
音声言語評価装置、方法、及びプログラム
【課題】テキストレベルの言語表現への変換を行うことなく、また事前知識を要することなく、入力された音声信号が示す言語の種類を評価する。
【解決手段】音素表現計算部13で、学習用音声信号から抽出されたメルスペクトルをNMFにより分解して言語の種類毎に音素表現Hと配合比率Uとを求め、音素表現Hを音素表現記憶部14に言語の種類毎に記憶する。評価用音声信号が入力されると、特徴情報抽出部12で、メルスペクトルを抽出し、音素配合比率計算部15で、抽出されたメルスペクトルと、音素表現記憶部14に記憶された音素表現Hとに基づいて、言語の種類毎に配合比率Uを計算する。言語類似性評価部16で、計算された配合比率Uと音素表現記憶部14に記憶された音素表現Hとの積を言語の種類毎に各々計算し、評価用音声信号から抽出されたメルスペクトルとの類似度に基づいて、評価用音声信号が示す言語の種類を評価する。
【解決手段】音素表現計算部13で、学習用音声信号から抽出されたメルスペクトルをNMFにより分解して言語の種類毎に音素表現Hと配合比率Uとを求め、音素表現Hを音素表現記憶部14に言語の種類毎に記憶する。評価用音声信号が入力されると、特徴情報抽出部12で、メルスペクトルを抽出し、音素配合比率計算部15で、抽出されたメルスペクトルと、音素表現記憶部14に記憶された音素表現Hとに基づいて、言語の種類毎に配合比率Uを計算する。言語類似性評価部16で、計算された配合比率Uと音素表現記憶部14に記憶された音素表現Hとの積を言語の種類毎に各々計算し、評価用音声信号から抽出されたメルスペクトルとの類似度に基づいて、評価用音声信号が示す言語の種類を評価する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、音声言語評価装置、方法、及びプログラムに係り、特に、入力された音声信号が示す言語の種類を評価する音声言語評価装置、方法、及びプログラムに関する。
【背景技術】
【0002】
従来、音声信号からその音声信号が示す言語の種類を識別することが行われており、そのための技術が多数提案されている(例えば、特許文献1、特許文献2、非特許文献1、及び非特許文献2参照)。このような音声信号が示す言語の種類を識別する技術としては、主に、音情報だけでなくテキストレベルの文法を活用したものと、音情報だけを用い音素レベルの特徴を活用したものとに分類できる。
【0003】
テキストレベルの文法を用いる手法として、例えば、特許文献1記載の技術では、語彙文法モデルや意味規則等を用いた自然言語解析処理により、言語の認識及び解析を行っている。また、音素レベルの特徴を活用した手法としては、母音などの各言語に含まれる音への類似性を考慮して、言語の分類を行う手法が数多く提案されている。例えば、特許文献2記載の技術では、事前知識としていくつかの音声アルファベットを仮定して、テキストではなく音素情報を用いて、言語の認識を行っている。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開平8−106374号公報
【特許文献2】特開2001−109490号公報
【非特許文献】
【0005】
【非特許文献1】Zissman, M.A."Comparison of four approaches to automatic language identification of telephone speech," IEEE Trans. on Speech and Audio Processing, Vol.4, No.1, pp. 31-44, Jan. 1996.
【非特許文献2】Yeshwant K. et.al "Reviewing Automatic Language Identification," IEEE Signal Processing Magazine, pp. 33-41, Oct. 1994
【発明の概要】
【発明が解決しようとする課題】
【0006】
しかしながら、テキストレベルの文法を用いる手法は、文字を持たず文法が解析されていない言語への適用は困難である、という問題がある。例えば、特許文献1記載の技術では、自然言語解析処理を必要とし、文字言語が存在しない言語へは適用できない。
【0007】
また、音素レベルの特徴を活用する場合には、例えば、特許文献2に記載の技術のように、事前知識を必要とし、分析の行われていない多くの文字を持たない言語への適用は困難である、という問題がある。
【0008】
本発明は、上記の課題を解決するためになされたもので、テキストレベルの言語表現への変換を行うことなく、また事前知識を要することなく、入力された音声信号が示す言語の種類を評価することができる音声言語評価装置、方法、及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0009】
上記目的を達成するために、本発明の音声言語評価装置は、言語の種類が未知の評価用音声信号から評価用特徴情報を抽出する抽出手段と、言語の種類が既知の複数の学習用音声信号から抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより得られた音素毎の基底ベクトルで表された言語の種類毎の音素表現と、前記抽出手段により抽出された評価用特徴情報とに基づいて、該評価用特徴情報に配合された各音素の基底ベクトルの比率を示す配合比率を、言語の種類毎に計算する配合比率計算手段と、前記評価用特徴情報と、前記配合比率計算手段により計算された言語の種類毎の配合比率と前記言語の種類毎の音素表現との積で示される情報各々との類似度に基づいて、該評価用特徴情報に対応する評価用音声信号が示す言語の種類を評価する評価手段と、を含んで構成されている。
【0010】
本発明の音声言語評価装置によれば、抽出手段が、言語の種類が未知の評価用音声信号から評価用特徴情報を抽出する。また、言語の種類が既知の複数の学習用音声信号から抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより、音素毎の基底ベクトルで表された言語の種類毎の音素表現が予め得られている。そして、配合比率計算手段が、予め得られた言語の種類毎の音素表現と、抽出手段により抽出された評価用特徴情報とに基づいて、評価用特徴情報に配合された各音素の基底ベクトルの比率を示す配合比率を、言語の種類毎に計算する。そして、評価手段が、評価用特徴情報と、配合比率計算手段により計算された言語の種類毎の配合比率と言語の種類毎の音素表現との積で示される情報各々との類似度に基づいて、評価用特徴情報に対応する評価用音声信号が示す言語の種類を評価する。
【0011】
このように、学習用音声信号を非負値行列分解して得られた言語の種類毎の音素表現と、その音素表現と評価用特徴情報とに基づいて計算された配合比率との積で示される情報と評価用特徴情報との類似度により、評価用音声信号が示す言語の種類を評価するため、テキストレベルの言語表現への変換を行うことなく、また事前知識を要することなく、入力された音声信号が示す言語の種類を評価することができる。
【0012】
また、前記音素表現を、時系列構造の音素表現とすることができる。これにより、音の連続的な変化における微妙な音素の変化も考慮して、入力された音声信号が示す言語の種類を評価することができる。
【0013】
また、前記評価手段は、前記類似度が最も高くなるときの音素表現に対応する言語の種類を、前記評価用音声信号が示す言語の種類であると識別するか、または、言語の種類毎の類似度に基づいて、言語の種類間の系統的関連性を示す言語系統樹を作成することができる。
【0014】
また、前記配合比率計算手段は、発話者の性別及び年齢の少なくとも一方が既知の学習用音声信号から抽出された学習用特徴情報より得られた言語の種類並びに性別及び年齢別の少なくとも一方毎の音素表現に基づいて、言語の種類並びに性別及び年齢別の少なくとも一方毎に前記配合比率を計算することができる。
【0015】
また、前記抽出手段は、前記複数の学習用音声信号から前記言語の種類毎の学習用特徴情報を抽出し、前記抽出手段により抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより前記言語の種類毎の音素表現を計算する音素表現計算手段を含んで構成することができる。
【0016】
また、本発明の音声言語評価方法は、抽出手段と、配合比率計算手段と、評価手段とを含む音声言語評価装置における音声言語評価方法であって、前記抽出手段は、言語の種類が未知の評価用音声信号から評価用特徴情報を抽出し、前記配合比率計算手段は、言語の種類が既知の複数の学習用音声信号から抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより得られた音素毎の基底ベクトルで表された言語の種類毎の音素表現と、前記抽出手段により抽出された評価用特徴情報とに基づいて、該評価用特徴情報に配合された各音素の基底ベクトルの比率を示す配合比率を、言語の種類毎に計算し、前記評価手段は、前記評価用特徴情報と、前記配合比率計算手段により計算された言語の種類毎の配合比率と前記言語の種類毎の音素表現との積で示される情報各々との類似度に基づいて、該評価用特徴情報に対応する音声信号が示す言語の種類を評価する方法である。
【0017】
また、音素表現計算手段を更に含む音声言語評価装置における音声言語評価方法では、前記抽出手段は、前記複数の学習用音声信号から前記言語の種類毎の学習用特徴情報を抽出し、前記音素表現計算手段は、前記抽出手段により抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより前記言語の種類毎の音素表現を計算する。
【0018】
また、本発明の音声言語評価プログラムは、コンピュータを、上記の音声言語評価装置を構成する各手段として機能させるためのプログラムである。
【発明の効果】
【0019】
以上説明したように、本発明の音声言語評価装置、方法、及びプログラムによれば、学習用音声信号を非負値行列分解して得られた言語の種類毎の音素表現と、その音素表現と評価用特徴情報とに基づいて計算された配合比率との積で示される情報と評価用特徴情報との類似度により、評価用音声信号が示す言語の種類を評価するため、テキストレベルの言語表現への変換を行うことなく、また事前知識を要することなく、入力された音声信号が示す言語の種類を評価することができる、という効果が得られる。
【図面の簡単な説明】
【0020】
【図1】第1の実施の形態に係る音声言語評価装置の構成を示す概略図である。
【図2】非負値行列分解のイメージ図である。
【図3】中国語の音素表現の一例を示すグラフである。
【図4】スペイン語の音素表現の一例を示すグラフである。
【図5】第1の実施の形態に係る音声言語評価装置における学習処理ルーチンの内容を示すフローチャートである。
【図6】第1の実施の形態に係る音声言語評価装置における評価処理ルーチンの内容を示すフローチャートである。
【図7】時系列の音素表現に対する非負値行列分解のイメージ図である。
【図8】英語の時系列の音素表現の一例を示すグラフである。
【図9】ドイツ語の時系列の音素表現の一例を示すグラフである。
【図10】スウェーデン語の時系列の音素表現の一例を示すグラフである。
【図11】フランス語の時系列の音素表現の一例を示すグラフである。
【図12】ある音声信号に対する類似値の一例を示すグラフである。
【図13】言語系統樹の出力の一例を示す図である。
【図14】時系列の音素表現を利用した言語分類の一例を示すグラフである。
【発明を実施するための形態】
【0021】
以下、図面を参照して本発明の実施の形態を詳細に説明する。
【0022】
第1の実施の形態に係る音声言語評価装置1は、CPUと、RAMと、後述する学習処理及び評価処理を含む音声言語評価処理ルーチンを実行するためのプログラムを記憶したROMとを備えたコンピュータで構成されている。
【0023】
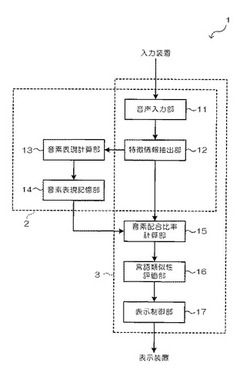
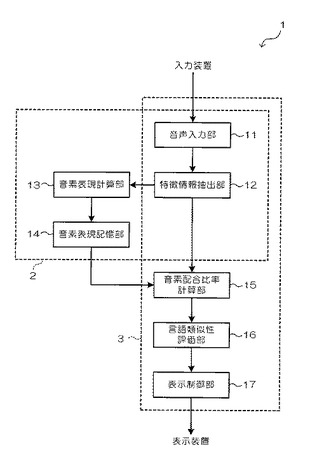
このコンピュータは、機能的には、図1に示すように、音声信号を入力する音声信号入力部11と、音声信号から特徴情報を抽出する特徴情報抽出部12と、事前学習のために、言語の種類及び性別毎に得られた特徴情報に対して音素表現を計算する音素表現計算部13と、言語の種類及び性別毎の音素表現が記憶される音素表現記憶部14と、言語評価のために、特徴情報抽出部12から得られた特徴情報に対し、音素表現記憶部14に記憶された言語の種類及び性別毎の音素表現各々を用いて配合比率を計算する音素配合比率計算部15と、言語の種類毎の音素配合比率を解析して、各言語との類似性を評価する言語類似性評価部16と、評価結果が表示装置に表示されるように制御する表示制御部17とを含んだ構成で表すことができる。
【0024】
また、音声信号入力部11、特徴情報抽出部12、音素表現計算部13、及び音素表現記憶部14が学習部2として機能し、音声信号入力部11、特徴情報抽出部12、音素配合比率計算部15、言語類似性評価部16、及び表示制御部17が評価部3として機能する。すなわち、音声信号入力部11及び特徴情報抽出部12は、学習部2及び評価部3で共通に用いられる。
【0025】
音声信号入力部11には、例えば、電子的に記録されたファイルまたはマイクなどの入力装置から、デジタル化された音声信号が入力される。学習段階では、言語の種類及び発話者の性別(男女別)が既知の音声信号(学習用音声信号)が入力される。また、評価段階では、言語の種類が未知で、発話者の性別が既知または未知の音声信号(評価用音声信号)が入力される。
【0026】
特徴情報抽出部12は、音声信号入力部11から得られるデジタル化された音声信号から、特徴情報を抽出する。本実施の形態では、特徴情報として、メルスペクトルを抽出する場合について説明する。なお、特徴情報は、音素表現やその識別方法に何を使うかにより異なる特徴(例えば、スペクトルと主成分分析(PCA)、メルケプストラムとベクトル量子化など)を抽出するようにしてもよい。学習段階では、学習用音声信号から言語の種類及び性別毎にメルスペクトルを抽出し、これを学習用特徴情報とする。また、評価段階では、評価用音声信号からメルスペクトルを抽出し、これを評価用特徴情報とする。
【0027】
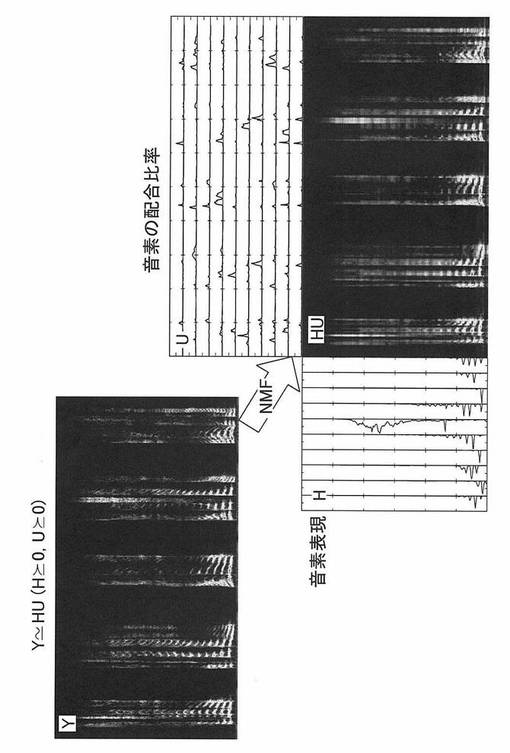
音素表現計算部13では、特徴情報抽出部12により学習用特徴情報として抽出された言語の種類及び性別毎のメルスペクトルを分析して、音声信号内に繰り返し現れる音素構造を抽出する。このような方法には、例えば、音のような非負の情報を取り扱うのに適した非負値行列分解(NMF:Non-negative Matrix Factorization)を用いることができる(例えば、「D. D. Lee, H. S. Seung, “Learning the part of objects by non-negative matrix factorization,” Nature Vol.401, pp. 788-791, 1999.」参照)。NMFは、自動採譜やモノラル混合信号からの音源の分離に適用されている(例えば、「P. Smaragdis, J. C. Brown, “Non-Negative Matrix Factorization for Music Transcription,”ln Proc. 2003 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA2003), pp. 177-180,2003.」及び「T. Virtanen, “Monaural sound source separation by nonnegative matrix factorization with temporal continuity and sparseness criteria,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 15, pp. 1066−1074, 2007.」参照)
NMFによって音声信号を音素へ分解するイメージを図2に示す。図中Yは、特徴情報抽出部12で抽出されたメルスペクトルを、図中Hは、音素表現(音素毎の基底ベクトルを並べたもの。音素の基底ベクトルを、以下では単に「音素」ともいう)を、図中Uは、各音素がYにどのくらいの比率で配合されているかを示す配合比率を表す。NMFによる繰り返し演算で、メルスペクトルYと、音素表現Hと配合比率Uとの積との差を最小化することにより、適切な音素表現H及び配合比率Uを求めることができる。評価段階では、音素表現Hのみを利用するため、求めた音素表現Hを出力する。
【0028】
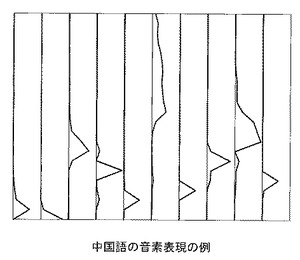
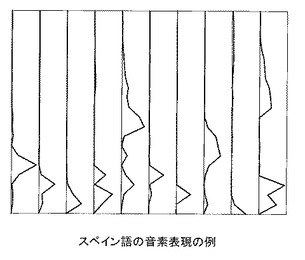
ここでは、NMFでメルスペクトルYと、音素表現Hと配合比率Uとの積との差を最小化するために用いる距離尺度にKL(Kullback-Leibler)−ダイバージェンスを用いる。なお、KL−ダイバージェンスではなく、板倉斎藤距離やユークリッド距離を用いてもよい。メルスペクトルを入力とし、KL−ダイバージェンスを距離尺度として作成した中国語の音素表現を図3に示す。同図では、10個の音素を横方向に並べ、音素各々の縦軸を周波数、横軸をその強さとして、音素表現を表している。同様に表したスペイン語の音素表現を図4に示す。スペイン語と中国語とで、似通った音素とそうではない音素とが存在する。このような特徴は、各言語の母音の種類の差に相当すると推察される。
【0029】
音素表現記憶部14には、音素表現計算部13から出力された音素表現Hが、男女別に言語の種類毎に記憶される。なお、ここでは、音素表現を男女別に言語の種類毎に記憶する構成としたが、特徴情報や距離の定義によっては、男女をまとめてもよいし、年齢別等さらに細かく分類してもよい。
【0030】
音素配合比率計算部15は、特徴情報抽出部12で評価用特徴情報として抽出されたメルスペクトルが入力される。NMFでは、図2の上式のように、音声信号のメルスペクトルYを、音素表現Hと配合比率Uとの積で近似的に表現することができる。音素配合比率計算部15は、この近似表現に基づいて、入力されたメルスペクトルYと、音素表現記憶部14に男女別に記憶された言語の種類毎の音素表現Hとに基づいて、言語の種類毎に配合比率Uを計算する。
【0031】
ここで、評価用音声信号の発話者の性別が既知の場合には、音素表現記憶部14に記憶された男女別の言語の種類毎の音素表現Hのうち、発話者の性別に対応した音素表現Hを用いて配合比率Uを計算する。発話者の性別が未知の場合には、記憶された音素表現Hの全てを用いて、言語の種類及び性別毎に配合比率Uを計算する。
【0032】
言語類似性評価部16は、音素配合比率計算部15で計算された配合比率Uと音素表現記憶部14に記憶された音素表現Hとの積を言語の種類毎に各々計算し、特徴情報抽出部12から出力された評価用音声信号のメルスペクトルYとの類似度を計算する。類似度は、UとHとの積とYとの差分(距離)とすることができる。これにより、入力された音声信号が示す言語の種類と各言語の種類の音素表現との類似性が距離として表現される。この距離が最も近い場合の計算に用いられた音素表現Hに対応する言語の種類を、評価用音声信号が示す言語の種類に最も類似する言語の種類であると評価する。
【0033】
また、言語類似性評価部16は、計算された類似度を用いて、言語の体系化のために、入力された音声信号に対する言語系統樹を評価結果として求めてもよい。言語系統樹の作成方法としては、群平均法(UPGMA:UnweightedPair-Group Method using Average)などを用いることができる。UPGMAは、段階的な言語系統樹の作成方法であり、最小距離となる2つの言語を結合していく処理を繰り返す方法である。結合された言語グループとの距離の計算にはグループ内のそれぞれの言語との距離の平均値を用いる。
【0034】
なお、評価用音声信号の発話者の性別が未知の場合には、男性版の音素表現を用いた場合の類似度、女性版の音素表現を用いた場合の類似度の両方を計算し、類似度が高い方の音素表現に対応する性別も合わせて評価結果として求めるようにするとよい。
【0035】
表示制御部17は、言語類似性評価部16による評価結果が表示装置に表示されるように制御する。例えば、評価用音声信号が示す言語の種類に最も類似する言語の種類が何であるかを文字で表示したり、評価用音声信号と各言語の種類の音素表現との類似度を棒グラフ等で表示したりすることができる。また、言語系統樹を求めた場合には、求めた言語系統樹を表示するようにするとよい。
【0036】
なお、ここでは、評価結果を表示装置に表示する場合について説明したが、音声出力装置により音声で評価結果を出力するようにしてもよい。例えば、評価用音声信号が示す言語の種類に最も類似する言語の種類が何であるかを音声で表示したり、最も類似する言語の種類の学習データ中の音声を出力したりすることができる。
【0037】
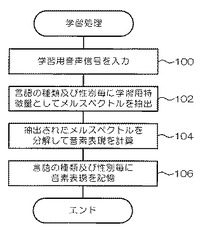
次に、第1の実施の形態に係る音声言語評価装置1の作用について説明する。評価用音声信号が示す言語の種類を評価する評価処理に先立って、図5に示す学習処理ルーチンが実行される。
【0038】
ステップ100で、電子的に記録されたファイルまたはマイクなどの入力装置から、デジタル化された学習用音声信号が入力される。
【0039】
次に、ステップ102で、上記ステップ100で入力された学習用音声信号から、学習用特徴情報としてメルスペクトルを抽出する。ここで抽出された学習用特徴情報は、言語の種類及び性別毎の特徴情報である。
【0040】
次に、ステップ104で、上記ステップ102で抽出されたメルスペクトルを、言語の種類及び性別毎にNMFにより音素に分解し、音素表現Hと配合比率Uとする。
【0041】
次に、ステップ106で、上記ステップ104で計算された音素表現Hを、音素表現記憶部14に男女別に言語の種類毎に記憶して処理を終了する。
【0042】
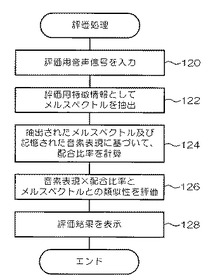
そして、上記の学習処理ルーチンが実行されて、音素表現記憶部14に男女別に言語の種類毎の音素表現Hが記憶された状態で、図6に示す評価処理ルーチンが実行される。
【0043】
ステップ120で、評価用音声信号を入力する。ここで入力された評価用音声信号は、発話者の性別が既知であるとする。
【0044】
次に、ステップ122で、学習処理のステップ102と同様の処理により、上記ステップ120で入力された評価用音声信号から、評価用特徴情報としてメルスペクトルを抽出する。
【0045】
次に、ステップ124で、上記ステップ122で評価用音声信号から抽出されたメルスペクトルYと、音素表現記憶部14に記憶された発話者の性別に対応した言語の種類毎の音素表現Hとに基づいて、言語の種類毎に配合比率Uを計算する。
【0046】
次に、ステップ126で、上記ステップ124で計算された言語の種類毎の配合比率Uと音素表現記憶部14に記憶された発話者の性別に対応した言語の種類毎の音素表現Hとの積を各々計算し、上記ステップ122で抽出されたメルスペクトルYとの類似度を計算する。この類似度が最も高い場合の計算に用いられた音素表現Hに対応する言語の種類を、評価用音声信号が示す言語の種類に最も類似する言語の種類であると評価する。また、計算された類似度を用いて、言語の種類の体系化のために、入力された評価用音声信号に対する系統樹を評価結果として求める。
【0047】
次に、ステップ128で、上記ステップ126での評価結果を表示装置に表示して、処理を終了する。
【0048】
以上説明したように、第1の実施の形態の音声言語評価装置によれば、学習用音声信号から抽出された学習用特徴情報を非負値行列分割により音素表現とその配合比率とで表現した場合の音素表現を言語の種類毎に記憶しておき、評価用音声信号から抽出された評価用特徴情報と記憶された言語の種類毎の音素表現とに基づいて、言語の種類毎に配合比率を計算し、評価用特徴情報と、記憶された言語の種類毎の音素表現と計算された配合比率との積との類似度に基づいて、評価用音声信号が示す言語の種類がどの言語の種類に類似するかを評価する。このように、テキストレベルの言語表現への変換を行うことなく、また事前知識を要することなく、音声信号のみを用いて、入力された音声信号が示す言語の種類を評価することができる。
【0049】
また、評価用音声信号が示す言語の種類と各言語の種類との類似性を用いて言語系統樹を求めることができ、言語の種類間の関係性に対する新たな文化的歴史的新知見も期待できる。
【0050】
次に、第2の実施の形態について説明する。なお、第2の実施の形態に係る音声言語評価装置は、音素表現計算部13において、時系列の音素表現を用いる点が第1の実施の形態と異なるため、その点について説明する。
【0051】
言語の特性は母音の種類などにより分類されるが、特に連続音のように、母音などの各音素の音量が連続的に変化する場合には、前の音素から後の音素に連続的に変化していく中で、認識が困難になる状況がある(例えば、「おはよう」の「よ」から「う」にかけての音の変化)。第2の実施の形態では、このような連続音における音の微妙な変化も考慮に入れて、言語の種類を評価する。
【0052】
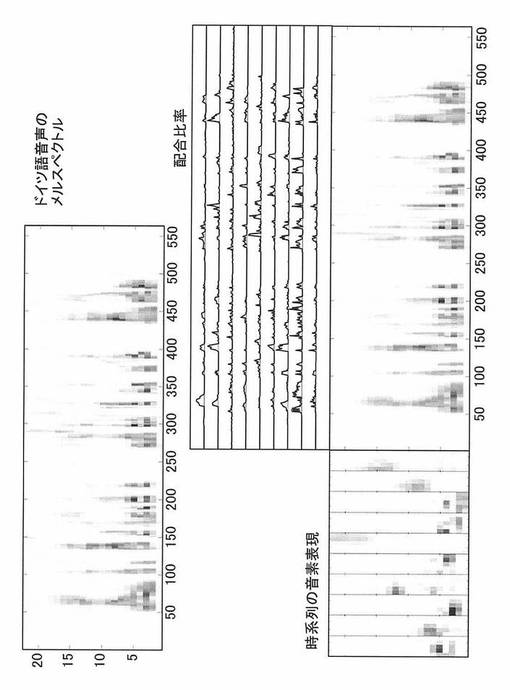
第2の実施の形態における音素表現計算部13は、図7に示すように、時系列構造を持った音素に対し、非負値行列分解(Non-negative Matrix Deconvolution、NMFD、例えば、「Paris Smaragdis, “Non-negative Matrix Factor Deconvolution; Extraction of Multiple Sound Sources from Monophonic Inputs,” Independent Component Analysis and Blind Signal Separation, Lecture Notes in Computer Science, 2004, Volume 3195/2004, 494-499」参照)を用いて時系列の音素表現を計算する。
【0053】
NMFDで計算した英語、ドイツ語、スウェーデン語、及びフランス語の時系列の音素表現を図8〜11に示す。ここでは、12個の音素を横に並べた音素表現となっている。各音素の内部では、横に5つの時系列の変化を表し、縦が周波数を表している。内部の各四角形が暗いほど強い値であることを示す。すなわち、各音素がメルスペクトルの時間推移を表現している。
【0054】
第2の実施の形態における学習処理及び評価処理については、第1の実施の形態の学習処理及び評価処理においてNMFにより音素表現を計算した点が、上記のNMFDを用いて時系列の音素表現を計算する点と異なるだけであるので、説明を省略する。
【0055】
以上説明したように、第2の実施の形態の音声言語評価装置によれば、第1の実施の形態の効果に加え、音の連続的な変化における微妙な音素の変化も考慮して、適切に評価用音声信号が示す言語の種類を評価することができる。
【0056】
ここで、本発明の効果を説明するために、評価結果の一例について説明する。
【0057】
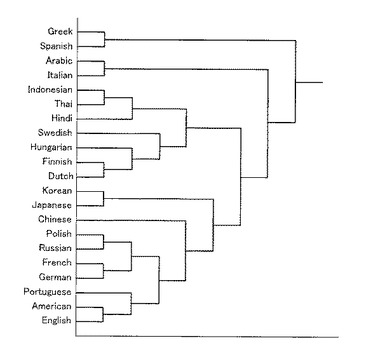
21言語の音声コーパスから音素表現を作成し、ある女性の日本語入力に対し、類似度を比較した評価結果を図12に示す。距離を類似値に変換するため、exp(−距離値)を類似値とした。同図に示すとおり、日本語との類似値が最も高く、入力された音声信号が示す言語の種類が日本語であると正しく識別できることが確認できた。
【0058】
同様の方法を各言語間で繰り返し、UPGMA法で言語系統樹を作成した結果を図13に示す。同図の評価結果は、必ずしも言語学的分類の言語系統樹とは一致していないが、地理的な近さは反映したものとなっており、音素と言語の種類とのなんらかの関係を示唆していると思われる。
【0059】
次に、NMFDを用いて、英語、ドイツ語、スウェーデン語、及びフランス語の4言語について、距離を測定した結果を図14に示す。縦軸が学習した音素の変化であり、横軸は入力した音声の言語の種類である。各四角形内が黒いほど類似しており、白いほど違いが大きいことを示している。同図からわかるように、全ての入力された言語の種類に対して最も類似する言語の種類が正解の言語の種類となっており、NMFDを用いた識別が有効であることがわかる。さらにスウェーデン語の音素は他の言語との違いが大きく、ドイツ語の音素は他の言語に類似している。一般に英語よりもスウェーデン語やフランス語は母音の種類が多く、ドイツ語は母音の種類が少ない。このような傾向の影響を受けているように思われる。
【0060】
なお、上記の実施の形態では、学習部と評価部とを1つのコンピュータで構成する場合について説明したが、各々別のコンピュータで構成するようにしてもよい。
【0061】
また、本発明は、上述した実施形態に限定されるものではなく、この発明の要旨を逸脱しない範囲内で様々な変形や応用が可能である。
【0062】
例えば、上述の音声言語評価装置は、内部にコンピュータシステムを有しているが、「コンピュータシステム」は、WWWシステムを利用している場合であれば、ホームページ提供環境(あるいは表示環境)も含むものとする。
【0063】
また、本願明細書中において、プログラムが予めインストールされている実施形態として説明したが、当該プログラムを、コンピュータ読み取り可能な記録媒体に格納して提供することも可能である。
【符号の説明】
【0064】
1 音声言語評価装置
2 学習部
3 評価部
11 音声信号入力部
12 特徴情報抽出部
13 音素表現計算部
14 音素表現記憶部
15 音素配合比率計算部
16 言語類似性評価部
17 表示制御部
【技術分野】
【0001】
本発明は、音声言語評価装置、方法、及びプログラムに係り、特に、入力された音声信号が示す言語の種類を評価する音声言語評価装置、方法、及びプログラムに関する。
【背景技術】
【0002】
従来、音声信号からその音声信号が示す言語の種類を識別することが行われており、そのための技術が多数提案されている(例えば、特許文献1、特許文献2、非特許文献1、及び非特許文献2参照)。このような音声信号が示す言語の種類を識別する技術としては、主に、音情報だけでなくテキストレベルの文法を活用したものと、音情報だけを用い音素レベルの特徴を活用したものとに分類できる。
【0003】
テキストレベルの文法を用いる手法として、例えば、特許文献1記載の技術では、語彙文法モデルや意味規則等を用いた自然言語解析処理により、言語の認識及び解析を行っている。また、音素レベルの特徴を活用した手法としては、母音などの各言語に含まれる音への類似性を考慮して、言語の分類を行う手法が数多く提案されている。例えば、特許文献2記載の技術では、事前知識としていくつかの音声アルファベットを仮定して、テキストではなく音素情報を用いて、言語の認識を行っている。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開平8−106374号公報
【特許文献2】特開2001−109490号公報
【非特許文献】
【0005】
【非特許文献1】Zissman, M.A."Comparison of four approaches to automatic language identification of telephone speech," IEEE Trans. on Speech and Audio Processing, Vol.4, No.1, pp. 31-44, Jan. 1996.
【非特許文献2】Yeshwant K. et.al "Reviewing Automatic Language Identification," IEEE Signal Processing Magazine, pp. 33-41, Oct. 1994
【発明の概要】
【発明が解決しようとする課題】
【0006】
しかしながら、テキストレベルの文法を用いる手法は、文字を持たず文法が解析されていない言語への適用は困難である、という問題がある。例えば、特許文献1記載の技術では、自然言語解析処理を必要とし、文字言語が存在しない言語へは適用できない。
【0007】
また、音素レベルの特徴を活用する場合には、例えば、特許文献2に記載の技術のように、事前知識を必要とし、分析の行われていない多くの文字を持たない言語への適用は困難である、という問題がある。
【0008】
本発明は、上記の課題を解決するためになされたもので、テキストレベルの言語表現への変換を行うことなく、また事前知識を要することなく、入力された音声信号が示す言語の種類を評価することができる音声言語評価装置、方法、及びプログラムを提供することを目的とする。
【課題を解決するための手段】
【0009】
上記目的を達成するために、本発明の音声言語評価装置は、言語の種類が未知の評価用音声信号から評価用特徴情報を抽出する抽出手段と、言語の種類が既知の複数の学習用音声信号から抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより得られた音素毎の基底ベクトルで表された言語の種類毎の音素表現と、前記抽出手段により抽出された評価用特徴情報とに基づいて、該評価用特徴情報に配合された各音素の基底ベクトルの比率を示す配合比率を、言語の種類毎に計算する配合比率計算手段と、前記評価用特徴情報と、前記配合比率計算手段により計算された言語の種類毎の配合比率と前記言語の種類毎の音素表現との積で示される情報各々との類似度に基づいて、該評価用特徴情報に対応する評価用音声信号が示す言語の種類を評価する評価手段と、を含んで構成されている。
【0010】
本発明の音声言語評価装置によれば、抽出手段が、言語の種類が未知の評価用音声信号から評価用特徴情報を抽出する。また、言語の種類が既知の複数の学習用音声信号から抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより、音素毎の基底ベクトルで表された言語の種類毎の音素表現が予め得られている。そして、配合比率計算手段が、予め得られた言語の種類毎の音素表現と、抽出手段により抽出された評価用特徴情報とに基づいて、評価用特徴情報に配合された各音素の基底ベクトルの比率を示す配合比率を、言語の種類毎に計算する。そして、評価手段が、評価用特徴情報と、配合比率計算手段により計算された言語の種類毎の配合比率と言語の種類毎の音素表現との積で示される情報各々との類似度に基づいて、評価用特徴情報に対応する評価用音声信号が示す言語の種類を評価する。
【0011】
このように、学習用音声信号を非負値行列分解して得られた言語の種類毎の音素表現と、その音素表現と評価用特徴情報とに基づいて計算された配合比率との積で示される情報と評価用特徴情報との類似度により、評価用音声信号が示す言語の種類を評価するため、テキストレベルの言語表現への変換を行うことなく、また事前知識を要することなく、入力された音声信号が示す言語の種類を評価することができる。
【0012】
また、前記音素表現を、時系列構造の音素表現とすることができる。これにより、音の連続的な変化における微妙な音素の変化も考慮して、入力された音声信号が示す言語の種類を評価することができる。
【0013】
また、前記評価手段は、前記類似度が最も高くなるときの音素表現に対応する言語の種類を、前記評価用音声信号が示す言語の種類であると識別するか、または、言語の種類毎の類似度に基づいて、言語の種類間の系統的関連性を示す言語系統樹を作成することができる。
【0014】
また、前記配合比率計算手段は、発話者の性別及び年齢の少なくとも一方が既知の学習用音声信号から抽出された学習用特徴情報より得られた言語の種類並びに性別及び年齢別の少なくとも一方毎の音素表現に基づいて、言語の種類並びに性別及び年齢別の少なくとも一方毎に前記配合比率を計算することができる。
【0015】
また、前記抽出手段は、前記複数の学習用音声信号から前記言語の種類毎の学習用特徴情報を抽出し、前記抽出手段により抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより前記言語の種類毎の音素表現を計算する音素表現計算手段を含んで構成することができる。
【0016】
また、本発明の音声言語評価方法は、抽出手段と、配合比率計算手段と、評価手段とを含む音声言語評価装置における音声言語評価方法であって、前記抽出手段は、言語の種類が未知の評価用音声信号から評価用特徴情報を抽出し、前記配合比率計算手段は、言語の種類が既知の複数の学習用音声信号から抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより得られた音素毎の基底ベクトルで表された言語の種類毎の音素表現と、前記抽出手段により抽出された評価用特徴情報とに基づいて、該評価用特徴情報に配合された各音素の基底ベクトルの比率を示す配合比率を、言語の種類毎に計算し、前記評価手段は、前記評価用特徴情報と、前記配合比率計算手段により計算された言語の種類毎の配合比率と前記言語の種類毎の音素表現との積で示される情報各々との類似度に基づいて、該評価用特徴情報に対応する音声信号が示す言語の種類を評価する方法である。
【0017】
また、音素表現計算手段を更に含む音声言語評価装置における音声言語評価方法では、前記抽出手段は、前記複数の学習用音声信号から前記言語の種類毎の学習用特徴情報を抽出し、前記音素表現計算手段は、前記抽出手段により抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより前記言語の種類毎の音素表現を計算する。
【0018】
また、本発明の音声言語評価プログラムは、コンピュータを、上記の音声言語評価装置を構成する各手段として機能させるためのプログラムである。
【発明の効果】
【0019】
以上説明したように、本発明の音声言語評価装置、方法、及びプログラムによれば、学習用音声信号を非負値行列分解して得られた言語の種類毎の音素表現と、その音素表現と評価用特徴情報とに基づいて計算された配合比率との積で示される情報と評価用特徴情報との類似度により、評価用音声信号が示す言語の種類を評価するため、テキストレベルの言語表現への変換を行うことなく、また事前知識を要することなく、入力された音声信号が示す言語の種類を評価することができる、という効果が得られる。
【図面の簡単な説明】
【0020】
【図1】第1の実施の形態に係る音声言語評価装置の構成を示す概略図である。
【図2】非負値行列分解のイメージ図である。
【図3】中国語の音素表現の一例を示すグラフである。
【図4】スペイン語の音素表現の一例を示すグラフである。
【図5】第1の実施の形態に係る音声言語評価装置における学習処理ルーチンの内容を示すフローチャートである。
【図6】第1の実施の形態に係る音声言語評価装置における評価処理ルーチンの内容を示すフローチャートである。
【図7】時系列の音素表現に対する非負値行列分解のイメージ図である。
【図8】英語の時系列の音素表現の一例を示すグラフである。
【図9】ドイツ語の時系列の音素表現の一例を示すグラフである。
【図10】スウェーデン語の時系列の音素表現の一例を示すグラフである。
【図11】フランス語の時系列の音素表現の一例を示すグラフである。
【図12】ある音声信号に対する類似値の一例を示すグラフである。
【図13】言語系統樹の出力の一例を示す図である。
【図14】時系列の音素表現を利用した言語分類の一例を示すグラフである。
【発明を実施するための形態】
【0021】
以下、図面を参照して本発明の実施の形態を詳細に説明する。
【0022】
第1の実施の形態に係る音声言語評価装置1は、CPUと、RAMと、後述する学習処理及び評価処理を含む音声言語評価処理ルーチンを実行するためのプログラムを記憶したROMとを備えたコンピュータで構成されている。
【0023】
このコンピュータは、機能的には、図1に示すように、音声信号を入力する音声信号入力部11と、音声信号から特徴情報を抽出する特徴情報抽出部12と、事前学習のために、言語の種類及び性別毎に得られた特徴情報に対して音素表現を計算する音素表現計算部13と、言語の種類及び性別毎の音素表現が記憶される音素表現記憶部14と、言語評価のために、特徴情報抽出部12から得られた特徴情報に対し、音素表現記憶部14に記憶された言語の種類及び性別毎の音素表現各々を用いて配合比率を計算する音素配合比率計算部15と、言語の種類毎の音素配合比率を解析して、各言語との類似性を評価する言語類似性評価部16と、評価結果が表示装置に表示されるように制御する表示制御部17とを含んだ構成で表すことができる。
【0024】
また、音声信号入力部11、特徴情報抽出部12、音素表現計算部13、及び音素表現記憶部14が学習部2として機能し、音声信号入力部11、特徴情報抽出部12、音素配合比率計算部15、言語類似性評価部16、及び表示制御部17が評価部3として機能する。すなわち、音声信号入力部11及び特徴情報抽出部12は、学習部2及び評価部3で共通に用いられる。
【0025】
音声信号入力部11には、例えば、電子的に記録されたファイルまたはマイクなどの入力装置から、デジタル化された音声信号が入力される。学習段階では、言語の種類及び発話者の性別(男女別)が既知の音声信号(学習用音声信号)が入力される。また、評価段階では、言語の種類が未知で、発話者の性別が既知または未知の音声信号(評価用音声信号)が入力される。
【0026】
特徴情報抽出部12は、音声信号入力部11から得られるデジタル化された音声信号から、特徴情報を抽出する。本実施の形態では、特徴情報として、メルスペクトルを抽出する場合について説明する。なお、特徴情報は、音素表現やその識別方法に何を使うかにより異なる特徴(例えば、スペクトルと主成分分析(PCA)、メルケプストラムとベクトル量子化など)を抽出するようにしてもよい。学習段階では、学習用音声信号から言語の種類及び性別毎にメルスペクトルを抽出し、これを学習用特徴情報とする。また、評価段階では、評価用音声信号からメルスペクトルを抽出し、これを評価用特徴情報とする。
【0027】
音素表現計算部13では、特徴情報抽出部12により学習用特徴情報として抽出された言語の種類及び性別毎のメルスペクトルを分析して、音声信号内に繰り返し現れる音素構造を抽出する。このような方法には、例えば、音のような非負の情報を取り扱うのに適した非負値行列分解(NMF:Non-negative Matrix Factorization)を用いることができる(例えば、「D. D. Lee, H. S. Seung, “Learning the part of objects by non-negative matrix factorization,” Nature Vol.401, pp. 788-791, 1999.」参照)。NMFは、自動採譜やモノラル混合信号からの音源の分離に適用されている(例えば、「P. Smaragdis, J. C. Brown, “Non-Negative Matrix Factorization for Music Transcription,”ln Proc. 2003 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA2003), pp. 177-180,2003.」及び「T. Virtanen, “Monaural sound source separation by nonnegative matrix factorization with temporal continuity and sparseness criteria,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 15, pp. 1066−1074, 2007.」参照)
NMFによって音声信号を音素へ分解するイメージを図2に示す。図中Yは、特徴情報抽出部12で抽出されたメルスペクトルを、図中Hは、音素表現(音素毎の基底ベクトルを並べたもの。音素の基底ベクトルを、以下では単に「音素」ともいう)を、図中Uは、各音素がYにどのくらいの比率で配合されているかを示す配合比率を表す。NMFによる繰り返し演算で、メルスペクトルYと、音素表現Hと配合比率Uとの積との差を最小化することにより、適切な音素表現H及び配合比率Uを求めることができる。評価段階では、音素表現Hのみを利用するため、求めた音素表現Hを出力する。
【0028】
ここでは、NMFでメルスペクトルYと、音素表現Hと配合比率Uとの積との差を最小化するために用いる距離尺度にKL(Kullback-Leibler)−ダイバージェンスを用いる。なお、KL−ダイバージェンスではなく、板倉斎藤距離やユークリッド距離を用いてもよい。メルスペクトルを入力とし、KL−ダイバージェンスを距離尺度として作成した中国語の音素表現を図3に示す。同図では、10個の音素を横方向に並べ、音素各々の縦軸を周波数、横軸をその強さとして、音素表現を表している。同様に表したスペイン語の音素表現を図4に示す。スペイン語と中国語とで、似通った音素とそうではない音素とが存在する。このような特徴は、各言語の母音の種類の差に相当すると推察される。
【0029】
音素表現記憶部14には、音素表現計算部13から出力された音素表現Hが、男女別に言語の種類毎に記憶される。なお、ここでは、音素表現を男女別に言語の種類毎に記憶する構成としたが、特徴情報や距離の定義によっては、男女をまとめてもよいし、年齢別等さらに細かく分類してもよい。
【0030】
音素配合比率計算部15は、特徴情報抽出部12で評価用特徴情報として抽出されたメルスペクトルが入力される。NMFでは、図2の上式のように、音声信号のメルスペクトルYを、音素表現Hと配合比率Uとの積で近似的に表現することができる。音素配合比率計算部15は、この近似表現に基づいて、入力されたメルスペクトルYと、音素表現記憶部14に男女別に記憶された言語の種類毎の音素表現Hとに基づいて、言語の種類毎に配合比率Uを計算する。
【0031】
ここで、評価用音声信号の発話者の性別が既知の場合には、音素表現記憶部14に記憶された男女別の言語の種類毎の音素表現Hのうち、発話者の性別に対応した音素表現Hを用いて配合比率Uを計算する。発話者の性別が未知の場合には、記憶された音素表現Hの全てを用いて、言語の種類及び性別毎に配合比率Uを計算する。
【0032】
言語類似性評価部16は、音素配合比率計算部15で計算された配合比率Uと音素表現記憶部14に記憶された音素表現Hとの積を言語の種類毎に各々計算し、特徴情報抽出部12から出力された評価用音声信号のメルスペクトルYとの類似度を計算する。類似度は、UとHとの積とYとの差分(距離)とすることができる。これにより、入力された音声信号が示す言語の種類と各言語の種類の音素表現との類似性が距離として表現される。この距離が最も近い場合の計算に用いられた音素表現Hに対応する言語の種類を、評価用音声信号が示す言語の種類に最も類似する言語の種類であると評価する。
【0033】
また、言語類似性評価部16は、計算された類似度を用いて、言語の体系化のために、入力された音声信号に対する言語系統樹を評価結果として求めてもよい。言語系統樹の作成方法としては、群平均法(UPGMA:UnweightedPair-Group Method using Average)などを用いることができる。UPGMAは、段階的な言語系統樹の作成方法であり、最小距離となる2つの言語を結合していく処理を繰り返す方法である。結合された言語グループとの距離の計算にはグループ内のそれぞれの言語との距離の平均値を用いる。
【0034】
なお、評価用音声信号の発話者の性別が未知の場合には、男性版の音素表現を用いた場合の類似度、女性版の音素表現を用いた場合の類似度の両方を計算し、類似度が高い方の音素表現に対応する性別も合わせて評価結果として求めるようにするとよい。
【0035】
表示制御部17は、言語類似性評価部16による評価結果が表示装置に表示されるように制御する。例えば、評価用音声信号が示す言語の種類に最も類似する言語の種類が何であるかを文字で表示したり、評価用音声信号と各言語の種類の音素表現との類似度を棒グラフ等で表示したりすることができる。また、言語系統樹を求めた場合には、求めた言語系統樹を表示するようにするとよい。
【0036】
なお、ここでは、評価結果を表示装置に表示する場合について説明したが、音声出力装置により音声で評価結果を出力するようにしてもよい。例えば、評価用音声信号が示す言語の種類に最も類似する言語の種類が何であるかを音声で表示したり、最も類似する言語の種類の学習データ中の音声を出力したりすることができる。
【0037】
次に、第1の実施の形態に係る音声言語評価装置1の作用について説明する。評価用音声信号が示す言語の種類を評価する評価処理に先立って、図5に示す学習処理ルーチンが実行される。
【0038】
ステップ100で、電子的に記録されたファイルまたはマイクなどの入力装置から、デジタル化された学習用音声信号が入力される。
【0039】
次に、ステップ102で、上記ステップ100で入力された学習用音声信号から、学習用特徴情報としてメルスペクトルを抽出する。ここで抽出された学習用特徴情報は、言語の種類及び性別毎の特徴情報である。
【0040】
次に、ステップ104で、上記ステップ102で抽出されたメルスペクトルを、言語の種類及び性別毎にNMFにより音素に分解し、音素表現Hと配合比率Uとする。
【0041】
次に、ステップ106で、上記ステップ104で計算された音素表現Hを、音素表現記憶部14に男女別に言語の種類毎に記憶して処理を終了する。
【0042】
そして、上記の学習処理ルーチンが実行されて、音素表現記憶部14に男女別に言語の種類毎の音素表現Hが記憶された状態で、図6に示す評価処理ルーチンが実行される。
【0043】
ステップ120で、評価用音声信号を入力する。ここで入力された評価用音声信号は、発話者の性別が既知であるとする。
【0044】
次に、ステップ122で、学習処理のステップ102と同様の処理により、上記ステップ120で入力された評価用音声信号から、評価用特徴情報としてメルスペクトルを抽出する。
【0045】
次に、ステップ124で、上記ステップ122で評価用音声信号から抽出されたメルスペクトルYと、音素表現記憶部14に記憶された発話者の性別に対応した言語の種類毎の音素表現Hとに基づいて、言語の種類毎に配合比率Uを計算する。
【0046】
次に、ステップ126で、上記ステップ124で計算された言語の種類毎の配合比率Uと音素表現記憶部14に記憶された発話者の性別に対応した言語の種類毎の音素表現Hとの積を各々計算し、上記ステップ122で抽出されたメルスペクトルYとの類似度を計算する。この類似度が最も高い場合の計算に用いられた音素表現Hに対応する言語の種類を、評価用音声信号が示す言語の種類に最も類似する言語の種類であると評価する。また、計算された類似度を用いて、言語の種類の体系化のために、入力された評価用音声信号に対する系統樹を評価結果として求める。
【0047】
次に、ステップ128で、上記ステップ126での評価結果を表示装置に表示して、処理を終了する。
【0048】
以上説明したように、第1の実施の形態の音声言語評価装置によれば、学習用音声信号から抽出された学習用特徴情報を非負値行列分割により音素表現とその配合比率とで表現した場合の音素表現を言語の種類毎に記憶しておき、評価用音声信号から抽出された評価用特徴情報と記憶された言語の種類毎の音素表現とに基づいて、言語の種類毎に配合比率を計算し、評価用特徴情報と、記憶された言語の種類毎の音素表現と計算された配合比率との積との類似度に基づいて、評価用音声信号が示す言語の種類がどの言語の種類に類似するかを評価する。このように、テキストレベルの言語表現への変換を行うことなく、また事前知識を要することなく、音声信号のみを用いて、入力された音声信号が示す言語の種類を評価することができる。
【0049】
また、評価用音声信号が示す言語の種類と各言語の種類との類似性を用いて言語系統樹を求めることができ、言語の種類間の関係性に対する新たな文化的歴史的新知見も期待できる。
【0050】
次に、第2の実施の形態について説明する。なお、第2の実施の形態に係る音声言語評価装置は、音素表現計算部13において、時系列の音素表現を用いる点が第1の実施の形態と異なるため、その点について説明する。
【0051】
言語の特性は母音の種類などにより分類されるが、特に連続音のように、母音などの各音素の音量が連続的に変化する場合には、前の音素から後の音素に連続的に変化していく中で、認識が困難になる状況がある(例えば、「おはよう」の「よ」から「う」にかけての音の変化)。第2の実施の形態では、このような連続音における音の微妙な変化も考慮に入れて、言語の種類を評価する。
【0052】
第2の実施の形態における音素表現計算部13は、図7に示すように、時系列構造を持った音素に対し、非負値行列分解(Non-negative Matrix Deconvolution、NMFD、例えば、「Paris Smaragdis, “Non-negative Matrix Factor Deconvolution; Extraction of Multiple Sound Sources from Monophonic Inputs,” Independent Component Analysis and Blind Signal Separation, Lecture Notes in Computer Science, 2004, Volume 3195/2004, 494-499」参照)を用いて時系列の音素表現を計算する。
【0053】
NMFDで計算した英語、ドイツ語、スウェーデン語、及びフランス語の時系列の音素表現を図8〜11に示す。ここでは、12個の音素を横に並べた音素表現となっている。各音素の内部では、横に5つの時系列の変化を表し、縦が周波数を表している。内部の各四角形が暗いほど強い値であることを示す。すなわち、各音素がメルスペクトルの時間推移を表現している。
【0054】
第2の実施の形態における学習処理及び評価処理については、第1の実施の形態の学習処理及び評価処理においてNMFにより音素表現を計算した点が、上記のNMFDを用いて時系列の音素表現を計算する点と異なるだけであるので、説明を省略する。
【0055】
以上説明したように、第2の実施の形態の音声言語評価装置によれば、第1の実施の形態の効果に加え、音の連続的な変化における微妙な音素の変化も考慮して、適切に評価用音声信号が示す言語の種類を評価することができる。
【0056】
ここで、本発明の効果を説明するために、評価結果の一例について説明する。
【0057】
21言語の音声コーパスから音素表現を作成し、ある女性の日本語入力に対し、類似度を比較した評価結果を図12に示す。距離を類似値に変換するため、exp(−距離値)を類似値とした。同図に示すとおり、日本語との類似値が最も高く、入力された音声信号が示す言語の種類が日本語であると正しく識別できることが確認できた。
【0058】
同様の方法を各言語間で繰り返し、UPGMA法で言語系統樹を作成した結果を図13に示す。同図の評価結果は、必ずしも言語学的分類の言語系統樹とは一致していないが、地理的な近さは反映したものとなっており、音素と言語の種類とのなんらかの関係を示唆していると思われる。
【0059】
次に、NMFDを用いて、英語、ドイツ語、スウェーデン語、及びフランス語の4言語について、距離を測定した結果を図14に示す。縦軸が学習した音素の変化であり、横軸は入力した音声の言語の種類である。各四角形内が黒いほど類似しており、白いほど違いが大きいことを示している。同図からわかるように、全ての入力された言語の種類に対して最も類似する言語の種類が正解の言語の種類となっており、NMFDを用いた識別が有効であることがわかる。さらにスウェーデン語の音素は他の言語との違いが大きく、ドイツ語の音素は他の言語に類似している。一般に英語よりもスウェーデン語やフランス語は母音の種類が多く、ドイツ語は母音の種類が少ない。このような傾向の影響を受けているように思われる。
【0060】
なお、上記の実施の形態では、学習部と評価部とを1つのコンピュータで構成する場合について説明したが、各々別のコンピュータで構成するようにしてもよい。
【0061】
また、本発明は、上述した実施形態に限定されるものではなく、この発明の要旨を逸脱しない範囲内で様々な変形や応用が可能である。
【0062】
例えば、上述の音声言語評価装置は、内部にコンピュータシステムを有しているが、「コンピュータシステム」は、WWWシステムを利用している場合であれば、ホームページ提供環境(あるいは表示環境)も含むものとする。
【0063】
また、本願明細書中において、プログラムが予めインストールされている実施形態として説明したが、当該プログラムを、コンピュータ読み取り可能な記録媒体に格納して提供することも可能である。
【符号の説明】
【0064】
1 音声言語評価装置
2 学習部
3 評価部
11 音声信号入力部
12 特徴情報抽出部
13 音素表現計算部
14 音素表現記憶部
15 音素配合比率計算部
16 言語類似性評価部
17 表示制御部
【特許請求の範囲】
【請求項1】
言語の種類が未知の評価用音声信号から評価用特徴情報を抽出する抽出手段と、
言語の種類が既知の複数の学習用音声信号から抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより得られた音素毎の基底ベクトルで表された言語の種類毎の音素表現と、前記抽出手段により抽出された評価用特徴情報とに基づいて、該評価用特徴情報に配合された各音素の基底ベクトルの比率を示す配合比率を、言語の種類毎に計算する配合比率計算手段と、
前記評価用特徴情報と、前記配合比率計算手段により計算された言語の種類毎の配合比率と前記言語の種類毎の音素表現との積で示される情報各々との類似度に基づいて、該評価用特徴情報に対応する評価用音声信号が示す言語の種類を評価する評価手段と、
を含む音声言語評価装置。
【請求項2】
前記音素表現を、時系列構造の音素表現とした請求項1記載の音声言語評価装置。
【請求項3】
前記評価手段は、前記類似度が最も高くなるときの音素表現に対応する言語の種類を、前記評価用音声信号が示す言語の種類であると識別するか、または、言語の種類毎の類似度に基づいて、言語の種類間の系統的関連性を示す言語系統樹を作成する請求項1または請求項2記載の音声言語評価装置。
【請求項4】
前記配合比率計算手段は、発話者の性別及び年齢の少なくとも一方が既知の学習用音声信号から抽出された学習用特徴情報より得られた言語の種類並びに性別及び年齢別の少なくとも一方毎の音素表現に基づいて、言語の種類並びに性別及び年齢別の少なくとも一方毎に前記配合比率を計算する請求項1〜請求項3のいずれか1項記載の音声言語評価装置。
【請求項5】
前記抽出手段は、前記複数の学習用音声信号から前記言語の種類毎の学習用特徴情報を抽出し、
前記抽出手段により抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより前記言語の種類毎の音素表現を計算する音素表現計算手段
を含む請求項1〜請求項4のいずれか1項記載の音声言語評価装置。
【請求項6】
抽出手段と、配合比率計算手段と、評価手段とを含む音声言語評価装置における音声言語評価方法であって、
前記抽出手段は、言語の種類が未知の評価用音声信号から評価用特徴情報を抽出し、
前記配合比率計算手段は、言語の種類が既知の複数の学習用音声信号から抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより得られた音素毎の基底ベクトルで表された言語の種類毎の音素表現と、前記抽出手段により抽出された評価用特徴情報とに基づいて、該評価用特徴情報に配合された各音素の基底ベクトルの比率を示す配合比率を、言語の種類毎に計算し、
前記評価手段は、前記評価用特徴情報と、前記配合比率計算手段により計算された言語の種類毎の配合比率と前記言語の種類毎の音素表現との積で示される情報各々との類似度に基づいて、該評価用特徴情報に対応する評価用音声信号が示す言語の種類を評価する
音声言語評価方法。
【請求項7】
前記音声言語評価装置は、音素表現計算手段を更に含み、
前記抽出手段は、前記複数の学習用音声信号から前記言語の種類毎の学習用特徴情報を抽出し、
前記音素表現計算手段は、前記抽出手段により抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより前記言語の種類毎の音素表現を計算する
請求項6記載の音声言語評価方法。
【請求項8】
コンピュータを、請求項1〜請求項5のいずれか1項記載の音声言語評価装置を構成する各手段として機能させるための音声言語評価プログラム。
【請求項1】
言語の種類が未知の評価用音声信号から評価用特徴情報を抽出する抽出手段と、
言語の種類が既知の複数の学習用音声信号から抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより得られた音素毎の基底ベクトルで表された言語の種類毎の音素表現と、前記抽出手段により抽出された評価用特徴情報とに基づいて、該評価用特徴情報に配合された各音素の基底ベクトルの比率を示す配合比率を、言語の種類毎に計算する配合比率計算手段と、
前記評価用特徴情報と、前記配合比率計算手段により計算された言語の種類毎の配合比率と前記言語の種類毎の音素表現との積で示される情報各々との類似度に基づいて、該評価用特徴情報に対応する評価用音声信号が示す言語の種類を評価する評価手段と、
を含む音声言語評価装置。
【請求項2】
前記音素表現を、時系列構造の音素表現とした請求項1記載の音声言語評価装置。
【請求項3】
前記評価手段は、前記類似度が最も高くなるときの音素表現に対応する言語の種類を、前記評価用音声信号が示す言語の種類であると識別するか、または、言語の種類毎の類似度に基づいて、言語の種類間の系統的関連性を示す言語系統樹を作成する請求項1または請求項2記載の音声言語評価装置。
【請求項4】
前記配合比率計算手段は、発話者の性別及び年齢の少なくとも一方が既知の学習用音声信号から抽出された学習用特徴情報より得られた言語の種類並びに性別及び年齢別の少なくとも一方毎の音素表現に基づいて、言語の種類並びに性別及び年齢別の少なくとも一方毎に前記配合比率を計算する請求項1〜請求項3のいずれか1項記載の音声言語評価装置。
【請求項5】
前記抽出手段は、前記複数の学習用音声信号から前記言語の種類毎の学習用特徴情報を抽出し、
前記抽出手段により抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより前記言語の種類毎の音素表現を計算する音素表現計算手段
を含む請求項1〜請求項4のいずれか1項記載の音声言語評価装置。
【請求項6】
抽出手段と、配合比率計算手段と、評価手段とを含む音声言語評価装置における音声言語評価方法であって、
前記抽出手段は、言語の種類が未知の評価用音声信号から評価用特徴情報を抽出し、
前記配合比率計算手段は、言語の種類が既知の複数の学習用音声信号から抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより得られた音素毎の基底ベクトルで表された言語の種類毎の音素表現と、前記抽出手段により抽出された評価用特徴情報とに基づいて、該評価用特徴情報に配合された各音素の基底ベクトルの比率を示す配合比率を、言語の種類毎に計算し、
前記評価手段は、前記評価用特徴情報と、前記配合比率計算手段により計算された言語の種類毎の配合比率と前記言語の種類毎の音素表現との積で示される情報各々との類似度に基づいて、該評価用特徴情報に対応する評価用音声信号が示す言語の種類を評価する
音声言語評価方法。
【請求項7】
前記音声言語評価装置は、音素表現計算手段を更に含み、
前記抽出手段は、前記複数の学習用音声信号から前記言語の種類毎の学習用特徴情報を抽出し、
前記音素表現計算手段は、前記抽出手段により抽出された言語の種類毎の学習用特徴情報を非負値行列分解することにより前記言語の種類毎の音素表現を計算する
請求項6記載の音声言語評価方法。
【請求項8】
コンピュータを、請求項1〜請求項5のいずれか1項記載の音声言語評価装置を構成する各手段として機能させるための音声言語評価プログラム。
【図1】


【図3】
【図4】
【図5】
【図6】
【図12】

【図13】
【図2】
【図7】
【図8】

【図9】

【図10】

【図11】

【図14】

【図3】
【図4】
【図5】
【図6】
【図12】
【図13】
【図2】
【図7】
【図8】
【図9】
【図10】
【図11】
【図14】
【公開番号】特開2013−61402(P2013−61402A)
【公開日】平成25年4月4日(2013.4.4)
【国際特許分類】
【出願番号】特願2011−198383(P2011−198383)
【出願日】平成23年9月12日(2011.9.12)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【出願人】(504202472)大学共同利用機関法人情報・システム研究機構 (119)
【Fターム(参考)】
【公開日】平成25年4月4日(2013.4.4)
【国際特許分類】
【出願日】平成23年9月12日(2011.9.12)
【出願人】(000004226)日本電信電話株式会社 (13,992)
【出願人】(504202472)大学共同利用機関法人情報・システム研究機構 (119)
【Fターム(参考)】
[ Back to top ]