
音声化システム、音声化方法、音声化サーバ及び音声化プログラム
【課題】テキストを、テキストに含まれる単語の少なくとも一部を読み上げた音声データとして取得するための音声化システム、音声化方法、音声化サーバ及び音声化プログラムであって、文書とそれを読み上げた音声との相互参照が容易であるような形で音声データを提供可能なものを提供する。
【解決手段】テキストに含まれる単語を抽出し、抽出された単語と、利用者のレベル情報に基づいて利用者のレベル以上の読み上げ難易度の単語を抽出し、抽出された単語を読み上げた音声データを取得し、テキストに音声データへのリンクアンカーを埋め込んでHTMLファイルを作成し、これを端末に送信する。
【解決手段】テキストに含まれる単語を抽出し、抽出された単語と、利用者のレベル情報に基づいて利用者のレベル以上の読み上げ難易度の単語を抽出し、抽出された単語を読み上げた音声データを取得し、テキストに音声データへのリンクアンカーを埋め込んでHTMLファイルを作成し、これを端末に送信する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、テキストを、テキストに含まれる単語の少なくとも一部を読み上げた音声データとして取得するための音声化システム、音声化方法、音声化サーバ及び音声化プログラムに関する。
【背景技術】
【0002】
外国語、特に日本語のように表意文字に固有語の発音を割り当てているもの(所謂訓読み)や、英語のように複数の言語から単語及びその発音規則を借用しているもの、或いはロシア語のようにアクセントの位置によって母音の発音が変化するようなものを習得しようとする際には、その言語を習得しようとする人(以下習得者と称す)にとって身近な文書(例えば習得者に取って興味のある分野のニュース記事や、技術文書)と、その文書を読み上げた音声とを相互参照しながら学習を進めていくことが有効である。
【0003】
ここで、習得者にとって興味のある分野は習得者ごとに異なり、多岐の分野に渡っている。そこで、インターネットを介して公衆に開示されている各種ニュース記事や技術文書等の文書を取得し、これを読み上げた音声データを生成し、この音声データと文書とを相互参照しながら学習を進めていくことが考えられる。このような学習を可能とするシステムとして、特許文献1のようなものがある。
【特許文献1】特開2005−70304
【0004】
特許文献1には、ゲートウェイサーバ型の音声読み上げサーバが開示されている。すなわち、インターネット上で公開されている文書を読み上げた音声データの取得を希望する場合は、音声読み上げサーバの利用者はインターネットに接続されている端末(PCなど)でウェブブラウザなどのユーザエージェントを実行し、このユーザエージェントを操作して音声読み上げサーバにHTTPリクエストを送信する。この時、このHTTPリクエストには、音声データの取得を希望する文書を示すURL(Uniform Resource Locator)が含まれる。
【0005】
音声読み上げサーバは、このURLに対応する文書を取得し、次いでこの文書からテキスト部分のみを抜き出す。例えば、文書がHTMLで記述されたものであるなら、タグやコメント、SGML宣言などを除去したテキスト部分のみを取り出すことになる。音声読み上げサーバは、この抜き出されたテキスト部分を読み上げた音声データを音声合成等を使用して生成する。最後に、音声読み上げサーバはこの音声データそのもの、或いはこの音声データのURLをHTTPリクエストに対するレスポンスとして送信する。かくして、使用者は音声データを取得し、文書とこの文書を読み上げた音声の双方を参照可能となる。
【発明の開示】
【発明が解決しようとする課題】
【0006】
上記の構成は、インターネット上で公開されている任意の文書を読み上げた音声データを取得するものである。上記の構成においてはある文書について、その文書全体、或いはその文書のまとまった一部分(1段落、1頁など)を読み上げた音声データが取得されるものである。その言語をネイティブ言語としない言語学習者にとって、学習の際に重要となるのは、特定の語がどのように発音されるかである。しかしながら、上記構成においては、ある程度まとまった文章単位で読み上げが行われるので、特にその言語をネイティブ言語としていないものにとって、いま読み上げられているのが文書中のどの部分であるかを判別するのは容易ではないケースも多い。すなわち、特許文献1の構成は、自然言語の学習という観点からは、上記の理由から必ずしも優れたものとはいえなかった。
【0007】
本発明は上記の問題に鑑みてなされたものであり、言語習得者にとって利用しやすい、すなわち文書とそれを読み上げた音声との相互参照が容易であるような形で音声データを提供可能な音声化システム、音声化方法、音声化サーバ及び音声化プログラムを提供することを目的とする。
【課題を解決するための手段】
【0008】
上記の目的を解決するため、本発明においては、テキストに関するテキスト情報及び利用者のレベル情報を端末から受信し、受信したテキスト情報に基づいてテキストを取得し、レベル情報に基づいて取得したテキストに含まれる単語の中から使用者のレベル以上の読み上げ難易度の単語を抽出し、抽出された単語を読み上げた音声データを取得し、テキストに該音声データへのリンクアンカーを埋め込んでHTMLファイルを作成し、作成されたHTMLファイルを該端末に送信する。
【0009】
従って、本発明の構成によれば、システムの利用者である言語学習者の習得レベルに応じた単語のみに対する音声データが作成される。加えて、利用者は読み上げを希望するテキストにこの音声データへのリンクアンカーが埋め込まれたHTMLファイルを受けとることになる。このHTMLファイルを開くと、文書の所々の単語にリンクアンカーが割り当てられたハイパーテキスト文書が表示され、利用者はこのリンクアンカーを操作してその単語の音声データを取得・再生することによって、特定の単語の発音を理解することができる。
【0010】
好ましくは、テキスト情報とは、テキストのURLを含むか、テキスト自身を含む。また、抽出された単語を読み上げた音声データを、音声合成によって生成する構成としてもよい。また、所定のネットワークは、例えばインターネットである。
【発明の効果】
【0011】
以上のように、本発明によれば、文書とそれを読み上げた音声との相互参照が容易であるような形で音声データを提供可能な音声化システムが実現される。
【発明を実施するための最良の形態】
【0012】
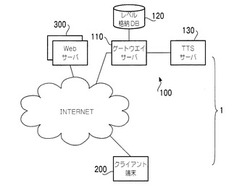
以下、本発明の実施の形態に付き、図面を参照して詳細に説明する。図1は、本実施形態による音声化システムの全体を示す概念図である。本実施形態においては、音声化システム1は、音声化サーバ100と端末200とを備える。
【0013】
端末200は、ダイヤルアップ接続やxDSL接続などによってインターネットに接続可能な端末である。また、端末200は、例えばウェブブラウザを実行可能なPCであり、音声化システム1の利用者は、この端末200上でウェブブラウザを実行・操作して、音声化サーバ100より所望の文書の単語の音声データを得る。端末200は、音声データを再生するためのデバイス(PCM音源及び、スピーカまたはヘッドホン)を備えており、音声化サーバ100から得た音声データを再生することが可能である。
【0014】
音声化サーバ100は、インターネットに接続されている音声化ゲートウェイサーバ110と、このゲートウェイサーバ110とLAN(Local Area Network)経由で接続されているレベル格納データベース120及びTTS(Text−To−Speech)サーバ130を有する。
【0015】
音声化ゲートウェイサーバ110は、HTTP(HyperText Transfer Protocol)に基づいて端末200との間でデータの送受信が可能な、一種のWebサーバである。また、音声化ゲートウェイサーバ110は、HTTPユーザエージェントとしての機能をも有しており、端末200からのリクエストに基づいて、インターネット上の他のウェブサーバ300から文書データを取得することができる。
【0016】
レベル格納データベース120とは、ある単語とこの単語を平易に読み上げられるだけの語学習得レベルとを対比させたデータベースである。音声化ゲートウェイサーバ110は、文書中に含まれる任意の単語について、その単語に関連づけられた語学習得レベルを取得可能である。
【0017】
TTSサーバ130は、音声化ゲートウェイサーバ110からテキストを受信すると、このテキストを読み上げた音声データを音声合成によって生成し、これを音声化ゲートウェイサーバ110に送信する。
【0018】
以上説明した構成においては、音声化ゲートウェイサーバ110のみがインターネットに接続され、レベル格納データベース120及びTTSサーバ130はこの音声化ゲートウェイサーバ110とLAN経由で接続されている。しかしながら本発明は上記構成に限定されるものではない。例えば、レベル格納データベース120及びTTSサーバ130の何れか一方または双方がインターネットに接続されており、これらと音声化ゲートウェイサーバ110とがインターネットを介してデータのやり取りをおこなっても良い。また、本実施形態においては音声化ゲートウェイサーバ110、レベル格納データベース120、TTSサーバ130が夫々別々の装置として示されているが、単一のサーバ装置が音声化ゲートウェイサーバ110、レベル格納データベース120、TTSサーバ130としての機能を兼ね備える構成もまた、本発明の範囲内である。
【0019】
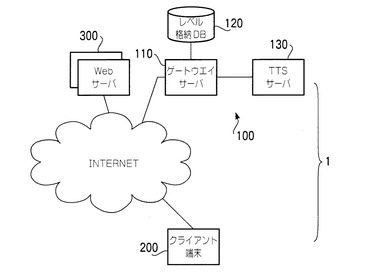
以上説明した構成によって、文書の音声データを端末200の使用者(語学習得者)が得るまでの手順に付き説明する。まず、使用者がウェブブラウザを操作して、音声化ゲートウェイサーバ110に接続する。接続が完了すると、図2のように文書URL入力用ページがブラウザの文書表示エリアに表示される。
【0020】
この文書URL入力用ページには、テキスト行入力コントロール(single−line text input control)T1、ボタンB1、ラジオボタンR1が表示される。テキスト行入力コントロールT1は、端末200の使用者が、音声読み上げを希望する文書(プレーンテキスト、HTML文書等)のURLを入力するための領域である。使用者は、端末200のキーボードを操作して、このテキスト行入力コントロールT1に文字を入力することができる。
【0021】
ラジオボタンR1は、図2中に縦方向に4つ並べられており、この4つのラジオボタンR1の何れかを選択することによって、使用者の語学習得レベルを選択するものである。使用者は、端末200のマウスを操作することによって、カーソルCを所望のラジオボタンR1に移動させ、次いでマウスのボタンをクリックすることによって所望のラジオボタンを選択することができる。
【0022】
ボタンB1は、テキスト行入力コントロールT1及びラジオボタンR1の内容を音声化ゲートウェイサーバ110に送信するためのボタンである。使用者は、端末200のマウスを操作することによって、カーソルCをボタンに重ね、次いでマウスのボタンをクリックすることによってテキスト行入力コントロールT1及びラジオボタンR1の内容を送信する。
【0023】
すなわち、使用者は、キーボード等を用いて所望の文書のURLをテキスト行入力コントロールT1に入力し、使用者自身の語学習得レベルに応じたラジオボタンR1を選択し、最後にボタンB1を操作して、所望の文書のURL及び使用者自身の語学習得レベルをゲートウェイサーバ110に送信する。
【0024】
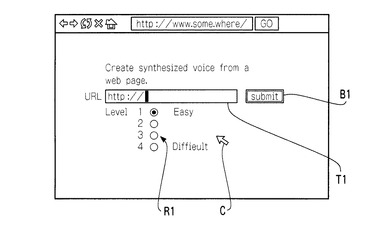
ゲートウェイサーバ110は、端末200から文書のURLと使用者の語学習得レベルを受信すると、図3のフローチャートに示されるルーチンを実行する。このルーチンが開始すると、最初にステップS1が実行される。
【0025】
ステップS1では、ゲートウェイサーバ110は、端末200から送信されたURLに対応する文書があるかどうかの確認をおこなう。このURLに対応する文書が無い、若しくはこのURLに対応する文書はあるがゲートウェイサーバ110が対応していないエンコーディングの文書であった、といった場合は(S1:NO)、ステップS11を実行する。ステップS11では、エラーメッセージを端末200に送信する。一方、ステップS1において、端末200から送信されたURLに対応する文書があり、且つその文書がゲートウェイサーバ110が対応していないエンコーディングで記述されていることが確認された場合は(S1:YES)、ステップS2に進む。
【0026】
ステップS2では、ゲートウェイサーバ110は、ユーザエージェント機能を利用してURLに対応する外部のウェブサーバ300から文書をダウンロードする。次いで、ステップS3に進む。
【0027】
ステップS3では、文書の整形がおこなわれる。すなわち、文書がHTMLファイルである場合は、不要なタグやコメントやSGML宣言などを除去し、純粋な文書のみを抽出する。また、文書が整形済の(すなわち、所定の文字数ごとに強制的に改行コードが挿入されている)プレーンテキストである場合は、改行コードを除去する。さらに、文書の言語が日本語のように単語同士を区切る文字を持たないものであるならば、文書の形態解析を行って、文書を単語ごとに分割する。これらの文書の整形方法については既知であるため、詳細な説明は省略する。次いで、ステップS4に進む。
【0028】
ステップS4では、ステップS3で整形を行った文書に含まれる単語を文書の先頭から順に一つずつ抽出する。この際、日本語における助詞や助動詞、英語におけるbe動詞や代名詞、助動詞など、一つの文書内に多く出現し、また語学学習者にとってもきわめて平易であることが既知である単語については抽出しない構成としてもよい。次いでステップS5に進む。
【0029】
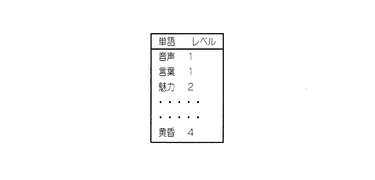
ステップS5では、ゲートウェイサーバ110は、ステップS4で抽出された単語について、レベル格納データベース120に問い合わせを行う。レベル格納データベース120では、図4のように単語の各々について、そのレベルを参照できるようになっている。言語が日本語であるならば、初等教育で習う単語や音読みのみで発音可能な単語については低いレベルが割り当てられ、漢字単体の音読みにも訓読みにも無い発音が割り当てられているような単語については高いレベルが割り当てられるようになっている。レベル格納データベース120は、ゲートウェイサーバ110より単語のテキストを受信すると、この単語のレベルをゲートウェイサーバ110に送り返す。かくして、ゲートウェイサーバ110は、その単語の難易度レベルを取得する。ゲートウェイサーバ110は、次いで、ステップS6(図3)を実行する。
【0030】
ステップS6では、ゲートウェイサーバ110はステップS5で取得した単語の難易度レベルと、本ルーチンの開始時に端末200から受け取っている使用者の言語習得レベルとを比較する。ここで、単語の難易度レベルが使用者の言語習得レベル以上であるなら(S6:YES)、この単語を読み上げた音声データが必要であると判断し、ステップS7に進む。一方、ステップS6において単語の難易度レベルが使用者の言語習得レベル未満であるなら(S6:NO)、この単語については音声データを用意する必要はないと判断し、ステップS4にもどり、文書内に次に現れる単語の抽出を行う。
【0031】
ステップS7では、ゲートウェイサーバ110はTTSサーバ130に問い合わせを行う。具体的には、ゲートウェイサーバ110はステップS4で抽出した単語のテキストをTTSサーバ130に送信する。TTSサーバ130は、音声合成によってこの単語を読み上げた音声データを作成し、これをゲートウェイサーバ110に送り返す。ゲートウェイサーバ110は、受信したデータをサーバのストレージ手段に保存する。なお、ストレージ手段の容量が使用済みの音声データによって圧迫されるのを防止するため、ステップS7の実行から一定時間後(例えば1時間後)に、音声データを消去する構成としてもよい。次いで、ステップS8に進む。
【0032】
ステップS8では、ステップS7で得た音声データへのリンクアンカー(HTMLにおけるA要素)をステップS3で整形した文書に埋め込む。次いで、ステップS9に進む。
【0033】
ステップS9では、文書の最後まで単語の検索(ステップS4)が完了したかどうかの判定が行われる。文書の最後まで単語の検索が済んだのであれば(S9:YES)、ステップS10に進む。一方、文書の最後まで単語の検索を終えていないのであれば(S9:NO)、まだ抽出すべき単語が残されている可能性があるということなので、ステップS4に戻り、他の単語の抽出を行う。
【0034】
ステップS10では、ステップS3によって一旦整形され、ステップS8にてリンクアンカーが埋め込まれた文書に、ヘッダやタイトル要素など、HTMLファイルとして必要なデータが追記され、HTMLファイルが作成される。次いで、ゲートウェイサーバ110は、このHTMLファイルを端末200に送信し、本ルーチンを終了させる。
【0035】
端末200は、このHTMLファイルを受信すると、ブラウザを制御してこのHTMLファイルをWebページとして表示する。ブラウザに表示されるWebページの一例を図5に示す。図5に示されるように、文書中には音声データへのリンクが設けられた単語が強調表現(本実施形態においては下線)で表示され、端末200の使用者はこのリンクを操作する(例えばカーソルをこの単語に重ねてマウスのボタンをクリックする)ことによって、この単語を読み上げた音声データをダウンロードして聴くことができる。
【0036】
以上のように、本実施形態によれば、文書中の単語を読み上げた音声データが文書中にリンクとして示されたHTML文書を端末200の使用者は取得できるので、テキストである文書と、その文書中の単語を読み上げた音声とを相互参照しながら自然言語の学習を効率的に進めていくことが出来るようになる。さらに、言語習得者のレベルに応じて音声と関連づけられる単語は変化するので、言語習得者は自分のレベルにあったHTML文書を取得できる。
【0037】
なお、本実施形態においては、端末200から所望の文書のURLを送信する構成としているが、代わりに、文書自身を直接音声化ゲートウェイサーバに送信する構成としてもよい。
【図面の簡単な説明】
【0038】
【図1】本発明の実施の形態による音声化システムの全体を示す概念図である。
【図2】本発明の実施の形態において、端末に表示される文書URL入力ページを示したものである。
【図3】本発明の実施の形態において、音声化ゲートウェイサーバによって実行されるプログラムのフローである。
【図4】本発明の実施の形態において、レベル格納データベースに格納されたデータの一例を示したものである。
【図5】本発明の実施の形態において、端末に表示されたWebページを示したものである。
【符号の説明】
【0039】
1 音声化システム
100 音声化サーバ
110 音声化ゲートウェイサーバ
120 レベル格納データベース
130 TTSサーバ
200 端末
300 ウェブサーバ
【技術分野】
【0001】
本発明は、テキストを、テキストに含まれる単語の少なくとも一部を読み上げた音声データとして取得するための音声化システム、音声化方法、音声化サーバ及び音声化プログラムに関する。
【背景技術】
【0002】
外国語、特に日本語のように表意文字に固有語の発音を割り当てているもの(所謂訓読み)や、英語のように複数の言語から単語及びその発音規則を借用しているもの、或いはロシア語のようにアクセントの位置によって母音の発音が変化するようなものを習得しようとする際には、その言語を習得しようとする人(以下習得者と称す)にとって身近な文書(例えば習得者に取って興味のある分野のニュース記事や、技術文書)と、その文書を読み上げた音声とを相互参照しながら学習を進めていくことが有効である。
【0003】
ここで、習得者にとって興味のある分野は習得者ごとに異なり、多岐の分野に渡っている。そこで、インターネットを介して公衆に開示されている各種ニュース記事や技術文書等の文書を取得し、これを読み上げた音声データを生成し、この音声データと文書とを相互参照しながら学習を進めていくことが考えられる。このような学習を可能とするシステムとして、特許文献1のようなものがある。
【特許文献1】特開2005−70304
【0004】
特許文献1には、ゲートウェイサーバ型の音声読み上げサーバが開示されている。すなわち、インターネット上で公開されている文書を読み上げた音声データの取得を希望する場合は、音声読み上げサーバの利用者はインターネットに接続されている端末(PCなど)でウェブブラウザなどのユーザエージェントを実行し、このユーザエージェントを操作して音声読み上げサーバにHTTPリクエストを送信する。この時、このHTTPリクエストには、音声データの取得を希望する文書を示すURL(Uniform Resource Locator)が含まれる。
【0005】
音声読み上げサーバは、このURLに対応する文書を取得し、次いでこの文書からテキスト部分のみを抜き出す。例えば、文書がHTMLで記述されたものであるなら、タグやコメント、SGML宣言などを除去したテキスト部分のみを取り出すことになる。音声読み上げサーバは、この抜き出されたテキスト部分を読み上げた音声データを音声合成等を使用して生成する。最後に、音声読み上げサーバはこの音声データそのもの、或いはこの音声データのURLをHTTPリクエストに対するレスポンスとして送信する。かくして、使用者は音声データを取得し、文書とこの文書を読み上げた音声の双方を参照可能となる。
【発明の開示】
【発明が解決しようとする課題】
【0006】
上記の構成は、インターネット上で公開されている任意の文書を読み上げた音声データを取得するものである。上記の構成においてはある文書について、その文書全体、或いはその文書のまとまった一部分(1段落、1頁など)を読み上げた音声データが取得されるものである。その言語をネイティブ言語としない言語学習者にとって、学習の際に重要となるのは、特定の語がどのように発音されるかである。しかしながら、上記構成においては、ある程度まとまった文章単位で読み上げが行われるので、特にその言語をネイティブ言語としていないものにとって、いま読み上げられているのが文書中のどの部分であるかを判別するのは容易ではないケースも多い。すなわち、特許文献1の構成は、自然言語の学習という観点からは、上記の理由から必ずしも優れたものとはいえなかった。
【0007】
本発明は上記の問題に鑑みてなされたものであり、言語習得者にとって利用しやすい、すなわち文書とそれを読み上げた音声との相互参照が容易であるような形で音声データを提供可能な音声化システム、音声化方法、音声化サーバ及び音声化プログラムを提供することを目的とする。
【課題を解決するための手段】
【0008】
上記の目的を解決するため、本発明においては、テキストに関するテキスト情報及び利用者のレベル情報を端末から受信し、受信したテキスト情報に基づいてテキストを取得し、レベル情報に基づいて取得したテキストに含まれる単語の中から使用者のレベル以上の読み上げ難易度の単語を抽出し、抽出された単語を読み上げた音声データを取得し、テキストに該音声データへのリンクアンカーを埋め込んでHTMLファイルを作成し、作成されたHTMLファイルを該端末に送信する。
【0009】
従って、本発明の構成によれば、システムの利用者である言語学習者の習得レベルに応じた単語のみに対する音声データが作成される。加えて、利用者は読み上げを希望するテキストにこの音声データへのリンクアンカーが埋め込まれたHTMLファイルを受けとることになる。このHTMLファイルを開くと、文書の所々の単語にリンクアンカーが割り当てられたハイパーテキスト文書が表示され、利用者はこのリンクアンカーを操作してその単語の音声データを取得・再生することによって、特定の単語の発音を理解することができる。
【0010】
好ましくは、テキスト情報とは、テキストのURLを含むか、テキスト自身を含む。また、抽出された単語を読み上げた音声データを、音声合成によって生成する構成としてもよい。また、所定のネットワークは、例えばインターネットである。
【発明の効果】
【0011】
以上のように、本発明によれば、文書とそれを読み上げた音声との相互参照が容易であるような形で音声データを提供可能な音声化システムが実現される。
【発明を実施するための最良の形態】
【0012】
以下、本発明の実施の形態に付き、図面を参照して詳細に説明する。図1は、本実施形態による音声化システムの全体を示す概念図である。本実施形態においては、音声化システム1は、音声化サーバ100と端末200とを備える。
【0013】
端末200は、ダイヤルアップ接続やxDSL接続などによってインターネットに接続可能な端末である。また、端末200は、例えばウェブブラウザを実行可能なPCであり、音声化システム1の利用者は、この端末200上でウェブブラウザを実行・操作して、音声化サーバ100より所望の文書の単語の音声データを得る。端末200は、音声データを再生するためのデバイス(PCM音源及び、スピーカまたはヘッドホン)を備えており、音声化サーバ100から得た音声データを再生することが可能である。
【0014】
音声化サーバ100は、インターネットに接続されている音声化ゲートウェイサーバ110と、このゲートウェイサーバ110とLAN(Local Area Network)経由で接続されているレベル格納データベース120及びTTS(Text−To−Speech)サーバ130を有する。
【0015】
音声化ゲートウェイサーバ110は、HTTP(HyperText Transfer Protocol)に基づいて端末200との間でデータの送受信が可能な、一種のWebサーバである。また、音声化ゲートウェイサーバ110は、HTTPユーザエージェントとしての機能をも有しており、端末200からのリクエストに基づいて、インターネット上の他のウェブサーバ300から文書データを取得することができる。
【0016】
レベル格納データベース120とは、ある単語とこの単語を平易に読み上げられるだけの語学習得レベルとを対比させたデータベースである。音声化ゲートウェイサーバ110は、文書中に含まれる任意の単語について、その単語に関連づけられた語学習得レベルを取得可能である。
【0017】
TTSサーバ130は、音声化ゲートウェイサーバ110からテキストを受信すると、このテキストを読み上げた音声データを音声合成によって生成し、これを音声化ゲートウェイサーバ110に送信する。
【0018】
以上説明した構成においては、音声化ゲートウェイサーバ110のみがインターネットに接続され、レベル格納データベース120及びTTSサーバ130はこの音声化ゲートウェイサーバ110とLAN経由で接続されている。しかしながら本発明は上記構成に限定されるものではない。例えば、レベル格納データベース120及びTTSサーバ130の何れか一方または双方がインターネットに接続されており、これらと音声化ゲートウェイサーバ110とがインターネットを介してデータのやり取りをおこなっても良い。また、本実施形態においては音声化ゲートウェイサーバ110、レベル格納データベース120、TTSサーバ130が夫々別々の装置として示されているが、単一のサーバ装置が音声化ゲートウェイサーバ110、レベル格納データベース120、TTSサーバ130としての機能を兼ね備える構成もまた、本発明の範囲内である。
【0019】
以上説明した構成によって、文書の音声データを端末200の使用者(語学習得者)が得るまでの手順に付き説明する。まず、使用者がウェブブラウザを操作して、音声化ゲートウェイサーバ110に接続する。接続が完了すると、図2のように文書URL入力用ページがブラウザの文書表示エリアに表示される。
【0020】
この文書URL入力用ページには、テキスト行入力コントロール(single−line text input control)T1、ボタンB1、ラジオボタンR1が表示される。テキスト行入力コントロールT1は、端末200の使用者が、音声読み上げを希望する文書(プレーンテキスト、HTML文書等)のURLを入力するための領域である。使用者は、端末200のキーボードを操作して、このテキスト行入力コントロールT1に文字を入力することができる。
【0021】
ラジオボタンR1は、図2中に縦方向に4つ並べられており、この4つのラジオボタンR1の何れかを選択することによって、使用者の語学習得レベルを選択するものである。使用者は、端末200のマウスを操作することによって、カーソルCを所望のラジオボタンR1に移動させ、次いでマウスのボタンをクリックすることによって所望のラジオボタンを選択することができる。
【0022】
ボタンB1は、テキスト行入力コントロールT1及びラジオボタンR1の内容を音声化ゲートウェイサーバ110に送信するためのボタンである。使用者は、端末200のマウスを操作することによって、カーソルCをボタンに重ね、次いでマウスのボタンをクリックすることによってテキスト行入力コントロールT1及びラジオボタンR1の内容を送信する。
【0023】
すなわち、使用者は、キーボード等を用いて所望の文書のURLをテキスト行入力コントロールT1に入力し、使用者自身の語学習得レベルに応じたラジオボタンR1を選択し、最後にボタンB1を操作して、所望の文書のURL及び使用者自身の語学習得レベルをゲートウェイサーバ110に送信する。
【0024】
ゲートウェイサーバ110は、端末200から文書のURLと使用者の語学習得レベルを受信すると、図3のフローチャートに示されるルーチンを実行する。このルーチンが開始すると、最初にステップS1が実行される。
【0025】
ステップS1では、ゲートウェイサーバ110は、端末200から送信されたURLに対応する文書があるかどうかの確認をおこなう。このURLに対応する文書が無い、若しくはこのURLに対応する文書はあるがゲートウェイサーバ110が対応していないエンコーディングの文書であった、といった場合は(S1:NO)、ステップS11を実行する。ステップS11では、エラーメッセージを端末200に送信する。一方、ステップS1において、端末200から送信されたURLに対応する文書があり、且つその文書がゲートウェイサーバ110が対応していないエンコーディングで記述されていることが確認された場合は(S1:YES)、ステップS2に進む。
【0026】
ステップS2では、ゲートウェイサーバ110は、ユーザエージェント機能を利用してURLに対応する外部のウェブサーバ300から文書をダウンロードする。次いで、ステップS3に進む。
【0027】
ステップS3では、文書の整形がおこなわれる。すなわち、文書がHTMLファイルである場合は、不要なタグやコメントやSGML宣言などを除去し、純粋な文書のみを抽出する。また、文書が整形済の(すなわち、所定の文字数ごとに強制的に改行コードが挿入されている)プレーンテキストである場合は、改行コードを除去する。さらに、文書の言語が日本語のように単語同士を区切る文字を持たないものであるならば、文書の形態解析を行って、文書を単語ごとに分割する。これらの文書の整形方法については既知であるため、詳細な説明は省略する。次いで、ステップS4に進む。
【0028】
ステップS4では、ステップS3で整形を行った文書に含まれる単語を文書の先頭から順に一つずつ抽出する。この際、日本語における助詞や助動詞、英語におけるbe動詞や代名詞、助動詞など、一つの文書内に多く出現し、また語学学習者にとってもきわめて平易であることが既知である単語については抽出しない構成としてもよい。次いでステップS5に進む。
【0029】
ステップS5では、ゲートウェイサーバ110は、ステップS4で抽出された単語について、レベル格納データベース120に問い合わせを行う。レベル格納データベース120では、図4のように単語の各々について、そのレベルを参照できるようになっている。言語が日本語であるならば、初等教育で習う単語や音読みのみで発音可能な単語については低いレベルが割り当てられ、漢字単体の音読みにも訓読みにも無い発音が割り当てられているような単語については高いレベルが割り当てられるようになっている。レベル格納データベース120は、ゲートウェイサーバ110より単語のテキストを受信すると、この単語のレベルをゲートウェイサーバ110に送り返す。かくして、ゲートウェイサーバ110は、その単語の難易度レベルを取得する。ゲートウェイサーバ110は、次いで、ステップS6(図3)を実行する。
【0030】
ステップS6では、ゲートウェイサーバ110はステップS5で取得した単語の難易度レベルと、本ルーチンの開始時に端末200から受け取っている使用者の言語習得レベルとを比較する。ここで、単語の難易度レベルが使用者の言語習得レベル以上であるなら(S6:YES)、この単語を読み上げた音声データが必要であると判断し、ステップS7に進む。一方、ステップS6において単語の難易度レベルが使用者の言語習得レベル未満であるなら(S6:NO)、この単語については音声データを用意する必要はないと判断し、ステップS4にもどり、文書内に次に現れる単語の抽出を行う。
【0031】
ステップS7では、ゲートウェイサーバ110はTTSサーバ130に問い合わせを行う。具体的には、ゲートウェイサーバ110はステップS4で抽出した単語のテキストをTTSサーバ130に送信する。TTSサーバ130は、音声合成によってこの単語を読み上げた音声データを作成し、これをゲートウェイサーバ110に送り返す。ゲートウェイサーバ110は、受信したデータをサーバのストレージ手段に保存する。なお、ストレージ手段の容量が使用済みの音声データによって圧迫されるのを防止するため、ステップS7の実行から一定時間後(例えば1時間後)に、音声データを消去する構成としてもよい。次いで、ステップS8に進む。
【0032】
ステップS8では、ステップS7で得た音声データへのリンクアンカー(HTMLにおけるA要素)をステップS3で整形した文書に埋め込む。次いで、ステップS9に進む。
【0033】
ステップS9では、文書の最後まで単語の検索(ステップS4)が完了したかどうかの判定が行われる。文書の最後まで単語の検索が済んだのであれば(S9:YES)、ステップS10に進む。一方、文書の最後まで単語の検索を終えていないのであれば(S9:NO)、まだ抽出すべき単語が残されている可能性があるということなので、ステップS4に戻り、他の単語の抽出を行う。
【0034】
ステップS10では、ステップS3によって一旦整形され、ステップS8にてリンクアンカーが埋め込まれた文書に、ヘッダやタイトル要素など、HTMLファイルとして必要なデータが追記され、HTMLファイルが作成される。次いで、ゲートウェイサーバ110は、このHTMLファイルを端末200に送信し、本ルーチンを終了させる。
【0035】
端末200は、このHTMLファイルを受信すると、ブラウザを制御してこのHTMLファイルをWebページとして表示する。ブラウザに表示されるWebページの一例を図5に示す。図5に示されるように、文書中には音声データへのリンクが設けられた単語が強調表現(本実施形態においては下線)で表示され、端末200の使用者はこのリンクを操作する(例えばカーソルをこの単語に重ねてマウスのボタンをクリックする)ことによって、この単語を読み上げた音声データをダウンロードして聴くことができる。
【0036】
以上のように、本実施形態によれば、文書中の単語を読み上げた音声データが文書中にリンクとして示されたHTML文書を端末200の使用者は取得できるので、テキストである文書と、その文書中の単語を読み上げた音声とを相互参照しながら自然言語の学習を効率的に進めていくことが出来るようになる。さらに、言語習得者のレベルに応じて音声と関連づけられる単語は変化するので、言語習得者は自分のレベルにあったHTML文書を取得できる。
【0037】
なお、本実施形態においては、端末200から所望の文書のURLを送信する構成としているが、代わりに、文書自身を直接音声化ゲートウェイサーバに送信する構成としてもよい。
【図面の簡単な説明】
【0038】
【図1】本発明の実施の形態による音声化システムの全体を示す概念図である。
【図2】本発明の実施の形態において、端末に表示される文書URL入力ページを示したものである。
【図3】本発明の実施の形態において、音声化ゲートウェイサーバによって実行されるプログラムのフローである。
【図4】本発明の実施の形態において、レベル格納データベースに格納されたデータの一例を示したものである。
【図5】本発明の実施の形態において、端末に表示されたWebページを示したものである。
【符号の説明】
【0039】
1 音声化システム
100 音声化サーバ
110 音声化ゲートウェイサーバ
120 レベル格納データベース
130 TTSサーバ
200 端末
300 ウェブサーバ
【特許請求の範囲】
【請求項1】
所定のネットワークを介して互いに接続された端末及び音声化サーバを備えた音声化システムであって、
前記端末が、
テキストに関するテキスト情報及び利用者のレベル情報を入力する情報入力手段と、
該テキスト情報及び該レベル情報を前記音声化サーバに送信する通信手段と、
表示手段と、を有し、
前記音声化サーバが、
該テキスト情報に対応するテキストを取得するテキスト取得手段と、
該レベル情報に基づいて利用者のレベル以上の読み上げ難易度を有する単語を該テキストから抽出する単語抽出手段と、
前記単語抽出手段によって抽出された単語の音声データを取得する音声データ取得手段と、
該テキストに音声データへのリンクアンカーが埋めこまれたHTMLデータを作成するHTMLデータ作成手段と、
前記HTMLデータ作成手段によって作成されたHTMLデータを前記端末に送信するデータ送信手段と、を有し、
前記表示手段は、前記音声化サーバより受信したHTMLデータを表示する、
ことを特徴とする音声化システム。
【請求項2】
前記音声化サーバは、単語と、その単語の読み上げ難易度とが互いに関連づけられて格納された難易度データベースをさらに有し、
前記単語抽出手段は、該テキストに含まれる単語の各々について前記難易度データベースに問い合わせを行って各単語の読み上げ難易度を取得することによって、利用者のレベル以上の読み上げ難易度を有する単語を該テキストから抽出する、
ことを特徴とする請求項1に記載の音声化システム。
【請求項3】
該テキスト情報は該テキストのURLを含む、ことを特徴とする請求項1又は2に記載の音声化システム。
【請求項4】
該テキスト情報は該テキスト自身を含む、ことを特徴とする請求項1又は2に記載の音声化システム。
【請求項5】
該テキストは、該所定のネットワークに接続されたコンテンツ提供サーバによって提供されている、ことを特徴とする請求項3に記載の音声化システム。
【請求項6】
該コンテンツ提供サーバはWebサーバである、ことを特徴とする請求項5に記載の音声化システム。
【請求項7】
前記音声化サーバが、前記単語抽出手段が抽出した単語のからその単語を読み上げた音声データを音声合成によって生成する音声合成ユニットをさらに有する、ことを特徴とする請求項1から6のいずれかに記載の音声化システム。
【請求項8】
該所定のネットワークがインターネットである、ことを特徴とする請求項1から7のいずれかに記載の音声化システム。
【請求項9】
テキストに関するテキスト情報及び利用者のレベル情報を端末から受信し、
該受信したテキスト情報に基づいてテキストを取得し、
該レベル情報に基づいて、該テキストに含まれる単語の中から該利用者のレベル以上の読み上げ難易度の単語を抽出し、
該抽出された単語を読み上げた音声データを取得し、
該テキストに該音声データへのリンクアンカーを埋め込んでHTMLファイルを作成し、
該作成されたHTMLファイルを該端末に送信する、
ことを特徴とする音声化方法。
【請求項10】
該テキスト情報は、該テキストのURLを含む、ことを特徴とする請求項9に記載の音声化方法。
【請求項11】
該テキスト情報は、該テキスト自身を含む、ことを特徴とする請求項9又は10に記載の音声化方法。
【請求項12】
該テキストは、該所定のネットワークに接続されたコンテンツ提供サーバによって提供されている、ことを特徴とする請求項10に記載の音声化方法。
【請求項13】
該コンテンツ提供サーバはWebサーバである、ことを特徴とする請求項12に記載の音声化方法。
【請求項14】
該抽出された単語を読み上げた音声データを、音声合成によって生成する、ことを特徴とする請求項9から13のいずれかに記載の音声化方法。
【請求項15】
テキストに関するテキスト情報及び利用者のレベル情報を端末から受信するテキスト受信手段と、
該受信したテキスト情報に基づいてテキストを取得するテキスト取得手段と、
該レベル情報に基づいて、該テキストに含まれる単語の中から、該使用者のレベル以上の読み上げ難易度の単語を抽出する単語抽出手段と、
該抽出された単語を読み上げた音声データを取得する音声データ取得手段と、
該テキストに該音声データへのリンクアンカーを埋め込んでHTMLデータを作成するHTMLデータ作成手段と、
該作成されたHTMLデータを該端末に送信するデータ送信手段と、
を有する、音声化サーバ。
【請求項16】
テキストに関するテキスト情報及び利用者のレベル情報を端末から受信するテキスト受信手順と、
該受信したテキスト情報に基づいてテキストを取得するテキスト取得手順と、
該レベル情報に基づいて、該テキストに含まれる単語の中から該使用者のレベル以上の読み上げ難易度の単語を抽出する単語抽出手順と、
該抽出された単語を読み上げた音声データを取得する音声データ取得手順と、
該テキストに該音声データへのリンクアンカーを埋め込んでHTMLデータを作成するHTMLデータ作成手順と、
該作成されたHTMLデータを該端末に送信するデータ送信手順と、
を実行するための音声化プログラム。
【請求項1】
所定のネットワークを介して互いに接続された端末及び音声化サーバを備えた音声化システムであって、
前記端末が、
テキストに関するテキスト情報及び利用者のレベル情報を入力する情報入力手段と、
該テキスト情報及び該レベル情報を前記音声化サーバに送信する通信手段と、
表示手段と、を有し、
前記音声化サーバが、
該テキスト情報に対応するテキストを取得するテキスト取得手段と、
該レベル情報に基づいて利用者のレベル以上の読み上げ難易度を有する単語を該テキストから抽出する単語抽出手段と、
前記単語抽出手段によって抽出された単語の音声データを取得する音声データ取得手段と、
該テキストに音声データへのリンクアンカーが埋めこまれたHTMLデータを作成するHTMLデータ作成手段と、
前記HTMLデータ作成手段によって作成されたHTMLデータを前記端末に送信するデータ送信手段と、を有し、
前記表示手段は、前記音声化サーバより受信したHTMLデータを表示する、
ことを特徴とする音声化システム。
【請求項2】
前記音声化サーバは、単語と、その単語の読み上げ難易度とが互いに関連づけられて格納された難易度データベースをさらに有し、
前記単語抽出手段は、該テキストに含まれる単語の各々について前記難易度データベースに問い合わせを行って各単語の読み上げ難易度を取得することによって、利用者のレベル以上の読み上げ難易度を有する単語を該テキストから抽出する、
ことを特徴とする請求項1に記載の音声化システム。
【請求項3】
該テキスト情報は該テキストのURLを含む、ことを特徴とする請求項1又は2に記載の音声化システム。
【請求項4】
該テキスト情報は該テキスト自身を含む、ことを特徴とする請求項1又は2に記載の音声化システム。
【請求項5】
該テキストは、該所定のネットワークに接続されたコンテンツ提供サーバによって提供されている、ことを特徴とする請求項3に記載の音声化システム。
【請求項6】
該コンテンツ提供サーバはWebサーバである、ことを特徴とする請求項5に記載の音声化システム。
【請求項7】
前記音声化サーバが、前記単語抽出手段が抽出した単語のからその単語を読み上げた音声データを音声合成によって生成する音声合成ユニットをさらに有する、ことを特徴とする請求項1から6のいずれかに記載の音声化システム。
【請求項8】
該所定のネットワークがインターネットである、ことを特徴とする請求項1から7のいずれかに記載の音声化システム。
【請求項9】
テキストに関するテキスト情報及び利用者のレベル情報を端末から受信し、
該受信したテキスト情報に基づいてテキストを取得し、
該レベル情報に基づいて、該テキストに含まれる単語の中から該利用者のレベル以上の読み上げ難易度の単語を抽出し、
該抽出された単語を読み上げた音声データを取得し、
該テキストに該音声データへのリンクアンカーを埋め込んでHTMLファイルを作成し、
該作成されたHTMLファイルを該端末に送信する、
ことを特徴とする音声化方法。
【請求項10】
該テキスト情報は、該テキストのURLを含む、ことを特徴とする請求項9に記載の音声化方法。
【請求項11】
該テキスト情報は、該テキスト自身を含む、ことを特徴とする請求項9又は10に記載の音声化方法。
【請求項12】
該テキストは、該所定のネットワークに接続されたコンテンツ提供サーバによって提供されている、ことを特徴とする請求項10に記載の音声化方法。
【請求項13】
該コンテンツ提供サーバはWebサーバである、ことを特徴とする請求項12に記載の音声化方法。
【請求項14】
該抽出された単語を読み上げた音声データを、音声合成によって生成する、ことを特徴とする請求項9から13のいずれかに記載の音声化方法。
【請求項15】
テキストに関するテキスト情報及び利用者のレベル情報を端末から受信するテキスト受信手段と、
該受信したテキスト情報に基づいてテキストを取得するテキスト取得手段と、
該レベル情報に基づいて、該テキストに含まれる単語の中から、該使用者のレベル以上の読み上げ難易度の単語を抽出する単語抽出手段と、
該抽出された単語を読み上げた音声データを取得する音声データ取得手段と、
該テキストに該音声データへのリンクアンカーを埋め込んでHTMLデータを作成するHTMLデータ作成手段と、
該作成されたHTMLデータを該端末に送信するデータ送信手段と、
を有する、音声化サーバ。
【請求項16】
テキストに関するテキスト情報及び利用者のレベル情報を端末から受信するテキスト受信手順と、
該受信したテキスト情報に基づいてテキストを取得するテキスト取得手順と、
該レベル情報に基づいて、該テキストに含まれる単語の中から該使用者のレベル以上の読み上げ難易度の単語を抽出する単語抽出手順と、
該抽出された単語を読み上げた音声データを取得する音声データ取得手順と、
該テキストに該音声データへのリンクアンカーを埋め込んでHTMLデータを作成するHTMLデータ作成手順と、
該作成されたHTMLデータを該端末に送信するデータ送信手順と、
を実行するための音声化プログラム。
【図1】


【図2】
【図3】
【図4】
【図5】

【図2】
【図3】
【図4】
【図5】
【公開番号】特開2008−96489(P2008−96489A)
【公開日】平成20年4月24日(2008.4.24)
【国際特許分類】
【出願番号】特願2006−274814(P2006−274814)
【出願日】平成18年10月6日(2006.10.6)
【出願人】(000000527)ペンタックス株式会社 (1,878)
【公開日】平成20年4月24日(2008.4.24)
【国際特許分類】
【出願日】平成18年10月6日(2006.10.6)
【出願人】(000000527)ペンタックス株式会社 (1,878)
[ Back to top ]