
音声情報解析装置および音声情報解析プログラム

【課題】大まかな位置情報と音声情報とに基づいて、複数の人物がそれぞれ参加している会話グループを特定する可能な音声情報解析装置を提供する。
【解決手段】発話中の複数の人物を、位置情報に基づき、複数の会話グループに分ける組み合わせ候補を生成する生成部と、各組み合わせ候補の各会話グループにおける複数の発話音声を時系列に従って配列する配列部と、配列された発話音声に含まれる発話ペアごとに、韻律情報とパラ言語情報との少なくとも一方を含む特徴情報を抽出する抽出部と、発話ペアが会話の一部である場合に特徴情報が従う確率分布に基づいて、各発話ペアが会話の一部であることの尤もらしさを示す第1尤度を算出する第1算出部と、各発話ペアの第1尤度に基づいて、配列された全ての発話音声が会話を形成している確率を示す第2尤度を算出する第2算出部と、組み合わせ候補に含まれる各会話グループの第2尤度に基づいて、当該組み合わせ候補の尤もらしさを示す第3尤度を算出する第3算出部とを有する。
【解決手段】発話中の複数の人物を、位置情報に基づき、複数の会話グループに分ける組み合わせ候補を生成する生成部と、各組み合わせ候補の各会話グループにおける複数の発話音声を時系列に従って配列する配列部と、配列された発話音声に含まれる発話ペアごとに、韻律情報とパラ言語情報との少なくとも一方を含む特徴情報を抽出する抽出部と、発話ペアが会話の一部である場合に特徴情報が従う確率分布に基づいて、各発話ペアが会話の一部であることの尤もらしさを示す第1尤度を算出する第1算出部と、各発話ペアの第1尤度に基づいて、配列された全ての発話音声が会話を形成している確率を示す第2尤度を算出する第2算出部と、組み合わせ候補に含まれる各会話グループの第2尤度に基づいて、当該組み合わせ候補の尤もらしさを示す第3尤度を算出する第3算出部とを有する。
【発明の詳細な説明】
【技術分野】
【0001】
本件開示は、複数の人物によって発話された音声情報を解析する音声情報解析装置および音声情報解析プログラムに関する。
【背景技術】
【0002】
展示会場内やオフィス内に滞在する複数の人物が、それぞれどのようなグループを形成して会話しているのかを特定することにより、コミュニケーションの活性化や効率的な人事管理が可能となる場合がある。
【0003】
複数の人物が会話に参加しているグループを特定する手法としては、互いに近接していて少なくとも一方が発話している場合に、当該人物同士が対話していると判断する技法が提案されている(特許文献1参照)。この技法では、各人物に会話音声の取得と近接した人物の識別情報を取得するための端末を所持させ、この端末で収集した情報を対話している人物の特定に利用している。また、同様の機能を有する端末を各人物に所持させ、互いに近接している人物の端末を介して収集した音声情報を解析することによって求めた発話期間の重複率に基づき、個々のグループに参加している人物を特定する技法も提案されている(特許文献2参照)。
【0004】
また、個々の人物が所持する端末を介して収集した所定以上の音圧を持つ音声が相互に類似しており、かつ、互いの発話期間に重複が少ない人物同士が対話していると判断する技法も提案されている(特許文献3参照)。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2009−224909号公報
【特許文献2】再公表WO2007/105436号公報
【特許文献3】特開2008−242318号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
特許文献1や特許文献2の技法は、展示会場などに滞在する個々の人物に、近接する他の人物を特定する機能を持つ端末を配布し、装着してもらう必要がある。多数の人物が滞在する場所において、このような特定の用途に利用される端末を配布して装着させることは、情報を収集する側にとっても、また、端末を装着させられる側にとっても負担になる。
【0007】
一方、特許文献3の技法は、展示会場などを訪れた人物が所持している携帯端末などの機能を利用して音声情報を収集することができる反面、混雑した状態などでは、背景ノイズの影響により、音声情報の類似性を正確に判断できない可能性がある。
【0008】
また、例えば、複数のグループが互いに近接している場合などには、発話期間の重複率のみに基づいて、各人物がどのグループに参加しているかを判断することは困難である。
【0009】
本件開示は、大まかな位置情報と音声情報とに基づいて、複数の人物がそれぞれ参加している会話グループを特定することが可能な音声情報解析装置および音声情報解析プログラムを提供することを目的とする。
【課題を解決するための手段】
【0010】
一つの観点による音声情報解析装置は、複数の人物それぞれが発話した音声を表す音声情報を取得する取得部と、前記複数の人物それぞれの位置を示す位置情報を収集する収集部と、前記各人物の音声情報と前記各人物の位置情報とに基づいて、会話をしている可能性がある複数の人物を含む複数の会話グループを求め、求めた会話グループの組み合わせから会話をしている可能性の高い会話グループの組み合わせを組み合わせ候補として生成する生成部と、前記組み合わせ候補に含まれる各会話グループに属する前記複数の人物による複数の発話音声を時系列に従って配列する配列部と、前記配列部によって会話グループごとに配列された前記複数の発話音声において連続する2つの発話音声として特定される発話ペアごとに、前記発話ペアに対応する音声情報から、韻律的な特徴を示す韻律情報とパラ言語的な特徴に対応するパラ言語情報との少なくとも一方を含む特徴情報を抽出する抽出部と、前記特徴情報と、前記発話ペアが会話の一部である場合に当該特徴情報が従う確率分布とに基づいて、前記各発話ペアが会話の一部であることの尤もらしさを示す第1尤度を算出する第1算出部と、前記第1算出部で前記各発話ペアについて得られた前記第1尤度に基づいて、前記配列部によって会話グループごとに配列された前記複数の発話音声の全てが、当該会話グループに属する各人物による会話に含まれている確率を示す第2尤度を算出する第2算出部と、前記各組み合わせ候補に含まれる各会話グループについて算出した前記第2尤度に基づいて、当該組み合わせ候補が、前記複数の人物が形成している複数の会話グループの組み合わせを反映している確率を示す第3尤度を算出する第3算出部とを有する。
【0011】
また、別の観点による音声情報解析プログラムは、複数の人物それぞれが発話した音声を表す音声情報および前記複数の人物それぞれの位置を示す位置情報を取得し、前記各人物の音声情報と前記各人物の位置情報とに基づいて、会話をしている可能性がある複数の人物を含む複数の会話グループを求め、求めた会話グループの組み合わせから会話をしている可能性の高い会話グループの組み合わせを組み合わせ候補として生成し、前記各組み合わせ候補に含まれる各会話グループに属する前記複数の人物の発話音声を時系列に従って並べ替えることにより、前記各会話グループにおける発話音声の出現順序を示す発話音声の配列を生成し、前記各会話グループに対応する前記発話音声の配列に含まれる各発話音声と当該発話音声に連続する発話音声とを含む発話ペアごとに、前記発話ペアに含まれる2つの発話音声に対応する音声情報から、韻律情報とパラ言語情報との少なくとも一方を含む特徴情報を抽出し、前記特徴情報と、前記発話ペアが会話の一部である場合に当該特徴情報が従う確率分布とに基づいて、前記各発話ペアが会話の一部である確率を示す第1尤度を算出し、前記各会話グループに対応する発話音声の配列に含まれる前記発話ペアについて算出した前記第1尤度に基づいて、前記発話音声の配列に含まれる全ての発話音声が、当該会話グループに属する各人物による会話に含まれている確率を示す第2尤度を算出し、前記各組み合わせ候補に含まれる各会話グループについて算出した前記第2尤度に基づいて、当該組み合わせ候補が、前記複数の人物が形成している複数の会話グループの組み合わせを反映している確率を示す第3尤度を算出する処理をコンピュータに実行させる。
【発明の効果】
【0012】
本件開示の音声情報解析装置および音声情報解析プログラムによれば、大まかな位置情報と音声情報とに基づいて、複数の人物がそれぞれ参加している会話グループを特定することが可能である。
【図面の簡単な説明】
【0013】
【図1】音声情報解析装置の一実施形態を示す図である。
【図2】位置情報の収集手法を説明する図である。
【図3】発話期間の重複を説明する図である。
【図4】会話グループの組み合わせ候補の絞込み例を示す図である。
【図5】会話グループごとに配列された発話音声の例を示す図である。
【図6】生成部および配列部の一実施形態を示す図である。
【図7】発話リストおよび近接人物リストの一例を示す図である。
【図8】発話配列リストの一例を示す図である。
【図9】抽出部の一実施形態を示す図である。
【図10】発話間隔を示す情報の一例を示す図である。
【図11】第1算出部の一実施形態を示す図である。
【図12】確率分布モデルの一例を示す図である。
【図13】確率テーブルの例を示す図である。
【図14】音声情報解析装置のハードウェア構成例を示す図である。
【図15】音声情報解析処理のフローチャートの一例を示す図である。
【図16】会話グループを特定する処理のフローチャートの一例を示す図である。
【図17】各組み合わせ候補の尤度を算出する処理のフローチャートの例を示す図である。
【発明を実施するための形態】
【0014】
以下、図面に基づいて、本発明の実施形態について詳細に説明する。
図1は、音声情報解析装置の一実施形態を示している。
【0015】
図1に例示した音声情報解析装置10は、取得部11と、収集部12と、生成部13と、配列部14と、抽出部15と、第1算出部16と、第2算出部17と、第3算出部18とを含んでいる。
【0016】
図1に例示した取得部11は、複数の人物C1〜Cnそれぞれが発話した音声を表す音声情報を取得する。例えば、取得部11は、複数の人物C1〜Cnそれぞれが所持する携帯端末T1〜Tnを介して、各人物C1〜Cnの音声情報を取得してもよい。
【0017】
また、図1に例示した収集部12は、各人物C1〜Cnの位置を少なくとも一つの基準位置からの距離を用いて示す位置情報を収集する。例えば、収集部12は、各人物C1〜Cnが所持する携帯端末T1〜Tnの位置を示す情報を、各人物C1〜Cnの位置情報として収集してもよい。なお、各携帯端末T1〜Tnの位置を示す情報は、個々の携帯端末T1〜Tnに含まれるGPS(Global Positioning System)機能によって得られる位置情報でもよい。
【0018】
また、収集部12は、図2に示すように、例えば、人物C1〜Cnが滞在する室内に配置された中継装置S1,S2を介して、各携帯端末T1〜Tnとの距離を示す情報を収集することによって、各携帯端末T1〜Tnの位置を示す情報を得てもよい。
【0019】
図2は、位置情報の収集手法を説明する図である。図2において、符号A,B,C,D,E,F,Gは、人物C1〜Cnの例である。また、図2において、符号R1は、人物A,B,C,D,E,F,Gが滞在している展示会場などの場所を示している。また、図2において、符号S1,S2は、それぞれ、上述した展示会場R1に設置された中継装置を示している。
【0020】
図2に例示した中継装置S1,S2は、展示会場R1内に滞在している人物A,B,C,D,E,F,Gがそれぞれ所持している携帯端末に、ネットワークへの無線アクセスを提供する機能を有している。このような中継装置S1,S2は、展示会場R1内の人物A,B,C,D,E,F,Gが所持している携帯端末をネットワークに接続させる過程で、これらの携帯端末と中継装置S1,S2との間の距離を示す情報を収集している。例えば、中継装置S1,S2は、これらの携帯端末から到来する無線信号の強度や遅延の大きさなどに基づいて、自装置に近接している携帯端末をそれぞれ判別している。
【0021】
図2の例では、人物Aの携帯端末から経路ra1を介して中継装置S1に到達した無線信号と人物Gの携帯端末から経路rg1を介して中継装置S1に到達した無線信号とを比較することにより、人物Aの方が人物Gよりも中継装置S1に近いことが分かる。同様に、人物Aの携帯端末から経路ra2を介して中継装置S2に到達した無線信号と人物Gの携帯端末から経路rg2を介して中継装置S2に到達した無線信号とを比較することにより、人物Gの方が人物Aよりも中継装置S2に近いことが分かる。このようにして、2つの中継装置S1、S2がそれぞれ各人物A〜Hの携帯端末について収集した情報に基づいて、図1に例示した収集部12は、人物A〜Hがそれぞれ中継装置S1、S2のどちらに近いかを判別してもよい。そして、この判別結果を、収集部12は、2つの中継装置S1,S2からの距離を用いて示す位置情報として、図1に例示した生成部13に渡してもよい。
【0022】
生成部13は、各人物C1〜Cnの音声情報から得られる各人物C1〜Cnが発話している期間と各人物C1〜Cnの位置情報とに基づいて、人物C1〜Cnによって形成される複数の会話グループの組み合わせについての組み合わせ候補を生成する。
【0023】
生成部13は、まず、上述した収集部12で得られた人物C1〜Cnの位置情報に基づいて、各人物C1〜Cnを互いに近い位置にいる人物をそれぞれ含む複数のグループに分ける。例えば、生成部13は、中継装置S1,S2からの距離を示す位置情報に基づいて、図2に例示した人物A〜Hを、中継装置S1の近くにいる人物A〜Eを含むグループgr1と、中継装置S2の近くにいる人物F,Gを含むグループgr1とに分けてもよい。
【0024】
このようにして、生成部13は、対話している人物は互いに近い位置にいるという位置情報に基づく制約を満たすように、人物C1〜Cnを複数のグループに分けることができる。
【0025】
次に、生成部13は、次に述べるようにして、人物C1〜Cnの音声情報に基づいて、位置情報に基づいて形成した複数のグループそれぞれについて、会話している可能性のある人物を含む会話グループを生成する。
【0026】
まず、生成部13は、音声情報に基づいて、各人物が発話している期間である発話期間をそれぞれ特定する。次いで、生成部13は、位置情報に基づいて形成したグループそれぞれに含まれる人物の中から、発話期間が重複している人物のペアを検出する。
【0027】
図3は、発話期間の重複を説明する図である。図3に示した横軸は、時間tを示す。また、図3に示した符号A,B,C,D,Eは、図2に例示したグループgr1に含まれる人物A,B,C,D,Eに対応している。
【0028】
図3において、各人物A,B,C,D,Eに対応する横軸上に示した矩形は、それぞれの人物の発話音声を示している。また、各矩形の横方向の長さは、それぞれの発話音声に対応する発話期間の長さを示し、各矩形の位置は、時間軸上の位置を示している。なお、図3において、各発話音声を、符号「V」と話者を示す符号と時系列を示す番号とを組み合わせた符号で示した。例えば、人物Aのj番目の発話音声を符号VAjで示した。
【0029】
図3に例示した人物Aの発話音声VA1,VA2の発話期間と人物Cの発話音声VC1の発話期間とを比べると、これらが、それぞれ符号τac1,τac2で示した期間に亘って重複していることが分かる。そして、この重複している期間τac1,τac2が、人物Aの2つの発話音声に対応する発話期間に占める割合を示す発話重複率が、値1に近い、高い値となることも分かる。また、図3に例示した人物Bの発話音声VB1,VB2の発話期間と人物Cの発話音声VC1の発話期間とを比べると、これらが、それぞれ符号τbc1,τbc2で示した期間に亘って重複していることが分かる。また、同様に、この重複している期間τbc1,τbc2が、人物Bの2つの発話音声に対応する発話期間に占める発話重複率が、値1に近い、高い値となることも分かる。
【0030】
図1に例示した生成部13は、例えば、人物C1〜Cnに含まれる二人の組み合わせごとに求めた発話重複率が所定の閾値を超えるか否かに基づいて、発話期間が互いに重複している人物のペアを検出することができる。
【0031】
ここで、互いの発話期間についての発話重複率が高い値となっている人物のペアが互いに会話している可能性が低い。つまり、上述したようにして検出した発話期間が互いに重複している人物のペアは、互いに対話していない人物のペアである。例えば、図3に例示した人物A,Cおよび人物B,Cのペアのように、互いの発話期間の大部分が重複している人物のペアは、対話していない人物のペアの例である。
【0032】
したがって、生成部13は、対話していない人物のペア、すなわち、発話が互いに重複する人物のペアを会話グループが含まないという発話期間の重複に基づく制約を満たすように、会話グループの組み合わせ候補を生成することが望ましい。
【0033】
生成部13は、次に述べるようにして、位置情報に基づく制約と発話期間の重複に基づく制約との両方を満たす会話グループの組み合わせ候補を生成する。
【0034】
例えば、生成部13は、まず、位置情報に基づいて形成した各グループに含まれる複数の人物の中で発話している人物を複数含む会話グループについて、全ての組み合わせを列挙する。そして、生成部13は、列挙された全ての会話グループの組み合わせを、発話期間の重複に基づく制約を満たすか否かによって絞り込むことにより、少なくとも一つの組み合わせ候補を生成してもよい。
【0035】
図4は、会話グループの組み合わせ候補の絞込み例を示している。図4(A)は、図2に例示した人物A〜Gについて、生成部13が、位置情報の制約を考慮して生成する会話グループの全ての組み合わせを示す。また、図4(B)は、図3に例示した発話期間の重複に基づく制約を考慮して、生成部13が、図4(A)に例示した全ての組み合わせを絞り込むことによって得られた会話グループの組み合わせ候補を示す。
【0036】
図4(A)に例示した全ての組み合わせに含まれる組み合わせ1は、図2に例示したグループgr1に含まれる全ての人物A〜Eを含む会話グループ1と、図2に例示したグループgr2に含まれる人物F,Gを含む会話グループ2とを含んでいる。一方、図4(A)に例示した組み合わせ2〜組み合わせ11は、いずれも、上述した人物F,Gを含む会話グループ3を含んでいる。そして、これらの組み合わせ2〜組み合わせ11に含まれる会話グループ1,2は、上述した人物A〜Eを二人のグループと三人のグループに分ける際に考えられる組み合わせに相当している。
【0037】
図4(A)に例示した組み合わせ3,7,8は、発話期間が重複している人物Aと人物Cのペアを含む会話グループを含んでいる。また、図4(A)に例示した組み合わせ4〜6は、発話期間が重複しているあるいは人物Bと人物Cのペアを含む会話グループを含んでいる。更に、図4(A)に例示した組み合わせ1,11は、上述した人物Aと人物Cのペアおよび人物Bと人物Cのペアとの両方を含む会話グループを含んでいる。つまり、これらの組み合わせ1と組み合わせ3〜8および組み合わせ11は、発話期間の重複に基づく制約を満たさない組み合わせである。
【0038】
生成部13は、図4(A)に例示した11通りの組み合わせから、上述した発話期間の重複に基づく制約を満たさない組み合わせを排除することにより、図4(B)に例示した3通りの会話グループの組み合わせ候補1,2,3に絞り込む。なお、図4(B)においては、組み合わせ候補1,2,3をそれぞれ「候補1」、「候補2」、「候補3」として示している。
【0039】
なお、会話グループの数に限定はなく、例えば、図2に例示した以上の数の人物について会話グループを特定する処理を行う場合などに、生成部13は、4以上の会話グループを含む組み合わせ候補を生成することもできる。
【0040】
このようにして生成された会話グループの組み合わせ候補について、図1に例示した配列部14は、各組み合わせ候補に含まれる会話グループそれぞれに属する複数の人物の発話音声を時系列に従って配列する。
【0041】
図5は、会話グループごとに配列された発話音声の例を示している。図5に示した横軸は、時間tを示している。なお、図5に含まれる要素のうち、図3に示した要素と同等のものについては、同一の符号を付して示し、その説明は省略する。
【0042】
図5(A)は、図4(B)に例示した組み合わせ候補1に含まれる会話グループ1に相当する会話グループG11と会話グループ2に相当する会話グループ12にそれぞれ属する各人物による発話音声が出現する順序を示している。また、図5(B)は、図4(B)に例示した組み合わせ候補2に含まれる会話グループ1に相当する会話グループG21と会話グループ2に相当する会話グループ22にそれぞれ属する各人物による発話音声が出現する順序を示している。同様に、図5(C)は、図4(B)に例示した組み合わせ候補3に含まれる会話グループ1に相当する会話グループG31と会話グループ2に相当する会話グループ32にそれぞれ属する各人物による発話音声が出現する順序を示している。なお、図4(B)に例示した3つの組み合わせ候補1〜3に共通して含まれている会話グループ3に含まれる人物F,Gによる各発話音声は、組み合わせ候補ごとに出現順序が変化しないので、図5では図示を省略している。
【0043】
図5(A)〜図5(C)を互いに比較すれば、各組み合わせ候補に含まれる会話グループに属している人物の組み合わせの違いに応じて、各会話グループにそれぞれ属する各人物による発話音声に後続する発話音声が異なっている場合があることが分かる。例えば、会話グループG12においては、人物Cによる発話音声VC1に人物Eによる発話音声VE2が後続しているのに対して、会話グループG22においては、発話音声VC1には人物Dによる発話音声VD1が後続している。
【0044】
ここで、例えば、図5(A)に会話グループG11に対応して示した発話音声VA1,VB1,VA2,VB2が、二人の人物A,Bによる会話である場合に、出現順序に従って連続する発話音声それぞれの特徴には、当該会話の特徴が反映される。
【0045】
例えば、盛んに発話がなされることによって会話が盛り上がっている場合に、連続する発話音声間の間隔である発話間隔は短い場合が多い。また、会話が盛り上がっている場合に、各発話音声はパワーが大きいことが多く、また、当該会話に含まれる各発話音声の発話速度は速くなる場合が多く、更に、各発話音声の音声基本周波数は高くなる場合が多い。このように、会話に含まれる各発話音声が有するパワーや発話速度および音声基本周波数を含む個々の発話音声の韻律的な特徴と、発話間隔などの会話全体としての韻律的な特徴との間には相関関係がある。そして、このような相関関係は、会話において連続する2つの発話音声それぞれの韻律的な特徴と、この二つの発話音声についての発話間隔との関係に反映される。つまり、会話グループごとに配列された複数の発話音声に含まれる連続する2つの発話音声がそれぞれ有する韻律的な特徴と発話間隔との間に相関関係があることは、これらの発話音声が会話の一部である場合に満たす韻律的な特徴についての条件の一つである。なお、以下の説明では、会話グループごとに配列された複数の発話音声に含まれる連続する2つの発話音声を、発話ペアと称する。
【0046】
また一方、会話に含まれる各発話音声には、この会話に参加している人物それぞれの感情や意図および態度を含む話者の意識的な表現が、声の高さや抑揚などを含むパラ言語的な特徴として反映されている。以下の説明では、発話音声に反映されたパラ言語的な特徴から推測される話者の感情や意図および態度を含む話者の意識的な表現を示す情報をパラ言語情報と称する。
【0047】
複数の人物の間で会話が成立している場合に、会話に参加している人物が発話音声に反映させるパラ言語情報の組み合わせの中には、連続して現れる可能性の高い組み合わせと連続して現れる可能性の低い組み合わせとがある。例えば、会話に参加している人物の一方による発話音声に反映された感情が「怒り」である場合に、この発話音声に連続して「喜び」が反映された発話音声が現れる可能性は、自然な会話の中においては非常に低い。このように、発話音声に反映されるパラ言語情報の一つである話者の感情を示す発話感情には、会話の中で連続して現れる可能性が高い組み合わせと、逆に、連続して現れる可能性が低い組み合わせとが存在する。同様に、それぞれパラ言語情報の一つである話者の意図を示す発話意図および話者の態度を示す発話態度についても、連続する発話音声に対応する組み合わせとして出現する可能性が高い組み合わせと、出現する可能性の低い組み合わせとが存在する。このように、会話に含まれる各発話音声に反映されたパラ言語情報の種別が特定された場合に、当該発話音声に後続する発話音声に反映される可能性の高いパラ言語情報の種別が限定される場合が多い。つまり、発話ペアに含まれる個々の発話音声に反映されたパラ言語情報の種別の組み合わせが会話内で出現する可能性の高い組み合わせであることは、当該発話ペアが会話の一部である場合に満たすパラ言語的な特徴についての条件の一つである。
【0048】
したがって、各発話ペアが、上述した韻律的な特徴についての条件とパラ言語的な特徴についての条件との少なくとも一方を満たしている度合いを調べることで、この発話ペアが会話の一部であることの尤もらしさを評価することができる。
【0049】
図1に例示した抽出部15は、会話グループごとに配列された複数の発話音声に含まれる発話ペアごとに、対応する音声情報から、韻律的な特徴を示す韻律情報とパラ言語的な特徴に対応するパラ言語情報との少なくとも一方を含む特徴情報を抽出する。
【0050】
また、図1に例示した第1算出部16は、抽出部15によって得られた特徴情報と、発話ペアが会話の一部である場合に当該特徴情報が従う確率分布とに基づいて、当該発話ペアが会話の一部であることの尤もらしさを示す第1尤度を算出する。例えば、第1算出部16は、発話ペアに対応する音声情報から抽出された韻律情報と韻律的な特徴についての条件を示す確率分布とに基づいて、当該発話ペアが会話の一部である可能性の高さを示す韻律尤度を評価する。また、第1算出部16は、発話ペアに対応する音声情報から抽出されたパラ言語情報と上述したパラ言語的な特徴についての条件を示す確率分布とに基づいて、当該発話ペアが会話の一部である可能性の高さを示すパラ言語尤度を評価する。そして、第1算出部16は、例えば、上述したようにして求めた韻律尤度とパラ言語尤度との積を第1尤度として算出してもよい。
【0051】
このようにして、図1に例示した第1算出部16は、各発話ペアに対応する音声情報から抽出された特徴情報が、韻律的な特徴についての条件およびパラ言語的な特徴についての条件をそれぞれ満たしている度合いを反映した第1尤度を算出することができる。
【0052】
なお、第1算出部16において、上述した韻律尤度およびパラ言語尤度をそれぞれ算出する処理については、それぞれの処理において用いる確率分布の説明と併せて、図9〜図13を用いて改めて述べる。
【0053】
図1に例示した第2算出部17は、第1算出部16で各発話ペアについて得られた第1尤度に基づいて、会話グループごとに配列された全ての発話音声が、当該会話グループに属する各人物による会話に含まれている確率を示す第2尤度を算出する。
【0054】
第2算出部17は、例えば、配列部14が会話グループごとに発話音声を配列した順序に従って、第1算出部16で得られた各発話ペアについての第1尤度の相乗平均を算出することにより、当該会話グループについての第2尤度を求めてもよい。
【0055】
そして、図1に例示した第3算出部18は、各組み合わせ候補に含まれる各会話グループについて算出された第2尤度に基づいて、当該組み合わせ候補が、複数の人物が形成している複数の会話グループの組み合わせを反映している確率を示す第3尤度を算出する。
【0056】
第3算出部18は、例えば、各組み合わせ候補に含まれる複数の会話グループについて第2算出部17で得られた第2尤度の相乗平均を算出することにより、当該組み合わせ候補についての第3尤度を求めてもよい。
【0057】
このようにして得られた第3尤度は、生成部13で生成された複数の組み合わせ候補それぞれが、人物C1〜Cnが形成している会話グループの組み合わせを反映している可能性の高さを示している。すなわち、第3尤度が最も高い値となった会話グループの組み合わせが、最も尤もらしい会話グループの組み合わせを示している。つまり、各組み合わせ候補について得られた第3尤度に基づいて、人物C1〜Cnが形成している会話グループの組み合わせを特定することができる。
【0058】
このように、本件開示の音声情報解析装置10によれば、大まかな位置情報と音声情報とに基づいて、複数の人物がそれぞれ参加している会話グループを特定することが可能である。
【0059】
次に、図1に例示した音声情報解析装置10に含まれる各部の実施形態について説明する。
図6は、生成部13および配列部14の一実施形態を示している。なお、図6に示した構成要素のうち、図1に示した構成要素と同等のものについては、同一の符号を付して示し、その説明は省略する。
【0060】
図6に例示した取得部11は、図1に例示した人物C1〜Cnが所持する携帯端末T1〜Tnを介して収集した人物C1〜Cnの発話音声を示す音声情報を蓄積する音声情報蓄積部111を含んでいる。音声情報蓄積部111は、各人物C1〜Cnに対応する音声情報として、例えば、携帯端末T1〜Tnのマイクロホンなどを介して得られる音声信号を所定のサンプリング間隔ごとに蓄積してもよい。なお、図6に例示した取得部11は、携帯端末T1〜Tnのマイクロホンで得られた音声信号のサンプリング結果を、例えば、図2に例示した中継装置S1,S2を介して受け取ることができる。
【0061】
また、図6に例示した収集部12は、図1に例示した人物C1〜Cnが所持する携帯端末T1〜Tnを介して収集した人物C1〜Cnの位置を示す位置情報を蓄積する位置情報蓄積部121を含んでいる。位置情報蓄積部121は、各人物C1〜Cnに対応する位置情報として、例えば、図2に例示した中継装置S1,S2それぞれが無線アクセスを提供している携帯端末を示す情報を、所定のサンプリング間隔ごとに蓄積してもよい。なお、図6に例示した収集部12は、図2に例示した中継装置S1,S2を介して、それぞれが無線アクセスを提供している携帯端末を示す情報を受け取ることができる。
【0062】
また、図6に例示した生成部13は、発話判定部131と、発話リスト132と、位置分類部133と、近接人物リスト134と、組み合わせ列挙部135と、重複率算出部136と、絞込み部137とを含んでいる。
【0063】
発話判定部131は、上述した音声情報蓄積部111に蓄積された各人物に対応する音声情報に基づいて、各サンプリングタイミングにおいて各人物が発話しているか否かを判定する。発話判定部131は、例えば、各サンプリングタイミングについての判定処理を、当該サンプリングタイミングを含む所定の時間内における音声信号の強度の平均値に基づいて行ってもよい。そして、発話判定部131は、各人物についてサンプリングタイミングごとに得られた判定結果を、発話リスト132に格納する。
【0064】
なお、発話判定部131は、音声情報解析装置10によって、会話グループの特定処理を行う対象となる期間Tdにおいて得られた音声情報について、上述した判定処理を行ってもよい。この会話グループの特定を行う対象となる期間Tdとしては、所望の期間を指定することができる。
【0065】
図7(A)は、図2に例示した人物A〜Gについて、発話判定部131の処理によって得られる発話リスト132の一例を示している。図7(A)の時刻欄に示した符号tは、会話グループの特定処理を行う対象となる期間Tdの終了時刻を示す。また、符号t−Tは、終了時刻tから会話グループの特定を行う対象となる期間Tdの長さTを遡った時刻、すなわち、会話グループの特定を行う対象となる期間Tdの開始時刻を示す。また、図7(A)の時刻欄に示した符号hは、サンプリング間隔を示す。
【0066】
図7(A)に例示した人物A〜Gについて、各サンプリングタイミングに対応して示した数値「1」は、発話判定部131により当該人物が発話している旨の判定結果が得られたことを示している。一方、各サンプリングタイミングに対応して示した数値「0」は、発話判定部131により、当該人物が発話していない旨の判定結果が得られたことを示している。
【0067】
また、図6に例示した位置分類部133は、上述した位置情報蓄積部121に蓄積された位置情報に基づいて、図1に例示した人物C1〜Cnを会話が可能な程度に近接している複数のグループに分類する。位置分類部133は、上述した発話判定部131と同様に、会話グループの特定を行う対象となる期間Tdにおいて得られた位置情報に基づいて、後述する分類処理を行ってもよい。
【0068】
図2に例示した各中継装置S1,S2が無線アクセスを提供している携帯端末の識別情報が、位置情報蓄積部121に蓄積されている場合に、位置分類部133は、次のようにして各携帯端末を保持している人物C1〜Cnを複数のグループに分類してもよい。位置分類部133は、例えば、上述した期間Tdに亘って同一の中継装置から無線アクセスの提供を受けた複数の携帯端末の識別情報にそれぞれ対応付けられた人物を互いに近接している人物として判別する。そして、この判別結果に基づいて、位置分類部133は、各中継装置が無線アクセスを提供可能な範囲内に、上述した期間Tdに亘って滞在していた複数の人物を、当該中継装置に対応するグループに分類する。
【0069】
図7(B)は、図2に例示した人物A〜Gについて、位置分類部133の処理によって得られる近接人物リスト134の一例を示している。
【0070】
図7(B)に例示した近接人物リスト134は、図2に例示した中継装置S1に近接する範囲に滞在している人物として、この中継装置S1が無線アクセスを提供している携帯端末をそれぞれ所持している人物A,B,C,D,Eを含んでいる。また、図7(B)に例示した近接人物リスト134は、図2に例示した中継装置S2に近接する範囲に滞在している人物として、この中継装置S2が無線アクセスを提供している携帯端末をそれぞれ所持している人物F,Gを含んでいる。
【0071】
このようにして得られた近接人物リスト134と上述した発話リスト132とに基づいて、組み合わせ列挙部135は、図1に例示した人物C1〜Cnが形成している可能性のある会話グループの全ての組み合わせを列挙する。
【0072】
組み合わせ列挙部135は、例えば、上述した期間Tdの指定を受けたときに、発話リスト132に含まれるこの期間Tdに対応する判定結果に基づいて、この期間Tdにおいて発話があった人物を抽出する。次いで、組み合わせ列挙部135は、近接人物リスト134を参照することにより、上述した期間Tdにおいて発話があった人物それぞれが位置情報に基づいて分類されたグループを示す情報を取得する。そして、位置情報に基づいて分類された各グループに属する人物が4人以上であった場合に、組み合わせ列挙部135は、そのグループに含まれる人物を更にそれぞれ複数の人物を含む会話グループに振り分ける組み合わせの全てを数え上げる処理を行う。
【0073】
例えば、時刻tから時間Tを遡った時刻t−Tを開始時刻とする期間Tdが指定された場合に、組み合わせ列挙部135は、図7(A)に例示した発話リスト132の時刻t−Tから時刻tまでに対応して保持された情報に基づいて、発話があった人物を抽出する。なお、図7(A)において、各サンプリングタイミングを示す時刻は、上述した時刻tと時間Tとサンプリング間隔hを用いて表すことができる。この期間Tdにおいて、全ての人物A〜Gが発話していることを発話リスト132が示す場合に、図7(B)に例示した近接人物リスト134で示されたグループ分けは、そのまま発話している人物についての位置情報に基づくグループ分けを示す。この場合に、組み合わせ列挙部135は、人物A〜Eを含む人物のグループと、人物F,Gを含む人物のグループとについて、図4(A)に例示したような組み合わせを列挙すればよい。
【0074】
このようにして組み合わせ列挙部135によって生成された全ての組み合わせから、図6に例示した絞込み部137は、重複率算出部136によって算出された発話重複率に基づいて、会話が成立している可能性の低い組み合わせを排除する。これにより、絞込み部137は、会話が成立している可能性を持つ会話グループの組み合わせ候補を絞り込む。
【0075】
図6に例示した重複率算出部136は、発話重複率を算出するために、例えば、まず、発話リスト132に含まれる人物のペアごとに、上述した期間Tdにおいて同一の時刻に対応して発話があった旨の判定結果が保持されている回数を計数する。そして、この計数結果で示される重複回数を、当該ペアに含まれる各人物について発話があった旨の判定結果が保持されている回数で除算することにより、重複率算出部136は、当該ペアの互いに対する発話重複率を求めてもよい。
【0076】
絞込み部137は、例えば、少なくとも一方の人物について算出された発話重複率が所定の閾値を超えているペアを含む会話グループが含まれている組み合わせを、会話が成立している可能性の低い組み合わせとして排除してもよい。
【0077】
なお、上述した閾値は、例えば、複数の人物が会話している際の音声情報に基づいて、この会話に参加している人物のペアそれぞれについて発話重複率を算出する実験を行った結果に基づいて設定してもよい。例えば、上述した閾値は、この実験の過程で算出された発話重複率の最大値よりも大きい値に設定することができる。
【0078】
上述した処理を行うことにより、絞込み部137は、図4(A)のように列挙された多数の組み合わせから、会話が成立している可能性を持つ会話グループの組み合わせ候補に絞り込むことができる。そして、絞込み部137は、このようにして絞り込まれた組み合わせ候補を、配列部14に渡す。
【0079】
図6に例示した配列部14は、整列処理部141と発話配列リスト142とを含んでいる。整列処理部141は、絞込み部137から受け取った組み合わせ候補ごとに、発話リスト132とに基づいて、当該組み合わせ候補に含まれる各会話グループに属する人物の発話音声を時系列に従って整列させる。そして、この整列処理結果に基づいて、整列処理部141は、各会話グループに対応する会話において各発話音声が出現する順序を示す情報を発話配列リスト142に格納する。
【0080】
例えば、整列処理部141は、組み合わせ候補に含まれる会話グループごとに、当該会話グループに含まれる人物について発話リスト132を参照することにより、各人物の発話音声が連続して取得されている期間を示す個々の発話期間をそれぞれ特定する。このとき、整列処理部141は、各人物について特定された個々の発話期間に対応する発話音声に、当該人物を示す識別情報と個々の発話音声の出現順序を示す番号とを組み合わせた識別情報を付与してもよい。そして、整列処理部141は、例えば、各組み合わせ候補に含まれる会話グループごとに、当該会話グループに属する各人物の発話音声に対応する発話期間の開始時刻に基づいて、これらの発話音声を時系列に従って整列させてもよい。また、整列処理部141は、各発話音声に付与した識別情報を用いて、発話配列リスト142に格納する情報を表してもよい。
【0081】
図8は、発話配列リスト142の一例を示している。なお、図8に示した要素のうち、図5に示した要素と同等のものについては、同一の符号を付して示し、その説明は省略する。
【0082】
図8(A)は、図4(B)に例示した3つの組み合わせ候補それぞれに含まれる会話グループごとに、当該会話グループに属する人物の発話音声が出現する順序を示している。なお、図8において、符号VF1,VF2は、人物Fの発話音声を示し、符号VG1,VG2は、人物Gの発話音声を示す。
【0083】
例えば、図8(A)において、組み合わせ候補1に含まれる会話グループ1に対応する各欄に示した符号VA1,VB1,VA2,VB2は、図5(A)に当該会話グループを示す符号G11に対応して示した発話音声の出現順序を示している。同様に、図8(A)において、各組み合わせ候補1〜3に含まれる会話グループ3に対応する会話において、対応する各欄に示した符号VF1,VG1,VF2,VG2は、人物Fの発話音声と人物Gの発話音声とが交互に出現している様子を示している。
【0084】
このような発話配列リスト142によれば、各組み合わせ候補に含まれる会話グループそれぞれにおける発話音声の出現順で示される発話ペアを、当該会話グループに対応する隣接する欄に示された符号の組み合わせに基づいて特定することができる。
【0085】
なお、発話配列リスト142は、上述した整列処理部141が各発話音声を整列させる処理の過程で特定した各発話音声の開始時刻および終了時刻を示す情報を含んでもよい。
【0086】
図8(B)は、発話配列リスト142に含まれる各発話音声の開始時刻および終了時刻を示す情報の一例として、図2に例示した人物A〜Gによってなされた各発話音声の開始時刻および終了時刻を示している。
【0087】
図8(B)において、人物A〜Gによってなされた各発話音声の開始時刻を、符号「t」に人物およびその人物についての発話音声の順序を示す番号とを組み合わせた添え字を付加するとともに、符号「s」とを組み合わせて示した。同様に、図8(B)において、人物A〜Gによってなされた各発話音声の終了時刻を、符号「t」に人物およびその人物についての発話音声の順序を示す番号とを組み合わせた添え字を付加するとともに、符号「e」とを組み合わせて示した。
【0088】
例えば、図8(B)において、符号「tA1−s」は、人物Aの第1の発話音声の開始時刻を示し、符号「tA1−e」は、人物Aの第1の発話音声の終了時刻を示す。
【0089】
次に、このようにして得られた発話配列リスト142を用いて、抽出部15が、音声情報蓄積部111に蓄積された音声情報から、各発話音声の特徴情報を抽出する処理について説明する。
【0090】
図9は、抽出部15の一実施形態を示している。なお、図9に示した構成要素のうち、図1あるいは図6に示した構成要素と同等のものについては、同一の符号を付して示し、その説明は省略する。
【0091】
図9に例示した抽出部15は、韻律情報抽出部151とパラ言語情報抽出部152と、発話特徴蓄積部153と、間隔情報蓄積部154とを含んでいる。発話特徴蓄積部153は、韻律情報抽出部151およびパラ言語情報抽出部152が、各発話音声を表す音声情報からそれぞれ抽出した韻律情報およびパラ言語情報を、当該発話音声を示す識別情報に対応して蓄積する。また、間隔情報蓄積部154は、韻律情報抽出部151が、発話配列リスト142に含まれる各会話グループにおける発話音声の出現順序を示す情報で示される発話ペアごとに抽出した発話間隔を示す情報を蓄積する。
【0092】
図9に例示した韻律情報抽出部151は、発話パワー算出部151−pと、発話速度算出部151―vと、基本周波数算出部151−fと、持続時間抽出部151−sと、発話間隔算出部151−dを含んでいる。
【0093】
図9に例示した発話パワー算出部151−pは、音声情報蓄積部111に各人物に対応して蓄積された音声情報に含まれる個々の発話音声を表す音声信号の強度に基づいて、各発話音声について発話パワーを算出する。そして、発話パワー算出部151−pは、各発話音声について算出した発話パワーを、例えば、当該発話音声を示す識別情報に対応して、発話特徴蓄積部153に蓄積してもよい。
【0094】
また、図9に例示した発話速度算出部151−vは、音声情報蓄積部111に各人物に対応して蓄積された音声情報に含まれる個々の発話音声を表す音声信号の強度の変化に基づいて、各発話音声について発話速度を算出する。そして、発話速度算出部151−vは、各発話音声について算出した発話速度を、例えば、当該発話音声を示す識別情報に対応して、発話特徴蓄積部153に蓄積してもよい。
【0095】
また、図9に例示した基本周波数算出部151−fは、音声情報蓄積部111に各人物に対応して蓄積された音声情報に含まれる個々の発話音声を表す音声信号に基づいて、各発話音声の声の高さを示す基本周波数を算出する。そして、基本周波数算出部151−fは、各発話音声について算出した基本周波数を、例えば、当該発話音声を示す識別情報に対応して、発話特徴蓄積部153に蓄積してもよい。
【0096】
一方、図9に例示した持続時間算出部151−sは、上述した発話配列リスト142に含まれる各発話音声の開始時刻および終了時刻を示す情報に基づいて、各発話音声の持続時間を算出する。そして、持続時間算出部151−sは、各発話音声について算出した持続時間を、例えば、当該発話音声を示す識別情報に対応して、発話特徴蓄積部153に蓄積してもよい。
【0097】
また、図9に例示した発話間隔算出部151−dは、上述した発話配列リスト142にに基づいて、各組み合わせ候補に含まれる会話グループごとに、各発話ペアの発話間隔を算出する。例えば、発話間隔算出部151−dは、まず、発話配列リスト142によって示される発話音声の出現順に基づいて、各組み合わせ候補に含まれる会話グループごとに、各発話音声を含む発話ペアを特定する。そして、発話間隔算出部151−dは、発話配列リスト142に含まれる各発話音声の開始時刻および終了時刻を示す情報を参照することにより、当該発話ペアの前側の発話音声の終了時刻と後側の発話音声の開始時刻とをそれぞれ取得する。このようにして得られた前側の発話音声の終了時刻から後側の発話音声の開始時刻を差し引くことにより、発話間隔算出部151−dは、当該発話ペアの発話間隔を求めてもよい。そして、発話間隔算出部151−dは、各発話ペアについて算出した発話間隔を、例えば、各組み合わせ候補に含まれる会話グループそれぞれに対応して、発話間隔蓄積部154に蓄積してもよい。
【0098】
図10は、発話間隔蓄積部154に蓄積された発話間隔を示す情報の一例を示している。図10に例示した発話間隔を示す情報は、図8(A)に例示した各会話グループに対応する各発話音声を含む発話ペアについて得られた発話間隔を示している。
【0099】
なお、図10において、各発話ペアの発話間隔を、符号「t」に組み合わせ候補を特定する番号と会話グループを特定する番号とを組み合わせた添え字を付加するとともに、当該発話ペアの出現順序を示す番号を組み合わせて示した。
【0100】
例えば、図10において、組み合わせ候補1に含まれる会話グループ1に対応して示された符号「t11−1」は、図8(A)に例示した符号「VA1」,「VB1」で示される第1の発話ペアについて得られた発話間隔を示す。
【0101】
このようにして、図9に例示した韻律情報抽出部151は、各発話音声に対応する発話パワー、発話速度、基本周波数および持続時間とともに、各発話ペアに対応する発話間隔を含む韻律情報を抽出することができる。
【0102】
なお、韻律情報抽出部151は、図9の例示に限られず、発話パワー算出部151−pと、発話速度算出部151―vと、基本周波数算出部151−fと、持続時間抽出部151−sと、発話間隔算出部151−dを様々な組み合わせで含んでもよい。例えば、韻律情報抽出部151は、発話間隔算出部151−dと、発話パワー算出部151−p、発話速度算出部151−vおよび基本周波数算出部151−fの少なくとも一つを組み合わせて含んでいることが望ましい。
【0103】
一方、図9に例示したパラ言語情報抽出部152は、感情推定部152−eと、意図推定部152−pと、態度推定部152−aとを含んでいる。感情推定部152−e、意図推定部152−pおよび態度推定部152−aは、それぞれ各人物に対応して音声情報蓄積部111に蓄積された音声情報に基づいて、各発話音声について発話感情、発話意図および発話態度を推定する。
【0104】
感情推定部152−e、意図推定部152−pおよび態度推定部152−aは、音声情報蓄積部111から各発話音声を表す音声情報を切り出す際に、上述した発話配列リスト142に含まれる各発話音声の開始時刻および終了時刻を示す情報を利用してもよい。なお、感情推定部152−e、意図推定部152−pおよび態度推定部152−aが、各発話音声からそれぞれ発話感情、発話意図および発話態度を推定する処理には、公知技術を利用することができる。
【0105】
例えば、感情推定部152−eは、各発話音声に対応する音声情報の基本周波数を含む音声の特徴に基づいて、発話音声に反映された感情が「怒り」、「悲しみ」、「嫌悪」、「驚き」、「喜び」のいずれに分類されるかを推定してもよい。例えば、感情推定部152−eは、上述した各種の感情が反映された標準的な音声の基本周波数を示す基準周波数を用いて、各発話音声にどの種類の感情が反映されているかを推定してもよい。つまり、感情推定部152−eは、各発話音声の基本周波数に最も近い基準周波数に対応する感情の種類が、当該発話音声に反映されていると推定してもよい。また、感情推定部152−eは、発話感情についての正解付きデータを用いた学習によって、上述した5種類の感情を含む発話感情の種別それぞれに対応する基準周波数を含む音声情報の特徴を集積することにより、発話感情の推定精度を向上することもできる。なお、感情推定部152−eは、上述した基本周波数算出部151−fあるいは発話特徴蓄積部153から各発話音声の基本周波数を示す情報を受け取り、この情報を発話感情の推定に利用してもよい。
【0106】
また、意図推定部152−pは、各発話音声に対応する音声情報で表される抑揚を含む特徴に基づいて、発話音声に反映された話者の意図が「勧誘」、「疑問」、「同意」、「断定」のいずれに分類されるかを推定してもよい。また、意図推定部152−pは、発話意図についての正解付きデータを用いた学習によって、上述した4種類の発話意図を含む発話意図の種別それぞれに対応する音声情報の特徴を集積することにより、発話意図の推定精度を向上することもできる。
【0107】
また、態度推定部152−aは、各発話音声に対応する音声情報で表される抑揚を含む特徴に基づいて、発話音声に反映された話者の態度が「丁寧」、「改まった」、「くだけた」、「ぞんざい」のいずれに分類されるかを推定してもよい。また、態度推定部152−aは、発話態度についての正解付きデータを用いた学習によって、上述した4種類の発話態度を含む発話態度の種別それぞれに対応する音声情報の特徴を集積することにより、発話態度の推定精度を向上することもできる。
【0108】
感情推定部152−e、意図推定部152−pおよび態度推定部152−aは、それぞれによる推定処理で得られた推定結果を、推定対象の発話音声を示す識別情報に対応して、発話特徴蓄積部153に蓄積してもよい。
【0109】
このようにして、図9に例示したパラ言語情報抽出部152により、各発話音声に対応して、発話感情、発話意図および発話態度を含むパラ言語情報を抽出し、発話特徴蓄積部153に蓄積することができる。
【0110】
なお、パラ言語情報抽出部152は、図9の例示に限らず、感情推定部152−e、意図推定部152−pおよび態度推定部152−aの少なくとも一つを含んでいれば、どのような組み合わせで含んでいてもよい。
【0111】
次に、上述したようにして抽出された韻律情報およびパラ言語情報に基づいて、各発話ペアについて第1尤度を算出する方法について説明する。
【0112】
図11は、図6に示した第1算出部16の一実施形態を示している。なお、図11に示した構成要素のうち、図1および図9に示した構成要素と同等のものについては、同一の符号を付して示し、その説明は省略する。
【0113】
図11に例示した第1算出部16は、確率演算部161と、パラメータ保持部162と、韻律尤度算出部163とを含んでいる。また、第1算出部16は、上述した3種類のパラ言語情報にそれぞれ対応する3つの確率テーブル165e,165p,165aと、テーブル参照部164と、パラ言語尤度算出部166とを含んでいる。また、第1算出部16は、韻律尤度算出部163によって後述するようにして算出される韻律尤度と、パラ言語尤度算出部166によって後述するようにして算出されるパラ言語尤度とを乗算することにより、第1尤度を算出する乗算部167を有する。
【0114】
図11に例示した確率演算部161は、発話特徴蓄積部153および発話間隔蓄積部154に蓄積された韻律情報に基づいて、韻律的な特徴についての条件ごとに、発話配列リスト142で示される各発話ペアが当該条件を満たしている確率を算出する。確率演算部161は、発話配列リスト142に基づいて、注目する発話音声を含む発話ペアを特定する。そして、確率演算部161は、この発話ペアに含まれる2つの発話音声に対応して発話特徴蓄積部153に蓄積された韻律情報を取得する。このようにして取得した韻律情報に基づいて、確率演算部161は、各条件に対応する確率分布モデルを用いて、韻律的な特徴についての条件それぞれを当該発話ペアが満たしている確率を算出する。
【0115】
図12は、確率分布モデルの一例を示している。図12(A)において、横軸は、発話ペアについて抽出された韻律情報の一つである発話間隔tを示し、縦軸は、確率P(t)を示す。
【0116】
例えば、韻律的な特徴についての条件の一つである発話パワーと発話間隔との相関関係は、次のような確率モデルによって表すことができる。確率モデルは、例えば、ある発話音声に後続する発話音声の発話パワーが大きい場合に、図12(A)に例示したグラフQ1のように、発話間隔tが小さい値τ1において確率Pがピークを持つことが望ましい。同時に、ある発話音声に後続する発話音声の発話パワーが小さい場合に、図12(A)に例示したグラフQ2のように、値τ1よりも大きい値τ2において確率Pがピークを持つ確率モデルが望ましい。
【0117】
このような確率モデルに基づく確率分布は、発話パワーをハイパーパラメータとした正規分布を用いて表すことができる。例えば、注目する会話グループにおけるj番目の発話音声とj+1番目の発話音声とについての発話間隔t(j)が、j+1番目の発話音声が発話パワーs(j+1)を持つ場合に出現する確率P(t(j)|s(j+1))は、式(1)のように表される。
【0118】
【数1】

【0119】
なお、式(1)に示した確率分布において、発話パワーs(j)を反映した正規分布の平均値μ(s(j))について、発話パワーs(j)が正の範囲において平均値μ(s(j))が正の値を持ち、発話パワーs(j)が大きいほど値が小さくなるモデルを用いた。平均値μ(s(j))についてのこのモデルは、パラメータμsとパラメータαsとで示される指数関数を用いて、式(2)のように表される。また、図12(B)は、平均値μ(s(j))についてのモデルの一例を示している。
μ(s(j))=μs・exp(−αs・s(j)) ・・・(2)
上述したパラメータμsおよびパラメータαsの値と正規分布の標準偏差σsの値は、例えば、発話パワーと発話間隔についての正解付き学習データを用いた学習によって、それぞれ適切な値に設定することができる。また、これらのパラメータμs、パラメータαsおよび標準偏差σsの値は、例えば、発話パワーと発話間隔との相関関係についての確率モデルを示す情報として、図11に例示したパラメータ保持部162に保持しておくことができる。
【0120】
そして、確率演算部161は、パラメータ保持部162に上述した確率モデルに対応して保持された各パラメータの値を用いることにより、上述した式(1)に基づいて、注目する発話ペアについて上述した確率P(t(j)|s(j+1))を算出することができる。
【0121】
なお、発話パワーと発話間隔との相関関係についての確率モデルは、上述した確率モデルに限らず、例えば、前側の発話音声の発話パワーあるいは発話ペアの平均の発話パワーと発話間隔との相関関係を示す確率モデルでもよい。
【0122】
同様に、発話音声の発話速度と発話間隔tとの相関関係も、発話速度が速い場合に確率P(t)がピークを持つ発話間隔値が、発話速度が遅い場合に確率P(t)がピークを持つ発話間隔値よりも小さくなる確率モデルで表すことが望ましい。そして、このような確率モデルに基づく確率分布もまた、発話速度をハイパーパラメータとした正規分布を用いて表すことができる。
【0123】
例えば、注目する会話グループにおけるj番目の発話音声とj+1番目の発話音声とについての発話間隔t(j)が、j+1番目の発話音声が発話速度v(j+1)を持つ場合に出現する確率P(t(j)|v(j+1))は、式(3)のように表される。
【0124】
【数2】
【0125】
なお、式(3)において、発話速度v(j)を反映した正規分布の平均値μ(v(j))は、上述した発話パワーと同様のモデルを用いて、式(4)のように、パラメータμvとパラメータαvとで示される指数関数を用いて表すことができる。
μ(v(j))=μv・exp(−αv・v(j)) ・・・(4)
上述したパラメータμvおよびパラメータαvの値と正規分布の標準偏差σvの値は、例えば、発話速度と発話間隔についての正解付き学習データを用いた学習によって、それぞれ適切な値に設定することができる。また、これらのパラメータμv、パラメータαvおよび標準偏差σvの値は、例えば、発話速度と発話間隔との相関関係についての確率モデルを示す情報として、図11に例示したパラメータ保持部162に保持しておくことができる。
【0126】
そして、確率演算部161は、パラメータ保持部162に上述した確率モデルに対応して保持された各パラメータの値を用いることにより、上述した式(3)に基づいて、注目する発話ペアについて上述した確率P(t(j)|v(j+1))を算出することができる。
【0127】
なお、発話速度と発話間隔との相関関係についての確率モデルは、上述した確率モデルに限らず、例えば、前側の発話音声の発話速度あるいは発話ペアの平均の発話速度と発話間隔との相関関係を示す確率モデルでもよい。
【0128】
同様に、発話音声の基本周波数と発話間隔tとの相関関係も、基本周波数が高い場合に確率P(t)がピークを持つ発話間隔値が、基本周波数が低い場合に確率P(t)がピークを持つ発話間隔値よりも小さくなる確率モデルで表すことが望ましい。そして、このような確率モデルに基づく確率分布もまた、基本周波数をハイパーパラメータとした正規分布を用いて表すことができる。
【0129】
例えば、注目する会話グループにおけるj番目の発話音声とj+1番目の発話音声とについての発話間隔t(j)が、j+1番目の発話音声が基本周波数f(j+1)を持つ場合に出現する確率P(t(j)|f(j+1))は、式(5)のように表される。
【0130】
【数3】
【0131】
なお、式(5)において、基本周波数f(j)を反映した正規分布の平均値μ(f(j))は、上述した発話パワーと同様のモデルを用いて、式(6)のように、パラメータμfとパラメータαfとで示される指数関数を用いて表すことができる。
μ(f(j))=μf・exp(−αf・f(j)) ・・・(6)
上述したパラメータμfおよびパラメータαfの値と正規分布の標準偏差σfの値は、例えば、基本周波数と発話間隔についての正解付き学習データを用いた学習によって、それぞれ適切な値に設定することができる。また、これらのパラメータμf、パラメータαfおよび標準偏差σfの値は、例えば、基本周波数と発話間隔との相関関係についての確率モデルを示す情報として、図11に例示したパラメータ保持部162に保持しておくことができる。
【0132】
そして、確率演算部161は、パラメータ保持部162に上述した確率モデルに対応して保持された各パラメータの値を用いることにより、上述した式(5)に基づいて、注目する発話ペアについて上述した確率P(t(j)|f(j+1))を算出することができる。
【0133】
なお、基本周波数と発話間隔との相関関係についての確率モデルは、上述した確率モデルに限らず、例えば、前側の発話音声の基本周波数あるいは発話ペアの平均の基本周波数と発話間隔との相関関係を示す確率モデルでもよい。
【0134】
一方、連続する発話音声それぞれの持続時間の組み合わせについても、自然な会話において頻繁に現れる尤もらしい組み合わせと、自然な会話においてほとんど現れない尤もらしくない組み合わせがある。したがって、この持続時間の組み合わせもまた、韻律的な特徴についての条件の一つとして、各発話ペアが会話の一部として出現する確率の算出に利用することができる。
【0135】
発話音声の持続時間についての確率モデルは、持続時間が短い発話音声同士の組み合わせと、持続時間が長い発話音声と持続時間が短い発話音声との組み合わせについて、持続時間が長い発話音声同士の組み合わせに比べて高い確率を与えることが望ましい。
【0136】
このような確率モデルに基づく確率分布は、シグモイド関数などを用いて表すことができる。例えば、注目する会話グループにおけるj番目の発話音声とj+1番目の発話音声に対応する持続時間として、持続時間d(j)と持続時間d(j+1)の組み合わせが出現する確率P(d(j)|d(j+1))は、式(7)のように表される。なお、式(7)において、パラメータβは、確率分布の滑らかさを示し、パラメータγは、持続時間の長短を判別する基準を示す。また、係数Cは、正規化係数である。
【0137】
【数4】
【0138】
上述したパラメータβおよびパラメータγの値は、例えば、発話音声の持続時間の組み合わせについての正解付き学習データを用いた学習によって、それぞれ適切な値に設定することができる。また、これらのパラメータβおよびパラメータγの値は、例えば、発話音声の持続時間の組み合わせについての確率モデルを示す情報として、図11に例示したパラメータ保持部162に保持しておくことができる。
【0139】
そして、確率演算部161は、パラメータ保持部162に保持されたこれらのパラメータβおよびパラメータγの値を用いることにより、上述した式(7)により、注目する発話ペアについて上述した確率P(d(j)|d(j+1))を算出することができる。
【0140】
上述したようにして、図11に例示した確率演算部161は、韻律的な特徴についての条件それぞれに基づいて、各発話ペアが会話の一部として出現する確率をそれぞれ求めることができる。
【0141】
図11に例示した韻律尤度算出部163は、確率演算部161によって算出された韻律的な特徴についての条件それぞれに基づく確率から、各発話ペアの韻律的な特徴が、会話に含まれる発話音声の特徴に合致している度合いを示す韻律尤度を算出する。
【0142】
韻律尤度算出部163は、例えば、上述した式(1)、(3)、(5)、(7)を用いてそれぞれ算出される確率に、個別の重みを乗じた上で相乗平均を算出することにより、韻律尤度を求めてもよい。このようにして、韻律的な特徴についての各条件に基づいて、確率演算部161によって算出された確率P(t(j)|s(j+1))、確率P(t(j)|v(j+1))、確率P(t(j)|f(j+1))および確率P(d(j)|d(j+1))を反映した韻律尤度を求めることができる。
【0143】
なお、図11に例示した確率演算部161は、発話特徴蓄積部153に蓄積された韻律情報の種類に応じて、上述した4つの条件を含む韻律的な特徴についての条件の少なくとも一つに基づいて、各発話ペアが会話の一部として出現する確率を算出すればよい。また、図11に例示した韻律尤度算出部163は、確率算出部161が各発話ペアについて算出した少なくとも一つの条件に基づく確率を、重みつきで相乗平均することにより、韻律尤度を算出すればよい。また、発話特徴蓄積部153に蓄積された韻律情報の種類が1種類である場合は、この韻律情報に基づいて確率演算部161で得られた確率がそのまま韻律尤度となるので、韻律尤度算出部163を省略してもよい。
【0144】
次に、各発話ペアについて抽出されたパラ言語的な特徴が、会話に含まれる発話音声の特徴に合致している度合いを示すパラ言語尤度を算出する方法について説明する。
【0145】
図11に例示した3つの確率テーブル165e,165p,165aは、発話ペアに含まれる各発話音声について得られるパラ言語情報に含まれる発話感情、発話意図および発話態度の組み合わせについての条件付確率分布を示す情報を保持している。
【0146】
図13は、3つの確率テーブル165e,165p,165aそれぞれの一例を示している。
【0147】
図13(A)は、5種類の発話感情「怒り」、「悲しみ」、「嫌悪」、「驚き」および「喜び」の組み合わせが、発話ペアに含まれる2つの発話音声に対応するパラ言語情報として抽出される条件付確率分布を示している。
【0148】
図13(A)に例示した確率テーブル165eにおいて、注目する会話グループにおけるj番目の発話音声の発話感情を列方向に示し、j+1番目の発話音声の発話感情を行方向に示した。また、j番目の発話音声の発話感情とj+1番目の発話音声の発話感情との組み合わせについての条件付確率を、符号「P」に2つの発話音声に対応する発話感情をそれぞれ示す符号を組み合わせた添え字をつけて示した。なお、図13(A)に例示した確率テーブル165eにおいて、発話感情「怒り」、「悲しみ」、「嫌悪」、「驚き」および「喜び」を示す符号として、それぞれ符号「a」、「s」、「h」、「w」および「j」を用いた。
【0149】
確率テーブル165eに含まれる各組み合わせについての条件付確率は、例えば、発話感情の組み合わせについての正解付き学習データを用いた学習によって、それぞれ適切な値に設定することができる。なお、正解付き学習データとして、例えば、音声認識技術を用いることによって音声情報から文字で表現される情報を抽出した結果を用いて発話感情を推定した結果を用いてもよい。このような学習データを用いた学習を行うことにより、各組み合わせについての条件付確率の値を高い精度で決定することができる。
【0150】
図13(B)は、4種類の発話意図「勧誘」、「疑問」、「同意」および「断定」の組み合わせが、発話ペアに含まれる2つの発話音声に対応するパラ言語情報として抽出される条件付確率分布を示している。
【0151】
図13(B)に例示した確率テーブル165pにおいて、注目する会話グループにおけるj番目の発話音声の発話意図を列方向に示し、j+1番目の発話音声の発話意図を行方向に示した。また、j番目の発話音声の発話意図とj+1番目の発話音声の発話意図との組み合わせについての条件付確率を、符号「P」に2つの発話音声に対応する発話意図をそれぞれ示す符号を組み合わせた添え字をつけて示した。なお、図13(B)に例示した確率テーブル165pにおいて、発話意図「勧誘」、「疑問」、「同意」および「断定」を示す符号として、それぞれ符号「i」、「q」、「c」、および「d」を用いた。
【0152】
確率テーブル165pに含まれる各組み合わせについての条件付確率は、例えば、発話意図の組み合わせについての正解付き学習データを用いた学習によって、それぞれ適切な値に設定することができる。なお、正解付き学習データとして、例えば、音声認識技術を用いることによって音声情報から文字で表現される情報を抽出した結果を用いて発話意図を推定した結果を用いてもよい。このような学習データを用いた学習を行うことにより、各組み合わせについての条件付確率の値を高い精度で決定することができる。
【0153】
図13(C)は、4種類の発話態度「丁寧」、「改まった」、「くだけた」および「ぞんざい」の組み合わせが、発話ペアに含まれる2つの発話音声に対応するパラ言語情報として抽出される条件付確率分布を示している。
【0154】
図13(C)に例示した確率テーブル165aにおいて、注目する会話グループにおけるj番目の発話音声の発話態度を列方向に示し、j+1番目の発話音声の発話態度を行方向に示した。また、j番目の発話音声の発話態度とj+1番目の発話音声の発話態度との組み合わせについての条件付確率を、符号「P」に2つの発話音声に対応する発話態度をそれぞれ示す符号を組み合わせた添え字をつけて示した。なお、図13(C)に例示した確率テーブル165aにおいて、発話態度「丁寧」、「改まった」、「くだけた」および「ぞんざい」を示す符号として、それぞれ符号「p」、「f」、「u」、および「r」を用いた。
【0155】
確率テーブル165aに含まれる各組み合わせについての条件付確率は、例えば、発話態度の組み合わせについての正解付き学習データを用いた学習によって、それぞれ適切な値に設定することができる。なお、正解付き学習データとして、例えば、音声認識技術を用いることによって音声情報から文字で表現される情報を抽出した結果を用いて発話態度を推定した結果を用いてもよい。このような学習データを用いた学習を行うことにより、各組み合わせについての条件付確率の値を高い精度で決定することができる。
【0156】
図11に例示したテーブル参照部164は、上述した確率テーブル165e,165p,165aを参照することにより、発話配列リスト142で示される各発話ペアに対応するパラ言語情報の組み合わせが会話において出現する確率を取得する。
【0157】
テーブル参照部164は、例えば、まず、発話特徴蓄積部153から、各発話ペアに含まれる二つの発話音声に対応してそれぞれ蓄積されたパラ言語情報を取得する。そして、テーブル参照部164は、取得したパラ言語情報に含まれる発話感情、発話意図および発話態度の組み合わせに対応して確率テーブル165e,165p,165aにそれぞれ保持された確率を読み出せばよい。このようにして、テーブル参照部164は、各発話ペアに含まれる二つの発話音声からそれぞれ抽出された発話感情、発話意図および発話態度の組み合わせが会話において出現する確率をそれぞれ得ることができる。
【0158】
例えば、発話ペアの一方の発話音声から発話感情「喜び」を含むパラ言語情報が抽出され、他方の発話音声から発話感情「驚き」を含むパラ言語情報が抽出された場合に、上述したテーブル参照部164は、確率テーブル165eから確率Pjwを取得する。
【0159】
また、発話ペアの一方の発話音声から発話意図「同意」を含むパラ言語情報が抽出され、他方の発話音声から発話意図「疑問」を含むパラ言語情報が抽出された場合に、上述したテーブル参照部164は、確率テーブル165pから確率Pcqを取得する。
【0160】
同様に、発話ペアの一方の発話音声から発話態度「丁寧」を含むパラ言語情報が抽出され、他方の発話音声から発話態度「くだけた」を含むパラ言語情報が抽出された場合に、上述したテーブル参照部164は、確率テーブル165aから確率Ppuを取得する。
【0161】
図11に例示したパラ言語尤度算出部166は、テーブル参照部164で得られた発話感情、発話意図、発話態度についての確率に基づいて、各発話ペアのパラ言語的な特徴が、会話に含まれる発話音声の特徴に合致している度合いを示すパラ言語尤度を算出する。
【0162】
パラ言語尤度算出部166は、例えば、上述したテーブル参照部164が確率テーブル165e,165p,165aから取得した確率に、個別の重みを乗じた上で相乗平均を算出することにより、パラ言語尤度を求めてもよい。このようにして、発話感情、発話意図および発話態度の組み合わせについてのパラ言語的な特徴についての各条件が反映された確率テーブル165e,165p,165aから取得した各確率を反映したパラ言語尤度を求めることができる。
【0163】
なお、図11に例示したテーブル参照部164は、発話特徴蓄積部153に蓄積されたパラ言語情報の種類に応じて、パラ言語的な特徴についての条件の少なくとも一つに基づいて、各発話ペアが会話の一部として出現する確率を算出すればよい。また、図11に例示したパラ言語尤度算出部166は、テーブル参照部164が各発話ペアについて取得した少なくとも一つの条件に基づく確率を、重みつきで相乗平均することにより、パラ言語尤度を算出すればよい。また、発話特徴蓄積部153に蓄積されたパラ言語情報の種類が1種類である場合は、このパラ言語情報に基づいてテーブル参照部164で得られた確率がそのままパラ言語尤度となるので、パラ言語尤度算出部166を省略してもよい。
【0164】
図11に例示した第1算出部16は、このようにして求められた韻律尤度とパラ言語尤度とを、乗算部167が乗算することにより、各発話ペアが会話の一部であることの尤もらしさを示す第1尤度を求める。
【0165】
このようにして得られた第1尤度L1は、韻律尤度Lrとパラ言語尤度Lpとを用いて、式(9)のように表すことができる。
L1=Lr・Lp ・・・(9)
この第1尤度L1は、各発話ペアが会話の一部であることの尤もらしさを、当該発話ペアに含まれる二つの発話音声の韻律的な特徴とパラ言語的な特徴との双方に注目して評価した結果を示している。つまり、各発話ペアについて得られた第1尤度L1は、当該発話ペアに含まれる2つの発話音声が、韻律的につながっている可能性が高く、しかも、パラ言語的にもつながっている可能性が高い場合にのみ、高い値を示す。
【0166】
したがって、上述したようにして、韻律尤度とパラ言語尤度とを反映した第1尤度L1を算出することにより、より、高い確度で、各発話ペアが会話の一部であることの尤もらしさを評価することができる。
【0167】
そして、各組み合わせ候補に含まれる会話グループにおける発話順に並べられた発話音声をそれぞれ含む発話ペアについて、上述したようにして得られた第1尤度L1に基づいて、図6に例示した第2算出部17は次のようにして第2尤度を算出する。
【0168】
第2算出部17は、例えば、発話配列リスト142において、各会話グループに対応して配列されたM個の発話音声それぞれを含む発話ペアに対応する第1尤度L1の相乗平均として、第2尤度L2を算出してもよい。例えば、図8に例示した発話配列リスト142で示された組み合わせ候補1の会話グループ1に対応する第2尤度は、この会話グループ1に対応して配列された4つの発話音声から特定される3つの発話ペアのそれぞれの第1尤度を相乗平均した値である。発話順に並べられたM個の発話音声のうち、j番目の発話音声を含む発話ペアについて得られた第1尤度L1(j)を用いれば、第2算出部17によって算出される第2尤度L2は、式(10)のように表すことができる。
【0169】
【数5】
【0170】
このようにして、第2算出部17によって各組み合わせ候補に含まれる会話グループごとに算出された第2尤度L2は、当該会話グループに属する人物による発話音声の全てが会話を形成している可能性の高さを示している。
【0171】
したがって、図6に例示した第3算出部18は、絞込み部137で得られた各組み合わせ候補に含まれる会話グループごとに第2算出部17で得られた第2尤度L2を相乗平均することにより、当該組み合わせ候補についての第3尤度L3を算出することができる。
【0172】
注目する組み合わせ候補に含まれるN個の会話グループのうち、k番目の会話グループについて得られた第2尤度L2(k)を用いれば、第3算出部18によって当該組み合わせ候補について求められる第3尤度L3は、式(11)のように表すことができる。
【0173】
【数6】
【0174】
このようにして第3算出部18によって各組み合わせ候補について算出された第3尤度L3は、各組み合わせ候補が、図1に例示した複数の人物C1〜Cnが形成している複数の会話グループの組み合わせを反映している確率を示している。したがって、第3算出部18によって得られた第3尤度L3の高さに基づいて、複数の人物C1〜Cnが形成している複数の会話グループの組み合わせを特定することができる。
【0175】
上述したように、図11に例示した第1算出部16を有する音声情報解析装置10によれば、確度の高い第1尤度L1に基づいて、個々の会話グループについての第2尤度L2および各組み合わせ候補についての第3尤度L3を求めることができる。これにより、第3尤度L3に基づいて特定した会話グループの組み合わせが正しい組み合わせである確率を高めることができる。
【0176】
また、以上に説明した本件開示の音声情報解析装置10は、音声情報に含まれる音韻情報に基づく意味解析技術を用いることなく、複数の人物が形成している会話グループを特定することができる。したがって、本件開示の音声情報解析装置10の実現には、多数の人物の音声に対して意味解析技術を適用する場合に必要とされるような膨大な処理能力を必要としない。また、意味解析技術を用いないことにより、本件開示の音声情報解析装置10は、会話グループを特定する対象となる多数の人物の発言内容に含まれるプライヴァシーの保護にも配慮することができる。
【0177】
本件開示の音声情報解析装置10は、例えば、パーソナルコンピュータなどのコンピュータ装置を用いて実現することができる。
図14は、音声情報解析装置のハードウェア構成例を示している。
【0178】
図14に例示したコンピュータ装置20は、プロセッサ21と、メモリ22と、ハードディスク装置23と、表示装置24と、入力装置25と、光学ドライブ装置26と、ネットワークインタフェース28とを含んでいる。図14に例示したプロセッサ21と、メモリ22と、ハードディスク装置23と、表示装置24と、入力装置25と、光学ドライブ装置26と、ネットワークインタフェース28とは、バスを介して互いに接続されている。図14に例示した光学ドライブ装置26は、光ディスクなどのリムーバブルディスク27を装着可能であり、装着したリムーバブルディスク27に記録された情報の読出および記録を行う。また、図14に例示した音声情報解析装置10は、プロセッサ21と、メモリ22と、ハードディスク装置23と、表示装置24と、ネットワークインタフェース28とを含んでいる。
【0179】
図14に例示した入力装置25は、例えば、キーボードやマウスなどである。音声情報解析装置10の操作者は、入力装置25を操作することにより、音声情報解析装置10に含まれる各部に対して、例えば、会話グループを特定する処理を開始させる指示などを入力することができる。
【0180】
また、図14に例示したネットワークインタフェース28は、それぞれ異なる位置に設置されたm個の中継装置S1〜Smに接続されている。
【0181】
メモリ22は、コンピュータ装置20のオペレーティングシステムとともに、プロセッサ21が上述した音声情報解析処理を実行するためのアプリケーションプログラムを格納している。なお、上述した音声情報解析処理を実行するためのアプリケーションプログラムは、例えば、光ディスクなどのリムーバブルディスク27に記録して頒布することができる。そして、このリムーバブルディスク27を光学ドライブ装置26に装着して読み込み処理を行うことにより、音声情報解析処理を実行するためのアプリケーションプログラムを、メモリ22およびハードディスク装置23に格納させてもよい。また、ネットワークインタフェース28を介してインターネットなどのネットワークに接続することで、ネットワーク経由で、音声情報解析処理のためのアプリケーションプログラムをメモリ22およびハードディスク装置23に読み込ませることもできる。
【0182】
また、図14に例示したハードディスク装置23は、音声情報解析処理のためのアプリケーションプログラムに含まれる各種のデータを格納する。例えば、ハードディスク装置23は、音声情報から発話感情、発話意図および発話態度を推定するために利用する基準を示す情報を格納してもよい。また、ハードディスク装置23が、上述した式(1)、(3)、(5)、(7)に含まれる各パラメータを保持することにより、図11に例示したパラメータ保持部162の機能を実現してもよい。更に、ハードディスク装置23が、各種のパラ言語情報の組み合わせについての条件付確率分布を示す情報を保持することにより、図11に例示した確率テーブル165e、165p、165aを実現してもよい。
【0183】
また、プロセッサ21は、メモリ22に格納されたアプリケーションプログラムを実行することにより、図1に例示した取得部11、収集部12、生成部13、配列部14の機能を果たしてもよい。また、プロセッサ21は、メモリ22に格納されたアプリケーションプログラムを実行することにより、図1に例示した抽出部15、第1算出部16、第2算出部17および第3算出部18の機能を果たしてもよい。
【0184】
図15は、音声情報解析処理のフローチャートの一例を示している。図15に示したステップS1〜ステップS6の各処理は、上述した音声情報解析処理のためのアプリケーションプログラムに含まれる処理の一例である。また、これらのステップS1〜ステップS6の各処理は、図14に例示したプロセッサ21によって実行される。
【0185】
プロセッサ21は、図14に例示したネットワークインタフェース28と、中継装置S1〜Smおよび携帯端末T1〜Tnを介して、これらの携帯端末T1〜Tnを所持する各人物の発話音声を示す音声情報を取得する(ステップS1)。
【0186】
また、プロセッサ21は、図14に例示したネットワークインタフェース28を介して、中継装置S1〜Smから、それぞれが無線アクセスを提供している携帯端末を示す情報を、携帯端末T1〜Tnの所持者の位置を示す位置情報として収集する(ステップS2)。
【0187】
次いで、プロセッサ21は、ステップS1およびステップS2で得られた音声情報および位置情報を、例えば、ハードディスク装置23に設けた音声情報蓄積部111および位置情報蓄積部121にそれぞれ蓄積する(ステップS3)。
【0188】
このように、プロセッサ21が、ステップS1〜ステップS3の処理を実行することにより、図6に例示した音声情報蓄積部111と位置情報蓄積部121とをそれぞれ含む取得部11および収集部12の機能を実現することができる。
【0189】
次いで、プロセッサ12は、図14に例示した入力装置25を介して、会話グループを特定する処理を開始する旨の指示が入力されたか否かを判定する(ステップS4)。
【0190】
例えば、会話グループを特定する処理の開始を指示するメッセージが、入力装置25を介してプロセッサ21に渡されたときに、プロセッサ21は、ステップS4の肯定判定ルートに進む。そして、上述したメッセージを受け取った時刻tから後述する会話グループを特定する処理を実行することにより、会話グループを特定する(ステップS5)。その後、プロセッサ21は、ステップS6の処理に進む。
【0191】
一方、会話グループを特定する処理の開始を指示するメッセージが入力装置25から渡されなかった場合に、プロセッサ21は、ステップS4の否定判定ルートに進む。ステップS4の否定判定ルートにおいて、プロセッサ21は、音声情報解析処理を継続するか否かを判定する(ステップS6)。
【0192】
例えば、入力装置25を介して、音声情報解析処理の終了が指示された場合に、プロセッサ21は、ステップS6の否定判定ルートに従って、音声情報解析処理を終了する。一方、音声情報解析処理の終了が指示されていない場合に、プロセッサ21は、ステップS6の肯定判定ルートに従って、ステップS1の処理に戻り、音声情報解析処理を続行する。
【0193】
次に、音声情報解析処理に含まれる会話グループを特定する処理を、図14に例示した音声情報解析装置10によって実現する方法について説明する。
【0194】
図16は、会話グループを特定する処理のフローチャートの一例を示している。図16に示したステップS301〜ステップS310の各処理は、上述した音声情報解析処理のフローチャートに例示したステップS5の処理の一例である。また、これらのステップS301〜ステップS310の各処理は、図14に例示したプロセッサ21によって実行される。
【0195】
プロセッサ21は、会話グループを特定する処理を、会話グループを特定する処理を開始する旨のメッセージを受け取った時刻tから時間Tを遡った時刻t−Tを開始時刻とする期間Tdに対応して蓄積された音声情報および位置情報に基づいて実行する。
【0196】
まず、プロセッサ21は、上述した期間Tdに含まれる各サンプリング時刻に対応して音声情報蓄積部111に蓄積された音声信号の強度に基づいて、当該サンプリング時刻において各人物が発話中であるか否かを判定する(ステップS301)。そして、プロセッサ21は、ステップS301の処理で得られた判定結果を、例えば、ハードディスク装置23に設けた発話リスト132に集積する(ステップS302)。このように、プロセッサ21が、ステップS301,S302の処理を実行することにより、図6に例示した発話判定部131の機能を実現してもよい。
【0197】
また、プロセッサ21は、上述した期間Tdに含まれる各サンプリング時刻に対応して位置情報蓄積部121に蓄積された位置情報に基づいて、当該サンプリング時刻において各人物に近接する中継装置Sxを特定する(ステップS303)。なお、中継装置Sxは、図14に例示した中継装置S1〜Smのいずれかである。そして、プロセッサ21は、ステップS303の処理で得られた結果に基づいて、各中継装置S1〜Smに近接する人物の集合を、例えば、ハードディスク装置23に設けた近接人物リスト134に集積する(ステップS304)。このように、プロセッサ21が、ステップS303,S304の処理を実行することにより、図6に例示した位置分類部133の機能を実現してもよい。
【0198】
次いで、プロセッサ21は、上述したステップS301の処理において、期間Tdにおける発話が検出された人物を、近接人物リスト134に基づいて、近接している中継装置Sxごとにグループ分けする(ステップS305)。そして、プロセッサ21は、各中継装置S1〜Smに対応する各グループに属する人物が形成している可能性のある会話グループについての組み合わせを列挙する(ステップS306)。このように、プロセッサ21が、ステップS305,S306の処理を実行することにより、図6に例示した組み合わせ列挙部135の機能を実現してもよい。
【0199】
次に、プロセッサ21は、上述した発話リスト132に含まれる情報に基づいて、発話期間が重複している人物の組み合わせを検出する(ステップS307)。プロセッサ21は、例えば、発話リスト132に含まれる人物のペアごとに、上述した期間Tdにおいて同一の時刻に対応して発話中である旨の判定結果が保持されている回数を計数した結果に基づいて、発話重複率を算出してもよい。このようにして得られた発話重複率が上述した所定の閾値を超える組み合わせを、プロセッサ21は、発話期間が重複している人物の組み合わせとして検出してもよい。そして、プロセッサ21は、ステップS306の処理で列挙した会話グループの組み合わせから、ステップS307の処理で検出した人物の組み合わせを含む会話グループが属する組み合わせを排除することにより、組み合わせ候補を絞り込む(ステップS308)。このように、プロセッサ21が、ステップS307,S308の処理を実行することにより、図6に例示した重複率算出部136および絞込み部137の機能を実現してもよい。
【0200】
このようにして得られた会話グループの組み合わせ候補について、プロセッサ21は、後述するようにして、図14に例示した携帯端末T1〜Tnを所持する人物が形成している会話グループの組み合わせとしての尤もらしさを評価する(ステップS309)。
【0201】
そして、ステップS309の処理による評価結果に基づいて、プロセッサ21は、最尤の組み合わせ候補を、図14に例示した携帯端末T1〜Tnを所持する人物が形成している会話グループの組み合わせとして特定する。
【0202】
次に、会話グループを特定する処理に含まれる各組み合わせ候補の尤もらしさを評価する処理を、図14に例示した音声情報解析装置10によって実現する方法について説明する。
【0203】
図17は、各組み合わせ候補の尤もらしさを評価する処理のフローチャートの一例を示している。図17に示したステップS311〜ステップS325の各処理は、上述した会話グループを特定する処理のフローチャートに例示したステップS309の処理の一例である。また、これらのステップS311〜ステップS325の各処理は、図14に例示したプロセッサ21によって実行される。
【0204】
まず、プロセッサ21は、評価対象の組み合わせ候補の中で注目する組み合わせ候補を示す組み合わせ候補番号kに初期値1を設定する(ステップS311)。なお、以下の説明において、組み合わせ候補番号kで示される組み合わせ候補を組み合わせ候補kと称する。
【0205】
次いで、プロセッサ21は、評価対象の組み合わせ候補に含まれる会話グループの中で注目する会話グループを示す会話グループ番号iに初期値1を設定する(ステップS312)。なお、以下の説明において、会話グループ番号iで示される会話グループを会話グループiと称する。
【0206】
次に、プロセッサ21は、組み合わせ候補kに含まれる会話グループiに属する各人物による発話音声を時系列に従ってソートする(ステップS313)。例えば、プロセッサ21は、発話リスト132に基づいて、各人物による個々の発話音声の開始時刻を特定し、特定した開始時刻が早い順に各発話音声を並べることによって、上述したソート処理を実行してもよい。
【0207】
次いで、プロセッサ21は、会話グループiについてソートされた発話音声の中で注目する発話音声を示す発話番号jに初期値1を設定する(ステップS314)。なお、以下の説明において、発話番号jの発話音声を発話音声M(j)で示す。
【0208】
次に、プロセッサ21は、音声情報蓄積部111から、発話音声M(j)に対応する特徴情報を抽出する(ステップS315)。ステップS315の処理において、プロセッサ21は、例えば、発話音声M(j)に対応する音声情報に基づいて、発話パワー、発話速度、基本周波数および持続時間を含む韻律情報を、発話音声M(j)に対応する特徴情報の一部として抽出してもよい。また、プロセッサ21は、ステップS315の処理において、発話感情、発話意図および発話態度を含むパラ言語情報を、発話音声M(j)に対応する特徴情報の一部として抽出してもよい。更に、発話番号jが値2以上である場合に、プロセッサ21は、ステップS315の処理において、発話音声M(j)の開始時刻と発話音声M(j−1)の終了時刻との差で示される発話間隔を、発話音声M(j)に対応する特徴情報の一部として抽出してもよい。このようなステップS315の処理をプロセッサ21が実行することは、図1に例示した抽出部15を実現する手法の一例である。
【0209】
なお、プロセッサ21は、ステップS315の処理において抽出した特徴情報を、他の組み合わせ候補に含まれる会話グループについての処理において利用できるように、メモリ22あるいはハードディスク装置23内に保持しておいてもよい。例えば、プロセッサ21は、組み合わせ候補1についての処理の過程で、ハードディスク装置23に設けた発話特徴蓄積部153に、個々の発話音声を識別する識別情報に対応して、個々の発話音声に対応する音声情報から抽出した特徴情報を蓄積してもよい。そして、候補番号2以降の組み合わせ候補kについての処理では、ステップS313の処理において、プロセッサ21が、発話音声の識別情報と、組み合わせ候補kの会話グループiにおける発話番号jとを対応付ければよい。これにより、プロセッサ21は、ステップS315の処理において、改めて音声情報から韻律情報およびパラ言語情報を抽出する代わりに、発話特徴蓄積部153に蓄積された抽出済みの特徴情報を利用することができる。
【0210】
次いで、プロセッサ21は、発話番号jが初期値1であるか否かを判定する(ステップS316)。発話番号jが値2以上である場合に(ステップS316の否定判定)、プロセッサ21は、ステップS317において、発話音声M(j)と発話音声M(j−1)とを含む発話ペアについて、この発話ペアが会話の一部である可能性の高さを示す第1尤度を算出する。
【0211】
ステップS317において、プロセッサ21は、次のようにして、発話音声M(j)を含む発話ペアについての第1尤度L1(j)を求める。まず、プロセッサ21は、ステップS315の処理で抽出した特徴情報に含まれる韻律情報と、上述した式(1)、(3)、(5)、(7)および式(8)とを用いて、この発話ペアの韻律尤度Lrを算出する。また、プロセッサ21は、ステップS315の処理で抽出した特徴情報に含まれるパラ言語情報と、上述した確率テーブル165e,165p,165aおよび式(9)とを用いて、この発話ペアのパラ言語尤度Lpを算出する。そして、プロセッサ21は、このようにして得られた韻律尤度Lrとパラ言語尤度Lpとを乗算することにより、この発話ペアについての第1尤度L1(j)を算出する。このように、プロセッサ21が、ステップS317の処理を実行することにより、図11に例示した第1算出部16の機能を実現することができる。
【0212】
ステップS316の肯定判定ルートにおいて、プロセッサ21は、上述したステップS317の処理の終了後に、ステップS318の処理に進む。一方、ステップS316の肯定判定の場合に、プロセッサ21は、ステップS317の処理をスキップして、ステップS318の処理に進む。
【0213】
ステップS318において、プロセッサ21は、ステップS313で並べられた全ての発話音声についての処理が終了したか否かを判定する。未処理の発話音声がある場合に、プロセッサ21は、ステップS318の否定判定ルートに従って処理を進め、ステップS319において、発話番号jに値1を加算してから、ステップS315の処理に戻る。そして、プロセッサ21は、新たな発話音声M(j)についての処理を開始する。
【0214】
このようにして、ステップS315〜ステップS319の処理を繰り返し実行することにより、プロセッサ21は、ステップS313で並べられた各発話音声M(j)を含む発話ペアについて第1尤度L1(j)を算出する。そして、ステップS313で並べられた全ての発話音声についての処理が終了したときに、プロセッサ21は、ステップS318の肯定判定ルートに従って、ステップS320の処理に進む。
【0215】
ステップS320において、プロセッサ21は、上述した式(10)を用いて、各発話音声M(j)を含む発話ペアについて算出した第1尤度L1(j)から、組み合わせ候補kに含まれる会話グループiについての第2尤度L2(i)を算出する。このように、プロセッサ21が、ステップS320の処理を実行することにより、図1に例示した第2算出部17の機能を実現することができる。
【0216】
その後、プロセッサ21は、組み合わせ候補kに含まれる全ての会話グループについての処理が終了したか否かを判定する(ステップS321)。未処理の会話グループがある場合に、プロセッサ21は、ステップS321の否定判定ルートに従って処理を進め、ステップS322において、グループ番号iに値1を加算してから、ステップS314の処理に戻る。そして、プロセッサ21は、新たな会話グループiについての処理を開始する。
【0217】
このようにして、ステップS314〜ステップS322の処理を繰り返し実行することにより、プロセッサ21は、組み合わせ候補kに含まれる各会話グループiについて第2尤度L2(i)を算出する。そして、組み合わせ候補kに含まれる全ての会話グループについての処理が終了したときに、プロセッサ21は、ステップS321の肯定判定ルートに従って、ステップS323の処理に進む。
【0218】
ステップS323において、プロセッサ21は、上述した式(11)に示したように、各会話グループについて算出した第2尤度L2(i)を相乗平均することにより、組み合わせ候補kについての第3尤度L3(k)を算出する。このように、プロセッサ21が、ステップS323の処理を実行することにより、図1に例示した第3算出部18の機能を実現することができる。
【0219】
その後、プロセッサ21は、全ての組み合わせ候補についての処理が終了したか否かを判定する(ステップS324)。未処理の組み合わせ候補がある場合に、プロセッサ21は、ステップS324の否定判定ルートに従って処理を進め、ステップS325において、候補番号kに値1を加算してから、ステップS312の処理に戻る。そして、プロセッサ21は、組み合わせ候補kについての処理を開始する。
【0220】
このようにして、ステップS312〜ステップS325の処理を繰り返し実行することにより、プロセッサ21は、各組み合わせ候補について第3尤度L3(k)を算出する。そして、全ての組み合わせ候補についての処理が終了したときに、プロセッサ21は、ステップS324の肯定判定ルートに従って、各組み合わせ候補の尤もらしさを評価する処理を終了する。
【0221】
このように、図14に例示したコンピュータ装置20のプロセッサ21が、音声情報処理のためのアプリケーションプログラムを実行することによって、本件開示の音声情報解析装置10を実現することができる。
【0222】
以上に説明したように、本件開示の音声情報解析装置10は、会話グループの特定処理の対象となる複数の人物が所持している携帯端末などの汎用の情報機器を介して収集可能な音声情報と概略の位置情報とに基づいて会話グループの特定が可能である。このため、本件開示の音声情報解析装置10は、会話グループの特定処理の対象となる複数の人物それぞれについて厳密な位置情報を取得するための専用の情報端末などを必要としない。したがって、音声情報を収集する側の負担および会話グループの特定処理の対象となる複数の人物側の負担を、ともに軽減することができる。
【0223】
以上の説明に関して、更に、以下の各項を開示する。
(付記1) 複数の人物それぞれが発話した音声を表す音声情報を取得する取得部と、
前記複数の人物それぞれの位置を示す位置情報を収集する収集部と、
前記各人物の音声情報と前記各人物の位置情報とに基づいて、会話をしている可能性がある複数の人物を含む複数の会話グループを求め、求めた会話グループの組み合わせから会話をしている可能性の高い会話グループの組み合わせを組み合わせ候補として生成する生成部と、
前記組み合わせ候補に含まれる各会話グループに属する前記複数の人物による複数の発話音声を時系列に従って配列する配列部と、
前記前記配列部によって会話グループごとに配列された前記複数の発話音声において連続する2つの発話音声として特定される発話ペアごとに、前記発話ペアに対応する音声情報から、韻律的な特徴を示す韻律情報とパラ言語的な特徴に対応するパラ言語情報との少なくとも一方を含む特徴情報を抽出する抽出部と、
前記特徴情報と、前記発話ペアが会話の一部である場合に当該特徴情報が従う確率分布とに基づいて、前記各発話ペアが会話の一部であることの尤もらしさを示す第1尤度を算出する第1算出部と、
前記第1算出部で前記各発話ペアについて得られた前記第1尤度に基づいて、前記配列部によって会話グループごとに配列された前記複数の発話音声の全てが、当該会話グループに属する各人物による会話に含まれている確率を示す第2尤度を算出する第2算出部と
前記各組み合わせ候補に含まれる各会話グループについて算出した前記第2尤度に基づいて、当該組み合わせ候補が、前記複数の人物が形成している複数の会話グループの組み合わせを反映している確率を示す第3尤度を算出する第3算出部と
を備えたことを特徴とする音声解析装置。
(付記2) 付記1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話ペアに属する発話音声のパワーを示す発話パワーと2つの発話相互の時間間隔を示す発話間隔とを含む韻律情報を抽出し、
前記第1算出部は、
前記発話パワーが大きいほど、小さい前記発話間隔の確率が高くなる特性を有する確率分布に基づいて、前記韻律情報に含まれる前記発話パワーを持つ発話音声が前記発話間隔で出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
(付記3) 付記1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話ペアに属する発話音声における発話速度と2つの発話音声相互の時間間隔を示す発話間隔とを含む韻律情報を抽出し、
前記第1算出部は、前記発話速度が速いほど、小さい前記発話間隔の確率が高くなる特性を有する確率分布に基づいて、前記韻律情報に含まれる前記前側の発話音声の発話速度と前記発話間隔との組み合わせが出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
(付記4) 付記1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話ペアに属する発話音声の基本周波数と2つの発話音声相互の時間間隔を示す発話間隔とを含む韻律情報を抽出し、
前記第1算出部は、前記基本周波数が高いほど、小さい前記発話間隔の確率が高くなる特性を有する確率分布に基づいて、前記韻律情報に含まれる前記前側の発話音声の発話速度と前記発話間隔との組み合わせが出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
(付記5) 付記1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話ペアに属する2つの発話音声の持続時間を含む韻律情報を抽出し、
前記第1算出部は、会話中に連続して現れる2つの発話音声の持続時間についての学習によって得られた確率分布モデルに基づいて、前記韻律情報に含まれる2つの持続時間を持つ発話音声が連続していることの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
(付記6) 付記1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話音声に付随する感情の種別を推定する感情推定部を有し、
前記感情推定部によって、前記発話ペアに属する2つの発話音声について推定された前記感情の種別をそれぞれ示す感情情報を含むパラ言語情報を抽出し、
前記第1算出部は、会話に含まれる発話音声に付随する可能性を有する複数種別の感情の組み合わせが会話中で連続して現れる事象についての条件付確率分布に基づいて、前記パラ言語情報に含まれる前記2つの感情情報でそれぞれ示される種別の感情を伴う発話音声が連続して出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
(付記7) 付記1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話音声が発話された際の話者の意図を推定する意図推定部を有し、
前記意図推定部によって、前記発話ペアに属する2つの発話音声に対応して推定された前記話者の意図の種別をそれぞれ示す意図情報を含むパラ言語情報を抽出し、
前記第1算出部は、会話における話者の意図として出現する可能性を有する複数種別の意図の組み合わせが会話中で連続して現れる事象についての条件付確率分布に基づいて、前記パラ言語情報に含まれる2つの意図情報でそれぞれ示される種別の意図を伴う発話音声が連続して出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
(付記8) 付記1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話音声が発話された際の話者の態度を推定する態度推定部を有し、
前記態度推定部によって、前記発話ペアに属する2つの発話音声に対応する前記話者の態度の種別をそれぞれ示す態度情報を含むパラ言語情報を抽出し、
前記第1算出部は、会話における話者の態度として出現する可能性を有する複数種別の態度の組み合わせが会話中で連続して現れる事象についての条件付確率分布に基づいて、前記パラ言語情報に含まれる2つの態度情報でそれぞれ示される種別の態度を伴う発話音声が連続して出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
(付記9) 複数の人物それぞれが発話した音声を表す音声情報および前記複数の人物それぞれの位置を示す位置情報を取得し、
前記各人物の音声情報と前記各人物の位置情報とに基づいて、会話をしている可能性がある複数の人物を含む複数の会話グループを求め、求めた会話グループの組み合わせから会話をしている可能性の高い会話グループの組み合わせを組み合わせ候補として生成し、
前記組み合わせ候補に含まれる各会話グループに属する前記複数の人物の発話音声を時系列に従って並べ替えることにより、前記各会話グループにおける発話音声の出現順序を示す発話音声の配列を生成し、
前記各会話グループに対応する前記発話音声の配列に含まれる各発話音声と当該発話音声に連続する発話音声とを含む発話ペアごとに、前記発話ペアに含まれる2つの発話音声に対応する音声情報から、韻律情報とパラ言語情報との少なくとも一方を含む特徴情報を抽出し、
前記特徴情報と、前記発話ペアが会話の一部である場合に当該特徴情報が従う確率分布とに基づいて、前記各発話ペアが会話の一部である確率を示す第1尤度を算出し、
前記各会話グループに対応する発話音声の配列に含まれる前記発話ペアについて算出した前記第1尤度に基づいて、前記発話音声の配列に含まれる全ての発話音声が、当該会話グループに属する各人物による会話に含まれている確率を示す第2尤度を算出し、
前記各組み合わせ候補に含まれる各会話グループについて算出した前記第2尤度に基づいて、当該組み合わせ候補が、前記複数の人物が形成している複数の会話グループの組み合わせを反映している確率を示す第3尤度を算出する
処理をコンピュータに実行させることを特徴とする音声解析プログラム。
【符号の説明】
【0224】
10…音声情報解析装置;11…取得部;12…収集部;13…生成部;14…配列部;15…抽出部;16…第1算出部;17…第2算出部;18…第3算出部;111…音声情報蓄積部;121…位置情報蓄積部;131…発話判定部;132…発話リスト;133…位置分類部;134…近接人物リスト;135…組み合わせ列挙部;136…重複率算出部;137…絞込み部;141…整列処理部;142…発話配列リスト;151−p…発話パワー算出部;151−v…発話速度算出部;151−f…基本周波数算出部;151−s…持続時間抽出部;151−d…発話間隔算出部;152−e…感情推定部;152−p…意図推定部;152−a…態度推定部;153…発話特徴蓄積部;154…間隔情報蓄積部;161…確率演算部;162…パラメータ保持部;163…韻律尤度算出部;164…テーブル参照部;165e,165p,165a…確率テーブル;166…パラ言語尤度算出部;167…乗算部;21…プロセッサ;22…メモリ;23…ハードディスク装置(HDD);24…表示装置;25…入力装置;26…光学ドライブ装置;27…リムーバブルディスク;28…ネットワークインタフェース;S1,S2…中継装置;C1〜Cn、A,B,C,D,E,F,G…人物;T1〜Tn…携帯端末
【技術分野】
【0001】
本件開示は、複数の人物によって発話された音声情報を解析する音声情報解析装置および音声情報解析プログラムに関する。
【背景技術】
【0002】
展示会場内やオフィス内に滞在する複数の人物が、それぞれどのようなグループを形成して会話しているのかを特定することにより、コミュニケーションの活性化や効率的な人事管理が可能となる場合がある。
【0003】
複数の人物が会話に参加しているグループを特定する手法としては、互いに近接していて少なくとも一方が発話している場合に、当該人物同士が対話していると判断する技法が提案されている(特許文献1参照)。この技法では、各人物に会話音声の取得と近接した人物の識別情報を取得するための端末を所持させ、この端末で収集した情報を対話している人物の特定に利用している。また、同様の機能を有する端末を各人物に所持させ、互いに近接している人物の端末を介して収集した音声情報を解析することによって求めた発話期間の重複率に基づき、個々のグループに参加している人物を特定する技法も提案されている(特許文献2参照)。
【0004】
また、個々の人物が所持する端末を介して収集した所定以上の音圧を持つ音声が相互に類似しており、かつ、互いの発話期間に重複が少ない人物同士が対話していると判断する技法も提案されている(特許文献3参照)。
【先行技術文献】
【特許文献】
【0005】
【特許文献1】特開2009−224909号公報
【特許文献2】再公表WO2007/105436号公報
【特許文献3】特開2008−242318号公報
【発明の概要】
【発明が解決しようとする課題】
【0006】
特許文献1や特許文献2の技法は、展示会場などに滞在する個々の人物に、近接する他の人物を特定する機能を持つ端末を配布し、装着してもらう必要がある。多数の人物が滞在する場所において、このような特定の用途に利用される端末を配布して装着させることは、情報を収集する側にとっても、また、端末を装着させられる側にとっても負担になる。
【0007】
一方、特許文献3の技法は、展示会場などを訪れた人物が所持している携帯端末などの機能を利用して音声情報を収集することができる反面、混雑した状態などでは、背景ノイズの影響により、音声情報の類似性を正確に判断できない可能性がある。
【0008】
また、例えば、複数のグループが互いに近接している場合などには、発話期間の重複率のみに基づいて、各人物がどのグループに参加しているかを判断することは困難である。
【0009】
本件開示は、大まかな位置情報と音声情報とに基づいて、複数の人物がそれぞれ参加している会話グループを特定することが可能な音声情報解析装置および音声情報解析プログラムを提供することを目的とする。
【課題を解決するための手段】
【0010】
一つの観点による音声情報解析装置は、複数の人物それぞれが発話した音声を表す音声情報を取得する取得部と、前記複数の人物それぞれの位置を示す位置情報を収集する収集部と、前記各人物の音声情報と前記各人物の位置情報とに基づいて、会話をしている可能性がある複数の人物を含む複数の会話グループを求め、求めた会話グループの組み合わせから会話をしている可能性の高い会話グループの組み合わせを組み合わせ候補として生成する生成部と、前記組み合わせ候補に含まれる各会話グループに属する前記複数の人物による複数の発話音声を時系列に従って配列する配列部と、前記配列部によって会話グループごとに配列された前記複数の発話音声において連続する2つの発話音声として特定される発話ペアごとに、前記発話ペアに対応する音声情報から、韻律的な特徴を示す韻律情報とパラ言語的な特徴に対応するパラ言語情報との少なくとも一方を含む特徴情報を抽出する抽出部と、前記特徴情報と、前記発話ペアが会話の一部である場合に当該特徴情報が従う確率分布とに基づいて、前記各発話ペアが会話の一部であることの尤もらしさを示す第1尤度を算出する第1算出部と、前記第1算出部で前記各発話ペアについて得られた前記第1尤度に基づいて、前記配列部によって会話グループごとに配列された前記複数の発話音声の全てが、当該会話グループに属する各人物による会話に含まれている確率を示す第2尤度を算出する第2算出部と、前記各組み合わせ候補に含まれる各会話グループについて算出した前記第2尤度に基づいて、当該組み合わせ候補が、前記複数の人物が形成している複数の会話グループの組み合わせを反映している確率を示す第3尤度を算出する第3算出部とを有する。
【0011】
また、別の観点による音声情報解析プログラムは、複数の人物それぞれが発話した音声を表す音声情報および前記複数の人物それぞれの位置を示す位置情報を取得し、前記各人物の音声情報と前記各人物の位置情報とに基づいて、会話をしている可能性がある複数の人物を含む複数の会話グループを求め、求めた会話グループの組み合わせから会話をしている可能性の高い会話グループの組み合わせを組み合わせ候補として生成し、前記各組み合わせ候補に含まれる各会話グループに属する前記複数の人物の発話音声を時系列に従って並べ替えることにより、前記各会話グループにおける発話音声の出現順序を示す発話音声の配列を生成し、前記各会話グループに対応する前記発話音声の配列に含まれる各発話音声と当該発話音声に連続する発話音声とを含む発話ペアごとに、前記発話ペアに含まれる2つの発話音声に対応する音声情報から、韻律情報とパラ言語情報との少なくとも一方を含む特徴情報を抽出し、前記特徴情報と、前記発話ペアが会話の一部である場合に当該特徴情報が従う確率分布とに基づいて、前記各発話ペアが会話の一部である確率を示す第1尤度を算出し、前記各会話グループに対応する発話音声の配列に含まれる前記発話ペアについて算出した前記第1尤度に基づいて、前記発話音声の配列に含まれる全ての発話音声が、当該会話グループに属する各人物による会話に含まれている確率を示す第2尤度を算出し、前記各組み合わせ候補に含まれる各会話グループについて算出した前記第2尤度に基づいて、当該組み合わせ候補が、前記複数の人物が形成している複数の会話グループの組み合わせを反映している確率を示す第3尤度を算出する処理をコンピュータに実行させる。
【発明の効果】
【0012】
本件開示の音声情報解析装置および音声情報解析プログラムによれば、大まかな位置情報と音声情報とに基づいて、複数の人物がそれぞれ参加している会話グループを特定することが可能である。
【図面の簡単な説明】
【0013】
【図1】音声情報解析装置の一実施形態を示す図である。
【図2】位置情報の収集手法を説明する図である。
【図3】発話期間の重複を説明する図である。
【図4】会話グループの組み合わせ候補の絞込み例を示す図である。
【図5】会話グループごとに配列された発話音声の例を示す図である。
【図6】生成部および配列部の一実施形態を示す図である。
【図7】発話リストおよび近接人物リストの一例を示す図である。
【図8】発話配列リストの一例を示す図である。
【図9】抽出部の一実施形態を示す図である。
【図10】発話間隔を示す情報の一例を示す図である。
【図11】第1算出部の一実施形態を示す図である。
【図12】確率分布モデルの一例を示す図である。
【図13】確率テーブルの例を示す図である。
【図14】音声情報解析装置のハードウェア構成例を示す図である。
【図15】音声情報解析処理のフローチャートの一例を示す図である。
【図16】会話グループを特定する処理のフローチャートの一例を示す図である。
【図17】各組み合わせ候補の尤度を算出する処理のフローチャートの例を示す図である。
【発明を実施するための形態】
【0014】
以下、図面に基づいて、本発明の実施形態について詳細に説明する。
図1は、音声情報解析装置の一実施形態を示している。
【0015】
図1に例示した音声情報解析装置10は、取得部11と、収集部12と、生成部13と、配列部14と、抽出部15と、第1算出部16と、第2算出部17と、第3算出部18とを含んでいる。
【0016】
図1に例示した取得部11は、複数の人物C1〜Cnそれぞれが発話した音声を表す音声情報を取得する。例えば、取得部11は、複数の人物C1〜Cnそれぞれが所持する携帯端末T1〜Tnを介して、各人物C1〜Cnの音声情報を取得してもよい。
【0017】
また、図1に例示した収集部12は、各人物C1〜Cnの位置を少なくとも一つの基準位置からの距離を用いて示す位置情報を収集する。例えば、収集部12は、各人物C1〜Cnが所持する携帯端末T1〜Tnの位置を示す情報を、各人物C1〜Cnの位置情報として収集してもよい。なお、各携帯端末T1〜Tnの位置を示す情報は、個々の携帯端末T1〜Tnに含まれるGPS(Global Positioning System)機能によって得られる位置情報でもよい。
【0018】
また、収集部12は、図2に示すように、例えば、人物C1〜Cnが滞在する室内に配置された中継装置S1,S2を介して、各携帯端末T1〜Tnとの距離を示す情報を収集することによって、各携帯端末T1〜Tnの位置を示す情報を得てもよい。
【0019】
図2は、位置情報の収集手法を説明する図である。図2において、符号A,B,C,D,E,F,Gは、人物C1〜Cnの例である。また、図2において、符号R1は、人物A,B,C,D,E,F,Gが滞在している展示会場などの場所を示している。また、図2において、符号S1,S2は、それぞれ、上述した展示会場R1に設置された中継装置を示している。
【0020】
図2に例示した中継装置S1,S2は、展示会場R1内に滞在している人物A,B,C,D,E,F,Gがそれぞれ所持している携帯端末に、ネットワークへの無線アクセスを提供する機能を有している。このような中継装置S1,S2は、展示会場R1内の人物A,B,C,D,E,F,Gが所持している携帯端末をネットワークに接続させる過程で、これらの携帯端末と中継装置S1,S2との間の距離を示す情報を収集している。例えば、中継装置S1,S2は、これらの携帯端末から到来する無線信号の強度や遅延の大きさなどに基づいて、自装置に近接している携帯端末をそれぞれ判別している。
【0021】
図2の例では、人物Aの携帯端末から経路ra1を介して中継装置S1に到達した無線信号と人物Gの携帯端末から経路rg1を介して中継装置S1に到達した無線信号とを比較することにより、人物Aの方が人物Gよりも中継装置S1に近いことが分かる。同様に、人物Aの携帯端末から経路ra2を介して中継装置S2に到達した無線信号と人物Gの携帯端末から経路rg2を介して中継装置S2に到達した無線信号とを比較することにより、人物Gの方が人物Aよりも中継装置S2に近いことが分かる。このようにして、2つの中継装置S1、S2がそれぞれ各人物A〜Hの携帯端末について収集した情報に基づいて、図1に例示した収集部12は、人物A〜Hがそれぞれ中継装置S1、S2のどちらに近いかを判別してもよい。そして、この判別結果を、収集部12は、2つの中継装置S1,S2からの距離を用いて示す位置情報として、図1に例示した生成部13に渡してもよい。
【0022】
生成部13は、各人物C1〜Cnの音声情報から得られる各人物C1〜Cnが発話している期間と各人物C1〜Cnの位置情報とに基づいて、人物C1〜Cnによって形成される複数の会話グループの組み合わせについての組み合わせ候補を生成する。
【0023】
生成部13は、まず、上述した収集部12で得られた人物C1〜Cnの位置情報に基づいて、各人物C1〜Cnを互いに近い位置にいる人物をそれぞれ含む複数のグループに分ける。例えば、生成部13は、中継装置S1,S2からの距離を示す位置情報に基づいて、図2に例示した人物A〜Hを、中継装置S1の近くにいる人物A〜Eを含むグループgr1と、中継装置S2の近くにいる人物F,Gを含むグループgr1とに分けてもよい。
【0024】
このようにして、生成部13は、対話している人物は互いに近い位置にいるという位置情報に基づく制約を満たすように、人物C1〜Cnを複数のグループに分けることができる。
【0025】
次に、生成部13は、次に述べるようにして、人物C1〜Cnの音声情報に基づいて、位置情報に基づいて形成した複数のグループそれぞれについて、会話している可能性のある人物を含む会話グループを生成する。
【0026】
まず、生成部13は、音声情報に基づいて、各人物が発話している期間である発話期間をそれぞれ特定する。次いで、生成部13は、位置情報に基づいて形成したグループそれぞれに含まれる人物の中から、発話期間が重複している人物のペアを検出する。
【0027】
図3は、発話期間の重複を説明する図である。図3に示した横軸は、時間tを示す。また、図3に示した符号A,B,C,D,Eは、図2に例示したグループgr1に含まれる人物A,B,C,D,Eに対応している。
【0028】
図3において、各人物A,B,C,D,Eに対応する横軸上に示した矩形は、それぞれの人物の発話音声を示している。また、各矩形の横方向の長さは、それぞれの発話音声に対応する発話期間の長さを示し、各矩形の位置は、時間軸上の位置を示している。なお、図3において、各発話音声を、符号「V」と話者を示す符号と時系列を示す番号とを組み合わせた符号で示した。例えば、人物Aのj番目の発話音声を符号VAjで示した。
【0029】
図3に例示した人物Aの発話音声VA1,VA2の発話期間と人物Cの発話音声VC1の発話期間とを比べると、これらが、それぞれ符号τac1,τac2で示した期間に亘って重複していることが分かる。そして、この重複している期間τac1,τac2が、人物Aの2つの発話音声に対応する発話期間に占める割合を示す発話重複率が、値1に近い、高い値となることも分かる。また、図3に例示した人物Bの発話音声VB1,VB2の発話期間と人物Cの発話音声VC1の発話期間とを比べると、これらが、それぞれ符号τbc1,τbc2で示した期間に亘って重複していることが分かる。また、同様に、この重複している期間τbc1,τbc2が、人物Bの2つの発話音声に対応する発話期間に占める発話重複率が、値1に近い、高い値となることも分かる。
【0030】
図1に例示した生成部13は、例えば、人物C1〜Cnに含まれる二人の組み合わせごとに求めた発話重複率が所定の閾値を超えるか否かに基づいて、発話期間が互いに重複している人物のペアを検出することができる。
【0031】
ここで、互いの発話期間についての発話重複率が高い値となっている人物のペアが互いに会話している可能性が低い。つまり、上述したようにして検出した発話期間が互いに重複している人物のペアは、互いに対話していない人物のペアである。例えば、図3に例示した人物A,Cおよび人物B,Cのペアのように、互いの発話期間の大部分が重複している人物のペアは、対話していない人物のペアの例である。
【0032】
したがって、生成部13は、対話していない人物のペア、すなわち、発話が互いに重複する人物のペアを会話グループが含まないという発話期間の重複に基づく制約を満たすように、会話グループの組み合わせ候補を生成することが望ましい。
【0033】
生成部13は、次に述べるようにして、位置情報に基づく制約と発話期間の重複に基づく制約との両方を満たす会話グループの組み合わせ候補を生成する。
【0034】
例えば、生成部13は、まず、位置情報に基づいて形成した各グループに含まれる複数の人物の中で発話している人物を複数含む会話グループについて、全ての組み合わせを列挙する。そして、生成部13は、列挙された全ての会話グループの組み合わせを、発話期間の重複に基づく制約を満たすか否かによって絞り込むことにより、少なくとも一つの組み合わせ候補を生成してもよい。
【0035】
図4は、会話グループの組み合わせ候補の絞込み例を示している。図4(A)は、図2に例示した人物A〜Gについて、生成部13が、位置情報の制約を考慮して生成する会話グループの全ての組み合わせを示す。また、図4(B)は、図3に例示した発話期間の重複に基づく制約を考慮して、生成部13が、図4(A)に例示した全ての組み合わせを絞り込むことによって得られた会話グループの組み合わせ候補を示す。
【0036】
図4(A)に例示した全ての組み合わせに含まれる組み合わせ1は、図2に例示したグループgr1に含まれる全ての人物A〜Eを含む会話グループ1と、図2に例示したグループgr2に含まれる人物F,Gを含む会話グループ2とを含んでいる。一方、図4(A)に例示した組み合わせ2〜組み合わせ11は、いずれも、上述した人物F,Gを含む会話グループ3を含んでいる。そして、これらの組み合わせ2〜組み合わせ11に含まれる会話グループ1,2は、上述した人物A〜Eを二人のグループと三人のグループに分ける際に考えられる組み合わせに相当している。
【0037】
図4(A)に例示した組み合わせ3,7,8は、発話期間が重複している人物Aと人物Cのペアを含む会話グループを含んでいる。また、図4(A)に例示した組み合わせ4〜6は、発話期間が重複しているあるいは人物Bと人物Cのペアを含む会話グループを含んでいる。更に、図4(A)に例示した組み合わせ1,11は、上述した人物Aと人物Cのペアおよび人物Bと人物Cのペアとの両方を含む会話グループを含んでいる。つまり、これらの組み合わせ1と組み合わせ3〜8および組み合わせ11は、発話期間の重複に基づく制約を満たさない組み合わせである。
【0038】
生成部13は、図4(A)に例示した11通りの組み合わせから、上述した発話期間の重複に基づく制約を満たさない組み合わせを排除することにより、図4(B)に例示した3通りの会話グループの組み合わせ候補1,2,3に絞り込む。なお、図4(B)においては、組み合わせ候補1,2,3をそれぞれ「候補1」、「候補2」、「候補3」として示している。
【0039】
なお、会話グループの数に限定はなく、例えば、図2に例示した以上の数の人物について会話グループを特定する処理を行う場合などに、生成部13は、4以上の会話グループを含む組み合わせ候補を生成することもできる。
【0040】
このようにして生成された会話グループの組み合わせ候補について、図1に例示した配列部14は、各組み合わせ候補に含まれる会話グループそれぞれに属する複数の人物の発話音声を時系列に従って配列する。
【0041】
図5は、会話グループごとに配列された発話音声の例を示している。図5に示した横軸は、時間tを示している。なお、図5に含まれる要素のうち、図3に示した要素と同等のものについては、同一の符号を付して示し、その説明は省略する。
【0042】
図5(A)は、図4(B)に例示した組み合わせ候補1に含まれる会話グループ1に相当する会話グループG11と会話グループ2に相当する会話グループ12にそれぞれ属する各人物による発話音声が出現する順序を示している。また、図5(B)は、図4(B)に例示した組み合わせ候補2に含まれる会話グループ1に相当する会話グループG21と会話グループ2に相当する会話グループ22にそれぞれ属する各人物による発話音声が出現する順序を示している。同様に、図5(C)は、図4(B)に例示した組み合わせ候補3に含まれる会話グループ1に相当する会話グループG31と会話グループ2に相当する会話グループ32にそれぞれ属する各人物による発話音声が出現する順序を示している。なお、図4(B)に例示した3つの組み合わせ候補1〜3に共通して含まれている会話グループ3に含まれる人物F,Gによる各発話音声は、組み合わせ候補ごとに出現順序が変化しないので、図5では図示を省略している。
【0043】
図5(A)〜図5(C)を互いに比較すれば、各組み合わせ候補に含まれる会話グループに属している人物の組み合わせの違いに応じて、各会話グループにそれぞれ属する各人物による発話音声に後続する発話音声が異なっている場合があることが分かる。例えば、会話グループG12においては、人物Cによる発話音声VC1に人物Eによる発話音声VE2が後続しているのに対して、会話グループG22においては、発話音声VC1には人物Dによる発話音声VD1が後続している。
【0044】
ここで、例えば、図5(A)に会話グループG11に対応して示した発話音声VA1,VB1,VA2,VB2が、二人の人物A,Bによる会話である場合に、出現順序に従って連続する発話音声それぞれの特徴には、当該会話の特徴が反映される。
【0045】
例えば、盛んに発話がなされることによって会話が盛り上がっている場合に、連続する発話音声間の間隔である発話間隔は短い場合が多い。また、会話が盛り上がっている場合に、各発話音声はパワーが大きいことが多く、また、当該会話に含まれる各発話音声の発話速度は速くなる場合が多く、更に、各発話音声の音声基本周波数は高くなる場合が多い。このように、会話に含まれる各発話音声が有するパワーや発話速度および音声基本周波数を含む個々の発話音声の韻律的な特徴と、発話間隔などの会話全体としての韻律的な特徴との間には相関関係がある。そして、このような相関関係は、会話において連続する2つの発話音声それぞれの韻律的な特徴と、この二つの発話音声についての発話間隔との関係に反映される。つまり、会話グループごとに配列された複数の発話音声に含まれる連続する2つの発話音声がそれぞれ有する韻律的な特徴と発話間隔との間に相関関係があることは、これらの発話音声が会話の一部である場合に満たす韻律的な特徴についての条件の一つである。なお、以下の説明では、会話グループごとに配列された複数の発話音声に含まれる連続する2つの発話音声を、発話ペアと称する。
【0046】
また一方、会話に含まれる各発話音声には、この会話に参加している人物それぞれの感情や意図および態度を含む話者の意識的な表現が、声の高さや抑揚などを含むパラ言語的な特徴として反映されている。以下の説明では、発話音声に反映されたパラ言語的な特徴から推測される話者の感情や意図および態度を含む話者の意識的な表現を示す情報をパラ言語情報と称する。
【0047】
複数の人物の間で会話が成立している場合に、会話に参加している人物が発話音声に反映させるパラ言語情報の組み合わせの中には、連続して現れる可能性の高い組み合わせと連続して現れる可能性の低い組み合わせとがある。例えば、会話に参加している人物の一方による発話音声に反映された感情が「怒り」である場合に、この発話音声に連続して「喜び」が反映された発話音声が現れる可能性は、自然な会話の中においては非常に低い。このように、発話音声に反映されるパラ言語情報の一つである話者の感情を示す発話感情には、会話の中で連続して現れる可能性が高い組み合わせと、逆に、連続して現れる可能性が低い組み合わせとが存在する。同様に、それぞれパラ言語情報の一つである話者の意図を示す発話意図および話者の態度を示す発話態度についても、連続する発話音声に対応する組み合わせとして出現する可能性が高い組み合わせと、出現する可能性の低い組み合わせとが存在する。このように、会話に含まれる各発話音声に反映されたパラ言語情報の種別が特定された場合に、当該発話音声に後続する発話音声に反映される可能性の高いパラ言語情報の種別が限定される場合が多い。つまり、発話ペアに含まれる個々の発話音声に反映されたパラ言語情報の種別の組み合わせが会話内で出現する可能性の高い組み合わせであることは、当該発話ペアが会話の一部である場合に満たすパラ言語的な特徴についての条件の一つである。
【0048】
したがって、各発話ペアが、上述した韻律的な特徴についての条件とパラ言語的な特徴についての条件との少なくとも一方を満たしている度合いを調べることで、この発話ペアが会話の一部であることの尤もらしさを評価することができる。
【0049】
図1に例示した抽出部15は、会話グループごとに配列された複数の発話音声に含まれる発話ペアごとに、対応する音声情報から、韻律的な特徴を示す韻律情報とパラ言語的な特徴に対応するパラ言語情報との少なくとも一方を含む特徴情報を抽出する。
【0050】
また、図1に例示した第1算出部16は、抽出部15によって得られた特徴情報と、発話ペアが会話の一部である場合に当該特徴情報が従う確率分布とに基づいて、当該発話ペアが会話の一部であることの尤もらしさを示す第1尤度を算出する。例えば、第1算出部16は、発話ペアに対応する音声情報から抽出された韻律情報と韻律的な特徴についての条件を示す確率分布とに基づいて、当該発話ペアが会話の一部である可能性の高さを示す韻律尤度を評価する。また、第1算出部16は、発話ペアに対応する音声情報から抽出されたパラ言語情報と上述したパラ言語的な特徴についての条件を示す確率分布とに基づいて、当該発話ペアが会話の一部である可能性の高さを示すパラ言語尤度を評価する。そして、第1算出部16は、例えば、上述したようにして求めた韻律尤度とパラ言語尤度との積を第1尤度として算出してもよい。
【0051】
このようにして、図1に例示した第1算出部16は、各発話ペアに対応する音声情報から抽出された特徴情報が、韻律的な特徴についての条件およびパラ言語的な特徴についての条件をそれぞれ満たしている度合いを反映した第1尤度を算出することができる。
【0052】
なお、第1算出部16において、上述した韻律尤度およびパラ言語尤度をそれぞれ算出する処理については、それぞれの処理において用いる確率分布の説明と併せて、図9〜図13を用いて改めて述べる。
【0053】
図1に例示した第2算出部17は、第1算出部16で各発話ペアについて得られた第1尤度に基づいて、会話グループごとに配列された全ての発話音声が、当該会話グループに属する各人物による会話に含まれている確率を示す第2尤度を算出する。
【0054】
第2算出部17は、例えば、配列部14が会話グループごとに発話音声を配列した順序に従って、第1算出部16で得られた各発話ペアについての第1尤度の相乗平均を算出することにより、当該会話グループについての第2尤度を求めてもよい。
【0055】
そして、図1に例示した第3算出部18は、各組み合わせ候補に含まれる各会話グループについて算出された第2尤度に基づいて、当該組み合わせ候補が、複数の人物が形成している複数の会話グループの組み合わせを反映している確率を示す第3尤度を算出する。
【0056】
第3算出部18は、例えば、各組み合わせ候補に含まれる複数の会話グループについて第2算出部17で得られた第2尤度の相乗平均を算出することにより、当該組み合わせ候補についての第3尤度を求めてもよい。
【0057】
このようにして得られた第3尤度は、生成部13で生成された複数の組み合わせ候補それぞれが、人物C1〜Cnが形成している会話グループの組み合わせを反映している可能性の高さを示している。すなわち、第3尤度が最も高い値となった会話グループの組み合わせが、最も尤もらしい会話グループの組み合わせを示している。つまり、各組み合わせ候補について得られた第3尤度に基づいて、人物C1〜Cnが形成している会話グループの組み合わせを特定することができる。
【0058】
このように、本件開示の音声情報解析装置10によれば、大まかな位置情報と音声情報とに基づいて、複数の人物がそれぞれ参加している会話グループを特定することが可能である。
【0059】
次に、図1に例示した音声情報解析装置10に含まれる各部の実施形態について説明する。
図6は、生成部13および配列部14の一実施形態を示している。なお、図6に示した構成要素のうち、図1に示した構成要素と同等のものについては、同一の符号を付して示し、その説明は省略する。
【0060】
図6に例示した取得部11は、図1に例示した人物C1〜Cnが所持する携帯端末T1〜Tnを介して収集した人物C1〜Cnの発話音声を示す音声情報を蓄積する音声情報蓄積部111を含んでいる。音声情報蓄積部111は、各人物C1〜Cnに対応する音声情報として、例えば、携帯端末T1〜Tnのマイクロホンなどを介して得られる音声信号を所定のサンプリング間隔ごとに蓄積してもよい。なお、図6に例示した取得部11は、携帯端末T1〜Tnのマイクロホンで得られた音声信号のサンプリング結果を、例えば、図2に例示した中継装置S1,S2を介して受け取ることができる。
【0061】
また、図6に例示した収集部12は、図1に例示した人物C1〜Cnが所持する携帯端末T1〜Tnを介して収集した人物C1〜Cnの位置を示す位置情報を蓄積する位置情報蓄積部121を含んでいる。位置情報蓄積部121は、各人物C1〜Cnに対応する位置情報として、例えば、図2に例示した中継装置S1,S2それぞれが無線アクセスを提供している携帯端末を示す情報を、所定のサンプリング間隔ごとに蓄積してもよい。なお、図6に例示した収集部12は、図2に例示した中継装置S1,S2を介して、それぞれが無線アクセスを提供している携帯端末を示す情報を受け取ることができる。
【0062】
また、図6に例示した生成部13は、発話判定部131と、発話リスト132と、位置分類部133と、近接人物リスト134と、組み合わせ列挙部135と、重複率算出部136と、絞込み部137とを含んでいる。
【0063】
発話判定部131は、上述した音声情報蓄積部111に蓄積された各人物に対応する音声情報に基づいて、各サンプリングタイミングにおいて各人物が発話しているか否かを判定する。発話判定部131は、例えば、各サンプリングタイミングについての判定処理を、当該サンプリングタイミングを含む所定の時間内における音声信号の強度の平均値に基づいて行ってもよい。そして、発話判定部131は、各人物についてサンプリングタイミングごとに得られた判定結果を、発話リスト132に格納する。
【0064】
なお、発話判定部131は、音声情報解析装置10によって、会話グループの特定処理を行う対象となる期間Tdにおいて得られた音声情報について、上述した判定処理を行ってもよい。この会話グループの特定を行う対象となる期間Tdとしては、所望の期間を指定することができる。
【0065】
図7(A)は、図2に例示した人物A〜Gについて、発話判定部131の処理によって得られる発話リスト132の一例を示している。図7(A)の時刻欄に示した符号tは、会話グループの特定処理を行う対象となる期間Tdの終了時刻を示す。また、符号t−Tは、終了時刻tから会話グループの特定を行う対象となる期間Tdの長さTを遡った時刻、すなわち、会話グループの特定を行う対象となる期間Tdの開始時刻を示す。また、図7(A)の時刻欄に示した符号hは、サンプリング間隔を示す。
【0066】
図7(A)に例示した人物A〜Gについて、各サンプリングタイミングに対応して示した数値「1」は、発話判定部131により当該人物が発話している旨の判定結果が得られたことを示している。一方、各サンプリングタイミングに対応して示した数値「0」は、発話判定部131により、当該人物が発話していない旨の判定結果が得られたことを示している。
【0067】
また、図6に例示した位置分類部133は、上述した位置情報蓄積部121に蓄積された位置情報に基づいて、図1に例示した人物C1〜Cnを会話が可能な程度に近接している複数のグループに分類する。位置分類部133は、上述した発話判定部131と同様に、会話グループの特定を行う対象となる期間Tdにおいて得られた位置情報に基づいて、後述する分類処理を行ってもよい。
【0068】
図2に例示した各中継装置S1,S2が無線アクセスを提供している携帯端末の識別情報が、位置情報蓄積部121に蓄積されている場合に、位置分類部133は、次のようにして各携帯端末を保持している人物C1〜Cnを複数のグループに分類してもよい。位置分類部133は、例えば、上述した期間Tdに亘って同一の中継装置から無線アクセスの提供を受けた複数の携帯端末の識別情報にそれぞれ対応付けられた人物を互いに近接している人物として判別する。そして、この判別結果に基づいて、位置分類部133は、各中継装置が無線アクセスを提供可能な範囲内に、上述した期間Tdに亘って滞在していた複数の人物を、当該中継装置に対応するグループに分類する。
【0069】
図7(B)は、図2に例示した人物A〜Gについて、位置分類部133の処理によって得られる近接人物リスト134の一例を示している。
【0070】
図7(B)に例示した近接人物リスト134は、図2に例示した中継装置S1に近接する範囲に滞在している人物として、この中継装置S1が無線アクセスを提供している携帯端末をそれぞれ所持している人物A,B,C,D,Eを含んでいる。また、図7(B)に例示した近接人物リスト134は、図2に例示した中継装置S2に近接する範囲に滞在している人物として、この中継装置S2が無線アクセスを提供している携帯端末をそれぞれ所持している人物F,Gを含んでいる。
【0071】
このようにして得られた近接人物リスト134と上述した発話リスト132とに基づいて、組み合わせ列挙部135は、図1に例示した人物C1〜Cnが形成している可能性のある会話グループの全ての組み合わせを列挙する。
【0072】
組み合わせ列挙部135は、例えば、上述した期間Tdの指定を受けたときに、発話リスト132に含まれるこの期間Tdに対応する判定結果に基づいて、この期間Tdにおいて発話があった人物を抽出する。次いで、組み合わせ列挙部135は、近接人物リスト134を参照することにより、上述した期間Tdにおいて発話があった人物それぞれが位置情報に基づいて分類されたグループを示す情報を取得する。そして、位置情報に基づいて分類された各グループに属する人物が4人以上であった場合に、組み合わせ列挙部135は、そのグループに含まれる人物を更にそれぞれ複数の人物を含む会話グループに振り分ける組み合わせの全てを数え上げる処理を行う。
【0073】
例えば、時刻tから時間Tを遡った時刻t−Tを開始時刻とする期間Tdが指定された場合に、組み合わせ列挙部135は、図7(A)に例示した発話リスト132の時刻t−Tから時刻tまでに対応して保持された情報に基づいて、発話があった人物を抽出する。なお、図7(A)において、各サンプリングタイミングを示す時刻は、上述した時刻tと時間Tとサンプリング間隔hを用いて表すことができる。この期間Tdにおいて、全ての人物A〜Gが発話していることを発話リスト132が示す場合に、図7(B)に例示した近接人物リスト134で示されたグループ分けは、そのまま発話している人物についての位置情報に基づくグループ分けを示す。この場合に、組み合わせ列挙部135は、人物A〜Eを含む人物のグループと、人物F,Gを含む人物のグループとについて、図4(A)に例示したような組み合わせを列挙すればよい。
【0074】
このようにして組み合わせ列挙部135によって生成された全ての組み合わせから、図6に例示した絞込み部137は、重複率算出部136によって算出された発話重複率に基づいて、会話が成立している可能性の低い組み合わせを排除する。これにより、絞込み部137は、会話が成立している可能性を持つ会話グループの組み合わせ候補を絞り込む。
【0075】
図6に例示した重複率算出部136は、発話重複率を算出するために、例えば、まず、発話リスト132に含まれる人物のペアごとに、上述した期間Tdにおいて同一の時刻に対応して発話があった旨の判定結果が保持されている回数を計数する。そして、この計数結果で示される重複回数を、当該ペアに含まれる各人物について発話があった旨の判定結果が保持されている回数で除算することにより、重複率算出部136は、当該ペアの互いに対する発話重複率を求めてもよい。
【0076】
絞込み部137は、例えば、少なくとも一方の人物について算出された発話重複率が所定の閾値を超えているペアを含む会話グループが含まれている組み合わせを、会話が成立している可能性の低い組み合わせとして排除してもよい。
【0077】
なお、上述した閾値は、例えば、複数の人物が会話している際の音声情報に基づいて、この会話に参加している人物のペアそれぞれについて発話重複率を算出する実験を行った結果に基づいて設定してもよい。例えば、上述した閾値は、この実験の過程で算出された発話重複率の最大値よりも大きい値に設定することができる。
【0078】
上述した処理を行うことにより、絞込み部137は、図4(A)のように列挙された多数の組み合わせから、会話が成立している可能性を持つ会話グループの組み合わせ候補に絞り込むことができる。そして、絞込み部137は、このようにして絞り込まれた組み合わせ候補を、配列部14に渡す。
【0079】
図6に例示した配列部14は、整列処理部141と発話配列リスト142とを含んでいる。整列処理部141は、絞込み部137から受け取った組み合わせ候補ごとに、発話リスト132とに基づいて、当該組み合わせ候補に含まれる各会話グループに属する人物の発話音声を時系列に従って整列させる。そして、この整列処理結果に基づいて、整列処理部141は、各会話グループに対応する会話において各発話音声が出現する順序を示す情報を発話配列リスト142に格納する。
【0080】
例えば、整列処理部141は、組み合わせ候補に含まれる会話グループごとに、当該会話グループに含まれる人物について発話リスト132を参照することにより、各人物の発話音声が連続して取得されている期間を示す個々の発話期間をそれぞれ特定する。このとき、整列処理部141は、各人物について特定された個々の発話期間に対応する発話音声に、当該人物を示す識別情報と個々の発話音声の出現順序を示す番号とを組み合わせた識別情報を付与してもよい。そして、整列処理部141は、例えば、各組み合わせ候補に含まれる会話グループごとに、当該会話グループに属する各人物の発話音声に対応する発話期間の開始時刻に基づいて、これらの発話音声を時系列に従って整列させてもよい。また、整列処理部141は、各発話音声に付与した識別情報を用いて、発話配列リスト142に格納する情報を表してもよい。
【0081】
図8は、発話配列リスト142の一例を示している。なお、図8に示した要素のうち、図5に示した要素と同等のものについては、同一の符号を付して示し、その説明は省略する。
【0082】
図8(A)は、図4(B)に例示した3つの組み合わせ候補それぞれに含まれる会話グループごとに、当該会話グループに属する人物の発話音声が出現する順序を示している。なお、図8において、符号VF1,VF2は、人物Fの発話音声を示し、符号VG1,VG2は、人物Gの発話音声を示す。
【0083】
例えば、図8(A)において、組み合わせ候補1に含まれる会話グループ1に対応する各欄に示した符号VA1,VB1,VA2,VB2は、図5(A)に当該会話グループを示す符号G11に対応して示した発話音声の出現順序を示している。同様に、図8(A)において、各組み合わせ候補1〜3に含まれる会話グループ3に対応する会話において、対応する各欄に示した符号VF1,VG1,VF2,VG2は、人物Fの発話音声と人物Gの発話音声とが交互に出現している様子を示している。
【0084】
このような発話配列リスト142によれば、各組み合わせ候補に含まれる会話グループそれぞれにおける発話音声の出現順で示される発話ペアを、当該会話グループに対応する隣接する欄に示された符号の組み合わせに基づいて特定することができる。
【0085】
なお、発話配列リスト142は、上述した整列処理部141が各発話音声を整列させる処理の過程で特定した各発話音声の開始時刻および終了時刻を示す情報を含んでもよい。
【0086】
図8(B)は、発話配列リスト142に含まれる各発話音声の開始時刻および終了時刻を示す情報の一例として、図2に例示した人物A〜Gによってなされた各発話音声の開始時刻および終了時刻を示している。
【0087】
図8(B)において、人物A〜Gによってなされた各発話音声の開始時刻を、符号「t」に人物およびその人物についての発話音声の順序を示す番号とを組み合わせた添え字を付加するとともに、符号「s」とを組み合わせて示した。同様に、図8(B)において、人物A〜Gによってなされた各発話音声の終了時刻を、符号「t」に人物およびその人物についての発話音声の順序を示す番号とを組み合わせた添え字を付加するとともに、符号「e」とを組み合わせて示した。
【0088】
例えば、図8(B)において、符号「tA1−s」は、人物Aの第1の発話音声の開始時刻を示し、符号「tA1−e」は、人物Aの第1の発話音声の終了時刻を示す。
【0089】
次に、このようにして得られた発話配列リスト142を用いて、抽出部15が、音声情報蓄積部111に蓄積された音声情報から、各発話音声の特徴情報を抽出する処理について説明する。
【0090】
図9は、抽出部15の一実施形態を示している。なお、図9に示した構成要素のうち、図1あるいは図6に示した構成要素と同等のものについては、同一の符号を付して示し、その説明は省略する。
【0091】
図9に例示した抽出部15は、韻律情報抽出部151とパラ言語情報抽出部152と、発話特徴蓄積部153と、間隔情報蓄積部154とを含んでいる。発話特徴蓄積部153は、韻律情報抽出部151およびパラ言語情報抽出部152が、各発話音声を表す音声情報からそれぞれ抽出した韻律情報およびパラ言語情報を、当該発話音声を示す識別情報に対応して蓄積する。また、間隔情報蓄積部154は、韻律情報抽出部151が、発話配列リスト142に含まれる各会話グループにおける発話音声の出現順序を示す情報で示される発話ペアごとに抽出した発話間隔を示す情報を蓄積する。
【0092】
図9に例示した韻律情報抽出部151は、発話パワー算出部151−pと、発話速度算出部151―vと、基本周波数算出部151−fと、持続時間抽出部151−sと、発話間隔算出部151−dを含んでいる。
【0093】
図9に例示した発話パワー算出部151−pは、音声情報蓄積部111に各人物に対応して蓄積された音声情報に含まれる個々の発話音声を表す音声信号の強度に基づいて、各発話音声について発話パワーを算出する。そして、発話パワー算出部151−pは、各発話音声について算出した発話パワーを、例えば、当該発話音声を示す識別情報に対応して、発話特徴蓄積部153に蓄積してもよい。
【0094】
また、図9に例示した発話速度算出部151−vは、音声情報蓄積部111に各人物に対応して蓄積された音声情報に含まれる個々の発話音声を表す音声信号の強度の変化に基づいて、各発話音声について発話速度を算出する。そして、発話速度算出部151−vは、各発話音声について算出した発話速度を、例えば、当該発話音声を示す識別情報に対応して、発話特徴蓄積部153に蓄積してもよい。
【0095】
また、図9に例示した基本周波数算出部151−fは、音声情報蓄積部111に各人物に対応して蓄積された音声情報に含まれる個々の発話音声を表す音声信号に基づいて、各発話音声の声の高さを示す基本周波数を算出する。そして、基本周波数算出部151−fは、各発話音声について算出した基本周波数を、例えば、当該発話音声を示す識別情報に対応して、発話特徴蓄積部153に蓄積してもよい。
【0096】
一方、図9に例示した持続時間算出部151−sは、上述した発話配列リスト142に含まれる各発話音声の開始時刻および終了時刻を示す情報に基づいて、各発話音声の持続時間を算出する。そして、持続時間算出部151−sは、各発話音声について算出した持続時間を、例えば、当該発話音声を示す識別情報に対応して、発話特徴蓄積部153に蓄積してもよい。
【0097】
また、図9に例示した発話間隔算出部151−dは、上述した発話配列リスト142にに基づいて、各組み合わせ候補に含まれる会話グループごとに、各発話ペアの発話間隔を算出する。例えば、発話間隔算出部151−dは、まず、発話配列リスト142によって示される発話音声の出現順に基づいて、各組み合わせ候補に含まれる会話グループごとに、各発話音声を含む発話ペアを特定する。そして、発話間隔算出部151−dは、発話配列リスト142に含まれる各発話音声の開始時刻および終了時刻を示す情報を参照することにより、当該発話ペアの前側の発話音声の終了時刻と後側の発話音声の開始時刻とをそれぞれ取得する。このようにして得られた前側の発話音声の終了時刻から後側の発話音声の開始時刻を差し引くことにより、発話間隔算出部151−dは、当該発話ペアの発話間隔を求めてもよい。そして、発話間隔算出部151−dは、各発話ペアについて算出した発話間隔を、例えば、各組み合わせ候補に含まれる会話グループそれぞれに対応して、発話間隔蓄積部154に蓄積してもよい。
【0098】
図10は、発話間隔蓄積部154に蓄積された発話間隔を示す情報の一例を示している。図10に例示した発話間隔を示す情報は、図8(A)に例示した各会話グループに対応する各発話音声を含む発話ペアについて得られた発話間隔を示している。
【0099】
なお、図10において、各発話ペアの発話間隔を、符号「t」に組み合わせ候補を特定する番号と会話グループを特定する番号とを組み合わせた添え字を付加するとともに、当該発話ペアの出現順序を示す番号を組み合わせて示した。
【0100】
例えば、図10において、組み合わせ候補1に含まれる会話グループ1に対応して示された符号「t11−1」は、図8(A)に例示した符号「VA1」,「VB1」で示される第1の発話ペアについて得られた発話間隔を示す。
【0101】
このようにして、図9に例示した韻律情報抽出部151は、各発話音声に対応する発話パワー、発話速度、基本周波数および持続時間とともに、各発話ペアに対応する発話間隔を含む韻律情報を抽出することができる。
【0102】
なお、韻律情報抽出部151は、図9の例示に限られず、発話パワー算出部151−pと、発話速度算出部151―vと、基本周波数算出部151−fと、持続時間抽出部151−sと、発話間隔算出部151−dを様々な組み合わせで含んでもよい。例えば、韻律情報抽出部151は、発話間隔算出部151−dと、発話パワー算出部151−p、発話速度算出部151−vおよび基本周波数算出部151−fの少なくとも一つを組み合わせて含んでいることが望ましい。
【0103】
一方、図9に例示したパラ言語情報抽出部152は、感情推定部152−eと、意図推定部152−pと、態度推定部152−aとを含んでいる。感情推定部152−e、意図推定部152−pおよび態度推定部152−aは、それぞれ各人物に対応して音声情報蓄積部111に蓄積された音声情報に基づいて、各発話音声について発話感情、発話意図および発話態度を推定する。
【0104】
感情推定部152−e、意図推定部152−pおよび態度推定部152−aは、音声情報蓄積部111から各発話音声を表す音声情報を切り出す際に、上述した発話配列リスト142に含まれる各発話音声の開始時刻および終了時刻を示す情報を利用してもよい。なお、感情推定部152−e、意図推定部152−pおよび態度推定部152−aが、各発話音声からそれぞれ発話感情、発話意図および発話態度を推定する処理には、公知技術を利用することができる。
【0105】
例えば、感情推定部152−eは、各発話音声に対応する音声情報の基本周波数を含む音声の特徴に基づいて、発話音声に反映された感情が「怒り」、「悲しみ」、「嫌悪」、「驚き」、「喜び」のいずれに分類されるかを推定してもよい。例えば、感情推定部152−eは、上述した各種の感情が反映された標準的な音声の基本周波数を示す基準周波数を用いて、各発話音声にどの種類の感情が反映されているかを推定してもよい。つまり、感情推定部152−eは、各発話音声の基本周波数に最も近い基準周波数に対応する感情の種類が、当該発話音声に反映されていると推定してもよい。また、感情推定部152−eは、発話感情についての正解付きデータを用いた学習によって、上述した5種類の感情を含む発話感情の種別それぞれに対応する基準周波数を含む音声情報の特徴を集積することにより、発話感情の推定精度を向上することもできる。なお、感情推定部152−eは、上述した基本周波数算出部151−fあるいは発話特徴蓄積部153から各発話音声の基本周波数を示す情報を受け取り、この情報を発話感情の推定に利用してもよい。
【0106】
また、意図推定部152−pは、各発話音声に対応する音声情報で表される抑揚を含む特徴に基づいて、発話音声に反映された話者の意図が「勧誘」、「疑問」、「同意」、「断定」のいずれに分類されるかを推定してもよい。また、意図推定部152−pは、発話意図についての正解付きデータを用いた学習によって、上述した4種類の発話意図を含む発話意図の種別それぞれに対応する音声情報の特徴を集積することにより、発話意図の推定精度を向上することもできる。
【0107】
また、態度推定部152−aは、各発話音声に対応する音声情報で表される抑揚を含む特徴に基づいて、発話音声に反映された話者の態度が「丁寧」、「改まった」、「くだけた」、「ぞんざい」のいずれに分類されるかを推定してもよい。また、態度推定部152−aは、発話態度についての正解付きデータを用いた学習によって、上述した4種類の発話態度を含む発話態度の種別それぞれに対応する音声情報の特徴を集積することにより、発話態度の推定精度を向上することもできる。
【0108】
感情推定部152−e、意図推定部152−pおよび態度推定部152−aは、それぞれによる推定処理で得られた推定結果を、推定対象の発話音声を示す識別情報に対応して、発話特徴蓄積部153に蓄積してもよい。
【0109】
このようにして、図9に例示したパラ言語情報抽出部152により、各発話音声に対応して、発話感情、発話意図および発話態度を含むパラ言語情報を抽出し、発話特徴蓄積部153に蓄積することができる。
【0110】
なお、パラ言語情報抽出部152は、図9の例示に限らず、感情推定部152−e、意図推定部152−pおよび態度推定部152−aの少なくとも一つを含んでいれば、どのような組み合わせで含んでいてもよい。
【0111】
次に、上述したようにして抽出された韻律情報およびパラ言語情報に基づいて、各発話ペアについて第1尤度を算出する方法について説明する。
【0112】
図11は、図6に示した第1算出部16の一実施形態を示している。なお、図11に示した構成要素のうち、図1および図9に示した構成要素と同等のものについては、同一の符号を付して示し、その説明は省略する。
【0113】
図11に例示した第1算出部16は、確率演算部161と、パラメータ保持部162と、韻律尤度算出部163とを含んでいる。また、第1算出部16は、上述した3種類のパラ言語情報にそれぞれ対応する3つの確率テーブル165e,165p,165aと、テーブル参照部164と、パラ言語尤度算出部166とを含んでいる。また、第1算出部16は、韻律尤度算出部163によって後述するようにして算出される韻律尤度と、パラ言語尤度算出部166によって後述するようにして算出されるパラ言語尤度とを乗算することにより、第1尤度を算出する乗算部167を有する。
【0114】
図11に例示した確率演算部161は、発話特徴蓄積部153および発話間隔蓄積部154に蓄積された韻律情報に基づいて、韻律的な特徴についての条件ごとに、発話配列リスト142で示される各発話ペアが当該条件を満たしている確率を算出する。確率演算部161は、発話配列リスト142に基づいて、注目する発話音声を含む発話ペアを特定する。そして、確率演算部161は、この発話ペアに含まれる2つの発話音声に対応して発話特徴蓄積部153に蓄積された韻律情報を取得する。このようにして取得した韻律情報に基づいて、確率演算部161は、各条件に対応する確率分布モデルを用いて、韻律的な特徴についての条件それぞれを当該発話ペアが満たしている確率を算出する。
【0115】
図12は、確率分布モデルの一例を示している。図12(A)において、横軸は、発話ペアについて抽出された韻律情報の一つである発話間隔tを示し、縦軸は、確率P(t)を示す。
【0116】
例えば、韻律的な特徴についての条件の一つである発話パワーと発話間隔との相関関係は、次のような確率モデルによって表すことができる。確率モデルは、例えば、ある発話音声に後続する発話音声の発話パワーが大きい場合に、図12(A)に例示したグラフQ1のように、発話間隔tが小さい値τ1において確率Pがピークを持つことが望ましい。同時に、ある発話音声に後続する発話音声の発話パワーが小さい場合に、図12(A)に例示したグラフQ2のように、値τ1よりも大きい値τ2において確率Pがピークを持つ確率モデルが望ましい。
【0117】
このような確率モデルに基づく確率分布は、発話パワーをハイパーパラメータとした正規分布を用いて表すことができる。例えば、注目する会話グループにおけるj番目の発話音声とj+1番目の発話音声とについての発話間隔t(j)が、j+1番目の発話音声が発話パワーs(j+1)を持つ場合に出現する確率P(t(j)|s(j+1))は、式(1)のように表される。
【0118】
【数1】
【0119】
なお、式(1)に示した確率分布において、発話パワーs(j)を反映した正規分布の平均値μ(s(j))について、発話パワーs(j)が正の範囲において平均値μ(s(j))が正の値を持ち、発話パワーs(j)が大きいほど値が小さくなるモデルを用いた。平均値μ(s(j))についてのこのモデルは、パラメータμsとパラメータαsとで示される指数関数を用いて、式(2)のように表される。また、図12(B)は、平均値μ(s(j))についてのモデルの一例を示している。
μ(s(j))=μs・exp(−αs・s(j)) ・・・(2)
上述したパラメータμsおよびパラメータαsの値と正規分布の標準偏差σsの値は、例えば、発話パワーと発話間隔についての正解付き学習データを用いた学習によって、それぞれ適切な値に設定することができる。また、これらのパラメータμs、パラメータαsおよび標準偏差σsの値は、例えば、発話パワーと発話間隔との相関関係についての確率モデルを示す情報として、図11に例示したパラメータ保持部162に保持しておくことができる。
【0120】
そして、確率演算部161は、パラメータ保持部162に上述した確率モデルに対応して保持された各パラメータの値を用いることにより、上述した式(1)に基づいて、注目する発話ペアについて上述した確率P(t(j)|s(j+1))を算出することができる。
【0121】
なお、発話パワーと発話間隔との相関関係についての確率モデルは、上述した確率モデルに限らず、例えば、前側の発話音声の発話パワーあるいは発話ペアの平均の発話パワーと発話間隔との相関関係を示す確率モデルでもよい。
【0122】
同様に、発話音声の発話速度と発話間隔tとの相関関係も、発話速度が速い場合に確率P(t)がピークを持つ発話間隔値が、発話速度が遅い場合に確率P(t)がピークを持つ発話間隔値よりも小さくなる確率モデルで表すことが望ましい。そして、このような確率モデルに基づく確率分布もまた、発話速度をハイパーパラメータとした正規分布を用いて表すことができる。
【0123】
例えば、注目する会話グループにおけるj番目の発話音声とj+1番目の発話音声とについての発話間隔t(j)が、j+1番目の発話音声が発話速度v(j+1)を持つ場合に出現する確率P(t(j)|v(j+1))は、式(3)のように表される。
【0124】
【数2】
【0125】
なお、式(3)において、発話速度v(j)を反映した正規分布の平均値μ(v(j))は、上述した発話パワーと同様のモデルを用いて、式(4)のように、パラメータμvとパラメータαvとで示される指数関数を用いて表すことができる。
μ(v(j))=μv・exp(−αv・v(j)) ・・・(4)
上述したパラメータμvおよびパラメータαvの値と正規分布の標準偏差σvの値は、例えば、発話速度と発話間隔についての正解付き学習データを用いた学習によって、それぞれ適切な値に設定することができる。また、これらのパラメータμv、パラメータαvおよび標準偏差σvの値は、例えば、発話速度と発話間隔との相関関係についての確率モデルを示す情報として、図11に例示したパラメータ保持部162に保持しておくことができる。
【0126】
そして、確率演算部161は、パラメータ保持部162に上述した確率モデルに対応して保持された各パラメータの値を用いることにより、上述した式(3)に基づいて、注目する発話ペアについて上述した確率P(t(j)|v(j+1))を算出することができる。
【0127】
なお、発話速度と発話間隔との相関関係についての確率モデルは、上述した確率モデルに限らず、例えば、前側の発話音声の発話速度あるいは発話ペアの平均の発話速度と発話間隔との相関関係を示す確率モデルでもよい。
【0128】
同様に、発話音声の基本周波数と発話間隔tとの相関関係も、基本周波数が高い場合に確率P(t)がピークを持つ発話間隔値が、基本周波数が低い場合に確率P(t)がピークを持つ発話間隔値よりも小さくなる確率モデルで表すことが望ましい。そして、このような確率モデルに基づく確率分布もまた、基本周波数をハイパーパラメータとした正規分布を用いて表すことができる。
【0129】
例えば、注目する会話グループにおけるj番目の発話音声とj+1番目の発話音声とについての発話間隔t(j)が、j+1番目の発話音声が基本周波数f(j+1)を持つ場合に出現する確率P(t(j)|f(j+1))は、式(5)のように表される。
【0130】
【数3】
【0131】
なお、式(5)において、基本周波数f(j)を反映した正規分布の平均値μ(f(j))は、上述した発話パワーと同様のモデルを用いて、式(6)のように、パラメータμfとパラメータαfとで示される指数関数を用いて表すことができる。
μ(f(j))=μf・exp(−αf・f(j)) ・・・(6)
上述したパラメータμfおよびパラメータαfの値と正規分布の標準偏差σfの値は、例えば、基本周波数と発話間隔についての正解付き学習データを用いた学習によって、それぞれ適切な値に設定することができる。また、これらのパラメータμf、パラメータαfおよび標準偏差σfの値は、例えば、基本周波数と発話間隔との相関関係についての確率モデルを示す情報として、図11に例示したパラメータ保持部162に保持しておくことができる。
【0132】
そして、確率演算部161は、パラメータ保持部162に上述した確率モデルに対応して保持された各パラメータの値を用いることにより、上述した式(5)に基づいて、注目する発話ペアについて上述した確率P(t(j)|f(j+1))を算出することができる。
【0133】
なお、基本周波数と発話間隔との相関関係についての確率モデルは、上述した確率モデルに限らず、例えば、前側の発話音声の基本周波数あるいは発話ペアの平均の基本周波数と発話間隔との相関関係を示す確率モデルでもよい。
【0134】
一方、連続する発話音声それぞれの持続時間の組み合わせについても、自然な会話において頻繁に現れる尤もらしい組み合わせと、自然な会話においてほとんど現れない尤もらしくない組み合わせがある。したがって、この持続時間の組み合わせもまた、韻律的な特徴についての条件の一つとして、各発話ペアが会話の一部として出現する確率の算出に利用することができる。
【0135】
発話音声の持続時間についての確率モデルは、持続時間が短い発話音声同士の組み合わせと、持続時間が長い発話音声と持続時間が短い発話音声との組み合わせについて、持続時間が長い発話音声同士の組み合わせに比べて高い確率を与えることが望ましい。
【0136】
このような確率モデルに基づく確率分布は、シグモイド関数などを用いて表すことができる。例えば、注目する会話グループにおけるj番目の発話音声とj+1番目の発話音声に対応する持続時間として、持続時間d(j)と持続時間d(j+1)の組み合わせが出現する確率P(d(j)|d(j+1))は、式(7)のように表される。なお、式(7)において、パラメータβは、確率分布の滑らかさを示し、パラメータγは、持続時間の長短を判別する基準を示す。また、係数Cは、正規化係数である。
【0137】
【数4】
【0138】
上述したパラメータβおよびパラメータγの値は、例えば、発話音声の持続時間の組み合わせについての正解付き学習データを用いた学習によって、それぞれ適切な値に設定することができる。また、これらのパラメータβおよびパラメータγの値は、例えば、発話音声の持続時間の組み合わせについての確率モデルを示す情報として、図11に例示したパラメータ保持部162に保持しておくことができる。
【0139】
そして、確率演算部161は、パラメータ保持部162に保持されたこれらのパラメータβおよびパラメータγの値を用いることにより、上述した式(7)により、注目する発話ペアについて上述した確率P(d(j)|d(j+1))を算出することができる。
【0140】
上述したようにして、図11に例示した確率演算部161は、韻律的な特徴についての条件それぞれに基づいて、各発話ペアが会話の一部として出現する確率をそれぞれ求めることができる。
【0141】
図11に例示した韻律尤度算出部163は、確率演算部161によって算出された韻律的な特徴についての条件それぞれに基づく確率から、各発話ペアの韻律的な特徴が、会話に含まれる発話音声の特徴に合致している度合いを示す韻律尤度を算出する。
【0142】
韻律尤度算出部163は、例えば、上述した式(1)、(3)、(5)、(7)を用いてそれぞれ算出される確率に、個別の重みを乗じた上で相乗平均を算出することにより、韻律尤度を求めてもよい。このようにして、韻律的な特徴についての各条件に基づいて、確率演算部161によって算出された確率P(t(j)|s(j+1))、確率P(t(j)|v(j+1))、確率P(t(j)|f(j+1))および確率P(d(j)|d(j+1))を反映した韻律尤度を求めることができる。
【0143】
なお、図11に例示した確率演算部161は、発話特徴蓄積部153に蓄積された韻律情報の種類に応じて、上述した4つの条件を含む韻律的な特徴についての条件の少なくとも一つに基づいて、各発話ペアが会話の一部として出現する確率を算出すればよい。また、図11に例示した韻律尤度算出部163は、確率算出部161が各発話ペアについて算出した少なくとも一つの条件に基づく確率を、重みつきで相乗平均することにより、韻律尤度を算出すればよい。また、発話特徴蓄積部153に蓄積された韻律情報の種類が1種類である場合は、この韻律情報に基づいて確率演算部161で得られた確率がそのまま韻律尤度となるので、韻律尤度算出部163を省略してもよい。
【0144】
次に、各発話ペアについて抽出されたパラ言語的な特徴が、会話に含まれる発話音声の特徴に合致している度合いを示すパラ言語尤度を算出する方法について説明する。
【0145】
図11に例示した3つの確率テーブル165e,165p,165aは、発話ペアに含まれる各発話音声について得られるパラ言語情報に含まれる発話感情、発話意図および発話態度の組み合わせについての条件付確率分布を示す情報を保持している。
【0146】
図13は、3つの確率テーブル165e,165p,165aそれぞれの一例を示している。
【0147】
図13(A)は、5種類の発話感情「怒り」、「悲しみ」、「嫌悪」、「驚き」および「喜び」の組み合わせが、発話ペアに含まれる2つの発話音声に対応するパラ言語情報として抽出される条件付確率分布を示している。
【0148】
図13(A)に例示した確率テーブル165eにおいて、注目する会話グループにおけるj番目の発話音声の発話感情を列方向に示し、j+1番目の発話音声の発話感情を行方向に示した。また、j番目の発話音声の発話感情とj+1番目の発話音声の発話感情との組み合わせについての条件付確率を、符号「P」に2つの発話音声に対応する発話感情をそれぞれ示す符号を組み合わせた添え字をつけて示した。なお、図13(A)に例示した確率テーブル165eにおいて、発話感情「怒り」、「悲しみ」、「嫌悪」、「驚き」および「喜び」を示す符号として、それぞれ符号「a」、「s」、「h」、「w」および「j」を用いた。
【0149】
確率テーブル165eに含まれる各組み合わせについての条件付確率は、例えば、発話感情の組み合わせについての正解付き学習データを用いた学習によって、それぞれ適切な値に設定することができる。なお、正解付き学習データとして、例えば、音声認識技術を用いることによって音声情報から文字で表現される情報を抽出した結果を用いて発話感情を推定した結果を用いてもよい。このような学習データを用いた学習を行うことにより、各組み合わせについての条件付確率の値を高い精度で決定することができる。
【0150】
図13(B)は、4種類の発話意図「勧誘」、「疑問」、「同意」および「断定」の組み合わせが、発話ペアに含まれる2つの発話音声に対応するパラ言語情報として抽出される条件付確率分布を示している。
【0151】
図13(B)に例示した確率テーブル165pにおいて、注目する会話グループにおけるj番目の発話音声の発話意図を列方向に示し、j+1番目の発話音声の発話意図を行方向に示した。また、j番目の発話音声の発話意図とj+1番目の発話音声の発話意図との組み合わせについての条件付確率を、符号「P」に2つの発話音声に対応する発話意図をそれぞれ示す符号を組み合わせた添え字をつけて示した。なお、図13(B)に例示した確率テーブル165pにおいて、発話意図「勧誘」、「疑問」、「同意」および「断定」を示す符号として、それぞれ符号「i」、「q」、「c」、および「d」を用いた。
【0152】
確率テーブル165pに含まれる各組み合わせについての条件付確率は、例えば、発話意図の組み合わせについての正解付き学習データを用いた学習によって、それぞれ適切な値に設定することができる。なお、正解付き学習データとして、例えば、音声認識技術を用いることによって音声情報から文字で表現される情報を抽出した結果を用いて発話意図を推定した結果を用いてもよい。このような学習データを用いた学習を行うことにより、各組み合わせについての条件付確率の値を高い精度で決定することができる。
【0153】
図13(C)は、4種類の発話態度「丁寧」、「改まった」、「くだけた」および「ぞんざい」の組み合わせが、発話ペアに含まれる2つの発話音声に対応するパラ言語情報として抽出される条件付確率分布を示している。
【0154】
図13(C)に例示した確率テーブル165aにおいて、注目する会話グループにおけるj番目の発話音声の発話態度を列方向に示し、j+1番目の発話音声の発話態度を行方向に示した。また、j番目の発話音声の発話態度とj+1番目の発話音声の発話態度との組み合わせについての条件付確率を、符号「P」に2つの発話音声に対応する発話態度をそれぞれ示す符号を組み合わせた添え字をつけて示した。なお、図13(C)に例示した確率テーブル165aにおいて、発話態度「丁寧」、「改まった」、「くだけた」および「ぞんざい」を示す符号として、それぞれ符号「p」、「f」、「u」、および「r」を用いた。
【0155】
確率テーブル165aに含まれる各組み合わせについての条件付確率は、例えば、発話態度の組み合わせについての正解付き学習データを用いた学習によって、それぞれ適切な値に設定することができる。なお、正解付き学習データとして、例えば、音声認識技術を用いることによって音声情報から文字で表現される情報を抽出した結果を用いて発話態度を推定した結果を用いてもよい。このような学習データを用いた学習を行うことにより、各組み合わせについての条件付確率の値を高い精度で決定することができる。
【0156】
図11に例示したテーブル参照部164は、上述した確率テーブル165e,165p,165aを参照することにより、発話配列リスト142で示される各発話ペアに対応するパラ言語情報の組み合わせが会話において出現する確率を取得する。
【0157】
テーブル参照部164は、例えば、まず、発話特徴蓄積部153から、各発話ペアに含まれる二つの発話音声に対応してそれぞれ蓄積されたパラ言語情報を取得する。そして、テーブル参照部164は、取得したパラ言語情報に含まれる発話感情、発話意図および発話態度の組み合わせに対応して確率テーブル165e,165p,165aにそれぞれ保持された確率を読み出せばよい。このようにして、テーブル参照部164は、各発話ペアに含まれる二つの発話音声からそれぞれ抽出された発話感情、発話意図および発話態度の組み合わせが会話において出現する確率をそれぞれ得ることができる。
【0158】
例えば、発話ペアの一方の発話音声から発話感情「喜び」を含むパラ言語情報が抽出され、他方の発話音声から発話感情「驚き」を含むパラ言語情報が抽出された場合に、上述したテーブル参照部164は、確率テーブル165eから確率Pjwを取得する。
【0159】
また、発話ペアの一方の発話音声から発話意図「同意」を含むパラ言語情報が抽出され、他方の発話音声から発話意図「疑問」を含むパラ言語情報が抽出された場合に、上述したテーブル参照部164は、確率テーブル165pから確率Pcqを取得する。
【0160】
同様に、発話ペアの一方の発話音声から発話態度「丁寧」を含むパラ言語情報が抽出され、他方の発話音声から発話態度「くだけた」を含むパラ言語情報が抽出された場合に、上述したテーブル参照部164は、確率テーブル165aから確率Ppuを取得する。
【0161】
図11に例示したパラ言語尤度算出部166は、テーブル参照部164で得られた発話感情、発話意図、発話態度についての確率に基づいて、各発話ペアのパラ言語的な特徴が、会話に含まれる発話音声の特徴に合致している度合いを示すパラ言語尤度を算出する。
【0162】
パラ言語尤度算出部166は、例えば、上述したテーブル参照部164が確率テーブル165e,165p,165aから取得した確率に、個別の重みを乗じた上で相乗平均を算出することにより、パラ言語尤度を求めてもよい。このようにして、発話感情、発話意図および発話態度の組み合わせについてのパラ言語的な特徴についての各条件が反映された確率テーブル165e,165p,165aから取得した各確率を反映したパラ言語尤度を求めることができる。
【0163】
なお、図11に例示したテーブル参照部164は、発話特徴蓄積部153に蓄積されたパラ言語情報の種類に応じて、パラ言語的な特徴についての条件の少なくとも一つに基づいて、各発話ペアが会話の一部として出現する確率を算出すればよい。また、図11に例示したパラ言語尤度算出部166は、テーブル参照部164が各発話ペアについて取得した少なくとも一つの条件に基づく確率を、重みつきで相乗平均することにより、パラ言語尤度を算出すればよい。また、発話特徴蓄積部153に蓄積されたパラ言語情報の種類が1種類である場合は、このパラ言語情報に基づいてテーブル参照部164で得られた確率がそのままパラ言語尤度となるので、パラ言語尤度算出部166を省略してもよい。
【0164】
図11に例示した第1算出部16は、このようにして求められた韻律尤度とパラ言語尤度とを、乗算部167が乗算することにより、各発話ペアが会話の一部であることの尤もらしさを示す第1尤度を求める。
【0165】
このようにして得られた第1尤度L1は、韻律尤度Lrとパラ言語尤度Lpとを用いて、式(9)のように表すことができる。
L1=Lr・Lp ・・・(9)
この第1尤度L1は、各発話ペアが会話の一部であることの尤もらしさを、当該発話ペアに含まれる二つの発話音声の韻律的な特徴とパラ言語的な特徴との双方に注目して評価した結果を示している。つまり、各発話ペアについて得られた第1尤度L1は、当該発話ペアに含まれる2つの発話音声が、韻律的につながっている可能性が高く、しかも、パラ言語的にもつながっている可能性が高い場合にのみ、高い値を示す。
【0166】
したがって、上述したようにして、韻律尤度とパラ言語尤度とを反映した第1尤度L1を算出することにより、より、高い確度で、各発話ペアが会話の一部であることの尤もらしさを評価することができる。
【0167】
そして、各組み合わせ候補に含まれる会話グループにおける発話順に並べられた発話音声をそれぞれ含む発話ペアについて、上述したようにして得られた第1尤度L1に基づいて、図6に例示した第2算出部17は次のようにして第2尤度を算出する。
【0168】
第2算出部17は、例えば、発話配列リスト142において、各会話グループに対応して配列されたM個の発話音声それぞれを含む発話ペアに対応する第1尤度L1の相乗平均として、第2尤度L2を算出してもよい。例えば、図8に例示した発話配列リスト142で示された組み合わせ候補1の会話グループ1に対応する第2尤度は、この会話グループ1に対応して配列された4つの発話音声から特定される3つの発話ペアのそれぞれの第1尤度を相乗平均した値である。発話順に並べられたM個の発話音声のうち、j番目の発話音声を含む発話ペアについて得られた第1尤度L1(j)を用いれば、第2算出部17によって算出される第2尤度L2は、式(10)のように表すことができる。
【0169】
【数5】
【0170】
このようにして、第2算出部17によって各組み合わせ候補に含まれる会話グループごとに算出された第2尤度L2は、当該会話グループに属する人物による発話音声の全てが会話を形成している可能性の高さを示している。
【0171】
したがって、図6に例示した第3算出部18は、絞込み部137で得られた各組み合わせ候補に含まれる会話グループごとに第2算出部17で得られた第2尤度L2を相乗平均することにより、当該組み合わせ候補についての第3尤度L3を算出することができる。
【0172】
注目する組み合わせ候補に含まれるN個の会話グループのうち、k番目の会話グループについて得られた第2尤度L2(k)を用いれば、第3算出部18によって当該組み合わせ候補について求められる第3尤度L3は、式(11)のように表すことができる。
【0173】
【数6】
【0174】
このようにして第3算出部18によって各組み合わせ候補について算出された第3尤度L3は、各組み合わせ候補が、図1に例示した複数の人物C1〜Cnが形成している複数の会話グループの組み合わせを反映している確率を示している。したがって、第3算出部18によって得られた第3尤度L3の高さに基づいて、複数の人物C1〜Cnが形成している複数の会話グループの組み合わせを特定することができる。
【0175】
上述したように、図11に例示した第1算出部16を有する音声情報解析装置10によれば、確度の高い第1尤度L1に基づいて、個々の会話グループについての第2尤度L2および各組み合わせ候補についての第3尤度L3を求めることができる。これにより、第3尤度L3に基づいて特定した会話グループの組み合わせが正しい組み合わせである確率を高めることができる。
【0176】
また、以上に説明した本件開示の音声情報解析装置10は、音声情報に含まれる音韻情報に基づく意味解析技術を用いることなく、複数の人物が形成している会話グループを特定することができる。したがって、本件開示の音声情報解析装置10の実現には、多数の人物の音声に対して意味解析技術を適用する場合に必要とされるような膨大な処理能力を必要としない。また、意味解析技術を用いないことにより、本件開示の音声情報解析装置10は、会話グループを特定する対象となる多数の人物の発言内容に含まれるプライヴァシーの保護にも配慮することができる。
【0177】
本件開示の音声情報解析装置10は、例えば、パーソナルコンピュータなどのコンピュータ装置を用いて実現することができる。
図14は、音声情報解析装置のハードウェア構成例を示している。
【0178】
図14に例示したコンピュータ装置20は、プロセッサ21と、メモリ22と、ハードディスク装置23と、表示装置24と、入力装置25と、光学ドライブ装置26と、ネットワークインタフェース28とを含んでいる。図14に例示したプロセッサ21と、メモリ22と、ハードディスク装置23と、表示装置24と、入力装置25と、光学ドライブ装置26と、ネットワークインタフェース28とは、バスを介して互いに接続されている。図14に例示した光学ドライブ装置26は、光ディスクなどのリムーバブルディスク27を装着可能であり、装着したリムーバブルディスク27に記録された情報の読出および記録を行う。また、図14に例示した音声情報解析装置10は、プロセッサ21と、メモリ22と、ハードディスク装置23と、表示装置24と、ネットワークインタフェース28とを含んでいる。
【0179】
図14に例示した入力装置25は、例えば、キーボードやマウスなどである。音声情報解析装置10の操作者は、入力装置25を操作することにより、音声情報解析装置10に含まれる各部に対して、例えば、会話グループを特定する処理を開始させる指示などを入力することができる。
【0180】
また、図14に例示したネットワークインタフェース28は、それぞれ異なる位置に設置されたm個の中継装置S1〜Smに接続されている。
【0181】
メモリ22は、コンピュータ装置20のオペレーティングシステムとともに、プロセッサ21が上述した音声情報解析処理を実行するためのアプリケーションプログラムを格納している。なお、上述した音声情報解析処理を実行するためのアプリケーションプログラムは、例えば、光ディスクなどのリムーバブルディスク27に記録して頒布することができる。そして、このリムーバブルディスク27を光学ドライブ装置26に装着して読み込み処理を行うことにより、音声情報解析処理を実行するためのアプリケーションプログラムを、メモリ22およびハードディスク装置23に格納させてもよい。また、ネットワークインタフェース28を介してインターネットなどのネットワークに接続することで、ネットワーク経由で、音声情報解析処理のためのアプリケーションプログラムをメモリ22およびハードディスク装置23に読み込ませることもできる。
【0182】
また、図14に例示したハードディスク装置23は、音声情報解析処理のためのアプリケーションプログラムに含まれる各種のデータを格納する。例えば、ハードディスク装置23は、音声情報から発話感情、発話意図および発話態度を推定するために利用する基準を示す情報を格納してもよい。また、ハードディスク装置23が、上述した式(1)、(3)、(5)、(7)に含まれる各パラメータを保持することにより、図11に例示したパラメータ保持部162の機能を実現してもよい。更に、ハードディスク装置23が、各種のパラ言語情報の組み合わせについての条件付確率分布を示す情報を保持することにより、図11に例示した確率テーブル165e、165p、165aを実現してもよい。
【0183】
また、プロセッサ21は、メモリ22に格納されたアプリケーションプログラムを実行することにより、図1に例示した取得部11、収集部12、生成部13、配列部14の機能を果たしてもよい。また、プロセッサ21は、メモリ22に格納されたアプリケーションプログラムを実行することにより、図1に例示した抽出部15、第1算出部16、第2算出部17および第3算出部18の機能を果たしてもよい。
【0184】
図15は、音声情報解析処理のフローチャートの一例を示している。図15に示したステップS1〜ステップS6の各処理は、上述した音声情報解析処理のためのアプリケーションプログラムに含まれる処理の一例である。また、これらのステップS1〜ステップS6の各処理は、図14に例示したプロセッサ21によって実行される。
【0185】
プロセッサ21は、図14に例示したネットワークインタフェース28と、中継装置S1〜Smおよび携帯端末T1〜Tnを介して、これらの携帯端末T1〜Tnを所持する各人物の発話音声を示す音声情報を取得する(ステップS1)。
【0186】
また、プロセッサ21は、図14に例示したネットワークインタフェース28を介して、中継装置S1〜Smから、それぞれが無線アクセスを提供している携帯端末を示す情報を、携帯端末T1〜Tnの所持者の位置を示す位置情報として収集する(ステップS2)。
【0187】
次いで、プロセッサ21は、ステップS1およびステップS2で得られた音声情報および位置情報を、例えば、ハードディスク装置23に設けた音声情報蓄積部111および位置情報蓄積部121にそれぞれ蓄積する(ステップS3)。
【0188】
このように、プロセッサ21が、ステップS1〜ステップS3の処理を実行することにより、図6に例示した音声情報蓄積部111と位置情報蓄積部121とをそれぞれ含む取得部11および収集部12の機能を実現することができる。
【0189】
次いで、プロセッサ12は、図14に例示した入力装置25を介して、会話グループを特定する処理を開始する旨の指示が入力されたか否かを判定する(ステップS4)。
【0190】
例えば、会話グループを特定する処理の開始を指示するメッセージが、入力装置25を介してプロセッサ21に渡されたときに、プロセッサ21は、ステップS4の肯定判定ルートに進む。そして、上述したメッセージを受け取った時刻tから後述する会話グループを特定する処理を実行することにより、会話グループを特定する(ステップS5)。その後、プロセッサ21は、ステップS6の処理に進む。
【0191】
一方、会話グループを特定する処理の開始を指示するメッセージが入力装置25から渡されなかった場合に、プロセッサ21は、ステップS4の否定判定ルートに進む。ステップS4の否定判定ルートにおいて、プロセッサ21は、音声情報解析処理を継続するか否かを判定する(ステップS6)。
【0192】
例えば、入力装置25を介して、音声情報解析処理の終了が指示された場合に、プロセッサ21は、ステップS6の否定判定ルートに従って、音声情報解析処理を終了する。一方、音声情報解析処理の終了が指示されていない場合に、プロセッサ21は、ステップS6の肯定判定ルートに従って、ステップS1の処理に戻り、音声情報解析処理を続行する。
【0193】
次に、音声情報解析処理に含まれる会話グループを特定する処理を、図14に例示した音声情報解析装置10によって実現する方法について説明する。
【0194】
図16は、会話グループを特定する処理のフローチャートの一例を示している。図16に示したステップS301〜ステップS310の各処理は、上述した音声情報解析処理のフローチャートに例示したステップS5の処理の一例である。また、これらのステップS301〜ステップS310の各処理は、図14に例示したプロセッサ21によって実行される。
【0195】
プロセッサ21は、会話グループを特定する処理を、会話グループを特定する処理を開始する旨のメッセージを受け取った時刻tから時間Tを遡った時刻t−Tを開始時刻とする期間Tdに対応して蓄積された音声情報および位置情報に基づいて実行する。
【0196】
まず、プロセッサ21は、上述した期間Tdに含まれる各サンプリング時刻に対応して音声情報蓄積部111に蓄積された音声信号の強度に基づいて、当該サンプリング時刻において各人物が発話中であるか否かを判定する(ステップS301)。そして、プロセッサ21は、ステップS301の処理で得られた判定結果を、例えば、ハードディスク装置23に設けた発話リスト132に集積する(ステップS302)。このように、プロセッサ21が、ステップS301,S302の処理を実行することにより、図6に例示した発話判定部131の機能を実現してもよい。
【0197】
また、プロセッサ21は、上述した期間Tdに含まれる各サンプリング時刻に対応して位置情報蓄積部121に蓄積された位置情報に基づいて、当該サンプリング時刻において各人物に近接する中継装置Sxを特定する(ステップS303)。なお、中継装置Sxは、図14に例示した中継装置S1〜Smのいずれかである。そして、プロセッサ21は、ステップS303の処理で得られた結果に基づいて、各中継装置S1〜Smに近接する人物の集合を、例えば、ハードディスク装置23に設けた近接人物リスト134に集積する(ステップS304)。このように、プロセッサ21が、ステップS303,S304の処理を実行することにより、図6に例示した位置分類部133の機能を実現してもよい。
【0198】
次いで、プロセッサ21は、上述したステップS301の処理において、期間Tdにおける発話が検出された人物を、近接人物リスト134に基づいて、近接している中継装置Sxごとにグループ分けする(ステップS305)。そして、プロセッサ21は、各中継装置S1〜Smに対応する各グループに属する人物が形成している可能性のある会話グループについての組み合わせを列挙する(ステップS306)。このように、プロセッサ21が、ステップS305,S306の処理を実行することにより、図6に例示した組み合わせ列挙部135の機能を実現してもよい。
【0199】
次に、プロセッサ21は、上述した発話リスト132に含まれる情報に基づいて、発話期間が重複している人物の組み合わせを検出する(ステップS307)。プロセッサ21は、例えば、発話リスト132に含まれる人物のペアごとに、上述した期間Tdにおいて同一の時刻に対応して発話中である旨の判定結果が保持されている回数を計数した結果に基づいて、発話重複率を算出してもよい。このようにして得られた発話重複率が上述した所定の閾値を超える組み合わせを、プロセッサ21は、発話期間が重複している人物の組み合わせとして検出してもよい。そして、プロセッサ21は、ステップS306の処理で列挙した会話グループの組み合わせから、ステップS307の処理で検出した人物の組み合わせを含む会話グループが属する組み合わせを排除することにより、組み合わせ候補を絞り込む(ステップS308)。このように、プロセッサ21が、ステップS307,S308の処理を実行することにより、図6に例示した重複率算出部136および絞込み部137の機能を実現してもよい。
【0200】
このようにして得られた会話グループの組み合わせ候補について、プロセッサ21は、後述するようにして、図14に例示した携帯端末T1〜Tnを所持する人物が形成している会話グループの組み合わせとしての尤もらしさを評価する(ステップS309)。
【0201】
そして、ステップS309の処理による評価結果に基づいて、プロセッサ21は、最尤の組み合わせ候補を、図14に例示した携帯端末T1〜Tnを所持する人物が形成している会話グループの組み合わせとして特定する。
【0202】
次に、会話グループを特定する処理に含まれる各組み合わせ候補の尤もらしさを評価する処理を、図14に例示した音声情報解析装置10によって実現する方法について説明する。
【0203】
図17は、各組み合わせ候補の尤もらしさを評価する処理のフローチャートの一例を示している。図17に示したステップS311〜ステップS325の各処理は、上述した会話グループを特定する処理のフローチャートに例示したステップS309の処理の一例である。また、これらのステップS311〜ステップS325の各処理は、図14に例示したプロセッサ21によって実行される。
【0204】
まず、プロセッサ21は、評価対象の組み合わせ候補の中で注目する組み合わせ候補を示す組み合わせ候補番号kに初期値1を設定する(ステップS311)。なお、以下の説明において、組み合わせ候補番号kで示される組み合わせ候補を組み合わせ候補kと称する。
【0205】
次いで、プロセッサ21は、評価対象の組み合わせ候補に含まれる会話グループの中で注目する会話グループを示す会話グループ番号iに初期値1を設定する(ステップS312)。なお、以下の説明において、会話グループ番号iで示される会話グループを会話グループiと称する。
【0206】
次に、プロセッサ21は、組み合わせ候補kに含まれる会話グループiに属する各人物による発話音声を時系列に従ってソートする(ステップS313)。例えば、プロセッサ21は、発話リスト132に基づいて、各人物による個々の発話音声の開始時刻を特定し、特定した開始時刻が早い順に各発話音声を並べることによって、上述したソート処理を実行してもよい。
【0207】
次いで、プロセッサ21は、会話グループiについてソートされた発話音声の中で注目する発話音声を示す発話番号jに初期値1を設定する(ステップS314)。なお、以下の説明において、発話番号jの発話音声を発話音声M(j)で示す。
【0208】
次に、プロセッサ21は、音声情報蓄積部111から、発話音声M(j)に対応する特徴情報を抽出する(ステップS315)。ステップS315の処理において、プロセッサ21は、例えば、発話音声M(j)に対応する音声情報に基づいて、発話パワー、発話速度、基本周波数および持続時間を含む韻律情報を、発話音声M(j)に対応する特徴情報の一部として抽出してもよい。また、プロセッサ21は、ステップS315の処理において、発話感情、発話意図および発話態度を含むパラ言語情報を、発話音声M(j)に対応する特徴情報の一部として抽出してもよい。更に、発話番号jが値2以上である場合に、プロセッサ21は、ステップS315の処理において、発話音声M(j)の開始時刻と発話音声M(j−1)の終了時刻との差で示される発話間隔を、発話音声M(j)に対応する特徴情報の一部として抽出してもよい。このようなステップS315の処理をプロセッサ21が実行することは、図1に例示した抽出部15を実現する手法の一例である。
【0209】
なお、プロセッサ21は、ステップS315の処理において抽出した特徴情報を、他の組み合わせ候補に含まれる会話グループについての処理において利用できるように、メモリ22あるいはハードディスク装置23内に保持しておいてもよい。例えば、プロセッサ21は、組み合わせ候補1についての処理の過程で、ハードディスク装置23に設けた発話特徴蓄積部153に、個々の発話音声を識別する識別情報に対応して、個々の発話音声に対応する音声情報から抽出した特徴情報を蓄積してもよい。そして、候補番号2以降の組み合わせ候補kについての処理では、ステップS313の処理において、プロセッサ21が、発話音声の識別情報と、組み合わせ候補kの会話グループiにおける発話番号jとを対応付ければよい。これにより、プロセッサ21は、ステップS315の処理において、改めて音声情報から韻律情報およびパラ言語情報を抽出する代わりに、発話特徴蓄積部153に蓄積された抽出済みの特徴情報を利用することができる。
【0210】
次いで、プロセッサ21は、発話番号jが初期値1であるか否かを判定する(ステップS316)。発話番号jが値2以上である場合に(ステップS316の否定判定)、プロセッサ21は、ステップS317において、発話音声M(j)と発話音声M(j−1)とを含む発話ペアについて、この発話ペアが会話の一部である可能性の高さを示す第1尤度を算出する。
【0211】
ステップS317において、プロセッサ21は、次のようにして、発話音声M(j)を含む発話ペアについての第1尤度L1(j)を求める。まず、プロセッサ21は、ステップS315の処理で抽出した特徴情報に含まれる韻律情報と、上述した式(1)、(3)、(5)、(7)および式(8)とを用いて、この発話ペアの韻律尤度Lrを算出する。また、プロセッサ21は、ステップS315の処理で抽出した特徴情報に含まれるパラ言語情報と、上述した確率テーブル165e,165p,165aおよび式(9)とを用いて、この発話ペアのパラ言語尤度Lpを算出する。そして、プロセッサ21は、このようにして得られた韻律尤度Lrとパラ言語尤度Lpとを乗算することにより、この発話ペアについての第1尤度L1(j)を算出する。このように、プロセッサ21が、ステップS317の処理を実行することにより、図11に例示した第1算出部16の機能を実現することができる。
【0212】
ステップS316の肯定判定ルートにおいて、プロセッサ21は、上述したステップS317の処理の終了後に、ステップS318の処理に進む。一方、ステップS316の肯定判定の場合に、プロセッサ21は、ステップS317の処理をスキップして、ステップS318の処理に進む。
【0213】
ステップS318において、プロセッサ21は、ステップS313で並べられた全ての発話音声についての処理が終了したか否かを判定する。未処理の発話音声がある場合に、プロセッサ21は、ステップS318の否定判定ルートに従って処理を進め、ステップS319において、発話番号jに値1を加算してから、ステップS315の処理に戻る。そして、プロセッサ21は、新たな発話音声M(j)についての処理を開始する。
【0214】
このようにして、ステップS315〜ステップS319の処理を繰り返し実行することにより、プロセッサ21は、ステップS313で並べられた各発話音声M(j)を含む発話ペアについて第1尤度L1(j)を算出する。そして、ステップS313で並べられた全ての発話音声についての処理が終了したときに、プロセッサ21は、ステップS318の肯定判定ルートに従って、ステップS320の処理に進む。
【0215】
ステップS320において、プロセッサ21は、上述した式(10)を用いて、各発話音声M(j)を含む発話ペアについて算出した第1尤度L1(j)から、組み合わせ候補kに含まれる会話グループiについての第2尤度L2(i)を算出する。このように、プロセッサ21が、ステップS320の処理を実行することにより、図1に例示した第2算出部17の機能を実現することができる。
【0216】
その後、プロセッサ21は、組み合わせ候補kに含まれる全ての会話グループについての処理が終了したか否かを判定する(ステップS321)。未処理の会話グループがある場合に、プロセッサ21は、ステップS321の否定判定ルートに従って処理を進め、ステップS322において、グループ番号iに値1を加算してから、ステップS314の処理に戻る。そして、プロセッサ21は、新たな会話グループiについての処理を開始する。
【0217】
このようにして、ステップS314〜ステップS322の処理を繰り返し実行することにより、プロセッサ21は、組み合わせ候補kに含まれる各会話グループiについて第2尤度L2(i)を算出する。そして、組み合わせ候補kに含まれる全ての会話グループについての処理が終了したときに、プロセッサ21は、ステップS321の肯定判定ルートに従って、ステップS323の処理に進む。
【0218】
ステップS323において、プロセッサ21は、上述した式(11)に示したように、各会話グループについて算出した第2尤度L2(i)を相乗平均することにより、組み合わせ候補kについての第3尤度L3(k)を算出する。このように、プロセッサ21が、ステップS323の処理を実行することにより、図1に例示した第3算出部18の機能を実現することができる。
【0219】
その後、プロセッサ21は、全ての組み合わせ候補についての処理が終了したか否かを判定する(ステップS324)。未処理の組み合わせ候補がある場合に、プロセッサ21は、ステップS324の否定判定ルートに従って処理を進め、ステップS325において、候補番号kに値1を加算してから、ステップS312の処理に戻る。そして、プロセッサ21は、組み合わせ候補kについての処理を開始する。
【0220】
このようにして、ステップS312〜ステップS325の処理を繰り返し実行することにより、プロセッサ21は、各組み合わせ候補について第3尤度L3(k)を算出する。そして、全ての組み合わせ候補についての処理が終了したときに、プロセッサ21は、ステップS324の肯定判定ルートに従って、各組み合わせ候補の尤もらしさを評価する処理を終了する。
【0221】
このように、図14に例示したコンピュータ装置20のプロセッサ21が、音声情報処理のためのアプリケーションプログラムを実行することによって、本件開示の音声情報解析装置10を実現することができる。
【0222】
以上に説明したように、本件開示の音声情報解析装置10は、会話グループの特定処理の対象となる複数の人物が所持している携帯端末などの汎用の情報機器を介して収集可能な音声情報と概略の位置情報とに基づいて会話グループの特定が可能である。このため、本件開示の音声情報解析装置10は、会話グループの特定処理の対象となる複数の人物それぞれについて厳密な位置情報を取得するための専用の情報端末などを必要としない。したがって、音声情報を収集する側の負担および会話グループの特定処理の対象となる複数の人物側の負担を、ともに軽減することができる。
【0223】
以上の説明に関して、更に、以下の各項を開示する。
(付記1) 複数の人物それぞれが発話した音声を表す音声情報を取得する取得部と、
前記複数の人物それぞれの位置を示す位置情報を収集する収集部と、
前記各人物の音声情報と前記各人物の位置情報とに基づいて、会話をしている可能性がある複数の人物を含む複数の会話グループを求め、求めた会話グループの組み合わせから会話をしている可能性の高い会話グループの組み合わせを組み合わせ候補として生成する生成部と、
前記組み合わせ候補に含まれる各会話グループに属する前記複数の人物による複数の発話音声を時系列に従って配列する配列部と、
前記前記配列部によって会話グループごとに配列された前記複数の発話音声において連続する2つの発話音声として特定される発話ペアごとに、前記発話ペアに対応する音声情報から、韻律的な特徴を示す韻律情報とパラ言語的な特徴に対応するパラ言語情報との少なくとも一方を含む特徴情報を抽出する抽出部と、
前記特徴情報と、前記発話ペアが会話の一部である場合に当該特徴情報が従う確率分布とに基づいて、前記各発話ペアが会話の一部であることの尤もらしさを示す第1尤度を算出する第1算出部と、
前記第1算出部で前記各発話ペアについて得られた前記第1尤度に基づいて、前記配列部によって会話グループごとに配列された前記複数の発話音声の全てが、当該会話グループに属する各人物による会話に含まれている確率を示す第2尤度を算出する第2算出部と
前記各組み合わせ候補に含まれる各会話グループについて算出した前記第2尤度に基づいて、当該組み合わせ候補が、前記複数の人物が形成している複数の会話グループの組み合わせを反映している確率を示す第3尤度を算出する第3算出部と
を備えたことを特徴とする音声解析装置。
(付記2) 付記1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話ペアに属する発話音声のパワーを示す発話パワーと2つの発話相互の時間間隔を示す発話間隔とを含む韻律情報を抽出し、
前記第1算出部は、
前記発話パワーが大きいほど、小さい前記発話間隔の確率が高くなる特性を有する確率分布に基づいて、前記韻律情報に含まれる前記発話パワーを持つ発話音声が前記発話間隔で出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
(付記3) 付記1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話ペアに属する発話音声における発話速度と2つの発話音声相互の時間間隔を示す発話間隔とを含む韻律情報を抽出し、
前記第1算出部は、前記発話速度が速いほど、小さい前記発話間隔の確率が高くなる特性を有する確率分布に基づいて、前記韻律情報に含まれる前記前側の発話音声の発話速度と前記発話間隔との組み合わせが出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
(付記4) 付記1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話ペアに属する発話音声の基本周波数と2つの発話音声相互の時間間隔を示す発話間隔とを含む韻律情報を抽出し、
前記第1算出部は、前記基本周波数が高いほど、小さい前記発話間隔の確率が高くなる特性を有する確率分布に基づいて、前記韻律情報に含まれる前記前側の発話音声の発話速度と前記発話間隔との組み合わせが出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
(付記5) 付記1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話ペアに属する2つの発話音声の持続時間を含む韻律情報を抽出し、
前記第1算出部は、会話中に連続して現れる2つの発話音声の持続時間についての学習によって得られた確率分布モデルに基づいて、前記韻律情報に含まれる2つの持続時間を持つ発話音声が連続していることの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
(付記6) 付記1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話音声に付随する感情の種別を推定する感情推定部を有し、
前記感情推定部によって、前記発話ペアに属する2つの発話音声について推定された前記感情の種別をそれぞれ示す感情情報を含むパラ言語情報を抽出し、
前記第1算出部は、会話に含まれる発話音声に付随する可能性を有する複数種別の感情の組み合わせが会話中で連続して現れる事象についての条件付確率分布に基づいて、前記パラ言語情報に含まれる前記2つの感情情報でそれぞれ示される種別の感情を伴う発話音声が連続して出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
(付記7) 付記1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話音声が発話された際の話者の意図を推定する意図推定部を有し、
前記意図推定部によって、前記発話ペアに属する2つの発話音声に対応して推定された前記話者の意図の種別をそれぞれ示す意図情報を含むパラ言語情報を抽出し、
前記第1算出部は、会話における話者の意図として出現する可能性を有する複数種別の意図の組み合わせが会話中で連続して現れる事象についての条件付確率分布に基づいて、前記パラ言語情報に含まれる2つの意図情報でそれぞれ示される種別の意図を伴う発話音声が連続して出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
(付記8) 付記1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話音声が発話された際の話者の態度を推定する態度推定部を有し、
前記態度推定部によって、前記発話ペアに属する2つの発話音声に対応する前記話者の態度の種別をそれぞれ示す態度情報を含むパラ言語情報を抽出し、
前記第1算出部は、会話における話者の態度として出現する可能性を有する複数種別の態度の組み合わせが会話中で連続して現れる事象についての条件付確率分布に基づいて、前記パラ言語情報に含まれる2つの態度情報でそれぞれ示される種別の態度を伴う発話音声が連続して出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
(付記9) 複数の人物それぞれが発話した音声を表す音声情報および前記複数の人物それぞれの位置を示す位置情報を取得し、
前記各人物の音声情報と前記各人物の位置情報とに基づいて、会話をしている可能性がある複数の人物を含む複数の会話グループを求め、求めた会話グループの組み合わせから会話をしている可能性の高い会話グループの組み合わせを組み合わせ候補として生成し、
前記組み合わせ候補に含まれる各会話グループに属する前記複数の人物の発話音声を時系列に従って並べ替えることにより、前記各会話グループにおける発話音声の出現順序を示す発話音声の配列を生成し、
前記各会話グループに対応する前記発話音声の配列に含まれる各発話音声と当該発話音声に連続する発話音声とを含む発話ペアごとに、前記発話ペアに含まれる2つの発話音声に対応する音声情報から、韻律情報とパラ言語情報との少なくとも一方を含む特徴情報を抽出し、
前記特徴情報と、前記発話ペアが会話の一部である場合に当該特徴情報が従う確率分布とに基づいて、前記各発話ペアが会話の一部である確率を示す第1尤度を算出し、
前記各会話グループに対応する発話音声の配列に含まれる前記発話ペアについて算出した前記第1尤度に基づいて、前記発話音声の配列に含まれる全ての発話音声が、当該会話グループに属する各人物による会話に含まれている確率を示す第2尤度を算出し、
前記各組み合わせ候補に含まれる各会話グループについて算出した前記第2尤度に基づいて、当該組み合わせ候補が、前記複数の人物が形成している複数の会話グループの組み合わせを反映している確率を示す第3尤度を算出する
処理をコンピュータに実行させることを特徴とする音声解析プログラム。
【符号の説明】
【0224】
10…音声情報解析装置;11…取得部;12…収集部;13…生成部;14…配列部;15…抽出部;16…第1算出部;17…第2算出部;18…第3算出部;111…音声情報蓄積部;121…位置情報蓄積部;131…発話判定部;132…発話リスト;133…位置分類部;134…近接人物リスト;135…組み合わせ列挙部;136…重複率算出部;137…絞込み部;141…整列処理部;142…発話配列リスト;151−p…発話パワー算出部;151−v…発話速度算出部;151−f…基本周波数算出部;151−s…持続時間抽出部;151−d…発話間隔算出部;152−e…感情推定部;152−p…意図推定部;152−a…態度推定部;153…発話特徴蓄積部;154…間隔情報蓄積部;161…確率演算部;162…パラメータ保持部;163…韻律尤度算出部;164…テーブル参照部;165e,165p,165a…確率テーブル;166…パラ言語尤度算出部;167…乗算部;21…プロセッサ;22…メモリ;23…ハードディスク装置(HDD);24…表示装置;25…入力装置;26…光学ドライブ装置;27…リムーバブルディスク;28…ネットワークインタフェース;S1,S2…中継装置;C1〜Cn、A,B,C,D,E,F,G…人物;T1〜Tn…携帯端末
【特許請求の範囲】
【請求項1】
複数の人物それぞれが発話した音声を表す音声情報を取得する取得部と、
前記複数の人物それぞれの位置を示す位置情報を収集する収集部と、
前記各人物の音声情報と前記各人物の位置情報とに基づいて、会話をしている可能性がある複数の人物を含む複数の会話グループを求め、求めた会話グループの組み合わせから会話をしている可能性の高い会話グループの組み合わせを組み合わせ候補として生成する生成部と、
前記組み合わせ候補に含まれる各会話グループに属する前記複数の人物による複数の発話音声を時系列に従って配列する配列部と、
前記配列部によって会話グループごとに配列された前記複数の発話音声において連続する2つの発話音声として特定される発話ペアごとに、前記発話ペアに対応する音声情報から、韻律的な特徴を示す韻律情報とパラ言語的な特徴に対応するパラ言語情報との少なくとも一方を含む特徴情報を抽出する抽出部と、
前記特徴情報と、前記発話ペアが会話の一部である場合に当該特徴情報が従う確率分布とに基づいて、前記各発話ペアが会話の一部であることの尤もらしさを示す第1尤度を算出する第1算出部と、
前記第1算出部で前記各発話ペアについて得られた前記第1尤度に基づいて、前記配列部によって会話グループごとに配列された前記複数の発話音声の全てが、当該会話グループに属する各人物による会話に含まれている確率を示す第2尤度を算出する第2算出部と、
前記各組み合わせ候補に含まれる各会話グループについて算出した前記第2尤度に基づいて、当該組み合わせ候補が、前記複数の人物が形成している複数の会話グループの組み合わせを反映している確率を示す第3尤度を算出する第3算出部と
を備えたことを特徴とする音声解析装置。
【請求項2】
請求項1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話ペアに属する発話音声のパワーを示す発話パワーと2つの発話相互の時間間隔を示す発話間隔とを含む韻律情報を抽出し、
前記第1算出部は、
前記発話パワーが大きいほど、小さい前記発話間隔の確率が高くなる特性を有する確率分布に基づいて、前記韻律情報に含まれる前記発話パワーを持つ発話音声が前記発話間隔で出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
【請求項3】
請求項1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話音声に付随する感情の種別を推定する感情推定部を有し、
前記感情推定部によって、前記発話ペアに属する2つの発話音声について推定された前記感情の種別をそれぞれ示す感情情報を含むパラ言語情報を抽出し、
前記第1算出部は、会話に含まれる発話音声に付随する可能性を有する複数種別の感情の組み合わせが会話中で連続して現れる事象についての条件付確率分布に基づいて、前記パラ言語情報に含まれる前記2つの感情情報でそれぞれ示される種別の感情を伴う発話音声が連続して出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
【請求項4】
複数の人物それぞれが発話した音声を表す音声情報および前記複数の人物それぞれの位置を示す位置情報を取得し、
前記各人物の音声情報と前記各人物の位置情報とに基づいて、会話をしている可能性がある複数の人物を含む複数の会話グループを求め、求めた会話グループの組み合わせから会話をしている可能性の高い会話グループの組み合わせを組み合わせ候補として生成し、
前記組み合わせ候補に含まれる各会話グループに属する前記複数の人物の発話音声を時系列に従って並べ替えることにより、前記各会話グループにおける発話音声の出現順序を示す発話音声の配列を生成し、
前記各会話グループに対応する前記発話音声の配列に含まれる各発話音声と当該発話音声に連続する発話音声とを含む発話ペアごとに、前記発話ペアに含まれる2つの発話音声に対応する音声情報から、韻律情報とパラ言語情報との少なくとも一方を含む特徴情報を抽出し、
前記特徴情報と、前記発話ペアが会話の一部である場合に当該特徴情報が従う確率分布とに基づいて、前記各発話ペアが会話の一部である確率を示す第1尤度を算出し、
前記各会話グループに対応する発話音声の配列に含まれる前記発話ペアについて算出した前記第1尤度に基づいて、前記発話音声の配列に含まれる全ての発話音声が、当該会話グループに属する各人物による会話に含まれている確率を示す第2尤度を算出し、
前記各組み合わせ候補に含まれる各会話グループについて算出した前記第2尤度に基づいて、当該組み合わせ候補が、前記複数の人物が形成している複数の会話グループの組み合わせを反映している確率を示す第3尤度を算出する
処理をコンピュータに実行させることを特徴とする音声解析プログラム。
【請求項1】
複数の人物それぞれが発話した音声を表す音声情報を取得する取得部と、
前記複数の人物それぞれの位置を示す位置情報を収集する収集部と、
前記各人物の音声情報と前記各人物の位置情報とに基づいて、会話をしている可能性がある複数の人物を含む複数の会話グループを求め、求めた会話グループの組み合わせから会話をしている可能性の高い会話グループの組み合わせを組み合わせ候補として生成する生成部と、
前記組み合わせ候補に含まれる各会話グループに属する前記複数の人物による複数の発話音声を時系列に従って配列する配列部と、
前記配列部によって会話グループごとに配列された前記複数の発話音声において連続する2つの発話音声として特定される発話ペアごとに、前記発話ペアに対応する音声情報から、韻律的な特徴を示す韻律情報とパラ言語的な特徴に対応するパラ言語情報との少なくとも一方を含む特徴情報を抽出する抽出部と、
前記特徴情報と、前記発話ペアが会話の一部である場合に当該特徴情報が従う確率分布とに基づいて、前記各発話ペアが会話の一部であることの尤もらしさを示す第1尤度を算出する第1算出部と、
前記第1算出部で前記各発話ペアについて得られた前記第1尤度に基づいて、前記配列部によって会話グループごとに配列された前記複数の発話音声の全てが、当該会話グループに属する各人物による会話に含まれている確率を示す第2尤度を算出する第2算出部と、
前記各組み合わせ候補に含まれる各会話グループについて算出した前記第2尤度に基づいて、当該組み合わせ候補が、前記複数の人物が形成している複数の会話グループの組み合わせを反映している確率を示す第3尤度を算出する第3算出部と
を備えたことを特徴とする音声解析装置。
【請求項2】
請求項1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話ペアに属する発話音声のパワーを示す発話パワーと2つの発話相互の時間間隔を示す発話間隔とを含む韻律情報を抽出し、
前記第1算出部は、
前記発話パワーが大きいほど、小さい前記発話間隔の確率が高くなる特性を有する確率分布に基づいて、前記韻律情報に含まれる前記発話パワーを持つ発話音声が前記発話間隔で出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
【請求項3】
請求項1に記載の音声解析装置において、
前記抽出部は、前記各発話ペアにそれぞれ対応する音声情報から、当該発話音声に付随する感情の種別を推定する感情推定部を有し、
前記感情推定部によって、前記発話ペアに属する2つの発話音声について推定された前記感情の種別をそれぞれ示す感情情報を含むパラ言語情報を抽出し、
前記第1算出部は、会話に含まれる発話音声に付随する可能性を有する複数種別の感情の組み合わせが会話中で連続して現れる事象についての条件付確率分布に基づいて、前記パラ言語情報に含まれる前記2つの感情情報でそれぞれ示される種別の感情を伴う発話音声が連続して出現することの尤もらしさを反映する前記第1尤度を算出する
ことを特徴とする音声解析装置。
【請求項4】
複数の人物それぞれが発話した音声を表す音声情報および前記複数の人物それぞれの位置を示す位置情報を取得し、
前記各人物の音声情報と前記各人物の位置情報とに基づいて、会話をしている可能性がある複数の人物を含む複数の会話グループを求め、求めた会話グループの組み合わせから会話をしている可能性の高い会話グループの組み合わせを組み合わせ候補として生成し、
前記組み合わせ候補に含まれる各会話グループに属する前記複数の人物の発話音声を時系列に従って並べ替えることにより、前記各会話グループにおける発話音声の出現順序を示す発話音声の配列を生成し、
前記各会話グループに対応する前記発話音声の配列に含まれる各発話音声と当該発話音声に連続する発話音声とを含む発話ペアごとに、前記発話ペアに含まれる2つの発話音声に対応する音声情報から、韻律情報とパラ言語情報との少なくとも一方を含む特徴情報を抽出し、
前記特徴情報と、前記発話ペアが会話の一部である場合に当該特徴情報が従う確率分布とに基づいて、前記各発話ペアが会話の一部である確率を示す第1尤度を算出し、
前記各会話グループに対応する発話音声の配列に含まれる前記発話ペアについて算出した前記第1尤度に基づいて、前記発話音声の配列に含まれる全ての発話音声が、当該会話グループに属する各人物による会話に含まれている確率を示す第2尤度を算出し、
前記各組み合わせ候補に含まれる各会話グループについて算出した前記第2尤度に基づいて、当該組み合わせ候補が、前記複数の人物が形成している複数の会話グループの組み合わせを反映している確率を示す第3尤度を算出する
処理をコンピュータに実行させることを特徴とする音声解析プログラム。
【図1】

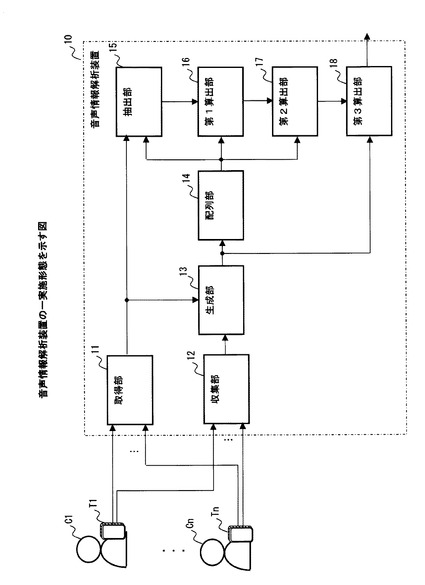
【図2】
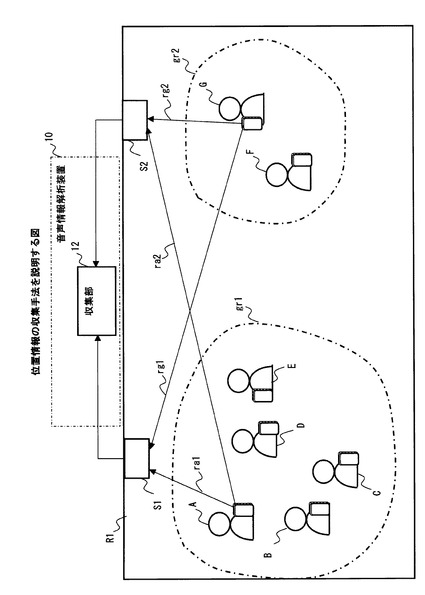
【図3】
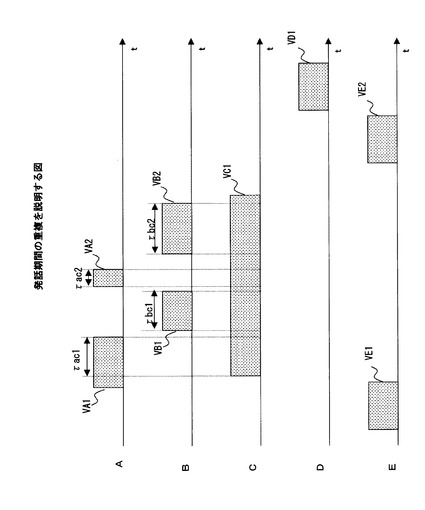
【図4】
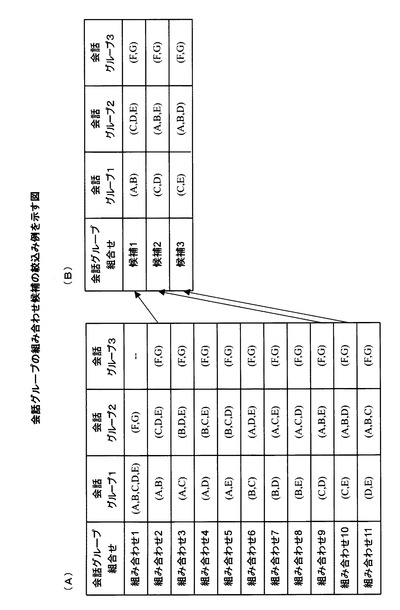
【図5】
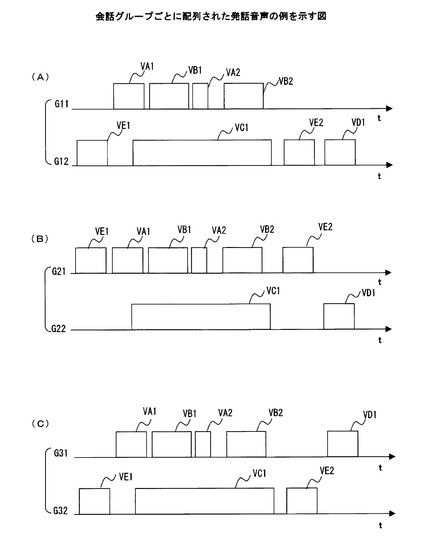
【図6】
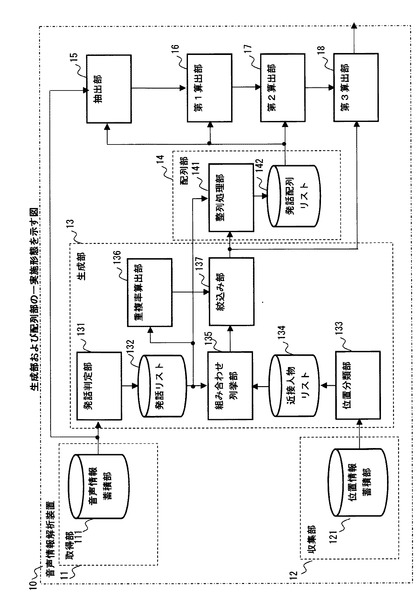
【図7】
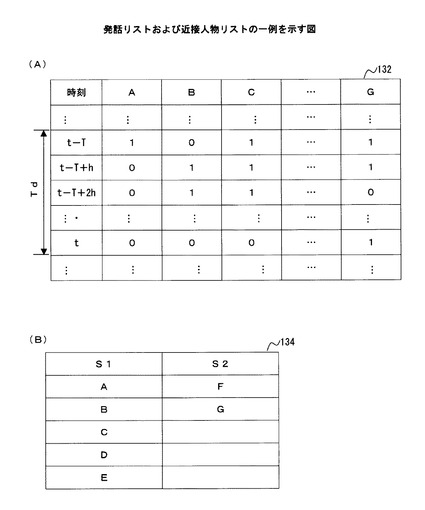
【図8】
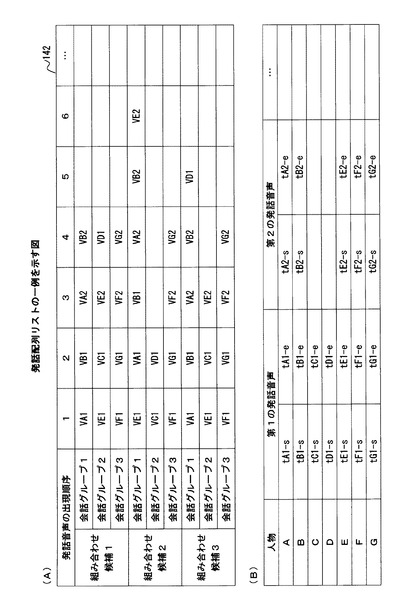
【図9】
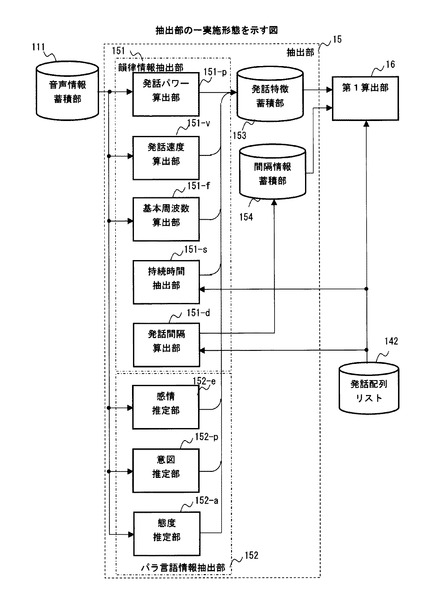
【図10】

【図11】
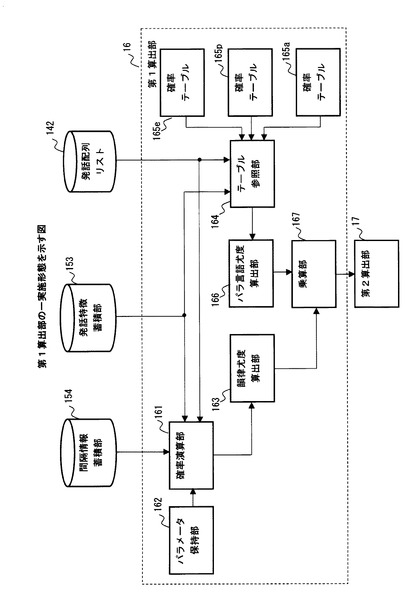
【図12】

【図13】
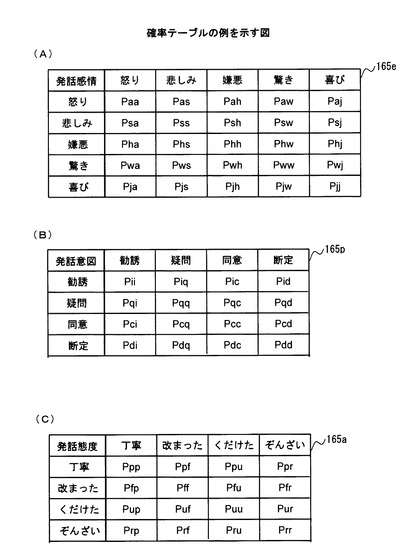
【図14】
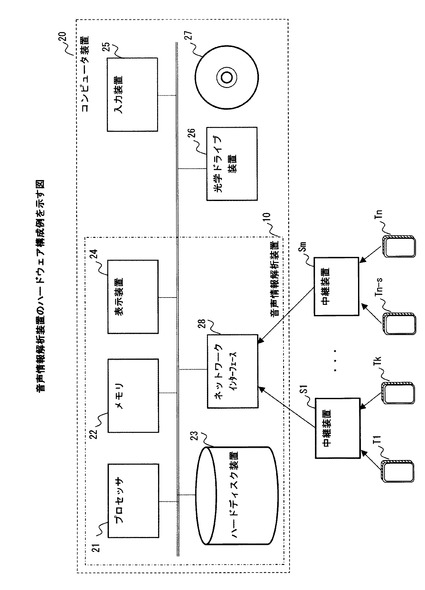
【図15】
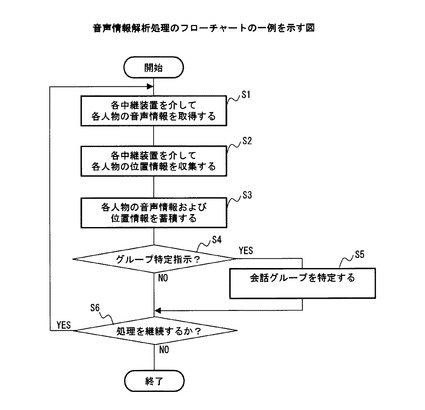
【図16】

【図17】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【図16】
【図17】
【公開番号】特開2013−115622(P2013−115622A)
【公開日】平成25年6月10日(2013.6.10)
【国際特許分類】
【出願番号】特願2011−260262(P2011−260262)
【出願日】平成23年11月29日(2011.11.29)
【出願人】(000005223)富士通株式会社 (25,993)
【Fターム(参考)】
【公開日】平成25年6月10日(2013.6.10)
【国際特許分類】
【出願日】平成23年11月29日(2011.11.29)
【出願人】(000005223)富士通株式会社 (25,993)
【Fターム(参考)】
[ Back to top ]