
音声信号の復元装置及びコンピュータプログラム
【課題】長い消失区間に対しても音声を復元する事ができる音声信号の復元装置を提供する。
【解決手段】音声信号の復元装置は、入力される音声信号データ列に消失区間があるか否かを判定し、判定結果を示す第1の信号を出力するモニタ部48と、音響モデル42と言語モデル44とを用いて音声認識を行なう音声認識部46と、音声認識部46の認識結果から音声合成を行なう音声合成部52と、モニタ部48により制御され,消失区間では音声合成部52の出力を、それ以外では入力音声データを、それぞれ選択する信号混合部56とを含む。
【解決手段】音声信号の復元装置は、入力される音声信号データ列に消失区間があるか否かを判定し、判定結果を示す第1の信号を出力するモニタ部48と、音響モデル42と言語モデル44とを用いて音声認識を行なう音声認識部46と、音声認識部46の認識結果から音声合成を行なう音声合成部52と、モニタ部48により制御され,消失区間では音声合成部52の出力を、それ以外では入力音声データを、それぞれ選択する信号混合部56とを含む。
【発明の詳細な説明】
【0001】
【発明の属する技術分野】
この発明は、パケットを用いる音声通信に関し、特に、パケットロス等により引き起こされる音声の途切れを解消するための技術に関する。
【0002】
【従来の技術】
従来の回線交換方式の電話に代わり、パケット交換方式の電話が普及しつつある。無線を用いた携帯電話でも、かなりの部分がパケット交換方式となっている。また、IP(Internet Protocol)電話と呼ばれるインターネット上で使用されるパケット交換方式の電話の普及も著しい。通信のための帯域を使う効率を考えると、近い将来、電話の大部分が回線交換方式からパケット交換方式になるものと予想される。
【0003】
パケット交換方式を用いた音声通信で問題となるのは、音声の途切れ(プチプチいう状態の事。「音とび」とも呼ばれる。)である。こうした音声の途切れが生じる原因としては、パケットロス又は無線局の切替え(ハンドオーバ)がある。
【0004】
パケットロスは、ネットワーク上のあるノードにトラヒックが集中して輻輳が生じたり、パケット転送の待ち時間に伴うジッタの吸収に失敗したりしてパケットを廃棄する事により生じる。一般に音声パケットはリアルタイム性が要求されるため、伝送プロトコルとしてUDP(User Datagram Protocol)が用いられ、パケットの再送は行なわれない。そのためこの間の音声信号データは失われる。この様に音声信号データが失われる期間の事を本明細書では消失区間と呼ぶ。
【0005】
特にアナログ通信と異なり、デジタル通信では音声の途切れの間には全く相手の音声が聞こえなくなるため、こうした音声の途切れを解消する事が望まれる。
【0006】
こうした問題を解決するために知られている従来の1手法は、ITU(国際電気通信連合)によりITU G.711 Appendix 1として勧告されている手法である。その名称は、「G.711を用いたパケットロス隠蔽のための高品質でかつ複雑さの低いアルゴリズム(A high quality low−complexity algorithm for packet loss concealment with G.711)である。
【0007】
この手法では、パケットロスが発生した時に、その前の信号をピッチ同期で繰返す。すなわちこの手法は、パケットロスが発生した区間は、前の音素が続いている事を前提としている。この手法は、現在いくつかのIP電話で実際に使用されている。
【0008】
【特許文献1】
特開2001−100782号公報
【発明が解決しようとする課題】
従来の手法では、直前の音素が続いているという前提であるため、復元する消失区間は最大で6フレーム(60ms)である。それ以上の復元は行なわない。また、原理的に2音素以上の欠落には対応できない。しかし、明らかに、より長い消失区間に対しても音声の復元を行なう様にする事が望ましい。また、2音素以上の欠落であっても復元できる様にする事が望まれる。
【0009】
それゆえに本発明の目的は、従来より長い消失区間に対しても音声を復元する事ができる音声信号の復元装置を提供する事である。
【0010】
この発明の他の目的は、従来より長い消失区間に対しても、かつその区間に2音素以上の欠落があっても、音声信号を復元できる音声信号の復元装置を提供する事である。
【0011】
【課題を解決するための手段】
本発明の第1の局面に係る音声信号の復元装置は、入力される音声信号データ列に消失区間があるか否かを判定し、判定結果を示す第1の信号を出力するための判定手段と、入力される音声信号データ列に対して、音響モデルと言語モデルとを用いて音声認識を行ない、認識結果を出力するための音声認識手段と、音声認識手段の認識結果から音声合成を行なって音声信号を出力するための音声合成手段と、第1の信号に応答して変化する混合比で、入力される音声信号データ列と音声合成手段の出力とを混合して出力するための混合手段とを含む。
【0012】
好ましくは、音声認識手段は、隠れマルコフモデルを音響モデルとして用いるものであり、音声認識手段は、第1の信号に応答し、入力される音声信号データ列の消失区間では、隠れマルコフモデルにおける出力尤度を全ての状態において等しいものとして音響モデル尤度を計算する事により音声認識を行なう。
【0013】
より好ましくは音声認識手段は、入力される音声信号データ列の消失区間の音声を、当該消失区間の直前及び直後の音声信号データ列に基づいて、音響モデルと音声信号とを用いて音声認識するための手段を含む。
【0014】
音声認識手段は、入力される音声信号データ列の消失区間の音声を、当該消失区間の直前の音声信号データ列に基づいて、音響モデルと音声信号とを用いて音声認識するための手段を含んでもよい。
【0015】
好ましくは、言語モデルは、符号帳の符号の出現に関する言語モデルを含んでもよい。
【0016】
さらに好ましくは、混合手段は、第1の信号に応答して、入力される音声信号データ列に消失区間がないときとは入力される音声信号データ列の混合比が大となり、消失区間があるときは音声合成手段の出力する音声信号の混合比が大となる様に、入力される音声信号データ列と音声合成手段の出力とを混合して出力するための手段を含む。
【0017】
混合して出力するための手段は、第1の信号に応答して、入力される音声信号データ列に消失区間がないときには入力される音声信号データ列を、消失区間があるときは音声合成手段の出力する音声信号を、それぞれ選択して出力するための選択手段を含んでもよい。
【0018】
本発明の第2の局面に係るコンピュータプログラムは、コンピュータにより実行されると、当該コンピュータを上記したいずれかの音声信号の復元装置として動作させるコンピュータプログラムである。
【0019】
【発明の実施の形態】
従来の手法は、信号の欠落区間に関しては、信号処理的な手法を用いてボトムアップに信号の復元又は補間を行なってきた。従来技術の項で説明した例がその典型である。しかし、その様な信号処理的な手法を用いた場合には復元できる信号の長さに限界がある事は明らかである。そこで、全く異なる手法により音声信号を復元する事ができれば従来技術の限界を破る事ができる可能性がある。
【0020】
そこで、本実施の形態の音声信号の復元装置では、統計的言語情報及び統計的音韻情報を用いて、トップダウンで音声信号を復元する。より具体的には、特許文献1に紹介されている様な、入力音声の一部に欠落がある場合でもその欠落を含んで音声認識を行なう事ができる音声認識手法を用いて受信音声信号の欠落部の音素片を推定し、この音素片情報より音声合成技術を用いて音声波形を合成し欠落部を復元する。
【0021】
−基本概念−
以下、本実施の形態の基礎となる欠落部の音声信号の復元方法の基本概念について説明する。
【0022】
【数1】

−実施方法−
しかし、基本概念として述べた様に式(1)を直接最大化する事は実際には困難である。そこで本実施の形態の装置では、以下の手順で式(1)を最大化する。
【0023】
【数2】
−構成−
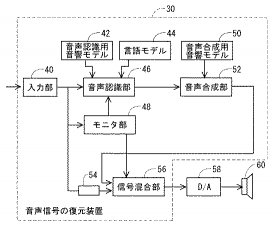
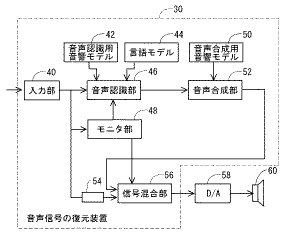
図1に、本実施の形態に係る音声信号の復元装置のブロック図を示す。この復元装置は、たとえばIP電話の一部として用いられる。図1を参照して、この音声信号の復元装置30は、入来する音声パケットの各々から音声信号データ部分を抽出して順次出力する入力部40と、入力部40から時系列的に出力される音声信号データに対して、音声認識を行なって、認識結果として状態時系列を出力するための音声認識部46と、音声認識部46が音声認識の際に使用する音声認識用音響モデル42及び言語モデル44とを含む。音声認識用音響モデル42は、音響モデルとして、予め学習済みの多数のHMM(隠れマルコフモデル)を含む。言語モデル44は、たとえばある言語コーパスから統計的に得られた、想定されているある自然言語における単語のつながり方に関する知識(確率モデル)を含む。この言語モデル44については、予め当該言語のコーパスから作成しておく。
【0024】
音声信号の復元装置30はさらに、入来する各パケットを監視し、パケットロスが発生しているか否かを示す付随情報を音声認識部46に与えるためのモニタ部48と、音声認識部46から出力された音素系列に基づいて音声合成を行ない、デジタルの音声信号を出力するための音声合成部52と、音声合成部52が音声合成の際に用いる音声合成用音響モデル50と、入力部40からの出力に対して音声認識部46での音声認識及び音声合成部52での音声合成に要する時間に見合う遅延を与えるためのバッファ54と、バッファ54の出力及び音声合成部52の出力を受け、モニタ部48に制御されて、パケットロスが発生していない期間ではバッファ54の出力の混合比が大となる様に、またパケットロスが発生している期間では音声合成部52の出力の混合比が大となる様に、信号を混合して出力するための信号混合部56とを含む。
【0025】
信号混合部56の出力は、たとえばD/A(Digital−to−Analog)コンバータ58に与えられ、図示しない増幅器を経てスピーカ60に与えられる。
【0026】
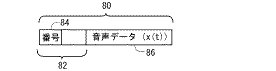
図2に入力部40に入来する音声パケット80の構成を概略的に示す。図2を参照して、音声パケット80は、ヘッダ82と、音声信号データ86とを含む。ヘッダ82はパケット番号フィールド84を含む。モニタ部48は、このパケット番号フィールド84に格納されているパケット番号を見て、パケットロスがあったか否かを判定する。
【0027】
音声認識部46が行なう音声認識の詳細については、特許文献1の記載と同様である。具体的には、音声認識部46は、次の様にして音声認識を行なう。
【0028】
音声認識部46に音声信号として与えられるのは、パケットから抽出されたデジタルの音声信号データ列(数1で示すx(i)など)である。音声認識部46はこの音声信号データ列を、たとえばMFCC(メル・フリーケンシ・ケプストラム係数)分析を行なうことにより音声のフレームごとの特徴ベクトルに変換する。
【0029】
音声認識部46は、こうして得られた個々の特徴ベクトルごとに、特徴ベクトルに対する音響モデルのアーク毎の尤度を計算する。ここでアークとは、HMM音響モデルにおいて、ある状態から次の状態への遷移が可能な経路を示す。
【0030】
HMM音響モデルにおけるアーク毎の尤度は、ある状態がある特徴ベクトルを出力する出力確率と、その状態から当該アークを通って状態遷移が生ずるであろう遷移確率との積で表される。通常は、尤度は、計算の都合上、確率値の対数をとって対数尤度とし、積を和に変えて演算する事が多い。
【0031】
音声認識部46はさらに、この様にしてHMM音響モデルにより得られた音響尤度と、言語モデル44が与える言語尤度とを用いて、前述の数2に示された原理により音声認識を行ない、音声信号(音素系列)の復元を行なう。この過程で、特徴ベクトルと、認識結果の音素系列(又は単語系列、状態系列、分布系列)との時間的対応付けも同時に定められる。
【0032】
パケットロスの間の状態遷移では、失われた情報を何らかの仮定を用いて推定する事なしに、残された情報のみで音声認識を行なう。これを「MissingFeature Theory」と呼ぶ。その詳細は特許文献1に開示されている。そのために、音声認識部46は、パケットロスの期間のフレームでは、特徴ベクトルの要素がすべて失われたものとして扱う。すなわち、当該フレームの出力尤度は、全ての状態で等しいものとし、音響モデルの遷移確率と、言語尤度とを用いて探索を行なう。
【0033】
−動作−
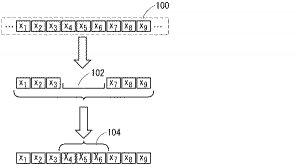
図1に示す装置は以下の様に動作する。図3に示す様に、音声信号データ列100(音声信号データx1〜x9など)がパケットとして送信されたが、そのうち音声信号データx4〜x6に対応する部分102が失われたものとする。
【0034】
入力部40は、これら音声信号データ列を音声認識部46、モニタ部48、及びバッファ54に与える。モニタ部48は、入力される音声信号データ列中にパケットロスがあるか否かを判断し、パケットロスがある場合にはその旨を示す付随情報を音声認識部46に与える。音声認識部46は、入力される音声信号データ列に対して常に音声認識用音響モデル42及び言語モデル44を用いた音声認識を行ない、結果の状態時系列を音声合成部52に与える。ただし音声認識部46は、モニタ部48からの付随情報によりパケットロスがあると判定されている間は、前述した通り尤度最大の条件で状態遷移を行なう。
【0035】
音声合成部52は、音声認識部46から出力される音素系列に基づき、音響合成用音響モデル50を用いて音声合成を行なってその波形を表す音声信号を信号混合部56に与える。
【0036】
バッファ54は、音声認識部46による音声認識と音声合成部52による音声合成に見合う時間だけ音声信号を遅延させて信号混合部56に与える。
【0037】
モニタ部48は、パケットロスが生じたときには、そのパケットロスに対応する期間では音声合成部52の出力の混合比が、それ以外の期間ではバッファ54の出力の混合比が、それぞれ大きくなる様に信号混合部56による信号の混合を制御する。典型的には、信号混合部56はそのパケットロスに対応する期間では音声合成部52の出力のみを、それ以外の期間ではバッファ54の出力のみを選択して出力する。混合された音声信号はD/Aコンバータに与えられ、アナログ信号に変換されてスピーカ60により音声に変換される。
【0038】
この結果、図3に示す様にパケットロスがあった期間102は、音声合成部52の出力X4〜X6により補完される。この補完は、音響モデルだけでなく、言語モデルという言語に関する知識を用いて行なわれる。たとえば、1音節分の音声信号がまるまる欠落してしまっても、前後のコンテキストから統計的にその音節を予測する事が可能である。そして、予測された音節を用いて音声合成を行なって音声の欠落部分を補う。そのため、従来の手法と比較してより長い消失時間に対しても対応する事ができる。また、原理的には、複数の音素が欠落した場合でもそれらを復元する事が可能である。
【0039】
−コンピュータによる実現−
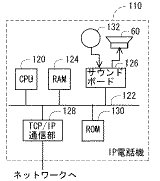
本発明に係る音声信号の復元装置30は、コンピュータハードウェア及びその上で実行されるコンピュータプログラムにより実現できる。そのため、携帯電話又はIP電話など、実質的にコンピュータハードウェア及びコンピュータプログラムにより動作する装置に組み込んで使用する事ができる。図4に、その一例としてIP電話機110のブロック図を示す。
【0040】
図4を参照して、このIP電話機110は、中央演算処理装置(CPU)120と、CPU120が接続されたバス122と、いずれもこのバス122に接続されたRAM(Random Access Memory)124、ROM(Read−Only Memory)130、及びネットワークに接続されTCP(Transfer Control Protocol)/IP通信により音声信号データのパケットを送受信するためのTCP/IP通信部128と、バス122に接続されたサウンドボード126と、サウンドボード126に接続されたマイク132及びスピーカ60とを含む。
【0041】
上記した音声信号の復元装置30を実現するコンピュータプログラム及びそのためのデータ(音声認識用音響モデル42、言語モデル44及び音声合成用音響モデル50など)は、ROM130に格納される。CPU120が、ROM130からこのコンピュータプログラムの各命令を読み出して実行する事により、上記した音声信号の復元装置30が実現できる。なお、音声認識部46としてはモニタ部48からの付加情報に応じて状態遷移の尤度を変化させる事ができる様にする事を条件として、通常の音声認識プログラムを用いる事ができる。音声合成部52としても通常の音声合成プログラムを利用できる。
【0042】
モニタ部48は、本質的には音声信号データの消失区間を検出し、その区間に応じた付随情報及び信号混合部56の制御信号を出力できるものであればよい。
【0043】
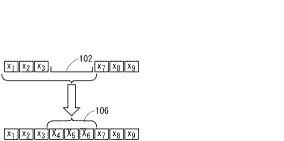
なお、この実施の形態では、図3に示す様に消失区間の直前及び直後の情報を用いて消失区間を補完した。しかし、本発明はその様な実施の形態に限定されるわけではない。特に時間遅れを避け、リアルタイム処理をする事が望まれる場合には、消失区間の直前区間の音声信号データのみを用いて(消失区間の後の区間の情報を用いずに)消失区間を含んで音声認識を行なう事もできる。この場合を図5に例示する。すなわち、消失区間102に先立つ音声信号である音声信号データ列x1〜x3を用い、消失区間も含めて音声認識を行なう事で消失区間の音素片を推定する。その結果であるX4〜X6を用いて消失区間106を補完する。
【0044】
また、Mフレーム分の遅延を許容し、前述の式(3)により表される確率を最大にする様に消失区間を推定する様に音声認識部46を構成する事も可能である。
【0045】
上記した実施の形態の音声信号の復元装置30では、言語モデルとして自然言語を想定している。しかし言語モデルはその様な自然言語に関するものに限定されるわけではない。たとえば、コーデック等で使用される符号帳の各符号を一つの音素と見て、それらに対する統計的情報から言語モデル44を作成する事もできる。また、自然言語の言語モデルを用いる場合であっても、いわゆる単語を単位とするのではなく、統計的なまとまりを持った区間を単語として扱って言語モデルを作成する様にしてもよい。
【0046】
ボトムアップクラスタリングなどの技術により音素片を自動的に分類する事で、既存の音素とは異なる擬似音素片を作成して用いてもよい。
【0047】
また、本実施の形態では、図1に示すように音声認識用音響モデル42と音響合成用音響モデル50とを別に用意した。しかし本発明はそのような実施の形態に限定されるわけではない。たとえば、音声認識部46と音声合成部52とが使用する音響モデルを共通のものとすることもできる。
【0048】
今回開示された実施の形態は単に例示であって、本発明が上記した実施の形態のみに制限されるわけではない。本発明の範囲は、発明の詳細な説明の記載を参酌した上で、特許請求の範囲の各請求項によって示され、そこに記載された文言と均等の意味及び範囲内でのすべての変更を含む。
【図面の簡単な説明】
【図1】本発明の一実施の形態に係る音声信号の復元装置のブロック図である。
【図2】音声パケットの構成を示す図である。
【図3】本発明の一実施の形態の装置の動作を説明するための図である。
【図4】本発明の一実施の形態の装置を組み込んだIP電話機のブロック図である。
【図5】本発明の一実施の形態の装置の変形例の動作を説明するための図である。
【符号の説明】
30 音声信号の復元装置、40 入力部、42 音声認識用音響モデル、44 言語モデル、46 音声認識部、48 モニタ部、50 音響合成用音響モデル、52 音声合成部、54 バッファ、56 信号混合部
【0001】
【発明の属する技術分野】
この発明は、パケットを用いる音声通信に関し、特に、パケットロス等により引き起こされる音声の途切れを解消するための技術に関する。
【0002】
【従来の技術】
従来の回線交換方式の電話に代わり、パケット交換方式の電話が普及しつつある。無線を用いた携帯電話でも、かなりの部分がパケット交換方式となっている。また、IP(Internet Protocol)電話と呼ばれるインターネット上で使用されるパケット交換方式の電話の普及も著しい。通信のための帯域を使う効率を考えると、近い将来、電話の大部分が回線交換方式からパケット交換方式になるものと予想される。
【0003】
パケット交換方式を用いた音声通信で問題となるのは、音声の途切れ(プチプチいう状態の事。「音とび」とも呼ばれる。)である。こうした音声の途切れが生じる原因としては、パケットロス又は無線局の切替え(ハンドオーバ)がある。
【0004】
パケットロスは、ネットワーク上のあるノードにトラヒックが集中して輻輳が生じたり、パケット転送の待ち時間に伴うジッタの吸収に失敗したりしてパケットを廃棄する事により生じる。一般に音声パケットはリアルタイム性が要求されるため、伝送プロトコルとしてUDP(User Datagram Protocol)が用いられ、パケットの再送は行なわれない。そのためこの間の音声信号データは失われる。この様に音声信号データが失われる期間の事を本明細書では消失区間と呼ぶ。
【0005】
特にアナログ通信と異なり、デジタル通信では音声の途切れの間には全く相手の音声が聞こえなくなるため、こうした音声の途切れを解消する事が望まれる。
【0006】
こうした問題を解決するために知られている従来の1手法は、ITU(国際電気通信連合)によりITU G.711 Appendix 1として勧告されている手法である。その名称は、「G.711を用いたパケットロス隠蔽のための高品質でかつ複雑さの低いアルゴリズム(A high quality low−complexity algorithm for packet loss concealment with G.711)である。
【0007】
この手法では、パケットロスが発生した時に、その前の信号をピッチ同期で繰返す。すなわちこの手法は、パケットロスが発生した区間は、前の音素が続いている事を前提としている。この手法は、現在いくつかのIP電話で実際に使用されている。
【0008】
【特許文献1】
特開2001−100782号公報
【発明が解決しようとする課題】
従来の手法では、直前の音素が続いているという前提であるため、復元する消失区間は最大で6フレーム(60ms)である。それ以上の復元は行なわない。また、原理的に2音素以上の欠落には対応できない。しかし、明らかに、より長い消失区間に対しても音声の復元を行なう様にする事が望ましい。また、2音素以上の欠落であっても復元できる様にする事が望まれる。
【0009】
それゆえに本発明の目的は、従来より長い消失区間に対しても音声を復元する事ができる音声信号の復元装置を提供する事である。
【0010】
この発明の他の目的は、従来より長い消失区間に対しても、かつその区間に2音素以上の欠落があっても、音声信号を復元できる音声信号の復元装置を提供する事である。
【0011】
【課題を解決するための手段】
本発明の第1の局面に係る音声信号の復元装置は、入力される音声信号データ列に消失区間があるか否かを判定し、判定結果を示す第1の信号を出力するための判定手段と、入力される音声信号データ列に対して、音響モデルと言語モデルとを用いて音声認識を行ない、認識結果を出力するための音声認識手段と、音声認識手段の認識結果から音声合成を行なって音声信号を出力するための音声合成手段と、第1の信号に応答して変化する混合比で、入力される音声信号データ列と音声合成手段の出力とを混合して出力するための混合手段とを含む。
【0012】
好ましくは、音声認識手段は、隠れマルコフモデルを音響モデルとして用いるものであり、音声認識手段は、第1の信号に応答し、入力される音声信号データ列の消失区間では、隠れマルコフモデルにおける出力尤度を全ての状態において等しいものとして音響モデル尤度を計算する事により音声認識を行なう。
【0013】
より好ましくは音声認識手段は、入力される音声信号データ列の消失区間の音声を、当該消失区間の直前及び直後の音声信号データ列に基づいて、音響モデルと音声信号とを用いて音声認識するための手段を含む。
【0014】
音声認識手段は、入力される音声信号データ列の消失区間の音声を、当該消失区間の直前の音声信号データ列に基づいて、音響モデルと音声信号とを用いて音声認識するための手段を含んでもよい。
【0015】
好ましくは、言語モデルは、符号帳の符号の出現に関する言語モデルを含んでもよい。
【0016】
さらに好ましくは、混合手段は、第1の信号に応答して、入力される音声信号データ列に消失区間がないときとは入力される音声信号データ列の混合比が大となり、消失区間があるときは音声合成手段の出力する音声信号の混合比が大となる様に、入力される音声信号データ列と音声合成手段の出力とを混合して出力するための手段を含む。
【0017】
混合して出力するための手段は、第1の信号に応答して、入力される音声信号データ列に消失区間がないときには入力される音声信号データ列を、消失区間があるときは音声合成手段の出力する音声信号を、それぞれ選択して出力するための選択手段を含んでもよい。
【0018】
本発明の第2の局面に係るコンピュータプログラムは、コンピュータにより実行されると、当該コンピュータを上記したいずれかの音声信号の復元装置として動作させるコンピュータプログラムである。
【0019】
【発明の実施の形態】
従来の手法は、信号の欠落区間に関しては、信号処理的な手法を用いてボトムアップに信号の復元又は補間を行なってきた。従来技術の項で説明した例がその典型である。しかし、その様な信号処理的な手法を用いた場合には復元できる信号の長さに限界がある事は明らかである。そこで、全く異なる手法により音声信号を復元する事ができれば従来技術の限界を破る事ができる可能性がある。
【0020】
そこで、本実施の形態の音声信号の復元装置では、統計的言語情報及び統計的音韻情報を用いて、トップダウンで音声信号を復元する。より具体的には、特許文献1に紹介されている様な、入力音声の一部に欠落がある場合でもその欠落を含んで音声認識を行なう事ができる音声認識手法を用いて受信音声信号の欠落部の音素片を推定し、この音素片情報より音声合成技術を用いて音声波形を合成し欠落部を復元する。
【0021】
−基本概念−
以下、本実施の形態の基礎となる欠落部の音声信号の復元方法の基本概念について説明する。
【0022】
【数1】
−実施方法−
しかし、基本概念として述べた様に式(1)を直接最大化する事は実際には困難である。そこで本実施の形態の装置では、以下の手順で式(1)を最大化する。
【0023】
【数2】
−構成−
図1に、本実施の形態に係る音声信号の復元装置のブロック図を示す。この復元装置は、たとえばIP電話の一部として用いられる。図1を参照して、この音声信号の復元装置30は、入来する音声パケットの各々から音声信号データ部分を抽出して順次出力する入力部40と、入力部40から時系列的に出力される音声信号データに対して、音声認識を行なって、認識結果として状態時系列を出力するための音声認識部46と、音声認識部46が音声認識の際に使用する音声認識用音響モデル42及び言語モデル44とを含む。音声認識用音響モデル42は、音響モデルとして、予め学習済みの多数のHMM(隠れマルコフモデル)を含む。言語モデル44は、たとえばある言語コーパスから統計的に得られた、想定されているある自然言語における単語のつながり方に関する知識(確率モデル)を含む。この言語モデル44については、予め当該言語のコーパスから作成しておく。
【0024】
音声信号の復元装置30はさらに、入来する各パケットを監視し、パケットロスが発生しているか否かを示す付随情報を音声認識部46に与えるためのモニタ部48と、音声認識部46から出力された音素系列に基づいて音声合成を行ない、デジタルの音声信号を出力するための音声合成部52と、音声合成部52が音声合成の際に用いる音声合成用音響モデル50と、入力部40からの出力に対して音声認識部46での音声認識及び音声合成部52での音声合成に要する時間に見合う遅延を与えるためのバッファ54と、バッファ54の出力及び音声合成部52の出力を受け、モニタ部48に制御されて、パケットロスが発生していない期間ではバッファ54の出力の混合比が大となる様に、またパケットロスが発生している期間では音声合成部52の出力の混合比が大となる様に、信号を混合して出力するための信号混合部56とを含む。
【0025】
信号混合部56の出力は、たとえばD/A(Digital−to−Analog)コンバータ58に与えられ、図示しない増幅器を経てスピーカ60に与えられる。
【0026】
図2に入力部40に入来する音声パケット80の構成を概略的に示す。図2を参照して、音声パケット80は、ヘッダ82と、音声信号データ86とを含む。ヘッダ82はパケット番号フィールド84を含む。モニタ部48は、このパケット番号フィールド84に格納されているパケット番号を見て、パケットロスがあったか否かを判定する。
【0027】
音声認識部46が行なう音声認識の詳細については、特許文献1の記載と同様である。具体的には、音声認識部46は、次の様にして音声認識を行なう。
【0028】
音声認識部46に音声信号として与えられるのは、パケットから抽出されたデジタルの音声信号データ列(数1で示すx(i)など)である。音声認識部46はこの音声信号データ列を、たとえばMFCC(メル・フリーケンシ・ケプストラム係数)分析を行なうことにより音声のフレームごとの特徴ベクトルに変換する。
【0029】
音声認識部46は、こうして得られた個々の特徴ベクトルごとに、特徴ベクトルに対する音響モデルのアーク毎の尤度を計算する。ここでアークとは、HMM音響モデルにおいて、ある状態から次の状態への遷移が可能な経路を示す。
【0030】
HMM音響モデルにおけるアーク毎の尤度は、ある状態がある特徴ベクトルを出力する出力確率と、その状態から当該アークを通って状態遷移が生ずるであろう遷移確率との積で表される。通常は、尤度は、計算の都合上、確率値の対数をとって対数尤度とし、積を和に変えて演算する事が多い。
【0031】
音声認識部46はさらに、この様にしてHMM音響モデルにより得られた音響尤度と、言語モデル44が与える言語尤度とを用いて、前述の数2に示された原理により音声認識を行ない、音声信号(音素系列)の復元を行なう。この過程で、特徴ベクトルと、認識結果の音素系列(又は単語系列、状態系列、分布系列)との時間的対応付けも同時に定められる。
【0032】
パケットロスの間の状態遷移では、失われた情報を何らかの仮定を用いて推定する事なしに、残された情報のみで音声認識を行なう。これを「MissingFeature Theory」と呼ぶ。その詳細は特許文献1に開示されている。そのために、音声認識部46は、パケットロスの期間のフレームでは、特徴ベクトルの要素がすべて失われたものとして扱う。すなわち、当該フレームの出力尤度は、全ての状態で等しいものとし、音響モデルの遷移確率と、言語尤度とを用いて探索を行なう。
【0033】
−動作−
図1に示す装置は以下の様に動作する。図3に示す様に、音声信号データ列100(音声信号データx1〜x9など)がパケットとして送信されたが、そのうち音声信号データx4〜x6に対応する部分102が失われたものとする。
【0034】
入力部40は、これら音声信号データ列を音声認識部46、モニタ部48、及びバッファ54に与える。モニタ部48は、入力される音声信号データ列中にパケットロスがあるか否かを判断し、パケットロスがある場合にはその旨を示す付随情報を音声認識部46に与える。音声認識部46は、入力される音声信号データ列に対して常に音声認識用音響モデル42及び言語モデル44を用いた音声認識を行ない、結果の状態時系列を音声合成部52に与える。ただし音声認識部46は、モニタ部48からの付随情報によりパケットロスがあると判定されている間は、前述した通り尤度最大の条件で状態遷移を行なう。
【0035】
音声合成部52は、音声認識部46から出力される音素系列に基づき、音響合成用音響モデル50を用いて音声合成を行なってその波形を表す音声信号を信号混合部56に与える。
【0036】
バッファ54は、音声認識部46による音声認識と音声合成部52による音声合成に見合う時間だけ音声信号を遅延させて信号混合部56に与える。
【0037】
モニタ部48は、パケットロスが生じたときには、そのパケットロスに対応する期間では音声合成部52の出力の混合比が、それ以外の期間ではバッファ54の出力の混合比が、それぞれ大きくなる様に信号混合部56による信号の混合を制御する。典型的には、信号混合部56はそのパケットロスに対応する期間では音声合成部52の出力のみを、それ以外の期間ではバッファ54の出力のみを選択して出力する。混合された音声信号はD/Aコンバータに与えられ、アナログ信号に変換されてスピーカ60により音声に変換される。
【0038】
この結果、図3に示す様にパケットロスがあった期間102は、音声合成部52の出力X4〜X6により補完される。この補完は、音響モデルだけでなく、言語モデルという言語に関する知識を用いて行なわれる。たとえば、1音節分の音声信号がまるまる欠落してしまっても、前後のコンテキストから統計的にその音節を予測する事が可能である。そして、予測された音節を用いて音声合成を行なって音声の欠落部分を補う。そのため、従来の手法と比較してより長い消失時間に対しても対応する事ができる。また、原理的には、複数の音素が欠落した場合でもそれらを復元する事が可能である。
【0039】
−コンピュータによる実現−
本発明に係る音声信号の復元装置30は、コンピュータハードウェア及びその上で実行されるコンピュータプログラムにより実現できる。そのため、携帯電話又はIP電話など、実質的にコンピュータハードウェア及びコンピュータプログラムにより動作する装置に組み込んで使用する事ができる。図4に、その一例としてIP電話機110のブロック図を示す。
【0040】
図4を参照して、このIP電話機110は、中央演算処理装置(CPU)120と、CPU120が接続されたバス122と、いずれもこのバス122に接続されたRAM(Random Access Memory)124、ROM(Read−Only Memory)130、及びネットワークに接続されTCP(Transfer Control Protocol)/IP通信により音声信号データのパケットを送受信するためのTCP/IP通信部128と、バス122に接続されたサウンドボード126と、サウンドボード126に接続されたマイク132及びスピーカ60とを含む。
【0041】
上記した音声信号の復元装置30を実現するコンピュータプログラム及びそのためのデータ(音声認識用音響モデル42、言語モデル44及び音声合成用音響モデル50など)は、ROM130に格納される。CPU120が、ROM130からこのコンピュータプログラムの各命令を読み出して実行する事により、上記した音声信号の復元装置30が実現できる。なお、音声認識部46としてはモニタ部48からの付加情報に応じて状態遷移の尤度を変化させる事ができる様にする事を条件として、通常の音声認識プログラムを用いる事ができる。音声合成部52としても通常の音声合成プログラムを利用できる。
【0042】
モニタ部48は、本質的には音声信号データの消失区間を検出し、その区間に応じた付随情報及び信号混合部56の制御信号を出力できるものであればよい。
【0043】
なお、この実施の形態では、図3に示す様に消失区間の直前及び直後の情報を用いて消失区間を補完した。しかし、本発明はその様な実施の形態に限定されるわけではない。特に時間遅れを避け、リアルタイム処理をする事が望まれる場合には、消失区間の直前区間の音声信号データのみを用いて(消失区間の後の区間の情報を用いずに)消失区間を含んで音声認識を行なう事もできる。この場合を図5に例示する。すなわち、消失区間102に先立つ音声信号である音声信号データ列x1〜x3を用い、消失区間も含めて音声認識を行なう事で消失区間の音素片を推定する。その結果であるX4〜X6を用いて消失区間106を補完する。
【0044】
また、Mフレーム分の遅延を許容し、前述の式(3)により表される確率を最大にする様に消失区間を推定する様に音声認識部46を構成する事も可能である。
【0045】
上記した実施の形態の音声信号の復元装置30では、言語モデルとして自然言語を想定している。しかし言語モデルはその様な自然言語に関するものに限定されるわけではない。たとえば、コーデック等で使用される符号帳の各符号を一つの音素と見て、それらに対する統計的情報から言語モデル44を作成する事もできる。また、自然言語の言語モデルを用いる場合であっても、いわゆる単語を単位とするのではなく、統計的なまとまりを持った区間を単語として扱って言語モデルを作成する様にしてもよい。
【0046】
ボトムアップクラスタリングなどの技術により音素片を自動的に分類する事で、既存の音素とは異なる擬似音素片を作成して用いてもよい。
【0047】
また、本実施の形態では、図1に示すように音声認識用音響モデル42と音響合成用音響モデル50とを別に用意した。しかし本発明はそのような実施の形態に限定されるわけではない。たとえば、音声認識部46と音声合成部52とが使用する音響モデルを共通のものとすることもできる。
【0048】
今回開示された実施の形態は単に例示であって、本発明が上記した実施の形態のみに制限されるわけではない。本発明の範囲は、発明の詳細な説明の記載を参酌した上で、特許請求の範囲の各請求項によって示され、そこに記載された文言と均等の意味及び範囲内でのすべての変更を含む。
【図面の簡単な説明】
【図1】本発明の一実施の形態に係る音声信号の復元装置のブロック図である。
【図2】音声パケットの構成を示す図である。
【図3】本発明の一実施の形態の装置の動作を説明するための図である。
【図4】本発明の一実施の形態の装置を組み込んだIP電話機のブロック図である。
【図5】本発明の一実施の形態の装置の変形例の動作を説明するための図である。
【符号の説明】
30 音声信号の復元装置、40 入力部、42 音声認識用音響モデル、44 言語モデル、46 音声認識部、48 モニタ部、50 音響合成用音響モデル、52 音声合成部、54 バッファ、56 信号混合部
【特許請求の範囲】
【請求項1】
入力される音声信号データ列に消失区間があるか否かを判定し、判定結果を示す第1の信号を出力するための判定手段と、
入力される音声信号データ列に対して、音響モデルと言語モデルとを用いて音声認識を行ない、認識結果を出力するための音声認識手段と、
前記音声認識手段の認識結果から音声合成を行なって音声信号を出力するための音声合成手段と、
前記第1の信号に応答して変化する混合比で、前記入力される音声信号データ列と前記音声合成手段の出力とを混合して出力するための混合手段とを含む、音声信号の復元装置。
【請求項2】
前記音声認識手段は、隠れマルコフモデルを音響モデルとして用いるものであり、
前記音声認識手段は、前記第1の信号に応答し、前記入力される音声信号データ列の消失区間では、前記隠れマルコフモデルにおける出力尤度を全ての状態において等しいものとして音響モデル尤度を計算する事により音声認識を行なう、請求項1に記載の音声信号の復元装置。
【請求項3】
前記音声認識手段は、前記入力される音声信号データ列の消失区間の音声を、当該消失区間の直前及び直後の音声信号データ列に基づいて、前記音響モデルと前記言語モデルとを用いて音声認識するための手段を含む、請求項1に記載の音声信号の復元装置。
【請求項4】
前記音声認識手段は、前記入力される音声信号データ列の消失区間の音声を、当該消失区間の直前の音声信号データ列に基づいて、前記音響モデルと前記言語モデルとを用いて音声認識するための手段を含む、請求項1に記載の音声信号の復元装置。
【請求項5】
前記言語モデルは、符号帳の符号の出現に関する言語モデルを含む、請求項1〜請求項4のいずれかに記載の音声信号の復元装置。
【請求項6】
前記混合手段は、前記第1の信号に応答して、前記入力される音声信号データ列に消失区間がないときとは前記入力される音声信号データ列の混合比が大となり、消失区間があるときは前記音声合成手段の出力する音声信号の混合比が大となる様に、前記入力される音声信号データ列と前記音声合成手段の出力とを混合して出力するための手段を含む、請求項1〜請求項5のいずれかに記載の音声信号の復元装置。
【請求項7】
前記混合して出力するための手段は、前記第1の信号に応答して、前記入力される音声信号データ列に消失区間がないときには前記入力される音声信号データ列を、消失区間があるときは前記音声合成手段の出力する音声信号を、それぞれ選択して出力するための選択手段を含む、請求項6に記載の音声信号の復元装置。
【請求項8】
コンピュータにより実行されると、当該コンピュータを請求項1〜請求項7のいずれかに記載の音声信号の復元装置として動作させる、コンピュータプログラム。
【請求項1】
入力される音声信号データ列に消失区間があるか否かを判定し、判定結果を示す第1の信号を出力するための判定手段と、
入力される音声信号データ列に対して、音響モデルと言語モデルとを用いて音声認識を行ない、認識結果を出力するための音声認識手段と、
前記音声認識手段の認識結果から音声合成を行なって音声信号を出力するための音声合成手段と、
前記第1の信号に応答して変化する混合比で、前記入力される音声信号データ列と前記音声合成手段の出力とを混合して出力するための混合手段とを含む、音声信号の復元装置。
【請求項2】
前記音声認識手段は、隠れマルコフモデルを音響モデルとして用いるものであり、
前記音声認識手段は、前記第1の信号に応答し、前記入力される音声信号データ列の消失区間では、前記隠れマルコフモデルにおける出力尤度を全ての状態において等しいものとして音響モデル尤度を計算する事により音声認識を行なう、請求項1に記載の音声信号の復元装置。
【請求項3】
前記音声認識手段は、前記入力される音声信号データ列の消失区間の音声を、当該消失区間の直前及び直後の音声信号データ列に基づいて、前記音響モデルと前記言語モデルとを用いて音声認識するための手段を含む、請求項1に記載の音声信号の復元装置。
【請求項4】
前記音声認識手段は、前記入力される音声信号データ列の消失区間の音声を、当該消失区間の直前の音声信号データ列に基づいて、前記音響モデルと前記言語モデルとを用いて音声認識するための手段を含む、請求項1に記載の音声信号の復元装置。
【請求項5】
前記言語モデルは、符号帳の符号の出現に関する言語モデルを含む、請求項1〜請求項4のいずれかに記載の音声信号の復元装置。
【請求項6】
前記混合手段は、前記第1の信号に応答して、前記入力される音声信号データ列に消失区間がないときとは前記入力される音声信号データ列の混合比が大となり、消失区間があるときは前記音声合成手段の出力する音声信号の混合比が大となる様に、前記入力される音声信号データ列と前記音声合成手段の出力とを混合して出力するための手段を含む、請求項1〜請求項5のいずれかに記載の音声信号の復元装置。
【請求項7】
前記混合して出力するための手段は、前記第1の信号に応答して、前記入力される音声信号データ列に消失区間がないときには前記入力される音声信号データ列を、消失区間があるときは前記音声合成手段の出力する音声信号を、それぞれ選択して出力するための選択手段を含む、請求項6に記載の音声信号の復元装置。
【請求項8】
コンピュータにより実行されると、当該コンピュータを請求項1〜請求項7のいずれかに記載の音声信号の復元装置として動作させる、コンピュータプログラム。
【図1】

【図2】
【図3】
【図4】
【図5】
【図2】
【図3】
【図4】
【図5】
【公開番号】特開2004−272128(P2004−272128A)
【公開日】平成16年9月30日(2004.9.30)
【国際特許分類】
【出願番号】特願2003−65832(P2003−65832)
【出願日】平成15年3月12日(2003.3.12)
【国等の委託研究の成果に係る記載事項】(出願人による申告)国などの委託研究の成果に係る特許出願(通信・放送機構、平成14年4月1日付け委託研究テーマ「大規模コーパスベース音声対話翻訳技術の研究開発」、産業再生法第30条の適用を受けるもの)
【出願人】(393031586)株式会社国際電気通信基礎技術研究所 (905)
【Fターム(参考)】
【公開日】平成16年9月30日(2004.9.30)
【国際特許分類】
【出願日】平成15年3月12日(2003.3.12)
【国等の委託研究の成果に係る記載事項】(出願人による申告)国などの委託研究の成果に係る特許出願(通信・放送機構、平成14年4月1日付け委託研究テーマ「大規模コーパスベース音声対話翻訳技術の研究開発」、産業再生法第30条の適用を受けるもの)
【出願人】(393031586)株式会社国際電気通信基礎技術研究所 (905)
【Fターム(参考)】
[ Back to top ]