
通信システムの動作特性
【課題】オーディオ−ビジュアル(視聴覚)刺激の主観的な品質測定を行う。
【解決手段】刺激のオーディオおよびビジュアル要素12,22間の実際の同期エラー38sを測定し、刺激31におけるオーディオおよびビジュアルキューの性質を識別し、前記エラーおよび特徴から主観的な品質の測度を生成することによって測定される。キューの性質は同期エラーの所定値についての知覚の重要性に影響を与え、これを使用して、適切なときにこのようなエラーに対する公差を緩和するか、または人間の被験者によって知覚されるのと同じように信号品質の正確な測度を与えることができる。
【解決手段】刺激のオーディオおよびビジュアル要素12,22間の実際の同期エラー38sを測定し、刺激31におけるオーディオおよびビジュアルキューの性質を識別し、前記エラーおよび特徴から主観的な品質の測度を生成することによって測定される。キューの性質は同期エラーの所定値についての知覚の重要性に影響を与え、これを使用して、適切なときにこのようなエラーに対する公差を緩和するか、または人間の被験者によって知覚されるのと同じように信号品質の正確な測度を与えることができる。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は信号処理に関する。本発明は、通信システムの試験およびインストレーションと、後述するような他の使用とに関する。“通信システム”という用語は、電話またはテレビジョンネットワークと施設、公衆アドレスシステム、コンピュータインターフェイス、およびそれに類似するものを包含する。
【背景技術】
【0002】
通信サービス提供段階を依頼およびモニタするときは、設計上の動作のアクセプタビリティを評価する客観的で反復可能な動作測定(値)、すなわち測度(メトリックス)を使用することが望ましい。しかしながらシステム動作の主要な観点(キーアスペクト)では主観的な品質測定、すなわち製品およびサービスにおける顧客の満足を判断することが中心である。現代の通信および同報通信システムの複雑さのために、とくにデータ低減技術を使用すると、従来技術の測定は、知覚した動作を確実に予測するには不適切になってしまう。主観的な試験は、人間の観察者を使用すると費用が高く、時間がかかり、しばしば、とくにフィールド使用において実行不可能である。複雑なシステムについての知覚された(主観的な)動作の客観的な評価は、人間の感覚機能の特性をエミュレートした新しく生成された測定技術の開発によって可能になった。例えば、信号対雑音比のような客観的な測定における劣等な値は、不可聴音の歪みから生じることがある。ヒアリングで行われるマスキングのモデルは、可聴音の歪みと不可聴音の歪みとを区別することができる。
【0003】
人間の感覚機能のモデルを使用して主観的な動作の理解をさらに向上したものは、知覚モデリング(perceptual modelling)として知られている。
【0004】
本発明の発明者は、知覚モデル、および非線形の言語システムに適した試験信号を目指す一連の先行の親出願として、WO94/00922号、WO94/01011号、およびWO95/15035号をもっている。
【0005】
オーディオシステム、とくに言語システムにおけるエラーの主観的な関連を判断するために、人間のヒアリングのモデルに基づく評価アルゴリズムが生成された。劣化した信号と参照信号との間の可聴の差を予測するのは知覚解析のセンサレイヤ(層)(sensory layer)であり、一方で次に全体的な信号品質に対する主観的な効果にしたがって可聴エラーをカテゴリ分類するのは知覚層(perceptual layer)であると考えられる。
【0006】
可聴知覚モデルに類似したアプローチは、ビジュアルにおける知覚モデルにも対応する。この場合にセンサ層は、センサ機構の全体的な精神物理学(gross psychophysics)、とくに時空的感度(人間の視覚(ビジュアル)フィルタとして知られている)、および空間周波数(spatial frequency)と、方向と、時間周波数(temporal frequency)とによるマスキングを再生する。
【0007】
多数の視覚についての知覚モデルは開発中であり、文献ではその一部を提案した。
【0008】
マルチモードシステムの主観的な動作は、個々のオーディオおよびビデオ成分の品質だけでなく、それらの間の相互作用(インタラクション)にも依存する。このような効果は“品質の不整合(クオリティミスマッチ)”を含み、1つのモダリティ(modality、様相)で示される品質は、別のモダリティにおける知覚に影響を与える。この影響は、品質の不整合を増す。
【0009】
信号の情報内容(インフォメーションコンテンツ)も重要である。これは着手したタスクに関係しているが、タスク中に変わることがある。したがって“内容”とは、タスクの所定部分中におけるオーディオ/ビジュアル(視聴覚)材料の性質を指す。
【0010】
取り上げられたタスクまたはアクティビティ(課題または活動)は、知覚した動作に対して実質的な効果をもつ。簡単な例として、ビデオ成分が所定のタスクをほとんど占めているとき、ビデオ部分のエラーは最大の重要性をもつことになる。同時によく注意すべき要点(アテンショナルサリエンス、すなわち“注意の把握(attention grabbing)”)を含むオーディオエラーも重要になる。着手したタスクの性質は、モダリティ間の注意の一部に影響を与えるが、タスクが要求されていないときは、よりランダムに変化することができる。
【0011】
しかしながらこれらの要因において重要なことは、これらの要因が概して、規定すること、および客観的な測定を行うのに使用することが難しいことである。それにも関らず、本発明の発明者は、相互のモードの影響を識別した。
【発明の概要】
【0012】
本発明にしたがって、オーディオ−ビジュアル刺激(stimulus)の主観的な品質を判断する方法であって:
オーディオ−ビジュアル(視聴覚)要素の刺激間の実際の同期エラーを測定する段階と;
刺激におけるオーディオおよびビジュアルキューの特徴を識別する段階と;
前記エラーおよび特徴から主観的な品質の測度(メトリックス)を生成する段階とを含む方法を提供する。
【0013】
本発明の別の態様にしたがって、オーディオ−視覚(ビジュアル)刺激の主観的な品質を判断する装置であって、刺激のオーディオおよび視覚要素間の実際の同期エラーを測定する手段と、刺激中のオーディオおよび視覚(ビジュアル)キューの特徴の識別手段と、前記同期エラーおよび特徴から主観的な品質の測度(メトリックス)を生成する手段とを含む装置を提供する。
【0014】
人間の主観は、それが関係しているキューのタイプに依存して所定の同期エラーの異なる感度をもつことが実験から観察された。したがってある種のキュータイプを含んでいる劣等に同期した刺激は他のキューの形成を含んでいる均等に劣等に同期した刺激よりも低い品質をもつものとして知覚される。テレビジョン放送では長年にわたって同期の許容性を本質的に検討してきた。しかしながら臨場感技術(テレプレゼンステクノロジイ)の出現のために、同期をダイナミックに制御しなければならない。オーディオ/ビデオ同期エラー検出は、開始したタスク、刺激(内容、コンテンツ)の特徴、およびエラーによって、オーディオがビデオよりも先行するか、または遅れることか否かに依存する(文献[ITU-T Recommendation J.100, “Tolerances for transmission time differences between vision and sound components of a television signal”, 1990]参照)。
【0015】
本明細書において後述することになる結果は、一定のタイプの内容に対して同期の公差(許容範囲)を緩和し、このタイプでは同期エラーの主観性は相当に大きい範囲の値にわたり比較的に低いままであることを示している。
【0016】
一般に、情報内容は客観的な試験によって測定可能ではないが、同期エラーに対して人間の感覚機能が依存し、客観的な試験によって識別可能な一定のキューのタイプが識別されている。
【0017】
同期エラーは、測定するのに比較的簡単でもあり、したがって本発明では、ネットワークオペレータが客観的な測定によって、キューの性質に関係して現在のエラーが知覚上重要であるか、否かを判断することができる。
【0018】
オーディオおよび視覚キューの特徴を使用して、1以上の同期エラー公差値、例えば人間の主観性によって測定されるような異なる度合いの知覚エラーに対応できる値を生成することが好ましい。オーディオ−視覚刺激は、このような公差値を越える同期エラーの発生をモニタして、定量的な出力を供給することができる。刺激を生成する手段を動的に制御して、例えば先に届いた刺激にバッファをかけることによって、または後から届いた刺激から要素を取除くことによって、前記許容値との所定の関係で同期を維持することができる。同期の維持において、オーディオ視覚(ビジュアル)システムに対して相当な要求を行うことができる。バッファリングにはメモリ容量が必要である。その代わりに、チャンネルが輻輳しているとき、一方または他方のチャンネル(サウンドまたは映像)のデー
タパケットは、所定のレベルへの同期を維持するのに犠牲にしなければならないことがあり、そのチャンネルの信号品質を下げてしまう。より緩和された公差レベルを一定の回数だけ適用できるとき、より大きな同期エラーを許可して、要求されるチャンネル容量、または損失したデータ量、あるいはその両者を低減することができる。
【0019】
それぞれ異なる刺激タイプを保持しているいくつかのチャンネルが使用中のとき、これらのチャンネルを制御して、それらは全て同じ知覚品質値をもつが、同期エラー、それら自体は異なっていてもよい。
【0020】
本発明の別のアプリケーションでは、視覚環境においてオーディオ−視覚イベントを実時間で生成し、とくにアニメーション化された発話中の顔(talking face)のような合成で作った人を実時間で最適化する。このプロセスは、合成した頭部のビゼーム(viseme)(口部の形状)の移動と、表示される言語を生成する音響波形データとを整合して、口部の実際のアバター(avatar)を生成することができる。
【0021】
ここで本発明の実施形態を添付の図面を参照して例示的に記載することにする。
【図面の簡単な説明】
【0022】
【図1】マルチセンサ知覚測定システムの主要な構成要素の模式的な形状を示す図。
【図2】図1のシステムの同期の知覚測定構成要素を示す図。
【図3】同期測定構成要素によってモデル化される振舞いを示す実験的データを示す図。
【図4】同期測定構成要素によってモデル化される振舞いを示す実験的データを示す図。
【図5】図2のシステムを使用して、アバターのビゼームの生成を模式的に示す図。
【発明を実施するための形態】
【0023】
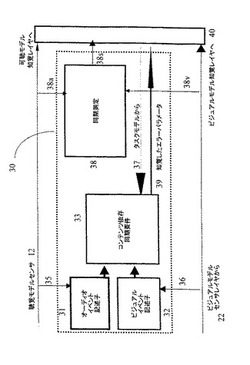
マルチセンサモデルの適切なアーキテクチャを図1に示した。主要な構成要素は:
・オーディオおよびビジュアルセンサモデル10、20と;
・顧客モデル30であって、図2に詳しく示した同期知覚モデルを含むクロスモードモデル30と;
・シナリオ指定の知覚層40とを含む。
【0024】
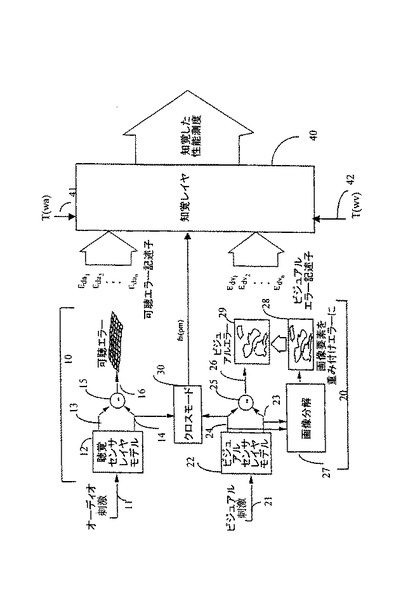
可聴センサ層のモデル構成要素10は、オーディオ刺激の入力11を含み、入力11は可聴センサ層モデル12に用意されている。可聴モデル12は種々の聴覚バンドの知覚的重要性、および刺激の時間要素を測定し、可聴バンド(ピッチ)および時間の関数として可聴エラーを表わす出力16を生成する。この可聴エラーは知覚的に修正されたオーディオ刺激13と参照信号14との比較によって導き出すことができ、この差は減算ユニット15によって判断されて、一連の係数Eda1,Eda2,…,Edanによって定められる可聴バンドおよび時間の関数として主観的なエラーのマトリックスの形態で出力16を与える。その代わりに、モデルは、例えば国際特許明細書番号第WO96/06496号に記載された方法にしたがって、参照信号を使用せずに出力16を生成することができる。
【0025】
類似のプロセスは、ビジュアルセンサ層モデル20を使用して実行される。しかしながらこのコンテキストでは、別の段階が要求される。ビジュアルセンサ層モデル22によって生成されるイメージ(画像)は分解ユニット27において解析されて、エラーがとくに重要である要素を識別し、国際特許明細書番号第WO97/32428号に記載されているように重み付けされる。とくに画像要素の本体(body)内では、境界は知覚上エラーよりも重要である。重み付け生成器28において生成される重み付け関数は、可視エラー計算ユニット29の出力26へ適用されて、上述の可聴エラーマトリックスのそれと類似した“可視エラーマトリックス”を生成する。このマトリックスは、一連の係数Edv1,Edv2,…,Edvnによって定めることができる。画像はそれら自体二次元であり、したがって動画像(moving image)では可視エラーマトリックスは少なくとも3次元をもつことになる。
【0026】
さらに、可聴および可視エラーマトリックスにおける個々の係数はベクトル特性であってもよいことにも注意すべきである。
【0027】
受け取った信号品質に影響を与える多数のクロスモード効果がある。クロスモードモデル30によってモデル化される効果はモダリティ(ビジョン(映像)およびオーディオ)とこのモダリティを関係付けるタイミング効果との間の品質バランスを含んでもよい。このようなタイミング効果は、シーケンス化(1つのモダリティのイベントシーケンスは、別のモダリティのイベントシーケンスに対するユーザの感度に影響を与える)と、同期(異なるモードのイベント間の相関関係)を含む。
【0028】
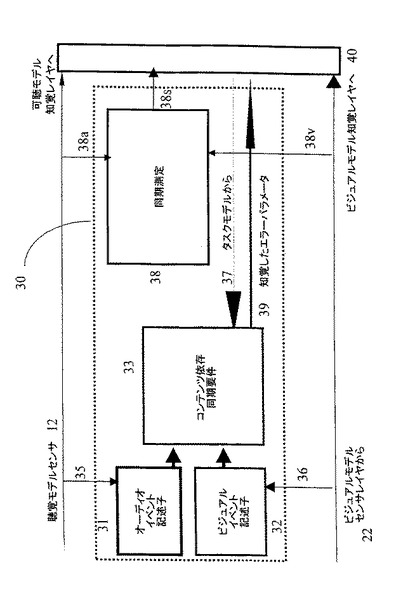
本発明のマルチモードモデルの1つの主要な構成要素は同期である。モデルのこの部分は図2に示した。入力間の同期の度合いは、同期測定ユニット38において判断される。これは、ビジュアルセンサ層からの入力(入力38v)と可聴センサ層(入力38a)からの入力とをとるが、この2つの信号における各遅延が関係している。同期測定ユニット38はこれらの2つの遅延における差を判断し、2つの信号間の相対的な遅延を表わす出力38vを生成する。これは、何れかの信号における絶対的な遅延ではないが、知覚上重要である。このような同期の不足は従来技術のシステムで判断されているが、後に記載するように、このような同期エラーの知覚的な重要性は刺激の性質にしたがって変化する。
【0029】
このために、クロスモードモデル30はさらにオーディオおよびビデオデータ流(入力35、36)および選択的に着手したタスク(入力37)に関する情報を使用して、同期エラーの主観性も判断する。
【0030】
この実施形態では、信号のオーディオ構成要素を記述する客観的パラメータは、プロセッサ31内で入力35から生成されたオーディオ記述子(ディスクリプタ)である。これらのオーディオ記述子は、所定長をもつ一連のオーバーラップしている短い時間間隔上のRMSエネルギと、信号のピークおよび減衰パラメータとである。これらの値は、個々のオーディオイベントの全体的な形状および継続維持時間の表示を与える。
【0031】
ビデオ構成要素を記述するパラメータは、プロセッサ32における入力36から生成されるビデオ記述子であり、このビデオ記述子には、例えば移動(モーション)ベクトル(文献[Netravali A N, Haskell B G, “Digital Pictures; representation and compression”, Plenum Press, ISBN 0-306-42791-5. June 1991]の第5章参照)、および主観的な重要性を記述する持続性をもつパラメータ、および時間でのこの重要性の減衰である。
【0032】
これらのパラメータは別のプロセッサ33によって使用されて、刺激の内容の性質を判断し、そこから同期エラー知覚可能性値を生成し、この値(39)は同期エラーの実際の値と一緒に、知覚モデル40へ出力される。次に知覚モデル40は同期エラー値と知覚可能性値とを比較して知覚品質値を生成し、この比較品質値は知覚モデル40によって使用されるクロスモード結合関数fnpmに寄与する。
【0033】
このモデルの数学的構造をつぎのように要約することができる:
Eda1,Eda2,…,Edanは、 オーディオエラー記述子であり、
Edv1,Edv2,…,Edvnは、 ビデオエラー記述子である。
【0034】
したがって、所定のタスクについて:
fnawsは、オーディオエラーの主観性を計算するための重み付けした関数であり、
fnvwsは、オーディオエラーの主観性を計算するための重み付けした関数であり、
fnpmは、既に記載したクロスモードの組合せ関数である。この関数は他の重み付け値を含んでもよく、他のクロスモードファクタ、例えば品質の不整合およびタスクに関係する要素を考慮することができる。
【0035】
タスク指定の知覚された測度PM、すなわちモデル40からの出力は次に示す通りである:
PM=fnpm[fnaws{Eda1,Eda2,…,Edan},fwvws{Edv1,Edv2,…,Edvn}]
知覚層モデル40は、特定のタスク用に構成されるか、または付加的な可変入力Twa,Twvによって、実行されるタスクの性質を示すモデル(入力41,42)へ付加し、タスクにしたがって関数fnpmにおける重み付けを変化させることができる。例えば、ビデオ会議機能においては、オーディオ信号品質は概して視覚信号の品質よりも重要である。しかしながらビデオ会議は、会議に参加する個人の視点から調べられるべきドキュメント(文書)へスイッチする(切換子)とき、画像に対する視覚の有意性はより重要になり、視覚および可聴要素の間でどんな重み付けが適切であるかに影響を与える。これらの値Twa,Twvはさらに同期知覚測定用関数38へフィードバックされ、同期エラーの主観性を、関係するタスクにしたがって変化させることもできる。タスクに関係する高レベルの認知の予備知覚、モダリティ(様相)間で分かれる注意、タスクによって導き出されるストレスの度合い、およびユーザの経験レベルの全てが主観的な品質認識に影響を与える。
【0036】
関数fnawsおよびfnvws、それら自体はタスクの重み付け関数とされて、個々の係数Eda1,Edv1,などの関係する重要度が、動作測度PM’の予測値を与えることに関与しているタスクにしたがって変化できるようにする:
PM’=fn’pm[fn’aws{Eda1,Eda2,…,Edan,Twn},fm’vws{Edv1,Edv2,…,Edvn,Twv}]
これにより聴覚および視覚のモダリティにおけるエラーの主観性の多次元の記述子が生成される。
【0037】
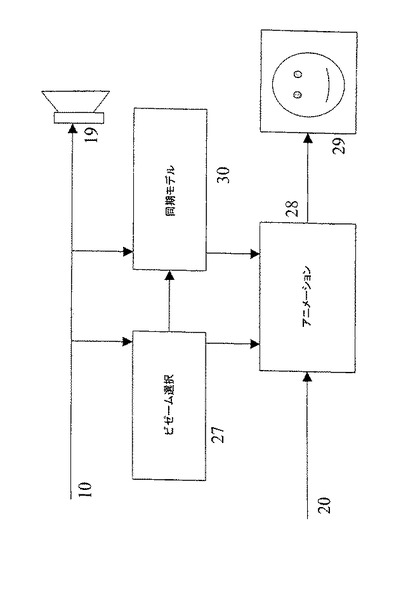
図5の構成において、スクリーン上に表示されるアバター29は、言語内容が導き出されるオーディオ入力10、およびアニメーションユニット28内のアバターのアニメーションに基本的なジェスチャデータを与える入力20から生成される。オーディオ入力10は、スピーカシステム19およびアニメーションプロセスへも供給される。プロセスは、発した音声に適したビゼーム(viseme)の選択を要求して、これを使用して、アニメーションユニット28を制御する。サウンドと同期されたビゼームをもつことが望ましいが、アニメーションプロセスはこれを達成するのを困難にしている。いくつかのビゼームは他のビゼームよりも同期エラーの公差が大きいので、オーディオ入力10および選択されたビゼームの識別子を同期モデル30へ適用することによって(図2参照)この公差を判断し、より大きい公差をもつビゼームの継続期間を延長および短縮することによって、アニメーションプロセス28を制御するのに使用して、より公差の小さいビゼームの同期を向上することができる。
【0038】
これらの実施形態ではプロセッサ33において導き出された値は刺激タイプに依存している。この相互関係を示している実験結果から選んだものを次に記載して、同期エラーの知覚の関係性に対する刺激の影響を示すようにした。
【0039】
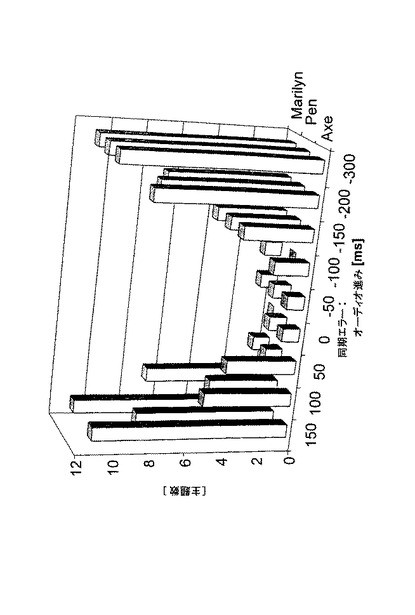
図3は、これらの刺激タイプにおける平均の同期エラーを検出する主題の数を示している。これらの刺激タイプには:
(1)簡潔な視覚キューの例として、視界へ入ったり、出たりするオブジェクトと;
(2)より長い視覚キューの例として、視界へ入ったり、残ったりするオブジェクトと;
(3)言語キュー(画面に登場する話し手(talking head))とがある。各視覚キューは、視覚キュー内のオブジェクトによって生成される可聴キューを伴う。
【0040】
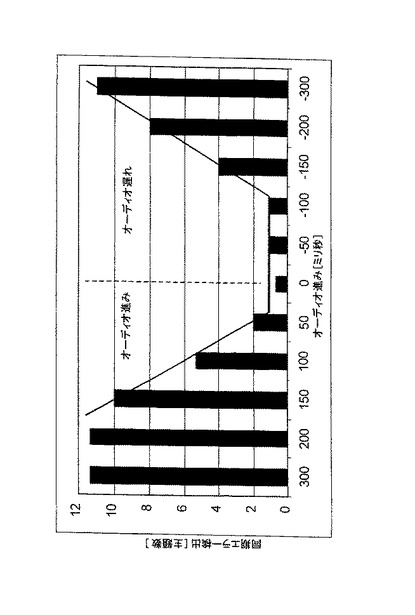
図3から、同期エラーの知覚可能性には時間的な非対称性の潜在的な特徴があることが分かる。オーディオ信号が視覚信号に先行している同期エラーは、視覚信号がオーディオ信号に同じ間隔だけ先行している同期エラーよりも知覚的により重要である。これは、おそらくは、自然界では関係する物理信号は相当に異なる速度(音速では340メートル/秒、光速では30万キロメートル/秒)で移動するので、オーディオキューを対応する視覚キューの後で受信するのに使用されるからである。
【0041】
結果の一般的な形態は、ITUのRecommendation J.100において与えられた勧告された同期の閾値、すなわちオーディオの20ミリ秒の先行、オーディオの40ミリ秒のラグを反映している。この勧告は全内容のタイプごとに固定値を与え、同期エラーが知覚できないことを保証することを意図されている。このアプローチは、同報通信(放送)システムの仕様に適している。
【0042】
しかしながら同期エラーは短い視覚キューまたは視覚言語キューよりも、長い視覚キューにおいてより多く検出されることが分かった。図4は、これらの2つの刺激タイプ、および“画面に登場する話し手(トーキングヘッド)”の結果を示しており、“画面に登場する話し手”については、人間の主題がより一般的な内容と比較される言語の知覚に対して高度に特定されるので特別な場合である。選択された2つの非言語音の刺激は、両者とも比較的に突発的であり、したがってこれらは連続的なノイズよりも同期に対してより大きい需要となる。
【0043】
これらは比較を簡単にするための単一のグラフ上に示した。
【0044】
これらの結果の主要な特徴は次に記載する通りである:
(i)エラー検出の非対称における一般的な傾向は、全ての刺激タイプに対して明らかである;
(ii)音を生成する物体が現れ、その後視界内に残る長い(“斧(axe)”)刺激は、継続期間/区別において、この物体は音と共に現れるが、直ぐに視界から再び消えてしまうよりより小さい(“ペン(pen)状の”)刺激に対するよりもエラー検出の可能性が高くなる;
(iii)言語(“Marilyn”)刺激についてのエラー検出は、オーディオがビデオよりも遅れるときは、他の2つの刺激と一致するが、オーディオがビデオよりも先行するときは、他の刺激のいずれかよりも大きくなる。
【0045】
したがって同期エラー検出の確率は、視覚の刺激の継続期間および識別性(distinctness)において変化する。さらに言語においてオーディオ信号がビデオ信号に先行するとき同期エラーに対する感度が高い。この後者の結果は既に記載した理由、すなわち言語知覚中の言語流の構文要素(semantic element)の継続期間よりも、“エラー”イベントのタイミングがより正確であるので分析できないという理由で予測不可能である(文献(Handel, S “Listening: an introduction to the perception of auditory events”, MIT Press, 1989)の第7章参照)。実際には、おそらくは、子音の始まりのような一定の意味単位継続期間が短いために、課題は画面に登場する話し手/言語刺激におけるオーディオ先行による同期エラーに非常に高感度なことが明らかである。
【技術分野】
【0001】
本発明は信号処理に関する。本発明は、通信システムの試験およびインストレーションと、後述するような他の使用とに関する。“通信システム”という用語は、電話またはテレビジョンネットワークと施設、公衆アドレスシステム、コンピュータインターフェイス、およびそれに類似するものを包含する。
【背景技術】
【0002】
通信サービス提供段階を依頼およびモニタするときは、設計上の動作のアクセプタビリティを評価する客観的で反復可能な動作測定(値)、すなわち測度(メトリックス)を使用することが望ましい。しかしながらシステム動作の主要な観点(キーアスペクト)では主観的な品質測定、すなわち製品およびサービスにおける顧客の満足を判断することが中心である。現代の通信および同報通信システムの複雑さのために、とくにデータ低減技術を使用すると、従来技術の測定は、知覚した動作を確実に予測するには不適切になってしまう。主観的な試験は、人間の観察者を使用すると費用が高く、時間がかかり、しばしば、とくにフィールド使用において実行不可能である。複雑なシステムについての知覚された(主観的な)動作の客観的な評価は、人間の感覚機能の特性をエミュレートした新しく生成された測定技術の開発によって可能になった。例えば、信号対雑音比のような客観的な測定における劣等な値は、不可聴音の歪みから生じることがある。ヒアリングで行われるマスキングのモデルは、可聴音の歪みと不可聴音の歪みとを区別することができる。
【0003】
人間の感覚機能のモデルを使用して主観的な動作の理解をさらに向上したものは、知覚モデリング(perceptual modelling)として知られている。
【0004】
本発明の発明者は、知覚モデル、および非線形の言語システムに適した試験信号を目指す一連の先行の親出願として、WO94/00922号、WO94/01011号、およびWO95/15035号をもっている。
【0005】
オーディオシステム、とくに言語システムにおけるエラーの主観的な関連を判断するために、人間のヒアリングのモデルに基づく評価アルゴリズムが生成された。劣化した信号と参照信号との間の可聴の差を予測するのは知覚解析のセンサレイヤ(層)(sensory layer)であり、一方で次に全体的な信号品質に対する主観的な効果にしたがって可聴エラーをカテゴリ分類するのは知覚層(perceptual layer)であると考えられる。
【0006】
可聴知覚モデルに類似したアプローチは、ビジュアルにおける知覚モデルにも対応する。この場合にセンサ層は、センサ機構の全体的な精神物理学(gross psychophysics)、とくに時空的感度(人間の視覚(ビジュアル)フィルタとして知られている)、および空間周波数(spatial frequency)と、方向と、時間周波数(temporal frequency)とによるマスキングを再生する。
【0007】
多数の視覚についての知覚モデルは開発中であり、文献ではその一部を提案した。
【0008】
マルチモードシステムの主観的な動作は、個々のオーディオおよびビデオ成分の品質だけでなく、それらの間の相互作用(インタラクション)にも依存する。このような効果は“品質の不整合(クオリティミスマッチ)”を含み、1つのモダリティ(modality、様相)で示される品質は、別のモダリティにおける知覚に影響を与える。この影響は、品質の不整合を増す。
【0009】
信号の情報内容(インフォメーションコンテンツ)も重要である。これは着手したタスクに関係しているが、タスク中に変わることがある。したがって“内容”とは、タスクの所定部分中におけるオーディオ/ビジュアル(視聴覚)材料の性質を指す。
【0010】
取り上げられたタスクまたはアクティビティ(課題または活動)は、知覚した動作に対して実質的な効果をもつ。簡単な例として、ビデオ成分が所定のタスクをほとんど占めているとき、ビデオ部分のエラーは最大の重要性をもつことになる。同時によく注意すべき要点(アテンショナルサリエンス、すなわち“注意の把握(attention grabbing)”)を含むオーディオエラーも重要になる。着手したタスクの性質は、モダリティ間の注意の一部に影響を与えるが、タスクが要求されていないときは、よりランダムに変化することができる。
【0011】
しかしながらこれらの要因において重要なことは、これらの要因が概して、規定すること、および客観的な測定を行うのに使用することが難しいことである。それにも関らず、本発明の発明者は、相互のモードの影響を識別した。
【発明の概要】
【0012】
本発明にしたがって、オーディオ−ビジュアル刺激(stimulus)の主観的な品質を判断する方法であって:
オーディオ−ビジュアル(視聴覚)要素の刺激間の実際の同期エラーを測定する段階と;
刺激におけるオーディオおよびビジュアルキューの特徴を識別する段階と;
前記エラーおよび特徴から主観的な品質の測度(メトリックス)を生成する段階とを含む方法を提供する。
【0013】
本発明の別の態様にしたがって、オーディオ−視覚(ビジュアル)刺激の主観的な品質を判断する装置であって、刺激のオーディオおよび視覚要素間の実際の同期エラーを測定する手段と、刺激中のオーディオおよび視覚(ビジュアル)キューの特徴の識別手段と、前記同期エラーおよび特徴から主観的な品質の測度(メトリックス)を生成する手段とを含む装置を提供する。
【0014】
人間の主観は、それが関係しているキューのタイプに依存して所定の同期エラーの異なる感度をもつことが実験から観察された。したがってある種のキュータイプを含んでいる劣等に同期した刺激は他のキューの形成を含んでいる均等に劣等に同期した刺激よりも低い品質をもつものとして知覚される。テレビジョン放送では長年にわたって同期の許容性を本質的に検討してきた。しかしながら臨場感技術(テレプレゼンステクノロジイ)の出現のために、同期をダイナミックに制御しなければならない。オーディオ/ビデオ同期エラー検出は、開始したタスク、刺激(内容、コンテンツ)の特徴、およびエラーによって、オーディオがビデオよりも先行するか、または遅れることか否かに依存する(文献[ITU-T Recommendation J.100, “Tolerances for transmission time differences between vision and sound components of a television signal”, 1990]参照)。
【0015】
本明細書において後述することになる結果は、一定のタイプの内容に対して同期の公差(許容範囲)を緩和し、このタイプでは同期エラーの主観性は相当に大きい範囲の値にわたり比較的に低いままであることを示している。
【0016】
一般に、情報内容は客観的な試験によって測定可能ではないが、同期エラーに対して人間の感覚機能が依存し、客観的な試験によって識別可能な一定のキューのタイプが識別されている。
【0017】
同期エラーは、測定するのに比較的簡単でもあり、したがって本発明では、ネットワークオペレータが客観的な測定によって、キューの性質に関係して現在のエラーが知覚上重要であるか、否かを判断することができる。
【0018】
オーディオおよび視覚キューの特徴を使用して、1以上の同期エラー公差値、例えば人間の主観性によって測定されるような異なる度合いの知覚エラーに対応できる値を生成することが好ましい。オーディオ−視覚刺激は、このような公差値を越える同期エラーの発生をモニタして、定量的な出力を供給することができる。刺激を生成する手段を動的に制御して、例えば先に届いた刺激にバッファをかけることによって、または後から届いた刺激から要素を取除くことによって、前記許容値との所定の関係で同期を維持することができる。同期の維持において、オーディオ視覚(ビジュアル)システムに対して相当な要求を行うことができる。バッファリングにはメモリ容量が必要である。その代わりに、チャンネルが輻輳しているとき、一方または他方のチャンネル(サウンドまたは映像)のデー
タパケットは、所定のレベルへの同期を維持するのに犠牲にしなければならないことがあり、そのチャンネルの信号品質を下げてしまう。より緩和された公差レベルを一定の回数だけ適用できるとき、より大きな同期エラーを許可して、要求されるチャンネル容量、または損失したデータ量、あるいはその両者を低減することができる。
【0019】
それぞれ異なる刺激タイプを保持しているいくつかのチャンネルが使用中のとき、これらのチャンネルを制御して、それらは全て同じ知覚品質値をもつが、同期エラー、それら自体は異なっていてもよい。
【0020】
本発明の別のアプリケーションでは、視覚環境においてオーディオ−視覚イベントを実時間で生成し、とくにアニメーション化された発話中の顔(talking face)のような合成で作った人を実時間で最適化する。このプロセスは、合成した頭部のビゼーム(viseme)(口部の形状)の移動と、表示される言語を生成する音響波形データとを整合して、口部の実際のアバター(avatar)を生成することができる。
【0021】
ここで本発明の実施形態を添付の図面を参照して例示的に記載することにする。
【図面の簡単な説明】
【0022】
【図1】マルチセンサ知覚測定システムの主要な構成要素の模式的な形状を示す図。
【図2】図1のシステムの同期の知覚測定構成要素を示す図。
【図3】同期測定構成要素によってモデル化される振舞いを示す実験的データを示す図。
【図4】同期測定構成要素によってモデル化される振舞いを示す実験的データを示す図。
【図5】図2のシステムを使用して、アバターのビゼームの生成を模式的に示す図。
【発明を実施するための形態】
【0023】
マルチセンサモデルの適切なアーキテクチャを図1に示した。主要な構成要素は:
・オーディオおよびビジュアルセンサモデル10、20と;
・顧客モデル30であって、図2に詳しく示した同期知覚モデルを含むクロスモードモデル30と;
・シナリオ指定の知覚層40とを含む。
【0024】
可聴センサ層のモデル構成要素10は、オーディオ刺激の入力11を含み、入力11は可聴センサ層モデル12に用意されている。可聴モデル12は種々の聴覚バンドの知覚的重要性、および刺激の時間要素を測定し、可聴バンド(ピッチ)および時間の関数として可聴エラーを表わす出力16を生成する。この可聴エラーは知覚的に修正されたオーディオ刺激13と参照信号14との比較によって導き出すことができ、この差は減算ユニット15によって判断されて、一連の係数Eda1,Eda2,…,Edanによって定められる可聴バンドおよび時間の関数として主観的なエラーのマトリックスの形態で出力16を与える。その代わりに、モデルは、例えば国際特許明細書番号第WO96/06496号に記載された方法にしたがって、参照信号を使用せずに出力16を生成することができる。
【0025】
類似のプロセスは、ビジュアルセンサ層モデル20を使用して実行される。しかしながらこのコンテキストでは、別の段階が要求される。ビジュアルセンサ層モデル22によって生成されるイメージ(画像)は分解ユニット27において解析されて、エラーがとくに重要である要素を識別し、国際特許明細書番号第WO97/32428号に記載されているように重み付けされる。とくに画像要素の本体(body)内では、境界は知覚上エラーよりも重要である。重み付け生成器28において生成される重み付け関数は、可視エラー計算ユニット29の出力26へ適用されて、上述の可聴エラーマトリックスのそれと類似した“可視エラーマトリックス”を生成する。このマトリックスは、一連の係数Edv1,Edv2,…,Edvnによって定めることができる。画像はそれら自体二次元であり、したがって動画像(moving image)では可視エラーマトリックスは少なくとも3次元をもつことになる。
【0026】
さらに、可聴および可視エラーマトリックスにおける個々の係数はベクトル特性であってもよいことにも注意すべきである。
【0027】
受け取った信号品質に影響を与える多数のクロスモード効果がある。クロスモードモデル30によってモデル化される効果はモダリティ(ビジョン(映像)およびオーディオ)とこのモダリティを関係付けるタイミング効果との間の品質バランスを含んでもよい。このようなタイミング効果は、シーケンス化(1つのモダリティのイベントシーケンスは、別のモダリティのイベントシーケンスに対するユーザの感度に影響を与える)と、同期(異なるモードのイベント間の相関関係)を含む。
【0028】
本発明のマルチモードモデルの1つの主要な構成要素は同期である。モデルのこの部分は図2に示した。入力間の同期の度合いは、同期測定ユニット38において判断される。これは、ビジュアルセンサ層からの入力(入力38v)と可聴センサ層(入力38a)からの入力とをとるが、この2つの信号における各遅延が関係している。同期測定ユニット38はこれらの2つの遅延における差を判断し、2つの信号間の相対的な遅延を表わす出力38vを生成する。これは、何れかの信号における絶対的な遅延ではないが、知覚上重要である。このような同期の不足は従来技術のシステムで判断されているが、後に記載するように、このような同期エラーの知覚的な重要性は刺激の性質にしたがって変化する。
【0029】
このために、クロスモードモデル30はさらにオーディオおよびビデオデータ流(入力35、36)および選択的に着手したタスク(入力37)に関する情報を使用して、同期エラーの主観性も判断する。
【0030】
この実施形態では、信号のオーディオ構成要素を記述する客観的パラメータは、プロセッサ31内で入力35から生成されたオーディオ記述子(ディスクリプタ)である。これらのオーディオ記述子は、所定長をもつ一連のオーバーラップしている短い時間間隔上のRMSエネルギと、信号のピークおよび減衰パラメータとである。これらの値は、個々のオーディオイベントの全体的な形状および継続維持時間の表示を与える。
【0031】
ビデオ構成要素を記述するパラメータは、プロセッサ32における入力36から生成されるビデオ記述子であり、このビデオ記述子には、例えば移動(モーション)ベクトル(文献[Netravali A N, Haskell B G, “Digital Pictures; representation and compression”, Plenum Press, ISBN 0-306-42791-5. June 1991]の第5章参照)、および主観的な重要性を記述する持続性をもつパラメータ、および時間でのこの重要性の減衰である。
【0032】
これらのパラメータは別のプロセッサ33によって使用されて、刺激の内容の性質を判断し、そこから同期エラー知覚可能性値を生成し、この値(39)は同期エラーの実際の値と一緒に、知覚モデル40へ出力される。次に知覚モデル40は同期エラー値と知覚可能性値とを比較して知覚品質値を生成し、この比較品質値は知覚モデル40によって使用されるクロスモード結合関数fnpmに寄与する。
【0033】
このモデルの数学的構造をつぎのように要約することができる:
Eda1,Eda2,…,Edanは、 オーディオエラー記述子であり、
Edv1,Edv2,…,Edvnは、 ビデオエラー記述子である。
【0034】
したがって、所定のタスクについて:
fnawsは、オーディオエラーの主観性を計算するための重み付けした関数であり、
fnvwsは、オーディオエラーの主観性を計算するための重み付けした関数であり、
fnpmは、既に記載したクロスモードの組合せ関数である。この関数は他の重み付け値を含んでもよく、他のクロスモードファクタ、例えば品質の不整合およびタスクに関係する要素を考慮することができる。
【0035】
タスク指定の知覚された測度PM、すなわちモデル40からの出力は次に示す通りである:
PM=fnpm[fnaws{Eda1,Eda2,…,Edan},fwvws{Edv1,Edv2,…,Edvn}]
知覚層モデル40は、特定のタスク用に構成されるか、または付加的な可変入力Twa,Twvによって、実行されるタスクの性質を示すモデル(入力41,42)へ付加し、タスクにしたがって関数fnpmにおける重み付けを変化させることができる。例えば、ビデオ会議機能においては、オーディオ信号品質は概して視覚信号の品質よりも重要である。しかしながらビデオ会議は、会議に参加する個人の視点から調べられるべきドキュメント(文書)へスイッチする(切換子)とき、画像に対する視覚の有意性はより重要になり、視覚および可聴要素の間でどんな重み付けが適切であるかに影響を与える。これらの値Twa,Twvはさらに同期知覚測定用関数38へフィードバックされ、同期エラーの主観性を、関係するタスクにしたがって変化させることもできる。タスクに関係する高レベルの認知の予備知覚、モダリティ(様相)間で分かれる注意、タスクによって導き出されるストレスの度合い、およびユーザの経験レベルの全てが主観的な品質認識に影響を与える。
【0036】
関数fnawsおよびfnvws、それら自体はタスクの重み付け関数とされて、個々の係数Eda1,Edv1,などの関係する重要度が、動作測度PM’の予測値を与えることに関与しているタスクにしたがって変化できるようにする:
PM’=fn’pm[fn’aws{Eda1,Eda2,…,Edan,Twn},fm’vws{Edv1,Edv2,…,Edvn,Twv}]
これにより聴覚および視覚のモダリティにおけるエラーの主観性の多次元の記述子が生成される。
【0037】
図5の構成において、スクリーン上に表示されるアバター29は、言語内容が導き出されるオーディオ入力10、およびアニメーションユニット28内のアバターのアニメーションに基本的なジェスチャデータを与える入力20から生成される。オーディオ入力10は、スピーカシステム19およびアニメーションプロセスへも供給される。プロセスは、発した音声に適したビゼーム(viseme)の選択を要求して、これを使用して、アニメーションユニット28を制御する。サウンドと同期されたビゼームをもつことが望ましいが、アニメーションプロセスはこれを達成するのを困難にしている。いくつかのビゼームは他のビゼームよりも同期エラーの公差が大きいので、オーディオ入力10および選択されたビゼームの識別子を同期モデル30へ適用することによって(図2参照)この公差を判断し、より大きい公差をもつビゼームの継続期間を延長および短縮することによって、アニメーションプロセス28を制御するのに使用して、より公差の小さいビゼームの同期を向上することができる。
【0038】
これらの実施形態ではプロセッサ33において導き出された値は刺激タイプに依存している。この相互関係を示している実験結果から選んだものを次に記載して、同期エラーの知覚の関係性に対する刺激の影響を示すようにした。
【0039】
図3は、これらの刺激タイプにおける平均の同期エラーを検出する主題の数を示している。これらの刺激タイプには:
(1)簡潔な視覚キューの例として、視界へ入ったり、出たりするオブジェクトと;
(2)より長い視覚キューの例として、視界へ入ったり、残ったりするオブジェクトと;
(3)言語キュー(画面に登場する話し手(talking head))とがある。各視覚キューは、視覚キュー内のオブジェクトによって生成される可聴キューを伴う。
【0040】
図3から、同期エラーの知覚可能性には時間的な非対称性の潜在的な特徴があることが分かる。オーディオ信号が視覚信号に先行している同期エラーは、視覚信号がオーディオ信号に同じ間隔だけ先行している同期エラーよりも知覚的により重要である。これは、おそらくは、自然界では関係する物理信号は相当に異なる速度(音速では340メートル/秒、光速では30万キロメートル/秒)で移動するので、オーディオキューを対応する視覚キューの後で受信するのに使用されるからである。
【0041】
結果の一般的な形態は、ITUのRecommendation J.100において与えられた勧告された同期の閾値、すなわちオーディオの20ミリ秒の先行、オーディオの40ミリ秒のラグを反映している。この勧告は全内容のタイプごとに固定値を与え、同期エラーが知覚できないことを保証することを意図されている。このアプローチは、同報通信(放送)システムの仕様に適している。
【0042】
しかしながら同期エラーは短い視覚キューまたは視覚言語キューよりも、長い視覚キューにおいてより多く検出されることが分かった。図4は、これらの2つの刺激タイプ、および“画面に登場する話し手(トーキングヘッド)”の結果を示しており、“画面に登場する話し手”については、人間の主題がより一般的な内容と比較される言語の知覚に対して高度に特定されるので特別な場合である。選択された2つの非言語音の刺激は、両者とも比較的に突発的であり、したがってこれらは連続的なノイズよりも同期に対してより大きい需要となる。
【0043】
これらは比較を簡単にするための単一のグラフ上に示した。
【0044】
これらの結果の主要な特徴は次に記載する通りである:
(i)エラー検出の非対称における一般的な傾向は、全ての刺激タイプに対して明らかである;
(ii)音を生成する物体が現れ、その後視界内に残る長い(“斧(axe)”)刺激は、継続期間/区別において、この物体は音と共に現れるが、直ぐに視界から再び消えてしまうよりより小さい(“ペン(pen)状の”)刺激に対するよりもエラー検出の可能性が高くなる;
(iii)言語(“Marilyn”)刺激についてのエラー検出は、オーディオがビデオよりも遅れるときは、他の2つの刺激と一致するが、オーディオがビデオよりも先行するときは、他の刺激のいずれかよりも大きくなる。
【0045】
したがって同期エラー検出の確率は、視覚の刺激の継続期間および識別性(distinctness)において変化する。さらに言語においてオーディオ信号がビデオ信号に先行するとき同期エラーに対する感度が高い。この後者の結果は既に記載した理由、すなわち言語知覚中の言語流の構文要素(semantic element)の継続期間よりも、“エラー”イベントのタイミングがより正確であるので分析できないという理由で予測不可能である(文献(Handel, S “Listening: an introduction to the perception of auditory events”, MIT Press, 1989)の第7章参照)。実際には、おそらくは、子音の始まりのような一定の意味単位継続期間が短いために、課題は画面に登場する話し手/言語刺激におけるオーディオ先行による同期エラーに非常に高感度なことが明らかである。
【特許請求の範囲】
【請求項1】
オーディオ−ビジュアル刺激の主観的な品質を判断する方法であって:
オーディオ−ビジュアル要素の刺激間の実際の同期エラーを測定する段階と;
刺激内のオーディオおよびビジュアルキューの特徴を識別する段階と;
前記エラーおよび特徴から主観的な品質の測度を生成する段階とを含む方法。
【請求項2】
オーディオおよびビジュアルキューの特徴を使用して、同期エラーの公差値を生成する請求項1記載の方法。
【請求項3】
オーディオ−ビジュアルの刺激が、このような公差値を越えた同期エラーの発生についてモニタされる請求項2記載の方法。
【請求項4】
刺激を生成する手段を制御して、前記公差値との所定の関係における同期を維持する請求項3記載の方法。
【請求項5】
主観的な品質についての測定結果を使用して、アバターアニメーションプロセスの実行を制御する請求項4記載の方法。
【請求項6】
オーディオ−ビジュアル刺激の主観的な品質を判断する装置であって、刺激のオーディオおよびビジュアル要素間の実際の同期エラーを測定する手段と、刺激中のオーディオおよびビジュアルキューの特徴の識別手段と、前記同期エラーおよび特徴から主観的な品質の測度を生成する手段とを含む装置。
【請求項7】
キューの特徴を識別する手段が、同期エラー公差値を生成する請求項6記載の装置。
【請求項8】
前記公差値を越えた同期エラーの発生に対してオーディオ−ビジュアル刺激をモニタする手段を含む請求項7記載の装置。
【請求項9】
前記公差値との所定の関係で同期を維持する刺激を生成する手段を制御する手段を含む請求項8記載の装置。
【請求項10】
アニメーション化された画像を生成するための主観的な品質測定手段によって制御されるアニメーションプロセス手段をさらに含む請求項9記載の装置。
【請求項1】
オーディオ−ビジュアル刺激の主観的な品質を判断する方法であって:
オーディオ−ビジュアル要素の刺激間の実際の同期エラーを測定する段階と;
刺激内のオーディオおよびビジュアルキューの特徴を識別する段階と;
前記エラーおよび特徴から主観的な品質の測度を生成する段階とを含む方法。
【請求項2】
オーディオおよびビジュアルキューの特徴を使用して、同期エラーの公差値を生成する請求項1記載の方法。
【請求項3】
オーディオ−ビジュアルの刺激が、このような公差値を越えた同期エラーの発生についてモニタされる請求項2記載の方法。
【請求項4】
刺激を生成する手段を制御して、前記公差値との所定の関係における同期を維持する請求項3記載の方法。
【請求項5】
主観的な品質についての測定結果を使用して、アバターアニメーションプロセスの実行を制御する請求項4記載の方法。
【請求項6】
オーディオ−ビジュアル刺激の主観的な品質を判断する装置であって、刺激のオーディオおよびビジュアル要素間の実際の同期エラーを測定する手段と、刺激中のオーディオおよびビジュアルキューの特徴の識別手段と、前記同期エラーおよび特徴から主観的な品質の測度を生成する手段とを含む装置。
【請求項7】
キューの特徴を識別する手段が、同期エラー公差値を生成する請求項6記載の装置。
【請求項8】
前記公差値を越えた同期エラーの発生に対してオーディオ−ビジュアル刺激をモニタする手段を含む請求項7記載の装置。
【請求項9】
前記公差値との所定の関係で同期を維持する刺激を生成する手段を制御する手段を含む請求項8記載の装置。
【請求項10】
アニメーション化された画像を生成するための主観的な品質測定手段によって制御されるアニメーションプロセス手段をさらに含む請求項9記載の装置。
【図1】


【図2】
【図3】
【図4】
【図5】
【図2】
【図3】
【図4】
【図5】
【公開番号】特開2010−63107(P2010−63107A)
【公開日】平成22年3月18日(2010.3.18)
【国際特許分類】
【外国語出願】
【出願番号】特願2009−207075(P2009−207075)
【出願日】平成21年9月8日(2009.9.8)
【分割の表示】特願2000−557629(P2000−557629)の分割
【原出願日】平成11年6月15日(1999.6.15)
【出願人】(390028587)ブリティッシュ・テレコミュニケーションズ・パブリック・リミテッド・カンパニー (104)
【氏名又は名称原語表記】BRITISH TELECOMMUNICATIONS PUBLIC LIMITED COMPANY
【Fターム(参考)】
【公開日】平成22年3月18日(2010.3.18)
【国際特許分類】
【出願番号】特願2009−207075(P2009−207075)
【出願日】平成21年9月8日(2009.9.8)
【分割の表示】特願2000−557629(P2000−557629)の分割
【原出願日】平成11年6月15日(1999.6.15)
【出願人】(390028587)ブリティッシュ・テレコミュニケーションズ・パブリック・リミテッド・カンパニー (104)
【氏名又は名称原語表記】BRITISH TELECOMMUNICATIONS PUBLIC LIMITED COMPANY
【Fターム(参考)】
[ Back to top ]