
集積回路装置及び電子機器

【課題】グラフィックス処理性能をスケーラブルに調整可能であり、目標とする処理性能に応じて、最適なシステムを構築することのできる集積回路装置を提供する。
【解決手段】目標性能に応じた数の集積回路をカスケード接続することにより、グラフィックス処理性能をスケーラブルに拡張又は縮小できるという知見に基づく。第1の集積回路1と、第2の集積回路2と、第1の集積回路1と第2の集積回路2を接続する通信用バス4と、第1の集積回路1の演算結果を第2の集積回路2に出力するための入出力用バス5を含む。
【解決手段】目標性能に応じた数の集積回路をカスケード接続することにより、グラフィックス処理性能をスケーラブルに拡張又は縮小できるという知見に基づく。第1の集積回路1と、第2の集積回路2と、第1の集積回路1と第2の集積回路2を接続する通信用バス4と、第1の集積回路1の演算結果を第2の集積回路2に出力するための入出力用バス5を含む。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は,グラフィックス処理を実行可能な集積回路装置,及びこれを実装した電子機器に関する。具体的に説明すると,本発明は,複数の集積回路をカスケード接続することにより,グラフィックス処理性能をスケーラブルに拡張可能な集積回路装置,及びこれを実装した電子機器に関するものである。
【背景技術】
【0002】
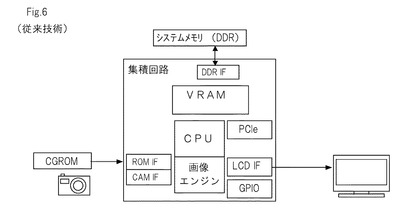
従来から,例えばLSI(Large Scale Integration)のような集積回路を用いてグラフィックス処理を行うことが知られている。図6は,集積回路を単体で用いた従来のグラフィックス処理システムを示している。従来のシステムでは,ストリームデータや描画コマンドのような画像データが格納されているCGROMや,画像データを取得するカメラ(撮像素子)のような媒体から,入力インターフェイスを介して,画像データが入力される。入力された画像データは,CPUによって,VRAM又はシステムメモリに展開された上で,画像エンジンよって画像処理が実行される。そして,画像処理が施された処理画像データは,出力インターフェイスを介して,例えば液晶ディスプレイ(LCD)のような表示装置に出力される。
【0003】
また,グラフィックス処理性能を向上させるために,複数のグラフィックプロセッサを接続して実装する従来の技術として,例えば,特開2000−222590号公報(特許文献1)や,特開2007−179225号公報(特許文献2)に開示された発明が知られている。
【0004】
特許文献1に開示された発明は,複数のグラフィックスプロセッサにより並行して描画処理を行う画像処理装置に関する。この発明では,グラフィックスプロセッサに入力された属性データ及びグラフィックスコマンドから,それぞれのグラフィックスプロセッサにおける処理の負荷を計算し,その負荷が,所定の閾値を超えたグラフィックスプロセッサについては,描画処理を停止させるものである。
【0005】
また,特許文献2に開示された発明は,ユーザの利用目的に応じて,描画処理能力の異なるグラフィックスチップを切り換え可能な情報処理装置に関する。この発明では,チップ内に,比較的に処理能力の低い内蔵グラフィックチップを内蔵し,チップ外に,比較的に処理能力が高い外部グラフィックスチップを備えている。そして,ユーザは,グラフィックス切替スイッチを介して,内蔵グラフィックスチップと外部グラフィックスチップのいずれにおいて画像処理を行うかを選択できるようになっている。
【先行技術文献】
【特許文献】
【0006】
【特許文献1】特開2000−222590号公報
【特許文献2】特開2007−179225号公報
【発明の概要】
【発明が解決しようとする課題】
【0007】
上記した特許文献1及び特許文献2に開示された技術のように,複数のグラフィックスチップを設けることで,基本的には,設置したグラフィックスチップの数に応じて,グラフィックス処理性能を向上させることが可能である。
【0008】
しかしながら,従来の発明においては,一定の目標性能を得られるように回路が構築されたものであるため,一度組み上げた回路に対してグラフィックスチップを追加したり,組み上げた回路からグラフィックスチップを取り外すことが困難であった。このため,変化する目標性能に応じて,回路のグラフィックス処理性能をスケーラブルに調整することはできなかった。すなわち,例えば,目標とする描画性能や動画・静止画デコード性能が高い場合には,回路規模を大きくすることによりその目標性能を満たすことができるものの,一旦製作した回路規模を縮小することは困難であることから,それほど高い性能を必要としない画像処理を行う場合に,組み上げた回路規模が冗長なものとなってしまっていた。
【0009】
また,例えば,図6に示したような独立した集積回路を2つ以上設け,それぞれについてシステムを構築することにより,グラフィックス処理性能を向上させることも理論上は可能である。しかし,同一のシステムをパラレルに組み上げると,それぞれの集積回路について周辺デバイス等を備えることが必要となるため,製造におけるシステムコストが肥大化することとなる。
【0010】
このため,現在では,画像処理システムにおけるグラフィックス処理性能をスケーラブルに拡張又は縮小することができ,目標とする処理性能に応じて,最適なシステムを構築することのできる技術が求められている。
【課題を解決するための手段】
【0011】
そこで,本発明の発明者は,上記の従来発明の問題点を解決する手段について鋭意検討した結果,目標性能に応じた数だけ集積回路を実装し,これらをカスケード接続することにより,グラフィックス処理性能をスケーラブルに拡張又は縮小することのできる集積回路装置を得ることができるという知見を得た。そして,本発明者は,上記知見に基づけば,従来技術の課題を解決できることに想到し,本発明を完成させた。
具体的に本発明は,以下の構成を有する。
【0012】
本発明は,グラフィックス処理を行うための集積回路装置に関するものである。
本発明の集積回路装置は,第1の集積回路(1)と,第2の集積回路(2)と,第1の集積回路(1)と第2の集積回路(2)を接続する通信用バス(4)と,第1の集積回路(1)の演算結果を第2の集積回路(2)に出力するための入出力用バス(5)を含む。
ここで,第1の集積回路(1)は,
第1の中央処理部(11)と,
画像データが入力される第1の入力インターフェイス(12)と,
第1の中央処理部(11)の制御に基づき,通信用バス(4)を介して,第1の入力インターフェイス(12)に入力された前記画像データの一部を,第2の集積回路(2)へ転送する第1の通信インターフェイス(13)と,
第1の中央処理部(11)の制御に基づいて,画像データを画像処理する第1の画像エンジン(14)と,
第1の画像エンジン(14)により画像処理された第1の処理画像データを,入出力用バス(5)を介して,第2の集積回路(2)へ出力する第1の出力インターフェイス(15)と,を具備する。
また,第2の集積回路(2)は,
通信用バス(4)を介して,第1の集積回路(1)から転送された画像データの一部を受け取る第2の通信インターフェイス(23)と,
第2の通信インターフェイス(23)が受け取った画像データの一部を,第1の中央処理部(11)の制御に基づいて,画像処理する第2の画像エンジン(24)と,
入出力用バス(5)を介して,第1の集積回路(1)から出力された第1の処理画像データが入力される第2の入力インターフェイスと(22),
第2の入力インターフェイス(22)に入力された第1の処理画像データと,第2の画像エンジン(24)が画像処理した第2の処理画像データを,統合し,出力する第2の出力インターフェイス(25)と,を具備する。
【0013】
本発明では,上記構成のように,第1の集積回路(1)と第2の集積回路(2)とを接続する。第1の集積回路(1)と第2の集積回路(2)は,基本的に,同一のグラフィックス処理性能を有し,回路構成も同一であるため,両者を接続することにより,通常の2倍のグラフィックス処理性能を得ることができる。また,第1の集積回路(1)と第2の集積回路(2)を接続するインターフェイス(通信用バス(4)と入出力用バス(5))取り外すことにより,目標性能に応じて,グラフィックス処理性能をスケーラブルに拡張又は縮小することができる。また,上記構成のように,第1の集積回路(1)と第2の集積回路(2)を接続することにより,周辺デバイス(例えばCGROM等)を共有して使用することができるためシステムコストの増加を最小限に抑えることができる。さらに,本発明では,一つ中央処理部(CPU)によって,集積回路装置全体の統治制御が行われるため,各々の集積回路間での通信を行う必要がなく,集中制御が可能となる。従って,例えばグラフィックス処理に使用するソフトウェアの開発が容易になる。
【0014】
また,本発明では,第1の集積回路(1)から第2の集積回路(2)へ画像データを転送する通信用のインターフェイスと,第1の集積回路(2)の演算結果を第2の集積回路(2)へ出力する入出力用のインターフェイスが,それぞれ別途設けられている。このため,第1の集積回路(1)の第1の中央処理部(11)が,第2の集積回路(2)を制御するために使用するバスと,第1の集積回路(2)の演算結果を第2の集積回路(2)へ出力するバスとを分けることができる。このため,第第1の集積回路(1)と第2の集積回路(2)間における相互通信の干渉問題も回避でき,画像処理のさらなる高速化を図ることができる。
【0015】
本発明において,第1の集積回路(1)は第1のシステムメモリ(10)に接続されており,第2の集積回路(2)は第2のシステムメモリ(20)に接続されていることが好ましい。
すなわち,第1の集積回路(1)において,第1の入力インターフェイス(12)に入力された画像データは,第1の中央処理部(11)の制御に基づき,第1のシステムメモリ(10)に展開され,第1の画像エンジン(14)において画像処理される。
同様に,第2の集積回路(2)において,第2の通信インターフェイス(23)により受け取った画像データの一部は,第1の中央処理部(11)の制御に基づき,第2のシステムメモリ(20)に展開され,第2の画像エンジン(24)において画像処理される。
【0016】
このように,本発明では,第1の集積回路(1)及び第2の集積回路(2)が,それぞれ独立してシステムメモリ(10,20)を有することが好ましい。画像エンジンは,画像処理を行う際に,システムメモリに展開された画像データを,システムメモリの記憶空間を利用して画像処理を実行する。本発明では,第1の画像エンジン(14)及び第2の画像エンジン(24)により並列的に画像処理が行われるが,2つの画像エンジンが共通のシステムメモリを利用して画像処理を行うと,システムメモリへのアクセスが頻繁となり,その結果,グラフィックス処理に遅延が生じることが懸念される。そこで,本発明の好ましい態様においては,それぞれの集積回路に独立したシステムメモリを接続することにより,上記問題点を解消することとしている。
【0017】
本発明は,第1の集積回路(1)と第2の集積回路(2)において,割り込み処理を行うための割り込み用バス(6)をさらに含むことが好ましい。
【0018】
本発明においては,割り込みバス(6)を介して,第2の集積回路(2)から第1の集積回路(1)の第1の中央処理部(11)に対して,画像処理終了の信号を伝送する割り込み処理を行う。これにより,第1の中央処理部(11)は,その処理性能を低下させることなく,第2の集積回路(2)における処理の完了を知ることができる。このため,第1の中央処理部(11)の制御に基づいて,効率的にグラフィックス処理を行うことができる。また,本発明では,通信用バス(4),入出力用バス(5),及び割り込み用バス(6)が別途独立して設けられているため,第1の集積回路(1)と第2の集積回路(2)間における相互通信の干渉問題も回避できる。
【0019】
本発明の他の実施形態に係る集積回路装置は,第1の集積回路(1)と,第2の集積回路(2)と,第3の集積回路(3)と,第1の集積回路(1)を第2の集積回路(2)及び第3の集積回路(3)に接続する通信用バス(4)と,第1の集積回路(1)の演算結果を第2の集積回路(2)に出力するための第1の入出力用バス(5a)と,第2の集積回路(2)の演算結果を第3の集積回路(3)に出力するための第2の入出力用バス(5a)とを含む。
第1の集積回路(1)は,
第1の中央処理部(11)と,
画像データが入力される第1の入力インターフェイス(12)と,
第1の中央処理部(11)の制御に基づき,通信用バス(4)を介して,第1の入力インターフェイス(12)に入力された画像データの一部を,第2の集積回路(2)及び第3の集積回路(3)へ転送する第1の通信インターフェイス(13)と,
第1の中央処理部(11)の制御に基づいて,画像データを画像処理する第1の画像エンジン(14)と,
第1の画像エンジン(14)により画像処理された第1の処理画像データを,第1の入出力用バス(5a)を介して,第2の集積回路(2)へ出力する第1の出力インターフェイス(15)を具備する。
第2の集積回路(2)は,
通信用バス(4)を介して,第1の集積回路(1)から転送された画像データの一部を受け取る第2の通信インターフェイス(23)と,
第2の通信インターフェイス(23)が受け取った画像データの一部を,第1の中央処理部(11)の制御に基づいて,画像処理する第2の画像エンジン(24)と,
第1の入出力用バス(5a)を介して,第1の集積回路(1)から出力された第1の処理画像データが入力される第2の入力インターフェイス(22)と,
第2の入力インターフェイス(22)に入力された第1の処理画像データと,第2の画像エンジン(24)が画像処理した第2の処理画像データを,統合した統合データを,第2の入出力バス(5b)を介して,第3の集積回路へ出力する第2の出力インターフェイス(25)とを具備する。
第3の集積回路(3)は,
通信用バス(4)を介して,第1の集積回路(1)から転送された画像データの一部を受け取る第3の通信インターフェイス(33)と,
第3の通信インターフェイス(33)が受け取った画像データの一部を,第1の中央処理部(11)の制御に基づいて,画像処理する第3の画像エンジン(34)と,
第2の入出力用バス(5b)を介して,第2の集積回路(2)から出力された統合データが入力される第3の入力インターフェイス(32)と,
第3の入力インターフェイス(32)に入力された統合データと,第3の画像エンジン(34)が画像処理した第3の処理画像データを,統合し,出力する第3の出力インターフェイス(35)とを具備する。
【0020】
本発明では,上記構成のように,第1の集積回路(1),第2の集積回路(2),及び第3の集積回路(3)を接続する。第1の集積回路(1),第2の集積回路(2),及び第3の集積回路は,基本的に,同一のグラフィックス処理性能を有し,回路構成も同一であるため,これらを接続することにより,通常の3倍のグラフィックス処理性能を得ることができる。また,これらの集積回路(1〜3)は,インターフェイス(通信用バス(4)と入出力用バス(5))を介して容易に増減することができるため,目標性能に応じて,グラフィックス処理性能をスケーラブルに拡張又は縮小することができる。
【0021】
本発明の他の実施形態は,上記した集積回路装置を実装するコンピュータである。
【0022】
本発明の他の実施形態は,上記した集積回路装置を実装するゲーム機である。
【図面の簡単な説明】
【0023】
【図1】図1は,本発明の実施形態における主要部の回路構成を示すブロック図である。
【図2】図2は,本発明の他の実施形態における主要部の回路構成を示すブロック図である。
【図3】図3は,本発明の他の実施形態における主要部の回路構成を示すブロック図である
【図4】図4は,本発明の実施形態に係るコンピュータの回路構成を示すブロック図である。
【図5】図5は,本発明の実施形態に係るゲーム機の回路構成を示すブロック図である。
【図6】図6は,従来の集積回路の回路構成を示すブロック図である。
【発明を実施するための形態】
【0024】
以下,図面を用いて本発明を実施するための形態について説明する。本発明は,以下に説明する形態に限定されるものではなく,以下の形態から当業者が自明な範囲で適宜修正したものも含む。
【0025】
(1.第1の実施形態)
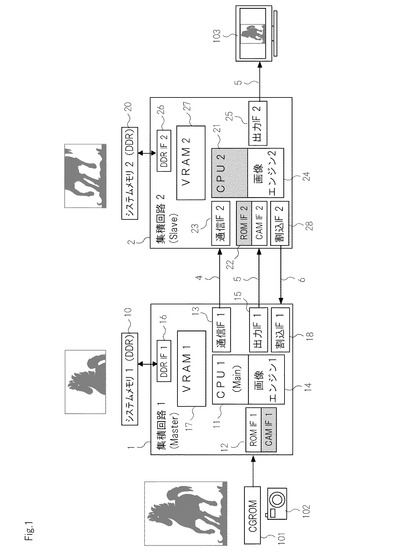
図1は,本発明の第1の実施形態における主要部の回路構成を示すブロック図である。図1に示される実施形態においては,第1の集積回路(1)と第2の集積回路(2)が,通信用バス(4),入出力用バス(5),及び割り込み用バス(6)を介して互いに接続され,信号の授受が可能となっている。図1に示されるように,第1の集積回路(1)と第2の集積回路(2)は,略同一の回路構成を有しており,それぞれが,中央処理部(以下,CPUともいう),画像エンジン,VRAM,及びその他インターフェイスを備えている。このため,第1の集積回路(1)及び第2の集積回路(2)は,相互に接続しない場合であっても,それぞれが,単独でグラフィックス処理用の集積回路としても機能する。図1に示された実施形態においては,第1の集積回路(1)における第1の中央処理部(11)によって,情報処理や機器制御が行われ,第1の中央処理部(11)の制御に基づき,グラフィックス処理が実行される。
【0026】
(1−1.第1の集積回路)
まず,第1の集積回路(1)における回路構成について説明する。
第1の集積回路(1)は,第1の中央処理部(11),第1の入力インターフェイス(12),第1の通信インターフェイス(13),第1の画像エンジン(14),第1の出力インターフェイス(15),第1のシステムメモリインターフェイス(16),第1のVRAM(17),及び第2の割り込み用インターフェイス(18)を含む。
【0027】
第1の中央処理部(11)は,システム全体における情報処理や機器制御を担当し,グラフィック処理を実行するプログラムを制御するための装置である。不揮発性メモリ101内には,例えば,第1の中央処理部(11)が読み出す各コマンドに対応した表示制御データや,キャラクタ・背景のデータ,ストリームデータ,描画コマンド,表示制御プログラムのような画像データが格納されている。そして,第1の中央処理部(11)は,入力インターフェイス(12)を介して,これらの画像データを読み出し,情報の加工を行う装置に対して分別処理を行う。不揮発性メモリ101の例は,CGROMである。また,不揮発性メモリ101は,EEPROMやフラッシュメモリであってもよい。また,第1の中央処理部(11)は,カメラのような撮像素子(102)から画像データを取得することとしてもよい。また,第1の中央処理部(11)内には,作業領域を構成するRAMが備えられていてもよい。
【0028】
第1の中央処理部(11)は,分別処理において,画像データの一部分を,第1の集積回路(1)における第1の画像エンジン(14)に振り分け,画像データの他の部分を,後述する第2の集積回路(2)における第2の画像エンジン(24)に振り分ける。第1の中央処理部(11)は,例えば,表示装置に表示する際の領域に応じて画像データを振り分けてもよいし,画像データのRGBごとに振り分けることとしてもよい。このとき,第1の中央処置部(11)は,入力された画像データの必要処理量を計算し,画像エンジンの描画可能性を基準として,振り分け処理を行うこととしてもよい。また,例えば,背景の画像データを第1の画像エンジン(14)において処理させ,キャラクタの画像データを第2の画像エンジン(24)において処理させる等,画像データの属性に応じて振り分けを行うこととしてもよい。また,例えば,立体映像表示を行う場合には,例えば,左目用の画像を第1の画像エンジン(14)において処理させ,右目用の画像を第2の画像エンジン(24)において処理させることとしてもよい。
【0029】
第1の入力インターフェイス(12)は,画像データを取得するためのインターフェイスである。第1の入力インターフェイス(12)は,例えば,CGROM(101)に格納されている画像データが入力されるROMインターフェイスや,カメラのような撮像素子(102)から画像データを取得するCAMインターフェイスを有する。第1の入力インターフェイスは,パラレル接続方式のものを用いてもよいし,シリアル接続方式のものを用いてもよい。第1の入力インターフェイス(12)に入力されたデータは,上述したように,第1の中央処理部(11)に伝達される。
なお,図1に示された実施形態においては,ROMインターフェイスを介して,CGROM(101)に格納されている画像データが入力されるため,CAMインターフェイスは使用しない。このため,CAMインターフェイスは薄墨を施して表示している。
【0030】
第1の通信インターフェイス(13)は,メイン制御を行う第1の中央処理部(11)と,その制御下にある第2の集積回路(2)の第2の中央処理部(21)を,通信用バス(4)を介して接続するための手段である。通信インターフェイス(13)は,例えば,USB(Universal Serial Bus規格),PCI(Peripheral
Component Interconnect)規格や,PCIe(PCI Express)規格,SCSI(Small Computer System Interface)規格,シリアルSCSI規格の汎用高速バスを接続するためのインターフェイスである。
【0031】
第1の画像エンジン(14)は,第1の中央処理部(11)により分別された画像データを,第1の中央処理部(11)からの指令に基づいて画像処理するための装置である。第1の中央処理部(11)により分別されたストリームデータや描画コマンドのような画像データは,第1のシステムメモリ(10)や第1のVRAM(16)に展開され,第1の画像エンジン(14)により,3Dグラフィックス処理描画や,ビデオ動画デコード処理が実行される。第1の画像エンジン(14)は,入力された画像データを解析し,解析結果に応じて所定の画像処理を行い,処理画像を第1のシステムメモリ(10)に記録する。
【0032】
第1の出力インターフェイス(15)は,第1の画像エンジン(14)により画像処理された処理画像データを,入出力用バス(5)を介して,第2の集積回路(2)へ出力するためのインターフェイスである。第1の出力インターフェイス(15)は,後述する第2の集積回路(2)における第2の入力インターフェイスに対応した規格で形成される。例えば,第1の出力インターフェイス(15)には,第1の集積回路(1)を単独で使用した場合においても,液晶ディスプレイ(103)に対して,処理画像データを出力できるインターフェイスを採用することが好ましい。第1の出力インターフェイス(15)の例は,LCDパラレルRGB出力インターフェイスである。
【0033】
第1のシステムメモリインターフェイス(16)は,第1の集積回路(1)とシステムメモリ(DDR)(10)を接続するためのインターフェイスである。
【0034】
第1のVRAM(17)や第1のシステムメモリ(10)は,第1の中央処理部(11)や第1の画像エンジン(14)の作業空間として機能する記憶装置である。第1の中央処理部(11)は,第1の入力インターフェイス(12)を介して取得した画像データを,第1のVRAM(17)や第1のシステムメモリ(10)に展開する。第1の画像エンジン(14)は第1のVRAM(17)や第1のシステムメモリ(10)を使用して画像データを処理する。
【0035】
第1の割り込み用インターフェイス(18)は,割り込み用バス(6)を介して,第2の集積回路(2)からの割り込み信号を受信するためのインターフェイスである。割り込み処理においては,第2の集積回路(2)から,第1の集積回路(1)の第1の中央処理部(11)に対して割り込み信号が送られ,第2の集積回路(2)におけるグラフィックス処理の完了が伝達される。割り込み処理が行われた場合,第1の中央処理部(11)は,例えば,その時行っていた処理を中断し,第2の集積回路(2)から受け取った信号に応じた処理を行うこととしてもよい。
【0036】
(1−2.第2の集積回路)
次に,第2の集積回路(2)における回路構成について説明する。
図1に示されるように,第2の集積回路(2)は,第2の中央処理部(21),第2の入力インターフェイス(22),第2の通信インターフェイス(23),第2の画像エンジン(24),第2の出力インターフェイス(25),第2のシステムメモリインターフェイス(26),第2のVRAM(27),及び第2の割り込み用インターフェイス(28)を含む。
【0037】
このように,第2の集積回路(2)は,上述した第1の集積回路(1)と同一の回路構成を有することが好ましい。第2の集積回路(2)は,第1の集積回路(1)の複製であってもよい。つまり,第1の集積回路(1)の第1の中央処理部(11),第1の入力インターフェイス(12),第1の通信インターフェイス(13),第1の画像エンジン(14),第1の出力インターフェイス(15),第1のシステムメモリインターフェイス(16),第1のVRAM(17),及び第2の割り込み用インターフェイス(18)は,それぞれ,第2の集積回路(2)の第2の中央処理部(21),第2の入力インターフェイス(22),第2の通信インターフェイス(23),第2の画像エンジン(24),第2の出力インターフェイス(25),第2のシステムメモリインターフェイス(26),第2のVRAM(27),及び第2の割り込み用インターフェイス(28)に相当する。ただし,当然のことながら,第2の集積回路(2)は,第1の集積回路(1)と異なる構成を有するものであってもよい。
【0038】
図1に示されるように,第1の集積回路(1)の第1の通信インターフェイス(11)と,第2の集積回路(2)の第2の通信インターフェイス(21)は,通信用バス(4)を介して,接続されている。また,第1の集積回路(1)の第1の出力インターフェイス(13)と,第2の集積回路(2)の第2の入力インターフェイス(23)は,入出力用バス(5)を介して接続されている。さらに,第1の集積回路(1)の第1の割り込み用インターフェイス(18)と,第2の集積回路(2)の第2の割り込み用インターフェイス(28)は,割り込み用バス(6)を介して接続されている。
【0039】
本実施形態においては,第2の集積回路(2)における第2入力インターフェイス(23)として,カメラのような撮像素子から画像データを取得する既存のCAMインターフェイスが使用される。このため,入出力用バス(5)を介した第1の集積回路(1)と第2の集積回路(2)間において,新たな転送手段を設けることなく,データ転送を行うことができる。
なお,本実施形態において,第2の入力インターフェイスにおけるROMインターフェイスは使用されないため,薄墨を施して表示している。
【0040】
上記のようにして,第1の集積回路(1)と第2の集積回路(2)が接続されると,いずれの集積回路を主(Master)とし,いずれの集積回路を従(Slave)として機能させるかが決定される。図1に示された実施形態においては,入力インターフェイス(12)にCGROM101が接続された第1の集積回路(1)が,主たる集積回路として機能している。従たる集積回路である第2の集積回路(2)では,第2の中央処理部(12)の機能が停止しており,情報処理や機器制御が第1の中央処理部(11)の制御に従うよう設定されている。
【0041】
第2の集積回路(2)は,第1の集積回路(1)と,CGRM(101)を共有している。このため,CGRM(101)から第1の集積回路(2)に入力された画像データの一部は,第1の中央処理部(11)の制御によって,第2の集積回路(2)の第2のVRAM又は第2のシステムメモリ(20)に展開される。第2の集積回路(2)は,第1の集積回路(1)から受け取った画像データの一部を,第2の画像エンジン(24)によって処理し,処理の完了を第1の中央処理部(11)に伝達する。そして,第2の集積回路(2)は,第1の集積回路(1)から出力された処理画像データと,第2の画像エンジンにより処理した処理画像データを,統合・合成し,LCDモニタ(103)に出力する。
【0042】
第2の集積回路(2)における各構成の説明については,上述した第1の集積回路(1)における各構成と同一であるため,ここでは,第1の集積回路(1)における説明を引用して省略する。
【0043】
(1−3.処理フロー)
以下,本発明の実施形態における処理フローについて説明する。
図1においては,本発明の実施形態の処理フローを説明するために,一つの画像データを,上下二つに分割し,上部分を第1の集積回路(1)において画像処理し,下部分を第2の集積回路(2)において画像処理し,最終的に,これら二つの処理画像データを統合して,LCDモニタ(103)に出力する例が示されている。
なお,2つの集積回路におけるグラフィック処理の例は,これに限定されるものではない。例えば,立体表示ディスプレイ用の画像処理を行う場合,第1の集積回路(1)において左目用の画像データを処理し,第2の集積回路(2)において右目用の画像データを処理することとしても良い。また,第1の集積回路(1)において背景部分の画像データを処理し,第2の集積回路(2)においてキャラクタ部分の画像データを処理することとしてもよい。
【0044】
まず,CGROM(101)に格納されているストリームデータや描画コマンド等の画像データは,第1の入力インターフェイス(12)を介して,第1の集積回路(1)に入力される。
【0045】
画像データが入力されると,第1の集積回路(1)は,第1の中央処理部(11)で分別処理を行う。分別処理においては,第1の集積回路(1)用の画像データは,第1のシステムメモリ(10)に展開される。一方,第2の集積回路用の画像データは,第1の通信インターフェイス(13)から出力され,通信用バス(4)を介して,第2の通信インターフェイス(23)に入力される。第2の集積回路(2)は,画像データが入力されると,その画像データを第2のシステムメモリ(20)に展開する。
【0046】
このように,第1の集積回路(1)と第2の集積回路(2)は,周辺デバイス(特に,CGROM等の不揮発性メモリ101)を共有して使用することができるため,システムコストの増加を最小に抑えることが可能である。
【0047】
その後,第1の中央処理部(11)は,第1の画像エンジン(14)を起動すると同時に,第1の通信インターフェイス(13)と第2の通信インターフェイス(23)の通信を介して,第2の集積回路(2)の第2の画像エンジン(24)を起動させる。
【0048】
起動した第1の画像エンジン(14)と第2の画像エンジン(24)は,それぞれ,システムメモリ(10,20)やVRAM(17,27)を使用して画像処理実行する。各画像エンジン(14,24)においては,例えば,3Dグラフィックス描画処理や,ビデオ動画デコード処理が実行される。
【0049】
このように,第1の画像エンジン(1)と第2の画像エンジン(2)は,並列的に画像処理を行っていく。このため,本発明の実施形態は,例えば図6に示された単体の集積回路において画像処理を行う従来の装置と比較して,2倍のグラフィック処理性能を得ることができる。
【0050】
各画像エンジン(14,24)において画像処理が終了すると,画像処理後の処理画像データは,それぞれ,第1のシステムメモリ(10)及び第2のシステムメモリ(20)に格納される。また,第2の画像エンジン(24)は,第1の中央処理部(11)に対し,割り込み用バス(6)を介して,画像処理の終了を通知する。このため,第1の中央処理部(11)は,割り込み通知によって,第2の集積回路(2)における画像処理の終了を認識できる。
【0051】
このように,本発明の実施形態では,第1の集積回路(1)に実装された第1の中央処理部(11)によって,システム全体の統治制御を行うことができるため,各集積回路間での通信を最小限とすることができる。
【0052】
その後,第1の中央処理部(11)は,第1のシステムメモリ(10)に格納した処理画像データを,第1の出力インターフェイス(15)を制御して,第2の集積回路(2)の第2の入力インターフェイス(22)に出力する。
【0053】
このとき,第1の出力インターフェイス(15)としては,例えば,LCD パラレルRGB 出力インターフェイスを使用することができる。また,第2の入力インターフェイス(22)としては,例えば,Camera パラレルRGB 入力インターフェイスを使用することができる。これらの第1の出力インターフェイス(15)や第2の入力インターフェイス(22)は,集積回路が単体の場合であっても,画像データをLCDモニタに出力するインターフェイスや,画像データを取得するインターフェイスとして機能するものである。従って,本発明の実施形態によれば,既存の画像データ出力用のインターフェイスと,既存の画像データ取得用のインターフェイスを,集積回路間におけるデータ転送用のインターフェイスとして利用することができる。このため,集積回路間において,新たなデータ転送手段を設けることなく,高スループットのデータ転送を行うことができる。すなわち,本発明によれば,集積回路間での通信のために専用のインターフェイスを設けなくとも,既存インターフェイスを流用して集積回路間の通信を行うことができるため,回路規模の増大を回避できる。
【0054】
第2の集積回路(2)は,第2の入力インターフェイス(22)を介して,第1の集積回路(1)によって処理された処理画像データを受け取ると,当該処理画像データを,第2のシステムメモリ(20)に格納する。このため,第2のシステムメモリ(20)上には,第1の集積回路(1)における処理画像データ(第1の処理画像データ)と,第2の集積回路(2)における処理画像データ(第2の処理画像データ)が展開される。
【0055】
そして,第1の中央処理部(11)は,通信用バス(4)における通信を介して,第2の出力インターフェイス(25)を制御し,第2のシステムメモリ(20)上に展開されている第1の処理画像データと第2の処理画像データの統合・合成を行う。統合・合成された統合データは,第2の出力インターフェイス(25)を介して,LCDモニタ(103)に出力される。
【0056】
以上のように,本発明の実施形態によれば,2つの集積回路間において,CGROM等の共有化を図ることができ,また,新たに集積回路間の通信手段(バス等)を設ける必要もないため,BOMコストの増加を最小に抑えつつ,グラフィック処理性能を2倍に拡張させることが可能となる。
【0057】
(2.第2の実施形態)
以下,図2及び図3を参酌して,本発明の第2の実施形態について説明する。
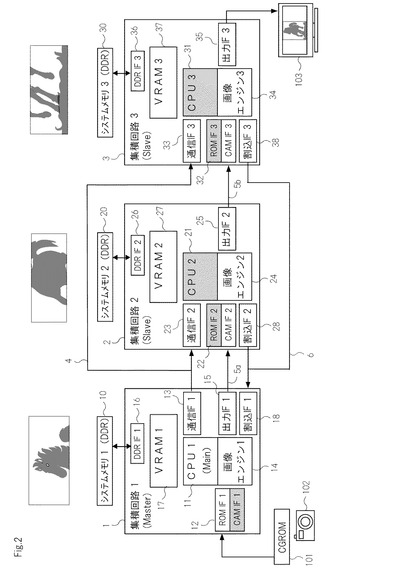
図2は,第1の集積回路(1),第2の集積回路(2),及び第3の集積回路(3)を互いにカスケード接続した実施形態を示している。
図2に示されるように,本実施形態においては,第1の集積回路を主たる回路(Master)とし,第2の集積回路(2)及び第3の集積回路(3)を従たる回路(Slave)として構築したものである。
【0058】
第1の集積回路(1)及び第2の集積回路(2)の各構成は,図1における実施形態におけるものと同一であるため,重複する点については説明を省略する。
【0059】
また,本実施形態においては,第1の集積回路(1)に,第2の集積回路(2)及び第3の集積回路(3)が接続されている。第3の集積回路は,図2に示されるように,第3の中央処理部(31),第3の入力インターフェイス(32),第3の通信インターフェイス(33),第3の画像エンジン(34),第3の出力インターフェイス(35),第3のシステムメモリインターフェイス(36),第3のVRAM(37),及び第3の割り込み用インターフェイス(38)を含む。これらの構成は,上述した第1の集積回路(1)及び第2の集積回路(3)におけるものと同一である。このため,第3の集積回路(3)は,上述した第1の集積回路(1)や第2の集積回路(2)と同一の回路構成を有することが好ましい。また,第3の集積回路(3)は,第1の集積回路(1)又は第2の集積回路(2)の複製であってもよい。ただし,当然のことながら,第3の集積回路(3)は,第1の集積回路(1)や第2の集積回路(2)と異なる構成を含むものであってもよい。
【0060】
本実施例においては,図2に示されるように,複数のレーン数を有するPCIeやPCIのような通信用バス(4)を介して,第1の集積回路(1)に,第2の集積回路(2)及び第3の集積回路(3)が接続されている。すなわち,第1の集積回路(1)と主たる回路(Master)とし,第2の集積回路(2)及び第3の集積回路(3)を従たる回路(Slave)として,1対2の接続が行われる。従って,本実施形態においては,例えば,一つの画像を三つに分割し,第1の集積回路(1)において上段部を画像処理し,第2の集積回路(2)において中段部を画像処理し,第3の集積回路(3)において下段部を画像処理することが可能である。
【0061】
本実施形態では,第1の集積回路(1)に実装された第1の中央処理部(11)が,通信用バス(4)における通信を介して,第2の集積回路(2)の第2の画像エンジン(24)や,第2の出力インターフェイス(25),第3の集積回路(3)の第3の画像エンジン(34),第3の出力インターフェイス(35)を制御する。このように,本実施形態では,第1の中央処理部(11)によって,システム全体の統治制御が行われる。なお,第2の集積回路(2)や第3の集積回路(3)も,それぞれ,第2の中央処理部(21)や第3の中央処理部(31)を有しているものの,これらの機能は停止している。
【0062】
第1の集積回路(1),第2の集積回路(2),及び第3の集積回路(3)は,CGROM(101)を共有している。CGROM(101)から,第1の集積回路(1)に画像データが入力されると,第1の中央処理部(11)は,画像データを,第1の集積回路(1),第2の集積回路(2),及び第3の集積回路(3)に分別し,それぞれのシステムメモリ(10,20,30)に展開する。
【0063】
その後,第1の中央処理部(11)は,第1の画像エンジン(14)を起動させると同時に,通信用バス(4)を介して,第2の画像エンジン(24)及び第3の画像エンジン(34)を起動させる。そして,3つの画像エンジン(14,24,34)によって,並列的に画像処理が実行される。
【0064】
第2の画像エンジン(24)及び第3の画像エンジン(34)において画像処理が終了すると,割り込み用バス(6)を介して,割り込み通知が,第1の中央処理部(11)に伝達される。
【0065】
第1の集積回路(1)において処理された第1の処理画像データは,第1の出力インターフェイス(15)から,第1の入出力用バス(5a)を介して,第2の入力インターフェイス(22)に入力される。
【0066】
第1の処理画像データは,第2のシステムメモリ(20)に格納された後,第2の集積回路(2)において処理された第2の処理画像データと統合される。統合データは,第2の出力インターフェイス(25)から,第2の入出力用バス(5b)を介して,第3の集積回路(3)へ送られる。
【0067】
第3の集積回路(3)は,第3の入力インターフェイスによって,第2の集積回路(2)から出力された統合データを取得する。第1の中央処理部(11)は,通信用バス(4)を介して,第3の入力インターフェイス(32)を制御し,統合データをシステムメモリ(30)に格納する。そして,第1の中央処理部(11)は,通信用バス(4)を介して,第3の出力インターフェイス(35)を制御し,統合データと,第3の画像エンジン34で生成した第3の処理画像データを統合・合成して,LCDモニタ(103)に出力する。
【0068】
このように,3つの集積回路をカスケード接続により,集積回路を単体で使用した場合と比較し,3倍のグラフィック処理性能を得ることができる。また,図2に示されるように,各集積回路は,周辺デバイス(CGROM等)を共有して使用することができるため,集積回路数が増加した場合であってもシステムコストの増加を最小限とすることができる。
【0069】
また,本発明においては,接続する集積回路の数は,2つ又は3つに限られるものではなく,4つ以上とすることも可能である。この場合,n個のカスケード接続によりn倍のグラフィック処理性能が得ることが可能となる。従って,必要とされる性能に応じて,適宜,接続する集積回路の数を増減することにより,スケーラブルにグラフィック処理性能を調整することができる。
【0070】
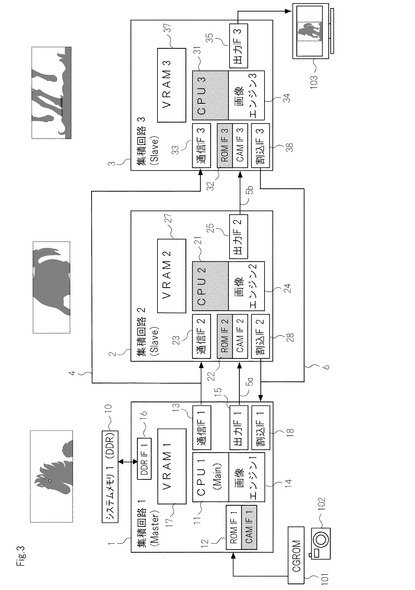
また,図3に示されるように,第2の集積回路(2)及び第3の集積回路(3)においては,システムメモリとの接続を省略することもできる。例えば,第2の集積回路(2)及び第3の集積回路(3)において内蔵するVRAM(27,37)の容量が画像処理容量に対して十分に大きい場合や,第2の画像エンジン(24)及び第3の画像エンジン(34)で生成した画像データをシステムメモリを介さずに直接出力用インターフェイス(25,35)に転送できる場合においては,システムメモリが不要となり,更なるシステムコストの節約が可能である。
【0071】
(3.コンピュータ)
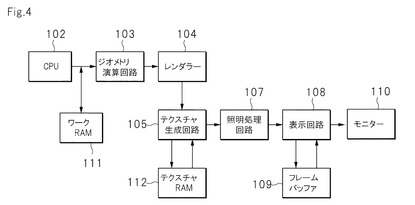
図4は,本発明のある実施態様(コンピュータ)を示すブロック図である。この実施態様は,コンピュータグラフィックスによるコンピュータ(グラフィック用コンピュータなど)に関する。図4に示されるとおり,このコンピュータは,中央処理装置(CPU)102,ジオメトリ演算回路103等のジオメトリ演算部,レンダラー104等の描画部,テクスチャ生成回路105等のテクスチャ生成部,照光処理回路107等の照光処理部,表示回路108等の表示情報作成部,フレームバッファ109,及びモニター110を具備する。これらの要素は,バスなどにより接続され,相互にデータを伝達できる。そのほか,図示しないメインメモリや,各種テーブル,ワーク領域となるワークメモリ111,テクスチャを格納するテクスチャメモリ112を具備する記憶部を有しても良い。各部を構成するハードウェアは,例えばバスを介して連結されている。なお,記憶部は,VRAM等のRAMや,CR−ROM,DVD,ハードディスクにより構成されても良い。
【0072】
中央処理装置(CPU)102は,画像を生成するためのプログラムを制御するための装置である。ワークメモリ111は,CPU102で使用するデータ及びディスプレイリストを記憶してもよい。そして,CPU102は,メインメモリに記憶されたプログラムを読み出して,所定の処理を行ってもよい。ただし,ハードウェア処理のみにより所定の処理を行っても良い。CPU102は,たとえばワークメモリ111から,ワールド座標の3次元オブジェクトデータとしてのポリゴンデータを読出し,ポリゴンデータをジオメトリ演算回路103へ出力する。具体的には,メインプロセッサ,コプロセッサ,データ処理プロセッサ,四則演算回路又は汎用演算回路を適宜有するものがあげられる。これらは例えばバスにより連結され,信号の授受が可能とされる。また,圧縮された情報を伸張するためのデータ伸張プロセッサを備えても良い。
【0073】
CPU102は,ワークメモリ111から,ポリゴンデータを読出し,ポリゴンデータをジオメトリ演算回路103へ出力する。ジオメトリ演算回路103は,入力されたポリゴンデータに対して,視点を原点とする視点座標系のデータに座標変換するなどの処理を行う。ジオメトリ演算回路103は,処理したポリゴンデータを,レンダラー104へ出力する。レンダラー104は,ポリゴン単位のデータをピクセル単位のデータに変換する。レンダラー104とテクスチャ生成回路105は,テクスチャメモリ112に記憶されるテクスチャデータに基づき,ピクセル単位のテクスチャカラーを生成する。テクスチャ生成回路105は,テクスチャカラー情報を有するピクセル単位のデータを,照光処理回路107へ出力する。照光処理回路107は,テクスチャカラー情報を有するポリゴンに対し,ピクセル単位で法線ベクトル,重心座標などを利用して陰影付けを行う。照光処理回路107は,陰影付けした画像データを,表示回路108へ出力する。表示回路108は,照光処理回路107から入力された画像データをフレームバッファ109に書き込み,またフレームバッファ109に書き込まれた画像データを読み出し,表示画像情報を得る。また,このとき同時にエッジバッファ等の情報を用いることで,2D/3Dの合成処理を行うことができる。表示回路108は,表示画像情報をモニター110へ出力する。モニター110は,入力された表示画像情報にしたがって,コンピュータグラフィックス画像を表示する。
【0074】
(4.ゲーム機)
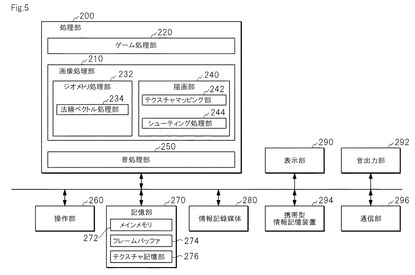
図5は,本発明のある実施形態(ゲーム機)のブロック図である。このブロック図で表される実施形態は,特に携帯用,家庭用又は業務用のゲーム機として好適に利用されうる。そこで,以下では,ゲーム機として説明する。なお,同図に示されるゲーム機は,少なくとも処理部200を含めばよく(又は処理部200と記憶部270,又は処理部200と記憶部270と情報記憶媒体280を含んでもよく),それ以外のブロック(例えば操作部260,表示部290,音出力部292,携帯型情報記憶装置294,通信部296)については,任意の構成要素とすることができる。
【0075】
システムの電源がONになると,情報記憶媒体280に格納される情報の一部又は全部は,例えば,記憶部270に転送される。そして,ゲーム処理用のプログラムが,例えばメインメモリ272に格納され,様々なデータが,テクスチャ記憶部276や,図示しないテーブルなどに格納される。
【0076】
操作部260からの操作情報は,例えば,図示しないシリアルインターフェイスやバスを介して,処理部200へ伝えられ,音処理や,様々な画像処理が行われる。音処理部250により処理された音情報は,バスを介して音出力部292へ伝えられ,音として放出される。また,メモリカードなどの携帯型情報記憶装置294に記憶されたセーブ情報なども,図示しないシリアルインターフェイスやバスを介して,処理部200へ伝えられ所定のデータが記憶部270から読み出される。
【0077】
画像処理部210が,ゲーム処理部220からの指示等にしたがって,各種の画像処理を行う。具体的には,ジオメトリ演算部232が,座標変換,クリッピング処理,透視変換,又は光源計算などの種々のジオメトリ演算(3次元座標演算)を行う。そして,ジオメトリ処理後(透視変換後)のオブジェクトデータ(オブジェクトの頂点座標,頂点テクスチャ座標,又は輝度データ等)は,例えば,記憶部270のメインメモリ272に格納されて,保存される。次に,描画部240が,ジオメトリ演算後(透視変換後)のオブジェクトデータと,テクスチャ記憶部276に記憶されるテクスチャに基づいて,オブジェクトをフレームバッファ274に描画する。
【0078】
フレームバッファ274に格納された情報は,バスを介して表示部290へ伝えられ,描画されることとなる。このようにして,コンピュータグラフィックを有するゲーム機として機能する。
【0079】
なお,本発明の実施形態は,上述したコンピュータやゲーム機に限定されるものではなく,コンピュータグラフィックス処理が実行される種々の電子機器に適用することができる。
【産業上の利用可能性】
【0080】
本発明によれば,グラフィックス処理性能をスケーラブルに調整可能な集積回路装置を提供できる。従って,本発明は,コンピュータ産業において好適に利用し得る。
【符号の説明】
【0081】
1 第1の集積回路
2 第2の集積回路
3 第3の集積回路
4 通信用バス
5 入出力用バス
5a 第1の入出力用バス
5b 第2の入出力用バス
6 割り込み用バス
10 第1のシステムメモリ
11 第1の中央処理部
12 第1の入力インターフェイス
13 第1の通信インターフェイス
14 第1の画像エンジン
15 第1の出力インターフェイス
16 第1のシステムメモリインターフェイス
17 第1のVRAM
18 第1の割り込み用インターフェイス
20 第2のシステムメモリ
21 第2の中央処理部
22 第2の入力インターフェイス
23 第2の通信インターフェイス
24 第2の画像エンジン
25 第2の出力インターフェイス
26 第2のシステムメモリインターフェイス
27 第2のVRAM
28 第2の割り込み用インターフェイス
30 第3のシステムメモリ
31 第3の中央処理部
32 第3の入力インターフェイス
33 第3の通信インターフェイス
34 第3の画像エンジン
35 第3の出力インターフェイス
26 第3のシステムメモリインターフェイス
27 第3のVRAM
28 第3の割り込み用インターフェイス
【技術分野】
【0001】
本発明は,グラフィックス処理を実行可能な集積回路装置,及びこれを実装した電子機器に関する。具体的に説明すると,本発明は,複数の集積回路をカスケード接続することにより,グラフィックス処理性能をスケーラブルに拡張可能な集積回路装置,及びこれを実装した電子機器に関するものである。
【背景技術】
【0002】
従来から,例えばLSI(Large Scale Integration)のような集積回路を用いてグラフィックス処理を行うことが知られている。図6は,集積回路を単体で用いた従来のグラフィックス処理システムを示している。従来のシステムでは,ストリームデータや描画コマンドのような画像データが格納されているCGROMや,画像データを取得するカメラ(撮像素子)のような媒体から,入力インターフェイスを介して,画像データが入力される。入力された画像データは,CPUによって,VRAM又はシステムメモリに展開された上で,画像エンジンよって画像処理が実行される。そして,画像処理が施された処理画像データは,出力インターフェイスを介して,例えば液晶ディスプレイ(LCD)のような表示装置に出力される。
【0003】
また,グラフィックス処理性能を向上させるために,複数のグラフィックプロセッサを接続して実装する従来の技術として,例えば,特開2000−222590号公報(特許文献1)や,特開2007−179225号公報(特許文献2)に開示された発明が知られている。
【0004】
特許文献1に開示された発明は,複数のグラフィックスプロセッサにより並行して描画処理を行う画像処理装置に関する。この発明では,グラフィックスプロセッサに入力された属性データ及びグラフィックスコマンドから,それぞれのグラフィックスプロセッサにおける処理の負荷を計算し,その負荷が,所定の閾値を超えたグラフィックスプロセッサについては,描画処理を停止させるものである。
【0005】
また,特許文献2に開示された発明は,ユーザの利用目的に応じて,描画処理能力の異なるグラフィックスチップを切り換え可能な情報処理装置に関する。この発明では,チップ内に,比較的に処理能力の低い内蔵グラフィックチップを内蔵し,チップ外に,比較的に処理能力が高い外部グラフィックスチップを備えている。そして,ユーザは,グラフィックス切替スイッチを介して,内蔵グラフィックスチップと外部グラフィックスチップのいずれにおいて画像処理を行うかを選択できるようになっている。
【先行技術文献】
【特許文献】
【0006】
【特許文献1】特開2000−222590号公報
【特許文献2】特開2007−179225号公報
【発明の概要】
【発明が解決しようとする課題】
【0007】
上記した特許文献1及び特許文献2に開示された技術のように,複数のグラフィックスチップを設けることで,基本的には,設置したグラフィックスチップの数に応じて,グラフィックス処理性能を向上させることが可能である。
【0008】
しかしながら,従来の発明においては,一定の目標性能を得られるように回路が構築されたものであるため,一度組み上げた回路に対してグラフィックスチップを追加したり,組み上げた回路からグラフィックスチップを取り外すことが困難であった。このため,変化する目標性能に応じて,回路のグラフィックス処理性能をスケーラブルに調整することはできなかった。すなわち,例えば,目標とする描画性能や動画・静止画デコード性能が高い場合には,回路規模を大きくすることによりその目標性能を満たすことができるものの,一旦製作した回路規模を縮小することは困難であることから,それほど高い性能を必要としない画像処理を行う場合に,組み上げた回路規模が冗長なものとなってしまっていた。
【0009】
また,例えば,図6に示したような独立した集積回路を2つ以上設け,それぞれについてシステムを構築することにより,グラフィックス処理性能を向上させることも理論上は可能である。しかし,同一のシステムをパラレルに組み上げると,それぞれの集積回路について周辺デバイス等を備えることが必要となるため,製造におけるシステムコストが肥大化することとなる。
【0010】
このため,現在では,画像処理システムにおけるグラフィックス処理性能をスケーラブルに拡張又は縮小することができ,目標とする処理性能に応じて,最適なシステムを構築することのできる技術が求められている。
【課題を解決するための手段】
【0011】
そこで,本発明の発明者は,上記の従来発明の問題点を解決する手段について鋭意検討した結果,目標性能に応じた数だけ集積回路を実装し,これらをカスケード接続することにより,グラフィックス処理性能をスケーラブルに拡張又は縮小することのできる集積回路装置を得ることができるという知見を得た。そして,本発明者は,上記知見に基づけば,従来技術の課題を解決できることに想到し,本発明を完成させた。
具体的に本発明は,以下の構成を有する。
【0012】
本発明は,グラフィックス処理を行うための集積回路装置に関するものである。
本発明の集積回路装置は,第1の集積回路(1)と,第2の集積回路(2)と,第1の集積回路(1)と第2の集積回路(2)を接続する通信用バス(4)と,第1の集積回路(1)の演算結果を第2の集積回路(2)に出力するための入出力用バス(5)を含む。
ここで,第1の集積回路(1)は,
第1の中央処理部(11)と,
画像データが入力される第1の入力インターフェイス(12)と,
第1の中央処理部(11)の制御に基づき,通信用バス(4)を介して,第1の入力インターフェイス(12)に入力された前記画像データの一部を,第2の集積回路(2)へ転送する第1の通信インターフェイス(13)と,
第1の中央処理部(11)の制御に基づいて,画像データを画像処理する第1の画像エンジン(14)と,
第1の画像エンジン(14)により画像処理された第1の処理画像データを,入出力用バス(5)を介して,第2の集積回路(2)へ出力する第1の出力インターフェイス(15)と,を具備する。
また,第2の集積回路(2)は,
通信用バス(4)を介して,第1の集積回路(1)から転送された画像データの一部を受け取る第2の通信インターフェイス(23)と,
第2の通信インターフェイス(23)が受け取った画像データの一部を,第1の中央処理部(11)の制御に基づいて,画像処理する第2の画像エンジン(24)と,
入出力用バス(5)を介して,第1の集積回路(1)から出力された第1の処理画像データが入力される第2の入力インターフェイスと(22),
第2の入力インターフェイス(22)に入力された第1の処理画像データと,第2の画像エンジン(24)が画像処理した第2の処理画像データを,統合し,出力する第2の出力インターフェイス(25)と,を具備する。
【0013】
本発明では,上記構成のように,第1の集積回路(1)と第2の集積回路(2)とを接続する。第1の集積回路(1)と第2の集積回路(2)は,基本的に,同一のグラフィックス処理性能を有し,回路構成も同一であるため,両者を接続することにより,通常の2倍のグラフィックス処理性能を得ることができる。また,第1の集積回路(1)と第2の集積回路(2)を接続するインターフェイス(通信用バス(4)と入出力用バス(5))取り外すことにより,目標性能に応じて,グラフィックス処理性能をスケーラブルに拡張又は縮小することができる。また,上記構成のように,第1の集積回路(1)と第2の集積回路(2)を接続することにより,周辺デバイス(例えばCGROM等)を共有して使用することができるためシステムコストの増加を最小限に抑えることができる。さらに,本発明では,一つ中央処理部(CPU)によって,集積回路装置全体の統治制御が行われるため,各々の集積回路間での通信を行う必要がなく,集中制御が可能となる。従って,例えばグラフィックス処理に使用するソフトウェアの開発が容易になる。
【0014】
また,本発明では,第1の集積回路(1)から第2の集積回路(2)へ画像データを転送する通信用のインターフェイスと,第1の集積回路(2)の演算結果を第2の集積回路(2)へ出力する入出力用のインターフェイスが,それぞれ別途設けられている。このため,第1の集積回路(1)の第1の中央処理部(11)が,第2の集積回路(2)を制御するために使用するバスと,第1の集積回路(2)の演算結果を第2の集積回路(2)へ出力するバスとを分けることができる。このため,第第1の集積回路(1)と第2の集積回路(2)間における相互通信の干渉問題も回避でき,画像処理のさらなる高速化を図ることができる。
【0015】
本発明において,第1の集積回路(1)は第1のシステムメモリ(10)に接続されており,第2の集積回路(2)は第2のシステムメモリ(20)に接続されていることが好ましい。
すなわち,第1の集積回路(1)において,第1の入力インターフェイス(12)に入力された画像データは,第1の中央処理部(11)の制御に基づき,第1のシステムメモリ(10)に展開され,第1の画像エンジン(14)において画像処理される。
同様に,第2の集積回路(2)において,第2の通信インターフェイス(23)により受け取った画像データの一部は,第1の中央処理部(11)の制御に基づき,第2のシステムメモリ(20)に展開され,第2の画像エンジン(24)において画像処理される。
【0016】
このように,本発明では,第1の集積回路(1)及び第2の集積回路(2)が,それぞれ独立してシステムメモリ(10,20)を有することが好ましい。画像エンジンは,画像処理を行う際に,システムメモリに展開された画像データを,システムメモリの記憶空間を利用して画像処理を実行する。本発明では,第1の画像エンジン(14)及び第2の画像エンジン(24)により並列的に画像処理が行われるが,2つの画像エンジンが共通のシステムメモリを利用して画像処理を行うと,システムメモリへのアクセスが頻繁となり,その結果,グラフィックス処理に遅延が生じることが懸念される。そこで,本発明の好ましい態様においては,それぞれの集積回路に独立したシステムメモリを接続することにより,上記問題点を解消することとしている。
【0017】
本発明は,第1の集積回路(1)と第2の集積回路(2)において,割り込み処理を行うための割り込み用バス(6)をさらに含むことが好ましい。
【0018】
本発明においては,割り込みバス(6)を介して,第2の集積回路(2)から第1の集積回路(1)の第1の中央処理部(11)に対して,画像処理終了の信号を伝送する割り込み処理を行う。これにより,第1の中央処理部(11)は,その処理性能を低下させることなく,第2の集積回路(2)における処理の完了を知ることができる。このため,第1の中央処理部(11)の制御に基づいて,効率的にグラフィックス処理を行うことができる。また,本発明では,通信用バス(4),入出力用バス(5),及び割り込み用バス(6)が別途独立して設けられているため,第1の集積回路(1)と第2の集積回路(2)間における相互通信の干渉問題も回避できる。
【0019】
本発明の他の実施形態に係る集積回路装置は,第1の集積回路(1)と,第2の集積回路(2)と,第3の集積回路(3)と,第1の集積回路(1)を第2の集積回路(2)及び第3の集積回路(3)に接続する通信用バス(4)と,第1の集積回路(1)の演算結果を第2の集積回路(2)に出力するための第1の入出力用バス(5a)と,第2の集積回路(2)の演算結果を第3の集積回路(3)に出力するための第2の入出力用バス(5a)とを含む。
第1の集積回路(1)は,
第1の中央処理部(11)と,
画像データが入力される第1の入力インターフェイス(12)と,
第1の中央処理部(11)の制御に基づき,通信用バス(4)を介して,第1の入力インターフェイス(12)に入力された画像データの一部を,第2の集積回路(2)及び第3の集積回路(3)へ転送する第1の通信インターフェイス(13)と,
第1の中央処理部(11)の制御に基づいて,画像データを画像処理する第1の画像エンジン(14)と,
第1の画像エンジン(14)により画像処理された第1の処理画像データを,第1の入出力用バス(5a)を介して,第2の集積回路(2)へ出力する第1の出力インターフェイス(15)を具備する。
第2の集積回路(2)は,
通信用バス(4)を介して,第1の集積回路(1)から転送された画像データの一部を受け取る第2の通信インターフェイス(23)と,
第2の通信インターフェイス(23)が受け取った画像データの一部を,第1の中央処理部(11)の制御に基づいて,画像処理する第2の画像エンジン(24)と,
第1の入出力用バス(5a)を介して,第1の集積回路(1)から出力された第1の処理画像データが入力される第2の入力インターフェイス(22)と,
第2の入力インターフェイス(22)に入力された第1の処理画像データと,第2の画像エンジン(24)が画像処理した第2の処理画像データを,統合した統合データを,第2の入出力バス(5b)を介して,第3の集積回路へ出力する第2の出力インターフェイス(25)とを具備する。
第3の集積回路(3)は,
通信用バス(4)を介して,第1の集積回路(1)から転送された画像データの一部を受け取る第3の通信インターフェイス(33)と,
第3の通信インターフェイス(33)が受け取った画像データの一部を,第1の中央処理部(11)の制御に基づいて,画像処理する第3の画像エンジン(34)と,
第2の入出力用バス(5b)を介して,第2の集積回路(2)から出力された統合データが入力される第3の入力インターフェイス(32)と,
第3の入力インターフェイス(32)に入力された統合データと,第3の画像エンジン(34)が画像処理した第3の処理画像データを,統合し,出力する第3の出力インターフェイス(35)とを具備する。
【0020】
本発明では,上記構成のように,第1の集積回路(1),第2の集積回路(2),及び第3の集積回路(3)を接続する。第1の集積回路(1),第2の集積回路(2),及び第3の集積回路は,基本的に,同一のグラフィックス処理性能を有し,回路構成も同一であるため,これらを接続することにより,通常の3倍のグラフィックス処理性能を得ることができる。また,これらの集積回路(1〜3)は,インターフェイス(通信用バス(4)と入出力用バス(5))を介して容易に増減することができるため,目標性能に応じて,グラフィックス処理性能をスケーラブルに拡張又は縮小することができる。
【0021】
本発明の他の実施形態は,上記した集積回路装置を実装するコンピュータである。
【0022】
本発明の他の実施形態は,上記した集積回路装置を実装するゲーム機である。
【図面の簡単な説明】
【0023】
【図1】図1は,本発明の実施形態における主要部の回路構成を示すブロック図である。
【図2】図2は,本発明の他の実施形態における主要部の回路構成を示すブロック図である。
【図3】図3は,本発明の他の実施形態における主要部の回路構成を示すブロック図である
【図4】図4は,本発明の実施形態に係るコンピュータの回路構成を示すブロック図である。
【図5】図5は,本発明の実施形態に係るゲーム機の回路構成を示すブロック図である。
【図6】図6は,従来の集積回路の回路構成を示すブロック図である。
【発明を実施するための形態】
【0024】
以下,図面を用いて本発明を実施するための形態について説明する。本発明は,以下に説明する形態に限定されるものではなく,以下の形態から当業者が自明な範囲で適宜修正したものも含む。
【0025】
(1.第1の実施形態)
図1は,本発明の第1の実施形態における主要部の回路構成を示すブロック図である。図1に示される実施形態においては,第1の集積回路(1)と第2の集積回路(2)が,通信用バス(4),入出力用バス(5),及び割り込み用バス(6)を介して互いに接続され,信号の授受が可能となっている。図1に示されるように,第1の集積回路(1)と第2の集積回路(2)は,略同一の回路構成を有しており,それぞれが,中央処理部(以下,CPUともいう),画像エンジン,VRAM,及びその他インターフェイスを備えている。このため,第1の集積回路(1)及び第2の集積回路(2)は,相互に接続しない場合であっても,それぞれが,単独でグラフィックス処理用の集積回路としても機能する。図1に示された実施形態においては,第1の集積回路(1)における第1の中央処理部(11)によって,情報処理や機器制御が行われ,第1の中央処理部(11)の制御に基づき,グラフィックス処理が実行される。
【0026】
(1−1.第1の集積回路)
まず,第1の集積回路(1)における回路構成について説明する。
第1の集積回路(1)は,第1の中央処理部(11),第1の入力インターフェイス(12),第1の通信インターフェイス(13),第1の画像エンジン(14),第1の出力インターフェイス(15),第1のシステムメモリインターフェイス(16),第1のVRAM(17),及び第2の割り込み用インターフェイス(18)を含む。
【0027】
第1の中央処理部(11)は,システム全体における情報処理や機器制御を担当し,グラフィック処理を実行するプログラムを制御するための装置である。不揮発性メモリ101内には,例えば,第1の中央処理部(11)が読み出す各コマンドに対応した表示制御データや,キャラクタ・背景のデータ,ストリームデータ,描画コマンド,表示制御プログラムのような画像データが格納されている。そして,第1の中央処理部(11)は,入力インターフェイス(12)を介して,これらの画像データを読み出し,情報の加工を行う装置に対して分別処理を行う。不揮発性メモリ101の例は,CGROMである。また,不揮発性メモリ101は,EEPROMやフラッシュメモリであってもよい。また,第1の中央処理部(11)は,カメラのような撮像素子(102)から画像データを取得することとしてもよい。また,第1の中央処理部(11)内には,作業領域を構成するRAMが備えられていてもよい。
【0028】
第1の中央処理部(11)は,分別処理において,画像データの一部分を,第1の集積回路(1)における第1の画像エンジン(14)に振り分け,画像データの他の部分を,後述する第2の集積回路(2)における第2の画像エンジン(24)に振り分ける。第1の中央処理部(11)は,例えば,表示装置に表示する際の領域に応じて画像データを振り分けてもよいし,画像データのRGBごとに振り分けることとしてもよい。このとき,第1の中央処置部(11)は,入力された画像データの必要処理量を計算し,画像エンジンの描画可能性を基準として,振り分け処理を行うこととしてもよい。また,例えば,背景の画像データを第1の画像エンジン(14)において処理させ,キャラクタの画像データを第2の画像エンジン(24)において処理させる等,画像データの属性に応じて振り分けを行うこととしてもよい。また,例えば,立体映像表示を行う場合には,例えば,左目用の画像を第1の画像エンジン(14)において処理させ,右目用の画像を第2の画像エンジン(24)において処理させることとしてもよい。
【0029】
第1の入力インターフェイス(12)は,画像データを取得するためのインターフェイスである。第1の入力インターフェイス(12)は,例えば,CGROM(101)に格納されている画像データが入力されるROMインターフェイスや,カメラのような撮像素子(102)から画像データを取得するCAMインターフェイスを有する。第1の入力インターフェイスは,パラレル接続方式のものを用いてもよいし,シリアル接続方式のものを用いてもよい。第1の入力インターフェイス(12)に入力されたデータは,上述したように,第1の中央処理部(11)に伝達される。
なお,図1に示された実施形態においては,ROMインターフェイスを介して,CGROM(101)に格納されている画像データが入力されるため,CAMインターフェイスは使用しない。このため,CAMインターフェイスは薄墨を施して表示している。
【0030】
第1の通信インターフェイス(13)は,メイン制御を行う第1の中央処理部(11)と,その制御下にある第2の集積回路(2)の第2の中央処理部(21)を,通信用バス(4)を介して接続するための手段である。通信インターフェイス(13)は,例えば,USB(Universal Serial Bus規格),PCI(Peripheral
Component Interconnect)規格や,PCIe(PCI Express)規格,SCSI(Small Computer System Interface)規格,シリアルSCSI規格の汎用高速バスを接続するためのインターフェイスである。
【0031】
第1の画像エンジン(14)は,第1の中央処理部(11)により分別された画像データを,第1の中央処理部(11)からの指令に基づいて画像処理するための装置である。第1の中央処理部(11)により分別されたストリームデータや描画コマンドのような画像データは,第1のシステムメモリ(10)や第1のVRAM(16)に展開され,第1の画像エンジン(14)により,3Dグラフィックス処理描画や,ビデオ動画デコード処理が実行される。第1の画像エンジン(14)は,入力された画像データを解析し,解析結果に応じて所定の画像処理を行い,処理画像を第1のシステムメモリ(10)に記録する。
【0032】
第1の出力インターフェイス(15)は,第1の画像エンジン(14)により画像処理された処理画像データを,入出力用バス(5)を介して,第2の集積回路(2)へ出力するためのインターフェイスである。第1の出力インターフェイス(15)は,後述する第2の集積回路(2)における第2の入力インターフェイスに対応した規格で形成される。例えば,第1の出力インターフェイス(15)には,第1の集積回路(1)を単独で使用した場合においても,液晶ディスプレイ(103)に対して,処理画像データを出力できるインターフェイスを採用することが好ましい。第1の出力インターフェイス(15)の例は,LCDパラレルRGB出力インターフェイスである。
【0033】
第1のシステムメモリインターフェイス(16)は,第1の集積回路(1)とシステムメモリ(DDR)(10)を接続するためのインターフェイスである。
【0034】
第1のVRAM(17)や第1のシステムメモリ(10)は,第1の中央処理部(11)や第1の画像エンジン(14)の作業空間として機能する記憶装置である。第1の中央処理部(11)は,第1の入力インターフェイス(12)を介して取得した画像データを,第1のVRAM(17)や第1のシステムメモリ(10)に展開する。第1の画像エンジン(14)は第1のVRAM(17)や第1のシステムメモリ(10)を使用して画像データを処理する。
【0035】
第1の割り込み用インターフェイス(18)は,割り込み用バス(6)を介して,第2の集積回路(2)からの割り込み信号を受信するためのインターフェイスである。割り込み処理においては,第2の集積回路(2)から,第1の集積回路(1)の第1の中央処理部(11)に対して割り込み信号が送られ,第2の集積回路(2)におけるグラフィックス処理の完了が伝達される。割り込み処理が行われた場合,第1の中央処理部(11)は,例えば,その時行っていた処理を中断し,第2の集積回路(2)から受け取った信号に応じた処理を行うこととしてもよい。
【0036】
(1−2.第2の集積回路)
次に,第2の集積回路(2)における回路構成について説明する。
図1に示されるように,第2の集積回路(2)は,第2の中央処理部(21),第2の入力インターフェイス(22),第2の通信インターフェイス(23),第2の画像エンジン(24),第2の出力インターフェイス(25),第2のシステムメモリインターフェイス(26),第2のVRAM(27),及び第2の割り込み用インターフェイス(28)を含む。
【0037】
このように,第2の集積回路(2)は,上述した第1の集積回路(1)と同一の回路構成を有することが好ましい。第2の集積回路(2)は,第1の集積回路(1)の複製であってもよい。つまり,第1の集積回路(1)の第1の中央処理部(11),第1の入力インターフェイス(12),第1の通信インターフェイス(13),第1の画像エンジン(14),第1の出力インターフェイス(15),第1のシステムメモリインターフェイス(16),第1のVRAM(17),及び第2の割り込み用インターフェイス(18)は,それぞれ,第2の集積回路(2)の第2の中央処理部(21),第2の入力インターフェイス(22),第2の通信インターフェイス(23),第2の画像エンジン(24),第2の出力インターフェイス(25),第2のシステムメモリインターフェイス(26),第2のVRAM(27),及び第2の割り込み用インターフェイス(28)に相当する。ただし,当然のことながら,第2の集積回路(2)は,第1の集積回路(1)と異なる構成を有するものであってもよい。
【0038】
図1に示されるように,第1の集積回路(1)の第1の通信インターフェイス(11)と,第2の集積回路(2)の第2の通信インターフェイス(21)は,通信用バス(4)を介して,接続されている。また,第1の集積回路(1)の第1の出力インターフェイス(13)と,第2の集積回路(2)の第2の入力インターフェイス(23)は,入出力用バス(5)を介して接続されている。さらに,第1の集積回路(1)の第1の割り込み用インターフェイス(18)と,第2の集積回路(2)の第2の割り込み用インターフェイス(28)は,割り込み用バス(6)を介して接続されている。
【0039】
本実施形態においては,第2の集積回路(2)における第2入力インターフェイス(23)として,カメラのような撮像素子から画像データを取得する既存のCAMインターフェイスが使用される。このため,入出力用バス(5)を介した第1の集積回路(1)と第2の集積回路(2)間において,新たな転送手段を設けることなく,データ転送を行うことができる。
なお,本実施形態において,第2の入力インターフェイスにおけるROMインターフェイスは使用されないため,薄墨を施して表示している。
【0040】
上記のようにして,第1の集積回路(1)と第2の集積回路(2)が接続されると,いずれの集積回路を主(Master)とし,いずれの集積回路を従(Slave)として機能させるかが決定される。図1に示された実施形態においては,入力インターフェイス(12)にCGROM101が接続された第1の集積回路(1)が,主たる集積回路として機能している。従たる集積回路である第2の集積回路(2)では,第2の中央処理部(12)の機能が停止しており,情報処理や機器制御が第1の中央処理部(11)の制御に従うよう設定されている。
【0041】
第2の集積回路(2)は,第1の集積回路(1)と,CGRM(101)を共有している。このため,CGRM(101)から第1の集積回路(2)に入力された画像データの一部は,第1の中央処理部(11)の制御によって,第2の集積回路(2)の第2のVRAM又は第2のシステムメモリ(20)に展開される。第2の集積回路(2)は,第1の集積回路(1)から受け取った画像データの一部を,第2の画像エンジン(24)によって処理し,処理の完了を第1の中央処理部(11)に伝達する。そして,第2の集積回路(2)は,第1の集積回路(1)から出力された処理画像データと,第2の画像エンジンにより処理した処理画像データを,統合・合成し,LCDモニタ(103)に出力する。
【0042】
第2の集積回路(2)における各構成の説明については,上述した第1の集積回路(1)における各構成と同一であるため,ここでは,第1の集積回路(1)における説明を引用して省略する。
【0043】
(1−3.処理フロー)
以下,本発明の実施形態における処理フローについて説明する。
図1においては,本発明の実施形態の処理フローを説明するために,一つの画像データを,上下二つに分割し,上部分を第1の集積回路(1)において画像処理し,下部分を第2の集積回路(2)において画像処理し,最終的に,これら二つの処理画像データを統合して,LCDモニタ(103)に出力する例が示されている。
なお,2つの集積回路におけるグラフィック処理の例は,これに限定されるものではない。例えば,立体表示ディスプレイ用の画像処理を行う場合,第1の集積回路(1)において左目用の画像データを処理し,第2の集積回路(2)において右目用の画像データを処理することとしても良い。また,第1の集積回路(1)において背景部分の画像データを処理し,第2の集積回路(2)においてキャラクタ部分の画像データを処理することとしてもよい。
【0044】
まず,CGROM(101)に格納されているストリームデータや描画コマンド等の画像データは,第1の入力インターフェイス(12)を介して,第1の集積回路(1)に入力される。
【0045】
画像データが入力されると,第1の集積回路(1)は,第1の中央処理部(11)で分別処理を行う。分別処理においては,第1の集積回路(1)用の画像データは,第1のシステムメモリ(10)に展開される。一方,第2の集積回路用の画像データは,第1の通信インターフェイス(13)から出力され,通信用バス(4)を介して,第2の通信インターフェイス(23)に入力される。第2の集積回路(2)は,画像データが入力されると,その画像データを第2のシステムメモリ(20)に展開する。
【0046】
このように,第1の集積回路(1)と第2の集積回路(2)は,周辺デバイス(特に,CGROM等の不揮発性メモリ101)を共有して使用することができるため,システムコストの増加を最小に抑えることが可能である。
【0047】
その後,第1の中央処理部(11)は,第1の画像エンジン(14)を起動すると同時に,第1の通信インターフェイス(13)と第2の通信インターフェイス(23)の通信を介して,第2の集積回路(2)の第2の画像エンジン(24)を起動させる。
【0048】
起動した第1の画像エンジン(14)と第2の画像エンジン(24)は,それぞれ,システムメモリ(10,20)やVRAM(17,27)を使用して画像処理実行する。各画像エンジン(14,24)においては,例えば,3Dグラフィックス描画処理や,ビデオ動画デコード処理が実行される。
【0049】
このように,第1の画像エンジン(1)と第2の画像エンジン(2)は,並列的に画像処理を行っていく。このため,本発明の実施形態は,例えば図6に示された単体の集積回路において画像処理を行う従来の装置と比較して,2倍のグラフィック処理性能を得ることができる。
【0050】
各画像エンジン(14,24)において画像処理が終了すると,画像処理後の処理画像データは,それぞれ,第1のシステムメモリ(10)及び第2のシステムメモリ(20)に格納される。また,第2の画像エンジン(24)は,第1の中央処理部(11)に対し,割り込み用バス(6)を介して,画像処理の終了を通知する。このため,第1の中央処理部(11)は,割り込み通知によって,第2の集積回路(2)における画像処理の終了を認識できる。
【0051】
このように,本発明の実施形態では,第1の集積回路(1)に実装された第1の中央処理部(11)によって,システム全体の統治制御を行うことができるため,各集積回路間での通信を最小限とすることができる。
【0052】
その後,第1の中央処理部(11)は,第1のシステムメモリ(10)に格納した処理画像データを,第1の出力インターフェイス(15)を制御して,第2の集積回路(2)の第2の入力インターフェイス(22)に出力する。
【0053】
このとき,第1の出力インターフェイス(15)としては,例えば,LCD パラレルRGB 出力インターフェイスを使用することができる。また,第2の入力インターフェイス(22)としては,例えば,Camera パラレルRGB 入力インターフェイスを使用することができる。これらの第1の出力インターフェイス(15)や第2の入力インターフェイス(22)は,集積回路が単体の場合であっても,画像データをLCDモニタに出力するインターフェイスや,画像データを取得するインターフェイスとして機能するものである。従って,本発明の実施形態によれば,既存の画像データ出力用のインターフェイスと,既存の画像データ取得用のインターフェイスを,集積回路間におけるデータ転送用のインターフェイスとして利用することができる。このため,集積回路間において,新たなデータ転送手段を設けることなく,高スループットのデータ転送を行うことができる。すなわち,本発明によれば,集積回路間での通信のために専用のインターフェイスを設けなくとも,既存インターフェイスを流用して集積回路間の通信を行うことができるため,回路規模の増大を回避できる。
【0054】
第2の集積回路(2)は,第2の入力インターフェイス(22)を介して,第1の集積回路(1)によって処理された処理画像データを受け取ると,当該処理画像データを,第2のシステムメモリ(20)に格納する。このため,第2のシステムメモリ(20)上には,第1の集積回路(1)における処理画像データ(第1の処理画像データ)と,第2の集積回路(2)における処理画像データ(第2の処理画像データ)が展開される。
【0055】
そして,第1の中央処理部(11)は,通信用バス(4)における通信を介して,第2の出力インターフェイス(25)を制御し,第2のシステムメモリ(20)上に展開されている第1の処理画像データと第2の処理画像データの統合・合成を行う。統合・合成された統合データは,第2の出力インターフェイス(25)を介して,LCDモニタ(103)に出力される。
【0056】
以上のように,本発明の実施形態によれば,2つの集積回路間において,CGROM等の共有化を図ることができ,また,新たに集積回路間の通信手段(バス等)を設ける必要もないため,BOMコストの増加を最小に抑えつつ,グラフィック処理性能を2倍に拡張させることが可能となる。
【0057】
(2.第2の実施形態)
以下,図2及び図3を参酌して,本発明の第2の実施形態について説明する。
図2は,第1の集積回路(1),第2の集積回路(2),及び第3の集積回路(3)を互いにカスケード接続した実施形態を示している。
図2に示されるように,本実施形態においては,第1の集積回路を主たる回路(Master)とし,第2の集積回路(2)及び第3の集積回路(3)を従たる回路(Slave)として構築したものである。
【0058】
第1の集積回路(1)及び第2の集積回路(2)の各構成は,図1における実施形態におけるものと同一であるため,重複する点については説明を省略する。
【0059】
また,本実施形態においては,第1の集積回路(1)に,第2の集積回路(2)及び第3の集積回路(3)が接続されている。第3の集積回路は,図2に示されるように,第3の中央処理部(31),第3の入力インターフェイス(32),第3の通信インターフェイス(33),第3の画像エンジン(34),第3の出力インターフェイス(35),第3のシステムメモリインターフェイス(36),第3のVRAM(37),及び第3の割り込み用インターフェイス(38)を含む。これらの構成は,上述した第1の集積回路(1)及び第2の集積回路(3)におけるものと同一である。このため,第3の集積回路(3)は,上述した第1の集積回路(1)や第2の集積回路(2)と同一の回路構成を有することが好ましい。また,第3の集積回路(3)は,第1の集積回路(1)又は第2の集積回路(2)の複製であってもよい。ただし,当然のことながら,第3の集積回路(3)は,第1の集積回路(1)や第2の集積回路(2)と異なる構成を含むものであってもよい。
【0060】
本実施例においては,図2に示されるように,複数のレーン数を有するPCIeやPCIのような通信用バス(4)を介して,第1の集積回路(1)に,第2の集積回路(2)及び第3の集積回路(3)が接続されている。すなわち,第1の集積回路(1)と主たる回路(Master)とし,第2の集積回路(2)及び第3の集積回路(3)を従たる回路(Slave)として,1対2の接続が行われる。従って,本実施形態においては,例えば,一つの画像を三つに分割し,第1の集積回路(1)において上段部を画像処理し,第2の集積回路(2)において中段部を画像処理し,第3の集積回路(3)において下段部を画像処理することが可能である。
【0061】
本実施形態では,第1の集積回路(1)に実装された第1の中央処理部(11)が,通信用バス(4)における通信を介して,第2の集積回路(2)の第2の画像エンジン(24)や,第2の出力インターフェイス(25),第3の集積回路(3)の第3の画像エンジン(34),第3の出力インターフェイス(35)を制御する。このように,本実施形態では,第1の中央処理部(11)によって,システム全体の統治制御が行われる。なお,第2の集積回路(2)や第3の集積回路(3)も,それぞれ,第2の中央処理部(21)や第3の中央処理部(31)を有しているものの,これらの機能は停止している。
【0062】
第1の集積回路(1),第2の集積回路(2),及び第3の集積回路(3)は,CGROM(101)を共有している。CGROM(101)から,第1の集積回路(1)に画像データが入力されると,第1の中央処理部(11)は,画像データを,第1の集積回路(1),第2の集積回路(2),及び第3の集積回路(3)に分別し,それぞれのシステムメモリ(10,20,30)に展開する。
【0063】
その後,第1の中央処理部(11)は,第1の画像エンジン(14)を起動させると同時に,通信用バス(4)を介して,第2の画像エンジン(24)及び第3の画像エンジン(34)を起動させる。そして,3つの画像エンジン(14,24,34)によって,並列的に画像処理が実行される。
【0064】
第2の画像エンジン(24)及び第3の画像エンジン(34)において画像処理が終了すると,割り込み用バス(6)を介して,割り込み通知が,第1の中央処理部(11)に伝達される。
【0065】
第1の集積回路(1)において処理された第1の処理画像データは,第1の出力インターフェイス(15)から,第1の入出力用バス(5a)を介して,第2の入力インターフェイス(22)に入力される。
【0066】
第1の処理画像データは,第2のシステムメモリ(20)に格納された後,第2の集積回路(2)において処理された第2の処理画像データと統合される。統合データは,第2の出力インターフェイス(25)から,第2の入出力用バス(5b)を介して,第3の集積回路(3)へ送られる。
【0067】
第3の集積回路(3)は,第3の入力インターフェイスによって,第2の集積回路(2)から出力された統合データを取得する。第1の中央処理部(11)は,通信用バス(4)を介して,第3の入力インターフェイス(32)を制御し,統合データをシステムメモリ(30)に格納する。そして,第1の中央処理部(11)は,通信用バス(4)を介して,第3の出力インターフェイス(35)を制御し,統合データと,第3の画像エンジン34で生成した第3の処理画像データを統合・合成して,LCDモニタ(103)に出力する。
【0068】
このように,3つの集積回路をカスケード接続により,集積回路を単体で使用した場合と比較し,3倍のグラフィック処理性能を得ることができる。また,図2に示されるように,各集積回路は,周辺デバイス(CGROM等)を共有して使用することができるため,集積回路数が増加した場合であってもシステムコストの増加を最小限とすることができる。
【0069】
また,本発明においては,接続する集積回路の数は,2つ又は3つに限られるものではなく,4つ以上とすることも可能である。この場合,n個のカスケード接続によりn倍のグラフィック処理性能が得ることが可能となる。従って,必要とされる性能に応じて,適宜,接続する集積回路の数を増減することにより,スケーラブルにグラフィック処理性能を調整することができる。
【0070】
また,図3に示されるように,第2の集積回路(2)及び第3の集積回路(3)においては,システムメモリとの接続を省略することもできる。例えば,第2の集積回路(2)及び第3の集積回路(3)において内蔵するVRAM(27,37)の容量が画像処理容量に対して十分に大きい場合や,第2の画像エンジン(24)及び第3の画像エンジン(34)で生成した画像データをシステムメモリを介さずに直接出力用インターフェイス(25,35)に転送できる場合においては,システムメモリが不要となり,更なるシステムコストの節約が可能である。
【0071】
(3.コンピュータ)
図4は,本発明のある実施態様(コンピュータ)を示すブロック図である。この実施態様は,コンピュータグラフィックスによるコンピュータ(グラフィック用コンピュータなど)に関する。図4に示されるとおり,このコンピュータは,中央処理装置(CPU)102,ジオメトリ演算回路103等のジオメトリ演算部,レンダラー104等の描画部,テクスチャ生成回路105等のテクスチャ生成部,照光処理回路107等の照光処理部,表示回路108等の表示情報作成部,フレームバッファ109,及びモニター110を具備する。これらの要素は,バスなどにより接続され,相互にデータを伝達できる。そのほか,図示しないメインメモリや,各種テーブル,ワーク領域となるワークメモリ111,テクスチャを格納するテクスチャメモリ112を具備する記憶部を有しても良い。各部を構成するハードウェアは,例えばバスを介して連結されている。なお,記憶部は,VRAM等のRAMや,CR−ROM,DVD,ハードディスクにより構成されても良い。
【0072】
中央処理装置(CPU)102は,画像を生成するためのプログラムを制御するための装置である。ワークメモリ111は,CPU102で使用するデータ及びディスプレイリストを記憶してもよい。そして,CPU102は,メインメモリに記憶されたプログラムを読み出して,所定の処理を行ってもよい。ただし,ハードウェア処理のみにより所定の処理を行っても良い。CPU102は,たとえばワークメモリ111から,ワールド座標の3次元オブジェクトデータとしてのポリゴンデータを読出し,ポリゴンデータをジオメトリ演算回路103へ出力する。具体的には,メインプロセッサ,コプロセッサ,データ処理プロセッサ,四則演算回路又は汎用演算回路を適宜有するものがあげられる。これらは例えばバスにより連結され,信号の授受が可能とされる。また,圧縮された情報を伸張するためのデータ伸張プロセッサを備えても良い。
【0073】
CPU102は,ワークメモリ111から,ポリゴンデータを読出し,ポリゴンデータをジオメトリ演算回路103へ出力する。ジオメトリ演算回路103は,入力されたポリゴンデータに対して,視点を原点とする視点座標系のデータに座標変換するなどの処理を行う。ジオメトリ演算回路103は,処理したポリゴンデータを,レンダラー104へ出力する。レンダラー104は,ポリゴン単位のデータをピクセル単位のデータに変換する。レンダラー104とテクスチャ生成回路105は,テクスチャメモリ112に記憶されるテクスチャデータに基づき,ピクセル単位のテクスチャカラーを生成する。テクスチャ生成回路105は,テクスチャカラー情報を有するピクセル単位のデータを,照光処理回路107へ出力する。照光処理回路107は,テクスチャカラー情報を有するポリゴンに対し,ピクセル単位で法線ベクトル,重心座標などを利用して陰影付けを行う。照光処理回路107は,陰影付けした画像データを,表示回路108へ出力する。表示回路108は,照光処理回路107から入力された画像データをフレームバッファ109に書き込み,またフレームバッファ109に書き込まれた画像データを読み出し,表示画像情報を得る。また,このとき同時にエッジバッファ等の情報を用いることで,2D/3Dの合成処理を行うことができる。表示回路108は,表示画像情報をモニター110へ出力する。モニター110は,入力された表示画像情報にしたがって,コンピュータグラフィックス画像を表示する。
【0074】
(4.ゲーム機)
図5は,本発明のある実施形態(ゲーム機)のブロック図である。このブロック図で表される実施形態は,特に携帯用,家庭用又は業務用のゲーム機として好適に利用されうる。そこで,以下では,ゲーム機として説明する。なお,同図に示されるゲーム機は,少なくとも処理部200を含めばよく(又は処理部200と記憶部270,又は処理部200と記憶部270と情報記憶媒体280を含んでもよく),それ以外のブロック(例えば操作部260,表示部290,音出力部292,携帯型情報記憶装置294,通信部296)については,任意の構成要素とすることができる。
【0075】
システムの電源がONになると,情報記憶媒体280に格納される情報の一部又は全部は,例えば,記憶部270に転送される。そして,ゲーム処理用のプログラムが,例えばメインメモリ272に格納され,様々なデータが,テクスチャ記憶部276や,図示しないテーブルなどに格納される。
【0076】
操作部260からの操作情報は,例えば,図示しないシリアルインターフェイスやバスを介して,処理部200へ伝えられ,音処理や,様々な画像処理が行われる。音処理部250により処理された音情報は,バスを介して音出力部292へ伝えられ,音として放出される。また,メモリカードなどの携帯型情報記憶装置294に記憶されたセーブ情報なども,図示しないシリアルインターフェイスやバスを介して,処理部200へ伝えられ所定のデータが記憶部270から読み出される。
【0077】
画像処理部210が,ゲーム処理部220からの指示等にしたがって,各種の画像処理を行う。具体的には,ジオメトリ演算部232が,座標変換,クリッピング処理,透視変換,又は光源計算などの種々のジオメトリ演算(3次元座標演算)を行う。そして,ジオメトリ処理後(透視変換後)のオブジェクトデータ(オブジェクトの頂点座標,頂点テクスチャ座標,又は輝度データ等)は,例えば,記憶部270のメインメモリ272に格納されて,保存される。次に,描画部240が,ジオメトリ演算後(透視変換後)のオブジェクトデータと,テクスチャ記憶部276に記憶されるテクスチャに基づいて,オブジェクトをフレームバッファ274に描画する。
【0078】
フレームバッファ274に格納された情報は,バスを介して表示部290へ伝えられ,描画されることとなる。このようにして,コンピュータグラフィックを有するゲーム機として機能する。
【0079】
なお,本発明の実施形態は,上述したコンピュータやゲーム機に限定されるものではなく,コンピュータグラフィックス処理が実行される種々の電子機器に適用することができる。
【産業上の利用可能性】
【0080】
本発明によれば,グラフィックス処理性能をスケーラブルに調整可能な集積回路装置を提供できる。従って,本発明は,コンピュータ産業において好適に利用し得る。
【符号の説明】
【0081】
1 第1の集積回路
2 第2の集積回路
3 第3の集積回路
4 通信用バス
5 入出力用バス
5a 第1の入出力用バス
5b 第2の入出力用バス
6 割り込み用バス
10 第1のシステムメモリ
11 第1の中央処理部
12 第1の入力インターフェイス
13 第1の通信インターフェイス
14 第1の画像エンジン
15 第1の出力インターフェイス
16 第1のシステムメモリインターフェイス
17 第1のVRAM
18 第1の割り込み用インターフェイス
20 第2のシステムメモリ
21 第2の中央処理部
22 第2の入力インターフェイス
23 第2の通信インターフェイス
24 第2の画像エンジン
25 第2の出力インターフェイス
26 第2のシステムメモリインターフェイス
27 第2のVRAM
28 第2の割り込み用インターフェイス
30 第3のシステムメモリ
31 第3の中央処理部
32 第3の入力インターフェイス
33 第3の通信インターフェイス
34 第3の画像エンジン
35 第3の出力インターフェイス
26 第3のシステムメモリインターフェイス
27 第3のVRAM
28 第3の割り込み用インターフェイス
【特許請求の範囲】
【請求項1】
グラフィックス処理を行うための集積回路装置であって,
第1の集積回路(1)と,
第2の集積回路(2)と,
前記第1の集積回路(1)と前記第2の集積回路(2)を接続する通信用バス(4)と,
前記第1の集積回路(1)の演算結果を前記第2の集積回路(2)に出力するための入出力用バス(5)を含み,
前記第1の集積回路(1)は,
第1の中央処理部(11)と,
画像データが入力される第1の入力インターフェイス(12)と,
前記第1の中央処理部(11)の制御に基づき,前記通信用バス(4)を介して,前記第1の入力インターフェイス(12)に入力された前記画像データの一部を,前記第2の集積回路(2)へ転送する第1の通信インターフェイス(13)と,
前記第1の中央処理部(11)の制御に基づいて,前記画像データを画像処理する第1の画像エンジン(14)と,
前記第1の画像エンジン(14)により画像処理された第1の処理画像データを,前記入出力用バス(5)を介して,前記第2の集積回路(2)へ出力する第1の出力インターフェイス(15)と,を具備し,
前記第2の集積回路(2)は,
前記通信用バス(4)を介して,前記第1の集積回路(1)から転送された前記画像データの一部を受け取る第2の通信インターフェイス(23)と,
前記第2の通信インターフェイス(23)により受け取った前記画像データの一部を,前記第1の中央処理部(11)の制御に基づいて,画像処理する第2の画像エンジン(24)と,
前記入出力用バス(5)を介して,前記第1の集積回路(1)から出力された前記第1の処理画像データが入力される第2の入力インターフェイス(22)と,
前記第2の入力インターフェイス(22)に入力された前記第1の処理画像データと,前記第2の画像エンジン(24)が画像処理した第2の処理画像データを,統合し,出力する第2の出力インターフェイス(25)と,を具備する
集積回路装置。
【請求項2】
前記第1の集積回路(1)は,第1のシステムメモリ(10)に接続されており,
前記第1の入力インターフェイス(12)に入力された前記画像データは,前記第1の中央処理部(11)の制御に基づき,前記第1のシステムメモリ(10)に展開され,前記第1の画像エンジン(14)において画像処理され,
前記第2の集積回路(2)は,第2のシステムメモリ(20)に接続されており,
前記第2の通信インターフェイス(23)により受け取った前記画像データの一部は,前記第1の中央処理部(11)の制御に基づき,前記第2のシステムメモリ(20)に展開され,前記第2の画像エンジン(24)において画像処理される
請求項1に記載の集積回路装置。
【請求項3】
前記第1の集積回路(1)と前記第2の集積回路(2)において,割り込み処理を行うための割り込み用バス(6)をさらに含む
請求項1又は請求項2に記載の集積回路装置。
【請求項4】
グラフィックス処理を行うための集積回路装置であって,
第1の集積回路(1)と,
第2の集積回路(2)と,
第3の集積回路(3)と,
前記第1の集積回路(1)を,前記第2の集積回路(2)及び前記第3の集積回路(3)に接続する通信用バス(4)と,
前記第1の集積回路(1)の演算結果を前記第2の集積回路(2)に出力するための第1の入出力用バス(5a)と,
前記第2の集積回路(2)の演算結果を前記第3の集積回路(3)に出力するための第2の入出力用バス(5b)と,を含み,
前記第1の集積回路(1)は,
第1の中央処理部(11)と,
画像データが入力される第1の入力インターフェイス(12)と,
前記第1の中央処理部(11)の制御に基づき,前記通信用バス(4)を介して,前記第1の入力インターフェイス(12)に入力された前記画像データの一部を,前記第2の集積回路(2)及び前記第3の集積回路(3)へ転送する第1の通信インターフェイス(13)と,
前記第1の中央処理部(11)の制御に基づいて,前記画像データを画像処理する第1の画像エンジン(14)と,
前記第1の画像エンジン(14)により画像処理された第1の処理画像データを,前記第1の入出力用バス(5a)を介して,前記第2の集積回路(2)へ出力する第1の出力インターフェイス(15)と,を具備し,
前記第2の集積回路(2)は,
前記通信用バス(4)を介して,前記第1の集積回路(1)から転送された前記画像データの一部を受け取る第2の通信インターフェイス(23)と,
前記第2の通信インターフェイス(23)が受け取った前記画像データの一部を,前記第1の中央処理部(11)の制御に基づいて,画像処理する第2の画像エンジン(24)と,
前記第1の入出力用バス(5a)を介して,前記第1の集積回路(1)から出力された前記第1の処理画像データが入力される第2の入力インターフェイス(22)と,
前記第2の入力インターフェイス(22)に入力された前記第1の処理画像データと,前記第2の画像エンジン(24)が画像処理した第2の処理画像データを統合し,統合データを,前記第2の入出力バス(5b)を介して,前記第3の集積回路へ出力する第2の出力インターフェイス(25)と,を具備し,
前記第3の集積回路(3)は,
前記通信用バス(4)を介して,前記第1の集積回路(1)から転送された前記画像データの一部を受け取る第3の通信インターフェイス(33)と,
前記第3の通信インターフェイス(33)が受け取った前記画像データの一部を,前記第1の中央処理部(11)の制御に基づいて,画像処理する第3の画像エンジン(34)と,
前記第2の入出力用バス(5b)を介して,前記第2の集積回路(2)から出力された前記統合データが入力される第3の入力インターフェイス(32)と,
前記第3の入力インターフェイス(32)に入力された前記統合データと,前記第3の画像エンジン(34)が画像処理した第3の処理画像データを,統合し,出力する第3の出力インターフェイス(35)と,を具備する
集積回路装置。
【請求項5】
請求項1から請求項4のいずれかに記載の集積回路装置を実装したコンピュータ。
【請求項6】
請求項1から請求項4のいずれかに記載の集積回路装置を実装したゲーム機。
【請求項1】
グラフィックス処理を行うための集積回路装置であって,
第1の集積回路(1)と,
第2の集積回路(2)と,
前記第1の集積回路(1)と前記第2の集積回路(2)を接続する通信用バス(4)と,
前記第1の集積回路(1)の演算結果を前記第2の集積回路(2)に出力するための入出力用バス(5)を含み,
前記第1の集積回路(1)は,
第1の中央処理部(11)と,
画像データが入力される第1の入力インターフェイス(12)と,
前記第1の中央処理部(11)の制御に基づき,前記通信用バス(4)を介して,前記第1の入力インターフェイス(12)に入力された前記画像データの一部を,前記第2の集積回路(2)へ転送する第1の通信インターフェイス(13)と,
前記第1の中央処理部(11)の制御に基づいて,前記画像データを画像処理する第1の画像エンジン(14)と,
前記第1の画像エンジン(14)により画像処理された第1の処理画像データを,前記入出力用バス(5)を介して,前記第2の集積回路(2)へ出力する第1の出力インターフェイス(15)と,を具備し,
前記第2の集積回路(2)は,
前記通信用バス(4)を介して,前記第1の集積回路(1)から転送された前記画像データの一部を受け取る第2の通信インターフェイス(23)と,
前記第2の通信インターフェイス(23)により受け取った前記画像データの一部を,前記第1の中央処理部(11)の制御に基づいて,画像処理する第2の画像エンジン(24)と,
前記入出力用バス(5)を介して,前記第1の集積回路(1)から出力された前記第1の処理画像データが入力される第2の入力インターフェイス(22)と,
前記第2の入力インターフェイス(22)に入力された前記第1の処理画像データと,前記第2の画像エンジン(24)が画像処理した第2の処理画像データを,統合し,出力する第2の出力インターフェイス(25)と,を具備する
集積回路装置。
【請求項2】
前記第1の集積回路(1)は,第1のシステムメモリ(10)に接続されており,
前記第1の入力インターフェイス(12)に入力された前記画像データは,前記第1の中央処理部(11)の制御に基づき,前記第1のシステムメモリ(10)に展開され,前記第1の画像エンジン(14)において画像処理され,
前記第2の集積回路(2)は,第2のシステムメモリ(20)に接続されており,
前記第2の通信インターフェイス(23)により受け取った前記画像データの一部は,前記第1の中央処理部(11)の制御に基づき,前記第2のシステムメモリ(20)に展開され,前記第2の画像エンジン(24)において画像処理される
請求項1に記載の集積回路装置。
【請求項3】
前記第1の集積回路(1)と前記第2の集積回路(2)において,割り込み処理を行うための割り込み用バス(6)をさらに含む
請求項1又は請求項2に記載の集積回路装置。
【請求項4】
グラフィックス処理を行うための集積回路装置であって,
第1の集積回路(1)と,
第2の集積回路(2)と,
第3の集積回路(3)と,
前記第1の集積回路(1)を,前記第2の集積回路(2)及び前記第3の集積回路(3)に接続する通信用バス(4)と,
前記第1の集積回路(1)の演算結果を前記第2の集積回路(2)に出力するための第1の入出力用バス(5a)と,
前記第2の集積回路(2)の演算結果を前記第3の集積回路(3)に出力するための第2の入出力用バス(5b)と,を含み,
前記第1の集積回路(1)は,
第1の中央処理部(11)と,
画像データが入力される第1の入力インターフェイス(12)と,
前記第1の中央処理部(11)の制御に基づき,前記通信用バス(4)を介して,前記第1の入力インターフェイス(12)に入力された前記画像データの一部を,前記第2の集積回路(2)及び前記第3の集積回路(3)へ転送する第1の通信インターフェイス(13)と,
前記第1の中央処理部(11)の制御に基づいて,前記画像データを画像処理する第1の画像エンジン(14)と,
前記第1の画像エンジン(14)により画像処理された第1の処理画像データを,前記第1の入出力用バス(5a)を介して,前記第2の集積回路(2)へ出力する第1の出力インターフェイス(15)と,を具備し,
前記第2の集積回路(2)は,
前記通信用バス(4)を介して,前記第1の集積回路(1)から転送された前記画像データの一部を受け取る第2の通信インターフェイス(23)と,
前記第2の通信インターフェイス(23)が受け取った前記画像データの一部を,前記第1の中央処理部(11)の制御に基づいて,画像処理する第2の画像エンジン(24)と,
前記第1の入出力用バス(5a)を介して,前記第1の集積回路(1)から出力された前記第1の処理画像データが入力される第2の入力インターフェイス(22)と,
前記第2の入力インターフェイス(22)に入力された前記第1の処理画像データと,前記第2の画像エンジン(24)が画像処理した第2の処理画像データを統合し,統合データを,前記第2の入出力バス(5b)を介して,前記第3の集積回路へ出力する第2の出力インターフェイス(25)と,を具備し,
前記第3の集積回路(3)は,
前記通信用バス(4)を介して,前記第1の集積回路(1)から転送された前記画像データの一部を受け取る第3の通信インターフェイス(33)と,
前記第3の通信インターフェイス(33)が受け取った前記画像データの一部を,前記第1の中央処理部(11)の制御に基づいて,画像処理する第3の画像エンジン(34)と,
前記第2の入出力用バス(5b)を介して,前記第2の集積回路(2)から出力された前記統合データが入力される第3の入力インターフェイス(32)と,
前記第3の入力インターフェイス(32)に入力された前記統合データと,前記第3の画像エンジン(34)が画像処理した第3の処理画像データを,統合し,出力する第3の出力インターフェイス(35)と,を具備する
集積回路装置。
【請求項5】
請求項1から請求項4のいずれかに記載の集積回路装置を実装したコンピュータ。
【請求項6】
請求項1から請求項4のいずれかに記載の集積回路装置を実装したゲーム機。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図2】
【図3】
【図4】
【図5】
【図6】
【公開番号】特開2013−3986(P2013−3986A)
【公開日】平成25年1月7日(2013.1.7)
【国際特許分類】
【出願番号】特願2011−136805(P2011−136805)
【出願日】平成23年6月20日(2011.6.20)
【特許番号】特許第4843744号(P4843744)
【特許公報発行日】平成23年12月21日(2011.12.21)
【出願人】(502401703)株式会社ディジタルメディアプロフェッショナル (26)
【Fターム(参考)】
【公開日】平成25年1月7日(2013.1.7)
【国際特許分類】
【出願日】平成23年6月20日(2011.6.20)
【特許番号】特許第4843744号(P4843744)
【特許公報発行日】平成23年12月21日(2011.12.21)
【出願人】(502401703)株式会社ディジタルメディアプロフェッショナル (26)
【Fターム(参考)】
[ Back to top ]