
車室内音声対話装置
【課題】自動車の走行の安全性を損なわずに、短時間でユーザに情報を提供する。
【解決手段】自動車内における乗員の乗車位置を検知する乗員検知部と、テキスト情報を音声に変換して出力する音声出力部と、前記テキスト情報を画像に変換して表示する画像表示部と、前記乗員検知部の検知結果に基づいて、前記音声出力部又は前記画像表示部のいずれか一方を選択し、前記選択された前記音声出力部又は前記画像表示部に前記テキスト情報を出力させる切り替え部と、を備える。
【解決手段】自動車内における乗員の乗車位置を検知する乗員検知部と、テキスト情報を音声に変換して出力する音声出力部と、前記テキスト情報を画像に変換して表示する画像表示部と、前記乗員検知部の検知結果に基づいて、前記音声出力部又は前記画像表示部のいずれか一方を選択し、前記選択された前記音声出力部又は前記画像表示部に前記テキスト情報を出力させる切り替え部と、を備える。
【発明の詳細な説明】
【技術分野】
【0001】
本願明細書で開示される技術は、車室内に搭載される音声対話装置に関する。
【背景技術】
【0002】
自動車に搭載されるカーナビゲーションシステムには、音声対話機能を備えるものが広く使われている(例えば特許文献1参照)。従来、音声対話機能を実現するために必要な音声認識技術及び音声合成技術が広く検討されている。音声認識技術は、マイクロホンを通して入力された音声波形をテキスト化する技術である。音声合成技術は、テキストから音声波形を生成する技術である。音声認識技術と音声合成技術を組み合わせることで、カーナビゲーションシステムがユーザと音声で会話することが可能となる。また、車室内で録音した音声波形には様々な騒音が重畳するため、音声認識率が大幅に劣化するという問題がある。この問題に対して、複数のマイクロホン素子を有するマイクロホンアレイを用いて騒音を抑圧し、所望の音声のみを抽出する音源分離技術が広く検討されている。
【特許文献1】特開2004−109323号公報
【発明の開示】
【発明が解決しようとする課題】
【0003】
従来のカーナビゲーションシステムでは、ドライバが発話することを前提に作られているため、受理する音声認識辞書の内容を全て音声合成で読み上げるような構成になっていた。しかし、選択肢を全て読み上げるのにかかる時間が長いため、音声対話が終了するまでの時間が長くなってしまうという課題があった。一方、選択肢は、読み上げられる代わりにディスプレイに表示されてもよい。しかし、ディスプレイに選択肢を表示する方法は、音声対話が終了するまでの時間が短いという利点はあるものの、ドライバが音声対話を行う場合に使用することは好ましくない。自動車を運転中のドライバがディスプレイを目視することによって安全性が損なわれるためである。
【課題を解決するための手段】
【0004】
本願で開示する代表的な発明は、自動車内における乗員の乗車位置を検知する乗員検知部と、テキスト情報を音声に変換して出力する音声出力部と、前記テキスト情報を画像に変換して表示する画像表示部と、前記乗員検知部の検知結果に基づいて、前記音声出力部又は前記画像表示部のいずれか一方を選択し、前記選択された前記音声出力部又は前記画像表示部に前記テキスト情報を出力させる切り替え部と、を備えることを特徴とする。
【発明の効果】
【0005】
本発明の一実施形態によれば、選択肢提示手段判定部によって、車内にドライバのみが存在するか否かが判定され、その判定の結果にしたがって最適な提示手段が選択される。例えば、ドライバのみ存在する場合は、音声合成によって音声認識辞書の内容が読み上げられ、ドライバ以外の同乗者が存在する場合は、タスク時間短縮化のため、同乗者が回答するよう誘導した後、ディスプレイ上に選択肢が表示される。これによって、安全性を損なうことなく、タスク時間の短い音声対話が実現し、迅速なカーナビゲーションシステムの操作が可能となる。
【発明を実施するための最良の形態】
【0006】
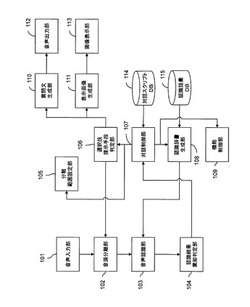
図1は、本発明の第1の実施形態の音声対話装置の機能ブロック図である。
【0007】
本実施形態の音声対話装置は、例えば、自動車に搭載されるカーナビゲーションシステムのアプリケーションとして使われることが想定される。以下、この想定の下、実施形態を説明する。なお、自動車には、一人の運転者(ドライバ)を含む一人以上のユーザが乗車する。
【0008】
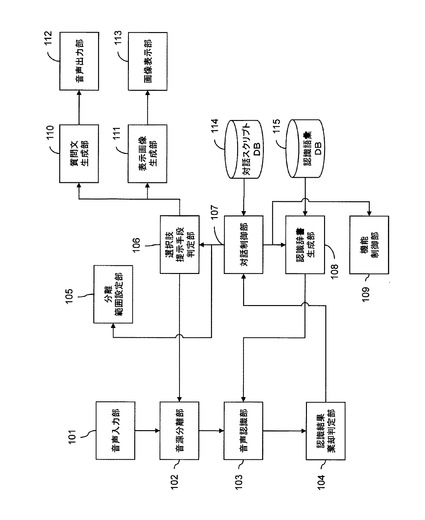
図2は、本発明の第1の実施形態の音声対話装置のハードウェア構成のブロック図である。
【0009】
本実施形態のシステムは、少なくとも二つ以上のマイクロホン素子からなるマイクロホンアレイ1201を備える。マイクロホンアレイ1201は、それぞれのマイクロホン素子位置における音圧レベルを計測する。
【0010】
マイクロホンアレイ1201によって計測されたアナログの音圧値は、AD変換装置1202でサンプリングされ、デジタルデータに変換される。AD変換装置1202は、アナログのローパスフィルタ(図示省略)などを用いて、サンプリングレートの0.5倍以上の周波数成分を除去した後の音圧値をサンプリングしてもよい。
【0011】
サンプリングされたデジタル音圧データは、中央演算装置1203に送られる。中央演算装置1203では、デジタル音圧データ中の音源方向の推定、位相差の補正及び音声認識や対話処理といったプログラムを実行する。
【0012】
中央演算装置1203によって実行されるプログラムは、データとして記憶媒体1205に記憶される。
【0013】
プログラム実行時に必要な一時的なデータは、揮発性メモリ1204又は記憶媒体1205に記憶されてもよい。その他、プログラム実行に必要な事前データは、記憶媒体1205に事前に記憶される。記憶媒体1205は、例えば、ハードディスクドライブ(HDD)又はフラッシュメモリのような大容量の不揮発性記憶媒体である。一方、揮発性メモリ1204は、例えば、ダイナミックランダムアクセスメモリ(DRAM)のような高速な記憶装置である。
【0014】
例えば、図1に示す対話スクリプトデータベース(DB)114及び認識語彙DB115は、記憶媒体1205に格納される。図1に示す上記のデータベース以外の各部は、記憶媒体1205に格納されたプログラムを中央演算装置1203が実行することによって実現される。ただし、音声入力部101は、AD変換装置1202によって実現されてもよい。上記のデータベース及びプログラムは、記憶媒体1205に格納され、必要に応じてそれらの全部又は一部が揮発性メモリ1204にコピーされてもよい。
【0015】
マイクロホンで受音したアナログ音声は、音声入力部101において、デジタル音声に変換される。変換されたデジタル音声は音源分離部102に送られる。音源分離部102において、デジタル音声中に含まれる雑音成分が除去され、所望の音声を強調した信号が得られる。所望の音声か否かは、音源方向の情報から判断される。例えば、所望の音声が自動車を運転するドライバである場合は、マイクロホンから見たドライバの相対方向が所望の音源方向として設定され、その所望の音源方向から到来する音声が所望の音声と判断される。
【0016】
所望の音源方向は分離範囲設定部105によって設定される。分離範囲設定部105は、対話制御部107の出力結果に基づき、所望の音源方向を設定する。
【0017】
音源分離部102が取り出した所望の音声成分は、音声認識部103に送られる。音声認識部103は、送られてきた音声波形の発話内容を認識し、文字列に変換したものを出力する。音声認識部103が実行する音声認識処理は、例えば、隠れマルコフモデルに基づくもの、又は、動的計画法に基づくものなど、いかなるものであってもよい。
【0018】
音声認識処理は、入力された音声波形の発話内容が、所与の語彙の中のどの語と最も近いかを判定し、最も近い語を出力する一種のパターンマッチング処理である。音声認識に用いるために予め保持される語彙は、音声認識処理を開始する前に、予め認識辞書生成部108にて作られる。
【0019】
音声認識部103は、さらに、認識結果の尤度を計算する。認識結果の尤度とは、入力された音声波形の発話内容と最も近いと判定された語と、その発話内容と、の近さの度合いを示す尺度である。尤度は、公知の種々の方法によって算出することができる。
【0020】
音声認識部103によって生成される文字列に変換された発話内容(すなわち認識結果)及びその認識結果の尤度は、認識結果棄却判定部104に送られる。認識結果棄却判定部104は、認識結果の尤度の情報に基づいて、認識結果を受理するか棄却するかを判定する。例えば、認識結果の尤度の情報から生成される認識結果の事後確率が閾値を超える場合に受理すると判定されてもよい。一方、事後確率が閾値以下の場合、所与の語彙のいずれとも異なる語が発話されたと推定されるため、認識結果を棄却すると判定されてもよい。
【0021】
認識結果棄却判定部104で受理された認識結果は対話制御部107に送られる。認識結果が棄却された場合は、音声認識処理が続行されてもよい。音声認識処理の開始後、一定時間以内に認識結果が受理されなかった場合、認識結果棄却判定部104は、認識結果が無かったという情報を対話制御部107に送信してもよい。対話制御部107は、その情報に基づき、次の行動を決定してもよい。例えば、対話制御部107は、「もう一度発話してください」と発話を促すガイダンスを出力した後、音声認識処理を再度実行するように各部を制御してもよい。
【0022】
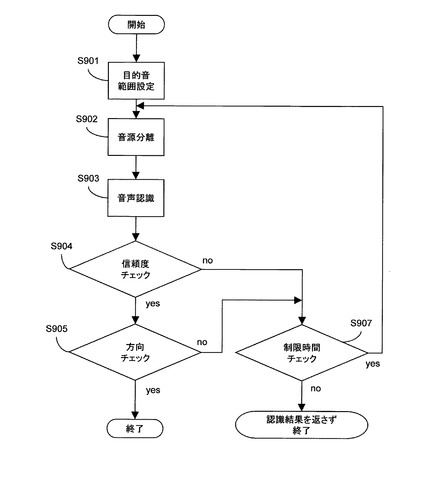
図3は、本発明の第1の実施形態において実行される音声認識処理を示すフローチャートである。
【0023】
具体的には、図3は、音源分離部102、音声認識部103及び認識結果棄却判定部104によって実行される具体的な音声認識処理の流れを示す。
【0024】
目的音範囲設定S901において、音源分離部102は、分離範囲設定部105によって設定された範囲に基づき、目的音の存在範囲を設定する。例えば、方位角と仰角のそれぞれについて目的音の存在範囲が設定される。例えば、方位角が−30度から+30度まで、及び仰角を−90度から90度までと設定されてもよい。
【0025】
音源分離S902において、音源分離部102は、設定された目的音存在範囲の情報に基づき、目的音方向の音を抽出する。
【0026】
音声認識S903において、音声認識部103は、音源分離S902において抽出された目的音方向の音の発話内容を、音声認識辞書及び音のモデルを用いて認識する。
【0027】
信頼度チェックS904において、認識結果棄却判定部104は、音声認識結果の信頼度を示す尺度(例えば、音声認識結果に付随する音響尤度から計算される事後確率など)が予め設定された閾値を上回っているか否かを判定する。信頼度を示す尺度が閾値を上回っている場合、認識された音声は、コマンドを入力するために発話されたものであると推定される。例えば、後述するように選択肢がユーザに提示されると、ユーザがそれに応じて選択肢の一つを発話する。このような発話は、コマンドを入力するための発話の一例である。この場合、処理は方向チェックS905に進む。
【0028】
一方、信頼度を示す尺度が閾値を下回っている場合、認識された音声はコマンドを入力するために発話されたものでない(例えば雑音のような、コマンドとは無関係に入力された音声等である)と推定される。この場合、処理は制限時間チェックS907に進む。
【0029】
方向チェックS905において、認識結果棄却判定部104は、音声認識波形の時間長をTとし、音声認識波形の音源方向を数式(1)によって算出し、その方向が所与の目的音範囲内か否かを判定する。
【0030】
【数1】

【0031】
θ(f,τ)は時間τにおける周波数fの音源方向であり、その算出方法は後述する。fmaxは音声認識波形の最大周波数成分である。
【0032】
音源方向が目的音範囲内であった場合、認識結果棄却判定部104は、認識結果を返して処理を終了する。後述するように、ユーザに対して選択肢が提示された後で図3に示す処理が実行された場合、上記のように返された認識結果は、選択肢の提示に対する応答(すなわち、提示された選択肢の一つを発話したもの)として処理される。
【0033】
音源方向が目的音範囲外であった場合、処理は制限時間チェックS907に進む。制限時間チェックS907において、認識結果棄却判定部104は、音声認識を開始してから経過した時間が所与の制限時間内であるか否かを判定する。経過した時間が所与の制限時間内である場合、処理は音源分離S902に戻り、目的音方向の音の抽出が再度実行される。経過した時間が制限時間を超えている場合、認識結果を返さずに処理が終了する。
【0034】
上記の音源分離S902及び音声認識S903は、音声入力部101が取得するリアルタイムの音声波形に対する処理である。つまり時々刻々入力されてくる新しい音声波形に対して上記の処理が施される。
【0035】
図4は、本発明の第1の実施形態の音源分離部102が実行する詳細な処理の流れを示す説明図である。
【0036】
図4の処理は、音声入力部101が一定量(例えば数十ms程度)の音声データを取得する度に実行される。
【0037】
複数のマイクロホン素子によって収録された音声波形は、マイクロホン素子毎に、DFT1001にて離散フーリエ変換を施される。マイクロホン素子(i)毎の、サンプリング時間(t)の音圧データは数式(2)によって表される。
【0038】
【数2】
【0039】
事前に音声波形のハミング窓又はハニング窓を時間領域の信号に掛け合わせた後、離散フーリエ変換が施されてもよい。ハミング窓又はハニング窓の窓関数を掛け合わせることで、高精度な時間周波数領域の信号を得ることができる。
【0040】
離散フーリエ変換による時間周波数領域信号への変換は数式(3)によって行われる。変換後の信号は、数式(4)によって表される。
【0041】
【数3】
【0042】
【数4】
【0043】
ここでτはフレームインデックスと呼ばれ、時間周波数領域信号への変換した回数と等しくなる。w(n)はハニング窓又はハミング窓の窓関数である。フーリエ変換の際のフレームサイズとする。
【0044】
周波数毎ベクトル化1002において、音源分離部102は、変換後の同じ時間周波数毎領域に属するマイク毎の信号をまとめあげて、数式(5)で定義されるベクトルX(f,τ)を生成する。Mはマイク素子数とする。
【0045】
【数5】
【0046】
音源定位1003において、音源分離部102は、時間周波数毎に、数式(6)で定義されるステアリングベクトルa(θ,f)とX(f,τ)との内積の最大値を与える音源方向θを数式(7)で計算する。cは音速とする。
【0047】
【数6】
【0048】
【数7】
【0049】
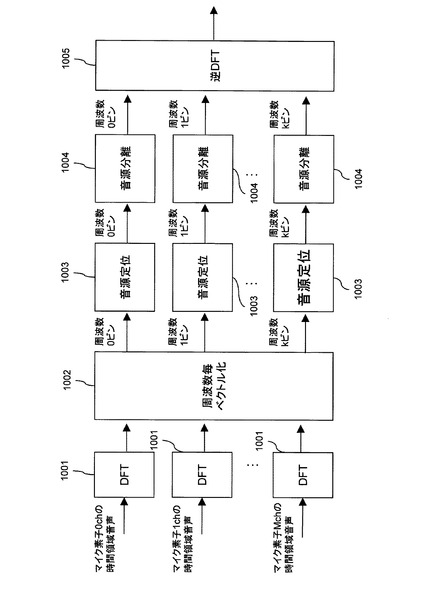
図5は、本発明の第1の実施形態の音源分離1004において時間周波数毎に実行される処理を示すフローチャートである。
【0050】
音源分離部102は、目的音範囲かどうかS1101において、時間周波数毎の音源方向θが所定の目的音範囲内であるか否かを判定する。音源方向θが目的音範囲内であった場合、音源分離部102は、ベクトルn(f,τ)をゼロベクトルに設定し、ベクトルs(f,τ)をX(f,τ)に設定した後、目的音共分散更新S1102に進む。目的音範囲外の場合、音源分離部102は、ベクトルn(f,τ)をX(f,τ)に設定し、雑音共分散更新S1103に進む。
【0051】
目的音共分散更新S1102において、音源分離部102は、ベクトルs(f,τ)を用いて共分散行列Rs(f)を数式(8)のように更新する。
【0052】
【数8】
【0053】
雑音共分散更新S1103において、音源分離部102は、ベクトルn(f,τ)を用いて共分散行列R(f)を数式(9)のように更新する。ここでαは所与の更新レートとする。
【0054】
【数9】
【0055】
音源分離部102は、共分散行列Rs(f)及びR(f)を用いて音源分離フィルタw(f,τ)を数式(10)によって求める。eig_vectorは最大固有値となる固有ベクトルを与える関数とする。
【0056】
【数10】
【0057】
フィルタリングS1105において、音源分離部102は、入力信号X(f,τ)及び音源分離フィルタw(f,τ)から雑音抑圧信号s(f,τ)を数式(11)によって求める。
【0058】
【数11】
【0059】
ポストフィルタリングS1106において、音源分離部102は、雑音抑圧信号s(f,τ)にウィナーフィルタ又はスペクトルサブトラクション処理を施すことによって、残留雑音成分を抑圧する。そして、音源分離部102は、残留雑音抑圧後の時間周波数信号を出力し、処理を終了する。
【0060】
逆DFT1005において、音源分離部102は、求めた周波数毎の雑音抑圧信号に逆離散フーリエ変換を施すことによって、時間領域信号を生成した後、その時間領域信号を出力する。
【0061】
対話制御部107は、対話スクリプトDB114に保持された対話スクリプトに基づき、ユーザとの音声対話を制御する。
【0062】
図6は、本発明の第1の実施形態における対話スクリプトに基づく対話を示すフローチャートである。
【0063】
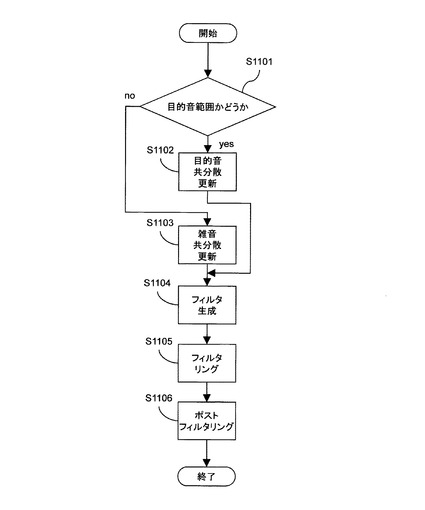
図6に記載の対話フローの例では、ユーザとの対話開始後、まずコマンド名称S301において、対話制御部107は、ユーザが実行したいコマンドの名称を認識する。認識に際し、対話制御部107は、ユーザに対して、「コマンド名称をどうぞ」などの発話を促すガイダンスを出力してもよい。さらに、対話制御部107は、「この中からお選びください」などのコメントとともに画面に表示されるコマンドリストの中から、実行したいコマンドを選ばせてもよいし、コマンドリストの内容を読み上げた音声を、音声合成システムなどを使用して生成し、その音声を出力してもよい。
【0064】
本実施形態において、画面にコマンドリストを表示するか、コマンドリストを読み上げるかは、ユーザの着座情報などに基づいて切り替えられる。この切り替えは、後述する選択肢の提示方法の選択と同様にして実行されてもよい。例えば、ドライバのみ乗車している場合、コマンドリストを読み上げるように制御されてもよい。一方、同乗者(すなわちドライバ以外のユーザ)が自動車内に存在する場合、音声対話に要する時間を短くするために、「同乗者の方、この中からお選びください」などの、同乗者が画面を見て答えることを促すガイダンスを流した後、コマンドリストを画面に表示するように制御されてもよい。これによって、自動車の走行の安全性を確保しながら、素早いコマンド入力が実現される。
【0065】
図6において、コマンド名称S301終了後、認識したコマンド(すなわち、ユーザによってコマンドリストから選択されたコマンド)に応じて処理を切り替える。例えば認識したコマンドが目的地設定であった場合は、次に具体的な目的地を認識する目的地設定S302が実行される。
【0066】
目的地設定S302では、「目的地をおっしゃって下さい」のように目的地をユーザが発話するように促すガイダンスが出力されてもよいし、「目的地をこの中からお選びください」と発話する音声が出力された後、目的地のリストが画面に表示されてもよいし、目的地のリストが読み上げられてもよい。画面に表示される目的地のリストの例については、後で図12を参照して説明する。
【0067】
前述のコマンド名称S301と同様に、同乗者がいるか否かに応じて、安全性を損なわない提示手段のうち、最も目的地設定に要する時間が短くなるような提示手段が選択される。
【0068】
コマンド名称S301において認識されたコマンドが自動車機器操作であった場合、自動車機器操作S303が実行される。自動車機器操作S303において、対話制御部107は、エアコンのOn/Off又は音楽等の制御といった自動車内部機器を操作するためのユーザコマンドを認識する。このとき、対話制御部107は、「操作したい機器名称及び操作内容をおっしゃって下さい」といったガイダンスを音声出力部112に出力させてもよいし、音声コマンドで操作可能なコマンド一覧を画面に表示するように画像表示部113を制御してもよい。前述の目的地設定S302と同様に、最も自動車内部機器操作に要する時間が短くなるような提示手段が選択される。
【0069】
コマンド名称S301において認識されたコマンドが周辺施設検索であった場合、周辺施設検索S304が実行される。周辺施設検索S304において、対話制御部107は、ユーザが所望する周辺施設を検索し、検索された施設を目的地として設定する処理を、音声インタフェースを用いて実行する。具体的には、対話制御部107は、「周辺施設をおっしゃって下さい」といったようにユーザ発話を促すガイダンスを音声出力部112に出力させてもよいし、「この中から選んでください」といったガイダンスを出力させた後、画面に周辺施設のリストを表示し、画面を見ながらユーザが発話するように促してもよい。前述の自動車機器操作S303と同様に、最も自動車内部機器操作に要する時間が短くなるような提示手段が選択される。
【0070】
S302からS304までのいずれかの処理が終了した後、対話制御部107は対話を終了する。
【0071】
以上は、カーナビゲーションシステムにおける対話スクリプトに基づく対話の一例である。対話スクリプトは、条件分岐とシステムの実行コマンドの情報とを保持する形式で記述可能な言語によって記述される限り、どのような形式で記述されてもよい。例えば、Voice XMLのようなXML形式で対話スクリプトが記述されてもよいし、プログラム言語の一種であるスクリプト言語でプログラムコードとして対話スクリプトが記述されてもよい。
【0072】
対話制御部107は、対話スクリプトに基づき、音声認識部103、音源分離部102、音声出力部112及び画像表示部113の動作を制御する。例えば、前述のコマンドリストを認識する対話において、認識辞書生成部108は、音声認識を開始する前に、認識に用いる認識辞書を切り替える。認識辞書生成部108は有限オートマトン形式で記載された音声認識辞書を生成する。
【0073】
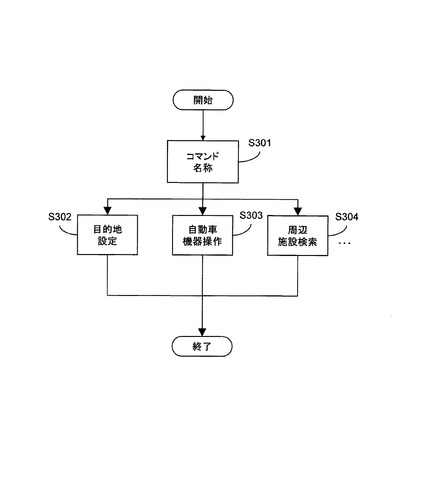
図7は、本発明の第1の実施形態において使用される音声認識辞書の一例を示す説明図である。
【0074】
この例では、6つのノードと6つのアークがネットワーク化された形で認識辞書が表現されている。この例の認識辞書を用いた場合、ユーザ発話は「目的地」と「語尾」とが連続した文、又は、「電話番号」と「語尾」とが連続した文のいずれかであることが仮定される。「目的地」、「語尾」及び「電話番号」は、アークと呼ばれる、複数の単語をまとめて表現したラベルである。各アークは更に単語リストに展開される。
【0075】
図8は、本発明の第1の実施形態におけるアークごとの単語リストの一例を示す説明図である。
【0076】
図8は、「目的地」のアークが展開された単語リストの例を示さす。図8の例では、目的地を示す単語のリストに、「中央研究所」及び「機械研究所」のような施設の固有名詞が含まれる。この他の目的地として、例えば、「レストラン」のような施設の一般名詞が含まれてもよいし(図12参照)、「東京都」のような地名が含まれてもよい。
【0077】
このように各アークは単語リストに展開される。これによって、例えば「目的地」と「語尾」が連続した文の数は、「目的地」の単語リストに含まれる単語の数に「語尾」の単語リストに含まれる単語の数を掛け合わせた数になる。単語リストは認識語彙DB115に蓄えられており、認識辞書に応じて必要な語彙が取り出される。
【0078】
音声認識部103は、各単語を音素毎又は音素片毎に分割し、各音素又は音素片に対応した音のモデルを並べたものをパターンとし、入力音声と最も近いパターンを出力する。音のモデルは、音素又は音素片ごとに、LPCケプストラム、MFCC、それらの差分値(Δ)、それらのΔΔ、又は、パワーの時間差分値など、を特徴量とした混合正規分布で表現される。また特徴量算出時に平均値の減算処理(ケプストラム平均値減算処理)などによって伝達系の歪みを補正してもよい。
【0079】
入力音声と最も近いパターンは、前向き・後ろ向きアルゴリズムに基づく最尤推定において、最大尤度を与える状態遷移パスのみを計算するように近似したビタビアルゴリズムによって算出される。尤度は、入力音声とパターンとの距離に基づいて定義される。音声認識部103は最大尤度を与える状態遷移パスを計算し、その状態遷移パスから単語系列を逆引きする。これによってある一つの文字列が得られ、その文字列が出力される。さらに、最大尤度そのもの、又は、最大尤度を加工することによって得られた事後確率p(O|X)が出力される。ここで、p(O|X)は、入力音声Xを条件とした認識結果Oの事後確率(すなわち、入力音声Xに対する認識結果Oが正しい結果である確率を示す値)である。
【0080】
ユーザ発話は、必ずしも音声認識辞書で表現される文であるとは限らない。また、車室内では所望のユーザ発話以外の走行音などの雑音が存在するため、認識対象の音声が雑音であることも多い。このような場合でも、音声認識部103では入力音声に最も近いパターンを出力するため、出力されたすべての音声認識の結果を確信し受理することは望ましくない。
【0081】
出力された音声認識結果の尤度又は事後確率が所定の閾値より小さい場合、認識対象の音声が雑音であったか又は音声認識辞書で表現される文以外の発話が成された可能性が高いため、そのような音声認識結果は棄却するべきである。認識結果棄却判定部104は、音声認識部103が出力する認識結果の尤度又は事後確率に基づき、認識結果を受理するか棄却するかを判定する(信頼度チェックS904)。さらに、認識結果棄却判定部104は、音声認識を行った波形の音源方向を推定し、その音源方向が所望の音源方向の範囲外(すなわち目的音範囲外)であった場合に、その認識結果を棄却してもよい。
【0082】
一般的に音声認識部103が受理可能な文(テキスト)に関する情報をユーザは事前に知らない。したがって、音声認識開始前に、いかなる文が受理可能であるかをユーザに提示する必要がある。選択肢を提示する方法としては、音声合成技術を用いて受理可能な文の一部を読み上げること、又は、受理可能な文の一部を、カーナビゲーションシステムが備えるディスプレイの画面上に表示すること、などが考えられる。
【0083】
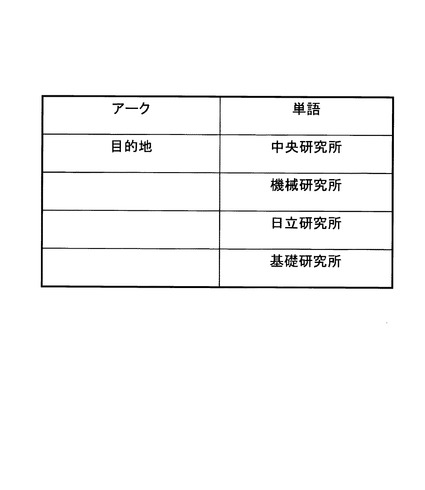
図9は、本発明の第1の実施形態の音声対話装置を含むカーナビゲーションシステムのハードウェア構成のブロック図である。
【0084】
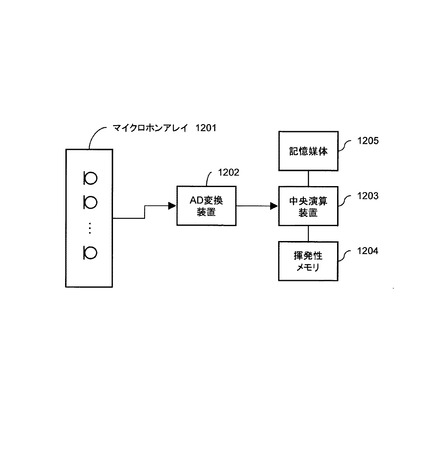
本実施形態のカーナビゲーションシステムは、中央演算装置1603と、その中央演算装置に接続されるスピーカ1601、記憶媒体1602、座席センサ1604、ディスプレイ1605、マイクロホン1606及び速度センサ1607と、を備える。
【0085】
中央演算装置1603は、音声認識及び音源分離などのソフトウェア処理を実行する。
【0086】
記憶媒体1602には、認識辞書などの情報が保持される。
【0087】
ガイダンス音などの再生音は、スピーカ1601から出力される。スピーカ1601は超音波スピーカなどの超指向性スピーカであってもよい。
【0088】
運転席、助手席、後部座席などの各座席に設置された座席センサ1604によって、同乗者が存在するか否かが判定される。座席センサ1604は、各座席にユーザが乗車しているか否かを示す情報を出力するものである限り、例えば、重量センサ又は各座席方向にビームを有する超音波センサ等、いかなる種類のものであってもよい。
【0089】
ディスプレイ1605には、コマンドリストなど認識語彙に関する情報、及び、地図などが表示される。
【0090】
車載の速度センサ1607が取得した、自動車の速度を示す情報は、中央演算装置1603内に取り込まれ、走行状況(例えば自動車が走行中であるか否か)を判断するために使われる。
【0091】
マイクロホン1606は、ユーザ発話を収録するために用いられる。音声認識部103は、マイクロホン1606を通して収録した音声を認識する。マイクロホン1606の代わりに、複数のマイクロホン素子からなるマイクロホンアレイ(例えば、図2に示すマイクロホンアレイ1201)が用いられてもよい。
【0092】
マイクロホンアレイを用いることで、単一のマイクロホンでは得ることが困難な音源方向に関する情報を得たり、目的話者の方向にビームを当てて、その方向の話者が発話した音声のみを抽出したりすることができる。音源分離部102は、マイクロホンアレイを用いて、特定方向の話者が発話した音声のみを抽出してもよい。
【0093】
なお、図9に示すマイクロホン1606及び中央演算装置1603は、それぞれ、図2に示すマイクロホンアレイ1201及び中央演算装置1203に相当する。図9に示す記憶媒体1602は、図2に示す揮発性メモリ1204及び記憶媒体1205の少なくとも一方に相当する。
【0094】
選択肢提示手段判定部106は、カーナビゲーションシステムに付属のユーザ提示装置を用いた提示手段の中から、安全性を損なわないという条件下で、タスク終了時間(すなわち、ユーザ提示装置が選択肢をユーザに提示し、選択肢をユーザが理解し、選択肢のいずれかをユーザが発話するのに要する時間)が短い手段を選択する。図9に記載されたカーナビゲーションシステムは、ユーザ提示装置として、スピーカ1601及びディスプレイ1605を備える。この場合、ユーザ提示手段としては、音声合成を用いて選択肢を読み上げる音声をスピーカ1601から出力するという方法と、ディスプレイ1605上に選択肢を表示するという方法の二つが考えられる。
【0095】
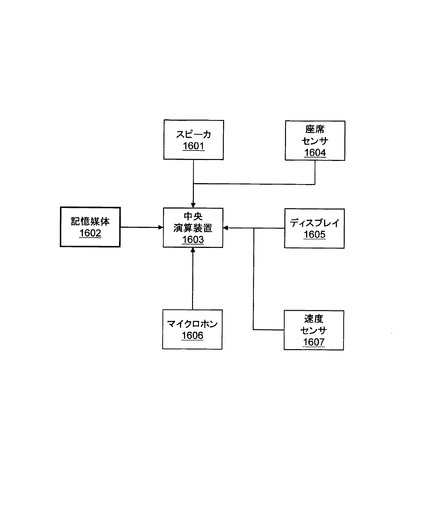
図10は、本発明の第1の実施形態の選択肢提示手段判定部106が実行する処理を示すフローチャートである。
【0096】
同乗者判定S701において、選択肢提示手段判定部106は、ドライバ以外の同乗者が乗車しているか否かを判定する。例えば、助手席(又は後部座席)の座席センサ1604の出力に基づいて、同乗者が乗車しているか否かが判定されてもよい。
【0097】
次のタスク終了時間判定S702において、選択肢提示手段判定部106は、各提示手段を用いてユーザに選択肢を提示した場合のタスク終了時間を推定する。タスク終了時間の推定値は、提示装置が選択肢を提示するのに要する時間に、予めプリセットされた平均音声認識終了時間を加算したものであってもよいし、各提示装置を使った音声対話装置を被験者に予め使用してもらった際に測定した平均タスク終了時間であってもよい。
【0098】
最短終了時間手段選択S703において、選択肢提示手段判定部106は、同乗者判定S701の結果に基づいて判定された、車内環境の安全性を損なわない提示装置のうち、タスク終了時間判定S702において推定したタスク終了時間が最も短い提示装置を選択する。どの提示装置が選択されたかを示す情報が、選択肢提示手段判定部106から出力される。
【0099】
なお、安全な提示手段が一つしかない場合、タスク終了時間判定S702は実行されなくてもよい。その場合、最短終了時間手段選択S703において、その一つしかない安全な提示手段が選択される。
【0100】
同乗者判定の結果に基づく、車内環境の安全性を損なわない提示装置の選択について以下に具体的に示す。ここでは、図9に記載された二つの提示装置、すなわち、音声合成を用いて選択肢を読み上げるスピーカ1601、及び、選択肢を表示するディスプレイ1605を例として説明する。
【0101】
ディスプレイ1605をドライバが見るという行為は、運転中のドライバの注意をそぐ可能性(すなわち、それによって安全性が損なわれる可能性)がある。このため、ドライバが選択肢を見ながら選択肢を選ぶという行為は、好ましくない。そのため、音声合成によって選択肢を読み上げることが、安全な提示方法の一つとして考えられる。
【0102】
このため、同乗者判定S701の結果、ドライバ以外の同乗者が存在しないと判定された場合、図9に示す提示装置を用いた提示方法のうち、ディスプレイ1605上に選択肢を表示するという方法は選択されずに、音声合成を用いて選択肢を読み上げるという方法が選択される。すなわち、使用されるべき提示装置として、ディスプレイ1605ではなく、スピーカ1601が選択される。
【0103】
一方、同乗者判定S701の結果、ドライバ以外の同乗者が存在すると判定された場合、ドライバ以外の同乗者がディスプレイ1605を見ながら選択肢を選ぶという行為は安全性を損なわない。したがって、この場合、音声合成を用いて選択肢を読み上げるという方法と、ディスプレイ1605上に選択肢を表示するという方法のうち最も推定タスク終了時間が最も短い提示方法が選ばれる。
【0104】
既に説明したように、タスク終了時間は、ユーザ提示装置が選択肢をユーザに提示するのに要する時間、及び、提示された選択肢をユーザが理解し、それらの選択肢のいずれかをユーザが発話するのに要する時間の合計である。
【0105】
ユーザ提示装置がスピーカ1601である場合、それが選択肢をユーザに提示するのに要する時間は、おおむね、選択肢を読み上げる音声の合成に要する時間、及び、合成された音声の出力に要する時間の合計に相当する。この時間の推定値は、例えば、中央演算装置1603等のハードウェアの処理性能、及び、選択肢として提示されるべきテキストの長さ等に基づいて算出することができる。
【0106】
一方、ユーザ提示装置がディスプレイ1605である場合、それが選択肢をユーザに提示するのに要する時間は、おおむね、ディスプレイ1605に表示されるべき画像のデータを生成するのに要する時間、及び、生成された画像をディスプレイ1605に表示するのに要する時間の合計に相当する。この時間の推定値は、例えば、中央演算装置1603等のハードウェアの処理性能、及び、生成される画像のデータ量に基づいて算出することができる。
【0107】
提示された選択肢をユーザが理解し、それらの選択肢のいずれかをユーザが発話するのに要する時間として、あらかじめ所定の値が保持されていてもよい。例えば、被験者が各提示装置を使用した場合に要した時間をあらかじめ実際に計測し、その計測された時間を音声対話装置が保持してもよい。
【0108】
ただし、実際には、タスク終了時間は、ユーザが選択肢を理解し、それらのいずれかを発話するのに要する時間より、むしろ、ユーザ提示装置が選択肢をユーザに提示するのに要する時間によって大きく左右されると考えられる。その場合、タスク終了時間として、ユーザ提示装置が選択肢をユーザに提示するのに要する時間のみが算出され、比較されてもよい。その場合、同乗者がいると判定されると、選択肢をディスプレイ1605上に表示するのに要する時間と、選択肢を読み上げるのに要する時間とが算出され、両者が比較される。その結果、例えば、選択肢をディスプレイ1605上に表示するのに要する時間が短いと判定された場合、提示装置としてディスプレイ1605が選択される。
【0109】
さらに、実際には、同一の選択肢が提示される場合、選択肢をディスプレイ1605上に表示するのに要する時間は、選択肢を読み上げるのに要する時間より短くなるのが一般的である。このため、上記の二つの提示方法がいずれも安全性を損なわないと判定された場合、常に(すなわち、推定タスク終了時間を算出することなく)、選択肢をディスプレイ1605上に表示するという提示方法が最も推定タスク終了時間が短い提示方法として選択されてもよい。
【0110】
ディスプレイ1605上に選択肢を表示する方法が選択された場合において、ディスプレイとして指向性ディスプレイが用いられる場合、指向性をドライバ以外の同乗者に向けるように設定されてもよい。また音声再生用スピーカ1601として指向性スピーカが用いられる場合、これから選択肢を入力するユーザ(すなわち、ドライバ以外の同乗者)の方向に指向性を向けてもよい。
【0111】
図10に示す処理は、対話制御部107がユーザと対話する方法を選択するために実行される。例えば、図10に示す処理は、対話制御部107が図6に示す処理を開始する前に実行されてもよいし、対話制御部107が各コマンドを処理するたびに実行されてもよい。
【0112】
図11は、本発明の第1の実施形態において出力されるガイダンス音声の例を示す説明図である。
【0113】
具体的には、図11は、同乗者がいる場合といない場合のガイダンス音声の出力例を示す。同乗者がいない場合、音声合成で読み上げた選択肢の中から選ぶように誘導するガイダンス音声(図11の例では、ガイダンス文「これから読み上げる施設名の中からお選びください」を読み上げる音声)が出力される。
【0114】
一方、同乗者がいる場合、ディスプレイ1605上に表示された選択肢の中から選ぶように誘導するガイダンス音声(図11の例では、ガイダンス文「同乗者の方がお答えください。これから画面に表示される施設名一覧の中からお選びください」を読み上げる音声)が出力される。同乗者がいる場合であっても、ドライバがディスプレイ1605を見ることを誘導してしまうことは好ましくないため、同乗者が答えるように誘導することも必要である。
【0115】
図12は、本発明の第1の実施形態においてディスプレイ1605に表示される選択肢の例を示す説明図である。
【0116】
具体的には、図12は、ディスプレイ1605上に選択肢を表示するという方法が選択された場合に表示される画面の表示例を示す。図12では、例として、設定したい目的地の選択肢(例えば、「レストラン」及び「自宅」等)が画面上に表示される。図12のように選択肢を画面上に表示することで、音声合成を用いて選択肢を読み上げるという方法と比べると、ユーザが選択肢を把握するまでの時間を短縮することができる。
【0117】
質問文生成部110は、選択肢提示手段判定部106の判定結果と同乗者の有無に基づき、質問文を生成する。質問文は、それを出力する必要が生じるたびにリアルタイムに生成されてもよいし、予め条件毎に文がプリセットされていてもよい。さらに、質問文中に同乗者の名前を含めることによって、ある特定の同乗者に回答を促してもよい。そのようにすることで、特定の同乗者の音声のみ抽出すればよくなるため、認識性能を向上可能となる。同乗者の名前を質問文に含めるためには、予めその同乗者の名前を登録する必要がある。
【0118】
図13は、本発明の第1の実施形態において選択肢の提示のために実行される処理の一例を示すフローチャートである。
【0119】
最初に、助手席判定S1701において、選択肢提示手段判定部106は、助手席に同乗者が乗車しているか否かを判定する。この判定は、図10の同乗者判定S701と同様の方法で実行される。
【0120】
助手席に同乗者が乗車していると判定された場合、ガイダンス出力1_S1702において、選択肢提示手段判定部106は、同乗者がいる場合のガイダンス音声を出力する(図11参照)。
【0121】
次に、画面に選択肢表示S1704において、選択肢提示手段判定部106は、選択肢をディスプレイ1605に表示する。具体的には、選択肢提示手段判定部106からの指示に基づいて、表示されるべき画像を表示画像生成部111が生成し、生成された画像を画像表示部113がディスプレイ1605に表示させる。
【0122】
一方、助手席に同乗者が乗車していないと判定された場合、ガイダンス出力2_S1703において、選択肢提示手段判定部106は、同乗者がいない場合のガイダンス音声を出力する(図11参照)。
【0123】
次に、音声で選択肢読み上げS1705において、選択肢提示手段判定部106は、選択肢を読み上げる音声を出力する。具体的には、選択肢提示手段判定部106からの指示に基づいて、出力されるべき選択肢を含む質問文を質問文生成部110が生成し、生成された質問文を読み上げる音声を音声出力部112がスピーカ1601に出力させる。
【0124】
画面に選択肢表示S1704又は音声で選択肢読み上げS1705が実行された後、音声認識S1706が実行される。具体的には、図3等を参照して説明したように、音声入力部101がユーザからの音声入力を受信し、その入力された音声を音源分離部102及び音声認識部103が処理することによって、入力された音声が認識される。
【0125】
このとき、助手席判定S1701の結果に基づいて目的音の範囲が設定されてもよい(図3の目的音範囲設定S901)。例えば、同乗者がいると判定された場合、目的音範囲設定S901において、マイクロホン1606から同乗者(例えば助手席に着席しているユーザ)への方向を含む所定の範囲が目的音の範囲として設定されてもよい。その場合、目的音の範囲内からの音声(すなわち同乗者が発話した音声)は、受理される。受理された音声は、選択肢の提示に対する応答として処理される。一方、目的音の範囲外からの音声(例えば運転者が発話した音声)は、棄却されるため、選択肢の提示に対する応答として処理されない。
【0126】
なお、上記図11及び図13は、同乗者がいない場合の選択肢提示方法として選択肢を読み上げることが選択され、同乗者がいる場合の選択肢提示方法として選択肢を表示することが選択される場合を例として示した。しかし、例えば、助手席判定S1701において、図10に示したものと同様の処理が実行されてもよい。その結果、助手席に同乗者が乗車している場合であっても、選択肢提示方法として選択肢を読み上げることが選択される場合もある。その場合、ガイダンス出力2_S1703及び音声で選択肢読み上げS1705が実行される。
【0127】
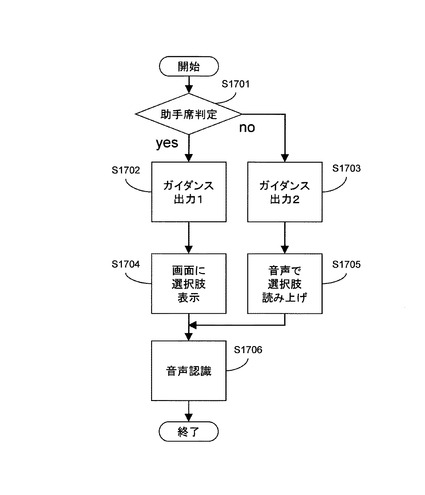
図14は、本発明の第1の実施形態における同乗者の名前登録の処理を示すフローチャートである。
【0128】
この処理は、カーナビゲーションシステム起動直後に実行される。助手席座席センサチェックS801において、座席センサ1604の情報に基づいて、助手席に人がいるか否かが判定される。
【0129】
助手席に人がいる場合、処理は名前認識S802に進む。名前認識S802において、音声認識辞書が全ての音節系列を受理可能なように設定された後、音声認識が実行される。このようにすることによって、任意の人の名前を認識することができる。音声認識によって認識された名前は、それが助手席の結果であるというラベルが付けられた後、記憶媒体1602に保存される。質問文生成時に、記憶媒体1602に保存された名前認識結果が参照される。
【0130】
助手席に人がいない場合、又は、名前認識S802が実行された後、処理は後部座席センサチェックS803に進み、後部座席に人がいるか否かが判定される。人がいる場合、処理は名前認識S804に進む。名前認識S804において、音声認識辞書が全ての音節系列を受理可能なように設定された後、音声認識が実行される。音声認識によって認識された名前は、それが後部座席の結果であるというラベルを付けられた後、記憶媒体1602に保存される。質問文生成時に、記憶媒体1602に保存された名前認識結果が参照される。
【0131】
後部座席に人がいない場合は、処理を終了する。また、名前認識S804後は、処理を終了する。
【0132】
音声出力部112は、質問文生成部110が生成した質問文を音声合成音に変換し、変換した音声合成音をスピーカ1601から出力する。表示画像生成部111は、選択肢提示手段判定部106の判定結果及び同乗者の有無に基づき、画面に情報を表示する必要がある場合は、表示画像を生成する。ここで生成される画像は、図12に例示したように選択肢を画面上にテキスト情報として表示するものであってもよいし、選択肢毎に予めプリセットされた画像を画面上に表示するものであってもよい。後者の場合、例えば、選択肢に含まれるレストランの画像が画面上に表示されてもよい。画像表示部113は、表示画像生成部111が生成した画像をディスプレイ1605上に表示する。
【0133】
機能制御部109は、音声認識結果に基づき、車室内機器を制御する。
【0134】
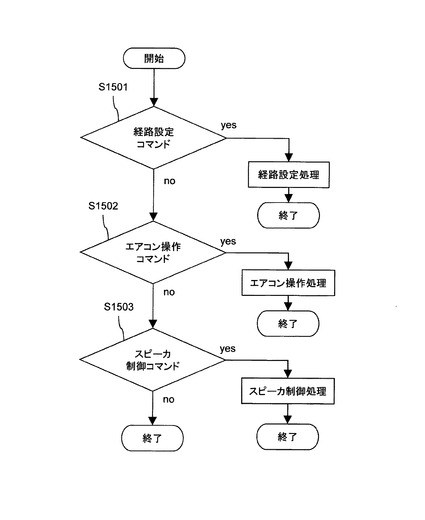
図15は、本発明の第1の実施形態の機能制御部109が実行する処理を示すフローチャートである。
【0135】
経路設定コマンドS1501において、機能制御部109は、音声認識結果が経路設定に関するものであるか否かを判定する。この判定は、音声認識結果の候補毎にその結果が経路設定に関するものか否かを示すフラグをあらかじめ設定しておくことで実現される。
【0136】
音声認識結果が経路設定に関するものである場合、機能制御部109は、カーナビゲーションシステムの経路設定処理を呼び出し、処理を終了する。
【0137】
音声認識結果が経路設定に関するものでなかった場合、機能制御部109は、次にエアコン操作コマンドS1502において、音声認識結果がエアコン操作コマンドに関するものか否かを判定する。この判定は、音声認識結果の候補毎に、その結果がエアコン操作コマンドに関するものか否かを示すフラグをあらかじめ設定しておくことで実現される。
【0138】
音声認識結果がエアコン操作コマンドに関するものである場合、機能制御部109は、カーナビゲーションシステム上のエアコン操作処理を呼び出し、処理を終了する。
【0139】
音声認識結果がエアコン操作処理に関するものでなかった場合、次にスピーカ制御コマンドS1503において、機能制御部109は、音声認識結果がスピーカ制御に関するものか否かを判定する。音声認識結果がスピーカ制御に関するものであった場合、機能制御部109は、カーナビゲーションシステム上のスピーカ制御処理を呼び出し、処理を終了する。
【0140】
以上、本発明の第1の実施形態によれば、自動車にドライバ以外のユーザが乗車しているか否かが判定され、その判定結果に基づいて、ユーザに対する情報提示方法が選択される。それによって、安全性を損なわず、かつ、短時間の音声対話が実現される。
【0141】
次に、本発明の第2の実施形態について説明する。第2の実施形態は、第1の実施形態と同様のハードウェアによって実現される(図2及び図9参照)。さらに、第2の実施形態では、以下に説明する相違点を除き、第1の実施形態と同様の処理が実行される。
【0142】
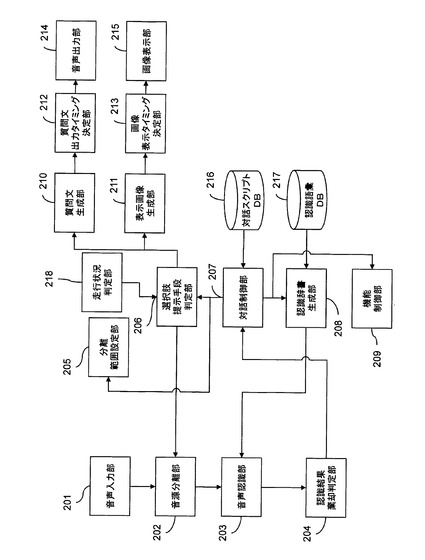
図16は、本発明の第2の実施形態の音声対話装置の機能ブロック図である。
【0143】
図16に示す各部のうち、音声入力部201、音源分離部202、音声認識部203、認識結果棄却判定部204、分離範囲設定部205、選択肢提示手段判定部206、対話制御部207、認識辞書生成部208、機能制御部209、認識語彙DB217、対話スクリプトDB216、質問文生成部210、表示画像生成部211、音声出力部214及び画像表示部215は、それぞれ、第1の実施形態における音声入力部101、音源分離部102、音声認識部103、認識結果棄却判定部104、分離範囲設定部105、選択肢提示手段判定部106、対話制御部107、認識辞書生成部108、機能制御部109、認識語彙DB115、対話スクリプトDB114、質問文生成部110、表示画像生成部111、音声出力部112及び画像表示部113と同等の機能を有する。
【0144】
第2の実施形態の音声対話装置は、さらに、質問文出力タイミング決定部212、画像表示タイミング決定部213及び走行状況判定部218を備える。これらも、記憶媒体1205に格納されたプログラムを中央演算装置1203が実行することによって実現される。
【0145】
走行状況判定部218は、車速の情報に基づいて、現在の走行状況、例えば、現在運転中なのか静止中なのかを判定する。さらに、走行状況判定部218は、カーナビゲーションシステムの地図情報を利用して、現在地が高速道路上であるといった情報、及び、現在交差点で静止中であるといった状況まで判定してもよい。
【0146】
具体的には、図9に示すカーナビゲーションシステムが、自動車の現在位置情報を取得する測位装置(図示省略)を備える。走行状況判定部218は、測位装置が取得した現在位置情報と、記憶媒体1602に格納された地図情報とを参照することによって、現在地が高速道路上であるか否かなどを判定することができる。
【0147】
判定した走行状況に基づき、選択肢提示手段判定部206は、カーナビゲーションシステムに付属のユーザ提示装置を用いた提示手段の中から、安全性を損なわないという条件下で、タスク終了時間(すなわち、ユーザ提示装置が選択肢をユーザに提示し、選択肢をユーザが理解し、選択肢のいずれかをユーザが発話するまでに要する時間)が短い手段を選択する。ディスプレイ1605をドライバが見るという行為は、ドライバの注意をそぐ可能性(すなわち、それによって安全性が損なわれる可能性)がある。このため、ドライバが運転中に選択肢を見ながら選択肢を選ぶという行為は、好ましくない。
【0148】
このため、同乗者判定S701によってドライバ以外の同乗者が存在しないと判定された場合、判定した走行状況に基づいて選択肢提示手段が判定される。具体的には、走行状況が静止中(すなわち車が停止している状態)である場合、ディスプレイ1605上に選択肢を表示するという方法が選択される。一方、走行状況が走行中である場合、ドライバに静止可能な場所に車を止めることを誘導するガイダンスを再生して、ドライバが車を止めたことを走行状況判定で確認した後、ディスプレイ1605上に選択肢を表示するという方法が選択される。
【0149】
質問文出力タイミング決定部212は、質問文を読み上げる音声を出力するタイミングを走行状況に応じて制御する。具体的には、走行状況が走行中である場合、質問文出力タイミング決定部212は、ドライバに静止可能な場所に車を止めることを誘導するガイダンスを再生した後、静止状態になったタイミングで、画面上の選択肢の中から選ぶことを誘導する質問文を出力するように制御する。
【0150】
画像表示タイミング決定部213は、同様に、ディスプレイ1605上に選択肢を表示するタイミングを走行状況に応じて制御する。具体的には、画像表示タイミング決定部213は、静止状態になったタイミングで、ディスプレイ1605の画面上に選択肢を表示するように制御する。
【0151】
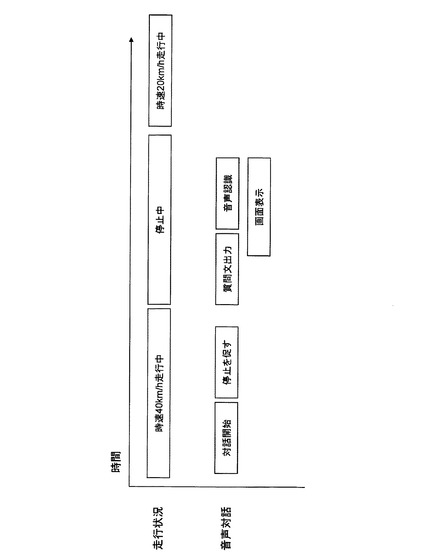
図17は、本発明の第2の実施形態における走行状況及び音声対話のタイミングチャートである。
【0152】
図17の例では、音声対話を開始した時点において時速40km/hで走行中であったため、質問文出力タイミング決定部212は、ドライバに停止をすることを促すガイダンスを再生するように音声出力部214を制御する。その後、質問文出力タイミング決定部212は、車が停止したことを確認した後、質問文を出力するように音声出力部214を制御する。
【0153】
画像表示タイミング決定部213は、車が停止したことを確認した後、選択肢をディスプレイ1605の画面に表示するように画像表示部215を制御する。その後、音声認識部203等による音声認識が開始される。
【0154】
図18は、本発明の第2の実施形態において選択肢の提示のために実行される処理の一例を示すフローチャートである。
【0155】
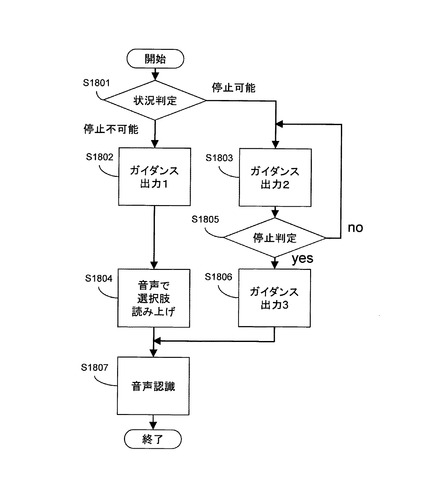
以下、ドライバ以外の同乗者が乗車しておらず、かつ、車が走行中である場合に図18の処理が実行される例を示す。
【0156】
最初に、状況判定S1801において、走行状況判定部218は、車を停止可能であるか否かを判定する。例えば、走行状況判定部218は、現在地が高速道路上である場合、車を停止可能でないと判定し、現在地が一般道路上である場合、車を停止可能であると判定してもよい。
【0157】
車を停止可能でないと判定された場合、ガイダンス出力1_S1802において、選択肢提示手段判定部106は、車を停止可能でない場合のガイダンス音声を出力する。例えば、選択肢提示手段判定部106は、図11に示した同乗者がいない場合の質問文を読み上げる音声を出力するように質問文生成部210を制御してもよい。
【0158】
次に、音声で選択肢読み上げS1804において、選択肢提示手段判定部106は、選択肢を読み上げる音声を出力する。具体的には、選択肢提示手段判定部106からの指示に基づいて、出力されるべき選択肢を含む質問文を質問文生成部110が生成し、生成された質問文を読み上げる音声を音声出力部112がスピーカ1601に出力させる。
【0159】
一方、車を停止可能であると判定された場合、ガイダンス出力2_S1803において、選択肢提示手段判定部106は、車を停止可能である場合のガイダンス音声を出力する。例えば、選択肢提示手段106は、ドライバに静止可能な場所に車を止めることを誘導するガイダンスを出力するように質問文生成部210を制御してもよい。
【0160】
次に、停止判定S1805において、質問文出力タイミング決定部212は、車が停止したか否かを判定する。車がまだ停止していないと判定された場合、処理はガイダンス出力2_S1803に戻り、再び車を止めることを誘導するガイダンスが出力される。
【0161】
一方、車が停止したと判定された場合、質問文出力タイミング決定部212は、ガイダンス出力3_S1806において、車が停止した場合のガイダンス音声を出力する。例えば、質問文出力タイミング決定部212は、質問文生成部210が生成した、同乗者がいる場合の質問文(例えば図11参照)を読み上げる音声を出力するように、音声出力部214を制御してもよい。なお、上記の例では実際には同乗者がいないが、車が停止しているため、ドライバがディスプレイ1605を見ても安全性は損なわれない。
【0162】
さらに、停止判定S1805において、画像表示タイミング決定部213は、車が停止したか否かを判定する。車がまだ停止していないと判定された場合、処理はガイダンス出力2_S1803に戻り、再び車を止めることを誘導するガイダンスが出力される。
【0163】
一方、車が停止したと判定された場合、画像表示タイミング決定部213は、ガイダンス出力3_S1806において、選択肢をディスプレイ1605の画面に表示する。例えば、画像表示タイミング決定部213は、表示画像生成部211が生成した選択肢の表示画像(例えば図12参照)を表示するように、画像表示部215を制御してもよい。
【0164】
音声で選択肢読み上げS1804又はガイダンス出力3_S1806が実行された後、音声認識S1807が実行される。このステップは、第1の実施形態の音声認識S1706と同様である。
【0165】
なお、前記図18は、ドライバ以外の同乗者が乗車しておらず、かつ、車が走行中である場合を例として説明した。例えば、本実施形態においても、第1の実施形態と同様、図13に示す助手席判定S1701が実行され、同乗者がいないと判定された場合に図18に示す処理が開始されてもよい。一方、同乗者がいると判定された場合には、第1の実施形態と同様、ガイダンス出力1_S1702及び画面に選択肢表示S1704が実行されてもよい。
【0166】
さらに、図18は、車が走行中でない場合に実行されてもよい。例えば、状況判定S1801において、まず車が走行中であるか否かが判定され、走行中であると判定され場合に停止可能であるか否かが判定されてもよい。車が走行中でないと判定された場合、処理はガイダンス出力2_S1803及び停止判定S1805が省略され、ガイダンス出力3_S1806が実行されてもよい。
【0167】
以上、本発明の第2の実施形態によれば、自動車にドライバのみが乗車している場合であっても、安全性を損なわず、かつ、短時間で音声対話を実行できる情報提示方法が選択される。
【0168】
以上の本発明の第1及び第2の実施形態は、選択肢を示すテキスト情報をユーザに提示し、その提示に対する応答として選択肢のいずれかをユーザが発話する処理を例として説明した。しかし、これらの実施形態は、任意のテキスト情報の提示及びそれに対するユーザからの応答を処理するために適用することができる。
【図面の簡単な説明】
【0169】
【図1】本発明の第1の実施形態の音声対話装置の機能ブロック図である。
【図2】本発明の第1の実施形態の音声対話装置のハードウェア構成のブロック図である。
【図3】本発明の第1の実施形態において実行される音声認識処理を示すフローチャートである。
【図4】本発明の第1の実施形態の音源分離部が実行する詳細な処理の流れを示す説明図である。
【図5】本発明の第1の実施形態の音源分離において時間周波数毎に実行される処理を示すフローチャートである。
【図6】本発明の第1の実施形態における対話スクリプトに基づく対話を示すフローチャートである。
【図7】本発明の第1の実施形態において使用される音声認識辞書の一例を示す説明図である。
【図8】本発明の第1の実施形態におけるアークごとの単語リストの一例を示す説明図である。
【図9】本発明の第1の実施形態の音声対話装置を含むカーナビゲーションシステムのハードウェア構成のブロック図である。
【図10】本発明の第1の実施形態の選択肢提示手段判定部が実行する処理を示すフローチャートである。
【図11】本発明の第1の実施形態において出力されるガイダンス音声の例を示す説明図である。
【図12】本発明の第1の実施形態においてディスプレイに表示される選択肢の例を示す説明図である。
【図13】本発明の第1の実施形態において選択肢の提示のために実行される処理の一例を示すフローチャートである。
【図14】本発明の第1の実施形態における同乗者の名前登録の処理を示すフローチャートである。
【図15】本発明の第1の実施形態の機能制御部が実行する処理を示すフローチャートである。
【図16】本発明の第2の実施形態の音声対話装置の機能ブロック図である。
【図17】本発明の第2の実施形態における走行状況及び音声対話のタイミングチャートである。
【図18】本発明の第2の実施形態において選択肢の提示のために実行される処理の一例を示すフローチャートである。
【符号の説明】
【0170】
101、201 音声入力部
102、202 音源分離部
103、203 音声認識部
104、204 認識結果棄却判定部
105、205 分離範囲設定部
106、206 選択肢提示手段判定部
107、207 対話制御部
108、208 認識辞書生成部
109、209 機能制御部
110、210 質問文生成部
111、211 表示画像生成部
112、214 音声出力部
113、215 画像表示部
114、216 対話スクリプトDB
115、217 認識語彙DB
212 質問文出力タイミング決定部
213 画像表示タイミング決定部
218 走行状況判定部
S301 コマンド名称
S302 目的地設定
S303 自動車機器操作
S304 周辺施設検索
S305 時間周波数分解
S701 同乗者判定
S702 タスク終了時間判定
S703 最短終了時間手段選択
S801 助手席座席センサチェック
S802 名前認識
S803 後部座席センサチェック
S804 名前認識
S901 目的音範囲設定
S902 音源分離
1001 DFT
1002 周波数毎ベクトル化
1003 音源定位
1004 音源分離
1005 逆DFT
S1101 目的音範囲かどうか
S1102 目的音共分散更新
S1103 雑音共分散更新
S1104 フィルタ生成
S1105 フィルタリング
S1106 ポストフィルタリング
1201 マイクロホンアレイ
1202 AD変換装置
1203、1603 中央演算装置
1204 揮発性メモリ
1205、1602 記憶媒体
S1501 経路設定コマンド
S1502 エアコン操作コマンド
S1503 スピーカ制御コマンド
1601 スピーカ
1604 座席センサ
1605 ディスプレイ
1606 マイクロホン
1607 速度センサ
【技術分野】
【0001】
本願明細書で開示される技術は、車室内に搭載される音声対話装置に関する。
【背景技術】
【0002】
自動車に搭載されるカーナビゲーションシステムには、音声対話機能を備えるものが広く使われている(例えば特許文献1参照)。従来、音声対話機能を実現するために必要な音声認識技術及び音声合成技術が広く検討されている。音声認識技術は、マイクロホンを通して入力された音声波形をテキスト化する技術である。音声合成技術は、テキストから音声波形を生成する技術である。音声認識技術と音声合成技術を組み合わせることで、カーナビゲーションシステムがユーザと音声で会話することが可能となる。また、車室内で録音した音声波形には様々な騒音が重畳するため、音声認識率が大幅に劣化するという問題がある。この問題に対して、複数のマイクロホン素子を有するマイクロホンアレイを用いて騒音を抑圧し、所望の音声のみを抽出する音源分離技術が広く検討されている。
【特許文献1】特開2004−109323号公報
【発明の開示】
【発明が解決しようとする課題】
【0003】
従来のカーナビゲーションシステムでは、ドライバが発話することを前提に作られているため、受理する音声認識辞書の内容を全て音声合成で読み上げるような構成になっていた。しかし、選択肢を全て読み上げるのにかかる時間が長いため、音声対話が終了するまでの時間が長くなってしまうという課題があった。一方、選択肢は、読み上げられる代わりにディスプレイに表示されてもよい。しかし、ディスプレイに選択肢を表示する方法は、音声対話が終了するまでの時間が短いという利点はあるものの、ドライバが音声対話を行う場合に使用することは好ましくない。自動車を運転中のドライバがディスプレイを目視することによって安全性が損なわれるためである。
【課題を解決するための手段】
【0004】
本願で開示する代表的な発明は、自動車内における乗員の乗車位置を検知する乗員検知部と、テキスト情報を音声に変換して出力する音声出力部と、前記テキスト情報を画像に変換して表示する画像表示部と、前記乗員検知部の検知結果に基づいて、前記音声出力部又は前記画像表示部のいずれか一方を選択し、前記選択された前記音声出力部又は前記画像表示部に前記テキスト情報を出力させる切り替え部と、を備えることを特徴とする。
【発明の効果】
【0005】
本発明の一実施形態によれば、選択肢提示手段判定部によって、車内にドライバのみが存在するか否かが判定され、その判定の結果にしたがって最適な提示手段が選択される。例えば、ドライバのみ存在する場合は、音声合成によって音声認識辞書の内容が読み上げられ、ドライバ以外の同乗者が存在する場合は、タスク時間短縮化のため、同乗者が回答するよう誘導した後、ディスプレイ上に選択肢が表示される。これによって、安全性を損なうことなく、タスク時間の短い音声対話が実現し、迅速なカーナビゲーションシステムの操作が可能となる。
【発明を実施するための最良の形態】
【0006】
図1は、本発明の第1の実施形態の音声対話装置の機能ブロック図である。
【0007】
本実施形態の音声対話装置は、例えば、自動車に搭載されるカーナビゲーションシステムのアプリケーションとして使われることが想定される。以下、この想定の下、実施形態を説明する。なお、自動車には、一人の運転者(ドライバ)を含む一人以上のユーザが乗車する。
【0008】
図2は、本発明の第1の実施形態の音声対話装置のハードウェア構成のブロック図である。
【0009】
本実施形態のシステムは、少なくとも二つ以上のマイクロホン素子からなるマイクロホンアレイ1201を備える。マイクロホンアレイ1201は、それぞれのマイクロホン素子位置における音圧レベルを計測する。
【0010】
マイクロホンアレイ1201によって計測されたアナログの音圧値は、AD変換装置1202でサンプリングされ、デジタルデータに変換される。AD変換装置1202は、アナログのローパスフィルタ(図示省略)などを用いて、サンプリングレートの0.5倍以上の周波数成分を除去した後の音圧値をサンプリングしてもよい。
【0011】
サンプリングされたデジタル音圧データは、中央演算装置1203に送られる。中央演算装置1203では、デジタル音圧データ中の音源方向の推定、位相差の補正及び音声認識や対話処理といったプログラムを実行する。
【0012】
中央演算装置1203によって実行されるプログラムは、データとして記憶媒体1205に記憶される。
【0013】
プログラム実行時に必要な一時的なデータは、揮発性メモリ1204又は記憶媒体1205に記憶されてもよい。その他、プログラム実行に必要な事前データは、記憶媒体1205に事前に記憶される。記憶媒体1205は、例えば、ハードディスクドライブ(HDD)又はフラッシュメモリのような大容量の不揮発性記憶媒体である。一方、揮発性メモリ1204は、例えば、ダイナミックランダムアクセスメモリ(DRAM)のような高速な記憶装置である。
【0014】
例えば、図1に示す対話スクリプトデータベース(DB)114及び認識語彙DB115は、記憶媒体1205に格納される。図1に示す上記のデータベース以外の各部は、記憶媒体1205に格納されたプログラムを中央演算装置1203が実行することによって実現される。ただし、音声入力部101は、AD変換装置1202によって実現されてもよい。上記のデータベース及びプログラムは、記憶媒体1205に格納され、必要に応じてそれらの全部又は一部が揮発性メモリ1204にコピーされてもよい。
【0015】
マイクロホンで受音したアナログ音声は、音声入力部101において、デジタル音声に変換される。変換されたデジタル音声は音源分離部102に送られる。音源分離部102において、デジタル音声中に含まれる雑音成分が除去され、所望の音声を強調した信号が得られる。所望の音声か否かは、音源方向の情報から判断される。例えば、所望の音声が自動車を運転するドライバである場合は、マイクロホンから見たドライバの相対方向が所望の音源方向として設定され、その所望の音源方向から到来する音声が所望の音声と判断される。
【0016】
所望の音源方向は分離範囲設定部105によって設定される。分離範囲設定部105は、対話制御部107の出力結果に基づき、所望の音源方向を設定する。
【0017】
音源分離部102が取り出した所望の音声成分は、音声認識部103に送られる。音声認識部103は、送られてきた音声波形の発話内容を認識し、文字列に変換したものを出力する。音声認識部103が実行する音声認識処理は、例えば、隠れマルコフモデルに基づくもの、又は、動的計画法に基づくものなど、いかなるものであってもよい。
【0018】
音声認識処理は、入力された音声波形の発話内容が、所与の語彙の中のどの語と最も近いかを判定し、最も近い語を出力する一種のパターンマッチング処理である。音声認識に用いるために予め保持される語彙は、音声認識処理を開始する前に、予め認識辞書生成部108にて作られる。
【0019】
音声認識部103は、さらに、認識結果の尤度を計算する。認識結果の尤度とは、入力された音声波形の発話内容と最も近いと判定された語と、その発話内容と、の近さの度合いを示す尺度である。尤度は、公知の種々の方法によって算出することができる。
【0020】
音声認識部103によって生成される文字列に変換された発話内容(すなわち認識結果)及びその認識結果の尤度は、認識結果棄却判定部104に送られる。認識結果棄却判定部104は、認識結果の尤度の情報に基づいて、認識結果を受理するか棄却するかを判定する。例えば、認識結果の尤度の情報から生成される認識結果の事後確率が閾値を超える場合に受理すると判定されてもよい。一方、事後確率が閾値以下の場合、所与の語彙のいずれとも異なる語が発話されたと推定されるため、認識結果を棄却すると判定されてもよい。
【0021】
認識結果棄却判定部104で受理された認識結果は対話制御部107に送られる。認識結果が棄却された場合は、音声認識処理が続行されてもよい。音声認識処理の開始後、一定時間以内に認識結果が受理されなかった場合、認識結果棄却判定部104は、認識結果が無かったという情報を対話制御部107に送信してもよい。対話制御部107は、その情報に基づき、次の行動を決定してもよい。例えば、対話制御部107は、「もう一度発話してください」と発話を促すガイダンスを出力した後、音声認識処理を再度実行するように各部を制御してもよい。
【0022】
図3は、本発明の第1の実施形態において実行される音声認識処理を示すフローチャートである。
【0023】
具体的には、図3は、音源分離部102、音声認識部103及び認識結果棄却判定部104によって実行される具体的な音声認識処理の流れを示す。
【0024】
目的音範囲設定S901において、音源分離部102は、分離範囲設定部105によって設定された範囲に基づき、目的音の存在範囲を設定する。例えば、方位角と仰角のそれぞれについて目的音の存在範囲が設定される。例えば、方位角が−30度から+30度まで、及び仰角を−90度から90度までと設定されてもよい。
【0025】
音源分離S902において、音源分離部102は、設定された目的音存在範囲の情報に基づき、目的音方向の音を抽出する。
【0026】
音声認識S903において、音声認識部103は、音源分離S902において抽出された目的音方向の音の発話内容を、音声認識辞書及び音のモデルを用いて認識する。
【0027】
信頼度チェックS904において、認識結果棄却判定部104は、音声認識結果の信頼度を示す尺度(例えば、音声認識結果に付随する音響尤度から計算される事後確率など)が予め設定された閾値を上回っているか否かを判定する。信頼度を示す尺度が閾値を上回っている場合、認識された音声は、コマンドを入力するために発話されたものであると推定される。例えば、後述するように選択肢がユーザに提示されると、ユーザがそれに応じて選択肢の一つを発話する。このような発話は、コマンドを入力するための発話の一例である。この場合、処理は方向チェックS905に進む。
【0028】
一方、信頼度を示す尺度が閾値を下回っている場合、認識された音声はコマンドを入力するために発話されたものでない(例えば雑音のような、コマンドとは無関係に入力された音声等である)と推定される。この場合、処理は制限時間チェックS907に進む。
【0029】
方向チェックS905において、認識結果棄却判定部104は、音声認識波形の時間長をTとし、音声認識波形の音源方向を数式(1)によって算出し、その方向が所与の目的音範囲内か否かを判定する。
【0030】
【数1】
【0031】
θ(f,τ)は時間τにおける周波数fの音源方向であり、その算出方法は後述する。fmaxは音声認識波形の最大周波数成分である。
【0032】
音源方向が目的音範囲内であった場合、認識結果棄却判定部104は、認識結果を返して処理を終了する。後述するように、ユーザに対して選択肢が提示された後で図3に示す処理が実行された場合、上記のように返された認識結果は、選択肢の提示に対する応答(すなわち、提示された選択肢の一つを発話したもの)として処理される。
【0033】
音源方向が目的音範囲外であった場合、処理は制限時間チェックS907に進む。制限時間チェックS907において、認識結果棄却判定部104は、音声認識を開始してから経過した時間が所与の制限時間内であるか否かを判定する。経過した時間が所与の制限時間内である場合、処理は音源分離S902に戻り、目的音方向の音の抽出が再度実行される。経過した時間が制限時間を超えている場合、認識結果を返さずに処理が終了する。
【0034】
上記の音源分離S902及び音声認識S903は、音声入力部101が取得するリアルタイムの音声波形に対する処理である。つまり時々刻々入力されてくる新しい音声波形に対して上記の処理が施される。
【0035】
図4は、本発明の第1の実施形態の音源分離部102が実行する詳細な処理の流れを示す説明図である。
【0036】
図4の処理は、音声入力部101が一定量(例えば数十ms程度)の音声データを取得する度に実行される。
【0037】
複数のマイクロホン素子によって収録された音声波形は、マイクロホン素子毎に、DFT1001にて離散フーリエ変換を施される。マイクロホン素子(i)毎の、サンプリング時間(t)の音圧データは数式(2)によって表される。
【0038】
【数2】
【0039】
事前に音声波形のハミング窓又はハニング窓を時間領域の信号に掛け合わせた後、離散フーリエ変換が施されてもよい。ハミング窓又はハニング窓の窓関数を掛け合わせることで、高精度な時間周波数領域の信号を得ることができる。
【0040】
離散フーリエ変換による時間周波数領域信号への変換は数式(3)によって行われる。変換後の信号は、数式(4)によって表される。
【0041】
【数3】
【0042】
【数4】
【0043】
ここでτはフレームインデックスと呼ばれ、時間周波数領域信号への変換した回数と等しくなる。w(n)はハニング窓又はハミング窓の窓関数である。フーリエ変換の際のフレームサイズとする。
【0044】
周波数毎ベクトル化1002において、音源分離部102は、変換後の同じ時間周波数毎領域に属するマイク毎の信号をまとめあげて、数式(5)で定義されるベクトルX(f,τ)を生成する。Mはマイク素子数とする。
【0045】
【数5】
【0046】
音源定位1003において、音源分離部102は、時間周波数毎に、数式(6)で定義されるステアリングベクトルa(θ,f)とX(f,τ)との内積の最大値を与える音源方向θを数式(7)で計算する。cは音速とする。
【0047】
【数6】
【0048】
【数7】
【0049】
図5は、本発明の第1の実施形態の音源分離1004において時間周波数毎に実行される処理を示すフローチャートである。
【0050】
音源分離部102は、目的音範囲かどうかS1101において、時間周波数毎の音源方向θが所定の目的音範囲内であるか否かを判定する。音源方向θが目的音範囲内であった場合、音源分離部102は、ベクトルn(f,τ)をゼロベクトルに設定し、ベクトルs(f,τ)をX(f,τ)に設定した後、目的音共分散更新S1102に進む。目的音範囲外の場合、音源分離部102は、ベクトルn(f,τ)をX(f,τ)に設定し、雑音共分散更新S1103に進む。
【0051】
目的音共分散更新S1102において、音源分離部102は、ベクトルs(f,τ)を用いて共分散行列Rs(f)を数式(8)のように更新する。
【0052】
【数8】
【0053】
雑音共分散更新S1103において、音源分離部102は、ベクトルn(f,τ)を用いて共分散行列R(f)を数式(9)のように更新する。ここでαは所与の更新レートとする。
【0054】
【数9】
【0055】
音源分離部102は、共分散行列Rs(f)及びR(f)を用いて音源分離フィルタw(f,τ)を数式(10)によって求める。eig_vectorは最大固有値となる固有ベクトルを与える関数とする。
【0056】
【数10】
【0057】
フィルタリングS1105において、音源分離部102は、入力信号X(f,τ)及び音源分離フィルタw(f,τ)から雑音抑圧信号s(f,τ)を数式(11)によって求める。
【0058】
【数11】
【0059】
ポストフィルタリングS1106において、音源分離部102は、雑音抑圧信号s(f,τ)にウィナーフィルタ又はスペクトルサブトラクション処理を施すことによって、残留雑音成分を抑圧する。そして、音源分離部102は、残留雑音抑圧後の時間周波数信号を出力し、処理を終了する。
【0060】
逆DFT1005において、音源分離部102は、求めた周波数毎の雑音抑圧信号に逆離散フーリエ変換を施すことによって、時間領域信号を生成した後、その時間領域信号を出力する。
【0061】
対話制御部107は、対話スクリプトDB114に保持された対話スクリプトに基づき、ユーザとの音声対話を制御する。
【0062】
図6は、本発明の第1の実施形態における対話スクリプトに基づく対話を示すフローチャートである。
【0063】
図6に記載の対話フローの例では、ユーザとの対話開始後、まずコマンド名称S301において、対話制御部107は、ユーザが実行したいコマンドの名称を認識する。認識に際し、対話制御部107は、ユーザに対して、「コマンド名称をどうぞ」などの発話を促すガイダンスを出力してもよい。さらに、対話制御部107は、「この中からお選びください」などのコメントとともに画面に表示されるコマンドリストの中から、実行したいコマンドを選ばせてもよいし、コマンドリストの内容を読み上げた音声を、音声合成システムなどを使用して生成し、その音声を出力してもよい。
【0064】
本実施形態において、画面にコマンドリストを表示するか、コマンドリストを読み上げるかは、ユーザの着座情報などに基づいて切り替えられる。この切り替えは、後述する選択肢の提示方法の選択と同様にして実行されてもよい。例えば、ドライバのみ乗車している場合、コマンドリストを読み上げるように制御されてもよい。一方、同乗者(すなわちドライバ以外のユーザ)が自動車内に存在する場合、音声対話に要する時間を短くするために、「同乗者の方、この中からお選びください」などの、同乗者が画面を見て答えることを促すガイダンスを流した後、コマンドリストを画面に表示するように制御されてもよい。これによって、自動車の走行の安全性を確保しながら、素早いコマンド入力が実現される。
【0065】
図6において、コマンド名称S301終了後、認識したコマンド(すなわち、ユーザによってコマンドリストから選択されたコマンド)に応じて処理を切り替える。例えば認識したコマンドが目的地設定であった場合は、次に具体的な目的地を認識する目的地設定S302が実行される。
【0066】
目的地設定S302では、「目的地をおっしゃって下さい」のように目的地をユーザが発話するように促すガイダンスが出力されてもよいし、「目的地をこの中からお選びください」と発話する音声が出力された後、目的地のリストが画面に表示されてもよいし、目的地のリストが読み上げられてもよい。画面に表示される目的地のリストの例については、後で図12を参照して説明する。
【0067】
前述のコマンド名称S301と同様に、同乗者がいるか否かに応じて、安全性を損なわない提示手段のうち、最も目的地設定に要する時間が短くなるような提示手段が選択される。
【0068】
コマンド名称S301において認識されたコマンドが自動車機器操作であった場合、自動車機器操作S303が実行される。自動車機器操作S303において、対話制御部107は、エアコンのOn/Off又は音楽等の制御といった自動車内部機器を操作するためのユーザコマンドを認識する。このとき、対話制御部107は、「操作したい機器名称及び操作内容をおっしゃって下さい」といったガイダンスを音声出力部112に出力させてもよいし、音声コマンドで操作可能なコマンド一覧を画面に表示するように画像表示部113を制御してもよい。前述の目的地設定S302と同様に、最も自動車内部機器操作に要する時間が短くなるような提示手段が選択される。
【0069】
コマンド名称S301において認識されたコマンドが周辺施設検索であった場合、周辺施設検索S304が実行される。周辺施設検索S304において、対話制御部107は、ユーザが所望する周辺施設を検索し、検索された施設を目的地として設定する処理を、音声インタフェースを用いて実行する。具体的には、対話制御部107は、「周辺施設をおっしゃって下さい」といったようにユーザ発話を促すガイダンスを音声出力部112に出力させてもよいし、「この中から選んでください」といったガイダンスを出力させた後、画面に周辺施設のリストを表示し、画面を見ながらユーザが発話するように促してもよい。前述の自動車機器操作S303と同様に、最も自動車内部機器操作に要する時間が短くなるような提示手段が選択される。
【0070】
S302からS304までのいずれかの処理が終了した後、対話制御部107は対話を終了する。
【0071】
以上は、カーナビゲーションシステムにおける対話スクリプトに基づく対話の一例である。対話スクリプトは、条件分岐とシステムの実行コマンドの情報とを保持する形式で記述可能な言語によって記述される限り、どのような形式で記述されてもよい。例えば、Voice XMLのようなXML形式で対話スクリプトが記述されてもよいし、プログラム言語の一種であるスクリプト言語でプログラムコードとして対話スクリプトが記述されてもよい。
【0072】
対話制御部107は、対話スクリプトに基づき、音声認識部103、音源分離部102、音声出力部112及び画像表示部113の動作を制御する。例えば、前述のコマンドリストを認識する対話において、認識辞書生成部108は、音声認識を開始する前に、認識に用いる認識辞書を切り替える。認識辞書生成部108は有限オートマトン形式で記載された音声認識辞書を生成する。
【0073】
図7は、本発明の第1の実施形態において使用される音声認識辞書の一例を示す説明図である。
【0074】
この例では、6つのノードと6つのアークがネットワーク化された形で認識辞書が表現されている。この例の認識辞書を用いた場合、ユーザ発話は「目的地」と「語尾」とが連続した文、又は、「電話番号」と「語尾」とが連続した文のいずれかであることが仮定される。「目的地」、「語尾」及び「電話番号」は、アークと呼ばれる、複数の単語をまとめて表現したラベルである。各アークは更に単語リストに展開される。
【0075】
図8は、本発明の第1の実施形態におけるアークごとの単語リストの一例を示す説明図である。
【0076】
図8は、「目的地」のアークが展開された単語リストの例を示さす。図8の例では、目的地を示す単語のリストに、「中央研究所」及び「機械研究所」のような施設の固有名詞が含まれる。この他の目的地として、例えば、「レストラン」のような施設の一般名詞が含まれてもよいし(図12参照)、「東京都」のような地名が含まれてもよい。
【0077】
このように各アークは単語リストに展開される。これによって、例えば「目的地」と「語尾」が連続した文の数は、「目的地」の単語リストに含まれる単語の数に「語尾」の単語リストに含まれる単語の数を掛け合わせた数になる。単語リストは認識語彙DB115に蓄えられており、認識辞書に応じて必要な語彙が取り出される。
【0078】
音声認識部103は、各単語を音素毎又は音素片毎に分割し、各音素又は音素片に対応した音のモデルを並べたものをパターンとし、入力音声と最も近いパターンを出力する。音のモデルは、音素又は音素片ごとに、LPCケプストラム、MFCC、それらの差分値(Δ)、それらのΔΔ、又は、パワーの時間差分値など、を特徴量とした混合正規分布で表現される。また特徴量算出時に平均値の減算処理(ケプストラム平均値減算処理)などによって伝達系の歪みを補正してもよい。
【0079】
入力音声と最も近いパターンは、前向き・後ろ向きアルゴリズムに基づく最尤推定において、最大尤度を与える状態遷移パスのみを計算するように近似したビタビアルゴリズムによって算出される。尤度は、入力音声とパターンとの距離に基づいて定義される。音声認識部103は最大尤度を与える状態遷移パスを計算し、その状態遷移パスから単語系列を逆引きする。これによってある一つの文字列が得られ、その文字列が出力される。さらに、最大尤度そのもの、又は、最大尤度を加工することによって得られた事後確率p(O|X)が出力される。ここで、p(O|X)は、入力音声Xを条件とした認識結果Oの事後確率(すなわち、入力音声Xに対する認識結果Oが正しい結果である確率を示す値)である。
【0080】
ユーザ発話は、必ずしも音声認識辞書で表現される文であるとは限らない。また、車室内では所望のユーザ発話以外の走行音などの雑音が存在するため、認識対象の音声が雑音であることも多い。このような場合でも、音声認識部103では入力音声に最も近いパターンを出力するため、出力されたすべての音声認識の結果を確信し受理することは望ましくない。
【0081】
出力された音声認識結果の尤度又は事後確率が所定の閾値より小さい場合、認識対象の音声が雑音であったか又は音声認識辞書で表現される文以外の発話が成された可能性が高いため、そのような音声認識結果は棄却するべきである。認識結果棄却判定部104は、音声認識部103が出力する認識結果の尤度又は事後確率に基づき、認識結果を受理するか棄却するかを判定する(信頼度チェックS904)。さらに、認識結果棄却判定部104は、音声認識を行った波形の音源方向を推定し、その音源方向が所望の音源方向の範囲外(すなわち目的音範囲外)であった場合に、その認識結果を棄却してもよい。
【0082】
一般的に音声認識部103が受理可能な文(テキスト)に関する情報をユーザは事前に知らない。したがって、音声認識開始前に、いかなる文が受理可能であるかをユーザに提示する必要がある。選択肢を提示する方法としては、音声合成技術を用いて受理可能な文の一部を読み上げること、又は、受理可能な文の一部を、カーナビゲーションシステムが備えるディスプレイの画面上に表示すること、などが考えられる。
【0083】
図9は、本発明の第1の実施形態の音声対話装置を含むカーナビゲーションシステムのハードウェア構成のブロック図である。
【0084】
本実施形態のカーナビゲーションシステムは、中央演算装置1603と、その中央演算装置に接続されるスピーカ1601、記憶媒体1602、座席センサ1604、ディスプレイ1605、マイクロホン1606及び速度センサ1607と、を備える。
【0085】
中央演算装置1603は、音声認識及び音源分離などのソフトウェア処理を実行する。
【0086】
記憶媒体1602には、認識辞書などの情報が保持される。
【0087】
ガイダンス音などの再生音は、スピーカ1601から出力される。スピーカ1601は超音波スピーカなどの超指向性スピーカであってもよい。
【0088】
運転席、助手席、後部座席などの各座席に設置された座席センサ1604によって、同乗者が存在するか否かが判定される。座席センサ1604は、各座席にユーザが乗車しているか否かを示す情報を出力するものである限り、例えば、重量センサ又は各座席方向にビームを有する超音波センサ等、いかなる種類のものであってもよい。
【0089】
ディスプレイ1605には、コマンドリストなど認識語彙に関する情報、及び、地図などが表示される。
【0090】
車載の速度センサ1607が取得した、自動車の速度を示す情報は、中央演算装置1603内に取り込まれ、走行状況(例えば自動車が走行中であるか否か)を判断するために使われる。
【0091】
マイクロホン1606は、ユーザ発話を収録するために用いられる。音声認識部103は、マイクロホン1606を通して収録した音声を認識する。マイクロホン1606の代わりに、複数のマイクロホン素子からなるマイクロホンアレイ(例えば、図2に示すマイクロホンアレイ1201)が用いられてもよい。
【0092】
マイクロホンアレイを用いることで、単一のマイクロホンでは得ることが困難な音源方向に関する情報を得たり、目的話者の方向にビームを当てて、その方向の話者が発話した音声のみを抽出したりすることができる。音源分離部102は、マイクロホンアレイを用いて、特定方向の話者が発話した音声のみを抽出してもよい。
【0093】
なお、図9に示すマイクロホン1606及び中央演算装置1603は、それぞれ、図2に示すマイクロホンアレイ1201及び中央演算装置1203に相当する。図9に示す記憶媒体1602は、図2に示す揮発性メモリ1204及び記憶媒体1205の少なくとも一方に相当する。
【0094】
選択肢提示手段判定部106は、カーナビゲーションシステムに付属のユーザ提示装置を用いた提示手段の中から、安全性を損なわないという条件下で、タスク終了時間(すなわち、ユーザ提示装置が選択肢をユーザに提示し、選択肢をユーザが理解し、選択肢のいずれかをユーザが発話するのに要する時間)が短い手段を選択する。図9に記載されたカーナビゲーションシステムは、ユーザ提示装置として、スピーカ1601及びディスプレイ1605を備える。この場合、ユーザ提示手段としては、音声合成を用いて選択肢を読み上げる音声をスピーカ1601から出力するという方法と、ディスプレイ1605上に選択肢を表示するという方法の二つが考えられる。
【0095】
図10は、本発明の第1の実施形態の選択肢提示手段判定部106が実行する処理を示すフローチャートである。
【0096】
同乗者判定S701において、選択肢提示手段判定部106は、ドライバ以外の同乗者が乗車しているか否かを判定する。例えば、助手席(又は後部座席)の座席センサ1604の出力に基づいて、同乗者が乗車しているか否かが判定されてもよい。
【0097】
次のタスク終了時間判定S702において、選択肢提示手段判定部106は、各提示手段を用いてユーザに選択肢を提示した場合のタスク終了時間を推定する。タスク終了時間の推定値は、提示装置が選択肢を提示するのに要する時間に、予めプリセットされた平均音声認識終了時間を加算したものであってもよいし、各提示装置を使った音声対話装置を被験者に予め使用してもらった際に測定した平均タスク終了時間であってもよい。
【0098】
最短終了時間手段選択S703において、選択肢提示手段判定部106は、同乗者判定S701の結果に基づいて判定された、車内環境の安全性を損なわない提示装置のうち、タスク終了時間判定S702において推定したタスク終了時間が最も短い提示装置を選択する。どの提示装置が選択されたかを示す情報が、選択肢提示手段判定部106から出力される。
【0099】
なお、安全な提示手段が一つしかない場合、タスク終了時間判定S702は実行されなくてもよい。その場合、最短終了時間手段選択S703において、その一つしかない安全な提示手段が選択される。
【0100】
同乗者判定の結果に基づく、車内環境の安全性を損なわない提示装置の選択について以下に具体的に示す。ここでは、図9に記載された二つの提示装置、すなわち、音声合成を用いて選択肢を読み上げるスピーカ1601、及び、選択肢を表示するディスプレイ1605を例として説明する。
【0101】
ディスプレイ1605をドライバが見るという行為は、運転中のドライバの注意をそぐ可能性(すなわち、それによって安全性が損なわれる可能性)がある。このため、ドライバが選択肢を見ながら選択肢を選ぶという行為は、好ましくない。そのため、音声合成によって選択肢を読み上げることが、安全な提示方法の一つとして考えられる。
【0102】
このため、同乗者判定S701の結果、ドライバ以外の同乗者が存在しないと判定された場合、図9に示す提示装置を用いた提示方法のうち、ディスプレイ1605上に選択肢を表示するという方法は選択されずに、音声合成を用いて選択肢を読み上げるという方法が選択される。すなわち、使用されるべき提示装置として、ディスプレイ1605ではなく、スピーカ1601が選択される。
【0103】
一方、同乗者判定S701の結果、ドライバ以外の同乗者が存在すると判定された場合、ドライバ以外の同乗者がディスプレイ1605を見ながら選択肢を選ぶという行為は安全性を損なわない。したがって、この場合、音声合成を用いて選択肢を読み上げるという方法と、ディスプレイ1605上に選択肢を表示するという方法のうち最も推定タスク終了時間が最も短い提示方法が選ばれる。
【0104】
既に説明したように、タスク終了時間は、ユーザ提示装置が選択肢をユーザに提示するのに要する時間、及び、提示された選択肢をユーザが理解し、それらの選択肢のいずれかをユーザが発話するのに要する時間の合計である。
【0105】
ユーザ提示装置がスピーカ1601である場合、それが選択肢をユーザに提示するのに要する時間は、おおむね、選択肢を読み上げる音声の合成に要する時間、及び、合成された音声の出力に要する時間の合計に相当する。この時間の推定値は、例えば、中央演算装置1603等のハードウェアの処理性能、及び、選択肢として提示されるべきテキストの長さ等に基づいて算出することができる。
【0106】
一方、ユーザ提示装置がディスプレイ1605である場合、それが選択肢をユーザに提示するのに要する時間は、おおむね、ディスプレイ1605に表示されるべき画像のデータを生成するのに要する時間、及び、生成された画像をディスプレイ1605に表示するのに要する時間の合計に相当する。この時間の推定値は、例えば、中央演算装置1603等のハードウェアの処理性能、及び、生成される画像のデータ量に基づいて算出することができる。
【0107】
提示された選択肢をユーザが理解し、それらの選択肢のいずれかをユーザが発話するのに要する時間として、あらかじめ所定の値が保持されていてもよい。例えば、被験者が各提示装置を使用した場合に要した時間をあらかじめ実際に計測し、その計測された時間を音声対話装置が保持してもよい。
【0108】
ただし、実際には、タスク終了時間は、ユーザが選択肢を理解し、それらのいずれかを発話するのに要する時間より、むしろ、ユーザ提示装置が選択肢をユーザに提示するのに要する時間によって大きく左右されると考えられる。その場合、タスク終了時間として、ユーザ提示装置が選択肢をユーザに提示するのに要する時間のみが算出され、比較されてもよい。その場合、同乗者がいると判定されると、選択肢をディスプレイ1605上に表示するのに要する時間と、選択肢を読み上げるのに要する時間とが算出され、両者が比較される。その結果、例えば、選択肢をディスプレイ1605上に表示するのに要する時間が短いと判定された場合、提示装置としてディスプレイ1605が選択される。
【0109】
さらに、実際には、同一の選択肢が提示される場合、選択肢をディスプレイ1605上に表示するのに要する時間は、選択肢を読み上げるのに要する時間より短くなるのが一般的である。このため、上記の二つの提示方法がいずれも安全性を損なわないと判定された場合、常に(すなわち、推定タスク終了時間を算出することなく)、選択肢をディスプレイ1605上に表示するという提示方法が最も推定タスク終了時間が短い提示方法として選択されてもよい。
【0110】
ディスプレイ1605上に選択肢を表示する方法が選択された場合において、ディスプレイとして指向性ディスプレイが用いられる場合、指向性をドライバ以外の同乗者に向けるように設定されてもよい。また音声再生用スピーカ1601として指向性スピーカが用いられる場合、これから選択肢を入力するユーザ(すなわち、ドライバ以外の同乗者)の方向に指向性を向けてもよい。
【0111】
図10に示す処理は、対話制御部107がユーザと対話する方法を選択するために実行される。例えば、図10に示す処理は、対話制御部107が図6に示す処理を開始する前に実行されてもよいし、対話制御部107が各コマンドを処理するたびに実行されてもよい。
【0112】
図11は、本発明の第1の実施形態において出力されるガイダンス音声の例を示す説明図である。
【0113】
具体的には、図11は、同乗者がいる場合といない場合のガイダンス音声の出力例を示す。同乗者がいない場合、音声合成で読み上げた選択肢の中から選ぶように誘導するガイダンス音声(図11の例では、ガイダンス文「これから読み上げる施設名の中からお選びください」を読み上げる音声)が出力される。
【0114】
一方、同乗者がいる場合、ディスプレイ1605上に表示された選択肢の中から選ぶように誘導するガイダンス音声(図11の例では、ガイダンス文「同乗者の方がお答えください。これから画面に表示される施設名一覧の中からお選びください」を読み上げる音声)が出力される。同乗者がいる場合であっても、ドライバがディスプレイ1605を見ることを誘導してしまうことは好ましくないため、同乗者が答えるように誘導することも必要である。
【0115】
図12は、本発明の第1の実施形態においてディスプレイ1605に表示される選択肢の例を示す説明図である。
【0116】
具体的には、図12は、ディスプレイ1605上に選択肢を表示するという方法が選択された場合に表示される画面の表示例を示す。図12では、例として、設定したい目的地の選択肢(例えば、「レストラン」及び「自宅」等)が画面上に表示される。図12のように選択肢を画面上に表示することで、音声合成を用いて選択肢を読み上げるという方法と比べると、ユーザが選択肢を把握するまでの時間を短縮することができる。
【0117】
質問文生成部110は、選択肢提示手段判定部106の判定結果と同乗者の有無に基づき、質問文を生成する。質問文は、それを出力する必要が生じるたびにリアルタイムに生成されてもよいし、予め条件毎に文がプリセットされていてもよい。さらに、質問文中に同乗者の名前を含めることによって、ある特定の同乗者に回答を促してもよい。そのようにすることで、特定の同乗者の音声のみ抽出すればよくなるため、認識性能を向上可能となる。同乗者の名前を質問文に含めるためには、予めその同乗者の名前を登録する必要がある。
【0118】
図13は、本発明の第1の実施形態において選択肢の提示のために実行される処理の一例を示すフローチャートである。
【0119】
最初に、助手席判定S1701において、選択肢提示手段判定部106は、助手席に同乗者が乗車しているか否かを判定する。この判定は、図10の同乗者判定S701と同様の方法で実行される。
【0120】
助手席に同乗者が乗車していると判定された場合、ガイダンス出力1_S1702において、選択肢提示手段判定部106は、同乗者がいる場合のガイダンス音声を出力する(図11参照)。
【0121】
次に、画面に選択肢表示S1704において、選択肢提示手段判定部106は、選択肢をディスプレイ1605に表示する。具体的には、選択肢提示手段判定部106からの指示に基づいて、表示されるべき画像を表示画像生成部111が生成し、生成された画像を画像表示部113がディスプレイ1605に表示させる。
【0122】
一方、助手席に同乗者が乗車していないと判定された場合、ガイダンス出力2_S1703において、選択肢提示手段判定部106は、同乗者がいない場合のガイダンス音声を出力する(図11参照)。
【0123】
次に、音声で選択肢読み上げS1705において、選択肢提示手段判定部106は、選択肢を読み上げる音声を出力する。具体的には、選択肢提示手段判定部106からの指示に基づいて、出力されるべき選択肢を含む質問文を質問文生成部110が生成し、生成された質問文を読み上げる音声を音声出力部112がスピーカ1601に出力させる。
【0124】
画面に選択肢表示S1704又は音声で選択肢読み上げS1705が実行された後、音声認識S1706が実行される。具体的には、図3等を参照して説明したように、音声入力部101がユーザからの音声入力を受信し、その入力された音声を音源分離部102及び音声認識部103が処理することによって、入力された音声が認識される。
【0125】
このとき、助手席判定S1701の結果に基づいて目的音の範囲が設定されてもよい(図3の目的音範囲設定S901)。例えば、同乗者がいると判定された場合、目的音範囲設定S901において、マイクロホン1606から同乗者(例えば助手席に着席しているユーザ)への方向を含む所定の範囲が目的音の範囲として設定されてもよい。その場合、目的音の範囲内からの音声(すなわち同乗者が発話した音声)は、受理される。受理された音声は、選択肢の提示に対する応答として処理される。一方、目的音の範囲外からの音声(例えば運転者が発話した音声)は、棄却されるため、選択肢の提示に対する応答として処理されない。
【0126】
なお、上記図11及び図13は、同乗者がいない場合の選択肢提示方法として選択肢を読み上げることが選択され、同乗者がいる場合の選択肢提示方法として選択肢を表示することが選択される場合を例として示した。しかし、例えば、助手席判定S1701において、図10に示したものと同様の処理が実行されてもよい。その結果、助手席に同乗者が乗車している場合であっても、選択肢提示方法として選択肢を読み上げることが選択される場合もある。その場合、ガイダンス出力2_S1703及び音声で選択肢読み上げS1705が実行される。
【0127】
図14は、本発明の第1の実施形態における同乗者の名前登録の処理を示すフローチャートである。
【0128】
この処理は、カーナビゲーションシステム起動直後に実行される。助手席座席センサチェックS801において、座席センサ1604の情報に基づいて、助手席に人がいるか否かが判定される。
【0129】
助手席に人がいる場合、処理は名前認識S802に進む。名前認識S802において、音声認識辞書が全ての音節系列を受理可能なように設定された後、音声認識が実行される。このようにすることによって、任意の人の名前を認識することができる。音声認識によって認識された名前は、それが助手席の結果であるというラベルが付けられた後、記憶媒体1602に保存される。質問文生成時に、記憶媒体1602に保存された名前認識結果が参照される。
【0130】
助手席に人がいない場合、又は、名前認識S802が実行された後、処理は後部座席センサチェックS803に進み、後部座席に人がいるか否かが判定される。人がいる場合、処理は名前認識S804に進む。名前認識S804において、音声認識辞書が全ての音節系列を受理可能なように設定された後、音声認識が実行される。音声認識によって認識された名前は、それが後部座席の結果であるというラベルを付けられた後、記憶媒体1602に保存される。質問文生成時に、記憶媒体1602に保存された名前認識結果が参照される。
【0131】
後部座席に人がいない場合は、処理を終了する。また、名前認識S804後は、処理を終了する。
【0132】
音声出力部112は、質問文生成部110が生成した質問文を音声合成音に変換し、変換した音声合成音をスピーカ1601から出力する。表示画像生成部111は、選択肢提示手段判定部106の判定結果及び同乗者の有無に基づき、画面に情報を表示する必要がある場合は、表示画像を生成する。ここで生成される画像は、図12に例示したように選択肢を画面上にテキスト情報として表示するものであってもよいし、選択肢毎に予めプリセットされた画像を画面上に表示するものであってもよい。後者の場合、例えば、選択肢に含まれるレストランの画像が画面上に表示されてもよい。画像表示部113は、表示画像生成部111が生成した画像をディスプレイ1605上に表示する。
【0133】
機能制御部109は、音声認識結果に基づき、車室内機器を制御する。
【0134】
図15は、本発明の第1の実施形態の機能制御部109が実行する処理を示すフローチャートである。
【0135】
経路設定コマンドS1501において、機能制御部109は、音声認識結果が経路設定に関するものであるか否かを判定する。この判定は、音声認識結果の候補毎にその結果が経路設定に関するものか否かを示すフラグをあらかじめ設定しておくことで実現される。
【0136】
音声認識結果が経路設定に関するものである場合、機能制御部109は、カーナビゲーションシステムの経路設定処理を呼び出し、処理を終了する。
【0137】
音声認識結果が経路設定に関するものでなかった場合、機能制御部109は、次にエアコン操作コマンドS1502において、音声認識結果がエアコン操作コマンドに関するものか否かを判定する。この判定は、音声認識結果の候補毎に、その結果がエアコン操作コマンドに関するものか否かを示すフラグをあらかじめ設定しておくことで実現される。
【0138】
音声認識結果がエアコン操作コマンドに関するものである場合、機能制御部109は、カーナビゲーションシステム上のエアコン操作処理を呼び出し、処理を終了する。
【0139】
音声認識結果がエアコン操作処理に関するものでなかった場合、次にスピーカ制御コマンドS1503において、機能制御部109は、音声認識結果がスピーカ制御に関するものか否かを判定する。音声認識結果がスピーカ制御に関するものであった場合、機能制御部109は、カーナビゲーションシステム上のスピーカ制御処理を呼び出し、処理を終了する。
【0140】
以上、本発明の第1の実施形態によれば、自動車にドライバ以外のユーザが乗車しているか否かが判定され、その判定結果に基づいて、ユーザに対する情報提示方法が選択される。それによって、安全性を損なわず、かつ、短時間の音声対話が実現される。
【0141】
次に、本発明の第2の実施形態について説明する。第2の実施形態は、第1の実施形態と同様のハードウェアによって実現される(図2及び図9参照)。さらに、第2の実施形態では、以下に説明する相違点を除き、第1の実施形態と同様の処理が実行される。
【0142】
図16は、本発明の第2の実施形態の音声対話装置の機能ブロック図である。
【0143】
図16に示す各部のうち、音声入力部201、音源分離部202、音声認識部203、認識結果棄却判定部204、分離範囲設定部205、選択肢提示手段判定部206、対話制御部207、認識辞書生成部208、機能制御部209、認識語彙DB217、対話スクリプトDB216、質問文生成部210、表示画像生成部211、音声出力部214及び画像表示部215は、それぞれ、第1の実施形態における音声入力部101、音源分離部102、音声認識部103、認識結果棄却判定部104、分離範囲設定部105、選択肢提示手段判定部106、対話制御部107、認識辞書生成部108、機能制御部109、認識語彙DB115、対話スクリプトDB114、質問文生成部110、表示画像生成部111、音声出力部112及び画像表示部113と同等の機能を有する。
【0144】
第2の実施形態の音声対話装置は、さらに、質問文出力タイミング決定部212、画像表示タイミング決定部213及び走行状況判定部218を備える。これらも、記憶媒体1205に格納されたプログラムを中央演算装置1203が実行することによって実現される。
【0145】
走行状況判定部218は、車速の情報に基づいて、現在の走行状況、例えば、現在運転中なのか静止中なのかを判定する。さらに、走行状況判定部218は、カーナビゲーションシステムの地図情報を利用して、現在地が高速道路上であるといった情報、及び、現在交差点で静止中であるといった状況まで判定してもよい。
【0146】
具体的には、図9に示すカーナビゲーションシステムが、自動車の現在位置情報を取得する測位装置(図示省略)を備える。走行状況判定部218は、測位装置が取得した現在位置情報と、記憶媒体1602に格納された地図情報とを参照することによって、現在地が高速道路上であるか否かなどを判定することができる。
【0147】
判定した走行状況に基づき、選択肢提示手段判定部206は、カーナビゲーションシステムに付属のユーザ提示装置を用いた提示手段の中から、安全性を損なわないという条件下で、タスク終了時間(すなわち、ユーザ提示装置が選択肢をユーザに提示し、選択肢をユーザが理解し、選択肢のいずれかをユーザが発話するまでに要する時間)が短い手段を選択する。ディスプレイ1605をドライバが見るという行為は、ドライバの注意をそぐ可能性(すなわち、それによって安全性が損なわれる可能性)がある。このため、ドライバが運転中に選択肢を見ながら選択肢を選ぶという行為は、好ましくない。
【0148】
このため、同乗者判定S701によってドライバ以外の同乗者が存在しないと判定された場合、判定した走行状況に基づいて選択肢提示手段が判定される。具体的には、走行状況が静止中(すなわち車が停止している状態)である場合、ディスプレイ1605上に選択肢を表示するという方法が選択される。一方、走行状況が走行中である場合、ドライバに静止可能な場所に車を止めることを誘導するガイダンスを再生して、ドライバが車を止めたことを走行状況判定で確認した後、ディスプレイ1605上に選択肢を表示するという方法が選択される。
【0149】
質問文出力タイミング決定部212は、質問文を読み上げる音声を出力するタイミングを走行状況に応じて制御する。具体的には、走行状況が走行中である場合、質問文出力タイミング決定部212は、ドライバに静止可能な場所に車を止めることを誘導するガイダンスを再生した後、静止状態になったタイミングで、画面上の選択肢の中から選ぶことを誘導する質問文を出力するように制御する。
【0150】
画像表示タイミング決定部213は、同様に、ディスプレイ1605上に選択肢を表示するタイミングを走行状況に応じて制御する。具体的には、画像表示タイミング決定部213は、静止状態になったタイミングで、ディスプレイ1605の画面上に選択肢を表示するように制御する。
【0151】
図17は、本発明の第2の実施形態における走行状況及び音声対話のタイミングチャートである。
【0152】
図17の例では、音声対話を開始した時点において時速40km/hで走行中であったため、質問文出力タイミング決定部212は、ドライバに停止をすることを促すガイダンスを再生するように音声出力部214を制御する。その後、質問文出力タイミング決定部212は、車が停止したことを確認した後、質問文を出力するように音声出力部214を制御する。
【0153】
画像表示タイミング決定部213は、車が停止したことを確認した後、選択肢をディスプレイ1605の画面に表示するように画像表示部215を制御する。その後、音声認識部203等による音声認識が開始される。
【0154】
図18は、本発明の第2の実施形態において選択肢の提示のために実行される処理の一例を示すフローチャートである。
【0155】
以下、ドライバ以外の同乗者が乗車しておらず、かつ、車が走行中である場合に図18の処理が実行される例を示す。
【0156】
最初に、状況判定S1801において、走行状況判定部218は、車を停止可能であるか否かを判定する。例えば、走行状況判定部218は、現在地が高速道路上である場合、車を停止可能でないと判定し、現在地が一般道路上である場合、車を停止可能であると判定してもよい。
【0157】
車を停止可能でないと判定された場合、ガイダンス出力1_S1802において、選択肢提示手段判定部106は、車を停止可能でない場合のガイダンス音声を出力する。例えば、選択肢提示手段判定部106は、図11に示した同乗者がいない場合の質問文を読み上げる音声を出力するように質問文生成部210を制御してもよい。
【0158】
次に、音声で選択肢読み上げS1804において、選択肢提示手段判定部106は、選択肢を読み上げる音声を出力する。具体的には、選択肢提示手段判定部106からの指示に基づいて、出力されるべき選択肢を含む質問文を質問文生成部110が生成し、生成された質問文を読み上げる音声を音声出力部112がスピーカ1601に出力させる。
【0159】
一方、車を停止可能であると判定された場合、ガイダンス出力2_S1803において、選択肢提示手段判定部106は、車を停止可能である場合のガイダンス音声を出力する。例えば、選択肢提示手段106は、ドライバに静止可能な場所に車を止めることを誘導するガイダンスを出力するように質問文生成部210を制御してもよい。
【0160】
次に、停止判定S1805において、質問文出力タイミング決定部212は、車が停止したか否かを判定する。車がまだ停止していないと判定された場合、処理はガイダンス出力2_S1803に戻り、再び車を止めることを誘導するガイダンスが出力される。
【0161】
一方、車が停止したと判定された場合、質問文出力タイミング決定部212は、ガイダンス出力3_S1806において、車が停止した場合のガイダンス音声を出力する。例えば、質問文出力タイミング決定部212は、質問文生成部210が生成した、同乗者がいる場合の質問文(例えば図11参照)を読み上げる音声を出力するように、音声出力部214を制御してもよい。なお、上記の例では実際には同乗者がいないが、車が停止しているため、ドライバがディスプレイ1605を見ても安全性は損なわれない。
【0162】
さらに、停止判定S1805において、画像表示タイミング決定部213は、車が停止したか否かを判定する。車がまだ停止していないと判定された場合、処理はガイダンス出力2_S1803に戻り、再び車を止めることを誘導するガイダンスが出力される。
【0163】
一方、車が停止したと判定された場合、画像表示タイミング決定部213は、ガイダンス出力3_S1806において、選択肢をディスプレイ1605の画面に表示する。例えば、画像表示タイミング決定部213は、表示画像生成部211が生成した選択肢の表示画像(例えば図12参照)を表示するように、画像表示部215を制御してもよい。
【0164】
音声で選択肢読み上げS1804又はガイダンス出力3_S1806が実行された後、音声認識S1807が実行される。このステップは、第1の実施形態の音声認識S1706と同様である。
【0165】
なお、前記図18は、ドライバ以外の同乗者が乗車しておらず、かつ、車が走行中である場合を例として説明した。例えば、本実施形態においても、第1の実施形態と同様、図13に示す助手席判定S1701が実行され、同乗者がいないと判定された場合に図18に示す処理が開始されてもよい。一方、同乗者がいると判定された場合には、第1の実施形態と同様、ガイダンス出力1_S1702及び画面に選択肢表示S1704が実行されてもよい。
【0166】
さらに、図18は、車が走行中でない場合に実行されてもよい。例えば、状況判定S1801において、まず車が走行中であるか否かが判定され、走行中であると判定され場合に停止可能であるか否かが判定されてもよい。車が走行中でないと判定された場合、処理はガイダンス出力2_S1803及び停止判定S1805が省略され、ガイダンス出力3_S1806が実行されてもよい。
【0167】
以上、本発明の第2の実施形態によれば、自動車にドライバのみが乗車している場合であっても、安全性を損なわず、かつ、短時間で音声対話を実行できる情報提示方法が選択される。
【0168】
以上の本発明の第1及び第2の実施形態は、選択肢を示すテキスト情報をユーザに提示し、その提示に対する応答として選択肢のいずれかをユーザが発話する処理を例として説明した。しかし、これらの実施形態は、任意のテキスト情報の提示及びそれに対するユーザからの応答を処理するために適用することができる。
【図面の簡単な説明】
【0169】
【図1】本発明の第1の実施形態の音声対話装置の機能ブロック図である。
【図2】本発明の第1の実施形態の音声対話装置のハードウェア構成のブロック図である。
【図3】本発明の第1の実施形態において実行される音声認識処理を示すフローチャートである。
【図4】本発明の第1の実施形態の音源分離部が実行する詳細な処理の流れを示す説明図である。
【図5】本発明の第1の実施形態の音源分離において時間周波数毎に実行される処理を示すフローチャートである。
【図6】本発明の第1の実施形態における対話スクリプトに基づく対話を示すフローチャートである。
【図7】本発明の第1の実施形態において使用される音声認識辞書の一例を示す説明図である。
【図8】本発明の第1の実施形態におけるアークごとの単語リストの一例を示す説明図である。
【図9】本発明の第1の実施形態の音声対話装置を含むカーナビゲーションシステムのハードウェア構成のブロック図である。
【図10】本発明の第1の実施形態の選択肢提示手段判定部が実行する処理を示すフローチャートである。
【図11】本発明の第1の実施形態において出力されるガイダンス音声の例を示す説明図である。
【図12】本発明の第1の実施形態においてディスプレイに表示される選択肢の例を示す説明図である。
【図13】本発明の第1の実施形態において選択肢の提示のために実行される処理の一例を示すフローチャートである。
【図14】本発明の第1の実施形態における同乗者の名前登録の処理を示すフローチャートである。
【図15】本発明の第1の実施形態の機能制御部が実行する処理を示すフローチャートである。
【図16】本発明の第2の実施形態の音声対話装置の機能ブロック図である。
【図17】本発明の第2の実施形態における走行状況及び音声対話のタイミングチャートである。
【図18】本発明の第2の実施形態において選択肢の提示のために実行される処理の一例を示すフローチャートである。
【符号の説明】
【0170】
101、201 音声入力部
102、202 音源分離部
103、203 音声認識部
104、204 認識結果棄却判定部
105、205 分離範囲設定部
106、206 選択肢提示手段判定部
107、207 対話制御部
108、208 認識辞書生成部
109、209 機能制御部
110、210 質問文生成部
111、211 表示画像生成部
112、214 音声出力部
113、215 画像表示部
114、216 対話スクリプトDB
115、217 認識語彙DB
212 質問文出力タイミング決定部
213 画像表示タイミング決定部
218 走行状況判定部
S301 コマンド名称
S302 目的地設定
S303 自動車機器操作
S304 周辺施設検索
S305 時間周波数分解
S701 同乗者判定
S702 タスク終了時間判定
S703 最短終了時間手段選択
S801 助手席座席センサチェック
S802 名前認識
S803 後部座席センサチェック
S804 名前認識
S901 目的音範囲設定
S902 音源分離
1001 DFT
1002 周波数毎ベクトル化
1003 音源定位
1004 音源分離
1005 逆DFT
S1101 目的音範囲かどうか
S1102 目的音共分散更新
S1103 雑音共分散更新
S1104 フィルタ生成
S1105 フィルタリング
S1106 ポストフィルタリング
1201 マイクロホンアレイ
1202 AD変換装置
1203、1603 中央演算装置
1204 揮発性メモリ
1205、1602 記憶媒体
S1501 経路設定コマンド
S1502 エアコン操作コマンド
S1503 スピーカ制御コマンド
1601 スピーカ
1604 座席センサ
1605 ディスプレイ
1606 マイクロホン
1607 速度センサ
【特許請求の範囲】
【請求項1】
自動車内における乗員の乗車位置を検知する乗員検知部と、
テキスト情報を音声に変換して出力する音声出力部と、
前記テキスト情報を画像に変換して表示する画像表示部と、
前記乗員検知部の検知結果に基づいて、前記音声出力部又は前記画像表示部のいずれか一方を選択し、前記選択された前記音声出力部又は前記画像表示部に前記テキスト情報を出力させる切り替え部と、を備えることを特徴とする音声対話装置。
【請求項2】
運転者以外の乗員が乗車している場合、前記テキスト情報を前記画像表示部に出力させることを選択し、前記運転者以外の乗員が乗車していない場合、前記テキスト情報を前記音声出力部に出力させることを選択することを特徴とする請求項1に記載の音声対話装置。
【請求項3】
前記音声対話装置は、
さらに、複数のマイクロホンを備え、
前記運転者以外の乗員が乗車していると判定された場合、前記運転者以外の乗員が応答するように促す音声を前記音声出力部から出力し、
前記運転者以外の乗員が応答するように促す音声が出力された後、前記複数のマイクロホンが音声を受信すると、前記受信した音声の音源方向を特定し、
前記特定された音源方向が、前記複数のマイクロホンから前記運転者以外の乗員への方向を含む所定の範囲内であるか否かを判定し、
前記特定された音源方向が前記所定の範囲内である場合、前記受信した音声を、前記画像表示部に表示されたテキスト情報に対する応答として処理することを特徴とする請求項2に記載の音声対話装置。
【請求項4】
前記音声対話装置は、
前記運転者以外の乗員が乗車している場合、前記テキスト情報の前記画像表示部への表示に要する第1時間、及び、前記テキスト情報を読み上げる音声の前記音声出力部からの出力に要する第2時間を推定し、
前記第1時間が前記第2時間より短い場合、前記テキスト情報を前記画像表示部に出力させることを選択し、前記第2時間が前記第1時間より短い場合、前記テキスト情報を前記音声出力部に出力させることを選択し、
前記運転者以外の乗員が乗車していない場合、前記テキスト情報を前記音声出力部に出力させることを選択することを特徴とする請求項1に記載の音声対話装置。
【請求項5】
前記自動車は、さらに、前記自動車が走行中であるか否かを示す情報を出力する速度センサを備え、
前記音声対話装置は、
前記速度センサからの出力に基づいて、前記自動車が走行中であるか否かを判定し、
前記自動車が走行中であると判定された場合、前記運転者に自動車の停止を促す音声を前記音声出力部から出力し、
前記自動車が停止中であると判定された場合、前記テキスト情報を含む画像を前記画像表示部に表示することを特徴とする請求項1に記載の音声対話装置。
【請求項6】
前記音声対話装置は、前記運転者以外の乗員が乗車していない場合、前記自動車が走行中であるか否かを判定し、前記運転者以外の乗員が乗車している場合、前記自動車が走行中であるか否かを判定しないことを特徴とする請求項5に記載の音声対話装置。
【請求項7】
前記自動車は、さらに、前記自動車の現在位置情報を取得する測位装置を備え、
前記音声対話装置は、
前記測位装置が取得した前記自動車の現在位置情報に基づいて、前記自動車を停止させることができるか否かを判定し、
前記自動車を停止させることができると判定された場合、前記運転者に自動車の停止を促す音声を前記音声出力部から出力し、
前記自動車を停止させることができないと判定された場合、前記テキスト情報を読み上げる音声を前記音声出力部から出力することを特徴とする請求項5に記載の音声対話装置。
【請求項8】
前記音声対話装置は、前記現在位置情報に基づいて、前記自動車が高速道路を走行中であると判定された場合、前記自動車を停止させることができないと判定することを特徴とする請求項7に記載の音声対話装置。
【請求項9】
テキスト情報を音声に変換して出力する音声出力部と、前記テキスト情報を画像に変換して出力する画像表示部と、を備える音声対話装置による音声対話方法において、
自動車内における乗員の乗車位置を検知する乗員検知手順と、
前記乗員検知手順によって検出された乗員の位置に基づいて、前記音声出力部又は前記画像表示部のいずれか一方を選択し、選択された前記音声出力部又は前記画像表示部が前記テキスト情報を出力する切り替え手順と、を含むことを特徴とする音声対話方法。
【請求項10】
前記切り替え手順は、運転者以外の乗員が乗車している場合、前記テキスト情報を前記画像表示部に出力させることを選択し、前記運転者以外の乗員が乗車していない場合、前記テキスト情報を前記音声出力部に出力させることを選択する手順を含むことを特徴とする請求項9に記載の音声対話方法。
【請求項11】
前記音声対話装置は、さらに、複数のマイクロホンを備え、
前記音声対話方法は、さらに、
前記運転者以外の乗員が乗車していると判定された場合、前記運転者以外の乗員が応答するように促す音声を前記音声出力部から出力する手順と、
前記運転者以外の乗員が応答するように促す音声が出力された後、前記複数のマイクロホンが音声を受信すると、前記受信した音声の音源方向を特定する手順と、
前記特定された音源方向が、前記複数のマイクロホンから前記運転者以外の乗員への方向を含む所定の範囲内であるか否かを判定する手順と、
前記特定された音源方向が前記所定の範囲内である場合、前記受信した音声を、前記画像表示部に表示されたテキスト情報に対する応答として処理する手順と、を含むことを特徴とする請求項10に記載の音声対話方法。
【請求項12】
前記切り替え手順は、前記運転者以外の乗員が乗車している場合、前記テキスト情報の前記画像表示部への表示に要する第1時間、及び、前記テキスト情報を読み上げる音声の前記音声出力部からの出力に要する第2時間を推定し、前記第1時間が前記第2時間より短い場合、前記テキスト情報を前記画像表示部に出力させることを選択し、前記第2時間が前記第1時間より短い場合、前記テキスト情報を前記音声出力部に出力させることを選択し、前記運転者以外の乗員が乗車していない場合、前記テキスト情報を前記音声出力部に出力させることを選択する手順を含むことを特徴とする請求項9に記載の音声対話方法。
【請求項13】
前記自動車は、さらに、前記自動車が走行中であるか否かを示す情報を出力する速度センサを備え、
前記音声対話方法は、さらに、
前記速度センサからの出力に基づいて、前記自動車が走行中であるか否かを判定する手順と、
前記自動車が走行中であると判定された場合、前記運転者に自動車の停止を促す音声を前記音声出力部から出力する手順と、
前記自動車が停止中であると判定された場合、前記テキスト情報を含む画像を前記画像表示部に表示する手順と、を含むことを特徴とする請求項9に記載の音声対話方法。
【請求項14】
前記自動車が走行中であるか否かを判定する手順は、前記運転者以外の乗員が乗車していない場合に実行され、前記運転者以外の乗員が乗車している場合には実行されないことを特徴とする請求項13に記載の音声対話方法。
【請求項15】
前記自動車は、さらに、前記自動車の現在位置情報を取得する測位装置を備え、
前記音声対話方法は、さらに、
前記測位装置が取得した前記自動車の現在位置情報に基づいて、前記自動車を停止させることができるか否かを判定する手順と、
前記自動車を停止させることができると判定された場合、前記運転者に自動車の停止を促すメッセージを前記音声出力部から出力する手順と、
前記自動車を停止させることができないと判定された場合、前記テキスト情報を読み上げる音声を前記音声出力部から出力する手順と、を含むことを特徴とする請求項13に記載の音声対話方法。
【請求項16】
前記自動車を停止させることができるか否かを判定する手順は、前記現在位置情報に基づいて、前記自動車が高速道路を走行中であると判定された場合、前記自動車を停止させることができないと判定する手順を含むことを特徴とする請求項15に記載の音声対話方法。
【請求項1】
自動車内における乗員の乗車位置を検知する乗員検知部と、
テキスト情報を音声に変換して出力する音声出力部と、
前記テキスト情報を画像に変換して表示する画像表示部と、
前記乗員検知部の検知結果に基づいて、前記音声出力部又は前記画像表示部のいずれか一方を選択し、前記選択された前記音声出力部又は前記画像表示部に前記テキスト情報を出力させる切り替え部と、を備えることを特徴とする音声対話装置。
【請求項2】
運転者以外の乗員が乗車している場合、前記テキスト情報を前記画像表示部に出力させることを選択し、前記運転者以外の乗員が乗車していない場合、前記テキスト情報を前記音声出力部に出力させることを選択することを特徴とする請求項1に記載の音声対話装置。
【請求項3】
前記音声対話装置は、
さらに、複数のマイクロホンを備え、
前記運転者以外の乗員が乗車していると判定された場合、前記運転者以外の乗員が応答するように促す音声を前記音声出力部から出力し、
前記運転者以外の乗員が応答するように促す音声が出力された後、前記複数のマイクロホンが音声を受信すると、前記受信した音声の音源方向を特定し、
前記特定された音源方向が、前記複数のマイクロホンから前記運転者以外の乗員への方向を含む所定の範囲内であるか否かを判定し、
前記特定された音源方向が前記所定の範囲内である場合、前記受信した音声を、前記画像表示部に表示されたテキスト情報に対する応答として処理することを特徴とする請求項2に記載の音声対話装置。
【請求項4】
前記音声対話装置は、
前記運転者以外の乗員が乗車している場合、前記テキスト情報の前記画像表示部への表示に要する第1時間、及び、前記テキスト情報を読み上げる音声の前記音声出力部からの出力に要する第2時間を推定し、
前記第1時間が前記第2時間より短い場合、前記テキスト情報を前記画像表示部に出力させることを選択し、前記第2時間が前記第1時間より短い場合、前記テキスト情報を前記音声出力部に出力させることを選択し、
前記運転者以外の乗員が乗車していない場合、前記テキスト情報を前記音声出力部に出力させることを選択することを特徴とする請求項1に記載の音声対話装置。
【請求項5】
前記自動車は、さらに、前記自動車が走行中であるか否かを示す情報を出力する速度センサを備え、
前記音声対話装置は、
前記速度センサからの出力に基づいて、前記自動車が走行中であるか否かを判定し、
前記自動車が走行中であると判定された場合、前記運転者に自動車の停止を促す音声を前記音声出力部から出力し、
前記自動車が停止中であると判定された場合、前記テキスト情報を含む画像を前記画像表示部に表示することを特徴とする請求項1に記載の音声対話装置。
【請求項6】
前記音声対話装置は、前記運転者以外の乗員が乗車していない場合、前記自動車が走行中であるか否かを判定し、前記運転者以外の乗員が乗車している場合、前記自動車が走行中であるか否かを判定しないことを特徴とする請求項5に記載の音声対話装置。
【請求項7】
前記自動車は、さらに、前記自動車の現在位置情報を取得する測位装置を備え、
前記音声対話装置は、
前記測位装置が取得した前記自動車の現在位置情報に基づいて、前記自動車を停止させることができるか否かを判定し、
前記自動車を停止させることができると判定された場合、前記運転者に自動車の停止を促す音声を前記音声出力部から出力し、
前記自動車を停止させることができないと判定された場合、前記テキスト情報を読み上げる音声を前記音声出力部から出力することを特徴とする請求項5に記載の音声対話装置。
【請求項8】
前記音声対話装置は、前記現在位置情報に基づいて、前記自動車が高速道路を走行中であると判定された場合、前記自動車を停止させることができないと判定することを特徴とする請求項7に記載の音声対話装置。
【請求項9】
テキスト情報を音声に変換して出力する音声出力部と、前記テキスト情報を画像に変換して出力する画像表示部と、を備える音声対話装置による音声対話方法において、
自動車内における乗員の乗車位置を検知する乗員検知手順と、
前記乗員検知手順によって検出された乗員の位置に基づいて、前記音声出力部又は前記画像表示部のいずれか一方を選択し、選択された前記音声出力部又は前記画像表示部が前記テキスト情報を出力する切り替え手順と、を含むことを特徴とする音声対話方法。
【請求項10】
前記切り替え手順は、運転者以外の乗員が乗車している場合、前記テキスト情報を前記画像表示部に出力させることを選択し、前記運転者以外の乗員が乗車していない場合、前記テキスト情報を前記音声出力部に出力させることを選択する手順を含むことを特徴とする請求項9に記載の音声対話方法。
【請求項11】
前記音声対話装置は、さらに、複数のマイクロホンを備え、
前記音声対話方法は、さらに、
前記運転者以外の乗員が乗車していると判定された場合、前記運転者以外の乗員が応答するように促す音声を前記音声出力部から出力する手順と、
前記運転者以外の乗員が応答するように促す音声が出力された後、前記複数のマイクロホンが音声を受信すると、前記受信した音声の音源方向を特定する手順と、
前記特定された音源方向が、前記複数のマイクロホンから前記運転者以外の乗員への方向を含む所定の範囲内であるか否かを判定する手順と、
前記特定された音源方向が前記所定の範囲内である場合、前記受信した音声を、前記画像表示部に表示されたテキスト情報に対する応答として処理する手順と、を含むことを特徴とする請求項10に記載の音声対話方法。
【請求項12】
前記切り替え手順は、前記運転者以外の乗員が乗車している場合、前記テキスト情報の前記画像表示部への表示に要する第1時間、及び、前記テキスト情報を読み上げる音声の前記音声出力部からの出力に要する第2時間を推定し、前記第1時間が前記第2時間より短い場合、前記テキスト情報を前記画像表示部に出力させることを選択し、前記第2時間が前記第1時間より短い場合、前記テキスト情報を前記音声出力部に出力させることを選択し、前記運転者以外の乗員が乗車していない場合、前記テキスト情報を前記音声出力部に出力させることを選択する手順を含むことを特徴とする請求項9に記載の音声対話方法。
【請求項13】
前記自動車は、さらに、前記自動車が走行中であるか否かを示す情報を出力する速度センサを備え、
前記音声対話方法は、さらに、
前記速度センサからの出力に基づいて、前記自動車が走行中であるか否かを判定する手順と、
前記自動車が走行中であると判定された場合、前記運転者に自動車の停止を促す音声を前記音声出力部から出力する手順と、
前記自動車が停止中であると判定された場合、前記テキスト情報を含む画像を前記画像表示部に表示する手順と、を含むことを特徴とする請求項9に記載の音声対話方法。
【請求項14】
前記自動車が走行中であるか否かを判定する手順は、前記運転者以外の乗員が乗車していない場合に実行され、前記運転者以外の乗員が乗車している場合には実行されないことを特徴とする請求項13に記載の音声対話方法。
【請求項15】
前記自動車は、さらに、前記自動車の現在位置情報を取得する測位装置を備え、
前記音声対話方法は、さらに、
前記測位装置が取得した前記自動車の現在位置情報に基づいて、前記自動車を停止させることができるか否かを判定する手順と、
前記自動車を停止させることができると判定された場合、前記運転者に自動車の停止を促すメッセージを前記音声出力部から出力する手順と、
前記自動車を停止させることができないと判定された場合、前記テキスト情報を読み上げる音声を前記音声出力部から出力する手順と、を含むことを特徴とする請求項13に記載の音声対話方法。
【請求項16】
前記自動車を停止させることができるか否かを判定する手順は、前記現在位置情報に基づいて、前記自動車が高速道路を走行中であると判定された場合、前記自動車を停止させることができないと判定する手順を含むことを特徴とする請求項15に記載の音声対話方法。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】

【図12】

【図13】
【図14】

【図15】
【図16】
【図17】
【図18】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【公開番号】特開2010−102163(P2010−102163A)
【公開日】平成22年5月6日(2010.5.6)
【国際特許分類】
【出願番号】特願2008−274124(P2008−274124)
【出願日】平成20年10月24日(2008.10.24)
【出願人】(591132335)株式会社ザナヴィ・インフォマティクス (745)
【Fターム(参考)】
【公開日】平成22年5月6日(2010.5.6)
【国際特許分類】
【出願日】平成20年10月24日(2008.10.24)
【出願人】(591132335)株式会社ザナヴィ・インフォマティクス (745)
【Fターム(参考)】
[ Back to top ]