
辞書を用いてパンクロマチック画像及びマルチスペクトル画像をパンシャープン化する方法
【課題】辞書を用いてパンクロマチック画像及びマルチスペクトル画像をパンシャープン化する方法を提供する。
【解決手段】単一のパンクロマチック(Pan)画像102と、単一のマルチスペクトル(MS)画像101とが、Pan画像及びMS画像から特徴を抽出することによってパンシャープン化160される。特徴は、欠落値を有しない特徴と、欠落値を有する特徴とに分解される。欠落値を有しない特徴から辞書が学習される。辞書を用いて、欠落値を有する特徴の値が学習される。MS画像は、予測値を含むPan画像と合成されて、合成画像にされ、次に、合成画像がパンシャープン化される。
【解決手段】単一のパンクロマチック(Pan)画像102と、単一のマルチスペクトル(MS)画像101とが、Pan画像及びMS画像から特徴を抽出することによってパンシャープン化160される。特徴は、欠落値を有しない特徴と、欠落値を有する特徴とに分解される。欠落値を有しない特徴から辞書が学習される。辞書を用いて、欠落値を有する特徴の値が学習される。MS画像は、予測値を含むPan画像と合成されて、合成画像にされ、次に、合成画像がパンシャープン化される。
【発明の詳細な説明】
【技術分野】
【0001】
この発明は、包括的には、画像をパンシャープン化することに関し、より詳細には、辞書を用いてパンクロマチック画像及びマルチスペクトル画像を鮮明化することに関する。
【背景技術】
【0002】
QuickBird、IKONOS、及びALOS等の多数の衛星撮像システムが、2つの種類の画像、すなわちパンクロマチック(Pan)及びマルチスペクトル(MS)を生成する。Pan画像は、色情報なしで高い空間解像度を提供するのに対し、MS画像は色スペクトル情報を提供するが、低減された空間解像度で提供する。
【0003】
ターゲット識別及び物質識別等の様々な画像用途について、高空間品質及び高スペクトル品質の双方を有するMS画像を得ることが必要である。画像品質を向上させるために、パンシャープン化によって、高解像度のパンクロマチック画像と低解像度のマルチスペクトル画像とが合成され、単一の高解像度のカラー画像が生成される。通常、パンシャープン化によって、3つ又は4つ以上の低解像度のスペクトル帯域に加えて、対応する高解像度のパンクロマチック帯域から、高解像度のカラー画像が生成される。
【0004】
輝度−色相飽和(IHS)、主成分分析(PCA)、ウェーブレットベースの合成、変分法等の、複数のパンシャープン化方法が知られている。これらの方法は異なっているように見えるが、これらの方法の基本ステップは類似している。
【0005】
第1に、低解像度(LR)MS画像は、高解像度(HR)Pan画像と同じサイズになるように補間される。
【0006】
第2に、Pan画像の高周波成分は、補間されたMS画像と、方法に依存した形で合成される。例えば、IHSに基づく方法では、補間されたMS画像の輝度(I)成分がPan画像と置き換えられるのに対し、PCAに基づく方法では、補間されたMS画像の主成分がPan画像と置き換えられる。
【0007】
第3に、合成データは画像領域に変換され、合成画像が得られる。
【0008】
パンシャープン化されたMS画像は通常、良好な空間解像度を有するが、多くの場合に色歪みを呈する。色精度を改善し、色歪みを低減するために、それぞれが特定の合成技法又は画像セットに特化した様々な方法が既知である。これらの方法のほとんどが、Pan画像の高周波成分を、補間されたMS画像にどのように挿入するかに焦点を当てているが、合成プロセスの初期化時にMSを補間することによって生じる歪みを考慮していない。
【0009】
圧縮センシング、スパース表現、及び辞書学習(DL)が、この問題に対処する新たなツールを提供する。具体的には、辞書学習がパンシャープン化問題に適用されており、ここでHR Pan画像及びLR MS画像は圧縮測定値として扱われる。学習済み辞書におけるスパース性を正則化プライア(regularization prior)として用いて、HR MS画像を、スパース復元問題を解くことによって復元することができる。
【0010】
しかしながら、これらの方法は、辞書をトレーニングするのに多数のHR MSトレーニング画像を必要とし、これらの画像は通常、実際には利用可能でない。
【発明の概要】
【発明が解決しようとする課題】
【0011】
パンシャープン化は、高解像度(HR)パンクロマチック(Pan)画像を用いて、対応する低解像度(LR)マルチスペクトル(MS)画像を鮮明化する画像合成プロセスである。パンシャープン化されたMS画像は通常、高い空間解像度を有するが、色歪みを呈する。
【課題を解決するための手段】
【0012】
この発明の実施の形態は、MS画像の補間によって生じる色歪みを低減する、辞書学習を用いたパンシャープン化方法を提供する。合成前にLR MS画像を補間する代わりに、反復プロセスを用いて、学習済み辞書のスパース表現に基づいて改善されたMS画像を生成する。
【0013】
従来技術と対照的に、この発明による辞書は、単一のPan画像及び単一のMS画像から学習される。すなわち、この発明による方法は、より大きな組の画像を辞書の使用前にトレーニングすることを必要としない。そのかわり、この方法は、パンシャープン化されるPan画像及びMS画像を直接対象にする。
【発明の効果】
【0014】
この発明の実施の形態は、多数のトレーニング画像を必要とすることなく、MS画像を補間することによって生じる色歪みを低減する、辞書学習(DL)に基づくパンシャープン化方法を提供する。
【0015】
従来のパンシャープン化方法と比較して、この発明によるDLに基づくパンシャープン化方法の新規性は、3つの態様に存する。
【0016】
この方法は、LR MS画像を単に補間する代わりに、DLを用いて、改善された解像度を有するMS画像を生成することに焦点を当てている。このため、この方法は、MS画像を補間することによって初期化される任意の従来技術によるパンシャープン化方法と組み合わせることができる。
【0017】
この方法は、辞書を学習するのに多数のHR MS画像を必要とせず、鮮明化される必要がある画像のみを必要とする。
【0018】
この方法は、画像のスパース性及び整合性に従ってMS画像を更新し、より少ない歪みを有するMS画像を得る反復手順を提供する。
【0019】
加えて、この発明によるDLベースの方法を、最小限の変更で、ハイパースペクトルデータに適用することができる。
【0020】
この発明による辞書学習に基づくパンシャープン化プロセスは、複数の利点を有する。辞書学習に基づくパンシャープン化方法を含む、従来技術のパンシャープン化方法と比較して、この発明による方法は、トレーニングのために大量の高解像度のMS画像を必要とせず、MS補間プロセスを用いる他のパンシャープン化アルゴリズムと組み合わせることができる。この発明による辞書学習プロセスは、僅かな変更で、ハイパースペクトルデータを合成するように容易に拡張することができる。
【図面の簡単な説明】
【0021】
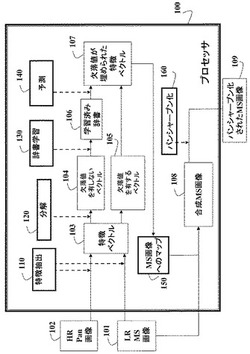
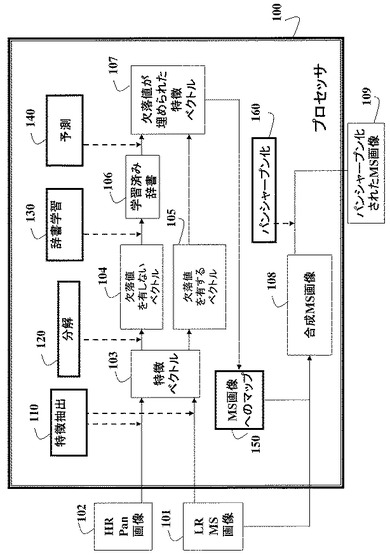
【図1】この発明の実施の形態による、辞書を用いたパンクロマチック画像及びマルチスペクトル画像のパンシャープン化の流れ図である。
【図2】この発明の実施の形態による、欠落データを予測するための目的関数を最小にする手順の疑似コードのブロック図である。
【図3】従来のパンシャープン化と、この発明の実施の形態によるパンシャープン化とを比較する画像である。
【発明を実施するための形態】
【0022】
辞書学習に基づくパンシャープン化
辞書学習は、信号をスパースに表すのに用いることができる、一組のベクトル(アトム)を学習するプロセスである。y=Dαによって表される信号y∈Rn×1を考える。ここで、D∈Rn×kは、その列としてアトムを含む辞書であり、α∈Rk×1は表現ベクトルである。辞書を用いて、対象の自然信号のクラスにおいて構造を捕捉する。具体的には、信号をスパースなαによって表すことができる場合、すなわち、Dからの幾つかのアトムの線形結合が、僅かな誤差で信号yを表すことができる場合、その信号は辞書Dにおいてスパースである。ベクトルαの係数のほとんどがゼロであり、非ゼロであるものが非常に少ない場合、ベクトルαはスパースである。
【0023】
例えば、自然画像の特徴は、例えば、離散コサイン変換(DCT)又はウェーブレット基底を用いて、綿密に設計された辞書においてスパースに表すことができる。通常、設計された辞書は、実施が効率的であり、設計が信号に依存しないという利点を有する。
【0024】
代替的な選択は、トレーニングデータY={y1,…,yL}から辞書を学習することである。より具体的には、この発明では、入力から直接辞書を学習することを望み、すなわち、パンシャープン化される入力画像がこの発明によるトレーニングデータである。
【0025】
図1に示すように、この方法への入力はLR MS画像101及びHR Pan画像102である。これらの2つの画像は、この発明による辞書を学習するためのトレーニングデータである。
【0026】
特徴103は、ベクトルの形態で入力画像から抽出される(110)。ベクトル103は、欠落値を有しないベクトル104と、欠落値を有するベクトル105とに分解される。
【0027】
欠落値を有しないベクトル104を用いて、辞書学習130を用いて辞書106を構築する。
【0028】
欠落値は、欠落値を有するベクトルについて、辞書を用いて予測され(埋められ)(140)、次にMS画像にマッピングされる(150)。
【0029】
辞書を用いて、合成されたMS画像108が得られる。
【0030】
従来のパンシャープン化を適用して、パンシャープン化されたMS画像109を得ることができる。
【0031】
上記のステップは、メモリ及び入力/出力インターフェースに接続された、当該技術分野において既知のプロセッサ100において実行することができる。次に、ステップを更に詳細に説明する。
【0032】
パンシャープン化において、この発明の目的は、HR Pan画像102及びLR MS画像101から、パンシャープン化されたHR MS画像 109を再構成することである。この発明では、異なる物質が異なるパンクロマチック値及び色値を呈することを利用して、辞書学習を用いて色スペクトルの構造を探る。
【0033】
この目的を達成するために、MS画像及びPan画像から抽出される色特徴及びPan特徴103を結合する信号ベクトルx x=[(xMS)T(xPan)T]Tを考える。MS画像は低解像度を有するので、高解像度画像係数のうちの幾つかはパンクロマチック情報xPanのみを含み、色情報xMSを含まない。
【0034】
このため、既存の信号ベクトルX={x}から辞書106を学習し、対応するパンクロマチック情報xPan及び学習済み辞書を用いてxMSの欠落値を予測する。
【0035】
パンシャープン化問題を検討すると、ここで、1つのLR MS画像及び1つのHR Pan画像のみが入力として利用可能である。一般性を損なうことなく、LR MS画像はM個の帯域からなり、それぞれ(ピクセル)サイズI×Jであり、Pan画像はサイズNI×NJであり、LR MS画像のN倍の解像度を有すると仮定する。例えば、QuickBird及びIKONOSの衛星撮像システムでは、M=4及びN=4である。
【0036】
LR MS画像内の各ピクセルは、HR Pan画像内のP×Pのパッチに対応する。全てのI×J個のLR MSピクセルについて、I×J個のサイズP×Pの対応するパッチが存在し、逆もまた同様である。I×J個のパッチは、互いに重複する場合もしない場合もあり、通常、Pan画像全体を覆う。例えば、P=Nの場合、パッチは重複せず、Pan画像を厳密にタイル貼りする。
【0037】
この発明では、これらのパッチを用いて辞書を学習する。その辞書を用いて、サイズNI×NJのMS画像を形成するために、それぞれ1つのMSピクセルにマッピングする、サイズP×Pの重複したパッチの全てを考慮する。このマッピングプロセスによって、全てのHR MSピクセルに対してトレーニングされた辞書を用いることが可能になる。
【0038】
トレーニングデータ
パンシャープン化プロセス160前に、Pan画像及びMS画像が互いに位置合わせされると仮定する。位置合わせは、LR MS画像内のピクセルロケーションと、対応するHR Panパッチ内の対応するピクセルとの間の対応も暗に意味する。例えば、LR MSピクセルのピクセルロケーションは、中でも、HR Panパッチの角部、HR Panパッチの中心、又はパッチ中心付近のピクセルに対応する場合がある。例として、これから、パッチサイズP=Nであり、全体画像をタイル貼りするパッチの右上の角部との対応を考える。
【0039】
トレーニングデータは以下のように構築される。
【0040】
【数1】

【0041】
は、平均値
【0042】
【数2】
【0043】
を有するMS画像内のピクセル(i,j)の色値のM次元ベクトル104を表し、
【0044】
【数3】
【0045】
は、平均値
【0046】
【数4】
【0047】
を有し、ピクセル(N(i−1)+1,N(j−1)+1)及び(Ni,Nj)において角部を有する、Pan画像内の対応するP×Pのパッチの階調値のP2次元ベクトル105を表すものとする。
【0048】
通常、辞書学習手順は、各トレーニングデータベクトルの平均値を減算する。しかしながら、我々の経験では、色スペクトル及びPanパッチの平均値が、パンシャープン化に重要であることが示されている。したがって、これらの平均値を、トレーニングデータベクトルの追加特徴として保持することができる。
【0049】
換言すれば、MS画像内の各ピクセルについて、M+1次元のMS特徴ベクトル
【0050】
【数5】
【0051】
を考え、(ここで、i=1,2,…,I及びJ=1,2,…,J)、対応するPanパッチごとに、N2+1次元のPan特徴ベクトル
【0052】
【数6】
【0053】
を考える。
【0054】
トレーニングデータベクトルは、
【0055】
【数7】
【0056】
によって特徴ベクトル103を結合し、それによってLR MS画像内の空間情報を予測する(140)ことができる。MS画像内の全てのピクセルについて、(M+P2+2)×(IJ)個のトレーニングデータ行列Y={yi,j}を形成する。トレーニングデータベクトルは、HR画像102及びMS画像101の双方から抽出された、欠落値を有しない特徴ベクトル103から構築される。Pan画像。K−SVDを用いて辞書をトレーニングする。
【0057】
トレーニングデータベクトルから辞書を学習するために、以下の最小化問題を解く。
【0058】
【数8】
【0059】
ここで、α=[α1,α2,…,αL]は、L個のトレーニングデータベクトルに対応する一組のスパースな係数ベクトルであり、T0は所望のスパース性であり、||・||Fはフロベニウスノルムを表す。トレーニングデータベクトルは、MS画像内のピクセルのうちの幾つか又は全て、及びPan画像内の対応するパッチから導出される。
【0060】
試験データ
試験データは、Panパッチが重複することを除いて、同様に構築される。
【0061】
【数9】
【0062】
が試験データベクトルを表すとする。ここで、p=1,2,…,NI及びq=1,2,…,NJである。試験データ行列は、X=[(XMS)T(XPan)T]Tである。利用可能なHR MS画像を有しないので、試験データ行列内のMS関連エントリーのほとんどが欠落しており、辞書から予測されることになる。
【0063】
反復更新
学習済み辞書を所与として、試験データ内の欠落データを予測する。1つのオプションは、辞書学習に基づく画像修復と同様に、欠落データを予測することである。修復は、データが欠落した孤立したパッチを再構成することができる。
【0064】
不都合なことに、欠落データは試験データ行列においてランダムに分布しているのではなく、スペクトル特徴ベクトル105全体にわたって一様分布しているので、この手法は良好に機能しない。
【0065】
直感的に、異なる色が同じ階調に対応する可能性があるので、色情報を一切知ることなく階調値に従ってピクセルの色を予測することは不可能である。
【0066】
この問題を解くために、試験データに対する制約が必要である。補間されたLR MS画像がHR MS画像の推定値であることを考えると、補間されたMS画像と、学習済み辞書からの予測との間の距離に対する制約を課すことができる。換言すれば、補間されたLR MS画像を、雑音レベルに対する制約を有する、HR MS画像の雑音のあるものとして扱う。
【0067】
目的関数は
【0068】
【数10】
【0069】
であり、ここで、
EMSは、(M+P2+2)×(M+P2+2)の恒等行列の最初の(M+1)個の行であり、
EPanは、(M+P2+2)×(M+P2+2)の最後の(P2+1)個の行であり、
(オーバーバー)XMSは線形補間されたMS画像のMS特徴を表す。
X、(オーバーバー)XMS、及びXPanは全て同じ数の列を有し、L’は補間されたMS画像のサイズであり、通常NI×NJに等しい。
【0070】
重みλは、補間されたMS画像の寄与を制御する。λ=∞であるとき、式(2)の解は、補間されたMS画像であり、λ=0であるとき、式(2)は画像修復に等しい。式(2)は、図2に示すような反復手順によって解かれる。(ハット)Xを得た後、(ハット)XをMS画像(ハット)Zにマッピングすることができる。
【0071】
換言すれば、再構成された画像は、学習済み辞書によって、僅かな誤差でスパースに表すことができ、また、再構成された画像は補間された画像に非常に近いはずである。
【0072】
図2において、入力ステップ1は誤差許容値ε0、反復数K、重みλ、及び許容レベルT0を受信し、ステップ2において、補間された画像として出力推定値が初期化される。誤差が許容レベルよりも大きく、反復数がK未満である限り、反復が実行される。ステップ内の他の変数は上述されている。
【0073】
図3に示すように、トレーニングデータはHR MS画像情報を一切含まないので、DLベースのMS画像は依然としてぼやけている可能性がある。それにもかかわらず、DLベースのMS解像度は、従来の補間されたMS画像301よりもはるかに良好である。結果として、更なるパンシャープン化160を用いて、より少ない色歪みを達成することができる。
【技術分野】
【0001】
この発明は、包括的には、画像をパンシャープン化することに関し、より詳細には、辞書を用いてパンクロマチック画像及びマルチスペクトル画像を鮮明化することに関する。
【背景技術】
【0002】
QuickBird、IKONOS、及びALOS等の多数の衛星撮像システムが、2つの種類の画像、すなわちパンクロマチック(Pan)及びマルチスペクトル(MS)を生成する。Pan画像は、色情報なしで高い空間解像度を提供するのに対し、MS画像は色スペクトル情報を提供するが、低減された空間解像度で提供する。
【0003】
ターゲット識別及び物質識別等の様々な画像用途について、高空間品質及び高スペクトル品質の双方を有するMS画像を得ることが必要である。画像品質を向上させるために、パンシャープン化によって、高解像度のパンクロマチック画像と低解像度のマルチスペクトル画像とが合成され、単一の高解像度のカラー画像が生成される。通常、パンシャープン化によって、3つ又は4つ以上の低解像度のスペクトル帯域に加えて、対応する高解像度のパンクロマチック帯域から、高解像度のカラー画像が生成される。
【0004】
輝度−色相飽和(IHS)、主成分分析(PCA)、ウェーブレットベースの合成、変分法等の、複数のパンシャープン化方法が知られている。これらの方法は異なっているように見えるが、これらの方法の基本ステップは類似している。
【0005】
第1に、低解像度(LR)MS画像は、高解像度(HR)Pan画像と同じサイズになるように補間される。
【0006】
第2に、Pan画像の高周波成分は、補間されたMS画像と、方法に依存した形で合成される。例えば、IHSに基づく方法では、補間されたMS画像の輝度(I)成分がPan画像と置き換えられるのに対し、PCAに基づく方法では、補間されたMS画像の主成分がPan画像と置き換えられる。
【0007】
第3に、合成データは画像領域に変換され、合成画像が得られる。
【0008】
パンシャープン化されたMS画像は通常、良好な空間解像度を有するが、多くの場合に色歪みを呈する。色精度を改善し、色歪みを低減するために、それぞれが特定の合成技法又は画像セットに特化した様々な方法が既知である。これらの方法のほとんどが、Pan画像の高周波成分を、補間されたMS画像にどのように挿入するかに焦点を当てているが、合成プロセスの初期化時にMSを補間することによって生じる歪みを考慮していない。
【0009】
圧縮センシング、スパース表現、及び辞書学習(DL)が、この問題に対処する新たなツールを提供する。具体的には、辞書学習がパンシャープン化問題に適用されており、ここでHR Pan画像及びLR MS画像は圧縮測定値として扱われる。学習済み辞書におけるスパース性を正則化プライア(regularization prior)として用いて、HR MS画像を、スパース復元問題を解くことによって復元することができる。
【0010】
しかしながら、これらの方法は、辞書をトレーニングするのに多数のHR MSトレーニング画像を必要とし、これらの画像は通常、実際には利用可能でない。
【発明の概要】
【発明が解決しようとする課題】
【0011】
パンシャープン化は、高解像度(HR)パンクロマチック(Pan)画像を用いて、対応する低解像度(LR)マルチスペクトル(MS)画像を鮮明化する画像合成プロセスである。パンシャープン化されたMS画像は通常、高い空間解像度を有するが、色歪みを呈する。
【課題を解決するための手段】
【0012】
この発明の実施の形態は、MS画像の補間によって生じる色歪みを低減する、辞書学習を用いたパンシャープン化方法を提供する。合成前にLR MS画像を補間する代わりに、反復プロセスを用いて、学習済み辞書のスパース表現に基づいて改善されたMS画像を生成する。
【0013】
従来技術と対照的に、この発明による辞書は、単一のPan画像及び単一のMS画像から学習される。すなわち、この発明による方法は、より大きな組の画像を辞書の使用前にトレーニングすることを必要としない。そのかわり、この方法は、パンシャープン化されるPan画像及びMS画像を直接対象にする。
【発明の効果】
【0014】
この発明の実施の形態は、多数のトレーニング画像を必要とすることなく、MS画像を補間することによって生じる色歪みを低減する、辞書学習(DL)に基づくパンシャープン化方法を提供する。
【0015】
従来のパンシャープン化方法と比較して、この発明によるDLに基づくパンシャープン化方法の新規性は、3つの態様に存する。
【0016】
この方法は、LR MS画像を単に補間する代わりに、DLを用いて、改善された解像度を有するMS画像を生成することに焦点を当てている。このため、この方法は、MS画像を補間することによって初期化される任意の従来技術によるパンシャープン化方法と組み合わせることができる。
【0017】
この方法は、辞書を学習するのに多数のHR MS画像を必要とせず、鮮明化される必要がある画像のみを必要とする。
【0018】
この方法は、画像のスパース性及び整合性に従ってMS画像を更新し、より少ない歪みを有するMS画像を得る反復手順を提供する。
【0019】
加えて、この発明によるDLベースの方法を、最小限の変更で、ハイパースペクトルデータに適用することができる。
【0020】
この発明による辞書学習に基づくパンシャープン化プロセスは、複数の利点を有する。辞書学習に基づくパンシャープン化方法を含む、従来技術のパンシャープン化方法と比較して、この発明による方法は、トレーニングのために大量の高解像度のMS画像を必要とせず、MS補間プロセスを用いる他のパンシャープン化アルゴリズムと組み合わせることができる。この発明による辞書学習プロセスは、僅かな変更で、ハイパースペクトルデータを合成するように容易に拡張することができる。
【図面の簡単な説明】
【0021】
【図1】この発明の実施の形態による、辞書を用いたパンクロマチック画像及びマルチスペクトル画像のパンシャープン化の流れ図である。
【図2】この発明の実施の形態による、欠落データを予測するための目的関数を最小にする手順の疑似コードのブロック図である。
【図3】従来のパンシャープン化と、この発明の実施の形態によるパンシャープン化とを比較する画像である。
【発明を実施するための形態】
【0022】
辞書学習に基づくパンシャープン化
辞書学習は、信号をスパースに表すのに用いることができる、一組のベクトル(アトム)を学習するプロセスである。y=Dαによって表される信号y∈Rn×1を考える。ここで、D∈Rn×kは、その列としてアトムを含む辞書であり、α∈Rk×1は表現ベクトルである。辞書を用いて、対象の自然信号のクラスにおいて構造を捕捉する。具体的には、信号をスパースなαによって表すことができる場合、すなわち、Dからの幾つかのアトムの線形結合が、僅かな誤差で信号yを表すことができる場合、その信号は辞書Dにおいてスパースである。ベクトルαの係数のほとんどがゼロであり、非ゼロであるものが非常に少ない場合、ベクトルαはスパースである。
【0023】
例えば、自然画像の特徴は、例えば、離散コサイン変換(DCT)又はウェーブレット基底を用いて、綿密に設計された辞書においてスパースに表すことができる。通常、設計された辞書は、実施が効率的であり、設計が信号に依存しないという利点を有する。
【0024】
代替的な選択は、トレーニングデータY={y1,…,yL}から辞書を学習することである。より具体的には、この発明では、入力から直接辞書を学習することを望み、すなわち、パンシャープン化される入力画像がこの発明によるトレーニングデータである。
【0025】
図1に示すように、この方法への入力はLR MS画像101及びHR Pan画像102である。これらの2つの画像は、この発明による辞書を学習するためのトレーニングデータである。
【0026】
特徴103は、ベクトルの形態で入力画像から抽出される(110)。ベクトル103は、欠落値を有しないベクトル104と、欠落値を有するベクトル105とに分解される。
【0027】
欠落値を有しないベクトル104を用いて、辞書学習130を用いて辞書106を構築する。
【0028】
欠落値は、欠落値を有するベクトルについて、辞書を用いて予測され(埋められ)(140)、次にMS画像にマッピングされる(150)。
【0029】
辞書を用いて、合成されたMS画像108が得られる。
【0030】
従来のパンシャープン化を適用して、パンシャープン化されたMS画像109を得ることができる。
【0031】
上記のステップは、メモリ及び入力/出力インターフェースに接続された、当該技術分野において既知のプロセッサ100において実行することができる。次に、ステップを更に詳細に説明する。
【0032】
パンシャープン化において、この発明の目的は、HR Pan画像102及びLR MS画像101から、パンシャープン化されたHR MS画像 109を再構成することである。この発明では、異なる物質が異なるパンクロマチック値及び色値を呈することを利用して、辞書学習を用いて色スペクトルの構造を探る。
【0033】
この目的を達成するために、MS画像及びPan画像から抽出される色特徴及びPan特徴103を結合する信号ベクトルx x=[(xMS)T(xPan)T]Tを考える。MS画像は低解像度を有するので、高解像度画像係数のうちの幾つかはパンクロマチック情報xPanのみを含み、色情報xMSを含まない。
【0034】
このため、既存の信号ベクトルX={x}から辞書106を学習し、対応するパンクロマチック情報xPan及び学習済み辞書を用いてxMSの欠落値を予測する。
【0035】
パンシャープン化問題を検討すると、ここで、1つのLR MS画像及び1つのHR Pan画像のみが入力として利用可能である。一般性を損なうことなく、LR MS画像はM個の帯域からなり、それぞれ(ピクセル)サイズI×Jであり、Pan画像はサイズNI×NJであり、LR MS画像のN倍の解像度を有すると仮定する。例えば、QuickBird及びIKONOSの衛星撮像システムでは、M=4及びN=4である。
【0036】
LR MS画像内の各ピクセルは、HR Pan画像内のP×Pのパッチに対応する。全てのI×J個のLR MSピクセルについて、I×J個のサイズP×Pの対応するパッチが存在し、逆もまた同様である。I×J個のパッチは、互いに重複する場合もしない場合もあり、通常、Pan画像全体を覆う。例えば、P=Nの場合、パッチは重複せず、Pan画像を厳密にタイル貼りする。
【0037】
この発明では、これらのパッチを用いて辞書を学習する。その辞書を用いて、サイズNI×NJのMS画像を形成するために、それぞれ1つのMSピクセルにマッピングする、サイズP×Pの重複したパッチの全てを考慮する。このマッピングプロセスによって、全てのHR MSピクセルに対してトレーニングされた辞書を用いることが可能になる。
【0038】
トレーニングデータ
パンシャープン化プロセス160前に、Pan画像及びMS画像が互いに位置合わせされると仮定する。位置合わせは、LR MS画像内のピクセルロケーションと、対応するHR Panパッチ内の対応するピクセルとの間の対応も暗に意味する。例えば、LR MSピクセルのピクセルロケーションは、中でも、HR Panパッチの角部、HR Panパッチの中心、又はパッチ中心付近のピクセルに対応する場合がある。例として、これから、パッチサイズP=Nであり、全体画像をタイル貼りするパッチの右上の角部との対応を考える。
【0039】
トレーニングデータは以下のように構築される。
【0040】
【数1】
【0041】
は、平均値
【0042】
【数2】
【0043】
を有するMS画像内のピクセル(i,j)の色値のM次元ベクトル104を表し、
【0044】
【数3】
【0045】
は、平均値
【0046】
【数4】
【0047】
を有し、ピクセル(N(i−1)+1,N(j−1)+1)及び(Ni,Nj)において角部を有する、Pan画像内の対応するP×Pのパッチの階調値のP2次元ベクトル105を表すものとする。
【0048】
通常、辞書学習手順は、各トレーニングデータベクトルの平均値を減算する。しかしながら、我々の経験では、色スペクトル及びPanパッチの平均値が、パンシャープン化に重要であることが示されている。したがって、これらの平均値を、トレーニングデータベクトルの追加特徴として保持することができる。
【0049】
換言すれば、MS画像内の各ピクセルについて、M+1次元のMS特徴ベクトル
【0050】
【数5】
【0051】
を考え、(ここで、i=1,2,…,I及びJ=1,2,…,J)、対応するPanパッチごとに、N2+1次元のPan特徴ベクトル
【0052】
【数6】
【0053】
を考える。
【0054】
トレーニングデータベクトルは、
【0055】
【数7】
【0056】
によって特徴ベクトル103を結合し、それによってLR MS画像内の空間情報を予測する(140)ことができる。MS画像内の全てのピクセルについて、(M+P2+2)×(IJ)個のトレーニングデータ行列Y={yi,j}を形成する。トレーニングデータベクトルは、HR画像102及びMS画像101の双方から抽出された、欠落値を有しない特徴ベクトル103から構築される。Pan画像。K−SVDを用いて辞書をトレーニングする。
【0057】
トレーニングデータベクトルから辞書を学習するために、以下の最小化問題を解く。
【0058】
【数8】
【0059】
ここで、α=[α1,α2,…,αL]は、L個のトレーニングデータベクトルに対応する一組のスパースな係数ベクトルであり、T0は所望のスパース性であり、||・||Fはフロベニウスノルムを表す。トレーニングデータベクトルは、MS画像内のピクセルのうちの幾つか又は全て、及びPan画像内の対応するパッチから導出される。
【0060】
試験データ
試験データは、Panパッチが重複することを除いて、同様に構築される。
【0061】
【数9】
【0062】
が試験データベクトルを表すとする。ここで、p=1,2,…,NI及びq=1,2,…,NJである。試験データ行列は、X=[(XMS)T(XPan)T]Tである。利用可能なHR MS画像を有しないので、試験データ行列内のMS関連エントリーのほとんどが欠落しており、辞書から予測されることになる。
【0063】
反復更新
学習済み辞書を所与として、試験データ内の欠落データを予測する。1つのオプションは、辞書学習に基づく画像修復と同様に、欠落データを予測することである。修復は、データが欠落した孤立したパッチを再構成することができる。
【0064】
不都合なことに、欠落データは試験データ行列においてランダムに分布しているのではなく、スペクトル特徴ベクトル105全体にわたって一様分布しているので、この手法は良好に機能しない。
【0065】
直感的に、異なる色が同じ階調に対応する可能性があるので、色情報を一切知ることなく階調値に従ってピクセルの色を予測することは不可能である。
【0066】
この問題を解くために、試験データに対する制約が必要である。補間されたLR MS画像がHR MS画像の推定値であることを考えると、補間されたMS画像と、学習済み辞書からの予測との間の距離に対する制約を課すことができる。換言すれば、補間されたLR MS画像を、雑音レベルに対する制約を有する、HR MS画像の雑音のあるものとして扱う。
【0067】
目的関数は
【0068】
【数10】
【0069】
であり、ここで、
EMSは、(M+P2+2)×(M+P2+2)の恒等行列の最初の(M+1)個の行であり、
EPanは、(M+P2+2)×(M+P2+2)の最後の(P2+1)個の行であり、
(オーバーバー)XMSは線形補間されたMS画像のMS特徴を表す。
X、(オーバーバー)XMS、及びXPanは全て同じ数の列を有し、L’は補間されたMS画像のサイズであり、通常NI×NJに等しい。
【0070】
重みλは、補間されたMS画像の寄与を制御する。λ=∞であるとき、式(2)の解は、補間されたMS画像であり、λ=0であるとき、式(2)は画像修復に等しい。式(2)は、図2に示すような反復手順によって解かれる。(ハット)Xを得た後、(ハット)XをMS画像(ハット)Zにマッピングすることができる。
【0071】
換言すれば、再構成された画像は、学習済み辞書によって、僅かな誤差でスパースに表すことができ、また、再構成された画像は補間された画像に非常に近いはずである。
【0072】
図2において、入力ステップ1は誤差許容値ε0、反復数K、重みλ、及び許容レベルT0を受信し、ステップ2において、補間された画像として出力推定値が初期化される。誤差が許容レベルよりも大きく、反復数がK未満である限り、反復が実行される。ステップ内の他の変数は上述されている。
【0073】
図3に示すように、トレーニングデータはHR MS画像情報を一切含まないので、DLベースのMS画像は依然としてぼやけている可能性がある。それにもかかわらず、DLベースのMS解像度は、従来の補間されたMS画像301よりもはるかに良好である。結果として、更なるパンシャープン化160を用いて、より少ない色歪みを達成することができる。
【特許請求の範囲】
【請求項1】
単一のパンクロマチック(Pan)画像と単一のマルチスペクトル(MS)画像とをパンシャープン化する方法であって、
前記Pan画像及び前記MS画像から、ベクトルの形態で特徴を抽出するステップと、
前記特徴を、欠落値を有しない特徴と、欠落値を有する特徴とに分解するステップと、
前記欠落値を有しない特徴から辞書を学習するステップと、
前記辞書を用いて、前記欠落値を有する特徴の値を予測するステップと、
前記MS画像を、前記予測された値を含む前記Pan画像と合成して合成画像にするステップと、
前記合成画像をパンシャープン化するステップと、
を含み、
前記各ステップはプロセッサにおいて実行される、単一のパンクロマチック画像と単一のマルチスペクトル画像とをパンシャープン化する方法。
【請求項2】
前記Pan画像からの前記特徴は該Pan画像のパッチである、請求項1に記載の方法。
【請求項3】
前記Pan画像の前記パッチは該Pan画像全体を覆う、請求項2に記載の方法。
【請求項4】
前記Pan画像の前記パッチは該Pan画像全体をタイル貼りする、請求項2に記載の方法。
【請求項5】
前記MS画像の前記特徴は該MS画像のピクセルの値である、請求項1に記載の方法。
【請求項6】
前記MS画像のピクセルは前記Pan画像のパッチに対応する、請求項2または5に記載の方法。
【請求項7】
前記特徴は、前記Pan画像内のパッチ及び前記MS画像の平均値も含む、請求項2または5に記載の方法。
【請求項8】
前記辞書は信号をスパースに表し、該信号は、前記MS画像及び前記Pan画像からそれぞれ抽出された色特徴及びPan特徴を結合する、請求項1に記載の方法。
【請求項9】
前記Pan画像及び前記MS画像を互いに位置合わせするステップを更に含む、請求項1に記載の方法。
【請求項10】
前記辞書学習は、
【数1】
を解き、ここで、YはL個のトレーニングデータベクトルの行列であり、Dは前記辞書であり、α=[α1,α2,…,αL]はL個のトレーニングデータベクトルに対応する一組のスパースな係数ベクトルであり、T0は所望のスパース性であり、||・||Fはフロベニウスノルムを表す、請求項1に記載の方法。
【請求項11】
前記トレーニングデータベクトルは、前記Pan画像の特徴ベクトルを、前記MS画像の特徴ベクトルと結合する、請求項10に記載の方法。
【請求項12】
前記学習は、K−特異値分解(SVD)を用いる、請求項10に記載の方法。
【請求項13】
欠落データは、前記Pan画像及び前記MS画像において一様分布する、請求項1に記載の方法。
【請求項14】
前記MS画像は、低解像度(LR)画像であり、補間されたLR MS画像は、高解像度(HR)MS画像の推定値である、請求項1に記載の方法。
【請求項15】
補間されたMS画像は、雑音レベルに対する制約を有する、前記HR MS画像の雑音のあるものとして用いられる、請求項7に記載の方法。
【請求項16】
目的関数
【数2】
を最小にするステップを更に含み、ここで、Xは前記Pan画像及び前記MS画像を表す一組のL’個のベクトルであり、(チルダ)Dは前記辞書であり、α=[α1,α2,…,αL]は、該辞書(チルダ)D内のXを表す一組のスパースな係数ベクトルであり、T0は所望のスパース性であり、||・||Fはフロベニウスノルムを表し、λは重み付けベクトルであり、EMSは恒等行列の最初の数行であり、EPANは恒等行列の最後の数行である、請求項1に記載の方法。
【請求項1】
単一のパンクロマチック(Pan)画像と単一のマルチスペクトル(MS)画像とをパンシャープン化する方法であって、
前記Pan画像及び前記MS画像から、ベクトルの形態で特徴を抽出するステップと、
前記特徴を、欠落値を有しない特徴と、欠落値を有する特徴とに分解するステップと、
前記欠落値を有しない特徴から辞書を学習するステップと、
前記辞書を用いて、前記欠落値を有する特徴の値を予測するステップと、
前記MS画像を、前記予測された値を含む前記Pan画像と合成して合成画像にするステップと、
前記合成画像をパンシャープン化するステップと、
を含み、
前記各ステップはプロセッサにおいて実行される、単一のパンクロマチック画像と単一のマルチスペクトル画像とをパンシャープン化する方法。
【請求項2】
前記Pan画像からの前記特徴は該Pan画像のパッチである、請求項1に記載の方法。
【請求項3】
前記Pan画像の前記パッチは該Pan画像全体を覆う、請求項2に記載の方法。
【請求項4】
前記Pan画像の前記パッチは該Pan画像全体をタイル貼りする、請求項2に記載の方法。
【請求項5】
前記MS画像の前記特徴は該MS画像のピクセルの値である、請求項1に記載の方法。
【請求項6】
前記MS画像のピクセルは前記Pan画像のパッチに対応する、請求項2または5に記載の方法。
【請求項7】
前記特徴は、前記Pan画像内のパッチ及び前記MS画像の平均値も含む、請求項2または5に記載の方法。
【請求項8】
前記辞書は信号をスパースに表し、該信号は、前記MS画像及び前記Pan画像からそれぞれ抽出された色特徴及びPan特徴を結合する、請求項1に記載の方法。
【請求項9】
前記Pan画像及び前記MS画像を互いに位置合わせするステップを更に含む、請求項1に記載の方法。
【請求項10】
前記辞書学習は、
【数1】
を解き、ここで、YはL個のトレーニングデータベクトルの行列であり、Dは前記辞書であり、α=[α1,α2,…,αL]はL個のトレーニングデータベクトルに対応する一組のスパースな係数ベクトルであり、T0は所望のスパース性であり、||・||Fはフロベニウスノルムを表す、請求項1に記載の方法。
【請求項11】
前記トレーニングデータベクトルは、前記Pan画像の特徴ベクトルを、前記MS画像の特徴ベクトルと結合する、請求項10に記載の方法。
【請求項12】
前記学習は、K−特異値分解(SVD)を用いる、請求項10に記載の方法。
【請求項13】
欠落データは、前記Pan画像及び前記MS画像において一様分布する、請求項1に記載の方法。
【請求項14】
前記MS画像は、低解像度(LR)画像であり、補間されたLR MS画像は、高解像度(HR)MS画像の推定値である、請求項1に記載の方法。
【請求項15】
補間されたMS画像は、雑音レベルに対する制約を有する、前記HR MS画像の雑音のあるものとして用いられる、請求項7に記載の方法。
【請求項16】
目的関数
【数2】
を最小にするステップを更に含み、ここで、Xは前記Pan画像及び前記MS画像を表す一組のL’個のベクトルであり、(チルダ)Dは前記辞書であり、α=[α1,α2,…,αL]は、該辞書(チルダ)D内のXを表す一組のスパースな係数ベクトルであり、T0は所望のスパース性であり、||・||Fはフロベニウスノルムを表し、λは重み付けベクトルであり、EMSは恒等行列の最初の数行であり、EPANは恒等行列の最後の数行である、請求項1に記載の方法。
【図1】

【図2】

【図3】

【図2】
【図3】
【公開番号】特開2013−109759(P2013−109759A)
【公開日】平成25年6月6日(2013.6.6)
【国際特許分類】
【外国語出願】
【出願番号】特願2012−241525(P2012−241525)
【出願日】平成24年11月1日(2012.11.1)
【出願人】(000006013)三菱電機株式会社 (33,312)
【Fターム(参考)】
【公開日】平成25年6月6日(2013.6.6)
【国際特許分類】
【出願番号】特願2012−241525(P2012−241525)
【出願日】平成24年11月1日(2012.11.1)
【出願人】(000006013)三菱電機株式会社 (33,312)
【Fターム(参考)】
[ Back to top ]