
音声合成装置、方法およびプログラム
【課題】利用可能なデータサイズや通信ビットレートが非常に限られた環境で、原音声の特徴をより再現して合成する。
【解決手段】一連の音声合成用情報に基づき音声を合成する音声合成装置であって、音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、音声合成装置は、所定の声質の音声を合成する場合、共通情報の内容を修正情報に基づき変更する修正手段と、前記修正された情報に基づき音声波形を合成する音声合成手段とを備える、さらに共通情報に基づき音声波形生成のための制御指令を生成する制御指令生成手段と、所定の声質の音声を合成する場合、修正情報に基づき生成された制御指令を修正する制御指令修正手段と、修正された制御指令に基づき音声波形を生成する音声波形生成手段とを備える。
【解決手段】一連の音声合成用情報に基づき音声を合成する音声合成装置であって、音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、音声合成装置は、所定の声質の音声を合成する場合、共通情報の内容を修正情報に基づき変更する修正手段と、前記修正された情報に基づき音声波形を合成する音声合成手段とを備える、さらに共通情報に基づき音声波形生成のための制御指令を生成する制御指令生成手段と、所定の声質の音声を合成する場合、修正情報に基づき生成された制御指令を修正する制御指令修正手段と、修正された制御指令に基づき音声波形を生成する音声波形生成手段とを備える。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、事前に収録された音声の特徴に基づき、音声波形を生成する音声合成装置、方法およびプログラムに関する。
【背景技術】
【0002】
音声に特化した高効率な音声符号化方式として、CELP(Code Excited Linear Prediction)方式が知られている。CELP方式は音声波形の物理的な特徴に関する知見に基づいた方法だが、音声の言語的制約を直接的には用いていないため、どのような言語のどのようなスタイルの音声でも高効率に符号化可能な特徴を有する。しかし、符号化された音声のビットレートは最低でも数kbps(bits
per second)となる。これに対し、言語的な情報から音声を合成する技術は、一般に音声合成技術に属する。音声合成技術の代表的な利用方法は、テキスト音声変換(Text-To-Speech)だが、ここでは例えば、テキストを解析して得られる、音素の種類や韻律的特徴を表記した記号をその入力とし、音声波形を生成する装置を特に音声合成装置と呼び、その入力を構成する記号を、音声合成用記号と呼ぶ。音声合成用記号には様々な形式がありうるが、ここでは、一連の音声を構成する音韻的情報と、主としてポーズや声の高さとして表現される韻律的情報を同時に表記したものを考える。そのような音声合成記号の例として、JEITA(電子情報技術産業協会)規格IT−4002「日本語テキスト音声合成用記号」(非特許文献1)がある。
【0003】
音声合成装置における音声波形の生成方法には様々な方式があるが、ここではその代表的な方式として、接続合成方式と、分析合成方式の2つを説明する。
【0004】
接続合成方式は、あらかじめ音声を大量に収集し、その音声断片(以下音声素片という)をあらかじめデータベース化しておき、合成時には指定された合成目標情報の各パラメータに近く、かつ、前後の音声素片との接続関係の良好な音声素片を、素片データベースから選択して合成を行う方式である。各音声素片には、音素情報、音響パラメータ、音声コーパス内での出現環境等のパラメータが付されている。
【0005】
接続合成方式においては、音声合成記号列によって指定される合成目標情報に基づき、使用する音声素片の選択(以後、素片選択と呼ぶ。)を行うが、この素片選択は、コストと呼ぶ歪み尺度、つまり、選択した音声素片により合成される音声波形の、目標とする合成音声波形からの劣化度合いを示す指標に基づき行われる。コストは、通常、合成目標情報と音声素片との誤差を示すターゲットコストと、音声素片間の不連続の程度を示す接続コストに分けることができ、素片選択は全体のコストを最小とするように行われる。
【0006】
素片のデータベースについては、音声波形をそのまま格納しても良いし、あるいは、素片をCELP等により圧縮したデータを格納しても良い。音声波形を蓄積した場合は、素片を波形上で接続することで最終的な出力音声波形が合成される。一方、CELP等を用いて素片を圧縮した場合は、それを復号した波形上で素片を接続するだけでなく、復号前のパラメータレベルで先に接続しておき、それをまとめて復号することで音声波形を生成する手法もある。
【0007】
一方、分析合成方式は、音声を分析した結果得られる、音声の特徴パラメータ上で操作を行い、特徴パラメータから音声波形を信号処理により生成する方式である。ここでは特に、CELP方式と同様の、音源とフィルタを組み合わせた音源・フィルタモデル等に基づき、信号処理で音声波形を合成する方法を対象とする。音源・フィルタモデルでは、音声の響きをつくるフィルタを適当な音源で駆動することで、音声波形を信号処理的に合成するが、ここではCELP方式とは異なり、インパルス列や白色雑音源といった比較的に単純な構成の音源で駆動する場合を主に考える。また以下では、音源のパラメータとフィルタのパラメータをまとめて音声合成パラメータと呼ぶ。音声合成パラメータは、スペクトルの特徴を表現するためのMFCC(Mel-Frequency Cepstral Coefficient)や、声の高さに対応する、波形の基本周波数(F0)などの複数のパラメータで構成される。また、フィルタにはAR(自己回帰)型のフィルタや、MFCCを直接そのパラメータとする、MLSA(メル対数スペクトル近似)フィルタ(非特許文献2)等が用いられる。
【0008】
例えば子音のような音声を合成するためには、音声合成パラメータを時間的に変化させることが必要なため、この方法では、例えば5ms程度の一定周期で音声合成パラメータを更新し、その特徴を変化させながら音声を合成することが一般的である。この一定周期の1周期分は一般に1フレームと呼ばれる。したがって、この構成で音声を合成するためには、音声合成用記号からフレーム毎の音声合成パラメータの値を決める必要がある。
【0009】
その方法の1つとして、音声合成パラメータ時系列の時間変化を適当なモデルに基づきモデル化し、そのモデルパラメータを音声合成用記号からまず予測することで生成し、得られたモデルから音声合成パラメータ時系列を生成することで、任意の音声を合成可能とする方法が用いられる。以下では、このモデルのことを音声生成モデルと呼ぶ。例えば、ある音素の音声合成パラメータの特徴が時間的に3つの状態に分かれ、各状態のフレーム数について、その統計的特徴を現すベクトルを最初の状態から順にd1、d2、d3とし、この3つのベクトルの要素を連結して1つのベクトルdを作り、また、各状態の統計的特徴を現すベクトルを最初の状態から順にv1、v2、v3とすれば、その音素を合成するための音声合成パラメータの特徴は、音声生成モデルのパラメータを構成するd、v1、v2、v3の4つのベクトルで表すことができる。
【0010】
このように全ての音素がこのように4つのベクトルで表すことができると仮定し、予めそれぞれのベクトルについて、最適なコードブックを作成しておく。あるいは、v1、v2、v3は同じコードブックを用いて表しても良い。音声合成の際は、まず、音声合成用記号から各音素の音声生成モデルのパラメータを構成する最適なコードブックのベクトルをそれぞれ予測し、各音素を合成するため音声生成モデルを構築する。そして、それらの音声生成モデルを時間順に連結して1発声分の音声生成モデルとし、そのモデルに基づき最適な音声合成パラメータ時系列を求める。この音声合成パラメータ時系列に基づき、音源・フィルタを制御することで、音声波形は生成される。
【0011】
以上、上記のような音声合成方式を用いることにより、音声合成記号列の形で表現された数百bps程度のデータから音声波形を生成することができる。
【先行技術文献】
【非特許文献】
【0012】
【非特許文献1】「日本語テキスト音声合成用記号」JEITA規格 IT−4002、2005年3月
【非特許文献2】今井聖、住田一男、古市千枝子、「音声合成のためのメル対数スペクトル近似(MLSA)フィルタ」、電子情報通信学会論文誌(A), J66-A, 2, pp.122-129, Feb. 1983.
【発明の概要】
【発明が解決しようとする課題】
【0013】
利用可能なデータサイズや通信ビットレートが非常に限られた環境で、予め準備された音声メッセージを再生する場合を考える。特にここでは、二次元バーコードなど、記憶容量が限られた対象に、音声データを格納する場合を主にその対象とする。音声の声質や読み上げスタイルに対する好みは、ユーザによりそれぞれ異なると考えられるので、ユーザの満足度を高めるためには、あらかじめ様々な声質や読み上げスタイルでの音声をそのバリエーションとして準備しておくことが望ましい。以下では説明のために、個々のバリエーション間の差異は全て「声質」の差異であると考える。よって以下における「声質」とは、音声学的な定義の意味で限定されたものではなく、より一般化された音声の個性を表す。
【0014】
もしデータサイズの制限がなければ、従来の音声符号化技術で、声質毎に独立してそれぞれ音声を符号化すれば良い。しかし従来の音声符号化方式では品質を維持するために、ある程度のデータサイズが必要で、声質の違いごとにそれぞれ音声を符号化するので、データサイズは声質の数に比例する。このため、限られたデータサイズで品質を確保しつつ、声質の数を増やすことは困難である。
【0015】
一方、音声合成技術を用いることで、音声合成装置のサイズはある程度大きいものの、音声合成記号列のみで音声を合成することができる。ある声質の音声を出力する音声合成装置は、同種の声質の音声データをあらかじめ例えば数十分から数十時間といった規模で大量に収集しておき、それを用いて構成することができる。また音声合成記号列は、音声符号化されたデータよりも通常ずっと小さく、容易に二次元バーコードなどに記録可能である。さらに、事前に複数の声質のデータからそれぞれ音声合成装置用のデータを構築しそれを装置に組み込んでおくことで、装置の利用時に、そのデータを切り替えることで、出力される音声の声質を比較的容易に変更することができる。しかし、一般に音声合成装置は、音声合成記号列を構成する言語的情報のみから対象の音声の特徴を予測して音声を合成しており、自然音声を音声符号化した場合と比較し、元となった音声の再現性は低く、自然性で大きく劣るという問題がある。
【0016】
以上に示すように、従来技術では、記憶容量が限られている場合に、音声メッセージの自然性と、声質の多様性を両立させることができなかった。
【0017】
したがって、本発明は、利用可能なデータサイズや通信ビットレートが非常に限られた環境で、原音声の特徴をより再現して合成することができる音声合成装置、方法およびプログラムを提供することを目的とする。
【課題を解決するための手段】
【0018】
上記目的を実現するため本発明による音声合成装置は、一連の音声合成用情報に基づき音声を合成する音声合成装置であって、前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、所定の声質の音声を合成する場合、前記共通情報の内容を前記修正情報に基づき変更する修正手段と、前記修正された情報に基づき音声波形を合成する音声合成手段と、
を備える。
【0019】
上記目的を実現するため本発明による音声合成装置は、一連の音声合成用情報に基づき音声を合成する音声合成装置であって、前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、前記共通情報に基づき音声波形生成のための制御指令を生成する制御指令生成手段と、所定の声質の音声を合成する場合、前記修正情報に基づき前記生成された制御指令を修正する制御指令修正手段と、前記修正された制御指令に基づき音声波形を生成する音声波形生成手段とを備える。
【0020】
また、前記共通情報は、音韻記号と韻律記号で構成されることも好ましい。
【0021】
また、前記音声合成装置は、合成する音声の声質を複数の声質の中から選択する手段をさらに備えることも好ましい。
【0022】
上記目的を実現するため本発明による音声合成方法は、一連の音声合成用情報に基づき音声を合成する音声合成方式であって、前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、所定の声質の音声を合成する場合、前記共通情報の内容を前記修正情報に基づき変更する修正ステップと、前記修正された情報に基づき音声波形を合成する音声合成ステップとを備える。
【0023】
上記目的を実現するため本発明による音声合成方法は、一連の音声合成用情報に基づき音声を合成する音声合成方式であって、前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、前記共通情報に基づき音声波形生成のための制御指令を生成する制御指令生成ステップと、所定の声質の音声を合成する場合、前記修正情報に基づき前記生成された制御指令を修正する制御指令修正ステップと、前記修正された制御指令に基づき音声波形を生成する音声波形生成ステップとを備える。
【0024】
上記目的を実現するため本発明によるプログラムは、上記に記載の音声合成装置としてコンピュータを機能させる。
【発明の効果】
【0025】
本発明により、音声合成用情報を、声質とは独立した情報である共通情報と、声質毎に異なる修正情報に分けることで、同一発話内容の音声については、共通情報を共用して修正情報のみを追加することで、効率的に符号化することができる。この際、音声波形生成のための指令情報が元となる自然音声の特徴に近付くような修正情報を作成しておくことで、元となる音声の特長を再現する自然性の高い音声を出力することができる。
【0026】
また、共通情報を従来の音声合成技術と同様の言語的な情報だけで構成する場合は、ユーザが望む声質に対応した修正情報が音声合成用情報に含まれていない場合でも、従来の技術による音声合成が可能なので、自然性は低下するが、ユーザの望む声質の音声を合成することができる。
【0027】
また、共通情報を修正の対象とすることにより、言語的な表現が発声の一部で異なる場合であっても、共通情報を共用することができる。
【0028】
以上の特徴から、類似の発話内容で声質の異なる複数の音声を、従来の音声符号化方式よりも必要な記憶容量のサイズを抑え、かつ、従来の音声合成技術をそのまま用いた場合よりも原音声の特徴をより再現して合成することができる。
【図面の簡単な説明】
【0029】
【図1】本発明の第1の実施形態による音声合成装置のブロック図である。
【図2】第1の実施形態による音声合成のフローチャートを示す。
【図3】本発明の第2の実施形態による音声合成装置のブロック図である。
【図4】第2の実施形態による音声合成のフローチャートを示す。
【図5】本発明の第3の実施形態による音声合成装置のブロック図である。
【図6】第3の実施形態による音声合成のフローチャートを示す。
【発明を実施するための形態】
【0030】
本発明を実施するための最良の実施形態について、以下では図面を用いて詳細に説明する。なお、以下において、“単位音声”とは、本発明による音声合成装置における、音声の最小処理単位である。単位音声の具体例としては、音素、音節、単語がある。ただしここでは、単位音声は、例えば前後の音素の種類といった音韻環境に関する違い、またアクセントやイントネーション、話速といった韻律的特徴の違いを考慮した分類が行われているものとする。また“音声合成用記号”とは、1発声の音声に含まれる単位音声のそれぞれの種類を記述するための一連の記号である。
【0031】
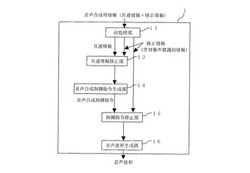
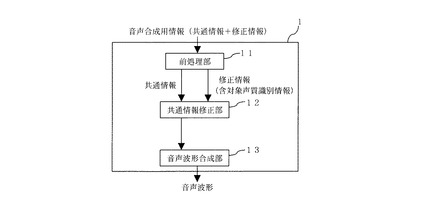
図1は、本発明の第1の実施形態による音声合成装置のブロック図である。図1によると、音声合成装置1は、音声合成用情報に対する前処理部11と、共通情報修正部12と、音声波形合成部13を備えている。図2は、第1の実施形態による音声合成のフローチャートを示す。
【0032】
S11.まず前処理部11では、音声合成用情報を処理し、共通情報と修正情報を取り出す。共通情報の例としては、JEITA IT−4002で規定される記号のような、音声合成用の音韻情報と韻律情報を同時に記述するための記号がある。共通情報の作成には音声認識技術を用いても良いが、一般に、音声は予め用意された原稿を読み上げたものが多いため、このような共通情報であれば、日本語テキスト音声変換技術を用いて、漢字仮名交じりテキストの音声原稿から比較的高精度に自動で作成することができる。また自動処理による誤りや、実際の発声との間で生じる誤差は、人手により容易に修正することができる。また、修正情報には、対象声質を識別する識別情報が含まれている。
S12.ここで共通情報修正部12は、前処理部11の出力である共通情報および修正情報をその入力とする。共通情報修正部12は、音声波形合成部13の波形生成対象声質が、修正情報の対象声質と一致するか確認する。
S13.一致する場合、共通情報修正部12は、修正情報に基づき共通情報を修正し出力する。一方、音声波形合成部13の波形生成対象声質が、修正情報の対象声質と異なる場合、共通情報修正部12は、入力された共通情報をそのまま出力する。
S14.共通情報修正部12の出力に基づき、音声波形合成部13で音声波形が合成され、音声合成装置1の出力として出力される。
【0033】
修正情報の例としては、共通情報の先頭からi番目の記号を記号Aで置換することを示す符号、先頭からj番目の記号の直前に記号Bを挿入することを示す符号、および先頭からk番目の記号を削除する符号を並べたものがある。修正の際は、先頭の符号から順に対応する操作を行うことで、共通情報は修正される。例えば音節を単位とするような共通情報を用いている場合において、共通情報では頭高型アクセントになっている「デ’ンシャ.」(ただしここで記号「’」はその場所にアクセント核があることを示す)を、修正情報対象の声質では平板型アクセントで読む場合、2番目の記号を削除する符号1つをその修正情報とすることで、頭高型アクセントの「デ’ンシャ.」は、平板型アクセントの「デンシャ.」に修正される。同様の修正により、ポーズ挿入位置の違いや、「デ’スネ.」と「デ’スワ.」といった表現の細かな違いも修正することができる。
【0034】
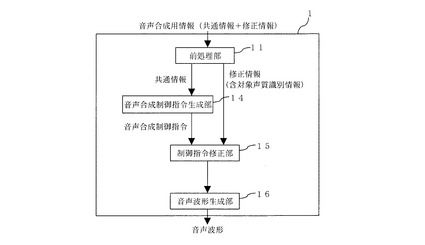
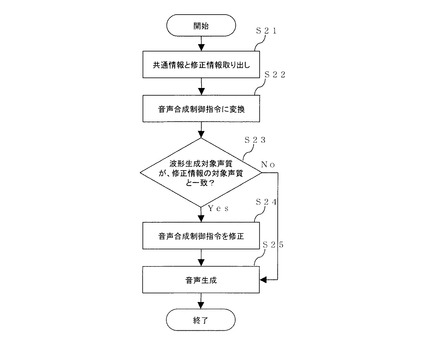
図3は、本発明の第2の実施形態による音声合成装置のブロック図である。図3によると、音声合成装置1は、前処理部11と、音声合成制御指令生成部14と、制御指令修正部15と、音声波形生成部16を備えている。なお、ここでの音声合成制御指令生成部14と音声波形生成部16を組み合わせたものが、第1の実施形態における音声波形合成部13に相当する。図4は、第2の実施形態による音声合成のフローチャートを示す。
【0035】
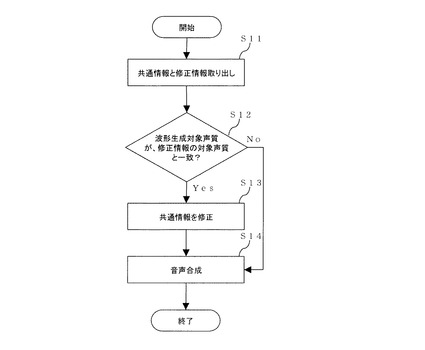
S21.前処理部11は、音声合成用情報を処理し、共通情報と修正情報を取り出す。
S22.音声合成制御指令生成部14は、取り出された共通情報を、音声波形生成のための音声合成制御指令に変換する。
S23.制御指令修正部15は、前記の制御指令が入力されると、音声波形生成部16の波形生成対象声質が修正情報の対象声質と一致する場合がどうか確認する。
S24.一致する場合、制御指令修正部15は、別途入力された修正情報に基づき制御指令を修正する。一致しない場合、制御指令修正部15は、制御指令をそのまま出力する。
S25.制御指令修正部15の出力情報に基づき音声波形生成部16で音声波形が生成され、音声合成装置1の出力として出力される。
【0036】
ここで制御指令の例として、まず音声合成方式として接続合成方式を用いる場合においては、素片IDがある。この場合、接続合成方式において必要となる素片選択処理は音声合成制御指令生成部14で行われ、素片の接続する処理は音声波形生成部16で行われる。一方、分析合成方式を用いる場合は、制御指令として、音声合成パラメータ時系列が例として挙げられる。これは具体的には、MFCCやF0のパラメータ時系列である。この場合は、音声合成制御指令生成部14で音声生成モデルから音声合成パラメータ時系列を生成する処理が行われる。
【0037】
あるいは、音声生成モデルのパラメータを、ここでの制御指令としてもよい。この場合は、音声波形生成部16で音声生成モデルから音声合成パラメータ時系列を生成する処理が行われる。
【0038】
また、この場合の修正情報の例としては、それぞれのパラメータのある値に関する、置換操作を表す符号の列がある。またこの本実施形態においても修正情報には、対象声質を識別する識別情報が含まれている。
【0039】
この修正情報を、音声合成装置1から出力される音声のスペクトルに関する特徴や基本周波数に関する特徴が、元となる音声のそれぞれの特徴に近付くように構成することで、修正を行わない場合よりも、より原音声の特徴に近い音声を出力することができる。
【0040】
例えば、全ての特徴ベクトルの全ての要素について、それぞれ値の修正を試行し、その結果、合成される音声の特徴が、元となる音声の特徴に最も近付いた試行の修正を、修正情報の1つの要素とする。これを(1)修正が所定の回数に達する、あるいは修正情報全体のサイズが所定の制限値に達する、または(2)合成される音声と、元となる音声との間の特徴の差異が所定の基準よりも小さくなる、まで繰り返し修正情報の要素を蓄積していくことで、修正情報を作成することができる。
【0041】
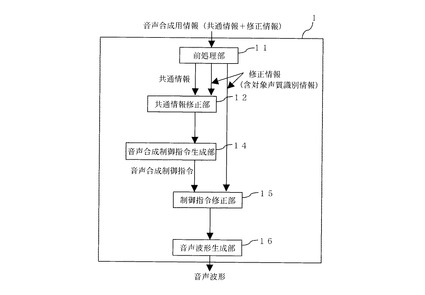
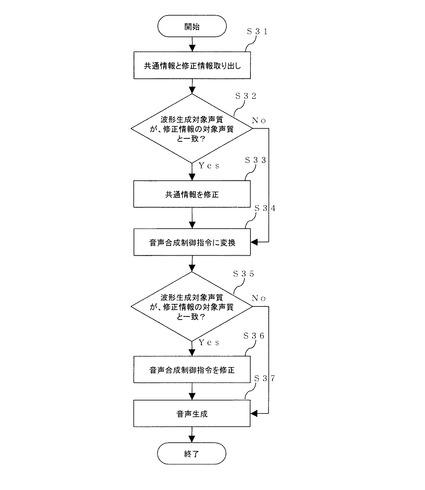
また、先の2つの修正処理を組み合わせた装置構成とし、両者の修正情報が混在するような音声合成用制御指令を構成してもよい。図5はこの構成を有する本発明の第3の実施形態による音声合成装置のブロック図である。図5によると、音声合成装置1は、前処理部11と、共通情報修正部12と、音声合成制御指令生成部14と、制御指令修正部15と、音声波形生成部16を備えている。図6は、第3の実施形態による音声合成のフローチャートを示す。
【0042】
S31.前処理部11は、音声合成用情報を処理し、共通情報と修正情報を取り出す。
S32.共通情報修正部12は、音声波形生成部16の波形生成対象声質が、修正情報の対象声質と一致するか確認する。
S33.一致する場合、共通情報修正部12は、修正情報に基づき共通情報を修正し出力する。一方、音声波形生成部16の波形生成対象声質が、修正情報の対象声質と異なる場合、共通情報修正部12は、入力された共通情報をそのまま出力する。
S34.音声合成制御指令生成部14は、取り出された共通情報を、音声波形生成のための音声合成制御指令に変換する。
S35.制御指令修正部15は、前記の制御指令が入力されると、音声波形生成部16の波形生成対象声質が修正情報の対象声質と一致する場合がどうか確認する。
S36.一致する場合、制御指令修正部15は、別途入力された修正情報に基づき制御指令を修正する。一致しない場合、制御指令修正部15は、制御指令をそのまま出力する。
S37.制御指令修正部15の出力情報に基づき音声波形生成部16で音声波形が生成され、音声合成装置1の出力として出力される。
【0043】
共通情報が音声合成用の音韻情報と韻律情報で構成されるような場合、共通情報を直接修正することにより、小さい修正情報で、出力される合成音声を大きく変更することができるが、共通情報の修正では、音声波形生成部16への指令の修正では可能な音声の微修正が不可能なため、これを組み合わせることは有効である。
【0044】
この場合の修正情報の作成は、例えば、まず共通情報の修正情報を作成し、その結果合成される音声において品質上問題が生じている部分について、音声波形生成部16への指令の修正するような修正情報を追加する、といった手段で実現される。
【0045】
また、1つの共通情報と、複数種類の声質に対する修正情報をまとめて一連の音声合成用情報を構成しても良い。この場合、音声波形生成処理において、あらかじめ用意された複数種類の声質の中で、ユーザの好みの声質で音声波形を生成する場合、修正情報の用意された声質については、より原音声の特徴に近い音声を、修正情報がない場合でも、従来の音声合成装置で可能な水準でその対象声質の音声を出力することができる。人気が高いと予想される声質についてのみ修正情報を作成することで、全体のデータサイズを抑えつつ、効率的にユーザ全体のニーズに応えることができる。
【0046】
また、以上述べた実施形態は全て本発明を例示的に示すものであって限定的に示すものではなく、本発明は他の種々の変形態様および変更態様で実施することができる。従って本発明の範囲は特許請求の範囲およびその均等範囲によってのみ規定されるものである。
【符号の説明】
【0047】
1 音声合成装置
11 前処理部
12 共通情報修正部
13 音声波形合成部
14 音声合成制御指令生成部
15 制御指令修正部
16 音声波形生成部
【技術分野】
【0001】
本発明は、事前に収録された音声の特徴に基づき、音声波形を生成する音声合成装置、方法およびプログラムに関する。
【背景技術】
【0002】
音声に特化した高効率な音声符号化方式として、CELP(Code Excited Linear Prediction)方式が知られている。CELP方式は音声波形の物理的な特徴に関する知見に基づいた方法だが、音声の言語的制約を直接的には用いていないため、どのような言語のどのようなスタイルの音声でも高効率に符号化可能な特徴を有する。しかし、符号化された音声のビットレートは最低でも数kbps(bits
per second)となる。これに対し、言語的な情報から音声を合成する技術は、一般に音声合成技術に属する。音声合成技術の代表的な利用方法は、テキスト音声変換(Text-To-Speech)だが、ここでは例えば、テキストを解析して得られる、音素の種類や韻律的特徴を表記した記号をその入力とし、音声波形を生成する装置を特に音声合成装置と呼び、その入力を構成する記号を、音声合成用記号と呼ぶ。音声合成用記号には様々な形式がありうるが、ここでは、一連の音声を構成する音韻的情報と、主としてポーズや声の高さとして表現される韻律的情報を同時に表記したものを考える。そのような音声合成記号の例として、JEITA(電子情報技術産業協会)規格IT−4002「日本語テキスト音声合成用記号」(非特許文献1)がある。
【0003】
音声合成装置における音声波形の生成方法には様々な方式があるが、ここではその代表的な方式として、接続合成方式と、分析合成方式の2つを説明する。
【0004】
接続合成方式は、あらかじめ音声を大量に収集し、その音声断片(以下音声素片という)をあらかじめデータベース化しておき、合成時には指定された合成目標情報の各パラメータに近く、かつ、前後の音声素片との接続関係の良好な音声素片を、素片データベースから選択して合成を行う方式である。各音声素片には、音素情報、音響パラメータ、音声コーパス内での出現環境等のパラメータが付されている。
【0005】
接続合成方式においては、音声合成記号列によって指定される合成目標情報に基づき、使用する音声素片の選択(以後、素片選択と呼ぶ。)を行うが、この素片選択は、コストと呼ぶ歪み尺度、つまり、選択した音声素片により合成される音声波形の、目標とする合成音声波形からの劣化度合いを示す指標に基づき行われる。コストは、通常、合成目標情報と音声素片との誤差を示すターゲットコストと、音声素片間の不連続の程度を示す接続コストに分けることができ、素片選択は全体のコストを最小とするように行われる。
【0006】
素片のデータベースについては、音声波形をそのまま格納しても良いし、あるいは、素片をCELP等により圧縮したデータを格納しても良い。音声波形を蓄積した場合は、素片を波形上で接続することで最終的な出力音声波形が合成される。一方、CELP等を用いて素片を圧縮した場合は、それを復号した波形上で素片を接続するだけでなく、復号前のパラメータレベルで先に接続しておき、それをまとめて復号することで音声波形を生成する手法もある。
【0007】
一方、分析合成方式は、音声を分析した結果得られる、音声の特徴パラメータ上で操作を行い、特徴パラメータから音声波形を信号処理により生成する方式である。ここでは特に、CELP方式と同様の、音源とフィルタを組み合わせた音源・フィルタモデル等に基づき、信号処理で音声波形を合成する方法を対象とする。音源・フィルタモデルでは、音声の響きをつくるフィルタを適当な音源で駆動することで、音声波形を信号処理的に合成するが、ここではCELP方式とは異なり、インパルス列や白色雑音源といった比較的に単純な構成の音源で駆動する場合を主に考える。また以下では、音源のパラメータとフィルタのパラメータをまとめて音声合成パラメータと呼ぶ。音声合成パラメータは、スペクトルの特徴を表現するためのMFCC(Mel-Frequency Cepstral Coefficient)や、声の高さに対応する、波形の基本周波数(F0)などの複数のパラメータで構成される。また、フィルタにはAR(自己回帰)型のフィルタや、MFCCを直接そのパラメータとする、MLSA(メル対数スペクトル近似)フィルタ(非特許文献2)等が用いられる。
【0008】
例えば子音のような音声を合成するためには、音声合成パラメータを時間的に変化させることが必要なため、この方法では、例えば5ms程度の一定周期で音声合成パラメータを更新し、その特徴を変化させながら音声を合成することが一般的である。この一定周期の1周期分は一般に1フレームと呼ばれる。したがって、この構成で音声を合成するためには、音声合成用記号からフレーム毎の音声合成パラメータの値を決める必要がある。
【0009】
その方法の1つとして、音声合成パラメータ時系列の時間変化を適当なモデルに基づきモデル化し、そのモデルパラメータを音声合成用記号からまず予測することで生成し、得られたモデルから音声合成パラメータ時系列を生成することで、任意の音声を合成可能とする方法が用いられる。以下では、このモデルのことを音声生成モデルと呼ぶ。例えば、ある音素の音声合成パラメータの特徴が時間的に3つの状態に分かれ、各状態のフレーム数について、その統計的特徴を現すベクトルを最初の状態から順にd1、d2、d3とし、この3つのベクトルの要素を連結して1つのベクトルdを作り、また、各状態の統計的特徴を現すベクトルを最初の状態から順にv1、v2、v3とすれば、その音素を合成するための音声合成パラメータの特徴は、音声生成モデルのパラメータを構成するd、v1、v2、v3の4つのベクトルで表すことができる。
【0010】
このように全ての音素がこのように4つのベクトルで表すことができると仮定し、予めそれぞれのベクトルについて、最適なコードブックを作成しておく。あるいは、v1、v2、v3は同じコードブックを用いて表しても良い。音声合成の際は、まず、音声合成用記号から各音素の音声生成モデルのパラメータを構成する最適なコードブックのベクトルをそれぞれ予測し、各音素を合成するため音声生成モデルを構築する。そして、それらの音声生成モデルを時間順に連結して1発声分の音声生成モデルとし、そのモデルに基づき最適な音声合成パラメータ時系列を求める。この音声合成パラメータ時系列に基づき、音源・フィルタを制御することで、音声波形は生成される。
【0011】
以上、上記のような音声合成方式を用いることにより、音声合成記号列の形で表現された数百bps程度のデータから音声波形を生成することができる。
【先行技術文献】
【非特許文献】
【0012】
【非特許文献1】「日本語テキスト音声合成用記号」JEITA規格 IT−4002、2005年3月
【非特許文献2】今井聖、住田一男、古市千枝子、「音声合成のためのメル対数スペクトル近似(MLSA)フィルタ」、電子情報通信学会論文誌(A), J66-A, 2, pp.122-129, Feb. 1983.
【発明の概要】
【発明が解決しようとする課題】
【0013】
利用可能なデータサイズや通信ビットレートが非常に限られた環境で、予め準備された音声メッセージを再生する場合を考える。特にここでは、二次元バーコードなど、記憶容量が限られた対象に、音声データを格納する場合を主にその対象とする。音声の声質や読み上げスタイルに対する好みは、ユーザによりそれぞれ異なると考えられるので、ユーザの満足度を高めるためには、あらかじめ様々な声質や読み上げスタイルでの音声をそのバリエーションとして準備しておくことが望ましい。以下では説明のために、個々のバリエーション間の差異は全て「声質」の差異であると考える。よって以下における「声質」とは、音声学的な定義の意味で限定されたものではなく、より一般化された音声の個性を表す。
【0014】
もしデータサイズの制限がなければ、従来の音声符号化技術で、声質毎に独立してそれぞれ音声を符号化すれば良い。しかし従来の音声符号化方式では品質を維持するために、ある程度のデータサイズが必要で、声質の違いごとにそれぞれ音声を符号化するので、データサイズは声質の数に比例する。このため、限られたデータサイズで品質を確保しつつ、声質の数を増やすことは困難である。
【0015】
一方、音声合成技術を用いることで、音声合成装置のサイズはある程度大きいものの、音声合成記号列のみで音声を合成することができる。ある声質の音声を出力する音声合成装置は、同種の声質の音声データをあらかじめ例えば数十分から数十時間といった規模で大量に収集しておき、それを用いて構成することができる。また音声合成記号列は、音声符号化されたデータよりも通常ずっと小さく、容易に二次元バーコードなどに記録可能である。さらに、事前に複数の声質のデータからそれぞれ音声合成装置用のデータを構築しそれを装置に組み込んでおくことで、装置の利用時に、そのデータを切り替えることで、出力される音声の声質を比較的容易に変更することができる。しかし、一般に音声合成装置は、音声合成記号列を構成する言語的情報のみから対象の音声の特徴を予測して音声を合成しており、自然音声を音声符号化した場合と比較し、元となった音声の再現性は低く、自然性で大きく劣るという問題がある。
【0016】
以上に示すように、従来技術では、記憶容量が限られている場合に、音声メッセージの自然性と、声質の多様性を両立させることができなかった。
【0017】
したがって、本発明は、利用可能なデータサイズや通信ビットレートが非常に限られた環境で、原音声の特徴をより再現して合成することができる音声合成装置、方法およびプログラムを提供することを目的とする。
【課題を解決するための手段】
【0018】
上記目的を実現するため本発明による音声合成装置は、一連の音声合成用情報に基づき音声を合成する音声合成装置であって、前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、所定の声質の音声を合成する場合、前記共通情報の内容を前記修正情報に基づき変更する修正手段と、前記修正された情報に基づき音声波形を合成する音声合成手段と、
を備える。
【0019】
上記目的を実現するため本発明による音声合成装置は、一連の音声合成用情報に基づき音声を合成する音声合成装置であって、前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、前記共通情報に基づき音声波形生成のための制御指令を生成する制御指令生成手段と、所定の声質の音声を合成する場合、前記修正情報に基づき前記生成された制御指令を修正する制御指令修正手段と、前記修正された制御指令に基づき音声波形を生成する音声波形生成手段とを備える。
【0020】
また、前記共通情報は、音韻記号と韻律記号で構成されることも好ましい。
【0021】
また、前記音声合成装置は、合成する音声の声質を複数の声質の中から選択する手段をさらに備えることも好ましい。
【0022】
上記目的を実現するため本発明による音声合成方法は、一連の音声合成用情報に基づき音声を合成する音声合成方式であって、前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、所定の声質の音声を合成する場合、前記共通情報の内容を前記修正情報に基づき変更する修正ステップと、前記修正された情報に基づき音声波形を合成する音声合成ステップとを備える。
【0023】
上記目的を実現するため本発明による音声合成方法は、一連の音声合成用情報に基づき音声を合成する音声合成方式であって、前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、前記共通情報に基づき音声波形生成のための制御指令を生成する制御指令生成ステップと、所定の声質の音声を合成する場合、前記修正情報に基づき前記生成された制御指令を修正する制御指令修正ステップと、前記修正された制御指令に基づき音声波形を生成する音声波形生成ステップとを備える。
【0024】
上記目的を実現するため本発明によるプログラムは、上記に記載の音声合成装置としてコンピュータを機能させる。
【発明の効果】
【0025】
本発明により、音声合成用情報を、声質とは独立した情報である共通情報と、声質毎に異なる修正情報に分けることで、同一発話内容の音声については、共通情報を共用して修正情報のみを追加することで、効率的に符号化することができる。この際、音声波形生成のための指令情報が元となる自然音声の特徴に近付くような修正情報を作成しておくことで、元となる音声の特長を再現する自然性の高い音声を出力することができる。
【0026】
また、共通情報を従来の音声合成技術と同様の言語的な情報だけで構成する場合は、ユーザが望む声質に対応した修正情報が音声合成用情報に含まれていない場合でも、従来の技術による音声合成が可能なので、自然性は低下するが、ユーザの望む声質の音声を合成することができる。
【0027】
また、共通情報を修正の対象とすることにより、言語的な表現が発声の一部で異なる場合であっても、共通情報を共用することができる。
【0028】
以上の特徴から、類似の発話内容で声質の異なる複数の音声を、従来の音声符号化方式よりも必要な記憶容量のサイズを抑え、かつ、従来の音声合成技術をそのまま用いた場合よりも原音声の特徴をより再現して合成することができる。
【図面の簡単な説明】
【0029】
【図1】本発明の第1の実施形態による音声合成装置のブロック図である。
【図2】第1の実施形態による音声合成のフローチャートを示す。
【図3】本発明の第2の実施形態による音声合成装置のブロック図である。
【図4】第2の実施形態による音声合成のフローチャートを示す。
【図5】本発明の第3の実施形態による音声合成装置のブロック図である。
【図6】第3の実施形態による音声合成のフローチャートを示す。
【発明を実施するための形態】
【0030】
本発明を実施するための最良の実施形態について、以下では図面を用いて詳細に説明する。なお、以下において、“単位音声”とは、本発明による音声合成装置における、音声の最小処理単位である。単位音声の具体例としては、音素、音節、単語がある。ただしここでは、単位音声は、例えば前後の音素の種類といった音韻環境に関する違い、またアクセントやイントネーション、話速といった韻律的特徴の違いを考慮した分類が行われているものとする。また“音声合成用記号”とは、1発声の音声に含まれる単位音声のそれぞれの種類を記述するための一連の記号である。
【0031】
図1は、本発明の第1の実施形態による音声合成装置のブロック図である。図1によると、音声合成装置1は、音声合成用情報に対する前処理部11と、共通情報修正部12と、音声波形合成部13を備えている。図2は、第1の実施形態による音声合成のフローチャートを示す。
【0032】
S11.まず前処理部11では、音声合成用情報を処理し、共通情報と修正情報を取り出す。共通情報の例としては、JEITA IT−4002で規定される記号のような、音声合成用の音韻情報と韻律情報を同時に記述するための記号がある。共通情報の作成には音声認識技術を用いても良いが、一般に、音声は予め用意された原稿を読み上げたものが多いため、このような共通情報であれば、日本語テキスト音声変換技術を用いて、漢字仮名交じりテキストの音声原稿から比較的高精度に自動で作成することができる。また自動処理による誤りや、実際の発声との間で生じる誤差は、人手により容易に修正することができる。また、修正情報には、対象声質を識別する識別情報が含まれている。
S12.ここで共通情報修正部12は、前処理部11の出力である共通情報および修正情報をその入力とする。共通情報修正部12は、音声波形合成部13の波形生成対象声質が、修正情報の対象声質と一致するか確認する。
S13.一致する場合、共通情報修正部12は、修正情報に基づき共通情報を修正し出力する。一方、音声波形合成部13の波形生成対象声質が、修正情報の対象声質と異なる場合、共通情報修正部12は、入力された共通情報をそのまま出力する。
S14.共通情報修正部12の出力に基づき、音声波形合成部13で音声波形が合成され、音声合成装置1の出力として出力される。
【0033】
修正情報の例としては、共通情報の先頭からi番目の記号を記号Aで置換することを示す符号、先頭からj番目の記号の直前に記号Bを挿入することを示す符号、および先頭からk番目の記号を削除する符号を並べたものがある。修正の際は、先頭の符号から順に対応する操作を行うことで、共通情報は修正される。例えば音節を単位とするような共通情報を用いている場合において、共通情報では頭高型アクセントになっている「デ’ンシャ.」(ただしここで記号「’」はその場所にアクセント核があることを示す)を、修正情報対象の声質では平板型アクセントで読む場合、2番目の記号を削除する符号1つをその修正情報とすることで、頭高型アクセントの「デ’ンシャ.」は、平板型アクセントの「デンシャ.」に修正される。同様の修正により、ポーズ挿入位置の違いや、「デ’スネ.」と「デ’スワ.」といった表現の細かな違いも修正することができる。
【0034】
図3は、本発明の第2の実施形態による音声合成装置のブロック図である。図3によると、音声合成装置1は、前処理部11と、音声合成制御指令生成部14と、制御指令修正部15と、音声波形生成部16を備えている。なお、ここでの音声合成制御指令生成部14と音声波形生成部16を組み合わせたものが、第1の実施形態における音声波形合成部13に相当する。図4は、第2の実施形態による音声合成のフローチャートを示す。
【0035】
S21.前処理部11は、音声合成用情報を処理し、共通情報と修正情報を取り出す。
S22.音声合成制御指令生成部14は、取り出された共通情報を、音声波形生成のための音声合成制御指令に変換する。
S23.制御指令修正部15は、前記の制御指令が入力されると、音声波形生成部16の波形生成対象声質が修正情報の対象声質と一致する場合がどうか確認する。
S24.一致する場合、制御指令修正部15は、別途入力された修正情報に基づき制御指令を修正する。一致しない場合、制御指令修正部15は、制御指令をそのまま出力する。
S25.制御指令修正部15の出力情報に基づき音声波形生成部16で音声波形が生成され、音声合成装置1の出力として出力される。
【0036】
ここで制御指令の例として、まず音声合成方式として接続合成方式を用いる場合においては、素片IDがある。この場合、接続合成方式において必要となる素片選択処理は音声合成制御指令生成部14で行われ、素片の接続する処理は音声波形生成部16で行われる。一方、分析合成方式を用いる場合は、制御指令として、音声合成パラメータ時系列が例として挙げられる。これは具体的には、MFCCやF0のパラメータ時系列である。この場合は、音声合成制御指令生成部14で音声生成モデルから音声合成パラメータ時系列を生成する処理が行われる。
【0037】
あるいは、音声生成モデルのパラメータを、ここでの制御指令としてもよい。この場合は、音声波形生成部16で音声生成モデルから音声合成パラメータ時系列を生成する処理が行われる。
【0038】
また、この場合の修正情報の例としては、それぞれのパラメータのある値に関する、置換操作を表す符号の列がある。またこの本実施形態においても修正情報には、対象声質を識別する識別情報が含まれている。
【0039】
この修正情報を、音声合成装置1から出力される音声のスペクトルに関する特徴や基本周波数に関する特徴が、元となる音声のそれぞれの特徴に近付くように構成することで、修正を行わない場合よりも、より原音声の特徴に近い音声を出力することができる。
【0040】
例えば、全ての特徴ベクトルの全ての要素について、それぞれ値の修正を試行し、その結果、合成される音声の特徴が、元となる音声の特徴に最も近付いた試行の修正を、修正情報の1つの要素とする。これを(1)修正が所定の回数に達する、あるいは修正情報全体のサイズが所定の制限値に達する、または(2)合成される音声と、元となる音声との間の特徴の差異が所定の基準よりも小さくなる、まで繰り返し修正情報の要素を蓄積していくことで、修正情報を作成することができる。
【0041】
また、先の2つの修正処理を組み合わせた装置構成とし、両者の修正情報が混在するような音声合成用制御指令を構成してもよい。図5はこの構成を有する本発明の第3の実施形態による音声合成装置のブロック図である。図5によると、音声合成装置1は、前処理部11と、共通情報修正部12と、音声合成制御指令生成部14と、制御指令修正部15と、音声波形生成部16を備えている。図6は、第3の実施形態による音声合成のフローチャートを示す。
【0042】
S31.前処理部11は、音声合成用情報を処理し、共通情報と修正情報を取り出す。
S32.共通情報修正部12は、音声波形生成部16の波形生成対象声質が、修正情報の対象声質と一致するか確認する。
S33.一致する場合、共通情報修正部12は、修正情報に基づき共通情報を修正し出力する。一方、音声波形生成部16の波形生成対象声質が、修正情報の対象声質と異なる場合、共通情報修正部12は、入力された共通情報をそのまま出力する。
S34.音声合成制御指令生成部14は、取り出された共通情報を、音声波形生成のための音声合成制御指令に変換する。
S35.制御指令修正部15は、前記の制御指令が入力されると、音声波形生成部16の波形生成対象声質が修正情報の対象声質と一致する場合がどうか確認する。
S36.一致する場合、制御指令修正部15は、別途入力された修正情報に基づき制御指令を修正する。一致しない場合、制御指令修正部15は、制御指令をそのまま出力する。
S37.制御指令修正部15の出力情報に基づき音声波形生成部16で音声波形が生成され、音声合成装置1の出力として出力される。
【0043】
共通情報が音声合成用の音韻情報と韻律情報で構成されるような場合、共通情報を直接修正することにより、小さい修正情報で、出力される合成音声を大きく変更することができるが、共通情報の修正では、音声波形生成部16への指令の修正では可能な音声の微修正が不可能なため、これを組み合わせることは有効である。
【0044】
この場合の修正情報の作成は、例えば、まず共通情報の修正情報を作成し、その結果合成される音声において品質上問題が生じている部分について、音声波形生成部16への指令の修正するような修正情報を追加する、といった手段で実現される。
【0045】
また、1つの共通情報と、複数種類の声質に対する修正情報をまとめて一連の音声合成用情報を構成しても良い。この場合、音声波形生成処理において、あらかじめ用意された複数種類の声質の中で、ユーザの好みの声質で音声波形を生成する場合、修正情報の用意された声質については、より原音声の特徴に近い音声を、修正情報がない場合でも、従来の音声合成装置で可能な水準でその対象声質の音声を出力することができる。人気が高いと予想される声質についてのみ修正情報を作成することで、全体のデータサイズを抑えつつ、効率的にユーザ全体のニーズに応えることができる。
【0046】
また、以上述べた実施形態は全て本発明を例示的に示すものであって限定的に示すものではなく、本発明は他の種々の変形態様および変更態様で実施することができる。従って本発明の範囲は特許請求の範囲およびその均等範囲によってのみ規定されるものである。
【符号の説明】
【0047】
1 音声合成装置
11 前処理部
12 共通情報修正部
13 音声波形合成部
14 音声合成制御指令生成部
15 制御指令修正部
16 音声波形生成部
【特許請求の範囲】
【請求項1】
一連の音声合成用情報に基づき音声を合成する音声合成装置であって、
前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、
所定の声質の音声を合成する場合、前記共通情報の内容を前記修正情報に基づき変更する修正手段と、
前記修正された情報に基づき音声波形を合成する音声合成手段と、
を備えることを特徴とする音声合成装置。
【請求項2】
一連の音声合成用情報に基づき音声を合成する音声合成装置であって、
前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、
前記共通情報に基づき音声波形生成のための制御指令を生成する制御指令生成手段と、
所定の声質の音声を合成する場合、前記修正情報に基づき前記生成された制御指令を修正する制御指令修正手段と、
前記修正された制御指令に基づき音声波形を生成する音声波形生成手段と、
を備えることを特徴とする音声合成装置。
【請求項3】
前記共通情報は、音韻記号と韻律記号で構成されることを特徴とする、請求項1または2に記載の音声合成装置。
【請求項4】
合成する音声の声質を複数の声質の中から選択する手段をさらに備えることを特徴とする請求項1から3のいずれか1項に記載の音声合成装置。
【請求項5】
一連の音声合成用情報に基づき音声を合成する音声合成方式であって、
前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、
所定の声質の音声を合成する場合、前記共通情報の内容を前記修正情報に基づき変更する修正ステップと、
前記修正された情報に基づき音声波形を合成する音声合成ステップと
を備えることを特徴とする音声合成方法。
【請求項6】
一連の音声合成用情報に基づき音声を合成する音声合成方式であって、
前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、
前記共通情報に基づき音声波形生成のための制御指令を生成する制御指令生成ステップと、
所定の声質の音声を合成する場合、前記修正情報に基づき前記生成された制御指令を修正する制御指令修正ステップと、
前記修正された制御指令に基づき音声波形を生成する音声波形生成ステップと、
を備えることを特徴とする音声合成方法。
【請求項7】
請求項1から4のいずれか1項に記載の音声合成装置としてコンピュータを機能させることを特徴とするプログラム。
【請求項1】
一連の音声合成用情報に基づき音声を合成する音声合成装置であって、
前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、
所定の声質の音声を合成する場合、前記共通情報の内容を前記修正情報に基づき変更する修正手段と、
前記修正された情報に基づき音声波形を合成する音声合成手段と、
を備えることを特徴とする音声合成装置。
【請求項2】
一連の音声合成用情報に基づき音声を合成する音声合成装置であって、
前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、
前記共通情報に基づき音声波形生成のための制御指令を生成する制御指令生成手段と、
所定の声質の音声を合成する場合、前記修正情報に基づき前記生成された制御指令を修正する制御指令修正手段と、
前記修正された制御指令に基づき音声波形を生成する音声波形生成手段と、
を備えることを特徴とする音声合成装置。
【請求項3】
前記共通情報は、音韻記号と韻律記号で構成されることを特徴とする、請求項1または2に記載の音声合成装置。
【請求項4】
合成する音声の声質を複数の声質の中から選択する手段をさらに備えることを特徴とする請求項1から3のいずれか1項に記載の音声合成装置。
【請求項5】
一連の音声合成用情報に基づき音声を合成する音声合成方式であって、
前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、
所定の声質の音声を合成する場合、前記共通情報の内容を前記修正情報に基づき変更する修正ステップと、
前記修正された情報に基づき音声波形を合成する音声合成ステップと
を備えることを特徴とする音声合成方法。
【請求項6】
一連の音声合成用情報に基づき音声を合成する音声合成方式であって、
前記音声合成用情報は、対象声質に関係なく音声を合成するための共通情報と、所定の声質を音声合成する場合に機能する修正情報で構成され、
前記共通情報に基づき音声波形生成のための制御指令を生成する制御指令生成ステップと、
所定の声質の音声を合成する場合、前記修正情報に基づき前記生成された制御指令を修正する制御指令修正ステップと、
前記修正された制御指令に基づき音声波形を生成する音声波形生成ステップと、
を備えることを特徴とする音声合成方法。
【請求項7】
請求項1から4のいずれか1項に記載の音声合成装置としてコンピュータを機能させることを特徴とするプログラム。
【図1】


【図2】
【図3】
【図4】
【図5】
【図6】
【図2】
【図3】
【図4】
【図5】
【図6】
【公開番号】特開2010−224419(P2010−224419A)
【公開日】平成22年10月7日(2010.10.7)
【国際特許分類】
【出願番号】特願2009−73997(P2009−73997)
【出願日】平成21年3月25日(2009.3.25)
【出願人】(000208891)KDDI株式会社 (2,700)
【公開日】平成22年10月7日(2010.10.7)
【国際特許分類】
【出願日】平成21年3月25日(2009.3.25)
【出願人】(000208891)KDDI株式会社 (2,700)
[ Back to top ]