
通話録音装置、通話録音プログラム、音声認識サーバ、音声認識プログラム、通話録音システムおよび通話録音方法
【課題】通話における上り音声と下り音声を分離して再生可能で、データ容量の小さい録音データを生成する。
【解決手段】通話録音装置1は、モノラル化メイン音声データ61を生成し、下り音声データのレベルが所定値以上である場合、モノラル化メイン音声データ61に、真を設定した分離ビットを設定する。ダブルトークが検出された場合、通話録音装置1は、モノラル化メイン音声データ61に、真を設定したダブルトークビットを設定し、モノラル化サブ音声データ62を生成する。音声認識サーバ2は、ダブルトークビットが真の場合、モノラル化メイン音声データ61とモノラル化サブ音声データ62から、上り音声データおよび下り音声データを生成して出力する。音声認識サーバ2は、ダブルトークビットが偽でかつ分離ビットが真の場合、モノラル化メイン音声データ61を下り音声データとして出力し、分離ビットが偽の場合、上り音声データとして出力する。
【解決手段】通話録音装置1は、モノラル化メイン音声データ61を生成し、下り音声データのレベルが所定値以上である場合、モノラル化メイン音声データ61に、真を設定した分離ビットを設定する。ダブルトークが検出された場合、通話録音装置1は、モノラル化メイン音声データ61に、真を設定したダブルトークビットを設定し、モノラル化サブ音声データ62を生成する。音声認識サーバ2は、ダブルトークビットが真の場合、モノラル化メイン音声データ61とモノラル化サブ音声データ62から、上り音声データおよび下り音声データを生成して出力する。音声認識サーバ2は、ダブルトークビットが偽でかつ分離ビットが真の場合、モノラル化メイン音声データ61を下り音声データとして出力し、分離ビットが偽の場合、上り音声データとして出力する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、通話における上り音声と下り音声を分離して再生可能な録音データを出力する通話録音装置、通話録音プログラム、録音データを再生する音声認識サーバ、音声認識プログラム、録音データを出力および再生する通話録音システムおよび通話録音方法に関する。
【背景技術】
【0002】
従来、コールセンターなどにおいて、オペレータと顧客の通話内容を録音する通話録音装置が知られている。通話の録音データは、通話内容の確認や顧客サービス向上のために参照される場合がある。従って、オペレータの顧客への通話と、顧客のオペレータへの通話とを、それぞれ区別して記録することが好ましい。
【0003】
そのため、通話の録音データを、上りの通話と下りの通話とに分離して記録する技術がある(特許文献1参照。)。この特許文献1に記載の技術では、使用者の通話の上り音声通話と、相手側の通話の下り音声通話を別々に録音する。これにより、例えば使用者の音声で使用者が話した単語やフレーズを入力することにより、使用者の通話の上り音声通話から、その音声波形と略一致する波形を持つ録音データを検索することができる。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開2006−165846号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかしながら、特許文献1に記載の方法では、上り音声通話と下り音声通話を分離して記録するため、分離しないで記録する場合に比べて、録音データの容量が2倍になってしまう。コールセンターなどにおいては特に、多数の通話を録音する必要がある。従って録音データの容量が2倍になってしまうと、システム全体で、記録媒体のコストが増大してしまう問題がある。
【0006】
そこで、上りの通話と下りの通話を分離して再生可能で、かつ、データ容量の小さい録音データを生成可能な通話録音装置の開発が期待されている。
【0007】
従って本発明の目的は、上りの通話と下りの通話を分離して再生可能で、データ容量の小さい録音データの通話録音装置、通話録音プログラム、音声認識サーバ、音声認識プログラム、通話録音システムおよび通話録音方法を提供することである。
【課題を解決するための手段】
【0008】
上記課題を解決するために、本発明の第1の特徴は、通話における第1の音声と第2の音声を分離して再生可能な録音データを生成する通話録音装置に関する。すなわち本発明の第1の特徴に係る通話録音装置は、第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成し、第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定し、第1の音声データと第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、第1の音声データと第2の音声データとの差分から、モノラル化サブ音声データを生成するモノラル化手段を備える。
【0009】
ここでモノラル化手段は、第2の音声データのレベルが所定値以上であるフレームのビットに、分離ビットを設定するとともに、ダブルトークを検出したフレームのビットに、ダブルトークビットを設定し、ダブルトークが検出されたフレームについて、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、第1の音声データと第2の音声データとの差分から、モノラル化サブ音声データを生成することが好ましい。
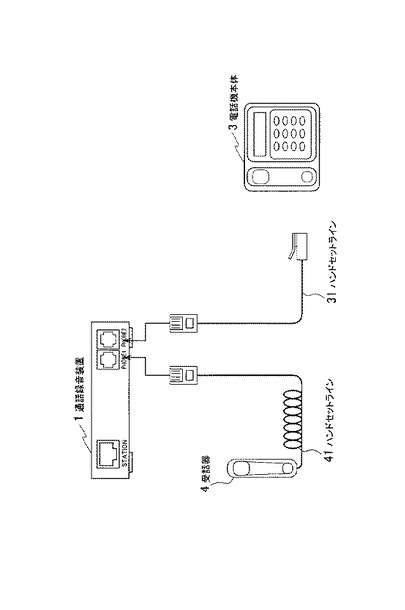
【0010】
また通話録音装置は、電話機本体と第1のハンドセットラインで接続されるとともに、受話器と第2のハンドセットラインで接続され、第1の音声データおよび第2の音声データは、第1および第2のハンドセットラインから取得したアナログ音声を、デジタル化したデータである。
【0011】
本発明の第2の特徴は、通話における第1の音声と第2の音声を分離して再生可能な録音データを生成する通話録音装置に用いられる通話録音プログラムに関する。すなわち本発明の第2の特徴に係る通話録音プログラムは、第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成し、第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定し、第1の音声データと第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、第1の音声データと第2の音声データとの差分から、モノラル化サブ音声データを生成するモノラル化手段として、通話録音装置に内蔵されたコンピュータを機能させる。
【0012】
ここでモノラル化手段は、第2の音声データのレベルが所定値以上であるフレームのビットに、分離ビットを設定するとともに、ダブルトークを検出したフレームのビットに、ダブルトークビットを設定し、ダブルトークが検出されたフレームについて、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、第1の音声データと第2の音声データとの差分から、モノラル化サブ音声データを生成する。
【0013】
本発明の第3の特徴は、第1の音声と第2の音声を分離して再生する音声認識サーバに関する。すなわち本発明の第3の特徴に係る音声認識サーバは、第1の音声データと第2の音声データを合成して生成され、第2の音声データのレベルが所定値以上であることを示す分離ビットと、第1の音声データと第2の音声データのダブルトークを示すダブルトークビットとを含むモノラル化メイン音声データと、ダブルトークが検出された際、第1の音声データと第2の音声データとの差分から生成されたモノラル化サブ音声データと、が記憶された記憶装置と、モノラル化メイン音声データから分離ビットとダブルトークビットを取得し、ダブルトークビットが真の場合、モノラル化メイン音声データとモノラル化サブ音声データから、第1の音声データおよび第2の音声データを生成して出力し、ダブルトークビットが偽でかつ分離ビットが真の場合、モノラル化メイン音声データを第2の音声データとして出力し、分離ビットが偽の場合、モノラル化メイン音声データを第1の音声データとして出力するステレオ化手段を備える。
【0014】
ここで分離ビットは、第2の音声データのレベルが所定値以上であるフレームのビットに設定され、ダブルトークビットは、ダブルトークを検出したフレームのビットに設定されても良い。この場合ステレオ化手段は、ダブルトークビットが真のフレームについて、モノラル化メイン音声データとモノラル化サブ音声データから、当該フレームの第1の音声データおよび第2の音声データを生成して出力し、ダブルトークビットが偽でかつ分離ビットが真のフレームについて、モノラル化メイン音声データから、当該フレームの第2の音声データを出力し、ダブルトークビットが偽でかつ分離ビットが偽のフレームについて、モノラル化メイン音声データから、当該フレームの第1の音声データを出力する。
【0015】
本発明の第4の特徴は、第1の音声と第2の音声を分離して再生する音声認識サーバに用いる音声認識プログラムに関する。すなわち本発明の第4の特徴に係る音声認識プログラムは、コンピュータを、第1の音声データと第2の音声データを合成して生成され、第2の音声データのレベルが所定値以上であることを示す分離ビットと、第1の音声データと第2の音声データのダブルトークを示すダブルトークビットとを含むモノラル化メイン音声データと、ダブルトークが検出された際、第1の音声データと第2の音声データとの差分から生成されたモノラル化サブ音声データとを取得して、記憶装置に記憶する録音データ取得手段と、モノラル化メイン音声データから分離ビットを取得するとともに、モノラル化メイン音声データからダブルトークビットを取得し、ダブルトークビットが真の場合、モノラル化メイン音声データとモノラル化サブ音声データから、第1の音声データおよび第2の音声データを生成して出力し、ダブルトークビットが偽でかつ分離ビットが真の場合、モノラル化メイン音声データを第2の音声データとして出力し、分離ビットが偽の場合、モノラル化メイン音声データを第1の音声データとして出力するステレオ化手段として機能させる。
【0016】
ここで分離ビットは、モノラル化メイン音声データにおいて、第2の音声データのレベルが所定値以上であるフレームのビットに設定され、ダブルトークビットは、モノラル化メイン音声データにおいて、ダブルトークを検出したフレームのビットに設定されても良い。この場合ステレオ化手段は、ダブルトークビットが真のフレームについて、モノラル化メイン音声データとモノラル化サブ音声データから、当該フレームの第1の音声データおよび第2の音声データを生成して出力し、ダブルトークビットが偽でかつ分離ビットが真のフレームについて、モノラル化メイン音声データから、当該フレームの第2の音声データを出力し、ダブルトークビットが偽でかつ分離ビットが偽のフレームについて、モノラル化メイン音声データから、当該フレームの第1の音声データを出力する。
【0017】
本発明の第5の特徴は、通話における第1の音声と第2の音声を分離して再生可能な録音データを生成し、再生する通話録音システムに関する。本発明の第5の特徴に係る通話録音システムは、通話録音装置と、音声認識サーバと、を備える。通話録音装置は、第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成し、第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定し、第1の音声データと第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、第1の音声データと第2の音声データとの差分から、モノラル化サブ音声データを生成するモノラル化手段を備える。音声認識サーバは、第1の音声データと第2の音声データを合成して生成され、第2の音声データのレベルが所定値以上であることを示す分離ビットと、第1の音声データと第2の音声データのダブルトークを示すダブルトークビットとを含むモノラル化メイン音声データと、ダブルトークが検出された際、第1の音声データと第2の音声データとの差分から生成されたモノラル化サブ音声データと、が記憶された記憶装置と、モノラル化メイン音声データから分離ビットを取得するとともに、モノラル化メイン音声データからダブルトークビットを取得し、ダブルトークビットが真の場合、モノラル化メイン音声データとモノラル化サブ音声データから、第1の音声データおよび第2の音声データを生成して出力し、ダブルトークビットが偽でかつ分離ビットが真の場合、モノラル化メイン音声データを第2の音声データとして出力し、分離ビットが偽の場合、モノラル化メイン音声データを第1の音声データとして出力するステレオ化手段を備える。
【0018】
本発明の第6の特徴は、通話における第1の音声と第2の音声を分離して再生可能な録音データを生成する通話録音方法に関する。本発明の第6の特徴に係る通話録音方法は、第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成するステップと、第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定するステップと、第1の音声データと第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、第1の音声データと第2の音声データとの差分から、モノラル化サブ音声データを生成するステップと、を備える。
【0019】
ここで録音データを再生する際、モノラル化メイン音声データから分離ビットを取得するとともに、モノラル化メイン音声データからダブルトークビットを取得するステップと、ダブルトークビットが真の場合、モノラル化メイン音声データとモノラル化サブ音声データから、第1の音声データおよび第2の音声データを生成して出力するステップと、ダブルトークビットが偽でかつ分離ビットが真の場合、モノラル化メイン音声データを第2の音声データとして出力するステップと、分離ビットが偽の場合、モノラル化メイン音声データを第1の音声データとして出力するステップと、をさらに備えることが好ましい。
【発明の効果】
【0020】
本発明によれば、通話における上り音声と下り音声を分離して再生可能で、データ容量の小さい録音データの通話録音装置、通話録音プログラム、音声認識サーバ、音声認識プログラム、通話録音システムおよび通話録音方法を提供することができる。
【図面の簡単な説明】
【0021】
【図1】本発明の実施の形態に係る通話録音システムのシステム構成を説明する図である。
【図2】本発明の実施の形態に係る通話録音装置の接続を説明する図である。
【図3】本発明の実施の形態に係る通話録音システムにおいて送受信されるデータを説明する図である。
【図4】本発明の実施の形態に係る通話録音装置のハードウェア構成図である。
【図5】本発明の実施の形態に係る通話録音装置のモノラル化手段によるモノラル化処理を説明するフローチャートである。
【図6】本発明の実施の形態に係る通話録音装置のモノラル化手段の機能ブロックを説明する図である。
【図7】本発明の実施の形態に係るモノラル化処理において、上り音声データおよび下り音声データの各フレームについて、フレームのサンプルごとにモノラル化する処理を説明する図である。
【図8】本発明の実施の形態に係るモノラル化処理において、フレームごとにモノラル化される処理を説明する図である。
【図9】本発明の実施の形態に係るモノラル化メイン音声データの構成を説明する図である。
【図10】本発明の実施の形態に係る音声認識サーバのハードウェア構成および機能ブロックを説明する図である。
【図11】本発明の実施の形態に係る音声認識サーバのステレオ化手段によるステレオ化処理を説明するフローチャートである。
【図12】本発明の実施の形態に係る音声認識サーバのステレオ化手段の機能ブロックを説明する図である。
【図13】本発明の実施の形態に係る通話録音システムの録音データの容量の削減効果を説明する図である。
【発明を実施するための形態】
【0022】
次に、図面を参照して、本発明の実施の形態を説明する。以下の図面の記載において、同一または類似の部分には同一または類似の符号を付している。
【0023】
(通話録音システム)
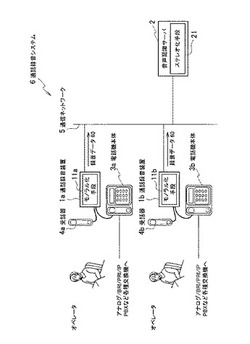
図1を参照して、本発明の実施の形態に係る通話録音システム6を説明する。通話録音システム6は、通話における第1の音声と第2の音声を分離して再生可能な録音データ60を生成し、再生する。本発明の実施の形態に係る通話録音システム6は、コールセンターに設置されることを想定する。従って、第1の音声とは、例えば、コールセンターのオペレータが顧客に通話する音声で、第2の音声とは、顧客がオペレータに通話する音声である。本発明の実施の形態係る録音データ60は、コールセンターにおける顧客とオペレータの通話を、分離して視聴することができる。また録音データ60は、従来のステレオ形式のデータより、容量の小さいデータである。
【0024】
本発明の通話録音システム6は、会話では、ほとんどの時間帯は交互に送話され、同時に送話される時間帯が限られるという特徴に着目している。本発明の実施の形態において、同時に送話される時間帯を、ダブルトークと称す。一般的な通話において、一方の話者が話している最中に、別の話者が相槌を打つ場合などに、ダブルトークが発生する。従って、全体の会話時間に対するダブルトークの時間は、かなり限定される。
【0025】
そこで本発明の実施の形態に係る通話録音システム6においては、会話中の各時間、どちらの話者が通話しているかを示す識別情報(分離ビット)と、ダブルトーク時であることを示す情報(ダブルトークビット)とを利用して、双方の音声を録音しつつ、分離して視聴することができ、また容量の小さい録音データ60を生成することができる。
【0026】
通話録音システム6は、第1の通話録音装置1a、第2の通話録音装置1b、音声認識サーバ2、第1の電話機本体3a、第1の受話器4a、第2の電話機本体3bおよび第2の受話器4bを備える。第1の通話録音装置1a、第2の通話録音装置1bおよび音声認識サーバ2は、通信ネットワーク5によって相互に通信可能に接続される。通信ネットワーク5は、例えばコールセンター内のLANである。
【0027】
図1に示す例において、通話録音装置、電話機本体および受話器は2つずつ備える場合を説明するが、これらは一つずつ備えても良いし、三つ以上備えても良い。本発明の実施の形態において、第1の通話録音装置1aおよび第2の通話録音装置1bを特に区別しない場合、通話録音装置1と記載する場合がある。同様に、第1の電話機本体3aおよび第2の電話機本体3bを特に区別しない場合、電話機本体3と記載する場合がある。第1の受話器4aおよび第2の受話器4を特に区別しない場合、受話器4と記載する場合がある。
【0028】
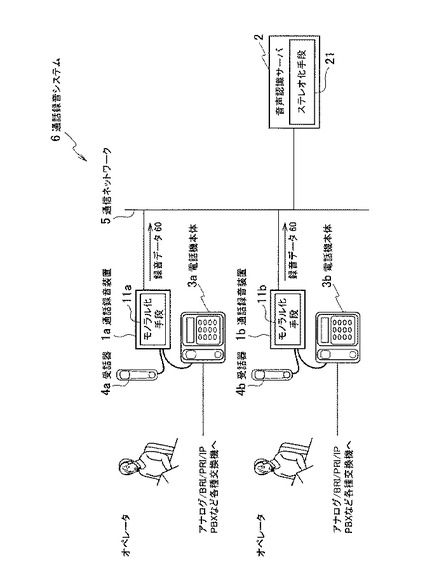
図2に示すように通話録音装置1は、電話機本体3および受話器4に接続される。電話機本体3の受話器用モジュラーラックと、通話録音装置1の第1のモジュラージャックとがハンドセットライン31で接続され、通話録音装置1の第2のモジュラージャックと受話器4のモジュラージャックとが、ハンドセットライン41で接続される。通話録音装置1は、ハンドセットライン31および41間に流れる信号を取得して、録音データ60を生成する。さらに通話録音装置1は、生成した録音データ60を、音声認識サーバ2に送信する。
【0029】
音声認識サーバ2は、一般的なコンピュータであって、所定の処理を実行する音声認識プログラムがインストールされて実現される。音声認識サーバ2は、通話録音装置1から録音データ60を受信すると、録音データ60から、第1の音声と第2の音声とを分離して再生することができる。
【0030】
電話機本体3は、交換機を介して、顧客と通話する。オペレータは電話機本体3を操作し、受話器4を介して、顧客からの通話を聞き取り、通話内容を顧客に伝える。
【0031】
ここで、本発明の実施の形態に係る通話録音装置1は、電話機本体3と受話器4間のアナログ信号を取得するので、電話機本体3の種別を問わない。従って、本発明の実施の形態に係る通話録音システム6は、アナログPBX、BRI(Basic Rate Interface)PBX、PRI(Primary Rate Interface)PBX、IP(Internet Protocol)PBXなど、あらゆる種類の交換機や電話機に対応することができる。
【0032】
図3を参照して、本発明の実施の形態に係る通話録音システム6において、装置間で送受信されるデータを説明する。通話録音装置1は、電話機本体3および受話器4間のハンドセットライン31および41から、上り音声データ51と下り音声データ52とを取得する。この上り音声データ51と下り音声データ52は、アナログ信号である。本発明の実施の形態において、上り音声データ51に関するデータ信号を(L)と、下り音声データ52に関するデータ信号を(R)と表記する場合がある。
【0033】
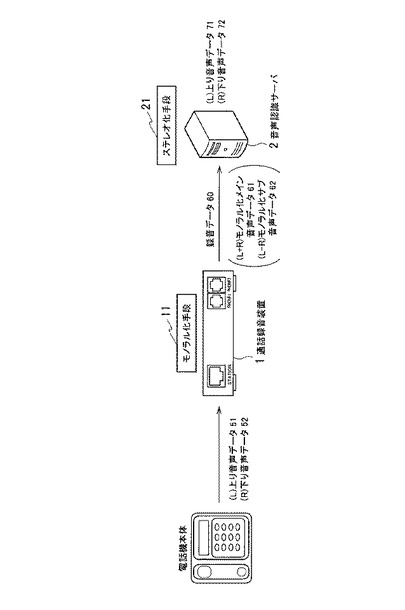
通話録音装置1は、上り音声データ51と下り音声データ52とを受信すると、モノラル化手段11によって、上り音声データ51と下り音声データ52とをモノラル化し、録音データ60を出力する。録音データ60は、モノラル化メイン音声データ61と、モノラル化サブ音声データ62とを含む。
【0034】
モノラル化メイン音声データ61は、上り音声データ51と下り音声データ52とを混合して生成される。モノラル化メイン音声データ61には、各フレームに、分離ビットおよびダブルトークビットが含まれる。この分離ビットは、フレームが、上り音声か下り音声かを識別するフラグである。分離ビットは、モノラル化メイン音声データにおいて、下り音声データ52のレベルが所定値以上であるフレームのビットに設定される。またダブルトークビットは、フレームが、ダブルトークを検出したか否かを識別するフラグである。ダブルトークビットは、モノラル化メイン音声データ61において、ダブルトークを検出したフレームのビットに設定される。
【0035】
本発明の実施の形態において、分離ビットおよびダブルトークビットは、各フレームの末尾に挿入される場合について説明するが、末尾でなくても良い。分離ビットおよびダブルトークビットは、各フレームの所定位置に挿入されても良い。
【0036】
モノラル化サブ音声データ62は、上り音声データ51と下り音声データ52との差分から生成される。後述するように、モノラル化サブ音声データ62は、ダブルトークが発生したフレームについてのみ生成される。従って、モノラル化サブ音声データ62は、モノラル化メイン音声データ61と比べて、再生時間において短く、容量においても小さい。
【0037】
音声認識サーバ2は、録音データ60を取得すると、ステレオ化手段21によって録音データ60をステレオ化し、上り音声データ71と下り音声データ72を出力する。ここで、音声認識サーバ2は、ステレオ化手段21によって録音データ60をステレオ化することにより、上り通話と下り通話とを分離して出力できるだけではなく、モノラル化メイン音声データ61を出力し、分離しないで出力することもできる。
【0038】
このモノラル化メイン音声データ61には、上記で説明した通り、各フレームに分離ビットとダブルトークビットとが含まれる。ここで、1フレームを20msecに設定することにより、20msecごとに2ビットのノイズが入ることになるが、一般的な人間が視聴するには何ら問題にはならない。なおここで、1フレームの時間長20msecは、音声データの一般的なフレームの時間長である。
【0039】
(通話録音装置)
図4を参照して、本発明の実施の形態に係る通話録音装置1を説明する。本発明の実施の形態に係る通話録音装置1は、絶縁トランス101、CODEC102、コントローラ103、内蔵記憶媒体104、RAM105、ROM106および通信制御装置107を備える。
【0040】
絶縁トランス101は、ハンドセットライン31および41間の信号に影響を与えることなく、アナログ音声データとして、上り音声データ51および下り音声データ52を取得する。従って、通話録音装置1が通電されていない間でも、電話機本体3および受話器4間の信号の送受信には影響がない。絶縁トランス101が取得したアナログ音声データは、CODEC102に入力される。
【0041】
CODEC102は、アナログ音声データである上り音声データ51および下り音声データ52を、デジタルデータに変換する。CODEC102は、上り音声データ51および下り音声データ52を、例えば、それぞれ8kHzでサンプリングし、上り音声および下り音声のそれぞれについて、16ビットのPCM信号を出力する。CODEC102によって生成されたPCM信号は、コントローラ103に入力される。
【0042】
コントローラ103は、通話録音装置1の処理を制御する。このときコントローラ103は、内蔵記憶媒体104、RAM105、ROM106などに記憶されたデータを読み出したり、データを書き込んだりして処理する。
【0043】
コントローラ103は、モノラル化手段11を備える。モノラル化手段11は、例えば、コントローラがコンピュータCPUの場合、ファームウェアプログラムなどによって実現されても良い。モノラル化手段11は、基盤回路によって実現されても良い。モノラル化手段11は、CODEC102から入力された上り音声および下り音声のPCM信号が入力されると、録音データ60を生成し、通信制御装置107に入力する。
【0044】
モノラル化手段11は、上り音声データ(第1の音声データ)と下り音声データ(第2の音声データ)とを合成して、モノラル化メイン音声データ61を生成する。またモノラル化手段11は、下りの音声データのレベルが所定値以上である場合、モノラル化メイン音声データ61に、真を設定した分離ビットを設定する。さらにモノラル化手段11は、上り音声データと下り音声データのダブルトークが検出された場合、モノラル化メイン音声データ61に、真を設定したダブルトークビットを設定し、上り音声データと下り音声データとの差分から、モノラル化サブ音声データ62を生成する。
【0045】
ここで、モノラル化手段11は、上り音声データおよび下り音声データのフレームごとに、処理する。具体的にはモノラル化手段11は、下り音声データのレベルが所定値以上であるフレームのビットに、分離ビットを設定するとともに、ダブルトークを検出したフレームのビットに、ダブルトークビットを設定する。またモノラル化手段11は、ダブルトークが検出されたフレームについて、このモノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、上り音声データと下り音声データとの差分から、モノラル化サブ音声データ62を生成する。
【0046】
内蔵記憶媒体104は、大容量の記憶媒体で、例えば、SDカードである。RAM105は、コントローラ103が処理する際の一時データを書き込んだり読み込んだりする記憶媒体である。ROM106は、例えばコントローラ103で実行されるプログラムが記憶される。コントローラ103は、ROM106に書き込まれたプログラムを読み出して処理を実行する。プログラムは、ROM106でなく、書換可能なメモリに書き込まれても良い。
【0047】
通信制御装置107は、通信ネットワーク5と通信するためのインタフェースである。通信制御装置107は、コントローラ103から録音データ60が入力されると、録音データ60を、通信ネットワーク5に送出する。録音データ60は、通信ネットワーク5を介して音声認識サーバ2に送信される。
【0048】
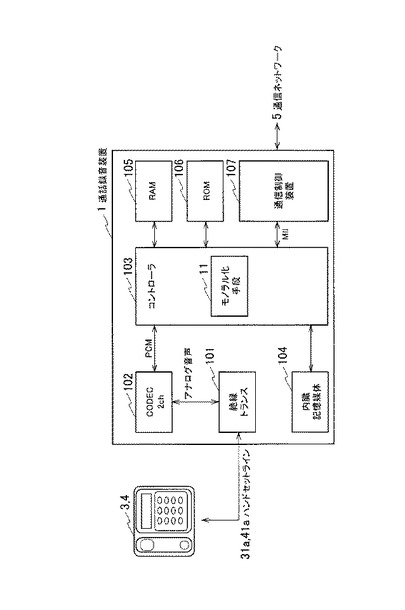
図5を参照して、モノラル化手段11によるモノラル化処理を説明する。
【0049】
モノラル化手段11は、CODEC102から入力された上り音声および下り音声それぞれのPCM信号について、複数のフレームに分割し、各フレームについてステップS101からステップS111の処理を繰り返す。本発明の実施の形態において、フレームの時間長は20msecであるので、モノラル化手段11は、各信号について20msecごと(160サンプルごと)の複数のフレームに分割する。ここで、上り音声データ51のPCM信号の処理対象のフレームを、上り音声フレームデータ(L)と称し、下り音声データ52のPCM信号の処理対象のフレームを、下り音声フレームデータ(R)と称する。
【0050】
まずステップS101においてモノラル化手段11は、処理対象のフレームの上り音声フレームデータ(L)と、下り音声フレームデータ(R)を取得する。さらにステップS102においてモノラル化手段11は、ステップS101で取得した上り音声フレームデータ(L)と、下り音声フレームデータ(R)それぞれのレベルを算出する。モノラル化手段11は例えば、各データの実効値(RMS)からレベルを算出する。
【0051】
ステップS103においてモノラル化手段11は、上り音声フレームデータ(L)と、下り音声フレームデータ(R)を合成して、モノラル化メイン音声フレームデータ(L+R)を生成する。
【0052】
ステップS104においてモノラル化手段11は、ステップS102で算出した下り音声フレームデータ(R)のレベルが、所定値以上であるか否かを判定する。所定値以上である場合、ステップS105においてモノラル化手段11は、この処理対象のフレームの分離ビットに”1”(真)を設定する。所定値以上でない場合、ステップS106においてモノラル化手段11は、この処理対象の分離ビットに”0”(偽)を設定する。
【0053】
ここで別実施例も開示する。この分離ビットは、処理対象のフレームが、上り音声か下り音声かを識別するフラグである。そこでモノラル化手段11は、ステップS104において、上り音声フレームデータ(L)と下り音声フレームデータ(R)のいずれのレベルが高いかを比較し、下り音声フレームデータ(R)のレベルが高い場合に分離ビットに”1”を設定し、上り音声フレームデータ(L)のレベルが高い場合に分離ビットに”0”を設定しても良い。
【0054】
ステップS107においてモノラル化手段11は、上り音声フレームデータ(L)のレベルと下り音声フレームデータ(R)のレベルとを比較して、ダブルトークであるか否かを判定する。モノラル化手段11は、例えば、両方のレベルがともに所定値より高い、または同じくらいのレベルなどの場合、ダブルトークが発生していると判断する。
【0055】
ダブルトークが発生している場合、ステップS108においてモノラル化手段11は、ダブルトークビットに”1”を設定する。さらにステップS109においてモノラル化手段11は、上り音声フレームデータ(L)と、下り音声フレームデータ(R)との差分から、処理対象のフレームについて、モノラル化サブ音声フレームデータ(L−R)を生成する。一方、ダブルトークが発生していない場合、ステップS110においてモノラル化手段11は、ダブルトークビットに”0”を設定し、処理対象のフレームについて、モノラル化サブ音声フレームデータを生成しない。
【0056】
ステップS111においてモノラル化手段11は、ステップS103で生成したモノラル化メイン音声フレームデータ(L+R)の末尾2ビットのデータを破棄し、ステップS105で設定した分離ビットのフラグと、ステップS108で設定したダブルトークビットのフラグを埋め込む。
【0057】
全てのフレームについて、ステップS101ないしステップS111の処理が終了すると、ステップS112においてモノラル化手段11は、モノラル化メイン音声データ61と、モノラル化サブ音声データ62とを生成する。モノラル化手段11は、ステップS111で生成した各フレームのモノラル化メイン音声フレームデータ(L+R)から、モノラル化メイン音声データ61を生成する。モノラル化手段11は、ステップS109で生成した、ダブルトークが発生した各フレームのモノラル化サブ音声フレームデータ(L−R)から、モノラル化サブ音声データ62を生成する。
【0058】
このようにモノラル化手段11は、ダブルトークが検出された場合のみ、モノラル化サブ音声フレームデータ(L−R)を生成するので、上り音声データ51と下り音声データ52とをそれぞれ分離して記録する場合に比べて、少ない容量の録音データ60を生成することができる。また、モノラル化メイン音声データ61として、上り音声データ51と下り音声データ52とを混合したデータが含まれているので、分離して視聴する必要がない場合、このモノラル化メイン音声データ61を視聴すれば良い。なお、各フレームに2ビットのノイズが挿入されるが、一般的な人間の視聴において問題がない範囲であると考えられる。
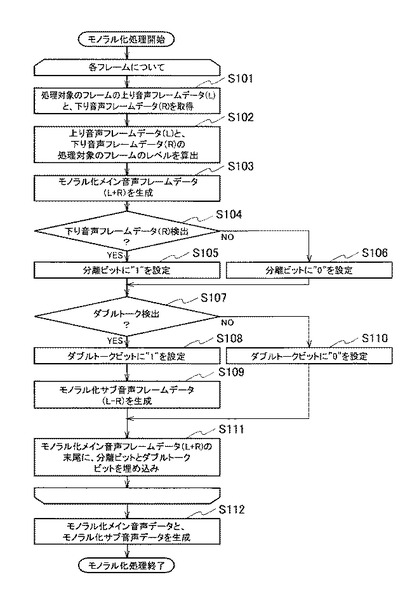
【0059】
図6を参照して、モノラル化手段11の機能ブロックの実装例を説明する。モノラル化手段11は、合成演算手段112、差分演算手段113、レベル検出手段114、μLaw変換手段115、比較手段116、ダブルトーク検出手段117、分離ビット設定手段118およびダブルトークビット設定手段119を備える。
【0060】
モノラル化手段11には、上り音声データ51および下り音声データ52がCODEC102によってそれぞれ変換されたPCM信号が入力される。上り音声データ51および下り音声データ52のそれぞれのPCM信号は、合成演算手段112、差分演算手段113、およびレベル検出手段114に入力される。
【0061】
合成演算手段112は、上り音声データ51のPCM信号(第1の音声データ)と下り音声データ52のPCM信号(第2の音声データ)とを合成して、モノラル化メイン音声データ61のPCM信号を生成する。差分演算手段113は、上り音声データ51のPCM信号(第1の音声データ)と下り音声データ52のPCM信号(第2の音声データ)との差分から、モノラル化サブ音声データ62のPCM信号を生成する。合成演算手段112および差分演算手段113によって生成されたPCM信号は、μLaw変換手段115に入力される。
【0062】
μLaw変換手段115は、合成演算手段112から入力されたPCM信号を圧縮して、μLaw変換して、モノラル化メイン音声データ61として出力する。また、μLaw変換手段115は、差分演算手段113から入力されたPCM信号をμLaw変換して、ダブルトークが検出された場合、モノラル化サブ音声データ62として出力する。μLaw変換手段115は、各PCM信号を、16ビットから8ビットに圧縮して出力する。
【0063】
レベル検出手段114は、CODEC102から上り音声データ51および下り音声データ52のそれぞれのPCM信号が入力されると、それぞれのPCM信号についてレベルを検出する。レベル検出手段114は、それぞれのPCM信号のレベルと、比較手段116およびダブルトーク検出手段117に入力する。
【0064】
比較手段116は、下り音声データ52のPCM信号のレベルが所定値以上であるか否かを比較して、分離ビット設定手段118に通知する。分離ビット設定手段118は、下り音声データ52のPCM信号のレベルが所定値以上であると通知されると、分離ビット設定手段118は、モノラル化メイン音声データ61の所定位置に、真を設定した分離ビットを設定する。具体的には分離ビット設定手段118は、モノラル化メイン音声データ61において、下り音声データのPCM信号のレベルが所定値以上であるフレームのビットに、真を設定した分離ビットを設定する。
【0065】
ダブルトーク検出手段117は、上り音声データ51のPCM信号のレベルと下り音声データ51のPCM信号のレベルに基づいて、ダブルトークを検出し、ダブルトークが検出されたか否かを、ダブルトークビット設定手段119に通知する。ダブルトークビット設定手段119は、ダブルトークが検出されたと通知されると、分離ビット設定手段118は、モノラル化メイン音声データの所定位置に、真を設定したダブルトークビットを設定する。具体的にはダブルトークビット設定手段119は、モノラル化メイン音声データにおいて、ダブルトークが検出されたフレームのビットに、真を設定したダブルトークビットを設定する。
【0066】
さらにダブルトーク検出手段117は、ダブルトークが検出された場合、差分演算手段113の出力信号であってμLaw変換された信号を、モノラル化サブ音声データ62として出力するよう制御する。
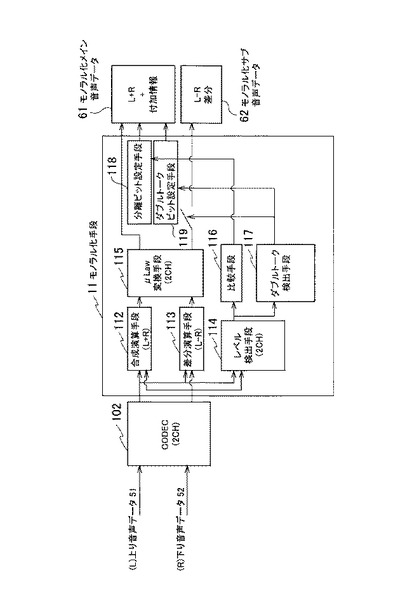
【0067】
図7を参照して、本発明の実施の形態に係るモノラル化手段11の合成演算手段112および差分演算手段113を詳述する。図5を参照して説明した通り、合成演算手段112および差分演算手段113は、上り音声フレームデータ(L)および下り音声フレームデータ(R)のフレーム単位で処理する。さらに詳述すると、合成演算手段112および差分演算手段113は、図7を参照するように、フレームの中のサンプル単位で信号を処理する。本発明の実施の形態において一つのフレームの時間長は20msecで、CODEC102は8kHzでサンプリングする。従って、一つのフレームには160サンプルが含まれる。1サンプルは、16ビットで構成される。
【0068】
図7は、合成演算手段112および差分演算手段113が、CODEC102から出力された上り音声データ51のPCM信号の所定のフレームの上り音声フレームデータと、下り音声データ52のPCM信号の所定のフレームの下り音声フレームデータとを処理する場合を説明する。上り音声フレームデータおよび下り音声フレームデータは、それぞれ、n番目のサンプルからn+159番目のサンプルを含む。
【0069】
合成演算手段112は、上り音声フレームデータ(L)のn番目のサンプルと、下り音声フレームデータ(R)のn番目のサンプルを加算して2で割る。同様に、合成演算手段112n+1は、上り音声フレームデータ(L)のn+1番目のサンプルと、下り音声フレームデータ(R)のn+1番目のサンプルを加算して2で割る。このような処理を160回繰り返すことにより、合成演算手段112は、1フレームのモノラル化メイン音声フレームデータ(L+R)を出力することができる。
【0070】
同様に、差分演算手段113は、上り音声フレームデータ(L)のn番目のサンプルと、下り音声フレームデータ(R)のn番目のサンプルの差分を2で割る。同様に、差分演算手段113n+1は、上り音声フレームデータ(L)のn+1番目のサンプルと、下り音声フレームデータ(R)のn+1番目のサンプルの差分を2で割る。このような処理を160回繰り返すことにより、差分演算手段113は、1フレームのモノラル化サブ音声フレームデータ(L−R)を出力することができる。
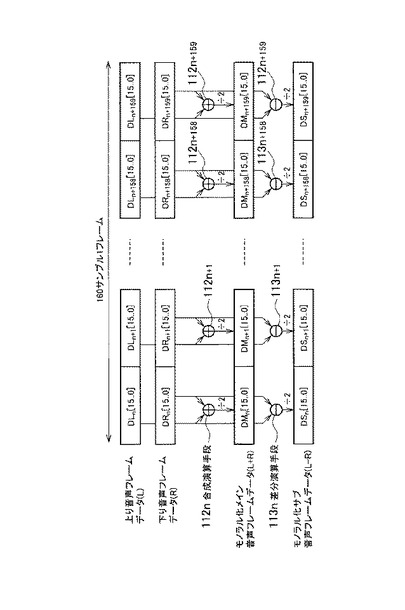
【0071】
図8を参照して、本発明の実施の形態に係るモノラル化手段11において、レベル検出手段114、μLaw変換手段115、比較手段116およびダブルトーク検出手段117の処理を説明する。
【0072】
μLaw変換手段115は、フレームの単位で、上り音声フレームデータ(L)と下り音声フレームデータ(R)について、μLaw変換する。μLaw変換手段は、上り音声フレームデータFL0と上り音声フレームデータFR0のそれぞれのサンプルを、16ビットから8ビットに圧縮する。これにより、μLaw変換手段115は、DMn[7..0]からDMn+159[7..0]を生成する。なお、本発明の実施の形態において、μLaw変換後のモノラル化メイン音声フレームデータ(L+R)の最下位2ビット、具体的には、DMn+159[1..0]のデータは破棄され、後に、分離ビット設定手段118およびダブルトークビット設定手段119によって、分離ビットおよびダブルトークビットが設定される。
【0073】
レベル検出手段114は、上り音声フレームデータ(L)と下り音声フレームデータ(R)を処理するため、2チャンネルの処理手段を備える。レベル検出手段114aは、上り音声フレームデータ(L)のレベルを検出して、比較手段116およびダブルトーク検出手段117に入力する。レベル検出手段114bは、下り音声フレームデータ(R)のレベルを検出して、比較手段116およびダブルトーク検出手段117に入力する。
【0074】
比較手段116は、上り音声フレームデータ(L)のレベルと下り音声フレームデータ(R)のレベルとを比較して、下り音声フレームデータのレベルが高い場合、分離ビット設定手段118に、分離ビットに”1”を設定させ、そうでない場合、分離ビットに”0”を設定させる。分離ビット設定手段118は、モノラル化メイン音声フレームデータ(L+R)の最下位ビット、具体的には、DMn+159[0]に、分離ビット”0”または”1”を設定する。
【0075】
ダブルトーク検出手段117は、上り音声フレームデータ(L)のレベルと下り音声フレームデータ(R)のレベルとを比較して、ともにレベルが高い場合、ダブルトークと判断して、ダブルトークビット設定手段119に、ダブルトークビットに”1”を設定させ、そうでない場合、ダブルトークビットに”0”を設定させる。分離ビット設定手段118は、モノラル化メイン音声フレームデータ(L+R)の最下位+1ビット、具体的には、DMn+159[1]に、ダブルトークビット”0”または”1”を設定する。ここで、このダブルトークビットが”0”の場合、具体的にはこのフレームではダブルトークが検出されなかった場合、このフレームについてモノラル化サブ音声フレームデータ(L−R)は出力されない。
【0076】
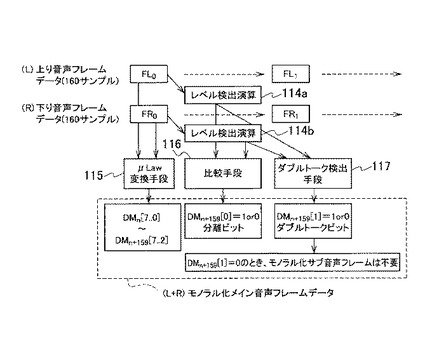
図9を参照して、モノラル化メイン音声フレームデータの構造を説明する。モノラル化メイン音声フレームデータ(L+R)は、160サンプルで構成される。各サンプルは8ビットで構成される。モノラル化メイン音声フレームデータ(L+R)の末尾2ビットには、ダブルトークビットおよび分離ビットが設定される。
【0077】
このようにモノラル化メイン音声フレームデータ(L+R)において、2ビットのノイズが発生する。モノラル化メイン音声フレームデータ(L+R)を連結して、モノラル化メイン音声データ61を生成する。本発明の実施の形態においてサンプリング周波数が8kHzであるので、モノラル化メイン音声データ61に、50Hzごとにノイズが含まれることになる。しかしこのノイズは、非常に微弱なノイズであり、モノラル化メイン音声フレームデータの視聴には影響を与えることはない。
【0078】
(音声認識サーバ)
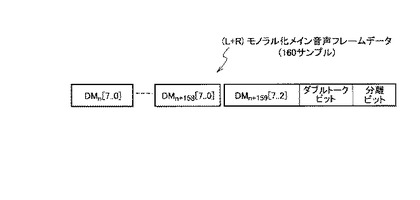
図10を参照して、本発明の最良の実施の形態に係る音声認識サーバ2を説明する。図10に示すように音声認識サーバ2は、記憶装置221、中央処理制御装置222、通信制御装置231、入力装置232、スピーカー233などを備える一般的なコンピュータである。音声認識サーバ2は、所定の処理を実行する音声認識プログラムが、一般的なコンピュータにインストールされ実行されることにより実現される。ここで、記憶装置221は、ハードディスクなどである。通信制御装置231は、LANカードやLANポートである。入力装置232は、マウスやキーボードである。
【0079】
記憶装置221は、音声認識プログラムを記憶するとともに、モノラル化メイン音声データ、モノラル化サブ音声データ62、上り音声データ71、下り音声データ72および録音管理データ73を記憶する。モノラル化メイン音声データ61およびモノラル化サブ音声データ62は、録音データ60として通話録音装置1から受信するデータである。上り音声データ71および下り音声データ72は、モノラル化メイン音声データ61およびモノラル化サブ音声データ62から生成され、上り音声と下り音声とを分離したデータである。
【0080】
モノラル化メイン音声データ61、モノラル化サブ音声データ62、上り音声データ71および下り音声データ72は、後述する中央処理制御装置の各手段によって出力されるデータである。
【0081】
録音管理データ73は、モノラル化メイン音声データ61、上り音声データ71および下り音声データ72を検索するための、これらのデータの識別子と、属性情報などが対応づけられたデータである。属性情報とは、データ生成日時、オペレータ氏名、顧客名、対応種別、音声種別などである。ここで音声種別は、音声認識サーバ2において再生可能な音声データの種別である。音声種別は例えば、モノラル化メイン音声データ61を示すモノラル音声、上り音声データ71を示す上り音声、下り音声データ72を示す下り音声などである。
【0082】
中央処理制御装置222は、録音データ取得手段20、ステレオ化手段21および検索手段22を備える。録音データ取得手段20、ステレオ化手段21および検索手段は、音声認識プログラムがインストールされ実行されることによって、中央処理制御装置222に実装される。
【0083】
録音データ取得手段20は、通話録音装置1から、通信制御装置231を介して、録音データ60を取得し、記憶装置221に記憶する。この録音データ60は、モノラル化メイン音声データ61とモノラル化サブ音声データ62とを含む。モノラル化メイン音声データ61とモノラル化サブ音声データ62は、通話録音装置1で生成される。モノラル化メイン音声データ61には、分離ビットとダブルトークビットが設定される。
【0084】
モノラル化メイン音声データ61は、上り音声データ(第1の音声データ)と下り音声データ(第2の音声データ)を合成して生成され、下り音声データのレベルが所定値以上であることを示す分離ビットと、上り音声データと下り音声データのダブルトークを示すダブルトークビットとを含む。分離ビットは、下り音声データのレベルが所定値以上であるフレームのビットに設定され、ダブルトークビットは、ダブルトークを検出したフレームのビットに設定される。
【0085】
このモノラル化メイン音声データ61は、上り音声と下り音声が混合したデータであるので、このままでも聞くことは可能である。また、本発明の実施の形態に係るステレオ化手段21によって、モノラル化メイン音声データ61およびモノラル化サブ音声データ62に基づいて、上り音声と下り音声に分離して聞くこともできる。
【0086】
ステレオ化手段21は、モノラル化メイン音声データ61およびモノラル化サブ音声データ62から上り音声および下り音声を分離して、上り音声データ71および下り音声データ72を生成する。
【0087】
ステレオ化手段21は、モノラル化メイン音声データ61から分離ビットとダブルトークビットを取得する。ダブルトークビットが真の場合、ステレオ化手段21は、モノラル化メイン音声データ61とモノラル化サブ音声データ62から、上り音声データ71および下り音声データ72を生成して出力する。ダブルトークビットが偽でかつ分離ビットが真の場合、ステレオ化手段21は、モノラル化メイン音声データ61を下り音声データ72として出力し、分離ビットが偽の場合、モノラル化メイン音声データ61を上り音声データ71として出力する。
【0088】
ここで、ステレオ化手段21は、モノラル化メイン音声データ61およびモノラル化サブ音声データ62のフレームごとに、処理する。具体的にはステレオ化手段21は、ダブルトークビットが真のフレームについて、モノラル化メイン音声データ61とモノラル化サブ音声データ62から、このフレームの上り音声データ71および下り音声データ72を生成して出力する。ステレオ化手段21は、ダブルトークビットが偽でかつ分離ビットが真のフレームについて、モノラル化メイン音声データ61から、このフレームの下り音声データ72を出力する。ステレオ化手段21は、ダブルトークビットが偽でかつ分離ビットが偽のフレームについて、モノラル化メイン音声データ61から、このフレームの上り音声データ71を出力する。
【0089】
検索手段22は、録音管理データ73を参照して、所望の音声データを検索する。例えば入力装置232から入力された検索条件が入力されると、検索手段22は、入力された検索条件に合致する属性を録音管理データ73から検索し、さらに、その合致する属性を持つ音声データを、モノラル化メイン音声データ61、上り音声データ71および下り音声データ72から取得する。検索手段22はさらに、取得した音声データを再生し、スピーカー233から出力する。
【0090】
ここでユーザは、入力装置232を介して、「○月○日の、XXオペレータが△△さんへの通話内容」などと入力することができる。このような条件が入力されると、検索手段22は、オペレータの顧客への通話のみの音声データを検索し、スピーカー233から出力することができる。
【0091】
図11を参照して、ステレオ化手段21によるステレオ化処理を説明する。
【0092】
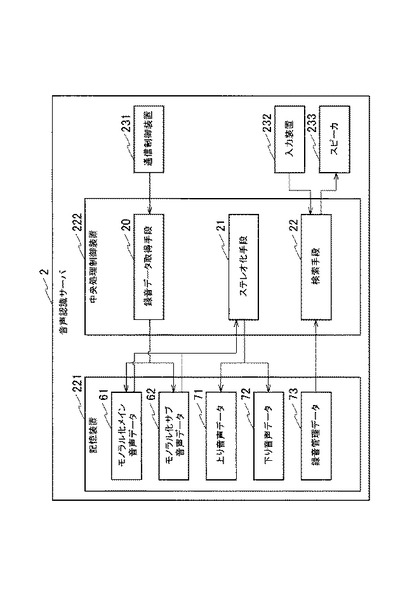
ステレオ化手段21は、モノラル化メイン音声データ61を複数のフレームに分割し、各フレームについて、ステップS201ないしステップS208の処理を繰り返す。本発明の実施の形態において、フレームの時間長は20msecであるので、ステレオ化手段21は、モノラル化メイン音声データ61を20msecごと(160サンプルごと)の複数のフレームに分割する。ここで、モノラル化メイン音声データ61の処理対象のフレームを、モノラル化メイン音声フレームデータ(L+R)と称し、このフレームに対応するモノラル化サブ音声データ62のフレームを、モノラル化サブ音声フレームデータ(L−R)と称する。
【0093】
まずステップS201においてステレオ化手段21は、処理対象のフレームの所定位置から、ダブルトークビットを取得する。このダブルトークビットは、図8などに示されるように、処理対象のフレームの最後から2番目のビットに設定されるので、ステレオ化手段21は、このビットの値を取得する。
【0094】
ステップS202においてステレオ化手段21は、処理対象のフレームでダブルトークが検出されたか否かを判定する。具体的にステレオ化手段21は、ステップS201で取得したダブルトークビットが”1”の場合、処理対象のフレームでダブルトークが検出されたと判定し、”0”の場合、処理対象のフレームでダブルトークが検出されなかったと判定する。
【0095】
ダブルトークが検出された場合、ステップS203においてステレオ化手段21は、モノラル化音声フレームデータ(L+R)とモノラル化サブ音声フレームデータ(L−R)とから、上り音声フレームデータ(L)と下り音声フレームデータ(R)とを生成する。
【0096】
一方ダブルトークが検出されなかった場合、ステップS204においてステレオ化手段21は、処理対象のフレームの所定位置から、分離ビットを取得する。この分離ビットは、図11などに示されるように、処理対象のフレームの最後のビットに設定されるので、ステレオ化手段21は、このビットの値を取得する。
【0097】
ステップS205においてステレオ化手段21は、処理対象のフレームから、下り音声データが検出されるか否かを判定する。具体的にステレオ化手段21は、ステップS204で取得した分離ビットが”1”の場合、処理対象のフレームで下り音声データが検出されたと判定し、”0”の場合、処理対象のフレームで下り音声データが検出されなかったと判定する。
【0098】
ステップS205において下り音声データが検出された場合、ステップS206においてステレオ化手段21は、モノラル化メイン音声フレームデータ(L+R)を、下り音声フレームデータ(R)として生成する。このとき、ステレオ化手段21は、上り音声フレームデータ(L)の出力をゼロとして、具体的には無音として扱う。
【0099】
一方ステップS205において下り音声データが検出されなかった場合、ステップS207においてステレオ化手段21は、モノラル化メイン音声フレームデータ(L+R)を、上り音声フレームデータ(L)として生成する。このとき、ステレオ化手段21は、下り音声フレームデータ(R)の出力をゼロとして、具体的には無音として扱う。
【0100】
全てのフレームについてステップS201ないしステップS207の処理が終了すると、ステレオ化手段21は、上り音声データ71および下り音声データ72を生成する。具体的にはステレオ化手段21は、ステップS203、ステップS206またはステップS207で生成された上り音声フレームデータ(L)を連結して上り音声データ71を生成するとともに、下り音声フレームデータ(R)を連結して下り音声データ72を生成する。ここで、ステレオ化手段21は、無音として扱ったフレームについては、無音であることを示すデータを連結する。ステレオ化手段21は、生成した上り音声データ71および下り音声データ72を記憶装置221に記憶する。
【0101】
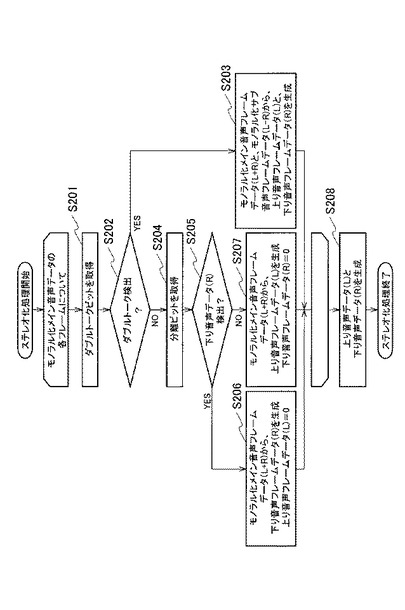
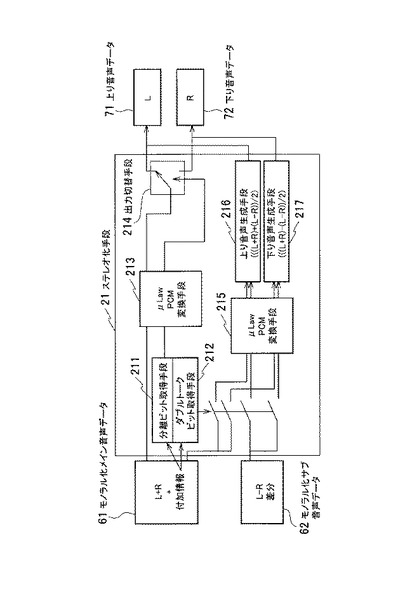
図12を参照して、ステレオ化手段21の機能ブロックの実装例を説明する。ステレオ化手段21は、分離ビット取得手段211、ダブルトークビット取得手段212、第1のμLawPCM変換手段213、出力切替手段214、第2のμLawPCM変換手段215、上り音声生成手段216および下り音声生成手段217を備える。
【0102】
モノラル化メイン音声データ61は、分離ビット取得手段211およびダブルトークビット取得手段212に入力されるとともに、第1のμLawPCM変換手段213に入力される。
【0103】
分離ビット取得手段211は、モノラル化メイン音声データ61から分離ビットを取得する。ここで分離ビットは、下り音声データのレベルが所定値以上である、モノラル化メイン音声データのフレームのビットに設定される。分離ビット取得手段211は、取得した分離ビットを、第1のμLawPCM変換手段213に入力し、出力切替手段214の出力を制御する。
【0104】
ダブルトークビット取得手段212は、モノラル化メイン音声データ61からダブルトークビットを取得する。ここでダブルトークビットは、ダブルトークを検出した、モノラル化メイン音声データのフレームのビットに設定される。
【0105】
第1のμLawPCM変換手段213は、入力されたモノラル化メイン音声データ61および分離ビットを、8ビットから16ビットに伸張して出力する。出力された信号は、出力切替手段214に入力される。
【0106】
出力切替手段214は、ダブルトークビットが”0”(偽)でかつ分離ビットが”1”(真)の場合、モノラル化メイン音声データ61を下り音声データ72として出力する。具体的には出力切替手段214は、ダブルトークビットが”0”でかつ分離ビットが”1”のフレームについて、モノラル化メイン音声データ61から、このフレームの下り音声データ72を出力する。一方、分離ビットが”0”(偽)の場合、モノラル化メイン音声データ61を上り音声データ71として出力する。具体的には出力切替手段214は、ダブルトークビットが”0”でかつ分離ビットが”0”のフレームについて、モノラル化メイン音声データ61から、このフレームの上り音声データ71を出力する。
【0107】
出力切替手段214は、分離ビット取得手段211の制御に従って、モノラル化メイン音声データ61の伸張信号を、上り音声データ71として出力するか、下り音声データ72として出力するかを制御する。分離ビットが”0”の場合、出力切替手段214は、モノラル化メイン音声データ61の伸張信号を、上り音声データ71として出力し、”1”の場合、下り音声データ72として出力する。
【0108】
ここで、ダブルトークビットは、モノラル化メイン音声データ61およびモノラル化サブ音声データ62の第2のμLawPCM変換手段215への入力を制御する。ダブルトークビットが”1”の場合、モノラル化メイン音声データ61およびモノラル化サブ音声データ62が第2のμLawPCM変換手段215に入力される。一方ダブルトークビットが”0”の場合、第2のμLawPCM変換手段215には信号は入力されない。
【0109】
第2のμLawPCM変換手段215は、モノラル化メイン音声データ61およびモノラル化サブ音声データ62が入力されると、入力されたモノラル化メイン音声データ61およびモノラル化サブ音声データ62をそれぞれ、8ビットから16ビットに伸張して出力する。出力された信号は、上り音声生成手段216および下り音声生成手段217にそれぞれ入力される。
【0110】
上り音声生成手段216は、ダブルトークビットが”1”(真)の場合、モノラル化メイン音声データ61とモノラル化サブ音声データ62から、上り音声データ71を生成して出力する。上り音声生成手段216は、モノラル化メイン音声データ61(L+R))とモノラル化サブ音声データ62(L−R)とを加算して2で割ることにより、上り音声データ71を出力する。ここで上り音声生成手段216は、ダブルトークビットが真のフレームについて、モノラル化メイン音声データ61とモノラル化サブ音声データ62から、このフレームの上り音声データ71を生成して出力する。
【0111】
下り音声生成手段217は、ダブルトークビットが”1”(真)の場合、モノラル化メイン音声データ61とモノラル化サブ音声データ62から、下り音声データ72を生成して出力する。下り音声生成手段217は、モノラル化メイン音声データ61(L+R))とモノラル化サブ音声データ62(L−R)との差分を2で割ることにより、下り音声データ72を出力する。下り音声生成手段217は、ダブルトークビットが真のフレームについて、モノラル化メイン音声データ61とモノラル化サブ音声データ62から、このフレームの下り音声データ72を生成して出力する。
【0112】
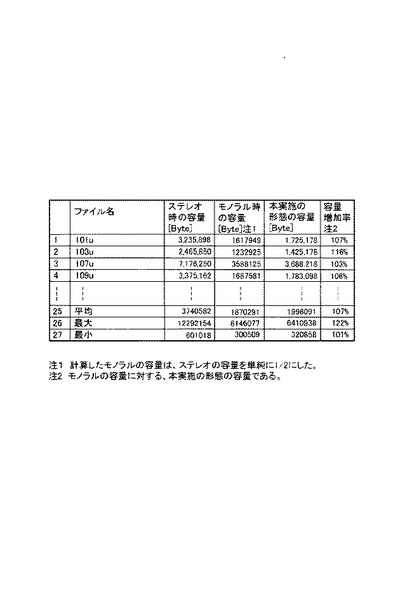
図13を参照して、本発明の実施の形態に係る通話録音システム6の効果を説明する。図13においては、各通話について、上り下りの音声を分離してステレオで録音した場合の容量、上り下りの音声を分離せずモノラルで録音した場合の容量、本実施の形態に係る方法で録音した場合の容量を比較している。図13はさらに、モノラルで録音した場合の容量に対する本実施の形態に係る方法で録音した場合の容量の割合を記載している。
【0113】
図13に示す通り、本実施の形態に係る方法では、モノラル時の容量から数パーセント増加しているものの、ステレオ時の容量よりもかなり少ないことがわかる。また、上述した通り、本実施の形態に係る録音データ60は、通話における上り音声と下り音声を分離して再生可能である。従って本発明の実施の形態に係る通話録音システム6は、通話における上り音声と下り音声を分離して再生可能で、かつ、データ容量の小さい録音データ60を生成することができる。
【0114】
(その他の実施の形態)
上記のように、本発明の実施の形態によって記載したが、この開示の一部をなす論述および図面はこの発明を限定するものであると理解すべきではない。この開示から当業者には様々な代替実施の形態、実施例および運用技術が明らかとなる。
【0115】
例えば、本発明の最良の実施の形態に記載した音声認識サーバは、図1に示すように一つのハードウェア上に構成されても良いし、その機能や処理数に応じて複数のハードウェア上に構成されても良い。また、既存の情報処理システム上に実現されても良い。
【0116】
また、本発明の実施の形態においては、録音データを音声認識サーバで再生する場合について説明したが、録音データは、例えば通話録音装置などの他の装置で再生されても良い。
【0117】
本発明はここでは記載していない様々な実施の形態等を含むことは勿論である。従って、本発明の技術的範囲は上記の説明から妥当な特許請求の範囲に係る発明特定事項によってのみ定められるものである。
【符号の説明】
【0118】
1 通話録音装置
2 音声認識サーバ
3 電話機本体
4 受話器
5 通信ネットワーク
6 通話録音システム
11 モノラル化手段
20 録音データ取得手段
21 ステレオ化手段
22 検索手段
31、41 ハンドセットライン
51、71 上り音声データ
52、72 下り音声データ
60 録音データ
61 モノラル化メイン音声データ
62 モノラル化サブ音声データ
73 録音管理データ
101 絶縁トランス
102 CODEC
103 コントローラ
104 内蔵記憶媒体
105 RAM
106 ROM
107、231 通信制御装置
112 合成演算手段
113 差分演算手段
114 レベル検出手段
115 μLaw変換手段
116 比較手段
117 ダブルトーク検出手段
118 分離ビット設定手段
119 ダブルトークビット設定手段
211 分離ビット取得手段
212 ダブルトークビット取得手段
213、215 μLawPCM変換手段
214 出力切替手段
216 上り音声生成手段
217 下り音声生成手段
221 記憶装置
222 中央処理制御装置
232 入力装置
233 スピーカー
【技術分野】
【0001】
本発明は、通話における上り音声と下り音声を分離して再生可能な録音データを出力する通話録音装置、通話録音プログラム、録音データを再生する音声認識サーバ、音声認識プログラム、録音データを出力および再生する通話録音システムおよび通話録音方法に関する。
【背景技術】
【0002】
従来、コールセンターなどにおいて、オペレータと顧客の通話内容を録音する通話録音装置が知られている。通話の録音データは、通話内容の確認や顧客サービス向上のために参照される場合がある。従って、オペレータの顧客への通話と、顧客のオペレータへの通話とを、それぞれ区別して記録することが好ましい。
【0003】
そのため、通話の録音データを、上りの通話と下りの通話とに分離して記録する技術がある(特許文献1参照。)。この特許文献1に記載の技術では、使用者の通話の上り音声通話と、相手側の通話の下り音声通話を別々に録音する。これにより、例えば使用者の音声で使用者が話した単語やフレーズを入力することにより、使用者の通話の上り音声通話から、その音声波形と略一致する波形を持つ録音データを検索することができる。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開2006−165846号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかしながら、特許文献1に記載の方法では、上り音声通話と下り音声通話を分離して記録するため、分離しないで記録する場合に比べて、録音データの容量が2倍になってしまう。コールセンターなどにおいては特に、多数の通話を録音する必要がある。従って録音データの容量が2倍になってしまうと、システム全体で、記録媒体のコストが増大してしまう問題がある。
【0006】
そこで、上りの通話と下りの通話を分離して再生可能で、かつ、データ容量の小さい録音データを生成可能な通話録音装置の開発が期待されている。
【0007】
従って本発明の目的は、上りの通話と下りの通話を分離して再生可能で、データ容量の小さい録音データの通話録音装置、通話録音プログラム、音声認識サーバ、音声認識プログラム、通話録音システムおよび通話録音方法を提供することである。
【課題を解決するための手段】
【0008】
上記課題を解決するために、本発明の第1の特徴は、通話における第1の音声と第2の音声を分離して再生可能な録音データを生成する通話録音装置に関する。すなわち本発明の第1の特徴に係る通話録音装置は、第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成し、第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定し、第1の音声データと第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、第1の音声データと第2の音声データとの差分から、モノラル化サブ音声データを生成するモノラル化手段を備える。
【0009】
ここでモノラル化手段は、第2の音声データのレベルが所定値以上であるフレームのビットに、分離ビットを設定するとともに、ダブルトークを検出したフレームのビットに、ダブルトークビットを設定し、ダブルトークが検出されたフレームについて、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、第1の音声データと第2の音声データとの差分から、モノラル化サブ音声データを生成することが好ましい。
【0010】
また通話録音装置は、電話機本体と第1のハンドセットラインで接続されるとともに、受話器と第2のハンドセットラインで接続され、第1の音声データおよび第2の音声データは、第1および第2のハンドセットラインから取得したアナログ音声を、デジタル化したデータである。
【0011】
本発明の第2の特徴は、通話における第1の音声と第2の音声を分離して再生可能な録音データを生成する通話録音装置に用いられる通話録音プログラムに関する。すなわち本発明の第2の特徴に係る通話録音プログラムは、第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成し、第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定し、第1の音声データと第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、第1の音声データと第2の音声データとの差分から、モノラル化サブ音声データを生成するモノラル化手段として、通話録音装置に内蔵されたコンピュータを機能させる。
【0012】
ここでモノラル化手段は、第2の音声データのレベルが所定値以上であるフレームのビットに、分離ビットを設定するとともに、ダブルトークを検出したフレームのビットに、ダブルトークビットを設定し、ダブルトークが検出されたフレームについて、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、第1の音声データと第2の音声データとの差分から、モノラル化サブ音声データを生成する。
【0013】
本発明の第3の特徴は、第1の音声と第2の音声を分離して再生する音声認識サーバに関する。すなわち本発明の第3の特徴に係る音声認識サーバは、第1の音声データと第2の音声データを合成して生成され、第2の音声データのレベルが所定値以上であることを示す分離ビットと、第1の音声データと第2の音声データのダブルトークを示すダブルトークビットとを含むモノラル化メイン音声データと、ダブルトークが検出された際、第1の音声データと第2の音声データとの差分から生成されたモノラル化サブ音声データと、が記憶された記憶装置と、モノラル化メイン音声データから分離ビットとダブルトークビットを取得し、ダブルトークビットが真の場合、モノラル化メイン音声データとモノラル化サブ音声データから、第1の音声データおよび第2の音声データを生成して出力し、ダブルトークビットが偽でかつ分離ビットが真の場合、モノラル化メイン音声データを第2の音声データとして出力し、分離ビットが偽の場合、モノラル化メイン音声データを第1の音声データとして出力するステレオ化手段を備える。
【0014】
ここで分離ビットは、第2の音声データのレベルが所定値以上であるフレームのビットに設定され、ダブルトークビットは、ダブルトークを検出したフレームのビットに設定されても良い。この場合ステレオ化手段は、ダブルトークビットが真のフレームについて、モノラル化メイン音声データとモノラル化サブ音声データから、当該フレームの第1の音声データおよび第2の音声データを生成して出力し、ダブルトークビットが偽でかつ分離ビットが真のフレームについて、モノラル化メイン音声データから、当該フレームの第2の音声データを出力し、ダブルトークビットが偽でかつ分離ビットが偽のフレームについて、モノラル化メイン音声データから、当該フレームの第1の音声データを出力する。
【0015】
本発明の第4の特徴は、第1の音声と第2の音声を分離して再生する音声認識サーバに用いる音声認識プログラムに関する。すなわち本発明の第4の特徴に係る音声認識プログラムは、コンピュータを、第1の音声データと第2の音声データを合成して生成され、第2の音声データのレベルが所定値以上であることを示す分離ビットと、第1の音声データと第2の音声データのダブルトークを示すダブルトークビットとを含むモノラル化メイン音声データと、ダブルトークが検出された際、第1の音声データと第2の音声データとの差分から生成されたモノラル化サブ音声データとを取得して、記憶装置に記憶する録音データ取得手段と、モノラル化メイン音声データから分離ビットを取得するとともに、モノラル化メイン音声データからダブルトークビットを取得し、ダブルトークビットが真の場合、モノラル化メイン音声データとモノラル化サブ音声データから、第1の音声データおよび第2の音声データを生成して出力し、ダブルトークビットが偽でかつ分離ビットが真の場合、モノラル化メイン音声データを第2の音声データとして出力し、分離ビットが偽の場合、モノラル化メイン音声データを第1の音声データとして出力するステレオ化手段として機能させる。
【0016】
ここで分離ビットは、モノラル化メイン音声データにおいて、第2の音声データのレベルが所定値以上であるフレームのビットに設定され、ダブルトークビットは、モノラル化メイン音声データにおいて、ダブルトークを検出したフレームのビットに設定されても良い。この場合ステレオ化手段は、ダブルトークビットが真のフレームについて、モノラル化メイン音声データとモノラル化サブ音声データから、当該フレームの第1の音声データおよび第2の音声データを生成して出力し、ダブルトークビットが偽でかつ分離ビットが真のフレームについて、モノラル化メイン音声データから、当該フレームの第2の音声データを出力し、ダブルトークビットが偽でかつ分離ビットが偽のフレームについて、モノラル化メイン音声データから、当該フレームの第1の音声データを出力する。
【0017】
本発明の第5の特徴は、通話における第1の音声と第2の音声を分離して再生可能な録音データを生成し、再生する通話録音システムに関する。本発明の第5の特徴に係る通話録音システムは、通話録音装置と、音声認識サーバと、を備える。通話録音装置は、第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成し、第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定し、第1の音声データと第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、第1の音声データと第2の音声データとの差分から、モノラル化サブ音声データを生成するモノラル化手段を備える。音声認識サーバは、第1の音声データと第2の音声データを合成して生成され、第2の音声データのレベルが所定値以上であることを示す分離ビットと、第1の音声データと第2の音声データのダブルトークを示すダブルトークビットとを含むモノラル化メイン音声データと、ダブルトークが検出された際、第1の音声データと第2の音声データとの差分から生成されたモノラル化サブ音声データと、が記憶された記憶装置と、モノラル化メイン音声データから分離ビットを取得するとともに、モノラル化メイン音声データからダブルトークビットを取得し、ダブルトークビットが真の場合、モノラル化メイン音声データとモノラル化サブ音声データから、第1の音声データおよび第2の音声データを生成して出力し、ダブルトークビットが偽でかつ分離ビットが真の場合、モノラル化メイン音声データを第2の音声データとして出力し、分離ビットが偽の場合、モノラル化メイン音声データを第1の音声データとして出力するステレオ化手段を備える。
【0018】
本発明の第6の特徴は、通話における第1の音声と第2の音声を分離して再生可能な録音データを生成する通話録音方法に関する。本発明の第6の特徴に係る通話録音方法は、第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成するステップと、第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定するステップと、第1の音声データと第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、第1の音声データと第2の音声データとの差分から、モノラル化サブ音声データを生成するステップと、を備える。
【0019】
ここで録音データを再生する際、モノラル化メイン音声データから分離ビットを取得するとともに、モノラル化メイン音声データからダブルトークビットを取得するステップと、ダブルトークビットが真の場合、モノラル化メイン音声データとモノラル化サブ音声データから、第1の音声データおよび第2の音声データを生成して出力するステップと、ダブルトークビットが偽でかつ分離ビットが真の場合、モノラル化メイン音声データを第2の音声データとして出力するステップと、分離ビットが偽の場合、モノラル化メイン音声データを第1の音声データとして出力するステップと、をさらに備えることが好ましい。
【発明の効果】
【0020】
本発明によれば、通話における上り音声と下り音声を分離して再生可能で、データ容量の小さい録音データの通話録音装置、通話録音プログラム、音声認識サーバ、音声認識プログラム、通話録音システムおよび通話録音方法を提供することができる。
【図面の簡単な説明】
【0021】
【図1】本発明の実施の形態に係る通話録音システムのシステム構成を説明する図である。
【図2】本発明の実施の形態に係る通話録音装置の接続を説明する図である。
【図3】本発明の実施の形態に係る通話録音システムにおいて送受信されるデータを説明する図である。
【図4】本発明の実施の形態に係る通話録音装置のハードウェア構成図である。
【図5】本発明の実施の形態に係る通話録音装置のモノラル化手段によるモノラル化処理を説明するフローチャートである。
【図6】本発明の実施の形態に係る通話録音装置のモノラル化手段の機能ブロックを説明する図である。
【図7】本発明の実施の形態に係るモノラル化処理において、上り音声データおよび下り音声データの各フレームについて、フレームのサンプルごとにモノラル化する処理を説明する図である。
【図8】本発明の実施の形態に係るモノラル化処理において、フレームごとにモノラル化される処理を説明する図である。
【図9】本発明の実施の形態に係るモノラル化メイン音声データの構成を説明する図である。
【図10】本発明の実施の形態に係る音声認識サーバのハードウェア構成および機能ブロックを説明する図である。
【図11】本発明の実施の形態に係る音声認識サーバのステレオ化手段によるステレオ化処理を説明するフローチャートである。
【図12】本発明の実施の形態に係る音声認識サーバのステレオ化手段の機能ブロックを説明する図である。
【図13】本発明の実施の形態に係る通話録音システムの録音データの容量の削減効果を説明する図である。
【発明を実施するための形態】
【0022】
次に、図面を参照して、本発明の実施の形態を説明する。以下の図面の記載において、同一または類似の部分には同一または類似の符号を付している。
【0023】
(通話録音システム)
図1を参照して、本発明の実施の形態に係る通話録音システム6を説明する。通話録音システム6は、通話における第1の音声と第2の音声を分離して再生可能な録音データ60を生成し、再生する。本発明の実施の形態に係る通話録音システム6は、コールセンターに設置されることを想定する。従って、第1の音声とは、例えば、コールセンターのオペレータが顧客に通話する音声で、第2の音声とは、顧客がオペレータに通話する音声である。本発明の実施の形態係る録音データ60は、コールセンターにおける顧客とオペレータの通話を、分離して視聴することができる。また録音データ60は、従来のステレオ形式のデータより、容量の小さいデータである。
【0024】
本発明の通話録音システム6は、会話では、ほとんどの時間帯は交互に送話され、同時に送話される時間帯が限られるという特徴に着目している。本発明の実施の形態において、同時に送話される時間帯を、ダブルトークと称す。一般的な通話において、一方の話者が話している最中に、別の話者が相槌を打つ場合などに、ダブルトークが発生する。従って、全体の会話時間に対するダブルトークの時間は、かなり限定される。
【0025】
そこで本発明の実施の形態に係る通話録音システム6においては、会話中の各時間、どちらの話者が通話しているかを示す識別情報(分離ビット)と、ダブルトーク時であることを示す情報(ダブルトークビット)とを利用して、双方の音声を録音しつつ、分離して視聴することができ、また容量の小さい録音データ60を生成することができる。
【0026】
通話録音システム6は、第1の通話録音装置1a、第2の通話録音装置1b、音声認識サーバ2、第1の電話機本体3a、第1の受話器4a、第2の電話機本体3bおよび第2の受話器4bを備える。第1の通話録音装置1a、第2の通話録音装置1bおよび音声認識サーバ2は、通信ネットワーク5によって相互に通信可能に接続される。通信ネットワーク5は、例えばコールセンター内のLANである。
【0027】
図1に示す例において、通話録音装置、電話機本体および受話器は2つずつ備える場合を説明するが、これらは一つずつ備えても良いし、三つ以上備えても良い。本発明の実施の形態において、第1の通話録音装置1aおよび第2の通話録音装置1bを特に区別しない場合、通話録音装置1と記載する場合がある。同様に、第1の電話機本体3aおよび第2の電話機本体3bを特に区別しない場合、電話機本体3と記載する場合がある。第1の受話器4aおよび第2の受話器4を特に区別しない場合、受話器4と記載する場合がある。
【0028】
図2に示すように通話録音装置1は、電話機本体3および受話器4に接続される。電話機本体3の受話器用モジュラーラックと、通話録音装置1の第1のモジュラージャックとがハンドセットライン31で接続され、通話録音装置1の第2のモジュラージャックと受話器4のモジュラージャックとが、ハンドセットライン41で接続される。通話録音装置1は、ハンドセットライン31および41間に流れる信号を取得して、録音データ60を生成する。さらに通話録音装置1は、生成した録音データ60を、音声認識サーバ2に送信する。
【0029】
音声認識サーバ2は、一般的なコンピュータであって、所定の処理を実行する音声認識プログラムがインストールされて実現される。音声認識サーバ2は、通話録音装置1から録音データ60を受信すると、録音データ60から、第1の音声と第2の音声とを分離して再生することができる。
【0030】
電話機本体3は、交換機を介して、顧客と通話する。オペレータは電話機本体3を操作し、受話器4を介して、顧客からの通話を聞き取り、通話内容を顧客に伝える。
【0031】
ここで、本発明の実施の形態に係る通話録音装置1は、電話機本体3と受話器4間のアナログ信号を取得するので、電話機本体3の種別を問わない。従って、本発明の実施の形態に係る通話録音システム6は、アナログPBX、BRI(Basic Rate Interface)PBX、PRI(Primary Rate Interface)PBX、IP(Internet Protocol)PBXなど、あらゆる種類の交換機や電話機に対応することができる。
【0032】
図3を参照して、本発明の実施の形態に係る通話録音システム6において、装置間で送受信されるデータを説明する。通話録音装置1は、電話機本体3および受話器4間のハンドセットライン31および41から、上り音声データ51と下り音声データ52とを取得する。この上り音声データ51と下り音声データ52は、アナログ信号である。本発明の実施の形態において、上り音声データ51に関するデータ信号を(L)と、下り音声データ52に関するデータ信号を(R)と表記する場合がある。
【0033】
通話録音装置1は、上り音声データ51と下り音声データ52とを受信すると、モノラル化手段11によって、上り音声データ51と下り音声データ52とをモノラル化し、録音データ60を出力する。録音データ60は、モノラル化メイン音声データ61と、モノラル化サブ音声データ62とを含む。
【0034】
モノラル化メイン音声データ61は、上り音声データ51と下り音声データ52とを混合して生成される。モノラル化メイン音声データ61には、各フレームに、分離ビットおよびダブルトークビットが含まれる。この分離ビットは、フレームが、上り音声か下り音声かを識別するフラグである。分離ビットは、モノラル化メイン音声データにおいて、下り音声データ52のレベルが所定値以上であるフレームのビットに設定される。またダブルトークビットは、フレームが、ダブルトークを検出したか否かを識別するフラグである。ダブルトークビットは、モノラル化メイン音声データ61において、ダブルトークを検出したフレームのビットに設定される。
【0035】
本発明の実施の形態において、分離ビットおよびダブルトークビットは、各フレームの末尾に挿入される場合について説明するが、末尾でなくても良い。分離ビットおよびダブルトークビットは、各フレームの所定位置に挿入されても良い。
【0036】
モノラル化サブ音声データ62は、上り音声データ51と下り音声データ52との差分から生成される。後述するように、モノラル化サブ音声データ62は、ダブルトークが発生したフレームについてのみ生成される。従って、モノラル化サブ音声データ62は、モノラル化メイン音声データ61と比べて、再生時間において短く、容量においても小さい。
【0037】
音声認識サーバ2は、録音データ60を取得すると、ステレオ化手段21によって録音データ60をステレオ化し、上り音声データ71と下り音声データ72を出力する。ここで、音声認識サーバ2は、ステレオ化手段21によって録音データ60をステレオ化することにより、上り通話と下り通話とを分離して出力できるだけではなく、モノラル化メイン音声データ61を出力し、分離しないで出力することもできる。
【0038】
このモノラル化メイン音声データ61には、上記で説明した通り、各フレームに分離ビットとダブルトークビットとが含まれる。ここで、1フレームを20msecに設定することにより、20msecごとに2ビットのノイズが入ることになるが、一般的な人間が視聴するには何ら問題にはならない。なおここで、1フレームの時間長20msecは、音声データの一般的なフレームの時間長である。
【0039】
(通話録音装置)
図4を参照して、本発明の実施の形態に係る通話録音装置1を説明する。本発明の実施の形態に係る通話録音装置1は、絶縁トランス101、CODEC102、コントローラ103、内蔵記憶媒体104、RAM105、ROM106および通信制御装置107を備える。
【0040】
絶縁トランス101は、ハンドセットライン31および41間の信号に影響を与えることなく、アナログ音声データとして、上り音声データ51および下り音声データ52を取得する。従って、通話録音装置1が通電されていない間でも、電話機本体3および受話器4間の信号の送受信には影響がない。絶縁トランス101が取得したアナログ音声データは、CODEC102に入力される。
【0041】
CODEC102は、アナログ音声データである上り音声データ51および下り音声データ52を、デジタルデータに変換する。CODEC102は、上り音声データ51および下り音声データ52を、例えば、それぞれ8kHzでサンプリングし、上り音声および下り音声のそれぞれについて、16ビットのPCM信号を出力する。CODEC102によって生成されたPCM信号は、コントローラ103に入力される。
【0042】
コントローラ103は、通話録音装置1の処理を制御する。このときコントローラ103は、内蔵記憶媒体104、RAM105、ROM106などに記憶されたデータを読み出したり、データを書き込んだりして処理する。
【0043】
コントローラ103は、モノラル化手段11を備える。モノラル化手段11は、例えば、コントローラがコンピュータCPUの場合、ファームウェアプログラムなどによって実現されても良い。モノラル化手段11は、基盤回路によって実現されても良い。モノラル化手段11は、CODEC102から入力された上り音声および下り音声のPCM信号が入力されると、録音データ60を生成し、通信制御装置107に入力する。
【0044】
モノラル化手段11は、上り音声データ(第1の音声データ)と下り音声データ(第2の音声データ)とを合成して、モノラル化メイン音声データ61を生成する。またモノラル化手段11は、下りの音声データのレベルが所定値以上である場合、モノラル化メイン音声データ61に、真を設定した分離ビットを設定する。さらにモノラル化手段11は、上り音声データと下り音声データのダブルトークが検出された場合、モノラル化メイン音声データ61に、真を設定したダブルトークビットを設定し、上り音声データと下り音声データとの差分から、モノラル化サブ音声データ62を生成する。
【0045】
ここで、モノラル化手段11は、上り音声データおよび下り音声データのフレームごとに、処理する。具体的にはモノラル化手段11は、下り音声データのレベルが所定値以上であるフレームのビットに、分離ビットを設定するとともに、ダブルトークを検出したフレームのビットに、ダブルトークビットを設定する。またモノラル化手段11は、ダブルトークが検出されたフレームについて、このモノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、上り音声データと下り音声データとの差分から、モノラル化サブ音声データ62を生成する。
【0046】
内蔵記憶媒体104は、大容量の記憶媒体で、例えば、SDカードである。RAM105は、コントローラ103が処理する際の一時データを書き込んだり読み込んだりする記憶媒体である。ROM106は、例えばコントローラ103で実行されるプログラムが記憶される。コントローラ103は、ROM106に書き込まれたプログラムを読み出して処理を実行する。プログラムは、ROM106でなく、書換可能なメモリに書き込まれても良い。
【0047】
通信制御装置107は、通信ネットワーク5と通信するためのインタフェースである。通信制御装置107は、コントローラ103から録音データ60が入力されると、録音データ60を、通信ネットワーク5に送出する。録音データ60は、通信ネットワーク5を介して音声認識サーバ2に送信される。
【0048】
図5を参照して、モノラル化手段11によるモノラル化処理を説明する。
【0049】
モノラル化手段11は、CODEC102から入力された上り音声および下り音声それぞれのPCM信号について、複数のフレームに分割し、各フレームについてステップS101からステップS111の処理を繰り返す。本発明の実施の形態において、フレームの時間長は20msecであるので、モノラル化手段11は、各信号について20msecごと(160サンプルごと)の複数のフレームに分割する。ここで、上り音声データ51のPCM信号の処理対象のフレームを、上り音声フレームデータ(L)と称し、下り音声データ52のPCM信号の処理対象のフレームを、下り音声フレームデータ(R)と称する。
【0050】
まずステップS101においてモノラル化手段11は、処理対象のフレームの上り音声フレームデータ(L)と、下り音声フレームデータ(R)を取得する。さらにステップS102においてモノラル化手段11は、ステップS101で取得した上り音声フレームデータ(L)と、下り音声フレームデータ(R)それぞれのレベルを算出する。モノラル化手段11は例えば、各データの実効値(RMS)からレベルを算出する。
【0051】
ステップS103においてモノラル化手段11は、上り音声フレームデータ(L)と、下り音声フレームデータ(R)を合成して、モノラル化メイン音声フレームデータ(L+R)を生成する。
【0052】
ステップS104においてモノラル化手段11は、ステップS102で算出した下り音声フレームデータ(R)のレベルが、所定値以上であるか否かを判定する。所定値以上である場合、ステップS105においてモノラル化手段11は、この処理対象のフレームの分離ビットに”1”(真)を設定する。所定値以上でない場合、ステップS106においてモノラル化手段11は、この処理対象の分離ビットに”0”(偽)を設定する。
【0053】
ここで別実施例も開示する。この分離ビットは、処理対象のフレームが、上り音声か下り音声かを識別するフラグである。そこでモノラル化手段11は、ステップS104において、上り音声フレームデータ(L)と下り音声フレームデータ(R)のいずれのレベルが高いかを比較し、下り音声フレームデータ(R)のレベルが高い場合に分離ビットに”1”を設定し、上り音声フレームデータ(L)のレベルが高い場合に分離ビットに”0”を設定しても良い。
【0054】
ステップS107においてモノラル化手段11は、上り音声フレームデータ(L)のレベルと下り音声フレームデータ(R)のレベルとを比較して、ダブルトークであるか否かを判定する。モノラル化手段11は、例えば、両方のレベルがともに所定値より高い、または同じくらいのレベルなどの場合、ダブルトークが発生していると判断する。
【0055】
ダブルトークが発生している場合、ステップS108においてモノラル化手段11は、ダブルトークビットに”1”を設定する。さらにステップS109においてモノラル化手段11は、上り音声フレームデータ(L)と、下り音声フレームデータ(R)との差分から、処理対象のフレームについて、モノラル化サブ音声フレームデータ(L−R)を生成する。一方、ダブルトークが発生していない場合、ステップS110においてモノラル化手段11は、ダブルトークビットに”0”を設定し、処理対象のフレームについて、モノラル化サブ音声フレームデータを生成しない。
【0056】
ステップS111においてモノラル化手段11は、ステップS103で生成したモノラル化メイン音声フレームデータ(L+R)の末尾2ビットのデータを破棄し、ステップS105で設定した分離ビットのフラグと、ステップS108で設定したダブルトークビットのフラグを埋め込む。
【0057】
全てのフレームについて、ステップS101ないしステップS111の処理が終了すると、ステップS112においてモノラル化手段11は、モノラル化メイン音声データ61と、モノラル化サブ音声データ62とを生成する。モノラル化手段11は、ステップS111で生成した各フレームのモノラル化メイン音声フレームデータ(L+R)から、モノラル化メイン音声データ61を生成する。モノラル化手段11は、ステップS109で生成した、ダブルトークが発生した各フレームのモノラル化サブ音声フレームデータ(L−R)から、モノラル化サブ音声データ62を生成する。
【0058】
このようにモノラル化手段11は、ダブルトークが検出された場合のみ、モノラル化サブ音声フレームデータ(L−R)を生成するので、上り音声データ51と下り音声データ52とをそれぞれ分離して記録する場合に比べて、少ない容量の録音データ60を生成することができる。また、モノラル化メイン音声データ61として、上り音声データ51と下り音声データ52とを混合したデータが含まれているので、分離して視聴する必要がない場合、このモノラル化メイン音声データ61を視聴すれば良い。なお、各フレームに2ビットのノイズが挿入されるが、一般的な人間の視聴において問題がない範囲であると考えられる。
【0059】
図6を参照して、モノラル化手段11の機能ブロックの実装例を説明する。モノラル化手段11は、合成演算手段112、差分演算手段113、レベル検出手段114、μLaw変換手段115、比較手段116、ダブルトーク検出手段117、分離ビット設定手段118およびダブルトークビット設定手段119を備える。
【0060】
モノラル化手段11には、上り音声データ51および下り音声データ52がCODEC102によってそれぞれ変換されたPCM信号が入力される。上り音声データ51および下り音声データ52のそれぞれのPCM信号は、合成演算手段112、差分演算手段113、およびレベル検出手段114に入力される。
【0061】
合成演算手段112は、上り音声データ51のPCM信号(第1の音声データ)と下り音声データ52のPCM信号(第2の音声データ)とを合成して、モノラル化メイン音声データ61のPCM信号を生成する。差分演算手段113は、上り音声データ51のPCM信号(第1の音声データ)と下り音声データ52のPCM信号(第2の音声データ)との差分から、モノラル化サブ音声データ62のPCM信号を生成する。合成演算手段112および差分演算手段113によって生成されたPCM信号は、μLaw変換手段115に入力される。
【0062】
μLaw変換手段115は、合成演算手段112から入力されたPCM信号を圧縮して、μLaw変換して、モノラル化メイン音声データ61として出力する。また、μLaw変換手段115は、差分演算手段113から入力されたPCM信号をμLaw変換して、ダブルトークが検出された場合、モノラル化サブ音声データ62として出力する。μLaw変換手段115は、各PCM信号を、16ビットから8ビットに圧縮して出力する。
【0063】
レベル検出手段114は、CODEC102から上り音声データ51および下り音声データ52のそれぞれのPCM信号が入力されると、それぞれのPCM信号についてレベルを検出する。レベル検出手段114は、それぞれのPCM信号のレベルと、比較手段116およびダブルトーク検出手段117に入力する。
【0064】
比較手段116は、下り音声データ52のPCM信号のレベルが所定値以上であるか否かを比較して、分離ビット設定手段118に通知する。分離ビット設定手段118は、下り音声データ52のPCM信号のレベルが所定値以上であると通知されると、分離ビット設定手段118は、モノラル化メイン音声データ61の所定位置に、真を設定した分離ビットを設定する。具体的には分離ビット設定手段118は、モノラル化メイン音声データ61において、下り音声データのPCM信号のレベルが所定値以上であるフレームのビットに、真を設定した分離ビットを設定する。
【0065】
ダブルトーク検出手段117は、上り音声データ51のPCM信号のレベルと下り音声データ51のPCM信号のレベルに基づいて、ダブルトークを検出し、ダブルトークが検出されたか否かを、ダブルトークビット設定手段119に通知する。ダブルトークビット設定手段119は、ダブルトークが検出されたと通知されると、分離ビット設定手段118は、モノラル化メイン音声データの所定位置に、真を設定したダブルトークビットを設定する。具体的にはダブルトークビット設定手段119は、モノラル化メイン音声データにおいて、ダブルトークが検出されたフレームのビットに、真を設定したダブルトークビットを設定する。
【0066】
さらにダブルトーク検出手段117は、ダブルトークが検出された場合、差分演算手段113の出力信号であってμLaw変換された信号を、モノラル化サブ音声データ62として出力するよう制御する。
【0067】
図7を参照して、本発明の実施の形態に係るモノラル化手段11の合成演算手段112および差分演算手段113を詳述する。図5を参照して説明した通り、合成演算手段112および差分演算手段113は、上り音声フレームデータ(L)および下り音声フレームデータ(R)のフレーム単位で処理する。さらに詳述すると、合成演算手段112および差分演算手段113は、図7を参照するように、フレームの中のサンプル単位で信号を処理する。本発明の実施の形態において一つのフレームの時間長は20msecで、CODEC102は8kHzでサンプリングする。従って、一つのフレームには160サンプルが含まれる。1サンプルは、16ビットで構成される。
【0068】
図7は、合成演算手段112および差分演算手段113が、CODEC102から出力された上り音声データ51のPCM信号の所定のフレームの上り音声フレームデータと、下り音声データ52のPCM信号の所定のフレームの下り音声フレームデータとを処理する場合を説明する。上り音声フレームデータおよび下り音声フレームデータは、それぞれ、n番目のサンプルからn+159番目のサンプルを含む。
【0069】
合成演算手段112は、上り音声フレームデータ(L)のn番目のサンプルと、下り音声フレームデータ(R)のn番目のサンプルを加算して2で割る。同様に、合成演算手段112n+1は、上り音声フレームデータ(L)のn+1番目のサンプルと、下り音声フレームデータ(R)のn+1番目のサンプルを加算して2で割る。このような処理を160回繰り返すことにより、合成演算手段112は、1フレームのモノラル化メイン音声フレームデータ(L+R)を出力することができる。
【0070】
同様に、差分演算手段113は、上り音声フレームデータ(L)のn番目のサンプルと、下り音声フレームデータ(R)のn番目のサンプルの差分を2で割る。同様に、差分演算手段113n+1は、上り音声フレームデータ(L)のn+1番目のサンプルと、下り音声フレームデータ(R)のn+1番目のサンプルの差分を2で割る。このような処理を160回繰り返すことにより、差分演算手段113は、1フレームのモノラル化サブ音声フレームデータ(L−R)を出力することができる。
【0071】
図8を参照して、本発明の実施の形態に係るモノラル化手段11において、レベル検出手段114、μLaw変換手段115、比較手段116およびダブルトーク検出手段117の処理を説明する。
【0072】
μLaw変換手段115は、フレームの単位で、上り音声フレームデータ(L)と下り音声フレームデータ(R)について、μLaw変換する。μLaw変換手段は、上り音声フレームデータFL0と上り音声フレームデータFR0のそれぞれのサンプルを、16ビットから8ビットに圧縮する。これにより、μLaw変換手段115は、DMn[7..0]からDMn+159[7..0]を生成する。なお、本発明の実施の形態において、μLaw変換後のモノラル化メイン音声フレームデータ(L+R)の最下位2ビット、具体的には、DMn+159[1..0]のデータは破棄され、後に、分離ビット設定手段118およびダブルトークビット設定手段119によって、分離ビットおよびダブルトークビットが設定される。
【0073】
レベル検出手段114は、上り音声フレームデータ(L)と下り音声フレームデータ(R)を処理するため、2チャンネルの処理手段を備える。レベル検出手段114aは、上り音声フレームデータ(L)のレベルを検出して、比較手段116およびダブルトーク検出手段117に入力する。レベル検出手段114bは、下り音声フレームデータ(R)のレベルを検出して、比較手段116およびダブルトーク検出手段117に入力する。
【0074】
比較手段116は、上り音声フレームデータ(L)のレベルと下り音声フレームデータ(R)のレベルとを比較して、下り音声フレームデータのレベルが高い場合、分離ビット設定手段118に、分離ビットに”1”を設定させ、そうでない場合、分離ビットに”0”を設定させる。分離ビット設定手段118は、モノラル化メイン音声フレームデータ(L+R)の最下位ビット、具体的には、DMn+159[0]に、分離ビット”0”または”1”を設定する。
【0075】
ダブルトーク検出手段117は、上り音声フレームデータ(L)のレベルと下り音声フレームデータ(R)のレベルとを比較して、ともにレベルが高い場合、ダブルトークと判断して、ダブルトークビット設定手段119に、ダブルトークビットに”1”を設定させ、そうでない場合、ダブルトークビットに”0”を設定させる。分離ビット設定手段118は、モノラル化メイン音声フレームデータ(L+R)の最下位+1ビット、具体的には、DMn+159[1]に、ダブルトークビット”0”または”1”を設定する。ここで、このダブルトークビットが”0”の場合、具体的にはこのフレームではダブルトークが検出されなかった場合、このフレームについてモノラル化サブ音声フレームデータ(L−R)は出力されない。
【0076】
図9を参照して、モノラル化メイン音声フレームデータの構造を説明する。モノラル化メイン音声フレームデータ(L+R)は、160サンプルで構成される。各サンプルは8ビットで構成される。モノラル化メイン音声フレームデータ(L+R)の末尾2ビットには、ダブルトークビットおよび分離ビットが設定される。
【0077】
このようにモノラル化メイン音声フレームデータ(L+R)において、2ビットのノイズが発生する。モノラル化メイン音声フレームデータ(L+R)を連結して、モノラル化メイン音声データ61を生成する。本発明の実施の形態においてサンプリング周波数が8kHzであるので、モノラル化メイン音声データ61に、50Hzごとにノイズが含まれることになる。しかしこのノイズは、非常に微弱なノイズであり、モノラル化メイン音声フレームデータの視聴には影響を与えることはない。
【0078】
(音声認識サーバ)
図10を参照して、本発明の最良の実施の形態に係る音声認識サーバ2を説明する。図10に示すように音声認識サーバ2は、記憶装置221、中央処理制御装置222、通信制御装置231、入力装置232、スピーカー233などを備える一般的なコンピュータである。音声認識サーバ2は、所定の処理を実行する音声認識プログラムが、一般的なコンピュータにインストールされ実行されることにより実現される。ここで、記憶装置221は、ハードディスクなどである。通信制御装置231は、LANカードやLANポートである。入力装置232は、マウスやキーボードである。
【0079】
記憶装置221は、音声認識プログラムを記憶するとともに、モノラル化メイン音声データ、モノラル化サブ音声データ62、上り音声データ71、下り音声データ72および録音管理データ73を記憶する。モノラル化メイン音声データ61およびモノラル化サブ音声データ62は、録音データ60として通話録音装置1から受信するデータである。上り音声データ71および下り音声データ72は、モノラル化メイン音声データ61およびモノラル化サブ音声データ62から生成され、上り音声と下り音声とを分離したデータである。
【0080】
モノラル化メイン音声データ61、モノラル化サブ音声データ62、上り音声データ71および下り音声データ72は、後述する中央処理制御装置の各手段によって出力されるデータである。
【0081】
録音管理データ73は、モノラル化メイン音声データ61、上り音声データ71および下り音声データ72を検索するための、これらのデータの識別子と、属性情報などが対応づけられたデータである。属性情報とは、データ生成日時、オペレータ氏名、顧客名、対応種別、音声種別などである。ここで音声種別は、音声認識サーバ2において再生可能な音声データの種別である。音声種別は例えば、モノラル化メイン音声データ61を示すモノラル音声、上り音声データ71を示す上り音声、下り音声データ72を示す下り音声などである。
【0082】
中央処理制御装置222は、録音データ取得手段20、ステレオ化手段21および検索手段22を備える。録音データ取得手段20、ステレオ化手段21および検索手段は、音声認識プログラムがインストールされ実行されることによって、中央処理制御装置222に実装される。
【0083】
録音データ取得手段20は、通話録音装置1から、通信制御装置231を介して、録音データ60を取得し、記憶装置221に記憶する。この録音データ60は、モノラル化メイン音声データ61とモノラル化サブ音声データ62とを含む。モノラル化メイン音声データ61とモノラル化サブ音声データ62は、通話録音装置1で生成される。モノラル化メイン音声データ61には、分離ビットとダブルトークビットが設定される。
【0084】
モノラル化メイン音声データ61は、上り音声データ(第1の音声データ)と下り音声データ(第2の音声データ)を合成して生成され、下り音声データのレベルが所定値以上であることを示す分離ビットと、上り音声データと下り音声データのダブルトークを示すダブルトークビットとを含む。分離ビットは、下り音声データのレベルが所定値以上であるフレームのビットに設定され、ダブルトークビットは、ダブルトークを検出したフレームのビットに設定される。
【0085】
このモノラル化メイン音声データ61は、上り音声と下り音声が混合したデータであるので、このままでも聞くことは可能である。また、本発明の実施の形態に係るステレオ化手段21によって、モノラル化メイン音声データ61およびモノラル化サブ音声データ62に基づいて、上り音声と下り音声に分離して聞くこともできる。
【0086】
ステレオ化手段21は、モノラル化メイン音声データ61およびモノラル化サブ音声データ62から上り音声および下り音声を分離して、上り音声データ71および下り音声データ72を生成する。
【0087】
ステレオ化手段21は、モノラル化メイン音声データ61から分離ビットとダブルトークビットを取得する。ダブルトークビットが真の場合、ステレオ化手段21は、モノラル化メイン音声データ61とモノラル化サブ音声データ62から、上り音声データ71および下り音声データ72を生成して出力する。ダブルトークビットが偽でかつ分離ビットが真の場合、ステレオ化手段21は、モノラル化メイン音声データ61を下り音声データ72として出力し、分離ビットが偽の場合、モノラル化メイン音声データ61を上り音声データ71として出力する。
【0088】
ここで、ステレオ化手段21は、モノラル化メイン音声データ61およびモノラル化サブ音声データ62のフレームごとに、処理する。具体的にはステレオ化手段21は、ダブルトークビットが真のフレームについて、モノラル化メイン音声データ61とモノラル化サブ音声データ62から、このフレームの上り音声データ71および下り音声データ72を生成して出力する。ステレオ化手段21は、ダブルトークビットが偽でかつ分離ビットが真のフレームについて、モノラル化メイン音声データ61から、このフレームの下り音声データ72を出力する。ステレオ化手段21は、ダブルトークビットが偽でかつ分離ビットが偽のフレームについて、モノラル化メイン音声データ61から、このフレームの上り音声データ71を出力する。
【0089】
検索手段22は、録音管理データ73を参照して、所望の音声データを検索する。例えば入力装置232から入力された検索条件が入力されると、検索手段22は、入力された検索条件に合致する属性を録音管理データ73から検索し、さらに、その合致する属性を持つ音声データを、モノラル化メイン音声データ61、上り音声データ71および下り音声データ72から取得する。検索手段22はさらに、取得した音声データを再生し、スピーカー233から出力する。
【0090】
ここでユーザは、入力装置232を介して、「○月○日の、XXオペレータが△△さんへの通話内容」などと入力することができる。このような条件が入力されると、検索手段22は、オペレータの顧客への通話のみの音声データを検索し、スピーカー233から出力することができる。
【0091】
図11を参照して、ステレオ化手段21によるステレオ化処理を説明する。
【0092】
ステレオ化手段21は、モノラル化メイン音声データ61を複数のフレームに分割し、各フレームについて、ステップS201ないしステップS208の処理を繰り返す。本発明の実施の形態において、フレームの時間長は20msecであるので、ステレオ化手段21は、モノラル化メイン音声データ61を20msecごと(160サンプルごと)の複数のフレームに分割する。ここで、モノラル化メイン音声データ61の処理対象のフレームを、モノラル化メイン音声フレームデータ(L+R)と称し、このフレームに対応するモノラル化サブ音声データ62のフレームを、モノラル化サブ音声フレームデータ(L−R)と称する。
【0093】
まずステップS201においてステレオ化手段21は、処理対象のフレームの所定位置から、ダブルトークビットを取得する。このダブルトークビットは、図8などに示されるように、処理対象のフレームの最後から2番目のビットに設定されるので、ステレオ化手段21は、このビットの値を取得する。
【0094】
ステップS202においてステレオ化手段21は、処理対象のフレームでダブルトークが検出されたか否かを判定する。具体的にステレオ化手段21は、ステップS201で取得したダブルトークビットが”1”の場合、処理対象のフレームでダブルトークが検出されたと判定し、”0”の場合、処理対象のフレームでダブルトークが検出されなかったと判定する。
【0095】
ダブルトークが検出された場合、ステップS203においてステレオ化手段21は、モノラル化音声フレームデータ(L+R)とモノラル化サブ音声フレームデータ(L−R)とから、上り音声フレームデータ(L)と下り音声フレームデータ(R)とを生成する。
【0096】
一方ダブルトークが検出されなかった場合、ステップS204においてステレオ化手段21は、処理対象のフレームの所定位置から、分離ビットを取得する。この分離ビットは、図11などに示されるように、処理対象のフレームの最後のビットに設定されるので、ステレオ化手段21は、このビットの値を取得する。
【0097】
ステップS205においてステレオ化手段21は、処理対象のフレームから、下り音声データが検出されるか否かを判定する。具体的にステレオ化手段21は、ステップS204で取得した分離ビットが”1”の場合、処理対象のフレームで下り音声データが検出されたと判定し、”0”の場合、処理対象のフレームで下り音声データが検出されなかったと判定する。
【0098】
ステップS205において下り音声データが検出された場合、ステップS206においてステレオ化手段21は、モノラル化メイン音声フレームデータ(L+R)を、下り音声フレームデータ(R)として生成する。このとき、ステレオ化手段21は、上り音声フレームデータ(L)の出力をゼロとして、具体的には無音として扱う。
【0099】
一方ステップS205において下り音声データが検出されなかった場合、ステップS207においてステレオ化手段21は、モノラル化メイン音声フレームデータ(L+R)を、上り音声フレームデータ(L)として生成する。このとき、ステレオ化手段21は、下り音声フレームデータ(R)の出力をゼロとして、具体的には無音として扱う。
【0100】
全てのフレームについてステップS201ないしステップS207の処理が終了すると、ステレオ化手段21は、上り音声データ71および下り音声データ72を生成する。具体的にはステレオ化手段21は、ステップS203、ステップS206またはステップS207で生成された上り音声フレームデータ(L)を連結して上り音声データ71を生成するとともに、下り音声フレームデータ(R)を連結して下り音声データ72を生成する。ここで、ステレオ化手段21は、無音として扱ったフレームについては、無音であることを示すデータを連結する。ステレオ化手段21は、生成した上り音声データ71および下り音声データ72を記憶装置221に記憶する。
【0101】
図12を参照して、ステレオ化手段21の機能ブロックの実装例を説明する。ステレオ化手段21は、分離ビット取得手段211、ダブルトークビット取得手段212、第1のμLawPCM変換手段213、出力切替手段214、第2のμLawPCM変換手段215、上り音声生成手段216および下り音声生成手段217を備える。
【0102】
モノラル化メイン音声データ61は、分離ビット取得手段211およびダブルトークビット取得手段212に入力されるとともに、第1のμLawPCM変換手段213に入力される。
【0103】
分離ビット取得手段211は、モノラル化メイン音声データ61から分離ビットを取得する。ここで分離ビットは、下り音声データのレベルが所定値以上である、モノラル化メイン音声データのフレームのビットに設定される。分離ビット取得手段211は、取得した分離ビットを、第1のμLawPCM変換手段213に入力し、出力切替手段214の出力を制御する。
【0104】
ダブルトークビット取得手段212は、モノラル化メイン音声データ61からダブルトークビットを取得する。ここでダブルトークビットは、ダブルトークを検出した、モノラル化メイン音声データのフレームのビットに設定される。
【0105】
第1のμLawPCM変換手段213は、入力されたモノラル化メイン音声データ61および分離ビットを、8ビットから16ビットに伸張して出力する。出力された信号は、出力切替手段214に入力される。
【0106】
出力切替手段214は、ダブルトークビットが”0”(偽)でかつ分離ビットが”1”(真)の場合、モノラル化メイン音声データ61を下り音声データ72として出力する。具体的には出力切替手段214は、ダブルトークビットが”0”でかつ分離ビットが”1”のフレームについて、モノラル化メイン音声データ61から、このフレームの下り音声データ72を出力する。一方、分離ビットが”0”(偽)の場合、モノラル化メイン音声データ61を上り音声データ71として出力する。具体的には出力切替手段214は、ダブルトークビットが”0”でかつ分離ビットが”0”のフレームについて、モノラル化メイン音声データ61から、このフレームの上り音声データ71を出力する。
【0107】
出力切替手段214は、分離ビット取得手段211の制御に従って、モノラル化メイン音声データ61の伸張信号を、上り音声データ71として出力するか、下り音声データ72として出力するかを制御する。分離ビットが”0”の場合、出力切替手段214は、モノラル化メイン音声データ61の伸張信号を、上り音声データ71として出力し、”1”の場合、下り音声データ72として出力する。
【0108】
ここで、ダブルトークビットは、モノラル化メイン音声データ61およびモノラル化サブ音声データ62の第2のμLawPCM変換手段215への入力を制御する。ダブルトークビットが”1”の場合、モノラル化メイン音声データ61およびモノラル化サブ音声データ62が第2のμLawPCM変換手段215に入力される。一方ダブルトークビットが”0”の場合、第2のμLawPCM変換手段215には信号は入力されない。
【0109】
第2のμLawPCM変換手段215は、モノラル化メイン音声データ61およびモノラル化サブ音声データ62が入力されると、入力されたモノラル化メイン音声データ61およびモノラル化サブ音声データ62をそれぞれ、8ビットから16ビットに伸張して出力する。出力された信号は、上り音声生成手段216および下り音声生成手段217にそれぞれ入力される。
【0110】
上り音声生成手段216は、ダブルトークビットが”1”(真)の場合、モノラル化メイン音声データ61とモノラル化サブ音声データ62から、上り音声データ71を生成して出力する。上り音声生成手段216は、モノラル化メイン音声データ61(L+R))とモノラル化サブ音声データ62(L−R)とを加算して2で割ることにより、上り音声データ71を出力する。ここで上り音声生成手段216は、ダブルトークビットが真のフレームについて、モノラル化メイン音声データ61とモノラル化サブ音声データ62から、このフレームの上り音声データ71を生成して出力する。
【0111】
下り音声生成手段217は、ダブルトークビットが”1”(真)の場合、モノラル化メイン音声データ61とモノラル化サブ音声データ62から、下り音声データ72を生成して出力する。下り音声生成手段217は、モノラル化メイン音声データ61(L+R))とモノラル化サブ音声データ62(L−R)との差分を2で割ることにより、下り音声データ72を出力する。下り音声生成手段217は、ダブルトークビットが真のフレームについて、モノラル化メイン音声データ61とモノラル化サブ音声データ62から、このフレームの下り音声データ72を生成して出力する。
【0112】
図13を参照して、本発明の実施の形態に係る通話録音システム6の効果を説明する。図13においては、各通話について、上り下りの音声を分離してステレオで録音した場合の容量、上り下りの音声を分離せずモノラルで録音した場合の容量、本実施の形態に係る方法で録音した場合の容量を比較している。図13はさらに、モノラルで録音した場合の容量に対する本実施の形態に係る方法で録音した場合の容量の割合を記載している。
【0113】
図13に示す通り、本実施の形態に係る方法では、モノラル時の容量から数パーセント増加しているものの、ステレオ時の容量よりもかなり少ないことがわかる。また、上述した通り、本実施の形態に係る録音データ60は、通話における上り音声と下り音声を分離して再生可能である。従って本発明の実施の形態に係る通話録音システム6は、通話における上り音声と下り音声を分離して再生可能で、かつ、データ容量の小さい録音データ60を生成することができる。
【0114】
(その他の実施の形態)
上記のように、本発明の実施の形態によって記載したが、この開示の一部をなす論述および図面はこの発明を限定するものであると理解すべきではない。この開示から当業者には様々な代替実施の形態、実施例および運用技術が明らかとなる。
【0115】
例えば、本発明の最良の実施の形態に記載した音声認識サーバは、図1に示すように一つのハードウェア上に構成されても良いし、その機能や処理数に応じて複数のハードウェア上に構成されても良い。また、既存の情報処理システム上に実現されても良い。
【0116】
また、本発明の実施の形態においては、録音データを音声認識サーバで再生する場合について説明したが、録音データは、例えば通話録音装置などの他の装置で再生されても良い。
【0117】
本発明はここでは記載していない様々な実施の形態等を含むことは勿論である。従って、本発明の技術的範囲は上記の説明から妥当な特許請求の範囲に係る発明特定事項によってのみ定められるものである。
【符号の説明】
【0118】
1 通話録音装置
2 音声認識サーバ
3 電話機本体
4 受話器
5 通信ネットワーク
6 通話録音システム
11 モノラル化手段
20 録音データ取得手段
21 ステレオ化手段
22 検索手段
31、41 ハンドセットライン
51、71 上り音声データ
52、72 下り音声データ
60 録音データ
61 モノラル化メイン音声データ
62 モノラル化サブ音声データ
73 録音管理データ
101 絶縁トランス
102 CODEC
103 コントローラ
104 内蔵記憶媒体
105 RAM
106 ROM
107、231 通信制御装置
112 合成演算手段
113 差分演算手段
114 レベル検出手段
115 μLaw変換手段
116 比較手段
117 ダブルトーク検出手段
118 分離ビット設定手段
119 ダブルトークビット設定手段
211 分離ビット取得手段
212 ダブルトークビット取得手段
213、215 μLawPCM変換手段
214 出力切替手段
216 上り音声生成手段
217 下り音声生成手段
221 記憶装置
222 中央処理制御装置
232 入力装置
233 スピーカー
【特許請求の範囲】
【請求項1】
通話における第1の音声と第2の音声を分離して再生可能な録音データを生成する通話録音装置であって、
第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成し、
前記第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定し、
前記第1の音声データと前記第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、前記第1の音声データと前記第2の音声データとの差分から、モノラル化サブ音声データを生成するモノラル化手段
を備えることを特徴とする通話録音装置。
【請求項2】
前記モノラル化手段は、
前記第2の音声データのレベルが所定値以上であるフレームのビットに、前記分離ビットを設定するとともに、ダブルトークを検出したフレームのビットに、前記ダブルトークビットを設定し、
ダブルトークが検出されたフレームについて、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、前記第1の音声データと前記第2の音声データとの差分から、モノラル化サブ音声データを生成する
ことを特徴とする請求項1に記載の通話録音装置。
【請求項3】
当該通話録音装置は、電話機本体と第1のハンドセットラインで接続されるとともに、受話器と第2のハンドセットラインで接続され、
前記第1の音声データおよび前記第2の音声データは、前記第1および第2のハンドセットラインから取得したアナログ音声を、デジタル化したデータである
ことを特徴とする請求項1に記載の通話録音装置。
【請求項4】
通話における第1の音声と第2の音声を分離して再生可能な録音データを生成する通話録音装置に用いられる通話録音プログラムであって、
第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成し、
前記第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定し、
前記第1の音声データと前記第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、前記第1の音声データと前記第2の音声データとの差分から、モノラル化サブ音声データを生成するモノラル化手段
として、通話録音装置に内蔵されたコンピュータを機能させるための通話録音プログラム。
【請求項5】
前記モノラル化手段は、
前記第2の音声データのレベルが所定値以上であるフレームのビットに、前記分離ビットを設定するとともに、ダブルトークを検出したフレームのビットに、前記ダブルトークビットを設定し、
ダブルトークが検出されたフレームについて、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、前記第1の音声データと前記第2の音声データとの差分から、モノラル化サブ音声データを生成する
ことを特徴とする請求項4に記載の通話録音プログラム。
【請求項6】
第1の音声と第2の音声を分離して再生する音声認識サーバであって、
第1の音声データと第2の音声データを合成して生成され、第2の音声データのレベルが所定値以上であることを示す分離ビットと、前記第1の音声データと前記第2の音声データのダブルトークを示すダブルトークビットとを含むモノラル化メイン音声データと、
ダブルトークが検出された際、前記第1の音声データと前記第2の音声データとの差分から生成されたモノラル化サブ音声データと、が記憶された記憶装置と、
前記モノラル化メイン音声データから前記分離ビットと前記ダブルトークビットを取得し、
ダブルトークビットが真の場合、前記モノラル化メイン音声データと前記モノラル化サブ音声データから、前記第1の音声データおよび第2の音声データを生成して出力し、
ダブルトークビットが偽でかつ前記分離ビットが真の場合、前記モノラル化メイン音声データを第2の音声データとして出力し、
前記分離ビットが偽の場合、前記モノラル化メイン音声データを第1の音声データとして出力するステレオ化手段
を備えることを特徴とする音声認識サーバ。
【請求項7】
前記分離ビットは、前記第2の音声データのレベルが所定値以上であるフレームのビットに設定され、
前記ダブルトークビットは、ダブルトークを検出したフレームのビットに設定され、
前記ステレオ化手段は、
前記ダブルトークビットが真のフレームについて、前記モノラル化メイン音声データと前記モノラル化サブ音声データから、当該フレームの前記第1の音声データおよび第2の音声データを生成して出力し、
前記ダブルトークビットが偽でかつ前記分離ビットが真のフレームについて、前記モノラル化メイン音声データから、当該フレームの第2の音声データを出力し、
前記ダブルトークビットが偽でかつ前記分離ビットが偽のフレームについて、前記モノラル化メイン音声データから、当該フレームの第1の音声データを出力する
ことを特徴とする請求項6に記載の音声認識サーバ。
【請求項8】
第1の音声と第2の音声を分離して再生する音声認識サーバに用いる音声認識プログラムであって、
コンピュータを、
第1の音声データと第2の音声データを合成して生成され、第2の音声データのレベルが所定値以上であることを示す分離ビットと、前記第1の音声データと前記第2の音声データのダブルトークを示すダブルトークビットとを含むモノラル化メイン音声データと、
ダブルトークが検出された際、前記第1の音声データと前記第2の音声データとの差分から生成されたモノラル化サブ音声データとを取得して、記憶装置に記憶する録音データ取得手段と、
前記モノラル化メイン音声データから前記分離ビットを取得するとともに、前記モノラル化メイン音声データから前記ダブルトークビットを取得し、
ダブルトークビットが真の場合、前記モノラル化メイン音声データと前記モノラル化サブ音声データから、前記第1の音声データおよび第2の音声データを生成して出力し、
ダブルトークビットが偽でかつ前記分離ビットが真の場合、前記モノラル化メイン音声データを第2の音声データとして出力し、
前記分離ビットが偽の場合、前記モノラル化メイン音声データを第1の音声データとして出力するステレオ化手段
として機能させるための音声認識プログラム。
【請求項9】
前記分離ビットは、モノラル化メイン音声データにおいて、前記第2の音声データのレベルが所定値以上であるフレームのビットに設定され、
前記ダブルトークビットは、前記モノラル化メイン音声データにおいて、ダブルトークを検出したフレームのビットに設定され、
前記ステレオ化手段は、
前記ダブルトークビットが真のフレームについて、前記モノラル化メイン音声データと前記モノラル化サブ音声データから、当該フレームの前記第1の音声データおよび第2の音声データを生成して出力し、
前記ダブルトークビットが偽でかつ前記分離ビットが真のフレームについて、前記モノラル化メイン音声データから、当該フレームの第2の音声データを出力し、
前記ダブルトークビットが偽でかつ前記分離ビットが偽のフレームについて、前記モノラル化メイン音声データから、当該フレームの第1の音声データを出力する
ことを特徴とする請求項8に記載の音声認識プログラム。
【請求項10】
通話における第1の音声と第2の音声を分離して再生可能な録音データを生成し、再生する通話録音システムであって、
通話録音装置と、音声認識サーバと、を備え、
前記通話録音装置は、
第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成し、
前記第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定し、
前記第1の音声データと前記第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、前記第1の音声データと前記第2の音声データとの差分から、モノラル化サブ音声データを生成するモノラル化手段を備え、
前記音声認識サーバは、
第1の音声データと第2の音声データを合成して生成され、第2の音声データのレベルが所定値以上であることを示す分離ビットと、前記第1の音声データと前記第2の音声データのダブルトークを示すダブルトークビットとを含むモノラル化メイン音声データと、
ダブルトークが検出された際、前記第1の音声データと前記第2の音声データとの差分から生成されたモノラル化サブ音声データと、が記憶された記憶装置と、
前記モノラル化メイン音声データから前記分離ビットを取得するとともに、前記モノラル化メイン音声データから前記ダブルトークビットを取得し、
ダブルトークビットが真の場合、前記モノラル化メイン音声データと前記モノラル化サブ音声データから、前記第1の音声データおよび第2の音声データを生成して出力し、
ダブルトークビットが偽でかつ前記分離ビットが真の場合、前記モノラル化メイン音声データを第2の音声データとして出力し、
前記分離ビットが偽の場合、前記モノラル化メイン音声データを第1の音声データとして出力するステレオ化手段
を備えることを特徴とする通話録音システム。
【請求項11】
通話における第1の音声と第2の音声を分離して再生可能な録音データを生成する通話録音方法であって、
第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成するステップと、
前記第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定するステップと、
前記第1の音声データと前記第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、前記第1の音声データと前記第2の音声データとの差分から、モノラル化サブ音声データを生成するステップと、
を備えることを特徴とする通話録音方法。
【請求項12】
前記録音データを再生する際、
前記モノラル化メイン音声データから前記分離ビットを取得するとともに、前記モノラル化メイン音声データから前記ダブルトークビットを取得するステップと、
ダブルトークビットが真の場合、前記モノラル化メイン音声データと前記モノラル化サブ音声データから、前記第1の音声データおよび第2の音声データを生成して出力するステップと、
ダブルトークビットが偽でかつ前記分離ビットが真の場合、前記モノラル化メイン音声データを第2の音声データとして出力するステップと、
前記分離ビットが偽の場合、前記モノラル化メイン音声データを第1の音声データとして出力するステップと、
をさらに備えることを特徴とする請求項11に記載の通話録音方法。
【請求項1】
通話における第1の音声と第2の音声を分離して再生可能な録音データを生成する通話録音装置であって、
第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成し、
前記第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定し、
前記第1の音声データと前記第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、前記第1の音声データと前記第2の音声データとの差分から、モノラル化サブ音声データを生成するモノラル化手段
を備えることを特徴とする通話録音装置。
【請求項2】
前記モノラル化手段は、
前記第2の音声データのレベルが所定値以上であるフレームのビットに、前記分離ビットを設定するとともに、ダブルトークを検出したフレームのビットに、前記ダブルトークビットを設定し、
ダブルトークが検出されたフレームについて、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、前記第1の音声データと前記第2の音声データとの差分から、モノラル化サブ音声データを生成する
ことを特徴とする請求項1に記載の通話録音装置。
【請求項3】
当該通話録音装置は、電話機本体と第1のハンドセットラインで接続されるとともに、受話器と第2のハンドセットラインで接続され、
前記第1の音声データおよび前記第2の音声データは、前記第1および第2のハンドセットラインから取得したアナログ音声を、デジタル化したデータである
ことを特徴とする請求項1に記載の通話録音装置。
【請求項4】
通話における第1の音声と第2の音声を分離して再生可能な録音データを生成する通話録音装置に用いられる通話録音プログラムであって、
第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成し、
前記第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定し、
前記第1の音声データと前記第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、前記第1の音声データと前記第2の音声データとの差分から、モノラル化サブ音声データを生成するモノラル化手段
として、通話録音装置に内蔵されたコンピュータを機能させるための通話録音プログラム。
【請求項5】
前記モノラル化手段は、
前記第2の音声データのレベルが所定値以上であるフレームのビットに、前記分離ビットを設定するとともに、ダブルトークを検出したフレームのビットに、前記ダブルトークビットを設定し、
ダブルトークが検出されたフレームについて、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、前記第1の音声データと前記第2の音声データとの差分から、モノラル化サブ音声データを生成する
ことを特徴とする請求項4に記載の通話録音プログラム。
【請求項6】
第1の音声と第2の音声を分離して再生する音声認識サーバであって、
第1の音声データと第2の音声データを合成して生成され、第2の音声データのレベルが所定値以上であることを示す分離ビットと、前記第1の音声データと前記第2の音声データのダブルトークを示すダブルトークビットとを含むモノラル化メイン音声データと、
ダブルトークが検出された際、前記第1の音声データと前記第2の音声データとの差分から生成されたモノラル化サブ音声データと、が記憶された記憶装置と、
前記モノラル化メイン音声データから前記分離ビットと前記ダブルトークビットを取得し、
ダブルトークビットが真の場合、前記モノラル化メイン音声データと前記モノラル化サブ音声データから、前記第1の音声データおよび第2の音声データを生成して出力し、
ダブルトークビットが偽でかつ前記分離ビットが真の場合、前記モノラル化メイン音声データを第2の音声データとして出力し、
前記分離ビットが偽の場合、前記モノラル化メイン音声データを第1の音声データとして出力するステレオ化手段
を備えることを特徴とする音声認識サーバ。
【請求項7】
前記分離ビットは、前記第2の音声データのレベルが所定値以上であるフレームのビットに設定され、
前記ダブルトークビットは、ダブルトークを検出したフレームのビットに設定され、
前記ステレオ化手段は、
前記ダブルトークビットが真のフレームについて、前記モノラル化メイン音声データと前記モノラル化サブ音声データから、当該フレームの前記第1の音声データおよび第2の音声データを生成して出力し、
前記ダブルトークビットが偽でかつ前記分離ビットが真のフレームについて、前記モノラル化メイン音声データから、当該フレームの第2の音声データを出力し、
前記ダブルトークビットが偽でかつ前記分離ビットが偽のフレームについて、前記モノラル化メイン音声データから、当該フレームの第1の音声データを出力する
ことを特徴とする請求項6に記載の音声認識サーバ。
【請求項8】
第1の音声と第2の音声を分離して再生する音声認識サーバに用いる音声認識プログラムであって、
コンピュータを、
第1の音声データと第2の音声データを合成して生成され、第2の音声データのレベルが所定値以上であることを示す分離ビットと、前記第1の音声データと前記第2の音声データのダブルトークを示すダブルトークビットとを含むモノラル化メイン音声データと、
ダブルトークが検出された際、前記第1の音声データと前記第2の音声データとの差分から生成されたモノラル化サブ音声データとを取得して、記憶装置に記憶する録音データ取得手段と、
前記モノラル化メイン音声データから前記分離ビットを取得するとともに、前記モノラル化メイン音声データから前記ダブルトークビットを取得し、
ダブルトークビットが真の場合、前記モノラル化メイン音声データと前記モノラル化サブ音声データから、前記第1の音声データおよび第2の音声データを生成して出力し、
ダブルトークビットが偽でかつ前記分離ビットが真の場合、前記モノラル化メイン音声データを第2の音声データとして出力し、
前記分離ビットが偽の場合、前記モノラル化メイン音声データを第1の音声データとして出力するステレオ化手段
として機能させるための音声認識プログラム。
【請求項9】
前記分離ビットは、モノラル化メイン音声データにおいて、前記第2の音声データのレベルが所定値以上であるフレームのビットに設定され、
前記ダブルトークビットは、前記モノラル化メイン音声データにおいて、ダブルトークを検出したフレームのビットに設定され、
前記ステレオ化手段は、
前記ダブルトークビットが真のフレームについて、前記モノラル化メイン音声データと前記モノラル化サブ音声データから、当該フレームの前記第1の音声データおよび第2の音声データを生成して出力し、
前記ダブルトークビットが偽でかつ前記分離ビットが真のフレームについて、前記モノラル化メイン音声データから、当該フレームの第2の音声データを出力し、
前記ダブルトークビットが偽でかつ前記分離ビットが偽のフレームについて、前記モノラル化メイン音声データから、当該フレームの第1の音声データを出力する
ことを特徴とする請求項8に記載の音声認識プログラム。
【請求項10】
通話における第1の音声と第2の音声を分離して再生可能な録音データを生成し、再生する通話録音システムであって、
通話録音装置と、音声認識サーバと、を備え、
前記通話録音装置は、
第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成し、
前記第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定し、
前記第1の音声データと前記第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、前記第1の音声データと前記第2の音声データとの差分から、モノラル化サブ音声データを生成するモノラル化手段を備え、
前記音声認識サーバは、
第1の音声データと第2の音声データを合成して生成され、第2の音声データのレベルが所定値以上であることを示す分離ビットと、前記第1の音声データと前記第2の音声データのダブルトークを示すダブルトークビットとを含むモノラル化メイン音声データと、
ダブルトークが検出された際、前記第1の音声データと前記第2の音声データとの差分から生成されたモノラル化サブ音声データと、が記憶された記憶装置と、
前記モノラル化メイン音声データから前記分離ビットを取得するとともに、前記モノラル化メイン音声データから前記ダブルトークビットを取得し、
ダブルトークビットが真の場合、前記モノラル化メイン音声データと前記モノラル化サブ音声データから、前記第1の音声データおよび第2の音声データを生成して出力し、
ダブルトークビットが偽でかつ前記分離ビットが真の場合、前記モノラル化メイン音声データを第2の音声データとして出力し、
前記分離ビットが偽の場合、前記モノラル化メイン音声データを第1の音声データとして出力するステレオ化手段
を備えることを特徴とする通話録音システム。
【請求項11】
通話における第1の音声と第2の音声を分離して再生可能な録音データを生成する通話録音方法であって、
第1の音声データと第2の音声データとを合成して、モノラル化メイン音声データを生成するステップと、
前記第2の音声データのレベルが所定値以上である場合、当該モノラル化メイン音声データに、真を設定した分離ビットを設定するステップと、
前記第1の音声データと前記第2の音声データのダブルトークが検出された場合、当該モノラル化メイン音声データに、真を設定したダブルトークビットを設定するとともに、前記第1の音声データと前記第2の音声データとの差分から、モノラル化サブ音声データを生成するステップと、
を備えることを特徴とする通話録音方法。
【請求項12】
前記録音データを再生する際、
前記モノラル化メイン音声データから前記分離ビットを取得するとともに、前記モノラル化メイン音声データから前記ダブルトークビットを取得するステップと、
ダブルトークビットが真の場合、前記モノラル化メイン音声データと前記モノラル化サブ音声データから、前記第1の音声データおよび第2の音声データを生成して出力するステップと、
ダブルトークビットが偽でかつ前記分離ビットが真の場合、前記モノラル化メイン音声データを第2の音声データとして出力するステップと、
前記分離ビットが偽の場合、前記モノラル化メイン音声データを第1の音声データとして出力するステップと、
をさらに備えることを特徴とする請求項11に記載の通話録音方法。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【公開番号】特開2012−257175(P2012−257175A)
【公開日】平成24年12月27日(2012.12.27)
【国際特許分類】
【出願番号】特願2011−130307(P2011−130307)
【出願日】平成23年6月10日(2011.6.10)
【出願人】(593222595)株式会社ネイクス (18)
【Fターム(参考)】
【公開日】平成24年12月27日(2012.12.27)
【国際特許分類】
【出願日】平成23年6月10日(2011.6.10)
【出願人】(593222595)株式会社ネイクス (18)
【Fターム(参考)】
[ Back to top ]