
質量分析システム
【課題】同一タンパク質に由来するペプチド種を重複して分析することを回避することができる質量分析システムを提供する。
【解決手段】1回目の分析において、MS2マススペクトルから試料に含まれるタンパク質のうちタンパク質データベースに既に格納されているタンパク質候補をリアルタイムにて推定する。2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、タンパク質候補に含まれるペプチドを親イオンの選択対象から除外する。
【解決手段】1回目の分析において、MS2マススペクトルから試料に含まれるタンパク質のうちタンパク質データベースに既に格納されているタンパク質候補をリアルタイムにて推定する。2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、タンパク質候補に含まれるペプチドを親イオンの選択対象から除外する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は質量分析システムおよび質量分析方法に関し、特にタンパク質、ポリペプチド等の生体高分子を分析するための質量分析システム、分析方法に関する。
【背景技術】
【0002】
一般的な質量分析方法では、対象となる試料をイオン化して、それらのイオンを質量分析装置へ送る。質量分析装置では、送られてきたイオンに対して質量(m)と価数(z)の比からなる質量対電荷比(m/z)毎にイオン強度を測定する。この結果として、横軸が質量対電荷比(m/z)、縦軸がイオン強度のマススペクトルを得ることができる。
【0003】
質量分析方法には、試料をイオン化しそのまま測定するMS分析法と試料をイオン化して測定した後に、ある特定のイオンを選択し解離させて測定するタンデム質量分析法がある。タンデム質量分析法において解離の対象となるイオンを親イオンと呼ぶ。タンデム質量分析法では、解離させたイオンから得たマススペクトルから更に親イオンを選択し解離させて質量分析するといったように、多段に解離と質量分析を行う機能がある。以降、n段目の質量分析をMSn質量分析と呼ぶ。また、試料をイオン化して測定して得られるマススペクトルをMSマススペクトル、MSマススペクトルより選択した親イオンを解離させて測定して得られるマススペクトルをMS2マススペクトル、MS2マススペクトルより選択した親イオンを解離させて測定して得られるマススペクトルをMS3マススペクトル等と呼ぶ。
【0004】
タンデム質量分析が行えるほとんどの質量分析装置では、MSマススペクトルから親イオンを自動的に選択してイオン解離を行う機能を有する。
【0005】
生体試料のような様々な成分を多く含む試料に対しては、クロマトグラフと質量分析装置を組み合わせたシステムが多用される。クロマトグラフにおいて物質のカラムへの吸着度の違い等から試料中の成分が時間的に分離されることにより、質量分析装置では分離が困難なイオン種の分離が可能となる。
【0006】
質量分析システムでは、1度の測定において分析を繰り返して行う。このとき、同一タンパク質に由来するペプチド種を重複して解離して分析する。同成分を重複して分析することは試料や時間を浪費することとなる。そこで同成分の重複分析を行わないための手法が特許文献1や特許文献2に記載されている。
【0007】
(1)特許文献1の方法では、タンデム質量分析においてN回目までに解離を行ったイオンの情報(イオン質量、イオン強度、マススペクトルの質など)をリアルタイムに内部データベースとして登録する。この内部データベースの情報を利用してN+1回目の測定において親イオン選択の制限を行う。
【0008】
(2)特許文献2の方法では、タンデム質量分析において保持時間を用いて親イオンの選択を制限する。具体的には、MS2マススペクトルデータからアミノ酸配列を予測し、そのアミノ酸配列から予想される保持時間と実際の保持時間を比較する。比較の結果、一致する場合はそのアミノ酸配列を信頼性の高いデータとみなして測定を終了し、一致しない場合には他の親イオンの解離またはMS3質量分析を行いさらに情報の取得を行う。
【0009】
【特許文献1】特開2005−91344
【特許文献2】特開2005−241251
【発明の開示】
【発明が解決しようとする課題】
【0010】
特許文献1に記載された方法では、親イオンの選択に制限を与えることができるのは、同一質量の成分のみである。タンパク質を酵素で分解し生成するペプチドは複数ある。あるペプチドを分析したときに、そこからタンパク質が十分に予想しうる場合は、そのタンパク質に由来するペプチド以外のものを分析することが効率的といえるが、特許文献1の方法では既に分析したペプチドしか選択の制限を行えない。
【0011】
また、特許文献2に記載された方法では、特許文献1と同様に親イオンの選択の制限を行えるのはある質量の成分のみであり、同一タンパク質に由来するペプチドの選択の制限を行うことはできない。
【0012】
本発明の目的は、同一タンパク質に由来するペプチド種を重複して解離して分析することを回避することができる質量分析システムを提供することにある。
【課題を解決するための手段】
【0013】
本発明によると、1回目の分析において、MS2マススペクトルを用いて試料に含まれるタンパク質のうちタンパク質データベースに既に格納されているタンパク質候補をリアルタイムにて推定する。2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、タンパク質候補に含まれるペプチド以外のペプチドを親イオンとして選択する。
【発明の効果】
【0014】
本発明によれば、同一タンパク質に由来するペプチド種を重複して解離して分析することを回避することができる。
【発明を実施するための最良の形態】
【0015】
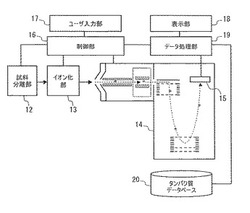
以下に本発明の実施例を示す。図1を参照して本発明による質量分析装置の概要を説明する。本例の質量分析装置は、試料分離部12、イオン化部13、質量分析部14、イオン検出部15、制御部16、ユーザ入力部17、表示部18、データ処理部19、及び、タンパク質データベース20を有する。
【0016】
上述のように、質量分析方法には、試料をイオン化し、それを質量分析し、MSマススペクトルを得るMS質量分析法と、MSマススペクトルから1個のペプチドを親イオンとして選択し、それを解離させ、質量分析し、MS2マススペクトルを得るタンデム質量分析法がある。タンデム質量分析法は、解離段階ごとに親イオンの分子構造情報を得られるため、親イオンの構造を推定する上で有効となる。以下では、タンデム質量分析法について説明する。
【0017】
試料分離部12は、液体クロマトグラフ(LC)、ガスクロマトグラフ(GC)等によって構成される。イオン化部13は、エレクトロスプレーイオン化(ESI)、大気圧化学イオン化(APCI)、電子イオン化(EI)、化学イオン化(CI)等のイオン化方法を用いてイオン化を行う。これらのイオン化法のうち、分析の対象とする試料や分析の目的に応じたイオン化法が選択される。
【0018】
質量分析部14は、タンデム質量分析が可能な四重極型質量分析装置、イオントラップ型質量分析装置等によって構成される。親イオンの解離方法には、衝突解離(Collision Induced Dissociation)法や電子捕獲解離(Electron Capture Dissociation)法などがある。衝突解離法はヘリウムなどのバッファーガスをイオンに衝突させて解離する方法であり、電子捕解離法は、低エネルギーの電子を照射し、親イオンに多量に低エネルギー電子を捕獲させることにより解離する方法である。イオン検出部15は、質量対電荷比(m/z)毎にイオン強度を測定する。
【0019】
制御部16は、タンデム質量分析法の一連の分析過程を制御する。ユーザ入力部17は、分析処理や装置を制御するためのユーザインターフェースである。表示部18は、マススペクトル等の分析結果を表示する。データ処理部19は、MSマススペクトルの生成、親イオンの選択、MS2マススペクトルの生成等を行う。タンパク質データベース20は、タンパク質に関する既知のデータを格納する。
【0020】
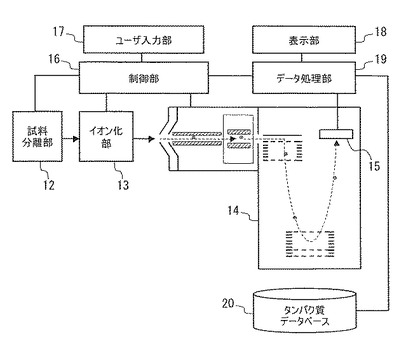
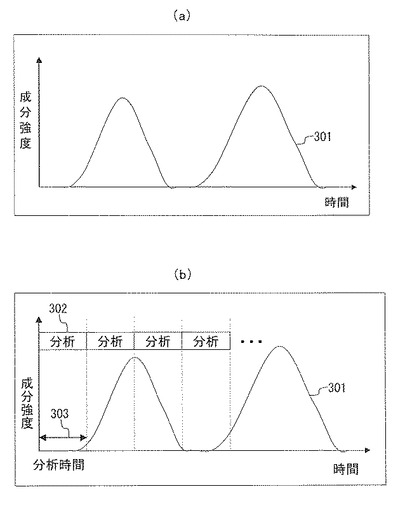
図2を参照して、タンデム質量分析法によってタンパク質を測定する一般的な処理の概要を説明する。先ずステップS101にて、試料分離部12に、試料を含む溶液を導入する。ステップS102にて、試料分離部12は、試料を分離する。上述のように、試料の分離法には、液体クロマトグラフ(LC)、ガスクロマトグラフ(GC)等がある。図3(a)は、試料の分離結果を示す。上述のようにカラムへの吸着度等の差から、時間的に分離された成分の強度のピークが現れる。このように試料の時間的な分離結果をクロマトグラム301と呼ぶ。
【0021】
ステップS103にて、イオン化部13は、このように時間的に分離された試料をイオン化する。ステップS104にて、質量分析部14は質量分析を行う。これをMS質量分析と称する。ステップS105にて、MS質量分析の結果を得る。これをMSマススペクトルと称する。ステップS106にて、MSマススペクトルより、1個のペプチドを親イオンとして選択して解離する。通常、MSマススペクトルのピークのうち最も強度が大きいピークを親イオンとして選択する。ステップS107にて、解離したイオンを質量分析部14によって質量分析を行う。これをMS2質量分析と称する。ステップS108にて、MS2質量分析の結果を得る。これを、MS2マススペクトルと称する。
【0022】
MSマススペクトル及びMS2マススペクトルは、横軸が質量対電荷比(m/z)、縦軸がイオン強度のピーク(細い棒グラフ)である。MS2マススペクトルには、試料のタンパク質の分子構造を推定するための情報が含まれており、この情報を元にしてタンパク質を推定することが可能である。
【0023】
ステップS103のイオン化から、ステップS104のMS質量分析、ステップS105のMSマススペクトルの取得、ステップS106の親イオンの選択及び解離、ステップS107のMS2質量分析、ステップS108のMS2マススペクトルの取得までの一連の処理を分析と称する。ステップS109にて、再分析を行うか否かを判定する、再分析を行う場合にはステップS103に戻る。再分析を行わない場合には、ステップS110に進む。ステップS110にて、MS2マススペクトル対する後処理を行う。後処理では、ノイズ除去、ピーク判定、同位体ピーク除去等を行い、既知のタンパク質の情報が蓄積されたタンパク質データベース20を検索して、タンパク質の同定を行う。
【0024】
図3(a)は、上述のように試料分離部12によって得られたクロマトグラム301の例を示す。クロマトグラムは、時間的に分離された成分強度のピークを含む。図3(b)は、クロマトグラフ301と分析サイクルの関係を示す。分析302は、図2のステップS103のイオン化から、ステップS108のMS2マススペクトルの取得までの一連の処理である。図示のように、クロマトグラムが得られると、各成分毎に分析302が繰返し行われていることが判る。1回の分析302に要する分析時間303は、分析条件や装置条件等により異なる。1回の測定で多くの分析302を行うためには、分析時間303は短いことが望ましい。
【0025】
このように時間的に分離して得られるクロマトグラフ301に対して、繰り返し分析302を行うことで、様々なイオンのMS2マススペクトルが取得できる。それによって、試料に含まれるタンパク質の構造情報を蓄積していくのが一般的である。
【0026】
タンデム質量分析方法では、タンパク質の同定結果の精度や同定するタンパク質の数は、MS2マススペクトルに依存し、MSマススペクトルからどのように親イオンを選択するかが重要となる。
【0027】
そこで、本発明では、1回目の分析にて、MS2マススペクトルを取得すると、そのアミノ酸解読を行い、リアルタイムで、タンパク質データベースを検索する。タンパク質データベース20に、同一のアミノ酸配列が存在する場合には、そのアミノ酸配列が由来するタンパク質は既に実験済みであると考える。そこで、2回目の分析にて、そのタンパク質に由来する全てのペプチドを親イオンの選択対象から除外する。即ち、そのタンパク質に由来するペプチド以外のペプチドを親イオンとして選択する。こうして、既に、タンパク質データベース20に格納されているタンパク質に由来するペプチドの重複測定を回避することができる。
【0028】
図4、図5及び図6を参照して本発明によるタンデム質量分析方法の第1の例を説明する。ステップS201からステップS208までは、図2を参照して説明した従来のタンデム質量分析方法と同一であってよい。即ち、ステップS201にて、試料分離部12に、試料を含む溶液を導入する。ステップS202にて、試料分離部12は、試料を分離する。ステップS203にて、イオン化部13は、試料をイオン化する。ステップS204にて、質量分析部14は、MS質量分析を行う。ステップS205にて、MSマススペクトルを得る。ステップS206にて、MSマススペクトルより1個のペプチドを親イオンとして選択し、解離する。ステップS207にて、質量分析部14は、解離した親イオンに対してMS2質量分析を行う。ステップS208にて、MS2マススペクトルを得る。
【0029】
ステップS209にて、データ処理部19は、MS2マススペクトルを用いてタンパク質候補の推定を行う。即ち、MS2マススペクトルからアミノ酸配列を解読し、それをタンパク質データベース20から検索する。検索結果として、そのアミノ酸配列を含むと推定されるタンパク質を列挙する。こうしてタンパク質候補のリストを得る。タンパク質候補は、タンパク質データベース20を検索して得られたものである。このようなタンパク質に関するデータは十分に得られていると考えられる。従って、このようなタンパク質候補については重複して分析を行う必要はない。そこで、2回目の分析にて、タンパク質候補に含まれるペプチドを親イオンの選択対象から除外する。
【0030】
タンパク質候補の推定方法の例は、後に、図7を参照して説明する。データ処理部19は、各タンパク質候補の推定精度を計算する。
【0031】
ステップS210にて、データ処理部19は、推定精度が閾値Xより大きいタンパク質候補があるか否かを判定する。推定精度が閾値Xより大きいタンパク質候補がある場合には、ステップS211に進み、推定精度が閾値Xより大きいタンパク質候補がない場合には、1回目の分析は終了し、次の2回目の分析に移る。
【0032】
ステップS211にて、データ処理部19は、推定精度が閾値Xよりも大きいタンパク質候補のペプチド情報の取得を行う。即ち、推定精度が閾値Xよりも大きいタンパク質候補に由来するペプチドの質量を求める。ペプチド情報の取得処理の詳細は、後に、図8を参照して説明する。
【0033】
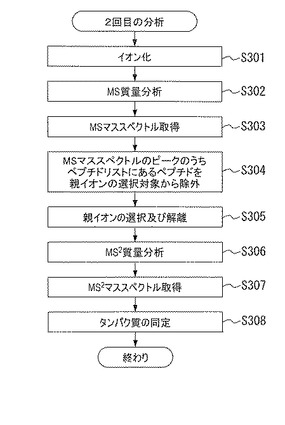
ステップS212にて、データ処理部19は、ペプチド情報の登録を行う。即ち、ペプチドの質量(m)をペプチドリスト600に登録する。ペプチドリスト600は、図6(a)に示すように、ペプチド名601、そのアミノ酸配列602、及び、その質量603のリストである。
【0034】
こうして、MS2マススペクトルを用いてタンパク質候補を推定し、推定したタンパク質候補に関するペプチド情報の取得及び登録処理が終了すると、1回目の分析は終了し、次の2回目の分析に移る。
【0035】
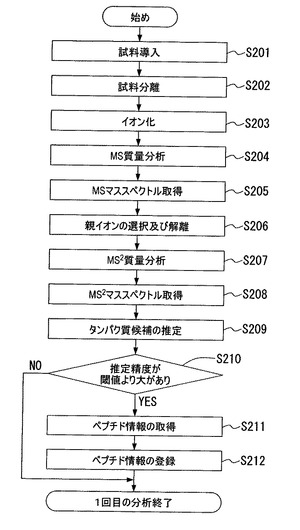
図5を参照して本発明による質量分析方法の第1の例の2回目の分析を説明する。ステップS301にて、イオン化部13は、試料をイオン化する。ステップS302にて、質量分析部14は、MS質量分析を行う。ステップS303にて、MSマススペクトルを得る。
【0036】
ステップS304にて、データ処理部19は、MSマススペクトルのピークのうち、ペプチドリスト600に含まれるデータを親イオンの選択対象より除外する。図6(b)は、MSマススペクトルを示す。この例では、×印のデータの質量がペプチドリストに含まれる。従って、×印のデータを親イオンの選択対象から除外する。
【0037】
ステップS305にて、MSマススペクトルより1個のペプチドを親イオンとして選択し、解離する。上述のように、MSマススペクトルのピークからペプチドリスト600のデータと同一のデータは除外されている。ステップS306にて、質量分析部14は、解離した親イオンに対してMS2質量分析を行う。ステップS307にて、MS2マススペクトルを得る。ステップS308にて、MS2マススペクトルの後処理を行い、タンパク質を同定する。
【0038】
こうして、2回目の分析が終了する。図4の1回目の分析と図5の2回目の分析を比較すると、図5の2回目の分析ではステップS304の処理が付加されている点が異なる。
【0039】
図6を参照して、本発明の質量分析方法の主要部を説明する。図6(a)は、ペプチドリスト600の例を示す。ペプチドリスト600は、ペプチド名601、ペプチド配列602、ペプチド配列の質量603のデータを含み、タンパク質候補毎に作成される。従って、各ペプチドリスト600にはタンパク質名が付与されている。ステップS303にて得られるMSマススペクトルは、横軸が質量対電荷比(m/z)、縦軸がイオン強度のピーク(細い棒グラフ)である。本発明によると2回目以降の分析では、ステップS305の親イオンの選択の処理の前に、ステップS306にてペプチドリスト600を参照し、そこに登録されている質量(m)と同一のマススペクトルのピークを除外する。ペプチドリスト600に登録されているデータは、タンパク質データベース20から得たものである。従って、そのようなペプチド由来のタンパク質に関しては既に、十分に情報が得られていると考えられる。従って、このようなペプチドリスト600に登録されているペプチドを、親イオンの選択対象から除去することにより、重複した分析を回避することができる。
【0040】
図6の例では、MSマススペクトルにて×印のピークの質量がペプチドリストに含まれる。従って、×印のピークを、親イオンの選択対象から除去する。
【0041】
尚、MSマススペクトルのピークの横軸は質量対電荷比(m/z)である。一方、ペプチドリストにはペプチドの質量が登録されている。そこで、両者を比較するには、MSマススペクトルのピークの質量対電荷比(m/z)を質量(m)へ変換する必要がある。そこでMSマススペクトル上に現れる同位体ピーク同士のピーク間隔より価数(z)を求め、それを質量対電荷比(m/z)に乗算すればよい。
【0042】
また、MSマススペクトルのピークの質量とペプチドリストの質量は完全に一致している必要は無く、略等しければよい。例えば、MSマススペクトルのピークの質量mが求められたら、それを中心とする質量範囲(m±Δm)を設定する。ペプチドリストの質量が、質量範囲(m±Δm)に含まれる場合には、一致すると判定してよい。
【0043】
図7を参照して、図4のステップS209のタンパク質候補の推定処理の詳細を説明する。ステップS71にて、データ処理部19は、MS2マススペクトルよりアミノ酸配列の解読を行う。即ち、親イオンとして選択したペプチドのアミノ酸配列の解読を行う。アミノ酸解読の対象となるMS2マススペクトルは、今回の分析にて取得したMS2マススペクトルばかりでなく前回の分析にて取得したMS2マススペクトルも含む。例えば、今回の分析が2回目の分析なら、1回目から2回目までに取得したMS2マススペクトルを用いる。
【0044】
分析毎に、その回に得られたMS2マススペクトルよりアミノ酸配列の解読を行ってもよいが、分析毎に、過去の回から今回までに得られた全てのMS2マススペクトルよりアミノ酸配列の解読を行ってもよい。
【0045】
アミノ酸配列の解読には、de novoシーケンス法を用いてよい。この方法では、MS2マススペクトルに存在するピーク間隔を読み取ることによりアミノ酸配列の解読する。
【0046】
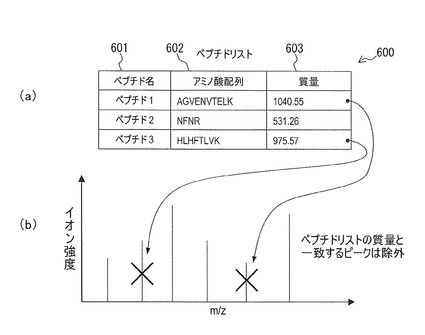
ステップS72にて、データ処理部19は、解読されたアミノ酸配列をキーにして、タンパク質データベース20を検索する。即ち、MS2マススペクトルより解読して得たアミノ酸配列を含むタンパク質をタンパク質データベース20から検索し、それをタンパク質候補とする。
【0047】
データ処理部19は、タンパク質候補リスト700を作成する。タンパク質候補リスト700は、タンパク質名701、その推定精度702、及びそのタンパク質を構成するアミノ酸配列703を含む。
【0048】
本例では、推定精度は、タンパク質データベース20から検索して得たタンパク質に含まれるアミノ酸に対するMS2マススペクトルから解読したアミノ酸配列の含有率である。例えば、「タンパク質1」の推定精度は30%である。これは、「タンパク質1」に含まれるアミノ酸配列のうち、MS2マススペクトルから解読したアミノ酸配列の割合が30%であり、残りの70%はMS2マススペクトルから解読したアミノ酸配列以外のアミノ酸配列であることを意味する。
【0049】
図8を参照して、ステップS211のタンパク質候補に関するペプチド情報の取得処理を説明する。ペプチド情報の取得処理では、タンパク質候補をペプチドに分解する。ただし、過去の分析において既にペプチド分解され、ペプチドリストに登録されたタンパク質候補については、重複となるため除外する。タンパク質は消化酵素によって切断され、断片化する。この断片化されたものがペプチドである。消化酵素によって切断されるアミノ酸が決まっているため、消化酵素によってどのようにタンパク質がペプチド化されるかがわかる。
【0050】
図8は、消化酵素としてトリプシンを使用した例を示す。トリプシンを消化酵素として用いると、タンパク質のアミノ酸配列は、リシン(K)とアルギニン(R)の間で切断される。図示のように、タンパク質候補801は、トリプシンによって切断され、複数のペプチド802が生成される。これらのペプチド802に含まれるアミノ酸の質量は既知だから、各ペプチドの質量を算出803することができる。ステップS212にて、各タンパク質候補に対して、タンパク質名、アミノ酸名、アミノ酸配列、及び、質量をペプチドリスト600へ登録する。
【0051】
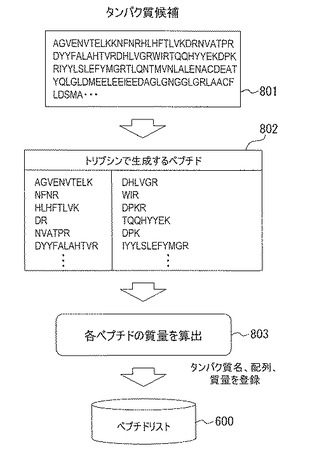
図9に、本発明による質量分析システムのユーザインターフェース(UI)、即ち、表示部18の入力画面の例を示す。本例の入力画面900は、ピーク排除実施条件901及びタンパク質検索条件904を含む。ピーク排除実施条件901は、推定精度閾値(%)902、及び、質量一致精度(amu)903を含む。タンパク質検索条件904は、MS2解析質量精度(amu)905、消化酵素906、タンパク質データベース907、及び、分類(Taxnomy)908を含む。
【0052】
ピーク排除実施条件901は、分析全体に関わるパラメータを設定するフィールドである。推定精度閾値(%)902は、図4のステップS210の推定精度の比較処理に用いる閾値Xを設定するフィールドである。質量一致精度(amu)903は、図5のステップS304のMSマススペクトルのピークのうちペプチドリストにあるデータを親イオンの選択対象から除去する処理に用いる。即ち、MS2マススペクトルのピークとペプチドリストのペプチドの質量を比較する際の質量範囲(Δm)を指定するためのフィールドである。
【0053】
タンパク質検索条件904は、図4のステップS209のMS2マススペクトルからタンパク質候補を推定する処理に関するパラメータ等を設定するフィールドである。MS2解析質量精度(amu)905は、図7のステップS71のアミノ酸配列の解読処理において、MS2マススペクトルのピーク間隔とアミノ酸質量を一致とみなす質量誤差範囲を指定するフィールドである。消化酵素フィールド906、タンパク質データベースフィールド907、分類(Taxnomy)フィールド908は、図7のステップS72のデータベース検索処理において、タンパク質データベース20の検索を行う条件を指定するフィールドである。本例では、タンパク質データベース20の検索条件として3つの条件を用いるが、他の条件、例えば、使用した装置の種類やタンパク質の修飾の条件等を用いることも可能である。但し、消化酵素906は、ステップS211のペプチド情報の取得処理において、タンパク質のアミノ酸配列からペプチド配列を取得する際にも使用するため、必須の指定項目である。
【0054】
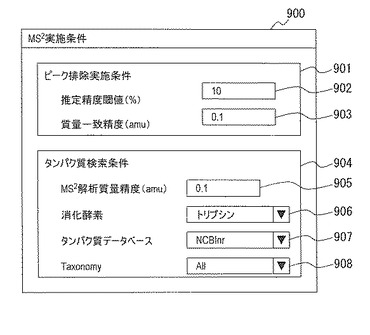
図10に、本発明による質量分析システムのユーザインターフェース(UI)、即ち、表示部18の出力画面の例を示す。本例の出力画面1000は、タンパク質リスト1001、クロマトグラム表示部1005、MSマススペクトル表示部1006、及び、MS2マススペクトル表示部1007を有する。タンパク質リスト1001には、タンパク質1002が順に表示され、最後に、その他1003が表示される。タンパク質1002は、図7に示したタンパク質候補リスト700のタンパク質701である。
【0055】
タンパク質1002の1つをクリックすると、そのタンパク質候補に含まれるアミノ酸配列のうち、MS2マススペクトルから解読したアミノ酸配列1004が表示される。タンパク質候補1002の1つをダブルクリックすると、図11に示すように、そのタンパク質の全アミノ酸配列1100が別ウインドウに表示される。例えば、「タンパク質2」に含まれるアミノ酸配列の30%は、MS2マススペクトルから解読したアミノ酸配列であり、70%は、MS2マススペクトルから解読したアミノ酸配列以外のアミノ酸配列である。「タンパク質2」をクリックすると30%のアミノ酸配列が表示され、「タンパク質2」をダブルクリックすると全てのアミノ酸配列が別ウインドウに表示される。
【0056】
その他1003には、MS2マススペクトルから解読されたアミノ酸配列のうち、どのタンパク質にも由来しないアミノ酸配列が表示される。
【0057】
アミノ酸配列1004の1つを選択すると、それが太字表示に切り替えられ、このアミノ酸配列を解読したときに用いられたMS2マススペクトルがMS2マススペクトル表示部1007に表示され、親イオンを選択するときに用いられたMSマススペクトルがMSマススペクトル表示部1006に表示され、試料の分離結果であるクロマトグラムがクロマトグラム表示部42に表示される。
【0058】
MSマススペクトル画面1006において、親イオンとして選択されたピークは他のピークとは異なる色で表示され、その質量の値が表示される。MS2マススペクトル画面1007では、ピーク間隔に対して読み取ったアミノ酸配列が表示される。
【0059】
次に本発明による質量分析方法の第2の例を説明する。図4及び図5に示した第1の例では、ステップS209にて、de novoシーケンス法を用いてMS2マススペクトルからアミノ酸配列の解読を行い、タンパク質候補の推定を行った。本例では、既知のタンパク質から検定用のMS2マススペクトルを予めタンパク質データベース20に用意する。この検定用のMS2マススペクトルと、分析で取得したMS2マススペクトルを比較することにより、タンパク質候補の推定を行う。例えば、MASCOTにおけるMS/MS Ion Searchを用いる。
【0060】
次に本発明による質量分析方法の第3の例を説明する。図4及び図5に示した第1の例では、MS質量分析とMS2質量分析の2段の質量分析を行った。本例では、ステップS209のタンパク質候補の推定処理において、推定精度が低い場合には、3段以上の質量分析を行う。上述のように、ステップS209のタンパク質候補の推定処理の詳細は図7に示されている。図7のステップS71のアミノ酸配列の解読処理において、MS2マススペクトルから十分にアミノ酸配列が解読できない場合には、MS3質量分析を行う。即ち、MS2マススペクトルから1個の親イオンを選択し、解離し、MS3質量分析を行う。
【0061】
本例によると、図7のステップS71のアミノ酸配列の解読処理において、アミノ酸配列の解読数の閾値Nを設定する。この閾値Nは、固定値でも構わないが、図9に示した入力画面900にてユーザが設定できることが好ましい。
【0062】
ステップS209のタンパク質候補の推定処理において、MS2マススペクトルを解読して得たアミノ酸数を閾値Nと比較し、閾値Nを満たさない場合は、MS3質量分析を行う。図7を参照して説明したように、ステップS71にて、データ処理部19は、MS2マススペクトル及びMS3マススペクトルよりアミノ酸配列の解読を行う。解読数が閾値N以上である場合には、ステップS210に進む。解読数が閾値Nに満たない場合は、MS4質量分析を行う。MS2マススペクトル、MS3マススペクトル及びMS4マススペクトルよりアミノ酸配列の解読を行う。こうして、解読数が閾値N以上となるまで、MSn質量分析を繰り返す。これにより、MS2質量分析では、十分に分解されないようなイオンについて対応することができる。
【0063】
次に本発明による質量分析方法の第4の例を説明する。図4及び図5に示した例1では、ステップS211にて、推定精度が高いタンパク質候補に対してペプチド情報の取得を行い、ステップS212にてペプチドの質量(m)をペプチドリスト600に登録した。しかしながら、本例では、試料に既知のタンパク質が含まれている場合には、それをペプチドリストに登録する。それ以外のタンパク質については、図7に示した方法によりペプチド情報を取得して登録する。また、同一試料について繰り返し分析を行う場合は、過去のペプチドリストを継続して利用することにより、重複分析を回避し効率のよい試料の測定を行うことができる。
【0064】
図12及び図13を参照して、本発明による質量分析方法の第5の例を説明する。第1の例では、ステップS305にて、MSマススペクトルのピークから1つのピークを選んで、それを親イオンとした。1回の分析では、MSマススペクトルに現れた一つペプチドのアミノ酸配列の情報のみが得られる。従って、MSマススペクトルのピークのうち親イオンとして選択されたピーク以外のピークの情報が有効的に利用されていない。そこで、本例では、MSマススペクトルの情報を効率的に利用する。
【0065】
図12を参照して本発明による質量分析方法の第5の例の1回目の分析を説明する。ステップS401〜ステップS409までは、図4に示した第1の例のステップS201〜ステップS209までと同様であってよい。
【0066】
本例によると、ステップS410にて、推定した全てのタンパク質候補についてペプチド情報の取得を行う。図4に示した第1の例では、推定精度が閾値Xよりも大きいタンパク質候補についてペプチド情報を取得した。しかしながら、本例では、全てのタンパク質候補についてペプチド情報の取得を行う。
【0067】
ステップS411にて、ペプチド情報を2つのペプチドリストに振り分ける。タンパク質候補の推定精度を予め設定した閾値Yと比較する。ステップS412にて、推定精度が閾値Yよりも大きいタンパク質候補のペプチドの質量を、第1のペプチドリストに登録する。ステップS413にて、推定精度が閾値Y以下のタンパク質候補のペプチドの質量を、第2のペプチドリストに登録する。こうして1回目の分析を終了し、次に2回目の分析を行う。
【0068】
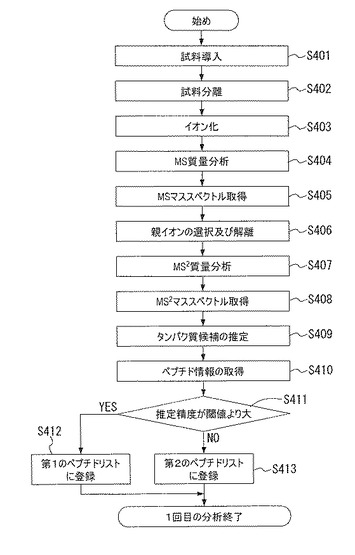
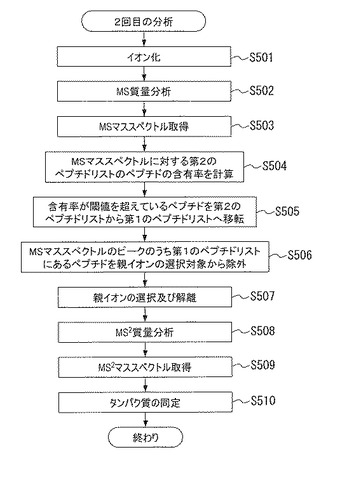
図13を参照して本発明による質量分析方法の第5の例の2回目の分析を説明する。ステップS501にて、イオン化部13は、試料をイオン化する。ステップS502にて、質量分析部14は、MS質量分析を行う。ステップS503にて、MSマススペクトルを得る。
【0069】
ステップS504にて、データ処理部19は、第2のペプチドリストのペプチドの質量に対応するピークがMSマススペクトルに存在するか否かを調べる。即ち、MSマススペクトルにおける第2のペプチドリストのペプチドの含有率を算出する。ステップS505にて、その含有率が閾値Zを超えているタンパク質候補を抽出し、そのペプチドの質量を第2のペプチドリストから第1のペプチドリストに移転する。本例では、第2のペプチドリストのペプチドであっても、2回目の分析にて、MSマススペクトルに対する含有率が閾値Zを超えている場合には、そのタンパク質候補は、タンパク質データベース20に格納されていると考えられる。従って、このようなタンパク質候補については重複して分析を行う必要はない。こうして、第1のペプチドリストに移転されたペプチドは、親イオンの選択対象から除外される。
【0070】
ステップS506にて、データ処理部19は、MSマススペクトルのピークのうち、第1のペプチドリストに含まれるデータを親イオンの選択対象より除外する。ステップS507にて、MSマススペクトルより1個のペプチドを親イオンとして選択し、解離する。上述のように、MSマススペクトルのピークから第1のペプチドリストのデータと同一のデータは除外されている。
【0071】
ステップS508からステップS510の処理は、ステップS306からステップS308の処理と同様であってよい。
【0072】
こうして本例では、2回目の分析にて得られたMSマススペクトルの情報を有効に利用してタンパク質候補に由来するペプチドが他に存在するかについて判定を行うことができる。
【0073】
図14を参照して、本発明による質量分析方法の第6の例を説明する。第5の例では、2回目の分析において、第2のペプチドリストのペプチドは、MSマススペクトルにおける含有率が高いものを第1のペプチドリストに移転する。本例では、2回目の分析において、第2のペプチドリストのペプチドを、親イオンの選択の優先順位を設定するために使用する。
【0074】
本例では、1回目の分析は、第5の例と同様である。即ち、図12のステップS401からステップS413が1回目の分析である。
【0075】
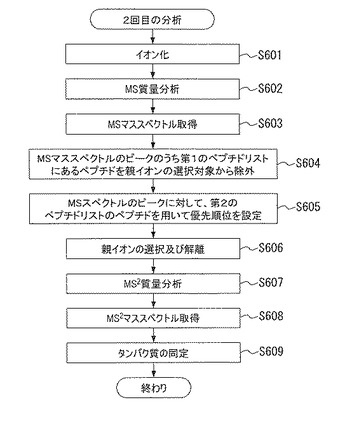
図14を参照して本発明による質量分析方法の第6の例の2回目の分析を説明する。ステップS601にて、イオン化部13は、試料をイオン化する。ステップS602にて、質量分析部14は、MS質量分析を行う。ステップS603にて、MSマススペクトルを得る。
【0076】
ステップS604にて、データ処理部19は、MSマススペクトルのピークのうち第1のペプチドリストにあるデータを親イオンの選択対象から除外する。ステップS605にて、データ処理部19は、MSマススペクトルの残ったピークに対して親イオンを選択するための優先順位を設定する。優先順位は、MSマススペクトルの残った全てのピークに対して、第2のペプチドリストのペプチドの質量と比較する。一致するピークに対してボーナスを与える。タンパク質候補毎に、このような比較とボーナスの付与を行い、ピーク毎のボーナスの累計値を求める。この累計値の大きい順を、親イオンとして選択する優先順位とする。ここで、ピークとペプチドの質量が一致したときに与えるボーナスはある固定の値でも構わないが、タンパク質候補の推定精度等の条件よって変動するようなものが好ましい。例えば、推定精度が高いタンパク質候補の場合には、高いボーナスを設定し、推定精度が低いタンパク質候補の場合には、低いボーナスを設定する。このようにタンパク質候補の推定精度に基づいてボーナスを設定し、優先順位を与えることにより、試料中に含有している可能性が高いと考えられるタンパク質に由来するペプチドを親イオンとして選択することができる。
【0077】
ステップS606にて、データ処理部19は、親イオンを選択し、それを解離する。親イオンの選択対象は、MSマススペクトルのピークのうち第1のペプチドリストにあるデータを除外した残りのピークである。これらのピークから優先順位の最も高いピークを親イオンとして選択する。
【0078】
ステップS607からステップS609は図13のステップS508からステップS510の処理と同様であってよい。
【0079】
以上、本発明の例を説明したが本発明は上述の例に限定されるものではなく、特許請求の範囲に記載された発明の範囲にて様々な変更が可能であることは当業者に容易に理解されよう。
【図面の簡単な説明】
【0080】
【図1】本発明の質量分析システムの構成を示す図である。
【図2】従来のタンデム質量分析方法の処理の概略を示す図である。
【図3】試料分離部によって得られるクロマトグラムと分析の繰返しを示す図である。
【図4】本発明のタンデム質量分析方法の第1の例の1回目の分析処理の概略を示す図である。
【図5】本発明のタンデム質量分析方法の第1の例の2回目の分析処理の概略を示す図である。
【図6】本発明のタンデム質量分析方法の第1の例の2回目の分析処理において、MSマススペクトルのピークから親イオンの選択対象から除外する処理を説明するための図である。
【図7】本発明のタンデム質量分析方法の第1の例の1回目の分析処理において、タンパク質候補の推定処理を説明するための図である。
【図8】本発明のタンデム質量分析方法の第1の例の1回目の分析処理において、ペプチド情報の取得処理を説明するための図である。
【図9】本発明の質量分析システムの入力画面の例を示す図である。
【図10】本発明の質量分析システムの出力画面の例を示す図である。
【図11】本発明の質量分析システムの出力画面において、分析結果のアミノ酸配列を表示する例を示す図である。
【図12】本発明のタンデム質量分析方法の第5の例の1回目の分析処理を説明するための図である。
【図13】本発明のタンデム質量分析方法の第5の例の2回目の分析処理を説明するための図である。
【図14】本発明のタンデム質量分析方法の第6の例の2回目の分析処理を説明するための図である。
【符号の説明】
【0081】
12…試料分離部、13…イオン化部、14…質量分析部、15…イオン検出部、16…制御部、17…ユーザ入力部、18…表示部、19…データ処理部、20…タンパク質データベース
【技術分野】
【0001】
本発明は質量分析システムおよび質量分析方法に関し、特にタンパク質、ポリペプチド等の生体高分子を分析するための質量分析システム、分析方法に関する。
【背景技術】
【0002】
一般的な質量分析方法では、対象となる試料をイオン化して、それらのイオンを質量分析装置へ送る。質量分析装置では、送られてきたイオンに対して質量(m)と価数(z)の比からなる質量対電荷比(m/z)毎にイオン強度を測定する。この結果として、横軸が質量対電荷比(m/z)、縦軸がイオン強度のマススペクトルを得ることができる。
【0003】
質量分析方法には、試料をイオン化しそのまま測定するMS分析法と試料をイオン化して測定した後に、ある特定のイオンを選択し解離させて測定するタンデム質量分析法がある。タンデム質量分析法において解離の対象となるイオンを親イオンと呼ぶ。タンデム質量分析法では、解離させたイオンから得たマススペクトルから更に親イオンを選択し解離させて質量分析するといったように、多段に解離と質量分析を行う機能がある。以降、n段目の質量分析をMSn質量分析と呼ぶ。また、試料をイオン化して測定して得られるマススペクトルをMSマススペクトル、MSマススペクトルより選択した親イオンを解離させて測定して得られるマススペクトルをMS2マススペクトル、MS2マススペクトルより選択した親イオンを解離させて測定して得られるマススペクトルをMS3マススペクトル等と呼ぶ。
【0004】
タンデム質量分析が行えるほとんどの質量分析装置では、MSマススペクトルから親イオンを自動的に選択してイオン解離を行う機能を有する。
【0005】
生体試料のような様々な成分を多く含む試料に対しては、クロマトグラフと質量分析装置を組み合わせたシステムが多用される。クロマトグラフにおいて物質のカラムへの吸着度の違い等から試料中の成分が時間的に分離されることにより、質量分析装置では分離が困難なイオン種の分離が可能となる。
【0006】
質量分析システムでは、1度の測定において分析を繰り返して行う。このとき、同一タンパク質に由来するペプチド種を重複して解離して分析する。同成分を重複して分析することは試料や時間を浪費することとなる。そこで同成分の重複分析を行わないための手法が特許文献1や特許文献2に記載されている。
【0007】
(1)特許文献1の方法では、タンデム質量分析においてN回目までに解離を行ったイオンの情報(イオン質量、イオン強度、マススペクトルの質など)をリアルタイムに内部データベースとして登録する。この内部データベースの情報を利用してN+1回目の測定において親イオン選択の制限を行う。
【0008】
(2)特許文献2の方法では、タンデム質量分析において保持時間を用いて親イオンの選択を制限する。具体的には、MS2マススペクトルデータからアミノ酸配列を予測し、そのアミノ酸配列から予想される保持時間と実際の保持時間を比較する。比較の結果、一致する場合はそのアミノ酸配列を信頼性の高いデータとみなして測定を終了し、一致しない場合には他の親イオンの解離またはMS3質量分析を行いさらに情報の取得を行う。
【0009】
【特許文献1】特開2005−91344
【特許文献2】特開2005−241251
【発明の開示】
【発明が解決しようとする課題】
【0010】
特許文献1に記載された方法では、親イオンの選択に制限を与えることができるのは、同一質量の成分のみである。タンパク質を酵素で分解し生成するペプチドは複数ある。あるペプチドを分析したときに、そこからタンパク質が十分に予想しうる場合は、そのタンパク質に由来するペプチド以外のものを分析することが効率的といえるが、特許文献1の方法では既に分析したペプチドしか選択の制限を行えない。
【0011】
また、特許文献2に記載された方法では、特許文献1と同様に親イオンの選択の制限を行えるのはある質量の成分のみであり、同一タンパク質に由来するペプチドの選択の制限を行うことはできない。
【0012】
本発明の目的は、同一タンパク質に由来するペプチド種を重複して解離して分析することを回避することができる質量分析システムを提供することにある。
【課題を解決するための手段】
【0013】
本発明によると、1回目の分析において、MS2マススペクトルを用いて試料に含まれるタンパク質のうちタンパク質データベースに既に格納されているタンパク質候補をリアルタイムにて推定する。2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、タンパク質候補に含まれるペプチド以外のペプチドを親イオンとして選択する。
【発明の効果】
【0014】
本発明によれば、同一タンパク質に由来するペプチド種を重複して解離して分析することを回避することができる。
【発明を実施するための最良の形態】
【0015】
以下に本発明の実施例を示す。図1を参照して本発明による質量分析装置の概要を説明する。本例の質量分析装置は、試料分離部12、イオン化部13、質量分析部14、イオン検出部15、制御部16、ユーザ入力部17、表示部18、データ処理部19、及び、タンパク質データベース20を有する。
【0016】
上述のように、質量分析方法には、試料をイオン化し、それを質量分析し、MSマススペクトルを得るMS質量分析法と、MSマススペクトルから1個のペプチドを親イオンとして選択し、それを解離させ、質量分析し、MS2マススペクトルを得るタンデム質量分析法がある。タンデム質量分析法は、解離段階ごとに親イオンの分子構造情報を得られるため、親イオンの構造を推定する上で有効となる。以下では、タンデム質量分析法について説明する。
【0017】
試料分離部12は、液体クロマトグラフ(LC)、ガスクロマトグラフ(GC)等によって構成される。イオン化部13は、エレクトロスプレーイオン化(ESI)、大気圧化学イオン化(APCI)、電子イオン化(EI)、化学イオン化(CI)等のイオン化方法を用いてイオン化を行う。これらのイオン化法のうち、分析の対象とする試料や分析の目的に応じたイオン化法が選択される。
【0018】
質量分析部14は、タンデム質量分析が可能な四重極型質量分析装置、イオントラップ型質量分析装置等によって構成される。親イオンの解離方法には、衝突解離(Collision Induced Dissociation)法や電子捕獲解離(Electron Capture Dissociation)法などがある。衝突解離法はヘリウムなどのバッファーガスをイオンに衝突させて解離する方法であり、電子捕解離法は、低エネルギーの電子を照射し、親イオンに多量に低エネルギー電子を捕獲させることにより解離する方法である。イオン検出部15は、質量対電荷比(m/z)毎にイオン強度を測定する。
【0019】
制御部16は、タンデム質量分析法の一連の分析過程を制御する。ユーザ入力部17は、分析処理や装置を制御するためのユーザインターフェースである。表示部18は、マススペクトル等の分析結果を表示する。データ処理部19は、MSマススペクトルの生成、親イオンの選択、MS2マススペクトルの生成等を行う。タンパク質データベース20は、タンパク質に関する既知のデータを格納する。
【0020】
図2を参照して、タンデム質量分析法によってタンパク質を測定する一般的な処理の概要を説明する。先ずステップS101にて、試料分離部12に、試料を含む溶液を導入する。ステップS102にて、試料分離部12は、試料を分離する。上述のように、試料の分離法には、液体クロマトグラフ(LC)、ガスクロマトグラフ(GC)等がある。図3(a)は、試料の分離結果を示す。上述のようにカラムへの吸着度等の差から、時間的に分離された成分の強度のピークが現れる。このように試料の時間的な分離結果をクロマトグラム301と呼ぶ。
【0021】
ステップS103にて、イオン化部13は、このように時間的に分離された試料をイオン化する。ステップS104にて、質量分析部14は質量分析を行う。これをMS質量分析と称する。ステップS105にて、MS質量分析の結果を得る。これをMSマススペクトルと称する。ステップS106にて、MSマススペクトルより、1個のペプチドを親イオンとして選択して解離する。通常、MSマススペクトルのピークのうち最も強度が大きいピークを親イオンとして選択する。ステップS107にて、解離したイオンを質量分析部14によって質量分析を行う。これをMS2質量分析と称する。ステップS108にて、MS2質量分析の結果を得る。これを、MS2マススペクトルと称する。
【0022】
MSマススペクトル及びMS2マススペクトルは、横軸が質量対電荷比(m/z)、縦軸がイオン強度のピーク(細い棒グラフ)である。MS2マススペクトルには、試料のタンパク質の分子構造を推定するための情報が含まれており、この情報を元にしてタンパク質を推定することが可能である。
【0023】
ステップS103のイオン化から、ステップS104のMS質量分析、ステップS105のMSマススペクトルの取得、ステップS106の親イオンの選択及び解離、ステップS107のMS2質量分析、ステップS108のMS2マススペクトルの取得までの一連の処理を分析と称する。ステップS109にて、再分析を行うか否かを判定する、再分析を行う場合にはステップS103に戻る。再分析を行わない場合には、ステップS110に進む。ステップS110にて、MS2マススペクトル対する後処理を行う。後処理では、ノイズ除去、ピーク判定、同位体ピーク除去等を行い、既知のタンパク質の情報が蓄積されたタンパク質データベース20を検索して、タンパク質の同定を行う。
【0024】
図3(a)は、上述のように試料分離部12によって得られたクロマトグラム301の例を示す。クロマトグラムは、時間的に分離された成分強度のピークを含む。図3(b)は、クロマトグラフ301と分析サイクルの関係を示す。分析302は、図2のステップS103のイオン化から、ステップS108のMS2マススペクトルの取得までの一連の処理である。図示のように、クロマトグラムが得られると、各成分毎に分析302が繰返し行われていることが判る。1回の分析302に要する分析時間303は、分析条件や装置条件等により異なる。1回の測定で多くの分析302を行うためには、分析時間303は短いことが望ましい。
【0025】
このように時間的に分離して得られるクロマトグラフ301に対して、繰り返し分析302を行うことで、様々なイオンのMS2マススペクトルが取得できる。それによって、試料に含まれるタンパク質の構造情報を蓄積していくのが一般的である。
【0026】
タンデム質量分析方法では、タンパク質の同定結果の精度や同定するタンパク質の数は、MS2マススペクトルに依存し、MSマススペクトルからどのように親イオンを選択するかが重要となる。
【0027】
そこで、本発明では、1回目の分析にて、MS2マススペクトルを取得すると、そのアミノ酸解読を行い、リアルタイムで、タンパク質データベースを検索する。タンパク質データベース20に、同一のアミノ酸配列が存在する場合には、そのアミノ酸配列が由来するタンパク質は既に実験済みであると考える。そこで、2回目の分析にて、そのタンパク質に由来する全てのペプチドを親イオンの選択対象から除外する。即ち、そのタンパク質に由来するペプチド以外のペプチドを親イオンとして選択する。こうして、既に、タンパク質データベース20に格納されているタンパク質に由来するペプチドの重複測定を回避することができる。
【0028】
図4、図5及び図6を参照して本発明によるタンデム質量分析方法の第1の例を説明する。ステップS201からステップS208までは、図2を参照して説明した従来のタンデム質量分析方法と同一であってよい。即ち、ステップS201にて、試料分離部12に、試料を含む溶液を導入する。ステップS202にて、試料分離部12は、試料を分離する。ステップS203にて、イオン化部13は、試料をイオン化する。ステップS204にて、質量分析部14は、MS質量分析を行う。ステップS205にて、MSマススペクトルを得る。ステップS206にて、MSマススペクトルより1個のペプチドを親イオンとして選択し、解離する。ステップS207にて、質量分析部14は、解離した親イオンに対してMS2質量分析を行う。ステップS208にて、MS2マススペクトルを得る。
【0029】
ステップS209にて、データ処理部19は、MS2マススペクトルを用いてタンパク質候補の推定を行う。即ち、MS2マススペクトルからアミノ酸配列を解読し、それをタンパク質データベース20から検索する。検索結果として、そのアミノ酸配列を含むと推定されるタンパク質を列挙する。こうしてタンパク質候補のリストを得る。タンパク質候補は、タンパク質データベース20を検索して得られたものである。このようなタンパク質に関するデータは十分に得られていると考えられる。従って、このようなタンパク質候補については重複して分析を行う必要はない。そこで、2回目の分析にて、タンパク質候補に含まれるペプチドを親イオンの選択対象から除外する。
【0030】
タンパク質候補の推定方法の例は、後に、図7を参照して説明する。データ処理部19は、各タンパク質候補の推定精度を計算する。
【0031】
ステップS210にて、データ処理部19は、推定精度が閾値Xより大きいタンパク質候補があるか否かを判定する。推定精度が閾値Xより大きいタンパク質候補がある場合には、ステップS211に進み、推定精度が閾値Xより大きいタンパク質候補がない場合には、1回目の分析は終了し、次の2回目の分析に移る。
【0032】
ステップS211にて、データ処理部19は、推定精度が閾値Xよりも大きいタンパク質候補のペプチド情報の取得を行う。即ち、推定精度が閾値Xよりも大きいタンパク質候補に由来するペプチドの質量を求める。ペプチド情報の取得処理の詳細は、後に、図8を参照して説明する。
【0033】
ステップS212にて、データ処理部19は、ペプチド情報の登録を行う。即ち、ペプチドの質量(m)をペプチドリスト600に登録する。ペプチドリスト600は、図6(a)に示すように、ペプチド名601、そのアミノ酸配列602、及び、その質量603のリストである。
【0034】
こうして、MS2マススペクトルを用いてタンパク質候補を推定し、推定したタンパク質候補に関するペプチド情報の取得及び登録処理が終了すると、1回目の分析は終了し、次の2回目の分析に移る。
【0035】
図5を参照して本発明による質量分析方法の第1の例の2回目の分析を説明する。ステップS301にて、イオン化部13は、試料をイオン化する。ステップS302にて、質量分析部14は、MS質量分析を行う。ステップS303にて、MSマススペクトルを得る。
【0036】
ステップS304にて、データ処理部19は、MSマススペクトルのピークのうち、ペプチドリスト600に含まれるデータを親イオンの選択対象より除外する。図6(b)は、MSマススペクトルを示す。この例では、×印のデータの質量がペプチドリストに含まれる。従って、×印のデータを親イオンの選択対象から除外する。
【0037】
ステップS305にて、MSマススペクトルより1個のペプチドを親イオンとして選択し、解離する。上述のように、MSマススペクトルのピークからペプチドリスト600のデータと同一のデータは除外されている。ステップS306にて、質量分析部14は、解離した親イオンに対してMS2質量分析を行う。ステップS307にて、MS2マススペクトルを得る。ステップS308にて、MS2マススペクトルの後処理を行い、タンパク質を同定する。
【0038】
こうして、2回目の分析が終了する。図4の1回目の分析と図5の2回目の分析を比較すると、図5の2回目の分析ではステップS304の処理が付加されている点が異なる。
【0039】
図6を参照して、本発明の質量分析方法の主要部を説明する。図6(a)は、ペプチドリスト600の例を示す。ペプチドリスト600は、ペプチド名601、ペプチド配列602、ペプチド配列の質量603のデータを含み、タンパク質候補毎に作成される。従って、各ペプチドリスト600にはタンパク質名が付与されている。ステップS303にて得られるMSマススペクトルは、横軸が質量対電荷比(m/z)、縦軸がイオン強度のピーク(細い棒グラフ)である。本発明によると2回目以降の分析では、ステップS305の親イオンの選択の処理の前に、ステップS306にてペプチドリスト600を参照し、そこに登録されている質量(m)と同一のマススペクトルのピークを除外する。ペプチドリスト600に登録されているデータは、タンパク質データベース20から得たものである。従って、そのようなペプチド由来のタンパク質に関しては既に、十分に情報が得られていると考えられる。従って、このようなペプチドリスト600に登録されているペプチドを、親イオンの選択対象から除去することにより、重複した分析を回避することができる。
【0040】
図6の例では、MSマススペクトルにて×印のピークの質量がペプチドリストに含まれる。従って、×印のピークを、親イオンの選択対象から除去する。
【0041】
尚、MSマススペクトルのピークの横軸は質量対電荷比(m/z)である。一方、ペプチドリストにはペプチドの質量が登録されている。そこで、両者を比較するには、MSマススペクトルのピークの質量対電荷比(m/z)を質量(m)へ変換する必要がある。そこでMSマススペクトル上に現れる同位体ピーク同士のピーク間隔より価数(z)を求め、それを質量対電荷比(m/z)に乗算すればよい。
【0042】
また、MSマススペクトルのピークの質量とペプチドリストの質量は完全に一致している必要は無く、略等しければよい。例えば、MSマススペクトルのピークの質量mが求められたら、それを中心とする質量範囲(m±Δm)を設定する。ペプチドリストの質量が、質量範囲(m±Δm)に含まれる場合には、一致すると判定してよい。
【0043】
図7を参照して、図4のステップS209のタンパク質候補の推定処理の詳細を説明する。ステップS71にて、データ処理部19は、MS2マススペクトルよりアミノ酸配列の解読を行う。即ち、親イオンとして選択したペプチドのアミノ酸配列の解読を行う。アミノ酸解読の対象となるMS2マススペクトルは、今回の分析にて取得したMS2マススペクトルばかりでなく前回の分析にて取得したMS2マススペクトルも含む。例えば、今回の分析が2回目の分析なら、1回目から2回目までに取得したMS2マススペクトルを用いる。
【0044】
分析毎に、その回に得られたMS2マススペクトルよりアミノ酸配列の解読を行ってもよいが、分析毎に、過去の回から今回までに得られた全てのMS2マススペクトルよりアミノ酸配列の解読を行ってもよい。
【0045】
アミノ酸配列の解読には、de novoシーケンス法を用いてよい。この方法では、MS2マススペクトルに存在するピーク間隔を読み取ることによりアミノ酸配列の解読する。
【0046】
ステップS72にて、データ処理部19は、解読されたアミノ酸配列をキーにして、タンパク質データベース20を検索する。即ち、MS2マススペクトルより解読して得たアミノ酸配列を含むタンパク質をタンパク質データベース20から検索し、それをタンパク質候補とする。
【0047】
データ処理部19は、タンパク質候補リスト700を作成する。タンパク質候補リスト700は、タンパク質名701、その推定精度702、及びそのタンパク質を構成するアミノ酸配列703を含む。
【0048】
本例では、推定精度は、タンパク質データベース20から検索して得たタンパク質に含まれるアミノ酸に対するMS2マススペクトルから解読したアミノ酸配列の含有率である。例えば、「タンパク質1」の推定精度は30%である。これは、「タンパク質1」に含まれるアミノ酸配列のうち、MS2マススペクトルから解読したアミノ酸配列の割合が30%であり、残りの70%はMS2マススペクトルから解読したアミノ酸配列以外のアミノ酸配列であることを意味する。
【0049】
図8を参照して、ステップS211のタンパク質候補に関するペプチド情報の取得処理を説明する。ペプチド情報の取得処理では、タンパク質候補をペプチドに分解する。ただし、過去の分析において既にペプチド分解され、ペプチドリストに登録されたタンパク質候補については、重複となるため除外する。タンパク質は消化酵素によって切断され、断片化する。この断片化されたものがペプチドである。消化酵素によって切断されるアミノ酸が決まっているため、消化酵素によってどのようにタンパク質がペプチド化されるかがわかる。
【0050】
図8は、消化酵素としてトリプシンを使用した例を示す。トリプシンを消化酵素として用いると、タンパク質のアミノ酸配列は、リシン(K)とアルギニン(R)の間で切断される。図示のように、タンパク質候補801は、トリプシンによって切断され、複数のペプチド802が生成される。これらのペプチド802に含まれるアミノ酸の質量は既知だから、各ペプチドの質量を算出803することができる。ステップS212にて、各タンパク質候補に対して、タンパク質名、アミノ酸名、アミノ酸配列、及び、質量をペプチドリスト600へ登録する。
【0051】
図9に、本発明による質量分析システムのユーザインターフェース(UI)、即ち、表示部18の入力画面の例を示す。本例の入力画面900は、ピーク排除実施条件901及びタンパク質検索条件904を含む。ピーク排除実施条件901は、推定精度閾値(%)902、及び、質量一致精度(amu)903を含む。タンパク質検索条件904は、MS2解析質量精度(amu)905、消化酵素906、タンパク質データベース907、及び、分類(Taxnomy)908を含む。
【0052】
ピーク排除実施条件901は、分析全体に関わるパラメータを設定するフィールドである。推定精度閾値(%)902は、図4のステップS210の推定精度の比較処理に用いる閾値Xを設定するフィールドである。質量一致精度(amu)903は、図5のステップS304のMSマススペクトルのピークのうちペプチドリストにあるデータを親イオンの選択対象から除去する処理に用いる。即ち、MS2マススペクトルのピークとペプチドリストのペプチドの質量を比較する際の質量範囲(Δm)を指定するためのフィールドである。
【0053】
タンパク質検索条件904は、図4のステップS209のMS2マススペクトルからタンパク質候補を推定する処理に関するパラメータ等を設定するフィールドである。MS2解析質量精度(amu)905は、図7のステップS71のアミノ酸配列の解読処理において、MS2マススペクトルのピーク間隔とアミノ酸質量を一致とみなす質量誤差範囲を指定するフィールドである。消化酵素フィールド906、タンパク質データベースフィールド907、分類(Taxnomy)フィールド908は、図7のステップS72のデータベース検索処理において、タンパク質データベース20の検索を行う条件を指定するフィールドである。本例では、タンパク質データベース20の検索条件として3つの条件を用いるが、他の条件、例えば、使用した装置の種類やタンパク質の修飾の条件等を用いることも可能である。但し、消化酵素906は、ステップS211のペプチド情報の取得処理において、タンパク質のアミノ酸配列からペプチド配列を取得する際にも使用するため、必須の指定項目である。
【0054】
図10に、本発明による質量分析システムのユーザインターフェース(UI)、即ち、表示部18の出力画面の例を示す。本例の出力画面1000は、タンパク質リスト1001、クロマトグラム表示部1005、MSマススペクトル表示部1006、及び、MS2マススペクトル表示部1007を有する。タンパク質リスト1001には、タンパク質1002が順に表示され、最後に、その他1003が表示される。タンパク質1002は、図7に示したタンパク質候補リスト700のタンパク質701である。
【0055】
タンパク質1002の1つをクリックすると、そのタンパク質候補に含まれるアミノ酸配列のうち、MS2マススペクトルから解読したアミノ酸配列1004が表示される。タンパク質候補1002の1つをダブルクリックすると、図11に示すように、そのタンパク質の全アミノ酸配列1100が別ウインドウに表示される。例えば、「タンパク質2」に含まれるアミノ酸配列の30%は、MS2マススペクトルから解読したアミノ酸配列であり、70%は、MS2マススペクトルから解読したアミノ酸配列以外のアミノ酸配列である。「タンパク質2」をクリックすると30%のアミノ酸配列が表示され、「タンパク質2」をダブルクリックすると全てのアミノ酸配列が別ウインドウに表示される。
【0056】
その他1003には、MS2マススペクトルから解読されたアミノ酸配列のうち、どのタンパク質にも由来しないアミノ酸配列が表示される。
【0057】
アミノ酸配列1004の1つを選択すると、それが太字表示に切り替えられ、このアミノ酸配列を解読したときに用いられたMS2マススペクトルがMS2マススペクトル表示部1007に表示され、親イオンを選択するときに用いられたMSマススペクトルがMSマススペクトル表示部1006に表示され、試料の分離結果であるクロマトグラムがクロマトグラム表示部42に表示される。
【0058】
MSマススペクトル画面1006において、親イオンとして選択されたピークは他のピークとは異なる色で表示され、その質量の値が表示される。MS2マススペクトル画面1007では、ピーク間隔に対して読み取ったアミノ酸配列が表示される。
【0059】
次に本発明による質量分析方法の第2の例を説明する。図4及び図5に示した第1の例では、ステップS209にて、de novoシーケンス法を用いてMS2マススペクトルからアミノ酸配列の解読を行い、タンパク質候補の推定を行った。本例では、既知のタンパク質から検定用のMS2マススペクトルを予めタンパク質データベース20に用意する。この検定用のMS2マススペクトルと、分析で取得したMS2マススペクトルを比較することにより、タンパク質候補の推定を行う。例えば、MASCOTにおけるMS/MS Ion Searchを用いる。
【0060】
次に本発明による質量分析方法の第3の例を説明する。図4及び図5に示した第1の例では、MS質量分析とMS2質量分析の2段の質量分析を行った。本例では、ステップS209のタンパク質候補の推定処理において、推定精度が低い場合には、3段以上の質量分析を行う。上述のように、ステップS209のタンパク質候補の推定処理の詳細は図7に示されている。図7のステップS71のアミノ酸配列の解読処理において、MS2マススペクトルから十分にアミノ酸配列が解読できない場合には、MS3質量分析を行う。即ち、MS2マススペクトルから1個の親イオンを選択し、解離し、MS3質量分析を行う。
【0061】
本例によると、図7のステップS71のアミノ酸配列の解読処理において、アミノ酸配列の解読数の閾値Nを設定する。この閾値Nは、固定値でも構わないが、図9に示した入力画面900にてユーザが設定できることが好ましい。
【0062】
ステップS209のタンパク質候補の推定処理において、MS2マススペクトルを解読して得たアミノ酸数を閾値Nと比較し、閾値Nを満たさない場合は、MS3質量分析を行う。図7を参照して説明したように、ステップS71にて、データ処理部19は、MS2マススペクトル及びMS3マススペクトルよりアミノ酸配列の解読を行う。解読数が閾値N以上である場合には、ステップS210に進む。解読数が閾値Nに満たない場合は、MS4質量分析を行う。MS2マススペクトル、MS3マススペクトル及びMS4マススペクトルよりアミノ酸配列の解読を行う。こうして、解読数が閾値N以上となるまで、MSn質量分析を繰り返す。これにより、MS2質量分析では、十分に分解されないようなイオンについて対応することができる。
【0063】
次に本発明による質量分析方法の第4の例を説明する。図4及び図5に示した例1では、ステップS211にて、推定精度が高いタンパク質候補に対してペプチド情報の取得を行い、ステップS212にてペプチドの質量(m)をペプチドリスト600に登録した。しかしながら、本例では、試料に既知のタンパク質が含まれている場合には、それをペプチドリストに登録する。それ以外のタンパク質については、図7に示した方法によりペプチド情報を取得して登録する。また、同一試料について繰り返し分析を行う場合は、過去のペプチドリストを継続して利用することにより、重複分析を回避し効率のよい試料の測定を行うことができる。
【0064】
図12及び図13を参照して、本発明による質量分析方法の第5の例を説明する。第1の例では、ステップS305にて、MSマススペクトルのピークから1つのピークを選んで、それを親イオンとした。1回の分析では、MSマススペクトルに現れた一つペプチドのアミノ酸配列の情報のみが得られる。従って、MSマススペクトルのピークのうち親イオンとして選択されたピーク以外のピークの情報が有効的に利用されていない。そこで、本例では、MSマススペクトルの情報を効率的に利用する。
【0065】
図12を参照して本発明による質量分析方法の第5の例の1回目の分析を説明する。ステップS401〜ステップS409までは、図4に示した第1の例のステップS201〜ステップS209までと同様であってよい。
【0066】
本例によると、ステップS410にて、推定した全てのタンパク質候補についてペプチド情報の取得を行う。図4に示した第1の例では、推定精度が閾値Xよりも大きいタンパク質候補についてペプチド情報を取得した。しかしながら、本例では、全てのタンパク質候補についてペプチド情報の取得を行う。
【0067】
ステップS411にて、ペプチド情報を2つのペプチドリストに振り分ける。タンパク質候補の推定精度を予め設定した閾値Yと比較する。ステップS412にて、推定精度が閾値Yよりも大きいタンパク質候補のペプチドの質量を、第1のペプチドリストに登録する。ステップS413にて、推定精度が閾値Y以下のタンパク質候補のペプチドの質量を、第2のペプチドリストに登録する。こうして1回目の分析を終了し、次に2回目の分析を行う。
【0068】
図13を参照して本発明による質量分析方法の第5の例の2回目の分析を説明する。ステップS501にて、イオン化部13は、試料をイオン化する。ステップS502にて、質量分析部14は、MS質量分析を行う。ステップS503にて、MSマススペクトルを得る。
【0069】
ステップS504にて、データ処理部19は、第2のペプチドリストのペプチドの質量に対応するピークがMSマススペクトルに存在するか否かを調べる。即ち、MSマススペクトルにおける第2のペプチドリストのペプチドの含有率を算出する。ステップS505にて、その含有率が閾値Zを超えているタンパク質候補を抽出し、そのペプチドの質量を第2のペプチドリストから第1のペプチドリストに移転する。本例では、第2のペプチドリストのペプチドであっても、2回目の分析にて、MSマススペクトルに対する含有率が閾値Zを超えている場合には、そのタンパク質候補は、タンパク質データベース20に格納されていると考えられる。従って、このようなタンパク質候補については重複して分析を行う必要はない。こうして、第1のペプチドリストに移転されたペプチドは、親イオンの選択対象から除外される。
【0070】
ステップS506にて、データ処理部19は、MSマススペクトルのピークのうち、第1のペプチドリストに含まれるデータを親イオンの選択対象より除外する。ステップS507にて、MSマススペクトルより1個のペプチドを親イオンとして選択し、解離する。上述のように、MSマススペクトルのピークから第1のペプチドリストのデータと同一のデータは除外されている。
【0071】
ステップS508からステップS510の処理は、ステップS306からステップS308の処理と同様であってよい。
【0072】
こうして本例では、2回目の分析にて得られたMSマススペクトルの情報を有効に利用してタンパク質候補に由来するペプチドが他に存在するかについて判定を行うことができる。
【0073】
図14を参照して、本発明による質量分析方法の第6の例を説明する。第5の例では、2回目の分析において、第2のペプチドリストのペプチドは、MSマススペクトルにおける含有率が高いものを第1のペプチドリストに移転する。本例では、2回目の分析において、第2のペプチドリストのペプチドを、親イオンの選択の優先順位を設定するために使用する。
【0074】
本例では、1回目の分析は、第5の例と同様である。即ち、図12のステップS401からステップS413が1回目の分析である。
【0075】
図14を参照して本発明による質量分析方法の第6の例の2回目の分析を説明する。ステップS601にて、イオン化部13は、試料をイオン化する。ステップS602にて、質量分析部14は、MS質量分析を行う。ステップS603にて、MSマススペクトルを得る。
【0076】
ステップS604にて、データ処理部19は、MSマススペクトルのピークのうち第1のペプチドリストにあるデータを親イオンの選択対象から除外する。ステップS605にて、データ処理部19は、MSマススペクトルの残ったピークに対して親イオンを選択するための優先順位を設定する。優先順位は、MSマススペクトルの残った全てのピークに対して、第2のペプチドリストのペプチドの質量と比較する。一致するピークに対してボーナスを与える。タンパク質候補毎に、このような比較とボーナスの付与を行い、ピーク毎のボーナスの累計値を求める。この累計値の大きい順を、親イオンとして選択する優先順位とする。ここで、ピークとペプチドの質量が一致したときに与えるボーナスはある固定の値でも構わないが、タンパク質候補の推定精度等の条件よって変動するようなものが好ましい。例えば、推定精度が高いタンパク質候補の場合には、高いボーナスを設定し、推定精度が低いタンパク質候補の場合には、低いボーナスを設定する。このようにタンパク質候補の推定精度に基づいてボーナスを設定し、優先順位を与えることにより、試料中に含有している可能性が高いと考えられるタンパク質に由来するペプチドを親イオンとして選択することができる。
【0077】
ステップS606にて、データ処理部19は、親イオンを選択し、それを解離する。親イオンの選択対象は、MSマススペクトルのピークのうち第1のペプチドリストにあるデータを除外した残りのピークである。これらのピークから優先順位の最も高いピークを親イオンとして選択する。
【0078】
ステップS607からステップS609は図13のステップS508からステップS510の処理と同様であってよい。
【0079】
以上、本発明の例を説明したが本発明は上述の例に限定されるものではなく、特許請求の範囲に記載された発明の範囲にて様々な変更が可能であることは当業者に容易に理解されよう。
【図面の簡単な説明】
【0080】
【図1】本発明の質量分析システムの構成を示す図である。
【図2】従来のタンデム質量分析方法の処理の概略を示す図である。
【図3】試料分離部によって得られるクロマトグラムと分析の繰返しを示す図である。
【図4】本発明のタンデム質量分析方法の第1の例の1回目の分析処理の概略を示す図である。
【図5】本発明のタンデム質量分析方法の第1の例の2回目の分析処理の概略を示す図である。
【図6】本発明のタンデム質量分析方法の第1の例の2回目の分析処理において、MSマススペクトルのピークから親イオンの選択対象から除外する処理を説明するための図である。
【図7】本発明のタンデム質量分析方法の第1の例の1回目の分析処理において、タンパク質候補の推定処理を説明するための図である。
【図8】本発明のタンデム質量分析方法の第1の例の1回目の分析処理において、ペプチド情報の取得処理を説明するための図である。
【図9】本発明の質量分析システムの入力画面の例を示す図である。
【図10】本発明の質量分析システムの出力画面の例を示す図である。
【図11】本発明の質量分析システムの出力画面において、分析結果のアミノ酸配列を表示する例を示す図である。
【図12】本発明のタンデム質量分析方法の第5の例の1回目の分析処理を説明するための図である。
【図13】本発明のタンデム質量分析方法の第5の例の2回目の分析処理を説明するための図である。
【図14】本発明のタンデム質量分析方法の第6の例の2回目の分析処理を説明するための図である。
【符号の説明】
【0081】
12…試料分離部、13…イオン化部、14…質量分析部、15…イオン検出部、16…制御部、17…ユーザ入力部、18…表示部、19…データ処理部、20…タンパク質データベース
【特許請求の範囲】
【請求項1】
試料を分離する試料分離部と、分離した試料をイオン化するイオン化部と、イオン化した試料の質量分析を行う質量分析部と、質量対電荷比(m/z)毎にイオン強度を測定するイオン検出部と、タンパク質に関するデータを格納したタンパク質データベースと、を有し、
試料をイオン化するイオン化処理、該イオン化した試料を質量分析してMSマススペクトルを得るMS質量分析処理、該MSマススペクトルのピークから親イオンを選択して解離する親イオン選択及び解離処理、及び、解離した親イオンを質量分析してMS2マススペクトルを得るMS2質量分析処理、を含む分析を繰り返して実行するとき、
1回目の分析において、上記MS2マススペクトルを用いて試料に含まれるタンパク質のうち上記タンパク質データベースに格納されているタンパク質候補をリアルタイムにて推定し、
2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、上記タンパク質候補に含まれるペプチド以外のペプチドを親イオンとして選択することを特徴とする質量分析システム。
【請求項2】
請求項1記載の質量分析システムにおいて、1回目の分析において、上記タンパク質候補を推定するとき、上記MS2マススペクトルのピークからアミノ酸配列を解読し、該解読したアミノ酸配列を検索キーとして上記タンパク質データベースを検索することを特徴とする質量分析システム。
【請求項3】
請求項1記載の質量分析システムにおいて、1回目の分析において、上記タンパク質候補の推定精度を計算し、2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、上記推定精度が所定の閾値より大きいタンパク質候補に含まれるペプチド以外のペプチドを親イオンとして選択することを特徴とする質量分析システム。
【請求項4】
請求項3記載の質量分析システムにおいて、上記推定精度は、上記タンパク質データベースから検索したタンパク質候補の全アミノ酸配列に対して、MSマススペクトルから解読したアミノ酸配列が含まれる割合によって表わされることを特徴とする質量分析システム。
【請求項5】
請求項3記載の質量分析システムにおいて、1回目の分析において、上記推定精度が所定の閾値より大きいタンパク質候補に含まれるペプチドに関する情報を取得してペプチドリストを作成し、2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、該ペプチドリストに含まれるペプチド以外のペプチドを親イオンとして選択することを特徴とする質量分析システム。
【請求項6】
請求項5記載の質量分析システムにおいて、1回目の分析において、上記ペプチド情報を取得するとき、上記タンパク質候補を酵素によって分解し、得られたペプチドの質量を各アミノ酸の質量から計算することを特徴とする質量分析システム。
【請求項7】
請求項5記載の質量分析システムにおいて、1回目の分析において、上記ペプチド情報を取得するとき、試料に既知のタンパク質が含まれている場合には、該既知のタンパク質のペプチドを上記ペプチドリストに登録することを特徴とする質量分析システム。
【請求項8】
請求項1記載の質量分析システムにおいて、1回目の分析において、上記タンパク質候補を推定するとき、既知のタンパク質について検定用のMS2マススペクトルを予め求め、それを上記タンパク質データベースに登録し、この検定用のMS2マススペクトルと、1回目の分析で取得したMS2マススペクトルを比較することにより、タンパク質候補の推定を行うことを特徴とする質量分析システム。
【請求項9】
請求項1記載の質量分析システムにおいて、1回目の分析において、上記MS2マススペクトルからタンパク質候補を推定するとき、推定精度が低い場合には、該MS2マススペクトルのピークから親イオンを選択して解離する親イオン選択及び解離処理、及び、解離した親イオンを質量分析してMS3マススペクトルを得るMS3質量分析処理、を行うことを特徴とする質量分析システム。
【請求項10】
請求項1記載の質量分析システムにおいて、
1回目の分析において、上記タンパク質候補の推定精度を計算し、上記タンパク質候補に含まれるペプチドに関する情報を取得し、上記タンパク質候補のうち上記推定精度が所定の閾値より大きいタンパク質候補のペプチドに関する情報を第1のペプチドリストに登録し、上記タンパク質候補のうち上記推定精度が所定の閾値に満たないタンパク質候補のペプチドに関する情報を第2のペプチドリストに登録し、2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、上記第1のペプチドリストのペプチド以外のペプチドを親イオンとして選択することを特徴とする質量分析システム。
【請求項11】
請求項10記載の質量分析システムにおいて、2回目の分析において、MSマススペクトルのピークに対する第2のペプチドリストのペプチドの含有率を計算し、該含有率が所定の閾値を超えているペプチドを第2のペプチドリストから第1のペプチドリストに移転することを特徴とする質量分析システム。
【請求項12】
請求項10記載の質量分析システムにおいて、2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、上記第1のペプチドリストのペプチドを親イオンの選択対象から除去し、更に、MSマススペクトルの残ったピークに対して親イオンを選択するための優先順位を設定することを特徴とする質量分析システム。
【請求項13】
請求項12記載の質量分析システムにおいて、2回目の分析において、親イオンを選択するための優先順位を設定するとき、MSマススペクトルの残ったピークを第2のペプチドリストのペプチドと比較し、一致するピークに対してボーナスを与え、タンパク質候補毎に、このような比較とボーナスの付与を行い、MSマススペクトルの残った全てのピーク毎のボーナスの累計値を求め、この累計値の大きい順を、上記優先順位とすることを特徴とする質量分析システム。
【請求項14】
試料を分離する試料分離部と、分離した試料をイオン化するイオン化部と、イオン化した試料の質量分析を行う質量分析部と、質量対電荷比(m/z)毎にイオン強度を測定するイオン検出部と、タンパク質に関するデータを格納したタンパク質データベースと、を有し、
試料をイオン化するイオン化処理、該イオン化した試料を質量分析してMSマススペクトルを得るMS質量分析処理、該MSマススペクトルのピークから親イオンを選択して解離する親イオン選択及び解離処理、及び、解離した親イオンを質量分析してMS2マススペクトルを得るMS2質量分析処理、を含む分析を繰り返して実行するとき、
1回目の分析において、上記MS2マススペクトルから試料に含まれるタンパク質のうち上記タンパク質データベースに既に格納されているタンパク質候補をリアルタイムにて推定し、上記タンパク質候補の推定精度を計算し、上記タンパク質候補に含まれるペプチドに関する情報を取得し、上記タンパク質候補のうち上記推定精度が所定の閾値より大きいタンパク質候補のペプチドに関する情報を第1のペプチドリストに登録し、上記タンパク質候補のうち上記推定精度が所定の閾値に満たないタンパク質候補のペプチドに関する情報を第2のペプチドリストに登録し、
2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、上記第1のペプチドリストのペプチドを親イオンの選択対象から除外し、更に、MSマススペクトルの残ったピークに対して親イオンを選択するための優先順位を設定することを特徴とする質量分析システム。
【請求項15】
請求項14記載の質量分析システムにおいて、2回目の分析において、MSマススペクトルのピークに対する第2のペプチドリストのペプチドの含有率を計算し、該含有率が所定の閾値を超えているペプチドを第2のペプチドリストから第1のペプチドリストに移転することを特徴とする質量分析システム。
【請求項16】
請求項14記載の質量分析システムにおいて、2回目の分析において、親イオンを選択するための優先順位を設定するとき、MSマススペクトルの残ったピークを第2のペプチドリストのペプチドと比較し、一致するピークが多い順を、上記優先順位とすることを特徴とする質量分析システム。
【請求項17】
請求項14記載の質量分析システムにおいて、2回目の分析において、親イオンを選択するための優先順位を設定するとき、MSマススペクトルの残ったピークを第2のペプチドリストのペプチドと比較し、一致するピークに対してボーナスを与え、タンパク質候補毎に、このような比較とボーナスの付与を行い、MSマススペクトルの残った全てのピーク毎のボーナスの累計値を求め、この累計値の大きい順を、親イオンとして選択する優先順位とすることを特徴とする質量分析システム。
【請求項18】
試料をイオン化するイオン化処理、該イオン化した試料を質量分析してMSマススペクトルを得るMS質量分析処理、該MSマススペクトルのピークから親イオンを選択して解離する親イオン選択及び解離処理、及び、解離した親イオンを質量分析してMS2マススペクトルを得るMS2質量分析処理、を含む分析を繰り返して試料に含まれるタンパク質を同定するタンデム型質量分析方法において、
1回目の分析において、上記MS2マススペクトルから試料に含まれるタンパク質のうち上記タンパク質データベースに既に格納されているタンパク質候補をリアルタイムにて推定し、
2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、上記タンパク質候補に含まれるペプチド以外のペプチドを親イオンとして選択することを特徴とするタンデム型質量分析方法。
【請求項19】
請求項18記載のタンデム型質量分析方法において、1回目の分析において、上記タンパク質候補の推定精度を計算し、上記タンパク質候補に含まれるペプチドに関する情報を取得し、上記タンパク質候補のうち上記推定精度が所定の閾値より大きいタンパク質候補のペプチドに関する情報を第1のペプチドリストに登録し、上記タンパク質候補のうち上記推定精度が所定の閾値に満たないタンパク質候補のペプチドに関する情報を第2のペプチドリストに登録し、2回目の分析において、MSマススペクトルのピークに対する第2のペプチドリストのペプチドの含有率を計算し、該含有率が所定の閾値を超えているペプチドを第2のペプチドリストから第1のペプチドリストに移転し、親イオンの選択を行うとき、MSマススペクトルのピークのうち、上記第1のペプチドリストに含まれるペプチド以外のペプチドを親イオンとして選択することを特徴とするタンデム型質量分析方法。
【請求項20】
請求項18記載のタンデム型質量分析方法において、2回目の分析において、上記第1のペプチドリストのペプチドを親イオンの選択対象から除外し、更に、MSマススペクトルの残ったピークに対して親イオンを選択するための優先順位を設定することを特徴とするタンデム型質量分析方法。
【請求項1】
試料を分離する試料分離部と、分離した試料をイオン化するイオン化部と、イオン化した試料の質量分析を行う質量分析部と、質量対電荷比(m/z)毎にイオン強度を測定するイオン検出部と、タンパク質に関するデータを格納したタンパク質データベースと、を有し、
試料をイオン化するイオン化処理、該イオン化した試料を質量分析してMSマススペクトルを得るMS質量分析処理、該MSマススペクトルのピークから親イオンを選択して解離する親イオン選択及び解離処理、及び、解離した親イオンを質量分析してMS2マススペクトルを得るMS2質量分析処理、を含む分析を繰り返して実行するとき、
1回目の分析において、上記MS2マススペクトルを用いて試料に含まれるタンパク質のうち上記タンパク質データベースに格納されているタンパク質候補をリアルタイムにて推定し、
2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、上記タンパク質候補に含まれるペプチド以外のペプチドを親イオンとして選択することを特徴とする質量分析システム。
【請求項2】
請求項1記載の質量分析システムにおいて、1回目の分析において、上記タンパク質候補を推定するとき、上記MS2マススペクトルのピークからアミノ酸配列を解読し、該解読したアミノ酸配列を検索キーとして上記タンパク質データベースを検索することを特徴とする質量分析システム。
【請求項3】
請求項1記載の質量分析システムにおいて、1回目の分析において、上記タンパク質候補の推定精度を計算し、2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、上記推定精度が所定の閾値より大きいタンパク質候補に含まれるペプチド以外のペプチドを親イオンとして選択することを特徴とする質量分析システム。
【請求項4】
請求項3記載の質量分析システムにおいて、上記推定精度は、上記タンパク質データベースから検索したタンパク質候補の全アミノ酸配列に対して、MSマススペクトルから解読したアミノ酸配列が含まれる割合によって表わされることを特徴とする質量分析システム。
【請求項5】
請求項3記載の質量分析システムにおいて、1回目の分析において、上記推定精度が所定の閾値より大きいタンパク質候補に含まれるペプチドに関する情報を取得してペプチドリストを作成し、2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、該ペプチドリストに含まれるペプチド以外のペプチドを親イオンとして選択することを特徴とする質量分析システム。
【請求項6】
請求項5記載の質量分析システムにおいて、1回目の分析において、上記ペプチド情報を取得するとき、上記タンパク質候補を酵素によって分解し、得られたペプチドの質量を各アミノ酸の質量から計算することを特徴とする質量分析システム。
【請求項7】
請求項5記載の質量分析システムにおいて、1回目の分析において、上記ペプチド情報を取得するとき、試料に既知のタンパク質が含まれている場合には、該既知のタンパク質のペプチドを上記ペプチドリストに登録することを特徴とする質量分析システム。
【請求項8】
請求項1記載の質量分析システムにおいて、1回目の分析において、上記タンパク質候補を推定するとき、既知のタンパク質について検定用のMS2マススペクトルを予め求め、それを上記タンパク質データベースに登録し、この検定用のMS2マススペクトルと、1回目の分析で取得したMS2マススペクトルを比較することにより、タンパク質候補の推定を行うことを特徴とする質量分析システム。
【請求項9】
請求項1記載の質量分析システムにおいて、1回目の分析において、上記MS2マススペクトルからタンパク質候補を推定するとき、推定精度が低い場合には、該MS2マススペクトルのピークから親イオンを選択して解離する親イオン選択及び解離処理、及び、解離した親イオンを質量分析してMS3マススペクトルを得るMS3質量分析処理、を行うことを特徴とする質量分析システム。
【請求項10】
請求項1記載の質量分析システムにおいて、
1回目の分析において、上記タンパク質候補の推定精度を計算し、上記タンパク質候補に含まれるペプチドに関する情報を取得し、上記タンパク質候補のうち上記推定精度が所定の閾値より大きいタンパク質候補のペプチドに関する情報を第1のペプチドリストに登録し、上記タンパク質候補のうち上記推定精度が所定の閾値に満たないタンパク質候補のペプチドに関する情報を第2のペプチドリストに登録し、2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、上記第1のペプチドリストのペプチド以外のペプチドを親イオンとして選択することを特徴とする質量分析システム。
【請求項11】
請求項10記載の質量分析システムにおいて、2回目の分析において、MSマススペクトルのピークに対する第2のペプチドリストのペプチドの含有率を計算し、該含有率が所定の閾値を超えているペプチドを第2のペプチドリストから第1のペプチドリストに移転することを特徴とする質量分析システム。
【請求項12】
請求項10記載の質量分析システムにおいて、2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、上記第1のペプチドリストのペプチドを親イオンの選択対象から除去し、更に、MSマススペクトルの残ったピークに対して親イオンを選択するための優先順位を設定することを特徴とする質量分析システム。
【請求項13】
請求項12記載の質量分析システムにおいて、2回目の分析において、親イオンを選択するための優先順位を設定するとき、MSマススペクトルの残ったピークを第2のペプチドリストのペプチドと比較し、一致するピークに対してボーナスを与え、タンパク質候補毎に、このような比較とボーナスの付与を行い、MSマススペクトルの残った全てのピーク毎のボーナスの累計値を求め、この累計値の大きい順を、上記優先順位とすることを特徴とする質量分析システム。
【請求項14】
試料を分離する試料分離部と、分離した試料をイオン化するイオン化部と、イオン化した試料の質量分析を行う質量分析部と、質量対電荷比(m/z)毎にイオン強度を測定するイオン検出部と、タンパク質に関するデータを格納したタンパク質データベースと、を有し、
試料をイオン化するイオン化処理、該イオン化した試料を質量分析してMSマススペクトルを得るMS質量分析処理、該MSマススペクトルのピークから親イオンを選択して解離する親イオン選択及び解離処理、及び、解離した親イオンを質量分析してMS2マススペクトルを得るMS2質量分析処理、を含む分析を繰り返して実行するとき、
1回目の分析において、上記MS2マススペクトルから試料に含まれるタンパク質のうち上記タンパク質データベースに既に格納されているタンパク質候補をリアルタイムにて推定し、上記タンパク質候補の推定精度を計算し、上記タンパク質候補に含まれるペプチドに関する情報を取得し、上記タンパク質候補のうち上記推定精度が所定の閾値より大きいタンパク質候補のペプチドに関する情報を第1のペプチドリストに登録し、上記タンパク質候補のうち上記推定精度が所定の閾値に満たないタンパク質候補のペプチドに関する情報を第2のペプチドリストに登録し、
2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、上記第1のペプチドリストのペプチドを親イオンの選択対象から除外し、更に、MSマススペクトルの残ったピークに対して親イオンを選択するための優先順位を設定することを特徴とする質量分析システム。
【請求項15】
請求項14記載の質量分析システムにおいて、2回目の分析において、MSマススペクトルのピークに対する第2のペプチドリストのペプチドの含有率を計算し、該含有率が所定の閾値を超えているペプチドを第2のペプチドリストから第1のペプチドリストに移転することを特徴とする質量分析システム。
【請求項16】
請求項14記載の質量分析システムにおいて、2回目の分析において、親イオンを選択するための優先順位を設定するとき、MSマススペクトルの残ったピークを第2のペプチドリストのペプチドと比較し、一致するピークが多い順を、上記優先順位とすることを特徴とする質量分析システム。
【請求項17】
請求項14記載の質量分析システムにおいて、2回目の分析において、親イオンを選択するための優先順位を設定するとき、MSマススペクトルの残ったピークを第2のペプチドリストのペプチドと比較し、一致するピークに対してボーナスを与え、タンパク質候補毎に、このような比較とボーナスの付与を行い、MSマススペクトルの残った全てのピーク毎のボーナスの累計値を求め、この累計値の大きい順を、親イオンとして選択する優先順位とすることを特徴とする質量分析システム。
【請求項18】
試料をイオン化するイオン化処理、該イオン化した試料を質量分析してMSマススペクトルを得るMS質量分析処理、該MSマススペクトルのピークから親イオンを選択して解離する親イオン選択及び解離処理、及び、解離した親イオンを質量分析してMS2マススペクトルを得るMS2質量分析処理、を含む分析を繰り返して試料に含まれるタンパク質を同定するタンデム型質量分析方法において、
1回目の分析において、上記MS2マススペクトルから試料に含まれるタンパク質のうち上記タンパク質データベースに既に格納されているタンパク質候補をリアルタイムにて推定し、
2回目の分析において、親イオンの選択を行うとき、MSマススペクトルのピークのうち、上記タンパク質候補に含まれるペプチド以外のペプチドを親イオンとして選択することを特徴とするタンデム型質量分析方法。
【請求項19】
請求項18記載のタンデム型質量分析方法において、1回目の分析において、上記タンパク質候補の推定精度を計算し、上記タンパク質候補に含まれるペプチドに関する情報を取得し、上記タンパク質候補のうち上記推定精度が所定の閾値より大きいタンパク質候補のペプチドに関する情報を第1のペプチドリストに登録し、上記タンパク質候補のうち上記推定精度が所定の閾値に満たないタンパク質候補のペプチドに関する情報を第2のペプチドリストに登録し、2回目の分析において、MSマススペクトルのピークに対する第2のペプチドリストのペプチドの含有率を計算し、該含有率が所定の閾値を超えているペプチドを第2のペプチドリストから第1のペプチドリストに移転し、親イオンの選択を行うとき、MSマススペクトルのピークのうち、上記第1のペプチドリストに含まれるペプチド以外のペプチドを親イオンとして選択することを特徴とするタンデム型質量分析方法。
【請求項20】
請求項18記載のタンデム型質量分析方法において、2回目の分析において、上記第1のペプチドリストのペプチドを親イオンの選択対象から除外し、更に、MSマススペクトルの残ったピークに対して親イオンを選択するための優先順位を設定することを特徴とするタンデム型質量分析方法。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】

【図12】
【図13】
【図14】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【公開番号】特開2008−39608(P2008−39608A)
【公開日】平成20年2月21日(2008.2.21)
【国際特許分類】
【出願番号】特願2006−214828(P2006−214828)
【出願日】平成18年8月7日(2006.8.7)
【出願人】(501387839)株式会社日立ハイテクノロジーズ (4,325)
【Fターム(参考)】
【公開日】平成20年2月21日(2008.2.21)
【国際特許分類】
【出願日】平成18年8月7日(2006.8.7)
【出願人】(501387839)株式会社日立ハイテクノロジーズ (4,325)
【Fターム(参考)】
[ Back to top ]