
音声処理装置、音声処理方法、および音声処理プログラム
【課題】他の音声処理装置を使用する他のユーザが音声を聞き取れるように、適正な音量の音声をユーザに発声させる音声処理装置、音声処理方法、および音声処理プログラムを提供する。
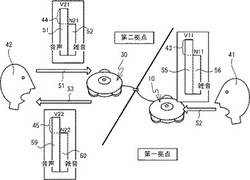
【解決手段】音声処理装置10は、音声処理装置30が集音した第二ユーザ42の音声51の音量V21および雑音52の音量N21を特定する。音声処理装置10は、特定した音声51の音量V21と雑音52の音量N21との差分44(V21−N21)に基づき、音声処理装置10が集音した雑音56の音量N11に加算する増分43を特定する。音声処理装置10は、増分43を加算した結果の音量V11である目標音量55以上の音声を第一ユーザ41に発声させるように、第一ユーザ41に通知する。第一ユーザ41が発声した音声は、音声処理装置30から出力され、第二ユーザに到達する(S3)。
【解決手段】音声処理装置10は、音声処理装置30が集音した第二ユーザ42の音声51の音量V21および雑音52の音量N21を特定する。音声処理装置10は、特定した音声51の音量V21と雑音52の音量N21との差分44(V21−N21)に基づき、音声処理装置10が集音した雑音56の音量N11に加算する増分43を特定する。音声処理装置10は、増分43を加算した結果の音量V11である目標音量55以上の音声を第一ユーザ41に発声させるように、第一ユーザ41に通知する。第一ユーザ41が発声した音声は、音声処理装置30から出力され、第二ユーザに到達する(S3)。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、ユーザから発声された音声の音量を通知する機能を備えた音声処理装置、音声処理方法、および音声処理プログラムに関する。
【背景技術】
【0002】
マイクによって集音した音声を、遠隔地に設置された他の音声処理装置に対してネットワークを介して送信すると同時に、ネットワークを介して遠隔地の音声を受信し、スピーカから出力する音声処理装置が知られている。このような音声処理装置は、遠隔会議システム等において広く使用されている。音声処理装置の一例として、スピーカフォンが挙げられる。
【0003】
通常、スピーカから出力される音には、音声と雑音とが含まれている。スピーカから出力される音声をユーザが明確に聞き取るためには、雑音の音量に対する音声の音量はより大きい方が望ましい。従ってユーザは、他の音声処理装置を使用する他のユーザが自分の音声をはっきりと聞き分けて認識できるように、より大きな声で発声し、より大きな音量の音声を他の音声処理装置のスピーカから出力させることが好ましい。例えば特許文献1では、集音された音声の音量と雑音の音量との割合に応じてランプを点灯させることによって、ユーザに大きな声で発声させ、音声を認識するために必要な音量の音声を得る技術が提案されている。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開平6−75588号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
他拠点のユーザが、スピーカから送信された自拠点のユーザの音声を雑音と切り分けて認識するための条件は、他拠点の音声処理装置が使用される環境に応じて変化する。例えば他拠点の音環境が悪く、雑音の音量が大きい場合、自拠点のマイクによって集音される音のうち、雑音の音量に比べて音声の音量を相当大きくしなければ、他拠点のユーザは自拠点のユーザの音声を雑音と切り分けて認識することができない。このため、特許文献1に記載された技術を利用し、自拠点のユーザに大きな声で発声させた場合でも、他拠点のスピーカから出力される自拠点のユーザの音声の音量が不十分となる場合がある。この場合、他拠点のユーザは、スピーカから出力される自拠点のユーザの音声を十分認識することができないという問題点がある。
【0006】
本発明の目的は、他の音声処理装置を使用する他のユーザが音声を聞き取れるように、適正な音量の音声をユーザに発声させる音声処理装置、音声処理方法、および音声処理プログラムを提供することである。
【課題を解決するための手段】
【0007】
本発明の第一態様に係る音声処理装置は、他拠点に設置された他拠点マイクを介して集音された音に関する情報である音情報を取得する第一取得手段と、前記第一取得手段によって取得された前記音情報に基づいて、音声の音量および雑音の音量を特定する第一特定手段と、自拠点に設置された音声処理装置に接続された自拠点マイクを介して集音された音に基づいて、音声の音量および雑音の音量を特定する第二特定手段と、前記第一特定手段によって特定された前記音量、および、前記第二特定手段によって特定された前記音量に基づいて、前記音声処理装置が前記自拠点マイクを介して集音する前記音声の目標とする音量である目標音量を特定する第三特定手段と、前記第三特定手段によって特定された前記目標音量に関連する情報をユーザに通知する通知手段とを備えている。
【0008】
第一態様によれば、音声処理装置は、適切な音量でユーザに音声を発声させることができる。これによって、他拠点装置を使用する他のユーザは、他拠点装置を介してユーザの音声を明確に認識できるようになる。音声処理装置は、音声および雑音の音量に基づいて目標音量を定め、ユーザに通知することができるので、自拠点の雑音の音量と比較して十分な大きさの音量で、ユーザに音声を発声させることができる。これによって他のユーザは、他拠点装置に接続された他拠点スピーカから出力される音声を、雑音と明確に区別して認識することができる。
【0009】
第一態様において、前記第三特定手段は、前記第一特定手段によって特定された前記音声の音量と前記雑音の音量との差分または割合に基づき、前記目標音量を特定してもよい。音声処理装置では、他拠点装置において集音された音声および雑音の音量に基づいて目標音量が特定されることになる。従って、目標音量でユーザに音声を発声させることによって、他拠点毎に雑音環境が異なる場合でも、他のユーザは音声を雑音と明確に区別して認識することができる。音声処理装置は、他の音声処理装置が設置されている環境に応じて、目標音量を最適化することができる。
【0010】
第一態様において、前記通知手段は、前記第三特定手段によって特定された前記目標音量と、前記第二特定手段によって特定された前記音声の音量との関係を示す情報を通知してもよい。音声処理装置のユーザは、発声した音声の音量が目標音量に対してどの程度であるかを認識することができる。従ってユーザは、目標音量を容易に判断し、音声の音量が目標音量に近づくように発声することができる。
【0011】
第一態様において、前記通知手段は、前記第三特定手段によって特定された前記目標音量が、前記自拠点マイクを介して集音することが可能な最大音量を超えた場合に、最大音量を超えた旨をユーザに通知してもよい。これによって音声処理装置は、目標音量を集音することができない旨を、予めユーザに通知することができる。
【0012】
第一態様において、自拠点に設置された他の音声処理装置である自拠点他装置から、前記音声の音量および前記目標音量を取得する第二取得手段を備え、前記通知手段は、前記第二取得手段によって取得された前記音声の音量が、前記第二特定手段によって特定された前記音声の音量よりも大きい場合に、前記第二取得手段によって取得された前記目標音量を示す情報を、前記第三特定手段によって特定された前記目標音量を示す情報の代わりにユーザに通知してもよい。これによって音声処理装置は、自拠点内の音声処理装置および自拠点装置のうち、ユーザに最も近い位置に設置された装置において特定された目標音量をユーザに通知することができる。従って、自拠点に音声処理装置および自拠点装置が設置されている場合に、最適な目標音量を示す共通の情報を、音声処理装置および自拠点他装置からユーザに通知することができる。
【0013】
第一態様において、前記第一取得手段は、複数の他拠点の其々に設置された他拠点マイクを介して集音された複数の前記音情報を取得し、前記第一特定手段は、前記第一取得手段によって取得された前記複数の音情報に対応する複数の前記音声の音量のうち最も小さい前記音声の音量を特定し、前記複数の音情報に対応する複数の前記雑音の音量のうちもっとも大きい前記雑音の音量を特定してもよい。これによって音声処理装置は、音声の音量に対する雑音の音量が最も大きい環境に対応するように、目標音量を定めることができる。従って、目標音量でユーザに音声を発声させることによって、音声処理装置毎に雑音環境が異なる場合でも、他のユーザは、音声を雑音と明確に区別して認識することができる。
【0014】
本発明の第二態様に係る音声処理方法は、他拠点に設置された他拠点マイクを介して集音された音に関する情報である音情報を、自拠点に設置された音声処理装置が取得する第一取得ステップと、前記第一取得ステップによって取得された前記音情報に基づいて、前記音声処理装置が音声の音量および雑音の音量を特定する第一特定ステップと、前記音声処理装置が、接続された自拠点マイクを介して集音された音に基づいて、音声の音量および雑音の音量を特定する第二特定ステップと、前記第一特定ステップによって特定された前記音量、および、前記第二特定ステップによって特定された前記音量のうち少なくともいずれかに基づいて、前記音声処理装置が前記自拠点マイクを介して集音する前記音声の目標とする音量である目標音量を特定する第三特定ステップと、前記第三特定ステップによって特定された前記目標音量に関連する情報を、前記音声処理装置がユーザに通知する通知ステップとを備えている。第二態様によれば、第一態様と同様の効果を奏することができる。
【0015】
本発明の第三態様に係る音声処理プログラムは、他拠点に設置された他拠点マイクを介して集音された音に関する情報である音情報を取得する第一取得ステップと、前記第一取得ステップによって取得された前記音情報に基づいて、音声の音量および雑音の音量を特定する第一特定ステップと、自拠点に設置された音声処理装置に接続された自拠点マイクを介して集音された音に基づいて、音声の音量および雑音の音量を特定する第二特定ステップと、前記第一特定ステップによって特定された前記音量、および、前記第二特定ステップによって特定された前記音量のうち少なくともいずれかに基づいて、前記音声処理装置が前記自拠点マイクを介して集音する前記音声の目標とする音量である目標音量を特定する第三特定ステップと、前記第三特定ステップによって特定された前記目標音量に関連する情報をユーザに通知する通知ステップとを音声処理装置のコンピュータに実行させる。第三態様によれば、第一態様と同様の効果を奏することができる。
【図面の簡単な説明】
【0016】
【図1】音声処理装置10、30を含む会議システム1の概要、および音声処理装置10の電気的構成を示す図である。
【図2】音声および雑音の音量を説明するための図である。
【図3】目標音量Tを説明するための説明図である。
【図4】関数70を示すグラフである。
【図5】メイン処理を示すフローチャートである。
【図6】第一特定処理を示すフローチャートである。
【図7】第三特定処理を示すフローチャートである。
【図8】出力部28に表示される通知画面61〜63を示す図である。
【図9】出力部28に表示される通知画面71〜73を示す図である。
【発明を実施するための形態】
【0017】
以下、本発明の一実施形態について、図面を参照して説明する。これらの図面は、本発明が採用しうる技術的特徴を説明するために用いられるものである。記載されている装置の構成、各種処理のフローチャート等は、それのみに限定する趣旨ではなく、単なる説明例である。
【0018】
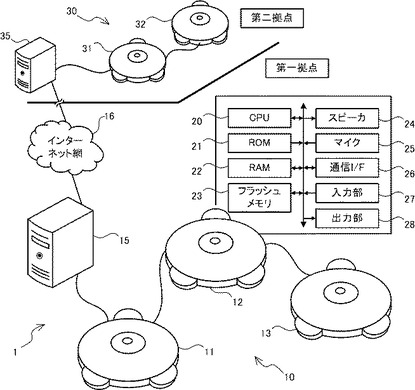
図1を参照し、会議システム1の概要について説明する。会議システム1は、音声処理装置11、12、13、31、32、および、PC15、35を備えている。音声処理装置11、12、13、およびPC15は、同一拠点(以下、第一拠点もいう。)に設置されている。音声処理装置31、32、および、PC35は、第一拠点とは異なる拠点(以下、第二拠点という。)に設置されている。音声処理装置11、12、13、およびPC15は、通信ケーブルによってディジーチェーン接続している。ディジーチェーンとは、複数の装置を数珠つなぎに連結する接続方法を示す。PC15は、インターネット網16にも接続している。同様に、音声処理装置31、32、およびPC35は、通信ケーブルによってディジーチェーン接続している。PC35は、インターネット網16にも接続している。以下、音声処理装置11、12、13を区別しない場合または総称する場合、これらを音声処理装置10という。音声処理装置31、32を区別しない場合または総称する場合、これらを音声処理装置30という。
【0019】
第一拠点に設置された音声処理装置10は、PC15、インターネット網16、およびPC35を介し、第二拠点に設置された音声処理装置30と通信を行うことができる。音声処理装置10は、マイク25(後述)によって集音した音声のデータを音声処理装置30に送信すると同時に、音声処理装置30から音声のデータを受信し、スピーカ24(後述)から音声を出力する。音声処理装置10を使用する第一拠点のユーザは、音声処理装置30を使用する第二拠点のユーザとの間で、音声による遠隔会議を行うことができる。以下、第一拠点のユーザを第一ユーザといい、第二拠点のユーザを第二ユーザという。
【0020】
また会議システム1では、音声処理装置11、12、13を第一拠点内の広い領域に点在させることができる。そして、第二拠点に設置された音声処理装置30から送信された音声のデータに基づく音声を、音声処理装置11、12、13のスピーカ24から出力させることができる。これによって、スピーカ24から出力される音声が広範にわたる領域で聞こえるようにすることができる。また音声処理装置10は、第一拠点の音声を隅々まで集音し、第二拠点に設置された音声処理装置30に対してデータを送信することができる。
【0021】
なお会議システム1において、PC15、35に其々ディスプレイおよびカメラが接続されてもよい。PC15は、カメラによって撮影された第一拠点の映像のデータを、インターネット網16を介してPC35に送信すると同時に、インターネット網16を介してPC35から映像のデータを受信し、ディスプレイに映像を表示してもよい。これによって第一拠点の第一ユーザは、第二拠点の第二のユーザとの間で、映像および音声による遠隔会議を行うことができる。
【0022】
音声処理装置10の電気的構成について説明する。音声処理装置30の電気的構成は、音声処理装置10の電気的構成と同一である。音声処理装置10は、音声処理装置10の制御を司るCPU20を備えている。CPU20は、ROM21、RAM22、フラッシュメモリ23、スピーカ24、マイク25、通信インタフェース(以下、通信I/Fという。)26、入力部27、および出力部28と電気的に接続している。ROM21には、ブートプログラム、BIOS、OS等が記憶される。RAM22には、タイマやカウンタ、一時的なデータが記憶される。フラッシュメモリ23には、CPU20の制御プログラムが記憶される。通信I/F26は、他の音声処理装置10およびPC15と通信を行うためのインタフェースである。なお音声処理装置10は、異なる二つの他の装置と接続することによってディジーチェーン接続を実現している。このため、異なる二つの他の装置の其々と通信を行うために、通信I/F26は二つ以上設けられる。入力部27は、音声処理装置10に各種設定を行うためのボタンである。出力部28は、ユーザに情報を通知するための液晶ディスプレイである。
【0023】
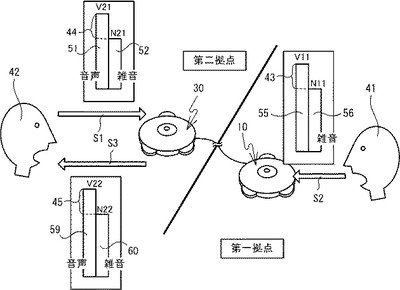
図2を参照し、第一拠点および第二拠点における音声および雑音の関係について説明する。第二拠点の第二ユーザ42から音声51(音量V21)が発声されたとする。音声51は、第二拠点内を伝播して音声処理装置30に到達する(S1)。音声処理装置30のマイク25によって、第二ユーザ42の音声51が集音される。また音声処理装置30のマイク25は、第二ユーザ42の音声51を集音すると同時に、第二拠点内で発生している雑音52(音量N21)も集音する。音声処理装置30は、集音した第二ユーザ42の音声51および雑音52をデータ化し、音声処理装置10に対して送信する。音声処理装置10は、音声処理装置30から受信したデータに基づき、第二ユーザ42の音声をスピーカ24から出力する。
【0024】
第一拠点でも同様に、第一ユーザ41から音声55が発声される。第一ユーザ41の音声55は第一拠点内を伝播する(S2)。音声処理装置10のマイク25によって、音声55(音量V11)および雑音56(音量N11)が集音される。音声処理装置10は、集音した第一ユーザ41の音声55および雑音56をデータ化し、音声処理装置30に送信する。
【0025】
音声処理装置30は、音声処理装置10からデータを受信する。音声処理装置30は、受信したデータに基づき、第一ユーザ41の音声59(音量V22)および雑音60(音量N22)をスピーカ24から出力する。第一拠点の音声処理装置10のマイク25において集音された音声55の音量(V11)と雑音56の音量(N11)との関係は、第二拠点の音声処理装置30のスピーカ24から出力される音声59の音量(V22)と雑音60の音量(N22)との関係に反映される。音声処理装置30のスピーカ24から出力された音声59および雑音60は、第二拠点内を伝播し(S3)、第二ユーザ42に到達する。
【0026】
第二ユーザ42が第一ユーザ41の音声を雑音と区別して認識するためには、少なくとも音声59の音量V22が雑音60の音量N22よりも大きい必要がある。また、第二拠点内で雑音52が発生している場合、第二ユーザ42には、音声処理装置30のスピーカ24から出力される音声59および雑音60に加えて、第二拠点内で発生している雑音52も聞こえている。従って、第二ユーザ42が第一ユーザ41の音声を更に良好に認識するためには、音声59の音量V22は、スピーカ24から出力される雑音60の音量N22や第二拠点内の雑音52の音量52と比較して大きくなることが好ましい。
【0027】
第一ユーザ41は、第二ユーザ42に自分の音声を良好に認識させるために、できるだけ大きな声で音声55を発声することが好ましい。しかしながら第一ユーザ41は、第二拠点内で発生している雑音52の音量の程度がわからないので、どの程度大きな音量で音声55を発声した場合に第二ユーザ42が音声59を認識できるかを判断することができない。これに対して本実施形態では、音声処理装置10は、音声処理装置30のマイク25において集音された音声51および雑音52のデータに基づき、音声51の音量V21と雑音の音量N21との差分44を算出する。音声処理装置10は、算出した差分44に基づき、第二ユーザ42が第一ユーザ41の音声59を雑音52、60と区別して認識するために必要な第一ユーザ41の音声の音量を、集音する音声の目標とする音量(以下、目標音量という。)として特定し、第一ユーザ41に通知する。ここで第二拠点の第二ユーザ42は、第二拠点内で発生している雑音52や、音声処理装置30の間の距離を考慮して音声51を発声していることが想定される。このため音声処理装置10は、第一ユーザ41によって発声される音声55と雑音56との差分43が、少なくとも差分44よりも大きくなるように目標音声を特定する。第一ユーザ41が通知に応じ、目標音量以上の音量で音声を発声することによって、第二ユーザ42は、第一ユーザ41の音声59を、音声処理装置30のスピーカ24から出力される雑音60や第二拠点内の雑音52と区別して認識することが可能となる。以下詳説する。
【0028】
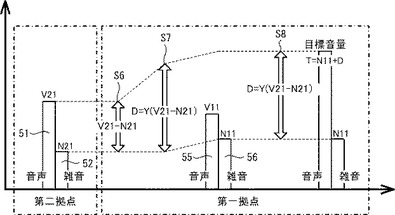
図3を参照し、第一拠点の音声処理装置10において目標音量を特定するための方法について説明する。はじめに音声処理装置10は、第二拠点の音声処理装置30がマイク25を介して集音した音声51の音量V21および雑音52の音量N21(図2参照)を特定する。次に音声処理装置10は、音量V21から音量N21を減算することによって差分(V21−N21)を算出する(S6)。なお音声処理装置10は、差分(V22−N21)に基づき、第二拠点における音声処理装置30と第二ユーザ42との間のおおよその距離を推定することができる。音声処理装置30と第二ユーザ42との間の距離が短い場合、音声処理装置30に到達する第二ユーザ42の音声の音量は大きくなるので、差分も大きくなるためである。一方、音声処理装置30と第二ユーザ42との間の距離が長い場合、音声処理装置30に到達する第二ユーザ42の音声の音量は小さくなるので、差分も小さくなるためである。
【0029】
次に音声処理装置10は、算出した差分(V21−N21)に所定の変数Yを乗算し、増分Dを算出する(S7)。
D=Y(V21−N21)
変数Yは、フラッシュメモリ23に記憶された関数70(図4参照)を用いて算出される。図4は、フラッシュメモリ23に記憶された関数70を説明するためのグラフである。関数70では、差分(横軸)の増加に伴い、変数Yは急激に減少する。そして、差分が所定の閾値よりも大きくなった場合、変数Yの減少傾向は小さくなる。変数Yが急激に減少する領域、すなわち、雑音に対して音声が比較的小さい領域では、音声の認識に十分な音量を確保するため、積極的に変数Yを制御している。一方、変数Yの減少傾向が小さい領域、すなわち、雑音に対して音声が比較的大きい領域では、差分が大きくなっても音声の認識度合いに大きな影響を及ぼさないので、積極的な変数Yの制御を行わない。変数Yは、差分(V21−N21)に関数70を適用することによって、一意に特定される。関数70を適用した場合、差分(V21−N21)の増加に伴ってYは小さくなる傾向となる。
【0030】
また図4に示すように、音声処理装置10は、音声処理装置30の種類や、音声処理装置30が設置されている環境に応じて、異なる関数71、72、73を用い、変数Yを算出する。これによって音声処理装置10は、音声処理装置30の種類や、音声処理装置30が設置されている環境に応じて、第二拠点での音声の減衰量を適切に特定し、最適な目標音量を特定することができる。例えば、大きな音声を出力可能な音声処理装置30が第二拠点に設置されている場合、より広い場所での使用が想定されるので、音声処理装置30と第二ユーザ42との間の距離は大きくなることが考えられる。この場合、音声処理装置10では、より大きな変数Yが選択されるように、関数73が選択される。これによって、音声の減衰分をより積極的に補完することができる。また、図4で示した関数は、一実施例として比例関数の連結としたが、これに限るものではなく、例えば2次関数と連結するようにしてもよい。
【0031】
図3に示すように、音声処理装置10は、音声処理装置10に設けられたマイク25を介して集音した音声55の音量V11および雑音56の音量N11(図2参照)を特定する。音声処理装置10は、特定した雑音56の音量N11に、S7で算出した増分D(Y(V21−N21))を加算することによって、目標音量Tを算出する(S8)。
T=N11+D=N11+Y(V21−N21)
【0032】
音声処理装置10は、特定した目標音量を通知するための画面を、出力部28に表示する。これによって音声処理装置10は、目標音量を第一ユーザ41に通知し、目標音量で音声を発声するように促す。ここで、第一ユーザ41から発声された音声が第一拠点内を伝播し(S2、図2参照)、目標音量以上の音量で音声処理装置10のマイク25によって集音されたとする。集音された第一ユーザ41の音声55は、音声処理装置10のマイク25によって同様に集音された雑音56(図2参照)と共にデータ化され、音声処理装置30に対して送信される。音声処理装置30は、音声処理装置10から受信したデータに基づき、第一ユーザ41の音声59(音量V22)および雑音60(音量N22)(図2参照)をスピーカ24から出力する。出力された第一ユーザ41の音声59および雑音60は、第二拠点内を伝播(S3、図2参照)し、第二ユーザ42に到達する。ここで、第一ユーザ41から発声された音声は、目標音量以上の音量で集音されているので、音声59の音量V22と雑音60の音量N22との差分45(V22−N22)(図2参照)は、第二ユーザ42によって発声された音声51の音量V21と雑音52の音量N21との差分43(V21−N21)(図2参照)よりも大きくなる。従って第二ユーザ42は、第一ユーザ41の音声を雑音と明確に区別して認識することができる。
【0033】
以上のように、音声処理装置10では、音声処理装置30において集音された音声51の音量V21および雑音52の音量N21に基づいて目標音量が特定されることになる。従って、目標音量以上の音量で第一ユーザ41に音声を発声させることによって、第二拠点毎に音環境が異なる場合でも、第二ユーザ42は第一ユーザ41の音声59を雑音60と明確に区別して認識することができる。
【0034】
図5から図7を参照し、音声処理装置10が実行するメイン処理について説明する。以下説明するメイン処理は、フラッシュメモリ23に記憶されている音声処理プログラムに従って、音声処理装置10のCPU20が実行する。メイン処理は、音声処理装置10の電源がONされた場合に、フラッシュメモリ23に記憶されたメイン処理用のプログラムが起動されて開始される。そして、CPU20がこのプログラムを実行することにより行われる。なお以下では、図1における第一拠点に設置された音声処理装置11のCPU20において実行されるメイン処理を例に挙げて説明する。従って音声処理装置11は、第一拠点内で音声処理装置12、13と直接接続した状態となっている。また音声処理装置11は、PC15、35、およびインターネット網16を介して、第二拠点に設置された音声処理装置31、32と接続した状態となっている。
【0035】
なおメイン処理では、自拠点に対応する音声の音量(以下、自拠点音声音量という。)および雑音の音量(以下、自拠点雑音音量という。)、並びに、他拠点に対応する音声の音量(以下、他拠点音声音量という。)および雑音の音量(以下、他拠点雑音音量という。)をRAM22に記憶して使用する。
【0036】
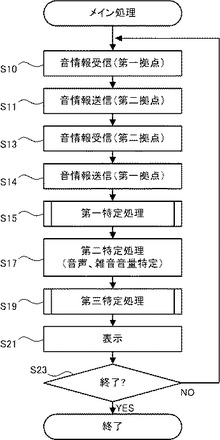
図3に示すように、メイン処理が開始されると、CPU20は、音声処理装置12、13から送信された音情報を受信する(S10)。CPU20は、音声処理装置11に設けられたマイク25を介して音を集音する。CPU20は、集音した音をデータ化し、S10で音声処理装置12、13から受信した音情報とミキシングして、第二拠点に設置された音声処理装置31に対して送信する(S11)。次にCPU20は、音声処理装置31から送信された音情報を受信し(S13)、音声処理装置12、13に対して転送する(S14)。CPU20は、受信した音情報を、RAM22に記憶する。CPU20は、RAM22に記憶した音情報のうち、第二拠点に設置された音声処理装置31から受信した音情報に基づいて、音声の音量および雑音の音量を特定する処理(第一特定処理、図6参照)を実行する(S15)。
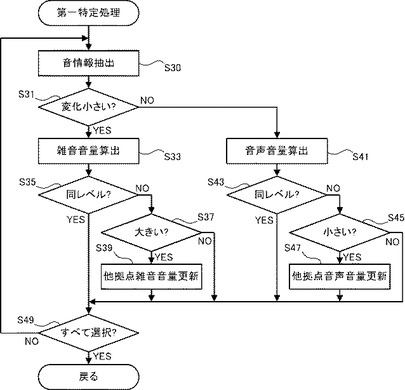
【0037】
図6を参照し、第一特定処理について説明する。CPU20は、S13(図5参照)で受信し、RAM22に記憶した音情報から、所定単位(例えば5秒)のデータを抽出する(S30)。CPU20は、抽出した音情報の音量の変化の程度(音量のレベル差)が、所定時間(例えば3秒)以上連続して所定レベル(例えば10dB)以下となるか否を判断する。CPU20は、抽出した音情報音量の変化の程度が所定時間以上連続して所定レベル以下であった場合(S31:YES)、CPU20は、音には雑音のみが含まれており、音声が含まれていないと判断する。CPU20は、所定時間内の音の音量の平均(例えば、等価騒音レベル)を算出し、雑音の音量として特定する(S33)。以下、特定した雑音の音量を、特定雑音音量という。
【0038】
CPU20は、S35〜S39の処理によって、第二拠点に設置された音声処理装置31、32において集音された音に含まれる雑音の音量の最大値を特定し、他拠点雑音音量としてRAM22に記憶する。詳細は次のとおりである。CPU20は、RAM22に記憶された他拠点雑音音量と、特定雑音音量とを比較する(S35)。RAM22に記憶された他拠点雑音音量と特定雑音音量とが同レベルである場合(S35:YES)、CPU20は、RAM22に記憶された他拠点雑音音量を更新せず、処理はS49に進む。一方、RAM22に記憶された他拠点雑音音量と特定雑音音量とが大きく相違する場合(S35:NO)、CPU20は、特定雑音音量が他拠点雑音音量よりも大きいかを判断する(S37)。特定雑音音量が他拠点雑音音量よりも大きい場合(S37:YES)、新たな他拠点雑音音量として特定雑音音量をRAM22に記憶することで、他拠点雑音音量を更新する(S39)。処理はS49に進む。一方、特定雑音音量が他拠点雑音音量以下である場合(S37:NO)、CPU20は、RAM22に記憶された他拠点雑音音量を更新せず、処理はS49に進む。
【0039】
一方でCPU20は、S13(図5参照)で受信した音情報によって特定される音の音量が、所定時間内に所定レベルを超えた場合、音量の変化の程度が大きいと判断する(S31:NO)。この場合CPU20は、音声が音に含まれていると判断する。CPU20は、所定時間内の音の音量の平均(例えば、等価雑音レベル)を算出し、音声の音量として特定する(S41)。以下、特定した音声の音量を、特定音声音量という。
【0040】
CPU20は、S43〜S47の処理によって、第二拠点に設置された音声処理装置31、32において集音された音に含まれる音声の音量の最小値を特定し、他拠点音声情報としてRAM22に記憶する。詳細は次のとおりである。CPU20は、RAM22に記憶された他拠点音声音量と、特定音声音量とを比較する(S43)。RAM22に記憶された他拠点音声音量と特定音声音量とが同レベルである場合(S43:YES)、CPU20は、RAM22に記憶された他拠点音声音量を更新せず、処理はS49に進む。一方、RAM22に記憶された他拠点音声音量と特定音声音量とが大きく相違する場合(S43:NO)、CPU20は、特定音声音量が他拠点音声音量よりも小さいかを判断する(S45)。特定音声音量が他拠点音声音量よりも小さい場合(S45:YES)、新たな他拠点音声音量として特定音声音量をRAM22に記憶することで、他拠点音声音量を更新する(S47)。処理はS49に進む。一方、特定音声音量が他拠点音声音量以上である場合(S45:NO)、CPU20は、RAM22に記憶された他拠点音声音量を更新せず、処理はS49に進む。
【0041】
CPU20は、S13(図5参照)においてRAM22に記憶した音情報の全てを、S30にて抽出したかを判断する(S49)。CPU20は、S30において選択していない音情報がRAM22に残っている場合(S49:NO)、残りの音情報の処理を行うために、処理はS30に戻る。一方、S30において全ての音情報を選択している場合(S49:YES)、第一特定処理は終了し、処理はメイン処理(図5参照)に戻る。
【0042】
以上のようにしてRAM22に記憶された他拠点音声音量は、第二拠点に設置された音声処理装置31、32において集音された音声の音量のうち最も小さい音量を表している。また他拠点雑音音量は、第二拠点に設置された音声処理装置31、32において集音された雑音の音量のうち最も大きい音量を表している。従って、他拠点音声音量と他拠点雑音音量との関係は、音声の音量に対して雑音の音量が最も大きくなる、言い換えれば、音声に対して雑音が最も大きく影響する環境における関係を示していることになる。なお、図3を参照して説明したように、音声処理装置10は、第二拠点の音声処理装置30において集音された音声の音量と雑音の音量との関係に基づいて目標音量を特定する。従って特定される目標音量は、音声に対して雑音が最も大きく影響する環境においても音声を雑音と区別して認識させることが可能な目標音量に相当する。従って音声処理装置10は、第二拠点および音声処理装置30周辺の音環境が悪い場合でも、第二ユーザが第一ユーザの音声を雑音と明確に区別できるように、第一ユーザに音声を発声させることができる。
【0043】
図5に示すように、第一特定処理(S15)の終了後、CPU20は、第二特定処理を実行する(S17)。第二特定処理において、CPU20は、S11(図5参照)にて集音した音から、第一ユーザの音声および雑音を分離し、音声の音量および雑音の音量を特定する。特定された音声の音量は、自拠点音声音量としてRAM22に記憶される。特定された雑音の音量は、自拠点雑音音量としてRAM22に記憶される。
【0044】
なお、音声と雑音とを音から分離する方法として、周知の様々な方法を用いることができる。例えばCPU20は、第一特定処理(図6参照)において音声および雑音を音から分離した方法と同一方法を用いてもよい。また例えばCPU20は、バンドパスフィルタを用い、音声および雑音を周波数的に分離することによって、音声と雑音とを音から分離してもよい。
【0045】
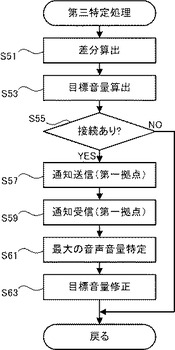
第二特定処理(S17)の終了後、CPU20は、RAM22に記憶された自拠点音声音量、自拠点雑音音量、他拠点音声音量、および他拠点雑音音量に基づいて目標音量を特定する処理(第三特定処理、図7参照)を実行する(S19)。図7を参照し、第三特定処理について説明する。CPU20は、RAM22に記憶された他拠点音声音量と他拠点雑音音量との差分を算出する(S51)(S6(図3参照))。次にCPU20は、算出された差分を関数70(図4参照)に適用することによって、変数Yを特定する。CPU20は、特定した変数Yと、S51で算出した差分とを乗算することによって、増分Dを算出する(S7、図3参照)。CPU20は、算出した増分Dに、RAM22に記憶した自拠点雑音音量を加算することによって、目標音量を特定する(S53)(S8、図3参照)。
【0046】
なおこの時点で、第一拠点に設置された音声処理装置12、13においても同様に目標音量が算出されている。CPU20は、第一拠点に設置された音声処理装置11、12、13の其々の出力部28から、同一の目標音量を通知するための情報を表示して第一ユーザに認識させるために、S55〜S63の処理を行う。はじめにCPU20は、第一拠点に他の音声処理装置10が設置されているかを判断する(S55)。ここで図1とは異なり、第一拠点に音声処理装置12、13が設置されておらず、音声処理装置11に音声処理装置12、13が接続されていない場合(S55:NO)、S53で特定された目標音量はそのまま有効となるので、第三特定処理は終了し、処理はメイン処理(図5参照)に戻る。
【0047】
一方、図1に示すように、第一拠点に音声処理装置11、12、13が設置されており、互いに接続されている場合(S55:YES)、CPU20は、S53で特定した目標音量と自拠点音声音量とを通知するための通知データを、音声処理装置11のIDを付与して音声処理装置12、13に対して送信する(S57)。次いでCPU20は、音声処理装置12、13から同様に送信された通知データを受信する(S59)。
【0048】
CPU20は、音声処理装置11に設けられたマイク25によって集音された音声の音量を、第二特定処理(S17(図5参照))によって特定している。そしてCPU20は、特定した音声の音量を、自拠点音声音量としてRAM22に記憶している(S17(図5参照))。またCPU20は、S59で受信した通知データに基づき、音声処理装置12、13の其々によって集音された音声の音量を取得することができる。音声処理装置12、13の其々によって集音された音声の音量と、自拠点音声音量とを比較し、最大の音量の音声が集音された音声処理装置10を特定する(S61)。CPU20は、特定した音声処理装置10によって算出された目標音量を、S59で受信した通知データによって通知された目標音量、または、S53で算出した目標音量の中から選択する。CPU10は、S53で算出した目標音量を、上述のようにして選択した目標音量によって修正する(S63)。この場合、後述する表示処理(S21、図5参照)では、修正された目標音量を示す情報が、S53で特定された目標音量を示す情報をの代わりに出力部28(図1参照)に表示されることになる。第三特定処理は終了し、処理はメイン処理(図5参照)に戻る。
【0049】
以上の処理を行うことで、音声処理装置11は、第一拠点に設置された音声処理装置11、12、13のうち、第一ユーザに最も近い位置に設置された音声処理装置10において算出された目標音量を特定することができる。マイク25によって集音された音声の音量が大きい程、ユーザは音声処理装置10の近くにいることが想定されるためである。このように音声処理装置10は、第一拠点に設置された音声処理装置10の其々によって特定された目標音量のうち最適な目標音量を特定し、第一ユーザに対して通知することができる。
【0050】
図5に示すように、第三特定処理(S19)の終了後、CPU20は、第三特定処理によって特定された目標音量を第一ユーザに通知する通知画面を、出力部28に表示する(S21)。図8を参照し、出力部28に表示される通知画面61〜63について説明する。なお通知画面61〜63は、其々、異なる条件で出力部28に表示される通知画面を示している。
【0051】
通知画面61〜63には、第一表示部64、第二表示部65、および第三表示部66が設けられている。第一表示部64は、マイク25によって集音することが可能な音の音量を10段階表示するための表示部である。第一表示部64は、上下方向に並んだ10つの長方形641、および、各長方形の左側に配置された数字642を備えている。数字642は、下端からの段数を示している。第二表示部65は、マイク25によって実際に集音された音声の音量を示す表示部である。第二表示部65は、第一表示部64の長方形の内部を塗り潰すように表示される。第三表示部66は、目標音量を示すための表示部である。第三表示部66は、第一表示部64の長方形の枠線よりも太い枠線であり、第一表示部64の長方形に重ねて表示される。例えば通知画面61は、マイク25によって実際に集音された音声の音量が5であり、目標音量が7であることを示している。また通知画面62は、マイク25によって実際に集音された音声の音量が7であり、目標音量が5であることを示している。
【0052】
CPU20は、マイク25によって集音することが可能な音の音量に対する、RAM22に記憶された自拠点音声音量の割合を算出することによって、第二表示部65を第一表示部64のどの段階まで表示するかを決定する。例えば、マイク25によって集音することが可能な音の音量10に対して、自拠点音声音量が5である場合、通知画面61に示すように、第二表示部65は、第一表示部64における1〜5番目の長方形641の内部に表示される。またCPU20は、マイク25において集音することが可能な音の音量10に対して、目標音量が7と特定された場合、通知画面61に示すように、第三表示部66は、第一表示部64における7〜10番目の長方形641に重ねて表示される。
【0053】
例えば、第一ユーザが音声処理装置11に対して音声を発生し、出力部28に通知画面61が表示された場合、第一ユーザは、発声した音声の音量(5)が目標音量(7)に達していないことを認識できる。また第一ユーザは、もう少し大きな声で音声を発声することによって、音声の音量が目標音量に到達することを認識できる。また例えば、第一ユーザが音声処理装置11に対して音声を発生し、出力部28に通知画面62が表示された場合、第一ユーザは、発声した音声の音量(7)が目標音量(5)に達しており、第二ユーザが音声を雑音と区別して認識できる状態にあることを確認することができる。このように第一ユーザは、発声した音声の音量が目標音量に対してどの程度であるかを認識することができる。このため第一ユーザは、音声の音量が目標音量に近づくように心がけて発声することができる。
【0054】
さらに通知画面63では、第一表示部64および第二表示部65のみ表示されており、第三表示部66が表示されていない。このように第三表示部66が表示されない状態は、マイク25において受信可能な音の最大音量よりも目標音量の方が大きくなっていることを示している。このことは、マイク25において受信可能な最大の音量で第一ユーザが音声を発声しても、音声の音量は目標音量に達しないことを意味している。従って第一ユーザがいくら大きな声で音声を発声したとしても、第二ユーザは音声を雑音と区別して認識することができないことになる。このように音声処理装置11は、第一ユーザが大きな音量の音声を発声したとしても、マイク25が目標音量で音声を集音することができない旨を、予め第一ユーザに通知することができる。
【0055】
図5に示すように、通知画面61〜63を出力部28に表示した後、CPU20は、遠隔会議を終了する指示を、入力部27を介して検出したかを判断する(S23)。CPU20は、遠隔会議を終了する指示を検出していない場合(S23:NO)、通知表示61〜63を継続して出力部28に表示させるため、処理はS10に戻る。一方、遠隔会議を終了する指示を検出した場合(S23:YES)、メイン処理を終了する。
【0056】
以上説明したように、音声処理装置10は、目標音量を算出して第一ユーザに通知することによって、適切な音量でユーザに音声を発声させることができる。これによって、第二拠点に設置された音声処理装置31、32を使用する第二ユーザは、音声処理装置31、32を介して第一ユーザの音声を明確に認識できるようになる。音声処理装置10は、他拠点音声音量および他拠点雑音音量に基づいて目標音量を特定するので、雑音の音量と比較して十分な大きさの音量で、第一ユーザに音声を発声させることができる。これによって第二ユーザは、音声処理装置31、32に設けられたスピーカ24から出力される第一ユーザの音声を、雑音と明確に区別して認識することができる。
【0057】
音声処理装置10は、同一拠点内に複数の音声処理装置10が設置されている場合、これらの音声処理装置10のうち、集音される音声の音量が最も大きい音声処理装置10がユーザの音声を最も効率よく集音していると判断する。また音声処理装置10は、効率よく集音している音声処理装置10が、ユーザの音声を最も集音しやすい、言い換えれば、ユーザに最も近い位置に設置されていると判断する。この場合、該当する音声処理装置10において特定された目標音量を示す情報が、同一拠点内に設置されたすべての音声処理装置10の出力部28から表示される。複数の音声処理装置10で別々の情報が表示されると、ユーザはどの情報を信じてよいかわからなくなるためである。音声処理装置10は、共通の目標音量を示す情報を表示することで、ユーザに目標音量を統一的に通知することができる。
【0058】
なお、S13の処理を行うCPU20が本発明の「第一取得手段」に相当する。S15の処理を行うCPU20が本発明の「第一特定手段」に相当する。S17の処理を行うCPU20が本発明の「第二特定手段」に相当する。S53の処理を行うCPU20が本発明の「第三特定手段」に相当する。S21の処理を行うCPU20が本発明の「通知手段」に相当する。S13、S59の処理を行うCPU20が本発明の「第二取得手段」に相当する。S13の処理が本発明の「第一取得ステップ」に相当する。S15の処理が本発明の「第一特定ステップ」に相当する。S17の処理が本発明の「第二特定ステップ」に相当する。S53の処理が本発明の「第三特定ステップ」に相当する。S21の処理が本発明の「通知ステップ」に相当する。
【0059】
なお本発明は上述の実施形態に限定されず、種々の変更が可能である。図1のシステム構成は本発明の一例であり、他のシステム構成であってもよい。例えばインターネット網16の代わりに、固定電話網、移動電話網、専用通信網等、周知の様々な外部通信網が使用され、自拠点と他拠点との間で通信が実行されてもよい。音声処理装置10は、PC15の代わりに、音声処理装置10以外の様々な機器(固定電話機、携帯電話機、ルータ、モデム等)を介して外部通信網と接続してもよい。また音声処理装置10は、外部通信網と直接接続してもよい。
【0060】
上述では、音声処理装置10にスピーカ24およびマイク25が設けられていたが、音声処理装置10はスピーカ24およびマイク25を備えていなくてもよく、外付けのスピーカおよびマイクを接続して使用してもよい。上述では、RAM22に記憶された他拠点音声音量と他拠点雑音音量との差分に基づき、目標音量を算出した。これに対し、音声処理装置10は、他拠点音声音量と他拠点雑音音量との割合に基づき、目標音量を算出してもよい。また音声処理装置10は、自拠点音声音量、自拠点雑音音量、他拠点音声音量、および他拠点雑音音量のうちいずれかの情報のみに基づいて、目標音量を算出してもよい。音声処理装置10は、目標音量のみを第一ユーザに通知し、第一ユーザの発声した音声の音量は通知しなくてもよい。また例えば音声処理装置10は、第一ユーザの発声した音声が目標音量に達しているか否かを通知する情報のみを、出力部28に表示してもよい。
【0061】
音声処理装置11は、第一拠点に設置された他の音声処理装置12、13との間で目標音量を調整し、共通の目標音量を出力部28に表示していた。これに対して音声処理装置10は、其々において特定された目標音量を別々に出力部28に出力してもよい。音声処理装置10は、第一ユーザが複数である場合、全てのユーザの音を音情報として他の音声処理装置10、30に送信しても良いし、ユーザ毎に異なる音情報を送信してもよい。また音声処理装置10は、ユーザ毎に異なる音情報を受信した場合、ユーザ毎に異なる目標音量を特定し、ユーザを識別する情報と共に出力部28に表示することによってユーザに通知してもよい。
【0062】
上述における通知画面61〜63は別の態様であってもよい。図8では、第一表示部64の枠線に対して、第三表示部66の枠線を太くすることによって、双方を区別していた。例えば、第一表示部64の枠線の色と、第三表示部66の枠線の色とを変えることによって、双方を区別してもよい。具体的には、例えば、第一表示64の枠線を赤色とし、第三表示部66の枠線を青色としてもよい。また通知画面63の第一表示部64の枠線の色が、通知画面61、62の枠線の色と異なるように表示してもよい。これによって、第一ユーザが大きな音量の音声を発声したとしても、マイク25が目標音量で音声を集音することができない旨を、明確に通知することができる。
【0063】
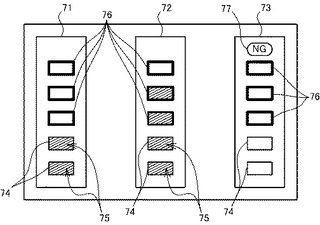
図9を参照し、出力部28に表示する通知画面の別の例である、通知画面71〜73について説明する。通知画面71〜73には、第一表示部74、第二表示部75、および第三表示部76が設けられている。第一表示部74は、上下に並んだ二つの長方形である。第三表示部76は、第一表示部74の長方形の上側に配置された、上下に並んだ3つの長方形である。第三表示部76の長方形の枠線は、第一表示部74の長方形の枠線よりも太い。第二表示部75は、第一表示部74および第三表示部76の内部を塗り潰すように表示される。
【0064】
通知画面71〜73では、第一表示部74と第三表示部76との境界部分によって目標音量が示される。第二表示部75は、マイク25によって実際に集音された音声の音量を示す表示部である。通知画面71〜73では、通知画面61〜63と異なり、目標音量のレベルが変化しても、第三表示部76の数は変化せず、常に3つの長方形によって示される。
【0065】
CPU20は、RAM22に記憶された自拠点音声音量が、目標音量に対してどの程度の大きさであるかを算出することによって、第二表示部75を第一表示部74および第三表示部76のうちどの段階まで表示するかを決定する。例えばCPU20は、自拠点音声音量が目標音量と同レベルである場合、通知画面71に示すように、第一表示部74の二つの長方形の内部に第二表示部75を表示する。またCPU20は、自拠点音声音量が7であるのに対して目標音量が5である場合、通知画面72に示すように、第一表示部74の二つの長方形、および、第三表示部76の3つの長方形のうち下から2つ分の長方形の内部に、第二表示部75を表示する。通知画面71〜73では、目標音量を示す境界が常に画面の上下略中央部分に配置されるため、第一ユーザは、目標音量をより直感的に認識することができる。
【0066】
これに対して通知画面73は、マイク25において受信可能な音の最大音量よりも目標音量の方が大きくなっている場合の表示態様を示している。この場合、CPU20は、第三表示部76の上部に「NG」の文字77を表示させる。このように音声処理装置10は、通知画面71〜73を出力部28に表示させることによって、第一ユーザが大きな音量の音声を発声したとしても、マイク25が目標音量で音声を集音することができない旨を、通知画面61〜63と比較してより明確に第一ユーザに通知することができる。
【符号の説明】
【0067】
1 会議システム
10、11、12、30、31、32 音声処理装置
24 スピーカ
25 マイク
28 出力部
61、62、63、71、72、73 通知画面
【技術分野】
【0001】
本発明は、ユーザから発声された音声の音量を通知する機能を備えた音声処理装置、音声処理方法、および音声処理プログラムに関する。
【背景技術】
【0002】
マイクによって集音した音声を、遠隔地に設置された他の音声処理装置に対してネットワークを介して送信すると同時に、ネットワークを介して遠隔地の音声を受信し、スピーカから出力する音声処理装置が知られている。このような音声処理装置は、遠隔会議システム等において広く使用されている。音声処理装置の一例として、スピーカフォンが挙げられる。
【0003】
通常、スピーカから出力される音には、音声と雑音とが含まれている。スピーカから出力される音声をユーザが明確に聞き取るためには、雑音の音量に対する音声の音量はより大きい方が望ましい。従ってユーザは、他の音声処理装置を使用する他のユーザが自分の音声をはっきりと聞き分けて認識できるように、より大きな声で発声し、より大きな音量の音声を他の音声処理装置のスピーカから出力させることが好ましい。例えば特許文献1では、集音された音声の音量と雑音の音量との割合に応じてランプを点灯させることによって、ユーザに大きな声で発声させ、音声を認識するために必要な音量の音声を得る技術が提案されている。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開平6−75588号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
他拠点のユーザが、スピーカから送信された自拠点のユーザの音声を雑音と切り分けて認識するための条件は、他拠点の音声処理装置が使用される環境に応じて変化する。例えば他拠点の音環境が悪く、雑音の音量が大きい場合、自拠点のマイクによって集音される音のうち、雑音の音量に比べて音声の音量を相当大きくしなければ、他拠点のユーザは自拠点のユーザの音声を雑音と切り分けて認識することができない。このため、特許文献1に記載された技術を利用し、自拠点のユーザに大きな声で発声させた場合でも、他拠点のスピーカから出力される自拠点のユーザの音声の音量が不十分となる場合がある。この場合、他拠点のユーザは、スピーカから出力される自拠点のユーザの音声を十分認識することができないという問題点がある。
【0006】
本発明の目的は、他の音声処理装置を使用する他のユーザが音声を聞き取れるように、適正な音量の音声をユーザに発声させる音声処理装置、音声処理方法、および音声処理プログラムを提供することである。
【課題を解決するための手段】
【0007】
本発明の第一態様に係る音声処理装置は、他拠点に設置された他拠点マイクを介して集音された音に関する情報である音情報を取得する第一取得手段と、前記第一取得手段によって取得された前記音情報に基づいて、音声の音量および雑音の音量を特定する第一特定手段と、自拠点に設置された音声処理装置に接続された自拠点マイクを介して集音された音に基づいて、音声の音量および雑音の音量を特定する第二特定手段と、前記第一特定手段によって特定された前記音量、および、前記第二特定手段によって特定された前記音量に基づいて、前記音声処理装置が前記自拠点マイクを介して集音する前記音声の目標とする音量である目標音量を特定する第三特定手段と、前記第三特定手段によって特定された前記目標音量に関連する情報をユーザに通知する通知手段とを備えている。
【0008】
第一態様によれば、音声処理装置は、適切な音量でユーザに音声を発声させることができる。これによって、他拠点装置を使用する他のユーザは、他拠点装置を介してユーザの音声を明確に認識できるようになる。音声処理装置は、音声および雑音の音量に基づいて目標音量を定め、ユーザに通知することができるので、自拠点の雑音の音量と比較して十分な大きさの音量で、ユーザに音声を発声させることができる。これによって他のユーザは、他拠点装置に接続された他拠点スピーカから出力される音声を、雑音と明確に区別して認識することができる。
【0009】
第一態様において、前記第三特定手段は、前記第一特定手段によって特定された前記音声の音量と前記雑音の音量との差分または割合に基づき、前記目標音量を特定してもよい。音声処理装置では、他拠点装置において集音された音声および雑音の音量に基づいて目標音量が特定されることになる。従って、目標音量でユーザに音声を発声させることによって、他拠点毎に雑音環境が異なる場合でも、他のユーザは音声を雑音と明確に区別して認識することができる。音声処理装置は、他の音声処理装置が設置されている環境に応じて、目標音量を最適化することができる。
【0010】
第一態様において、前記通知手段は、前記第三特定手段によって特定された前記目標音量と、前記第二特定手段によって特定された前記音声の音量との関係を示す情報を通知してもよい。音声処理装置のユーザは、発声した音声の音量が目標音量に対してどの程度であるかを認識することができる。従ってユーザは、目標音量を容易に判断し、音声の音量が目標音量に近づくように発声することができる。
【0011】
第一態様において、前記通知手段は、前記第三特定手段によって特定された前記目標音量が、前記自拠点マイクを介して集音することが可能な最大音量を超えた場合に、最大音量を超えた旨をユーザに通知してもよい。これによって音声処理装置は、目標音量を集音することができない旨を、予めユーザに通知することができる。
【0012】
第一態様において、自拠点に設置された他の音声処理装置である自拠点他装置から、前記音声の音量および前記目標音量を取得する第二取得手段を備え、前記通知手段は、前記第二取得手段によって取得された前記音声の音量が、前記第二特定手段によって特定された前記音声の音量よりも大きい場合に、前記第二取得手段によって取得された前記目標音量を示す情報を、前記第三特定手段によって特定された前記目標音量を示す情報の代わりにユーザに通知してもよい。これによって音声処理装置は、自拠点内の音声処理装置および自拠点装置のうち、ユーザに最も近い位置に設置された装置において特定された目標音量をユーザに通知することができる。従って、自拠点に音声処理装置および自拠点装置が設置されている場合に、最適な目標音量を示す共通の情報を、音声処理装置および自拠点他装置からユーザに通知することができる。
【0013】
第一態様において、前記第一取得手段は、複数の他拠点の其々に設置された他拠点マイクを介して集音された複数の前記音情報を取得し、前記第一特定手段は、前記第一取得手段によって取得された前記複数の音情報に対応する複数の前記音声の音量のうち最も小さい前記音声の音量を特定し、前記複数の音情報に対応する複数の前記雑音の音量のうちもっとも大きい前記雑音の音量を特定してもよい。これによって音声処理装置は、音声の音量に対する雑音の音量が最も大きい環境に対応するように、目標音量を定めることができる。従って、目標音量でユーザに音声を発声させることによって、音声処理装置毎に雑音環境が異なる場合でも、他のユーザは、音声を雑音と明確に区別して認識することができる。
【0014】
本発明の第二態様に係る音声処理方法は、他拠点に設置された他拠点マイクを介して集音された音に関する情報である音情報を、自拠点に設置された音声処理装置が取得する第一取得ステップと、前記第一取得ステップによって取得された前記音情報に基づいて、前記音声処理装置が音声の音量および雑音の音量を特定する第一特定ステップと、前記音声処理装置が、接続された自拠点マイクを介して集音された音に基づいて、音声の音量および雑音の音量を特定する第二特定ステップと、前記第一特定ステップによって特定された前記音量、および、前記第二特定ステップによって特定された前記音量のうち少なくともいずれかに基づいて、前記音声処理装置が前記自拠点マイクを介して集音する前記音声の目標とする音量である目標音量を特定する第三特定ステップと、前記第三特定ステップによって特定された前記目標音量に関連する情報を、前記音声処理装置がユーザに通知する通知ステップとを備えている。第二態様によれば、第一態様と同様の効果を奏することができる。
【0015】
本発明の第三態様に係る音声処理プログラムは、他拠点に設置された他拠点マイクを介して集音された音に関する情報である音情報を取得する第一取得ステップと、前記第一取得ステップによって取得された前記音情報に基づいて、音声の音量および雑音の音量を特定する第一特定ステップと、自拠点に設置された音声処理装置に接続された自拠点マイクを介して集音された音に基づいて、音声の音量および雑音の音量を特定する第二特定ステップと、前記第一特定ステップによって特定された前記音量、および、前記第二特定ステップによって特定された前記音量のうち少なくともいずれかに基づいて、前記音声処理装置が前記自拠点マイクを介して集音する前記音声の目標とする音量である目標音量を特定する第三特定ステップと、前記第三特定ステップによって特定された前記目標音量に関連する情報をユーザに通知する通知ステップとを音声処理装置のコンピュータに実行させる。第三態様によれば、第一態様と同様の効果を奏することができる。
【図面の簡単な説明】
【0016】
【図1】音声処理装置10、30を含む会議システム1の概要、および音声処理装置10の電気的構成を示す図である。
【図2】音声および雑音の音量を説明するための図である。
【図3】目標音量Tを説明するための説明図である。
【図4】関数70を示すグラフである。
【図5】メイン処理を示すフローチャートである。
【図6】第一特定処理を示すフローチャートである。
【図7】第三特定処理を示すフローチャートである。
【図8】出力部28に表示される通知画面61〜63を示す図である。
【図9】出力部28に表示される通知画面71〜73を示す図である。
【発明を実施するための形態】
【0017】
以下、本発明の一実施形態について、図面を参照して説明する。これらの図面は、本発明が採用しうる技術的特徴を説明するために用いられるものである。記載されている装置の構成、各種処理のフローチャート等は、それのみに限定する趣旨ではなく、単なる説明例である。
【0018】
図1を参照し、会議システム1の概要について説明する。会議システム1は、音声処理装置11、12、13、31、32、および、PC15、35を備えている。音声処理装置11、12、13、およびPC15は、同一拠点(以下、第一拠点もいう。)に設置されている。音声処理装置31、32、および、PC35は、第一拠点とは異なる拠点(以下、第二拠点という。)に設置されている。音声処理装置11、12、13、およびPC15は、通信ケーブルによってディジーチェーン接続している。ディジーチェーンとは、複数の装置を数珠つなぎに連結する接続方法を示す。PC15は、インターネット網16にも接続している。同様に、音声処理装置31、32、およびPC35は、通信ケーブルによってディジーチェーン接続している。PC35は、インターネット網16にも接続している。以下、音声処理装置11、12、13を区別しない場合または総称する場合、これらを音声処理装置10という。音声処理装置31、32を区別しない場合または総称する場合、これらを音声処理装置30という。
【0019】
第一拠点に設置された音声処理装置10は、PC15、インターネット網16、およびPC35を介し、第二拠点に設置された音声処理装置30と通信を行うことができる。音声処理装置10は、マイク25(後述)によって集音した音声のデータを音声処理装置30に送信すると同時に、音声処理装置30から音声のデータを受信し、スピーカ24(後述)から音声を出力する。音声処理装置10を使用する第一拠点のユーザは、音声処理装置30を使用する第二拠点のユーザとの間で、音声による遠隔会議を行うことができる。以下、第一拠点のユーザを第一ユーザといい、第二拠点のユーザを第二ユーザという。
【0020】
また会議システム1では、音声処理装置11、12、13を第一拠点内の広い領域に点在させることができる。そして、第二拠点に設置された音声処理装置30から送信された音声のデータに基づく音声を、音声処理装置11、12、13のスピーカ24から出力させることができる。これによって、スピーカ24から出力される音声が広範にわたる領域で聞こえるようにすることができる。また音声処理装置10は、第一拠点の音声を隅々まで集音し、第二拠点に設置された音声処理装置30に対してデータを送信することができる。
【0021】
なお会議システム1において、PC15、35に其々ディスプレイおよびカメラが接続されてもよい。PC15は、カメラによって撮影された第一拠点の映像のデータを、インターネット網16を介してPC35に送信すると同時に、インターネット網16を介してPC35から映像のデータを受信し、ディスプレイに映像を表示してもよい。これによって第一拠点の第一ユーザは、第二拠点の第二のユーザとの間で、映像および音声による遠隔会議を行うことができる。
【0022】
音声処理装置10の電気的構成について説明する。音声処理装置30の電気的構成は、音声処理装置10の電気的構成と同一である。音声処理装置10は、音声処理装置10の制御を司るCPU20を備えている。CPU20は、ROM21、RAM22、フラッシュメモリ23、スピーカ24、マイク25、通信インタフェース(以下、通信I/Fという。)26、入力部27、および出力部28と電気的に接続している。ROM21には、ブートプログラム、BIOS、OS等が記憶される。RAM22には、タイマやカウンタ、一時的なデータが記憶される。フラッシュメモリ23には、CPU20の制御プログラムが記憶される。通信I/F26は、他の音声処理装置10およびPC15と通信を行うためのインタフェースである。なお音声処理装置10は、異なる二つの他の装置と接続することによってディジーチェーン接続を実現している。このため、異なる二つの他の装置の其々と通信を行うために、通信I/F26は二つ以上設けられる。入力部27は、音声処理装置10に各種設定を行うためのボタンである。出力部28は、ユーザに情報を通知するための液晶ディスプレイである。
【0023】
図2を参照し、第一拠点および第二拠点における音声および雑音の関係について説明する。第二拠点の第二ユーザ42から音声51(音量V21)が発声されたとする。音声51は、第二拠点内を伝播して音声処理装置30に到達する(S1)。音声処理装置30のマイク25によって、第二ユーザ42の音声51が集音される。また音声処理装置30のマイク25は、第二ユーザ42の音声51を集音すると同時に、第二拠点内で発生している雑音52(音量N21)も集音する。音声処理装置30は、集音した第二ユーザ42の音声51および雑音52をデータ化し、音声処理装置10に対して送信する。音声処理装置10は、音声処理装置30から受信したデータに基づき、第二ユーザ42の音声をスピーカ24から出力する。
【0024】
第一拠点でも同様に、第一ユーザ41から音声55が発声される。第一ユーザ41の音声55は第一拠点内を伝播する(S2)。音声処理装置10のマイク25によって、音声55(音量V11)および雑音56(音量N11)が集音される。音声処理装置10は、集音した第一ユーザ41の音声55および雑音56をデータ化し、音声処理装置30に送信する。
【0025】
音声処理装置30は、音声処理装置10からデータを受信する。音声処理装置30は、受信したデータに基づき、第一ユーザ41の音声59(音量V22)および雑音60(音量N22)をスピーカ24から出力する。第一拠点の音声処理装置10のマイク25において集音された音声55の音量(V11)と雑音56の音量(N11)との関係は、第二拠点の音声処理装置30のスピーカ24から出力される音声59の音量(V22)と雑音60の音量(N22)との関係に反映される。音声処理装置30のスピーカ24から出力された音声59および雑音60は、第二拠点内を伝播し(S3)、第二ユーザ42に到達する。
【0026】
第二ユーザ42が第一ユーザ41の音声を雑音と区別して認識するためには、少なくとも音声59の音量V22が雑音60の音量N22よりも大きい必要がある。また、第二拠点内で雑音52が発生している場合、第二ユーザ42には、音声処理装置30のスピーカ24から出力される音声59および雑音60に加えて、第二拠点内で発生している雑音52も聞こえている。従って、第二ユーザ42が第一ユーザ41の音声を更に良好に認識するためには、音声59の音量V22は、スピーカ24から出力される雑音60の音量N22や第二拠点内の雑音52の音量52と比較して大きくなることが好ましい。
【0027】
第一ユーザ41は、第二ユーザ42に自分の音声を良好に認識させるために、できるだけ大きな声で音声55を発声することが好ましい。しかしながら第一ユーザ41は、第二拠点内で発生している雑音52の音量の程度がわからないので、どの程度大きな音量で音声55を発声した場合に第二ユーザ42が音声59を認識できるかを判断することができない。これに対して本実施形態では、音声処理装置10は、音声処理装置30のマイク25において集音された音声51および雑音52のデータに基づき、音声51の音量V21と雑音の音量N21との差分44を算出する。音声処理装置10は、算出した差分44に基づき、第二ユーザ42が第一ユーザ41の音声59を雑音52、60と区別して認識するために必要な第一ユーザ41の音声の音量を、集音する音声の目標とする音量(以下、目標音量という。)として特定し、第一ユーザ41に通知する。ここで第二拠点の第二ユーザ42は、第二拠点内で発生している雑音52や、音声処理装置30の間の距離を考慮して音声51を発声していることが想定される。このため音声処理装置10は、第一ユーザ41によって発声される音声55と雑音56との差分43が、少なくとも差分44よりも大きくなるように目標音声を特定する。第一ユーザ41が通知に応じ、目標音量以上の音量で音声を発声することによって、第二ユーザ42は、第一ユーザ41の音声59を、音声処理装置30のスピーカ24から出力される雑音60や第二拠点内の雑音52と区別して認識することが可能となる。以下詳説する。
【0028】
図3を参照し、第一拠点の音声処理装置10において目標音量を特定するための方法について説明する。はじめに音声処理装置10は、第二拠点の音声処理装置30がマイク25を介して集音した音声51の音量V21および雑音52の音量N21(図2参照)を特定する。次に音声処理装置10は、音量V21から音量N21を減算することによって差分(V21−N21)を算出する(S6)。なお音声処理装置10は、差分(V22−N21)に基づき、第二拠点における音声処理装置30と第二ユーザ42との間のおおよその距離を推定することができる。音声処理装置30と第二ユーザ42との間の距離が短い場合、音声処理装置30に到達する第二ユーザ42の音声の音量は大きくなるので、差分も大きくなるためである。一方、音声処理装置30と第二ユーザ42との間の距離が長い場合、音声処理装置30に到達する第二ユーザ42の音声の音量は小さくなるので、差分も小さくなるためである。
【0029】
次に音声処理装置10は、算出した差分(V21−N21)に所定の変数Yを乗算し、増分Dを算出する(S7)。
D=Y(V21−N21)
変数Yは、フラッシュメモリ23に記憶された関数70(図4参照)を用いて算出される。図4は、フラッシュメモリ23に記憶された関数70を説明するためのグラフである。関数70では、差分(横軸)の増加に伴い、変数Yは急激に減少する。そして、差分が所定の閾値よりも大きくなった場合、変数Yの減少傾向は小さくなる。変数Yが急激に減少する領域、すなわち、雑音に対して音声が比較的小さい領域では、音声の認識に十分な音量を確保するため、積極的に変数Yを制御している。一方、変数Yの減少傾向が小さい領域、すなわち、雑音に対して音声が比較的大きい領域では、差分が大きくなっても音声の認識度合いに大きな影響を及ぼさないので、積極的な変数Yの制御を行わない。変数Yは、差分(V21−N21)に関数70を適用することによって、一意に特定される。関数70を適用した場合、差分(V21−N21)の増加に伴ってYは小さくなる傾向となる。
【0030】
また図4に示すように、音声処理装置10は、音声処理装置30の種類や、音声処理装置30が設置されている環境に応じて、異なる関数71、72、73を用い、変数Yを算出する。これによって音声処理装置10は、音声処理装置30の種類や、音声処理装置30が設置されている環境に応じて、第二拠点での音声の減衰量を適切に特定し、最適な目標音量を特定することができる。例えば、大きな音声を出力可能な音声処理装置30が第二拠点に設置されている場合、より広い場所での使用が想定されるので、音声処理装置30と第二ユーザ42との間の距離は大きくなることが考えられる。この場合、音声処理装置10では、より大きな変数Yが選択されるように、関数73が選択される。これによって、音声の減衰分をより積極的に補完することができる。また、図4で示した関数は、一実施例として比例関数の連結としたが、これに限るものではなく、例えば2次関数と連結するようにしてもよい。
【0031】
図3に示すように、音声処理装置10は、音声処理装置10に設けられたマイク25を介して集音した音声55の音量V11および雑音56の音量N11(図2参照)を特定する。音声処理装置10は、特定した雑音56の音量N11に、S7で算出した増分D(Y(V21−N21))を加算することによって、目標音量Tを算出する(S8)。
T=N11+D=N11+Y(V21−N21)
【0032】
音声処理装置10は、特定した目標音量を通知するための画面を、出力部28に表示する。これによって音声処理装置10は、目標音量を第一ユーザ41に通知し、目標音量で音声を発声するように促す。ここで、第一ユーザ41から発声された音声が第一拠点内を伝播し(S2、図2参照)、目標音量以上の音量で音声処理装置10のマイク25によって集音されたとする。集音された第一ユーザ41の音声55は、音声処理装置10のマイク25によって同様に集音された雑音56(図2参照)と共にデータ化され、音声処理装置30に対して送信される。音声処理装置30は、音声処理装置10から受信したデータに基づき、第一ユーザ41の音声59(音量V22)および雑音60(音量N22)(図2参照)をスピーカ24から出力する。出力された第一ユーザ41の音声59および雑音60は、第二拠点内を伝播(S3、図2参照)し、第二ユーザ42に到達する。ここで、第一ユーザ41から発声された音声は、目標音量以上の音量で集音されているので、音声59の音量V22と雑音60の音量N22との差分45(V22−N22)(図2参照)は、第二ユーザ42によって発声された音声51の音量V21と雑音52の音量N21との差分43(V21−N21)(図2参照)よりも大きくなる。従って第二ユーザ42は、第一ユーザ41の音声を雑音と明確に区別して認識することができる。
【0033】
以上のように、音声処理装置10では、音声処理装置30において集音された音声51の音量V21および雑音52の音量N21に基づいて目標音量が特定されることになる。従って、目標音量以上の音量で第一ユーザ41に音声を発声させることによって、第二拠点毎に音環境が異なる場合でも、第二ユーザ42は第一ユーザ41の音声59を雑音60と明確に区別して認識することができる。
【0034】
図5から図7を参照し、音声処理装置10が実行するメイン処理について説明する。以下説明するメイン処理は、フラッシュメモリ23に記憶されている音声処理プログラムに従って、音声処理装置10のCPU20が実行する。メイン処理は、音声処理装置10の電源がONされた場合に、フラッシュメモリ23に記憶されたメイン処理用のプログラムが起動されて開始される。そして、CPU20がこのプログラムを実行することにより行われる。なお以下では、図1における第一拠点に設置された音声処理装置11のCPU20において実行されるメイン処理を例に挙げて説明する。従って音声処理装置11は、第一拠点内で音声処理装置12、13と直接接続した状態となっている。また音声処理装置11は、PC15、35、およびインターネット網16を介して、第二拠点に設置された音声処理装置31、32と接続した状態となっている。
【0035】
なおメイン処理では、自拠点に対応する音声の音量(以下、自拠点音声音量という。)および雑音の音量(以下、自拠点雑音音量という。)、並びに、他拠点に対応する音声の音量(以下、他拠点音声音量という。)および雑音の音量(以下、他拠点雑音音量という。)をRAM22に記憶して使用する。
【0036】
図3に示すように、メイン処理が開始されると、CPU20は、音声処理装置12、13から送信された音情報を受信する(S10)。CPU20は、音声処理装置11に設けられたマイク25を介して音を集音する。CPU20は、集音した音をデータ化し、S10で音声処理装置12、13から受信した音情報とミキシングして、第二拠点に設置された音声処理装置31に対して送信する(S11)。次にCPU20は、音声処理装置31から送信された音情報を受信し(S13)、音声処理装置12、13に対して転送する(S14)。CPU20は、受信した音情報を、RAM22に記憶する。CPU20は、RAM22に記憶した音情報のうち、第二拠点に設置された音声処理装置31から受信した音情報に基づいて、音声の音量および雑音の音量を特定する処理(第一特定処理、図6参照)を実行する(S15)。
【0037】
図6を参照し、第一特定処理について説明する。CPU20は、S13(図5参照)で受信し、RAM22に記憶した音情報から、所定単位(例えば5秒)のデータを抽出する(S30)。CPU20は、抽出した音情報の音量の変化の程度(音量のレベル差)が、所定時間(例えば3秒)以上連続して所定レベル(例えば10dB)以下となるか否を判断する。CPU20は、抽出した音情報音量の変化の程度が所定時間以上連続して所定レベル以下であった場合(S31:YES)、CPU20は、音には雑音のみが含まれており、音声が含まれていないと判断する。CPU20は、所定時間内の音の音量の平均(例えば、等価騒音レベル)を算出し、雑音の音量として特定する(S33)。以下、特定した雑音の音量を、特定雑音音量という。
【0038】
CPU20は、S35〜S39の処理によって、第二拠点に設置された音声処理装置31、32において集音された音に含まれる雑音の音量の最大値を特定し、他拠点雑音音量としてRAM22に記憶する。詳細は次のとおりである。CPU20は、RAM22に記憶された他拠点雑音音量と、特定雑音音量とを比較する(S35)。RAM22に記憶された他拠点雑音音量と特定雑音音量とが同レベルである場合(S35:YES)、CPU20は、RAM22に記憶された他拠点雑音音量を更新せず、処理はS49に進む。一方、RAM22に記憶された他拠点雑音音量と特定雑音音量とが大きく相違する場合(S35:NO)、CPU20は、特定雑音音量が他拠点雑音音量よりも大きいかを判断する(S37)。特定雑音音量が他拠点雑音音量よりも大きい場合(S37:YES)、新たな他拠点雑音音量として特定雑音音量をRAM22に記憶することで、他拠点雑音音量を更新する(S39)。処理はS49に進む。一方、特定雑音音量が他拠点雑音音量以下である場合(S37:NO)、CPU20は、RAM22に記憶された他拠点雑音音量を更新せず、処理はS49に進む。
【0039】
一方でCPU20は、S13(図5参照)で受信した音情報によって特定される音の音量が、所定時間内に所定レベルを超えた場合、音量の変化の程度が大きいと判断する(S31:NO)。この場合CPU20は、音声が音に含まれていると判断する。CPU20は、所定時間内の音の音量の平均(例えば、等価雑音レベル)を算出し、音声の音量として特定する(S41)。以下、特定した音声の音量を、特定音声音量という。
【0040】
CPU20は、S43〜S47の処理によって、第二拠点に設置された音声処理装置31、32において集音された音に含まれる音声の音量の最小値を特定し、他拠点音声情報としてRAM22に記憶する。詳細は次のとおりである。CPU20は、RAM22に記憶された他拠点音声音量と、特定音声音量とを比較する(S43)。RAM22に記憶された他拠点音声音量と特定音声音量とが同レベルである場合(S43:YES)、CPU20は、RAM22に記憶された他拠点音声音量を更新せず、処理はS49に進む。一方、RAM22に記憶された他拠点音声音量と特定音声音量とが大きく相違する場合(S43:NO)、CPU20は、特定音声音量が他拠点音声音量よりも小さいかを判断する(S45)。特定音声音量が他拠点音声音量よりも小さい場合(S45:YES)、新たな他拠点音声音量として特定音声音量をRAM22に記憶することで、他拠点音声音量を更新する(S47)。処理はS49に進む。一方、特定音声音量が他拠点音声音量以上である場合(S45:NO)、CPU20は、RAM22に記憶された他拠点音声音量を更新せず、処理はS49に進む。
【0041】
CPU20は、S13(図5参照)においてRAM22に記憶した音情報の全てを、S30にて抽出したかを判断する(S49)。CPU20は、S30において選択していない音情報がRAM22に残っている場合(S49:NO)、残りの音情報の処理を行うために、処理はS30に戻る。一方、S30において全ての音情報を選択している場合(S49:YES)、第一特定処理は終了し、処理はメイン処理(図5参照)に戻る。
【0042】
以上のようにしてRAM22に記憶された他拠点音声音量は、第二拠点に設置された音声処理装置31、32において集音された音声の音量のうち最も小さい音量を表している。また他拠点雑音音量は、第二拠点に設置された音声処理装置31、32において集音された雑音の音量のうち最も大きい音量を表している。従って、他拠点音声音量と他拠点雑音音量との関係は、音声の音量に対して雑音の音量が最も大きくなる、言い換えれば、音声に対して雑音が最も大きく影響する環境における関係を示していることになる。なお、図3を参照して説明したように、音声処理装置10は、第二拠点の音声処理装置30において集音された音声の音量と雑音の音量との関係に基づいて目標音量を特定する。従って特定される目標音量は、音声に対して雑音が最も大きく影響する環境においても音声を雑音と区別して認識させることが可能な目標音量に相当する。従って音声処理装置10は、第二拠点および音声処理装置30周辺の音環境が悪い場合でも、第二ユーザが第一ユーザの音声を雑音と明確に区別できるように、第一ユーザに音声を発声させることができる。
【0043】
図5に示すように、第一特定処理(S15)の終了後、CPU20は、第二特定処理を実行する(S17)。第二特定処理において、CPU20は、S11(図5参照)にて集音した音から、第一ユーザの音声および雑音を分離し、音声の音量および雑音の音量を特定する。特定された音声の音量は、自拠点音声音量としてRAM22に記憶される。特定された雑音の音量は、自拠点雑音音量としてRAM22に記憶される。
【0044】
なお、音声と雑音とを音から分離する方法として、周知の様々な方法を用いることができる。例えばCPU20は、第一特定処理(図6参照)において音声および雑音を音から分離した方法と同一方法を用いてもよい。また例えばCPU20は、バンドパスフィルタを用い、音声および雑音を周波数的に分離することによって、音声と雑音とを音から分離してもよい。
【0045】
第二特定処理(S17)の終了後、CPU20は、RAM22に記憶された自拠点音声音量、自拠点雑音音量、他拠点音声音量、および他拠点雑音音量に基づいて目標音量を特定する処理(第三特定処理、図7参照)を実行する(S19)。図7を参照し、第三特定処理について説明する。CPU20は、RAM22に記憶された他拠点音声音量と他拠点雑音音量との差分を算出する(S51)(S6(図3参照))。次にCPU20は、算出された差分を関数70(図4参照)に適用することによって、変数Yを特定する。CPU20は、特定した変数Yと、S51で算出した差分とを乗算することによって、増分Dを算出する(S7、図3参照)。CPU20は、算出した増分Dに、RAM22に記憶した自拠点雑音音量を加算することによって、目標音量を特定する(S53)(S8、図3参照)。
【0046】
なおこの時点で、第一拠点に設置された音声処理装置12、13においても同様に目標音量が算出されている。CPU20は、第一拠点に設置された音声処理装置11、12、13の其々の出力部28から、同一の目標音量を通知するための情報を表示して第一ユーザに認識させるために、S55〜S63の処理を行う。はじめにCPU20は、第一拠点に他の音声処理装置10が設置されているかを判断する(S55)。ここで図1とは異なり、第一拠点に音声処理装置12、13が設置されておらず、音声処理装置11に音声処理装置12、13が接続されていない場合(S55:NO)、S53で特定された目標音量はそのまま有効となるので、第三特定処理は終了し、処理はメイン処理(図5参照)に戻る。
【0047】
一方、図1に示すように、第一拠点に音声処理装置11、12、13が設置されており、互いに接続されている場合(S55:YES)、CPU20は、S53で特定した目標音量と自拠点音声音量とを通知するための通知データを、音声処理装置11のIDを付与して音声処理装置12、13に対して送信する(S57)。次いでCPU20は、音声処理装置12、13から同様に送信された通知データを受信する(S59)。
【0048】
CPU20は、音声処理装置11に設けられたマイク25によって集音された音声の音量を、第二特定処理(S17(図5参照))によって特定している。そしてCPU20は、特定した音声の音量を、自拠点音声音量としてRAM22に記憶している(S17(図5参照))。またCPU20は、S59で受信した通知データに基づき、音声処理装置12、13の其々によって集音された音声の音量を取得することができる。音声処理装置12、13の其々によって集音された音声の音量と、自拠点音声音量とを比較し、最大の音量の音声が集音された音声処理装置10を特定する(S61)。CPU20は、特定した音声処理装置10によって算出された目標音量を、S59で受信した通知データによって通知された目標音量、または、S53で算出した目標音量の中から選択する。CPU10は、S53で算出した目標音量を、上述のようにして選択した目標音量によって修正する(S63)。この場合、後述する表示処理(S21、図5参照)では、修正された目標音量を示す情報が、S53で特定された目標音量を示す情報をの代わりに出力部28(図1参照)に表示されることになる。第三特定処理は終了し、処理はメイン処理(図5参照)に戻る。
【0049】
以上の処理を行うことで、音声処理装置11は、第一拠点に設置された音声処理装置11、12、13のうち、第一ユーザに最も近い位置に設置された音声処理装置10において算出された目標音量を特定することができる。マイク25によって集音された音声の音量が大きい程、ユーザは音声処理装置10の近くにいることが想定されるためである。このように音声処理装置10は、第一拠点に設置された音声処理装置10の其々によって特定された目標音量のうち最適な目標音量を特定し、第一ユーザに対して通知することができる。
【0050】
図5に示すように、第三特定処理(S19)の終了後、CPU20は、第三特定処理によって特定された目標音量を第一ユーザに通知する通知画面を、出力部28に表示する(S21)。図8を参照し、出力部28に表示される通知画面61〜63について説明する。なお通知画面61〜63は、其々、異なる条件で出力部28に表示される通知画面を示している。
【0051】
通知画面61〜63には、第一表示部64、第二表示部65、および第三表示部66が設けられている。第一表示部64は、マイク25によって集音することが可能な音の音量を10段階表示するための表示部である。第一表示部64は、上下方向に並んだ10つの長方形641、および、各長方形の左側に配置された数字642を備えている。数字642は、下端からの段数を示している。第二表示部65は、マイク25によって実際に集音された音声の音量を示す表示部である。第二表示部65は、第一表示部64の長方形の内部を塗り潰すように表示される。第三表示部66は、目標音量を示すための表示部である。第三表示部66は、第一表示部64の長方形の枠線よりも太い枠線であり、第一表示部64の長方形に重ねて表示される。例えば通知画面61は、マイク25によって実際に集音された音声の音量が5であり、目標音量が7であることを示している。また通知画面62は、マイク25によって実際に集音された音声の音量が7であり、目標音量が5であることを示している。
【0052】
CPU20は、マイク25によって集音することが可能な音の音量に対する、RAM22に記憶された自拠点音声音量の割合を算出することによって、第二表示部65を第一表示部64のどの段階まで表示するかを決定する。例えば、マイク25によって集音することが可能な音の音量10に対して、自拠点音声音量が5である場合、通知画面61に示すように、第二表示部65は、第一表示部64における1〜5番目の長方形641の内部に表示される。またCPU20は、マイク25において集音することが可能な音の音量10に対して、目標音量が7と特定された場合、通知画面61に示すように、第三表示部66は、第一表示部64における7〜10番目の長方形641に重ねて表示される。
【0053】
例えば、第一ユーザが音声処理装置11に対して音声を発生し、出力部28に通知画面61が表示された場合、第一ユーザは、発声した音声の音量(5)が目標音量(7)に達していないことを認識できる。また第一ユーザは、もう少し大きな声で音声を発声することによって、音声の音量が目標音量に到達することを認識できる。また例えば、第一ユーザが音声処理装置11に対して音声を発生し、出力部28に通知画面62が表示された場合、第一ユーザは、発声した音声の音量(7)が目標音量(5)に達しており、第二ユーザが音声を雑音と区別して認識できる状態にあることを確認することができる。このように第一ユーザは、発声した音声の音量が目標音量に対してどの程度であるかを認識することができる。このため第一ユーザは、音声の音量が目標音量に近づくように心がけて発声することができる。
【0054】
さらに通知画面63では、第一表示部64および第二表示部65のみ表示されており、第三表示部66が表示されていない。このように第三表示部66が表示されない状態は、マイク25において受信可能な音の最大音量よりも目標音量の方が大きくなっていることを示している。このことは、マイク25において受信可能な最大の音量で第一ユーザが音声を発声しても、音声の音量は目標音量に達しないことを意味している。従って第一ユーザがいくら大きな声で音声を発声したとしても、第二ユーザは音声を雑音と区別して認識することができないことになる。このように音声処理装置11は、第一ユーザが大きな音量の音声を発声したとしても、マイク25が目標音量で音声を集音することができない旨を、予め第一ユーザに通知することができる。
【0055】
図5に示すように、通知画面61〜63を出力部28に表示した後、CPU20は、遠隔会議を終了する指示を、入力部27を介して検出したかを判断する(S23)。CPU20は、遠隔会議を終了する指示を検出していない場合(S23:NO)、通知表示61〜63を継続して出力部28に表示させるため、処理はS10に戻る。一方、遠隔会議を終了する指示を検出した場合(S23:YES)、メイン処理を終了する。
【0056】
以上説明したように、音声処理装置10は、目標音量を算出して第一ユーザに通知することによって、適切な音量でユーザに音声を発声させることができる。これによって、第二拠点に設置された音声処理装置31、32を使用する第二ユーザは、音声処理装置31、32を介して第一ユーザの音声を明確に認識できるようになる。音声処理装置10は、他拠点音声音量および他拠点雑音音量に基づいて目標音量を特定するので、雑音の音量と比較して十分な大きさの音量で、第一ユーザに音声を発声させることができる。これによって第二ユーザは、音声処理装置31、32に設けられたスピーカ24から出力される第一ユーザの音声を、雑音と明確に区別して認識することができる。
【0057】
音声処理装置10は、同一拠点内に複数の音声処理装置10が設置されている場合、これらの音声処理装置10のうち、集音される音声の音量が最も大きい音声処理装置10がユーザの音声を最も効率よく集音していると判断する。また音声処理装置10は、効率よく集音している音声処理装置10が、ユーザの音声を最も集音しやすい、言い換えれば、ユーザに最も近い位置に設置されていると判断する。この場合、該当する音声処理装置10において特定された目標音量を示す情報が、同一拠点内に設置されたすべての音声処理装置10の出力部28から表示される。複数の音声処理装置10で別々の情報が表示されると、ユーザはどの情報を信じてよいかわからなくなるためである。音声処理装置10は、共通の目標音量を示す情報を表示することで、ユーザに目標音量を統一的に通知することができる。
【0058】
なお、S13の処理を行うCPU20が本発明の「第一取得手段」に相当する。S15の処理を行うCPU20が本発明の「第一特定手段」に相当する。S17の処理を行うCPU20が本発明の「第二特定手段」に相当する。S53の処理を行うCPU20が本発明の「第三特定手段」に相当する。S21の処理を行うCPU20が本発明の「通知手段」に相当する。S13、S59の処理を行うCPU20が本発明の「第二取得手段」に相当する。S13の処理が本発明の「第一取得ステップ」に相当する。S15の処理が本発明の「第一特定ステップ」に相当する。S17の処理が本発明の「第二特定ステップ」に相当する。S53の処理が本発明の「第三特定ステップ」に相当する。S21の処理が本発明の「通知ステップ」に相当する。
【0059】
なお本発明は上述の実施形態に限定されず、種々の変更が可能である。図1のシステム構成は本発明の一例であり、他のシステム構成であってもよい。例えばインターネット網16の代わりに、固定電話網、移動電話網、専用通信網等、周知の様々な外部通信網が使用され、自拠点と他拠点との間で通信が実行されてもよい。音声処理装置10は、PC15の代わりに、音声処理装置10以外の様々な機器(固定電話機、携帯電話機、ルータ、モデム等)を介して外部通信網と接続してもよい。また音声処理装置10は、外部通信網と直接接続してもよい。
【0060】
上述では、音声処理装置10にスピーカ24およびマイク25が設けられていたが、音声処理装置10はスピーカ24およびマイク25を備えていなくてもよく、外付けのスピーカおよびマイクを接続して使用してもよい。上述では、RAM22に記憶された他拠点音声音量と他拠点雑音音量との差分に基づき、目標音量を算出した。これに対し、音声処理装置10は、他拠点音声音量と他拠点雑音音量との割合に基づき、目標音量を算出してもよい。また音声処理装置10は、自拠点音声音量、自拠点雑音音量、他拠点音声音量、および他拠点雑音音量のうちいずれかの情報のみに基づいて、目標音量を算出してもよい。音声処理装置10は、目標音量のみを第一ユーザに通知し、第一ユーザの発声した音声の音量は通知しなくてもよい。また例えば音声処理装置10は、第一ユーザの発声した音声が目標音量に達しているか否かを通知する情報のみを、出力部28に表示してもよい。
【0061】
音声処理装置11は、第一拠点に設置された他の音声処理装置12、13との間で目標音量を調整し、共通の目標音量を出力部28に表示していた。これに対して音声処理装置10は、其々において特定された目標音量を別々に出力部28に出力してもよい。音声処理装置10は、第一ユーザが複数である場合、全てのユーザの音を音情報として他の音声処理装置10、30に送信しても良いし、ユーザ毎に異なる音情報を送信してもよい。また音声処理装置10は、ユーザ毎に異なる音情報を受信した場合、ユーザ毎に異なる目標音量を特定し、ユーザを識別する情報と共に出力部28に表示することによってユーザに通知してもよい。
【0062】
上述における通知画面61〜63は別の態様であってもよい。図8では、第一表示部64の枠線に対して、第三表示部66の枠線を太くすることによって、双方を区別していた。例えば、第一表示部64の枠線の色と、第三表示部66の枠線の色とを変えることによって、双方を区別してもよい。具体的には、例えば、第一表示64の枠線を赤色とし、第三表示部66の枠線を青色としてもよい。また通知画面63の第一表示部64の枠線の色が、通知画面61、62の枠線の色と異なるように表示してもよい。これによって、第一ユーザが大きな音量の音声を発声したとしても、マイク25が目標音量で音声を集音することができない旨を、明確に通知することができる。
【0063】
図9を参照し、出力部28に表示する通知画面の別の例である、通知画面71〜73について説明する。通知画面71〜73には、第一表示部74、第二表示部75、および第三表示部76が設けられている。第一表示部74は、上下に並んだ二つの長方形である。第三表示部76は、第一表示部74の長方形の上側に配置された、上下に並んだ3つの長方形である。第三表示部76の長方形の枠線は、第一表示部74の長方形の枠線よりも太い。第二表示部75は、第一表示部74および第三表示部76の内部を塗り潰すように表示される。
【0064】
通知画面71〜73では、第一表示部74と第三表示部76との境界部分によって目標音量が示される。第二表示部75は、マイク25によって実際に集音された音声の音量を示す表示部である。通知画面71〜73では、通知画面61〜63と異なり、目標音量のレベルが変化しても、第三表示部76の数は変化せず、常に3つの長方形によって示される。
【0065】
CPU20は、RAM22に記憶された自拠点音声音量が、目標音量に対してどの程度の大きさであるかを算出することによって、第二表示部75を第一表示部74および第三表示部76のうちどの段階まで表示するかを決定する。例えばCPU20は、自拠点音声音量が目標音量と同レベルである場合、通知画面71に示すように、第一表示部74の二つの長方形の内部に第二表示部75を表示する。またCPU20は、自拠点音声音量が7であるのに対して目標音量が5である場合、通知画面72に示すように、第一表示部74の二つの長方形、および、第三表示部76の3つの長方形のうち下から2つ分の長方形の内部に、第二表示部75を表示する。通知画面71〜73では、目標音量を示す境界が常に画面の上下略中央部分に配置されるため、第一ユーザは、目標音量をより直感的に認識することができる。
【0066】
これに対して通知画面73は、マイク25において受信可能な音の最大音量よりも目標音量の方が大きくなっている場合の表示態様を示している。この場合、CPU20は、第三表示部76の上部に「NG」の文字77を表示させる。このように音声処理装置10は、通知画面71〜73を出力部28に表示させることによって、第一ユーザが大きな音量の音声を発声したとしても、マイク25が目標音量で音声を集音することができない旨を、通知画面61〜63と比較してより明確に第一ユーザに通知することができる。
【符号の説明】
【0067】
1 会議システム
10、11、12、30、31、32 音声処理装置
24 スピーカ
25 マイク
28 出力部
61、62、63、71、72、73 通知画面
【特許請求の範囲】
【請求項1】
他拠点に設置された他拠点マイクを介して集音された音に関する情報である音情報を取得する第一取得手段と、
前記第一取得手段によって取得された前記音情報に基づいて、音声の音量および雑音の音量を特定する第一特定手段と、
自拠点に設置された音声処理装置に接続された自拠点マイクを介して集音された音に基づいて、音声の音量および雑音の音量を特定する第二特定手段と、
前記第一特定手段によって特定された前記音量、および、前記第二特定手段によって特定された前記音量に基づいて、前記音声処理装置が前記自拠点マイクを介して集音する前記音声の目標とする音量である目標音量を特定する第三特定手段と、
前記第三特定手段によって特定された前記目標音量に関連する情報をユーザに通知する通知手段と
を備えたことを特徴とする音声処理装置。
【請求項2】
前記第三特定手段は、
前記第一特定手段によって特定された前記音声の音量と前記雑音の音量との差分または割合に基づき、前記目標音量を特定することを特徴とする請求項1に記載の音声処理装置。
【請求項3】
前記通知手段は、
前記第三特定手段によって特定された前記目標音量と、前記第二特定手段によって特定された前記音声の音量との関係を示す情報を通知することを特徴とする請求項1または2に記載の音声処理装置。
【請求項4】
前記通知手段は、
前記第三特定手段によって特定された前記目標音量が、前記自拠点マイクを介して集音することが可能な最大音量を超えた場合に、最大音量を超えた旨をユーザに通知することを特徴とする請求項1または2に記載の音声処理装置。
【請求項5】
自拠点に設置された他の音声処理装置である自拠点他装置から、前記音声の音量および前記目標音量を取得する第二取得手段を備え、
前記通知手段は、
前記第二取得手段によって取得された前記音声の音量が、前記第二特定手段によって特定された前記音声の音量よりも大きい場合に、前記第二取得手段によって取得された前記目標音量を示す情報を、前記第三特定手段によって特定された前記目標音量を示す情報の代わりにユーザに通知することを特徴とする請求項1から4のいずれかに記載の音声処理装置。
【請求項6】
前記第一取得手段は、複数の他拠点の其々に設置された他拠点マイクを介して集音された複数の前記音情報を取得し、
前記第一特定手段は、
前記第一取得手段によって取得された前記複数の音情報に対応する複数の前記音声の音量のうち最も小さい前記音声の音量を特定し、前記複数の音情報に対応する複数の前記雑音の音量のうちもっとも大きい前記雑音の音量を特定することを特徴とする請求項1から5のいずれかに記載の音声処理装置。
【請求項7】
他拠点に設置された他拠点マイクを介して集音された音に関する情報である音情報を、自拠点に設置された音声処理装置が取得する第一取得ステップと、
前記第一取得ステップによって取得された前記音情報に基づいて、前記音声処理装置が音声の音量および雑音の音量を特定する第一特定ステップと、
前記音声処理装置が、接続された自拠点マイクを介して集音された音に基づいて、音声の音量および雑音の音量を特定する第二特定ステップと、
前記第一特定ステップによって特定された前記音量、および、前記第二特定ステップによって特定された前記音量のうち少なくともいずれかに基づいて、前記音声処理装置が前記自拠点マイクを介して集音する前記音声の目標とする音量である目標音量を特定する第三特定ステップと、
前記第三特定ステップによって特定された前記目標音量に関連する情報を、前記音声処理装置がユーザに通知する通知ステップと
を備えたことを特徴とする音声処理方法。
【請求項8】
他拠点に設置された他拠点マイクを介して集音された音に関する情報である音情報を取得する第一取得ステップと、
前記第一取得ステップによって取得された前記音情報に基づいて、音声の音量および雑音の音量を特定する第一特定ステップと、
自拠点に設置された音声処理装置に接続された自拠点マイクを介して集音された音に基づいて、音声の音量および雑音の音量を特定する第二特定ステップと、
前記第一特定ステップによって特定された前記音量、および、前記第二特定ステップによって特定された前記音量のうち少なくともいずれかに基づいて、前記音声処理装置が前記自拠点マイクを介して集音する前記音声の目標とする音量である目標音量を特定する第三特定ステップと、
前記第三特定ステップによって特定された前記目標音量に関連する情報をユーザに通知する通知ステップと
を音声処理装置のコンピュータに実行させるための音声処理プログラム。
【請求項1】
他拠点に設置された他拠点マイクを介して集音された音に関する情報である音情報を取得する第一取得手段と、
前記第一取得手段によって取得された前記音情報に基づいて、音声の音量および雑音の音量を特定する第一特定手段と、
自拠点に設置された音声処理装置に接続された自拠点マイクを介して集音された音に基づいて、音声の音量および雑音の音量を特定する第二特定手段と、
前記第一特定手段によって特定された前記音量、および、前記第二特定手段によって特定された前記音量に基づいて、前記音声処理装置が前記自拠点マイクを介して集音する前記音声の目標とする音量である目標音量を特定する第三特定手段と、
前記第三特定手段によって特定された前記目標音量に関連する情報をユーザに通知する通知手段と
を備えたことを特徴とする音声処理装置。
【請求項2】
前記第三特定手段は、
前記第一特定手段によって特定された前記音声の音量と前記雑音の音量との差分または割合に基づき、前記目標音量を特定することを特徴とする請求項1に記載の音声処理装置。
【請求項3】
前記通知手段は、
前記第三特定手段によって特定された前記目標音量と、前記第二特定手段によって特定された前記音声の音量との関係を示す情報を通知することを特徴とする請求項1または2に記載の音声処理装置。
【請求項4】
前記通知手段は、
前記第三特定手段によって特定された前記目標音量が、前記自拠点マイクを介して集音することが可能な最大音量を超えた場合に、最大音量を超えた旨をユーザに通知することを特徴とする請求項1または2に記載の音声処理装置。
【請求項5】
自拠点に設置された他の音声処理装置である自拠点他装置から、前記音声の音量および前記目標音量を取得する第二取得手段を備え、
前記通知手段は、
前記第二取得手段によって取得された前記音声の音量が、前記第二特定手段によって特定された前記音声の音量よりも大きい場合に、前記第二取得手段によって取得された前記目標音量を示す情報を、前記第三特定手段によって特定された前記目標音量を示す情報の代わりにユーザに通知することを特徴とする請求項1から4のいずれかに記載の音声処理装置。
【請求項6】
前記第一取得手段は、複数の他拠点の其々に設置された他拠点マイクを介して集音された複数の前記音情報を取得し、
前記第一特定手段は、
前記第一取得手段によって取得された前記複数の音情報に対応する複数の前記音声の音量のうち最も小さい前記音声の音量を特定し、前記複数の音情報に対応する複数の前記雑音の音量のうちもっとも大きい前記雑音の音量を特定することを特徴とする請求項1から5のいずれかに記載の音声処理装置。
【請求項7】
他拠点に設置された他拠点マイクを介して集音された音に関する情報である音情報を、自拠点に設置された音声処理装置が取得する第一取得ステップと、
前記第一取得ステップによって取得された前記音情報に基づいて、前記音声処理装置が音声の音量および雑音の音量を特定する第一特定ステップと、
前記音声処理装置が、接続された自拠点マイクを介して集音された音に基づいて、音声の音量および雑音の音量を特定する第二特定ステップと、
前記第一特定ステップによって特定された前記音量、および、前記第二特定ステップによって特定された前記音量のうち少なくともいずれかに基づいて、前記音声処理装置が前記自拠点マイクを介して集音する前記音声の目標とする音量である目標音量を特定する第三特定ステップと、
前記第三特定ステップによって特定された前記目標音量に関連する情報を、前記音声処理装置がユーザに通知する通知ステップと
を備えたことを特徴とする音声処理方法。
【請求項8】
他拠点に設置された他拠点マイクを介して集音された音に関する情報である音情報を取得する第一取得ステップと、
前記第一取得ステップによって取得された前記音情報に基づいて、音声の音量および雑音の音量を特定する第一特定ステップと、
自拠点に設置された音声処理装置に接続された自拠点マイクを介して集音された音に基づいて、音声の音量および雑音の音量を特定する第二特定ステップと、
前記第一特定ステップによって特定された前記音量、および、前記第二特定ステップによって特定された前記音量のうち少なくともいずれかに基づいて、前記音声処理装置が前記自拠点マイクを介して集音する前記音声の目標とする音量である目標音量を特定する第三特定ステップと、
前記第三特定ステップによって特定された前記目標音量に関連する情報をユーザに通知する通知ステップと
を音声処理装置のコンピュータに実行させるための音声処理プログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】

【図9】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【公開番号】特開2013−80994(P2013−80994A)
【公開日】平成25年5月2日(2013.5.2)
【国際特許分類】
【出願番号】特願2011−218494(P2011−218494)
【出願日】平成23年9月30日(2011.9.30)
【出願人】(000005267)ブラザー工業株式会社 (13,856)
【Fターム(参考)】
【公開日】平成25年5月2日(2013.5.2)
【国際特許分類】
【出願日】平成23年9月30日(2011.9.30)
【出願人】(000005267)ブラザー工業株式会社 (13,856)
【Fターム(参考)】
[ Back to top ]