
障害処理装置、それを用いた情報処理装置及び情報処理装置の障害処理方法
【課題】障害箇所の特定を最適化する可能な障害処理装置を提供する。
【解決手段】情報処理装置は、検出訂正部3と、障害ログ制御部5と、診断制御部4と、診断部6と、管理制御部8とを具備する。検出訂正部3は、メモリ1から読み出されたデータのエラーを検出・訂正し、エラー情報を出力する。障害ログ制御部5は、エラー情報を、複数の障害発生要因の各々毎に、障害ログ情報として管理する。診断制御部4は、障害ログ情報を参照して、複数の障害発生要因のいずれかでのエラーの発生回数が閾値に達したとき、障害通知を出力する。診断部6は、障害通知に応答して、発生回数が前記閾値に達するまでの障害ログ情報を障害ログ制御部5から取得する。
【解決手段】情報処理装置は、検出訂正部3と、障害ログ制御部5と、診断制御部4と、診断部6と、管理制御部8とを具備する。検出訂正部3は、メモリ1から読み出されたデータのエラーを検出・訂正し、エラー情報を出力する。障害ログ制御部5は、エラー情報を、複数の障害発生要因の各々毎に、障害ログ情報として管理する。診断制御部4は、障害ログ情報を参照して、複数の障害発生要因のいずれかでのエラーの発生回数が閾値に達したとき、障害通知を出力する。診断部6は、障害通知に応答して、発生回数が前記閾値に達するまでの障害ログ情報を障害ログ制御部5から取得する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、障害処理装置、それを用いた情報処理装置及び情報処理装置の障害処理方法に関する。
【背景技術】
【0002】
一般的に、高信頼性を求められるコンピュータシステムは、メモリ内のデータやデータ伝送路上のデータを保護するためにECC(Error Correction Code)を利用している。メモリに誤ったデータが記録された場合や伝送路上に誤ったデータが送出された場合、ECCを用いて、例えば以下のような障害処理方式を行っている。まず、データのエラーが訂正可能か否かを検出する。そして、訂正可能エラーの場合、エラーしたbitを訂正してコンピュータシステムを動作継続する。訂正不可能なエラーの場合、訂正不可能であることを検出すると共に、コンピュータシステムの動作継続が不可能であると判断して、システムダウンさせる。
【0003】
メモリ等で発生するエラーの要因には、ハードウェアにおける論理設計ミスや回路設計ミスにより発生するものや、半導体素子や配線の劣化等によるハードウェア破壊により発生するもの等がある。また、α線等が原因でメモリ上のbitエラーを一時的に引き起こすようなソフトエラーもある。更に、コンピュータシステムの電源環境や設置環境による温度異常等により引き起こされるエラーもある。
【0004】
このような様々な状況・要因の下で、障害が多数発生することが考えられる。一般的に、コンピュータシステムに障害が発生すると、診断装置へ障害報告が行われる。この障害報告を契機として、診断装置が障害箇所のログ情報採取のような割り込み処理を実行する。しかし、様々な要因の下、障害が多発すると、診断装置の処理能力以上の割り込み処理が頻発する場合が想定される。その場合、診断装置が割り込み処理をロストしてしまう問題が発生し、必要な障害処理が出来なくなってしまう問題が発生する。
【0005】
従来は、上述のような障害多発による割り込み処理を軽減させるために、訂正可能エラー検出以後、一定期間障害検出を抑止することやエラー発生回数を閾値で管理することによって、割り込み処理のロストを防止している。但し、この抑止期間中や閾値管理中に検出する訂正可能エラーは訂正される。
【0006】
関連する技術として、特開2010−26831号公報に障害自動通報装置が開示されている。障害自動通報装置は、情報処理システムの障害データ収集部と、障害発生頻度の閾値管理部と、自動通報制御部と、自動通報を発生させる日時、通報対象とする障害の発生期間、通報対象とする障害の種類を指定できる強制自動通報起動部と、を有している。指定期間内で発生した発生頻度の閾値管理を行っている障害が発生頻度の閾値に達しない状態であっても指定の日時に自動通報を強制的に行う。
【0007】
特開平09−128303号公報にメモリ管理装置が開示されている。メモリ管理装置は、メモリECCを搭載しページ化仮想記憶を採用するコンピュータシステムの装置である。メモリ管理装置は、メモリECCのコレクタブルエラーを履歴情報としてページ単位に保持する履歴情報保持手段と、ページ割り当て要求が発生したときに、割り当てページに対して書き込みが行なわれるか否か検知し、書き込みが行なわれるときには、履歴情報保持手段にECCコレクタブルエラーの履歴が保持されていないページを割り当て、書き込みが行なわれないときには、ECCコレクタブルエラーの履歴有無に関わらずに任意のページを割り当てるページ割り当て手段とを具備する。ECCエラーの再発を極力抑える。
【0008】
特開平06−59920号公報にデータ障害検出回路が開示されている。データ障害検出回路は、複数ビットからなるデータのエラービットの位置を示すビットエラー信号を受けてビットエラーが固定障害なのか間欠障害なのかを検出する。データ障害検出回路は、データの各ビットに対応する複数のカウンタを有し、ビットエラー信号が示すエラービットのエラー発生回数を計数してビット毎のエラー発生回数を示す信号を送出するエラー計数手段と、ビットエラー信号が示す正常なビットに対応するカウンタの計数値を0にするリセット信号を送出するリセット手段と、エラー発生回数を示す信号を受けて、エラー発生回数が所定回数に達したカウンタに対応するビットが固定障害であると判定する手段と、エラー発生回数を示す信号およびリセット信号を受け、リセットされるカウンタの計数値が0でないときに、このカウンタに対応するビットが間欠障害であると判定する手段とを備える。
【0009】
特開2008−27284号公報に障害処理システム、障害処理方法、障害処理装置およびプログラムが開示されている。障害処理システムは、情報通信システムと障害処理装置とを備える。障害処理装置は、情報通信システムの特定個所で訂正不可能エラーが発生する前に発生する訂正可能エラー発生回数を計数する手段と、計数値に基づいて閾値を設定する設定手段と、特定個所を修復した後に、特定個所での訂正可能エラー発生回数が閾値と一致したときに情報通信システムに対して通知を行う通知手段とを有する。
【0010】
特開平10−3408号公報に障害監視カウンタ制御方式が開示されている。障害監視カウンタ制御方式は、監視対象装置それぞれで発生した障害を計数する障害監視カウンタを制御する。障害監視カウンタ制御方式は、監視タイマによる所定監視時間を設けている。この所定監視時間を超過した際には前記障害監視カウンタおよび監視タイマをクリアし、かつ前記所定監視時間内に所定回数以内の障害を発生した監視対象装置を修復してシステムを稼働させたまま挿入稼働する活線挿抜処理を完了した際には前記障害監視カウンタのみをクリアする。
【先行技術文献】
【特許文献】
【0011】
【特許文献1】特開2010−26831号公報
【特許文献2】特開平09−128303号公報
【特許文献3】特開平06−59920号公報
【特許文献4】特開2008−27284号公報
【特許文献5】特開平10−3408号公報
【発明の概要】
【発明が解決しようとする課題】
【0012】
しかし、このような一定期間障害検出を抑止する方式やエラー発生回数の閾値で管理する方式の場合、障害報告を抑止する一定期間やエラー発生回数が閾値に到達までの期間には障害報告も抑止される。すなわち、障害ログ情報の採取のような処理が実施されないため、上記の障害報告抑止期間や閾値到達までの期間は、障害が発生していない期間として扱われる。そのため、この期間中に同様な障害が多発してしまうと、訂正不可能エラーに発展し、システムダウンに繋がる恐れがある。
【0013】
また、OS(Operating System)やソフトウェアには、メモリをページ単位に分け、このページ毎に発生するメモリの訂正可能エラー回数をカウントし、エラー回数が閾値に達すると、障害メモリページを論理的に切り離す機能を備えている。エラー回数のカウントアップ契機は、ハードウェアから報告される障害ログ情報である。しかし、上述のような一定期間障害検出を抑止する方式やエラー発生回数の閾値で管理する方式の場合、障害ログ情報が採取されないため、OSやソフトウェアの上記機能が発揮できず、その効果が得られていない問題が生じていた。
【0014】
本発明の目的は、情報処理装置における障害箇所の特定を最適化すると共に、障害の予兆監視を効率的に行うことが可能な障害処理装置、それを用いた情報処理装置及び情報処理装置の障害処理方法を提供することにある。
【課題を解決するための手段】
【0015】
本発明の障害処理装置は、検出訂正部と、障害ログ制御部と、診断制御部とを具備している。検出訂正部は、メモリから読み出されたデータのエラーを検出・訂正し、エラー情報を出力する。障害ログ制御部は、エラー情報を、複数の障害発生要因の各々毎に、障害ログ情報として管理する。診断制御部は、障害ログ情報を参照して、複数の障害発生要因のいずれかでのエラーの発生回数が閾値に達したとき、障害通知を出力する。診断制御部は、障害通知後の障害ログの要求に応答して発生回数が閾値に達するまでの障害ログ情報を出力する。
【0016】
本発明の情報処理装置は、障害処理装置と、診断部と、管理制御部とを具備している。障害処理装置は上記のとおりである。診断部は、障害通知に応答して、障害処理装置から、発生回数が閾値に達するまでの障害ログ情報を取得する。管理制御部は、障害処理装置が取得した障害ログ情報に基づいて、複数の障害発生要因のうちの閾値に対応する障害発生要因を取り除く。
【0017】
本発明の障害処理方法は、メモリから読み出されたデータのエラーを検出・訂正し、エラー情報を出力するステップと;エラー情報を、複数の障害発生要因の各々毎に、障害ログ情報として管理するステップと;障害ログ情報を参照して、複数の障害発生要因のいずれかでのエラーの発生回数が閾値に達したとき、障害通知を出力するステップと;障害通知に応答して、発生回数が閾値に達するまでの障害ログ情報を取得するステップと;取得された障害ログ情報に基づいて、複数の障害発生要因のうちの閾値に対応する障害発生要因を取り除くステップとを具備している。
【発明の効果】
【0018】
本発明により、情報処理装置における障害箇所の特定を最適化すると共に、障害の予兆監視を効率的に行うことが可能な障害処理装置、それを用いた情報処理装置及び情報処理装置の障害処理方法を提供することができる。
【図面の簡単な説明】
【0019】
【図1】図1は、本発明の実施の形態に係る障害処理装置を用いた情報処理装置のハードウェア構成を示すブロック図である。
【図2】図2は、図1に示すハードウェア構成に対して、コンピュータシステムを管理するソフトウェア(OS)の概略構成を示すブロック図である。
【図3】図3は、本発明の実施の形態に係る障害処理装置を用いた情報処理装置の動作を示すフローチャートである。
【発明を実施するための形態】
【0020】
以下、本発明の障害処理装置及び障害処理方法の実施の形態に関して、添付図面を参照して説明する。
【0021】
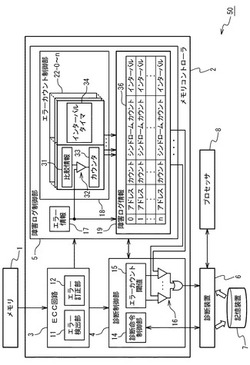
本発明の実施の形態に係る障害処理装置を用いた情報処理装置の構成について説明する。図1は、本発明の実施の形態に係る障害処理装置を用いた情報処理装置のハードウェア構成を示すブロック図である。情報処理装置50は、メモリ1と、メモリコントローラ2と、診断装置6と、プロセッサ8と、記憶装置7とを具備している。情報処理装置50は、コンピュータシステムに例示される。
【0022】
メモリ1は、RAM(Random Access Memory)に例示されるメモリ(主記憶装置)である。メモリ1に書き込まれるデータは、ECC(Error Correction Code)によりデータ破壊から保護されている。メモリ1からデータが読み出されると、ECC回路3(後述)によりECCチェックが行われる。
【0023】
メモリコントローラ2は、メモリ1の制御を行うメモリコントローラである。本図においては、メモリコントローラ2のうち、本実施の形態の内容に係る障害処理に関する構成のみを図示している。他の構成については、従来と同様の構成を用いることができる。メモリコントローラ2は、ECC回路3と、診断制御部4と、障害ログ制御部5とを備えている。
【0024】
ECC回路3は、メモリ1から読み出されたデータに対してECCチェックを行う回路である。エラー検出部11とエラー訂正部12とを含んで着る。エラー検出部11は、メモリ1から読み出されたデータにエラーが有るか否か、及び、そのエラーは訂正可能エラーか否かを検出する。メモリ1から読み出されたデータに訂正可能エラーがある場合、エラー訂正部12は、エラーbitを訂正する。その後、ECC回路3は、障害ログ制御部5に対して、ログ情報として、障害が検出されたアドレスやECCシンドローム(障害情報)を送出する。メモリ1から読み出されたデータに訂正不可能なエラーがある場合、ECC回路3は、エラー検出のみを行い、診断制御部4を介して診断装置6に障害報告を行う。なお、訂正不可能なエラー検出をした時の動作は、本実施の形態の本質ではなく、従来知られた方法を用いることができるため、特に言及しない。
【0025】
診断制御部4は、ECC回路3から報告される障害通知制御、障害ログ制御部5から報告される障害発生状況の閾値管理、及び、障害ログ情報の採取時に行われる診断命令の制御を行う。診断制御部4は、診断命令制御部14とエラーカウント閾値保持部15と比較部16とを含んでいる。
【0026】
診断命令制御部14は、診断装置6及びプロセッサ8からの診断命令の制御を行う。メモリコントローラ2への各種設定命令や、障害処理における障害ログ情報36(後述)の採取命令の制御を行う。プロセッサ8は、障害ログ情報保持部19の障害ログ情報36を、診断命令制御部14を介して採取する。
【0027】
エラーカウント閾値保持部15は、障害ログ情報保持部19(後述)に格納されている複数のカウント値の各々毎の閾値が設定されている。本実施の形態では、このエラーカウント閾値保持部15は、障害ログ情報36で管理する全エントリの閾値を一元管理するものとしており、エントリ毎に複数の閾値がユニークに設定されるようにしても良い。尚、この閾値設定は、ハードウェアにより初期値として値を設定(例:初期値3)する方法もしくは、ソフトウェア(OS)により設定する方法のどちらでも良い。
【0028】
比較部16は、障害ログ制御部5でカウントされる各エントリのカウント値と、エラーカウント閾値保持部15に格納された当該エントリの閾値とを比較する。そして、カウント値が閾値に達すると、診断装置6に対して障害通知を行う。
【0029】
障害ログ制御部5は、ECC回路3により障害検出(エラー検出)されたログ情報(障害情報を含む)の制御を行う。障害ログ制御部5は、エラー情報保持部17と、エラーカウント制御部18と、障害ログ情報保持部19とを含んでいる。
【0030】
エラー情報保持部17は、ECC回路3より受け取る障害情報(エラー情報)を保持するレジスタである。エラー情報保持部17は、その障害情報をエラーカウント制御部18及び障害ログ制御部19に出力する。障害情報は、障害が検出されたアドレスやECCシンドロームを含んでいる。
【0031】
エラーカウント制御部18は、障害情報に基づいて、障害が発生したアドレスに対して、エラー回数(障害回数)のカウント制御を行う。具体的には、エラーカウント制御部18は、メモリ1に設定される複数のアドレス空間の各々毎に、障害が発生した場合のエラー回数のカウント制御及び障害発生間隔の監視を行う。ただし、メモリ1に設定される複数のアドレス空間は、例えば、以下のように設定される。既述のように、OSやソフトウェアは、それらがメモリを複数のページに分け、ページ毎に発生するメモリの訂正可能エラー回数をカウントし、エラー回数が閾値に達したページが発生すると、当該ページを障害メモリページとして論理的に切り離す機能を有している。従って、複数のアドレス空間は、この機能を有効に働かせることができるように、当該複数のページに対応するように設定されることが好ましい。エラーカウント制御部18は、複数のエントリ部22を有している。
【0032】
複数のエントリ部22(−i、i=0〜n)は、複数のアドレス空間に対応して設けられている。各エントリ部22は、障害情報に基づいて、対応するアドレス空間において発生した、エラー回数と障害発生間隔を計測する。エントリ部22は、比較情報保持部31と、比較部32と、カウンタ33と、インターバルタイマ34とを含んでいる。
【0033】
比較情報保持部31は、第1レジスタと、第2レジスタとを有している。第1レジスタには、自身が属しているエントリ部22が障害情報を登録する対象のアドレス空間が設定されている。第1レジスタのアドレス空間はECCチェックの動作前に予め設定される。第2レジスタは、障害情報(エラー情報)に基づいて、障害が発生した時に、そのアドレス空間で発生したECCシンドロームが登録される。第2レジスタは初期的には何も登録されていない。ECCチェックが開始され、エラー情報を受け取って初めてECCシンドロームが登録されていく。
【0034】
このアドレス空間は、メモリコントローラ2の配下で管理されるメモリを、複数の空間(例示:OS等におけるページ単位)に分割したものであり、比較情報保持部31には、アドレス空間を示すメモリ空間の上限値及び下限値が設定される。例えば、メモリ空間を4KB単位に分割する場合、エントリ部22−0の比較情報保持部31の下限値には、32’h0000_0000、上限値には、32’h0000_0FFFの値が設定される。(本表記の32’h0000_0000及び32’h0000_0FFFは、32bitのアドレスを16進数で表したものである。)この設定は、コンピュータシステムのメモリ容量を管理するソフトウェア(OS)により、最適な値が計算されて行われる。なお、これらは設定の一例であり、本発明はこのような設定方法のみに限定されるものではない。
【0035】
比較部32は、エラー情報保持部17の障害情報(エラー情報)が示すアドレスと比較情報保持部31のアドレス空間とを比較する。エラー情報保持部17のアドレスが比較情報保持部31のアドレス空間に含まれる場合、一致を示す信号がカウンタ33に出力される。また、比較部32は、エラー情報保持部17の障害情報(エラー情報)が示すECCシンドロームと比較情報保持部31のECCシンドロームとを比較する。エラー情報保持部17のECCシンドロームが比較情報保持部31のECCシンドロームに含まれる場合、一致を示す信号がカウンタ33に出力される。含まれない場合、その含まれないECCシンドロームが比較情報保持部31に新たに登録される。
【0036】
カウンタ33は、障害発生アドレス用の第1カウンタとECCシンドローム用の第2カウンタとを含んでいる。第1カウンタは、エラー情報保持部17のアドレスが比較情報保持部31のアドレス空間に含まれていることを示す信号に応答して、カウンタをインクリメントしていく。第2カウンタは、エラー情報保持部17のECCシンドロームが比較情報保持部31のECCシンドロームに含まれることを示す信号に応答して、カウンタをインクリメントしていく。
【0037】
インターバルタイマ34は、障害の発生以後、比較情報保持部31に一致する障害の発生間隔を監視するタイマである。例えば、カウンタ33のカウントがインクリメントする間隔を計測し、障害発生間隔として出力する。
【0038】
本実施の形態の場合、上述のように、メモリ1に複数のアドレス空間を設定し、各アドレス空間をレンジ判定(下限値から上限値までのレンジ)して、そのアドレス空間毎にエントリ部22を持つようにしている。しかし、これは設定の一例であり、本発明はこの例に限定されるものではなく、エラーアドレス毎にエントリ部22を登録しても良い。また、それら複数のアドレス空間や、複数のエラーアドレスや、角アドレスでの複数のECCシンドロームは、それらが障害の元になっていることから、複数の障害発生要因とも見ることができる。
【0039】
障害ログ情報保持部19は、エラーカウント制御部18により管理されている障害発生回数(カウンタ33)、障害検出されたアドレスやECCシンドローム(比較情報保持部31)、障害発生間隔を示す情報(インターバルタイマ34)を障害ログ情報36として格納するレジスタ群である。エラーカウント制御部18と同様のエントリ数(複数のエントリ部22と同数)を有している。障害ログ情報36は、エントリ部22−iの番号(図中、“0、1、…n”)、障害が発生したアドレス(図中、“アドレス”)、そのアドレスが含まれるアドレス空間内で発生した障害発生回数(図中、“カウント”)、その障害に関するECCシンドローム及びその発生回数(図中、“シンドローム、カウント”)、及び、そのアドレス空間内での障害発生間隔((図中、“インターバル”)を、互いに関連付けて格納する。すなわち、障害ログ情報36の各エントリは、対応するエントリ部22−i(対応するメモリページ)に関する、障害発生アドレス、その障害発生回数、そのECCシンドローム及びその発生回数、及び、その障害発生間隔を含んでいる。エラー情報保持部17の障害情報のアドレスが、エラーカウント制御部18の比較情報保持部31のアドレス空間に含まれるエントリに対して、格納が行われる。
【0040】
この場合、一つのエントリにおいて、障害発生アドレスについては、下限値から上限値までの範囲に含まれる複数(種類)のアドレスが記載される可能性がある。ただし、その障害発生回数については、その複数(種類)のアドレスの各々での障害発生回数を総合した回数が記載される。更に、その複数(種類)のアドレスの各々に対して、複数(種類)のECCシンドロームが記載される可能性がある。その場合、その発生回数については、その複数(種類)のECCシンドロームの各々の発生回数が記載される。なお、障害発生間隔については、その複数(種類)のアドレスの各々毎に障害発生する間隔が記載される。
【0041】
なお、本実施の形態では、障害ログ情報36の中にアドレスを格納している。しかし、エラーカウント(障害発生回数の計数)を行うアドレス空間の設定はソフトウェア(OS)で行っており、ソフトウェア(OS)は設定段階でエントリ毎に指定するアドレス空間を把握している。そのため、アドレスの格納は行わなくても良い。
【0042】
診断装置6は、コンピュータシステムの診断制御を行う装置であり、メモリコントローラ2からの障害通知を受け、障害ログ情報36の採取、障害復旧処理のような制御を行う。
【0043】
プロセッサ8は、プロセッサ(例示:CPU)である。本プロセッサ8上で、ソフトウェアまたはOSによるプログラムが実行される。
【0044】
記憶装置7は、診断装置6により、採取された障害ログを格納する記憶装置である。ハードディスクや不揮発性メモリ等で構成されるのが一般的である。
【0045】
少なくとも上記のECC回路3と、診断制御部4と、障害ログ制御部5とを含む構成(それらの動作に関わるソフトウェアを含んでも良い)は、訂正可能なエラー(障害)を検出・訂正し、障害ログ情報を管理し、障害発生に関する閾値管理をしている障害処理装置を構成していると見ることもできる。
【0046】
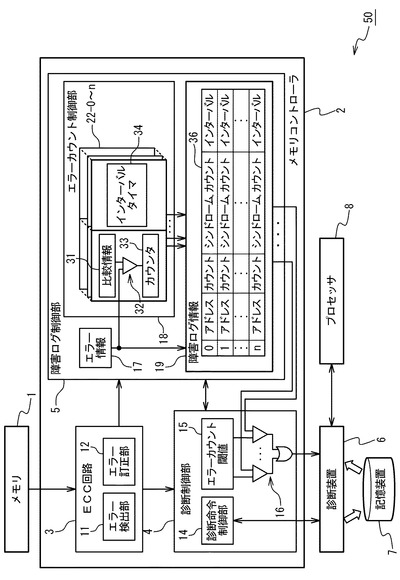
図2は、図1に示すハードウェア構成に対して、コンピュータシステムを管理するソフトウェア(OS)の概略構成を示すブロック図である。図2は、プロセッサ8上で動作するプログラムの一部を示している。
ソフトウェア(OS)60は、コンピュータシステムを管理するソフトウェアまたはOSである。メモリコントローラ2への各種設定をプロセッサ8に指示する。本実施の形態では、プロセッサ8からの命令は診断装置6を介して行うこととしている。
【0047】
また、ソフトウェア(OS)60は、コンピュータシステムが使用しているメモリをページ単位に分け、このページ毎に発生するエラー回数をカウントし、エラー回数が閾値に達すると、障害メモリページを論理的に切り離すという障害処理機能を備えている。診断装置6とプロセッサ8との間には通信機能が備えられている。ソフトウェア(OS)60は、診断装置6によって採取された障害ログ情報を、プロセッサ8を介して取得する。そして、自身が有する構成制御部61の構成制御機能及びメモリ管理部62のメモリ管理機能によって、上述のような障害メモリページの切り離しを行う。
【0048】
なお、診断装置6やプロセッサ8及びソフトウェア(OS)60に関わる詳細動作については、本発明の本質ではなく、従来から備えられている機能であるため、これ以上のことは特に言及しない。
【0049】
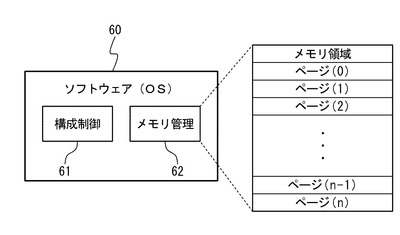
次に、本発明の実施の形態に係る障害処理装置を用いた情報処理装置の動作について説明する。図3は、本発明の実施の形態に係る障害処理装置を用いた情報処理装置の動作を示すフローチャートである。
【0050】
メモリ1に書き込まれるデータは、ECCによるデータ保護が行われている。メモリ1からデータが読み出される(ステップS1)と、ECC回路3はエラー検出部11でECCチェックを行う(ステップS2)。以下では、主に、メモリ1から読み出されたデータに、訂正可能エラーが発生していた場合について説明する。
【0051】
エラー検出部11がECCチェックにより訂正可能エラーが発生していることを検出した場合(ステップS2:CE(Correctable Error))、ECC回路3のエラー訂正部12はエラーしているbitのエラー訂正を行う(ステップS3)。この時、障害ログ制御部5に対して、エラー情報(障害情報)として、障害を検出したアドレスやECCシンドロームを送出する。エラーが検出されない場合(ステップS2:NoE(No Error))、障害に関する処理を行わずにデータ読み出しが継続される(ステップS1)。
【0052】
また、メモリ1から読み出したデータに訂正不可能なエラーがある場合(ステップS2:UE(Uncorrectable Error))は、エラー検出のみを行い、診断制御部4を介して診断装置6に障害報告が行われ(ステップS8)、訂正不可能なエラーがある場合に対応した処理が行われる(ステップS9)。なお、訂正不可能なエラー検出した場合でのステップS8、S9での動作については、本発明の本質ではなく、従来と同様の方法で対応することが可能であるため、ここでは特に言及しない。
【0053】
ECC回路3からエラー情報(障害情報)を受け取った障害ログ制御部5は、障害ログ情報の制御を開始する。エラー情報保持部17は、このエラー情報を格納する(ステップS4)。エラーカウント制御部18は、このエラー情報に基づいて、エラーカウント制御を行う(ステップS5)。障害ログ情報保持部19は、このエラー情報及びそれに関する情報をエラー情報保持部17及びエラーカウント制御部18から受け取り、障害ログ情報36を生成する(ステップS6)。
【0054】
ここで、エラーカウント制御部18では、障害が発生したアドレス空間毎に、エラー発生回数の制御を行う。上述のように、エラーカウント制御部18は、複数のアドレス空間の各々単位でエラー発生回数がカウント出来るように複数のエントリ部22−1〜nを持っている。各エントリ部22は、比較情報保持部31を持っている。比較情報保持部31には、各エントリ部22に対してエラー回数を管理するアドレス空間が設定される。この設定は、コンピュータシステムのメモリ容量を管理するソフトウェア(OS)60によって、最適な値が計算されて行われる。
【0055】
一例として、このエントリ部22に対してメモリ空間を4KB単位に分割する場合の設定方法を説明する。比較情報保持部31は、アドレス空間を指定するために、アドレスの上限値及び下限値が設定されるようになっている。エントリ部22−0(エントリ0)を先頭アドレスから4KBまでを設定する場合、下限値は32’h0000_0000、上限値は、32’h0000_0FFFの値が設定される。次の4KBをエントリ部22−1(エントリ1)に設定する場合、下限値は32’h0000_1000、上限値は、32’h0000_1FFFとなる。このようにして、それぞれのエントリ部22−i(i=1〜n)に対して設定が行われる。また、この比較情報保持部31には、ECC回路3より送出される障害発生したときのECCシンドロームの登録も行う。
【0056】
ここで、障害が発生したアドレスが、エントリ部22−0(エントリ0)の空間に一致する32’h0000_0000番地であった場合におけるステップS5、S6について、以下に説明する。
【0057】
エントリ部22−0では、比較部32が、エラー情報保持部17で保持しているアドレスの番地と、比較情報保持部31に設定されているアドレス空間とを比較する。そして、エラー情報保持部17のアドレスの番地が、比較情報保持部31のアドレス空間に含まれている場合、エントリ部22−0に該当するアドレスであると認識し、カウンタ33のエラー回数用のカウンタをインクリメントする。このカウンタ33のカウント値は、障害ログ情報保持部19に出力される(ステップS5)。エントリ部22−0のカウント値及びアドレスの番地は、障害ログ情報保持部19の障害ログ情報36のエントリ部22−0(エントリ0)のカウント領域及びアドレス領域に書き込まれる(ステップS6)。
【0058】
また、上記の動作と同様に、比較部32が、エラー情報保持部17で保持している障害が発生した時のECCシンドロームと、そのエントリ部22−0の比較情報保持部31に登録されているECCシンドロームとを比較する。そして、エラー情報保持部17のECCシンドロームと、比較情報保持部31のECCシンドロームとが一致しない場合(未だ登録されていないECCシンドロームの場合)、この時のECCシンドロームを比較情報保持部31に残し、登録する(ステップS5)。この時のECCシンドロームは、更に、障害ログ情報保持部19の障害ログ情報36のエントリ部22−0(エントリ0)のシンドローム、カウント領域に登録されるが、カウント値は0となる(ステップS6)。この場合(初めてのECCシンドロームの場合)は、間欠故障と判断される。
【0059】
一方、エラー情報保持部17のECCシンドロームと、比較情報保持部31のECCシンドロームとが一致する場合(既に登録されたECCシンドロームの場合)、カウンタ33のECCシンドローム用のカウンタをインクリメントする。このカウンタ33のカウント値は、障害ログ情報保持部19に出力される(ステップS5)。ECCシンドロームのカウント値は、障害ログ情報保持部19の障害ログ情報36のエントリ部22−0(エントリ0)のシンドローム、カウント領域に、当該ECCシンドロームと関連付けられて書き込まれる(ステップS6)。
【0060】
更に、インターバルタイマ34は、障害発生以後の発生間隔を監視するためタイマを起動する。1回目に発生したタイマ値は0として障害ログ情報保持部19の障害ログ情報36のエントリ部22−0のインターバル領域に登録される。それ以降の障害発生の時には、インターバルタイマ34で計測されたタイマ値又はインターバル値がエントリ部22−0のインターバル領域に登録される。
【0061】
この時点で、障害ログ情報保持部19の障害ログ情報36には、エントリ部22−0(図中、エントリ“0”の欄)のみに障害ログが書き込まれている。その具体的な内容は、例えば、次のようになる。図中の“アドレス”欄にはアドレス番地が書込まれる。図中の“カウント”欄には1(エラー発生回数)が書込まれる。また、図中の“シンドローム、カウント”欄には、未だ登録されていないECCシンドロームの場合にはECCシンドローム及び0(間欠障害)が、既に登録されたECCシンドロームの場合にはECCシンドローム及び1(ECCシンドロームの発生回)が、それぞれ書き込まれている。
【0062】
次に、診断制御部4において、エラー発生回数が閾値に達しているか否かをチェックする(ステップS7)。エラーカウント閾値保持部15には、エラー発生回数又はECCシンドローム回数の閾値が設定されている。本実施の形態では、一例として閾値が3である場合について説明する。
【0063】
なお、診断制御部4は常時、障害ログ情報保持部19の障害ログ情報36を監視している。すなわち、比較部16は、エラーカウント閾値保持部15で設定されている閾値と、障害ログ情報保持部19の障害ログ情報36のカウント値又はシンドローム、カウント値とが一致するか否かを監視している。上記の例では、障害が発生した回数が1回又はECCシンドローム回数が1回であるため、障害ログ情報保持部19のカウント値(1)又はシンドローム、カウント値(1)とエラーカウント閾値保持部15で設定されている閾値(3)とは一致しない。そのため、この時点では、診断装置6への障害通知は行われない(ステップS7:No)。
【0064】
以上のステップS1〜ステップS7(No)が、エラー発生回数又はECCシンドローム回数が閾値に達していない場合の動作である。そして、エラー発生回数又はECCシンドローム回数が閾値に到達する(ステップS7:Yes)まで、コンピュータシステムは継続動作を行う。エラー発生回数又はECCシンドローム回数が閾値に到達するまでの動作は、上述同様であるため、その説明を省略する。
【0065】
次に、エラー発生回数又はECCシンドローム回数が閾値(例示:3)に到達した場合(ステップS7:Yes)の動作について説明する。
障害ログ情報保持部19のエントリ部22−0(エントリ0)に設定されているアドレス空間内でのエラー発生回数又は障害が発生したECCシンドローム回数が3になると、比較部16は、エラーカウント閾値保持部15の閾値と、障害ログ情報保持部19のカウント値又はシンドローム、カウント値とが一致したことを検出する(ステップS7:Yes)。それにより、診断制御部4(の比較部16)は診断装置6に診断報告として障害通知を行う(ステップS8)。
【0066】
診断装置6は、障害通知を契機として、障害ログ情報36の採取を行う。診断装置6が、診断制御部4に対して、障害ログ情報36の採取命令を行うことで障害処理を開始する。診断制御部4は、診断装置6から本命令を受け取ると、メモリコントローラ2が保有する障害ログ情報保持部19から障害ログ情報36を読み出して、診断装置6に送信する。障害ログ情報36を採取した診断装置6は、採取した障害ログを記憶装置7に格納する。
【0067】
この記憶装置7に格納された障害ログ情報36は、診断装置6とプロセッサ8との間での通信により、障害状態としてソフトウェア(OS)60に受け渡される。ソフトウェア(OS)60は、この障害状態(障害ログ情報36)に基づいて、メモリ1の障害状態を解析し、ソフトウェア(OS)が管理しているエラー発生回数の閾値に達していれば、障害メモリページを論理的に切り離す障害処理を行う(ステップS9)。あるいは、この障害状態(障害ログ情報36)に示される閾値に到達するまでの経過を解析して、追加的な他の障害処理を行っても良い。
【0068】
本障害ログ情報36においては、障害発生回数は3回を示しており、ソフトウェア(OS)60は、閾値に達したことを認識し、障害メモリページを論理的に切り離す障害処理動作を開始する。切り離し対象となる障害メモリページは、障害ログのアドレス情報より、アドレス空間のうち32’h0000_0000〜32’h0000_0FFFであると判定され、ソフトウェア(OS)60は、本アドレス空間の切り離し処理を実施する。
【0069】
以上のようにして、本発明の実施の形態に係る障害処理装置を用いた情報処理装置の動作が実施される。
【0070】
本実施の形態においては、従来のように、ハードウェアによる障害発生回数の閾値管理が行われていないコンピュータシステムであっても、ソフトウェアやOSは、ハードウェアの障害状態を監視することが可能である。そして、ソフトウェアやOSが目的としている障害処理動作が害されることなく効率的に処理することが出来る。
【0071】
従来の場合には、障害発生の度に障害処理を実施していた。これまでに述べたように、このような方式の場合、割り込み処理の多発、また間欠障害の特定が非効率になり、ソフトウェア及びOSによる障害処理動作の負担が増大してしまう問題があった。
【0072】
しかし、本実施の形態においては、エラー発生回数に加えて、更に、同一ECCシンドロームの障害発生回数、又は、障害発生間隔を障害ログ情報として監視している。そのため、エラー頻度の特定や固定及び間欠障害の切り分けが可能となる。また、このような情報を採取出来ることから、上記のソフトウェア(OS)による障害メモリページを論理的に切り離す障害処理動作に加えて、障害部位の切り離し指摘割合の最適化も行うことが出来る。これは、従来の障害ログの場合、例えば、メモリ障害が発生した場合、障害部位の切り離し指摘を行う際、経路上の部位もしくはメモリとメモリコントローラを固定の割合(パーセンテージ)を固定値で指摘していた。しかし、本実施の形態においては、ECCシンドロームの回数や発生間隔を参照することが出来るため、障害状態によって、指摘割合を可変にすることが可能である。
【0073】
このような障害処理方式を実現させることにより、ソフトウェアやOSによる障害処理方式の最適化と、放置しておくとシステムダウンに繋がり兼ねない障害メモリページの切り離しを効率良く実施することで、システムダウンの発生確率を軽減させることが可能である。
【0074】
本発明は、従来の障害処理技術を踏襲し、かつ障害検出機能を強化する効果を得ることができる。
すなわち、従来技術である障害検出機能は、障害多発による割り込み処理の軽減を目的として閾値管理を実施している。その閾値管理期間中には障害ログ情報の採取のような処理が実施されず、障害が発生していない期間として扱われるため、この期間中に同様な障害が多発してしまうと、訂正不可能エラーに発展し、システムダウンに繋がる恐れがある。しかし、本発明では、この閾値管理期間中の障害ログ採取を可能とし、障害ログに応じて適切な障害処理を継続的に行っているので、この閾値管理期間の間に発生する恐れがあるシステムダウンの発生確率を軽減させることが可能である。
【0075】
更には、従来OSやソフトウェアによって行われていた障害発生回数の閾値管理機能を障害ログ制御部5等のようなメモリページに対応したハードウェアに持たせているため、ハードウェアとソフトウェアにより連動する障害処理機能において、OSやソフトウェアの目的とする障害監視の効果が得られ、また、固定及び間欠障害の切り分けや障害部位の切り離し指摘割合の最適化(可変)を行うことが可能である。
【0076】
本発明は上記各実施の形態に限定されず、本発明の技術思想の範囲内において、各実施の形態は適宜変形又は変更され得ることは明らかである。
【符号の説明】
【0077】
1 メモリ
2 メモリコントローラ
3 ECC回路
4 診断制御部
5 障害ログ制御部
6 診断装置
7 記憶装置
8 プロセッサ
11 エラー検出部
12 エラー訂正部
14 診断命令制御部
15 エラーカウント閾値保持部
16 比較部
17 エラー情報保持部
18 エラーカウント制御部
19 障害ログ情報保持部
22、22−1〜n エントリ部
31 比較情報保持部
32 比較部
33 カウンタ
34 インターバルタイマ
50 情報処理装置
60 ソフトウェア(OS)
61 構成制御部
62 メモリ管理部
【技術分野】
【0001】
本発明は、障害処理装置、それを用いた情報処理装置及び情報処理装置の障害処理方法に関する。
【背景技術】
【0002】
一般的に、高信頼性を求められるコンピュータシステムは、メモリ内のデータやデータ伝送路上のデータを保護するためにECC(Error Correction Code)を利用している。メモリに誤ったデータが記録された場合や伝送路上に誤ったデータが送出された場合、ECCを用いて、例えば以下のような障害処理方式を行っている。まず、データのエラーが訂正可能か否かを検出する。そして、訂正可能エラーの場合、エラーしたbitを訂正してコンピュータシステムを動作継続する。訂正不可能なエラーの場合、訂正不可能であることを検出すると共に、コンピュータシステムの動作継続が不可能であると判断して、システムダウンさせる。
【0003】
メモリ等で発生するエラーの要因には、ハードウェアにおける論理設計ミスや回路設計ミスにより発生するものや、半導体素子や配線の劣化等によるハードウェア破壊により発生するもの等がある。また、α線等が原因でメモリ上のbitエラーを一時的に引き起こすようなソフトエラーもある。更に、コンピュータシステムの電源環境や設置環境による温度異常等により引き起こされるエラーもある。
【0004】
このような様々な状況・要因の下で、障害が多数発生することが考えられる。一般的に、コンピュータシステムに障害が発生すると、診断装置へ障害報告が行われる。この障害報告を契機として、診断装置が障害箇所のログ情報採取のような割り込み処理を実行する。しかし、様々な要因の下、障害が多発すると、診断装置の処理能力以上の割り込み処理が頻発する場合が想定される。その場合、診断装置が割り込み処理をロストしてしまう問題が発生し、必要な障害処理が出来なくなってしまう問題が発生する。
【0005】
従来は、上述のような障害多発による割り込み処理を軽減させるために、訂正可能エラー検出以後、一定期間障害検出を抑止することやエラー発生回数を閾値で管理することによって、割り込み処理のロストを防止している。但し、この抑止期間中や閾値管理中に検出する訂正可能エラーは訂正される。
【0006】
関連する技術として、特開2010−26831号公報に障害自動通報装置が開示されている。障害自動通報装置は、情報処理システムの障害データ収集部と、障害発生頻度の閾値管理部と、自動通報制御部と、自動通報を発生させる日時、通報対象とする障害の発生期間、通報対象とする障害の種類を指定できる強制自動通報起動部と、を有している。指定期間内で発生した発生頻度の閾値管理を行っている障害が発生頻度の閾値に達しない状態であっても指定の日時に自動通報を強制的に行う。
【0007】
特開平09−128303号公報にメモリ管理装置が開示されている。メモリ管理装置は、メモリECCを搭載しページ化仮想記憶を採用するコンピュータシステムの装置である。メモリ管理装置は、メモリECCのコレクタブルエラーを履歴情報としてページ単位に保持する履歴情報保持手段と、ページ割り当て要求が発生したときに、割り当てページに対して書き込みが行なわれるか否か検知し、書き込みが行なわれるときには、履歴情報保持手段にECCコレクタブルエラーの履歴が保持されていないページを割り当て、書き込みが行なわれないときには、ECCコレクタブルエラーの履歴有無に関わらずに任意のページを割り当てるページ割り当て手段とを具備する。ECCエラーの再発を極力抑える。
【0008】
特開平06−59920号公報にデータ障害検出回路が開示されている。データ障害検出回路は、複数ビットからなるデータのエラービットの位置を示すビットエラー信号を受けてビットエラーが固定障害なのか間欠障害なのかを検出する。データ障害検出回路は、データの各ビットに対応する複数のカウンタを有し、ビットエラー信号が示すエラービットのエラー発生回数を計数してビット毎のエラー発生回数を示す信号を送出するエラー計数手段と、ビットエラー信号が示す正常なビットに対応するカウンタの計数値を0にするリセット信号を送出するリセット手段と、エラー発生回数を示す信号を受けて、エラー発生回数が所定回数に達したカウンタに対応するビットが固定障害であると判定する手段と、エラー発生回数を示す信号およびリセット信号を受け、リセットされるカウンタの計数値が0でないときに、このカウンタに対応するビットが間欠障害であると判定する手段とを備える。
【0009】
特開2008−27284号公報に障害処理システム、障害処理方法、障害処理装置およびプログラムが開示されている。障害処理システムは、情報通信システムと障害処理装置とを備える。障害処理装置は、情報通信システムの特定個所で訂正不可能エラーが発生する前に発生する訂正可能エラー発生回数を計数する手段と、計数値に基づいて閾値を設定する設定手段と、特定個所を修復した後に、特定個所での訂正可能エラー発生回数が閾値と一致したときに情報通信システムに対して通知を行う通知手段とを有する。
【0010】
特開平10−3408号公報に障害監視カウンタ制御方式が開示されている。障害監視カウンタ制御方式は、監視対象装置それぞれで発生した障害を計数する障害監視カウンタを制御する。障害監視カウンタ制御方式は、監視タイマによる所定監視時間を設けている。この所定監視時間を超過した際には前記障害監視カウンタおよび監視タイマをクリアし、かつ前記所定監視時間内に所定回数以内の障害を発生した監視対象装置を修復してシステムを稼働させたまま挿入稼働する活線挿抜処理を完了した際には前記障害監視カウンタのみをクリアする。
【先行技術文献】
【特許文献】
【0011】
【特許文献1】特開2010−26831号公報
【特許文献2】特開平09−128303号公報
【特許文献3】特開平06−59920号公報
【特許文献4】特開2008−27284号公報
【特許文献5】特開平10−3408号公報
【発明の概要】
【発明が解決しようとする課題】
【0012】
しかし、このような一定期間障害検出を抑止する方式やエラー発生回数の閾値で管理する方式の場合、障害報告を抑止する一定期間やエラー発生回数が閾値に到達までの期間には障害報告も抑止される。すなわち、障害ログ情報の採取のような処理が実施されないため、上記の障害報告抑止期間や閾値到達までの期間は、障害が発生していない期間として扱われる。そのため、この期間中に同様な障害が多発してしまうと、訂正不可能エラーに発展し、システムダウンに繋がる恐れがある。
【0013】
また、OS(Operating System)やソフトウェアには、メモリをページ単位に分け、このページ毎に発生するメモリの訂正可能エラー回数をカウントし、エラー回数が閾値に達すると、障害メモリページを論理的に切り離す機能を備えている。エラー回数のカウントアップ契機は、ハードウェアから報告される障害ログ情報である。しかし、上述のような一定期間障害検出を抑止する方式やエラー発生回数の閾値で管理する方式の場合、障害ログ情報が採取されないため、OSやソフトウェアの上記機能が発揮できず、その効果が得られていない問題が生じていた。
【0014】
本発明の目的は、情報処理装置における障害箇所の特定を最適化すると共に、障害の予兆監視を効率的に行うことが可能な障害処理装置、それを用いた情報処理装置及び情報処理装置の障害処理方法を提供することにある。
【課題を解決するための手段】
【0015】
本発明の障害処理装置は、検出訂正部と、障害ログ制御部と、診断制御部とを具備している。検出訂正部は、メモリから読み出されたデータのエラーを検出・訂正し、エラー情報を出力する。障害ログ制御部は、エラー情報を、複数の障害発生要因の各々毎に、障害ログ情報として管理する。診断制御部は、障害ログ情報を参照して、複数の障害発生要因のいずれかでのエラーの発生回数が閾値に達したとき、障害通知を出力する。診断制御部は、障害通知後の障害ログの要求に応答して発生回数が閾値に達するまでの障害ログ情報を出力する。
【0016】
本発明の情報処理装置は、障害処理装置と、診断部と、管理制御部とを具備している。障害処理装置は上記のとおりである。診断部は、障害通知に応答して、障害処理装置から、発生回数が閾値に達するまでの障害ログ情報を取得する。管理制御部は、障害処理装置が取得した障害ログ情報に基づいて、複数の障害発生要因のうちの閾値に対応する障害発生要因を取り除く。
【0017】
本発明の障害処理方法は、メモリから読み出されたデータのエラーを検出・訂正し、エラー情報を出力するステップと;エラー情報を、複数の障害発生要因の各々毎に、障害ログ情報として管理するステップと;障害ログ情報を参照して、複数の障害発生要因のいずれかでのエラーの発生回数が閾値に達したとき、障害通知を出力するステップと;障害通知に応答して、発生回数が閾値に達するまでの障害ログ情報を取得するステップと;取得された障害ログ情報に基づいて、複数の障害発生要因のうちの閾値に対応する障害発生要因を取り除くステップとを具備している。
【発明の効果】
【0018】
本発明により、情報処理装置における障害箇所の特定を最適化すると共に、障害の予兆監視を効率的に行うことが可能な障害処理装置、それを用いた情報処理装置及び情報処理装置の障害処理方法を提供することができる。
【図面の簡単な説明】
【0019】
【図1】図1は、本発明の実施の形態に係る障害処理装置を用いた情報処理装置のハードウェア構成を示すブロック図である。
【図2】図2は、図1に示すハードウェア構成に対して、コンピュータシステムを管理するソフトウェア(OS)の概略構成を示すブロック図である。
【図3】図3は、本発明の実施の形態に係る障害処理装置を用いた情報処理装置の動作を示すフローチャートである。
【発明を実施するための形態】
【0020】
以下、本発明の障害処理装置及び障害処理方法の実施の形態に関して、添付図面を参照して説明する。
【0021】
本発明の実施の形態に係る障害処理装置を用いた情報処理装置の構成について説明する。図1は、本発明の実施の形態に係る障害処理装置を用いた情報処理装置のハードウェア構成を示すブロック図である。情報処理装置50は、メモリ1と、メモリコントローラ2と、診断装置6と、プロセッサ8と、記憶装置7とを具備している。情報処理装置50は、コンピュータシステムに例示される。
【0022】
メモリ1は、RAM(Random Access Memory)に例示されるメモリ(主記憶装置)である。メモリ1に書き込まれるデータは、ECC(Error Correction Code)によりデータ破壊から保護されている。メモリ1からデータが読み出されると、ECC回路3(後述)によりECCチェックが行われる。
【0023】
メモリコントローラ2は、メモリ1の制御を行うメモリコントローラである。本図においては、メモリコントローラ2のうち、本実施の形態の内容に係る障害処理に関する構成のみを図示している。他の構成については、従来と同様の構成を用いることができる。メモリコントローラ2は、ECC回路3と、診断制御部4と、障害ログ制御部5とを備えている。
【0024】
ECC回路3は、メモリ1から読み出されたデータに対してECCチェックを行う回路である。エラー検出部11とエラー訂正部12とを含んで着る。エラー検出部11は、メモリ1から読み出されたデータにエラーが有るか否か、及び、そのエラーは訂正可能エラーか否かを検出する。メモリ1から読み出されたデータに訂正可能エラーがある場合、エラー訂正部12は、エラーbitを訂正する。その後、ECC回路3は、障害ログ制御部5に対して、ログ情報として、障害が検出されたアドレスやECCシンドローム(障害情報)を送出する。メモリ1から読み出されたデータに訂正不可能なエラーがある場合、ECC回路3は、エラー検出のみを行い、診断制御部4を介して診断装置6に障害報告を行う。なお、訂正不可能なエラー検出をした時の動作は、本実施の形態の本質ではなく、従来知られた方法を用いることができるため、特に言及しない。
【0025】
診断制御部4は、ECC回路3から報告される障害通知制御、障害ログ制御部5から報告される障害発生状況の閾値管理、及び、障害ログ情報の採取時に行われる診断命令の制御を行う。診断制御部4は、診断命令制御部14とエラーカウント閾値保持部15と比較部16とを含んでいる。
【0026】
診断命令制御部14は、診断装置6及びプロセッサ8からの診断命令の制御を行う。メモリコントローラ2への各種設定命令や、障害処理における障害ログ情報36(後述)の採取命令の制御を行う。プロセッサ8は、障害ログ情報保持部19の障害ログ情報36を、診断命令制御部14を介して採取する。
【0027】
エラーカウント閾値保持部15は、障害ログ情報保持部19(後述)に格納されている複数のカウント値の各々毎の閾値が設定されている。本実施の形態では、このエラーカウント閾値保持部15は、障害ログ情報36で管理する全エントリの閾値を一元管理するものとしており、エントリ毎に複数の閾値がユニークに設定されるようにしても良い。尚、この閾値設定は、ハードウェアにより初期値として値を設定(例:初期値3)する方法もしくは、ソフトウェア(OS)により設定する方法のどちらでも良い。
【0028】
比較部16は、障害ログ制御部5でカウントされる各エントリのカウント値と、エラーカウント閾値保持部15に格納された当該エントリの閾値とを比較する。そして、カウント値が閾値に達すると、診断装置6に対して障害通知を行う。
【0029】
障害ログ制御部5は、ECC回路3により障害検出(エラー検出)されたログ情報(障害情報を含む)の制御を行う。障害ログ制御部5は、エラー情報保持部17と、エラーカウント制御部18と、障害ログ情報保持部19とを含んでいる。
【0030】
エラー情報保持部17は、ECC回路3より受け取る障害情報(エラー情報)を保持するレジスタである。エラー情報保持部17は、その障害情報をエラーカウント制御部18及び障害ログ制御部19に出力する。障害情報は、障害が検出されたアドレスやECCシンドロームを含んでいる。
【0031】
エラーカウント制御部18は、障害情報に基づいて、障害が発生したアドレスに対して、エラー回数(障害回数)のカウント制御を行う。具体的には、エラーカウント制御部18は、メモリ1に設定される複数のアドレス空間の各々毎に、障害が発生した場合のエラー回数のカウント制御及び障害発生間隔の監視を行う。ただし、メモリ1に設定される複数のアドレス空間は、例えば、以下のように設定される。既述のように、OSやソフトウェアは、それらがメモリを複数のページに分け、ページ毎に発生するメモリの訂正可能エラー回数をカウントし、エラー回数が閾値に達したページが発生すると、当該ページを障害メモリページとして論理的に切り離す機能を有している。従って、複数のアドレス空間は、この機能を有効に働かせることができるように、当該複数のページに対応するように設定されることが好ましい。エラーカウント制御部18は、複数のエントリ部22を有している。
【0032】
複数のエントリ部22(−i、i=0〜n)は、複数のアドレス空間に対応して設けられている。各エントリ部22は、障害情報に基づいて、対応するアドレス空間において発生した、エラー回数と障害発生間隔を計測する。エントリ部22は、比較情報保持部31と、比較部32と、カウンタ33と、インターバルタイマ34とを含んでいる。
【0033】
比較情報保持部31は、第1レジスタと、第2レジスタとを有している。第1レジスタには、自身が属しているエントリ部22が障害情報を登録する対象のアドレス空間が設定されている。第1レジスタのアドレス空間はECCチェックの動作前に予め設定される。第2レジスタは、障害情報(エラー情報)に基づいて、障害が発生した時に、そのアドレス空間で発生したECCシンドロームが登録される。第2レジスタは初期的には何も登録されていない。ECCチェックが開始され、エラー情報を受け取って初めてECCシンドロームが登録されていく。
【0034】
このアドレス空間は、メモリコントローラ2の配下で管理されるメモリを、複数の空間(例示:OS等におけるページ単位)に分割したものであり、比較情報保持部31には、アドレス空間を示すメモリ空間の上限値及び下限値が設定される。例えば、メモリ空間を4KB単位に分割する場合、エントリ部22−0の比較情報保持部31の下限値には、32’h0000_0000、上限値には、32’h0000_0FFFの値が設定される。(本表記の32’h0000_0000及び32’h0000_0FFFは、32bitのアドレスを16進数で表したものである。)この設定は、コンピュータシステムのメモリ容量を管理するソフトウェア(OS)により、最適な値が計算されて行われる。なお、これらは設定の一例であり、本発明はこのような設定方法のみに限定されるものではない。
【0035】
比較部32は、エラー情報保持部17の障害情報(エラー情報)が示すアドレスと比較情報保持部31のアドレス空間とを比較する。エラー情報保持部17のアドレスが比較情報保持部31のアドレス空間に含まれる場合、一致を示す信号がカウンタ33に出力される。また、比較部32は、エラー情報保持部17の障害情報(エラー情報)が示すECCシンドロームと比較情報保持部31のECCシンドロームとを比較する。エラー情報保持部17のECCシンドロームが比較情報保持部31のECCシンドロームに含まれる場合、一致を示す信号がカウンタ33に出力される。含まれない場合、その含まれないECCシンドロームが比較情報保持部31に新たに登録される。
【0036】
カウンタ33は、障害発生アドレス用の第1カウンタとECCシンドローム用の第2カウンタとを含んでいる。第1カウンタは、エラー情報保持部17のアドレスが比較情報保持部31のアドレス空間に含まれていることを示す信号に応答して、カウンタをインクリメントしていく。第2カウンタは、エラー情報保持部17のECCシンドロームが比較情報保持部31のECCシンドロームに含まれることを示す信号に応答して、カウンタをインクリメントしていく。
【0037】
インターバルタイマ34は、障害の発生以後、比較情報保持部31に一致する障害の発生間隔を監視するタイマである。例えば、カウンタ33のカウントがインクリメントする間隔を計測し、障害発生間隔として出力する。
【0038】
本実施の形態の場合、上述のように、メモリ1に複数のアドレス空間を設定し、各アドレス空間をレンジ判定(下限値から上限値までのレンジ)して、そのアドレス空間毎にエントリ部22を持つようにしている。しかし、これは設定の一例であり、本発明はこの例に限定されるものではなく、エラーアドレス毎にエントリ部22を登録しても良い。また、それら複数のアドレス空間や、複数のエラーアドレスや、角アドレスでの複数のECCシンドロームは、それらが障害の元になっていることから、複数の障害発生要因とも見ることができる。
【0039】
障害ログ情報保持部19は、エラーカウント制御部18により管理されている障害発生回数(カウンタ33)、障害検出されたアドレスやECCシンドローム(比較情報保持部31)、障害発生間隔を示す情報(インターバルタイマ34)を障害ログ情報36として格納するレジスタ群である。エラーカウント制御部18と同様のエントリ数(複数のエントリ部22と同数)を有している。障害ログ情報36は、エントリ部22−iの番号(図中、“0、1、…n”)、障害が発生したアドレス(図中、“アドレス”)、そのアドレスが含まれるアドレス空間内で発生した障害発生回数(図中、“カウント”)、その障害に関するECCシンドローム及びその発生回数(図中、“シンドローム、カウント”)、及び、そのアドレス空間内での障害発生間隔((図中、“インターバル”)を、互いに関連付けて格納する。すなわち、障害ログ情報36の各エントリは、対応するエントリ部22−i(対応するメモリページ)に関する、障害発生アドレス、その障害発生回数、そのECCシンドローム及びその発生回数、及び、その障害発生間隔を含んでいる。エラー情報保持部17の障害情報のアドレスが、エラーカウント制御部18の比較情報保持部31のアドレス空間に含まれるエントリに対して、格納が行われる。
【0040】
この場合、一つのエントリにおいて、障害発生アドレスについては、下限値から上限値までの範囲に含まれる複数(種類)のアドレスが記載される可能性がある。ただし、その障害発生回数については、その複数(種類)のアドレスの各々での障害発生回数を総合した回数が記載される。更に、その複数(種類)のアドレスの各々に対して、複数(種類)のECCシンドロームが記載される可能性がある。その場合、その発生回数については、その複数(種類)のECCシンドロームの各々の発生回数が記載される。なお、障害発生間隔については、その複数(種類)のアドレスの各々毎に障害発生する間隔が記載される。
【0041】
なお、本実施の形態では、障害ログ情報36の中にアドレスを格納している。しかし、エラーカウント(障害発生回数の計数)を行うアドレス空間の設定はソフトウェア(OS)で行っており、ソフトウェア(OS)は設定段階でエントリ毎に指定するアドレス空間を把握している。そのため、アドレスの格納は行わなくても良い。
【0042】
診断装置6は、コンピュータシステムの診断制御を行う装置であり、メモリコントローラ2からの障害通知を受け、障害ログ情報36の採取、障害復旧処理のような制御を行う。
【0043】
プロセッサ8は、プロセッサ(例示:CPU)である。本プロセッサ8上で、ソフトウェアまたはOSによるプログラムが実行される。
【0044】
記憶装置7は、診断装置6により、採取された障害ログを格納する記憶装置である。ハードディスクや不揮発性メモリ等で構成されるのが一般的である。
【0045】
少なくとも上記のECC回路3と、診断制御部4と、障害ログ制御部5とを含む構成(それらの動作に関わるソフトウェアを含んでも良い)は、訂正可能なエラー(障害)を検出・訂正し、障害ログ情報を管理し、障害発生に関する閾値管理をしている障害処理装置を構成していると見ることもできる。
【0046】
図2は、図1に示すハードウェア構成に対して、コンピュータシステムを管理するソフトウェア(OS)の概略構成を示すブロック図である。図2は、プロセッサ8上で動作するプログラムの一部を示している。
ソフトウェア(OS)60は、コンピュータシステムを管理するソフトウェアまたはOSである。メモリコントローラ2への各種設定をプロセッサ8に指示する。本実施の形態では、プロセッサ8からの命令は診断装置6を介して行うこととしている。
【0047】
また、ソフトウェア(OS)60は、コンピュータシステムが使用しているメモリをページ単位に分け、このページ毎に発生するエラー回数をカウントし、エラー回数が閾値に達すると、障害メモリページを論理的に切り離すという障害処理機能を備えている。診断装置6とプロセッサ8との間には通信機能が備えられている。ソフトウェア(OS)60は、診断装置6によって採取された障害ログ情報を、プロセッサ8を介して取得する。そして、自身が有する構成制御部61の構成制御機能及びメモリ管理部62のメモリ管理機能によって、上述のような障害メモリページの切り離しを行う。
【0048】
なお、診断装置6やプロセッサ8及びソフトウェア(OS)60に関わる詳細動作については、本発明の本質ではなく、従来から備えられている機能であるため、これ以上のことは特に言及しない。
【0049】
次に、本発明の実施の形態に係る障害処理装置を用いた情報処理装置の動作について説明する。図3は、本発明の実施の形態に係る障害処理装置を用いた情報処理装置の動作を示すフローチャートである。
【0050】
メモリ1に書き込まれるデータは、ECCによるデータ保護が行われている。メモリ1からデータが読み出される(ステップS1)と、ECC回路3はエラー検出部11でECCチェックを行う(ステップS2)。以下では、主に、メモリ1から読み出されたデータに、訂正可能エラーが発生していた場合について説明する。
【0051】
エラー検出部11がECCチェックにより訂正可能エラーが発生していることを検出した場合(ステップS2:CE(Correctable Error))、ECC回路3のエラー訂正部12はエラーしているbitのエラー訂正を行う(ステップS3)。この時、障害ログ制御部5に対して、エラー情報(障害情報)として、障害を検出したアドレスやECCシンドロームを送出する。エラーが検出されない場合(ステップS2:NoE(No Error))、障害に関する処理を行わずにデータ読み出しが継続される(ステップS1)。
【0052】
また、メモリ1から読み出したデータに訂正不可能なエラーがある場合(ステップS2:UE(Uncorrectable Error))は、エラー検出のみを行い、診断制御部4を介して診断装置6に障害報告が行われ(ステップS8)、訂正不可能なエラーがある場合に対応した処理が行われる(ステップS9)。なお、訂正不可能なエラー検出した場合でのステップS8、S9での動作については、本発明の本質ではなく、従来と同様の方法で対応することが可能であるため、ここでは特に言及しない。
【0053】
ECC回路3からエラー情報(障害情報)を受け取った障害ログ制御部5は、障害ログ情報の制御を開始する。エラー情報保持部17は、このエラー情報を格納する(ステップS4)。エラーカウント制御部18は、このエラー情報に基づいて、エラーカウント制御を行う(ステップS5)。障害ログ情報保持部19は、このエラー情報及びそれに関する情報をエラー情報保持部17及びエラーカウント制御部18から受け取り、障害ログ情報36を生成する(ステップS6)。
【0054】
ここで、エラーカウント制御部18では、障害が発生したアドレス空間毎に、エラー発生回数の制御を行う。上述のように、エラーカウント制御部18は、複数のアドレス空間の各々単位でエラー発生回数がカウント出来るように複数のエントリ部22−1〜nを持っている。各エントリ部22は、比較情報保持部31を持っている。比較情報保持部31には、各エントリ部22に対してエラー回数を管理するアドレス空間が設定される。この設定は、コンピュータシステムのメモリ容量を管理するソフトウェア(OS)60によって、最適な値が計算されて行われる。
【0055】
一例として、このエントリ部22に対してメモリ空間を4KB単位に分割する場合の設定方法を説明する。比較情報保持部31は、アドレス空間を指定するために、アドレスの上限値及び下限値が設定されるようになっている。エントリ部22−0(エントリ0)を先頭アドレスから4KBまでを設定する場合、下限値は32’h0000_0000、上限値は、32’h0000_0FFFの値が設定される。次の4KBをエントリ部22−1(エントリ1)に設定する場合、下限値は32’h0000_1000、上限値は、32’h0000_1FFFとなる。このようにして、それぞれのエントリ部22−i(i=1〜n)に対して設定が行われる。また、この比較情報保持部31には、ECC回路3より送出される障害発生したときのECCシンドロームの登録も行う。
【0056】
ここで、障害が発生したアドレスが、エントリ部22−0(エントリ0)の空間に一致する32’h0000_0000番地であった場合におけるステップS5、S6について、以下に説明する。
【0057】
エントリ部22−0では、比較部32が、エラー情報保持部17で保持しているアドレスの番地と、比較情報保持部31に設定されているアドレス空間とを比較する。そして、エラー情報保持部17のアドレスの番地が、比較情報保持部31のアドレス空間に含まれている場合、エントリ部22−0に該当するアドレスであると認識し、カウンタ33のエラー回数用のカウンタをインクリメントする。このカウンタ33のカウント値は、障害ログ情報保持部19に出力される(ステップS5)。エントリ部22−0のカウント値及びアドレスの番地は、障害ログ情報保持部19の障害ログ情報36のエントリ部22−0(エントリ0)のカウント領域及びアドレス領域に書き込まれる(ステップS6)。
【0058】
また、上記の動作と同様に、比較部32が、エラー情報保持部17で保持している障害が発生した時のECCシンドロームと、そのエントリ部22−0の比較情報保持部31に登録されているECCシンドロームとを比較する。そして、エラー情報保持部17のECCシンドロームと、比較情報保持部31のECCシンドロームとが一致しない場合(未だ登録されていないECCシンドロームの場合)、この時のECCシンドロームを比較情報保持部31に残し、登録する(ステップS5)。この時のECCシンドロームは、更に、障害ログ情報保持部19の障害ログ情報36のエントリ部22−0(エントリ0)のシンドローム、カウント領域に登録されるが、カウント値は0となる(ステップS6)。この場合(初めてのECCシンドロームの場合)は、間欠故障と判断される。
【0059】
一方、エラー情報保持部17のECCシンドロームと、比較情報保持部31のECCシンドロームとが一致する場合(既に登録されたECCシンドロームの場合)、カウンタ33のECCシンドローム用のカウンタをインクリメントする。このカウンタ33のカウント値は、障害ログ情報保持部19に出力される(ステップS5)。ECCシンドロームのカウント値は、障害ログ情報保持部19の障害ログ情報36のエントリ部22−0(エントリ0)のシンドローム、カウント領域に、当該ECCシンドロームと関連付けられて書き込まれる(ステップS6)。
【0060】
更に、インターバルタイマ34は、障害発生以後の発生間隔を監視するためタイマを起動する。1回目に発生したタイマ値は0として障害ログ情報保持部19の障害ログ情報36のエントリ部22−0のインターバル領域に登録される。それ以降の障害発生の時には、インターバルタイマ34で計測されたタイマ値又はインターバル値がエントリ部22−0のインターバル領域に登録される。
【0061】
この時点で、障害ログ情報保持部19の障害ログ情報36には、エントリ部22−0(図中、エントリ“0”の欄)のみに障害ログが書き込まれている。その具体的な内容は、例えば、次のようになる。図中の“アドレス”欄にはアドレス番地が書込まれる。図中の“カウント”欄には1(エラー発生回数)が書込まれる。また、図中の“シンドローム、カウント”欄には、未だ登録されていないECCシンドロームの場合にはECCシンドローム及び0(間欠障害)が、既に登録されたECCシンドロームの場合にはECCシンドローム及び1(ECCシンドロームの発生回)が、それぞれ書き込まれている。
【0062】
次に、診断制御部4において、エラー発生回数が閾値に達しているか否かをチェックする(ステップS7)。エラーカウント閾値保持部15には、エラー発生回数又はECCシンドローム回数の閾値が設定されている。本実施の形態では、一例として閾値が3である場合について説明する。
【0063】
なお、診断制御部4は常時、障害ログ情報保持部19の障害ログ情報36を監視している。すなわち、比較部16は、エラーカウント閾値保持部15で設定されている閾値と、障害ログ情報保持部19の障害ログ情報36のカウント値又はシンドローム、カウント値とが一致するか否かを監視している。上記の例では、障害が発生した回数が1回又はECCシンドローム回数が1回であるため、障害ログ情報保持部19のカウント値(1)又はシンドローム、カウント値(1)とエラーカウント閾値保持部15で設定されている閾値(3)とは一致しない。そのため、この時点では、診断装置6への障害通知は行われない(ステップS7:No)。
【0064】
以上のステップS1〜ステップS7(No)が、エラー発生回数又はECCシンドローム回数が閾値に達していない場合の動作である。そして、エラー発生回数又はECCシンドローム回数が閾値に到達する(ステップS7:Yes)まで、コンピュータシステムは継続動作を行う。エラー発生回数又はECCシンドローム回数が閾値に到達するまでの動作は、上述同様であるため、その説明を省略する。
【0065】
次に、エラー発生回数又はECCシンドローム回数が閾値(例示:3)に到達した場合(ステップS7:Yes)の動作について説明する。
障害ログ情報保持部19のエントリ部22−0(エントリ0)に設定されているアドレス空間内でのエラー発生回数又は障害が発生したECCシンドローム回数が3になると、比較部16は、エラーカウント閾値保持部15の閾値と、障害ログ情報保持部19のカウント値又はシンドローム、カウント値とが一致したことを検出する(ステップS7:Yes)。それにより、診断制御部4(の比較部16)は診断装置6に診断報告として障害通知を行う(ステップS8)。
【0066】
診断装置6は、障害通知を契機として、障害ログ情報36の採取を行う。診断装置6が、診断制御部4に対して、障害ログ情報36の採取命令を行うことで障害処理を開始する。診断制御部4は、診断装置6から本命令を受け取ると、メモリコントローラ2が保有する障害ログ情報保持部19から障害ログ情報36を読み出して、診断装置6に送信する。障害ログ情報36を採取した診断装置6は、採取した障害ログを記憶装置7に格納する。
【0067】
この記憶装置7に格納された障害ログ情報36は、診断装置6とプロセッサ8との間での通信により、障害状態としてソフトウェア(OS)60に受け渡される。ソフトウェア(OS)60は、この障害状態(障害ログ情報36)に基づいて、メモリ1の障害状態を解析し、ソフトウェア(OS)が管理しているエラー発生回数の閾値に達していれば、障害メモリページを論理的に切り離す障害処理を行う(ステップS9)。あるいは、この障害状態(障害ログ情報36)に示される閾値に到達するまでの経過を解析して、追加的な他の障害処理を行っても良い。
【0068】
本障害ログ情報36においては、障害発生回数は3回を示しており、ソフトウェア(OS)60は、閾値に達したことを認識し、障害メモリページを論理的に切り離す障害処理動作を開始する。切り離し対象となる障害メモリページは、障害ログのアドレス情報より、アドレス空間のうち32’h0000_0000〜32’h0000_0FFFであると判定され、ソフトウェア(OS)60は、本アドレス空間の切り離し処理を実施する。
【0069】
以上のようにして、本発明の実施の形態に係る障害処理装置を用いた情報処理装置の動作が実施される。
【0070】
本実施の形態においては、従来のように、ハードウェアによる障害発生回数の閾値管理が行われていないコンピュータシステムであっても、ソフトウェアやOSは、ハードウェアの障害状態を監視することが可能である。そして、ソフトウェアやOSが目的としている障害処理動作が害されることなく効率的に処理することが出来る。
【0071】
従来の場合には、障害発生の度に障害処理を実施していた。これまでに述べたように、このような方式の場合、割り込み処理の多発、また間欠障害の特定が非効率になり、ソフトウェア及びOSによる障害処理動作の負担が増大してしまう問題があった。
【0072】
しかし、本実施の形態においては、エラー発生回数に加えて、更に、同一ECCシンドロームの障害発生回数、又は、障害発生間隔を障害ログ情報として監視している。そのため、エラー頻度の特定や固定及び間欠障害の切り分けが可能となる。また、このような情報を採取出来ることから、上記のソフトウェア(OS)による障害メモリページを論理的に切り離す障害処理動作に加えて、障害部位の切り離し指摘割合の最適化も行うことが出来る。これは、従来の障害ログの場合、例えば、メモリ障害が発生した場合、障害部位の切り離し指摘を行う際、経路上の部位もしくはメモリとメモリコントローラを固定の割合(パーセンテージ)を固定値で指摘していた。しかし、本実施の形態においては、ECCシンドロームの回数や発生間隔を参照することが出来るため、障害状態によって、指摘割合を可変にすることが可能である。
【0073】
このような障害処理方式を実現させることにより、ソフトウェアやOSによる障害処理方式の最適化と、放置しておくとシステムダウンに繋がり兼ねない障害メモリページの切り離しを効率良く実施することで、システムダウンの発生確率を軽減させることが可能である。
【0074】
本発明は、従来の障害処理技術を踏襲し、かつ障害検出機能を強化する効果を得ることができる。
すなわち、従来技術である障害検出機能は、障害多発による割り込み処理の軽減を目的として閾値管理を実施している。その閾値管理期間中には障害ログ情報の採取のような処理が実施されず、障害が発生していない期間として扱われるため、この期間中に同様な障害が多発してしまうと、訂正不可能エラーに発展し、システムダウンに繋がる恐れがある。しかし、本発明では、この閾値管理期間中の障害ログ採取を可能とし、障害ログに応じて適切な障害処理を継続的に行っているので、この閾値管理期間の間に発生する恐れがあるシステムダウンの発生確率を軽減させることが可能である。
【0075】
更には、従来OSやソフトウェアによって行われていた障害発生回数の閾値管理機能を障害ログ制御部5等のようなメモリページに対応したハードウェアに持たせているため、ハードウェアとソフトウェアにより連動する障害処理機能において、OSやソフトウェアの目的とする障害監視の効果が得られ、また、固定及び間欠障害の切り分けや障害部位の切り離し指摘割合の最適化(可変)を行うことが可能である。
【0076】
本発明は上記各実施の形態に限定されず、本発明の技術思想の範囲内において、各実施の形態は適宜変形又は変更され得ることは明らかである。
【符号の説明】
【0077】
1 メモリ
2 メモリコントローラ
3 ECC回路
4 診断制御部
5 障害ログ制御部
6 診断装置
7 記憶装置
8 プロセッサ
11 エラー検出部
12 エラー訂正部
14 診断命令制御部
15 エラーカウント閾値保持部
16 比較部
17 エラー情報保持部
18 エラーカウント制御部
19 障害ログ情報保持部
22、22−1〜n エントリ部
31 比較情報保持部
32 比較部
33 カウンタ
34 インターバルタイマ
50 情報処理装置
60 ソフトウェア(OS)
61 構成制御部
62 メモリ管理部
【特許請求の範囲】
【請求項1】
メモリから読み出されたデータのエラーを検出・訂正し、エラー情報を出力する検出訂正部と、
前記エラー情報を、複数の障害発生要因の各々毎に、障害ログ情報として管理する障害ログ制御部と、
前記障害ログ情報を参照して、前記複数の障害発生要因のいずれかでの前記エラーの発生回数が閾値に達したとき、障害通知を出力する診断制御部と
を具備し、
前記診断制御部は、前記障害通知後の障害ログの要求に応答して、前記発生回数が前記閾値に達するまでの前記障害ログ情報を出力する
障害処理装置。
【請求項2】
請求項1に記載の障害処理装置において、
前記エラー情報は、前記データのアドレスに関する情報を含み、
前記複数の障害発生要因は、前記メモリ内に設定された複数の領域であり、
前記障害ログ制御部は、前記エラー情報の前記アドレスに基づいて、前記複数の領域の各々毎に、前記エラー情報を前記障害ログ情報として管理する
障害処理装置。
【請求項3】
請求項2に記載の障害処理装置において、
前記エラー情報は、更に、前記データ内のエラー位置に関する情報を含み、
前記診断制御部は、前記障害ログ情報を参照して、前記複数の領域のいずれかでの前記発生回数又は前記エラー位置での前記発生回数が前記閾値に達したとき、前記障害通知を出力する
障害処理装置。
【請求項4】
請求項3に記載の障害処理装置において、
前記障害ログ制御部は、
前記エラー情報を記憶するエラー情報保持部と、
前記複数の領域の各々毎に設けられた複数のカウント制御部と、
前記障害ログ情報を保持する障害ログ保持部と
を備え、
前記複数のカウント制御部の各々は、前記複数の領域の各々のうちの自身に対応付けられた領域に含まれるアドレスを有する前記エラー情報を取得し、前記アドレスに関する第1カウント値、及び、前記エラー位置に関する第2カウント値をインクリメントし、
前記アドレス、前記第1カウント値、前記エラー位置及び前記第2カウント値を前記障害ログ情報として前記障害ログ保持部へ出力し、
前記診断制御部は、
前記第1カウント値用の第1閾値、及び、前記第2カウント値用の第2閾値の少なくとも一方を保持するカウント閾値保持部と、
前記第1カウント値と前記第1閾値との一致、又は、前記第2カウント値と前記第2閾値との一致の少なくとも一方に基づいて、前記障害通知を出力する比較部と
を備える
障害処理装置。
【請求項5】
請求項1乃至4のいずれか一項に記載の障害処理装置と、
前記障害通知に応答して、前記障害処理装置から、前記発生回数が前記閾値に達するまでの前記障害ログ情報を取得する診断部と、
前記障害処理装置から取得した障害ログ情報に基づいて、前記複数の障害発生要因のうちの前記閾値に対応する障害発生要因を取り除く管理制御部と
を具備する
情報処理装置。
【請求項6】
メモリから読み出されたデータのエラーを検出・訂正し、エラー情報を出力するステップと、
前記エラー情報を、複数の障害発生要因の各々毎に、障害ログ情報として管理するステップと、
前記障害ログ情報を参照して、前記複数の障害発生要因のいずれかでの前記エラーの発生回数が閾値に達したとき、障害通知を出力するステップと、
前記障害通知に応答して、前記発生回数が前記閾値に達するまでの前記障害ログ情報を取得するステップと、
前記取得された障害ログ情報に基づいて、前記複数の障害発生要因のうちの前記閾値に対応する障害発生要因を取り除くステップと
を具備する
障害処理方法。
【請求項7】
請求項6に記載の障害処理方法において、
前記エラー情報は、前記データのアドレスに関する情報を含み、
前記複数の障害発生要因は、前記メモリ内に設定された複数の領域であり、
前記障害ログ情報として管理するステップは、
前記エラー情報の前記アドレスに基づいて、前記複数の領域の各々毎に、前記エラー情報を前記障害ログ情報として管理するステップを備える
障害処理方法。
【請求項8】
請求項7に記載の障害処理方法において、
前記エラー情報は、更に、前記データ内のエラー位置に関する情報を含み、
前記障害通知を出力するステップは、
前記障害ログ情報を参照して、前記複数の領域のいずれかでの前記発生回数又は前記エラー位置での前記発生回数が前記閾値に達したとき、前記障害通知を出力するステップを備える
障害処理方法。
【請求項9】
請求項8に記載の障害処理方法において、
前記障害ログ情報を管理するステップは、
前記複数の領域の各々毎に、自身に対応付けられた領域に含まれるアドレスを有する前記エラー情報を取得し、前記アドレスに関する第1カウント値、及び、前記エラー位置に関する第2カウント値をインクリメントするステップと、
前記アドレス、前記第1カウント値、前記エラー位置及び前記第2カウント値を前記障害ログ情報として格納するステップと
を備え、
前記障害通知を出力するステップは、
前記第1カウント値用の第1閾値、及び、前記第2カウント値用の第2閾値の少なくとも一方を保持するステップと、
前記第1カウント値と前記第1閾値との一致、又は、前記第2カウント値と前記第2閾値との一致の少なくとも一方に基づいて、前記障害通知を出力するステップと
を備える
障害処理方法。
【請求項1】
メモリから読み出されたデータのエラーを検出・訂正し、エラー情報を出力する検出訂正部と、
前記エラー情報を、複数の障害発生要因の各々毎に、障害ログ情報として管理する障害ログ制御部と、
前記障害ログ情報を参照して、前記複数の障害発生要因のいずれかでの前記エラーの発生回数が閾値に達したとき、障害通知を出力する診断制御部と
を具備し、
前記診断制御部は、前記障害通知後の障害ログの要求に応答して、前記発生回数が前記閾値に達するまでの前記障害ログ情報を出力する
障害処理装置。
【請求項2】
請求項1に記載の障害処理装置において、
前記エラー情報は、前記データのアドレスに関する情報を含み、
前記複数の障害発生要因は、前記メモリ内に設定された複数の領域であり、
前記障害ログ制御部は、前記エラー情報の前記アドレスに基づいて、前記複数の領域の各々毎に、前記エラー情報を前記障害ログ情報として管理する
障害処理装置。
【請求項3】
請求項2に記載の障害処理装置において、
前記エラー情報は、更に、前記データ内のエラー位置に関する情報を含み、
前記診断制御部は、前記障害ログ情報を参照して、前記複数の領域のいずれかでの前記発生回数又は前記エラー位置での前記発生回数が前記閾値に達したとき、前記障害通知を出力する
障害処理装置。
【請求項4】
請求項3に記載の障害処理装置において、
前記障害ログ制御部は、
前記エラー情報を記憶するエラー情報保持部と、
前記複数の領域の各々毎に設けられた複数のカウント制御部と、
前記障害ログ情報を保持する障害ログ保持部と
を備え、
前記複数のカウント制御部の各々は、前記複数の領域の各々のうちの自身に対応付けられた領域に含まれるアドレスを有する前記エラー情報を取得し、前記アドレスに関する第1カウント値、及び、前記エラー位置に関する第2カウント値をインクリメントし、
前記アドレス、前記第1カウント値、前記エラー位置及び前記第2カウント値を前記障害ログ情報として前記障害ログ保持部へ出力し、
前記診断制御部は、
前記第1カウント値用の第1閾値、及び、前記第2カウント値用の第2閾値の少なくとも一方を保持するカウント閾値保持部と、
前記第1カウント値と前記第1閾値との一致、又は、前記第2カウント値と前記第2閾値との一致の少なくとも一方に基づいて、前記障害通知を出力する比較部と
を備える
障害処理装置。
【請求項5】
請求項1乃至4のいずれか一項に記載の障害処理装置と、
前記障害通知に応答して、前記障害処理装置から、前記発生回数が前記閾値に達するまでの前記障害ログ情報を取得する診断部と、
前記障害処理装置から取得した障害ログ情報に基づいて、前記複数の障害発生要因のうちの前記閾値に対応する障害発生要因を取り除く管理制御部と
を具備する
情報処理装置。
【請求項6】
メモリから読み出されたデータのエラーを検出・訂正し、エラー情報を出力するステップと、
前記エラー情報を、複数の障害発生要因の各々毎に、障害ログ情報として管理するステップと、
前記障害ログ情報を参照して、前記複数の障害発生要因のいずれかでの前記エラーの発生回数が閾値に達したとき、障害通知を出力するステップと、
前記障害通知に応答して、前記発生回数が前記閾値に達するまでの前記障害ログ情報を取得するステップと、
前記取得された障害ログ情報に基づいて、前記複数の障害発生要因のうちの前記閾値に対応する障害発生要因を取り除くステップと
を具備する
障害処理方法。
【請求項7】
請求項6に記載の障害処理方法において、
前記エラー情報は、前記データのアドレスに関する情報を含み、
前記複数の障害発生要因は、前記メモリ内に設定された複数の領域であり、
前記障害ログ情報として管理するステップは、
前記エラー情報の前記アドレスに基づいて、前記複数の領域の各々毎に、前記エラー情報を前記障害ログ情報として管理するステップを備える
障害処理方法。
【請求項8】
請求項7に記載の障害処理方法において、
前記エラー情報は、更に、前記データ内のエラー位置に関する情報を含み、
前記障害通知を出力するステップは、
前記障害ログ情報を参照して、前記複数の領域のいずれかでの前記発生回数又は前記エラー位置での前記発生回数が前記閾値に達したとき、前記障害通知を出力するステップを備える
障害処理方法。
【請求項9】
請求項8に記載の障害処理方法において、
前記障害ログ情報を管理するステップは、
前記複数の領域の各々毎に、自身に対応付けられた領域に含まれるアドレスを有する前記エラー情報を取得し、前記アドレスに関する第1カウント値、及び、前記エラー位置に関する第2カウント値をインクリメントするステップと、
前記アドレス、前記第1カウント値、前記エラー位置及び前記第2カウント値を前記障害ログ情報として格納するステップと
を備え、
前記障害通知を出力するステップは、
前記第1カウント値用の第1閾値、及び、前記第2カウント値用の第2閾値の少なくとも一方を保持するステップと、
前記第1カウント値と前記第1閾値との一致、又は、前記第2カウント値と前記第2閾値との一致の少なくとも一方に基づいて、前記障害通知を出力するステップと
を備える
障害処理方法。
【図1】


【図2】
【図3】
【図2】
【図3】
【公開番号】特開2012−108726(P2012−108726A)
【公開日】平成24年6月7日(2012.6.7)
【国際特許分類】
【出願番号】特願2010−256954(P2010−256954)
【出願日】平成22年11月17日(2010.11.17)
【出願人】(000168285)エヌイーシーコンピュータテクノ株式会社 (572)
【Fターム(参考)】
【公開日】平成24年6月7日(2012.6.7)
【国際特許分類】
【出願日】平成22年11月17日(2010.11.17)
【出願人】(000168285)エヌイーシーコンピュータテクノ株式会社 (572)
【Fターム(参考)】
[ Back to top ]