
頭部動作制御情報生成装置
【課題】ロボットと人間とのコミュニケーションをより円滑にできるよう、ロボットの頭部の動きを制御する頭部動作制御情報生成装置を提供する。
【解決手段】頭部動作生成装置86は、ヒューマノイド型ロボットの頭部の動きを、当該ロボットが発生する音声に同期して制御する制御情報を生成する装置であり、句ごとに付されている談話機能タグごとに、複数の頭部動作をどのような確率で実行するかを規定する確率モデル群100と、入力された句に付された注釈に基づいて、確率モデル群100の中から確率モデルを選択し、選択された確率モデルにしたがった確率で、入力された所定の単位の音声データに対応する頭部動作コマンドをロボットの制御部90に出力する頭部動作コマンド生成部104を含む。
【解決手段】頭部動作生成装置86は、ヒューマノイド型ロボットの頭部の動きを、当該ロボットが発生する音声に同期して制御する制御情報を生成する装置であり、句ごとに付されている談話機能タグごとに、複数の頭部動作をどのような確率で実行するかを規定する確率モデル群100と、入力された句に付された注釈に基づいて、確率モデル群100の中から確率モデルを選択し、選択された確率モデルにしたがった確率で、入力された所定の単位の音声データに対応する頭部動作コマンドをロボットの制御部90に出力する頭部動作コマンド生成部104を含む。
【発明の詳細な説明】
【技術分野】
【0001】
この発明はロボットによる人間とのコミュニケーションの改善に関し、特に、ヒューマノイド型ロボットの頭部を、その発話内容にあわせて自然に動かすための技術に関する。
【背景技術】
【0002】
発話中、人間は自然に頭を動かす。これらの動きは時には、相手に対して明確な意味を伝えるよう意図的になされることがある。例えば頷くのは同意を表し、首を振るのは不同意を表す。しかし多くの場合、頭の動きは無意識にされる。そうした動きは、ときには話者が意図するもの以上の情報を相手に伝えることがある。したがって、ヒューマノイド型ロボットにおいて、話の内容に応じて頭を適切に動かすことができれば、相手とのコミュニケーションがより円滑になることが期待される。
【0003】
この種の技術として、特許文献1に挙げたものがある。特許文献1は、発話するロボットなどにおいて、音声信号に予め頷くタイミングを決める信号を付しておき、音声信号から頷くためのタイミング信号を検出すると、その信号にあわせてロボットが頷くよう、ロボットの首を制御する技術を開示している。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開2009-069789号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
人間とロボットとの有効なコミュニケーションを図る上で、ロボットの発話にあわせてその頭を動かすことが重要であることは、上記特許文献1においても記載されているとおりである。しかし、どのような方法でロボットの頭を動かせば人間にとって自然に感じられ、かつロボットの発話の意味を理解することが容易になるかについてはまだ適当な方法が提案されていない。特許文献1に記載の技術では、頭部の動きを予めプログラムすることに関する記載しかなく、どのように頭部を動かせば自然な動きとして感じられるかについては開示されていない。
【0006】
それゆえに本発明の目的は、ロボットと人間とのコミュニケーションをより円滑にできるよう、ロボットの頭部の動きを制御する頭部動作制御情報生成装置を提供することである。
【0007】
本発明の他の目的は、ロボットの頭部の動きを発話の内容にふさわしく変化させ、自然に感じさせる頭部動作制御情報生成装置を提供することである。
【課題を解決するための手段】
【0008】
本発明のある局面に係る頭部動作制御情報生成装置は、ヒューマノイド型ロボットの頭部の動きを、当該ロボットが発生する音声に同期して制御する制御情報を生成する。音声は、予め所定の単位に分割された音声データにより規定される。所定の単位の各々には、当該単位に割当てられた音声データにより発声される音声による談話機能を示す談話機能タグを含む注釈が付されている。この頭部動作制御情報生成装置は、談話機能タグごとに、複数の頭部動作をどのような確率で実行するかを規定する確率モデルを記憶するための確率モデル記憶手段と、音声データの所定の単位の入力を受け、当該単位に付された注釈に基づいて決定される確率モデルを、確率モデル記憶手段に記憶された確率モデルの中から選択するための確率モデル選択手段と、確率モデル選択手段により選択された確率モデルにしたがった確率で、入力された所定の単位の音声データに対応する頭部動作コマンドを生成し、ヒューマノイドロボット型ロボットの制御部に出力するための頭部コマンド生成手段と、を含む。
【0009】
音声データの所定の単位に付された談話機能タグが同一であっても、頭部コマンドが確率モデルにより選択されるため、ヒューマノイドロボットの頭部の動きは場合により異なる。同じ状況で常に同じ動きをする場合と比較して、不自然に感じられる動きを少なくすることができる。確率モデルを適切に準備しておくことにより、談話機能タグに応じた適切で自然な形でロボットの頭部を制御することができる。その結果、ロボットと人間とのコミュニケーションをより円滑にできるよう、ロボットの頭部の動きを制御する頭部動作コマンド生成装置を提供すること、及びロボットの頭部の動きを発話の内容にふさわしく変化させ、自然に感じさせる頭部動作コマンド生成装置を提供することができる。
【0010】
好ましくは、音声データには、話者を特定する話者特定情報、話者と談話相手との関係を特定する関係特定情報、及び発話時の非言語的情報、の任意の組合せからなる、談話モードを指定する談話モード情報が付されている。確率モデル選択手段は、談話モード情報と談話機能タグとの組合せに応じて予め準備された複数個の確率モデルを記憶している。確率モデル選択手段は、音声データに付された談話モード情報と、入力された所定の単位とに応じて複数個の確率モデルの内の一つを選択するための手段を含む。
【0011】
人間同士の対話では、話者、話者と談話相手との関係、及び発話時の話者の態度・感情などの非言語的情報に関連する事情により異なることが実験により分かった。したがって、これらの組合せに応じた確率モデルを予め準備し、発話時の談話モードに応じてこれらに適合した確率モデルにしたがって頭部動作を選択することで、談話相手に単に音声だけでないより多くの情報を与えることができる。
【0012】
より好ましくは、頭部コマンド生成手段は、確率モデル選択手段により選択された確率モデルにしたがった確率で、入力された所定の単位の音声データに対応する頭部動作を発生させるか否かを決定するための頭部動作決定手段と、複数の頭部動作の各々に対し、当該頭部動作に対応する頭部の時間的動きを規定する形状情報を記憶するための形状情報記憶手段と、頭部動作決定手段により何らかの頭部動作を発生させることが決定されたことに応答して、当該頭部動作の種類により予め決まっているタイミングで、当該頭部動作に対応する形状情報を形状情報記憶手段から読出してロボットの頭部を制御するための制御コマンドを生成し制御部に出力するための形状読出手段とを含む。
【0013】
頭部動作を発生させるタイミングを決定するのは単純なルールでも実現できる。予め頭部動作ごとに、その頭部動作を実現するための時間的な動きを表す形状情報を記憶しておき、決定されたタイミングでその形状情報から制御コマンドを生成する、という簡単な処理で、談話相手とのコミュニケーションを円滑にすることができる。
【0014】
さらに好ましくは、ロボットの頭部の動きは、ロボットの頭部の3軸周りの回転のうち、ピッチ角に関連するものである。頭部コマンド生成手段はさらに、ロボットの発話時の頭部の時間的動きを規定する、予め準備された頭部動作の形状を記憶するための発話時頭部形状記憶手段と、形状読出手段と制御部との間に接続され、音声データによりロボットが発話する期間であることが示されていることに応答して、形状読出手段により出力される制御コマンドに、発話時頭部形状情報記憶手段から読出した頭部動作の形状を重畳して制御部に与えるための手段とを含む。
【0015】
実験から、特にピッチ角については、発話者が話しているときには特定の動きをすることが判明した。ただし、発話者によりこの動きは異なる可能性がある。そこで、このように予め準備された特定の頭部動作の形状を記憶しておく構成で、想定される発話者により、発話時に特徴的な頭部の動きを再現できる。
【0016】
ロボットの頭部の動きは、ロボットの頭部の3軸のうち任意の組合せの軸周りの回転に関するものであってもよい。この場合、確率モデル記憶手段、確率モデル選択手段、及び頭部コマンド生成手段は、いずれも任意の組合せを構成する軸ごとに独立に頭部制御コマンドを生成する。
【0017】
本発明によれば、上記した構成により、ロボットと人間とのコミュニケーションをより円滑にできるよう、ロボットの頭部の動きを制御する頭部動作コマンド生成装置を提供することが可能になる。さらに、ロボットの頭部の動きを発話の内容にふさわしく変化させ、自然に感じさせる頭部動作コマンド生成装置を提供することもできる。
【図面の簡単な説明】
【0018】
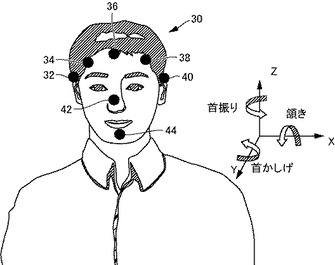
【図1】本発明の実施の形態を実現するために行なった人間の頭部のモーションキャプチャ時の設定を示す図である。
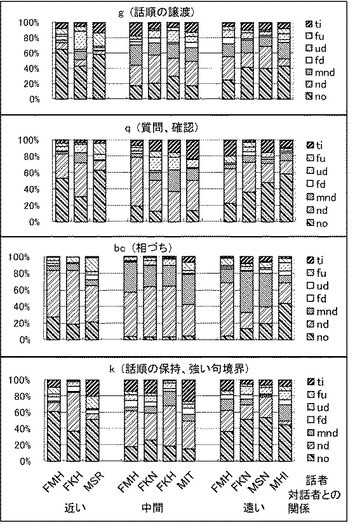
【図2】上記実験の結果得られた被験者の頭部の動き、各被験者と談話相手との関係、及び発話の内容の関係を示すグラフである。
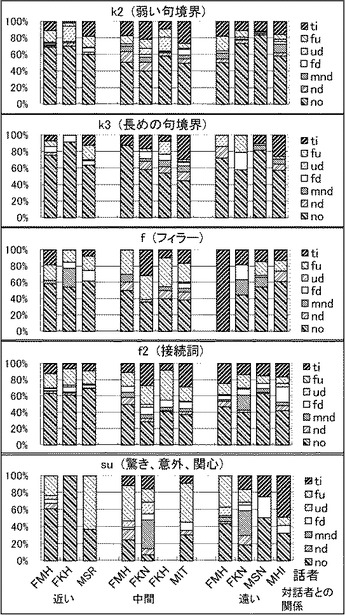
【図3】上記実験の結果得られた被験者の頭部の動き、各被験者と談話相手との関係、及び発話の内容の関係を示すグラフである。
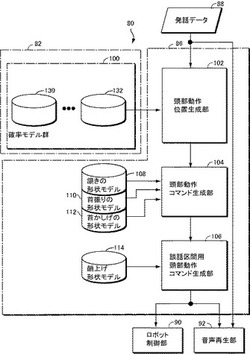
【図4】第1の実施の形態で制御の対象となるロボットの頭部の動きを実現するアクチュエータの配置を示す図である。
【図5】本発明の第1の実施の形態に係る頭部動作生成装置の機能的ブロック図である。
【図6】図5に示す頭部動作位置生成部を実現するプログラムをブロック図的なフローチャートで示した模式図である。
【図7】本発明の第1の実施の形態で用いた、ロボットの頭部の頷きを実現するための頷き角度(上向きを正とする。)の時間的変化を示すグラフである。
【図8】本発明の第1の実施の形態で用いた、連続した複数の頷き動作を実現するための頷き角度の時間的変化を示すグラフである。
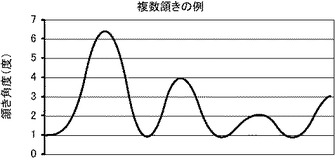
【図9】本発明の第1の実施の形態で用いた、ロボットが発話中のロボットの頷き角度の時間的変化を示すグラフである。
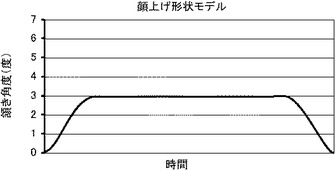
【図10】本発明の第1の実施の形態における、発話から頭部動作コマンドを生成する際の頷き角度の時間的変化の生成過程を示すグラフである。
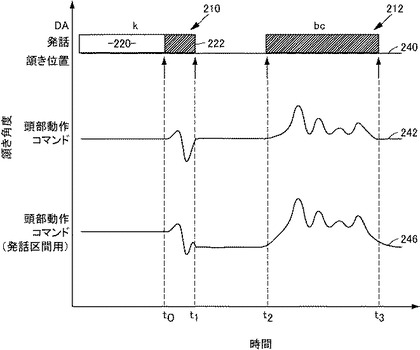
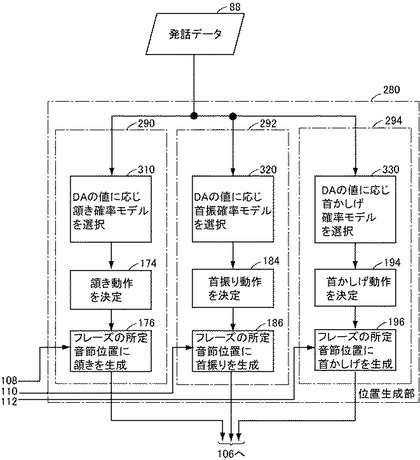
【図11】本発明の第2の実施の形態に係る頭部動作生成装置の頭部動作位置生成部を実現するプログラムをブロック図的なフローチャートで示した図である。
【発明を実施するための形態】
【0019】
以下の説明及び図面では、同一の部品には同一の参照番号を付してある。それらの名称及び機能も同一である。したがってそれらについての詳細な説明は繰返さない。
【0020】
[実験]
後述する本発明の実施の形態を実現するにあたり、人間の発話と頭部の動きとの関係、及び人間の頭部の動きを談話相手がどのように理解するかについての実験を行なった。この結果から、後述するように比較的単純な構成のモデルを得ることができ、それによって本発明の実施の形態に係るロボットの頭部動作生成装置を実現することができた。
【0021】
<実験の設定>
─データ─
実験には7人の被験者(男性4人、女性3人の発話者)を用いた。テーブル1にこれら被験者のリストと、これら被験者と対話した相手(談話相手)と、談話相手及び被験者の関係とを示す。
【0022】
【表1】

これら発話者と、談話相手とのいくつかの組合せごとに、自由な対話による談話(10分−15分間)を何セッションか収録した。収録した談話セッションの総数は19であった。各発話者についてのセッション数は、FMH×FKH(2)、FKN×FKH(2)、FMH×MHI(1)、FKN×MHI(1)、FMH×MSN(1)、FKN×MSN(1)、FMH×MIT(3)、FKN×MIT(3)、FMH×MSR(5)であった。
【0023】
対話者の双方について、同時に音声及び動きデータの収録を行なった。対話者の間の距離は、双方のモーションキャプチャが同時に可能な範囲で、できるだけ近くなるように設定した。結果として、両者の間の距離は1mとなった。収録には指向性マイクロホンを用い、これら指向性マイクロホンを各対話者に向けて設置した。
【0024】
話者の各々の頭部に7個の半球形のパッシブ反射マーカを装着し、赤外線を用いた市販のモーションキャプチャ装置で話者の頭部の動きデータを取得した。図1に、反射マーカの位置を示す。図1を参照して、話者30の頭部の周囲に5つのマーカ32,34,36,38及び40を装着した。話者30の鼻の頂部にはマーカ42を、あごにはマーカ44を、さらに装着した。頭部及び鼻のマーカ32−42により頭部の座標を得、あごのマーカ44の位置(鼻のマーカ42に対する相対位置)により、動きデータと発話データとの間の対応付けを行なうようにした。
【0025】
頭部の動きは、図1の右側に示す3軸(XYZ軸)により表した。「頷き」、「首振り」及び「首かしげ」とは、図1の座標軸において、それぞれX軸周り、Z軸周り、及びY軸周りに首を回転させることをいう。これらは航空工学においてピッチ、ヨー、及びロールと呼ばれているものとそれぞれ同様である。これらの軸周りの回転角度をそれぞれピッチ角、ヨー角及びロール角と呼ぶ。
【0026】
頭部の回転角度は、マーカの座標を用い、M.B. Stegmann, D.D. Gomez, “A brief introduction to statistical shape analysis,” http://www2.imm.dtu.dk/pubdb/views/edoc_download.php/403/pdf/imm403.pdf,2002に紹介された特異値分解にもとづいて算出した。すなわち、ユニタリ行列U、対角行列D、ユニタリ行列Vの組合せが、以下の式(1)により表される特異値分解により得られる。
【0027】
【数1】
ただし、reference及びtargetはそれぞれ、中立位置及び現在位置の3Dマーカ位置を、それらの重心を原点とする新たな座標系に平行移動させた座標を表す。中立位置は、被験者がまっすぐ前方を向いているときに得られたものである。回転を表す行列は次の式(2)により得られる。
【0028】
【数2】
この回転行列Rの要素から、次の式(3)−(5)によって回転角度が算出される。
ただし、sqrt、^、及びatan2はそれぞれ、Matlab(登録商標)の平方関数、べき乗関数、及びアークタンジェント関数である。
【0029】
こうして得た発話データに対し、日本語のネイティブ・スピーカが手作業で句単位に分割し、文字起こしをした。分割の結果、全部で16920句が得られた。
【0030】
─頭部動作のタグ─
日本語による対話の間で何らかの意味がある部分と考えられる分について、そのときの頭部の動きに以下のような頭部動作タグからなる注釈を手作業により付した。
【0031】
・no:動きなし
・nd:単一の頷き(顔下げ─顔上げの動き)
・mnd:句とともに複数回の頷きが生じた
・fd:顔下げ
・ud:顔上げ─顔下げ(1回)
・fu:顔上げ
・ti:句内で顔かしげ
・sh:句内で顔振り(左右の動き)
頷きが常に頭部の上下への動きにより表されるとは限らない。例えば顔を軽く傾けることでも頷きと見られることがある。このようにして注釈をつけた後、最も程度の大きかった動きについて考察した。
【0032】
3つの角度の時間変化、及びビデオ画像に基づいて、1人の被験者が頭部動きに関し、上記頭部動作タグセットによる注釈付けを音声情報に対して行なった。このラベルを他の被験者がチェックし、訂正した。いずれの被験者も本件発明者のアシスタントである。第1の被験者がつけた注釈のうち、5%が第2の被験者により修正された。
【0033】
テーブル2に、各頭部の動きタグを用いた注釈の分布を示す。頷き(ndとmndの合計)が最も頻繁に生ずる頭部の動きであることが分かる。「その他」欄は、被験者が分類に確信が持てなかった動きに関する句についてのものである。
【0034】
【表2】
─談話機能タグ─
データセット中の各句について、以下のような談話機能タグの組から選択した談話機能タグを注釈として付した。この際、肯定又は否定の反応、驚き・意外さの表れの感情表現、及び発話交替などについて考察した。
【0035】
・k(keep):発話者が発話者としての地位(話順)を保持している。強い句境界において、短いポーズ又は明瞭なピッチのリセットが生じる。
【0036】
・k2(keep):(句の間にポーズが存在しない)発話途中の弱い句境界
・k3(keep):考えているときなど、話者が句の末尾を延ばしながら、しかし話順は保持している(ポーズが続く場合も続かない場合もある。)。
【0037】
・f(filler:フィラー):話者が次の発話を考えているか準備している。例えば「うーん」、「えーと」、又は「あのー」など。
【0038】
・f2(conjunctions:接続詞):長く延ばされないフィラーと同様に考えることができる。例えば「だから」、「じゃあ」、「で」など。
【0039】
・g(give:話順の譲):話者が発話を終わり、対話の相手に発話者の地位を渡す。
【0040】
・q(質問):話者が対話の相手に対して質問をしたり、同意を求めたりする。
【0041】
・bc(相づち):話者が対話の相手に対して相づち(同意の反応)を見せる。例えば頷きながら「うん」と言う。
【0042】
・su(驚き/意外/感心)発話者が対話の相手に対して表情のある反応(驚き/意外/感心)を示す。例えば「へー」、「うそ!」、「ああ」など。
【0043】
・dn(denial,negation:否認、否定):首振り動作を伴う「いいえ」、「ううん」など。
【0044】
上に記載した分類は完全なものではないが、人間とロボットのコミュニケーションという観点から見るとこれらで十分であると考えられる。
【0045】
第1の被験者が談話機能タグによる注釈を句ごとに付した後、第2の被験者が注釈のチェック及び修正を行なった。これら被験者は頭部動作タグによる注釈を付したのと同じ被験者である。第2の被験者は全注釈のうち5.9%を訂正した。
【0046】
テーブル3は、各談話機能タグによる注釈の分布を示す。テーブル3において、「その他」は、被験者がどの談話機能タグを付したらよいか判断できなかった句を含む。この中にはさらに、挨拶のような、g(話順の譲渡)のサブカテゴリの間投詞、並びにbc(単純な相づち)及びsu(驚き/意外/感心)以外の間投詞が含まれる。
【0047】
【表3】
─頭部動作及び談話機能─
図2及び図3に、各談話機能の機能に対する頭部動作の分布を示す。これらグラフは、各発話者と談話相手との関係に応じたグループ(各図の最下部のx軸に示す。)に分けて示してある。y軸には各頭部動作タグの生起した確率を示してある。
【0048】
図2及び図3を参照して、頷き(nd)及び複数頷き(mnd)が相づち(bc)において高い頻度で生ずることが分かる。頷きはまた、強い句境界(k、g、q)でも頻繁に観測された。質問(q)では、通常は句の末尾が上昇するように発音されるが、頷きは、顔上げ─顔下げ動作、又は顔上げ動作より頻繁に観測された。ピッチ(F0形状)と頭部動作との相関が低くなるのはこれが原因であると思われる。
【0049】
頷きの観測頻度は、発話途中の弱い句境界(k2)と、話者が考えていたり、発話を完了していないことを示したりしている句境界(k3、f、f2)とにおいて、より低くなる。こうした談話機能カテゴリでは、顔の動きのない状態(no)が大部分である。
【0050】
複数頷き(mnd)のシーケンスをより詳細に観察すると、これらの動きは、発話者が談話相手の話に対して強い同意、理解、又は興味を表現しているときに、発話全体にわたって発生する傾向があることが分かった。
【0051】
驚き、意外、感心など(su)を表す句の場合、上記データ内での発生頻度はより低かった。頭部の動きなし(no)、顔上げ動作(fu)、及び首かしげ(ti)が大部分であった。
【0052】
─同一話者及び話者間による変化─
上記実験からはまた、頭部動作の頻度は話者により異なることが明らかとなった。
【0053】
例えば、4人の男性話者のうちの2人(MSN及びMHI)は他に比べて頭部動作がはるかに少なかった。この事実からは、話者の社会的地位が談話相手(研究助手)よりも高いことが影響しているのではないかと考えられる。他に考えられることとしては、話者と談話相手との年齢差が影響しているかもしれない。
【0054】
同一話者での変化を検討すると、談話相手との個人的関係によって頭部の動きの頻度が影響を受けるようである。図2及び図3において、話者と談話相手との関係は3段階に分けてある。すなわち、「近い」(家族、ボーイフレンド)、「遠い」(世代及び社会的地位の相違)、「中間」(友人、友人の友人、友人の親類)である。「中間」と「遠い」との区別のためには、社会的地位だけでなく、実際の個人の間の関係も考慮した。例えば話者と談話相手とが顔をあわせるのがはじめてか否か、という要因も考慮してある。
【0055】
上の結果からはさらに、話者が談話相手と近い関係にあるときには、頭部の動きの頻度がかなり低いことが分かった。例えば、話者FMHの場合、彼女の母又は彼女のボーイフレンドと話しているとき(FMH×「近い」)には、g、q、bc及びkでは頭部動きなし(no)が高い頻度で発生し、頷き(nd,mnd)は小さな頻度でしか生じなかった。同様に、相づち(bc)では、FMH×「近い」の組合せで大部分の動きが頷き(nd)であったのに対し、FMHが初めて見る相手との対話のときには複数頷き(mnd)の頻度が高くなる。この事実は、頭部の動き(特に頷き)については、談話相手の話に自分が興味を持っていることを示すなど、態度を表明するために使用する、ということによって説明されると思われる。家族に対してはあまり気を使わない振る舞いが多くなり、その結果頭部の動きが少なくなる。発話交替の発話(k)についていえば、FMH×「中間」の組合せのときには頷きが頻繁に発生するが、FMH×「遠い」の組合せのときには頻度は下がる。この事実は、FMHが、MSN及びMHI(「遠い」談話相手)と話しているときには自分を抑えるのに対し、友人の友人であり年齢も近いMIT(「中間の」談話相手)と話しているときには、より自信を持って話す、ということで説明できる。
【0056】
話者FKNについては、FKH,MHI及びMSNと話しているときには、bc(相づち)では、単一頷き(nd)と比較して複数頷き(mnd)の頻度が高かった。これらの談話相手が話者FKNより年長でありかつこれらの相手にあうのが初めてであったせいだろうと思われる。それに対して友人MITと話しているときには単一の頷きが大部分であった。k及びgでは、FKH,MHI及びMSNと話しているときには特に支配的な動きは見られなかった。この事実はFMHの場合と同様であり、FKNが初めて会った相手(FKH,MHI及びMSN)に対してはFKNは自分を主張せず、MHIと話すときにはより自信を持っていた、ということにより説明できる。
【0057】
話者FKHの場合には、娘(FMH)と話しているときには、娘の友人(FKN)と話しているときより頭部動きなし(no)が高い頻度だった。また、FKNと話しているときには複数頷き(mnd)がより高い頻度で現れたことにも注目できる。
【0058】
<ルールベースの頷き発生>
以上の結果から、談話中に最もよく生ずる頭部の動きは頷きであることが分かるが、それ以外の頭部の動きの頻度にも、談話相手、及び談話機能により一定の傾向があることが分かる。したがって、以下の実施の形態では、ルールベースの頭部動作生成モデルとそれを用いてロボットの頭部動作コマンドを生成する装置を提案する。なお、以下の説明では主として頭部動作、特に頷きについて説明するが、首振り及び首かしげなどについても同様の考え方で頭部動作コマンドを生成することができる。
【0059】
最初に、ロボットに与えられる発話データからロボットの頷きのタイミングのみを生成する非常に簡単な確率モデルを考える。このモデルでは、頷きは強い句境界を持つ発話(k、g、q)及び相づち(bc)の最終音節の中央で生成される。
【0060】
こうしたモデルは、図2及び図3に示すものと同様の実験結果を統計的に処理することにより、確率モデルとして得られる。上の実験では、頭部の動作に対する要因として考えられるものと実際の頭部の動きとの関係を明確にするために、要因として考えられるものを絞っているが、同様の考え方により例えば各句(又は発話全体)を発話するときに付随させるべき態度・感情などの非言語的情報(音声言語以外によって伝達される情報)に関連すると思われる情報についても、予め談話記録の句ごとにラベル付けをしておくことで同様の統計的情報を得ることができる。
【0061】
本実施の形態では、話者/談話相手との関係/態度・感情の組合せごとに(これらの組合せをそれぞれ簡略のためにここでは、これらの任意の組合せを単に「談話モード」と呼び、談話モードを特定するために音声データに付されるラベルを「談話モード情報」と呼ぶことにする。)、談話機能カテゴリから頷きに関する頭部動作がそれぞれどのような確率で得られるか、を与える確率モデルを予め準備するものとする。これらの確率モデルは、上記したのと同様の実験結果を統計的に処理することにより容易に得ることができる。各頭部動作については、句内のどの音節位置で動作を行なうかを示す情報が付されている。
【0062】
こうした確率モデルを使用する以下の実施の形態では、ロボットに与えられる発話データは、音声データと、音声からの句の切り出し情報と、句ごとに区切られた音素ラベルのシーケンスと、各句に割当てられた談話機能タグとを含むものとする。各音素ラベルには、その音素に対応する音声の、句内での発話時刻を特定する情報も付されている。発話データはさらに、話者と談話相手との関係(「近い」、「遠い」または「中間」)という情報と、各句に付随させるべき態度・感情などを示す談話モード情報とを含む。
【0063】
こうした確率モデルが、頷き動作だけでなく、首振り、首かしげなどについても得ることができることは、当該技術分野における技術者には容易に理解できるであろう。なおこの場合、頭部動作を開始させるタイミングについても実験結果から得る必要がある。例えば上記した頷き動作は、最後の音節で発生させているが、首振り動作については複数頷きと同様、発話全体にわたり続くことが分かっている。そうした情報についても予め実験により取得しておく必要がある。
【0064】
頭部動作について、所定の動作(頷き)を発生させるか否かが決まり、どのタイミングで頷きを発生させるかが決まれば、そのタイミングで、予め準備しておいた各動作の形状を頭部制御のための制御信号の形状に重畳すればよい。
【0065】
なお、上の実験では触れていないが、発話期間中には人間は顔をやや上方にあげる(上を向く。)ことも実験から分かった。その角度は頷き角度にして3度(上向きを正とする。)程度である。以下の実施の形態では、発話時のこの顔上げ動作についても取り入れている。
【0066】
[第1の実施の形態]
<構成>
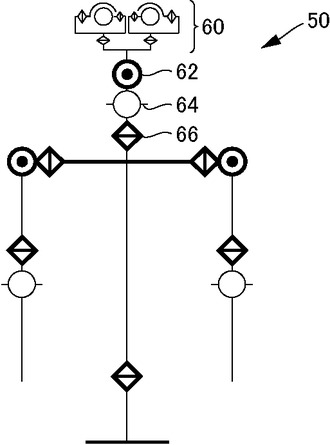
図4を参照して、制御対象となるロボット50の頭部60の駆動系は、頭部60をy軸周りに回転させるモータ62と、x軸周りに回転させるモータ64と、z軸周りに回転させるモータ66とを含む。頷き動作ではモータ64を、首振り動作ではモータ66を、首かしげではモータ62を、それぞれ動作させればよい。
【0067】
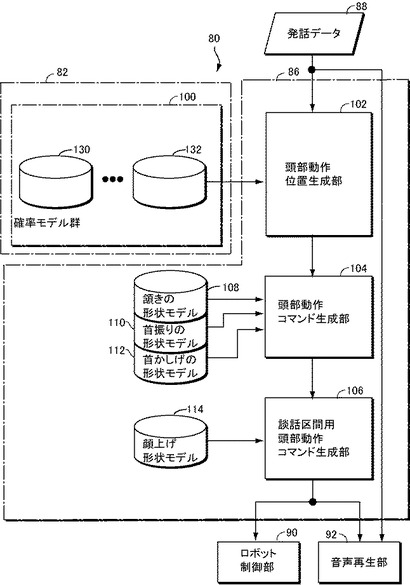
図5を参照して、本実施の形態に係るロボット80は、上記したものと同様の実験結果を統計的に処理することにより得られた確率モデルからなる確率モデル群100を記憶するための記憶装置82と、このロボット80が発話すべき発話データを記憶した発話データ記憶装置88と、発話データが与えられると、発話データの各句ごとに、付された談話機能タグと、記憶装置82に記憶された確率モデル群100を使用して、このロボットの頭部動作を制御する頭部動作コマンドを生成するための頭部動作生成装置86と、発話データ記憶装置88に記憶された発話データと、頭部動作生成装置86からの頭部動作コマンドとに基づき、頭部動作が音声と同期するように音声を再生するための音声再生部92と、頭部動作生成装置86からの頭部動作コマンドに応答して、図4に示すモータ62,64及び66を制御するためのロボット制御部90とを含む。図5において、ロボット80のうち、頭部動作に関連しない箇所は説明を明確にするために図示していない。
【0068】
確率モデル群100は、それぞれ話者/談話相手との関係/態度・感情の予め定められた組合せごとに、ある談話機能タグに対してどの頭部動作がどのような確率で得られるかを記述した確率モデル130,…,132を含む。例えば確率モデル130は話者A、談話相手との関係が「近い」、態度は「普通」という組合せで、談話機能タグに対しどのような頭部動作がどのような確率で得られるかを記述している。なお、本実施の形態では、例えば頷きの場合には、談話機能タグ=k、g、q及びbcのときには頻度が高く、他の場合には頻度が低かったことに鑑み、談話機能タグがk、g、q及びbcのいずれかのときにのみに頷き動作を発生させ、それ以外の談話機能タグについては頭部動作を発生させないようにする。したがって確率モデル群100に含まれる確率モデル130については、上記した4つの談話機能タグについての確率モデルしか含まれていない。
【0069】
頭部動作生成装置86は、発話データ記憶装置88から発話データを読出し、各句に付された談話機能タグに基づいて、句ごとに、xyz軸それぞれの周りの回転を生成するか否か、生成するならそのタイミングはどうなるかを定めて、xyz軸の3軸について、ロボットの頭部動作コマンドに動きを重畳すべきタイミングを示す情報を出力するための頭部動作位置生成部102と、3軸の頭部動作コマンドにそれぞれ重畳されるべき頷き動作の形状モデル、首振り動作の形状モデル、及び首かしげ動作の形状モデルをそれぞれ記憶するための記憶装置108,110及び112と、頭部動作位置生成部102から出力される3軸の頭部動作位置のタイミングを示す情報に基づき、必要であればそれぞれ記憶装置108,110,112に記憶された頷き、首振り、及び首かしげの形状モデルにより特定される形状が重畳された頭部動作コマンドを生成し出力するための頭部動作コマンド生成部104と、上記した実験結果に基づき、頭部動作コマンド生成部104から出力される3軸の頭部動作コマンドのうち、発話時に頷きに関連する頭部動作コマンド(ピッチ角制御信号)に重畳されるべき顔上げ形状モデルを予め記憶する記憶装置114と、頭部動作コマンド生成部104から出力される3軸の頭部動作コマンドを発話データとともに受けるように接続され、発話データのうち談話区間については記憶装置114に記憶された顔上げ形状モデルを重畳し、ロボット制御部90に与えるための談話区間用頭部動作コマンド生成部106とを含む。
【0070】
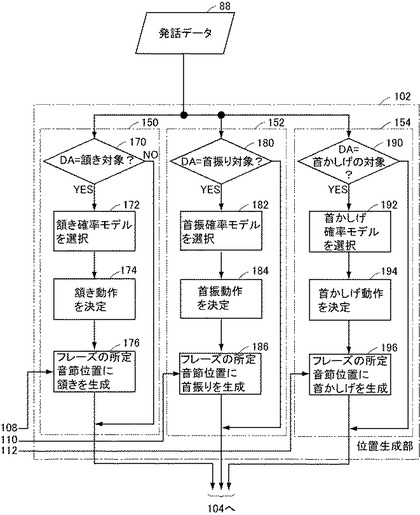
図6を参照して、頭部動作位置生成部102は、発話データ記憶装置88から発話データを受けて、確率モデル群100内で発話データにより定められる適切な確率モデルにより、頷きを生成するか否か、頷きを生成する場合にはそのタイミングはいつにするかを決定し、頷きタイミングを示す情報として出力するための頷き位置生成部150と、頷き位置生成部150と同様、発話データに基づいて、確率モデル群100内で発話データにより定められる適切な確率モデルにより首振り動作を行なうか否かを決定し、行なうならそのタイミングはいつにするかを決定して首振りタイミングを示す情報として出力するための首振り位置生成部152と、頷き位置生成部150及び首振り位置生成部152と同様、発話データに基づいて、確率モデル群100内で発話データにより定められる適切な確率モデルにより首かしげ動作を行なうか否かを決定し、行なうならそのタイミングはいつにするかを決定して首かしげタイミングを示す情報として出力するための首かしげ位置生成部154とを含む。頷き位置生成部150、首振り位置生成部152、及び首かしげ位置生成部154はいずれも、実質的にはコンピュータハードウェア及びそのコンピュータハードウェアで実行されるコンピュータプログラムにより実現される。
【0071】
頷き位置生成部150を実現するプログラムルーチンは、発話データ内の句に付された談話機能タグが頷きの対象(k、g、q及びbcのいずれか)か否かを判定し、判定結果により制御の流れを分岐させるステップ170と、確率モデル群100の中から、発話データに付された話者、話者と談話相手との関係、態度・感情を指定する情報、及び句に付された談話機能タグの値に応じて決まる確率モデルを選択するステップ172と、ステップ172において選択された確率モデルと乱数とにより、頭部の頷きに属する動作としてどのような動作を行なわせるかを決定するステップ174と、ステップ174で決定された動作の種類にしたがって、句のどの音節位置に頷きを生成するかを決定し、頷き位置を示す情報を出力して処理を終了するステップ176とを含む。ステップ170で談話機能タグが頷き対象ではないと判定された場合、頷きタイミングなしであることを示す情報を出力して処理を終了する。
【0072】
首振り位置生成部152を実現するプログラムは、頷き位置生成部150と略同様の処理をするステップ180,182及び184を含む。首振り位置生成部152において異なるのは、ステップ180で判定する談話機能タグが首振り判定のためのタグであることと、ステップ182で使用する確率モデルが、首振りの種類を決定するためのものであることとである。ステップ180で判定に使用する談話機能タグは、頷きについて既に述べたものと同様の実験により定める。確率モデルについても同様である。
【0073】
同様に、首かしげ位置生成部154を実現するプログラムは、頷き位置生成部150のステップ170,172及び174とそれぞれ略同様の処理をするステップ190,192及び194を含む。首かしげ位置生成部154において異なるのは、ステップ190で判定する談話機能タグが首かしげ判定のためのタグであることと、ステップ192で使用する確率モデルが、首かしげの種類を決定するためのものであることとである。ステップ190で判定に使用する談話機能タグも、頷きについて既に述べたものと同様の実験により定める。確率モデルについても同様である。
【0074】
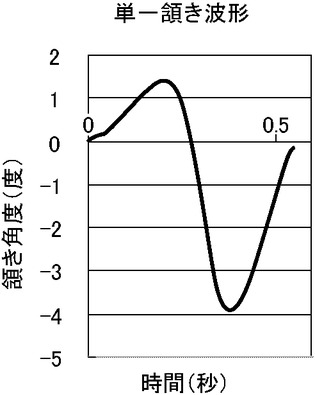
図7に、記憶装置108に記憶される単一の頷き動作の形状を示す。図7に示す形状は、人間が頷く際の顔の動きから典型的な動きとして生成したものである。図7に示すように、人間の自然な頷きでは、顔を下向きにする直前にごく短い間、顔を上に向ける時間があり、その後に大きく下に動かし、さらにそのあと正面を向く。このような動きをロボットにさせることにより、人間が見て自然な形でロボットが頷くようにロボットの動きを制御することができる。なお、この頷き動作の形状の場合、波形の先頭及び末尾を句の末尾の文末の開始位置及び終了位置と一致させるように適宜時間軸を伸縮させることが好ましい。ただし、そのような時間軸上の伸縮をしなければならないわけではない。このように、波形の先頭及び末尾を句のどの位置にそれぞれ一致させるかは、形状に付随する情報として予め記憶装置108に記憶させておき、ステップ176,186及び196の処理ではその情報にしたがって波形の開始位置及び終了位置を定める。
【0075】
図8は、頷き動作の形状の他の一例として、複数頷き(mnd)の典型的な形状を示す。この動作の形状も、図5の記憶装置108に記憶されており、図6のステップ172において複数頷きが選択されたときに頷き位置を決定するために使用される。既に述べたように、複数頷きの場合には、句の全体にわたって頭部動作が行なわれる。したがってこの場合には、波形の先頭が句の先頭と一致し、波形の末尾が句の末尾と一致するように頷きのタイミングを定める。
【0076】
記憶装置108には、これ以外にも、頷き動作の形状に属する形状を複数個記憶している。どのような形状を使用するかは、設計により定めればよい。ただしこの場合、確率モデルによって選択される形状の種類と、記憶装置108に記憶される形状の種類との間に矛盾がないようにしておく必要がある。
【0077】
同様に、記憶装置110には首振りのための形状モデルが記憶され、記憶装置112には首かしげのための形状モデルが記憶される。
【0078】
図9を参照して、記憶装置114に記憶される顔上げ形状モデルは、句の最初にゆるやかに立ち上がったあと、3度程度の頷き角度で発話の間持続し、句の最後の部分で緩やかに立ち下がる。実際に人間の発話を観察した結果、発話時には人間はこのような行動をとることが多く、談話相手から見たときもその方が自然に見えるという結果が得られた。そこで、本実施の形態では、ロボットの発話時には、このような顔上げ形状モデルを頭部動作コマンド生成部104から出力される頷きの頭部動作コマンドに重畳することとする。ロボットが発話している期間については発話データから得ることができる。
【0079】
<動作>
図5〜図9を参照して、ロボット80の頭部動作生成装置86は以下のように動作する。
【0080】
既に述べたような実験をし、その結果を統計的に処理することにより、図5に示す確率モデル群100は予め準備されているものとする。発話データとして、発話すべき音声データと、その句の切り出し情報と、句ごとの音素ラベルのシーケンスと、各句に割当てられた談話機能タグと、ロボットの音声として想定されている話者を特定する情報と、ロボットと談話相手との関係を示す情報と、話者と談話相手との関係(「近い」、「遠い」または「中間」)を示す情報と、各句に付随させるべき態度・感情などを示す談話モード情報とを含むものが頭部動作生成装置86に与えられる。各音素ラベルには、その音素に対応する音声の、句内での発話時刻を特定する情報も付されている。
【0081】
特に図6を参照して、例えば頷き位置生成部150を構成するコンピュータプログラムは、与えられた句に割当てられた談話機能タグが頷き対象であるか否かを判定する(ステップ170)。もしも談話機能タグが頷き対象でなければ頷きなしという情報を頭部動作コマンド生成部104に与える。もしも談話機能タグが頷き対象であるときには、確率モデル群100の中から、発話データにより指定された話者に関する情報と、その話者と談話相手との関係を示す情報と、態度・感情などを示す談話モード情報と、指定された談話機能タグとにより確率モデルを選択する(ステップ172)。こうして選択された確率モデルに基づき、公知の方法で発生した乱数を用いて、頷き関連の動作としてどのような動作をロボットに行なわせるかを選択する(ステップ174)。動作が決まれば、その動作に伴って句内のどの位置(音節に関連して特定される位置)からその動作を開始させるか、及びどの位置でその動作が終了するようにするかが決定される(ステップ176)。こうして得られたタイミング情報が頭部動作コマンド生成部104(図5参照)に与えられる。
【0082】
同様にして、首振り位置生成部152は首振りに関するタイミング情報を、首かしげ位置生成部154は首かしげに関するタイミング情報を生成して、それぞれ頭部動作コマンド生成部104に与える。
【0083】
頭部動作コマンド生成部104は、例えば頷きについていうと以下のようにして頭部動作コマンドを作成する。図10を参照して、説明のために、与えられた発話の音声が句210及び212を含むものとし、これらにそれぞれ談話機能フラグk及びbcが付されているものとする。説明及び図を簡単にするため、ここでは話者を特定する情報、話者と談話相手との関係を示す情報、態度・感情を示す談話モード情報などについては示していない。なお、句210は、最終音節222とそれ以前の音節シーケンス220とを含むものとする。
【0084】
乱数及び確率モデルを用いた頷き動作の決定処理(図6のステップ174)により、談話機能フラグkの句210については単一頷き(nd)が、談話機能フラグbcの句212については複数頷きmndが、それぞれ選択されたものとする。
【0085】
頭部動作コマンド生成部104は、ロボットのための頷き動作コマンドとして、最初に平坦な頷き動作コマンド240を生成する。各句に対して割当てられた頷き動作に対応する頷き動作の形状を、各頷き動作コマンドごとに句内で予め定められたタイミングでこの頷き動作コマンドに重畳していくことにより、最終的な頷き動作コマンド246が得られる。
【0086】
句210については、選択された頷き動作が単一の頷きであるため、最終音節222の開始位置以後に図7に示す形状を重畳する。一方、句212については、選択された頷き動作が複数頷きであるため、句212の全体にわたり、図8に示す複数頷きの形状を時間軸上で伸縮させて重畳する。以上の処理の結果、図10に示す頭部動作コマンド242が得られる。
【0087】
本実施の形態ではさらに、ロボット80の発話時には図9に示す顔上げ形状モデルを頭部動作コマンド242に重畳する。その結果、図10に示す頭部動作コマンド(発話区間用)246が得られる。この頭部動作コマンドを図5に示すロボット制御部90及び音声再生部92に与えることにより、ロボット80の頭部が、発話の内容、ロボットと談話相手との間に想定されている関係、ロボットが発話時に示すべき態度及び感情に応じた自然な動きで頷き、首振り、首かしげを行なう。
【0088】
以上のようにこの実施の形態によれば、予め実験により得られた結果を統計的に処理して、話者/話者と談話相手との関係/態度・感情に応じ、談話機能タグによってどのような頭部動作をどのような確率で行なうかを決定するための確率モデルを予め準備しておく。ロボットの発話時には、特に頭部動作の頻度が高い談話機能タグ(例えば頷き動作のときにはk、g、q、bcなど)には、ロボットに想定されている話者/話者と談話相手との関係/指定された態度・感情、及び談話機能タグに応じた確率モデルを選択し、どのような頭部動作を行なうかを乱数で決定し、決定された頭部動作の形状を、頭部動作ごとに予め設定されているタイミングで頭部動作コマンドに重畳する。これら以外の談話タグについてはこのような処理は行なわない。こうした処理を頷き、首振り、及び首かしげのそれぞれについて独立で行なって、得られた頭部動作コマンドをロボット制御部90に送ることで、ロボット制御部90が頭部の3軸周りの動きを制御する。この結果、ロボットに想定されている話者、談話相手との間に想定されている関係、並びに指定された態度及び感情と、各句に付された談話機能タグとに応じ、自然な形でロボットの頭部を動作させることができる。したがって、ロボットと談話相手とのコミュニケーションが円滑になり、かつ談話相手はロボットの感情(として想定されるもの)、態度、ロボットが談話相手に対してどのような関係にあるか(想定されているか)などに関する情報を自然に理解することができる。
【0089】
[第2の実施の形態]
上記第1の実施の形態では、特定の談話機能タグのときのみ、頭部動作コマンドに所定の形状を重畳している。しかし、想定される全ての談話機能タグについて、必要なら頭部動作コマンドを生成するようにしてもよい。第2の実施の形態はそのような構成をとっている。
【0090】
図11を参照して、この実施の形態に係るロボットの頭部動作位置生成部280は、図5及び図6に示す頭部動作位置生成部102に代えて用いることができる。この頭部動作位置生成部280も、コンピュータハードウェア上で実行されるコンピュータプログラムにより、コンピュータハードウェアとコンピュータプログラムとの協働により実現することができる。
【0091】
頭部動作位置生成部280は、発話データ記憶装置88から発話データを受けて、確率モデル群100内で発話データにより定められる適切な確率モデルにより、頷きを生成するか否か、頷きを生成する場合にはそのタイミングはいつにするかを決定し、頷きタイミングを示す情報として出力するための頷き位置生成部290と、頷き位置生成部290と同様、発話データに基づいて、確率モデル群100内で発話データにより定められる適切な確率モデルにより首振り動作を行なうか否かを決定し、行なうならそのタイミングはいつにするかを決定して首振りタイミングを示す情報として出力するための首振り位置生成部292と、頷き位置生成部290及び首振り位置生成部292と同様、発話データに基づいて、確率モデル群100内で発話データにより定められる適切な確率モデルにより首かしげ動作を行なうか否かを決定し、行なうならそのタイミングはいつにするかを決定して首かしげタイミングを示す情報として出力するための首かしげ位置生成部294とを含む。
【0092】
頷き位置生成部290、首振り位置生成部292及び首かしげ位置生成部294は互いに似た構成を有する。
【0093】
頷き位置生成部290を実現するプログラムルーチンは、発話データに付された、ロボットに想定されている話者/話者と談話相手との関係/態度及び感情等、を指定する情報と、発話データの各句に付された談話機能タグとに基づいて、図5に示す確率モデル群100内からこれら情報の値により定まる頷き動作決定のための確率モデルを選択するステップ310と、ステップ310において選択された確率モデルと乱数とにより、頷きに属する動作としてどのような動作をロボットに行なわせるかを決定するステップ174と、ステップ174で決定された動作の種類にしたがって、句のどの音節位置に頷きを生成するかを決定し、頷き位置を示す情報を出力して処理を終了するステップ176とを含む。
【0094】
首振り位置生成部292を実現するプログラムルーチンも同様に、発話データに付された、ロボットに想定されている話者/話者と談話相手との関係/態度及び感情等、を指定する情報と、発話データの各句に付された談話機能タグとに基づいて、図5に示す確率モデル群100内からこれら情報の値により定まる首振り動作決定のための確率モデルを選択するステップ320と、ステップ320において選択された確率モデルと乱数とにより、首振りに属する動作としてどのような動作をロボットに行なわせるかを決定するステップ184と、ステップ184で決定された動作の種類にしたがって、句のどの音節位置に首振りを生成するかを決定し、首振り位置を示す情報を出力して処理を終了するステップ186とを含む。
【0095】
首かしげ位置生成部294を実現するプログラムルーチンも同様に、発話データに付された、ロボットに想定されている話者/話者と談話相手との関係/態度及び感情等、を指定する情報と、発話データの各句に付された談話機能タグとに基づいて、図5に示す確率モデル群100内からこれら情報の値により定まる首かしげ動作決定のための確率モデルを選択するステップ330と、ステップ330において選択された確率モデルと乱数とにより、首振りに属する動作としてどのような動作をロボットに行なわせるかを決定するステップ194と、ステップ194で決定された動作の種類にしたがって、句のどの音節位置に首かしげを生成するかを決定し、首かしげ位置を示す情報を出力して処理を終了するステップ196とを含む。
【0096】
この実施の形態では、全ての談話機能タグについて、第1の実施の形態で述べたものと同様の頭部動作制御を行なうことができる。ロボットの頭部動作がより多彩なものとなり、人間の実際の頭部動作に近い動きを実現させることができる。
【0097】
なお、上記第1及び第2の実施の形態のいずれにおいても、頷きと、首振りと、首かしげとについての頭部動作コマンドを独立に生成しているが、これらについて例えば「首振りをしているときは頷き動作はさせない」、又は「複数頷きと複数首振りとは同時には行なわない」のような制約を設けてもよい。さらに、図11のステップ310,320,330を一つにまとめ、談話機能タグにより3つの確率モデルが常に一組となって選択されるようにしても、第2の実施の形態と同じことになる。頷き位置生成部290、首振り位置生成部292、及び首かしげ位置生成部294のいずれか1つ又は2つのみを乱数などにより選択して動作させるようにし、選択されなかった処理部については同時には動作させないようにすることもできる。
【0098】
上記実施の形態では、頷き、首振り、及び首かしげの3つを実現しているが、これらのうち任意の1つのみ、又は任意の2つの組合せのみを採用するようにしてもよい。
【0099】
また上記実施の形態では、頷きに関する頭部動作コマンドについて、発話時には顔上げ形状を重畳している。しかしこのような顔上げ形状の重畳が必須ではないこと、仮に顔上げ形状の重畳を行なうとしてもその角度が3度には限定されず、自然に見える範囲で任意に選択できること、顔上げ角度そのものを、ロボットの稼動時に変化させることも可能であること、そのための判断基準として既に述べたように、ロボットに想定されている話者、談話相手との関係、態度・感情などを用いることもできることはいうまでもない。
【0100】
上記実施の形態では、談話機能タグを句単位に付してある。談話ではこうした単位で頭部の動きが変化することが多いためである。しかし、談話機能タグを付す単位が句に限定されるわけではないことはいうまでもない。また、上記実施の形態では、発話データに音節シーケンスが付属しており、かつ各音節の開始時刻を示す情報も得られることが前提とされている。こうした構成により、頭部動作の開始タイミングなどを容易に決定することができる。しかし、音素の開始時刻などに関する情報を用いない構成もあり得る。例えば発話の最終音節に頭部動作を生じさせる場合、発話のパワーを句の末尾からさかのぼり、最初のピークを越えた(末尾の音節の終端部が見つかった。)後、MFCC(Mel Frequency Cepstrum Coefficient)の値の変化を調べ、ΔMFCCの値があるしきい値を上回った時点をその最後の音節の開始位置と判定することで上記した実施の形態と同様の処理を実現できる。句全体にわたり頭部動作を行なう場合には、句の最初と最後とが明確であるため、こうした問題は生じない。又は、各句のうち、頭部動作の開始タイミングに関係する音節の開始位置に関する情報のみ、予めバッチ処理で作成し発話データに付するようにしておいてもよい。
【0101】
さらに、上で頭部動作について開示したものと同様の考えが、頭部動作だけでなく手足の動き、上半身の動き、目の動きなどにも適用可能であることはいうまでもないであろう。
【0102】
今回開示された実施の形態は単に例示であって、本発明が上記した実施の形態のみに制限されるわけではない。本発明の範囲は、発明の詳細な説明の記載を参酌した上で、特許請求の範囲の各請求項によって示され、そこに記載された文言と均等の意味及び範囲内での全ての変更を含む。
【符号の説明】
【0103】
30 話者
32,34,36,38,40,42,44 マーカ
80 ロボット
82,108,110,112,114 記憶装置
86 頭部動作生成装置
88 発話データ記憶装置
90 ロボット制御部
92 音声再生部
100 確率モデル群
102 頭部動作位置生成部
104 頭部動作コマンド生成部
106 談話区間用頭部動作コマンド生成部
114 記憶装置
130,132 確率モデル
150,290 頷き位置生成部
152,292 首振り位置生成部
154,294 首かしげ位置生成部
【技術分野】
【0001】
この発明はロボットによる人間とのコミュニケーションの改善に関し、特に、ヒューマノイド型ロボットの頭部を、その発話内容にあわせて自然に動かすための技術に関する。
【背景技術】
【0002】
発話中、人間は自然に頭を動かす。これらの動きは時には、相手に対して明確な意味を伝えるよう意図的になされることがある。例えば頷くのは同意を表し、首を振るのは不同意を表す。しかし多くの場合、頭の動きは無意識にされる。そうした動きは、ときには話者が意図するもの以上の情報を相手に伝えることがある。したがって、ヒューマノイド型ロボットにおいて、話の内容に応じて頭を適切に動かすことができれば、相手とのコミュニケーションがより円滑になることが期待される。
【0003】
この種の技術として、特許文献1に挙げたものがある。特許文献1は、発話するロボットなどにおいて、音声信号に予め頷くタイミングを決める信号を付しておき、音声信号から頷くためのタイミング信号を検出すると、その信号にあわせてロボットが頷くよう、ロボットの首を制御する技術を開示している。
【先行技術文献】
【特許文献】
【0004】
【特許文献1】特開2009-069789号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
人間とロボットとの有効なコミュニケーションを図る上で、ロボットの発話にあわせてその頭を動かすことが重要であることは、上記特許文献1においても記載されているとおりである。しかし、どのような方法でロボットの頭を動かせば人間にとって自然に感じられ、かつロボットの発話の意味を理解することが容易になるかについてはまだ適当な方法が提案されていない。特許文献1に記載の技術では、頭部の動きを予めプログラムすることに関する記載しかなく、どのように頭部を動かせば自然な動きとして感じられるかについては開示されていない。
【0006】
それゆえに本発明の目的は、ロボットと人間とのコミュニケーションをより円滑にできるよう、ロボットの頭部の動きを制御する頭部動作制御情報生成装置を提供することである。
【0007】
本発明の他の目的は、ロボットの頭部の動きを発話の内容にふさわしく変化させ、自然に感じさせる頭部動作制御情報生成装置を提供することである。
【課題を解決するための手段】
【0008】
本発明のある局面に係る頭部動作制御情報生成装置は、ヒューマノイド型ロボットの頭部の動きを、当該ロボットが発生する音声に同期して制御する制御情報を生成する。音声は、予め所定の単位に分割された音声データにより規定される。所定の単位の各々には、当該単位に割当てられた音声データにより発声される音声による談話機能を示す談話機能タグを含む注釈が付されている。この頭部動作制御情報生成装置は、談話機能タグごとに、複数の頭部動作をどのような確率で実行するかを規定する確率モデルを記憶するための確率モデル記憶手段と、音声データの所定の単位の入力を受け、当該単位に付された注釈に基づいて決定される確率モデルを、確率モデル記憶手段に記憶された確率モデルの中から選択するための確率モデル選択手段と、確率モデル選択手段により選択された確率モデルにしたがった確率で、入力された所定の単位の音声データに対応する頭部動作コマンドを生成し、ヒューマノイドロボット型ロボットの制御部に出力するための頭部コマンド生成手段と、を含む。
【0009】
音声データの所定の単位に付された談話機能タグが同一であっても、頭部コマンドが確率モデルにより選択されるため、ヒューマノイドロボットの頭部の動きは場合により異なる。同じ状況で常に同じ動きをする場合と比較して、不自然に感じられる動きを少なくすることができる。確率モデルを適切に準備しておくことにより、談話機能タグに応じた適切で自然な形でロボットの頭部を制御することができる。その結果、ロボットと人間とのコミュニケーションをより円滑にできるよう、ロボットの頭部の動きを制御する頭部動作コマンド生成装置を提供すること、及びロボットの頭部の動きを発話の内容にふさわしく変化させ、自然に感じさせる頭部動作コマンド生成装置を提供することができる。
【0010】
好ましくは、音声データには、話者を特定する話者特定情報、話者と談話相手との関係を特定する関係特定情報、及び発話時の非言語的情報、の任意の組合せからなる、談話モードを指定する談話モード情報が付されている。確率モデル選択手段は、談話モード情報と談話機能タグとの組合せに応じて予め準備された複数個の確率モデルを記憶している。確率モデル選択手段は、音声データに付された談話モード情報と、入力された所定の単位とに応じて複数個の確率モデルの内の一つを選択するための手段を含む。
【0011】
人間同士の対話では、話者、話者と談話相手との関係、及び発話時の話者の態度・感情などの非言語的情報に関連する事情により異なることが実験により分かった。したがって、これらの組合せに応じた確率モデルを予め準備し、発話時の談話モードに応じてこれらに適合した確率モデルにしたがって頭部動作を選択することで、談話相手に単に音声だけでないより多くの情報を与えることができる。
【0012】
より好ましくは、頭部コマンド生成手段は、確率モデル選択手段により選択された確率モデルにしたがった確率で、入力された所定の単位の音声データに対応する頭部動作を発生させるか否かを決定するための頭部動作決定手段と、複数の頭部動作の各々に対し、当該頭部動作に対応する頭部の時間的動きを規定する形状情報を記憶するための形状情報記憶手段と、頭部動作決定手段により何らかの頭部動作を発生させることが決定されたことに応答して、当該頭部動作の種類により予め決まっているタイミングで、当該頭部動作に対応する形状情報を形状情報記憶手段から読出してロボットの頭部を制御するための制御コマンドを生成し制御部に出力するための形状読出手段とを含む。
【0013】
頭部動作を発生させるタイミングを決定するのは単純なルールでも実現できる。予め頭部動作ごとに、その頭部動作を実現するための時間的な動きを表す形状情報を記憶しておき、決定されたタイミングでその形状情報から制御コマンドを生成する、という簡単な処理で、談話相手とのコミュニケーションを円滑にすることができる。
【0014】
さらに好ましくは、ロボットの頭部の動きは、ロボットの頭部の3軸周りの回転のうち、ピッチ角に関連するものである。頭部コマンド生成手段はさらに、ロボットの発話時の頭部の時間的動きを規定する、予め準備された頭部動作の形状を記憶するための発話時頭部形状記憶手段と、形状読出手段と制御部との間に接続され、音声データによりロボットが発話する期間であることが示されていることに応答して、形状読出手段により出力される制御コマンドに、発話時頭部形状情報記憶手段から読出した頭部動作の形状を重畳して制御部に与えるための手段とを含む。
【0015】
実験から、特にピッチ角については、発話者が話しているときには特定の動きをすることが判明した。ただし、発話者によりこの動きは異なる可能性がある。そこで、このように予め準備された特定の頭部動作の形状を記憶しておく構成で、想定される発話者により、発話時に特徴的な頭部の動きを再現できる。
【0016】
ロボットの頭部の動きは、ロボットの頭部の3軸のうち任意の組合せの軸周りの回転に関するものであってもよい。この場合、確率モデル記憶手段、確率モデル選択手段、及び頭部コマンド生成手段は、いずれも任意の組合せを構成する軸ごとに独立に頭部制御コマンドを生成する。
【0017】
本発明によれば、上記した構成により、ロボットと人間とのコミュニケーションをより円滑にできるよう、ロボットの頭部の動きを制御する頭部動作コマンド生成装置を提供することが可能になる。さらに、ロボットの頭部の動きを発話の内容にふさわしく変化させ、自然に感じさせる頭部動作コマンド生成装置を提供することもできる。
【図面の簡単な説明】
【0018】
【図1】本発明の実施の形態を実現するために行なった人間の頭部のモーションキャプチャ時の設定を示す図である。
【図2】上記実験の結果得られた被験者の頭部の動き、各被験者と談話相手との関係、及び発話の内容の関係を示すグラフである。
【図3】上記実験の結果得られた被験者の頭部の動き、各被験者と談話相手との関係、及び発話の内容の関係を示すグラフである。
【図4】第1の実施の形態で制御の対象となるロボットの頭部の動きを実現するアクチュエータの配置を示す図である。
【図5】本発明の第1の実施の形態に係る頭部動作生成装置の機能的ブロック図である。
【図6】図5に示す頭部動作位置生成部を実現するプログラムをブロック図的なフローチャートで示した模式図である。
【図7】本発明の第1の実施の形態で用いた、ロボットの頭部の頷きを実現するための頷き角度(上向きを正とする。)の時間的変化を示すグラフである。
【図8】本発明の第1の実施の形態で用いた、連続した複数の頷き動作を実現するための頷き角度の時間的変化を示すグラフである。
【図9】本発明の第1の実施の形態で用いた、ロボットが発話中のロボットの頷き角度の時間的変化を示すグラフである。
【図10】本発明の第1の実施の形態における、発話から頭部動作コマンドを生成する際の頷き角度の時間的変化の生成過程を示すグラフである。
【図11】本発明の第2の実施の形態に係る頭部動作生成装置の頭部動作位置生成部を実現するプログラムをブロック図的なフローチャートで示した図である。
【発明を実施するための形態】
【0019】
以下の説明及び図面では、同一の部品には同一の参照番号を付してある。それらの名称及び機能も同一である。したがってそれらについての詳細な説明は繰返さない。
【0020】
[実験]
後述する本発明の実施の形態を実現するにあたり、人間の発話と頭部の動きとの関係、及び人間の頭部の動きを談話相手がどのように理解するかについての実験を行なった。この結果から、後述するように比較的単純な構成のモデルを得ることができ、それによって本発明の実施の形態に係るロボットの頭部動作生成装置を実現することができた。
【0021】
<実験の設定>
─データ─
実験には7人の被験者(男性4人、女性3人の発話者)を用いた。テーブル1にこれら被験者のリストと、これら被験者と対話した相手(談話相手)と、談話相手及び被験者の関係とを示す。
【0022】
【表1】
これら発話者と、談話相手とのいくつかの組合せごとに、自由な対話による談話(10分−15分間)を何セッションか収録した。収録した談話セッションの総数は19であった。各発話者についてのセッション数は、FMH×FKH(2)、FKN×FKH(2)、FMH×MHI(1)、FKN×MHI(1)、FMH×MSN(1)、FKN×MSN(1)、FMH×MIT(3)、FKN×MIT(3)、FMH×MSR(5)であった。
【0023】
対話者の双方について、同時に音声及び動きデータの収録を行なった。対話者の間の距離は、双方のモーションキャプチャが同時に可能な範囲で、できるだけ近くなるように設定した。結果として、両者の間の距離は1mとなった。収録には指向性マイクロホンを用い、これら指向性マイクロホンを各対話者に向けて設置した。
【0024】
話者の各々の頭部に7個の半球形のパッシブ反射マーカを装着し、赤外線を用いた市販のモーションキャプチャ装置で話者の頭部の動きデータを取得した。図1に、反射マーカの位置を示す。図1を参照して、話者30の頭部の周囲に5つのマーカ32,34,36,38及び40を装着した。話者30の鼻の頂部にはマーカ42を、あごにはマーカ44を、さらに装着した。頭部及び鼻のマーカ32−42により頭部の座標を得、あごのマーカ44の位置(鼻のマーカ42に対する相対位置)により、動きデータと発話データとの間の対応付けを行なうようにした。
【0025】
頭部の動きは、図1の右側に示す3軸(XYZ軸)により表した。「頷き」、「首振り」及び「首かしげ」とは、図1の座標軸において、それぞれX軸周り、Z軸周り、及びY軸周りに首を回転させることをいう。これらは航空工学においてピッチ、ヨー、及びロールと呼ばれているものとそれぞれ同様である。これらの軸周りの回転角度をそれぞれピッチ角、ヨー角及びロール角と呼ぶ。
【0026】
頭部の回転角度は、マーカの座標を用い、M.B. Stegmann, D.D. Gomez, “A brief introduction to statistical shape analysis,” http://www2.imm.dtu.dk/pubdb/views/edoc_download.php/403/pdf/imm403.pdf,2002に紹介された特異値分解にもとづいて算出した。すなわち、ユニタリ行列U、対角行列D、ユニタリ行列Vの組合せが、以下の式(1)により表される特異値分解により得られる。
【0027】
【数1】
ただし、reference及びtargetはそれぞれ、中立位置及び現在位置の3Dマーカ位置を、それらの重心を原点とする新たな座標系に平行移動させた座標を表す。中立位置は、被験者がまっすぐ前方を向いているときに得られたものである。回転を表す行列は次の式(2)により得られる。
【0028】
【数2】
この回転行列Rの要素から、次の式(3)−(5)によって回転角度が算出される。
ただし、sqrt、^、及びatan2はそれぞれ、Matlab(登録商標)の平方関数、べき乗関数、及びアークタンジェント関数である。
【0029】
こうして得た発話データに対し、日本語のネイティブ・スピーカが手作業で句単位に分割し、文字起こしをした。分割の結果、全部で16920句が得られた。
【0030】
─頭部動作のタグ─
日本語による対話の間で何らかの意味がある部分と考えられる分について、そのときの頭部の動きに以下のような頭部動作タグからなる注釈を手作業により付した。
【0031】
・no:動きなし
・nd:単一の頷き(顔下げ─顔上げの動き)
・mnd:句とともに複数回の頷きが生じた
・fd:顔下げ
・ud:顔上げ─顔下げ(1回)
・fu:顔上げ
・ti:句内で顔かしげ
・sh:句内で顔振り(左右の動き)
頷きが常に頭部の上下への動きにより表されるとは限らない。例えば顔を軽く傾けることでも頷きと見られることがある。このようにして注釈をつけた後、最も程度の大きかった動きについて考察した。
【0032】
3つの角度の時間変化、及びビデオ画像に基づいて、1人の被験者が頭部動きに関し、上記頭部動作タグセットによる注釈付けを音声情報に対して行なった。このラベルを他の被験者がチェックし、訂正した。いずれの被験者も本件発明者のアシスタントである。第1の被験者がつけた注釈のうち、5%が第2の被験者により修正された。
【0033】
テーブル2に、各頭部の動きタグを用いた注釈の分布を示す。頷き(ndとmndの合計)が最も頻繁に生ずる頭部の動きであることが分かる。「その他」欄は、被験者が分類に確信が持てなかった動きに関する句についてのものである。
【0034】
【表2】
─談話機能タグ─
データセット中の各句について、以下のような談話機能タグの組から選択した談話機能タグを注釈として付した。この際、肯定又は否定の反応、驚き・意外さの表れの感情表現、及び発話交替などについて考察した。
【0035】
・k(keep):発話者が発話者としての地位(話順)を保持している。強い句境界において、短いポーズ又は明瞭なピッチのリセットが生じる。
【0036】
・k2(keep):(句の間にポーズが存在しない)発話途中の弱い句境界
・k3(keep):考えているときなど、話者が句の末尾を延ばしながら、しかし話順は保持している(ポーズが続く場合も続かない場合もある。)。
【0037】
・f(filler:フィラー):話者が次の発話を考えているか準備している。例えば「うーん」、「えーと」、又は「あのー」など。
【0038】
・f2(conjunctions:接続詞):長く延ばされないフィラーと同様に考えることができる。例えば「だから」、「じゃあ」、「で」など。
【0039】
・g(give:話順の譲):話者が発話を終わり、対話の相手に発話者の地位を渡す。
【0040】
・q(質問):話者が対話の相手に対して質問をしたり、同意を求めたりする。
【0041】
・bc(相づち):話者が対話の相手に対して相づち(同意の反応)を見せる。例えば頷きながら「うん」と言う。
【0042】
・su(驚き/意外/感心)発話者が対話の相手に対して表情のある反応(驚き/意外/感心)を示す。例えば「へー」、「うそ!」、「ああ」など。
【0043】
・dn(denial,negation:否認、否定):首振り動作を伴う「いいえ」、「ううん」など。
【0044】
上に記載した分類は完全なものではないが、人間とロボットのコミュニケーションという観点から見るとこれらで十分であると考えられる。
【0045】
第1の被験者が談話機能タグによる注釈を句ごとに付した後、第2の被験者が注釈のチェック及び修正を行なった。これら被験者は頭部動作タグによる注釈を付したのと同じ被験者である。第2の被験者は全注釈のうち5.9%を訂正した。
【0046】
テーブル3は、各談話機能タグによる注釈の分布を示す。テーブル3において、「その他」は、被験者がどの談話機能タグを付したらよいか判断できなかった句を含む。この中にはさらに、挨拶のような、g(話順の譲渡)のサブカテゴリの間投詞、並びにbc(単純な相づち)及びsu(驚き/意外/感心)以外の間投詞が含まれる。
【0047】
【表3】
─頭部動作及び談話機能─
図2及び図3に、各談話機能の機能に対する頭部動作の分布を示す。これらグラフは、各発話者と談話相手との関係に応じたグループ(各図の最下部のx軸に示す。)に分けて示してある。y軸には各頭部動作タグの生起した確率を示してある。
【0048】
図2及び図3を参照して、頷き(nd)及び複数頷き(mnd)が相づち(bc)において高い頻度で生ずることが分かる。頷きはまた、強い句境界(k、g、q)でも頻繁に観測された。質問(q)では、通常は句の末尾が上昇するように発音されるが、頷きは、顔上げ─顔下げ動作、又は顔上げ動作より頻繁に観測された。ピッチ(F0形状)と頭部動作との相関が低くなるのはこれが原因であると思われる。
【0049】
頷きの観測頻度は、発話途中の弱い句境界(k2)と、話者が考えていたり、発話を完了していないことを示したりしている句境界(k3、f、f2)とにおいて、より低くなる。こうした談話機能カテゴリでは、顔の動きのない状態(no)が大部分である。
【0050】
複数頷き(mnd)のシーケンスをより詳細に観察すると、これらの動きは、発話者が談話相手の話に対して強い同意、理解、又は興味を表現しているときに、発話全体にわたって発生する傾向があることが分かった。
【0051】
驚き、意外、感心など(su)を表す句の場合、上記データ内での発生頻度はより低かった。頭部の動きなし(no)、顔上げ動作(fu)、及び首かしげ(ti)が大部分であった。
【0052】
─同一話者及び話者間による変化─
上記実験からはまた、頭部動作の頻度は話者により異なることが明らかとなった。
【0053】
例えば、4人の男性話者のうちの2人(MSN及びMHI)は他に比べて頭部動作がはるかに少なかった。この事実からは、話者の社会的地位が談話相手(研究助手)よりも高いことが影響しているのではないかと考えられる。他に考えられることとしては、話者と談話相手との年齢差が影響しているかもしれない。
【0054】
同一話者での変化を検討すると、談話相手との個人的関係によって頭部の動きの頻度が影響を受けるようである。図2及び図3において、話者と談話相手との関係は3段階に分けてある。すなわち、「近い」(家族、ボーイフレンド)、「遠い」(世代及び社会的地位の相違)、「中間」(友人、友人の友人、友人の親類)である。「中間」と「遠い」との区別のためには、社会的地位だけでなく、実際の個人の間の関係も考慮した。例えば話者と談話相手とが顔をあわせるのがはじめてか否か、という要因も考慮してある。
【0055】
上の結果からはさらに、話者が談話相手と近い関係にあるときには、頭部の動きの頻度がかなり低いことが分かった。例えば、話者FMHの場合、彼女の母又は彼女のボーイフレンドと話しているとき(FMH×「近い」)には、g、q、bc及びkでは頭部動きなし(no)が高い頻度で発生し、頷き(nd,mnd)は小さな頻度でしか生じなかった。同様に、相づち(bc)では、FMH×「近い」の組合せで大部分の動きが頷き(nd)であったのに対し、FMHが初めて見る相手との対話のときには複数頷き(mnd)の頻度が高くなる。この事実は、頭部の動き(特に頷き)については、談話相手の話に自分が興味を持っていることを示すなど、態度を表明するために使用する、ということによって説明されると思われる。家族に対してはあまり気を使わない振る舞いが多くなり、その結果頭部の動きが少なくなる。発話交替の発話(k)についていえば、FMH×「中間」の組合せのときには頷きが頻繁に発生するが、FMH×「遠い」の組合せのときには頻度は下がる。この事実は、FMHが、MSN及びMHI(「遠い」談話相手)と話しているときには自分を抑えるのに対し、友人の友人であり年齢も近いMIT(「中間の」談話相手)と話しているときには、より自信を持って話す、ということで説明できる。
【0056】
話者FKNについては、FKH,MHI及びMSNと話しているときには、bc(相づち)では、単一頷き(nd)と比較して複数頷き(mnd)の頻度が高かった。これらの談話相手が話者FKNより年長でありかつこれらの相手にあうのが初めてであったせいだろうと思われる。それに対して友人MITと話しているときには単一の頷きが大部分であった。k及びgでは、FKH,MHI及びMSNと話しているときには特に支配的な動きは見られなかった。この事実はFMHの場合と同様であり、FKNが初めて会った相手(FKH,MHI及びMSN)に対してはFKNは自分を主張せず、MHIと話すときにはより自信を持っていた、ということにより説明できる。
【0057】
話者FKHの場合には、娘(FMH)と話しているときには、娘の友人(FKN)と話しているときより頭部動きなし(no)が高い頻度だった。また、FKNと話しているときには複数頷き(mnd)がより高い頻度で現れたことにも注目できる。
【0058】
<ルールベースの頷き発生>
以上の結果から、談話中に最もよく生ずる頭部の動きは頷きであることが分かるが、それ以外の頭部の動きの頻度にも、談話相手、及び談話機能により一定の傾向があることが分かる。したがって、以下の実施の形態では、ルールベースの頭部動作生成モデルとそれを用いてロボットの頭部動作コマンドを生成する装置を提案する。なお、以下の説明では主として頭部動作、特に頷きについて説明するが、首振り及び首かしげなどについても同様の考え方で頭部動作コマンドを生成することができる。
【0059】
最初に、ロボットに与えられる発話データからロボットの頷きのタイミングのみを生成する非常に簡単な確率モデルを考える。このモデルでは、頷きは強い句境界を持つ発話(k、g、q)及び相づち(bc)の最終音節の中央で生成される。
【0060】
こうしたモデルは、図2及び図3に示すものと同様の実験結果を統計的に処理することにより、確率モデルとして得られる。上の実験では、頭部の動作に対する要因として考えられるものと実際の頭部の動きとの関係を明確にするために、要因として考えられるものを絞っているが、同様の考え方により例えば各句(又は発話全体)を発話するときに付随させるべき態度・感情などの非言語的情報(音声言語以外によって伝達される情報)に関連すると思われる情報についても、予め談話記録の句ごとにラベル付けをしておくことで同様の統計的情報を得ることができる。
【0061】
本実施の形態では、話者/談話相手との関係/態度・感情の組合せごとに(これらの組合せをそれぞれ簡略のためにここでは、これらの任意の組合せを単に「談話モード」と呼び、談話モードを特定するために音声データに付されるラベルを「談話モード情報」と呼ぶことにする。)、談話機能カテゴリから頷きに関する頭部動作がそれぞれどのような確率で得られるか、を与える確率モデルを予め準備するものとする。これらの確率モデルは、上記したのと同様の実験結果を統計的に処理することにより容易に得ることができる。各頭部動作については、句内のどの音節位置で動作を行なうかを示す情報が付されている。
【0062】
こうした確率モデルを使用する以下の実施の形態では、ロボットに与えられる発話データは、音声データと、音声からの句の切り出し情報と、句ごとに区切られた音素ラベルのシーケンスと、各句に割当てられた談話機能タグとを含むものとする。各音素ラベルには、その音素に対応する音声の、句内での発話時刻を特定する情報も付されている。発話データはさらに、話者と談話相手との関係(「近い」、「遠い」または「中間」)という情報と、各句に付随させるべき態度・感情などを示す談話モード情報とを含む。
【0063】
こうした確率モデルが、頷き動作だけでなく、首振り、首かしげなどについても得ることができることは、当該技術分野における技術者には容易に理解できるであろう。なおこの場合、頭部動作を開始させるタイミングについても実験結果から得る必要がある。例えば上記した頷き動作は、最後の音節で発生させているが、首振り動作については複数頷きと同様、発話全体にわたり続くことが分かっている。そうした情報についても予め実験により取得しておく必要がある。
【0064】
頭部動作について、所定の動作(頷き)を発生させるか否かが決まり、どのタイミングで頷きを発生させるかが決まれば、そのタイミングで、予め準備しておいた各動作の形状を頭部制御のための制御信号の形状に重畳すればよい。
【0065】
なお、上の実験では触れていないが、発話期間中には人間は顔をやや上方にあげる(上を向く。)ことも実験から分かった。その角度は頷き角度にして3度(上向きを正とする。)程度である。以下の実施の形態では、発話時のこの顔上げ動作についても取り入れている。
【0066】
[第1の実施の形態]
<構成>
図4を参照して、制御対象となるロボット50の頭部60の駆動系は、頭部60をy軸周りに回転させるモータ62と、x軸周りに回転させるモータ64と、z軸周りに回転させるモータ66とを含む。頷き動作ではモータ64を、首振り動作ではモータ66を、首かしげではモータ62を、それぞれ動作させればよい。
【0067】
図5を参照して、本実施の形態に係るロボット80は、上記したものと同様の実験結果を統計的に処理することにより得られた確率モデルからなる確率モデル群100を記憶するための記憶装置82と、このロボット80が発話すべき発話データを記憶した発話データ記憶装置88と、発話データが与えられると、発話データの各句ごとに、付された談話機能タグと、記憶装置82に記憶された確率モデル群100を使用して、このロボットの頭部動作を制御する頭部動作コマンドを生成するための頭部動作生成装置86と、発話データ記憶装置88に記憶された発話データと、頭部動作生成装置86からの頭部動作コマンドとに基づき、頭部動作が音声と同期するように音声を再生するための音声再生部92と、頭部動作生成装置86からの頭部動作コマンドに応答して、図4に示すモータ62,64及び66を制御するためのロボット制御部90とを含む。図5において、ロボット80のうち、頭部動作に関連しない箇所は説明を明確にするために図示していない。
【0068】
確率モデル群100は、それぞれ話者/談話相手との関係/態度・感情の予め定められた組合せごとに、ある談話機能タグに対してどの頭部動作がどのような確率で得られるかを記述した確率モデル130,…,132を含む。例えば確率モデル130は話者A、談話相手との関係が「近い」、態度は「普通」という組合せで、談話機能タグに対しどのような頭部動作がどのような確率で得られるかを記述している。なお、本実施の形態では、例えば頷きの場合には、談話機能タグ=k、g、q及びbcのときには頻度が高く、他の場合には頻度が低かったことに鑑み、談話機能タグがk、g、q及びbcのいずれかのときにのみに頷き動作を発生させ、それ以外の談話機能タグについては頭部動作を発生させないようにする。したがって確率モデル群100に含まれる確率モデル130については、上記した4つの談話機能タグについての確率モデルしか含まれていない。
【0069】
頭部動作生成装置86は、発話データ記憶装置88から発話データを読出し、各句に付された談話機能タグに基づいて、句ごとに、xyz軸それぞれの周りの回転を生成するか否か、生成するならそのタイミングはどうなるかを定めて、xyz軸の3軸について、ロボットの頭部動作コマンドに動きを重畳すべきタイミングを示す情報を出力するための頭部動作位置生成部102と、3軸の頭部動作コマンドにそれぞれ重畳されるべき頷き動作の形状モデル、首振り動作の形状モデル、及び首かしげ動作の形状モデルをそれぞれ記憶するための記憶装置108,110及び112と、頭部動作位置生成部102から出力される3軸の頭部動作位置のタイミングを示す情報に基づき、必要であればそれぞれ記憶装置108,110,112に記憶された頷き、首振り、及び首かしげの形状モデルにより特定される形状が重畳された頭部動作コマンドを生成し出力するための頭部動作コマンド生成部104と、上記した実験結果に基づき、頭部動作コマンド生成部104から出力される3軸の頭部動作コマンドのうち、発話時に頷きに関連する頭部動作コマンド(ピッチ角制御信号)に重畳されるべき顔上げ形状モデルを予め記憶する記憶装置114と、頭部動作コマンド生成部104から出力される3軸の頭部動作コマンドを発話データとともに受けるように接続され、発話データのうち談話区間については記憶装置114に記憶された顔上げ形状モデルを重畳し、ロボット制御部90に与えるための談話区間用頭部動作コマンド生成部106とを含む。
【0070】
図6を参照して、頭部動作位置生成部102は、発話データ記憶装置88から発話データを受けて、確率モデル群100内で発話データにより定められる適切な確率モデルにより、頷きを生成するか否か、頷きを生成する場合にはそのタイミングはいつにするかを決定し、頷きタイミングを示す情報として出力するための頷き位置生成部150と、頷き位置生成部150と同様、発話データに基づいて、確率モデル群100内で発話データにより定められる適切な確率モデルにより首振り動作を行なうか否かを決定し、行なうならそのタイミングはいつにするかを決定して首振りタイミングを示す情報として出力するための首振り位置生成部152と、頷き位置生成部150及び首振り位置生成部152と同様、発話データに基づいて、確率モデル群100内で発話データにより定められる適切な確率モデルにより首かしげ動作を行なうか否かを決定し、行なうならそのタイミングはいつにするかを決定して首かしげタイミングを示す情報として出力するための首かしげ位置生成部154とを含む。頷き位置生成部150、首振り位置生成部152、及び首かしげ位置生成部154はいずれも、実質的にはコンピュータハードウェア及びそのコンピュータハードウェアで実行されるコンピュータプログラムにより実現される。
【0071】
頷き位置生成部150を実現するプログラムルーチンは、発話データ内の句に付された談話機能タグが頷きの対象(k、g、q及びbcのいずれか)か否かを判定し、判定結果により制御の流れを分岐させるステップ170と、確率モデル群100の中から、発話データに付された話者、話者と談話相手との関係、態度・感情を指定する情報、及び句に付された談話機能タグの値に応じて決まる確率モデルを選択するステップ172と、ステップ172において選択された確率モデルと乱数とにより、頭部の頷きに属する動作としてどのような動作を行なわせるかを決定するステップ174と、ステップ174で決定された動作の種類にしたがって、句のどの音節位置に頷きを生成するかを決定し、頷き位置を示す情報を出力して処理を終了するステップ176とを含む。ステップ170で談話機能タグが頷き対象ではないと判定された場合、頷きタイミングなしであることを示す情報を出力して処理を終了する。
【0072】
首振り位置生成部152を実現するプログラムは、頷き位置生成部150と略同様の処理をするステップ180,182及び184を含む。首振り位置生成部152において異なるのは、ステップ180で判定する談話機能タグが首振り判定のためのタグであることと、ステップ182で使用する確率モデルが、首振りの種類を決定するためのものであることとである。ステップ180で判定に使用する談話機能タグは、頷きについて既に述べたものと同様の実験により定める。確率モデルについても同様である。
【0073】
同様に、首かしげ位置生成部154を実現するプログラムは、頷き位置生成部150のステップ170,172及び174とそれぞれ略同様の処理をするステップ190,192及び194を含む。首かしげ位置生成部154において異なるのは、ステップ190で判定する談話機能タグが首かしげ判定のためのタグであることと、ステップ192で使用する確率モデルが、首かしげの種類を決定するためのものであることとである。ステップ190で判定に使用する談話機能タグも、頷きについて既に述べたものと同様の実験により定める。確率モデルについても同様である。
【0074】
図7に、記憶装置108に記憶される単一の頷き動作の形状を示す。図7に示す形状は、人間が頷く際の顔の動きから典型的な動きとして生成したものである。図7に示すように、人間の自然な頷きでは、顔を下向きにする直前にごく短い間、顔を上に向ける時間があり、その後に大きく下に動かし、さらにそのあと正面を向く。このような動きをロボットにさせることにより、人間が見て自然な形でロボットが頷くようにロボットの動きを制御することができる。なお、この頷き動作の形状の場合、波形の先頭及び末尾を句の末尾の文末の開始位置及び終了位置と一致させるように適宜時間軸を伸縮させることが好ましい。ただし、そのような時間軸上の伸縮をしなければならないわけではない。このように、波形の先頭及び末尾を句のどの位置にそれぞれ一致させるかは、形状に付随する情報として予め記憶装置108に記憶させておき、ステップ176,186及び196の処理ではその情報にしたがって波形の開始位置及び終了位置を定める。
【0075】
図8は、頷き動作の形状の他の一例として、複数頷き(mnd)の典型的な形状を示す。この動作の形状も、図5の記憶装置108に記憶されており、図6のステップ172において複数頷きが選択されたときに頷き位置を決定するために使用される。既に述べたように、複数頷きの場合には、句の全体にわたって頭部動作が行なわれる。したがってこの場合には、波形の先頭が句の先頭と一致し、波形の末尾が句の末尾と一致するように頷きのタイミングを定める。
【0076】
記憶装置108には、これ以外にも、頷き動作の形状に属する形状を複数個記憶している。どのような形状を使用するかは、設計により定めればよい。ただしこの場合、確率モデルによって選択される形状の種類と、記憶装置108に記憶される形状の種類との間に矛盾がないようにしておく必要がある。
【0077】
同様に、記憶装置110には首振りのための形状モデルが記憶され、記憶装置112には首かしげのための形状モデルが記憶される。
【0078】
図9を参照して、記憶装置114に記憶される顔上げ形状モデルは、句の最初にゆるやかに立ち上がったあと、3度程度の頷き角度で発話の間持続し、句の最後の部分で緩やかに立ち下がる。実際に人間の発話を観察した結果、発話時には人間はこのような行動をとることが多く、談話相手から見たときもその方が自然に見えるという結果が得られた。そこで、本実施の形態では、ロボットの発話時には、このような顔上げ形状モデルを頭部動作コマンド生成部104から出力される頷きの頭部動作コマンドに重畳することとする。ロボットが発話している期間については発話データから得ることができる。
【0079】
<動作>
図5〜図9を参照して、ロボット80の頭部動作生成装置86は以下のように動作する。
【0080】
既に述べたような実験をし、その結果を統計的に処理することにより、図5に示す確率モデル群100は予め準備されているものとする。発話データとして、発話すべき音声データと、その句の切り出し情報と、句ごとの音素ラベルのシーケンスと、各句に割当てられた談話機能タグと、ロボットの音声として想定されている話者を特定する情報と、ロボットと談話相手との関係を示す情報と、話者と談話相手との関係(「近い」、「遠い」または「中間」)を示す情報と、各句に付随させるべき態度・感情などを示す談話モード情報とを含むものが頭部動作生成装置86に与えられる。各音素ラベルには、その音素に対応する音声の、句内での発話時刻を特定する情報も付されている。
【0081】
特に図6を参照して、例えば頷き位置生成部150を構成するコンピュータプログラムは、与えられた句に割当てられた談話機能タグが頷き対象であるか否かを判定する(ステップ170)。もしも談話機能タグが頷き対象でなければ頷きなしという情報を頭部動作コマンド生成部104に与える。もしも談話機能タグが頷き対象であるときには、確率モデル群100の中から、発話データにより指定された話者に関する情報と、その話者と談話相手との関係を示す情報と、態度・感情などを示す談話モード情報と、指定された談話機能タグとにより確率モデルを選択する(ステップ172)。こうして選択された確率モデルに基づき、公知の方法で発生した乱数を用いて、頷き関連の動作としてどのような動作をロボットに行なわせるかを選択する(ステップ174)。動作が決まれば、その動作に伴って句内のどの位置(音節に関連して特定される位置)からその動作を開始させるか、及びどの位置でその動作が終了するようにするかが決定される(ステップ176)。こうして得られたタイミング情報が頭部動作コマンド生成部104(図5参照)に与えられる。
【0082】
同様にして、首振り位置生成部152は首振りに関するタイミング情報を、首かしげ位置生成部154は首かしげに関するタイミング情報を生成して、それぞれ頭部動作コマンド生成部104に与える。
【0083】
頭部動作コマンド生成部104は、例えば頷きについていうと以下のようにして頭部動作コマンドを作成する。図10を参照して、説明のために、与えられた発話の音声が句210及び212を含むものとし、これらにそれぞれ談話機能フラグk及びbcが付されているものとする。説明及び図を簡単にするため、ここでは話者を特定する情報、話者と談話相手との関係を示す情報、態度・感情を示す談話モード情報などについては示していない。なお、句210は、最終音節222とそれ以前の音節シーケンス220とを含むものとする。
【0084】
乱数及び確率モデルを用いた頷き動作の決定処理(図6のステップ174)により、談話機能フラグkの句210については単一頷き(nd)が、談話機能フラグbcの句212については複数頷きmndが、それぞれ選択されたものとする。
【0085】
頭部動作コマンド生成部104は、ロボットのための頷き動作コマンドとして、最初に平坦な頷き動作コマンド240を生成する。各句に対して割当てられた頷き動作に対応する頷き動作の形状を、各頷き動作コマンドごとに句内で予め定められたタイミングでこの頷き動作コマンドに重畳していくことにより、最終的な頷き動作コマンド246が得られる。
【0086】
句210については、選択された頷き動作が単一の頷きであるため、最終音節222の開始位置以後に図7に示す形状を重畳する。一方、句212については、選択された頷き動作が複数頷きであるため、句212の全体にわたり、図8に示す複数頷きの形状を時間軸上で伸縮させて重畳する。以上の処理の結果、図10に示す頭部動作コマンド242が得られる。
【0087】
本実施の形態ではさらに、ロボット80の発話時には図9に示す顔上げ形状モデルを頭部動作コマンド242に重畳する。その結果、図10に示す頭部動作コマンド(発話区間用)246が得られる。この頭部動作コマンドを図5に示すロボット制御部90及び音声再生部92に与えることにより、ロボット80の頭部が、発話の内容、ロボットと談話相手との間に想定されている関係、ロボットが発話時に示すべき態度及び感情に応じた自然な動きで頷き、首振り、首かしげを行なう。
【0088】
以上のようにこの実施の形態によれば、予め実験により得られた結果を統計的に処理して、話者/話者と談話相手との関係/態度・感情に応じ、談話機能タグによってどのような頭部動作をどのような確率で行なうかを決定するための確率モデルを予め準備しておく。ロボットの発話時には、特に頭部動作の頻度が高い談話機能タグ(例えば頷き動作のときにはk、g、q、bcなど)には、ロボットに想定されている話者/話者と談話相手との関係/指定された態度・感情、及び談話機能タグに応じた確率モデルを選択し、どのような頭部動作を行なうかを乱数で決定し、決定された頭部動作の形状を、頭部動作ごとに予め設定されているタイミングで頭部動作コマンドに重畳する。これら以外の談話タグについてはこのような処理は行なわない。こうした処理を頷き、首振り、及び首かしげのそれぞれについて独立で行なって、得られた頭部動作コマンドをロボット制御部90に送ることで、ロボット制御部90が頭部の3軸周りの動きを制御する。この結果、ロボットに想定されている話者、談話相手との間に想定されている関係、並びに指定された態度及び感情と、各句に付された談話機能タグとに応じ、自然な形でロボットの頭部を動作させることができる。したがって、ロボットと談話相手とのコミュニケーションが円滑になり、かつ談話相手はロボットの感情(として想定されるもの)、態度、ロボットが談話相手に対してどのような関係にあるか(想定されているか)などに関する情報を自然に理解することができる。
【0089】
[第2の実施の形態]
上記第1の実施の形態では、特定の談話機能タグのときのみ、頭部動作コマンドに所定の形状を重畳している。しかし、想定される全ての談話機能タグについて、必要なら頭部動作コマンドを生成するようにしてもよい。第2の実施の形態はそのような構成をとっている。
【0090】
図11を参照して、この実施の形態に係るロボットの頭部動作位置生成部280は、図5及び図6に示す頭部動作位置生成部102に代えて用いることができる。この頭部動作位置生成部280も、コンピュータハードウェア上で実行されるコンピュータプログラムにより、コンピュータハードウェアとコンピュータプログラムとの協働により実現することができる。
【0091】
頭部動作位置生成部280は、発話データ記憶装置88から発話データを受けて、確率モデル群100内で発話データにより定められる適切な確率モデルにより、頷きを生成するか否か、頷きを生成する場合にはそのタイミングはいつにするかを決定し、頷きタイミングを示す情報として出力するための頷き位置生成部290と、頷き位置生成部290と同様、発話データに基づいて、確率モデル群100内で発話データにより定められる適切な確率モデルにより首振り動作を行なうか否かを決定し、行なうならそのタイミングはいつにするかを決定して首振りタイミングを示す情報として出力するための首振り位置生成部292と、頷き位置生成部290及び首振り位置生成部292と同様、発話データに基づいて、確率モデル群100内で発話データにより定められる適切な確率モデルにより首かしげ動作を行なうか否かを決定し、行なうならそのタイミングはいつにするかを決定して首かしげタイミングを示す情報として出力するための首かしげ位置生成部294とを含む。
【0092】
頷き位置生成部290、首振り位置生成部292及び首かしげ位置生成部294は互いに似た構成を有する。
【0093】
頷き位置生成部290を実現するプログラムルーチンは、発話データに付された、ロボットに想定されている話者/話者と談話相手との関係/態度及び感情等、を指定する情報と、発話データの各句に付された談話機能タグとに基づいて、図5に示す確率モデル群100内からこれら情報の値により定まる頷き動作決定のための確率モデルを選択するステップ310と、ステップ310において選択された確率モデルと乱数とにより、頷きに属する動作としてどのような動作をロボットに行なわせるかを決定するステップ174と、ステップ174で決定された動作の種類にしたがって、句のどの音節位置に頷きを生成するかを決定し、頷き位置を示す情報を出力して処理を終了するステップ176とを含む。
【0094】
首振り位置生成部292を実現するプログラムルーチンも同様に、発話データに付された、ロボットに想定されている話者/話者と談話相手との関係/態度及び感情等、を指定する情報と、発話データの各句に付された談話機能タグとに基づいて、図5に示す確率モデル群100内からこれら情報の値により定まる首振り動作決定のための確率モデルを選択するステップ320と、ステップ320において選択された確率モデルと乱数とにより、首振りに属する動作としてどのような動作をロボットに行なわせるかを決定するステップ184と、ステップ184で決定された動作の種類にしたがって、句のどの音節位置に首振りを生成するかを決定し、首振り位置を示す情報を出力して処理を終了するステップ186とを含む。
【0095】
首かしげ位置生成部294を実現するプログラムルーチンも同様に、発話データに付された、ロボットに想定されている話者/話者と談話相手との関係/態度及び感情等、を指定する情報と、発話データの各句に付された談話機能タグとに基づいて、図5に示す確率モデル群100内からこれら情報の値により定まる首かしげ動作決定のための確率モデルを選択するステップ330と、ステップ330において選択された確率モデルと乱数とにより、首振りに属する動作としてどのような動作をロボットに行なわせるかを決定するステップ194と、ステップ194で決定された動作の種類にしたがって、句のどの音節位置に首かしげを生成するかを決定し、首かしげ位置を示す情報を出力して処理を終了するステップ196とを含む。
【0096】
この実施の形態では、全ての談話機能タグについて、第1の実施の形態で述べたものと同様の頭部動作制御を行なうことができる。ロボットの頭部動作がより多彩なものとなり、人間の実際の頭部動作に近い動きを実現させることができる。
【0097】
なお、上記第1及び第2の実施の形態のいずれにおいても、頷きと、首振りと、首かしげとについての頭部動作コマンドを独立に生成しているが、これらについて例えば「首振りをしているときは頷き動作はさせない」、又は「複数頷きと複数首振りとは同時には行なわない」のような制約を設けてもよい。さらに、図11のステップ310,320,330を一つにまとめ、談話機能タグにより3つの確率モデルが常に一組となって選択されるようにしても、第2の実施の形態と同じことになる。頷き位置生成部290、首振り位置生成部292、及び首かしげ位置生成部294のいずれか1つ又は2つのみを乱数などにより選択して動作させるようにし、選択されなかった処理部については同時には動作させないようにすることもできる。
【0098】
上記実施の形態では、頷き、首振り、及び首かしげの3つを実現しているが、これらのうち任意の1つのみ、又は任意の2つの組合せのみを採用するようにしてもよい。
【0099】
また上記実施の形態では、頷きに関する頭部動作コマンドについて、発話時には顔上げ形状を重畳している。しかしこのような顔上げ形状の重畳が必須ではないこと、仮に顔上げ形状の重畳を行なうとしてもその角度が3度には限定されず、自然に見える範囲で任意に選択できること、顔上げ角度そのものを、ロボットの稼動時に変化させることも可能であること、そのための判断基準として既に述べたように、ロボットに想定されている話者、談話相手との関係、態度・感情などを用いることもできることはいうまでもない。
【0100】
上記実施の形態では、談話機能タグを句単位に付してある。談話ではこうした単位で頭部の動きが変化することが多いためである。しかし、談話機能タグを付す単位が句に限定されるわけではないことはいうまでもない。また、上記実施の形態では、発話データに音節シーケンスが付属しており、かつ各音節の開始時刻を示す情報も得られることが前提とされている。こうした構成により、頭部動作の開始タイミングなどを容易に決定することができる。しかし、音素の開始時刻などに関する情報を用いない構成もあり得る。例えば発話の最終音節に頭部動作を生じさせる場合、発話のパワーを句の末尾からさかのぼり、最初のピークを越えた(末尾の音節の終端部が見つかった。)後、MFCC(Mel Frequency Cepstrum Coefficient)の値の変化を調べ、ΔMFCCの値があるしきい値を上回った時点をその最後の音節の開始位置と判定することで上記した実施の形態と同様の処理を実現できる。句全体にわたり頭部動作を行なう場合には、句の最初と最後とが明確であるため、こうした問題は生じない。又は、各句のうち、頭部動作の開始タイミングに関係する音節の開始位置に関する情報のみ、予めバッチ処理で作成し発話データに付するようにしておいてもよい。
【0101】
さらに、上で頭部動作について開示したものと同様の考えが、頭部動作だけでなく手足の動き、上半身の動き、目の動きなどにも適用可能であることはいうまでもないであろう。
【0102】
今回開示された実施の形態は単に例示であって、本発明が上記した実施の形態のみに制限されるわけではない。本発明の範囲は、発明の詳細な説明の記載を参酌した上で、特許請求の範囲の各請求項によって示され、そこに記載された文言と均等の意味及び範囲内での全ての変更を含む。
【符号の説明】
【0103】
30 話者
32,34,36,38,40,42,44 マーカ
80 ロボット
82,108,110,112,114 記憶装置
86 頭部動作生成装置
88 発話データ記憶装置
90 ロボット制御部
92 音声再生部
100 確率モデル群
102 頭部動作位置生成部
104 頭部動作コマンド生成部
106 談話区間用頭部動作コマンド生成部
114 記憶装置
130,132 確率モデル
150,290 頷き位置生成部
152,292 首振り位置生成部
154,294 首かしげ位置生成部
【特許請求の範囲】
【請求項1】
ヒューマノイド型ロボットの頭部の動きを、当該ロボットが発生する音声に同期して制御する制御情報を生成するための頭部動作制御情報生成装置であって、
前記音声は予め所定の単位に分割された音声データにより規定され、前記所定の単位の各々には、当該単位に割当てられた音声データにより発声される音声による談話機能を示す談話機能タグを含む注釈が付されており、
談話機能タグごとに、複数の頭部動作をどのような確率で実行するかを規定する確率モデルを記憶するための確率モデル記憶手段と、
前記音声データの前記所定の単位の入力を受け、当該単位に付された注釈に基づいて決定される確率モデルを、前記確率モデル記憶手段に記憶された確率モデルの中から選択するための確率モデル選択手段と、
前記確率モデル選択手段により選択された確率モデルにしたがった確率で、前記入力された所定の単位の音声データに対応する頭部動作コマンドを生成し、前記ヒューマノイドロボット型ロボットの制御部に出力するための頭部コマンド生成手段と、を含む、頭部動作制御情報生成装置。
【請求項2】
請求項1に記載の頭部動作制御情報生成装置であって、
前記音声データには、話者を特定する話者特定情報、話者と談話相手との関係を特定する関係特定情報、及び発話時の非言語的情報、の任意の組合せからなる、談話モードを指定する談話モード情報が付されており、
前記確率モデル選択手段は、前記談話モード情報と前記談話機能タグとの組合せに応じて予め準備された複数個の確率モデルを記憶しており、
前記確率モデル選択手段は、前記音声データに付された談話モード情報と、前記入力された所定の単位とに応じて前記複数個の確率モデルの内の一つを選択するための手段を含む、請求項1に記載の頭部動作制御情報生成装置。
【請求項3】
請求項1又は請求項2に記載の頭部動作制御情報生成装置であって、
前記頭部コマンド生成手段は、
前記確率モデル選択手段により選択された確率モデルにしたがった確率で、前記入力された所定の単位の音声データに対応する頭部動作を発生させるか否かを決定するための頭部動作決定手段と、
前記複数の頭部動作の各々に対し、当該頭部動作に対応する頭部の時間的動きを規定する形状情報を記憶するための形状情報記憶手段と、
前記頭部動作決定手段により何らかの頭部動作を発生させることが決定されたことに応答して、当該頭部動作の種類により予め決まっているタイミングで、当該頭部動作に対応する形状情報を前記形状情報記憶手段から読出して前記ロボットの頭部を制御するための制御コマンドを生成し前記制御部に出力するための形状読出手段とを含む、請求項1又は請求項2に記載の頭部動作制御情報生成装置。
【請求項4】
請求項3に記載の頭部動作制御情報生成装置であって、
前記ロボットの頭部の動きは、前記ロボットの頭部の3軸周りの回転のうち、ピッチ角に関連するものであって、
前記頭部コマンド生成手段はさらに、
前記ロボットの発話時の頭部の時間的動きを規定する、予め準備された頭部動作の形状を記憶するための発話時頭部形状記憶手段と、
前記形状読出手段と前記制御部との間に接続され、前記音声データにより前記ロボットが発話する期間であることが示されていることに応答して、前記形状読出手段により出力される制御コマンドに、前記発話時頭部形状記憶手段から読出した頭部動作の形状を重畳して前記制御部に与えるための手段とを含む、請求項3に記載の頭部動作制御情報生成装置。
【請求項5】
請求項1〜請求項3のいずれかに記載の頭部動作制御情報生成装置であって、
前記ロボットの頭部の動きは、前記ロボットの頭部の3軸のうち任意の組合せの軸周りの回転に関するものであって、
前記確率モデル記憶手段、前記確率モデル選択手段、及び前記頭部コマンド生成手段は、いずれも前記任意の組合せを構成する軸ごとに独立に頭部制御コマンドを生成する、請求項1〜請求項3のいずれかに記載の頭部動作制御情報生成装置。
【請求項1】
ヒューマノイド型ロボットの頭部の動きを、当該ロボットが発生する音声に同期して制御する制御情報を生成するための頭部動作制御情報生成装置であって、
前記音声は予め所定の単位に分割された音声データにより規定され、前記所定の単位の各々には、当該単位に割当てられた音声データにより発声される音声による談話機能を示す談話機能タグを含む注釈が付されており、
談話機能タグごとに、複数の頭部動作をどのような確率で実行するかを規定する確率モデルを記憶するための確率モデル記憶手段と、
前記音声データの前記所定の単位の入力を受け、当該単位に付された注釈に基づいて決定される確率モデルを、前記確率モデル記憶手段に記憶された確率モデルの中から選択するための確率モデル選択手段と、
前記確率モデル選択手段により選択された確率モデルにしたがった確率で、前記入力された所定の単位の音声データに対応する頭部動作コマンドを生成し、前記ヒューマノイドロボット型ロボットの制御部に出力するための頭部コマンド生成手段と、を含む、頭部動作制御情報生成装置。
【請求項2】
請求項1に記載の頭部動作制御情報生成装置であって、
前記音声データには、話者を特定する話者特定情報、話者と談話相手との関係を特定する関係特定情報、及び発話時の非言語的情報、の任意の組合せからなる、談話モードを指定する談話モード情報が付されており、
前記確率モデル選択手段は、前記談話モード情報と前記談話機能タグとの組合せに応じて予め準備された複数個の確率モデルを記憶しており、
前記確率モデル選択手段は、前記音声データに付された談話モード情報と、前記入力された所定の単位とに応じて前記複数個の確率モデルの内の一つを選択するための手段を含む、請求項1に記載の頭部動作制御情報生成装置。
【請求項3】
請求項1又は請求項2に記載の頭部動作制御情報生成装置であって、
前記頭部コマンド生成手段は、
前記確率モデル選択手段により選択された確率モデルにしたがった確率で、前記入力された所定の単位の音声データに対応する頭部動作を発生させるか否かを決定するための頭部動作決定手段と、
前記複数の頭部動作の各々に対し、当該頭部動作に対応する頭部の時間的動きを規定する形状情報を記憶するための形状情報記憶手段と、
前記頭部動作決定手段により何らかの頭部動作を発生させることが決定されたことに応答して、当該頭部動作の種類により予め決まっているタイミングで、当該頭部動作に対応する形状情報を前記形状情報記憶手段から読出して前記ロボットの頭部を制御するための制御コマンドを生成し前記制御部に出力するための形状読出手段とを含む、請求項1又は請求項2に記載の頭部動作制御情報生成装置。
【請求項4】
請求項3に記載の頭部動作制御情報生成装置であって、
前記ロボットの頭部の動きは、前記ロボットの頭部の3軸周りの回転のうち、ピッチ角に関連するものであって、
前記頭部コマンド生成手段はさらに、
前記ロボットの発話時の頭部の時間的動きを規定する、予め準備された頭部動作の形状を記憶するための発話時頭部形状記憶手段と、
前記形状読出手段と前記制御部との間に接続され、前記音声データにより前記ロボットが発話する期間であることが示されていることに応答して、前記形状読出手段により出力される制御コマンドに、前記発話時頭部形状記憶手段から読出した頭部動作の形状を重畳して前記制御部に与えるための手段とを含む、請求項3に記載の頭部動作制御情報生成装置。
【請求項5】
請求項1〜請求項3のいずれかに記載の頭部動作制御情報生成装置であって、
前記ロボットの頭部の動きは、前記ロボットの頭部の3軸のうち任意の組合せの軸周りの回転に関するものであって、
前記確率モデル記憶手段、前記確率モデル選択手段、及び前記頭部コマンド生成手段は、いずれも前記任意の組合せを構成する軸ごとに独立に頭部制御コマンドを生成する、請求項1〜請求項3のいずれかに記載の頭部動作制御情報生成装置。
【図1】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【図9】
【図10】
【図11】
【公開番号】特開2011−167820(P2011−167820A)
【公開日】平成23年9月1日(2011.9.1)
【国際特許分類】
【出願番号】特願2010−35614(P2010−35614)
【出願日】平成22年2月22日(2010.2.22)
【国等の委託研究の成果に係る記載事項】(出願人による申告)総務省「高齢者・障害者のためのユビキタスネットワークロボット技術の研究開発」
【出願人】(393031586)株式会社国際電気通信基礎技術研究所 (905)
【Fターム(参考)】
【公開日】平成23年9月1日(2011.9.1)
【国際特許分類】
【出願日】平成22年2月22日(2010.2.22)
【国等の委託研究の成果に係る記載事項】(出願人による申告)総務省「高齢者・障害者のためのユビキタスネットワークロボット技術の研究開発」
【出願人】(393031586)株式会社国際電気通信基礎技術研究所 (905)
【Fターム(参考)】
[ Back to top ]