
集合認識システム、集合認識方法、符号化装置、復号化装置およびプログラム
【課題】識別子の集合が適正であるかを確認し、集合に不足が生じた場合には、欠落した識別子の総数、あるいは、識別子の番号を推定可能とする。
【解決手段】符号化装置1は、識別子の集合を、相互に重なり合う複数の部分集合に分割し、それぞれの部分集合に属する識別子を用いて交換可能な方法で算出した付加符号語を、部分集合に属する識別子に対応する識別媒体に書き込む。復号化装置2は、識別子、及び該識別子から算出される付加符号語を読み取り、同一の付加符号語を保持する識別子の集合にグループ分けし、グループに属する全ての識別子の値を用いて、付加符号語を生成したときと同じ演算によって評価符号語を算出し、付加符号語と評価符号語とが同一である場合には、識別子の集合の完全性を確認し、同一でない場合には、欠落した識別子の総数、もしくは欠落した識別子の値を推定する。
【解決手段】符号化装置1は、識別子の集合を、相互に重なり合う複数の部分集合に分割し、それぞれの部分集合に属する識別子を用いて交換可能な方法で算出した付加符号語を、部分集合に属する識別子に対応する識別媒体に書き込む。復号化装置2は、識別子、及び該識別子から算出される付加符号語を読み取り、同一の付加符号語を保持する識別子の集合にグループ分けし、グループに属する全ての識別子の値を用いて、付加符号語を生成したときと同じ演算によって評価符号語を算出し、付加符号語と評価符号語とが同一である場合には、識別子の集合の完全性を確認し、同一でない場合には、欠落した識別子の総数、もしくは欠落した識別子の値を推定する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、複数の識別子が形成する集合の完全性を距離的・時間的に離れた状況で確認する際に、集合を形成してから確認するまでに欠落した識別子の総数、あるいは、欠落した識別子の数値を推定する技術に関する。
【背景技術】
【0002】
近年、リーダ/ライタと電子タグとから構成されるRFIDシステム(RFID:Radio Frequency Identification)や、バーコードに代表される自動認識装置は、それぞれの特徴を活かし、交通システムや、物品管理など、様々に利用されている。特に、RFIDシステムでは、複数の電子タグに記憶されている識別子を実質的に同時に読み取ることや、電子タグに付加情報を書き込むことも技術的に可能である。また、最近では、バーコードにも、商品番号だけでなく、付加情報も書き加えられるようになった。例えば、このような電子タグやバーコードなどの識別媒体が管理対象となる物品等に貼付され、管理される。
【0003】
電子タグの読み取り技術の向上によって、個々の電子タグを効率よく読み取ることができるようになると共に、読み取り技術を用いて様々な応用が提案されている。
例えば、特許文献1では、電子タグに短距離トランシーバと長距離トランシーバ機能とを配備し、電子タグ同士が相互に通信することで一群のコンテナから所定のコンテナを探す手段を提供している。
【0004】
一方、電子タグの情報セキュリティの観点からは、識別子の組み合わせの適正性を確認する技術が提案されている。非特許文献1では、読み取り装置を介して、複数の電子タグが情報を伝達することで最終的にグループを1つの値で表し、その適正性を別途設置した認証機能によって確認することが提案されている。また、非特許文献2では、グループ確認までの時間制限を設けることによって、不足のタグがある場合に、悪意のある読取装置が、揃っていない識別子を含め、グループが揃っていると報告することを防止している。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開平10−506357号公報
【非特許文献】
【0006】
【非特許文献1】A. Juels,”Strengthening EPC tags against cloning”, 4th ACM Workshop on Wireless Security,2005年,p.67−p.76
【非特許文献2】J. Saito、他1名,"Grouping proof for RFID Tags", 19th IEEE International Conference on Advanced Information Networking and Applications,2005年,p.621−p.624
【発明の概要】
【発明が解決しようとする課題】
【0007】
上述したように、自動認識技術によって、電子タグ等の個々の識別子を大量に、かつ迅速に読み取ることができるようになった。しかしながら、従来技術において、個々の識別子を読み取っただけでは、そこに存在すべきでない識別子があることや、逆にあるべき識別子がないことを検出することはできない。例えば、本来50品目の物品を梱包すべきところ、48品目しか梱包されていなかったとしても、それが欠品しているのか、本来48品目であるのかは、納品リストなどの手段で別途確認するしかなかった。
【0008】
特許文献1の方法は、複数の識別子を用いて、物品の発見や、読み取り信頼性を高める目的で開発されており、識別子がグループとして保有する情報に関するものではない。
非特許文献1、2の方法は、いずれも読み取り装置が信頼できないことを前提としているため、電子タグが入力した情報に対して、情報を生成する機能を有することと、グループとなる電子タグに秘密鍵が配布できることを前提としている。
このように、従来技術では、識別子が有する識別符号の集合によって生じる情報を、識別子だけでは伝達できていないことが根本的な問題である。
【0009】
本発明は、このような事情を考慮してなされたものであり、その目的は、複数の識別子を個体識別した上で、読み取った識別子の集合が過不足なく、適正であるかを確認し、集合に不足が生じた場合には、欠落した識別子の総数、あるいは、識別子の番号を推定することができる集合認識システム、集合認識方法、符号化装置、復号化装置およびプログラムを提供することにある。
【課題を解決するための手段】
【0010】
上述した課題を解決するために、本発明は、複数の識別子の集合に含まれる識別子が記憶されている複数の識別媒体の識別子を、相互に重なりのある複数の部分集合に分類する第1の部分集合分類部と、第1の部分集合分類部により分類された複数の部分集合毎に、部分集合に属する全ての識別子に基づいて、予め定められた交換可能な演算方法によって部分集合を識別する付加符号情報を算出する付加符号情報生成部と、付加符号情報生成部により算出された付加符号情報であって、付加符号情報によって識別される部分集合に属する識別媒体に、識別媒体の識別子に対応付けられて記憶される付加符号情報を出力する付加符号出力部と、を具備する符号化装置と、符号化装置から出力された付加符号情報が記憶された複数の識別媒体の識別子を、同一の付加符号情報が対応付けられた識別子の部分集合に分類する第2の部分集合分類部と、第2の部分集合分類部により分類された複数の部分集合毎に、部分集合に属する全ての識別子に基づいて、付加符号情報を算出した演算方法と同一の演算方法によって部分集合を識別する評価符号情報を算出する評価符号情報演算部と、付加符号情報と評価符号情報との同一性に基づいて、識別媒体に記憶された識別子の集合の完全性を判定する判定部と、を具備する復号化装置と、を備えることを特徴とする集合認識システムである。
【0011】
また、本発明は、符号化装置の付加符号語情報部が、各部分集合に属する全ての識別子の値に排他的論理和を施すことによって部分集合毎に付加符号情報を算出することを特徴とする。
【0012】
また、本発明は、復号化装置の判定部が、付加符号情報と評価符号情報とが合致しない場合には、欠落した識別子の総数、あるいは、欠落した識別子の値の少なくともいずれか一方を算出することを特徴とする。
【0013】
また、本発明は、復号化装置の判定部が、付加符号情報と評価符号情報とが合致しない場合には、評価符号情報と付加符号情報との差分から、識別子の独立成分を抽出し、該独立成分の数を、欠落した識別子の総数として算出することを特徴とする。
【0014】
また、本発明は、符号化装置が、複数の識別子の集合に含まれる識別子が記憶されている複数の識別媒体の識別子を、相互に重なりのある複数の部分集合に分類するステップと、分類した複数の部分集合毎に、部分集合に属する全ての識別子に基づいて、予め定められた交換可能な演算方法によって部分集合を識別する付加符号情報を算出するステップと、算出した付加符号情報であって、付加符号情報によって識別される部分集合に属する識別媒体に、識別媒体の識別子に対応付けられて記憶される付加符号情報を出力するステップと、復号化装置が、符号化装置から出力された付加符号情報が記憶された複数の識別媒体の識別子を、同一の付加符号情報が対応付けられた識別子の部分集合に分類するステップと、分類した複数の部分集合毎に、部分集合に属する全ての識別子に基づいて、付加符号情報を算出した演算方法と同一の演算方法によって部分集合を識別する評価符号情報を算出するステップと、付加符号情報と評価符号情報との同一性に基づいて、識別媒体に記憶された識別子の集合の完全性を判定するステップと、を備えることを特徴とする集合認識方法である。
【0015】
また、本発明は、複数の識別子の集合に含まれる識別子が記憶されている複数の識別媒体の識別子を、相互に重なりのある複数の部分集合に分類する部分集合分類部と、部分集合分類部により分類された複数の部分集合毎に、部分集合に属する全ての識別子に基づいて、予め定められた交換可能な演算方法によって部分集合を識別する付加符号情報を算出する付加符号情報生成部と、付加符号情報生成部により算出された付加符号情報であって、付加符号情報によって識別される部分集合に属する識別媒体に、識別媒体の識別子に対応付けられて記憶される付加符号情報を出力する付加符号出力部と、を備えることを特徴とする符号化装置である。
【0016】
また、本発明は、複数の識別子の集合に含まれる識別子が、相互に重なりのある複数の部分集合に分類された部分集合を識別する付加符号情報が記憶された複数の識別媒体の識別子を、同一の付加符号情報が対応付けられた識別子の部分集合に分類する部分集合分類部と、部分集合分類部により分類された複数の部分集合毎に、部分集合に属する全ての識別子に基づいて、付加符号情報を算出した演算方法と同一の演算方法によって部分集合を識別する評価符号情報を算出する評価符号情報演算部と、付加符号情報と評価符号情報との同一性に基づいて、識別媒体に記憶された識別子の集合の完全性を判定する判定部と、を備えることを特徴とする復号化装置である。
【0017】
また、本発明は、上述の符号化装置としてコンピュータを機能させるプログラムである。
【0018】
また、本発明は、上述の復号化装置としてコンピュータを機能させるプログラムである。
【発明の効果】
【0019】
この発明によれば、複数の識別子を個体識別した上で、読み取った識別子の集合が過不足なく、適正であるかを確認し、集合に不足が生じた場合には、欠落した識別子の総数、あるいは、識別子の番号を推定することができる。
【図面の簡単な説明】
【0020】
【図1】本発明の実施形態による集合認識システムの概略構成を示すブロック図である。
【図2】本実施形態による符号化装置1、及び復号化装置2の構成を示すブロック図である。
【図3】本実施形態による符号装置1における部分集合への分類を示す概念図である。
【図4】本実施形態による符号装置1における付加符号語の書き込み結果を示す概念図である。
【図5】本実施形態による復号化装置2で読み取られる識別子の例を示す概念図である。
【図6】本実施形態において、評価符号語と付加符号語との関係を示す概念図である。
【図7】本実施形態による復号化装置2において、欠落した識別子の同定方法を説明するための概念図である。
【図8】本実施形態において、複数の識別子の欠落の例を説明するための概念図である。
【図9】本実施形態において、評価符号語を示す概念図である。
【図10】本実施形態において、欠落した識別子の線形結合(排他的論理和)を示す概念図である。
【図11】本実施形態において、独立成分の抽出例を示す概念図である。
【図12】本実施形態において、独立成分の抽出例を示す概念図である。
【図13】本実施形態による集合認識システムにおける復号化装置2での欠落数の推定動作(アルゴリズム)を説明するためのフローチャートである。
【発明を実施するための形態】
【0021】
以下、本発明の一実施形態を、図面を参照して説明する。
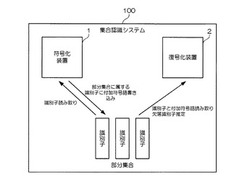
図1は、本発明の実施形態による集合認識システムの概略構成を示すブロック図である。本実施形態における集合認識システム100は、複数の識別媒体のそれぞれを識別する識別子の集合を、相互に重なり合う複数の部分集合に分割し、それぞれの部分集合に属する識別子を交換可能な方法(計算する順序によって値が変化しない方法)で組み合わせて算出した付加符号語(付加符号情報)を、部分集合に属する識別媒体(例えば、RFIDタグ等の電子タグや、バーコード)に書き込む符号化装置1と、識別媒体から、識別子および該識別子から算出される付加符号語を読み取り、同一の付加符号語を保持する識別子の集合にグループ分けし、グループ毎に、当該グループに属する全ての識別子の値を用いて、付加符号語を生成したものと同じ演算によって評価符号語(評価符号情報)を算出し、読み取った付加符号語と算出した評価符号語との同一性から識別子の集合の完全性を確認し、識別子の集合が完全でない場合に、さらに、付加符号語と評価符号語との差分を独立成分に分解することにより、欠落した識別子の総数、もしくは欠落した識別子の値を推定する復号化装置2とを備えている。
【0022】
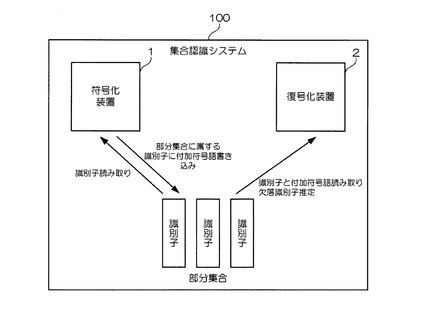
図2(a)、(b)は、本実施形態による符号化装置1、及び復号化装置2の構成を示すブロック図である。符号化装置1は、識別媒体の識別子を部分集合に分割し、部分集合に応じて付加符号語を付与する。復号化装置2は、識別子と付加符号語を読み取って処理することで、集合の完全性、及び欠落していた場合には、その数の推定数を算出する欠落・混入推定器を含む。
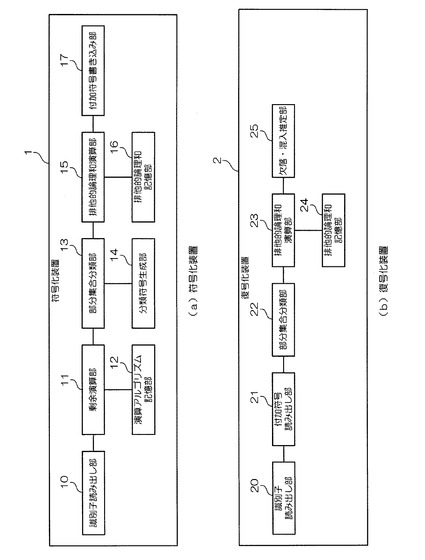
図2(a)において、符号化装置1は、識別子読み出し部10、剰余演算部11、演算アルゴリズム記憶部12、部分集合分類部13、分類符号生成部14、排他的論理和演算部15、排他的論理和記憶部16、及び付加符号書き込み部17から構成されている。
【0023】
識別子読み出し部10は、集合を構成する識別子が記憶された識別媒体から、識別子を読み取る。例えば、識別子読み出し部10には、RFIDタグリーダ/ライタが適用できる。剰余演算部11は、後述するように、必要に応じて、識別子読み出し部10が読み取った識別子のハッシュ値を、識別符号語として算出する。演算アルゴリズム記憶部12は、剰余演算部11が剰余演算に用いる演算アルゴリズムを記憶する。
【0024】
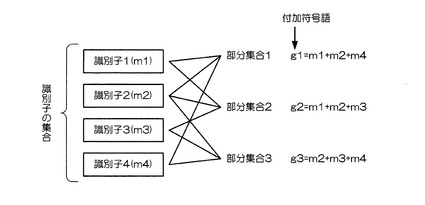
部分集合分類部13は、識別子読み出し部10によって読み出された、複数の識別子の集合に含まれる識別子が記憶されている複数の識別媒体の識別子を、相互に重なりのある複数の部分集合に分類する。部分集合の数は、識別子の予測欠落数と読み出した識別子との総数によって定める。図3は、部分集合分類部13によって分類する部分集合の例を示す概念図である。ここでは、4つの識別子(m1〜m4)を、相互に重なりのある3つの部分集合(g1〜g3)に分類している。
【0025】
ここで、部分集合分類部13において部分集合を決定する際、基本的には、予測欠落数よりも部分集合の数を多く設定する。また、部分集合同士が線形結合とならないように配慮する。線形結合の場合には、部分集合数を増やしても欠落した識別子の推定に寄与しないためである。
【0026】
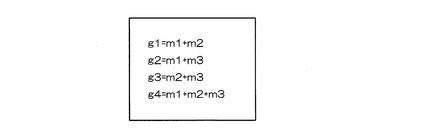
すなわち、例えば、m1、m2、m3、m4を識別子のハッシュ値とし、g1、g2、g3を部分集合毎に定められる付加符号語とし、次のように3つの部分集合を構成した場合、次式(1)、(2)、(3)のように表される。
g1=m1+m2 (1)
g2=m1+m2+m3+m4 (2)
g3= m3+m4 (3)
【0027】
これでは、数式(1)と数式(3)の線形結合が、数式(2)であるため、部分集合の数式(3)があっても、識別子の誤りを検知する効果が向上するわけではない。
分類符号生成部14は、部分集合分類部13によって分類された部分集合に付与する分類符号を生成する。
【0028】
排他的論理和演算部15は、部分集合分類部13により分類された複数の部分集合毎に、その部分集合に属する全ての識別子に基づいて、予め定められた交換可能な演算方法によってその部分集合を識別する付加符号情報を算出する。ここで、識別子は、電子タグの場合には、電子タグチップのIDや、ハードウェアアドレス、EPCなどの貼付する物品の識別子など、唯一性を担保されている番号を用いる。識別子が長い場合には、そのハッシュ値や、CRCを用いて算出した識別符号語を用いる。異なる識別子に対して、同じ識別符号語が与えられる可能性を十分低くするように、識別符号語を選択することが大切である。交換可能な演算式の典型は、排他的論理和である。
【0029】
排他的論理和記憶部16は、排他的論理和演算部15による演算結果を記憶する。
付加符号書き込み部17は、排他的論理和演算部15により算出された付加符号語であって、その付加符号語によって識別される部分集合に属する識別媒体に、その識別媒体の識別子に対応付けられて記憶される付加符号情報を出力する。この例では、付加符号書き込み部17が、RFIDタグリーダ/ライタの機能を備えることとし、部分集合毎に算出された付加符号語を、電子タグ等の識別媒体に書き込む。
【0030】
図2(b)において、復号化装置2は、識別子読み出し部20、付加符号読み出し部21、部分集合分類部22、排他的論理和演算部23、排他的論理和記憶部24、及び欠落・混入推定部25から構成されている。
【0031】
識別子読み出し部20は、識別媒体に記憶された識別子を読み込む。例えば、識別子読み出し部20には、RFIDタグリーダ/ライタが適用できる。
付加符号読み出し部21は、読み込んだ識別子に書かれた付加符号語を読み込む。
部分集合分類部22は、符号化装置1から出力された付加符号語が記憶された複数の識別媒体の識別子を、同一の付加符号情報が対応付けられた識別子の部分集合に分類する。すなわち、部分集合分類部22は、同じ付加符号語を有する識別子から、部分集合を再構成する。
【0032】
排他的論理和演算部23は、部分集合分類部22により分類された複数の部分集合毎に、その部分集合に属する全ての識別子に基づいて、符号化装置1が付加符号情報を算出した演算方法と同一の演算方法(排他的論理和)によって部分集合を識別する評価符号語を算出する。
排他的論理和記憶部24は、排他的論理和演算部23による演算結果を記憶する。
【0033】
欠落・混入推定部25は、付加符号読み出し部21によって読み出された付加符号語と排他的論理和演算部23によって算出された評価符号語との同一性に基づいて、識別媒体に記憶された識別子の集合の完全性を判定する。ここで、欠落・混入推定部25は、評価符号語と読み取った付加符号語とが一致するか否かを判定する。全ての付加符号語と評価符号語とが合致すると判定した場合には、集合は、完全に再現されている。合致しないと判定した場合には、評価符号語と付加符号語との差分(排他的論理和の場合には、差分も排他的論理和)から、識別子、あるいは識別符号語の独立成分を抽出する。その独立成分の数が、欠落した識別子、あるいは識別符号語の予想数となる。
【0034】
次に、本実施形態による集合自動認識方法について詳細に説明する。
図4は、本実施形態による符号装置1における付加符号語の書き込み結果を示す概念図である。図5は、本実施形態による復号化装置2で読み取られる識別子の例を示す概念図である。図6は、本実施形態において、評価符号語と付加符号語との関係を示す概念図である。図7は、本実施形態による復号化装置2において、欠落した識別子の同定方法を説明するための概念図である。
【0035】
本実施形態による集合自動認識方法は、集合を構成する識別子を、互いに重なり合う複数の部分集合に分割する。互いに重なり合う複数の部分集合とすることで、識別子、あるいは、識別子から算出された識別符号語間に数学的な拘束条件を付与することができる。例えば、図3に示したように、4つの識別子を、相互に重なり合う3つの部分集合に分類する。
【0036】
そして、識別子に関して交換可能な演算(計算する順序によって値が変化しない演算)、代表的には、排他的論理和を用いて、3つの付加符号語g1、g2、g3を算出する。これによって、4つの識別子m1、m2、m3、m4は、冗長な拘束を有することになる。また、交換可能な演算を用いることによって、同一の集合であれば、演算の順番によらず、一定の付加符号語が得られる。上記付加符号語を、図4に示すように、電子タグ等の識別媒体の書き込み領域に書き込んでおく。以上が符号装置1の機能である。識別子をどのように組み合わせて、付加符号語を構成するかについては、識別媒体の書き込み容量、演算の複雑性、欠落する識別子の期待値などの条件を勘案して適切な方法を選択する。
【0037】
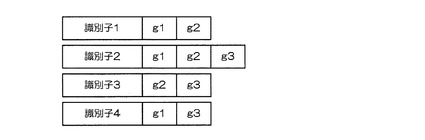
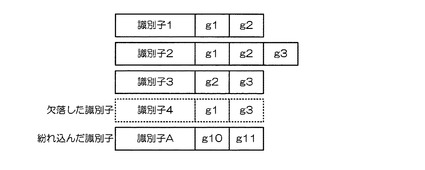
このように識別媒体に記憶された識別子を時間的、場所的に離れた状況で、読み取り、集合の完全性を確認する際には、まず、読み取り可能な識別媒体から識別子と、書き込まれた付加符号語とをすべて読み取る。例えば、識別子4の識別媒体が欠落し、識別子Aの識別媒体が偶然紛れ込んだとする。
【0038】
ここで、識別子としては、上述のように、例えば電子タグのチップIDなど、唯一性が担保されている番号を用いることや、識別子からハッシュ値を求めて識別符号語として用いることで、1つでも識別子が異なれば、識別符号語が実質的に合致しないようにすることが可能である。これを利用すると、偶然紛れ込んだ識別媒体の識別子には、付加符号語g1、g2、g3、g4以外の付加符号語が書き込まれていると考えてよい。
【0039】
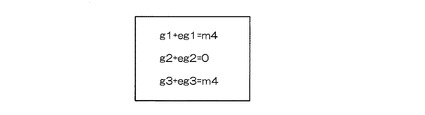
このため、例え、同一部分集合要素(例えば、g10)に属する識別子が1つ以上、紛れ込んだ場合であっても、付加符号語g1、g2、g3に属する識別子の検出と、付加符号語g10に属する識別子の検出とは、互いに影響を及ぼすことのない2つの識別子検出プロセスとなるだけである。一方、識別子4が欠落した状態で、識別子1から識別子3を用いて、符号化装置1と同様にして評価符号語eg1、eg2、eg3を算出し、読み取った付加符号語g1、g2、g3と比較すると、図6に示すように、識別子4がないため、付加符号語g2以外は、同一とならない。
【0040】
この段階で、元々あった識別子の集合が完全に保持されていないことが確認できる。次に、gi(i=1,2,3)からegi成分を取り除くことで、欠落している識別子を推測することができる。例えば、先ほどのように交換可能な演算として排他的論理和を用いると、足し算も引き算も同じであるため、図7に示すようになる。3つの式の右辺でゼロ以外の独立成分は、m4の1つであるため、識別子m4が1つ欠落していることが推定できる。この方法を拡張することで、識別子が複数欠落している場合にも対応できる。
【0041】
図8は、本実施形態において、複数の識別子の欠落の例を説明するための概念図である。図9は、本実施形態において、評価符号語を示す概念図である。図10は、本実施形態において、欠落した識別子の線形結合(排他的論理和)を示す概念図である。図11は、本実施形態において、独立成分の抽出例を示す概念図である。また、図12は、本実施形態において、独立成分の抽出例を示す概念図である。
【0042】
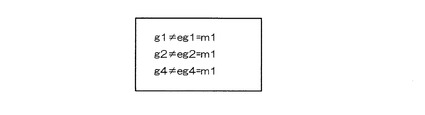
例えば、図8に示すように、3つの識別子m1、m2、m3が、4つのグループを作ることを考える。前述の例と同様、「+」は識別子の排他的論理和を表す。ここで、m2とm3が欠落すると評価符号語は、図9に示すようになり、全ての付加符号語g1、g2、g4と評価符号語eg1、eg2、eg4とが合致しない。付加符号語g1、g2、g4と評価符号語eg1、eg2、eg4との排他的論理和は、図10に示すようになる。
【0043】
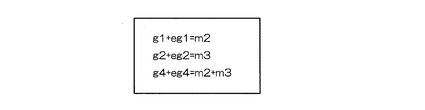
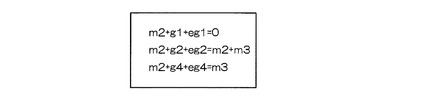
図10に示す3つの式から、まず、識別子m2を取り出して、残りの成分と識別子m2との排他的論理和をとると、図11に示すようになる(図11では、理解を助けるため、識別子m2を取り出した式自体にも、識別子m2を排他的論理和を施した結果を示している)。次に、m2+m3をノンゼロの式に排他的論理和すると、図12に示すようになる(図12では、理解を助けるため、m2+m3を取り出した式自体にも、m2+m3を排他的論理和を施した結果を示している)。これまでに、m2とm2+m3とが独立成分として抽出されているので、図12において、ノンゼロとなる右辺(m2)は、既出の成分であり、欠落した識別子数が2つであることが推測できる。
【0044】
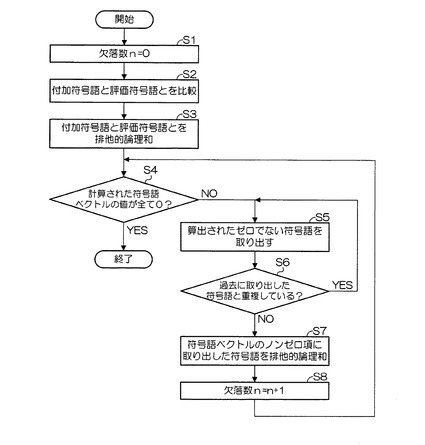
図13は、本実施形態による集合認識システムにおける復号化装置2での欠落数の推定動作(アルゴリズム)を説明するためのフローチャートである。識別子読み出し部20は、識別媒体に記憶されている識別子を読み出し、付加符号読み出し部21は、識別媒体に記憶されている付加符号を読み出す。部分集合分類部22は、識別子読み出し部20によって読み出された複数の識別子を部分集合に分類し、部分集合毎の識別情報である評価符号語を算出する。復号化装置2は、欠落数を「0」とする(ステップS1)。排他的論理和23は、付加符号語と評価符号語とを比較し(ステップS2)、付加符号語と評価符号語との排他的論理和をとることにより、符号語ベクトルを算出する(ステップS3)。欠落・混入推定部25は、算出された符号語ベクトルの値が全て「0」であるか否かを判定し(ステップS4)、全て「0」でない場合には(ステップS4のNO)、算出されたゼロでない符号語を取り出し(ステップS5)、過去に取り出した符号語と重複しているか否かを判定する(ステップS6)。そして、過去に取り出した符号語と重複している場合には(ステップS6のYES)、ステップS5に戻り、上述した動作を繰り返す。
【0045】
一方、過去に取り出した符号語と重複していない場合には(ステップS6のNO)、欠落・混入推定部25は、符号語ベクトルのノンゼロ項に取り出した符号語の排他的論理和により、独立成分を抽出する(ステップS7)。復号化装置2は、欠落数を1つインクリメントし(ステップS8)、ステップS4に戻り、上述した動作を繰り返す。
そして、算出された符号語ベクトルの値が全て「0」となると(ステップS4のYES)、当該処理を終了する。
【0046】
なお、本実施形態の符号化装置1と復号化装置2とのコンピュータ装置が備える機能は、例えばRFIDリーダ/ライタが備えるようにしても良いし、RFIDリーダ/ライタが接続された汎用のコンピュータ装置(PC(パーソナルコンピュータ)など)が備えるようにしても良い。
【0047】
上述した実施形態によれば、識別子が付けられた物理的、あるいは論理的な集合が、時間的、あるいは距離的に離れた状況で、確認される場合に、集合の完全性を確認することができるとともに、識別子が欠落した場合に、欠落した識別子の総数、もしくは欠落した識別子の値を推定することができる。
【0048】
また、本実施形態によれば、サプライチェーンなどで、出荷した物品の集合が完全に配達されたか、欠落していたとしたら大体いくつかを知ることができる。これを利用すると、電子タグなどを利用した大量の物品の読み取り確実性が、例え、100%でなかったとしても、読み取れた電子タグ数と欠落したタグ数の推定数との関係と、読み取り確実性の関係から、コストをかけて、全数読み直しをしなくても、「ほぼ存在する」というオペレーションが可能である。電子タグが破損したり、どうしても読み取れない位置に電子タグが貼られてしまったりすることも許容できる可能性があり、コスト削減につながる。
【0049】
なお、図2に示す各部の機能を実現するためのプログラムをコンピュータ読み取り可能な記録媒体に記録して、この記録媒体に記録されたプログラムをコンピュータシステムに読み込ませ、実行することにより各部の処理を行ってもよい。なお、ここでいう「コンピュータシステム」とは、OSや周辺機器等のハードウェアを含むものとする。
また、「コンピュータシステム」は、WWWシステムを利用している場合であれば、ホームページ提供環境(あるいは表示環境)も含むものとする。
【0050】
また、「コンピュータ読み取り可能な記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、CD−ROM等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶装置のことをいう。さらに「コンピュータ読み取り可能な記録媒体」とは、インターネット等のネットワークや電話回線等の通信回線を介してプログラムを送信する場合の通信線のように、短時間の間、動的にプログラムを保持するもの、その場合のサーバやクライアントとなるコンピュータシステム内部の揮発性メモリのように、一定時間プログラムを保持しているものも含むものとする。また上記プログラムは、前述した機能の一部を実現するためのものであっても良く、さらに前述した機能をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるものであっても良い。
【符号の説明】
【0051】
1 符号化装置
2 復号化装置
10 識別子読み出し部
11 剰余演算部
12 演算アルゴリズム記憶部
13 部分集合分類部
14 分類符号生成部
15 排他的論理和演算部
16 排他的論理和記憶部
17 付加符号書き込み部
20 識別子読み出し部
21 付加符号読み出し部
22 部分集合分類部
23 排他的論理和演算部
24 排他的論理和記憶部
25 欠落・混入推定部
100 集合認識システム
【技術分野】
【0001】
本発明は、複数の識別子が形成する集合の完全性を距離的・時間的に離れた状況で確認する際に、集合を形成してから確認するまでに欠落した識別子の総数、あるいは、欠落した識別子の数値を推定する技術に関する。
【背景技術】
【0002】
近年、リーダ/ライタと電子タグとから構成されるRFIDシステム(RFID:Radio Frequency Identification)や、バーコードに代表される自動認識装置は、それぞれの特徴を活かし、交通システムや、物品管理など、様々に利用されている。特に、RFIDシステムでは、複数の電子タグに記憶されている識別子を実質的に同時に読み取ることや、電子タグに付加情報を書き込むことも技術的に可能である。また、最近では、バーコードにも、商品番号だけでなく、付加情報も書き加えられるようになった。例えば、このような電子タグやバーコードなどの識別媒体が管理対象となる物品等に貼付され、管理される。
【0003】
電子タグの読み取り技術の向上によって、個々の電子タグを効率よく読み取ることができるようになると共に、読み取り技術を用いて様々な応用が提案されている。
例えば、特許文献1では、電子タグに短距離トランシーバと長距離トランシーバ機能とを配備し、電子タグ同士が相互に通信することで一群のコンテナから所定のコンテナを探す手段を提供している。
【0004】
一方、電子タグの情報セキュリティの観点からは、識別子の組み合わせの適正性を確認する技術が提案されている。非特許文献1では、読み取り装置を介して、複数の電子タグが情報を伝達することで最終的にグループを1つの値で表し、その適正性を別途設置した認証機能によって確認することが提案されている。また、非特許文献2では、グループ確認までの時間制限を設けることによって、不足のタグがある場合に、悪意のある読取装置が、揃っていない識別子を含め、グループが揃っていると報告することを防止している。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開平10−506357号公報
【非特許文献】
【0006】
【非特許文献1】A. Juels,”Strengthening EPC tags against cloning”, 4th ACM Workshop on Wireless Security,2005年,p.67−p.76
【非特許文献2】J. Saito、他1名,"Grouping proof for RFID Tags", 19th IEEE International Conference on Advanced Information Networking and Applications,2005年,p.621−p.624
【発明の概要】
【発明が解決しようとする課題】
【0007】
上述したように、自動認識技術によって、電子タグ等の個々の識別子を大量に、かつ迅速に読み取ることができるようになった。しかしながら、従来技術において、個々の識別子を読み取っただけでは、そこに存在すべきでない識別子があることや、逆にあるべき識別子がないことを検出することはできない。例えば、本来50品目の物品を梱包すべきところ、48品目しか梱包されていなかったとしても、それが欠品しているのか、本来48品目であるのかは、納品リストなどの手段で別途確認するしかなかった。
【0008】
特許文献1の方法は、複数の識別子を用いて、物品の発見や、読み取り信頼性を高める目的で開発されており、識別子がグループとして保有する情報に関するものではない。
非特許文献1、2の方法は、いずれも読み取り装置が信頼できないことを前提としているため、電子タグが入力した情報に対して、情報を生成する機能を有することと、グループとなる電子タグに秘密鍵が配布できることを前提としている。
このように、従来技術では、識別子が有する識別符号の集合によって生じる情報を、識別子だけでは伝達できていないことが根本的な問題である。
【0009】
本発明は、このような事情を考慮してなされたものであり、その目的は、複数の識別子を個体識別した上で、読み取った識別子の集合が過不足なく、適正であるかを確認し、集合に不足が生じた場合には、欠落した識別子の総数、あるいは、識別子の番号を推定することができる集合認識システム、集合認識方法、符号化装置、復号化装置およびプログラムを提供することにある。
【課題を解決するための手段】
【0010】
上述した課題を解決するために、本発明は、複数の識別子の集合に含まれる識別子が記憶されている複数の識別媒体の識別子を、相互に重なりのある複数の部分集合に分類する第1の部分集合分類部と、第1の部分集合分類部により分類された複数の部分集合毎に、部分集合に属する全ての識別子に基づいて、予め定められた交換可能な演算方法によって部分集合を識別する付加符号情報を算出する付加符号情報生成部と、付加符号情報生成部により算出された付加符号情報であって、付加符号情報によって識別される部分集合に属する識別媒体に、識別媒体の識別子に対応付けられて記憶される付加符号情報を出力する付加符号出力部と、を具備する符号化装置と、符号化装置から出力された付加符号情報が記憶された複数の識別媒体の識別子を、同一の付加符号情報が対応付けられた識別子の部分集合に分類する第2の部分集合分類部と、第2の部分集合分類部により分類された複数の部分集合毎に、部分集合に属する全ての識別子に基づいて、付加符号情報を算出した演算方法と同一の演算方法によって部分集合を識別する評価符号情報を算出する評価符号情報演算部と、付加符号情報と評価符号情報との同一性に基づいて、識別媒体に記憶された識別子の集合の完全性を判定する判定部と、を具備する復号化装置と、を備えることを特徴とする集合認識システムである。
【0011】
また、本発明は、符号化装置の付加符号語情報部が、各部分集合に属する全ての識別子の値に排他的論理和を施すことによって部分集合毎に付加符号情報を算出することを特徴とする。
【0012】
また、本発明は、復号化装置の判定部が、付加符号情報と評価符号情報とが合致しない場合には、欠落した識別子の総数、あるいは、欠落した識別子の値の少なくともいずれか一方を算出することを特徴とする。
【0013】
また、本発明は、復号化装置の判定部が、付加符号情報と評価符号情報とが合致しない場合には、評価符号情報と付加符号情報との差分から、識別子の独立成分を抽出し、該独立成分の数を、欠落した識別子の総数として算出することを特徴とする。
【0014】
また、本発明は、符号化装置が、複数の識別子の集合に含まれる識別子が記憶されている複数の識別媒体の識別子を、相互に重なりのある複数の部分集合に分類するステップと、分類した複数の部分集合毎に、部分集合に属する全ての識別子に基づいて、予め定められた交換可能な演算方法によって部分集合を識別する付加符号情報を算出するステップと、算出した付加符号情報であって、付加符号情報によって識別される部分集合に属する識別媒体に、識別媒体の識別子に対応付けられて記憶される付加符号情報を出力するステップと、復号化装置が、符号化装置から出力された付加符号情報が記憶された複数の識別媒体の識別子を、同一の付加符号情報が対応付けられた識別子の部分集合に分類するステップと、分類した複数の部分集合毎に、部分集合に属する全ての識別子に基づいて、付加符号情報を算出した演算方法と同一の演算方法によって部分集合を識別する評価符号情報を算出するステップと、付加符号情報と評価符号情報との同一性に基づいて、識別媒体に記憶された識別子の集合の完全性を判定するステップと、を備えることを特徴とする集合認識方法である。
【0015】
また、本発明は、複数の識別子の集合に含まれる識別子が記憶されている複数の識別媒体の識別子を、相互に重なりのある複数の部分集合に分類する部分集合分類部と、部分集合分類部により分類された複数の部分集合毎に、部分集合に属する全ての識別子に基づいて、予め定められた交換可能な演算方法によって部分集合を識別する付加符号情報を算出する付加符号情報生成部と、付加符号情報生成部により算出された付加符号情報であって、付加符号情報によって識別される部分集合に属する識別媒体に、識別媒体の識別子に対応付けられて記憶される付加符号情報を出力する付加符号出力部と、を備えることを特徴とする符号化装置である。
【0016】
また、本発明は、複数の識別子の集合に含まれる識別子が、相互に重なりのある複数の部分集合に分類された部分集合を識別する付加符号情報が記憶された複数の識別媒体の識別子を、同一の付加符号情報が対応付けられた識別子の部分集合に分類する部分集合分類部と、部分集合分類部により分類された複数の部分集合毎に、部分集合に属する全ての識別子に基づいて、付加符号情報を算出した演算方法と同一の演算方法によって部分集合を識別する評価符号情報を算出する評価符号情報演算部と、付加符号情報と評価符号情報との同一性に基づいて、識別媒体に記憶された識別子の集合の完全性を判定する判定部と、を備えることを特徴とする復号化装置である。
【0017】
また、本発明は、上述の符号化装置としてコンピュータを機能させるプログラムである。
【0018】
また、本発明は、上述の復号化装置としてコンピュータを機能させるプログラムである。
【発明の効果】
【0019】
この発明によれば、複数の識別子を個体識別した上で、読み取った識別子の集合が過不足なく、適正であるかを確認し、集合に不足が生じた場合には、欠落した識別子の総数、あるいは、識別子の番号を推定することができる。
【図面の簡単な説明】
【0020】
【図1】本発明の実施形態による集合認識システムの概略構成を示すブロック図である。
【図2】本実施形態による符号化装置1、及び復号化装置2の構成を示すブロック図である。
【図3】本実施形態による符号装置1における部分集合への分類を示す概念図である。
【図4】本実施形態による符号装置1における付加符号語の書き込み結果を示す概念図である。
【図5】本実施形態による復号化装置2で読み取られる識別子の例を示す概念図である。
【図6】本実施形態において、評価符号語と付加符号語との関係を示す概念図である。
【図7】本実施形態による復号化装置2において、欠落した識別子の同定方法を説明するための概念図である。
【図8】本実施形態において、複数の識別子の欠落の例を説明するための概念図である。
【図9】本実施形態において、評価符号語を示す概念図である。
【図10】本実施形態において、欠落した識別子の線形結合(排他的論理和)を示す概念図である。
【図11】本実施形態において、独立成分の抽出例を示す概念図である。
【図12】本実施形態において、独立成分の抽出例を示す概念図である。
【図13】本実施形態による集合認識システムにおける復号化装置2での欠落数の推定動作(アルゴリズム)を説明するためのフローチャートである。
【発明を実施するための形態】
【0021】
以下、本発明の一実施形態を、図面を参照して説明する。
図1は、本発明の実施形態による集合認識システムの概略構成を示すブロック図である。本実施形態における集合認識システム100は、複数の識別媒体のそれぞれを識別する識別子の集合を、相互に重なり合う複数の部分集合に分割し、それぞれの部分集合に属する識別子を交換可能な方法(計算する順序によって値が変化しない方法)で組み合わせて算出した付加符号語(付加符号情報)を、部分集合に属する識別媒体(例えば、RFIDタグ等の電子タグや、バーコード)に書き込む符号化装置1と、識別媒体から、識別子および該識別子から算出される付加符号語を読み取り、同一の付加符号語を保持する識別子の集合にグループ分けし、グループ毎に、当該グループに属する全ての識別子の値を用いて、付加符号語を生成したものと同じ演算によって評価符号語(評価符号情報)を算出し、読み取った付加符号語と算出した評価符号語との同一性から識別子の集合の完全性を確認し、識別子の集合が完全でない場合に、さらに、付加符号語と評価符号語との差分を独立成分に分解することにより、欠落した識別子の総数、もしくは欠落した識別子の値を推定する復号化装置2とを備えている。
【0022】
図2(a)、(b)は、本実施形態による符号化装置1、及び復号化装置2の構成を示すブロック図である。符号化装置1は、識別媒体の識別子を部分集合に分割し、部分集合に応じて付加符号語を付与する。復号化装置2は、識別子と付加符号語を読み取って処理することで、集合の完全性、及び欠落していた場合には、その数の推定数を算出する欠落・混入推定器を含む。
図2(a)において、符号化装置1は、識別子読み出し部10、剰余演算部11、演算アルゴリズム記憶部12、部分集合分類部13、分類符号生成部14、排他的論理和演算部15、排他的論理和記憶部16、及び付加符号書き込み部17から構成されている。
【0023】
識別子読み出し部10は、集合を構成する識別子が記憶された識別媒体から、識別子を読み取る。例えば、識別子読み出し部10には、RFIDタグリーダ/ライタが適用できる。剰余演算部11は、後述するように、必要に応じて、識別子読み出し部10が読み取った識別子のハッシュ値を、識別符号語として算出する。演算アルゴリズム記憶部12は、剰余演算部11が剰余演算に用いる演算アルゴリズムを記憶する。
【0024】
部分集合分類部13は、識別子読み出し部10によって読み出された、複数の識別子の集合に含まれる識別子が記憶されている複数の識別媒体の識別子を、相互に重なりのある複数の部分集合に分類する。部分集合の数は、識別子の予測欠落数と読み出した識別子との総数によって定める。図3は、部分集合分類部13によって分類する部分集合の例を示す概念図である。ここでは、4つの識別子(m1〜m4)を、相互に重なりのある3つの部分集合(g1〜g3)に分類している。
【0025】
ここで、部分集合分類部13において部分集合を決定する際、基本的には、予測欠落数よりも部分集合の数を多く設定する。また、部分集合同士が線形結合とならないように配慮する。線形結合の場合には、部分集合数を増やしても欠落した識別子の推定に寄与しないためである。
【0026】
すなわち、例えば、m1、m2、m3、m4を識別子のハッシュ値とし、g1、g2、g3を部分集合毎に定められる付加符号語とし、次のように3つの部分集合を構成した場合、次式(1)、(2)、(3)のように表される。
g1=m1+m2 (1)
g2=m1+m2+m3+m4 (2)
g3= m3+m4 (3)
【0027】
これでは、数式(1)と数式(3)の線形結合が、数式(2)であるため、部分集合の数式(3)があっても、識別子の誤りを検知する効果が向上するわけではない。
分類符号生成部14は、部分集合分類部13によって分類された部分集合に付与する分類符号を生成する。
【0028】
排他的論理和演算部15は、部分集合分類部13により分類された複数の部分集合毎に、その部分集合に属する全ての識別子に基づいて、予め定められた交換可能な演算方法によってその部分集合を識別する付加符号情報を算出する。ここで、識別子は、電子タグの場合には、電子タグチップのIDや、ハードウェアアドレス、EPCなどの貼付する物品の識別子など、唯一性を担保されている番号を用いる。識別子が長い場合には、そのハッシュ値や、CRCを用いて算出した識別符号語を用いる。異なる識別子に対して、同じ識別符号語が与えられる可能性を十分低くするように、識別符号語を選択することが大切である。交換可能な演算式の典型は、排他的論理和である。
【0029】
排他的論理和記憶部16は、排他的論理和演算部15による演算結果を記憶する。
付加符号書き込み部17は、排他的論理和演算部15により算出された付加符号語であって、その付加符号語によって識別される部分集合に属する識別媒体に、その識別媒体の識別子に対応付けられて記憶される付加符号情報を出力する。この例では、付加符号書き込み部17が、RFIDタグリーダ/ライタの機能を備えることとし、部分集合毎に算出された付加符号語を、電子タグ等の識別媒体に書き込む。
【0030】
図2(b)において、復号化装置2は、識別子読み出し部20、付加符号読み出し部21、部分集合分類部22、排他的論理和演算部23、排他的論理和記憶部24、及び欠落・混入推定部25から構成されている。
【0031】
識別子読み出し部20は、識別媒体に記憶された識別子を読み込む。例えば、識別子読み出し部20には、RFIDタグリーダ/ライタが適用できる。
付加符号読み出し部21は、読み込んだ識別子に書かれた付加符号語を読み込む。
部分集合分類部22は、符号化装置1から出力された付加符号語が記憶された複数の識別媒体の識別子を、同一の付加符号情報が対応付けられた識別子の部分集合に分類する。すなわち、部分集合分類部22は、同じ付加符号語を有する識別子から、部分集合を再構成する。
【0032】
排他的論理和演算部23は、部分集合分類部22により分類された複数の部分集合毎に、その部分集合に属する全ての識別子に基づいて、符号化装置1が付加符号情報を算出した演算方法と同一の演算方法(排他的論理和)によって部分集合を識別する評価符号語を算出する。
排他的論理和記憶部24は、排他的論理和演算部23による演算結果を記憶する。
【0033】
欠落・混入推定部25は、付加符号読み出し部21によって読み出された付加符号語と排他的論理和演算部23によって算出された評価符号語との同一性に基づいて、識別媒体に記憶された識別子の集合の完全性を判定する。ここで、欠落・混入推定部25は、評価符号語と読み取った付加符号語とが一致するか否かを判定する。全ての付加符号語と評価符号語とが合致すると判定した場合には、集合は、完全に再現されている。合致しないと判定した場合には、評価符号語と付加符号語との差分(排他的論理和の場合には、差分も排他的論理和)から、識別子、あるいは識別符号語の独立成分を抽出する。その独立成分の数が、欠落した識別子、あるいは識別符号語の予想数となる。
【0034】
次に、本実施形態による集合自動認識方法について詳細に説明する。
図4は、本実施形態による符号装置1における付加符号語の書き込み結果を示す概念図である。図5は、本実施形態による復号化装置2で読み取られる識別子の例を示す概念図である。図6は、本実施形態において、評価符号語と付加符号語との関係を示す概念図である。図7は、本実施形態による復号化装置2において、欠落した識別子の同定方法を説明するための概念図である。
【0035】
本実施形態による集合自動認識方法は、集合を構成する識別子を、互いに重なり合う複数の部分集合に分割する。互いに重なり合う複数の部分集合とすることで、識別子、あるいは、識別子から算出された識別符号語間に数学的な拘束条件を付与することができる。例えば、図3に示したように、4つの識別子を、相互に重なり合う3つの部分集合に分類する。
【0036】
そして、識別子に関して交換可能な演算(計算する順序によって値が変化しない演算)、代表的には、排他的論理和を用いて、3つの付加符号語g1、g2、g3を算出する。これによって、4つの識別子m1、m2、m3、m4は、冗長な拘束を有することになる。また、交換可能な演算を用いることによって、同一の集合であれば、演算の順番によらず、一定の付加符号語が得られる。上記付加符号語を、図4に示すように、電子タグ等の識別媒体の書き込み領域に書き込んでおく。以上が符号装置1の機能である。識別子をどのように組み合わせて、付加符号語を構成するかについては、識別媒体の書き込み容量、演算の複雑性、欠落する識別子の期待値などの条件を勘案して適切な方法を選択する。
【0037】
このように識別媒体に記憶された識別子を時間的、場所的に離れた状況で、読み取り、集合の完全性を確認する際には、まず、読み取り可能な識別媒体から識別子と、書き込まれた付加符号語とをすべて読み取る。例えば、識別子4の識別媒体が欠落し、識別子Aの識別媒体が偶然紛れ込んだとする。
【0038】
ここで、識別子としては、上述のように、例えば電子タグのチップIDなど、唯一性が担保されている番号を用いることや、識別子からハッシュ値を求めて識別符号語として用いることで、1つでも識別子が異なれば、識別符号語が実質的に合致しないようにすることが可能である。これを利用すると、偶然紛れ込んだ識別媒体の識別子には、付加符号語g1、g2、g3、g4以外の付加符号語が書き込まれていると考えてよい。
【0039】
このため、例え、同一部分集合要素(例えば、g10)に属する識別子が1つ以上、紛れ込んだ場合であっても、付加符号語g1、g2、g3に属する識別子の検出と、付加符号語g10に属する識別子の検出とは、互いに影響を及ぼすことのない2つの識別子検出プロセスとなるだけである。一方、識別子4が欠落した状態で、識別子1から識別子3を用いて、符号化装置1と同様にして評価符号語eg1、eg2、eg3を算出し、読み取った付加符号語g1、g2、g3と比較すると、図6に示すように、識別子4がないため、付加符号語g2以外は、同一とならない。
【0040】
この段階で、元々あった識別子の集合が完全に保持されていないことが確認できる。次に、gi(i=1,2,3)からegi成分を取り除くことで、欠落している識別子を推測することができる。例えば、先ほどのように交換可能な演算として排他的論理和を用いると、足し算も引き算も同じであるため、図7に示すようになる。3つの式の右辺でゼロ以外の独立成分は、m4の1つであるため、識別子m4が1つ欠落していることが推定できる。この方法を拡張することで、識別子が複数欠落している場合にも対応できる。
【0041】
図8は、本実施形態において、複数の識別子の欠落の例を説明するための概念図である。図9は、本実施形態において、評価符号語を示す概念図である。図10は、本実施形態において、欠落した識別子の線形結合(排他的論理和)を示す概念図である。図11は、本実施形態において、独立成分の抽出例を示す概念図である。また、図12は、本実施形態において、独立成分の抽出例を示す概念図である。
【0042】
例えば、図8に示すように、3つの識別子m1、m2、m3が、4つのグループを作ることを考える。前述の例と同様、「+」は識別子の排他的論理和を表す。ここで、m2とm3が欠落すると評価符号語は、図9に示すようになり、全ての付加符号語g1、g2、g4と評価符号語eg1、eg2、eg4とが合致しない。付加符号語g1、g2、g4と評価符号語eg1、eg2、eg4との排他的論理和は、図10に示すようになる。
【0043】
図10に示す3つの式から、まず、識別子m2を取り出して、残りの成分と識別子m2との排他的論理和をとると、図11に示すようになる(図11では、理解を助けるため、識別子m2を取り出した式自体にも、識別子m2を排他的論理和を施した結果を示している)。次に、m2+m3をノンゼロの式に排他的論理和すると、図12に示すようになる(図12では、理解を助けるため、m2+m3を取り出した式自体にも、m2+m3を排他的論理和を施した結果を示している)。これまでに、m2とm2+m3とが独立成分として抽出されているので、図12において、ノンゼロとなる右辺(m2)は、既出の成分であり、欠落した識別子数が2つであることが推測できる。
【0044】
図13は、本実施形態による集合認識システムにおける復号化装置2での欠落数の推定動作(アルゴリズム)を説明するためのフローチャートである。識別子読み出し部20は、識別媒体に記憶されている識別子を読み出し、付加符号読み出し部21は、識別媒体に記憶されている付加符号を読み出す。部分集合分類部22は、識別子読み出し部20によって読み出された複数の識別子を部分集合に分類し、部分集合毎の識別情報である評価符号語を算出する。復号化装置2は、欠落数を「0」とする(ステップS1)。排他的論理和23は、付加符号語と評価符号語とを比較し(ステップS2)、付加符号語と評価符号語との排他的論理和をとることにより、符号語ベクトルを算出する(ステップS3)。欠落・混入推定部25は、算出された符号語ベクトルの値が全て「0」であるか否かを判定し(ステップS4)、全て「0」でない場合には(ステップS4のNO)、算出されたゼロでない符号語を取り出し(ステップS5)、過去に取り出した符号語と重複しているか否かを判定する(ステップS6)。そして、過去に取り出した符号語と重複している場合には(ステップS6のYES)、ステップS5に戻り、上述した動作を繰り返す。
【0045】
一方、過去に取り出した符号語と重複していない場合には(ステップS6のNO)、欠落・混入推定部25は、符号語ベクトルのノンゼロ項に取り出した符号語の排他的論理和により、独立成分を抽出する(ステップS7)。復号化装置2は、欠落数を1つインクリメントし(ステップS8)、ステップS4に戻り、上述した動作を繰り返す。
そして、算出された符号語ベクトルの値が全て「0」となると(ステップS4のYES)、当該処理を終了する。
【0046】
なお、本実施形態の符号化装置1と復号化装置2とのコンピュータ装置が備える機能は、例えばRFIDリーダ/ライタが備えるようにしても良いし、RFIDリーダ/ライタが接続された汎用のコンピュータ装置(PC(パーソナルコンピュータ)など)が備えるようにしても良い。
【0047】
上述した実施形態によれば、識別子が付けられた物理的、あるいは論理的な集合が、時間的、あるいは距離的に離れた状況で、確認される場合に、集合の完全性を確認することができるとともに、識別子が欠落した場合に、欠落した識別子の総数、もしくは欠落した識別子の値を推定することができる。
【0048】
また、本実施形態によれば、サプライチェーンなどで、出荷した物品の集合が完全に配達されたか、欠落していたとしたら大体いくつかを知ることができる。これを利用すると、電子タグなどを利用した大量の物品の読み取り確実性が、例え、100%でなかったとしても、読み取れた電子タグ数と欠落したタグ数の推定数との関係と、読み取り確実性の関係から、コストをかけて、全数読み直しをしなくても、「ほぼ存在する」というオペレーションが可能である。電子タグが破損したり、どうしても読み取れない位置に電子タグが貼られてしまったりすることも許容できる可能性があり、コスト削減につながる。
【0049】
なお、図2に示す各部の機能を実現するためのプログラムをコンピュータ読み取り可能な記録媒体に記録して、この記録媒体に記録されたプログラムをコンピュータシステムに読み込ませ、実行することにより各部の処理を行ってもよい。なお、ここでいう「コンピュータシステム」とは、OSや周辺機器等のハードウェアを含むものとする。
また、「コンピュータシステム」は、WWWシステムを利用している場合であれば、ホームページ提供環境(あるいは表示環境)も含むものとする。
【0050】
また、「コンピュータ読み取り可能な記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、CD−ROM等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶装置のことをいう。さらに「コンピュータ読み取り可能な記録媒体」とは、インターネット等のネットワークや電話回線等の通信回線を介してプログラムを送信する場合の通信線のように、短時間の間、動的にプログラムを保持するもの、その場合のサーバやクライアントとなるコンピュータシステム内部の揮発性メモリのように、一定時間プログラムを保持しているものも含むものとする。また上記プログラムは、前述した機能の一部を実現するためのものであっても良く、さらに前述した機能をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるものであっても良い。
【符号の説明】
【0051】
1 符号化装置
2 復号化装置
10 識別子読み出し部
11 剰余演算部
12 演算アルゴリズム記憶部
13 部分集合分類部
14 分類符号生成部
15 排他的論理和演算部
16 排他的論理和記憶部
17 付加符号書き込み部
20 識別子読み出し部
21 付加符号読み出し部
22 部分集合分類部
23 排他的論理和演算部
24 排他的論理和記憶部
25 欠落・混入推定部
100 集合認識システム
【特許請求の範囲】
【請求項1】
複数の識別子の集合に含まれる識別子が記憶されている複数の識別媒体の前記識別子を、相互に重なりのある複数の部分集合に分類する第1の部分集合分類部と、
前記第1の部分集合分類部により分類された複数の部分集合毎に、当該部分集合に属する全ての識別子に基づいて、予め定められた交換可能な演算方法によって当該部分集合を識別する付加符号情報を算出する付加符号情報生成部と、
前記付加符号情報生成部により算出された前記付加符号情報であって、当該付加符号情報によって識別される前記部分集合に属する前記識別媒体に、当該識別媒体の識別子に対応付けられて記憶される前記付加符号情報を出力する付加符号出力部と、を具備する符号化装置と、
前記符号化装置から出力された前記付加符号情報が記憶された複数の前記識別媒体の識別子を、同一の付加符号情報が対応付けられた前記識別子の部分集合に分類する第2の部分集合分類部と、
前記第2の部分集合分類部により分類された複数の部分集合毎に、当該部分集合に属する全ての識別子に基づいて、前記付加符号情報を算出した前記演算方法と同一の演算方法によって当該部分集合を識別する評価符号情報を算出する評価符号情報演算部と、
前記付加符号情報と前記評価符号情報との同一性に基づいて、前記識別媒体に記憶された前記識別子の集合の完全性を判定する判定部と、を具備する復号化装置と、
を備えることを特徴とする集合認識システム。
【請求項2】
前記符号化装置の前記付加符号語情報部は、
前記各部分集合に属する全ての識別子の値に排他的論理和を施すことによって部分集合毎に付加符号情報を算出する
ことを特徴とする請求項1に記載の集合認識システム。
【請求項3】
前記復号化装置の前記判定部は、
前記付加符号情報と前記評価符号情報とが合致しない場合には、欠落した識別子の総数、あるいは、欠落した識別子の値の少なくともいずれか一方を算出する
ことを特徴とする請求項1または2のいずれか1項に記載の集合認識システム。
【請求項4】
前記復号化装置の前記判定部は、
前記付加符号情報と前記評価符号情報とが合致しない場合には、前記評価符号情報と前記付加符号情報との差分から、前記識別子の独立成分を抽出し、該独立成分の数を、前記欠落した識別子の総数として算出する
ことを特徴とする請求項1から請求項3までのいずれか1項に記載の集合認識システム。
【請求項5】
符号化装置が、
複数の識別子の集合に含まれる識別子が記憶されている複数の識別媒体の前記識別子を、相互に重なりのある複数の部分集合に分類するステップと、
分類した複数の部分集合毎に、当該部分集合に属する全ての識別子に基づいて、予め定められた交換可能な演算方法によって当該部分集合を識別する付加符号情報を算出するステップと、
算出した前記付加符号情報であって、当該付加符号情報によって識別される前記部分集合に属する前記識別媒体に、当該識別媒体の識別子に対応付けられて記憶される前記付加符号情報を出力するステップと、
復号化装置が、
前記符号化装置から出力された前記付加符号情報が記憶された複数の前記識別媒体の識別子を、同一の付加符号情報が対応付けられた前記識別子の部分集合に分類するステップと、
分類した複数の部分集合毎に、当該部分集合に属する全ての識別子に基づいて、前記付加符号情報を算出した前記演算方法と同一の演算方法によって当該部分集合を識別する評価符号情報を算出するステップと、
前記付加符号情報と前記評価符号情報との同一性に基づいて、前記識別媒体に記憶された前記識別子の集合の完全性を判定するステップと、
を備えることを特徴とする集合認識方法。
【請求項6】
複数の識別子の集合に含まれる識別子が記憶されている複数の識別媒体の前記識別子を、相互に重なりのある複数の部分集合に分類する部分集合分類部と、
前記部分集合分類部により分類された複数の部分集合毎に、当該部分集合に属する全ての識別子に基づいて、予め定められた交換可能な演算方法によって当該部分集合を識別する付加符号情報を算出する付加符号情報生成部と、
前記付加符号情報生成部により算出された前記付加符号情報であって、当該付加符号情報によって識別される前記部分集合に属する前記識別媒体に、当該識別媒体の識別子に対応付けられて記憶される前記付加符号情報を出力する付加符号出力部と、
を備えることを特徴とする符号化装置。
【請求項7】
複数の識別子の集合に含まれる前記識別子が、相互に重なりのある複数の部分集合に分類された当該部分集合を識別する付加符号情報が記憶された複数の前記識別媒体の識別子を、同一の付加符号情報が対応付けられた前記識別子の部分集合に分類する部分集合分類部と、
前記部分集合分類部により分類された複数の部分集合毎に、当該部分集合に属する全ての識別子に基づいて、前記付加符号情報を算出した演算方法と同一の演算方法によって当該部分集合を識別する評価符号情報を算出する評価符号情報演算部と、
前記付加符号情報と前記評価符号情報との同一性に基づいて、前記識別媒体に記憶された前記識別子の集合の完全性を判定する判定部と、
を備えることを特徴とする復号化装置。
【請求項8】
請求項6に記載の符号化装置としてコンピュータを機能させるプログラム。
【請求項9】
請求項7に記載の復号化装置としてコンピュータを機能させるプログラム。
【請求項1】
複数の識別子の集合に含まれる識別子が記憶されている複数の識別媒体の前記識別子を、相互に重なりのある複数の部分集合に分類する第1の部分集合分類部と、
前記第1の部分集合分類部により分類された複数の部分集合毎に、当該部分集合に属する全ての識別子に基づいて、予め定められた交換可能な演算方法によって当該部分集合を識別する付加符号情報を算出する付加符号情報生成部と、
前記付加符号情報生成部により算出された前記付加符号情報であって、当該付加符号情報によって識別される前記部分集合に属する前記識別媒体に、当該識別媒体の識別子に対応付けられて記憶される前記付加符号情報を出力する付加符号出力部と、を具備する符号化装置と、
前記符号化装置から出力された前記付加符号情報が記憶された複数の前記識別媒体の識別子を、同一の付加符号情報が対応付けられた前記識別子の部分集合に分類する第2の部分集合分類部と、
前記第2の部分集合分類部により分類された複数の部分集合毎に、当該部分集合に属する全ての識別子に基づいて、前記付加符号情報を算出した前記演算方法と同一の演算方法によって当該部分集合を識別する評価符号情報を算出する評価符号情報演算部と、
前記付加符号情報と前記評価符号情報との同一性に基づいて、前記識別媒体に記憶された前記識別子の集合の完全性を判定する判定部と、を具備する復号化装置と、
を備えることを特徴とする集合認識システム。
【請求項2】
前記符号化装置の前記付加符号語情報部は、
前記各部分集合に属する全ての識別子の値に排他的論理和を施すことによって部分集合毎に付加符号情報を算出する
ことを特徴とする請求項1に記載の集合認識システム。
【請求項3】
前記復号化装置の前記判定部は、
前記付加符号情報と前記評価符号情報とが合致しない場合には、欠落した識別子の総数、あるいは、欠落した識別子の値の少なくともいずれか一方を算出する
ことを特徴とする請求項1または2のいずれか1項に記載の集合認識システム。
【請求項4】
前記復号化装置の前記判定部は、
前記付加符号情報と前記評価符号情報とが合致しない場合には、前記評価符号情報と前記付加符号情報との差分から、前記識別子の独立成分を抽出し、該独立成分の数を、前記欠落した識別子の総数として算出する
ことを特徴とする請求項1から請求項3までのいずれか1項に記載の集合認識システム。
【請求項5】
符号化装置が、
複数の識別子の集合に含まれる識別子が記憶されている複数の識別媒体の前記識別子を、相互に重なりのある複数の部分集合に分類するステップと、
分類した複数の部分集合毎に、当該部分集合に属する全ての識別子に基づいて、予め定められた交換可能な演算方法によって当該部分集合を識別する付加符号情報を算出するステップと、
算出した前記付加符号情報であって、当該付加符号情報によって識別される前記部分集合に属する前記識別媒体に、当該識別媒体の識別子に対応付けられて記憶される前記付加符号情報を出力するステップと、
復号化装置が、
前記符号化装置から出力された前記付加符号情報が記憶された複数の前記識別媒体の識別子を、同一の付加符号情報が対応付けられた前記識別子の部分集合に分類するステップと、
分類した複数の部分集合毎に、当該部分集合に属する全ての識別子に基づいて、前記付加符号情報を算出した前記演算方法と同一の演算方法によって当該部分集合を識別する評価符号情報を算出するステップと、
前記付加符号情報と前記評価符号情報との同一性に基づいて、前記識別媒体に記憶された前記識別子の集合の完全性を判定するステップと、
を備えることを特徴とする集合認識方法。
【請求項6】
複数の識別子の集合に含まれる識別子が記憶されている複数の識別媒体の前記識別子を、相互に重なりのある複数の部分集合に分類する部分集合分類部と、
前記部分集合分類部により分類された複数の部分集合毎に、当該部分集合に属する全ての識別子に基づいて、予め定められた交換可能な演算方法によって当該部分集合を識別する付加符号情報を算出する付加符号情報生成部と、
前記付加符号情報生成部により算出された前記付加符号情報であって、当該付加符号情報によって識別される前記部分集合に属する前記識別媒体に、当該識別媒体の識別子に対応付けられて記憶される前記付加符号情報を出力する付加符号出力部と、
を備えることを特徴とする符号化装置。
【請求項7】
複数の識別子の集合に含まれる前記識別子が、相互に重なりのある複数の部分集合に分類された当該部分集合を識別する付加符号情報が記憶された複数の前記識別媒体の識別子を、同一の付加符号情報が対応付けられた前記識別子の部分集合に分類する部分集合分類部と、
前記部分集合分類部により分類された複数の部分集合毎に、当該部分集合に属する全ての識別子に基づいて、前記付加符号情報を算出した演算方法と同一の演算方法によって当該部分集合を識別する評価符号情報を算出する評価符号情報演算部と、
前記付加符号情報と前記評価符号情報との同一性に基づいて、前記識別媒体に記憶された前記識別子の集合の完全性を判定する判定部と、
を備えることを特徴とする復号化装置。
【請求項8】
請求項6に記載の符号化装置としてコンピュータを機能させるプログラム。
【請求項9】
請求項7に記載の復号化装置としてコンピュータを機能させるプログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】

【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【公開番号】特開2012−8783(P2012−8783A)
【公開日】平成24年1月12日(2012.1.12)
【国際特許分類】
【出願番号】特願2010−143836(P2010−143836)
【出願日】平成22年6月24日(2010.6.24)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【出願人】(899000079)学校法人慶應義塾 (742)
【Fターム(参考)】
【公開日】平成24年1月12日(2012.1.12)
【国際特許分類】
【出願日】平成22年6月24日(2010.6.24)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【出願人】(899000079)学校法人慶應義塾 (742)
【Fターム(参考)】
[ Back to top ]