
音声認識装置、音声認識方法、及び音声認識ロボット

【課題】未登録語を登録する際、ユーザが音声のみを用いて認識した音韻を訂正することができる音声認識装置、音声認識方法、及び音声認識ロボットを提供する。
【解決手段】音声入力部は音声を入力し、音韻認識部は入力された音声の音韻を認識して訂正発話を示す第1の音韻列を生成し、マッチング部は第1の音韻列と元発話を示す第2の音韻列とをマッチングを行い、音韻訂正部はマッチングを行った結果に基づき第2の音韻列の音韻を訂正する。
【解決手段】音声入力部は音声を入力し、音韻認識部は入力された音声の音韻を認識して訂正発話を示す第1の音韻列を生成し、マッチング部は第1の音韻列と元発話を示す第2の音韻列とをマッチングを行い、音韻訂正部はマッチングを行った結果に基づき第2の音韻列の音韻を訂正する。
【発明の詳細な説明】
【技術分野】
【0001】
本発明は、音声認識装置、音声認識方法、及び音声認識ロボットに関する。
【背景技術】
【0002】
ロボットを様々な環境で使用するために、ユーザとの音声による対話を通じてロボットに未知語を教示する技術が検討されている。しかし、未知語を構成する音韻を認識する際、従来の音声認識装置では認識誤りを完全に排除することはできない。そのため、認識誤りを訂正する技術が提案されている。例えば、特許文献1に記載の音声認識装置は、入力音声に含まれる単語を予め記憶されている単語と比較し、認識結果を画面に表示し、ユーザによるマニュアル操作に応じて、表示された認識結果から訂正単語を選択する。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2006−146008号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、特許文献1に記載の音声認識装置は、認識結果を表示する画面や操作入力を受け付ける入力デバイスを要するため、ロボットに応用することは現実的ではないという課題があった。
【0005】
本発明は上記の点に鑑みてなされたものであり、未登録語を登録する際、ユーザが入力デバイスを用いずに音声のみを用いて認識した音韻を訂正することができる音声認識装置、音声認識方法、及び音声認識ロボットを提供する。
【課題を解決するための手段】
【0006】
(1)本発明は上記の課題を解決するためになされたものであり、本発明は、音声を入力する音声入力部と、入力された音声の音韻を認識して訂正発話を示す第1の音韻列を生成する音韻認識部と、前記第1の音韻列と元発話を示す第2の音韻列とをマッチングを行うマッチング部と、前記マッチングを行った結果に基づき前記第2の音韻列の音韻を訂正する音韻訂正部と、を備えることを特徴とする音声認識装置である。
【0007】
(2)本発明はまた、上述の音声認識装置であって、前記音韻訂正部は、前記音韻列の各音韻に対する信頼度に基づき選択された音韻に訂正すること、を特徴とする音声認識装置である。
【0008】
(3)本発明はまた、上述の音声認識装置であって、前記音韻訂正部は、前記信頼度に基づく正解率が予め設定された値よりも低い場合、認識誤りと判断すること、を特徴とする音声認識装置である。
【0009】
(4)本発明はまた、上述の音声認識装置であって、前記マッチング部は、入力音声に含まれる音韻の種別と認識される音韻の種別の組ごとの頻度に基づき前記第1の音韻列の音韻と前記第2の音韻列の音韻との間の距離を算出し前記距離に基づきマッチング結果を決定すること、を特徴とする音声認識装置である。
【0010】
(5)本発明はまた、上述の音声認識装置であって、前記訂正した第2の音韻列に基づく音声を再生する音声再生部と、認識結果を示す応答パターンを記憶する対話応答パターン記憶部と、入力された音声の音韻に合致する前記応答パターンに基づき、前記訂正した第2の音韻列からなる単語情報を単語記憶部に記憶するか、前記音声再生部に利用者に発話を促す音声を再生させるか、いずれか一方を実行する対話処理部と、を備えること、を特徴とする音声認識装置である。
【発明の効果】
【0011】
本発明によれば、利用者が発した訂正発話に係る入力音声の第1の音韻列とのマッチング結果に基づき、元発話を示す第2の音韻列を訂正するため、利用者が入力した音声のみに基づき音韻を訂正することができる。
【0012】
第2の本発明によれば、さらに、各音韻に対する信頼度に基づいて選択された音韻に訂正するため、信頼性に裏付けられた音韻に訂正することができる。
【0013】
第3の本発明によれば、さらに、音韻に対する正解率が低い場合に、認識誤りと判断するため、正解率の低い音韻に訂正することを回避することができる。
【0014】
第4の本発明によれば、さらに、第1の音韻列の音韻について、その音韻が認識される音韻の種別ごとの確率に基づいて算出された第2の音韻列との間の距離からマッチング結果を決定するため、認識誤りを考慮したマッチングを実現することができる。
【0015】
第5の本発明によれば、さらに、訂正した音韻列を示す音声を再生し、利用者による応答を示す入力音声に応じて、訂正した音韻列からなる単語情報を記憶するか、発話を促す音声を再生する。そのため、利用者に訂正した音韻列に係る音声による応答を促し、応答により訂正した音韻列からなる単語情報が登録されるか、利用者に再度発話を促すため、音声のみによる音韻認識誤りの訂正を円滑に実現できる。
【図面の簡単な説明】
【0016】
【図1】本発明の第1の実施形態に係る音声認識装置1の構成を示す概略図である。
【図2】本実施形態に係る音韻の種別ごとのGPPと正解率の関係の一例を示す図である。
【図3】始終端フリーDPマッチング法の処理を示す流れ図である。
【図4】DPマッチング法の処理を示す流れ図である。
【図5】本実施形態に係る混同行列情報の一例を示す図である。
【図6】本実施形態に係る第1の音韻列と第2の音韻列とのマッチング結果の一例を示す図である。
【図7】本実施形態に係る第1の音韻列と第2の音韻列とのマッチング結果のその他の例を示す図である。
【図8】本実施形態に係る各音韻列に含まれる音韻ごとのGPP及び正解率の一例を示す図である。
【図9】本実施形態に係る各音韻列に含まれる音韻ごとのGPP及び正解率のその他の例を示す図である。
【図10】本実施形態に係る各音韻列に含まれる音韻ごとのGPP及び正解率のその他の例を示す図である。
【図11】本実施形態におけるパターン情報の例を示す図である。
【図12】本実施形態に係る音声認識装置1と利用者との間の対話の一例を示す。
【図13】本実施形態に係る音声認識装置1における音声認識処理を示す流れ図である。
【図14】音声認識装置1による単語正解率と音韻正解精度の一例を示す図である。
【図15】本発明の第2の実施形態に係る音声認識装置3の構成を示す概略図である。
【発明を実施するための形態】
【0017】
(第1の実施形態)
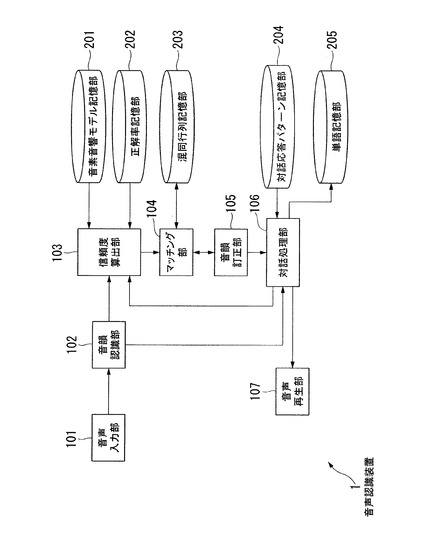
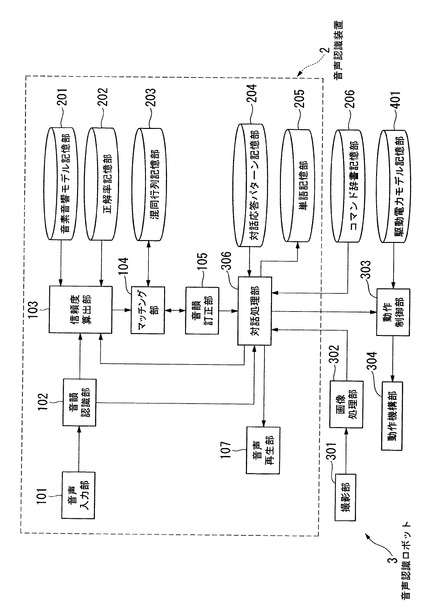
以下、図面を参照しながら本発明の実施形態について詳しく説明する。図1は、本実施形態に係る音声認識装置1の構成を示す概略図である。音声認識装置1は、音声入力部101、音韻認識部102、信頼度算出部103、マッチング部104、音韻訂正部105、対話処理部106、音声再生部107、音素音響モデル記憶部201、正解率記憶部202、混同行列記憶部203、対話応答パターン記憶部204及び単語記憶部205を含んで構成される。
【0018】
音声入力部101は、利用者が発した音声による空気の振動を音声信号に変換し、変換した音声信号を音韻認識部102に出力する。音声入力部101は、例えば人間が発するする音声の周波数帯域(例えば、200Hz−4kHz)の音波を受信するマイクロホンである。
【0019】
音韻認識部102は、音声入力部101から入力されたアナログ音声信号をディジタル音声信号に変換する。ここで、音韻認識部102は、入力されたアナログ信号を、例えば、サンプリング周波数を16kHzとし、振幅を16ビットの2進データにパルス符号変調(Pulse Code Modulation;PCM)して、量子化された信号サンプルに変換する。音韻認識部102は、変換されたディジタル音声信号から音声特徴量を算出する。音声特徴量は、例えば25次元のメル尺度ケプストラム(Mel−Frequency Cepstrum Coefficient;MFCC)である。
【0020】
音韻認識部102は、算出した音声特徴量に基づき、公知の音韻認識方法により利用者の発音を示す音韻を認識し、認識された音韻から構成される音韻列を生成する。音韻認識部102は、例えば、隠れマルコフモデル(Hidden Markov Model;HMM)を用いて音韻を認識するが、他の方法を用いてもよい。音韻とは、ある言語において話者が同一と認識する音声の最小基本単位をいう。本実施形態では、音韻とは音素と同義である。音韻認識部102は、生成した音韻列と算出した音声特徴量の時系列データである音声特徴量ベクトルを信頼度算出部103及び対話処理部106に出力する。
【0021】
信頼度算出部103は、音韻認識部102又は対話処理部106から入力された音韻列及び音声特徴量ベクトルに基づき音韻ごとに信頼度を算出する。信頼度とは、音韻の認識結果としての信頼性を示す変数である。信頼度算出部103は、信頼度として例えば一般化事後確率(Generalized Posterior Probability;GPP)と正解率を算出するが、他の変数を算出してもよい。
【0022】
例えば、信頼度算出部103は、音声特徴量ベクトルx1が与えられているとき、開始時刻sから終了時刻tまで継続する音韻uに対するGPPは、式(1)(Lijuan Wang et.al;“Phonetic Transcripstion Verification with Generalized Posterior Probability,”、「Interspeech2005」、2005、p.1950 参照)を用いて算出する。
【0023】
【数1】

【0024】
式(1)で、Tはベクトルの転置を示す。Mは音韻列(Phoneme Graph)における、経路(path)における音韻数を示す。m、nは、経路上の音韻を示すインデックスである。αは、音響モデルに対する指数重み係数(exponential weight)を示す。p(x1T)は、音声特徴量ベクトルx1が与えられる確率である。p(xsmtm|um)は、音韻umの該当部分、即ち開始時刻をsm、終了時刻をtmとする音声特徴量ベクトルxsmtmに対する条件付確率である。
【0025】
音素音響モデル記憶部201には、音声特徴量ベクトルx1が与えられる確率p(x1T)と、音韻umの音声特徴量ベクトルxsmtmに対する条件付確率p(xsmtm|um)が予め記憶されている。信頼度算出部103は、音韻認識部102から入力された音声特徴量ベクトルx1に対応する確率p(x1T)と音韻umの音声特徴量ベクトルxsmtmに対する条件付確率p(xsmtm|um)を音素音響モデル記憶部201から読み出し、式(1)に従ってGPPを算出する。
【0026】
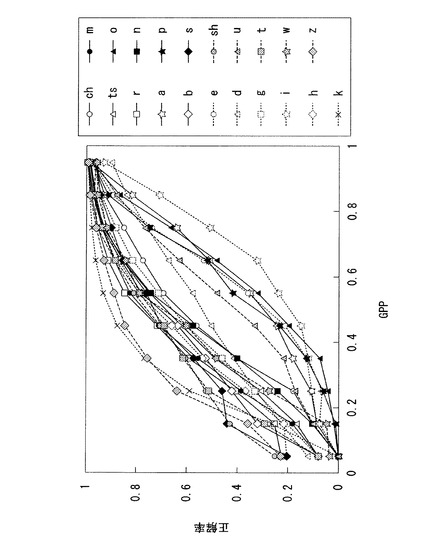
信頼度算出部103は、音韻ごとに算出したGPPに基づき正解率を決定する。正解率とは、音韻認識部102の認識結果として正しい音韻が得られる確率である。具体的には、正解率記憶部202に、予め音韻ごとのGPPと正解率との関係を記憶しておく。そこで、信頼度算出部103は、音韻ごとに算出したGPPに対応する正解率を正解率記憶部202から読み出して決定する。日本語の発音を構成する音韻の種別ごとのGPPと正解率との関係の一例を図2に示す。図2において、横軸はGPP、縦軸は正解率を示す。また、各線は、音韻ごとのGPPに対する正解率を示す。図2は、何れの音韻についても、GPPが増加するにつれ正解率も増加することを示す。また、GPPも正解率も最小値はゼロであり、最大値は1である。但し、音韻の種別により正解率やその増加率は一定ではない。信頼度算出部103は、音韻列とこれを構成する音韻ごとの正解率(又はGPP)をマッチング部104に出力する。
【0027】
マッチング部104は、信頼度算出部103から音韻列(以下、第1の音韻列と呼ぶ)とこれを構成する音韻ごとの正解率(又はGPP)が新たに入力される。また、マッチング部104は、過去に入力又は訂正された音韻列(以下、第2の音韻列と呼ぶ)とこれを構成する音韻ごとの正解率(又はGPP)が音韻訂正部105から入力され、これらを記憶する。マッチング部104は、第1の音韻列と第2の音韻列についてマッチング処理(照合)を実行する。マッチング部104は、マッチング処理において、例えば始終端フリーDPマッチング法(両端点フリーDP法又はLevel Buiding法ともいう)を使用するが、これに限らず他の方法を用いてもよい。
【0028】
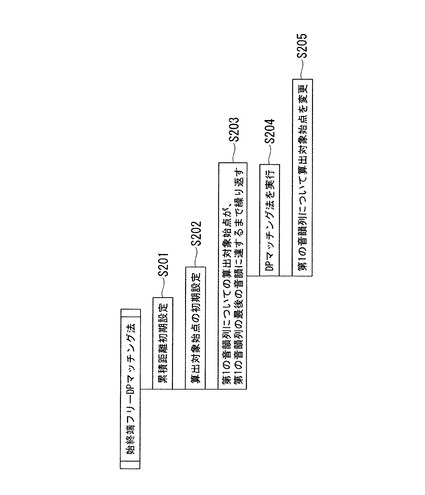
ここで、始終端フリーDPマッチング法の処理について図3を用いて説明する。図3は、始終端フリーDPマッチング法の処理を示す流れ図である。
(ステップS201)マッチング部104は、累積距離をゼロと初期設定する。
(ステップS202)マッチング部104は、第1の音韻列の最初の音韻と、第2の音韻列に含まれる音韻のうち一つを、後述する距離を算出する対象とする音韻のうち最初の音韻(以下、算出対象始点と呼ぶ)と初期設定する。
(ステップS203)マッチング部104は、第1の音韻列についての算出対象始点のうち第1の音韻列について最後の音韻に達するまでステップS204及びS205を繰り返す。
(ステップS204)マッチング部104は、DPマッチング法(始点及び終点が固定)を実行する。
(ステップS205)マッチング部104は、第1の音韻列についての算出対象始点をその次の音韻に進める。
【0029】
マッチング部104は、上述の処理を算出対象始点となる第2の音韻列に含まれる音韻全てについて実行し、それぞれの場合について累積距離を算出する。マッチング部104は、算出された累積距離を最小とする算出対象始点、即ち第1の音韻列と第2の音韻列との対応関係がマッチング結果として決定される。即ちマッチング結果は、第1の音韻列に含まれる音韻と第2の音韻列に含まれる音韻の対(pair)からなるマッチング情報である。
【0030】
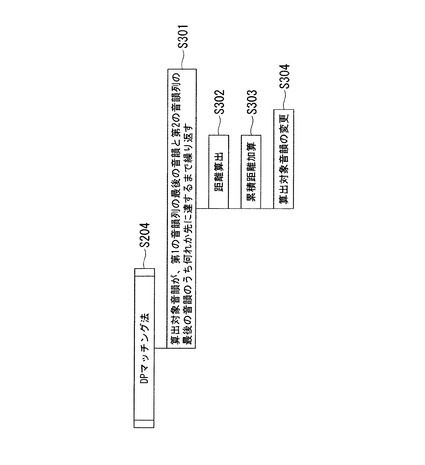
次に、ステップS204で実行されるDPマッチング法の処理について図4を用いて説明する。図4は、DPマッチング法の処理を示す流れ図である。
(ステップS301)マッチング部104は、距離を算出する対象とする音韻(算出対象音韻)が、第1の音韻列の最後の音韻及び第2の音韻列の最後の音韻のうち何れか先に達するまでステップS302〜S304の処理を繰り返す。
(ステップS302)マッチング部104は、算出対象音韻間の距離を後述するように算出する。
(ステップS305)マッチング部104は、算出した距離を累積距離に加算する。
(ステップS306)マッチング部104は、算出対象音韻を、第1の音韻列、第2の音韻列各々について直後の音韻に変更する。
【0031】
なお、マッチング部104は、上述のマッチング処理において第1の音韻列の一部に音声入力中の音韻が存在しない場合(挿入誤り)が生じる場合を考慮し、挿入誤りも一種の音韻として距離を算出する。同様に、マッチング部104は、第2の音韻列の一部に認識結果としての音韻が存在しない場合(脱落誤り)が生じる場合を考慮し、脱落誤りも後述のように一種の音韻として距離を算出する。
【0032】
マッチング部104は、例えば上述のステップS302において算出対象音韻である第1の音韻列に含まれる1つの音韻αと第2の音韻列に含まれる1つの音韻βとの間の距離d(α,β)を、例えば式(2)により算出する。
【0033】
【数2】
【0034】
式(2)において、P(α,β)は、認識結果である音韻α(認識結果音韻(recognized phoneme))の音声入力中の音韻(以下、発話目的音韻(input phoneme)と呼ぶ)と認識結果音韻βの発話目的音韻が一致する確率である。発話目的音韻として可能性がある音韻をγとすると、P(α,β)は、式(3)で表される。
【0035】
【数3】
【0036】
式(3)において、P(α|γ)は、発話目的音韻γが認識結果音韻αに認識される確率を示す。P(β|γ)は、発話目的音韻γが認識結果音韻βに認識される確率を示す。P(γ)は、発話目的音韻γが出現する確率を示す。
混同行列記憶部203には、例えば、発話目的音韻γが認識結果音韻αに認識される頻度を要素とする混同行列情報(confusion matrix)を予め記憶しておく。マッチング部104は、混同行列記憶部203に記憶された混同行列情報から、認識結果音韻αに認識される頻度と認識結果音韻βに認識される頻度を読み出し、P(α|γ)、P(β|γ)及びP(γ)を算出する。マッチング部104は、式(3)に基づきP(α,β)を算出し、式(2)に基づき、d(α,β)を算出する。
【0037】
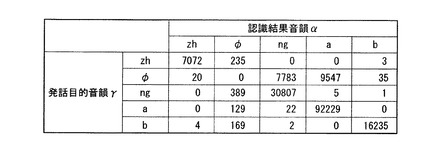
混同行列情報の一例を図5に示す。図5は、本実施形態に係る混同行列情報の一例を示す図である。図5において、行は発話目的音韻γとしてzh、φ、ng、a及びbを示す。列は、認識結果音韻αとしてzh、φ、ng、a及びbを示す。数値は、認識結果音韻α及び発話目的音韻γの組ごとの度数を示す。例えば、発話目的音韻γがzhであるとき、認識結果音韻αがzhと認識される度数が7072回である。ここで、混同行列情報の行と列、つまり発話目的音韻γと認識結果音韻αが一致する場合(認識結果が正しい場合)の度数を示す。混同行列情報の行と列、つまり発話目的音韻γと認識結果音韻αが異なる場合(認識結果が誤る場合)の度数を示す。図5の例では、認識結果が正しい場合のほうが誤る場合よりも多い。式(2)を考慮すれば、発話目的音韻γと認識結果音韻αが一致する場合のほうが異なる場合よりも距離が大きくなる。なお、発話目的音韻γがφであるとは、発話目的音韻が存在しない挿入誤りを示す。認識結果音韻αがφであるとは、認識結果音韻が存在しない脱落誤りを示す。
【0038】
図6は、第1の音韻列と第2の音韻列とのマッチング結果の一例を示す図である。図6の例では、第1の音韻列は「disu」、第2の音韻列は「jisupurei」である。ここで、第1の音韻列「disu」は、第2の音韻列のうち「jisu」の部分に対応している。
図7は、第1の音韻列と第2の音韻列とのマッチング結果のその他の例を示す図である。図7の例では、第1の音韻列は「boodo」、第2の音韻列は「kiibonono」である。ここで、第1の音韻列の「bo」の部分のうち第2の音韻列のうち「bo」の部分に対応している。また、第1の音韻列の「odo」の部分が、第2の音韻列のうち「ono」の部分に対応している。なお、第2の音韻列のうち6番目の音韻「n」に対応する第1の音韻列の音韻は存在しない。
【0039】
上述のように、図6や図7に示す例のように、音韻列間で音韻数が異なる場合があるが、マッチング部104は、上述の始終端フリーDPマッチング法のように、一方の音韻列の途中の音韻が他方の音韻列の始端に対応させることができるマッチング処理を行う。その結果、このような場合にも音韻列間のマッチング情報を決定することができる。
従って、利用者が認識結果として第2の音韻列を訂正するために、第1の音韻列を示す音声で応答する場合に、第2の音韻列のうち認識誤りに対応する部分だけを応答してもよい。
また、図7に示す例のように、一方の音韻列の一部分と他の部分が離れる場合があるが、マッチング部104は、挿入誤りや脱落誤りを考慮することで、このような場合にも音韻列間のマッチング情報を決定することができる。
【0040】
図1に戻り、マッチング部104は、第1の音韻列、第2の音韻列、マッチング情報及び各音韻列に含まれる音韻ごとの正解率を音韻訂正部105に出力する。
【0041】
音韻訂正部105は、マッチング部104から第1の音韻列、第2の音韻列、マッチング情報及び各音韻列に含まれる音韻ごとの正解率を入力する。音韻訂正部105は、入力された第1の音韻列に含まれる音韻と第2の音韻列に含まれる音韻とを、マッチング情報を参照して対応付け、自己が備える記憶領域に記憶する。
【0042】
図8は、本実施形態に係る各音韻列に含まれる音韻ごとのGPP及び正解率の一例を示す図である。図8は、第1の音韻列、これに含まれる音韻ごとのGPP、正解率、第2の音韻列、これに含まれる音韻ごとのGPP、正解率及び後述する処理による訂正後の音韻列を示す。図8によれば、第1の音韻列に含まれる音韻“d”、“i”、“s”及び“u”に対応するGPPは、0.75、0.73、0.48及び0.76、正解率は、0.92、0.80、0.73及び0.78となる。第2の音韻列に含まれる音韻“j”、“i”、“s”、“u”、“p”、“u”、“r”、“e”及び“i”に対応するGPPは、0.21、0.62、0.53、0.92、0.44、0.91、0.54、0.66及び0.88、正解率は、0.06、0.52、0.75、0.96、0.28、0.94、0.85、0.50及び0.85となる。また、訂正後の音韻列は、“disupurei”となる。なお、図8の表の上部に示されている数値1〜9は、音韻の順序を示すインデックスである。
【0043】
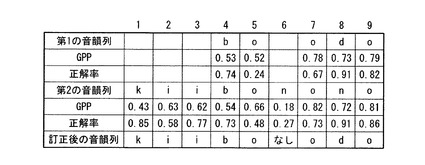
図9は、本実施形態に係る各音韻列に含まれる音韻ごとのGPP及び正解率のその他の例を示す図である。図9は、第1の音韻列、これに含まれる音韻ごとのGPP、正解率、第2の音韻列、これに含まれる音韻ごとのGPP、正解率及び後述する処理による訂正後の音韻列を示す。図9によれば、第1の音韻列に含まれる音韻“b”、“o”、“o”、“d”及び“o”に対応するGPPは、0.53、0.52、0.78、0.73及び0.79、正解率は、0.74、0.24、0.67、0.91及び0.82となる。第2の音韻列に含まれる音韻“k”、“i”、“i”、“b”、“o”、“n”、“o”、“n”及び“o”に対応するGPPは、0.43、0.63、0.62、0.54、0.66、0.18、0.82、0.72及び0.81、正解率は、0.85、0.58、0.77、0.73、0.48、0.27、0.73、0.91及び0.86となる。また、訂正後の音韻列は、“kiiboodo”となる。なお、図9の表の上部に示されている数値1〜9は、音韻の順序を示すインデックスである。
【0044】
図10は、本実施形態に係る各音韻列に含まれる音韻ごとのGPP及び正解率のその他の例を示す図である。図10は、第1の音韻列、これに含まれる音韻ごとのGPP、正解率、第2の音韻列、これに含まれる音韻ごとのGPP、正解率及び後述する処理による訂正後の音韻列を示す。図10によれば、第1の音韻列に含まれる音韻“m”、“e”、“m”、“o” 、“o”、“r”、“i”及び“i”に対応するGPPは、0.68、0.84、0.76、0.53、0.23、0.83、0.75及び0.96、正解率は、0.72、0.79、0.79、0.71、0.34、0.77、0.65及び0.93となる。第2の音韻列に含まれる音韻“m”、“e”、“m”及び“o”に対応するGPPは、0.59、0.69、0.65及び0.82、正解率は、0.65、0.61、0.70及び0.86となる。また、訂正後の音韻列は、“memorii”となる。なお、図10の表の上部に示されている数値1〜8は、音韻の順序を示すインデックスである。
【0045】
音韻訂正部105は、入力された第2の音韻列を、第1の音韻列、マッチング情報及び正解率に基づいて訂正して、訂正後の音韻列を決定する。
ここで、音韻訂正部105は、第1の音韻列に含まれる音韻に対応する第2の音韻列に含まれる音韻が異なる場合には、それらの音韻のうち各々に対応する正解率が高いほうの音韻を、訂正後の音韻列に含まれる音韻と決定する。
例えば、図8において第2の音韻列の1番目の音韻“j”は対応する第1の音韻列の音韻“d”と異なる。音韻“d”に対応する正解率は0.92と、音韻“j”に対応する正解率0.06よりも高いため、音韻訂正部105は、訂正後の音韻列の1番目の音韻を“d”と決定する。
【0046】
音韻訂正部105は、第1の音韻列に含まれる音韻に対応する第2の音韻列に含まれる音韻が同一である場合には、その同一の音韻を訂正後の音韻列に含まれる音韻と決定する。
第2の音韻列に含まれる音韻に対応する音韻が第1の音韻列に存在しない場合は、音韻訂正部105は、第2の音韻列に含まれる音韻を訂正後の音韻列に含まれる音韻と決定する。但し、その第2の音韻列に含まれる音韻に対応する正解率が予め設定された値(例えば、0.5)よりも小さい場合、音韻訂正部105は、その音韻を訂正後の音韻列に含めずに除外する。例えば、図9において、第2の音韻列の第6番目の音韻“n”に対応する正解率は0.27と、予め設定された値0.5よりも小さいため、この音韻nを訂正後の音韻列に含めずに除外する
【0047】
また、第1の音韻列に含まれる音韻に対応する音韻が第2の音韻列に存在しない場合は、音韻訂正部105は、その第1の音韻列に対応する音韻を、訂正後の音韻列に含める。
但し、その第1の音韻列に含まれる音韻に対応する正解率が予め設定された値よりも小さい場合、音韻訂正部105は、その音韻を訂正後の音韻列に含めずに除外する。例えば、図10において、第1の音韻列の第5番目の音韻“o”に対応する正解率は0.34と、予め設定された値0.5よりも小さいため、この音韻oを訂正後の音韻列に含めずに除外する
音韻訂正部105は、第2の音韻列に対応する訂正後の音韻列を決定したら、決定した訂正後の音韻列とその音韻列に含まれる音韻ごとの正解率をマッチング部104に出力する。マッチング部104は、この訂正後の音韻列を新たな第2の音韻列とする。また、音韻訂正部105は、この訂正後の音韻列(第2の音韻列)を対話処理部106に出力する。
【0048】
なお、本実施形態では、音韻訂正部105は、上述のように各音韻列に含まれる音韻ごとの正解率に基づき訂正後の音韻列を決定することに限られない。音韻訂正部105は、マッチング部から各音韻列に含まれる音韻ごとのGPPを正解率の代わりに入力され、この音韻ごとのGPPに基づいて訂正後の音韻列を決定してもよい。ここで、音韻訂正部105は、音韻ごとのGPPが予め設定された閾値よりも小さい場合、訂正後の音韻列からその音韻を除外する。この閾値は、例えば、音韻の種別によらず一定の正解率に対応する値である。その場合、音韻の種別によりGPPと正解率の関係が異なるため(図2参照)、この閾値も音韻の種別によって異なる。また、音韻訂正部105は、正解率の代わりに訂正後の音韻列に含まれる音韻ごとのGPPをマッチング部104に出力する。
【0049】
対話応答パターン記憶部204は、例えば、図11に示すパターン情報を予め記憶する。図11は、本実施形態におけるパターン情報の例を示す図である。パターン情報には、要求パターンと応答パターンを含む。要求パターンには、初期要求パターン、確認要求パターンと訂正要求パターンを含む。応答パターンには、肯定パターン、否定パターン、初期応答パターン及び訂正要求回答パターンを含む。各パターンの具体的な内容については後述する。
【0050】
図1に戻り、対話処理部106は、初めに利用者からの認識対象となる音韻列を音声で入力するために、対話応答パターン記憶部204から、利用者にその音韻列を音声で応答することを要求する対話パターン情報(初期要求パターン)を読み出す。即ち、初期要求パターンとは、音声認識装置1が提示するメッセージのパターンを示す音韻列を含む情報であって、利用者に認識対象となる音韻列を初めて音声で応答することを促すものである。初期要求パターンは、例えば図11の「korewa naninani desu to nobetekudasai」である。この例は、利用者に「korewa ≪ … ≫ desu」と音声で回答を促すものであって、≪ … ≫の部分に、例えば名詞を示す音韻列が含まれる。対話処理部106は、この初期要求パターンを初期要求音韻列として音声再生部107に出力する。
【0051】
対話処理部106は、音韻認識部102から音韻列が入力されると、対話応答パターン記憶部204から、利用者に認識結果としての音韻列に対する確認を要求する対話パターン情報(確認要求パターン)を読み出す。即ち、確認要求パターンとは、音声認識装置1が提示するメッセージのパターンを示す音韻列を含む情報であって、利用者に、利用者の回答に基づいて訂正された後の音韻列に対して認識結果が正しいか否かを音声で回答することを促すものである。確認要求パターンは、例えば図11の「< … > deiidesuka」 である。< … >の部分は、訂正後の音韻列が挿入される部分であることを示す。
【0052】
対話処理部106は、確認要求パターンに、訂正後の音韻列を挿入して、利用者に認識結果の確認を要求するメッセージを示す音韻列(確認要求音韻列)を生成する。つまり、確認要求音韻列は、挿入した音韻列が正しいか否かを利用者に音声で回答すること促すメッセージを示す音韻列となる。例えば、訂正後の音韻列が「disupurei」であるとき、確認要求音韻列は「disupurei deiidesuka」と「ディスプレイでいいですか」を示す音韻列となる。対話処理部106は、この確認要求音韻列を音声再生部107に出力する。
【0053】
対話処理部106は、後述する処理を実行して音韻認識部102から入力された音韻列が訂正後の音韻列としての認識結果として誤っていることを示す音韻列であるか判定する。対話処理部106は、音韻認識部102から入力された音韻列が訂正後の音韻列としての認識結果として誤っていることを示す音韻列であると認識したとき、対話応答パターン記憶部204から、利用者に正しい音韻列を音声で応答することを要求する対話パターン情報(訂正要求パターン)を読み出す。訂正要求パターンとは、音声認識装置1が提示するメッセージのパターンを示す音韻列を含む情報であって、利用者に正しい音韻列を音声で回答することを促す音韻列である。訂正要求パターンは、例えば図11の「tadashikuwa naninani desu to nobetekudasai」である。この例は、利用者に「tadashikuwa ≪ … ≫ desu」と音声で回答を促す音韻列であって、≪ … ≫の部分に正しい音韻列が含まれる。対話処理部106は、この訂正要求パターンを訂正要求音韻列として音声再生部107に出力する。
【0054】
対話処理部106は、音韻認識部102から音韻列と音声特徴量ベクトルが入力される。対話処理部106は、入力された音韻列に基づき対話応答パターン記憶部204から利用者からの音声による応答の類型を示す応答パターン情報(応答パターン)を読み出す。応答パターンは、例えば、図11の「hai」、「un」、「so」、等、訂正後の音韻列が認識結果として正しいことを示す音韻列(肯定パターン)や、図11の「iie」、「ee」、「chigau」、等、訂正後の音韻列が認識結果として誤っていることを示す音韻列(否定パターン)を含む。また、応答パターンは、初めて利用者が認識対象として回答するメッセージのパターンを示す音韻列(初期応答パターン)と、認識結果として正しい音韻列を利用者が回答するメッセージのパターンを示す音韻列(訂正応答パターン)を含む。
【0055】
初期応答パターンは、例えば、図11の「korewa ≪ … ≫ desu」である。≪ … ≫を除く部分は、初期要求パターンから、「naninani」と、回答としての音韻列を含める部分と、「to nobetekudasai」と利用者への指示を示す部分を除いた部分に一致する。即ち、初期要求パターンは、初期応答として利用者に要求するパターンを示す部分が初期応答パターンと共通する。
訂正応答パターンは、例えば、図11の「tadashikuwa ≪ … ≫ desu」である。≪ … ≫を除く部分は、訂正要求パターンから、「naninani」と、回答としての音韻列を含める部分と、「to nobetekudasai」と利用者への指示を示す部分を除いた部分に一致する。即ち、訂正要求パターンは、訂正応答として利用者に要求するパターンを示す部分が訂正応答パターンと共通する。
≪ … ≫の部分は、回答としての認識対象の音韻列を含む部分であることを示す。
【0056】
図1に戻り、対話処理部106は、音韻認識部102から入力された音韻列と対話応答パターン記憶部204から読み出した応答パターン情報にマッチング処理を実行して、入力された音韻列に最も合致する応答パターンを決定する。マッチング処理において、対話処理部106は、例えば上述の始終端フリーDPマッチング法を実行する。
対話処理部106は、決定した応答パターン情報が肯定パターンのうちの一つである場合、利用者の応答に基づき訂正された訂正後の音韻列を単語情報として単語記憶部205に記憶させる。即ち、対話処理部106は、音韻認識部102から入力された音韻列が訂正後の音韻列が認識結果として正しいことを示す音韻列と認識する。これにより、音声認識装置1は、新たに記憶した音韻列を、認識対象の語彙として用いることができることになる。
対話処理部106は、決定した応答パターン情報が否定パターンのうちの一つである場合、音韻認識部102から入力された音韻列が訂正後の音韻列が認識結果として誤っていることを示す音韻列と認識する。このとき、対話処理部106は、上述のように対話応答パターン記憶部204から、訂正要求パターンを読み出す。
【0057】
対話処理部106は、決定した応答パターン情報が初期応答パターン又は訂正応答パターンであるとき、音韻認識部102から入力された音韻列が認識対象となる音韻列を含む音韻列と認識する。このとき、対話処理部106は、初期応答パターン又は訂正応答パターンの≪…≫に対応する、音韻認識部102から入力された音韻列の部分を抽出し、この部分を新たな第1の音韻列とする。対話処理部106は、音韻認識部102から入力された音声特徴量ベクトルから抽出された第1の音韻列と対応する音声特徴量ベクトルを抽出する。対話処理部106は、抽出された第1の音韻列と音声特徴量ベクトルを信頼度算出部103に出力する。
【0058】
音声再生部107は、対話処理部106から入力された初期要求音韻列、訂正要求音韻列又は確認要求音韻列から、公知のテキスト・音声合成方法を用いて、音声信号を生成する。音声再生部107は、生成した音声信号に基づく音声を再生する。音声再生部107は、確認要求音韻列に基づき、例えば、「disupurei deiidesuka」と「ディスプレイでいいですか」というメッセージを表す音声を再生する。これにより、利用者に「disupurei」という訂正後の音韻列が認識結果として正しいか否かを回答することを促すことができる。
【0059】
音声再生部107は、初期要求音韻列に基づき、例えば、「korewa naninani desu」と「これはナニナニです、と述べてください」というメッセージを示す音声を再生する。これにより、利用者に「korewa ≪ … ≫ desu」と、≪ … ≫の部分に初めて認識対象となる音韻列を音声で回答することを促すことができる。
音声再生部107は、訂正要求音韻列に基づき、例えば、「tadashikuwa naninani desu」と「正しくはナニナニです、と述べてください」というメッセージを示す音声を再生する。これにより、利用者に「tadashikuwa ≪ … ≫ desu」と、≪ … ≫の部分に正しい音韻列を音声で回答することを促すことができる。
【0060】
次に、音声認識装置1が実行する音声認識処理について説明する。音声認識装置1は、この音声認識処理を実行することにより、利用者と例えば図12に示す音声による対話を行い新たな単語を記憶することができる。
図12は、本実施形態に係る音声認識装置1と利用者との間の対話の一例を示す図である。図12において、Sは、音声認識装置1が再生する音声の内容を示す。Uは、利用者が発する音声の内容を示す。C1〜C8は、音声の順序を示す。
C1は、音声認識装置1が「これはナニナニです、と述べてください。」と初期要求音韻列“korewa naninani desu to nobete kudasai”に基づく音声を再生することを示す。これにより、音声認識装置1は、利用者に対し、音声で音韻列を“korewa ≪…≫ desu”という初期応答パターンで回答することを要求している。
C2は、利用者が「これはディスプレイです」と音声で回答することを示す。これにより、利用者は、C1で要求された初期応答パターンで音韻列「ディスプレイ」が示す音韻列“disupurei”を回答している。
【0061】
C3は、音声認識装置1が「これはジスプレイでいいですか?」と確認要求音韻列“jisupurei deiidesuka”に基づく音声を再生することを示す。これにより、音声認識装置1は、利用者に対し認識された音韻列“jisupurei”に対して、認識結果として正しいか否かを回答することを要求している。
C4は、利用者が「いいえ」と音声で回答することを示す。これにより、利用者は、C3により認識結果が誤りであることを示す否定パターン“iie”を回答している。
C5は、音声認識装置1が「正しくはナニナニです、と述べてください。」と訂正要求音韻列“tadashikuwa naninani desu to nobete kudasai”に基づく音声を再生することを示す。これにより、音声認識装置1は、利用者に対し、音声で音韻列を“tadashikuwa ≪…≫ desu”という初訂正応答パターンで回答することを要求している。
【0062】
C6は、利用者が「正しくはディスです」と音声で回答することを示す。これにより、利用者は、C5で要求された訂正応答パターンで音声認識装置1が認識結果として誤った部分“jisu”に対応する音韻列“disu”を回答している。
C7は、音声認識装置1が「これはディスプレイでいいですか?」と確認要求音韻列“disupurei deiidesuka”に基づく音声を再生することを示す。これにより、音声認識装置1は、利用者に対し認識及び訂正された音韻列“disupurei”に対して、認識結果として正しいか否かを回答することを要求している。
C8は、利用者が「はい」と音声で回答することを示す。これにより、利用者は、C3により認識結果が正しいことを示す肯定パターン“hai”を回答している。
【0063】
このような対話を実現するために音声認識装置1は、図13に示す処理を実行する。図13は、本実施形態に係る音声認識処理を示す流れ図である。
(ステップS101)音声認識装置1は、音声認識方法を実行するための変数について初期設定を行う。例えば、対話処理部106は、利用者に正しい音韻列を音声で応答することを要求する回数Mを6に設定し、その応答回数をカウントする変数iを1に設定する。その後、ステップS102に進む。
【0064】
(ステップS102)対話処理部106は、対話応答パターン記憶部204から、初期要求パターンを読み出す。対話処理部106は、読み出した初期要求パターンを初期要求音韻列として音声再生部107に出力する。
音声再生部107は、対話処理部106から入力された初期要求音韻列から、公知のテキスト・音声合成方法を用いて音声信号を生成する。音声再生部107は、生成した音声信号に基づき音声を再生する(例えば図12のC1)。これにより、音声認識装置1は、利用者に認識対象となる音韻列を音声で回答することを促すことができる。
(ステップS103)音声入力部101は、利用者が発した音声(例えば図12のC2)に基づく音声信号を入力され、入力された音声信号を音韻認識部102に出力する。その後、ステップS104に進む。
【0065】
(ステップS104)音韻認識部102は、音声入力部101から入力された音声信号から音声特徴量を算出する。音韻認識部102は、算出した音声特徴量に基づき、既知の音韻認識方法により利用者の発音を示す音韻を認識し、認識された音韻から構成される音韻列を生成する。音韻認識部102は、生成した音韻列と算出した音声特徴量の時系列データである音声特徴量ベクトルを対話処理部106に出力する。
対話処理部106は、音韻認識部102から入力した音韻列と対話応答パターン記憶部204から読み出した応答パターン情報(図11参照)にマッチング処理を実行して、入力された音韻列に最も合致する応答パターンを決定する。マッチング処理において、対話処理部106は、例えば上述の始終端フリーDPマッチング法を用いてマッチング処理を実行する。
【0066】
対話処理部106は、決定した応答パターン情報が初期応答パターン(図11参照)であるとき、音韻認識部102から入力された音韻列が正しい音韻列を含む音韻列と認識する。このとき、対話処理部106は、初期応答パターンの≪…≫に対応する、音韻認識部102から入力された音韻列の部分を抽出し、この部分を新たな第1の音韻列とする。対話処理部106は、新たな第1の音韻列に対応する新たな音声特徴量ベクトルを音韻認識部102から入力された音声特徴量ベクトルから抽出する。対話処理部106は、新たな第1の音韻列と音声特徴量ベクトルを信頼度算出部103に出力する。その後、ステップS105に進む。
【0067】
(ステップS105)信頼度算出部103は、対話処理部106から入力された音声特徴量ベクトルx1Tに対する確率p(x1T)と、音韻認識部102から入力された音韻列に含まれる各音韻umのその音声特徴量の該当部分xsmtmに対する条件付確率p(xsmtm|um)を音素音響モデル記憶部201から読み出す。信頼度算出部103は、読み出した確率p(x1T)及び条件付確率p(xsmtm|um)を用いて、式(1)に従って信頼度、例えばGPPを算出する。
信頼度算出部103は、その音韻列に含まれる音韻ごとに算出したGPPに対応する正解率を正解率記憶部202から読み出す。信頼度算出部103は、音韻列とこの音韻列を構成する音韻ごとのGPPと正解率をマッチング部104に出力する。
マッチング部104は、信頼度算出部103から音韻列とこれを構成する音韻ごとのGPPと正解率を入力され、入力された音韻列とこの音韻列を構成する音韻ごとのGPPと正解率を記憶する。ここで、信頼度算出部103から入力された音韻列を第2の音韻列とする。その後、ステップS106に進む。
【0068】
(ステップS106)対話処理部106は、音韻認識部102から音韻列が入力され、対話応答パターン記憶部204から確認要求パターンを読み出す。対話処理部106は、確認要求パターンの< … >の部分に入力された音韻列を挿入し、確認要求音韻列を生成する。対話処理部106は、生成した確認要求音韻列を音声再生部107に出力する。音声再生部107は、対話処理部から入力された確認要求音韻列から生成した音声信号に基づく音声(例えば図12のC3)を再生する。これにより、音声認識装置1は、利用者に認識結果を音声で出力し、認識結果が正しいか否かを音声で回答することを促す。その後、ステップS107に進む。
【0069】
(ステップS107)音声入力部101は、利用者が回答した音声に基づく音声信号(例えば図12のC4)を入力され、入力された音声信号を音韻認識部102に出力する。音韻認識部102は、音声入力部101から入力された音声信号から音声特徴量を算出する。
音韻認識部102は、算出した音声特徴量に基づき、公知の音韻認識方法により利用者の発音を示す音韻を認識し、認識された音韻から構成される音韻列を生成する。音韻認識部102は、生成した音韻列を対話処理部106に出力する。
対話処理部106は、音韻認識部102から入力された音韻列と対話応答パターン記憶部204から読み出した応答パターン情報に対してマッチング処理を実行して、入力された音韻列に最も合致する応答パターンを決定する。その後、ステップS108に進む。
【0070】
(ステップS108)対話処理部106は、決定した応答パターン情報が肯定パターンのうちの一つであるか否かを判断する。対話処理部106が、応答パターン情報が肯定パターンのうちの一つ(例えば図12のC8)と判断した場合(ステップS108 Y)、即ち、マッチング部104に入力された第2の音韻列が認識結果として正しい場合には、この音韻列を単語記憶部205に記憶させる。その後、処理を終了する。
対話処理部106が、応答パターン情報が肯定パターンでない(例えば図12のC4)と判断した場合(ステップS108 N)、即ち、マッチング部104に入力された第2の音韻列が認識結果として誤りの場合には、ステップS109に進む。
【0071】
(ステップS109)対話処理部106は、カウント回数iが繰り返し回数Mに達したか否か判断する。対話処理部106が、カウント回数iが繰り返し回数Mに達したと判断した場合(ステップS109 Y)、処理を終了する。対話処理部106が、カウント回数iが繰り返し回数Mに達していない場合(ステップS109 N)、ステップS110に進む。
(ステップS110)対話処理部106は、対話応答パターン記憶部204から、訂正要求パターンを読み出す。対話処理部106は、この訂正要求パターンを訂正要求音韻列として音声再生部107に出力する。
音声再生部107は、対話処理部106から入力された訂正要求音韻列から、公知のテキスト・音声合成技術により音声信号を生成する。音声再生部107は、生成した音声信号に基づき音声(例えば図12のC5)を再生する。これにより、利用者に訂正されるべき音韻列を音声で応答することを促すことができる。その後、ステップS111に進む。
【0072】
(ステップS111)音声入力部101は、利用者が発した音声(例えば図12のC6)に基づく音声信号が再度入力され、入力された音声信号を音韻認識部102に出力する。その後、ステップS112に進む。
(ステップS112)音韻認識部102は、音声入力部101から入力された音声信号から音声特徴量を算出する。音韻認識部102は、算出した音声特徴量に基づき、既知の音韻認識方法を用いて音韻を認識し、認識された音韻から構成される音韻列を生成する。音韻認識部102は、生成した音韻列と算出した音声特徴量の時系列データからなる音声特徴量ベクトルを対話処理部106に出力する。
対話処理部106は、音韻認識部102から入力された音韻列と対話応答パターン記憶部204から読み出した応答パターン情報にマッチング処理を実行して、入力された音韻列に最も合致する応答パターンを決定する。応答パターンが訂正応答パターンと決定されたとき、対話処理部106は、訂正応答パターンの≪…≫に対応する、音韻認識部102から入力された音韻列の部分を抽出し、この部分を新たな第1の音韻列とする。対話処理部106は、新たな第1の音韻列に対応する新たな音声特徴量ベクトルを音韻認識部102から入力された音声特徴量ベクトルから抽出する。対話処理部106は、新たな第1の音韻列と音声特徴量ベクトルを信頼度算出部103に出力する。その後、ステップS113に進む。
【0073】
(ステップS113)信頼度算出部103は、対話処理部106から第1の音韻列と音声特徴量ベクトルを入力される。
信頼度算出部103は、対話処理部106から入力された音声特徴量ベクトルx1Tに対する確率p(x1T)を音素音響モデル記憶部201から読み出す。信頼度算出部103は、対話処理部106から入力された第1の音韻列に含まれる各音韻umのその音声特徴量の該当部分xsmtmに対する条件付確率p(xsmtm|um)を音素音響モデル記憶部201から読み出す。信頼度算出部103は、読み出した確率p(x1T)及び条件付確率p(xsmtm|um)を用いて式(1)に従って信頼度の1つの指標としてGPPを算出する。信頼度算出部103は、その音韻列に含まれる音韻ごとに算出したGPPに対応する正解率を正解率記憶部202から読み出して信頼度のその他の指標として決定する。信頼度算出部103は、第1の音韻列とこれを構成する音韻ごとの正解率をマッチング部104に出力する。その後、ステップS114に進む。
【0074】
(ステップS114)マッチング部104は、信頼度算出部103から第1の音韻列とこれを構成する音韻ごとの正解率が入力される。マッチング部104は、第1の音韻列と第2の音韻列について、例えば始終端フリーDPマッチング法を用いてマッチング処理を実行する。マッチング部104は、マッチング処理において混同行列記憶部203から読み出した混同行列情報に基づき算出された累積距離を最小とする第1の音韻列と第2の音韻列との対応関係を示すマッチング情報を生成する。マッチング部104は、第1の音韻列、第2の音韻列、生成したマッチング情報及び各音韻列に含まれる音韻ごとの正解率を音韻訂正部105に出力する。その後、ステップS115に進む。
【0075】
(ステップS115)音韻訂正部105は、マッチング部104から入力された第2の音韻列を、第1の音韻列、マッチング情報及び正解率に基づいて訂正して、訂正後の音韻列を決定する。ここで、音韻訂正部105は、第1の音韻列に含まれる音韻に対応する第2の音韻列に含まれる音韻が異なる場合には、それらの音韻のうち各々に対応する正解率が高いほうの音韻を、訂正後の音韻列に含まれる音韻と決定する。
音韻訂正部105は、第1の音韻列に含まれる音韻に対応する第2の音韻列に含まれる音韻が同一である場合には、その同一の音韻を訂正後の音韻列に含まれる音韻と決定する。また、第2の音韻列に含まれる音韻に対応する第1の音韻列に含まれる音韻が存在しない場合は、音韻訂正部105は、第2の音韻列に含まれる音韻を訂正後の音韻列に含まれる音韻と決定する。但し、その第2の音韻列に含まれる音韻に対応する正解率が予め設定された値よりも小さい場合、音韻訂正部105は、その音韻を訂正後の音韻列に含めずに除外する。
【0076】
音韻訂正部105は、第2の音韻列に対応する訂正後の音韻列を決定した後、決定した訂正後の音韻列とその音韻列に含まれる音韻ごとの正解率をマッチング部104に出力する。マッチング部104では、この訂正後の音韻列を新たな第2の音韻列とする。また、音韻訂正部105は、この訂正後の音韻列(第2の音韻列)を対話処理部106に出力する。その後、ステップS116に進む。
【0077】
(ステップS116)対話処理部106は、音韻訂正部105から訂正後の音韻列(第2の音韻列)が入力されたことにより、対話応答パターン記憶部204から、確認要求パターンを読み出す。対話処理部106は、確認要求パターンに訂正後の音韻列を挿入して確認要求音韻列を生成する。対話処理部106は、この確認要求音韻列を音声再生部107に出力する。
音声再生部107は、対話処理部106から入力された確認要求音韻列から、公知のテキスト・音声合成方法を用いて、音声信号を生成し、生成した音声信号に基づく音声(例えば図12のC7)を再生する。これにより、利用者に訂正後の音韻列が認識結果として正しいか否かを回答することを促すことができる。その後、ステップS117に進む。
【0078】
(ステップS117)音声入力部101は、利用者が回答した音声(例えば図12のC8)に基づく音声信号が入力され、入力された音声信号を音韻認識部102に出力する。音韻認識部102は、音声入力部101から入力された音声信号から音声特徴量を算出する。
音韻認識部102は、算出した音声特徴量に基づき、公知の音韻認識方法により利用者の発音を示す音韻を認識し、認識された音韻から構成される音韻列を生成する。音韻認識部102は、生成した音韻列と算出した音声特徴量の時系列データである音声特徴量ベクトルを対話処理部106に出力する。
対話処理部106は、音韻認識部102から入力された音韻列と対話応答パターン記憶部204から読み出した応答パターン情報にマッチング処理を実行して、入力された音韻列に最も合致する応答パターンを決定する。その後、ステップS118に進む。
(ステップS118)対話処理部106は、利用者による応答回数をカウントする変数iを1だけ増加させる。その後、ステップS108に進む。
【0079】
なお、混同行列記憶部203に記憶される混同行列情報は、予め記憶された一定の値であってもよいが、これには限られない。訂正後の音韻列が正しいと判断されたとき、マッチング部104は、その直前に音韻訂正部105による音韻訂正処理に係る各音韻列に含まれる音韻に基づいて、混同行列情報を更新してもよい。
具体的には、マッチング部104は、次の処理を実行してもよい。ステップS108において、対話処理部106が、決定した応答パターン情報が肯定パターンのうちの一つと判断した場合(ステップS108 Y)、マッチング部104に入力された第2の音韻列、即ち訂正後の音韻列が認識結果として正しいこととなる。従って、マッチング部104は、最近実行されたステップS115(音韻訂正処理)において、第2の音韻列(訂正の対象)に含まれる音韻のうち第1の音韻列(最後に入力された音声に基づく)と共通する音韻を各々発話目的音韻γ及び認識目的音韻αとする混同行列情報の行列要素が示す頻度に1ずつ加算する。マッチング部104は、加算された値を、その行列要素の頻度とする。
例えば、第1の音韻列が“φa”、第2の音韻列が”ba”であるとき、発話目的音韻γ及び認識目的音韻αがともにaである行列要素の値92229に1を加算して92230とする。
【0080】
上述のように、対話処理部106が、決定した応答パターン情報が肯定パターンのうちの一つと判断した場合(ステップS108 Y)、第2の音韻列に含まれる音韻であって、ステップS115を実行して変更された音韻は、認識結果として誤っていたこととなる。従って、マッチング部104は、直前に実行したステップS115において、第2の音韻列(訂正の対象)に含まれる音韻のうち第1の音韻列(最後に入力された音声に基づく)に含まれる音韻に代わった音韻(正しい認識結果)を発話目的音韻γとし、その訂正前の音韻(認識誤り)を認識目的音韻αとする混同行列情報の行列要素が示す頻度に1ずつ加算する。マッチング部104は、加算された値を、その行列要素の頻度とする。
例えば、第1の音韻列が“φa”、第2の音韻列が”ba”であるとき、発話目的音韻γがb及び認識目的音韻αがφである行列要素の値169に1を加算して170とする。
これにより、発話目的音韻γが認識結果音韻αに認識される頻度を要素とする混同行列情報が、利用者の発話特性や残響などの使用環境に適応し、認識誤りが生じる頻度を低減することができる。さらに、利用者の音声入力による音韻訂正がより円滑に行われる。
【0081】
上述したように、本実施形態によれば、音声認識装置1と利用者との間で、例えば図12に示す対話がなされたとき、利用者が入力した音声のみに基づき認識した音韻を訂正することができる。
また、音韻訂正部105は、音韻列に含まれる各音韻に対する信頼度に基づいて選択された音韻に訂正するため、信頼性に裏付けられた音韻に訂正することができる。また、音韻訂正部105は、音韻列に含まれる音韻に対する正解率が低い場合に、認識誤りと判断するため、正解率の低い音韻に訂正することを回避することができる。
【0082】
ここで、音声認識装置1を用い、40個の単語を用いて単語正解率と音韻正解精度を検証した結果について説明する。試行回数は、各単語につき100回である。単語正解率とは、正しい音韻列が認識された試行回数の全試行回数に対する割合である。音韻正解精度とは、全試行回数における真の音韻数CNから置換音韻数CSと脱落音韻数CDと挿入音韻数CIを減じた音韻数の真の音韻数CIに対する割合である。
但し、音韻認識部102は、母音の長さの修正を行わず、発話目的音韻γ及び認識結果音韻αにおいて長母音と短母音を同一視した。また、混同行列記憶部203に記憶される混同行列情報は、予め記憶された一定の値である。
【0083】
ここで、マッチング部104は、第1の音韻列の音韻が認識される音韻ごとの確率に基づいて算出された第2の音韻列との間の距離からマッチング結果を決定するため、認識誤りを考慮したマッチングを実現することができる。
また、対話処理部106は、訂正した音韻列に基づく音声を再生し、入力した音声が示す応答に応じて、訂正した音韻列からなる単語情報を記憶するか、発話を促す内容を示す音声を再生させる。そのため、利用者に訂正した音韻列に係る音声による応答を促し、応答により訂正した音韻列からなる単語情報が登録されるか、利用者に再度発話を促すため、利用者の音声のみによる音韻認識誤りの訂正を円滑に実現することができる。
【0084】
図14は、音声認識装置1による単語正解率(word accuracy)と音韻正解精度(phoneme accuracy)の一例を示す図である。図14において、縦軸は、単語正解率及び音韻正解精度である。横軸は、訂正発話の回数(number of corrective utterances)、つまり繰り返し回数Mを示す。ここで、訂正発話の回数が多くなるほど、単語正解率、音韻正解精度が向上することが示される。例えば、訂正発話の回数がゼロのとき、単語正解率は8%、音韻正解精度は70%に過ぎない。訂正発話の回数が1回のとき、単語正解率は40%、音韻正解精度は80%である。訂正発話の回数が2回のとき、単語正解率は60%、音韻正解精度は90%である。訂正発話の回数が3回のとき、単語正解率は66%、音韻正解精度は92%である。この検証結果は、音声認識装置1は、当初は部分的に音韻を正しく認識できるが音韻列全体として正しく認識できない状態であっても、利用者との音声による対話を繰り返すことにより音韻列全体の認識率を向上できることを示す。これにより、音声認識装置1は、利用者と音声のみの対話を実行することにより音韻列が示す未知語を円滑に獲得できることを示す。
【0085】
(第2の実施形態)
次に、本発明の第2の実施形態について図を参照して説明する。図15は、本実施形態に係る音声認識ロボット3の構成を示す概略図である。図15において、音声認識ロボット3は、音声認識装置2の他に、コマンド辞書記憶部206、撮影部301、画像処理部302、動作制御部303、動作機構部304、及び駆動電力モデル記憶部401を含んで構成される。音声認識装置2は、対話処理部106に代え対話処理部306を有する点で音声認識装置1と異なり、その他の構成及び作用は他の構成部分と共通する。以下、第1の実施形態との差異点を主に説明する。
【0086】
コマンド辞書記憶部206は、操作対象となる物体を示す単語情報とその位置情報を含むロボットコマンド情報を記憶する。コマンド辞書記憶部206に記憶されている単語情報の一部又は全部は、単語記憶部205に記憶された音韻列を複製したものである。従って、音声認識装置2は、前述の音声認識処理によりロボットコマンド情報を補充することができる。
対話処理部306は、音韻認識部102から入力された音韻列とコマンド辞書記憶部206から読み出した単語情報についてマッチング処理を実行し、入力された音韻列と最も合致する単語情報を決定する。対話処理部306は、決定した単語情報に対応するロボットコマンド情報をコマンド辞書記憶部206から読み出し、動作制御部303に出力する。
【0087】
駆動電力モデル記憶部401には、物体を示す単語情報、位置情報及び動作機構部304の一部を構成する機構部に供給する電力の時系列データを対応づけた電力モデル情報を予め記憶しておく。
動作制御部303は、対話処理部306からロボットコマンド情報が入力される。
【0088】
動作制御部303は、入力されたロボットコマンド情報に含まれる単語情報及び位置情報に対応する電力モデル情報を駆動電力モデル部401から読み出し、機構部に供給する電力の時系列データを決定する。動作制御部303は、決定した電力の時系列データに基づき、その機構部へ電力を供給する。なお、機構部とは、例えば、マニピュレータ(manipulator)や多指グラスパ(multi−finger grasper)である。
動作制御部303から電力が供給された部品が動作することにより、その機構部を含んで構成される動作機構部304は、利用者が発話した音韻列で示される単語情報を含むロボットコマンドに応じた動作を実行する。
【0089】
撮影部301は、アナログ画像信号を撮影し、撮影したアナログ画像信号を画像処理部302に出力する。
画像処理部302は、撮影部301から入力されたアナログ画像信号をアナログ・ディジタル(A/D)変換してディジタル画像信号を生成する。
画像処理部302は、生成したディジタル画像信号から画像特徴量を算出する。算出される画像特徴量は、例えば、被写体の輪郭(エッジ)である。輪郭を算出するためには、例えば、水平方向及び垂直方向各々に隣接する画素間の画素値の差分値を算出し、算出された差分値の絶対値について、予め設定された周波数以上の成分を除外するようにフィルタリング処理を行う。フィルタリング処理が行われた画像信号のうち、予め設定された所定の値を越える画素の部分を輪郭と決定する。
画像処理部302は、算出した画像特徴量を対話処理部306に出力する。
【0090】
対話処理部306は、画像処理部302から入力された画像特徴量を、音韻認識部102から入力された音韻列に対応する単語情報を含むロボットコマンド情報としてコマンド辞書記憶部206に記憶する。例えば、利用者が撮影部301に被写体を撮影させながら、被写体の名称(単語情報)を発声すると、ロボットコマンド情報の一部として算出した画像特徴量を補充することができる。これにより、利用者が発話した音声だけではなく、撮影された画像をロボットコマンド情報と特定するための手がかりが得られる。
【0091】
即ち、対話処理部306は、音韻列のみならず、画像処理部302から入力された画像特徴量が、コマンド辞書記憶部206のロボットコマンド情報に含まれる画像特徴量とのマッチング処理を実行する。対話処理部306は、例えば、画像処理部302から入力された画像特徴量にも最も合致する画像特徴量を含むロボットコマンド情報を決定し、決定したロボットコマンド情報を動作制御部303に出力する。
【0092】
これにより、音声認識ロボット3は、認識誤りが生じうる音声認識だけに頼らず、画像認識によっても状況に適したロボットコマンドを特定できるので、利用者は音声により音声認識ロボット3に最適な動作を指示することができる。
【0093】
以上、説明したように、本実施形態に係る音声認識ロボット3と利用者との対話を通じ、利用者が入力した音声のみに基づき認識した音韻を訂正することができ、訂正した音韻に基づきロボットコマンドを補充することができる。ひいては、音声認識ロボット3が実現できる機能を容易に拡充することができる。また、画像情報を補充することにより、利用者によるロボットへの動作の指示を最適化することができる。
【0094】
上述した実施形態は、日本語の音韻、音韻列、要求パターン及び応答パターンを用いるが、これには限定されない。上述した実施形態は、他の言語、例えば英語の音韻、音韻列、要求パターン及び応答パターンを用いることもできる。
【0095】
なお、上述した実施形態における音声認識装置1及び2の一部、例えば、信頼度算出部103、マッチング部104、音韻訂正部105、対話処理部106、306、及び画像処理部302をコンピュータで実現するようにしても良い。その場合、この制御機能を実現するためのプログラムをコンピュータ読み取り可能な記録媒体に記録して、この記録媒体に記録されたプログラムをコンピュータシステムに読み込ませ、実行することによって実現しても良い。なお、ここでいう「コンピュータシステム」とは、音声認識装置1並びに2、及び音声認識ロボット3に内蔵されたコンピュータシステムであって、OSや周辺機器等のハードウェアを含むものとする。また、「コンピュータ読み取り可能な記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、CD−ROM等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶装置のことをいう。さらに「コンピュータ読み取り可能な記録媒体」とは、インターネット等のネットワークや電話回線等の通信回線を介してプログラムを送信する場合の通信線のように、短時間、動的にプログラムを保持するもの、その場合のサーバやクライアントとなるコンピュータシステム内部の揮発性メモリのように、一定時間プログラムを保持しているものも含んでも良い。また上記プログラムは、前述した機能の一部を実現するためのものであっても良く、さらに前述した機能をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるものであっても良い。
また、上述した実施形態における音声認識装置1並びに2、及び音声認識ロボット3の一部、または全部を、LSI(Large Scale Integration)等の集積回路として実現しても良い。音声認識装置1並びに2、及び音声認識ロボット3の各機能ブロックは個別にプロセッサ化してもよいし、一部、または全部を集積してプロセッサ化しても良い。また、集積回路化の手法はLSIに限らず専用回路、または汎用プロセッサで実現しても良い。また、半導体技術の進歩によりLSIに代替する集積回路化の技術が出現した場合、当該技術による集積回路を用いても良い。
【0096】
以上、図面を参照してこの発明の一実施形態について詳しく説明してきたが、具体的な構成は上述のものに限られることはなく、この発明の要旨を逸脱しない範囲内において様々な設計変更等をすることが可能である。
【符号の説明】
【0097】
1、2…音声認識装置、3…音声認識ロボット、
101…音声入力部、102…音韻認識部、103…信頼度算出部、
104…マッチング部、105…音韻訂正部、106、306…対話処理部、
107…音声再生部、201…音素音響モデル記憶部、202…正解率記憶部、
203…混同行列記憶部、204…対話応答パターン記憶部、205…単語記憶部、
206…コマンド辞書記憶部、301…撮影部、302…画像処理部、
303…動作制御部、304…動作機構部、401…駆動電力モデル記憶部
【技術分野】
【0001】
本発明は、音声認識装置、音声認識方法、及び音声認識ロボットに関する。
【背景技術】
【0002】
ロボットを様々な環境で使用するために、ユーザとの音声による対話を通じてロボットに未知語を教示する技術が検討されている。しかし、未知語を構成する音韻を認識する際、従来の音声認識装置では認識誤りを完全に排除することはできない。そのため、認識誤りを訂正する技術が提案されている。例えば、特許文献1に記載の音声認識装置は、入力音声に含まれる単語を予め記憶されている単語と比較し、認識結果を画面に表示し、ユーザによるマニュアル操作に応じて、表示された認識結果から訂正単語を選択する。
【先行技術文献】
【特許文献】
【0003】
【特許文献1】特開2006−146008号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、特許文献1に記載の音声認識装置は、認識結果を表示する画面や操作入力を受け付ける入力デバイスを要するため、ロボットに応用することは現実的ではないという課題があった。
【0005】
本発明は上記の点に鑑みてなされたものであり、未登録語を登録する際、ユーザが入力デバイスを用いずに音声のみを用いて認識した音韻を訂正することができる音声認識装置、音声認識方法、及び音声認識ロボットを提供する。
【課題を解決するための手段】
【0006】
(1)本発明は上記の課題を解決するためになされたものであり、本発明は、音声を入力する音声入力部と、入力された音声の音韻を認識して訂正発話を示す第1の音韻列を生成する音韻認識部と、前記第1の音韻列と元発話を示す第2の音韻列とをマッチングを行うマッチング部と、前記マッチングを行った結果に基づき前記第2の音韻列の音韻を訂正する音韻訂正部と、を備えることを特徴とする音声認識装置である。
【0007】
(2)本発明はまた、上述の音声認識装置であって、前記音韻訂正部は、前記音韻列の各音韻に対する信頼度に基づき選択された音韻に訂正すること、を特徴とする音声認識装置である。
【0008】
(3)本発明はまた、上述の音声認識装置であって、前記音韻訂正部は、前記信頼度に基づく正解率が予め設定された値よりも低い場合、認識誤りと判断すること、を特徴とする音声認識装置である。
【0009】
(4)本発明はまた、上述の音声認識装置であって、前記マッチング部は、入力音声に含まれる音韻の種別と認識される音韻の種別の組ごとの頻度に基づき前記第1の音韻列の音韻と前記第2の音韻列の音韻との間の距離を算出し前記距離に基づきマッチング結果を決定すること、を特徴とする音声認識装置である。
【0010】
(5)本発明はまた、上述の音声認識装置であって、前記訂正した第2の音韻列に基づく音声を再生する音声再生部と、認識結果を示す応答パターンを記憶する対話応答パターン記憶部と、入力された音声の音韻に合致する前記応答パターンに基づき、前記訂正した第2の音韻列からなる単語情報を単語記憶部に記憶するか、前記音声再生部に利用者に発話を促す音声を再生させるか、いずれか一方を実行する対話処理部と、を備えること、を特徴とする音声認識装置である。
【発明の効果】
【0011】
本発明によれば、利用者が発した訂正発話に係る入力音声の第1の音韻列とのマッチング結果に基づき、元発話を示す第2の音韻列を訂正するため、利用者が入力した音声のみに基づき音韻を訂正することができる。
【0012】
第2の本発明によれば、さらに、各音韻に対する信頼度に基づいて選択された音韻に訂正するため、信頼性に裏付けられた音韻に訂正することができる。
【0013】
第3の本発明によれば、さらに、音韻に対する正解率が低い場合に、認識誤りと判断するため、正解率の低い音韻に訂正することを回避することができる。
【0014】
第4の本発明によれば、さらに、第1の音韻列の音韻について、その音韻が認識される音韻の種別ごとの確率に基づいて算出された第2の音韻列との間の距離からマッチング結果を決定するため、認識誤りを考慮したマッチングを実現することができる。
【0015】
第5の本発明によれば、さらに、訂正した音韻列を示す音声を再生し、利用者による応答を示す入力音声に応じて、訂正した音韻列からなる単語情報を記憶するか、発話を促す音声を再生する。そのため、利用者に訂正した音韻列に係る音声による応答を促し、応答により訂正した音韻列からなる単語情報が登録されるか、利用者に再度発話を促すため、音声のみによる音韻認識誤りの訂正を円滑に実現できる。
【図面の簡単な説明】
【0016】
【図1】本発明の第1の実施形態に係る音声認識装置1の構成を示す概略図である。
【図2】本実施形態に係る音韻の種別ごとのGPPと正解率の関係の一例を示す図である。
【図3】始終端フリーDPマッチング法の処理を示す流れ図である。
【図4】DPマッチング法の処理を示す流れ図である。
【図5】本実施形態に係る混同行列情報の一例を示す図である。
【図6】本実施形態に係る第1の音韻列と第2の音韻列とのマッチング結果の一例を示す図である。
【図7】本実施形態に係る第1の音韻列と第2の音韻列とのマッチング結果のその他の例を示す図である。
【図8】本実施形態に係る各音韻列に含まれる音韻ごとのGPP及び正解率の一例を示す図である。
【図9】本実施形態に係る各音韻列に含まれる音韻ごとのGPP及び正解率のその他の例を示す図である。
【図10】本実施形態に係る各音韻列に含まれる音韻ごとのGPP及び正解率のその他の例を示す図である。
【図11】本実施形態におけるパターン情報の例を示す図である。
【図12】本実施形態に係る音声認識装置1と利用者との間の対話の一例を示す。
【図13】本実施形態に係る音声認識装置1における音声認識処理を示す流れ図である。
【図14】音声認識装置1による単語正解率と音韻正解精度の一例を示す図である。
【図15】本発明の第2の実施形態に係る音声認識装置3の構成を示す概略図である。
【発明を実施するための形態】
【0017】
(第1の実施形態)
以下、図面を参照しながら本発明の実施形態について詳しく説明する。図1は、本実施形態に係る音声認識装置1の構成を示す概略図である。音声認識装置1は、音声入力部101、音韻認識部102、信頼度算出部103、マッチング部104、音韻訂正部105、対話処理部106、音声再生部107、音素音響モデル記憶部201、正解率記憶部202、混同行列記憶部203、対話応答パターン記憶部204及び単語記憶部205を含んで構成される。
【0018】
音声入力部101は、利用者が発した音声による空気の振動を音声信号に変換し、変換した音声信号を音韻認識部102に出力する。音声入力部101は、例えば人間が発するする音声の周波数帯域(例えば、200Hz−4kHz)の音波を受信するマイクロホンである。
【0019】
音韻認識部102は、音声入力部101から入力されたアナログ音声信号をディジタル音声信号に変換する。ここで、音韻認識部102は、入力されたアナログ信号を、例えば、サンプリング周波数を16kHzとし、振幅を16ビットの2進データにパルス符号変調(Pulse Code Modulation;PCM)して、量子化された信号サンプルに変換する。音韻認識部102は、変換されたディジタル音声信号から音声特徴量を算出する。音声特徴量は、例えば25次元のメル尺度ケプストラム(Mel−Frequency Cepstrum Coefficient;MFCC)である。
【0020】
音韻認識部102は、算出した音声特徴量に基づき、公知の音韻認識方法により利用者の発音を示す音韻を認識し、認識された音韻から構成される音韻列を生成する。音韻認識部102は、例えば、隠れマルコフモデル(Hidden Markov Model;HMM)を用いて音韻を認識するが、他の方法を用いてもよい。音韻とは、ある言語において話者が同一と認識する音声の最小基本単位をいう。本実施形態では、音韻とは音素と同義である。音韻認識部102は、生成した音韻列と算出した音声特徴量の時系列データである音声特徴量ベクトルを信頼度算出部103及び対話処理部106に出力する。
【0021】
信頼度算出部103は、音韻認識部102又は対話処理部106から入力された音韻列及び音声特徴量ベクトルに基づき音韻ごとに信頼度を算出する。信頼度とは、音韻の認識結果としての信頼性を示す変数である。信頼度算出部103は、信頼度として例えば一般化事後確率(Generalized Posterior Probability;GPP)と正解率を算出するが、他の変数を算出してもよい。
【0022】
例えば、信頼度算出部103は、音声特徴量ベクトルx1が与えられているとき、開始時刻sから終了時刻tまで継続する音韻uに対するGPPは、式(1)(Lijuan Wang et.al;“Phonetic Transcripstion Verification with Generalized Posterior Probability,”、「Interspeech2005」、2005、p.1950 参照)を用いて算出する。
【0023】
【数1】
【0024】
式(1)で、Tはベクトルの転置を示す。Mは音韻列(Phoneme Graph)における、経路(path)における音韻数を示す。m、nは、経路上の音韻を示すインデックスである。αは、音響モデルに対する指数重み係数(exponential weight)を示す。p(x1T)は、音声特徴量ベクトルx1が与えられる確率である。p(xsmtm|um)は、音韻umの該当部分、即ち開始時刻をsm、終了時刻をtmとする音声特徴量ベクトルxsmtmに対する条件付確率である。
【0025】
音素音響モデル記憶部201には、音声特徴量ベクトルx1が与えられる確率p(x1T)と、音韻umの音声特徴量ベクトルxsmtmに対する条件付確率p(xsmtm|um)が予め記憶されている。信頼度算出部103は、音韻認識部102から入力された音声特徴量ベクトルx1に対応する確率p(x1T)と音韻umの音声特徴量ベクトルxsmtmに対する条件付確率p(xsmtm|um)を音素音響モデル記憶部201から読み出し、式(1)に従ってGPPを算出する。
【0026】
信頼度算出部103は、音韻ごとに算出したGPPに基づき正解率を決定する。正解率とは、音韻認識部102の認識結果として正しい音韻が得られる確率である。具体的には、正解率記憶部202に、予め音韻ごとのGPPと正解率との関係を記憶しておく。そこで、信頼度算出部103は、音韻ごとに算出したGPPに対応する正解率を正解率記憶部202から読み出して決定する。日本語の発音を構成する音韻の種別ごとのGPPと正解率との関係の一例を図2に示す。図2において、横軸はGPP、縦軸は正解率を示す。また、各線は、音韻ごとのGPPに対する正解率を示す。図2は、何れの音韻についても、GPPが増加するにつれ正解率も増加することを示す。また、GPPも正解率も最小値はゼロであり、最大値は1である。但し、音韻の種別により正解率やその増加率は一定ではない。信頼度算出部103は、音韻列とこれを構成する音韻ごとの正解率(又はGPP)をマッチング部104に出力する。
【0027】
マッチング部104は、信頼度算出部103から音韻列(以下、第1の音韻列と呼ぶ)とこれを構成する音韻ごとの正解率(又はGPP)が新たに入力される。また、マッチング部104は、過去に入力又は訂正された音韻列(以下、第2の音韻列と呼ぶ)とこれを構成する音韻ごとの正解率(又はGPP)が音韻訂正部105から入力され、これらを記憶する。マッチング部104は、第1の音韻列と第2の音韻列についてマッチング処理(照合)を実行する。マッチング部104は、マッチング処理において、例えば始終端フリーDPマッチング法(両端点フリーDP法又はLevel Buiding法ともいう)を使用するが、これに限らず他の方法を用いてもよい。
【0028】
ここで、始終端フリーDPマッチング法の処理について図3を用いて説明する。図3は、始終端フリーDPマッチング法の処理を示す流れ図である。
(ステップS201)マッチング部104は、累積距離をゼロと初期設定する。
(ステップS202)マッチング部104は、第1の音韻列の最初の音韻と、第2の音韻列に含まれる音韻のうち一つを、後述する距離を算出する対象とする音韻のうち最初の音韻(以下、算出対象始点と呼ぶ)と初期設定する。
(ステップS203)マッチング部104は、第1の音韻列についての算出対象始点のうち第1の音韻列について最後の音韻に達するまでステップS204及びS205を繰り返す。
(ステップS204)マッチング部104は、DPマッチング法(始点及び終点が固定)を実行する。
(ステップS205)マッチング部104は、第1の音韻列についての算出対象始点をその次の音韻に進める。
【0029】
マッチング部104は、上述の処理を算出対象始点となる第2の音韻列に含まれる音韻全てについて実行し、それぞれの場合について累積距離を算出する。マッチング部104は、算出された累積距離を最小とする算出対象始点、即ち第1の音韻列と第2の音韻列との対応関係がマッチング結果として決定される。即ちマッチング結果は、第1の音韻列に含まれる音韻と第2の音韻列に含まれる音韻の対(pair)からなるマッチング情報である。
【0030】
次に、ステップS204で実行されるDPマッチング法の処理について図4を用いて説明する。図4は、DPマッチング法の処理を示す流れ図である。
(ステップS301)マッチング部104は、距離を算出する対象とする音韻(算出対象音韻)が、第1の音韻列の最後の音韻及び第2の音韻列の最後の音韻のうち何れか先に達するまでステップS302〜S304の処理を繰り返す。
(ステップS302)マッチング部104は、算出対象音韻間の距離を後述するように算出する。
(ステップS305)マッチング部104は、算出した距離を累積距離に加算する。
(ステップS306)マッチング部104は、算出対象音韻を、第1の音韻列、第2の音韻列各々について直後の音韻に変更する。
【0031】
なお、マッチング部104は、上述のマッチング処理において第1の音韻列の一部に音声入力中の音韻が存在しない場合(挿入誤り)が生じる場合を考慮し、挿入誤りも一種の音韻として距離を算出する。同様に、マッチング部104は、第2の音韻列の一部に認識結果としての音韻が存在しない場合(脱落誤り)が生じる場合を考慮し、脱落誤りも後述のように一種の音韻として距離を算出する。
【0032】
マッチング部104は、例えば上述のステップS302において算出対象音韻である第1の音韻列に含まれる1つの音韻αと第2の音韻列に含まれる1つの音韻βとの間の距離d(α,β)を、例えば式(2)により算出する。
【0033】
【数2】
【0034】
式(2)において、P(α,β)は、認識結果である音韻α(認識結果音韻(recognized phoneme))の音声入力中の音韻(以下、発話目的音韻(input phoneme)と呼ぶ)と認識結果音韻βの発話目的音韻が一致する確率である。発話目的音韻として可能性がある音韻をγとすると、P(α,β)は、式(3)で表される。
【0035】
【数3】
【0036】
式(3)において、P(α|γ)は、発話目的音韻γが認識結果音韻αに認識される確率を示す。P(β|γ)は、発話目的音韻γが認識結果音韻βに認識される確率を示す。P(γ)は、発話目的音韻γが出現する確率を示す。
混同行列記憶部203には、例えば、発話目的音韻γが認識結果音韻αに認識される頻度を要素とする混同行列情報(confusion matrix)を予め記憶しておく。マッチング部104は、混同行列記憶部203に記憶された混同行列情報から、認識結果音韻αに認識される頻度と認識結果音韻βに認識される頻度を読み出し、P(α|γ)、P(β|γ)及びP(γ)を算出する。マッチング部104は、式(3)に基づきP(α,β)を算出し、式(2)に基づき、d(α,β)を算出する。
【0037】
混同行列情報の一例を図5に示す。図5は、本実施形態に係る混同行列情報の一例を示す図である。図5において、行は発話目的音韻γとしてzh、φ、ng、a及びbを示す。列は、認識結果音韻αとしてzh、φ、ng、a及びbを示す。数値は、認識結果音韻α及び発話目的音韻γの組ごとの度数を示す。例えば、発話目的音韻γがzhであるとき、認識結果音韻αがzhと認識される度数が7072回である。ここで、混同行列情報の行と列、つまり発話目的音韻γと認識結果音韻αが一致する場合(認識結果が正しい場合)の度数を示す。混同行列情報の行と列、つまり発話目的音韻γと認識結果音韻αが異なる場合(認識結果が誤る場合)の度数を示す。図5の例では、認識結果が正しい場合のほうが誤る場合よりも多い。式(2)を考慮すれば、発話目的音韻γと認識結果音韻αが一致する場合のほうが異なる場合よりも距離が大きくなる。なお、発話目的音韻γがφであるとは、発話目的音韻が存在しない挿入誤りを示す。認識結果音韻αがφであるとは、認識結果音韻が存在しない脱落誤りを示す。
【0038】
図6は、第1の音韻列と第2の音韻列とのマッチング結果の一例を示す図である。図6の例では、第1の音韻列は「disu」、第2の音韻列は「jisupurei」である。ここで、第1の音韻列「disu」は、第2の音韻列のうち「jisu」の部分に対応している。
図7は、第1の音韻列と第2の音韻列とのマッチング結果のその他の例を示す図である。図7の例では、第1の音韻列は「boodo」、第2の音韻列は「kiibonono」である。ここで、第1の音韻列の「bo」の部分のうち第2の音韻列のうち「bo」の部分に対応している。また、第1の音韻列の「odo」の部分が、第2の音韻列のうち「ono」の部分に対応している。なお、第2の音韻列のうち6番目の音韻「n」に対応する第1の音韻列の音韻は存在しない。
【0039】
上述のように、図6や図7に示す例のように、音韻列間で音韻数が異なる場合があるが、マッチング部104は、上述の始終端フリーDPマッチング法のように、一方の音韻列の途中の音韻が他方の音韻列の始端に対応させることができるマッチング処理を行う。その結果、このような場合にも音韻列間のマッチング情報を決定することができる。
従って、利用者が認識結果として第2の音韻列を訂正するために、第1の音韻列を示す音声で応答する場合に、第2の音韻列のうち認識誤りに対応する部分だけを応答してもよい。
また、図7に示す例のように、一方の音韻列の一部分と他の部分が離れる場合があるが、マッチング部104は、挿入誤りや脱落誤りを考慮することで、このような場合にも音韻列間のマッチング情報を決定することができる。
【0040】
図1に戻り、マッチング部104は、第1の音韻列、第2の音韻列、マッチング情報及び各音韻列に含まれる音韻ごとの正解率を音韻訂正部105に出力する。
【0041】
音韻訂正部105は、マッチング部104から第1の音韻列、第2の音韻列、マッチング情報及び各音韻列に含まれる音韻ごとの正解率を入力する。音韻訂正部105は、入力された第1の音韻列に含まれる音韻と第2の音韻列に含まれる音韻とを、マッチング情報を参照して対応付け、自己が備える記憶領域に記憶する。
【0042】
図8は、本実施形態に係る各音韻列に含まれる音韻ごとのGPP及び正解率の一例を示す図である。図8は、第1の音韻列、これに含まれる音韻ごとのGPP、正解率、第2の音韻列、これに含まれる音韻ごとのGPP、正解率及び後述する処理による訂正後の音韻列を示す。図8によれば、第1の音韻列に含まれる音韻“d”、“i”、“s”及び“u”に対応するGPPは、0.75、0.73、0.48及び0.76、正解率は、0.92、0.80、0.73及び0.78となる。第2の音韻列に含まれる音韻“j”、“i”、“s”、“u”、“p”、“u”、“r”、“e”及び“i”に対応するGPPは、0.21、0.62、0.53、0.92、0.44、0.91、0.54、0.66及び0.88、正解率は、0.06、0.52、0.75、0.96、0.28、0.94、0.85、0.50及び0.85となる。また、訂正後の音韻列は、“disupurei”となる。なお、図8の表の上部に示されている数値1〜9は、音韻の順序を示すインデックスである。
【0043】
図9は、本実施形態に係る各音韻列に含まれる音韻ごとのGPP及び正解率のその他の例を示す図である。図9は、第1の音韻列、これに含まれる音韻ごとのGPP、正解率、第2の音韻列、これに含まれる音韻ごとのGPP、正解率及び後述する処理による訂正後の音韻列を示す。図9によれば、第1の音韻列に含まれる音韻“b”、“o”、“o”、“d”及び“o”に対応するGPPは、0.53、0.52、0.78、0.73及び0.79、正解率は、0.74、0.24、0.67、0.91及び0.82となる。第2の音韻列に含まれる音韻“k”、“i”、“i”、“b”、“o”、“n”、“o”、“n”及び“o”に対応するGPPは、0.43、0.63、0.62、0.54、0.66、0.18、0.82、0.72及び0.81、正解率は、0.85、0.58、0.77、0.73、0.48、0.27、0.73、0.91及び0.86となる。また、訂正後の音韻列は、“kiiboodo”となる。なお、図9の表の上部に示されている数値1〜9は、音韻の順序を示すインデックスである。
【0044】
図10は、本実施形態に係る各音韻列に含まれる音韻ごとのGPP及び正解率のその他の例を示す図である。図10は、第1の音韻列、これに含まれる音韻ごとのGPP、正解率、第2の音韻列、これに含まれる音韻ごとのGPP、正解率及び後述する処理による訂正後の音韻列を示す。図10によれば、第1の音韻列に含まれる音韻“m”、“e”、“m”、“o” 、“o”、“r”、“i”及び“i”に対応するGPPは、0.68、0.84、0.76、0.53、0.23、0.83、0.75及び0.96、正解率は、0.72、0.79、0.79、0.71、0.34、0.77、0.65及び0.93となる。第2の音韻列に含まれる音韻“m”、“e”、“m”及び“o”に対応するGPPは、0.59、0.69、0.65及び0.82、正解率は、0.65、0.61、0.70及び0.86となる。また、訂正後の音韻列は、“memorii”となる。なお、図10の表の上部に示されている数値1〜8は、音韻の順序を示すインデックスである。
【0045】
音韻訂正部105は、入力された第2の音韻列を、第1の音韻列、マッチング情報及び正解率に基づいて訂正して、訂正後の音韻列を決定する。
ここで、音韻訂正部105は、第1の音韻列に含まれる音韻に対応する第2の音韻列に含まれる音韻が異なる場合には、それらの音韻のうち各々に対応する正解率が高いほうの音韻を、訂正後の音韻列に含まれる音韻と決定する。
例えば、図8において第2の音韻列の1番目の音韻“j”は対応する第1の音韻列の音韻“d”と異なる。音韻“d”に対応する正解率は0.92と、音韻“j”に対応する正解率0.06よりも高いため、音韻訂正部105は、訂正後の音韻列の1番目の音韻を“d”と決定する。
【0046】
音韻訂正部105は、第1の音韻列に含まれる音韻に対応する第2の音韻列に含まれる音韻が同一である場合には、その同一の音韻を訂正後の音韻列に含まれる音韻と決定する。
第2の音韻列に含まれる音韻に対応する音韻が第1の音韻列に存在しない場合は、音韻訂正部105は、第2の音韻列に含まれる音韻を訂正後の音韻列に含まれる音韻と決定する。但し、その第2の音韻列に含まれる音韻に対応する正解率が予め設定された値(例えば、0.5)よりも小さい場合、音韻訂正部105は、その音韻を訂正後の音韻列に含めずに除外する。例えば、図9において、第2の音韻列の第6番目の音韻“n”に対応する正解率は0.27と、予め設定された値0.5よりも小さいため、この音韻nを訂正後の音韻列に含めずに除外する
【0047】
また、第1の音韻列に含まれる音韻に対応する音韻が第2の音韻列に存在しない場合は、音韻訂正部105は、その第1の音韻列に対応する音韻を、訂正後の音韻列に含める。
但し、その第1の音韻列に含まれる音韻に対応する正解率が予め設定された値よりも小さい場合、音韻訂正部105は、その音韻を訂正後の音韻列に含めずに除外する。例えば、図10において、第1の音韻列の第5番目の音韻“o”に対応する正解率は0.34と、予め設定された値0.5よりも小さいため、この音韻oを訂正後の音韻列に含めずに除外する
音韻訂正部105は、第2の音韻列に対応する訂正後の音韻列を決定したら、決定した訂正後の音韻列とその音韻列に含まれる音韻ごとの正解率をマッチング部104に出力する。マッチング部104は、この訂正後の音韻列を新たな第2の音韻列とする。また、音韻訂正部105は、この訂正後の音韻列(第2の音韻列)を対話処理部106に出力する。
【0048】
なお、本実施形態では、音韻訂正部105は、上述のように各音韻列に含まれる音韻ごとの正解率に基づき訂正後の音韻列を決定することに限られない。音韻訂正部105は、マッチング部から各音韻列に含まれる音韻ごとのGPPを正解率の代わりに入力され、この音韻ごとのGPPに基づいて訂正後の音韻列を決定してもよい。ここで、音韻訂正部105は、音韻ごとのGPPが予め設定された閾値よりも小さい場合、訂正後の音韻列からその音韻を除外する。この閾値は、例えば、音韻の種別によらず一定の正解率に対応する値である。その場合、音韻の種別によりGPPと正解率の関係が異なるため(図2参照)、この閾値も音韻の種別によって異なる。また、音韻訂正部105は、正解率の代わりに訂正後の音韻列に含まれる音韻ごとのGPPをマッチング部104に出力する。
【0049】
対話応答パターン記憶部204は、例えば、図11に示すパターン情報を予め記憶する。図11は、本実施形態におけるパターン情報の例を示す図である。パターン情報には、要求パターンと応答パターンを含む。要求パターンには、初期要求パターン、確認要求パターンと訂正要求パターンを含む。応答パターンには、肯定パターン、否定パターン、初期応答パターン及び訂正要求回答パターンを含む。各パターンの具体的な内容については後述する。
【0050】
図1に戻り、対話処理部106は、初めに利用者からの認識対象となる音韻列を音声で入力するために、対話応答パターン記憶部204から、利用者にその音韻列を音声で応答することを要求する対話パターン情報(初期要求パターン)を読み出す。即ち、初期要求パターンとは、音声認識装置1が提示するメッセージのパターンを示す音韻列を含む情報であって、利用者に認識対象となる音韻列を初めて音声で応答することを促すものである。初期要求パターンは、例えば図11の「korewa naninani desu to nobetekudasai」である。この例は、利用者に「korewa ≪ … ≫ desu」と音声で回答を促すものであって、≪ … ≫の部分に、例えば名詞を示す音韻列が含まれる。対話処理部106は、この初期要求パターンを初期要求音韻列として音声再生部107に出力する。
【0051】
対話処理部106は、音韻認識部102から音韻列が入力されると、対話応答パターン記憶部204から、利用者に認識結果としての音韻列に対する確認を要求する対話パターン情報(確認要求パターン)を読み出す。即ち、確認要求パターンとは、音声認識装置1が提示するメッセージのパターンを示す音韻列を含む情報であって、利用者に、利用者の回答に基づいて訂正された後の音韻列に対して認識結果が正しいか否かを音声で回答することを促すものである。確認要求パターンは、例えば図11の「< … > deiidesuka」 である。< … >の部分は、訂正後の音韻列が挿入される部分であることを示す。
【0052】
対話処理部106は、確認要求パターンに、訂正後の音韻列を挿入して、利用者に認識結果の確認を要求するメッセージを示す音韻列(確認要求音韻列)を生成する。つまり、確認要求音韻列は、挿入した音韻列が正しいか否かを利用者に音声で回答すること促すメッセージを示す音韻列となる。例えば、訂正後の音韻列が「disupurei」であるとき、確認要求音韻列は「disupurei deiidesuka」と「ディスプレイでいいですか」を示す音韻列となる。対話処理部106は、この確認要求音韻列を音声再生部107に出力する。
【0053】
対話処理部106は、後述する処理を実行して音韻認識部102から入力された音韻列が訂正後の音韻列としての認識結果として誤っていることを示す音韻列であるか判定する。対話処理部106は、音韻認識部102から入力された音韻列が訂正後の音韻列としての認識結果として誤っていることを示す音韻列であると認識したとき、対話応答パターン記憶部204から、利用者に正しい音韻列を音声で応答することを要求する対話パターン情報(訂正要求パターン)を読み出す。訂正要求パターンとは、音声認識装置1が提示するメッセージのパターンを示す音韻列を含む情報であって、利用者に正しい音韻列を音声で回答することを促す音韻列である。訂正要求パターンは、例えば図11の「tadashikuwa naninani desu to nobetekudasai」である。この例は、利用者に「tadashikuwa ≪ … ≫ desu」と音声で回答を促す音韻列であって、≪ … ≫の部分に正しい音韻列が含まれる。対話処理部106は、この訂正要求パターンを訂正要求音韻列として音声再生部107に出力する。
【0054】
対話処理部106は、音韻認識部102から音韻列と音声特徴量ベクトルが入力される。対話処理部106は、入力された音韻列に基づき対話応答パターン記憶部204から利用者からの音声による応答の類型を示す応答パターン情報(応答パターン)を読み出す。応答パターンは、例えば、図11の「hai」、「un」、「so」、等、訂正後の音韻列が認識結果として正しいことを示す音韻列(肯定パターン)や、図11の「iie」、「ee」、「chigau」、等、訂正後の音韻列が認識結果として誤っていることを示す音韻列(否定パターン)を含む。また、応答パターンは、初めて利用者が認識対象として回答するメッセージのパターンを示す音韻列(初期応答パターン)と、認識結果として正しい音韻列を利用者が回答するメッセージのパターンを示す音韻列(訂正応答パターン)を含む。
【0055】
初期応答パターンは、例えば、図11の「korewa ≪ … ≫ desu」である。≪ … ≫を除く部分は、初期要求パターンから、「naninani」と、回答としての音韻列を含める部分と、「to nobetekudasai」と利用者への指示を示す部分を除いた部分に一致する。即ち、初期要求パターンは、初期応答として利用者に要求するパターンを示す部分が初期応答パターンと共通する。
訂正応答パターンは、例えば、図11の「tadashikuwa ≪ … ≫ desu」である。≪ … ≫を除く部分は、訂正要求パターンから、「naninani」と、回答としての音韻列を含める部分と、「to nobetekudasai」と利用者への指示を示す部分を除いた部分に一致する。即ち、訂正要求パターンは、訂正応答として利用者に要求するパターンを示す部分が訂正応答パターンと共通する。
≪ … ≫の部分は、回答としての認識対象の音韻列を含む部分であることを示す。
【0056】
図1に戻り、対話処理部106は、音韻認識部102から入力された音韻列と対話応答パターン記憶部204から読み出した応答パターン情報にマッチング処理を実行して、入力された音韻列に最も合致する応答パターンを決定する。マッチング処理において、対話処理部106は、例えば上述の始終端フリーDPマッチング法を実行する。
対話処理部106は、決定した応答パターン情報が肯定パターンのうちの一つである場合、利用者の応答に基づき訂正された訂正後の音韻列を単語情報として単語記憶部205に記憶させる。即ち、対話処理部106は、音韻認識部102から入力された音韻列が訂正後の音韻列が認識結果として正しいことを示す音韻列と認識する。これにより、音声認識装置1は、新たに記憶した音韻列を、認識対象の語彙として用いることができることになる。
対話処理部106は、決定した応答パターン情報が否定パターンのうちの一つである場合、音韻認識部102から入力された音韻列が訂正後の音韻列が認識結果として誤っていることを示す音韻列と認識する。このとき、対話処理部106は、上述のように対話応答パターン記憶部204から、訂正要求パターンを読み出す。
【0057】
対話処理部106は、決定した応答パターン情報が初期応答パターン又は訂正応答パターンであるとき、音韻認識部102から入力された音韻列が認識対象となる音韻列を含む音韻列と認識する。このとき、対話処理部106は、初期応答パターン又は訂正応答パターンの≪…≫に対応する、音韻認識部102から入力された音韻列の部分を抽出し、この部分を新たな第1の音韻列とする。対話処理部106は、音韻認識部102から入力された音声特徴量ベクトルから抽出された第1の音韻列と対応する音声特徴量ベクトルを抽出する。対話処理部106は、抽出された第1の音韻列と音声特徴量ベクトルを信頼度算出部103に出力する。
【0058】
音声再生部107は、対話処理部106から入力された初期要求音韻列、訂正要求音韻列又は確認要求音韻列から、公知のテキスト・音声合成方法を用いて、音声信号を生成する。音声再生部107は、生成した音声信号に基づく音声を再生する。音声再生部107は、確認要求音韻列に基づき、例えば、「disupurei deiidesuka」と「ディスプレイでいいですか」というメッセージを表す音声を再生する。これにより、利用者に「disupurei」という訂正後の音韻列が認識結果として正しいか否かを回答することを促すことができる。
【0059】
音声再生部107は、初期要求音韻列に基づき、例えば、「korewa naninani desu」と「これはナニナニです、と述べてください」というメッセージを示す音声を再生する。これにより、利用者に「korewa ≪ … ≫ desu」と、≪ … ≫の部分に初めて認識対象となる音韻列を音声で回答することを促すことができる。
音声再生部107は、訂正要求音韻列に基づき、例えば、「tadashikuwa naninani desu」と「正しくはナニナニです、と述べてください」というメッセージを示す音声を再生する。これにより、利用者に「tadashikuwa ≪ … ≫ desu」と、≪ … ≫の部分に正しい音韻列を音声で回答することを促すことができる。
【0060】
次に、音声認識装置1が実行する音声認識処理について説明する。音声認識装置1は、この音声認識処理を実行することにより、利用者と例えば図12に示す音声による対話を行い新たな単語を記憶することができる。
図12は、本実施形態に係る音声認識装置1と利用者との間の対話の一例を示す図である。図12において、Sは、音声認識装置1が再生する音声の内容を示す。Uは、利用者が発する音声の内容を示す。C1〜C8は、音声の順序を示す。
C1は、音声認識装置1が「これはナニナニです、と述べてください。」と初期要求音韻列“korewa naninani desu to nobete kudasai”に基づく音声を再生することを示す。これにより、音声認識装置1は、利用者に対し、音声で音韻列を“korewa ≪…≫ desu”という初期応答パターンで回答することを要求している。
C2は、利用者が「これはディスプレイです」と音声で回答することを示す。これにより、利用者は、C1で要求された初期応答パターンで音韻列「ディスプレイ」が示す音韻列“disupurei”を回答している。
【0061】
C3は、音声認識装置1が「これはジスプレイでいいですか?」と確認要求音韻列“jisupurei deiidesuka”に基づく音声を再生することを示す。これにより、音声認識装置1は、利用者に対し認識された音韻列“jisupurei”に対して、認識結果として正しいか否かを回答することを要求している。
C4は、利用者が「いいえ」と音声で回答することを示す。これにより、利用者は、C3により認識結果が誤りであることを示す否定パターン“iie”を回答している。
C5は、音声認識装置1が「正しくはナニナニです、と述べてください。」と訂正要求音韻列“tadashikuwa naninani desu to nobete kudasai”に基づく音声を再生することを示す。これにより、音声認識装置1は、利用者に対し、音声で音韻列を“tadashikuwa ≪…≫ desu”という初訂正応答パターンで回答することを要求している。
【0062】
C6は、利用者が「正しくはディスです」と音声で回答することを示す。これにより、利用者は、C5で要求された訂正応答パターンで音声認識装置1が認識結果として誤った部分“jisu”に対応する音韻列“disu”を回答している。
C7は、音声認識装置1が「これはディスプレイでいいですか?」と確認要求音韻列“disupurei deiidesuka”に基づく音声を再生することを示す。これにより、音声認識装置1は、利用者に対し認識及び訂正された音韻列“disupurei”に対して、認識結果として正しいか否かを回答することを要求している。
C8は、利用者が「はい」と音声で回答することを示す。これにより、利用者は、C3により認識結果が正しいことを示す肯定パターン“hai”を回答している。
【0063】
このような対話を実現するために音声認識装置1は、図13に示す処理を実行する。図13は、本実施形態に係る音声認識処理を示す流れ図である。
(ステップS101)音声認識装置1は、音声認識方法を実行するための変数について初期設定を行う。例えば、対話処理部106は、利用者に正しい音韻列を音声で応答することを要求する回数Mを6に設定し、その応答回数をカウントする変数iを1に設定する。その後、ステップS102に進む。
【0064】
(ステップS102)対話処理部106は、対話応答パターン記憶部204から、初期要求パターンを読み出す。対話処理部106は、読み出した初期要求パターンを初期要求音韻列として音声再生部107に出力する。
音声再生部107は、対話処理部106から入力された初期要求音韻列から、公知のテキスト・音声合成方法を用いて音声信号を生成する。音声再生部107は、生成した音声信号に基づき音声を再生する(例えば図12のC1)。これにより、音声認識装置1は、利用者に認識対象となる音韻列を音声で回答することを促すことができる。
(ステップS103)音声入力部101は、利用者が発した音声(例えば図12のC2)に基づく音声信号を入力され、入力された音声信号を音韻認識部102に出力する。その後、ステップS104に進む。
【0065】
(ステップS104)音韻認識部102は、音声入力部101から入力された音声信号から音声特徴量を算出する。音韻認識部102は、算出した音声特徴量に基づき、既知の音韻認識方法により利用者の発音を示す音韻を認識し、認識された音韻から構成される音韻列を生成する。音韻認識部102は、生成した音韻列と算出した音声特徴量の時系列データである音声特徴量ベクトルを対話処理部106に出力する。
対話処理部106は、音韻認識部102から入力した音韻列と対話応答パターン記憶部204から読み出した応答パターン情報(図11参照)にマッチング処理を実行して、入力された音韻列に最も合致する応答パターンを決定する。マッチング処理において、対話処理部106は、例えば上述の始終端フリーDPマッチング法を用いてマッチング処理を実行する。
【0066】
対話処理部106は、決定した応答パターン情報が初期応答パターン(図11参照)であるとき、音韻認識部102から入力された音韻列が正しい音韻列を含む音韻列と認識する。このとき、対話処理部106は、初期応答パターンの≪…≫に対応する、音韻認識部102から入力された音韻列の部分を抽出し、この部分を新たな第1の音韻列とする。対話処理部106は、新たな第1の音韻列に対応する新たな音声特徴量ベクトルを音韻認識部102から入力された音声特徴量ベクトルから抽出する。対話処理部106は、新たな第1の音韻列と音声特徴量ベクトルを信頼度算出部103に出力する。その後、ステップS105に進む。
【0067】
(ステップS105)信頼度算出部103は、対話処理部106から入力された音声特徴量ベクトルx1Tに対する確率p(x1T)と、音韻認識部102から入力された音韻列に含まれる各音韻umのその音声特徴量の該当部分xsmtmに対する条件付確率p(xsmtm|um)を音素音響モデル記憶部201から読み出す。信頼度算出部103は、読み出した確率p(x1T)及び条件付確率p(xsmtm|um)を用いて、式(1)に従って信頼度、例えばGPPを算出する。
信頼度算出部103は、その音韻列に含まれる音韻ごとに算出したGPPに対応する正解率を正解率記憶部202から読み出す。信頼度算出部103は、音韻列とこの音韻列を構成する音韻ごとのGPPと正解率をマッチング部104に出力する。
マッチング部104は、信頼度算出部103から音韻列とこれを構成する音韻ごとのGPPと正解率を入力され、入力された音韻列とこの音韻列を構成する音韻ごとのGPPと正解率を記憶する。ここで、信頼度算出部103から入力された音韻列を第2の音韻列とする。その後、ステップS106に進む。
【0068】
(ステップS106)対話処理部106は、音韻認識部102から音韻列が入力され、対話応答パターン記憶部204から確認要求パターンを読み出す。対話処理部106は、確認要求パターンの< … >の部分に入力された音韻列を挿入し、確認要求音韻列を生成する。対話処理部106は、生成した確認要求音韻列を音声再生部107に出力する。音声再生部107は、対話処理部から入力された確認要求音韻列から生成した音声信号に基づく音声(例えば図12のC3)を再生する。これにより、音声認識装置1は、利用者に認識結果を音声で出力し、認識結果が正しいか否かを音声で回答することを促す。その後、ステップS107に進む。
【0069】
(ステップS107)音声入力部101は、利用者が回答した音声に基づく音声信号(例えば図12のC4)を入力され、入力された音声信号を音韻認識部102に出力する。音韻認識部102は、音声入力部101から入力された音声信号から音声特徴量を算出する。
音韻認識部102は、算出した音声特徴量に基づき、公知の音韻認識方法により利用者の発音を示す音韻を認識し、認識された音韻から構成される音韻列を生成する。音韻認識部102は、生成した音韻列を対話処理部106に出力する。
対話処理部106は、音韻認識部102から入力された音韻列と対話応答パターン記憶部204から読み出した応答パターン情報に対してマッチング処理を実行して、入力された音韻列に最も合致する応答パターンを決定する。その後、ステップS108に進む。
【0070】
(ステップS108)対話処理部106は、決定した応答パターン情報が肯定パターンのうちの一つであるか否かを判断する。対話処理部106が、応答パターン情報が肯定パターンのうちの一つ(例えば図12のC8)と判断した場合(ステップS108 Y)、即ち、マッチング部104に入力された第2の音韻列が認識結果として正しい場合には、この音韻列を単語記憶部205に記憶させる。その後、処理を終了する。
対話処理部106が、応答パターン情報が肯定パターンでない(例えば図12のC4)と判断した場合(ステップS108 N)、即ち、マッチング部104に入力された第2の音韻列が認識結果として誤りの場合には、ステップS109に進む。
【0071】
(ステップS109)対話処理部106は、カウント回数iが繰り返し回数Mに達したか否か判断する。対話処理部106が、カウント回数iが繰り返し回数Mに達したと判断した場合(ステップS109 Y)、処理を終了する。対話処理部106が、カウント回数iが繰り返し回数Mに達していない場合(ステップS109 N)、ステップS110に進む。
(ステップS110)対話処理部106は、対話応答パターン記憶部204から、訂正要求パターンを読み出す。対話処理部106は、この訂正要求パターンを訂正要求音韻列として音声再生部107に出力する。
音声再生部107は、対話処理部106から入力された訂正要求音韻列から、公知のテキスト・音声合成技術により音声信号を生成する。音声再生部107は、生成した音声信号に基づき音声(例えば図12のC5)を再生する。これにより、利用者に訂正されるべき音韻列を音声で応答することを促すことができる。その後、ステップS111に進む。
【0072】
(ステップS111)音声入力部101は、利用者が発した音声(例えば図12のC6)に基づく音声信号が再度入力され、入力された音声信号を音韻認識部102に出力する。その後、ステップS112に進む。
(ステップS112)音韻認識部102は、音声入力部101から入力された音声信号から音声特徴量を算出する。音韻認識部102は、算出した音声特徴量に基づき、既知の音韻認識方法を用いて音韻を認識し、認識された音韻から構成される音韻列を生成する。音韻認識部102は、生成した音韻列と算出した音声特徴量の時系列データからなる音声特徴量ベクトルを対話処理部106に出力する。
対話処理部106は、音韻認識部102から入力された音韻列と対話応答パターン記憶部204から読み出した応答パターン情報にマッチング処理を実行して、入力された音韻列に最も合致する応答パターンを決定する。応答パターンが訂正応答パターンと決定されたとき、対話処理部106は、訂正応答パターンの≪…≫に対応する、音韻認識部102から入力された音韻列の部分を抽出し、この部分を新たな第1の音韻列とする。対話処理部106は、新たな第1の音韻列に対応する新たな音声特徴量ベクトルを音韻認識部102から入力された音声特徴量ベクトルから抽出する。対話処理部106は、新たな第1の音韻列と音声特徴量ベクトルを信頼度算出部103に出力する。その後、ステップS113に進む。
【0073】
(ステップS113)信頼度算出部103は、対話処理部106から第1の音韻列と音声特徴量ベクトルを入力される。
信頼度算出部103は、対話処理部106から入力された音声特徴量ベクトルx1Tに対する確率p(x1T)を音素音響モデル記憶部201から読み出す。信頼度算出部103は、対話処理部106から入力された第1の音韻列に含まれる各音韻umのその音声特徴量の該当部分xsmtmに対する条件付確率p(xsmtm|um)を音素音響モデル記憶部201から読み出す。信頼度算出部103は、読み出した確率p(x1T)及び条件付確率p(xsmtm|um)を用いて式(1)に従って信頼度の1つの指標としてGPPを算出する。信頼度算出部103は、その音韻列に含まれる音韻ごとに算出したGPPに対応する正解率を正解率記憶部202から読み出して信頼度のその他の指標として決定する。信頼度算出部103は、第1の音韻列とこれを構成する音韻ごとの正解率をマッチング部104に出力する。その後、ステップS114に進む。
【0074】
(ステップS114)マッチング部104は、信頼度算出部103から第1の音韻列とこれを構成する音韻ごとの正解率が入力される。マッチング部104は、第1の音韻列と第2の音韻列について、例えば始終端フリーDPマッチング法を用いてマッチング処理を実行する。マッチング部104は、マッチング処理において混同行列記憶部203から読み出した混同行列情報に基づき算出された累積距離を最小とする第1の音韻列と第2の音韻列との対応関係を示すマッチング情報を生成する。マッチング部104は、第1の音韻列、第2の音韻列、生成したマッチング情報及び各音韻列に含まれる音韻ごとの正解率を音韻訂正部105に出力する。その後、ステップS115に進む。
【0075】
(ステップS115)音韻訂正部105は、マッチング部104から入力された第2の音韻列を、第1の音韻列、マッチング情報及び正解率に基づいて訂正して、訂正後の音韻列を決定する。ここで、音韻訂正部105は、第1の音韻列に含まれる音韻に対応する第2の音韻列に含まれる音韻が異なる場合には、それらの音韻のうち各々に対応する正解率が高いほうの音韻を、訂正後の音韻列に含まれる音韻と決定する。
音韻訂正部105は、第1の音韻列に含まれる音韻に対応する第2の音韻列に含まれる音韻が同一である場合には、その同一の音韻を訂正後の音韻列に含まれる音韻と決定する。また、第2の音韻列に含まれる音韻に対応する第1の音韻列に含まれる音韻が存在しない場合は、音韻訂正部105は、第2の音韻列に含まれる音韻を訂正後の音韻列に含まれる音韻と決定する。但し、その第2の音韻列に含まれる音韻に対応する正解率が予め設定された値よりも小さい場合、音韻訂正部105は、その音韻を訂正後の音韻列に含めずに除外する。
【0076】
音韻訂正部105は、第2の音韻列に対応する訂正後の音韻列を決定した後、決定した訂正後の音韻列とその音韻列に含まれる音韻ごとの正解率をマッチング部104に出力する。マッチング部104では、この訂正後の音韻列を新たな第2の音韻列とする。また、音韻訂正部105は、この訂正後の音韻列(第2の音韻列)を対話処理部106に出力する。その後、ステップS116に進む。
【0077】
(ステップS116)対話処理部106は、音韻訂正部105から訂正後の音韻列(第2の音韻列)が入力されたことにより、対話応答パターン記憶部204から、確認要求パターンを読み出す。対話処理部106は、確認要求パターンに訂正後の音韻列を挿入して確認要求音韻列を生成する。対話処理部106は、この確認要求音韻列を音声再生部107に出力する。
音声再生部107は、対話処理部106から入力された確認要求音韻列から、公知のテキスト・音声合成方法を用いて、音声信号を生成し、生成した音声信号に基づく音声(例えば図12のC7)を再生する。これにより、利用者に訂正後の音韻列が認識結果として正しいか否かを回答することを促すことができる。その後、ステップS117に進む。
【0078】
(ステップS117)音声入力部101は、利用者が回答した音声(例えば図12のC8)に基づく音声信号が入力され、入力された音声信号を音韻認識部102に出力する。音韻認識部102は、音声入力部101から入力された音声信号から音声特徴量を算出する。
音韻認識部102は、算出した音声特徴量に基づき、公知の音韻認識方法により利用者の発音を示す音韻を認識し、認識された音韻から構成される音韻列を生成する。音韻認識部102は、生成した音韻列と算出した音声特徴量の時系列データである音声特徴量ベクトルを対話処理部106に出力する。
対話処理部106は、音韻認識部102から入力された音韻列と対話応答パターン記憶部204から読み出した応答パターン情報にマッチング処理を実行して、入力された音韻列に最も合致する応答パターンを決定する。その後、ステップS118に進む。
(ステップS118)対話処理部106は、利用者による応答回数をカウントする変数iを1だけ増加させる。その後、ステップS108に進む。
【0079】
なお、混同行列記憶部203に記憶される混同行列情報は、予め記憶された一定の値であってもよいが、これには限られない。訂正後の音韻列が正しいと判断されたとき、マッチング部104は、その直前に音韻訂正部105による音韻訂正処理に係る各音韻列に含まれる音韻に基づいて、混同行列情報を更新してもよい。
具体的には、マッチング部104は、次の処理を実行してもよい。ステップS108において、対話処理部106が、決定した応答パターン情報が肯定パターンのうちの一つと判断した場合(ステップS108 Y)、マッチング部104に入力された第2の音韻列、即ち訂正後の音韻列が認識結果として正しいこととなる。従って、マッチング部104は、最近実行されたステップS115(音韻訂正処理)において、第2の音韻列(訂正の対象)に含まれる音韻のうち第1の音韻列(最後に入力された音声に基づく)と共通する音韻を各々発話目的音韻γ及び認識目的音韻αとする混同行列情報の行列要素が示す頻度に1ずつ加算する。マッチング部104は、加算された値を、その行列要素の頻度とする。
例えば、第1の音韻列が“φa”、第2の音韻列が”ba”であるとき、発話目的音韻γ及び認識目的音韻αがともにaである行列要素の値92229に1を加算して92230とする。
【0080】
上述のように、対話処理部106が、決定した応答パターン情報が肯定パターンのうちの一つと判断した場合(ステップS108 Y)、第2の音韻列に含まれる音韻であって、ステップS115を実行して変更された音韻は、認識結果として誤っていたこととなる。従って、マッチング部104は、直前に実行したステップS115において、第2の音韻列(訂正の対象)に含まれる音韻のうち第1の音韻列(最後に入力された音声に基づく)に含まれる音韻に代わった音韻(正しい認識結果)を発話目的音韻γとし、その訂正前の音韻(認識誤り)を認識目的音韻αとする混同行列情報の行列要素が示す頻度に1ずつ加算する。マッチング部104は、加算された値を、その行列要素の頻度とする。
例えば、第1の音韻列が“φa”、第2の音韻列が”ba”であるとき、発話目的音韻γがb及び認識目的音韻αがφである行列要素の値169に1を加算して170とする。
これにより、発話目的音韻γが認識結果音韻αに認識される頻度を要素とする混同行列情報が、利用者の発話特性や残響などの使用環境に適応し、認識誤りが生じる頻度を低減することができる。さらに、利用者の音声入力による音韻訂正がより円滑に行われる。
【0081】
上述したように、本実施形態によれば、音声認識装置1と利用者との間で、例えば図12に示す対話がなされたとき、利用者が入力した音声のみに基づき認識した音韻を訂正することができる。
また、音韻訂正部105は、音韻列に含まれる各音韻に対する信頼度に基づいて選択された音韻に訂正するため、信頼性に裏付けられた音韻に訂正することができる。また、音韻訂正部105は、音韻列に含まれる音韻に対する正解率が低い場合に、認識誤りと判断するため、正解率の低い音韻に訂正することを回避することができる。
【0082】
ここで、音声認識装置1を用い、40個の単語を用いて単語正解率と音韻正解精度を検証した結果について説明する。試行回数は、各単語につき100回である。単語正解率とは、正しい音韻列が認識された試行回数の全試行回数に対する割合である。音韻正解精度とは、全試行回数における真の音韻数CNから置換音韻数CSと脱落音韻数CDと挿入音韻数CIを減じた音韻数の真の音韻数CIに対する割合である。
但し、音韻認識部102は、母音の長さの修正を行わず、発話目的音韻γ及び認識結果音韻αにおいて長母音と短母音を同一視した。また、混同行列記憶部203に記憶される混同行列情報は、予め記憶された一定の値である。
【0083】
ここで、マッチング部104は、第1の音韻列の音韻が認識される音韻ごとの確率に基づいて算出された第2の音韻列との間の距離からマッチング結果を決定するため、認識誤りを考慮したマッチングを実現することができる。
また、対話処理部106は、訂正した音韻列に基づく音声を再生し、入力した音声が示す応答に応じて、訂正した音韻列からなる単語情報を記憶するか、発話を促す内容を示す音声を再生させる。そのため、利用者に訂正した音韻列に係る音声による応答を促し、応答により訂正した音韻列からなる単語情報が登録されるか、利用者に再度発話を促すため、利用者の音声のみによる音韻認識誤りの訂正を円滑に実現することができる。
【0084】
図14は、音声認識装置1による単語正解率(word accuracy)と音韻正解精度(phoneme accuracy)の一例を示す図である。図14において、縦軸は、単語正解率及び音韻正解精度である。横軸は、訂正発話の回数(number of corrective utterances)、つまり繰り返し回数Mを示す。ここで、訂正発話の回数が多くなるほど、単語正解率、音韻正解精度が向上することが示される。例えば、訂正発話の回数がゼロのとき、単語正解率は8%、音韻正解精度は70%に過ぎない。訂正発話の回数が1回のとき、単語正解率は40%、音韻正解精度は80%である。訂正発話の回数が2回のとき、単語正解率は60%、音韻正解精度は90%である。訂正発話の回数が3回のとき、単語正解率は66%、音韻正解精度は92%である。この検証結果は、音声認識装置1は、当初は部分的に音韻を正しく認識できるが音韻列全体として正しく認識できない状態であっても、利用者との音声による対話を繰り返すことにより音韻列全体の認識率を向上できることを示す。これにより、音声認識装置1は、利用者と音声のみの対話を実行することにより音韻列が示す未知語を円滑に獲得できることを示す。
【0085】
(第2の実施形態)
次に、本発明の第2の実施形態について図を参照して説明する。図15は、本実施形態に係る音声認識ロボット3の構成を示す概略図である。図15において、音声認識ロボット3は、音声認識装置2の他に、コマンド辞書記憶部206、撮影部301、画像処理部302、動作制御部303、動作機構部304、及び駆動電力モデル記憶部401を含んで構成される。音声認識装置2は、対話処理部106に代え対話処理部306を有する点で音声認識装置1と異なり、その他の構成及び作用は他の構成部分と共通する。以下、第1の実施形態との差異点を主に説明する。
【0086】
コマンド辞書記憶部206は、操作対象となる物体を示す単語情報とその位置情報を含むロボットコマンド情報を記憶する。コマンド辞書記憶部206に記憶されている単語情報の一部又は全部は、単語記憶部205に記憶された音韻列を複製したものである。従って、音声認識装置2は、前述の音声認識処理によりロボットコマンド情報を補充することができる。
対話処理部306は、音韻認識部102から入力された音韻列とコマンド辞書記憶部206から読み出した単語情報についてマッチング処理を実行し、入力された音韻列と最も合致する単語情報を決定する。対話処理部306は、決定した単語情報に対応するロボットコマンド情報をコマンド辞書記憶部206から読み出し、動作制御部303に出力する。
【0087】
駆動電力モデル記憶部401には、物体を示す単語情報、位置情報及び動作機構部304の一部を構成する機構部に供給する電力の時系列データを対応づけた電力モデル情報を予め記憶しておく。
動作制御部303は、対話処理部306からロボットコマンド情報が入力される。
【0088】
動作制御部303は、入力されたロボットコマンド情報に含まれる単語情報及び位置情報に対応する電力モデル情報を駆動電力モデル部401から読み出し、機構部に供給する電力の時系列データを決定する。動作制御部303は、決定した電力の時系列データに基づき、その機構部へ電力を供給する。なお、機構部とは、例えば、マニピュレータ(manipulator)や多指グラスパ(multi−finger grasper)である。
動作制御部303から電力が供給された部品が動作することにより、その機構部を含んで構成される動作機構部304は、利用者が発話した音韻列で示される単語情報を含むロボットコマンドに応じた動作を実行する。
【0089】
撮影部301は、アナログ画像信号を撮影し、撮影したアナログ画像信号を画像処理部302に出力する。
画像処理部302は、撮影部301から入力されたアナログ画像信号をアナログ・ディジタル(A/D)変換してディジタル画像信号を生成する。
画像処理部302は、生成したディジタル画像信号から画像特徴量を算出する。算出される画像特徴量は、例えば、被写体の輪郭(エッジ)である。輪郭を算出するためには、例えば、水平方向及び垂直方向各々に隣接する画素間の画素値の差分値を算出し、算出された差分値の絶対値について、予め設定された周波数以上の成分を除外するようにフィルタリング処理を行う。フィルタリング処理が行われた画像信号のうち、予め設定された所定の値を越える画素の部分を輪郭と決定する。
画像処理部302は、算出した画像特徴量を対話処理部306に出力する。
【0090】
対話処理部306は、画像処理部302から入力された画像特徴量を、音韻認識部102から入力された音韻列に対応する単語情報を含むロボットコマンド情報としてコマンド辞書記憶部206に記憶する。例えば、利用者が撮影部301に被写体を撮影させながら、被写体の名称(単語情報)を発声すると、ロボットコマンド情報の一部として算出した画像特徴量を補充することができる。これにより、利用者が発話した音声だけではなく、撮影された画像をロボットコマンド情報と特定するための手がかりが得られる。
【0091】
即ち、対話処理部306は、音韻列のみならず、画像処理部302から入力された画像特徴量が、コマンド辞書記憶部206のロボットコマンド情報に含まれる画像特徴量とのマッチング処理を実行する。対話処理部306は、例えば、画像処理部302から入力された画像特徴量にも最も合致する画像特徴量を含むロボットコマンド情報を決定し、決定したロボットコマンド情報を動作制御部303に出力する。
【0092】
これにより、音声認識ロボット3は、認識誤りが生じうる音声認識だけに頼らず、画像認識によっても状況に適したロボットコマンドを特定できるので、利用者は音声により音声認識ロボット3に最適な動作を指示することができる。
【0093】
以上、説明したように、本実施形態に係る音声認識ロボット3と利用者との対話を通じ、利用者が入力した音声のみに基づき認識した音韻を訂正することができ、訂正した音韻に基づきロボットコマンドを補充することができる。ひいては、音声認識ロボット3が実現できる機能を容易に拡充することができる。また、画像情報を補充することにより、利用者によるロボットへの動作の指示を最適化することができる。
【0094】
上述した実施形態は、日本語の音韻、音韻列、要求パターン及び応答パターンを用いるが、これには限定されない。上述した実施形態は、他の言語、例えば英語の音韻、音韻列、要求パターン及び応答パターンを用いることもできる。
【0095】
なお、上述した実施形態における音声認識装置1及び2の一部、例えば、信頼度算出部103、マッチング部104、音韻訂正部105、対話処理部106、306、及び画像処理部302をコンピュータで実現するようにしても良い。その場合、この制御機能を実現するためのプログラムをコンピュータ読み取り可能な記録媒体に記録して、この記録媒体に記録されたプログラムをコンピュータシステムに読み込ませ、実行することによって実現しても良い。なお、ここでいう「コンピュータシステム」とは、音声認識装置1並びに2、及び音声認識ロボット3に内蔵されたコンピュータシステムであって、OSや周辺機器等のハードウェアを含むものとする。また、「コンピュータ読み取り可能な記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、CD−ROM等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶装置のことをいう。さらに「コンピュータ読み取り可能な記録媒体」とは、インターネット等のネットワークや電話回線等の通信回線を介してプログラムを送信する場合の通信線のように、短時間、動的にプログラムを保持するもの、その場合のサーバやクライアントとなるコンピュータシステム内部の揮発性メモリのように、一定時間プログラムを保持しているものも含んでも良い。また上記プログラムは、前述した機能の一部を実現するためのものであっても良く、さらに前述した機能をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるものであっても良い。
また、上述した実施形態における音声認識装置1並びに2、及び音声認識ロボット3の一部、または全部を、LSI(Large Scale Integration)等の集積回路として実現しても良い。音声認識装置1並びに2、及び音声認識ロボット3の各機能ブロックは個別にプロセッサ化してもよいし、一部、または全部を集積してプロセッサ化しても良い。また、集積回路化の手法はLSIに限らず専用回路、または汎用プロセッサで実現しても良い。また、半導体技術の進歩によりLSIに代替する集積回路化の技術が出現した場合、当該技術による集積回路を用いても良い。
【0096】
以上、図面を参照してこの発明の一実施形態について詳しく説明してきたが、具体的な構成は上述のものに限られることはなく、この発明の要旨を逸脱しない範囲内において様々な設計変更等をすることが可能である。
【符号の説明】
【0097】
1、2…音声認識装置、3…音声認識ロボット、
101…音声入力部、102…音韻認識部、103…信頼度算出部、
104…マッチング部、105…音韻訂正部、106、306…対話処理部、
107…音声再生部、201…音素音響モデル記憶部、202…正解率記憶部、
203…混同行列記憶部、204…対話応答パターン記憶部、205…単語記憶部、
206…コマンド辞書記憶部、301…撮影部、302…画像処理部、
303…動作制御部、304…動作機構部、401…駆動電力モデル記憶部
【特許請求の範囲】
【請求項1】
音声を入力する音声入力部と、
入力された音声の音韻を認識して訂正発話を示す第1の音韻列を生成する音韻認識部と、
前記第1の音韻列と元発話を示す第2の音韻列とをマッチングを行うマッチング部と、
前記マッチングを行った結果に基づき前記第2の音韻列の音韻を訂正する音韻訂正部と、を備えること
を特徴とする音声認識装置。
【請求項2】
前記音韻訂正部は、
前記音韻列の各音韻に対する信頼度に基づき選択された音韻に訂正すること、
を特徴とする請求項1に記載の音声認識装置。
【請求項3】
前記音韻訂正部は、
前記信頼度に基づく正解率が予め設定された値よりも低い場合、認識誤りと判断すること、
を特徴とする請求項2に記載の音声認識装置。
【請求項4】
前記マッチング部は、
入力音声に含まれる音韻の種別と認識される音韻の種別の組ごとの頻度に基づき
前記第1の音韻列の音韻と前記第2の音韻列の音韻との間の距離を算出し
前記距離に基づきマッチング結果を決定すること、
を特徴とする請求項1に記載の音声認識装置。
【請求項5】
前記訂正した第2の音韻列に基づく音声を再生する音声再生部と、
認識結果を示す応答パターンを記憶する対話応答パターン記憶部と、
入力された音声の音韻に合致する前記応答パターンに基づき、前記訂正した第2の音韻列からなる単語情報を単語記憶部に記憶するか、前記音声再生部に利用者に発話を促す音声を再生させるか、いずれか一方を実行する対話処理部と、を備えること、
を特徴とする請求項1に記載の音声認識装置。
【請求項6】
音声認識装置における音声認識方法において、
前記音声認識装置が、音声を入力する第1の過程と、
前記音声認識装置が、入力された音声の音韻を認識して訂正発話を示す第1の音韻列を生成する第2の過程と、
前記音声認識装置が、前記第1の音韻列と元発話を示す第2の音韻列とをマッチングを行う第3の過程と、
前記音声認識装置が、前記マッチングを行った結果に基づき前記第2の音韻列の音韻を訂正する第4の過程を有すること
を特徴とする音声認識方法。
【請求項7】
音声を入力する音声入力部と、
入力された音声の音韻を認識して訂正発話を示す第1の音韻列を生成する音韻認識部と、
前記第1の音韻列と元発話を示す第2の音韻列とをマッチングを行うマッチング部と、
前記マッチングを行った結果に基づき前記第2の音韻列の音韻を訂正する音韻訂正部と、を備えること
を特徴とする音声認識ロボット。
【請求項1】
音声を入力する音声入力部と、
入力された音声の音韻を認識して訂正発話を示す第1の音韻列を生成する音韻認識部と、
前記第1の音韻列と元発話を示す第2の音韻列とをマッチングを行うマッチング部と、
前記マッチングを行った結果に基づき前記第2の音韻列の音韻を訂正する音韻訂正部と、を備えること
を特徴とする音声認識装置。
【請求項2】
前記音韻訂正部は、
前記音韻列の各音韻に対する信頼度に基づき選択された音韻に訂正すること、
を特徴とする請求項1に記載の音声認識装置。
【請求項3】
前記音韻訂正部は、
前記信頼度に基づく正解率が予め設定された値よりも低い場合、認識誤りと判断すること、
を特徴とする請求項2に記載の音声認識装置。
【請求項4】
前記マッチング部は、
入力音声に含まれる音韻の種別と認識される音韻の種別の組ごとの頻度に基づき
前記第1の音韻列の音韻と前記第2の音韻列の音韻との間の距離を算出し
前記距離に基づきマッチング結果を決定すること、
を特徴とする請求項1に記載の音声認識装置。
【請求項5】
前記訂正した第2の音韻列に基づく音声を再生する音声再生部と、
認識結果を示す応答パターンを記憶する対話応答パターン記憶部と、
入力された音声の音韻に合致する前記応答パターンに基づき、前記訂正した第2の音韻列からなる単語情報を単語記憶部に記憶するか、前記音声再生部に利用者に発話を促す音声を再生させるか、いずれか一方を実行する対話処理部と、を備えること、
を特徴とする請求項1に記載の音声認識装置。
【請求項6】
音声認識装置における音声認識方法において、
前記音声認識装置が、音声を入力する第1の過程と、
前記音声認識装置が、入力された音声の音韻を認識して訂正発話を示す第1の音韻列を生成する第2の過程と、
前記音声認識装置が、前記第1の音韻列と元発話を示す第2の音韻列とをマッチングを行う第3の過程と、
前記音声認識装置が、前記マッチングを行った結果に基づき前記第2の音韻列の音韻を訂正する第4の過程を有すること
を特徴とする音声認識方法。
【請求項7】
音声を入力する音声入力部と、
入力された音声の音韻を認識して訂正発話を示す第1の音韻列を生成する音韻認識部と、
前記第1の音韻列と元発話を示す第2の音韻列とをマッチングを行うマッチング部と、
前記マッチングを行った結果に基づき前記第2の音韻列の音韻を訂正する音韻訂正部と、を備えること
を特徴とする音声認識ロボット。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】

【図7】

【図8】

【図9】
【図10】

【図11】

【図12】

【図13】

【図14】

【図15】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図12】
【図13】
【図14】
【図15】
【公開番号】特開2011−158902(P2011−158902A)
【公開日】平成23年8月18日(2011.8.18)
【国際特許分類】
【出願番号】特願2011−11198(P2011−11198)
【出願日】平成23年1月21日(2011.1.21)
【出願人】(000005326)本田技研工業株式会社 (23,863)
【出願人】(393031586)株式会社国際電気通信基礎技術研究所 (905)
【Fターム(参考)】
【公開日】平成23年8月18日(2011.8.18)
【国際特許分類】
【出願日】平成23年1月21日(2011.1.21)
【出願人】(000005326)本田技研工業株式会社 (23,863)
【出願人】(393031586)株式会社国際電気通信基礎技術研究所 (905)
【Fターム(参考)】
[ Back to top ]