
超解像画像処理装置及び超解像画像処理用辞書作成装置
【課題】少ないハードウェアリソースで高速に処理できる、極めて実用的な超解像画像処理装置101と、この超解像画像処理装置101が利用する辞書テーブルを作成する超解像画像処理用辞書作成装置109を提供する。
【解決手段】
汎用性の高い超解像画像処理を短時間に実行するため、本実施形態の超解像画像処理装置101は、先ず、処理対象とする画像をシーンに分けた。そして、シーンに適合する辞書テーブル106を用いて、失われた高周波成分を辞書に対するツリー検索にて類推した。そして、辞書テーブル106の検索を高速化するため、主成分分析を用いて、検索キーとなるインデックスビットマップをスカラ値である第一主成分及び第二主成分に変換すると共に、第一主成分と第二主成分とでグルーピングを施し、その平均値を算出することで、辞書テーブル106の必要レコード数を大幅に低減することに成功した。
【解決手段】
汎用性の高い超解像画像処理を短時間に実行するため、本実施形態の超解像画像処理装置101は、先ず、処理対象とする画像をシーンに分けた。そして、シーンに適合する辞書テーブル106を用いて、失われた高周波成分を辞書に対するツリー検索にて類推した。そして、辞書テーブル106の検索を高速化するため、主成分分析を用いて、検索キーとなるインデックスビットマップをスカラ値である第一主成分及び第二主成分に変換すると共に、第一主成分と第二主成分とでグルーピングを施し、その平均値を算出することで、辞書テーブル106の必要レコード数を大幅に低減することに成功した。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、超解像画像処理装置及び超解像画像処理用辞書作成装置に適用して好適な技術に関する。
より詳細には、低解像度の原画像から高解像度の画像を出力する、超解像画像処理装置と、この超解像画像処理装置が利用する辞書テーブルを作成する超解像画像処理用辞書作成装置に関する。
【背景技術】
【0002】
超解像技術とは、低解像度の原画像から高解像度の画像を生成することで、違和感の少ない拡大画像を得るための技術である。この超解像技術は、テレビやパソコン等といった画像閲覧装置の高解像度化に伴い、注目され、一部の民生機器等で採用されている。
例えば、携帯電話に付属する比較的低解像度のカメラで撮影した画像を高解像度のディスプレイで閲覧する場合や、アナログテレビ時代に作成された低解像度の動画コンテンツを高解像度のテレビで閲覧する場合、或は低解像度の動画ストリーミングデータを高解像度のディスプレイで閲覧する場合等に、この超解像技術が用いられる。
更には、監視カメラ等の撮影画像データを高詳細化することで、社会基盤の安全性向上に寄与できる可能性もある。
【0003】
前述のように、超解像技術は違和感のない拡大画像を得るための技術であるが、これは転じて「失われた高周波成分を類推する」技術である。
例えば、ある画像データのピクセルサイズを縦横半分ずつ、1/4倍に縮小する場合、隣り合う二つのピクセルの平均値を算出して、一つのピクセルに変換する。この平均値演算は、積分の一種といえる。そして、ピクセルの羅列を信号として捉えた場合、平均値演算を行ってピクセルを間引くことは、信号の高周波成分を除去することと等価である。
逆に、ある画像データのピクセルサイズを縦横4倍ずつ、4倍に拡大する場合、一番簡単な方法としては、隣り合う二つのピクセルの中間値を算出して、間のピクセルを得る方法であるが、この算出方法では失われた高周波成分が再現されない。このため、中間値演算による拡大画像はあたかもピンぼけのような、境界線が曖昧な画像になる。
つまり、超解像技術は、ピクセルのパターンを解析して、適切と思われるピクセルを算出し、元画像の隣接するピクセル同士の間に埋めることで、「失われた高周波成分を類推する」技術である。
【0004】
発明者は、超解像画像処理をリアルタイムで処理できるための技術を開発している。より詳細には、画像データを位置とスケールで指定される小さな波の重ね合わせに分解し解析する手法である「モルフォロジカル・ウェーブレット変換」を、整数であるマックスプラス代数で記述することで、全体の見通しをよくすると共に数式を簡素化した「MPウェーブレット変換」を開発している。MPウェーブレット変換の概要については非特許文献1に開示されている。
【先行技術文献】
【非特許文献】
【0005】
【非特許文献1】「2次元Max-Plus ウェーブレット変換・逆変換実証回路の作製」小野 雅晃、延原 肇[2011年6月10日検索]、インターネット<URL:http://www.tech.tsukuba.ac.jp/2010/report/n03_report2010.pdf>
【発明の概要】
【発明が解決しようとする課題】
【0006】
非特許文献1に開示されるウェーブレット変換・逆変換実証回路は、MPウェーブレット変換の再現性を確認するための実験であり、実応用に必要な技術的課題を解決出来ていなかった。それは、データ量及び計算量を減らすことである。
【0007】
本発明はかかる課題を解決し、少ないハードウェアリソースで高速に処理できる、極めて実用的な超解像画像処理装置と、この超解像画像処理装置が利用する辞書テーブルを作成する超解像画像処理用辞書作成装置を提供することを目的とする。
【課題を解決するための手段】
【0008】
上記課題を解決するために、本発明の超解像画像処理装置は、入力画像データから所定数のピクセルよりなるインデックスビットマップを生成するインデックス作成部と、インデックスビットマップに対して、第一主成分基底ベクトルとの内積を演算して第一主成分を算出し、第一主成分基底ベクトルとの内積を演算して第二主成分を算出する内積演算部と、第一主成分及び第二主成分を用いて辞書テーブルを検索し、第一主成分及び第二主成分に最も近いレコードを得る比較部と、レコードに含まれている高周波成分とインデックスビットマップを用いて超解像ビットマップを算出する超解像ビットマップ生成部とを具備する。
【0009】
また、上記課題を解決するために、本発明の超解像画像処理用辞書作成装置は、一時テーブルと、サンプル画像ファイルから所定のアドレスのピクセルを含む一つの範囲に含まれる複数のピクセルを分割ビットマップとして取り出した後、分割ビットマップを四以上の数の領域である分解ビットマップとして等分して、複数の分解ビットマップをそれぞれ一時テーブルの分解ビットマップ格納フィールド群に格納する分解処理部と、分解ビットマップ格納フィールド群に格納されている複数の分解ビットマップに対して所定の代数変換処理を施して、得られた演算結果である変換ビットマップをそれぞれ一時テーブルの変換ビットマップ格納フィールド群に格納する代数変換処理部と、変換ビットマップ格納フィールド群に格納されている複数の変換ビットマップからインデックスとなるデータ列に対して主成分分析を実行して、超解像画像処理装置に用いる第一主成分基底ベクトルと第二主成分基底ベクトルを算出する主成分分析処理部と、一時テーブルの各レコードのインデックスと第一主成分基底ベクトルを内積演算してインデックスの第一主成分を算出して一時テーブルの第一主成分フィールドに格納すると共に、インデックスと第二主成分基底ベクトルを内積演算してインデックスの第二主成分を算出して一時テーブルの第二主成分フィールドに格納する内積演算部と、一時テーブルのレコードを第一主成分フィールドの値及び第二主成分フィールドの値でグルーピングする頻度分割処理部と、頻度分割処理部によってグルーピングされた一時テーブルの複数のレコードに含まれる各スカラ値に対して平均値を算出して、超解像画像処理装置に用いる辞書テーブルを作成する平均値演算部とを具備する。
【0010】
汎用性の高い超解像画像処理を短時間に実行するため、本発明の超解像画像処理装置は、処理対象とする画像をシーンに分けて、そのシーンに適合する辞書テーブルを用いて、失われた高周波成分を辞書に対するツリー検索にて類推する。
辞書テーブルは検索を高速化するため、主成分分析を用いて、検索キーとなるインデックスビットマップをスカラ値である第一主成分及び第二主成分に変換すると共に、第一主成分と第二主成分とでグルーピングを施し、その平均値を算出することで、辞書テーブルの必要レコード数が大幅に低減されている。
【発明の効果】
【0011】
本発明により、少ないハードウェアリソースで高速に処理できる、極めて実用的な超解像画像処理装置と、この超解像画像処理装置が利用する辞書テーブルを作成する超解像画像処理用辞書作成装置を提供できる。
【図面の簡単な説明】
【0012】
【図1】本発明の実施形態の例である、超解像画像処理装置と辞書作成装置の概略図である。
【図2】辞書作成装置の機能ブロック図である。
【図3】一時テーブルのフィールド構成図である。
【図4】辞書作成装置による辞書作成処理のフローチャートである。
【図5】辞書作成装置が実行する辞書作成処理による、画像データから辞書テーブルが生成される過程を示す概要図である。
【図6】辞書作成装置が実行する辞書作成処理による、画像データから辞書テーブルが生成される過程を示す概要図である。
【図7】分割ビットマップと分解ビットマップとの関係を示す概略図である。
【図8】分割ビットマップと分解ビットマップとの関係を示す概略図である。
【図9】辞書テーブルの構成を示す概略図である。
【図10】超解像画像処理装置の機能ブロック図である。
【図11】超解像画像処理装置による超解像画像処理のフローチャートである。
【図12】辞書作成装置による辞書検索及びMPウェーブレット逆変換処理のフローチャートである。
【図13】辞書作成装置による辞書検索及びMPウェーブレット逆変換処理のフローチャートである。
【図14】比較部が実行する、辞書テーブルのツリー検索の仕組みを示す概略図である。
【発明を実施するための形態】
【0013】
[全体構成]
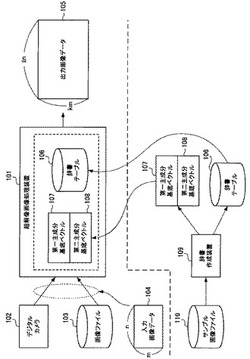
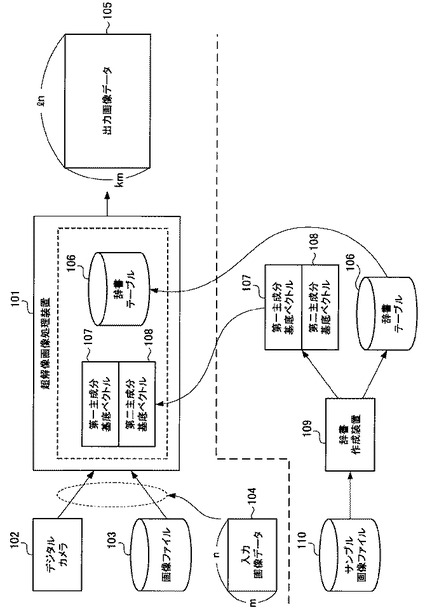
図1は、本発明の実施形態の例である、超解像画像処理装置と辞書作成装置の概略図である。
超解像画像処理装置101は、デジタルカメラ102や画像ファイル103等から、縦mピクセル×横nピクセルの入力画像データ104を受け取ると、縦k・mピクセル×横l・nピクセルの出力画像データ105を生成する。ここで、k、l、m及びnは2以上の自然数である。したがって、超解像画像処理装置101は、最低限、縦2倍及び横2倍の、4倍に拡大した画像を生成する。
超解像画像処理装置101が処理する画像は、静止画像であっても動画像であってもよい。本実施形態では説明を簡単にするため、静止画像を中心に説明する。
【0014】
超解像画像処理装置101は、入力画像データ104に対して超解像画像処理を施して出力画像データ105を生成する際、失われた高周波成分を類推するために、辞書テーブル106と、第一主成分基底ベクトル107と、第二主成分基底ベクトル108を用いる。これらのデータは辞書作成装置109によって生成され、予め超解像画像処理装置101に組み込まれる。
辞書作成装置109は、一つ以上のサンプル画像ファイル110を受け取ると、後述する所定の演算処理を行うことで、辞書テーブル106と、第一主成分基底ベクトル107と、第二主成分基底ベクトル108を生成する。
ここで、辞書テーブル106、第一主成分基底ベクトル107及び第二主成分基底ベクトル108は、これら三つで一つの組である。これ以降、辞書テーブル106、第一主成分基底ベクトル107及び第二主成分基底ベクトル108をまとめて「辞書テーブル等」と呼ぶ。
【0015】
図1では、超解像画像処理装置101の具体的な実装形態について明記していないが、超解像画像処理装置101は画像データを処理する演算装置であるので、如何様にも実装可能である。
例えば、周知のパソコンにインストールするプログラムとして実現することができる。その際、辞書テーブル等はハードディスク装置等の不揮発性ストレージに格納されるであろう。
また、デジタルカメラ102のファームウェアとして、デジタルカメラ102に組み込むこともできる。
更には、FPGA(Field Programmable Gate Array)等のPLD(programmable logic device)やASIC(Application Specific Integrated Circuit)等を用いて実現することもできる。特に本実施形態の超解像画像処理装置101は、そのベースとなるMPウェーブレット変換が整数の加減算及び比較演算のみで構成されるため、これらハードウェアの実装面積は極めて少なく済む。
【0016】
図1では、辞書作成装置109の具体的な実装形態について明記していないが、辞書作成装置109はサンプル画像ファイル110から辞書テーブル等を生成する演算装置であるので、如何様にも実装可能である。辞書作成装置109は、例えばパソコン等にインストールされて実行されるプログラムで実現され、超解像画像処理装置101が製造される工場等の生産現場に設けられ、シーンに応じた辞書テーブル等を生成する。
シーンとは、画像の特色である。例えば風景の撮影画像であったり、医療用レントゲン画像であったり、或はアニメーション等である。風景の撮影画像の場合、そのピクセルパターンには中間色や中間輝度が多く現れる。一方、アニメーションの画像の場合、輪郭が明確であり、色彩や輝度がある境界で急激に変化する(エッジの効いた)ピクセルパターンが多く見受けられる。このように、画像にはそのシーンに応じた特色がある。そこで、サンプル画像ファイル110はシーンに応じた画像が集められ、辞書テーブル等の基となる。どのようなシーンに対しても最適な超解像処理ができる万能な辞書テーブル等を作成することは困難であるが、シーンに最適化した辞書テーブル等を作成することで、超解像画像処理装置101が適用されるシーンに適した辞書テーブル等を与えることができる。勿論、複数の辞書テーブル等を用意して、超解像画像処理装置101がシーンに応じて辞書テーブル等を切り替えることで、シーンに最適な超解像画像処理を実現することができる。また、シーンを細分化すればするほど、そのシーンにより適合した辞書テーブル等を作成することができ、以てより再現度の高い超解像画像処理を実現することができる。
【0017】
辞書テーブル等、つまり辞書テーブル106、第一主成分基底ベクトル107及び第二主成分基底ベクトル108は、その名称から明らかなように、周知の主成分分析を経て形成されている。このため、辞書テーブル106と、第一主成分基底ベクトル107及び第二主成分基底ベクトル108は密接な関係を有する。この関係の詳細は、辞書作成装置109の説明にて後述する。
【0018】
なお、説明を容易にするために、これ以降の実施形態の説明では、辞書作成装置109及び超解像画像処理装置101が取り扱う画像は白黒の静止画像であり、一つのピクセルは8ビットであるものとする。このため、一つのピクセルは0〜255の輝度データである。
【0019】
[辞書作成装置109:全体構成]
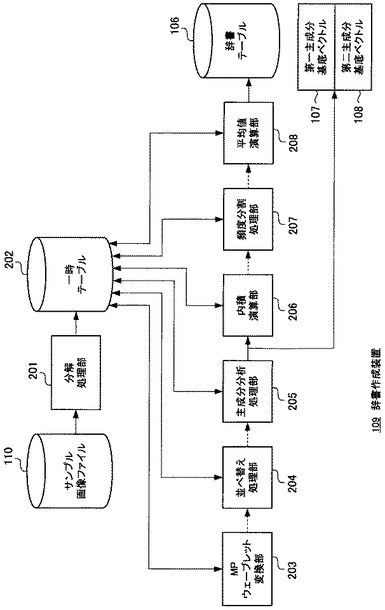
図2は、辞書作成装置109の機能ブロック図である。
図3は、一時テーブルのフィールド構成図である。
一以上のサンプル画像ファイル110は、分解処理部201によって所定の大きさの分割ビットマップに分解されて、一時テーブル202の「分解ビットマップ−1」フィールド、「分解ビットマップ−2」フィールド、「分解ビットマップ−3」フィールド及び「分解ビットマップ−4」フィールドに格納される。
次に、代数変換処理部ともいえるMPウェーブレット変換部203は、一時テーブル202の「分解ビットマップ−1」フィールドのデータを読み込み、MPウェーブレット変換を施して、得られた変換ビットマップを「変換ビットマップ−1」フィールドに格納する。
同様に、MPウェーブレット変換部203は、一時テーブル202の「分解ビットマップ−2」フィールドのデータを読み込み、MPウェーブレット変換を施して、得られた変換ビットマップを「変換ビットマップ−2」フィールドに格納する。
同様に、MPウェーブレット変換部203は、一時テーブル202の「分解ビットマップ−3」フィールドのデータを読み込み、MPウェーブレット変換を施して、得られた変換ビットマップを「変換ビットマップ−3」フィールドに格納する。
同様に、MPウェーブレット変換部203は、一時テーブル202の「分解ビットマップ−4」フィールドのデータを読み込み、MPウェーブレット変換を施して、得られた変換ビットマップを「変換ビットマップ−4」フィールドに格納する。
【0020】
次に、並べ替え処理部204は、一時テーブル202の「変換ビットマップ−1」フィールド、「変換ビットマップ−2」フィールド、「変換ビットマップ−3」フィールド及び「変換ビットマップ−4」フィールドのデータを読み込み、並べ替え処理を施して、夫々「インデックス」フィールド、「第一高周波」フィールド、「第二高周波」フィールド及び「第三高周波」フィールドに格納する。
次に、主成分分析処理部205は、一時テーブル202の全レコードの「インデックス」フィールドのデータを読み込み、周知の主成分分析を行い、第一主成分基底ベクトル107と、第二主成分基底ベクトル108を算出する。
次に、内積演算部206は、一時テーブル202の「インデックス」フィールドのデータと、第一主成分基底ベクトル107とを内積演算し、得られた第一主成分データを「第一主成分」フィールドに格納する。
同様に、内積演算部206は、一時テーブル202の「インデックス」フィールドのデータと、第二主成分基底ベクトル108とを内積演算し、得られた第二主成分データを「第二主成分」フィールドに格納する。
【0021】
次に、頻度分割処理部207は、一時テーブル202の全てのレコードについて、「第一主成分」フィールドのデータでソートした上で、予め定めたレコード数でグルーピングを施し、同一グループについて番号を付す。この番号は、一時テーブル202の「第一主成分グループ番号」フィールドに格納される。
更に頻度分割処理部207は、一時テーブル202の「第一主成分グループ番号」フィールドの値が等しいレコードについて、「第二主成分」フィールドのデータでソートした上で、予め定めたレコード数でグルーピングを施し、同一グループについて番号を付す。この番号は、一時テーブル202の「第二主成分グループ番号」フィールドに格納される。
【0022】
最後に、平均値演算部208は、一時テーブル202の「第一主成分グループ番号」フィールドの値と「第二主成分グループ番号」フィールドの値が等しいレコードについて、「第一主成分」フィールドの値の平均値を算出して、辞書テーブル106の「第一主成分」フィールドに格納する。
同様に、「第二主成分」フィールドの値の平均値を算出して、辞書テーブル106の「第二主成分」フィールドに格納する。
同様に、「第一高周波」フィールドに格納される各スカラ値毎にそれぞれ平均値を算出して、辞書テーブル106の「第一高周波」フィールドに格納する。
同様に、「第二高周波」フィールドに格納される各スカラ値毎にそれぞれ平均値を算出して、辞書テーブル106の「第二高周波」フィールドに格納する。
同様に、「第三高周波」フィールドに格納される各スカラ値毎にそれぞれ平均値を算出して、辞書テーブル106の「第三高周波」フィールドに格納する。
【0023】
以上説明したように、辞書作成装置109は、サンプル画像ファイル110から処理対象とする分割ビットマップを得て、これを複数の分解ビットマップに分けて一時テーブル202のレコードに格納した上で、MPウェーブレット変換部203、並べ替え処理部204、主成分分析処理部205、内積演算部206、そして頻度分割処理部207と、順番に処理を施すことで、一時テーブル202の各フィールドに演算結果を格納する。そして最後に平均値演算部208によって、一時テーブル202よりレコード数の少ない辞書テーブル106を作成する。
【0024】
[辞書作成装置109:フローチャート]
図4は、辞書作成装置109による辞書作成処理のフローチャートである。
処理を開始すると(S401)、分解処理部201はサンプル画像ファイル110を読み込み、km×lnピクセルの分割ビットマップに分割する。更にこの分割ビットマップを、m×nピクセルの分解ビットマップに分解して、一時テーブル202の「分解ビットマップ−1」フィールド、「分解ビットマップ−2」フィールド、…「分解ビットマップ−(k×l)」フィールドに格納する(S402)。
次に、MPウェーブレット変換部203は、一時テーブル202の分解ビットマップが格納されているフィールドのデータを読み込み、MPウェーブレット変換を施して、得られた変換ビットマップを変換ビットマップを格納するフィールドに格納する。この動作をk×l回繰り返す(S403)。
【0025】
次に、並べ替え処理部204は、一時テーブル202の「変換ビットマップ−1」フィールド、「変換ビットマップ−2」フィールド、…「変換ビットマップ−(k×l)」フィールドのデータを読み込み、並べ替え処理を施して、夫々「インデックス」フィールド、「第一高周波」フィールド、「第二高周波」フィールド…「第(k×l)高周波」フィールドに格納する(S404)。
次に、主成分分析処理部205は、一時テーブル202の全レコードの「インデックス」フィールドのデータを読み込み、周知の主成分分析を行い、第一主成分基底ベクトル107と、第二主成分基底ベクトル108を算出する(S405)。
次に、内積演算部206は、一時テーブル202の「インデックス」フィールドのデータと第一主成分基底ベクトル107とを内積演算して、得られた第一主成分データを「第一主成分」フィールドに格納し、一時テーブル202の「インデックス」フィールドのデータと第二主成分基底ベクトル108とを内積演算して、得られた第二主成分データを「第二主成分」フィールドに格納する(S406)。
【0026】
次に、頻度分割処理部207は、一時テーブル202の全てのレコードについて「第一主成分」フィールドのデータでソートした上で、予め定めたレコード数でグルーピングを施し、同一グループについて番号を付す(S407)。この番号は、一時テーブル202の「第一主成分グループ番号」フィールドに格納される。
更に頻度分割処理部207は、一時テーブル202の「第一主成分グループ番号」フィールドの値が等しいレコードについて、「第二主成分」フィールドのデータでソートした上で、予め定めたレコード数でグルーピングを施し、同一グループについて番号を付す(S408)。この番号は、一時テーブル202の「第二主成分グループ番号」フィールドに格納される。
【0027】
最後に、平均値演算部208は、一時テーブル202の「第一主成分グループ番号」フィールドの値と「第二主成分グループ番号」フィールドの値が等しいレコードについて、「第一主成分」フィールドの値の平均値を算出して、辞書テーブル106の「第一主成分」フィールドに格納する。
同様に、「第二主成分」フィールドの値の平均値を算出して、辞書テーブル106の「第二主成分」フィールドに格納する。
同様に、「第一高周波」フィールドに格納される各スカラ値毎にそれぞれ平均値を算出して、辞書テーブル106の「第一高周波」フィールドに格納する。
同様に、「第二高周波」フィールドに格納される各スカラ値毎にそれぞれ平均値を算出して、辞書テーブル106の「第二高周波」フィールドに格納する。
同様に、「第(k×l−1)高周波」フィールドに格納される各スカラ値毎にそれぞれ平均値を算出して、辞書テーブル106の「第(k×l−1)高周波」フィールドに格納する(S409)。そして、一連の処理を終了する(S410)。
【0028】
[辞書作成装置109:データ処理の詳細]
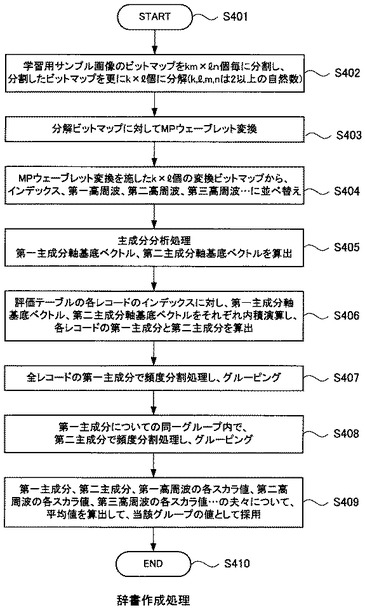
図5(a)、(b)、(c)、(d)及び(e)と、図6(f)及び(g)は、辞書作成装置109が実行する辞書作成処理による、画像データから辞書テーブル106が生成される過程を示す概要図である。なお、図5及び図6では説明を簡単にするため、k、l、m及びnは「2」に設定して説明する。
先ず、分解処理部201は図5(a)に示す、サンプル画像ファイル110から縦4ピクセル×横4ピクセルよりなる、16ピクセルの分割ビットマップ501を抜き出す。これが一時テーブル202の1レコード分に相当する。なお、分解処理部201はサンプル画像ファイル110から1ピクセルずつずらして分割ビットマップ501を抜き出して、一時テーブル202のレコードとして追記する。
次に、分解処理部201は図5(b)に示すように、分割ビットマップ501を縦と横に二等分して、合計4個の分解ビットマップ502a、502b、502c及び502dを作成する。そして、この分解ビットマップ502a、502b、502c及び502dが、分解処理部201によって一時テーブル202のフィールドとして格納される。
「分解ビットマップ−1」フィールドには、分割ビットマップ501の「1、2、5、6」番目のピクセルである分解ビットマップ502aが格納される。
「分解ビットマップ−2」フィールドには、分割ビットマップ501の「3、4、7、8」番目のピクセルである分解ビットマップ502bが格納される。
「分解ビットマップ−3」フィールドには、分割ビットマップ501の「9、10、13、14」番目のピクセルである分解ビットマップ502cが格納される。
「分解ビットマップ−4」フィールドには、分割ビットマップ501の「11、12、15、16」番目のピクセルである分解ビットマップ502dが格納される。
こうして、一時テーブル202の「分解ビットマップ−1」フィールド、「分解ビットマップ−2」フィールド、「分解ビットマップ−3」フィールド及び「分解ビットマップ−4」フィールドに、分解処理部201による分解処理されたデータ列が記録される。
【0029】
次に、MPウェーブレット変換部203は図5(c)に示すように、分解ビットマップ502にMPウェーブレット変換を施す。
今、分解ビットマップ502が「x、y、z、w」というピクセルで構成されている場合、MPウェーブレット変換は、以下の(1)式で変換ビットマップ503に変換する。
【0030】
a=min(x,y,z,w)
h=y−x
v=z−x
d=w−x (1)
【0031】
したがって、MPウェーブレット変換部203は図5(d)に示すように、分割ビットマップ501の「1、2、5、6」番目のピクセルよりなる「分解ビットマップ−1」フィールドに格納されている分解ビットマップ502aのデータを読み込み、「a1、h1、v1、d1」という「変換ビットマップ−1」データを作成する。
同様に、MPウェーブレット変換部203は、分割ビットマップ501の「3、4、7、8」番目のピクセルよりなる「分解ビットマップ−2」フィールドに格納されている分解ビットマップ502bのデータを読み込み、「a2、h2、v2、d2」という「変換ビットマップ−2」データを作成する。
同様に、MPウェーブレット変換部203は、分割ビットマップ501の「9、10、13、14」番目のピクセルよりなる「分解ビットマップ−3」フィールドに格納されている分解ビットマップ502cのデータを読み込み、「a3、h3、v3、d3」という「変換ビットマップ−3」データを作成する。
同様に、MPウェーブレット変換部203は、分割ビットマップ501の「11、12、15、16」番目のピクセルよりなる「分解ビットマップ−4」フィールドに格納されている分解ビットマップ502dのデータを読み込み、「a4、h4、v4、d4」という「変換ビットマップ−3」データを作成する。
こうして、一時テーブル202の「変換ビットマップ−1」フィールド、「変換ビットマップ−2」フィールド、「変換ビットマップ−3」フィールド及び「変換ビットマップ−4」フィールドに、MPウェーブレット変換部203による演算結果の値であるデータ列が記録される。
【0032】
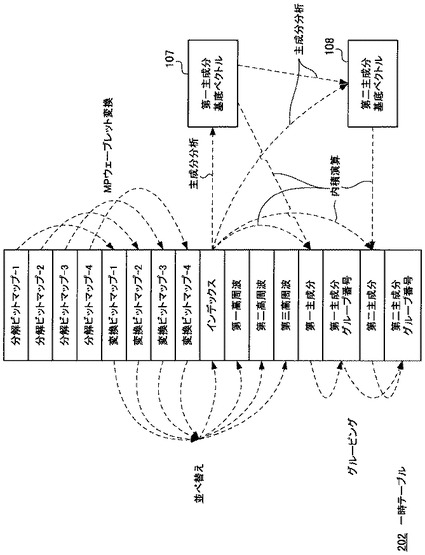
次に、並べ替え処理部204は図5(e)に示すように、「変換ビットマップ−1」フィールドのデータ、「変換ビットマップ−2」フィールドのデータ、「変換ビットマップ−3」フィールドのデータ及び「変換ビットマップ−4」フィールドのデータから、各々の同じ位置に配置されているスカラ値を集めて並べ替えを行う。
具体的には、「変換ビットマップ−1」フィールドのデータの「a1」と、「変換ビットマップ−2」フィールドのデータの「a2」と、「変換ビットマップ−3」フィールドのデータの「a3」と、「変換ビットマップ−4」フィールドのデータの「a4」とを集めて、「a1、a2、a3、a4」よりなる「インデックス」を作成し、一時テーブル202の「インデックス」フィールドに格納する。
同様に、「変換ビットマップ−1」フィールドのデータの「h1」と、「変換ビットマップ−2」フィールドのデータの「h2」と、「変換ビットマップ−3」フィールドのデータの「h3」と、「変換ビットマップ−4」フィールドのデータの「h4」とを集めて、「h1、h2、h3、h4」よりなる「第一高周波」を作成し、一時テーブル202の「第一高周波」フィールドに格納する。
同様に、「変換ビットマップ−1」フィールドのデータの「v1」と、「変換ビットマップ−2」フィールドのデータの「v2」と、「変換ビットマップ−3」フィールドのデータの「v3」と、「変換ビットマップ−4」フィールドのデータの「v4」とを集めて、「v1、v2、v3、v4」よりなる「第二高周波」を作成し、一時テーブル202の「第二高周波」フィールドに格納する。
同様に、「変換ビットマップ−1」フィールドのデータの「d1」と、「変換ビットマップ−2」フィールドのデータの「d2」と、「変換ビットマップ−3」フィールドのデータの「d3」と、「変換ビットマップ−4」フィールドのデータの「d4」とを集めて、「d1、d2、d3、d4」よりなる「第三高周波」を作成し、一時テーブル202の「第三高周波」フィールドに格納する。
こうして、一時テーブル202の「インデックス」フィールド、「第一高周波」フィールド、「第二高周波」フィールド及び「第三高周波」フィールドに、並べ替え処理部204による並べ替え処理されたデータ列が記録される。
【0033】
次に、主成分分析処理部205は、一時テーブル202の全レコードの「インデックス」フィールドを読み込み、主成分分析を行い、第一主成分基底ベクトル107と、第二主成分基底ベクトル108を算出する。
次に、内積演算部206は、一時テーブル202の「インデックス」フィールドのデータと、第一主成分基底ベクトル107とを内積演算し、得られた第一主成分データを「第一主成分」フィールドに格納する。
同様に、内積演算部206は、一時テーブル202の「インデックス」フィールドのデータと、第二主成分基底ベクトル108とを内積演算し、得られた第二主成分データを「第二主成分」フィールドに格納する。
こうして、一時テーブル202の「第一主成分」フィールド及び「第二主成分」フィールドに、内積演算部206による演算結果のスカラ値が記録される。
【0034】
次に、頻度分割処理部207は、一時テーブル202の全てのレコードについて、「第一主成分」フィールドのデータでソートした上で、予め定めたレコード数でグルーピングを施し、同一グループについて番号を付す。この番号は、一時テーブル202の「第一主成分グループ番号」フィールドに格納される。
更に頻度分割処理部207は、一時テーブル202の「第一主成分グループ番号」フィールドの値が等しいレコードについて、「第二主成分」フィールドのデータでソートした上で、予め定めたレコード数でグルーピングを施し、同一グループについて番号を付す。この番号は、一時テーブル202の「第二主成分グループ番号」フィールドに格納される。
こうして、一時テーブル202の「第一主成分グループ番号」フィールド及び「第二主成分グループ番号」フィールドに、頻度分割処理部207によるグループ番号が記録される。
【0035】
最後に、平均値演算部208は、図6(f)に示すように、一時テーブル202の「第一主成分グループ番号」フィールドの値と「第二主成分グループ番号」フィールドの値が等しいレコードについて、「第一主成分」フィールドの値の平均値を算出して、辞書テーブル106の「第一主成分」フィールドに格納する。
同様に、「第二主成分」フィールドの値の平均値を算出して、辞書テーブル106の「第二主成分」フィールドに格納する。
同様に、「第一高周波」フィールドに格納される「h1」データの平均値を算出し、「h2」データの平均値を算出し、「h3」データの平均値を算出し、「h4」データの平均値を算出して、これら「h1、h2、h3、h4」の平均値を辞書テーブル106の「第一高周波」フィールドに格納する。
同様に、「第二高周波」フィールドに格納される「v1」データの平均値を算出し、「v2」データの平均値を算出し、「v3」データの平均値を算出し、「v4」データの平均値を算出して、これら「v1、v2、v3、v4」の平均値を辞書テーブル106の「第二高周波」フィールドに格納する。
同様に、「第三高周波」フィールドに格納される「d1」データの平均値を算出し、「d2」データの平均値を算出し、「d3」データの平均値を算出し、「d4」データの平均値を算出して、これら「d1、d2、d3、d4」の平均値を辞書テーブル106の「第三高周波」フィールドに格納する。
こうして、図6(g)に示すように、平均値である「第一主成分」フィールドと、平均値である「第二主成分」フィールドと、平均値の集合である「第一高周波」フィールドと、平均値の集合である「第二高周波」フィールドと、平均値の集合である「第三高周波」フィールドよりなる、辞書テーブルのレコードが作成される。
【0036】
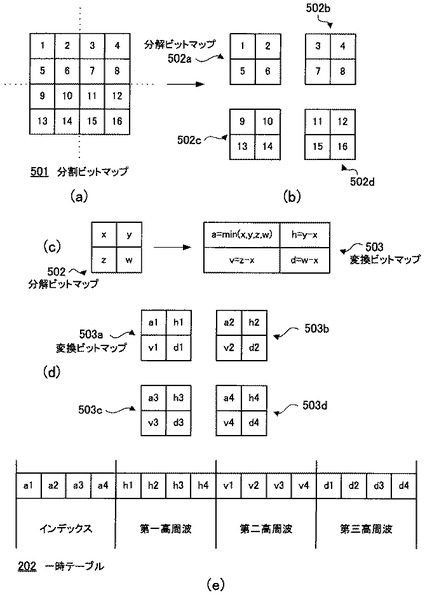
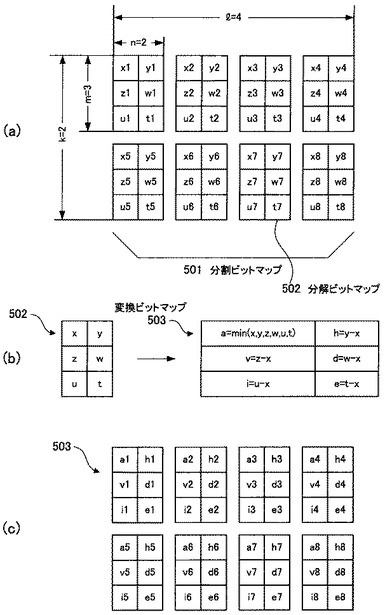
図7(a)、(b)及び(c)と、図8(d)は、分割ビットマップ501と分解ビットマップ502との関係を示す概略図である。図7及び図8では、一例としてk=2、l=4、m=3、n=2として説明する。
図7(a)に示すように、分割ビットマップ501は、縦が2×3=6ピクセル、横が2×4=8ピクセルの、合計48ピクセルで構成される。
分解ビットマップ502は、縦(=m)が3ピクセル、横(=n)が2ピクセルの、合計6ピクセルで構成される。分解ビットマップ502は(x、y、z、w、u、t)というピクセルで構成される。
この分解ビットマップ502は、図7(b)に示すように、MPウェーブレット変換部203によって、縦(=m)が3個、横(=n)が2個の、合計6個の変換ビットマップ503に変換される。変換ビットマップ503の数は分解ビットマップ502の数と等しい。図7(a)の場合、分解ビットマップ502が8個あるので、図7(c)に示すように変換ビットマップ503は8個生成される。
次に、図8(d)に示すように、並べ替え処理部204は、変換ビットマップ503の同じ位置に配置されているデータを集めて、インデックス、第一高周波、第二高周波、第三高周波、第四高周波、及び第五高周波を作成する。これらのデータは、縦2個(=k)、横4個(=l)の要素で構成され、6個(=m×n)形成される。
【0037】
[辞書作成装置109:辞書テーブル106の構成]
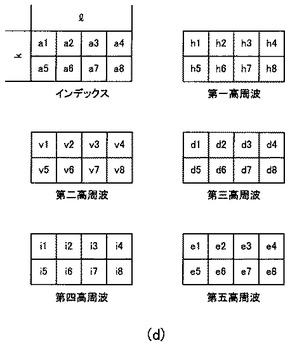
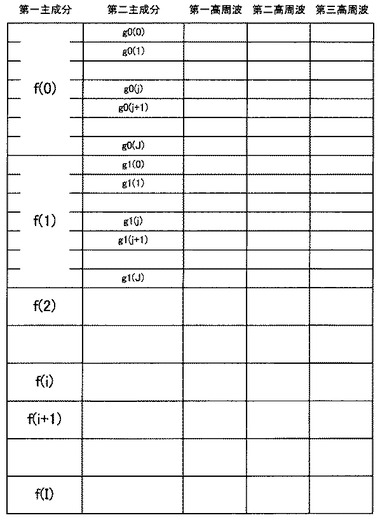
図9は、辞書テーブル106の構成を示す概略図である。
辞書テーブル106のフィールド構成は図6(g)に示したように、平均値である「第一主成分」フィールドと、平均値である「第二主成分」フィールドと、平均値の集合である「第一高周波」フィールドと、平均値の集合である「第二高周波」フィールドと、平均値の集合である「第三高周波」フィールドよりなる。
今、「第一主成分」フィールドの値をf(i)(iは1以上且つ辞書テーブル106の全レコード数までの自然数)とし、「第二主成分」フィールドの値をgi(j)(jは1以上の自然数)とすると、辞書テーブル106には「第一主成分」フィールドの値f(i)が等しい複数のレコードが存在する。そして、それらのレコードは「第二主成分」フィールドの値でユニークである(一意性を有する)。
「第一主成分」フィールドの値と、「第二主成分」フィールドの値は、後述する超解像画像処理装置101がツリー検索を実行するための検索キーである。
【0038】
[超解像画像処理装置101:全体構成]
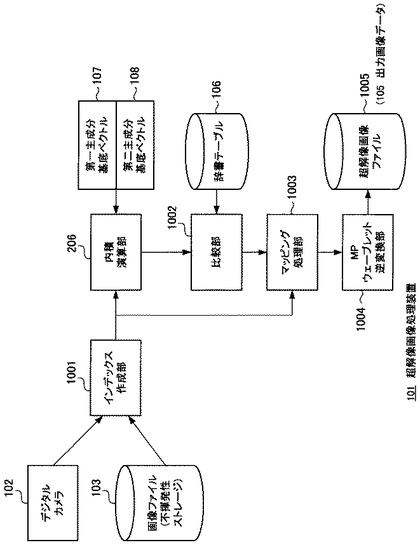
図10は、超解像画像処理装置101の機能ブロック図である。
デジタルカメラ102や、不揮発性ストレージに格納されている画像ファイル103等から得られる入力画像データ104は、インデックス作成部1001に供給される。インデックス作成部1001は、入力画像データ104から縦mピクセル×横nピクセルのインデックスビットマップを生成する。このインデックスビットマップは、辞書テーブル106の仕様に合わせて作られる。例えば、図5及び図6の例の場合、2×2=4ピクセルのインデックスビットマップをつくることとなる。インデックス作成部1001は、2×2=4ピクセルのインデックスビットマップを、入力画像データ104から横に2ピクセルずつ、縦に2ピクセルずつずらしながら連続的に作成する。
なお、周知のBMP、JPEG、GIF或はPNG等、所定の圧縮処理を含むものもある、複数の異なるフォーマットの画像データを図示しないRAM内にビットマップとして展開する処理は、このインデックス作成部1001に含まれるものとする。
【0039】
インデックス作成部1001が作成するインデックスビットマップは、内積演算部206によって、第一主成分基底ベクトル107と、第二主成分基底ベクトル108と、夫々に内積演算が行われる。この結果、インデックスビットマップから第一主成分と第二主成分が算出される。
ここで、インデックスビットマップは縦mピクセル×横nピクセル(本例の場合は4ピクセル)の「行列データ」であるのに対し、第一主成分及び第二主成分は夫々「スカラ値」である。この、行列データをスカラ値に変換することが、本実施形態の超解像画像処理装置101における大きな特色の一つであり、高速動作のために必要な技術である。
【0040】
内積演算部206によって算出された第一主成分及び第二主成分は、比較部1002に入力される。比較部1002は、辞書テーブル106の「第一主成分」フィールドと「第二主成分」フィールドを見てツリー検索を行い、内積演算部206によって算出された第一主成分及び第二主成分に最も近いレコードを見つける。そして、見つけたレコードに含まれている「第一高周波」フィールド、「第二高周波」フィールド及び「第三高周波」フィールドのデータを、インデックス作成部1001が作成したインデックスと共にマッピング処理部1003に引き渡す。
マッピング処理部1003は、内積演算部206から引き渡されたインデックス、第一高周波、第二高周波及び第三高周波のデータを並べ替えて、図示しないRAM内に配置する。配置は、図5(d)に示すように、インデックス、第一高周波、第二高周波及び第三高周波の同じ配置のデータを一つの組とする。
図5(d)の場合、インデックスの第一番目のデータ、第一高周波の第一番目のデータ、第二高周波の第一番目のデータ及び第三高周波の第一番目のデータを一つの組にする。
同様に、インデックスの第二番目のデータ、第一高周波の第二番目のデータ、第二高周波の第二番目のデータ及び第三高周波の第二番目のデータを一つの組にする。
同様に、インデックスの第三番目のデータ、第一高周波の第三番目のデータ、第二高周波の第三番目のデータ及び第三高周波の第三番目のデータを一つの組にする。
同様に、インデックスの第四番目のデータ、第一高周波の第四番目のデータ、第二高周波の第四番目のデータ及び第三高周波の第四番目のデータを一つの組にする。
【0041】
こうして組にされたデータは、超解像ビットマップ生成部ともいえるMPウェーブレット逆変換部1004によってMPウェーブレット逆変換演算処理が施され、インデックスビットマップのk×l倍のピクセル数である(本実施形態の場合は4×2×2=16ピクセル)超解像ビットマップが生成される。
今、変換ビットマップ503が「a、h、v、d」というピクセルで構成されている場合、MPウェーブレット逆変換は、以下の(2)式で分解ビットマップ502に逆変換する。
【0042】
x=a+max(−d,−h,−v,0)
y=a+max(h−v,h−d,h,0)
z=a+max(v−h,v−d,v,0)
w=a+max(d−h,d−v,d,0) (2)
【0043】
こうして、インデックス作成部1001が入力画像データ104から生成するインデックスビットマップは、MPウェーブレット逆変換部1004から順次超解像ビットマップに変換され、最終的に入力画像データ104のk×l倍のピクセル数である出力画像データ105である超解像画像ファイル1005が生成される。
【0044】
[超解像画像処理装置101:フローチャート]
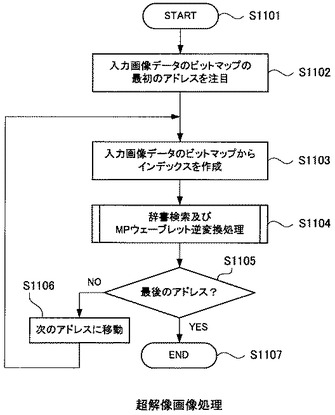
図11は、超解像画像処理装置101による超解像画像処理のフローチャートである。
処理を開始すると(S1101)、インデックス作成部1001は、入力画像データ104を図示しないRAM内にビットマップ展開した後、そのビットマップの最初のアドレスを注目する(S1102)。
【0045】
これ以降はループである。
インデックス作成部1001は、現在注目しているRAM内のアドレスから、インデックスビットマップを作成する(S1103)。
作成したインデックスビットマップは、辞書検索及びMPウェーブレット逆変換処理が施される(S1104)。
そして、現在処理を終えたインデックスビットマップは、入力画像データ104のビットマップの、処理すべき最後のアドレスのものなのか否かを確認する(S1105)。未だ処理対象とすべきインデックスビットマップが存在するのであれば(S1105のNO)、入力画像データ104のビットマップの、次のアドレスに移動して(S1106)、再びステップS1103から処理を繰り返す。
ステップS1105において、処理対象とすべきインデックスビットマップが存在しないのであれば(S1105のYES)、一連の処理を終了する(S1107)。
【0046】
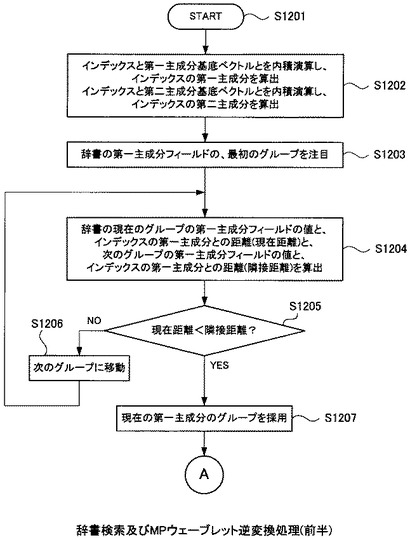
図12及び図13は、辞書作成装置109による辞書検索及びMPウェーブレット逆変換処理のフローチャートである。図11のステップS1104の処理の詳細である。
処理を開始すると(S1201)、内積演算部206は、インデックス作成部1001から引き渡されたインデックスビットマップを、第一主成分基底ベクトル107と内積演算を行い、第一主成分を算出する。同様に、インデックスビットマップを、第二主成分基底ベクトル108と内積演算を行い、第二主成分を算出する(S1202)。
【0047】
次に、比較部1002は内積演算部206から引き渡された第一主成分と、辞書テーブル106の第一主成分フィールドの値との比較を行う。
先ず、比較部1002は辞書テーブル106のレコードを第一主成分フィールドでグルーピングして、更にソートした上で、第一主成分フィールドの最小値のグループを注目する(S1203)。
【0048】
これ以降はループである。
比較部1002は辞書テーブル106の現在注目しているグループにおける第一主成分フィールドの値と、内積演算部206から引き渡された第一主成分との距離(以下「現在距離」)を算出する。
次に、比較部1002は辞書テーブル106の現在注目しているグループの、隣のグループにおける第一主成分フィールドの値と、内積演算部206から引き渡された第一主成分との距離(以下「隣接距離」)を算出する(S1204)。そして、算出した距離同士を比較する(S1205)。
現在距離が隣接距離より大きい値である場合(S1205のNO)は、比較対象とする辞書テーブル106のグループを次のグループに移動して(S1206)、再びステップS1204から繰り返す。
現在距離が隣接距離以下の値になった場合(S1205のYES)は、現在注目している第一主成分のグループを選択する(S1207)。
【0049】
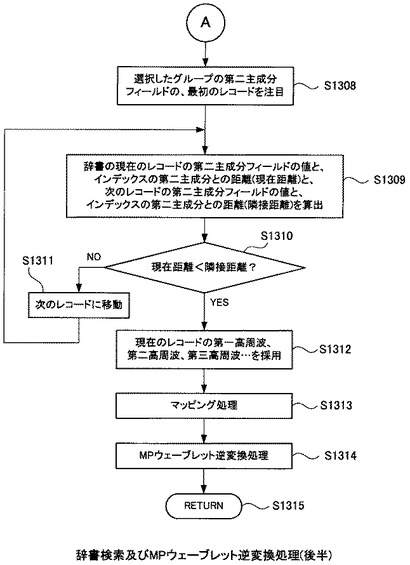
図13を参照して、引き続きフローチャートの説明を続ける。
比較部1002は、ステップS1207で選択した、辞書テーブル106の第一主成分のグループに対し、内積演算部206から引き渡された第二主成分を用いて更に絞り込みを行う。
つまり、内積演算部206から引き渡された第二主成分と、ステップS1207で選択した辞書テーブル106における第一主成分のグループに属するレコードの、第二主成分フィールドの値との比較を行う。
先ず、比較部1002はステップS1207で選択した辞書テーブル106における第一主成分のグループに属する辞書テーブル106のレコードを第二主成分フィールドでソートした上で、第二主成分フィールドの最小値のレコードを注目する(S1308)。
【0050】
これ以降はループである。
比較部1002は辞書テーブル106の現在注目しているレコードにおける第二主成分フィールドの値と、内積演算部206から引き渡された第二主成分との距離(以下「現在距離」)を算出する。
次に、比較部1002は辞書テーブル106の現在注目しているレコードの、次のレコードにおける第二主成分フィールドの値と、内積演算部206から引き渡された第二主成分との距離(以下「隣接距離」)を算出する(S1309)。そして、算出した距離同士を比較する(S1310)。
現在距離が隣接距離より大きい値である場合(S1310のNO)は、比較対象とする辞書テーブル106のレコードを次のレコードに移動して(S1311)、再びステップS1309から繰り返す。
現在距離が隣接距離以下の値になった場合(S1310のYES)は、現在注目している第二主成分のレコードに属する、第一高周波フィールド、第二高周波フィールド及び第三高周波フィールドの値を選択する(S1312)。
【0051】
比較部1002の絞込み検索によって選択された第一高周波、第二高周波及び第三高周波のデータはマッピング処理部1003に引き渡される。マッピング処理部1003は、インデックスと共に第一高周波、第二高周波及び第三高周波のデータを並べ替える(S1313)。
並べ替えられたデータはMPウェーブレット逆変換処理部に引き渡される。
MPウェーブレット逆変換処理部は並べ替えられたデータにMPウェーブレット逆変換処理を施し、超解像ビットマップを出力して(S1314)、一連の処理を終了する(S1315)。
【0052】
[超解像画像処理装置101:辞書テーブル106のツリー検索]
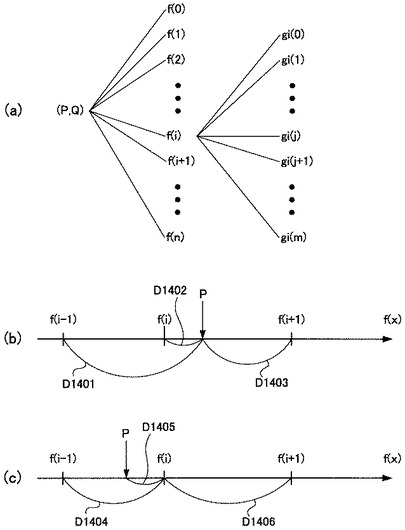
図14(a)、(b)及び(c)は、比較部1002が実行する、辞書テーブル106のツリー検索の仕組みを示す概略図である。
内積演算部206によって算出されたインデックスビットマップの第一主成分と第二主成分が、それぞれ(P,Q)であるとする。
第一主成分Pは、辞書テーブル106の第一主成分フィールドの値f(i)との距離、すなわち|P−f(i)|が算出される。iは1番目から順にインクリメントされ、第一主成分Pとの距離が算出されると共に、直前の距離と比較され、直前の距離が短い場合に、その直前の第一主成分フィールドのグループが採用される。
図14(b)及び(c)は、横軸が第一主成分の数直線である。第一主成分Pがf(i)に最も近く、且つf(i)より大きな値である場合、第一主成分Pがf(i)に最も近く、且つf(i)より小さな値である場合の、いずれの場合であっても、以下の式(2)が成り立つ。
【0053】
|P−f(i−1)|>|P−f(i)|
|P−f(i)|≦|P−f(i+1)| (2)
【0054】
図14(b)の場合、距離D1402を直前の距離D1401と比較すると、D1401>D1402という関係である。次に、距離D1403を直前の距離D1402と比較すると、D1402<D1403という関係であり、現在注目している距離と直前の距離との大小関係が反転する。
図14(c)の場合、距離D1405を直前の距離D1404と比較すると、D1404>D1405という関係である。次に、距離D1406を直前の距離D1405と比較すると、D1405<D1406という関係であり、現在注目している距離と直前の距離との大小関係が反転する。
このように、第一主成分Pに対し、辞書テーブル106の第一主成分フィールドの値f(i)を最小値から上げていく(iを0からインクリメントする)と、第一主成分Pとの大小関係が途中で変わる。この時点の辞書テーブル106の第一主成分フィールドの値f(i)が、第一主成分Pに最も近い距離のグループである。
【0055】
[辞書作成装置109及び超解像画像処理装置101の仕組み]
画像を微視的に観察すると、画像の種類に応じて、隣接するビットマップにはある種の相関性が見受けられる。そこで、微視的にビットマップを抜き出して、その相関性に基づいてビットマップを補完することで、失われた高周波成分を類推することができる。相関性を有する、ということは、ビットマップの補完に用いるデータを辞書テーブル106にして検索をかけることで実現できることを意味する。更に、相関性を有する、ということは、相関性の類似する同一のカテゴリやグループに属するパターンが多いことを示している。
発明者は、MPウェーブレット逆変換処理に辞書を用いて超解像画像処理を実現することを最初に思いついた。予め、辞書に極小なビットマップのパターンと、これに対応する、補完用ビットマップパターンを組にして保持しておく。そして、入力画像データ104から極小なビットマップを抜き出して辞書検索を行い、検索にヒットした補完用ビットマップパターンを用いて、超解像画像処理を実現する。
【0056】
入力画像データ104から作成される極小なビットマップの数は膨大なものとなり、その数はそのまま辞書に対する検索と超解像画像処理の回数となる。したがって、辞書アクセス及び超解像画像処理に要する時間は極力短いことが望ましい。
発明者は、超解像画像処理に要する時間を短縮するために、MPウェーブレット変換を開発した。
そして発明者は今般、超解像画像処理に用いる辞書アクセスに要する時間を短縮するために、主成分分析を用いた辞書の最適化を開発した。
【0057】
説明を簡単にするため、図5及び図6を例にして説明する。
辞書のレコード数を低減する最も素朴な方法としては、クラスタリングが挙げられる。インデックス、第一高周波、第二高周波及び第三高周波の数値パターンが類似するレコードを複数集めて、各々の平均値を取る。しかし、この場合、インデックスに含まれるデータは4個の要素を持つ行列である。複数の要素を持ち、それぞれの要素に重み付けがない場合、検索速度の向上は期待できない。また、クラスタリングの場合、インデックスに含まれる要素数が多くなればなるほど、指数関数的に検索速度が遅くなることが容易に想像できる。
【0058】
前述の検索速度の問題に関し、発明者は、多次元のデータをより少ない次元のデータに置き換える主成分分析が有効であることに気が付いた。主成分分析を用いれば、どれほど要素数の多い行列データの集合であっても、第一主成分及び第二主成分というスカラ値で表現することができる。なお、必要であれば第三主成分以降も設けることができる。
【0059】
主成分分析は、多次元の行列データの集合に対して重心を算出した後、その重心を通過して全ての行列データが最も大きく散らばる軸、すなわち分散が最大になる軸を第一主成分軸として算出する。なお、実際に算出するものは第一主成分軸の基底ベクトルである。この第一主成分基底ベクトル107に、目的となる行列とを内積演算すると、第一主成分軸上における重心からの距離を算出できる。
そして更に、重心を通過し、第一主成分軸と直交し、且つ分散が最大になる軸を第二主成分軸として算出する。これも実際に算出するものは第二主成分軸の基底ベクトルである。この第二主成分基底ベクトル108も、目的となる行列とを内積演算すると、第二主成分軸上における重心からの距離を算出できる。
【0060】
実際に画像データのビットマップに主成分分析を行うと、第一主成分軸及び第二主成分軸上のそれぞれに、データが密集する箇所が幾つか発生する。これは、画像データの性質に基づく傾向で、類似するビットマップが頻出するところである。このように、ばらつき具合に特徴ある傾向を示すデータ群に対し、主成分軸上で均等な数によるグルーピングを行う。そして、グルーピングを行った結果、同じグループに属するデータ群に対し、平均値を算出して、そのグループの代表値とする。
第一主成分軸と第二主成分軸は直交関係にあるので、最初に第一主成分で検索してレコードの絞り込みを行い、次に同じ第一主成分に属する複数のレコードに対して第二主成分で更に絞り込みを行う。これは周知のツリー検索であり、辞書に対するアクセス回数を効果的に低減する方法である。
【0061】
本実施形態は、以下のような応用例が考えられる。
(1)上述の実施形態では、白黒の静止画を対象とする装置を説明したが、超解像画像処理装置101の入力画像データ104(ソース)は動画像であってもよい。この場合、インデックスビットマップは時間軸を考慮したものとなる。例えば、時間軸上で隣り合う2枚の画像を対象にして、縦2ピクセル×横2ピクセル×2サンプル数=8ピクセルをインデックスとし、第一高周波、第二高周波及び第三高周波を生成する。
【0062】
(2)上述の実施形態では、白黒の静止画を対象とする装置を説明したが、超解像画像処理装置101の入力画像データ104(ソース)はカラー画像であってもよい。この場合、インデックスビットマップは三原色を考慮したものとなる。つまり、各々のビットマップを構成するピクセルの個数が単純に三倍になる。
勿論、扱う画像はカラーの動画像であってもよい。
【0063】
(3)例えば、アニメーションやコンピュータグラフィックス等の別の映像に実写の人物を合成する、周知のクロマキー合成によって生成される画像データの場合、一つの画像データ内に複数の全く異なる特徴を備えた部分が混在することとなる。このような画像データの場合は、予め異なる特徴の画像部分とを切り分けて、夫々に適した辞書テーブル等を用いて超解像画像処理を施すことが望ましい。
【0064】
(4)周知のように、主成分分析では、主成分分析の対象となる行列の要素数が膨大で、第一主成分軸と第二主成分軸だけでは集合の絞り込みを良好に実施できない場合に、第一主成分軸及び第二主成分軸の双方に直交し、最も分散が大きい第三主成分軸を算出することが行われる。そして、主成分軸は第四、第五…と、その用途に応じて増やすことも可能である。これは本実施形態の超解像画像処理装置101及び辞書作成装置109にも同じことが言える。つまり、辞書テーブル等に含まれる主成分軸の基底ベクトルは、必ずしも第一主成分軸と第二主成分軸だけではなく、必要に応じて第三主成分軸を含めることができる。そして、その際、辞書テーブル106にもこれに応じて「第三主成分」フィールド等が追加されることとなる。
【0065】
(5)本実施形態の辞書作成装置109では、並べ替え処理部204という処理手順を設けているが、これは説明の便宜上、データの扱いを理解し易くするために明示的に記述した処理内容である。実際の装置では、このような実データのコピーを行わずとも、周知のポインタ操作で同等の処理をより高速に実現できる。
同様のことは、超解像画像処理装置101のマッピング処理部1003にも当てはまる。
【0066】
本実施形態においては、超解像画像処理装置101と、これに用いる辞書作成装置109を開示した。
汎用性の高い超解像画像処理を短時間に実行するため、本実施形態の超解像画像処理装置101は、先ず、処理対象とする画像をシーンに分けた。そして、シーンに適合する辞書テーブル106を用いて、失われた高周波成分を辞書に対するツリー検索にて類推した。
そして、辞書テーブル106の検索を高速化するため、主成分分析を用いて、検索キーとなるインデックスビットマップをスカラ値である第一主成分及び第二主成分に変換すると共に、第一主成分と第二主成分とでグルーピングを施し、その平均値を算出することで、辞書テーブル106の必要レコード数を大幅に低減することに成功した。
これらの技術の採用により、少ない計算量で高速に実行できる、汎用性が高く実用的な超解像画像処理装置101を実現できる。
【0067】
以上、本発明の実施形態例について説明したが、本発明は上記実施形態例に限定されるものではなく、特許請求の範囲に記載した本発明の要旨を逸脱しない限りにおいて、他の変形例、応用例を含む。
【符号の説明】
【0068】
101…超解像画像処理装置、102…デジタルカメラ、103…画像ファイル、104…入力画像データ、105…出力画像データ、106…辞書テーブル、107…第一主成分基底ベクトル、108…第二主成分基底ベクトル、109…辞書作成装置、110…サンプル画像ファイル、201…分解処理部、202…一時テーブル、203…MPウェーブレット変換部、204…処理部、205…主成分分析処理部、206…内積演算部、207…頻度分割処理部、208…平均値演算部、501…分割ビットマップ、502…分解ビットマップ、503…変換ビットマップ、1001…インデックス作成部、1002…比較部、1003…マッピング処理部、1004…MPウェーブレット逆変換部、1005…超解像画像ファイル
【技術分野】
【0001】
本発明は、超解像画像処理装置及び超解像画像処理用辞書作成装置に適用して好適な技術に関する。
より詳細には、低解像度の原画像から高解像度の画像を出力する、超解像画像処理装置と、この超解像画像処理装置が利用する辞書テーブルを作成する超解像画像処理用辞書作成装置に関する。
【背景技術】
【0002】
超解像技術とは、低解像度の原画像から高解像度の画像を生成することで、違和感の少ない拡大画像を得るための技術である。この超解像技術は、テレビやパソコン等といった画像閲覧装置の高解像度化に伴い、注目され、一部の民生機器等で採用されている。
例えば、携帯電話に付属する比較的低解像度のカメラで撮影した画像を高解像度のディスプレイで閲覧する場合や、アナログテレビ時代に作成された低解像度の動画コンテンツを高解像度のテレビで閲覧する場合、或は低解像度の動画ストリーミングデータを高解像度のディスプレイで閲覧する場合等に、この超解像技術が用いられる。
更には、監視カメラ等の撮影画像データを高詳細化することで、社会基盤の安全性向上に寄与できる可能性もある。
【0003】
前述のように、超解像技術は違和感のない拡大画像を得るための技術であるが、これは転じて「失われた高周波成分を類推する」技術である。
例えば、ある画像データのピクセルサイズを縦横半分ずつ、1/4倍に縮小する場合、隣り合う二つのピクセルの平均値を算出して、一つのピクセルに変換する。この平均値演算は、積分の一種といえる。そして、ピクセルの羅列を信号として捉えた場合、平均値演算を行ってピクセルを間引くことは、信号の高周波成分を除去することと等価である。
逆に、ある画像データのピクセルサイズを縦横4倍ずつ、4倍に拡大する場合、一番簡単な方法としては、隣り合う二つのピクセルの中間値を算出して、間のピクセルを得る方法であるが、この算出方法では失われた高周波成分が再現されない。このため、中間値演算による拡大画像はあたかもピンぼけのような、境界線が曖昧な画像になる。
つまり、超解像技術は、ピクセルのパターンを解析して、適切と思われるピクセルを算出し、元画像の隣接するピクセル同士の間に埋めることで、「失われた高周波成分を類推する」技術である。
【0004】
発明者は、超解像画像処理をリアルタイムで処理できるための技術を開発している。より詳細には、画像データを位置とスケールで指定される小さな波の重ね合わせに分解し解析する手法である「モルフォロジカル・ウェーブレット変換」を、整数であるマックスプラス代数で記述することで、全体の見通しをよくすると共に数式を簡素化した「MPウェーブレット変換」を開発している。MPウェーブレット変換の概要については非特許文献1に開示されている。
【先行技術文献】
【非特許文献】
【0005】
【非特許文献1】「2次元Max-Plus ウェーブレット変換・逆変換実証回路の作製」小野 雅晃、延原 肇[2011年6月10日検索]、インターネット<URL:http://www.tech.tsukuba.ac.jp/2010/report/n03_report2010.pdf>
【発明の概要】
【発明が解決しようとする課題】
【0006】
非特許文献1に開示されるウェーブレット変換・逆変換実証回路は、MPウェーブレット変換の再現性を確認するための実験であり、実応用に必要な技術的課題を解決出来ていなかった。それは、データ量及び計算量を減らすことである。
【0007】
本発明はかかる課題を解決し、少ないハードウェアリソースで高速に処理できる、極めて実用的な超解像画像処理装置と、この超解像画像処理装置が利用する辞書テーブルを作成する超解像画像処理用辞書作成装置を提供することを目的とする。
【課題を解決するための手段】
【0008】
上記課題を解決するために、本発明の超解像画像処理装置は、入力画像データから所定数のピクセルよりなるインデックスビットマップを生成するインデックス作成部と、インデックスビットマップに対して、第一主成分基底ベクトルとの内積を演算して第一主成分を算出し、第一主成分基底ベクトルとの内積を演算して第二主成分を算出する内積演算部と、第一主成分及び第二主成分を用いて辞書テーブルを検索し、第一主成分及び第二主成分に最も近いレコードを得る比較部と、レコードに含まれている高周波成分とインデックスビットマップを用いて超解像ビットマップを算出する超解像ビットマップ生成部とを具備する。
【0009】
また、上記課題を解決するために、本発明の超解像画像処理用辞書作成装置は、一時テーブルと、サンプル画像ファイルから所定のアドレスのピクセルを含む一つの範囲に含まれる複数のピクセルを分割ビットマップとして取り出した後、分割ビットマップを四以上の数の領域である分解ビットマップとして等分して、複数の分解ビットマップをそれぞれ一時テーブルの分解ビットマップ格納フィールド群に格納する分解処理部と、分解ビットマップ格納フィールド群に格納されている複数の分解ビットマップに対して所定の代数変換処理を施して、得られた演算結果である変換ビットマップをそれぞれ一時テーブルの変換ビットマップ格納フィールド群に格納する代数変換処理部と、変換ビットマップ格納フィールド群に格納されている複数の変換ビットマップからインデックスとなるデータ列に対して主成分分析を実行して、超解像画像処理装置に用いる第一主成分基底ベクトルと第二主成分基底ベクトルを算出する主成分分析処理部と、一時テーブルの各レコードのインデックスと第一主成分基底ベクトルを内積演算してインデックスの第一主成分を算出して一時テーブルの第一主成分フィールドに格納すると共に、インデックスと第二主成分基底ベクトルを内積演算してインデックスの第二主成分を算出して一時テーブルの第二主成分フィールドに格納する内積演算部と、一時テーブルのレコードを第一主成分フィールドの値及び第二主成分フィールドの値でグルーピングする頻度分割処理部と、頻度分割処理部によってグルーピングされた一時テーブルの複数のレコードに含まれる各スカラ値に対して平均値を算出して、超解像画像処理装置に用いる辞書テーブルを作成する平均値演算部とを具備する。
【0010】
汎用性の高い超解像画像処理を短時間に実行するため、本発明の超解像画像処理装置は、処理対象とする画像をシーンに分けて、そのシーンに適合する辞書テーブルを用いて、失われた高周波成分を辞書に対するツリー検索にて類推する。
辞書テーブルは検索を高速化するため、主成分分析を用いて、検索キーとなるインデックスビットマップをスカラ値である第一主成分及び第二主成分に変換すると共に、第一主成分と第二主成分とでグルーピングを施し、その平均値を算出することで、辞書テーブルの必要レコード数が大幅に低減されている。
【発明の効果】
【0011】
本発明により、少ないハードウェアリソースで高速に処理できる、極めて実用的な超解像画像処理装置と、この超解像画像処理装置が利用する辞書テーブルを作成する超解像画像処理用辞書作成装置を提供できる。
【図面の簡単な説明】
【0012】
【図1】本発明の実施形態の例である、超解像画像処理装置と辞書作成装置の概略図である。
【図2】辞書作成装置の機能ブロック図である。
【図3】一時テーブルのフィールド構成図である。
【図4】辞書作成装置による辞書作成処理のフローチャートである。
【図5】辞書作成装置が実行する辞書作成処理による、画像データから辞書テーブルが生成される過程を示す概要図である。
【図6】辞書作成装置が実行する辞書作成処理による、画像データから辞書テーブルが生成される過程を示す概要図である。
【図7】分割ビットマップと分解ビットマップとの関係を示す概略図である。
【図8】分割ビットマップと分解ビットマップとの関係を示す概略図である。
【図9】辞書テーブルの構成を示す概略図である。
【図10】超解像画像処理装置の機能ブロック図である。
【図11】超解像画像処理装置による超解像画像処理のフローチャートである。
【図12】辞書作成装置による辞書検索及びMPウェーブレット逆変換処理のフローチャートである。
【図13】辞書作成装置による辞書検索及びMPウェーブレット逆変換処理のフローチャートである。
【図14】比較部が実行する、辞書テーブルのツリー検索の仕組みを示す概略図である。
【発明を実施するための形態】
【0013】
[全体構成]
図1は、本発明の実施形態の例である、超解像画像処理装置と辞書作成装置の概略図である。
超解像画像処理装置101は、デジタルカメラ102や画像ファイル103等から、縦mピクセル×横nピクセルの入力画像データ104を受け取ると、縦k・mピクセル×横l・nピクセルの出力画像データ105を生成する。ここで、k、l、m及びnは2以上の自然数である。したがって、超解像画像処理装置101は、最低限、縦2倍及び横2倍の、4倍に拡大した画像を生成する。
超解像画像処理装置101が処理する画像は、静止画像であっても動画像であってもよい。本実施形態では説明を簡単にするため、静止画像を中心に説明する。
【0014】
超解像画像処理装置101は、入力画像データ104に対して超解像画像処理を施して出力画像データ105を生成する際、失われた高周波成分を類推するために、辞書テーブル106と、第一主成分基底ベクトル107と、第二主成分基底ベクトル108を用いる。これらのデータは辞書作成装置109によって生成され、予め超解像画像処理装置101に組み込まれる。
辞書作成装置109は、一つ以上のサンプル画像ファイル110を受け取ると、後述する所定の演算処理を行うことで、辞書テーブル106と、第一主成分基底ベクトル107と、第二主成分基底ベクトル108を生成する。
ここで、辞書テーブル106、第一主成分基底ベクトル107及び第二主成分基底ベクトル108は、これら三つで一つの組である。これ以降、辞書テーブル106、第一主成分基底ベクトル107及び第二主成分基底ベクトル108をまとめて「辞書テーブル等」と呼ぶ。
【0015】
図1では、超解像画像処理装置101の具体的な実装形態について明記していないが、超解像画像処理装置101は画像データを処理する演算装置であるので、如何様にも実装可能である。
例えば、周知のパソコンにインストールするプログラムとして実現することができる。その際、辞書テーブル等はハードディスク装置等の不揮発性ストレージに格納されるであろう。
また、デジタルカメラ102のファームウェアとして、デジタルカメラ102に組み込むこともできる。
更には、FPGA(Field Programmable Gate Array)等のPLD(programmable logic device)やASIC(Application Specific Integrated Circuit)等を用いて実現することもできる。特に本実施形態の超解像画像処理装置101は、そのベースとなるMPウェーブレット変換が整数の加減算及び比較演算のみで構成されるため、これらハードウェアの実装面積は極めて少なく済む。
【0016】
図1では、辞書作成装置109の具体的な実装形態について明記していないが、辞書作成装置109はサンプル画像ファイル110から辞書テーブル等を生成する演算装置であるので、如何様にも実装可能である。辞書作成装置109は、例えばパソコン等にインストールされて実行されるプログラムで実現され、超解像画像処理装置101が製造される工場等の生産現場に設けられ、シーンに応じた辞書テーブル等を生成する。
シーンとは、画像の特色である。例えば風景の撮影画像であったり、医療用レントゲン画像であったり、或はアニメーション等である。風景の撮影画像の場合、そのピクセルパターンには中間色や中間輝度が多く現れる。一方、アニメーションの画像の場合、輪郭が明確であり、色彩や輝度がある境界で急激に変化する(エッジの効いた)ピクセルパターンが多く見受けられる。このように、画像にはそのシーンに応じた特色がある。そこで、サンプル画像ファイル110はシーンに応じた画像が集められ、辞書テーブル等の基となる。どのようなシーンに対しても最適な超解像処理ができる万能な辞書テーブル等を作成することは困難であるが、シーンに最適化した辞書テーブル等を作成することで、超解像画像処理装置101が適用されるシーンに適した辞書テーブル等を与えることができる。勿論、複数の辞書テーブル等を用意して、超解像画像処理装置101がシーンに応じて辞書テーブル等を切り替えることで、シーンに最適な超解像画像処理を実現することができる。また、シーンを細分化すればするほど、そのシーンにより適合した辞書テーブル等を作成することができ、以てより再現度の高い超解像画像処理を実現することができる。
【0017】
辞書テーブル等、つまり辞書テーブル106、第一主成分基底ベクトル107及び第二主成分基底ベクトル108は、その名称から明らかなように、周知の主成分分析を経て形成されている。このため、辞書テーブル106と、第一主成分基底ベクトル107及び第二主成分基底ベクトル108は密接な関係を有する。この関係の詳細は、辞書作成装置109の説明にて後述する。
【0018】
なお、説明を容易にするために、これ以降の実施形態の説明では、辞書作成装置109及び超解像画像処理装置101が取り扱う画像は白黒の静止画像であり、一つのピクセルは8ビットであるものとする。このため、一つのピクセルは0〜255の輝度データである。
【0019】
[辞書作成装置109:全体構成]
図2は、辞書作成装置109の機能ブロック図である。
図3は、一時テーブルのフィールド構成図である。
一以上のサンプル画像ファイル110は、分解処理部201によって所定の大きさの分割ビットマップに分解されて、一時テーブル202の「分解ビットマップ−1」フィールド、「分解ビットマップ−2」フィールド、「分解ビットマップ−3」フィールド及び「分解ビットマップ−4」フィールドに格納される。
次に、代数変換処理部ともいえるMPウェーブレット変換部203は、一時テーブル202の「分解ビットマップ−1」フィールドのデータを読み込み、MPウェーブレット変換を施して、得られた変換ビットマップを「変換ビットマップ−1」フィールドに格納する。
同様に、MPウェーブレット変換部203は、一時テーブル202の「分解ビットマップ−2」フィールドのデータを読み込み、MPウェーブレット変換を施して、得られた変換ビットマップを「変換ビットマップ−2」フィールドに格納する。
同様に、MPウェーブレット変換部203は、一時テーブル202の「分解ビットマップ−3」フィールドのデータを読み込み、MPウェーブレット変換を施して、得られた変換ビットマップを「変換ビットマップ−3」フィールドに格納する。
同様に、MPウェーブレット変換部203は、一時テーブル202の「分解ビットマップ−4」フィールドのデータを読み込み、MPウェーブレット変換を施して、得られた変換ビットマップを「変換ビットマップ−4」フィールドに格納する。
【0020】
次に、並べ替え処理部204は、一時テーブル202の「変換ビットマップ−1」フィールド、「変換ビットマップ−2」フィールド、「変換ビットマップ−3」フィールド及び「変換ビットマップ−4」フィールドのデータを読み込み、並べ替え処理を施して、夫々「インデックス」フィールド、「第一高周波」フィールド、「第二高周波」フィールド及び「第三高周波」フィールドに格納する。
次に、主成分分析処理部205は、一時テーブル202の全レコードの「インデックス」フィールドのデータを読み込み、周知の主成分分析を行い、第一主成分基底ベクトル107と、第二主成分基底ベクトル108を算出する。
次に、内積演算部206は、一時テーブル202の「インデックス」フィールドのデータと、第一主成分基底ベクトル107とを内積演算し、得られた第一主成分データを「第一主成分」フィールドに格納する。
同様に、内積演算部206は、一時テーブル202の「インデックス」フィールドのデータと、第二主成分基底ベクトル108とを内積演算し、得られた第二主成分データを「第二主成分」フィールドに格納する。
【0021】
次に、頻度分割処理部207は、一時テーブル202の全てのレコードについて、「第一主成分」フィールドのデータでソートした上で、予め定めたレコード数でグルーピングを施し、同一グループについて番号を付す。この番号は、一時テーブル202の「第一主成分グループ番号」フィールドに格納される。
更に頻度分割処理部207は、一時テーブル202の「第一主成分グループ番号」フィールドの値が等しいレコードについて、「第二主成分」フィールドのデータでソートした上で、予め定めたレコード数でグルーピングを施し、同一グループについて番号を付す。この番号は、一時テーブル202の「第二主成分グループ番号」フィールドに格納される。
【0022】
最後に、平均値演算部208は、一時テーブル202の「第一主成分グループ番号」フィールドの値と「第二主成分グループ番号」フィールドの値が等しいレコードについて、「第一主成分」フィールドの値の平均値を算出して、辞書テーブル106の「第一主成分」フィールドに格納する。
同様に、「第二主成分」フィールドの値の平均値を算出して、辞書テーブル106の「第二主成分」フィールドに格納する。
同様に、「第一高周波」フィールドに格納される各スカラ値毎にそれぞれ平均値を算出して、辞書テーブル106の「第一高周波」フィールドに格納する。
同様に、「第二高周波」フィールドに格納される各スカラ値毎にそれぞれ平均値を算出して、辞書テーブル106の「第二高周波」フィールドに格納する。
同様に、「第三高周波」フィールドに格納される各スカラ値毎にそれぞれ平均値を算出して、辞書テーブル106の「第三高周波」フィールドに格納する。
【0023】
以上説明したように、辞書作成装置109は、サンプル画像ファイル110から処理対象とする分割ビットマップを得て、これを複数の分解ビットマップに分けて一時テーブル202のレコードに格納した上で、MPウェーブレット変換部203、並べ替え処理部204、主成分分析処理部205、内積演算部206、そして頻度分割処理部207と、順番に処理を施すことで、一時テーブル202の各フィールドに演算結果を格納する。そして最後に平均値演算部208によって、一時テーブル202よりレコード数の少ない辞書テーブル106を作成する。
【0024】
[辞書作成装置109:フローチャート]
図4は、辞書作成装置109による辞書作成処理のフローチャートである。
処理を開始すると(S401)、分解処理部201はサンプル画像ファイル110を読み込み、km×lnピクセルの分割ビットマップに分割する。更にこの分割ビットマップを、m×nピクセルの分解ビットマップに分解して、一時テーブル202の「分解ビットマップ−1」フィールド、「分解ビットマップ−2」フィールド、…「分解ビットマップ−(k×l)」フィールドに格納する(S402)。
次に、MPウェーブレット変換部203は、一時テーブル202の分解ビットマップが格納されているフィールドのデータを読み込み、MPウェーブレット変換を施して、得られた変換ビットマップを変換ビットマップを格納するフィールドに格納する。この動作をk×l回繰り返す(S403)。
【0025】
次に、並べ替え処理部204は、一時テーブル202の「変換ビットマップ−1」フィールド、「変換ビットマップ−2」フィールド、…「変換ビットマップ−(k×l)」フィールドのデータを読み込み、並べ替え処理を施して、夫々「インデックス」フィールド、「第一高周波」フィールド、「第二高周波」フィールド…「第(k×l)高周波」フィールドに格納する(S404)。
次に、主成分分析処理部205は、一時テーブル202の全レコードの「インデックス」フィールドのデータを読み込み、周知の主成分分析を行い、第一主成分基底ベクトル107と、第二主成分基底ベクトル108を算出する(S405)。
次に、内積演算部206は、一時テーブル202の「インデックス」フィールドのデータと第一主成分基底ベクトル107とを内積演算して、得られた第一主成分データを「第一主成分」フィールドに格納し、一時テーブル202の「インデックス」フィールドのデータと第二主成分基底ベクトル108とを内積演算して、得られた第二主成分データを「第二主成分」フィールドに格納する(S406)。
【0026】
次に、頻度分割処理部207は、一時テーブル202の全てのレコードについて「第一主成分」フィールドのデータでソートした上で、予め定めたレコード数でグルーピングを施し、同一グループについて番号を付す(S407)。この番号は、一時テーブル202の「第一主成分グループ番号」フィールドに格納される。
更に頻度分割処理部207は、一時テーブル202の「第一主成分グループ番号」フィールドの値が等しいレコードについて、「第二主成分」フィールドのデータでソートした上で、予め定めたレコード数でグルーピングを施し、同一グループについて番号を付す(S408)。この番号は、一時テーブル202の「第二主成分グループ番号」フィールドに格納される。
【0027】
最後に、平均値演算部208は、一時テーブル202の「第一主成分グループ番号」フィールドの値と「第二主成分グループ番号」フィールドの値が等しいレコードについて、「第一主成分」フィールドの値の平均値を算出して、辞書テーブル106の「第一主成分」フィールドに格納する。
同様に、「第二主成分」フィールドの値の平均値を算出して、辞書テーブル106の「第二主成分」フィールドに格納する。
同様に、「第一高周波」フィールドに格納される各スカラ値毎にそれぞれ平均値を算出して、辞書テーブル106の「第一高周波」フィールドに格納する。
同様に、「第二高周波」フィールドに格納される各スカラ値毎にそれぞれ平均値を算出して、辞書テーブル106の「第二高周波」フィールドに格納する。
同様に、「第(k×l−1)高周波」フィールドに格納される各スカラ値毎にそれぞれ平均値を算出して、辞書テーブル106の「第(k×l−1)高周波」フィールドに格納する(S409)。そして、一連の処理を終了する(S410)。
【0028】
[辞書作成装置109:データ処理の詳細]
図5(a)、(b)、(c)、(d)及び(e)と、図6(f)及び(g)は、辞書作成装置109が実行する辞書作成処理による、画像データから辞書テーブル106が生成される過程を示す概要図である。なお、図5及び図6では説明を簡単にするため、k、l、m及びnは「2」に設定して説明する。
先ず、分解処理部201は図5(a)に示す、サンプル画像ファイル110から縦4ピクセル×横4ピクセルよりなる、16ピクセルの分割ビットマップ501を抜き出す。これが一時テーブル202の1レコード分に相当する。なお、分解処理部201はサンプル画像ファイル110から1ピクセルずつずらして分割ビットマップ501を抜き出して、一時テーブル202のレコードとして追記する。
次に、分解処理部201は図5(b)に示すように、分割ビットマップ501を縦と横に二等分して、合計4個の分解ビットマップ502a、502b、502c及び502dを作成する。そして、この分解ビットマップ502a、502b、502c及び502dが、分解処理部201によって一時テーブル202のフィールドとして格納される。
「分解ビットマップ−1」フィールドには、分割ビットマップ501の「1、2、5、6」番目のピクセルである分解ビットマップ502aが格納される。
「分解ビットマップ−2」フィールドには、分割ビットマップ501の「3、4、7、8」番目のピクセルである分解ビットマップ502bが格納される。
「分解ビットマップ−3」フィールドには、分割ビットマップ501の「9、10、13、14」番目のピクセルである分解ビットマップ502cが格納される。
「分解ビットマップ−4」フィールドには、分割ビットマップ501の「11、12、15、16」番目のピクセルである分解ビットマップ502dが格納される。
こうして、一時テーブル202の「分解ビットマップ−1」フィールド、「分解ビットマップ−2」フィールド、「分解ビットマップ−3」フィールド及び「分解ビットマップ−4」フィールドに、分解処理部201による分解処理されたデータ列が記録される。
【0029】
次に、MPウェーブレット変換部203は図5(c)に示すように、分解ビットマップ502にMPウェーブレット変換を施す。
今、分解ビットマップ502が「x、y、z、w」というピクセルで構成されている場合、MPウェーブレット変換は、以下の(1)式で変換ビットマップ503に変換する。
【0030】
a=min(x,y,z,w)
h=y−x
v=z−x
d=w−x (1)
【0031】
したがって、MPウェーブレット変換部203は図5(d)に示すように、分割ビットマップ501の「1、2、5、6」番目のピクセルよりなる「分解ビットマップ−1」フィールドに格納されている分解ビットマップ502aのデータを読み込み、「a1、h1、v1、d1」という「変換ビットマップ−1」データを作成する。
同様に、MPウェーブレット変換部203は、分割ビットマップ501の「3、4、7、8」番目のピクセルよりなる「分解ビットマップ−2」フィールドに格納されている分解ビットマップ502bのデータを読み込み、「a2、h2、v2、d2」という「変換ビットマップ−2」データを作成する。
同様に、MPウェーブレット変換部203は、分割ビットマップ501の「9、10、13、14」番目のピクセルよりなる「分解ビットマップ−3」フィールドに格納されている分解ビットマップ502cのデータを読み込み、「a3、h3、v3、d3」という「変換ビットマップ−3」データを作成する。
同様に、MPウェーブレット変換部203は、分割ビットマップ501の「11、12、15、16」番目のピクセルよりなる「分解ビットマップ−4」フィールドに格納されている分解ビットマップ502dのデータを読み込み、「a4、h4、v4、d4」という「変換ビットマップ−3」データを作成する。
こうして、一時テーブル202の「変換ビットマップ−1」フィールド、「変換ビットマップ−2」フィールド、「変換ビットマップ−3」フィールド及び「変換ビットマップ−4」フィールドに、MPウェーブレット変換部203による演算結果の値であるデータ列が記録される。
【0032】
次に、並べ替え処理部204は図5(e)に示すように、「変換ビットマップ−1」フィールドのデータ、「変換ビットマップ−2」フィールドのデータ、「変換ビットマップ−3」フィールドのデータ及び「変換ビットマップ−4」フィールドのデータから、各々の同じ位置に配置されているスカラ値を集めて並べ替えを行う。
具体的には、「変換ビットマップ−1」フィールドのデータの「a1」と、「変換ビットマップ−2」フィールドのデータの「a2」と、「変換ビットマップ−3」フィールドのデータの「a3」と、「変換ビットマップ−4」フィールドのデータの「a4」とを集めて、「a1、a2、a3、a4」よりなる「インデックス」を作成し、一時テーブル202の「インデックス」フィールドに格納する。
同様に、「変換ビットマップ−1」フィールドのデータの「h1」と、「変換ビットマップ−2」フィールドのデータの「h2」と、「変換ビットマップ−3」フィールドのデータの「h3」と、「変換ビットマップ−4」フィールドのデータの「h4」とを集めて、「h1、h2、h3、h4」よりなる「第一高周波」を作成し、一時テーブル202の「第一高周波」フィールドに格納する。
同様に、「変換ビットマップ−1」フィールドのデータの「v1」と、「変換ビットマップ−2」フィールドのデータの「v2」と、「変換ビットマップ−3」フィールドのデータの「v3」と、「変換ビットマップ−4」フィールドのデータの「v4」とを集めて、「v1、v2、v3、v4」よりなる「第二高周波」を作成し、一時テーブル202の「第二高周波」フィールドに格納する。
同様に、「変換ビットマップ−1」フィールドのデータの「d1」と、「変換ビットマップ−2」フィールドのデータの「d2」と、「変換ビットマップ−3」フィールドのデータの「d3」と、「変換ビットマップ−4」フィールドのデータの「d4」とを集めて、「d1、d2、d3、d4」よりなる「第三高周波」を作成し、一時テーブル202の「第三高周波」フィールドに格納する。
こうして、一時テーブル202の「インデックス」フィールド、「第一高周波」フィールド、「第二高周波」フィールド及び「第三高周波」フィールドに、並べ替え処理部204による並べ替え処理されたデータ列が記録される。
【0033】
次に、主成分分析処理部205は、一時テーブル202の全レコードの「インデックス」フィールドを読み込み、主成分分析を行い、第一主成分基底ベクトル107と、第二主成分基底ベクトル108を算出する。
次に、内積演算部206は、一時テーブル202の「インデックス」フィールドのデータと、第一主成分基底ベクトル107とを内積演算し、得られた第一主成分データを「第一主成分」フィールドに格納する。
同様に、内積演算部206は、一時テーブル202の「インデックス」フィールドのデータと、第二主成分基底ベクトル108とを内積演算し、得られた第二主成分データを「第二主成分」フィールドに格納する。
こうして、一時テーブル202の「第一主成分」フィールド及び「第二主成分」フィールドに、内積演算部206による演算結果のスカラ値が記録される。
【0034】
次に、頻度分割処理部207は、一時テーブル202の全てのレコードについて、「第一主成分」フィールドのデータでソートした上で、予め定めたレコード数でグルーピングを施し、同一グループについて番号を付す。この番号は、一時テーブル202の「第一主成分グループ番号」フィールドに格納される。
更に頻度分割処理部207は、一時テーブル202の「第一主成分グループ番号」フィールドの値が等しいレコードについて、「第二主成分」フィールドのデータでソートした上で、予め定めたレコード数でグルーピングを施し、同一グループについて番号を付す。この番号は、一時テーブル202の「第二主成分グループ番号」フィールドに格納される。
こうして、一時テーブル202の「第一主成分グループ番号」フィールド及び「第二主成分グループ番号」フィールドに、頻度分割処理部207によるグループ番号が記録される。
【0035】
最後に、平均値演算部208は、図6(f)に示すように、一時テーブル202の「第一主成分グループ番号」フィールドの値と「第二主成分グループ番号」フィールドの値が等しいレコードについて、「第一主成分」フィールドの値の平均値を算出して、辞書テーブル106の「第一主成分」フィールドに格納する。
同様に、「第二主成分」フィールドの値の平均値を算出して、辞書テーブル106の「第二主成分」フィールドに格納する。
同様に、「第一高周波」フィールドに格納される「h1」データの平均値を算出し、「h2」データの平均値を算出し、「h3」データの平均値を算出し、「h4」データの平均値を算出して、これら「h1、h2、h3、h4」の平均値を辞書テーブル106の「第一高周波」フィールドに格納する。
同様に、「第二高周波」フィールドに格納される「v1」データの平均値を算出し、「v2」データの平均値を算出し、「v3」データの平均値を算出し、「v4」データの平均値を算出して、これら「v1、v2、v3、v4」の平均値を辞書テーブル106の「第二高周波」フィールドに格納する。
同様に、「第三高周波」フィールドに格納される「d1」データの平均値を算出し、「d2」データの平均値を算出し、「d3」データの平均値を算出し、「d4」データの平均値を算出して、これら「d1、d2、d3、d4」の平均値を辞書テーブル106の「第三高周波」フィールドに格納する。
こうして、図6(g)に示すように、平均値である「第一主成分」フィールドと、平均値である「第二主成分」フィールドと、平均値の集合である「第一高周波」フィールドと、平均値の集合である「第二高周波」フィールドと、平均値の集合である「第三高周波」フィールドよりなる、辞書テーブルのレコードが作成される。
【0036】
図7(a)、(b)及び(c)と、図8(d)は、分割ビットマップ501と分解ビットマップ502との関係を示す概略図である。図7及び図8では、一例としてk=2、l=4、m=3、n=2として説明する。
図7(a)に示すように、分割ビットマップ501は、縦が2×3=6ピクセル、横が2×4=8ピクセルの、合計48ピクセルで構成される。
分解ビットマップ502は、縦(=m)が3ピクセル、横(=n)が2ピクセルの、合計6ピクセルで構成される。分解ビットマップ502は(x、y、z、w、u、t)というピクセルで構成される。
この分解ビットマップ502は、図7(b)に示すように、MPウェーブレット変換部203によって、縦(=m)が3個、横(=n)が2個の、合計6個の変換ビットマップ503に変換される。変換ビットマップ503の数は分解ビットマップ502の数と等しい。図7(a)の場合、分解ビットマップ502が8個あるので、図7(c)に示すように変換ビットマップ503は8個生成される。
次に、図8(d)に示すように、並べ替え処理部204は、変換ビットマップ503の同じ位置に配置されているデータを集めて、インデックス、第一高周波、第二高周波、第三高周波、第四高周波、及び第五高周波を作成する。これらのデータは、縦2個(=k)、横4個(=l)の要素で構成され、6個(=m×n)形成される。
【0037】
[辞書作成装置109:辞書テーブル106の構成]
図9は、辞書テーブル106の構成を示す概略図である。
辞書テーブル106のフィールド構成は図6(g)に示したように、平均値である「第一主成分」フィールドと、平均値である「第二主成分」フィールドと、平均値の集合である「第一高周波」フィールドと、平均値の集合である「第二高周波」フィールドと、平均値の集合である「第三高周波」フィールドよりなる。
今、「第一主成分」フィールドの値をf(i)(iは1以上且つ辞書テーブル106の全レコード数までの自然数)とし、「第二主成分」フィールドの値をgi(j)(jは1以上の自然数)とすると、辞書テーブル106には「第一主成分」フィールドの値f(i)が等しい複数のレコードが存在する。そして、それらのレコードは「第二主成分」フィールドの値でユニークである(一意性を有する)。
「第一主成分」フィールドの値と、「第二主成分」フィールドの値は、後述する超解像画像処理装置101がツリー検索を実行するための検索キーである。
【0038】
[超解像画像処理装置101:全体構成]
図10は、超解像画像処理装置101の機能ブロック図である。
デジタルカメラ102や、不揮発性ストレージに格納されている画像ファイル103等から得られる入力画像データ104は、インデックス作成部1001に供給される。インデックス作成部1001は、入力画像データ104から縦mピクセル×横nピクセルのインデックスビットマップを生成する。このインデックスビットマップは、辞書テーブル106の仕様に合わせて作られる。例えば、図5及び図6の例の場合、2×2=4ピクセルのインデックスビットマップをつくることとなる。インデックス作成部1001は、2×2=4ピクセルのインデックスビットマップを、入力画像データ104から横に2ピクセルずつ、縦に2ピクセルずつずらしながら連続的に作成する。
なお、周知のBMP、JPEG、GIF或はPNG等、所定の圧縮処理を含むものもある、複数の異なるフォーマットの画像データを図示しないRAM内にビットマップとして展開する処理は、このインデックス作成部1001に含まれるものとする。
【0039】
インデックス作成部1001が作成するインデックスビットマップは、内積演算部206によって、第一主成分基底ベクトル107と、第二主成分基底ベクトル108と、夫々に内積演算が行われる。この結果、インデックスビットマップから第一主成分と第二主成分が算出される。
ここで、インデックスビットマップは縦mピクセル×横nピクセル(本例の場合は4ピクセル)の「行列データ」であるのに対し、第一主成分及び第二主成分は夫々「スカラ値」である。この、行列データをスカラ値に変換することが、本実施形態の超解像画像処理装置101における大きな特色の一つであり、高速動作のために必要な技術である。
【0040】
内積演算部206によって算出された第一主成分及び第二主成分は、比較部1002に入力される。比較部1002は、辞書テーブル106の「第一主成分」フィールドと「第二主成分」フィールドを見てツリー検索を行い、内積演算部206によって算出された第一主成分及び第二主成分に最も近いレコードを見つける。そして、見つけたレコードに含まれている「第一高周波」フィールド、「第二高周波」フィールド及び「第三高周波」フィールドのデータを、インデックス作成部1001が作成したインデックスと共にマッピング処理部1003に引き渡す。
マッピング処理部1003は、内積演算部206から引き渡されたインデックス、第一高周波、第二高周波及び第三高周波のデータを並べ替えて、図示しないRAM内に配置する。配置は、図5(d)に示すように、インデックス、第一高周波、第二高周波及び第三高周波の同じ配置のデータを一つの組とする。
図5(d)の場合、インデックスの第一番目のデータ、第一高周波の第一番目のデータ、第二高周波の第一番目のデータ及び第三高周波の第一番目のデータを一つの組にする。
同様に、インデックスの第二番目のデータ、第一高周波の第二番目のデータ、第二高周波の第二番目のデータ及び第三高周波の第二番目のデータを一つの組にする。
同様に、インデックスの第三番目のデータ、第一高周波の第三番目のデータ、第二高周波の第三番目のデータ及び第三高周波の第三番目のデータを一つの組にする。
同様に、インデックスの第四番目のデータ、第一高周波の第四番目のデータ、第二高周波の第四番目のデータ及び第三高周波の第四番目のデータを一つの組にする。
【0041】
こうして組にされたデータは、超解像ビットマップ生成部ともいえるMPウェーブレット逆変換部1004によってMPウェーブレット逆変換演算処理が施され、インデックスビットマップのk×l倍のピクセル数である(本実施形態の場合は4×2×2=16ピクセル)超解像ビットマップが生成される。
今、変換ビットマップ503が「a、h、v、d」というピクセルで構成されている場合、MPウェーブレット逆変換は、以下の(2)式で分解ビットマップ502に逆変換する。
【0042】
x=a+max(−d,−h,−v,0)
y=a+max(h−v,h−d,h,0)
z=a+max(v−h,v−d,v,0)
w=a+max(d−h,d−v,d,0) (2)
【0043】
こうして、インデックス作成部1001が入力画像データ104から生成するインデックスビットマップは、MPウェーブレット逆変換部1004から順次超解像ビットマップに変換され、最終的に入力画像データ104のk×l倍のピクセル数である出力画像データ105である超解像画像ファイル1005が生成される。
【0044】
[超解像画像処理装置101:フローチャート]
図11は、超解像画像処理装置101による超解像画像処理のフローチャートである。
処理を開始すると(S1101)、インデックス作成部1001は、入力画像データ104を図示しないRAM内にビットマップ展開した後、そのビットマップの最初のアドレスを注目する(S1102)。
【0045】
これ以降はループである。
インデックス作成部1001は、現在注目しているRAM内のアドレスから、インデックスビットマップを作成する(S1103)。
作成したインデックスビットマップは、辞書検索及びMPウェーブレット逆変換処理が施される(S1104)。
そして、現在処理を終えたインデックスビットマップは、入力画像データ104のビットマップの、処理すべき最後のアドレスのものなのか否かを確認する(S1105)。未だ処理対象とすべきインデックスビットマップが存在するのであれば(S1105のNO)、入力画像データ104のビットマップの、次のアドレスに移動して(S1106)、再びステップS1103から処理を繰り返す。
ステップS1105において、処理対象とすべきインデックスビットマップが存在しないのであれば(S1105のYES)、一連の処理を終了する(S1107)。
【0046】
図12及び図13は、辞書作成装置109による辞書検索及びMPウェーブレット逆変換処理のフローチャートである。図11のステップS1104の処理の詳細である。
処理を開始すると(S1201)、内積演算部206は、インデックス作成部1001から引き渡されたインデックスビットマップを、第一主成分基底ベクトル107と内積演算を行い、第一主成分を算出する。同様に、インデックスビットマップを、第二主成分基底ベクトル108と内積演算を行い、第二主成分を算出する(S1202)。
【0047】
次に、比較部1002は内積演算部206から引き渡された第一主成分と、辞書テーブル106の第一主成分フィールドの値との比較を行う。
先ず、比較部1002は辞書テーブル106のレコードを第一主成分フィールドでグルーピングして、更にソートした上で、第一主成分フィールドの最小値のグループを注目する(S1203)。
【0048】
これ以降はループである。
比較部1002は辞書テーブル106の現在注目しているグループにおける第一主成分フィールドの値と、内積演算部206から引き渡された第一主成分との距離(以下「現在距離」)を算出する。
次に、比較部1002は辞書テーブル106の現在注目しているグループの、隣のグループにおける第一主成分フィールドの値と、内積演算部206から引き渡された第一主成分との距離(以下「隣接距離」)を算出する(S1204)。そして、算出した距離同士を比較する(S1205)。
現在距離が隣接距離より大きい値である場合(S1205のNO)は、比較対象とする辞書テーブル106のグループを次のグループに移動して(S1206)、再びステップS1204から繰り返す。
現在距離が隣接距離以下の値になった場合(S1205のYES)は、現在注目している第一主成分のグループを選択する(S1207)。
【0049】
図13を参照して、引き続きフローチャートの説明を続ける。
比較部1002は、ステップS1207で選択した、辞書テーブル106の第一主成分のグループに対し、内積演算部206から引き渡された第二主成分を用いて更に絞り込みを行う。
つまり、内積演算部206から引き渡された第二主成分と、ステップS1207で選択した辞書テーブル106における第一主成分のグループに属するレコードの、第二主成分フィールドの値との比較を行う。
先ず、比較部1002はステップS1207で選択した辞書テーブル106における第一主成分のグループに属する辞書テーブル106のレコードを第二主成分フィールドでソートした上で、第二主成分フィールドの最小値のレコードを注目する(S1308)。
【0050】
これ以降はループである。
比較部1002は辞書テーブル106の現在注目しているレコードにおける第二主成分フィールドの値と、内積演算部206から引き渡された第二主成分との距離(以下「現在距離」)を算出する。
次に、比較部1002は辞書テーブル106の現在注目しているレコードの、次のレコードにおける第二主成分フィールドの値と、内積演算部206から引き渡された第二主成分との距離(以下「隣接距離」)を算出する(S1309)。そして、算出した距離同士を比較する(S1310)。
現在距離が隣接距離より大きい値である場合(S1310のNO)は、比較対象とする辞書テーブル106のレコードを次のレコードに移動して(S1311)、再びステップS1309から繰り返す。
現在距離が隣接距離以下の値になった場合(S1310のYES)は、現在注目している第二主成分のレコードに属する、第一高周波フィールド、第二高周波フィールド及び第三高周波フィールドの値を選択する(S1312)。
【0051】
比較部1002の絞込み検索によって選択された第一高周波、第二高周波及び第三高周波のデータはマッピング処理部1003に引き渡される。マッピング処理部1003は、インデックスと共に第一高周波、第二高周波及び第三高周波のデータを並べ替える(S1313)。
並べ替えられたデータはMPウェーブレット逆変換処理部に引き渡される。
MPウェーブレット逆変換処理部は並べ替えられたデータにMPウェーブレット逆変換処理を施し、超解像ビットマップを出力して(S1314)、一連の処理を終了する(S1315)。
【0052】
[超解像画像処理装置101:辞書テーブル106のツリー検索]
図14(a)、(b)及び(c)は、比較部1002が実行する、辞書テーブル106のツリー検索の仕組みを示す概略図である。
内積演算部206によって算出されたインデックスビットマップの第一主成分と第二主成分が、それぞれ(P,Q)であるとする。
第一主成分Pは、辞書テーブル106の第一主成分フィールドの値f(i)との距離、すなわち|P−f(i)|が算出される。iは1番目から順にインクリメントされ、第一主成分Pとの距離が算出されると共に、直前の距離と比較され、直前の距離が短い場合に、その直前の第一主成分フィールドのグループが採用される。
図14(b)及び(c)は、横軸が第一主成分の数直線である。第一主成分Pがf(i)に最も近く、且つf(i)より大きな値である場合、第一主成分Pがf(i)に最も近く、且つf(i)より小さな値である場合の、いずれの場合であっても、以下の式(2)が成り立つ。
【0053】
|P−f(i−1)|>|P−f(i)|
|P−f(i)|≦|P−f(i+1)| (2)
【0054】
図14(b)の場合、距離D1402を直前の距離D1401と比較すると、D1401>D1402という関係である。次に、距離D1403を直前の距離D1402と比較すると、D1402<D1403という関係であり、現在注目している距離と直前の距離との大小関係が反転する。
図14(c)の場合、距離D1405を直前の距離D1404と比較すると、D1404>D1405という関係である。次に、距離D1406を直前の距離D1405と比較すると、D1405<D1406という関係であり、現在注目している距離と直前の距離との大小関係が反転する。
このように、第一主成分Pに対し、辞書テーブル106の第一主成分フィールドの値f(i)を最小値から上げていく(iを0からインクリメントする)と、第一主成分Pとの大小関係が途中で変わる。この時点の辞書テーブル106の第一主成分フィールドの値f(i)が、第一主成分Pに最も近い距離のグループである。
【0055】
[辞書作成装置109及び超解像画像処理装置101の仕組み]
画像を微視的に観察すると、画像の種類に応じて、隣接するビットマップにはある種の相関性が見受けられる。そこで、微視的にビットマップを抜き出して、その相関性に基づいてビットマップを補完することで、失われた高周波成分を類推することができる。相関性を有する、ということは、ビットマップの補完に用いるデータを辞書テーブル106にして検索をかけることで実現できることを意味する。更に、相関性を有する、ということは、相関性の類似する同一のカテゴリやグループに属するパターンが多いことを示している。
発明者は、MPウェーブレット逆変換処理に辞書を用いて超解像画像処理を実現することを最初に思いついた。予め、辞書に極小なビットマップのパターンと、これに対応する、補完用ビットマップパターンを組にして保持しておく。そして、入力画像データ104から極小なビットマップを抜き出して辞書検索を行い、検索にヒットした補完用ビットマップパターンを用いて、超解像画像処理を実現する。
【0056】
入力画像データ104から作成される極小なビットマップの数は膨大なものとなり、その数はそのまま辞書に対する検索と超解像画像処理の回数となる。したがって、辞書アクセス及び超解像画像処理に要する時間は極力短いことが望ましい。
発明者は、超解像画像処理に要する時間を短縮するために、MPウェーブレット変換を開発した。
そして発明者は今般、超解像画像処理に用いる辞書アクセスに要する時間を短縮するために、主成分分析を用いた辞書の最適化を開発した。
【0057】
説明を簡単にするため、図5及び図6を例にして説明する。
辞書のレコード数を低減する最も素朴な方法としては、クラスタリングが挙げられる。インデックス、第一高周波、第二高周波及び第三高周波の数値パターンが類似するレコードを複数集めて、各々の平均値を取る。しかし、この場合、インデックスに含まれるデータは4個の要素を持つ行列である。複数の要素を持ち、それぞれの要素に重み付けがない場合、検索速度の向上は期待できない。また、クラスタリングの場合、インデックスに含まれる要素数が多くなればなるほど、指数関数的に検索速度が遅くなることが容易に想像できる。
【0058】
前述の検索速度の問題に関し、発明者は、多次元のデータをより少ない次元のデータに置き換える主成分分析が有効であることに気が付いた。主成分分析を用いれば、どれほど要素数の多い行列データの集合であっても、第一主成分及び第二主成分というスカラ値で表現することができる。なお、必要であれば第三主成分以降も設けることができる。
【0059】
主成分分析は、多次元の行列データの集合に対して重心を算出した後、その重心を通過して全ての行列データが最も大きく散らばる軸、すなわち分散が最大になる軸を第一主成分軸として算出する。なお、実際に算出するものは第一主成分軸の基底ベクトルである。この第一主成分基底ベクトル107に、目的となる行列とを内積演算すると、第一主成分軸上における重心からの距離を算出できる。
そして更に、重心を通過し、第一主成分軸と直交し、且つ分散が最大になる軸を第二主成分軸として算出する。これも実際に算出するものは第二主成分軸の基底ベクトルである。この第二主成分基底ベクトル108も、目的となる行列とを内積演算すると、第二主成分軸上における重心からの距離を算出できる。
【0060】
実際に画像データのビットマップに主成分分析を行うと、第一主成分軸及び第二主成分軸上のそれぞれに、データが密集する箇所が幾つか発生する。これは、画像データの性質に基づく傾向で、類似するビットマップが頻出するところである。このように、ばらつき具合に特徴ある傾向を示すデータ群に対し、主成分軸上で均等な数によるグルーピングを行う。そして、グルーピングを行った結果、同じグループに属するデータ群に対し、平均値を算出して、そのグループの代表値とする。
第一主成分軸と第二主成分軸は直交関係にあるので、最初に第一主成分で検索してレコードの絞り込みを行い、次に同じ第一主成分に属する複数のレコードに対して第二主成分で更に絞り込みを行う。これは周知のツリー検索であり、辞書に対するアクセス回数を効果的に低減する方法である。
【0061】
本実施形態は、以下のような応用例が考えられる。
(1)上述の実施形態では、白黒の静止画を対象とする装置を説明したが、超解像画像処理装置101の入力画像データ104(ソース)は動画像であってもよい。この場合、インデックスビットマップは時間軸を考慮したものとなる。例えば、時間軸上で隣り合う2枚の画像を対象にして、縦2ピクセル×横2ピクセル×2サンプル数=8ピクセルをインデックスとし、第一高周波、第二高周波及び第三高周波を生成する。
【0062】
(2)上述の実施形態では、白黒の静止画を対象とする装置を説明したが、超解像画像処理装置101の入力画像データ104(ソース)はカラー画像であってもよい。この場合、インデックスビットマップは三原色を考慮したものとなる。つまり、各々のビットマップを構成するピクセルの個数が単純に三倍になる。
勿論、扱う画像はカラーの動画像であってもよい。
【0063】
(3)例えば、アニメーションやコンピュータグラフィックス等の別の映像に実写の人物を合成する、周知のクロマキー合成によって生成される画像データの場合、一つの画像データ内に複数の全く異なる特徴を備えた部分が混在することとなる。このような画像データの場合は、予め異なる特徴の画像部分とを切り分けて、夫々に適した辞書テーブル等を用いて超解像画像処理を施すことが望ましい。
【0064】
(4)周知のように、主成分分析では、主成分分析の対象となる行列の要素数が膨大で、第一主成分軸と第二主成分軸だけでは集合の絞り込みを良好に実施できない場合に、第一主成分軸及び第二主成分軸の双方に直交し、最も分散が大きい第三主成分軸を算出することが行われる。そして、主成分軸は第四、第五…と、その用途に応じて増やすことも可能である。これは本実施形態の超解像画像処理装置101及び辞書作成装置109にも同じことが言える。つまり、辞書テーブル等に含まれる主成分軸の基底ベクトルは、必ずしも第一主成分軸と第二主成分軸だけではなく、必要に応じて第三主成分軸を含めることができる。そして、その際、辞書テーブル106にもこれに応じて「第三主成分」フィールド等が追加されることとなる。
【0065】
(5)本実施形態の辞書作成装置109では、並べ替え処理部204という処理手順を設けているが、これは説明の便宜上、データの扱いを理解し易くするために明示的に記述した処理内容である。実際の装置では、このような実データのコピーを行わずとも、周知のポインタ操作で同等の処理をより高速に実現できる。
同様のことは、超解像画像処理装置101のマッピング処理部1003にも当てはまる。
【0066】
本実施形態においては、超解像画像処理装置101と、これに用いる辞書作成装置109を開示した。
汎用性の高い超解像画像処理を短時間に実行するため、本実施形態の超解像画像処理装置101は、先ず、処理対象とする画像をシーンに分けた。そして、シーンに適合する辞書テーブル106を用いて、失われた高周波成分を辞書に対するツリー検索にて類推した。
そして、辞書テーブル106の検索を高速化するため、主成分分析を用いて、検索キーとなるインデックスビットマップをスカラ値である第一主成分及び第二主成分に変換すると共に、第一主成分と第二主成分とでグルーピングを施し、その平均値を算出することで、辞書テーブル106の必要レコード数を大幅に低減することに成功した。
これらの技術の採用により、少ない計算量で高速に実行できる、汎用性が高く実用的な超解像画像処理装置101を実現できる。
【0067】
以上、本発明の実施形態例について説明したが、本発明は上記実施形態例に限定されるものではなく、特許請求の範囲に記載した本発明の要旨を逸脱しない限りにおいて、他の変形例、応用例を含む。
【符号の説明】
【0068】
101…超解像画像処理装置、102…デジタルカメラ、103…画像ファイル、104…入力画像データ、105…出力画像データ、106…辞書テーブル、107…第一主成分基底ベクトル、108…第二主成分基底ベクトル、109…辞書作成装置、110…サンプル画像ファイル、201…分解処理部、202…一時テーブル、203…MPウェーブレット変換部、204…処理部、205…主成分分析処理部、206…内積演算部、207…頻度分割処理部、208…平均値演算部、501…分割ビットマップ、502…分解ビットマップ、503…変換ビットマップ、1001…インデックス作成部、1002…比較部、1003…マッピング処理部、1004…MPウェーブレット逆変換部、1005…超解像画像ファイル
【特許請求の範囲】
【請求項1】
入力画像データから所定数のピクセルよりなるインデックスビットマップを生成するインデックス作成部と、
前記インデックスビットマップに対して、第一主成分基底ベクトルとの内積を演算して第一主成分を算出し、第一主成分基底ベクトルとの内積を演算して第二主成分を算出する内積演算部と、
前記第一主成分及び前記第二主成分を用いて辞書テーブルを検索し、前記第一主成分及び前記第二主成分に最も近いレコードを得る比較部と、
前記レコードに含まれている高周波成分と前記インデックスビットマップを用いて超解像ビットマップを算出する超解像ビットマップ生成部と
を具備する超解像画像処理装置。
【請求項2】
前記比較部は、前記辞書テーブルを前記第一主成分で絞り込み検索した後、前記第二主成分でレコードを特定する、
請求項1記載の超解像画像処理装置。
【請求項3】
一時テーブルと、
サンプル画像ファイルから所定のアドレスのピクセルを含む一つの範囲に含まれる複数のピクセルを分割ビットマップとして取り出した後、前記分割ビットマップを四以上の数の領域である分解ビットマップとして等分して、複数の前記分解ビットマップをそれぞれ前記一時テーブルの分解ビットマップ格納フィールド群に格納する分解処理部と、
前記分解ビットマップ格納フィールド群に格納されている複数の前記分解ビットマップに対して所定の代数変換処理を施して、得られた演算結果である変換ビットマップをそれぞれ前記一時テーブルの変換ビットマップ格納フィールド群に格納する代数変換処理部と、
前記変換ビットマップ格納フィールド群に格納されている複数の前記変換ビットマップからインデックスとなるデータ列に対して主成分分析を実行して、超解像画像処理装置に用いる第一主成分基底ベクトルと第二主成分基底ベクトルを算出する主成分分析処理部と、
前記一時テーブルの各レコードの前記インデックスと前記第一主成分基底ベクトルを内積演算して前記インデックスの第一主成分を算出して前記一時テーブルの第一主成分フィールドに格納すると共に、前記インデックスと前記第二主成分基底ベクトルを内積演算して前記インデックスの第二主成分を算出して前記一時テーブルの第二主成分フィールドに格納する内積演算部と、
前記一時テーブルのレコードを前記第一主成分フィールドの値及び前記第二主成分フィールドの値でグルーピングする頻度分割処理部と、
前記頻度分割処理部によってグルーピングされた前記一時テーブルの複数のレコードに含まれる各スカラ値に対して平均値を算出して、前記超解像画像処理装置に用いる辞書テーブルを作成する平均値演算部と
を具備する超解像画像処理用辞書作成装置。
【請求項1】
入力画像データから所定数のピクセルよりなるインデックスビットマップを生成するインデックス作成部と、
前記インデックスビットマップに対して、第一主成分基底ベクトルとの内積を演算して第一主成分を算出し、第一主成分基底ベクトルとの内積を演算して第二主成分を算出する内積演算部と、
前記第一主成分及び前記第二主成分を用いて辞書テーブルを検索し、前記第一主成分及び前記第二主成分に最も近いレコードを得る比較部と、
前記レコードに含まれている高周波成分と前記インデックスビットマップを用いて超解像ビットマップを算出する超解像ビットマップ生成部と
を具備する超解像画像処理装置。
【請求項2】
前記比較部は、前記辞書テーブルを前記第一主成分で絞り込み検索した後、前記第二主成分でレコードを特定する、
請求項1記載の超解像画像処理装置。
【請求項3】
一時テーブルと、
サンプル画像ファイルから所定のアドレスのピクセルを含む一つの範囲に含まれる複数のピクセルを分割ビットマップとして取り出した後、前記分割ビットマップを四以上の数の領域である分解ビットマップとして等分して、複数の前記分解ビットマップをそれぞれ前記一時テーブルの分解ビットマップ格納フィールド群に格納する分解処理部と、
前記分解ビットマップ格納フィールド群に格納されている複数の前記分解ビットマップに対して所定の代数変換処理を施して、得られた演算結果である変換ビットマップをそれぞれ前記一時テーブルの変換ビットマップ格納フィールド群に格納する代数変換処理部と、
前記変換ビットマップ格納フィールド群に格納されている複数の前記変換ビットマップからインデックスとなるデータ列に対して主成分分析を実行して、超解像画像処理装置に用いる第一主成分基底ベクトルと第二主成分基底ベクトルを算出する主成分分析処理部と、
前記一時テーブルの各レコードの前記インデックスと前記第一主成分基底ベクトルを内積演算して前記インデックスの第一主成分を算出して前記一時テーブルの第一主成分フィールドに格納すると共に、前記インデックスと前記第二主成分基底ベクトルを内積演算して前記インデックスの第二主成分を算出して前記一時テーブルの第二主成分フィールドに格納する内積演算部と、
前記一時テーブルのレコードを前記第一主成分フィールドの値及び前記第二主成分フィールドの値でグルーピングする頻度分割処理部と、
前記頻度分割処理部によってグルーピングされた前記一時テーブルの複数のレコードに含まれる各スカラ値に対して平均値を算出して、前記超解像画像処理装置に用いる辞書テーブルを作成する平均値演算部と
を具備する超解像画像処理用辞書作成装置。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】

【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【公開番号】特開2013−26659(P2013−26659A)
【公開日】平成25年2月4日(2013.2.4)
【国際特許分類】
【出願番号】特願2011−156515(P2011−156515)
【出願日】平成23年7月15日(2011.7.15)
【出願人】(504171134)国立大学法人 筑波大学 (510)
【Fターム(参考)】
【公開日】平成25年2月4日(2013.2.4)
【国際特許分類】
【出願日】平成23年7月15日(2011.7.15)
【出願人】(504171134)国立大学法人 筑波大学 (510)
【Fターム(参考)】
[ Back to top ]