】
2元線形SVM問題のため、下記をトレーニングセットとし、
【0063】
【数4】
学習過程の目的は、下記数式(4)の目的関数を最小化するものとなる。
【0064】
【数5】
【0065】
ここで、ハイパーパラメータλ>0が正規化項の強さを制御し、bがオリジナルSVM問題におけるバイアス項を示す。損失l(f(xi),yi)は、凸関数であり、連続的な導関数の2階微分を示す。上記数式(3)、(5)及び(6)から、下記数式(7)により線形SVMの重みを推定するために、SGDを使用することができる。
【0066】
【数6】
【0067】
<1−3>Adjusted−SOINN
次に、本実施の形態において用いる自己増殖型ニューラルネットワークについて簡単に説明する。自己増殖型ニューラルネットワークとして、例えば、Adjusted−SOINN(Self-Organizing Incremental Neural Network)が提案されている。Adjusted−SOINNは、自己組織化かつ追加学習可能なニューラルネットワークであり、オンラインの教師無し識別学習のためのメカニズムである(特開2008−217242号公報、非特許文献「F. Shen & O. Hasegawa, "An incremental network for on-line unsupervised classification and topology learning, " Neural Networks, 19(1):90-106, 2006.」、及び非特許文献「F. Shen & O. Hasegawa, "An on-line learning mechanism for unsupervised classification and topology representation," in CVPR, 2005.」参照)。
【0068】
本実施の形態においては、教師あり学習であるが、入力画像の特徴量の学習に、Adjusted−SOINNを利用するものとする。
【0069】
Adjusted−SOINNは、重みベクトルとして表わされるノードが、自律的に増殖及び消滅することを特徴とする。ノード同士は、所定の条件を満たす場合に、エッジと呼ばれる仮想的な線で結合される。Adjusted−SOINNは、このエッジをたどって互いに到達できるノード同士を同じクラスタとみなすことにより、クラスタリングを行う。また、エッジは年齢と呼ばれるパラメータを持っており、Adjusted−SOINNは、所定の年齢に達したエッジを削除する。これにより、ノイズとみなし得るノードを所定のタイミングで削除可能としている。
【0070】
図4を用いて、Adjusted−SOINNの学習アルゴリズム、すなわちAdjusted−SOINNに新たなノードが入力された場合のAdjusted−SOINNの動作について説明する。
【0071】
S301:重みベクトルを持つ入力ノードが、Adjusted−SOINN(属性識別器生成装置10)に新たに入力される。この重みベクトルは、特徴量抽出部12にて抽出された特徴量である。
【0072】
S302:Adjusted−SOINN、本実施の形態においては、勝者ノード抽出部131は、入力ノードと既存のノードとの間の距離、典型的にはユークリッド距離を計算する。ユークリッド距離とは、下記数式(8)により定義される距離をいう。下記数式(8)において、dはユークリッド距離、f及びgはそれぞれn次元のベクトルを示す。
【0073】
【数7】
【0074】
勝者ノード抽出部131は、この計算結果より、このユークリッド距離が最も近いノード(第1勝者ノード)と2番目に近いノード(第2勝者ノード)とを決定する。
【0075】
S303:次に、ノード挿入部133は、この第1勝者ノード及び第2勝者ノードが有する類似度閾値をそれぞれ計算する。ここで、類似度閾値とは、あるノードが隣接ノード(エッジで接続されたノード)を持つ場合、その隣接ノードとの最大距離をいう。あるノードが隣接ノードを持たない場合は、そのノードとそれ以外のノードとの最小距離をいう。類似度閾値は、下記数式(9)により求められる。下記数式(9)において、Nはノードiの隣接ノードの集合、Wはノードiの重みベクトル、Aはノード全体の集合を示す。
【0076】
【数8】
【0077】
ノード挿入部133は、これらの類似度閾値と、上述の入力ノードと第1勝者ノード及び第2勝者ノードとのユークリッド距離とを相互に比較する。比較の結果、入力ノードと第1勝者ノード及び第2勝者ノードとのユークリッド距離が、第1勝者ノード又は第2勝者ノードの類似度閾値よりも大きい場合、入力ノードは、第1勝者ノード及び第2勝者ノードとは異なるクラスタに属するとみなされる。この場合、Adjusted−SOINNは、入力ノードの位置に新たなノードを挿入すべきと判定する。一方、入力ノードと第1勝者ノード及び第2勝者ノードとのユークリッド距離が、第1勝者ノード及び第2勝者ノードの類似度閾値よりも小さい場合、入力ノード、第1勝者及び第2勝者はいずれも同一のクラスタに属するとみなされる。この場合、ノード挿入部133は、新たなノードを挿入すべきでないと判定する。
【0078】
S304:S303において、新たなノードを挿入すべきと判定された場合、勝者ノード抽出部131は、入力ノードの位置に新たなノードを挿入する。
【0079】
S305:S303において、新たなノードを挿入すべきでないと判定された場合、xエッジ管理部135は、第1勝者ノードと第2勝者ノードとの間にエッジが存在するか否かを判定する。
【0080】
S306:S305において、第1勝者ノードと第2勝者ノードの間にエッジが存在しないと判定された場合、エッジ管理部135は、それらの間にエッジを生成する。このような処理が、K−Meanのような他のクラスタリング手法とAdjusted−SOINNとで著しく異なる点である。Adjusted−SOINNでは、その新たに入力されたノードは、クラスタを形成するためにネットワークに単純には追加されない。その代わりに、Adjusted−SOINNにおいて存在するノードをエッジにより接続していくことでクラスタが形成される。Adjusted−SOINNにおける現在のノードと入力パターンとが著しく異なる場合においてのみ、新たなノードを生成することから、このようなクラスタ形成処理によれば、長期間における実行に対してメモリの節約に大きな貢献をもたらす。
【0081】
S307:エッジ管理部135は、S305においてエッジが存在しないと判定した場合、S305において生成したエッジの年齢を0とする。一方、S305においてエッジが存在すると判定した場合、既に存在していたエッジの年齢を0とする。加えて、エッジ管理部135は、第1勝者ノードに接続されている全てのエッジの年齢をインクリメントする。
【0082】
S308:次に、エッジ管理部135は、あらかじめ定められた閾値(age)を超えた年齢を有するエッジを削除する。ageは、ノイズ等の影響により誤って生成されるエッジを削除するために設定されるパラメータである。ageに小さな値を設定すれば、エッジは削除されやすくなり、ノイズの影響は防ぎやすくなるが、ageが極端に小さければ、エッジが頻繁に削除されるようになり、学習結果が不安定になる。一方、ageが大きすぎれば、ノイズの影響で生成されたエッジを適切に取り除くことができない。したがって、ageには、実験等により算出された適切な値を設定することが好ましい。
【0083】
S309:次に、ノード重み更新部137は、第1勝者ノード及び第1勝者ノードとエッジを介して直接接続されている隣接ノードの重みベクトルを、以下の数式(10)、数式(11)により更新する。数式(10)、数式(11)において、ΔWiはノードiの重みベクトルの更新量、ΔWjはノードjの重みベクトルの更新量を示す。また、iは第1勝者ノード、jは隣接ノード、Wkは入力ノードの重みベクトル、Miはノードiがこれまで第1勝者ノードになった回数を示す。これにより、入力ノードを新たなノードとして挿入しない場合には、入力ノードは、第1勝者ノード及び隣接ノードにいわば吸収される形となる。なお、本実施の形態においては、第1勝者ノード及びその隣接ノードの重みを更新するものとして説明するが、第1勝者ノードのみ、又は第1勝者ノードに加えて第2勝者ノードの重みを更新するようにしてもよい。
【0084】
【数9】
【0085】
【数10】
【0086】
S310:次に、ノード削除部139は、以下の2つの条件を満たすノードを、すべてのノードの中から抽出し、削除対象と判定する。
【0087】
1つ目の条件は、入力されたノードの数が、あらかじめ定められた設定値、例えば定数λの倍数にあたるか否かを判定する。この設定値は、ノイズとみなし得るノードを定期的に削除するために設定されるパラメータである。λに小さな値を設定すれば、頻繁にノイズ処理を実施することができるが、λが極端に小さければ、実際にはノイズでないノードまで誤って削除してしまう。一方、λが大きすぎれば、ノイズの影響で生成されたノードを適切に取り除くことができない。それで、λには、実験により算出された適切な値を設定することが好ましい。
【0088】
2つ目の条件は、ノードの隣接ノード数があらかじめ定められた閾値η以下であることである。閾値ηは、ノード群のうち低密度の領域、すなわちノイズとみなし得るノードを定義するためのパラメータである。
【0089】
S311:ノード削除部139は、ステップS310において削除対象として抽出されたノードを削除する。
【0090】
S312:入力されたノードの数が、あらかじめ定められた定数ρに達したならば、Adjusted−SOINNは学習を完了する。未だ達していない場合は、次の入力ノードの入力を受付け、上述した手順により学習を継続する。
【0091】
なお、図4に示す例では、入力されたノード数がλの倍数のタイミングで、ノードを削除するか否かを判定するものとして説明したが、各ノード毎に年齢をカウントし、所定の年齢、例えば年齢がλに到達したノード(入力された後に、新たな入力がλ回されたノード)について、削除するか否かの判定を行ってもよい。入力されたノード数が所定の数に達したタイミングで削除処理を行うと、最初の頃に入力されたノードと、最後の方に入力されたノードとの間で不平等の判断がなされる場合がるが、ノードの年齢をカウントすることで、いずれのノードも同様な条件で削除判定することができる。
【0092】
さらに、自己増殖型ニューラルネットワークはAdjusted−SOINNに限定されず、Enhanced−SOINN(特開2008−217246)などを利用するものとしてもよい。また、オンラインかつ追加学習可能という観点からは、事前にネットワークの構成やサイズを決定する必要があるためにその性能に制限が加えられるものの、自己増殖型ニューラルネットワークとして、ニューラルガス(NG)(T. M. Martinetz, and S. G. Berkovich, and K. J. Schulten, "Neural-gas," network for vector quantization and its application to time-series prediction, " IEEE Trans. On Neural Networks, vol. 4, no. 4, pp. 558-569, 1996.)やGrowing neural gas(GAG)(B. Fritzke, "A Growing Neural Gas Network Learns Topologies, " In Advances in Neural Information Processing System, vol. 7, pp. 625-632, 1995.)を用いることもできる。
【0093】
<2>本発明の実施の形態2.
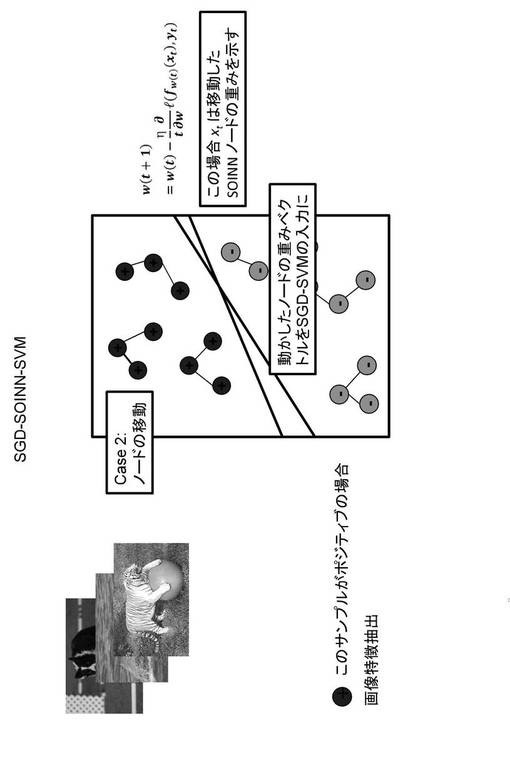
次に、本発明の実施の形態2にかかる属性識別器生成装置について説明する。上述の実施の形態1は、完全なオンライン学習が不可能であったのに対し、本実施の形態にかかる属性識別器生成装置は、完全なオンライン学習が可能となる。
【0094】
属性識別器生成装置の構成は、図2に示す属性識別器生成装置10と同様である。ただし、実施の形態1にかかる属性識別器生成装置10は、ある所定数の教師画像を入力し、その特徴量を学習した後で、分離境界学習部15により、分離境界を学習していたのに対し、本実施の形態にかかる属性識別器生成装置は、教師画像を入力する毎に、特徴量学習部13で特徴を学習すると共に分離境界学習部15により分離境界を学習する。これにより、完全オンラインの学習が可能となる。
【0095】
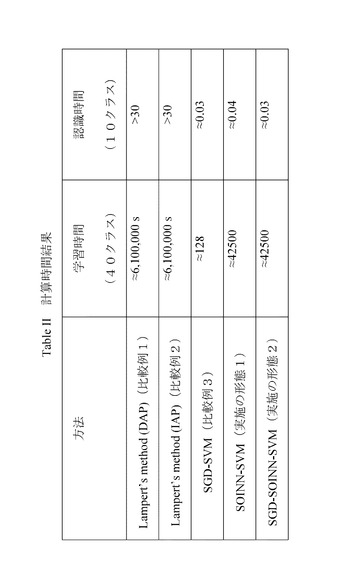
図5は、本実施の形態にかかる属性識別器の学習方法を示すフローチャートである。また、図6は、本実施の形態にかかる属性識別器の学習方法を説明する図である。図7及び図8は、SOINNにデータを入力した場合に、そのデータを新たなノードとして挿入する場合及びノードを挿入せず、第1勝者の重みベクトルを更新する場合の学習方法を説明する図である。
【0096】
図5に示すように、先ず、SOINNに入力するデータ{xi,aym}を取得する(ステップS11)(図6の1参照)。1つの属性(ポジティブ、ネガティブ)につき、1つのSOINNが対応する点、SOINNに入力する特徴量ベクトルとして、SIFT特徴量、SURF特徴量、rg−SIFT特徴量、PHOG特徴量、cq特徴量、Lss−histogram特徴量等を使用することができる点などは、実施の形態1と同様である。特徴量抽出部12は、教師画像から特徴量を抽出する。
【0097】
次に、SOINNにデータ{xi,aym}を入力する(ステップS12)(図6の2参照)。このとき、aym=1のときは、ポジティブサンプル(その属性を有する)として、aym=0のときは、ネガティブサンプル(その属性を有しない)として、SOINNに入力する。なお、図2に示す例では、教師画像がラベリング部11に入力され、ラベリング部11により、ラベル{aym}が付され、特徴量抽出部12により、特徴量{xi}が抽出されるものとしているが、特徴量抽出部12を抽出した後、ラベル付けして、SOINNに入力するようにしてもよい。
【0098】
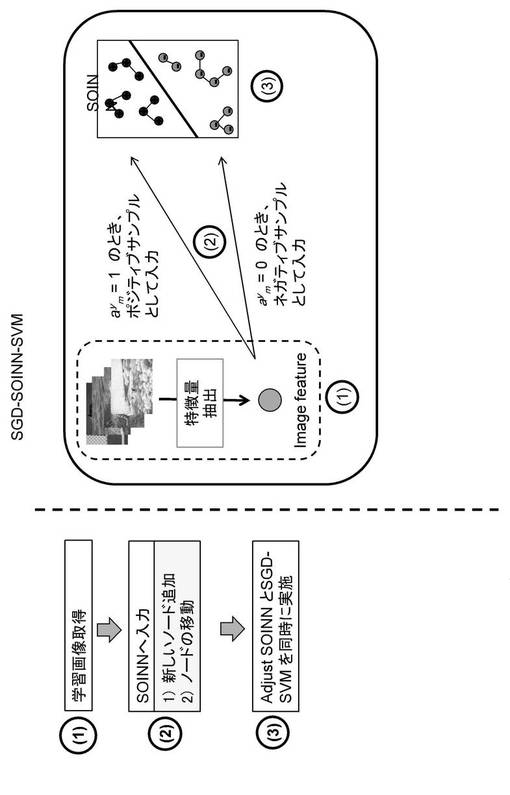
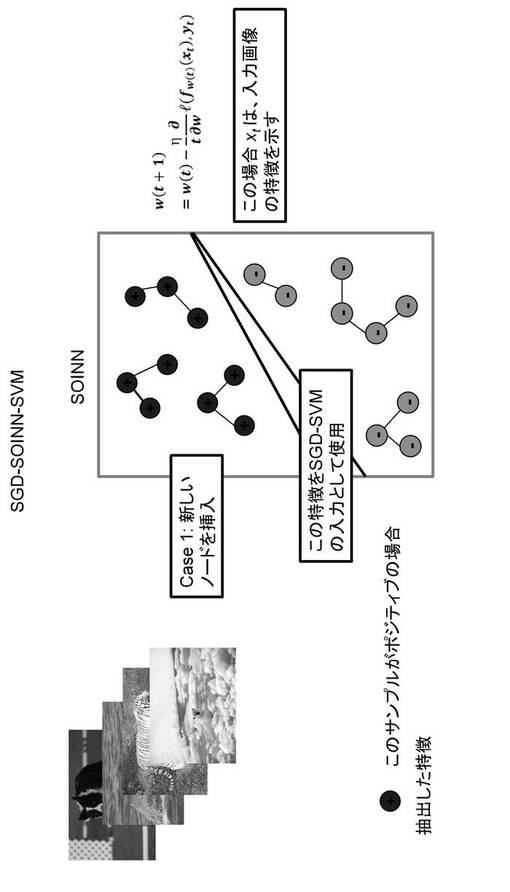
SOINNに入力されたデータは、勝者ノード抽出部131により、第1勝者ノード、第2勝者ノードが抽出され、ノード挿入部133により、新たにノードを挿入するか否かが判定される。次に、新たにノードが追加される場合(図6の2−1)、図7)と、ノードを追加しない場合(図6の2−2)、図8)について説明する。
【0099】
SOINNに教師データを入力したら、同時にSGD−SVMにより、分離境界を学習する(ステップS13)。図7に示すように、新しいノードを追加する場合は、この特徴(入力ノードの重みベクトル)をSGD−SVMの入力(重みベクトルSk_new,aym)とする。
【0100】
一方、新たに入力ノードを挿入しない場合、図8に示すように、ノード重み更新部137により、上述した数式(10)、数式(11)に従ってノード重みが更新される。この場合、更新したノード重みベクトルをSGD−SVMの入力(Sk_move,aym)として入力する。いずれも、上述の数式(7)に従って、分離境界を更新する。
【0101】
以上のようにして、教師画像からSOINNの入力データを生成し、SOINNに入力し、SGD−SVMによりポジティブノードとネガティブノードの分離境界を学習していき、所定の数のサンプルで学習をしたら、終了する(ステップS14)。
【0102】
本実施の形態においては、教師画像(ラベル付きデータ)からその特徴量を学習し、各属性についてポジティブノードとネガティブノードを同一のSOINNに入力して、その分離境界を学習するようにしたので、完全なオンライでの学習が可能となる。すなわち、当該属性識別器生成装置10を例えばロボットに搭載し、ある程度学習が終了したら、対象物体を認識しつつ、学習することも可能となる。また、教師画像から抽出する特徴量の数×対象物体を認識するための属性の数のSOINNで学習を行うことで、転移学習が可能な認識装置を構成することができる。
【0103】
<3>本発明の実施の形態3.
次に、本発明の実施の形態3にかかるクラス識別システムについて説明する。本実施の形態にかかるクラス識別システムは、上述の実施の形態1又は2により学習された属性識別器を使用して、未知のクラスを識別するシステムである。
【0104】
図9は、本実施の形態にかかるクラス識別システムを示す図である。図9に示すように、クラス識別システム200は、データセット220、特徴量抽出部212、ラベリング部211、属性認識部210、属性出力部217及びクラス認識結果出力部219を有する。
【0105】
特徴量抽出部212は、入力データから特徴量を重みベクトルとして抽出する。特徴量抽出部212の入力データは、属性識別器の学習フェーズでは教師データであり、認識フェーズでは、未知クラスの認識対象データである。特徴量抽出部212は、特徴量としては、上述したように、SIFT特徴量、SURF特徴量、rg−SIFT特徴量、PHOG特徴量、cq特徴量、Lss−histogram特徴量等(特徴量F1,F2,・・・,Fk)を抽出する。
【0106】
属性認識部210は、上述の属性識別器生成装置10により生成された複数の属性識別器201(2011〜201M)を有している。属性識別器201は、特徴量抽出部212により抽出された重みベクトル(F1〜Fk)毎に、属性の数M個分設けられており、当該入力データが各属性を有しているか否かを判断する。すなわち、属性認識部210は、認識対象データに含まれるクラスがいずれの属性を有するか判断することができ、クラスを識別するために必要な数(特徴数×属性数)の属性識別器201を備える。
【0107】
属性出力部217は、属性認識部210で識別された属性を属性ベクトルとして出力する。
【0108】
クラス認識結果出力部219は、クラスと属性の関係を有するクラス−属性辞書データ221に基づき、属性出力部217から出力された属性ベクトルに対するクラスを検出し、検出結果として出力する。
【0109】
ここで、本実施の形態にかかるクラス識別システム200は、ラベリング部211を有しており、教師データを入力する場合は、特徴量抽出部212で抽出された特徴量に、属性のラベルを付すことができ、このラベル付き特徴量を使用して属性識別器を学習することができる。
【0110】
すなわち、属性認識部210は、例えば上述の実施の形態2に示す、Adjusted−SOINNからなる特徴量学習部13及び重みの推定に確率的勾配降下法(SGD)を使用したSVMからなる分離境界学習部15を有するものとすることができる。これにより、データセット220として、教師データを与えれば、属性識別器を学習することができる。
【0111】
なお、クラス識別器としては、ラベリング部211を備える必要はなく、属性認識部210は、学習終了後の学習結果を属性識別器として具備すればよい。クラス識別システム200は、通信部を備えたパーソナルコンピュータ(PC)等と同様の構成とすることができ、通信部を介して必要な属性識別器を取得するようにしてもよい。
【0112】
また、辞書データ221を有して、属性識別結果をクラスに変換して出力するようにしたが、与えられる未知クラスのデータの識別結果として、属性ベクトルを出力するようにしてもよい。例えば、本クラス識別システム200をスピーカを具備したロボット等に搭載した場合、入力データの識別結果として、属性ベクトルに基づき、入力データの特徴、例えばライオンのように足が4本で肉食の動物である、○○と同様に熱帯地域に生息している、等の情報を出力させることができる。
【0113】
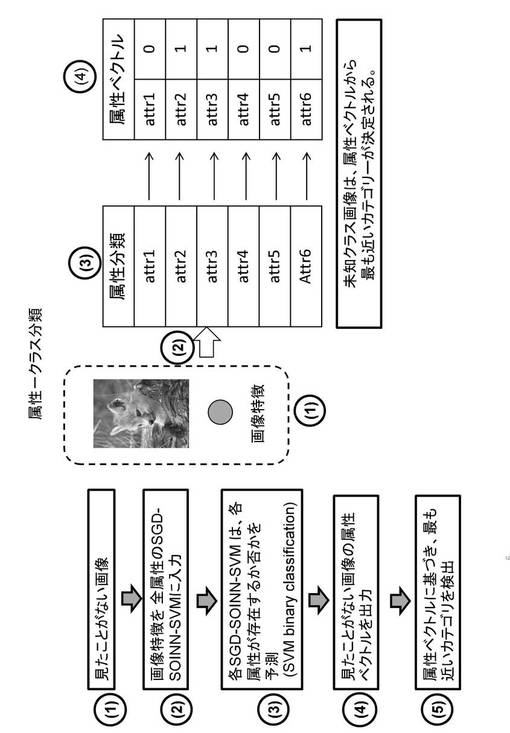
次に、本実施の形態にかかるクラス識別方法について説明する。図10は、画像、属性及びクラスの関係を説明する図、図11は、クラス識別方法を示す図である。図10に示すように、画像の特徴Xから、この画像がいずれの属性を有するか否かを検出することができる。先ず、図11の(1)に示すように、未知クラスの画像がクラス識別システム200に入力される。入力画像は、特徴量抽出部212により、特徴量を抽出する。これを属性認識部210に入力し(図11の(2))、それぞれの属性が存在する(ポジティブ)、
又は存在しない(ネガティブ)を判定する(図11の(3))。例えば、ここでは、属性attr1〜attr6の6つの属性について、その有無が検出される。
【0114】
つまり、特徴量を重みベクトルとして、学習済みのSOINNに入力した場合に、図7、図8に示すような分離境界のポジティブ側に入力ノードが位置すれば、当該属性についてはポジティブである。一方、分離境界のネガティブ側に入力ノードが位置すれば、当該属性はネガティブである。
【0115】
そうして、判定された結果は、属性出力部217から属性ベクトル(属性記述子)として出力される(図11の(4))。
【0116】
図10に示すように、学習クラスYの属性aを学習することで、未知クラスZを属性で認識することができる。例えば、未知クラスの画像の属性を出力するだけでなく、所定の属性を有する画像を抽出することも可能である。
【0117】
<4>ハードウェア構成
以上に説明した属性識別器生成装置10における属性識別器生成処理、クラス識別システム200におけるクラス識別処理システム200、属性認識部210における属性認識処理等の各処理は、専用コンピュータ、又はパーソナルコンピュータ(PC)などのコンピュータにより実現可能である。但し、コンピュータは、物理的に単一である必要はなく、分散処理を実行する場合には、複数であってもよい。図12は、属性識別器生成装置10やクラス識別システム200を実施するコンピュータの一例を示す図である。図12に示すように、コンピュータ500は、CPU501(Central Processing Unit)、ROM502(Read Only Memory)及びRAM503(Random Access Memory)を有し、これらがバス504を介して相互に接続されている。なお、コンピュータを動作させるためのOSソフトなどは、説明を省略するが、この属性識別器生成装置10、クラス識別システム200、属性認識部210等を構築するコンピュータも当然備えているものとする。
【0118】
また、バス504には入出力インターフェース505も接続されている。入出力インターフェース505には、例えば、キーボード、マウス、センサなどよりなる入力部506、CRT、LCDなどよりなるディスプレイ、並びにヘッドフォンやスピーカなどよりなる出力部507、ハードディスクなどより構成される記憶部508、モデム、ターミナルアダプタなどより構成される通信部509などが接続されている。
【0119】
CPU501は、ROM502に記憶されている各種プログラム、又は記憶部508からRAM503にロードされた各種プログラムに従って各種の処理を実行する。本実施例においては、例えば、特徴量学習部13による特徴量学習処理、分離境界学習部15による分離境界学習処理を含む、属性識別器生成装置10における属性識別器生成処理、特徴量抽出部212における特徴量抽出処理、属性認識部210における属性認識処理、クラス認識結果出力部219におけるクラス認識結果出力処理等を含む、クラス識別システム200におけるクラス認識処理等の処理を実行する。RAM503にはまた、CPU501が各種の処理を実行する上において必要なデータなども適宜記憶される。
【0120】
ここで、各種コンピュータプログラムは、様々なタイプの非一時的なコンピュータ可読媒体(non-transitory computer readable medium)を用いて格納され、コンピュータに供給することができる。非一時的なコンピュータ可読媒体は、様々なタイプの実体のある記録媒体(tangible storage medium)を含む。非一時的なコンピュータ可読媒体の例は、磁気記録媒体(例えばフレキシブルディスク、磁気テープ、ハードディスクドライブ)、光磁気記録媒体(例えば光磁気ディスク)、CD−ROM(Read Only Memory)、CD−R、CD−R/W、半導体メモリ(例えば、マスクROM、PROM(Programmable ROM)、EPROM(Erasable PROM)、フラッシュROM、RAM(random access memory))を含む。また、プログラムは、様々なタイプの一時的なコンピュータ可読媒体(transitory computer readable medium)によってコンピュータに供給されてもよい。一時的なコンピュータ可読媒体の例は、電気信号、光信号、及び電磁波を含む。一時的なコンピュータ可読媒体は、電線及び光ファイバ等の有線通信路、又は無線通信路を介して、プログラムをコンピュータに供給できる。
【0121】
通信部509は、例えば図示しないインターネットを介しての通信処理を行ったり、CPU501から提供されたデータを送信したり、通信相手から受信したデータをCPU501、RAM503、記憶部508に出力したりする。例えば、属性認識部210は、属性識別器生成装置10により学習された属性識別器を、インターネットを介して入手することができる。記憶部508はCPU501との間でやり取りし、情報の保存・消去を行う。通信部509は又、他の装置との間で、アナログ信号又はディジタル信号の通信処理を行う。
【0122】
入出力インターフェース505は、必要に応じてドライブ510が接続され、例えば、磁気ディスク511、光ディスク512、フレキシブルディスク513、又は半導体メモリ514などが適宜装着され、それらから読み出されたコンピュータプログラムが必要に応じて記憶部508にインストールされる。
【0123】
<5>実施例
以下、本発明にかかる属性識別器生成装置10により実際に属性識別器を学習により生成し、これを使用した認識率の実際に求めた本発明の実施例について説明する。実施例としては、先に研究がなされている非特許文献1(以下、比較例とする。)と同一のデータセットを使用し学習した結果をテストした。
【0124】
学習には、24000枚、40クラスの教師データを使用した。教師データは、40の全く異なるクラスの画像データからなる。また認識率テストには、6180枚、10の未知のクラスの画像を使用した。学習及び認識には、比較例と同様に、85の属性、6つの特徴量(カラーヒストグラム、局所自己相似性(local self similarity(Shechtman, E. and Irani, M.: Matching Local Self-Similarities across Images and Videos. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2007))、pHOG(Bosch, A., Zisserman, A. and Munoz, X.: Representing shape with a spatial pyramid kernel. In Computer Vision and Image Understanding (CVIU) (2007))、SIFT(Lowe, D.G.: Distinctive image features from scale-invariant keypoints. IJCV (2004))、RGSIFT(Sande, K., Gevers, T., Snoek, C.: Evaluation of color descriptors for object and scene recognition. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (2008))、及びSURF(Bay, H., Ess. A., Tuytelaars, T. and Gool. L. V.: SURF: Speeded Up Robust Features. In Computer Vision and Image Understanding (CVIU), Vol. 110, No. 3, pp. 346-359 (2008)))を使用した。
【0125】
図13及び図14は、本発明の実施例及び比較例にかかる平均認識率及びその計算時間を示す。図13に示すように、本実施の形態1及び2の方法、つまり、教師データを入力する毎にSOINNとSGD−SVMを実施した場合、全教師データをSOINNで学習してから分離境界を学習した場合、共に比較例2より高い認識率となった。なお、比較例1は、完全オフライン手法であり、全ての学習データに対する最適な識別器を用意することができるため、認識率が高くなっている。これに対して、本発明は、学習データが追加されると仮定して学習を実行する。よって、教示画像が入力されているその時の学習データに適する識別器で識別を行うため、識別率が比較例1より若干低いものとなっているが、完全オンラインでの学習が可能である。
【0126】
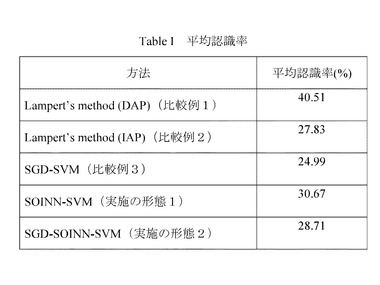
さらに、図14に示すように、比較例1、2の学習時間は、40クラスで約1ヶ月と極めて長時間であるのに対し、本実施の形態1、2の方法であると約10分で学習が終了する。すなわち、92.25%学習時間を短縮することができる。
【0127】
さらに、比較例1、2の方法では、1画像のクラス認識するために30秒かかっているのに対し、本実施の形態1、2の方法であると、数ミリ秒で画像1枚の認識結果を得ることができる。比較例1、2のように、オンラインで学習できないのに加えて、1枚の画像のクラス識別に30秒という長い時間を要すると、例えばロボット等に当該システムを搭載してリアルタイムに画像を取得し、認識するようなことは不可能となる。
【0128】
なお、比較例3は、SGD−SVMを利用したオンラインでの学習が可能な方法であり、学習時間、認識時間共に、本実施の形態1、2の方法と同等であるが、本実施の形態1、2のように、SOINNを利用してないため、認識率が劣る。ここで、本実施例は、比較例1、2が提供している画像を元に実施しているが、認識率は、学習画像を増やせば向上すると考えられる。例えばさらなる教師画像にノイズが多く含まれている場合、本実施の形態1、2にかかる認識率は向上するものと考えられる。一方で、比較例3は、SOINNを利用していないため、ノイズの影響が大きいと考えられ、学習時間の増加に対する認識率の向上は、本実施の形態1、2、の方法以下であると予想できる。
【0129】
以上、本実施の形態にかかる方法による属性識別器の学習により、比較例と同等の認識率で、かつ学習時間、認識時間を、92.25%削減することができた。
【0130】
なお、本発明は上述した実施の形態のみに限定されるものではなく、本発明の要旨を逸脱しない範囲において種々の変更が可能であることは勿論である。
【符号の説明】
【0131】
10 属性識別器生成装置
11 ラベリング部
12 特徴量抽出部
13 特徴量学習部
15 分離境界学習部
131 勝者ノード抽出部
133 ノード挿入部
135 エッジ管理部
137 ノード重み更新部
139 ノード削除部
200 クラス識別システム
201 属性識別器
210 属性認識部
211 ラベリング部
212 特徴量抽出部
217 属性出力部
219 クラス認識結果出力部
220 データセット
221 辞書データ
【技術分野】
【0001】
本発明は、識別対象であるクラスをその特徴である属性により認識することで転移学習を可能とする技術に関し、クラスを認識するための識別器生成装置、方法及びプログラム、並びに、それらを利用したクラス認識器、方法及びプログラムに関する。
【背景技術】
【0002】
対象認識や対象識別についての個々の研究が、ここ10年の間に大きな発達を遂げている。顔や車両のような特定の物体を検出するタスクについては、とても強力な検出器や認識器が利用可能である。このような検出器や認識器は、対象の特徴を示す低次元の特徴量(例えば、SIFT、SURFなど)と、サポートベクトルマシーン(SVM)などの現代的な機械学習メカニズムと、の組み合わせにより得ることができる。しかしながらこのような手法では、良好な精度を得るために人手によりラベル付けされた多数の教師データを通常必要とし、各個別のクラスを学習するためには一般的に数10万枚のサンプル画像を必要とする。
【0003】
また、多くの対象を認識する必要がある場合には他の問題が発生することがある。このような多くの対象を認識するという問題を解決するためには、これまでの手法では、各対象カテゴリーに対してそれぞれ新たな検出器を作った上で、それら検出器を学習する必要がある。しかしながら、新たな各検出器を効率的に学習する場合においても、上述したのと同様にして、人手によりラベル付けされた多数の教師データを必要とし、各個別のクラスを学習するために、一般的に数10万枚のサンプル画像を必要とする。
【0004】
コンピュータの見地から見れば、例えば何らかの効率的で自動的なラベリングツールが利用可能であれば、多数の学習データセットを用意することはそれほど大変なことではないと考えられるかもしれない。インターネットを介して多数の画像の集合へは簡単にアクセスすることができ、コンピュータハードウェアのパフォーマンスは近年では劇的に向上してきた。それにもかかわらず、ロボットのような知的エージェントの利用には、このようなことは当てはまらない。知的ロボットに対しては、ロボットはインターネットへのアクセスが限定されると共にハードウェア資源も限られており、また、実用的な実世界でのタスクがあまりにも一般的なものであるために、事前に学習された検出器のみを利用するものとしてはとてもこのタスクを解決することはできそうにない。従って最近では、多くの研究者達が、対象の属性(例えば非特許文献1に例示される。)や、対象の部分を考慮することによる対象認識についてより興味を持つようになってきた。
【0005】
複数の対象同士の間には、通常、何らかの共通属性が存在する(例えば、ライオン、タイガー、ドッグ、キャットなどでは、全て4本足の動物であるという共通の属性が存在する。)。非特許文献1において提案されているように、人間は、例から学習してそれを十分に抽象化することによって、少なくとも30000の関連のある対象クラスを区別することができる(人間は、高次元の特徴記述が与えられた時には、完全に未知の対象クラスであっても検出することができる。)。このことはつまり、1つの対象クラスにおいて発見された属性の知識が、同じ属性を含む他の異なる対象クラスへの利用のために転移されているものと考えられている。コンピュータビジョンにおける多くのこれまでの貴重な成果が、転移された属性を利用することで、未知の対象クラスの検出がまさに可能となることを既に示している(例えば、非特許文献1を参照されたい。)。
【先行技術文献】
【非特許文献】
【0006】
【非特許文献1】Lampert, C., Nickisch, H., Harmeling, S.: Learning to detect unseen object classes by between-class attribute transfer. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition, (2009)
【発明の概要】
【発明が解決しようとする課題】
【0007】
共通属性の学習の可能性とそれら属性を新規クラスの検出への利用に転移させることは、現在のロボティクスでは極めて有効である。簡単に説明するため、オフィス内での移動ロボットの利用を想定する。ロボットを他の部屋へと移動させて我々のために対象Bを取ってくるようにロボットに命令したい場合に、そのような対象Bの画像をロボットに提示するために我々が用意しているという状況は、とてもありえそうなことではない。対象の画像を必要とせずにロボットに命令を与える唯一の方法は、対象の属性を言葉で説明することである。これは、対象の1つのクラスからの属性をロボットに学習させ、さらに、その学習させた属性を転移させて未知クラスに属する新たな対象の認識へ利用させることで、解決されるべきである。
【0008】
しかしながら、属性の学習及び転移によって未知対象クラスの検出が可能となることがこれまでに示されたにも関わらず、これまでに提案された属性の転移及び学習手法をロボットでの利用に応用することについては以下に述べるような課題がある。
【0009】
まず、従来手法では、学習した属性は他の対象クラスでの利用に転移可能であるものの、各属性検出器を学習する事前の学習段階に関して、完全にバッチ処理となっている。従来手法では、任意の1つの属性の検出器を学習するために、巨大な教師画像データセットを必要とする。また、ロボットで利用するためには、システムは、教師画像を取得したときにはいつでもより柔軟に学習すべきであり、さらに、必要な場合にはいつでも識別すべきである。従って、完全に追加的な、属性の学習及び転移手法が必要である。
【0010】
ここで、非特許文献1に開示された従来手法を例に課題を説明する。非特許文献1に開示された従来手法では、個別の属性それぞれについての識別器を学習する必要がある。テスト段階では、各属性識別器が各属性についての確率を予測し、ベイズ理論に基づいて最終的な確率スコアが計算される。各属性識別器はSVMによって学習され、学習には数時間を必要とする。これを全ての属性(85個の属性)について行うと、あまりにも計算負荷が高くなり、ロボティクスや他のオンラインアプリケーションには事実上利用することができない。また、全ての属性に対してSVMを再度学習することは非現実的であることから、新たな入力教師データを追加的に学習することができない。
【0011】
そこで、本願出願人は、先に、このような問題点を解決するためになされたものであり、オンラインかつ追加学習が可能な属性の学習及び転移システム、及び、学習及び転移方法にかかる発明について出願している(特願2010−204650)。
【0012】
これに対し、本発明は、さらに認識率を向上した識別器生成装置、方法及びプログラム、並びにクラス認識器、方法及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0013】
本発明に係る識別器生成装置は、ある属性を有するか否かを識別する属性識別器を、教師データの特徴量を学習することにより生成する識別器生成装置であって、入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとするラベリング部と、前記教師データの特徴量を重みベクトルとして抽出する特徴量抽出部と、自己増殖型ネットワークにより、前記特徴量抽出部が抽出した特徴量を学習する特徴量学習部と、前記各重みベクトルが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)により当該ポジティブノードとネガティブノードの分離境界を学習する分離境界学習部とを有する。
【0014】
ここで、前記特徴量学習部は、前記特徴量抽出部にて抽出された重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノード及び2番目に近いノードをそれぞれ第1勝者ノード及び第2勝者ノードとして抽出する勝者ノード抽出部と、前記入力ノードと、前記第1及び第2勝者ノードとの距離に基づき、当該入力ノードを新たなノードとして挿入するか否かを判定するノード挿入判定部と、前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードと前記第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とし、エッジがある場合はその年齢を0とし、さらに前記第1勝者ノードが有する全エッジの年齢をインクリメントし、所定の年齢に達したエッジを削除するエッジ管理部と、前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードの重みベクトルを当該入力ノードの重みベクトルに基づき更新するノード重み更新部と、所定のタイミングで、そのノード密度に応じてノードを削除するノード削除部とを有するものである。
【0015】
本発明においては、属性を有するか否かがラベル付けされた教師データを使用し、自己増殖型ネットワークにより、その特徴量を学習すると共に、属性が有するか否かの分離境界をサポートベクタマシンにより学習する。これにより、処理時間を短縮しつつ、属性を有するか否かの境界を正確に学習することができ、認識率を向上することができる。
【0016】
また、前記教師データを前記特徴量学習部に入力する毎に、前記分離境界学習部により前記分離境界を生成又は更新するものとすることができ、これにより、完全オンラインの学習が可能となる。
【0017】
さらに、複数の前記教師データを前記特徴量学習部に入力して特徴量を学習した後、前記分離境界学習部により前記分離境界を生成又は更新することができ、非オンラインでの学習も可能となる。
【0018】
さらにまた、前記ノード削除部は、前記教師データを前記特徴量学習部に入力する毎に、全ノードの年齢をインクリメントし、全ノードのうち所定の年齢に達するノードについて、所定数未満のノードとエッジで接続されているノードを削除するようにすることができ、ノードの削除処理をより正確に行うことができる。
【0019】
また、前記SVMは、線形SVMであり、重みの推定に確率的勾配降下法(stochastic gradient descent (SGD))を使用したものとすることができ、完全オンラインの学習が可能となる。
【0020】
さらに、前記特徴量学習部における自己増殖型ネットワークは、Self-Organizing and Incremental Neural Networks(SOINN)とすることができ、ノイズにロバストかつ高速演算、完全オンライン学習が可能となる。
【0021】
本発明に係る識別器生成方法は、ある属性を有するか否かを識別する属性識別器を、教師データの特徴量を学習することにより生成する識別器生成方法であって、入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとするラベリング工程と、前記教師データの特徴量を重みベクトルとして抽出する特徴量抽出工程と、自己増殖型ネットワークにより、前記特徴量抽出工程にて抽出された特徴量を学習する特徴量学習工程と、前記各重みベクトルが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)により当該ポジティブノードとネガティブノードの分離境界を学習する分離境界生成工程とを有する。
【0022】
ここで、前記特徴量学習工程は、前記特徴量抽出工程にて抽出された重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノード及び2番目に近いノードをそれぞれ第1勝者ノード及び第2勝者ノードとして抽出する勝者ノード抽出工程と、前記入力ノードと、前記第1及び第2勝者ノードとの距離に基づき、当該入力ノードを新たなノードとして挿入するか否かを判定するノード挿入判定工程と、前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードと前記第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とし、エッジがある場合はその年齢を0とし、さらに前記第1勝者ノードが有する全エッジの年齢をインクリメントし、所定の年齢に達したエッジを削除するエッジ管理工程と、前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードの重みベクトルを当該入力ノードの重みベクトルに基づき更新するノード重み更新工程と、所定のタイミングで、そのノード密度に応じてノードを削除するノード削除工程とを有するものである。
【0023】
本発明に係るプログラムは、ある属性を有するか否かを識別する属性識別器を、教師データの特徴量を学習することにより生成する処理をコンピュータに実行させるためのプログラムであって、入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとするラベリング処理と、前記教師データの特徴量を重みベクトルとして抽出する特徴量抽出処理と、自己増殖型ネットワークにより、前記特徴量抽出処理にて抽出された特徴量を学習する特徴量学習処理と、前記各重みベクトルが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)により当該ポジティブノードとネガティブノードの分離境界を学習する分離境界生成処理とを実行するものである。
【0024】
前記特徴量学習処理では、前記特徴量抽出処理にて抽出された重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノード及び2番目に近いノードをそれぞれ第1勝者ノード及び第2勝者ノードとして抽出する勝者ノード抽出処理と、前記入力ノードと、前記第1及び第2勝者ノードとの距離に基づき、当該入力ノードを新たなノードとして挿入するか否かを判定するノード挿入判定処理と、前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードと前記第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とし、エッジがある場合はその年齢を0とし、さらに前記第1勝者ノードが有する全エッジの年齢をインクリメントし、所定の年齢に達したエッジを削除するエッジ管理処理と、前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードの重みベクトルを当該入力ノードの重みベクトルに基づき更新するノード重み更新処理と、所定のタイミングで、そのノード密度に応じてノードを削除するノード削除処理とが実行されるものである。
【0025】
本発明に係るクラス識別器は、入力データから特徴量を重みベクトルとして抽出する特徴量抽出部と、前記特徴量抽出部により抽出された重みベクトルから、当該入力データがいずれの属性を有しているかを判断する、複数の属性識別器からなる属性認識部と、属性認識部で識別された属性を属性ベクトルとして出力する属性出力部とを備える。
この属性識別器は、上述の識別器生成装置で学習され生成されたものであって、属性認識部は、前記入力データに含まれる認識対象であるクラスがいずれの属性を有するか判断するものであり、当該クラスを識別するために必要な数の属性に対応する前記属性識別器を備えるものである。
【0026】
本発明においては、上述の識別器生成装置により学習された属性識別器を複数備えることで、クラスを複数の属性としてとらえることができ、転移学習により、未知のクラスであっても、その属性を識別することができる。
【0027】
この場合、前記属性認識部は、前記入力データから抽出する特徴量の種類をN種類(Nは1以上の自然数)、クラスを識別するために必要な数の属性をM個(Mは1以上の自然数)とすると、N×Mの属性識別器を有するものとすることができる。ポジティブとネガティブで異なる属性識別器を使用するのに比して、演算量を低減することができる。
【0028】
クラスと属性の関係を有するクラス−属性辞書に基づき、前記属性出力部から出力された属性ベクトルに対するクラスを検出し、検出結果として出力するクラス認識結果出力部を更に有するものとすることができ、辞書データを具備すれば、学習していない未知のクラスであっても、認識することができる。
【0029】
本発明にかかるクラス識別方法は、入力データから特徴量を重みベクトルとして抽出する特徴量抽出工程と、前記特徴量抽出工程にて抽出された重みベクトルから、複数の属性識別器により、当該入力データがいずれの属性を有しているかを判断する属性認識工程と、属性認識工程にて識別された属性を属性ベクトルとして出力する属性出力工程とを備える。
前記属性識別器は、上述の識別器生成方法で学習され生成されたものであって、前記属性認識工程では、前記入力データに含まれる認識対象であるクラスがいずれの属性を有するか判断するものであり、当該クラスを識別するために必要な数の属性に対応する前記属性識別器を使用するものである。
【0030】
本発明にかかるプログラムは、入力データから特徴量を重みベクトルとして抽出する特徴量抽出処理と、前記特徴量抽出処理にて抽出された重みベクトルから、複数の属性識別器により、当該入力データがいずれの属性を有しているかを判断する属性認識処理と、属性認識処理にて識別された属性を属性ベクトルとして出力する属性出力処理とをコンピュータに実行させるためのプログラムである。
そして、前記属性識別器は、上述の識別器生成プログラムで学習され生成されたものであり、前記属性認識処理では、前記入力データに含まれる認識対象であるクラスがいずれの属性を有するか判断するものであり、当該クラスを識別するために必要な数の属性に対応する前記属性識別器を使用するものである。
【発明の効果】
【0031】
本発明によれば、高速に学習、認識することができる識別器生成装置、方法及びプログラム、並びにクラス認識器、方法及びプログラムを提供することができる。
【図面の簡単な説明】
【0032】
【図1】属性を使用した転移学習システムの概念を示す図である。
【図2】本発明の実施の形態1にかかる属性識別器生成装置を示す図である。
【図3】本発明の実施の形態1にかかる属性識別器の学習方法を示すフローチャートである。
【図4】本発明の実施の形態1にかかる属性識別器生成装置におけるAdjusted−SOINNの動作を示すフローチャートである。
【図5】本発明の実施の形態2にかかる属性識別器の学習方法を示すフローチャートである。
【図6】本発明の実施の形態2にかかる属性識別器の学習方法を説明する図である。
【図7】本発明の実施の形態2にかかる属性識別器の学習時、SOINNにデータを入力した場合に、そのデータを新たなノードとして挿入する場合を説明する図である。
【図8】本発明の実施の形態2にかかる属性識別器の学習時、SOINNにデータを入力した場合に、ノードを挿入せず、第1勝者の重みベクトルを更新する場合を説明する図である。
【図9】本発明の実施の形態3にかかるクラス識別システムを示す図である。
【図10】画像、属性及びクラスの関係を説明する図である。
【図11】本発明の実施の形態3にかかるクラス識別方法を示す図である。
【図12】本発明の実施の形態にかかる属性識別器生成装置やクラス識別システムを実施するコンピュータの一例を示す図である。
【図13】本発明の実施例及び比較例にかかる平均認識率を示す図である。
【図14】本発明の実施例及び比較例にかかる計算時間を示す。
【図15】参考例にかかる属性識別器生成装置を説明するための図である。
【発明を実施するための形態】
【0033】
以下、本発明を適用した具体的な実施の形態について、図面を参照しながら詳細に説明する。この実施の形態は、本発明を、識別対象であるクラスをその特徴である属性により認識する転移学習に使用する属性識別器を、教師データの特徴量を学習することにより生成する識別器生成装置に適用したものである。
【0034】
先ず、ここでは、本発明の理解を容易とするため、属性を使用した転移学習について説明する。図1は、システム構造の概念を示す図である。図1は、直接属性予測モデル(direct attribute prediction (DAP)model)を示している(非特許文献参照)。このモデルの役割は、画像の特徴量xから属性を検出することである。
【0035】
最下層にあるのが画像の特徴空間Xであり、中間層は、画像の属性ベクトルa1〜aMを示している。最上層のY(y1〜yN)は、個別のクラスラベルを示し、クラスレベルZ(z1〜zL)は、クラスレベルYと異なるクラスレベルを示す。本実施の形態においては、Yが学習クラスであり、Zが認識テストに使用する未知のクラスを示す。
【0036】
転移学習では、学習クラスYが有する属性ベクトルay∈Aを学習する。本実施の形態においては、属性ベクトルay=(ay1,...,ayM)であり、各要素は、aym∈{1,0}で示される。すなわち、各属性ベクトルの1つの要素(1つの属性)は、それを有している(ポジティブ、aym=1)か、有していない(ポジティブ、aym=0)のいずれかで表現される。各属性ベクトルの各要素毎に、学習クラスYが示されている画像の特徴量Xを学習することで、属性ベクトルaに対応する特徴量(重みベクトル)Xを学習する。すなわち、クラスYの特徴量を学習するのではなく、属性ベクトルaの各要素(1つの属性)に対応する特徴量Xを学習し、どの属性ベクトルaを有するものがどのクラスYであるかを学習する。
【0037】
これにより、新しい未知のクラスZの画像が入力された場合、その特徴量からクラスZの属性を認識することができる。すなわち、クラスZの名前は不明であっても、どのような属性を有するものであるかは認識することができる。識別器は、未知のクラスZが入力された場合に、どのような属性を有するものであるかを出力することもできるし、属性とクラスの関係を示す辞書データを備え、この辞書データを参照することで、未知のクラス名を答えることも可能とする。
【0038】
このように転移学習とは、識別対象であるクラスの特徴を学習するのではなく、クラスの属性を学習することで、未知のクラスの検出を可能とするものである。なお、以下の実施の形態においては、入力データは、クラスが表示された画像のデータとして説明するが、入力データは、画像に限らず、音声その他のデータであってもよい。
【0039】
ここで、本実施の形態においては、ある属性を具備するか否かを示す2値SVMを属性識別器として使用する。その重みの推定に確率的勾配降下法(stochastic gradient descent (SGD))を使用(以下、SGD−SVMともいう。)する。
【0040】
しかしながら、重みパラメータを、SGDを使用して更新すると、1サンプルが考慮されるため、ノイズに影響されやすい。これを解決するために、本発明においては、入力画像の特徴を直接使用する代わりに、SVMの入力データとして、後述するSOINN(Self-Organizing and Incremental Neural Networks)ノードを使用する。SOINNによってノイズを抑制することができ、ノイズ除去ステップも有するのでノイズが入力されるためにSGDの重み更新に発生するエラーを低減することができる。
【0041】
<1>本発明の実施の形態1.
<1−1>属性識別器生成装置の構成
次に、本発明の実施の形態1について説明する。図2は、本実施の形態にかかる属性識別器生成装置を示す図である。図2に示すように、属性識別器生成装置10は、ラベリング部11、特徴量抽出部12、特徴量学習部13及び分離境界学習部15を有する。ここで特徴量学習部13は、後述する自己増殖型ネットワークSOINNで構成され、特徴量抽出部12により抽出された属性の特徴量が学習される。分離境界学習部15は、SVMにより分離境界を学習する。ラベリング部11は、入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとする。なお、予めラベリングしたデータを特徴量抽出部12に入力するようにしてもよい。また、特徴量を抽出した後で、ラベリングして教師データとしてもよい。
【0042】
特徴量抽出部12は、教師データから特徴量を重みベクトルとして抽出する。例えば教師データ及び入力データが画像データである場合には、SIFT、SURFなどの特徴量を抽出する。なお、SIFT、SURF以外にも、rg−SIFT特徴量、PHOG特徴量、cq特徴量、Lss−histogram特徴量など公知の特徴量のうちいずれか1つを抽出してもよいし、複数の種類の特徴量を抽出するものとしてもよい。また、教師データ及び入力データは画像データに限定されず、音声データなどであってもよい。特徴量抽出部12で抽出された重みベクトルは、ラベルと共に、入力ノードとして特徴量学習部13に入力される。分離境界学習部15は、特徴量学習部13において学習された各ノードが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)によりポジティブノードとネガティブノードの分離境界を学習する。
【0043】
ここで、本実施の形態にかかる属性識別器生成装置10では、1つの属性について、それを備えているか(ポジティブ)、備えていないか(ネガティブ)を識別する属性識別器を学習して生成する。つまり、あるクラス(例えば動物)を表現する属性が例えばM個(Mは1以上の自然数)ある場合、M個の属性識別器が学習されることになる。さらに、入力画像からN種類(Nは1以上の自然数)の特徴量を抽出する場合は、各特徴量について各属性を学習するため、N×M個の属性識別器にて、各特徴ごと、各属性毎に、その特徴量が学習される。
【0044】
ここで、特徴量学習部13は、勝者ノード抽出部131、ノード挿入部133、エッジ管理部135、ノード重み更新部137及びノード削除部139を有する。
【0045】
勝者ノード抽出部131は、特徴量抽出部12にて抽出された重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノードを第1勝者ノードとして抽出し、2番目に近いノードを第2勝者ノードとして抽出する。
【0046】
ノード挿入部133は、入力ノードと第1勝者ノードとの間の距離、及び入力ノードと第2勝者ノードとの間の距離に基づき、その入力ノードを新たなノードとして挿入するか否かを判定する。
【0047】
エッジ管理部135は、入力ノードを新たなノードとして挿入しない場合、第1勝者ノードと第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とする。エッジがある場合はその年齢を0とし、さらに第1勝者ノードに接続されている全てのエッジの年齢をインクリメントし、さらに、所定の年齢に達したエッジを削除する。
【0048】
ノード重み更新部137は、入力ノードを新たなノードとして挿入しない場合、第1勝者ノードの重みベクトルを入力ノードの重みベクトルに基づき更新する。なお、第2勝者ノードの重みベクトルも更新するようにしてもよい。
【0049】
ノード削除部139は、所定のタイミングで、そのノード密度に応じてノードを削除する。例えば、入力データ数が100の倍数となるタイミングでノードを削除することができる。又は、ノードのエッジの年齢をカウントし、年齢が100の倍数となるタイミングで、各ノード個別にノードの削除を行ってもよい。
【0050】
本実施の形態においては、教師画像をSOINNに全て入力し、特徴量を学習した後で、SGD−SVMにより、ポジティブとネガティブの分離境界を学習する。1つのSOINNにより、入力データがある属性を有している(ポジティブ)又は有していない(ネガティブ)を識別することができるので、ポジティブと、ネガティブと別々のSOINNを要していた先願(特願2010−204650、参考例という。)に対し、SOINNの数を2分の1にすることができる。
【0051】
すなわち、本実施の形態においては、教師画像から抽出する特徴量の数=N種類(Nは1以上の自然数)とし、認識対象のクラスを識別するのに必要な属性をM個(Mは1以上の自然数)とすると、N×M個のSOINNにより、各属性(ポジティブ、ネガティブ)に対応する特徴量が学習されることになる。
【0052】
図15は、参考例にかかる属性識別器生成装置を説明するための図である。図15に示すように、教師画像(training data)から特徴量を抽出するまでは本実施の形態と同様である。ただし、本実施の形態のように、SGD−SVMを使用してポジティブとネガティブの境界を学習するのではなく、SOINNに入力するが、各属性について、ポジティブとネガティブで別個のSOINNを用意して学習する。よって、SOINNの個数は、2×属性の数×特徴量の数となる。
【0053】
本実施の形態においては、ネガティブノードとポジティブノードとで同一のSOINNを使用するため、実施が容易となる。先願の方法であると、ネットワークにあるノードに対する最近傍法で識別を行う。この場合、空間上に近傍ノードがなければ、距離のみの識別となるため、識別結果が学習データに大きく依存してしまう。これに対して、実施の形態にかかる属性識別器生成装置10により生成された属性識別器を使用して、入力データがいずれの属性にぞくするかを識別する場合、SGD−SVMにより学習し分離境界で識別を行う。分離境界も学習データに依存するが、学習データがない空間であっても、学習データに基づいた適切な識別が可能となり、先願と比べると識別力を向上することができる。
【0054】
なお、本実施の形態においては、属性識別器生成装置10が、ラベリング部11及び特徴量抽出部12を有するものとして説明したが、入力画像から特徴量を抽出し、これにラベリングした教師データを予め用意し、特徴量学習部13に入力するようにしてもよい。この場合は、ラベリング部11及び特徴量抽出部12は、不要である。すなわち、属性識別器生成装置10に入力するまえに特徴量を抽出してもよく、又はラベリングして教師データとしてもよい。
【0055】
図3は、本実施の形態にかかる属性識別器の学習方法を示すフローチャートである。先ず、教師画像からSOINNの入力データとして特徴量を取得する(ステップS1)。すなわち、この場合、特徴量として、SIFT特徴量、SURF特徴量、rg−SIFT特徴量、PHOG特徴量、cq特徴量、Lss−histogram特徴量など公知の特徴量のうち、いずれか1つを抽出するものとしてもよいし、複数の種類の特徴量を抽出するものとしてもよい。属性の数=m{1〜M}とするとき、m番目のSOINNには、{xi,aym}が入力される。ここで、xiはクラスyの特徴量、aymは、m番目の属性の2値の値(1又は0)を示す。
【0056】
すなわち、教師画像がいずれの属性を有するかがラベリングされており、抽出された特徴量にも、いずれの属性を有するか否かがラベリングされている。次に、取得したデータ{xi,aym}をSOINNに入力する(ステップS2)。上述したように、SOINNは、各属性毎に設けられる。例えばあるクラス(例えば、動物)を認識するための属性が85個ある場合、85個の属性に対応したSOINNで学習が行われる。教師画像は、各85個の属性それぞれについて、当該属性を有する、有しない、の情報がラベルづけされており、このラベル付けされた情報に基づき、各属性毎に、それを有する場合、有しない場合の特徴量が学習されていく
【0057】
そして、特徴量の学習が終了するまで、このステップS1、S2を繰り返す(ステップS3:No)。そして、特徴量の学習が終了したら、SDG−SVMにより、ネガティブノードとポジティブノードの分離境界を学習する(ステップS4)。以上により、ある属性を有するか(ポジティブ)、有しないか(ネガティブ)を識別することができる属性識別器を、教師画像を使用して学習により、生成することができる。
【0058】
なお、本実施の形態においては、SOINNに教師画像の特徴量全部を入力し、特徴量の学習が終了した後、分離境界を学習するものとして説明したが、所定の枚数、例えば100枚毎に、教師画像の特徴量の学習が終了したら、分離境界を学習する、等のようにしてもよい。
【0059】
<1−2>確率的勾配降下法(stochastic gradient descent:SGD)−SVM(Support Vector Machine)
次に、SGD−SVMについて説明する。入力データ(入力ベクトル)をx、出力データ(出力ベクトル)をyとしたとき、推定関数f:x→yを、入力ベクトルxに基づき、出力ベクトルyを推定するものと定義する。損失関数l(f(x),y)は、推定関数の出力と、実際の値との間のエラーを示すものと定義される。ここで、期待リスクE(f)を最小とする関数fを推定することを目的とし、期待リスクE(f)は、下記数式(1)により求めることができる。
【0060】
【数1】
ここで、nは学習サンプル、zi=(xi,yi)で、i=1,2,...,nを示すものとする。そして、経験的リスクを最小化する関数fを下記数式(2)により求める。
【0061】
【数2】
により、線形にパラメータ化される。基準勾配降下法は、重みベクトルwの勾配の傾きを使用して経験的リスクを最小化するために提案された。この傾きを計算し、最適化パラメータwを更新するために、1つの完全な学習セットにより学習する必要がある。さらに、大域的最適を得るためには、多くの繰り返しが必要である。ここで、確率的勾配降下法は、各繰り返しでサンプルziを抽出し、下記数式(3)の時間依存因子を使用して重みベクトルwを繰り返し更新することで、経験的リスクを最小化する。
【0062】
【数3】
2元線形SVM問題のため、下記をトレーニングセットとし、
【0063】
【数4】
学習過程の目的は、下記数式(4)の目的関数を最小化するものとなる。
【0064】
【数5】
【0065】
ここで、ハイパーパラメータλ>0が正規化項の強さを制御し、bがオリジナルSVM問題におけるバイアス項を示す。損失l(f(xi),yi)は、凸関数であり、連続的な導関数の2階微分を示す。上記数式(3)、(5)及び(6)から、下記数式(7)により線形SVMの重みを推定するために、SGDを使用することができる。
【0066】
【数6】
【0067】
<1−3>Adjusted−SOINN
次に、本実施の形態において用いる自己増殖型ニューラルネットワークについて簡単に説明する。自己増殖型ニューラルネットワークとして、例えば、Adjusted−SOINN(Self-Organizing Incremental Neural Network)が提案されている。Adjusted−SOINNは、自己組織化かつ追加学習可能なニューラルネットワークであり、オンラインの教師無し識別学習のためのメカニズムである(特開2008−217242号公報、非特許文献「F. Shen & O. Hasegawa, "An incremental network for on-line unsupervised classification and topology learning, " Neural Networks, 19(1):90-106, 2006.」、及び非特許文献「F. Shen & O. Hasegawa, "An on-line learning mechanism for unsupervised classification and topology representation," in CVPR, 2005.」参照)。
【0068】
本実施の形態においては、教師あり学習であるが、入力画像の特徴量の学習に、Adjusted−SOINNを利用するものとする。
【0069】
Adjusted−SOINNは、重みベクトルとして表わされるノードが、自律的に増殖及び消滅することを特徴とする。ノード同士は、所定の条件を満たす場合に、エッジと呼ばれる仮想的な線で結合される。Adjusted−SOINNは、このエッジをたどって互いに到達できるノード同士を同じクラスタとみなすことにより、クラスタリングを行う。また、エッジは年齢と呼ばれるパラメータを持っており、Adjusted−SOINNは、所定の年齢に達したエッジを削除する。これにより、ノイズとみなし得るノードを所定のタイミングで削除可能としている。
【0070】
図4を用いて、Adjusted−SOINNの学習アルゴリズム、すなわちAdjusted−SOINNに新たなノードが入力された場合のAdjusted−SOINNの動作について説明する。
【0071】
S301:重みベクトルを持つ入力ノードが、Adjusted−SOINN(属性識別器生成装置10)に新たに入力される。この重みベクトルは、特徴量抽出部12にて抽出された特徴量である。
【0072】
S302:Adjusted−SOINN、本実施の形態においては、勝者ノード抽出部131は、入力ノードと既存のノードとの間の距離、典型的にはユークリッド距離を計算する。ユークリッド距離とは、下記数式(8)により定義される距離をいう。下記数式(8)において、dはユークリッド距離、f及びgはそれぞれn次元のベクトルを示す。
【0073】
【数7】
【0074】
勝者ノード抽出部131は、この計算結果より、このユークリッド距離が最も近いノード(第1勝者ノード)と2番目に近いノード(第2勝者ノード)とを決定する。
【0075】
S303:次に、ノード挿入部133は、この第1勝者ノード及び第2勝者ノードが有する類似度閾値をそれぞれ計算する。ここで、類似度閾値とは、あるノードが隣接ノード(エッジで接続されたノード)を持つ場合、その隣接ノードとの最大距離をいう。あるノードが隣接ノードを持たない場合は、そのノードとそれ以外のノードとの最小距離をいう。類似度閾値は、下記数式(9)により求められる。下記数式(9)において、Nはノードiの隣接ノードの集合、Wはノードiの重みベクトル、Aはノード全体の集合を示す。
【0076】
【数8】
【0077】
ノード挿入部133は、これらの類似度閾値と、上述の入力ノードと第1勝者ノード及び第2勝者ノードとのユークリッド距離とを相互に比較する。比較の結果、入力ノードと第1勝者ノード及び第2勝者ノードとのユークリッド距離が、第1勝者ノード又は第2勝者ノードの類似度閾値よりも大きい場合、入力ノードは、第1勝者ノード及び第2勝者ノードとは異なるクラスタに属するとみなされる。この場合、Adjusted−SOINNは、入力ノードの位置に新たなノードを挿入すべきと判定する。一方、入力ノードと第1勝者ノード及び第2勝者ノードとのユークリッド距離が、第1勝者ノード及び第2勝者ノードの類似度閾値よりも小さい場合、入力ノード、第1勝者及び第2勝者はいずれも同一のクラスタに属するとみなされる。この場合、ノード挿入部133は、新たなノードを挿入すべきでないと判定する。
【0078】
S304:S303において、新たなノードを挿入すべきと判定された場合、勝者ノード抽出部131は、入力ノードの位置に新たなノードを挿入する。
【0079】
S305:S303において、新たなノードを挿入すべきでないと判定された場合、xエッジ管理部135は、第1勝者ノードと第2勝者ノードとの間にエッジが存在するか否かを判定する。
【0080】
S306:S305において、第1勝者ノードと第2勝者ノードの間にエッジが存在しないと判定された場合、エッジ管理部135は、それらの間にエッジを生成する。このような処理が、K−Meanのような他のクラスタリング手法とAdjusted−SOINNとで著しく異なる点である。Adjusted−SOINNでは、その新たに入力されたノードは、クラスタを形成するためにネットワークに単純には追加されない。その代わりに、Adjusted−SOINNにおいて存在するノードをエッジにより接続していくことでクラスタが形成される。Adjusted−SOINNにおける現在のノードと入力パターンとが著しく異なる場合においてのみ、新たなノードを生成することから、このようなクラスタ形成処理によれば、長期間における実行に対してメモリの節約に大きな貢献をもたらす。
【0081】
S307:エッジ管理部135は、S305においてエッジが存在しないと判定した場合、S305において生成したエッジの年齢を0とする。一方、S305においてエッジが存在すると判定した場合、既に存在していたエッジの年齢を0とする。加えて、エッジ管理部135は、第1勝者ノードに接続されている全てのエッジの年齢をインクリメントする。
【0082】
S308:次に、エッジ管理部135は、あらかじめ定められた閾値(age)を超えた年齢を有するエッジを削除する。ageは、ノイズ等の影響により誤って生成されるエッジを削除するために設定されるパラメータである。ageに小さな値を設定すれば、エッジは削除されやすくなり、ノイズの影響は防ぎやすくなるが、ageが極端に小さければ、エッジが頻繁に削除されるようになり、学習結果が不安定になる。一方、ageが大きすぎれば、ノイズの影響で生成されたエッジを適切に取り除くことができない。したがって、ageには、実験等により算出された適切な値を設定することが好ましい。
【0083】
S309:次に、ノード重み更新部137は、第1勝者ノード及び第1勝者ノードとエッジを介して直接接続されている隣接ノードの重みベクトルを、以下の数式(10)、数式(11)により更新する。数式(10)、数式(11)において、ΔWiはノードiの重みベクトルの更新量、ΔWjはノードjの重みベクトルの更新量を示す。また、iは第1勝者ノード、jは隣接ノード、Wkは入力ノードの重みベクトル、Miはノードiがこれまで第1勝者ノードになった回数を示す。これにより、入力ノードを新たなノードとして挿入しない場合には、入力ノードは、第1勝者ノード及び隣接ノードにいわば吸収される形となる。なお、本実施の形態においては、第1勝者ノード及びその隣接ノードの重みを更新するものとして説明するが、第1勝者ノードのみ、又は第1勝者ノードに加えて第2勝者ノードの重みを更新するようにしてもよい。
【0084】
【数9】
【0085】
【数10】
【0086】
S310:次に、ノード削除部139は、以下の2つの条件を満たすノードを、すべてのノードの中から抽出し、削除対象と判定する。
【0087】
1つ目の条件は、入力されたノードの数が、あらかじめ定められた設定値、例えば定数λの倍数にあたるか否かを判定する。この設定値は、ノイズとみなし得るノードを定期的に削除するために設定されるパラメータである。λに小さな値を設定すれば、頻繁にノイズ処理を実施することができるが、λが極端に小さければ、実際にはノイズでないノードまで誤って削除してしまう。一方、λが大きすぎれば、ノイズの影響で生成されたノードを適切に取り除くことができない。それで、λには、実験により算出された適切な値を設定することが好ましい。
【0088】
2つ目の条件は、ノードの隣接ノード数があらかじめ定められた閾値η以下であることである。閾値ηは、ノード群のうち低密度の領域、すなわちノイズとみなし得るノードを定義するためのパラメータである。
【0089】
S311:ノード削除部139は、ステップS310において削除対象として抽出されたノードを削除する。
【0090】
S312:入力されたノードの数が、あらかじめ定められた定数ρに達したならば、Adjusted−SOINNは学習を完了する。未だ達していない場合は、次の入力ノードの入力を受付け、上述した手順により学習を継続する。
【0091】
なお、図4に示す例では、入力されたノード数がλの倍数のタイミングで、ノードを削除するか否かを判定するものとして説明したが、各ノード毎に年齢をカウントし、所定の年齢、例えば年齢がλに到達したノード(入力された後に、新たな入力がλ回されたノード)について、削除するか否かの判定を行ってもよい。入力されたノード数が所定の数に達したタイミングで削除処理を行うと、最初の頃に入力されたノードと、最後の方に入力されたノードとの間で不平等の判断がなされる場合がるが、ノードの年齢をカウントすることで、いずれのノードも同様な条件で削除判定することができる。
【0092】
さらに、自己増殖型ニューラルネットワークはAdjusted−SOINNに限定されず、Enhanced−SOINN(特開2008−217246)などを利用するものとしてもよい。また、オンラインかつ追加学習可能という観点からは、事前にネットワークの構成やサイズを決定する必要があるためにその性能に制限が加えられるものの、自己増殖型ニューラルネットワークとして、ニューラルガス(NG)(T. M. Martinetz, and S. G. Berkovich, and K. J. Schulten, "Neural-gas," network for vector quantization and its application to time-series prediction, " IEEE Trans. On Neural Networks, vol. 4, no. 4, pp. 558-569, 1996.)やGrowing neural gas(GAG)(B. Fritzke, "A Growing Neural Gas Network Learns Topologies, " In Advances in Neural Information Processing System, vol. 7, pp. 625-632, 1995.)を用いることもできる。
【0093】
<2>本発明の実施の形態2.
次に、本発明の実施の形態2にかかる属性識別器生成装置について説明する。上述の実施の形態1は、完全なオンライン学習が不可能であったのに対し、本実施の形態にかかる属性識別器生成装置は、完全なオンライン学習が可能となる。
【0094】
属性識別器生成装置の構成は、図2に示す属性識別器生成装置10と同様である。ただし、実施の形態1にかかる属性識別器生成装置10は、ある所定数の教師画像を入力し、その特徴量を学習した後で、分離境界学習部15により、分離境界を学習していたのに対し、本実施の形態にかかる属性識別器生成装置は、教師画像を入力する毎に、特徴量学習部13で特徴を学習すると共に分離境界学習部15により分離境界を学習する。これにより、完全オンラインの学習が可能となる。
【0095】
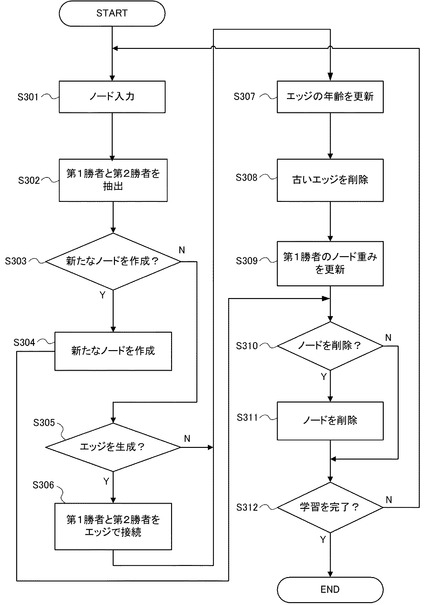
図5は、本実施の形態にかかる属性識別器の学習方法を示すフローチャートである。また、図6は、本実施の形態にかかる属性識別器の学習方法を説明する図である。図7及び図8は、SOINNにデータを入力した場合に、そのデータを新たなノードとして挿入する場合及びノードを挿入せず、第1勝者の重みベクトルを更新する場合の学習方法を説明する図である。
【0096】
図5に示すように、先ず、SOINNに入力するデータ{xi,aym}を取得する(ステップS11)(図6の1参照)。1つの属性(ポジティブ、ネガティブ)につき、1つのSOINNが対応する点、SOINNに入力する特徴量ベクトルとして、SIFT特徴量、SURF特徴量、rg−SIFT特徴量、PHOG特徴量、cq特徴量、Lss−histogram特徴量等を使用することができる点などは、実施の形態1と同様である。特徴量抽出部12は、教師画像から特徴量を抽出する。
【0097】
次に、SOINNにデータ{xi,aym}を入力する(ステップS12)(図6の2参照)。このとき、aym=1のときは、ポジティブサンプル(その属性を有する)として、aym=0のときは、ネガティブサンプル(その属性を有しない)として、SOINNに入力する。なお、図2に示す例では、教師画像がラベリング部11に入力され、ラベリング部11により、ラベル{aym}が付され、特徴量抽出部12により、特徴量{xi}が抽出されるものとしているが、特徴量抽出部12を抽出した後、ラベル付けして、SOINNに入力するようにしてもよい。
【0098】
SOINNに入力されたデータは、勝者ノード抽出部131により、第1勝者ノード、第2勝者ノードが抽出され、ノード挿入部133により、新たにノードを挿入するか否かが判定される。次に、新たにノードが追加される場合(図6の2−1)、図7)と、ノードを追加しない場合(図6の2−2)、図8)について説明する。
【0099】
SOINNに教師データを入力したら、同時にSGD−SVMにより、分離境界を学習する(ステップS13)。図7に示すように、新しいノードを追加する場合は、この特徴(入力ノードの重みベクトル)をSGD−SVMの入力(重みベクトルSk_new,aym)とする。
【0100】
一方、新たに入力ノードを挿入しない場合、図8に示すように、ノード重み更新部137により、上述した数式(10)、数式(11)に従ってノード重みが更新される。この場合、更新したノード重みベクトルをSGD−SVMの入力(Sk_move,aym)として入力する。いずれも、上述の数式(7)に従って、分離境界を更新する。
【0101】
以上のようにして、教師画像からSOINNの入力データを生成し、SOINNに入力し、SGD−SVMによりポジティブノードとネガティブノードの分離境界を学習していき、所定の数のサンプルで学習をしたら、終了する(ステップS14)。
【0102】
本実施の形態においては、教師画像(ラベル付きデータ)からその特徴量を学習し、各属性についてポジティブノードとネガティブノードを同一のSOINNに入力して、その分離境界を学習するようにしたので、完全なオンライでの学習が可能となる。すなわち、当該属性識別器生成装置10を例えばロボットに搭載し、ある程度学習が終了したら、対象物体を認識しつつ、学習することも可能となる。また、教師画像から抽出する特徴量の数×対象物体を認識するための属性の数のSOINNで学習を行うことで、転移学習が可能な認識装置を構成することができる。
【0103】
<3>本発明の実施の形態3.
次に、本発明の実施の形態3にかかるクラス識別システムについて説明する。本実施の形態にかかるクラス識別システムは、上述の実施の形態1又は2により学習された属性識別器を使用して、未知のクラスを識別するシステムである。
【0104】
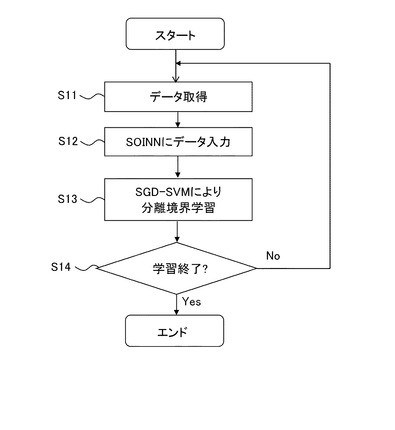
図9は、本実施の形態にかかるクラス識別システムを示す図である。図9に示すように、クラス識別システム200は、データセット220、特徴量抽出部212、ラベリング部211、属性認識部210、属性出力部217及びクラス認識結果出力部219を有する。
【0105】
特徴量抽出部212は、入力データから特徴量を重みベクトルとして抽出する。特徴量抽出部212の入力データは、属性識別器の学習フェーズでは教師データであり、認識フェーズでは、未知クラスの認識対象データである。特徴量抽出部212は、特徴量としては、上述したように、SIFT特徴量、SURF特徴量、rg−SIFT特徴量、PHOG特徴量、cq特徴量、Lss−histogram特徴量等(特徴量F1,F2,・・・,Fk)を抽出する。
【0106】
属性認識部210は、上述の属性識別器生成装置10により生成された複数の属性識別器201(2011〜201M)を有している。属性識別器201は、特徴量抽出部212により抽出された重みベクトル(F1〜Fk)毎に、属性の数M個分設けられており、当該入力データが各属性を有しているか否かを判断する。すなわち、属性認識部210は、認識対象データに含まれるクラスがいずれの属性を有するか判断することができ、クラスを識別するために必要な数(特徴数×属性数)の属性識別器201を備える。
【0107】
属性出力部217は、属性認識部210で識別された属性を属性ベクトルとして出力する。
【0108】
クラス認識結果出力部219は、クラスと属性の関係を有するクラス−属性辞書データ221に基づき、属性出力部217から出力された属性ベクトルに対するクラスを検出し、検出結果として出力する。
【0109】
ここで、本実施の形態にかかるクラス識別システム200は、ラベリング部211を有しており、教師データを入力する場合は、特徴量抽出部212で抽出された特徴量に、属性のラベルを付すことができ、このラベル付き特徴量を使用して属性識別器を学習することができる。
【0110】
すなわち、属性認識部210は、例えば上述の実施の形態2に示す、Adjusted−SOINNからなる特徴量学習部13及び重みの推定に確率的勾配降下法(SGD)を使用したSVMからなる分離境界学習部15を有するものとすることができる。これにより、データセット220として、教師データを与えれば、属性識別器を学習することができる。
【0111】
なお、クラス識別器としては、ラベリング部211を備える必要はなく、属性認識部210は、学習終了後の学習結果を属性識別器として具備すればよい。クラス識別システム200は、通信部を備えたパーソナルコンピュータ(PC)等と同様の構成とすることができ、通信部を介して必要な属性識別器を取得するようにしてもよい。
【0112】
また、辞書データ221を有して、属性識別結果をクラスに変換して出力するようにしたが、与えられる未知クラスのデータの識別結果として、属性ベクトルを出力するようにしてもよい。例えば、本クラス識別システム200をスピーカを具備したロボット等に搭載した場合、入力データの識別結果として、属性ベクトルに基づき、入力データの特徴、例えばライオンのように足が4本で肉食の動物である、○○と同様に熱帯地域に生息している、等の情報を出力させることができる。
【0113】
次に、本実施の形態にかかるクラス識別方法について説明する。図10は、画像、属性及びクラスの関係を説明する図、図11は、クラス識別方法を示す図である。図10に示すように、画像の特徴Xから、この画像がいずれの属性を有するか否かを検出することができる。先ず、図11の(1)に示すように、未知クラスの画像がクラス識別システム200に入力される。入力画像は、特徴量抽出部212により、特徴量を抽出する。これを属性認識部210に入力し(図11の(2))、それぞれの属性が存在する(ポジティブ)、
又は存在しない(ネガティブ)を判定する(図11の(3))。例えば、ここでは、属性attr1〜attr6の6つの属性について、その有無が検出される。
【0114】
つまり、特徴量を重みベクトルとして、学習済みのSOINNに入力した場合に、図7、図8に示すような分離境界のポジティブ側に入力ノードが位置すれば、当該属性についてはポジティブである。一方、分離境界のネガティブ側に入力ノードが位置すれば、当該属性はネガティブである。
【0115】
そうして、判定された結果は、属性出力部217から属性ベクトル(属性記述子)として出力される(図11の(4))。
【0116】
図10に示すように、学習クラスYの属性aを学習することで、未知クラスZを属性で認識することができる。例えば、未知クラスの画像の属性を出力するだけでなく、所定の属性を有する画像を抽出することも可能である。
【0117】
<4>ハードウェア構成
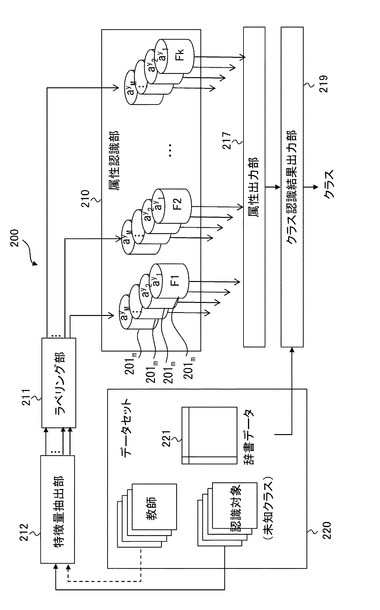
以上に説明した属性識別器生成装置10における属性識別器生成処理、クラス識別システム200におけるクラス識別処理システム200、属性認識部210における属性認識処理等の各処理は、専用コンピュータ、又はパーソナルコンピュータ(PC)などのコンピュータにより実現可能である。但し、コンピュータは、物理的に単一である必要はなく、分散処理を実行する場合には、複数であってもよい。図12は、属性識別器生成装置10やクラス識別システム200を実施するコンピュータの一例を示す図である。図12に示すように、コンピュータ500は、CPU501(Central Processing Unit)、ROM502(Read Only Memory)及びRAM503(Random Access Memory)を有し、これらがバス504を介して相互に接続されている。なお、コンピュータを動作させるためのOSソフトなどは、説明を省略するが、この属性識別器生成装置10、クラス識別システム200、属性認識部210等を構築するコンピュータも当然備えているものとする。
【0118】
また、バス504には入出力インターフェース505も接続されている。入出力インターフェース505には、例えば、キーボード、マウス、センサなどよりなる入力部506、CRT、LCDなどよりなるディスプレイ、並びにヘッドフォンやスピーカなどよりなる出力部507、ハードディスクなどより構成される記憶部508、モデム、ターミナルアダプタなどより構成される通信部509などが接続されている。
【0119】
CPU501は、ROM502に記憶されている各種プログラム、又は記憶部508からRAM503にロードされた各種プログラムに従って各種の処理を実行する。本実施例においては、例えば、特徴量学習部13による特徴量学習処理、分離境界学習部15による分離境界学習処理を含む、属性識別器生成装置10における属性識別器生成処理、特徴量抽出部212における特徴量抽出処理、属性認識部210における属性認識処理、クラス認識結果出力部219におけるクラス認識結果出力処理等を含む、クラス識別システム200におけるクラス認識処理等の処理を実行する。RAM503にはまた、CPU501が各種の処理を実行する上において必要なデータなども適宜記憶される。
【0120】
ここで、各種コンピュータプログラムは、様々なタイプの非一時的なコンピュータ可読媒体(non-transitory computer readable medium)を用いて格納され、コンピュータに供給することができる。非一時的なコンピュータ可読媒体は、様々なタイプの実体のある記録媒体(tangible storage medium)を含む。非一時的なコンピュータ可読媒体の例は、磁気記録媒体(例えばフレキシブルディスク、磁気テープ、ハードディスクドライブ)、光磁気記録媒体(例えば光磁気ディスク)、CD−ROM(Read Only Memory)、CD−R、CD−R/W、半導体メモリ(例えば、マスクROM、PROM(Programmable ROM)、EPROM(Erasable PROM)、フラッシュROM、RAM(random access memory))を含む。また、プログラムは、様々なタイプの一時的なコンピュータ可読媒体(transitory computer readable medium)によってコンピュータに供給されてもよい。一時的なコンピュータ可読媒体の例は、電気信号、光信号、及び電磁波を含む。一時的なコンピュータ可読媒体は、電線及び光ファイバ等の有線通信路、又は無線通信路を介して、プログラムをコンピュータに供給できる。
【0121】
通信部509は、例えば図示しないインターネットを介しての通信処理を行ったり、CPU501から提供されたデータを送信したり、通信相手から受信したデータをCPU501、RAM503、記憶部508に出力したりする。例えば、属性認識部210は、属性識別器生成装置10により学習された属性識別器を、インターネットを介して入手することができる。記憶部508はCPU501との間でやり取りし、情報の保存・消去を行う。通信部509は又、他の装置との間で、アナログ信号又はディジタル信号の通信処理を行う。
【0122】
入出力インターフェース505は、必要に応じてドライブ510が接続され、例えば、磁気ディスク511、光ディスク512、フレキシブルディスク513、又は半導体メモリ514などが適宜装着され、それらから読み出されたコンピュータプログラムが必要に応じて記憶部508にインストールされる。
【0123】
<5>実施例
以下、本発明にかかる属性識別器生成装置10により実際に属性識別器を学習により生成し、これを使用した認識率の実際に求めた本発明の実施例について説明する。実施例としては、先に研究がなされている非特許文献1(以下、比較例とする。)と同一のデータセットを使用し学習した結果をテストした。
【0124】
学習には、24000枚、40クラスの教師データを使用した。教師データは、40の全く異なるクラスの画像データからなる。また認識率テストには、6180枚、10の未知のクラスの画像を使用した。学習及び認識には、比較例と同様に、85の属性、6つの特徴量(カラーヒストグラム、局所自己相似性(local self similarity(Shechtman, E. and Irani, M.: Matching Local Self-Similarities across Images and Videos. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2007))、pHOG(Bosch, A., Zisserman, A. and Munoz, X.: Representing shape with a spatial pyramid kernel. In Computer Vision and Image Understanding (CVIU) (2007))、SIFT(Lowe, D.G.: Distinctive image features from scale-invariant keypoints. IJCV (2004))、RGSIFT(Sande, K., Gevers, T., Snoek, C.: Evaluation of color descriptors for object and scene recognition. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (2008))、及びSURF(Bay, H., Ess. A., Tuytelaars, T. and Gool. L. V.: SURF: Speeded Up Robust Features. In Computer Vision and Image Understanding (CVIU), Vol. 110, No. 3, pp. 346-359 (2008)))を使用した。
【0125】
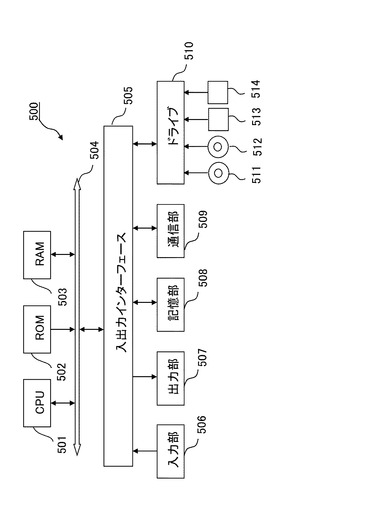
図13及び図14は、本発明の実施例及び比較例にかかる平均認識率及びその計算時間を示す。図13に示すように、本実施の形態1及び2の方法、つまり、教師データを入力する毎にSOINNとSGD−SVMを実施した場合、全教師データをSOINNで学習してから分離境界を学習した場合、共に比較例2より高い認識率となった。なお、比較例1は、完全オフライン手法であり、全ての学習データに対する最適な識別器を用意することができるため、認識率が高くなっている。これに対して、本発明は、学習データが追加されると仮定して学習を実行する。よって、教示画像が入力されているその時の学習データに適する識別器で識別を行うため、識別率が比較例1より若干低いものとなっているが、完全オンラインでの学習が可能である。
【0126】
さらに、図14に示すように、比較例1、2の学習時間は、40クラスで約1ヶ月と極めて長時間であるのに対し、本実施の形態1、2の方法であると約10分で学習が終了する。すなわち、92.25%学習時間を短縮することができる。
【0127】
さらに、比較例1、2の方法では、1画像のクラス認識するために30秒かかっているのに対し、本実施の形態1、2の方法であると、数ミリ秒で画像1枚の認識結果を得ることができる。比較例1、2のように、オンラインで学習できないのに加えて、1枚の画像のクラス識別に30秒という長い時間を要すると、例えばロボット等に当該システムを搭載してリアルタイムに画像を取得し、認識するようなことは不可能となる。
【0128】
なお、比較例3は、SGD−SVMを利用したオンラインでの学習が可能な方法であり、学習時間、認識時間共に、本実施の形態1、2の方法と同等であるが、本実施の形態1、2のように、SOINNを利用してないため、認識率が劣る。ここで、本実施例は、比較例1、2が提供している画像を元に実施しているが、認識率は、学習画像を増やせば向上すると考えられる。例えばさらなる教師画像にノイズが多く含まれている場合、本実施の形態1、2にかかる認識率は向上するものと考えられる。一方で、比較例3は、SOINNを利用していないため、ノイズの影響が大きいと考えられ、学習時間の増加に対する認識率の向上は、本実施の形態1、2、の方法以下であると予想できる。
【0129】
以上、本実施の形態にかかる方法による属性識別器の学習により、比較例と同等の認識率で、かつ学習時間、認識時間を、92.25%削減することができた。
【0130】
なお、本発明は上述した実施の形態のみに限定されるものではなく、本発明の要旨を逸脱しない範囲において種々の変更が可能であることは勿論である。
【符号の説明】
【0131】
10 属性識別器生成装置
11 ラベリング部
12 特徴量抽出部
13 特徴量学習部
15 分離境界学習部
131 勝者ノード抽出部
133 ノード挿入部
135 エッジ管理部
137 ノード重み更新部
139 ノード削除部
200 クラス識別システム
201 属性識別器
210 属性認識部
211 ラベリング部
212 特徴量抽出部
217 属性出力部
219 クラス認識結果出力部
220 データセット
221 辞書データ
【特許請求の範囲】
【請求項1】
ある属性を有するか否かを識別する属性識別器を、教師データの特徴量を学習することにより生成する識別器生成装置であって、
入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとするラベリング部と、
前記教師データの特徴量を重みベクトルとして抽出する特徴量抽出部と、
自己増殖型ネットワークにより、前記特徴量抽出部が抽出した特徴量を学習する特徴量学習部と、
前記各重みベクトルが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)により当該ポジティブノードとネガティブノードの分離境界を学習する分離境界学習部とを有し、
前記特徴量学習部は、
前記特徴量抽出部にて抽出された重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノード及び2番目に近いノードをそれぞれ第1勝者ノード及び第2勝者ノードとして抽出する勝者ノード抽出部と、
前記入力ノードと、前記第1及び第2勝者ノードとの距離に基づき、当該入力ノードを新たなノードとして挿入するか否かを判定するノード挿入判定部と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードと前記第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とし、エッジがある場合はその年齢を0とし、さらに前記第1勝者ノードが有する全エッジの年齢をインクリメントし、所定の年齢に達したエッジを削除するエッジ管理部と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードの重みベクトルを当該入力ノードの重みベクトルに基づき更新するノード重み更新部と、
所定のタイミングで、そのノード密度に応じてノードを削除するノード削除部とを有する識別器生成装置。
【請求項2】
前記教師データを前記特徴量学習部に入力する毎に、前記分離境界学習部により前記分離境界を生成又は更新する、請求項1記載の識別器生成装置。
【請求項3】
複数の前記教師データを前記特徴量学習部に入力して特徴量を学習した後、前記分離境界学習部により前記分離境界を生成又は更新する、請求項1記載の識別器生成装置。
【請求項4】
前記ノード削除部は、前記教師データを前記特徴量学習部に入力する毎に、全ノードの年齢をインクリメントし、全ノードのうち所定の年齢に達するノードについて、所定数未満のノードとエッジで接続されているノードを削除する、請求項1乃至3のいずれか1項記載の識別器生成装置。
【請求項5】
前記SVMは、線形SVMであり、重みの推定に確率的勾配降下法(stochastic gradient descent (SGD))を使用したものである、請求項1乃至4のいずれか1項記載の識別器生成装置。
【請求項6】
ある属性を有するか否かを識別する属性識別器を、教師データの特徴量を学習することにより生成する識別器生成装置であって、
入力データの特徴量を重みベクトルとして抽出し、当該特徴量に、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けした教師データを入力とし、自己増殖型ネットワークにより、前記特徴量を学習する特徴量学習部と、
前記各重みベクトルが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)により当該ポジティブノードとネガティブノードの分離境界を学習する分離境界学習部とを有し、
前記特徴量学習部は、
前記重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノード及び2番目に近いノードをそれぞれ第1勝者ノード及び第2勝者ノードとして抽出する勝者ノード抽出部と、
前記入力ノードと、前記第1及び第2勝者ノードとの距離に基づき、当該入力ノードを新たなノードとして挿入するか否かを判定するノード挿入判定部と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードと前記第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とし、エッジがある場合はその年齢を0とし、さらに前記第1勝者ノードが有する全エッジの年齢をインクリメントし、所定の年齢に達したエッジを削除するエッジ管理部と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードの重みベクトルを当該入力ノードの重みベクトルに基づき更新するノード重み更新部と、
所定のタイミングで、そのノード密度に応じてノードを削除するノード削除部とを有する識別器生成装置。
【請求項7】
ある属性を有するか否かを識別する属性識別器を、教師データの特徴量を学習することにより生成する識別器生成方法であって、
入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとするラベリング工程と、
前記教師データの特徴量を重みベクトルとして抽出する特徴量抽出工程と、
自己増殖型ネットワークにより、前記特徴量抽出工程にて抽出された特徴量を学習する特徴量学習工程と、
前記各重みベクトルが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)により当該ポジティブノードとネガティブノードの分離境界を学習する分離境界生成工程とを有し、
前記特徴量学習工程は、
前記特徴量抽出工程にて抽出された重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノード及び2番目に近いノードをそれぞれ第1勝者ノード及び第2勝者ノードとして抽出する勝者ノード抽出工程と、
前記入力ノードと、前記第1及び第2勝者ノードとの距離に基づき、当該入力ノードを新たなノードとして挿入するか否かを判定するノード挿入判定工程と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードと前記第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とし、エッジがある場合はその年齢を0とし、さらに前記第1勝者ノードが有する全エッジの年齢をインクリメントし、所定の年齢に達したエッジを削除するエッジ管理工程と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードの重みベクトルを当該入力ノードの重みベクトルに基づき更新するノード重み更新工程と、
所定のタイミングで、そのノード密度に応じてノードを削除するノード削除工程とを有する識別器生成方法。
【請求項8】
新たな前記教師データ入力する毎に、前記教師データから特徴量を学習する前記特徴量学習工程と、分離境界を学習する前記分離境界学習工程とを繰り返す、請求項7記載の識別器生成方法。
【請求項9】
複数の前記教師データから前記特徴量学習工程にて特徴量を学習した後、前記分離境界学習工程にて前記分離境界を生成又は更新する、請求項7記載の識別器生成方法。
【請求項10】
ある属性を有するか否かを識別する属性識別器を、教師データの特徴量を学習することにより生成する処理をコンピュータに実行させるためのプログラムであって、
入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとするラベリング処理と、
前記教師データの特徴量を重みベクトルとして抽出する特徴量抽出処理と、
自己増殖型ネットワークにより、前記特徴量抽出処理にて抽出された特徴量を学習する特徴量学習処理と、
前記各重みベクトルが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)により当該ポジティブノードとネガティブノードの分離境界を学習する分離境界生成処理とを実行するものであって、
前記特徴量学習処理では、
前記特徴量抽出処理にて抽出された重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノード及び2番目に近いノードをそれぞれ第1勝者ノード及び第2勝者ノードとして抽出する勝者ノード抽出処理と、
前記入力ノードと、前記第1及び第2勝者ノードとの距離に基づき、当該入力ノードを新たなノードとして挿入するか否かを判定するノード挿入判定処理と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードと前記第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とし、エッジがある場合はその年齢を0とし、さらに前記第1勝者ノードが有する全エッジの年齢をインクリメントし、所定の年齢に達したエッジを削除するエッジ管理処理と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードの重みベクトルを当該入力ノードの重みベクトルに基づき更新するノード重み更新処理と、
所定のタイミングで、そのノード密度に応じてノードを削除するノード削除処理とが実行される、プログラム。
【請求項11】
入力データから特徴量を重みベクトルとして抽出する特徴量抽出部と、
前記特徴量抽出部により抽出された重みベクトルから、当該入力データがいずれの属性を有しているかを判断する、複数の属性識別器からなる属性認識部と、
属性認識部で識別された属性を属性ベクトルとして出力する属性出力部とを備え、
前記属性識別器は、請求項1乃至6に記載の識別器生成装置で学習され生成されたものであって、
前記属性認識部は、前記入力データに含まれる認識対象であるクラスがいずれの属性を有するか判断するものであり、当該クラスを識別するために必要な数の属性に対応する前記属性識別器を備える、クラス識別器。
【請求項12】
前記属性認識部は、前記入力データから抽出する特徴量の種類をN種類(Nは1以上の自然数)、クラスを識別するために必要な数の属性をM個(Mは1以上の自然数)とすると、N×Mの属性識別器を有する、請求項11記載のクラス識別器。
【請求項13】
クラスと属性の関係を有するクラス−属性辞書に基づき、前記属性出力部から出力された属性ベクトルに対するクラスを検出し、検出結果として出力するクラス認識結果出力部を更に有する、請求項10又は11記載のクラス識別器。
【請求項14】
入力データから特徴量を重みベクトルとして抽出する特徴量抽出工程と、
前記特徴量抽出工程にて抽出された重みベクトルから、複数の属性識別器により、当該入力データがいずれの属性を有しているかを判断する属性認識工程と、
属性認識工程にて識別された属性を属性ベクトルとして出力する属性出力工程とを備え、
前記属性識別器は、請求項7乃至9に記載の識別器生成方法で学習され生成されたものであって、
前記属性認識工程では、前記入力データに含まれる認識対象であるクラスがいずれの属性を有するか判断するものであり、当該クラスを識別するために必要な数の属性に対応する前記属性識別器を使用する、クラス識別方法。
【請求項15】
入力データから特徴量を重みベクトルとして抽出する特徴量抽出処理と、
前記特徴量抽出処理にて抽出された重みベクトルから、複数の属性識別器により、当該入力データがいずれの属性を有しているかを判断する属性認識処理と、
属性認識処理にて識別された属性を属性ベクトルとして出力する属性出力処理とをコンピュータに実行させるためのプログラムであって、
前記属性識別器は、請求項10に記載の識別器生成プログラムで学習され生成されたものであり、
前記属性認識処理では、前記入力データに含まれる認識対象であるクラスがいずれの属性を有するか判断するものであり、当該クラスを識別するために必要な数の属性に対応する前記属性識別器を使用する、プログラム。
【請求項1】
ある属性を有するか否かを識別する属性識別器を、教師データの特徴量を学習することにより生成する識別器生成装置であって、
入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとするラベリング部と、
前記教師データの特徴量を重みベクトルとして抽出する特徴量抽出部と、
自己増殖型ネットワークにより、前記特徴量抽出部が抽出した特徴量を学習する特徴量学習部と、
前記各重みベクトルが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)により当該ポジティブノードとネガティブノードの分離境界を学習する分離境界学習部とを有し、
前記特徴量学習部は、
前記特徴量抽出部にて抽出された重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノード及び2番目に近いノードをそれぞれ第1勝者ノード及び第2勝者ノードとして抽出する勝者ノード抽出部と、
前記入力ノードと、前記第1及び第2勝者ノードとの距離に基づき、当該入力ノードを新たなノードとして挿入するか否かを判定するノード挿入判定部と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードと前記第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とし、エッジがある場合はその年齢を0とし、さらに前記第1勝者ノードが有する全エッジの年齢をインクリメントし、所定の年齢に達したエッジを削除するエッジ管理部と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードの重みベクトルを当該入力ノードの重みベクトルに基づき更新するノード重み更新部と、
所定のタイミングで、そのノード密度に応じてノードを削除するノード削除部とを有する識別器生成装置。
【請求項2】
前記教師データを前記特徴量学習部に入力する毎に、前記分離境界学習部により前記分離境界を生成又は更新する、請求項1記載の識別器生成装置。
【請求項3】
複数の前記教師データを前記特徴量学習部に入力して特徴量を学習した後、前記分離境界学習部により前記分離境界を生成又は更新する、請求項1記載の識別器生成装置。
【請求項4】
前記ノード削除部は、前記教師データを前記特徴量学習部に入力する毎に、全ノードの年齢をインクリメントし、全ノードのうち所定の年齢に達するノードについて、所定数未満のノードとエッジで接続されているノードを削除する、請求項1乃至3のいずれか1項記載の識別器生成装置。
【請求項5】
前記SVMは、線形SVMであり、重みの推定に確率的勾配降下法(stochastic gradient descent (SGD))を使用したものである、請求項1乃至4のいずれか1項記載の識別器生成装置。
【請求項6】
ある属性を有するか否かを識別する属性識別器を、教師データの特徴量を学習することにより生成する識別器生成装置であって、
入力データの特徴量を重みベクトルとして抽出し、当該特徴量に、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けした教師データを入力とし、自己増殖型ネットワークにより、前記特徴量を学習する特徴量学習部と、
前記各重みベクトルが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)により当該ポジティブノードとネガティブノードの分離境界を学習する分離境界学習部とを有し、
前記特徴量学習部は、
前記重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノード及び2番目に近いノードをそれぞれ第1勝者ノード及び第2勝者ノードとして抽出する勝者ノード抽出部と、
前記入力ノードと、前記第1及び第2勝者ノードとの距離に基づき、当該入力ノードを新たなノードとして挿入するか否かを判定するノード挿入判定部と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードと前記第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とし、エッジがある場合はその年齢を0とし、さらに前記第1勝者ノードが有する全エッジの年齢をインクリメントし、所定の年齢に達したエッジを削除するエッジ管理部と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードの重みベクトルを当該入力ノードの重みベクトルに基づき更新するノード重み更新部と、
所定のタイミングで、そのノード密度に応じてノードを削除するノード削除部とを有する識別器生成装置。
【請求項7】
ある属性を有するか否かを識別する属性識別器を、教師データの特徴量を学習することにより生成する識別器生成方法であって、
入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとするラベリング工程と、
前記教師データの特徴量を重みベクトルとして抽出する特徴量抽出工程と、
自己増殖型ネットワークにより、前記特徴量抽出工程にて抽出された特徴量を学習する特徴量学習工程と、
前記各重みベクトルが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)により当該ポジティブノードとネガティブノードの分離境界を学習する分離境界生成工程とを有し、
前記特徴量学習工程は、
前記特徴量抽出工程にて抽出された重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノード及び2番目に近いノードをそれぞれ第1勝者ノード及び第2勝者ノードとして抽出する勝者ノード抽出工程と、
前記入力ノードと、前記第1及び第2勝者ノードとの距離に基づき、当該入力ノードを新たなノードとして挿入するか否かを判定するノード挿入判定工程と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードと前記第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とし、エッジがある場合はその年齢を0とし、さらに前記第1勝者ノードが有する全エッジの年齢をインクリメントし、所定の年齢に達したエッジを削除するエッジ管理工程と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードの重みベクトルを当該入力ノードの重みベクトルに基づき更新するノード重み更新工程と、
所定のタイミングで、そのノード密度に応じてノードを削除するノード削除工程とを有する識別器生成方法。
【請求項8】
新たな前記教師データ入力する毎に、前記教師データから特徴量を学習する前記特徴量学習工程と、分離境界を学習する前記分離境界学習工程とを繰り返す、請求項7記載の識別器生成方法。
【請求項9】
複数の前記教師データから前記特徴量学習工程にて特徴量を学習した後、前記分離境界学習工程にて前記分離境界を生成又は更新する、請求項7記載の識別器生成方法。
【請求項10】
ある属性を有するか否かを識別する属性識別器を、教師データの特徴量を学習することにより生成する処理をコンピュータに実行させるためのプログラムであって、
入力データに、ある属性を有するか否かを示すポジティブ又はネガティブ情報をラベル付けして教師データとするラベリング処理と、
前記教師データの特徴量を重みベクトルとして抽出する特徴量抽出処理と、
自己増殖型ネットワークにより、前記特徴量抽出処理にて抽出された特徴量を学習する特徴量学習処理と、
前記各重みベクトルが有するポジティブ又はネガティブ情報に基づき、サポートベクタマシン(SVM)により当該ポジティブノードとネガティブノードの分離境界を学習する分離境界生成処理とを実行するものであって、
前記特徴量学習処理では、
前記特徴量抽出処理にて抽出された重みベクトルを入力ノードとし、当該入力ノードと各ノードとの間の距離を算出し、当該入力ノードと最も近いノード及び2番目に近いノードをそれぞれ第1勝者ノード及び第2勝者ノードとして抽出する勝者ノード抽出処理と、
前記入力ノードと、前記第1及び第2勝者ノードとの距離に基づき、当該入力ノードを新たなノードとして挿入するか否かを判定するノード挿入判定処理と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードと前記第2勝者ノードとの間にエッジがない場合はエッジを生成しその年齢を0とし、エッジがある場合はその年齢を0とし、さらに前記第1勝者ノードが有する全エッジの年齢をインクリメントし、所定の年齢に達したエッジを削除するエッジ管理処理と、
前記入力ノードを新たなノードとして挿入しない場合、前記第1勝者ノードの重みベクトルを当該入力ノードの重みベクトルに基づき更新するノード重み更新処理と、
所定のタイミングで、そのノード密度に応じてノードを削除するノード削除処理とが実行される、プログラム。
【請求項11】
入力データから特徴量を重みベクトルとして抽出する特徴量抽出部と、
前記特徴量抽出部により抽出された重みベクトルから、当該入力データがいずれの属性を有しているかを判断する、複数の属性識別器からなる属性認識部と、
属性認識部で識別された属性を属性ベクトルとして出力する属性出力部とを備え、
前記属性識別器は、請求項1乃至6に記載の識別器生成装置で学習され生成されたものであって、
前記属性認識部は、前記入力データに含まれる認識対象であるクラスがいずれの属性を有するか判断するものであり、当該クラスを識別するために必要な数の属性に対応する前記属性識別器を備える、クラス識別器。
【請求項12】
前記属性認識部は、前記入力データから抽出する特徴量の種類をN種類(Nは1以上の自然数)、クラスを識別するために必要な数の属性をM個(Mは1以上の自然数)とすると、N×Mの属性識別器を有する、請求項11記載のクラス識別器。
【請求項13】
クラスと属性の関係を有するクラス−属性辞書に基づき、前記属性出力部から出力された属性ベクトルに対するクラスを検出し、検出結果として出力するクラス認識結果出力部を更に有する、請求項10又は11記載のクラス識別器。
【請求項14】
入力データから特徴量を重みベクトルとして抽出する特徴量抽出工程と、
前記特徴量抽出工程にて抽出された重みベクトルから、複数の属性識別器により、当該入力データがいずれの属性を有しているかを判断する属性認識工程と、
属性認識工程にて識別された属性を属性ベクトルとして出力する属性出力工程とを備え、
前記属性識別器は、請求項7乃至9に記載の識別器生成方法で学習され生成されたものであって、
前記属性認識工程では、前記入力データに含まれる認識対象であるクラスがいずれの属性を有するか判断するものであり、当該クラスを識別するために必要な数の属性に対応する前記属性識別器を使用する、クラス識別方法。
【請求項15】
入力データから特徴量を重みベクトルとして抽出する特徴量抽出処理と、
前記特徴量抽出処理にて抽出された重みベクトルから、複数の属性識別器により、当該入力データがいずれの属性を有しているかを判断する属性認識処理と、
属性認識処理にて識別された属性を属性ベクトルとして出力する属性出力処理とをコンピュータに実行させるためのプログラムであって、
前記属性識別器は、請求項10に記載の識別器生成プログラムで学習され生成されたものであり、
前記属性認識処理では、前記入力データに含まれる認識対象であるクラスがいずれの属性を有するか判断するものであり、当該クラスを識別するために必要な数の属性に対応する前記属性識別器を使用する、プログラム。
【図1】

【図2】
【図3】
【図4】
【図5】
【図9】
【図12】
【図13】
【図14】
【図6】
【図7】
【図8】
【図10】
【図11】
【図15】
【図2】
【図3】
【図4】
【図5】
【図9】
【図12】
【図13】
【図14】
【図6】
【図7】
【図8】
【図10】
【図11】
【図15】
【公開番号】特開2013−25398(P2013−25398A)
【公開日】平成25年2月4日(2013.2.4)
【国際特許分類】
【出願番号】特願2011−157044(P2011−157044)
【出願日】平成23年7月15日(2011.7.15)
【出願人】(304021417)国立大学法人東京工業大学 (1,821)
【出願人】(000003207)トヨタ自動車株式会社 (59,920)
【公開日】平成25年2月4日(2013.2.4)
【国際特許分類】
【出願日】平成23年7月15日(2011.7.15)
【出願人】(304021417)国立大学法人東京工業大学 (1,821)
【出願人】(000003207)トヨタ自動車株式会社 (59,920)
[ Back to top ]