
辞書作成方法及び識別用辞書を記憶する記憶媒体
【課題】紙葉類のクラスを効率的に推定し、かつ、媒体変動にロバストなパターン識別が可能となる辞書作成方法及び識別用辞書を記憶する記憶媒体を提供する。
【解決手段】一実施形態に係る辞書作成方法は、識別すべき複数種類の基準となる紙葉類の画像を入力し、前記入力した画像を所定の複数の領域に分割し、前記紙葉類の種類毎に、前記分割した各領域毎の相違度を算出し、前記算出した相違度に基づいて、各領域毎に重み付けを行い、前記重み付けされた複数の領域のうち、重みの大きい順に予め設定される数の領域を選択し、前記選択した領域と、前記入力した画像とを辞書として登録する。
【解決手段】一実施形態に係る辞書作成方法は、識別すべき複数種類の基準となる紙葉類の画像を入力し、前記入力した画像を所定の複数の領域に分割し、前記紙葉類の種類毎に、前記分割した各領域毎の相違度を算出し、前記算出した相違度に基づいて、各領域毎に重み付けを行い、前記重み付けされた複数の領域のうち、重みの大きい順に予め設定される数の領域を選択し、前記選択した領域と、前記入力した画像とを辞書として登録する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、たとえば、有価証券等の紙葉類の自動鑑査装置において、紙葉類から得られる画像パターンとあらかじめ設定される基準パターンとを比較することにより当該紙葉類の種類や真偽等を識別する辞書作成方法及び識別用辞書を記憶する記憶媒体に関する。
【背景技術】
【0002】
一般に、デジタル画像パターン(以下、単にパターンと称す)の識別処理は、高度な識別を目指すほど高解像度のセンサ入力を必要とする傾向にあるが、同時に実用性の観点から、少ない計算コストと実時間での処理を実現しなければならない。
【0003】
そこで、パターンの一部(画素あるいは画素の集合)を選択して処理するための様々な方法が提案されている。一般に、パターンは冗長性を多く含んでいるので、適切な選択を行なえば、解像度を保持したまま少ない計算量で充分な識別性能が得られる。
【0004】
たとえば、ランダムな画素選択を行なうことで処理対象画素を絞り込み、高解像度と高速処理とを両立した技術が知られている(たとえば、特許文献1参照)。この公知技術では、画素選択が検査ごとにランダムに実施されることから、検査部位の探知が事実上不可能となり、信頼性を向上させている。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開平9−134464号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
しかしながら、上記した公知技術では、位置的な重み付けについては考慮されておらず、むしろ信頼性の観点から、選択される画素がパターン全領域に均等に分布することが望ましいとされていた。確かに、検査部位の探知を困難にするという目的では、パターン全領域から均等に画素を選択するのが理想的であるが、一般に、パターンの全領域を画一的に処理して識別結果を得る方法は、局所的な特徴を充分に識別できなかったり、逆に、局所的な媒体変動(汚れ、かすれ等)が識別性能に影響を及ぼしたりという問題がある。
したがって、高速性および信頼性を保ちつつ局所的な特徴を充分に識別し得る識別方法が求められていた。
また、パターンの一部を選択して処理する際、紙葉類の搬送状態等に起因する紙葉類のスライドやスキュー、印刷濃度変動の影響を受けることがある。
【0007】
そこで、本発明は、紙葉類の画像パターンを複数の領域(画素あるいは画素の集合)に分割し、重み付けや選択を行ない、領域ごとに識別結果を得て、その論理的な組み合わせで全体の識別結果を決定することにより、紙葉類のクラスを効率的に推定し、かつ、媒体変動にロバストなパターン識別が可能となる辞書作成方法及び識別用辞書を記憶する記憶媒体を提供することを目的とする。
【課題を解決するための手段】
【0008】
一実施形態に係る辞書作成方法は、識別すべき複数種類の基準となる紙葉類の画像を入力し、前記入力した画像を所定の複数の領域に分割し、前記紙葉類の種類毎に、前記分割した各領域毎の相違度を算出し、前記算出した相違度に基づいて、各領域毎に重み付けを行い、前記重み付けされた複数の領域のうち、重みの大きい順に予め設定される数の領域を選択し、前記選択した領域と、前記入力した画像とを辞書として登録する。
【図面の簡単な説明】
【0009】
【図1】本発明の実施の形態に係る紙葉類識別装置の構成を概略的に示すブロック図。
【図2】第1の実施の形態に係る紙葉類の識別処理を説明するためのフローチャート。
【図3】パターンの領域分割および分割パラメータを説明するための図。
【図4】クラスAの基準パターンの一例を示す図。
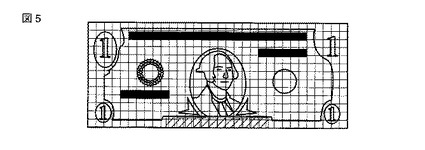
【図5】クラスAの基準パターンに対する領域分割の様子を模式的に表した図。
【図6】クラスBの基準パターンの一例を示す図。
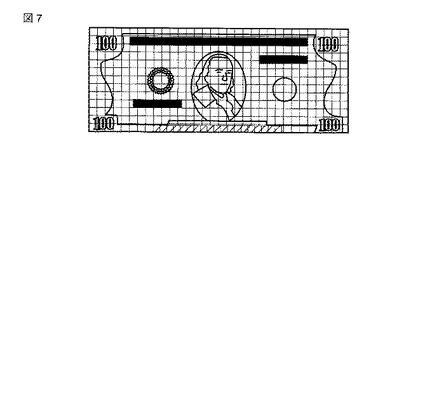
【図7】クラスBの基準パターンに対する領域分割の様子を模式的に表した図。
【図8】第2の実施の形態に係る紙葉類の識別処理を説明するためのフローチャート。
【図9】第2の実施の形態に係る紙葉類の識別処理の変形例を説明するためのフローチャート。
【図10】第3の実施の形態に係る紙葉類の識別処理を説明するためのフローチャート。
【図11】第4の実施の形態に係る紙葉類の識別処理を説明するためのフローチャート。
【図12】第4の実施の形態に係る紙葉類の識別処理の変形例を説明するためのフローチャート。
【図13】第5の実施の形態に係る紙葉類の識別処理を説明するためのフローチャート。
【図14】第6の実施の形態に係る紙葉類の識別処理を説明するためのフローチャート。
【図15】第6の実施の形態における紙葉類の搬送状態を説明するための模式図。
【図16】第7の実施の形態に係る紙葉類の識別処理を説明するためのフローチャート。
【図17】第7の実施の形態における座標の振らせ方を説明するための模式図。
【図18】第7の実施の形態における濃度の振らせ方を説明するための模式図。
【発明を実施するための形態】
【0010】
以下、本発明の実施の形態について図面を参照して説明する。
なお、本発明に係る紙葉類識別装置は、紙葉類(媒体)の画像パターンに基づいて、当該紙葉類の種類や真偽を識別するもので、たとえば、有価証券(紙幣等)などの紙葉類上に印刷された画像を光学的に読取って得られる画像パターン(画像データ)に基づいて、当該紙葉類の種類(クラス、金種)や真偽を識別するものである。
【0011】
まず、第1の実施の形態について説明する。
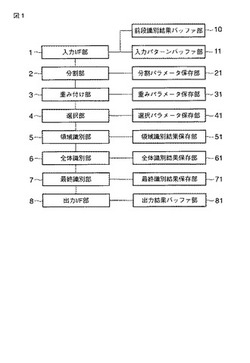
図1は、本発明の実施の形態に係る紙葉類識別装置の構成を概略的に示すものである。この紙葉類識別装置は、紙葉類上の画像を光学的に読取って得られる画像パターン(入力パターン)を入力する入力インタフェイス(I/F)部1、前段の識別結果や識別処理の候補を一時的に蓄積する前段識別結果バッファ部10、入力される画像パターン(入力パターン)を一時的に蓄積する入力パターンバッファ部11、入力された画像パターンを複数の領域に分割する領域分割手段としての分割部2、分割パラメータを保存する分割パラメータ保存部21、分割された領域に対し重み付けを行なう重み付け手段としての重み付け部3、重みパラメータを保存する重みパラメータ保存部31、重み付けされた領域から識別に用いる領域を選択する領域選択手段としての選択部4、選択パラメータを保存する選択パラメータ保存部41、選択された領域ごとの基準パターンとの識別結果を取得する識別結果取得手段としての領域識別部5、領域ごとの識別結果を保存する領域識別結果保存部51、全体の識別結果を決定する全体識別部6、全体識別結果を保存する全体識別結果保存部61、領域ごとの識別結果の論理的な組み合わせで全体の識別結果を決定する識別結果決定手段としての最終識別部7、最終の識別結果を保存する最終識別結果保存部71、識別結果を出力する出力インタフェイス(I/F)部8、および、出力結果を一時的に蓄積する出力結果バッファ部81を有して構成される。
【0012】
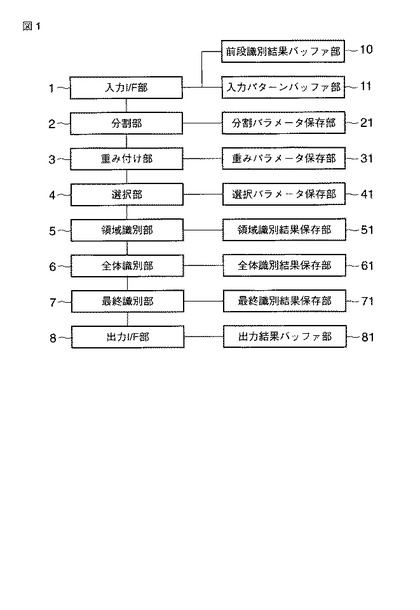
図2は、第1の実施の形態に係る識別処理を説明するフローチャートを示しており、以下、このフローチャートに基づき識別処理を説明する。
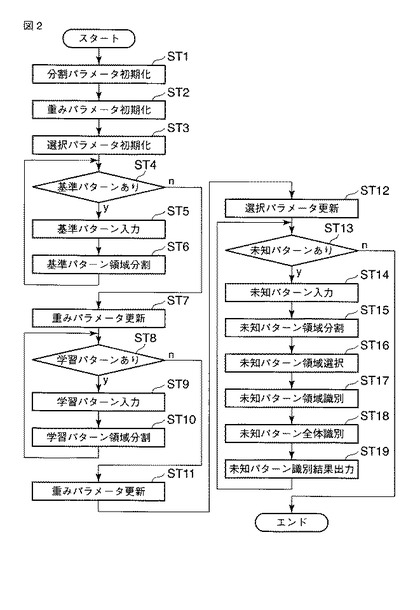
まず、分割パラメータを初期化する(ST1)。ここで、分割パラメータとは、パターンの領域分割を表現する具体的な数値のこととする。たとえば、図3では、入力されたパターンを横32×縦13(計416)の格子状に均等に領域分割する例を示している。このとき、分割パラメータは、たとえば、
pi={hi,vi,li,di}
のように表される。ただし、piはi番目領域の分割パラメータ(1≦i≦416)、hiはi番目領域の始点水平座標、viはi番目領域の始点垂直座標、liはi番目領域の水平幅、diはi番目領域の垂直高さである。分割パラメータの初期化では、piに具体的な数値を代入する。
【0013】
次に、重みパラメータを初期化する(ST2)。重みパラメータは、領域の重要度を表すものであるが、初期状態ではどの領域がどれだけ重要なのかは不明なので、ここでは全て同じ値とする。すなわち、
wi=1/416
である。wiはi番目領域の重みパラメータである。
【0014】
さらに、選択パラメータを初期化する(ST3)。ここで、選択パラメータをQとすると、選択パラメータQは、選択率q0と選択領域番号qj(j≧1)とに分けられる。すなわち、
Q={q0,q1,q2,‥‥}
である。選択率は、全領域に対する選択領域の割合である。すなわち、
0.0≦q0≦1.0
である。また、そのときの選択された領域の番号を選択領域番号とする。選択領域番号の数は選択率に応じて定まる。選択領域番号の値は、本実施の形態では、
1≦qj≦416
の範囲となる。初期状態では、どの領域がどれだけ重要なのかは不明なので、適当な値を登録する。たとえば、選択率q0=0.25ならば、選択パラメータQは、
Q={0.25,1,2,‥‥,104}
のように初期化する。
【0015】
パラメータの初期化が完了すると、基準パターンが入力される。なお、本実施の形態では、説明をわかりやすくするためにパターンのクラス数を「2」とし、2クラス識別問題とする。図4、図5および図6、図7は、クラスの異なる2つのパターンを模式的に図示したものである。このとき、基準パターンとは、媒体の汚損や入力変動の影響のない、クラスの基準となるべきパターンのことである。基準パターンは、1クラスにつき1つである。
【0016】
また、基準パターンの属するクラスは既知である。このような基準パターンが入力されると、領域分割が行なわれる。図4に示す基準パターン(クラスA)に対して、図5に示す領域分割がなされるものである。また、図6に示す基準パターン(クラスB)に対して図7に示す領域分割がなされるものである。図5および図7は、領域分割の様子を模式的に表したものである。基準パターンの入力と領域分割は、全てのクラスについて繰り返し実行される(ST4〜ST6)
全てのクラスの基準パターン入力と領域分割が完了すると、重みパラメータが更新される(ST7)。この段階では、クラス間の相違によって重みパラメータが更新される。たとえば、2つのクラスAおよびBの基準パターンをa(0)およびb(0)と表し、1つの領域に含まれる画素の数をNとすると、特徴量は、たとえば、
f(a(0), i) = {a(0, i, 1), a(0, i, 2), … , a(0, i, n), … , a(0, i, N)}
f(b(0), i) = {b(0, i, 1), b(0, i, 2), … , b(0, i, n), … , b(0, i, N)}
のように表される。ただし、f(a(0), i)およびf(b(0), i)は、それぞれa(0)およびb(0)のi番目領域の特徴量である(1≦i≦416)。また、a(0, i, n)およびb(0, i, n)は、それぞれa(0)およびb(0)のi番目領域のn番目画素の画素値である(1≦n≦N)。
【0017】
すなわち、特徴量は、N個の画素値によって決まるN次元ベクトルである。このとき、重みパラメータは以下のように算出される。
wi = D(f(a(0),i), f(b(0),i)) / Σi{D(f(a(0),i), f(b(0),i))}
ただし、D(f(a(0),i), f(b(0),i))は、i番目領域におけるa(0)とb(0)とのユークリッド距離であり、
D(f(a(0),i), f(b(0),i)) = sqrt[Σn{b(0,i,n)-a(0,i,n)}2]
で表される。すなわち、重みパラメータは、領域ごとの基準パターン間距離を全領域の基準パターン間距離の総和で割った値となる。一般に、クラスを代表する基準パターン間の距離が大きい領域ほどクラス間の識別に有利と考えてよいので、領域重み付けの第一段階としては妥当である。
【0018】
しかしながら、対象パターンによってはクラス内で変動する領域が存在する場合がある。たとえば、スタンプ、シグネチャ、記番号などである。クラス間の識別をより安定なものとするためには、これらの領域の重みを低くすべきである。そこで、本実施の形態では学習パターンを用いて重みパラメータをチューニングする。ここで、学習パターンとは、上記基準パターンを除き、その属するクラスが既知であるサンプルのことである。学習パターンは、ある程度のサンプル数があり、その属するクラスのパターン全体集合の分布を反映したものであることが望ましい。このような学習パターンが入力されると、上記基準パターンと同様に領域分割が行なわれる。学習パターンの入力と領域分割は、全てのクラスの全てのサンプルについて繰り返し実行される。(ST8〜ST10)
全てのクラスの全てのサンプルの学習パターン入力と領域分割が完了すると、重みパラメータが更新される(ST11)。この段階では、クラス内の変動によって重みパラメータが更新される。たとえば、クラスAおよびBのそれぞれM個の学習パターンをa(k)およびb(k)と表すと(1≦k≦M)、
s(a,i)=Σk‖f(a(k),i)−μ(a,i)‖
s(b,i)=Σk‖f(b(k),i)−μ(b,i)‖
は変動を表す値である。ただし、s(a,i)およびs(b,i)は、それぞれクラスAおよびBのi番目領域の変動値、μ(a(k),i)およびμ(b(k),i)は、それぞれクラスAおよびBのi番目領域の平均ベクトルである。すなわち、本実施の形態での変動値は、クラスごとの学習パターンの標準偏差を領域ごとに算出したものである。このとき、重みパラメータは以下のように更新される。
wi←wi/{s(a)+s(b,i)}
すなわち、元の重みの値をクラスAおよびBの変動値の和で割ったものである。更新後、さらに以下のように正規化する。
wi←wi/Σiwi
このようにして、クラス間の相違とクラス内の変動とを考慮した重みパラメータが決定される。
【0019】
次に、選択パラメータを更新する(ST12)。本実施の形態では、重みの大きい順に上位から選択率Qの分だけ選択する。たとえば、選択率q0=0.25ならば、重みの大きい順に上位から、416の4分の1である104個の領域の番号を選択領域番号qjとして登録する。以上のようにして、クラス間の相違とクラス内の変動に基づいた領域の重み付けおよび選択がなされ、学習フェーズが完了する。
【0020】
続いて、識別フェーズについて説明する。識別フェーズでは、未知のパターンが入力され、その識別結果が出力される。ここで、未知のパターンとは、その属するクラスが未知であるサンプルのことである。このような未知パターンが入力されると(ST13,ST14)、基準パターンや学習パターンと同様に領域分割が行なわれる(ST15)。
次に、上記選択パラメータで指定された領域を選択する(ST16)。さらに、選択された領域について、領域ごとに識別処理を行なう(ST17〜ST19)。
【0021】
本発明では、識別処理自体のアルゴリズムについて特に限定されるものではないが、2クラスの識別問題の場合、識別処理の結果が「クラスA」、「クラスB」、「リジェクト」のいずれかとなることとする。最も原始的な識別アルゴリズムは、基準パターンと未知パターンとのユークリッド距離を用いるものである。たとえば、未知パターンをxとし、未知パターンxに対するi番目領域の識別結果をz(x,i)とすると、
z(x, i) = クラスA (もし、D(f(x,i), f(b(0),i)) > D(f(x,i), f(a(0),i))+ε ならば)
z(x, i) = クラスB (もし、D(f(x,i), f(a(0),i)) > D(f(x,i), f(b(0),i))+ε ならば)
z(x, i) = リジェクト(もし、|D(f(x,i), f(a(0),i)) - D(f(x,i), f(b(0),i))|≦ε なら ば)
のように表される。ただし、εはクラス間の有意な差を定義するための適当な定数である。
【0022】
次に、領域ごとの識別結果を基に全体の識別結果を決定する。前述した通り、本発明は、領域ごとに一旦識別結果を得て、その多数決、論理式、あるいは、それらの重み付けで全体の識別結果を決定することを特徴の1つとしている。
【0023】
従来、たとえば、前述したような領域ごとのユークリッド距離を算出し、領域ごとに識別結果を出さず、その単純平均や重み付き平均を求め全体の識別判定を行なうものがあったが、局所的な特徴を充分に識別できなかったり、逆に、局所的な媒体変動(汚れ、かすれ等)が識別性能に影響を及ぼしたりという問題がある。
【0024】
本実施の形態によれば、局所的な特徴を他所に左右されず、局所的な変動を他所に影響を与えず、捉えることができるため、より高精度な識別処理が実現できる。たとえば、未知パターンをxとし、未知パターンxに対する全体識別結果をz(x)とすると、多数決であれば、
z(x) = クラスA (もし、ΣiI(z(x,i)=クラスA) が最も多いならば)
z(x) = クラスB (もし、ΣiI(z(x,i)=クラスB) が最も多いならば)
z(x) = リジェクト (もし、ΣiI(z(x,i)=リジェクト) が最も多いならば)
のように表される。ただし、ΣiI(z(x,i)=クラスA)、ΣiI(z(x,i)=クラスB)、ΣiI(z(x,i)=リジェクト)は、領域の識別結果がそれぞれクラスA、クラスB、リジェクトとなった領域の数である。
【0025】
また、ΣiI(z(x,i)=クラスA)、ΣiI(z(x,i)=クラスB)、ΣiI(z(x,i)=リジェクト)の関係を論理式で表し、全体の識別結果を決定することもできる。たとえば、
もし、ΣiI(z(x,i)=クラスB)/ΣiI(z(x,i)=クラスA)<α、かつ、
(ΣiI(z(x,i)=クラスA)+ΣiI(z(x,i)=クラスB))>ΣiI(z(x,i)=リジェクト)+β
ならば、
z(x) = クラスA
もし、ΣiI(z(x,i)=クラスA) / ΣiI(z(x,i)=クラスB)<α=リジェクト)+β
ならば、
z(x) = クラスB
それ以外ならば、
z(x) = リジェクト
のように表される。ただし、αはクラス間の有意な差を定義するための適当な定数、βはリジェクトの割合を調整するための適当な定数である。このように、全体識別の振る舞いがパラメータ(αやβなど)によって簡単に調整可能である点も本実施の形態の特徴である。
【0026】
さらに、上記多数決や論理式に重みパラメータの重みを考慮し、重み付け多数決や重み付け論理式とすることもできる。すなわち、
z(x) = クラスA (もし、Σi wi I(z(x,i)=クラスA) が最も多いならば)
z(x) = クラスB (もし、Σi wi I(z(x,i)=クラスB) が最も多いならば)
z(x) = リジェクト (もし、Σi wi I(z(x,i)=リジェクト) が最も多いならば)
あるいは、
もし、Σi wi I(z(x,i)=クラスB) / Σi wi I(z(x,i)=クラスA) < α 、かつ、(Σi wi I(z(x,i)=クラスA) + Σi wi I(z(x,i)=クラスB)) > Σi wi I(z(x,i)=リジェクト)+β
ならば、
z(x) = クラスA
もし、Σi wi I(z(x,i)=クラスA) / Σi wi I(z(x,i)=クラスB) < α 、かつ、(Σi wi I(z(x,i)=クラスA) + Σi wi I(z(x,i)=クラスB)) > Σi wi I(z(x,i)=リジェクト)+β
ならば、
z(x) = クラスB
それ以外ならば、
z(x) = リジェクト
などである。
以上のような処理により得られた未知パターンの識別結果z(x)が出力される(ST19)。
【0027】
このように、第1の実施の形態によれば、紙葉類の画像パターンを複数の領域(画素あるいは画素の集合)に分割し、重み付けや選択を行ない、領域ごとに識別結果を得て、その論理的な組み合わせで全体の識別結果を決定することにより、紙葉類のクラスを効率的に推定し、かつ、媒体変動にロバストなパターン識別が可能となる。
特に、クラス間の相違とクラス内の変動に基づいて領域の重み付けや選択を行なうので、計算量を削減できるとともに、パターン全体を画一的に処理する方法に比べて高い識別性能が得られる。
【0028】
また、領域ごとに一旦識別結果を求め、それらの多数決、論理式、あるいは、それらの重み付けで全体の識別結果を決定するので、領域ごとの特徴量の単純平均などに比べ、局所的な特徴を他所に左右されず、局所的な変動を他所に影響を与えず、捉えることができ、かつ、全体識別の振る舞いがパラメータによって簡単に調整可能である。
【0029】
次に、第2の実施の形態について説明する。
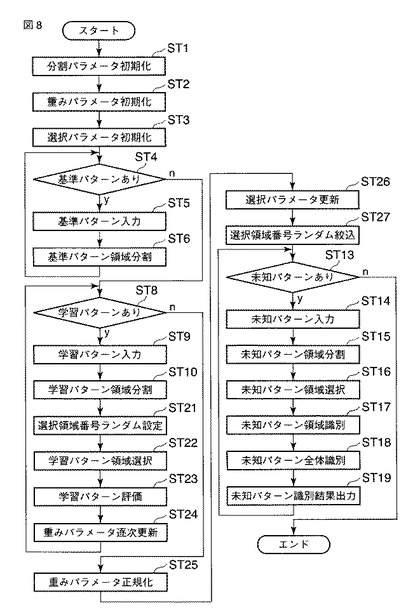
図8は、第2の実施の形態に係る識別処理を説明するフローチャートを示している。分割パラメータの初期化、重みパラメータの初期化、選択パラメータの初期化(ST1,ST2,ST3)については第1の実施の形態と同様であるので、ここでは説明を省略する。第2の実施の形態では、学習パターンを入力しながらランダムな領域選択を繰り返し、評価に応じて重みパラメータを逐次最適化していく。
【0030】
パラメータの初期化が完了すると、第1の実施形態と同様に基準パターンが入力される(ST4〜ST6)。なお、第2の実施の形態でも、説明をわかりやすくするためにパターンのクラス数を「2」とし、2クラス識別問題とする。基準パターンとは、媒体の汚損や入力変動の影響のない、クラスの基準となるべきパターンのことである。基準パターンは、1クラスにつき1つである。また、基準パターンの属するクラスは既知である。
【0031】
このような基準パターンが入力されると、領域分割が行なわれる。基準パターンの入力と領域分割は、全てのクラスについて繰り返し実行される。第2の実施の形態では、第1の実施の形態のような基準パターンを用いた重みパラメータの更新は行なわない。
【0032】
続いて、第1の実施の形態と同様に学習パターンが入力される(ST8,ST9)。学習パターンは、ある程度のサンプル数があり、その属するクラスのパターン全体集合の分布を反映したものであることが望ましい。学習パターンが入力されると、領域分割が行なわれる(ST10)。
【0033】
ここで、選択領域番号がランダムに設定される(ST21)。たとえば、選択率q0=0.25ならば、416の4分の1である104個の領域の番号を重複せずランダムに抽出し、選択領域番号qjとして登録する(ST22)。
【0034】
次に、ランダムに選択された領域について評価を実施する(ST23)。基本的な評価の方策としては、入力された学習パターンの識別に有効であれば、そのとき選択された領域の重みパラメータを増加させ、無効であれば、そのとき選択された領域の重みパラメータを減少させる。どのように有効、無効を判断するかについて本発明は限定するものではないが、最も原始的な評価アルゴリズムは、基準パターンと学習パターンとのユークリッド距離を用いるものである。たとえば、2つのクラスの基準パターンをa(0)およびb(0)とし、クラスAに属する学習パターンをyとすると、
もし、Σi D(f(y,i), f(b(0),i)) > D(f(y,i), f(a(0),i))+θ ならば、
wi ← wi + δ
それ以外ならば、
wi ← wi - δ
とする。ただし、θはその領域選択が有効かどうかを定義するための適当な定数、δはwiに対して小さな修正項(δ>0)である。このような重みパラメータの更新が、全ての学習パターンについて繰り返し実行され(ST24)、更新後、さらに以下のように正規化される(ST25)。
wi ← wi /Σi wi
このようにして、ランダムな領域選択と評価とを交互に繰り返し、その評価に基づいた重みパラメータが決定される。
【0035】
次に、選択パラメータを更新するが、その内容は第1の実施の形態と同様、重みの大きい順に上位から選択領域番号として登録する(ST26)ものである。ただし、第2の実施の形態では、上記選択領域番号をさらにランダムに絞り込む(ST27)ことを特徴としている。以上のようにして、学習フェーズが完了する。
【0036】
第2の実施の形態の識別フェーズ(未知パターンの入力以降(ST13〜ST19))については、第1の実施の形態と同様である。最終的に、未知パターンの識別結果が出力される。
【0037】
なお、ランダムな領域選択を行なわずに、全領域ごとの評価を繰り返し、評価に応じて重みパラメータを逐次最適化していく方法もある。図9は、第2の実施の形態でランダムな領域選択を行なわない場合のフローチャートを示したものである。フローチャートの各処理については、上で(図8で)述べたものと同様であるため説明を省略する。
【0038】
このように、第2の実施の形態によれば、ランダムに選択された領域あるいは全領域ごとの評価を繰り返し、その評価に基づいて領域の重みを逐次更新するので、実データに即したパラメータでの識別が可能となる。
また、選択された領域に対しランダムマスクをかけて絞り込むことで、識別性能と信頼性を両立できる。
【0039】
次に、第3の実施の形態について説明する。
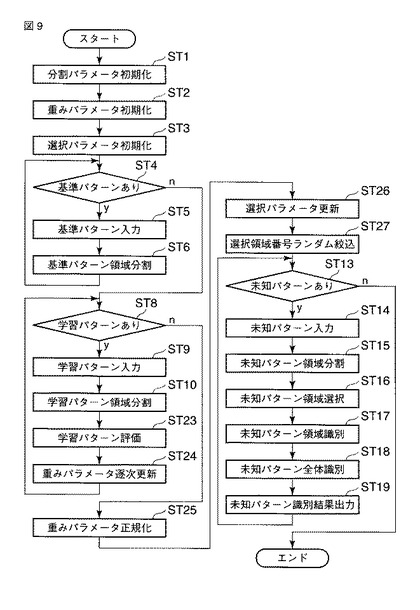
図10は、第3の実施の形態に係る識別処理を説明するフローチャートを示している。パラメータの初期化は、第1の実施の形態における分割パラメータの初期化、重みパラメータの初期化、選択パラメータの初期化のことであり、ここでは説明を省略する。第3の実施の形態では、複数回の領域選択による複数の識別結果の多数決、論理式、あるいは、それらの重み付けで最終的な識別結果を決定することを特徴としている。
【0040】
まず、複数回の領域選択を実施する(ST31、ST32)。領域選択のアルゴリズムは、第1の実施の形態によるものでも、第2の実施の形態によるものでも構わない。ループ回数をLOOPMAXとすると、LOOPMAX通りの選択パラメータQloopが得られる。
Qloop (1≦loop≦LOOPMAX)
以上のようにして、学習フェーズが完了する(ST33〜ST35)。
【0041】
続いて、識別フェーズについて説明する。識別フェーズでは、未知パターンが入力され(ST36、ST37)、その識別結果が出力されるが(ST38)、第1の実施の形態や第2の実施の形態と異なり、LOOPMAX通りの選択パラメータに基づくLOOPMAX通りの未知パターン処理が行なわれ、結果としてLOOPMAX通りの全体の識別結果が得られる(ST39〜ST42)。未知パターンをxとし、選択パラメータQloopに基づいた未知パターンxに対する全体の識別結果をz(x,loop)とする。
【0042】
すると、最終識別が行なわれる(ST43)。前述した通り、本実施の形態は、複数回の領域選択による複数の識別結果の多数決、論理式、あるいは、それらの重み付けで最終的な識別結果を決定することを特徴としている。たとえば、多数決であれば、
z(x) = クラスA (もし、ΣloopI(z(x,loop)=クラスA) が最も多いならば)
z(x) = クラスB (もし、ΣloopI(z(x,loop)=クラスB) が最も多いならば)
z(x) = リジェクト (もし、ΣloopI(z(x,loop)=リジェクト) が最も多いならば)
のように表される。ただし、ΣloopI(z(x,loop)=クラスA)、ΣloopI(z(x,loop)=クラスB)、ΣloopI(z(x,loop)=リジェクト)は、全体の識別結果がそれぞれクラスA、クラスB、リジェクトとなった数である。
【0043】
また、ΣloopI(z(x,loop)=クラスA)、ΣloopI(z(x,loop)=クラスB)、ΣloopI(z(x,loop)=リジェクト)の関係を論理式で表し、最終の識別結果を決定することもできる。たとえば、
もし、ΣloopI(z(x,loop)=クラスB) / ΣloopI(z(x,loop)=クラスA) < α 、かつ、(ΣloopI(z(x,loop)=クラスA) + ΣloopI(z(x,loop)=クラスB)) > ΣloopI(z(x,loop)=リジェクト)+β
ならば、
z(x) = クラスA
もし、ΣloopI(z(x,loop)=クラスA) / ΣloopI(z(x,loop)=クラスB) < α 、かつ、(ΣloopI(z(x,loop)=クラスA) + ΣloopI(z(x,loop)=クラスB)) > ΣloopI(z(x,loop)=リジェクト)+β
ならば、
z(x) = クラスB
それ以外ならば、
z(x) = リジェクト
のように表される。ただし、αはクラス間の有意な差を定義するための適当な定数、βはリジェクトの割合を調整するための適当な定数である。
【0044】
さらに、上記多数決や論理式に重みパラメータの重みを考慮し、重み付け多数決や重み付け論理式とすることもできる。すなわち、
z(x) = クラスA (もし、Σloop wi I(z(x,loop)=クラスA) が最も多いならば)
z(x) = クラスB (もし、Σloop wi I(z(x,loop)=クラスB) が最も多いならば)
z(x) = リジェクト (もし、Σloop wi I(z(x,loop)=リジェクト) が最も多いならば)
あるいは、
もし、Σloop wi I(z(x,loop)=クラスB) / Σloop wi I(z(x,loop)=クラスA) < α 、かつ、(Σloop wi I(z(x,loop)=クラスA) + Σloop wi I(z(x,loop)=クラスB)) > Σloop wi I(z(x,loop)=リジェクト)+β
ならば、
z(x) = クラスA
もし、Σloop wi I(z(x,loop)=クラスA) / Σloop wi I(z(x,loop)=クラスB) < α 、かつ、(Σloop wi I(z(x,loop)=クラスA) + Σloop wi I(z(x,loop)=クラスB)) > Σloop wi I(z(x,loop)=リジェクト)+β
ならば、
z(x) = クラスB
それ以外ならば、
z(x) = リジェクト
などである。
【0045】
以上のような処理により得られた未知パターンの識別結果z(x)が出力される(ST44)。
【0046】
このように、第3の実施の形態によれば、複数回の領域選択による複数の識別結果の多数決、論理式、あるいは、それらの重み付けで最終的な識別結果を決定すれば、様々な見方で識別した結果を統合できるので、1回の領域選択よりもロバストな識別性能が得られる。
【0047】
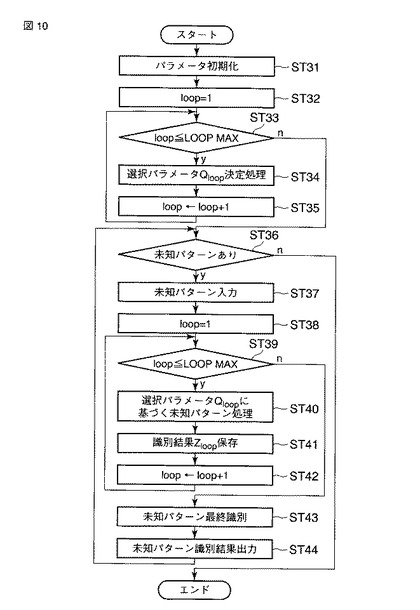
次に、第4の実施の形態について説明する。
図11は、第4の実施の形態に係る識別処理を説明するフローチャートを示している。第4の実施形態では、前段に置かれる別の識別手段から得られる前段の識別処理結果の1位、2位ないし上位の複数(n個)の候補、あるいは、識別したい任意の順位の少なくとも2つ以上の候補、たとえば、識別したい任意の順位の2つないしn個の候補を識別処理候補とし、それらを組み合わせて最終的な識別結果を決定することを特徴としている。
【0048】
まず、前段の識別処理結果を入力する(ST51)。本実施の形態は、前段識別処理のアルゴリズムについてとくに限定するものではないが、一般に識別処理の結果は「順位、クラス(カテゴリ)、スコア(類似度)」の組で表される。たとえば、
1、$1、990
2、$100、900
3、$20、500
4、‥‥
のようなものである。
【0049】
次に、識別処理の候補を選択する(ST52)。たとえば、上記の例で、前段の識別処理結果の1位候補のスコア(990)と2位候補のスコア(900)との差が少なく、前段の識別処理がリジェクト判定したとする。そのとき、本実施の形態では、1位候補($1)と2位候補($100)の2つのクラスを識別処理候補として登録する。あるいは、識別したい任意の順位の2つの候補を選択してもよい。たとえば、別の例で、
1、$20(旧)、990
2、$20(新)、980
3、$1、900
4、‥‥
のようなものがあったとする。1位候補($20(旧))と2位候補($20(新))はスコアが接近しているが、世代が異なるのみで額面は同じ、つまり、詳細識別の必要のない場合がある。そのような場合は、たとえば、1位候補($20(旧))と3位候補($1)を選択する。
【0050】
このようにして、識別処理の候補を選択した後は、未知パターンを入力し(ST53、ST54)、識別処理の候補に関して未知パターンの処理を行なう(ST55)。その内容については、上記で説明した他の実施の形態と同様であるため、ここでは説明を省略する。
【0051】
以上のような処理により得られた未知パターンの識別結果z(x)が出力される(ST56)。
【0052】
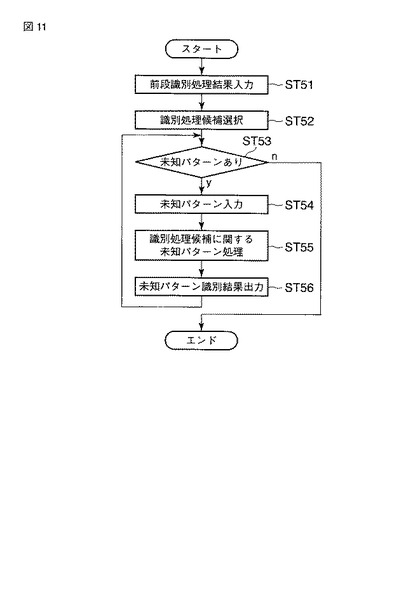
なお、上記第4の実施の形態では、前段の識別処理に誤り(エラー)がないものとしているが、実際の場面では、前段の識別処理がエラーを起こすことも考えられる。たとえば、前段の識別処理では1位候補が$20(旧)で、2位候補が$20(新)であるが、正解は$20(新)である、といった場合である。そこで、前段の識別処理結果からの候補選択を2つではなくn個とし、n個の候補に関して未知パターンの処理を行ない、その処理結果から、最終的な識別結果を決定する方法がある。
【0053】
図12は、第4の実施の形態でn個の候補に関して処理し、最終的な識別結果を決定する場合のフローチャートを示している。図11に対して、1次未知パターン識別結果を組み合わせる処理(ST57)が追加されている。1次未知パターン識別結果zij(x)は、i番目の候補とj番目の候補とによる未知パターン識別結果である。上記した
1、$20(旧)、990
2、$20(新)、980
3、$1、900
の場合で説明すると、たとえば、1次未知パターン識別結果が
z12(x)=$20(新)
z13(x)=リジェクト
z23(x)=$20(新)
であるとする。前段の識別処理結果の1位候補が$20(旧)であるにもかかわらず、z12(x)が$20(新)という結果となった。また、z13(x)がリジェクトである。このような場合、前段の識別処理がエラーを起こしていると判断し、z23(x)の結果を最終的な未知パターンの識別結果とする、といった方法などが考えられる。
【0054】
このように、第4の実施の形態によれば、前段に置かれる別の識別手段から得られる前段の識別処理結果の1位、2位ないし上位の複数(n個)の候補、あるいは、識別したい任意の順位の少なくとも2つ以上の候補を識別処理候補とし、それらを組み合わせて最終的な識別結果を決定することすることで、処理すべきクラス数を削減できるとともに、前段の識別処理でリジェクト判定された場合でも、前述したような本発明の高い識別能力によりアクセプト判定が可能となる場合がある。
【0055】
次に、第5の実施の形態について説明する。
図13は、第5の実施の形態に係る識別処理を説明するフローチャートを示している。第5の実施の形態では、紙葉類に筆記や印刷されるシグネチャやスタンプなど、特徴が不定であり、除外すべきであることが既知である領域を除外領域としてあらかじめ登録し、それ以降、除外領域以外を対象として処理することを特徴としている。
【0056】
そこで、たとえば、領域ごとに除外領域フラグを設け、当該除外領域フラグを除外領域ならば「1」を、そうでなければ「0」を設定することで(ST61)、除外領域か否かを判断できるようにする。除外領域フラグ設定以降の処理(ST61)については、上記で説明した他の実施の形態と同様であるため、ここでは説明を省略する。
【0057】
このように、第5の実施の形態によれば、あらかじめ既知の除外領域を登録することで、除外領域以外を対象として領域選択以降の処理を行なうことができるので、高速かつ安定した識別が可能となる。
【0058】
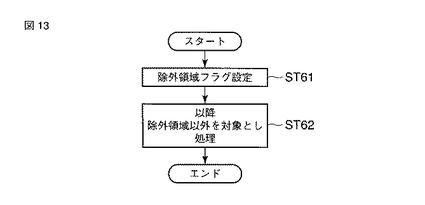
次に、第6の実施の形態について説明する。
図14は、第6の実施の形態に係る識別処理を説明するフローチャートを示している。第6の実施の形態では、紙葉類の搬送状態などに起因する紙葉類のスライドやスキューを検出し(ST71)、その検出したスライド量、スキュー量からあらかじめ用意されたオフセット換算表により該当するオフセット値を読込み(ST72)、そのオフセット値により各領域の座標を変換する(ST73)。座標変換以降は領域分割からの処理(ST74)に進む。領域分割からの処理については、上記で説明した他の実施の形態と同様であるため、ここでは説明を省略する。
【0059】
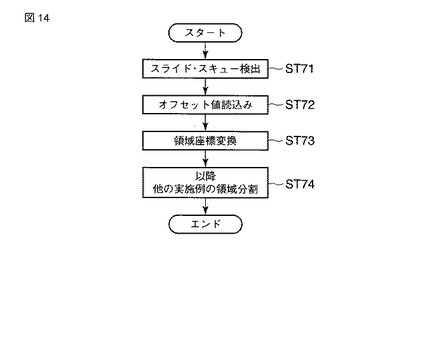
図15は、第6の実施の形態を説明するための紙葉類の模式図である。紙葉類Pが搬送されると、たとえば、透過光センサにより、紙葉類Pの位置が検出される。ここで、紙葉類Pの理想的な搬送状態により入力された場合の紙葉類Pの位置(基準位置)を
(XLT,YLT), (XRT,YRT), (XLB,YLB), (XRB,YRB)
で表す。ただし、(XLT,YLT)は紙葉類Pの左上端点座標、(XRT,YRT)は紙葉類Pの右上端点座標、(XLB,YLB)は紙葉類Pの左下端点座標、(XRB,YRB)は紙葉類Pの右下端点座標である。
【0060】
次に、紙葉類Pの搬送状態などに起因するスライドやスキューの影響を受けて入力された場合の紙葉類Pの位置を
(X’LT,Y’LT), (X’RT,Y’RT), (X’LB,Y’LB), (X’RB,Y’RB)
で表す。ただし、(X’LT,Y’LT)は紙葉類Pの左上端点座標、(X’RT,Y’RT)は紙葉類Pの右上端点座標、(X’LB,Y’LB)は紙葉類Pの左下端点座標、(X’RB,Y’RB)は紙葉類Pの右下端点座標である。このとき、紙葉類Pのスライド量は、たとえば、以下のように算出される。
△XC = X’C - XC
△YC = Y’C - YC
ただし、
XC = (XLT + XRT + XLB + XRB) / 4
YC = (YLT + YRT + YLB + YRB) / 4
X’C = (X’LT + X’RT + X’LB + X’RB) / 4
Y’C = (Y’LT + Y’RT + Y’LB + Y’RB) / 4
である。すなわち、理想的な場合とスライド、スキューの影響を受けた場合のそれぞれについて4つの端点座標の重心を求め、両者の差をスライド量とする方法である。
【0061】
また、スキュー量は、たとえば、以下のように算出される。
θ = arctan [ (Y’RT - Y’LT) / (X’RT - X’LT) ]
あるいは、
θ = arctan [ (Y’RB - Y’LB) / (X’RB - X’LB) ]
すなわち、紙葉類Pの左上端点座標と右上端点座標、あるいは、左下端点座標と右下端点座標から傾きを求め、スキュー量を算出する方法である。
【0062】
このようにして得られるスライド量△XC、△YCおよびスキュー量θから、以下のようにして各領域の座標が変換される。
X’i = Xicos [θ] - Yisin [θ] + △XC
Y’i = Xisin [θ] + Yicos [θ] + △YC
ただし、(Xi,Yi)は理想的な場合のi番目領域の座標、 (X’i,Y’i) はスライド、スキューの影響を考慮した場合のi番目領域の座標である。
【0063】
なお、arctan、cos、sinなどの三角関数は計算量が多いため、あらかじめ部分的な計算結果をオフセット換算表に登録し、処理時にはオフセット換算表から該当するオフセット値を読込み利用する方法が考えられる。
【0064】
このように、第6の実施の形態によれば、紙葉類の搬送状態などに起因する紙葉類のスライドやスキューを検出し、そのスライド量、スキュー量からあらかじめ用意されたオフセット換算表により該当するオフセット値を読込み、そのオフセット値により各領域の座標を変換することで、以降の領域分割を高速かつ正確に行なうことができる。
【0065】
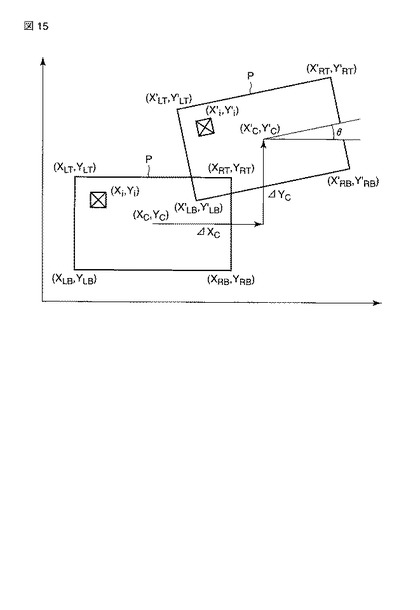
次に、第7の実施の形態について説明する。
図16は、第7の実施の形態に係る識別処理を説明するフローチャートを示している。第7の実施の形態では、領域ごとに識別結果を得る際、対象とする1つないし2つのパターンについて、座標、濃度を一定の範囲で振らせて処理を繰り返し、それらの処理に基づいて識別結果を決定することを特徴とする。
【0066】
今、座標、濃度を振らせた状態をパラメータで表すことにし、それを「ずらしパラメータ」と呼ぶことにする。ずらしパラメータは、たとえば、以下のようなものである。
ri = {αi,βi,γi,δi}
ただし、riはj番目のずらしパラメータ (1≦j≦J)、αは水平方向オフセット、βは垂直方向オフセット、γは濃度ゲイン、δは濃度オフセットを表す要素である。αやβのとりうる範囲としては、たとえば、基準±1(画素)などである。また、γのとりうる範囲としては基準±20(%)など、δのとりうる範囲としては基準±2(レベル)などである。
【0067】
本実施の形態では、J通りのずらしパラメータについて、設定されたずらしパラメータによりクラスcの基準パターンc(0)のi番目領域の特徴量 f(c(0),i) を、ずらし特徴量 f’(c(0),i) に変換し(ST81〜ST84)、そのずらし特徴量に対して処理を実施する(ST85,ST86)。
【0068】
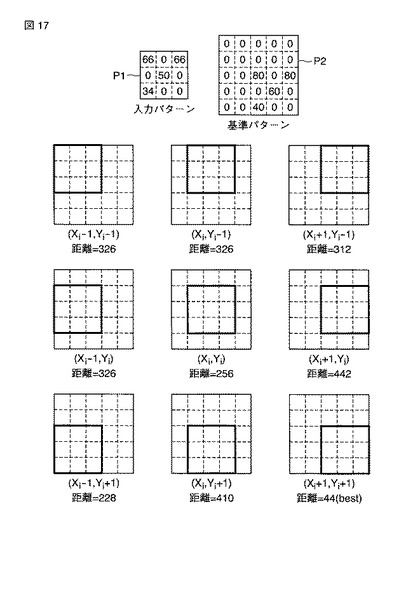
ここで、座標の振らせ方について説明する。図17は、座標の振らせ方を説明するための模式図である。図17では、座標に関するオフセット量であるα、βのとり得る範囲を基準±1(画素)としている。今、図17に示すような切り出された入力パターン(i番目領域)P1と、同じく図17に示すような基準パターンP2との距離を算出することを考える。図17において、 (Xi,Yi) はi番目領域の基準座標である。α=0、β=0(基準座標)のとき、距離は「256」である。
【0069】
なお、ここでの距離は、説明を簡単にするためにユークリッド距離ではなく、2つのパターン間の画素どうしの濃度差を合計したものとする。たとえば、α=0、β=0(基準座標)のときの距離は、
|0-66|+|0-0|+|0-66|+|0-0|+|80-50|+|0-0|+|0-34|+|0-0|+|60-0|=256
となる。図17では、α=1、β=1のときに距離が最小(44)となることを示している。
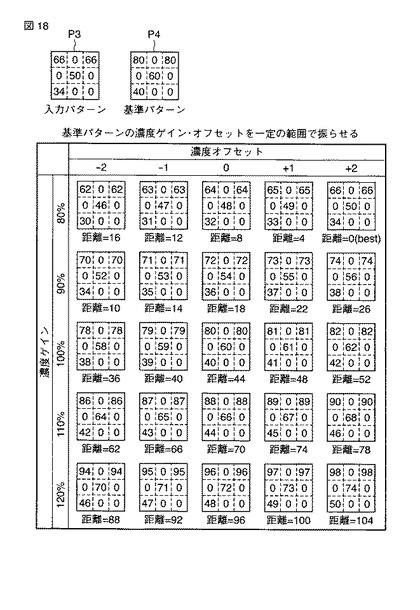
【0070】
次に、濃度の振らせ方について説明する。図18は、濃度の振らせ方を説明するための模式図である。図18では、濃度ゲイン量γのとりうる範囲を基準±20(%)、濃度オフセット量δのとりうる範囲を基準±2(レベル)としている。今、図18に示すような入力パターンP3と基準パターンP4との距離を算出することを考える。なお、距離の定義については、上記同様に2つのパターン間の画素どうしの濃度差を合計したものとする。たとえば、γ=100、δ=0(基準濃度)のときの距離は「44」である。図18では、γ=80、δ=2のときに距離が最小(0)となることを示している。
【0071】
こうして座標や濃度を一定の範囲で振らせることで、合計J通りの処理結果が得られる。最後に、それらJ通りの処理結果に基づいて、最終的な領域識別結果を決定する(ST87)。最も単純な決定方法の例としては、J通りのうち最小となる距離の値を採用することがあげられる。上記の例では、α=1、β=1、γ=80、δ=2のときに距離が最小(0)となるため、この値を採用する。なお、別の決定方法としては、J通りの距離の平均を採用するなどが考えられる。
【0072】
このように、第7の実施の形態によれば、領域ごとに識別結果を得る際、対象とする1つないし2つのパターンについて座標、濃度を一定の範囲で振らせて処理を繰り返し、それらの処理に基づいて識別結果を決定することで、紙葉類の搬送状態などに起因するスライド、スキュー、照明変動などが発生し、領域の特徴量に一定範囲の誤差が生じた場合でも、その影響を考慮した特徴量の変換が行なわれ、以降の領域識別を正確に行なうことができる。
【0073】
なお、本発明は前記実施の形態に限定されるものではない。たとえば、多クラスの識別問題は2クラス識別問題の重ね合わせに帰結するので、本発明が適用できる。また、領域識別アルゴリズムは、ユークリッド距離を用いるものに限らず、たとえば、単純類似度法、部分空間法、ベクトル量子化法など様々な方法が適用可能である。
【符号の説明】
【0074】
1…入力インタフェイス部、2…分割部(領域分割手段)、3…重み付け部(重み付け手段)、4…選択部(領域選択手段)、5…領域識別部(識別結果取得手段)、6…全体識別部、7…最終識別部(識別結果決定手段)、8…出力インタフェイス部。
【技術分野】
【0001】
本発明は、たとえば、有価証券等の紙葉類の自動鑑査装置において、紙葉類から得られる画像パターンとあらかじめ設定される基準パターンとを比較することにより当該紙葉類の種類や真偽等を識別する辞書作成方法及び識別用辞書を記憶する記憶媒体に関する。
【背景技術】
【0002】
一般に、デジタル画像パターン(以下、単にパターンと称す)の識別処理は、高度な識別を目指すほど高解像度のセンサ入力を必要とする傾向にあるが、同時に実用性の観点から、少ない計算コストと実時間での処理を実現しなければならない。
【0003】
そこで、パターンの一部(画素あるいは画素の集合)を選択して処理するための様々な方法が提案されている。一般に、パターンは冗長性を多く含んでいるので、適切な選択を行なえば、解像度を保持したまま少ない計算量で充分な識別性能が得られる。
【0004】
たとえば、ランダムな画素選択を行なうことで処理対象画素を絞り込み、高解像度と高速処理とを両立した技術が知られている(たとえば、特許文献1参照)。この公知技術では、画素選択が検査ごとにランダムに実施されることから、検査部位の探知が事実上不可能となり、信頼性を向上させている。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開平9−134464号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
しかしながら、上記した公知技術では、位置的な重み付けについては考慮されておらず、むしろ信頼性の観点から、選択される画素がパターン全領域に均等に分布することが望ましいとされていた。確かに、検査部位の探知を困難にするという目的では、パターン全領域から均等に画素を選択するのが理想的であるが、一般に、パターンの全領域を画一的に処理して識別結果を得る方法は、局所的な特徴を充分に識別できなかったり、逆に、局所的な媒体変動(汚れ、かすれ等)が識別性能に影響を及ぼしたりという問題がある。
したがって、高速性および信頼性を保ちつつ局所的な特徴を充分に識別し得る識別方法が求められていた。
また、パターンの一部を選択して処理する際、紙葉類の搬送状態等に起因する紙葉類のスライドやスキュー、印刷濃度変動の影響を受けることがある。
【0007】
そこで、本発明は、紙葉類の画像パターンを複数の領域(画素あるいは画素の集合)に分割し、重み付けや選択を行ない、領域ごとに識別結果を得て、その論理的な組み合わせで全体の識別結果を決定することにより、紙葉類のクラスを効率的に推定し、かつ、媒体変動にロバストなパターン識別が可能となる辞書作成方法及び識別用辞書を記憶する記憶媒体を提供することを目的とする。
【課題を解決するための手段】
【0008】
一実施形態に係る辞書作成方法は、識別すべき複数種類の基準となる紙葉類の画像を入力し、前記入力した画像を所定の複数の領域に分割し、前記紙葉類の種類毎に、前記分割した各領域毎の相違度を算出し、前記算出した相違度に基づいて、各領域毎に重み付けを行い、前記重み付けされた複数の領域のうち、重みの大きい順に予め設定される数の領域を選択し、前記選択した領域と、前記入力した画像とを辞書として登録する。
【図面の簡単な説明】
【0009】
【図1】本発明の実施の形態に係る紙葉類識別装置の構成を概略的に示すブロック図。
【図2】第1の実施の形態に係る紙葉類の識別処理を説明するためのフローチャート。
【図3】パターンの領域分割および分割パラメータを説明するための図。
【図4】クラスAの基準パターンの一例を示す図。
【図5】クラスAの基準パターンに対する領域分割の様子を模式的に表した図。
【図6】クラスBの基準パターンの一例を示す図。
【図7】クラスBの基準パターンに対する領域分割の様子を模式的に表した図。
【図8】第2の実施の形態に係る紙葉類の識別処理を説明するためのフローチャート。
【図9】第2の実施の形態に係る紙葉類の識別処理の変形例を説明するためのフローチャート。
【図10】第3の実施の形態に係る紙葉類の識別処理を説明するためのフローチャート。
【図11】第4の実施の形態に係る紙葉類の識別処理を説明するためのフローチャート。
【図12】第4の実施の形態に係る紙葉類の識別処理の変形例を説明するためのフローチャート。
【図13】第5の実施の形態に係る紙葉類の識別処理を説明するためのフローチャート。
【図14】第6の実施の形態に係る紙葉類の識別処理を説明するためのフローチャート。
【図15】第6の実施の形態における紙葉類の搬送状態を説明するための模式図。
【図16】第7の実施の形態に係る紙葉類の識別処理を説明するためのフローチャート。
【図17】第7の実施の形態における座標の振らせ方を説明するための模式図。
【図18】第7の実施の形態における濃度の振らせ方を説明するための模式図。
【発明を実施するための形態】
【0010】
以下、本発明の実施の形態について図面を参照して説明する。
なお、本発明に係る紙葉類識別装置は、紙葉類(媒体)の画像パターンに基づいて、当該紙葉類の種類や真偽を識別するもので、たとえば、有価証券(紙幣等)などの紙葉類上に印刷された画像を光学的に読取って得られる画像パターン(画像データ)に基づいて、当該紙葉類の種類(クラス、金種)や真偽を識別するものである。
【0011】
まず、第1の実施の形態について説明する。
図1は、本発明の実施の形態に係る紙葉類識別装置の構成を概略的に示すものである。この紙葉類識別装置は、紙葉類上の画像を光学的に読取って得られる画像パターン(入力パターン)を入力する入力インタフェイス(I/F)部1、前段の識別結果や識別処理の候補を一時的に蓄積する前段識別結果バッファ部10、入力される画像パターン(入力パターン)を一時的に蓄積する入力パターンバッファ部11、入力された画像パターンを複数の領域に分割する領域分割手段としての分割部2、分割パラメータを保存する分割パラメータ保存部21、分割された領域に対し重み付けを行なう重み付け手段としての重み付け部3、重みパラメータを保存する重みパラメータ保存部31、重み付けされた領域から識別に用いる領域を選択する領域選択手段としての選択部4、選択パラメータを保存する選択パラメータ保存部41、選択された領域ごとの基準パターンとの識別結果を取得する識別結果取得手段としての領域識別部5、領域ごとの識別結果を保存する領域識別結果保存部51、全体の識別結果を決定する全体識別部6、全体識別結果を保存する全体識別結果保存部61、領域ごとの識別結果の論理的な組み合わせで全体の識別結果を決定する識別結果決定手段としての最終識別部7、最終の識別結果を保存する最終識別結果保存部71、識別結果を出力する出力インタフェイス(I/F)部8、および、出力結果を一時的に蓄積する出力結果バッファ部81を有して構成される。
【0012】
図2は、第1の実施の形態に係る識別処理を説明するフローチャートを示しており、以下、このフローチャートに基づき識別処理を説明する。
まず、分割パラメータを初期化する(ST1)。ここで、分割パラメータとは、パターンの領域分割を表現する具体的な数値のこととする。たとえば、図3では、入力されたパターンを横32×縦13(計416)の格子状に均等に領域分割する例を示している。このとき、分割パラメータは、たとえば、
pi={hi,vi,li,di}
のように表される。ただし、piはi番目領域の分割パラメータ(1≦i≦416)、hiはi番目領域の始点水平座標、viはi番目領域の始点垂直座標、liはi番目領域の水平幅、diはi番目領域の垂直高さである。分割パラメータの初期化では、piに具体的な数値を代入する。
【0013】
次に、重みパラメータを初期化する(ST2)。重みパラメータは、領域の重要度を表すものであるが、初期状態ではどの領域がどれだけ重要なのかは不明なので、ここでは全て同じ値とする。すなわち、
wi=1/416
である。wiはi番目領域の重みパラメータである。
【0014】
さらに、選択パラメータを初期化する(ST3)。ここで、選択パラメータをQとすると、選択パラメータQは、選択率q0と選択領域番号qj(j≧1)とに分けられる。すなわち、
Q={q0,q1,q2,‥‥}
である。選択率は、全領域に対する選択領域の割合である。すなわち、
0.0≦q0≦1.0
である。また、そのときの選択された領域の番号を選択領域番号とする。選択領域番号の数は選択率に応じて定まる。選択領域番号の値は、本実施の形態では、
1≦qj≦416
の範囲となる。初期状態では、どの領域がどれだけ重要なのかは不明なので、適当な値を登録する。たとえば、選択率q0=0.25ならば、選択パラメータQは、
Q={0.25,1,2,‥‥,104}
のように初期化する。
【0015】
パラメータの初期化が完了すると、基準パターンが入力される。なお、本実施の形態では、説明をわかりやすくするためにパターンのクラス数を「2」とし、2クラス識別問題とする。図4、図5および図6、図7は、クラスの異なる2つのパターンを模式的に図示したものである。このとき、基準パターンとは、媒体の汚損や入力変動の影響のない、クラスの基準となるべきパターンのことである。基準パターンは、1クラスにつき1つである。
【0016】
また、基準パターンの属するクラスは既知である。このような基準パターンが入力されると、領域分割が行なわれる。図4に示す基準パターン(クラスA)に対して、図5に示す領域分割がなされるものである。また、図6に示す基準パターン(クラスB)に対して図7に示す領域分割がなされるものである。図5および図7は、領域分割の様子を模式的に表したものである。基準パターンの入力と領域分割は、全てのクラスについて繰り返し実行される(ST4〜ST6)
全てのクラスの基準パターン入力と領域分割が完了すると、重みパラメータが更新される(ST7)。この段階では、クラス間の相違によって重みパラメータが更新される。たとえば、2つのクラスAおよびBの基準パターンをa(0)およびb(0)と表し、1つの領域に含まれる画素の数をNとすると、特徴量は、たとえば、
f(a(0), i) = {a(0, i, 1), a(0, i, 2), … , a(0, i, n), … , a(0, i, N)}
f(b(0), i) = {b(0, i, 1), b(0, i, 2), … , b(0, i, n), … , b(0, i, N)}
のように表される。ただし、f(a(0), i)およびf(b(0), i)は、それぞれa(0)およびb(0)のi番目領域の特徴量である(1≦i≦416)。また、a(0, i, n)およびb(0, i, n)は、それぞれa(0)およびb(0)のi番目領域のn番目画素の画素値である(1≦n≦N)。
【0017】
すなわち、特徴量は、N個の画素値によって決まるN次元ベクトルである。このとき、重みパラメータは以下のように算出される。
wi = D(f(a(0),i), f(b(0),i)) / Σi{D(f(a(0),i), f(b(0),i))}
ただし、D(f(a(0),i), f(b(0),i))は、i番目領域におけるa(0)とb(0)とのユークリッド距離であり、
D(f(a(0),i), f(b(0),i)) = sqrt[Σn{b(0,i,n)-a(0,i,n)}2]
で表される。すなわち、重みパラメータは、領域ごとの基準パターン間距離を全領域の基準パターン間距離の総和で割った値となる。一般に、クラスを代表する基準パターン間の距離が大きい領域ほどクラス間の識別に有利と考えてよいので、領域重み付けの第一段階としては妥当である。
【0018】
しかしながら、対象パターンによってはクラス内で変動する領域が存在する場合がある。たとえば、スタンプ、シグネチャ、記番号などである。クラス間の識別をより安定なものとするためには、これらの領域の重みを低くすべきである。そこで、本実施の形態では学習パターンを用いて重みパラメータをチューニングする。ここで、学習パターンとは、上記基準パターンを除き、その属するクラスが既知であるサンプルのことである。学習パターンは、ある程度のサンプル数があり、その属するクラスのパターン全体集合の分布を反映したものであることが望ましい。このような学習パターンが入力されると、上記基準パターンと同様に領域分割が行なわれる。学習パターンの入力と領域分割は、全てのクラスの全てのサンプルについて繰り返し実行される。(ST8〜ST10)
全てのクラスの全てのサンプルの学習パターン入力と領域分割が完了すると、重みパラメータが更新される(ST11)。この段階では、クラス内の変動によって重みパラメータが更新される。たとえば、クラスAおよびBのそれぞれM個の学習パターンをa(k)およびb(k)と表すと(1≦k≦M)、
s(a,i)=Σk‖f(a(k),i)−μ(a,i)‖
s(b,i)=Σk‖f(b(k),i)−μ(b,i)‖
は変動を表す値である。ただし、s(a,i)およびs(b,i)は、それぞれクラスAおよびBのi番目領域の変動値、μ(a(k),i)およびμ(b(k),i)は、それぞれクラスAおよびBのi番目領域の平均ベクトルである。すなわち、本実施の形態での変動値は、クラスごとの学習パターンの標準偏差を領域ごとに算出したものである。このとき、重みパラメータは以下のように更新される。
wi←wi/{s(a)+s(b,i)}
すなわち、元の重みの値をクラスAおよびBの変動値の和で割ったものである。更新後、さらに以下のように正規化する。
wi←wi/Σiwi
このようにして、クラス間の相違とクラス内の変動とを考慮した重みパラメータが決定される。
【0019】
次に、選択パラメータを更新する(ST12)。本実施の形態では、重みの大きい順に上位から選択率Qの分だけ選択する。たとえば、選択率q0=0.25ならば、重みの大きい順に上位から、416の4分の1である104個の領域の番号を選択領域番号qjとして登録する。以上のようにして、クラス間の相違とクラス内の変動に基づいた領域の重み付けおよび選択がなされ、学習フェーズが完了する。
【0020】
続いて、識別フェーズについて説明する。識別フェーズでは、未知のパターンが入力され、その識別結果が出力される。ここで、未知のパターンとは、その属するクラスが未知であるサンプルのことである。このような未知パターンが入力されると(ST13,ST14)、基準パターンや学習パターンと同様に領域分割が行なわれる(ST15)。
次に、上記選択パラメータで指定された領域を選択する(ST16)。さらに、選択された領域について、領域ごとに識別処理を行なう(ST17〜ST19)。
【0021】
本発明では、識別処理自体のアルゴリズムについて特に限定されるものではないが、2クラスの識別問題の場合、識別処理の結果が「クラスA」、「クラスB」、「リジェクト」のいずれかとなることとする。最も原始的な識別アルゴリズムは、基準パターンと未知パターンとのユークリッド距離を用いるものである。たとえば、未知パターンをxとし、未知パターンxに対するi番目領域の識別結果をz(x,i)とすると、
z(x, i) = クラスA (もし、D(f(x,i), f(b(0),i)) > D(f(x,i), f(a(0),i))+ε ならば)
z(x, i) = クラスB (もし、D(f(x,i), f(a(0),i)) > D(f(x,i), f(b(0),i))+ε ならば)
z(x, i) = リジェクト(もし、|D(f(x,i), f(a(0),i)) - D(f(x,i), f(b(0),i))|≦ε なら ば)
のように表される。ただし、εはクラス間の有意な差を定義するための適当な定数である。
【0022】
次に、領域ごとの識別結果を基に全体の識別結果を決定する。前述した通り、本発明は、領域ごとに一旦識別結果を得て、その多数決、論理式、あるいは、それらの重み付けで全体の識別結果を決定することを特徴の1つとしている。
【0023】
従来、たとえば、前述したような領域ごとのユークリッド距離を算出し、領域ごとに識別結果を出さず、その単純平均や重み付き平均を求め全体の識別判定を行なうものがあったが、局所的な特徴を充分に識別できなかったり、逆に、局所的な媒体変動(汚れ、かすれ等)が識別性能に影響を及ぼしたりという問題がある。
【0024】
本実施の形態によれば、局所的な特徴を他所に左右されず、局所的な変動を他所に影響を与えず、捉えることができるため、より高精度な識別処理が実現できる。たとえば、未知パターンをxとし、未知パターンxに対する全体識別結果をz(x)とすると、多数決であれば、
z(x) = クラスA (もし、ΣiI(z(x,i)=クラスA) が最も多いならば)
z(x) = クラスB (もし、ΣiI(z(x,i)=クラスB) が最も多いならば)
z(x) = リジェクト (もし、ΣiI(z(x,i)=リジェクト) が最も多いならば)
のように表される。ただし、ΣiI(z(x,i)=クラスA)、ΣiI(z(x,i)=クラスB)、ΣiI(z(x,i)=リジェクト)は、領域の識別結果がそれぞれクラスA、クラスB、リジェクトとなった領域の数である。
【0025】
また、ΣiI(z(x,i)=クラスA)、ΣiI(z(x,i)=クラスB)、ΣiI(z(x,i)=リジェクト)の関係を論理式で表し、全体の識別結果を決定することもできる。たとえば、
もし、ΣiI(z(x,i)=クラスB)/ΣiI(z(x,i)=クラスA)<α、かつ、
(ΣiI(z(x,i)=クラスA)+ΣiI(z(x,i)=クラスB))>ΣiI(z(x,i)=リジェクト)+β
ならば、
z(x) = クラスA
もし、ΣiI(z(x,i)=クラスA) / ΣiI(z(x,i)=クラスB)<α=リジェクト)+β
ならば、
z(x) = クラスB
それ以外ならば、
z(x) = リジェクト
のように表される。ただし、αはクラス間の有意な差を定義するための適当な定数、βはリジェクトの割合を調整するための適当な定数である。このように、全体識別の振る舞いがパラメータ(αやβなど)によって簡単に調整可能である点も本実施の形態の特徴である。
【0026】
さらに、上記多数決や論理式に重みパラメータの重みを考慮し、重み付け多数決や重み付け論理式とすることもできる。すなわち、
z(x) = クラスA (もし、Σi wi I(z(x,i)=クラスA) が最も多いならば)
z(x) = クラスB (もし、Σi wi I(z(x,i)=クラスB) が最も多いならば)
z(x) = リジェクト (もし、Σi wi I(z(x,i)=リジェクト) が最も多いならば)
あるいは、
もし、Σi wi I(z(x,i)=クラスB) / Σi wi I(z(x,i)=クラスA) < α 、かつ、(Σi wi I(z(x,i)=クラスA) + Σi wi I(z(x,i)=クラスB)) > Σi wi I(z(x,i)=リジェクト)+β
ならば、
z(x) = クラスA
もし、Σi wi I(z(x,i)=クラスA) / Σi wi I(z(x,i)=クラスB) < α 、かつ、(Σi wi I(z(x,i)=クラスA) + Σi wi I(z(x,i)=クラスB)) > Σi wi I(z(x,i)=リジェクト)+β
ならば、
z(x) = クラスB
それ以外ならば、
z(x) = リジェクト
などである。
以上のような処理により得られた未知パターンの識別結果z(x)が出力される(ST19)。
【0027】
このように、第1の実施の形態によれば、紙葉類の画像パターンを複数の領域(画素あるいは画素の集合)に分割し、重み付けや選択を行ない、領域ごとに識別結果を得て、その論理的な組み合わせで全体の識別結果を決定することにより、紙葉類のクラスを効率的に推定し、かつ、媒体変動にロバストなパターン識別が可能となる。
特に、クラス間の相違とクラス内の変動に基づいて領域の重み付けや選択を行なうので、計算量を削減できるとともに、パターン全体を画一的に処理する方法に比べて高い識別性能が得られる。
【0028】
また、領域ごとに一旦識別結果を求め、それらの多数決、論理式、あるいは、それらの重み付けで全体の識別結果を決定するので、領域ごとの特徴量の単純平均などに比べ、局所的な特徴を他所に左右されず、局所的な変動を他所に影響を与えず、捉えることができ、かつ、全体識別の振る舞いがパラメータによって簡単に調整可能である。
【0029】
次に、第2の実施の形態について説明する。
図8は、第2の実施の形態に係る識別処理を説明するフローチャートを示している。分割パラメータの初期化、重みパラメータの初期化、選択パラメータの初期化(ST1,ST2,ST3)については第1の実施の形態と同様であるので、ここでは説明を省略する。第2の実施の形態では、学習パターンを入力しながらランダムな領域選択を繰り返し、評価に応じて重みパラメータを逐次最適化していく。
【0030】
パラメータの初期化が完了すると、第1の実施形態と同様に基準パターンが入力される(ST4〜ST6)。なお、第2の実施の形態でも、説明をわかりやすくするためにパターンのクラス数を「2」とし、2クラス識別問題とする。基準パターンとは、媒体の汚損や入力変動の影響のない、クラスの基準となるべきパターンのことである。基準パターンは、1クラスにつき1つである。また、基準パターンの属するクラスは既知である。
【0031】
このような基準パターンが入力されると、領域分割が行なわれる。基準パターンの入力と領域分割は、全てのクラスについて繰り返し実行される。第2の実施の形態では、第1の実施の形態のような基準パターンを用いた重みパラメータの更新は行なわない。
【0032】
続いて、第1の実施の形態と同様に学習パターンが入力される(ST8,ST9)。学習パターンは、ある程度のサンプル数があり、その属するクラスのパターン全体集合の分布を反映したものであることが望ましい。学習パターンが入力されると、領域分割が行なわれる(ST10)。
【0033】
ここで、選択領域番号がランダムに設定される(ST21)。たとえば、選択率q0=0.25ならば、416の4分の1である104個の領域の番号を重複せずランダムに抽出し、選択領域番号qjとして登録する(ST22)。
【0034】
次に、ランダムに選択された領域について評価を実施する(ST23)。基本的な評価の方策としては、入力された学習パターンの識別に有効であれば、そのとき選択された領域の重みパラメータを増加させ、無効であれば、そのとき選択された領域の重みパラメータを減少させる。どのように有効、無効を判断するかについて本発明は限定するものではないが、最も原始的な評価アルゴリズムは、基準パターンと学習パターンとのユークリッド距離を用いるものである。たとえば、2つのクラスの基準パターンをa(0)およびb(0)とし、クラスAに属する学習パターンをyとすると、
もし、Σi D(f(y,i), f(b(0),i)) > D(f(y,i), f(a(0),i))+θ ならば、
wi ← wi + δ
それ以外ならば、
wi ← wi - δ
とする。ただし、θはその領域選択が有効かどうかを定義するための適当な定数、δはwiに対して小さな修正項(δ>0)である。このような重みパラメータの更新が、全ての学習パターンについて繰り返し実行され(ST24)、更新後、さらに以下のように正規化される(ST25)。
wi ← wi /Σi wi
このようにして、ランダムな領域選択と評価とを交互に繰り返し、その評価に基づいた重みパラメータが決定される。
【0035】
次に、選択パラメータを更新するが、その内容は第1の実施の形態と同様、重みの大きい順に上位から選択領域番号として登録する(ST26)ものである。ただし、第2の実施の形態では、上記選択領域番号をさらにランダムに絞り込む(ST27)ことを特徴としている。以上のようにして、学習フェーズが完了する。
【0036】
第2の実施の形態の識別フェーズ(未知パターンの入力以降(ST13〜ST19))については、第1の実施の形態と同様である。最終的に、未知パターンの識別結果が出力される。
【0037】
なお、ランダムな領域選択を行なわずに、全領域ごとの評価を繰り返し、評価に応じて重みパラメータを逐次最適化していく方法もある。図9は、第2の実施の形態でランダムな領域選択を行なわない場合のフローチャートを示したものである。フローチャートの各処理については、上で(図8で)述べたものと同様であるため説明を省略する。
【0038】
このように、第2の実施の形態によれば、ランダムに選択された領域あるいは全領域ごとの評価を繰り返し、その評価に基づいて領域の重みを逐次更新するので、実データに即したパラメータでの識別が可能となる。
また、選択された領域に対しランダムマスクをかけて絞り込むことで、識別性能と信頼性を両立できる。
【0039】
次に、第3の実施の形態について説明する。
図10は、第3の実施の形態に係る識別処理を説明するフローチャートを示している。パラメータの初期化は、第1の実施の形態における分割パラメータの初期化、重みパラメータの初期化、選択パラメータの初期化のことであり、ここでは説明を省略する。第3の実施の形態では、複数回の領域選択による複数の識別結果の多数決、論理式、あるいは、それらの重み付けで最終的な識別結果を決定することを特徴としている。
【0040】
まず、複数回の領域選択を実施する(ST31、ST32)。領域選択のアルゴリズムは、第1の実施の形態によるものでも、第2の実施の形態によるものでも構わない。ループ回数をLOOPMAXとすると、LOOPMAX通りの選択パラメータQloopが得られる。
Qloop (1≦loop≦LOOPMAX)
以上のようにして、学習フェーズが完了する(ST33〜ST35)。
【0041】
続いて、識別フェーズについて説明する。識別フェーズでは、未知パターンが入力され(ST36、ST37)、その識別結果が出力されるが(ST38)、第1の実施の形態や第2の実施の形態と異なり、LOOPMAX通りの選択パラメータに基づくLOOPMAX通りの未知パターン処理が行なわれ、結果としてLOOPMAX通りの全体の識別結果が得られる(ST39〜ST42)。未知パターンをxとし、選択パラメータQloopに基づいた未知パターンxに対する全体の識別結果をz(x,loop)とする。
【0042】
すると、最終識別が行なわれる(ST43)。前述した通り、本実施の形態は、複数回の領域選択による複数の識別結果の多数決、論理式、あるいは、それらの重み付けで最終的な識別結果を決定することを特徴としている。たとえば、多数決であれば、
z(x) = クラスA (もし、ΣloopI(z(x,loop)=クラスA) が最も多いならば)
z(x) = クラスB (もし、ΣloopI(z(x,loop)=クラスB) が最も多いならば)
z(x) = リジェクト (もし、ΣloopI(z(x,loop)=リジェクト) が最も多いならば)
のように表される。ただし、ΣloopI(z(x,loop)=クラスA)、ΣloopI(z(x,loop)=クラスB)、ΣloopI(z(x,loop)=リジェクト)は、全体の識別結果がそれぞれクラスA、クラスB、リジェクトとなった数である。
【0043】
また、ΣloopI(z(x,loop)=クラスA)、ΣloopI(z(x,loop)=クラスB)、ΣloopI(z(x,loop)=リジェクト)の関係を論理式で表し、最終の識別結果を決定することもできる。たとえば、
もし、ΣloopI(z(x,loop)=クラスB) / ΣloopI(z(x,loop)=クラスA) < α 、かつ、(ΣloopI(z(x,loop)=クラスA) + ΣloopI(z(x,loop)=クラスB)) > ΣloopI(z(x,loop)=リジェクト)+β
ならば、
z(x) = クラスA
もし、ΣloopI(z(x,loop)=クラスA) / ΣloopI(z(x,loop)=クラスB) < α 、かつ、(ΣloopI(z(x,loop)=クラスA) + ΣloopI(z(x,loop)=クラスB)) > ΣloopI(z(x,loop)=リジェクト)+β
ならば、
z(x) = クラスB
それ以外ならば、
z(x) = リジェクト
のように表される。ただし、αはクラス間の有意な差を定義するための適当な定数、βはリジェクトの割合を調整するための適当な定数である。
【0044】
さらに、上記多数決や論理式に重みパラメータの重みを考慮し、重み付け多数決や重み付け論理式とすることもできる。すなわち、
z(x) = クラスA (もし、Σloop wi I(z(x,loop)=クラスA) が最も多いならば)
z(x) = クラスB (もし、Σloop wi I(z(x,loop)=クラスB) が最も多いならば)
z(x) = リジェクト (もし、Σloop wi I(z(x,loop)=リジェクト) が最も多いならば)
あるいは、
もし、Σloop wi I(z(x,loop)=クラスB) / Σloop wi I(z(x,loop)=クラスA) < α 、かつ、(Σloop wi I(z(x,loop)=クラスA) + Σloop wi I(z(x,loop)=クラスB)) > Σloop wi I(z(x,loop)=リジェクト)+β
ならば、
z(x) = クラスA
もし、Σloop wi I(z(x,loop)=クラスA) / Σloop wi I(z(x,loop)=クラスB) < α 、かつ、(Σloop wi I(z(x,loop)=クラスA) + Σloop wi I(z(x,loop)=クラスB)) > Σloop wi I(z(x,loop)=リジェクト)+β
ならば、
z(x) = クラスB
それ以外ならば、
z(x) = リジェクト
などである。
【0045】
以上のような処理により得られた未知パターンの識別結果z(x)が出力される(ST44)。
【0046】
このように、第3の実施の形態によれば、複数回の領域選択による複数の識別結果の多数決、論理式、あるいは、それらの重み付けで最終的な識別結果を決定すれば、様々な見方で識別した結果を統合できるので、1回の領域選択よりもロバストな識別性能が得られる。
【0047】
次に、第4の実施の形態について説明する。
図11は、第4の実施の形態に係る識別処理を説明するフローチャートを示している。第4の実施形態では、前段に置かれる別の識別手段から得られる前段の識別処理結果の1位、2位ないし上位の複数(n個)の候補、あるいは、識別したい任意の順位の少なくとも2つ以上の候補、たとえば、識別したい任意の順位の2つないしn個の候補を識別処理候補とし、それらを組み合わせて最終的な識別結果を決定することを特徴としている。
【0048】
まず、前段の識別処理結果を入力する(ST51)。本実施の形態は、前段識別処理のアルゴリズムについてとくに限定するものではないが、一般に識別処理の結果は「順位、クラス(カテゴリ)、スコア(類似度)」の組で表される。たとえば、
1、$1、990
2、$100、900
3、$20、500
4、‥‥
のようなものである。
【0049】
次に、識別処理の候補を選択する(ST52)。たとえば、上記の例で、前段の識別処理結果の1位候補のスコア(990)と2位候補のスコア(900)との差が少なく、前段の識別処理がリジェクト判定したとする。そのとき、本実施の形態では、1位候補($1)と2位候補($100)の2つのクラスを識別処理候補として登録する。あるいは、識別したい任意の順位の2つの候補を選択してもよい。たとえば、別の例で、
1、$20(旧)、990
2、$20(新)、980
3、$1、900
4、‥‥
のようなものがあったとする。1位候補($20(旧))と2位候補($20(新))はスコアが接近しているが、世代が異なるのみで額面は同じ、つまり、詳細識別の必要のない場合がある。そのような場合は、たとえば、1位候補($20(旧))と3位候補($1)を選択する。
【0050】
このようにして、識別処理の候補を選択した後は、未知パターンを入力し(ST53、ST54)、識別処理の候補に関して未知パターンの処理を行なう(ST55)。その内容については、上記で説明した他の実施の形態と同様であるため、ここでは説明を省略する。
【0051】
以上のような処理により得られた未知パターンの識別結果z(x)が出力される(ST56)。
【0052】
なお、上記第4の実施の形態では、前段の識別処理に誤り(エラー)がないものとしているが、実際の場面では、前段の識別処理がエラーを起こすことも考えられる。たとえば、前段の識別処理では1位候補が$20(旧)で、2位候補が$20(新)であるが、正解は$20(新)である、といった場合である。そこで、前段の識別処理結果からの候補選択を2つではなくn個とし、n個の候補に関して未知パターンの処理を行ない、その処理結果から、最終的な識別結果を決定する方法がある。
【0053】
図12は、第4の実施の形態でn個の候補に関して処理し、最終的な識別結果を決定する場合のフローチャートを示している。図11に対して、1次未知パターン識別結果を組み合わせる処理(ST57)が追加されている。1次未知パターン識別結果zij(x)は、i番目の候補とj番目の候補とによる未知パターン識別結果である。上記した
1、$20(旧)、990
2、$20(新)、980
3、$1、900
の場合で説明すると、たとえば、1次未知パターン識別結果が
z12(x)=$20(新)
z13(x)=リジェクト
z23(x)=$20(新)
であるとする。前段の識別処理結果の1位候補が$20(旧)であるにもかかわらず、z12(x)が$20(新)という結果となった。また、z13(x)がリジェクトである。このような場合、前段の識別処理がエラーを起こしていると判断し、z23(x)の結果を最終的な未知パターンの識別結果とする、といった方法などが考えられる。
【0054】
このように、第4の実施の形態によれば、前段に置かれる別の識別手段から得られる前段の識別処理結果の1位、2位ないし上位の複数(n個)の候補、あるいは、識別したい任意の順位の少なくとも2つ以上の候補を識別処理候補とし、それらを組み合わせて最終的な識別結果を決定することすることで、処理すべきクラス数を削減できるとともに、前段の識別処理でリジェクト判定された場合でも、前述したような本発明の高い識別能力によりアクセプト判定が可能となる場合がある。
【0055】
次に、第5の実施の形態について説明する。
図13は、第5の実施の形態に係る識別処理を説明するフローチャートを示している。第5の実施の形態では、紙葉類に筆記や印刷されるシグネチャやスタンプなど、特徴が不定であり、除外すべきであることが既知である領域を除外領域としてあらかじめ登録し、それ以降、除外領域以外を対象として処理することを特徴としている。
【0056】
そこで、たとえば、領域ごとに除外領域フラグを設け、当該除外領域フラグを除外領域ならば「1」を、そうでなければ「0」を設定することで(ST61)、除外領域か否かを判断できるようにする。除外領域フラグ設定以降の処理(ST61)については、上記で説明した他の実施の形態と同様であるため、ここでは説明を省略する。
【0057】
このように、第5の実施の形態によれば、あらかじめ既知の除外領域を登録することで、除外領域以外を対象として領域選択以降の処理を行なうことができるので、高速かつ安定した識別が可能となる。
【0058】
次に、第6の実施の形態について説明する。
図14は、第6の実施の形態に係る識別処理を説明するフローチャートを示している。第6の実施の形態では、紙葉類の搬送状態などに起因する紙葉類のスライドやスキューを検出し(ST71)、その検出したスライド量、スキュー量からあらかじめ用意されたオフセット換算表により該当するオフセット値を読込み(ST72)、そのオフセット値により各領域の座標を変換する(ST73)。座標変換以降は領域分割からの処理(ST74)に進む。領域分割からの処理については、上記で説明した他の実施の形態と同様であるため、ここでは説明を省略する。
【0059】
図15は、第6の実施の形態を説明するための紙葉類の模式図である。紙葉類Pが搬送されると、たとえば、透過光センサにより、紙葉類Pの位置が検出される。ここで、紙葉類Pの理想的な搬送状態により入力された場合の紙葉類Pの位置(基準位置)を
(XLT,YLT), (XRT,YRT), (XLB,YLB), (XRB,YRB)
で表す。ただし、(XLT,YLT)は紙葉類Pの左上端点座標、(XRT,YRT)は紙葉類Pの右上端点座標、(XLB,YLB)は紙葉類Pの左下端点座標、(XRB,YRB)は紙葉類Pの右下端点座標である。
【0060】
次に、紙葉類Pの搬送状態などに起因するスライドやスキューの影響を受けて入力された場合の紙葉類Pの位置を
(X’LT,Y’LT), (X’RT,Y’RT), (X’LB,Y’LB), (X’RB,Y’RB)
で表す。ただし、(X’LT,Y’LT)は紙葉類Pの左上端点座標、(X’RT,Y’RT)は紙葉類Pの右上端点座標、(X’LB,Y’LB)は紙葉類Pの左下端点座標、(X’RB,Y’RB)は紙葉類Pの右下端点座標である。このとき、紙葉類Pのスライド量は、たとえば、以下のように算出される。
△XC = X’C - XC
△YC = Y’C - YC
ただし、
XC = (XLT + XRT + XLB + XRB) / 4
YC = (YLT + YRT + YLB + YRB) / 4
X’C = (X’LT + X’RT + X’LB + X’RB) / 4
Y’C = (Y’LT + Y’RT + Y’LB + Y’RB) / 4
である。すなわち、理想的な場合とスライド、スキューの影響を受けた場合のそれぞれについて4つの端点座標の重心を求め、両者の差をスライド量とする方法である。
【0061】
また、スキュー量は、たとえば、以下のように算出される。
θ = arctan [ (Y’RT - Y’LT) / (X’RT - X’LT) ]
あるいは、
θ = arctan [ (Y’RB - Y’LB) / (X’RB - X’LB) ]
すなわち、紙葉類Pの左上端点座標と右上端点座標、あるいは、左下端点座標と右下端点座標から傾きを求め、スキュー量を算出する方法である。
【0062】
このようにして得られるスライド量△XC、△YCおよびスキュー量θから、以下のようにして各領域の座標が変換される。
X’i = Xicos [θ] - Yisin [θ] + △XC
Y’i = Xisin [θ] + Yicos [θ] + △YC
ただし、(Xi,Yi)は理想的な場合のi番目領域の座標、 (X’i,Y’i) はスライド、スキューの影響を考慮した場合のi番目領域の座標である。
【0063】
なお、arctan、cos、sinなどの三角関数は計算量が多いため、あらかじめ部分的な計算結果をオフセット換算表に登録し、処理時にはオフセット換算表から該当するオフセット値を読込み利用する方法が考えられる。
【0064】
このように、第6の実施の形態によれば、紙葉類の搬送状態などに起因する紙葉類のスライドやスキューを検出し、そのスライド量、スキュー量からあらかじめ用意されたオフセット換算表により該当するオフセット値を読込み、そのオフセット値により各領域の座標を変換することで、以降の領域分割を高速かつ正確に行なうことができる。
【0065】
次に、第7の実施の形態について説明する。
図16は、第7の実施の形態に係る識別処理を説明するフローチャートを示している。第7の実施の形態では、領域ごとに識別結果を得る際、対象とする1つないし2つのパターンについて、座標、濃度を一定の範囲で振らせて処理を繰り返し、それらの処理に基づいて識別結果を決定することを特徴とする。
【0066】
今、座標、濃度を振らせた状態をパラメータで表すことにし、それを「ずらしパラメータ」と呼ぶことにする。ずらしパラメータは、たとえば、以下のようなものである。
ri = {αi,βi,γi,δi}
ただし、riはj番目のずらしパラメータ (1≦j≦J)、αは水平方向オフセット、βは垂直方向オフセット、γは濃度ゲイン、δは濃度オフセットを表す要素である。αやβのとりうる範囲としては、たとえば、基準±1(画素)などである。また、γのとりうる範囲としては基準±20(%)など、δのとりうる範囲としては基準±2(レベル)などである。
【0067】
本実施の形態では、J通りのずらしパラメータについて、設定されたずらしパラメータによりクラスcの基準パターンc(0)のi番目領域の特徴量 f(c(0),i) を、ずらし特徴量 f’(c(0),i) に変換し(ST81〜ST84)、そのずらし特徴量に対して処理を実施する(ST85,ST86)。
【0068】
ここで、座標の振らせ方について説明する。図17は、座標の振らせ方を説明するための模式図である。図17では、座標に関するオフセット量であるα、βのとり得る範囲を基準±1(画素)としている。今、図17に示すような切り出された入力パターン(i番目領域)P1と、同じく図17に示すような基準パターンP2との距離を算出することを考える。図17において、 (Xi,Yi) はi番目領域の基準座標である。α=0、β=0(基準座標)のとき、距離は「256」である。
【0069】
なお、ここでの距離は、説明を簡単にするためにユークリッド距離ではなく、2つのパターン間の画素どうしの濃度差を合計したものとする。たとえば、α=0、β=0(基準座標)のときの距離は、
|0-66|+|0-0|+|0-66|+|0-0|+|80-50|+|0-0|+|0-34|+|0-0|+|60-0|=256
となる。図17では、α=1、β=1のときに距離が最小(44)となることを示している。
【0070】
次に、濃度の振らせ方について説明する。図18は、濃度の振らせ方を説明するための模式図である。図18では、濃度ゲイン量γのとりうる範囲を基準±20(%)、濃度オフセット量δのとりうる範囲を基準±2(レベル)としている。今、図18に示すような入力パターンP3と基準パターンP4との距離を算出することを考える。なお、距離の定義については、上記同様に2つのパターン間の画素どうしの濃度差を合計したものとする。たとえば、γ=100、δ=0(基準濃度)のときの距離は「44」である。図18では、γ=80、δ=2のときに距離が最小(0)となることを示している。
【0071】
こうして座標や濃度を一定の範囲で振らせることで、合計J通りの処理結果が得られる。最後に、それらJ通りの処理結果に基づいて、最終的な領域識別結果を決定する(ST87)。最も単純な決定方法の例としては、J通りのうち最小となる距離の値を採用することがあげられる。上記の例では、α=1、β=1、γ=80、δ=2のときに距離が最小(0)となるため、この値を採用する。なお、別の決定方法としては、J通りの距離の平均を採用するなどが考えられる。
【0072】
このように、第7の実施の形態によれば、領域ごとに識別結果を得る際、対象とする1つないし2つのパターンについて座標、濃度を一定の範囲で振らせて処理を繰り返し、それらの処理に基づいて識別結果を決定することで、紙葉類の搬送状態などに起因するスライド、スキュー、照明変動などが発生し、領域の特徴量に一定範囲の誤差が生じた場合でも、その影響を考慮した特徴量の変換が行なわれ、以降の領域識別を正確に行なうことができる。
【0073】
なお、本発明は前記実施の形態に限定されるものではない。たとえば、多クラスの識別問題は2クラス識別問題の重ね合わせに帰結するので、本発明が適用できる。また、領域識別アルゴリズムは、ユークリッド距離を用いるものに限らず、たとえば、単純類似度法、部分空間法、ベクトル量子化法など様々な方法が適用可能である。
【符号の説明】
【0074】
1…入力インタフェイス部、2…分割部(領域分割手段)、3…重み付け部(重み付け手段)、4…選択部(領域選択手段)、5…領域識別部(識別結果取得手段)、6…全体識別部、7…最終識別部(識別結果決定手段)、8…出力インタフェイス部。
【特許請求の範囲】
【請求項1】
識別すべき複数種類の基準となる紙葉類の画像を入力し、
前記入力した画像を所定の複数の領域に分割し、
前記紙葉類の種類毎に、前記分割した各領域毎の相違度を算出し、
前記算出した相違度に基づいて、各領域毎に重み付けを行い、
前記重み付けされた複数の領域のうち、重みの大きい順に予め設定される数の領域を選択し、
前記選択した領域と、前記入力した画像とを辞書として登録する、
ことを特徴とする辞書作成方法。
【請求項2】
複数枚の紙葉類の画像に基づいて、種類毎に、前記分割した各領域毎の標準偏差を算出し、
1枚の紙葉類の画像に基づいて重みパラメータを算出し、
前記算出した重みパラメータを前記算出した標準偏差により除算し、
前記除算により算出する値に対して正規化を行い、重みを決定する、
ことを特徴とする請求項1に記載の辞書作成方法。
【請求項3】
予め既知の除外領域を登録し、
前記登録された除外領域以外を対象として領域を選択することを特徴とする請求項1に記載の辞書作成方法。
【請求項4】
紙葉類を識別する紙葉類識別装置に用いられる識別用辞書を記憶する記憶媒体であって、識別すべき複数種類の基準となる紙葉類の画像を所定の複数の領域に分割し、前記紙葉類の種類毎に、前記分割した各領域毎の相違度を算出し、前記算出した相違度に基づいて、各領域毎に重み付けを行い、前記重み付けされた複数の領域のうち、重みの大きい順に予め設定される数の領域を選択し、前記選択された領域と前記入力された画像とを有する識別用辞書を記憶する記憶媒体。
【請求項1】
識別すべき複数種類の基準となる紙葉類の画像を入力し、
前記入力した画像を所定の複数の領域に分割し、
前記紙葉類の種類毎に、前記分割した各領域毎の相違度を算出し、
前記算出した相違度に基づいて、各領域毎に重み付けを行い、
前記重み付けされた複数の領域のうち、重みの大きい順に予め設定される数の領域を選択し、
前記選択した領域と、前記入力した画像とを辞書として登録する、
ことを特徴とする辞書作成方法。
【請求項2】
複数枚の紙葉類の画像に基づいて、種類毎に、前記分割した各領域毎の標準偏差を算出し、
1枚の紙葉類の画像に基づいて重みパラメータを算出し、
前記算出した重みパラメータを前記算出した標準偏差により除算し、
前記除算により算出する値に対して正規化を行い、重みを決定する、
ことを特徴とする請求項1に記載の辞書作成方法。
【請求項3】
予め既知の除外領域を登録し、
前記登録された除外領域以外を対象として領域を選択することを特徴とする請求項1に記載の辞書作成方法。
【請求項4】
紙葉類を識別する紙葉類識別装置に用いられる識別用辞書を記憶する記憶媒体であって、識別すべき複数種類の基準となる紙葉類の画像を所定の複数の領域に分割し、前記紙葉類の種類毎に、前記分割した各領域毎の相違度を算出し、前記算出した相違度に基づいて、各領域毎に重み付けを行い、前記重み付けされた複数の領域のうち、重みの大きい順に予め設定される数の領域を選択し、前記選択された領域と前記入力された画像とを有する識別用辞書を記憶する記憶媒体。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】

【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【図18】
【公開番号】特開2012−181855(P2012−181855A)
【公開日】平成24年9月20日(2012.9.20)
【国際特許分類】
【出願番号】特願2012−101694(P2012−101694)
【出願日】平成24年4月26日(2012.4.26)
【分割の表示】特願2006−176735(P2006−176735)の分割
【原出願日】平成18年6月27日(2006.6.27)
【出願人】(000003078)株式会社東芝 (54,554)
【Fターム(参考)】
【公開日】平成24年9月20日(2012.9.20)
【国際特許分類】
【出願日】平成24年4月26日(2012.4.26)
【分割の表示】特願2006−176735(P2006−176735)の分割
【原出願日】平成18年6月27日(2006.6.27)
【出願人】(000003078)株式会社東芝 (54,554)
【Fターム(参考)】
[ Back to top ]