
質量分析データを処理する方法、その方法を実行するコンピュータプログラム、そのコンピュータプログラムを含むコンピュータプログラム製品、その方法を実行するデータ処理手段を含むフーリエ変換質量分析機及びその方法を実行するデータ処理手段を含む液体クロマトグラフィー質量分析機
【課題】質量分析データの処理において、貴重な情報が失われずに、データセットのサイズを減少することである。
【解決手段】フーリエ変換質量分析データを処理する方法は、時間領域過渡の一部のフーリエ変換を実施するステップと、その変換されたデータからイオンの存在を示す信号ピークを識別するステップとを備える。ピークが識別されると、全過渡は変換され、部分過渡変換において識別されたピークは、変換された全過渡の真のピークを見つけるために使用される。ランダムノイズから生じた「偽」ピークの数は、分解能と相関することが明らかとなっているので、真のピークを識別するために部分的過渡を使用する。次に、全データセットの異なる部分が変換されてから相関されうる。あらゆるノイズはランダムであるため、偽ピークは2つの部分変換において異なる位置に発生するはずである。
【解決手段】フーリエ変換質量分析データを処理する方法は、時間領域過渡の一部のフーリエ変換を実施するステップと、その変換されたデータからイオンの存在を示す信号ピークを識別するステップとを備える。ピークが識別されると、全過渡は変換され、部分過渡変換において識別されたピークは、変換された全過渡の真のピークを見つけるために使用される。ランダムノイズから生じた「偽」ピークの数は、分解能と相関することが明らかとなっているので、真のピークを識別するために部分的過渡を使用する。次に、全データセットの異なる部分が変換されてから相関されうる。あらゆるノイズはランダムであるため、偽ピークは2つの部分変換において異なる位置に発生するはずである。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、質量分析データ、特に、限定はしないが、フーリエ変換イオンサイクロトロン共鳴質量分析(FTMS)から得られるデータを処理する方法に関する。
【背景技術】
【0002】
一般に分光分析、特に質量分析は、極めて豊富なデータセットを生成する。このことは、二重収束磁場型質量分析、飛行時間型質量分析、およびフーリエ変換質量分析(FTMS)を使用して取得されるデータのような高分解能質量分析データの場合には、特に当てはまる。たとえば、FTMSにおいてm/z200〜2000からの標準的な取得には、百万データポイントの測定を伴う。毎秒1回スキャンの測定(通常、液体クロマトグラフィー/質量分析(LC/MS)用途向け)は、結果として7.2GB/時(約170GB/日)の速度の生データの生成をもたらす。
【0003】
通常、これらのスペクトルは、コンピュータメモリまたは代替のコンピュータ可読媒体に格納され、そのため格納には大量のメモリが必要とされる。そのような分光分析データの大部分(おそらく99%)は、貴重な情報を含むことはないが、その代わりほとんどが、その全体の大きさおよび標準偏差を除いては分析的に有用性のないノイズで構成されている。
【0004】
現在、質量分析機は、データセット全体を格納するか、または2つの方法のうちの1つによりデータセットのサイズを減少させようと試みることがある。
【0005】
第1の方法は、単に、質量スペクトルにおいて見い出されたピークのリストを格納する(つまり、各ピークの位置および大きさを格納する)ことである。この方法には、ユーザーまたはソフトウェアが、ピーク形状、背景、信号対雑音比、または付加的仮定なくしては生成されえないその他の情報などのさらなる特徴についてデータを再評価することができないという欠点がある。スペクトルのオフピーク部分に関する情報は、さらに手動または自動で情報が処理される場合に、極めて重要である。信号対雑音比は、イベントの有意性に関する重要な手掛かりをもたらす。さらに、ピークのグループは、グループ内のピークの位置および強度の単なる自動処理よりもはるかに高度な技能によりスペクトルを評価することができる熟達したユーザーにとって、非常に有益である。
【0006】
格納すべきデータファイルのサイズを減少させる第2の方法は、オペレータがしきい値をあらかじめ選択し、このしきい値よりも値が大きいスペクトルのデータポイントのみをソフトウェアが格納することにより達成される。オペレータがしきい値を正しく推測する場合、ピークに属するデータポイントのみが格納される。これは、ピーク形状に関する情報を保持するという利点を有する。しかし、この方法には、しきい値レベルを正しく設定するためにオペレータの技能に依存するという欠点がある。しきい値レベルが過度に低く設定される場合、通常大量のノイズデータポイントがピークデータポイントと共に格納されることになり、しきい値が過度に高く設定される場合、ピーク形状に関連する貴重な情報はピークの基部のデータポイントが失われる際に失われてしまう。したがって、そのようなソフトウェアをうまく使用することは、熟達したオペレータ以外には困難である。加えて、ノイズに関連する情報は格納されず、そのような情報はすべて失われる。
【0007】
FTMSデータにおけるノイズの分析の改良は、非特許文献1において、および単独で非特許文献2においてハンナ(Hanna)により説明されている。ハンナが説明する方法では、スペクトルのノイズ排除レベルとして使用されるしきい値を取得するために、FTMS質量スペクトルに存在するノイズの統計的分析を使用する。ピークリストは、このしきい値を超えるデータから取得される。
【先行技術文献】
【非特許文献】
【0008】
【非特許文献1】Swansea,Advances in Mass Spectrometry 1985:proceedings of the 10th International Mass Spectrometry Conference,1985年9月9〜13日、John Wiley and Sons
【非特許文献2】D.A.Hanna,“NOISE ANALYSIS FOR MASS SPECTRA”,Advances in Mass Spectrometry 1985,Proceedings of the 10th International Mass Spectrometry Conference,1986,pp1211−1212
【発明の概要】
【発明が解決しようとする課題】
【0009】
ハンナの論文に説明されている技法は、達成されるべき適切なノイズしきい値のより優れた推定を可能にするが、それでもなお、これらにはいくつかの欠点がある。第1に、該技法は、ピーク位置およびそれらの強さの判別をもたらすのみであり、ピーク形状およびスペクトルノイズに関する貴重な情報は失われる。第2に、ノイズ分布のパラメータを取得するために、これらのパラメータが安定するまで何回かの反復が必要となるので、該技法は計算処理上比較的高価である。
【課題を解決するための手段】
【0010】
この背景に対して、また本発明の参考となる態様から、本発明は、フーリエ変換質量分析データを処理する方法であって、質量電荷比の範囲に関して時間領域におけるFTMSデータのセットを取得するステップと、取得された時間領域データのサブセットを周波数領域に変換するステップと、第1のしきい値を周波数領域データのサブセットに適用して、前記範囲の質量電荷比を有するイオンの存在を示すピークデータからノイズデータを識別するステップと、取得された時間領域データの全データセットを実質的に周波数領域に変換するステップと、ピークデータを含めるためにピークデータからノイズデータが識別された変換済みデータサブセットの領域に対応するその変換済み全データセット内の領域を識別するステップとを備える方法に属する。
【0011】
本発明の参考となるこの態様の処理技法は、格納されるべきデータファイルを圧縮するために「標準」しきい値においてランダムノイズスパイクを除去するか、または低いしきい値を使用してさらに小さい実際の信号を見いだすか(ただし、ここでデータファイルは圧縮されないことがある)のいずれであっても、ランダムノイズに対する識別を向上させる。本発明は、分解能が増大するのに応じて(時間領域データポイントの数に相当)、しきい値を超えるランダムノイズピークの数が増大するが、「実際の(real)」信号ピーク、つまり選択された範囲内の質量電荷比を有するイオンの存在を純粋に表すピークの数にはほとんどまたは全く増加は見られない、という観察結果に基づく。分解能が減少するのに応じて、ランダムピークの数も減少する、という逆もまた当てはまる。事実、実際の信号ピークの数はすべての分解能において比較的一定していることが確認されている。これは、ランダムノイズがガウス分布であると仮定すれば、存在するデータポイントが多ければ、それに応じて任意の所定のしきい値を超えるデータポイントの数も多くなるからである。周波数領域データポイントの数は、時間領域データポイントの数に比例する。したがって、より少ない時間領域データセットは、より少ないランダムノイズピークをもたらし、このことは、全データセットをしきい値分けする根拠として使用されうる。
【0012】
時間領域における全FTMSデータセットのほんの一部を周波数領域に変換することにより、分解能が減少するために所定のしきい値において見い出される偽ピークの数が比較的少なくなる。しきい値の上方に伸びるピークが識別されると(好ましくは、そのようなピークの位置)、全データセットが変換されることができるが、低分解能においてあらかじめ識別されている位置周辺のデータだけが、分析および/または保存される必要がある。つまり、低分解能において事前にしきい値を適用した結果、偽ピークは無視されうるので、周波数領域の全データセットにしきい値が単に適用された場合に見い出されるであろう多数の偽ピークの問題が回避される。
【0013】
本発明の参考となる態様において、全変換からの実質的にすべてのデータが表示および/または格納されうるが、それは部分的な過渡(transient)の変換において「実際の」データであると識別された領域に限られる(これらは第1のしきい値を超えるので)。すなわち、第2の強度しきい値は全変換に適用される必要はなく、たとえば、データの総量は主として、ノイズデータのみを含む走査された範囲内の周波数/質量範囲を識別し(第1のしきい値の部分的過渡変換への適用を通じて)、全過渡変換においてこれらの対応する領域を単に拒否することによって減少される。しかし、追加のまたは代替の実施形態において、第2のしきい値は、全過渡変換においてデータに適用されることができ、その第2のしきい値を超えるデータのみが表示、格納などのために保持される。その第2のしきい値は、第1のしきい値と同じであっても、または異なっていてもよい。
【0014】
本発明の実施形態によれば、フーリエ変換質量分析(FTMS)データを処理する方法であって、質量電荷比(m/z)の範囲に関して時間領域において取得されたFTMSデータの第1のセットを周波数領域に変換するステップと、FTMSデータの前記第1のセットとは異なる、時間領域のFTMSデータの第2のセットを周波数領域に変換するステップと、周波数領域のデータの各セットに共通のピークを識別するように、周波数領域のFTMSデータの第1のセットを周波数領域のFTMSデータの第2のセットと相関させるステップとを備える方法が提供される。
【0015】
本発明のこの実施形態は、ノイズが基本的にランダムであるという事実を活用する。そのように、時間領域の全データセットの異なる部分は、周波数領域に変換されるときに、たとえばピークが「実際の」ピークである場合、同じ相対的位置においてピークを提示するはずであるが、ランダムノイズから生じたデータのピークは統計的に、全データセットの2つの別個のサブセットにおいて同じ場所では発生しないはずである。
【0016】
第1および第2のデータセットは、同じ過渡の異なる部分から取得されうる(ただし重複は可能である)。代替として、第1および第2のデータセットは、異なる過渡のサブセットであってもよい。後者の場合、もちろん、2つの間の相関が有意であるように、m/z範囲の少なくとも部分的な重複が各過渡内に含まれることが望ましい。
【0017】
1つの実施形態において、サブセットは相互に重複することができ、たとえば、全データセットの第1の25%および第1の50%がそれぞれ変換されて相互相関されてもよい。代替として、別個のサブセットが変換されてもよい(たとえば、第1の25%および第2の25%)。さらになお、時間領域FTMSデータの第1および第2のセットは、全く別の過渡からのものであってもよい。
【0018】
多数の同位体ピークが発生する、より大型の分子のピークを識別する方法もまた開示されるが、これは2つのしきい値に依存する。開示される方法は、データ圧縮を可能にするので(つまり格納されうるノイズデータの量を減少させることにより)、単に有利であるわけではないことも理解されるであろう。特に相関の手法により、低強度の「実際の」ピークの検出が、たとえフルスペクトルでノイズフロアよりも低強度である場合であっても可能になる。
【0019】
本発明の参考となる態様および実施形態となる態様は決して相互排他的ではないことが、当然理解されるべきである。好ましい実施態様は、実際に、この2つの態様を組み合わせる。したがって、本発明の別の実施形態によれば、質量分析データを処理する方法であって、質量電荷比の範囲に関して時間領域における質量分析データのセットを取得するステップと、その取得された時間領域データの第1のサブセットを周波数領域に変換するステップと、その取得された時間領域データの第2サブセットを周波数領域に変換するステップと、取得された時間領域データの全データセットを実質的に周波数領域に変換するステップと、周波数領域の前記第1および第2のサブセットのうちの少なくとも1つに第1のしきい値を適用して、ピークデータを含むそのデータの1つまたは複数の領域を識別するステップと、周波数領域のデータの第1のサブセットを周波数領域のデータの第2のサブセットと相関させて、各々の前記サブセットに共通のデータの1つまたは複数の領域を識別するステップとを備える方法が提供される。
【0020】
一般に、本発明は、FTMSデータの改良されたしきい値分け技法(thresholding technique)、つまり、縮小されたデータセットを生成するときに、ピークまたはスペクトル領域が全データセットに含まれるかまたは全データセットから除外される決定プロセスへの改良された手法を提供する。本発明は、以下の基準の2つ以上の数学的または論理的な組合せに基づいている。
1.時間領域データのサブセクションにおける存在量(abundance)(過渡)
2.同じデータセットの異なるサブセクションにおける有意な存在量(任意の種類の重複するサブセクションを含む)
3.全データセットにおける存在量
4.異なるデータセットにおける存在量
5.2つ以上の異なるデータセットにおける存在量
6.以前の基準により適格とされたピーク間の位相相関
7.頻繁に発生するピークに関する情報(集計されるか、または統計的に評価されうる)
8.空白であることが判明したピークに関する情報(つまり、サンプルイオンがない場合に生成されたスペクトル)。これらは再度、集計されるか、または統計的に評価されうる。
【0021】
異なる基準に使用される有意レベルは異なっていてもよい。論理演算は、たとえばAND、OR、XOR、NOT、包含など任意のタイプであってもよい。数学演算は、乗算、加算、変換、結果と「主しきい値(master threshold)」との比較、またはそれ以外であってもよい。
【発明の効果】
【0022】
本発明によれば、質量分析データの処理において、ピーク形状およびスペクトルノイズに関する貴重な情報が失われずに、データセットのサイズを減少することができる。
【図面の簡単な説明】
【0023】
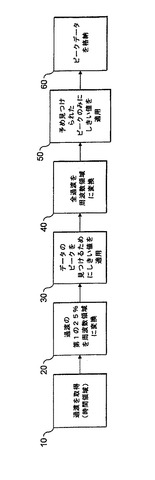
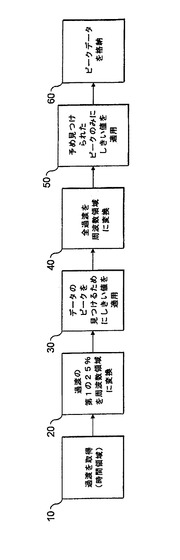
【図1】イオンとさらにランダムノイズも存在することにより生じた両方のピークを含む、質量スペクトルの形式で全FTMSデータセットを示す図である。
【図2】本発明の参考となる態様を具現するFTMSデータを処理する方法を示すフローチャートである。
【図3】本発明の1つの実施形態によるデータ処理方式を示すフローチャートである。
【図4】従来技術によるしきい値分け技法を使用して生成されるフーリエ変換質量スペクトルを示す図である。
【図5】本発明の実施形態の改良されたしきい値分け技法を使用して生成されるフーリエ変換質量スペクトルを示す図である。
【図6】本発明の参考態様にも適用できるもう1つの実施形態によるデータ処理方式を示すフローチャートである。
【図7】図6のデータ処理方式と類似するが、一部変形を伴うデータ処理方式を示すフローチャートである。
【図8】本発明のさらにもう1つの実施形態を示すフローチャートである。
【発明を実施するための形態】
【0024】
本発明がさらに容易に理解されうるために、これ以降、例示のみを目的として、添付の図面が参照される。
【0025】
フーリエ変換イオンサイクロトロン共鳴質量分析(FTMS)において、周知のように、イオンはイオン源において生成され、通常リニアイオントラップのように格納装置から測定セルに注入される。セルに保持されるイオンへの均一磁場およびrf電(励起)場の印加は、イオンをそのセル内でサイクロトロン周波数で軌道を描いて旋回させる。イオンは、セル内の検出電極においてイメージ電流によって検出される。
【0026】
本技法により取得される生データは、時間領域にあり、過渡(transient)として知られる。過渡が得られると、従来技術のFTMSにおいては、以下の技法により質量スペクトルが取得される。最初に、過渡がアポダイズされ(apodise)、ゼロ充填される。次に、周波数領域へのデータのフーリエ変換が実行される。これは、実数部および虚数部で構成される1組の値から成る複素周波数スペクトルをもたらす。その後、式P=(Im2+Re2)1/2を使用して、マグニチュードスペクトル(magnitude spectrum)がポイントごとに得られる。これは、較正式を適用することにより、質量スペクトルに変換される。結果として得られた質量スペクトルの例が図1に示される。データは、1つまたは複数のピーク(図1において質量数を示すラベルが付けられている)および大量のノイズを含むことが理解されよう。
【0027】
全FTMSデータセットを変換して格納することは、極めて大きい記憶容量を必要とする可能性のある、比較的多大な時間を要する作業である。格納された情報の多くは、実際、分析的にほとんど価値がないか、または全く価値がないノイズである。格納されるデータの総量を縮小するため、従来技術では単に周波数領域のデータにしきい値を適用し、そのしきい値を下回るすべてのデータポイントを除去していた。背景技術において説明されているように、データを過度に圧縮するかまたは過少に圧縮して、多くのノイズが残されたり、真のピークが誤って除去されたりするおそれもあるため、固定のしきい値の場合、これは融通のきかないメカニズムである。
【0028】
図2は、本発明の参考となる態様を具現するFTMSデータを処理する方法のフローチャートを示す。ステップ10において、時間領域における過渡は、前述の方法でFTMSによって取得される。ステップ20において、この過渡の全体ではないがその一部が、周波数領域にフーリエ変換される。フーリエ変換される過渡の量は、計算の速度と精度との間のトレードオフである。一方では、全過渡の比較的小さい割合を変換することは、迅速に完了されうる。もう一方では、周波数領域に変換される過渡の割合が小さすぎる場合に、データ内の真のピークが失われることもある。図2の参考となる態様では、過渡の25%を採用し、通常これは第1の25%である。第1の25%を採用することの利点は、過渡のその25%の後続の処理を、全過渡のうちの残りが取得される前に開始できることである。
【0029】
周波数領域のデータは、FTMS装置による評価のために選択された範囲内の質量電荷比を有するイオンの存在を表すピークを含む。周波数領域のデータはまた、実際にはランダムノイズの結果であるが真のピークであると誤って判別される可能性のある多数のデータポイントも含む。しかし、本発明の概要で説明されているように、そのようなピークの数は、分解能の低下に伴って減少する。したがって、全過渡のうちのわずか25%のフーリエ変換は、ランダムノイズピークの数も減少させるはずである。
【0030】
したがって、ステップ30において、ステップ20で得られた部分フーリエ変換に強度しきい値が適用される。しきい値は、真のピークを廃棄するリスクを最小限にするため、比較的控えめに選択される。それでもなお、部分データセット内の偽ピークの数が減少したため、強度しきい値を超える偽ピーク(つまり、ランダムノイズピーク)が通過されるリスクも低減される。
【0031】
次に、ステップ40において、全過渡が周波数領域にフーリエ変換される。次に、ステップ50において、全過渡のフーリエ変換により取得された周波数領域データに、強度しきい値が適用される。このしきい値は、ステップ30において適用されたしきい値と同じであっても、またはそれよりも低いものであってもよい。しかし、重要なことに、ステップ50において適用されたしきい値は、ステップ30で確認された真のデータピークの位置の周辺の周波数領域スペクトル(または質量スペクトル)の領域でのみ適用される。つまり、これらのピークの領域の間のデータポイントは、ステップ30において適用された強度しきい値を下回っていることになり、これ以上検討されることはない。
【0032】
ステップ60において、ステップ50で適用されたしきい値を超えるピークデータが格納される。このような方法でランダムノイズを除去することにより、おそらく90〜95%あるいはそれ以上の圧縮が達成されうるが、ピークに関連するデータ自体は損なわれることも、圧縮されることもない。さらに、同時係属出願第PCT/EP04/010736号に説明されているように、ピークの間のデータはランダムノイズであると仮定されるので、ランダムノイズデータがガウス分布であると仮定し確定されたガウス・パラメータを使用してそれを再構成することにより、擬似スペクトルは再構成されうる。
【0033】
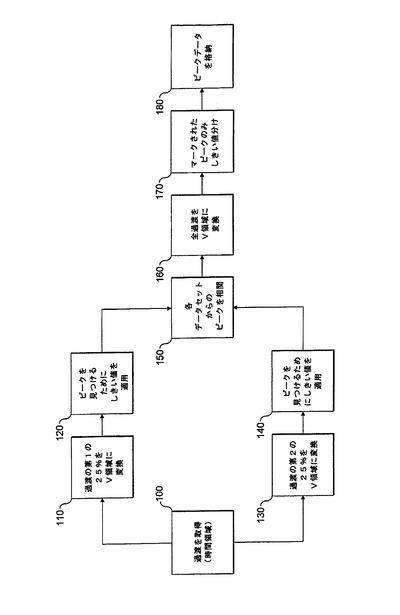
図3は、本発明の実施形態によるFTMSデータを処理する方法のフローチャートを示す。ステップ100において、オペレータによって選択された全分解能を使用して、過渡がもう一度取得される(つまり、全過渡が取得される)。全データ過渡の収集と同時か、またはそれ以降に、ステップ110において、その過渡の第1の25%が、図2のステップ20のように、周波数領域に変換される。図3のステップ120において、データ内の真のピークを見つけるために、今度は周波数領域において、過渡の第1の25%に、強度しきい値が適用される。前回と同様に、真のデータピークが見落とされるリスクを最小限にするため、比較的控えめなしきい値が採用されうる。
【0034】
ステップ130において、過渡の第2の25%が、周波数領域に変換される。これは、元のデータセットの重複する25%、または後続の25%(つまり、ステップ100で必要とされた元の時間領域過渡の25〜50%)であってもよい。次に、強度しきい値は、そのデータ内の真のデータピークを識別するために、もう一度そのデータにも適用される。ステップ140において適用されたしきい値は、ステップ120において適用された強度しきい値と同じであっても、異なっていてもよい。特に、ステップ130において異なるサイズのデータセットがステップ110に関して変換される場合(たとえば、元の時間領域過渡の50%がステップ130において変換される場合)、ステップ140において適用されるしきい値は、ステップ120において適用されるしきい値よりもわずかに高くなる可能性がある(後者の場合、さらに多くの過渡がフーリエ変換されたため、偽データピークのリスクが高まっている)。
【0035】
ステップ150において、処理ステップ120および140の結果として取得されたデータセットは、比較されるか、または相関される。ステップ120および140に続いて取得されるスペクトルの各々において同じ場所に2つの信号が現れるはずである。しかし、ノイズが真にランダムであり全時間領域データセット(過渡)の異なるセクション間で相関されないと仮定すると、ノイズピークは、2つの異なるスペクトルの同じ位置には現れない。したがって、それぞれステップ120および140の結果として得られた2つのスペクトルにおいて相互に相関するピークの位置を識別することにより、またピークが一致しないデータの領域を廃棄することにより、データセット全体に対する「前置フィルタ(prefilter)」が生成されうる。
【0036】
次に、ステップ160において、全過渡は、周波数領域にフーリエ変換される。しきい値(ステップ120および140において部分データセットに適用されたしきい値よりも高くなりうる)は、周波数領域の全過渡に適用されるが、それはステップ100〜150の前置フィルタリングの技法を使用して識別されたピークの領域に限られる。格納されたピークデータ、つまり、ステップ170で適用された強度しきい値を超えるデータは、ステップ180において格納される。図2の本発明の参考となる態様と同様に、廃棄されたランダムノイズは、それがガウス分布であると仮定することにより再構築されうる。
【0037】
現在、変換された部分過渡に比較的「ゆるい」しきい値を適用することが好ましいが(ステップ120および140)、これは必須のステップではないことが理解されるであろう。これは計算処理上高価であるが、しきい値データだけではなく、各データサブセットからのデータのすべてを相関させることが可能である。この手順は、真のピークが失われるリスクを軽減することになる。
【0038】
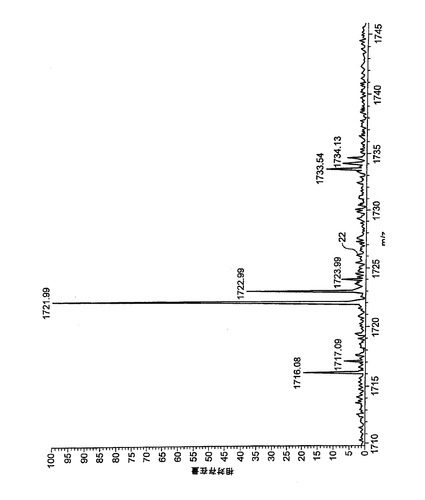
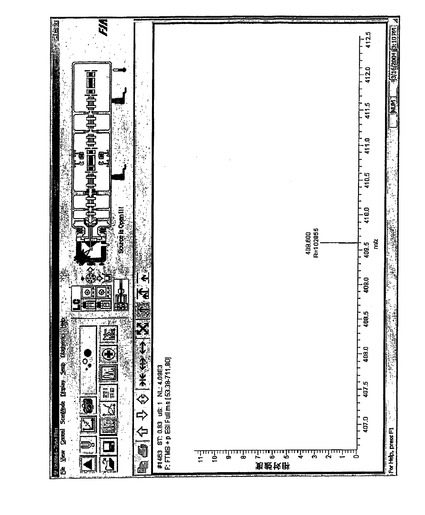
図3の方法の利点は、図4および図5において説明される。図4は、409.6kHzにおける「実際の」ピークと、実際の信号ピーク周囲の他の場所における複数のランダムノイズピークを含む人為的な時間領域信号を示す。409.6kHzにおける実信号の強度は、強度しきい値のすぐ上である。
【0039】
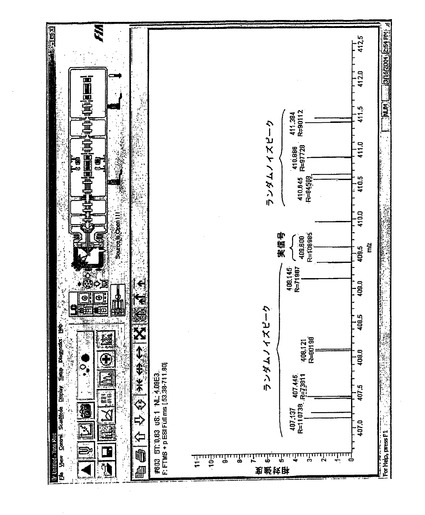
図4は、しきい値が前置フィルタリングなしで全フーリエ変換された過渡に適用される従来技術の技法を適用した結果を示す。全質量スペクトルである図1に対して、図4は「基線(base line)」ノイズを含まないが(しきい値の適用により除去された)、14のランダムノイズピークがあり、そのノイズのいくつかは409.6kHzにおける実信号よりも高い強度を有していることが分かる。
【0040】
全時間領域データセットの第1および第2の四半分が別個に変換される図3の改良された方式を適用し、時間領域過渡からの個別の周波数領域変換の検査を通じて、「有効な」ピークのリストが作成される。図5は、比較の結果を示す。ランダムノイズによるピークはすべて消失したが、質量電荷比のこの領域の1つの有効な信号は残っている。実信号は、たとえ図4のランダムノイズピークのいずれよりも低い強度を有していても残ることは注目に値する。したがって、ここに説明されている方法が単に、(前述の図3のステップ180におけるように)格納されるデータ量が減少されるようにするためにデータセットサイズを縮小することに限定されているわけではないことを理解されたい。当該方法はまた、標準の方法に匹敵するサイズのデータセットを生成するためにも使用されうるが、はるかに低い検出しきい値を使用する。これにより、データの全体量を増加させることなく、単純な強度しきい値を現在下回っている信号の検出が可能になる。
【0041】
図3において、2つのデータサブセットのピークの位置は、データ内の実際のピークを識別するために使用されるが、他のパラメータは、データ内の真のピークを識別する代わりに、またはそれに加えて、相関されうる。たとえば、ピークの強度は、(一致するピーク強度が「真の」ピークとして識別されるように)2つのデータサブセットの間で相関されうる。加えて、または代替として、実信号の位相は、過渡の1つのセグメントから次のセグメントへと一貫性があるが、これに反して、ランダム信号の位相はランダムであるはずである。したがって、位相の一貫性は、追加または代替の要因として使用されうる。信号に対して電荷状態が判別されうる場合、関連付けられている同位体ピークの位置は予測されうる。次いで、これらの同位体のウィンドウは、さらなる改良として、最終的なしきい値分け(thresholding)領域に含まれうる。さらにもう1つの改良として、複数のデータセットからのデータが採用されうる。この概念については、以下で図8に関連してさらに説明される。好ましい実施形態において、位置および位相(少なくとも)は共に採用される。
【0042】
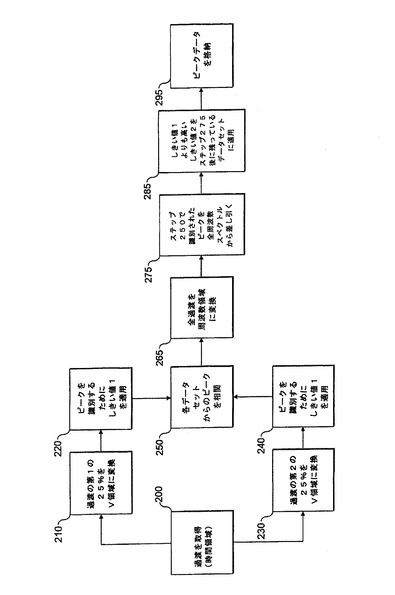
図6は、本発明の参考となる態様にも適用可能なもう1つの実施形態を示す。図6の実施形態は、いくつかの信号の特異性に対処するため、図3に説明されている実施形態へのさらなる変更を含む。具体的には、より大型の分子が、独特の時間領域信号または過渡を生成する。多数の等間隔の同位体ピークにより、強い「ビートパターン(beat pattern)」が生成されうる(ホフスタドラー(Hofstadler)他共著「Isotopic beat patterns in Fourier transform ion cyclotron resonance mass spectrometry:implications for high resolution mass measurement by biopolymers」、International Journal of Mass Spectrometry & Ion Processes 132:109〜127(1994年)を参照)。図3に説明されている2セグメントのしきい値の手法を使用して、2つの時間領域データセグメントのうちの1つは、全時間領域データの「波腹(anti-node)」と相関することができる。したがって、このセグメントにはしきい値を超える信号は現れず、そのため、たとえ2つのデータセットの一方に強い信号が現れることがあっても、「共通の」ピークは発生することはない。前もって波腹の位置を予測する方法はないので、時間領域過渡の選択されたサブセクションに波腹が現れないことを保証する方法はない。この問題に対する解決策は、2つの別個のしきい値を使用することである。
【0043】
図6を参照すると、ステップ200において、上記と同様に全過渡が要求される。ステップ210において、過渡の第1の25%が周波数領域に変換され、次いでステップ220において、第1の低い強度しきい値(しきい値1)がこのしきい値のピークを識別するために適用される。ステップ230に示されるように過渡の第2の25%が周波数領域に変換されると、同様の技法がこれに適用される。ステップ240において、しきい値1がこの周波数領域データに適用され、そのピークが識別される。
【0044】
ステップ250において、ステップ220および240からの2つのデータセットは、共通のピークを識別するために相関される。しかし、ステップ260において、より高いしきい値(しきい値2)も、ステップ220および240に続いて取得されたデータサブセットに適用され、前述の強いビートパターンにより、大型のピーク(実際のピークと仮定される)が誤って廃棄されないようになっている。
【0045】
変更された前置フィルタが生成されると、つまり、真のピークの位置がステップ260において判別されると、ステップ270において、全過渡が周波数領域に変換され、その後ステップ280において第3のしきい値がデータ領域の全データ変換に適用されるが、それはステップ250および260に続いて判別された領域に限られる。上記と同様に、ステップ290において、ピークデータが格納されうる。
【0046】
同様のマグニチュード(magnitude)の2つの部分変換について説明されたが、当然のことながら、異なるマグニチュードの時間領域のデータサブセット、および/または重複するデータセットが採用されうる。
【0047】
図7において、図6の手法に若干変更を加えた手法が示される。図6および図7に類似性があるので、類似するステップを示すために同じ参照番号が採用されている。
【0048】
特に、図6および図7においてステップ200〜250は同じである、つまり、過渡の2つの別個の部分は周波数領域に変換され、第1の比較的低いしきい値(しきい値1)を使用してピークが検出され、次いで各データセットで一致するピークを見つけるために相関される。
【0049】
しかし、ステップ265において、各データサブセットにより高いしきい値を適用する代わりに、次のステップとして過渡全体が周波数領域に変換される。次に、ステップ275において、ステップ200〜250を介してピークとして識別された領域は、全周波数領域データセットから差し引かれるか、あるいは除外される。ステップ285において、残りのデータセットは、第1のしきい値よりも高い第2のしきい値に従う。これは、この第2のしきい値に到達した場合、たとえ前処理ステップがそのしきい値を見つけることができなかったとしても、全スペクトルからピークが省略されないことを確認する。
【0050】
ステップ295において、周波数領域の全データセットからのデータは格納されるが、それは相関前処理(ステップ200〜250)と残りのデータのより高レベルのしきい値処理との組合せを通じてピークであると識別される領域に限られる。
【0051】
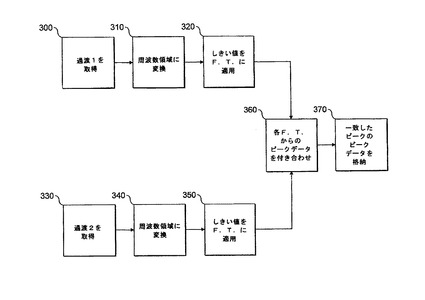
図8のフローチャートにおいて、もう1つの実施形態が示される。ここで、2つの完全に別個の時間領域データセットからのピークは、相関される。ステップ300で開始し、サンプルからイオンの第1のセットのFTMSセルへの注入に続いて(通常上流のイオンフィルタ/イオン格納配置を介して)、第1の過渡がこれらのサンプルイオンから取得される。ステップ310において、これは周波数領域に変換され、ステップ320において、しきい値が周波数領域のフーリエ変換に適用される。ステップ330において、第2の過渡が得られる。通常、これは、第1の過渡の収集と、その第1の過渡を作成したそれらのイオンのセルをその後空にすることに続いて、FTMSセルに注入されたイオンの新しいセットから取得される。第2の過渡は、ステップ340において、周波数領域に変換される。ステップ350において、しきい値は、周波数領域のそのフーリエ変換にも適用される。
【0052】
ステップ320および350において適用されたしきい値は、同じであっても、異なっていてもよい。同様に、ステップ300および330においてそれぞれ得られた第1および第2の過渡は全体が周波数領域に変換されうるが、その代わりに、しきい値が適用される前にステップ310および340において、各々別個の過渡の一部のみが周波数領域に変換されうる。さらに、通常、第1の過渡が得られるサンプルイオンの質量範囲は、第2の過渡をもたらすサンプルイオンの質量範囲と対応するが、質量範囲は同一である必要はない。上流イオンフィルタ/トラップのパラメータを調整することにより、異なる質量範囲がFTMSセルに注入されうるが、もちろんこれらは少なくとも重複する必要がある。
【0053】
ステップ360において、各フーリエ変換からの相関またはデータ付き合わせが行われる(これは、2つの過渡が得られる質量範囲が少なくとも部分的に重複しなければならない理由である)。このために、真のピークの位置は識別され、ステップ370において、それらの真のピークに関してデータが格納されうる。全過渡がステップ310および340で変換されると仮定すれば、図3および図6の実施形態の2つのステップのプロセスは回避される。しかし、図8の実施形態には、いくつかの欠点がある。具体的には、第1のデータセットの処理は、第2のデータセットが収集されていなければ完了できない。
【0054】
たとえば、サンプルイオン(既知のm/zであるかどうかにかかわらず)について同一の過渡の一部または異なる過渡に依存するのではなく、その代わりに「空白の(blank)」スペクトル(つまり、サンプルイオンがない場合)を分析することが可能であるなど、さまざまな他の実施形態が当業者には明らかとなろう。一般に、これは、FTMS装置の起動時に行われうる。現時点では、FTMS測定セル内にイオンがない場合に常駐ノイズピークが探し出されうる。そのような常駐ノイズピークの場所は格納される。一般に、前述のように、システムソフトウェアは、異なるスペクトルで位相の変化するピークを探す。次いで、これらの位相がずれた信号はスペクトルから差し引かれる。このようにすることの1つの利点は、本発明の実施形態により対処されうるホワイトノイズと共に、単一周波数電子ノイズ(システムの偽/ノイズのピークの主要源)を低減することである。
【0055】
本発明の実施形態は、イオンサイクロトロン共鳴によって生成される過渡の分析に関連して説明されたが、たとえば、本発明は、(通常)質量スペクトルへの最終的なフーリエ変換のための時間領域過渡として取得される、FT−IR、FT−NMR、またはSARから取得されたデータ、Orbitrap(米国特許第5886346号を参照)などの静電型トラップ(electrostatic trap)に同等に適用可能である、というように、決して限定されることはないことを理解されたい。概念はまた、米国特許第4755670号および米国特許第6403955号に説明されているような、動電型トラップ(electrodynamic trap)から得られるデータへの適用にも適している。実際、本発明は、静電飛行時間型(TOF)質量分析の出力に適用される(たとえば、ベナー、W.H.(1997年)「A Gated Electrostatic Ion Trap To Repetitiously Measure the Charge and m/z of Large Electrospray Ions」Analytical Chemistry 69、4162〜4168ページを参照)。さらに、フーリエ変換は、採用されうる周波数変換の唯一の形式ではない。本発明は、たとえばアダマール変換またはラプラス変換で同様に使用されうる。A.ブロック、N.ロドリゲス、およびR.N.ザル共著、「Hadamard Transform Time−of−Flight Mass Spectrometry(HT−TOFMS)」Anal Chem.70、3735〜3741(1998年)も参照されたい。したがって、本発明は実際に、周期的信号を生成する任意のMS方法に適用可能であることが理解されよう。
【産業上の利用可能性】
【0056】
本発明は、質量スペクトルへの最終的なフーリエ変換のための時間領域過渡の分析に利用できる。
【技術分野】
【0001】
本発明は、質量分析データ、特に、限定はしないが、フーリエ変換イオンサイクロトロン共鳴質量分析(FTMS)から得られるデータを処理する方法に関する。
【背景技術】
【0002】
一般に分光分析、特に質量分析は、極めて豊富なデータセットを生成する。このことは、二重収束磁場型質量分析、飛行時間型質量分析、およびフーリエ変換質量分析(FTMS)を使用して取得されるデータのような高分解能質量分析データの場合には、特に当てはまる。たとえば、FTMSにおいてm/z200〜2000からの標準的な取得には、百万データポイントの測定を伴う。毎秒1回スキャンの測定(通常、液体クロマトグラフィー/質量分析(LC/MS)用途向け)は、結果として7.2GB/時(約170GB/日)の速度の生データの生成をもたらす。
【0003】
通常、これらのスペクトルは、コンピュータメモリまたは代替のコンピュータ可読媒体に格納され、そのため格納には大量のメモリが必要とされる。そのような分光分析データの大部分(おそらく99%)は、貴重な情報を含むことはないが、その代わりほとんどが、その全体の大きさおよび標準偏差を除いては分析的に有用性のないノイズで構成されている。
【0004】
現在、質量分析機は、データセット全体を格納するか、または2つの方法のうちの1つによりデータセットのサイズを減少させようと試みることがある。
【0005】
第1の方法は、単に、質量スペクトルにおいて見い出されたピークのリストを格納する(つまり、各ピークの位置および大きさを格納する)ことである。この方法には、ユーザーまたはソフトウェアが、ピーク形状、背景、信号対雑音比、または付加的仮定なくしては生成されえないその他の情報などのさらなる特徴についてデータを再評価することができないという欠点がある。スペクトルのオフピーク部分に関する情報は、さらに手動または自動で情報が処理される場合に、極めて重要である。信号対雑音比は、イベントの有意性に関する重要な手掛かりをもたらす。さらに、ピークのグループは、グループ内のピークの位置および強度の単なる自動処理よりもはるかに高度な技能によりスペクトルを評価することができる熟達したユーザーにとって、非常に有益である。
【0006】
格納すべきデータファイルのサイズを減少させる第2の方法は、オペレータがしきい値をあらかじめ選択し、このしきい値よりも値が大きいスペクトルのデータポイントのみをソフトウェアが格納することにより達成される。オペレータがしきい値を正しく推測する場合、ピークに属するデータポイントのみが格納される。これは、ピーク形状に関する情報を保持するという利点を有する。しかし、この方法には、しきい値レベルを正しく設定するためにオペレータの技能に依存するという欠点がある。しきい値レベルが過度に低く設定される場合、通常大量のノイズデータポイントがピークデータポイントと共に格納されることになり、しきい値が過度に高く設定される場合、ピーク形状に関連する貴重な情報はピークの基部のデータポイントが失われる際に失われてしまう。したがって、そのようなソフトウェアをうまく使用することは、熟達したオペレータ以外には困難である。加えて、ノイズに関連する情報は格納されず、そのような情報はすべて失われる。
【0007】
FTMSデータにおけるノイズの分析の改良は、非特許文献1において、および単独で非特許文献2においてハンナ(Hanna)により説明されている。ハンナが説明する方法では、スペクトルのノイズ排除レベルとして使用されるしきい値を取得するために、FTMS質量スペクトルに存在するノイズの統計的分析を使用する。ピークリストは、このしきい値を超えるデータから取得される。
【先行技術文献】
【非特許文献】
【0008】
【非特許文献1】Swansea,Advances in Mass Spectrometry 1985:proceedings of the 10th International Mass Spectrometry Conference,1985年9月9〜13日、John Wiley and Sons
【非特許文献2】D.A.Hanna,“NOISE ANALYSIS FOR MASS SPECTRA”,Advances in Mass Spectrometry 1985,Proceedings of the 10th International Mass Spectrometry Conference,1986,pp1211−1212
【発明の概要】
【発明が解決しようとする課題】
【0009】
ハンナの論文に説明されている技法は、達成されるべき適切なノイズしきい値のより優れた推定を可能にするが、それでもなお、これらにはいくつかの欠点がある。第1に、該技法は、ピーク位置およびそれらの強さの判別をもたらすのみであり、ピーク形状およびスペクトルノイズに関する貴重な情報は失われる。第2に、ノイズ分布のパラメータを取得するために、これらのパラメータが安定するまで何回かの反復が必要となるので、該技法は計算処理上比較的高価である。
【課題を解決するための手段】
【0010】
この背景に対して、また本発明の参考となる態様から、本発明は、フーリエ変換質量分析データを処理する方法であって、質量電荷比の範囲に関して時間領域におけるFTMSデータのセットを取得するステップと、取得された時間領域データのサブセットを周波数領域に変換するステップと、第1のしきい値を周波数領域データのサブセットに適用して、前記範囲の質量電荷比を有するイオンの存在を示すピークデータからノイズデータを識別するステップと、取得された時間領域データの全データセットを実質的に周波数領域に変換するステップと、ピークデータを含めるためにピークデータからノイズデータが識別された変換済みデータサブセットの領域に対応するその変換済み全データセット内の領域を識別するステップとを備える方法に属する。
【0011】
本発明の参考となるこの態様の処理技法は、格納されるべきデータファイルを圧縮するために「標準」しきい値においてランダムノイズスパイクを除去するか、または低いしきい値を使用してさらに小さい実際の信号を見いだすか(ただし、ここでデータファイルは圧縮されないことがある)のいずれであっても、ランダムノイズに対する識別を向上させる。本発明は、分解能が増大するのに応じて(時間領域データポイントの数に相当)、しきい値を超えるランダムノイズピークの数が増大するが、「実際の(real)」信号ピーク、つまり選択された範囲内の質量電荷比を有するイオンの存在を純粋に表すピークの数にはほとんどまたは全く増加は見られない、という観察結果に基づく。分解能が減少するのに応じて、ランダムピークの数も減少する、という逆もまた当てはまる。事実、実際の信号ピークの数はすべての分解能において比較的一定していることが確認されている。これは、ランダムノイズがガウス分布であると仮定すれば、存在するデータポイントが多ければ、それに応じて任意の所定のしきい値を超えるデータポイントの数も多くなるからである。周波数領域データポイントの数は、時間領域データポイントの数に比例する。したがって、より少ない時間領域データセットは、より少ないランダムノイズピークをもたらし、このことは、全データセットをしきい値分けする根拠として使用されうる。
【0012】
時間領域における全FTMSデータセットのほんの一部を周波数領域に変換することにより、分解能が減少するために所定のしきい値において見い出される偽ピークの数が比較的少なくなる。しきい値の上方に伸びるピークが識別されると(好ましくは、そのようなピークの位置)、全データセットが変換されることができるが、低分解能においてあらかじめ識別されている位置周辺のデータだけが、分析および/または保存される必要がある。つまり、低分解能において事前にしきい値を適用した結果、偽ピークは無視されうるので、周波数領域の全データセットにしきい値が単に適用された場合に見い出されるであろう多数の偽ピークの問題が回避される。
【0013】
本発明の参考となる態様において、全変換からの実質的にすべてのデータが表示および/または格納されうるが、それは部分的な過渡(transient)の変換において「実際の」データであると識別された領域に限られる(これらは第1のしきい値を超えるので)。すなわち、第2の強度しきい値は全変換に適用される必要はなく、たとえば、データの総量は主として、ノイズデータのみを含む走査された範囲内の周波数/質量範囲を識別し(第1のしきい値の部分的過渡変換への適用を通じて)、全過渡変換においてこれらの対応する領域を単に拒否することによって減少される。しかし、追加のまたは代替の実施形態において、第2のしきい値は、全過渡変換においてデータに適用されることができ、その第2のしきい値を超えるデータのみが表示、格納などのために保持される。その第2のしきい値は、第1のしきい値と同じであっても、または異なっていてもよい。
【0014】
本発明の実施形態によれば、フーリエ変換質量分析(FTMS)データを処理する方法であって、質量電荷比(m/z)の範囲に関して時間領域において取得されたFTMSデータの第1のセットを周波数領域に変換するステップと、FTMSデータの前記第1のセットとは異なる、時間領域のFTMSデータの第2のセットを周波数領域に変換するステップと、周波数領域のデータの各セットに共通のピークを識別するように、周波数領域のFTMSデータの第1のセットを周波数領域のFTMSデータの第2のセットと相関させるステップとを備える方法が提供される。
【0015】
本発明のこの実施形態は、ノイズが基本的にランダムであるという事実を活用する。そのように、時間領域の全データセットの異なる部分は、周波数領域に変換されるときに、たとえばピークが「実際の」ピークである場合、同じ相対的位置においてピークを提示するはずであるが、ランダムノイズから生じたデータのピークは統計的に、全データセットの2つの別個のサブセットにおいて同じ場所では発生しないはずである。
【0016】
第1および第2のデータセットは、同じ過渡の異なる部分から取得されうる(ただし重複は可能である)。代替として、第1および第2のデータセットは、異なる過渡のサブセットであってもよい。後者の場合、もちろん、2つの間の相関が有意であるように、m/z範囲の少なくとも部分的な重複が各過渡内に含まれることが望ましい。
【0017】
1つの実施形態において、サブセットは相互に重複することができ、たとえば、全データセットの第1の25%および第1の50%がそれぞれ変換されて相互相関されてもよい。代替として、別個のサブセットが変換されてもよい(たとえば、第1の25%および第2の25%)。さらになお、時間領域FTMSデータの第1および第2のセットは、全く別の過渡からのものであってもよい。
【0018】
多数の同位体ピークが発生する、より大型の分子のピークを識別する方法もまた開示されるが、これは2つのしきい値に依存する。開示される方法は、データ圧縮を可能にするので(つまり格納されうるノイズデータの量を減少させることにより)、単に有利であるわけではないことも理解されるであろう。特に相関の手法により、低強度の「実際の」ピークの検出が、たとえフルスペクトルでノイズフロアよりも低強度である場合であっても可能になる。
【0019】
本発明の参考となる態様および実施形態となる態様は決して相互排他的ではないことが、当然理解されるべきである。好ましい実施態様は、実際に、この2つの態様を組み合わせる。したがって、本発明の別の実施形態によれば、質量分析データを処理する方法であって、質量電荷比の範囲に関して時間領域における質量分析データのセットを取得するステップと、その取得された時間領域データの第1のサブセットを周波数領域に変換するステップと、その取得された時間領域データの第2サブセットを周波数領域に変換するステップと、取得された時間領域データの全データセットを実質的に周波数領域に変換するステップと、周波数領域の前記第1および第2のサブセットのうちの少なくとも1つに第1のしきい値を適用して、ピークデータを含むそのデータの1つまたは複数の領域を識別するステップと、周波数領域のデータの第1のサブセットを周波数領域のデータの第2のサブセットと相関させて、各々の前記サブセットに共通のデータの1つまたは複数の領域を識別するステップとを備える方法が提供される。
【0020】
一般に、本発明は、FTMSデータの改良されたしきい値分け技法(thresholding technique)、つまり、縮小されたデータセットを生成するときに、ピークまたはスペクトル領域が全データセットに含まれるかまたは全データセットから除外される決定プロセスへの改良された手法を提供する。本発明は、以下の基準の2つ以上の数学的または論理的な組合せに基づいている。
1.時間領域データのサブセクションにおける存在量(abundance)(過渡)
2.同じデータセットの異なるサブセクションにおける有意な存在量(任意の種類の重複するサブセクションを含む)
3.全データセットにおける存在量
4.異なるデータセットにおける存在量
5.2つ以上の異なるデータセットにおける存在量
6.以前の基準により適格とされたピーク間の位相相関
7.頻繁に発生するピークに関する情報(集計されるか、または統計的に評価されうる)
8.空白であることが判明したピークに関する情報(つまり、サンプルイオンがない場合に生成されたスペクトル)。これらは再度、集計されるか、または統計的に評価されうる。
【0021】
異なる基準に使用される有意レベルは異なっていてもよい。論理演算は、たとえばAND、OR、XOR、NOT、包含など任意のタイプであってもよい。数学演算は、乗算、加算、変換、結果と「主しきい値(master threshold)」との比較、またはそれ以外であってもよい。
【発明の効果】
【0022】
本発明によれば、質量分析データの処理において、ピーク形状およびスペクトルノイズに関する貴重な情報が失われずに、データセットのサイズを減少することができる。
【図面の簡単な説明】
【0023】
【図1】イオンとさらにランダムノイズも存在することにより生じた両方のピークを含む、質量スペクトルの形式で全FTMSデータセットを示す図である。
【図2】本発明の参考となる態様を具現するFTMSデータを処理する方法を示すフローチャートである。
【図3】本発明の1つの実施形態によるデータ処理方式を示すフローチャートである。
【図4】従来技術によるしきい値分け技法を使用して生成されるフーリエ変換質量スペクトルを示す図である。
【図5】本発明の実施形態の改良されたしきい値分け技法を使用して生成されるフーリエ変換質量スペクトルを示す図である。
【図6】本発明の参考態様にも適用できるもう1つの実施形態によるデータ処理方式を示すフローチャートである。
【図7】図6のデータ処理方式と類似するが、一部変形を伴うデータ処理方式を示すフローチャートである。
【図8】本発明のさらにもう1つの実施形態を示すフローチャートである。
【発明を実施するための形態】
【0024】
本発明がさらに容易に理解されうるために、これ以降、例示のみを目的として、添付の図面が参照される。
【0025】
フーリエ変換イオンサイクロトロン共鳴質量分析(FTMS)において、周知のように、イオンはイオン源において生成され、通常リニアイオントラップのように格納装置から測定セルに注入される。セルに保持されるイオンへの均一磁場およびrf電(励起)場の印加は、イオンをそのセル内でサイクロトロン周波数で軌道を描いて旋回させる。イオンは、セル内の検出電極においてイメージ電流によって検出される。
【0026】
本技法により取得される生データは、時間領域にあり、過渡(transient)として知られる。過渡が得られると、従来技術のFTMSにおいては、以下の技法により質量スペクトルが取得される。最初に、過渡がアポダイズされ(apodise)、ゼロ充填される。次に、周波数領域へのデータのフーリエ変換が実行される。これは、実数部および虚数部で構成される1組の値から成る複素周波数スペクトルをもたらす。その後、式P=(Im2+Re2)1/2を使用して、マグニチュードスペクトル(magnitude spectrum)がポイントごとに得られる。これは、較正式を適用することにより、質量スペクトルに変換される。結果として得られた質量スペクトルの例が図1に示される。データは、1つまたは複数のピーク(図1において質量数を示すラベルが付けられている)および大量のノイズを含むことが理解されよう。
【0027】
全FTMSデータセットを変換して格納することは、極めて大きい記憶容量を必要とする可能性のある、比較的多大な時間を要する作業である。格納された情報の多くは、実際、分析的にほとんど価値がないか、または全く価値がないノイズである。格納されるデータの総量を縮小するため、従来技術では単に周波数領域のデータにしきい値を適用し、そのしきい値を下回るすべてのデータポイントを除去していた。背景技術において説明されているように、データを過度に圧縮するかまたは過少に圧縮して、多くのノイズが残されたり、真のピークが誤って除去されたりするおそれもあるため、固定のしきい値の場合、これは融通のきかないメカニズムである。
【0028】
図2は、本発明の参考となる態様を具現するFTMSデータを処理する方法のフローチャートを示す。ステップ10において、時間領域における過渡は、前述の方法でFTMSによって取得される。ステップ20において、この過渡の全体ではないがその一部が、周波数領域にフーリエ変換される。フーリエ変換される過渡の量は、計算の速度と精度との間のトレードオフである。一方では、全過渡の比較的小さい割合を変換することは、迅速に完了されうる。もう一方では、周波数領域に変換される過渡の割合が小さすぎる場合に、データ内の真のピークが失われることもある。図2の参考となる態様では、過渡の25%を採用し、通常これは第1の25%である。第1の25%を採用することの利点は、過渡のその25%の後続の処理を、全過渡のうちの残りが取得される前に開始できることである。
【0029】
周波数領域のデータは、FTMS装置による評価のために選択された範囲内の質量電荷比を有するイオンの存在を表すピークを含む。周波数領域のデータはまた、実際にはランダムノイズの結果であるが真のピークであると誤って判別される可能性のある多数のデータポイントも含む。しかし、本発明の概要で説明されているように、そのようなピークの数は、分解能の低下に伴って減少する。したがって、全過渡のうちのわずか25%のフーリエ変換は、ランダムノイズピークの数も減少させるはずである。
【0030】
したがって、ステップ30において、ステップ20で得られた部分フーリエ変換に強度しきい値が適用される。しきい値は、真のピークを廃棄するリスクを最小限にするため、比較的控えめに選択される。それでもなお、部分データセット内の偽ピークの数が減少したため、強度しきい値を超える偽ピーク(つまり、ランダムノイズピーク)が通過されるリスクも低減される。
【0031】
次に、ステップ40において、全過渡が周波数領域にフーリエ変換される。次に、ステップ50において、全過渡のフーリエ変換により取得された周波数領域データに、強度しきい値が適用される。このしきい値は、ステップ30において適用されたしきい値と同じであっても、またはそれよりも低いものであってもよい。しかし、重要なことに、ステップ50において適用されたしきい値は、ステップ30で確認された真のデータピークの位置の周辺の周波数領域スペクトル(または質量スペクトル)の領域でのみ適用される。つまり、これらのピークの領域の間のデータポイントは、ステップ30において適用された強度しきい値を下回っていることになり、これ以上検討されることはない。
【0032】
ステップ60において、ステップ50で適用されたしきい値を超えるピークデータが格納される。このような方法でランダムノイズを除去することにより、おそらく90〜95%あるいはそれ以上の圧縮が達成されうるが、ピークに関連するデータ自体は損なわれることも、圧縮されることもない。さらに、同時係属出願第PCT/EP04/010736号に説明されているように、ピークの間のデータはランダムノイズであると仮定されるので、ランダムノイズデータがガウス分布であると仮定し確定されたガウス・パラメータを使用してそれを再構成することにより、擬似スペクトルは再構成されうる。
【0033】
図3は、本発明の実施形態によるFTMSデータを処理する方法のフローチャートを示す。ステップ100において、オペレータによって選択された全分解能を使用して、過渡がもう一度取得される(つまり、全過渡が取得される)。全データ過渡の収集と同時か、またはそれ以降に、ステップ110において、その過渡の第1の25%が、図2のステップ20のように、周波数領域に変換される。図3のステップ120において、データ内の真のピークを見つけるために、今度は周波数領域において、過渡の第1の25%に、強度しきい値が適用される。前回と同様に、真のデータピークが見落とされるリスクを最小限にするため、比較的控えめなしきい値が採用されうる。
【0034】
ステップ130において、過渡の第2の25%が、周波数領域に変換される。これは、元のデータセットの重複する25%、または後続の25%(つまり、ステップ100で必要とされた元の時間領域過渡の25〜50%)であってもよい。次に、強度しきい値は、そのデータ内の真のデータピークを識別するために、もう一度そのデータにも適用される。ステップ140において適用されたしきい値は、ステップ120において適用された強度しきい値と同じであっても、異なっていてもよい。特に、ステップ130において異なるサイズのデータセットがステップ110に関して変換される場合(たとえば、元の時間領域過渡の50%がステップ130において変換される場合)、ステップ140において適用されるしきい値は、ステップ120において適用されるしきい値よりもわずかに高くなる可能性がある(後者の場合、さらに多くの過渡がフーリエ変換されたため、偽データピークのリスクが高まっている)。
【0035】
ステップ150において、処理ステップ120および140の結果として取得されたデータセットは、比較されるか、または相関される。ステップ120および140に続いて取得されるスペクトルの各々において同じ場所に2つの信号が現れるはずである。しかし、ノイズが真にランダムであり全時間領域データセット(過渡)の異なるセクション間で相関されないと仮定すると、ノイズピークは、2つの異なるスペクトルの同じ位置には現れない。したがって、それぞれステップ120および140の結果として得られた2つのスペクトルにおいて相互に相関するピークの位置を識別することにより、またピークが一致しないデータの領域を廃棄することにより、データセット全体に対する「前置フィルタ(prefilter)」が生成されうる。
【0036】
次に、ステップ160において、全過渡は、周波数領域にフーリエ変換される。しきい値(ステップ120および140において部分データセットに適用されたしきい値よりも高くなりうる)は、周波数領域の全過渡に適用されるが、それはステップ100〜150の前置フィルタリングの技法を使用して識別されたピークの領域に限られる。格納されたピークデータ、つまり、ステップ170で適用された強度しきい値を超えるデータは、ステップ180において格納される。図2の本発明の参考となる態様と同様に、廃棄されたランダムノイズは、それがガウス分布であると仮定することにより再構築されうる。
【0037】
現在、変換された部分過渡に比較的「ゆるい」しきい値を適用することが好ましいが(ステップ120および140)、これは必須のステップではないことが理解されるであろう。これは計算処理上高価であるが、しきい値データだけではなく、各データサブセットからのデータのすべてを相関させることが可能である。この手順は、真のピークが失われるリスクを軽減することになる。
【0038】
図3の方法の利点は、図4および図5において説明される。図4は、409.6kHzにおける「実際の」ピークと、実際の信号ピーク周囲の他の場所における複数のランダムノイズピークを含む人為的な時間領域信号を示す。409.6kHzにおける実信号の強度は、強度しきい値のすぐ上である。
【0039】
図4は、しきい値が前置フィルタリングなしで全フーリエ変換された過渡に適用される従来技術の技法を適用した結果を示す。全質量スペクトルである図1に対して、図4は「基線(base line)」ノイズを含まないが(しきい値の適用により除去された)、14のランダムノイズピークがあり、そのノイズのいくつかは409.6kHzにおける実信号よりも高い強度を有していることが分かる。
【0040】
全時間領域データセットの第1および第2の四半分が別個に変換される図3の改良された方式を適用し、時間領域過渡からの個別の周波数領域変換の検査を通じて、「有効な」ピークのリストが作成される。図5は、比較の結果を示す。ランダムノイズによるピークはすべて消失したが、質量電荷比のこの領域の1つの有効な信号は残っている。実信号は、たとえ図4のランダムノイズピークのいずれよりも低い強度を有していても残ることは注目に値する。したがって、ここに説明されている方法が単に、(前述の図3のステップ180におけるように)格納されるデータ量が減少されるようにするためにデータセットサイズを縮小することに限定されているわけではないことを理解されたい。当該方法はまた、標準の方法に匹敵するサイズのデータセットを生成するためにも使用されうるが、はるかに低い検出しきい値を使用する。これにより、データの全体量を増加させることなく、単純な強度しきい値を現在下回っている信号の検出が可能になる。
【0041】
図3において、2つのデータサブセットのピークの位置は、データ内の実際のピークを識別するために使用されるが、他のパラメータは、データ内の真のピークを識別する代わりに、またはそれに加えて、相関されうる。たとえば、ピークの強度は、(一致するピーク強度が「真の」ピークとして識別されるように)2つのデータサブセットの間で相関されうる。加えて、または代替として、実信号の位相は、過渡の1つのセグメントから次のセグメントへと一貫性があるが、これに反して、ランダム信号の位相はランダムであるはずである。したがって、位相の一貫性は、追加または代替の要因として使用されうる。信号に対して電荷状態が判別されうる場合、関連付けられている同位体ピークの位置は予測されうる。次いで、これらの同位体のウィンドウは、さらなる改良として、最終的なしきい値分け(thresholding)領域に含まれうる。さらにもう1つの改良として、複数のデータセットからのデータが採用されうる。この概念については、以下で図8に関連してさらに説明される。好ましい実施形態において、位置および位相(少なくとも)は共に採用される。
【0042】
図6は、本発明の参考となる態様にも適用可能なもう1つの実施形態を示す。図6の実施形態は、いくつかの信号の特異性に対処するため、図3に説明されている実施形態へのさらなる変更を含む。具体的には、より大型の分子が、独特の時間領域信号または過渡を生成する。多数の等間隔の同位体ピークにより、強い「ビートパターン(beat pattern)」が生成されうる(ホフスタドラー(Hofstadler)他共著「Isotopic beat patterns in Fourier transform ion cyclotron resonance mass spectrometry:implications for high resolution mass measurement by biopolymers」、International Journal of Mass Spectrometry & Ion Processes 132:109〜127(1994年)を参照)。図3に説明されている2セグメントのしきい値の手法を使用して、2つの時間領域データセグメントのうちの1つは、全時間領域データの「波腹(anti-node)」と相関することができる。したがって、このセグメントにはしきい値を超える信号は現れず、そのため、たとえ2つのデータセットの一方に強い信号が現れることがあっても、「共通の」ピークは発生することはない。前もって波腹の位置を予測する方法はないので、時間領域過渡の選択されたサブセクションに波腹が現れないことを保証する方法はない。この問題に対する解決策は、2つの別個のしきい値を使用することである。
【0043】
図6を参照すると、ステップ200において、上記と同様に全過渡が要求される。ステップ210において、過渡の第1の25%が周波数領域に変換され、次いでステップ220において、第1の低い強度しきい値(しきい値1)がこのしきい値のピークを識別するために適用される。ステップ230に示されるように過渡の第2の25%が周波数領域に変換されると、同様の技法がこれに適用される。ステップ240において、しきい値1がこの周波数領域データに適用され、そのピークが識別される。
【0044】
ステップ250において、ステップ220および240からの2つのデータセットは、共通のピークを識別するために相関される。しかし、ステップ260において、より高いしきい値(しきい値2)も、ステップ220および240に続いて取得されたデータサブセットに適用され、前述の強いビートパターンにより、大型のピーク(実際のピークと仮定される)が誤って廃棄されないようになっている。
【0045】
変更された前置フィルタが生成されると、つまり、真のピークの位置がステップ260において判別されると、ステップ270において、全過渡が周波数領域に変換され、その後ステップ280において第3のしきい値がデータ領域の全データ変換に適用されるが、それはステップ250および260に続いて判別された領域に限られる。上記と同様に、ステップ290において、ピークデータが格納されうる。
【0046】
同様のマグニチュード(magnitude)の2つの部分変換について説明されたが、当然のことながら、異なるマグニチュードの時間領域のデータサブセット、および/または重複するデータセットが採用されうる。
【0047】
図7において、図6の手法に若干変更を加えた手法が示される。図6および図7に類似性があるので、類似するステップを示すために同じ参照番号が採用されている。
【0048】
特に、図6および図7においてステップ200〜250は同じである、つまり、過渡の2つの別個の部分は周波数領域に変換され、第1の比較的低いしきい値(しきい値1)を使用してピークが検出され、次いで各データセットで一致するピークを見つけるために相関される。
【0049】
しかし、ステップ265において、各データサブセットにより高いしきい値を適用する代わりに、次のステップとして過渡全体が周波数領域に変換される。次に、ステップ275において、ステップ200〜250を介してピークとして識別された領域は、全周波数領域データセットから差し引かれるか、あるいは除外される。ステップ285において、残りのデータセットは、第1のしきい値よりも高い第2のしきい値に従う。これは、この第2のしきい値に到達した場合、たとえ前処理ステップがそのしきい値を見つけることができなかったとしても、全スペクトルからピークが省略されないことを確認する。
【0050】
ステップ295において、周波数領域の全データセットからのデータは格納されるが、それは相関前処理(ステップ200〜250)と残りのデータのより高レベルのしきい値処理との組合せを通じてピークであると識別される領域に限られる。
【0051】
図8のフローチャートにおいて、もう1つの実施形態が示される。ここで、2つの完全に別個の時間領域データセットからのピークは、相関される。ステップ300で開始し、サンプルからイオンの第1のセットのFTMSセルへの注入に続いて(通常上流のイオンフィルタ/イオン格納配置を介して)、第1の過渡がこれらのサンプルイオンから取得される。ステップ310において、これは周波数領域に変換され、ステップ320において、しきい値が周波数領域のフーリエ変換に適用される。ステップ330において、第2の過渡が得られる。通常、これは、第1の過渡の収集と、その第1の過渡を作成したそれらのイオンのセルをその後空にすることに続いて、FTMSセルに注入されたイオンの新しいセットから取得される。第2の過渡は、ステップ340において、周波数領域に変換される。ステップ350において、しきい値は、周波数領域のそのフーリエ変換にも適用される。
【0052】
ステップ320および350において適用されたしきい値は、同じであっても、異なっていてもよい。同様に、ステップ300および330においてそれぞれ得られた第1および第2の過渡は全体が周波数領域に変換されうるが、その代わりに、しきい値が適用される前にステップ310および340において、各々別個の過渡の一部のみが周波数領域に変換されうる。さらに、通常、第1の過渡が得られるサンプルイオンの質量範囲は、第2の過渡をもたらすサンプルイオンの質量範囲と対応するが、質量範囲は同一である必要はない。上流イオンフィルタ/トラップのパラメータを調整することにより、異なる質量範囲がFTMSセルに注入されうるが、もちろんこれらは少なくとも重複する必要がある。
【0053】
ステップ360において、各フーリエ変換からの相関またはデータ付き合わせが行われる(これは、2つの過渡が得られる質量範囲が少なくとも部分的に重複しなければならない理由である)。このために、真のピークの位置は識別され、ステップ370において、それらの真のピークに関してデータが格納されうる。全過渡がステップ310および340で変換されると仮定すれば、図3および図6の実施形態の2つのステップのプロセスは回避される。しかし、図8の実施形態には、いくつかの欠点がある。具体的には、第1のデータセットの処理は、第2のデータセットが収集されていなければ完了できない。
【0054】
たとえば、サンプルイオン(既知のm/zであるかどうかにかかわらず)について同一の過渡の一部または異なる過渡に依存するのではなく、その代わりに「空白の(blank)」スペクトル(つまり、サンプルイオンがない場合)を分析することが可能であるなど、さまざまな他の実施形態が当業者には明らかとなろう。一般に、これは、FTMS装置の起動時に行われうる。現時点では、FTMS測定セル内にイオンがない場合に常駐ノイズピークが探し出されうる。そのような常駐ノイズピークの場所は格納される。一般に、前述のように、システムソフトウェアは、異なるスペクトルで位相の変化するピークを探す。次いで、これらの位相がずれた信号はスペクトルから差し引かれる。このようにすることの1つの利点は、本発明の実施形態により対処されうるホワイトノイズと共に、単一周波数電子ノイズ(システムの偽/ノイズのピークの主要源)を低減することである。
【0055】
本発明の実施形態は、イオンサイクロトロン共鳴によって生成される過渡の分析に関連して説明されたが、たとえば、本発明は、(通常)質量スペクトルへの最終的なフーリエ変換のための時間領域過渡として取得される、FT−IR、FT−NMR、またはSARから取得されたデータ、Orbitrap(米国特許第5886346号を参照)などの静電型トラップ(electrostatic trap)に同等に適用可能である、というように、決して限定されることはないことを理解されたい。概念はまた、米国特許第4755670号および米国特許第6403955号に説明されているような、動電型トラップ(electrodynamic trap)から得られるデータへの適用にも適している。実際、本発明は、静電飛行時間型(TOF)質量分析の出力に適用される(たとえば、ベナー、W.H.(1997年)「A Gated Electrostatic Ion Trap To Repetitiously Measure the Charge and m/z of Large Electrospray Ions」Analytical Chemistry 69、4162〜4168ページを参照)。さらに、フーリエ変換は、採用されうる周波数変換の唯一の形式ではない。本発明は、たとえばアダマール変換またはラプラス変換で同様に使用されうる。A.ブロック、N.ロドリゲス、およびR.N.ザル共著、「Hadamard Transform Time−of−Flight Mass Spectrometry(HT−TOFMS)」Anal Chem.70、3735〜3741(1998年)も参照されたい。したがって、本発明は実際に、周期的信号を生成する任意のMS方法に適用可能であることが理解されよう。
【産業上の利用可能性】
【0056】
本発明は、質量スペクトルへの最終的なフーリエ変換のための時間領域過渡の分析に利用できる。
【特許請求の範囲】
【請求項1】
周期的信号を有する質量分析データを処理する方法であって、
a.評価のために選択された質量電荷比の範囲内について、時間領域における前記質量分析データを取得するステップと、
b.前記取得された前記時間領域における前記質量分析データの中の第1のサブセットを周波数領域に変換するステップと、
c.前記時間領域における前記質量分析データの中のサブセットで、前記第1のサブセットとは異なる第2のサブセットを前記周波数領域に変換するステップと、
d.前記第1のサブセットの前記変換後の値に第1の閾値を適用するステップと、
e.前記第1の閾値と協働して、前記範囲内の質量電荷比を有するイオンの存在を示すピークデータからノイズデータを区別するように設定された第2の閾値を前記第2のサブセットの前記変換後の値に適用し、前記区別された前記ピークデータの質量電荷比を見出すステップと、
f.前記第2のサブセットの前記変換と前記第2の閾値の適用とが行われた値のピークデータ領域の信号パラメータと、前記第1のサブセットの前記変換と前記第1の閾値の適用とが行われた値のピークデータ領域の信号パラメータとを比較し、質量電荷比が同じとなる共通のピークを識別するステップと、
を備えることを特徴とする方法。
【請求項2】
請求項1に記載の方法であって、
前記ステップfにおける比較の後で、
g.前記時間領域において取得された前記質量分析データの全部を前記周波数領域に変換するステップと、
h.前記範囲内の質量電荷比を有するイオンの存在を示すピークデータから前記ノイズデータを区別するために、前記変換後のデータの前記共通のピークの領域に第3の閾値を適用するステップと、
を備えることを特徴とする方法。
【請求項3】
請求項2に記載の方法であって、前記変換後のデータの中から前記区別されたピークデータの領域の外にあるデータを前記ノイズデータとして拒否するステップをさらに備えることを特徴とする方法。
【請求項4】
請求項2または3に記載の方法であって、
前記時間領域における前記第1のサブセットおよび前記第2のサブセットは、前記時間領域におけるデータの全部の中で互いに重複しないサブセットであることを特徴とする方法。
【請求項5】
請求項1から請求項3のいずれか1に記載の方法であって、
前記信号パラメータがピーク位置であることを特徴とする方法。
【請求項6】
請求項1から請求項5のいずれか1に記載の方法であって、
前記ステップfは、さらに、
k.前記周波数領域に変換後の前記第1のサブセットの複数のピークの位相と、前記周波数領域に変換後の前記第2のサブセットの複数のピークの位相とを比較するステップと、
l.前記周波数領域に変換後の前記第1のサブセットおよび前記周波数領域に変換後の前記第2のサブセットの間で一貫性のある位相を有する複数のピークを識別するステップと、
を含むことを特徴とする方法。
【請求項7】
請求項2に記載の方法であって、
前記ステップfに加えて、前記ステップhに先立ち、
m.前記変換後のデータから、前記識別されたピークに関連するデータを除去するステップを備えることを特徴とする方法。
【請求項8】
請求項3から請求項7のいずれか1に記載の方法であって、
請求項2に依存するときは、さらに、
前記変換後のデータの中から前記第3の閾値を適用した前記ピークデータのみを格納するステップを備えることを特徴とする方法。
【請求項9】
請求項7または請求項8に記載の方法であって、さらに、
第1の閾値と第2の閾値と第3の閾値とを超える前記ピークデータを格納し、前記変換後のデータにおいて残ったデータを前記ノイズデータとして拒否するステップをさらに備えることを特徴とする方法。
【請求項10】
請求項1から請求項9のいずれか1に記載の方法であって、前記時間領域における質量分析データを前記周波数領域における質量分析データへの変換は、フーリエ変換、アダマール変換、ラプラス変換のグループから選択されることを特徴とする方法。
【請求項11】
プログラム要素を備えるコンピュータプログラムであって、前記プログラムは実行されると、請求項1から請求項10のいずれか1に記載の方法を実行することを特徴とするコンピュータプログラム。
【請求項12】
請求項11に記載のコンピュータプログラムを含むことを特徴とするコンピュータプログラム製品。
【請求項13】
請求項1から請求項10のいずれか1に記載の方法を実施するように構成されたデータ処理手段を含むことを特徴とするフーリエ変換質量分析機。
【請求項14】
請求項1から請求項10のいずれか1に記載の方法を実施するように構成されたデータ処理手段を含むことを特徴とする液体クロマトグラフィー質量分析機。
【請求項1】
周期的信号を有する質量分析データを処理する方法であって、
a.評価のために選択された質量電荷比の範囲内について、時間領域における前記質量分析データを取得するステップと、
b.前記取得された前記時間領域における前記質量分析データの中の第1のサブセットを周波数領域に変換するステップと、
c.前記時間領域における前記質量分析データの中のサブセットで、前記第1のサブセットとは異なる第2のサブセットを前記周波数領域に変換するステップと、
d.前記第1のサブセットの前記変換後の値に第1の閾値を適用するステップと、
e.前記第1の閾値と協働して、前記範囲内の質量電荷比を有するイオンの存在を示すピークデータからノイズデータを区別するように設定された第2の閾値を前記第2のサブセットの前記変換後の値に適用し、前記区別された前記ピークデータの質量電荷比を見出すステップと、
f.前記第2のサブセットの前記変換と前記第2の閾値の適用とが行われた値のピークデータ領域の信号パラメータと、前記第1のサブセットの前記変換と前記第1の閾値の適用とが行われた値のピークデータ領域の信号パラメータとを比較し、質量電荷比が同じとなる共通のピークを識別するステップと、
を備えることを特徴とする方法。
【請求項2】
請求項1に記載の方法であって、
前記ステップfにおける比較の後で、
g.前記時間領域において取得された前記質量分析データの全部を前記周波数領域に変換するステップと、
h.前記範囲内の質量電荷比を有するイオンの存在を示すピークデータから前記ノイズデータを区別するために、前記変換後のデータの前記共通のピークの領域に第3の閾値を適用するステップと、
を備えることを特徴とする方法。
【請求項3】
請求項2に記載の方法であって、前記変換後のデータの中から前記区別されたピークデータの領域の外にあるデータを前記ノイズデータとして拒否するステップをさらに備えることを特徴とする方法。
【請求項4】
請求項2または3に記載の方法であって、
前記時間領域における前記第1のサブセットおよび前記第2のサブセットは、前記時間領域におけるデータの全部の中で互いに重複しないサブセットであることを特徴とする方法。
【請求項5】
請求項1から請求項3のいずれか1に記載の方法であって、
前記信号パラメータがピーク位置であることを特徴とする方法。
【請求項6】
請求項1から請求項5のいずれか1に記載の方法であって、
前記ステップfは、さらに、
k.前記周波数領域に変換後の前記第1のサブセットの複数のピークの位相と、前記周波数領域に変換後の前記第2のサブセットの複数のピークの位相とを比較するステップと、
l.前記周波数領域に変換後の前記第1のサブセットおよび前記周波数領域に変換後の前記第2のサブセットの間で一貫性のある位相を有する複数のピークを識別するステップと、
を含むことを特徴とする方法。
【請求項7】
請求項2に記載の方法であって、
前記ステップfに加えて、前記ステップhに先立ち、
m.前記変換後のデータから、前記識別されたピークに関連するデータを除去するステップを備えることを特徴とする方法。
【請求項8】
請求項3から請求項7のいずれか1に記載の方法であって、
請求項2に依存するときは、さらに、
前記変換後のデータの中から前記第3の閾値を適用した前記ピークデータのみを格納するステップを備えることを特徴とする方法。
【請求項9】
請求項7または請求項8に記載の方法であって、さらに、
第1の閾値と第2の閾値と第3の閾値とを超える前記ピークデータを格納し、前記変換後のデータにおいて残ったデータを前記ノイズデータとして拒否するステップをさらに備えることを特徴とする方法。
【請求項10】
請求項1から請求項9のいずれか1に記載の方法であって、前記時間領域における質量分析データを前記周波数領域における質量分析データへの変換は、フーリエ変換、アダマール変換、ラプラス変換のグループから選択されることを特徴とする方法。
【請求項11】
プログラム要素を備えるコンピュータプログラムであって、前記プログラムは実行されると、請求項1から請求項10のいずれか1に記載の方法を実行することを特徴とするコンピュータプログラム。
【請求項12】
請求項11に記載のコンピュータプログラムを含むことを特徴とするコンピュータプログラム製品。
【請求項13】
請求項1から請求項10のいずれか1に記載の方法を実施するように構成されたデータ処理手段を含むことを特徴とするフーリエ変換質量分析機。
【請求項14】
請求項1から請求項10のいずれか1に記載の方法を実施するように構成されたデータ処理手段を含むことを特徴とする液体クロマトグラフィー質量分析機。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】

【図7】
【図8】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【公開番号】特開2012−88332(P2012−88332A)
【公開日】平成24年5月10日(2012.5.10)
【国際特許分類】
【出願番号】特願2011−290308(P2011−290308)
【出願日】平成23年12月29日(2011.12.29)
【分割の表示】特願2007−543516(P2007−543516)の分割
【原出願日】平成17年11月23日(2005.11.23)
【出願人】(501192059)サーモ フィニガン リミテッド ライアビリティ カンパニー (42)
【Fターム(参考)】
【公開日】平成24年5月10日(2012.5.10)
【国際特許分類】
【出願日】平成23年12月29日(2011.12.29)
【分割の表示】特願2007−543516(P2007−543516)の分割
【原出願日】平成17年11月23日(2005.11.23)
【出願人】(501192059)サーモ フィニガン リミテッド ライアビリティ カンパニー (42)
【Fターム(参考)】
[ Back to top ]